- 投稿日:2021-02-25T23:24:07+09:00
AWS12ヶ月無料枠オススメ3選
始めに
プログラミング勉強をしていて、AWSの無料枠にはお世話になったのですが、そこで使って良かったもの・使用してみたいものを個人的に残しときたいなと思い書きました。
AWSの12ヶ月無料枠とは
AWSのアカウント登録をしてから、12ヶ月間のみ無料で使用できるサービスのことです。
AWS12ヶ月無料枠①Amazon EC2
AWSを使う大体の人が使うサービスだと思います。AWS上に仮想サーバーを構築して自由に利用できるのが特徴です。ユーザーの必要に応じてスペックを変更できるのがEC2の魅力です。
750時間の使用時間と20GBのディスク容量が無料で使用できます。
※Amazon Linuxが無料利用枠の対象である一方で、Windowsは対象とはなっていません。
AWS12ヶ月無料枠②Amazon RDS
データベース機能を提供するサービスです。RDSの場合はサーバの準備が不要で、構築後すぐにデータベースの利用が可能となります。
MySQL、PostgreSQL、MariaDBなどの一般的なデータベースを、簡単な操作で作成することができます。750時間の使用時間と20GBのディスク容量および20GBのスナップショットが無料で使用できます。
※microインスタンスのみが対象となります。
AWS12ヶ月無料枠③Amazon S3
データ容量を気にすることなく保存することができるサービスです。その場に応じて自由な使い道が想定され、より柔軟なデータ保存が実行できるのが特徴となっています。
ウェブサイト、バックアップおよび復元、アーカイブなど、様々な用途に対応することができます。5GBの標準ストレージと20000回のアップロード・2000回のダウンロードが無料で使用できます。
※僕自身この機能は使用したことがないので使用してみたいです。
参考
AWSの無料枠でできること3選|AWS無料枠を使用する際の注意点3つ
参考にさせていただきました!ありがとうございます!最後に
12ヶ月間の有効期限が切れた後やサービス使用量が制限を超えた場合は、料金を支払う必要があるので注意してください!
- 投稿日:2021-02-25T23:09:55+09:00
autogluon.tabularのTabularDatasetによるデータの取得ができなくなってしまった件と解決方法について(2021/02/25に検知)
はじめに
先月、Google ColaboratoryでAutoGluonをinstall & importする方法という記事を書きました。しかし、改めてAutoGluon1を実行しようとしたところ以下のようなエラーが出てしまいました(2021/02/25)。具体的には、
autogluon.tabularのTabularDatasetによるデータの取得ができなくなってしましました。from autogluon.tabular import TabularDataset, TabularPredictor train_data = TabularDataset(file_path='https://autogluon.s3.amazonaws.com/datasets/Inc/train.csv') test_data = TabularDataset(file_path='https://autogluon.s3.amazonaws.com/datasets/Inc/test.csv') predictor = TabularPredictor(label='class').fit(train_data, time_limit=60) # Fit models for 60s leaderboard = predictor.leaderboard(test_data)※一部マスク済み
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-1-XXXXXXXXXXXX> in <module>() 1 from autogluon.tabular import TabularDataset, TabularPredictor 2 ----> 3 train_data = TabularDataset(file_path='https://autogluon.s3.amazonaws.com/datasets/Inc/train.csv') 4 test_data = TabularDataset(file_path='https://autogluon.s3.amazonaws.com/datasets/Inc/test.csv') 5 predictor = TabularPredictor(label='class').fit(train_data, time_limit=60) # Fit models for 60s TypeError: __init__() missing 1 required positional argument: 'data'結論
引数の
file_path=が不要になったようです。README2も気が付いたら更新されていたみたいです。from autogluon.tabular import TabularDataset, TabularPredictor train_data = TabularDataset('https://autogluon.s3.amazonaws.com/datasets/Inc/train.csv') test_data = TabularDataset('https://autogluon.s3.amazonaws.com/datasets/Inc/test.csv') predictor = TabularPredictor(label='class').fit(train_data, time_limit=60) # Fit models for 60s leaderboard = predictor.leaderboard(test_data)(省略) AutoGluon training complete, total runtime = 64.75s ... TabularPredictor saved. To load, use: TabularPredictor.load("AutogluonModels/ag-20210225_133323/") model score_test score_val pred_time_test pred_time_val fit_time pred_time_test_marginal pred_time_val_marginal fit_time_marginal stack_level can_infer fit_order 0 WeightedEnsemble_L2 0.874706 0.8848 3.773335 1.229578 44.071734 0.014430 0.005951 1.228042 2 True 11 1 LightGBM 0.873375 0.8800 0.076524 0.041000 1.121325 0.076524 0.041000 1.121325 1 True 7 2 CatBoost 0.872351 0.8768 0.026494 0.017763 5.229808 0.026494 0.017763 5.229808 1 True 9 3 XGBoost 0.870713 0.8756 0.131061 0.035778 1.921347 0.131061 0.035778 1.921347 1 True 10 4 LightGBMXT 0.870202 0.8756 0.166172 0.062271 1.544986 0.166172 0.062271 1.544986 1 True 8 5 RandomForestGini 0.859863 0.8600 0.830060 0.215768 10.372102 0.830060 0.215768 10.372102 1 True 1 6 RandomForestEntr 0.858225 0.8612 0.820438 0.315851 12.771529 0.820438 0.315851 12.771529 1 True 2 7 ExtraTreesGini 0.845839 0.8468 1.310977 0.315492 9.186114 1.310977 0.315492 9.186114 1 True 3 8 ExtraTreesEntr 0.845737 0.8432 1.312058 0.315819 9.196487 1.312058 0.315819 9.196487 1 True 4 9 KNeighborsUnif 0.773365 0.7752 0.108653 0.109507 0.389895 0.108653 0.109507 0.389895 1 True 5 10 KNeighborsDist 0.762514 0.7660 0.288525 0.110196 0.306585 0.288525 0.110196 0.306585 1 True 6まとめ
autogluon.tabularのTabularDatasetによるデータの取得ができなくなってしまった件と解決方法について紹介しました。引き続きAutoGluonをはじめとするAutoMLをどんどん体験していきましょう!
- 投稿日:2021-02-25T21:41:35+09:00
Amazon RDS for SQL Server の "Always on"
⬛️内容
Amazon RDS for SQL Server で Standard Edition で Always On Availability Group が利用可能に
[Feb 23, 2021]Amazon RDS for SQL Server now supports Always On Availability Groups for Standard Edition普段、AWS RDS を利用する際は、MySQLを利用することが多いのですが、エンジンのタイプが異なると、マルチAZの選択がどうなるのかと気になり、多少やって見た系の記事です。
⬛️やって見た系
最新アップデート情報の内容の通り、
エンジンタイプには「Microsoft SQL Server」
エディションには「SQL Server Standard Edition」
を選択する。
マルチAZ配置では「あり」もしくは「なし」しか選べないようになっている。
では、"Always on"か"Mirroring"どちらが指定されるのか?
※こちらの説明にあるとおり、"Always On" とは SQL Server の「高可用性」を実現する機能であり、"Mirroring"に変わる機能。
"Mirroring"は非推奨のようであり、"Always On" に対応したMicrosoft SQL Server のマルチ AZ 配置を確認すべき。
設定は自動的に行われ、RDS はデプロイする SQL Server のバージョンに基づいて、"Always on"か"Mirroring"かが選択され、マネージコンソールから確認することが可能なようです。
フェイルオーバーで再起動をしてみると、40秒程度でフェイルオーバーしているようです。
二月 25, 2021, 12:34:33 午後 UTC Multi-AZ instance failover started. 二月 25, 2021, 12:34:58 午後 UTC Multi-AZ instance failover completed 二月 25, 2021, 12:35:13 午後 UTC Multi-AZ failover to standby complete - DNS propagation may take a few minutesなお、現在"Mirroring"から"Always on"に自動では変更されません。
"Mirroring"から"Always on"に変更したい場合は、シングル構成に変更して、再度マルチAZ構成変更する必要があるようです。⬛️リンク



- 投稿日:2021-02-25T21:07:49+09:00
Amazon FSx for Lustre 使ってみた part2
プレロード
状態確認
S3にアップロードした後、ファイルストレージにロードされた状態だと
exists archivedと表示される。$ sudo lfs hsm_state /mnt/fsx/FSxLustre20210225T110202Z/test2.txt /mnt/fsx/FSxLustre20210225T110202Z/test2.txt: (0x00000009) exists archived, archive_id:1S3にアップロードした後、まだロードされていない状態だと
released exists archivedと表示される。$ sudo lfs hsm_state /mnt/fsx/FSxLustre20210225T110202Z/test3.txt /mnt/fsx/FSxLustre20210225T110202Z/test3.txt: (0x0000000d) released exists archived, archive_id:1この時間差は次節のプレロードによって解消されるらしい。
なお、フォルダの中身をまとめて確認できる。
$ sudo lfs hsm_state /mnt/fsx/FSxLustre20210225T110202Z/* /mnt/fsx/FSxLustre20210225T110202Z/test2.txt: (0x00000009) exists archived, archive_id:1 /mnt/fsx/FSxLustre20210225T110202Z/test3.txt: (0x00000009) exists archived, archive_id:1 /mnt/fsx/FSxLustre20210225T110202Z/test4.txt: (0x00000009) exists archived, archive_id:1 /mnt/fsx/FSxLustre20210225T110202Z/test5.txt: (0x0000000d) released exists archived, archive_id:1プレロード
Amazon FSx copies data from your Amazon S3 data repository when a file is first accessed. Because of this approach, the initial read or write to a file incurs a small amount of latency. If your application is sensitive to this latency, and you know which files or directories your application needs to access, you can optionally preload contents of individual files or directories.
日本語訳
Amazon FSxは、ファイルが最初にアクセスされたときにAmazon S3データリポジトリからデータをコピーする。このアプローチのため、ファイルへの最初の読み取りや書き込みには少量の遅延が発生します。アプリケーションがこの待ち時間に敏感で、アプリケーションがアクセスする必要のあるファイルやディレクトリがわかっている場合、オプションで個々のファイルやディレクトリのコンテンツをプリロードすることができます。
$ sudo lfs hsm_restore /mnt/fsx/FSxLustre20210225T110202Z/test2.txtYou can use the hsm_action command to verify that the file's contents have finished loading into the file system. A return value of NOOP indicates that the file has successfully been loaded. Run the following commands from a compute instance with the file system mounted.
日本語訳
hsm_actionコマンドを使用して、ファイルの内容がファイルシステムへのロードが終了したことを確認することができます。NOOPが返ってきた場合は、ファイルが正常にロードされたことを示します。
$ sudo lfs hsm_action /mnt/fsx/FSxLustre20210225T110202Z/test2.txt /mnt/fsx/FSxLustre20210225T110202Z/test2.txt: NOOPデータリポジトリ
ディレクトリmydirをS3にアップロードする。ここでマウントポイントは/mnt/fsxである。
$ ls /mnt/fsx/mydir/ mytest1.txt mytest2.txt画像のようにマウントポイント配下のディレクトリを指定する。
- ステータス
- データリポジトリを使ったアップロード後のS3の状態
リリース
If you want to create storage space on your file system, you can release files from your file system. Releasing a file retains the file listing and metadata, but removes the local copy of that file's contents.
日本語訳
ファイルシステムにストレージスペースを作成したい場合は、ファイルシステムからファイルを解放することができます。ファイルをリリースすると、ファイルの一覧とメタデータは保持されますが、そのファイルのコンテンツのローカルコピーは削除されます。
$ sudo lfs hsm_release /mnt/fsx/test1.txt $ sudo lfs hsm_state /mnt/fsx/test1.txt /mnt/fsx/test1.txt: (0x0000000d) released exists archived, archive_id:1リリースの後、プレロードによって再度ファイルシステムにロード可能である。
参考記事
Preloading files into your file system
https://docs.aws.amazon.com/fsx/latest/LustreGuide/preload-file-contents-hsm.htmlOverview of data repositories
https://docs.aws.amazon.com/fsx/latest/LustreGuide/overview-data-repo.htmlReleasing data from your file system
https://docs.aws.amazon.com/fsx/latest/LustreGuide/release-files.html



- 投稿日:2021-02-25T19:58:15+09:00
Mac (M1)にeksctlを上手くインストールできないときの解決策
最近、kubernetesの勉強をしております。
その際、EKSを使おうと、MacBook Air(M1)にeksctlを入れようとしたのですが、上手くインストールできませんでした。
具体的にはbrewでインストールしようとしました。brew install weaveworks/tap/eksctlしかし、下記エラーが出てしまいました。。。
Updating Homebrew... ==> Auto-updated Homebrew! Updated 1 tap (homebrew/core). ==> New Formulae go@1.15 ==> Updated Formulae Updated 23 formulae. ==> Installing eksctl from weaveworks/tap ==> Cloning https://github.com/kubernetes/kubernetes.git Updating /Users/××××××/Library/Caches/Homebrew/kubernetes-cli--git ==> Checking out tag v1.20.4 HEAD is now at e87da0bd Release commit for Kubernetes v1.20.4 HEAD is now at e87da0bd Release commit for Kubernetes v1.20.4 ==> Downloading https://github.com/weaveworks/eksctl/releases/download/0.38.0/eksctl_Dar Already downloaded: /Users/×××××/Library/Caches/Homebrew/downloads/2f6b84c0a198a6a4fc02f1d9dfe0de667aea70e1e39795e724139d3a4aa3a26c--eksctl_Darwin_amd64.tar.gz ==> Installing dependencies for weaveworks/tap/eksctl: kubernetes-cli ==> Installing weaveworks/tap/eksctl dependency: kubernetes-cli ==> make WHAT=cmd/kubectl Last 15 lines from /Users/×××××/Library/Logs/Homebrew/kubernetes-cli/01.make: ./vendor/k8s.io/code-generator/cmd/prerelease-lifecycle-gen touch: _output/bin/go-bindata: No such file or directory make[1]: *** [_output/bin/go-bindata] Error 1 make[1]: *** Waiting for unfinished jobs.... touch: _output/bin/prerelease-lifecycle-gen: No such file or directory make[1]: *** [_output/bin/prerelease-lifecycle-gen] Error 1 touch: _output/bin/defaulter-gen: No such file or directory make[1]: *** [_output/bin/defaulter-gen] Error 1 touch: _output/bin/deepcopy-gen: No such file or directory make[1]: *** [_output/bin/deepcopy-gen] Error 1 touch: _output/bin/conversion-gen: No such file or directory make[1]: *** [_output/bin/conversion-gen] Error 1 touch: _output/bin/openapi-gen: No such file or directory make[1]: *** [_output/bin/openapi-gen] Error 1 make: *** [generated_files] Error 2 Do not report this issue to Homebrew/brew or Homebrew/core! These open issues may also help: kubernetes-cli: Add support for darwin/arm64 https://github.com/Homebrew/homebrew-core/pull/69931 kubernetes-cli: build for Apple Silicon https://github.com/Homebrew/homebrew-core/pull/68455解決策
いろいろ調べましたが、まだ解決されていないのか、結局のところ、brewでインストールできませんでした。
AWSの公式ドキュメントを読んでいたとき、手動でダウンロードできるようなので、やってみました!リリースのアーカイブを手動でダウンロードします https://github.com/weaveworks/eksctl/releases/download/0.36.0/eksctl_Darwin_amd64.tar.gz、eksctl を展開し、実行します。
参照元:https://docs.aws.amazon.com/ja_jp/eks/latest/userguide/eksctl.html手順
1 上記URLから、フォルダを指定してダウンロードし、展開します。
2 下記コマンドでPATHの通っている場所を調べ、展開したコマンドをコピーしてください。私の場合は/usr/local/bin配下にコピーしました。
echo $PATHsudo cp eksctl /usr/local/bin3 下記コマンドを実行し、バージョンが表示されれば、無事完了です。
eksctl version 0.36.0
- 投稿日:2021-02-25T19:51:37+09:00
AWSを勉強しての備忘録
AWS Cloud Tech を通して学習した内容を備忘録として記述します。
AWSとは
Amazon.comにより提供されているクラウドコンピューティングサービス。
AWSとは、Amazon Web Servicesの略で、Amazonが提供している100以上のクラウドコンピューティングサービスの総称。
従来の「オンプレミス」とは違い、初期費用なし、メンテナンスなし、料金は使った分だけで今すぐ使用することができる便利なサービス。主要サービス
VPC
仮想プライベートクラウドを提供する商用クラウドコンピューティングサービス。AWSクラウド空間上に自分だけのクラウド空間を作れる。広いAWSさんの土地に自分だけの土地を確保するみたいなこと。EC2
安全でサイズ変更可能なコンピューティング性能をクラウド内で提供するウェブサービス。AWS上に自分がほしいスペックのサーバー自由に構築できる。VPCで確保した土地に自分の好みの家をつくるみたいなこと。IAM
AWS リソースへのアクセスを安全に管理するためのウェブサービス。VPCやEC2にアクセスできるユーザーを管理するもの。AWS上に確保した土地や作った家に入れる人を管理する機能みたいなこと。RDS
AWSのフルマネージドなリレーショナルデータベースのサービス。AWS上に確保した土地や作った家の中で必要な家具や家電を管理する機能みたいなこと。(←あまりいい例えじゃない気がする。)基本的なAWS構成図
クロカワさんのレクチャー・資料を参考に「cacoo」で作ってみました。
主要サービス以外の解説
Availability Zone
リージョンごとにアベイラビリティーゾーンと呼ばれる複数の独立した場所、つまりサーバーが置かれた建物がある。インターネットゲートウェイ
VPCのコンポーネント(部品)の1つ。VPC内部とインターネットを通信をする機能。subnet
大きいネットワーク(VPC)を小さく分割したネットワーク。
Public subnetとPrivate subnetで分けてVPC外部とやり取りするものとVPC内部でのみやり取りするネットワークという感じで分けて使う場合もある。Security group
VPCインスタンスの仮想ファイアウォールとして機能している。レプリケーション
複製(レプリカ)の作成を意味する。2セット(稼働系と待機系)用意された環境において リアルタイムにデータ複製する技術のこと。
障害とか何かあれば瞬時に切り替わる仕組み。まとめ
AWSについて全くの素人がここまで学べました。
残りの教材も頑張っていきたいです。この記事はAWS初学者を導く体系的な動画学習サービス
「AWS CloudTech」の課題カリキュラムで作成しました。

- 投稿日:2021-02-25T19:39:06+09:00
【 Ruby on Rails 6.0 】AWS + Nginx + Unicornでデプロイ⑥
始めに
前回の内容でブラウザ上でRailsアプリを起動するところまで実装出来ました。
今回はNginxというWebサーバーをインストールしてリクエストとレスポンスをインタラクティブに可能にしていきたいと思います。目次
目次 内容 セクション1 EC2インスタンス作成 セクション2 Linuxサーバー構築 セクション3 データベース設定 セクション4 EC2上でGemをインストールし環境変数を設定 セクション5 Railsアプリを起動 セクション6 Nginxの導入(今回の内容) Nginxの導入
Nginx(エンジン・エックス)とは、Webサーバの一種です。
ユーザーのリクエストに対して静的コンテンツの取り出し処理を行い、そして動的コ ンテンツの生成をアプリケーションサーバに依頼するためのものになります。 早速インストールしていきましょう。Nginxをインストール
ターミナル(EC2)# Nginxをインストール [ec2-user@ip-172-31-25-189 ~]$ sudo amazon-linux-extras install nginx1Nginxの設定ファイルを編集
次に、Nginxが正しく動くように設定しましょう。
Nginxの設定は設定項目X 設定値x;という形式で入力していきます。
これも先ほどと同様に、vimコマンドを使ってターミナル上で編集していきます。 /etc以下のファイルなので、強い権限でないと書き込み、保存ができません。そのため、コマンドの頭にsudoをつけています。ターミナル(EC2)[ec2-user@ip-172-31-25-189 ~]$ sudo vim /etc/nginx/conf.d/rails.conf開けたら次のように編集します。
rails.confupstream app_server { # Unicornと連携させるための設定。 # アプリケーション名を自身のアプリ名に書き換えることに注意。今回であればおそらく server unix:/var/www/〇〇〇〇〇〇<アプリケーション名>/tmp/sockets/unicorn.sock; } # {}で囲った部分をブロックと呼ぶ。サーバの設定ができる server { # このプログラムが接続を受け付けるポート番号 listen 80; # 接続を受け付けるリクエストURL ここに書いていないURLではアクセスできない server_name XX.XXX.XXX.XX(Elastic IP); # クライアントからアップロードされてくるファイルの容量の上限を2ギガに設定。デフォルトは1メガなので大きめにしておく client_max_body_size 2g; # 接続が来た際のrootディレクトリ root /var/www/〇〇〇〇〇<アプリケーション名>/public; # assetsファイル(CSSやJavaScriptのファイルなど)にアクセスが来た際に適用される設定 location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; }
- 3行目の<アプリケーション名> となっている箇所は、ご自身のものに変更してください。
- 11行目のとなっている箇所も同様に、ご自身のものに変更してください。
- 14行目の<アプリケーション名>となっている箇所は、ご自身のものに変更してくだ さい。
nginxの権限を変更
POSTメソッドでもエラーが出ないようにするために、下記のコマンドも実行
ターミナル(EC2)[ec2-user@ip-172-31-25-189 ~]$ cd /var/lib [ec2-user@ip-172-31-25-189 lib]$ sudo chmod -R 775 nginxこれで、Nginxの設定が完了しました。
Nginxを起動して、設定ファイルを再読み込み
[ec2-user@ip-172-31-25-189 lib]$ cd ~ [ec2-user@ip-172-31-25-189 ~]$ sudo systemctl start nginx [ec2-user@ip-172-31-25-189 ~]$ sudo systemctl reload nginx # ステータス確認 [ec2-user@ip-172-31-25-189 ~]$ sudo systemctl status nginx ● nginx.service - The nginx HTTP and reverse proxy server Loaded: loaded (/usr/lib/systemd/system/nginx.service; disabled; vendor preset: disabled) Active: active (running) since 日 2021-02-21 04:20:53 UTC; 32s agounicorn.rbを修正
次にNginxを介した処理を行うためにunicornの設定を修正します。
unicorn.rb(ローカル)listen 3000 ↓以下のように修正 listen "#{app_path}/tmp/sockets/unicorn.sock"修正をしたら忘れずに、commitとpushをし、サーバ側で以下のコマンドを実行して修正点を反映させておきます。
ローカルの変更点を本番環境へ反映
ターミナル(EC2)[ec2-user@ip-172-31-25-189 ~]$ cd /var/www/アプリ名 # 本番環境に反映 [ec2-user@ip-172-31-23-189 <アプリ名>]$ git pull origin masterUnicornを再起動
Unicornのプロセスをkillして、再起動する作業を行います。
ターミナル(EC2)# プロセスを確認 [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ps aux | grep unicorn ec2-user 17877 0.4 18.1 588472 182840 ? Sl 01:55 0:02 unicorn_rails master -c config/unicorn.rb -E production -D ec2-user 17881 0.0 17.3 589088 175164 ? Sl 01:55 0:00 unicorn_rails worker[0] -c config/unicorn.rb -E production -D ec2-user 17911 0.0 0.2 110532 2180 pts/0 S+ 02:05 0:00 grep --color=auto unicorn # 続いて、unicorn_rails master(一番上)のプロセスをkillします。 [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ kill <確認したunicorn rails masterのPID(上のコードでは17877)> # unicornを起動します [ec2-user@ip-172-31-23-189 <アプリ名>]$ RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -Dブラウザで確認してみましょう
ブラウザからElastic IPでアクセスすると、アプリケーションにアクセスできます(:3000 をつける必要はありません)。なお、この時もunicornが起動している必要があります。
ローカルの変更を本番環境に反映させる手順まとめ
- 開発環境でgit push
- EC2インスタンスにSSHログイン
ターミナル(ローカル)# ssh.ディレクトリで行う ssh. $ ssh -i ダウンロードしたキーペア名.pem ec2-user@Elastic IPアドレス
- ローカルの変更を本番環境に反映
ターミナル(EC2)# アプリのディレクトリでに移動 [ec2-user@ip-172-31-23-189 <アプリ名>]$ cd /var/www/リポジトリ名 # 本番環境に反映 [ec2-user@ip-172-31-23-189 <アプリ名>]$ git pull origin master
- アセットのコンパイル
ターミナル(EC2)[ec2-user@ip-172-31-23-189 <アプリ名>]$ rails assets:precompile RAILS_ENV=production
- Unicorn起動
ターミナル(EC2)# プロセスを確認 [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ps aux | grep unicorn ec2-user 17877 0.4 18.1 588472 182840 ? Sl 01:55 0:02 unicorn_rails master -c config/unicorn.rb -E production -D ec2-user 17881 0.0 17.3 589088 175164 ? Sl 01:55 0:00 unicorn_rails worker[0] -c config/unicorn.rb -E production -D ec2-user 17911 0.0 0.2 110532 2180 pts/0 S+ 02:05 0:00 grep --color=auto unicorn # 続いて、unicorn_rails master(一番上)のプロセスをkillします。 [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ kill <確認したunicorn rails masterのPID(上のコードでは17877)> # unicornを起動します [ec2-user@ip-172-31-23-189 <アプリ名>]$ RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -DIPアドレスをうってブラウザで確認
IPアドレスにアクセスしてもエラーが出る時
エラーが出る時は以下の項目確認してみてください。
- 502 but gateway とエラーが出る場合は、nginxのlogの確認が必要になります。
- /var/log/nginx/error.logをlessまたはcatコマンドで確認する。
- サーバ側で、 /var/www/<レポジトリ名>/log/unicorn.stderr.log を less またはcatコマンドで確認し、エラーが出ていないか確認する(下に行くほど最新のログです。時刻表記がUTCであることに注意してください)
- Railsを起動しているか
- EC2インスタンスの再起動を行ってみる(※本番環境にてmysqlとnginxの起動が必要です。)
終わりに
以上で本番環境でRailsアプリを起動・操作できると思います!
しかし、現状だとローカル環境で変更点が発生した時に本番環境に反映させるのが工数が多く大変です。
なので次回の記事でこのデプロイ作業を自動化するためCapistranoというツールを導入したいと思います。
お疲れさまでした。。。
- 投稿日:2021-02-25T19:18:34+09:00
コマンドラインから(awscliで)CloudFrontのキャッシュ無効化する
手順
3つのコマンドを実行して達成可能。
- CloudFront の disutribution id を入手
- パスを無効化する
- 無効化の進捗状況を確認する
例の内訳
- {profile}
- 認証情報のプロファイル
- {hostname}
- ドメイン割り当て済みならFQDN
- {path}
- 無効化するパス。例えば
/aaa/bbb.json例
$ aws cloudfront list-distributions --profile {profile} | jq '.DistributionList.Items[] | .Id + " " + .Aliases.Items[0]' -r E************ {hostname} ... $ aws cloudfront create-invalidation --distribution-id E************ --paths "{path}" --profile {profile} { "Location": "https://cloudfront.amazonaws.com/2020-05-31/distribution/E************/invalidation/I17***********", "Invalidation": { "Id": "I17***********", "Status": "InProgress", "CreateTime": "2021-02-22T12:47:09.866Z", "InvalidationBatch": { "Paths": { "Quantity": 1, "Items": [ "{path}" ] }, "CallerReference": "cli-0000000000-000000" } } } $ aws cloudfront get-invalidation --id I17*********** --distribution-id E************ --profile {profile} | jq -r '.Invalidation | .CreateTime + " " + .Status' 2021-02-22T12:47:09.866Z Completed $ aws cloudfront get-invalidation --id I17*********** --distribution-id E************ --profile {profile} { "Invalidation": { "Id": "I17***********", "Status": "Completed", "CreateTime": "2021-02-22T12:47:09.866Z", "InvalidationBatch": { "Paths": { "Quantity": 1, "Items": [ "{path}" ] }, "CallerReference": "cli-0000000000-000000" } } }
- 投稿日:2021-02-25T19:08:45+09:00
AWSサービスを擬人化で覚える!主要サービスのまとめ
AWSにはとてもいろんなサービスがあり、AWSの資格試験の勉強をする際には、知らないサービスが出てきて戸惑うことがあるのではないでしょうか。
それぞれのサービスの特徴も文字情報だけでは理解しづらく、概要を掴むことも難しいなんてことも。
AWSを擬人化してサービス説明をすることで、わかりやすくイメージをつかめるようにしようという試みを行ってみました。DNS
Route 53
【AWS擬人化サービス紹介】Route53
(擬人化キャラがサービスの概要や特徴について語るページです)コンピュート、配信系
EC2とEBS
EC2
クラウド上で動くコンピューター。起動している時間だけお金がかかるので実体のあるPCを購入するより安く済む場合が多く、スペックも変更したいときにすぐ変更できる。AWSの一番基本的なサービス。EBS
EC2に接続されるストレージ。【AWS擬人化サービス紹介】EC2とEBS
(擬人化キャラがサービスの概要や特徴について語るページです)ELB
複数のEC2にリクエストを振り分けるロードバランサー。
ELBの中にレイヤー7で使えるALB、レイヤー4で使えるNLB、古くから存在するCLBの三種類が存在している。
【AWS擬人化サービス紹介】ELB
(擬人化キャラがサービスの概要や特徴について語るページです)Lambda
Node.js/Python/Javaなどで書かれたコードをサーバーの準備なしで実行できる。
他のAWSサービスでトリガーを設定し、Lambdaで処理を実行したり、APIGatewayと一緒にサーバーレスアーキテクチャのサービスを作成するのに使える。
【AWS擬人化サービス紹介】Lambda
(擬人化キャラがサービスの概要や特徴について語るページです)API Gateway
HTTPリクエストの受け口としてLambdaと一緒に使われることが多い。RestAPIを作成するのに使う。CloudFront
コンテンツをキャッシュして、オリジンサーバー(EC2など)の代わりに答えてくれるサービス。CloudFrontをつかうことでサーバーの負荷が減るし、ユーザーに近いCloudFrontが答るのでレスポンスも早くなる。DDOS対策やSSL対応もちゃんとできていて高セキュリティー。ストレージ系
S3
データを安く保存できるオブジェクトストレージ。
・容量無制限
・高い耐久性
・安価
・スケーラブルで安定した性能
が特徴
他のサービスの裏側で使われていることもある。
【AWS擬人化サービス紹介】Lambda
(擬人化キャラがサービスの概要や特徴について語るページです)Glacire
中長期間保管するデータをS3よりさらに安く保存できるサービス。
S3の1/3ほどの値段で保管できるが、データの取り出しには時間がかかる。
ファイルのアップロードにAWSのSDKを使う必要があったり、アーカイブIDを記録して削除時に指定しなければいけないなど取り扱いがすこし面倒。EFS
スケーラブルでシンプルなファイルストレージ
・課金は使った分だけ
・勝手に拡張してくれる
・データを複数のAZに分散して保存してくれるので安全な上、同時書き込みにも対応してくれる
という優秀な共有ストレージ(ただしLinuxオンリー)Docker系
ECS
AWSでDockerを扱うのに便利なサービス。EKS
Kubenetesのマネージドサービス。ECR
DockerImageを保管するサービス。












- 投稿日:2021-02-25T17:30:07+09:00
【APIGateway+Lambda】APIキーを必要とするAPIでアクセス制限
APIはすでに作成されておりデプロイ状態にある前提とします。
まずは使用量プランをクリック
作成
↓
作成に必要な設定を行います。
このリクエスト数を越えてしまうと
429 Too Many Requests というエラーが出てアクセスができなくなります。
APIキーを作成して使用料プランの作成を終えるとリソースのメソッドリクエストページ、APIχの必要性の欄に注意書きが出ています。
こちらをtrueに切り替えると使用量プランに紐づいたAPIキーがないとこのエンドポイントにはリクエストが届かなくなります。
設定したAPIキーは
APIキー→APIキー名→表示で確認できますのでコピーしておきましょう。実行
APIキーをヘッダーに含める場合はx-api-key:の後に設定されたキーを追加します。
キーが正しい場合
$ curl -X POST -H "x-api-key: correct_api_key" https://aj.execute-api.us-east-2.amazonaws.com/default >> {"message": "Request is Suceeded"}キーが違う場合
$ curl -X POST -H "x-api-key: incorrect_api_key" https://xxxxxxx.execute-api.us-east-2.amazonaws.com/default >> {"message":"Forbidden"}キーがない場合
$ curl -X POST https://xxxxxxx.execute-api.us-east-2.amazonaws.com/default >> {"message":"Forbidden"}







- 投稿日:2021-02-25T16:42:46+09:00
APIGatewayにパラメーターを送ってLambdaを実行する
先ずはLambda関数を作成
今回は与えらえた値を返すだけのtest_return_valuablesという
シンプルな関数をPythonで作成します。
APIGatewayでAPIを作成
REST APIを選択し構築。
さらにメソッド作成でPOSTを追加します。
これでPOSTメソッドをAPIとして使用できます。
Lambdaと統合
次にAPIGatewayから実行するLambdaを統合します。
リソースの画面からPOSTをクリック
統合タイプにデフォルトでLambdaが選択されているためそのまま統合したい関数を入力します。
Lambdaの統合はたったこれだけで完了します。
APIGatewayとの統合はシンプルで良いですね
それではこのAPIをデプロイして外部からアクセスできる様にしましょう。
デプロイを忘れるとエンドポイントが作成されていないため、外部からアクセスできません。
リソースを作成してるのにAPIが使えないのは直観ではわかりにくかったです…
ステージ選択→新しいステージを作成→わかりやすい名前で作成(今回はdefault)
それではコンソールからPOSTメソッド指定してリクエストを送ってみます。
ステージ作成時に表示されたAPIエンドポイントへリクエストを送ります
$ curl -X POST https://xxxxxxx.execute-api.us-east-2.amazonaws.com/default >> {}パラメーターが何もないため空欄が返されました。
APIGatewayとLambdaが正常に機能していることが分かります。しかしこのままクエリパラメータを送ってもLambdaには引数として渡すことはできません。
$ curl -X POST https://xxxxxxx.execute-api.us-east-2.amazonaws.com/default?name=hoge >> {}パラメーターをマッピングしてAWS側で受け取れようにしましょう。
マッピング
リソースの画面で統合リクエストを選択
↓
マッピングテンプレート
新たにマッピングテンプレートを追加します。
application/jsonと入力
上記のように
{
"受け取るパラメーター名": "$input.params('送る際のパラメーター名')"
}
のように記載すると、Lambda関数でevent変数としてパラメーターを使用できるようになります。$input.paramsはAPIGatewayを使用してパラメーターを送った際に自動的に格納される場所です。
最後にリソースを忘れずにデプロイしましょう!
デプロイされたリソースの反映には少し時間がかかるようなので、時間が経ってから再度更新されたエンドポイントへリクエストを送信
$ curl -X POST https://aj7i8pust1.execute-api.us-east-2.amazonaws.com/default?name=hoge >> {"name": "hoge"}無事パラメーターを送信できました。
アクセスを制限したい場合はapi-keyなども必須にすることもできます。
$ curl -X POST -H "x-api-key: correct_api_key" https://aj.execute-api.us-east-2.amazonaws.com/default?name=hoge >> {"name": "hoge"}key間違い
$ curl -X POST -H "x-api-key: incorrect_api_key" https://xxxxxxx.execute-api.us-east-2.amazonaws.com/default?name=hoge >> {"message":"Forbidden"}keyなし
$ curl -X POST -https://xxxxxxxx.execute-api.us-east-2.amazonaws.com/default?name=hoge >> {"message":"Forbidden"}>> APIキーの設定方法はこちら解説してますのでよろしければご覧くださいー







- 投稿日:2021-02-25T16:42:46+09:00
【APIGateway+Lambda】AWS外からのパラメーターを使用する
先ずはLambda関数を作成
今回は与えらえた値を返すだけのtest_return_valuablesという
シンプルな関数をPythonで作成します。
APIGatewayでAPIを作成
REST APIを選択し構築。
さらにメソッド作成でPOSTを追加します。
これでPOSTメソッドをAPIとして使用できます。
Lambdaと統合
次にAPIGatewayから実行するLambdaを統合します。
リソースの画面からPOSTをクリック
統合タイプにデフォルトでLambdaが選択されているためそのまま統合したい関数を入力します。
Lambdaの統合はたったこれだけで完了します。
APIGatewayとの統合はシンプルで良いですね
それではこのAPIをデプロイして外部からアクセスできる様にしましょう。
デプロイを忘れるとエンドポイントが作成されていないため、外部からアクセスできません。
リソースを作成してるのにAPIが使えないのは直観ではわかりにくかったです…
ステージ選択→新しいステージを作成→わかりやすい名前で作成(今回はdefault)
それではコンソールからPOSTメソッド指定してリクエストを送ってみます。
ステージ作成時に表示されたAPIエンドポイントへリクエストを送ります
$ curl -X POST https://xxxxxxx.execute-api.us-east-2.amazonaws.com/default >> {}パラメーターが何もないため空欄が返されました。
APIGatewayとLambdaが正常に機能していることが分かります。しかしこのままクエリパラメータを送ってもLambdaには引数として渡すことはできません。
$ curl -X POST https://xxxxxxx.execute-api.us-east-2.amazonaws.com/default?name=hoge >> {}パラメーターをマッピングしてAWS側で受け取れようにしましょう。
マッピング
リソースの画面で統合リクエストを選択
↓
マッピングテンプレート
新たにマッピングテンプレートを追加します。
application/jsonと入力
上記のように
{
"受け取るパラメーター名": "$input.params('送る際のパラメーター名')"
}
のように記載すると、Lambda関数でevent変数としてパラメーターを使用できるようになります。$input.paramsはAPIGatewayを使用してパラメーターを送った際に自動的に格納される場所です。
最後にリソースを忘れずにデプロイしましょう!
デプロイされたリソースの反映には少し時間がかかるようなので、時間が経ってから再度更新されたエンドポイントへリクエストを送信
$ curl -X POST https://aj7i8pust1.execute-api.us-east-2.amazonaws.com/default?name=hoge >> {"name": "hoge"}無事パラメーターを送信できました。
アクセスを制限したい場合はapi-keyなども必須にすることもできます。
$ curl -X POST -H "x-api-key: correct_api_key" https://aj.execute-api.us-east-2.amazonaws.com/default?name=hoge >> {"name": "hoge"}key間違い
$ curl -X POST -H "x-api-key: incorrect_api_key" https://xxxxxxx.execute-api.us-east-2.amazonaws.com/default?name=hoge >> {"message":"Forbidden"}keyなし
$ curl -X POST -https://xxxxxxxx.execute-api.us-east-2.amazonaws.com/default?name=hoge >> {"message":"Forbidden"}>> APIキーの設定方法はこちら解説してますのでよろしければご覧くださいー
- 投稿日:2021-02-25T14:58:26+09:00
【AWS】ECSで作ったDocker(Laravel)プロジェクトをRoute53、ALB、ACM、お名前ドットコムを使ってHTTPS化してみた
皆さんこんにちは!
今回はDockerで作ったLaravelプロジェクトをRoute53とALB(ApplicationLoadBalancer)とACM(AmazonCertificateManager)を使ってHTTPS化してみたいと思います!
前提条件
・既にDockerで作ったコンテナをECSで作成していること
・お名前ドットコムでドメインを登録していること補足
DockerをまだECSで作成していない方は以下の記事をご覧ください。
【AWS】AWS超初心者が、頑張ってDockerで作ったLaravelプロジェクトをECR、ECS、EC2を使ってAWS上で動かしてみた
また、お名前ドットコムでドメインを登録していない方は登録してから本記事をご覧ください。(お名前ドットコムでない場合も可ですが、その場合説明が異なる部分があると思うのでご了承ください)
リッスンポート
nginx/default.confserver { listen 80; root /work/laravel/public; index index.php; charset utf-8; error_log /var/log/nginx/error_test.log; location / { root /work/laravel/public; try_files $uri $uri/ /index.php$is_args$args; } location ~ \.php$ { fastcgi_split_path_info ^(.+\.php)(/.+)$; fastcgi_pass app:9000; fastcgi_index index.php; include fastcgi_params; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; fastcgi_param PATH_INFO $fastcgi_path_info; } }
nginxのコンテナではlisten 80;としているように、80番のポートをリッスンしています。ここが
443になっている場合は適時変えて頂くか、上記のようにlisten 80;としてください。参考記事
本記事を書くにあたって下記の記事を参考させて頂きました。
AWSでWebサイトをHTTPS化 その1:ELB(+ACM発行証明書)→EC2編
僕が説明不十分なところもあるので、分からない点がある場合はこちらの記事を見て頂くとよいかと。
それでは早速説明していきます!!
ACMでSSL証明書の発行
まず初めにHTTPS化するには、SSL証明書の発行を行います。
AWSはこのSSL証明書の発行が無料となっております。(AWS神)
サービス検索欄で「CertificateManager」を入力しましょう。
- 「証明書のリクエスト」をクリック
- 「パブリック証明書のリクエスト」を選択
- ドメイン名を入力(この後Route53で登録するドメインを入力。現段階ではRoute53にECS用のドメインを登録していないので、お好きなドメインをご入力ください。以下、説明用としてここで入力したドメイン名を
www.example.comとします。)- 「DNSの検証」を選択
- タグは登録してもしなくてもどちらでもいいです
- 「確定とリクエスト」をクリック
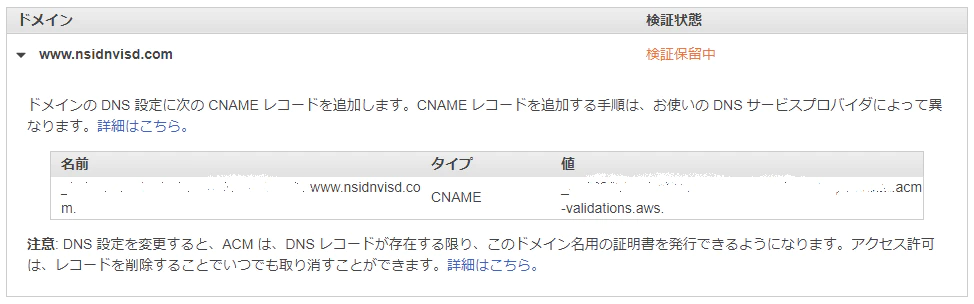
すると画像のように名前や値が表示されます。
これをお名前ドットコムで登録します。
「ドメインのDNS設定」から「DNSレコード設定を利用する」をクリック
そして画像のように先ほどCertificateManagerで発行した名前(ホスト名)と値(VALUE)を登録します。(画像のホスト名や値は適当です)
そしてAWSに戻ってRoute53で先ほどCertificateManagerで登録したドメイン名のホストゾーンを作成します。例で言うと
www.example.comと言う名前で登録します。※注意 既にホストゾーンを作成している場合は、新たにホストゾーンを作成しないでください。後ほど、既に作成してあるホストゾーンで先ほど作成したドメイン名をレコード名として作成してください。
そしたら、作成したホストゾーンの「レコードを作成」をクリック。
タイプを「CNAME」にしてお名前ドットコムで登録したときと同じように名前と値を入れて下さい。
CertificateManagerに戻り、「状況」が「発行済み」になればOK!(時間がかかる場合があります)
ALBでHTTPS登録
サービス検索欄で「ECS」と検索し、左のメニュー欄の「ロードバランシング」にある「ロードバランサー」をクリック。
「ロードバランサーの作成」をクリック。
- 「Application Load Balancer(HTTP、HTTPS)」を選択
- 手順1:名前を入力し、「ロードバランサーのプロトコル」をHTTPSにする(ポート番号が443になる)。「アベイラビリティーゾーン」の「VPC」はECSインスタンスで使用しているVPCを選択。「アベイラビリティーゾーン」にいくつかの候補が出るのですべてにチェック
- 手順2:「証明書タイプ」で「ACMから証明書を選択する」にチェック。「証明書の名前」で先ほど作成した証明書を選択
- 手順3:「新しいセキュリティグループを作成する」にチェック。適当にグループ名を入力し、「タイプ」を「HTTPS」にする
- 手順4:名前を適当に入力し、プロトコルは「HTTP」を選択
- 手順5:利用するインスタンスを選択し「登録済みに追加」をクリック
- 手順6:「作成」をクリック
無事作成されればOK!
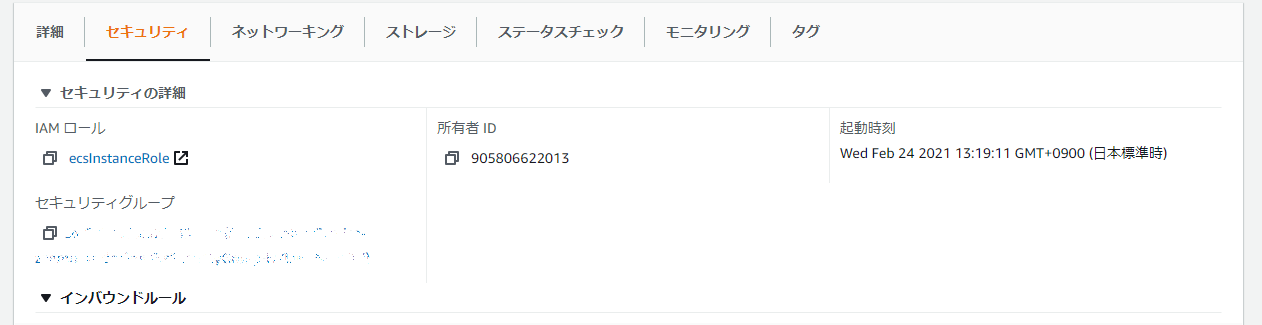
EC2インスタンスのセキュリティ登録
これで最後になるので、あともう一息頑張りましょう!
サービス検索欄で「EC2」と検索。
左のメニューの「インスタンス」の「インスタンス」をクリック。
利用するインスタンスの「インスタンスID」をクリック。
下にある「セキュリティ」タブから「セキュリティグループ」をクリック。
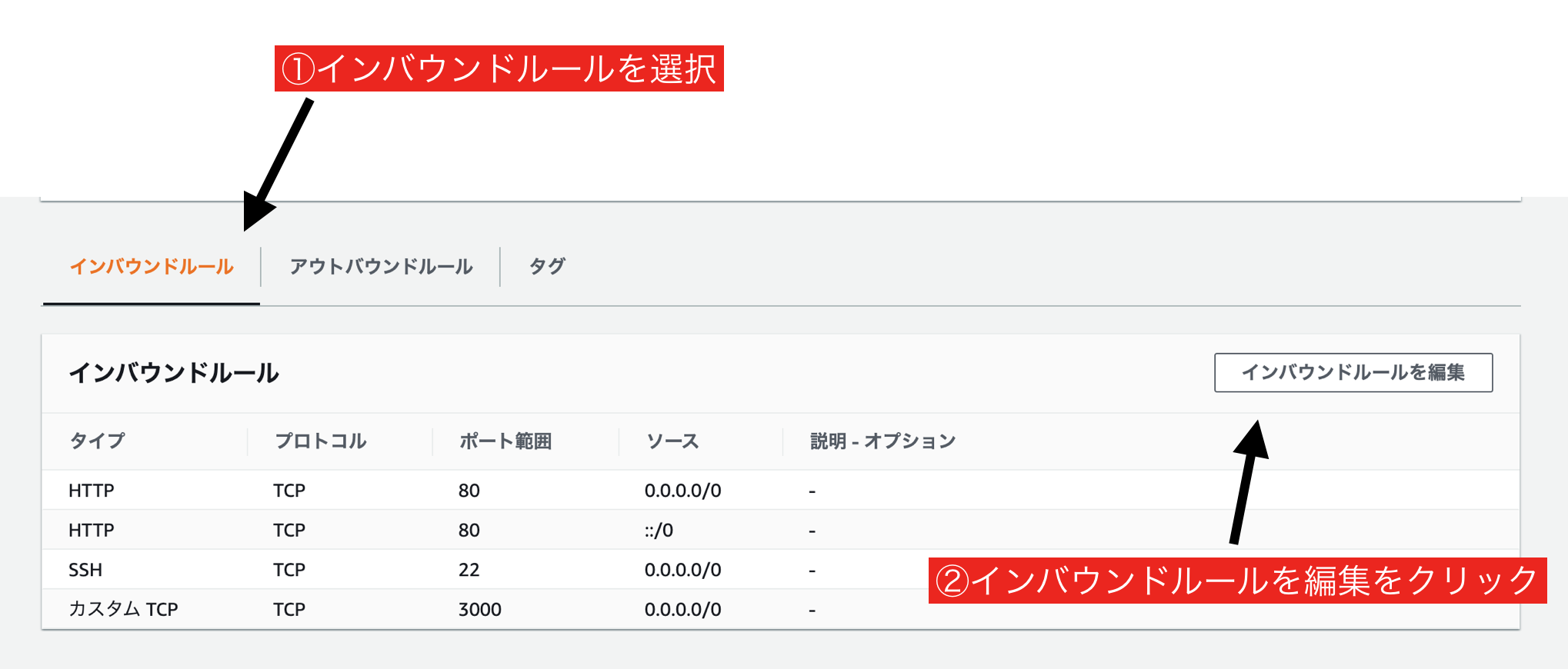
下の「インバウンドルール」から「インバウンドルールを編集」をクリック。
「タイプ」は「HTTP」、「ソース」は先ほど作成したALBのグループ名を選択。
「ルールを保存」をクリック。
これで、独自ドメインかつHTTPS化されたサイトにアクセスすることができます。
例で言うとhttps://www.example.comにアクセスするとDockerで作ったLaravelのサイトが開くようになります。
いかがだったでしょうか??
少し説明不足のところもあると思うので、何かご不明な点があれば遠慮せずにコメント欄にてお申し付けください。
以上、「【AWS】ECSで作ったDocker(Laravel)プロジェクトをRoute53、ALB、ACM、お名前ドットコムを使ってHTTPS化してみた」でした!
良ければ、LGTM、コメントお願いします。
また、何か間違っていることがあればご指摘頂けると幸いです。
他にも初心者さん向けに記事を投稿しているので、時間があれば他の記事も見て下さい!!
あと、最近「ココナラ」で環境構築のお手伝いをするサービスを始めました。
気になる方はぜひ一度ご相談ください!
Thank you for reading


- 投稿日:2021-02-25T14:52:41+09:00
PHPでAWS S3からディレクトリ単位でダウンロード
前提条件
AWS SDK for PHP 3.x を利用
やってみた感想
CommandPool利用のために配列を作成する必要がなく
コードもシンプルになるのでよいAWS S3 バケットを再帰的にダウンロード
同期転送
sample.php<?php use Aws\S3\S3Client; use Aws\S3\Transfer; $client = new S3Client([ 'region' => '****', 'version' => 'latest', ]); // from $source = 's3://bucket/foo'; // to ローカルディレクトリのパス $dest = '/path/to/destination/dir'; $manager = new Transfer( $client, $source, $dest, ); $manager->transfer();非同期転送
sample.php<?php use Aws\S3\S3Client; use Aws\S3\Transfer; $client = new S3Client([ 'region' => '****', 'version' => 'latest', ]); // from $source = 's3://bucket/foo'; // to ローカルディレクトリのパス $dest = '/path/to/destination/dir'; $manager = new Transfer( $client, $source, $dest, ); $promise = $manager->promise(); $promise ->then(function () { echo 'Done!'; }) ->otherwise(function ($reason) { echo 'Transfer failed'; });参考
- 投稿日:2021-02-25T14:48:37+09:00
Github Actions を使って AWS の S3 へデプロイする
Github Actions を使って AWS の S3 へデプロイするための環境設定手順を記載します
S3 バケットの作成
アップロードする先の S3 バケットを作成しておきましょう
AWS IAM の作成
S3 へアクセス可能な IAM ユーザーを作成します
- AWS IAM へ遷移する
- アクセス管理のユーザーへ遷移する
- ユーザーを追加ボタンを押下する
- ユーザー名に適当な名前「github」などを入力し、「プログラムによるアクセス」にチェックを付けて次のステップボタンを押下する
- アクセス許可の設定へ遷移するので、「既存のポリシーを直接アタッチ」を選択して「AmazonS3FullAccess」にチェックを付けて次のステップボタンを押下する
- タグの追加画面に遷移するので、次のステップボタンを押下する
- ユーザーの作成確認画面に遷移するので、ユーザーの作成ボタンを押下する
- ユーザーが作成されたら、「アクセスキー ID」「シークレットアクセスキー」をメモするか、.csvのダウンロードをしておく
Github リポジトリの Secrets へ AWS 接続情報を登録
Github リポジトリの Secrets へ AWS 接続情報を登録します
- S3 へアップロードする Github リポジトリの Settings を選択する
- Secrets メニューへ遷移する
- Actions secrets で、New repository secret ボタンを押下する
- 以下の内容で各追加する
Name Value AWS_ACCESS_KEY_ID (作成したIAMユーザーのアクセスキーID) AWS_SECRET_ACCESS_KEY (作成したIAMユーザーのシークレットアクセスキー) S3_BUCKET (アップロードする先の S3 バケット名) Github Actions 用のワークフローを定義
- Github で Actions へ遷移し、「set up a workflow yourself」のリンクをクリックする
- Edit new file に以下の内容を記載して、Start commit ボタンを押下し、コミットテキスト「Github Actions の設定を追加」などを入力して Commit new file ボタンを押下する
name: Amazon S3 Upload on: push: branches: - master jobs: build: runs-on: ubuntu-latest steps: - name: Checkout uses: actions/checkout@v2 - name: Configure AWS credentials uses: aws-actions/configure-aws-credentials@v1 with: aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }} aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }} aws-region: ap-northeast-1 - name: Upload to S3 env: S3_UPLOAD_BUCKET: ${{ secrets.S3_BUCKET }} run: | aws s3 sync . s3://$S3_UPLOAD_BUCKET/ --delete --exclude "README.md" --exclude ".git/*" --exclude ".github/*" --exclude ".gitignore"これで master ブランチへファイルをPUSHするごとに、S3 へファイルがアプロードされます
ワークフローの状態は、Github リポジトリの Actions へ遷移してみてください
プルリクエストマージ時にしたい場合や、S3 アップ後に CloudFront のキャッシュを削除したいなど、場合によってワークフローの定義を編集してください
- 投稿日:2021-02-25T13:27:45+09:00
AWS CodeCommit の使いづらい点
背景
AWSのサービスということもあり、コードレビューの自動化やCI/CD等AWSの他のサービスと組み合わせたアーキテクトが便利というCodeCommit。
これまでリポジトリ管理にGitBucketやGitHubを使ってきましたが、CodeCommitを始めて使いずらいと感じた点を少ないですがまとめました。使いづらい点
遅い
どの操作をするにも体感遅いです。これは時と場合によるかも。
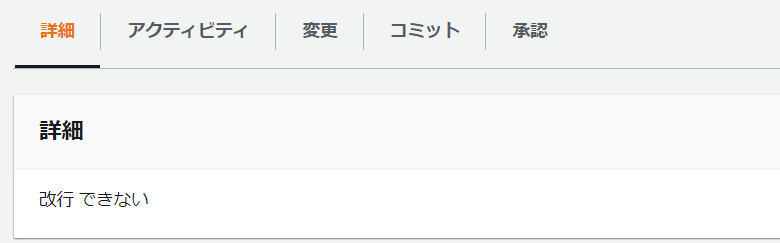
プルリクのコメントが改行されない
全て1行で表示されてしまい見にくいです。
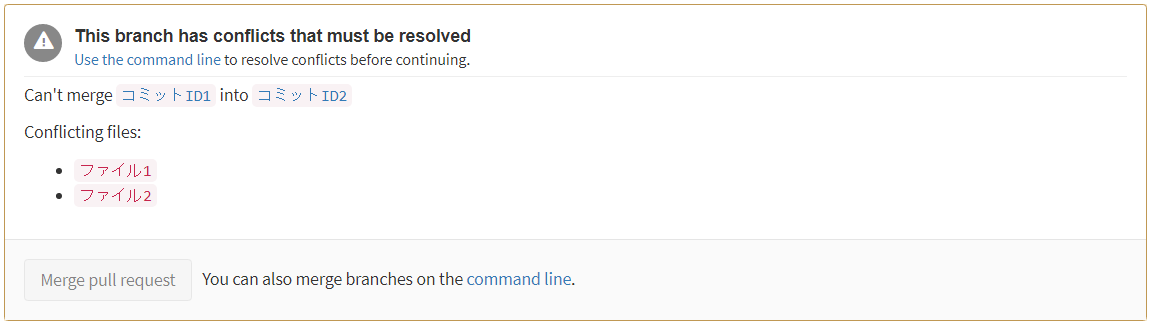
差分を表示できない
エラー『違いを表示できません。個別のファイルが大きすぎて表示できないか、ファイル間の全体的な違いが複雑すぎます。』と表示される場合がある。これは致命的です。ソース管理を奇麗にしろとも取れますが、基準が曖昧ですし不親切に感じます。
追記:ファイルの行数を3250行以下にしないと当該エラーが発生する。開発チームに連携した上で対応有無・時期未定とAWS公式回答。
cf. AWS CodeCommit のクォータ
cf. 公式フォーラムで未解決らしい
プルリクエストに対して、マージ先の最新のソースを取り込む機能がない
GitBucketにあったこんな機能です。これがないとレビューの度に最新のソースを取り込んでからPUSHし直してもらう必要があったりします。
因みにGitBucketの場合に、同じ個所に表示される競合(コンフリ)が発生した際のUIも分かりやすくて好きです。
別のリポジトリ管理を使う
完全プライベートリポジトリに絞ると、GitLab?(CodeGuruには対応していない)とかでしょうか。これいいよというのがあればご教授頂きたいです。


- 投稿日:2021-02-25T12:08:46+09:00
RailsアプリをAWSで自動デプロイ【ステップ2 DBの構築】
はじめに
最近Rilsのアプリケーションをデプロイする機会がありましたので、その方法を忘れない内に書き込みます。
何記事に分けて説明してます。
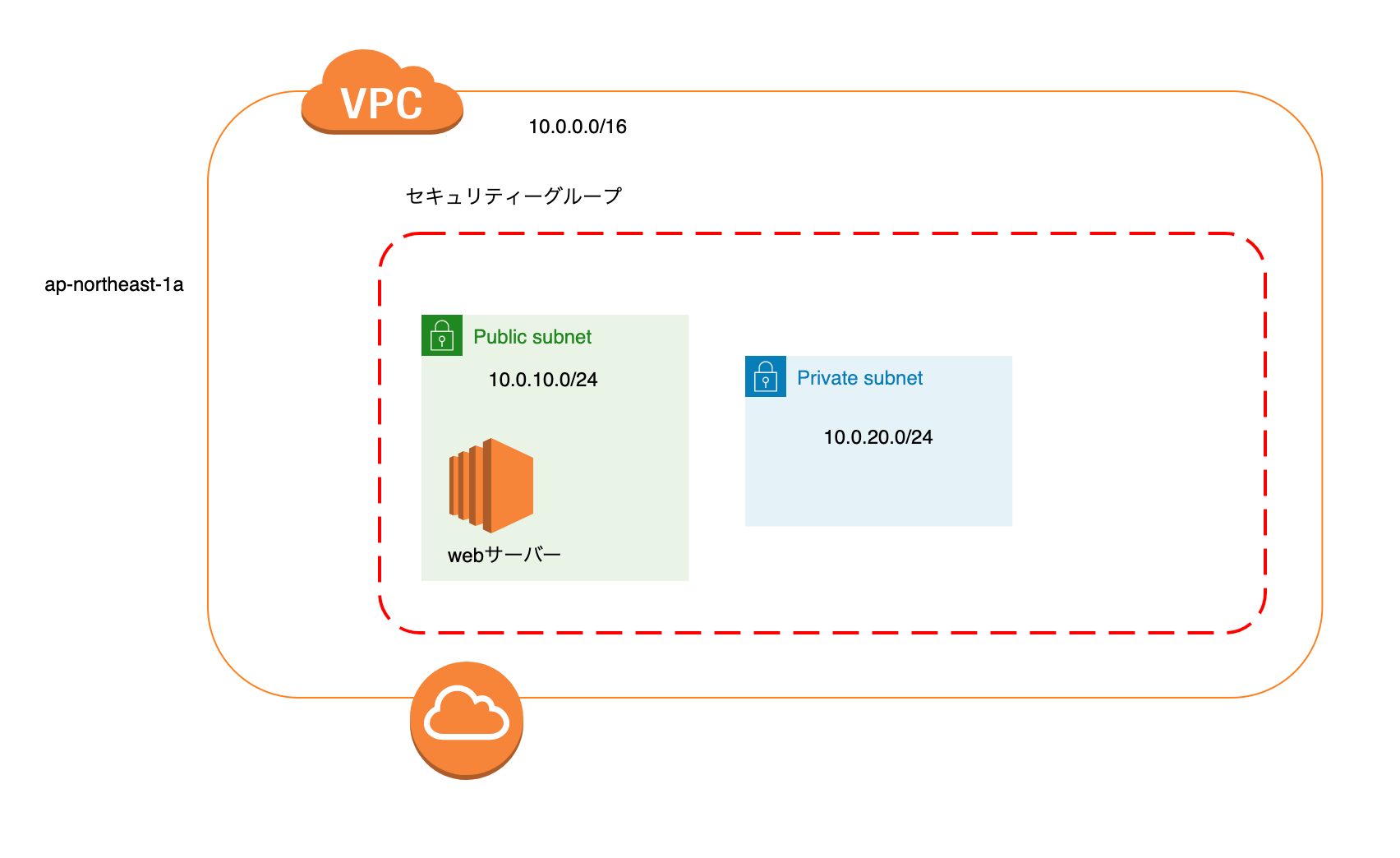
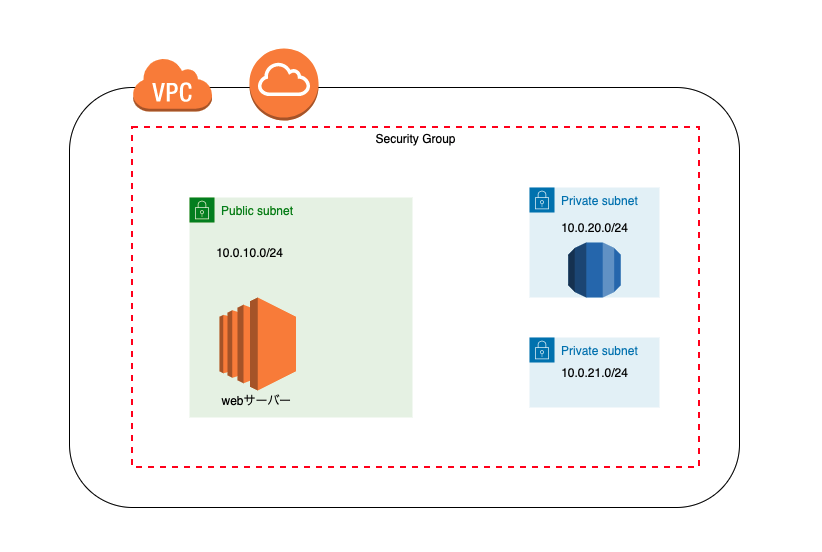
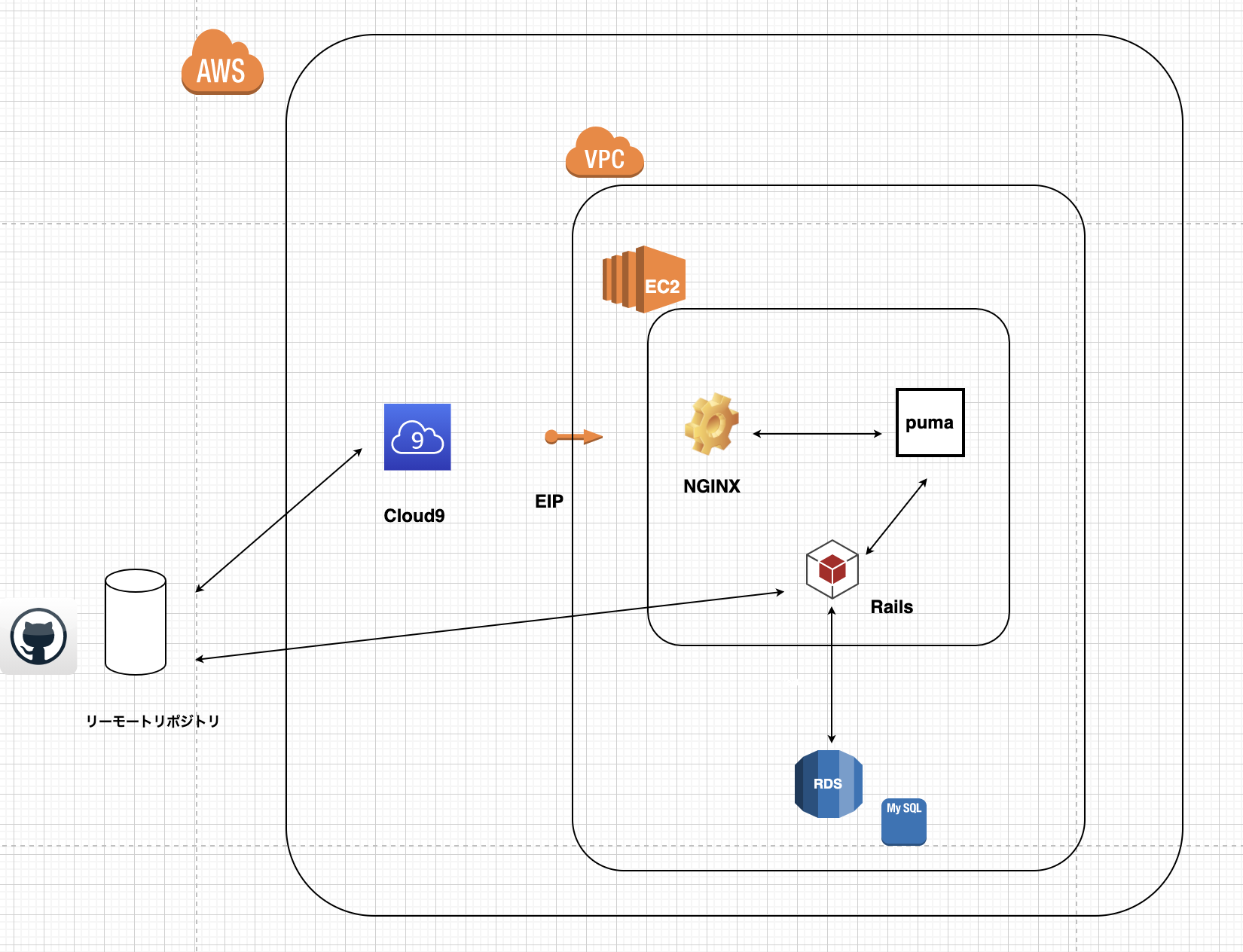
この記事では、RDSの構築まで解説します。現在のAWSの構成
RDSの構築
RDSとは、AWSのフルマネージドなリレーショナルデータベースのサービスです。
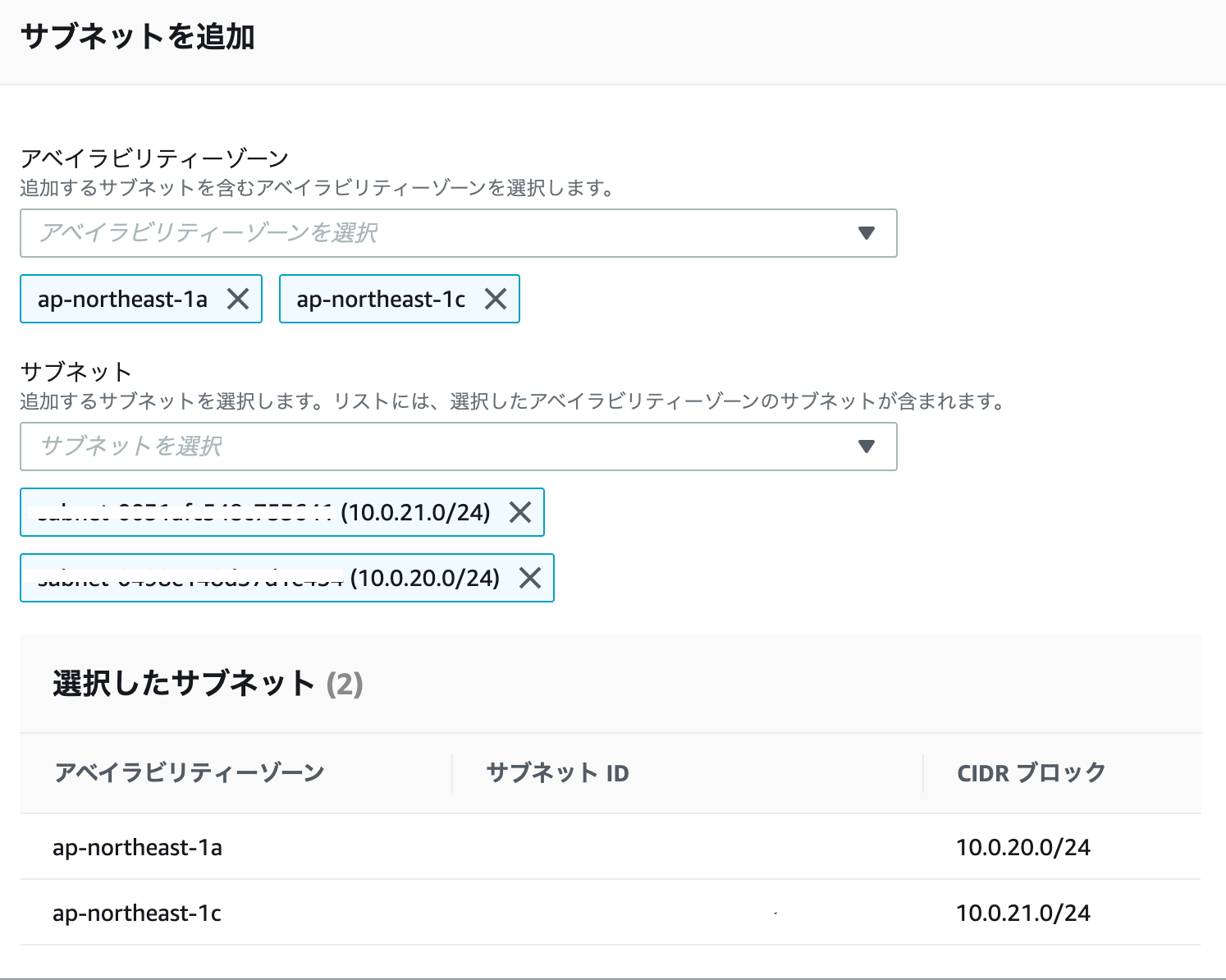
プライベートサブネットの作成
VPC:ステップ1で作成したVPCを指定します。 サブネット名:sample-privatesubnet-c アベイラビリティーゾーン:アジアパシフィック (東京) / ap-northeast-1c IPv4 CIDR ブロック:10.0.21.0/24セキュリティーグループ作成
セキュリティグループ名:sample-infra-db 説明:sample-infra-db VPC:ステップ1で作成したVPCを指定します。インバウンドルール
タイプ プロトコル ポート範囲 ソース 説明 MYSQL/Aurora TCP 3306 ステップ1で作成したセキュリティーグループを指定 DBサブネットグループの作成
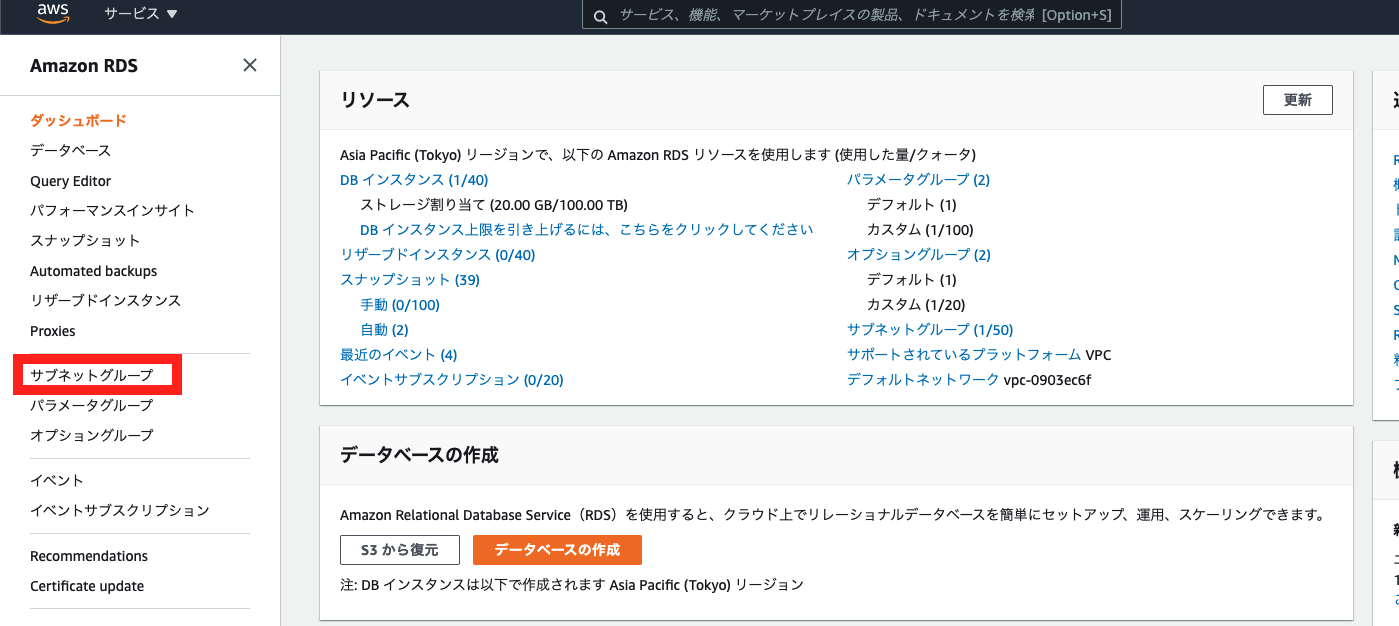
以下のリンクに移動します。
https://console.aws.amazon.com/rds/
名前:sample-infra-subnet-group 説明:sample-infra-subnet-group VPC:ステップ1で作成したVPCを指定します。ステップ1、2で作成したプライベートサブネットの追加を行います。
DBパラメーターグループの作成
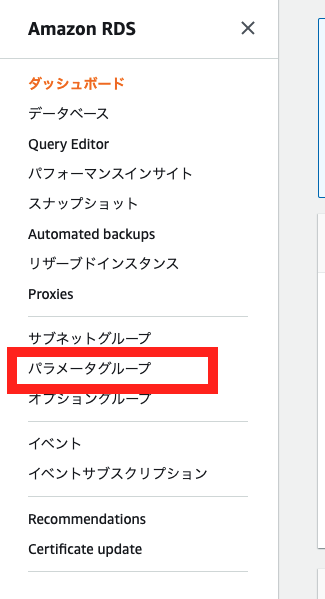
DBパラメーターグループとは、DBのパラメーターの設定をテンプレートとして登録できるサービス
パラメータグループファミリー:mysql8.0 グループ名:aws-infra-mysql80 説明:aws-infra-mysql80DBオプショングループの作成
オプショングループとは、DBの機能的部分を設定できるサービス
名前:aws-infra-mysql80 説明:aws-infra-mysql80 エンジン:mysql メジャーエンジンバージョン:8.0RDSの作成
エンジンのオプション
エンジンのタイプ:MySQL バージョン:MySQL8.0.21テンプレート
開発テスト #今回はテスト用で作成するので、開発テスト用を選択しました。設定
DB インスタンス識別子:sample-infra-web 認証情報の設定: マスターユーザー名:root パスワードの自動生成:✅DB インスタンスサイズ
DB インスタンスクラス:バースト可能クラス db.t3.microストレージ
ストレージタイプ:汎用SSD ストレージ割り当て:20 ストレージの自動スケーリング:無効可用性と耐久性
マルチ AZ 配置:スタンバイインスタンスを作成しない接続
Virtual Private Cloud (VPC):VPCを指定 サブネットグループ:ステップ2で作成したものを指定 パブリックアクセス可能:なし VPC セキュリティグループ:既存の選択 既存の VPC セキュリティグループ:ステップ2で作成したセキュリテーグループを指定 アベイラビリティーゾーン:ap-northeast-1a 追加の接続設定: データベースポート:3306追加設定
最初のデータベース名: DB パラメータグループ:aws-infra-mysql80 オプショングループ情報:aws-infra-mysql80 自動バックアップの有効化:✅ バックアップ保持期間:30日 バックアップウィンドウ:選択ウィンドウ 開始時間:21:00 #日本時間の午前6時に開始 期間:0.5 スナップショットにタグをコピー:✅ 暗号を有効化:✅ マイナーバージョン自動アップグレード:✅ メンテナンスウィンドウ:選択ウィンドウ 開始日:日曜日 開始時間:20:00 期間:0.5 削除保護:✅ここまで設定が完了しましたら、作成を行います!
最後に
本記事では、RDSの構築までを解説しました。
次回は、アプリをデプロイするところまで解説しようと思います。




- 投稿日:2021-02-25T11:04:26+09:00
【 Ruby on Rails 6.0 】AWS + Nginx + Unicornでデプロイ⑤
始めに
前回まででEC2上に必要なGemをインストールし本番環境用に環境変数を設定しました。今回はHTTP通信を設定しRailsアプリを起動する工程までをまとめたいと思います。
目次
目次 内容 セクション1 EC2インスタンス作成 セクション2 Linuxサーバー構築 セクション3 データベース設定 セクション4 EC2上でGemをインストールし環境変数を設定 セクション5 Railsアプリを起動(今回の内容) セクション6 Nginxの導入 ポート開放
立ち上げたばかりのEC2インスタンスはSSHでアクセスすることはできますが、HTTPなどの他の通信方法では一切つながらないようになっています。そのため、WEBサーバとして利用するEC2インスタンスは事前にHTTPがつながるように「ポート」を開放する必要があります。
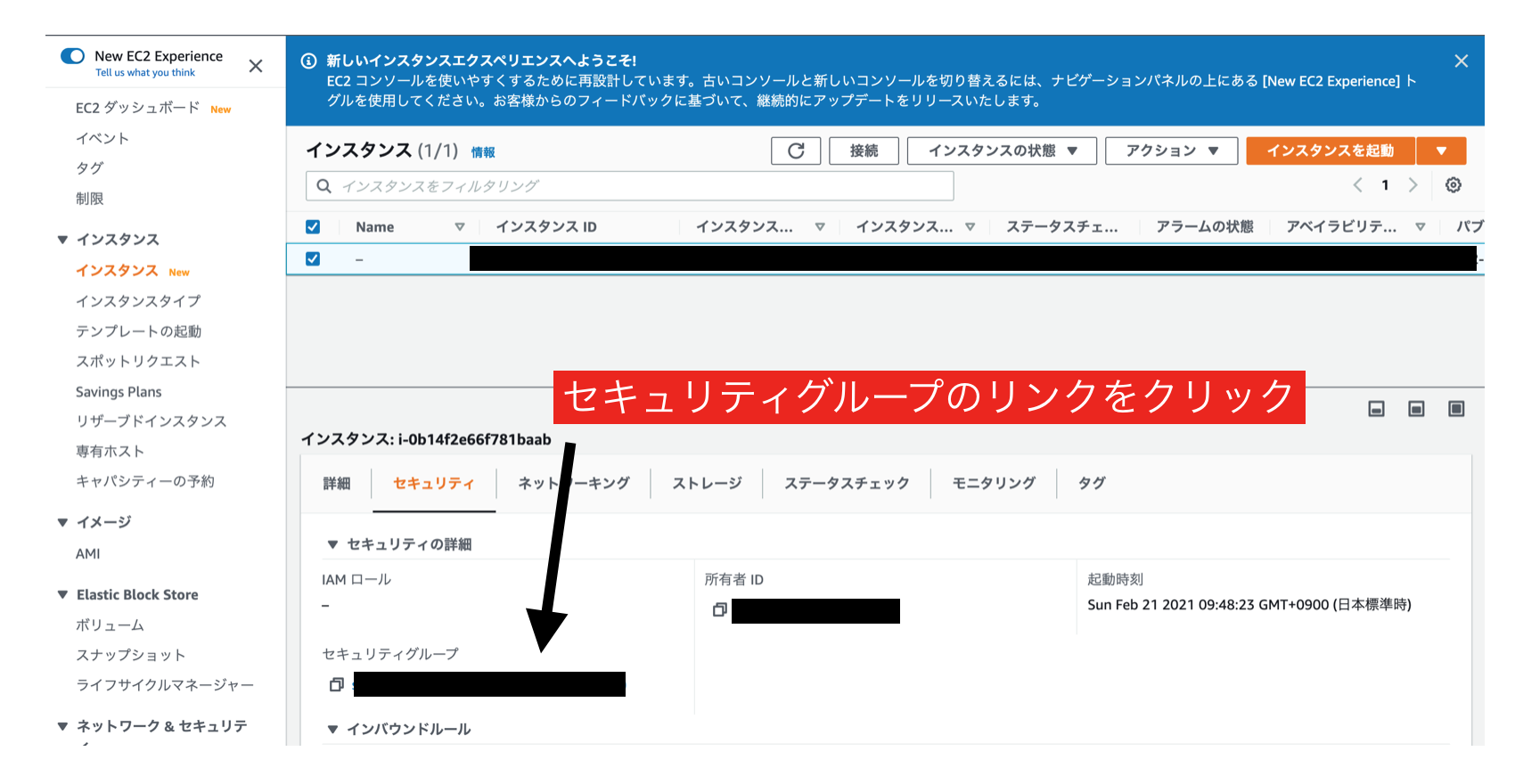
セキュリティグループのポートを設定
AWSのEC2インスタンス一覧画面から、対象のインスタンスを選択し、「セキュリティグ
ループ」のリンクをクリックします。
すると、インスタンスの属するセキュリティグループの設定画面に移動するので、「イン バウンド」タブの中の「編集」をクリックします。
モーダルが開くので、「ルールの追加」をクリックします。
タイプ カスタムTCPルール」 プロトコル TCP ポート範囲 3000 送信元 カスタム、0.0.0.0/0 「0.0.0.0」は「全てのアクセスを許可する」という意味です。
以上で、ポートの開放が完了です。
database.ymlの本番環境の設定を編集
本番環境のmysqlの設定に合わせるため、ローカルのdatabase.ymlを以下のように編集して下さい。
config/database.ymlproduction: <<: *default database: (ここは編集しないこと) username: root password: <%= ENV['DATABASE_PASSWORD'] socket: /var/lib/mysql/mysql.sockローカルでの編集をコミットして、GitHubにプッシュ
リモートリポジトリが更新されたため、サーバ上のアプリケーションにも反映させましょう。今回はすでにEC2とGithubは接続できているため、
git pullコマンドを利用します。
※別にブランチを切っている場合は、masterブランチにmergeしてから以下のコマンドを 実行しましょう。ターミナル(EC2)[ec2-user@ip-172-31-23-189 <app名>]$ git pull origin masterデータベースを作成しマイグレーションを実行
ターミナル(EC2)[ec2-user@ip-172-31-23-189 <app名>]$ rails db:create RAILS_ENV=production [ec2-user@ip-172-31-23-189 <app名>]$ rails db:migrate RAILS_ENV=productionもしここで
Mysql2::Error: Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock'というエラーが起こった場合、データベース が起動していない可能性があります。sudo systemctl start mariadbというコマン ドをターミナルから打ち込み、mysqlの起動を試してみましょう。アセットファイルをコンパイル
続いて、アセットファイルをコンパイルします。
アセットファイルとは、画像・CSS・ JavaScript等を管理しているファイルです。
コンパイルとはアセットファイルを圧縮し、 そのデータを転送するということです。
この作業を行わないと、本番環境でCSSが反映されずにビューが崩れてしまったり、エラーでブラウザが表示されない、などの問題が生じてしまいます。ターミナル(EC2)[ec2-user@ip-172-31-23-189 <アプリ名>]$ rails assets:precompile RAILS_ENV=production # 成功すると Yarn executable was not detected in the system. Download Yarn at https://yarnpkg.com/en/docs/install I, [2020-01-18T12:51:01.4345644 #1265] INFO -- : Writing /var/app/web-share/public/assets/member_photo_noimage_thumb-224a733c50d48aba6d9fdaded809788bbeb5ea5f6d6b8368adaebb95e58bcf53.png I, [2020-01-18T12:51:02.2615123#1265] INFO -- : Writing /var/app/appname/public/assets/application-bc071e28a78e2b63c9313afed5ad3476e00e3f0e5b12445c37214d1f1317be48.js I, [2020-01-18T12:51:02.2626434 #1265] INFO -- : Writing /var/app/appname/public/assets/application-bc071e28a78e2b63c9313afed5ad3476e00e3f0e5b12445c37214d1f1317be48.js.gz I, [2020-01-18T12:51:08.484546 #1265] INFO -- : Writing /var/app/appname/public/assets/application-8549fb9a804686e593d5c0f90a2412a39de85908e5fb58fdf6681d4b0073d891.css I, [2020-01-18T12:51:08.485454 #1265] INFO -- : Writing /var/app/appname/public/assets/application-8549fb9a804686e593d5c0f90a2412a39de85908e5fb58fdf6681d4b0073d891.css.gzここでyarnのエラーが発生したらnode.jsをupdateします。
Node.jsのアップデート
Node.jsのバージョン管理ツールnvmを使用してインストールします。
ターミナル(EC2)# 現在のバージョン確認 [ec2-user@ip-172-31-23-189 <アプリ名>]$ node -v v4.9.1 # Node.jsのバージョン管理ツールnvmをclone [ec2-user@ip-172-31-23-189 <アプリ名>]$ git clone git://github.com/creationix/nvm.git ~/.nvm [ec2-user@ip-172-31-23-189 <アプリ名>]$ echo . ~/.nvm/nvm.sh >> ~/.bashrc [ec2-user@ip-172-31-23-189 <アプリ名>]$ . ~/.bashrc # nvmバージョン確認 [ec2-user@ip-172-31-23-189 <アプリ名>]$ nvm --version 0.35.0 # インストールできるNode.jsの確認 [ec2-user@ip-172-31-23-189 <アプリ名>]$ nvm ls-remote # 最新の安定版をインストール [ec2-user@ip-172-31-23-189 <アプリ名>]$ nvm install stable # バージョン確認 [ec2-user@ip-172-31-23-189 <アプリ名>]$ node -v v12.12.0 # バージョンが最新になっていたら成功もう一度コンパイルを実行してみましょう。
Unicornのプロセスを確認
コンパイルが成功したら反映を確認するため、Railsを再起動します。しかし、まずは今動 いているUnicornをストップします。そのために、Unicornのプロセスを確認し、プロセスを止めます。ターミナルからプロセスを確認するには
psコマンドを利用します。ターミナル# unicorn起動 [ec2-user@ip-172-31-38-126 <リポジトリ名>]$ bundle exec unicorn_rails -c config/unicorn.rb -E production -D [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ps aux | grep unicorn ec2-user 17877 0.4 18.1 588472 182840 ? Sl 01:55 0:02 unicorn_rails master -c config/unicorn.rb -E production -D ec2-user 17881 0.0 17.3 589088 175164 ? Sl 01:55 0:00 unicorn_rails worker[0] -c config/unicorn.rb -E production -D ec2-user 17911 0.0 0.2 110532 2180 pts/0 S+ 02:05 0:00 grep --color=auto unicorn大事なのは左から2番目の列です。ここに表示されるのがプロセスのid、つまりPIDになります。
「unicorn_rails master」と表示されているプロセスがUnicornのプロセス本体です。この時のPIDは、17877となっています。killコマンドを入力してUnicornのプロセスを停止
ターミナル[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ kill <確認したunicorn rails masterのPID> # 再度確認する [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ps aux | grep unicorn ... ec2-user 17911 0.0 0.2 110532 2180 pts/0 S+ 02:05 0:00 grep --color=auto unicorn # できない場合は強制終了する [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ kill -9 [プロセスID]先頭にRAILS_SERVE_STATIC_FILES=1をつけて、unicornを起動
続いて再びunicornを起動しましょう。このときRAILS_SERVE_STATIC_FILES=1という指定を先頭に追加してください。これは、コンパイルされたアセットをRailsが見つけられるような指定になります。以下のようにコマンドを実行してください。
ターミナル[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -Dブラウザで確認
ブラウザで http://:3000/ にアクセスして、サイトが正常に表示されているか確認してみましょう。
Railsの起動がうまくできなかった時
上記のコマンドを実行してもRailsが起動しないときや、起動できてもIPアドレス:3000に
アクセスするとエラーが表示されていることがあります。以下の項目をチェックしてみてください。
- pushのし忘れ、またはEC2サーバ側でのpullのし忘れは無いか
- ローカルでの編集のpushやEC2でのgit pullを忘れていないか
- データベースの起動は正しく行えているか
- EC2サーバ側のSECRET_KEY_BASE等は正しく設定できているか
- EC2インスタンスの再起動を行ってみる
unicornのログを確認する
上記のポイントでも解決出来ない場合はunicornのログを確認してみましょう。
lessコマンドまたはcatコマンドを使えばログを見ることが出来ます。ターミナル(EC2)[ec2-user@ip-172-31-23-189 <app名>]$ less log/unicorn.stderr.log # 実行結果 I, [2021-02-21T02:28:26.245480 #7257] INFO -- : Refreshing Gem list I, [2021-02-21T02:28:28.232692 #7257] INFO -- : listening on addr=0.0.0.0:3000 fd=9 E, [2021-02-21T02:28:28.245079 #7257] ERROR -- : Unknown database 'app_production' (ActiveRecord::NoDatabaseError)ログはEnterキーを押せば下にスクロールすることが出来ます。(下にいくほど最新のログです。)
上の例ではUnknown databaseとなっているためrails db:createをし忘れている可能生があります。
もしくはdatabase.ymlの設定に誤りがあるかもしれません。
このようにログを頼りに原因を特定していきます。終わりに
今回の内容までで、Elastic IPアドレスを入力してブラウザ上でアプリが起動していることを確認出来ました。
次回はユーザーのリクエストに対してレスポンスを送れるようにWebサーバーを導入していきます。次回
Nginxの導入
- 投稿日:2021-02-25T10:51:42+09:00
EC2 サーバー構築(基本設定)
EC2 サーバー構築
概要
EC2インスタンスを初期に立ち上げた際にすることをまとめてみました。
過不足あれば今後編集していきたいと思います。環境
- Amazon Linux2
システム設定
yumのパッケージ更新
sudo yum -y updateタイムゾーン・ロケール設定
タイムゾーン確認
timedatectl statusタイムゾーンを日本時間に設定
sudo timedatectl set-timezone Asia/Tokyoロケール確認
localectl statusロケール変更
sudo localectl set-locale LANG=ja_JP.UTF-8ニックネーム設定
ホスト名に影響を与えずにシェルプロンプトを変更する
参考1. 環境変数定義
$ sudo sh -c 'echo "export NICKNAME={ニックネーム}" > /etc/profile.d/prompt.sh'例$ sudo sh -c 'echo "export NICKNAME=app01" > /etc/profile.d/prompt.sh'2. シェルプロンプトの設定編集
$ sudo vi /etc/bashrc\h (hostname を表す記号) を NICKNAME 変数の値に変更
/etc/bashrc[ "$PS1" = "\\s-\\v\\\$ " ] && PS1="[\u@\h \W]\\$ " ↓ [ "$PS1" = "\\s-\\v\\\$ " ] && PS1="[\u@\$NICKNAME \W]\\$ "3. シェルウィンドウのタイトルを新しいニックネームに設定
# ファイル作成 sudo touch /etc/sysconfig/bash-prompt-xterm # 実行権限付与 $ sudo chmod +x /etc/sysconfig/bash-prompt-xterm # ファイル編集 $ sudo vi /etc/sysconfig/bash-prompt-xterm/etc/sysconfig/bash-prompt-xtermecho -ne "\033]0;${USER}@${NICKNAME}:${PWD/#$HOME/~}\007"
- 投稿日:2021-02-25T09:45:57+09:00
AWSにデプロイ後、よく使うコマンド
EC2にSSHで接続し、git pullしてからよく使うコマンドまとめました。
- 使用頻度が多いものを自分用に簡単にまとめました。
環境
rails 5.2.4
ruby 2.6.3
Cloud9
MySQLAWSの構成
EC2にSSHで接続する方法 $ ssh -i ~/.ssh/キー名.pem ec2-user@xx.xx.xx.xx Nginxの再起動する方法 $ sudo systemctl restart nginx アプリ(puma)起動する方法 $ rails s -e production アプリ(puma)停止する方法 $ kill プロセスID どちらも同じです $ kill $(cat tmp/pids/puma.pid)本番環境でbundle installする時のコマンド $ bundle install --path vendor/bundle --without test development CSS・JS変更時に使うコマンド $ bundle exec rails assets:precompile RAILS_ENV=production 本番環境でrails db:migrateする時のコマンド $ bundle exec rails db:migrate RAILS_ENV=productionseeds.rb編集した場合は、本番環境のデータベースを削除してからやり直す方がいいです。
本番環境のデータはなくなるので使う際はご自身で判断してください。$ RAILS_ENV=production DISABLE_DATABASE_ENVIRONMENT_CHECK=1 bundle exec rails db:drop $ mysql -u root -p -h エンドポイント mysql> CREATE DATABASE 作成したいデータベース名; $ bundle exec rails db:migrate RAILS_ENV=production $ bundle exec rails db:seed RAILS_ENV=productionnginxエラーログ確認するコマンド $ sudo tail -f /var/log/nginx/error.log railsのエラーログ確認するコマンド $ sudo tail -f log/production.log全体の把握に時間がかかりたくさんのエラーを経験し心が折れそうになりました。
何度もEC2作り直ししましたのでAWSの知識もより深まりました。
今回は、S3を使っていないため今度はS3を使って構成することを考えてます?
- 投稿日:2021-02-25T09:01:10+09:00
Fargate とは?
勉強前イメージ
ECSと関連してる感じはするけど、
ECSの中の機能の一つ・・とかかな?調査
Fargate とは?
Amazon ECSとAmazon EKSでコンテナを実行する際の起動タイプの1つになります。
Amazon ECSについての詳細は こちら
ECSの概要はDockerコンテナを簡単に実行・停止出来る管理サービスになります。
そのDockerコンテナの起動タイプには以下2つがあり、そのうちの1つになります。
- EC2インスタンス
- Fargate
以下はECSでクラスタを作成する際の画面です。
Fargate のメリット
- デプロイ時にインスタンス選定の必要がない
コンテナ実行時にCPU・メモリの組み合わせを選択するだけで構築・運用に集中することが出来ます。
サーバの管理が不要になり、本来の作業に集中出来ます。
- キャパシティコントロールについて
コンテナの起動・スケーリングについては
Auto Scallingで調整されます。勉強後イメージ
EC2かFargateか・・・ってことか。
Fargateの方が楽なのは楽そうだね。参考

- 投稿日:2021-02-25T07:46:23+09:00
OpenCVをAWS Lambda + Python + Serverless Frameworkで動かす
OpenCVをAWS Lambda + Python + Serverless Frameworkで動かしてみました。
先日、PillowをLambdaで動かす記事を書きましたが、このときと違って、OpenCVはyumでインストールの必要なshared objectに依存しているのでだいぶ面倒でした。
手順概要
- serverless-python-requirements インストール
- Pythonサンプルコードを記述
- requirements.txt と serverless.yml と Dockerfile にOpenCV動作に必要な事項を記述
- あとはデプロイ
OpenCV特有は3のみです。
手順詳細
serverless-python-requirements インストール
AWS Lambda + Python + Serverless FrameworkにPythonのパッケージをインストールする方法は以前の記事に書きました。
これに従って、まずは
serverless createして、serverless-python-requirementsプラグインをインストールします。$ serverless create --template aws-python3 $ serverless plugin install -n serverless-python-requirementsServerlessFrameworkのバージョンはv2.18.0でした。
Pythonソースコード
handler.pyの内容です。OpenCVを参照できることを確認できる最小限です。import cv2 def hello(event, context): print("Hellow, OpenCV!") print(cv2.__version__)requirements.txt
OpenCVのパッケージ名を記述します。この1行のみです。
opencv-pythonserverless.yml
serverless.ymlの記載がもっとも面倒でした。成功例を書きます。service: sample frameworkVersion: '2' provider: name: aws runtime: python3.8 lambdaHashingVersion: 20201221 region: ap-northeast-1 functions: hello: handler: handler.hello events: - httpApi: "*" plugins: - serverless-python-requirements custom: pythonRequirements: dockerizePip: true dockerFile: Dockerfile dockerExtraFiles: - /usr/lib64/libGL.so.1 - /usr/lib64/libgthread-2.0.so.0 - /usr/lib64/libglib-2.0.so.0 - /usr/lib64/libGLX.so.0 - /usr/lib64/libX11.so.6 - /usr/lib64/libXext.so.6 - /usr/lib64/libGLdispatch.so.0 - /usr/lib64/libxcb.so.1 - /usr/lib64/libXau.so.6Dockerfile
Dockerfileを作成します。serverless.ymlからファイル名で参照しています。FROM lambci/lambda:build-python3.8 RUN yum install -y mesa-libGLデプロイと実行
デプロイ。
$ serverless deploy -vデプロイされたLambdaを実行するとCloudWatch Logsに以下が出力されました。
Hellow, OpenCV! 4.5.1serverless.yml を書くまでの道のり
最初は以下だけで動かそうとしました。
service: sample frameworkVersion: '2' provider: name: aws runtime: python3.8 lambdaHashingVersion: 20201221 region: ap-northeast-1 functions: hello: handler: handler.hello plugins: - serverless-python-requirementsこれでデプロイしてLambdaを実行すると、CloudWatch Logsに以下のエラーが吐かれました。
[ERROR] Runtime.ImportModuleError: Unable to import module 'handler': libGL.so.1: cannot open shared object file: No such file or directory
libGL.so.1というファイルが不足しているので、これを追加すればよいのですが、これは環境に依存していそうなので、手元にある同じファイル名をコピーしただけではたぶん動きません。Lambdaの動くAmazon Linux環境でこのファイルを用意する必要があります。これをするために
serverless.ymlにdockerの記述をします。以下の記述です。custom: pythonRequirements: dockerizePip: true dockerFile: Dockerfile dockerExtraFiles: - ...
Dockerfileも用意します。FROM lambci/lambda:build-python3.8 RUN yum install -y mesa-libGL # OpenCVに必要なパッケージをインストールこれを書くだけでserverlessがデプロイ時にDockerを起動して、Lambdaの動くAmazon Linux環境を再現し、その中でyumインストールしてくれます。
serverless.ymlのdockerExtraFilesに記載したファイルを、yumインストール後に抜き出して、Lambdaデプロイイメージに同梱してくれます。
dockerExtraFilesに書いたリストは、デプロイして実行時のエラーメッセージから1つずつ書き足して、成功するまで繰り返しました。エラーメッセージにはsoファイル名しか表示されませんので、以下のコマンドでLambdaの動くAmazon Linux環境の中に入ってみて、
yum install -y mesa-libGLしてから、soファイルのありかを探しました。$ docker run -it --rm lambci/lambda:build-python3.8 bashAmazon Linux上では
/usr/lib64/libGL.so.1は/usr/lib64/libGL.so.1.7.0へというように、すべてシンボリックリンクになっていますが、serverless.ymlには実態ではなくシンボリックリンクだけ記述すれば動きました。注意事項
ここに書いているsoファイルのリストはサンプルPythonコードを動かすために最小限のものです。エラーメッセージを見て、足りないsoファイルを追加するというのを繰り返しましたのみです。従ってOpenCVのすべての動作がこれだけで足りてるかどうかはわかりません。
ハマりどころ1
.serverless/requirements/の中にLambdaのイメージが展開されるのですが、Dockerで構築されるためか、soファイルがroot権限になり、試行錯誤の過程で serverless.yml の変更が権限不足で反映できないというトラブルがありました。原因がわかればroot権限でそのディレクトリを削除することで解決しましたが、それに気が付くまで時間をだいぶ消耗しました。ハマりどころ2
serverlessが内部でDockerを利用するため、serverless自体をDockerの中で動かしたらデプロイ時にDockerでエラーになりました。Dockerのvolumeも使っていたので、Dockerのsocket共有でもうまくいかず、あきらめました。
ハマりどころ3
最初はLambdaのLayerにOpenCVを入れたかったのですが、
LD_LIBRARY_PATHがLayerには通っていないため、OpenCVを動作させることはできませんでした。
- 投稿日:2021-02-25T05:01:43+09:00
【 Ruby on Rails 6.0 】AWS + Nginx + Unicornでデプロイ④
始めに
前回の記事ではEC2インスタンスにmariaDBというデータベースの設定を行いました。今回はインスタンス上でRailsアプリの起動に必要なGemをインストールし環境変数を設定する工程までをまとめたいと思います。
目次
目次 内容 セクション1 EC2インスタンス作成 セクション2 Linuxサーバー構築 セクション3 データベース設定 セクション4 EC2上でGemをインストールし環境変数を設定(今回の内容) セクション5 Railsアプリを起動 セクション6 Nginxの導入 EC2のサーバにアプリのコードをクローン
全世界に公開できるIPアドレスを持ったEC2サーバ上でRailsアプリを動かすためにアプリケーションのコードをGithubからEC2サーバへクローンします。
GithubにSSH鍵を登録
現状、EC2サーバにアプリケーションのコードをクローンしようとしても permission deniedとエラーが出てしまいます。これは、Githubから見てこのEC2インスタンスが何者かわからないためです。
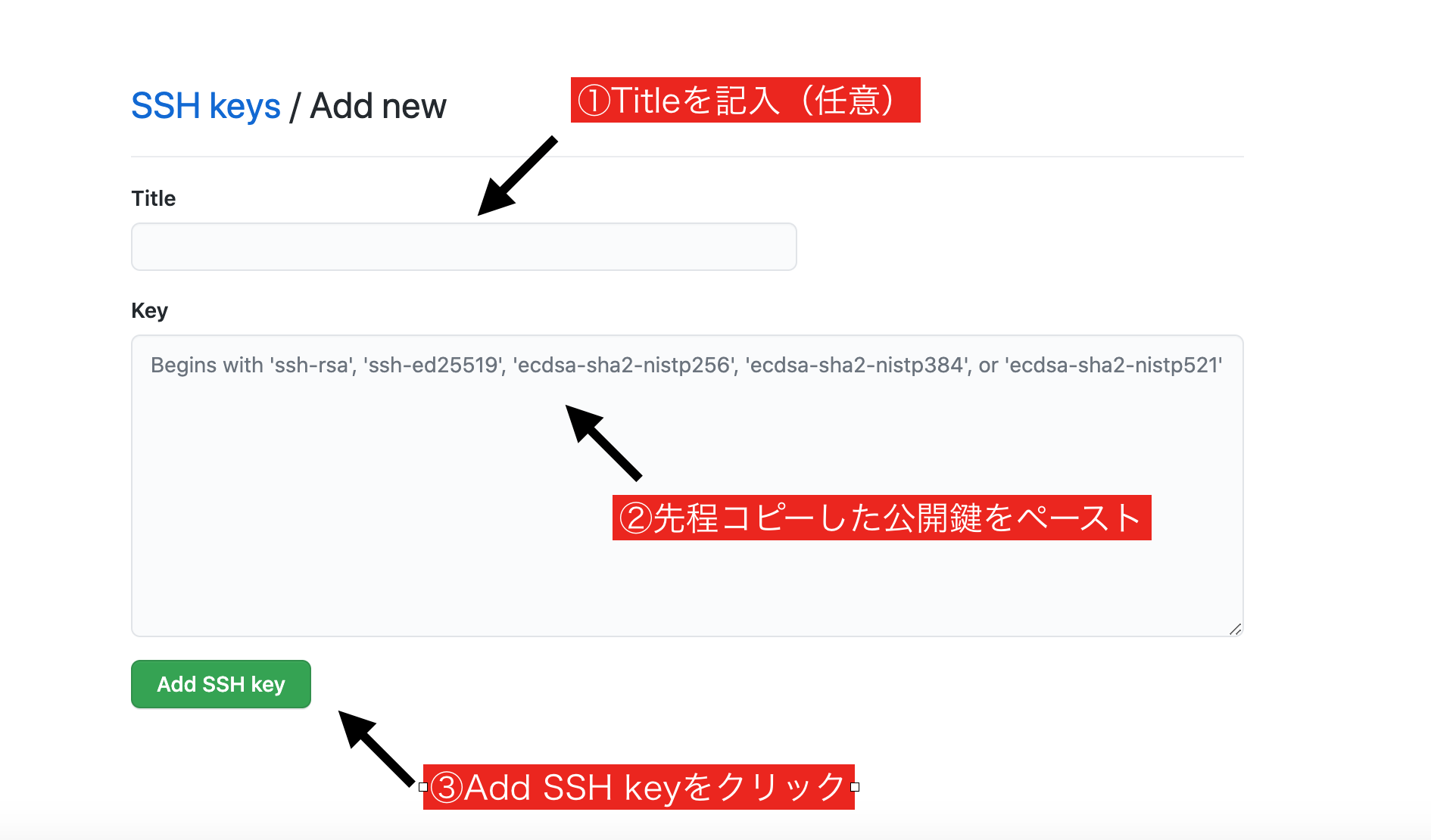
EC2インスタンスからGithubにアクセスするためには、作成したEC2インスタンスのSSH 公開鍵をGithubに登録する必要があります。 SSH鍵をGithubに登録すると、Githubはそれを認証に利用し、コードのクローンを許可してくれるようになります。
ターミナル[ec2-user@ip-172-31-23-189 ~]$ ssh-keygen -t rsa -b 4096 # 三段階ほど認証を求められるが全てyesでenterを押す Enter file in which to save the key (/home/ec2-user/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: # 以下の表示が出れば成功 Your identification has been saved in /home/ec2-user/.ssh/id_rsa. Your public key has been saved in /home/ec2-user/.ssh/id_rsa.pub. The key fingerprint is: 3a:8c:1d:d1:a9:22:c7:6e:6b:43:22:31:0f:ca:63:fa ec2-user@ip-172-31-23-189 The key's randomart image is: +--[ RSA 4096]----+ | + | | . . = | | = . o . | | * o . o | |= * S | |.* + . | | * + | | .E+ . | | .o | +-----------------+ # .SSH公開鍵を表示し、値をコピーするため、下記コマンドを実装 [ec2-user@ip-172-31-23-189 ~]$ cat ~/.ssh/id_rsa.pub # ssh~から最後の文字列までをコピーする ssh-rsa AAAAB3Nza・・・・・以下のURLからGithubにアクセスします。
https://github.com/settings/keys
アクセスしたら以下の画像のように操作します。
Githubに鍵を登録できたら、SSH接続できるか以下のコマンドで確認してみましょう。ターミナル[ec2-user@ip-172-31-23-189 ~]$ ssh -T git@github.com # 下記の表示が出たらyesを選択 The authenticity of host 'github.com (IP ADDRESS)' can't be established. RSA key fingerprint is 16:27:ac:a5:76:28:2d:36:63:1b:56:4d:eb:df:a6:48. Are you sure you want to continue connecting (yes/no)? # 成功したら下記の表示が出る [ec2-user@ip-172-31-23-189 ~]$ ssh -T git@github.com Hi <Githubユーザー名>! You've successfully authenticated, but GitHub does not provide shell access. # エラーが出たらログインし直してもう一度ssh接続する Warning: Permanently added the RSA host key for IP address 'XXXXXXXXX' to the list of known hosts.アプリケーションサーバの設定
アプリケーションサーバとは、ブラウザからの「リクエスト」を受け付けRailsアプリケ ーションを実際に動作させるソフトウェアのことです。
アプリケーションサーバが動いていれば、ブラウザからのリクエストを受け付けてRails アプリケーションが動作します。
という訳で、全世界に公開するEC2サーバ上でもアプリケーションサーバを動かす必要が あるのです。今回はUnicornというアプリケーションサーバーを使用します。Unicorn
全世界に公開されるサーバ上で良く利用されるアプリケーションサーバです。rails sコマンドの代わりに unicorn_rails コマンドで起動することができます。
この後、EC2サーバにSSH接続しUnicornを起動することで全世界からアクセスできるようにしていきます。Unicornをインストール
UnicornはRubyで作成されており、gem化されています。なのでローカルのGemfileを編集しましょう。
Gemfile# 追記(本番環境) group :production do gem 'unicorn', '5.4.1' # バージョン指定 endターミナル(ローカル)$ bundle installconfig/unicorn.rbを作成し、内容を以下のように編集
Unicornの設定ファイルとして、次の内容でファイルを作成しましょう。最初からは存在していないので、自分でconfig ディレクトリ以下に作成します。
この後すぐ、ファイルの中身がそれぞれ何を行なっているか説明しますので、まずはコピ ー&ペーストで作成したファイルに貼り付けましょう。config/unicorn.rbapp_path = File.expand_path('../../', __FILE__) #アプリケーションサーバの性能を決定する worker_processes 1 #アプリケーションの設置されているディレクトリを指定 working_directory app_path #Unicornの起動に必要なファイルの設置場所を指定 pid "#{app_path}/tmp/pids/unicorn.pid" #ポート番号を指定 listen 3000 #エラーのログを記録するファイルを指定 stderr_path "#{app_path}/log/unicorn.stderr.log" #通常のログを記録するファイルを指定 stdout_path "#{app_path}/log/unicorn.stdout.log" #Railsアプリケーションの応答を待つ上限時間を設定 timeout 60 #以下は応用的な設定なので説明は割愛 preload_app true GC.respond_to?(:copy_on_write_friendly=) && GC.copy_on_write_friendly = true check_client_connection false run_once = true before_fork do |server, worker| defined?(ActiveRecord::Base) && ActiveRecord::Base.connection.disconnect! if run_once run_once = false # prevent from firing again end old_pid = "#{server.config[:pid]}.oldbin" if File.exist?(old_pid) && server.pid != old_pid begin sig = (worker.nr + 1) >= server.worker_processes ? :QUIT : :TTOU Process.kill(sig, File.read(old_pid).to_i) rescue Errno::ENOENT, Errno::ESRCH => e logger.error e end end end after_fork do |_server, _worker| defined?(ActiveRecord::Base) && ActiveRecord::Base.establish_connection end変更修正をリモートリポジトリに反映
ここまで、ローカルのフォルダ内で変更修正を行ったので、こちらをリモートリポジトリへ反映します。変更修正をコミットしてプッシュしましょう。
この時必ず、masterブランチで行うようにしてください。もし、別ブランチでコミット&プッシュした場合は、リモートリポジトリでプルリクエストを作成し、ブランチをmasterへマージしてください。Githubからコードをクローン
続いて、Unicornの設定を済ませたコードをEC2インスタンスにクローンします。
/var/wwwディレクトリを作成し、権限をec2-userに変更
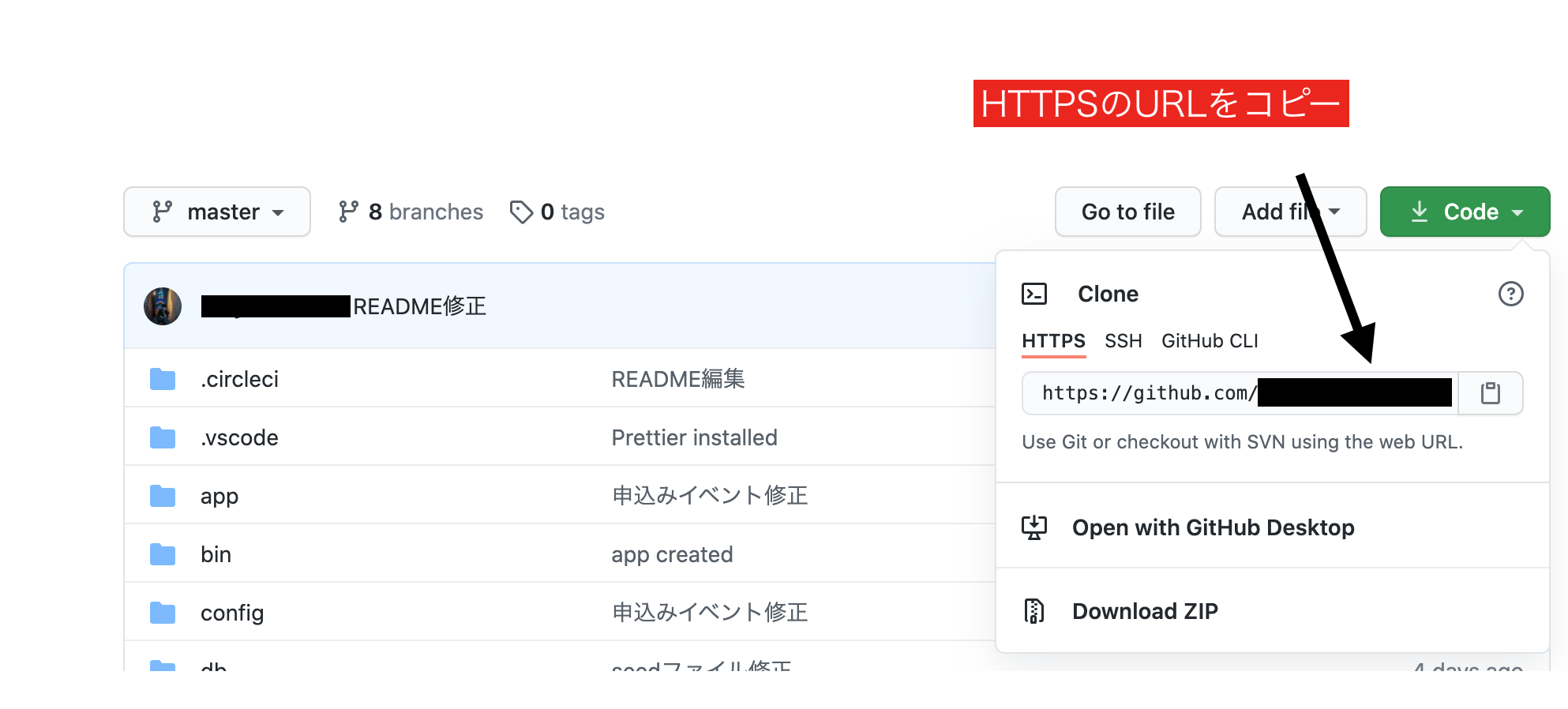
ターミナル(EC2)#/var/wwwディレクトリを作成(後述するCapistranoの初期値がwwwなので、ディレクトリをwwwに設定しています) [ec2-user@ip-172-31-23-189 ~]$ sudo mkdir /var/www/ #作成したwwwディレクトリの権限をec2-userに変更 [ec2-user@ip-172-31-23-189 ~]$ sudo chown ec2-user /var/www/Githubから「リポジトリURL」を取得
取得した「リポジトリURL」を使って、コードをクローンします。ターミナル(EC2)[ec2-user@ip-172-31-23-189 ~]$ cd /var/www/ [ec2-user@ip-172-31-23-189 www]$ git clone https://github.com/リポジトリURL # 成功したら以下の表示が出る remote: Enumerating objects: 298, done. remote: Counting objects: 100% (298/298), done. remote: Compressing objects: 100% (190/190), done. remote: Total 298 (delta 109), reused 274 (delta 86), pack-reused 0 Receiving objects: 100% (298/298), 58.53 KiB | 365.00 KiB/s, done. Resolving deltas: 100% (109/109), done.EC2の能力を拡張
現状動かしているEC2のインスタンスではコンピューターの能力が足りず、Gemのインストール時などにエラーが発生する可能性があります。具体的には、コンピューターの処理能力に関係するメモリというものが足りません。これは、無料で動かせるインスタンスの限界であるため仕方ありません。
そこで、今後の設定を行う前にメモリを増強する処理を行います。ターミナル# ホームディレクトリに移行 [ec2-user@ip-172-31-25-189 ~]$ cd ~ [ec2-user@ip-172-31-25-189 ~]$ sudo dd if=/dev/zero of=/swapfile1 bs=1M count=512 # 成功すると以下の表示が出る 512+0 レコード入力 512+0 レコード出力 536870912 バイト (537 MB) コピーされました、 5.19011 秒、 103 MB/秒 # 次は権限に制限をかけましょう(chmodコマンド) [ec2-user@ip-172-31-25-189 ~]$ sudo chmod 600 /swapfile1 # スワップ(swap)領域を作成する - mkswap [ec2-user@ip-172-31-25-189 ~]$ sudo mkswap /swapfile1 #成功すると下記の表示が出ます スワップ空間バージョン1を設定します、サイズ = 524284 KiB ラベルはありません, UUID=74a961ba-7a33-4c18-b1cd-9779bcda8ab1 # スワップ(swap)領域を有効化する - swapon [ec2-user@ip-172-31-25-189 ~]$ sudo swapon /swapfile1 [ec2-user@ip-172-31-25-189 ~]$ sudo sh -c 'echo "/swapfile1 none swap sw 0 0" >> /etc/fstab'gemをインストール
ターミナル(EC2)# まずは、EC2にダウンロードしたWEB Appを開く [ec2-user@ip-172-31-23-189 www]$ cd /var/www/アプリ名 # Rubyのバージョンを確認する [ec2-user@ip-172-31-23-189 <アプリ名>]$ ruby -v # 指定したrubyのバージョンが表示されれば成功です。 ruby 2.5.1p57 (2018-03-29 revision 63029) [x86_64-linux]本番環境でgemを管理するための bundlerをインストール
まず開発環境(ローカル)で開発してきたアプリにおいて、どのバージョンの bundlerが使われていたのか確認します。
ターミナル(ローカル)$ bundler -v # するとバージョンが表示されます Bundler version 2.1.4 # 人によってバージョンが違う可能性があります開発環境で仕様しているbundlerのバージョンがわかったので、同じバージョンのものを EC2サーバ側にも導入します。上記の場合では、bundler 2.1.4のバージョンを導入して
bundle installを実行します。ターミナル(EC2)# ローカルで確認したbundlerのバージョンを導入する [ec2-user@ip-172-31-23-189 <アプリ名>]$ gem install bundler -v 2.1.4 Fetching bundler-2.1.4.gem Successfully installed bundler-2.1.4 Parsing documentation for bundler-2.1.4 Installing ri documentation for bundler-2.1.4 Done installing documentation for bundler after 3 seconds 1 gem installed # 上記コマンドは、数分以上かかる場合もあります。 [ec2-user@ip-172-31-23-189 <アプリ名>]$ bundle install環境変数の設定
データベースのパスワードなどセキュリティのためにGithubにアップロードすることがで きない情報は、環境変数というものを利用して設定します。
環境変数は、Railsからは ENV['<環境変数名>'] という記述でその値を利用することができます。今回は、SECRET_KEY_BASE という環境変数を指定していきます。secret_key_baseを作成
ターミナル(EC2)[ec2-user@ip-172-31-23-189 <アプリ名>]$ rake secret # うまくいくと、 cdfasdfadgfsadfdgc314751a8dadfadf7c8b9a1dc888e... という感じで表示されます。 これをコピーしておきましょう環境変数は /etc/environment というファイルに保存することで、サーバ全体に適用さ れます。環境変数の書き込みはvimコマンドを使用して行います。
ターミナル[ec2-user@ip-172-31-23-189 <アプリ名>]$ sudo vim /etc/environment
上の様な画面になれば、iと打ち込んで入力モードに切り替えた後、下記の記述を打ち込みます。=の前後にスペースは入れません。/etc/environmentDATABASE_PASSWORD='データベースのrootユーザーのパスワード' SECRET_KEY_BASE='先程コピーしたsecret_key_base'書き込みができたら esc(エスケープキー)を押下後、
:wqと入力して内容を保存します。 保存できたら環境変数を適用するために一旦ログアウトします。ターミナル(EC2)[ec2-user@ip-172-31-23-189 <アプリ名>]$ exit logout Connection to XX.XXX.XXX.XX closed. # もう一度ログイン $ ssh -i ダウンロードした鍵の名前.pem ec2-user@Elastic IPアドレス # 設定した環境変数が適用されているか確認 $ env | grep SECRET_KEY_BASE SECRET_KEY_BASE='XXXXXXXXXXXXXXXXXXXXXXXXX' $ env | grep DATABASE_PASSWORD DATABASE_PASSWORD='XXXXXXXXXXXXX'これで環境変数が設定出来ました!
終わりに
ここまでで、EC2インスタンスにSSHログインしてアクセスすることが出来ました。
次回でHTTP通信を可能にしてRailsアプリを起動させる工程まで進めます。
お疲れさまでした。。。次回
Railsアプリを起動

- 投稿日:2021-02-25T03:56:02+09:00
MacでM5stack Core2 for AWS その2
0. はじめに
前回はQiitaを書くのに疲れてしまい、
投稿はESP-IDFまでと中途半端に終わってしまったので
今回はLチカまで進めます。
ドキュメントはここのAWS CLIのインストールからです。例によってエラーとの格闘です
1. AWS CLIインストール
AWSアカウントも何もないところからだと、ちと面倒ですが、
ココを乗り越えないと先に進めませんので、
ドキュメント通りにAWSのアカウント作成、AWS CLIのインストール、
aws configureを行います2. Minicondaインストール
ドキュメント通り進めます。
私はココのPython3.8のpkgをインストールしました。ドキュメントにある、edukit環境作成とedukit環境への切り替えは
下の通りうまくいきました(base) オレ@MacBook ~ % conda create -n edukit python=3.7 Collecting package metadata (current_repodata.json): done Solving environment: done ## Package Plan ## environment location: /Users/オレ/opt/miniconda3/envs/edukit added / updated specs: - python=3.7 The following packages will be downloaded: package | build ---------------------------|----------------- ca-certificates-2021.1.19 | hecd8cb5_0 121 KB certifi-2020.12.5 | py37hecd8cb5_0 140 KB openssl-1.1.1j | h9ed2024_0 2.2 MB pip-21.0.1 | py37hecd8cb5_0 1.8 MB python-3.7.9 | h26836e1_0 19.7 MB readline-8.1 | h9ed2024_0 333 KB setuptools-52.0.0 | py37hecd8cb5_0 721 KB wheel-0.36.2 | pyhd3eb1b0_0 33 KB ------------------------------------------------------------ Total: 25.0 MB The following NEW packages will be INSTALLED: ca-certificates pkgs/main/osx-64::ca-certificates-2021.1.19-hecd8cb5_0 certifi pkgs/main/osx-64::certifi-2020.12.5-py37hecd8cb5_0 libcxx pkgs/main/osx-64::libcxx-10.0.0-1 libedit pkgs/main/osx-64::libedit-3.1.20191231-h1de35cc_1 libffi pkgs/main/osx-64::libffi-3.3-hb1e8313_2 ncurses pkgs/main/osx-64::ncurses-6.2-h0a44026_1 openssl pkgs/main/osx-64::openssl-1.1.1j-h9ed2024_0 pip pkgs/main/osx-64::pip-21.0.1-py37hecd8cb5_0 python pkgs/main/osx-64::python-3.7.9-h26836e1_0 readline pkgs/main/osx-64::readline-8.1-h9ed2024_0 setuptools pkgs/main/osx-64::setuptools-52.0.0-py37hecd8cb5_0 sqlite pkgs/main/osx-64::sqlite-3.33.0-hffcf06c_0 tk pkgs/main/osx-64::tk-8.6.10-hb0a8c7a_0 wheel pkgs/main/noarch::wheel-0.36.2-pyhd3eb1b0_0 xz pkgs/main/osx-64::xz-5.2.5-h1de35cc_0 zlib pkgs/main/osx-64::zlib-1.2.11-h1de35cc_3 Proceed ([y]/n)? y Downloading and Extracting Packages setuptools-52.0.0 | 721 KB | ##################################### | 100% certifi-2020.12.5 | 140 KB | ##################################### | 100% wheel-0.36.2 | 33 KB | ##################################### | 100% ca-certificates-2021 | 121 KB | ##################################### | 100% readline-8.1 | 333 KB | ##################################### | 100% python-3.7.9 | 19.7 MB | ##################################### | 100% openssl-1.1.1j | 2.2 MB | ##################################### | 100% pip-21.0.1 | 1.8 MB | ##################################### | 100% Preparing transaction: done Verifying transaction: done Executing transaction: done # # To activate this environment, use # # $ conda activate edukit # # To deactivate an active environment, use # # $ conda deactivate次に環境の移動
(base) オレ@MacBookAir ~ % conda activate edukit (edukit) オレ@MacBookAir ~ %(base)から(edukit)に変わりました。
が、次のexport.shでまたコケました(edukit) オレ@MacBookAir ~ % . $HOME/esp/esp-idf/export.sh Setting IDF_PATH to '/Users/オレ/esp/esp-idf' Adding ESP-IDF tools to PATH... Using Python interpreter in /Users/オレ/opt/miniconda3/envs/edukit/bin/python Checking if Python packages are up to date... The following Python requirements are not satisfied: click>=5.0 pyserial>=3.0 future>=0.15.2 cryptography>=2.1.4 pyparsing>=2.0.3,<2.4.0 pyelftools>=0.22 gdbgui==0.13.2.0 pygdbmi<=0.9.0.2 reedsolo>=1.5.3,<=1.5.4 bitstring>=3.1.6 ecdsa>=0.16.0 Please follow the instructions found in the "Set up the tools" section of ESP-IDF Getting Started Guide Diagnostic information: IDF_PYTHON_ENV_PATH: (not set) Python interpreter used: /Users/オレ/opt/miniconda3/envs/edukit/bin/python Warning: python interpreter not running from IDF_PYTHON_ENV_PATH PATH: /Users/オレ/.espressif/tools/xtensa-esp32-elf/ 〜〜〜以下略〜〜〜Getting Started Guideを読みやがれと。。。
う〜ん、まあなんか
IDF_PYTHON_ENV_PATH: (not set)
が怪しそうだな。。。と思いつつも先に進める。。。3. デバイス証明書の取得と登録
(edukit) オレ@MacBookAir % cd Core2-for-AWS-IoT-EduKit/Blinky-Hello-World/utilities/AWS_IoT_registration_helper (edukit) オレ@MacBookAir AWS_IoT_registration_helper % pip3 install -r requirements.txtRequirement already satisfied: awscli>=1.18.202 in /Users/オレ/opt/miniconda3/envs/edukit/lib/python3.7/site-packages (from -r requirements.txt (line 1)) (1.19.11) Requirement already satisfied: cryptography>=2.7 in /Users/オレ/opt/miniconda3/envs/edukit/lib/python3.7/site-packages (from -r requirements.txt (line 2)) (3.4.6) Requirement already satisfied: pyasn1_modules==0.1.5 in /Users/オレ/opt/miniconda3/envs/edukit/lib/python3.7/site-packages (from -r requirements.txt (line 3)) (0.1.5) 〜〜〜中略〜〜〜 Requirement already satisfied: chardet<5,>=3.0.2 in /Users/オレ/opt/miniconda3/envs/edukit/lib/python3.7/site-packages (from requests->requests-aws4auth==1.0.1->-r requirements.txt (line 10)) (4.0.0) Requirement already satisfied: certifi>=2017.4.17 in /Users/オレ/opt/miniconda3/envs/edukit/lib/python3.7/site-packages (from requests->requests-aws4auth==1.0.1->-r requirements.txt (line 10)) (2020.12.5) (edukit) オレ@MacBookAir AWS_IoT_registration_helper %なんかうまくいった模様
早速、デバイス証明書の取得と登録
シリアルデバイスは前のページと同じく
/dev/cu.usbserial-0225F023
を指定(edukit) オレ@MacBookAir AWS_IoT_registration_helper % python registration_helper.py -p /dev/cu.usbserial-0225F023 Pyserial is not installed for /Users/オレ/opt/miniconda3/envs/edukit/bin/python. Check the README for installation instructions. Traceback (most recent call last): File "registration_helper.py", line 42, in <module> import esptool ModuleNotFoundError: No module named 'esptool' During handling of the above exception, another exception occurred: Traceback (most recent call last): File "registration_helper.py", line 49, in <module> import esptool File "/Users/オレ/esp/esp-idf/components/esptool_py/esptool/esptool.py", line 38, in <module> import serial ModuleNotFoundError: No module named 'serial'またエラー。。。
モジュールがないだけなので、何も考えずserialとesptoolをインストール!〜〜〜まずはserial〜〜〜 (edukit) オレ@MacBookAir AWS_IoT_registration_helper % pip install serial Collecting serial Downloading serial-0.0.97-py2.py3-none-any.whl (40 kB) |████████████████████████████████| 40 kB 4.5 MB/s Collecting future>=0.17.1 Using cached future-0.18.2.tar.gz (829 kB) Requirement already satisfied: pyyaml>=3.13 in /Users/オレ/opt/miniconda3/envs/edukit/lib/python3.7/site-packages (from serial) (5.3.1) Collecting iso8601>=0.1.12 Downloading iso8601-0.1.14-py2.py3-none-any.whl (9.5 kB) Building wheels for collected packages: future Building wheel for future (setup.py) ... done Created wheel for future: filename=future-0.18.2-py3-none-any.whl size=491059 sha256=52d0697b9ade772839886084076f64bc586b6c0869c69f501ce868c4d720f95a Stored in directory: /Users/オレ/Library/Caches/pip/wheels/56/b0/fe/4410d17b32f1f0c3cf54cdfb2bc04d7b4b8f4ae377e2229ba0 Successfully built future Installing collected packages: iso8601, future, serial Successfully installed future-0.18.2 iso8601-0.1.14 serial-0.0.97 〜〜〜つづいて esptool 〜〜〜 (edukit) オレ@MacBookAir AWS_IoT_registration_helper % pip install esptool Collecting esptool Downloading esptool-3.0.tar.gz (149 kB) |████████████████████████████████| 149 kB 9.1 MB/s Collecting bitstring>=3.1.6 Using cached bitstring-3.1.7.tar.gz (195 kB) 〜〜〜中略〜〜〜 Successfully built esptool bitstring reedsolo Installing collected packages: reedsolo, pyserial, bitstring, esptool Successfully installed bitstring-3.1.7 esptool-3.0 pyserial-3.5 reedsolo-1.5.4インストール完了!
ということで、再度チャレンジ(edukit) オレ@MacBookAir AWS_IoT_registration_helper % python registration_helper.py -p /dev/cu.usbserial-0225F023 〜〜〜なんかちょっとwarning...笑〜〜〜 Conda 'edukit' environment active... Python 3.7.x detected... AWS CLI configured for IoT endpoint: xxxxxxxxxxxxxx-ats.iot.us-west-2.amazonaws.com Checking module (1 of 13): awscli>=1.18.202 〜〜〜中略〜〜〜 Checking module (2 of 13): cryptography>=2.7 Requirement already satisfied: cryptography>=2.7 in /Users/オレ/opt/miniconda3/envs/edukit/lib/python3.7/site-packages (3.4.6) 〜〜〜13 of 13まで略〜〜〜 ----------------------------------------- Completed checking/installing package dependencies Generating ECDSA 256-bit prime field key... Generating self-signed x.509 certificate... Successfully created x.509 certificate with expiration in 365 days... Connecting.... Changing baud rate to 921600 Changed. RAM boot... Downloading 31364 bytes at 3ffb0000... done! Downloading 456 bytes at 3ffb8f28... done! Downloading 1028 bytes at 40080000... done! Downloading 107384 bytes at 40080404... done! Downloading 4 bytes at 4009a77c... done! All segments done, executing at 40081bf0 Wait for init - CLI Initialised >> >> Serial Number: 012345678901234567 Generating Manifest >> Crypto Authentication Root CA 002 -----BEGIN CERTIFICATE----- MIIB8TCCAZegAwIBAgIQd9NtlW7IrmI 〜〜〜中略〜〜〜MG1TrVv7HhhfdFyhYmA== -----END PUBLIC KEY----- Validate Device Certificate: OK 012345678901234567 reading slot 0 public key >> reading slot 1 public key >> reading slot 2 public key >> reading slot 3 public key >> reading slot 4 public key >> Generated the manifest file 012345678901234567_manifest.json in output_files Created policy Default Number of certificates: 1 Loading the manifest_item... Unique ID: 012345678901234567 Try importing certificate... Response: {'ResponseMetadata': {'RequestId': 'なんか', 'HTTPStatusCode': 200, 'HTTPHeaders': {'date': 'Fri, 19 Feb 2021 15:54:26 GMT', 'content-type': 'application/json', 'content-length': '209', 'connection': 'keep-alive', 'x-amzn-requestid': 'なんか', 'access-control-allow-origin': '*', 'x-amz-apigw-id': 'a__P5HbyPHcF6FA=', 'x-amzn-trace-id': 'Root=なんか'}, 'RetryAttempts': 0}, 'certificateArn': 'arn:aws:iot:us-west-2:なんか:cert/なんか', 'certificateId': 'なんか'} Certificate import complete - returning MANIFEST_IMPORT SUCCESS arn:aws:iot:us-west-2:なんか:cert/なんか arn:aws:iot:us-west-2:なんか:thing/012345678901234567 Number of ThingIDs to check: 1 Checking the manifest item(1) Unique ID: 012345678901234567 Manifest was loaded successfullyおお、うまくいったようです〜!
4. ESP32ファームウェアの更新
(edukit) オレ@MacBookAir AWS_IoT_registration_helper % cd ../.. (edukit) オレ@MacBookAir Blinky-Hello-World % aws iot describe-endpoint --endpoint-type iot:Data-ATS { "endpointAddress": "xxxxxxxxxxxxxx-ats.iot.us-west-2.amazonaws.com" }上で表示されたエンドポイントを控えておきます
xxxxxxxxxxxxxx-ats.iot.us-west-2.amazonaws.com ←これで、Kconfigによる設定
(edukit) オレ@MacBookAir Blinky-Hello-World % idf.py menuconfig The following Python requirements are not satisfied: pyparsing>=2.0.3,<2.4.0 pyelftools>=0.22 gdbgui==0.13.2.0 pygdbmi<=0.9.0.2 Please follow the instructions found in the "Set up the tools" section of ESP-IDF Getting Started Guide Diagnostic information: IDF_PYTHON_ENV_PATH: (not set) Python interpreter used: /Users/オレ/opt/miniconda3/envs/edukit/bin/python Warning: python interpreter not running from IDF_PYTHON_ENV_PATH PATH: /Users/オレ/.espressif/tools/ 〜〜〜中略〜〜〜 ESP-IDF v4.2-238-g8cd16b60fむー、またGuideを見やがれが出てConfig画面でない。。。
どうやら先にあったIDF_PYTHON_ENV_PATHがないのが気に入らないらしい。
が、そもそも何を設定するんだ???
ディレクトリを歩き回り、
/Users/オレ/opt/miniconda3/envs/edukit
こんなのがあったので、とりあえず(edukit) オレ@MacBookAir Blinky-Hello-World % export IDF_PYTHON_ENV_PATH="/Users/オレ/opt/miniconda3/envs/edukit"気を取り直して
(edukit) オレ@MacBookAir Blinky-Hello-World % idf.py menuconfig The following Python requirements are not satisfied: pyparsing>=2.0.3,<2.4.0 pyelftools>=0.22 gdbgui==0.13.2.0 pygdbmi<=0.9.0.2 To install the missing packages, please run "/Users/オレ/esp/esp-idf/install.sh" Diagnostic information: IDF_PYTHON_ENV_PATH: /Users/オレ/opt/miniconda3/envs/edukit Python interpreter used: /Users/オレ/opt/miniconda3/envs/edukit/bin/python ESP-IDF v4.2-238-g8cd16b60fお、さっきと違うエラー。
install.shを実行せよと。(edukit) オレ@MacBookAir Blinky-Hello-World % /Users/オレ/esp/esp-idf/install.sh Installing ESP-IDF tools Installing tools: xtensa-esp32-elf, xtensa-esp32s2-elf, esp32ulp-elf, esp32s2ulp-elf, openocd-esp32 Skipping xtensa-esp32-elf@esp-2020r3-8.4.0 (already installed) 〜〜〜中略〜〜〜 Installing Python environment and packages Creating a new Python environment in /Users/オレ/.espressif/python_env/idf4.2_py3.7_env 〜〜〜お、IDF_PYTHON_ENV_PATHに使えそうなのが表示された〜〜〜 Installing virtualenv Collecting virtualenv 〜〜〜中略〜〜〜 Successfully built Flask-Compress Installing collected packages: MarkupSafe, Werkzeug, python-engineio, Jinja2, itsdangerous, click, bidict, python-socketio, pycparser, greenlet, Flask, brotli, six, Pygments, pygdbmi, gevent, Flask-SocketIO, Flask-Compress, cffi, reedsolo, pyserial, pyparsing, pyelftools, gdbgui, future, ecdsa, cryptography, bitstring Successfully installed Flask-0.12.5 Flask-Compress-1.9.0 Flask-SocketIO-2.9.6 Jinja2-2.11.3 MarkupSafe-1.1.1 Pygments-2.8.0 Werkzeug-0.16.1 bidict-0.21.2 bitstring-3.1.7 brotli-1.0.9 cffi-1.14.5 click-7.1.2 cryptography-3.4.6 ecdsa-0.16.1 future-0.18.2 gdbgui-0.13.2.0 gevent-1.5.0 greenlet-1.0.0 itsdangerous-1.1.0 pycparser-2.20 pyelftools-0.27 pygdbmi-0.9.0.2 pyparsing-2.3.1 pyserial-3.5 python-engineio-4.0.0 python-socketio-5.0.4 reedsolo-1.5.4 six-1.15.0 All done! You can now run: . /Users/オレ/esp/esp-idf/export.sh (edukit) オレ@MacBookAir Blinky-Hello-World %なんかうまくいったっぽい
export.shを実行せよとのことなので. /Users/オレ/esp/esp-idf/export.sh Adding ESP-IDF tools to PATH... Using Python interpreter in /Users/オレ/.espressif/python_env/idf4.2_py3.7_env/bin/python Checking if Python packages are up to date... Python requirements from /Users/オレ/esp/esp-idf/requirements.txt are satisfied. Updated PATH variable: 〜〜〜中略〜〜〜 Done! You can now compile ESP-IDF projects. Go to the project directory and run: idf.py build (edukit) オレ@MacBookAir Blinky-Hello-World %今度はさらっとexport.shが完了!
この時点でIDF_PYTHON_ENV_PATHを確認すると(edukit) オレ@MacBookAir Blinky-Hello-World % echo $IDF_PYTHON_ENV_PATH /Users/オレ/.espressif/python_env/idf4.2_py3.7_envおぉ、ちゃんと設定されている!
ということは、Minicondaをインストールしたときに
export.shを実行する前に、適当なIDF_PYTHON_ENV_PATHを設定して
install.shを実行すればよかっただけな予感。。。というわけで再度チャレンジ!
(edukit) オレ@MacBookAir Blinky-Hello-World % idf.py menuconfig Executing action: menuconfigやっとでましたよ〜Config画面!
ここからはドキュメント通り、
先ほど控えておいたエンドポイントと自宅のWifi設定を入れて保存後に終了
すると同時にRunning cmake in directory /Users/オレ/m5stack/Core2-for-AWS-IoT-EduKit/Blinky-Hello-World/build Executing "cmake -G Ninja -DPYTHON_DEPS_CHECKED=1 -DESP_PLATFORM=1 -DCCACHE_ENABLE=0 /Users/オレ/m5stack/Core2-for-AWS-IoT-EduKit/Blinky-Hello-World"... -- Found Git: /usr/bin/git (found version "2.24.2 (Apple Git-127)") -- IDF_TARGET not set, using default target: esp32 -- The C compiler identification is GNU 8.4.0 -- The CXX compiler identification is GNU 8.4.0 -- The ASM compiler identification is GNU 〜〜〜中略〜〜〜 -- Configuring done -- Generating done -- Build files have been written to: 〜〜〜以下略〜〜〜無事Configできたっぽい
ではBuildを!
(edukit) オレ@MacBookAir Blinky-Hello-World % idf.py build Executing action: all (aliases: build) Running ninja in directory /Users/オレ/m5stack/Core2-for-AWS-IoT-EduKit/Blinky-Hello-World/build Executing "ninja all"... [0/1] Re-running CMake... -- Building ESP-IDF components for target esp32 〜〜〜なんとか走り始めました! ここから結構時間がかかります〜〜〜 [1244/1244] Generating binary image from built executable esptool.py v3.0 Generated /Users/オレ/m5stack/Core2-for-AWS-IoT-EduKit/Blinky-Hello-World/build/AWS_IoT_EduKit-Blinky-Hello-World.bin Project build complete. To flash, run this command: /Users/オレ/.espressif/python_env/idf4.2_py3.7_env/bin/python ../../../esp/esp-idf/components/esptool_py/esptool/esptool.py -p (PORT) -b 460800 --before default_reset --after hard_reset --chip esp32 write_flash --flash_mode dio --flash_size detect --flash_freq 80m 0x1000 build/bootloader/bootloader.bin 0x8000 build/partition_table/partition-table.bin 0x10000 build/AWS_IoT_EduKit-Blinky-Hello-World.bin or run 'idf.py -p (PORT) flash'おぉ、ついにbinができあがりました!
転送する前にドキュメント通りに古いファームを消します(edukit) オレ@MacBookAir Blinky-Hello-World % idf.py erase_flash -p /dev/cu.usbserial-0225F023 Executing action: erase_flash 〜〜〜中略〜〜〜 esptool.py v3.0 Serial port /dev/cu.usbserial-0225F023 Connecting........___ Chip is ESP32-D0WDQ6-V3 (revision 3) Features: WiFi, BT, Dual Core, 240MHz, VRef calibration in efuse, Coding Scheme None Crystal is 40MHz MAC: 24:0a:c4:f9:9f:ac Uploading stub... Running stub... Stub running... Changing baud rate to 460800 Changed. Erasing flash (this may take a while)... Chip erase completed successfully in 26.2s Hard resetting via RTS pin... Doneきえました!
では、転送します!(edukit) オレ@MacBookAir Blinky-Hello-World % idf.py flash monitor -p /dev/cu.usbserial-0225F023 Executing action: flash 〜〜〜中略(しばし待ちます)〜〜〜 I (7508) esp_netif_handlers: sta ip: xxx.xxx.xxx.xxx, mask: 255.255.255.0, gw: xxx.xxx.xxx.xxx I (7528) Blinky: Connecting to AWS IoT Core... I (7708) aws_iot: Attempting to use device certificate from ATECC608 I (20048) Blinky: Successfully connected to AWS IoT Core! I (20048) Blinky: Subscribing... I (20398) Blinky: Subscribed to topic: 012345678901234567/# I (20398) Blinky: I (20398) Blinky: ************************************** I (20398) Blinky: Client Id - 012345678901234567 I (20408) Blinky: **************************************やっとAWSに接続できました!!!
5. Lチカ
もうあとは簡単です。
ドキュメント通りにAWS IoT Coreコンソールで状態確認!
Publishの入力画面で
<Client ID>/blink
をtopicにpublishすると
M5Stackの横にあるLEDが点滅し、
もう一回同じようにpublishすると点灯状態になります!
Macのターミナルではこんな感じでモニターすることができます
(4回publishしています)I (635748) Blinky: Subscribe callback I (635748) Blinky: 012345678901234567/blink { "message": "Hello from AWS IoT console" } I (650488) Blinky: Subscribe callback I (650488) Blinky: 012345678901234567/blink { "message": "Hello from AWS IoT console" } I (731598) Blinky: Subscribe callback I (731598) Blinky: 012345678901234567/blink { "message": "Hello from AWS IoT console" } I (738968) Blinky: Subscribe callback I (738968) Blinky: 012345678901234567/blink { "message": "Hello from AWS IoT console" }6. とりあえず
IoTの勉強というよりも、環境設定のラボのようですが
とりあえずLチカのラボ終了!



- 投稿日:2021-02-25T02:05:01+09:00
Cognitoのロックアウトの条件洗い出してみた
ロックアウトとは
サインインに連続して失敗した場合、一時的または永久的にアカウントを使用できないようにする仕組みです。
ほぼ同じ意味の「アカウントロック」と言ったほうがピンとくる人は多いのですかね。
馴染みがあるものだと、iPhone のロック画面がこの仕組みになっています。
サインインを必要としているシステムには、ブルートフォースアタックの対策として入れておきたい仕組みです。Amazon Cognito にはあるのか
AWS の認証のサービスでお馴染みの Amazon Cognito さん。
このサービスは、全く知らない人でも画面をポチポチやっていれば簡単に構築できちゃいますし、Amplify をつかえば、さらに簡単に使えちゃうサービスになっております!(ただ詳しく知ろうとすると難しいんですよねー...)
さて、この AWS を使っていれば認証として多く利用されているであろう Cognito にはロックアウトはあるのかですが、答えは「あります」
Amazon Cognito 開発者ガイドの最初あたりの注記に記載されていました。
Cognitoは永久的なロックアウトはなく、一時的なロックアウトみたいです。あれ、、、思ったよりも情報が結構書かれていたんだけど、、、
前調べたときは全然情報がなく、ロックされる条件や期間については内部仕様だから公開していないよ!!的な感じだったようなきがするんですが、、、
あ、この記事はこれでおわりですね(笑)でもまぁ、一応 AWS CLI 叩いて試してみましょう。
AWS CLI でアカウントロック検証
サインイン(初回認証)はこんな感じで叩けます。
aws cognito-idp initiate-auth \ --auth-flow USER_PASSWORD_AUTH \ --client-id xxxxxxxxxxxxxxxx \ --auth-parameters USERNAME=xxxx,PASSWORD=xxxxxxで、パスワードを間違えてみると、、
An error occurred (NotAuthorizedException) when calling the InitiateAuth operation: Incorrect username or password.ユーザー名かパスワード間違えてるぞってエラーが返ってきます。
そんなの知ってるよってことで気にせず、連続で叩いてみます。2回目...3回目...4回目...5回目...6回目...
6回目でエラーが変わりました!!
An error occurred (NotAuthorizedException) when calling the InitiateAuth operation: Password attempts exceededパスワードの試行回数を超えましたってエラーですね。
ロックアウトの仕組みを確認することができました。あとは、思いつく限り色々とパターンを出して、まとめてみようと思います。
ロックアウトの仕様
色々と試した結果以下がわかりました。
- サインインの試行の失敗は 5 回まで許容
- ロック後の再試行の失敗許容回数は1回許容
- 規定の失敗回数に達すると、一時的なロックアウトが開始する
- ロック時間は最初は1秒。再試行後に失敗すると、時間は倍増し15分まで到達する
- 15分間サインインを再試行せずに待つと、ロックアウトがリセットされる
- パスワードリセットをしても、ロックアウトはリセットされず、ロック時間を待機する必要がある
補足として、最初のロック時間が1秒なので、早く叩かないとエラーを出力できないです。最初「6回失敗できちゃった!?」ってなりました。
※ この情報は2021/2/25時点のもので、AWS側都合により変更される場合あります。
最後に
セキュリティにかかわるものですので記事にするかは迷いましたが、公式に書いてあるので、良しとしました。
Cognitoのロックアウトを調べている人の参考になれば幸いです。参考資料
- 投稿日:2021-02-25T02:01:46+09:00
EFSで共有ストレージを作成し普段使い用Minecraftサーバの処理をロードバランサで負荷分散する
はじめに
ある時Minecraftサーバの処理自体を負荷分散するにはどうすればいいのだろうと考えていました。
PvPサーバのようにワールドデータが変更されないようにしてるやつなら、ワールドデータを複数のサーバに配置してロードバランシングすれば良いですが、普段友だちといっしょにMinecraftをする際はもちろんワールドデータは同じですし、ワールドデータの変更もされます(ブロックを配置したり消したりするので)。となると問題になってくるのはリアルタイムでのワールドデータの同期です。
どんなにMinecraftサーバ自体の処理を分散させることができても、スムーズなワールドデータのリアルタイム同期ができなければ意味がありません。
そこで見つけたのがこちらのサービス
AWS EFS
要はAWSが提供しているNFSです。今日はこちらを使って、ワールド用ストレージを複数のサーバに共有し、Minecraftの根本的な処理部分自体はロードバランサで負荷分散させる、といったことをやっていこうと思います。
要はこういうこと↓です。絵が下手で申し訳ないです。
EFSで共有ストレージを作成する
AWSコンソール画面でEFSを開け、ファイルシステムの作成を押すと↓みたいなモーダルがでます。
適当な名前をつけて作成しましょう。
EFSファイルシステム(Elastic File System ファイルシステムって頭痛が痛いみたいな名前ですね)を作成すると、こんなの↓が出ると思うので、名前のところをクリックしてネットワークタブを開けます。
セキュリティグループ名はあとで使うので、こいつをメモしておきましょう、
EC2インスタンスを作る
今回はお試しということで、インスタンスタイプt2.microのやつを2つ建てることにしました。
インスタンスの詳細の設定で、ファイルシステムの追加をしておきます。
こうすることでなんとマウントなどを自動でやってくれます。超便利ですね。
マウント先はデフォルトの/mnt/efs/fs1にしておきます。
インスタンスを作成したら、インスタンスのインバウンドルールで、先ほどコピーしたEFSのセキュリティグループをソースに2049を許可しておきます。また、カスタムTCPで25565番も許可しておきます。
Java等のインストール
どっちかのインスタンスに入って、
$ sudo apt update $ sudo apt install openjdk-8-jdkでJava8をインストールします。
入ったかの確認はjava -versionでできますが、インスタンスタイプによってはヒープサイズを指定しないとjava -versionすら実行できない可能性があります。
ヒープサイズを指定して実行する場合は
java -Xms64m -version
でいけると思います。これを別のインスタンスでも同じことをします。
Minecraft Serverのダウンロード/インストール
こちらにアクセスし、Minecraft Serverの最新版のダウンロードリンクをコピーする。本記事執筆時点では最新版は
1.16.5でした、どれか1つのインスタンスに入り、
$ cd /mnt/efs/fs1 $ sudo mkdir minecraft_server $ cd minecraft_server $ sudo curl -LO https://launcher.mojang.com/v1/objects/1b557e7b033b583cd9f66746b7a9ab1ec1673ced/server.jarでMinecraft Serverをダウンロードします。
そして、初回起動。今回使用しているインスタンスのメモリが1GBと小さいため、ヒープサイズは512MBとしていますが、必要に応じて変えてもらっていいです。$ sudo java -Xmx512M -Xms512M -jar /mnt/efs/fs1/minecraft_server/server.jar nogui初回は必ずエラーを吐きます。
$ sudo nano /mnt/efs/fs1/minecraft_server/eula.txtで、
eula=falseをeula=trueにしておきます。そして、2回目の実行
$ sudo java -Xmx512M -Xms512M -jar /mnt/efs/fs1/minecraft_server/server.jar noguiこれで多分実行できたと思います。
別サーバでも実行
別サーバでも
$ sudo java -Xmx512M -Xms512M -jar /mnt/efs/fs1/minecraft_server/server.jar noguiを実行します。しかし、実行すると以下のようなエラーが出てると思います。
[15:25:22] [main/INFO]: Environment: authHost='https://authserver.mojang.com', accountsHost='https://api.mojang.com', sessionHost='https://sessionserver.mojang.com', servicesHost='https://api.minecraftservices.com', name='PROD' [15:25:22] [main/FATAL]: Failed to start the minecraft server aex$a: /mnt/efs/fs1/minecraft_server/./world/session.lock: already locked (possibly by other Minecraft instance?) at aex$a.a(SourceFile:98) ~[server.jar:?] at aex.a(SourceFile:44) ~[server.jar:?] at cyg$a.<init>(SourceFile:287) ~[server.jar:?] at cyg.c(SourceFile:275) ~[server.jar:?] at net.minecraft.server.Main.main(SourceFile:118) [server.jar:?]今回は時間が無かったので卍暴力卍で解決しようと思います。
$ sudo rm /mnt/efs/fs1/minecraft_server/./world/session.lockこれでもう1度
$ sudo java -Xmx512M -Xms512M -jar /mnt/efs/fs1/minecraft_server/server.jar noguiを実行してみてください。今度は多分いけたと思います。
ロードバランサを作る。
おなじみのあの画面でロードバランサを作りましょう。
今回選択するのはNetwork Load Balancerです。
以下の点に注意します。
- リスナーのポートはTCPの25565番
- アベイラビリティゾーンはEC2インスタンスがある場所を選択
- ターゲットへのポートもTCPの25565番
- ヘルスチェックの設定は上書きを選択し、Portを25565にしておく
ロードバランサのグローバルIPを取る
AWSコンソール画面のEC2のサイドメニューに「ネットワークインターフェイス」を選択します。
ネットワークインターフェイスのフィルターでロードバランサの名前で検索し、先ほど作成したNLBのグローバルIPをメモしておきます。
Minecraftをプレイ
サーバを追加し、Server Addressは先ほどメモしたロードバランサのIPをペーストします。
後は良いMinecraftプレイを!
私たちについて
私が所属しているKISGについて最後に宣伝します。
Kosen Infrastructure Study Group略してKISGは、高専生によるインフラを勉強したりする会です。
月1で勉強会を開いたり、外部講師を招いて様々なインフラ関連技術の勉強をしています。
興味のある高専関係者はTwitter ID@FPC_COMMUNITYまで!







