- 投稿日:2021-01-08T23:57:20+09:00
[Blender×Python] オリジナルオブジェクトのつくりかた
目次
0.平面を生成する
1.立方体を生成する
2.四角錐を生成する
3.多角形を生成する
4.モディファイアを使う
5.ランダムな形状のメッシュを生成する
6.波状のメッシュを生成する0.平面を生成する
import bpy #平面を形成する頂点と面を定義する verts = [(0,0,0),(0,5,0),(5,5,0),(5,0,0)] faces = [(0,1,2,3)] #メッシュを定義する mesh = bpy.data.meshes.new("Plane_mesh") #頂点と面のデータからメッシュを生成する mesh.from_pydata(verts,[],faces) mesh.update(calc_edges=True) #メッシュのデータからオブジェクトを定義する obj = bpy.data.objects.new("Plane", mesh) #オブジェクトの生成場所をカーソルに指定する obj.location = bpy.context.scene.cursor.location #オブジェクトをシーンにリンク(表示)させる bpy.context.scene.collection.objects.link(obj)1.立方体を生成する
import bpy #立方体を形成する頂点と面を定義する verts = [(0,0,0),(0,5,0),(5,5,0),(5,0,0),(0,0,5),(0,5,5),(5,5,5),(5,0,5)] faces = [(0,1,2,3), (4,5,6,7), (0,4,5,1), (1,5,6,2), (2,6,7,3), (3,7,4,0)] #メッシュを定義する mesh = bpy.data.meshes.new("Cube_mesh") #頂点と面のデータからメッシュを生成する mesh.from_pydata(verts,[],faces) mesh.update(calc_edges=True) #メッシュのデータからオブジェクトを定義する obj = bpy.data.objects.new("Cube", mesh) #オブジェクトの生成場所をカーソルに指定する obj.location = bpy.context.scene.cursor.location #オブジェクトをシーンにリンク(表示)させる bpy.context.scene.collection.objects.link(obj)2.四角錐を生成する
import bpy #四角錐を形成する頂点と面を定義する verts = [(0,0,0),(0,5,0),(5,5,0),(5,0,0),(2.5,2.5,4.5)] faces = [(0,1,2,3), (0,4,1), (1,4,2), (2,4,3), (3,4,0)] #メッシュを定義する mesh = bpy.data.meshes.new("Pyramid_mesh") #頂点と面のデータからメッシュを生成する mesh.from_pydata(verts,[],faces) mesh.update(calc_edges=True) #メッシュのデータからオブジェクトを定義する obj = bpy.data.objects.new("Pyramid", mesh) #オブジェクトの生成場所をカーソルに指定する obj.location = bpy.context.scene.cursor.location #オブジェクトをシーンにリンク(表示)させる bpy.context.scene.collection.objects.link(obj)3.多角形を生成する
import bpy import math 何角形か指定する p = 5 #中心を起点に頂点を配置する verts = [(0,0,0)] for i in range(0,p + 1): x = 2 *math.pi / p * i verts.append([math.cos(x),math.sin(x),0]) #中心と円周上の2点の合計3点で面を形成する faces = [] for i in range(0,p): faces.append([0,i + 1,i + 2]) mesh = bpy.data.meshes.new("Polygon_mesh") mesh.from_pydata(verts, [], faces) obj = bpy.data.objects.new("Polygon", mesh) bpy.context.scene.collection.objects.link(obj) #編集モードにする bpy.context.view_layer.objects.active = obj bpy.ops.object.mode_set(mode='EDIT') #重複頂点を削除する bpy.ops.mesh.remove_doubles() #オブジェクトモードに戻る bpy.ops.object.mode_set(mode='OBJECT')4.モディファイアを使う
import bpy verts = [(0,0,0),(0,5,0),(5,5,0),(5,0,0),(0,0,5),(0,5,5),(5,5,5),(5,0,5)] faces = [(0,1,2,3), (7,6,5,4), (0,4,5,1), (1,5,6,2), (2,6,7,3), (3,7,4,0)] mesh = bpy.data.meshes.new("Cube_mesh") mesh.from_pydata(verts,[],faces) mesh.update(calc_edges=True) obj = bpy.data.objects.new("Cube", mesh) obj.location = bpy.context.scene.cursor.location #サブディビジョンサーフェスを適応する obj.modifiers.new("subd", type='SUBSURF') #サブディビジョンサーフェスのレベルを決定する obj.modifiers['subd'].levels = 3 bpy.context.scene.collection.objects.link(obj) #スムーズシェードを適応する mypolys = mesh.polygons for p in mypolys: p.use_smooth = True5.ランダムな形状のメッシュを生成する
import bpy import random verts = [] faces = [] #meshに関する変数 numX = 20 numY = 20 #波の形状に関する変数 amp = 0.5 scale = 1 #頂点座標を生成する for i in range (0, numX): for j in range(0,numY): x = scale * i y = scale * j z = (i*random.random())*amp vert = (x,y,z) verts.append(vert) #4つの頂点から面を生成する count = 0 for i in range (0, numY *(numX-1)): if count < numY-1: A = i B = i+1 C = (i+numY)+1 D = (i+numY) face = (A,B,C,D) faces.append(face) count = count + 1 else: count = 0 mesh = bpy.data.meshes.new("random mesh") mesh.from_pydata(verts,[],faces) mesh.update(calc_edges=True) obj = bpy.data.objects.new("random mesh",mesh) obj.location = bpy.context.scene.cursor.location bpy.context.scene.collection.objects.link(obj) #サブディビジョンサーフェスを適応する obj.modifiers.new("subd", type='SUBSURF') obj.modifiers['subd'].levels = 3 #スムーズシェードを適応する mypolys = mesh.polygons for p in mypolys: p.use_smooth = True6.波状のメッシュを生成する
import bpy import math verts = [] faces = [] # meshに関する変数 numX = 10 numY = 10 #波の形状に関する変数 freq = 1 amp = 1 scale = 1 #頂点座標を生成する for i in range (0, numX): for j in range(0,numY): x = scale * i y = scale * j z = scale*((amp*math.cos(i*freq))+(amp*math.sin(j*freq))) vert = (x,y,z) verts.append(vert) #4つの頂点から面を生成する count = 0 for i in range (0, numY *(numX-1)): if count < numY-1: A = i B = i+1 C = (i+numY)+1 D = (i+numY) face = (A,B,C,D) faces.append(face) count = count + 1 else: count = 0 mesh = bpy.data.meshes.new("wave") mesh.from_pydata(verts,[],faces) mesh.update(calc_edges=True) obj = bpy.data.objects.new("wave",mesh) obj.location = (0,0,0) bpy.context.scene.collection.objects.link(obj) #サブディビジョンサーフェスを適応する obj.modifiers.new("subd", type='SUBSURF') obj.modifiers['subd'].levels = 3 #スムーズシェードを適応する mypolys = mesh.polygons for p in mypolys: p.use_smooth = True







- 投稿日:2021-01-08T23:43:38+09:00
yukicoder contest 277 参戦記
yukicoder contest 277 参戦記
A 1329 Square Sqsq
Python だったら考察しなくても正面から踏み抜けるだろうと踏んで流したら通ってしまった(笑). Python を相手にするには 10107 くらい必要なようである.
from math import isqrt N = int(input()) print(len(str(isqrt(N))))B 1330 Multiply or Divide
コンテスト中は AC したものの、コンテスト後の追加テストによるリジャッジで落とされてしまった.
- 投稿日:2021-01-08T23:43:29+09:00
Effective Python 学習備忘録 7日目 【7/100】
はじめに
Twitterで一時期流行していた 100 Days Of Code なるものを先日知りました。本記事は、初学者である私が100日の学習を通してどの程度成長できるか記録を残すこと、アウトプットすることを目的とします。誤っている点、読みにくい点多々あると思います。ご指摘いただけると幸いです!
今回学習する教材
- Effective Python
- 8章構成
- 本章216ページ
今日の進捗
- 進行状況:61-64ページ
- 第3章:クラスと継承
- 本日学んだことの中で、よく忘れるところ、知らなかったところを書いていきます。
単純なインターフェースにはクラスの代わりに関数を使う
Pythonには、関数を引き渡すことによって振る舞いをカスタマイズできる組込みAPIが多数ある。このような仕組みをフックと呼び、APIは、実行中にそのコードをコールバックする。
例えば、defaultdictクラスをカスタマイズしたい場合、このデータ構造では、キーが見つからなかったら、そのたびに呼ばれる関数を与えることができる。キーが見つからないとログを取り、デフォルト値として0を返すフックを次のように定義する。def log_missing(): print('Key added') return 0初期状態の辞書と追加データ集合を使って、log_missingが実行される。
from collections import defaultdict current = {'green': 10, 'blue': 2} increments = [ ('red', 3), ('blue', 15), ('orange', 8) ] result = defaultdict(log_missing, current) print('Before: ', dict(result)) for key, amount in increments: result[key] += amount # resultに値が入るたびにlog_missingが呼び出される print('After: ', dict(result))出力結果
Before: {'green': 10, 'blue': 2} Key added Key added After: {'green': 10, 'blue': 17, 'red': 3, 'orange': 8}defaultdictに渡すデフォルト値のフックを見つからないキーの全個数を数えるようにするヘルパー関数を以下のように定義する。
from collections import defaultdict def increment_with_report(current, increments): added_count = 0 def missing(): nonlocal added_count # クロージャの状態 added_count += 1 # 呼び出されるたびに、1増やす return 0 result = defaultdict(missing, current) for key, amount in increments: result[key] += amount return result, added_count current = {'green': 10, 'blue': 2} increments = [ ('red', 3), ('blue', 15), ('orange', 8) ] result, count = increment_with_report(current, increments) print(count)出力結果
2他の方法として、カプセル化したクラスを定義する方法がある。
from collections import defaultdict class CountMissing(object): def __init__(self): self.added = 0 def missing(self): self.added += 1 return 0 current = {'green': 10, 'blue': 2} increments = [ ('red', 3), ('blue', 15), ('orange', 8) ] counter = CountMissing() result = defaultdict(counter.missing, current) for key, amount in increments: result[key] += amount print(counter.added)出力結果
2CountMissngクラスはdefaultdictが呼び出されるまで、何を目的としたクラスなのか理解が困難である。このような難解さを取り除くために、Pythonは、特殊メソッド call を定義できる。callは、オブジェクトが関数のように呼び出すことを許可する。
from collections import defaultdict class BetterCountMissing(object): def __init__(self): self.added = 0 def __call__(self): self.added += 1 return 0 current = {'green': 10, 'blue': 2} increments = [ ('red', 3), ('blue', 15), ('orange', 8) ] counter = BetterCountMissing() result = defaultdict(counter, current) # __call__により、メソッドではなくクラスを直接渡せるようになる for key, amount in increments: result[key] += amount print(counter.added)出力結果
2
- 投稿日:2021-01-08T23:11:24+09:00
selenium user data directory is already in use, please specify a unique value
- 投稿日:2021-01-08T22:27:31+09:00
学生証を鍵にしてみた?!
はじめに
はじめまして.今回の記事は合同ブログ3号目です.なんの合同ブログかといいますと,セキュリティキャンプのグループワークで”控え目関西人”として合同ブログを書くことになり,その3人目という感じです.今までの記事はこちらです.
https://modestkansaipeople.hatenablog.com/entry/tsudoinoba概要
大学3回生くらいになるとゼミ室に配属されると思いますが,そのゼミ室の鍵を物理キーにするのは信頼性は高いが,とても不便ですよね...情報系の学生なら自分で改善すればいいじゃん!ということで,信頼性を確保しつつ,利便性を上げます.利便性向上として学生が常に携帯しているだろう”学生証”を鍵にすることにしました.学生証の解析は先人がやってくくださっているので,ハードとソフトのシステムの構築だけです.
環境
- Raspberry Pi3 Model B (OS:Raspbian 32bit)
- python 3.*
- マイクロサーボ9g SG-90
- RC-S380
ソフト実装
鍵だけなら鍵を回す処理だけつくればいいのですが,教授の何気ない
「誰がゼミ室にいるかもそれでわかるといいよね♪入退室管理システムみたいな」
これにより要件が少し複雑になりました...錠を回すときだけ学生証をタッチするのではなく入退出の度にタッチされることになります.
要件
- 学生証から認証情報を取得
- 鍵の開け閉め
- 入室と退出の区別
- 鍵の開け閉めの条件
以上の4つが最低要件として定義しました.今までの記事やリポジトリを見たらわかる通り今までなにも作ったことがないので恐らく欠陥だらけ...
学生証から学生情報を抜き出す
学生証はNFCのためNFCリーダからアクセスします.
pythonではNFC用のライブラリの"nfcpy"を使用します.(公式:https://github.com/nfcpy/nfcpy.git)
PaSoRiを使うのに自分は権限がないって怒られた場合は下記のコマンドを実行してください.私はもうaliasしました...
2-2:1.0はusblibコマンドで出てきた自分のPaSoRiのやつにしてください.sudo sh -c "echo -n '2-2:1.0' > /sys/bus/usb/drivers/port100/unbind"cloneするとexampleにtagtool.pyがあるので,それを実行すると吸えるデータはすべて出力されます.もし,権限など実行時エラーがあれば解決方法まで出力されるため,一度これを実行することをおすすめします.単純にNFCの中の一部データが簡単に見れるので構造の把握のために実行しときましょう.
そうすると学生番号が保存されている領域とサイズが分かったのでそこを読み出すコードを書きます.
scan.py(一部抜粋)def read_idm_No(self, tag): # read IDm self.idm = binascii.hexlify(tag.idm).upper().decode('utf-8') # defined service code & block sc = nfc.tag.tt3.ServiceCode(0x120B >> 6, 0x120B & 0x3f) bc = nfc.tag.tt3.BlockCode(0, service=0) # read blockdata block_data = tag.read_without_encryption([sc], [bc]) self.No = block_data[0:8].decode("utf-8") return True学生番号が保存されている領域が書き込みが可能な領域のため鍵情報として学生番号とIDmを取得します.
錠を回す処理
サーボモータをPWM制御で操作します.出力制御は空回りしたり,強すぎたりしないように実験して調整したので,ここは使われる錠の種類によって変わると思います.
magic.pyimport RPi.GPIO as GPIO import time servo_GPIO = 18 def openSESAMI(): GPIO.setmode(GPIO.BCM) GPIO.setup(servo_GPIO, GPIO.OUT) servo = GPIO.PWM(servo_GPIO, 50) servo.start(0) servo.ChangeDutyCycle(3.3) time.sleep(0.5) servo.stop() GPIO.cleanup() def lockSESAMI(): GPIO.setmode(GPIO.BCM) GPIO.setup(servo_GPIO, GPIO.OUT) servo = GPIO.PWM(servo_GPIO, 50) servo.start(0) servo.ChangeDutyCycle(12.0) time.sleep(0.5) servo.stop() GPIO.cleanup()入退出管理処理と錠の開け閉めの条件
入退出管理として,NFCのタッチログを利用します.ログはusername/IDm/学生番号/H:M:Sを日付ごとに追行する形式にし,入退出はその日のログの各行のusernameを取得して,奇数回目か偶数回目かで判定する.
scan.py(一部抜粋)def check_room_state(self, user): path = 'logs/' + str(self.year) + '/' + str(self.mon) + '/' + str(self.day) + '/access.log' #file path with open(path) as f: logs = f.readlines() #get logs f.close() # nobody's room if not logs: return 2 cnt = 0 for i in logs: log_user = i.split(sep='/') #get username form logs if user == log_user[0]: cnt += 1 if cnt % 2 == 1: #when access time is even, enter the room return 0 else: #when access time is odd, leave the room return 1 def main(): sl = SmartLock() key_state = 2 room_state = 0 while True: print ("touch card:") sl.scan()#scan student card user = sl.authentication()#authentication sl.get_time() sl.Log(user)#take log if user == 0:#no regist user print("unknown") pass else: flag = sl.check_room_state(user) print(user, key_state, flag, room_state) if key_state == 2 or key_state == 0 and flag == 0 and room_state == 0: print("open") magic.openSESAMI() key_state = 1 room_state += 1 elif key_state == 1 and flag == 1 and room_state == 1: print("lock") magic.lockSESAMI() key_state = 0 room_state = 0 elif key_state == 1 and flag == 0: print("entry") room_state += 1 elif key_state == 1 and flag == 1 and room_state > 1: print("leave") room_state -= 1 else: print("ERROR!")鍵の状態と部屋にいる人数を変数として保持しておき,鍵が閉まっているかつ部屋の人数が0人で入室の時鍵を開けて,鍵が開いているかつ部屋の人数が1人で退出の時鍵を閉めます.それ以外は入退出による部屋の人数の変更のみ行います.
ハード実装
これでシステムは完成したのであとは実際に錠を回す物理実装だけです.
サーボモータ
うちの研究室では以前にも似たようなものが使われていたのですが,引継ぎの時に壊れて鍵が物理キーでも開けられない事件が発生したらしく,要件として,物理キーでも最悪開けられることが望ましいことが上げられました.そのためソフトにも関係しますが,通電していなければ軸が固定されない性質を生かして,鍵を開け閉めするときだけ通電するようにして,物理キーでもエスケープできるようにしました.
SG-90はそのままでは錠を回せないので引っかかりを作りました.サイコロは100均でいい感じのサイズだったので...3Dプリンタで作ってもよかったのですが,CADとか使ったことないので面倒でした...SG-90は5VピンとGNDピンと制御するために好きなGPIO制御ピンに挿してください.
ハード全体図
まとめ
あとはモータとかラズパイとかリーダーをドアにどう固定するかで完成です.学生証から学生番号とIDmを読み出すのはたくさん記事が上がってるのですぐに実装できました.そして認証のうまい実装方法が分からなかったのでDBを建てて問い合わせのレスポンスで実装しました.こちら改善方法募集です...鍵の開け閉めの条件式がごちゃごちゃしているのでこちらも改善したいです.でもまぁ,はじめてなにか作った割にはうまくできたんじゃないかと思ってます.
コード全体はこちらです https://github.com/raqqona/SmartLock_nfcそして最後にまた教授の一言により...
「お!いいねぇ じゃあ使えてないThingWorxあるんだけどそれにデータあげていい感じに見れるやつも作ってくれない?」
次回 ThingWorxにデータを上げて表示するまで作ってみた(ThingWorxなんて聞いたことないんですが...)


- 投稿日:2021-01-08T22:09:13+09:00
Jリーグの勝ち点推移がグラフで見れるよ!
概要
記事概要
今回作ったサービスの紹介をしつつ開発の流れやつまずきポイントを紹介します。
アプリ概要
- Jリーグのチームの勝ち点推移がグラフで見れる
- こちらからサービスに飛べます。
- Jリーグのデータサイトからスクレイピングしてデータをためて、APIとして配信してフロントから表示させています。

アプリ作成理由
- 川崎フロンターレの圧倒的な結果を視覚的にみたくなったから。
全体の構成
フロントのソースコードはGitHubにあげています。
構成図
使用技術
- Python
- AWS(Lambda,APIGateway,DaynamoDB)
- JavaScript(Nuxt.js,Chart.js)
作成の流れ&つまづきポイント
流れ
- JリーグのデータサイトをAWS LambdaでスクレイピングしてAWS DaynamoDBに蓄積
- AWS DaynamoDBのデータをAPIGateway&LambdaでAPIを作る
- Nuxt.jsでAPIを受け取りChart.jsで表示
- GitHubpagesでデプロイ
流れの詳細
参考にしたサイトなどを紹介しつつ開発の流れを説明します。
1.Lambdaでスクレイピング
スクレイピングは
requestsとbeautifulsoupを使っています。
Lambdaでサードパーティーのライブラリを使うには以下のサイトを参考にしましたLambdaでスクレイピングするならDockerイメージを使おう【Python】
さらにスクレイピングしたデータをDaynamoDBに送るにはPython Boto3という公式のライブラリで操作できます
・参考
公式のドキュメント
AWS LambdaからPython Boto3を使用してDynamoDBを操作してみた2.Lambda+APIGateway でAPI作成
DaynamoDBからデータをとってくるLambda関数とAPIGatewayを作ります。
かなり簡単です。
DaynamoDBからソートしてデータを取るのが難しかったので、Lambdaでソートし直すことにしました。辞書のリストを並べ替えるのもライブラリで簡単にできます。・参考
API Gateway + Lambda + DynamoDB
Pythonの辞書のリストを並び替える3.Nuxt.js ✖️ Chart.js
Nuxtでchart.jsを扱うのは以下を参考にしました。
APIをchart.jsで扱うには公式にサンプルがあるのでそれを参考に!
・参考Nuxt.jsでvue-chart.jsを使って簡単グラフ作成
公式感想
感想をだらだらと書きます。
- やっぱりLambda楽しい手軽に開発できて便利〜
- Chart.jsでも簡単にグラフ表示できていいね!
- JS力もUPさせたい!
今後の展望
今後やりたいことをだらだらと列挙していきます。
- セキュリティーの強化(APIkey入れるとか)
- APIテスト
- APIのドキュメント作成
- UIの改善
- CICD

- 投稿日:2021-01-08T21:54:21+09:00
RedashでPythonデータソースを追加する
はじめに
RedashでPythonデータソースを使えるようにするための設定の備忘録。
環境
$sw_vers ProductName: Mac OS X ProductVersion: 10.13.6 BuildVersion: 17G14042 $docker --version Docker version 20.10.0, build 7287ab3DockerベースでローカルにRedashをインストールしました。
Redashのバージョンはv8.0.0を使用しています。
インストール方法はこちらPythonデータソースを使うために必要な設定
デフォルトではPythonデータソースを使えないので、使えるようにするために
redash/settings/__init__.pyに記載されているdefault_query_runnersに
"redash.query_runner.python"を追加します。redash/settings/__init__.py(省略) 322 323 # Query Runners 324 default_query_runners = [ 325 "redash.query_runner.python", 326 "redash.query_runner.athena", 327 "redash.query_runner.big_query", 328 "redash.query_runner.google_spreadsheets", 329 "redash.query_runner.graphite", 330 "redash.query_runner.mongodb",その後、
docker-compose upを実行。
すでに実行している場合はdocker-compose restart。確認
ブラウザで
localhost:5000にアクセスして、Redashの画面を開いたあと、
Settings → Data Sources タブ → + New Data Source。
検索窓で「Python」と打つとPythonデータソースが選択できるようになりました。

- 投稿日:2021-01-08T21:04:30+09:00
軽く動く強化学習、基本のQ学習からニューラルネットやLSTMの応用まで、4種のエージェントと7種のタスク
はじめに
「ScratchでAIを学ぼう」の筆者です。この本では、初めての方でもきちんと分かることを目指し、ゲームを題材にしてQ学習を3段階で説明しました。
ここでは、その続編として、pythonで基本のQ学習、ニューラルネットの応用、また、多少実験的な試みになりますが、短期記憶ユニットであるLSTM/GRUの応用を紹介したいと思います。
使用するプログラムmemoryRLは、GitHubからダウンロードできます。GPUのない普通のPCでも短時間(長くても数分)で学習できることを想定しています。
まず、2つの例を見てください。
1つ目の例はmany_swamp と呼んでいるタスクです。ロボットを操作して、4つのゴール(青)を全て巡回できるとクリアとなり、エピソードが終わります。エピソード毎に壁とゴールの配置がランダムに変わります。アニメーションは、ニューラルネットを使ったQ学習(qnet)で学習させた結果です。
アニメーションの左側が環境全体を表しています。白黒の中央と右側の図は、実際に強化学習アルゴリズムが受け取る観測情報に対応します。観測情報は、2マス以内の周囲のゴール(中央)と壁(左)のパターンになります。
ロボットは2マスまでの周囲しか見えない設定なのですが、「壁はよける」、「ゴールに近づいたらそちらに曲がる」、「何もなければまっすぐ進む」、のようなアルゴリズムで動いているように見えます。このアルゴリズム自体を強化学習が作ったということです。マップはランダムに変わりますが、追加学習をすることなく対応しています。
ちなみに、この学習には、筆者の古いノートPCでも4分弱で終わりました (qnet, many_swamp, 33000 qstep, 3分40秒)。
※筆者のノートPCのCPUは、Intel Core i7-6600UでGPUなし。i7でも第6世代なので結構遅く、i5-7500Uの方が上のようです。 参考:CPU性能比較表 | 最新から定番のCPUまで簡単に比較2つめの例は、Tmaze_either と呼んでいるタスクです。青のゴールにたどり着けばクリアなのですが、ゴールが観測情報から消えてしまいます。観測から消えてもゴールはあるので、ゴールの位置を覚えておいて正しい方向にT字路を曲がる必要があります。つまり短期記憶が必要なタスクです。
このような問題は通常のQ学習ではできませんが、短期記憶ユニットであるLSTMを組み入れたQ学習で解くことが可能となりました。
以上が2つの例の紹介になりますが、このmemoryRLプロジェクトでは、このタスクを含む7つのバリエーションのタスクを、4種類の強化学習エージェントで試すことができます。
この記事ではmemryRLの使い方をメインに紹介しますが、学習の原理、実装方法など、更に詳しい解説は、以下にまとめていますので参考にしてください。
http://itoshi.main.jp/tech/0100-rl/rl_introduction/環境構築
ここでは、windows 10 を想定し、pythonでmemoryRLを動かすための環境構築を説明します。
Anaconda インストール
まず、pythonをするための基本環境として、anaconda をインストールします。
以下の記事が参考になります。
Windows版Anacondaのインストール仮想環境作成
次に、特定のpythonのバージョンやモジュールのバージョンの環境を設定するために、conda で仮想環境を作成します。
仮想環境について詳しく知るためには以下が参考になります。
【初心者向け】Anacondaで仮想環境を作ってみる
python japan, Conda コマンドスタートメニューからAnaconda Powershell Prompt を立ち上げます。
以下のコマンドで、mRLという名前の仮想環境をpython3.6 で作成します(mRLでなくてもよいですが、ここではmRLとして進めていきます)。
(base)> conda create -n mRL python=3.6以下で、mRLをアクティベートします(仮想環境に入る)。
(base)> conda activate mRLtensorflow, numpy, h5py をバージョン指定でインストールします。
(mRL)> pip install tensorflow==1.12.0 numpy==1.16.1 h5py==2.10.0opencv-pythonとmatplotlib は、最新のバージョンでインストールします。
(mRL)> pip install opencv-python matplotlib今後、この仮想環境 mRL に入ることで(> conda activate mRL)、今インストールしたモジュール(ライブラリ)の環境で、プログラムを動かすことができます。
memoryRLのダウンロードと展開
gitが使える方は、以下のコマンドでクローンすれば完了です。
(mRL)> git clone https://github.com/itoshin-tech/memoryRL.git以下、git を使っていない人用の説明です。
ブラウザで、次ののURLに行きます。
https://github.com/itoshin-tech/memoryRLCode から、Download zip を選び、PCの適当な場所に保存して解凍すると、memoryRL-master というフォルダが作られます
これで準備OKです。
memoryRLの実行
memoryRLを解凍して作成されたフォルダーに入ります。
(mRL)> cd C:\解凍した位置のパス\memoryRL-master\sim_swanptour.py を以下のコマンドで実行します。
(mRL)> python sim_swanptour.pyすると以下のように使い方が表示されます。
---- 使い方 --------------------------------------- 3つのパラメータを指定して実行します > python sim_swanptour.py [agt_type] [task_type] [process_type] [agt_type] : q, qnet, lstm, gru [task_type] :silent_ruin, open_field, many_swamp, Tmaze_both, Tmaze_either, ruin_1swamp, ruin_2swamp, [process_type] :learn/L, more/M, graph/G, anime/A 例 > python sim_swanptour.py q open_field L ---------------------------------------------------説明にあるように、python sim_swanptour.py の後に3つのパラメータをセットして使います。
agt_type とtask_type については後ほど図解しますが、パラメータの説明は以下のようになります。
[agt_type] 強化学習のアルゴリズム q Q学習 qnet ニューラルネットを使ったQ学習 lstm LSTMを使った短期記憶付きQ学習 gru GRUを使った短期記憶付きQ学習
[task_type] タスクのタイプ。
全てのタスクにおいて全ての青いゴールに辿り着けばクリアsilent_ruin マップ固定、ゴール数2。 open_field 壁なし、ゴール数1。ゴールの位置はランダムに変わる。 many_swamp 壁あり、ゴール数4。配置がランダムに変わる。 Tmaze_both T迷路。短期記憶が必要。 Tmaze_either T迷路。短期記憶が必要。 ruin_1swamp 壁あり、ゴール数1。 ruin_2swamp 壁あり、ゴール数2。高難易度。
[process type] プロセスの種類 learn/L 初めから学習する more/M 追加学習をする graph/G 学習曲線を表示する anime/A タスクを解いている様子をアニメーションで表示 では、具体的に、qnet (ニューラルネットを使ったQ学習) に many_swamp のタスクを学習させる場合を説明します。
学習を開始するので、最後のパラメータは、more か Lにします。
(mRL)> python sim_swanptour.py qnet many_swamp Lすると、以下のようにコンソールに学習過程の評価が表示され、全5000 stepの学習が行われます。
qnet many_swamp 1000 --- 5 sec, eval_rwd -3.19, eval_steps 30.00 qnet many_swamp 2000 --- 9 sec, eval_rwd -0.67, eval_steps 28.17 qnet many_swamp 3000 --- 14 sec, eval_rwd -0.21, eval_steps 26.59 qnet many_swamp 4000 --- 18 sec, eval_rwd -1.27, eval_steps 28.72 qnet many_swamp 5000 --- 23 sec, eval_rwd -1.29, eval_steps 28.901000回に1回、評価のプロセスがあり、そこで、eval_rwdとeval_stepが計算されます。eval_rwd は、その時の1エピソード中の平均報酬、eval_steps は平均step数です。評価プロセスでは、学習を停止し、行動選択のノイズも0にした状態で、100回のエピソードを行って平均を出しています。
eval_rwdやeval_step を指標として学習が目標値に進んだときにも学習は終了するようになっています(EARY_STOP)。目標値はタスク毎に設定されています。
最後に以下のような学習過程のグラフ(eval_rwd, eval_steps)が表示されます。
[q]を押すとグラフが消え終了します。
学習の結果後の動作アニメーションを見るには、最後のパラメータをanime か Aにします。
(mRL)> python sim_swanptour.py qnet many_swamp Aすると、以下のようなアニメーションが表示されます。
100エピソードが終わると終了します。[q]を押すと途中終了します。
アニメーションを見ると、適切に動けていなことが分かります。まだ学習が足りないのです(アニメーションの中央から右側の白黒の図はエージェントへの入力を表しています)。
そこで、追加学習します。最後のパラメータをmore か Mにして実行します(初めから学習する場合は L を使います)。
(mRL)> python sim_swanptour.py qnet many_swamp M
このコマンドを数回繰り返します。EARY_STOPが表示されて途中終了すると、学習が良いところまで進んだといえます。many_swampは、eval_rwd が1.4以上または、eval_steps が22以下になるとEARY_STOPとなります。qnet many_swamp 1000 --- 5 sec, eval_rwd 0.55, eval_steps 24.25 qnet many_swamp 2000 --- 9 sec, eval_rwd 0.92, eval_steps 23.52 qnet many_swamp 3000 --- 14 sec, eval_rwd 1.76, eval_steps 21.69 EARY_STOP_STEP 22 >= 21グラフが最後に表示されます。エピソード当たりの報酬(rwd)が増加し、ステップ数(Steps)が減少していることから、学習が進んでいたことが分かります。
アニメーションを見てみましょう。
(mRL)> python sim_swanptour.py qnet many_swamp Aたまに失敗しますが、だいたいうまくいっているようです。
今までに学習させたグラフを表示するには、最後のパラメータをgraph か Gにします。
(mRL)> python sim_swanptour.py qnet many_swamp G以上がsim_swamptour.py(池巡り)の使い方の説明です。
強化学習アルゴリズムの種類
[agt_type] で指定できる強化学習アルゴリズム(エージェント)は、 q, qnet, lstm, gru の4種類です。ここではその特徴を簡単に説明します。
q:通常のQ学習
基本のQ学習アルゴリズムです。各観察に対して各行動のQ値を変数(Qテーブル)に保存し、更新していきます。観測値は500個まで登録できる設定にしています。それ以上のパターンが観測されたらメモリーオーバーで強制終了となります。
qnet:ニューラルネットを使ったQ学習アルゴリズム
ニューラルネットワークでQ値を出力するよう学習します。入力は観測値で、出力は3つ値です。この3つの値が各行動のQ値に対応します。中間層は64個のReLUユニットです。
未知の観測値に対してもQ値を出力することができます。
lstm/gru: 記憶ユニットを使ったQ学習アルゴリズム
過去の入力にも依存した反応が可能な記憶ユニット(LSTM または GRU)を加えたモデルです。LSTMを使ったアルゴリズムをlstm、GRUを使ったアルゴリズムをgruとしています。
qやqnetは、観測値が同じであれば同じ行動しか出力することしかできませんが、lstmやgruはモデルは、過去の入力が異なれば今の観測値が同じでも異なる行動を出力することが原理的に可能です。
LSTMは自然言語処理のモデルでもよく使用されている記憶ユニットです。GRUはLSTMをシンプルにしたモデルです。
LeRU を64個、LSTMまたはGRU を32個を使用しています。
タスクの種類
[task_type] で指定できるタスクは、silent_ruin, open_field, many_swamp, Tmaze_both, Tmaze_either, ruin_1swamp, ruin2swamp の7種類です。ここではその特徴を簡単に説明します。
全タスクで共通のルール
全てのタスクで共通しているのは、ロボットが全てのゴール(青のマス)に訪れたらクリア、というルールです。
アルゴリズムが受け取る情報は、ロボットを中心とした、限られた視野におけるゴールと壁の情報です。各タスクの図の、右側の白黒の図がその情報に対応します。
報酬は、初めてのゴールにたどり着くと+1.0、壁に当たると-0.2、それ以外のステップで-0.1となります。
silent_ruin
ゴールは2か所ありますが、マップは常に同じです。そのために、観測のバリエーションは限られており、q でも学習が可能です。
open_field
壁はありませんが、ゴールの場所はエピソード毎にランダムに変わります。しかし、壁がないので観測のバリエーションは限られており、qでも学習が可能です。
many_swamp
ゴールと壁の位置がエピソード毎にランダムに決まるために、観測のバリエーションが多く、qではメモリーオーバーとなってしまい学習ができません。qnet での学習が可能です。
Tmaze_both
普通の強化学習ではできない問題です。
マップは固定ですが、片方のゴールにたどり着くと、スタート地点に戻されます。そして、訪れたゴールも見えたままです。この状態で、次は別な方のゴールに進まなければなりません。
スタート地点にロボットがいるとき、スタート直後でも、片方のゴールに訪れた後でも同じ観測となります。そのために、同じ観測に対して同じ行動しか選べないqやqnet は、適切な行動を学習種ることができません。過去の履歴で行動を変えることができる gru と lstm のみが学習可能です。
Tmaze_either
このTmazeは、左右のどちらかでゴールが出現しますが、2ステップ後にゴールが見えなくなります。
ロボットは2ステップでT迷路の分岐路に来ることになりますが、ゴールが見えていた方を覚えておき、そちらに向かうことが必要です。このタスクも、qやqnet ではできません。gruとlstmのみが学習可能です。
ruin_1swamp
壁が8個、ゴールは1つで、配置がランダムに変わります。回り込んでゴールにたどり着かなければならない場合もあり難易度は高めです。
ruin_2swamp
最高難易度のタスクです。ゴールは2つで、片方にたどり着くとスタート地点に戻されます。ゴールは訪れても消えません。Tmaze_both のランダムバージョンのようなタスクです。gruやlstmでも満足にはできませんでした。
ゴールを更に増やしたりフィールドを大きくすることで、更に難易度を上げることができます。将来このようなタスクでもしっかり解けるような強化学習アルゴリズムを開発したいものです。
参考
この記事ではmemryRLの使い方をメインに紹介しましたが、学習の原理、実装方法など、更に詳しい解説は、以下にまとめていますので参考にしてください。
http://itoshi.main.jp/tech/0100-rl/rl_introduction/

















- 投稿日:2021-01-08T21:00:03+09:00
Rosetta2を使わないApple Silicon MacのHomebrew環境構築(2020/01/08_22時更新※gcc入った)
はじめに
まだ出て間もないARM Mac向けにビルドされたプログラムはあまり多くないです。
かといってRosettaでIntel向けバイナリを動かしてると今後Appleアーキテクチャバイナリが出回り始めた時にどれがIntelバイナリなのかわからなくなって困りそう。
あとIntel版のdependsライブラリ入れててビルド通らねえとかありそう。なのでRosetta2は使わずに環境を構築しました。
なお、MacPortsはかつてよく環境を破壊された記憶が鮮明なのでHomebrewを使います。Command Line Toolsのインストール
% sudo xcodebuild -license # Qキーで規約は飛ばせる。"agree"と入力 % xcode-select --installでインストールしてください。
Homebrewのインストール
いつものコマンドをターミナルにコピペすると弾かれます。
% /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)" Homebrew is not (yet) supported on ARM processors! Rerun the Homebrew installer under Rosetta 2. If you really know what you are doing and are prepared for a very broken experience you can use another installation option for installing on ARM: https://docs.brew.sh/Installationなので公式ドキュメントの通り
/opt/homebrew にインストールしましょう(別に/usr/localに入れても問題ないと思うが)。% cd /opt % sudo mkdir homebrew && curl -L https://github.com/Homebrew/brew/tarball/master | tar xz --strip 1 -C homebrewインストールが完了したら、~/.zshrcに以下を書き込んでパスを通しましょう。
export PATH="/opt/homebrew/bin:$PATH" export PATH="/opt/homebrew/sbin:$PATH" export C_INCLUDE_PATH="/opt/homebrew/include:$C_INCLUDE_PATH" export CPLUS_INCLUDE_PATH="/opt/homebrew/include:$CPLUS_INCLUDE_PATH"Homebrewでパッケージをインストール
まず注意点として、Homebrewでパッケージをインストールした際にApple Silicon向けにビルドされたバイナリが即インストールされることは少なかったです。
基本的にインストール時にビルドプロセスが走ると思って問題ないです。GCC
インストール不可です
今(20210107)Homebrewで入手可能なバージョンは10.2.0です。
一方、gccをApple Siliconに対応させるには少なくともバージョン11が必要のようですが、このメジャーアップデートが来るのは2021年中頃のようです(HomebrewのGithub issuesより)。
従ってC/C++のプログラミングをメインでやってる方は、、、M1チップ搭載のMBA/MBP購入は先行投資気味になりそうですね。
もちろんApple謹製のClang(gcc/g++コマンドにリンクされてる)はAppleアーキテクチャですし使えます。があまりC/C++erからは評判良くないらしいですよね。2021/01/08追記 インストール出来るようになったっぽい!
ついさっき
brew updateしたところ、インストールできました。% brew install gcc Updating Homebrew... ==> Auto-updated Homebrew! Updated 2 taps (homebrew/core and homebrew/cask). ==> New Formulae jpeg-xl ==> Updated Formulae Updated 17 formulae. ==> Updated Casks Updated 6 casks. # (中略) ==> Installing dependencies for gcc: isl, mpfr and libmpc ==> Installing gcc dependency: isl ==> Pouring isl-0.23.arm64_big_sur.bottle.tar.gz ? /opt/homebrew/Cellar/isl/0.23: 72 files, 5.0MB ==> Installing gcc dependency: mpfr ==> Pouring mpfr-4.1.0.arm64_big_sur.bottle.tar.gz ? /opt/homebrew/Cellar/mpfr/4.1.0: 30 files, 5.2MB ==> Installing gcc dependency: libmpc ==> Pouring libmpc-1.2.1.arm64_big_sur.bottle.tar.gz ? /opt/homebrew/Cellar/libmpc/1.2.1: 13 files, 432.8KB ==> Installing gcc ==> Pouring gcc-10.2.0_2.arm64_big_sur.bottle.tar.gz ? /opt/homebrew/Cellar/gcc/10.2.0_2: 1,367 files, 312.4MB % gcc-10 --version gcc-10 (Homebrew GCC 10.2.0_2) 10.2.1 20201220 Copyright (C) 2020 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.少なくともGCC11が来ないと対応できないって話はなんだったのか。。
まあこれでC/C++erも安心してApple Siliconで遊べますね!Python3.9.x
インストール可能です。
ただしソースコードからビルドする形になります。
何回かインストールしなおしましたが、インストール時に自動でビルドが始まる時もあれば
--build-from-source オプションを付けないと進めない時もありました。OpenJDK(8,11,13,15,16EA,17EA)
これはHomebrewではビルド・インストールできませんでした。
なのでZuluのビルドを掴みましょう。おわりに
正直私は上記くらいしか使わないのでこれくらいしか書けませんが、
Apple Silicon搭載Macでインストールできるのか確認して欲しいパッケージなど
ありましたらコメントなどで書いてください。たまにやります。
あとこの記事も随時更新します。brew updateをしてるとわかりますが、毎日膨大な量のパッケージが追加・更新されてます。
Homebrew-coreのCommit数は平均800/dayくらいあり、パッケージのApple Silicon対応は確実に進んでいるとわかります。余談ですが、Jailbreak端末向けのバイナリってApple Silicon Macで動いたりしないんですかね?いつか調査するかも。
Qemuをビルドして(面倒だった)ARM版Win10を動作させた話は別の記事に書きます。
- 投稿日:2021-01-08T21:00:03+09:00
Rosetta2を使わないApple Silicon MacのHomebrew環境構築(2020/01/08更新※gcc入った)
はじめに
まだ出て間もないARM Mac向けにビルドされたプログラムはあまり多くないです。
かといってRosettaでIntel向けバイナリを動かしてると今後Appleアーキテクチャバイナリが出回り始めた時にどれがIntelバイナリなのかわからなくなって困りそう。
あとIntel版のdependsライブラリ入れててビルド通らねえとかありそう。なのでRosetta2は使わずに環境を構築しました。
なお、MacPortsはかつてよく環境を破壊された記憶が鮮明なのでHomebrewを使います。Command Line Toolsのインストール
% sudo xcodebuild -license # Qキーで規約は飛ばせる。"agree"と入力 % xcode-select --installでインストールしてください。
Homebrewのインストール
いつものコマンドをターミナルにコピペすると弾かれます。
% /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)" Homebrew is not (yet) supported on ARM processors! Rerun the Homebrew installer under Rosetta 2. If you really know what you are doing and are prepared for a very broken experience you can use another installation option for installing on ARM: https://docs.brew.sh/Installationなので公式ドキュメントの通り
/opt/homebrew にインストールしましょう(別に/usr/localに入れても問題ないと思うが)。% cd /opt % sudo mkdir homebrew && curl -L https://github.com/Homebrew/brew/tarball/master | tar xz --strip 1 -C homebrewインストールが完了したら、
~/.zshrcに以下を書き込んでパスを通しましょう。export PATH="/opt/homebrew/bin:$PATH" export PATH="/opt/homebrew/sbin:$PATH" export C_INCLUDE_PATH="/opt/homebrew/include:$C_INCLUDE_PATH" export CPLUS_INCLUDE_PATH="/opt/homebrew/include:$CPLUS_INCLUDE_PATH"Homebrewでパッケージをインストール
まず注意点として、Homebrewでパッケージをインストールした際にApple Silicon向けにビルドされたバイナリが即インストールされることは少なかったです。
基本的にインストール時にビルドプロセスが走ると思って問題ないです。GCC
インストール不可です
今(20210107)Homebrewで入手可能なバージョンは10.2.0です。
一方、gccをApple Siliconに対応させるには少なくともバージョン11が必要のようですが、このメジャーアップデートが来るのは2021年中頃のようです(HomebrewのGithub issuesより)。
従ってC/C++のプログラミングをメインでやってる方は、、、M1チップ搭載のMBA/MBP購入は先行投資気味になりそうですね。
もちろんApple謹製のClang(gcc/g++コマンドにリンクされてる)はAppleアーキテクチャですし使えます。があまりC/C++erからは評判良くないらしいですよね。2021/01/08追記 インストール出来るようになったっぽい!
ついさっき
brew updateしたところ、インストールできました。% brew install gcc Updating Homebrew... ==> Auto-updated Homebrew! Updated 2 taps (homebrew/core and homebrew/cask). ==> New Formulae jpeg-xl ==> Updated Formulae Updated 17 formulae. ==> Updated Casks Updated 6 casks. # (中略) ==> Installing dependencies for gcc: isl, mpfr and libmpc ==> Installing gcc dependency: isl ==> Pouring isl-0.23.arm64_big_sur.bottle.tar.gz ? /opt/homebrew/Cellar/isl/0.23: 72 files, 5.0MB ==> Installing gcc dependency: mpfr ==> Pouring mpfr-4.1.0.arm64_big_sur.bottle.tar.gz ? /opt/homebrew/Cellar/mpfr/4.1.0: 30 files, 5.2MB ==> Installing gcc dependency: libmpc ==> Pouring libmpc-1.2.1.arm64_big_sur.bottle.tar.gz ? /opt/homebrew/Cellar/libmpc/1.2.1: 13 files, 432.8KB ==> Installing gcc ==> Pouring gcc-10.2.0_2.arm64_big_sur.bottle.tar.gz ? /opt/homebrew/Cellar/gcc/10.2.0_2: 1,367 files, 312.4MB % gcc-10 --version gcc-10 (Homebrew GCC 10.2.0_2) 10.2.1 20201220 Copyright (C) 2020 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.少なくともGCC11が来ないと対応できないって話はなんだったのか。。
まあこれでC/C++erも安心してApple Siliconで遊べますね!Python3.9.x
インストール可能です。
ただしソースコードからビルドする形になります。
何回かインストールしなおしましたが、インストール時に自動でビルドが始まる時もあれば
--build-from-sourceオプションを付けないと進めない時もありました。OpenJDK(8,11,13,15,16EA,17EA)
これはHomebrewではビルドに失敗しインストールできませんでした。
なのでZuluのビルドを掴みましょう。おわりに
正直私は上記くらいしか使わないのでこれくらいしか書けませんが、
Apple Silicon搭載Macでインストールできるのか確認して欲しいパッケージなど
ありましたらコメントなどで書いてください。たまにやります。
あとこの記事も随時更新します。
brew updateをしてるとわかりますが、毎日膨大な量のパッケージが追加・更新されてます。
Homebrew-coreのCommit数は平均800/dayくらいあり、パッケージのApple Silicon対応は確実に進んでいるとわかります。余談ですが、Jailbreak端末向けのバイナリってApple Silicon Macで動いたりしないんですかね?いつか調査するかも。
Qemuをビルドして(面倒だった)ARM版Win10を動作させた話は別の記事に書きます。
- 投稿日:2021-01-08T20:30:02+09:00
ChangeFinder(変化点検知)を実装してみた
- 製造業出身のデータサイエンティストがお送りする記事
- 今回は時系列データの変化点を検知する異常検知手法のChangeFinderを実装(サンプルコード)しました。
はじめに
過去に異常検知手法や時系列データの解析手法を整理しておりますので、興味ある方はそちらも参照して頂けますと幸いです。
ChangeFinderとは
自己回帰モデル(ARモデル)の学習に「オンライン学習」と「忘却機能」を追加したSDARアルゴリズムを活用した手法が「ChangeFinder」です。山西先生がNEC在籍時代に発明した手法だそうです。詳細はデータマイニングによる異常検知に詳しく書かれておりますのでご参照ください。
下記に簡単にアルゴリズムを整理しておきます。
- SDARで確率密度を学習(第一段階)
- 各時点での変化点スコアを算出
- 変化点スコアを平準化
- SDARで確率密度を学習(第二段階)
- 各時点での変化点スコアを算出
ChangeFinderの実装
今回はchangefinderのライブラリーにサンプルコードがありましたので、そちらを活用しました。
pythonのコードは下記の通りです。
# 必要なライブラリーのインポート import numpy as np import changefinder import matplotlib.pyplot as plt %matplotlib inline最初に必要なライブラリーをimportします。
次に今回使用する3種類の正規分布に従う乱数を発生しさせます。data=np.concatenate([np.random.normal(0.7, 0.05, 300), np.random.normal(1.5, 0.05, 300), np.random.normal(0.6, 0.05, 300), np.random.normal(1.3, 0.05, 300)])次にChangeFinderで変化点スコアを算出します。
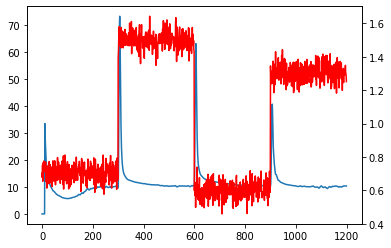
cf = changefinder.ChangeFinder(r=0.01, order=1, smooth=7) ret = [] for i in data: score = cf.update(i) ret.append(score)最後に結果を可視化します。
赤線が元のデータ、青線が変化点スコアです。fig = plt.figure() ax = fig.add_subplot(111) ax.plot(ret) ax2 = ax.twinx() ax2.plot(data,'r') plt.show()
今回、ChangeFinderで設定したパラメータは下記3つです。
- r:忘却パラメータ(小さくすると過去の影響が大きくなり、変化点のバラツキが大きくなります)
- order:ARモデルの次数
- smooth:平滑化の範囲(長くすれば長くするほど外れ値ではなく「変化」が捉えられますが、大きくしすぎるとそもそも変化そのものが捉えづらくなります)
今回のデータセットでは、変化点が顕著に分かるため上手く検知できているように見えますが、実際私が現場のデータで使った時はパラメータチューニングに苦労しました。
さいごに
最後まで読んで頂き、ありがとうございました。
今回は、時系列データの変化点を検知する異常検知手法のChangeFinderについてサンプルコードを確認しました。訂正要望がありましたら、ご連絡頂けますと幸いです。

- 投稿日:2021-01-08T20:29:34+09:00
不確かさを扱える新しい勾配ブースティングNGBoostを実装してみた
- 製造業出身のデータサイエンティストがお送りする記事
- 今回はデータ解析でよく使われる勾配ブースティングの派生アルゴリズムで、不確実性を考慮した予測が可能なNGBoostを実装してみました。
はじめに
scikit-learnを活用した機械学習の予測モデルは過去の記事に書いておりますので、そちらを参照ください。
今回はNGBoostのみ書きます。NGBoostとは
NGBoost(Natural Gradient Boosting)とは、「予測の不確かさ」を扱うことができる手法です。一般的な回帰モデルの場合は、1つの予測値を出力しますが、NGBoostでは、その値である確率も予測することができます。
基本的な考え方は、各入力における出力の確率分布をパラメータセットの形で表現し、勾配ブースティングの手法によりこのパラメータを算出します。
NGBoostは回帰問題だけでなく、分類問題などにも利用できます。
詳細は元の論文を読んでください。私も全てを完璧に理解できておりませんので、理論を理解しながら現場で使ってみたいと思っております。NGBoostの実装
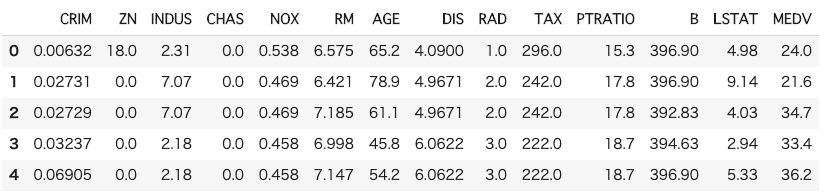
今回はUCI Machine Learning Repositoryで公開されているボストン住宅の価格データを用いて予測モデルを構築します。
項目 概要 データセット ・boston house-price サンプル数 ・506個 カラム数 ・14個 最初にライブラリーをインストールします。詳細な使い方はuser guideを参照ください。
pip install --upgrade git+https://github.com/stanfordmlgroup/ngboost.gitpythonのコードは下記の通りです。
import pandas as pd import numpy as np from sklearn.datasets import load_boston # データセットの読込み boston = load_boston() # データフレームの作成 # 説明変数の格納 df = pd.DataFrame(boston.data, columns = boston.feature_names) # 目的変数の追加 df['MEDV'] = boston.target # データの中身を確認 df.head()
具体的なモデルの学習は下記になります。
# ライブラリーのインポート from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split # 学習データと評価データを作成 x_train, x_test, y_train, y_test = train_test_split(df.iloc[:, 0:13], df.iloc[:, 13], test_size=0.2, random_state=2) #データを標準化 sc = StandardScaler() sc.fit(x_train) #学習用データで標準化 x_train_std = sc.transform(x_train) x_test_std = sc.transform(x_test) # スコア計算のためのライブラリ from sklearn.metrics import r2_score from sklearn.metrics import mean_absolute_error # ライブラリーのインポート from ngboost import NGBRegressor # モデルの学習 ngb = NGBRegressor() ngb.fit(x_train_std, y_train) # 予測 pred_ngb = ngb.predict(x_test_std) # 評価 # 決定係数(R2) r2_ngb = r2_score(y_test, pred_ngb) # 平均絶対誤差(MAE) mae_ngb = mean_absolute_error(y_test, pred_ngb) print("R2 : %.3f" % r2_ngb) print("MAE : %.3f" % mae_ngb) # 変数重要度 print("feature_importances = ", ngb.feature_importances_)出力結果は下記です。
[iter 0] loss=3.6377 val_loss=0.0000 scale=1.0000 norm=6.6433 [iter 100] loss=2.7355 val_loss=0.0000 scale=2.0000 norm=5.1141 [iter 200] loss=2.1841 val_loss=0.0000 scale=2.0000 norm=3.4826 [iter 300] loss=1.9234 val_loss=0.0000 scale=1.0000 norm=1.5236 [iter 400] loss=1.7831 val_loss=0.0000 scale=1.0000 norm=1.4034 R2 : 0.907 MAE : 2.066 feature_importances = [[0.07639064 0.00286589 0.03962475 0.01478072 0.05049657 0.20370851 0.06774932 0.14828321 0.02071867 0.06616878 0.06283506 0.07555015 0.17082773] [0.0834246 0.00451744 0.04685921 0.00659447 0.04612649 0.22176486 0.05597659 0.14181822 0.0302414 0.0725739 0.07465938 0.08480453 0.1306389 ]]予測値と実測値を散布図で表してみようと思います。
# ライブラリーのインポート import matplotlib.pyplot as plt %matplotlib inline plt.xlabel("pred_ngb") plt.ylabel("y_test") plt.scatter(pred_ngb, y_test) plt.show()
使用したデータは一緒なので過去にscikit-learnを使用して構築した手法MAEを比較してみたいと思います。
手法 MAE NGBoost 2.066 SVR 2.904 GBDT 2.097 RF 2.122 ElasticNet 3.080 Lasso 3.071 Ridge 3.093 パラメータチューニングも何も実施していないので、一概にNGBoostが一番良いとは言えませんが、良さそうですね。
さいごに
最後まで読んで頂き、ありがとうございました。
今回はとりあえずNGBoostをライブラリーを使って実装しただけなので、今後は実務でも使ってみようと思います。訂正要望がありましたら、ご連絡頂けますと幸いです。

- 投稿日:2021-01-08T20:23:15+09:00
ベイズ推定に基づく線形回帰(最小二乗推定,最尤推定,MAP推定,ベイズ推定)
背景
回帰問題の目的は,$N$個の観測値と対応する目標値からなる訓練データ集合が与えられたとき,新しい観測値に対する目標値の値を予測することである.今回扱う線形回帰モデルは,多項式は調節可能なパラメータの線形結合という特徴を利用した最も単純なモデルである.固定された基底関数の入力変数に関して非線型な関数の固定された集合結合をとることにより,有用な関数のクラスが得られる.
観測されたデータ$D={(x_i,y_i);i=1,2,...,n}$に対して,基底関数の線形結合に基づく回帰関数モデルを以下のように定義する.ここで$\Phi$を$x$の基底関数,$\epsilon$を誤差項とする.
y_i= \Phi w+ \epsilonベイズ線形回帰について
最小二乗推定
最小二乗推定は,回帰モデルによる予測誤差の二乗和$S(w)$を最小化する$\hat{w}$を求める手法である.$S(w)$を$w$で偏微分し,$\hat{w}$を求める.
S(w)=\epsilon^{T}\epsilon=(y-\Phi w)^T(y-\Phi w)\frac{dS(w)}{dw}=-\Phi^{T}y+\Phi^T\Phi w$\frac{dS(w)}{dw}=0$のときを考えると,
\hat{w}=(\Phi^T\Phi)^{-1}\Phi^{T}y従って,最小二乗推定による予測モデルは以下のようになる.
\hat{y}=\Phi\hat{w}=\Phi(\Phi^T\Phi)^{-1}y最尤推定
最尤推定は,尤度$P(y,w)$を最大化する$\hat{w}$を求める手法である.誤差項に正規分布を仮定したモデルを考える.このとき観測値$y$は平均$\Phi w$,分散行列$\sigma^2I_n$のn次元正規分布に従う.よって尤度は,以下のように与えられる.
y= \Phi w+ \epsilon,\epsilon \sim \mathcal{N}(0,\sigma^2I_n)P(y\mid w,\sigma^2)=\mathcal{N}(\Phi w,\sigma^2I_n) =\frac{1}{(2\pi\sigma^2)^{\frac{n}{2}}}exp\{-\frac{1}{2\sigma^2}(y-\Phi w)^T(y-\Phi w)\}$P(y\mid w)$の対数を$w$で偏微分し,$\hat{w}$を求める.
\log P(y\mid w) = -\frac{n}{2}\log(2\pi\sigma^2)-\frac{(y-\Phi w)^T(y-\Phi w)}{2\sigma^2}\frac{1}{P(y\mid w)}\frac{P(y\mid w)}{dw}=-(\Phi^{T}y+\Phi^{T}\Phi w)$\frac{dP(y\mid w)}{dw}=0$のときを考えると.
\hat{w}=(\Phi^T\Phi)^{-1}\Phi^{T}y従って,最尤推定による予測モデルは以下のようになる.
\hat{y}=\Phi\hat{w}=\Phi(\Phi^T\Phi)^{-1}yこれは,最小二乗法によって求められる予測モデルと同じである.
MAP推定
最小二乗法,最尤推定に基づく方法では,モデルパラメータの数が多く,観測データの数が小さい時に過学習を起こしやすいという問題点がある.過学習が生じると,汎化性能が期待できないため,過学習を防ぐことが重要となる.MAP推定は,$w$を確率変数として扱う.
$w$の事前分布と観測データの尤度関数を以下のように導入する.$\alpha$,$\beta$はハイパーパラメータとする.P(w;\alpha)=\mathcal{N}(w\mid0,\alpha^{-1}I_n)P(y \mid w;\beta)=\mathcal{N}(\Phi w,\beta^{-1}I_n)MAP推定では,$w$の事後分布$P(w \mid y)$を最大化する$\hat{w}$を求める手法である.
ベイズの定理より,P(w \mid y)=\frac{P(y \mid w)P(w)}{P(y)}ここで.$P(y|w)$は尤度を,$P(w)$は事前確率を表す.
P(w \mid y)=\frac{\frac{1}{(2\pi \beta^{-1})^{\frac{n}{2}}}exp\{-\frac{1}{2\beta^2}(y-\Phi w)^T(y-\Phi w)\frac{1}{(2\pi \alpha^{-1})^{\frac{n}{2}}}exp\{-\frac{1}{2\alpha^2}w^{T}w\} }{P(y)}P(w \mid y)=\frac{\frac{1}{ (2\pi)^{n}(\alpha\beta)^{-\frac{n}{2}} } exp\{-\frac{1}{2\beta^2} (y-\Phi w)^T(y-\Phi w) - \frac{1}{2\alpha^2} w^{T}w \} }{P(y)}$P(w \mid y)$を最大化する$\hat{w}$は,$Z=-\frac{1}{2\beta^2} (y-\Phi w)^T(y-\Phi w) - \frac{1}{2\alpha^2} w^{T}w $を最大化する$\hat{w}$に等しい.
\frac{dZ}{dw}=-\frac{1}{2\beta^{-1}}(-\Phi^T+\Phi^T\Phi w)- \frac{1}{2 \alpha^{-1}}w^{T}w$\frac{dZ}{dw}=0$のときを考えると,
\hat{w}=(-\frac{\alpha}{\beta}I_n+\Phi^T\Phi)^{-1}\Phi^{T}y従って,MAP推定による予測モデルは以下のようになる.
\hat{y}=\Phi\hat{w}=\Phi(-\frac{\alpha}{\beta}I_n+\Phi^T\Phi)^{-1}\Phi^{T}yベイズ推定
最小二乗法,最尤推定,MAP推定では,パラメータの推定値を一つの解として求めた.しかし,これではデータの予測にパラメータの不確かさを考慮することができない.事後分布をそのまま確率分布として取り扱うことで,パラメータ推定の不確かさを加味した予測分布を求める.MAP推定では,$P(w \mid y)$の最大化を考えたため,$P(D)$については無視できたが,ベイズ推定では考える必要がある.同時確率$P(y,w)$から一方の確率変数を取り除き,周辺確率$P(y)$を求める.
P(y)=\int P(y\mid w)P(w)dwP(w \mid y) = \frac{P(y \mid w)P(w)}{\int P(y\mid w)P(w)dw}ここで,ガウス分布に対するベイズの定理より,
P(w \mid y) = \mathcal{N}(\mu_N,\Sigma_N)参考文献1のP90ガウス分布の周辺分布と条件付き分布を用いて計算すると
\mu_N=(\frac{\alpha}{\beta}I_n+\Phi^{T}\Phi)^{-1}\Phi^{T}y\Sigma_{N}=(\alpha I_n + \beta \Phi^{T}\Phi)^{-1}従って,以上よりベイズ推定による予測モデルは以下のようになる.
\hat{y}=\Phi\hat{w}=\Phi(-\frac{\alpha}{\beta}I_n+\Phi^T\Phi)^{-1}\Phi^{T}y\Sigma_{N}=(\alpha I_n + \beta \Phi^{T}\Phi)^{-1}実験
$D={(x.train_i,y.train_i);i=1,2,...,15}$の訓練データに対して,最小二乗推定,最尤推定,MAP推定,ベイズ推定を用いて予測モデルを作成した.それぞれのモデルで$D={(x.test_i,y.test_i);i=1,2,...,100}$のテストデータに対して予測分布を確認した.
コードはこちら基底関数は以下のものを用いる.
f_j(x)=x^{j},j=0,1,...9ハイパーパラメータ$\alpha=10,\beta=10$とする.
- 最小二乗推定

- MAP推定

- ベイズ推定

決定係数$R^2$により点推定の評価を行う.決定係数とは回帰によって導いたモデルの当てはまりの良さを表現する値で、モデルによって予測した値が実際の値とどの程度一致しているかを表現する評価指標である.決定係数$R^2$は実際のデータを$(x_i,y_i)$、回帰式から推定されたデータを$(x_i,\bar{y_i})$として$R^2=1-\frac{\sum_{i=1}^n{(y_i-\hat{y_i})^2}}{\sum_{i=1}^n(y_i-\bar{y})^2}$で求められる.0から1の範囲で1に近づくほど良い値である.
尤度関数の分散$\beta$の値を変更する.
- $\beta=50$のときのベイズ推定

- $\beta=100$のときのベイズ推定

- $\beta=1000$のときのベイズ推定

まとめ
- 回帰問題に対して,最小二乗法,最尤推定,MAP推定,ベイズ推定を適応して計算した.訓練データが存在しない部分の予測精度が下がることがわかった.
- 点推定である最小二乗法,最尤推定,MAP推定については,今回の場合においてはMAP推定の方がより外れ値が減少し,すぐれたモデルを作成できることがわかる.
- ベイズ推定,MAP推定においては,尤度関数の分散を小さくするほど,誤差が小さくなるが,分散を小さくしすぎると過学習を起こして汎化性能が下がることがわかった.
参考文献
- C.M.ビショップ,"パターン認識と機械学習上ベイズ理論による統計的予測",シュプリンガー・ジャパン
- 須山 敦志,"ベイズ推論による機械学習入門", 株式会社講談社サイエンティフィク

- 投稿日:2021-01-08T20:19:14+09:00
【SIGNATE】【lightgbm】コンペ アメリカの都市エイムズの住宅価格予測 参加記録 (2/2)
はじめに
SIGNATEで開催されているBegginer向けコンペ
【第5回_Beginner限定コンペ】アメリカの都市エイムズの住宅価格予測 に参加したため、参加記録を書きます。
こちらの続き。やったこと3 (データの理解)
3-1 学習データ・検証データチェック
train.csv
データ数: 3000
カラム数: 47
data_description.txtに記載されている特徴量の約半分。運営が変なデータは消してくれてそうです。test.csv
データ数: 20003-2 欠損値チェック
LightGBMは欠損値も良い具合に扱ってくれるらしい(エラーにならないだけ?)ですが、
念のため、確認したところ全カラムで欠損数は0。考慮不要なデータでした。print(train_data.isnull().sum()) print(test_data.isnull().sum())目的変数の確認
'Sale Price' が予測すべき販売価格。
最大: 418000
最小: 80000sns.displot(train_data['SalePrice'], height=5, aspect=1)
割と正規分布に即したデータに見えるため、線形回帰モデルでもそのまま適用できそうに見えます。
250000$以上のデータが外れてるように見えなくもないですが決定木系ですし、
データ数もそこそこあるのでそのままにしときます。3-3 重要度の高いデータの確認
重要度が高い一部のデータは直接確認しました。
'Garage Cars', 'Garage Area' はseabornが固まってグラフ表示できなかったのでスキップ。fig, ax = plt.subplots(2, 2, figsize=(10, 10)) sns.histplot(x=train_data['BsmtFin SF 1'], ax=ax[0, 0]) sns.histplot(x=train_data['Bsmt Unf SF'], ax=ax[0, 1]) sns.histplot(x=train_data['Bsmt Full Bath'], ax=ax[1, 1]) sns.histplot(x=train_data['Total Bsmt SF'], ax=ax[1, 0])
テストデータも同じ傾向だったため特徴量として大きな問題はなさそうでした。
以下気になった特徴量。
- BsmtFin SF 1: 地下(種別1) の広さ (平方フィート)。
試しに 横軸 BsmtFin SF 1 (平方フィート), 縦軸 SalePrice ($) の 散布図を見ます。
1500平方フィート以上に100000\$ 以下のSale Priceは無く、
逆に250000\$の層が厚いことから確かに相関はありそうです。
500平方フィート付近にある400000\$ のデータは外れ値として消しても良いかと思いましたが、
決定木は外れ値に強いとのことで対処していないです。
真面目に見るならこの1データだけ高い値段が付いた理由が分かれば残し、不明なら削除とすべきかもしれません。
(BsmtFin SF 1が最も重要度が高いので、BsmtFin SF 1での外れ値の悪影響は 他の特徴量での優位性を上回ると考えて問答無用で消すべき?)
Total Bsmt SF: 地下の広さらしいですが、マイナスが入るのが変に見えます。
が、テスト対象にもマイナス値データがあるためそのままにしています。
但し、気持ち悪かったのでマイナスなら値を無理矢理0にしちゃいました。
'Garage Cars', 'Garage Area'も最小値から同じ状態だったため同じ対処をしてます。Garage Cars: 車の収容台数だと思うのですが、1.998002859 とか凄い中途半端な値で怪しい、、、影響度は高いので変にいじらずそのままです。
3-4 データ型の確認
1-2 ではtrain()を通すために一括でobject型をカテゴリカル型に変換してます。
これらの特徴量は 文字列=何らかの種別を表しており妥当かと思います。他の特徴量について、現在の型のままで良いか確認し、
結論として 以下のデータはカテゴリカルデータに変えました。
カラム名 概要 理由 MS SubClass Identifies the type of dwelling involved in the sale.
セール中の種別?各データは数値ですが
190 = 2 FAMILY CONVERSION - ALL STYLES AND AGES というような種別となってます。Overall Qual Rates the overall material and finish of the house.
で、物件の評価。各データは数値ですが
10 = Very Excellent というような10段階評価の種別となってます。Overall Cond Rates the overall condition of the house.
で、物件の評価。各データは数値ですが
10 = Very Excellent というような10段階評価の種別となってます。Year Built Original construction date
建築年年なのでカテゴリカルデータ化 Year Remod/Add Remodel date (same as construction date if no remodeling or additions)
改装年? ただ、Year Built > Year Remod/Add のデータが多いのが謎です。年なのでカテゴリカルデータ化 Mo Sold Month Sold (MM)
販売月月なのでカテゴリカルデータ化 Yr Sold Year Sold (YYYY)
販売年年なのでカテゴリカルデータ化 本当は各カテゴリカルデータに data_description.txtに書かれている種別以外のデータが混入してないか調べるべきですが、今までのデータの感じだと 割と整理されてるデータに見えたので やめました
3-5 特徴量追加
思いついた追加特徴量と採否は以下の感じです。
特徴量 想定 採否 販売年(Yr Sold) - 建築年(Year Built) 築年数のイメージ。 age列として採用。 改装年(Year Remod/Add) - 建築年(Year Built) 改装が無い場合、'Year Remod/Add' = 'Year Built' となるため、それを表現する特徴量を追加したかったです。それだけならBooleanで良いですが、どうせなら差も影響があるのではと思って差分計算してます。 sub_year列として採用。 ガレッジのサイズ(Garage Area) / 車の台数(Garage Cars) 車一台当たりの広さが計算できる?
ガレッジに余裕があれば高級感は出そうと考えました。不採用。Garage Carsのデータの中身に確信が持てなかったのと、アメリカは土地が広いのでそんな細かい広さとか気にしないぜってイメージ先行で。 インフレ率とか物価指数 Yr Soldは2006 - 2010 の4年間の範囲。
仮に年間インフレ率3%で考えると、2006年に10万\$の物件は2010年には11万2000\$ (計算合ってる?)になるはずなので、
例えば2000年における100ドルを基準に今年はいくらになってるか、みたいな値があると良いかと思いました。不採用。調べる手間が大きいのと、Yr Soldの年データに織り込まれてると信じてやめた。割と気になるので誰か試してほしい。 リーマンショック Yr Soldは2006 - 2010 の4年間の範囲。リーマンショックは2008年のため、その前後で住宅関係の価格に影響が出てる可能性は高いと考えました。 不採用。具体的な指標が思いつかなったのと、Yr Soldの年データに織り込まれてると信じてやめた。サブプライム住宅ローン危機辺りのニュースを調べれば何か良い指標はありそうですが。 結果3
特徴量編集時点の順位
RMSE: 26523.4069341
順位: 85/552 のため上位16%程度RMSEは30程度改善、順位はほぼ変わらずで余り効果はなかった。
追加した特徴量のimportanceを見た感触では、上位40%程度の重要度だったので
全く無駄ではなかったかもしれません。やったこと4 (パラメータ調整)
現時点ではLightGBMをほぼデフォルトパラメータで設定していたため、
過学習回避方向でパラメータ設定をしました。
参考URL
https://lightgbm.readthedocs.io/en/latest/Parameters-Tuning.html
あと、いろいろググったのが混ざってるかもしれません、、変更前
lgbm_params = { 'task': 'train', 'boosting_type': 'gbdt', 'objective': 'regression', 'metric': 'rmse', 'max_depth' : 10 } model = lgb.cv(lgbm_params, lgb_train, num_boost_round=1000, early_stopping_rounds=50, verbose_eval=50, nfold=7, shuffle=True, stratified=False, seed=42, return_cvbooster=True, )変更後
lgbm_params = { 'task': 'train', 'boosting_type': 'gbdt', 'objective': 'regression', 'metric': 'rmse', 'learning_rate': 0.01, 'max_depth' : 7, 'num_leaves': 80, 'bagging_fraction': 0.8, 'bagging_freq': 1, 'feature_fraction': 0.9, } model = lgb.cv(lgbm_params, lgb_train, num_boost_round=10000, early_stopping_rounds=100, verbose_eval=50, nfold=10, shuffle=True, stratified=False, seed=42, return_cvbooster=True, )変更パラメータ
パラメータ before -> after 修正イメージ learning_rate 0.1 -> 0.01 過学習気味だったので、10分の1にして細かく学習できるようにした。
代わりに num_boost_round を10倍にしている。max_depth 10 -> 7 一般的に5-10, 大きいほど過学習しやすいとの記憶なので下げた。 num_leaves ? -> 80 最大値 2^(max_depth) から 少し下げた値が良いとの公式Documentに従った。 bagging_fraction,
bagging_freq1 -> 0.8
1 -> 1バギングする割合。過学習回避に有効とのことなので少し下げた。 feature_fraction 1 -> 0.9 サブサンプリングする割合。過学習回避に有効とのことなので少し下げた。
bagging_fractionとの違いがあまり分かっていないが、bagging_fractionの解説「like feature_fraction, but this will randomly select part of data without resampling」 とのこと。https://github.com/Microsoft/LightGBM/blob/master/docs/Parameters.rst結果4
学習曲線
「やったこと1」で train()関数を実行したコードのパラメータだけを書き換えた学習曲線
左側が変更前、 右側が変更後
変更前は 27回目の学習がevalのピークだったのに対し、
変更後は 404回目が最も精度が良く、変更前に対してスコアが高い&右側方向のスコアの減少が少なくなっており過学習の抑制に繋がっている。パラメータ設定時点の順位
RMSE: 26196.7174197
順位: 30/553 のため上位6%程度全体的に効果があった。
RMSEは350程度改善、順位は50位上昇。やったこと5 (パラメータ探索)
パラメータ改善の余地がありそうだったため、パラメータ探索を実施。
optuna というライブラリを使うと一発でできるらしい。
LightGBMのcv()関数は LightGBMTunerCV() に置き換えるだけでOKという謳い文句だが、、、変更前
lgbm_params = { 'task': 'train', 'boosting_type': 'gbdt', 'objective': 'regression', 'metric': 'rmse', 'learning_rate': 0.01, 'max_depth' : 7, 'num_leaves': 80, 'bagging_fraction': 0.8, 'bagging_freq': 1, 'feature_fraction': 0.9, } model = lgb.cv(lgbm_params, lgb_train, num_boost_round=10000, early_stopping_rounds=100, verbose_eval=50, nfold=10, shuffle=True, stratified=False, seed=42, return_cvbooster=True, )変更後
lgbm_params = { 'task': 'train', 'boosting_type': 'gbdt', 'objective': 'regression', 'metric': 'rmse', # 探索させたいパラメータ削除 } tuner_cv = lgb.LightGBMTunerCV( lgbm_params, lgb_train, num_boost_round=10000, early_stopping_rounds=100, verbose_eval=20, nfold=10, shuffle=True, stratified=False, seed=42, return_cvbooster=True, ) tuner_cv.run()でまじでできました。cv()が20秒位だったのに対し、LightGBMTunerCVは7分程度かかる。
このパソコンで初めてCPUを有効活用したかも。print(tuner_cv.best_params) {'task': 'train', 'boosting_type': 'gbdt', 'objective': 'regression', 'metric': 'rmse', 'feature_pre_filter': False, 'lambda_l1': 0.12711821269550255, 'lambda_l2': 6.733049435313309e-05, 'num_leaves': 62, 'feature_fraction': 0.4, 'bagging_fraction': 1.0, 'bagging_freq': 0, 'min_child_samples': 20}メモ: import optuna とやってるソースコードはバージョンが古い模様。
結果5
optuna使用時点の順位
RMSE: 26718.3022355
順位: 119/557 のため上位21%程度全体的に大きく下がった。
自分でグリッドサーチ組むよりは良いのか?
best_params に max_depthが無いのが気になった。他のパラメータから計算できるから不要なだけかもしれない。
とりあえず今の自分にoptunaは使いこなせないことが分かった。まとめ2
データ変換・パラメータ設定を行って、上位6%程度まで入ることができました。
※ 開催中コンペかつ、最終日が休日にかかるため もっと下がるはず。まだパラメータ最適化で伸びしろはありそうなため、
余裕あればもう少しパラメータ探索等をやってみようかと思います。CatBoost はデフォルトパラメータが優秀ってどこかの記事に書いてあったので
こっちのアルゴリズムに置き換えた方が早いかも?




- 投稿日:2021-01-08T19:54:40+09:00
中級者へのModern Python
はじめに
本記事の読者対象
- Pythonの開発環境・ツールをさらに覚えたい方
- よりモダンに近いPython環境が欲しい方
想定していない方
- Python自体がはじめての方
- Python上級者
説明すること・しないこと
説明する
- ツールのおおまかな説明
- ツールを使用する理由・嬉しさ
- 参考になるドキュメント・URL
説明しない
- 具体的なコマンド
- 細かい文法
Modern Python
大学院で研究をするようになってから、かなりの時間Pythonを書くようになりました。
なぜならば、研究で利用しやすいライブラリが豊富であり、かつ研究のようなイテレーションがはやいプロジェクトに対して非常に有効であるためです。しかし、Pythonは短期的にコードを試して動作を変更できる分、安定した動作が難しくなってきます。
たとえば、C++などはコンパイルを通す必要があるため、設計をうまく考えて実装する必要があります。
一方、Pythonはスクリプト言語なので最悪闇の設計をすると設計が適当でもなんとかなってしまいます。
ただ、このような後先考えないコードは将来的に大きな負債になります。
実際、締め切りが近い論文に合わせて急ピッチで書いたコードが現在自分の前に立ちはだかり、また1から設計・実装し直す羽目になりました。Pythonは良くも悪くも以下のような特徴があります。
- 型を設定しなくていい
- その分、変数名に思いを馳せることになる
- モジュールが多い
- バージョンがずれる
- パッケージマネージャーが豊富
- どれを使えばいいのかが分かりづらい
- 設計が甘くて良い
- 読み辛くなる
今回は、これらの問題を解決できる可能性があるツールについてまとめます。
ただし、実際の使い方や詳細については割愛しているため、他記事を参考ください。自分もはやくPythonに慣れて中級者になっていきたいです。
パッケージマネージャー
Pythonのパッケージマネージャーには多くの種類の組み合わせがあります。
以前pythonの環境構築戦争にイラストで終止符をどうやら打てないという記事でPythonの環境の構築について説明しました。
そこから自分の理解もある程度進み、今のPythonの環境構築これでいいかな〜と感じるものがあったため、それについてまとめようと思います。パターン1: pyenv + pipenv
pyenvは複数のPythonのバージョンを管理できます。
具体的には、Python3.7、Python3.8、Python3.9をそれぞれインストールして好きに切り替えることができます。
このようにPythonのバージョンを切り替えることによって、複数のプロジェクトに対応できます。
たとえば、昔から続いているプロジェクトのコードはPython2.7でしか動かないんだ!みたいなこともあります。
そのため、pyenvでバージョンを切り替えられるとうれしいわけです。しかし、pyenvはバージョンを切り替えることはできますが、仮想環境を作成することはできません。
この仮想環境とはプロジェクトごとに利用する環境のことを本記事では指します。もし仮想環境を切り分けられない場合を考えてみます。
機械学習のプロジェクト開発を行った後、別のプロジェクトに割り当てられDjangoの開発になったとします。
このとき、機械学習のpytorchのライブラリはDjangoに直接必要はありません。
大量にライブラリが増えてくると動作も重くなり、必要なバージョンの整合性が取れなくなってきます。
そのため、プロジェクトごとにライブラリをインストールできるような仮想環境が必要なわけです。この問題を解決すべく、
pipenvはあるバージョンのPythonにおいて複数の仮想環境を作成することができます。
venvをラップするような便利な機能がpipenvにたくさん備わっているのでオススメです。
また、ここでは詳しくは述べませんが、ライブラリのバージョン管理をより賢く行えます。まとめると、
pyenvでPython自体のバージョンを管理し、pipenvで特定のPythonのバージョンにおける仮想環境を管理します。
Macではbrewでpipenv, pyenv両方インストールできます。パターン2: pyenv + poetry
pyenvはさきほど出てきました。
今回、新しく出てきたのはpoetryになります。poetryはrustっぽくライブラリ管理ができるマネージャーのようです。
まだ触ったことがないため詳しくないのですが、tomlファイル1つですべてを管理するらしいです。かなり新しいマネージャーのようなので、今度触ってみたいです。
参考URL
型の導入
Pythonは型付けをしなくても動くスクリプト言語です。
そのため、初期段階ではかなりのスピードで開発できますが、後半になってくると変数に思いを馳せる時間が長くなり、実行時エラーに悩まされることが多くなります。そこで、Python3.5から導入された
typingなどを利用して型安全にコーディングできます。
しかし、プログラム実行時、変数に異なる型の内容が入っていてもエラーを出さないことに注意が必要です。実行時に異なる型が入っていても止まりません。
しかし、IDEの恩恵を受けやすくなったり、第三者がコードの意味を理解しやすくなるため、積極的に書いていきましょう。typing
def greeting(name: str) -> str: return 'Hello ' + namePython3.5から、上記のように変数や関数などに型を指定できるようになりました。
型を指定することで、IDEの恩恵を受けやすくなります。
また、長期的に見るとコーディングの効率化に繋がります。
Finalキーワードもあり、定数などをより安全に設定できます。詳しくは参考URLを御覧ください。
data classes
データを格納するクラスを簡単に作成するデコレータなどを提供します。
from dataclasses import dataclass @dataclass class InventoryItem: """Class for keeping track of an item in inventory.""" name: str unit_price: float quantity_on_hand: int = 0 def total_cost(self) -> float: return self.unit_price * self.quantity_on_handnamedtuple
名前をつけたタプルを宣言できます。
書き換えられないデータを保証できるので、変更しないものを管理するには便利そうです。可能であれば
typing.NamedTupleを継承したクラスでタプルを宣言したほうがわかりやすいです。class Employee(NamedTuple): name: str id: intジェネリクス
pydantic
FastAPIで採用されているライブラリです。
実行時に型情報を提供してくれます。from datetime import datetime from typing import List, Optional from pydantic import BaseModel class User(BaseModel): id: int name = 'John Doe' signup_ts: Optional[datetime] = None friends: List[int] = [] external_data = { 'id': '123', 'signup_ts': '2019-06-01 12:22', 'friends': [1, 2, '3'], } user = User(**external_data)型があっていないデータが入ると実行時でも例外を投げてくれます。
(一方typingなどは実行時エラーを投げません。そのため、型でおかしい箇所がよりわかりやすく、堅牢性が上がります。)参考URL
- typings
- dataclasses
- namedtuple
- pydantic
- Pythonではじまる、型のある世界
- pydanticを使って実行時にも型情報が適用されるPythonコードを書く
- PythonとType Hintsで書くバックエンド
- Python 3.9 時代の型安全な Python の極め方
docstring
docstringは、関数やクラスなどの情報を表す文字列です。関数やクラスがどのような引数・属性を持つのか、どのような振る舞いをするのかを文字列で記述します。
def add(x:int, y:int) -> int: """add function. xとyの和を計算する。 Attributes ---------- x: int 足される数 y: int 足す引数 Returns ------- int Notes ----- こういう関数に普通はここまで書くことはない(わかるので) """ return x + ydocstringのメリット
docstringを書くことで以下のようなメリットがあります。
- 他のチームメンバーに関数やクラスの振る舞いを伝えることができる
- ドキュメントとコードの距離が近い
- IDEなどにおいて、型や補足情報がより詳細になる
- 後述しますが、
Sphinxというドキュメント自動作成ツールでdocstringを利用できる- なにより将来の自分のためになる
スタイルの種類
docstringの書き方にはいくつかの流儀があります。
主なものは以下の3つです。
- reStructuredText
- NumPy
それぞれ書き方に特徴があります。
自分の好きな書き方を参照するのが良さそうです。
また、チームでdocstringの書き方が決まっていればその書き方にならいましょう。docstringは書き方のリファレンスが少なく、何かのライブラリを参考にすると良さそうです。
参考URL
- NumPyスタイルPython Docstringsの例
- numpydoc docstring guide
- Pythonのドキュメントコメントの書き方(NumPyスタイル編)
- [Python]可読性を上げるための、docstringの書き方を学ぶ(NumPyスタイル)
- チームメイトのためにdocstringを書こう!
- numpy/numpy
- Pythonでdocstringを書く (Numpy-Style)
スタイルガイド
コードを複数人で書くと、それぞれ異なるコードの書き方の癖が現れます。
"or'、文字数、変数の付け方などさまざまです。異なるコードスタイルを統一的にするべく、コードチェック・Lint・フォーマッターなどがあります。
これらを用いることでより統一的なPythonコードを書くことができます。この節では、そのうち自分が使っているものについてのみ触れます。
そのため、これら以外にも他のLinterがあります。ぜひ調べてみてください。pep
pepは、python enhancement proposalの略で、ドキュメント・コーディング規約を指します。
Pythonをより良くするための提案書であり、有名なのはpep8です。pep8は標準ライブラリなどのコーディング規約となっており、多くのPythonのコードはこのpep8を基準にしています。
flake8
flake8はpipでインストールできるコードのフォーマットをチェックするツールです。
コーディング規約を守っているかをチェックしてくれます。flake8は以下3つのライブラリのラッパーになっています。
- PyFlakes
- pycodestyle
- mccabe
flake8は、一行の文字数など、細かい規約の設定を行うことができます。
また、以下のようなflake8プラグインをpipインストールすると、flake8のコマンドを実行したとき、自動でそれらのプラグインも実行してくれます。
- flake8-docstrings
- flake8-mypy
- flake8-isort
- flake8-print
black
blackはコードフォーマッターです。
flake8は規約違反の箇所を教えるものでしたが、blackは実際にコードをフォーマットします。blackの特徴は比較的新しくできたものであり、そして変更できる設定がかなり少ないです。
そのため、blackを使っておけば多くのプロジェクトで似たような強制フォーマットになります。blackは非常に使いやすいため、ぜひ使いたいですね。
mypy
mypyは、コードのアノテーション・型を静的解析して、間違っている型を教えてくれます。
mypyのおかげで、間違っている箇所の型を治すだけで良くなります。しかし、利用しているライブラリなどに対してエラーを出すこともあるため、そのときはスタブを生成したり、すでにpipで配布されているスタブをインストールする必要があります。
isort
isortは、pythonのimportの順番を修正します。
flake8にisortプラグインがあるため、順番がおかしいと警告されたときにisortをすると良さそうです。参考URL
- pep
- flake8
- black
- mypy
- Configuring Flake8
- IntelliJやPyCharmでPythonファイルの変更を検知してflake8で文法チェックをする
- Pythonによるパッケージ開発
- PythonでLintをする
設定ファイル
Pythonのプロジェクトを作る際はいくつかの設定ファイルが出てきます。
この節ではこれらの設定ファイルについて説明します。setup.py
setup.pyはプロジェクトを第三者に向けて配布するために利用するファイルです。setuptools`というモジュールを用いて、プロジェクトのファイルをpipでインストールできるようなパッケージを作成します。
パッケージの情報やインストールの方法、URLなどを記述します。# https://packaging.python.org/tutorials/packaging-projects/?highlight=setup.py#creating-setup-py import setuptools with open("README.md", "r", encoding="utf-8") as fh: long_description = fh.read() setuptools.setup( name="example-pkg-YOUR-USERNAME-HERE", # Replace with your own username version="0.0.1", author="Example Author", author_email="author@example.com", description="A small example package", long_description=long_description, long_description_content_type="text/markdown", url="https://github.com/pypa/sampleproject", packages=setuptools.find_packages(), classifiers=[ "Programming Language :: Python :: 3", "License :: OSI Approved :: MIT License", "Operating System :: OS Independent", ], python_requires='>=3.6', )普段何気なく書いている
pip install numpyというコマンドは、setup.pyで作成されたパッケージをオンライン(PyPI)から取得し、site-packagesというディレクトリに入れています。プロジェクトをパッケージとしてオンラインで公開したい場合は
setup.pyを書きましょう。MANIFEST.in
setup.pyでプロジェクトからパッケージを作成するときに、pythonファイル以外をパッケージに含みたいときがあります。
たとえば、画像ファイルや音声ファイルなどが考えられます。このとき、
MANIFEST.inというファイルを作成することによって、より簡単にさまざま々なファイルをパッケージに含めてビルドできます。setup.cfg
setup.pyはパッケージとして公開、インストールするために必要です。
しかし、直接Authorやインクルードするファイルなどを指定してしまうと、後から変更しづらくなります。そこて、設定ファイルである
setup.cfgを追加で作成することによって、
パッケージで使う情報を独立して管理できます。
setup.pyを実行したときにsetup.cfgがあった場合は、情報を取り出して内容を上書きし、それからパッケージを作成します。[metadata] name = my_package version = attr: src.VERSION description = My package description long_description = file: README.rst, CHANGELOG.rst, LICENSE.rst keywords = one, two license = BSD 3-Clause License classifiers = Framework :: Django License :: OSI Approved :: BSD License Programming Language :: Python :: 3 Programming Language :: Python :: 3.5 [options] zip_safe = False include_package_data = True packages = find: scripts = bin/first.py bin/second.py install_requires = requests importlib; python_version == "2.6"requirements.txt
pipでインストールしたパッケージのリストが表されたファイルです。
必ずしもrequirements.txtという名前でなくても構いませんが、慣習的にこの名前になっています。このファイルを作成してGitHubなどに含めることによって、
pip install -r requirements.txtで簡単に第三者がパッケージをインストールできます。しかし、依存性の解決に向いておらず、ライブラリのバージョンの更新をし辛いなどの問題がrequirements.txtには存在しています。
そのため、現在はpipenvではPipfile、poetryではpyproject.tomlという、別のパッケージ管理のファイルが利用されています。Pipfile/Pipfile.lock
Pipfile,Pipfile.lockはrequirements.txtの問題を解決したpipenvの管理ファイルです。Pipfileには、直接依存するライブラリが記入されます。
たとえば、requestsを使ってURLを叩くプロジェクトをつくる場合には以下のようなPipfileを作成します。[[source]] url = "https://pypi.python.org/simple" verify_ssl = true name = "pypi" [packages] requests = "*"このとき、
requestsは他のライブラリに依存しています。
たとえば、chardetと呼ばれるファイルの文字コードを判別するライブラリを内部で使用しています。ここで、
chardetのバージョンはPipfileには記入されません。
一方で、ライブラリすべてのバージョンがPipfile.lockに記入されます。このとき、直接使用したいトップレベルのライブラリは
Pipfileで管理できるため、簡単にバージョンのアップグレードを検討できます。
また、依存するライブラリすべてのバージョンはPipfile.lockで管理されるため、第三者が同じ実行環境を簡単に用意できます。
これによって、依存性の問題をファイルを分けることで解決できました。pyproject.toml
pyproject.tomlはPEP 518で定義された、パッケージの設定を管理するファイルです。
最近ではpoetryというパッケージマネージャーがこのファイルを利用していますが、
poetryに限った設定ファイルではないらしいです。
対応している任意のパッケージマネージャーがpyproject.tomlを使えます。これまでは、
requirements.txt,setup.py,setup.cfg,MANIFEST.inなど多くのファイルがパッケージ公開に必要でしたが
pyproject.tomlはこのファイルのみでこれらをすべて補う機能を果たします。現在pipenvを使っていますが、poetryならびにpyproject.tomlに興味が湧いたため使ってみようと思います。
tox.ini
toxは、Pythonのテストを自動化するライブラリです。
toxコマンドを打つことで、tox.iniに書かれたテストの内容をすべて自動実行してくれます。1つの
pytestぐらいであれば、毎回そのコマンドを打つだけで良いです。
しかし、配布するバージョンに合わせて、python2.7,python3.8,python3.9など複数バージョンでテストを行いたいことがあります。
また、flake8のようなコーディング規約を満たしているかのテストだけを行いたい場合もあります。そこで、toxならびに設定ファイルtox.iniを使うことで、1コマンドのみですべてのテストを自動実行できます。
しかも、toxはtoxが扱う特別なディレクトリ内部に他のバージョンのPython環境を作成します。
そのため、テストごとに仮想環境が作成され、テスト間の依存がないという嬉しさもあります。[tox] # 使用する環境を指定する # 名前が一致しているflake8-py38は[testenv:flake8-py38]を実行する # py38は[testenv:py38]がないため[testenv]を実行する envlist = py38 flake8-py38 mypy-py38 [testenv] deps = pipenv # テストで実行するコマンド # このコマンドはpipenv installするだけなので当然テストをパスする commands = pipenv install [testenv:flake8-py38] basepython = python3.8 description = 'check flake8-style is ok?' commands= pipenv install pipenv run flake8 gym_md # 設定ファイル # https://flake8.pycqa.org/en/latest/user/configuration.html#configuration-locations [flake8-py38] max-line-length = 88 [testenv:mypy-py38] basepython = python3.8 description = 'check my-py is ok?' commands = pipenv install pipenv run mypy gym_md参考URL
- tox
- poetry
- Python Packaging User Guide¶
- ソースコード配布物を作成する
- pythonのsetup.pyについてまとめる
- Python パッケージ管理技術まとめ
- 【Techの道も一歩から】第21回「setup.pyを書いてpipでインストール可能にしよう」
- Pipfile/Pipfile.lockの必要性 -requirements.txtを用いる手法と比較して-
- Pythonのパッケージ周りのベストプラクティスを理解する
- Python パッケージングの標準を知ろう
- Pythonによるパッケージ開発
PyPI
PyPIは、pythonのライブラリをアップロードできるサイトです。
pip installをした場合などは、ここからダウンロードされています。テスト
pythonには複数のテストツールがあります。
unittest
標準のテストライブラリは
unittestです。
標準パッケージに含まれているため、インストールせずにテストを書けます。TestCaseクラスを継承し、testから始まるメソッドを作ります。
import unittest class TestStringMethods(unittest.TestCase): def test_upper(self): self.assertEqual('foo'.upper(), 'FOO') def test_isupper(self): self.assertTrue('FOO'.isupper()) self.assertFalse('Foo'.isupper()) def test_split(self): s = 'hello world' self.assertEqual(s.split(), ['hello', 'world']) # check that s.split fails when the separator is not a string with self.assertRaises(TypeError): s.split(2) if __name__ == '__main__': unittest.main()pytest
pytestは、サードパーティ製のテストライブラリです。
pytestは関数をベースにテストを行い、unittestよりも詳細なエラーを出してくれます。たとえば、以下のように出力値が間違っていた場合に、間違えた場所とその値を出力します。
pytestは簡単にかけて出力値もわかりやすいため、私はpytestを使っています。# content of test_sample.py def inc(x): return x + 1 def test_answer(): assert inc(3) == 5$ pytest =========================== test session starts ============================ platform linux -- Python 3.x.y, pytest-6.x.y, py-1.x.y, pluggy-0.x.y cachedir: $PYTHON_PREFIX/.pytest_cache rootdir: $REGENDOC_TMPDIR collected 1 item test_sample.py F [100%] ================================= FAILURES ================================= _______________________________ test_answer ________________________________ def test_answer(): > assert inc(3) == 5 E assert 4 == 5 E + where 4 = inc(3) test_sample.py:6: AssertionError ========================= short test summary info ========================== FAILED test_sample.py::test_answer - assert 4 == 5 ============================ 1 failed in 0.12s =============================doctest
doctestは、さきほど出てきたdocstringでテストを実行することを可能とします。
doctestをインポートすると、もしdocstringに>>>で実行例が書いてあったらその通りの動作になるかをテストしてくれます。
pytestのように、複雑なテストを書くことはできません。
しかし、docstringの中にあるため、テストとして利用しながら実行例として第三者に提示できます。
そのため、コードがどのような動作をするのか理解しやすく、コードも変更しやすくなります。def square(x): """Return the square of x. >>> square(2) 4 >>> square(-2) 4 """ return x * x if __name__ == '__main__': import doctest doctest.testmod()tox
さきほど出て来ましたが、toxを書くことで複数のテスト・コマンドを自動化できます。
参考URL
ドキュメント
Sphinxは、きれいなドキュメントを簡単につくることができるツールです。
Pythonのライブラリのリファレンスの多くは、このSphinxで作成されています。
Sphinxは、
reStructuredTextと呼ばれるマークアップ言語を用いてドキュメントを作成します。
このとき、自動でドキュメントを作成する機能であるsphinx-apidocが付属しており、docstringをPythonコードにきちんと書いていれば、コマンド一発でドキュメントを作成できます。
そのため、docstringを書くと型や情報などを将来のために残すことができ、しかもそれがそのままリファレンスになります。
これによって、ドキュメントがコードに比べて更新されなくなり、ドキュメントが形骸化してしまうという負債も発生しづらくなりますね。ただし、
shpinx-apidocによって作成されるbstファイルはデフォルトのため、立派なものにするためには自分で追加編集する必要があります。参考URL
cookiecutter
cookiecutterは、Pythonのきれいなプロジェクトを簡単に作成することができるツールです。
利用できるテンプレートがGitHubで公開されており、このテンプレートを指定するとよく設計されたプロジェクトを簡単にローカルに作成できます。
boilerplateに自分の情報を設定しながら
ローカルに作成できるツールと考えると良さそうです。たとえば、cookiecutter-pypackageを指定すると簡単に以下が設定されたプロジェクトを作成できます。
- 洗練されたプロジェクト設計
- TravisCIを用いたテスト自動化
- Shpinxを用いたドキュメント作成
- toxを用いた複数環境でのテスト
- PyPIへの自動リリース
- CLIインターフェイス(click)
これまで説明してきたものが一括で用意できるのでうれしいですね。
参考URL
さいごに
Pythonの開発ツールについてまとめてきました。
まとめる中で、自分もまだまだ理解が浅い、使いこなせていないと実感しました。
pythonicなコードが書けるように、毎日練習していきたいです。


- 投稿日:2021-01-08T19:36:29+09:00
複数フォルダ内の画像をそれぞれフォルダごとに別々のpdfに一括で変換する
はじめに
画像がたくさんあるのですが、そのままバックアップしようとするとランダムウライトになるからか、転送時間が遅い。
だからシーケンシャルなファイルにしようと思った。
zip圧縮しようとしても上限は4GB。
7zipを使ってすべて一つのファイルにしようとしたらサイズが大きすぎて扱いづらい
バッチファイルから一気に変換しようとしてもフォルダ名が悪さしてうまく作れないものが出てくる。
ならばpdfにしてしまおうと思ってプログラムを探した。pythonで複数画像をPDFファイルに変換する
これが見つかったが、少し使いにくかった。今回のプログラムは、これをもう少し使いやすくしたプログラムです。
基本的なコードは変わりません。画像まとめ ├── 2015 │ ├── img1.jpg │ ├── img2.jpg │ ├── img3.jpg ├── 2016 │ ├── img10.jpg │ ├── img11.jpg │ ├── img12.jpg ├── 20170 │ ├── img21.jpg │ ├── img22.jpg │ ├── img23.jpg ├── 2018 │ ├── img42.jpg │ ├── img125.jpg │ ├── img1000.jpgこんなフォルダがあったときに、
画像まとめ ├── 2015.pdf ├── 2016.pdf ├── 2017.pdf ├── 2018.pdfという風に一気にpdfに変換させたいときに使用する。
環境
Anaconda
python3.7
windows10
おそらくmac,Linuxでは動きませんライブラリのインポート
pip install img2pdfコード
makingpdf1.1.pyimport img2pdf from pathlib import Path #単処理 def ImageToPdf(outputpath, imagepath): ''' outputpath: pathlib.Path() imagepath: pathlib.Path() ''' lists = list(imagepath.glob("**/*"))#単フォルダ内を検索 #pdfを作成 with open(outputpath,"wb") as f: #jpg,pngファイルだけpdfに結合 #Pathlib.WindowsPath()をstring型に変換しないとエラー f.write(img2pdf.convert([str(i) for i in lists if i.match("*.jpg") or i.match("*.png") or i.match("*.jpeg")])) print(outputpath.name + " :Done") #複数フォルダをループ処理する while True: #作業フォルダ base_path = input("フォルダをd&Pして") base_path = base_path.strip(" \' ") #作業フォルダ内のディレクトリだけを抽出する glob = Path(base_path).glob("*") imagefolderlist = list([item for item in list(glob) if item.is_dir()]) #outputpathに指定ディレクトリと同名を指定する outputpathlist = list([item.with_name(item.name + ".pdf") for item in imagefolderlist]) #ループ処理を行う for outputpath,imagepath in zip(outputpathlist,imagefolderlist): try: ImageToPdf(outputpath,imagepath) except: pass変更点
pythonで複数画像をPDFファイルに変換する
のプログラムではファルダを一つしか指定できなく、パスを事前に書かなければならず、使いにくかった。
そこで、フォルダをドラックアンドドロップしてどんどん変換できるようにした。
また、.jpegの拡張子に対応していなかったので対応させた。使い方
画像まとめ ├── 2015 │ ├── img1.jpg │ ├── img2.jpg │ ├── img3.jpg ├── 2016 │ ├── img10.jpg │ ├── img11.jpg │ ├── img12.jpg ├── 20170 │ ├── img21.jpg │ ├── img22.jpg │ ├── img23.jpg ├── 2018 │ ├── img42.jpg │ ├── img125.jpg │ ├── img1000.jpgこんなフォルダがあったときに、
コードを実行すると
フォルダをd&Pしてと出てくるので、pdfにしたいフォルダが入っているフォルダをドラッグアンドドロップしてエンターを押してください。
上の例だと、「2018」などの中身をpdfにしたいフォルダではなく、「画像まとめ」のフォルダをドラッグアンドドロップしてください。
そうすると「画像まとめ」のフォルダ内にpdfが作成されていきます。問題点
pngファイルの場合、アルファチャンネルが含まれるとpdfに変換できない。
#まとめ
フォルダで分けられた画像をpdfに一気に変換するときに便利。
- 投稿日:2021-01-08T18:29:19+09:00
Python オレオレ、コレだけはやっておけ 2021
はじめに
日頃から意識しておきたいテクニックを簡単にまとめました( ^ω^)
実行環境編
# mac # python 3.9.0 pyenv install 3.9.0 # 指定のpython versionをインストール pyenv virtualenv 3.9.0 py3.9.0 # py3.9.0という仮想環境を構築 pyenv local py3.9.0 # カレントディレクトリ配下ではpy3.9.0の環境を利用するパッケージ管理編
パッケージ管理は、再現性のある開発環境を作成するのに重要です!!
パッケージ管理には、poetryがおすすめです。PoetryはPythonでの依存関係管理とパッケージングのためのツールです。 Poetryを使うとプロジェクトが依存しているライブラリを宣言でき、それらを管理 (インストールおよびアップデート) してくれます。
コレだけ覚えようpip install poetry==1.1.4 # 仮想環境にpoetryをインストール poetry init # pyproject.tomlを生成 poetry add numpy=1.19.5 # ライブラリのインストール poetry add black -D # 開発用ライブラリのインストール poetry remove numpy # ライブラリの削除 poetry install # pyproject.tomlを元に、環境を再現する? のようなファイルが生成され、自動的にパッケージ管理をしてくれます!!
pyproject.toml[tool.poetry] name = "3.9" version = "0.1.0" description = "" authors = ["Your Name <you@example.com>"] [tool.poetry.dependencies] # インストールしたライブラリが記述されます python = "^3.9" numpy = "1.19.5" [tool.poetry.dev-dependencies] # 開発用のライブラリが記述されます black = "^20.8b1" [build-system] requires = ["poetry-core>=1.0.0"] build-backend = "poetry.core.masonry.api"poetry.lock依存環境が自動的に記載されますコードフォーマッタ編
手軽に綺麗なコードが書ける環境を手に入れましょう!!
- linter:コードの書き方が良くない部分をチェックしてくれるもの
- コードフォーマッタ:コードを自動整形してくれるもの
コレだけ覚えようpoetry add flake8 mypy black isort -Dこれらのツールで実際にコード整形を行ってみましょう。
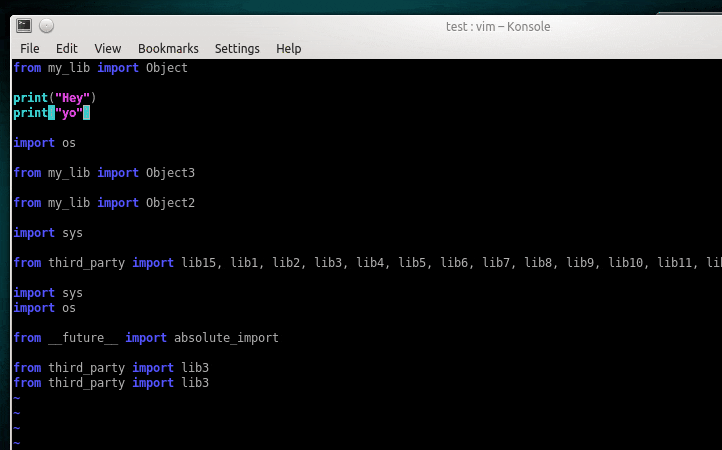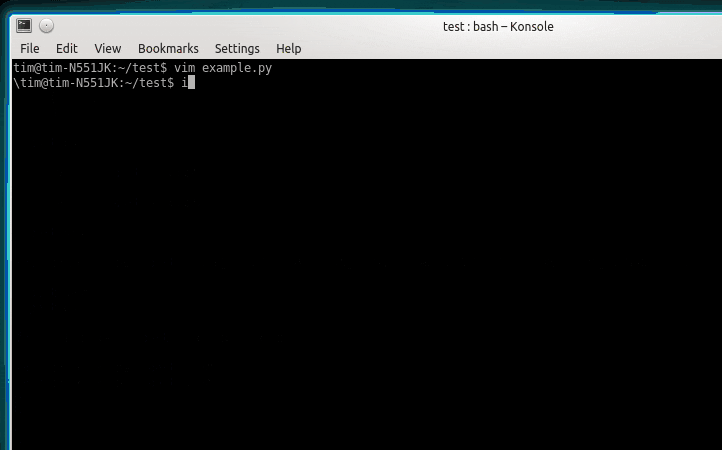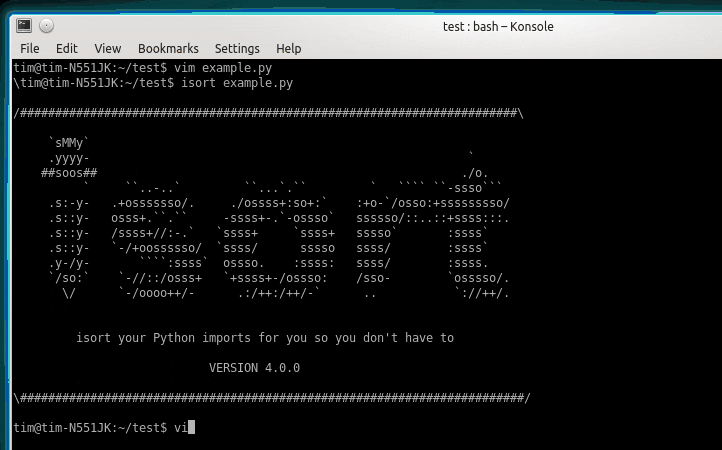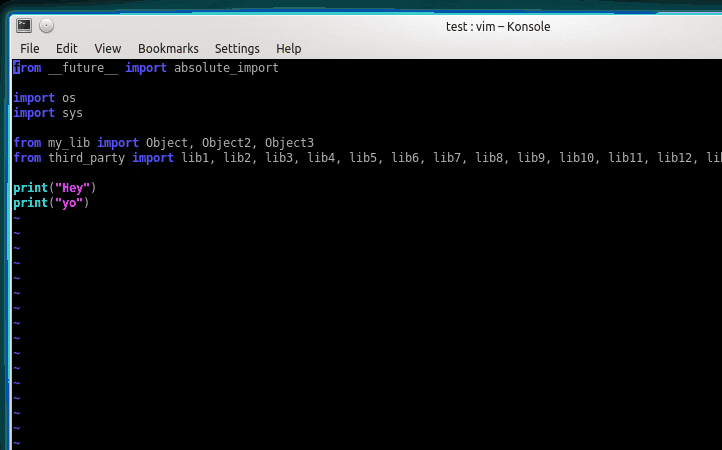
bad.pyimport numpy as np import os import sys print(sys.path) np.random.seed(seed=32) apple: str = 'リンゴ' apple = 100コレだけ覚えようflake8 bad.py --max-line-length=120 # デフォルトでは、1行の文字数が80と短いので、オプションで変更 # bad.py:2:1: F401 'os' imported but unused ← os、使ってないよ # bad.py:8:12: W292 no newline at end of file ← ファイルの最後に空行ないよ mypy bad.py --ignore-missing-imports --check-untyped-defs --no-strict-optional # bad.py:8: error: Incompatible types in assignment (expression has type "int", variable has type "str") ↑ str型の変数にintを挿入しようとしているよ # mypyは個人的に鬱陶しいので、緩めの制限にするオプションをつけています isort bad.py # Fixing bad.py black -l120 bad.py # reformatted bad.py # All done! ✨ ? ✨ # 1 file reformatted.good.pyimport sys # isortで並び替え # flake8が怒るので、osは手動で削除 import numpy as np print(sys.path) np.random.seed(seed=32) apple: str = "リンゴ" # blackがダブルクォテーションに自動整形 apple = "100" # mypyが怒るので、文字型を代入するように変更 # blackが空行を自動挿入ちなみに、
Python 3.9からアノテーションが?のように書けるようになったのですが、mypyがまだ対応できておらず、エラーになるようです…type.pynumbers: list[int] = [1, 2, 3]mypy type.py # type.py:1: error: "list" is not subscriptable, use "typing.List" instead ↑ 従来のtyping.Listを使ってね命名規則編
プログラム高速化編
さくっとできる高速化はやっておきたいものです!! (Cythonレベルは置いておく)
コレだけ覚えよう⭐️ループ処理: for文 (whileより高速) ⭐️算術演算 : numpy 左ほど高速でした(N=10000000) np.sum(np.arange(N)) < sum(range(N)) < sum([i for i in range(N)]) < np.sum(range(N)) ⭐️リストの初期化 : numpy np.empty(N) < [0] * N < list(range(N)) < [0 for i in range(N)] ⭐️appendはできるだけ回避 # 偶数を抽出するロジック good:X = [i for i in range(N) if i % 2 == 0] bad: X = [] for i in range(N): if i % 2 == 0: X.append(i) ⭐️条件 in を使うときには、集合(set)と照合しよう (listより超高速) nums = range(N) ≤ nums = set(range(N)) << nums = list(range(N)) X = [i for i in range(N) if i in nums] ⭐️いつでもindex指定が最強(key指定よりも。読みやすさとトレードオフ) num_values[i] < num_dict[i] ⭐️pandasでも同様 df = pd.DataFrame(data=range(N), columns=["A"]) df_values = df["A"].values [df_values[i] for i in range(N)] << [df.iat[i, 0] for i in range(N)], [df.at[i, "A"] for i in range(N)] ⭐️listはlist, numpyはnumpy 下手に混ぜると遅くなる [num_lists[i] for i in range(N)] < [num_numpy[i] for i in range(N)] ※番外編 ⭐️fileを開くなら with句 ⭐️辞書にアクセスするなら.get (keyエラーが出そうな場合) num_dict.get(i, DEFAULT)
- https://qiita.com/sotasato/items/cc36a532ba6487dd3dba
- https://python-guide-ja.readthedocs.io/en/latest/
おわりに
何かありましたら、コメント頂けると幸いです?
- 投稿日:2021-01-08T17:56:19+09:00
PyCaretの初心者向けまとめ(分類編)
はじめに
Pythonの機械学習ライブラリ「PyCaret」は、非常に簡単に動くライブラリですのでモデルの分析結果を出すまでは、初めての方でもサクサク出来るはずです。
ですが、モデルの種類や評価指標、解析結果の図の意味や見方がわからない場合「結局、どうしたらいいの?」という状況に陥ると思います。(私がそうでした・・・公式サイトは英語で、読むだけでも一苦労。)
このような中、共同でPyCaretを勉強してる方々の支えもあり色々と情報を仕入れることができましたので、私個人の備忘含め、PyCaretの全体像が理解できるようにこの記事に纏めてみました。※細かい内容では無いことを予めお伝えしておきます。
※この記事は「分類編」です。
「回帰編」は「PyCaretの初心者向けまとめ(回帰編)」を参照ください。1.PyCaretとは
1-1.PyCaretとは
「PyCaret」とは、様々な種類の機械学習を少しのコードで実現してくれる便利なライブラリです。
公式サイトでは次のように紹介されています。PyCaretは、Pythonのオープンソースのローコード機械学習ライブラリであり、仮説から考察までのサイクルタイムを短縮することを目的としています。
PyCaretを使用すると、選択したノートブック環境を使用して、データの準備からモデルのデプロイまで数秒で行うことができます。
https://pycaret.org/guide/ より引用
1-2.PyCaretのメリット
- コード実装が非常に簡単(数行で実装可能)
- データの前処理も自動で実施
- ハイパーパラメータの自動最適化が可能
- 色々な解析結果を図で確認が可能
1-3.PyCaretの実装手順
- PyCaretのインストール
- データの読み込み
- データの前処理
- 各種モデルの評価と精度の比較
- ハイパーパラメータの最適化
- モデルの精度の可視化
- モデルの確定
- 予測の実行
- 予測結果をCSVでダウンロード
2.環境・バージョン
- OS:windows10
- Jupyter Notebook:6.0.3
- PyCaret:2.2.1
3.PyCaretのインストール
まずは、pycaret のパッケージをインストールします。
※インストールに結構時間が掛かると思います。pip install pycaret4.データの読み込み
4-1.パッケージの読み込み
次に、必要なパッケージを読み込みます。
# パッケージの読み込み import pandas as pd from pycaret.classification import *今回は「分類」を行うので
pycaret.classificationとしました。
尚、モジュール一覧は次の通りです。
モジュール インポート方法 分類 pycaret.classification 回帰 pycaret.regression クラスタリング pycaret.clustering 異常検出 pycaret.anomaly 自然言語処理 pycaret.nlp アソシエーション分析 pycaret.arules 4-2.データの読み込み
次に、データを読み込みます。
手持ちデータか否かでやり方を分けて記載しています。
【今回の記事は手持ちではない場合で話を進めていきます。】手持ちデータではない場合(とりあえずPyCaretを動かしたい場合)
PyCaretに用意されているデータ【PyCaret’s Data Repository】より、チャーン分析を体験できる「社員」を使用します。
詳しくはコチラを参照してください。 https://pycaret.org/get-data/# 使用するデータの読み込み from pycaret.datasets import get_data data = get_data('employee')
それぞれの項目の説明は以下です。
項目名 説明 データ型 satisfaction_level 従業員の満足度(0-1スケールで1が最大) float64 last_evaluation 最後の評価(0-1スケールで1が最大) float64 number_project 割り当てられたプロジェクトの数 int64 average_montly_hours 平均の月労働時間 int64 time_spend_company 勤続年数 int64 Work_accident 仕事中の事故の有無のダミー変数(1:有、0:無) int64 promotion_last_5years 直近5年間での昇格の有無のダミー変数(1:有、0:無) int64 department 部署名 object salary 給料のランク object left 退職したか否かのダミー変数(1:退職、0:在職) int64 次に、読み込んだデータ(14,999レコード)の95%を学習データ、5%をテストデータ(Unseen Dataと呼ぶ)に分けます。※最後に実施する予測の実行時に未知のデータとしてUnseen Dataを活用するためです。
# 95%を学習データ、5%をテストデータ(Unseen Dataと呼ぶ)に分ける employee_data = data.sample(frac =0.95, random_state = 786).reset_index(drop=True) employee_data_unseen = data.drop(employee_data.index).reset_index(drop=True) print('Data for Modeling: ' + str(employee_data.shape)) print('Unseen Data For Predictions: ' + str(employee_data_unseen.shape))分割した結果が次の通りです。
(学習データが14,249レコード、テストデータが750レコードと分割されています。)
手持ちデータの場合(実務でPyCaretを動かす場合)
実務ではCSVファイルを読み込むケースが多いと思います。
その場合はPandasのpd.read_csvで次のように読み込んでください。# CSVデータの読み込み data = pd.read_csv('c:/path_to_data/file.csv')[補足1]
上記のように引数を何も指定しないと、CSVファイルはUTF-8で読み込みます。
CSVファイルをShift-JISで読み書きしたいときには、引数で指定する必要があります。(以下、例)
data = pd.read_csv('c:/path_to_data/file.csv', encoding = "shift-jis")[補足2]
WindowsでPythonを使う時の注意として、ファイルのパスを指定をする場合、
ファイルのパスを「¥」区切りで指定するとエラーになります。主な対処方法は次の2つです。パスの区切りを¥¥にする
data = pd.read_csv('c:\\path_to_data\\file.csv', encoding = "shift-jis")パスの区切りを/にする
data = pd.read_csv('c:/path_to_data/file.csv', encoding = "shift-jis")5.データの前処理
次に、PyCaretを起動します。
# PyCaretを起動 exp1 = setup(employee_data, target = 'left', ignore_features = None)目的変数は退職したか否かを意味する「left」としています。
※setupコマンドの説明は下表の通りです。
項目 説明 備考 第一引数 解析に用いる読み込んだデータ 必須 第二引数 予測に用いる目的変数の列名 必須 第三引数 分析から外す説明変数の列名 任意 実行すると次のように自動的にデータ型を設定してくれます。
データ型を変更せず、このまま続ける場合は"Enter"を押下します。データ型の変更が必要な場合は、"quit"と入力し"Enter"を押下します。
例えば、time_spend_company 列はCategoricalとして認識されていますが、Numericとして扱いたい場合は
setupコマンドを次のようにオプションを記述します。
※オプション一覧はこちらが非常に参考になります。# PyCaretを起動(データ型を変更する場合) exp1 = setup(employee_data, target = 'left', ignore_features = None, numeric_features = ['time_spend_company'])※
numeric_featuresオプションを使用し、, numeric_features = ['time_spend_company']を追加しています。これを実行すると、次のようにtime_spend_company 列がNumericとして変更されていることがわかります。
setupコマンドが完了すると次のようにセットアップ結果が表示されます。
データによっては算出できない項目もあるため、その場合は「False」や「None」と表示されます。
6.各種モデルの評価と精度の比較
6-1.モデルの比較
次に、モデルを比較します。
# モデルの比較 compare_models()これを実行すると次のように各種モデルを評価・比較し誤差の少ない順番に並べた一覧が表示されます。
(分類の場合、デフォルトではAccuracyで並べ替えられます。)
この例の場合、「Random Forest Classifier」というモデルの評価が高いことがわかります。
※各評価指標のトップが黄色で網掛けされます。
ただし、この分析ではハイパーパラメータの最適化までは行われていません。(この後に最適化を進めます。)
尚、処理の概要は次のようになっています。
- 偏りなく、満遍なく学習データを教師データと検証データに分割し、入れ替えることを指す「交差検証(クロスバリデーション)」を実施
- デフォルトでは、教師データと検証データを7:3で分割し、Fold=10(データを10分割して、教師データと検証データを入れ替えている)として各種モデルの平均のスコアを表示している
6-2.評価指標について
分類で使用される評価指標の概要と見方は次の通りです。(ここ重要です。)
まずはじめに(混同行列について)
まずはじめに、分類の評価指標の数式で使用される4つの区分「TP、FP、FN、TN」について説明します。
分類結果(正しく分類した数/誤って分類した数)をまとめた表のことを「混同行列」といいます。(下表参照)
特に2値分類(0か1かの分類)のモデルの性能を測る指標として使用されます。
Negative(=0)
と予測した(陰性)Positive(=1)
と予測した(陽性)実際にNegative
であった(陰性)TN (True Negative)
真陰性
正解が0の時に、
正しく0と予測した数FP (False Positive)
偽陽性
正解が0の時に、
間違って1と予測した数実際にPositive
であった(陽性)FN (False Negative)
偽陰性
正解が1の時に、
間違って0と予測した数TP (True Positive)
真陽性
正解が1の時に、
正しく1と予測した数Accuracy
Accuracy(正解率)では、予測結果が実際に当たっていた割合を表します。
数式は下記の通りです。\begin{eqnarray} Accuracy = \frac{TP+TN}{TP+FP+FN+TN} \end{eqnarray}$TP$ : (True Positive) 真陽性 正解が1の時に、正しく1と予測した数
$FN$ : (False Negative) 偽陰性 正解が1の時に、間違って0と予測した数
$FP$ : (False Positive) 偽陽性 正解が0の時に、間違って1と予測した数
$TN$ : (True Negative) 真陰性 正解が0の時に、正しく0と予測した数
項目 概要 判断基準 1に近いほど良い値 解釈 予測結果が実際に当たっていた割合 特徴 例えば、元データの95%がスパムである場合、単純に全てのメールをスパムと判断するモデルを作れば、正解率は95%となってしまうため、単純に正解率だけではモデルの性能を評価できない AUC
AUC(Area Under the Curve)は、陽性/陰性の閾値を変えながらRecallとSpecificityをプロットした曲線(ROC曲線(Receiver Operating Characteristic))の下の面積を表します。
イメージは下図の通りです。
(出典:SIGNATE)
項目 概要 判断基準 1に近いほど良い値 解釈 AUC=0.5は、ランダムに判断したのと同じ(予測が役に立たない)
AUC=1.0が理想だが、現実的にはほぼありえない特徴 他の指標と異なり、閾値を一意に特定せずに算出する Recall
Recall(真陽性率、再現率)では、実際に陽性であるもののうち、正しく陽性であると予測できた割合を表します。
数式は下記の通りです。\begin{eqnarray} Recall = \frac{TP}{TP+FN} \end{eqnarray}$TP$ : (True Positive) 真陽性 正解が1の時に、正しく1と予測した数
$FN$ : (False Negative) 偽陰性 正解が1の時に、間違って0と予測した数
項目 概要 判断基準 1に近いほど良い値 解釈 実際に陽性であるもののうち、正しく陽性であると予測できた割合
予測の時点でどれだけ当てることができたかという指標特徴 見落とし(FN)を限りなく0にしたい場合に重視する評価指標
※Precisionとはトレードオフの関係Precision
Precision(適合率)では、陽性であると予測したもののうち、実際に陽性だった割合を表します。
数式は下記の通りです。\begin{eqnarray} Precision = \frac{TP}{TP+FP} \end{eqnarray}$TP$ : (True Positive) 真陽性 正解が1の時に、正しく1と予測した数
$FP$ : (False Positive) 偽陽性 正解が0の時に、間違って1と予測した数
項目 概要 判断基準 1に近いほど良い値 解釈 陽性であると予測したもののうち、実際に陽性だった割合
予測したものがどれだけ正しかったかという指標特徴 誤判定(FP)を少なくしたい場合に重視する評価指標
※Recallとはトレードオフの関係F1
F1(F1-score)では、PrecisionとRecallの両方を加味した評価を表します。
数式は下記の通りです。\begin{eqnarray} F1 = \frac{2×(Precision×Recall)}{Precision+Recall} \end{eqnarray}$Precision$ : TP/(TP+FP)
$Recall$ : TP/(TP+FN)
項目 概要 判断基準 1に近いほど良い値 解釈 F1が高いモデルは、PrecisionとRecallのバランスが取れた良いモデル 特徴 PrecisionとRecallの調和平均 Kappa
Kappa(カッパ係数)は、同じ対象に対して2つの評価間の一致度を表す場合に用いられる統計量を表します。
数式は下記の通りです。\begin{eqnarray} Kappa = \frac{P_0 - P_C}{1 - P_C} \end{eqnarray}$P_0$ : 一致率
$P_C$ : 偶然の一致率
項目 概要 判断基準 1に近いほど良い値 解釈 <0:一致していない
0.00-0.20:わずかに一致
0.21-0.40:おおむね一致
0.41-0.60:適度に一致
0.61-0.80:かなり一致
0.81-1.00:ほとんど一致特徴 同じ対象に対して2つの評価間の一致度を表す場合に用いられる統計量
偶然一致することが期待される分を除いた残りがどれくらいの割合で一致したかを計算した値MCC
MCC(Matthews Correlation Coefficient)(マシューズ相関係数)は、二値分類問題で少数クラスを正とする習慣ができていない場合に使用する評価指標です。
数式は下記の通りです。MCC = \frac{((TP×TN) – (FP×FN))}{\sqrt{((TP+FP)×(TP+FN)×(TN+FP)×(TN+FN))}}\$TP$ : (True Positive) 真陽性 正解が1の時に、正しく1と予測した数
$FN$ : (False Negative) 偽陰性 正解が1の時に、間違って0と予測した数
$FP$ : (False Positive) 偽陽性 正解が0の時に、間違って1と予測した数
$TN$ : (True Negative) 真陰性 正解が0の時に、正しく0と予測した数
項目 概要 判断基準 1に近いほど良い値 解釈 -1と+1の間の値を取る
予測と実測が完璧にマッチすると+1
予測と実測が完全に不一致であると-1
ランダムな予測と同等であると0特徴 少数クラスを正とする習慣ができていない場合に使用する 評価指標をどう使い分けるか?
上記の通り様々な評価指標がありますが、ここではどれを使うべきなのかを説明します。
何を目標にするかによって、それに応じた評価指標を用いるようになります。
指針は次の通りといわれています。(1) 特定の閾値を設定せずに評価したい場合 ⇒ AUC
(2) 特定の閾値を設定して評価したい場合
(a) 陽性・陰性の重要度が同じ場合 ⇒ Accuracy
(b) 陽性がより重要である場合
(ⅰ) 以下の(ⅱ), (ⅲ)の両方に着目したい場合 ⇒ F1
(ⅱ) 陽性と予測されたうち、実際の陽性の割合が重要である場合 ⇒ Precision
(ⅲ) 実際の陽性のうち、陽性と予測される割合が重要である場合 ⇒ Recall尚、一般的には
PrecisionだけやRecallだけを重視してモデル構築することは無く、
その両方の調和平均であるF1を重視することが専らです。6-3.モデルの種類
分類では、次のモデルが搭載されています。
ID(引数) モデル名 概要 rf Random Forest Classifier ・ランダムフォレスト分類器
・決定木の王道といわれている
・決定木をたくさん集めて並列に扱う手法(バギング)lightgbm Light Gradient Boosting ・ライトジービーエム
・xgboostの軽量版的なモデル
・精度の上げるためには特徴量の調整が必要xgboost Extreme Gradient Boosting ・エックスジーブースト
・ブースティングという手法で決定木を直列に扱う
・精度が比較的高いが、学習に時間が掛かるcatboost CatBoost Classifier ・キャットブースト分類器
・決定木ベースの勾配ブースティングに基づくモデル
・カテゴリカル変数(質的変数)の扱い方が上手い
・決定木のツリー構造を最適にして過学習を防ぐ
・XgboostやLightGBMよりも精度が高くなる可能性があるet Extra Trees Classifier ・エクストラツリー分類器
・Random Forestと同じようにランダムな木を複数用意してバギングする
・ブートストラップサンプリングはせずに訓練データ全てを用いる
・シンプルで高速に動き、分類精度もRandom Forestに匹敵するgbc Gradient Boosting Classifier ・勾配ブースティング分類器
・弱い予測モデル(決定木)のアンサンブル形式で生成したものdt Decision Tree Classifier ・決定木分類器
・条件による分岐を「根」からたどることで、最も条件に合致する「葉」を検索するアルゴリズム
・決定木単体では弱い予測モデルada Ada Boost Classifier ・アダブースト分類器
・勾配ブースティング系アルゴリズムの走り
・直前の弱識別器で誤ったサンプルに対する重みを大きくして学習を行うknn K Nearest Neighbour ・K近傍法分類器
・次元の呪いのため、高次元データには向かない
・トレーニングデータ数・特徴量が増えると予測が遅くなるlr Logistic Regression ・ロジスティック回帰
・"回帰"という名称がつくが分類問題で使用される学習モデル
・確率やダミー変数について分析、予想したいときに用いるlda Linear Discriminant Analysis ・LDA(線形判別分析)
・主成分分析よりも更に精度が高い学習モデル
・分類するクラスの分離が最適化するよう変量のサブ空間を決める方法ridge Ridge Classifier ・リッジ回帰分類器
・過学習を抑える手法の一つ
・線形回帰に正則化項(ペナルティ項)としてL2ノルムを導入したモデルsvm SVM – Linear Kernel ・サポートベクターマシン(SVM)の一種
・SVMの中では一番単純で計算速度がはやい
・認識性能が優れた学習モデルの一つ
・未学習データに対して高い識別性能を得るための工夫があるnb Naives Bayes ・単純ベイズ
・文書データに対してよい結果を出すことで知られている
・データが与えられたときの全ての推定の確率を計算し、最も確率の高いものを推定結果として出力するqda Quadratic Discriminant Analysis ・QDA(二次判別分析)
・LDAと比べて、クラスごとのデータの分布が異なる場合でも柔軟にクラス分類を行うことができるrbfsvm SVM – Radial Kernel ・サポートベクターマシン(SVM)の一種
・データに関する事前知識がない場合に用いられる汎用的なカーネル
・最も用いられるカーネルの1つ
・認識性能が優れた学習モデルの一つ
・未学習データに対して高い識別性能を得るための工夫があるgpc Gaussian Process Classifier ・ガウス過程分類器
・平均値関数と共分散関数を既知とし与えられたデータがそのガウス過程に従っていると仮定すると未知の観測値の平均と分散がわかるmlp Multi Level Perceptron ・多層パーセプトロン(MLP)
・複数の形式ニューロンが多層に接続されたネットワーク
・現在の機械学習の基盤となっている※上表のIDは次項で記載の
create_modelの引数として使用します。7.ハイパーパラメータの最適化
7-1.モデルの作成
次に、モデルを作成します。
今回は、決定木系の王道といわれる「Random Forest(ランダムフォレスト)」のモデルを作成します。# Random Forestのモデルを作成 rf = create_model('rf')尚、
create_modelの引数は、windowsの場合は引数を記入する箇所で「Shift+Tab」のショートカットキーを使うとツールチップが表示されますので、コチラの内容を指定します。(上記、6-3.モデルの種類のID(引数)のことです。)
これを実行すると次のように初期設定である交差検証「10回」にて、検証が行われています。
Mean(平均値)、SD(標準偏差)も同時に表示されています。
7-2.ハイパーパラメータの最適化
次に、ハイパーパラメータの最適化を行います。
# Random Forestのモデルを最適化 tuned_rf = tune_model(rf, n_iter = 500, optimize = 'Accuracy')※tune_modelコマンドの説明は下表の通りです。
項目 説明 備考 第一引数 モデルの名称 必須 第二引数 ランダムグリッドサーチの回数 任意 第三引数 最適化の対象 ※デフォルトは「Accuracy」 任意 これを実行した結果(最適化後)と実行前を比較すると、最適化対象とした評価指標が増加し最適化が行われたことが確認できます。※PyCaretの最適化はランダムグリッドサーチが採用されています。
8.モデルの精度の可視化
次に解析した結果を可視化します。
# 解析結果の確認 evaluate_model(tuned_rf)これを実行すると、解析結果を選択できるタブが表示されます。
分類でプロットされるモデルの概要と見方はそれぞれ次の通りです。(ここ重要です。)
Hyperparameters(ハイパーパラメータ)
こちらは、ハイパーパラメータを確認できるプロットです。
AUC(Area Under the Curve)
こちらは、AUC(Area Under the Curve)です。
陽性/陰性の閾値を変えながらRecallとSpecificityをプロットした曲線(ROC曲線(Receiver Operating Characteristic))の下の面積を表します。イメージは下図の通りです。
尚、前述の評価指標では数値で確認ができますが、コチラでは視覚的に確認ができます。
(出典:SIGNATE)
AUC=0.5は、ランダムに判断したのと同じ(予測が役に立たない)
AUC=1.0が理想だが、現実的にはほぼありえません。
Confusion Matrix(混同行列)
こちらは、混同行列です。
分類結果(正しく分類した数/誤って分類した数)をまとめた表です。(下表参照)
特に2値分類(0か1かの分類)のモデルの性能を測る指標として使用されます。
尚、前述の評価指標ではこの混同行列の4つの区分を用いて算出した
各評価指標は数値で確認ができますが、コチラでは混同行列そのものを視覚的に確認ができます。
Negative(=0)
と予測した(陰性)Positive(=1)
と予測した(陽性)実際にNegative
であった(陰性)TN (True Negative)
真陰性
正解が0の時に、
正しく0と予測した数FP (False Positive)
偽陽性
正解が0の時に、
間違って1と予測した数実際にPositive
であった(陽性)FN (False Negative)
偽陰性
正解が1の時に、
間違って0と予測した数TP (True Positive)
真陽性
正解が1の時に、
正しく1と予測した数
※デフォルトでは、交差検証(クロスバリデーション)時に学習データを
教師データと検証データに7:3で分割しています。
そのため、この混同行列では、検証データの3割分の分類結果がまとめられています。
今回のケースでは、次の通りです。
種類 レコード数 学習データ 14,249 教師データ(7割) 9,974 検証データ(3割) 4,275 Threshold(識別しきい値)
こちらは、適合率(Precision)、再現率(Recall)、F1、およびキュー率を視覚化したプロットです。
求められる予測特性に対して、しきい値をどの程度に設定すればいいかの検討に利用できます。
最適なF1は、垂直の破線としてプロットに表示されます。この場合「0.46」となります。
Precision Recall(適合率・再現率曲線)
こちらは、横軸の再現率(Recall)に対して縦軸にプロットされた適合率(Precision)を確認できます。
塗りつぶされた領域が大きいほど、分類子は強力になります。赤い線は平均適合率を示しています。
適合率(Precision)と再現率(Recall)共に、どの程度のしきい値であれば予測特性を満たすかの検討に利用できます。
Prediction Error(クラス予測エラー)
こちらは、実際のクラス毎に、Positive(1)またはNegative(0)のどちらに予測をしたかを積み上げ棒グラフで表したものです。
モデルがどのクラスで問題を抱えているか、さらに重要なのは、クラスごとにどのような不正解を与えているかを可視化することができます。
これにより、異なるモデルの長所と短所、およびデータセットに特有の課題をよりよく理解することができます。
Class Report(分類レポート)
こちらは、モデルの適合率(Precision)、再現率(Recall)、F1、およびサポートスコアを表示します。
二段に分かれているのは、正例を1、負例を0とした場合の指標が上段で、正例を0、負例を1とした場合の指標が下段です。
尚、サポートスコアは、指定されたデータセット内のクラスの実際の出現数です。
Feature Selection(特徴量選択)
こちらは特徴量選択です。
特徴量(説明変数)の選択数に応じて予測スコアを折れ線グラフとして表示するものになっています。グラフの横軸が特徴量の数で、縦軸が予測精度を表し、予測精度が最大の特徴量数のところに縦に点線が引かれます。
今回の場合、特徴量の個数が17個のときに最大スコア「0.989」になったことがわかります。
特徴量選択の特徴量の選択優先順位は後述するFeature Importance(特徴量の重要度)の順位が高いもの(モデルの予測精度に大きく寄与している説明変数)から選択されています。
Learning Curve(学習曲線)
こちらは学習曲線です。
データ数に応じた予測精度を表示するグラフで、横軸にデータサイズ、縦軸に予測精度をプロットしています。
良いモデルの指標としてはデータが増えるごとにtraining scoreが減少し、cross validation scoreが増加することが望ましいといわれています。もし、cross validation scoreとtraining scoreの差が大きかった場合は、学習数が足りてない恐れがあるため、データ数を増やすことでモデルの精度の向上が図れるかもしれません。
Manifold Learning(多様体学習)
こちらは多様体学習です。
高次元データ(説明変数が複数あるもの)を2次元に落としてプロットしたグラフです。この多様体学習では、t-SNE(ティースニ) (t-Distributed Stochastic Neighbor Embedding)(t分布型確率的近傍埋め込み法)が使用されています。t-SNEの主な目的は、高次元データの視覚化です。したがって、データが2次元または3次元に埋め込まれる場合に最適に機能します。
新しい特徴量を加える場合や高次元のデータセットを扱う場合には、最も有用な特徴量だけを残して残りを捨てて特徴量の数を減らす(次元削減)のは良い考えだと言われています。なぜなら次元削減をすることでモデルが単純になって解釈しやすくなるだけでなく、汎化性能が向上するからです。
Calibration Curve(検量線)
こちらは、二値分類のモデルが出力する確率(一般には正例である確率)を横軸に、実際の割合を縦軸にプロットしたものを表します。
モデルの出力する確率が実際のものと一致していれば、曲線は原点を通る傾き1の直線になるはずです。
Validation Curve(検証曲線)
こちらは検証曲線です。先述の学習曲線に似ています。
ハイパーパラメーターの値を変えた時の予測精度を表示するグラフで、横軸にハイパーパラメータ、縦軸に予測精度をプロットしています。一つのハイパーパラメータがどれくらい寄与するか見たいときに使用します。適切なハイパーパラメータ(例:max_depth:木の深さ)の値はどこかを確認でき、訓練精度と検証精度の差が小さく、精度が高いものを選ぶようにします。(学習不足や過学習を確認することができます。)
尚、薄く塗りつぶされた範囲は、クロスバリデーション(交差検証)により求められた精度の最大値と最小値の範囲を表しています。
また、横軸のハイパーパラメータは使用する学習モデル(アルゴリズム)によって異なります。詳細は次の通りです。
学習モデル 横軸 Decision Tree Classifier
Random Forest Classifier
Gradient Boosting Classifier
Extra Trees Classifier
Extreme Gradient Boosting
Light Gradient Boosting
CatBoost Classifiermax_depth Logistic Regression
SVM(Linear)
SVM(RBF)C Multi Level Perceptron
Ridge Classifieralpha Ada Boost Classifier n_estimators K Nearest Neighbour n_neighbors Gaussian Process Classifier max_iter_predict Quadratic Discriminant Analysis reg_param Naives Bayes var_smoothing Dimensions(RadViz Visualizer)
こちらは、多変量データ可視化アルゴリズムです。
円周上に各特徴次元を一様に配置し、各特徴量を正規化して、中心から各円弧までの軸上に点をプロットします。このメカニズムにより、たくさんの次元を持つデータを円内に簡単に描画しすることができます。
Feature Importance(特徴量の重要度)
こちらは特徴量の重要度です。
目的変数に及ぼす影響が大きい順に上から特徴量が表示されています。(上位10位まで)
Feature Importance(ALL)(特徴量の重要度(全ての特徴量))
こちらは特徴量の重要度(全ての特徴量)です。
Feature Importance(特徴量の重要度)では、上位10位の特徴量が表示されていますが、ここでは解析に用いたデータの全ての特徴量を表示します。
Decision Boundary(決定境界)
こちらは、クラスを分類する決定境界は表します。
Lift Chart(リフトチャート)
こちらは、予測モデルの精度をはかるために使われます。
揚力曲線とベースラインの間の領域が大きいほど、モデルは優れています。
詳しくはコチラを参照ください。
Gain Chart(ゲインチャート)
こちらは、予測モデルの精度をはかるために使われます。
詳しくはコチラを参照ください。
Decision Tree(決定木)
※「Random Forest(ランダムフォレスト)」では表示されないため、「Decision Tree(決定木)」の結果で解説
こちらは決定木です。
木構造を用いて分類や回帰を行う機械学習の手法の一つで、比較的単純なモデルですが、モデルをツリーで表現できるので、どの説明変数が目的変数にどのように効いているのかが視覚的に分かりやすいというメリットがあります。▼全体
▼拡大図(ほぼ見えないですが・・・)
9.モデルの確定
次に、モデルを確定します。(当然ながら解析結果などを考慮したうえで)
#モデルの確定 final_rf = finalize_model(tuned_rf) print(final_rf)実行すると次のような最適化されたハイパーパラメータを確認することができます。
これで、学習済みのモデルができあがりました。
10.予測の実行
学習済みモデルが出来上がったら、冒頭で分割したUnseen Data(
employee_data_unseen)を、
今回作成した予測モデルに投入し、退職するか否かの予測を行わせてみます。#予測の実行 unseen_predictions = predict_model(final_rf, data = employee_data_unseen) print(unseen_predictions)これを実行すると次のように予測値が
Label、予測確率がScoreとして追加されているのが分かります。
本来は未知のデータについて、目的変数であるleftは分からないのですが、
冒頭で分割したUnseen Dataを使用しているためleftがデータに入っています。
未知なるデータの退職した否かleftと予測モデルが予測した予測値であるLabelを比べると、
完全に一致していることがわかります。(上下5レコードずつ、10レコードのみの表示ですが)
11.予測結果をCSVでダウンロード
次に、予測した結果をCSVファイルでダウンロードしてみます。
実務では予測した結果を何らかに利用することになるかと思います。#CSVファイルでダウンロードする unseen_predictions.to_csv('unseen_data_predicted_Label.csv')これを実行すると、次のようにCSVファイルがダウンロードされます。(冒頭5レコードのみ表示)
12.まとめ
実際に私がPyCaretを使ってみてPyCaretを扱う上で大切になるだろうと思ったことは次の4点でした。
- 大前提として取扱うデータをよく理解すること
- モデルの種類とそれぞれのモデルの特徴を理解すること
- 評価指標の種類と見方を理解すること
- 解析結果(図)の種類と見方を理解すること
※使いこなしてきたらデータ型やハイパーパラメータの調整ができることが大切になるのだろうと思いました。
13.参考文献
- PyCaret公式サイト
- scikitlearn公式サイト(データセット)
- RIGHTCODEブログ 機械学習の自動化を可能にする「PyCaret」の実力を把握してみる
- Tableauから始めるデータサイエンス PyCaret を使って東京の中古マンション価格を予測してみよう!
- PyCaretのsetup関数の引数について
- モデルの精度評価(分類問題)
- PyCaretでワインの品質を分類してみた
- Pythonでの従業員の解約の予測
- Accuracy/Recall/Precisionってややこしくない??
- PyCaret 2.2 : チュートリアル : 分類 – 二値分類 (初級)
- Yellowbrick Classification Visualizers
- データマイニングによるスコアリングと予測
14.最後に
いかがでしたでしょうか?
とりあえずPyCaretを使えて、全体像を理解いただけていれば幸いです。
細かい内容は無いので、隔靴掻痒(痒い所に手が届かない)な点はご容赦ください。PyCaretリリース前の時代を知らない私からすると便利なPyCaretにこれから頼ってしまいそうな予感です。(これで本当にいいのか?とも思いますが。)
この界隈の玄人の方からするとPyCaretは自動車でいうところのAT車のような感じで見られているのかな?とも思います。「MT車のシフトチェンジこそが、最大燃費を叩き出す!」みたいなイメージでしょうか?とにもかくにも、初心者の私にとっては、データサイエンスの取っ掛かりとしてPyCaretは最高のライブラリだと感じました。最後までお付き合いいただきましてありがとうございました。


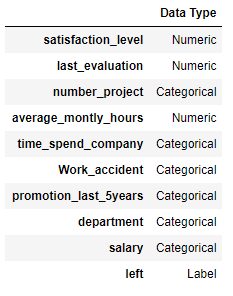

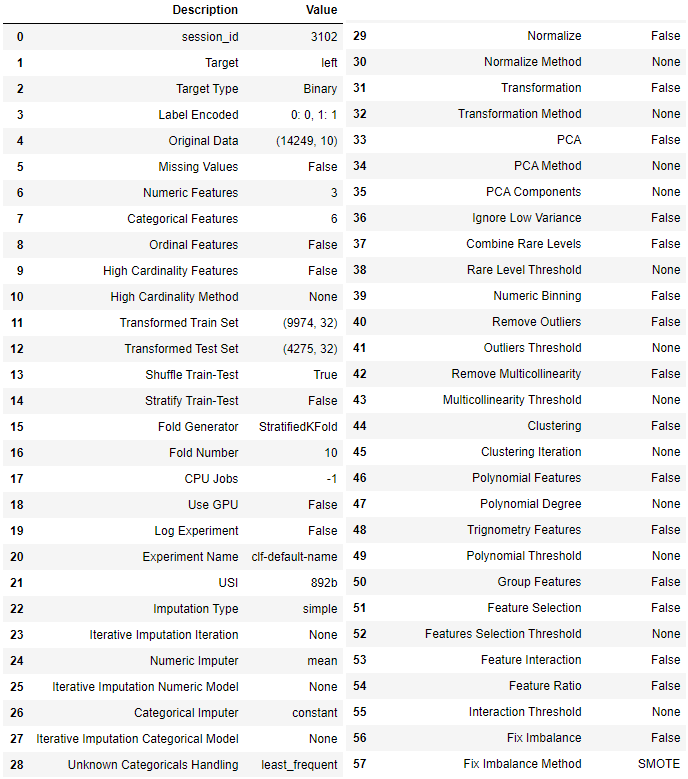
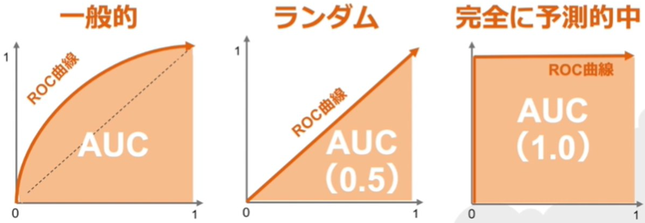
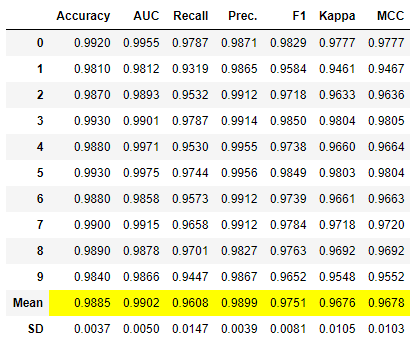

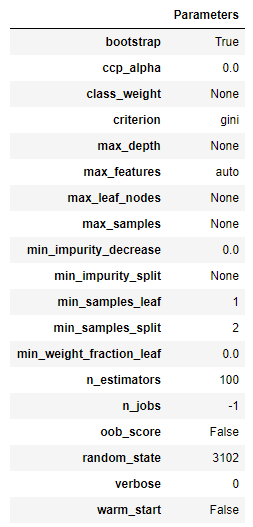
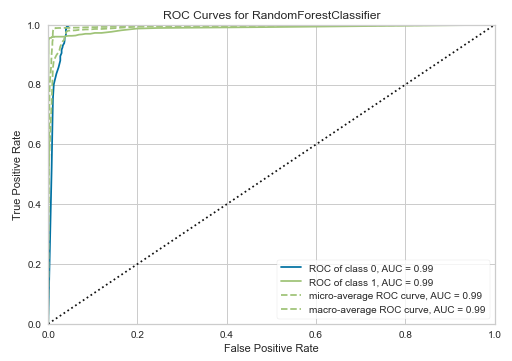
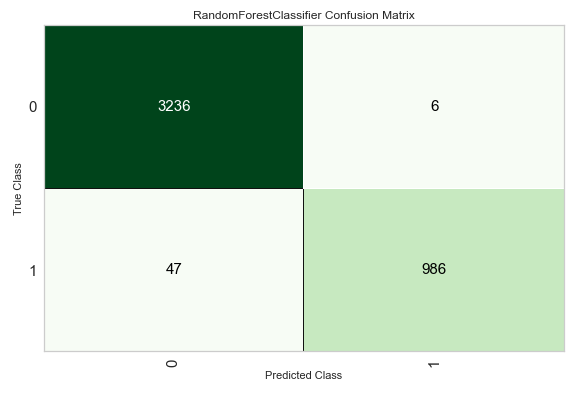
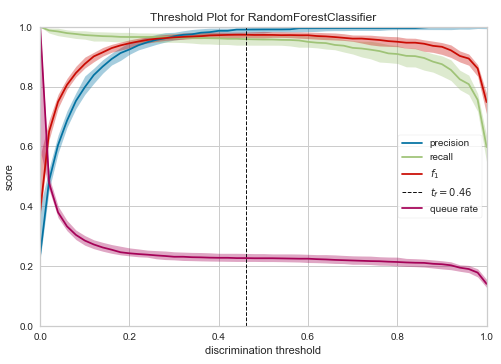
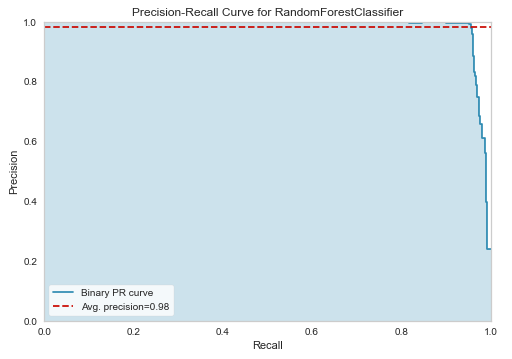
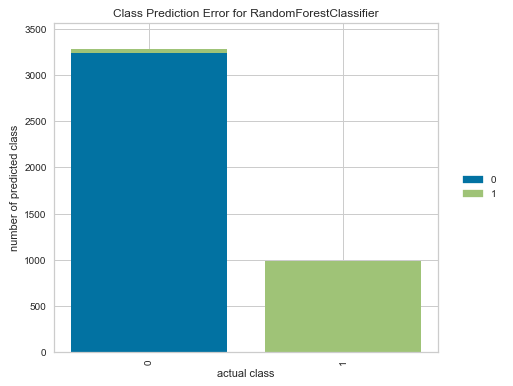
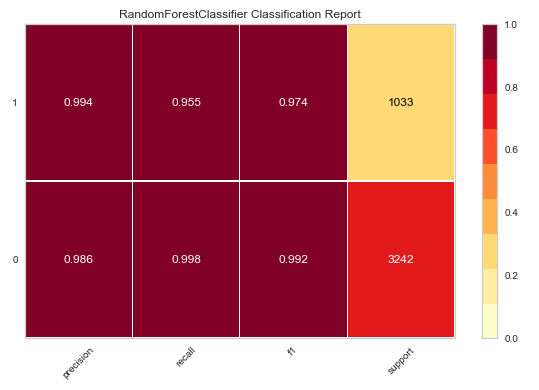
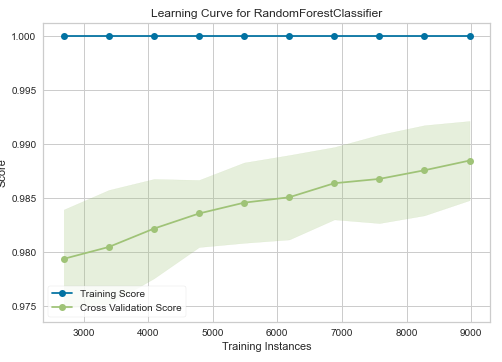
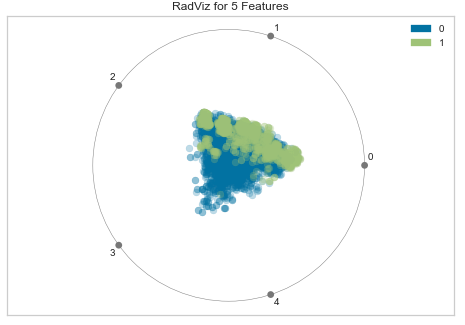
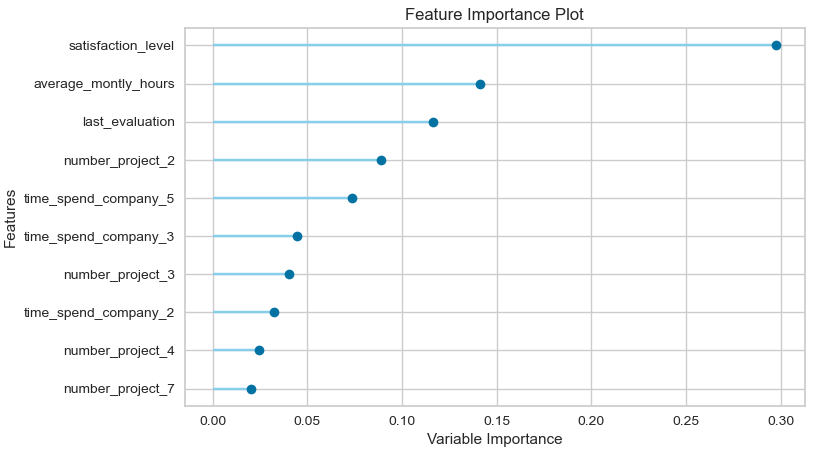
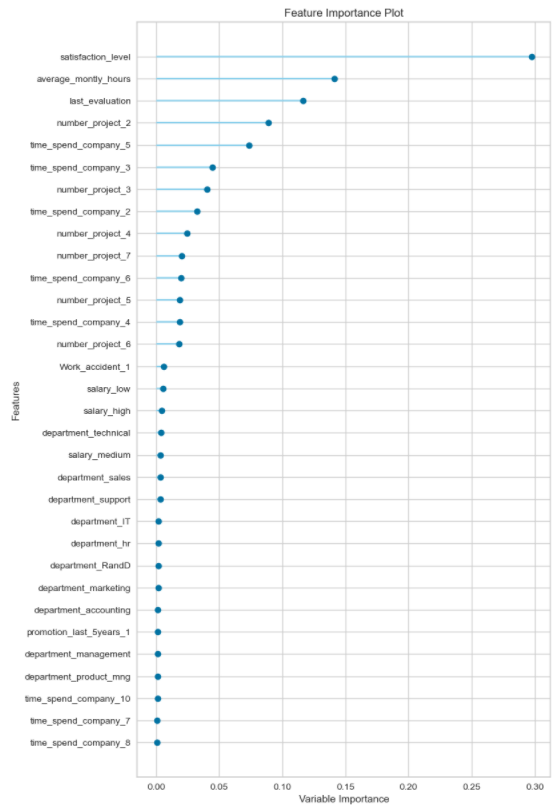
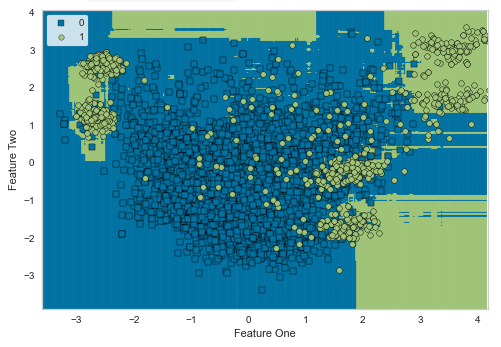
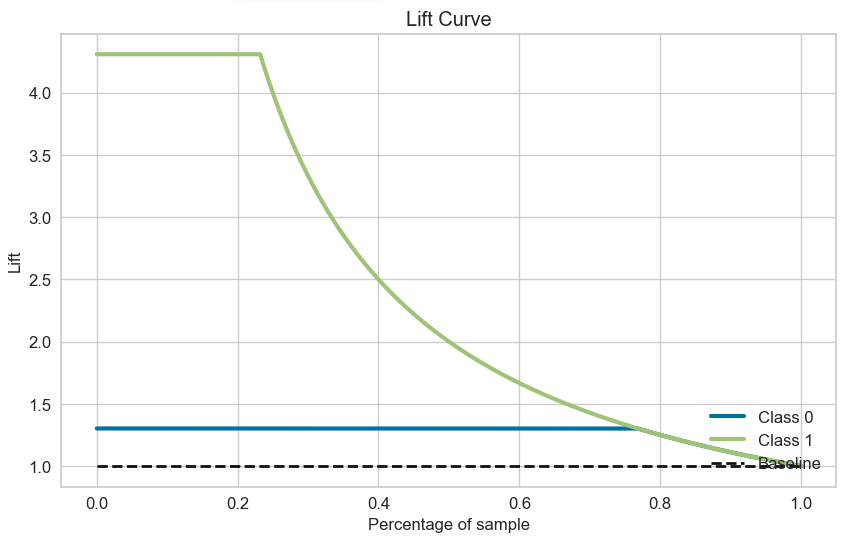

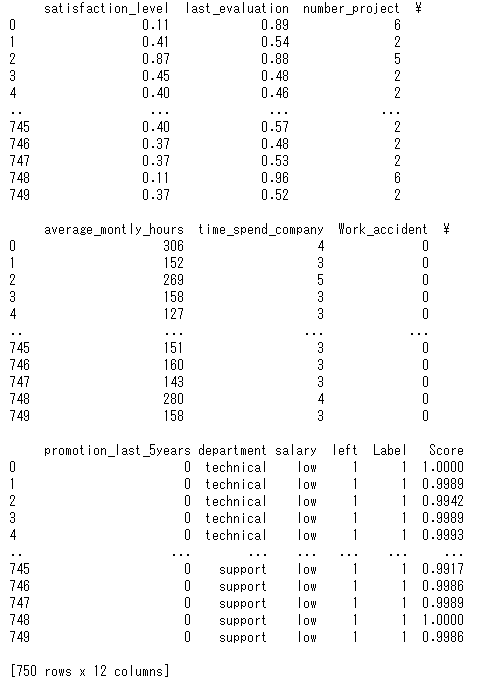
- 投稿日:2021-01-08T16:52:07+09:00
ラズパイ 起動したらpythonファイル実行を最速で設定する。
前提
- ラズパイの用意
- microSDにラズパイのOSがインストールされていて、ラズパイ を起動できる
- ラズパイ のコードは外付けのキーボード、マウス、ディスプレイを用いて記述している
やること
- 実行したいファイルの実行許可を与える
- ラズパイ 起動時に実行するコマンドを指定のファイルに記述する
実行したいファイルの実行許可を与える
まずはラズパイのターミナルで、実行したいファイルがあるディレクトリへ移動する。
私はデスクトップに保存したのでそこへ移動sudo chmod 755 ファイル名.拡張子私の場合は
Desktopsudo chmod 755 test.pyこれで実行権限オッケー。
起動時にファイルを実行するコマンドを記述
起動時に読み込まれるファイルは、/etc/rc.localにあります。
ターミナルで以下のコマンドを実行してください。sudo nano /etc/rc.local
echo 0の上で、起動時に実行したいコマンドを入力。// ここに記述 echo 0私の場合はデスクトップにあるPythonファイルを実行するので
python3 /home/pi/Desktop/test.pyこれで保存。
保存方法はctr+o, その後enterで保存、そしてctr+xで終了できます.これでGUI操作ではなく、ラズパイ を起動したら指定したファイルが実行されます。
おまけ
今回途中で出て来たchmodとは
途中で出てくるchmodは権限のことです。
そのファイルの権限をどうするのか、、。ということです。
今回755という権限を書きました。参考サイトによると
通常のディレクトリ、コマンド、CGIスクリプトなど。誰でも読込みと実行はできるが、書き込みは自分だけ。
という権限です。参考サイト
- 投稿日:2021-01-08T16:09:13+09:00
pythonで月の休日(土日・祝日)の日数を取得してみた
はじめに
動機
機械学習に必要なデータの作成をしている際に、月の休日日数を自動で取得する必要があったため作成しました。
平日(営業日)を判定する記事は多く見かけたのですが、休日判定(日数取得)に関するものが少なかったため、備忘録的な意味も込めて投稿することにしました。
使用ライブラリ
JPBizDay:日本の営業日を取得するライブラリ
datetime:pythonの標準ライブラリ、日付や時刻を操作するためのクラスを提供
calendar:pythonの標準ライブラリ、日時を扱う
実行環境
準備
まず、jpbizdayをインストールします。
colab上でインストールする場合はpipの前に!をつける必要があります。!pip install jpbizday次に必要なモジュールをimportします
import jpbizday import datetime import calendar実装
手順
1.本日の年・月を取得する
2.取得した年・月を元に今月の日数を取得
3.取得した年・月を元に今月の平日の日数を取得
4.今月の日数から平日の日数を引き、休日の日数を取得#本日の年・月の取得 dt_now = datetime.datetime.now() year = dt_now.year month = dt_now.month #今月の日数を取得 days = calendar.monthrange(year, month)[1] #平日の日数を取得 heijitu = jpbizday.month_bizdays(year, month) heijitu = len(a) #休日の日数を取得 holiday = days - heijitu print(holiday)
jpbizdayを使用したことで結構シンプルに実装できたのではないかと思います。
他の方法があるよ!こっちの実装方法の方がいいんじゃない?などのアドバイス等ありましたらお気軽にお願いいたします!
参考にさせていただいたサイト
- calendarモジュールの使い方
https://note.nkmk.me/python-days-weeks-of-the-month/- jpbizdayの使い方
https://pypi.org/project/jpbizday/
- 投稿日:2021-01-08T15:30:21+09:00
Pythonでマーケティング分析① 顧客分析(デシル分析, RFM分析)
はじめに
マーケティングの分析手法について、Pythonで実際のデータを触りながら学びたいと思い、その学習記録を残す目的で記事を書きました。今回は顧客分析手法のデシル分析とRFM分析になります。
使用データ
Kaggleで公開されているOnline Retail Data Setを使用します。
実行環境
Google Craboratoryで動かしています。Pythonと各ライブラリのバージョンは以下の通りです。
- Python: 3.6.9
- Numpy: 1.19.4
- Pandas: 1.1.5
- Matplotlib: 3.2.2
- Seaborn: 0.11.0
- Scikit-learn: 0.22.2.post1
顧客のセグメント分析概要
顧客をある特性ごとに分割することで、優良顧客を見つけたり、効率的に広告を打つことなどができるようになります。セグメント分けには性別や年齢などの属性を使う方法もありますが、ここでは購買履歴データを使用した2つの分析手法を扱います。
デシル分析とは
顧客を、購入金額順に並べて10分割することでセグメント分けする方法です。
RFM分析とは
以下3つの指標により顧客をセグメント分けする方法です。
- Recency:直近何日前に利用したか
- Frequency:ある期間中にどれくらいの頻度で利用したか
- Monetary:ある期間中に利用した合計金額
デシル分析の実装
データの読み込み, EDA, 前処理
# 基本モジュールのインポート import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns %matplotlib inlineデータ型を指定してデータを読み込みます。
# データ読み込み dtypes = { 'InvoiceNo': 'object', 'StockCode': 'object', 'Description': 'object', 'Quantity': 'int8', 'InvoiceDate': 'datetime64[ns]', 'UnitPrice': 'float64', 'CustomerID': 'object', 'Country': 'object' } raw_data = pd.read_csv('./data/OnlineRetail.csv', dtype=dtypes, engine='python')# 概要確認 print(raw_data.shape) raw_data.head(20) >>> (541909, 8)
各カラムを簡単に説明すると
- InvouceNo:発注番号
- StockCode:商品番号
- Description:商品説明
- Quantity:購入個数
- InvouceDate:購入日時
- UnitPrice:商品単価
- CustomerID:顧客番号
- Country:国
デシル分析では、Quantity, UnitPrice, CustomerIDを使用します。もう少しデータを調べてみると
# 欠損値などを確認 raw_data.info() >>> <class 'pandas.core.frame.DataFrame'> RangeIndex: 541909 entries, 0 to 541908 Data columns (total 8 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 InvoiceNo 541909 non-null object 1 StockCode 541909 non-null object 2 Description 540455 non-null object 3 Quantity 541909 non-null int8 4 InvoiceDate 541909 non-null datetime64[ns] 5 UnitPrice 541909 non-null float64 6 CustomerID 406829 non-null object 7 Country 541909 non-null object dtypes: datetime64[ns](1), float64(1), int8(1), object(5) memory usage: 29.5+ MBCustomerIDカラムに欠損があります。また、
# 数値変数の統計量確認 raw_data.describe()
QuantityとUnitPrice一部に負の値が入っていることがわかります。購入のキャンセル時などに負の値が入るなど何かしらのルールがあるみたいですが、今回は0以上のデータのみ使用することにします。また、CutomerIDが欠損したデータも除いておきます。
# クレンジング data = raw_data.query('Quantity >= 0 & UnitPrice >= 0').dropna(axis=0, subset=['CustomerID'])デシル分析
総額(数量×単価)カラムを作成しておきます。
# 総額 = 数量 × 単価を計算 data['TotalPrice'] = data['Quantity'] * data['UnitPrice']# 顧客ごとの購入総額を求める decil = data[['CustomerID', 'TotalPrice']].groupby('CustomerID').sum().reset_index() decil.head()
この値を用いて、上位から10%ずつに分割していきます。
#分位点を求める parties = decil.quantile(q=[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]).to_dict() parties >>> {'TotalPrice': {0.1: 151.812, 0.2: 240.62800000000001, 0.3: 340.95799999999997, 0.4: 474.1039999999999, 0.5: 656.6899999999999, 0.6: 905.4079999999998, 0.7: 1309.4160000000002, 0.8: 1954.0280000000002, 0.9: 3488.1160000000036}}# 分位点で分ける関数を定義 def cal_decil(x, col, df): if x <= df[col][0.1]: return 1 elif x <= df[col][0.2]: return 2 elif x <= df[col][0.3]: return 3 elif x <= df[col][0.4]: return 4 elif x <= df[col][0.5]: return 5 elif x <= df[col][0.6]: return 6 elif x <= df[col][0.7]: return 7 elif x <= df[col][0.8]: return 8 elif x <= df[col][0.9]: return 9 else: return 10# デシルスコアの算出 decil['Decil_score'] = decil['TotalPrice'].apply(cal_decil, args=('TotalPrice', parties)) decil.head()
顧客を1~10のランクに分割することができました。ここからは、各層が全体売り上げのどの程度貢献しているかみていきます。Pandasの
.cumsum()や.cumprod()メソッドを使うことで、累積和や累積比率を計算することができます。# 降順に並び替えて累積和・累積比率を求める decil = decil.sort_values('TotalPrice', ascending=False) decil['Cumsum'] = decil['TotalPrice'].cumsum() decil['Cumprod'] = decil['Cumsum'] / decil['Cumsum'].max() decil
# 各階層の売り上げが占める割合 decil[['Decil_score', 'Cumprod']].groupby('Decil_score').max() \ .reset_index().sort_values('Decil_score', ascending=False)
結果を見てみると、購入総額の上位10%の顧客で全体売り上げの約55%, 上位20%で約70%, 上位30%で約80%を占めていることがわかります。
RFM分析の実装
RFM分析では、InvoiceDate, TotalPrice(デシル分析で作成したカラム), CustomerIDを使用します。
RFM値の算出
Recencyを計算するためには、現在時刻(分析時の時刻)を指定する必要があります。購買データの最終時刻が
'2011-12-09 12:50:00'であるため、今回は現在時刻(NOW)を2011年12月10日(0:00)としておきます。# 履歴の最新時刻を取得 data['InvoiceDate'].max() >>> Timestamp('2011-12-09 12:50:00')# 現時刻を設定 import datetime as dt NOW = dt.datetime(2011,12,10)
CustomerIDでGroupByし、agg関数を使ってRecency, Frequency, Monetaryを以下のように求めます。# RFMの計算 rfm = data.groupby("CustomerID") \ .agg({"InvoiceDate": lambda date: (NOW - date.max()).days, "InvoiceNo": lambda num: num.nunique(), "TotalPrice": lambda price: price.sum()}).reset_index() # カラム名変更 rfm.rename(columns={'InvoiceDate': 'recency', 'InvoiceNo': 'frequency', 'TotalPrice': 'monetary'}, inplace=True) rfm.head()
セグメント分け
ここから、実際に算出した各指標を用いてセグメント分けしていきます。どのように分けるか(基準値や分割数)は状況により変える必要があります、今回は各指標について四分位点を用いて分割することにします。
四分位点でRFMスコアを求める
#3指標それぞれの四分位点を求める quantiles = rfm.quantile(q=[0.25,0.5,0.75]) quantiles_dict = quantiles.to_dict() print(quantiles_dict) >>> {'recency': {0.25: 17.0, 0.5: 50.0, 0.75: 142.0}, 'frequency': {0.25: 1.0, 0.5: 2.0, 0.75: 5.0}, 'monetary': {0.25: 300.67499999999995, 0.5: 656.6899999999999, 0.75: 1601.0}}# RFMを四分位点で分ける関数を定義 def cal_R(x, col, df): if x <= df[col][0.25]: return 1 elif x <= df[col][0.50]: return 2 elif x <= df[col][0.75]: return 3 else: return 4 def cal_FM(x, col, df): if x <= df[col][0.25]: return 4 elif x <= df[col][0.50]: return 3 elif x <= df[col][0.75]: return 2 else: return 1# 各種スコアの算出 rfm['R_score'] = rfm.recency.apply(cal_R, args=('recency', quantiles_dict)) rfm['F_score'] = rfm.frequency.apply(cal_FM, args=('frequency', quantiles_dict)) rfm['M_score'] = rfm.monetary.apply(cal_FM, args=('monetary', quantiles_dict)) # 3指標を統合したスコアの算出 rfm["RFM_score"] = rfm.R_score.astype(str)+ rfm.F_score.astype(str) + rfm.M_score.astype(str) rfm.reset_index(inplace=True) rfm.head()
求めたスコアを使って、例えば「スコア4が2項目以上あれば優良顧客」などのようにセグメント分けをしていきます。
クラスタリング(k-means)
セグメント分けには、教師なしの機械学習手法(クラスタリング)を用いることもあるようです。試しにk-means方を使ってのセグメント分けを実装してみます。
# 標準化 from sklearn.preprocessing import StandardScaler tmp = rfm[['R_score', 'F_score', 'M_score']] ss = StandardScaler() rfm_scaled = ss.fit_transform(tmp) print(rfm_scaled) >>> array([[ 1.34301118, 1.15405079, 1.34141302], [-1.33165772, -1.47067031, -1.34162009], [ 0.45145488, -0.59576328, -0.44727572], ..., [-1.33165772, 0.27914376, 1.34141302], [-1.33165772, -1.47067031, -1.34162009], [-0.44010142, -0.59576328, -1.34162009]])分割するクラスター数は分析者が指定する必要がありますが、最適なクラスター数を考える一つの手法として、分割数を変えた時のitertia値(クラスタ内二乗誤差の和)の変化をみる方法があります。詳しくはこちらの記事がわかりやすいので是非。
# クラスタリング(分割数の検討) from sklearn.cluster import KMeans inertias = {} for k in range(2, 10): km = KMeans(n_clusters=k, random_state=1) km.fit(rfm_scaled) inertias[k] = km.inertia_ pd.Series(inertias).plot() plt.xlabel("K (num of clusters)") plt.ylabel("Inertia Score")
やや判断が難しいですが、今回は4つのクラスターに分割することにします。
# k=4でクラスタリング k = 4 km = KMeans(n_clusters=k, random_state = 1) rfm["KMeans"] = km.fit_predict(rfm_scaled) rfm.head()
# 可視化 sns.pairplot(rfm[['R_score', 'F_score', 'M_score', 'KMeans']], hue="KMeans", palette='jet_r') plt.show()
# 各クラスターの要素数の確認 rfm['KMeans'].value_counts() >>> 0 1428 3 1112 1 997 2 782 Name: KMeans, dtype: int64おわりに
デシル分析とRFM分析をPythonで実装してみました。Pandasの良い練習にもなりますし、やはり意味のあるデータ分析の方がモチベーションも維持しやすいと感じました。次は、商品分析に挑戦してみようと思います。
※参考
https://library.musubu.in/articles/10537#
https://www.albert2005.co.jp/knowledge/marketing/customer_product_analysis/decyl_rfm
https://qiita.com/deaikei/items/11a10fde5bb47a2cf2c2











- 投稿日:2021-01-08T14:47:14+09:00
?トランプの一人用ゲーム「時計」の成功確率をモンテカルロ法で計算してみた話?
この記事について
この記事は、プログラミング初心者が覚えたてのモンテカルロ法を使ってみる話です。
登場するコードは超単純なのですが、長年の疑問を自分の手で解決できたことが非常に嬉しかったので記事にしました。
最終的に得られた確率(かなり綺麗な値)の数値的な意味については考察中なので、確率が得意という方は是非教えて下さい。「時計」とは
一人用トランプゲームの一種で、ルールはとても単純です。
なお、プレイヤーの意志を挟む余地がない完全ルールベースの運ゲーなので、楽しさは保証できません。[準備]
ジョーカーを抜きよく切った52枚のトランプを、画像のような形で13の山に分けます。
そしてこれを時計の文字盤になぞらえ、それぞれの山に数字を割り振ります。
余ってしまう中心の山には、ご都合主義で13を割り振ってください。
[ルール]
1. 13の山の1番上のカードをめくります。
2. めくったカードの番号を確認し、今度はその番号の山の1番上のカードをめくります。
3. 続けられる限り、2の作業を続けます。
4. 4枚目の13が出た時点で、それ以上めくるカードがなくなりゲーム終了となります。
5. すべてのカードをめくることができたら成功、それ以外は一律失敗とします。何が楽しいの?と思う方もいらっしゃると思いますが、13が出るたび寿命が縮んでいくようなこのスリル、意外と中毒性があります。
私自身、テスト前夜の現実逃避でトランプに手を伸ばし、「1回上がったら再開しよう」などと始めてしまったせいで今この記事を書くに至っています。
紙とペンと脳味噌で成功確率を考えてみた
直感的に、成功確率は1/13かなと思っていました。
イメージとしては、長さ52のリストの最後の要素が13なら成功、それ以外は失敗、という感じです。
しかし考えれば考えるほど、そう単純な話では収まらないような気がしてきました。
先ほどの例えでいえば時計は、リスト内を遷移する順番がリストの要素によって決定されるという仕組みです。
この複雑さ、紙とペンと脳味噌では少々荷が重いと判断し、習いたてのモンテカルロ法を使ってみることにしました。モンテカルロ法とは
モンテカルロ法を一言で説明するなら、
実際に何回もシミュレーションしてみて、成功する確率を調べる手法です。
今回は、Pythonに時計を何回も何回もやらせて、成功回数/試行回数を計測します。
円周率の計算などで有名な手法なので、ご存じの方が多いかもしれません。退屈なことはPythonにやらせよう
まず、カードをシャッフルし、52枚を並べる関数を作ります。
def shuffle(): #52枚のカードを並べる shuffle =[1,2,3,4,5,6,7,8,9,10,11,12,13] shuffle += shuffle + shuffle + shuffle random.shuffle(shuffle) return shuffleここからはゲームが始まるわけですが、
プレイヤーの意志を挟む余地がない完全ルールベースの運ゲーなので実装も簡単でした。
先に必要な情報をまとめておきます。先ほど作った52枚分のリストとカードの対応は、
インデックス:山
0~3:1の山
4~7:2の山
...
(N-1)*4 + i (0≦i≦3):Nの山
とします。また、「開く」という行為はリストの要素を0に書き換えることで表します。
def tokei(): cards = shuffle() #52枚のランダムな配列を用意 flag =0 number = 13 #最初に開く13 while flag == 0: #print(number) if cards[(number-1)*4] != 0: #その番号が初めて開かれる場合 next = cards[(number-1)*4] cards[(number-1)*4] = 0 number = next elif cards[(number-1)*4+1] != 0: #その番号が2回目に開かれる場合 next = cards[(number-1)*4+1] cards[(number-1)*4+1] = 0 number = next elif cards[(number-1)*4+2] != 0: #その番号が3回目に開かれる場合 next = cards[(number-1)*4+2] cards[(number-1)*4+2] = 0 number = next elif cards[(number-1)*4+3] != 0: #その番号が4回目に開かれる場合 next = cards[(number-1)*4+3] cards[(number-1)*4+3] = 0 number = next else: #13が4枚出ちゃった場合or終わった場合 flag =1 return sum(cards)いよいよモンテカルロ法の登場です。
def Monte_Carlo(n): N = 0 for i in range(n): if tokei() == 0: N += 1 return N/nさしあたりnを10000で実行してみます。
Monte_Carlo(10000)0.0787それっぽい値が出てきました。
統計は苦手ですが、100万回くらい試行すれば十分でしょうか。print("100回の試行では "+ str(Monte_Carlo(100))) print("1000回の試行では "+ str(Monte_Carlo(1000))) print("10000回の試行では "+ str(Monte_Carlo(10000))) print("100000回の試行では "+ str(Monte_Carlo(100000))) print("1000000回の試行では "+ str(Monte_Carlo(1000000))) print("1/13 = " + str(1/13))実行結果は以下の通りです。
100回の試行では 0.07 1000回の試行では 0.083 10000回の試行では 0.0736 100000回の試行では 0.07664 1000000回の試行では 0.076582 1/13 = 0.07692307692307693統計は苦手ですが、これは大体1/13に収束しそうだと言ってもいいですかね。
そういうことにしましょう。総括
自分の手でコードを書いて結論が出せて、滅茶苦茶楽しかったです。
whileが止まらなくなったり1枚目めくってゲームが終わっちゃったり、2枚目めくってゲームが終わっちゃったりしながらも、ググりながら頑張れました。
テスト前夜の現実逃避は怖いものです。
残る疑問は何故成功確率が1/13(もしくはそれに近い値)になるのか、ということですが、次のテスト前あたりで考えていきたいと思います。
これを読んでくださった方で、答えにたどり着いた方がいらっしゃいましたら、是非教えて下さい。


- 投稿日:2021-01-08T14:45:52+09:00
discord.py入門
雛形
雛形とはプログラムコードを書く上で型となる部分のことを指します
discord.pyの雛形
import discord token = "" #ここにトークンを代入 client = discord.Client() #Botの準備ができた時の処理 @client.event async def on_ready(): print("ready") #ここから下にその他の処理を書く↓ # —-ここまで—- client.run(token)イベントハンドラ
イベントハンドラとはdiscord上発生するイベントごとに処理を分けるための関数を指します。
イベントハンドラの記述方法は以下の通りです。
@client.event async def イベントハンドラ名(引数): 処理主なイベントハンドラ
イベントハンドラ名 引数 説明 on_messagemessage メッセージが送信された時に発生するイベント add_reactionreaction,user メッセージにリアクションが付与された時に発生する on_member_joinmember メンバーがサーバーに参加した時に発生する。 注意
同じイベントハンドラを複数登録すると、動かなくなります。ex)
#ダメな例 @client.event async def on_message(message): 処理 @client.event async def on_message(message): 処理イベントハンドラのリファレンス
discord.py API refarencediscord.pyの型
discord.pyには
strやintのようにdiscord.py独自の型があります主な型
discord.Message
メッセージの情報がまとまっている、
主な属性
属性 説明 返り値の型 content メッセージの内容を返します str author メッセージの送信者を返します discord.User channel メッセージを送信したチャンネルを返します。 discord.TextChannel id メッセージのIDを返します。 int guild メッセージが送信されたサーバーを返します discord.Guild discord.TextChannel
テキストチャンネルの情報がまとまっています
主な属性
属性 説明 返り値の型 name チャンネル名を返します。 str id チャンネルのIDを返します。 int category チャンネルの存在するカテゴリを返します discord.CtegoryChannel guild チャンネルが存在するサーバーを返します。 discord.Guild members チャンネルのメンバーリストを返します。 list[discrd.Members] discord.Role
ロールの情報がまとまっています。
主な属性
属性 説明 返り値の型 name ロール名を返します str id ロールのIDを返します int members ロールが付与されているメンバーリストを返します list[discord.Member] color ロールの色を返します discord.Colour permissions ロールの権限を返します。 discord.Permissions discord.Member
メンバーの情報がまとまっています。
属性 説明 返り値の型 name ユーザーの名前を返します str id ユーザーのIDを返します int avatar_url ユーザーのアバターのURLを返します discord.Asset roles ユーザーが所持しているロールリストを返します list[discord.Role] guild メンバーが存在してるサーバーを返します discord.Guild status メンバーのステータスを返します。 discord.Status discordを操作
それぞれの型には
属性(Attribute)だけではなく、メッセージを送ったり、ロール付与を行うためのメソッドがあります。
以下からはメソッドの説明と、よく使うメソッドを挙げていきます。awaitについて
discord.TextChannelの型にはメッセージを送信するメソッドであるsend()があります。
また、discord.Guildの型にはチャンネルを取得するメソッドであるget_channel(チャンネルのID)があります。一応それぞれのメソッドの概要をまとめておきます
メソッドを持つ型 メソッド メソッドの引数 メソッドの返り値 discord.TextChannel send content(str)... discord.Message discord.Guild get_channel チャンネルのID(int) abc.GuildChannel @client.event async def on_message(message): send_message = "メッセージを受け取りました。" #メッセージ内容 guild = message.guild #メッセージが送信されたサーバー channel = guild.get_channel(00000000000) #チャンネルを取得 await send_channel.send(send_message)#メッセージを送信6行目で使用した
send()メソッドにはawaitがついています。
一方5行目で使用したget_channelメソッドにはawaitはついていません。ここからはこのawaitについて解説していきますが、
難しければ、多少語弊はあるかもしれないですが、discord上で目に見える形で操作をする
ex( メッセージを送信,リアクションをつける,チャンネルを作るものには
awaitが必要であると思ってください。逆に、チャンネルを取得したり、ユーザーがフレンドか確認するといった,
情報を取得するような処理をするmethodにはawaitがつかないと解釈してくださいawaitの解説
awaitは実行する関数がコルーチンである際に先頭につけるものです
これをasync/await構文と呼びます。async が付く関数はコルーチン関数と呼ばれます、
コルーチン関数とは何か?
通常の関数は同期処理として実行されます。
つまり、関数Aを実行中に、関数Bを実行した場合、関数Aの処理は途中で中断され、関数Bの処理が始まります。関数Bが終了次第、関数Aの処理は再開します。
ですが、コルーチン関数は非同期処理として実行され、
別の処理と並行してタスクを実行できます。
import time def wait_A(): print("処理Aを開始") time.sleep(1) print("処理Aを終了") def wait_B(): print("処理Bを開始") time.sleep(2) print("処理Bを終了") def wait_C(): print("処理Cを開始") time.sleep(3) print("処理Cを終了") if __name__ == "__main__": wait_A() wait_B() wait_C()こちらのプログラムを実行します。
~出力~ 処理Aを開始 処理Aを終了 処理Bを開始 処理Bを終了 処理Cを開始 処理Cを終了となります。
これをコルーチン関数として定義します
import asyncio async def wait_A(): print("処理Aを開始") asyncio.sleep(3) print("処理Aを終了") async def wait_B(): print("処理Bを開始") asyncio.sleep(2) print("処理Bを終了") async def wait_C(): print("処理Cを開始") asyncio.sleep(1) print("処理Cを終了") if __name__ == "__main__": await wait_A() await wait_B() await wait_C()出力 処理Aを開始 処理Bを開始 処理Cを開始 処理Cを終了 処理Bを終了 処理Aを終了となります。
複数の処理を並行して実行していることがわかるでしょう。
つまり、discord.pyのモジュールにおいて、
型のメソッドがコルーチン関数として定義されていた場合にawaitをつける必要があります。型のメソッドが、コルーチン関数として定義されているか、されていないかの確認をするにはdiscord.pyのドキュメントを確認する必要があり、
各型の説明の先頭にMethodの項目があります。
その一覧の先頭にasyncがついているものはコルーチン関数メソッドです。色々なメッセージを送る
埋め込みメッセージ
@client.event async def on_message(message): if message.content == "/埋め込み": send_embed = discord.Embed(title="埋め込みのタイトル",description="埋め込みの説明",colour=discord.Colour.red()) send_embed.add_field(name="フィールドの名前",value="フィールドの説明書き") await message.channel.send(embed=embed)discord.Embedはdiscord.pyのデータクラスです。
4行目でデータクラスのインスタンス化を行い、その際に、タイトル,説明,色を指定できます。
add_fieldはEmbedデータクラスのメソッドでコルーチン関数ではありません。
add_fieldにはnameとvalueの引数の他に,inlineという引数があり、これにはbool値を指定できます。inlineのデフォルト値はTrueで、
他のフィールドと横に並列して表示させます。
inline=Falseにした場合
フィールドを縦に表示させます。画像を送信する。
await message.channel.send(File=discord.File("sample.png"))sendの引数にはFileを指定することができ、
Fileの引数はdiscord.Fileのデータクラスを指定します。
Fileの引数をインスタンス化する際に直接,ファイルのパスを文字列型で指定することで画像を送信することができます。1/8更新済み




- 投稿日:2021-01-08T11:07:20+09:00
複数ファイルを一括読み込み&縦に結合(DataFrame)
0:はじめに
業務のデータ分析をする際に、複数のファイルを扱うことはありませんか?
例えば、1年分のデータを(2019_01.csv,2019_02.csv, .. .. ,2019_12.csv)と12個のファイルを用意される場合を考えて見てください。
一つずつ読み込み・結合するのは面倒くさいですよね。。
ここで便利なコードを紹介します。
(今回はカレントディレクトリに複数ファイルがある場合を想定します。他のディレクトリにある場合は、各々で引数に指定のディレクトリを当てはめて下さい。)1:カレントディレクトリを取得
import os #カレントディレクトリ取得 current_dir = os.getcwd() current_dir #以下のような形でカレントディレクトリを取得できます >>> /Users/user_name/Date_science#カレントディレクトリ内部のフォルダを取得 os.listdir(current_dir) #以下のような形でカレントディレクトリ内の全ファイルを取得できます >>>["2019_01.csv","2019_02.csv","2019_03.csv","2019_04.csv",....,"2019_12.csv"]2:パスとファイル名を結合
tbl_order_file = os.path.join(current_dir,"2019_*.csv") tbl_order_file #ファイル名の「〜月」に当たる部分に「ワイルドカードの*」を指定することで、指定したファイルだけを表示できる。 #詳しくは3で。 >>>/Users/user_name/Date_science/2019_*.csv3:指定ファイルを抽出
#globモジュールでは、引数に指定されたパターンにマッチするファイルパス名を取得することができる import glob tbl_order_files = glob.glob(tbl_order_file) tbl_order_files #以下のような形で指定ファイルを一括操作出来ました。 >>>['/Users/user_name/Date_science/2019_01.csv', '/Users/user_name/Date_science/2019_02.csv', '/Users/user_name/Date_science/2019_03.csv', .................., .................., '/Users/user_name/Date_science/2019_12.csv']4:データフレーム結合
all_df = pd.DataFrame() for file in tbl_order_files: all_df = pd.read_csv(file) print(f"{file}:{len(order_data)}") all_df = pd.concat([all_df, order_data],ignore_index = True) #以下のような形で「どのファイルを」・「データ数」を出力させながら、データフレームを縦に結合させることが出来ます。 >>> 2019_01.csv:233301 2019_02.csv:233260 2019_03.csv:241139 ................., ................., 2019_12.csv:2411355:まとめ
import os import glob current_dir = os.getcwd() tbl_order_file = os.path.join(current_dir,"2019_*.csv") tbl_order_files = glob.glob(tbl_order_file) all_df = pd.DataFrame() for file in tbl_order_files: all_df = pd.read_csv(file) print(f"{file}:{len(order_data)}") all_df = pd.concat([all_df, order_data],ignore_index = True)
- 投稿日:2021-01-08T09:40:33+09:00
政府統計の総合窓口「e-Stat」のAPIを使って市区町村の境界データと目的の統計データをマージする!
はじめに
みなさま。今、世界で一番熱いWebアプリケーションをご存知でしょうか?
そう。
e-Statです。
政府の統計情報が分野・データ作成組織ごとに取りまとめられており、データの検索も可能。
さらにはグラフ・表など様々な形式で閲覧することのできるポータルサイトです。APIも用意され、サイトデザインも可愛いくてモダンーな感じに仕上がっていますね。
また、統計データを地図上で可視化する統計GISという機能も用意されているようです。
こちらは国勢調査・人口動態統計・医療施設調査など、特定の統計データを選択して地図上で可視化できる機能のようです。
ステキ!
こういうアプリケーションを見るとGIS屋としては当然いてもたってもいられず
「僕もこんなの作りたい!!!!!」
と思うわけです。
が、この「e-Stat」。素人が安易に手を出すと深い沼に落ちていくポイントがいくつもあったのでした…
目次
沼ポイント
ポイント①:データ多すぎ問題
e-Statには多岐にわたるデータが登録されています。
まず、「国土・気象」や「人口・世帯」など統計分野として17種類。
分野から探す組織として「内閣官房」・「経済産業省」など所管の政府統計が14省庁ほどあります。
組織から探す合計約150万件(!)のデータの中から自分に必要なデータを検索してくる必要があります。
さらにデータの形式は各分野・省庁バラバラでのため、目的の統計データを取得できたとしても有効に活用できるかは見てからのお楽しみ…という状態です。
ポイント②:API結構複雑だよ問題
僕はGIS分野のWebアプリケーションの作成を専門としているので、Webで利用できるAPIが用意されていたのは大歓迎だったのですが、政府統計の総合窓口(e-Stat)のAPI 仕様 3.0版を見ているとどうやらAPIは以下の7つも用意されているようです。
- 統計表情報取得
- メタ情報取得
- 統計データ取得
- データセット登録
- データセット参照
- データカタログ情報取得
- 統計データ一括取得
「仕様をよく読め」の一言で済む話かもしれませんが、とりあえず手軽に統計データを取得しようと思っても、目的のAPIがどれをなのかを調べる段階からのスタートになり、ちょっと辛いです。(データが多すぎなので仕方ない)
ポイント③:〇〇コード多すぎ問題
各種データは先ほど紹介した「統計分野」意外にもいくつかのコードで管理されています。
特にまとまったページは確認できなかったのですが、APIの仕様などなどを見ていると統計分野含め少なくとも4つほどの〇〇コード・IDが出てきました。
- 統計分野の小分類コード
- 政府統計コード
- 統計表ID
- 標準地域コード
結論から言うと、上記のコードと先ほど紹介したAPIのうち3種類を組み合わせて利用することで目的の統計データを入手することができるのですが、これらフレーズの意味を理解するだけでももしかしたら数時間〜数日かかってしまうのではないでしょうか?(僕はかかった)
一応、開発ガイドはあって、目的の統計データを取得するためのフローまで丁寧に記載されていますが、具体的に「どんな統計データを入手」できるのかがわからない上、添付画像が小さすぎて文字を読み取ることができず結局色々なページを探索して情報を集めることになります。
辛い。
ポイント④:意外とGISで使えるデータないよ問題
e-Statを利用するユーザーはおそらく統計データを元に様々な分析を行いたい!という方だと思います。
その中でもGISを利用した分析を行いたい方は多いのではないかなーと思うのですが、実際はGISで利用できるデータはそこまで多くありませんでした。
データを検索するページをよくみると、「データベース」として管理されているデータは263件/911件に対し、その他謎のファイルとして管理されているのが648件/911件になります。
しかも高確率でPDF。
自作のアプリケーションから手軽に利用できるようなデータではないでしょう。
ちなみにQ1 : API機能で利用できるデータを知りたい。の「提供データ」のリンク先を覗くと以下のようなページに飛ばされるので、APIとして利用できるのは150万件のうち約18万件のようです。
その他ちょこちょこしたつらみ
json出力かcsv出力かでURL変わんねん
- JSON出力:
…/getStatsData?<パラメータ群>- CSV出力:
…/getSimpleStatsData?<パラメータ群>(なんでやねん…)
csvで吐き出してんのに変な出力すな
"RESULT" "STATUS","0" "ERROR_MSG","正常に終了しました。" "DATE","2020-12-18T15:58:49.161+09:00" "TABLE_INF","0000010101" "STAT_NAME","00200502","社会・人口統計体系" "GOV_ORG","00200","総務省" "STATISTICS_NAME","都道府県データ 基礎データ" "TITLE","0000010101","A 人口・世帯" "CYCLE","年度次" "SURVEY_DATE","0" "OPEN_DATE","2020-03-06" "SMALL_AREA","0" "COLLECT_AREA","全国" "MAIN_CATEGORY","99","その他" "SUB_CATEGORY","99","その他" "OVERALL_TOTAL_NUMBER","486096" "UPDATED_DATE","2020-03-06" "STATISTICS_NAME_SPEC","都道府県データ","基礎データ","","","","" "TITLE_SPEC","","A 人口・世帯","","","" "CLASS_INF" "CLASS_OBJ_ID","CLASS_OBJ_NAME","CLASS_CODE","CLASS_NAME","CLASS_LEVEL","CLASS_UNIT","CLASS_PARENT_CODE","CLASS_ADD_INF"(いつ目的のcsv出てくんねん…)
あと、旧バージョンのAPIがいくつも残っていたりして情報を追うのが大変だったりとか色々…
e-stat-api-tools
と、いうことで色々とデータやAPIを舐め回してみましたが非常に便利ながらもちょこちょことしたハマりポイントを抱えるe-Stat。
僕と同じように「ちょっと敷居が高いな…」と思っている方も多いのではないでしょうか?
そんな迷える僕たちのためにMIERUNEが利用可能データ一覧の整備・主要APIのラッパーの作成を行った上で、市区町村境界ポリゴンと目的の統計データをマージしてGeoJSONで出力できるCLIツールを作成しました!
データ整備
政府統計コード
結論として目的の統計データを取得するには
統計データ取得APIに統計表IDとメタ情報(詳細項目情報)を入力する必要があるわけなんですが、ここまでたどり着くためには
統計表IDとメタ情報を別APIから取得してこなければなりません。e-StatのAPIでは、開発ガイドに記載の通り
統計表情報取得APIで政府統計コードや調査年月などを入力して目的の統計表の統計表IDを取得メタデータ情報取得APIに、取得した統計表IDを入力して、目的の統計表に係るメタ情報(詳細項目情報)を取得統計データ取得APIに統計表IDとメタ情報(詳細項目情報)を入力して目的の統計データを取得の流れで3つのAPIを叩いて目的の統計データを取得します。
(各種APIについては公式のAPI機能テストフォーム バージョン3.0で試せるのでどんなインプットでどんなレスポンスが返ってくるか眺めてみると理解が進むかなと思います。)
が、ファーストステップである
政府統計コードが政府統計コード一覧から参照できますが、PDFになっています。なのでまず初めにこのデータを機械判読できるようにtsvに変換しました。
リポジトリに格納してあるのでご自由にご利用ください。
government_statistics_codes.tsv
統計表ID
前述の政府統計コードを利用して統計表IDを取得しますが、e-Statのデータを眺めてみたり業界の動向を伺ってみたりしていると、GISで利用したくなる主要な統計データって社会・人口統計体系なのではないかな?と(勝手に)思いました。
なのでスムーズに社会・人口統計体系を利用できるように統計表ID一覧をリポジトリに格納しておきました。
default_stats_table_ids.csv
標準地域コード
標準地域コードとは「都道府県及び市町村の区域」を示すコードになります。
統計に用いる標準地域コード統計データ取得というよりは後述の境界データ取得に関わる部分になりますが、こちらもリポジトリに入れてあります。
2020/12現在のデータですので、市区町村の統合などありましたら市区町村を探すからダウンロードして更新してください。
Pythonラッパー
以下の主要APIについてはe-statパッケージでラッピングしているのでPythonから呼び出し可能になっておりますが、現段階ではまだ整備が完璧ではなくPyPIに登録されていないため、説明は省略します。
(いづれ対応します)
- 統計表情報取得API
- メタデータ情報取得API
- 統計データ取得API
CLIツール
前述のパッケージを利用してコマンドラインから以下の5つについて操作可能なツールを作成しました。
- ids:統計表ID一覧を取得
- meta:統計表メタデータを取得
- stats:統計データを取得
- boundary:境界データを取得
- merge-boundary:統計データと境界データを取得してマージする
各種コマンドの細かい利用方法はREADME.mdに詳しく記載しておりますのでご覧ください。
市区町村の境界データと目的の統計データをマージしてみる
ということでこのツールを利用して境界データと統計データをマージしてみましょう!
まずはe_stat_api_toolsをCloneし、
e_stat_api_sampleディレクトリに移動しましょう。% cd .../e_stat_api_sample % pwd .../e_stat_api_sampleその後、
pipenv installコマンドで必要なパッケージをインストールしていきます。pipenvがインストールされていない方は
% brew install pipenv又は
% pip install -U pip % pip install pipenvでインストールしてください。
本ツールではe-statのアプリケーションIDが必要になりますので利用ガイドに従いユーザー登録を済ませアプリケーションIDして、以下のコマンドを実行し
.envファイルを作成してください。※
<YOUR_APP_ID>には取得したアプリケーションIDを入力してください。% touch /e_stat_api_sample/e_stat/.env % echo "app_id=<YOUR_APP_ID>" >> /e_stat_api_sample/e_stat/.envアプリケーションIDを格納した
.envファイルを作成したらmerge-boundaryコマンドで以下の項目をインプットして実行します。-p, --pref_name TEXT 取得するshpファイルの都道府県名を入力 [required] -d, --download_dir TEXT ダウンロードするshpファイルを格納するディレクトリのパス文字列を入力 [required] -a, --area TEXT 取得する統計データの標準地域コードを入力 [required] -c, --class_code TEXT 取得する統計データの項目を入力 [required] -y, --year TEXT 取得する統計データの年度を入力 [required] -st, --stats_table_id TEXT 取得したい統計データの統計表IDを入力 [required] -o, --output_dir TEXT ダウンロードしたcsvを格納するディレクトリのパス文字列を入力 [required]具体的には以下のようなコマンドになります。
% pipenv run python -m e_stat merge-boundary \ -p 北海道 \ -d ./download_file \ -a 01101 \ -c A1101 \ -y 2000 \ -st 0000020101 \ -o ./created
merge-boundaryに限らずその5種類の各種コマンドはサンプルとしてshell scriptを用意していますので動作確認には以下のコマンドを利用できます。% bash merge_boundary.sh試しに
bash merge_boundary.shを実行すると以下のようなログが流れたのち、createdディレクトリにmerge_boundary.geojsonが生成されているはずです。% bash merge_boundary.sh 0.00B [00:00, ?B/s]url='https://www.e-stat.go.jp/gis/statmap-search/data?dlserveyId=A002005212015&code=01&coordSys=1&format=shape&downloadType=5', res.status_code=200 A002005212015DDSWC01.zipのダウンロードを開始します 15.8MB [00:05, 2.75MB/s] 読み込みファイル: .../e_stat_api_tools/download_file/A002005212015DDSWC01.zip .zipファイル内のshpファイルをgdfに変換します See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy super(GeoDataFrame, self).__setitem__(key, value) gdfを指定キー(AREA_CODE)で結合します。 gdfをgeojsonに変換します。 .../e_stat_api_tools/created/boundary.geojsonを書き出しました。 .../e_stat_api_tools/created/boundary.csvを書き出しました。 統計表を取得します。URL=http://api.e-stat.go.jp/rest/3.0/app/getSimpleStatsData?appId=9a10491cd87e8877b5410283228bb64b7805ff79&cdArea=01101&cdCat01=A1101&cdTime=2000100000&statsDataId=0000020101&lang=J&metaGetFlg=N&c&explanationGetFlg=N&annotationGetFlg=N§ionHeaderFlg=2 gdfをgeojsonに変換します。 .../e_stat_api_tools/created/merge_boundary.geojsonを書き出しました。 .../e_stat_api_tools/created/merge_boundary.csvを書き出しました。作成された
merge_boundary.geojsonをQGISで開いてみましょう!
01101つまり札幌市中央区の境界データに以下の統計データがマージされていることが確認できると思います。
- A1101(A 人口・世帯 総人口)
- 2000(2000年)
- 0000020101(社会・人口統計体系 市区町村データ)
おわりに
簡単にe-Statの境界データと統計データをマージできるツールを作成・紹介していきましたが、いかがでしたでしょうか?
オープンソース(MITライセンス)のツールとなっておりますので、機能の追加・改善など随時行っていきますが、不具合や要望などありましたらIssueにいただけますと幸いです。
弊社は様々なデータの可視化・分析、ツールの作成やWebGISの作成なども得意としており、これまで多くのお客様の多様なニーズに沿った機能を受注・開発してきております。もしご興味がございましたら、弊社ウェブサイトよりご気軽にお問い合わせくださいませ。
また地図配信サービスMapTilerを日本向けに展開しております。他社に比べ圧倒的に高いコストパフォーマンスでベクタータイル含む高品質な地図データを利用する事が出来ます。詳細はMapTiler.jpからどうぞ!










- 投稿日:2021-01-08T09:06:01+09:00
VRoidのcluster用VRM出力、結局どうすれば良いの?
現在、VRoid Studioからはcluster対応のVRMを出力する機能が備わっていますが、一方では「画質が汚い」とか「clusterの制限が厳しすぎる」と言う評価もあるようです。
Macやスマホでもアクセス可能な国産バーチャルSNSですので、なんとか楽な方法で課題を解決したいと思います。clusterへの出力は標準で対応している
現行のバージョンのVRoid Studioは標準でclusterへの出力に対応しています。
「撮影・エクスポート」タブのエクスポートから選択します。厳密には制限はこれだけではありませんが、clusterにアップロードするには以下の制限をクリアする必要があります。
* ポリゴン数: 32000以下
* マテリアル数: 8以下
* ボーン数: 128以下
マテリアル統合機能は2048pxで出力よりも4096pxで出力してリサイズしよう
VRoid Studioは、アトラス化の機能が2048pxで出力しようとすると、ちょっとばかしおバカな挙動をするので、できる限り4096pxで出力してからリサイズすることをお勧めします。
(縮小のスケールが50%ですらないってどう言うこと?)
なぜか髪のマテリアルが複数コピーされるおかしな挙動についてはどちらでも起きていますが、原因わかりません。
4096pxで出力するとそのままでclusterにアップロードできないのですが、この辺のソフト使えば2048pxにリサイズできるので、極力4096pxで出力してリサイズすることをお勧めします。
- VRMテクスチャ差し替え&最適化ツール #cluster #VRM
https://booth.pm/ja/items/2601784とはいえ、clusterで2048pxの解像度をフルに使えるのは、イベント主催者限定で、多少ピクセルが潰れるにしろ細部まで拡大しなければ割とどうにでもなるレベルなので、VRoidの出力をそのまま使っても極論どうでも良い気がします。
問題は、さらなる劣化を招く一般向けの512px強制縮小です。VReducerはclusterの一般ユーザーの救世主となるか?
一般ユーザー、モバイル表示、あるいはワールドで使えるVRMの最大解像度が事実上512pxに制限されているので、そこをどうにかしないといけません。
VRoidのアトラスの割り当てですと、512pxにリサイズされた時、肌とかワンピースの解像度は256x256pxになります。これはあまりに小さいでしょう。
でも512x512pxをまるまる1衣装に使えれば割とどうにかなると思いませんか?そう言うわけで、ワンピースなどの解像度を最優先でリサイズする方向でいきましょう。
VReducerはpythonで書かれカスタマイズ可能なソフトですので、衣装の解像度を極力稼ぐ方向でチューニングするなど柔軟性が高いと思います。VReducerの導入方法についてはとみねさんあたりも纏めていますからこちらの記事を参照してください
MacでのVReducerのインストール
Windowsユーザーの方が多いのでMacについてフォローしておくと、文中のコマンドのpipはpip3に、pythonはpython3に読み替えてください。必要に応じてHomebrewを導入してください。
M1のマシンではRosetta 2だとうまくいくようです。ターミナルを開いて% arch -x86_64 zshと打てばIntelマシンだと思い込んで動いてくれます。
VReducerを利用するときのエクスポート設定
今度はマテリアルを統合しない設定でVRoidからエクスポートすることになりますが、今度はマテリアルの統合をやめて、ポリゴン数とボーン数だけ制限内に収まるように調整してVRMをエクスポートします。
- ポリゴン数: 32000以下
- ボーン数: 128以下
VReducerの制約
ノーマルマップとかリムライト(スフィア)とかのマテリアル情報を吹っ飛ばしてしまいます。しかし、ここでは、それは大した問題ではないことにします。
- そもそも低解像度でノーマルマップとか意味あるの?
- 「VRoidらしくないテクスチャ」みたいなの流行ってるし、リムライトも大抵の人嫌いだよね?
そんな感じで消し飛ばしてしまっても別に痛くない人もいるわけだし、そこに納得いかない人は、BlenderやUnityと十分仲良くなってください。
VReducerの改造
早速、VReducerを改造していきましょう。
アトラス化によって衣装や肌テクスチャが他のテクスチャと結合されてしまうわけですから、アトラス化の処理を外せば良いだけです。
該当の処理を探してみると、vrm/reducer.pyの620行目あたりで何やらそれらしいことをしています。
察しの通り、ここがテクスチャをアトラス化する実処理でした。# マテリアルを結合 print('combine materials...') # (中略) # 服の結合 if cloth_place := get_cloth_place(gltf): gltf = combine_material(gltf, cloth_place['place'], cloth_place['main'], texture_size) # 体、顔、口 gltf = combine_material(gltf, { '_Face_': {'pos': (0, 0), 'size': (512, 512)}, '_FaceMouth_': {'pos': (512, 0), 'size': (512, 512)}, '_Body_': {'pos': (0, 512), 'size': (2048, 1536)} }, '_Face_', texture_size) # レンダータイプを変更 face_mat = find_vrm_material(gltf, '_Face_') face_mat['keywordMap']['_ALPHATEST_ON'] = True face_mat['tagMap']["RenderType"] = 'TransparentCutout' # アイライン、まつ毛 gltf = combine_material(gltf, { find_eye_extra_name(gltf): {'pos': (0, 0), 'size': (1024, 512)}, '_FaceEyeline_': {'pos': (0, 512), 'size': (1024, 512)}, '_FaceEyelash_': {'pos': (0, 1024), 'size': (1024, 512)} }, '_FaceEyeline_', texture_size) # 瞳孔、ハイライト、白目 gltf = combine_material(gltf, { '_EyeIris_': {'pos': (0, 0), 'size': (1024, 512)}, '_EyeHighlight_': {'pos': (0, 512), 'size': (1024, 512)}, '_EyeWhite_': {'pos': (0, 1024), 'size': (1024, 512)} }, '_EyeHighlight_', texture_size) # 髪の毛、頭の下毛 hair_back_material = find_vrm_material(gltf, '_HairBack_') if hair_back_material: hair_resize = {'_HairBack_': {'pos': (512, 0), 'size': (1024, 1024)}} hair_material = find_near_vrm_material(gltf, '_Hair_', hair_back_material) if hair_material: hair_resize[hair_material['name']] = {'pos': (0, 0), 'size': (512, 1024)} gltf = combine_material(gltf, hair_resize, hair_material['name'], texture_size)解像度>マテリアルの質感という絶対の真理
顔パーツはある程度縮小されても余裕あるのでアトラス化を進めてそのぶん体/衣装の解像度を稼げば良いわけです。
そう言うわけで、顔パーツは統合を進める一方で体と衣装(上)をアトラス化しないように書き換えてしまいましょう。
それがこのブランチとなります。あと、VRoid 0.12.1への対応も入れておきました。
https://github.com/yakumo-proj/VReducer/tree/benefit-512pxさて、使用前と使用後です。顔は大差ないにしろ首から下がまるで別物ですね。
リムライトが効いてないけど、そんなものより解像度って圧倒的に大事だと思うでしょう?
まあ、実際のところ、VReducer(改)を使っただけじゃなくてベースヘアをHairSampleのベースヘアに変更したり、衣装のブレンドシェイプに合わせて法線を修正したり(エクスポート時にポリゴン数を微妙に削減するだけでできる)とかやってるわけですが。
見栄えをもっと良くするには?
解像度512pxでやれることは限られていますが、clusterのデータの制限の余力で何かできることはあるでしょうか?
先のVReducerの出力をみてみましょう。(中略) vrm materials: 7 materials: 7 textures: 10 images: 10 meshes: 3 primitives: 18 Face(Clone).baked : 9 Body.baked : 6 Hair001.baked : 3マテリアル数は7です。マテリアルはあと1つですから余力があるとはいえませんが、1枚着重ねする程度は可能かもしれません(Unityの羅生門ツールとかで調べてみましょう)。
テクスチャは16枚までいけるので、ノーマルマップを復活させて衣装の立体感や質感を出す程度はできるかもしれません。512pxで十分見栄えするかどうかは疑問ですが。色々試してみてください。
あとBlenderやらUnityやらでもっと楽に超美麗なVRMに変換できた人は教えてください。512px基準でアバターアップロードしたらイベント用には解像度低すぎるけどどうすればいいの?
イベント用(2048px)とワールド用(512px)で作り分けて両方をアップロードしてください。そのためのアバターチェンジの仕組みです。



- 投稿日:2021-01-08T08:45:43+09:00
【適宜更新(予定)】基本的な可視化手法を整理してみた
- 製造業出身のデータサイエンティストがお送りする記事
- 今回は業務で良く使う可視化手法を整理してみました。
- 適宜更新できるようにしたいと思います。
はじめに
今回はAuto MPGのデータセットを使用して整理したいと思います。このデータセットは、1970年代後半から1980年台初めの自動車の燃費を現したデータです。
データの確認
# 必要なライブラリーのインストール import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline import os file_path = 'https://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data' file_name = os.path.splitext(os.path.basename(file_path))[0] column_names = ['MPG','Cylinders', 'Displacement', 'Horsepower', 'Weight', 'Acceleration', 'Model Year', 'Origin'] df = pd.read_csv( file_path, # ファイルパス names = column_names, # 列名を指定 na_values ='?', # ?は欠損値として読み込む comment = '\t', # TAB以降右はスキップ sep = ' ', # 空白行を区切りとする skipinitialspace = True, # カンマの後の空白をスキップ encoding = 'utf-8' ) df.head()
レコード数、カラム数の確認
# レコード数、カラム数の確認 df.shape欠損値の確認
# 欠損値数の確認 df.isnull().sum()DataFrameの各列の属性の確認
# DataFrameの各列の属性を確認 df.dtypes欠損値の可視化
欠損値に規則性があるかどうかの時に使用します。
現場に説明する際とかに分かりやすくて重宝します。plt.figure(figsize=(14,7)) sns.heatmap(df.isnull())
要約統計量の確認
# 要約統計量 df.describe()
ヒストグラムの作成
# ヒストグラム df['MPG'].plot(kind='hist', bins=12)
カーネル密度推定の作成
ヒストグラムはビンの大きさを変更すると形が変わって見えるので、カーネル密度推定で作成したグラフの方が良く使います。
# カーネル密度推定 sns.kdeplot(data=df['MPG'], shade=True)
散布図の作成
散布図+ヒストグラム
# 散布図+ヒストグラム sns.jointplot(x='Model Year', y='MPG', data=df, alpha=0.3)
六角形の散布図行列
# hexagonal bins sns.jointplot(x='Model Year', y='MPG', data=df, kind='hex')
六角形の散布図
少しモダンでおしゃれな散布図。
```phphexagonal bins
sns.jointplot(x='Model Year', y='MPG', data=df, kind='hex')
```カーネル密度推定の散布図
等高線風のグラフを生成。
# density estimates sns.jointplot(x='Model Year', y='MPG', data=df, kind='kde', shade=True)
散布図行列
# 散布図行列 sns.pairplot(df[["MPG", "Cylinders", "Displacement", "Weight"]], diag_kind="kde")
箱ひげ図の作成
データのばらつきを可視化。
countplot
# 年代別のcountplot ax = sns.countplot(x='Model Year', data=df, color='cornflowerblue')
箱ひげ図(boxplot)
# 箱ひげ図(boxplot) sns.boxplot(x='Model Year', y='MPG', data=df.sort_values('Model Year'), color='cornflowerblue')
violin plot
データの分布の密度を確認できるグラフ。
# violin plot sns.violinplot(x='Model Year', y='MPG', data=df.sort_values('Model Year'), color='cornflowerblue')
swarm plot
データの分布のドットで確認できるグラフ。
# swarm plot fig, ax = plt.subplots(figsize=(20, 5)) ax.tick_params(labelsize=20) sns.swarmplot(x='Model Year', y='MPG', data=df.sort_values('Model Year'))
ヒートマップ
相関係数行列
# 相関係数行列(値が0を含むrowを除く) df = df[(df!=0).all(axis=1)] corr = df.corr() corr
相関係数行列のヒートマップ
cmapの「coolwarm」の色合いが個人的には好きです。何も指定しないと微妙な色合いになって資料とかで見えにくいので。
# 相関係数のヒートマップ sns.heatmap(df.corr(), annot=True, cmap='coolwarm')
さいごに
最後まで読んで頂き、ありがとうございました。
今回は、基本的な可視化手法を整理してみました。
適宜自分のメモとして更新していこうと思います。訂正要望がありましたら、ご連絡頂けますと幸いです。















- 投稿日:2021-01-08T08:45:03+09:00
階層的クラスタリングを実装してみた
- 製造業出身のデータサイエンティストがお送りする記事
- 今回はクラスタリング手法の中で、K-means法を実装しました。
はじめに
前回、K-means法を実装しましたが、今回は階層的クラスタリング手法を実装してみました。
階層的クラスタリングとは
階層的クラスタリングとは、最も似ている組み合わせから順番にまとまり(クラスタ)にしていく方法です。
階層的クラスタリングの実装
pythonのコードは下記の通りです。
# 必要なライブラリーのインストール import numpy as np import pandas as pd # 可視化 import matplotlib as mpl import matplotlib.pyplot as plt import seaborn as sns from IPython.display import display %matplotlib inline sns.set_style('whitegrid') # 正規化のためのクラス from sklearn.preprocessing import StandardScaler # 階層クラスタリングに必要なものをインポート from scipy.cluster import hierarchy最初に必要なライブラリーをimportします。
今回もirisのデータを使って実装してみようと思います。# irisデータ from sklearn.datasets import load_iris # データ読み込み iris = load_iris() iris.keys() df_iris = iris.data df_target = iris.target target_names = iris.target_names df_labels = target_names[df_target] # データの正規化(平均0, 標準偏差1) scaler = StandardScaler() df_iris_std = scaler.fit_transform(df_iris)前処理は上記で終了です。
今回はウォード法を用いて階層クラスタリングを実施したいと思います。クラスタ同士の距離の定義の仕方は他にも色々ありますので、データに合わせて適切な手法を選択する必要があります。# 距離計算 dist = hierarchy.distance.pdist(df_iris_std, metric='euclidean') # クラスタリング linkage = hierarchy.linkage(dist, method='ward') # デンドログラム fig, ax = plt.subplots(figsize=(5,13)) ax = hierarchy.dendrogram(Z=linkage, orientation='right', labels=dataset_labels) fig.show()
さいごに
最後まで読んで頂き、ありがとうございました。
今回は、階層的クラスタリング法を実装しました。訂正要望がありましたら、ご連絡頂けますと幸いです。

- 投稿日:2021-01-08T08:29:30+09:00
PyPortfolioOpt(投資ポートフォリオ最適化ライブラリ)インストールエラー解消
PythonライブラリのPyPortfolioOpt(投資ポートフォリオ最適化)をインストールエラーを解消したときのメモ。
PyPortfolioOptを使うと、つみたてNISAやiDeCoなどで各資産(国内株式・国内債券・外国株式・外国債券など)への投資割合を、数理最適化を用いて算出できます。
環境
- macOS
- Docker
- Anaconda3
エラーメッセージ
pipでライブラリをインストールしようとしたらエラー。
$ pip install PyPorttfolioOptエラーメッセージ。
ERROR: Failed building wheel for scs Running setup.py clean for scs Failed to build cvxpy ecos scs ERROR: Could not build wheels for cvxpy which use PEP 517 and cannot be installed directly解決
cvxpy(数理最適化ライブラリ)をインストール。
pipでインストールしようとしたらエラーだったので、調べた結果、condaでインストール。conda install -c conda-forge cvxpy
- 投稿日:2021-01-08T08:26:09+09:00
文字列の切れ目の一致率の計算【python】
概要
切れ目の存在する2つの文字列において、切れ目の位置がどの程度一致しているかを計算するプログラムを書きました。
「〇〇で歌ってみた」というジャンルの替え歌において、本来の歌詞の文節の切れ目と替え歌歌詞の単語の切れ目がどの程度一致しているかを調べるために作りました。背景
「〇〇で歌ってみた」は特定カテゴリの名詞だけで本来の歌詞の発音を再現するように歌われた替え歌のことです。下図は童謡『ふるさと』の歌詞を駅名に置き換えた「〇〇で歌ってみた」の例です。
「〇〇で歌ってみた」では替え歌歌詞の単語の切れ目と本来の歌詞の文節の切れ目がどちらかというと一致するように作られる傾向があります。理由は定かではありませんが、一つにはそのほうが歌いやすいからという理由が考えられます。いくつかの替え歌において、どの程度一致しているかを調べたくなったので、2つの文章の文節一致率を評価するプログラムを書いてみることにしました。解きたい問題
文字列Aと文字列Bが与えられて、2つの文節一致率を求めることが目標です。
入力
簡単のため、2つの文字列のモウラ数は同じとします。また発音(読み方)と文節(単語)の切れ目は既知とします。発音はカタカナで、文節の切れ目はスラッシュで表記することとします。例えば下記のような文字列を入力として想定します。
- 文字列A(替え歌歌詞):カモメ/カモメ/カグー/ナガノゴリ/サイ/クイ/ツミ/ラット/ウシ/ロバ/ヒョウ/メナダ/アビ
- 文字列B(本来の歌詞):カゴメ/カゴメ/カゴノ/ナカノ/トリワ/イツ/イツ/デアッタ/ウシロノ/ショウメン/ダアレ
出力
文字列Aと文字列Bの文節一致率を出力します。
文節一致率は文字列Aの文節の切れ目のうち、文字列Bの文節の切れ目と同じ位置にあるものの割合と定義します。同じ位置であるかどうかは、その文節の切れ目の直前までに存在する文字列のモウラ数で判断します。また文字列の最後は文節の切れ目とはみなしません。例えば先に示したカゴメの例で、文字列Bのうち一致している切れ目をダブルクオテーションで示すと以下になります。
- 文字列A(替え歌歌詞):カモメ"/"カモメ"/"カグー"/"ナガノゴリ/サイ/クイ/ツミ/ラット"/"ウシ/ロバ"/"ヒョウ/メナダ/アビ
- 文字列B(本来の歌詞):カゴメ/カゴメ/カゴノ/ナカノ/トリワ/イツ/イツ/デアッタ/ウシロノ/ショウメン/ダアレ
文字列Bの文節の切れ目の数(=スラッシュの数)は12で、そのうち文字列Aの文節の切れ目と一致しているものは、5個です。文字数ではなくモウラ数(例えばヒョは2文字ですが、1モウラです)で数えることに注意してください。
環境
macOS Catalina 10.15.7
python 3.8.0コード
与えられた文字列をモウラの単位に分解してから、スラッシュの位置をカウントします。
import re #各条件を正規表現で表す c1 = '[ウクスツヌフムユルグズヅブプヴ][ヮァィェォ]' #ウ段+「ヮ/ァ/ィ/ェ/ォ」 c2 = '[イキシシニヒミリギジヂビピ][ャュェョ]' #イ段(「イ」を除く)+「ャ/ュ/ェ/ョ」 c3 = '[テデ][ャィュョ]' #「テ/デ」+「ャ/ィ/ュ/ョ」 c4 = '[ァ-ヴー]' #カタカナ1文字(長音含む) cond = '('+c1+'|'+c2+'|'+c3+'|'+c4+')' re_mora = re.compile(cond) #カタカナ文字列をモウラ単位に分割したリストを返す def mora_wakachi(kana_text): return re_mora.findall(kana_text) def phrase_partition_concordance(text1, text2): partition = "/" #文字列を区切り文字でスプリット kana_list1 = text1.split(partition) kana_list2 = text2.split(partition) #各要素をモウラに分割 kana_list1 = [mora_wakachi(k) for k in kana_list1] kana_list2 = [mora_wakachi(k) for k in kana_list2] #text1の文節位置を取得 partition_position1 = [0] for k in kana_list1: pos = partition_position1[-1] + len(k) partition_position1.append(pos) #最初と最後は文節位置から除く partition_position1 = partition_position1[1:-1] #text2の文節位置を取得 partition_position2 = [0] for k in kana_list2: pos = partition_position2[-1] + len(k) partition_position2.append(pos) #最初と最後は文節位置から除く partition_position2 = partition_position2[1:-1] #text1の文節位置がtext2の文節位置に含まれるかチェック same_pos_num = 0 for p in partition_position1: if p in partition_position2: same_pos_num += 1 #text1の文節の切れ目の数 partition_num = len(partition_position1) return same_pos_num / partition_num text1 = "カモメ/カモメ/カグー/ナガノゴリ/サイ/クイ/ツミ/ラット/ウシ/ロバ/ヒョウ/メナダ/アビ" text2 = "カゴメ/カゴメ/カゴノ/ナカノ/トリワ/イツ/イツ/デアッタ/ウシロノ/ショウメン/ダアレ" print(phrase_partition_concordance(text1,text2))
