- 投稿日:2021-01-08T22:09:13+09:00
Jリーグの勝ち点推移がグラフで見れるよ!
概要
記事概要
今回作ったサービスの紹介をしつつ開発の流れやつまずきポイントを紹介します。
アプリ概要
- Jリーグのチームの勝ち点推移がグラフで見れる
- こちらからサービスに飛べます。
- Jリーグのデータサイトからスクレイピングしてデータをためて、APIとして配信してフロントから表示させています。

アプリ作成理由
- 川崎フロンターレの圧倒的な結果を視覚的にみたくなったから。
全体の構成
フロントのソースコードはGitHubにあげています。
構成図
使用技術
- Python
- AWS(Lambda,APIGateway,DaynamoDB)
- JavaScript(Nuxt.js,Chart.js)
作成の流れ&つまづきポイント
流れ
- JリーグのデータサイトをAWS LambdaでスクレイピングしてAWS DaynamoDBに蓄積
- AWS DaynamoDBのデータをAPIGateway&LambdaでAPIを作る
- Nuxt.jsでAPIを受け取りChart.jsで表示
- GitHubpagesでデプロイ
流れの詳細
参考にしたサイトなどを紹介しつつ開発の流れを説明します。
1.Lambdaでスクレイピング
スクレイピングは
requestsとbeautifulsoupを使っています。
Lambdaでサードパーティーのライブラリを使うには以下のサイトを参考にしましたLambdaでスクレイピングするならDockerイメージを使おう【Python】
さらにスクレイピングしたデータをDaynamoDBに送るにはPython Boto3という公式のライブラリで操作できます
・参考
公式のドキュメント
AWS LambdaからPython Boto3を使用してDynamoDBを操作してみた2.Lambda+APIGateway でAPI作成
DaynamoDBからデータをとってくるLambda関数とAPIGatewayを作ります。
かなり簡単です。
DaynamoDBからソートしてデータを取るのが難しかったので、Lambdaでソートし直すことにしました。辞書のリストを並べ替えるのもライブラリで簡単にできます。・参考
API Gateway + Lambda + DynamoDB
Pythonの辞書のリストを並び替える3.Nuxt.js ✖️ Chart.js
Nuxtでchart.jsを扱うのは以下を参考にしました。
APIをchart.jsで扱うには公式にサンプルがあるのでそれを参考に!
・参考Nuxt.jsでvue-chart.jsを使って簡単グラフ作成
公式感想
感想をだらだらと書きます。
- やっぱりLambda楽しい手軽に開発できて便利〜
- Chart.jsでも簡単にグラフ表示できていいね!
- JS力もUPさせたい!
今後の展望
今後やりたいことをだらだらと列挙していきます。
- セキュリティーの強化(APIkey入れるとか)
- APIテスト
- APIのドキュメント作成
- UIの改善
- CICD

- 投稿日:2021-01-08T19:34:38+09:00
備忘録
- 投稿日:2021-01-08T19:34:38+09:00
AWS,Dockerによるインフラ構築練習 備忘録
- 投稿日:2021-01-08T18:22:42+09:00
AWS概要 ストレージについて
概要
もはや何番煎じているか分かりません。
1月から個人的に始めている未経験AWSチャレンジの一環として、CP試験に向けての個人的なメモとして記述します。※は書き方を模索中ですが、問題を通して思った感想になります
ストレージサービス(★★★:めっさ問題に出る)
データの特性やシステムの要件に応じてストレージを選択していこう
※ということは特性からストレージの選択問題や、その逆も然りと幅広く問題で扱われる
Amazon Simple Strage Service(Amazon S3)
高耐久(保存しているデータが失われる確率)・大容量のオブジェクトストレージサービス
※”オブジェクト”を”バケット”で保存という単語だけで選択肢を判断できる場合もあるので、覚えておくことに越したことはない。
Amazon Glacier(Glacier≒氷河:いかつい名前)
アーカイブを目的としているデータベース
※もうアーカイブという文言があったら、ほぼ1択に絞り込る。迅速・標準・大容量とオプションがあるが、今のところの問題では出会っていない。こちらもS3同様にオブジェクトストレージなので、複数選択問題でS3と一緒にチェックさせる問題はあった。
S3 :オブジェクト
Glacier:オブジェクトAmazon Elastic Block Store(EBS)
EC2を使用する際に、AZ内で自動的に複製される保存領域
EC2の中に領域がつくられるのではなく、EBSという領域がEC2とネットワークで繋がっているためEBSを増やす(容量を増やす、数を増やす)ことが出来る(ただし1つのEC2に、1つのEBSな)。※EBSはAZに複製されるので、AZに障害があるとデータが消える可能性はある。だから”スナップショット”を利用してバックアップをとるということを問うてくる問題は多い。
※それと名前にもある Block(ブロックアクセスという方法でデータにアクセスする)のも覚えておくと、意外と選択肢を絞ることに役立つ。
S3 :オブジェクト
EBS:ブロック
EFS:ファイルインスタンスストア(エフェメラルディスク:こちらの名前では見かけない)
EC2と物理的につながっているストレージサービスとして理解しています。
そのためEC2が消えたら、一緒に消えるのでデータももちろん消失します※上記のEBSと対比させる問題でお腹がいっぱいになる。細かい違いは各自に調べてもらうとしても、試験問題としては、消えるor消えないかくらいの違いしかない(先人達から避難の的になりそう)
EBS :データ消えない
インスタンスストア:データ消えるAmazon Elastic File System(EFS)
スケーラブルな共有ストレージサービス
※EC2と”複数”接続ができる保存領域として覚えておく。自動で複数のAZに保存されるので
EBS:単数
EFS:複数おしまい
CP試験ということもあると思うので、なによりサービスの差分がわかっていることが重要かなと思っています。
レベルが上がれば内容の細かさが問われてくるのでしょうが、現状では問題集を通して獲得した差分を記述させていただきました。理解が甘い、その理解が間違ってるあれば、お手数ですがご鞭撻お願いします。
そのご鞭撻により、よりよい学習へ繋げられればなと思っています。
- 投稿日:2021-01-08T17:32:17+09:00
React.js + AWSでプログラミング無しで自動ブラウザテストが出来るサーバレスWebアプリを作ったお話
敵「リリースした後に既存のコンテンツがおかしくなってないか"目視"でチェックしてね」
ぼく「はい (やりたくねぇ〜〜〜〜〜大体どんなパターン網羅して、どこまでチェックしたらいいんだ? 大体人間が目視でチェックしてもそのうち精度が落ちて結局見落としggg) 」
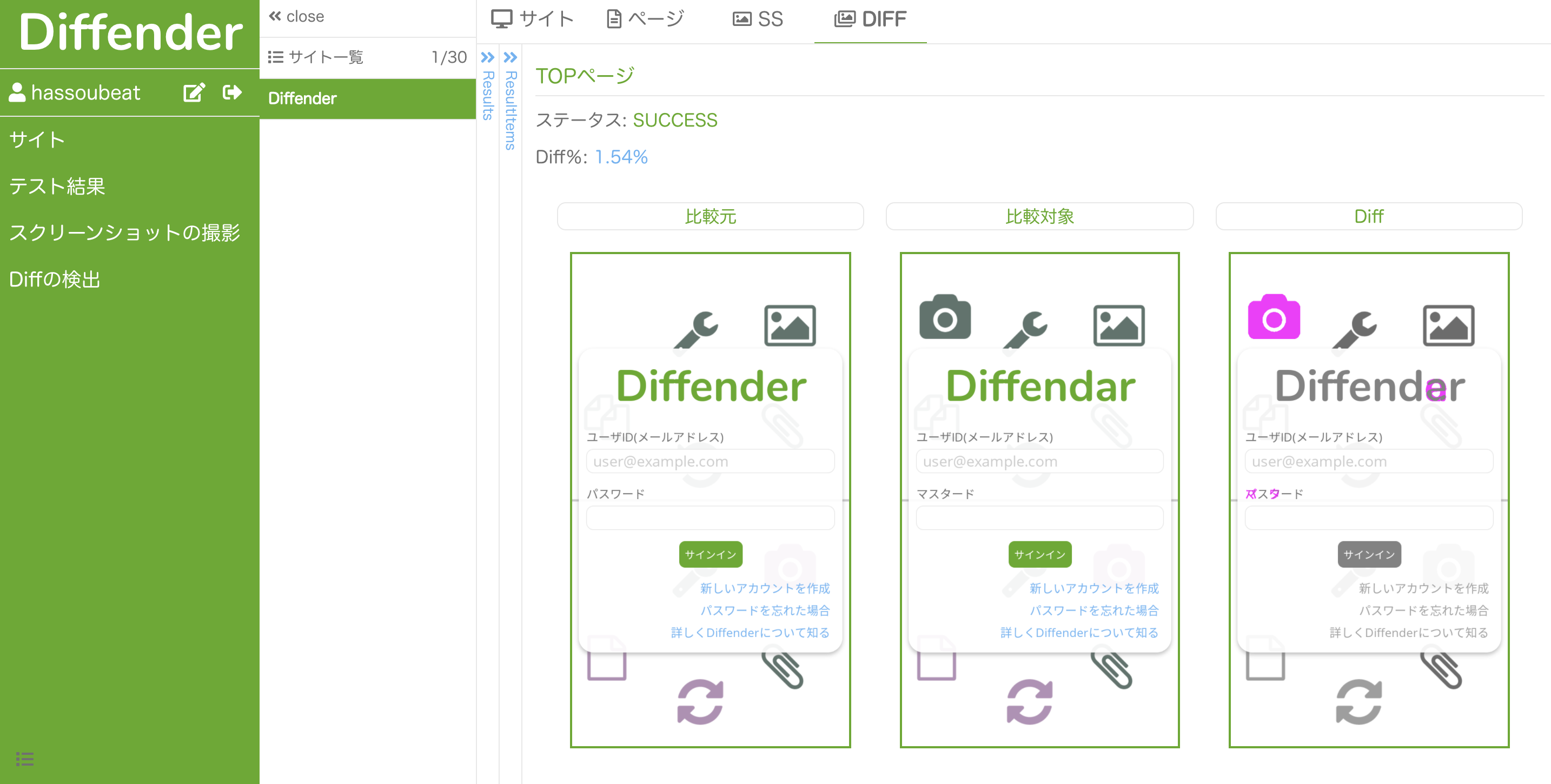
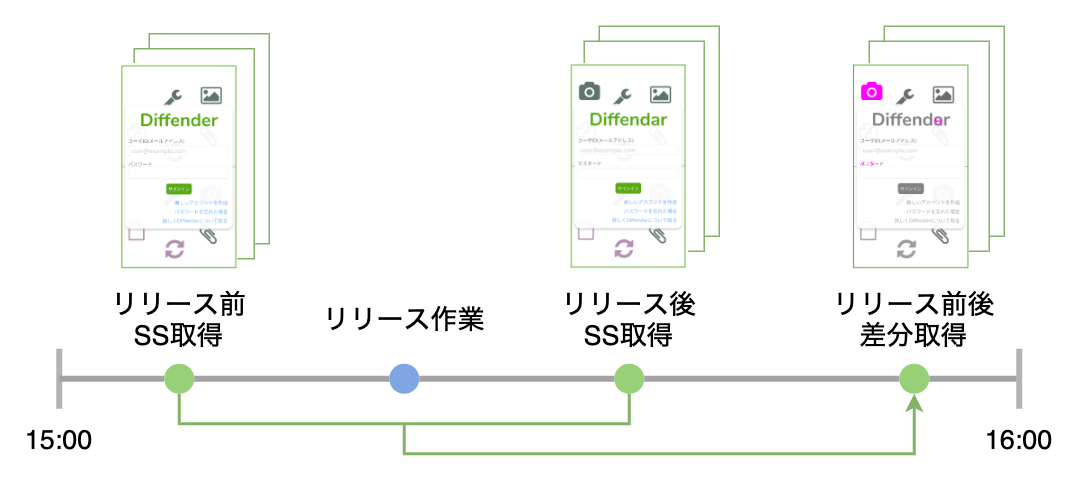
というのが発端で、以下のようにリリース前後のWebページのスクリーンショットを取得・比較して変更点を視覚的に検出するブラウザテストWebアプリを作りました。
実装したアプリ「Diffender」と利用した技術要素などについて紹介していきます。
作ったアプリ「Diffender」の紹介
何が出来るか?
Webページのスクリーンショットの取得、取得したスクリーンショット間の変更点の検出ができます。
こんな感じで2つスクリーンショットを取得した後に差分を取得することで、リリース前後で表示内容に想定外の変更がないことのチェックが行えます。一度テスト設定を作成した後は、ワンクリックで繰り返し同じ内容のテストを行えます。
ここ見てもらうのが一番はやいかもです
https://diffender.hassoubeat.com/aboutコンセプト
「エンジニア以外の人も簡単に自動ブラウザテスト」
従来の自動ブラウザテストはSeleniumとかPuppeteerなどを利用してブラウザ操作(クリック、テキスト入力)をプログラミングする必要があるため、エンジニア以外の人にはハードルが高いです。
そのハードルを下げるべく、プログラミングをしなくてもブラウザ操作が行えて、テスト結果がスクリーンショットとして出力されるため誰でも結果の正否が判断が行えるブラウザテストアプリを実装しました。
目視でデグレチェックという辛い作業からサヨナラ。
なんで作ったの?
① 非エンジニアのディレクターさんやステークホルダーの方でも見て分かるデグレ検証結果が欲しかった
品質の担保としてはユニットテストとかでもいいんですけど、そのユニットテストの実施内容が分からない非エンジニアの方でも実際に表示される画面のスクリーンショットの差分という形でリリース前後のテスト結果が見れると安心できるようにしたいなーと思ったのが一つ目です。
※ 勿論ユニットテストの代わりになるものではないです
② ブラウザテストの度プログラムを書きたくない、すぐ実行できるようにしたい
すでに触れていますが、従来のブラウザテストはSelenium、Puppeteerなどを利用してプログラミングを行う必要がありました。ハードルが高すぎる。。。
しまいにはプログラムを書いてもテスト大量のページが沢山あると、全ページのテスト完了までにすごい時間がかかります。
そこらへんを並列でササッと実行してくれるやつが欲しかったのが2つ目です。③ サーバレスSPAを実装する経験値が欲しかった
サーバレスSPAをゼロから構築する経験がなかったので、実際に設計・実装を通して経験値を積みたい!というのが3つ目。
(理由の8割くらい)最終的には形になるものが実装できましたが、効率の良い開発環境はもう少し改善の余地がありそうでした。
※ 主にAWSのローカルモック周りの最適解がよくわからない...アーキテクチャ
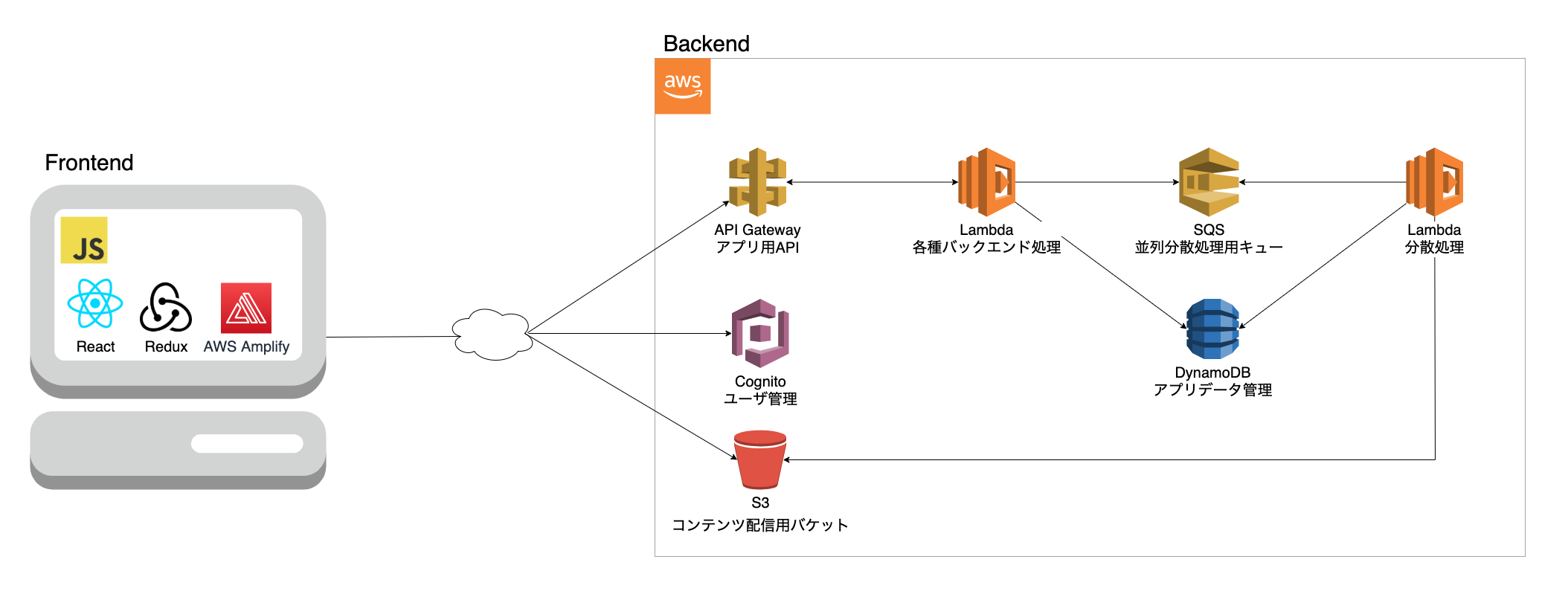
Diffenderのアーキテクチャはこんな感じです。
フロントエンドはReact.js、バックエンドはAWS関連サービスで実装しています。
言語はフロント、バックエンド両方JavaScript(Node.js)です。フロントエンド
JavaScript
今回はプレーンなJavaScriptで実装しました。
TypeScriptはまた今度...。React.js
UI構築用のJavaScriptフレームワーク。
Vue.jsと悩んだんですけど、JavaScriptのレベルアップにはReact.jsがいいみたいな記事をどっかで読んで選んでみました。
確かにJavaScriptの理解が深まった気がします。
(でも終始create react appの優しさに抱かれていた気が...自前でビルド設定のカスタマイズとかメンテナンスするのしんどそう)次はVue.jsでチャレンジしたいです。
Redux
アプリケーション全体の状態管理ライブラリ。
一番設計が難しかった気がする。
どこにビジネスロジックを集約するのがいいのか未だに最適解が分からない...。AWS Amplify
バックエンドリソースへのアクセス用ライブラリとして利用しました。
再考するとaxiosとかでも十分だったかもしれない。。。バックエンド
AWS Lambda
イベントトリガーで好きなコードを実行できるAWSサービス。
ランタイムはフロントと揃えてJavaScript(Node.js)サーバサイドの処理は全部Lambdaで実装しています。サーバレスバンザイ。
Provisioned Concurrencyはケチってコールドスタートなので、初回アクセス時はちょっと時間かかります。。。後述するSQSと組み合わせて、スクリーンショットの取得や差分の取得といった時間のかかる処理は並列処理にしています。
AWS API Gateway
簡単にREST APIの構築ができるようにするフルマネージドなAWSサービス。
フロントエンドからコールしたいLambdaのコードと連携してREST APIにしています。AWS SQS
AWSのフルマネージドなメッセージキューイングサービス。
Lambdaで時間のかかる処理を非同期で並列処理するために採用しました。
この構成お手軽なのに強力すぎる...。AWS DynamoDB
フルマネージドなNoSQLデータベースを提供するAWSサービス。
LambdaのRDS Proxyを使って使い慣れてるRDSを使うという方法も検討したんですが、RDS Proxyが高かったんでDynamoDBにしました(貧困)
RDBMSと違って独特の制約が多くて設計に苦労しました。GSIサイッキョ!でも後から取得したいクエリの種類が増えると、GSIの貼り直しが必要になったりしてつらみ。
早い段階での要件の洗い出しが大事だ。。。AWS Cognito
モバイル・Webアプリケーションでのユーザ作成・認証・管理機能をフルマネージドで提供するAWSサービス。
面倒なユーザ管理周りをスクラッチしたくなくて使いました。
分かったら便利だけど、やっぱり使い方が分かるまでのハードルが高いよ...
でもAPI Gatewayと認証の連携が簡単にできるのはAWSサービスで統一する良さを実感できました。AWS S3
容量無制限のデータ保存ができるオブジェクト型ストレージを提供するサービス。
撮影したスクリーンショットを格納先として利用してます。他にもWebページそのもののデプロイ先としてもAWS CloudFrontとセットで活用してます。
その他
AWS SAM
テンプレートファイルに記載された通りにAWSリソースをデプロイするInfrastructure as Codeを実現してくれるサービス。
AWSマネジメントコンソールでポチポチしてデプロイするよりも遥かにデプロイとリソース管理が楽になったけれど、
最終的には800行ぐらいの巨大ファイルになってビルド・デプロイに時間がかかるのがストレスフルでした。後発のAWS CDKを使ったらストレスフリーになったりするのかな。
作成期間
学習期間込みで大体週35〜40時間くらいで3ヶ月ちょっとくらい...。
課題
・(UI・UXが)哀れ
必要なクリック数、入力項目が多い。。。
実装する前にちゃんとしたワイヤーフレームを引いて、メインストリームの機能を利用するまでのクリック数などを検討すべきでした。・AWSサービスを絡めた開発のススメ方
開発当初は毎回コードをAWSにデプロイしてた。。。(時間がかかりすぎる)
単体テストコードを書いてローカルで実行するのが最速?
localstackみたいなサービス公式から出して...
AWS SAMのテンプレートの管理がヤバい。800行ぐらい行ってる。AWS CDK使うべき。。。他にも色々ありますが、キリがないので割愛。。。
最後に
やっぱり一つのサービスを全て一人で作るのは大変だけど、得るものも多い。。。
始める前はサーバレスSPAの実装ってまったくイメージがついてなかったんですが、今となっては動くものが作れてどこが良くなかったかという観点の振り返りまで出来るようになりました。
ただ有識者に聞いたら一発なところも手探りで進めていたのは非効率だなぁと思わずには居られない場面も多々ありました。
(React.js, AWSサービスの仕様・制約、効率的な開発環境などなど)気軽に聞けるエンジニア仲間みたいな人がいたら、もっと詰まらずにいいものが出来てたんじゃないかと強く思ったので
今年の抱負として、"えんじにあともだちをふやす" を掲げたいと思います。まる。その前に新しいお仕事が見つかるといいなぁ...(切実)









- 投稿日:2021-01-08T14:32:06+09:00
Amazon Linux 2 で LAMP をインストールして WordPress 環境を構築する。
はじめに
AWS公式ドキュメントに Amazon Linux による WordPress ブログのホスティング というのがあります。
ですが、前提条件となるLAMP環境がphp7.2を使った手順となっているため、最新バージョンをベースにしたものとは言い難いです。
また、現在(2021/01/08)のWordPressの要件を見ると 「PHP バージョン 7.4 以上」「MySQL バージョン 5.6 以上、または MariaDB バージョン 10.1 以上」などとなっているため要件を満たしていない状況です。
というわけで、今回はphp7.4とmysql8.0を使ったWordPress環境の構築を行いたいと思います。構築環境
今回のバージョンは以下となります。
環境情報OS:Amazon Linux 2 PHP:7.4 MySQL:8.0.22 WordPress:5.6また、EC2の立ち上げやSecurityGroupの設定等については触れませんので適宜対応してください。
ソフトウェアパッケージのアップデート
まずは全てのソフトウェアパッケージを最新の状態にするため、ソフトウェアの更新を実行します。
パッケージアップデート$ sudo yum update -yPHP
まず、phpのインストールを行います。AWSが用意しているリポジトリを利用してインストールを行い、必要になりそうなパッケージも追加でインストールしておきます。
インストール
Amazon Linux Extras リポジトリをインストールして、Amazon Linux 2 PHP パッケージの最新バージョンを取得します。
phpバージョン確認$ amazon-linux-extras list |grep php 15 php7.2 available \ 17 lamp-mariadb10.2-php7.2 available \ 31 php7.3 available \ 42 php7.4 available [ =stable ]現時点での最新バージョンはphp7.4のためphp7.4のリポジトリをインストールします。
リポジトリインストール$ sudo amazon-linux-extras enable php7.4 ~~ 省略 ~~ Now you can install: # yum clean metadata # yum install php-cli php-pdo php-fpm php-json php-mysqlndリポジトリをインストールすると
Now you can install:と表示されるので実行します。メタデータの削除$ sudo yum clean metadataphpインストール$ sudo yum install php-cli php-pdo php-fpm php-json php-mysqlnd追加パッケージのインストール
その他、必要になりそうなパッケージをインストールしておきます。
追加パッケージ$ sudo yum install php php-gd php-mbstring php-opcache php-xml php-commonバージョン確認
バージョン確認$ php -v PHP 7.4.11 (cli) (built: Oct 21 2020 19:12:26) ( NTS ) Copyright (c) The PHP Group Zend Engine v3.4.0, Copyright (c) Zend Technologies with Zend OPcache v7.4.11, Copyright (c), by Zend TechnologiesMySQL
次はmysqlのインストールです。
インストール
デフォルトだとリポジトリがないためMySQLのサイトからリポジトリを追加してインストールを行います。
リポジトリインストール$ sudo yum localinstall https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpmmysqlインストール$ sudo yum install --enablerepo=mysql80-community mysql-community-server mysql-community-develmysql起動$ sudo systemctl start mysqld.servicemysql自動起動の有効化$ sudo systemctl enable mysqld.service初回のrootパスワードは
mysql.logに出力されます。rootパスワード確認$ sudo grep password /var/log/mysqld.log 2021-01-06T02:45:38.728477Z 6 [Note] [MY-010454] [Server] A temporary password is generated for root@localhost: g1myqg3lgr#Mrootパスワード変更
rootパスワードの初回変更を行わないと操作ができないため、パスワードの再設定を行います。
ログイン$ mysql -uroot -pパスワードは同じものを設定しても大丈夫です。
パスワード変更mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'g1myqg3lgr#M';設定が完了したら一度ログアウトして再度ログインし直します。
データベース作成
ログインし直したら、まずデータベースの作成を行います。
データベース作成mysql> CREATE DATABASE wp_database;ユーザー作成
次にデータベースにアクセスできるWordPress用のユーザーを作成します。
ユーザー作成mysql> CREATE USER 'wp_user'@'localhost' IDENTIFIED BY 'g1myqg3lgr#M'; mysql> GRANT ALL PRIVILEGES ON `wp_database `.* TO "wp_user"@"localhost"; mysql> FLUSH PRIVILEGES;ログイン確認
ログイン確認$ mysql -uwp_user -pバージョン確認
バージョン確認$ mysql --version mysql Ver 8.0.22 for Linux on x86_64 (MySQL Community Server - GPL)Apache
phpをインストールした時点でapacheは依存関連でインストールされています。
そのため起動させるだけでOKです。起動
apacheを起動させ、自動起動設定を有効にします。
apache起動$ sudo systemctl start httpdapache自動起動の有効化$ sudo systemctl enable httpd確認
apacheバージョン確認$ httpd -v Server version: Apache/2.4.46 () Server built: Aug 24 2020 18:54:20WordPress
必要となるソフトウェア周りの準備ができたので、最後にWordPressのインストールを行います。
パッケージダウンロード
最新のパッケージをダウンロードします。
パッケージダウンロード$ wget https://wordpress.org/latest.tar.gzファイル名で
latest.tar.gzを指定すると最新のものがダウンロードされます。パッケージ解凍$ tar -xzf latest.tar.gzconf設定
wp-config-sample.phpファイルをwp-config.phpという名前でコピーします。wp-config.php作成$ cp wordpress/wp-config-sample.php wordpress/wp-config.phpコピーした
wp-config.phpにmysqlのところで作成したデータベースとユーザーを設定します。
また、Authentication Unique Keys and Saltsというセクションの部分でKEYとSALTを設定します。
以下のURLからランダムに生成されるキーセット値を取得して設定します。
https://api.wordpress.org/secret-key/1.1/salt/wp-config.php修正$ vim wordpress/wp-config.php $ diff wordpress/wp-config-sample.php wordpress/wp-config.php 23c23 < define( 'DB_NAME', 'database_name_here' ); --- > define( 'DB_NAME', 'wp_database' ); 26c26 < define( 'DB_USER', 'username_here' ); --- > define( 'DB_USER', 'wp_user' ); 29c29 < define( 'DB_PASSWORD', 'password_here' ); --- > define( 'DB_PASSWORD', 'g1myqg3lgr#M' ); 49,56c49,56 < define( 'AUTH_KEY', 'put your unique phrase here' ); < define( 'SECURE_AUTH_KEY', 'put your unique phrase here' ); < define( 'LOGGED_IN_KEY', 'put your unique phrase here' ); < define( 'NONCE_KEY', 'put your unique phrase here' ); < define( 'AUTH_SALT', 'put your unique phrase here' ); < define( 'SECURE_AUTH_SALT', 'put your unique phrase here' ); < define( 'LOGGED_IN_SALT', 'put your unique phrase here' ); < define( 'NONCE_SALT', 'put your unique phrase here' ); --- > define('AUTH_KEY', '****************************************************************'); > define('SECURE_AUTH_KEY', '****************************************************************'); > define('LOGGED_IN_KEY', '****************************************************************'); > define('NONCE_KEY', '****************************************************************'); > define('AUTH_SALT', '****************************************************************'); > define('SECURE_AUTH_SALT', '****************************************************************'); > define('LOGGED_IN_SALT', '****************************************************************'); > define('NONCE_SALT', '****************************************************************');コンテンツコピー
WordPress をドキュメントルートで実行するために、コンテンツを次のようにコピーします。
ここで気をつけるポイントはディレクトリ自体はコピーしないということです。コンテンツコピー$ sudo cp -r wordpress/* /var/www/html/WordPress のパーマリンク設定
WordPress のパーマリンクが正しく機能するには Apache の
.htaccessファイルを使用する必要がありますが、Amazon Linux はデフォルトで有効になっていません。Apache の ドキュメントルートですべての上書きができるように、<Directory "/var/www/html">で始まるセクションにあるAllowOverrideをAllに修正します。$ sudo cp -pi /etc/httpd/conf/httpd.conf /etc/httpd/conf/httpd.conf_org $ sudo vim /etc/httpd/conf/httpd.conf $ diff /etc/httpd/conf/httpd.conf /etc/httpd/conf/httpd.conf_org 151c151 < AllowOverride All --- > AllowOverride None権限修正
WordPressで利用できる機能の中にはドキュメントルートへの書き込み権限が必要なものがあります(管理画面を使った、メディアのアップロードなど)。
まず、
/var/wwwとそのコンテンツのファイル所有権を apacheユーザー/グループ に付与します。所有権変更$ sudo chown -R apache /var/www $ sudo chgrp -R apache /var/www次に
/var/wwwと、そのサブディレクトリのグループ書き込み権限設定を行います。
setgidを設定することで、作成されたファイルはディレクトリが属するグループに属するようにしています。権限変更(ディレクトリ)$ sudo chmod 2775 /var/www $ find /var/www -type d -exec sudo chmod 2775 {} \;
/var/wwwおよびそのサブディレクトリのファイル許可を繰り返し変更してグループの書き込み許可を追加します。権限変更(ファイル)$ find /var/www -type f -exec sudo chmod 0664 {} \;apache再起動
一通り設定したらapacheの再起動を行います(httpd.confも修正したので)。
再起動$ sudo systemctl restart httpdインストール
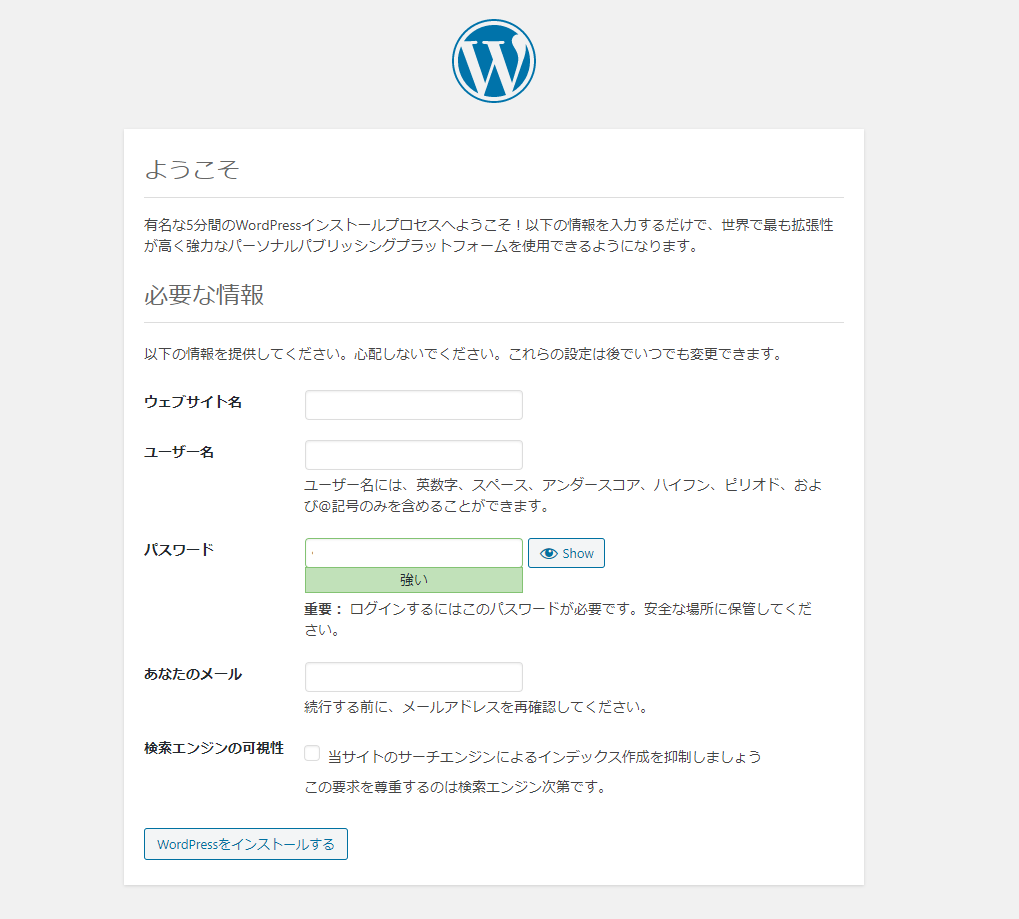
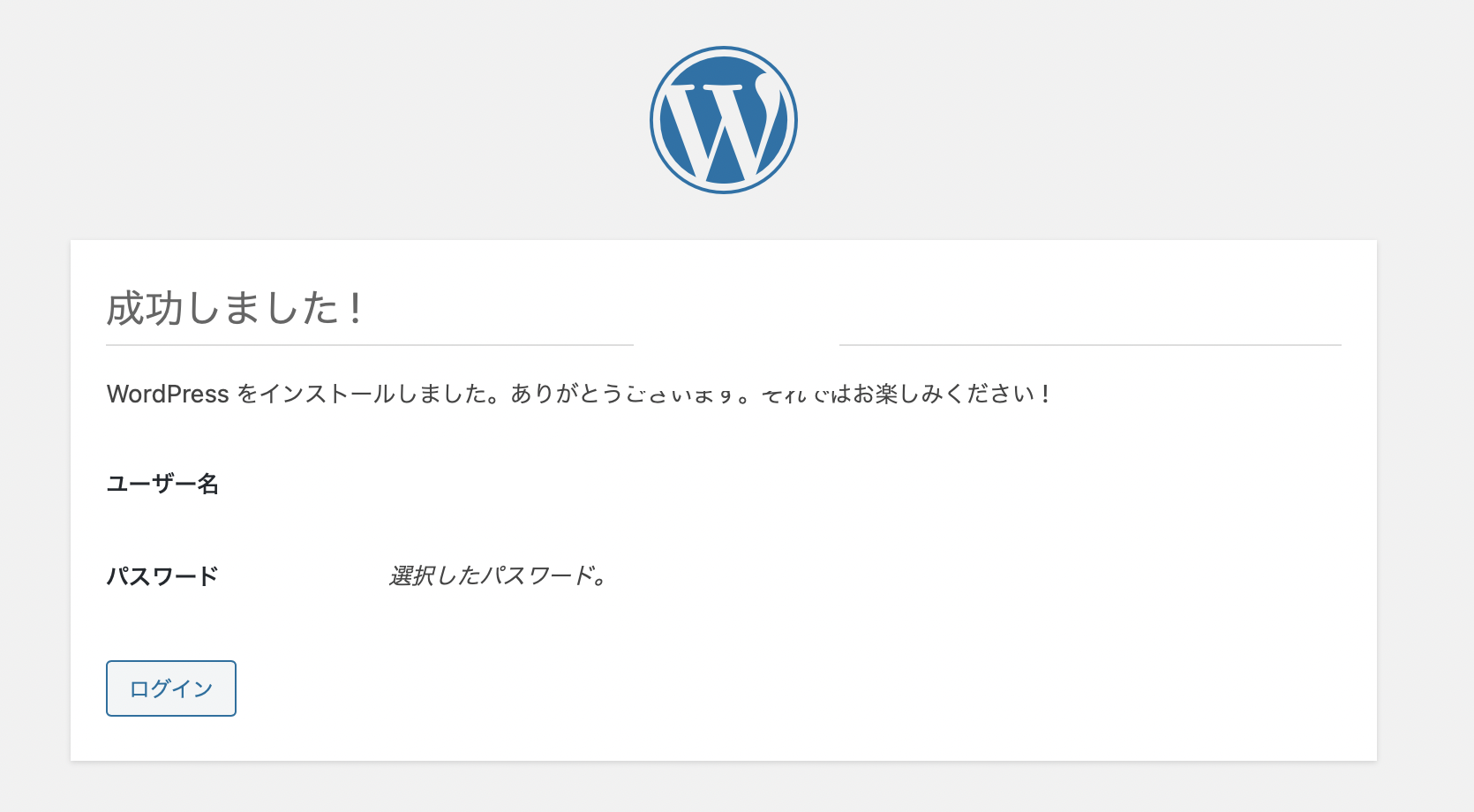
ブラウザアクセスを行いインストールを行います。
言語選択画面では 日本語 を選択します。
項目を入力して WordPressをインストール します。
成功しました! が表示されれば完了です。
おわりに
今回のやり方は汎用的な方法なので、今後phpやmysqlの新しいバージョンがリリースされた場合は、それに応じてバージョンを上げていけば対応できると思います。
参考
- ja.wordpress.org - WordPress を実行するには、以下のホスティング環境を推奨します。
- docs.aws.amazon.com - チュートリアル: Amazon Linux 2 に LAMP ウェブサーバーをインストールする (ステップ 1: LAMP サーバーを準備する)
- docs.aws.amazon.com - チュートリアル: Amazon Linux による WordPress ブログのホスティング
- MySQL 8.0 Reference Manual - 2.5.1 Installing MySQL on Linux Using the MySQL Yum Repository
- MySQL Community Downloads
- 投稿日:2021-01-08T12:24:27+09:00
AWS Elemental MediaLiveをAWS CLIでサクッと作成
新年明けましておめでとうございます
streampack risakoです。
年末年始はゆっくり過ごせましたか?私はあまり出かけずに寝正月を満喫しました笑
2021年もいろんなことを吸収してQiitaに残せるように頑張っていきます!今回は
AWS Elemental Medialive(以下MediaLive) inputとChannelをAWS CLI(以下、CLI)でサクッと作成する方法をご紹介します
AWSマネジメントコンソールから作成するより、慣れてしまえばCLIのほうが時間短縮になるので複数作成する場合などは重宝します。
よくMediaLive inputやchannelを作成するという方はぜひ参考にして頂けたら幸いですはじめに
- MediaLiveをCLIで作成する場合、JSON形式で記述した設ファイルを用意する必要があります。 あらかじめ作成しておきましょう。
- また、今回はAWS Elemental MediaStoreを使用します。 こちらも先に作成しておく必要があります。
JSONファイルの参考例をご紹介します。
注意:
JSONファイルは、必ず最初の文字を大文字にする必要があります。
小文字で作成してしまうとエラーが表示され、作成できません。input作成
{ "Name": "test-input", "Type": "RTMP_PUSH", "InputSecurityGroups": [ "000000" ], "Destinations": [ { "StreamName": "hoge/stream" } ] }変更が必要な箇所
項目 説明 備考 Name 任意のinput名を入力 Type 入力タイプを入力 JSONでのType記載方法はこちら InputSecurityGroups 入力セキュリティグループID 既存のセキュリティグループがある場合は、そのIDを記載 StreamName 任意のStreamNameを入力 今回はSINGLE_INPUTで作成するため1つですが、STANDARD_INPUTの場合は2つ記載します。注:Typeによって設定内容が変わる inputをCLIで作成する
$aws medialive --profile <名前付きプロファイル名> create-input --region <作成するリージョン> --cli-input-json file://<JSONファイル名> 【例】 $aws medialive --profile xxxx create-input --region ap-northeast-1 --cli-input-json file://test-input.jsonChannel作成
ABRが1つのシンプルなチャンネル設定の例です。
{ "Name": "test-channel", "InputAttachments": [ { "InputId": "xxxxx", "InputAttachmentName": "test-input", "InputSettings": { "SourceEndBehavior": "CONTINUE", "InputFilter": "AUTO", "FilterStrength": 1, "DeblockFilter": "DISABLED", "DenoiseFilter": "DISABLED", "AudioSelectors": [ { "Name": "Audio1" } ], "CaptionSelectors": [] } } ], "Destinations": [ { "Id": "hlsdestin", "Settings": [ { "Url": "mediastoressl://xxxx.data.mediastore.ap-northeast-1.amazonaws.com/demo/liveA" }, ], "MediaPackageSettings": [] } ], "EncoderSettings": { "AudioDescriptions": [ { "AudioSelectorName": "Audio1", "CodecSettings": { "AacSettings": { "InputType": "NORMAL", "Bitrate": 128000, "CodingMode": "CODING_MODE_2_0", "RawFormat": "NONE", "Spec": "MPEG4", "Profile": "LC", "RateControlMode": "CBR", "SampleRate": 48000 } }, "AudioTypeControl": "FOLLOW_INPUT", "LanguageCodeControl": "FOLLOW_INPUT", "Name": "audio_mid" } ], "CaptionDescriptions": [], "OutputGroups": [ { "OutputGroupSettings": { "HlsGroupSettings": { "AdMarkers": [], "CaptionLanguageSetting": "OMIT", "CaptionLanguageMappings": [], "HlsCdnSettings": { "HlsMediaStoreSettings": { "NumRetries": 10, "ConnectionRetryInterval": 1, "RestartDelay": 15, "FilecacheDuration": 300, "MediaStoreStorageClass": "TEMPORAL" } }, "InputLossAction": "EMIT_OUTPUT", "ManifestCompression": "NONE", "Destination": { "DestinationRefId": "hlsdestin" }, "IvInManifest": "INCLUDE", "IvSource": "FOLLOWS_SEGMENT_NUMBER", "ClientCache": "ENABLED", "TsFileMode": "SEGMENTED_FILES", "ManifestDurationFormat": "FLOATING_POINT", "SegmentationMode": "USE_SEGMENT_DURATION", "RedundantManifest": "DISABLED", "OutputSelection": "MANIFESTS_AND_SEGMENTS", "StreamInfResolution": "INCLUDE", "IFrameOnlyPlaylists": "DISABLED", "IndexNSegments": 15, "ProgramDateTime": "EXCLUDE", "ProgramDateTimePeriod": 600, "KeepSegments": 30, "SegmentLength": 2, "TimedMetadataId3Frame": "PRIV", "TimedMetadataId3Period": 10, "HlsId3SegmentTagging": "DISABLED", "CodecSpecification": "RFC_4281", "DirectoryStructure": "SINGLE_DIRECTORY", "SegmentsPerSubdirectory": 10000, "Mode": "LIVE" } }, "Name": "HLS Group", "Outputs": [ { "OutputSettings": { "HlsOutputSettings": { "NameModifier": "_mid", "HlsSettings": { "StandardHlsSettings": { "M3u8Settings": { "AudioFramesPerPes": 4, "AudioPids": "492-498", "NielsenId3Behavior": "NO_PASSTHROUGH", "PcrControl": "PCR_EVERY_PES_PACKET", "PmtPid": "480", "ProgramNum": 1, "Scte35Pid": "500", "Scte35Behavior": "NO_PASSTHROUGH", "TimedMetadataPid": "502", "TimedMetadataBehavior": "NO_PASSTHROUGH", "VideoPid": "481" }, "AudioRenditionSets": "program_audio" } }, "H265PackagingType": "HVC1" } }, "OutputName": "mid", "VideoDescriptionName": "video_mid", "AudioDescriptionNames": [ "audio_mid" ], "CaptionDescriptionNames": [] } ] } ], "TimecodeConfig": { "Source": "EMBEDDED" }, "VideoDescriptions": [ { "CodecSettings": { "H264Settings": { "AfdSignaling": "NONE", "ColorMetadata": "INSERT", "AdaptiveQuantization": "MEDIUM", "Bitrate": 2000000, "EntropyEncoding": "CABAC", "FlickerAq": "ENABLED", "FramerateControl": "SPECIFIED", "FramerateNumerator": 30, "FramerateDenominator": 1, "GopBReference": "DISABLED", "GopClosedCadence": 1, "GopNumBFrames": 1, "GopSize": 2, "GopSizeUnits": "SECONDS", "SubgopLength": "FIXED", "ScanType": "PROGRESSIVE", "Level": "H264_LEVEL_AUTO", "LookAheadRateControl": "MEDIUM", "NumRefFrames": 1, "ParControl": "INITIALIZE_FROM_SOURCE", "Profile": "MAIN", "RateControlMode": "CBR", "Syntax": "DEFAULT", "SceneChangeDetect": "ENABLED", "SpatialAq": "ENABLED", "TemporalAq": "ENABLED", "TimecodeInsertion": "DISABLED" } }, "Height": 720, "Name": "video_mid", "RespondToAfd": "NONE", "Sharpness": 50, "ScalingBehavior": "DEFAULT", "Width": 1280 } ] }, "RoleArn": "arn:aws:iam::xxxxx:role/MediaLiveAccessRole", "InputSpecification": { "Codec": "AVC", "Resolution": "HD", "MaximumBitrate": "MAX_20_MBPS" }, "LogLevel": "ERROR", "Tags": {}, "ChannelClass": "SINGLE_PIPELINE" }変更が必要な箇所
項目 説明 備考 Name Channel名 InputId 先ほど作成したInputID Url mediastoreのData endpoint https://ではなく、mediastoressl:// に変更が必要です。 AudioDescriptions 音声Bitrateなど、音声に関する設定を入力 VideoDescriptions 映像BitrateやFrame Rate、解像度など、映像に関する設定を入力 RoleArn MediaLiveのアクセス権をもつIAMRole 未作成の場合は、先に作成する必要があります。 ChannelClass 入力本数 SINGLE_PIPELINEeまたはSTANDARD ChannelをCLIで作成!
$ aws medialive --profile <名前付きプロファイル名> create-channel --region <作成するリージョン> --cli-input-json file://<JSONファイル名> 【例】 $ aws medialive --profile xxxx create-channel --region ap-northeast-1 --cli-input-json file://test-channel.json以上で、作成は終了です!
コンソール画面に作成されたinputやChannelがあれば正常に作成できています!
同じ設定のChannelを複数作成する時など、一つテンプレートを用意しておくととても便利ですね今回もお読みいただきありがとうございました
参考
https://docs.aws.amazon.com/cli/latest/reference/medialive/index.html
- 投稿日:2021-01-08T11:44:36+09:00
Amazon S3 概要及びバケット作成方法 メモ
- Amazon S3の概要とAWS CLIを用いたバケット作成方法についてメモする。
Amazon S3とは?
概要
- AWSが提供するオブジェクトストレージサービス。
- オブジェクトとそのメタデータ、ユニークIDから構成されるストレージ。
Amazon Simple Storage Serviceの略称。
ユースケース
- データの保護・移行
- 業務用オンプレサーバーのバックアップデータが肥大化してきた場合、など
- Webサーバーのコンテンツオフロード
- 画像ファイルなどが増えてきた場合、など
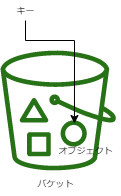
概念・用語
- オブジェクト
- S3に保存されるデータ。
- サイズ制限:0~5TB
- メタデータ
- オブジェクトの属性情報。
- キー
- オブジェクトの格納URL。
- 「バケット名+キー+バージョン」でユニークになる。
バケット
- オブジェクトの保存場所。
- バケット内のオブジェクト数制限なし。
- 各AWSアカウントでデフォルト100個まで作成可能。
- 名称はユニークである必要あり。
バケットポリシー
- バケットごとに指定するアクセス権限。
リージョン
- バケットを配置するAWSリージョン。
バケット作成方法
- シェルスクリプトからAWS CLIを叩いて、S3バケットを作成する。
※リージョンID(
YOUR_REGION_ID)やAWSアカウントID(YOUR_AWS_ACCOUNT_ID)は環境変数として展開済みであるものとする。1.バケット作成
- バケット
testbucketをリージョンを指定して作成する。aws s3api create-bucket --bucket testbucket --create-bucket-configuration LocationConstraint=${YOUR_REGION_ID}2.バケットへのバケットポリシー設定
- バケット
testbucketにバケットポリシーTestBucketPolicyを設定する。policy_for_testbucket_path=$(dirname $0)/json/TestBucketPolicy.json policy_for_testbucket=$(cat ${policy_for_testbucket_path}) tempfile=$(mktemp) echo ${policy_for_testbucket} | envsubst > ${tempfile} aws s3api put-bucket-policy --bucket testbucket --policy file://${tempfile} rm -f ${tempfile}
バケットポリシー例:
TestBucketPolicy.json
- AWSアカウントのユーザー
Hoge氏に、バケットtestbucketに対するアクションs3:GetObject、s3:GetBucketLocation、s3:ListBucketの実行許可を付与する。{ "Version": "2012-10-17", "Id": "TestPolicy", "Statement": [ { "Sid": "TestStatement", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::${YOUR_AWS_ACCOUNT_ID}:user/Hoge }, "Action": [ "s3:GetObject", "s3:GetBucketLocation", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::testbucket/*", "arn:aws:s3:::testbucket" ] } ] }3.バケットへのライフサイクルルール設定
- バケット
testbucketにライフサイクルルールTestBucketLifecycleRuleを設定する。lifecycle_rule_for_testbucket_path=$(dirname $0)/json/TestBucketLifecycleRule.json lifecycle_rule_for_testbucket=$(cat ${lifecycle_rule_for_testbucket_path}) tempfile=$(mktemp) echo ${lifecycle_rule_for_testbucket} | envsubst > ${tempfile} aws s3api put-bucket-lifecycle-configuration --bucket testbucket --lifecycle-configuration file://${tempfile} rm -f ${tempfile}
ライフサイクルルール例:
TestBucketLifecycleRule.json
logsオブジェクトのサブセットに有効期限30日を設定する。{ "Rules":[{ "ID":"TestBucketRule", "Filter": { "Prefix": "logs/" }, "Status":"Enabled", "Expiration":{"Days":30} }] }参考情報
- 投稿日:2021-01-08T11:43:19+09:00
AWS自動デプロイ
デプロイの自動化
これまで手動で行っていたデプロイ作業(「unicorn_railsコマンド」を使ってサーバーを立ち上げる手段)を、ローカルのターミナルからのコマンド1つで行えるようにします。そのために、「自動デプロイツール」と呼ばれるものを利用します。今回は、数ある自動デプロイツールの中でも、もっともポピュラーなCapistranoを実際に導入してみます。自動デプロイツールを利用することによって、デプロイ時に必要なコマンド操作が1回で済むようになります。
デプロイする際には以下の手順を踏みました。
「Capistrano」を利用すればEC2サーバーにログインする必要もありません。ローカルのターミナルからのコマンド1つで、これらの作業をいっぺんに完了できます。Capistranoの導入準備
Capistranoを利用するためのGemをインストールしましょう。
Gemfileを以下のように編集しましょう。(省略) group :development, :test do gem 'capistrano' gem 'capistrano-rbenv' gem 'capistrano-bundler' gem 'capistrano-rails' gem 'capistrano3-unicorn' end (省略)ローカル環境でbundle installしましょう。
gemを読み込めたら、ローカルで下記のコマンドを打ちます。% bundle exec cap installすると、ファイルが生成されます。
Capfile
「Capfile」では、Capistrano関連のライブラリのうちどれを読み込むかを指定できます。
Capistranoの機能を提供するコードはいくつかのライブラリ(Gem)に分かれています。そのため、Capistranoを動かすにはいくつかのライブラリを読み込む必要があります。production.rb
「production.rb」は、デプロイについての設定を書くファイルです。
GitHubへの接続に必要なsshキーの指定、デプロイ先のサーバのドメイン、AWSサーバへのログインユーザー名、サーバにログインしてからデプロイのために何をするか、といった設定を記載します。Capistrano全体の設定をしている「Capfile」を編集しましょう。
require "capistrano/setup" require "capistrano/deploy" require 'capistrano/rbenv' require 'capistrano/bundler' require 'capistrano/rails/assets' require 'capistrano/rails/migrations' require 'capistrano3/unicorn' Dir.glob("lib/capistrano/tasks/*.rake").each { |r| import r }「require」によって引数としておかれた文字列が指すディレクトリが読み込まれ、その中にデプロイに際して必要な動作がひととおり記述されています。
続いて、デプロイについての設定を記載するファイルを編集します。
「config/deployフォルダ」の配下にはproduction.rbとstaging.rbの2種類のファイルが生成されています。
これらは、デプロイする環境別の設定を記述するファイルです。今回はproduction.rb、つまり本番環境のものだけ編集します。具体的には下記の内容を記述していくこととなります。サーバーホスト名(or IPアドレス)
AWSのサーバーへログインできるユーザー名
サーバーロール(後述)
sshの設定
その他サーバーに紐づく任意の設定
それでは編集しましょう。config/deploy/production.rbserver '用意したElastic IP', user: 'ec2-user', roles: %w{app db web}次は、「deploy.rb」の設定です。
こちらのファイルには、production環境、staging環境どちらにも当てはまる設定を記述することとなります。
具体的には下記のような項目があります。アプリケーション名
gitのレポジトリ
利用するSCM
タスク
それぞれのタスクで実行するコマンド
それでは、編集しましょう。config/deploy.rb# capistranoのバージョンを記載。固定のバージョンを利用し続け、バージョン変更によるトラブルを防止する lock 'Capistranoのバージョン' # Capistranoのログの表示に利用する set :application, 'ご自身のアプリケーション名' # どのリポジトリからアプリをpullするかを指定する set :repo_url, 'git@github.com:Githubのユーザー名/レポジトリ名.git' # バージョンが変わっても共通で参照するディレクトリを指定 set :linked_dirs, fetch(:linked_dirs, []).push('log', 'tmp/pids', 'tmp/cache', 'tmp/sockets', 'vendor/bundle', 'public/system', 'public/uploads') set :rbenv_type, :user set :rbenv_ruby, 'このアプリで使用しているrubyのバージョン' #このQiita通りに進めた場合、’2.6.5’ です # どの公開鍵を利用してデプロイするか set :ssh_options, auth_methods: ['publickey'], keys: ['~/.ssh/ご自身のキーペア名.pem'] # プロセス番号を記載したファイルの場所 set :unicorn_pid, -> { "#{shared_path}/tmp/pids/unicorn.pid" } # Unicornの設定ファイルの場所 set :unicorn_config_path, -> { "#{current_path}/config/unicorn.rb" } set :keep_releases, 5 # デプロイ処理が終わった後、Unicornを再起動するための記述 after 'deploy:publishing', 'deploy:restart' namespace :deploy do task :restart do invoke 'unicorn:restart' end end「Capistranoのバージョン」は、Gemfile.lockに記載されています。
Gemfile.lock(省略) capistrano (3.11.0) (省略)deploy.rb内の記述をよく見ると、「set: 名前, 値」といった記述が多く使われています。これは、「DSL」というものの一種です。
DSL
「DSL」とは、ある特定の処理における効率をあげるために特化した形の文法を擬似的に用意したプログラムです。
上記の「set :名前, 値」について、これは言わば変数のようなものです。
たとえば「set: Name, Value」と定義した場合、「fetch Name」とすることでValueが取り出せます。
また、一度setした値はdeploy.rbやproduction.rbなどの全域で取り出すことができます。他にも、ファイル内には「desc '◯◯'`」や「task:XX do」といった記述がよく見受けられます。これは、先ほどCapfileでrequireしたものに加えて追加のタスクを記述している形です。ここで記述したものもcap deploy時に実行されることとなります。
さて、一度Capistranoによる自動デプロイを実行すると本番環境のアプリケーションのディレクトリが変化しました。
Capistranoによるアプリのバックアップなど、複数のディレクトリが作成されます。その中でも、とくに重要な3つのファイルについて解説します。releasesディレクトリ
「releasesディレクトリ」には、Capistranoを通じてデプロイされたアプリがひとまとめにされます。
ここに過去分のアプリが残っていることにより、デプロイ時に何か問題が発生しても前のバージョンに戻れます。
そして、その過去分の保存数を指定しているのがdeploy.rbの「set :keep_releases」の記述となります。今回は5つ、過去のバージョンを保存するよう設定しました。currentディレクトリ
「currentディレクトリ」には、releasesフォルダの中で一番新しいものが自動的にコピーされているような状態になっています。
つまり、「現在デプロイされている内容=current内の内容」ということになります。sharedディレクトリ
バージョンが変わっても共通で参照されるディレクトリが格納されるディレクトリです。具体的には、log、public、tmp、vendorディレクトリが格納されます。
Unicornの設定ファイルを編集
手動デプロイの時と比べ、自動デプロイ時にはRailsのアプリケーションのディレクトリが1段階深くなっています。そのため、数ヶ所変更を加える必要があります。
(編集前)⬇️config/unicorn.rb#サーバ上でのアプリケーションコードが設置されているディレクトリを変数に入れておく app_path = File.expand_path('../../', __FILE__) #アプリケーションサーバの性能を決定する worker_processes 1 #アプリケーションの設置されているディレクトリを指定 working_directory app_path #Unicornの起動に必要なファイルの設置場所を指定 pid "#{app_path}/tmp/pids/unicorn.pid" #ポート番号を指定 listen 3000 #エラーのログを記録するファイルを指定 stderr_path "#{app_path}/log/unicorn.stderr.log" #通常のログを記録するファイルを指定 stdout_path "#{app_path}/log/unicorn.stdout.log" (省略)↓↓↓↓↓↓ 以下のように編集 ↓↓↓↓↓↓
config/unicorn.rb#サーバ上でのアプリケーションコードが設置されているディレクトリを変数に入れておく app_path = File.expand_path('../../../', __FILE__) # 「../」が一つ増えている #アプリケーションサーバの性能を決定する worker_processes 1 #アプリケーションの設置されているディレクトリを指定 working_directory "#{app_path}/current" # 「current」を指定 #Unicornの起動に必要なファイルの設置場所を指定 pid "#{app_path}/shared/tmp/pids/unicorn.pid" # 「shared」の中を参照するよう変更 #ポート番号を指定 listen "#{app_path}/shared/tmp/sockets/unicorn.sock" # 「shared」の中を参照するよう変更 #エラーのログを記録するファイルを指定 stderr_path "#{app_path}/shared/log/unicorn.stderr.log" # 「shared」の中を参照するよう変更 #通常のログを記録するファイルを指定 stdout_path "#{app_path}/shared/log/unicorn.stdout.log" # 「shared」の中を参照するよう変更 (省略)Nginxの設定ファイルを編集
以下のコマンドを実行しエディタを立ち上げましょう。
$ sudo vim /etc/nginx/conf.d/rails.confvimコマンドで編集するので、まずは「i」と打ち込んで入力モードに切り替えます。
upstream app_server { # Unicornと連携させるための設定 server unix:/var/www/アプリケーション名/shared/tmp/sockets/unicorn.sock; } # {}で囲った部分をブロックと呼ぶ。サーバの設定ができる server { # このプログラムが接続を受け付けるポート番号 listen 80; # 接続を受け付けるリクエストURL ここに書いていないURLではアクセスできない server_name Elastic IP; # クライアントからアップロードされてくるファイルの容量の上限を2ギガに設定。デフォルトは1メガなので大きめにしておく client_max_body_size 2g; # 接続が来た際のrootディレクトリ root /var/www/アプリケーション名/current/public; # assetsファイル(CSSやJavaScriptのファイルなど)にアクセスが来た際に適用される設定 location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; root /var/www/アプリケーション名/current/public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; }3行目 「〜アプリケーション名/shared/tmp/〜」に編集
17行目 1行丸ごと追加
24行目 1行丸ごと追加
入力を終えたら「escキー」→「:wq」の順で実行し、保存しましょう。
Nginxの設定を変更したら、忘れずに再読込・再起動をしましょう。[ec2-user@ip-172-31-25-189 ~]$ sudo systemctl reload nginx [ec2-user@ip-172-31-25-189 ~]$ sudo systemctl restart nginxNginxの設定ファイルの編集は以上です。
データベースの起動を確認
データベースが立ち上がっていないとデプロイが失敗します。以下のコマンドでデータベースの状態を確認しておきましょう。
[ec2-user@ip-172-31-25-189 ~]$ sudo systemctl status mariadb以下のように、「active」と表示されれば起動しています。
● mariadb.service - MariaDB database server Loaded: loaded (/usr/lib/systemd/system/mariadb.service; disabled; vendor preset: disabled) Active: active (running) since 金 2020-07-17 03:46:51 UTC; 8s ago Process: 17044 ExecStartPost=/usr/libexec/mariadb-wait-ready $MAINPID (code=exited, status=0/SUCCESS) Process: 17008 ExecStartPre=/usr/libexec/mariadb-prepare-db-dir %n (code=exited, status=0/SUCCESS) Main PID: 17043 (mysqld_safe) CGroup: /system.slice/mariadb.service ├─17043 /bin/sh /usr/bin/mysqld_safe --basedir=/usr └─17206 /usr/libexec/mysqld --basedir=/usr --datadir=/var/lib/mysql --plugin-dir=/usr/lib64/mysql/plugin --log-error=/var/log/mariadb/mariadb.log --pid-file=/var/run/mariadb/mariadb.pid --so...万が一、「active」になっていない場合はsudo systemctl start mariadbを実行しましょう。
自動デプロイをする前に、unicornのプロセスをkillする必要があります。
というのも、すでにunicornのサーバーが立ち上がっている状態で自動デプロイをすると、二重でサーバーを立ち上げることになるためです。(自動デプロイもサーバーを立ち上げる役割を担っています)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ps aux | grep unicorn ec2-user 17877 0.4 18.1 588472 182840 ? Sl 01:55 0:02 unicorn_rails master -c config/unicorn.rb -E production -D ec2-user 17881 0.0 17.3 589088 175164 ? Sl 01:55 0:00 unicorn_rails worker[0] -c config/unicorn.rb -E production -D ec2-user 17911 0.0 0.2 110532 2180 pts/0 S+ 02:05 0:00 grep --color=auto unicorn# 上記の例だと「7877」 [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ kill プロセス番号ローカルでのコードの変更が、すべてmasterにpushされていることを確認しておきましょう。
以上で自動デプロイの準備は完了です。最後に自動デプロイを実行しましょう。
自動デプロイ
ローカルのターミナルに戻り、以下のコマンドで自動デプロイを実行しましょう。
# アプリケーションのディレクトリで実行しましょう % bundle exec cap production deployはじめての自動デプロイでは「bundler install」のタスクで時間がかかることがあります。5分経っても動かない場合は「EC2インスタンスの再起動」を実行しましょう。
[ec2-user@ip-172-31-25-189 ~]$ sudo systemctl restart mariadb [ec2-user@ip-172-31-25-189 ~]$ sudo systemctl restart nginxAWSこれにて投稿終了です。
- 投稿日:2021-01-08T06:27:18+09:00
静的Webサイト用S3バケットを用意してそのバケットだけに書き込めるアクセスキーを発行する
bucketを作成
- 例: バケット名 = test.example.com
- 作られたバケットを選んで「Permissions」タブを開く
- Block public access (bucket settings) に全てをOFF
- Access control list (ACL)にてEveryone (public access)にRead権限をつける
bucketのStatic website hostingを設定
- Static website hosting: Enable
- Hosting type: Host a static website
- Index document: index.html
- Error document: error.html
route53でウェブサイトエンドポイントに割り当てたいホストを割り当てる
- Aレコードを選ぶ
- Alias to S3 website endpoitを選ぶ
- リージョンとバケットを選ぶ
IAMを作成
- User name: test.example.com-s3fullaccess
- Access type: Programmatic access
- 権限はなしで一旦作成
- 作成後「Permissions」 -> 「Add inline policy」でJSONタブを開いて以下で設定
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "s3:*", "Resource": [ "arn:aws:s3:::test.example.com", "arn:aws:s3:::test.example.com/*" ] } ] }動作確認
- AWS cliからアップロードできることを確認
AWS_ACCESS_KEY_ID=XXXXXXX AWS_SECRET_ACCESS_KEY=XXXXXXXXXX AWS_DEFAULT_REGION=ap-northeast-1 aws s3 cp test.html s3://test.example.com/
- 別のバケットにはアップロードできないことを確認
AWS_ACCESS_KEY_ID=XXXXXXX AWS_SECRET_ACCESS_KEY=XXXXXXXXXX AWS_DEFAULT_REGION=ap-northeast-1 aws s3 cp test.html s3://test2.example.com/
- 割り当てたドメイン下で表示できることを確認
http://test.example.com/test.html
- ファイルを削除できることを確認
AWS_ACCESS_KEY_ID=XXXXXXX AWS_SECRET_ACCESS_KEY=XXXXXXXXXX AWS_DEFAULT_REGION=ap-northeast-1 aws s3 rm s3://test.example.com/test.html参考
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/EnableWebsiteHosting.html
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/IndexDocumentSupport.html
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/WebsiteAccessPermissionsReqd.html
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/cli-configure-envvars.html
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/cli-services-s3-commands.html#using-s3-commands-managing-objects-copy
- 投稿日:2021-01-08T00:51:45+09:00
メール機能ってどうやるの?amazonSES編
はじめに
前回に引き続き、メール機能について学習したのでアウトプットしていきます
今回はAmazon SESを使っていきます
Amazon SESを使う前提として
- (AWSアカウントをすでに作成済みの方はOKです!)
E メールアドレスまたはドメインの確認(ID検証)
- Amazon SES の使用を開始した時点では、E メールを送受信するためには、Amazon SES メールボックスシミュレーターと検証済み E メール ID のみであるためです。
今回はEメールアドレス検証を行っていきます。(ドメインの場合も同様)
Email Addressesを選択し、Verify a new Email Address からメールアドレスの検証を行ってください。

- アカウントの詳細を入力
が必要になってきます。
メール送信
Amazon SES では、
- Amazon SES コンソール
- Simple Mail Transfer Protocol (SMTP)インターフェイス
- Amazon SES API
など、E メールを送信するためのいくつかの方法を利用できます。
この中でAmazon SES APIを使ってみます
Amazon SES API
Amazon SES APIを用いることで以下のことができます。
- Amazon SES クエリ API を HTTPS 経由で直接呼び出し(ムズイらしい)
- AWS Command Line Interfaceの使用
- AWS Tools for Windows PowerShellの使用
- AWS SDK の使用
aws初心者の私は一番簡単にできそうなAWS SDKを使っていきます!
AWS SDKは Amazon SESオペレーションだけでなく、基本的な AWS 機能 (リクエスト認証、リクエストの再試行、エラー処理など) も提供します。AWS SDK 経由でAmazon SES API
Node.js 内の AWS SDK for JavaScriptを使用します!(SDKにはPythonやjava,PHPなど様々な言語に対応したものが用意されています)
セキュリティのベストプラクティスについては、AWS アカウントのアクセスキーではなくIAM ユーザーのアクセスキーを使用します。
AWS アカウントの認証情報によってすべての AWS リソースへのフルアクセス権を付与するため、この認証情報は安全な場所に保存しておき、AWS の日々の操作には IAM ユーザーの認証情報を使用するらしいです。では早速、AWS アクセスキーを作成していきましょう!
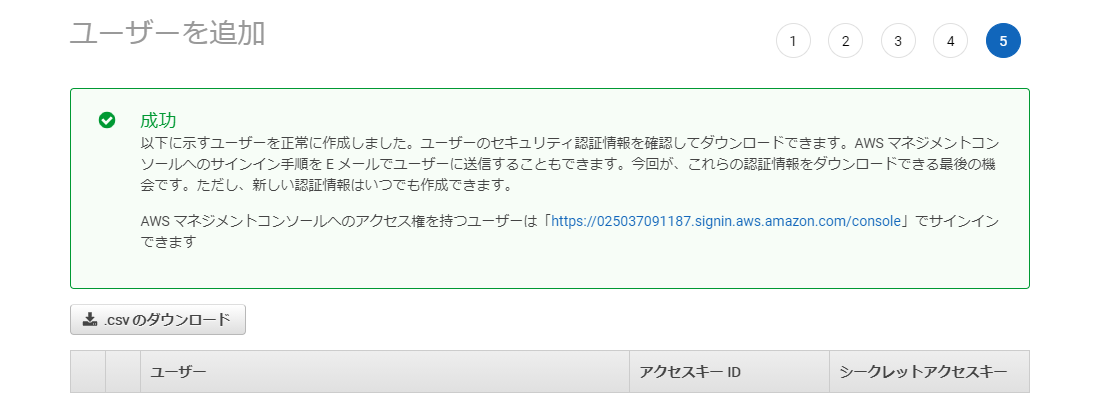
awsのベストプラクティスでは、AWS アクセスキーの作成手順として以下のように紹介されています。1: IAM ユーザーを作成し、そのユーザーのアクセス許可を可能な限り狭く定義します。
2: その IAM ユーザーにアクセスキーを作成します。
AWS アクセスキーは、アクセスキー ID とシークレットアクセスキーで構成されます。
SESの環境を構築
sdkをインストールします
npm install aws-sdk --saveaws-sdkで接続情報の設定
基本的にはIAMロールを使って行うらしいのですが、よくわからないので別の方法で!
クレデンシャル(~/.aws/credentials)もよく使われるらしいですが、今回はenvに設定しました~dotenv モジュールのインストール
$ npm install dotenvルートフォルダーに.envファイルを作り記述します。
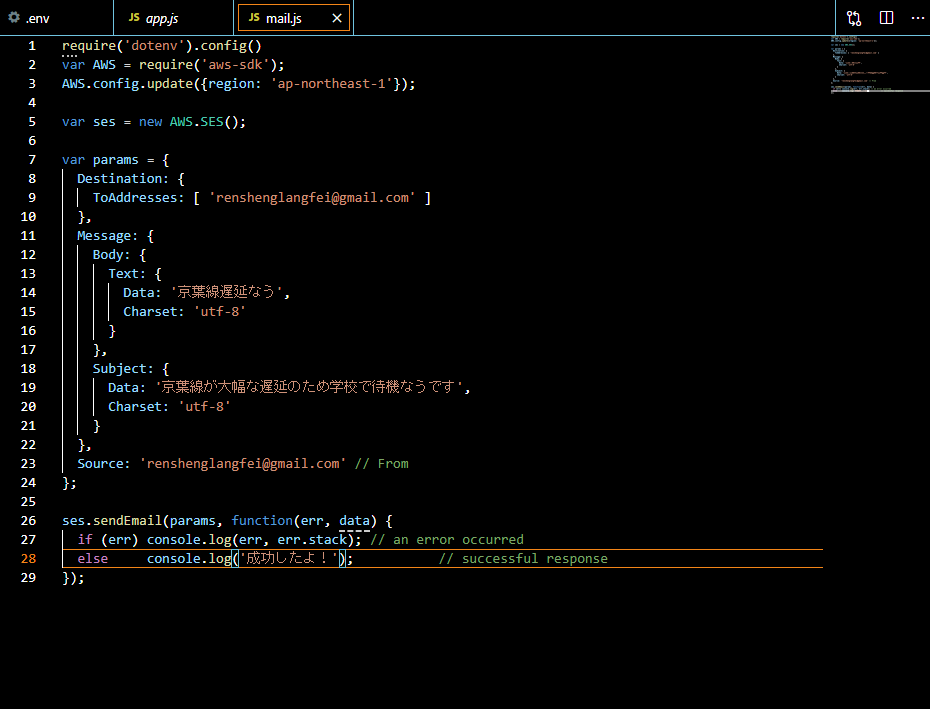
.envaws_access_key_id = アクセスキー aws_secret_access_key = シークレットアクセスキー最後にmail.jsをルートフォルダーに作り、最も簡単なE メールテンプレートの作成をします。
node mail.jsを実行すれば…
届きましたね。
おまけ
awsを使うにあたり調べた用語を紹介します
ロール
特定のアクセス権限を持ち、アカウントで作成できる IAM アイデンティティです。IAM ロールは、IAM ユーザーといくつかの類似点を持っています。ロールとユーザーは、両方とも、ID が AWS でできることとできないことを決定するアクセス許可ポリシーを持つ AWS ID です。ただし、ユーザーは 1 人の特定の人に一意に関連付けられますが、ロールはそれを必要とする任意の人が引き受けるようになっています。また、ロールには標準の長期認証情報 (パスワードやアクセスキーなど) も関連付けられません。代わりに、ロールを引き受けると、ロールセッション用の一時的なセキュリティ認証情報が提供されます。
- 投稿日:2021-01-08T00:01:24+09:00
VPCエンドポイント ってなんのこと?
勉強前イメージ
VPCの設定でエンドポイント設定できるって感じがする
ただ、エンドポイントってなんだろう・・・調査
VPCエンドポイント とは
VPCと他のサービス間の通信を可能にするVPCコンポーネント(仮想デバイス)です。
VPCエンドポイントを作成することで、VPC内のインスタンスとVPC外のサービスをプライベート接続で通信できるようになります。
セキュリティの問題でインターネットに接続せずにサービスと繋がりたいときに使用するものです。VPCエンドポイントの種類
VPCエンドポイントは以下の2つの種類があります。
- インターフェイスエンドポイント
- ゲートウェイエンドポイント
以下詳細に見ていきます
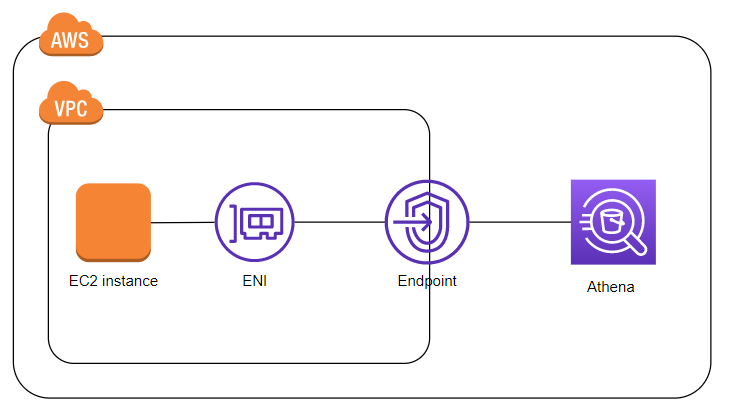
インターフェイスエンドポイント
こちらは
PrivateLinkと呼ばれるサービスを使って、各サービスを接続させることが出来ます
PrivateLinkの実体はVPC内のENI(Elastic Network Interface) になります
PrivateLink自体がIPアドレスを持ってVPCの中にエンドポイントが出来ます
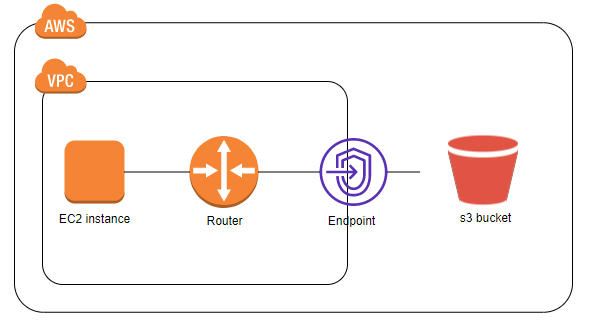
ゲートウェイエンドポイント
VPCのルートテーブル(ルーティング設定)を書き換えてのゲートウェイ経由でサービスへアクセスします
最初に出たエンドポイントで、S3とDynamoDBのみが対応しています。
2つの違い
- 対応サービス
インターフェイスエンドポイントはS3・DynamoDB以外のAWSプリンシパルサービスや独自サービスなど多くありますが、
ゲートウェイエンドポイントはS3とDynamoDBのみです。
- ポリシー
インターフェイスエンドポイントはフルアクセスで設定できませんが、
ゲートウェイエンドポイントは設定が可能です他にもいろいろ違う点はあります
AWSでの設定画面
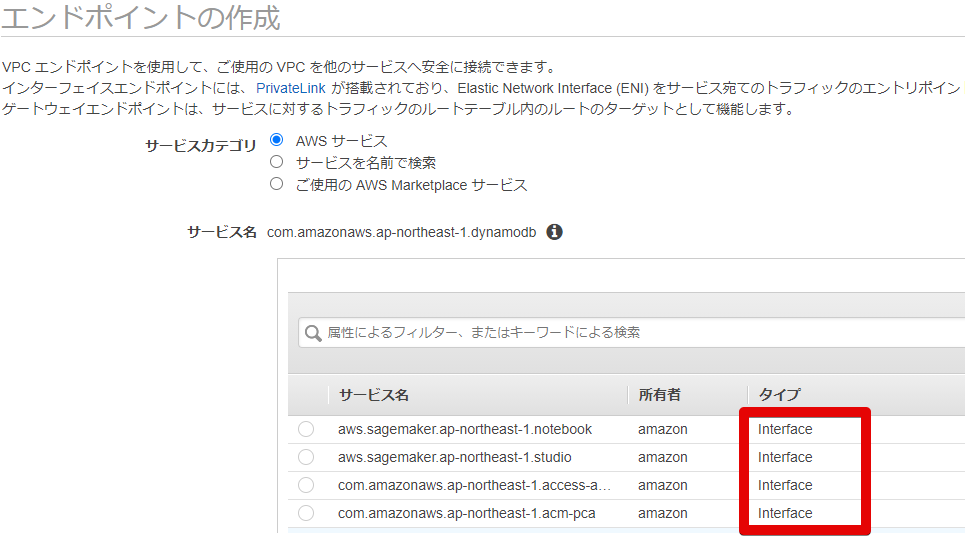
- インタフェースエンドポイント
タイプに
Interfaceと記載されているものになります。
ゲートウェイエンドポイントより多いです。
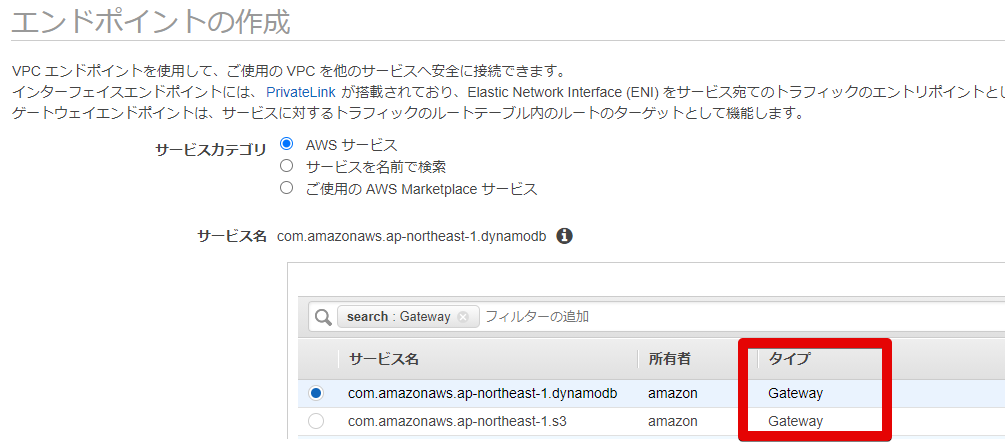
- ゲートウェイエンドポイント
タイプに
Gatewayと記載されているものが対応しているものになります。
こちらはdynamodbとs3のみの記載です
勉強後イメージ
インターネットに出ずとも他のサービスを繋げるための設定。
あんまりちゃんとした設定はしたことないけど、PJの要件とかでインターネットはだめ!って言われたらこういうのを使わないといけないんだろうね。参考