- 投稿日:2021-01-07T23:19:53+09:00
強化学習で酔っ払いの挙動を見る
強化学習を勉強したい
普段私は業務でAI/機械学習に触れています。
ただ今までは教師あり学習を中心に勉強してきたのもあり、教師なし学習や強化学習についてあまり触れたことが無いなと思いました。
そこで昨日、強化学習ハンズオンに最適なこちらの記事を拝見し、実際自分もやってみようと。やるにしても何かテーマが欲しいなぁと思いつつ記事を眺めていると、エージェントの動きに「あれこれ酔っ払いみたいじゃね?」と感じてしまいました。
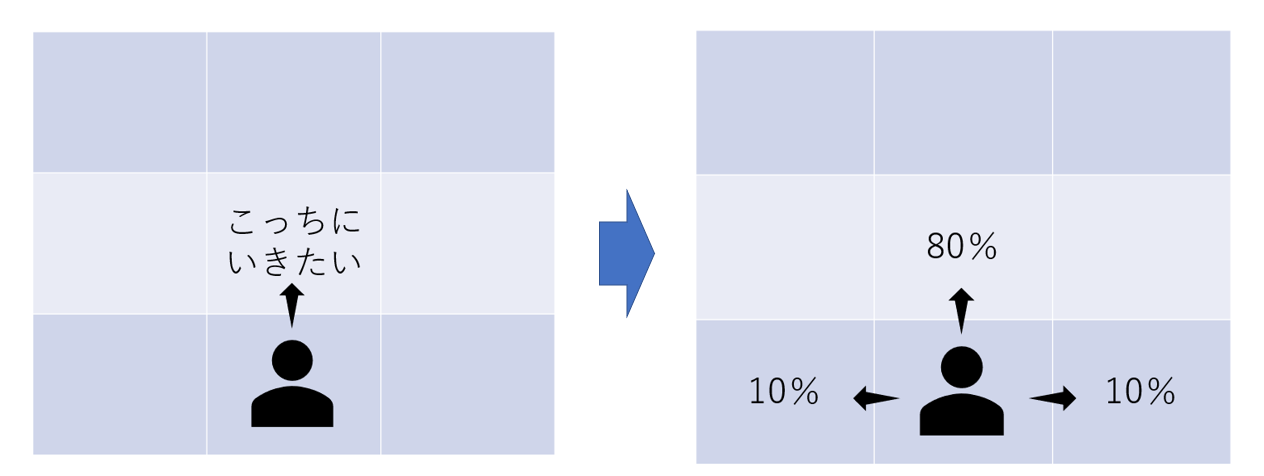
こちらの記事では、始点から終点までの最適経路を求める強化学習をテーマとしていました。
エージェントは80%の確率で希望の方向に進み、10%の確率で左方向、10%の確率で右方向へ行ってしまう設定になっています。
これを使えば「酔っ払いの挙動を再現できるのでは・・・?」と思い、ハンズオンがてら実験してみました。
コロナ前、居酒屋でべろべろになった記憶を思い出しながらご覧ください。
こちらの記事もむちゃくちゃ便利ですのでご覧になってくださいね。サンプルコード
ほぼこちらの記事にある通りで、酔っ払い変数beroberoを導入するために一部改変しています。
定義したメソッドの中身については↑の記事にあるGithubを参照ください。
改変した箇所だけ取り出します。#抽象クラス class MDP: #MDP:マルコフ決定過程(Markov decision processes #引数に酔っ払い度合いberoberoを定義 def __init__(self, init, actlist, terminals, gamma=.9,berobero=0.1): #init:初期状態 #actlist:行動 #erminals:終了状態 #gamma:割引関数 self.init = init self.actlist = actlist self.terminals = terminals #具象クラス class GridMDP(MDP): #引数に酔っ払い度合いberoberoを定義 def __init__(self, grid, terminals, init=(0, 0), gamma=.9,berobero=0.1): #gridは場を定義する行列 grid.reverse() # because we want row 0 on bottom, not on top MDP.__init__(self, init, actlist=orientations, terminals=terminals, gamma=gamma,berobero=berobero) self.grid = grid self.berobero=berobero self.rows = len(grid) self.cols = len(grid[0]) #遷移確率と次の行動のリスト #berobero=0がしらふ、0.1がほろよい、0.3でべろべろなイメージ #berobero=0.5で確実に蟹歩きになるので一周回って大丈夫的な def T(self, state, action): if action is None: return [(0.0, state)] else: return [(1-2*self.berobero, self.go(state, action)), (self.berobero, self.go(state, turn_right(action))), (self.berobero, self.go(state, turn_left(action)))]問題設定
始点から終点までエージェントが進むときに、報酬が最大になるような進み方を探します。
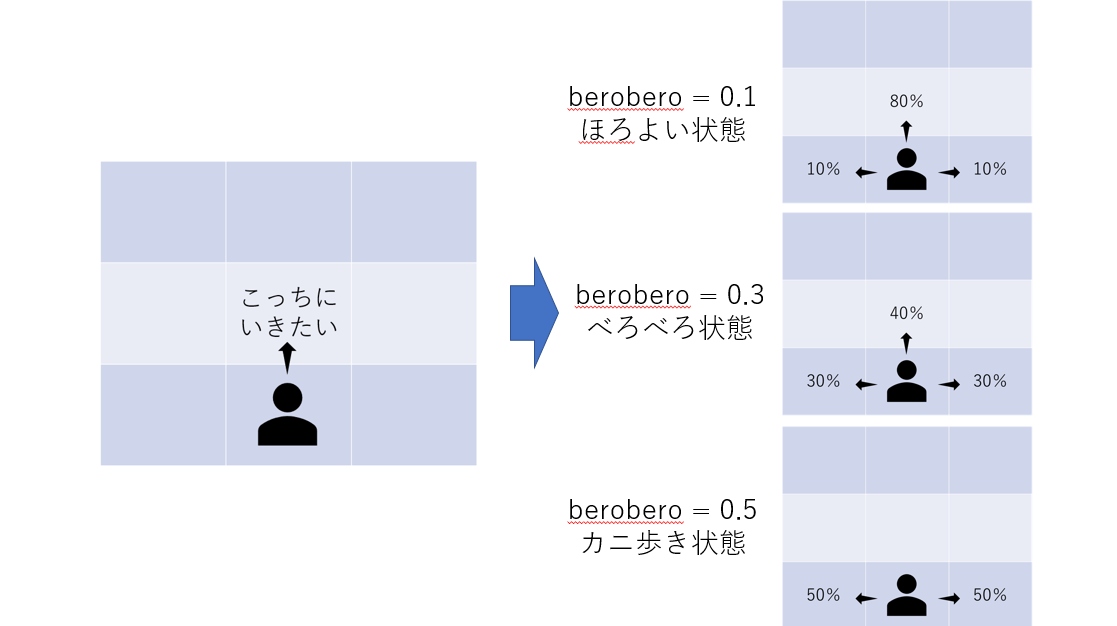
エージェントは一定の確率で希望とは違う方向にすすむ。beroberoの確率で左、beroberoの確率で右、1-2*beroberoの確率で希望通りの方向に進めます。
なので、berobero=0がしらふ、0.1がほろよい、0.3でべろべろなイメージです。
berobero=0.5で確実にカニ歩きになるので「一周回って大丈夫な人」をイメージしてください。
酔っぱらった時は壁沿いを歩く
実際に自分が酔っぱらった時、壁に手をついて壁沿いに移動したりしませんか?
座敷なんかだと「間失礼しまーす」と通るのが怖いので、最短で壁までいって壁に沿って移動するイメージがあります。
これをちょっとシミュレーションしてみたいと思います。出口の近くに人がいる時
まずはこちらの記事の例を使って検証してみます。
お店には柱が一本あり、出口のそばに人が一人いるパターンを考えます。
人にぶつからずに出口に出られる最適な経路を導きます。
酔っ払いなのであれば可能な限り右にすすんで人にぶつかるリスクは負いたくないものです。
なので直観的には上にいって突き当たってそのまま右にいくのが良さそうです。lossはそこに行ったときにもらう報酬で、-0.5にすると「移動するごとに-0.5される」みたいな部屋になります。
報酬のマイナスが大きいほど可能な限り最短で移動しようとします。
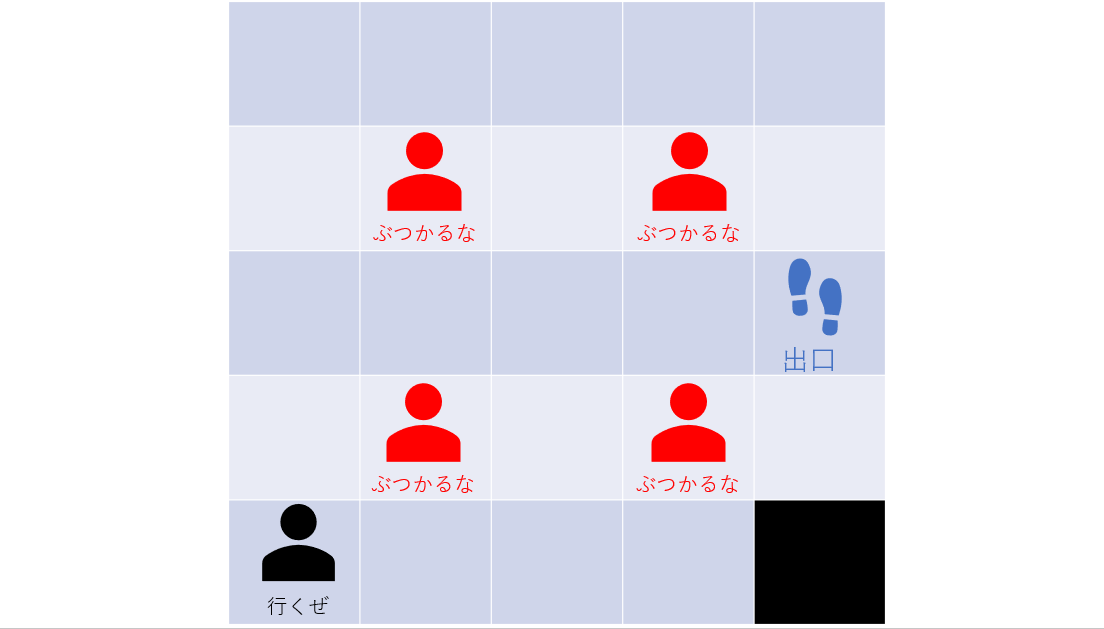
「早く出口に行かないと吐いちゃうぅぅぅ」みたいな設計はlossを使えばできそうですね。(今回はやりません)#もともとのパターン loss = 0 grid=[ [loss, loss, loss, +1], [loss, None, loss, -1], [loss, loss,loss,loss] ] #左下から数える sequential_decision_environment = GridMDP(grid,terminals=[(3, 2), (3, 1)],berobero=0.1) pi = best_policy(sequential_decision_environment, value_iteration(sequential_decision_environment, .01)) print_table(sequential_decision_environment.to_arrows(pi))ほろよいパターン
berobero=0.1の場合はこちら。
見方としては「そのマスからどっち向きに移動するのがもっとも妥当か」を矢印にして出力しています。
この場合、「始点から上へ行き右へ行くルートが最適だ」という結果になります。
直観的にも妥当そうですね。
べろべろパターン
berobero=0.3の場合はこちら。
面白いのは最初に左を向こうとするんですよね。
意地でも右方向には行かないという意志を感じます。
終点に入る直前も上方向を向くことで「右方向、最悪左に戻ってもよし」みたいにしているのが面白い。
カニ歩きパターン
berobero=0.5の場合がこちら。
もうこれ「やべぇ酔いすぎた・・・横方向に着実にすすんでいこ・・・」という強い意志を感じます。
右を向いて横歩きし、上を向いて横歩きすることで難なくゴール。
前に進めないことを逆手に取った悟りの境地を感じますね。
4つの座敷卓の飲み会から脱出する時
さて、いよいよ実践編です。
4つの卓の飲み会の奥の席から脱出することを考えます。
4つの卓を疑似的に4人の人に見立て、「間失礼しまーす」しながら出口へ行くか、遠回りでも壁沿いに行くかを見てみます。
ほろよいパターン
berobero=0.1の場合はこちら。
この場合は「間失礼しまーす」のパターンですね。
酔っぱらっていないので間を抜けても大丈夫だろう的な気持ちを感じます。
べろべろパターン
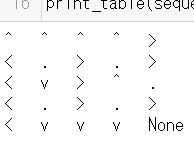
berobero=0.3の場合はこちら。
これです!!壁伝いに行こうとする強い意志を感じますね!!
酔っぱらったときはとにかく壁沿いにすすんで無難に行くべし!!ふと思ったんですがberobero=0.1にしてこれにならない理由って何故なんでしょう?
loss=0なので遠回りするデメリットは無いはずですし、これなら確実です。
ご存じの方はご教示いただけると嬉しいです!
カニ歩きパターン
berobero=0.5の場合がこちら。
前に進めないことを逆手にとってカニ歩きしているのがなんか面白いですね
べろべろになりすぎて危機感感じて冷静になっている姿がありありと浮かびます。
遠回りにもリスクがあるとき
先ほどは遠回りにリスクがありませんでしたが、今回は少しリスクをつけてみます。
近道で行こうが遠回りで行こうが「間失礼しまーす」が生じ、遠回りすると道が太くより安全に右側に進めるシチュエーションを考えます。
こんな居酒屋あるかい。
ほろよいパターン
berobero=0.1の場合はこちら。
この場合は右向きに「間失礼しまーす」のパターンですね。スタート地点で下方向を向いている現象って何故でしょう・・・?
「いやだぁあ出口行きたくなアアアアイィ」的な厭世的な嘆きを感じます。
べろべろパターン
berobero=0.3の場合はこちら。
安全択を取ったパターンですね。
None一つ上の場所で左を向くことで「右には絶対行かない」という強い意志を感じます。
カニ歩きパターン
berobero=0.5の場合がこちら。
カニ歩きを習得すれば人込みなぞ何のその。
さいごに
今回は強化学習ハンズオンが目的だったので条件検討はまだまだ甘いかもしれません。
特にloss=0で設定したので、そこが変わることによる挙動変化もみたいですね。
また今回は価値反復法という手法をモデルにしましたが、Q-learningについても実装してみたい。そしてお酒はほどほどに楽しく飲みましょう!!!!
最後まで読んでいただきありがとうございました!
是非是非LGTMしてくれると嬉しいです。







- 投稿日:2021-01-07T23:04:14+09:00
Pythonで関数実行時に引数の型アノテーションをチェックしてエラーにする
はじめに
Pythonをお使いの方なら既知ですが、Pythonでは型による強制力はありません。
型アノテーション(typing)がPython3.5で追加されるまでは型の記述もできませんでした。
コメントや変数名で空気を読むしかできないわけです。
(個人的に辞書は最悪でした)なので型アノテーションが実装されてからは本当に助かっています。
もう癖になっているので書かない方が違和感があります。
(同じ思いの方も多いかと思います笑)ただ依然として強制力はなく、mypyやVSCode拡張のPylanceでチェックができるに留まっています。
第三者にモジュールとして提供する場合はIFの型チェックはできないわけで実装の中でケアしないといけないです。
こういったケア(チェック処理)をわざわざ1つ1つに対して書くのは手間で本質的ではないので,
簡潔に書きたいというのがモチベーションです。アプローチ
Pythonにはデコレータという便利な機能があります。
デコレータを使うと関数の実行前に処理を実行できるので、
チェック処理をこの中で行ってあげるというアプローチになります。なので各関数ではデコレータだけ書いてしまえばOKということになります。
実装
以下のようなデコレータ関数を定義します。
error引数には型アノテーションの不一致があった際のErrorを指定できます。
check_all_collectionはCollection型の引数をチェックする際に全件チェックするかどうかを指定できます。""" 引数の型をチェックするデコレータ定義ファイル """ import functools import inspect from typing import Any, Union, Callable, _GenericAlias def check_args_type(error: Exception = TypeError, check_all_collection: bool = False): """ 引数の型がアノテーションの型と一致しているかチェックを行うデコレータ関数 Args: error: 不一致時のエラークラス check_all_collection: コレクション型の中身を全てチェックするか """ def _decorator(func: Callable): @functools.wraps(func) def args_type_check_wrapper(*args, **kwargs): sig = inspect.signature(func) try: for arg_key, arg_val in sig.bind(*args, **kwargs).arguments.items(): # アノテーションがタイプでない/空の場合は判定しない annotation = sig.parameters[arg_key].annotation if not isinstance(annotation, type) and not isinstance(annotation, _GenericAlias): continue if annotation == inspect._empty: continue # 一致判定 # Generic系のタイプだった場合は派生形・一部が一致していればOK is_match = __check_generic_alias(annotation, arg_val, check_all_collection) if not is_match: message = f"引数'{arg_key}'の型が正しくありません。annotaion:{annotation} request:{type(arg_val)}" raise error(message) except TypeError as exc: raise error("引数の型か数が一致しません。") from exc return func(*args, **kwargs) return args_type_check_wrapper return _decorator def __check_generic_alias( annotation: Union[_GenericAlias, type], request: Any, check_all_collection: bool = False ): """ GenericAliasの型チェック Args: annotation: アノテーションタイプ request: リクエスト check_all_collection: コレクション型の中身を全てチェックするか """ # Anyの場合は型チェックしない if annotation == Any: return True # 型チェック request_type = type(request) if isinstance(annotation, _GenericAlias): if annotation.__origin__ == request_type: # for collection ...list, dict, set # ----------- # list # ----------- if annotation.__origin__ == list and request: _annotation = annotation.__args__[0] if check_all_collection: # 全件チェックの場合は1つずつ確認 for _request in request: is_match = __check_generic_alias( _annotation, _request, check_all_collection ) if not is_match: return False return True else: # 全件チェックでない場合は先頭を取り出して確認 return __check_generic_alias( _annotation, request[0], check_all_collection ) # ----------- # dict # ----------- if annotation.__origin__ == dict and request: _annotation_key = annotation.__args__[0] _annotation_value = annotation.__args__[1] if check_all_collection: # 全件チェックの場合は1つずつ確認 for _request in request.keys(): is_match = __check_generic_alias( _annotation_key, _request, check_all_collection ) if not is_match: return False for _request in request.values(): is_match = __check_generic_alias( _annotation_value, _request, check_all_collection ) if not is_match: return False return True else: # 全件チェックでない場合は先頭を取り出して確認 is_match_key = __check_generic_alias( _annotation_key, list(request.keys())[0], check_all_collection ) is_match_value = __check_generic_alias( _annotation_value, list(request.values())[0], check_all_collection ) is_match = is_match_key and is_match_value return is_match # 中身が存在してない場合,originがあっていればOKとする if not request: return True else: # list/dictの場合はoriginが一致していないとエラーとする origin = annotation.__origin__ if origin == list or origin == dict: return False # それ以外は再帰的にチェック else: for arg in annotation.__args__: is_match = __check_generic_alias(arg, request) if is_match: return True else: # BoolはintのサブクラスなのでissubclassでTureとなる # 本来意味合いが違うのでNGとしたい if request_type == bool and annotation == int: return False return issubclass(request_type, annotation) return False使用例はその1。
# 一番シンプルなパターン @check_args_type() def test(value: int, is_valid: bool) -> float: """ (省略) """ return 0.0 def main(): # OK result = test(5, True) # NG -> TypeError result = test(0.0, False) # NG2 -> TypeError result = test(1, "True")使用例その2。
# Collectionの中身を全てチェックするパターン @check_args_type(check_all_collection=True) def test2(value: List[int]) -> List[float]: """ (省略) """ return [0.0] def main(): # OK result = test2([0, 5, 10, 20]) # NG -> TypeError result = test([0.0, 5.0, 10.0, 20.0]) # NG2 -> TypeError result = test([0, 5, "test"])Enumやgeneratorなど考慮不足の型があるかと思いますが、基本的な型であれば網羅できているかと思います。
(必要であれば追加していく形でお願いします)まとめ
関数実行時に引数の型アノテーションをチェックしてエラーにする方法を紹介しました。
これで型による強制力が発揮できます。
厳密性が求められる場面(IFなどの境界)では使えるかなと思います。PS)
契約プログラミングのように値まで確認できれば最高なので、拡張予定です。
- 投稿日:2021-01-07T22:50:15+09:00
Effective Python 学習備忘録 6日目 【6/100】
はじめに
Twitterで一時期流行していた 100 Days Of Code なるものを先日知りました。本記事は、初学者である私が100日の学習を通してどの程度成長できるか記録を残すこと、アウトプットすることを目的とします。誤っている点、読みにくい点多々あると思います。ご指摘いただけると幸いです!
今回学習する教材
- Effective Python
- 8章構成
- 本章216ページ
今日の進捗
- 進行状況:56-60ページ
- 第3章:クラスと継承
- 本日学んだことの中で、よく忘れるところ、知らなかったところを書いていきます。
辞書やタプルで記録管理するよりもヘルパークラスを使う
辞書やタプルで記録管理するのは、使いやすい反面、複雑になってしまうと可読性を著しく下げてしまう。
一例として、あるお店の売り上げを記録するクラスを定義する。class SimpleSalesRecord(object): def __init__(self): self._record = {} def add_shop_id(self, shop_id): self._record[shop_id] = [] def report_record(self, shop_id, price): self._record[shop_id].append(price) def average_price(self, shop_id): records = self._record[shop_id] return sum(records) / len(records) record = SimpleSalesRecord() record.add_shop_id(111) record.report_record(111, 90) record.report_record(111, 80) print(record.average_price(111))出力結果
850.0このクラスを拡張して、商品ごとの売上を管理するようにする場合を考える。
class ByitemSalesRecord(object): def __init__(self): self._record = {} def add_shop_id(self, shop_id): self._record[shop_id] = {} # リストから辞書に変更 def report_record(self, shop_id, item, price): by_item = self._record[shop_id] record_list = by_item.setdefault(item, []) record_list.append(price) def average_price(self, shop_id): by_item = self._record[shop_id] total, count = 0, 0 for prices in by_item.values(): total += sum(prices) count += len(prices) return total / count record = ByitemSalesRecord() record.add_shop_id(111) # shop_idが111の店を追加 record.report_record(111, 'Apple', 100) # 111店の売り上げを追加 record.report_record(111, 'Apple', 120) # 111店の売り上げを追加 print(record.average_price(111)) # 111店の売り上げの平均を算出出力結果
Apple: 110.0 Orange: 90.0さらに、賞味期限が近いものは値引きするという機能を実装する。
class DiscountSalesRecord(object): def __init__(self): self._record = {} def add_shop_id(self, shop_id): self._record[shop_id] = {} # リストから辞書に変更 def report_record(self, shop_id, item, price, weight): by_item = self._record[shop_id] record_list = by_item.setdefault(item, []) record_list.append((price, weight)) def average_price(self, shop_id): by_item = self._record[shop_id] price_sum, price_count = 0, 0 for item, prices in by_item.items(): item_avg, total_weight = 0, 0 for price, weight in prices: price_sum += price * weight price_count += 1 return price_sum / price_count record = DiscountSalesRecord() record.add_shop_id(111) # shop_idが111の店を追加 record.report_record(111, 'Apple', 100, 0.8) # 位置引数が何を意味するのか明確ではない record.report_record(111, 'Apple', 120, 1) print(record.average_price(111)) # 111店の売り上げの平均を算出average_priceメソッドでは、ループの中にループがあり、読みにくくなっている。このような複雑さが生じた場合は、辞書とタプルからクラス階層にシフトすべき頃合いである。
クラスへのリファクタリング
上記のコードをクラスへリファクタリングしたコードは以下のようになる。
collectionモジュールのnamedtupleは通常のタプルと異なり、キーワード引数でも指定可能。import collections Record = collections.namedtuple('Record', ('price', 'weight')) class Item(object): def __init__(self): self._records = [] def report_record(self, price, weight=1): self._records.append(Record(price, weight)) def average_price(self): total, total_weight = 0, 0 for record in self._records: total += record.price * record.weight return total / len(self._records) class Shop_ID(object): def __init__(self): self._shop_items = {} def item(self, name): if name not in self._shop_items: self._shop_items[name] = Item() return self._shop_items[name] def average_price(self): total, count = 0, 0 for shop_item in self._shop_items.values(): total += shop_item.average_price() count += 1 return total / count class SalesRecord(object): def __init__(self): self._shop_id = {} def shop_id(self, name): if name not in self._shop_id: self._shop_id[name] = Shop_ID() return self._shop_id[name] record = SalesRecord() shop_111 = record.shop_id(111) apple = shop_111.item('Apple') apple.report_record(100, 0.8) apple.report_record(100) print(shop_111.average_price())まとめ
- 値が他の辞書や長いタプルであるような辞書は作らない
- 辞書が複雑になったら、複数のヘルパークラスを使うように変更する
- 投稿日:2021-01-07T22:49:41+09:00
【Python】複数の画像の代表値をとる【Numpy】
目的
複数の画像の各ピクセルの代表値を使って画像を生成する。
例えば10枚の画像の平均画像を作りたい。準備
ライブラリのImport
import numpy as np from scipy import stats画像
10枚のRGB画像。
10枚の平均画像、中央値画像、最頻値画像をそれぞれ生成する。imgs.shape # (10, 128, 128, 3)平均
x.shapeでaxisに設定したい軸を確認できる。
img_mean = np.mean(imgs, axis=0) img_mean.shape # (128, 128, 3)中央値
img_median = np.median(imgs, axis=0) img_median.shape # (128, 128, 3)最頻値
numpyに最頻値を求めるライブラリがないのでscipy。
他にいい方法あるかも。# 返値がmodeとcountの2つあるのでmodeだけ拾う img_mode = stats.mode(imgs, axis=0)[0] # 形を他の代表値画像と合わせる img_mode.shape # (1, 128, 128, 3) img_mode = img_mode.reshape(128, 128, 3) img_mode.shape # (128, 128, 3)
- 投稿日:2021-01-07T22:09:46+09:00
pdf形式のレポート作成をPythonで自動化してみる
はじめに
・この記事では、家計簿アプリZaimからダウンロードしたデータを使います。もっと言えば、pythonを用いて、データから1年間の収入と支出をまとめたレポートをpdf形式で自動生成します。
・ソースコードと記事は、たぶん書き方が下手くそで美しくないところが多いと思いますが、許してください。
・筆者は「pythonを使いこなせば自動化できる!」って謳い文句につられてpythonを勉強し始めました。
でも、初心者に優しい実践的な自動化の具体例があまりないと思っています。(大きな偏見あり)
そこで、特に初心者の方に、pythonで自動化できるものには、こんなのがあるんだと知ってもらえると嬉しいです。家計簿アプリZaimってなに?
↓ とりあえず公式のホームページ
https://zaim.co.jp/筆者が愛用している家計簿アプリ。(2020年5月ぐらいから有料会員。)
月ごとの収入と支出等を、円グラフや積立棒グラフ等を使って分析できるのですごい便利。そして、Zaimの有料会員になると、集めてきたデータをcsv形式でダウンロードすることが出来る。(ファイルをQiitaの記事に載せる方法が分からなかったので、写真だけ。)
作成した各ファイル,フォルダの概要
↓ 作業フォルダの構造
簡単に言うと、
・dataフォルダの中に、Zaimからダウンロードしたデータファイルが入ってます。(ファイル名:Zaim.2020.csv)・font_dataフォルダは、pythonでpdfに書き込むためのフォントファイルが入ってます。(ファイル名:GenShinGothic-Monospace-Medium.ttf)
・analyze.pyでは、まず、Zaimからのデータファイル(Zaim.2020.csv)をpandas等で読み取ります。次に、pandas、numpyなどを使ってゴネゴネとデータを整形し、図を作ったり整形したデータを新しいファイルに出力したりします。
・format_dataフォルダでは、analyze.pyで整形したデータが、csv形式で入っています。(ファイル名:diff_money.csv)
・graphフォルダでは、analyze.pyで作成した画像データが、jpg形式で入っています。(ファイル名: in_money.jpg, out_money.jpg, money.jpg, difference_money.jpg)
・report_pdf.pyでは、まず、作成するpdfレポートの細かな設定をします。次に、graphフォルダ内のmoney.jpg, difference_money.jpgの画像をpdfに貼り付けます。そして、format_dataフォルダ内のdiff_money.csvから、1年間でどれだけの収支になったのかを読み取りpdfに書き込みます。その後、pdfファイルとして出力します。
・reportフォルダでは、report_pdf.pyで出力されたpdfデータが、pdfファイルとして入っています。(ファイル名:balance report.pdf)
analyze.pyのソースコード
↓ ソースコード
analyze.py ライブラリのインポートとグラフの体裁import pandas as pd import numpy as np import matplotlib.pyplot as plt from matplotlib import rcParams # グラフの体裁を整える rcParams['font.family'] = 'sans-serif' #使用するフォント rcParams['font.sans-serif'] = ['Hiragino Maru Gothic Pro', 'Yu Gothic', 'Meirio', 'Takao', 'IPAexGothic', 'IPAPGothic', 'VL PGothic', 'Noto Sans CJK JP'] rcParams['xtick.direction'] = 'in'#x軸の目盛線が内向き('in')か外向き('out')か双方向か('inout') rcParams['ytick.direction'] = 'in'#y軸の目盛線が内向き('in')か外向き('out')か双方向か('inout') rcParams['xtick.major.width'] = 1.0#x軸主目盛り線の線幅 rcParams['ytick.major.width'] = 1.0#y軸主目盛り線の線幅 rcParams['font.size'] = 15 #フォントの大きさ rcParams['axes.linewidth'] = 1.0# 軸の線幅edge linewidth。囲みの太さグラフの体裁は良い記事がいっぱいあるから美味しいとこをもらおう。
https://qiita.com/qsnsr123/items/325d21621cfe9e553c17analyze.py 関数の定義# 年月日を月ごとに使いやすい形へ変形 def devide_month(data): data = np.array(data) # 各月ごとのデータを入れるためのリストを用意 month_01, month_02, month_03, month_04 = list(), list(), list(), list() month_05, month_06, month_07, month_08 = list(), list(), list(), list() month_09, month_10, month_11, month_12 = list(), list(), list(), list() # dataから月ごとの日付とkeyを取得 for i in range(len(data.T[1])): # 1月のデータをmonth_01に格納 if data.T[1][i] == "01": # 日付とdataframeのkeyをmonth_1に格納 month_01.append([data.T[2][i], data.T[3][i]]) elif data.T[1][i] == "02": month_02.append([data.T[2][i], data.T[3][i]]) elif data.T[1][i] == "03": month_03.append([data.T[2][i], data.T[3][i]]) elif data.T[1][i] == "04": month_04.append([data.T[2][i], data.T[3][i]]) elif data.T[1][i] == "05": month_05.append([data.T[2][i], data.T[3][i]]) elif data.T[1][i] == "06": month_06.append([data.T[2][i], data.T[3][i]]) elif data.T[1][i] == "07": month_07.append([data.T[2][i], data.T[3][i]]) elif data.T[1][i] == "08": month_08.append([data.T[2][i], data.T[3][i]]) elif data.T[1][i] == "09": month_09.append([data.T[2][i], data.T[3][i]]) elif data.T[1][i] == "10": month_10.append([data.T[2][i], data.T[3][i]]) elif data.T[1][i] == "11": month_11.append([data.T[2][i], data.T[3][i]]) else: month_12.append([data.T[2][i], data.T[3][i]]) # 月ごとのデータをまとめる date_month = [ month_01, month_02, month_03, month_04, month_05, month_06, month_07, month_08, month_09, month_10, month_11, month_12, ] return date_month # dataframeから特定の種別のデータを引っ張って来る def collect_data_from_dataframe(dataframe, name, date_month): monthly_data = list() for i in range(len(date_month)): # 月の中にデータがあれば、dataframeからデータを取得 if date_month[i] != []: monthly_data.append(dataframe[name][int(date_month[i][0][1]):int(date_month[i][-1][1])+1].tolist()) else: monthly_data.append(None) return monthly_data # 月ごとの支出の合計金額をリストに格納する def monthly_sum_money(money): sum_list = list() for i in range(len(money)): if money[i] == None: sum_list.append(0) else: sum_list.append(np.sum(money[i])) return sum_listanalyze.py グラフのためのデータの準備# Zaimからダウンロードしたデータのパス read_data_path = "data/Zaim.2020.csv" # データを読み込んでpandasに格納。 df = pd.read_csv(read_data_path, encoding="shift-jis") key = 0 date_2020 = list() # 日付のデータを取り出す for date in df["日付"]: # 日付を年、月、日ごとに分割してリストに格納 date = date.split("-") # 日付と元々のデータフレームを対応させるために、keyを付け加える date.append(str(key)) # 日付とkeyを合わせたものをリストに加える date_2020.append(date) key += 1 # date_month.shape: [月][月のデータの番号][日,key] date_month_2020 = devide_month(date_2020) # 支出を月ごとにまとめて、リストで保持。 out_money = collect_data_from_dataframe(df, "支出", date_month_2020) # 支出の各月の合計を計算し、リストで保持。 out_money_monthly = monthly_sum_money(out_money) # 収入を月ごとにまとめて、リストで保持。 in_money = collect_data_from_dataframe(df, "収入", date_month_2020) # 収入の各月の合計を計算し、リストで保持。 in_money_monthly = monthly_sum_money(in_money) # 収支を計算、リスト形式で保持 difference_money = (np.array(in_money_monthly) - np.array(out_money_monthly)).tolist()グラフの作成と保存# グラフの保存先 save_file_path = "./graph/" # 年間の支出のグラフ # 去年の3月より前は完全にデータがないので省く(4月から12月まで) plt.plot(range(4, 13), np.array(out_money_monthly[3:])/10000, color="blue", label="支出") plt.xlabel('月') plt.ylabel('支出 [万円]') plt.grid(linestyle= '--') plt.xlim(1,12) plt.ylim(0,20) # 軸の目盛間隔などの設定。この場合、x軸は1から12まで1ずつの間隔となる。 plt.xticks(np.arange(1, 13, 1)) plt.yticks(np.arange(0, 21, 1)) # グラフの保存 plt.savefig(save_file_path + "out_money.jpg") plt.cla() # 年間の収入のグラフ plt.plot(range(4, 13), np.array(in_money_monthly[3:])/10000, color="red", label="収入") plt.xlabel('月') plt.ylabel('収入 [万円]') plt.grid(linestyle= '--') plt.xlim(1,12) plt.ylim(0,20) plt.xticks(np.arange(1, 13, 1)) plt.yticks(np.arange(0, 21, 1)) plt.savefig(save_file_path + "in_money.jpg") plt.cla() # 年間の支出と収入のグラフ # 収入は赤線で、支出は青線で表示 plt.plot(range(4, 13), np.array(in_money_monthly[3:])/10000, color="red", label="収入") plt.plot(range(4, 13), np.array(out_money_monthly[3:])/10000, color="blue", label="支出") plt.legend(loc="lower right") plt.xlabel('月') plt.ylabel('金額 [万円]') plt.grid(linestyle= '--') plt.xlim(1,12) plt.ylim(0,20) plt.xticks(np.arange(1, 13, 1)) plt.yticks(np.arange(0, 21, 1)) plt.savefig(save_file_path + "money.jpg") plt.cla() # 年間の収支のグラフ # 棒グラフで表現する際に、各月の収支がプラスかマイナスで色分けしたいため、データを二つに分ける。 positive_money = list() negative_money = list() positive_x = list() negative_x = list() # 収入と支出の差がプラスかマイナスでデータを分ける。 for i in range(len(difference_money)): if difference_money[i] >= 0: positive_money.append(difference_money[i]) positive_x.append(i+1) else: negative_money.append(difference_money[i]) negative_x.append(i+1) # 収支がプラスは赤色、収支がマイナスの月は青色で表現。 plt.bar(positive_x, np.array(positive_money)/10000, color="red", label="収支+") plt.bar(negative_x, np.array(negative_money)/10000, color="blue", label="収支-") plt.legend(loc="upper right") plt.xlabel('月') plt.ylabel('収支 [万円]') plt.grid(linestyle= '--') plt.xlim(1,12) plt.ylim(-8,8) plt.xticks(np.arange(1, 13, 1)) plt.yticks(np.arange(-8, 9, 1)) plt.savefig(save_file_path + "difference_money.jpg") plt.cla() # pdfレポートの自動作成のために、データを外部に出力 format_data_path = "format_data/" np.savetxt(format_data_path + "diff_money.csv", difference_money)report_pdf.pyのソースコード
この記事読んでないとpdfに出力する(書き込む?)やり方分からなくて出来ていなかったと思う。圧倒的感謝!
https://watlab-blog.com/2020/03/21/reportlab-pdf/import numpy as np from reportlab.pdfgen import canvas from reportlab.lib.units import mm from reportlab.pdfbase.pdfmetrics import registerFont from reportlab.pdfbase.ttfonts import TTFont # フォントを登録 registerFont(TTFont('GenShinGothic', './font_data/GenShinGothic-Monospace-Medium.ttf')) file_path = 'report/balance report.pdf' # 出力ファイル名を設定 graph_path_transition = "graph/money.jpg" graph_path_balance = "graph/difference_money.jpg" # 1年間の収支レポートを作成 paper = canvas.Canvas(file_path) # 白紙のキャンバスを用意 paper.saveState() # 初期化 paper.setFont('GenShinGothic', 20) # フォントを設定 # 横wと縦hの用紙サイズを設定 w = 210 * mm h = 297 * mm paper.setPageSize((w, h)) # 用紙のサイズをセット paper.drawString(w/2 - 90, h - 50, # テキストの書き込み '1年間の支出と収入') # 画像を埋め込み(画像ファイルのパス, 横位置, 縦位置, 画像横サイズ, 画像縦サイズ) paper.drawInlineImage(graph_path_transition, 31*mm, h-130*mm, 148*mm, 111*mm) paper.setFont('GenShinGothic', 15) # フォントを設定 paper.drawString(w/2 - 112.5, 160*mm, '図1 1年間の収入と支出の推移') # 2つ目の画像を埋め込み(画像ファイルのパス, 横位置, 縦位置, 画像横サイズ, 画像縦サイズ) paper.drawInlineImage(graph_path_balance, 31*mm, h-250*mm, 148*mm, 111*mm) paper.setFont('GenShinGothic', 15) # フォントを設定 paper.drawString(w/2 - 67.5, 40*mm, '図2 1年間の収支') # 収支の結果を記入 difference_money = np.loadtxt('format_data/diff_money.csv', delimiter=',') # 収支のデータを読み込む paper.setFont('GenShinGothic', 13) # フォントを設定 paper.drawString(w/2-100, 23*mm, f'1年間全体の収支は、{int(np.sum(difference_money))}円です。') paper.drawString(w/2-100, 14 * mm, f'つまり、1ヶ月あたり、{int(np.sum(difference_money)/len(difference_money))}円です。') paper.save() # PDFを保存実行結果
analyze.pyの実行結果
analyze.pyを実行した結果グラフは、in_money.jpg, out_money.jpg, money.jpg, difference_money.jpgの4つが作成されるが、内2つ(in_money.jpg, out_money.jpg)は、money.jpgと内容が被っているので割愛する。
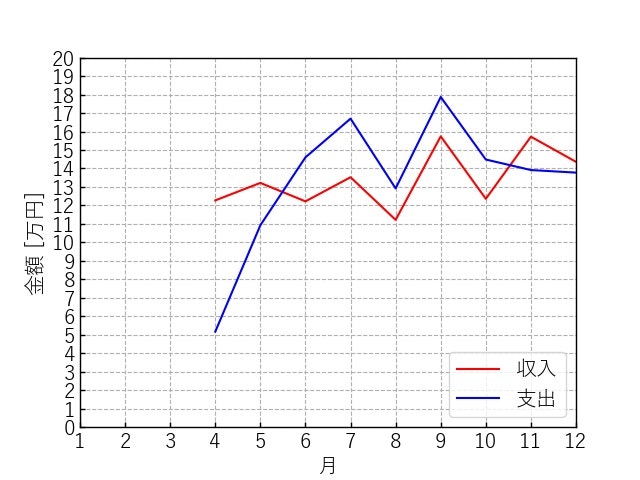
図1 1年間の収入と支出の推移(money.jpg)
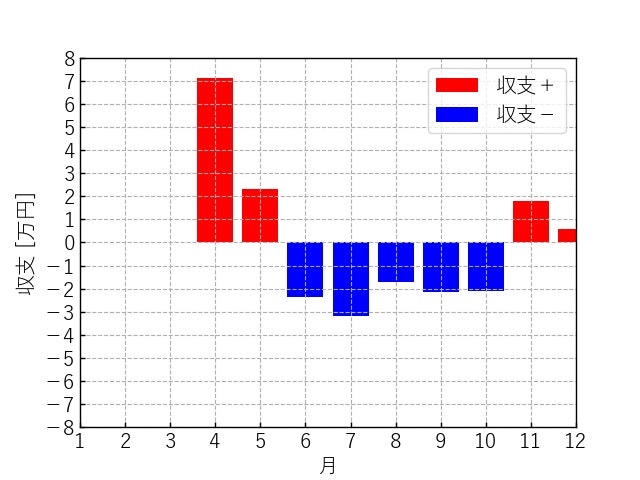
図2 1年間の収支の推移(difference_money.jpg)report_pdf.pyの実行結果
report_pdf.pyにより自動作成された家計簿レポートは次の通りになる。
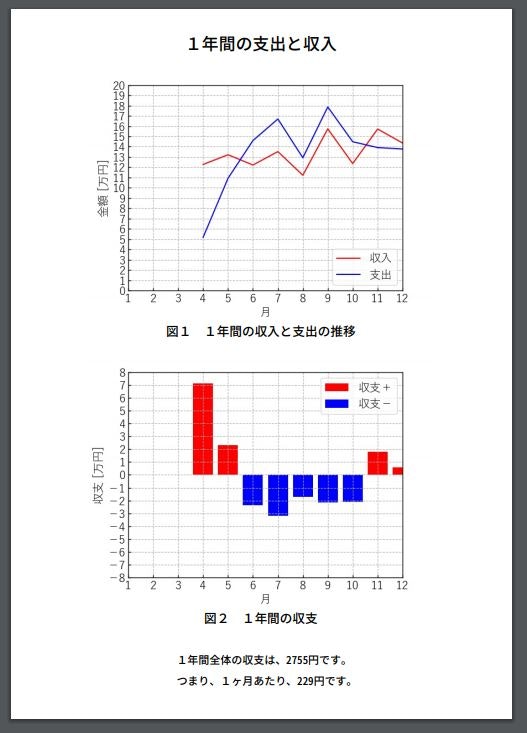
- 投稿日:2021-01-07T22:07:05+09:00
cv_bridgeをpython3(virtualenv)で使いたい時の解決法
経緯
ROSを使って色々イジイジしていたときのことです。カメラの入力ノードからRGBデータが送られてくるので、それを別のノードで受け取りたいと思い、cv_bridgeを使おうとしていました。下のような感じです。
from cv_bridge import CvBridge def prediction(msg): bridge = CvBridge() img = bridge.imgmsg_to_cv2(msg, "bgr8")しかし、ビルドして実行してみたところ、以下のようなエラーが発生しました。
File "/opt/ros/melodic/lib/python2.7/dist-packages/cv_bridge/core.py", line 91, in encoding_to_cvtype2 from cv_bridge.boost.cv_bridge_boost import getCvType ImportError: dynamic module does not define module export function (PyInit_cv_bridge_boost)調べてみると、cv_bridgeがpython2でビルドされていることが原因のようでした。自分は実行環境がpython3(virtualenv)だったので、cv_bridgeをソースコードからビルドする必要がありました。
環境
- ROS melodic
- python3.6(virtualenv)
- ubuntu18.04
- Jetson AGX Xavier
最初にやった方法
最初はこちらの方法を参考にしてやってみました。ローカルのpython3が実行環境の場合は、上手く行くのかもしれませんが、virtualenvを使っていた自分の環境ではうまく行きませんでした。一応共有しておきます。
$ cd catkin_ws $ catkin config -DPYTHON_EXECUTABLE=/usr/bin/python3 -DPYTHON_INCLUDE_DIR=/usr/include/python3.5m -DPYTHON_LIBRARY=/usr/lib/aarch64-linux-gnu/libpython3.5m.so $ catkin config --install $ git clone https://github.com/ros-perception/vision_opencv.git src/vision_opencv $ apt-cache show ros-melodic-cv-bridge | grep Version $ cd src/vision_opencv/ # たぶんの下のバージョンだった気がします。apt-cache showで出てきたものです。 $ git checkout 1.13.0 $ cd ../../ $ catkin build cv_bridge $ source install/setup.bash --extendvirtualenvを使っていた自分の環境では、cv_bridgeは無事にビルドされるのですが、ビルド後に自前の他のノードを一緒のcatkin_wsでビルド実行すると下のようなエラーが発生してしまいました。
RLException: [sample.launch] is neither a launch file in package [sample_proc] nor is [sample_proc] a launch file nameここから結構沼にハマってしまいました。犠牲者を減らすために、自分が解決した方法を共有します。
最終的な解決法
こちらのリポジトリの環境が、自分と同じようにvirtualenv上のpython3でcv_bridgeを使っていたので、そこからヒントを得ました。
大事なことは、2つあります。1つは、cv_bridgeのビルドを自前のワークスペースとは別のワークスペースで行うことです。もう1つは、自分のスクリプトのcv_bridgeをimportしている行の前で、python2.7のパスを削除することです。具体的な手順は以下の通りです。$ mkdir -p cv_bridge_ws/src $ git clone https://github.com/ros-perception/vision_opencv.git src/vision_opencv $ apt-cache show ros-kinetic-cv-bridge | grep Version $ cd src/vision_opencv/ # apt-cache showの結果でversionの値は変わります $ git checkout 1.13.0 $ cd ../../ # 環境により、DPYTHON_LIBRARYのaarch64-linux-gnuの部分は変わります $ catkin build $ catkin config -DCMAKE_BUILD_TYPE=Release -DPYTHON_EXECUTABLE=/usr/bin/python3 -DPYTHON_INCLUDE_DIR=/usr/include/python3.6m -DPYTHON_LIBRARY=/usr/lib/aarch64-linux-gnu/libpython3.6m.so $ source devel/setup.bash --extend $ cd ../catkin_ws # 自前のノードをビルド $ catkin build $ source devel/setup.bashさらに自分のスクリプトも変更します。
import sys sys.path.remove('/opt/ros/melodic/lib/python2.7/dist-packages') from cv_bridge import CvBridge def prediction(msg): bridge = CvBridge() img = bridge.imgmsg_to_cv2(msg, "bgr8")これにより、python2のcv_bridgeではなく、python3のcv_bridgeが実行時に呼び出されるようになります。
まとめ
もうmelodicはいやだ(笑)。noeticかROS2使いたい。
- 投稿日:2021-01-07T21:34:16+09:00
Pythonで連立一次方程式を解く(掃き出し法と分数表現)
はじめに
こんにちは、麻菜結です。必要に迫られてしこしこ作ったプログラムが良い感じに作れたので紹介する記事です。作ったのはそこそこ実用的な連立一次方程式を解くプログラムです。バグがあったら優しく教えてください。なお、掃き出し方そのものの説明は行わないのでご了承ください。
環境
環境はPython3系です。
> python --version Python 3.9.0プログラム
プログラムは以下に示すものです。
solve_PE.pyimport sys def hakidashi(m, show_matrix): num_line = len(m) num_column = len(m[0]) div = lambda a, b: 0 if b==0 else a / b for p in range(num_line): m[p] = [div(n, m[p][p]) for n in m[p]] for i in range(num_line): x = div(m[i][p], m[p][p]) for j in range(num_column): if(i != p): m[i][j] = m[i][j] - x * m[p][j] if(show_matrix): for e in m: print(e) return list(map(lambda m: m[-1], m)) def dec_to_frac(f, max_denominator, calc_accuracy): for i in range(1, max_denominator + 1): k1 = int(f * i) k2 = k1 + 1 if(abs((k1 / i) - f) < calc_accuracy): return f"{k1}/{i}" elif(abs((k2 / i) - f) < calc_accuracy): return f"{k2}/{i}" else: return "not found" def read_file(file_name, file_codec): c, m = [], [] with open(file_name, encoding=file_codec) as f: lists = list(f.readlines()) c = split_line(lists[0]) for l in lists[1:]: m.append(split_line(l, num=True)) return c, m def split_line(line, num=False): line = line.strip() line += "#" data_line = [] word = "" is_firstblank = True for e in line: if(" " == e and is_firstblank): data_line.append(word) is_firstblank = False word = "" elif("," == e): data_line.append(word) word = "" elif("#" == e): data_line.append(word) break else: is_firstblank = True word += e else: data_line.append(word) return [ float(x.strip()) if num else x.strip() for x in data_line if x not in ["", " "] ] if __name__ == "__main__": file_name = sys.argv[1] file_encode = "utf-8" max_denominator = 10000000 calc_accuracy = 0.0000000001 show_matrix = True c, m = read_file(file_name, file_encode) if(len(c) + 1 == len(m[0])): ans = hakidashi(m, show_matrix) for c, ans in zip(c, ans): f = dec_to_frac(ans, max_denominator, calc_accuracy) print(f"{c} = {ans} ({f})") else: print("data error", file=sys.stderr)以下はそれぞれの説明です。
掃き出し方
hakidashi()が該当関数です。特に工夫はありませんが、ゼロで割っちゃうエラーを回避するためにdivという関数を内部で定義しており、ゼロで割りそうなときは0を返すようにしてあります。リターンの直前に分数表現
dec_to_frac()が該当関数です。分母を変えつつ検証していって、許せる精度になったら分数表現にした文字列を返します。もし範囲に見当たらなかったときはnot foundを表示します。ここがforループで計算回数が多いのであんまりに重かったらmax_denominatorやcalc_accuracyの値を調整してください。こちらのサイトを参考にさせていただきました。
FloatToFraction (JavaScript版)ファイルの読み込み
read_file()とsplit_line()が該当関数です。
read_fileではコマンドラインからもらったファイル名からファイルデータを開き、split_lineに渡しています。cは文字ラベル(xとかyとか)を入れる配列、mは数値の配列データです。
split_lineは、カンマセパレートでもスペースセパレートでも読み込めるように、またはコメントを書き込めるように丁寧に分けるやつです。使い方
たとえば、以下のようなテキストを記述したファイルを使います。
mat1.txtx y z 4 2 1 26 1 6 3 48 4 1 5 34上のは以下の連立方程式を表しています。
$$
4x + 2y + z = 26 \\
x + 6y + 3z = 48 \\
4x + y + 5z = 34
$$> python solve_PE.py mat1.txt [1.0, 0.0, 0.0, 2.727272727272727] [0.0, 1.0, 0.0, 5.818181818181818] [0.0, 0.0, 1.0, 3.454545454545455] x = 2.727272727272727 (30/11) y = 5.818181818181818 (64/11) z = 3.454545454545455 (38/11)また、以下のように解が無い場合を考えます。
mat2.txtx1, x2 # 下式が上式の 3, 6, 9 # ただの二倍になっているので 6, 12, 18 # 解はないなお、
#はコメントを表し、実際にファイルに記述することが可能です。> python solve_PE.py mat2.txt [1.0, 2.0, 3.0] [0, 0, 0] x1 = 3.0 (3/1) x2 = 0 (0/1)値は適当に入れられていますが、上の行列が三角っぽくないのでおかしいことがわかります。
おわりに
お疲れさまでした。上手く動きましたか?百行も満たないのに結構使えるプログラムになったのでPythonすごいというのと、先人の考えたアルゴリズムすごいなという気持ちです(小学生並の感想)。やっぱ自分で組めると楽しいですね、こういうことに幸せを感じて生きていきたい。
最後まで読んでくださってありがとうございます。役に立ったなら幸いです。どうでもいいですけど、私の次は何か書こうかなというのは本当にあてになりませんね。自分で過去の記事を見てびっくりします。手がかじかんできたのでこの辺にします。ありがとうございました。
- 投稿日:2021-01-07T19:36:28+09:00
【Python】icrawlerで簡単に画像を集めよう!
機械学習の画像集めにicrawlerを利用したのでその紹介です。
icrawlerとは
pythonでwebクローリングを行い、画像を集めるためのフレームワークです。
非常に短いコードを記述するだけで画像を集めることができます。インストール
pip
$ pip install icrawleranaconda
$ conda install -c hellock icrawler使い方
from icrawler.builtin import BingImageCrawler crawler = BingImageCrawler(storage={"root_dir": './images'}) crawler.crawl(keyword='猫', max_num=100)
root_dirに画像の保存先ディレクトリを指定します。keywordに集めたい画像のキーワードを指定します。max_numに集める画像の枚数を指定します。BingImageCrawlerの部分を他のImageCrawlerに変えることもでき、GoogleやFlickerも利用できます。Google利用時に
json.decoder.JSONDecodeErrorが出る際の対処法
- google.pyを見つけます。
- 例(anaconda利用):
C:\Users\hoge\anaconda3\envs\env1\Lib\site-packages\icrawler\builtin\google.py- pip でインストールしている場合はパッケージの場所を検索できるのでそこから辿ってください
- https://qiita.com/t-fuku/items/83c721ed7107ffe5d8ff
- google.pyの
parseメソッドを下記に変更します。
parseメソッドは144行目あたりにあります。def parse(self, response): soup = BeautifulSoup( response.content.decode('utf-8', 'ignore'), 'lxml') #image_divs = soup.find_all('script') image_divs = soup.find_all(name='script') for div in image_divs: #txt = div.text txt = str(div) #if not txt.startswith('AF_initDataCallback'): if 'AF_initDataCallback' not in txt: continue if 'ds:0' in txt or 'ds:1' not in txt: continue #txt = re.sub(r"^AF_initDataCallback\({.*key: 'ds:(\d)'.+data:function\(\){return (.+)}}\);?$", # "\\2", txt, 0, re.DOTALL) #meta = json.loads(txt) #data = meta[31][0][12][2] #uris = [img[1][3][0] for img in data if img[0] == 1] uris = re.findall(r'http.*?\.(?:jpg|png|bmp)', txt) return [{'file_url': uri} for uri in uris]参考
https://github.com/hellock/icrawler
https://github.com/hellock/icrawler/issues/65
- 投稿日:2021-01-07T19:12:41+09:00
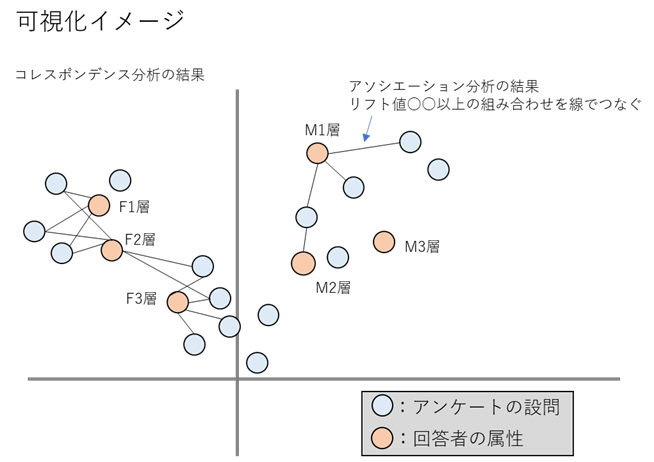
コレスポンデンス分析とアソシエーション分析を組み合わせる(属性特化型特徴抽出アソシエーションプロット)
はじめに
日本分類学会の学会誌「データ分析の理論と応用」のVol.5 (2016)に載っていた、"対応分析を用いたアソシエーションルールによるアンケート結果の可視化" についてアンケート以外にも使えるんじゃないか?と思ってPythonで実施してみた、という話。
networkxの練習も兼ねている。
書きなぐったようなクソコードをさらしていくスタイル。ざっくり内容説明
当該論文について、簡単に説明すると、コレスポンデンス分析の結果のプロット上に、アソシエーション分析の結果の組み合わせ同士を線で繋げてあげるイメージ。論文中では"属性特化型特徴抽出アソシエーションプロット"と呼ばれている。
論文中の例として、メディア層(属性)別の健康上の悩みアンケート結果に対して可視化を行っている。
可視化の結果、例えば「F3層は○○の悩みがある傾向で、一方F1層・F2層は××の悩みがある傾向だが、~~の悩みに関してはF2層F3層共通の悩みである」といったことがわかる。
POSデータへの適用
例えばID-POSデータを使って属性に当たる部分を地域や店舗、アンケートに当たる部分を購入商品カテゴリーやブランドの購入回数とすると、地域や店舗の購買傾向を可視化することができる。
実際に、計算機統計学 29巻 22号 の"売り上げ傾向による店舗の分類と購買傾向の分析と可視化"では店舗別の購買傾向について分析を行っている。
今回の試みも、POSデータに対して実施した。使用データ
kaggleのsuperstore_dataを使う。
4年間のグローバルスーパーストアの小売データで、Customer IDやProduct ID、Cityなどがあるが、店舗IDのようなものは無い。
店舗IDが無いので、今回は国と、商品サブカテゴリーの購買傾向を可視化する。<class 'pandas.core.frame.DataFrame'> RangeIndex: 51290 entries, 0 to 51289 Data columns (total 24 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Row ID 51290 non-null int64 1 Order ID 51290 non-null object 2 Order Date 51290 non-null datetime64[ns] 3 Ship Date 51290 non-null datetime64[ns] 4 Ship Mode 51290 non-null object 5 Customer ID 51290 non-null object 6 Customer Name 51290 non-null object 7 Segment 51290 non-null object 8 City 51290 non-null object 9 State 51290 non-null object 10 Country 51290 non-null object 11 Postal Code 9994 non-null float64 12 Market 51290 non-null object 13 Region 51290 non-null object 14 Product ID 51290 non-null object 15 Category 51290 non-null object 16 Sub-Category 51290 non-null object 17 Product Name 51290 non-null object 18 Sales 51290 non-null float64 19 Quantity 51290 non-null int64 20 Discount 51290 non-null float64 21 Profit 51290 non-null float64 22 Shipping Cost 51290 non-null float64 23 Order Priority 51290 non-null object dtypes: datetime64[ns](2), float64(5), int64(2), object(15) memory usage: 9.4+ MBコードを書く
準備
まず必要なパッケージをimport
# パッケージインポート import numpy as np import scipy import matplotlib as mpl import matplotlib.pyplot as plt import seaborn as sns import pandas as pd from pandas.plotting import register_matplotlib_converters import sklearn from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder import os import mlxtend from mlxtend.preprocessing import TransactionEncoder from mlxtend.frequent_patterns import apriori, association_rules, fpgrowth import networkx as nx import mca import codecs sns.set() # 日本語を使うときは必要になる(今回は不必要) font_path = 'C:\\Users\\[YOUR_USERNAME]\\Anaconda3\\envs\\[ENV_NAME]\\Lib\\site-packages\\matplotlib\\mpl-data\\fonts\\ttf\\ipaexg.ttf' font_prop = mpl.font_manager.FontProperties(fname=font_path) # それぞれのパッケージのバージョン """ numpy 1.18.1 scipy 1.4.1 matplotlib 3.1.3 seaborn 0.10.0 pandas 1.0.3 sklearn 0.22.1 mlxtend 0.17.3 networkx 2.5 mca 1.0.3 """データを読み込む。今回は処理を軽くするために8割のデータは捨てる。
with codecs.open('superstore_dataset2011-2015.csv', "r", "shift-jis", "ignore") as f: df = pd.read_csv(f, parse_dates=['Order Date','Ship Date'], dayfirst=True) # 後の処理のために一部のカラムを加工しておく df['Order Date']=pd.to_datetime(df['Order Date']) df['Ship Date']=pd.to_datetime(df['Ship Date']) df['Country']='Country_'+df['Country'] df['Sub-Category']='SubC_'+df['Sub-Category'] # 処理が重かったので、8割くらいのデータは捨てる df, gomi=train_test_split(df, test_size=0.8, random_state=0) display(df) # それぞれのカラムの値のユニークな数 """ Customer ID 1493 Category 3 ;['Office Supplies' 'Technology' 'Furniture'] Sub-Category 17 Product Name 3038 Region 13 Market 7 Country 137 State 891 City 2431 """
アソシエーション分析
まず、アソシエーション分析を行うためにエンコードなどデータ加工を行う。
※エンコードは昇順で番号が付けられていくので注意。今回はCountryがSub-Categoryよりも若い数字になるということを念頭にその後の処理を実施している。
※あれ?なんでわざわざエンコードなんかしたんだっけ…。しなくても全然問題ないんじゃ…?# Customer IDごとのCountryのdfとCustomer IDごとのSub-Categoryのdfをconcatしてエンコードする # エンコードは昇順で番号が付けられていく ro='Country' co='Sub-Category' def create_city_product_matrix(df): df_store=df.groupby(['Customer ID',ro,'Order Date'])[[co]].count().reset_index() df_product=df.groupby(['Customer ID',co,'Order Date'])[[ro]].count().reset_index() df_concat=pd.concat([df_store[['Customer ID',ro,'Order Date']].rename(columns={ro:co}),df_product[['Customer ID',co,'Order Date']]]) df_concat=df_concat.sort_values(by=['Customer ID','Order Date',co]) le = LabelEncoder() encoded = le.fit_transform(df_concat[co].values) df_concat['encoded'] = encoded return df_concat[['Customer ID',co,'encoded']], le# city_cnt:国のユニーク数(後の処理で使う);エンコード後の番号のCountryとSub-Categoryの分かれ目の数字 city_cnt=df[ro].unique().shape[0] df_label,le=create_city_product_matrix(df) df_label['flg']=1 display(df_label)
# Customer IDごとにエンコードした数字をlist化 df_list = df_label.groupby(["Customer ID"])["encoded"].apply(lambda x:list(x)).reset_index() display(df_list)
# アソシエーション分析のためのマート作成 te = TransactionEncoder() te_ary = te.fit(df_list['encoded']).transform(df_list['encoded']) df_mart = pd.DataFrame(te_ary, columns=te.columns_) #df_mart.columns=le.inverse_transform(df_mart.columns.values) display(df_mart)
アソシエーション分析を実施。
# 支持度5%以上のitemに絞る min_support=0.05 frequent_itemsets = fpgrowth(df_mart,min_support=min_support,use_colnames=True) # アソシエーション分析実行 rules = association_rules(frequent_itemsets,metric='support',min_threshold=min_support) display(rules)
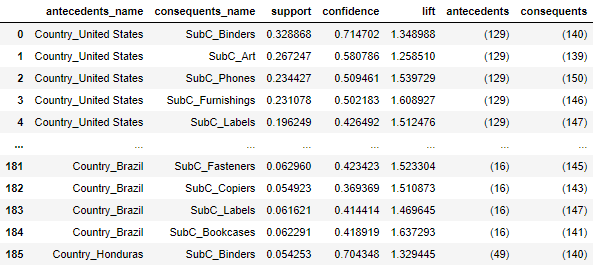
条件部にはCountryが来てほしいので、条件部にCounty、結論部にSub-Categoryが来るようにデータを抽出。
# 条件部にCounty、結論部にSub-Categoryが来るようにrulesを抽出 labels_no_frozen=[i for i in rules['antecedents'].values] labels_no=[list(i) for i in rules['antecedents'].values] consequents_no_frozen=[i for i in rules['consequents'].values] consequents_no=[list(i) for i in rules['consequents'].values] city_labels=[] product_labels=[] for i,k,l,n in zip(labels_no,labels_no_frozen,consequents_no,consequents_no_frozen): for j in i: # city_cnt-1以下 = Countryのエンコード後の番号 if j <= city_cnt-1: for m in l: # city_cnt-1より大きい = Sub-Categoryのエンコード後の番号 if m > city_cnt-1: # County番号を追加 city_labels.append(k) # Sub-Category番号を追加 product_labels.append(n) break break rules1=rules[(rules['antecedents'].isin(city_labels))&(rules['consequents'].isin(product_labels))&(rules["antecedents"].apply(lambda x: len(x))==1)&(rules["consequents"].apply(lambda x: len(x))==1)] max_support=rules1['support'].max() print('max_support',max_support) display(rules1)
後に、Sub-Category同士の組み合わせも可視化したいので、条件部にも結論部にもSub-Categoryが来るようにデータを抽出しておく。
# 条件部にも結論部にもSub-Categoryが来るようにrulesを抽出 labels_no_frozen=[i for i in rules['antecedents'].values] labels_no=[list(i) for i in rules['antecedents'].values] consequents_no_frozen=[i for i in rules['consequents'].values] consequents_no=[list(i) for i in rules['consequents'].values] city_labels=[] product_labels=[] for i,k,l,n in zip(labels_no,labels_no_frozen,consequents_no,consequents_no_frozen): for m in l: # city_cnt-1より大きい = Sub-Categoryのエンコード後の番号 if m > city_cnt-1: city_labels.append(k) product_labels.append(n) break break rules11=rules[(rules['antecedents'].isin(product_labels))&(rules['consequents'].isin(product_labels))&(rules["antecedents"].apply(lambda x: len(x))==1)&(rules["consequents"].apply(lambda x: len(x))==1)&(rules['support']<=max_support)] display(rules11)
アソシエーション分析の結果の表をデコードする。
# アソシエーション分析の結果の表を作る def create_association_matrix(rules1): # rules1のantecedentsをデコード antecedents_scale=pd.DataFrame(le.inverse_transform([list(i)[0] for i in rules1['antecedents'].unique()]),columns=[co]) antecedents_scale['antecedents']=[i for i in rules1['antecedents'].unique()] # rules1のconsequentsをデコード # 一応複数の組み合わせがあっても大丈夫なようにしている consequents=[list(i) for i in rules1['consequents'].unique()] consequents=[([le.inverse_transform([i])[0] for i in j]) for j in consequents] consequents_scale=pd.DataFrame(consequents,columns=[co]) consequents_scale['consequents']=[i for i in rules1['consequents'].unique()] rules3=pd.merge(rules1, antecedents_scale, on=['antecedents'], how='left').rename(columns={co:'antecedents_name'}) rules3=pd.merge(rules3, consequents_scale, on=['consequents'], how='left').rename(columns={co:'consequents_name'}) rules3=rules3.reindex(columns=['antecedents_name','consequents_name','support','confidence','lift','antecedents','consequents']) return rules3rules3=create_association_matrix(rules1) rules33=create_association_matrix(rules11) display(rules3) display(rules33)
アソシエーション分析の結果をネットワーク図で表現してみる。
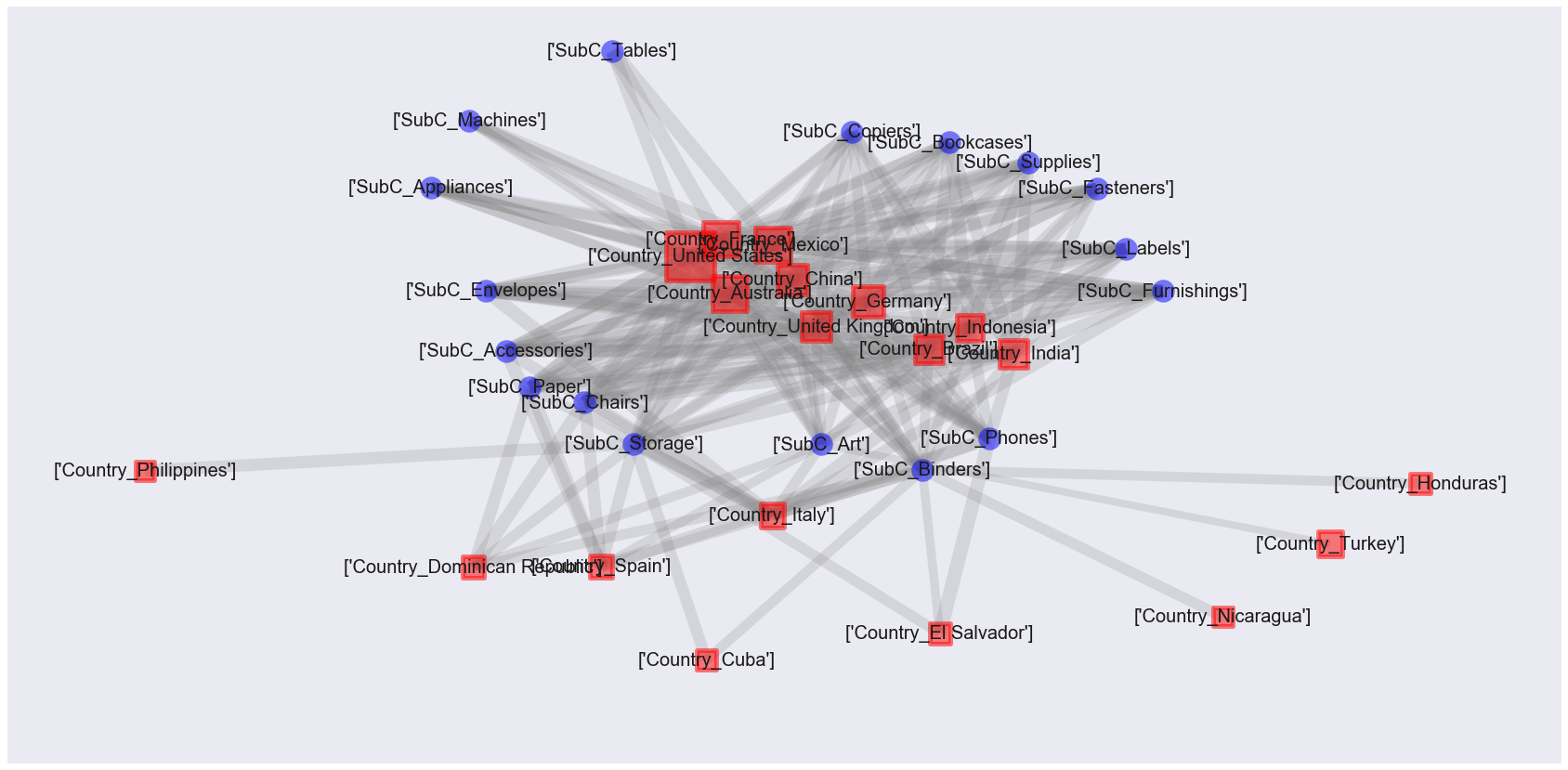
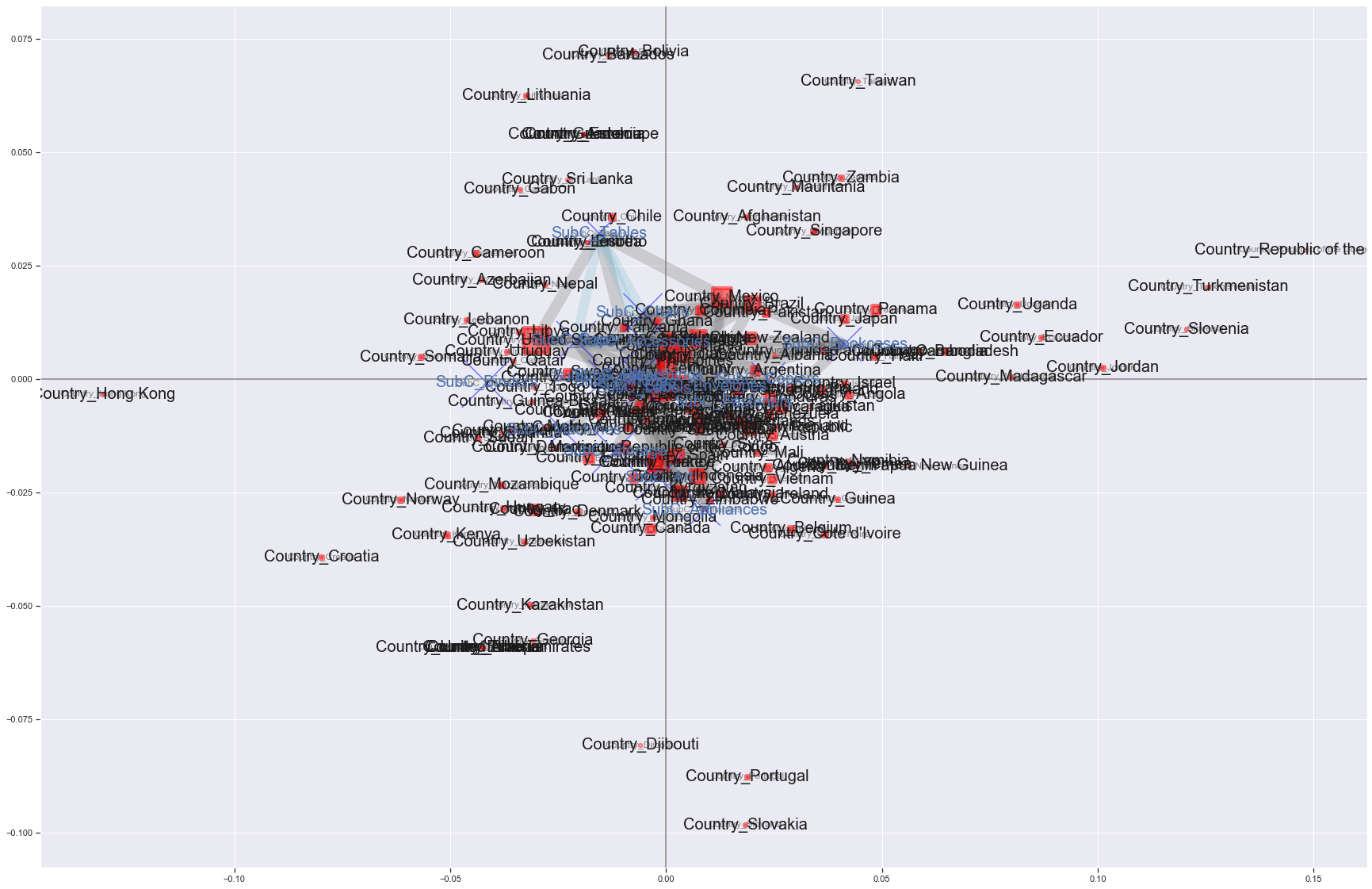
# Countryごとの人数をカウント def create_country_uu(df_label): count_UU=df_label.groupby([co,'Customer ID'])[['flg']].count().reset_index() count_UU['cnt']=1 count_UU=count_UU.groupby([co])[['cnt']].sum().reset_index() return count_UU # ノード、エッジを作る GA=nx.from_pandas_edgelist(rules1[['antecedents','consequents','lift']],source='antecedents',target='consequents', edge_attr=True) count_UU=create_country_uu(df_label) count_UU_mst=pd.DataFrame(le.inverse_transform([list(i)[0] for i, j in GA.nodes(data=True) if i in rules1['antecedents'].values]),columns=[co]) count_UU_mst=pd.merge(count_UU_mst, count_UU, on=[co],how='left').rename(columns={co:ro}) # ノードのマスタを作る(デコード) labels_no=[list(j) for j in [i for i in GA.nodes]] labels=[] for no in labels_no: labesl2=[] for label in no: labesl2.append(le.inverse_transform([label])[0]) labels.append(labesl2) new_labels2={} for i, j in zip(GA.nodes, labels): new_labels2[i]=j# アソシエーション分析の結果をネットワーク図で表現 def association_network(GA, rules1, count_UU_mst): fig, ax=plt.subplots(figsize=(30,15)) pos = nx.kamada_kawai_layout(GA,scale=0.06) # エッジの太さはリフト値に比例させる edge_width = [d['lift']*8 for (u,v,d) in GA.edges(data=True)] # Countryを正方形でプロット # ノードサイズはCountryごとのUU数に比例させる nx.draw_networkx_nodes(GA, pos, alpha=0.5, node_shape="s", linewidths=5, node_color='red', nodelist=[i for i, j in GA.nodes(data=True) if i in rules1['antecedents'].values], node_size=[4.*v for v in count_UU_mst['cnt'].values]) # Sub-Categoryを円形でプロット nx.draw_networkx_nodes(GA, pos, alpha=0.5, node_shape="o", linewidths=0, node_color='blue', node_size=600, nodelist=[i for i, j in GA.nodes(data=True) if i in rules1['consequents'].values]) # エッジをプロット nx.draw_networkx_edges(GA, pos, alpha=0.2, edge_color='grey', width=edge_width) #ラベルの設置をする datas = nx.draw_networkx_labels(GA,pos,new_labels2,font_size=20) # 日本語に対応できるようにするため、日本語が使えるフォントを設定 #for t in datas.values(): # t.set_fontproperties(font_prop) plt.grid(False) plt.show() association_network(GA, rules1, count_UU_mst)
これはまた見づらい図…。
赤い四角の大きさはその国のCustomer数に比例していて、灰色線の太さはリフト値に比例している。
先進国ではいろんなカテゴリーの商品が買われていて、発展途上国では一部のカテゴリーの商品が買われているような傾向にあると言えるかも。ただし、まだこの図ではノード同士の位置関係は意味をなしていない。
コレスポンデンス分析を合わせることにより、ノードの位置関係も意味を持つ図を作るのが今回の目的だ。コレスポンデンス分析
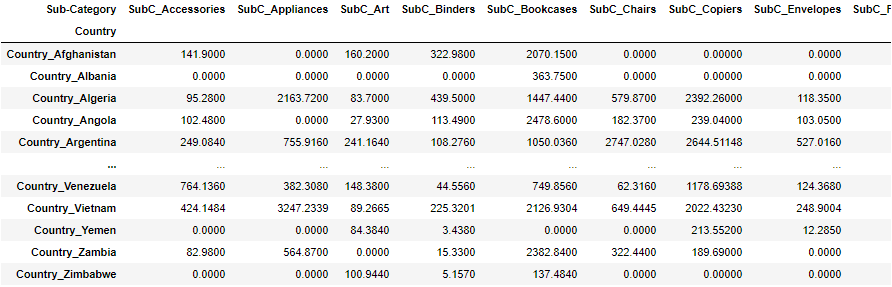
コレスポンデンス分析を行うためのマートを作成。
# CountryとSub-Categoryの売り上げのクロス表を作る df_corre=df.copy() df_corre=df_corre.pivot_table(index=ro, columns=co, values='Sales', aggfunc=lambda x:x.sum()).fillna(0) display(df_corre)
コレスポンデンス分析を実施。
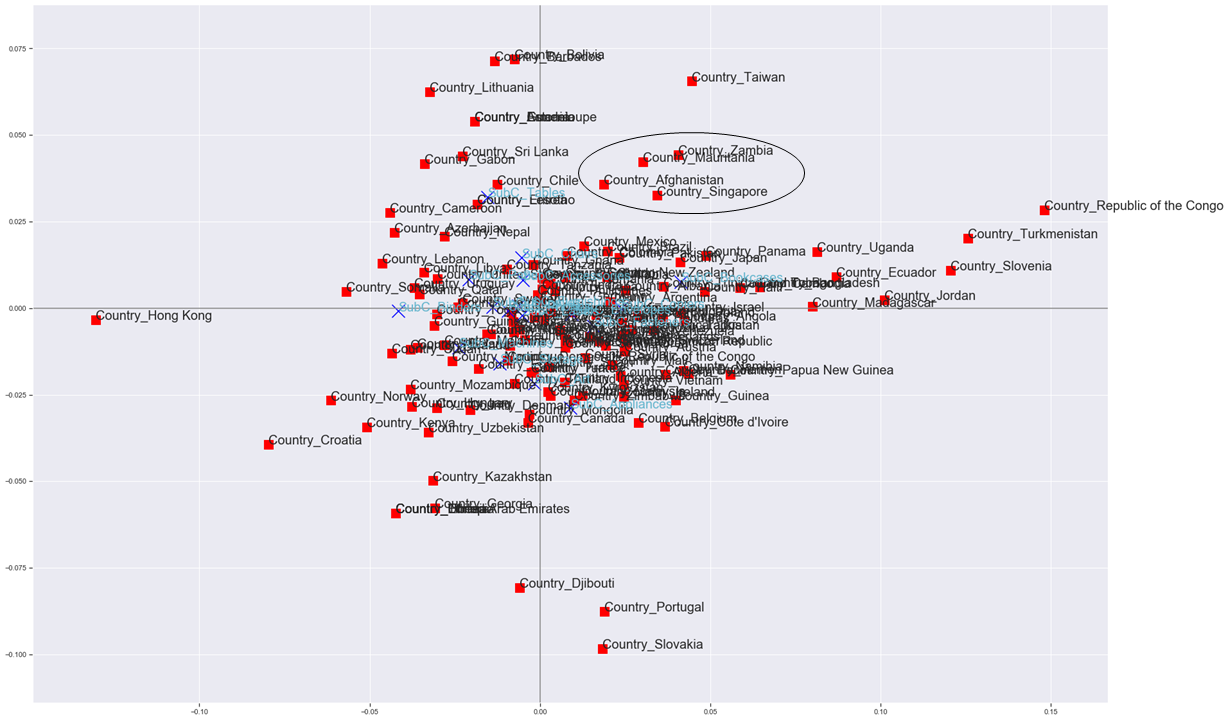
# コレスポンデンス分析をプロット fig, ax=plt.subplots(figsize=(30,20)) mca_counts = mca.MCA(df_corre) rows = mca_counts.fs_r(N=2) cols = mca_counts.fs_c(N=2) ax.scatter(rows[:,0], rows[:,1], c='red',marker='s', s=200) labels = df_corre.index.values for label,x,y in zip(labels,rows[:,0],rows[:,1]): ax.annotate(label,xy = (x, y),fontsize=20) ax.scatter(cols[:,0], cols[:,1], c='blue',marker='x', s=400) labels = df_corre.columns.values for label,x,y in zip(labels,cols[:,0],cols[:,1]): ax.annotate(label,xy = (x, y),fontsize=20, color='c') ax.tick_params(left=True, bottom=True, labelleft=True, labelbottom=True) ax.axhline(0, color='gray') ax.axvline(0, color='gray') plt.show()
重なってほとんど見えないけど、各国や商品カテゴリーの位置関係に意味を持つ図ができる。(ザンビアとモーリタニアとアフガニスタンとシンガポールの購買傾向が似ているとか。本当か…?)この図に、アソシエーション分析の結果のエッジを追加できれば、属性特化型特徴抽出アソシエーションプロットの完成である。
属性特化型特徴抽出アソシエーションプロット
まず、先ほどと同様にコレスポンデンス分析を実施。
mca_counts = mca.MCA(df_corre) rows = mca_counts.fs_r(N=2) cols = mca_counts.fs_c(N=2)先ほどはコレスポンデンス分析の結果をplt.scatterでプロットしたが、ここではnetworkxを使う。
# コレスポンデンス分析とアソシエーション分析の結果をnetwork図で表現 def mca_association_plot(df_corre, df_label, rows, cols, new_labels2 , strong_node_row=None, strong_node_col=None , xlim=[None, None], ylim=[None, None]): fig, ax=plt.subplots(figsize=(30,20)) uu_list=create_country_uu(df_label) # Countryを赤い四角でプロット G = nx.Graph() node_weights=[] for node, pos in zip(df_corre.index, rows): if strong_node_row is None: G.add_node(node) G.nodes[node]["pos"] = (pos[0], pos[1]) node_weights.append(uu_list[uu_list[co]==node]['cnt'].values[0]) else: if node in strong_node_row: G.add_node(node) G.nodes[node]["pos"] = (pos[0], pos[1]) node_weights.append(uu_list[uu_list[co]==node]['cnt'].values[0]) position=np.array([v['pos'] for (u,v) in G.nodes(data=True)]) pos = {n:(i[0], i[1]) for i, n in zip(position ,G.nodes)} nx.draw_networkx(G, pos=pos, node_color="red",ax=ax, linewidths=5, node_shape="s", node_size=[1.5*v for v in node_weights], alpha=0.5) new_labels2={} for i, j in zip(G.nodes, G.nodes): new_labels2[i]=j datas = nx.draw_networkx_labels(G,pos, new_labels2, font_size=20, font_color='k') #日本語に対応できるようにするため、日本語が使えるフォントを設定している #for t in datas.values(): # t.set_fontproperties(font_prop) # Sub-Categoryを青いバツ印でプロット G2 = nx.Graph() node_weights2=[] for node, pos in zip(df_corre.columns, cols): if strong_node_col is None: G2.add_node(node) G2.nodes[node]["pos"] = (pos[0], pos[1]) node_weights2.append(uu_list[uu_list[co]==node]['cnt'].values[0]) else: if node in strong_node_col: G2.add_node(node) G2.nodes[node]["pos"] = (pos[0], pos[1]) node_weights2.append(uu_list[uu_list[co]==node]['cnt'].values[0]) position2=np.array([v['pos'] for (u,v) in G2.nodes(data=True)]) pos2 = {n:(i[0], i[1]) for i, n in zip(position2 ,G2.nodes)} nx.draw_networkx(G2, pos=pos2, node_color="blue",ax=ax, node_shape="x", node_size=[5*v for v in node_weights2], alpha=0.5) new_labels2={} for i, j in zip(G2.nodes, G2.nodes): new_labels2[i]=j datas = nx.draw_networkx_labels(G2,pos2, new_labels2, font_size=20, font_color='b') #日本語に対応できるようにするため、日本語が使えるフォントを設定している #for t in datas.values(): # t.set_fontproperties(font_prop) # CountryとSub-Categoryの間のエッジをプロット(灰色でリフト値に比例して太くなる) U=nx.Graph() U.add_nodes_from(G.nodes(data=True)) #deals with isolated nodes U.add_nodes_from(G2.nodes(data=True)) for edge1, edge2, lift in zip(rules3[rules3['lift']>=1.6]['antecedents_name'].values, rules3[rules3['lift']>=1.6]['consequents_name'].values, rules3[rules3['lift']>=1.6]['lift'].values): if strong_node_col is None: U.add_edge(edge1, edge2, lift=lift) else: if edge2 in strong_node_col: U.add_edge(edge1, edge2, lift=lift) pos_all = {n:(i[0], i[1]) for i, n in zip(np.vstack((position, position2)) ,U.nodes)} edge_width = [d['lift']*8. for (u,v,d) in U.edges(data=True)] nx.draw_networkx_edges(U, pos=pos_all, alpha=0.3, edge_color='grey', width=edge_width, ax=ax) # Sub-CategoryとSub-Categoryの間のエッジをプロット(水色でリフト値に比例して太くなる) V=nx.Graph() V.add_nodes_from(G.nodes(data=True)) #deals with isolated nodes V.add_nodes_from(G2.nodes(data=True)) for edge1, edge2, lift in zip(rules33[rules33['lift']>=1.5]['antecedents_name'].values, rules33[rules33['lift']>=1.5]['consequents_name'].values, rules33[rules33['lift']>=1.5]['lift'].values): if strong_node_col is None: V.add_edge(edge1, edge2, lift=lift) else: if edge1 in strong_node_col and edge2 in strong_node_col: V.add_edge(edge1, edge2, lift=lift) pos_all2 = {n:(i[0], i[1]) for i, n in zip(np.vstack((position, position2)) ,V.nodes)} edge_width = [d['lift']*8. for (u,v,d) in V.edges(data=True)] nx.draw_networkx_edges(V, pos=pos_all2, alpha=0.2, edge_color='c', width=edge_width ,ax=ax) ax.tick_params(left=True, bottom=True, labelleft=True, labelbottom=True) ax.set_xlim(xlim[0], xlim[1]) ax.set_ylim(ylim[0], ylim[1]) ax.axhline(0, color='gray') ax.axvline(0, color='gray') plt.grid(True) plt.show()いざ実施。
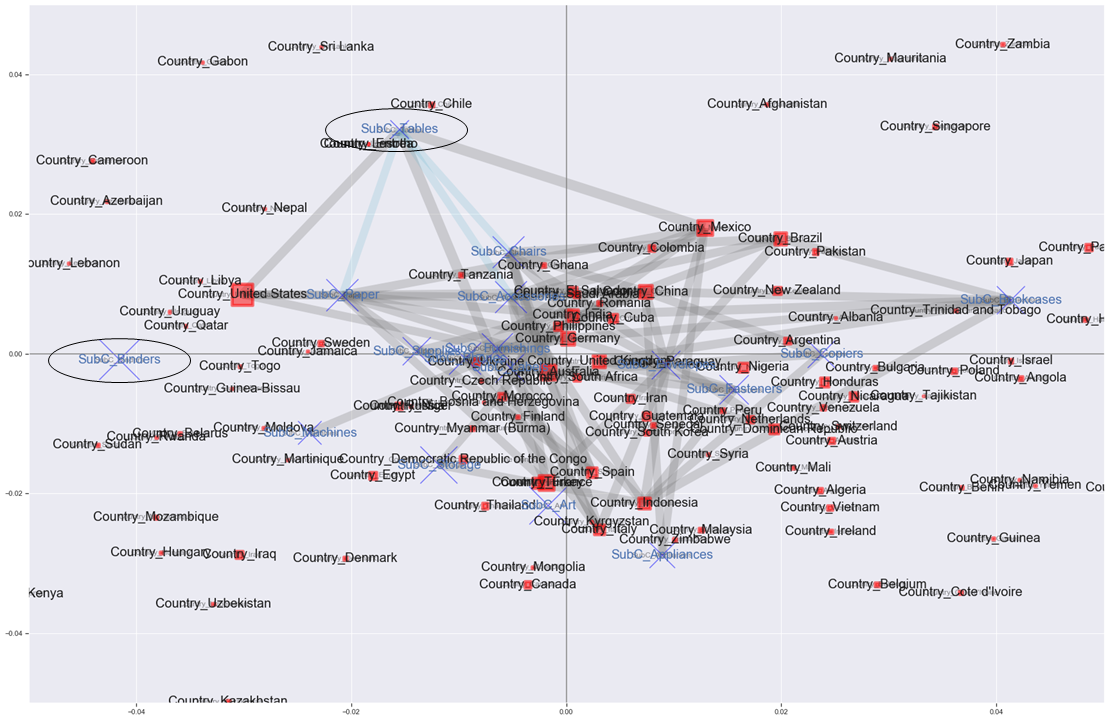
xlim=[None,None] ylim=[None,None] mca_association_plot(df_corre, df_label, rows, cols, new_labels2, strong_node_row=None, strong_node_col=None, xlim=xlim, ylim=ylim)
バーーーーン
コレスポンデンス分析の結果にアソシエーション分析の結果を反映させた図ができた。
灰色のエッジは国と商品サブカテゴリーとの関係、水色のエッジは商品サブカテゴリー同士の関係を表している。
エッジはリフト値が1.6以上(灰色)、1.5以上(水色)のものだけ引いている。
赤い四角と青いバツはCustomer IDのユニーク数に比例して大きくなる。
とはいっても重なってよく分からないので、真ん中をちょっと拡大して見る。xlim=[-0.05,0.05] ylim=[-0.05,0.05] mca_association_plot(df_corre, df_label, rows, cols, new_labels2, strong_node_row=None, strong_node_col=None, xlim=xlim, ylim=ylim)
拡大しても、よくわかんない(笑)。
でもアメリカは購入する客が最も多くて、Bindersが売れる傾向にある位置にいるけどエッジはつながっていなくて、Tablesとエッジがつながっているとかはわかる。
売り上げ的に目立つのはBindersかもしれないけど、全ての国の中でTablesを購入した客の割合より、実はアメリカでTablesを購入した客の割合の方が1.6倍以上高いよって感じか。よくわからんね。プロットされるノードを減らすため、支持度が0.05以上だった項目だけを対象に、再度プロットしてみる。
# 支持度0.05以上の項目だけ使う strong_single_product=list(set([[j for j in i][0] for i in frequent_itemsets['itemsets']])) strong_single_product=le.inverse_transform(strong_single_product) row_word = 'Country_' strong_node_row = [v for i, v in enumerate(strong_single_product) if row_word in v] strong_node_col = [v for i, v in enumerate(strong_single_product) if row_word not in v] xlim=[-0.05,0.05] ylim=[-0.05,0.05] mca_association_plot(df_corre, df_label, rows, cols, new_labels2, strong_node_row=strong_node_row, strong_node_col=strong_node_col, xlim=xlim, ylim=ylim)
結局エッジが飛び交いすぎて見にくい…。無理やり解釈していくと…。・左のアメリカ、真ん中のドイツ・イギリス、右上のブラジル・メキシコ、下のスペイン・イタリヤなど、それぞれ傾向が異なると考えられる
・全ての国の中でTablesを購入した客の割合より、メキシコでTablesを購入した客の割合の方が1.6倍以上高い
・ブラジルはメキシコと同じ傾向の国なので、Tablesを推してもいいかもしれない
・TablesとChairs, Paperの組み合わせも買う人が多いと言えるので、アメリカはChairをもっと推してもいいかもしれないとか?いや、解釈むずいわ。
とある国の店舗ごとの分析とかだったら解釈しやすいかもしれないな…。おわりに
属性特化型特徴抽出アソシエーションプロットを実施した。
しかし解釈がかなり難しかった…。
計算機統計学 29巻 22号 の"売り上げ傾向による店舗の分類と購買傾向の分析と可視化"と同じようなアプローチだとまた意味のある分析ができるかもしれない。
個人的にはnetworkxの練習になったからよかった。以上!


- 投稿日:2021-01-07T18:52:59+09:00
「【Ruby】配列から重複していない要素を取得する」を参考にSymPyLiveでやってみた。
(オリジナルポスト)
https://qiita.com/suzu12/items/af0ccbca88f33dec2fda#実践
https://qiita.com/suzu12/items/af0ccbca88f33dec2fdaSymPy Liveで
Pythonでリストから重複した要素を抽出して、Pythonでlistのlistを引き算をしています。
もっと短くなるような気がします。教えて下さい。sum( [i for i in [1,2,3] if i not in [x for x in set([1,2,3]) if [1,2,3].count(x) > 1]])
6
sum( [i for i in [3,2,3] if i not in [x for x in set([3,2,3]) if [3,2,3].count(x) > 1]])
2
sum( [i for i in [3,3,3] if i not in [x for x in set([3,3,3]) if [3,3,3].count(x) > 1]])
0
- 投稿日:2021-01-07T18:04:35+09:00
Python 3.8の新構文【代入式】
はじめに
Effective Python 第二版をよんで、感動した機能などを備忘録を兼ねてまとめておきたいと思います。チョイスは個人的な主観でやっているのでご承知おきください。。
代入式とは?
簡単にいうと、if文で使う変数の宣言を短く記述できるものです。
具体的には、ifの条件式のなかで :=(セイウチ演算子)を使って式の評価と変数への代入をひといきに行います。例えば、フルーツの在庫を表す辞書があるとします。
fruits = { 'apple': 10, 'banana': 8, 'lemon': 5, }リンゴジュースをつくるのに少なくとも4つのリンゴが必要な場合、ジュースを実際につくれるかどうかは下のように条件分岐できます。
n_apple = fruits.get('apple', 0) if n_apple >= 4: make_juice(n_apple) # n_apple個のリンゴでジュースを作る else: out_of_stock() # 在庫不足のためジュースを作らないこれをセイウチ演算子を使って同じような動作を記述すると、
# リンゴの個数の評価と変数への代入を同時に行う if (n_apple := fruits.get('apple', 0)) >= 4: make_juice(n_apple) else: out_of_stock()一見してコードが一行へっただけのように思えますが、このような書き方をすることで、n_appleがifの1つ目のブロックにしか使われないことを明確に表現することができます。
応用例
これだけだと、いまいち良さが理解できないと思うので、よりうれしい例を取り上げてみます。
バナナ→リンゴ→レモンの順番で優先順位をつけて在庫を消化したいとします。また、ジュースをつくるのに最低限必要なフルーツの個数はバナナは2本、リンゴは4個、レモンは1個とします。
おそらく、以下のような入れ子になったif-elseブロックを作るのではないでしょうか。n_banana = fruits.get('banana', 0) if n_banana >= 2: make_juice(n_banana) # バナナが2個以上ならバナナジュースを作る else: n_apple = fruits.get('apple', 0) if n_apple >= 4: make_juice(n_apple) # リンゴが4個以上ならリンゴジュースを作る else: n_lemon = fruits.get('lemon', 0) if n_lemon: make_juice(n_lemon) # レモンが1個以上ならレモンジュースを作る else: out_of_stock() # 在庫不足のためジュースを作らないこれはかなり冗長な感じがしますよね。セイウチ演算子を使うと以下のようになります。
if (n_banana := fruits.get('banana', 0)) >= 2: make_juice(n_banana) # バナナが2個以上ならバナナジュースを作る elif (n_apple := fruits.get('apple', 0)) >= 4:: make_juice(n_apple) # リンゴが4個以上ならリンゴジュースを作る elif n_lemon = fruits.get('lemon', 0): make_juice(n_lemon) # レモンが1個以上ならレモンジュースを作る else: out_of_stock() # 在庫不足のためジュースを作らない大分よみやすくなりました。
どうですか?これなら使ってみたくなったのではないでしょうか(笑)。
ただし、代入された変数を比較に使う場合には代入式を括弧でくくる必要があることに注意してください。do-while文的な使い方
もう少し応用的な使い方を紹介します。pythonにはdo/whileループがありませんが、whileブロックとbreak文で同じようなロジックを実装できます。
例えば、在庫の補充とジュースの瓶詰を繰り返しおこなう処理を考えます。在庫の補充がなくなった時点で処理を終了させます。
make_juice()関数は、フルーツの種類と個数を受け取って適切な本数(batch)の瓶づめジュースを返すように変更したとします。bottles = [] # 瓶を収納するケース while True: fruits = pick_fruit() # フルーツを補充 if not fruits: break # 補充がなければ終了 for fruit, count in fruits.items(): batch = make_juice(fruit, count) # フルーツごとに適切な本数に瓶詰め bottles.extend(batch) # 瓶をケースに追加このような処理も代入式で短く書くことができます。
bottles = [] # 瓶を収納するケース while fruits := pick_fruit(): # 補充したフルーツをfruits変数に代入&空かどうか評価 for fruit, count in fruits.items(): batch = make_juice(fruit, count) # フルーツごとに適切な本数に瓶詰め bottles.extend(batch) # 瓶をケースに追加代入文とbreakのためのifブロックが不要になったのがうれしいですね。
おわりに
セイウチ演算子、なかなか便利ですね。python3.8を仕事では使わないけど、この機能は3.7にもあってほしい。
参考文献
- 投稿日:2021-01-07T17:56:59+09:00
Pythonでファイルをダウンロードする
言語処理100本ノック 2020 (Rev 2)ではファイルをダウンロードしてから処理することが多い
いろんなやり方があるので収集してみる。
ファイルは第3章: 正規表現のjawiki-country.json.gz
requests
requests.pyimport requests url='https://nlp100.github.io/data/jawiki-country.json.gz' filename='jawiki-country.json.gz' urlData = requests.get(url).content with open(filename ,mode='wb') as f: # wb でバイト型を書き込める f.write(urlData)自分のやり方。
Requetsはwgetとおんなじ感じで使えるのがいい。ファイルの書き込みは定番のやり方
Python、Requestsを使ったダウンロードのように大きなファイルを扱うのもできるのでしょう。
requests2.pyimport requests import os url='https://nlp100.github.io/data/jawiki-country.json.gz' filename=os.path.basename(url) r = requests.get(url, stream=True) with open(filename, 'wb') as f: for chunk in r.iter_content(chunk_size=1024): if chunk: f.write(chunk) f.flush()直で書き込むにはこちら。
urllib.request
urllib_request.pyimport urllib.request url='https://nlp100.github.io/data/jawiki-country.json.gz' save_name='jawiki-country.json.gz' urllib.request.urlretrieve(url, save_name)今回で調べてみたら出てきました。
pythonでwebからのファイルのダウンロード
ファイルのセーブまでできるすぐれものpandas.read_X
read_X.pyimport pandas as pd url='https://nlp100.github.io/data/jawiki-country.json.gz' df=pd.read_json(url, lines=True)第2章で大活躍だったpandas
input/outputにある各コマンドはurlから直で読めて圧縮も自動で判別してくれる優れもの。
読み込むとデータフレームになってしまうので使いどころを選ぶけど、そのまま処理するのであればこちらでもいい。
まとめ
コマンドだと
wgetでなにも考えなくていいけど、プログラムからやる時はそれなりに考えないといけない。いずれかの方法でやっていけばいいと思います。
- 投稿日:2021-01-07T17:42:46+09:00
AWS Lambda で 超シンプルに任意のコンテナ Imageを使用する方法
概要
AWS LambdaでContainer Image Supportが発表されました。
AWS Lambda の新機能 – コンテナイメージのサポートしかし、AWS公式ドキュメントに書かれているサンプルコードは、
癖があって少しわかりづらい内容です。本記事では、出来るだけシンプルなデプロイ・実行方法について書いていきます。
対象読者
- Dockerやコンテナの知識がある。
- AWSのLambdaのざっくりとした知識がある。
- aws-cliをインストール・セットアップしている。
ハンズオン
以下の流れで行います。
1. ファイルの準備
2. Image作成・ローカルでの実行
3. Imageのデプロイ
4. Lambdaの設定・実行今回のディレクトリ構成です。
応用が効きやすいよう、できるだけシンプルにしました。# ディレクトリ構成 ├── Dockerfile ├── entry.sh └── app └── app.py(1) ファイルの準備
今回は、buster(debianイメージ。LinuxディストリビューションのOS)を使ってみましょう。
既にpythonがインストールされてるイメージを用います。
実際には、他のイメージでも問題ないです。ポイントは以下の2点になります。
- awslambdaricのインストール
- ローカルで動かしたい場合は、runtime interface emulatorのインストール
これらはentry.sh(後述)で使用することになります。各ファイルのソースコードを以下に示します。
- Dockerfile : Image作成
# Dockerfile FROM python:3.9-buster # runtime interface consoleのインストール RUN pip install awslambdaric # localで実行するために、runtime interface emulatorのinstall ADD https://github.com/aws/aws-lambda-runtime-interface-emulator/releases/latest/download/aws-lambda-rie /usr/bin/aws-lambda-rie RUN chmod 755 /usr/bin/aws-lambda-rie COPY entry.sh "/entry.sh" RUN chmod 755 /entry.sh # 実行ファイルをコンテナ内に配置。 ARG APP_DIR="/home/app/" WORKDIR ${APP_DIR} COPY app ${APP_DIR} ENTRYPOINT [ "/entry.sh" ] CMD [ "app.handler" ]
- app/app.py : 実行したいソースコード。
# app/app.py def handler(event, context): return "Hello world!!"
- entry.sh : ローカルであるか、AWS Lambda上のコンテナであるかを判断して aws-lambda-rieやawslambdaricを使用する。公式参照。
# app/entry.sh if [ -z "${AWS_LAMBDA_RUNTIME_API}" ]; then exec /usr/bin/aws-lambda-rie /usr/local/bin/python -m awslambdaric $1 else exec /usr/local/bin/python -m awslambdaric $1 fi※注意
/usr/local/bin/pythonとか/entry.shにしてるのは、lambdaの仕様で、コマンドは絶対バスで書く必要あるらしいです。
絶対パスでない場合、ローカルでは動きますが、Lambdaで実行すると以下のようなエラーが生じます。START RequestId: 80f9d98d-06b5-4ba8-b729-b2e6ac2abbe6 Version: $LATEST IMAGE Launch error: Couldn't find valid bootstrap(s): [python] Entrypoint: [](2) イメージの作成・ローカルでの実行
まずはイメージを作成します。
docker build -t container_lambda .次に、コンテナを立てると、デーモンが立ち上がります。
docker run -it --rm -p 9000:8080 container_lambda > NFO[0000] exec '/usr/local/bin/python' (cwd=/home/app, handler=app.handler)イベントを飛ばすには、以下のURLにpostを投げます。
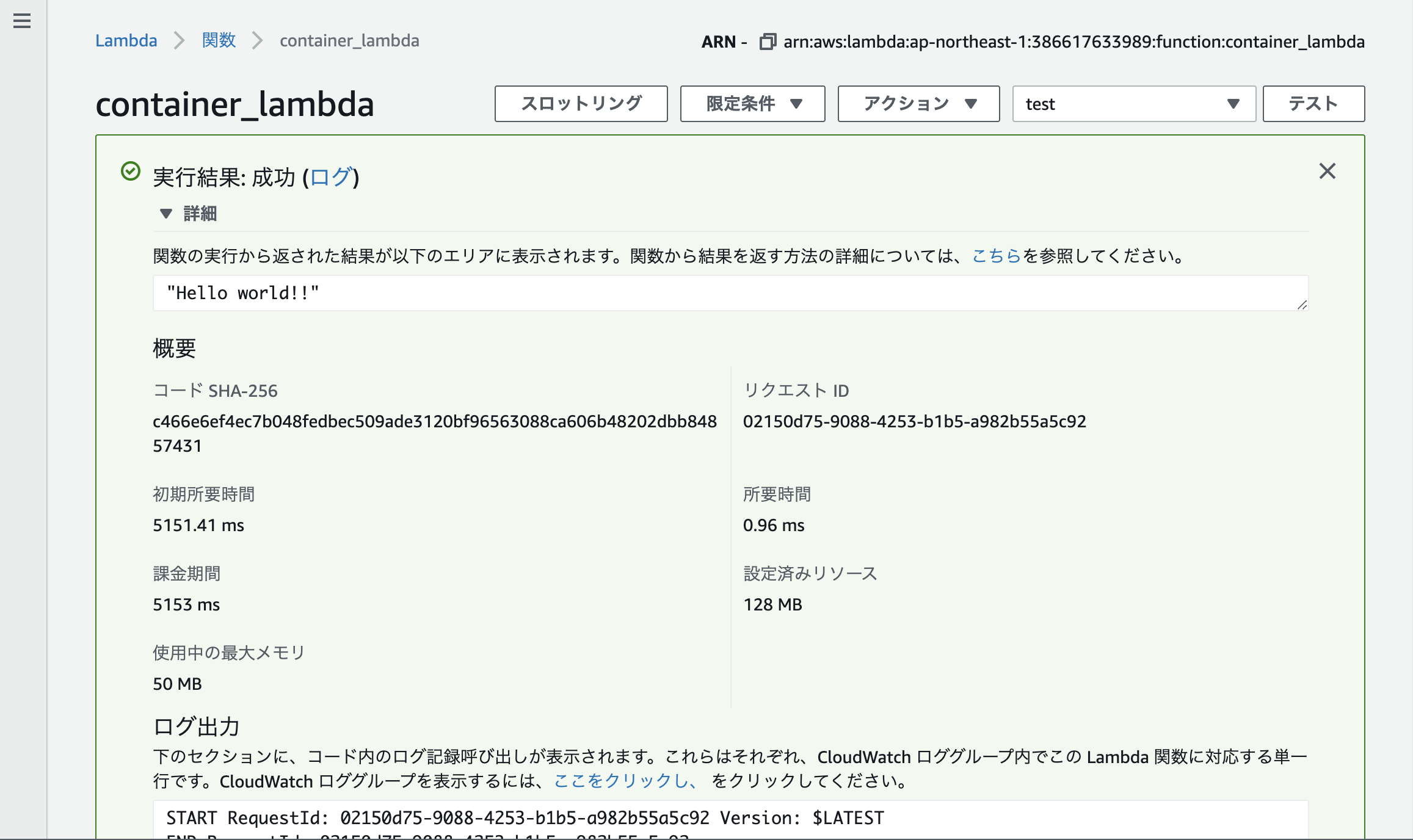
curl -XPOST "http://localhost:9002/2015-03-31/functions/function/invocations" -d '{}' > "Hello world!!"%すると
Hello World!!が返ってきました!
ローカルでの実行成功です。実行するファイルや関数を変えたいときは、CMDで指定するhandlerを変更しましょう。
(3) イメージのデプロイ
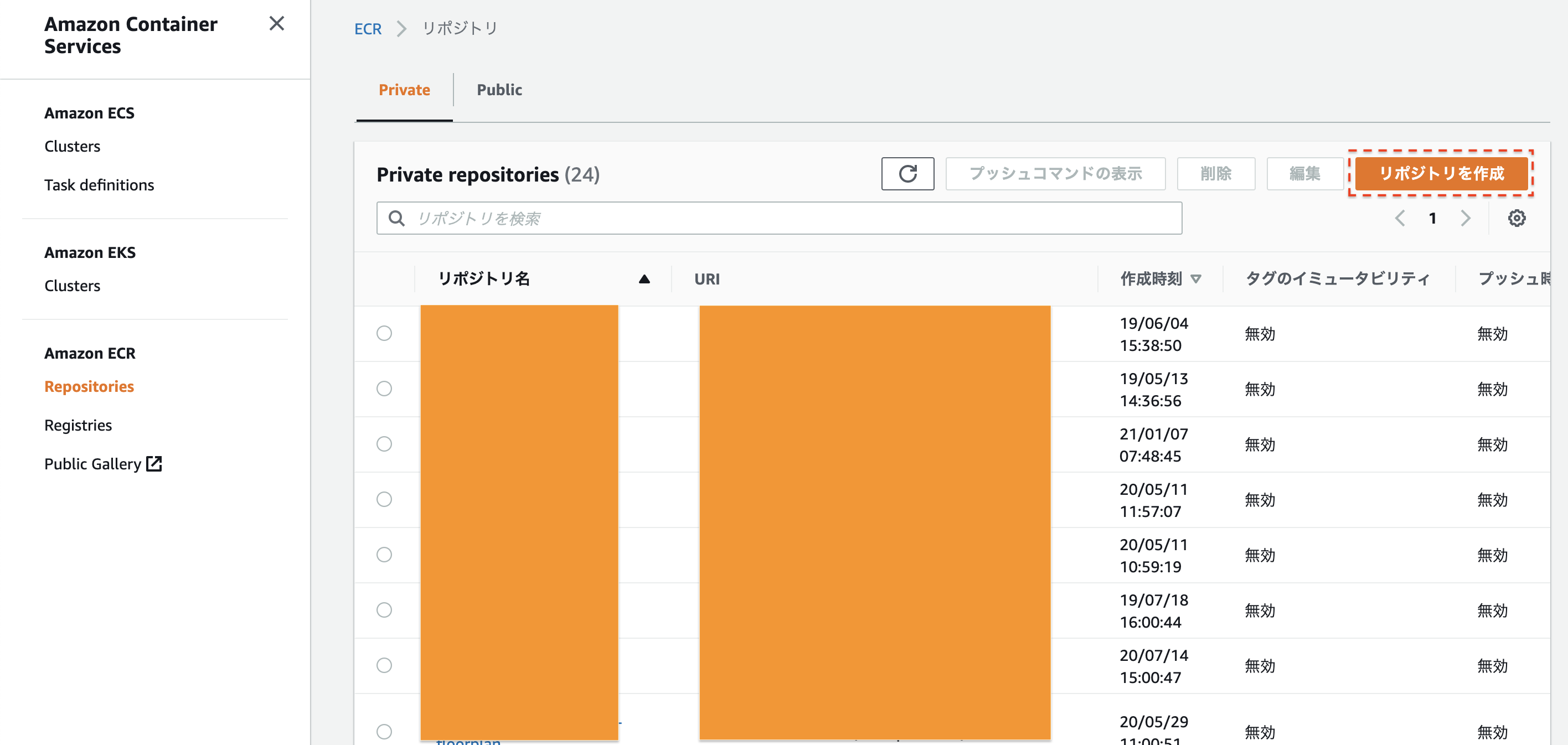
実際にLambdaで動かすために、AWSのElastic Container Registory(ECR)にイメージを登録します。
まずは、ECRの画面にうつりましょう。
リポジトリ作成を押します。
今回は、
container_lambdaという名前でリポジトリを作成します。
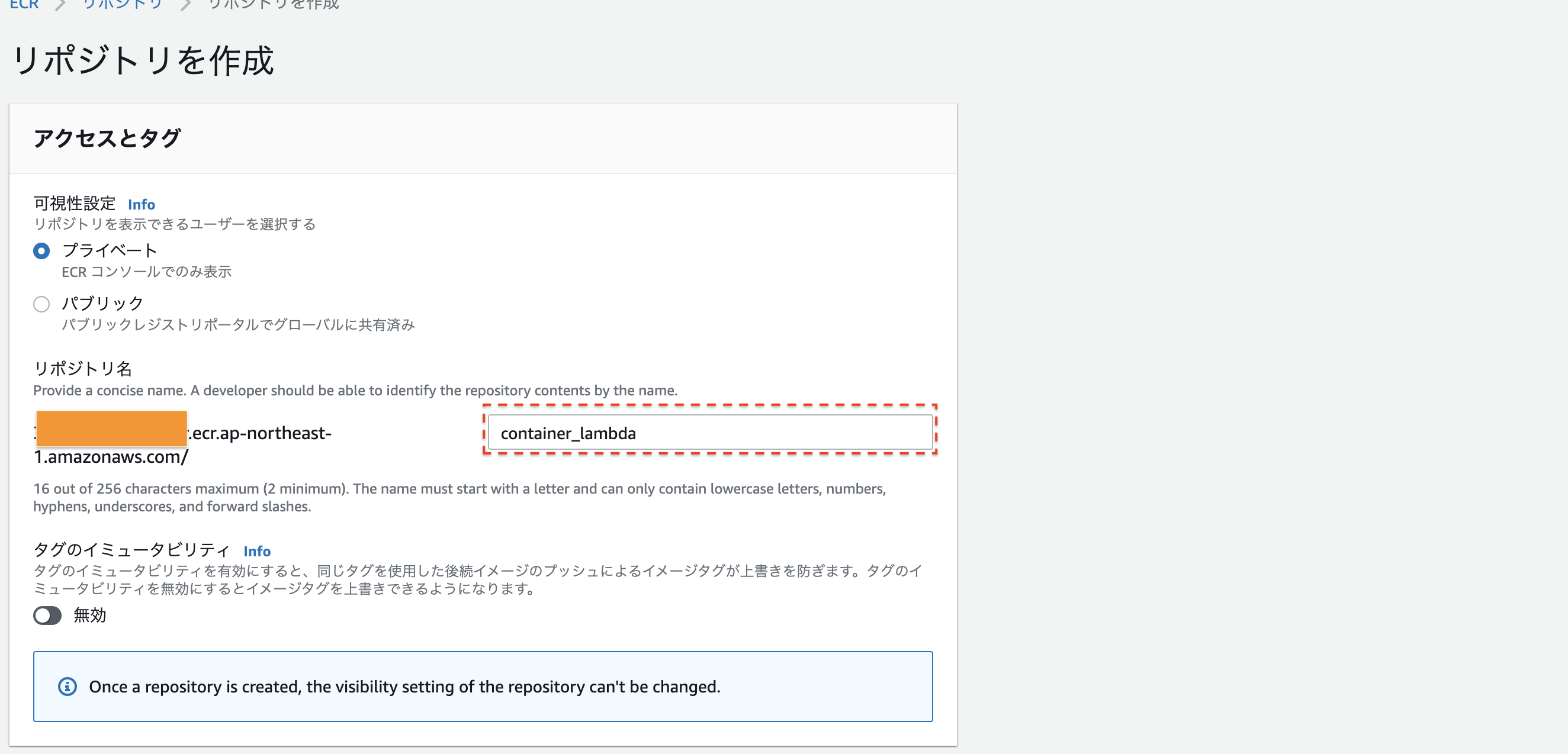
名前を決めたら、一番下のリポジトリ作成を押してください次に、このリポジトリにlocalのimageのpushします。
# imageの名前を指定。 IMAGENAME=container_lambda # ECRのURLを指定。 REGISTRYURL=xxxxxxxxx.ecr.ap-northeast-1.amazonaws.com # AWS ECR にログイン。 aws ecr get-login-password | docker login --username AWS --password-stdin $REGISTRYURL # imageの作成、およびAWS ECRへのデプロイ。 docker build -t ${IMAGENAME} . docker tag ${IMAGENAME} 386617633989.dkr.ecr.ap-northeast-1.amazonaws.com/${IMAGENAME} docker push 386617633989.dkr.ecr.ap-northeast-1.amazonaws.com/${IMAGENAME}これでimageをデプロイすることができました。
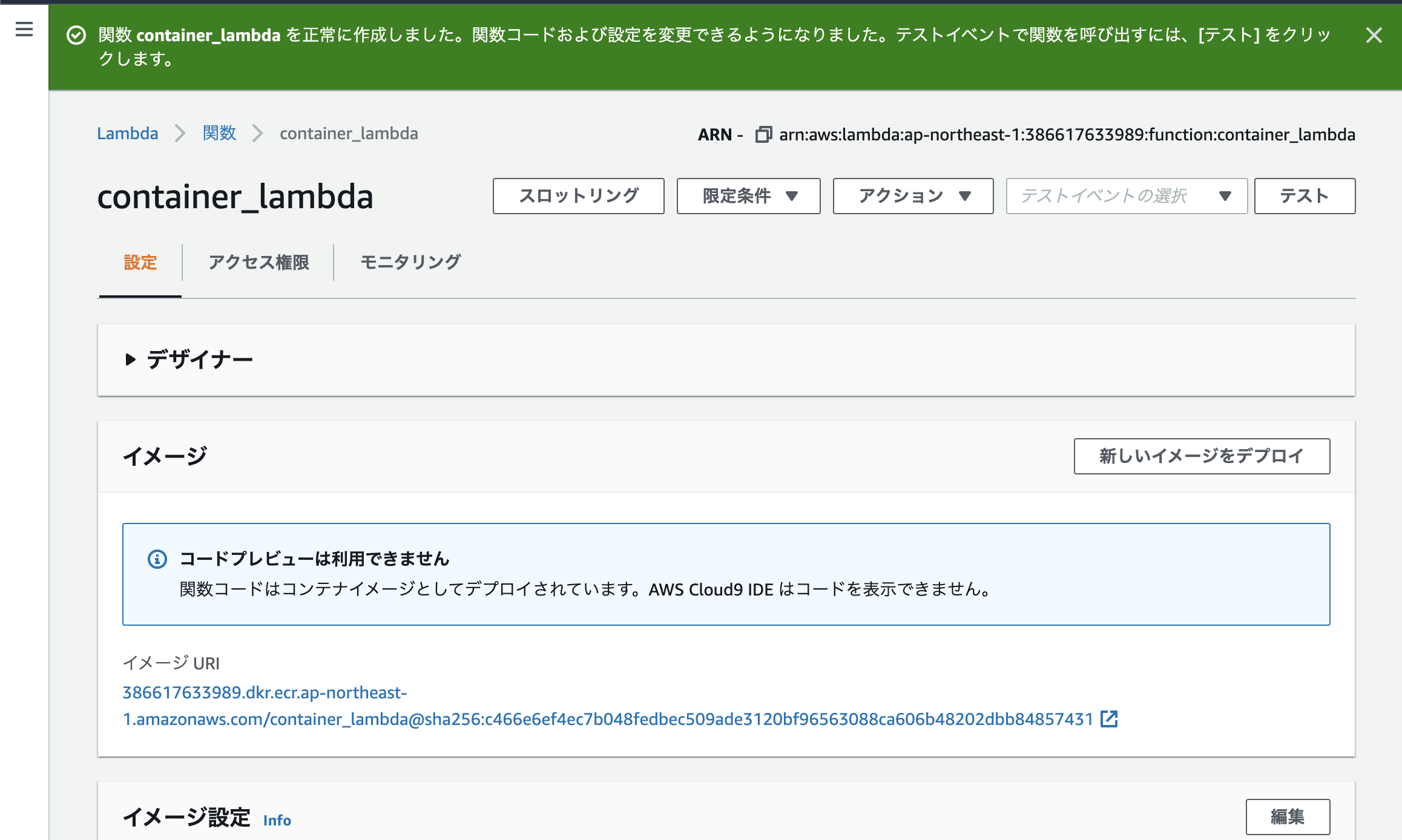
(4) Lambdaの設定・実行
最後にLambdaで実行しましょう!
まずはAWSコンソールから、Lambdaの画面に行き、関数の作成を押します。
コンテナイメージを選択- 関数名をつける(今回は
container_lambda)- 先ほどデプロイしたDocker Imageを指定
そして
関数の作成を押すと、画面が遷移します。 しばらくすると上の帯が緑になって、lambdaのセットアップが終わります。
右上のテストを定義し、実行してみると...
Hello world!!が返ってきました!まとめ
ということで、オリジナルランタイムでの実行をまとめてみました。
公式ドキュメントではわざとalpine系を使ったり、Dockerのmulti stage buiidしたりしてややこしそうですが、実際はもっと簡単にできることが分かったと思います。
Lambdaは、最大コア数6、メモリ10GBまでの対応も発表されり激アツです。簡単な機械学習APIもより作りやすくなりました。
AWS Lambda now supports up to 10 GB of memory and 6 vCPU cores for Lambda Functions非常に便利なので是非みなさんトライしてみてください!
次は、Detectron2という画像認識モデルをAWS Lambdaで動かしてみたいと思います!
- 投稿日:2021-01-07T17:15:45+09:00
rubyとpythonのif文の書き方の違い
- 投稿日:2021-01-07T17:10:15+09:00
PyTorch 学習メモ (Karasと同じモデルを作ってみた)
はじめに
前から、そろそろPyTorchも勉強しないとと思っていたのですが、まとまった時間が取れたので、書籍(PyTorchニューラルネット実装ハンドブック)片手に勉強してみました。
この記事を書く時点での筆者の前提知識は、
- TensorFlowとKerasは普通にわかっている
- PyTorchはまったくの初心者
です。似たような人は他にもいると思うので、その参考になれば幸いです。
PyTorchのざっくりした感想
なんといっても勉強を始めてまだ半日なので間違っているかもしれませんが、ざっくりした感想として、実装のややこしさは、KerasとTensorFlowのちょうど中間ぐらいかと思いました。
モデルの定義のところは、ほぼ、Kerasと同じ感じです。
逆に、学習のところは、かなりの量を裸のコードで書く必要があるという印象でした。ただ、他で動いているコードをコピーしただけで動いたので、そんなに大変ということでもなかったです。裏返すと、このあたりをきれいに隠蔽できているKerasは素晴らしいということなのかもしれません。アプローチの方法
書籍のコードを写経するのでは頭を使わないので、過去に試したことのあるCIFAR-10の分類をKerasで実装したのと、まったく同じ構造、同じアルゴリズムのモデルを作ってみることにしました。
自分で1から実装して初めて気付いたこともいくつかあったので、効率的な勉強方法だった気がします。実装コードと環境
以下で解説する実装コードは、下記Githubにアップしてあります。
やったことがある人はわかると思いますが、CIFAR-10は結構難しい例題でして、普通にモデルを作ると60%くらいしか精度がでません。
ここでご紹介するモデルは、確か、Kaggleに出ていた精度の高いモデルを構造だけ持ってきたものと思います。(Kaggleでは他にデータの前処理もやっていたが、そこは省略)。毎回精度は異なりますが、調子がいいと80%くらいまで行きます。https://github.com/makaishi2/sample-data/blob/master/notebooks/cifar10_keras.ipynb
https://github.com/makaishi2/sample-data/blob/master/notebooks/cifar10_pytorch.ipynb
環境はGoogle Colabを使いました。
Keras / PyTorch 関係は、追加導入は一切不要でした。追加導入したのは、matplotlibの日本語化モジュールだけだったと思います。さすが、Google Colab、こういう時にはとても便利です。コード解説
前置きはこの程度にして、実際のコードの解説に入りましょう。
データのロード
CIFAR-10の学習データに関しては、Keras同様、PyTorchでも関数が用意されていて、すぐにロードできました。
せっかくなので、この部分もコード比較をしてみます。Keras
# Kerasライブラリのインポート from keras.models import Sequential from keras.layers import Conv2D, MaxPooling2D, Dropout, Flatten, Dense, Activation # それ以外のライブラリのインポート !pip install japanize_matplotlib | tail -n 1 import matplotlib.pyplot as plt import japanize_matplotlib import numpy as np # 学習データ読み込み from keras.datasets import cifar10 (x_train, y_train), (x_test, y_test) = cifar10.load_data() classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') # 分類先クラス数の計算 class_labels_count = len(set(y_train.flatten())) # One Hot Encoding from keras.utils import np_utils y_train_ohe = np_utils.to_categorical(y_train, class_labels_count) y_test_ohe = np_utils.to_categorical(y_test, class_labels_count)PyTorch
# PyTooch関連ライブラリインポート import torch import torchvision import torch.nn as nn import torch.optim as optim import torch.nn.functional as F import torchvision.transforms as transforms # それ以外のライブラリインポート %matplotlib inline import numpy as np !pip install japanize_matplotlib | tail -n 1 import matplotlib.pyplot as plt import japanize_matplotlib # 分類クラス数 num_classes = 10 # 学習繰り返し回数 nb_epoch = 20 # 1回の学習で何枚の画像を使うか batch_size = 128 # 学習データ読み込み transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) train_loader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=2) testset = torchvision.datasets.CIFAR10(root='./data', train=False,download=True, transform=transform) test_loader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=2) classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')学習データの扱い方からPyTorchはKerasと違っていました。
DataSetとDataLoaderという、学習に特化したクラスが作られていて、これを利用する形になります。
DataSetとは、入力データと正解ラベル値のセットがタプルになっていて、そのIteratorとして用意されます。入力データはPyTorch固有のTensorというクラスの変数です。
いわゆる「ミニバッチ学習法」で用いるbatch_sizeの指定は、DataLoaderの中で行う形になります(このことに最初はまったく気付かなかった)。
もう1点、正解ラベルデータについても違いがあります。Kerasの場合は、正解データはOne Hot Encodingをする必要があります。コードの最後でその実装をしています。PyTorchでは、ラベル値のエンコードはフレームワークの内部でやってくれるようで、エンコーディングなしの値(6とか3とかの値)をそのまま学習時の正解値にできます。この点はPyTorchの方が便利なようです。入力データのイメージ表示
学習そのものとは関係ないのですが、せっかくなので、読み込んだ学習データのうち、先頭の10個をイメージ表示してみます。結果は下記のとおりです。
こんな単純なことでも、データの持ち方の違いからKeras / PyTorchで結構別の実装になります。
Keras
plt.figure(figsize=(15, 4)) for i in range(10): ax = plt.subplot(1, 10, i + 1) image = x_train[i] label = y_train[i][0] plt.imshow(image) ax.set_title(classes[label], fontsize=16) ax.get_xaxis().set_visible(False) ax.get_yaxis().set_visible(False) plt.show()PyTorch
plt.figure(figsize=(15, 4)) for i in range(10): ax = plt.subplot(1, 10, i + 1) image, label = trainset[i] np_image = image.numpy().copy() img = np.transpose(np_image, (1, 2, 0)) img2 = (img + 1)/2 plt.imshow(img2) ax.set_title(classes[label], fontsize=16) ax.get_xaxis().set_visible(False) ax.get_yaxis().set_visible(False) plt.show()
trainsetという変数からループを回して(image, label)のセットを一つずつ取り出す点が、一つ目のPyTorchの特徴です。
もう一つの違いは、imageデータを画面表示するのに、結構加工が必要な点です。Kerasの場合は、そもそものデータがnumpy配列になっていて、plt.imshow関数にそのまま渡せばそれで表示できたのですが、PyTorchの場合は、次の3段階の加工が必要でした。
- image変数がTensorクラスの変数なので、Numpyに変換する
- 軸の順番が違っているので
np.transpose関数で入れ替える- 学習データの範囲が [-1, 1]になっているので、これを [0, 1]の範囲に変更する
最後の話がなかなか気付かなかった点なのですが、わかってみると、データ読み込みの時に使っている
transforms.Normalize関数で加工することで、こういうデータになっているようです。
うまく、加工前の状態を別変数でもっておけばもっと効率いい実装にできるはずですが、PyTorch初心者で具体的にどうするかわからなかったので、いったんこれでよしとしています。モデルの生成
次のステップは一番本質的なモデルの生成です。こちらに関しては、Keras / PyTorchほぼ同等かなという印象です。
Keras
def cnn_model(x_train, class_labels_count): model = Sequential() model.add(Conv2D(32, (3, 3), padding="same", input_shape=x_train.shape[1:])) model.add(Activation('relu')) model.add(Conv2D(32, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Conv2D(64, (3, 3), padding='same')) model.add(Activation('relu')) model.add(Conv2D(64, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(512)) model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(class_labels_count)) model.add(Activation('softmax')) model.compile( loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'] ) return model # モデル生成 model = cnn_model(x_train, class_labels_count)PyTorch
# モデルクラスの定義 class cifar10_cnn(nn.Module): def __init__(self, num_classes): super(cifar10_cnn,self).__init__() self.conv1 = nn.Conv2d(3, 32, 3, padding=(1,1), padding_mode='replicate') self.conv2 = nn.Conv2d(32, 32, 3) self.conv3 = nn.Conv2d(32, 64, 3, padding=(1,1), padding_mode='replicate') self.conv4 = nn.Conv2d(64, 64, 3) self.relu = nn.ReLU(inplace=True) self.dropout1 = nn.Dropout(0.25) self.dropout2 = nn.Dropout(0.5) self.maxpool = nn.MaxPool2d((2,2)) self.classifier1 = nn.Linear(2304, 512) self.classifier2 = nn.Linear(512, num_classes) self.features = nn.Sequential( self.conv1, self.relu, self.conv2, self.relu, self.maxpool, self.dropout1, self.conv3, self.relu, self.conv4, self.relu, self.dropout1, self.maxpool) self.classifier = nn.Sequential( self.classifier1, self.relu, self.dropout2, self.classifier2) def forward(self, x): x = self.features(x) x = x.view(x.size(0), -1) x = self.classifier(x) return x # GPUの確認 device = 'cuda' if torch.cuda.is_available() else 'cpu' print(device) # モデルインスタンスの生成とGPUの割り当て net = cifar10_cnn(num_classes).to(device) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters())Kerasでは、モデルの定義は関数でできる(関数を使わずにベタにやってもできる)のに対して、PyTorchの場合はクラスを定義するのがお作法のようです。でも、実装コードの分量でいうと似たり寄ったりという印象です。
一点だけ、PyTorchで苦労した点があって、パディングに関してKerasみたいにシンプルにpadding='same'のような指定ができないみたいです。ググったらqiitaで記事で下記の記事を見つけたので、使わせてもらいました。https://qiita.com/syoyo/items/ddff3268b4dfa3ebb3d6
あと、PyTorchではモデルの構造を動的に宣言できるので、
nn.Linear(2304, 512)のマジックナンバー2304は、きっと計算で出せるのだろうなと思いつつ、動かすこと優先で先に進めました。PyTorchではGPUを使おうとする場合、
net = cifar10_cnn(num_classes).to(device)のようにデバイスの割り当てを明示的にする必要があるようです。Kerasでは、GPUがあれば勝手に使ってくれますので、その点はKerasの方が便利でした。モデルの構造確認
これで本当に同じ構造になったのか、確認してみましょう。Keras / PyTorchで構造を確認するためのコマンドとその出力を示します。
Keras
# モデルのサマリー表示 model.summary()結果
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 32, 32, 32) 896 _________________________________________________________________ activation (Activation) (None, 32, 32, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 30, 30, 32) 9248 _________________________________________________________________ activation_1 (Activation) (None, 30, 30, 32) 0 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 15, 15, 32) 0 _________________________________________________________________ dropout (Dropout) (None, 15, 15, 32) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 15, 15, 64) 18496 _________________________________________________________________ activation_2 (Activation) (None, 15, 15, 64) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 13, 13, 64) 36928 _________________________________________________________________ activation_3 (Activation) (None, 13, 13, 64) 0 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 6, 6, 64) 0 _________________________________________________________________ dropout_1 (Dropout) (None, 6, 6, 64) 0 _________________________________________________________________ flatten (Flatten) (None, 2304) 0 _________________________________________________________________ dense (Dense) (None, 512) 1180160 _________________________________________________________________ activation_4 (Activation) (None, 512) 0 _________________________________________________________________ dropout_2 (Dropout) (None, 512) 0 _________________________________________________________________ dense_1 (Dense) (None, 10) 5130 _________________________________________________________________ activation_5 (Activation) (None, 10) 0 ================================================================= Total params: 1,250,858 Trainable params: 1,250,858 Non-trainable params: 0 _________________________________________________________________PyTorch
# モデルのサマリー表示 from torchsummary import summary summary(net,(3,32,32))結果
---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Conv2d-1 [-1, 32, 32, 32] 896 Conv2d-2 [-1, 32, 32, 32] 896 ReLU-3 [-1, 32, 32, 32] 0 ReLU-4 [-1, 32, 32, 32] 0 ReLU-5 [-1, 32, 32, 32] 0 Conv2d-6 [-1, 32, 30, 30] 9,248 Conv2d-7 [-1, 32, 30, 30] 9,248 ReLU-8 [-1, 32, 30, 30] 0 ReLU-9 [-1, 32, 30, 30] 0 ReLU-10 [-1, 32, 30, 30] 0 MaxPool2d-11 [-1, 32, 15, 15] 0 MaxPool2d-12 [-1, 32, 15, 15] 0 Dropout-13 [-1, 32, 15, 15] 0 Dropout-14 [-1, 32, 15, 15] 0 Conv2d-15 [-1, 64, 15, 15] 18,496 Conv2d-16 [-1, 64, 15, 15] 18,496 ReLU-17 [-1, 64, 15, 15] 0 ReLU-18 [-1, 64, 15, 15] 0 ReLU-19 [-1, 64, 15, 15] 0 Conv2d-20 [-1, 64, 13, 13] 36,928 Conv2d-21 [-1, 64, 13, 13] 36,928 ReLU-22 [-1, 64, 13, 13] 0 ReLU-23 [-1, 64, 13, 13] 0 ReLU-24 [-1, 64, 13, 13] 0 Dropout-25 [-1, 64, 13, 13] 0 Dropout-26 [-1, 64, 13, 13] 0 MaxPool2d-27 [-1, 64, 6, 6] 0 MaxPool2d-28 [-1, 64, 6, 6] 0 Linear-29 [-1, 512] 1,180,160 Linear-30 [-1, 512] 1,180,160 ReLU-31 [-1, 512] 0 ReLU-32 [-1, 512] 0 ReLU-33 [-1, 512] 0 Dropout-34 [-1, 512] 0 Dropout-35 [-1, 512] 0 Linear-36 [-1, 10] 5,130 Linear-37 [-1, 10] 5,130 ================================================================ Total params: 2,501,716 Trainable params: 2,501,716 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.01 Forward/backward pass size (MB): 3.76 Params size (MB): 9.54 Estimated Total Size (MB): 13.31 ----------------------------------------------------------------要素の数は、すべての層でぴったり合っていて、なんとなくよさそうな感じです。
PyTorchの場合は、モデルのインスタンスであるnetという変数をそのまま実行すると、下のような情報も表示してくれます。netcifar10_cnn( (conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), padding_mode=replicate) (conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1)) (conv3): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), padding_mode=replicate) (conv4): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1)) (relu): ReLU(inplace=True) (dropout1): Dropout(p=0.25, inplace=False) (dropout2): Dropout(p=0.5, inplace=False) (maxpool): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False) (classifier1): Linear(in_features=2304, out_features=512, bias=True) (classifier2): Linear(in_features=512, out_features=10, bias=True) (features): Sequential( (0): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), padding_mode=replicate) (1): ReLU(inplace=True) (2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1)) (3): ReLU(inplace=True) (4): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False) (5): Dropout(p=0.25, inplace=False) (6): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), padding_mode=replicate) (7): ReLU(inplace=True) (8): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1)) (9): ReLU(inplace=True) (10): Dropout(p=0.25, inplace=False) (11): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False) ) (classifier): Sequential( (0): Linear(in_features=2304, out_features=512, bias=True) (1): ReLU(inplace=True) (2): Dropout(p=0.5, inplace=False) (3): Linear(in_features=512, out_features=10, bias=True) ) )学習
これで準備はすべて整いました。いよいよ学習を実施します。冒頭でも説明しましたが、この部分は(現在のところ)Kerasが圧倒的に簡単です。
Keras
# 学習繰り返し回数 nb_epoch = 20 # 1回の学習で何枚の画像を使うか batch_size = 128 # 学習 history = model.fit( x_train, y_train_ohe, batch_size=batch_size, epochs=nb_epoch, verbose=1, validation_data=(x_test, y_test_ohe), shuffle=True )PyTorch
学習 train_loss_list = [] train_acc_list = [] val_loss_list = [] val_acc_list = [] for epoch in range(nb_epoch): train_loss = 0 train_acc = 0 val_loss = 0 val_acc = 0 #train net.train() for i, (images, labels) in enumerate(train_loader): #view()での変換をしない images, labels = images.to(device), labels.to(device) optimizer.zero_grad() outputs = net(images) loss = criterion(outputs, labels) train_loss += loss.item() train_acc += (outputs.max(1)[1] == labels).sum().item() loss.backward() optimizer.step() avg_train_loss = train_loss / len(train_loader.dataset) avg_train_acc = train_acc / len(train_loader.dataset) #val net.eval() with torch.no_grad(): for images, labels in test_loader: #view()での変換をしない images = images.to(device) labels = labels.to(device) outputs = net(images) loss = criterion(outputs, labels) val_loss += loss.item() val_acc += (outputs.max(1)[1] == labels).sum().item() avg_val_loss = val_loss / len(test_loader.dataset) avg_val_acc = val_acc / len(test_loader.dataset) print ('Epoch [{}/{}], loss: {loss:.4f} val_loss: {val_loss:.4f}, val_acc: {val_acc:.4f}' .format(epoch+1, nb_epoch, i+1, loss=avg_train_loss, val_loss=avg_val_loss, val_acc=avg_val_acc)) train_loss_list.append(avg_train_loss) train_acc_list.append(avg_train_acc) val_loss_list.append(avg_val_loss) val_acc_list.append(avg_val_acc)それぞれの実行結果は、以下のようになります。
ただ、Kerasの方はフレームワークで用意されたfit関数の出力そのものなのに対して、PyTorchの方は、それに似せた出力をprint関数手組みで出しているだけなので、そもそも比較することが正しくないともいえます。Keras
Epoch 1/20 391/391 [==============================] - 7s 11ms/step - loss: 4.8051 - accuracy: 0.2355 - val_loss: 1.5342 - val_accuracy: 0.4480 Epoch 2/20 391/391 [==============================] - 4s 10ms/step - loss: 1.4853 - accuracy: 0.4612 - val_loss: 1.2996 - val_accuracy: 0.5420 Epoch 3/20 391/391 [==============================] - 4s 10ms/step - loss: 1.3215 - accuracy: 0.5309 - val_loss: 1.1627 - val_accuracy: 0.5996 Epoch 4/20 391/391 [==============================] - 4s 10ms/step - loss: 1.2014 - accuracy: 0.5732 - val_loss: 1.0446 - val_accuracy: 0.6388 Epoch 5/20 391/391 [==============================] - 4s 10ms/step - loss: 1.1124 - accuracy: 0.6070 - val_loss: 0.9813 - val_accuracy: 0.6627 Epoch 6/20 391/391 [==============================] - 4s 10ms/step - loss: 1.0317 - accuracy: 0.6355 - val_loss: 0.9245 - val_accuracy: 0.6772 Epoch 7/20 391/391 [==============================] - 4s 10ms/step - loss: 0.9625 - accuracy: 0.6639 - val_loss: 0.8732 - val_accuracy: 0.7022 Epoch 8/20 391/391 [==============================] - 4s 10ms/step - loss: 0.9309 - accuracy: 0.6748 - val_loss: 0.8433 - val_accuracy: 0.7064 Epoch 9/20 391/391 [==============================] - 4s 10ms/step - loss: 0.8730 - accuracy: 0.6922 - val_loss: 0.8197 - val_accuracy: 0.7174 Epoch 10/20 391/391 [==============================] - 4s 10ms/step - loss: 0.8575 - accuracy: 0.6982 - val_loss: 0.7722 - val_accuracy: 0.7310 Epoch 11/20 391/391 [==============================] - 4s 10ms/step - loss: 0.8030 - accuracy: 0.7178 - val_loss: 0.7756 - val_accuracy: 0.7272 Epoch 12/20 391/391 [==============================] - 4s 10ms/step - loss: 0.7841 - accuracy: 0.7244 - val_loss: 0.7372 - val_accuracy: 0.7468 Epoch 13/20 391/391 [==============================] - 4s 10ms/step - loss: 0.7384 - accuracy: 0.7429 - val_loss: 0.7738 - val_accuracy: 0.7340 Epoch 14/20 391/391 [==============================] - 4s 10ms/step - loss: 0.7321 - accuracy: 0.7462 - val_loss: 0.7177 - val_accuracy: 0.7501 Epoch 15/20 391/391 [==============================] - 4s 10ms/step - loss: 0.6976 - accuracy: 0.7530 - val_loss: 0.7478 - val_accuracy: 0.7477 Epoch 16/20 391/391 [==============================] - 4s 10ms/step - loss: 0.7047 - accuracy: 0.7537 - val_loss: 0.7160 - val_accuracy: 0.7608 Epoch 17/20 391/391 [==============================] - 4s 10ms/step - loss: 0.6638 - accuracy: 0.7682 - val_loss: 0.7111 - val_accuracy: 0.7630 Epoch 18/20 391/391 [==============================] - 4s 10ms/step - loss: 0.6509 - accuracy: 0.7709 - val_loss: 0.7099 - val_accuracy: 0.7610 Epoch 19/20 391/391 [==============================] - 4s 10ms/step - loss: 0.6346 - accuracy: 0.7770 - val_loss: 0.6933 - val_accuracy: 0.7691 Epoch 20/20 391/391 [==============================] - 4s 10ms/step - loss: 0.6119 - accuracy: 0.7833 - val_loss: 0.7006 - val_accuracy: 0.7619PyTorch
Epoch [1/20], loss: 0.0124 val_loss: 0.0104, val_acc: 0.5187 Epoch [2/20], loss: 0.0094 val_loss: 0.0081, val_acc: 0.6432 Epoch [3/20], loss: 0.0079 val_loss: 0.0075, val_acc: 0.6791 Epoch [4/20], loss: 0.0069 val_loss: 0.0066, val_acc: 0.7173 Epoch [5/20], loss: 0.0062 val_loss: 0.0060, val_acc: 0.7405 Epoch [6/20], loss: 0.0058 val_loss: 0.0057, val_acc: 0.7557 Epoch [7/20], loss: 0.0053 val_loss: 0.0054, val_acc: 0.7666 Epoch [8/20], loss: 0.0050 val_loss: 0.0054, val_acc: 0.7656 Epoch [9/20], loss: 0.0047 val_loss: 0.0052, val_acc: 0.7740 Epoch [10/20], loss: 0.0045 val_loss: 0.0052, val_acc: 0.7708 Epoch [11/20], loss: 0.0042 val_loss: 0.0051, val_acc: 0.7790 Epoch [12/20], loss: 0.0040 val_loss: 0.0051, val_acc: 0.7797 Epoch [13/20], loss: 0.0038 val_loss: 0.0051, val_acc: 0.7802 Epoch [14/20], loss: 0.0037 val_loss: 0.0050, val_acc: 0.7812 Epoch [15/20], loss: 0.0035 val_loss: 0.0049, val_acc: 0.7910 Epoch [16/20], loss: 0.0034 val_loss: 0.0049, val_acc: 0.7840 Epoch [17/20], loss: 0.0033 val_loss: 0.0049, val_acc: 0.7936 Epoch [18/20], loss: 0.0031 val_loss: 0.0049, val_acc: 0.7917 Epoch [19/20], loss: 0.0030 val_loss: 0.0048, val_acc: 0.8008 Epoch [20/20], loss: 0.0029 val_loss: 0.0050, val_acc: 0.7900学習曲線
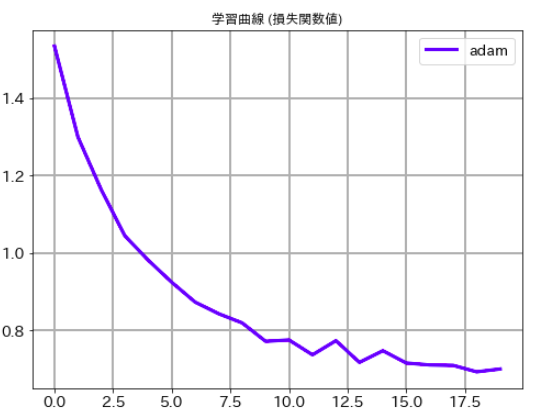
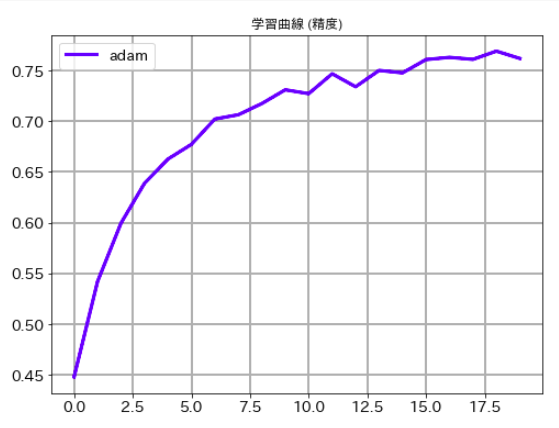
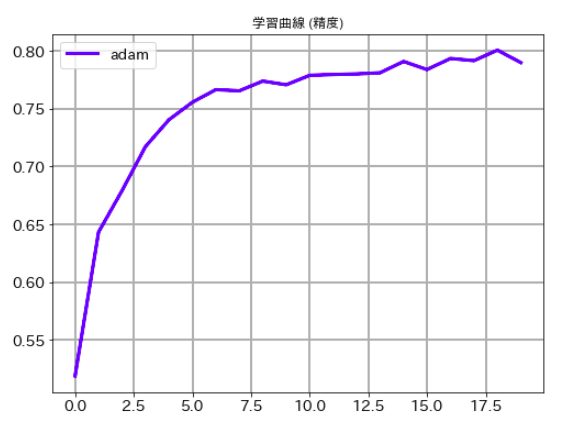
最後にそれぞれのケースの学習曲線ものせておきます。ご承知のとおり、deep learningでは乱数を使っている関係で一回ごとに精度が異なります。この結果だけでどちらのルレームワークがいいかは議論できませんので、その点はご注意下さい。
Keras
# 学習曲線 (損失関数値) plt.figure(figsize=(8,6)) plt.plot(history.history['val_loss'],label='adam', lw=3, c='b') plt.title('学習曲線 (損失関数値)') plt.xticks(size=14) plt.yticks(size=14) plt.grid(lw=2) plt.legend(fontsize=14) plt.show()
# 学習曲線 (精度) plt.figure(figsize=(8,6)) plt.plot(history.history['val_accuracy'],label='adam', lw=3, c='b') plt.title('学習曲線 (精度)') plt.xticks(size=14) plt.yticks(size=14) plt.grid(lw=2) plt.legend(fontsize=14) plt.show()
PyTorch
# 学習曲線 (損失関数値) plt.figure(figsize=(8,6)) plt.plot(val_loss_list,label='adam', lw=3, c='b') plt.title('学習曲線 (損失関数値)') plt.xticks(size=14) plt.yticks(size=14) plt.grid(lw=2) plt.legend(fontsize=14) plt.show()
# 学習曲線 (精度) plt.figure(figsize=(8,6)) plt.plot(val_acc_list,label='adam', lw=3, c='b') plt.title('学習曲線 (精度)') plt.xticks(size=14) plt.yticks(size=14) plt.grid(lw=2) plt.legend(fontsize=14) plt.show()
参考文献
PyTorchニューラルネットワーク 実装ハンドブック
宮本圭一郎 (著), 大川洋平 (著), 毛利拓也 (著)
秀和システム


- 投稿日:2021-01-07T14:39:05+09:00
Pythonで学ぶアルゴリズム 第15弾:並べ替え(選択ソート)
#Pythonで学ぶアルゴリズム< 選択ソート >
はじめに
基本的なアルゴリズムをPythonで実装し,アルゴリズムの理解を深める.
その第15弾として選択ソートを扱う.今回からしばらく並べ替えについてのアルゴリズムを学ぶ.なぜソートのアルゴリズムを学ぶのか?
・ライブラリの利用が一般的だが,その実装を知ることは大切
・ソートの考え方はほかのプログラムを作るにあたって参考になる部分が多い
・ループや条件分岐,リストの扱い,関数の作成,再帰呼び出しといったプログラミングの基本を学べるだけでなく,計算量の比較やその必要性を示す理想的な問題
・それぞれの処理はシンプルで,実装にそれほど時間がかかるわけでもなく,実用的なプログラムである選択ソート
リストの中で最小値を探し,その最小値と先頭の場所を入れ替える.続いて,2番目を基準として,先頭を除いた最小値を探しまた入れ替える.これを繰り返すことで,昇順(小さいもの順)に並べ替えることができる.そのイメージ図を次に示す.
上図のように,最小値と入れ替える基準を変えていくことで,昇順に並べ替えができることが分かる.実装
先ほどの手順に従ったプログラムのコードとそのときの出力を以下に示す.
コード
select_sort.py""" 2021/01/07 @Yuya Shimizu 選択ソート """ def select_sort(data): """選択ソート:自分よりも小さな値と場所を入れ替えて,昇順に並べ替える""" for i in range(len(data)): Min = i #入れ替え対象をセット for j in range(i+1, len(data)): #セットした値よりも小さな値があれば,その位置を最小値として記録 if data[j] < data[Min]: Min = j #いまの位置と最小値を入れ替え ⇒ 結果,左から小さい順に並ぶ data[i], data[Min] = data[Min], data[i] return data #並べ替えを終えたデータを返す if __name__ == '__main__': DATA = [6, 15, 4, 2, 8, 5, 11, 9, 7, 13] sort = select_sort(DATA.copy()) #後に比較するため,リストが変更されないようにcopyしたものを引数にする print(f"{DATA} → {sort}")出力
[6, 15, 4, 2, 8, 5, 11, 9, 7, 13] → [2, 4, 5, 6, 7, 8, 9, 11, 13, 15]ちゃんと昇順に並べ替えられていることが分かる.
今回は並べ替える前後での比較をしたいがために,あえてsortという変数に結果を格納し,さらに関数への引数はDATA.copy()というようにcopy関数により,引数に影響が出ないようにしている.並べ替えるだけなら,そのような操作は必要でなく,select_sort(DATA)とすればよい.選択ソートの計算量
最後に計算量について触れる.
1つ目の最小値を探すには残りの$n-1$個の要素との比較が必要で,同様に2つ目,3つ目では,$n-2$回,$n-3$回の比較が必要になる.したがって,全体での比較回数は$(n-1) + (n-2) + ... + 1 = \frac{n(n-1)}{2}$となる.$\frac{n(n-1)}{2} = \frac{1}{2}n^2 - \frac{1}{2}n$となるが,$n$が大きくなると第1項に対して第2項は十分小さく無視できるため,計算量はオーダー記法で表すと,$O(n^2)$となる.感想
特に難しいことはなく,今までの復習も併せてできそうだと感じた.今回は並べ替え1つ目選択ソートということで他との比較はできないが,これから学ぶほかの並べ替えアルゴリズムが楽しみであり,士気が高められる.また,オーダー記法についても慣れてきた気がする.
参考文献
Pythonで始めるアルゴリズム入門 伝統的なアルゴリズムで学ぶ定石と計算量
増井 敏克 著 翔泳社
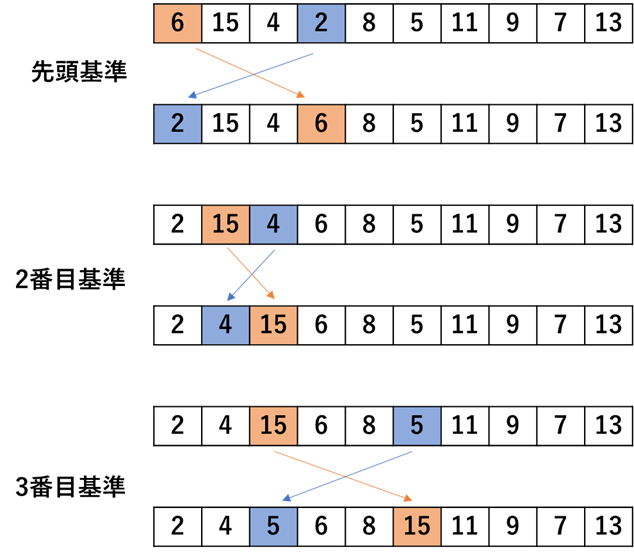
- 投稿日:2021-01-07T14:24:04+09:00
python3.8でlambda-uploader使用した時にpython3.8が見つからないとエラーを吐かれた時の原因調査
事の発端
AWSのLambda上にそれなりに複雑になる予定のpythonの関数を追加する事になったが、lambda上ではpipが使用できないため、外部モジュールを使用する関数を使用する場合、
[一つ一つ使用している外部モジュールを\Python〇〇\Lib\site-packages] から探し出し纏めてzip化するという賽の河原のようなおちねり作業が発生する。
当然ながら人間は信用ならない生物のため、こんな作業を毎回手作業でやろうものならパンジャンドラムとマーマイトをガンギメした某ブリテンの暴走青列車(ブルートレイン)の如く事故が発生する事故は起こるさ? 事故は人間が起こすものなんだよ!
(※加えてこの作業にとても時間が取られる)そこでlambda-uploaderを使用し、外部モジュールの抽出作業を任せてしまうことで効率化と事故発生率を少しでも下げようと画策した。
作業環境
- Windows10(64bit)
- python3.8(64bitインストーラ使用)3.8なのは2020/12月末時点でlambdaがpython3.8以降に対応していないから。
- 上記に加えてpythonのインストール箇所は(元来はおすすめされないけど、端末ごと引き継ぐ可能性があるため C:\Program Files以下。本来は各c:\users~以下)
lambda-uploaderを使用するためには
・lambda.json
→アップロードするlambda関数の概要を纏めた設定ファイル
・requirements.txt
→作ったlambda関数が使用する外部モジュールを定義するとこのファイルを参照して自動でピックアップ、zipの際にまとめてくれるみたいです。つまりpip freezeから自動でファイル生成するバッチを作れば一番リスキーな作業を自動化してくれます。
事故は起こさせない・event.json
→テスト時に投げるPOSTリクエストの内容で、GETリクエストのテストの場合は空でも良い
ということで今回は不要。他の参考内容 等でも記載がない場合が多いので必須ファイルでは無い模様。・〇〇.py
→aws lambdaのエントリーポイントであるdef lambda_handler(event, context):~関数の処理が記載されたpyファイル。
lambda-uploaderの手順としては上記で記載した設定ファイル達を元に、大まかに分けて以下3点を順に行う。
1. build
2. zip
3. upload(aws lambdaに)jsonファイルに以下の様に設定(セキュリティに関わる情報は伏せてます)して・・・
lambda.json{ "name": "testFunction", "description": "testFunction description.", "region": "ap-northeast-1", "handler": "lambda_function.lambda_handler", "role": "arn:aws:iam::XXXXXXXXXXXX:role/BlogenistBlogSample", "timeout": 30, "memory": 128, "runtime": "python3.8" ←明示的に指定しないとデフォルト(時代から捨てられつつあるpython2.7)でアップロードを行う。 }イクゾー デッデッデデデデン
そして(想定外の)事故は起きた
カーン
PS C:\workspace(python)\testcode\lambda> lambda-uploader Building Package â‰ï¸ Unexpected error. Please report this traceback. Uploader: 1.3.0 Botocore: 1.16.38 Boto3: 1.19.38 Traceback (most recent call last): File "c:\program files\python38\lib\site-packages\lambda_uploader\shell.py", line 194, in main _execute(args) File "c:\program files\python38\lib\site-packages\lambda_uploader\shell.py", line 83, in _execute pkg = package.build_package(pth, requirements, File "c:\program files\python38\lib\site-packages\lambda_uploader\package.py", line 51, in build_package pkg.build(ignore) File "c:\program files\python38\lib\site-packages\lambda_uploader\package.py", line 79, in build self.install_dependencies() File "c:\program files\python38\lib\site-packages\lambda_uploader\package.py", line 151, in install_dependencies self._build_new_virtualenv() File "c:\program files\python38\lib\site-packages\lambda_uploader\package.py", line 177, in _build_new_virtualenv python_exe = self._python_executable() File "c:\program files\python38\lib\site-packages\lambda_uploader\package.py", line 195, in _python_executable raise Exception('Unable to locate {} executable' Exception: Unable to locate python3.8 executable(´・ω・`)
Exception: Unable to locate python3.8 executable(´;ω;`)ブワッ
最後の行でビルド時にpython3.8が見つからないとエラーを吐瀉(オエ)られる。
原因を調べてみる
というわけで(最終的な実行環境のpython自体はaws上にあるのでpython.exeいる?とおもいつつ)原因調査開始。
PATHが通ってない?
→問題なし。[\python38] 及び [\Python38\Lib\site-packages]両方のPATHを環境変数設定で確認(というかインストール時にPATH通す設定で今まで散々コマンド使ってきているのでこの時点でPATHが原因というのはおかしい)マイナーバージョンも指定しないとだめ?ということでjsonのパラメータを"runtime": "python3.8.6"に修正
→Exception: Unable to locate python3.8.6 executable
(´・ω・`)(´・ω・`)いっそのことjsonのruntimeパラメータを削除
→Exception: Unable to locate python2.7 executable
(´・ω・`)(´・ω・`)(´・ω・`) ソリャソウダlambda-uploaderモジュールのバグかも知れないので最新版を見にgitへ(pypiに反映せずgit上だけ永遠に更新されているモジュールというのは案外多い)
↓
↓
(´;ω;`)ブワッ
エラー内容で色々で調べても引っかかって来ない
ということで、Tracebackがあるため、直接lambda-uploaderのソースコードを見に行く。
変に設定をいじっていないなら \Python38\Lib\site-packages\lambda_uploaderに目的のコードが有るためササッとディレクトリ開いて最後に処理が通った箇所付近File "c:\program files\python38\lib\site-packages\lambda_uploader\package.py", line 195, in _python_executable raise Exception('Unable to locate {} executable'を調査。
package.pydef _python_executable(self): if self._pyexec is not None: python_exe = find_executable(self._pyexec) if not python_exe: 195行目→ raise Exception('Unable to locate {} executable' .format(self._pyexec))find_executable関数の処理が怪しいと目星を付け更に呼び出し元を調査。
※vs codeでpython環境建てると複雑なコードでもインテリジェンスが便利なのでおすすめ。いつか開発環境構築を記事にしたい。spawn.pydef find_executable(executable, path=None): """Tries to find 'executable' in the directories listed in 'path'. A string listing directories separated by 'os.pathsep'; defaults to os.environ['PATH']. Returns the complete filename or None if not found. """ _, ext = os.path.splitext(executable) if (sys.platform == 'win32') and (ext != '.exe'): executable = executable + '.exe' if os.path.isfile(executable): return executable if path is None: path = os.environ.get('PATH', None) if path is None: try: path = os.confstr("CS_PATH") except (AttributeError, ValueError): # os.confstr() or CS_PATH is not available path = os.defpath # bpo-35755: Don't use os.defpath if the PATH environment variable is # set to an empty string # PATH='' doesn't match, whereas PATH=':' looks in the current directory if not path: return None paths = path.split(os.pathsep) for p in paths: f = os.path.join(p, executable) print(f) if os.path.isfile(f): print(f) # the file exists, we have a shot at spawn working return f return None上記コードを順番に流し見た限り、環境変数を取得して、分割(そのままだとセミコロンでつながった1行の文字列)、末尾に何かくっつけてファイルチェックしてるなーということで
for p in paths: f = os.path.join(p, executable) print(f) #困った時のprint文 if os.path.isfile(f): # the file exists, we have a shot at spawn working return f再び実行。
PS C:\workspace(python)\testcode\lambda> lambda-uploader Building Package ※↓がprintで吐かせた内容 C:\Program Files\Python38\Scripts\python3.8.exe C:\Program Files\Python38\python3.8.exe ・・・以下他の環境変数の末尾にpython3.8.exeをくっつけた文字列&Traceback上記を見た限りそんな変なことしてないなぁと思いつつ、エラーがpython3.8が見つからないというエラーのため、該当のディレクトリを見に行ったら・・・
(ω・`) (・ω・`) (´・ω・`) (´;ω;`)ブワッ
なんで?
それならjsonを書き換える。
ということでそもそも存在しないexeファイルを検索していたというのが原因でした。
そのため、"runtime": "python"と書けば動きはする。ビルドまでは。
明らかにおかしな動きなため、そのまま動かせばその後で詰まるだろうなと思いながら動かし。当然のようにアップロード処理で落ちました。
例外の内容がbotocore.errorfactory.InvalidParameterValueException: An error occurred (InvalidParameterValueException) when calling the UpdateFunctionConfiguration operation: Value python at 'runtime' failed to satisfy constraint: Member must satisfy enum value set: [java8, java11, nodejs10.x, nodejs12.x, python2.7, python3.6, python3.7, python3.8, dotnetcore2.1, go1.x, ruby2.5] or be a valid ARN※要約するとlambda.jsonのruntimeのパラメータにpythonバージョンを書け。又は本当に有効なARN設定してるの?
とあり、botocoreはawsの認証周りをしてくれる箇所のため、awsのサービスを操作するパッケージがいるのかなと調べてみたり(結論から言うと見当違いでした)botocoreモジュールにも手を加えてデバッグしたり、そもそもlambda-uploaderモジュールのソースコードがSyntaxWarning: "is" with a literal. Did you mean "=="?警告を出していて、やっぱりpython3.8では使えないのでは?と考えているうちに思いついた下記を試してみました。
PS C:\workspace(python)\testcode\lambda> lambda-uploader Building Package Uploading Package Finaws lambda上を確認しても正常にアップロード出来ていました。
ものすごくスッキリしない解決になってしまい申し訳ありません。しかし、python〇〇.exeなんて一体どういう流れで入ってくるのだろうか・・・?(vitualenvが先に割り込んで生成されたpython〇〇.exeを参照するのかと思ってたが中身を見てもvirtualenvより先に参照していた。)
誰か原因をご存知ならコメントでご指摘下さい。
結論
pythonの素晴らしいところはPIPしてきたモジュールを直接書き換え、デバッグして動作確認できるところ。(終わったらもとに戻すことを忘れずに)
また、lambda-uploaderは3年近く更新がなく、既存のコードも最近のpythonの仕様変更によりトラブルを抱え始めているため、今後は使えなくなる事を想定したほうが良いかもしれません。


- 投稿日:2021-01-07T14:21:19+09:00
Python の nan チェック
TL;DR
a is np.nanじゃなくてnp.isnan(a)を使おう。nan
nan (Not A Number) です。nan「数値」じゃなくて、その比較についてはIEEE754で定義されています。これは何と比較しても等しくならない。
nan == nanすらFalseです。Python の場合、math.nanとnp.nanがあります。(他にもあるかも知れないけれど。)一部で流通している誤解: 「
a is np.nanでチェックできるよ」
aがnanの場合、a == np.nanではチェックできません。なぜならば上述のとおり、IEEE754でそう決められているから。で、どうするかと言うと、いくつかのサイトではa is np.nanとすればいいよ、とあります。確かに多くの場合これでうまく行くのですが、これはどうやらnumpyやmathの実装上、たまたまうまく行く(同一のnanオブジェクトを参照するようになっている)ことが多い だけのようで、基本的に間違ったチェック方法と断じたいと思います。というわけで反例。
# 以下は Python 3.91 + numpy 1.19.4 で試しました。math の nan でも基本的に同じです。 import numpy as np a = np.nan b = a * 2 print(a) # => nan print(b) # => nan print(a is np.nan) # => True (これがよく使われる。これはok) print(b is np.nan) # => False (こういうことが起こる。)
nanに対して演算をしてしまうことはありますよね? その結果はやはり(当然?)nanです。ここでisで比較をしてしまうと、参照先が異なるようでFlaseになってしまいます。だからa is np.nanは(nan かどうかのチェックとしては)誤り。正解は?
素直に
np.isnan()を使うのが良いでしょう。わかりやすいし。定義を逆手に取った裏技(?)として自身との比較a == a(がFalseだったらnan) というのもあるのですが、混乱するのでぼくは遠慮しときます。悪者は誰か? (個人の感想です。あまりツッコまないでください。)
Python です(バッサリ)。
isなんてモノを導入したのが諸悪の根源だと。こういう直観的な機能が曖昧なbe動詞に「参照先の比較」という大切な働きをさせるから混乱が生じる。さらに悪いことに、isの式は読みようによっては(意味を勘違いしたままでも)英文的にわかりやすいので広まっちゃう。isなんかなくたって、id()があるんだから、それ使えば簡潔・正確・誤用防止といいことづくめなのに…。
- 投稿日:2021-01-07T14:02:26+09:00
matplotlibヒストグラムの縦軸と横軸が気持ち悪いので、いい感じにする
Python の matplotlib でヒストグラムをよく描くわけですが、その縦軸・横軸がときどき気に入らないので、それを微調整するためのメモです。
hist の縦軸と横軸
例として次のようなグラフをお見せします。
%matplotlib inline import matplotlib.pyplot as plt from scipy import stats norm_rvs = stats.norm.rvs(loc=50, scale=30, size=100, random_state=0)plt.hist(norm_rvs, bins=10, alpha=0.5, ec='navy') plt.show()
これを見て、
- うえ〜ん、ヒストグラムの棒の切れ目が中途半端な場所にあって気持ち悪いヨー!
- うえ〜ん、縦軸の目盛りが整数じゃないと気持ち悪いヨー!
ってなるわけです。
縦軸の目盛りを整数にしたい
次のようにすれば、ヒストグラムの棒の切れ目と、高さに関する情報が得られます。
Y, X, _ = plt.hist(norm_rvs, bins=10, alpha=0.5, ec='navy') print(X) print(Y) plt.show()[-26.58969448 -12.12146116 2.34677216 16.81500548 31.2832388 45.75147212 60.21970544 74.68793876 89.15617208 103.6244054 118.09263872] [ 1. 5. 7. 13. 17. 18. 16. 11. 7. 5.]
その情報を用いて縦軸を整数にしてみます。
import numpy as np Y, X, _ = plt.hist(norm_rvs, bins=10, alpha=0.5, ec='navy') y_max = int(max(Y)) + 1 plt.yticks(np.arange(0, y_max, 2)) # 1刻みにしても見にくいので2刻みにします plt.show()
棒の区切りをいい感じにしたい
横軸の範囲を指定して、binの本数をいい感じに調整します。
Y, X, _ = plt.hist(norm_rvs, bins=13, alpha=0.5, ec='navy', range=(-10, 120)) print(X) print(Y) y_max = int(max(Y)) + 1 plt.yticks(np.arange(0, y_max, 2)) plt.show()[-10. 0. 10. 20. 30. 40. 50. 60. 70. 80. 90. 100. 110. 120.] [ 3. 5. 6. 10. 11. 9. 15. 13. 9. 6. 5. 5. 2.]
複数のヒストグラムをいい感じにしたい
さて、複数のヒストグラムを並べて比較したいときがあると思いますが
norm_rvs2 = stats.norm.rvs(loc=75, scale=55, size=100, random_state=0)plt.hist(norm_rvs, bins=10, alpha=0.5, ec='navy') plt.hist(norm_rvs2, bins=10, alpha=0.5, ec='red') plt.show()
こんなふうに気持ち悪いヨ〜!ってなりがちですね。これも同じようにいい感じにしてみましょう。
bins = 20 range=(-50, 200) Y1, X1, _ = plt.hist(norm_rvs, bins=bins, alpha=0.5, ec='navy', range=range) Y2, X2, _ = plt.hist(norm_rvs2, bins=bins, alpha=0.5, ec='red', range=range) y_max = int(max(max(Y1), max(Y2))) + 1 plt.yticks(np.arange(0, y_max, 2)) plt.show()
個人的には、次のように縦に並べる方が好きです。
bins = 20 range=(-50, 200) fig, axes = plt.subplots(nrows=2, ncols=1, figsize=(8,8)) Y1, X1, _ = axes[0].hist(norm_rvs, bins=bins, alpha=0.5, ec='navy', range=range) Y2, X2, _ = axes[1].hist(norm_rvs2, bins=bins, alpha=0.5, ec='red', range=range) y_max = int(max(max(Y1), max(Y2))) + 1 axes[0].set_ylim([0, y_max]) axes[1].set_ylim([0, y_max]) axes[0].set_yticks(np.arange(0, y_max, 2)) axes[1].set_yticks(np.arange(0, y_max, 2)) plt.show()
現場からは以上です!
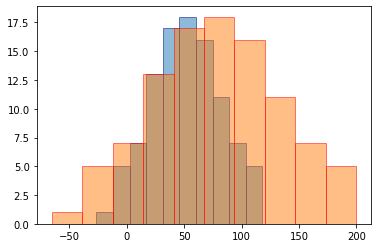
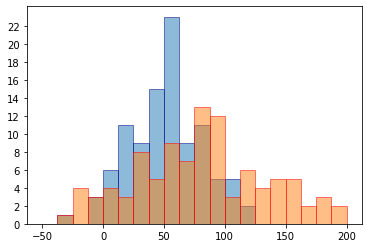
- 投稿日:2021-01-07T13:57:21+09:00
Pybulletでロボットアームシミュレーション [逆運動学を解いて6自由度アームで物体を掴む]
Pybulletでロボットを動かす
ロボットアームを自由に動かすためには順運動学と逆運動学が必要です。
この記事では逆運動学の数値解法についての解説と、Pybulletでの実装方法を載せています。
順運動学については前回の記事で解説しているので、順運動学について知りたい方はこちらを参考にして下さい。動作環境
Windows10
WSL2
Ubunu18.04
逆運動学
逆運動学とは
ロボットアームにおける逆運動学とは、ある位置まである姿勢で手先アームを到達させるための適切な関節角度を求めることを指します。
例えば「机の上のペンを取る」という動作をするには、ペンの位置を把握して、腕の関節角を調整することでペンの位置まで手を移動させる必要があります。
つまり、私たちはペンを掴むという動作をするとき、手がペンに届くようなちょうどいい関節角度を毎回見つけているという風に捉えることができます。
これがまさに逆運動学でやっていることです。逆運動学の解法
逆運動学の解法は解析解法と数値解法の2種類に分かれます。
解析解法
解析解法は、順運動学の数式を変形することで逆運動学の数式を導出する手法です。
解析解法のメリットは、数式が求まってさえしまえば常に正確な解を得られることです。2自由度アームなどの簡単に解析解が求まるアームを扱うときには解析解法が役に立ちます。
しかしデメリットとして、6自由度アームなどの自由度の高いアームになると解の導出がとても困難であったり、導出できたとしてもかなり面倒だったりします。数値解法
数値解法は、目標位置に近づくような関節角の微小変化を逐一計算することで、少しずつ目標位置と現在位置の差を埋めていく手法です。
数値解法のメリットは、6自由度アームなどの複雑なアームでも解を得ることができることです。
しかしデメリットとして、求解に時間がかかることや、目標位置と誤差が生まれてしまうことが挙げられます。今回は6自由度アームの逆運動学を求めていくので、数値解法を採用します。
数値解法
数値解法の具体的な説明については省略しますが、詳細はこちらの記事が参考になるかと思います。
数値解法にはいくつかの手法があります。
例えば上記の記事で紹介されているものでは最急降下法、Newton-Raphson法、Gauss-Newton法、Levenberg-Marquardt法、可変計量法、共役勾配法などがあります。今回はその中でも、再急降下法による逆運動学の数値解法を解説します。
要は、順運動学の式を微小区間において線形近似することで逆運動学の式に変形するという方法です。アームの手先座標・姿勢をA, そのときのアームの各関節角をΘとする.\\ A = [x, y, z, φ, θ, ψ]\\ Θ=[θ_1,θ_2, ・・・, θ_n]\\ 順運動学の式は\\ f(Θ) = A \\ と表せる.\ この順運動学の式を微分して線形関数に近似させると次式のようになる.\\ J \dot Θ = \dot A\\ (このJのことをヤコビ行列と言います.)\\ 式変形すると\\ \dot Θ = J^{-1} \dot A\\ヤコビ行列 $J$ の逆行列 $J^{-1}$ が求まれば、数値解法によって関節角を微小変化させ続けることで最終的に目標位置・姿勢に到達できます。
逆運動学のプログラムを実装
使用するロボットアームの選択
逆運動学を解く前に、まずは使用するロボットアームを決めなくてはいけません。
前回の記事で作成したVS-068というロボットアームを使用することにします。
このアームの寸法、関節可動域については前回の記事を参照して下さい。VS-068ロボットアーム
逆運動学のPythonコード
getPosition.pyimport numpy as np import math def fixPi(Js): js=Js for j in range(len(Js)): if js[j]>math.pi: js[j]=js[j]-int((js[j]+math.pi)/(2*math.pi))*2*math.pi elif js[j]<-math.pi: js[j]=js[j]-int((js[j]-math.pi)/(2*math.pi))*2*math.pi return js def forwardKinematicsThreeJoints3D(L, js): Ts = [] c0 = math.cos(js[0]) s0 = math.sin(js[0]) c1 = math.cos(js[1]) s1 = math.sin(js[1]) c2 = math.cos(js[2]) s2 = math.sin(js[2]) c3 = math.cos(js[3]) s3 = math.sin(js[3]) c4 = math.cos(js[4]) s4 = math.sin(js[4]) c5 = math.cos(js[5]) s5 = math.sin(js[5]) Ts.append(np.matrix([[c0, -s0, 0, 0], [s0, c0, 0, 0], [0, 0, 1, L[0]], [0, 0, 0, 1]])) Ts.append(np.matrix([[1, 0, 0, 0], [0, c1, -s1, -0.03], [0, s1, c1, L[1]], [0, 0, 0, 1]])) Ts.append(np.matrix([[1, 0, 0, 0], [0, c2, -s2, 0], [0, s2, c2, L[2]], [0, 0, 0, 1]])) Ts.append(np.matrix([[c3, -s3, 0, 0], [s3, c3, 0, 0], [0, 0, 1, L[3]], [0, 0, 0, 1]])) Ts.append(np.matrix([[1, 0, 0, 0], [0, c4, -s4, 0], [0, s4, c4, L[4]], [0, 0, 0, 1]])) Ts.append(np.matrix([[c5, -s5, 0, 0], [s5, c5, 0, 0], [0, 0, 1, L[5]], [0, 0, 0, 1]])) Ts.append(np.matrix([[1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, L[6]], [0, 0, 0, 1]])) TTs = Ts[0]*Ts[1]*Ts[2]*Ts[3]*Ts[4]*Ts[5]*Ts[6] return TTs def getxyz(L,js): TTs=forwardKinematicsThreeJoints3D(L, js) return [TTs[0,3],TTs[1,3],TTs[2,3]] def getOrientation(L,js): ZXZ=forwardKinematicsThreeJoints3D(L, js) theta = math.atan2(math.sqrt(ZXZ[2,0]**2+ZXZ[2,1]**2),ZXZ[2,2]) if abs(math.sin(theta))==0: theta=0 phi=0 psy=math.atan2(-ZXZ[0,1],ZXZ[0,0]) else: phi=math.atan2(ZXZ[0,2],-ZXZ[1,2]) psy=math.atan2(ZXZ[2,0],ZXZ[2,1]) if abs(math.sin(phi))==0: phi=0 if abs(math.sin(psy))==0: psy=0 #print("js:",js) #print("orientaton:",fixPi([phi,theta,psy])) return fixPi([phi,theta,psy]) def getDifferential(L,js): d=10e-4 vfx=[] djs=[js[i] for i in range(len(js))] for i in range(len(js)): djs[i]+=d vfx.append(fixPi((np.array(getOrientation(L,djs))-np.array(getOrientation(L,js)))/d)) djs[i]-=d return vfx #print("vfx:",getDifferential(L,js)) def move_P(K, theta, js): dtheta = theta-js if dtheta>0.0001 or -0.0001>dtheta: return K*dtheta else: return 0 def calcJointVelocity(L, vx, vy, vz, vtheta, js): #print(js) L0=L[0] L1=L[1] L2=L[2] L3=L[3] L4=L[4] L5=L[5] L6=L[6] c0 = math.cos(js[0]) s0 = math.sin(js[0]) c1 = math.cos(js[1]) s1 = math.sin(js[1]) c12 = math.cos(js[1]+js[2]) s12 = math.sin(js[1]+js[2]) c3 = math.cos(js[3]) s3 = math.sin(js[3]) c4 = math.cos(js[4]) s4 = math.sin(js[4]) c5 = math.cos(js[5]) s5 = math.sin(js[5]) D = getDifferential(L,js) """ 目標手先位置Vx, Vy, Vthetaと現在関節角度jsを使う """ J = np.matrix([ [c0*(s1*L2+s12*L3+s12*L4)+(L5+L6)*(-s0*s3*s4+c0*c12*c3*s4+c0*s12*c4), s0*(c1*L2+c12*L3+c12*L4)+(L5+L6)*(-s0*s12*c3*s4+s0*c12*c4), s0*(c12*L3+c12*L4)+(L5+L6)*(-s0*s12*c3*s4+s0*c12*c4), (L5+L6)*(c0*s3*c4+s0*c12*c3*c4-s0*s12*s4), ], [s0*(s1*L2+s12*L3+s12*L4)+(L5+L6)*(c0*s3*s4+s0*c12*c3*s4+s0*s12*c4), -c0*(c1*L2+c12*L3+c12*L4)+(L5+L6)*(c0*s12*c3*s4-c0*c12*c4), -c0*(c12*L3+c12*L4)+(L5+L6)*(c0*s12*c3*s4-c0*c12*c4), (L5+L6)*(s0*s3*c4-c0*c12*c3*c4+c0*s12*s4), ], [0, -s1*L2-s12*L3-s12*L4+(L5+L6)*(-c12*c3*s4-s12*c4), -s12*L3-s12*L4+(L5+L6)*(-c12*c3*s4-s12*c4), (L5+L6)*(-s12*c3*c4-c12*s4), ], [D[0][1], D[1][1], D[2][1], D[4][1]], ]) #print("J:",J.shape) #print(J) J_ = np.linalg.pinv(J) vjs = J_ * np.array([[vx], [vy], [vz], [vtheta]]) #print (vjs) return vjs def inverseKinematicsThreeJoints3D(L, x, y, z, theta, JS): dx=0.01 dy=0.01 dz=0.01 dtheta=0.01 js=JS i=0 while(True): print("####",i,"####") TTs = forwardKinematicsThreeJoints3D(L, js) ax = TTs[0,3] ay = TTs[1,3] az = TTs[2,3] ZXZ = getOrientation(L,js) atheta= ZXZ[1] print(ax,ay,az,atheta) vx=x-ax vy=y-ay vz=z-az vtheta=theta-atheta #print(vtheta) if math.sqrt(vx**2+vy**2+vz**2)<0.001 and abs(vtheta)<0.01: print("解が収束しました") break if i==1000: print("解が収束しませんでした。") break dx=0.01 if vx>=0.01 else -0.01 if vx<=-0.01 else vx dy=0.01 if vy>=0.01 else -0.01 if vy<=-0.01 else vy dz=0.01 if vz>=0.01 else -0.01 if vz<=-0.01 else vz dtheta=0.01 if vtheta>=0.01 else -0.01 if vtheta<=-0.01 else vtheta #print(dx,dy,dz,dtheta) vjs=calcJointVelocity(L, dx, dy, dz, dtheta, js) #print(vjs) js[0]+=float(vjs[0]) js[1]+=float(vjs[1]) js[2]+=float(vjs[2]) js[3]=0 js[4]+=float(vjs[3]) js[5]=0 i+=1 for j in range(len(js)): if js[j]>math.pi: js[j]=js[j]-int((js[j]+math.pi)/(2*math.pi))*2*math.pi elif js[j]<-math.pi: js[j]=js[j]-int((js[j]-math.pi)/(2*math.pi))*2*math.pi return js各関数の説明
関数 入力値 出力値 説明 fixPi(Js) 逆運動学を解いて求まった各関節角度 角度の範囲を$[-π, π]$に直した各関節角度 逆運動学を解いて出た値は$[-π, π]$に収まっていないため、角度を直すための関数 forwardKinematicsThreeJoints3D(L, js) アームの長さLと各関節角js 同時座標変換行列TTs 順運動学を解いて同時座標変換行列を導出する関数 getxyz(L,js) アームの長さLと各関節角js 手先座標[x, y, z] 同時座標変換行列から手先座標を求める関数 getOrientation(L,js) アームの長さLと各関節角js オイラー角(ZXZ軸) 同時座標変換行列から手先姿勢を求める関数 getDifferential(L,js) アームの長さLと各関節角js オイラー角の微分値(ZXZ軸) ヤコビ行列をつくるための微分関数 move_P(K, theta, js) P制御のゲインKと目標関節角thetaと各関節角js 各関節角の変化量 P制御を行う関数 calcJointVelocity(L, vx, vy, vz, vtheta, js) アームの長さLとX,Y,Z軸方向への移動変化量と各関節角js vx,vy,vzだけ移動するのに必要な各関節角の変化量 数値解法のための関数 inverseKinematicsThreeJoints3D(L, x, y, z, theta, JS) アームの長さLと目的座標[x,y,z]と目的姿勢thetaと初期関節角度JS 目的座標・姿勢になるための各関節角 逆運動学を解くメインの関数 先に数式で示したように、逆運動学を解く流れは
①順運動学の式を立てる
②順運動学の式を各関節角度で微分してヤコビ行列を得る
③ヤコビ行列の逆行列を取る
④逆行列と手先位置と手先姿勢の微小変化量から各関節角の微小変化量を求めるというアルゴリズムの繰り返しになっています。
このアルゴリズムをプログラムにすると
①の関数がforwardKinematicsThreeJoints3D(L, js)、
②と③の関数がcalcJointVelocity(L, vx, vy, vz, vtheta, js)、
④の関数がinverseKinematicsThreeJoints3D(L, x, y, z, theta, JS)
となります。
②でヤコビ行列の手先姿勢部分を得るためにgetDifferential(L,js)で微分しています。
①~④のアルゴリズムを繰り返して出た逆運動学の解は、範囲が[-π,π]に収まっていないため、関節角の可動域外の解になってしまうことがあるので、fixPi(Js)という関数で角度を[-π,π]の範囲に直しています。実行結果
試しに、手先位置[x, y, z] = [0.3, 0.3, 0.3]、手先姿勢90°となるような各関節角度を逆運動学で求めてみます。
L=[0.1975,0.1975,0.340,0.197,0.143,0.070,0.010] js=[math.pi/2,math.pi/2,0,0,0,0] Js=inverseKinematicsThreeJoints3D(L, 0.3, 0.3, 0.3, math.pi, js) print(Js)結果
数値解法のアルゴリズムを157回繰り返した結果、無事に各関節角が求まりました。
157回目での手先位置、手先姿勢の値をみると誤差はとても小さく収まっています。このコードの手先姿勢(オイラー角)について
オイラー角による手先姿勢の表現は通常、3回の軸回転で行います。
例えば上記のプログラムではZXZ軸回転によるオイラー角 $[φ, θ, ψ]$ で姿勢表現をしています。詳細はこちらを参照して下さい
既にお気づきかもしれませんが、今回の逆運動学プログラムではX軸回転のθのみしか姿勢を求めていません。
これは手先姿勢よりも手先位置 $[x,y,z]$ の精度を重視したプログラムであるためです。
理論的には6自由度のロボットアームを使えば、関節の可動範囲内ではあらゆる手先位置、手先姿勢を取ることが可能ですが、その分、逆運動学を解くのが難しくなります。
そのため、今回のプログラムコードでは手先姿勢をθのみに絞ることで、逆運動学の解を求めやすくしています。手先姿勢もしっかりと$[φ, θ, ψ]$で解きたい場合は、アームの初期状態を目的位置・姿勢に近い値にして解を求まりやすくするというような工夫をするという手があります。
また、そもそも今回用いたオイラー角での姿勢表現は、感覚的に理解しやすいため扱いやすいという反面、回転軸が揃うと自由度が3から2に下がってしまうジンバルロックという表現上の問題を抱えているため、それが解の収束性の悪さにつながることがあります。そのため、オイラー角の代わりにクォータニオンという4元数を用いる方法があるので、気になった方はぜひ試してみると良いと思います。
クォータニオンについて詳しく知りたい方は、こちらの記事が非常に参考になると思います。他にも位置と姿勢で優先順位を決めて、優先順位の低い方の誤差を最小にすることで逆運動学を解く優先度付き逆運動学という手法なども存在するそうです。
Pybulletで動作確認
Pybulletコード
逆運動学を解くことができたので、実際にPybulletでシミュレーションをしてみます。
auto_move.pyimport pybullet as p import time import math import numpy as np import random import getPosition as ps phisicsClient = p.connect(p.GUI) #物体の位置[x,y,z]をランダムに決定 random_r=random.uniform(0.2,0.5) random_theta=random.uniform(-math.pi,math.pi) x=random_r*math.cos(random_theta) y=random_r*math.sin(random_theta) z=0.01 L=[0.1975,0.1975,0.340,0.197,0.143,0.070,0.035] #アームの長さ theta = math.pi #目標姿勢を90°に設定 K=[0.1,0.1,0.1,0.1,0.1] #P制御のゲイン #URDF読み込み p.loadURDF("plane.urdf", basePosition = [0, 0, 0]) p.loadURDF("box.urdf", basePosition = [x, y, z]) obUids = p.loadURDF("vs_068.urdf", basePosition = [0, 0, 0]) robot = obUids gravId = p.addUserDebugParameter("gravity", -10, 10, -10) jointIds = [] paramIds = [] p.setPhysicsEngineParameter(numSolverIterations=10) p.changeDynamics(robot, -1, linearDamping=0, angularDamping=0) #Joint読み込み for j in range(p.getNumJoints(robot)): p.changeDynamics(robot, j, linearDamping=0, angularDamping=0) info = p.getJointInfo(robot, j) #print(info) jointName = info[1] jointType = info[2] if (jointType == p.JOINT_PRISMATIC or jointType == p.JOINT_REVOLUTE): jointIds.append(j) if j<7: paramIds.append(p.addUserDebugParameter(jointName.decode("utf-8"), -4, 4, 0)) else: paramIds.append(p.addUserDebugParameter(jointName.decode("utf-8"), 0, 0.015, 0)) #各関節角を設定 targetPos=[0 for i in range(len(paramIds))] #逆運動学を解いて目標関節角を得る goalTheta=ps.inverseKinematicsThreeJoints3D(L, x, y, z, math.pi, [0.1 for i in range(6)]) print(ps.getxyz(L, goalTheta)) print(goalTheta) goalTheta2=[] print("param:", len(paramIds)) #シミュレーションの開始 p.setRealTimeSimulation(1) while (1): p.setGravity(0, 0, p.readUserDebugParameter(gravId)) for i in range(len(paramIds)): c = paramIds[i] p.setJointMotorControl2(robot, jointIds[i], p.POSITION_CONTROL, targetPos[i], force=5 * 240.) #P制御 for i in range(6): if i!=2: targetPos[i]+=ps.move_P(K[0], goalTheta[i], targetPos[i]) else: targetPos[i]+=ps.move_P(K[0], goalTheta[i]-math.pi/2, targetPos[i]) #print(targetPos) time.sleep(0.05)実行結果
逆運動学を解くことで、紫色の目標物体までの関節角を求め、P制御によって物体までロボットアームを移動することに成功しています。
P制御や、PID制御について詳しく知りたい方はこちらの記事が参考になると思います。
最後に
この記事は早稲田大学の尾形研究室での活動の一環として書きました。
ロボットや深層学習について研究しているので、興味のある方は以下の研究室HPをご覧下さい。

- 投稿日:2021-01-07T13:38:12+09:00
wxPythonのテキストボックスを使う - wx.TextCtrl
やけどしたんで自然治療しています。治るかどうかは別として。
wx.TextCtrlとは
Pythonでは
input()を使うことでユーザーからの入力をうけとることができます。
しかし、inputではコンソール上でしかできないため、GUIに入力を受け取るためのウィジェットが必要になります。それで今回紹介するのはwx.TextCtrlです!
簡易的なメモ帳もできないことはありません。いつか紹介するwx.MenuBarとwx.Menuを使うとメモ帳ができます。それについてもいつか紹介していきたいと思います。おくだけのコード
textctrl = wx.TextCtrl(panel, -1, "", size=(300,-1), pos=(50,50))サイズは横300にしています。位置は適当にしているので、要変更!
サンプルコード
import wx app = wx.App(False) frame = wx.Frame(None,-1,"タイトル",size=(500,300)) panel = wx.Panel(frame,-1) textctrl=wx.TextCtrl(panel,-1,"",size=(300,-1),pos=(50,50)) frame.Show(True) app.MainLoop()でOKです、しかしおくだけじゃつまらない!
ということで、入力された文字列を取得する方法
以下のコードをコピー&ペーストしてください!
import wx def buttonClick1(event=None): text = textctrl.GetValue() wx.MessageBox("入力された文字列は「" + text + "」です") app = wx.App(False) frame = wx.Frame(None,-1,"タイトル",size=(500,300)) panel = wx.Panel(frame,-1) textctrl=wx.TextCtrl(panel,-1,"",size=(300,-1),pos=(50,50)) btn = wx.Button(panel,-1,"取得!",pos=(270,80)) btn.Bind(wx.EVT_BUTTON, buttonClick1) frame.Show(True) app.MainLoop()これには今までに紹介したいろいろな要素が入っていますね!
ボタン、メッセージボックスと。いろいろっつっても2つか。wx.TextCtrlに対して
GetValue()という関数をつかうとテキストボックスに入力された文字列がかえってきます。ボタンと組み合わせたらテキストエディタができるんじゃない?と思った人!いると思うので(いなくても)次はボタンとテキストボックスのみでテキストエディタをつくる方法を紹介します。複数行テキストボックス
テキストエディタをつくるには複数行のテキストボックスが必要になります。
全画面に表示させてみますimport wx app = wx.App(False) frame = wx.Frame(None,-1,"タイトル",size=(500,300)) panel = wx.Panel(frame,-1) textctrl=wx.TextCtrl(panel,-1,"",style=wx.TE_MULTILINE) sizer = wx.BoxSizer() sizer.Add(textctrl,1,wx.EXPAND|wx.ALL) panel.SetSizer(sizer) frame.Show(True) app.MainLoop()こんな感じです!
これから紹介するものは、複数行でも1行でも利用できます背景色の設定
textctrl=wx.TextCtrl ・・・のあとに次のコードを入力しますtextctrl.SetBackgroundColour("black")この例では黒にしていますが、他にもカラーコードを利用できます。
文字色の設定
textctrl=wx.TextCtrl ・・・のあとに次のコードを入力しますtextctrl.SetForegroundColour("yellow")この例では黄色にしていますが、他にもカラーコードを利用できます。
文字色も背景色も変更した
textctrl=wx.TextCtrl ・・・のあとに次のコードを入力しますtextctrl.SetBackgroundColour("black") textctrl.SetForegroundColour("yellow")そして、テキストボックスを複数行にすると...
見た目がだいぶ良くなったのではないか???
入力できなくする(無効にする)
つまり無効にするということです。最初から無効にしたいのであれば、
import wx app = wx.App(False) frame = wx.Frame(None,-1,"タイトル",size=(500,300)) panel = wx.Panel(frame,-1) textctrl=wx.TextCtrl(panel,-1,"",size=(300,-1),pos=(50,50)) textctrl.Disable() frame.Show(True) app.MainLoop()で問題ありません。
Disable()を使います。ボタンがクリックされたら無効にしたいのであれば、
import wx def buttonClick1(event=None): textctrl.Disable() app = wx.App(False) frame = wx.Frame(None,-1,"タイトル",size=(500,300)) panel = wx.Panel(frame,-1) textctrl=wx.TextCtrl(panel,-1,"",size=(300,-1),pos=(50,50)) btn = wx.Button(panel,-1,"無効",pos=(270,80)) btn.Bind(wx.EVT_BUTTON, buttonClick1) frame.Show(True) app.MainLoop()がいいと思います。あとからでも
Disable()は使えます。また、最初は無効だけどボタンがクリックされたら有効ししたいのであれば、
import wx def buttonClick1(event=None): textctrl.Enable() app = wx.App(False) frame = wx.Frame(None,-1,"タイトル",size=(500,300)) panel = wx.Panel(frame,-1) textctrl=wx.TextCtrl(panel,-1,"",size=(300,-1),pos=(50,50)) textctrl.Disable() btn = wx.Button(panel,-1,"有効",pos=(270,80)) btn.Bind(wx.EVT_BUTTON, buttonClick1) frame.Show(True) app.MainLoop()がいいと思います。
Enable()を使うと有効にできます。リードオンリー
import wx app = wx.App(False) frame = wx.Frame(None,-1,"タイトル",size=(500,300)) panel = wx.Panel(frame,-1) textctrl=wx.TextCtrl(panel,-1,"リードオンリー^^",size=(300,-1),pos=(50,50),style=TE_READONLY) textctrl.Disable() frame.Show(True) app.MainLoop()無効にしたときとあんまり変わらないんで使う必要はないと思います。
真ん中よせ、右よせ
テキストエディタ使う上で必要になると思います(多分...)
真ん中よせ:
textctrl=wx.TextCtrl(panel,-1,"",size=(300,-1),pos=(50,50)),style=wx.TE_CENTER
のようにstyle属性にwx.TE_CENTERを追加します。右よせ:
textctrl=wx.TextCtrl(panel,-1,"",size=(300,-1),pos=(50,50)),style=wx.TE_RIGHT
のようにstyle属性にwx.TE_RIGHTを追加します。おわりに
これでもまだかき足りません!!!いろいろと追記します!
コメント、気軽にどうぞ前の記事
wxPythonでボタンを扱う - wx.Button動作環境
Windows10
64bit
Python 3.9

- 投稿日:2021-01-07T12:43:17+09:00
ebaysdkでキーワード検索した結果をGoogleSpreadSheetsに書き込む
はじめに
ebayのAPIを利用するために必要なことは前回の記事をご覧ください。
今回はebaysdkというライブラリを使用してebayに出品されている商品を
キーワード検索で取得した情報をgspreadを使用して
Google Spread Sheetsに書き込むやり方を紹介したいと思います。下準備
まずはこちらの記事を参考に
Google Spread SheetsにPythonからアクセスするための必要な下準備を済ませてください。ライブラリのインストール
次に必要なライブラリをインストールしましょう。
pip install ebaysdk gspread oauth2client参考コード
※
spread_sheet_keyは記録用に作成したスプレッドシートのURLの
https://docs.google.com/spreadsheets/d/SPREADSHEET_KEY/edit#gid=0
SPREADSHEET_KEYの部分に当たります。このプログラムを実行するとこのようにスプレッドシートに取得した値が書き込まれます。
ebay_sdk.pyimport gspread from oauth2client.service_account import ServiceAccountCredentials from ebaysdk.finding import Connection as Finding from ebaysdk.exception import ConnectionError appkey = 取得したAPP KEY keyword = "Marvel Spiderman" # 検索したいキーワード jsonf = "~~~~~~~~~.json" # 下準備で保存したjsonファイル名 spread_sheet_key = "SPREADSHEET_KEY" # 分からない方は上記を参考にしてください # Google Spread Sheetsにアクセス def connect_gspread(jsonf, key): scope = ["https://spreadsheets.google.com/feeds", "https://www.googleapis.com/auth/drive"] credentials = ServiceAccountCredentials.from_json_keyfile_name(jsonf, scope) gc = gspread.authorize(credentials) worksheet = gc.open_by_key(key).sheet1 return worksheet # ebaysdkで取得した情報をスプレッドシートに書き込み def write_to_sheet(ws, response_dict): ws.update_title(keyword) # ワークシート名を検索したワードにする column = ["商品ID", "商品名", "通貨", "値段"] results = response_dict["searchResult"]["item"] for item in (results): column.append(item["itemId"]) column.append(item["title"]) column.append(item["sellingStatus"]["currentPrice"]["_currencyId"]) column.append(item["sellingStatus"]["currentPrice"]["value"]) cell_list = ws.range("A1:D" + str(len(results))) # 検索結果の数だけ範囲指定 for i, cell in enumerate(cell_list): cell.value = column[i] ws.update_cells(cell_list) # リクエストを減らすために一気に更新 try: api = Finding(appid=appkey, config_file=None) response = api.execute("findItemsAdvanced", { "keywords": keyword, "itemFilter": [ # {"name": "Condition", "value": "Used"}, {"name": "MinPrice", "value": "50", "paramName": "Currency", "paramValue": "USD"}, {"name": "MaxPrice", "value": "150", "paramName": "Currency", "paramValue": "USD"} ], "sortOrder": "CurrentPriceHighest" }) response_dict = response.dict() write_to_sheet(connect_gspread(jsonf, spread_sheet_key), response_dict) except ConnectionError as e: print(e) print(e.response.dict())まず初めに、以下のコードでebayのapiにアクセスしていて
キーワードでの検索結果をresponseに格納している
itemFilterでは最低価格と最高価格を指定しているが、他にも商品の状態(新品や中古)で絞ることもできる。try: api = Finding(appid=appkey, config_file=None) response = api.execute("findItemsAdvanced", { "keywords": keyword, "itemFilter": [ {"name": "MinPrice", "value": "50", "paramName": "Currency", "paramValue": "USD"}, {"name": "MaxPrice", "value": "150", "paramName": "Currency", "paramValue": "USD"} ], "sortOrder": "CurrentPriceHighest" })次に、
connect_gspread(jsonf, spread_sheet_key)でスプレッドシートにアクセスしていて
取得したワークシートの情報とレスポンスを辞書化したものをwrite_to_sheetの引数に渡しています。response_dict = response.dict() write_to_sheet(connect_gspread(jsonf, spread_sheet_key), response_dict)ワークシートの1行目は何の列なのかを分かりやすくする為にカラム名を入れたいので
column = ["商品ID", "商品名", "通貨", "値段"]としています。
次に、商品の検索結果だけが欲しいのでresults = response_dict["searchResult"]["item"]で、検索結果の商品情報を
resultsに格納して、検索でヒットした数の分の商品情報を
columnに順番に追加するようにしています。for item in (results): column.append(item["itemId"]) # 商品ID column.append(item["title"]) # 商品名 column.append(item["sellingStatus"]["currentPrice"]["_currencyId"]) # 通貨 column.append(item["sellingStatus"]["currentPrice"]["value"]) # 値段各自で欲しい情報を
columnに追加していってください。
この際に気をつけなければならないことがあります。
今回は["商品ID", "商品名", "通貨", "値段"]の順番なので、
この順番通りに各商品の情報をcolumnに追加していかなければなりません。
理由としては、
update_acellやupdate_cellで一つずつ更新することもできるのですが
これだと検索結果が多かった場合にリクエストが多くなってしまい
APIのリクエスト制限に引っかかってしまいます。なので大量のデータを一気に更新できるように、
update_cellsを使います。
このupdate_cellsの引数は一次元配列じゃないといけないので、順番に入れるようにしています。cell_list = ws.range("A1:D" + str(len(results))) for i, cell in enumerate(cell_list): cell.value = column[i] ws.update_cells(cell_list)
ws.range("A1:D" + str(len(results)))としているのは
例えば検索結果が3商品ヒットの場合
1行目はカラム名A1(商品ID)、B1(商品名)...
2行目から検索結果となりますよねA2(検索結果1の商品ID)、B2(検索結果1の商品名)...
そして3商品ヒットなので最後はD4(検索結果3の値段)となるようにしたいので
検索結果毎に動的に設定できるように"A1:D" + str(len(results))としてあります。
ws.range()は、ワークシート内の選択した範囲内のセルの情報が取得されます。なので取得したセルの情報を
cell_listに格納してfor i, cell in enumerate(cell_list): cell.value = column[i]
columnに入っている商品情報をcell_listの各セルに書き込んでいきます。ws.update_cells(cell_list)あとは
update_cellsで編集したcell_listを引数で渡せば、一気に更新できます。今回は、とりあえず動くように作りましたが
他に分かりやすく簡潔にできる方法などあれば教えて頂けると幸いです。


- 投稿日:2021-01-07T12:16:48+09:00
pipで依存関係を含めてまとめてアップグレードする
はじめに
多数の(相互)依存ライブラリから構成されているPythonライブラリで、一つだけアップグレードしてしまうとライブラリ間でバージョンが異なってうまく動かなくなってしまう場合があります。
そのため、依存関係も含めて一気にアップグレードしたい場合があります。方法
依存ライブラリも含めて一気にアップグレードする方法
pip install --upgrade --upgrade-strategy eager <パッケージ名>※逆に必要でない限り依存ライブラリをアップグレードしたくない場合は
pip install --upgrade --upgrade-strategy only-if-needed <パッケージ名>とします。
参考
https://docs.microsoft.com/ja-jp/python/api/overview/azure/ml/install?view=azure-ml-py
https://www.it-swarm-ja.tech/ja/python/pip%E3%82%92%E4%BD%BF%E7%94%A8%E3%81%97%E3%81%A6%E4%BE%9D%E5%AD%98%E9%96%A2%E4%BF%82%E3%82%92%E3%82%A2%E3%83%83%E3%83%97%E3%82%B0%E3%83%AC%E3%83%BC%E3%83%89%E3%81%9B%E3%81%9A%E3%81%AB%E3%83%91%E3%83%83%E3%82%B1%E3%83%BC%E3%82%B8%E3%82%92%E3%82%A2%E3%83%83%E3%83%97%E3%82%B0%E3%83%AC%E3%83%BC%E3%83%89%E3%81%97%E3%81%BE%E3%81%99%E3%81%8B%EF%BC%9F/969608431/
- 投稿日:2021-01-07T11:41:53+09:00
Google Colaboratoryでありますまいか
2020年のうちに読んでおきたい2020年アドベントカレンダーをピックアップ に伴いクソアプリアドベントカレンダーを読んだ。で、「友達がいなくて寂しいので友達を作った(LineBot)」(クソなタイトルである
) に伴い、Google Colaboratoryというものをよく知らなかったので調べた。
Google Colaboratory便利だ!便利なのにGSuiteで余り使われていない気がするから使おう!という記事です。
ポイント
- Python使える
- だから簡単なスプレッドシート、CSV、その他整形に使える
- そして共有簡単
概説:Google Colaboratoryで初めての機械学習
Colab ノートブックは、Colab がホストする Jupyter ノートブックです。Jupyter プロジェクトの詳細については、jupyter.org をご覧ください。
ともかくPythonコードを共有して実行できる、GSuite利用企業的には期待が広がるツール。機械学習というよりちょっとした神エクセル作るくらいならこれ使ったほうが夢あるよという話である。機械学習という言葉に恐れる必要はなく。以下基本中の基本から、できること、便利なことと、できないこと、べからずまでを書くので参考になると嬉しいです。
基本:Helloworld
テストコードを実行してみよう。再生ボタン押すだけ。
1. Python使える
普段Pythonを主開発で触らないのでこれはチャンス。
Slackにメッセージ送信もできます。Slackにメッセージ送信
以下、pythonとWebhookでSlackにメッセージ送信するPython。
Slackに送信する
PythonでSlackのIncoming Webhookを試してみる
Webhookはワークフロービルダーからも設定できるこれ。
でメッセージを送るとこうなる。
import requests, json; from bs4 import BeautifulSoup; web_hook_url = 'https://hooks.slack.com/services/xxxxxxxxxx/xxxxxxxxxx/xxxxxxxxxx' requests.post(web_hook_url, data = json.dumps({ 'text': 'Slackでありますまいか', # 送りたい内容ですぞ 'username': 'ありますまいか' # botの名前ですぞ }));Colab上ではこう。
以上。2. だから簡単なスプレッドシート、CSV、その他整形に使える
有用そうなのがこれ。某かのファイルからデータ読込ができる。
まずCSV:How to read csv to dataframe in Google Colab
これは見る限り Python Pandas PyInstallerで5日間で「操作ログ」CSV整形ツールを作る 等と組み合わせると便利。以下サンプルCSVを読み込んだところ。
ついでに操作ログも試してみたら動いた。
Colaboratoryのデータの入出力まとめ で網羅されているので参照のこと。
CSV集計
はてなブックマーク3万件にみる技術トレンド2020年まとめ 等よろしく問合せ傾向分析のようなことも試せそう。
3. そして共有簡単
で、せっかくなら皆に使ってもらいたいですよね。
はい、普段のGSuiteの使い方と一緒です。権限を与えてシェア。
ところで

そうなると。これGASとかと連携したら相当便利そうだなと思いませんでしょうか。私は思いました。以下は使用上の留意点です。
[できない] 自動実行
現状:できない。 ようです。
Selenium とか、無理やり定期実行させる仕掛け でどうにかしているようだ。少々トリッキー。[できないこともある] スクレイピング
冒頭の友達がいなくて寂しいので友達を作った(LineBot)で行われていたスクレイピングというものに戻ると、例えば以下が詳しい。PythonでHTMLを解析してデータ収集してみる? スクレイピングが最初からわかる『Python 2年生』
scraiping_sample.pyimport requests from bs4 import BeautifulSoup # Webページを取得して解析しますぞ load_url = "https://ameblo.jp/masayukimakino/entry-11084331526.html" html = requests.get(load_url) soup = BeautifulSoup(html.content, "html.parser") # すべてのstrongタグを検索して、その文字列を表示しますぞ for element in soup.find_all("strong"): # すべてのstrongタグを検索して表示しますまいか print(element.text)すると例えばこんなことができる。
スクレイピングは違法?3つの法律問題と対応策を弁護士が5分で解説 を読みましょう。利用目的
スクレイピングの対象
アクセス制限の遵守
利用規約Webスクレイピングの注意事項一覧
Webスクレイピングの法律周りの話をしよう!
を考えた上でうまくツール化する必要がある。よって要・勉強。Qiitaのトレンド(ランキング)を取得してSlackに送信する 等先人の記事を参考に。
社内資料などなどを内部的に解析するには便利そう。[十分に注意] Githubに保存
もう一つ、私がやらかしそうだったので反省文兼ねて追記。
Githubにコピーを保存する簡単機能もついています。
が、社内利用する場合にはそれがGithubに公開されてしまうことになるので十分注意。結論
冒頭に紹介したJupyterというやつ、まだJupyter Notebook使ってるの? VS CodeでJupyter生活 (.py)で快適Pythonライフを?! も参考にさらに発展利用させることができそう。
特にPython触ったことがない方、ちょっと試してみるにはお手軽です!
以上社内Gsuiteツールにまつわるお勧めでした。
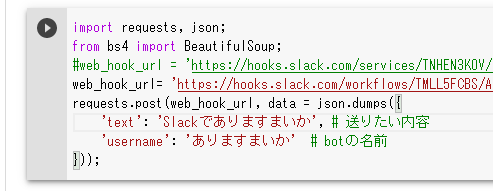

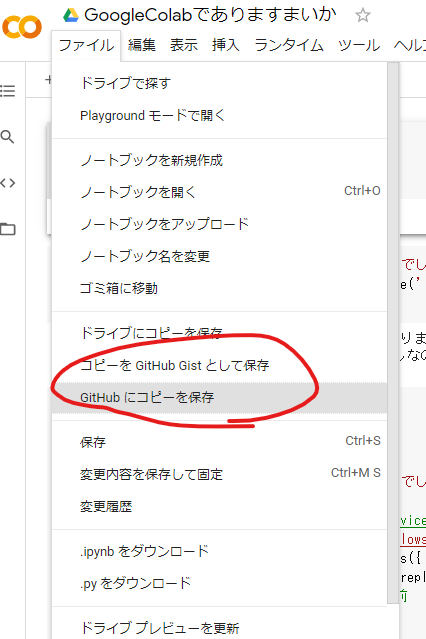
- 投稿日:2021-01-07T11:37:51+09:00
メモ:分かりにくい nonlocal
多分、使わない nonlocal だけど
Python 3.9.1 のドキュメント
9.2.1. スコープと名前空間の例が読みにくかったので、自分なりに解釈したコメントを追加。
def scope_test(): def do_local(): spam = "local spam" # do_local の spam に代入 # 何処からも参照されないので無意味な処理 # 動作説明には必要 def do_nonlocal(): nonlocal spam # do_nonlocal には spam が無い、と宣言 # 外側にある関数 (scope_test) の spam を使う # global の spam は使わない spam = "nonlocal spam" def do_global(): global spam # global の spam を使う、と宣言 spam = "global spam" # 以下の "spam" は scope_test のもの spam = "test spam" do_local() print("After local assignment:", spam) do_nonlocal() print("After nonlocal assignment:", spam) do_global() print("After global assignment:", spam) # 以下の "spam" は global のもの scope_test() print("In global scope:", spam)こんな感じかな。 global と nonlocal は参照範囲が排他になっている。
- 投稿日:2021-01-07T09:37:57+09:00
manimの作法 その13
概要
manimの作法、調べてみた。
VMobject、使ってみた。サンプルコード
from manimlib.imports import * class test(GraphScene): CONFIG = { "x_labeled_nums": [], "y_labeled_nums": [], "x_axis_label": "Temperature", "y_axis_label": "Pressure", "graph_origin": 2.5 * DOWN + 2 * LEFT, "corner_square_width": 4, "example_point_coords": (2, 5), } def construct(self): self.setup_axes() self.draw_arrow() self.add_example_coordinates() self.wander_continuously() def draw_arrow(self): square = Square(side_length = self.corner_square_width, stroke_color = WHITE, stroke_width = 0, ) square.to_corner(UP + LEFT, buff = 0) arrow = Arrow(square.get_right(), self.coords_to_point(*self.example_point_coords)) self.play(ShowCreation(arrow)) def add_example_coordinates(self): dot = Dot(self.coords_to_point(*self.example_point_coords)) dot.set_color(YELLOW) tex = TexMobject("(25^\\circ\\text{C}, 101 \\text{ kPa})") tex.next_to(dot, UP + RIGHT, buff = SMALL_BUFF) self.play(ShowCreation(dot)) self.play(Write(tex)) self.wait() self.play(FadeOut(tex)) def wander_continuously(self): path = VMobject().set_points_smoothly([ORIGIN, 2 * UP + RIGHT, 2 * DOWN + RIGHT, 5 * RIGHT, 4 * RIGHT + UP, 3 * RIGHT + 2 * DOWN, DOWN + LEFT, 2 * RIGHT]) point = self.coords_to_point(*self.example_point_coords) path.shift(point) path.set_color(GREEN) self.play(ShowCreation(path, run_time = 10, rate_func = linear)) self.wait()生成した動画
https://www.youtube.com/watch?v=sbNJTUT4G2c
以上。
- 投稿日:2021-01-07T09:31:56+09:00
manimの作法 その12
概要
manimの作法、調べてみた。
RubiksCube、使ってみた。サンプルコード
from manimlib.imports import * class RubiksCube(VGroup): CONFIG = { "colors": [ "#FFD500", # Yellow "#C41E3A", # Orange "#009E60", # Green "#FF5800", # Red "#0051BA", # Blue "#FFFFFF" # White ], } def __init__(self, **kwargs): digest_config(self, kwargs) vectors = [OUT, RIGHT, UP, LEFT, DOWN, IN] faces = [self.create_face(color, vector) for color, vector in zip(self.colors, vectors)] VGroup.__init__(self, *it.chain(*faces), **kwargs) self.set_shade_in_3d(True) def create_face(self, color, vector): squares = VGroup(*[self.create_square(color) for x in range(9)]) squares.arrange_in_grid(3, 3, buff = 0) squares.set_width(2) squares.move_to(OUT, OUT) squares.apply_matrix(z_to_vector(vector)) return squares def create_square(self, color): square = Square(stroke_width = 3, stroke_color = BLACK, fill_color = color, fill_opacity = 1, side_length = 1, ) square.flip() return square def get_face(self, vect): self.sort(lambda p: np.dot(p, vect)) return self[-(12 + 9):] class test(SpecialThreeDScene): def construct(self): cube = RubiksCube() cube.set_fill(opacity = 0.8) cube.set_stroke(width = 1) axes = self.get_axes() self.add(axes, cube) self.move_camera(phi = 70 * DEGREES, theta = -140 * DEGREES, ) self.begin_ambient_camera_rotation(rate = 0.02) self.wait(2) self.play(Rotate(cube, TAU / 4, RIGHT, run_time = 3)) self.wait(2) self.play(Rotate(cube, TAU / 4, UP, run_time = 3)) self.wait(2) self.play(Rotate(cube, -TAU / 3, np.ones(3), run_time = 3)) self.wait(2)生成した動画
https://www.youtube.com/watch?v=hjaVvJ49_nk
以上。
- 投稿日:2021-01-07T09:15:57+09:00
【メモ】Pythonでピボットテーブルをやってみた
- 製造業出身のデータサイエンティストがお送りする記事
- 今回は自分のメモとして記事に残しておきます。
はじめに
製造現場では、膨大なデータをExcelで分析する際にピボットテーブルを頻繁に使います。データを探索的に集計したいときに便利だからです。
Jupyter Notebookでもピボットテーブルってできないのかな?と思って調べていたらpivottablejsというライブラリーを使用したらできるということが分かりました。ピボットテーブルの実装
import pivottablejs import seaborn as sns sns.set_style('whitegrid') #データセットの読み込み df=sns.load_dataset('tips') pivottablejs.pivot_ui(df)
集計とかはドラック&ドロップでできます。
Excelと同じような感じでできますので、非常に便利です。

- 投稿日:2021-01-07T08:42:55+09:00
K-means法(クラスタリング手法)を実装してみた
- 製造業出身のデータサイエンティストがお送りする記事
- 今回はクラスタリング手法の中で、K-means法を実装しました。
クラスタリングとは
クラスタリングとは、ある集合を何らかの規則によって分類することです。機械学習においてクラスタリングは、「教師なし学習」に分類されます。
クラスタリングの計算方法はいくつかありますが、サンプル同士の類似性に基づいてグルーピングしています。クラスタリングの計算方法を大きく分類すると、「階層クラスタリング」と「非階層クラスタリング」の2つに分けられます。
今回実装するK-means法は「非階層クラスタリング」に分類されます。K-means法とは
クラスターの平均を用いて、あらかじめ決められたクラスター数に分類手法です。K-means法のアルゴリズム概要は下記にようになっております。
- クラスタの中心の初期値をk個決める
- 全てのサンプルとk個のクラスタとの中心距離を求め、最も近いクラスタに分類する
- 形成されたk個のクラスタの中心を求める
- 中心が変化しなくなるまで2と3の工程を繰り返す
K-means法の実装
pythonのコードは下記の通りです。
# 必要なライブラリーのインストール import numpy as np import pandas as pd # 可視化 import matplotlib as mpl import matplotlib.pyplot as plt import seaborn as sns from IPython.display import display %matplotlib inline sns.set_style('whitegrid') # 正規化のためのクラス from sklearn.preprocessing import StandardScaler # k-means法に必要なものをインポート from sklearn.cluster import KMeans最初に必要なライブラリーをimportします。
今回はirisのデータを使って実装してみようと思います。# irisデータ from sklearn.datasets import load_iris # データ読み込み iris = load_iris() iris.keys() # データフレームに格納 df_iris = pd.DataFrame(iris.data, columns=iris.feature_names) df_iris['target'] = iris.target # アヤメの種類(正解ラベル) df_iris.head() # 2変数の散布図(正解ラベルで色分け) plt.scatter(df_iris['petal length (cm)'], df_iris['petal width (cm)'], c=df_iris.target, cmap=mpl.cm.jet) plt.xlabel('petal_length') plt.ylabel('petal_width')
「petal_length」と「petal_width」の2変数で可視化してみました。
次に散布図行列で可視化してみたいと思います。# 散布図行列(正解ラベルで色分け) sns.pairplot(df_iris, hue='target', height=1.5)
次にエルボー法を用いて、クラスタ数を決めていきたいと思います。irisのデータだと3個に分ければ良いことは明確ですが、実際クラスタリングを使用する時は教師なし学習のため、クラスタ数を自分で決めなければいけません。そこで、クラスタ数を決めるための手法の一つとしてエルボー法があります。
# Elbow Method wcss = [] for i in range(1, 10): kmeans = KMeans(n_clusters = i, init = 'k-means++', max_iter = 300, n_init = 30, random_state = 0) kmeans.fit(df_iris.iloc[:, 2:4]) wcss.append(kmeans.inertia_) plt.plot(range(1, 10), wcss) plt.title('The elbow method') plt.xlabel('Number of clusters') plt.ylabel('WCSS') plt.show()
エルボー法の結果を見ても、クラスタ数は3以上増やしても意味がないことがわかるかと思います。
ここからモデリングをしていきたいと思います。
# モデリング clf = KMeans(n_clusters=3, random_state=1) clf.fit(df_iris.iloc[:, 2:4]) # 学習データのクラスタ番号 clf.labels_ # 未知データに対してクラスタ番号を付与 # 今回は学習データに対して予測しているので、`clf.labels_` と同じ結果 y_pred = clf.predict(df_iris.iloc[:, 2:4]) y_pred # 実際の種類とクラスタリングの結果を比較 fig, (ax1, ax2) = plt.subplots(figsize=(16, 4), ncols=2) # 実際の種類の分布 ax1.scatter(df_iris['petal length (cm)'], df_iris['petal width (cm)'], c=df_iris.target, cmap=mpl.cm.jet) ax1.set_xlabel('petal_length') ax1.set_ylabel('petal_width') ax1.set_title('Actual') # クラスター分析で分類されたクラスタの分布 ax2.scatter(df_iris['petal length (cm)'], df_iris['petal width (cm)'], c=y_pred, cmap=mpl.cm.jet) ax2.set_xlabel('petal_length') ax2.set_ylabel('petal_width') ax2.set_title('Predict')
さいごに
最後まで読んで頂き、ありがとうございました。
今回は、K-means法を実装しました。訂正要望がありましたら、ご連絡頂けますと幸いです。


- 投稿日:2021-01-07T08:26:22+09:00
AWSのSGフルオープンルールを自動削除する【EventBridge, Lambda】
はじめに
AWSのSGルール自動削除は、AWSマネージドだとsshやRDPのフルオープン以外はないと思います。
ちょうどEventBridgeやLambdaを触ってみたかったので、いろいろ調べつつ実装してみました。構成
SG作成 → EventBridgeで検出 → Lambdaで自動削除
要件定義
- 削除対象はSGのインバウンドルールで、許可されている送信元IPアドレスが
0.0.0.0/0,::/0となっているもの- 新規作成されたルールが対象
- 送信元IPアドレスがフルオープンになっているルールと、そうでないルールが一緒に作成された場合、フルオープンのルールのみを削除する
EventBridgeルールの作成
EventBridgeは、ルールにより一致した受信イベントを検出し、ターゲットとして登録したAWSリソースを呼び出してイベントを渡します。
呼び出されたAWSリソースは渡されたイベントを使用したりして、決められた処理を実行します。
今回、EventBridgeルールは二つ作成します。
どうにかして一つのルールで実装できないか検討しましたが、現状のイベントパターンで使用できるフィルタリングでは実装できないと思います。
もし実装できたらコメント欄で教えていただけると幸いです。イベントパターン
フルオープンSGを検出するためのイベントパターンを作成するので、検出対象のイベントがどのような形式なのかを確認します。
AWS公式ドキュメント
サポートされている AWS サービスからの EventBridge イベントの例
https://docs.aws.amazon.com/ja_jp/eventbridge/latest/userguide/event-types.html上記公式ドキュメントを確認すると、SGのイベントは見当たらないので、CloudTrail 経由で配信されたイベントが該当します。
書式は以下のとおりでした。イベントの書式例{ "version": "0", "id": "36eb8523-97d0-4518-b33d-ee3579ff19f0", "detail-type": "AWS API Call via CloudTrail", "source": "aws.s3", "account": "123456789012", "time": "2016-02-20T01:09:13Z", "region": "us-east-1", "resources": [], "detail": { "eventVersion": "1.03", "userIdentity": { "type": "Root", "principalId": "123456789012", "arn": "arn:aws:iam::123456789012:root", "accountId": "123456789012", "sessionContext": { "attributes": { "mfaAuthenticated": "false", "creationDate": "2016-02-20T01:05:59Z" } } }, "eventTime": "2016-02-20T01:09:13Z", "eventSource": "s3.amazonaws.com", "eventName": "CreateBucket", "awsRegion": "us-east-1", "sourceIPAddress": "100.100.100.100", "userAgent": "[S3Console/0.4]", "requestParameters": { "bucketName": "bucket-test-iad" }, "responseElements": null, "requestID": "9D767BCC3B4E7487", "eventID": "24ba271e-d595-4e66-a7fd-9c16cbf8abae", "eventType": "AwsApiCall" } }例ではS3のため、これをSGルール作成に置き換えます。
detailの中身はCloudTrailログでそのまま置き換えられる思いますので、実際にフルオープンSGを作成してCloudTrailログを確認し、その内容に置き換えます(後ほどイベントパターンで使うプロパティに星マークを付けています。)。
これで、検出対象のイベントが分かりました。イベントの書式例(SGルール作成版){ "version": "0", "id": "36eb8523-97d0-4518-b33d-ee3579ff19f0", ★"detail-type": "AWS API Call via CloudTrail", ★"source": "aws.ec2", "account": "123456789012", "time": "2016-02-20T01:09:13Z", "region": "us-east-1", "resources": [], "detail": { "eventVersion": "1.08", "userIdentity": { 略 }, "eventTime": "2021-01-09T04:08:28Z", ★ "eventSource": "ec2.amazonaws.com", ★ "eventName": "AuthorizeSecurityGroupIngress", "awsRegion": "us-east-1", "sourceIPAddress": "192.168.1.1", "userAgent": "console.ec2.amazonaws.com", "requestParameters": { "groupId": "sg-000000000000", "ipPermissions": { "items": [ { "ipProtocol": "-1", "groups": {}, "ipRanges": { "items": [ { ★ "cidrIp": "0.0.0.0/0" } ] }, "ipv6Ranges": { "items": [ { ★ "cidrIpv6": "::/0" } ] }, "prefixListIds": {} } ] } }, 以下略これからは、イベントパターンを作成します。
今回のイベントはAWSで定義したイベントパターンには該当しないので、自作します。
検出しなければならないイベントは、三つあり、
・IPv4のみフルオープン
・IPv6のみフルオープン
・IPv4・IPv6両方フルオープン
のSGルールです。
ルールを二つ作成するので、まず一つ目から。
完成したイベントパターンがこちらです。イベントパターン①{ "source": ["aws.ec2"], "detail-type": ["AWS API Call via CloudTrail"], "detail": { "eventSource": ["ec2.amazonaws.com"], "eventName": ["AuthorizeSecurityGroupIngress"], "requestParameters": { "ipPermissions": { "items": { "ipRanges": { "items": { "cidrIp": [ { "cidr": "0.0.0.0/0" } ] } } } } } } }このイベントパターンが検出する対象は
・IPv4のみフルオープン
・IPv4・IPv6両方フルオープン
のSGルールであり、IPv6のみフルオープンのSGルールは検出できません。
IPv6のみフルオープンのSGルールだけを検出するため、もう一つのEventBridgeルールは以下のイベントパターンにします。イベントパターン②{ "source": ["aws.ec2"], "detail-type": ["AWS API Call via CloudTrail"], "detail": { "eventSource": ["ec2.amazonaws.com"], "eventName": ["AuthorizeSecurityGroupIngress"], "requestParameters": { "ipPermissions": { "items": { "ipRanges": { "items": { "cidrIp": [ { "anything-but" : "0.0.0.0/0" }, { "exists": false } ] } }, "ipv6Ranges": { "items": { "cidrIpv6": [ "::/0" ] } } } } } } }イベントパターン①より少し複雑になっているのは、二つのEventBridgeルールが一つのイベントを二重に検出しないようにするためです。
イベントパターン②にipRangesプロパティの記載がない場合、IPv4・IPv6両方フルオープンのSGルール作成イベントが、イベントパターン①、②の両方で一致してしまい、二つのEventBridgeルールに検出されてしまいます。
その結果、同じLambdaで処理されることになり(Lambdaは二つに分けません。)、どちらかが必ずエラーとなります。
それを防ぐために、
・IPv6フルオープン かつ IPv4が指定されている または IPv4を許可していない
イベントに一致するものをイベントパターン②として作成しています。
これにより、IPv6のみフルオープンのSGルール作成イベントに限り、EventBridgeルールがイベントを検出します。対応関係をまとめると以下の表のとおりです。
パターン 検出 イベントパターン① IPv4のみフルオープン
IPv4・IPv6両方フルオープンイベントパターン② IPv6のみフルオープン また、それぞれのイベントパターンでコンテンツフィルタリングを使用しています。
詳細を知りたい方は以下のドキュメントをご覧ください。
なお、イベントパターン②の{ "anything-but" : "0.0.0.0/0" }で、 イベントパターン①のようにIPアドレスマッチングを使用していないのは、anything-but内でのIPアドレスマッチングの使用がサポートされていなかったからです。AWS公式ドキュメント
イベントパターンを使用したコンテンツベースのフィルタリング
https://docs.aws.amazon.com/ja_jp/eventbridge/latest/userguide/content-filtering-with-event-patterns.htmlターゲットに渡すイベント
EventBridgeはターゲットに渡すイベント内容をカスタマイズしたり、イベントの代わりにイベントと関係のないJSONを自作して渡すことができます。
今回は、Lambdaで必要な部分のみ渡すことにします。
マネージメントコンソール上の「入力の設定」→ 「一致したイベントの一部」を選択し、$.detail.requestParametersを入力します。
$.detail.requestParametersをJSONにすると以下のとおりです。
このJSONからグループIDなどを必要な情報を使用します。$.detail.requestParameters{ "groupId": "sg-000000000000", "ipPermissions": { "items": [ { "ipProtocol": "-1", "groups": {}, "ipRanges": { "items": [ { "cidrIp": "0.0.0.0/0" } ] }, "ipv6Ranges": { "items": [ { "cidrIpv6": "::/0" } ] }, "prefixListIds": {} } ] } }Lambda作成
Python3.6で作成しました。
SGルールを削除するrevoke_security_group_ingress()メソッドを使用しています。
完成したプログラムがこちらです。
コメントでも記載していますが、ec2.revoke_security_group_ingress()でポート番号の設定をしていないルールを削除する際、適当な数字をfromPortとtoPortに入れてec2.revoke_security_group_ingress()を実行してもエラーにならず削除できました。
最初は各ポートにNoneを入れて対応できないか試しましたが、int型でなければダメだと怒られました。Lambdaの関数import json import boto3 ec2 = boto3.client("ec2") def lambda_handler(event, context): ip_permissions_items = event["ipPermissions"]["items"] SGID = event["groupId"] for ip_permissions_item in ip_permissions_items: ip_protocol = ip_permissions_item["ipProtocol"] ip_ranges = ip_permissions_item["ipRanges"] ipv6_ranges = ip_permissions_item["ipv6Ranges"] # ipRangesのcidripが存在しフルオープンであればそのまま変数に格納し、それ以外はNoneを格納する if ip_ranges == {}: cidrip = None else: # 許可するIPアドレスが複数存在する場合もあるので順次IPアドレスを調べ、フルオープンがでた時点で変数に格納し抜け出す for ip_ranges_item in ip_ranges["items"]: if ip_ranges_item["cidrIp"] == "0.0.0.0/0": cidrip = ip_ranges_item["cidrIp"] break else: cidrip = None if ipv6_ranges == {}: cidripv6 = None else: for ipv6_ranges_item in ipv6_ranges["items"]: if ipv6_ranges_item["cidrIpv6"] == "::/0": cidripv6 = ipv6_ranges_item["cidrIpv6"] break else: cidripv6 = None # ポート設定はルールによっては存在しないため、あればそのまま変数に格納し、なければ適当な数字を格納する if "fromPort" and "toPort" in ip_permissions_item: from_port = ip_permissions_item["fromPort"] to_port = ip_permissions_item["toPort"] else: # int型でなければ削除時エラーが発生するため数値を格納 # ポートが存在しない場合の処理なので、どの数値でも問題ないと思われる(0,70000は支障なし) from_port = 0 to_port = 0 if cidrip == "0.0.0.0/0" and cidripv6 == "::/0": ec2.revoke_security_group_ingress( GroupId=SGID, IpPermissions=[ { "IpProtocol": ip_protocol, "FromPort": from_port, "ToPort": to_port, "IpRanges":[ { "CidrIp": cidrip } ], "Ipv6Ranges":[ { "CidrIpv6": cidripv6 } ] } ] ) elif cidrip == "0.0.0.0/0": ec2.revoke_security_group_ingress( GroupId=SGID, IpPermissions=[ { "IpProtocol": ip_protocol, "FromPort": from_port, "ToPort": to_port, "IpRanges":[ { "CidrIp": cidrip } ] } ] ) elif cidripv6 == "::/0": ec2.revoke_security_group_ingress( GroupId=SGID, IpPermissions=[ { "IpProtocol": ip_protocol, "FromPort": from_port, "ToPort": to_port, "Ipv6Ranges":[ { "CidrIpv6": cidripv6 } ] } ] )これでSGフルオープンルールの自動削除実装は終わりです。
私が試してみた限りはうまく動いているように見えましたが、欠陥があった場合はコメント欄から教えていただけると嬉しいです。
主に私個人の勉強のために記事を執筆しましたが、誰かのお役に立てれば幸いです。