- 投稿日:2021-01-07T22:08:37+09:00
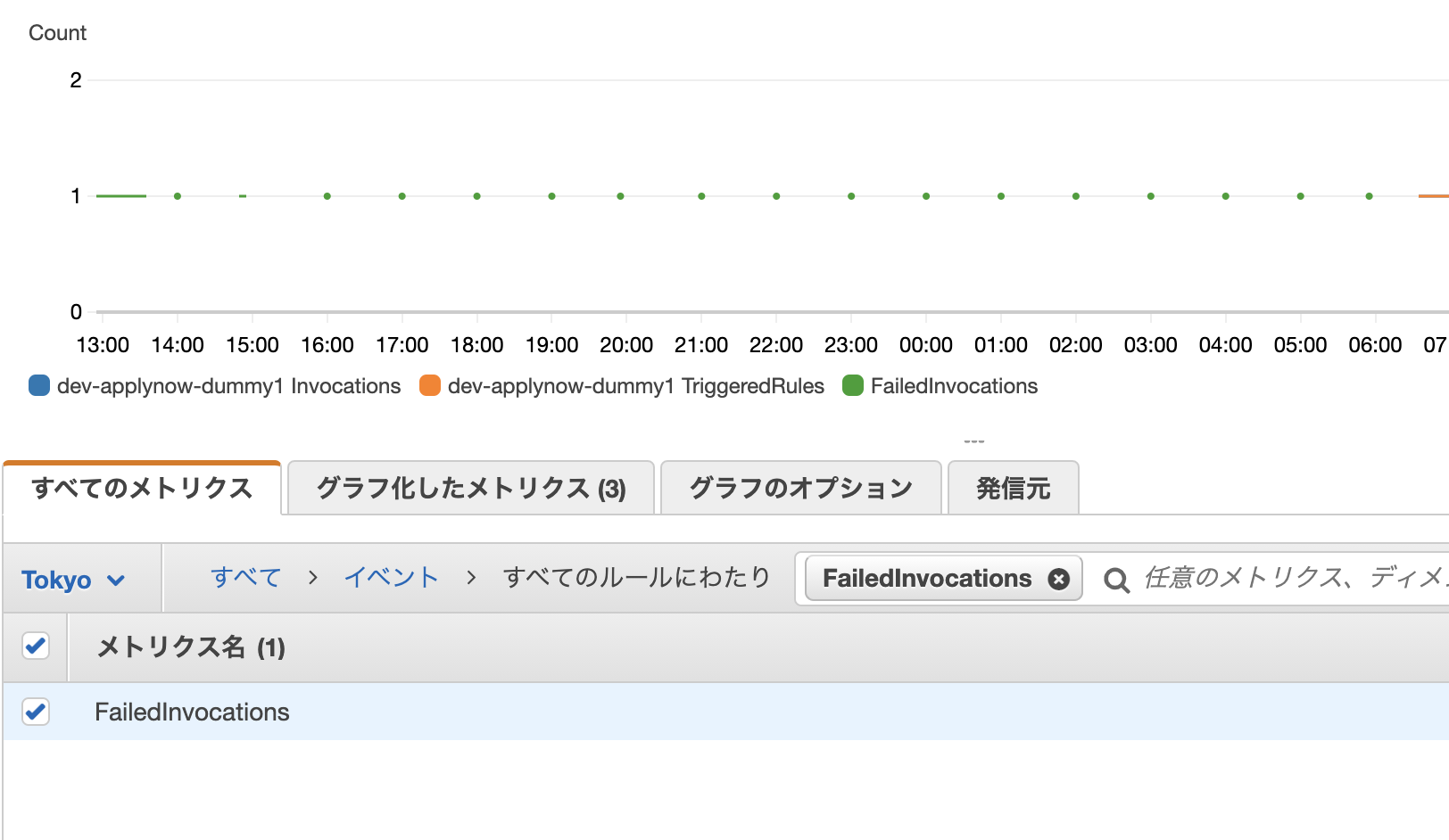
CloudWatchEvents(EventBridge)でFailedInvocationsが発生した時のエラーログの場所はCloudTrail
CloudWatchEvents(EventBridge)でタスクを実行した時に、
FailedInvocationsというエラーが発生した際のログの探し方です。FailedInvocationsとは
CloudWatchEvents(EventBridge)で、cronのように定期的にLambdaを実行したり、ECSでバッチを起動したりができますが、その際に呼び出しが失敗した時に発生するイベント(Metrics?)の事です。
Troubleshooting CloudWatch Events - Amazon CloudWatch Events
You can use the following alarm to notify you when your CloudWatch Events rules are broken.
設定が壊れてる時に発生するようです。
CloudWatchのメトリクスで、確認する事ができます。
「イベント」を選択するか、検索ボックスで「FailedInvocations」と入れれば良いです。
ログの場所
上記の通り、
FailedInvocationsが発生した事は確認できるのですが、なぜ発生したかはCloudWatchでは確認できません。CloudWatchLogsでも確認できません。ではどこかと言うと、
CloudTrailで確認ができます。CloudTrailはAWSでの設定変更やイベントのログを残す監査系のサービスです。
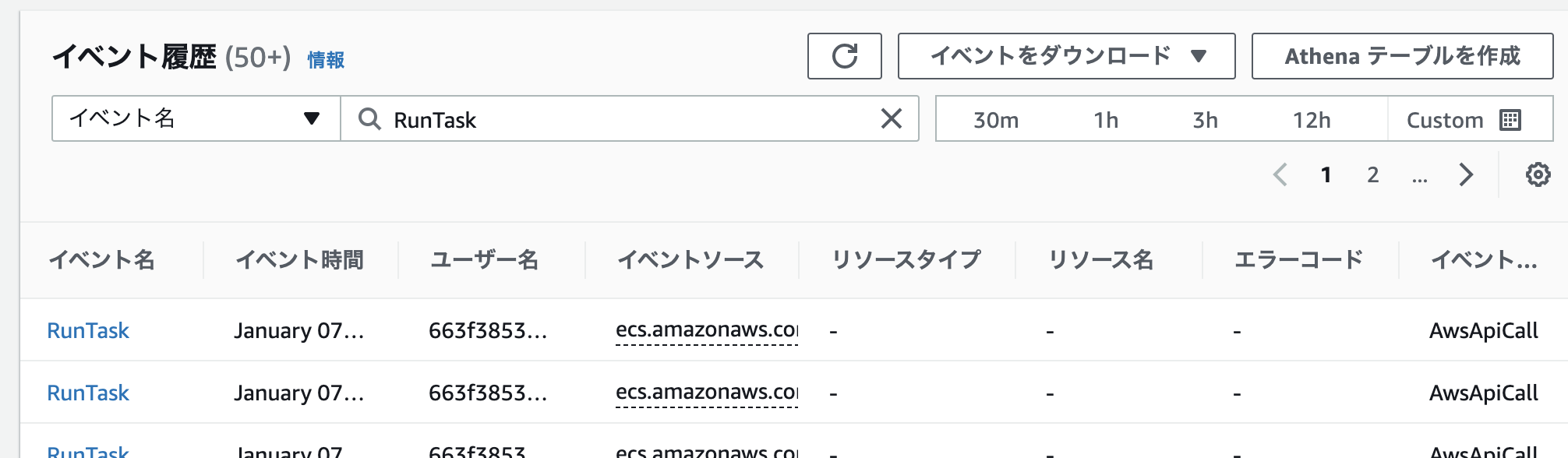
AWS CloudTrail とは - AWS CloudTrailCloudTrailのイベント履歴を開いたら、イベント名->
RunTaskで検索すると、CloudWatchEventが実行した時のイベントログが確認できます。
時刻とエラーコードを頼りに該当のイベントを探して詳細を確認します。
頑張ってjsonのログを探すと、errorMessageが書かれています。
この例だと、Networkの設定がおかしいという事がわかります。
参考
amazon web services - Cloudwatch failedinvocation error no logs available - Stack Overflow

- 投稿日:2021-01-07T21:22:54+09:00
ECSでタスクスケジューリングする時に最新のrevisionのタスク定義を参照する方法
ECS環境(Fargate含む)でバッチを動かす場合の選択肢として、ECSのScheduleTask機能を使う方法があります。
この方法で、常に最新のtask定義(task_definitions)の最新を参照する方法について説明します。ECSのタスクスケジューリング機能について
Amazon ECS タスクのスケジューリング - Amazon Elastic Container Service
Amazon ECS ScheduledTaskで実現するスマートなDockerベースのバッチ実行環境 - コネヒト開発者ブログ
AWS ECSを使ったバッチサーバ環境を試してみる - QiitaECSでバッチを動かす場合、いくつか選択肢がありますが、ECSのScheduleTask(スケジューリング)機能が便利です(詳しくは上記をリンクを参照ください)。ScheduleTaskを使うと、cron的に定期的にタスクを立ち上げて、定期的に処理を実行する事ができます。
このScheduleTaskはECSと統合されていますが、実際には
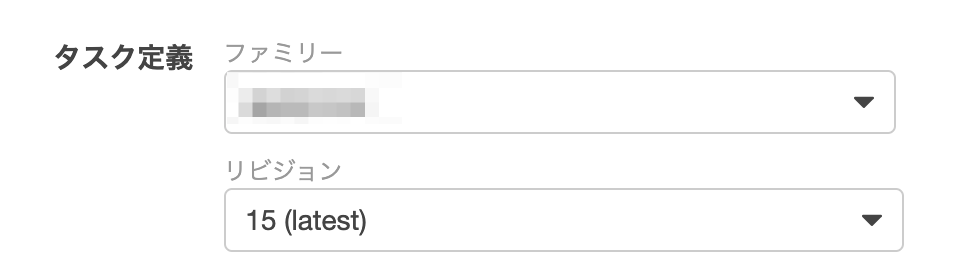
Amazon EventBridgeのrule機能になります。さらに、Amazon EventBridgeは、CloudWatch Eventsという名前だったもので、まだCloudWatchのコンソール画面から操作が可能です。最新を参照する@AWSコンソール画面
画面でいうとここで「最新」を選べば、起動時に最新のrevisionのtask_definitions(タスク定義)を使って、タスクが起動します。
が、ここで一つ罠がありまして、前述の通り、
ECSのスケジューリング機能 ≒ Amazon EventBridge ≒ CloudWatch Events
でして(≒の表現は誤解を招きそうですがこの記事の趣旨では無いので軽くスルーしてください)、同じ設定が、
- ECS
- EventBridge
- CloudWatch
の3画面で可能となっています。
この3画面のうち、ECSの画面から追加しようとした場合は、「最新」の選択肢がでてきません。残念。
というわけで、EventBridgeかCloudWatchの画面から作成する必要があります。
おそらくそのうち対応されると思いますがご注意ください。
最新を参照する@terraform
terraformだとこのようになります(抜粋なのでこのままじゃ動かないかも)。
resourcの名前はcloudwatchなので注意が必要です。resource "aws_cloudwatch_event_rule" "rule" { name = "name" schedule_expression = "cron(30 * * * ? *)" } resource "aws_cloudwatch_event_target" "target" { target_id = "name" rule = aws_cloudwatch_event_rule.rule.name arn = aws_ecs_cluster.main.arn ecs_target { launch_type = "EC2" task_count = 1 task_definition_arn = "arn:aws:ecs:ap-northeast-1:XXXXXXXX:task-definition/name" # ここがポイント } }ポイントは、
task_definition_arnでして、ここでrevisionを指定しなければ、画面で「最新」を選んだことになります。revisionを指定する場合は
arn:aws:ecs:ap-northeast-1:XXXXXXXX:task-definition/name:15のようになります。
補足
Terraform v0.13.5 で動作確認しました。

- 投稿日:2021-01-07T20:37:20+09:00
terraformで「Error: Failed getting task definition ClientException: Unable to describe task definition. "XXXXX"」
terraformで、
Error: Failed getting task definition ClientException: Unable to describe task definition. "XXXX"というエラーが出た時の対応です。
エラーが発生するtfファイル
resource "aws_ecs_task_definition" "test" { // 省略 } # Simply specify the family to find the latest ACTIVE revision in that family. data "aws_ecs_task_definition" "test" { task_definition = aws_ecs_task_definition.test.family }一見問題なさそうですが、新規作成の時にエラーが発生します。
対応
resource "aws_ecs_task_definition" "test" { // 省略 } # Simply specify the family to find the latest ACTIVE revision in that family. data "aws_ecs_task_definition" "test" { task_definition = aws_ecs_task_definition.test.family depends_on = [aws_ecs_task_definition.test] // 追加 }この様に、
depends_onで依存関係を明示してあげるとうまくいきます。参考
data.aws_ecs_task_definition: Failed getting task definition · Issue #1274 · hashicorp/terraform-provider-aws
aws_ecs_task_definition | Data Sources | hashicorp/aws | Terraform Registry※この記事を書いている段階で、terraformのドキュメントのexample通りに書いてもこの事象が発生します
補足
Terraform v0.13.5 で動作確認しました。
- 投稿日:2021-01-07T19:53:45+09:00
LambdaでDetectron2(物体検出)して、実行速度はかってみた。
概要
- モデル:resnet50 + frcnn
- lambdaのメモリサイズ:8192MB
結論先に書くと、
コールドスタートありで9秒ほど。
コールドスタートなしでなんと3秒!簡単にapi作るにはいいかもですね。
(メモ書きです。)
ファイル郡
FROM nvidia/cuda:10.1-cudnn7-devel ENV DEBIAN_FRONTEND noninteractive RUN apt-get update && apt-get install -y \ python3-opencv ca-certificates python3-dev git wget sudo \ cmake ninja-build && \ rm -rf /var/lib/apt/lists/* RUN ln -sv /usr/bin/python3 /usr/bin/python WORKDIR /home ENV PATH="/home/.local/bin:${PATH}" RUN wget https://bootstrap.pypa.io/get-pip.py && \ python3 get-pip.py && \ rm get-pip.py # install dependencies # See https://pytorch.org/ for other options if you use a different version of CUDA RUN pip install tensorboard RUN pip install torch==1.7 torchvision==0.8.1 -f https://download.pytorch.org/whl/cu101/torch_stable.html RUN pip install 'git+https://github.com/facebookresearch/fvcore' # install detectron2 RUN git clone https://github.com/facebookresearch/detectron2 detectron2_repo # set FORCE_CUDA because during `docker build` cuda is not accessible ENV FORCE_CUDA="0" # This will by default build detectron2 for all common cuda architectures and take a lot more time, # because inside `docker build`, there is no way to tell which architecture will be used. ARG TORCH_CUDA_ARCH_LIST="Kepler;Kepler+Tesla;Maxwell;Maxwell+Tegra;Pascal;Volta;Turing" ENV TORCH_CUDA_ARCH_LIST="${TORCH_CUDA_ARCH_LIST}" RUN pip install -e detectron2_repo # aws lambda run interface clientを iinstallする RUN pip install awslambdaric # opetion aws-rieを入れる。 ADD https://github.com/aws/aws-lambda-runtime-interface-emulator/releases/latest/download/aws-lambda-rie /usr/bin/aws-lambda-rie RUN chmod 755 /usr/bin/aws-lambda-rie # Set a fixed model cache directory. ENV FVCORE_CACHE="/tmp" ARG APP_DIR="/home/app/" WORKDIR ${APP_DIR} COPY app ${APP_DIR} ENTRYPOINT [ "/bin/bash", "entry.sh" ] CMD [ "icon_predict.main" ]
- entry.sh
#!/bin/sh if [ -z "${AWS_LAMBDA_RUNTIME_API}" ]; then exec /usr/bin/aws-lambda-rie /usr/bin/python -m awslambdaric $1 # exec /usr/bin/aws-lambda-rie /usr/bin/python3 -m awslambdaric else exec /usr/bin/python -m awslambdaric $1 fi
- icon_predict.py
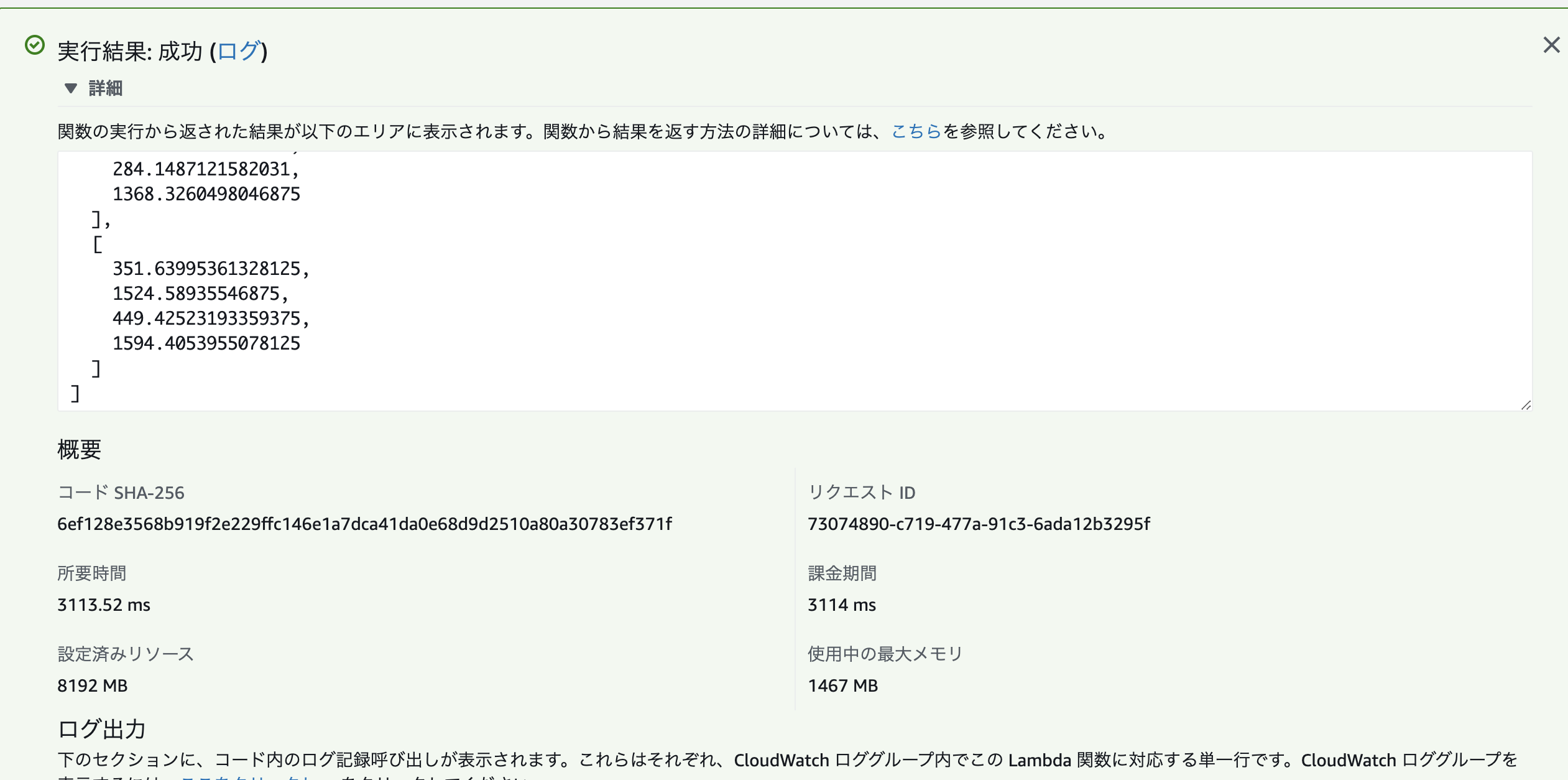
import os import sys import numpy as np import cv2 import torch import json import boto3 from torchvision import transforms, utils from detectron2 import model_zoo from detectron2.engine import DefaultPredictor from detectron2.config import get_cfg from detectron2.utils.visualizer import Visualizer, ColorMode from detectron2.data import MetadataCatalog, DatasetCatalog from detectron2.data.datasets import register_coco_instances # modelのダウンロード S3_BUCKET = [bucket名] s3 = boto3.resource('s3') model_path = [modelのpath名] s3_key = [modelのs3のkey名] if not os.path.exists(model_path): s3.Bucket(S3_BUCKET).download_file(s3_key, model_path) def gen_predictor(model_path): """ 事前にモデルを設定する。 """ device = os.getenv("DEVICE", "cpu") cfg = get_cfg() cfg.MODEL.DEVICE = device cfg.merge_from_file(model_zoo.get_config_file("PascalVOC-Detection/faster_rcnn_R_50_FPN.yaml")) cfg.MODEL.WEIGHTS = model_path # downloadで落としてきたモデル。 cfg.SOLVER.IMS_PER_BATCH = 1 cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128 # faster, and good enough for this toy dataset (default: 512) cfg.MODEL.ROI_HEADS.NUM_CLASSES = 6 # only has one class (ballon) cfg.MODEL.ROI_HEADS.NMS = 0.2 cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.8 # set the testing threshold for this model predictor = DefaultPredictor(cfg) return predictor def main(): img_path = "image.png" img = cv2.imread(img_path) predictor = gen_predictor(model_path) bigicon_predictions = predictor(img)["instances"].to("cpu") boxes = bigicon_predictions.pred_boxes.__dict__["tensor"].tolist() scores = bigicon_predictions.scores.tolist() print("boxes :", boxes) print("scores :", scores) print("-- Finished!! --") return boxes def handler(event, context): return main() if __name__ == "__main__": main()実行結果
テストすると3秒くらい。
- モデルをひとまずAPIにしたい。
- サーバレスで運用したい
- SageMakermめんどくさい...
- コストそんな高くしたくない...
って人にはそこそこ使える性能じゃないだろうか。
- 投稿日:2021-01-07T18:54:59+09:00
Amazon Linux2でrpm --importで外部repository追加できない俺のためのメモ
俺です
Metricbeatを突っ込もうとした時に字を読め問題に遭遇したのでメモを残します。
[ec2-user@ip-172-31-28-80 ~]$ cat /etc/system-release Amazon Linux release 2 (Karoo) [ec2-user@ip-172-31-28-80 ~]$ rpm -qa|grep relea system-release-2-13.amzn2.x86_64rpm --import
nai[root@ip-172-31-28-80 docker]# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch [root@ip-172-31-28-80 docker]# cd /etc/yum.repos.d/ [root@ip-172-31-28-80 yum.repos.d]# ll 合計 8 -rw-r--r-- 1 root root 1003 12月 8 00:40 amzn2-core.repo -rw-r--r-- 1 root root 1105 12月 21 20:04 amzn2-extras.repoyum-config-manager
dekita
[root@ip-172-31-28-80 yum.repos.d]# yum-config-manager --add-repo https://artifacts.elastic.co/GPG-KEY-elasticsearch 読み込んだプラグイン:extras_suggestions, langpacks, priorities, update-motd adding repo from: https://artifacts.elastic.co/GPG-KEY-elasticsearch [artifacts.elastic.co_GPG-KEY-elasticsearch] name=added from: https://artifacts.elastic.co/GPG-KEY-elasticsearch baseurl=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 [root@ip-172-31-28-80 yum.repos.d]# echo $? 0 [root@ip-172-31-28-80 yum.repos.d]# ll 合計 12 -rw-r--r-- 1 root root 1003 12月 8 00:40 amzn2-core.repo -rw-r--r-- 1 root root 1105 12月 21 20:04 amzn2-extras.repo -rw-r--r-- 1 root root 184 1月 7 07:55 artifacts.elastic.co_GPG-KEY-elasticsearch.repo[root@ip-172-31-28-80 yum.repos.d]# yum install metricbeat 読み込んだプラグイン:extras_suggestions, langpacks, priorities, update-motd amzn2-core | 3.7 kB 00:00:00 amzn2extra-docker | 3.0 kB 00:00:00 artifacts.elastic.co_GPG-KEY-elasticsearch | 1.3 kB 00:00:00 artifacts.elastic.co_GPG-KEY-elasticsearch/primary | 164 kB 00:00:00 artifacts.elastic.co_GPG-KEY-elasticsearch 544/544 依存性の解決をしています --> トランザクションの確認を実行しています。 ---> パッケージ metricbeat.x86_64 0:7.10.1-1 を インストール --> 依存性解決を終了しました。 依存性を解決しました ========================================================================================================================================================== Package アーキテクチャー バージョン リポジトリー 容量 ========================================================================================================================================================== インストール中: metricbeat x86_64 7.10.1-1 artifacts.elastic.co_GPG-KEY-elasticsearch 27 M トランザクションの要約 ========================================================================================================================================================== インストール 1 パッケージ 総ダウンロード容量: 27 M インストール容量: 93 M Is this ok [y/d/N]: y Downloading packages: metricbeat-oss-7.10.1-x86_64.rpm | 27 MB 00:00:03 Running transaction check Running transaction test Transaction test succeeded Running transaction インストール中 : metricbeat-7.10.1-1.x86_64 1/1 検証中 : metricbeat-7.10.1-1.x86_64 1/1 インストール: metricbeat.x86_64 0:7.10.1-1 完了しました! [root@ip-172-31-28-80 yum.repos.d]# rpm -qa|grep metricbeat metricbeat-7.10.1-1.x86_64
- 投稿日:2021-01-07T18:34:03+09:00
AWS CloudFormationのデプロイ済みスタックのテンプレートをYAMLで取得
デプロイ済みのスタックのテンプレートファイルがどうだったかを見たいときに、awscliの
aws cloudformation get-templateコマンドで見ることができます。$ aws cloudformation get-template --stack-name STACK_NAMEしかし、フォーマットはJSONで固定のようです。たとえデプロイ時はYAMLだったとしてもです。YAMLで見たい場合は、JSONからYAMLに変換する必要があります。
yqコマンドでYAMLに変換
yqというコマンドがあります。JSONを扱うjqコマンドのYAML版です。yq: Command-line YAML/XML processor - jq wrapper for YAML and XML documents — yq documentation
実行例
$ aws cloudformation get-template --stack-name STACK_NAME | yq . -yYAMLはJSONの上位互換なので、
yqコマンドはYAML、JSONどちらも入力に受け付けます。出力はデフォルトではJSONで、-yを付けることでYAML出力になります。yqコマンドのインストール
yqはPythonで書かれており、pipでインストールできます。$ pip install yq内部で
jqを呼び出しているようで、jqがないと次のようなエラーになります。yq: Error starting jq: FileNotFoundError: [Errno 2] No such file or directory: 'jq'. Is jq installed and available on PATH?
jqのインストールはUbuntuならば$ sudo apt install -y jqCentOS 8ならば
$ sudo yum install -y jqRubyのワンライナーでYAMLに変換
JSONからYAMLへの変換はRubyのワンライナーでもできます。
$ aws cloudformation get-template --stack-name STACK_NAME | ruby -rjson -ryaml -e 'puts YAML.dump(JSON.load(ARGF))'と書いてから、ついさっきYAMLはJSONの上位互換と書いたばかりなのを思い出しました。次のほうが短くて済みます。
$ aws cloudformation get-template --stack-name STACK_NAME | ruby -ryaml -e 'puts YAML.dump(YAML.load(ARGF))'
- 投稿日:2021-01-07T18:01:39+09:00
はじめてのterraform
※ terraformプロジェクトが既に運用されているけど初めてterraformに触れるよっていう前提です
そもそもterraformとは
超ざっくり言うとソースコードでインフラ構築できちゃうツールです
最初勘違いしてたんですが、AWSのサービスではないですtfenv導入
自分のPCにterraformをインストールする前にtfenvを導入します
terraformは割と頻繁にアップデートがあって、バージョンがちょっと違うだけでも動かなくなったりするのでrubyでいうrbenvのようなバージョン管理ツールを入れといた方が後々楽だと思います
$ brew install tfenv既にterraformを導入済み等の場合は、正しく動くようにコマンドを実行してくれって出てくるので忘れずに実行しましょう
// 例1 Please `brew unlink terraform` before continuing. // 例2 To force the link and overwrite all conflicting files: brew link --overwrite tfenvterraformをインストールするときは下記コマンドを実行します
$ tfenv install 0.12.29 // インストールしたいバージョン 又は latestインストール終わったらuseコマンドでそのバージョンを使うようにします
$ tfenv use 0.12.29最後に下記コマンドで正しく設定されたか確認します
$ terraform -v > Terraform v0.12.29他にtfenvでできることは下記の記事がわかりやすかったです
https://qiita.com/kamatama_41/items/ba59a070d8389aab7694前回構築した時のバージョンを確認する
先に書いたようにバージョンが違うと動かなくなる可能性が高いので、(別の人が)前回構築した時のバージョンと同じにするのが良さそうですよね
前回構築した時の情報はAWSのS3に保存されています(この辺はプロジェクトに寄って違ったりするかも?です)
tfstateファイル(xxxx.tfstate)を探して中身を見てみると、上から2つ目に"terraform_version"があると思います
これが前回構築した時のterraformのバージョンです
それからコードが変更されてなければこのterraformのバージョンを使えばうまくいく"はず"です実行してみる
terraformで構築するまでの大まかな流れは初期化して、確認して、構築!です
- プロジェクトの中はおそらく環境毎にフォルダ分けされてると思うので、構築したい環境に移動します
$ terraform initを実行して初期化します$ terraform planを実行して前回との差分を確認します- 問題なければ
$ terraform applyを実行するとインフラ構築されます(applyするとtfstateファイルが生成されるみたいです)
認証周り
init実行してクレデンシャルがどうのこうのとか、見つかんないよってエラーが出たらだいたい認証周りの不備の可能性大です
下記を特に見直してみるといいかもです(自分はアクセスキーが未発行の状態でinitしてました…orz)
- 秘密鍵と公開鍵が正しくセットされているか
- アクセスキーとシークレットアクセスキーが発行済みでちゃんと設定されているか
- 複数ある場合は切り替わっているか
超ざっくりな解説でしたが、これさえできれば最低限の運用はなんとかなりそうです!
- 投稿日:2021-01-07T17:42:46+09:00
AWS Lambda で 超シンプルに任意のコンテナ Imageを使用する方法
概要
AWS LambdaでContainer Image Supportが発表されました。
AWS Lambda の新機能 – コンテナイメージのサポートしかし、AWS公式ドキュメントに書かれているサンプルコードは、
癖があって少しわかりづらい内容です。本記事では、出来るだけシンプルなデプロイ・実行方法について書いていきます。
対象読者
- Dockerやコンテナの知識がある。
- AWSのLambdaのざっくりとした知識がある。
- aws-cliをインストール・セットアップしている。
ハンズオン
以下の流れで行います。
1. ファイルの準備
2. Image作成・ローカルでの実行
3. Imageのデプロイ
4. Lambdaの設定・実行今回のディレクトリ構成です。
応用が効きやすいよう、できるだけシンプルにしました。# ディレクトリ構成 ├── Dockerfile ├── entry.sh └── app └── app.py(1) ファイルの準備
今回は、buster(debianイメージ。LinuxディストリビューションのOS)を使ってみましょう。
既にpythonがインストールされてるイメージを用います。
実際には、他のイメージでも問題ないです。ポイントは以下の2点になります。
- awslambdaricのインストール
- ローカルで動かしたい場合は、runtime interface emulatorのインストール
これらはentry.sh(後述)で使用することになります。各ファイルのソースコードを以下に示します。
- Dockerfile : Image作成
# Dockerfile FROM python:3.9-buster # runtime interface consoleのインストール RUN pip install awslambdaric # localで実行するために、runtime interface emulatorのinstall ADD https://github.com/aws/aws-lambda-runtime-interface-emulator/releases/latest/download/aws-lambda-rie /usr/bin/aws-lambda-rie RUN chmod 755 /usr/bin/aws-lambda-rie COPY entry.sh "/entry.sh" RUN chmod 755 /entry.sh # 実行ファイルをコンテナ内に配置。 ARG APP_DIR="/home/app/" WORKDIR ${APP_DIR} COPY app ${APP_DIR} ENTRYPOINT [ "/entry.sh" ] CMD [ "app.handler" ]
- app/app.py : 実行したいソースコード。
# app/app.py def handler(event, context): return "Hello world!!"
- entry.sh : ローカルであるか、AWS Lambda上のコンテナであるかを判断して aws-lambda-rieやawslambdaricを使用する。公式参照。
# app/entry.sh if [ -z "${AWS_LAMBDA_RUNTIME_API}" ]; then exec /usr/bin/aws-lambda-rie /usr/local/bin/python -m awslambdaric $1 else exec /usr/local/bin/python -m awslambdaric $1 fi※注意
/usr/local/bin/pythonとか/entry.shにしてるのは、lambdaの仕様で、コマンドは絶対バスで書く必要あるらしいです。
絶対パスでない場合、ローカルでは動きますが、Lambdaで実行すると以下のようなエラーが生じます。START RequestId: 80f9d98d-06b5-4ba8-b729-b2e6ac2abbe6 Version: $LATEST IMAGE Launch error: Couldn't find valid bootstrap(s): [python] Entrypoint: [](2) イメージの作成・ローカルでの実行
まずはイメージを作成します。
docker build -t container_lambda .次に、コンテナを立てると、デーモンが立ち上がります。
docker run -it --rm -p 9000:8080 container_lambda > NFO[0000] exec '/usr/local/bin/python' (cwd=/home/app, handler=app.handler)イベントを飛ばすには、以下のURLにpostを投げます。
curl -XPOST "http://localhost:9002/2015-03-31/functions/function/invocations" -d '{}' > "Hello world!!"%すると
Hello World!!が返ってきました!
ローカルでの実行成功です。実行するファイルや関数を変えたいときは、CMDで指定するhandlerを変更しましょう。
(3) イメージのデプロイ
実際にLambdaで動かすために、AWSのElastic Container Registory(ECR)にイメージを登録します。
まずは、ECRの画面にうつりましょう。
リポジトリ作成を押します。
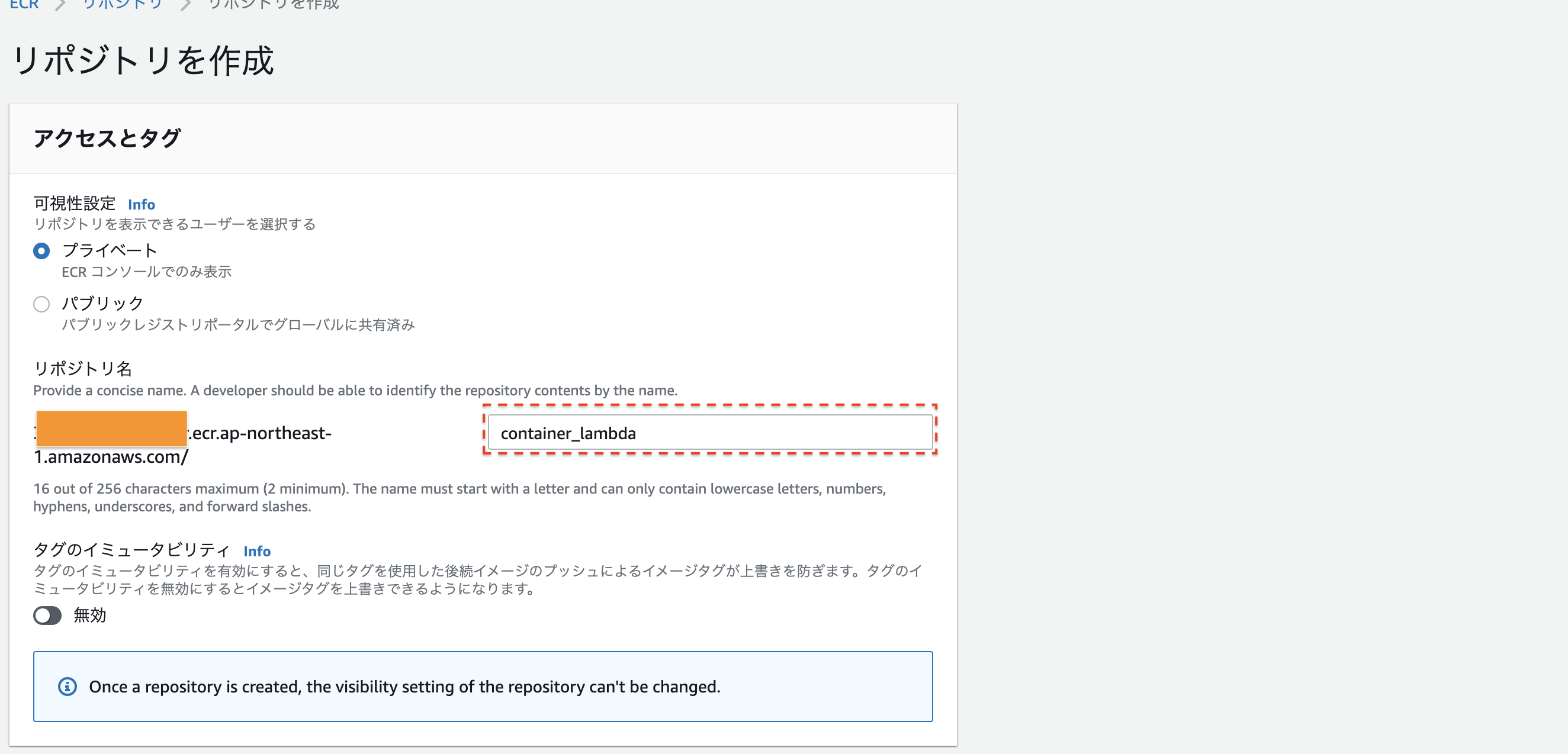
今回は、
container_lambdaという名前でリポジトリを作成します。
名前を決めたら、一番下のリポジトリ作成を押してください次に、このリポジトリにlocalのimageのpushします。
# imageの名前を指定。 IMAGENAME=container_lambda # ECRのURLを指定。 REGISTRYURL=xxxxxxxxx.ecr.ap-northeast-1.amazonaws.com # AWS ECR にログイン。 aws ecr get-login-password | docker login --username AWS --password-stdin $REGISTRYURL # imageの作成、およびAWS ECRへのデプロイ。 docker build -t ${IMAGENAME} . docker tag ${IMAGENAME} 386617633989.dkr.ecr.ap-northeast-1.amazonaws.com/${IMAGENAME} docker push 386617633989.dkr.ecr.ap-northeast-1.amazonaws.com/${IMAGENAME}これでimageをデプロイすることができました。
(4) Lambdaの設定・実行
最後にLambdaで実行しましょう!
まずはAWSコンソールから、Lambdaの画面に行き、関数の作成を押します。
コンテナイメージを選択- 関数名をつける(今回は
container_lambda)- 先ほどデプロイしたDocker Imageを指定
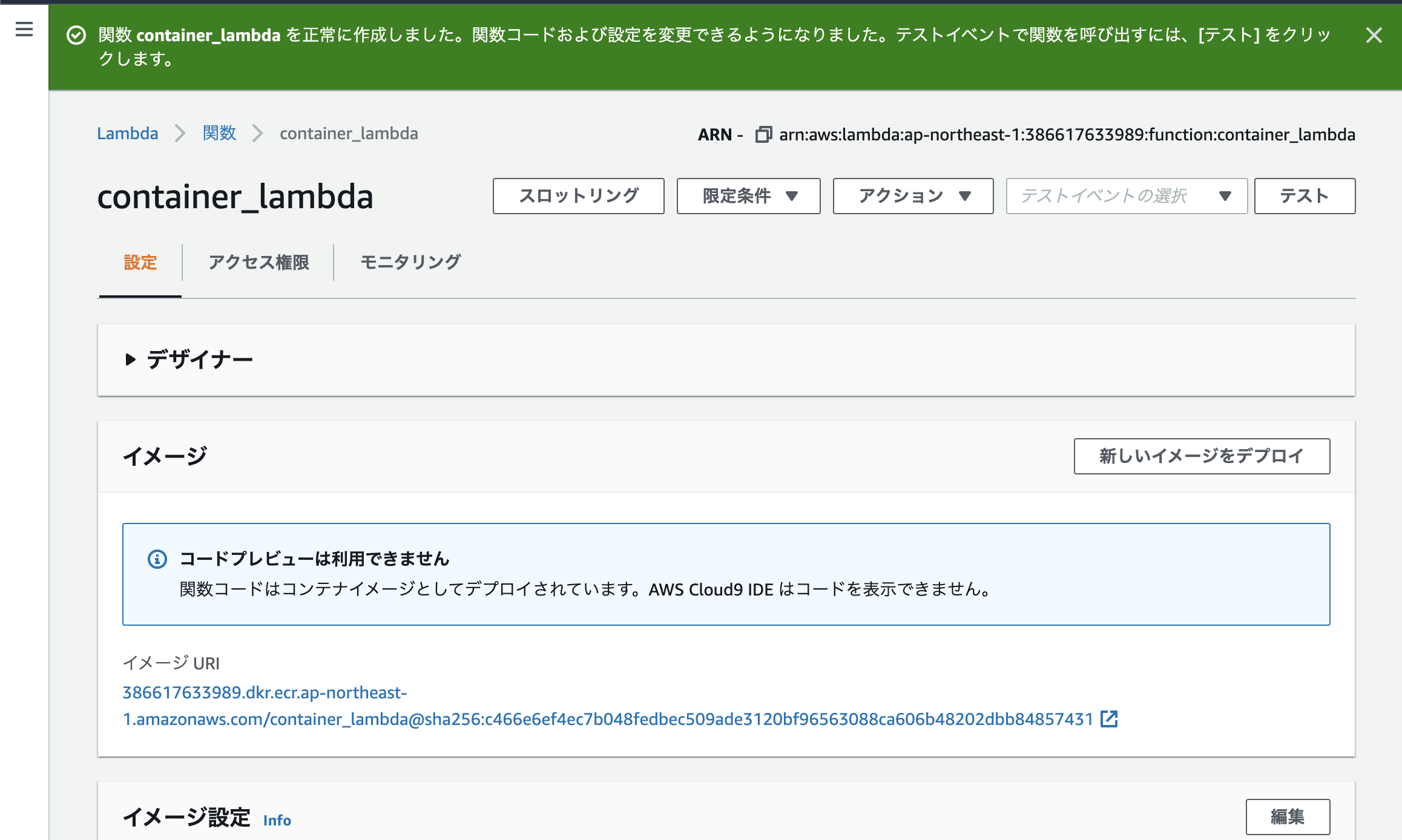
そして
関数の作成を押すと、画面が遷移します。 しばらくすると上の帯が緑になって、lambdaのセットアップが終わります。
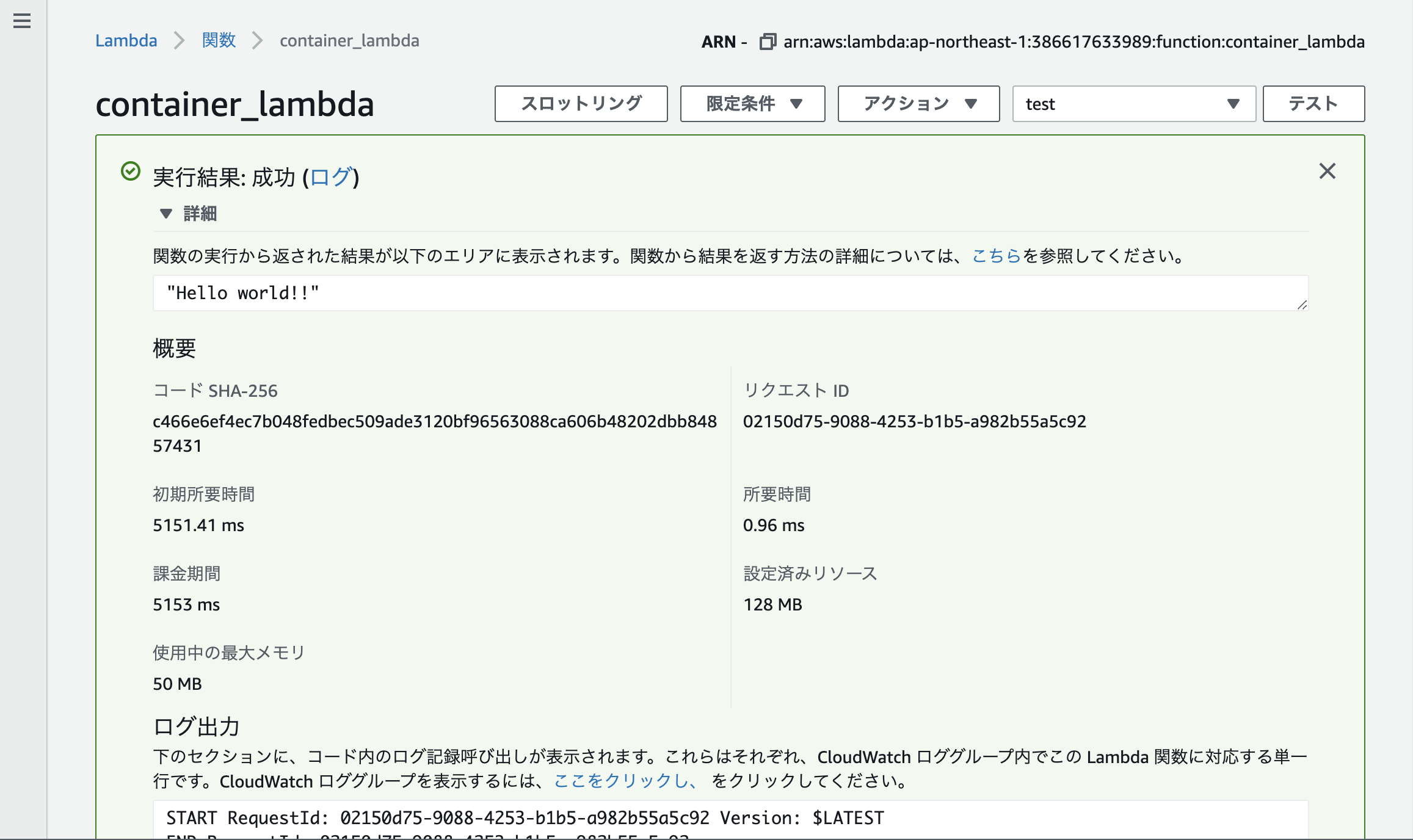
右上のテストを定義し、実行してみると...
Hello world!!が返ってきました!まとめ
ということで、オリジナルランタイムでの実行をまとめてみました。
公式ドキュメントではわざとalpine系を使ったり、Dockerのmulti stage buiidしたりしてややこしそうですが、実際はもっと簡単にできることが分かったと思います。
Lambdaは、最大コア数6、メモリ10GBまでの対応も発表されり激アツです。簡単な機械学習APIもより作りやすくなりました。
AWS Lambda now supports up to 10 GB of memory and 6 vCPU cores for Lambda Functions非常に便利なので是非みなさんトライしてみてください!
次は、Detectron2という画像認識モデルをAWS Lambdaで動かしてみたいと思います!
- 投稿日:2021-01-07T17:42:46+09:00
【AWS Lambda】Pythonで超シンプルに任意のコンテナ Imageを使用する
概要
AWS LambdaでContainer Image Supportが発表されました。
AWS Lambda の新機能 – コンテナイメージのサポートしかし、AWS公式ドキュメントに書かれているサンプルコードは、
癖があって少しわかりづらい内容です。本記事では、出来るだけシンプルなデプロイ・実行方法について書いていきます。
対象読者
- Dockerやコンテナの知識がある。
- AWSのLambdaのざっくりとした知識がある。
- aws-cliをインストール・セットアップしている。
ハンズオン
以下の流れで行います。
1. ファイルの準備
2. Image作成・ローカルでの実行
3. Imageのデプロイ
4. Lambdaの設定・実行今回のディレクトリ構成です。
応用が効きやすいよう、できるだけシンプルにしました。# ディレクトリ構成 ├── Dockerfile ├── entry.sh └── app └── app.py(1) ファイルの準備
今回は、buster(debianイメージ。LinuxディストリビューションのOS)を使ってみましょう。
既にpythonがインストールされてるイメージを用います。
実際には、他のイメージでも問題ないです。ポイントは以下の2点になります。
- awslambdaricのインストール
- ローカルで動かしたい場合は、runtime interface emulatorのインストール
これらはentry.sh(後述)で使用することになります。各ファイルのソースコードを以下に示します。
- Dockerfile : Image作成
# Dockerfile FROM python:3.9-buster # runtime interface consoleのインストール RUN pip install awslambdaric # localで実行するために、runtime interface emulatorのinstall ADD https://github.com/aws/aws-lambda-runtime-interface-emulator/releases/latest/download/aws-lambda-rie /usr/bin/aws-lambda-rie RUN chmod 755 /usr/bin/aws-lambda-rie COPY entry.sh "/entry.sh" RUN chmod 755 /entry.sh # 実行ファイルをコンテナ内に配置。 ARG APP_DIR="/home/app/" WORKDIR ${APP_DIR} COPY app ${APP_DIR} ENTRYPOINT [ "/entry.sh" ] CMD [ "app.handler" ]
- app/app.py : 実行したいソースコード。
# app/app.py def handler(event, context): return "Hello world!!"
- entry.sh : ローカルであるか、AWS Lambda上のコンテナであるかを判断して aws-lambda-rieやawslambdaricを使用する。公式参照。
# app/entry.sh if [ -z "${AWS_LAMBDA_RUNTIME_API}" ]; then exec /usr/bin/aws-lambda-rie /usr/local/bin/python -m awslambdaric $1 else exec /usr/local/bin/python -m awslambdaric $1 fi※注意
/usr/local/bin/pythonとか/entry.shにしてるのは、lambdaの仕様で、コマンドは絶対バスで書く必要あるらしいです。
絶対パスでない場合、ローカルでは動きますが、Lambdaで実行すると以下のようなエラーが生じます。START RequestId: 80f9d98d-06b5-4ba8-b729-b2e6ac2abbe6 Version: $LATEST IMAGE Launch error: Couldn't find valid bootstrap(s): [python] Entrypoint: [](2) イメージの作成・ローカルでの実行
まずはイメージを作成します。
docker build -t container_lambda .次に、コンテナを立てると、デーモンが立ち上がります。
docker run -it --rm -p 9000:8080 container_lambda > NFO[0000] exec '/usr/local/bin/python' (cwd=/home/app, handler=app.handler)イベントを飛ばすには、以下のURLにpostを投げます。
curl -XPOST "http://localhost:9002/2015-03-31/functions/function/invocations" -d '{}' > "Hello world!!"%すると
Hello World!!が返ってきました!
ローカルでの実行成功です。実行するファイルや関数を変えたいときは、CMDで指定するhandlerを変更しましょう。
(3) イメージのデプロイ
実際にLambdaで動かすために、AWSのElastic Container Registory(ECR)にイメージを登録します。
まずは、ECRの画面にうつりましょう。
リポジトリ作成を押します。
今回は、
container_lambdaという名前でリポジトリを作成します。
名前を決めたら、一番下のリポジトリ作成を押してください次に、このリポジトリにlocalのimageのpushします。
# imageの名前を指定。 IMAGENAME=container_lambda # ECRのURLを指定。 REGISTRYURL=xxxxxxxxx.ecr.ap-northeast-1.amazonaws.com # AWS ECR にログイン。 aws ecr get-login-password | docker login --username AWS --password-stdin $REGISTRYURL # imageの作成、およびAWS ECRへのデプロイ。 docker build -t ${IMAGENAME} . docker tag ${IMAGENAME} 386617633989.dkr.ecr.ap-northeast-1.amazonaws.com/${IMAGENAME} docker push 386617633989.dkr.ecr.ap-northeast-1.amazonaws.com/${IMAGENAME}これでimageをデプロイすることができました。
(4) Lambdaの設定・実行
最後にLambdaで実行しましょう!
まずはAWSコンソールから、Lambdaの画面に行き、関数の作成を押します。
コンテナイメージを選択- 関数名をつける(今回は
container_lambda)- 先ほどデプロイしたDocker Imageを指定
関数の作成を押すと、画面が遷移します。 しばらくすると上の帯が緑になって、lambdaのセットアップが終わります。
右上のテストを定義し、実行してみると...
Hello world!!が返ってきました!まとめ
ということで、オリジナルランタイムでの実行をまとめてみました。
公式ドキュメントではわざとalpine系を使ったり、Dockerのmulti stage buiidしたりしてややこしそうですが、実際はもっと簡単にできることが分かったと思います。
Lambdaは、最大コア数6、メモリ10GBまでの対応も発表されり激アツです。簡単な機械学習APIもより作りやすくなりました。
AWS Lambda now supports up to 10 GB of memory and 6 vCPU cores for Lambda Functions非常に便利なので是非みなさんトライしてみてください!
次は、Detectron2という画像認識モデルをAWS Lambdaで動かしてみたいと思います!
- 投稿日:2021-01-07T17:39:21+09:00
API GatewayからLambdaを呼び出すときにevent.bodyをオブジェクトで受け取る
はじめに
AWS API GatewayからLambdaを呼び出すこと、よくあると思います。
Lambdaではevent.bodyでリクエストボディを取得できますが、
デフォルトではこのbodyは文字列なので、
Content-Type:application/jsonの場合も「JSON文字列」になります。
そのため、一度JSONをパースしてあげないといけません。たとえばNode.jsの場合はこんな感じ。
index.jsexports.handler = async (event) => { const body = JSON.parse(event.body); console.log('api received!', body); const response = { statusCode: 200, body: JSON.stringify([body.hoge, body.fuga, body.piyo]), }; return response; };コード側で
JSON.parse()すること自体は大した手間ではないのですが、
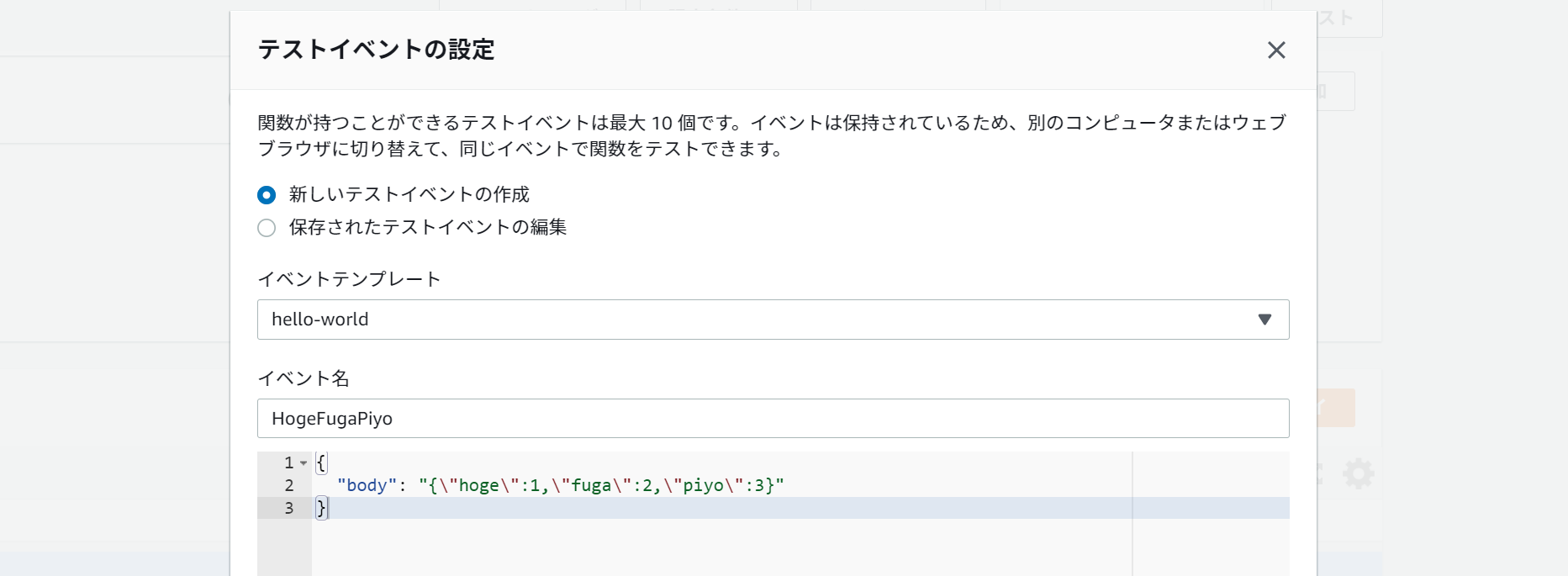
面倒くさいのがテストです。Lambdaの「テストイベントの設定」で、こんな感じで書きたいわけですよ。
{ "body": { "hoge": 1, "fuga": 2, "piyo": 3 } }しかしながら、これは「JSON文字列」ではなく「JSONオブジェクト」なので、
API Gatewayのevent.bodyとは互換性がありません。
こうしてやらなければならない。。。{ "body": "{\"hoge\":1,\"fuga\":2,\"piyo\":3}" }
これはねぇ、、、辛いですよね。
ダブルクォートのエスケープの嵐で、サクッと手書きで書くことは無理です。解決方法
API Gatewayの「マッピングテンプレート」という機能を使うと、
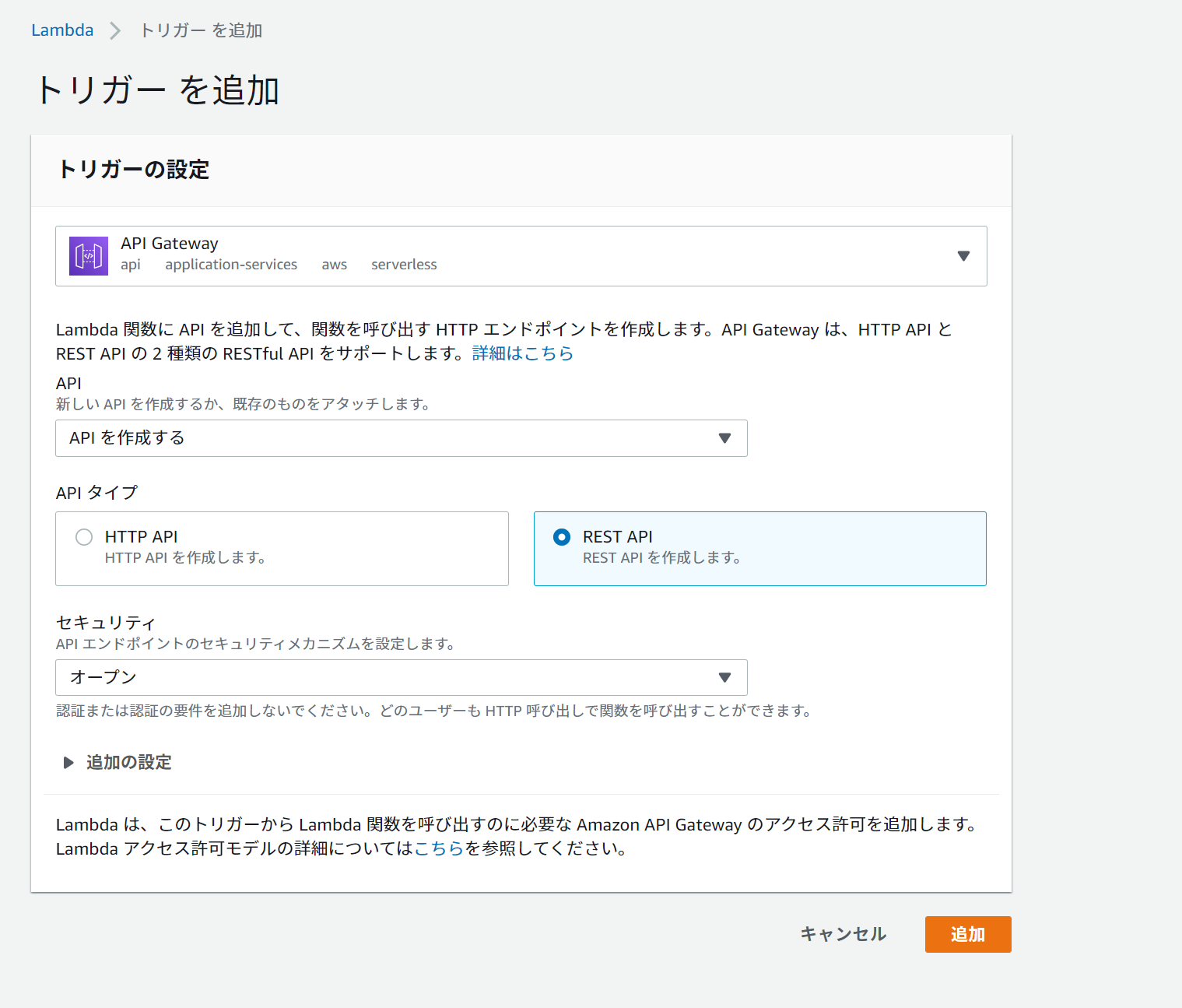
ちゃんとJSONをオブジェクトにしてからLambdaに飛ばすことができます。Lambda側のトリガー設定から新規REST APIを作成
- 検証用に、ごくごくシンプルな設定でAPIを作成
- 実運用では「オープン」は危険なので要注意
- HTTP APIではマッピングテンプレートが使えないので、REST APIにする
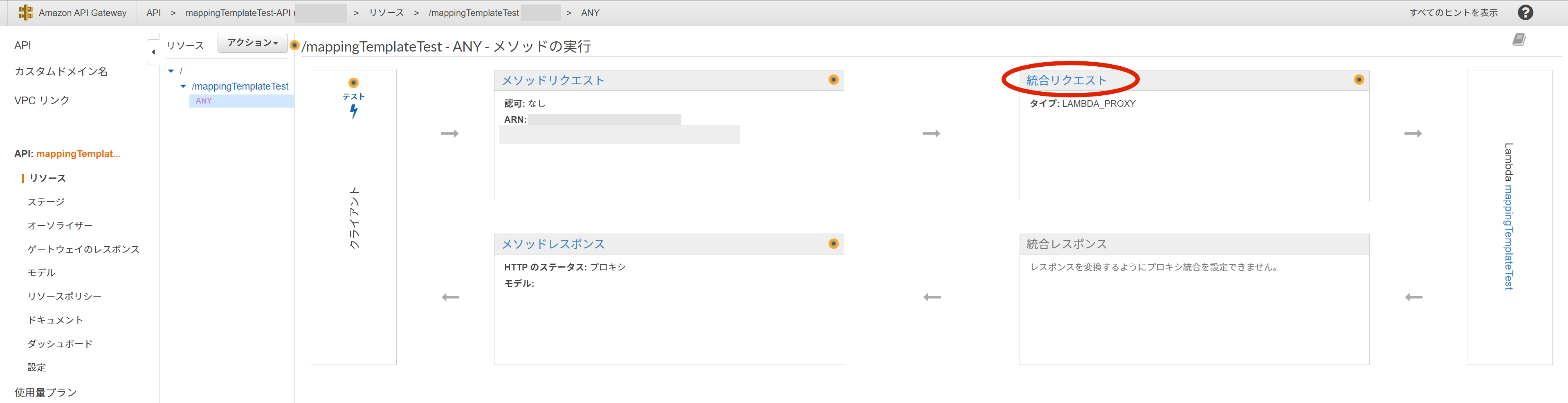
API Gatewayのリソース設定
- API Gatewayのリソース設定に飛んぶ
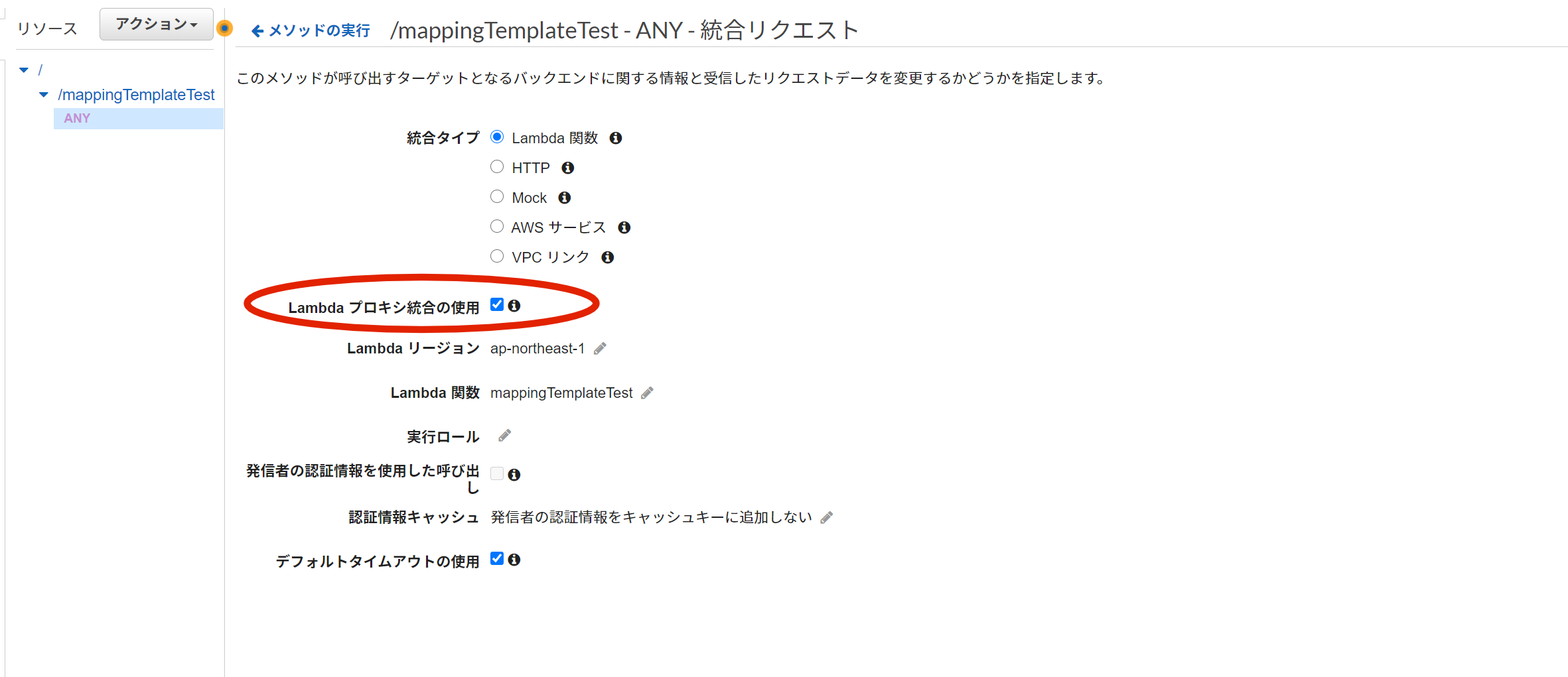
- 「ANY」メソッドの「統合リクエスト」を開く
Lambdaから作ったAPIは「Lambdaプロキシ統合の使用」がチェックされているので、このチェックを外す。
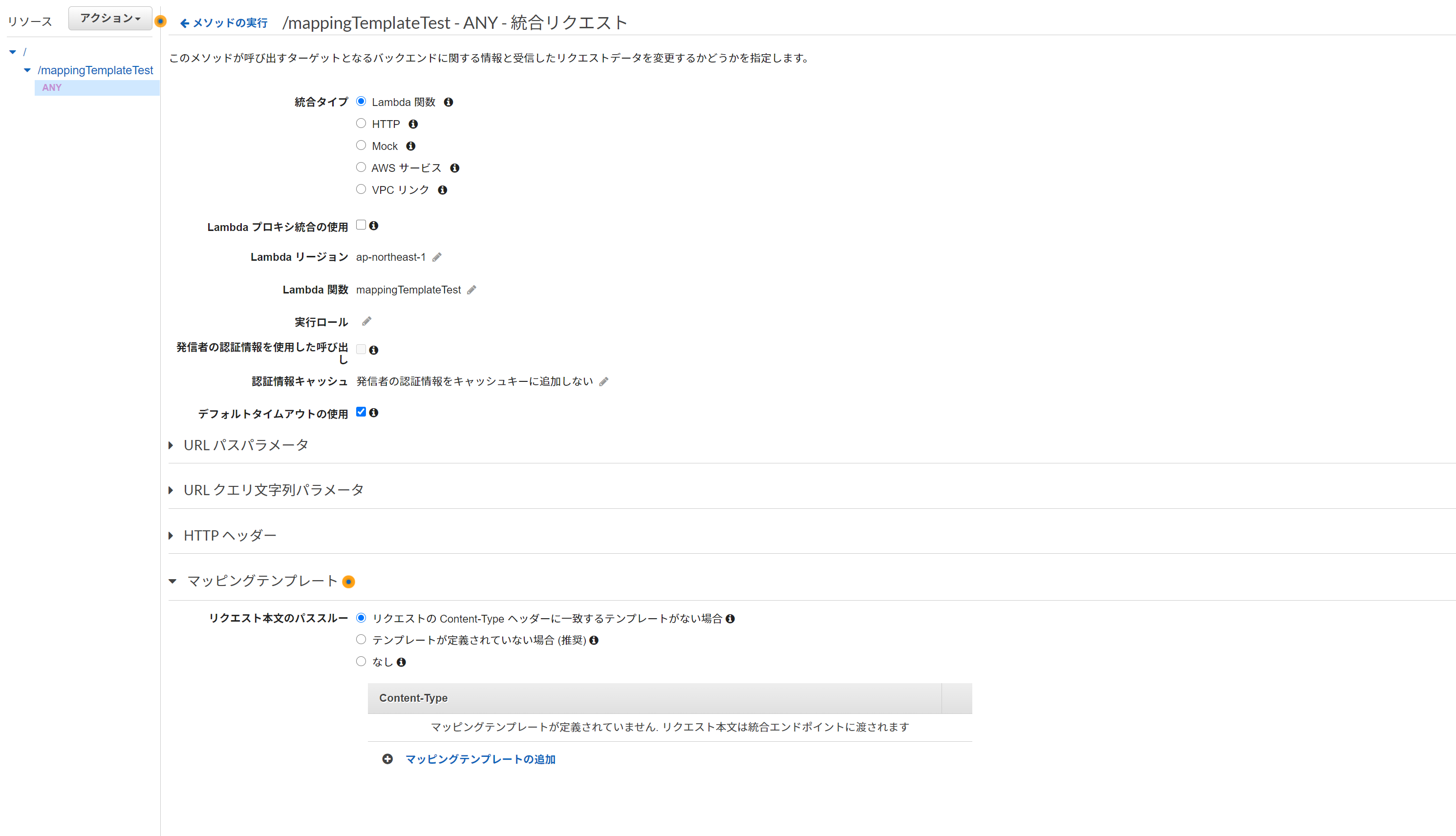
チェックを外すとすると詳細な設定項目が現れるので、「マッピングテンプレート」を開く
マッピングテンプレートの設定
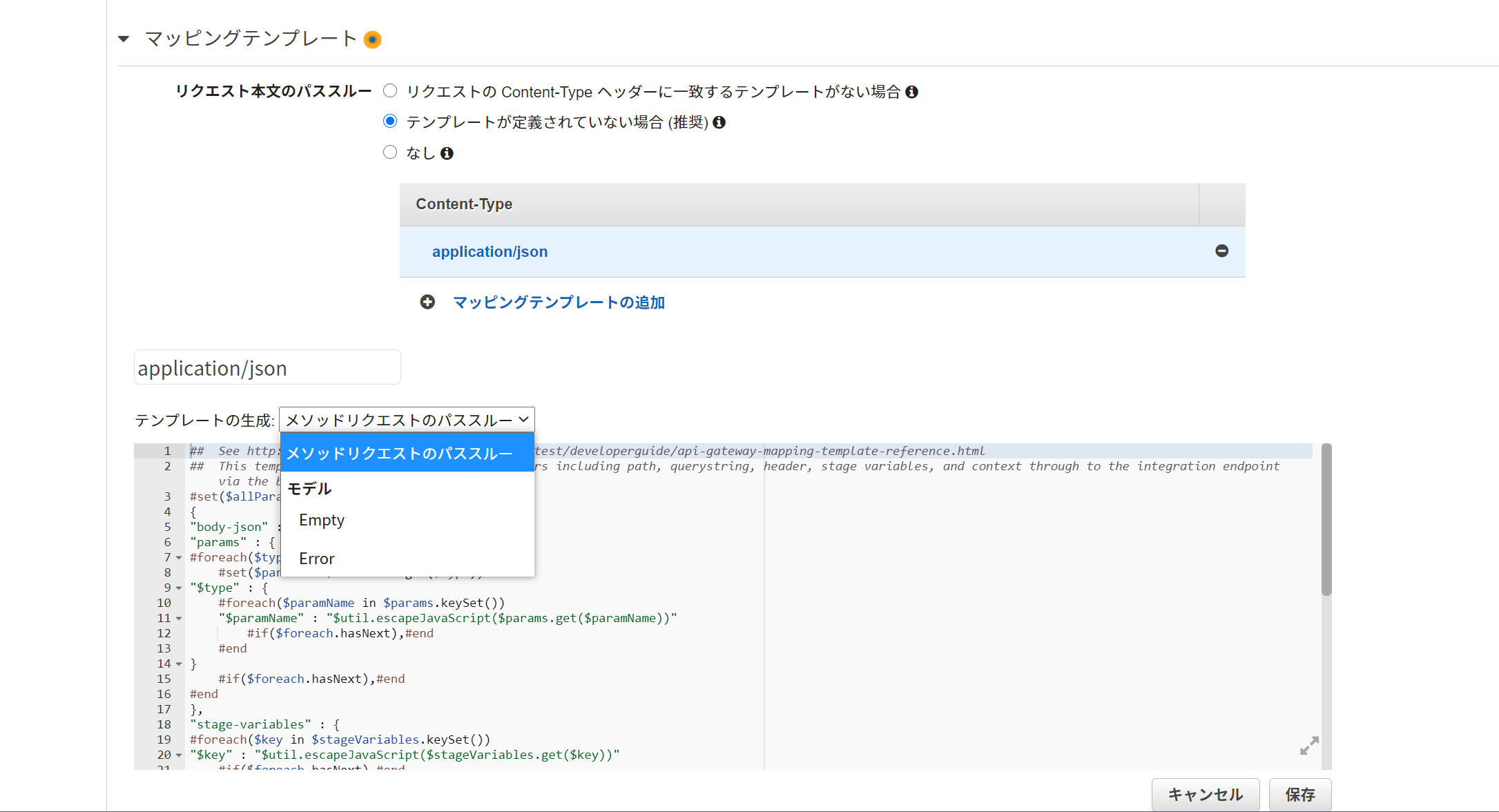
- リクエスト本文のパススルー:「テンプレートが定義されていない場合 (推奨)」を選択
- マッピングテンプレートの追加:「application/json」を入力
- テンプレートの生成:「メソッドリクエストのパススルー」を選択すると、いい感じのプリセットが入る
- 書式が独特なので、一から書くのが大変なのですよね。。このプリセットがとってもありがたい。
- ほとんどプリセットのままで良いのだけど、
body-jsonはcamelCaseのbodyJsonにしておくと、JavaScriptでは扱いやすい
- もしくはシンプルに
bodyでもOK- 編集したら「保存」
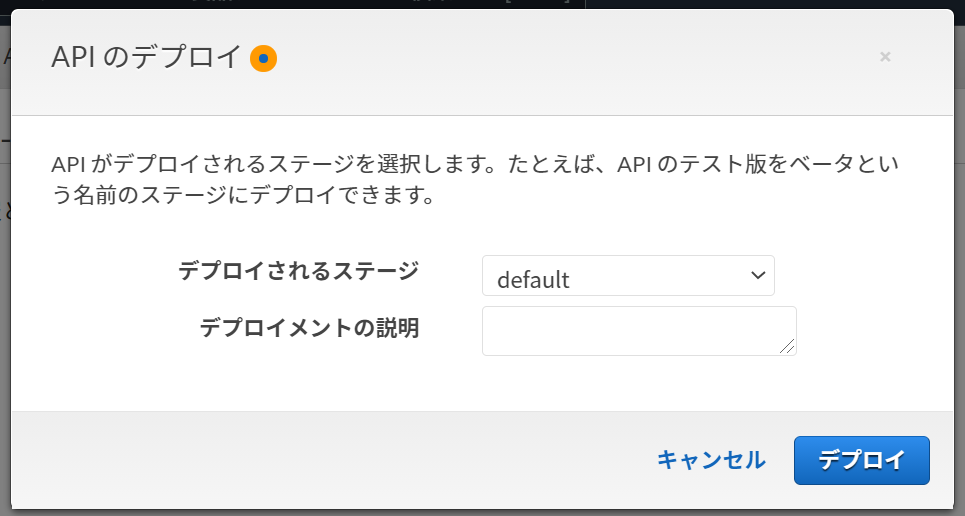
## This template will pass through all parameters including path, querystring, header, stage variables, and context through to the integration endpoint via the body/payload #set($allParams = $input.params()) { -"body-json" : $input.json('$'), +"bodyJson" : $input.json('$'), "params" : { #foreach($type in $allParams.keySet()) #set($params = $allParams.get($type))APIのデプロイ
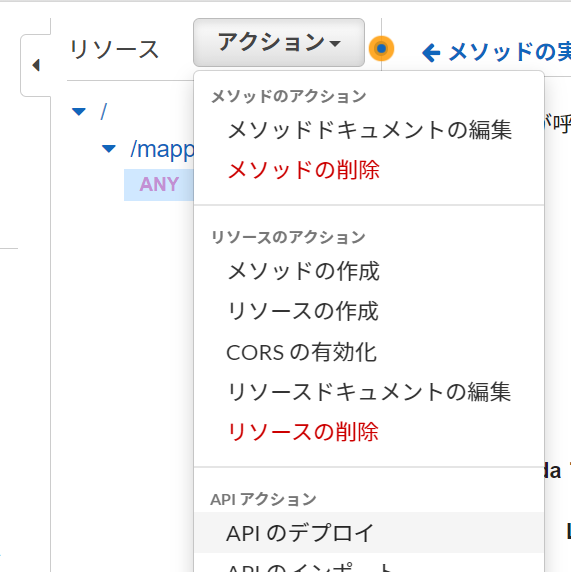
- アクションから「APIのデプロイ」を選択
- ステージ「default」を選んで、説明は書きたければ書いて、「デプロイ」
Lambdaの修正版と実行結果
「Lambdaプロキシ統合の使用」が外れたことで、
レスポンスの作り方も変わります。
statusCodeはAPI Gateway側で定義するので、
Lambdaではシンプルに、正常系のレスポンスをそのままreturnするだけ。index.jsexports.handler = async (event) => { const body = event.bodyJson; console.log('api received!', body); return [body.hoge, body.fuga, body.piyo]; };Lambdaテストイベント
{ "bodyJson": { "hoge": 1, "fuga": 2, "piyo": 3 } }PCターミナルからcurlでAPI叩いてテスト
$ curl -X POST https://example.amazonaws.com/default/mappingTemplateTest -H 'Content-Type:application/json' -d '{"hoge":1,"fuga":2,"piyo":3}' [1,2,3]いい感じですね!
参考サイト
AWS公式
* REST API のデータ変換の設定
* API Gateway で Lambda プロキシ統合を設定するブログ・Qiita
* [AWS]API Gatewayの本文マッピングテンプレートを理解する
* API Gateway + Lambda にFormからPOSTする時のマッピングテンプレートを作成しました
* API Gatewayのマッピングテンプレートの設定例ではまた~。
- 投稿日:2021-01-07T17:30:29+09:00
S3の特定のキーを持つオブジェクトのサイズを集計する
概要
S3の特定のキーを含むオブジェクトのサイズを集計するメモです。
ポイントはコード内にコメントしたので、必要であればご参照ください。コード
count_s3_objects.py#!/usr/bin/env python3 # -*- coding: utf-8 -*- import boto3 client = boto3.client('s3', aws_access_key_id='', aws_secret_access_key='', region_name='') size = 0 start_after = '' def getObjectList(size, start_after=''): next_start = '' param = { 'Bucket': 'hoge', # 一部分まででOK # 2020を含むオブジェクトが取得対象になります 'Prefix': 'access-log/2020', # 指定したKEYの次から取得するようになる 'StartAfter': start_after } # s3.Bucket().objects.all()は非推奨のため、list_objects_v2を使います # https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/s3.html#S3.Client.list_objects_v2 res = client.list_objects_v2(**param) # オブジェクトがなければContentsは空になります if 'Contents' in res: # オブジェクトの数 print('object counts:' + str(len(res['Contents']))) for con in res['Contents']: # サイズを加算する size += con['Size'] next_start = con['Key'] # 一度に1000までしか取得しないため、1000ある場合はTrueになる # その場合は次の処理で継続して取得する # Falseの場合は削除し、再帰処理を停止させる if res['IsTruncated'] == False: next_start = '' return size, next_start # 初回実行 size, start_after = getObjectList(size, start_after) # 後続がある場合は、再帰処理で取得する while start_after != '': print('start_after: ' + start_after) size, start_after = getObjectList(size, start_after) # 合計サイズを表示 print('size:' + str(size))
- 投稿日:2021-01-07T17:19:17+09:00
AWSスポットインスタンス基本
Auto Scaling / Spot Instances ハンズオンセミナー に参加した。
ハンズオンは、(能力的に)書けることは無いので
EC2のスポットインスタンスの基本についてだけまとめる。スポットインスタンスとは
EC2の購入オプションの一つ。
- オンデマンドインスタンス
- リザーブドインスタンス
- スポットインスタンス
スポットインスタンスのメリット
- 低コスト 最大9割引
- アベイラビリティゾーンの空き領域を利用している
仕組機能
- 価格は供給と需要に基づいて徐々に調整される。
- スポットインスタンスはAWSによって中断されることがあり中断される場合2分前に通知される。
- 中断されるのは、指定価格をスポットインスタンス価格が上回ったとき。
使いこなす4原則
- ステートレス:永続的に必要なものは置かない
- 再開可能なワークロード
- 疎結合:
- 分散:複数アベイラベリティゾーンと複数インスタンスタイプの活動:複数ビッティング(?)しておく
AutoScaling
- AutoScalingの種類
- EC2AutoScaling ←今回のハンズオン
- ApplicationAutoScaling
2016年登場 ECSとか、DynamoDBとか- AWS AutoScaling
過去の統計を元に増やしておく。(いくつか問題点があるので本番適用は検証の上検討)起動するインスタンスの設定
- LaunchConfiguration
- LaunchTemplate 推奨 AutoScaling購入オプションとインスタンスを組み合わせることができる
ScalingPolicy
TargetTrackingPolicy 今回
指定されたターゲット値に維持するためにスケールイン、アウトするSimpleScalingPolicy
ScalingPolicywithStepクールダウンウォームアップ
(補足)CodeDeploy
CodePipline
中断のエミュレートもある
- 投稿日:2021-01-07T17:00:01+09:00
マルチクラウド・データ保護の現実解 ~オンプレ、AWS、Azure 、GCP を集中管理するには? 検証結果とベストプラクティスを大公開~
はじめに
今回は、NetBackupによる、マルチクラウド環境のデータ保護について、紹介します。
【お知らせ】
2020/7/29にGAになったNetBackup8.3から、Veritas CloudPointのライセンスと機能が、NetBackupに統合されました。NetBackup Platform Complete Edition with Flexible キャパシティライセンスで、CloudPointの全機能が使用可能ですマルチクラウド環境のデータ保護の課題
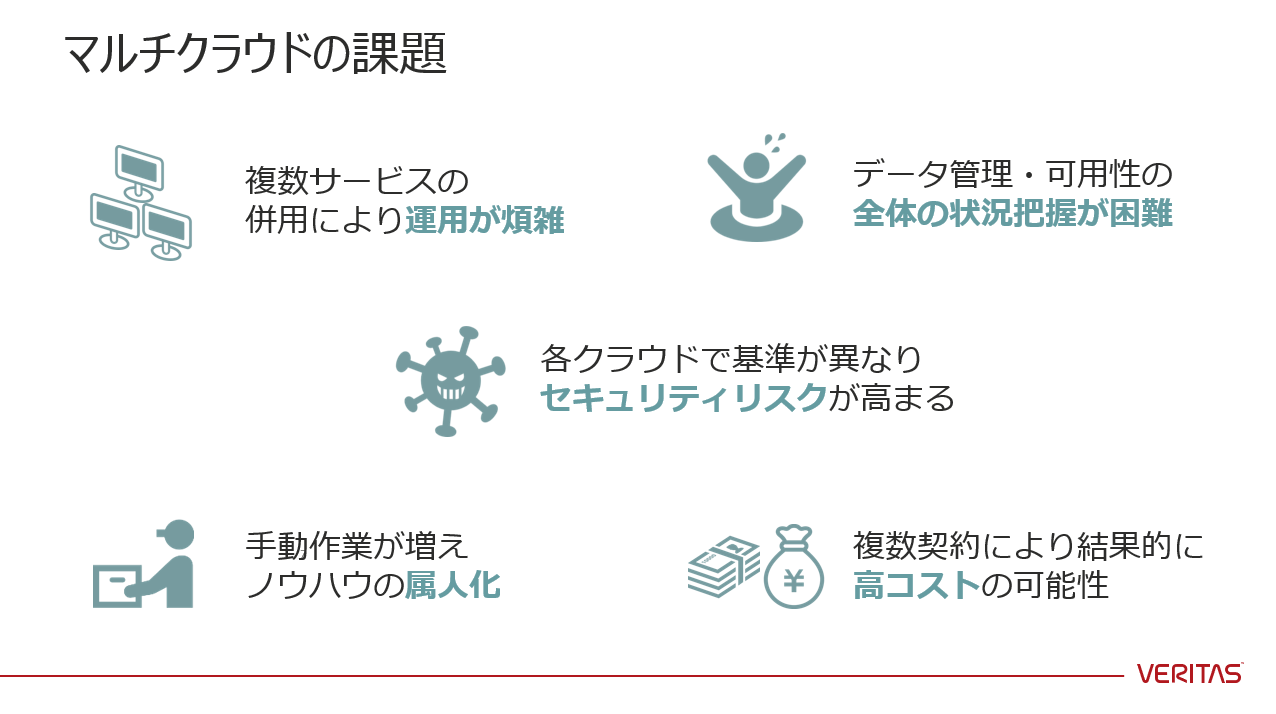
IDC Japanの調査結果によると、46%のユーザが2つ以上のクラウドプロバイダーを利用し、29%のユーザが2つ以上のIaaSを利用しているという結果になっています。
↑ 複数クラウドを同時に使用することにより、これらの課題に直面します。
↑ クラウド上でもデータ保護(バックアップ)は必要です。それは、クラウド利用者の自己責任となります。
↑ そんな中、各クラウドベンダーがバックアップ機能を拡充しています。
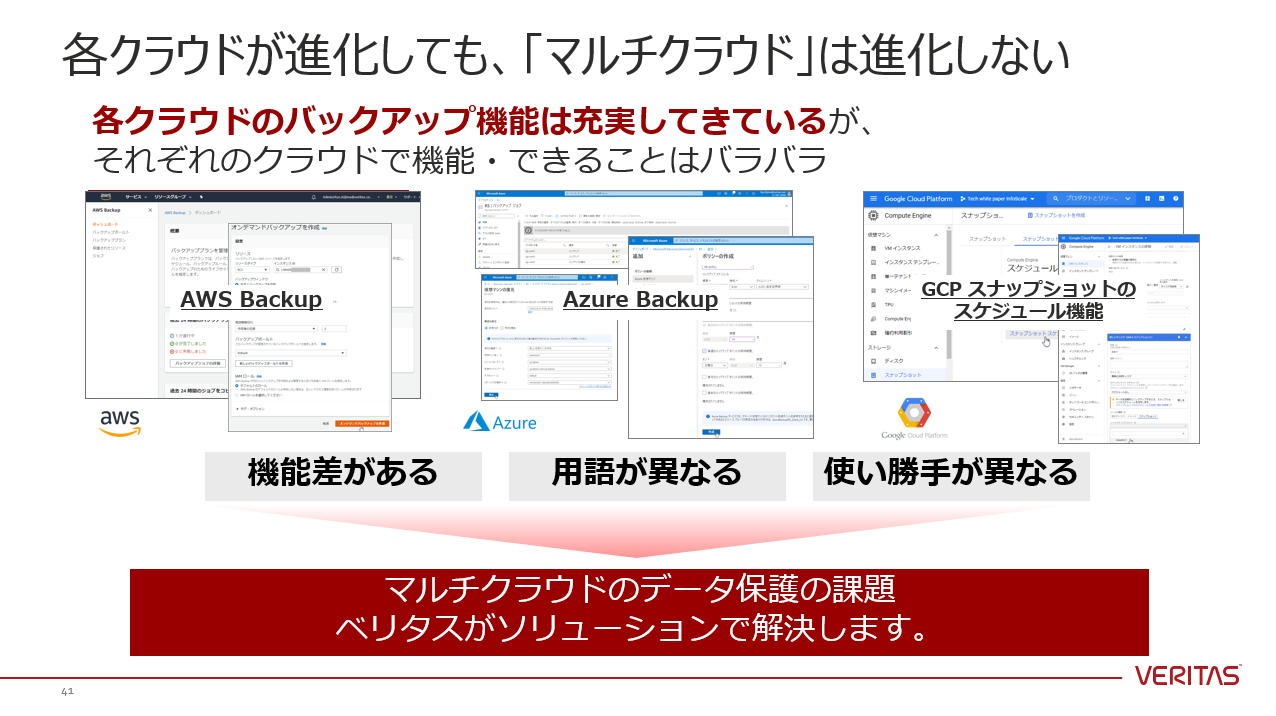
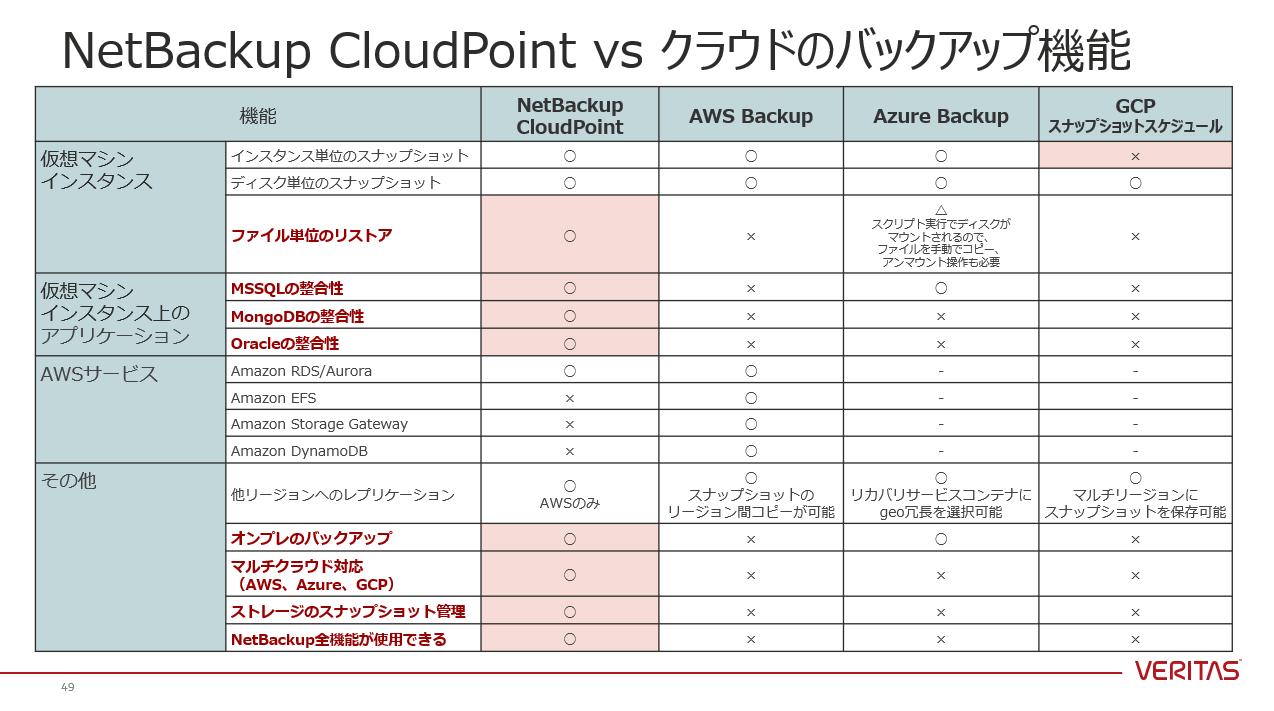
↑ しかし、各クラウドのバックアップ機能が進化しても、利用者にとっての【マルチクラウド】は進化しません。「機能差がある」「用語が異なる」「使い勝手が異なる」これら3つの課題は残り続けます。これらの課題に対して、ベリタスはソリューションで解決します。今回、各クラウドのバックアップ機能についても動作確認を行いました。詳細については、本記事末のSlideShareへのリンクをご参照ください。Veritas NetBackup CloudPointのメリット
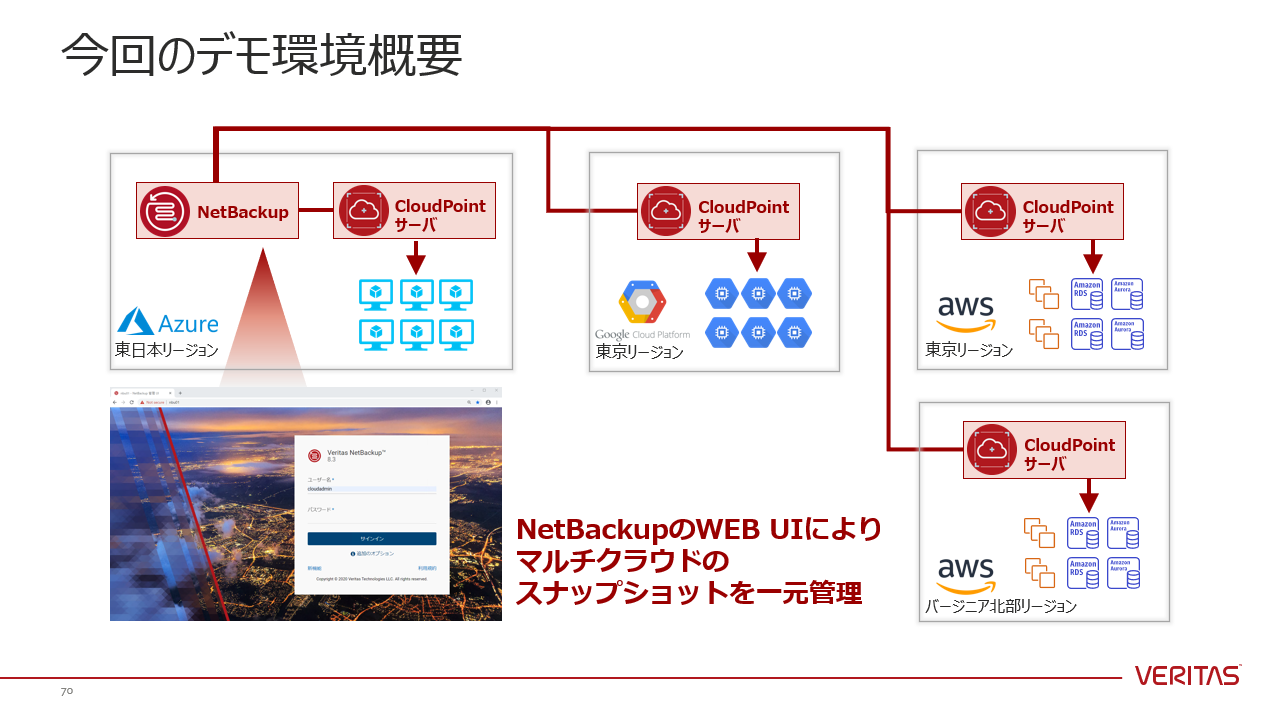
↑ CloudPointサーバを各クラウドに構築し、NetBackupと連携させることで、NetBackupのWEB UIより、マルチクラウドのスナップショットを一元管理することができます。
↑ お忙しい方のために、NetBackup CloudPointと各クラウドのバックアップ機能の機能差についてまとめましたので、ご確認ください。NetBackup CloudPoint により、高速・確実なバックアップ/リカバリにより、人的ミス・サイバーアタック・自然災害などから、リスクを回避できます。シンプルなシングルUIにより、オンプレとマルチクラウドの統合バックアップが実現でき、データ保護の運用コストの削減につながります。本記事では、「マルチクラウド環境のデータ保護の課題」「Veritas NetBackup CloudPointのメリット」について、ご紹介しました。
SlideShareにはフルバージョンの紹介資料を掲載しておりますので、下記より参照ください。
NetBackup CloudPointの構成・動作詳細・画面キャプチャ等を確認することができます。
マルチクラウド環境のデータ保護の現実解(AWS,Azure,GCP-Veritas NetBackup CloudPoint)
↑↑↑ SlideShareにリンクしています
- マルチクラウドの現状 ~メリットと課題~
- NetBackup CloudPoint 概要とメリット
- NetBackup CloudPoint 構成と動作詳細
- NetBackup CloudPoint 画面キャプチャ

商談のご相談はこちら
本稿からのお問合せをご記入の際には「お問合せ内容」に#GWCのタグを必ずご記入ください。
ご記入いただきました内容はベリタスのプライバシーポリシーに従って管理されます。その他のリンク
【まとめ記事】ベリタステクノロジーズ 全記事へのリンク集もよろしくお願いいたします。



- 投稿日:2021-01-07T16:35:07+09:00
EC2内にWebサーバーを設定
EC2内のサーバーの役割
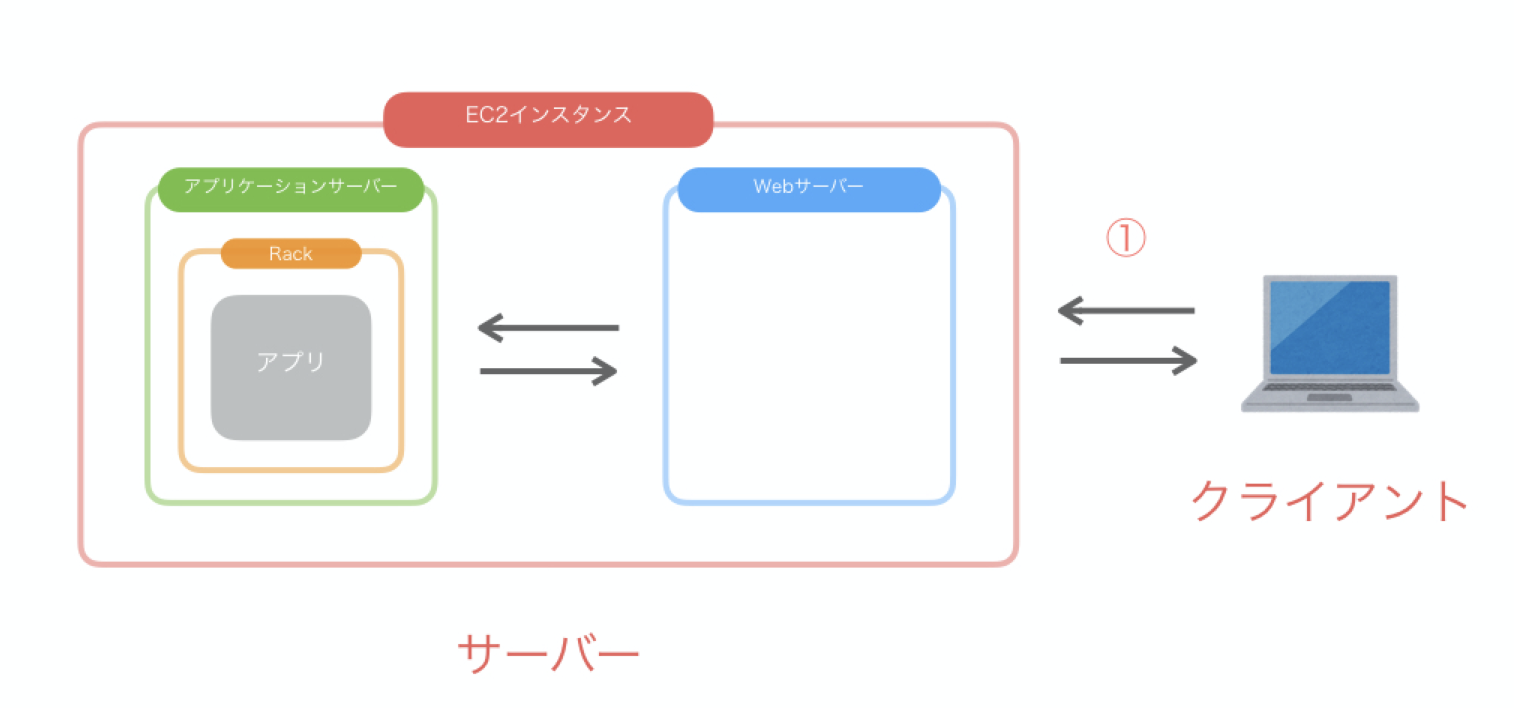
ユーザーが送るリクエストに対して、何らかのレスポンスを返す、これがサーバーの役割です。
サーバには複数の種類があり、ここではクローンしたアプリケーションを起動するために必要な「Webサーバー」と「アプリケーションサーバー」について理解を深めます。
「Webサーバー」とは、静的コンテンツのみをリクエストとしてクライアントに返します。ここでいう「クライアント」とは、サイトを閲覧するブラウザのことを示します。
「静的コンテンツ」とは、リクエストのたびに内容が変更されないファイルのことです。例として、表示するものが定まっているCSSや、画像ファイルなどがあります。
「アプリケーションサーバー」は、動的コンテンツを生成し、処理結果をWebサーバーに返すという役割を果たします。具体的には、アプリケーションサーバーが、アプリケーションサーバ内に設置されているアプリケーション本体にリクエスト処理の指令を出します。アプリケーション本体が処理を完了すると、アプリケーションサーバーはその処理結果をレスポンスとしてWebサーバーに返します。
「動的コンテンツ」とは、リクエストのたびに内容が変更されるファイルのことです。送られてくるリクエスト毎にデータベースから検索条件に該当するデータ取得し、表示する役割を果たしています。
アプリケーションサーバーとアプリケーション本体は、使用している言葉が違うので、連携することができません。この問題を解決してくれるのが「Rack」というプログラムです。
Rack
「Rack」とは、いわば翻訳プログラムになります。Rackが翻訳をすることにより、アプリケーションサーバーとアプリケーション本体がコミュニケーションを取ることができ、処理結果をWebサーバーに返すことができます。
一連の流れ↓
Webサーバー内で処理をすることが出来ないと判断した場合は、処理をアプリケーションサーバーに依頼します。Webサーバー内で処理が出来ないものとは、「動的コンテンツ」を生成し、リクエストとして返すものです。
アプリケーションサーバーに動的コンテンツの生成を依頼し、生成されたコンテンツがレスポンスとして返ってくるので、Webサーバはその結果をクライアントに返します。Nginx(エンジン・エックス)
「Nginx」とは、Webサーバーの一種です。ユーザーのリクエストに対して静的コンテンツのみ取り出し処理を行い、動的コンテンツの生成はアプリケーションサーバに依頼します。
Nginxを導入
[ec2-user@ip-172-31-25-189 ~]$ sudo amazon-linux-extras install nginx1Is this ok [y/d/N]:と出てきたら、yを選択して決定してください。
無事に完了すれば、Nginxがインストールできています。
次に、Nginxが正しく動くように設定しましょう。Nginxの設定は「設定項目X 設定値x;」という形式で入力します。
[ec2-user@ip-172-31-25-189 ~]$ sudo vim /etc/nginx/conf.d/rails.confうまくターミナル上でファイルを開けたら次のように編集してください。
/etc/nginx/conf.d/rails.confupstream app_server { # Unicornと連携させるための設定 server unix:/var/www/アプリケーション名/tmp/sockets/unicorn.sock; } # {}で囲った部分をブロックと呼ぶ。サーバの設定ができる server { # このプログラムが接続を受け付けるポート番号 listen 80; # 接続を受け付けるリクエストURL ここに書いていないURLではアクセスできない server_name Elastic IP; # クライアントからアップロードされてくるファイルの容量の上限を2ギガに設定。デフォルトは1メガなので大きめにしておく client_max_body_size 2g; # 接続が来た際のrootディレクトリ root /var/www/アプリケーション名/public; # assetsファイル(CSSやJavaScriptのファイルなど)にアクセスが来た際に適用される設定 location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; }「アプリケーション名」と「Elastic IP」の部分は適宜ご自身のものに置き換えましょう。
アプリケーション名 3 , 17行目
Elastic IP 11行目
入力を終えたら「escキー」→「:wq」の順で実行し、保存しましょう。次は、Nginxの権限を変更しましょう 。
設定が完了したら、POSTメソッドでもエラーが出ないようにするために、下記のコマンドも実行してください。[ec2-user@ip-172-31-25-189 ~]$ cd /var/lib [ec2-user@ip-172-31-25-189 lib]$ sudo chmod -R 775 nginxこれで、Nginxの設定が完了しました。
以下のコマンドを実行してNginx設定ファイルを再読み込みして起動しましょう。[ec2-user@ip-172-31-25-189 lib]$ cd ~ [ec2-user@ip-172-31-25-189 ~]$ sudo systemctl reload nginx [ec2-user@ip-172-31-25-189 ~]$ sudo systemctl start nginxUnicornの設定を変更
Nginxを介した処理に変更したため、Unicornの設定も修正します。
config/unicorn.rb(省略) listen 3000 (省略)これを以下に修正
config/unicorn.rb(省略) listen "#{app_path}/tmp/sockets/unicorn.sock"編集したら、リモートリポジトリへ「commit→push」しましょう。
次は、GitHubの変更点を本番環境へ反映させましょう。[ec2-user@ip-172-31-25-189 ~]$ cd /var/www/開発中のアプリケーション # GitHubの内容をEC2に反映させる [ec2-user@ip-172-31-23-189 <レポジトリ名>]$ git pull origin master次は、Unicornを再起動しましょう。
再起動の手順は、[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ps aux | grep unicorn ec2-user 17877 0.4 18.1 588472 182840 ? Sl 01:55 0:02 unicorn_rails master -c config/unicorn.rb -E production -D ec2-user 17881 0.0 17.3 589088 175164 ? Sl 01:55 0:00 unicorn_rails worker[0] -c config/unicorn.rb -E production -D ec2-user 17911 0.0 0.2 110532 2180 pts/0 S+ 02:05 0:00 grep --color=auto unicorn続いて、プロセスをkillします。
上記の例だと「7877」 [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ kill プロセス番号最後に、Unicornを起動します。
[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -Dここまでできたら、ブラウザからElastic IPでアクセスしましょう。
IPアドレスにアクセスしてもエラーが出る時
「502 but gateway」と出た時の対処方法
こちらのエラーはnginxのlogの確認が必要になります。以下のコマンドを実行し、ログを確認しましょう。
[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ sudo less /var/log/nginx/error.logこの中からエラーログを探しましょう。
次回はデプロイ作業を自動化です。
- 投稿日:2021-01-07T15:02:48+09:00
AWS CloudShell に .NET 5 をインストールして、Windows向けの実行ファイルを作ってみる
はじめに
AWS CloudShellはAWSのマネジメントコンソール上で、Amazon Linux2を起動してAWSの各機能をコマンドラインベースで実行するための機能です。Amazon Linux2はCentOS7に近い環境なので、yumを使って.NET Coreをインストールすることができます。
今回はAWS CloudShell上に.NET 5をインストールして、アプリをビルド→実行→Windows向けの実行ファイルのダウンロードをしてみます。
# だれがうれしいんだ!?という内容ですが、、、CloudShellの起動と.NET Core5のインストール
AWS マネジメントコンソールにログインして
>_なアイコンをクリックしてCloudShellを立ち上げます。
あとは、CentOS に .NET SDK または .NET ランタイムをインストールするの、CentOS7向けの手順を実行してセットアップしていきます。
まずはリポジトリにMicrosoftのリポジトリを追加してCloudShell$ sudo rpm -Uvh https://packages.microsoft.com/config/centos/7/packages-microsoft-prod.rpm Retrieving https://packages.microsoft.com/config/centos/7/packages-microsoft-prod.rpm warning: waiting for transaction lock on /var/lib/rpm/.rpm.lock Preparing... ################################# [100%] Updating / installing... 1:packages-microsoft-prod-1.0-1 ################################# [100%]インストールを実行すると、実際にパッケージをダウンロードするタイミングと、インストールの前に確認を求められるので両方とも
yで応答するればインストールは完了です。CloudShell$ sudo yum install dotnet-sdk-5.0 Loaded plugins: ovl, priorities packages-microsoft-com-prod | 3.0 kB 00:00:00 packages-microsoft-com-prod/primary_db | 278 kB 00:00:00 Resolving Dependencies --> Running transaction check ---> Package dotnet-sdk-5.0.x86_64 0:5.0.101-1 will be installed --> Processing Dependency: netstandard-targeting-pack-2.1 >= 2.1.0 for package: dotnet-sdk-5.0-5.0.101-1.x86_64 --> Processing Dependency: dotnet-runtime-5.0 for package: dotnet-sdk-5.0-5.0.101-1.x86_64 --> Processing Dependency: dotnet-targeting-pack-5.0 for package: dotnet-sdk-5.0-5.0.101-1.x86_64 --> Processing Dependency: dotnet-apphost-pack-5.0 for package: dotnet-sdk-5.0-5.0.101-1.x86_64 --> Processing Dependency: aspnetcore-runtime-5.0 for package: dotnet-sdk-5.0-5.0.101-1.x86_64 --> Processing Dependency: aspnetcore-targeting-pack-5.0 for package: dotnet-sdk-5.0-5.0.101-1.x86_64 --> Running transaction check ---> Package aspnetcore-runtime-5.0.x86_64 0:5.0.1-1 will be installed ---> Package aspnetcore-targeting-pack-5.0.x86_64 0:5.0.0-1 will be installed ---> Package dotnet-apphost-pack-5.0.x86_64 0:5.0.1-1 will be installed ---> Package dotnet-runtime-5.0.x86_64 0:5.0.1-1 will be installed --> Processing Dependency: dotnet-hostfxr-5.0 >= 5.0.1 for package: dotnet-runtime-5.0-5.0.1-1.x86_64 --> Processing Dependency: dotnet-runtime-deps-5.0 >= 5.0.1 for package: dotnet-runtime-5.0-5.0.1-1.x86_64 ---> Package dotnet-targeting-pack-5.0.x86_64 0:5.0.0-1 will be installed ---> Package netstandard-targeting-pack-2.1.x86_64 0:2.1.0-1 will be installed --> Running transaction check ---> Package dotnet-hostfxr-5.0.x86_64 0:5.0.1-1 will be installed --> Processing Dependency: dotnet-host >= 5.0.1 for package: dotnet-hostfxr-5.0-5.0.1-1.x86_64 ---> Package dotnet-runtime-deps-5.0.x86_64 0:5.0.1-1 will be installed --> Running transaction check ---> Package dotnet-host.x86_64 0:5.0.1-1 will be installed --> Finished Dependency Resolution Dependencies Resolved ================================================================================================= Package Arch Version Repository Size ================================================================================================= Installing: dotnet-sdk-5.0 x86_64 5.0.101-1 packages-microsoft-com-prod 80 M Installing for dependencies: aspnetcore-runtime-5.0 x86_64 5.0.1-1 packages-microsoft-com-prod 8.0 M aspnetcore-targeting-pack-5.0 x86_64 5.0.0-1 packages-microsoft-com-prod 2.1 M dotnet-apphost-pack-5.0 x86_64 5.0.1-1 packages-microsoft-com-prod 4.6 M dotnet-host x86_64 5.0.1-1 packages-microsoft-com-prod 64 k dotnet-hostfxr-5.0 x86_64 5.0.1-1 packages-microsoft-com-prod 170 k dotnet-runtime-5.0 x86_64 5.0.1-1 packages-microsoft-com-prod 29 M dotnet-runtime-deps-5.0 x86_64 5.0.1-1 packages-microsoft-com-prod 2.8 k dotnet-targeting-pack-5.0 x86_64 5.0.0-1 packages-microsoft-com-prod 3.1 M netstandard-targeting-pack-2.1 x86_64 2.1.0-1 packages-microsoft-com-prod 2.1 M Transaction Summary ================================================================================================= Install 1 Package (+9 Dependent packages) Total download size: 129 M Installed size: 369 M Is this ok [y/d/N]: y Downloading packages: warning: /var/cache/yum/x86_64/2/packages-microsoft-com-prod/packages/aspnetcore-targeting-pack-5.0.0.rpm: Header V4 RSA/SHA256 Signature, key ID be1229cf: NOKEY Public key for aspnetcore-targeting-pack-5.0.0.rpm is not installed (1/10): aspnetcore-targeting-pack-5.0.0.rpm | 2.1 MB 00:00:00 (2/10): dotnet-apphost-pack-5.0.1-x64.rpm | 4.6 MB 00:00:00 (3/10): dotnet-host-5.0.1-x64.rpm | 64 kB 00:00:00 (4/10): dotnet-hostfxr-5.0.1-x64.rpm | 170 kB 00:00:00 (5/10): aspnetcore-runtime-5.0.1-x64.rpm | 8.0 MB 00:00:01 (6/10): dotnet-runtime-deps-5.0.1-centos.7-x64.rpm | 2.8 kB 00:00:00 (7/10): dotnet-runtime-5.0.1-x64.rpm | 29 MB 00:00:01 (8/10): dotnet-targeting-pack-5.0.0-x64.rpm | 3.1 MB 00:00:00 (9/10): netstandard-targeting-pack-2.1.0-x64.rpm | 2.1 MB 00:00:00 (10/10): dotnet-sdk-5.0.101-x64.rpm | 80 MB 00:00:09 ------------------------------------------------------------------------------------------------- Total 11 MB/s | 129 MB 00:00:11 Retrieving key from https://packages.microsoft.com/keys/microsoft.asc Importing GPG key 0xBE1229CF: Userid : "Microsoft (Release signing) <gpgsecurity@microsoft.com>" Fingerprint: bc52 8686 b50d 79e3 39d3 721c eb3e 94ad be12 29cf From : https://packages.microsoft.com/keys/microsoft.asc Is this ok [y/N]: y Running transaction check Running transaction test Transaction test succeeded Running transaction Warning: RPMDB altered outside of yum. Installing : dotnet-targeting-pack-5.0-5.0.0-1.x86_64 1/10 Installing : aspnetcore-targeting-pack-5.0-5.0.0-1.x86_64 2/10 Installing : dotnet-host-5.0.1-1.x86_64 3/10 Installing : dotnet-hostfxr-5.0-5.0.1-1.x86_64 4/10 Installing : dotnet-runtime-deps-5.0-5.0.1-1.x86_64 5/10 Installing : dotnet-runtime-5.0-5.0.1-1.x86_64 6/10 Installing : aspnetcore-runtime-5.0-5.0.1-1.x86_64 7/10 Installing : netstandard-targeting-pack-2.1-2.1.0-1.x86_64 8/10 Installing : dotnet-apphost-pack-5.0-5.0.1-1.x86_64 9/10 Installing : dotnet-sdk-5.0-5.0.101-1.x86_64 10/10 This software may collect information about you and your use of the software, and send that to Microsoft. Please visit http://aka.ms/dotnet-cli-eula for more information. Welcome to .NET! --------------------- Learn more about .NET: https://aka.ms/dotnet-docs Use 'dotnet --help' to see available commands or visit: https://aka.ms/dotnet-cli-docs Telemetry --------- The .NET tools collect usage data in order to help us improve your experience. It is collected by Microsoft and shared with the community. You can opt-out of telemetry by setting the DOTNET_CLI_TELEMETRY_OPTOUT environment variable to '1' or 'true' using your favorite shell. Read more about .NET CLI Tools telemetry: https://aka.ms/dotnet-cli-telemetry Configuring... -------------- A command is running to populate your local package cache to improve restore speed and enable offline access. This command takes up to one minute to complete and only runs once. Verifying : dotnet-hostfxr-5.0-5.0.1-1.x86_64 1/10 Verifying : dotnet-apphost-pack-5.0-5.0.1-1.x86_64 2/10 Verifying : aspnetcore-targeting-pack-5.0-5.0.0-1.x86_64 3/10 Verifying : netstandard-targeting-pack-2.1-2.1.0-1.x86_64 4/10 Verifying : dotnet-runtime-5.0-5.0.1-1.x86_64 5/10 Verifying : aspnetcore-runtime-5.0-5.0.1-1.x86_64 6/10 Verifying : dotnet-targeting-pack-5.0-5.0.0-1.x86_64 7/10 Verifying : dotnet-sdk-5.0-5.0.101-1.x86_64 8/10 Verifying : dotnet-runtime-deps-5.0-5.0.1-1.x86_64 9/10 Verifying : dotnet-host-5.0.1-1.x86_64 10/10 Installed: dotnet-sdk-5.0.x86_64 0:5.0.101-1 Dependency Installed: aspnetcore-runtime-5.0.x86_64 0:5.0.1-1 aspnetcore-targeting-pack-5.0.x86_64 0:5.0.0-1 dotnet-apphost-pack-5.0.x86_64 0:5.0.1-1 dotnet-host.x86_64 0:5.0.1-1 dotnet-hostfxr-5.0.x86_64 0:5.0.1-1 dotnet-runtime-5.0.x86_64 0:5.0.1-1 dotnet-runtime-deps-5.0.x86_64 0:5.0.1-1 dotnet-targeting-pack-5.0.x86_64 0:5.0.0-1 netstandard-targeting-pack-2.1.x86_64 0:2.1.0-1 Complete!.NET 5がインストールされました。
CloudShell$ dotnet --version 5.0.101ビルドしてWindows向けの実行ファイルをダウンロードする
Console アプリを作成して実行してみる。
CloudShell$ mkdir consoleapp $ cd consoleapp $ dotnet new console $ dotnet run Hello World!Program.csを開き、
CloudShell$ ls bin obj Program.cs sample.csproj $ vi Program.csまぁ、よくある修正をして保存後、
Program.csusing System; namespace sample { class Program { static void Main(string[] args) { Console.WriteLine("Hello CloudShell"); } } }ビルドして実行すると反映されましたね。
CloudShell$ dotnet run Hello CloudShellWindows 向けにビルドします。
CloudShell$ dotnet publish -r win-x86 -c Release -p:PublishSingleFile=true Microsoft (R) Build Engine version 16.8.0+126527ff1 for .NET Copyright (C) Microsoft Corporation. All rights reserved. Determining projects to restore... All projects are up-to-date for restore. sample -> /home/cloudshell-user/sample/bin/Release/net5.0/win-x86/sample.dll sample -> /home/cloudshell-user/sample/bin/Release/net5.0/win-x86/publish/出来上がったファイルをtarで固めてダウンロードします。
CloudShell$ cd /home/cloudshell-user/sample/bin/Release/net5.0/win-x86/ $ tar cvfz ~/app.tar.gz publish/ publish/ publish/sample.exe publish/mscordaccore.dll publish/clrjit.dll publish/clrcompression.dll publish/sample.pdb publish/coreclr.dllActions → Download fileでファイルをダウンロードできます。
Windowsで実行してみる。
動きましたね!まとめ
- AWS CloudShell上でも入れれば.NET動くよ
- .NET のクロスコンパイラでWindows、Macの実行ファイルを作成できるよ
- ビルド方法によっては.NET ランタイムがインストールされていなくても動作するよ
CloudShellでは永続化されるのはHomeディレクトリ配下の1GBのファイルだけで、他は起動するたびに失われるので最初からインストールされているランタイムを使ったほうが良いですよね。PowerShell Coreも入っていますし。

- 投稿日:2021-01-07T14:24:04+09:00
python3.8でlambda-uploader使用した時にpython3.8が見つからないとエラーを吐かれた時の原因調査
事の発端
AWSのLambda上にそれなりに複雑になる予定のpythonの関数を追加する事になったが、lambda上ではpipが使用できないため、外部モジュールを使用する関数を使用する場合、
[一つ一つ使用している外部モジュールを\Python〇〇\Lib\site-packages] から探し出し纏めてzip化するという賽の河原のようなおちねり作業が発生する。
当然ながら人間は信用ならない生物のため、こんな作業を毎回手作業でやろうものならパンジャンドラムとマーマイトをガンギメした某ブリテンの暴走青列車(ブルートレイン)の如く事故が発生する事故は起こるさ? 事故は人間が起こすものなんだよ!
(※加えてこの作業にとても時間が取られる)そこでlambda-uploaderを使用し、外部モジュールの抽出作業を任せてしまうことで効率化と事故発生率を少しでも下げようと画策した。
作業環境
- Windows10(64bit)
- python3.8(64bitインストーラ使用)3.8なのは2020/12月末時点でlambdaがpython3.8以降に対応していないから。
- 上記に加えてpythonのインストール箇所は(元来はおすすめされないけど、端末ごと引き継ぐ可能性があるため C:\Program Files以下。本来は各c:\users~以下)
lambda-uploaderを使用するためには
・lambda.json
→アップロードするlambda関数の概要を纏めた設定ファイル
・requirements.txt
→作ったlambda関数が使用する外部モジュールを定義するとこのファイルを参照して自動でピックアップ、zipの際にまとめてくれるみたいです。つまりpip freezeから自動でファイル生成するバッチを作れば一番リスキーな作業を自動化してくれます。
事故は起こさせない・event.json
→テスト時に投げるPOSTリクエストの内容で、GETリクエストのテストの場合は空でも良い
ということで今回は不要。他の参考内容 等でも記載がない場合が多いので必須ファイルでは無い模様。・〇〇.py
→aws lambdaのエントリーポイントであるdef lambda_handler(event, context):~関数の処理が記載されたpyファイル。
lambda-uploaderの手順としては上記で記載した設定ファイル達を元に、大まかに分けて以下3点を順に行う。
1. build
2. zip
3. upload(aws lambdaに)jsonファイルに以下の様に設定(セキュリティに関わる情報は伏せてます)して・・・
lambda.json{ "name": "testFunction", "description": "testFunction description.", "region": "ap-northeast-1", "handler": "lambda_function.lambda_handler", "role": "arn:aws:iam::XXXXXXXXXXXX:role/BlogenistBlogSample", "timeout": 30, "memory": 128, "runtime": "python3.8" ←明示的に指定しないとデフォルト(時代から捨てられつつあるpython2.7)でアップロードを行う。 }イクゾー デッデッデデデデン
そして(想定外の)事故は起きた
カーン
PS C:\workspace(python)\testcode\lambda> lambda-uploader Building Package â‰ï¸ Unexpected error. Please report this traceback. Uploader: 1.3.0 Botocore: 1.16.38 Boto3: 1.19.38 Traceback (most recent call last): File "c:\program files\python38\lib\site-packages\lambda_uploader\shell.py", line 194, in main _execute(args) File "c:\program files\python38\lib\site-packages\lambda_uploader\shell.py", line 83, in _execute pkg = package.build_package(pth, requirements, File "c:\program files\python38\lib\site-packages\lambda_uploader\package.py", line 51, in build_package pkg.build(ignore) File "c:\program files\python38\lib\site-packages\lambda_uploader\package.py", line 79, in build self.install_dependencies() File "c:\program files\python38\lib\site-packages\lambda_uploader\package.py", line 151, in install_dependencies self._build_new_virtualenv() File "c:\program files\python38\lib\site-packages\lambda_uploader\package.py", line 177, in _build_new_virtualenv python_exe = self._python_executable() File "c:\program files\python38\lib\site-packages\lambda_uploader\package.py", line 195, in _python_executable raise Exception('Unable to locate {} executable' Exception: Unable to locate python3.8 executable(´・ω・`)
Exception: Unable to locate python3.8 executable(´;ω;`)ブワッ
最後の行でビルド時にpython3.8が見つからないとエラーを吐瀉(オエ)られる。
原因を調べてみる
というわけで(最終的な実行環境のpython自体はaws上にあるのでpython.exeいる?とおもいつつ)原因調査開始。
PATHが通ってない?
→問題なし。[\python38] 及び [\Python38\Lib\site-packages]両方のPATHを環境変数設定で確認(というかインストール時にPATH通す設定で今まで散々コマンド使ってきているのでこの時点でPATHが原因というのはおかしい)マイナーバージョンも指定しないとだめ?ということでjsonのパラメータを"runtime": "python3.8.6"に修正
→Exception: Unable to locate python3.8.6 executable
(´・ω・`)(´・ω・`)いっそのことjsonのruntimeパラメータを削除
→Exception: Unable to locate python2.7 executable
(´・ω・`)(´・ω・`)(´・ω・`) ソリャソウダlambda-uploaderモジュールのバグかも知れないので最新版を見にgitへ(pypiに反映せずgit上だけ永遠に更新されているモジュールというのは案外多い)
↓
↓
(´;ω;`)ブワッ
エラー内容で色々で調べても引っかかって来ない
ということで、Tracebackがあるため、直接lambda-uploaderのソースコードを見に行く。
変に設定をいじっていないなら \Python38\Lib\site-packages\lambda_uploaderに目的のコードが有るためササッとディレクトリ開いて最後に処理が通った箇所付近File "c:\program files\python38\lib\site-packages\lambda_uploader\package.py", line 195, in _python_executable raise Exception('Unable to locate {} executable'を調査。
package.pydef _python_executable(self): if self._pyexec is not None: python_exe = find_executable(self._pyexec) if not python_exe: 195行目→ raise Exception('Unable to locate {} executable' .format(self._pyexec))find_executable関数の処理が怪しいと目星を付け更に呼び出し元を調査。
※vs codeでpython環境建てると複雑なコードでもインテリジェンスが便利なのでおすすめ。いつか開発環境構築を記事にしたい。spawn.pydef find_executable(executable, path=None): """Tries to find 'executable' in the directories listed in 'path'. A string listing directories separated by 'os.pathsep'; defaults to os.environ['PATH']. Returns the complete filename or None if not found. """ _, ext = os.path.splitext(executable) if (sys.platform == 'win32') and (ext != '.exe'): executable = executable + '.exe' if os.path.isfile(executable): return executable if path is None: path = os.environ.get('PATH', None) if path is None: try: path = os.confstr("CS_PATH") except (AttributeError, ValueError): # os.confstr() or CS_PATH is not available path = os.defpath # bpo-35755: Don't use os.defpath if the PATH environment variable is # set to an empty string # PATH='' doesn't match, whereas PATH=':' looks in the current directory if not path: return None paths = path.split(os.pathsep) for p in paths: f = os.path.join(p, executable) print(f) if os.path.isfile(f): print(f) # the file exists, we have a shot at spawn working return f return None上記コードを順番に流し見た限り、環境変数を取得して、分割(そのままだとセミコロンでつながった1行の文字列)、末尾に何かくっつけてファイルチェックしてるなーということで
for p in paths: f = os.path.join(p, executable) print(f) #困った時のprint文 if os.path.isfile(f): # the file exists, we have a shot at spawn working return f再び実行。
PS C:\workspace(python)\testcode\lambda> lambda-uploader Building Package ※↓がprintで吐かせた内容 C:\Program Files\Python38\Scripts\python3.8.exe C:\Program Files\Python38\python3.8.exe ・・・以下他の環境変数の末尾にpython3.8.exeをくっつけた文字列&Traceback上記を見た限りそんな変なことしてないなぁと思いつつ、エラーがpython3.8が見つからないというエラーのため、該当のディレクトリを見に行ったら・・・
(ω・`) (・ω・`) (´・ω・`) (´;ω;`)ブワッ
なんで?
それならjsonを書き換える。
ということでそもそも存在しないexeファイルを検索していたというのが原因でした。
そのため、"runtime": "python"と書けば動きはする。ビルドまでは。
明らかにおかしな動きなため、そのまま動かせばその後で詰まるだろうなと思いながら動かし。当然のようにアップロード処理で落ちました。
例外の内容がbotocore.errorfactory.InvalidParameterValueException: An error occurred (InvalidParameterValueException) when calling the UpdateFunctionConfiguration operation: Value python at 'runtime' failed to satisfy constraint: Member must satisfy enum value set: [java8, java11, nodejs10.x, nodejs12.x, python2.7, python3.6, python3.7, python3.8, dotnetcore2.1, go1.x, ruby2.5] or be a valid ARN※要約するとlambda.jsonのruntimeのパラメータにpythonバージョンを書け。又は本当に有効なARN設定してるの?
とあり、botocoreはawsの認証周りをしてくれる箇所のため、awsのサービスを操作するパッケージがいるのかなと調べてみたり(結論から言うと見当違いでした)botocoreモジュールにも手を加えてデバッグしたり、そもそもlambda-uploaderモジュールのソースコードがSyntaxWarning: "is" with a literal. Did you mean "=="?警告を出していて、やっぱりpython3.8では使えないのでは?と考えているうちに思いついた下記を試してみました。
PS C:\workspace(python)\testcode\lambda> lambda-uploader Building Package Uploading Package Finaws lambda上を確認しても正常にアップロード出来ていました。
ものすごくスッキリしない解決になってしまい申し訳ありません。しかし、python〇〇.exeなんて一体どういう流れで入ってくるのだろうか・・・?(vitualenvが先に割り込んで生成されたpython〇〇.exeを参照するのかと思ってたが中身を見てもvirtualenvより先に参照していた。)
誰か原因をご存知ならコメントでご指摘下さい。
結論
pythonの素晴らしいところはPIPしてきたモジュールを直接書き換え、デバッグして動作確認できるところ。(終わったらもとに戻すことを忘れずに)
また、lambda-uploaderは3年近く更新がなく、既存のコードも最近のpythonの仕様変更によりトラブルを抱え始めているため、今後は使えなくなる事を想定したほうが良いかもしれません。


- 投稿日:2021-01-07T14:08:43+09:00
AWS CloudShell上にfdcloneをビルドしてインストールする
AWSでも2020/12からCloudShellが利用できるようになりました。
あくまでリモートShell環境であって、標準でインストールされているツール等は少なめです。初期状態では開発環境や居城として利用するには少し不便ですが、
ここではfdcloneをビルドしてインストールする方法を紹介します。gccとncursesライブラリのインストール
fdcloneのビルド&実行には以下の3つの追加インストールが必要です。
- gcc(fdcloneのビルドに必要)
- gcc-core(fdcloneの実行に必要)
- ncurses-devel(fdcloneの実行に必要)
初期状態ではインストールされていませんが、yum で追加インストールすることができます。
[cloudshell-user@ip-10-XX-XX-XX ~]$ sudo yum install gcc [cloudshell-user@ip-10-XX-XX-XX ~]$ sudo yum install gcc-core [cloudshell-user@ip-10-XX-XX-XX ~]$ sudo yum install ncurses-develfdcloneのソースをダウンロード
- FDclone なページ - Vector
https://hp.vector.co.jp/authors/VA012337/soft/fd/から、ソースファイル一式を入手します。wgetでダウンロードしましょう。
[cloudshell-user@ip-10-XX-XX-XX ~]$ wget https://hp.vector.co.jp/authors/VA012337/soft/fd/FD-3.01j.tar.gzダウンロードが終わったら、ファイルを解凍し、カレントディレクトリを移動します。
[cloudshell-user@ip-10-XX-XX-XX ~]$ tar zxvf FD-3.01j.tar.gz [cloudshell-user@ip-10-XX-XX-XX ~]$ cd FD-3.01jfdcloneのビルド
fdcloneをビルドします。ビルドが終わったら
fdが生成されているか確認しておきます。[cloudshell-user@ip-10-XX-XX-XX FD-3.01j]$ sudo make ... ... [cloudshell-user@ip-10-XX-XX-XX FD-3.01j]$ ls -al [cloudshell-user@ip-10-XX-XX-XX FD-3.01j]$ ls -al fdfdcloneの起動確認
ビルドに成功し、
fdが生成されているようでしたら、起動できるか確認しましょう。[cloudshell-user@ip-10-XX-XX-XX FD-3.01j]$ ./fdfdcloneのインストール
make installします。(/usr/local/binにコピーされます。)
[cloudshell-user@ip-10-XX-XX-XX FD-3.01j]$ sudo make install~/.fd2rcの配置
また、必要に応じて、_fdrc を ~/.fd2rc にコピーしておきます。
必要に応じてカスタマイズしておいてください。[cloudshell-user@ip-10-XX-XX-XX FD-3.01j]$ cp -p _fdrc ~/.fd2rc
- 投稿日:2021-01-07T13:33:26+09:00
Amazon SNS 概要及びトピック作成方法 メモ
Amazon SNSの概要とAWS CLIを使用したトピック作成方法についてメモする。
SNSとは?
SNS概要
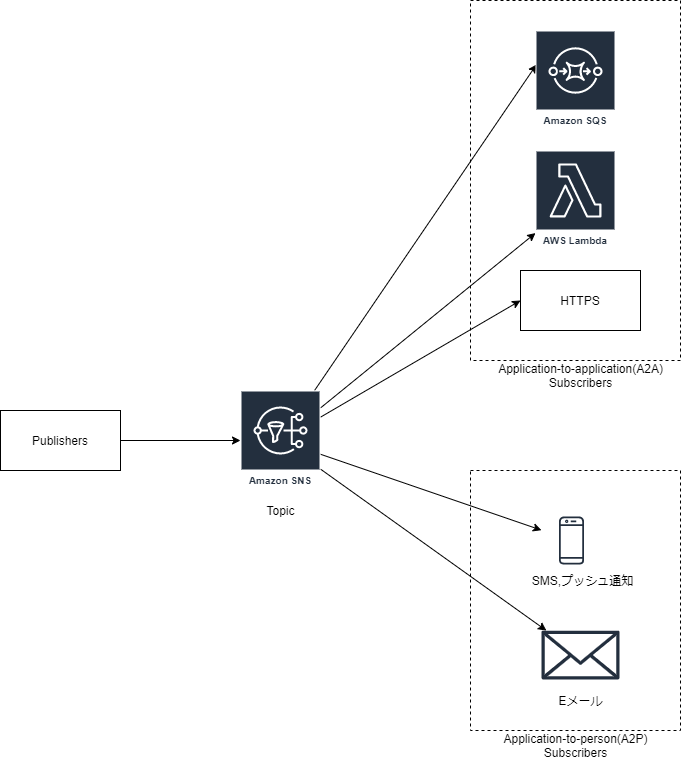
非同期形式のメッセージ配信機能を提供するAWSマネージドサービス
ユースケース
- アプリケーション連携
- SNS トピックに発行したメッセージを任意のエンドポイントにプッシュして並列非同期処理を実現したい場合。
- エンドポイント例:Amazon SQSキュー、HTTP(S) エンドポイント、 Lambda 関数など。
- ファンアウトシナリオと呼ばれる。
- アプリケーションアラート
- 事前定義した閾値超過などをトリガーとして通知を送りたい場合。
- 指定したユーザーにSMS や Eメールを送信できる。
- 例:インスタンスのCPU使用率の閾値超過など、イベントが発生したとき。
SNS概念・用語
- トピック
- 通信チャネルとして機能する論理アクセスポイント。
- 配信先をグルーピングし、配信先に対して一斉通知を行う。
- パブリッシュ
- トピックにメッセージを発行すること。
- メッセージを送信する主体を、発行者(Publisher)と呼ばれる。
- サブスクライブ
- トピックに発行されたメッセージを受信すること。
- メッセージを受信する主体を購読者(Subscriber)と呼ばれる。
- サポート受信形式:Amazon SQS 、 AWS Lambda 、HTTP、E メール、モバイルプッシュ通知、SMS など。
トピック作成
test_topicという名前のトピックを作成したい場合。aws sns create-topic --name test_topicトピックへの属性(Policy)設定
- トピック
test_topicに属性attribute_for_sns_topicを設定する場合
- 以下の例では、
Policy(Topicへのアクセス権)を設定している。- トピックに設定できる属性には、他にも配信ポリシーなどがある。
attribute_for_sns_topic_path=$(dirname $0)/json/AttributeForSNSTopic.json attribute_for_sns_topic=$(cat ${attribute_for_sns_topic_path}) tempfile=$(mktemp) echo ${attribute_for_sns_topic} | envsubst > ${tempfile} aws sns set-topic-attribute --topic-arn "arn:aws:${YOUR_REGION_ID}:${YOUR_AWS_ACCOUNT_ID}:test_topic" --attribute-name Policy --attribute-value file://${tempfile} rm -f ${tempfile}※リージョンID(
YOUR_REGION_ID)やAWSアカウントID(YOUR_AWS_ACCOUNT_ID)は環境変数として展開済みであるものとする。
AttributeForSNSTopic.json
- デフォルト+CloudWatchイベントからのパブリッシュを許可
{ "Version":"2012-10-17", "Id": "__default_policy_ID", "Statement":[ { "Sid":"__default_statement_ID", "Effect":"Allow", "Principal":{ "AWS":"*" }, "Action":[ "sns:Subscribe", "sns:Publish", // ... 要件に応じたアクションを指定する ], "Resource": "arn:aws:sns:${YOUR_REGION_ID}:${YOUR_AWS_ACCOUNT_ID}:test_topic", "Condition":{ "StringEquals":{ "aws:SourceOwner":"${YOUR_AWS_ACCOUNT_ID}" } } },{ "Sid":"Publish_Events_Grant", "Effect":"Allow", "Principal":{ "Service":"events.amazonaws.com" }, "Action":"sns:Publish", "Resource": "arn:aws:sns:${YOUR_REGION_ID}:${YOUR_AWS_ACCOUNT_ID}:test_topic" } ] }参考情報
- 投稿日:2021-01-07T09:19:25+09:00
ECRのuntaggedイメージ削除
備忘録です。
ご指摘等ありましたら教えていただけると幸いです。最近現場で、新システムのインフラにECSの導入→コード化をしています。
latest運用にしており、untaggedイメージが増産されていました。
なのでサイクルを決めて削除するように変更しました。下記コードは、
・ 1日のサイクルでuntaggedを削除
・ 1つだけイメージを残すecr.tfresource "aws_ecr_repository" "app" { name = local.service_name } # untaggedイメージの削除 resource "aws_ecr_lifecycle_policy" "app" { repository = aws_ecr_repository.app.name policy = <<EOF { "rules": [ { "rulePriority": 1, "description": "Expire images older than 1 days", "selection": { "tagStatus": "untagged", "countType": "sinceImagePushed", "countUnit": "days", "countNumber": 1 }, "action": { "type": "expire" } } ] } EOF }参考文献
https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/ecr_lifecycle_policy
https://docs.aws.amazon.com/ja_jp/AmazonECR/latest/userguide/lifecycle_policy_examples.html
- 投稿日:2021-01-07T08:26:22+09:00
AWSのSGフルオープンルールを自動削除する【EventBridge, Lambda】
はじめに
AWSのSGルール自動削除は、AWSマネージドだとsshやRDPのフルオープン以外はないと思います。
ちょうどEventBridgeやLambdaを触ってみたかったので、いろいろ調べつつ実装してみました。構成
SG作成 → EventBridgeで検出 → Lambdaで自動削除
要件定義
- 削除対象はSGのインバウンドルールで、許可されている送信元IPアドレスが
0.0.0.0/0,::/0となっているもの- 新規作成されたルールが対象
- 送信元IPアドレスがフルオープンになっているルールと、そうでないルールが一緒に作成された場合、フルオープンのルールのみを削除する
EventBridgeルールの作成
EventBridgeは、ルールにより一致した受信イベントを検出し、ターゲットとして登録したAWSリソースを呼び出してイベントを渡します。
呼び出されたAWSリソースは渡されたイベントを使用したりして、決められた処理を実行します。
今回、EventBridgeルールは二つ作成します。
どうにかして一つのルールで実装できないか検討しましたが、現状のイベントパターンで使用できるフィルタリングでは実装できないと思います。
もし実装できたらコメント欄で教えていただけると幸いです。イベントパターン
フルオープンSGを検出するためのイベントパターンを作成するので、検出対象のイベントがどのような形式なのかを確認します。
AWS公式ドキュメント
サポートされている AWS サービスからの EventBridge イベントの例
https://docs.aws.amazon.com/ja_jp/eventbridge/latest/userguide/event-types.html上記公式ドキュメントを確認すると、SGのイベントは見当たらないので、CloudTrail 経由で配信されたイベントが該当します。
書式は以下のとおりでした。イベントの書式例{ "version": "0", "id": "36eb8523-97d0-4518-b33d-ee3579ff19f0", "detail-type": "AWS API Call via CloudTrail", "source": "aws.s3", "account": "123456789012", "time": "2016-02-20T01:09:13Z", "region": "us-east-1", "resources": [], "detail": { "eventVersion": "1.03", "userIdentity": { "type": "Root", "principalId": "123456789012", "arn": "arn:aws:iam::123456789012:root", "accountId": "123456789012", "sessionContext": { "attributes": { "mfaAuthenticated": "false", "creationDate": "2016-02-20T01:05:59Z" } } }, "eventTime": "2016-02-20T01:09:13Z", "eventSource": "s3.amazonaws.com", "eventName": "CreateBucket", "awsRegion": "us-east-1", "sourceIPAddress": "100.100.100.100", "userAgent": "[S3Console/0.4]", "requestParameters": { "bucketName": "bucket-test-iad" }, "responseElements": null, "requestID": "9D767BCC3B4E7487", "eventID": "24ba271e-d595-4e66-a7fd-9c16cbf8abae", "eventType": "AwsApiCall" } }例ではS3のため、これをSGルール作成に置き換えます。
detailの中身はCloudTrailログでそのまま置き換えられる思いますので、実際にフルオープンSGを作成してCloudTrailログを確認し、その内容に置き換えます(後ほどイベントパターンで使うプロパティに星マークを付けています。)。
これで、検出対象のイベントが分かりました。イベントの書式例(SGルール作成版){ "version": "0", "id": "36eb8523-97d0-4518-b33d-ee3579ff19f0", ★"detail-type": "AWS API Call via CloudTrail", ★"source": "aws.ec2", "account": "123456789012", "time": "2016-02-20T01:09:13Z", "region": "us-east-1", "resources": [], "detail": { "eventVersion": "1.08", "userIdentity": { 略 }, "eventTime": "2021-01-09T04:08:28Z", ★ "eventSource": "ec2.amazonaws.com", ★ "eventName": "AuthorizeSecurityGroupIngress", "awsRegion": "us-east-1", "sourceIPAddress": "192.168.1.1", "userAgent": "console.ec2.amazonaws.com", "requestParameters": { "groupId": "sg-000000000000", "ipPermissions": { "items": [ { "ipProtocol": "-1", "groups": {}, "ipRanges": { "items": [ { ★ "cidrIp": "0.0.0.0/0" } ] }, "ipv6Ranges": { "items": [ { ★ "cidrIpv6": "::/0" } ] }, "prefixListIds": {} } ] } }, 以下略これからは、イベントパターンを作成します。
今回のイベントはAWSで定義したイベントパターンには該当しないので、自作します。
検出しなければならないイベントは、三つあり、
・IPv4のみフルオープン
・IPv6のみフルオープン
・IPv4・IPv6両方フルオープン
のSGルールです。
ルールを二つ作成するので、まず一つ目から。
完成したイベントパターンがこちらです。イベントパターン①{ "source": ["aws.ec2"], "detail-type": ["AWS API Call via CloudTrail"], "detail": { "eventSource": ["ec2.amazonaws.com"], "eventName": ["AuthorizeSecurityGroupIngress"], "requestParameters": { "ipPermissions": { "items": { "ipRanges": { "items": { "cidrIp": [ { "cidr": "0.0.0.0/0" } ] } } } } } } }このイベントパターンが検出する対象は
・IPv4のみフルオープン
・IPv4・IPv6両方フルオープン
のSGルールであり、IPv6のみフルオープンのSGルールは検出できません。
IPv6のみフルオープンのSGルールだけを検出するため、もう一つのEventBridgeルールは以下のイベントパターンにします。イベントパターン②{ "source": ["aws.ec2"], "detail-type": ["AWS API Call via CloudTrail"], "detail": { "eventSource": ["ec2.amazonaws.com"], "eventName": ["AuthorizeSecurityGroupIngress"], "requestParameters": { "ipPermissions": { "items": { "ipRanges": { "items": { "cidrIp": [ { "anything-but" : "0.0.0.0/0" }, { "exists": false } ] } }, "ipv6Ranges": { "items": { "cidrIpv6": [ "::/0" ] } } } } } } }イベントパターン①より少し複雑になっているのは、二つのEventBridgeルールが一つのイベントを二重に検出しないようにするためです。
イベントパターン②にipRangesプロパティの記載がない場合、IPv4・IPv6両方フルオープンのSGルール作成イベントが、イベントパターン①、②の両方で一致してしまい、二つのEventBridgeルールに検出されてしまいます。
その結果、同じLambdaで処理されることになり(Lambdaは二つに分けません。)、どちらかが必ずエラーとなります。
それを防ぐために、
・IPv6フルオープン かつ IPv4が指定されている または IPv4を許可していない
イベントに一致するものをイベントパターン②として作成しています。
これにより、IPv6のみフルオープンのSGルール作成イベントに限り、EventBridgeルールがイベントを検出します。対応関係をまとめると以下の表のとおりです。
パターン 検出 イベントパターン① IPv4のみフルオープン
IPv4・IPv6両方フルオープンイベントパターン② IPv6のみフルオープン また、それぞれのイベントパターンでコンテンツフィルタリングを使用しています。
詳細を知りたい方は以下のドキュメントをご覧ください。
なお、イベントパターン②の{ "anything-but" : "0.0.0.0/0" }で、 イベントパターン①のようにIPアドレスマッチングを使用していないのは、anything-but内でのIPアドレスマッチングの使用がサポートされていなかったからです。AWS公式ドキュメント
イベントパターンを使用したコンテンツベースのフィルタリング
https://docs.aws.amazon.com/ja_jp/eventbridge/latest/userguide/content-filtering-with-event-patterns.htmlターゲットに渡すイベント
EventBridgeはターゲットに渡すイベント内容をカスタマイズしたり、イベントの代わりにイベントと関係のないJSONを自作して渡すことができます。
今回は、Lambdaで必要な部分のみ渡すことにします。
マネージメントコンソール上の「入力の設定」→ 「一致したイベントの一部」を選択し、$.detail.requestParametersを入力します。
$.detail.requestParametersをJSONにすると以下のとおりです。
このJSONからグループIDなどを必要な情報を使用します。$.detail.requestParameters{ "groupId": "sg-000000000000", "ipPermissions": { "items": [ { "ipProtocol": "-1", "groups": {}, "ipRanges": { "items": [ { "cidrIp": "0.0.0.0/0" } ] }, "ipv6Ranges": { "items": [ { "cidrIpv6": "::/0" } ] }, "prefixListIds": {} } ] } }Lambda作成
Python3.6で作成しました。
SGルールを削除するrevoke_security_group_ingress()メソッドを使用しています。
完成したプログラムがこちらです。
コメントでも記載していますが、ec2.revoke_security_group_ingress()でポート番号の設定をしていないルールを削除する際、適当な数字をfromPortとtoPortに入れてec2.revoke_security_group_ingress()を実行してもエラーにならず削除できました。
最初は各ポートにNoneを入れて対応できないか試しましたが、int型でなければダメだと怒られました。Lambdaの関数import json import boto3 ec2 = boto3.client("ec2") def lambda_handler(event, context): ip_permissions_items = event["ipPermissions"]["items"] SGID = event["groupId"] for ip_permissions_item in ip_permissions_items: ip_protocol = ip_permissions_item["ipProtocol"] ip_ranges = ip_permissions_item["ipRanges"] ipv6_ranges = ip_permissions_item["ipv6Ranges"] # ipRangesのcidripが存在しフルオープンであればそのまま変数に格納し、それ以外はNoneを格納する if ip_ranges == {}: cidrip = None else: # 許可するIPアドレスが複数存在する場合もあるので順次IPアドレスを調べ、フルオープンがでた時点で変数に格納し抜け出す for ip_ranges_item in ip_ranges["items"]: if ip_ranges_item["cidrIp"] == "0.0.0.0/0": cidrip = ip_ranges_item["cidrIp"] break else: cidrip = None if ipv6_ranges == {}: cidripv6 = None else: for ipv6_ranges_item in ipv6_ranges["items"]: if ipv6_ranges_item["cidrIpv6"] == "::/0": cidripv6 = ipv6_ranges_item["cidrIpv6"] break else: cidripv6 = None # ポート設定はルールによっては存在しないため、あればそのまま変数に格納し、なければ適当な数字を格納する if "fromPort" and "toPort" in ip_permissions_item: from_port = ip_permissions_item["fromPort"] to_port = ip_permissions_item["toPort"] else: # int型でなければ削除時エラーが発生するため数値を格納 # ポートが存在しない場合の処理なので、どの数値でも問題ないと思われる(0,70000は支障なし) from_port = 0 to_port = 0 if cidrip == "0.0.0.0/0" and cidripv6 == "::/0": ec2.revoke_security_group_ingress( GroupId=SGID, IpPermissions=[ { "IpProtocol": ip_protocol, "FromPort": from_port, "ToPort": to_port, "IpRanges":[ { "CidrIp": cidrip } ], "Ipv6Ranges":[ { "CidrIpv6": cidripv6 } ] } ] ) elif cidrip == "0.0.0.0/0": ec2.revoke_security_group_ingress( GroupId=SGID, IpPermissions=[ { "IpProtocol": ip_protocol, "FromPort": from_port, "ToPort": to_port, "IpRanges":[ { "CidrIp": cidrip } ] } ] ) elif cidripv6 == "::/0": ec2.revoke_security_group_ingress( GroupId=SGID, IpPermissions=[ { "IpProtocol": ip_protocol, "FromPort": from_port, "ToPort": to_port, "Ipv6Ranges":[ { "CidrIpv6": cidripv6 } ] } ] )これでSGフルオープンルールの自動削除実装は終わりです。
私が試してみた限りはうまく動いているように見えましたが、欠陥があった場合はコメント欄から教えていただけると嬉しいです。
主に私個人の勉強のために記事を執筆しましたが、誰かのお役に立てれば幸いです。
- 投稿日:2021-01-07T01:41:38+09:00
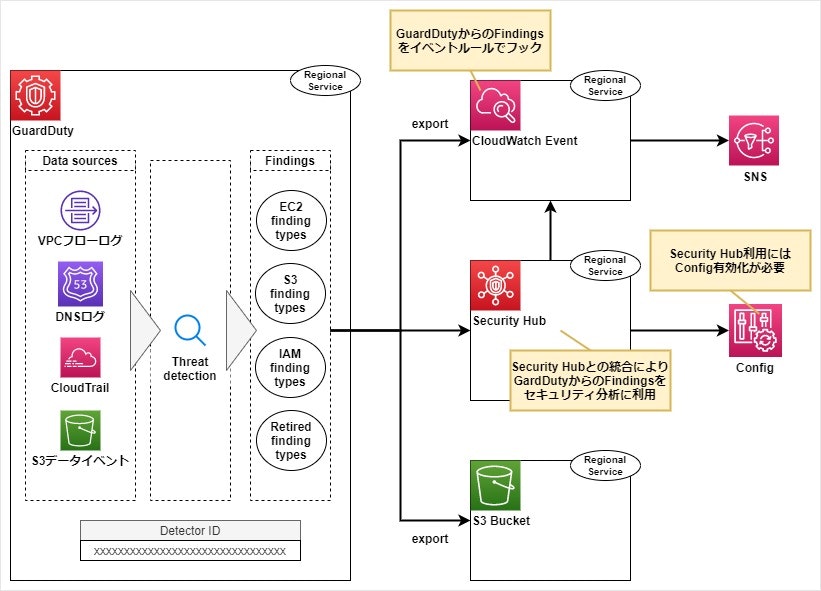
AWS GuardDuty 概要
概要
※この記事は目下記載中です
AWS のセキュリティ周り、特に GuardDuty の位置づけを理解するためにざっと調べた内容をまとめ。
まず、GuardDuty およびその周辺の AWS リソースの関連は以下のようなイメージ。
用語補足
用語 説明 Data source GuardDutyが解析するデータの発生源 (Cloud Trail、VPCフローログ、DNSログなど) Finding GuardDutyが検知したセキュリティ問題の兆候. いくつかのFinding typesがプリセットされている(参考)CloudWatch Eventを通しても確認でき、GuardDutyからCloudWatchへはHTTPSでFindingsを送信します AWS Security Hub AWS Config ※続き記載中...