- 投稿日:2020-11-26T23:07:50+09:00
Pythonで、持ちうる要素数の上限値と下限値が決められた配列リストを表現する自作データ型を定義する
この記事で行うこと
要素の数が、[ある数値以上、ある数値以下]であるlist配列であること、という型制約を持つ自作クラス(自作データ型)をPythonで宣言してみます。
このデータ型のインスタンスを生成するときに、コンストラクタに、上記の条件を破る引数を与えると、TypeErrorが発生して、Pythonは処理を終了します。
なお、このlist配列は、任意のデータ型のインスタンスを要素に持つことができるという条件も、おまけに付け加えてみます。
さらに、複数の異なるデータ型のインスタンスを要素に持つことも許容します。
上記の条件をすべて満たすデータ型を、Pythonで定義して、使ってみます。
( 関連記事 )
( 必要な外部資源 )
ここでは、以下のGitHubリポジトリにあるPython用のモジュールをgit cloneして、利用します。
・ (GitHubリポジトリ)vixrant/python-type-theory
Terminal% git clone https://github.com/vixrant/python-type-theory Cloning into 'python-type-theory'... remote: Enumerating objects: 79, done. remote: Counting objects: 100% (79/79), done. remote: Compressing objects: 100% (61/61), done. remote: Total 79 (delta 36), reused 50 (delta 18), pack-reused 0 Unpacking objects: 100% (79/79), done. %( 実行環境 )
・ IPython対話型インタプリタ(Python 3.9.0)
git cloneしたPythonスクリプトは、内部でinspect.getsource()メソッドを呼び出すのですが、Pythonの対話型インタプリタでこのメソッドを使うと、inspect.py, raise OSError('could not get source code')エラーが起きるためです。
iPythonの対話型インタプリタは、このエラーを発生させずに、inspect.getsource()メソッドを使うことができるようです。
なお、iPythonを使わずに、Python2系やPython3系を使う場合でも、Pythonのスクリプトファイルを実行する場合は、OSエラーを発生させずに、今回 git cloneしたモジュールを使うことができます。
では、はじめます。
( 利用するモジュールのインポート )
Python3.9from typing import List, Sequence, TypeVar from refinement import refine, reftype T = TypeVar('T')まず、ある条件を記述し、条件を満たしたかどうかを、boolean(bool)値で返すメソッドを定義します。
今回は、MinN( )メソッドと、MaxN( )メソッドという2つのメソッドを定義しました。
このメソッドには、@reftypeデコーダが付されています。
@reftypeデコーダを付けることで、データ型(自作クラス)が定義されます。Python3.9@reftype def MinN(i: int) -> bool: return i > 0 @reftype def MaxN(i: int) -> bool: return i > 0出来上がるデータ型(自作クラス)は、上記のメソッドに記述した条件式を満たす値だけを、持つことができる型になります。
MinN型とMaxN型という2つのデータ型(自作クラス)は、以下の条件を満たすインスタンスのみを生成することができます。
・ 条件1. int型の値を持つこと。
・ 条件2. 0より大きい値を持つこと。上記の2つの条件を充足することを義務付けられたデータ型(クラス)は、依存型(Dependent Type)と呼ばれています。
依存型(Dependent Type)クラスのインスタンスは、ある定められた条件を満たすデータ値だけを、インスタンスとして持つことを許されます。
・ Dependent Types と Refinement Types の違い
・ 型をさらに拡張するーーRefinement Typesについて「型をさらに拡張する」Webページからの引用先程も述べたように、例えばPositive-Integerであるならば、負の整数に関しては排除されるべきだろう。そのように考えるとするならば、次のような表現だってできるはずだ(以下の例は論文によるものである) (: max : [x : Int ] [y : Int] ~> (Refine [z : Int ] (and (>= z x) (>= z y)))) (define (max x y) (if (> x y) x y)) このように、型に属するであろう任意の要素を取ってきて、それに当てはまるかどうかをチェックすることによって、より厳密な型によるチェックが行える。この場合であるならば、「Int型に属するx、及びyは、必ずzというより上位の数を所持している」ということになる(考えてみればわかるように、もし、xやyに、上位のzの数が存在しないと仮定すると、関数定義において、(> x y)という比較は成りたたない)依存型は、「項(数値など)に依存して決まる型」と、定義されています。
ここでいう「項(数値など)」とは、そのデータ型がとりうる値を厳格に規定する条件値のことです。以下に例を挙げてみます。【 インスタンスが持つことのできる値の制約条件(型制約)の例 】
1. int型のデータの場合:値の数の範囲(例:「マイナス100〜プラス150」)
2. str型やList[T]型の場合:配列の長さ(要素の数、文字数)の下限値と上限値依存型という言葉は、Pythonの専門用語ではなく、関数型言語などのプログラミング言語の領域で使われている、プログラミング言語論の専門用語です。
IdrisやRacket(v6.11以降)と呼ばれるプログラミング言語が、これらの型を宣言し、静的な型検査を行うことができる言語です。
次に、新しいメソッドを定義します。
今度は、定義するメソッドに、@refineデコーダを付けたメソッドの中で、さらに、@reftypeデコレータが付いた別のメソッドを定義します。
Python3.9@refine def ListLengthChecker(min_length: MinN, max_length: MaxN): @reftype def LenLimit(l: list) -> bool: return (len(l) >= min_length) and (len(l) <= max_length) return LenLimitまず、内側にある@reftypeデコレータが付いたメソッドは、データ区間[min_length以上、max_length以下の値]という条件を満たすデータ値のみをとることが許されたデータ型を、定義するものです。
ここで、ListLengthChecker( )メソッドの型アノテーションを見ると、min_lengthとmin_lengthは、それぞれ、MinN型とMaxN型のインスタンスを持つこと、という定義がなされています。
MinN型とMaxN型は、最初に定義された、「0よりも大きな数値(int)を持つことだけが許容」されたデータ型でした。
ListLengthChecker( )メソッドには、@Refineデコーダが付いています。
ListLengthChecker メソッドに、@Refineデコーダを付けることで、新たにListLengthChecker型という新たなデータ型(クラス)が定義されます。Refinement Typeは、和訳では、「篩(ふるい)型」と呼ばれています。この型は、「型がとりうる値が、述語で修飾されている型」という説明のされ方をします。
Wikipedia(英語)の定義を引用してみます。
In type theory, a refinement type[1][2][3] is a type endowed with a predicate which is assumed to hold for any element of the refined type. Refinement types can express preconditions when used as function arguments or postconditions when used as return types:( 使い方 )
以下の2つのステップを踏みます。
【 ステップ1 】
ListLengthChecker型のコンストラクタに、2つの引数(min_length および max_length)を与えて、ListLengthChecker型のインスタンスを生成する。【 ステップ2 】
「ステップ1」で生成したListLengthCheckerr型のインスタンスに、任意のデータ型(T)を要素にもつ配列(Sequence)を引数に渡す。コードで書くと、次のようになります。
Python3.9temp_func = ListLengthChecker(min_length, max_length) result = temp_func(data_list)上記のコードを実行すると、以下の条件をすべて満たすかどうかが、上記のコードを実行する際に、自動的に型制約チェックが走ります。
・ 条件1. 引数として受け取ったMinN, MaxNは、int型の値を持つか。
・ 条件2. 引数として受け取ったMinN, MaxNは、0より大きい値を持つか。
・ 条件3. 引数として受け取ったSequence[T]型のインスタンス data_listの要素の数は、データ区間[min_length以上、max_length以下の値]の数値範囲の中にある値であるか。これら3つの型制約(条件)のうち、どれか1つでも満たされない制約があると、上記のコードは、「型制約エラー TypeError」を吐いて、処理が止まります。
mypyは、Pythonのスクリプトファイルを外側から「型制約チェック」を行いますが、ここでは、Pythonスクリプトまたは、Pythonの対話型インタプリタで上記のコードが実行される瞬間に、コード内部で、上記の「型制約」が充足されているかどうかのチェックが走ります。
それでは、以下のコードを1つのメソッドに包んでみます。
Python3.9temp_func = ListLengthChecker(min_length, max_length) result = temp_func(data_list)メソッド名として、list_length_checkerという名前を付けてみました。
Python3.9def LengthRestrictedList(data_list : Sequence[T], min_length : int, max_length : int) -> Sequence[T]: temp_func = ListLengthChecker(min_length, max_length) try: result = temp_func(data_list) except TypeError: error_message = "配列リストの長さが条件を満たしません。" print(error_message) result = [] return resultなお、引数として受け取るPythonのlist(配列)data_listの型アノテーションは、typingモジュールのSequence[T]でも、List[T]でも、どちらでも構いません。
今回は、data_listの中身の要素は、任意のデータ型を持てるよう許容してみたいと思います。そのため、typingモジュールのジェネリクス(総称型)の「型変数」であるT を指定しています。
data_listの中身の要素を、intやstrやcallableなどの特定のデータ型のインスタンスに限定したい場合は、List[int]やSequence[int]などと、定義します。
Python3.9def LengthRestrictedList2(data_list : List[T], min_length : int, max_length : int) -> List[T]: temp_func = ListLengthChecker(min_length, max_length) try: result = temp_func(data_list) except TypeError: error_message = "配列リストの長さが条件を満たしません。" print(error_message) result = [] return result( 挙動を確認 )
以下で見るように、すべてが、意図した通りの挙動を示しました。(成功!)
Python3.9result = LengthRestrictedList(["a", "b", "c", "e", "f"], 2, 7) print(result) # 実行結果 ['a', 'b', 'c', 'e', 'f'] result = LengthRestrictedList(["a", 1, "c", "e", "f"], 2, 7) print(result) # 実行結果 ['a', 1, 'c', 'e', 'f'] result = LengthRestrictedList(["a"], 2, 7) # 実行結果 配列リストの長さが条件を満たしません。 result = LengthRestrictedList(["a", 1, "c", "e", "f"], 7, 10) # 実行結果 配列リストの長さが条件を満たしません。 result = LengthRestrictedList2(["a", "b", "c", "e", "f"], 2, 7) print(result) # 実行結果 ['a', 'b', 'c', 'e', 'f'] result = LengthRestrictedList2(["a", 1, "c", "e", "f"], 2, 7) print(result) # 実行結果 ['a', 1, 'c', 'e', 'f'] del result # 実行結果 result = LengthRestrictedList2(["a", "b", "c", "e", "f"], 2, 7) print(result) # 実行結果 ['a', 'b', 'c', 'e', 'f'] result = LengthRestrictedList2(["a", 1, "c", "e", "f"], 2, 7) # 実行結果 print(result) ['a', 1, 'c', 'e', 'f'] result = LengthRestrictedList2(["a"], 2, 7) # 実行結果 配列リストの長さが条件を満たしません。 result = LengthRestrictedList2(["a", 1, "c", "e", "f"], 7, 10) # 実行結果 配列リストの長さが条件を満たしません。
- 投稿日:2020-11-26T20:56:33+09:00
応用数学「線形代数」
応用数学 (1章: 線形代数)
- 行列
- 単位行列
- 逆行列
- 固有値・固有ベクトル
- 固有値分解
- 特異値分解
上記の6項目を元に線形代数の理解に努める。
行列
スカラーを表にしたものであり、ベクトルを並べたものである。
行列積は「行」×「列」で新たな成分を求めること、連立方程式の研究の中から生まれたもの。
行列の積は\begin{pmatrix} a & b \\ c & d \end{pmatrix} \times \begin{pmatrix} e & f \\ g & h \end{pmatrix}を計算する。
単位行列
I = \ \begin{pmatrix} 1 & 0 & 0\\ 0 & 1 & 0\\ 0 & 0 & \ddots \end{pmatrix}
行列の中には、単位行列という種類のものがある。
単位行列は、かけてもかけられても相手が変化しない、「1」のような行列のことを指している。逆行列
ある行列Aに対して、その積が単位行列を生むような行列を逆行列という。
逆行列は掃き出し法によって求めることができる。\begin{pmatrix} 1 & 4 \\ 2 & 6 \end{pmatrix} \times \begin{pmatrix} x_1 \\ x_2 \end{pmatrix} = \begin{pmatrix} 10 \\ 7 \end{pmatrix}を\begin{pmatrix} 1 & 4 \\ 2 & 6 \end{pmatrix} \times \begin{pmatrix} x_1 \\ x_2 \end{pmatrix} = \begin{pmatrix} 1 & 0 \\ 0 & 1 \end{pmatrix} \begin{pmatrix} 10 \\ 7 \end{pmatrix}と考えて、左右の係数の行列に同じ行基本変形を実行していけば、
左辺は \begin{pmatrix} 1 & 0 \\ 0 & 1 \end{pmatrix} で、右辺には逆行列がもとまる。
つまり、AA^{-1} = A^{-1}A = I \ \ が成り立つ。行列式
行列式の特徴を追記する。
同じ行ベクトルが含まれていると行列式はゼロ
\begin{vmatrix} \vec{v_1} \\ \vdots \\ \vec{w} \\ \vdots \\ \vec{w} \\ \vdots \\ \vec{v_2} \end{vmatrix} = 01つのベクトルがλ倍されると行列式はλ倍される
\begin{vmatrix} \vec{v_1} \\ \vdots \\ \lambda\vec{v_i} \\ \vdots \\ \vec{v_2} \end{vmatrix} = \lambda \begin{vmatrix} \vec{v_1} \\ \vdots \\ \vec{v_i} \\ \vdots \\ \vec{v_2} \end{vmatrix}他の成分が全部同じでi番目のベクトルだけが違った場合、行列式の足し合わせになる
\begin{vmatrix} \vec{v_1} \\ \vdots \\ \vec{v_i} \ + \vec{w}\\ \vdots \\ \vec{v_2} \end{vmatrix} = \begin{vmatrix} \vec{v_1} \\ \vdots \\ \vec{v_i} \\ \vdots \\ \vec{v_2} \end{vmatrix} + \begin{vmatrix} \vec{v_1} \\ \vdots \\ \vec{w} \\ \vdots \\ \vec{v_2} \end{vmatrix}行を入れ替えると符号が変わる
\begin{vmatrix} \vec{v_1} \\ \vdots \\ \vec{v_s} \\ \vdots \\ \vec{v_t} \\ \vdots \\ \vec{v_2} \end{vmatrix} = - \begin{vmatrix} \vec{v_1} \\ \vdots \\ \vec{v_t} \\ \vdots \\ \vec{v_s} \\ \vdots \\ \vec{v_2} \end{vmatrix}固有値分解
正方形の行列を3つの行列の積に変換することを固有値分解という。
A = VλV^{-1}特異値分解
正方行列以外の行列を分解することを特異値分解という。
M\vec{v} = \sigma\vec{u} \\ M^T\vec{u} = \sigma\vec{v}これらは、
MV = US \\ M^TU = VS^T となり、\\ MM^T = USS^TU^{-1} と表すことができる。つまり、
MM^Tを固有値分解すれば、その左特異ベクトルと特異値の2乗が求められることがわかる。ただし、左特異ベクトルは単位ベクトルから作らなければいけないことに注意する必要がある。
- 投稿日:2020-11-26T20:55:33+09:00
pythonのloggingについてのメモ
loggingについて
python標準のlog書き出しライブラリであるloggingパッケージの使い方メモです
loggingの公式ドキュメント
https://docs.python.org/ja/3/library/logging.html#handler-objects参考にしたページ
ログ出力のための print と import logging はやめてほしい
https://qiita.com/amedama/items/b856b2f30c2f38665701python logging best practice
https://pieces.openpolitics.com/2012/04/python-logging-best-practices/pythonのlog出力
https://qiita.com/yopya/items/63155923602bf97dec53使い方
Loggerにレベルとフォーマットの管理をしてもらい、Handlerに書き出し先を管理してもらいます。
Logger
logging.getLogger()によりloggerインスタンスを作ることができます。引数としてlogger名を与えてフォーマットに含めるとここで指定したlogger名をlogに書き出すことができます
from logging import getLogger logger = getLogger('hoge')レベル
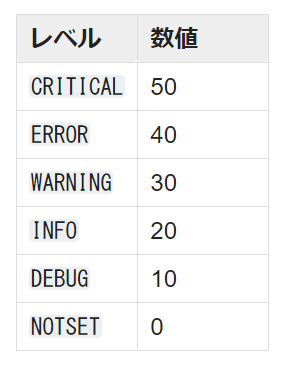
書き出しレベルを設定しておいて、閾値以下のlogは書き出さないようにすることが出来ます。細々とした情報はDEBUGのときにしか必要ないので、実運用時にはWARNING以上のlogしか書き出さない、というような事が出来るわけです。
これを上記で作ったloggerに追加することでレベルの閾値を指定できます。from logging import DEBUG logger.setLevel(DEBUG)Handler
logging.StreamHandler()によりstdoutに、logging.handlers.RotatingFileHandler()によりテキストファイルにlogを書き出せます。
stdoutfrom logging import StreamHandler handler = StreamHandler()file出力from logging import handlers handler = handlers.RotatingFileHandler(filename='./hoge.log')フォーマット
logのフォーマットも自由に指定することが出来ます
from logging import Formatter formatter = Formatter("[%(asctime)s] [%(process)d] [%(name)s] [%(levelname)s] %(message)s") handler.setFormatter(formatter)書き出し
以下のようにレベルを指定して書き出します
logger.debug('debugレベルで書き出します') logger.info('infoレベルで書き出します') logger.warning('warnレベルで書き出します') logger.error('errorレベルで書き出します') logger.critical('criticalレベルで書き出します')実際の使い方
こちらのページのやり方が分かりやすかったのでお借りしました。
https://qiita.com/yopya/items/63155923602bf97dec53上記のあれこれをClassにしておいて一括で使おうというやり方ですね。
logger.pyfrom logging import Formatter, handlers, StreamHandler, getLogger, DEBUG class Logger: def __init__(self, name=__name__, filename='./fuga.log', level=DEBUG): assert isinstance(filename, str), 'filename must be string: {}'.format(filename) self.logger = getLogger(name) self.logger.setLevel(level) formatter = Formatter("[%(asctime)s] [%(process)d] [%(name)s] [%(levelname)s] %(message)s") # stdout handler = StreamHandler() handler.setLevel(level) handler.setFormatter(formatter) self.logger.addHandler(handler) # file handler = handlers.RotatingFileHandler(filename=filename, maxBytes=1048576, backupCount=3) handler.setLevel(level) handler.setFormatter(formatter) self.logger.addHandler(handler) def debug(self, msg): self.logger.debug(msg) def info(self, msg): self.logger.info(msg) def warn(self, msg): self.logger.warning(msg) def error(self, msg): self.logger.error(msg) def critical(self, msg): self.logger.critical(msg)上記をimportして使ってみます
main.pyimport logger def main(): log = logger.Logger('hoge') log.debug('test debug') log.info('test info') log.warn('test warn') log.error('test error') log.critical('test critical') if __name__ == '__main__': main()hogeと書かれているのはloggerを作成したときに指定したlogger名なので、モジュールごとにこれを変えておけばどのモジュールが書いたログなのかも分かるようになります。
fuga.log[2020-11-26 18:10:53,002] [5760] [hoge] [DEBUG] test debug [2020-11-26 18:10:53,002] [5760] [hoge] [INFO] test info [2020-11-26 18:10:53,003] [5760] [hoge] [WARNING] test warn [2020-11-26 18:10:53,003] [5760] [hoge] [ERROR] test error [2020-11-26 18:10:53,003] [5760] [hoge] [CRITICAL] test criticalまた、levelをDEBUGではなくWARNに変更すると以下のように出力が制限されます。
fuga.log[2020-11-26 18:10:53,003] [5760] [hoge] [WARNING] test warn [2020-11-26 18:10:53,003] [5760] [hoge] [ERROR] test error [2020-11-26 18:10:53,003] [5760] [hoge] [CRITICAL] test criticalまとめ
とりあえず使うだけならとても簡単だけど、込み入ったモジュールでバグを素早く見つけられるようにするには結構ノウハウが必要になりそうなので、スマートな使い方を模索していきたい所存でござる
- 投稿日:2020-11-26T20:14:07+09:00
Fusion 360 APIのPythonでメリークルシミマス
環境
- Windows 10
- Fusion 360
- VSCode
- 2020年11月26日
Fusion 360 APIのPython
「OpenSCADだと無理なことをしたい」と思ってしまった良い子の諸君! Fusion 360にはPythonのAPIがあり、スクリプトとアドインが作れる。
Fusion 360 を Pythonで動かそう その1 スクリプトの新規作成
できることはOpenSCADよりずっと多い。
が、「できることが多い=APIが複雑」というトレードオフもある。また、Fusion 360 APIの設計がPythonを前提にしておらず(内部はC++)、そのミスマッチをAPIユーザに丸投げしていることが多い。
それだけでもダルくなるところ、さらにSWIGである。pybind11ではなくSWIG。まさしく あきれ はてたな…
とはいえなんとかやっていくしかない。本記事は、そのための工夫を記録している。VSCodeのコード補完とPythonの型アノテーション
コード補完なしでFusion 360 APIを使うのはマゾゲーなのでやめておこう。
言語サーバをPylanceからMicrosoftにする
Fusion 360 APIは、IDEがコード補完するための型推論の材料として、
C:%APPDATA%\Autodesk\Autodesk Fusion 360\API\Python\defsにスタブ的なものを提供している。しかしこれはPEP 484のスタブファイル(.pyiファイル)とは縁もゆかりもないもので、今のPylanceではうまく解釈されないことが多い。たとえば、app = adsk.core.Application.get()のappがAny型になる。とはいえget()の戻り値はApplication型と表示されるので、Pylanceのバグだとは思うが。
ともあれまずはsettings.jsonでpython.languageServer: "Microsoft"を設定して先に進む。スタブ的なものを書き換えて多少マトモにしたい
C:%APPDATA%\Autodeskの下はいつAutodeskに書き換えられるかわからない。スタブ的なもの(adskフォルダ)を安全なフォルダfooにコピーして、C:%APPDATA%\Autodesk\Autodesk Fusion 360\API\Python\defs\adskをそのフォルダへのジャンクションにしてしまう。そしてfooフォルダをgitで管理すれば大丈夫。ジェネリックな型アノテーション
C++とのミスマッチの要は
adsk.core.ObjectCollectionクラスである。Fusion 360 APIはコンテナとしてこれを使うことが多い。オブジェクトをデバッガで軽く調べたところ、iterableかつSizedのインターフェイスを持っているように見える。しかしスタブ的なものは恐ろしく不親切で、iterableにさえなっていない。
そこでcore.pyの末尾に追加:import typing as ty import collections.abc as abc T = ty.TypeVar('T') class ObjectCollectionT(ObjectCollection, abc.Iterable[T], abc.Sized): """ Generic collection used to handle lists of any object type. Type generics version. Abstract class for type hinting. """ def __init__(self): pass def item(self, index) -> T: passこの
ObjectCollectionTクラスは、型アノテーションの中だけで完結しなければならない。実行時に現れようとするとエラーになることに注意。
ObjectCollectionTクラスを使って、スタブ的なものに型アノテーションをつけていく。fusion.pyのBaseComponentクラスのfindBRepUsingRayにつけてみた例:def findBRepUsingRay( self, originPoint: core.Point3D, rayDirection: core.Vector3D, entityType: int, proximityTolerance: float, visibleEntitiesOnly: bool, hitPoints: core.ObjectCollectionT[core.Point3D] ) -> core.ObjectCollectionT['BRepFaces']: """ ...docstring... """ passこの作業をスタブ的なもの全部にやるのは99%無意味なので、自分が使うところだけやる。ちなみにAPIドキュメントのすべてがdocstringに書いてあるわけではないことに注意。
言語サーバを本当に再起動する
スタブ的なものを書き換えると、言語サーバがおかしくなることが多い。Ctrl+Shift+Pで
Python: Restart Language Serverをすると、言語サーバが再起動するかのように思えるが、それほど深くは再起動しないらしく、これでは治らないことが多い。settings.jsonのpython.languageServer: "Microsoft"のMicrosoftをいったんPylanceに書き換えてリロード、そしてMicrosoftに戻してまたリロード、これで本当に再起動する。
ObjectCollection.create()生成と同時に
ObjectCollectionT[T]へのダウンキャストをしたい。def CreateObjectCollectionT(cls): r: adsk.core.ObjectCollectionT[cls] = adsk.core.ObjectCollection.create() return rたぶん2行目はmypyにかけたらエラーになるが、コード補完したいだけなので放置。なお戻り値の型をアノテーションする方法は不明。これで
hitPoints = CreateObjectCollectionT(adsk.core.Point3D)のhitPointsの型がObjectCollectionT[Point3D]になる。なにか見つけたら追記する。
- 投稿日:2020-11-26T20:01:22+09:00
深層学習でスナックの売り上げ予測をしてみた。
ブログの目的
今回のブログでは、深層学習によって母親が個人経営するスナックの売り上げを予測していきます。
経営者である母は「在庫管理、雇用人数、設備投資、経営拡大」などの支出に関する判断にいつも悩まされています。。。そこで、確度の高い売り上げ予測ができれば、その苦労を少しでも減らせるかもと思いました。
機械学習の勉強を始めて早1ヶ月が経ち、ちょうど、実際のデータでモデル構築してみたいなと思い出してきたところでした。やり遂げられるか少し不安ですが、これまでの復習も兼ねながら挑戦していきたいと思います!!!また、これから機械学習を勉強する人への参考記事にもなったら良いなと思っています。機械学習のモデル構築の流れ
機械学習のアルゴリズムの種類はたくさんありますが、根幹の部分にあるモデル構築の流れは全てにおいて共通していました。機械学習の簡単な流れは以下のようになっています。今回のブログでも、この流れを意識しながらモデル構築していきます。
1.データ収集
2.データの前処理(重複や欠損データ等を取り除いて、データの精度を高める。)
3.機械学習の手法でデータを学習
4.テストデータで性能をテスト時系列データ解析について
今回の「スナックの売り上げ予測のモデル構築」は、時系列データ解析に該当します。時系列データとは、時間の経過と共に変化するデータのことを指します。時系列データ解析は、会社の売り上げや商品の売り上げの予測にも応用できるので、ビジネスシーンでもとても重要な分析技術とされています。
今回のブログではその中でも深層学習の手法を応用したRNN(Recurrent Neural Network)とLSTM(Long-short-term-memory)というアルゴリズムの使用を検討していきます。
RNN(Recurrent Neural Network)
RNNとは、深層学習によって時系列データを解析する機械学習アルゴリズムの一つです。中間層において、前の時点のデータを現時点の入力として自己ループすることがRNNの特徴です。これによってRNNでは、中間層におけるデータ同士の前後の文脈を保持したまま、情報の伝達が可能になります。そして、この性質が、時間の概念を持つデータの学習を可能にしました。
(https://qiita.com/KojiOhki/items/89cd7b69a8a6239d67caより引用)RNNの欠点
深層学習で時系列データの解析を可能にしたRNNですが、実は性能がそれほど高くはありません。その原因はRNNのループ構造によって活性化関数が何度も乗算されることにあります。時間の経過と共に、繰り返し活性化関数が乗算されることで、勾配の値が収束する勾配消失or演算量が指数的に増加する勾配爆発が起きてしまうのです。その結果、適切なデータ処理が難しくなってしまいます。また、これらの理由から、長期間の時系列データの学習にはRNNは向いていないことが分かります。
この欠点を解決した深層学習モデルが次に紹介するLSTM(Long-short-term-momory)です。LSTM(Long-short-term-memory)
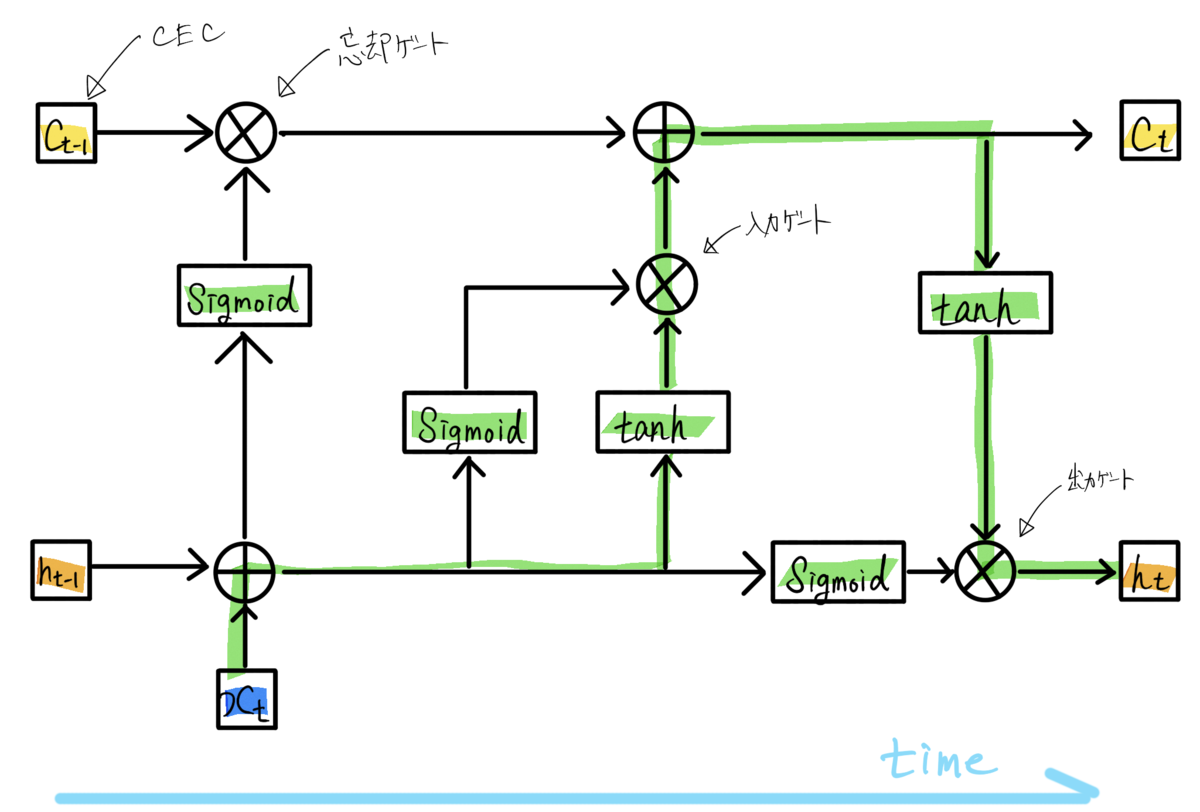
LSTMモデルでは、中間層のセルをLSTMブロックに置き換えることで、RNNの持つ「長期間の記憶を保持しながら学習できない」という欠点を克服しています。LETMブロックの基本的な構成は以下です。
・CEC:過去のデータを保存するユニット
・入力ゲート:前のユニットの入力の重みを調整するゲート
・出力ゲート:前のユニットの出力の重みを調整するゲート
・忘却ゲート:過去の情報が入っているCECの中身をどの程度残すかを調整するゲート
(https://sagantaf.hatenablog.com/entry/2019/06/04/225239より引用)LSTMでは、上述したゲートの機能によって、セルの状態に応じた情報の削除・追加が可能です。入力・出力の重みを調整・セル内のデータの調整によって、RNNの欠点であった勾配消失と勾配爆発の問題を解消しています。よって、長期間の時系列データ解析にも適応することができます。
以上の説明が、RNNとLSTMの理論的な話になります。今回のスナックの売り上げに関するデータは7年分で計82データあります。長さとしては中長期間のデータなので、RNNとLSTM両方のモデルで予測していき、結果の良いモデルを採用したいと思います。それでは実際にモデル構築をしていきます。
開発環境
OS: Windows10 python環境: Jupyter Notebookファイル構成
Forecast- |-Forecast.py(pythonファイル) |-sales_data- |-各種CSVファイルモデル構築の流れ
モデル構築の流れは先ほど紹介した以下の流れです。
1.データ収集
2.データの前処理(重複や欠損データ等を取り除いて、データの精度を高める。)
3.機械学習の手法でデータを学習
4.テストデータで性能をテスト0.必要モジュール
まずは必要なモジュールをimportします。実行環境に以下のコードを書きます。
Forecast.pyimport numpy as np import pandas as pd import matplotlib.pyplot as plt import math from keras.models import Sequential from keras.layers import Dense from keras.layers import SimpleRNN from keras.layers import LSTM from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import mean_squared_error1.データ収集
まずはデータ収集です。必死のお願いの末、母親が経営しているスナックの売り上げデータをゲットしました。月ごとの売り上げをまとめた2013-2019年のエクセルデータの形を整えてCSV形式に出力します。
収集データについて
データの説明
2013~2019年の月別のスナックの売り上げ記録。
基本統計量
sales データ数 8.400000e+01 平均 7.692972e+05 標準偏差 1.001658e+05 最小値 5.382170e+05 1/4分位数 7.006952e+05 中央値 7.594070e+05 3/4分位数 8.311492e+05 最大値 1.035008e+06年別の売り上げ平均
年が経過するごとに売り上げが上がっている傾向がありそうです。
2019 : 801197 円 2018 : 822819 円 2017 : 732294 円 2016 : 755799 円 2015 : 771255 円 2014 : 761587 円 2013 : 740128 円月別の売り上げ平均
一番売り上げが立っているのは12月、次に4月という結果になりました。年末の飲み会や年度初めの飲み会が多く開かれることが大きく関わっていそうです。こういった傾向もしっかり予測できたらと思います。
1 月: 758305 円 2 月: 701562 円 3 月: 750777 円 4 月: 805094 円 5 月: 785633 円 6 月: 778146 円 7 月: 752226 円 8 月: 763773 円 9 月: 689561 円 10 月: 765723 円 11 月: 779661 円 12 月: 901100 円時系列の周期変動とトレンドの考察
トレンドとは?
データの長期的な傾向を意味します。今回のテーマでは、長期的にスナックの売り上げが増加しているのか、それとも減少しているのかを示します。
周期変動とは?
周期変動があるデータは時間の経過に伴ってデータの値が上昇と下降を繰り返します。特に一年間での周期変動を季節変動と言います。今回のテーマに関しては、先ほどの考察で飲み会が多くなる12月と4月の売り上げの平均が高いことが分かりました。おそらく季節的な周期変動がありそうですね。
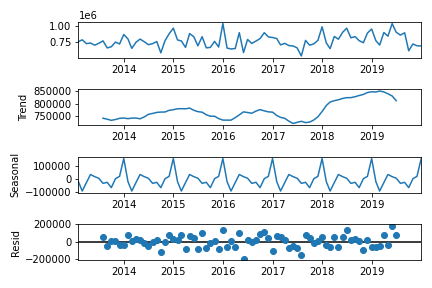
trend_seasonal.py# 通年売り上げのトレンドと季節性の考察 fig = sm.tsa.seasonal_decompose(df_sales_concat, freq=12).plot() plt.show()
予想通り、売り上げに関する増加トレンドがありました。また、4, 12月に売り上げが上がるという周期変動もありました。こういった内容に関しても、機械学習モデルで予測できたら良さそうですね。
時系列の自己共分散
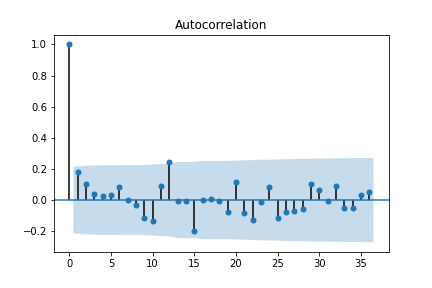
時系列の自己共分散とは、同じ時系列データの別々の時点同士での共分散を指します。k次の自己共分散とは、k時点離れたデータとの共分散を指します。この自己共分散をkの関数として見たものを自己相関関数といいます。この関数をグラフで表したものをコレログラムといいます。
corr.py#自己相関係数コレログラムの算出 df_sales_concat_acf = sm.tsa.stattools.acf(df_sales_concat, nlags=12) print(df_sales_concat_acf) sm.graphics.tsa.plot_acf(df_sales_concat, lags=12) fig = sm.graphics.tsa.plot_acf(df_sales_concat, lags=12)
コレログラムから、k=12の時に自己相関係数が高くなることが分かります。月別の売り上げを記録したデータなので、あるデータとその1年前のデータとの間に相関関係があることが分かります。
実際に使用したデータは以下のgoogle sheetsリンクに公開しています。
https://docs.google.com/spreadsheets/d/1-eOPORhaGfSCdXCScSsBsM586yXkt3e_xbOlG2K6zN8/edit?usp=sharingForecast.py#CSVファイルをDataFrame形式で読み込みます。 df_2019 = pd.read_csv('./sales_data/2019_sales.csv') df_2018 = pd.read_csv('./sales_data/2018_sales.csv') df_2017 = pd.read_csv('./sales_data/2017_sales.csv') df_2016 = pd.read_csv('./sales_data/2016_sales.csv') df_2015 = pd.read_csv('./sales_data/2015_sales.csv') df_2014 = pd.read_csv('./sales_data/2014_sales.csv') df_2013 = pd.read_csv('./sales_data/2013_sales.csv') #読み込んだDataFrameを結合して、一つのDataFrameにします。 df_sales_concat = pd.concat([df_2013, df_2014, df_2015,df_2016,df_2017,df_2018,df_2019], axis=0) #使用するFrameDataのインデックスを作成します。 index = pd.date_range("2013-01", "2019-12-31", freq='M') df_sales_concat.index = index #不必要なDataFrameの列を削除します。 del df_sales_concat['month'] #モデル構築で使用する実際の売り上げデータのみをdataset変数に格納します。 dataset = df_sales_concat.values dataset = dataset.astype('float32')2.データの前処理(データセットの作成)
次にデータの前処理です。具体的にはモデル構築に使用するデータセットを作成していきます。
Forecast.py# トレーニングデータとテストデータに分ける。比率は2:1=トレーニング:テストです。 train_size = int(len(dataset) * 0.67) train, test = dataset[0:train_size, :], dataset[train_size:len(dataset), :] # データのスケーリング。 #トレーニングデータを元にしたデータ標準化のためのインスタンスを作成しています。 scaler = MinMaxScaler(feature_range=(0, 1)) scaler_train = scaler.fit(train) train_scale = scaler_train.transform(train) test_scale = scaler_train.transform(test) # データセットの作成 look_back =1 train_X, train_Y = create_dataset(train_scale, look_back) test_X, test_Y = create_dataset(test_scale, look_back) #評価用のオリジナルデータセットの作成 train_X_original, train_Y_original = create_dataset(train, look_back) test_X_original, test_Y_original = create_dataset(test, look_back) # データの整形 train_X = train_X.reshape(train_X.shape[0], train_X.shape[1], 1) test_X = test_X.reshape(test_X.shape[0], test_X.shape[1], 1)3.LSTMモデルとRNNモデルの構築と学習
LSTMモデル構築
Forecast.pylstm_model = Sequential() lstm_model.add(LSTM(64, return_sequences=True, input_shape=(look_back, 1))) lstm_model.add(LSTM(32)) lstm_model.add(Dense(1)) lstm_model.compile(loss='mean_squared_error', optimizer='adam') ###学習 lstm_model.fit(train_X, train_Y, epochs=100, batch_size=64, verbose=2)RNNモデル構築
Forecast.pyrnn_model = Sequential() rnn_model.add(SimpleRNN(64, return_sequences=True, input_shape=(look_back, 1))) rnn_model.add(SimpleRNN(32)) rnn_model.add(Dense(1)) rnn_model.compile(loss='mean_squared_error', optimizer='adam') ###学習 rnn_model.fit(train_X, train_Y, epochs=100, batch_size=64, verbose=2)以上でデータセットからLSTMとRNNによる機械学習が完了しました。使用するクラスが異なるだけで、基本的な操作はどちらも同じです。次に結果をグラフにプロットするための処理です。
ここからはモデルをmodelと表示しますが、lstm_modelとrnn_modelの二つを指します。Forecast.py# 予測データの作成 train_predict = model.predict(train_X) test_predict = model.predict(test_X) # スケールしたデータを基に戻す。標準化された値を実際の予測値に変換します。 train_predict = scaler_train.inverse_transform(train_predict) train_Y = scaler_train.inverse_transform([train_Y]) test_predict = scaler_train.inverse_transform(test_predict) test_Y = scaler_train.inverse_transform([test_Y]) # 予測精度の計算 train_score = math.sqrt(mean_squared_error(train_Y_original, train_predict[:, 0])) print(train_score) print('Train Score: %.2f RMSE' % (train_score)) test_score = math.sqrt(mean_squared_error(test_Y_original, test_predict[:, 0])) print('Test Score: %.2f RMSE' % (test_score)) # プロットのためのデータ整形 train_predict_plot = np.empty_like(dataset) train_predict_plot[:, :] = np.nan train_predict_plot[look_back:len(train_predict)+look_back, :] = train_predict train_predict_plot = pd.DataFrame({'sales':list(train_predict_plot.reshape(train_predict_plot.shape[0],))}) train_predict_plot.index = index test_predict_plot = np.empty_like(dataset) test_predict_plot[:, :] = np.nan test_predict_plot[len(train_predict)+(look_back*2):len(dataset), :] = test_predict test_predict_plot = pd.DataFrame({'sales':list(test_predict_plot.reshape(test_predict_plot.shape[0],))}) test_predict_plot.index = index次は実際のデータをグラフにプロットしていきます。
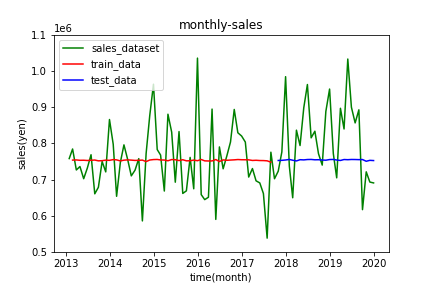
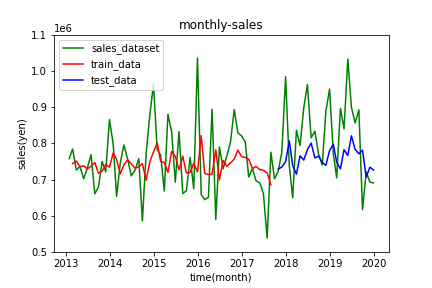
Forecast.py# グラフのメタ情報を出力する plt.title("monthly-sales") plt.xlabel("time(month)") plt.ylabel("sales") #データをプロットする plt.plot(dataset, label='sales_dataset', c='green') plt.plot(train_predict_plot, label='train_data', c='red') plt.plot(test_predict_plot, label='test_data', c='blue') #y軸の目盛りを調整する plt.yticks([500000, 600000, 700000, 800000, 900000, 1000000, 1100000]) #グラフをプロットする plt.legend() plt.show()4.結果
結果として出力されたRNNとLSTMのグラフをそれぞれ掲載します。
RNNによる予測
出力の値が完全に消失しています。。。パラメータをいろいろ変えましたが、結果に大きな変化はありませんでした。今回の84データの時間の長さでもRNNでの手法は向いていないことが分かります。
LSTMによる予測
RNNによる予測に比べると、売り上げの傾向をなんとなく予測できています。特に4月と12月で売り上げが増加する傾向をおさえることができています。
しかし全体として、実測値と大きく外れている点が多く見受けられます。モデルの良さの基準になるRMSEに関してもTrain Score: 94750.73 RMSE, Test Score: 115472.92 RMSEとなり、かなり大きい値になっています。あまり良い結果とは言えなそうです。まとめ
RNNで勾配消失を起こすデータセットでも、LSTMで詳しい時系列解析が実現できることがわかりました。しかし、LSTMでの予測でも売り上げの傾向を示すだけにとどまり、実際の値から大きく外れた値が多く見受けられます。これでは、確度の高い売り上げ予測とは言えず、経営判断になりうる収入データの予測にはなりえません。
考察
RNN、LSTMどちらに関しても、パラメータであるloop_back, epochs, batch_sizeのいろいろなパターンを試しましたが、特に性能が上がることはありませんでした。
原因としては、データの少なさとばらつきが想定できます。後に調べたところ、時系列解析でのデータ数84はかなり少ない数だそうです。機械学習モデルの構築には、データが命であるということを身にしみて感じました。しかし、何はともあれ、一か月の機械学習の復習と初学者への良い教材にはなったかと思います。これから機械学習エンジニアとしてレベルアップできるように、さらに精進していきます!
今回使用した全コード
Forecast.pyimport numpy as np import pandas as pd import matplotlib.pyplot as plt import math from keras.models import Sequential from keras.layers import Dense from keras.layers import SimpleRNN from keras.layers import LSTM from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import mean_squared_error # データセットの作成 def create_dataset(dataset, look_back): data_X, data_Y = [], [] for i in range(look_back, len(dataset)): data_X.append(dataset[i-look_back:i, 0]) data_Y.append(dataset[i, 0]) return np.array(data_X), np.array(data_Y) df_2019 = pd.read_csv('./sales_data/2019_sales.csv') df_2018 = pd.read_csv('./sales_data/2018_sales.csv') df_2017 = pd.read_csv('./sales_data/2017_sales.csv') df_2016 = pd.read_csv('./sales_data/2016_sales.csv') df_2015 = pd.read_csv('./sales_data/2015_sales.csv') df_2014 = pd.read_csv('./sales_data/2014_sales.csv') df_2013 = pd.read_csv('./sales_data/2013_sales.csv') df_sales_concat = pd.concat([df_2013, df_2014, df_2015,df_2016,df_2017,df_2018,df_2019], axis=0) index = pd.date_range("2013-01", "2019-12-31", freq='M') df_sales_concat.index = index del df_sales_concat['month'] dataset = df_sales_concat.values dataset = dataset.astype('float32') # トレーニングデータとテストデータに分ける train_size = int(len(dataset) * 0.67) train, test = dataset[0:train_size, :], dataset[train_size:len(dataset), :] # データのスケーリング scaler = MinMaxScaler(feature_range=(0, 1)) scaler_train = scaler.fit(train) train_scale = scaler_train.transform(train) test_scale = scaler_train.transform(test) # データの作成 look_back =1 train_X, train_Y = create_dataset(train_scale, look_back) test_X, test_Y = create_dataset(test_scale, look_back) # 評価用のデータセットの作成 train_X_original, train_Y_original = create_dataset(train, look_back) test_X_original, test_Y_original = create_dataset(test, look_back) # データの整形 train_X = train_X.reshape(train_X.shape[0], train_X.shape[1], 1) test_X = test_X.reshape(test_X.shape[0], test_X.shape[1], 1) # LSTMモデルの作成と学習 model = Sequential() model.add(LSTM(64, return_sequences=True, input_shape=(look_back, 1))) model.add(LSTM(32)) model.add(Dense(1)) model.compile(loss='mean_squared_error', optimizer='adam') model.fit(train_X, train_Y, epochs=100, batch_size=64, verbose=2) # 予測データの作成 train_predict = model.predict(train_X) test_predict = model.predict(test_X) # スケールしたデータを基に戻す。 train_predict = scaler_train.inverse_transform(train_predict) train_Y = scaler_train.inverse_transform([train_Y]) test_predict = scaler_train.inverse_transform(test_predict) test_Y = scaler_train.inverse_transform([test_Y]) # 予測精度の計算 train_score = math.sqrt(mean_squared_error(train_Y_original, train_predict[:, 0])) print(train_score) print('Train Score: %.2f RMSE' % (train_score)) test_score = math.sqrt(mean_squared_error(test_Y_original, test_predict[:, 0])) print('Test Score: %.2f RMSE' % (test_score)) # プロットのためのデータ整形 train_predict_plot = np.empty_like(dataset) train_predict_plot[:, :] = np.nan train_predict_plot[look_back:len(train_predict)+look_back, :] = train_predict train_predict_plot = pd.DataFrame({'sales':list(train_predict_plot.reshape(train_predict_plot.shape[0],))}) train_predict_plot.index = index test_predict_plot = np.empty_like(dataset) test_predict_plot[:, :] = np.nan test_predict_plot[len(train_predict)+(look_back*2):len(dataset), :] = test_predict test_predict_plot = pd.DataFrame({'sales':list(test_predict_plot.reshape(test_predict_plot.shape[0],))}) test_predict_plot.index = index # データのプロット plt.title("monthly-sales") plt.xlabel("time(month)") plt.ylabel("sales") plt.plot(dataset, label='sales_dataset', c='green') plt.plot(train_predict_plot, label='train_data', c='red') plt.plot(test_predict_plot, label='test_data', c='blue') plt.yticks([500000, 600000, 700000, 800000, 900000, 1000000, 1100000]) plt.legend() plt.show()

- 投稿日:2020-11-26T19:58:08+09:00
【SIGNATE】国勢調査からの収入予測をやってみた!!
はじめに
機械学習エンジニアを目指す方なら一度はやったことがあるであろう【SIGNATE】の国勢調査からの収入予測をやってみました。
環境情報
Python 3.6.5
【SIGNATE】国勢調査からの収入予測とは
教育年数や職業等の国勢調査データから年収が$50,000ドルを超えるかどうかを予測する2値分類問題です。
以下リンク
https://signate.jp/competitions/107内容
データの読み込みと可視化
データを読み込んで基本的な情報を確認.
python.pyimport pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib as mpl import seaborn as sns df = pd.read_csv('train.tsv', delimiter = '\t') df = df.drop('id', axis = 1) # データ量を確認. print(df.shape) # 欠損値の確認. print(df.isnull().sum())上記のソースコードを実行すると、下記の結果が返ってきます。
(16280, 15)
データの総数:16280
説明変数:14
目的変数:1
欠損値はなしということがわかりました。
目的変数を数値に置き換える。(<=50K → 0, >50K → 1)
python.pydf = df.replace({'Y': {'<=50K': 0, '>50K': 1}}) df['Y'].value_counts() 0 12288 1 3992 Name: Y, dtype: int64全体の30%は年収50,000$未満のようですね。
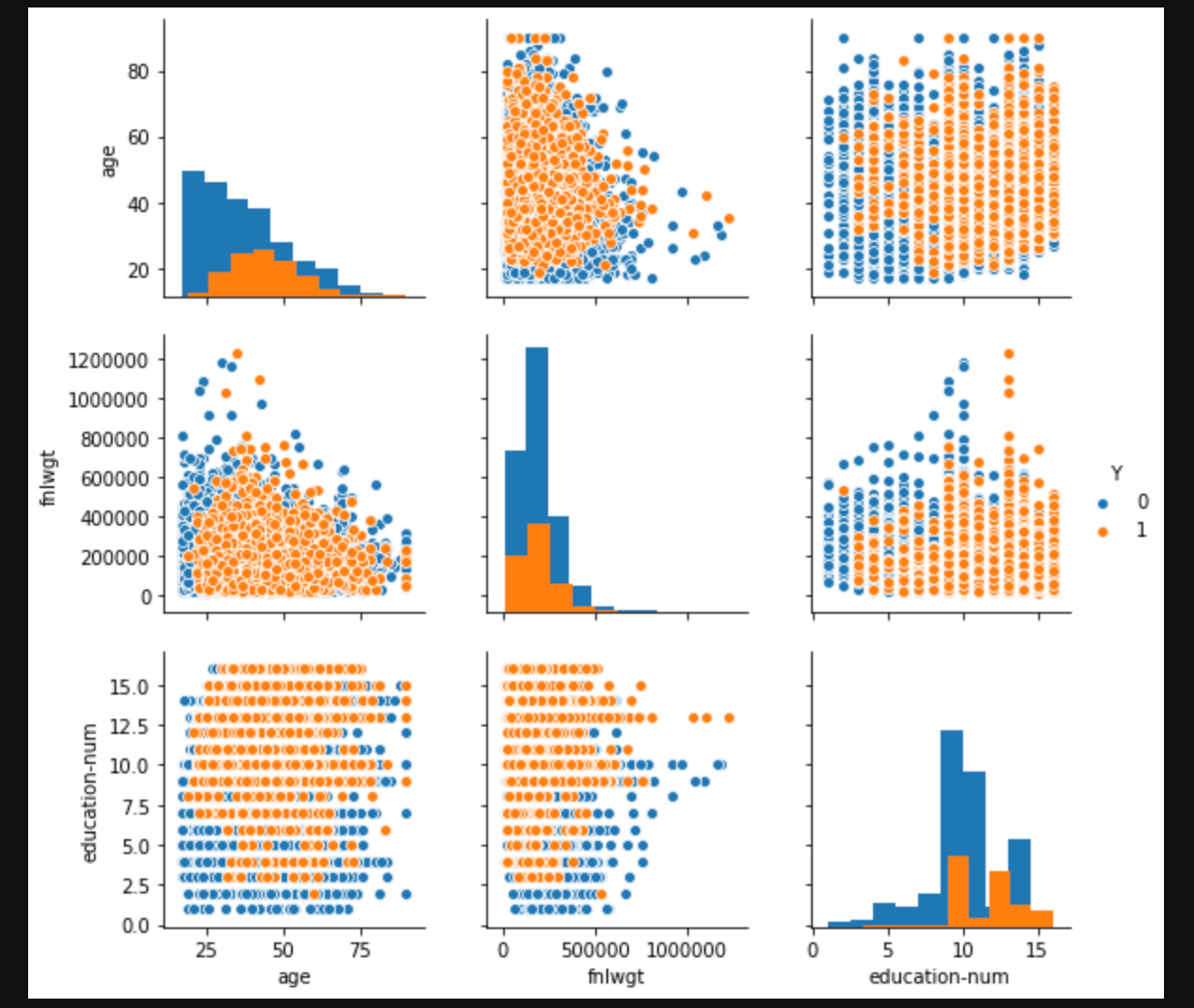
量的データを可視化
python.pysns.pairplot(df, hue="Y", diag_kind='hist', vars = ['age', 'fnlwgt', 'education-num'])
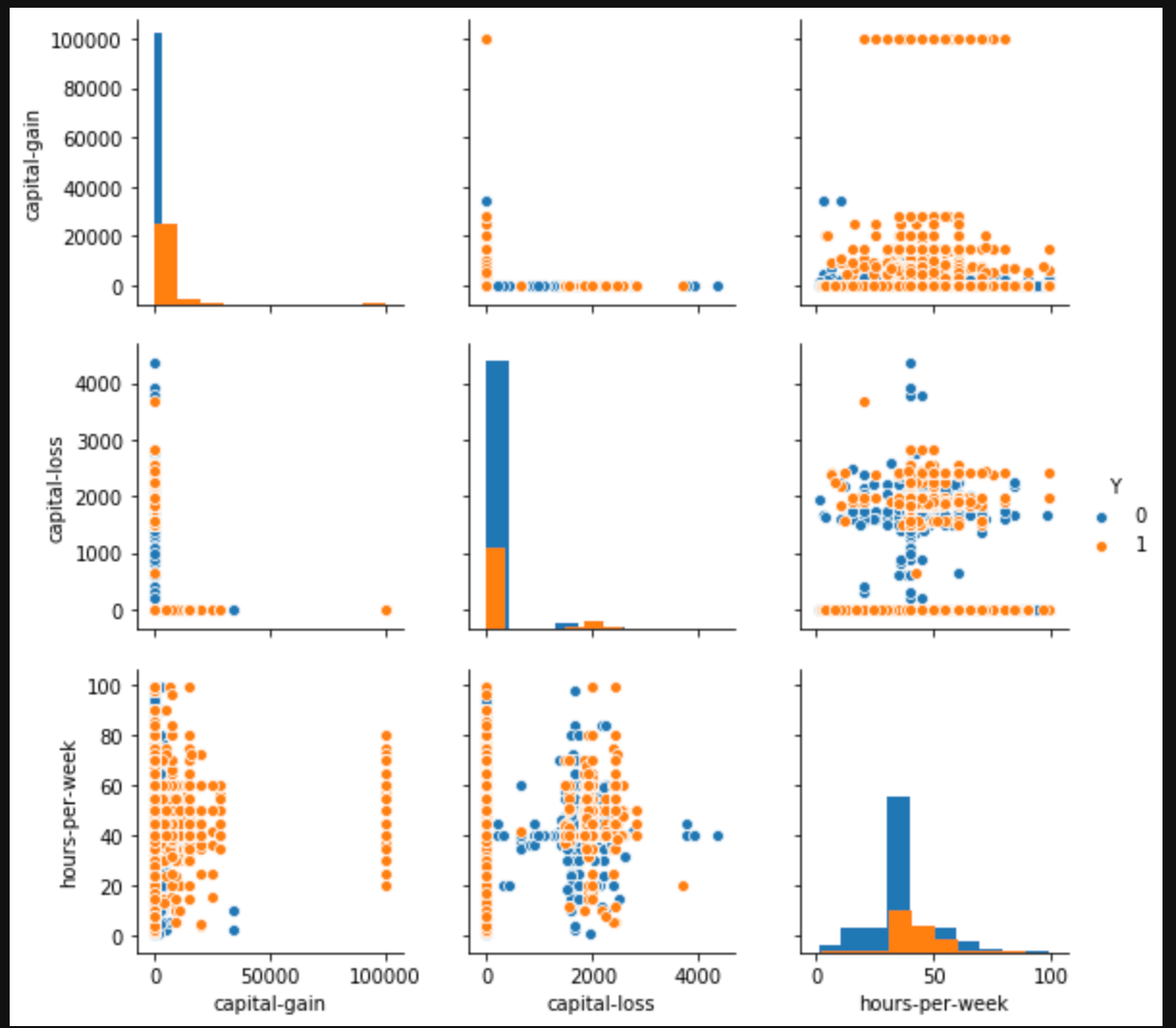
pytho.pysns.pairplot(df, hue="Y", diag_kind='hist', vars = ['capital-gain', 'capital-loss', 'hours-per-week'])
capital-lossとcapital-gainに特徴がありそうな感じがするけど、、、
よくわからない。。。クロス集計表で文字列のデータを確認
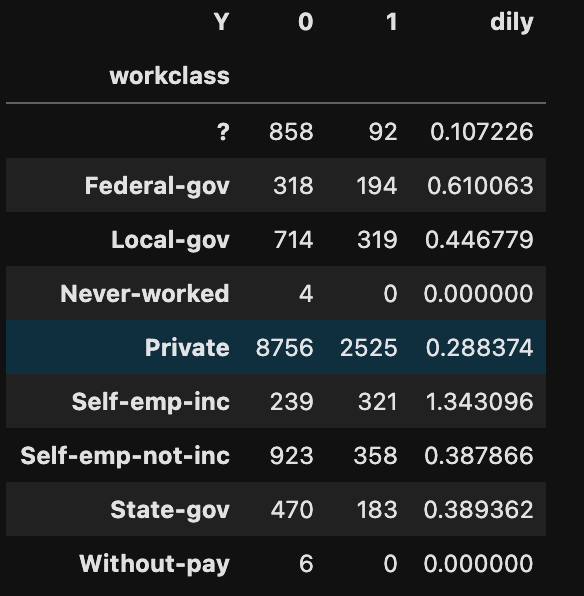
python.py# 職業クラス work = pd.crosstab(df['workclass'], df['Y']) work['dily'] = work[1] / work[0] print(work)
他のデータも確認したけど、よくわからなかったので、「dily」の値が近いものをまとめてみた。
?,nev,pri,with = 0
fed,loca,self,state = 1
self_emp_inc = 2データの前処理
python.py# まとめにくいものを削除 drop_list = ['occupation', 'native-country'] df = df.drop(drop_list, axis = 1) # 文字列データを数値に変換しつつ、「dily」の値が近いものをまとめる。 #職業クラス df= df.replace({'workclass':['?', 'Never-worked', 'Private', 'Without-pay']}, 0) df= df.replace({'workclass':['Federal-gov', 'Local-gov', 'Self-emp-not-inc', 'State-gov']}, 1) df= df.replace({'workclass':['Self-emp-inc']}, 2) #教育 df = df.replace({'education': ['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th', 'HS-grad', 'Preschool']}, 0) df = df.replace({'education': ['Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Prof-school', 'Some-college']}, 1) df = df.replace({'education': ['Doctorate', 'Masters', 'Prof-school']}, 2) # 配偶者の有無 df = df.replace({'marital-status': ['Divorced', 'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed']},0) df = df.replace({'marital-status': ['Married-AF-spouse', 'Married-civ-spouse']}, 1) # 関係 df = df.replace({'relationship': ['Not-in-family', 'Other-relative', 'Own-child', 'Unmarried']}, 0) df = df.replace({'relationship': ['Husband', 'Wife']}, 1) # 人種 df = df.replace({'race': ['Amer-Indian-Eskimo', 'Black', 'Other']}, 0) df = df.replace({'race': ['Asian-Pac-Islander', 'White']}, 1) # 性別 df['sex'] = df['sex'].replace('Female', 0).replace('Male', 1)訓練データと評価データに分類
python.pyfrom sklearn.model_selection import train_test_split train_set, test_set = train_test_split(df, test_size = 0.2, random_state = 4) #訓練データを説明変数(X_train)と目的変数(y_train)に分割 X_train = train_set.drop('Y', axis=1) y_train = train_set['Y'] #評価データを説明変数(X_train)と目的変数(y_train)に分割 X_test = test_set.drop('Y', axis=1) y_test = test_set['Y']最適モデルの検討
python.py# 必要なライブラリのインポート from sklearn.linear_model import LogisticRegression from sklearn.ensemble import RandomForestClassifier from sklearn.svm import SVC # 正解率 from sklearn.metrics import accuracy_score # 空のリストを用意 model_list = [] # リストにモデルを追加。 # ロジスティック回帰 model_list.append(LogisticRegression(solver='lbfgs')) #ランダムフォレスト model_list.append(RandomForestClassifier(n_estimators=100)) # サポートベクターマシン model_list.append(SVC(gamma='scale')) # for文でリストからモデルを取り出し、学習と予測、F1値での評価を行う for i in model_list: i.fit(X_train, y_train) pred = i.predict(X_test) print(accuracy_score(y_test, pred))出力結果は以下のとおり。
0.7954545454545454
0.8498157248157249
0.7757985257985258ランダムフォレストの精度が一番良いですね!!
パラメータの最適化(グリットサーチ)
python.py# グリットサーチ from sklearn.model_selection import GridSearchCV # 試すパラメータを指定 search_gs = { "max_depth": [5, 10, 15], "n_estimators":[50, 100], "min_samples_split": [4, 6], "min_samples_leaf": [3, 5], } # ランダムフォレストの定義 model_gs = RandomForestClassifier() # グリットサーチの定義 gs = GridSearchCV(model_gs, search_gs, cv = 3, # 交差検証の回数 ) # グリットサーチの実行 gs.fit(X_train, y_train) # 最適なパラメータの表示 print(gs.best_params_)最適なパラメータは以下のように表示されました。
{'max_depth': 10, 'min_samples_leaf': 3, 'min_samples_split': 4, 'n_estimators': 100}再度学習の実施及び評価
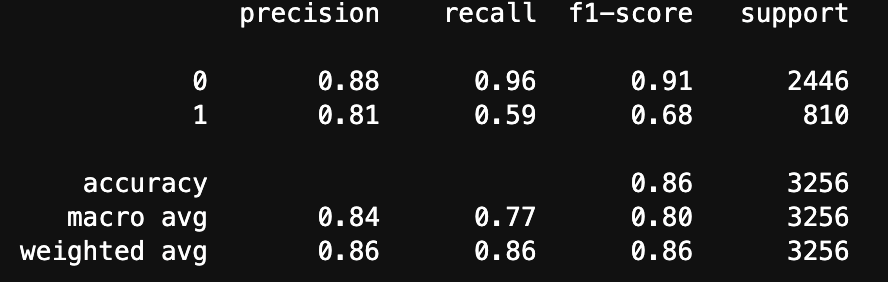
python.pyclf_gs = RandomForestClassifier(max_depth=10, min_samples_leaf= 3, max_features = 5, min_samples_split= 4, n_estimators= 100) model_gs = clf_gs.fit(X_train, y_train) pred_gs = model_gs.predict(X_test) # モデルの評価 from sklearn import metrics print(metrics.classification_report(y_test, pred_gs))結果は以下のとおり
正解率86%!
まあまあかな。結果の提出
python.py# テストデータの読み込み df1= pd.read_csv('test.tsv', delimiter = '\t') # 訓練データとデータの形式を揃える drop_list = ['id', 'occupation', 'native-country'] df1 = df1.drop(drop_list, axis = 1) #職業クラス df1= df1.replace({'workclass':['?', 'Never-worked', 'Private', 'Without-pay']}, 0) df1= df1.replace({'workclass':['Federal-gov', 'Local-gov', 'Self-emp-not-inc', 'State-gov']}, 1) df1= df1.replace({'workclass':['Self-emp-inc']}, 2) #教育 df1 = df1.replace({'education': ['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th', 'HS-grad', 'Preschool']}, 0) df1 = df1.replace({'education': ['Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Prof-school', 'Some-college']}, 1) df1 = df1.replace({'education': ['Doctorate', 'Masters', 'Prof-school']}, 2) # 配偶者の有無 df1 = df1.replace({'marital-status': ['Divorced', 'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed']},0) df1 = df1.replace({'marital-status': ['Married-AF-spouse', 'Married-civ-spouse']}, 1) # 関係 df1 = df1.replace({'relationship': ['Not-in-family', 'Other-relative', 'Own-child', 'Unmarried']}, 0) df1 = df1.replace({'relationship': ['Husband', 'Wife']}, 1) # 人種 df1 = df1.replace({'race': ['Amer-Indian-Eskimo', 'Black', 'Other']}, 0) df1 = df1.replace({'race': ['Asian-Pac-Islander', 'White']}, 1) # 性別 df1['sex'] = df1['sex'].replace('Female', 0).replace('Male', 1) # 学習済モデルで評価 pred_test = model_gs.predict(df1) # 結果をDataFrameへ変換 test = pd.DataFrame(pred_test, columns = ['sample_submit']) # 提出用の形式へ変換 test = test.replace({'sample_submit': {0: '<=50K', 1: '>50K'}}) # 提出用のIDを取得 df2= pd.read_csv('test.tsv', delimiter = '\t') test = pd.concat([df2['id'], test], axis=1) # csvデータで保存 test[['id', 'sample_submit']].to_csv('./submit.csv', header=False, index=False)結果は『0.8610650』で197位!!
まとめ
前処理をもっと工夫するか、XGBoostを使ってみればもっと精度が上がるかな。。
次は多項分類に挑戦します!!!

- 投稿日:2020-11-26T19:57:29+09:00
Pythonのgeopandasを使って、複数の言語特徴に基づいた地図を出力する
行いたいこと
松浦年男先生の記事 (https://note.com/yearman/n/n69fa3f2d583d) を大いに参考にしました。
言語地図を出力する場合、複数の特徴に基づいて地図を何枚か出力したいことがある。
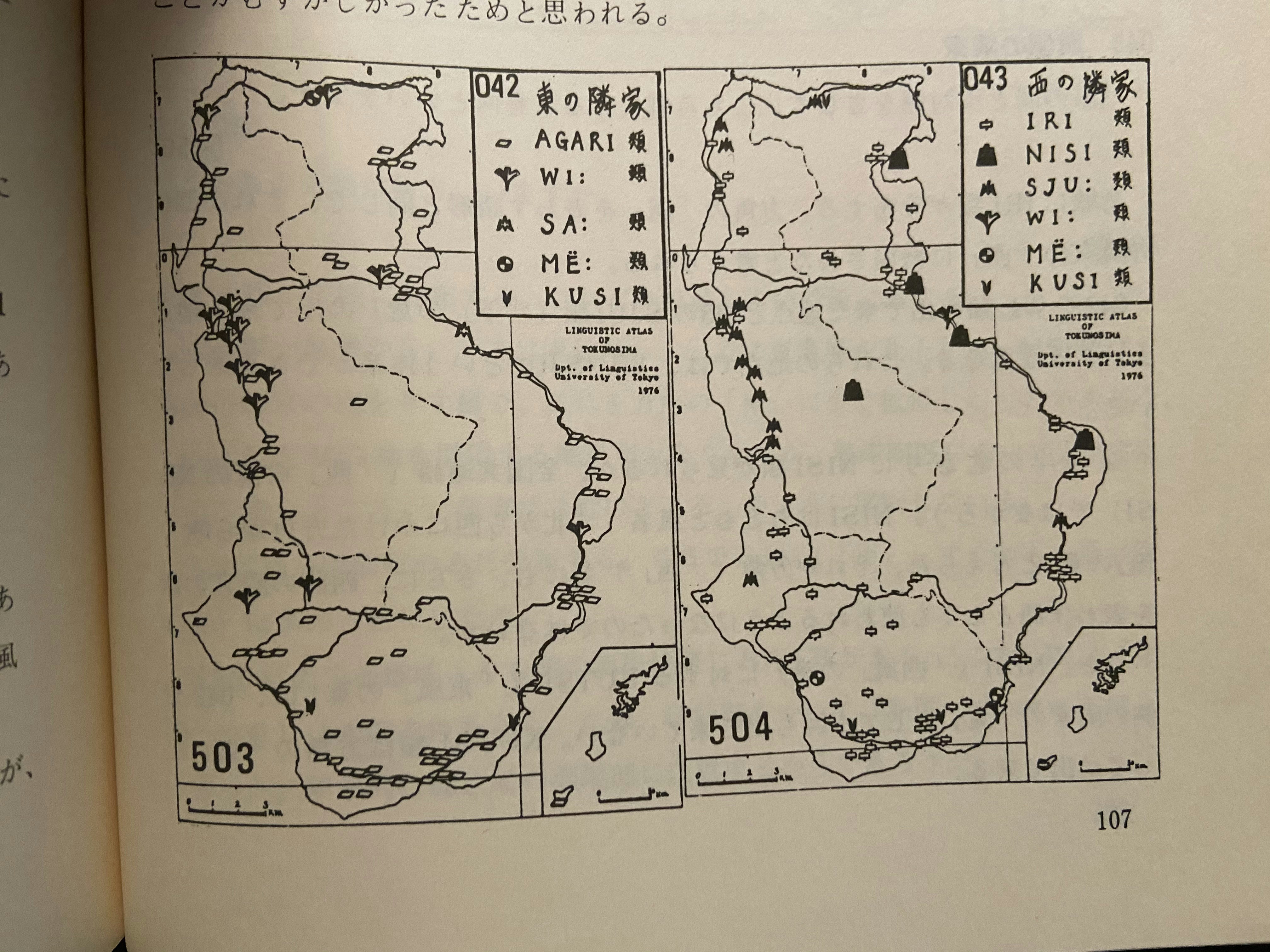
例えばこんな感じ。
柴田武・学生有志編(1977)「奄美徳之島のことばー分布から歴史へ」より引用ということで、Excelに入力したデータから自動で複数枚の地図を出力してくれるプログラムを組んだ。
map.pyimport numpy as np import math import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt df = gpd.read_file("africa.geojson") locations = pd.read_excel("coordinate.xlsx") prm_list = [] # 5列目以降 (=文法特徴と各言語の値が入っている列) を取得し、リストのリストにする。ここの値は自分のデータによって変えること。 for i in range(4,len(locations.columns)): a = locations.iloc[:, i].tolist() a = list(set(a)) a.insert(0,locations.iloc[:, i].name) prm_list.append(a) # カラーマップを取得。cmap(整数値)とすることで、色サイクルのN番目の色を取得できる。10で1サイクルなので、cmap(11)はcmap(1)と同じ値を返す。 cmap = plt.get_cmap("tab10") # エクセルの空欄値をどう処理するか。この値がTrueなら出力しない。Falseなら出力し、凡例には marker_name の文字列が表示される。 isBlankNeglected = True with plt.style.context("ggplot"): # このループでは、各文法特徴について一つの地図を描画する。 for prm in prm_list: df.plot(figsize=(8,8), edgecolor='black', facecolor='white', linewidth = 0.5); i = 0 # このループでは、各言語の具体的な値を取得し、地図上に描写する。 for item in prm[1:]: if isBlankNeglected == True and type(item)!= str:# NaNをとばす pass else: # NaNならN/Aという名前、それ以外は文法特徴を名前にする。 if type(item)!= str: label_name = "N/A" else: label_name = str(item) # query (検索条件) を設定する。 query = str(prm[0])+ " == " + '"' + str(item) + '"' # locations.query(クエリの文字列)とすることで、検索条件に適合する座標情報が取得できる。 location = locations.query(query) plt.scatter(location.longitude, location.latitude, marker='v', s=50, color=cmap(i), alpha=0.8, linewidths = 2, label = label_name) plt.legend(bbox_to_anchor=(1, 1), loc='upper right', borderaxespad=0, fontsize=18) i += 1 filename = prm[0] plt.savefig(filename + ".png", format="png", dpi=400, bbox_inches='tight', pad_inches=0) # plt.show() plt.close()必要なデータ
- 文法特徴と座標情報の入ったExcelファイル
- geojsonなどの地図情報
Excelファイルの作り方
Excelファイルは
coordinate.xlsxという名前にする。
D列目までに文法特徴以外の情報を入力する。
longitude, latitudeの列に座標を入力する。
画像では都市名、国名、経度、緯度のみを入力しているが、これ以外の情報が増えても (=文法特徴以外の情報がE列以降に続いても) よい。
文法特徴以外の情報の列を増やした場合、プログラムのmap.pyfor i in range(4,len(locations.columns)):という部分で文法情報としてE列以降を読み込むようにしているので、ここの数字を変更する (Pythonでは数字は0から数え始めるので、上記のプログラムの4という数字は五番目の列 = E列を意味する)。
ただし、文法特徴の列は、必ず右側に固めること (e.g. E列から文法特徴の列が始まった場合、その右側の列はすべて文法特徴の列であること)。地図データ
日本であれば、国土交通省などからgeojsonのファイルが入手できる。
目的に合わせて、都道府県ごとや市区町村ごとのファイルを入手する。今回はアフリカのデータを使用した (https://github.com/codeforamerica/click_that_hood/tree/master/public/data )。
使用方法
同じフォルダに
map.pyとcoordinate.xlsxとgeojsonをいれる。
その状態でmap.pyを走らせれば、そのフォルダに地図のpngファイルが出力される。こんな感じ。

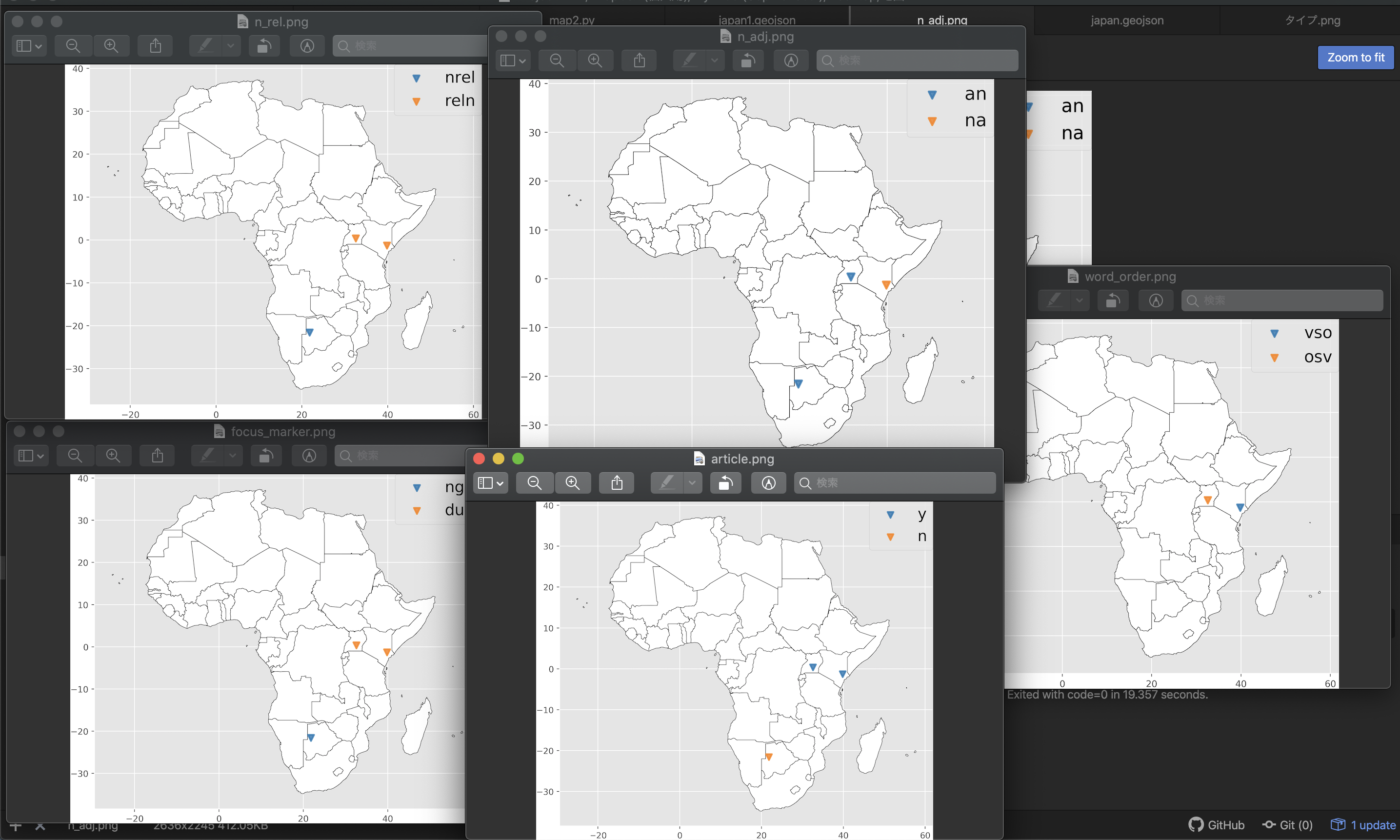
- 投稿日:2020-11-26T19:56:45+09:00
pythonのid関数の逆関数(idからオブジェクトを取得)
検索したけど以外と見つかりにくかったので、メモのつもりでここに書いておきます。
1. やりたいこと
hoge = "hello world"としてからi = id(hoge)としたとき、i == 1774920137984を得たとします。
ではidの逆関数のようなことはどうやればできるのでしょうか。例えば
idの逆関数をbiとするなら、
bi(1774920137984)が"hello world"を返すようにするにはどうすればいいのでしょうか2. 答え
警告: このやり方を実行した結果処理系がぶっ壊れても、筆者は責任を取りません
次のようにします。
import ctypes bi = lambda x ctypes.cast(x, ctypes.py_object).value print(bi(1774920137984)) # "hello world"おそらく、これは実行中のpythonがC言語で書かれている場合(ほとんどのpythonがこれらしい)に動作します。
Jython(Javaで書かれたpython)を利用している場合は、他のやり方があるのかもしれません。また、適当な数字を入れた場合や、変数に格納しなかったオブジェクトのidを入力すると、処理系がフリーズしたのち、勝手に終了しました。
3. 参考
https://www.366service.com/jp/qa/c912a3924b47b37e78f114dc052a52c0
- 投稿日:2020-11-26T18:25:42+09:00
AIに自分好みの美女を生成させる(二番煎じ)
はじめに
@Kim_Burton さんのAIに自分だけの美女を生成してもらうという記事を読んで,美女生成を実際に学習からトライしているのを見たのがきっかけです.
僕が先日フォーラム顔学2020で発表してきた内容とカスっていたので自分のやり方でこのテーマをマネしてみます.引用先の記事では一から学習を行っているので,画像の条件などをそろえるのも大変です.じゃあ学習しなければいいのでは?というのが僕の考えです.今日は自分のやってる研究を含めて少し紹介したいと思います.詳細や実装はまだ研究がまとまりきっていないので伏せます.
深層生成モデルと潜在変数について
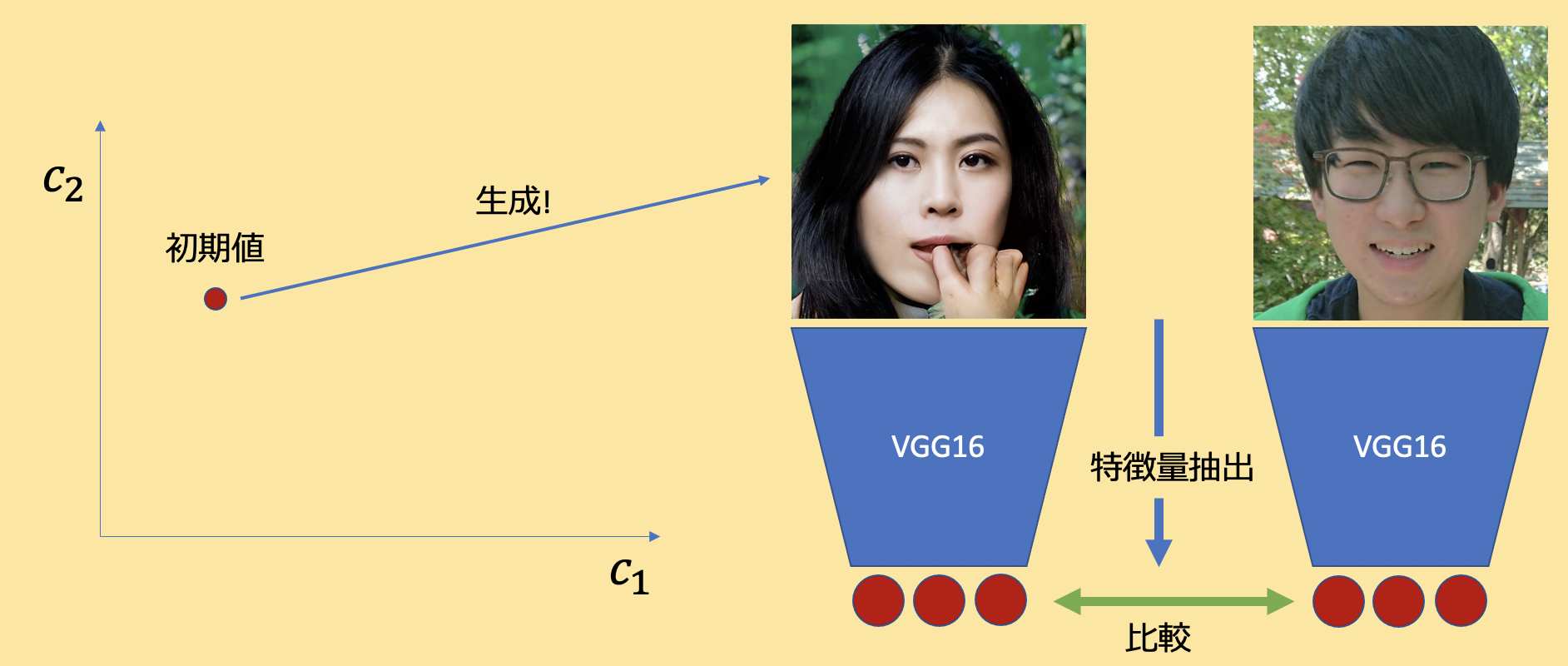
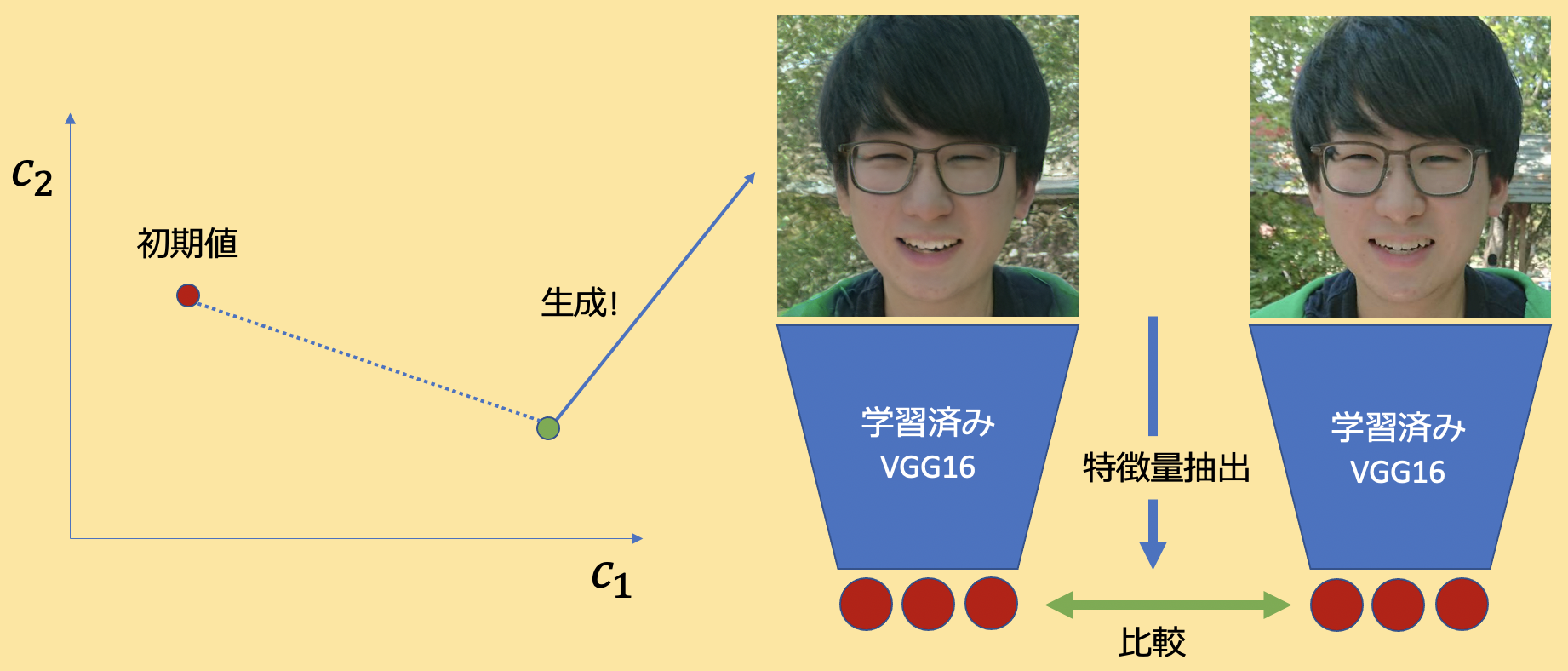
StyleGAN2は高解像度の顔画像生成モデルのSOTAです.NVIDIAが開発をしたモデルで,表現力が非常に高く潜在変数空間も滑らかなことで知られています.Image2StyleGANと呼ばれる技術も研究がなされており,データセットに存在しないような現実の顔画像でも再構成可能であることが分かっています.
近年の深層生成モデルは,基本的には潜在変数と生成画像が1:1対応をしています.なので,生成画像が所望の画像と同じになるように潜在変数に最適化処理をかけてあげれば実在する人の顔画像を再現することができます.
StyleGAN2で再実装して僕の顔でやってみた結果が以下です.そこそこの精度が出ていると思います.
右が本物で左が再構成画像です.
潜在変数に関する記事はこちらが非常にわかりやすいです.ともかく,深層生成モデルは潜在変数から画像を生成するので,1:1で対応づいているということがわかれば大丈夫です.
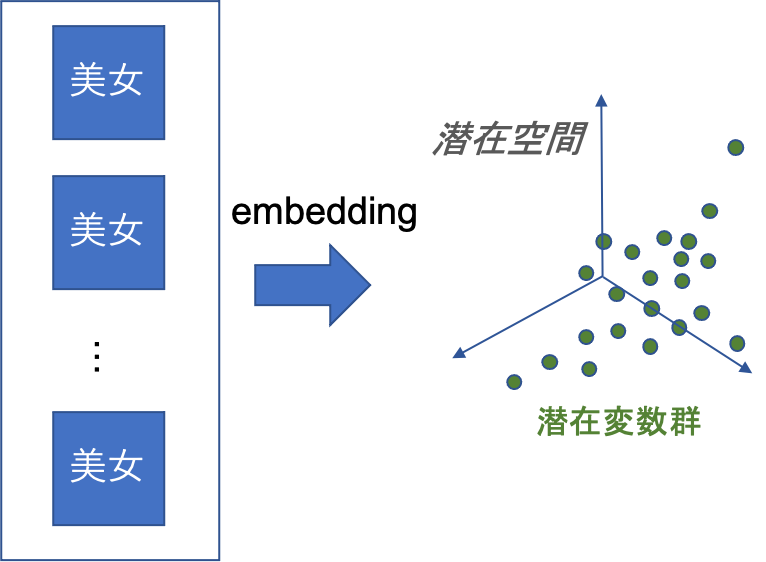
美女を生成する方法
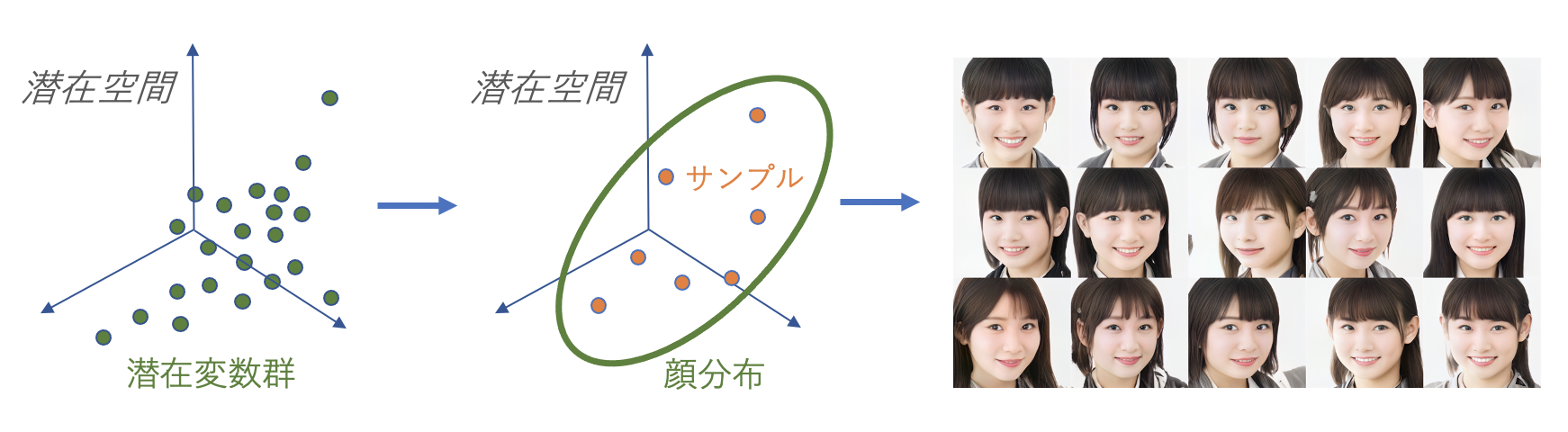
先ほども説明した通り,StyleGAN2は所望の顔画像を再現することができます.これはすなわち「ある人物の顔画像に対応する潜在変数を得ている」と言えます.なので,潜在変数空間上に好みの女性の画像をどんどん埋め込んで(Image Embedding)やってその分布を計算すれば,好みの美女分布を取得することができます.
分布さえ得られてしまえばあとはサンプリングで新たにその分布からサンプル潜在変数を取得して,好みの美女顔サンプルを生成するだけです.
AKB48から美女を生成する
あんまりアイドルに詳しくないので、とりあえず美女グループとしてAKB48さんの画像を使わせていただきました.
使った画像は公式サイトのメンバー一覧です.僕が画像を取ってきた時とものが変わっているので、生成画像のテイストが若干変わると思います.AKB48の方の顔を再構成したものを勝手にアップすると勝手に改変して公開したことになってしまう(著作者人格権など)のではないかと思うので,あくまでも分布を作成するまでに得た結果は公開しません.前述の手法でメンバーの顔を潜在変数空間上に埋め込んでその分布を計算,その分布からサンプル潜在変数を取ってきてStyleGAN2で生成しました.
どうでしょうか?それなりにちゃんと美女が生成できたと思います.こんな感じで、もう画像生成系は再学習が不要な時代になってきていると思います.巨人の肩に乗らせていただきましょう.
ちなみに,@Kim_Burton さんの記事でも挙げられているように平均顔は顔が集団として持つ特徴を捉えることができます.これは潜在変数空間上でもおそらく同じことが言えると思います.
一応AKB48の潜在変数空間上の平均顔もおまけで載せておきますね.重ね合わせ法を使わないので普通の平均顔みたいにぼやけたりしません.
さいごに
フォーラムでも発表しましたし、そろそろかなと思って少しだけ研究の内容を記事にしました.
実装の詳細やコードに関しては修論が落ち着いて気が向いたら公開しようと思います.それでは.参考

- 投稿日:2020-11-26T18:24:06+09:00
Pythonで理解するスパイキングニューロンモデル
スパイキングニューロンモデル
現在主流の機械学習モデル,ニューラルネットワークは脳の神経細胞を複数結合させたモデルである.
また,神経細胞を数理モデルとして表したモデルを一般的に,人工ニューロンとも言う.この人工ニューロンには様々なモデルが存在し,現在主流なものは形式ニューロンモデル (McCulloch & Pittsモデル) をベースにした,とてもシンプルなものである.
本記事では,形式ニューロンに加え,さらに詳細に神経細胞の挙動を表現したニューロンモデルをいくつか実装例と一緒に紹介する.
そういった,より詳細に定義されたニューロンモデルは一般的にスパイキングニューロンモデルと呼ばれる.
(正確には,スパイク列と呼ばれる時系列データを扱うニューロンモデル)また,スパイキングニューロンを使用した人工ニューラルネットワークをスパイキングニューラルネットワークと呼ぶ.
詳しく知りたい人はSpiking Neural Networkとは何なのかを参照.
前提知識
神経細胞は簡単に,以下の挙動や性質を持っている.
これらの挙動や性質をどこまで細かく定義するかが重要となる.
- ニューロンは膜電位と呼ばれる内部状態を持つ
- 膜電位は入力データとシナプス結合荷重(重み)と積和されたものに依存し変化する
- 膜電位がとある閾値(バイアス)を超えたとき発火しスパイクを生成する
形式ニューロンモデル
1943年に提案された最古(?)の人工ニューロンモデル.
別名,McCulloch & Pittsモデル.やってることは,とてもシンプルだが今のニューラルネットワークでは未だに採用されている.
import numpy as np class FormalNeuron: def __init__(self, bias): """ 形式ニューロンモデル :param bias: 発火閾値 """ self.bias = bias def calc(self, inputs, weights): """ 入力とシナプス結合荷重を積和し,出力を決定する :param inputs: :param weights: :return: {0, 1} """ input_data = np.dot(inputs, weights) return 1 if input_data > self.bias else 0 # もともとはステップ関数 if __name__ == '__main__': inputs = np.array([0.5, 0.4, 0.8]) # 入力データの初期化 weights = np.random.rand(3) # シナプス結合荷重(重み)の初期化 # 形式ニューロンを生成し計算 neuron = FormalNeuron(bias=0.5) out = neuron.calc(inputs, weights) print( f'Inputs : {inputs}\n' f'Weights : {weights}\n' f'Output : {out}' )Inputs : [0.5 0.4 0.8] Weights : [0.73876939 0.92170289 0.11853329] Output : 1ここでは入出力関数 (活性化関数) としてステップ関数を採用しているが,現在のニューラルネットワークではシグモイド関数やReLU関数など様々なものに置き換えられて情報表現の幅を増やしている.
しかし,神経細胞は本来{0,1}データを扱うもの.
現存のニューラルネットワークは,本来の神経細胞の挙動と大きな乖離があることは,知っておくべきだと思う.LIF: Leaky integrate-and-fire モデル
ここからが本題.
LIFは最もメジャーなスパイキングニューロンモデル.
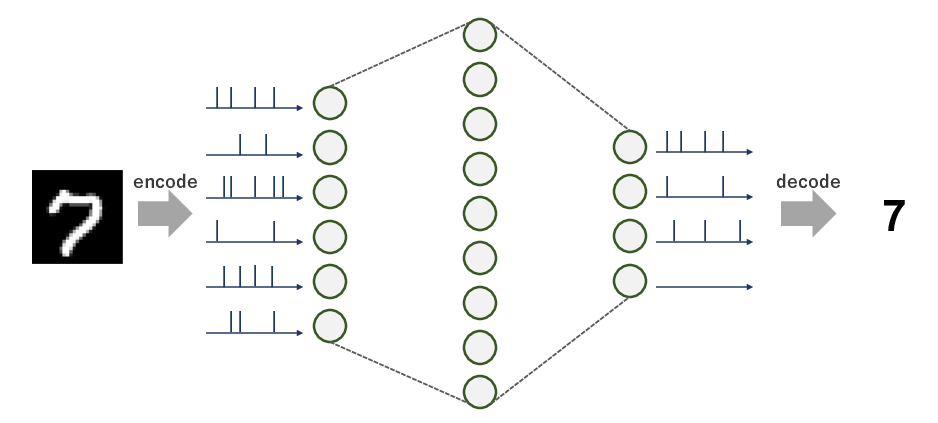
工学的なSNN研究では7~8割これが使われているのではないだろうか.これはSpiking Neural Networkとは何なのかでも簡単に紹介しているが,以下の式によって膜電位を計算する.
$$\tau_{m}\frac{dV(t)}{dt}=(-V(t)+E_{rest})+I(t) \ \ \ \ \ \ (1)$$
$$\tau_{i}\frac{dI(t)}{dt}=-I(t)+\sum_{j\in pre}{w_{j}s_{j}(t)} \ \ \ \ \ \ (2)$$実際,この式の形に止まらず,研究ごとに細かな仕様の違いはあるが,上の式が基本の形となる.
$(1)$式は膜電位$V(t)$を算出するための微分方程式である.
$\tau_{m}$は膜時定数などと呼ばれ,膜電位が時間経過によって静止膜電位$E_{rest}$に減衰する程度を司る.$I(t)$は入力電流で,この定義は様々あるが今回は$(2)$式で示すように,入力スパイク$s(t)$に対して重みを積和し,膜電位と同じく時間減衰を伴う形とした.
実際にグラフ描画してみるとわかるが,$(2)$の計算は$s(t)* e^{-t/\tau_{i}}$という,デジタル信号の畳み込み演算をやっていることと同義であることがわかる.
この膜電位がとある発火閾値を超えると,ニューロンの膜電位は急上昇し,それを発火 (fire)と呼ぶ.
そして突出した部分をスパイク (spike)と呼ぶ.実際にPythonで実装して,挙動を見てみよう.
import numpy as np import matplotlib.pyplot as plt class LIF: def __init__(self, rest: float = -65, ref: float = 3, th: float = -40, tc: float = 20, peak: float = 20): """ Leaky integrate-and-fire neuron :param rest: 静止膜電位 [mV] :param ref: 不応期 [ms] :param th: 発火閾値 [mV] :param tc: 膜時定数 [ms] :param peak: ピーク電位 [mV] """ self.rest = rest self.ref = ref self.th = th self.tc = tc self.peak = peak def calc(self, inputs, weights, time=300, dt=0.5, tci=10): """ 膜電位を計算する. 本来はスパイク時刻(発火時刻)も保持しておいてそれを出力データとする. :param inputs: :param weights: :param time: :param dt: :param tci: :return: """ i = 0 # 初期入力電流 v = self.rest # 初期膜電位 tlast = 0 # 最後に発火した時刻 monitor = [] # 膜電位の記録 for t in range(int(time/dt)): # 入力電流の計算 di = ((dt * t) > (tlast + self.ref)) * (-i + np.sum(inputs[:, t] * weights)) i += di * dt / tci # 膜電位の計算 dv = ((dt * t) > (tlast + self.ref)) * ((-v + self.rest) + i) v += dv * dt / self.tc # 発火処理 tlast = tlast + (dt * t - tlast) * (v >= self.th) # 発火したら発火時刻を記録 v = v + (self.peak - v) * (v >= self.th) # 発火したら膜電位をピークへ monitor.append(v) v = v + (self.rest - v) * (v >= self.th) # 発火したら静止膜電位に戻す return monitor if __name__ == '__main__': time = 300 # 実験時間 (観測時間) dt = 0.5 # 時間分解能 pre = 50 # 前ニューロンの数 inputs = np.zeros((pre, int(time/dt))) # 入力スパイク列の初期化 for i in inputs: i[::np.random.randint(10, 100)] = 1 # 適当にスパイクを等間隔で立ててみる i[0] = 0 # 最初のindexは0にしておく (なんとなく気持ち悪いから) # 重みの初期化 weights = np.random.rand(pre) + 20. # 今回は前ニューロン数少なめなので大きめな重みにしておく neuron = LIF() v = neuron.calc(inputs, weights) # 結果の描画 plt.figure(figsize=(12, 4)) # 入力データ plt.subplot(1, 2, 1) t = np.arange(0, time, dt) spikes = [t[i == 1] for i in inputs] for i, s in enumerate(spikes): plt.scatter(s, [i for _ in range(len(s))], s=5.0, c='tab:blue') plt.xlim(0, time) plt.ylim(-1, pre) plt.xlabel('time [ms]') plt.ylabel('Neuron index') # 膜電位 plt.subplot(1, 2, 2) plt.plot(t, v) plt.xlabel('time [ms]') plt.ylabel('Membrane potential [mV]') plt.show()
実装例としてはこんな感じになる.
グラフ左が前ニューロンからの入力スパイク列をラスタープロットしたもので,グラフ右はその入力を受け取ったニューロンの膜電位(内部状態)を描画している.これだけだと,工学的なモデル構築をするにはいろいろと足りないが,LIFモデルの挙動は確認できるはず.
ちなみに,膜電位の突出したところがスパイクである.形式ニューロンと比べ,複雑度がかなり増していることもわかるだろう.
なんといっても,時間次元を持っているのだから...Hodgkin-Huxley モデル
先ほどのLIFモデルより,かなり精緻に挙動を数理モデルに落とし込んだもの.
Hodgkin-Huxleyニューロンモデルを実装してみるで紹介しているので,詳細はここでは書かないが,簡単に紹介する.我々の脳内の神経細胞は,先ほどのLIFモデルからもわかるように一種の充電回路のような挙動を取る.
その際,時間的な漏れはカリウムイオンやナトリウムイオンなど様々なイオンの細胞内外への出入りによって発生する.
そのイオンの移動を細かく定義したものがHHモデルである.
現存のニューロンモデルの中では最も変態なモデル.主に,脳科学者・神経科学者向けのモデルで,ただの工学屋さんが使用することはほとんど無いだろう.
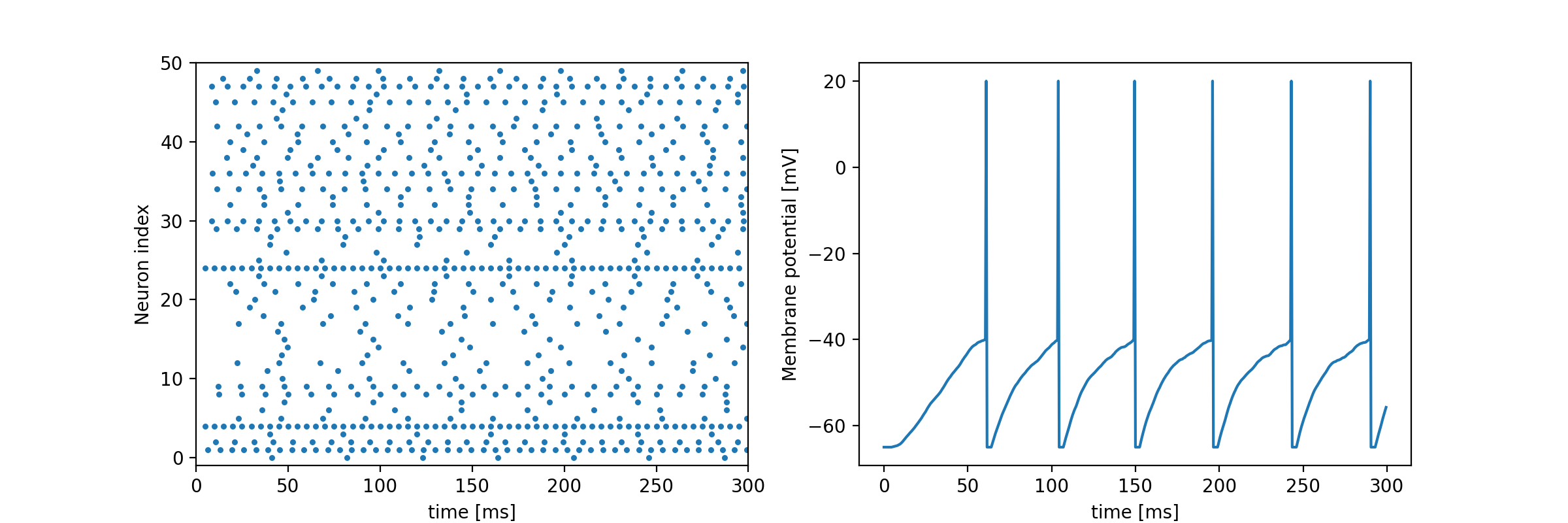
import numpy as np import matplotlib.pyplot as plt class HodgkinHuxley: def __init__(self, time, dt, rest=-65., Cm=1.0, gNa=120., gK=36., gl=0.3, ENa=50., EK=-77., El=-54.387): """ Initialize Neuron parameters :param time: experimental time :param dt: time step :param rest: resting potential :param Cm: membrane capacity :param gNa: Na+ channel conductance :param gK: K+ channel conductance :param gl: other (Cl) channel conductance :param ENa: Na+ equilibrium potential :param EK: K+ equilibrium potential :param El: other (Cl) equilibrium potentials """ self.time = time self.dt = dt self.rest = rest self.Cm = Cm self.gNa = gNa self.gK = gK self.gl = gl self.ENa = ENa self.EK = EK self.El = El def calc(self, i): """ compute membrane potential """ # initialize parameters v = self.rest n = 0.32 m = 0.05 h = 0.6 v_monitor = [] n_monitor = [] m_monitor = [] h_monitor = [] time = int(self.time / self.dt) # update time for t in range(time): # calc channel gating kinetics n += self.dn(v, n) m += self.dm(v, m) h += self.dh(v, h) # calc tiny membrane potential dv = (i[t] - self.gK * n**4 * (v - self.EK) - # K+ current self.gNa * m**3 * h * (v - self.ENa) - # Na+ current self.gl * (v - self.El)) / self.Cm # other current # calc new membrane potential v += dv * self.dt # record v_monitor.append(v) n_monitor.append(n) m_monitor.append(m) h_monitor.append(h) return v_monitor, n_monitor, m_monitor, h_monitor def dn(self, v, n): return (self.alpha_n(v) * (1 - n) - self.beta_n(v) * n) * self.dt def dm(self, v, m): return (self.alpha_m(v) * (1 - m) - self.beta_m(v) * m) * self.dt def dh(self, v, h): return (self.alpha_h(v) * (1 - h) - self.beta_h(v) * h) * self.dt def alpha_n(self, v): return 0.01 * (10 - (v - self.rest)) / (np.exp((10 - (v - self.rest))/10) - 1) def alpha_m(self, v): return 0.1 * (25 - (v - self.rest)) / (np.exp((25 - (v - self.rest))/10) - 1) def alpha_h(self, v): return 0.07 * np.exp(-(v - self.rest) / 20) def beta_n(self, v): return 0.125 * np.exp(-(v - self.rest) / 80) def beta_m(self, v): return 4 * np.exp(-(v - self.rest) / 18) def beta_h(self, v): return 1 / (np.exp((30 - (v - self.rest))/10) + 1) if __name__ == '__main__': # init experimental time and time-step time = 300 # 実験時間 (観測時間) dt = 2**-4 # 時間分解能 (HHモデルは結構小さめでないと上手く計算できない) # Hodgkin-Huxley Neuron neuron = HodgkinHuxley(time, dt) # 入力データ (面倒臭いので適当な矩形波とノイズを合成して作った) input_data = np.sin(0.5 * np.arange(0, time, dt)) input_data = np.where(input_data > 0, 20, 0) + 10 * np.random.rand(int(time/dt)) input_data_2 = np.cos(0.3 * np.arange(0, time, dt) + 0.5) input_data_2 = np.where(input_data_2 > 0, 10, 0) input_data += input_data_2 # 膜電位などを計算 v, m, n, h = neuron.calc(input_data) # plot plt.figure(figsize=(12, 6)) x = np.arange(0, time, dt) plt.subplot(3, 1, 1) plt.title('Hodgkin-Huxley Neuron model Simulation') plt.plot(x, input_data) plt.ylabel('I [μA/cm2]') plt.subplot(3, 1, 2) plt.plot(x, v) plt.ylabel('V [mV]') plt.subplot(3, 1, 3) plt.plot(x, n, label='n') plt.plot(x, m, label='m') plt.plot(x, h, label='h') plt.xlabel('time [ms]') plt.ylabel('Conductance param') plt.legend() plt.show()
コードが長すぎて読むのが嫌になってしまうが,挙動を見てみるとしっかりと膜電位と発火の様子がうかがえる.
LIFモデルでは発火閾値を静的に決定して,かなり力技でニューロンを発火させていたが,HHモデルでは発火閾値を明確に定義しなくともニューロンの挙動をイオンの出入りだけで表現できている.
詳しくは先ほどのリンクからどうぞ.
Izhikevichモデル
2003年に提案された比較的新しいニューロンモデル.
筆者は一番好き.Izhikevichニューロンは以下の2つの微分方程式からなる.
4つのハイパーパラメータ$(a,b,c,d)$と,4つの変数$(v,t,u,I)$から成り立っている.
個人的にはすごく美しいと思う.$$\frac{dv}{dt}=0.04v^{2} + 5v + 140 -u + I$$
$$\frac{du}{dt}=a(bv-u)$$
$${\rm if}\ \ v\geq30,\ \ {\rm then}\ \ v\leftarrow c,\ u\leftarrow u+d$$HHモデルよりシンプルでありながら,4つのパラメータの組み合わせで,様々なニューロンの挙動を模倣できるため,近年多くの研究で見かけるようになった.
import numpy as np import matplotlib.pyplot as plt class Izhikevich: def __init__(self, a, b, c, d): """ Izhikevich neuron model :param a: uのスケーリング係数 :param b: vに対するuの感受性度合い :param c: 静止膜電位 :param d: 発火後の膜電位が落ち着くまでを司る係数 """ self.a = a self.b = b self.c = c self.d = d def calc(self, inputs, weights, time=300, dt=0.5, tci=10): """ 膜電位(Membrane potential) v と回復変数(Recovery variable) u を計算する :param inputs: :param weights: :param time: :param dt: :param tci: :return: """ v = self.c u = self.d i = 0 monitor = {'v': [], 'u': []} for t in range(int(time/dt)): # 入力電流を計算 di = -i + np.sum(inputs[:, t] * weights) i += di * dt / tci # uを計算 du = self.a * (self.b * v - u) u += du * dt monitor['u'].append(u) # vを計算 dv = 0.04 * v**2 + 5 * v + 140 - u + i v += dv * dt monitor['v'].append(v) # 発火処理 if v >= 30: v = self.c u += self.d return monitor if __name__ == '__main__': time = 300 # 実験時間 (観測時間) dt = 0.5 # 時間分解能 pre = 50 # 前ニューロンの数 inputs = np.zeros((pre, int(time / dt))) # 入力スパイク列の初期化 for i in inputs: i[::np.random.randint(10, 100)] = 1 # 適当にスパイクを等間隔で立ててみる i[0] = 0 # 最初のindexは0にしておく (なんとなく気持ち悪いから) # 重みの初期化 weights = np.random.rand(pre) + 20. # 今回は前ニューロン数少なめなので大きめな重みにしておく # Izhikevichニューロンの生成 (今回はRegular Spiking Neuronのパラメータ) neuron = Izhikevich( a=0.02, b=0.2, c=-65, d=8 ) history = neuron.calc(inputs, weights, time=time, dt=dt) # 結果の描画 plt.figure(figsize=(12, 8)) # 入力データ plt.subplot(3, 1, 1) t = np.arange(0, time, dt) spikes = [t[i == 1] for i in inputs] for i, s in enumerate(spikes): plt.scatter(s, [i for _ in range(len(s))], s=5.0, c='tab:blue') plt.xlim(0, time) plt.ylim(-1, pre) plt.ylabel('Neuron index') # 膜電位 plt.subplot(3, 1, 2) plt.plot(t, history['v']) plt.ylabel('Membrane potential $v$ [mV]') # 膜電位 plt.subplot(3, 1, 3) plt.plot(t, history['u'], c='tab:orange') plt.xlabel('time [ms]') plt.ylabel('Recovery variable $u$') plt.show()
こちらも,HHと同様に発火については発火閾値を設けずとも,膜電位の挙動を再現できている.
ただし,静止膜電位へ戻す部分については強引である.Izhikevichニューロンについては,Web上で動作するシミュレータを前に作ったのでぜひ遊んでみて欲しい.
Izhikevich Neuron Simulator - Web上で動作するニューロンシミュレータまとめ
今回は,4つの代表的な人工ニューロンモデルについて紹介した.
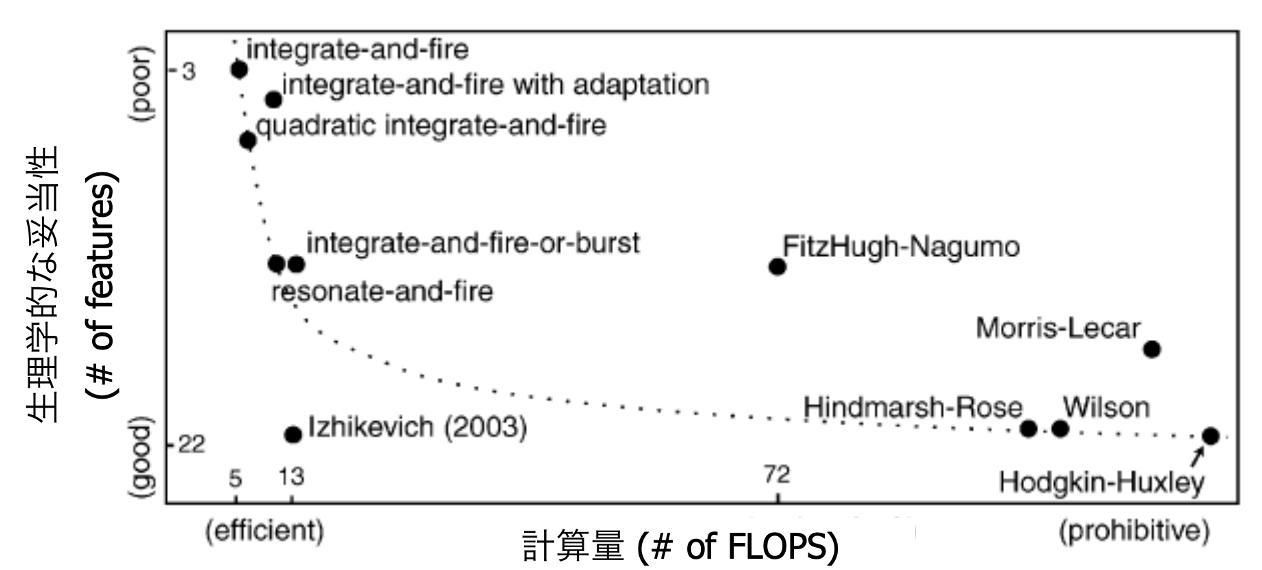
他にもニューロンモデルは存在するが,各モデルともメリットデメリットが存在する.それは,計算量と生物学的妥当性のトレードオフであり,以下の図でそれを示している.
HHモデルは生物学的妥当性はかなり強いものの,コードをみてわかるようにかなりの計算量である.
それに比べてLIFモデルは少ない計算量で挙動を確認できるが,生物学的妥当性は(比較的)劣る.どのニューロンモデルを使用するかは,その研究が工学的な立場か,はたまた生物学的な立場かに依存するでしょう.
とまあ,ここまで色々と真面目に(?)紹介してきたが,これを機に神経科学やSNN研究に興味を持ってくれる人が増えたら嬉しい限りです.
おしまい.
- 投稿日:2020-11-26T18:15:15+09:00
Pythonなんもわからん
クラスを作りなおしても前のクラスのデータを持っている
このコードがわからない。
from dataclasses import dataclass, field from typing import List @dataclass class Struct: x: str @dataclass class Container: content: List[Struct] = field(default_factory=list) @dataclass class ContainerWrapper: container: Container = Container() def append(self, s: Struct) -> None: self.container.content.append(s) return None def store_structs(self, s_list: List[Struct]) -> None: for s in s_list: self.append(s) return None s_list = [Struct("foo")] ContainerWrapper().store_structs(s_list) # recreated instance strangely contains old instance's data. wrapper = ContainerWrapper() print(wrapper.container) #=> Container(content=[Struct(x='foo')])なんで
ContentainerWrapperクラスを作り直したあとも作り直す前のインスタンスのデータを持っとるんや。
- 投稿日:2020-11-26T18:15:15+09:00
Pythonのdataclassの落とし穴
落とし穴: クラスを作りなおしても前のクラスのデータを持っている
このコードを走らせたときにハマった。
from dataclasses import dataclass, field from typing import List @dataclass class Struct: x: str @dataclass class Container: content: List[Struct] = field(default_factory=list) @dataclass class ContainerWrapper: container: Container = Container() def append(self, s: Struct) -> None: self.container.content.append(s) return None def store_structs(self, s_list: List[Struct]) -> None: for s in s_list: self.append(s) return None s_list = [Struct("foo")] ContainerWrapper().store_structs(s_list) # recreated instance strangely contains old instance's data. wrapper = ContainerWrapper() print(wrapper.container) #=> Container(content=[Struct(x='foo')])なんで
ContentainerWrapperクラスを作り直したあとも作り直す前のインスタンスのデータを持っとるんやってなっでハマった。種明かし: 実は
@dataclassに問題があるみたいPythonのドキュメントでは、
@dataclassデコレータを用いてデフォルトの値を設定すると、__init__()でデフォルト値を設定したのと同じように、インスタンス変数に値が代入されると主張している。すなわち、以下の2つのコードは等価であるはずだ。
from dataclasses import dataclass @dataclass class Foo: x: int = 0class Foo: def __init__(self, x: int = 0) -> None: self.x = xしかし、python 3.8.6と3.9.0で試してみた限り、
@dataclassを使って定義したデフォルト値はクラス変数として扱われてしまった。from dataclasses import dataclass @dataclass class Foo: x: int = 0 @classmethod def print_x(cls): print(cls.x) Foo.print_x() #=> 0クラス変数とインスタンス変数を取り違えれば問題が起こることはこの記事が詳しい。
- 投稿日:2020-11-26T17:32:25+09:00
内包表記の書き方【Python】
この記事では、
内包表記の書き方
について書いていきます。内包表記とは
内包表記とは、リストや辞書などののループ処理をシンプルに記述できる記法です。
[式 for 任意の変数名 in イテラブルオブジェクト]
の式で表されます。
使い方
まずは、random.randintで10個の1~100の要素を持ったリストを作ります。
import random s = [] for _ in range(10): x = random.randint(1, 100) s.append(x)次にリストsのすべての要素を3倍にする記法です。
for文と比較してみます。#for文 s_10x = [] for data in s: s_10x.append(data * 3) #内包表記 s_10x = [data * 3 for data in s]一行でかけるのでだいぶすっきりしているので見やすいと思います。
また、処理速度も早いのでなるべく内包表記を使用する方が良いと思います。pythonは他の言語に比べて処理速度が遅いと言われているので、覚えた方が良いと思います。
if文を用いた方法
次に、リストsから奇数のみを取得してみます。
こちらもfor文と比較してみます。#for文 s_odd = [] for data in s: if data % 2 != 0: s_odd.append(data) #内包表記 s_odd = [data for data in s if data % 2 != 0]if文は最後に付きます。
if elseを用いた方法
50以上だったら2倍、50未満の場合は10倍を書いていきます。
#for文 s_50 = [] for data in s: if data >= 50: s_50.append(data * 2) else: s_50.append(data * 10) #内包表記 s_50 = [data * 2 if data >= 50 else data * 10 for data in s]elseつくと場所が変わるので気をつけてください。
まとめ
今回は、
内包表記の書き方
について書いていきました。理解すれば意外と簡単なので、是非試してください。
ありがとうございました。
注意
この記事は、プログラミング初学者が書いており、内容に誤りがある場合がございます。
あしからずご了承願います。
また、誤りにお気づきの場合にはご指摘いただけると幸いです。
よろしくお願いいたします。
- 投稿日:2020-11-26T17:05:28+09:00
ABCI上でpytorch distributed data parallelによるマルチノード学習
なんの記事? pytorchのDistributedDataParallelについての日本語記事があまりにもなかったため,素人がまとめました. 並列処理がわからない人による,わからない人のための,とりあえず使えればいいや的なDDPの解説です. 基本的にABCIでの実行を前提に書かれていますが,それ以外の環境の人たちにも参考になれば幸いです. はじめに おなじみの機械学習フレームワークであるpytorch.気軽にDataParallelで並列処理の学習もできます. ですがfacebookなどの一流の機械学習エンジニアたちはDistributedDataParallelなるものを使った実装がちらほらみられます. そこでpytorchの解説記事を読むわけですが,これがびっくりするほどわからない. というわけで,ABCI上でのDistributedDataParallel(以下DDP)の使い方を自分なりに調べてまとめてみました. 並列処理がどのように動いているかとかの詳しい解説は正直筆者も理解していないので,コードベースでどのように書けば動くかについての解説になっています. なぜDDP? DDPは複数ノードでの並列学習のために実装されています.つまり複数マシンあるいは複数ノードで一つのモデルを学習したい人以外は基本的に使う必要がないです.ただ,本記事にたどりつく人は複数ノードを使いたいと言う特殊な需要を持っている方々であるかと思います.ちなみに自分は産総研のABCIを使用していてDDPをするようになりました.この解説もABCIを前提としているので所々他の環境では動かない・そもそも前提が違うなどの点もあるかと思いますがご了承ください. 最低限の知識 DDPを行う際のアーキテクチャです.マスターノードとそうでないノードがあり,それぞれに同じモデルを載せて学習します.ノードは別々のコンピューターと読み替えることもでき,DataParallelでは同一PCの異なるGPUの間で並列処理を行っていましたが,DistributedDataParallelではPCもGPUもまたいだ並列処理を行います. 二つのPCで一つのモデルの学習を行うので,ノード間の通信にTCPやその他通信を用いたりします.また,ノードごとのプロセスランク(図でいうところのGPUID)とノードを超えたプロセスランク(図でいうところのglobal rank)が考えられます. コード コードです. シェルスクリプト上でmain.pyを実行する形式です. multi.sh cat $SGE_JOB_HOSTLIST > ./hostfile HOST=${HOSTNAME:0:5} mpirun --hostfile ./hostfile -np $NHOSTS python main.py main.py import torch import torch.nn as nn import torch.multiprocessing as mp import torch.distributed as dist from torch.nn.parallel import DistributedDataParallel # DDPのセットアップ用関数 def setup(rank, world_size, port_num): current_dir = os.getcwd() with open(current_dir + "/hostfile") as f: host = f.readlines() host[0] = host[0].rstrip("\n") dist_url = "tcp://" + host[0] + ":" + str(port_num) print(dist_url) # initialize the process group dist.init_process_group( "nccl", init_method=dist_url, rank=rank, world_size=world_size ) print("tcp connected") # main関数 def main(gpu_rank, world_size, node_rank, gpu, port_num): """ Main """ # Setup Distributed Training # gpu_rank: 0~4 in ABCI, i.e. intra gpu rank # world size: total process num print(node_rank) rank = gpu * node_rank + gpu_rank # global gpu rank if rank == 0: print("num_gpu:{}".format(gpu)) print("global rank:{}".format(rank)) print("intra rank:{}".format(gpu_rank)) # set up communication setting between nodes setup(rank, world_size, port_num) ##########ここに学習の処理を書く############## ########################################## if __name__ == '__main__': # ddp setup node_rank = int(os.environ["OMPI_COMM_WORLD_RANK"]) # Process number in MPI size = int(os.environ["OMPI_COMM_WORLD_SIZE"]) # The all size of process print("node rank:{}".format(node_rank)) print("size of process:{}".format(size)) gpu = torch.cuda.device_count() # gpu num per node world_size = gpu * size # total gpu num print(world_size) port_num = 50000 mp.spawn(main, nprocs=gpu, args=(world_size, node_rank, gpu, port_num)) main.pyの中に学習処理を書けば動きます.デバッグ用にあえてprint文は残してありますがなくてもいいです. 解説 multi.sh cat $SGE_JOB_HOSTLIST > ./hostfile HOST=${HOSTNAME:0:5} 早速ABCI限定の話です. まずSGE_JOB_HOSTLISTなる環境変数を./hostfileというファイルに記録します.使用しているノード一覧を取得しているようです. 次にHOSTという環境変数をHOSTNAMEの一部からとってきています.ABCIではノードの名前になっていると思います. mpirun --hostfile ./hostfile -np $NHOSTS python main.py 並列処理のためにopenmpiを使い,その中でmain.pyを実行しています.したがってopenmpiが必要です.ABCIではmodule load openmpiで入れられます. $NHOSTSはホストの数,つまりノードの数です. main.py if __name__ == '__main__': # ddp setup node_rank = int(os.environ["OMPI_COMM_WORLD_RANK"]) # Process number in MPI size = int(os.environ["OMPI_COMM_WORLD_SIZE"]) # The all size of process print("node rank:{}".format(node_rank)) print("size of process:{}".format(size)) gpu = torch.cuda.device_count() # gpu num per node world_size = gpu * size # total gpu num print(world_size) # ポート番号の指定 port_num = 50000 # プロセスのスポーン mp.spawn(main, nprocs=gpu, args=(world_size, node_rank, gpu, port_num)) 環境変数の取得→ポート番号の指定→プロセスのスポーン という流れです. ノードの数とノード毎のGPUの数を把握するために環境変数の取得を行います. 次にポート番号を指定します.ポート番号といきなり言われても困惑すると思いますが,通信のために必要になります. 最後にプロセスの実行です.mp.spawn()によりmain関数をnprocs分だけ実行しています.今回はgpuの数だけプロセスを動かしていますね. def main(gpu_rank, world_size, node_rank, gpu, port_num): """ Main """ # Setup Distributed Training # gpu_rank: 0~4 in ABCI, i.e. intra gpu rank # world size: total process num print(node_rank) rank = gpu * node_rank + gpu_rank # global gpu rank if rank == 0: print("num_gpu:{}".format(gpu)) print("global rank:{}".format(rank)) print("intra rank:{}".format(gpu_rank)) # set up communication setting between nodes setup(rank, world_size, port_num) ##########ここに学習の処理を書く############## ########################################## mp.spawn()により実行されるmain関数の中身です.args=()で指定した引数が渡されています. 変数の中身の説明はコメントアウトの通りで,このうちrankがDDPの肝になります.rankはプロセスのIDになっていて,0がマスタープロセスです. このmain関数はmp.spawn()によって指定したプロセスの数だけ実行されていて,それぞれのプロセスにIDがついているわけですね. main関数でsetupを実行し,あとは通常通り学習を回します(model.toの指定が変わったりデータロードにdistributedsamplerが必要だったりしますがそこら辺はすでにあるコードをみてもらえばいいかなと思うので割愛します.) # DDPのセットアップ用関数 def setup(rank, world_size, port_num): current_dir = os.getcwd() with open(current_dir + "/hostfile") as f: host = f.readlines() host[0] = host[0].rstrip("\n") dist_url = "tcp://" + host[0] + ":" + str(port_num) print(dist_url) # initialize the process group dist.init_process_group( "nccl", init_method=dist_url, rank=rank, world_size=world_size ) print("tcp connected") DDPのセットアップ部分です.シェルスクリプトで作成したhostfileからhostIDを読み込み,その一番初めのhostをマスターノードとします. マスターノードとは並列処理を統括するノードのことで,dist.init_process_groupにそのアドレスを渡すことによりマスターノードを指定できます.このとき,tcpによる通信を使用しているのでポート番号を指定しています.(なぜtcpが出てくるのかと言うと,他のノード達の計算結果を通信によりマスターノードへ送る必要があるため.ここらへんの詳しい仕様は自分もよくわかっていないので詳しい方が解説記事を書いてくれたらなーとか思ってます) 解説は以上です.セットアップができればgithubの実装とかは割とDDP対応しているものが多いので実行できちゃうのではと思います. 個人的につまづいた点 モデルの保存について モデルの保存は,マスタープロセスにおいてのみ行いましょう. また,マスタープロセス以外のサブプロセスの処理が全て終了してから保存してあげる必要があります.したがって下の様に書きます. ###学習ループの中で#### ## 学習処理etc... ## dist.barrier() if int(rank)==0: torch.save(model.state_dict(), checkpoint_dir) #################### dist.barrier()により,全てのプロセスがここまで到達するのを待ち,rankが0(マスタープロセス)においてのみ保存をします. モデルの保存のみならず,チェックポイントや精度の記録などもマスタープロセスの時のみ行う様にしないと重複が起こるので気をつけましょう. tcpのポートについて dist_url = "tcp://" + host[0] + ":" + str(port_num) ポート番号を乱数で生成することにより重複を避けるテクニックが英語の記事で紹介されていますが.全てのプロセスにおいてdist_urlは同じである必要があります.乱数を生成させるタイミングを間違えるとマスタープロセスとなっているノードの別々のポートにそれぞれのプロセスがアクセスすることになってしまったりするので気をつけましょう.(私はこれでTCP connection errorがでまくってました) まとめ 実装ベースのDDP解説記事でした.ABCIを前提としているので汎用性は低いですが,これを機に少しでもDDPに関する日本語の解説記事が増えてくれればと思います. ABCIのDDP必勝テンプレ #!/bin/bash #$ -l h_rt=72:00:00 #$ -l rt_F=8 #$ -j y #$ -cwd cat $SGE_JOB_HOSTLIST > ./hostfile HOST=${HOSTNAME:0:5} export PATH="path/to/anaconda" conda activate envname source /etc/profile.d/modules.sh module load cuda/10.0/10.0.130.1 module load cudnn/7.6/7.6.2 module load openmpi module load nccl/2.5/2.5.6-1 mpirun --hostfile ./hostfile -np $NHOSTS python main.py
- 投稿日:2020-11-26T14:49:25+09:00
PyTorchで自作の損失関数を使う
はじめに
PyTorchで自作の損失関数の書き方、使い方を説明します。私が使っているPython, PyTorchの環境は以下の通りです。
動作環境
Python 3.7.9
torch 1.6.0+cu101PyTorch標準の損失関数に倣った書き方
PyTorchに元々あるtorch.nn.MSELossやtorch.nn.CrossEntropyLoss等に倣った書き方です。クラスとして損失関数を定義します。
class CustomLoss(nn.Module): def __init__(self): super().__init__() # 初期化処理 # self.param = ... def forward(self, outputs, targets): ''' outputs: 予測結果(ネットワークの出力) targets: 正解 ''' # 損失の計算 # loss = ... return loss使い方
PyTorch標準の損失関数と同じ使い方です。
''' model: ネットワーク inputs: ネットワークの入力 targets: 正解 ''' criterion = CustomLoss() outputs = model(inputs) loss = criterion(outputs, targets) loss.backward()単純な書き方
単純に関数として定義しても大丈夫です。
def CustomLoss(outputs, targets): ''' outputs: 予測結果 targets: 正解 ''' # 損失の計算 # loss = ... return loss使い方
''' model: ネットワーク inputs: ネットワークの入力 targets: 正解 ''' outputs = model(inputs) loss = CustomLoss(outputs, targets) loss.backward()backward(誤差逆伝播)に関する疑問
誤差逆伝播に使う勾配はどうなってるの?自作の損失関数の勾配は計算しなくていいの?という疑問のある人向けの説明です。
結論から言うと、自分で勾配を計算する必要はありません。ライブラリが自動的に計算してくれます。
PyTorchのforwardとbackwardについて詳しく紹介しているサイトがありましたので、掲載しておきます。
Pytorchの基礎 forwardとbackwardを理解する
https://zenn.dev/hirayuki/articles/bbc0eec8cd816c183408具体例を見ていきましょう。
入力を二乗する関数を作ってtensorを入力してみます。import torch def squring(x): return x**2 x = torch.tensor(1.0, requires_grad=True) out = squring(x) print(out) # tensor(1., grad_fn=<PowBackward0>)入力するtensorの引数requires_grad=Trueとしておくことで、backwardをした際に勾配が自動的に計算されます。
それでは、backwardをして勾配を自動的に計算させましょう。自動的に計算された勾配は、入力したtensorのx.gradに格納されています。
out.backward() print(x.grad) # tensor(2.)$x^2$の微分$2x$の結果がx.gradに計算されていることがわかります。
このようにPyTorchでは、勾配は自動的に計算されるので、自分で計算する必要はないわけです。参考資料
Pytorchの基礎 forwardとbackwardを理解する
https://zenn.dev/hirayuki/articles/bbc0eec8cd816c183408
- 投稿日:2020-11-26T14:34:29+09:00
OpenCV・traincascade.exeのカスケード分類器学習用の正解画像のアノテーション作成プログラム(python3.7)
はじめに
カスケード分類器のアノテーション作成プログラムが配布終わってた?ので自作
使用方法
正解オブジェクトをクリックしてマウスホイールで領域サイズ変更。比率は自分が使ったときの3:1になっているが適当に変えて使ってください。aで次の画像へ、dで指定したオブジェクト一つ削除、escで終了.
一枚に1つのオブジェクトがあることしか想定してない、増やす場合は一番下のfor文のところを適当に変えればたぶん動くmake_neg_img.py# # written by hdnkt 2020/10/26 # import os import cv2 import numpy as np #マウスイベントの処理と四角形領域の保持 class Img_maker: sx = 0 sy = 0 gx = 0 gy = 0 boxes = [] state = 0#0:押す前 1:押してる途中 def __init__(self): self.sx = 0 self.sy = 0 self.gx = 0 self.gy = 0 self.boxes = [] self.state = 0 #マウスイベントの処理 def mouse_event(self,event,x,y,flags,param): self.gx = x self.gy = y if event == cv2.EVENT_MOUSEWHEEL: if len(self.boxes)>0: if flags > 1: self.boxes[len(self.boxes)-1][2]+=12 self.boxes[len(self.boxes)-1][3]+=4 if flags < 0: self.boxes[len(self.boxes)-1][2]-=12 self.boxes[len(self.boxes)-1][3]-=4 if event == cv2.EVENT_LBUTTONDOWN: self.sx = x self.sy = y self.state = 1 if event == cv2.EVENT_LBUTTONUP: self.gx = 120 self.gy = 40 self.boxes.append([self.sx,self.sy,self.gx,self.gy]) self.state = 0 #一番新しい長方形領域削除 def pop_box(self): if len(self.boxes)<=0: return self.boxes.pop(len(self.boxes)-1) #指定された点の数 def size_boxes(self): return len(self.boxes) #点から領域計算 def calc(self): if len(self.boxes)==2: l=self.boxes[1][0]-self.boxes[0][0] return l*8//10 else: return 1 #領域全部教えます def get_boxes(self): for i in self.boxes: yield i #今何してる? 0:押し込んでいない 1:押し込み中 def get_state(self): return self.state #今描いてる四角の座標を返すよ 押し込み中しか呼ぶな def get_nowRect(self): if self.state == 0: return else: return self.sx,self.sy,self.gx,self.gy if __name__ == "__main__": pre_path = "#正解画像をいれてあるフォルダのパス#" go_path = "#アノテーションファイルを書き出す場所のパス#/annotation.txt" subject_num = os.listdir(pre_path) #はじめからなら0でいいよ print("どこからはじめる") start = int(input()) for i in range(start,len(subject_num)): i = subject_num[i] #画像を読み込み tmp_img = cv2.imread(pre_path+i) raw = tmp_img.copy() cv2.namedWindow(i) #画像メーカーをセットアップ img_Maker = Img_maker() cv2.setMouseCallback(i,img_Maker.mouse_event) #画面に画像を表示 while 1: #お絵かきするためにコピーを用意 tmp_img=raw.copy() if img_Maker.size_boxes()>0: for j in img_Maker.get_boxes(): cv2.rectangle(tmp_img, (j[0]-j[2]//2,j[1]-j[3]//2),(j[0]+j[2]//2,j[1]+j[3]//2), (255,255,255), thickness=2) cv2.imshow(i,tmp_img) end = False #キー操作 k = 0 k = cv2.waitKey(1) if k==ord("a"):#次の画像へ break if k==ord("d"):#一つ前の画像削除 img_Maker.pop_box() if k==27:#結果を保存していったん終了 end = True break #破壊する。それらは再生できない cv2.destroyAllWindows() print(i) for left in img_Maker.get_boxes(): print(left) #1サンプル分のアノテーション作成 with open(go_path,mode="a") as f: f.write("\n"+"path"+i+" 1 "+str(left[0]-left[2]//2)+" "+str(left[1]-left[3]//2)+" "+str(left[2])+" "+str(left[3])) if end: break
- 投稿日:2020-11-26T14:11:35+09:00
CartPoleゲームでDenseとLSTMを比較
はじめに
OpenAI GymのCartPoleゲームでDenseとLSTMネットワークの効果を比較します。
OpenAIからお借りしたイメージ
https://gym.openai.com/videos/2019-10-21--mqt8Qj1mwo/CartPole-v1/poster.jpg今回はTensorflowを使って、low-levelカスタマイズもあるので、前回 (Actor-Criticモデル強化学習でブロック崩しを挑戦 https://qiita.com/leolui2013/items/b2c5dbc19be5d025c176) より少し難しくなります。(自動微分と勾配テープ、トレーニングループの詳しい説明はTensorflowのドキュメンテーションにありますのでそちらに参考すると分かりやすいと思います。 https://www.tensorflow.org/guide/autodiff , https://www.tensorflow.org/guide/basic_training_loops )
モデルはA2C (Advantage Actor Critic)で、DenseとLSTMを比較するのでネットワークの構成以外にほとんどの変数が同じです。なぜ比較するかと、一番簡単な強化学習モデルはDenseネットワーク(画像ならCNN)だけど、その学習プロセスは1観察データに対して1予測アクションです。そしてLSTMは1シリーズの観察データを入力できますので、より複雑な問題を解けられると思います。ただしその反面は、1シリーズのデータを学習するために、かかる時間が何倍になると予想されます。
この記事は7月にGithubに投稿した記事に基づいて作成します。
https://github.com/leolui2004/cartpole_model_compareやり方
強化学習の部分は一番複雑です。分かりやすくしたいのでclassにします。最初はdenseネットワークのコードを紹介します。
import tensorflow as tf tf.keras.backend.set_floatx('float32') import numpy as np discount = 0.97 model_lr = 0.0001 # 学習率 class ActorCriticModel: def __init__(self, ActionNumber): self.ActionNumber = ActionNumber self.model = self.dense_model() self.opt = tf.keras.optimizers.Adam(model_lr) # 今回はAdamを使う # Dense層を構築 def dense_model(self): input = tf.keras.layers.Input((4,)) layer1 = tf.keras.layers.Dense(128, activation='linear')(input) layer2 = tf.keras.layers.Dense(32, activation='linear')(layer1) logits = tf.keras.layers.Dense(self.ActionNumber)(layer2) # actor部分 value = tf.keras.layers.Dense(1)(layer2) # critic部分 return tf.keras.Model(inputs=[input], outputs=[logits, value]) # アクションを予測する時logitsだけ必要 def predict(self, input): logits, _ = self.model.predict(input) return logits # ロス関数を定義 def compute_loss(self, done, state_, memory): # ゲーム終了していないと観察データ(state)を取得して使う if done: reward_sum = 0. else: reward_sum = self.model(tf.convert_to_tensor(state_, dtype=tf.float32))[-1][0] # 報酬を加算 discounted_rewards = [] for reward in memory.rewards[::-1]: reward_sum = reward + discount * reward_sum discounted_rewards.append(reward_sum) discounted_rewards.reverse() # A2Cのadvantageを考慮して全体ロスを計算 logits, values = self.model(tf.convert_to_tensor(np.vstack(memory.states), dtype=tf.float32)) advantage = discounted_rewards - values value_loss = advantage ** 2 policy = tf.nn.softmax(logits) entropy = tf.nn.softmax_cross_entropy_with_logits(labels=policy, logits=logits) policy_loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=memory.actions[0], logits=logits) policy_loss *= tf.stop_gradient(advantage) policy_loss -= 0.01 * entropy total_loss = tf.reduce_mean((0.5 * value_loss + policy_loss)) return total_loss # 勾配テープでトレーニング def train(self, done, state_, memory): state_ = tf.convert_to_tensor(state_, dtype=tf.float32) with tf.GradientTape() as tape: loss = self.compute_loss(done, state_, memory) grads = tape.gradient(loss, self.model.trainable_variables) self.opt.apply_gradients(zip(grads, self.model.trainable_variables)) def action_choose(self, state): logits = self.model.predict(state) # 予想したlogits(合計1ではない)を確率(合計1)に転換 probs = np.exp(logits[0][0])/sum(np.exp(logits[0][0])) # 確率に基づいてアクションを選ぶ action = np.random.choice(self.ActionNumber, p=probs) return actionそしてより簡単に途中で観察データを保存、削除するためにMemoryというclassを作成します。
class Memory: # 定義 def __init__(self): self.states = [] self.actions = [] self.rewards = [] # 保存 def store(self, state, action, reward): self.states.append(state) self.actions.append(action) self.rewards.append(reward) # 削除 def clear(self): self.states = [] self.actions = [] self.rewards = []次はゲームプレーの部分です。前回と違った部分は主に最初のランダムアクションがなくなりました。前回説明したことも省略します。
import gym import matplotlib.pyplot as plt env = gym.make('CartPole-v0') episode_limit = 1000 score_avg_freq = 20 score_list = [] # モデルやメモリclassを作成 ACM = ActorCriticModel(2) # CartPoleは左右アクションだけなので2にする memory = Memory() for episode in range(episode_limit): # 環境を初期化 state_list, state_next_list, action_list = [], [], [] score, score_memory, timestep = 0, 0, 0 memory.clear() done = False observation = env.reset() state = observation while not done: timestep += 1 # アクションを予測 action = ACM.action_choose(np.array(state)[np.newaxis, :]) observation_next, reward, done, info = env.step(action) state_next = observation_next state_list.append(state) state_next_list.append(state_next) action_list.append(action) score += reward score_memory += reward state = state_next # ゲーム終了もしくは10ステップごとにメモリに保存 if done or timestep == 10: memory.store(np.array(state_list), np.array(action_list), score_memory) if score_memory > 8: ACM.train(done, np.array(np.array(state_next)[None, :]), memory) state_list, state_next_list, action_list = [], [], [] score_memory, timestep = 0, 0 memory.clear() if done: score_list.append(score) print('Episode {} Score {}'.format(episode + 1, score)) env.close() score_avg_list = [] for i in range(1, episode_limit + 1): if i < score_avg_freq: score_avg_list.append(np.mean(score_list[:])) else: score_avg_list.append(np.mean(score_list[i - score_avg_freq:i])) plt.plot(score_avg_list) plt.show()最後にLSTMネットワークのコードを書きたいですがほぼ同じなので違った部分だけ書きます。
# Denseネットワークの回数は1000回に対してLSTMの方が遥かに多い episode_limit = 30000 score_avg_freq = 700 # class定義の部分とネットワークの構成も当然違う self.model = self.lstm_model() def lstm_model(self): input = tf.keras.layers.Input((2, 2)) # LSTMは基本不安定なので安定させるために3階層と適当なDropoutが必要 layer1 = tf.keras.layers.LSTM(32, return_sequences=True)(input) layer2 = tf.keras.layers.Dropout(0.2)(layer1) layer3 = tf.keras.layers.LSTM(64, return_sequences=True)(layer2) layer4 = tf.keras.layers.Dropout(0.2)(layer3) layer5 = tf.keras.layers.LSTM(128)(layer4) layer6 = tf.keras.layers.Dropout(0.2)(layer5) layer7 = tf.keras.layers.Dense(64, activation='linear')(layer6) layer8 = tf.keras.layers.Dense(32, activation='linear')(layer7) layer9 = tf.keras.layers.Dense(16, activation='linear')(layer8) logits = tf.keras.layers.Dense(self.ActionNumber)(layer9) value = tf.keras.layers.Dense(1)(layer9) return tf.keras.Model(inputs=[input], outputs=[logits, value]) # 観察データをシリーズに変換するためにエンコード関数を導入 def encode(a): b = [[0,0],[0,0]] b[0] = a[0:2] b[1] = a[2:] return b state = encode(observation) state_next = encode(observation_next)結果
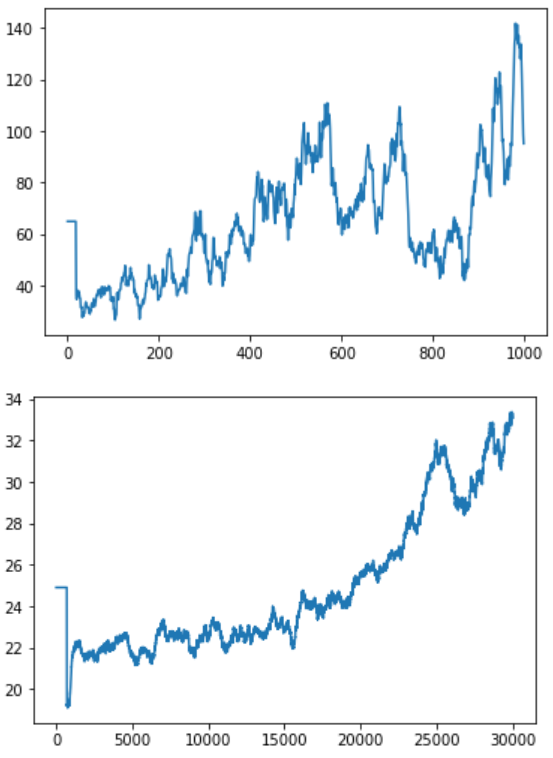
結果はこちらです。1枚目はDense層だけ使いました。2枚目はLSTM層を使いました。X軸訓練回数はDenseの方が1000回、LSTMの方が30000回です。Y軸はスコアです。
結論から言うと、LSTMは学習することが可能です。ただし効果が出るまでにこんなゲームにも10倍以上の訓練回数が必要とみられます。
もう一つ
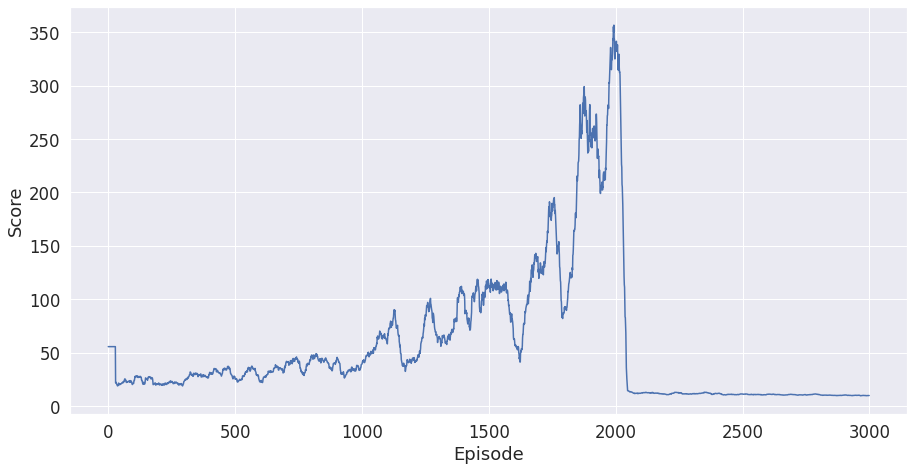
Denseの方を訓練する時この結果が出たことがあります。
これはCatastrophic Forgetting (破滅的忘却?) と言います。実際の理由は不明だけど、途中ですべて学習したことを忘れたら単に訓練回数を上げても解決できないです。この不安定の結果を解消するためにLSTMを推奨すると言われます。

- 投稿日:2020-11-26T13:33:34+09:00
【Python】GoogleColaboratory実行中のセッション切れを防止する策
個人的にスクレイピングする機会が多く、取得データの件数が多いとスクレイピング中にGoogleColaboratoryがセッション切れを起こして、イライラしてたので、対策をしたかった。
そもそもGoogleColaboratoryの仕様としては
・新しいインスタンスを起動してから12時間経過する
・セッションが切れてから90分経過する
と、インスタンスの状態がすべてクリアされてしまいます。ただ実際はインターネットの接続状況なども含めると30分ほどでセッションが切れてしまうこともあり、実質実行中常に張り付いていないといけない状態・・・
さすがに効率が悪いので、対策を考える。
セッション切れを防止するということは常にブラウザが起動している状態を維持すれば良い
↓
つまりリロードすればよい
↓
定期的にリロードするプログラムを組めばOKという感じで調べたところ、どうやらChromeのデベロッパーツールで定期的にリロードするコードを書けば良さそう。
Consoleウィンドウで
function ClickConnect(){
console.log("60sごとに再接続");
document.querySelector("colab-connect-button").click()
}
setInterval(ClickConnect,1000*60);
これを入力して実行することで、60秒ごとに再接続してくれます。
無用なセッション切れも防げるので、この手間は惜しまずやりたいですね。
- 投稿日:2020-11-26T13:30:48+09:00
【第3回】Python で競馬予想してみる ~ モデルの学習・検証 ~
前回の第2回までで、データの前処理まで完了
Python に関しては完全な初心者だが、Google 検索だけで何とかなるもんだ今回は、とりあえず モデルの学習・予測 まで一気に進めてみるのだ
開発環境
Anaconda3 のインストール
データの取得
ターゲットフロンティアの出力データを使用
ターゲットフロンティアのレース検索で CVS 出力
※第1回はここまで終了-------------------------------
データの前処理
CVS の読込みについて
20年分の全データを読み込んでみたら Wall time: 41.3 s
20年分の使うかもしれないデータだけを読込み
n 走前までのデータを連結
欠損地処理、データ型処理、目的変数の処理
※第2回はここまで終了-------------------------------
モデルの学習
機械学習の種類や選び方を、よく分かってないのだが、
他の方のコードでよく使われている sklearn のロジスティック回帰を使用build.ipynbfrom sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression # 説明変数をdataXに格納 dataX = rd.drop(['3着以内'], axis=1) # 目的変数をdataYに格納 dataY = rd['3着以内'] # データの分割を行う(学習用データ 0.8 評価用データ 0.2) stratify:層化抽出 X_train, X_test, y_train, y_test = train_test_split(dataX, dataY, test_size=0.2, stratify=dataY) # 分類器を作成(ロジスティック回帰) clf = LogisticRegression() # 学習 clf.fit(X_train, y_train)これだけで モデルの学習 は完了。簡単
モデルの評価
とりあえず、学習した結果から予測をしてみます
予測結果を、様々な指標で評価してみます詳しくは ↓ を参考に
build.ipynbfrom sklearn.metrics import accuracy_score from sklearn.metrics import confusion_matrix from sklearn.metrics import precision_score from sklearn.metrics import recall_score from sklearn.metrics import f1_score # 予測 y_pred = clf.predict(X_test) # 正解率を表示 print('正解率', accuracy_score(y_test, y_pred)) # 混同行列を表示 print('混同行列\n', confusion_matrix(y_test, y_pred, labels=[1, 0])) # 適合率を表示 print('適合率', precision_score(y_test, y_pred)) # 再現率を表示 print('再現率', recall_score(y_test, y_pred)) # F値を表示 print('F値', f1_score(y_test, y_pred))正解率 0.7828058218782488 混同行列 [[ 707 36705] [ 900 134828]] 適合率 0.4399502177971375 再現率 0.01889767988880573 F値 0.03623875547810041正解率は
0.7828058218782488
すごい!!と思ったが、これは4着以下と予想して4着以下になったのも含んでいるのだ「この馬はこない!」と予想して「予想が、当たった!当たった!」と喜んでいるのと同じなのだ
再現率は
0.01889767988880573
再現率は、実際に 3着以内 だった中で、どの程度正しく予測できているかの割合
混合行列の数字から ↓ の数式で算出される\frac{707}{707+36705}98%以上の取りこぼしがあるので、使い物にならん?
3着以内のデータ数と 4着以下のデータ数の不均衡を修正
アンダーサンプリングの最適化
4着以下のデータ比率を 2倍
学習データの 3着以内と 4着以下のデータ比率を調整して改善させよう(アンダーサンプリングというらしい)
アンダーサンプリングを最適化する方法があるのかもしれないが、わからないのでマニュアルで検証
とりあえず、4着以下のデータ比率を 2倍にするとbuild.ipynbfrom imblearn.under_sampling import RandomUnderSampler # 学習データをアンダーサンプリング f_count = y_train.value_counts()[1] * 2 t_count = y_train.value_counts()[1] rus = RandomUnderSampler(sampling_strategy={0:f_count, 1:t_count}) X_train_rus, y_train_rus = rus.fit_sample(X_train, y_train) # 学習 clf.fit(X_train_rus, y_train_rus) # 予測 y_pred = clf.predict(X_test) # 正解率を表示 print('アンダーサンプリング') print('正解率', accuracy_score(y_test, y_pred)) # 混同行列を表示 print('混同行列\n', confusion_matrix(y_test, y_pred, labels=[1, 0])) # 適合率を表示 print('適合率', precision_score(y_test, y_pred)) # 再現率を表示 print('再現率', recall_score(y_test, y_pred)) # F値を表示 print('F値', f1_score(y_test, y_pred))アンダーサンプリング 1:2 正解率 0.7591140117823727 混同行列 [[ 13926 23486] [ 18221 117507]] 適合率 0.4331974989890192 再現率 0.3722335079653587 F値 0.40040828649060506正解率は
0.7591140117823727、僅かに下がったが、
再現率は0.3722335079653587、かなり良化4着以下のデータ比率を 1倍
アンダーサンプリング 1:1 正解率 0.6473085364444958 混同行列 [[27155 10257] [50808 84920]] 適合率 0.34830624783551173 再現率 0.7258366299583021 F値 0.47072589382448543正解率は
0.6473085364444958、かなり低下、
適合率は0.34830624783551173、かなり低下
再現率は0.7258366299583021、かなり良化
これは、取りこぼしは少なくなるが負ける回数も増えるということか?
実際に馬券を買ったときのシミュレーションしてみないとなんとも言えないが、比率は 2倍のほうが良い感じ
馬券シミュレーションの段階で再検証ということで・・・とりあえず 2倍で続行
説明変数の標準化
今後、値が大きな説明変数などを使用することも考え標準化を実施
build.ipynbfrom sklearn.preprocessing import StandardScaler # 説明変数を標準化 sc = StandardScaler() X_train_rus_std = pd.DataFrame(sc.fit_transform(X_train_rus), columns=X_train_rus.columns) X_test_std = pd.DataFrame(sc.transform(X_test), columns=X_test.columns) # 学習 clf.fit(X_train_rus_std, y_train_rus) # 予測 y_pred = clf.predict(X_test_std) # 正解率を表示 print('アンダーサンプリング,標準化') print('正解率', accuracy_score(y_test, y_pred)) # 混同行列を表示 print('混同行列\n', confusion_matrix(y_test, y_pred, labels=[1, 0])) # 適合率を表示 print('適合率', precision_score(y_test, y_pred)) # 再現率を表示 print('再現率', recall_score(y_test, y_pred)) # F値を表示 print('F値', f1_score(y_test, y_pred))アンダーサンプリング,標準化 正解率 0.7581668014323669 混同行列 [[ 14143 23269] [ 18602 117126]] 適合率 0.43191326920140477 再現率 0.37803378595103176 F値 0.40318143592228856今回、標準化してもしなくても結果に影響はなし
今後、どのような説明変数を追加するかわからないので標準化は組み込んでおくのだ。第3回はここまで
- 投稿日:2020-11-26T12:23:07+09:00
Computer Vision : Pose Estimation Part2 - High Resolution Pose Estimation
目標
深層学習による姿勢推定の続きです。
Part2 では、Part1 で準備した事前学習モデルを用いて姿勢推定を行います。
NVIDIA GPU CUDA がインストールされていることを前提としています。導入
Computer Vision : Pose Estimation Part1 - ImageNet pretraining HRNet では、ImageNet から収集した画像を用いて CNN 事前学習モデルを訓練しました。
Part2 では、ニューラルネットワークによる姿勢推定モデルを作成して訓練します。
MPII Human Pose Dataset
姿勢推定のデータセットとして MPII Human Pose Dataset [1] を使用します。以下のリンクから Images と Annotations をダウンロードして解凍します。MPII Human Pose Dataset では 16個のキーポイントを予測します。
入力画像は BGRカラー画像でサイズは 320x480 として、16x80x120 のキーポイントに関する信頼度マップと画像中に含まれている人の数を出力します。
正解データとなるキーポイントの信頼度マップは、分散 2 のガウシアンフィルタを適用してから値の範囲を [0, 1] に正規化した 16x80x120 の単精度浮動小数点型配列を numpy file として保存しました。
ニューラルネットワークの構造
今回実装したニューラルネットワークの概略を下図に示します。
実装したモデルは非常にシンプルです。Part1 で事前学習した HRNet [2] が抽出した入力画像の 1/4 の解像度の特徴量マップに対して、以下の 2つのタスクを実行します。
- 画像中に含まれている人の数の予測
- キーポイントに関する信頼度マップの予測
画像中に含まれている人の数の予測では、1x1 の畳み込み層と Global Sum Pooling [3] を適用してから全結合で人の数を出力します。
キーポイントに関する信頼度マップの予測では、6層の 3x3 の畳み込みを適用してから 1x1 の畳み込みで信頼度マップを出力します。
それぞれ最後の層以外の活性化関数には Mish [4] を採用しました。
訓練における諸設定
学習するパラメータの初期値は分散 0.01 の正規分布に設定しました。
今回はマルチタスク損失関数を使用します。キーポイントに関する信頼度マップの損失関数にはキーポイント毎に平均 2乗誤差を使用します。画像中に含まれている人の数の損失関数は 2乗和誤差を使用します。
最適化アルゴリズムには Adam [5] を採用しました。Adam のハイパーパラメータ $β_1$ は 0.9、$β_2$ は CNTK のデフォルト値に設定しました。
学習率は、Cyclical Learning Rate (CLR) [6] を使って、最大学習率は 1e-4、ベース学習率は 1e-8、ステップサイズはエポック数の 10倍、方策は triangular2 に設定しました。
モデルの訓練はミニバッチサイズ 16 のミニバッチ学習によって 160 Epoch を実行しました。
実装
実行環境
ハードウェア
・CPU Intel(R) Core(TM) i7-5820K 3.30GHz
・GPU NVIDIA Quadro RTX 6000 24GBソフトウェア
・Windows 10 Pro 1909
・CUDA 10.0
・cuDNN 7.6
・Python 3.6.6
・cntk-gpu 2.7
・cntkx 0.1.53
・numpy 1.19.2
・opencv-contrib-python 4.4.0.42
・pandas 1.1.2
・scipy 1.5.2
・scikit-learn 0.23.2実行するプログラム
訓練データを作成するプログラムと訓練用のプログラムは GitHub で公開しています。
hrpe_keypoint.pyhrpe_training.py解説
今回の実装の要となる内容について補足します。
Counting Pose
姿勢推定では、画像中に含まれている人の数が 1人の場合は予測したキーポイントを簡単に繋ぎ合わせることができます。しかし画像中に含まれている人の数が 2人以上の場合は、予測したキーポイントを繋ぎ合わせる作業が重要な工程となります。
一般的に Top-Down と呼ばれる姿勢推定モデルでは、バウンディングボックスで人物を検出し、そのバウンディングボックス内の人物のキーポイントを予測して繋ぎ合わせます。ただし、検出される人数が増えると計算量も大きくなってしまうという欠点があります。
一方の Bottom-Up と呼ばれる姿勢推定モデルでは、キーポイントとどのキーポイントがどの人物の割り当てられるのかに関する情報を学習して、後処理においてキーポイントを繋ぎ合わせます。Part Affinity Fields を用いる OpenPose [7] や Associative Embedding [8] などが有名です。
今回実装した独自のモデル Counting Pose は、「ある人物に関して予測されたキーポイントはその人物の近くに存在する」という仮定を前提として極めてシンプルなモデルと後処理を実行します。
以下に Counting Pose の後処理を示します。
- 予測したキーポイントに関する信頼度マップをリサイズしてガウシアンフィルタでぼかします。
- Non Maximum Suppression を適用して各キーポイントの極大点を見つけます。
- 予測した画像中に含まれている人の数が 0 だった場合、何もしません。
- 予測した画像中に含まれている人の数が 1 以上だった場合、予測した人の数を元に $k$平均法でクラスタリングしてキーポイントの割り当て行い、それを元にしてキーポイントを繋ぎ合わせます。
結果
Training loss
訓練時の損失関数のログを可視化したものが下図です。横軸はエポック数、縦軸はそれぞれ損失関数の値を表しています。
Validation PCKh Score
これで姿勢推定モデルが訓練できたので、検証用データで性能評価してみました。
今回の性能評価には Percentage of Correct Key-points head (PCKh) を算出しました。閾値の値は 0.5 としました。
PCKh@0.5 66.7FPS and Demo
実行速度の指標である FPS も計測してみました。計測には Python の標準モジュール time を使用し、ハードウェアは GPU NVIDIA GeForce GTX 1060 6GB を使用しました。人が写っていない場合は FPS 9.8 です。
FPS 1.7訓練したモデルで姿勢推定を試した動画を以下に示します。
参考
Computer Vision : Pose Estimation Part1 - ImageNet pretraining HRNet
- Mykhaylo Andriluka, Leonid Pishchulin, Peter Gehler, and Bernt Schiele. "2D Human Pose Estimation: New Benchmark and State of the Art Analysis", the IEEE Conference on Computer Vision and Pattern Recognition. 2014. p. 3686-3693.
- Ke SUN, Bin Xiao, and Jingdong Wang. "Deep High-Resolution Representation Learning for Human Pose Estimation", IEEE conference on Computer Vision and Pattern Recognition (CVPR). 2019. p. 5693-5703.
- Shubhra Aich and Ian Stavness. "Global Sum Pooling: A Generalization Trick for Object Counting with Small Datasets of Large Images", arXiv preprint arXiv:1805.11123 (2018).
- Misra, Diganta. "Mish: A self regularized non-monotonic neural activation function" arXiv preprint arXiv:1908.08681 (2019).
- Diederik P. Kingma and Jimmy Lei Ba. "Adam: A method for stochastic optimization", arXiv preprint arXiv:1412.6980 (2014).
- Leslie N. Smith. "Cyclical Learning Rates for Training Neural Networks", 2017 IEEE Winter Conference on Applications of Computer Vision. 2017, p. 464-472.
- Zhe Cao, Gines Hidalgo, Tomas Simon, Shih-En Wei, and Yaser Sheikh. "OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields", arXiv preprint arXiv:1812.08008 (2018).
- Alejandro Newell, Zhiao Huang, and Jia Deng. "Associative Embedding: End-to-End Learning for Joint Detection and Grouping", Neural Information Processing Systems. 2017, p. 2277-2287.



- 投稿日:2020-11-26T12:19:29+09:00
Computer Vision : Pose Estimation Part1 - ImageNet pretraining HRNet
目標
深層学習による姿勢推定についてまとめました。
Part1 では、姿勢推定のためのバックボーンに使用する CNN の事前学習を行います。CNN の事前学習には 1,000カテゴリーの ImageNet の画像を使用します。
以下の順で紹介します。
- High-Resolution Net
- 訓練における諸設定
導入
ImageNet [1] のからのダウンロードと準備については、Computer Vision : Semantic Segmentation Part1 - ImageNet pretraining VoVNet で紹介しています。
High-Resolution Net
畳み込みニューラルネットワークのモデルとして、今回は High-Resolution Net (HRNet) [2] と HigherHRNet [3] を参考にしました。
HRNet の特色は複数の解像度を並列に保つことにあります。これにより高解像度に含まれる局所的な情報を保ち続けることができます。さらに各解像度は異なる解像度からの大域的な情報も考慮するので、より豊富な情報を獲得されることが期待できます。
今回は 4段階の解像度を用意しました。パラメータの総数は 22,477,792 です。
畳み込み層ではバイアスを使用せずに、Batch Normalization [4] を適用してから活性化関数へ入力します。活性化関数は Mish [5] を採用します。
最後の全結合層では、Batch Normalization は使用せずにバイアス項を使用します。
訓練における諸設定
入力画像は輝度値の最大値 255 で除算します。
各層のパラメータの初期値は He の正規分布 [6] に設定しました。
損失関数は Cross Entropy Error、最適化アルゴリズムは Stochastic Gradient Decent (SGD) with Momentum を採用しました。モーメンタムは 0.9 に固定しました。
学習率には、Cyclical Learning Rate (CLR) [7] を採用し、最大学習率は 0.1、ベース学習率は 1e-4、ステップサイズはエポック数の 10倍、方策は triangular2 に設定しました。
過学習対策として、L2 正則化の値を 0.0005 に設定しました。
モデルの訓練はミニバッチサイズ 64 のミニバッチ学習によって 100 Epoch を実行しました。
実装
実行環境
ハードウェア
・CPU Intel(R) Core(TM) i7-5820K 3.30GHz
・GPU NVIDIA Quadro RTX 6000 24GBソフトウェア
・Windows 10 Pro 1909
・CUDA 10.0
・cuDNN 7.6
・Python 3.6.6
・cntk-gpu 2.7
・cntkx 0.1.53
・numpy 1.19.2
・opencv-contrib-python 4.4.0.42
・pandas 1.1.2実行するプログラム
訓練用のプログラムは GitHub で公開しています。
hrnet_training.py結果
訓練時の損失関数と誤認識率のログを可視化したものが下図です。左のグラフが損失関数、右のグラフが誤認識率になっており、横軸はエポック数、縦軸はそれぞれ損失関数の値と誤認識率を表しています。
これでバックボーンとなる CNN 事前学習モデルができたので、Part2 では姿勢推定のための訓練を行います。
参考
ImageNet
Microsoft COCO Common Objects in ContextComputer Vision : Image Classification Part1 - Understanding COCO dataset
Computer Vision : Semantic Segmentation Part1 - ImageNet pretraining VoVNet
- Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. "ImageNet: A Large-Scale Hierarchical Image Database", IEEE conference on Computer Vision and Pattern Recognition (CVPR). 2009, p. 248-255.
- Ke SUN, Bin Xiao, and Jingdong Wang. "Deep High-Resolution Representation Learning for Human Pose Estimation", IEEE conference on Computer Vision and Pattern Recognition (CVPR). 2019. p. 5693-5703.
- Bowen Cheng, Bin Xiao, Jingdong Wang, Honghui Shi, Thomas S. Huang, and Lei Zhang. "HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation", IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2020. p. 5386-5395.
- Ioffe Sergey and Christian Szegedy. "Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift", arXiv preprint arXiv:1502.03167 (2015).
- Misra, Diganta. "Mish: A self regularized non-monotonic neural activation function." arXiv preprint arXiv:1908.08681 (2019).
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification", The IEEE International Conference on Computer Vision (ICCV). 2015, p. 1026-1034.
- Leslie N. Smith. "Cyclical Learning Rates for Training Neural Networks", 2017 IEEE Winter Conference on Applications of Computer Vision. 2017, p. 464-472.


- 投稿日:2020-11-26T12:13:49+09:00
boto3 の DEBUG ログを表示しない
Python コードのデバッグのために以下のようにログレベルを DEBUG に設定していると、boto3 関連のログがたくさん流れてきて邪魔なときがある。
import logging logging.basicConfig(level=logging.DEBUG) logger = logging.getLogger(__name__)boto3 関連の DEBUG ログを表示しないようにしたいときは、いくつかのロガーのログレベルを INFO 以上に引き上げればよい。
import logging for name in ["boto3", "botocore", "s3transfer", "urllib3"]: logging.getLogger(name).setLevel(logging.WARNING)ただし、boto3 以外のモジュールが urllib3 に依存していた場合はそのログも見えなくなってしまうので注意。
- 投稿日:2020-11-26T11:54:35+09:00
漫画データセットで遊ぶ1
ご挨拶
こんにちは、マンボウです。
データ分析に携わる人間なら、一度は耳にしたことがあるkaggle。
一般的に予測精度などのコンペティションに利用されることが多いですが、普通に色々分析してみても面白いんじゃないですかね?漫画レビューサイトのデータ
TOP RANKED MANGAS MyAnimeList (MAL)のデータを色々見てみたいと思います。
日本の漫画が多く、親しみが湧いたので。
データはこんな↓感じです。
出版社別の傾向を観察してみようかな
主に、以下の前処理を適用して、分析用データを作成。
- 掲載開始日を
Published_Datesから抜いて、何年前の漫画かに変換- 欠損が入ってると分析できないので欠損を除去
- 出版社に"None"が入ってるので除去
以下、登場作品数が5以上の出版社に絞って見てみます。どの出版社が評価されてる?
データには、
Score(評価)とFavorites(お気に入り数)があったので、出版社別に見てみたいと思います。ビッグコミックスピリッツは、高い評価を受けている作品が多い
お気に入り数はヤングジャンプ
どの作品が評価されている?
評価・お気に入り数で特徴があった2社の作品を見てみます。
ビッグコミックススピリッツ
だいたいどこも8.3前後が中央値なのに対して、xx世紀少年が全体の評価を押し上げていると言えます。
ヤングジャンプ
GANTZ、トーキョーグールがお気に入り数を押し上げていると言えます。
お気づきの方もいるかもしれませんが
上記2社の作品数は、他と比べて相対的に少ないです。
なので、ヒット一本で特徴的な傾向が出やすい、とは言えます。
言い方を変えると、少数精鋭とも言えます。
最後に
海外のレビューサイトなので、日本での評価とはまた違うのかもしれません。
マンボウはそんなに漫画に詳しくないので「なんでそれがそんなに評価が高いの?」といった定性的な考察はいまいちできません。
次回は、ジャンル別の評価などを見て、海外の嗜好性を深掘って見れたらと思います。全部ノンプログラミングで実施
これらは全部、プログラミング不要の分析ツールnehanで実施しました。
下記実際にデータ処理を行ったノードプロセスです。
無料トライアルをしたい!興味がある!場合はぜひお問い合わせください!nehan前処理ワークフロー
nehan分析ワークフロー










- 投稿日:2020-11-26T11:46:07+09:00
MacとVSCodeでDjangoアプリケーションの開発環境を構築する
はじめに
Mac&VSCode環境化でDjangoを使用したWebアプリケーションを作成する機会があったので備忘をかねての投稿です。Pythonのインストールからプロジェクトの作成まで順を追って解説していきます。
Pythonのインストール
はじめてPythonで開発をするという方はこちらからはじめます。今回はHomebrewを使用してインストールをすすめていきます!
pyenvのインストール
Pythonをインストールする前に、複数のPythonのバージョンを管理するためのツール「pyenv」をインストールします。ターミナルを開き下記のコマンドを実行します。
brew install pyenv pyenv -v #バージョンを表示して正常にインストールされているか確認する正常にインストールが完了したらpyenvのパスを設定していきましょう。ターミナルで
echo $SHELLを実行すると下記のどちらかが表示されると思います。/bin/bash #パターン1 /bin/zsh #パターン2パターン1:
/bin/bashの場合 ※ひとつずつ入力しても何も起こりませんが設定はできてますecho 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile echo 'eval "$(pyenv init -)"' >> ~/.bash_profile source ~/.bash_profileパターン2:
/bin/zshの場合echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.zshrc echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.zshrc echo 'eval "$(pyenv init -)"' >> ~/.zshrc source ~/.zshrc以上で以上でpyenvのpathの設定は完了です。
Pythonのインストール
つづいてPythonをインストールしていきます。まずはpyenvのコマンドをつかってインストール可能なPythonのバージョンを確認します。
pyenv install --list使用可能なバージョンが多数表示されますが、今回は3.8.0をインストールします。
pyenv install 3.8.0 #インストールするバージョンに合わせる下記のコマンドでpyenvがインストールしているPythonのバージョンを確認できます。
pyenv versions最後にMacにデフォルトで入っているPython2が作動しないように下記の設定をして完了です。
pyenv global 3.8.0 #インストールしたバージョン 〜〜〜〜〜 python3 --version #使用するバージョンの確認VSCodeの設定
今回はエディタとして Visual Studio Code(VSCode) を使用しますので、こちらでPythonの開発ができるよう最低限の設定をしていきます。
VSCodeのインストール
VSCodeのインストールが済んでいない場合はこちらでMac版をインストールします。
ダウンロードされた.zipファイルを展開するとVisual Studio Code.appが作成されます。これでインストールは完了です。拡張機能の追加
VSCodeでPythonを使用するには拡張機能を追加する必要があります。VSCodeのウェルカムウィンドウで下記のアイコンをクリックします。
検索窓に"python"と入力すると、関連する拡張機能がいくつかヒットします。下記のとおり選択してクリックしてください。
画像ではすでにインストール済みのため表示が違いますが、未インストールの場合は緑枠部分にインストールボタンがあるのでクリックします。
これでPythonコードを編集するための、最低限の準備が整いました。仮想環境の作成とDjangoのインストール
仮想環境とは
自身のコンピュータのローカルで、バージョン(Django自体やライブラリ)の異なるDjangoアプリケーションを一括に管理しようとするとエラーが発生してしまいます。 そこでアプリケーションごとに、それぞれに適した環境を用意してあげる必要があります。これが仮想環境です。
仮想環境の作成
まずは今回のプロジェクトで使用するフォルダを作成します。フォルダ名はわかりやすいように「Django」にしました。
続いてDjangoフォルダ内に仮想環境をつくります。
次のコマンドをターミナルで実行します。(python3 -m venv 仮想環境名)cd Django python3 -m venv my-app正しく実行されると、次の画像のようにDjangoフォルダ内に「my-app」という仮想環境が確認できます。
作成された仮想環境を使用するには、ターミナルでアクティベートを実行する必要があります。
(source 仮想環境名/bin/activate)source my-app/bin/activateアクティベートに成功すると、次の画像のように先頭に(my-app)と表示されるようになります。
以上で仮想環境の作成は完了です。(ディアクティベートはターミナルdeactivateを入力実行)Djangoのインストール
続いてDjangoのインストールをしていきます。Djangoのインストールにはpipコマンドを使用します。pipとはPythonのライブラリを管理するためのツールで、Pythonをインストールした時点で使用できます。
作業は簡単で、仮想環境をアクティベートした状態で次のコマンドを実行してください。pip install Django
Successfully installed... と表示されたら仮想環境へのDjangoのインストールは完了です。プロジェクトの作成
プロジェクトとは
Djangoにはプロジェクトとアプリと呼ばれる2つのディレクトリが存在します。 プロジェクトでは、主にアプリケーション全体に関連する設定等を行います
ex) 時間設定・言語設定・個々のアプリの登録・データベース etc..
プロジェクトの作成
ターミナルを開いて次のコマンドを実行するとプロジェクトが作成されます。今回はサンプルとして「簡易ツイッター」を作成する予定なので、プロジェクト名は
simple_twitterとしました。django-admin startproject simple_twitter
Djangoフォルダを開くと新たにsimple_twitterプロジェクトが作成されているのが確認できます。
次にプロジェクトの中身を見ていきます。manage.pyとsimple_twitterフォルダが確認できます。manage.pyは今後サーバーを動かす際やDBの変更がある場合に使用しますので、その際に説明をします。simple_twitterフォルダをクリックしてさらに中身を見ていきましょう。フォルダを開くと、5つのPythonファイルが確認できます。各ファイルの役割は下記のとおりです。
フォルダ名 概要 __init__.pyこのファイルを含むディレクトリをPythonにパッケージとして認識させる役割があります asgi.py非同期処理に対応したWebアプリケーションを動作させるための、Python製Webサーバーです settings.pyファイル名のとおり様々な設定を書いていくファイルです urls.pyアプリケーションの軸となるURLを設定していくファイルです wsgi.py本番環境等にデプロイする際にサーバーの設定を行います サーバーを立ち上げる
ターミナルを開き、cdコマンドで
Desktop/Django/simple_twitterに移動します。そしてsimple_twitterフォルダ内にmanage.pyが存在することをlsコマンドで確認し、次のコマンドでサーバーを立ち上げます。python manage.py runserver
Starting development server at http://127.0.0.1:8080/Quit the server with CONTROL-C.の表示が確認できれば、サーバーの立ち上げは成功です。この状態でhttp://127.0.0.1:8080/にアクセスしてみます。
上のようなページが表示されれば環境構築は完了です。あとは自身で作成したいアプリケーションの追加等をすれば開発をはじめることができます!さいごに
長々と書きましたが、慣れている人からしたらほんの数分で終わる作業だと思います。この記事が初めてDjangoで開発を始める方の参考になれば幸いです。また、メインのアプリケーション作成についても、時間があれば記事にしてみたいと思います!
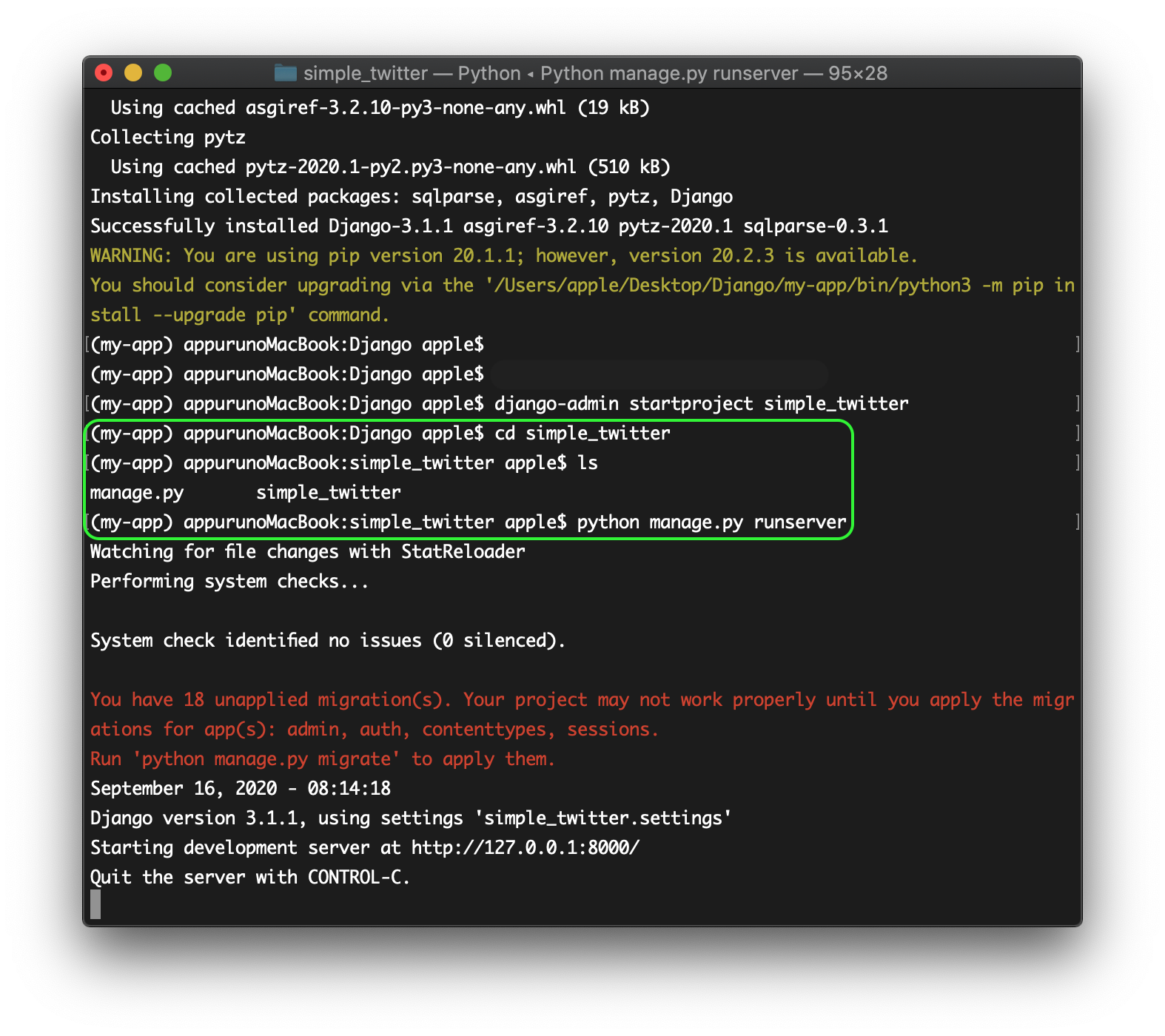
- 投稿日:2020-11-26T09:33:01+09:00
STFでAirtestを動かしてみる
はじめに
AirtestIDE でスマホアプリ(ゲーム)のテスト自動化をしています。そこで実際に作成したスクリプトや環境をつくるために実施したことを綴ってみたいと思います。
環境
macOS 10.15.7
Airtest IDE 1.2.6(Python)
Android 7.0(Xperia Z5 Premium)アクセストークンをつくる
「設定」メニューから、「認証キー」タブを開いて「+」をクリック。
ここで、アクセストークンを作成します。STFの端末を取得するまで
端末一覧を取得する
import requests import pprint def get_devices(): response = requests.get( 'https://stf.sample.net/api/v1/devices', headers = { 'Authorization': 'Bearer <token>' }, verify = False ) res = response.json() pprint.pprint(res)一覧を取得してどの端末を借りるか決めます。
今回は、Xperia Z5 Premium にします。
ここで、端末の serial を取得しておきます。端末を借りる
import json def reserve_device(serial): payload = { 'serial': serial } response = requests.post( 'https://stf.sample.net/api/v1/user/devices', headers = { 'Content-Type': 'application/json', 'Authorization': 'Bearer <token>' }, data = json.dumps(payload), verify = False ) res = response.json() pprint.pprint(res)先程の sereal を使って端末を借ります。
{'description': 'Device successfully added', 'success': True}
端末の状態が使用中になります。(自身のアカウントからみているので「Stop Automation」の表記になっている)端末へのリモート接続を有効にする
def connect_device(serial): payload = { 'serial': serial } response = requests.post( 'https://stf.sample.net/api/v1/user/devices/' + serial + '/remoteConnect', headers = { 'Content-Type': 'application/json', 'Authorization': 'Bearer <token>' }, data = json.dumps(payload), verify = False ) res = response.json() pprint.pprint(res){'remoteConnectUrl': '<ip>:<port>', 'success': True}当該端末への接続情報
<ip>:<port>が取得できます。STFの端末でAirtestのスクリプトを実行する
STFの端末を指定してAirtestIDEコマンドを実行します。
コマンドラインから実行する
$ cd $PROJECT_HOME $ /Applications/AirtestIDE.app/Contents/MacOS/AirtestIDE runner "<プロジェクト>.air" --device Android://127.0.0.1:5037/<ip>:<port> --log log先程取得した接続情報
<ip>:<port>を使用します。
※複数台同時実行も可能ですレポートを作成する
$ /Applications/AirtestIDE.app/Contents/MacOS/AirtestIDE reporter "<プロジェクト>.air" --log_root log --export exp作成されたレポートは
exp/<プロジェクト>.air/log.htmlから参照できます。端末を返却する
def release_device(serial): response = requests.delete( 'https://stf.sample.net/api/v1/user/devices/' + serial, headers = { 'Authorization': 'Bearer <token>' }, verify = False ) res = response.json()端末が開放され、貸出のステータスが元に戻ります。
おわりに
参考になった箇所などありましたでしょうか。実際にSTFでAirtestIDEコマンドを試そうとした際に、関連する情報が見つからず試行錯誤したことがありましたので、何かのお役に立てたなら幸いです。
参考
OSSなリモートスマホサービス(STF)が素敵すぎる
https://qiita.com/tabbyz/items/5f6cec37e1d525a8e4d5
Airtestを使ってUIのテストを自動化する話
https://qiita.com/johro/items/b77f5a8c3c3cf00bde30
Welcome to Airtest documentation!
https://airtest.readthedocs.io/en/latest/index.html
STF API
https://github.com/openstf/stf/blob/master/doc/API.md

- 投稿日:2020-11-26T07:53:18+09:00
異常検知関連の本5冊読んだので書評書く。
本記事のモチベーション
- 製造業では異常検知が結構案件として出てくる
- 異常検知は時系列系にも役立つ、というか見方を変えると異常検知のタスクだったとかある
といことで異常検知を学んでいきましたので備忘録
読んだ本
1冊目:統計的工程管理―製造のばらつきへの新たなる挑戦
著者:仁科 健 出版社: 朝倉書店 発売日: 2009/12/1感想
- 製造業向け、QC工程表とか腐らせずに管理できている会社ならこのレベルまで実現できているのか?
- やはり管理コストをかける半導体の話が多い様子
- X-bar管理などは有名だけど、累積和やV-maskのような単純な考え方で生成してくるデータの異常を知る方法は大変に面白かった
- 重回帰やARIMAも一部アリ
- 異常検知の異常度判定基準がISOやJISで参考に決められていることを初めて知った
余談
現実は管理手法よりも、「管理していこう」という合意を取り付けて危機感を持ってもらってデータ化するという壁がある...2冊目:異常検知と変化検知
著者:井手剛 出版社: 講談社 発売日: 2015/8/7感想
- 紹介されている方法が多い
- 初心者からするとレベルはかなり高かった
- 異常検知でのアプローチの方法はパターンがありそうで、特定の特徴量空間に落としてから異常なデータとの距離を測る
- 距離は確率分布で確率値を計算したりする場合もある
- ラベルがない場合は1class-SVMのように正常データの超球を定義してそこから外れたかどうかを判別する
- EMアルゴリズムの説明が非常にわかりやすかった
3冊目:入門 機械学習による異常検知―Rによる実践ガイド
著者:井手剛 出版社: コロナ社 発売日: 2015/2/19感想
- この本を一番初めに読んでおけばよかった
- 数学的な記述も多くて初心者にはレベルが高いかと思ったけれども、時間をかければ理解できるように工夫されていた
- 統計や線形代数の入門本をおさらいすることで読み進められる
- 付録参照の部分はさすがにレベルが高い
- タイトルにもある通り、Rを使って動かせるのでパッケージの中身まで確認できる程度にRに詳しければより理解しやすい
4冊目:データマイニングによる異常検知
著者:山西 健司 出版社: 共立出版 発売日: 2009/5/23感想
- EMアルゴリズムや平滑化を使って確率分布求めて珍しさを求める
- コマンドの遷移確率からロボットを検知する
- 自己相関からありえない波形を判断する
- など、他の本でも似たような記述はあるが、セキュリティやリアルタイムに増え続けるデータを想定した話が多くて具体的な使い道をイメージしやすかった
5冊目:Pythonと実例で学ぶ機械学習 識別・予測・異常検知
著者:福井健一 出版社: オーム社 発売日: 2018/11/27感想
- amazonレビューがすこぶる悪くて買う前に心配した
- どの本にも言えることだけど、悩んだら図書館で借りて様子見してからの購入をオススメする
以上






- 投稿日:2020-11-26T02:58:52+09:00
Pythonで依存型と篩型の型クラスを宣言できるコードをGitHubからDLしたら、うまく動いた!
問題意識の所在
自作クラスを宣言するときに、定義するクラスが用いるデータ型に制約を与えるだけでなく、そのクラスのインスタンスが持ちうる値の範囲や、長さの範囲についても制約を与えることができる言語は、依存型や篩型の型クラスを宣言できる言語として、知られています。篩型は、「ふるい」型と読みます。
Idrisやv6.11以降のRacket言語が、これらの型を宣言し、静的な型検査を行うことができる言語です。
・Dependent Types と Refinement Types の違い
・Refinement Types For Haskell
・型をさらに拡張するーーRefinement Typesについて
・LiquidHaskell のインストールと学習方法
・Liquid Haskell で普通の型システムの上を行け #NGK2017BScalaでは、次のWebページで解説されているように、篩型の型クラスを宣言できる機能がすでに実装されているようです。
refinedとは refinedはRefinement Type(篩型)をScalaで実現するためのライブラリで、既存の型に対して型レベルで満たすべき条件を指定することで、取りうる値を制限することができます。もともとはHaskellの同名のライブラリを移植したもののようですPythonでも、型アノテーションの導入(typingモジュール)や、静的な型検査を行うことができるmypyが登場する流れを受けて、データ型の型チェックを行うだけでなく、データ値の値の範囲や、配列の長さを型チェックの文脈で、静的にチェックできないか、調べてみました。
その結果、Pythonで依存型と篩型の型クラスを宣言できるようにするスクリプトが、GitHubで公開されていました。
・ (GitHubリポジトリ)vixrant/python-type-theory
以下のstackoverflowでのやり取りから、見つけたものです。
・ Can Python implement dependent types?
So, can we implement a type Vect, which can be used as indef append(a: Vect[m, T], b: Vect[n, T]) -> Vect[(m+n), T]: return a + b, where m and n are natural numbers, and T is any type?( 中略 ) I made a library which allows you to treat types as first-class, without hard-coding in advance like David said. Of course, it's hacky too, rewriting functions to make use of type hints. https://github.com/vixrant/python-type-theorygit cloneして、使ってみたところ、うまく動きました。
Terminal% git clone https://github.com/vixrant/python-type-theory Cloning into 'python-type-theory'... remote: Enumerating objects: 79, done. remote: Counting objects: 100% (79/79), done. remote: Compressing objects: 100% (61/61), done. remote: Total 79 (delta 36), reused 50 (delta 18), pack-reused 0 Unpacking objects: 100% (79/79), done. %ここでは、git cloneで取得したディレクトリにcdして作業をおこないます。
任意の階層パスのディレクトリから、取得したPythonスクリプトファイルを使うためには、パスを通す必要があります。・ @derodero24さんのQiita記事「【Python】自作モジュールへのパスの通し方」
今回は、パスは通さないで進めます。
Terminal% ls -lt | head total 2920 drwxr-xr-x 8 Afoguard staff 256 11 25 21:40 python-type-theory % ls -lt python-type-theory total 32 -rw-r--r-- 1 Afoguard staff 537 11 25 21:40 sample.py -rw-r--r-- 1 Afoguard staff 2083 11 25 21:40 refinement.py -rw-r--r-- 1 Afoguard staff 1398 11 25 21:40 ast_rewrite.py -rw-r--r-- 1 Afoguard staff 2532 11 25 21:40 README.md %iPythonの対話型インタプリタを立ち上げます。
git cloneしたPythonスクリプトは、内部でinspect.getsource()メソッドを呼び出すのですが、Pythonの対話型インタプリタでこのメソッドを使うと、inspect.py, raise OSError('could not get source code')エラーが起きるためです。
iPythonの対話型インタプリタは、このエラーを発生させずに、inspect.getsource()メソッドを使うことができるようです。
なお、iPythonを使わずに、Python2系やPython3系を使う場合でも、Pythonのスクリプトファイルを実行する場合は、OSエラーを発生させずに、今回 goit cloneしたモジュールを使うことができます。
( 参考 )
・teratail 「Pythonで対話インタプリタ上で宣言した関数の実装を見る方法」それでは、冒頭のgithubリポジトリに掲げられているサンプルコードを実行して、挙動を確認します。
型検査テスト1( 成功 )
Terminal% cd python-type-theory Afoguard% ipython Python 3.9.0 (default, Nov 19 2020, 22:16:24) Type 'copyright', 'credits' or 'license' for more information IPython 7.19.0 -- An enhanced Interactive Python. Type '?' for help. In [1]:@reftypeデコレータを付けて、次のメソッドを定義してみます。
・メソッド名:N
・ 「0よりも値の大きい、int型オブジェクト」であるかどうかを判定するメソッド
このメソッドの帰り値は、TrueかFalseのboolean値です。Python3In [1]: from refinement import refine, reftype In [2]: @reftype ...: def N(i: int) -> bool: ...: return i > 0 ...: In [3]:これで、自作クラスであるN型(クラス)が定義できました。
このクラスは、「0よりも値の大きい、int型オブジェクト」だけを持つことができます。それでは、コンストラクタに、「0よりも小さい値を持つint型オブジェクト」(負の符号を持つ整数)-4_を渡して、N型のインスタンスを生成してみます。
Python3In [3]: x = N(-4) --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-3-aff855616743> in <module> ----> 1 x = N(-4) ~/Desktop/python-type-theory/refinement.py in wrf(v) 49 def wrf(v): 50 if not wf(v): ---> 51 raise TypeError(f"Value {v} does not satify refinement {f.__name__}") 52 return v 53 TypeError: Value -4 does not satify refinement N In [4]:結果は、期待した通り、次の型エラーが発生しました。
Python3TypeError: Value -4 does not satify refinement Nそれでは、N型の型制約条件を満たす「0よりも小さいint型オブジェクト」である4(正の符号を持つ整数)_を渡して、N型のインスタンスを生成してみます。
Python3In [4]: x = N(4) In [5]: print(type(x)) <class 'int'> In [6]: print(x) 4 In [7]:無事に「4」の値を持つN型のインスタンスが生成されました。
型検査テスト2( 成功 )
次に、先ほどと同じように、@reftypeデコレータを付けて、「文字数が0よりも大きくて、(なお且つ)大文字で始まるstr型オブジェクト」であるかどうかを判定するメソッド CapitalisedNameを自作します。
このメソッドの帰り値は、TrueかFalseのboolean値です。Python3In [7]: @reftype ...: def CapitalisedName(s: str) -> bool: ...: return len(s) > 0 and s[0].isupper() ...: In [8]:これで、自作クラスであるCapitalisedName型(クラス)が定義できました。
このクラスは、「文字数が0よりも大きくて、(なお且つ)大文字で始まるstr型オブジェクト」だけを持つことができます。それでは、コンストラクタに、「小文字で始まる文字列(str型オブジェクト)」である'vikrant'を渡して、CapitalisedName型のインスタンスを生成してみます。
Python3In [8]: y = CapitalisedName('vikrant') --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-9-ca75b8144c65> in <module> ----> 1 y = CapitalisedName('vikrant') ~/Desktop/python-type-theory/refinement.py in wrf(v) 49 def wrf(v): 50 if not wf(v): ---> 51 raise TypeError(f"Value {v} does not satify refinement {f.__name__}") 52 return v 53 TypeError: Value vikrant does not satify refinement CapitalisedName In [9]:結果は、期待した通り、次の型エラーが発生しました。
Python3TypeError: Value vikrant does not satify refinement CapitalisedName「大文字で始まり、文字数が0(文字)より大きい文字列(str型オブジェクト)」である'Vikrant'をコンストラクトに渡すと、
型エラーを発生させることなく、CapitalisedName型インスタンスを生成させることができます。Python3In [9]: y = CapitalisedName('Vikrant') In [10]: print(type(y)) <class 'str'> In [11]: print((y)) Vikrant In [12]:自作した型制約付きのクラスを用いて、メソッドを定義してみる
型制約を満たす値をコンストラクタに渡した場合のみ、自作クラスからインスタンスを生成することができることが分かりました。
では、次に、「取りうる値」に制約を持つ自作型クラスを、自作メソッドを定義するときに付ける型アノテーションの中で用いてみます。
今度は、@refineデコレータを付けます。ここでは、githubリポジトリにあるサンプルコードを少し変えてみました。
Python3In [13]: @refine ...: def greet(name: CapitalisedName, dept: str, age: N) -> str: ...: return f"{name} さんは、 {dept}に所属する {age} 歳の社員です。" ...: In [14]:メソッドが定義できました。
それでは、第1引数"name"に、CapitalisedName型のインスタンスを渡して、greetメソッドを呼び出して実行してみます。
Python3In [14]: message = greet("Charles", "Python編集部", 37) In [15]: print(type(message)) <class 'str'> In [16]: print(message) Charles さんは、 Python編集部に所属する 37 歳の社員です。無事に動きました。
第1引数"name"に、小文字で始まる文字列を渡すと、CapitalisedName型が持つ「大文字で始まる」という値制約を破るため、エラーが発生します。
TypeError(f"Value {v} does not satify refinement {f.name}")が発生します。
(satifyはsatisfyの誤字だと思われます)Python3In [17]: message = greet("charles", "Python編集部", 37) --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-37-ae44d4c694b2> in <module> ----> 1 message = greet("charles", "Python編集部", 37) ~/Desktop/python-type-theory/refinement.py in wrapped(*args, **kwargs) 23 if k not in predicates: 24 continue ---> 25 predicates[k](v) 26 27 # Run the refined function ~/Desktop/python-type-theory/refinement.py in wrf(v) 49 def wrf(v): 50 if not wf(v): ---> 51 raise TypeError(f"Value {v} does not satify refinement {f.__name__}") 52 return v 53 TypeError: Value charles does not satify refinement CapitalisedName In [18]:次に、「大文字で始まり、文字数が7文字未満である」文字列という値の制約を持つ自作型クラスLengthRestrictedStringを定義してみます。
Python3In [18]: @reftype ...: def LengthRestrictedString(s: str) -> bool: ...: return len(s) < 7 and s[0].isupper() ...: In [19]:7文字を超える文字数の文字列を、定義したLengthRestrictedString型コンストラクタに渡してみます。
エラーが発生しました。意図した通りです。Python3In [20]: new_string = LengthRestrictedString("Having eaten too much, I came to feel so bad.") --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-42-c36e9d6a3330> in <module> ----> 1 new_string = LengthRestrictedString("Having eaten too much, I came to feel so bad.") ~/Desktop/python-type-theory/refinement.py in wrf(v) 49 def wrf(v): 50 if not wf(v): ---> 51 raise TypeError(f"Value {v} does not satify refinement {f.__name__}") 52 return v 53 TypeError: Value Having eaten too much, I came to feel so bad. does not satify refinement LengthRestrictedString In [21]:7文字を超えない文字数の文字列を、定義したLengthRestrictedString型コンストラクタに渡してみます。
こちらも意図した通り、エラーを出さずに、LengthRestrictedString型のインスタンスが生成できました。Python3In [21]: new_string = LengthRestrictedString("Bad.") In [22]: print(type(new_string)) <class 'str'> In [23]: print(new_string) Bad. In [24]:配列(List)の長さに制約を与える方法
GitHubレポジトリでは、次のサンプルコードが掲載されています。
Python3In [35]: @refine ...: def MinLenList(lim: N): ...: @reftype ...: def LenLimit(l: list) -> bool: ...: return len(l) >= lim ...: return LenLimit ...: In [36]:Python3In [37]: test_list Out[38]: ['a', 'abc', 'd']MinLenList()メソッドに3を与えて、要素数が3以上のリストかどうかを検査するメソッド(返り値はbool型)を定義します。
Python3In [39]: lengh_condiiton_checker_func = MinLenList(3) In [40]: print(type(lengh_condiiton_checker_func)) <class 'function'>次に、配列オブジェクトtest_listを与えてみます。
Python3In [41]: result = lengh_condiiton_checker_func(test_list) In [42]: print(result) ['a', 'abc', 'd']test_listは、要素数が3つで、MinLenList(3)型の型制約を満たすので、MinLenList(3)型のインスタンスの生成に成功しました。
次に、要素数が3より少ない配列を与えてみます。
Python3In [43]: test_list2 = [1, 2] In [44]: lengh_condition_checker_func2 = MinLenList(3) In [45]: result2 = lengh_condiiton_checker_func2(test_list2) --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-95-f28c0af3b174> in <module> ----> 1 result2 = lengh_condiiton_checker_func2(test_list2) ~/Desktop/python-type-theory/refinement.py in wrf(v) 49 def wrf(v): 50 if not wf(v): ---> 51 raise TypeError(f"Value {v} does not satify refinement {f.__name__}") 52 return v 53 TypeError: Value [1, 2] does not satify refinement LenLimit In [46]:意図した通り、エラーが発生しました。
配列の要素がすべて同じデータ型であるという制約は与えていないので、要素数が3個以上の配列でありさえすれば、型制約は満たします。
Python3In [47]: test_list3 = [1, 2, 'f', 9, 10, 15, 1] In [48]: lengh_condition_checker_func3 = MinLenList(3) In [49]: result = lengh_condiiton_checker_func3(test_list3) In [50]: result3 = lengh_condiiton_checker_func3(test_list3) In [51]: print(result3) [1, 2, 'f', 9, 10, 15, 1] In [52]:それでは、定義したlengh_condiiton_checker_func3型クラスを、自作メソッドの型アノテーションの中で用いてみます。
自作メソッドが受け取る第2引数に、lengh_condiiton_checker_func3型クラスのインスタンスを受け取るよう定義しました。Python3In [53]: @refine ...: def greet(name: str, scores: lengh_condiiton_checker_func3, age: N) -> str: ...: return f"{age} 歳の{name}さんのスコア履歴は、{scores}です。" ...: In [54]: In [55]: message = greet("Charles", [1, 'a'], 37) --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-108-28e9986b9cad> in <module> ----> 1 message = greet("Charles", [1, 'a'], 37) ~/Desktop/python-type-theory/refinement.py in wrapped(*args, **kwargs) 23 if k not in predicates: 24 continue ---> 25 predicates[k](v) 26 27 # Run the refined function ~/Desktop/python-type-theory/refinement.py in wrf(v) 49 def wrf(v): 50 if not wf(v): ---> 51 raise TypeError(f"Value {v} does not satify refinement {f.__name__}") 52 return v 53 TypeError: Value [1, 'a'] does not satify refinement LenLimit In [56]:第2引数に要素数が2つしかない配列を渡したため、意図した通り、第2引数の型制約を満たさないというエラーが発生しました。
次に、要素数が4の配列を第2引数に渡してみます。
Python3In [57]: message2 = greet("Charles", [1, 'a', 'b', 100], 37) In [58]: print(message2) 37 歳のCharlesさんのスコア履歴は、[1, 'a', 'b', 100]です。 In [59]:要素数が4の配列は、lengh_condiiton_checker_func3型クラスの値制約を満たすため、今度は実行に成功しました。
配列の長さ(要素数)に制約を与える:失敗コード事例
以下は実行エラーになった。
Python3In [24]: @reftype ...: def UpperBoundedList(l: list, upper_length_num : int) -> bool: ...: return (len(l) < upper_length_num) ...: --------------------------------------------------------------------------- AssertionError Traceback (most recent call last) <ipython-input-46-3cc4954bbae0> in <module> 1 @reftype ----> 2 def UpperBoundedList(l: list, upper_length_num : int) -> bool: 3 return (len(l) < upper_length_num) 4 ~/Desktop/python-type-theory/refinement.py in reftype(f) 37 def reftype(f: types.FunctionType): 38 assert type(f) == types.FunctionType, "Predicate should be a function" ---> 39 assert len(f.__annotations__) == 2, "Predicate should type hint the input parameter, the output should be bool" 40 assert f.__annotations__['return'] == bool, "Predicate should return a boolean value" 41 AssertionError: Predicate should type hint the input parameter, the output should be bool In [25]:以下もエラー
Python3In [26]: from typing import List, Sequence, TypeVar In [27]: T = TypeVar('T') In [28]: @reftype ...: def LengthUpperBoundedList(l: [T], n: int) -> T: ...: return (len(l) < n) ...: --------------------------------------------------------------------------- AssertionError Traceback (most recent call last) <ipython-input-52-1ea0ca96cec8> in <module> 1 @reftype ----> 2 def LengthUpperBoundedList(l: [T], n: int) -> T: 3 return (len(l) < n) 4 ~/Desktop/python-type-theory/refinement.py in reftype(f) 37 def reftype(f: types.FunctionType): 38 assert type(f) == types.FunctionType, "Predicate should be a function" ---> 39 assert len(f.__annotations__) == 2, "Predicate should type hint the input parameter, the output should be bool" 40 assert f.__annotations__['return'] == bool, "Predicate should return a boolean value" 41 AssertionError: Predicate should type hint the input parameter, the output should be bool In [29]:Python3In [30]: @reftype ...: def func_(x, n: int) -> bool: ...: condition = (len(x) < n) ...: return condition ...: In [31]: In [32]: test_list = ['a', 'abc', 'd'] In [33]: result = func_(test_list, 7) --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-80-3ea8e98e2aa1> in <module> ----> 1 result = func_(test_list, 7) TypeError: wrf() takes 1 positional argument but 2 were given In [34]:
- 投稿日:2020-11-26T02:23:58+09:00
Pytorch_geometric の前処理にて、複数の自作transformクラスを渡す方法
概要
グラフ関連のDeep Learningの研究をしているためPytorch_geometricにはお世話になっています。が、最近geometricのデータセットにアクセスするたびに複数の種類の前処理(transform)を行いたいと思って調べましたが意外と時間がかかったためメモ
実装方法
論文の引用関係データセットの'Cora'をインストールし、複数の前処理(transform)を行う場合、
from torch_geometric.datasets import Planetoid import torchvision.transforms as transforms transforms = transforms.Compose([TransA(), TransB(), ...]) dataset = Planetoid(root='./data', name='Cora', transform=transforms)上記のように渡したい複数の自作transform(TransA, TransB, ...)をリストとしてComposeに渡してあげます。そのオブジェクトをgeometric.datasetsの引数transformに渡せば、その順に前処理してくれます。
- 投稿日:2020-11-26T02:11:25+09:00
Pythonで、配列要素のデータ型と、配列の長さを型検査する依存型ライクなメソッドを作ってみた
定義したメソッド
自作クラスを宣言するときに、定義するクラスが用いるデータ型に制約を与えるのと同時に、そのクラスのインスタンスが持ちうる値の範囲や、長さの範囲にまで、制約を与えることができる言語は、依存型や篩型の型クラスを宣言できる言語として、知られています。
Idrisやv6.11以降のRacket言語が、これらの型を宣言し、静的な型検査を行うことができる言語です。
・Dependent Types と Refinement Types の違い
・Refinement Types For Haskell
・型をさらに拡張するーーRefinement Typesについて
・LiquidHaskell のインストールと学習方法
・Liquid Haskell で普通の型システムの上を行け #NGK2017Bこれらの言語は、関数型言語です。Haskellが、関数型言語として、Qiitaでも多くの良質な記事が書かれています。
元々は手続き型言語であったPythonでも、以下のように、関数型言語のスタイルを取り入れる動きが進行中です。
- 型アノテーションの導入(typingモジュール)
- 外部のツールとして、静的な型検査を行うmypyの登場
- mapやreduceの多様
- 破壊的代入が可能なListではなく、破壊的代入が言語レベルの仕様で禁止されているtuple型の利用を推奨するプログラミングスタイルの普及
こうした流れを受けて、この記事では、Pythonで「依存型」クラスを実現するための一歩として、ある配列オブジェクトの要素が持つデータ型と、配列全体の長さを検査するメソッドを定義してみました。
定義したメソッドの返り値は、bool型(TrueもしくはFalseのいずれか)です。
定義するメソッドが行う型検査の内容
- 第1引数に渡した配列の要素がすべてstr型のオブジェクトであるかどうか。
- 配列の要素数が第2引数に渡した数値未満であるかどうか。
以下、Ipythonの対話型インタプリタで実行しました。
Python3In [1]: from typing import List, Sequence, TypeVar In [2]: T = TypeVar('T') In [3]: def func_(x: List[T], n: int) -> bool: ...: condition_1 = (len(x) < n) ...: condition_2 = not(False in [isinstance(elem, str) for elem in x]) ...: condition = (condition_1 and condition_2) ...: return condition ...:( 動作確認 )
以下の2つの条件が揃った場合のみ、Trueが帰ることが確認できました。
( AND条件 )
1. 第1引数に渡した配列の要素がすべてstr型のオブジェクトである。
2. 配列の要素数が第2引数に渡した数値未満である。Python3In [4]: test_list = [1, 2, 3, "a", 1, 5, 9, 10, 17] In [5]: result = func_(test_list, 7) In [6]: print(result) False In [7]: test_lis2t = [1, 2, 3, "a", 1] In [8]: test_list2 = [1, 2, 3, "a", 1] In [9]: result = func_(test_list2, 7) In [10]: print(result) False In [11]: test_list = [1, 2, 3, 1, 5, 9, 10, 17] In [12]: result = func_(test_list, 7) In [13]: print(result) False In [14]: test_list2 = [1, 2, 3] In [15]: result = func_(test_list2, 7) In [16]: print(result) False In [17]: test_list3 = ["a", "b", "c", "d", "e", "f", "g", "h", "i"] In [18]: result3 = func_(test_list3, 7) In [19]: print(result3) False In [20]: test_list4 = ["a", "b", "c"] In [21]: result4 = func_(test_list4, 7) In [22]: print(result4) True In [23]: test_list5 = ["a", "b", 1, 3] In [24]: result5 = func_(test_list5, 7) In [25]: print(result5) False In [26]: