- 投稿日:2020-11-24T23:56:56+09:00
【Rails】bcryptを使ってログイン機能を作ったけど失敗した話
Railsでログインページを作っていました。
bcyrptのGemを使って作ろうとしたのですが、正しいメールアドレス・パスワードを登録し、ログインしようとしても「ログインに失敗しました」と表示され、なかなかできず…環境
Rails 5.2.4.4
DB:SQLite問題のあったコード
・gemfileにてcryptをインストール済み
・userモデルに has_secure_password を定義
・usersテーブルに password_digest:string を追加users_controller.rbclass UsersController < ApplicationController def sign_in_process user = User.find_by(email: params[:email]) if user && user.authenticate(params[:password]) user_sign_in(user) flash[:success] = 'ログインしました' redirect_to products_path else flash[:danger] = 'ログインに失敗しました' redirect_to sign_in_path end end enduser_sign_in(user)の部分はhelperで、
users_helper.rbdef user_sign_in(user) session[:user_id] = user.id endと書いています。
解決方法
paramsの後に[:user]を追加しました
users_controller.rbclass UsersController < ApplicationController def sign_in_process user = User.find_by(email: params[:user][:email]) if user && user.authenticate(params[:user][:password]) user_sign_in(user) flash[:success] = 'ログインしました' redirect_to products_path else flash[:danger] = 'ログインに失敗しました' redirect_to sign_in_path end end endログを見るとSQL文にメールアドレスがNULLと表示され、paramsの中にデータが入っていませんでした。
そのため、paramsの後に[:user]と書き、userモデルのemailカラム、passwordカラムに対応するようにしました。
- 投稿日:2020-11-24T23:32:27+09:00
Rails6 bootstrap
rails6にbootstrapをCDNで追加したところ、JSの動作不具合が多かった。下記の方法で実施すると不具合がなくなった為、備忘録として記述する。
参考URL: https://medium-company.com/rails-bootstrap/
Rails6標準の「yarn + webpacker」でBootstrapを導入
consoleyarn add jquery bootstrap popper.jsRails直下にあるpackage.jsonで確認
package.json{ "name": "test_pro", "private": true, "dependencies": { "@rails/actioncable": "^6.0.0", "@rails/activestorage": "^6.0.0", "@rails/ujs": "^6.0.0", "@rails/webpacker": "4.2.2", "bootstrap": "^4.5.0", "jquery": "^3.5.1", "popper.js": "^1.16.1", "turbolinks": "^5.2.0" }, "version": "0.1.0", "devDependencies": { "webpack-dev-server": "^3.11.0" } }YarnでインストールしたBootstrapパッケージを利用できるようにimport
app/javascript/packs/application.js に以下のコードを追加app/javascript/packs/application.jsimport 'bootstrap' import '../stylesheets/application'app/javascript/stylesheets/application.scss@import '~bootstrap/scss/bootstrap';config/webpack/environment.js を以下のように修正し、jQueryとPopper.jsを利用できるよう
config/webpack/environment.jsconst { environment } = require('@rails/webpacker') const webpack = require('webpack') environment.plugins.prepend('Provide', new webpack.ProvidePlugin({ $: 'jquery/src/jquery', jQuery: 'jquery/src/jquery', Popper: ['popper.js', 'default'] }) ) module.exports = environmentapp/views/layouts/application.erb.html の「stylesheet_link_tag」を「stylesheet_pack_tag」に変更
application.erb.html<%= stylesheet_pack_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' %>application.erb.html<meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">画像を保存する場合はapp/javascript下にimagesを作成。
cssの記述はapp/javascript/stylesheets/application.scssへ。
- 投稿日:2020-11-24T23:24:57+09:00
リレーションシップのダミーデータを作成する
環境
ruby '2.6.5'
rails '6.0.3'seeds.rb
# user User.create( email: 'aaaaaa@au.com', password: 'aaaaaa', account: 'arigatou' ) 5.times do email = Faker::Lorem.sentence(word_count: 8) + '@au.com' password = 'password' account = Faker::Lorem.sentence(word_count: 6) User.create!( email: email, password: password, account: account ) end # article users = User.all 5.times do content = Faker::Lorem.sentence(word_count: 50) users.each { |user| user.articles.create!(content: content) } end #relationship users = User.all user = users.first following = users[1..6] followers = users[1..6] following.each { |followed| user.follow!(followed) } followers.each { |follower| follower.follow!(user) }コード説明
以下の記述でログインする用のユーザーを作成
# user User.create( email: 'aaaaaa@au.com', password: 'aaaaaa', account: 'arigatou' )以下の記述で
5人のユーザーを作成します。
今回はemailとaccountカラムは一意に設定しているのでfakerでランダムに作成します。
バリデーションなどで文字数の指定をしている場合はバリデーションに合わせた数字に変更してください5.times do email = Faker::Lorem.sentence(word_count: 8) + '@au.com' password = 'password' account = Faker::Lorem.sentence(word_count: 6) User.create!( email: email, password: password, account: account ) end以下のコードは
作成したユーザー全てにarticleを作成させたいので
全てのuserを取得し、ランダムな文字列のcontentを作り、
each文でarticleを作成するという流れになります# article users = User.all 5.times do content = Faker::Lorem.sentence(word_count: 50) users.each { |user| user.articles.create!(content: content) } end最後にフォロー関係ですが
全てのユーザーを取得、
最初のユーザーをログインするユーザーと仮定し取得し、
それ以外のユーザーをフォロー、また他のユーザーにフォローされるという状況を作りたいので
following = users[1..6]
followers = users[1..6]
という記述になります
取得したユーザーをあとはeachでフォローしていく、してもらうという記述になります
なのでrails db:seedを行ったあとのリレーションは
user.firstは6人のユーザーにフォローされていて
user.firstは自分以外の6人にフォロされている状態になる#relastionship users = User.all user = users.first following = users[1..6] followers = users[1..6] following.each { |followed| user.follow!(followed) } followers.each { |follower| follower.follow!(user) }
- 投稿日:2020-11-24T23:01:21+09:00
クラス、メソッド、インスタンス変数の関係と命名(オブジェクト指向)
前提
クラス
クラスはオブジェクトであり、概念。
メソッド
メソッドはクラス(オブジェクト)の振る舞い。
インスタンス変数
インスタンス変数はクラスの属性、性質、状態を表すもの。
良い命名とは
基本的には
「クラス名+メソッド名」と並べた際に英語として適切であれば良い命名だといえる。
つまり基本はクラスが主語、メソッドが述語の関係。
もしくはクラスを操作対象のオブジェクトとみなした際の、命令形にしたときの対象となる。例えば「モンスター」クラスに「攻撃する」というメソッドがあれば
class Monster def attack end end monster = Monster.new monster.attack # モンスターは攻撃する # モンスターよ、攻撃しろ!のように命名すると良い。
命名を考える際に気をつけること
関係性を理解し言葉にできるか
あるオブジェクトの振る舞いがメソッドで、その構成要素/属性/性質がインスタンス変数。この関係性をまずは理解する。
そして対象のモノ(物事、概念、その他オブジェクト)がどんな物なのかを的確にイメージし、それを言葉にする。
そしてそれは「誰がみてもそう」という妥当性が重要となる。つまり
クラス名を見たときに、このクラスの内容を想像することができるかを常に想像すること。
この際、Informationやdataなどの抽象度の高い命名はできるだけ避けるようにする。オブジェクト↔メソッドを互いに想像できるか
「名前(クラス、オブジェクト)からその内容(メソッド、インスタンス変数)を想像できること」「内容からその名前を想像できること」どちらも考える必要がある。
するとメソッドやインスタンス変数が適切であるかもそこから見えてくる。よって
良い変数名、メソッド名、クラス名というのは名前がその中身を正しく表しているといえる。
そしてその内容こそがそのクラス(オブジェクト)の責務と呼ばれるものになりうる。
- 投稿日:2020-11-24T22:49:41+09:00
自分で作成したRubyのアプリを指定した場所から始まるように設定するには
modelやcontrollerを作成しているとして、
例えば、app/views/tweets/indexを最初に表示させたいとして
config/routes.rbに
Rails.application.routes.draw do
root to: 'tweets#index'
resources :tweets
endと記述すれば最初に表示できる。
「root to:」は最初に表示させたいview(今回の場合は、'tweets#index')を指定できる。
「resources :〜」はその後に記述するviewに向けてのルートを作成してくれる。
道路に例えると、「resources」で道を作り、「root to」でその道を選ぶという感じです。
- 投稿日:2020-11-24T22:40:40+09:00
Rubyで文字列を反転させる方法はreverse
ruby 2.7.0についての記事です
- reverse 文字列を文字単位で左右逆転した文字列を返す
公式ドキュメントStringクラスreverse- revers 配列でも使える
公式ドキュメントArryクラスreverses = "string".reverse # stringクラスで使う場合 puts s # => gnirts arry = ["a","b","c"] # arryクラスで使う場合 print arry.reverse # => ["c","b","a"]
- 投稿日:2020-11-24T22:24:30+09:00
Railsプロジェクトをdocker-composeで環境ごとに構築
Railsのプロジェクト(Redmine)をdocker-composeを用いて、
環境ごとに管理していきます
今回はdockerを用いた環境構築を主軸としたため、
webサーバーなどの詳しい説明は省きます作成:2020年11月24日
環境
Ubuntu18.04
Rails 5
Ruby 2.6.5
Redmine 4.0
nginx 1.15.8
Docker 19.03.13
docker-compose 3
MySQL 5.7必要なもの
Dockerとdocker-compsoeが動く環境(今回はUbuntu18.04で実行)
Redmineのソース
やる気ざっくりとした方法
環境ごとにcomposeファイルを作成
環境変数COMPOSE_FILEを環境ごとに指定するコンテナ構成
- 開発環境
app(rails), db(mysql)- 本番環境
app(rails, puma), db(mysql), web(nginx)フォルダ構成
docker-compose.develop.ymlが開発環境とテスト環境
docker-compose.prod.ymlが本番環境となる
開発環境のDockerファイルはDockerfile
本番環境はDockerfile.prodとなるredmine(プロジェクトroot) ├── app ├── bin ├── etc.... ├── config │ ├── database.yml(追加) │ ├── puma.rb(追加) │ └── etc... ├── container(追加) │ ├── app │ │ ├── Dockerfile │ │ └── Dockerfile.prod │ ├── db │ │ └── multibyte.cnf │ └── web │ ├── Dockerfile.prod │ └── nginx.conf ├── docker-compose.develop.yml(追加) └── docker-compose.prod.yml(追加)初期設定
環境に応じて、環境変数を設定する
docker-composeの仕様により、
COMPOSE_FILE環境変数を設定すると、設定した環境すべてにおいて、
docker-composeコマンドに適応されるので注意。
direnvの導入をおすすめする開発環境 $ export COMPOSE_FILE=docker-compose.develop.yml 本番環境 $ export COMPOSE_FILE=docker-compose.prod.ymlGemfile修正
pumaを本番環境に適応させる
Gemfilegroup :test, :production do gem 'puma', '~> 3.7' # 追加 end group :test do gem "rails-dom-testing" gem 'mocha', '>= 1.4.0' gem "simplecov", "~> 0.14.1", :require => false # For running system tests gem "capybara", '~> 2.13' gem "selenium-webdriver" # gem 'puma', '~> 3.7' 削除 endpuma.rb作成
config/puma.rbthreads_count = ENV.fetch("RAILS_MAX_THREADS") { 5 }.to_i threads threads_count, threads_count port ENV.fetch("PORT") { 3000 } plugin :tmp_restart app_root = File.expand_path("../..", __FILE__) bind "unix://#{app_root}/tmp/sockets/puma.sock" stdout_redirect "#{app_root}/log/puma.stdout.log", "#{app_root}/log/puma.stderr.log", truedatabase.yml作成(DB設定)
redmine公式ドキュメントに基づきdatabase.yml.exampleをもとに
database.ymlを作成database.yml# Default setup is given for MySQL with ruby1.9. # Examples for PostgreSQL, SQLite3 and SQL Server can be found at the end. # Line indentation must be 2 spaces (no tabs). production: adapter: mysql2 database: redmine host: db username: hoge password: "fugafuga_1" encoding: utf8 development: adapter: mysql2 database: redmine_development host: db username: root password: "" encoding: utf8 # Warning: The database defined as "test" will be erased and # re-generated from your development database when you run "rake". # Do not set this db to the same as development or production. test: adapter: mysql2 database: redmine_test host: db username: root password: "" encoding: utf8 # 省略、、、、、本番環境以外、パスなしrootで良ければproduction関連以外編集しなくてもよい
各ファイル詳細
開発、本番環境共用
実際の本番環境ではDBサーバーを別途用意するとは思いますが、、
cotainers/db/multibyte.cnf# 文字コードを設定しないとエラーとなるため [mysqld] character-set-server=utf8 collation-server=utf8_general_ci開発環境
appコンテナ
containers/app/DockerfileFROM ruby:2.6.5 RUN apt-get update -qq && apt-get install -y build-essential \ libpq-dev \ nodejs RUN mkdir /redmine WORKDIR /redmine COPY . /redmine RUN gem install bundler && bundle installcompose
docker-compose.develop.yml# DBを永続化したい場合、コメントを外す version: '3' services: app: build: context: ./ dockerfile: containers/app/Dockerfile command: bundle exec rails s -p 3000 -b 0.0.0.0 volumes: - .:/redmine ports: - "3000:3000" depends_on: - db db: image: mysql:5.7 environment: MYSQL_ALLOW_EMPTY_PASSWORD: "yes" ports: - 3306:3306 volumes: - ./containers/db/multibyte.cnf:/etc/mysql/conf.d/multibyte.cnf #- db-store:/var/lib/mysql #volumes: #db-store:本番環境
appコンテナ
containers/app/Dockerfile.prodFROM ruby:2.6.5 RUN apt-get update -qq && apt-get install -y build-essential \ libpq-dev \ nodejs RUN mkdir /redmine WORKDIR /redmine COPY . /redmine RUN gem install bundler && bundle install --without development testwebコンテナ
Dockerfile.prodFROM nginx:1.15.8 # インクルード用のディレクトリ内を削除 RUN rm -f /etc/nginx/conf.d/* # Nginxの設定ファイルをコンテナにコピー ADD nginx.conf /etc/nginx/myapp.conf # ビルド完了後にNginxを起動 CMD /usr/sbin/nginx -g 'daemon off;' -c /etc/nginx/myapp.confcontainers/db/nginx.confuser root; worker_processes 1; events{ worker_connections 512; } # ソケット接続 http { upstream redmine{ server unix:///redmine/tmp/sockets/puma.sock; } server { # simple load balancing listen 80; server_name localhost; #ログを記録しようとするとエラーが生じます #root /redmine/public; #access_log logs/access.log; #error_log logs/error.log; location / { proxy_pass http://redmine; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; } } }compose
docker-compose.prod.yml# DBコンテナはdatabase.ymlをもとに設定 # DBを永続化したい場合、コメントを外す version: '3' services: app: build: context: ./ dockerfile: containers/app/Dockerfile.prod command: bash -c "rm -f /redmine/tmp/pids/server.pid && bundle exec puma -e production -C config/puma.rb" volumes: - .:/redmine - public-data:/redmine/public - tmp-data:/redmine/tmp depends_on: - db web: build: context: containers/web/ dockerfile: Dockerfile.prod ports: - 80:80 volumes: - public-data:/redmine/public - tmp-data:/redmine/tmp depends_on: - app db: image: mysql:5.7 environment: MYSQL_USER: hoge MYSQL_PASSWORD: fugafuga_1 MYSQL_ROOT_PASSWORD: rootdayo MYSQL_DATABASE: redmine ports: - 3306 volumes: - ./containers/db/multibyte.cnf:/etc/mysql/conf.d/multibyte.cnf #- db-store:/var/lib/mysql volumes: #db-store: public-data: tmp-data:実行手順
開発環境
$ docker-compose build # DBを永続化した場合は最初だけ---------- # db作成(appはコンテナ名) $ docker-compose run app rake db:create # テーブル設定 $ docker-compose run app rake db:migrate # --------------------------------------- # 起動 $ docker-compose up -d # http://localhost:3000本番環境
$ docker-compose build # Redmine公式ドキュメントに基づき、シークレットトークン作成 # 実行は最初の一回だけでよい $ docker-compose run -e RAILS_ENV=production app bundle exec rake generate_secret_token # DBを永続化した場合は最初だけけ--------- # テーブル設定 $ docker-compose run -e RAILS_ENV=production app bundle exec rake db:migrate # --------------------------------------- # $ 起動 $ docker-compose up -d参考
Redmine GitHub
https://github.com/redmine/redmine
Redmineインストール
http://guide.redmine.jp/RedmineInstall/
docker-compose.ymlが環境別に複数ある場合はCOMPOSE_FILEを定義しておくと幸せになれる
https://suin.io/535GitHub
ソースをgithubにあげているので良かったら参考にしてください
https://github.com/kinako555/redmine_managed_docker.git
- 投稿日:2020-11-24T22:04:47+09:00
Rails 掃除提案アプリのアルゴリズム
はじめに
オリジナルアプリとして掃除提案アプリを開発しました。その際、苦労したところを忘れずに書き記します。
目次
1.掃除提案機能の説明
2.必要なカラムとその型
3.Rubyのコード1.掃除提案機能の説明
予め掃除箇所の情報を登録する。登録情報に応じて、毎日どこを掃除すれば良いか提案する機能である。なお登録情報は下記3つ。
・掃除箇所名
・掃除頻度(○日に一回掃除する)
・最後に掃除した日付提案のアルゴリズムとしては下記の通り。
①最後に掃除した日付と今日の日付から経過日数を算出する
②経過日数と掃除頻度を比較する
③結果に応じてtrueもしくはfalesを返す。
④falseとなった場合、提案(画面に表示)する。2.必要なカラムとその型
必要なカラムと型を下記に示す。状態は上記のtrueもしくはfalseが入るboolean型のカラムである。
登録情報 カラム名 型 掃除箇所 place string 清掃期間 period_cleaning integer 最後に清掃した日付 last_cleaned_date date 状態 status boolean マイグレーションファイルの記述も下記に示す。
2020***********_create_suggestions.rbclass CreateSuggestions < ActiveRecord::Migration[6.0] def change create_table :suggestions do |t| t.string :place, null: false t.integer :period_cleaning, null: false t.date :last_cleaned_date, null: false t.boolean :status, null: false t.timestamps end end end3.Rubyのコード
改めて提案のアルゴリズムを下記に示す。
①最後に掃除した日付と今日の日付から経過日数を算出する
②経過日数と掃除頻度を比較する
③結果に応じてtrueもしくはfalesを返す。
④falseとなった場合、提案(画面に表示)する。①〜④までのコードを下記のようにした。はじめにフォームから送られた掃除箇所の情報をインスタンス変数に代入する。次に変数this_dayに今日の日付を代入する。ここから①の経過日数を算出する(3行目:this_day - @suggestion.last_cleaned_date)。最後に掃除頻度(@suggestion.period_cleaning)to
経過日数(num_days)を比較し、trueもしくはfalseを状態(status)に代入する。def create @suggestion = Suggestion.new(suggestion_params) #suggestion_paramsはストロングパラメータ this_day = Date.today num_days = (this_day - @suggestion.last_cleaned_date).to_i @suggestion.status = !(@suggestion.period_cleaning <= num_days) end以上
- 投稿日:2020-11-24T21:26:42+09:00
Rubyの演算優先順位
Rubyでの演算処理は、以下の優先順位に従って実行される。
優先順位:高 :: [] +(単項), !, ~ ** -(単項) *, /, % +, - <<, >> & |, ^ \>, >=, <, <= <=>, ==, ===, !=, =~, !~ && || .., ... ?:(条件演算子) = (+=, -=, ...等も含む) not and, or 優先順位:低
- 投稿日:2020-11-24T21:18:26+09:00
Rails on Dockerのgemの永続化について
背景
Dockerを利用したアプリ開発を行っていて、ログイン機能を搭載したくbcryptをGemfileに追加したが以下のエラーが出続け解決不能に。
22: from /usr/local/bundle/gems/spring-2.1.1/bin/spring:49:in `<main>' 21: from /usr/local/bundle/gems/spring-2.1.1/lib/spring/client.rb:30:in `run' 20: from /usr/local/bundle/gems/spring-2.1.1/lib/spring/client/command.rb:7:in `call' 19: from /usr/local/bundle/gems/spring-2.1.1/lib/spring/client/server.rb:9:in `call' 18: from /usr/local/lib/ruby/2.6.0/rubygems/core_ext/kernel_require.rb:54:in `require' 17: from /usr/local/lib/ruby/2.6.0/rubygems/core_ext/kernel_require.rb:54:in `require' 16: from /usr/local/bundle/gems/spring-2.1.1/lib/spring/server.rb:9:in `<top (required)>' 15: from /usr/local/lib/ruby/2.6.0/rubygems/core_ext/kernel_require.rb:54:in `require' 14: from /usr/local/lib/ruby/2.6.0/rubygems/core_ext/kernel_require.rb:54:in `require' 13: from /usr/local/bundle/gems/spring-2.1.1/lib/spring/commands.rb:4:in `<top (required)>' 12: from /usr/local/bundle/gems/spring-2.1.1/lib/spring/commands.rb:33:in `<module:Spring>' 11: from /usr/local/lib/ruby/2.6.0/rubygems/core_ext/kernel_require.rb:54:in `require' 10: from /usr/local/lib/ruby/2.6.0/rubygems/core_ext/kernel_require.rb:54:in `require' 9: from /usr/local/lib/ruby/2.6.0/bundler/setup.rb:20:in `<top (required)>' 8: from /usr/local/lib/ruby/2.6.0/bundler.rb:107:in `setup' 7: from /usr/local/lib/ruby/2.6.0/bundler/runtime.rb:20:in `setup' 6: from /usr/local/lib/ruby/2.6.0/bundler/runtime.rb:108:in `block in definition_method' 5: from /usr/local/lib/ruby/2.6.0/bundler/definition.rb:226:in `requested_specs' 4: from /usr/local/lib/ruby/2.6.0/bundler/definition.rb:237:in `specs_for' 3: from /usr/local/lib/ruby/2.6.0/bundler/definition.rb:170:in `specs' 2: from /usr/local/lib/ruby/2.6.0/bundler/spec_set.rb:85:in `materialize' 1: from /usr/local/lib/ruby/2.6.0/bundler/spec_set.rb:85:in `map!' /usr/local/lib/ruby/2.6.0/bundler/spec_set.rb:91:in `block in materialize': Could not find bcrypt-3.1.16 in any of the sources (Bundler::GemNotFound)
解決方法
こちらのサイトの方法を試したが、一向に解決せず。。。
https://qiita.com/totto357/items/1741da83bf642dab99df
問題は実はDockerのgem一覧が永続化されていなかったからということが発覚。
https://nishinatoshiharu.com/datavolume-for-gem/gemの永続化を行なっていないとコンテナ上でbundle installを実行してもDockerイメージにはgemが保存されないためエラーが発生していたようです。
gemを永続化していないと新しいgemを入れるたびに、ビルドを実行しコンテナを起動しなければならないというわけです。
しかし、永続化を行えばコンテナ上でgemをインストールした際にイメージの再ビルドを行わなくて済むということのようです。
永続化の方法については上記のサイトがわかりやすいため参照ください。
- 投稿日:2020-11-24T21:03:53+09:00
[Rails]exists?メソッド、present?メソッド、presenceメソッドについて勉強してみた![初心者]
それぞれの違い
exists?メソッド
指定した条件のレコードがデータベースに存在するかどうか、真偽値で返すメソッド
present?メソッド
レコードの存在確認を行った後に、インスタンスを使って何か処理をしたい時に使用するメソッド
presenceメソッド
オブジェクトが存在すればそのオブジェクトを返し、オブジェクトが存在しなければnilを返すメソッドexists?メソッド
基本構文オブジェクト.exists?(条件)
exists?メソッドの引数に条件を指定すると、条件にマッチするレコードがあればtrueを返し、レコードがなければfalseを返します。指定したidのレコードを確認する方法
pry(main)> User.exists?(1) => true指定した条件のレコードを確認する方法
exists?メソッドの引数にハッシュ(カラム名: '値')を渡します。
pry(main)> User.exists?(name: '田中') => truewhereメソッドと併用する方法
pry(main)> User.where(name: '田中').exists? => truepresent?メソッド
基本構文オブジェクト.present?present?メソッドを使用したオブジェクトが存在すればtrueを返し、存在しなければfalseを返すメソッドです。
非常にexists?メソッドと似通っていて、混乱しそうですね。
使い分けとしては、if文など条件分岐をプログラムで書くときには使われることが多いです。使用例
app/views/users/index.html.erb<% if @users.present? %> <% @users.each do |user| %> <%= user.name %> <% else %> <div>ユーザーなし</div> <% end %> <% end %>presenceメソッド
基本構文オブジェクト.presencepresenceメソッドを使用したオブジェクトが存在すればそのオブジェクト自身を返し、存在しなければnilを返すメソッドです。
presenceメソッドはRailsのメソッドなので、Rubyで使おうとすると、エラーが出ます。使用例
app/model/user.rbclass User < ApplicationRecord def call name.presence || 'No Name' end endapp/controller/users_controller.rbclass UsersController < ApplicationController def show @user = User.call end endapp/views/users/show.html.erb<%= @user %>このように記載すると、@userのnameに値があればその値が表示され、なければ “No Name” と表示されます。
おわりに
とてもややこしいですね。
自分でまとめておきながら、混乱しています。
徐々に使っていって、手で覚えるしかないですね。
- 投稿日:2020-11-24T19:58:49+09:00
Ruby on Railsでの頻出単語(まとめ)
Ruby on Rails似て、よく出てくる単語の意味をまとめたものです。
辞書的に使っていただけると幸いです。[データベース関係]
rails g model テーブル名(はじめ大文字) カラム名:データ型
新しくテーブルとカラムを作るときに、ターミナルで使うrails g migration ファイル名
テーブルに新しくカラムを追加するときに、ターミナルで使うadd_column :テーブル名, :カラム名, :データ型
マイグレーションファイルに、新しいカラム名を追加するときに使うrails db:migrate
データベースに変更を加えるときに、ターミナルで使う
- 投稿日:2020-11-24T19:41:34+09:00
鋸入門
概要
HTML、XML、SAX、Readerのパーサ
- Xpath/CSSによる解析
- XML/HTMLの生成
- なんか気づくと入ってる
サンプル
こんなHTMLドキュメントがあったとして、ここから「各言語とそのリンク」を抽出したい
<html> <head> <title>Lightweight language</title> </head> <body id="test_id"> <h1>Lightweight language</h1> <div> <ul> <li> <a href="link_ruby" title="ruby">Ruby</a> </li> <li> <a href="link_python" title="python">Python</a> </li> <li> <a href="link_php" title="php">PHP</a> </li> <li> <a href="link_perl" title="perl">Perl</a> </li> </ul> </div> </body> </html>ググってサンプルをいじれば何となくできる
require 'open*uri' require 'nokogiri' html = Nokogiri::HTML.parse(open('/tmp/test.html')) html.css('body[id="test_id"] > div > ul > li').each do |li| p li.text p li.at('a')[:href] end;"Ruby" "link_ruby" "Python" "link_python" "PHP" "link_php" "Perl" "link_perl"少し調べてみると他にも色々できるっぽい
html = Nokogiri::HTML.parse(open('/tmp/test.html')) p html.text対象ドキュメントのテキスト内容を全てくっ付けて返してくれる
"LightweightlanguageLightweightlanguageRubyPythonPHPPerl"利用方法の大枠
ツリーを構築して検索してノードを参照する
- ツリーの構築
- HTMLやXMLのドキュメントをNokogiriで使うために、対象ドキュメントを解析し専用のデータ構造に変換する
- ツリーの検索
- 解析結果となるメモリ内のツリーをスキャンし、目当てのノードを特定する
- ノードの参照
- そのノードから目当てのデータを抽出する
冒頭の文を言い換えると、HTMLドキュメントを解析して Nokogiri::HTML::Document に変換して、Nokogiri::XML::Node に実装されている検索系メソッドを利用して探索を行い、目当ての Nokogiri::XML::NodeSet または Nokogiri::XML::Element を取得してそれに関する情報を取得する
html = Nokogiri::HTML.parse(open('/tmp/test.html')) html.css('body[id="test_id"] > div > ul > li').each do |li| p li.text p li.at('a')[:href] end;ツリーの構築
解析の種類
DOMの他にもSAXやReaderやPullがあるらしいけど、有名どころのDOMについて説明する
気になった人は調べて教えて
DOM 解析
Nokogiri では HTML/XML ドキュメントのどちらも解析できる
doc = Nokogiri::HTML.parse(html_document) # HTML ドキュメントの解析 doc = Nokogiri::XML.parse(xml_document) # XML ドキュメントの解析
- 第 1 引数には、IO オブジェクトまたは文字列オブジェクトを指定する
- open_uri を直接 Nokogiri に渡すことも可能(文字列を使用するより若干効率は上がるらしい?)
doc = Nokogiri::HTML(open("http://www.google.com/search?q=doughnuts"))- 第 3 引数には、対象ページの文字コードを指定する
- 解析対象の文字コードが UTF*8 以外の場合、大抵解析が失敗するので指定する
html = Nokogiri::HTML(open('/tmp/test.html'), nil, 'Shift*JIS')- 第 2 引数は URL、第 4 引数はオプション、どちらも大抵は指定せず事足りる
オブジェクトの可視化
html = Nokogiri::HTML(open('/tmp/test.html'))メモリ上ではどのようなオブジェクトが作られているのか
簡略化するとこんなツリー状のオブジェクトが作られている
図から読み取るべきポイントをざっと挙げてみる
- Nokogiriによって複数のオブジェクトが作成されている
- Nokogiri::XML::DocumentとかNokogiri::XML::Elementとか
- 全てのオブジェクトがノードである
- Nokogiri::XML::Nodeを継承していて、検索系のメソッドはNokogiri::XML::Nodeにまとまっているため、同じ検索メソッドがこれらオブジェクトに対して使える
各オブジェクトについて
他にも色々あるけど、作られているオブジェクトの説明を簡単に
- Nokogiri::XML::Node
- ノードに対する操作や検索処理を規定する
- 具体的には、Nokogiri::XML::Searchableをincludeして各種メソッドを実装
- SearchableはDOM検索のインターフェース
- Nokogiri::XML::NodeSet
- Nogogiri::XML::NodeSet < Enumerable < Object
- Nokogiri::XML::Searchable#css/#xpathの実行結果
- Nokogiri::XML::Node オブジェクトのリストを持つ
- Nokogiri::HTML::Document
- < Nokogiri::XML::Document < Nokogiri::XML::Node < Object
- Nokogiriによって解析されたHTMLドキュメント
- Nokogiri::HTML.parseの戻り値
- Nokogiri::XML::DTD
- < Nokogiri::XML::Node < Object
- 対象ドキュメントが DTD による文書構造に従っているかどうかを検証している?
- Nokogiri::XML::Element
- < Nokogiri::XML::Node < Object
- Nokogiriで HTML 要素を扱うためのオブジェクト
- C 拡張なのできっと早い
- Nokogiri::XML::Text
- < Nokogiri::XML::CharacterData < Nokogiri::XML::Node < Object
- Nokogiri で HTML テキストを扱うためのオブジェクト
ツリーの検索
検索方法
大まかに 3 種類かと
- XPath
- XML形式の文書から特定の部分を指定して抽出するための簡潔な構文
- CSS
- ウェブページのスタイルを指定するための言語
- その他
- child とか parentとか相対的に位置を特定する
よくある流れ
- Nokogiri::HTML::Document オブジェクトに対して、CSSセレクタやXPathで検索を行い、検索結果として Nokogiri::XML::NodeSet オブジェクトを得る
- NodeSet は Node のリストを持ち配列のように扱えるため、each や [] で該当ノードである Element を特定する
- CSS や Xpath は NodeSet を返すが、at や child など Element を返すものもあるので要確認
検索メソッド
よく使うであろう Nokogiri::XML::Node のメソッドについて
Nodeset と Element 両方に対して使えるXPath
親タグとして body(id="test_id"), div, ul を持つ li タグ全てを検索
html.xpath('//body[@id="test_id"]/div/ul/li').each do |li| p li.text p li.at('a')[:href] end; nil
- 引数について
- 冒頭の "/" が階層構造のルートを表す
- その他の "/" で各タグの階層情報を指定
- "/" の間に何もない場合は任意のタグに一致するワイルドカードとして使える
- "div" や "ul" はタグ名の指定
- 属性(例えばidの値とか)を指定するときは "タグ名[@属性名=xxx]" を使う
- 引数は複数指定できる
- 戻り値について
- NodeSet を返す
- 結果が無ければ空の NodeSet
CSS
親タグとして body(id="test_id"), div, ul を持つ li タグ全てを検索
html.css('body[id="test_id"] > div > ul > li').each do |li| p li.text p li.at('a')[:href] end; nil
- 引数について
- "/" の代わりに ">" または空白を使う
- ">" は親タグ直下のタグを指定したいときに使う
- xpathで言う//h3/a
- h3 直下に a が来る
- 空白はタグ間に任意のタグを許容したいときに使う
- xpathで言う//h3//a
- h3 と a 間に任意のタグを許容する
- 属性(例えばidの値とか)を指定するときは "タグ名[属性名=xxx]" を使う
- class 属性の包含を指定するときは タグ名.class名 を使う
- タグ名[属性名=xxx] は完全一致する必要がある
- テキストから検索したいときは タグ名:contains("テキスト") を使う
- html.at('a:contains("Ruby")')
- 引数は複数指定できる
- 戻り値について
- NodeSet を返す
- 結果が無ければ空の NodeSet
補足
- 便利メソッド
- search("検索")
- 引数に XPath または CSS を指定できる
- 戻り値として、NodeSetを返す、無ければ空の NodeSet
- at("検索")
- 引数に XPath または CSS を指定できる
- 戻り値として、最初のノードの Element を返す、無ければ nil
- ChromeやFirefox(Firebug)で指定タグのパスが抽出できる
- F12
- 基本的にCSSを使おう
- XPathよりも簡潔で明確なクエリを作成できることが多いらしいので
その他
ノードを指定して任意の相対ノードにアクセスできる
- child
- 最初の子ノードが Element で返る
- children
- 子ノード(Element)の配列が返る
- previous_sibling、previous
- 兄ノードが Element で返る
- 手前にあるノード?
- next_sibling、next
- 弟ノードが Element で返る
- 後にあるノード?
- parent
- 親ノードが Element で返る
- ancestors
- 祖先ノード(Element)の配列が返る
ノード情報の参照
ノードに関する情報を取得するためのメソッド
基本的に Nodeset と Element 両方に対して使えるが一部例外ありドキュメントの参照
Nokogiri::XML::Node と NodeSet で基本的には同じ API が使えるが、一部のメソッド(content、to_str)がない
NodeSet の場合、リスト内の全てのノードに対してメソッドを適用した結果を返してくれる
- to_s
- ノード全体のテキストをつなぎ合わせた文字列が返る
- content、text、inner_text、to_str
- 子孫ノードのテキスト内容をつなぎ合わせた文字列が返る
- エイリアス多
- to_html、 to_s
- ノード全体HTMLをつなぎ合わせた文字列が返る
- 本人ノードも含めた inner_html
- to_xhtml、 to_xml
- ノード全体を XHTML をつなぎ合わせた文字列が返る
- inner_html
- 子孫ノードの HTML をつなぎ合わせた文字列が返る
属性情報の参照
通常の Ruby ハッシュのように扱える
Element に対して使う
- ["属性名"]、get_attribute("属性名")
- 属性値を文字列で返す、無ければ nil
- key?("属性名")、has_attribute?("属性名")
- 属性の有無をtrue/falseで返す
- keys
- 属性名を文字列の配列で返す
- values
- 属性値を文字列の配列で返す
- attributes
- 属性名と属性オブジェクトのハッシュを返す
- attribute("属性名")
- 属性オブジェクトを返す
- each { |k,v| }
- 属性名と属性値を返しブロック呼び出し
おまけ
Wikipedia に今日の出来事を記載しているページがあるので取ってこよう
require 'open*uri' require 'nokogiri' require 'wikipedia' Wikipedia.Configure { domain 'ja.wikipedia.org' path 'w/api.php' } html = Nokogiri::HTML.parse(open('https://ja.wikipedia.org/wiki/Wikipedia:%E4%BB%8A%E6%97%A5%E3%81%AF%E4%BD%95%E3%81%AE%E6%97%A5')) events = html.css('div[id="mw*content*text"] > div[class="mw*parser*output"] > div > ul > li') random = rand(events.count) event = events[random] puts '今日は...' puts event.text puts '' event.children.map do |ele| if ele[:href] page = Wikipedia.find(ele[:href]) puts "#{ele.text}..." puts page.summary puts '' end end今日は... フランシスコ・ザビエルの船が鹿児島沖に到達(1549年 * 天文18年7月3日) フランシスコ・ザビエル... フランシスコ・デ・ザビエル(スペイン語: Francisco de Xavier または Francisco de Jasso y Azpilicueta, 1506年頃4月7日 * 1552年12月3日)は、スペインのナバラ王国生まれのカトリック教会の司祭、宣教師。イエズス会の創設メンバーの1人。バスク人。 ポルトガル王ジョアン3世の依頼でインドのゴアに派遣され、その後1549年(天文18年)に日本に初めてキリスト教を伝えたことで特に有名である。また、日本やインドなどで宣教を行い、聖パウロを超えるほど多くの人々をキリスト教信仰に導いたといわれている。カトリック教会の聖人で、記念日は12月3日。 1549年... 1549年(1549 ねん)は、西暦(ユリウス暦)による、平年。 天文... 天文(てんぶん、てんもん)は、日本の元号の一つ。享禄の後、弘治の前。1532年から1555年までの期間を指す。この時代の天皇は後奈良天皇。室町幕府将軍は足利義晴、足利義輝。 7月3日... 旧暦7月3日(きゅうれきしちがつみっか)は旧暦7月の3日目である。六曜は先負である。誰得…
余談
システム管理者の日とかプログラマーの日とかあるんだ、知らなかった
まとめ
- 当たり前の話ではあるけど専用のクライアントがあるならそれを使う
- 先に紹介したので言うと、Wikipedia は専用の gem があったけど、ページの取得が上手くいかなかったので nokogiri を使った
- ツリーを探索しているイメージを持つとわかりやすい
- 今自分が操作しているのが NodeSet なのか Element なのか知っていた方が混乱なさそう
- CSS や Xpath は NodeSet を返すが、at や child など Element を返す
- というか、DOM解析について言えば JQuery
- 大抵のケースでは最初のサンプルで事足りそう
- 取得部分の細かい指定が必要な場合には children 等を使う
- CSS で検索して NodeSet を取ってきて、それを each で回して各要素の情報を取得する
- 例えば、あるノード配下の全ての子ノードが欲しいなど
- テキストから検索するのは結構使いそう
- CSSで書くと html.at('a:contains("Ruby")') など


- 投稿日:2020-11-24T19:31:04+09:00
Refileの使い方
ImageMagickをインストール
本番サーバーとか開発環境に
image-magickがないと動かないのでインストールしておく。インストールされてるか確認$ convert -version #以下のようにVersion: ImageMagick バージョン名が表示されていればOK Version: ImageMagick 7.0.10-38 Q16 x86_64 2020-11-16 https://imagemagick.org Copyright: © 1999-2020 ImageMagick Studio LLC License: https://imagemagick.org/script/license.php Features: Cipher DPC HDRI Delegates (built-in): jng jpeg png tiff zlibインストール方法(Cloud9の場合)$ sudo yum -y install libpng-devel libjpeg-devel libtiff-devel gcc $ cd ~ $ wget http://www.imagemagick.org/download/ImageMagick.tar.gz $ tar -vxf ImageMagick.tar.gz $ ls $ cd ImageMagick-x.x.x-xx $ ./configure $ make $ sudo make installGemをインストール
Gemfilegem "refile", require: "refile/rails", github: 'manfe/refile' gem "refile-mini_magick"$ bundle install画像データを保存するカラムを追加
Userモデルに
thumbnailというカラム(サムネイル画像名を保存するカラム)を追加します。$ rails g migration AddThumbnailToUser thumbnail_id:stringclass AddThumbnailToUser < ActiveRecord::Migration[5.2] def change add_column :users, :thumbnail_id, :string end end$ rails db:migratemodelを修正
追加したカラム名から
_idを抜いた部分をattachmentとして設定app/models/user.rbclass User < ApplicationRecord attachment :thumbnail # 追加 endファイルアップロードのform
<%= f.attachment_field :thumbnail %>でフォームの画像アップロード部分を設置<%= form_with model: @user, local: true do |f| %> <div> <%= f.label :name %> <%= f.text_field :name, class: 'form-control' %> </div> <div> <%= f.attachment_field :thumbnail %> <!-- 追加 --> </div> <%= f.submit class: 'btn btn-success' %> <% end %>strong_parametersを修正
app/views/controllers/users_controller.rbclass UsersController < ApplicationController private def user_params params.require(:user).permit(:name, :thumbnail) # thumbnail_idではないので注意 end end画像を出力
<%= image_tag attachment_url(@user, :thumbnail, :fill, 100, 100) %>Runtime Errorが表示された場合
エラー画面内に表示されている
Refile.secret_key = 'hogehogeeeeee'をconfig/initializers/application_controller_renderer.rbに貼り付けてサーバーを再起動。
- 投稿日:2020-11-24T19:08:07+09:00
[ruby] shoulda-matcherでハマって仕事が進まなかった話
こちらはVISITS advent calendar 2020 7日目の記事です。
7日目と言いつつ、参加者少数につき土日お休みにさせてもらったので、7つ目ではありませんが、、RSpecでmodel specを書くときによくお世話になるshouldla-matcherで最近少しハマったので、その話を共有しておこうと思います。
仕事が進まないことはよくあるので、ここでは特に触れません。むしろ触れないでください。TL;DR
shoulda-matcherのvalidate_presence_ofなどは、テストを行う際対象カラムにnilや空文字に設定して挙動を確認する仕様になっているようです。
このため、validate_presence_ofに指定したカラムを特定の値に固定したり、今回自分がハマったように親の外部キーのような存在する前提のカラムにしてしまうと、予期せぬ挙動が発生するので注意が必要になります。
このため、もしvalidate_presence_ofのようなvalidatorを使ってテストする際は、nilが来ないはずでもnilが来るケースがあると思って対応しておくと良いと思います。
背景
今回親子関係にあるモデルで、子供側に親の値を条件にvalidationを入れる必要が出てきました。
テストとコードを実装後、既存のテストも同時に実行してみたところ、なぜかshoudla-matcherのテストで一部だけ落ちることに。テストのログを見る限り、追加した親モデルがnilになってるせいで落ちてるんですが、きちんと設定しているしそもそも他のカラムの同じvalidateは通ってるし、なんなんこのバグ、、みたいな感じになりました。
具体例
今回はRailsにRSpecを導入して実験してみます。
今回は親子関係のモデルで発生したので、具体例として
ParentとChildという2つのモデルで説明してみようと思います。テーブル構成は以下のようなイメージです。
class CreateParents < ActiveRecord::Migration[6.0] def change create_table :parents do |t| t.string :first_name, null: false t.string :last_name, null: false t.timestamps end end endclass CreateChildren < ActiveRecord::Migration[6.0] def change create_table :children do |t| t.references :parent, index: false t.integer :number, null: false t.string :first_name, null: false t.string :last_name, null: false t.timestamps t.index [:parent_id, :number], unique: true end end end
ParentとChildは1:Nな関係で、Childには必ずparent_idが存在する想定です。(optionalではない)
numberは第何子に相当するかを表すカラムだと思ってください。
unique関連でもテストが落ちたので、[parent_id, number]というカラムでuniqueになるような想定にしました。また、
Childのvalidationの条件にParentの値を用いて今回の事象に遭遇したため、last_nameカラムが一致するかどうかをカスタムのvalidationとして追加してみます。parent.rbclass Parent < ApplicationRecord has_many :children, dependent: :destroy endchild.rbclass Child < ApplicationRecord belongs_to :parent validates :parent_id, presence: true validates :parent_id, uniqueness: { scope: [:number] } validates :number, presence: true validates :number, uniqueness: { scope: [:parent_id] } # parent_id側でチェックしているが確認のため validate :last_name_should_be_the_same_as_parent def last_name_should_be_the_same_as_parent errors.add(:last_name, :should_be_the_same_as_parent) unless last_name == parent.last_name end end実行するテストは以下の通りです。
child_spec.rbrequire 'rails_helper' RSpec.describe Child, type: :model do let(:parent) { create :parent, last_name: 'Tanaka' } subject(:child) { build :child, parent: parent, last_name: 'Tanaka' } describe 'associations' do it { should belong_to(:parent) } end describe 'validations' do it { should validate_presence_of(:parent_id) } it { should validate_presence_of(:number) } it { should validate_uniqueness_of(:parent_id).scoped_to(:number) } it { should validate_uniqueness_of(:number).scoped_to(:parent_id) } end end通常はsubjectは設定しなくてもいいのですが、今回
last_nameでの比較が必要なため、factory_botでmodelを生成してvalidationを実行します。この状態でテストを実行すると、
$ rspec -fd Child associations is expected to belong to parent required: true (FAILED - 1) validations is expected to validate that :parent_id cannot be empty/falsy (FAILED - 2) is expected to validate that :number cannot be empty/falsy is expected to validate that :parent_id is case-sensitively unique within the scope of :number is expected to validate that :number is case-sensitively unique within the scope of :parent_id (FAILED - 3) : Failed examples: rspec ./spec/models/child_spec.rb:8 # Child associations is expected to belong to parent required: true rspec ./spec/models/child_spec.rb:12 # Child validations is expected to validate that :parent_id cannot be empty/falsy rspec ./spec/models/child_spec.rb:15 # Child validations is expected to validate that :number is case-sensitively unique within the scope of :parent_idということで、3つほど落ちました。
エラーはいずれもNoMethodError: undefined method `last_name' for nil:NilClass # ./app/models/child.rb:13:in `last_name_should_be_the_same_as_parent'ということで、
parentがnilになってるようです。
factory_botでもきちんと設定してるし、presenceもuniqueの方も全部落ちるならまだ分かるのに特定のものだけ落ちてるし、、で色々と混乱しました。試しに、デバッグログを追加してspec実行直前とエラー発生直前のchildを調べてみると...
child_spec.rb#validate_presence_of(it { Rails.logger.debug('== before validate_presence_of(:parent_id) ==') Rails.logger.debug(child.attributes) should validate_presence_of(:parent_id) }child.rb#last_name_should_be_the_same_as_parentdef last_name_should_be_the_same_as_parent logger.debug('== in last_name_should_be_the_same_as_parent ==') logger.debug(attributes) errors.add(:last_name, :should_be_the_same_as_parent) unless last_name == parent.last_name endlog/test.log== before validate_presence_of(:parent_id) == {"id"=>nil, "parent_id"=>50, "number"=>nil, "first_name"=>nil, "last_name"=>"Tanaka", "created_at"=>nil, "updated_at"=>nil} : == in last_name_should_be_the_same_as_parent == {"id"=>nil, "parent_id"=>nil, "number"=>nil, "first_name"=>nil, "last_name"=>"Tanaka", "created_at"=>nil, "updated_at"=>nil}spec実行前はparent_idが設定されていますが、validationの直前ではparent_idがnilになっていました。
validateの流れ
結論から言うと、shoulda-matcherのvalidate_presence_ofは内部的に、対象カラムに実際にnilや空文字を設定して、エラーが発生するかを確認している模様です。
このため、途中でエラーではなく例外が発生した場合、エラーが発生しなかったという扱いで落ちてしまうようでした。validate_presence_ofの場合
validate_presence_ofのケースでは、matches?の中で、disallowedなvaluesに対して想定通りエラーが変えるかを以下のような感じで検証していました。
lib/shoulda/matchers/active_model/validate_presence_of_matcher.rb#L142def matches?(subject) super(subject) possibly_ignore_interference_by_writer if secure_password_being_validated? ignore_interference_by_writer.default_to(when: :blank?) disallowed_values.all? do |value| disallows_and_double_checks_value_of!(value) end else (!expects_to_allow_nil? || allows_value_of(nil)) && disallowed_values.all? do |value| disallows_original_or_typecast_value?(value) # ここが実行される end end end
disallows_original_or_typecast_value?の内部では、disallow_value_matcherという失敗ケースのmatcherを作って、テストがコケるかをチェックしていました。
以下のmessageの引数には:blankが渡ってくるため、matcherが:blankを返すようであれば想定通り、といった挙動のようです。lib/shoulda/matchers/active_model/validation_matcher.rbdef disallows_value_of(value, message = nil, &block) matcher = disallow_value_matcher(value, message, &block) run_allow_or_disallow_matcher(matcher) endこの過程で、modelのerrorsに対して値がセットされるようであれば問題ないのですが、先程のように例外が発生してしまうと途中終了してしまいます。
validate_uniqueness_of
validate_uniqueness_ofはmatchesの条件が多いですが、今回は
matches_uniqueness_with_scopes?で引っかかりました。lib/shoulda/matchers/active_record/validate_uniqueness_of_matcher.rb#L336def matches?(given_record) @given_record = given_record @all_records = model.all matches_presence_of_attribute? && matches_presence_of_scopes? && matches_scopes_configuration? && matches_uniqueness_without_scopes? && matches_uniqueness_with_case_sensitivity_strategy? && matches_uniqueness_with_scopes? && matches_allow_nil? && matches_allow_blank? ensure Uniqueness::TestModels.remove_all end end内部では
setting_next_value_forというメソッドでscope(ここではparent_id)に対して今の設定値の次の値(100なら101など)を設定します。
おそらく重複のテストのためにかぶらないはずの次の値を設定することで、uniqueのチェックを行う模様です。最終的に追えなかったので憶測ではありますが、発行されたクエリを見る限り次の値の親を取得しようとしていた(が当然数値的に生成しただけでDBには存在しない)ため、
parentがnilとなって同じ箇所で例外が発生したようです。lib/shoulda/matchers/active_record/validate_uniqueness_of_matcher.rb#L775def setting_next_value_for(scope) previous_value = @all_records.map(&scope).compact.max next_value = if previous_value.blank? dummy_value_for(scope) else next_value_for(scope, previous_value) end set_attribute_on_new_record!(scope, next_value) yield ensure set_attribute_on_new_record!(scope, previous_value) endbelong_to
今回はvalidationではないbelong_toのassocication側でも例外となってコケていました。
belong_toの方では以下のようなmatchを当てる模様です。引っかかっていたのは最後のsubmatchers_match?のところです。
lib/shoulda/matchers/active_record/association_matcher.rb#L1148def matches?(subject) @subject = subject association_exists? && macro_correct? && validate_inverse_of_through_association && (polymorphic? || class_exists?) && foreign_key_exists? && primary_key_exists? && class_name_correct? && join_table_correct? && utosave_correct? && index_errors_correct? && conditions_correct? && validate_correct? && touch_correct? && submatchers_match? end
belong_toのshoulda-matcherを用いた場合、optionalをつけないとさきほどのsubmatcherの方でrequired_matcherが指定されますが、これによってparentに対してnilがdisallowされるかチェックされるような形になります。
この場合もmatcherの途中で例外が発生するため落ちる模様です。lib/shoulda/matchers/active_record/association_matchers/required_matcher.rb#L6def initialize(attribute_name, required) @attribute_name = attribute_name @required = required @submatcher = ActiveModel::DisallowValueMatcher.new(nil). for(attribute_name). with_message(validation_message_key) @missing_option = '' endじゃあどうするか?
単純に例外を防げばいいので、実装上問題なければnilガードしておくのが良さそうです。
def last_name_should_be_the_same_as_parent errors.add(:last_name, :should_be_the_same_as_parent) unless last_name == parent&.last_name end
parent_idにnilがセットされると当然このテストは通らないのですが、あくまでテスト対象となっているカラムでエラーが出るのか確認しているため、例外にならなければ大丈夫のようです。ただテストに合わせて実装を変えることにはなるので、実装方針次第ではテストを省略することや別の方法でテストすることを考えたり、さらには設計自体が悪い可能性もあるのでそこを考えてもよいかもしれません。
もし別の手段で回避する方法をご存知の方いらっしゃったらご教示いただきたいですm(__)m
- 投稿日:2020-11-24T18:18:56+09:00
このプログラムの考え方が知りたい...[Ruby]
ひな祭り
問題
あなたが持っている 10 体の人形を "A", "B", "C", "D", "E", "F", "G", "H", "I", "J" で表します。ひな壇の各段 (計 3 段) に並べる人形の数が与えられるので、各段にならべる人形の記号を改行区切りで出力してください。人形は必ずもとの A, B, C, ... の順番で並べます。
例)
各段にならべる人形の数: 2, 3, 5
→ 人形の並べ方:
AB
CDE
FGHIJ入力される値
入力は以下のフォーマットで与えられます。
h_1 h_2 h_3
ひな壇の 1 段目、2 段目、3 段目に並べる人形の数を表す整数 h_1, h_2, h_3 がこの順に半角スペース区切りで与えられます。入力は 1 行となり、末尾に改行が 1 つ入ります。期待する出力
ひな壇への人形の並べ方を以下の形式で出力してください。
s_1
s_2
s_3
ひな壇の 1 段目、2 段目、3 段目に並べる人形を表す文字列 s_1, s_2, s_3 をこの順に改行区切りで出力してください。s_i (1 ≦ i ≦ 3) は i 段目に並べる人形の記号をアルファベット順に結合した文字列です。
入力例1
2 3 5
出力例1
AB
CDE
FGHIJ入力例2
1 1 8
出力例2
A
B
CDEFGHIJ私の考え方
与えられる数値を
a = gets.split(" ").map(&:to_i)で 2 3 5 というように切り離す。
次にarray = {"A", "B", "C", "D", "E", "F", "G", "H", "I", "J" }としてsliceメソッド等で抜き出すのかなと思ったがそもそもこの時点で
Main.rb:3: syntax error, unexpected ',', expecting => array = {"A", "B", "C", "D", "E", "F", "G"... ^ Main.rb:3: syntax error, unexpected ',', expecting end-of-input array = {"A", "B", "C", "D", "E", "F", "G", "H"... ^というエラーが出る。
繰り返し文でputsするのかなとも思ったが、「AB」ときて「CDE」というように続きから出力する方法がわからない。
この問題はいろんなパターンがあると思うが、そもそもプログラミング脳になっていないので解けなかった。悔しい。
どなたか分かる方いらっしゃいましたらアドバイスください。。。以上!
- 投稿日:2020-11-24T17:10:32+09:00
initializeメソッドにて行う最もベーシックな初期化
まずinitializeメソッドとは、Rubyで
クラス名.newでインスタンスを生成したときに呼び出されるメソッドで、インスタンスの生成と同時に実行したい処理を記述します。
このとき、使用するインスタンス変数は全てこちらで初期化が必要です。initializeメソッドの書き方
例えば、このように
初期化の時点で代入してしまうものに関しては分かりやすいと思います。class ClassName def initialize @colors = ["black", "white", "gray", "red", "blue"] # 初期化の時点で値を代入している end def choose_color @colors.sample end endただ、このように
後から代入することが決まっていて、初期化時点では空の値の場合はどうしたら良いのか↓class ClassName def initialize # どう書けば良い? end def write_review puts "タイトルを入力してください" @title = gets.chomp # 初期化の時点では空、write_reviewメソッドを呼び出してから値を代入する end endこうします↓
class ClassName def initialize @title = "" end def write_review puts "タイトルを入力してください" @title = gets.chomp end endここから言えることはインスタンスを生成した際に代入できるのであればそうでよいが、実行後に値が代入されるのであれば、もっともベーシックな リテラルで初期化をする必要があるということです。
基本形は以下です。class ClassName def initialize @string = '' @integer = 0 # or nil end end
- 投稿日:2020-11-24T16:55:12+09:00
【Rails】N+1問題 (Bullet で検出し includes して対策)
はじめに
未経験からWeb系エンジニアへの転職を目指し、ポートフォリオ(投稿アプリ)を作成中です。
今回は、ポートフォリオにN+1問題を対応させてみたので、まとめてみました!前提
- Ruby2.7.0
- Ruby on Rails6.0.3
- MySQL8.0
N+1問題とは
- 必要以上にSQLの処理が行われて、システムのパフォーマンスが低下してしまうこと。
- レスポンスが遅く、ユーザビリティの低いサービスの原因の多くは、SQL周りにあることが多いらしい。
- SQLの発行回数を減らし、パフォーマンスを上げることが大事。
N+1問題の検出
まずは、N+1問題を検出するためBulletというgemを試してみる。
Gemfilegroup :development, :test do gem 'bullet' endターミナル$ bundleBulletは
config/environments/development.rbに設定を追加しないと動作しないのでファイルを編集する。config/environments/development.rbRails.application.configure do config.after_initialize do Bullet.enable = true # Bulletを有効化 Bullet.alert = true # JavaScriptのポップアップアラートを有効化 Bullet.bullet_logger = true # Rails.root/log/bullet.logに出力 Bullet.console = true # ブラウザのconsole.logに出力 Bullet.rails_logger = true # Railsのログに結果を出力 Bullet.add_footer = true # ページの左下に結果を表示 end endいざ、確認!
ローカル環境で投稿一覧画面にアクセスしてみると、N+1問題が検出され、この問題を解決するためには
.includes([:user])を追加すればよいとある。ターミナルuser: hako GET /posts/index USE eager loading detected Post => [:user] Add to your query: .includes([:user]) Call stack /Users/hako/portfolio/cafe_app/app/views/posts/index.html.erb:48:in `block in _app_views_posts_index_html_erb___2990704399900080110_90940' /Users/hako/portfolio/cafe_app/app/views/posts/index.html.erb:5:in `_app_views_posts_index_html_erb___2990704399900080110_90940'N+1問題の対策
そこで、
app/controllers/posts_controller.rbに.includes([:user])を追加してみる。app/controllers/posts_controller.rbclass PostsController < ApplicationController def index # @posts = Post.page(params[:page]).per(6).order(:created_at => :desc) # 編集前 @posts = Post.includes([:user]).page(params[:page]).per(6).order(:created_at => :desc) # 編集後 end end再アクセスしてみるとBulletによる警告が表示されなくなった!
今度は投稿へのコメントにアクセスしてみると、以下のメッセージが表示されたので、ターミナルuser: hako GET /posts/48 USE eager loading detected Comment => [:user] Add to your query: .includes([:user]) Call stack /Users/hako/portfolio/cafe_app/app/views/comments/_comment.html.erb:3:in `block in _app_views_comments__comment_html_erb__2537338689005093815_102800' /Users/hako/portfolio/cafe_app/app/views/comments/_comment.html.erb:2:in `_app_views_comments__comment_html_erb__2537338689005093815_102800' /Users/hako/portfolio/cafe_app/app/views/posts/show.html.erb:65:in `_app_views_posts_show_html_erb__3096142757258343957_102780'同様に、
.includes([:user])を追加。app/controllers/posts_controller.rbclass PostsController < ApplicationController def show @user = @post.user # @comments = @post.comments # 編集前 @comments = @post.comments.includes([:user]) # 編集後 @comment = @post.comments.build end endN+1問題が検出されなくなるまで、メッセージが表示される箇所に一つずつincludesを追加。
なお、Bulletを使っている中でN+1の警告を無視したい場合は、ホワイトリスト形式でconfig/initializer/bullet.rbに登録しておけば良いらしい。
今後いろいろ試してみたい。終わりに
以上の対策をした後、本番環境にアクセスしてみるとパフォーマンスが上がってびっくり!動作が早い早い!!
ユーザー側に立つと、パフォーマンスが遅いとそれだけでストレスだし、そのサービスを使いたいと思えないもの。
今後は、SQLの実行回数をいかに減らせるかを意識してコードを書いていこうと思う!
引き続き、SQL周りの知識も深めていきたい。初学者のため、理解不足な点が多々あると思います。気になった点やアドバイスなどありましたら、教えていただけますと幸いです!
参考サイト
・ポートフォリオのバージョンアップ2020 7/2 (N + 1 問題)
- 投稿日:2020-11-24T16:33:37+09:00
ドリル_Ruby問題 27 if,else問題 - 解説
問題
正の整数を入力します。その整数が、
10の倍数(10,20,30...)からの差が2以内であるときはTrue
それ以外はFalse
と出力するメソッドを作りましょう。出力例:
near_ten(12)→True near_ten(17)→False near_ten(19)→True模範解答
def near_ten(num) quotient = num % 10 if quotient <= 2 || quotient >= 8 puts "True" else puts "False" end end解説
「10の倍数からの差」を考えるためには、一の位の値に着目します。すなわち、一の位が「0,1,2,8,9」のどれかであれば「10の倍数からの差が2以内」と判断することができます。
num(二桁の値) % 10とすることにより一の位を求めることができます。
Rubyにおける%についてはドリル21解説でも説明しております。
quotient <= 2について、
quotientは2以下であるということから、
この条件にあうものは0,1,2になります。quotient >= 8について、
quotientは8以上であるということから、
この条件にあうものは8,9になります。よって
if quotient <= 2 || quotient >= 8こちらの条件式はquotientは2以下または8以上である。
ことからif文の中に入ることができる値は0,1,2,8,9のみとなります!
- 投稿日:2020-11-24T15:43:16+09:00
【脱初心者!!】Railsでmodelにスコープを定義する!
はじめに
最近までwhereやorderはついついcontrollerに書いてしまうことが多かったのですが、modelで定義した方がメリットが多いので今回はmodelにスコープを定義するやり方を解説していきます!
modelに定義するメリット
- controllerをみやすくシンプルにできる(Controllerを太らせないことが脱初心者への第一歩です!)
- modelに書くことによりテストが書きやすくなる!(RailsでいうとRspecのmodel_specでテストがかけますね!)
modelのスコープって何?
modelのスコープとは複数のクエリをまとめたメソッドのことです!!
where, order, join, limit, distinct ...etc
などでまとめることですね!さっそくやってみる
今回は予約テーブルのreservationsコントローラーを設定しています
reservaiontsテーブル
title(string)とstart_time(datetime)のカラムがあります。reservations.controller.rbclass ReservationsController < ApplicationController def index #ページネーションをつかっています(Reservation.allだと思ってください) @reservations = Reservation.paginate(page: params[:page]) #全ての予約からstart_timeが今日より後の予約を 降順で表示する @reservations_index = @reservations.where("start_time > ?", Date.today).order(start_time: :desc) endご覧の通り少しコントローラーが長くなり読みづらいです。
これをmodelに定義してみます。
reservation.rbclass Reservation < ApplicationRecord scope :future_reservations, -> { where("start_time > ?", Date.today).order(start_time: :desc) }解説するとscopeでまず定義しひとまずfuture_reservationsでメソッドを定義します。
その後はcontrollerの記述をリファクタリングするだけです!!ちなみに
reservation.rbscope :future_reservations, -> do where("start_time > ?", Date.today).order(start_time: :desc) endコードが長くなる場合はこちらの方が綺麗なので覚えておきましょう!!
reservations.controller.rbdef index @reservations = Reservation.paginate(page: params[:page]) @reservations_index = @reservations.future_reservations end最後にcontrollerにメソッドを書いてすっきりさせましょう!
お疲れ様でした!!!
- 投稿日:2020-11-24T14:53:11+09:00
[Rails]フォロー機能実装について
Railsでのフォロー機能実装に手間取ったので、
自分が理解した範囲で手順を書いていく。※プログラミング初心者のため、内容に不備や間違っている箇所があるかもしれません。
自分用のメモとして残していますが、もし不備等あればご指摘いただければと思います。開発環境
Ruby 2.6.3
Rails 5.2.4前提機能
ログイン機能(devise)
実装の流れ
① 中間テーブルを作成する
② Userモデル同士を参照するアソシエーションを記述する
③ follow、unfollowメソッドを定義する
④ フォローボタンを作成、コントローラを記述する
① 中間テーブルを作成する
「フォローするユーザ」と「フォローされるユーザ」を取得する際、
どちらも同じUserモデルを参照するため中間テーブルが必要になる。
中間テーブルについてはこちらの記事が大変わかりやすく、参考にさせていただいた。
https://qiita.com/morikuma709/items/1e389ddcdfc1102ef3f4まず、Relationshipモデルを作成
$ rails g model Relationshipcreate_relationship.rbclass CreateRelationships < ActiveRecord::Migration[5.2] def change create_table :relationships do |t| t.references :follower, foreign_key: true t.references :followed, foreign_key: true t.timestamps t.index [:follower_id, :followed_id], unique: true end end endカラムには「follower_id(フォローするユーザ)」と「followed_id(フォローされるユーザ)」を設定する。
どちらもUserモデルにて外部キーとして使用する(後述)のでreferencesで定義。
migrateを忘れずに。$ rails db:migrate② モデルの関連付け
relationship.rbclass Relationship < ApplicationRecord belongs_to :follwer, class_name: "User" belongs_to :follwed, class_name: "User" endここの書き方は単純。
先ほど設定した「follower_id」と「followed_id」の値からUsersテーブルのレコードを参照する。
ただ、「class_name: 'モデル名'」で参照するモデルを指定しなければいけないことに注意。続いてUserモデルを記述していく。
ここが個人的に一番混乱した。user.rb# フォローするユーザ has_many :active_relationships, class_name: "Relationship", foreign_key: "follower_id", dependent: :destroy # 自分がフォローしているユーザ has_many :followed_users, through: :active_relationships, source: :followed # フォローされるユーザ has_many :passive_relationships, class_name: "Relationship", foreign_key: "followed_id", dependent: :destroy # 自分をフォローしているユーザ has_many :following_users, through: :passive_relationships, source: :followerhas_manyに続くモデル名は新たに作成したもの。もちろんモデル自体は存在しない。
・フォローするユーザとフォローされるユーザを取得
今回はそれぞれ、「active_relationships」と「passive_relationships」とした。→active_relationshipsの場合
参照するモデルはRelationshipモデル(class_name: "Relationship")
さらに、値を参照するカラムは「follower_id」(foreign_key: "follower_id")・自分がフォローしているユーザと自分をフォローしているユーザ
こちらは「followed_users」と「following_users」とした。→followed_usersの場合
active_relationshipsユーザーからフォローされているユーザ
active_relationshipsを参照(through: :passive_relationships)
取得する値は「followed_id」(source: :followed)③ メソッドを定義する
Relationshipsコントローラのアクション内で使用するメソッドを定義する。
場所はUserモデル。user.rbdef follow(user_id) active_relationships.create(followed_id: user_id) end def unfollow(user_id) active_relationships.find_by(followed_id: user_id).destroy end def following?(user) followed_users.include?(user) end④ フォローボタン作成、コントローラを記述
続いてコントローラ
relationships_controller.rbclass RelationshipsController < ApplicationController def create current_user.follow(params[:user_id]) redirect_to request.referer end def destroy current_user.unfollow(params[:user_id]) redirect_to request.referer end endviewファイルにフォローボタンを作成する
users/show.html.erb<% if current_user.following?(@user) %> <%= link_to 'フォロー中', user_relationship_path(@user), method: :delete, class:"btn" %> <% else %> <%= link_to 'フォローする', user_relationships_path(@user), method: :post, class:"btn" %> <% end %>@userにはparams[:id]が格納されている。
current_user.following?(@user)で@userがfollowed_usersに含まれているかを判断する。以上でフォロー機能の実装は完了。
時間がある時に一覧ページ作成の流れも追記しようと思う。自分がたどり着いた考え方まとめ
active_relationships = フォローするユーザ
followed_users = active_relationshipsにフォローされているユーザ
passive_relationships = フォローされるユーザ
following_users = active_relationshipsをフォローしている初めてフォロー機能に触れた時、「する」「される」の関係がわからなくなり、アソシエーションの中身がぐちゃぐちゃになっていた。解決するのにだいぶ時間を使ってしまった。
モデルの名義やそもそものやり方は人それぞれなので、自分が理解できるやり方を見つけるのが一番だと感じた。
- 投稿日:2020-11-24T14:32:38+09:00
Code PipelineでJekyllをビルドしてS3+CloudFrontで静的配信する
はじめに
概要
Civichat(https://civichat.jp)をJekyllに変更し、S3+CloudFrontで配信するために調べていた時に記事が昔すぎ(2016年とか...)or英語だったのでせっかくだしCodePipelineやり方をまとめようと思った次第です
Civichatとは:あなたにぴったりの助成金などの公共制度がLINEでわかるサービスです。
https://civichat.jp/
Jekyllってなに?
Jekyllは、個人、プロジェクト、または組織のサイト向けの、シンプルなブログ対応の静的サイトジェネレーターです。 GitHubの共同創設者であるTom Preston-WernerによってRubyで書かれ、オープンソースのMITライセンスで配布されています。 (by Wikipedia)
要するにRubyでできた静的サイト生成ツールですね(Markdownで記事が書ける)
最近だと@Nuxt/Content とか Gatsby.js みたいな感じですね。なぜAWS? なぜCode Pipeline? なぜCode Build?
多分 Netlify とか Vercel とかでもできるはず....
今回はAWSに請求まとめたりしたいのと、AWSを使いたかったのでAWSです。手順
すでにGitHub上にJekyllのコード自体が存在して、ローカルで
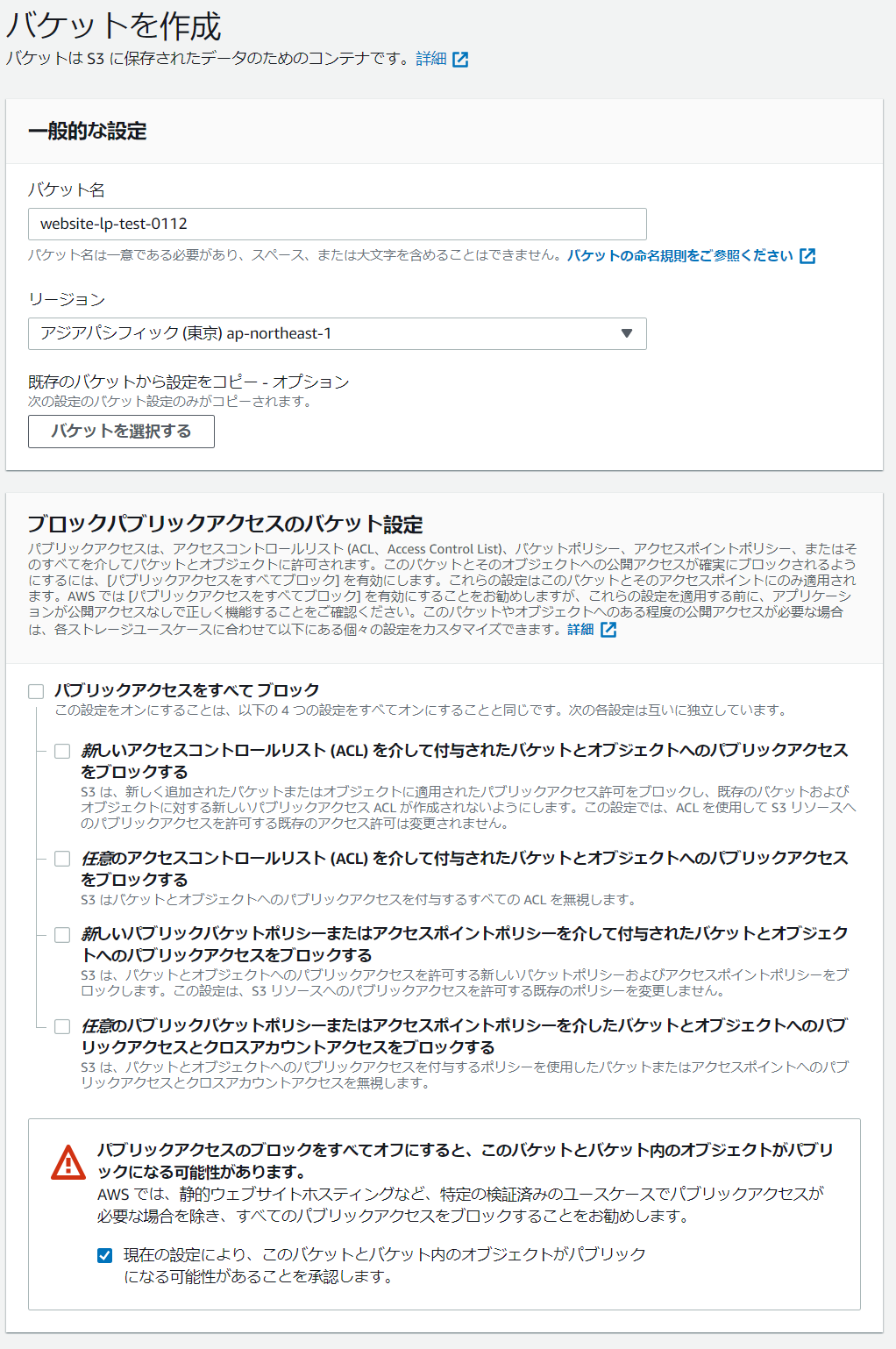
jekyll buildで_siteに出力されることを確認しているものとして書きますS3のバケットを用意する
普通にバケットを作りますが、パブリックアクセスのブロックは外しておきます。
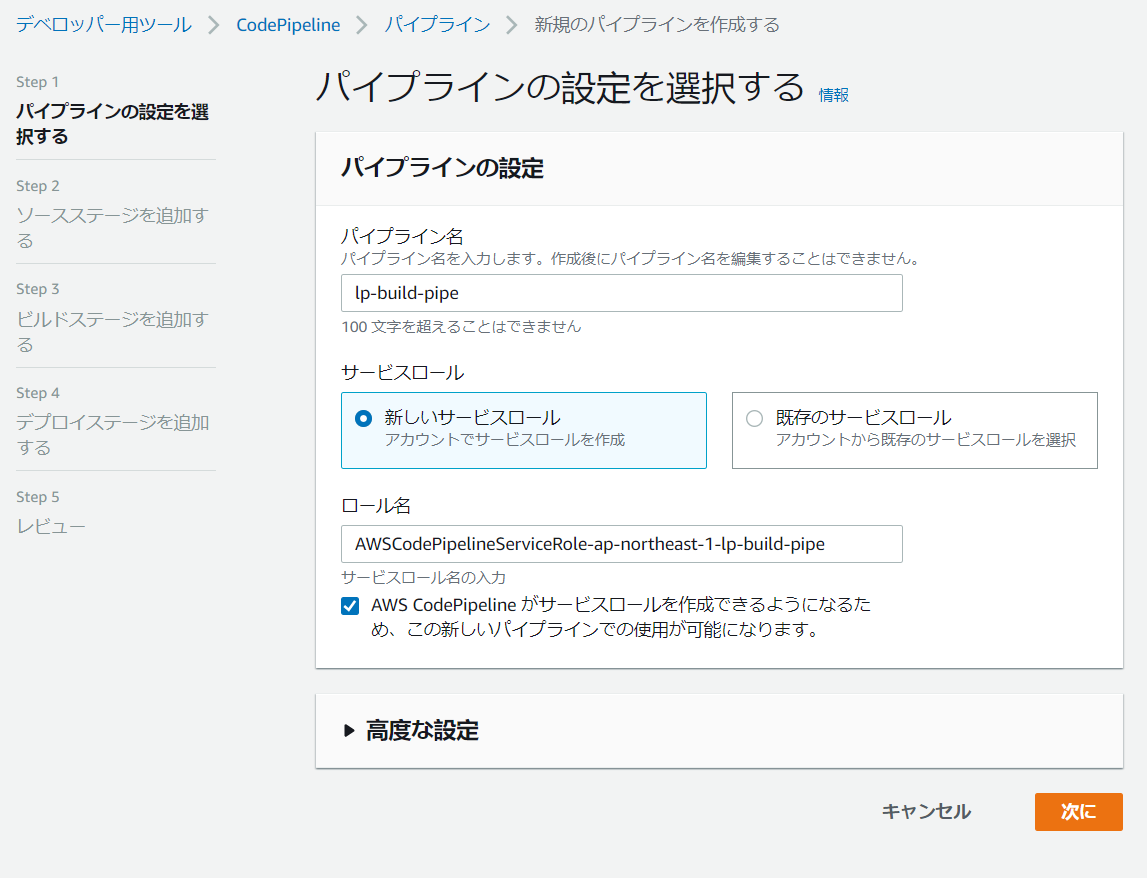
Code Pipelineでパイプラインを作る
パイプラインの設定
ここではパイプライン名を設定します
(このパイプライン名は変えられなくなるので注意)
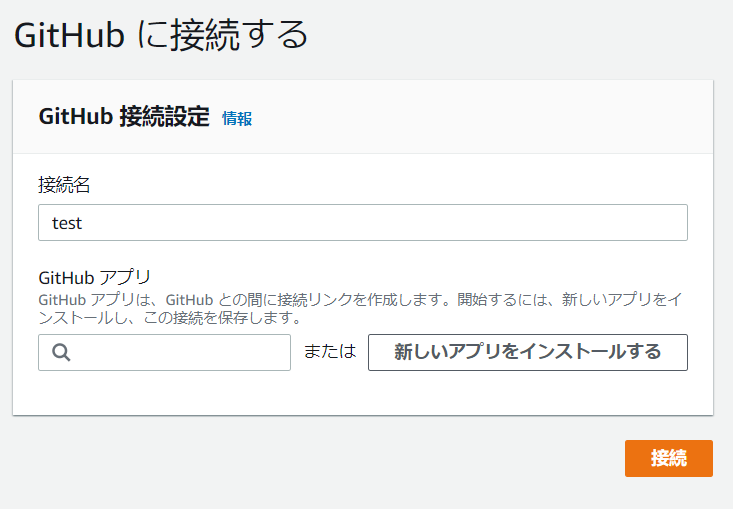
GitHubとの接続
今回はGithubのコミットをトリガーにするのでソースプロバイダーに
GitHub(バージョン2)を選択します。
GitHubに接続するをクリックし接続名を入力し、GitHubにAWS Connectorをインストールします
その後、インストールしたGitHubからリポジトリが取得できるようになるので、リポジトリ名とブランチ名を設定します。
(ねんのため塗りつぶしています)
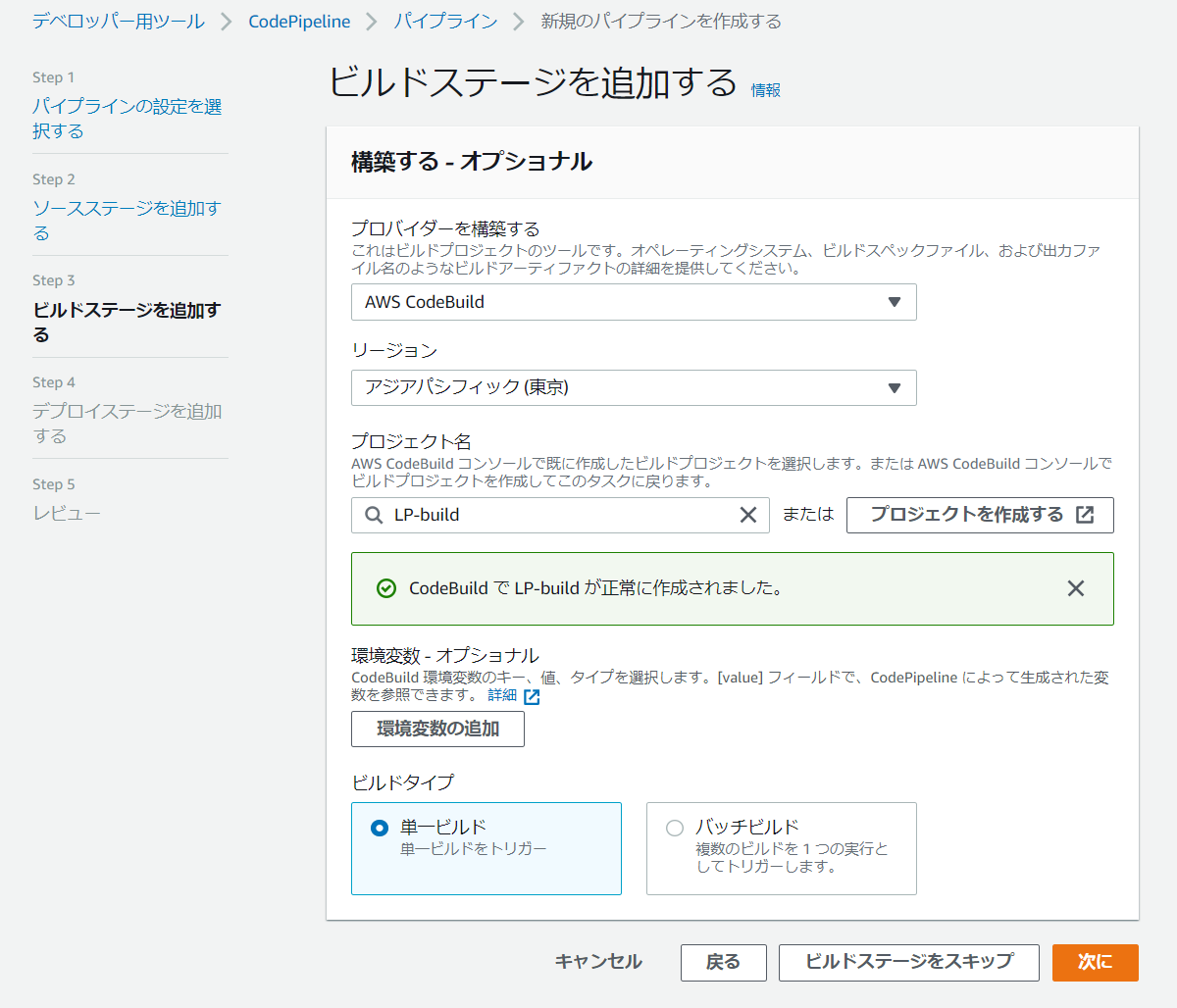
CodeBuildの設定
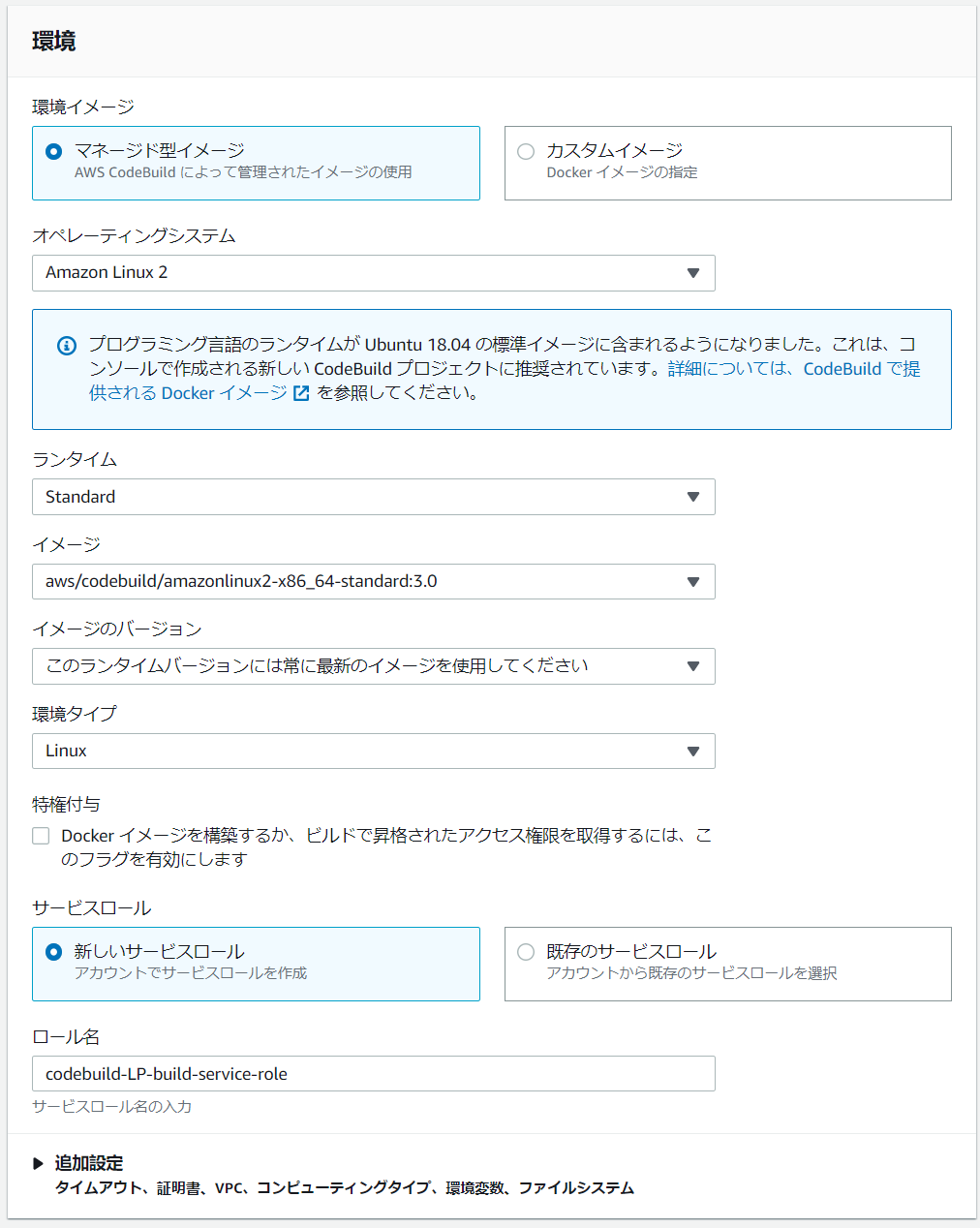
プロバイダにAWS CodeBuildを指定するとプロジェクトを作成するというボタンが出るのでクリック
するとCodeBuildの設定ページが表示されるので、以下のように設定します。プロジェクトの設定
プロジェクト名は適当に...
環境
せっかくなのでAmazon Linux 2を使いましょう
特権付与のチェックは今回は必要ないので外しておきます。
Buildspec
もしBuildspec.ymlをルートディレクトリに置けない場合にはその場所を指定してあげてください
バッチ設定・ログ設定
基本的にはそのままでよいはず
すべて設定が終わったらCodePipelineに戻るをクリックして戻ります。
戻るとAWSが自動的にプロジェクト名を入れてくれています(素敵!!)
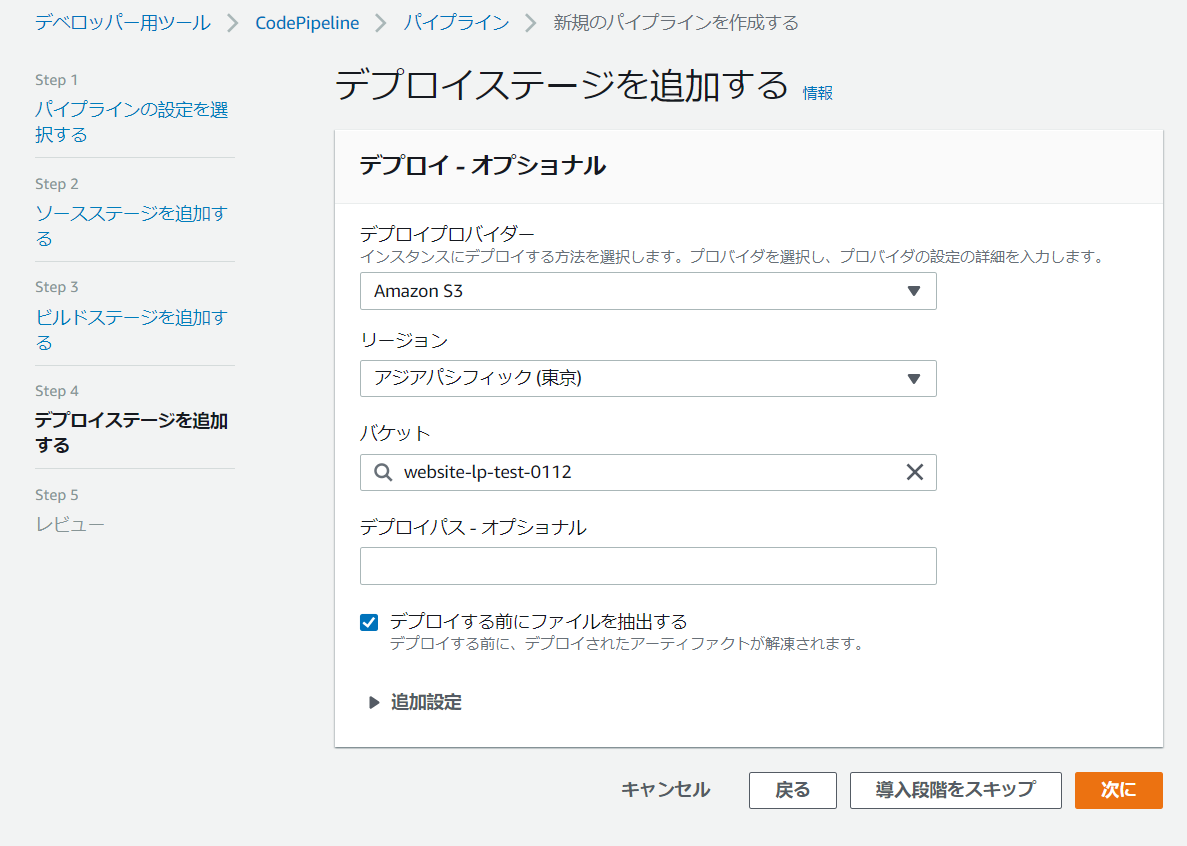
デプロイの設定
デプロイプロバイダにAmazon S3を選択するとバケットの選択ができるようになるので、初めに作成したバケットを選択します。
また、この時デプロイする前にファイルを抽出するにチェックをつけ忘れるとS3にビルドされたファイルがZipで出てしまうのでつけ忘れないようにしましょう
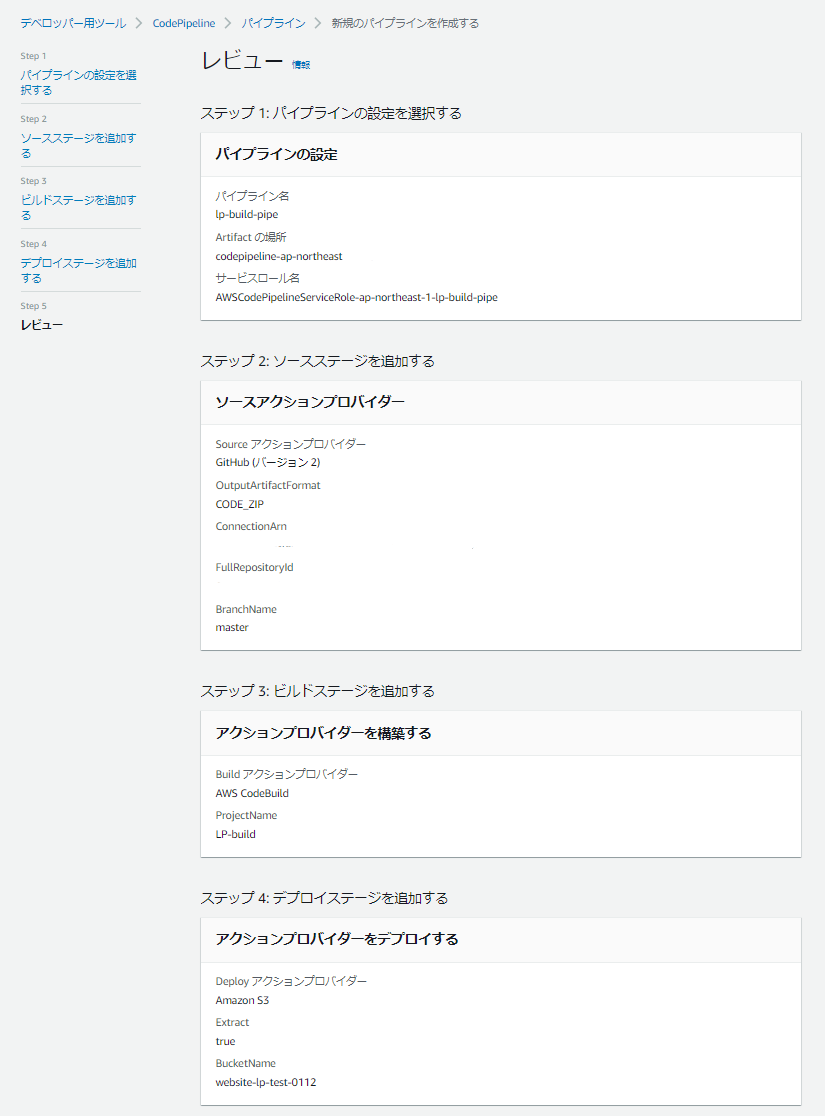
作成前の確認
いろいろまずそうなのは塗りつぶしてますが....
大事なのはFullRepositoryIdが正しいこと・ExtractがTrueであることなのでそれを確認しましょう
確認したらパイプラインを作成するをクリックしてパイプラインを作ります。
buildspec.ymlを作成する
今のままだとなんの処理をすればいいかをCodeBuildに伝えていないので、接続したリポジトリのルートディレクトリにbuildspec.ymlというのを作成し、以下の内容を記述します
buildspec.ymlversion: 0.2 phases: pre_build: commands: - export LC_ALL="en_US.utf8" - bundle install build: commands: - bundle exec jekyll build artifacts: base-directory: '_site' files: - '**/*'普通に
bundle installしてjekyll buildしているだけですが、
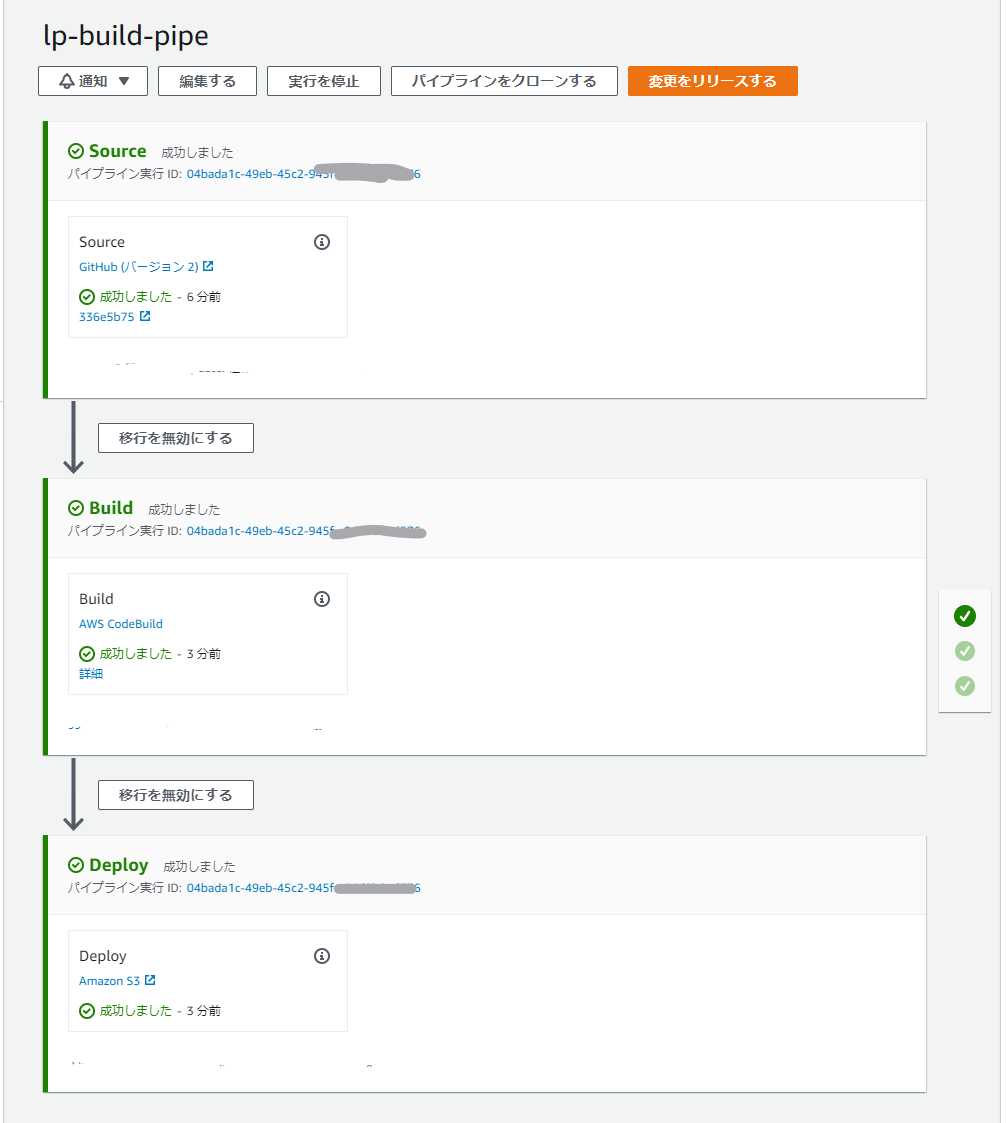
export LC_ALL="en_US.utf8でUTF-8に固定してあげないとjekyllがエラーを吐いてしまうのでお気をつけください。これらをCommit & Pushすると自動でPipelineが走って
このようになれば成功です!
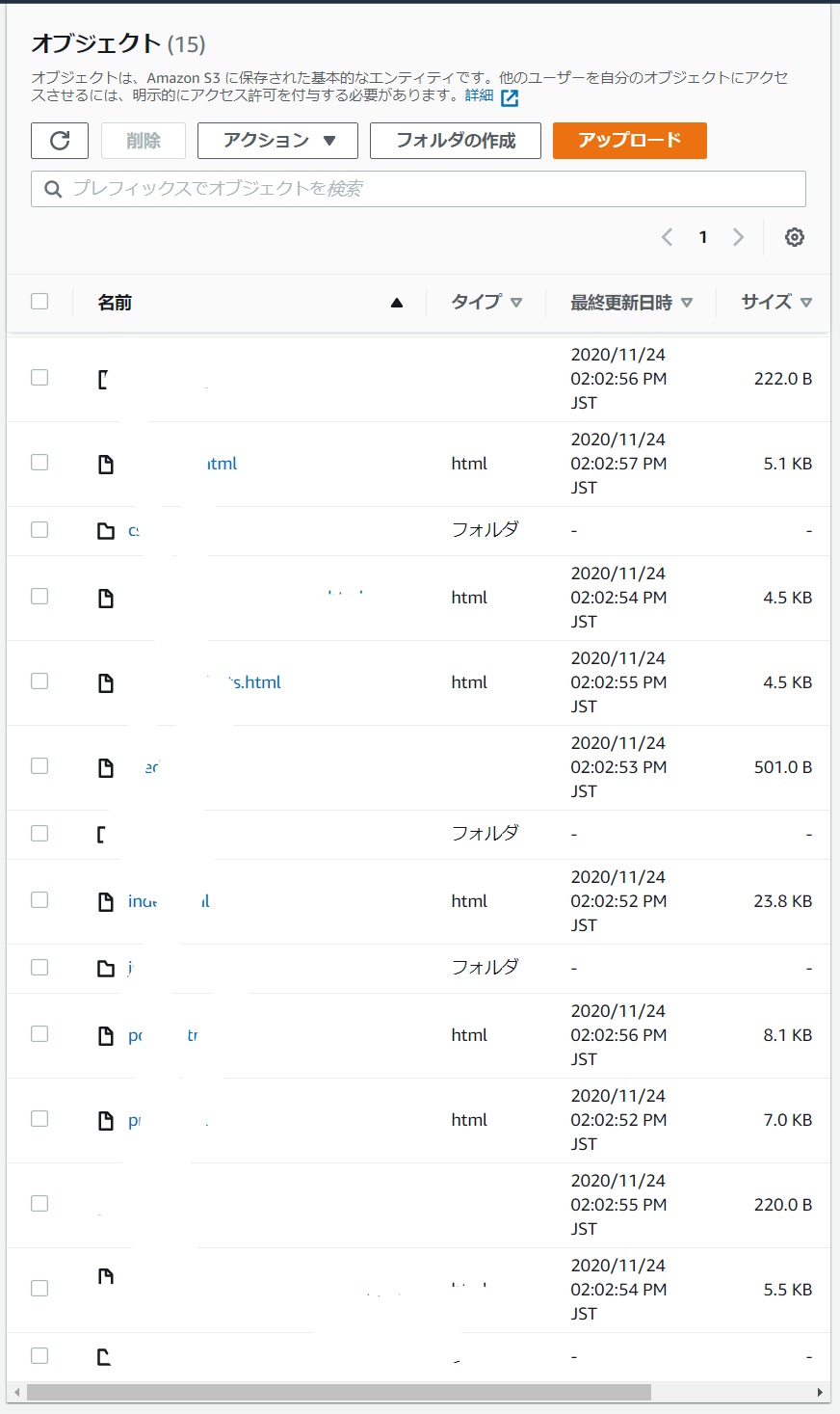
成果物を確認する
最初に確認したバケットを見ると以下のようにいろいろとファイルがあるはずです!
これでCDについては完成です!
CloudFront + S3の設定
Create Distributionをクリックし、WebのGet Startedを選択します
Origin Settings
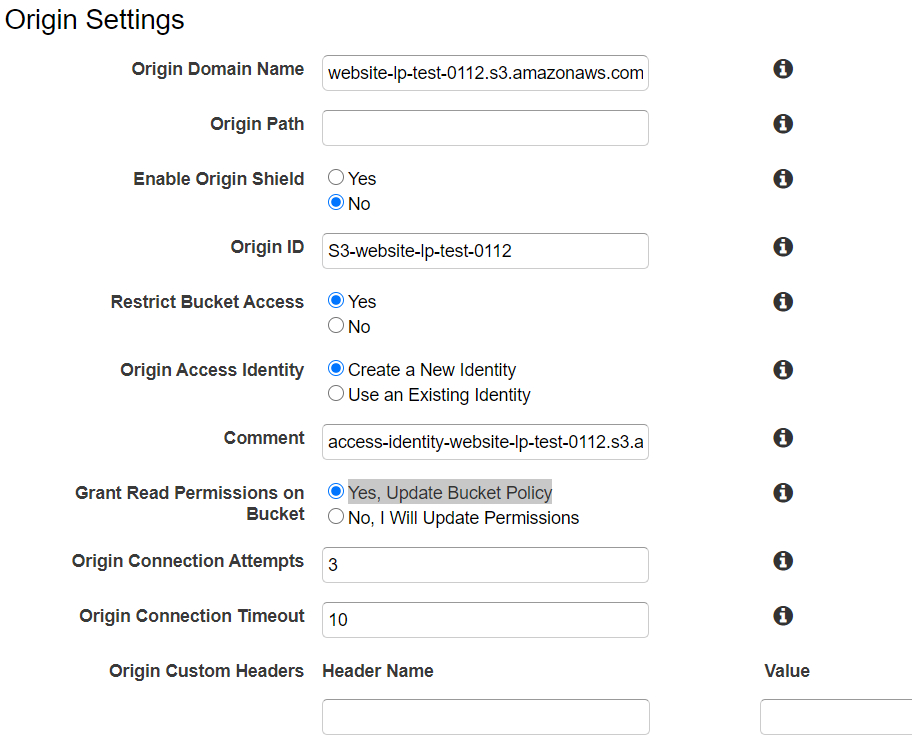
- Origin Domain Name : 最初に作成したS3のを選択
- Restrict Bucket Access : Yes
- Origin Access Identity : Create a New Identity
- Grant Read Permissions on Bucket : Yes, Update Bucket Policy ↑でS3バケットへのアクセス設定を変更しています
Default Cache Behavior Settings
お好みで (私はいつも
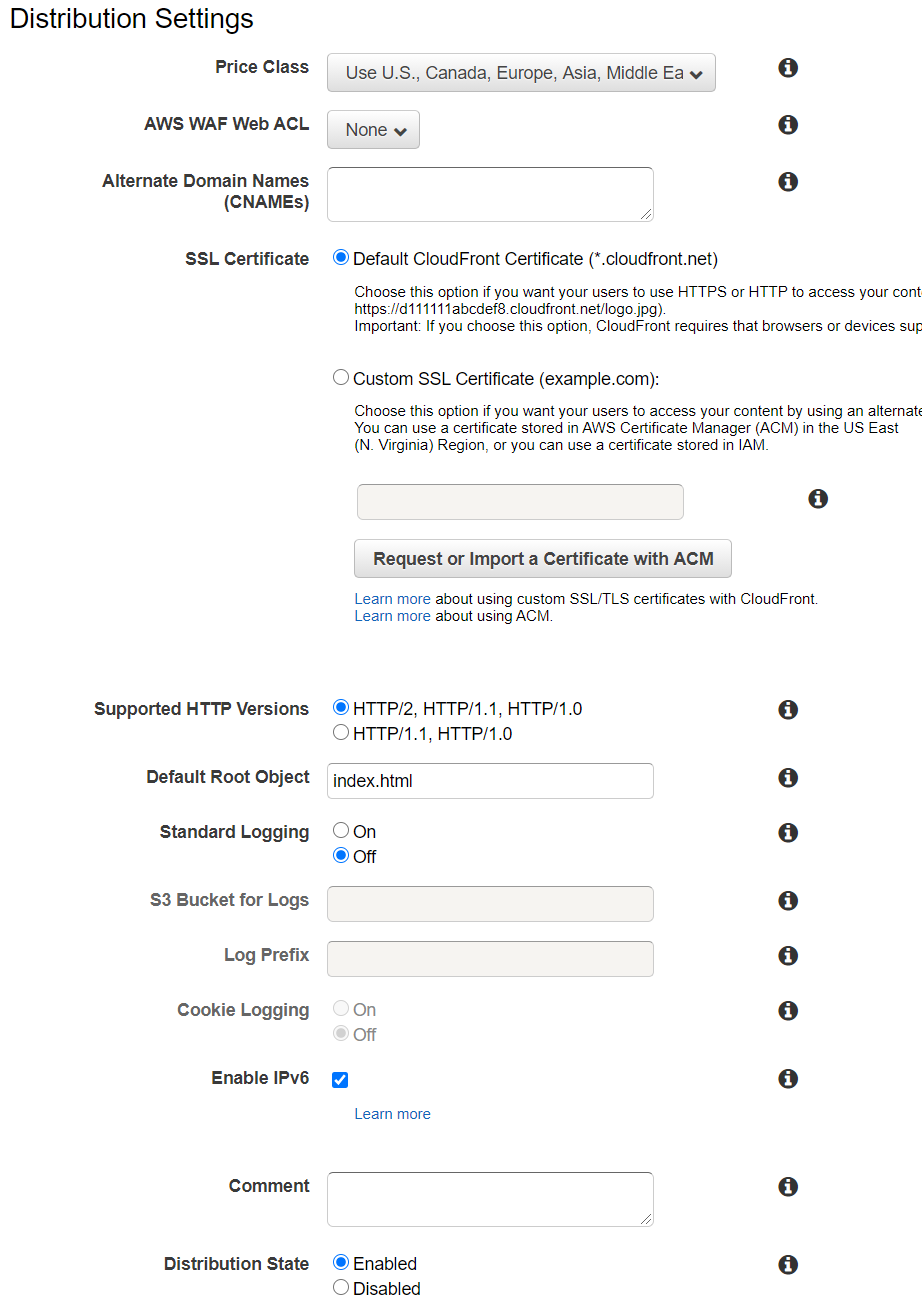
Viewer Protocol PolicyをRedirect HTTP to HTTPSにしています)Distribution Settings
- Price Class : お好み(Use U.S., Canada, Europe, Asia, Middle East and Africaで十分な気が)
- Alternate Domain Names(CNAMEs) : 必要なら
- SSL Certificate : 必要なら
- Default Root Object : index.html
- Standard Logging : 必要なら
設定後 Create Distribution をクリックして完了
StatusがIn ProgressからDeployedになったらDomain Nameに書いてある xxxxxxxxxxxxxxxx.cloudfront.netにアクセスしてみて、接続できれば全設定完了です。お疲れさまでした

この方法でbuildspec.ymlを変えてあげればNuxtだったり、Gatsbyでもできますが、その話はまた今度...機会があれば...ということで。
皆さんもぜひやってみてください!!
ではではー

- 投稿日:2020-11-24T14:17:51+09:00
javascript 基礎まとめ②
①の基礎まとめの続き
1.関数
Rubyでいう「メソッド」はJavaScriptでいう「関数」
Ruby だとdef メソッド名 処理内容 endこれがJavaScriptだと
function 関数名 (引数) { 処理内容 }例
function hello (){ console.log("こんにちは!") } hello()になる。
ちなみに、↑の書き方は「関数宣言」、↓が「関数式」
hello =function (){ console.log("こんにちは!") } hello() /// こんにちは!と表示される///この2つは読み込む順番が違う。関数式は
hello() hello =function (){ console.log("こんにちは!") } ///エラーになる///としても先にhello = function()、、、の方を読み込まれるので
この書き方はエラーになる。ちなみにこの
function (){は無名関数と言われている。
さらに
function (){}は
() =>{}と書換が可能
書いていくうちに頭は整理されるけど、見返すと
説明わかりづらすぎる。。。
※間違い等あればいただきたいです!
- 投稿日:2020-11-24T14:07:26+09:00
RubyでLINEのチャネルアクセストークンv2.1(JWT)を発行する
概要
RubyでLINEのMessaging APIで使用するチャネルアクセストークンv2.1(JWT)を発行します。
公式リファレンスは以下。
https://developers.line.biz/ja/docs/messaging-api/generate-json-web-token/前提
- アサーション署名キーを発行済みであること(未発行の場合は、上記公式リファレンスを参考に発行すること)
- JWTそのものの概要説明は省きます
背景
アサーション署名キーからJWTの発行に手間取ったので、残しておきます。
・公式リファレンスの実装例がJavaScriptしかない
・ググっても有用な情報が出てこなかった(Ruby初学者のため、間違いがありましたらコメントいただけると助かります。)
実装
gemのインストール
# Gemfile gem 'json-jwt'
bundle installJWT発行
require 'time' require 'json/jwt' # アサーション署名キーのJSONをパース jwk = JSON.parse(Constants::LINE_ASSERTION_SIGN_KEY) # ペイロードとヘッダーを定義(LINE公式リファレンスより) payload = { iss: Constants::LINE_CHANNEL_ID, sub: Constants::LINE_CHANNEL_ID, aud: "https://api.line.me/", exp: Time.now.to_i + 60 * 30, token_exp: 60 * 60 * 24 * 30 } header = { alg: "RS256",typ: "JWT",kid: jwk["kid"] } # 未署名のJWTを作成 jwt_nonsig = JSON::JWT.new(payload) jwt_nonsig.header = header # アサーション署名キーから秘密鍵を生成 private_key = JSON::JWK.new(jwk).to_key # 署名付きのJWTを生成 jwt = jwt_nonsig.sign(private_key).to_s ######## あとは公式リファレンスに沿って、APIにPOSTPOST例
curl -v -X POST https://api.line.me/oauth2/v2.1/token \ -H 'Content-Type: application/x-www-form-urlencoded' \ --data-urlencode 'grant_type=client_credentials' \ --data-urlencode 'client_assertion_type=urn:ietf:params:oauth:client-assertion-type:jwt-bearer' \ --data-urlencode '{発行したjwt}'はまったところ
そもそもアサーション署名キーの形式が謎
pem形式のような文字列がザーっと書いてある秘密鍵は見たことがあったが、アサーション署名キーのようなjson形式は初見で、JWTのgemでそのままの形式では使用できなかった。
⇒JWK Set 形式と呼ぶらしい。
https://qiita.com/trysmr/items/e8d4225ff6a603e9e21a
gem jwkを使用するとエラーになる
gem jwkもJWTのライブラリとして有名どころらしく、最初はこちらを使用したが、以下のエラーが発生した。
https://github.com/jwt/ruby-jwt# railsコンソール $ JWT::JWK.import(jwk) JWT::JWKError: Key type (kty) not provided"kty"には"RSA"が入っている。ソースを見たらktyに何かしら値が入っていればいいみたい?ので、jwkのハッシュをシンボル化して、再度実行。
# railsコンソール $ JWT::JWK.import(jwk.symbolize) NoMethodError: undefined method `tr' for nil:NilClass Did you mean? try from /usr/local/lib/ruby/2.6.0/base64.rb:101:in `urlsafe_decode64'学習不足です。あきらめました・・・
(JWT::JWKでbase64インスタントに対してtrメソッドが呼ばれているところまでは見れましたが、これ以上は時間がかかりそうなのでギブアップ)
- 投稿日:2020-11-24T14:07:26+09:00
RubyでLINEのアサーション署名キーからチャネルアクセストークンv2.1(JWT)を発行する
概要
RubyでLINEのMessaging APIで使用するチャネルアクセストークンv2.1(JWT)を発行します。
公式リファレンスは以下。
https://developers.line.biz/ja/docs/messaging-api/generate-json-web-token/前提
- アサーション署名キーを発行済みであること(未発行の場合は、上記公式リファレンスを参考に発行すること)
- JWTそのものの概要説明は省きます
背景
アサーション署名キーからJWTの発行に手間取ったので、残しておきます。
・公式リファレンスの実装例がJavaScriptしかない
・ググっても有用な情報が出てこなかった(Ruby初学者のため、間違いがありましたらコメントいただけると助かります。)
実装
gemのインストール
# Gemfile gem 'json-jwt'
bundle installJWT発行
require 'time' require 'json/jwt' # アサーション署名キーのJSONをパース jwk = JSON.parse(Constants::LINE_ASSERTION_SIGN_KEY) # ペイロードとヘッダーを定義(LINE公式リファレンスより) payload = { iss: Constants::LINE_CHANNEL_ID, sub: Constants::LINE_CHANNEL_ID, aud: "https://api.line.me/", exp: Time.now.to_i + 60 * 30, token_exp: 60 * 60 * 24 * 30 } header = { alg: "RS256",typ: "JWT",kid: jwk["kid"] } # 未署名のJWTを作成 jwt_nonsig = JSON::JWT.new(payload) jwt_nonsig.header = header # アサーション署名キーから秘密鍵を生成 private_key = JSON::JWK.new(jwk).to_key # 署名付きのJWTを生成 jwt = jwt_nonsig.sign(private_key).to_s ######## あとは公式リファレンスに沿って、APIにPOSTPOST例
curl -v -X POST https://api.line.me/oauth2/v2.1/token \ -H 'Content-Type: application/x-www-form-urlencoded' \ --data-urlencode 'grant_type=client_credentials' \ --data-urlencode 'client_assertion_type=urn:ietf:params:oauth:client-assertion-type:jwt-bearer' \ --data-urlencode '{発行したjwt}'はまったところ
そもそもアサーション署名キーの形式が謎
pem形式のような文字列がザーっと書いてある秘密鍵は見たことがあったが、アサーション署名キーのようなjson形式は初見で、JWTのgemでそのままの形式では使用できなかった。
⇒JWK Set 形式と呼ぶらしい。
https://qiita.com/trysmr/items/e8d4225ff6a603e9e21a
gem jwkを使用するとエラーになる
gem jwkもJWTのライブラリとして有名どころらしく、最初はこちらを使用したが、以下のエラーが発生した。
https://github.com/jwt/ruby-jwt# railsコンソール $ JWT::JWK.import(jwk) JWT::JWKError: Key type (kty) not provided"kty"には"RSA"が入っている。ソースを見たらktyに何かしら値が入っていればいいみたい(推測)で、読み込めていないのかな(推測)と思い、jwkのハッシュをシンボル化して、再度実行。
# railsコンソール $ JWT::JWK.import(jwk.symbolize) NoMethodError: undefined method `tr' for nil:NilClass Did you mean? try from /usr/local/lib/ruby/2.6.0/base64.rb:101:in `urlsafe_decode64'学習不足です。あきらめました・・・
(JWT::JWKでbase64インスタントに対してtrメソッドが呼ばれているところまでは見れましたが、これ以上は時間がかかりそうなのでギブアップ)
- 投稿日:2020-11-24T09:58:09+09:00
[Rails]リロードしないと投稿できないちょっとした不具合
Railsの学習中で、作った料理のレシピを共有するサイトを作成している時、
投稿画面でリロードしないとどこを押しても何も反応しないという現象が起きた。原因は至極単純なものだったが、恥ずかしながら解決に時間がかかってしまったため備忘録として残しておく。
現象
投稿画面に遷移したあと、フォームへの入力はできるが、
submitボタンを押しても何も起こらない。DBへの保存もできてない模様。
リロードをして再度記入、submitで投稿可能。原因
form_with(今回はnested_form_for)をdiv要素を跨いで書いてしまっていた。
_rescipe_form.html.erb<div class="row"> <%= nested_form_for recipe, local: true do |f| %> <div class="col-lg-4"> <h5>料理の写真</h5> <%= attachment_image_tag recipe, :recipe_image, fallback: "no_image.png", class: "img_prev", style: "height: 250px; width:300px;" %><br> <%= f.attachment_field :recipe_image %> </div> ~~~~~~(省略)~~~~~~~ <% if recipe.new_record? %> <%= f.submit 'レシピを公開する'%> <% else %> <%= f.submit 'レシピを書き換える' %> <% end %> </div> <% end %>まとめ
初歩的なところで躓き時間を使ってしまった。
この現象が起きた時、formの中身ばかりを見ていたので
入れ子構造がちゃんとなっているか、全体をよくみる癖を付けたい
- 投稿日:2020-11-24T09:29:53+09:00
スクール5週目 応用力の根底
今週は、応用カリキュラムも終盤に差し掛かり、課題図書(レスポンシブWebデザイン、Ruby応用、正規表現)を主に学びました。
プログラミングの奥深さを感じ取れた週になりました。【学習内容】
・サーバーの基礎知識
・レスポンシブWebデザイン
・Ruby応用
・正規表現サーバーの基礎知識
まず、サーバーの必要性、役割を学びます。その上でIPアドレス、WANとLAN、ドメインとDNS、ポート、WEBサーバー、HTTPの基礎を学習します。
次にサーバ向けによく利用されているOSであるLinuxについて学びます。Linuxの特徴としては、以下の点が挙げられます。
①オープンソースであり、誰でも自由に無償で利用できる
②品質の高い多くのソフトウェアが利用できる
③世界中でサーバ用途として広く利用されているため信頼性が高い
④操作を自動化するための仕組みが用意されており、サーバの運用が行いやすいそして次にSSHについて学習。SSHとは、暗号や認証の技術を利用して、安全にリモートコンピュータと通信するためのプロトコルのことです。利用するメリットとしては以下の点が挙げられます。
①通信を盗聴される危険性を回避して、安全に操作ができる
②サーバ上でのファイル操作、設定ファイルの編集ができる
③データのバックアップをしたいとき、サーバ上で圧縮(ZIP)して、ファイルの一括ダウンロードできるので、アップロード・ダウンロードの大量ファイルの時間短縮ができるレスポンシブWebデザイン
PCやタブレット、スマホなど様々なデバイスの大きさに対応し、閲覧しやすいデザインのWebサイトを作成する方法を学びました。
ユーザーがWEBサイトを閲覧する際、スマホで閲覧する比率は6割〜7割を超えると言われているそうです。そのため、WEB開発においても、スマホやタブレットでの閲覧を想定した見た目づくりがとても重要になってくるそうです。実際に私もボランティア団体のHPを作った際はスマホでの見え方を気にしながら作業をしていたので、レスポンシブの考え方は非常に常用だと感じました。
Ruby応用
これまで、Rubyの条件分岐にはif文を用いました。
しかし、Rubyにはif文以外にも条件分岐を表現する文法としてcase文があります。case文とは、条件分岐を表現するための文法です。複数の条件を指定する時に、if文のelsifを重ねるよりもシンプルにコードを書くことができます。並列する条件が多数ある場合は、if文よりもcase文を使った方がコードとして読みやすくなります。つまり、可読性を高められることだと思いました。
Sample.rbcountry = "Japan" if country == "Japan" puts "こんにちは" elsif country == "America" puts "Hello" elsif country == "France" puts "Bonjour" elsif country == "China" puts "你好" elsif country == "Italy" puts "Buon giorno" elsif country == "Germany" puts "Guten Tag" else puts "..." end次に繰り返し処理について学びました。
繰り返し処理で思い浮かぶのはeachメソッドだけでしたが、Rubyの繰り返し処理用の1つにwhile文があるそうです。
while文は繰り返し処理を行うためのRubyの構文です。指定した条件が真である間、処理を繰り返します。
Sample.rbnumber = 0 while number <= 10 puts number number += 1 end正規表現
今までさまざまなアプリケーションに触れてきた中で、「パスワードが6文字未満だったり、メールアドレスに@が入っていなかったりするとユーザー登録ができないのは、どのように判断されているのだろう?」 と疑問に思っていました。これらはすべて正規表現という技術を用いて実装されていたことをここで、初めて知りました。
正規表現とは、文字列の一部分を抽出・置換したり、文字列が制約を満たしているかを調べるための表現方法です。
例えば…
・電話番号からハイフンを取り除く
・パスワードに英数字8文字以上という制約
・メールアドレスからドメインの部分のみ抽出
・全角かな/カナ漢字の区別する
・passwordの英数字混合の判断他にもたくさんの正規表現があることを学びました。
最後のpasswordの英数字混合の判断する場合、以下の記述になります。irb(main):001:0> password = "T2o0k2y0o" irb(main):002:0> password.match(/\A(?=.*?[a-z])(?=.*?[\d])[a-z\d]+\z/i) => #<MatchData “T2o0k2y0o”>振り返り・感想

やはりプログラミングは暗記していけないと痛感させられました。なぜなら、passwordの英数字混合の判断だけでも一見どんな正規表現なのかが分かりません。そのため、プログラミングは暗記するのではなく、調べて理解して応用させることが大事だと改めて思いました。
また、コメントつけて上げると、後から誰かが見返しても丁寧で分かりやすいですし、テストコードの際に役立つと思いました。
- 投稿日:2020-11-24T09:29:53+09:00
スクール5週目
今週は、応用カリキュラムも終盤に差し掛かり、課題図書(レスポンシブWebデザイン、Ruby応用、正規表現)を主に学びました。
プログラミングの奥深さを感じ取れた週になりました。【学習内容】
・サーバーの基礎知識
・レスポンシブWebデザイン
・Ruby応用
・正規表現サーバーの基礎知識
まず、サーバーの必要性、役割を学びます。その上でIPアドレス、WANとLAN、ドメインとDNS、ポート、WEBサーバー、HTTPの基礎を学習します。
次にサーバ向けによく利用されているOSであるLinuxについて学びます。Linuxの特徴としては、以下の点が挙げられます。
①オープンソースであり、誰でも自由に無償で利用できる
②品質の高い多くのソフトウェアが利用できる
③世界中でサーバ用途として広く利用されているため信頼性が高い
④操作を自動化するための仕組みが用意されており、サーバの運用が行いやすいそして次にSSHについて学習。SSHとは、暗号や認証の技術を利用して、安全にリモートコンピュータと通信するためのプロトコルのことです。利用するメリットとしては以下の点が挙げられます。
①通信を盗聴される危険性を回避して、安全に操作ができる
②サーバ上でのファイル操作、設定ファイルの編集ができる
③データのバックアップをしたいとき、サーバ上で圧縮(ZIP)して、ファイルの一括ダウンロードできるので、アップロード・ダウンロードの大量ファイルの時間短縮ができるレスポンシブWebデザイン
PCやタブレット、スマホなど様々なデバイスの大きさに対応し、閲覧しやすいデザインのWebサイトを作成する方法を学びました。
ユーザーがWEBサイトを閲覧する際、スマホで閲覧する比率は6割〜7割を超えると言われているそうです。そのため、WEB開発においても、スマホやタブレットでの閲覧を想定した見た目づくりがとても重要になってくるそうです。実際に私もボランティア団体のHPを作った際はスマホでの見え方を気にしながら作業をしていたので、レスポンシブの考え方は非常に常用だと感じました。
Ruby応用
これまで、Rubyの条件分岐にはif文を用いました。
しかし、Rubyにはif文以外にも条件分岐を表現する文法としてcase文があります。case文とは、条件分岐を表現するための文法です。複数の条件を指定する時に、if文のelsifを重ねるよりもシンプルにコードを書くことができます。並列する条件が多数ある場合は、if文よりもcase文を使った方がコードとして読みやすくなります。つまり、可読性を高められることだと思いました。
Sample.rbcountry = "Japan" if country == "Japan" puts "こんにちは" elsif country == "America" puts "Hello" elsif country == "France" puts "Bonjour" elsif country == "China" puts "你好" elsif country == "Italy" puts "Buon giorno" elsif country == "Germany" puts "Guten Tag" else puts "..." end次に繰り返し処理について学びました。
繰り返し処理で思い浮かぶのはeachメソッドだけでしたが、Rubyの繰り返し処理用の1つにwhile文があるそうです。
while文は繰り返し処理を行うためのRubyの構文です。指定した条件が真である間、処理を繰り返します。
Sample.rbnumber = 0 while number <= 10 puts number number += 1 end正規表現
今までさまざまなアプリケーションに触れてきた中で、「パスワードが6文字未満だったり、メールアドレスに@が入っていなかったりするとユーザー登録ができないのは、どのように判断されているのだろう?」 と疑問に思っていました。これらはすべて正規表現という技術を用いて実装されていたことをここで、初めて知りました。
正規表現とは、文字列の一部分を抽出・置換したり、文字列が制約を満たしているかを調べるための表現方法です。
例えば…
・電話番号からハイフンを取り除く
・パスワードに英数字8文字以上という制約
・メールアドレスからドメインの部分のみ抽出
・全角かな/カナ漢字の区別する
・passwordの英数字混合の判断他にもたくさんの正規表現があることを学びました。
最後のpasswordの英数字混合の判断する場合、以下の記述になります。Sample.rbirb(main):001:0> password = "T2o0k2y0o" irb(main):002:0> password.match(/\A(?=.*?[a-z])(?=.*?[\d])[a-z\d]+\z/i) => #<MatchData “T2o0k2y0o”>振り返り・感想
やはりプログラミングは暗記していけないと痛感させられました。なぜなら、passwordの英数字混合の判断だけでも一見どんな正規表現なのかが分かりません。そのため、プログラミングは暗記するのではなく、調べて理解して応用させることが大事だと改めて思いました。また、コメントつけて上げると、後から誰かが見返しても丁寧で分かりやすいですし、テストコードの際に役立つと思いました。
- 投稿日:2020-11-24T02:16:50+09:00
【RSpec】traitの使い方を整理してみた
最近RSpecについて勉強している者です。
他の方のポートフォリオを拝見する機会がありまして、
「テストに書いてあるtraitって何だろう?」
と疑問に思ったため、現在理解している点についてアウトプットしました。
(「everyday rails - rspecによるrailsテスト入門」
を参考に勉強している途中です)間違っている点などありましたらご指摘よろしくお願いします。
traitの使い方
FactoryBotを用いて次のようなテストデータ(ファクトリ)を作成するとします。
spec/factories/user.rbFactoryBot.define do factory :user do name = "Taro" name { name } email = "test1@example.com" email { email } password = "pass123" password { password } end endUserというモデルにnameカラム、emailカラム、passwordカラムが存在しますね。
ここで
「emailだけ『test2@example.com』になっているファクトリを新しく作りたいな」
と考えたとします。その時は「継承」という機能を使うと便利です。spec/factories/user.rbFactoryBot.define do factory :user do name = "Taro" name { name } email = "test1@example.com" email { email } password = "pass123" password { password } #新しいファクトリを定義 factory :another_user do email = "test2@example.com" email { email } end end endなぜ「継承」を利用するのかというと、「記述が重複してしまうことを防ぐため」です。
継承を利用しない場合、今回のような規模なら問題ありませんが、これがもっとファクトリ内のインスタンス数が多い中で、「新しいファクトリを定義したい」となった場合、非常に手間です。例えば、「10個のインスタンスがある内の1個だけ属性値を変えたい」という場合でも、その10個全てを再定義しないといけませんから?そこで、継承を使うことで、「emailだけ『test2@example.com』のファクトリを新しく作る」ということが可能になります(つまり、記述の重複がなくなる!)。
しかし、複雑なオブジェクトを構築したいときや、テストデータに関する要件がもっと複雑になってきた時は、継承よりも「trait」の方が向いているそうです(こちらに関しては、現在勉強中です。こちらの方が、traitを使う本当の理由のようです)。
継承をtraitにしたい時は、次のように記述します。
spec/factories/user.rbFactoryBot.define do factory :user do name = "Taro" name { name } email = "test1@example.com" email { email } password = "pass123" password { password } #新しいファクトリを定義 trait :another_user do email = "test2@example.com" email { email } end end end定義したファクトリをspecファイルで呼び出したい時は、以下のように記述します。
user_spec.rbuser = FactoryBot.create(:user(モデル名), :another_user(ファクトリ名))このtraitを使用することでも、「記述が重複してしまうことを防ぐこと」ができます。
いかがでしたか?
traitは、複雑なオブジェクトを構築したいときや、テストデータに関する要件がもっと複雑になってきた時にこそ輝くそうなので、今後理解できたら、また内容を更新したいと思います。ここまで読んでいただきありがとうございました。