- 投稿日:2020-11-24T23:23:17+09:00
【Android】ObjectMetadata.setContentEncoding で文字化け【AWS】
AWS(s3) の Android サンプルコードを試していたのですが、
アップロードしたファイルの文字化けで手間取ったのでメモ。文字化けしたコードObjectMetadata metadata = new ObjectMetadata(); metadata.setContentType("text/plain"); metadata.setContentEncoding("UTF-8"); // "utf-8"も"UTF8"も試したけどダメうまくいったコードObjectMetadata metadata = new ObjectMetadata(); metadata.setContentType("text/plain;charset=utf-8");setContentEncodingなんて、期待しちゃうにきまってるじゃないですか。
- 投稿日:2020-11-24T23:12:04+09:00
【Java】0で割る割り算の例外処理
プログラミング勉強日記
2020年11月24日
Javaで電卓のプログラムを組んでいるときに0での割り算でエラーが出てプログラムが強制終了したので、その例外処理の方法を記述する。異常終了する場合
Javaでは条件を見たなさにと起こる例外があり、例外処理をしないとプログラムが異常終了することがある。以下のサンプルコードのように例外処理をしないと、異常終了する。
異常終了するサンプルコードpublic class Main { public static void main(String[] args) { int a = 123; int b = 0; int c; c = a / b; } }実行結果Exception in thread "main" java.lang.ArithmeticException: / by zero at ZeroDividException.main(ZeroDividException.java:7)このように0で割ってしまっているのでプログラムが強制終了する。
0での割り算における例外処理
プログラムの異常終了を防ぐために、例外処理を加える。
public class Main { public static void main(String[] args) { try{ int a = 123; int b = 0; int c; c = a / b; } catch(ArithmeticException e) { System.out.println("エラー(0で割っています)"); } } }実行結果エラー(0で割っています)例外処理をすっることで、エラーメッセージを表示させて強制終了を防ぐことができる。
参考文献
- 投稿日:2020-11-24T23:01:02+09:00
Java テキストファイル(.txt .csv)への出力 java.io.FileWriter



- 投稿日:2020-11-24T22:43:01+09:00
GitHub Actionsでテスト、lint、カバレッジ計測
この記事はMicroAd (マイクロアド) Advent Calendar 2020 - Qiitaの2日目の記事です。
やること
GitHub ActionsでJava/Kotlin製ライブラリ(ビルドツールはgradle)のCI環境を構築します。
具体的には、以下2項目を行います。
PRを出した際にテストとlintを走らせる- カバレッジを計測する
サンプルプロジェクトの内容
サンプルコードには以下の加算コードとそのテストコードなどが含まれています。
プロダクションコードpackage com.wrongwrong fun myAdd(a: Double, b: Double) = a + bコード全体は以下で公開しています。
テンプレートについて
ワークフローの基本的なテンプレートは
https://github.com/${ユーザー}/${リポジトリ}/actions/newに公開されているため、基本的にこれをコピペする形で話を進めます。
PRを出した際にテストとlintを走らせるテストと
lintは./gradlewから呼び出す形で実行するのが簡単です。テストを走らせる
まずテストを走らせてみます。
Java with Gradleテンプレートを参考に、${プロジェクトルート}/.github/workflows/ci.ymlを追加します。
内容に関しては、
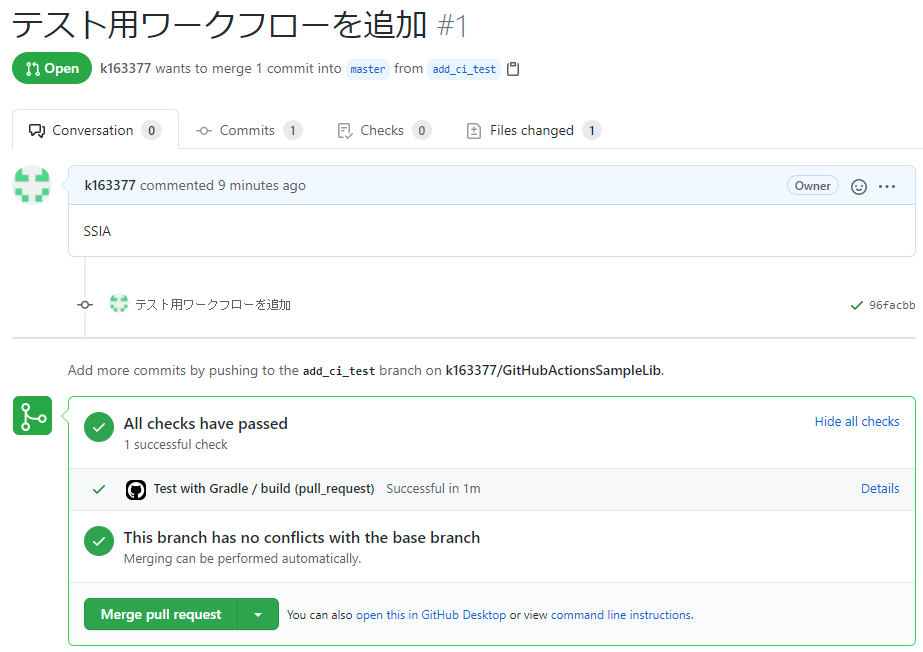
run: ./gradlew testでテストを呼び出していることが分かれば一旦大丈夫だと思います。ci.yml# This workflow will build a Java project with Gradle # For more information see: https://help.github.com/actions/language-and-framework-guides/building-and-testing-java-with-gradle name: Test with Gradle on: push: branches: [ master ] pull_request: branches: [ master ] jobs: build: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - name: Set up JDK 1.8 uses: actions/setup-java@v1 with: java-version: 1.8 - name: Grant execute permission for gradlew run: chmod +x gradlew - name: Test with Gradle run: ./gradlew testこれによりテストが走るようになりました。
lintを走らせる
次に
lintを走らせます。
lintはktlint gradle plugin(org.jlleitschuh.gradle.ktlint)を用いて行います。build.gradle.kts(抜粋)plugins { kotlin("jvm") version "1.4.10" id("org.jlleitschuh.gradle.ktlint") version "9.4.1" // 追加 }ワークフロー設定は、
run: ./gradlew ktlintするだけで行えます。
今回はテストの前にlintを走らせる形としました。ci.yml(抜粋)run: chmod +x gradlew # 下2行を追記 - name: ktlint check run: ./gradlew ktlintCheck - name: Test with Gradle run: ./gradlew test試しに
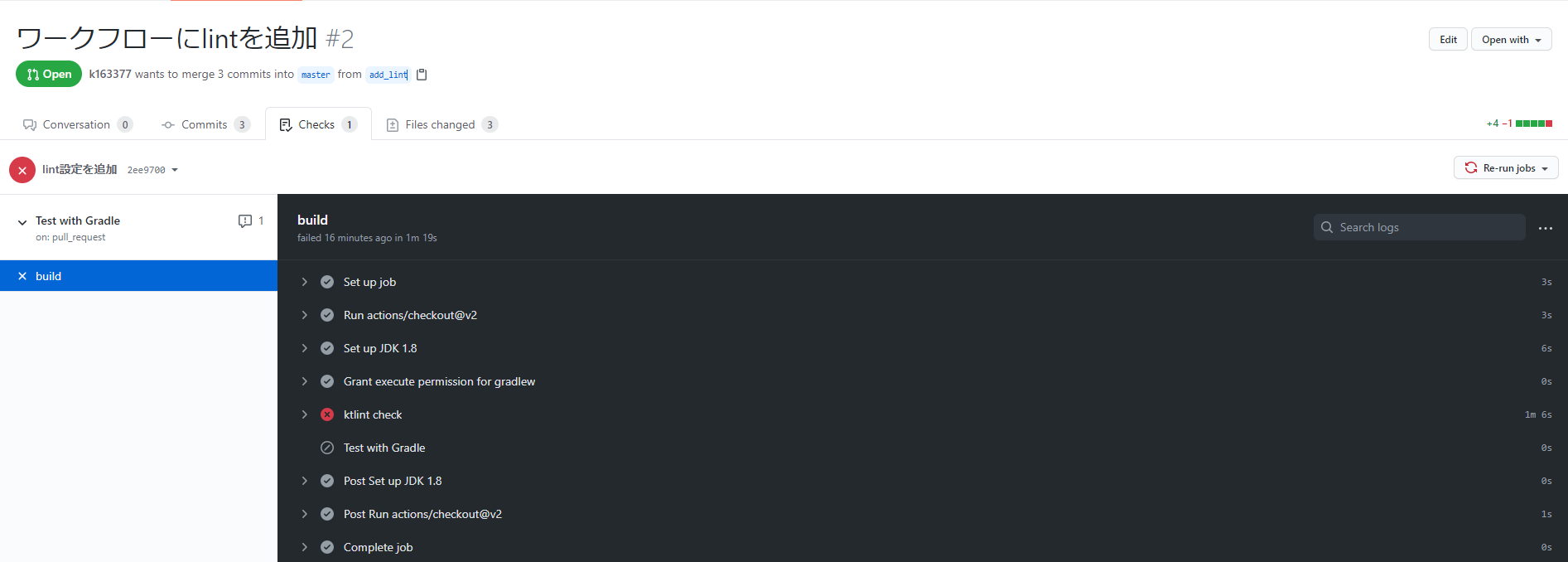
lintが引っかかる状態で実行した結果が以下です。
ktlint checkが追加され、失敗しています。
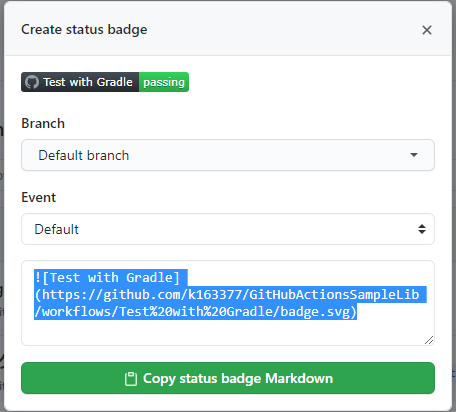
バッジを表示する
テストや
lintが出来たので、READMEにそのステータスバッジを出します。
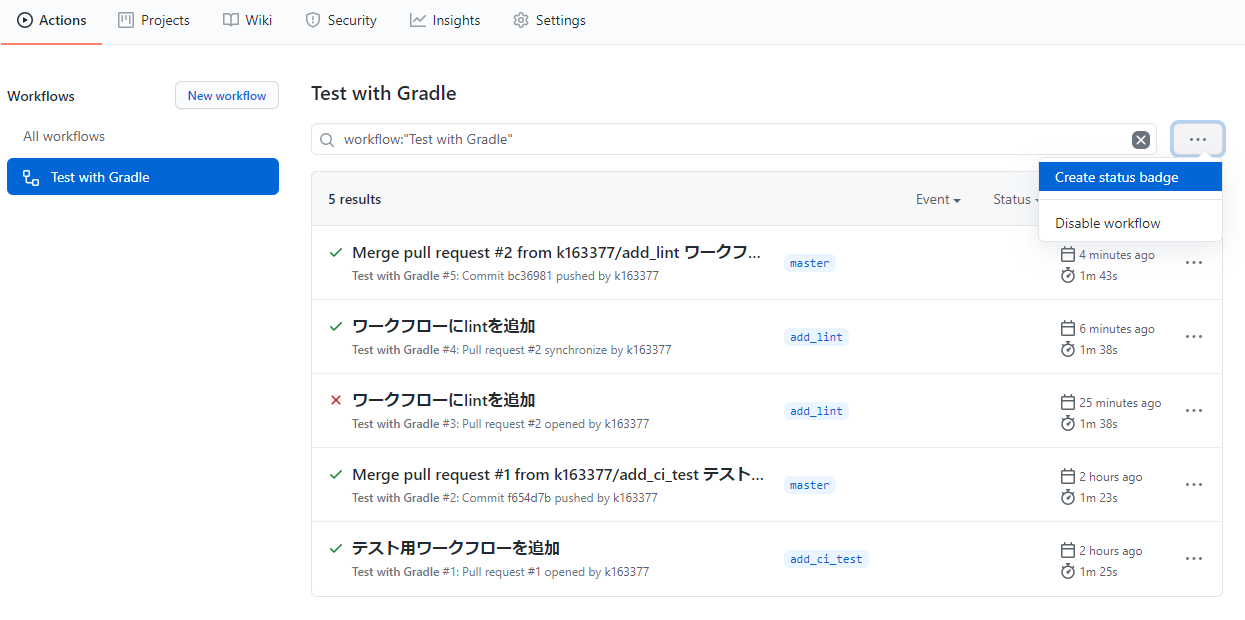
バッジは当該ワークフローからCreate status budgeすれば取得できます。
2. カバレッジを計測する
続いてテストのカバレッジを計測します。
今回はJaCoCoで生成したカバレッジファイルをCodecovにアップロードする形でこれを行います。JaCoCo関連の設定
まず
JaCoCo関連の設定を追加します。
詳しい説明は以前書いた記事の中で説明したためここでは省略します。build.gradle.kts(JaCoCo関連の抜粋)/* 略 */ plugins { /* 略 */ id("jacoco") } /* 略 */ tasks { /* 略 */ jacocoTestReport { reports { xml.isEnabled = true csv.isEnabled = false html.isEnabled = true } } test { useJUnitPlatform() // テスト終了時にjacocoのレポートを生成する finalizedBy(jacocoTestReport) } }ローカルで
./gradlew testした際に${プロジェクトルート}/build/reports/jacoco/にテストレポートが吐き出されていればJaCoCo関連の設定は完了です。Codecovのセットアップ
Codecovのセットアップに関しても、以前書いた記事の中で詳しく説明したためここでは省略します。
Repository Upload Tokenが取得できれば完了です。GitHub Actionsの設定
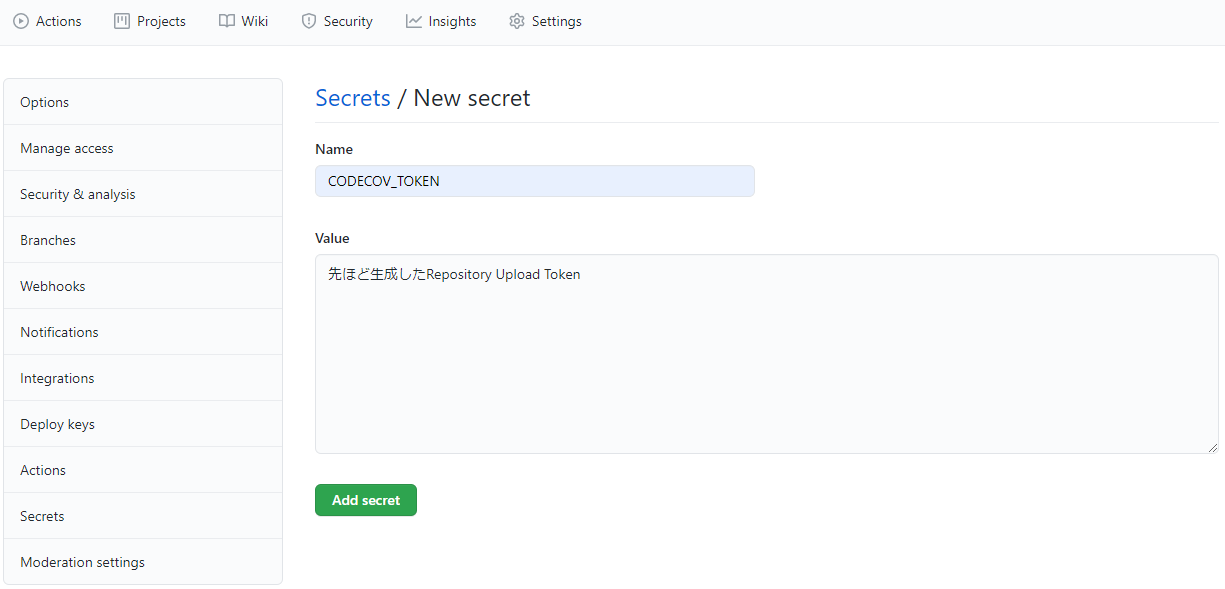
Repository Upload TokenをリポジトリのSecretsに追加
リポジトリの
Settings->Secrets->New repository secretに先ほど生成したRepository Upload Tokenを設定します。
キーの名前は後述するワークフローの設定で参照できれば何でもよいと思いますが、今回は
CODECOV_TOKENとします。
ワークフローの設定
以下4行を追加することでアップロードが行われるようになります。
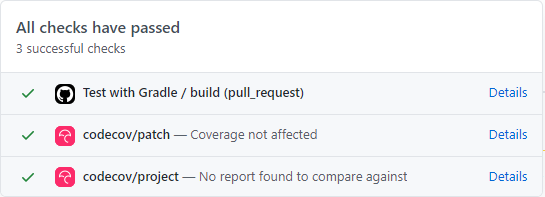
ci.yml(抜粋)run: chmod +x gradlew - name: ktlint check run: ./gradlew ktlintCheck - name: Test with Gradle run: ./gradlew test # 下4行を追記 - name: upload coverage uses: codecov/codecov-action@v1 with: token: ${{ secrets.CODECOV_TOKEN }}この状態でPRを作成することで、
codecov関係が動くようになりました。
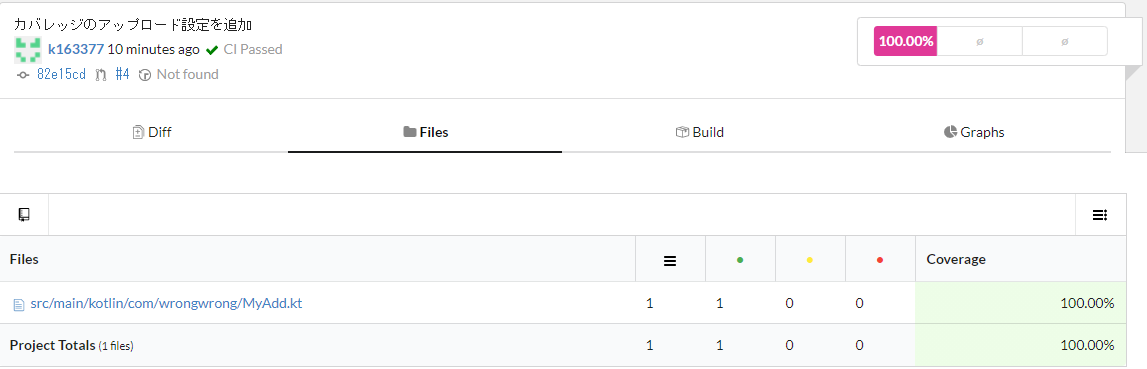
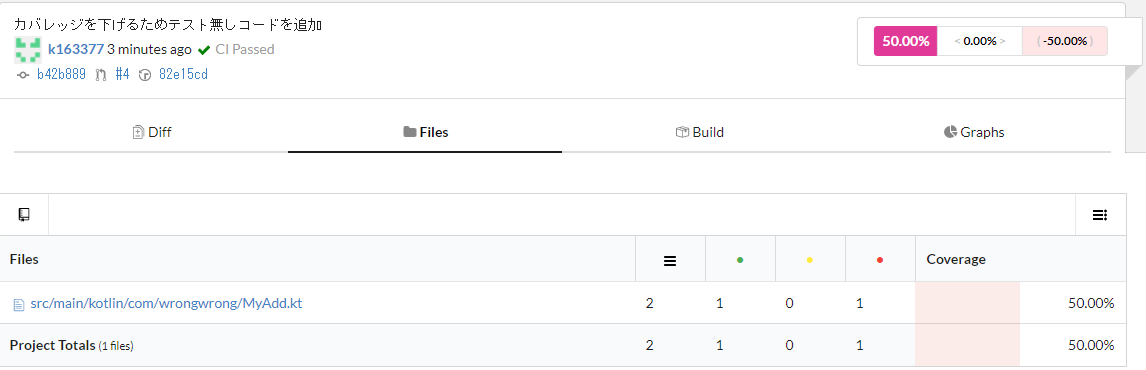
結果は以下のように確認できます。
テスト無しで関数を1つ追加した様子が以下です。
カバレッジが落ちていることが確認できます。
終わりに
GitHub ActionsでJava/Kotlin製ライブラリ(ビルドツールはgradle)のCI環境を構築してみました。感想としては「連携等で必要な操作も最低限で超簡単だしマジぱねえ」という感じです。
個人開発に関してはCircle CIからの乗り換えを決断しました。仕事で使っている
GitHub Enterpriseについては記事執筆時点(11/24)でActionsがまだ来ていませんが、2020中に来る来るという話なので、今から楽しみにしています。明日は@yassan168による
Hadoopネタの記事です。参考にさせて頂いた記事
- 投稿日:2020-11-24T20:21:21+09:00
【Java】super ( 一つ内側の[インスタンス]部分 )
super
Java の 「 super 」について学んだ内容のアウトプットです。
super とは
「super」は、「今より一つ内側のインスタンス部分」を表す予約語です。
これを利用すれば、親インスタンス部分 のメソッドやフィールドに、小インスタンスからアクセスすることが出来ます。
super の記述の仕方
コンストラクタをオーバーライドする際は1行目に「super()」と記述する必要があります。
親インスタンス部分のフィールドを利用する時
super.フィールド名親インスタンス部分のメソッドを呼び出す時
super.フィールド名([引数])superをつけないと?
例えば、親クラスに「attack()」 というメソッドがあり、子インスタンスからアクセスしようとする場合を例でいうと、結論、、
super をつけないと「外側で attack() を呼び続ける無限ループ」になってしまいます。
super をつけないということは
this.attackと同じ意味になってしまう。thisは「自分自身のインスタンスという意味」で、より正確には、「インスタンスの最も外側部分」を言う意味であるため上記の通り、メソッドの無い部分をずっとつづけることになる、ということになります。
「親の親」インスタンス部分へのアクセスは出来ない
下記のような継承関係の3つのクラスを例えにします。
Cクラスから生成されたインスタンスは3種構造になり、この時一番外側に相当するCインスタンスについて考えます。
Cクラスのメソッドは、一番外側のインスタンス部分(自分自身)には **this, そして親インスタンス部分へは super でアクセスが出来ます。
しかし、残念ながら親の親に当たるAクラスのインスタンスにはアクセスする手段が準備されていないため、C → A にはアクセスが出来ないということです。
- 投稿日:2020-11-24T20:21:21+09:00
【Java】super ( 一つ内側のインスタンス部分 )
super
Java の 「 super 」について学んだ内容のアウトプットです。
super とは
「super」は、「今より一つ内側のインスタンス部分」を表す予約語です。
これを利用すれば、親インスタンス部分 のメソッドやフィールドに、小インスタンスからアクセスすることが出来ます。
super の記述の仕方
コンストラクタをオーバーライドする際は1行目に「super()」と記述する必要があります。
親インスタンス部分のフィールドを利用する時
super.フィールド名親インスタンス部分のメソッドを呼び出す時
super.フィールド名([引数])superをつけないと?
例えば、親クラスに「attack()」 というメソッドがあり、子インスタンスからアクセスしようとする場合を例でいうと、結論、、
super をつけないと「外側で attack() を呼び続ける無限ループ」になってしまいます。
super をつけないということは
this.attackと同じ意味になってしまう。thisは「自分自身のインスタンスという意味」で、より正確には、「インスタンスの最も外側部分」を言う意味であるため上記の通り、メソッドの無い部分をずっとつづけることになる、ということになります。
「親の親」インスタンス部分へのアクセスは出来ない
下記のような継承関係の3つのクラスを例えにします。
Cクラスから生成されたインスタンスは3種構造になり、この時一番外側に相当するCインスタンスについて考えます。
Cクラスのメソッドは、一番外側のインスタンス部分(自分自身)には **this, そして親インスタンス部分へは super でアクセスが出来ます。
しかし、残念ながら親の親に当たるAクラスのインスタンスにはアクセスする手段が準備されていないため、C → A にはアクセスが出来ないということです。
- 投稿日:2020-11-24T19:26:38+09:00
eclipseのJunitテストでjava.lang.NoClassDefFoundErrorが発生した際の対処
- 投稿日:2020-11-24T18:19:46+09:00
Java バージョンアップによる Jenkins 起動不全
Ubuntu をアップデート後、Jenkins が起動しなくなってしまった。
Jenkins 起動不全
$ systemctl status jenkins.service ● jenkins.service - LSB: Start Jenkins at boot time Loaded: loaded (/etc/init.d/jenkins; generated) Active: failed (Result: exit-code) since Sun 2020-11-15 14:20:39 UTC; 19s ago Docs: man:systemd-sysv-generator(8) Process: 1591 ExecStart=/etc/init.d/jenkins start (code=exited, status=1/FAILURE) Nov 15 14:20:39 ip-172-31-83-123 systemd[1]: Starting LSB: Start Jenkins at boot time... Nov 15 14:20:39 ip-172-31-83-123 jenkins[1591]: Found an incorrect Java version Nov 15 14:20:39 ip-172-31-83-123 jenkins[1591]: Java version found: Nov 15 14:20:39 ip-172-31-83-123 jenkins[1591]: openjdk version "11.0.9.1" 2020-11-04 Nov 15 14:20:39 ip-172-31-83-123 jenkins[1591]: OpenJDK Runtime Environment (build 11.0.9.1+1-Ubuntu-0ubuntu1.18.04) Nov 15 14:20:39 ip-172-31-83-123 jenkins[1591]: OpenJDK 64-Bit Server VM (build 11.0.9.1+1-Ubuntu-0ubuntu1.18.04, mixed mode, sharing) Nov 15 14:20:39 ip-172-31-83-123 jenkins[1591]: Aborting Nov 15 14:20:39 ip-172-31-83-123 systemd[1]: jenkins.service: Control process exited, code=exited status=1 Nov 15 14:20:39 ip-172-31-83-123 systemd[1]: jenkins.service: Failed with result 'exit-code'. Nov 15 14:20:39 ip-172-31-83-123 systemd[1]: Failed to start LSB: Start Jenkins at boot time.解消方法
/etc/init.d/jenkinsを以下のように編集【Before】
# Which Java versions can be used to run Jenkins JAVA_ALLOWED_VERSIONS=( "18" "110" )【After】
# Which Java versions can be used to run Jenkins JAVA_ALLOWED_VERSIONS=( "18" "110" "11.09" )Jenkins 再起動
$ sudo systemctl restart jenkins Warning: The unit file, source configuration file or drop-ins of jenkins.service changed on disk. Run 'systemctl daemon-reload' to reload units.原因
以下のコマンドで Ubuntu をアップデートした際、Java のバージョンが上がってしまった模様
$ sudo apt update $ sudo apt dist-upgrade $ sudo apt autoremove参考記事
- 投稿日:2020-11-24T17:21:52+09:00
Javaのファイル管理
- 投稿日:2020-11-24T17:21:52+09:00
【Java】ディレクトリ内のファイルのコンパイル・実行
個人用メモ.なので一部表現があいまいです
javaファイルとclassファイルを別々のディレクトリにまとめたい
カレントディレクトリにて
javac -d <class directory> <src directory>/<java file>class directory : classファイルを置きたいディレクトリ
src directory : コンパイルしたいファイルがあるディレクトリ
java file : コンパイルしたいファイル【補足】
・クラスファイルの出力先ディレクトリを設定
・そのディレクトリはすでに存在している必要がある【例】
例えば,カレントディレクトリにsrc,classのディレクトリがあり,src内に
Foo.java, Bazz.javaがあるとき,src内のjavaファイルをコンパイルしたいjavac -d class src/Foo.java src/Bazz.javaもしくは
javac -d class src/*.javaによって class に Foo.class, Bazz.class ができる
ディレクトリ内のファイルの実行
カレントディレクトリにて
java -cp <class directory>/<class file>class directory : コンパイルされたファイルがあるディレクトリ
java file : コンパイルされたファイル【補足】
・クラスファイルを検索するディレクトリのリストを指定
・cpは,classpathの略【例】
カレントディレクトリにclassディレクトリがあり,そこにFoo.classがある場合java -cp class Foo拡張子はもちろん要りません.
- 投稿日:2020-11-24T16:50:56+09:00
JavaFX 環境設定手順 2020/11 ~インストールから実行まで~
Eclipce で JavaFX を使ってアプリケーションを開発したときの環境構築手順をまとめてみました。
使用したソフト等のバージョンは次の通りです。2020/11/24 現在
・OS -> Windows10
・JDK -> Java 11
・Eclipse -> Version: 2020-09 (4.17.0)
・JavaFX -> version=15
・SceneBuilder -> ファイルバージョン: 11.0.1.0本記事は以下の記事を参考にさせていただきました。
・【超初心者向け】JavaFX超入門※本記事では OpenJDK と Eclipse が使用できる環境を想定しています※
1. JavaFX の 設定
JavaFX のインストールからサンプルの実行までを目標としています。
1.1. インストール
まずは、EclipseでJavaFXプロジェクトを作成にするために、プラグインを実装していきます。
Eclipseのメニューバーから、
ヘルプ ⇒ Eclipse マーケットプレース をクリック。
検索欄から、「e(fx)clipse」プラグインをインストールしましょう。■対象プラグイン
※未ダウンロードの場合は「インストール済み」が「インストール」になります。次に、JavaFX をインストールしましょう。ダウンロードサイトへアクセスしてください。
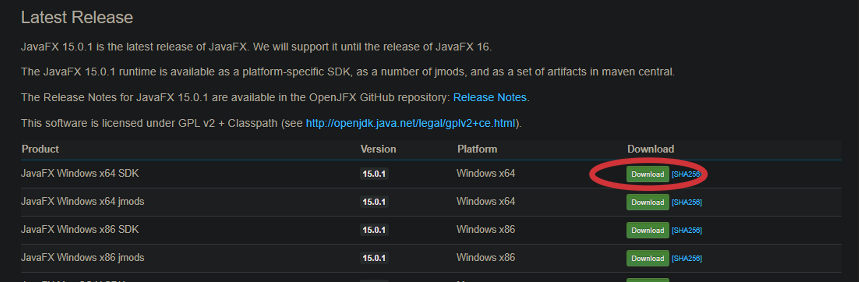
■ダウンロード画面(下へスクロール)
最新バージョンである「15.0.1」を環境にあわせてダウンロードします。
(今回は、OSが64ビットだったので「JavaFX Windows x64 SDK」を選択)ダウンロードしたzipファイルを解凍しましょう。
「C:\Program Files (x86)」の中にあるEclipseのフォルダに、「ユーザーライブラリ」フォルダを作成してそこに解凍しておくと便利です。1.2. JavaFX プロジェクト の 作成
1.3. JavaFX プロジェクト の 実行
SceneBuilder の 設定
2.1. インストール
2.2. SceneBuilder を 日本語化
2.3. SceneBuilder を Eclipse で 使用する
プロジェクト を jar 出力
- 投稿日:2020-11-24T16:50:56+09:00
JavaFX 環境設定 インストール⇒実行まで
Eclipce で JavaFX を使ってアプリケーションを開発したときの環境構築手順をまとめてみました。
使用したソフト等のバージョンは次の通りです。2020/11/24 現在
・OS -> Windows10
・JDK -> Java 11
・Eclipse -> Version: 2020-09 (4.17.0)
・JavaFX -> version=15
・SceneBuilder -> ファイルバージョン: 11.0.1.0本記事は以下の記事を参考にさせていただきました。
・【超初心者向け】JavaFX超入門※本記事では OpenJDK と Eclipse が使用できる環境を想定しています※
1. JavaFX の 設定
JavaFX のインストールからサンプルの実行までを目標としています。
1.1. インストール
まずは、EclipseでJavaFXプロジェクトを作成にするために、プラグインを実装していきます。
Eclipseのメニューバーから、
ヘルプ ⇒ Eclipse マーケットプレース をクリック。
検索欄から、「e(fx)clipse」プラグインをインストールしましょう。■対象プラグイン
※未ダウンロードの場合は「インストール済み」が「インストール」になります。次に、JavaFX をインストールしましょう。ダウンロードサイトへアクセスしてください。
■ダウンロード画面(下へスクロール)
最新バージョンである「15.0.1」を環境にあわせてダウンロードします。
(今回は、OSが64ビットだったので「JavaFX Windows x64 SDK」を選択)ダウンロードしたzipファイルを解凍しましょう。
「C:\Program Files (x86)」の中にあるEclipseのフォルダに、「ユーザーライブラリ」フォルダを作成してそこに解凍しておくと便利です。1.2. JavaFX プロジェクト の 作成
1.3. JavaFX プロジェクト の 実行
SceneBuilder の 設定
2.1. インストール
2.2. SceneBuilder を 日本語化
2.3. SceneBuilder を Eclipse で 使用する
プロジェクト を jar 出力
- 投稿日:2020-11-24T16:34:03+09:00
Java8から実装されたラムダ式とは
Java8から実装されたという「ラムダ式」。
一体どういったものなのか。
Java初心者の目線からまとめてみる。参考サイト
【Java 8で追加】ラムダ式とは?メリットや使い方をご紹介!
無名関数 -wikipedia
徹底解説! Javaのラムダ式はどういうもので、どう使えばいいのか!
[Java] Java8のラムダに超入門(書き方、関数型インターフェース、独自に定義、ラムダ受け取り処理)「ラムダ式」とは
参考サイトによると、
「関数型インターフェイスを実装したクラスのインスタンスを、ごく短いコーディング量でとても簡単に作れてしまう文法のこと」や、
「ラムダ式の特徴は、メソッドを変数のように扱える点にある。」といったように書かれている。要するに、関数型インターフェイスがすでにあるとして、
- 関数型インターフェイスの実装クラスの定義
- 実装クラスのインスタンスの作成
- そのメソッドの実行
を、ごく短いコードで書けてしまう素晴らしい技術といえるのかな?関数型インターフェイス
関数型インターフェースの条件は、大雑把に言って、定義されている抽象メソッドが1つだけあるインターフェース。
staticメソッドやデフォルトメソッドは含まれていても構わない(関数型インターフェースの条件としては無視される)。
また、Objectクラスにあるpublicメソッドがインターフェース内に抽象メソッドとして定義されている場合、そのメソッドも無視される。
(この条件を満たすインターフェースを、JDK1.8で「関数型インターフェース」と呼ぶようになった)ラムダ式の書式
(メソッドの引数列) -> {処理内容}2つの整数値を引数に取り、その和をメソッドに渡すケースをラムダ式で書くと以下のようになる。
(int x, int y) -> {return x + y;}「二つの整数値を加算した結果を返すメソッドに、引数を2つ(xとy)を与えて呼び出した」イメージ。
さらに引数の型を省略することができる
また、メソッドの処理内容に当たる部分が1行で記載できる場合には、{}を省略可能。(x, y) -> return x + y;実際に書いてみる
上記に倣って、「2つの数字を足し算する」という処理を例に実際に書いてみる。
ラムダ式を使わない例
まずは関数インターフェイス
Calcurator.javapublic class Calcurator { public int sum(int x, int y) }次に関数インターフェイスの実装クラス
CalcuratorImpl.javapublic class CalcuratorImpl implements Calucurator { public int sum(int x, int y) { return x + y; } }実際にsumメソッドを呼び出す処理
SumDemo.javaCalcurator c = new CalcuratorImple(); System.out.println(c.sum(1, 2));
ラムダ式を使った例
関数インターフェイスは変わらず。
Calcurator.javapublic class Calcurator { int sum(int x, int y); }実際にsumメソッドを呼び出したいモジュール内で実装クラスも定義してしまう。
SumDemo.javaCalcurator c = (x, y) -> return x + y; System.out.println(c.sum(1, 2));実装クラスを作ることなく、関数インターフェイスのメソッドを使用することができる。
- 投稿日:2020-11-24T16:15:50+09:00
【Java】オーバーライドメモ
オーバーライド
オーバーライドとは、継承関係において
「スーパークラスのメソッドの処理をサブクラスの同名のメソッドで重ねて処理結果を変えること」です。継承関係以外では、この現象は起こりません が、継承するサブクラスを作成するときは、
多少スーパークラスのことを知らないと意図せずオーバーライドしてしまうことがありますので注意してください。オーバーライドの仕組み
つまり 「スーパークラス と同名の メソッド がサブクラスにあれば、それが優先的に実行される。」
つまり「メソッド の内容が 上乗せされた」ような結果になります。
サンプルコード
こちらは継承元のスーパークラスです。
public class SuperOverride { public void testOverride() { System.out.println("オーバーライド前はこの表示が出ます"); } }こちらはスーパークラスを継承したサブクラスです。
// スーパークラスを継承します public class SubOverride extends SuperOverride { public void testOverride() { //testOverrideメソッドをオーバーライドします。 System.out.println("オーバーライドされるとこの表示になります"); } }こちらのクラスで実行します。
public class Main { public static void main(String[] args) { SubOverride subor = new SubOverride(); subor.testOverride(); } }実行結果
オーバーライドされるとこの表示になります上記のコードを解説すると
testOverrideメソッドを継承先のサブクラス SubOverride で上書きすることで、出力結果がオーバーライドされた内容になっています。
オーバーライドを回避する書き方(サンプル)
オーバーライドされていない出力をするならこのように記述します
// スーパークラスを継承します public class SubOverride extends SuperOverride { public void testOverride() { //testOverrideメソッドをオーバーライドします。 //スーパークラスのtestOverride メソッドの呼び出し super.testOverride(); } }コード内にもあるように
「super キーワードを指定して」、 testOverride() メソッドを呼び出しています。
こうすることでスーパークラスであるSuperOverrideクラスのtestOverride() メソッドが呼び出されます。オーバーライドの利用例
特定のサブクラスにおいて、当該メソッドの処理内容を修正・変更する という利用例があります。
「大本のスーパークラスに手を加えず、修正内容をサブクラスのみに適用したいとき」にオーバーライドは非常に便利だと思います。
とくに、RPGのキャラが行う特定のアクションを行う場合に、オーバーライドはよく用いられるようです。
すべてのキャラが固有で持っている 「attackメソッド」をオーバーライドして、
- ナッシーは「ねむりごな」
- ルージュラは「あくまのキッス」
- ダグトリオは「じわれ」
といった具合で内容を上乗せします。
【Nassy.java】
public void attack() { // ねむりごなの処理 }【kentaros.java】
public void attack() { // はかいこうせんの処理を書く }【Dugtrio.java】
public void attack() { // じわれの処理を書く }以上のように、それぞれ違う部分だけをプログラミングするだけで済むので、効率の良いコードを書けるようになると思います。
- 投稿日:2020-11-24T13:53:47+09:00
Mavenプロジェクトで単体テストを実行する
1.環境
前回作成したMavenで構築したJavaプロジェクトに、テストを追加する。
前回記事2.テストモジュールの作成
以下のフォルダ構成を作成する
C:\
└ maven\
└ demo\
└ src\
└ test\
└ java\
└ hello\VSCodeにて
Ctrl+Shift+@を入力してターミナル(PowerShell)を起動する
以下のコマンドでフォルダを作成してVSCodeでフォルダを開く> mkdir C:\maven\demo\src\test\java\hello > code -r C:\maven\demo以下のモジュールを作成
- src/test/java/hello/GreeterTest.javasrc/test/java/hello/GreeterTest.javapackage hello; import static org.hamcrest.CoreMatchers.containsString; import static org.junit.Assert.*; import org.junit.Test; public class GreeterTest { private Greeter greeter = new Greeter(); @Test public void greeterSaysHello() { assertThat(greeter.sayHello(), containsString("Hello")); } }Maven は、「surefire」というプラグインを使用して単体テストを実行する。
surefireのデフォルト構成は、src/test/java配下の*Test と一致する名前を持つすべてのクラスをコンパイルして実行する。3.テストの実行
mvn testコマンドを実行して、テストを実施する。> mvn test [INFO] Scanning for projects... [INFO] [INFO] -------------------< org.springframework:maven-test >------------------- [INFO] Building maven-test 0.1.0 [INFO] --------------------------------[ jar ]--------------------------------- [INFO] (中略) junit4/2.12.4/surefire-junit4-2.12.4.jar (37 kB at 100 kB/s) Results : Tests run: 1, Failures: 0, Errors: 0, Skipped: 0 [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 4.641 s [INFO] Finished at: 2020-11-24T13:38:48+09:00 [INFO] ------------------------------------------------------------------------ビルドの最後でJUnitによるテストが実行されていることがわかる。
このテストの結果としては、Failures/Errorsがともに0件であり、結果としてビルドは成功する。このテストがNGだった場合の動きを見てみる。
テスト用モジュールを以下のように修正。src/test/java/hello/GreeterTest.javapackage hello; import static org.hamcrest.CoreMatchers.containsString; import static org.junit.Assert.*; import org.junit.Test; public class GreeterTest { private Greeter greeter = new Greeter(); @Test public void greeterSaysHello() { // assertThat(greeter.sayHello(), containsString("Hello")); assertThat(greeter.sayHello(), containsString("Wello")); } }Greeter.classのsayHelloメソッドが返す文字列が"Wello"を含んでいるとテストOKとする。
Greeterは修正していないため、当然"Hello World!"を返すため、テストはNGとなるはず。------------------------------------------------------- T E S T S ------------------------------------------------------- Running hello.GreeterTest Tests run: 1, Failures: 1, Errors: 0, Skipped: 0, Time elapsed: 0.092 sec <<< FAILURE! greeterSaysHello(hello.GreeterTest) Time elapsed: 0.015 sec <<< FAILURE! java.lang.AssertionError: Expected: a string containing "Wello" but: was "Hello world!" (中略) Results : Failed tests: greeterSaysHello(hello.GreeterTest): (..) Tests run: 1, Failures: 1, Errors: 0, Skipped: 0 [INFO] ------------------------------------------------------------------------ [INFO] BUILD FAILURE [INFO] ------------------------------------------------------------------------ [INFO] Total time: 2.501 s [INFO] Finished at: 2020-11-24T13:49:03+09:00 [INFO] ------------------------------------------------------------------------ [ERROR] Failed to execute goal org.apache.maven.plugins:maven-surefire-plugin:2.12.4:test (default-test) on project maven-test: There are test failures.このように、テストの結果にFailureがあることで、ビルド自体もNGとなる。
参考
- 投稿日:2020-11-24T13:14:35+09:00
JavaSilver合格体験記(1Z0-808)
はじめに
JavaSilverはプログラミング初級者向けの資格です。
IT業界には5年ほどいますが、資格を持っていなかったため
自分の自信に少しでもなればと今回挑戦しました。
今更とか関係ないと思います。自慢をするための資格ではなく、自信をつけるための資格です。
この記事については合格するまでの勉強の過程を載せています。
合格当日の話や、合格後の証明書の話については別の方が記事してくれていますのでそちらをご参考ください。対象読者
JavaSilverの資格取得を目指している方
勉強に使用した書籍
黒本
徹底攻略 Java SE 8 Silver 問題集[1Z0-808]対応
白本
オラクル認定資格教科書 Javaプログラマ Silver SE 8 スピードマスター問題集失敗談
最初に、evernoteで黒本を1章ずつevernoteに内容を書き写しました。
そこで頭の中だけで解き、答え合わせをするという方法をとっていました。
結論:あまり意味がなかった。
理由は、書き写すことで満足をしてしまった。
あとは、後半の章は問題数が多いので途中で集中力が息切れしました。
時間を1ヶ月使ってしまいました。成功談
javaは業務で過去に使っていたので、7割くらいは内容を理解できていました。
そのため、それから模試だけに絞り勉強を開始しました。
下記のような手順で黒本、白本それぞれで実施しました。手順
①模試の初回実施
②①で間違えた箇所の解説を確認して、自分用の資料をまとめる
③模試の2回目実施
④③で間違えた箇所の解説を確認して、自分用の資料をまとめる
⑤模試の3回目実施
⑥⑤で間違えた箇所の解説を確認して、自分用の資料をまとめる
⑦⑥のまとめた問題だけ小テストを実施する
⑧間違え数が0問か1,2問になるまで⑤〜⑦を繰り返す試験結果
合格点:65%以上
正答率:87%工夫したこと
試験勉強しながら、勉強方法を試行錯誤しました。
理由としては、今回は今後資格を取得する上で土台となる考えになると思ったからです。
1.YouTubeで試験範囲の詳細確認
公式から試験範囲、注意点を解説した動画がYouTubeで公開されています。
2本で2時間ありますが、試験範囲が自分の中で把握できないまま取り組むより安心できると思います。
2.CBT方式対策
試験の方式を確認。
JavaSilverはCBT方式です。
CBT方式が分からない方は下記にサンプルがあるので確認してみてください。
CBT方式サンプル
そのため、CBT方式に寄せられるように、独自でevernoteを使って回答シートを作りました。
大したものではないですが、この記事にコメントかDMいただければフォーマットを配布します。
※ここに載せるには行が長いため貼りません。
実際に手書きだとできていたところがCBT方式に寄せてみると
チェック漏れで点数を落とすという体験ができました。
そのため、チェック漏れ対策を考えることができました。
3.メモリーツリー
勉強法を模索しているうちに、「ドラゴン桜」という漫画の存在を思い出しました。
そこで紹介されていた「メモリーツリー」
これは記憶定着にいいのではないかと思い採用しました。
勉強の使用した場面:苦手な箇所のみ。
得意な箇所は通常の勉強で吸収できると判断し、苦手強化のために使いました。
あとで実際の写真を載せる
※字の綺麗さについては突っ込まないでください。
4.合格のイメージをつける
合格者の投稿、Qiita,Twitterこの二つでキーワード検索[javasilver]などで調べると
勉強中の人や、合格者の投稿が検索結果として出てきます。
合格者の投稿をみて、自分は「合格するイメージ」をつけました。
それによってモチベーションの継続もできました。
5.総復習(出題ラリー)
試験日の前日は妻に問題をランダムで出してもらい、本当に理解ができているかを最終チェックしました。
友達などにもしお願いできるなら、してみてもいいと思います。
そのままではないのですがこれも「ドラゴン桜」を参考にしました。
6.図を書いてみる
この問題、解説見ても理解できないなと感じた問題に関しては
図を書いて自分の頭で整理させることを優先しました。
インターフェースは苦手だったので、図で整理して理解することで落とし込めました。
7.実機を動かしてみる
コンパイルエラー系の問題は机上ですべて理解しようとするより
実際に問題のプログラムを動かしてみた方が感覚で分かる場合があります。
おわりに
この記事を読まれてみて、ここがもうちょっと詳細知りたいなどあれば
随時可能な限りで別記事にして紹介していきます(この記事はこれで終わらせたいので)。
また、JavaSilverを取得された方でこんな効率的な勉強法あるよ!など紹介いただければ嬉しいです。
- 投稿日:2020-11-24T12:30:35+09:00
【Java】オーバーロードメモ
オーバーロード
オーバーロードについて学んだことのメモ書きです。
オーバーロードとは
「同名だが、引数の型や数が異なる」メソッド 又は コンストラクタ を 複数記述すること です。
呼び出す場合は、「引数の型 や 引数の数 が 同等」 な メソッド
又は コンストラクタ が呼ばれ処理を行います。オーバーロードのメリット
攻撃を行う「 attack 」、足し算を行う「 Plus 」など、メソッドの名前をわかりやすく、短く命名したかったり、適切な メソッド名が思い浮かばくてもともとあるメソッド名を使いまわしたい場面がでてくるとおもいます。
ですが、「原則的に同名のメソッドは定義することが出来ません。」
例えば、「 計算 」を行う名前の同じメソッドが存在すると、コンピューターが 「どの計算メソッドだよ!」ってわからなくなってしまうためです。ただし、引数の型や個数が違う場合は同名のメソッドがあっても、引数が違えばどれを呼べばいいのかコンピュータが判断できるようになり、同名のメソッドを定義することができます。
「引数 によって最終的な処理結果を変更」したり、「処理の結果にバリエーションをもたせたりすることが可能」ですごく便利。
オーバーロードの使い方
メソッドをオーバーロードする例です。
「 plus 」をいう同名のメソッドを複数記述していますが、与えられる引数の数によって返す値がことなります!public class Sum { public int plus(int a) { return a + 1; } public int plus(int a, int b) { return a + b; } public int plus(int a, int b, int c) { return a + b + c; } }コンストラクタをオーバーロードする例
public class Sum { private int a; private int b; private int c; public Sum(int a) { this.constructor(a, 0, 0); } public Sum(int a, int b) { this.constructor(a, b, 0); } public Sum(int a, int b, int c) { this.constructor(a, b, c); } private void constructor(int a, int b, int c) { this.a = a; this.b = b; this.c = c; System.out.println("abc = " + (this.a + this.b + this.c)); } }デフォルトコンストラクタ
通常、コンストラクタは、そのクラス内に何も記述しなければ デフォルトコンストラクタ が用意されます。
(※コード上にはないが、実処理( new クラス名 )のタイミングで空のコンストラクタ( public Sum() {} )を呼び出している状態となります。オーバーロードを生かしたコンストラクタ
冗長な記述を減らすことで、可読性が高い初期化処理の実現に役立ちます。
ですが、以下の場合はコンパイル時点で エラー「再帰的コンストラクター」 を吐いてしまい、処理を実現することができません。// A public Sum(int a) { this(a, 0, 0); // ←こちらはOK } // B public Sum(int a, int b) { this(a, b, 0); // ←こちらもOK } // C public Sum(int a, int b, int c) { this(a, b, c); // ←こちらを記述したタイミングでエラー }なぜエラーが起きるかというと、
「C自身が、自分のコンストラクタを呼び出すことによる処理の終結が無いから」です!
- A と B → C を呼び出す
- C → Cを呼び出す
結局Cにいきつくため、Cを読み込んだのと同じ状態になり、コンストラクタの処理が終わらない状態になります。
そのため、3つのコンストラクタ内で共通で使用できるメソッドを用意して一つの口で初期化できるようにしています。
例題
フルネームを出力するプログラムを組んでみました。
【fulNameMain.java】
package practice_overlord; public class fullNameMain { public static void main(String[] args) { FullName fullName = new FullName(); String printfullName = fullName.anchorName("ゴール", "D", "ロジャー"); System.out.println(printfullName); } }【FullName.java】
package practice_overlord; public class FullName { public String anchorName(String firstName) { return firstName + 1; } public String anchorName(String firstName, String lastName) { return firstName + " " + lastName; } public String anchorName(String firstName, String middleName, String lastName) { return firstName + " " + middleName + " " + lastName; } }
- 投稿日:2020-11-24T11:50:54+09:00
MavenでJavaプロジェクトを構築する
1.環境
Windows10
JDK8以降
開発環境:VSCode2.プロジェクトのセットアップ
2.1.プロジェクトディレクトリの作成
以下のフォルダ構成を作成する
C:\
└ maven\
└ demo\
└ src\
└ main\
└ java\
└ hello\VSCodeにて
Ctrl+Shift+@を入力してターミナル(PowerShell)を起動する
以下のコマンドでフォルダを作成してVSCodeでフォルダを開く> mkdir C:\maven\demo\src\main\java\hello > code -r C:\maven\demo2.2.モジュールの作成
以下2つのモジュールを作成
src/main/java/hello/HelloWorld.javapackage hello; public class HelloWorld { public static void main(String[] args) { Greeter greeter = new Greeter(); System.out.println(greeter.sayHello()); } }src/main/java/hello/Greeter.javapackage hello; public class Greeter { public String sayHello() { return "Hello world!"; } }3.Mavenビルドのセットアップ
3.1.Mavenのインストール
Apache Maven Projectから最新版のBinary zip archiveをダウンロードして解凍する
(今回は「C:\maven」に"apache-maven-3.6.3-bin.zip"を解凍する)解凍したMavenのbinフォルダをシステム環境変数Pathに追加する(VSCodeのターミナル(PowerShell))
> setx PATH "env:path;C:\maven\apache-maven-3.6.3\bin" > $ENV:Path.Split(";") ~ C:\maven\apache-maven-3.6.3\bin > mvn -version Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f) Maven home: C:\maven\apache-maven-3.6.3\bin\.. Java version: 15.0.1, vendor: Oracle Corporation, runtime: C:\Program Files\Java\jdk-15.0.1 Default locale: ja_JP, platform encoding: MS932 OS name: "windows 10", version: "10.0", arch: "amd64", family: "windows"3.2.pom.xmlを作成
プロジェクトルート(今回の場合は「C:\maven\demo\直下」に
pom.xmlファイルを作成するpom.xml<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.springframework</groupId> <artifactId>maven-test</artifactId> <packaging>jar</packaging> <version>0.1.0</version> <properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> </properties> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.2.4</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>hello.HelloWorld</mainClass> </transformer> </transformers> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>
<modelVersion>:常に4.0.0
<groupId>:プロジェクトが所属するグループまたは組織。
<artifactId>:プロジェクトのライブラリアーティファクト(.jarや.warファイル)に付けられる名前。
<version>:ビルド中のプロジェクトのバージョン。実運用時にはデプロイのたびにアップすると良さそう。
<packaging>:パッケージ方法。4.プロジェクトのビルド
4.1.Java コードをビルドする
以下のコマンドを実行してビルドする
> cd c:\maven\demo > mvn compile [INFO] Scanning for projects... [INFO] [INFO] -------------------< org.springframework:maven-test >------------------- [INFO] Building maven-test 0.1.0 [INFO] --------------------------------[ jar ]--------------------------------- [INFO] (中略) [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 3.567 s [INFO] Finished at: 2020-11-24T11:03:47+09:00 [INFO] ------------------------------------------------------------------------プロジェクトルートフォルダに「target」フォルダが作成され、classファイル等が作成されていることを確認する
以下ようなエラーが出た場合は、カレントディレクトリがプロジェクトルート(pom.xmlファイルが存在するフォルダ)になっていない可能性があるため、正しいフォルダに
cdする。[ERROR] The goal you specified requires a project to execute but there is no POM in this directory (C:\maven\demo). Please verify you invoked Maven from the correct directory. -> [Help 1]4.2.配布用パッケージを作成する
以下のコマンドを実行して配布用パッケージファイル(今回は.jarファイル)を作成する
> mvn package [INFO] Scanning for projects... [INFO] [INFO] -------------------< org.springframework:maven-test >------------------- [INFO] Building maven-test 0.1.0 [INFO] --------------------------------[ jar ]--------------------------------- [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 18.008 s [INFO] Finished at: 2020-11-24T11:26:26+09:00 [INFO] ------------------------------------------------------------------------targetフォルダ直下に
maven-test-0.1.0.jarファイルが作成されていることを確認。
pom.xmlファイルで指定したartifactId+versionがファイル名になっている。4.3.実行確認
jarファイルを実行するとHello world!が表示される。
> java -jar target\maven-test-0.1.0.jar Hello world!参考
- 投稿日:2020-11-24T11:13:21+09:00
【Java】継承についてメモ
継承
継承とは
「もともとあるクラスを利用して、新しいクラスを生み出すこと」です。
オブジェクト指向の勉強でもやりましたが、「このクラスはほとんど同じだけど、ここだけちがいます」っていうクラスをつくるときに使います。スーパークラスとサブクラス
オブジェクト指向的にポケモンで考えてみます。
ポケモンという、「身長、体重、名前、タイプなどのデータをもったもの」のクラスを継承して、ハガネール というクラスを生み出した場合だとということになります。
継承する方法
サブクラスを作成する時、以下のように「 extends スーパークラス名 」を記述して作ります。
そのあとで、以下のように「サブクラス にしか持っていない機能」を記述していきます。class サブクラス名 extends スーパークラス名 { 親クラスと違う処理 ... ...と、指定します。
サブクラス は空っぽの状態でも、すでに親クラスのフィールドとメソッドを引き継いでいて、「スーパークラスとはどこがちがうか」を書き込んでいきます。継承のメリット
主に以下の点が挙げられるかと思います。
- 同じような機能を持つ重複したコードを書かないようになるので、コードの再利用性が高くなる。
- メソッドを追加したり、オーバーライドすることができるので自由に拡張する。
逆に継承をしないデメリット
重複したコードを書くことで、このような問題がズルズルと増えていきます。
- 勘違いやミスやバグやを起こしてしまう可能性があり、メンテンスが難しくなる。
- 「機能の追加」や「改善」が難しくなり拡張性が下がる
効率よく少ないコードでプログラミングしないと、開発がどんどん難しくなり、コードを書くプログラマーにも大きな負担になります。
- 投稿日:2020-11-24T07:30:36+09:00
【Java・SpringBoot・Thymeleaf】エラーメッセージを実装(SpringBootアプリケーション実践編3)
ログインをして、ユーザー一覧を表示するアプリケーションを作成し、
Springでの開発について勉強していきます?
前回のデータバインドに引き続きバインド失敗時のエラーメッセージを実装します前回の記事?
【Java・SpringBoot・Thymeleaf】データバインド(SpringBootアプリケーション実践編2)エラーメッセージを実装
- src/main/resouces配下に
messages.propertiesというファイルを作成- その内に、各フィールドに対応するメッセージを設定する
パターン1
typeMismatch.<ModelAttributeのキー名>.<フィールド名>=<エラーメッセージ>src/main/resources/messages.propertiestypeMismatch.signupForm.age=数値を入力してください typeMismatch.signupForm.birthday=yyyy/MM/dd形式で入力してくださいパターン2
typeMismatch.<フィールド名>=<エラーメッセージ>- 複数のオブジェクトでageやbirthdayというフィールド名を使っていた場合、すべてにメッセージが適用される
src/main/resources/messages.propertiessrc/main/resources/messages.propertiestypeMismatch.age=数値を入力してください(パターン2) typeMismatch.birthday=yyyy/MM/dd形式で入力してください(パターン2)パターン3
typeMismatch.<フィールドのデータ型>=<エラーメッセージ>- 同じデータ型にメッセージが適用される
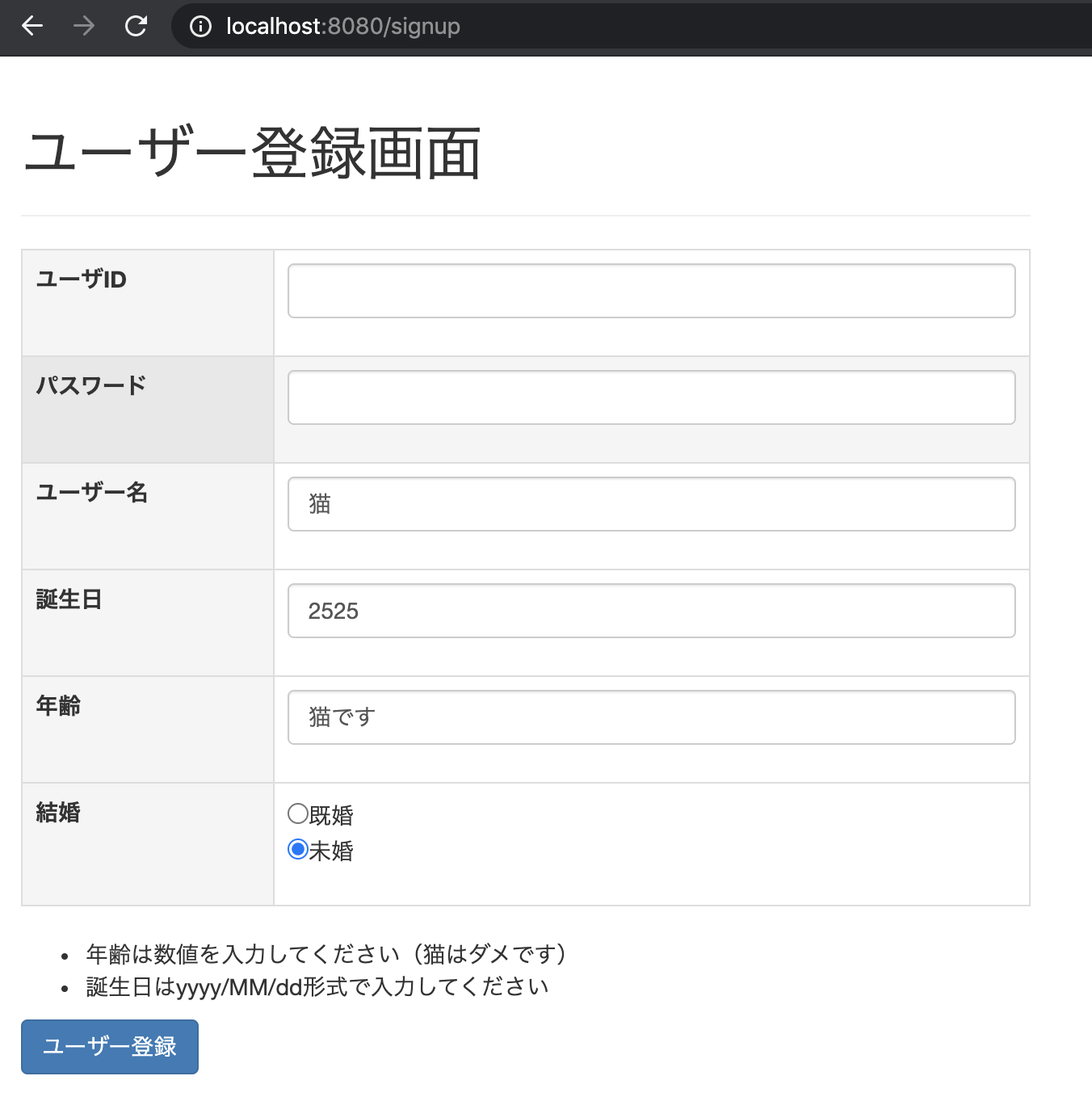
src/main/resources/messages.propertiessrc/main/resources/messages.propertiestypeMismatch.int=数値を入力してください(パターン3) typeMismatch.java.util.Date=yyyy/MM/dd形式で入力してください(パターン3)SpringBootを起動して、ログイン画面を確認!
- http://localhost:8080/login
- ユーザー登録ボタンをクリックするとログイン画面に遷移
- プロパティファイルを作成後、エラー文字列を入れると作成したエラーメッセージが表示されましたo(^_^)o
- 次回はメッセージプロパティファイルを複数用意して切り替える方法を実践します?
- 投稿日:2020-11-24T03:13:33+09:00
Javaでもenumerateが使いたい − 関数型インターフェースとAtomicIntegerとクロージャ
結論
import java.util.concurrent.atomic.AtomicInteger; import java.util.function.Consumer; import java.util.function.Function; import java.util.stream.Stream; import org.junit.Test; public class Test { /** * 単一の入力引数とインデックスを受け取って結果を返さない関数 * @param <T> 引数の型 */ @FunctionalInterface public interface ConsumerWithIndex<T> { public void accept(int i, T t); } /** * 1つの引数とインデックスを受け取って結果を生成する関数 * @param <T> 関数の入力の型 * @param <R> 関数の結果の型 */ @FunctionalInterface public interface FunctionWithIndex<T, R> { public R apply(int i, T t); } /** * 各要素をインデックスとともに処理する関数を作成します * @param <T> オペレーションの入力の型 * @param consumer 関数 * @return 関数 */ public <T> Consumer<? super T> enumerate(ConsumerWithIndex<? super T> consumer) { final AtomicInteger ai = new AtomicInteger(); return t -> consumer.accept(ai.getAndIncrement(), t); } /** * 各要素をインデックスとともに処理する関数を作成します * @param <T> 要素の型 * @param <R> 戻り値の型 * @param function 関数 * @return 関数 */ public <T, R> Function<? super T, R> enumerate(FunctionWithIndex<? super T, R> function) { final AtomicInteger ai = new AtomicInteger(); return t -> function.apply(ai.getAndIncrement(), t); } @Test public void test() { Stream.of("A", "B", "C", "D") .map(enumerate((i, e) -> { System.out.println("[Map] " + i + " : " + e); return e; })) .forEach(enumerate((i, e) -> { System.out.println("[Each] " + i + " : " + e); })); } }出力結果[Map] 0 : A [Each] 0 : A [Map] 1 : B [Each] 1 : B [Map] 2 : C [Each] 2 : C [Map] 3 : D [Each] 3 : Dはじめに
アドベントカレンダー初日ということで軽めの記事を。
ループ中のインデックスが欲しいことってありますよね?
ロジック上必要になることもあれば、デバッグやログとしてインデックスの情報が欲しいということもあると思います。しかしJavaのループ処理中でインデックスを取得したくなった場合、PythonのenumerateやJavaScriptのArray#forEach と比べると書き換えのコストが高いです。
python# インデックスなし for hoge in hogeList: # 処理 # インデックスあり for i, hoge in enumerate(hogeList): # 処理js// インデックスなし hogeList.forEach(hoge => { // 処理 }); // インデックスあり hogeList.forEach((hoge, i) => { // 処理 });Javaでも同様に、新たなインターフェースとメソッドを定義することで容易にループ内でインデックスを取得する方法の解説をしたいと思います。
インデックスを得るための書き換えとその問題点
例えば、以下のようなコードがあったとします。
拡張for文を使ったループ処理for (Hoge hoge : hogeList) { // hoge に対しての処理 }このとき、forの中でインデックスを扱いたい場合、次のように書き換える必要があります
カウンタ変数を使った書き換え(1)for (int i = 0; i < hogeList.size(); i++) { Hoge hoge = hogeList.get(i); // hoge に対しての処理 }カウンタ変数を使った書き換え(2)int i = 0; for (Hoge hoge : hogeList) { // hoge に対しての処理 i++; }
(1)の書き換えについて
この書き方の問題については多くは語りませんが、せっかく拡張for文が実装されているのに(通常の)for文で書くのはもったいないです。
(2)の書き換えについて
こちらは一見問題ないように思えますし、書き換えも比較的容易です。実際、大抵の場合はこの書き方で良いと思います。
しかし問題点もいくつかあります。
- カウンタ変数(
i)のスコープがfor文内に収まっていないこと- for文内に
continueがあった場合に、カウントし忘れてカウントがずれる恐れがあるさらに、Javaにおいてループ処理を書く方法はfor文だけではありません。
Iterable#forEach, Stream#map, Stream#forEach など、引数に関数を受け取るメソッドを利用することも多いです。その場合は(2)のような書き換えを行うことは難しいです。なぜなら、ラムダ式では
finalでないローカル変数を参照することができないためです。Iterable#forEachを使ったループ処理int i = 0; hogeList.forEach(hoge -> { // hoge に対しての処理 i++; // -> error: local variables referenced from a lambda expression must be final or effectively final });一応、ラムダ式を使わずに匿名クラスを用いることで回避は可能ですが、さすがに冗長すぎるのでナシでしょう。
Iterable#forEachを使ったループ処理_匿名クラス利用verhogeList.forEach(new Consumer<>() { int i = 0; @Override public void accept(Hoge hoge) { // hoge に対しての処理 i++; } });解決法と解説
基本的には匿名クラスを用いた例を改善することで問題を解決します。「この例は冗長すぎるためナシ」と言いましたが、冗長性を除けばそれ以外の問題点は解決できています。
これを簡潔に書くことでひとまずの解決法とします。いくつかのステップに分けて解説をしていきます。
関数型インターフェース
冗長性の解決は簡単で、匿名クラスを別メソッドに切ってしまえば良いです。
public <T> Consumer<? super T> enumerate() { return new Consumer<T>() { int i = 0; @Override public void accept(T t) { // インデックスと値を使った処理 i++; } }; }さて、この場合
// インデックスと値を使った処理←この部分を外部から渡してあげる必要があります。
外部から処理を渡すということは関数を渡してあげれば良いわけで、今回はインデックスと値を使うので、2つの引数をとるような関数を渡せるようにしてあげます。public <T> Consumer<? super T> enumerate(BiConsumer<Integer, ? super T> consumer) { return new Consumer<T>() { int i = 0; @Override public void accept(T t) { consumer.accept(i, t); i++; } }; }これで次のように処理を書くことができます。
hogeList.forEach(enumerate((i, hoge) -> { // hoge に対しての処理 }));これでも問題はないですが、
iの型がIntegerであることが気になります。これを回避するために、独自の関数型インターフェースを定義します。@FunctionalInterface public interface ConsumerWithIndex<T> { public void accept(int i, T t); } public <T> Consumer<? super T> enumerate(ConsumerWithIndex<? super T> consumer) { return new Consumer<T>() { int i = 0; @Override public void accept(T t) { consumer.accept(i++, t); } }; }これでも十分に使えます。
Stream#mapなどでも使いたい場合は、最初に示した通り、Functionを返すようなメソッドをオーバーロードしてあげれば良いです。
関数型インターフェースが全くわからないという方は、以前書いたStreamの記事を読んでみてください。これ以外にも「関数型インターフェース」で検索してみると色々な情報や実装例が見つかると思います。
[Java11] Stream まとめ -Streamによるメリット-#関数型インターフェースAtomicInteger
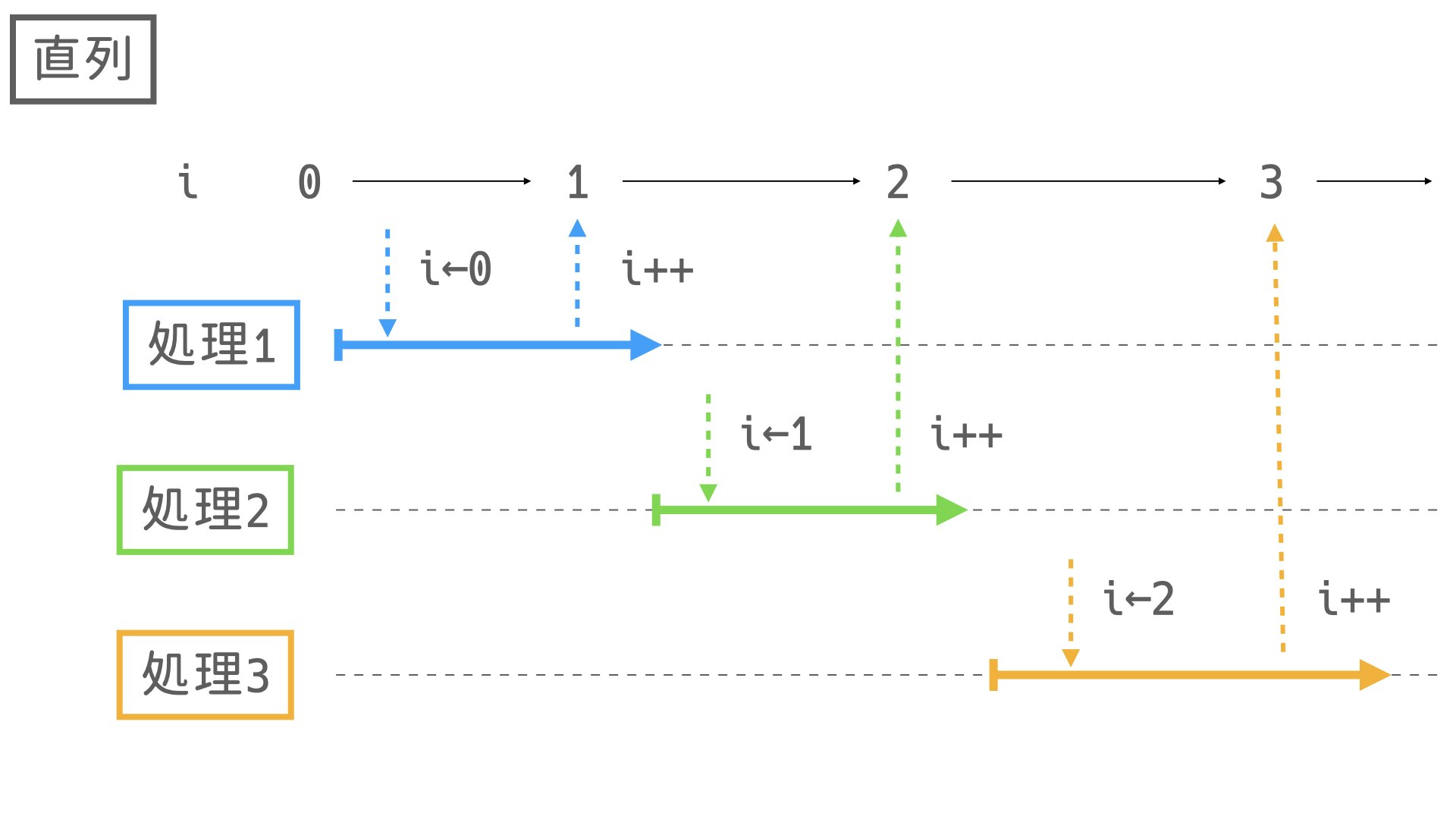
さて、実は上のコードには問題点があります。それは並列処理を行った場合に起きます。
final Long count = IntStream.range(0, 1_000_000).boxed() .map(enumerate((i, n) -> { return i; // インデックスを返す })) .distinct().count(); System.out.println(count);結果1000000至極当然の結果ですが、これを並列処理にすると問題が起きます。
final Long count = IntStream.range(0, 1_000_000).boxed() .parallel() // ← 追加 .map(enumerate((i, n) -> { return i; // インデックスを返す })) .distinct().count(); System.out.println(count);(1回目) 857839 (2回目) 886604 (3回目) 859839このように実行ごとに値が変わってしまいます。
これは並列処理によって、
iの値を取得してからインクリメントするまでに他のスレッドによって書き換えられるために起きます。
イメージしやすいように図を用意しました。
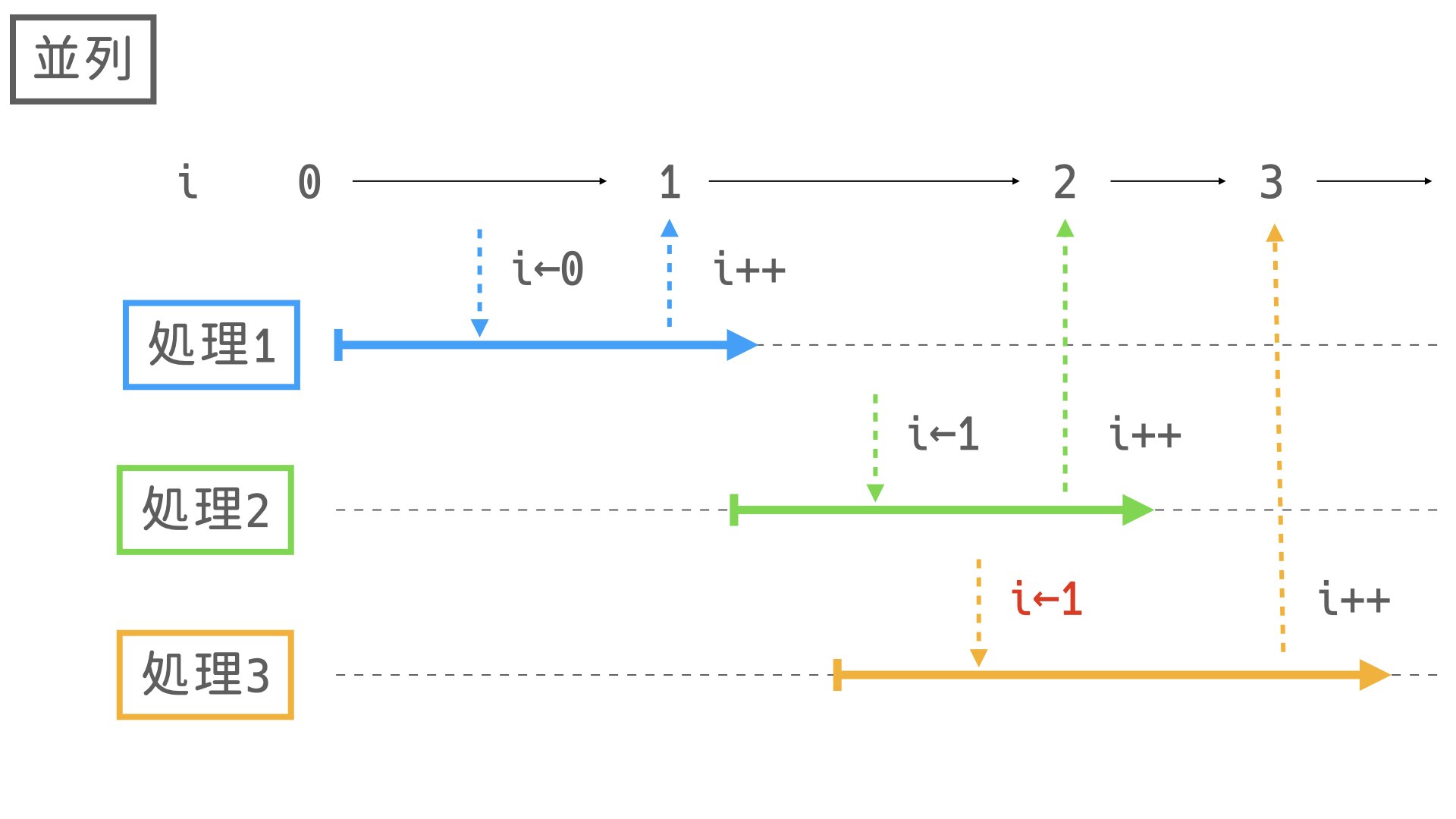
これを回避するために
AtomicIntegerを使用します。AtomicInteger とは
原子的な更新が可能なint値です。
AtomicInteger (Java Platform SE 8 )原子的とは「それ以上分解できない」を意味しており、今回のケースでは値の取得とインクリメントの作業が分解不可能であることを意味しています。
これにより「値を取得してからインクリメントするまでに他のスレッドによって書き換えられる」ということが起き得なくなります。public <T> Consumer<? super T> enumerate(ConsumerWithIndex<? super T> consumer) { return new Consumer<T>() { final AtomicInteger ai = new AtomicInteger(); @Override public void accept(T t) { consumer.accept(ai.getAndIncrement(), t); } }; }以下が動作のイメージです。
パフォーマンス
次のコードを実行して、intとAtomicIntegerでのパフォーマンスを比較します。
final long start = System.currentTimeMillis(); for (int c = 0; c < N; c++) { final Long total = IntStream.range(0, 1_000_000).boxed() .map(enumerate((i, n) -> { return i; // インデックスを返す })) .collect(Collectors.summingLong(i -> i)); } final long end = System.currentTimeMillis(); System.out.println((end - start) + "ms");
計測結果 N=100 N=1,000 N=10,000 int 1029ms 7125ms 68216ms AtomicInteger 1409ms 10758ms 100178ms AtomicIntegerが1.5倍遅いという結果になりました。
そもそもインデックスを扱う場面で並列処理をやりたいことってなくね?というツッコミはさておきこれで並列処理でも問題なく動くようになりました。
動作確認に数百件に1回だけ何か出力するとかの限られたケースでは使えるかもしれない。クロージャ
先の修正でカウンタ変数(
ai)がfinalな変数になりました。つまりラムダ式で書き換え可能になりました。ラムダ式verpublic <T> Consumer<? super T> enumerate(ConsumerWithIndex<? super T> consumer) { final AtomicInteger ai = new AtomicInteger(); return t -> consumer.accept(ai.getAndIncrement(), t); }クロージャとは
クロージャは、組み合わされた(囲まれた)関数と、その周囲の状態(レキシカル環境)への参照の組み合わせです。
クロージャ - JavaScript | MDN今回のケースでは、
(囲まれた)関数 ...t -> consumer.accept(ai.getAndIncrement(), t)
周囲の状態への参照 ...ai
ということになるため、この関数はクロージャであると言えます。Javaのラムダ式はfinalの変数しか参照できないという制限があるためか、クロージャではないという意見もあります。
パフォーマンス的には
AtomicIntegerを使わない書き方の方が良いですが、並列処理をしたい場合やラムダ式でスッキリ書きたい場合はAtommicIntegerを使った書き方をするのが良いと思います。最後に
軽めの記事をと思ったのですが、思ったより長くなってしまいました。
Javaは関数型プログラミングが得意な言語ではないですが、関数型プログラミングの考えを学ぶことで、より良いコードをかける場面というのはままあると思うので、関数型プログラミングを別言語で一度学んでみるのも良いかと思います。

- 投稿日:2020-11-24T03:04:10+09:00
モンティ・ホール問題をJavaで実験してみる
最近統計学に関する本を読んでいます。
その中にモンティ・ホール問題という問題を紹介しています。ちょっと直感に乖離しているの問題なので、プログラミングで実験してみよと思いました。
そのまま書くのもつまらないので、
FunctionalInterfaceやStrategy Patternを使って遊びました。1 問題について軽く
そのままウィキからコピーします。
(1) 3つのドア (A, B, C) に(景品、ヤギ、ヤギ)がランダムに入っている。
(2) プレーヤーはドアを1つ選ぶ。
(3) モンティは残りのドアのうち1つを必ず開ける。
(4) モンティの開けるドアは、必ずヤギの入っているドアである。
(5) モンティはプレーヤーにドアを選びなおしてよいと必ず言う。
2 コードを書く
2.1 Main
まず最終的に実行するMainクラスの部分を書きます。
public class Main { public static void main(String[] args) { // 最後に書く } private static boolean play(ChooseStrategy strategy) { Player player = new Player(strategy); Host host = new Host(); Stage stage = new Stage(); // Player make his first choice stage.doOperation(player::chooseDoor); // System.out.println(stage); // Host open a door stage.doOperation(host::openDoor); // System.out.println(stage); // Player make his second choice stage.doOperation(player::chooseAgain); // System.out.println(stage); return stage.isCorrect(); } }まず
playメソッドを見ていただくと、いくつかのことを行いました。
- プレーヤーを生成します。(ストラテジーを指定します、後で紹介)
- モンティを生成します。(ホスト)
- 三つドアを持っているステージを生成します。
次にゲームのルールに従ってそのまま実行手順を書いてみました。
- プレーヤーはステージに対してドアを選択しました。
- ホストはステージに対して一つのドアを開けました。
- プレーヤーは二回目(選びなおし)の選択を行いました。
- ステージを確認してプレーヤーの選択は当たってるかを返しました。
ストラクチャーは大体できたので、各部分を実装します。
2.2 ChooseStrategy
一回目のチョイスはランダムなのでdefaultでロジックを書きます。
二回目はストラテジーにより異なるので継承先に実装を任せます。/** * 一回目と二回目の選択ストラテジー */ @FunctionalInterface public interface ChooseStrategy { Random random = new Random(); default void chooseFirstTime(List<Door> doors) { doors.get(random.nextInt(doors.size())).setChosen(true); } void chooseSecondTime(List<Door> doors); }2.2.0 Door
上記のストラテジーには
Doorクラスが出ていたのでその中身を紹介します。各ドアの属性は以下の通りです。
ストラテジーはドアリストに対して操作します。@AllArgsConstructor @Data public class Door { int index; // is or not has the price boolean isAnswer; // is or not opened by host boolean isOpened; // is or not chosen by player boolean isChosen; }2.2.1 NotChangeChoiceStrategy
ここはちょっと面白いところですが、
もしプレーヤーは一回目の選択を変えないと決めた場合に何もしなくていいので、
ここも何も実装しなくて大丈夫です。public class NotChangeChoiceStrategy implements ChooseStrategy { @Override public void chooseSecondTime(List<Door> doors) { // do nothing } }2.2.2 ChangeChoiceStrategy
もし選択を変えると決めた場合に、
残りの二つのドアの状態を変えます。まず三つのドアの中に一つのドアが開けられたので除外して、
次に残りの二つのドアの選択状態を切り替えます。public class ChangeChoiceStrategy implements ChooseStrategy { @Override public void chooseSecondTime(List<Door> doors) { doors.stream().filter(d -> !d.isOpened()).forEach(d -> d.setChosen(!d.isChosen())); } }ここまででプレーヤーはどういう方法でドアを選択するかは定義できました。
次にプレーヤー自体を定義します。2.3 Player
めちゃくちゃ簡単ですが、
一回目と二回目の動きは全部ストラテジーにより行います。public class Player { private ChooseStrategy strategy; public Player(ChooseStrategy strategy) { this.strategy = strategy; } public void chooseDoor(List<Door> doors) { strategy.chooseFirstTime(doors); } public void chooseAgain(List<Door> doors) { strategy.chooseSecondTime(doors); } }2.4 Host
ホストは下記コードのようにまず開けるドアを確認してその中にランダムで一つをピックアップして開けます。
public class Host { /** * Host will open the door which does not have the price. * @param doors doors in stage */ public void openDoor(List<Door> doors) { doors = doors.stream().filter(this::canOpen).collect(Collectors.toList()); Collections.shuffle(doors); doors.get(0).setOpened(true); } // if a door is not the answer nor the chosen one, then can be opened. private boolean canOpen(Door door) { return !door.isAnswer() && !door.isChosen(); } }2.5 Stage
まずステージのインスタンスが作られた時に、ステージ内の三つのドアをランダムで生成します。
注目してもらいたいのは
doOperationです。
今回の考え方はステージはあくまでドアを状態を保存する場所で、
一切具体的なオペレーションが入ってないです。なので、ステージはあくまで自分が持っている
doorsをステージに操作したい人(プレーヤー・ホスト)に渡します。
該当の人がステージの定義した操作基準によってステージのドアを操作します。public class Stage { private List<Door> doors; private final Random random = new Random(); public Stage() { this.doors = randomInitDoors(); } private List<Door> randomInitDoors() { int trueIndex = random.nextInt(3); doors = new ArrayList<>(); for (int i = 0; i < 3; i++) { doors.add(new Door(i, i == trueIndex, false, false)); } return doors; } public void doOperation(StageOperation op) { op.doOperation(doors); } public boolean isCorrect() { return this.doors.stream().filter(Door::isAnswer).anyMatch(Door::isChosen); } @Override public String toString() { return "Stage{" + "doors=" + doors + '}'; } }では、
StageOperationについてみてみましょう。2.5.1 StageOperation
先ほどの
ChooseStrategyと似ているけど、
ChooseStrategyに定義された操作は継承先用の基準です。ここで定義された操作は任意のステージを操作したいクラス用のものです。
つまり、ステージを操作したければこのメソッドを実装してくださいの意味です。@FunctionalInterface public interface StageOperation { void doOperation(List<Door> doors); }たぶんここまで行くとわかってると思いますが、
もう一度最初のMainクラスを見ますと:
- player::chooseDoor
- host::openDoor
- player::chooseAgain
は全部暗黙で
StageOperation::doOperationを実現したメソッドです。なぜ
doOperationのパラムがStageOperationを求めているのに、全然違うメソッドを渡しても動作するの原因は、
メソッドのシグネチャが一緒からです。2.6 Main again
TIPS:ここにNotChangeChoiceStrategyを使ってなくて、
ラムダ式を使ってました。こういうふうにわざわざ各ストラテジーを書かずに、
使いたいときにラムダ式で直接定義するのも便利かもですね。public static void main(String[] args) { int count = 3000; int correct = 0; for (int i = 0; i < count; i++) { // we can also use in-line lambda to replace the implemented NotChangeChoiceStrategy // if (play(new NotChangeChoiceStrategy)) { if (play(doors -> {})) { correct++; } } System.out.printf("not change choice: %d / %d = %.2f%%%n", correct, count, correct * 1.0 / count); correct = 0; for (int i = 0; i < count; i++) { if (play(new ChangeChoiceStrategy())) { correct++; } } System.out.printf("change choice: %d / %d = %.2f%%%n", correct, count, correct * 1.0 / count); }ちなみに
ChangeChoiceStrategyもラムダ式で書けるのでぜひやってみてください。3 実行結果
not change choice: 998 / 3000 = 0.33% change choice: 1948 / 3000 = 0.65%やはり選択を変えたほうがいいですね。
- 投稿日:2020-11-24T02:14:55+09:00
【Java】オブジェクト指向メモ
オブジェクト指向
オブジェクト指向とは
「複雑な問題を効率よく解決するため」に生まれた考え方です。
具体的には、、
「作りたいもの(オブジェクト)を、一つ一つの部品に分けて作っていくこと。」
オブジェクト指向を、「ポケモン」に例えてみます。
オブジェクト指向によるゲーム設計をした場合、ポケモンを捕まえる流れを考えると
- 草むらで敵のポケモンと遭遇する
- 自分のポケモンを召喚する
- 戦って体力を減らす
- アイテム欄から「モンスターボール」を使う
- 捕まえたらポケモン図鑑に登録される
とそれぞれ 作業や処理を分担させて、一連の流れを完成 させます。
つまり、「 オブジェクト指向プログラミング 」は、「作業を分担して、様々な処理やデータの組み合わせで一つのものをつくったり、問題の解決を目指したプログラミング」という意味です。
反対に、オブジェクト指向によらない場合は、上記の作業を これら一連の流れをワンセットの処理として作ります。
どちらもそれぞれメリットデメリットがありますが、Javaは「オブジェクト指向型言語」と呼ばれるほど、相性がいいです。
クラス・プロパティ・メソッドを理解する
これら3つの理解は、オブジェクト指向を理解する上で避けては通れません。
これら3つを「
ポケモン」で例えるとこのような考え方になります。クラス
プロパティやオブジェクトをひとまとめにしたもの。
このポケモンは「 このようなデータをもっていて、こんな事ができる 」と書いたもので、
出来上がるものが「 オブジェクト 」なのに対し、「 クラスは設計図 」のようなもの。プロパティ
オブジェクトが持っているデータ。
ポケモンだと「No, 名前, 分類, タイプ, 高さ, 重さ...」といった情報をそれぞれ持っていて、それらの情報のことを指す。メソッド
ポケモンが「 攻撃する 」、「 鳴く 」、「 逃げる 」 などオブジェクトが持っている処理。
オブジェクト指向の概念
またもポケモンで例えてみます。
ポケモンには ピカチュウ、ケンタロス、ルージュラのようにいろいろな種類のポケモンがいます。どのキャラも全て「ポケモン」なので、「ポケモンクラス」をもとに継承されています。
Pokemon.java(ポケモンクラス)
package objectOriented; public class Pokemon { private int number = 0; // ナンバー private String name = null; // なまえ private String category = null; // ぶんるい private String type1 = null; // タイプ1 private String type2 = null; // タイプ2 private double height = 0; // たかさ private double weight = 0; // おもさ private String description = null; // せつめい private String sing = null; // なきごえ private int vitality = 0; // たいりょく // 戦闘ステータス // private int hit_point = 0; // private int power_point = 0; // private int sp_power_point = 0; // private int defense_point = 0; // private int sp_defense_point = 0; // private int speed_point = 0; // private String condition = null; // 状態ステータス String[] status_abnomal = { "", "どく", "まひ", "やけど", "こおり", "ねむり" }; // コンストラクタ public Pokemon() { } // 【START】getter setter ================= // getter・setter(ナンバー) public int getNumber() { return number; } public void setNumber(int number) { this.number = number; } // getter・setter(なまえ) public String getName() { return name; } public void setName(String name) { this.name = name; } // getter・setter(ぶんるい) public String getCategory() { return category; } public void setCategory(String category) { this.category = category; } // getter・setter(タイプ1) public String getType1() { return type1; } public void setType1(String type1) { this.type1 = type1; } // getter・setter(タイプ2) public String getType2() { return type2; } public void setType2(String type2) { this.type2 = type2; } // getter・setter(たかさ) public double getHeight() { return height; } public void setHeight(double height) { this.height = height; } // getter・setter(おもさ) public double getWeight() { return weight; } public void setWeight(double weight) { this.weight = weight; } // getter・setter(せつめい) public String getDescription() { return description; } public void setDescription(String description) { this.description = description; } // getter・setter(たいりょく) public int getVitality() { return vitality; } public void setVitality(int vitality) { this.vitality = vitality; } // getter・setter(なきごえ) public String getSing() { return sing; } public void setSing(String sing) { this.sing = sing; } // 【END】getter setter =================== }Pikachu.java(ピカチュウクラス)
package objectOriented; //ポケモンクラスを継承したクラスで、「10万ボルト」が使える。 public class Pikachu extends Pokemon { // コンストラクタ public Pikachu() { super.setNumber(025); super.setName("ピカチュウ"); super.setCategory("ねずみ"); super.setType1("でんき"); super.setHeight(0.4); super.setHeight(6.0); super.setDescription("つくる でんきが きょうりょくな ピカチュウほど ほっぺの ふくろは やわらかく よく のびるぞ"); super.setVitality(50); super.setSing("ピカァ!"); } public void bolt_thousand_10(Pokemon target) { String name = super.getName(); System.out.println(name + " の 10まんボルト!"); target.setVitality(target.getVitality() - 50); System.out.println(target.getName() + " に 50 のダメージ!"); } }kentaros.java
package objectOriented; //最強のポケモン。ポケモンクラスを継承したクラスで、「はかいこうせん」が使える。 public class Kentaros extends Pokemon { // コンストラクタ public Kentaros() { super.setNumber(128); super.setName("ケンタロス"); super.setCategory("あばれうしポケモン"); super.setType1("ノーマル"); super.setHeight(1.4); super.setHeight(88.4); super.setDescription("しっぽで じぶんの からだを たたきだしたら きけんだぞ。 もうスピードで つっこんでくる。"); super.setSing("gyyyyoooorrrp"); } // はかいこうせん メソッド public void destruction_beam(Pokemon target) { String name = super.getName(); System.out.println(name + " の はかいこうせん!"); target.setVitality(target.getVitality() - 50); System.out.println(target.getName() + " に 50 のダメージ!"); System.out.println(name + " はこうげきのはんどうでうごけない!"); } }Main.java(プログラムの主処理を行う)
package objectOriented; public class Main { public static void main(String[] args) { Pikachu pikachu = new Pikachu(); // ピカチュウ オブジェクトを生成 Kentaros kentaros = new Kentaros(); // ケンタロス オブジェクトを生成 // 野生のケンタロスと遭遇 System.out.println("あ! やせいの" + kentaros.getName() + "があらわれた!"); System.out.println("ゆけっ!" + pikachu.getName() + "!"); printSing(pikachu); System.out.println(); // ピカチュウ printDate(pikachu); pikachu.bolt_thousand_10(kentaros);// 10万ボルト System.out.println(); // ケンタロス printDate(kentaros); kentaros.destruction_beam(pikachu);// はかいこうせん } // データを見る private static void printDate(Pokemon target) { System.out.println("No." + target.getNumber()); System.out.println(target.getName()); System.out.println(target.getCategory() + "ポケモン"); System.out.println(target.getType1() + "タイプ"); System.out.println(target.getType2() + "タイプ"); System.out.println("たかさ: " + target.getHeight() + "m"); System.out.println("おもさ: " + target.getWeight() + "kg"); System.out.println(target.getDescription()); } // 鳴き声を出力。 public static void printSing(Pokemon target) { System.out.println("「" + target.getSing() + "」"); } }実行結果
あ! やせいのケンタロスがあらわれた! ゆけっ!ピカチュウ! 「ピカァ!」 No.21 ピカチュウ ねずみポケモン でんきタイプ nullタイプ たかさ: 6.0m おもさ: 0.0kg つくる でんきが きょうりょくな ピカチュウほど ほっぺの ふくろは やわらかく よく のびるぞ ピカチュウ の 10まんボルト! ケンタロス に 50 のダメージ! No.128 ケンタロス あばれうしポケモンポケモン ノーマルタイプ nullタイプ たかさ: 88.4m おもさ: 0.0kg しっぽで じぶんの からだを たたきだしたら きけんだぞ。 もうスピードで つっこんでくる。 ケンタロス の はかいこうせん! ピカチュウ に 50 のダメージ! ケンタロス はこうげきのはんどうでうごけない!Pokemonクラス
こちらには、ポケモンのベースとなるステータスのの設定をしてあります。
各プロパティは公開範囲が private なので、データを参照したり変更したりするには、
setName 、 getName といった setter 、 getter と呼ばれるメソッドを使う必要があります。Pikachu, kentarosクラス
extends PokemonでPokemonクラスを継承して、ポケモンが共通で持つデータをそのまま利用しています。
このように、必要最低限の「共通する基本情報」を用意しておくと、Pokemonクラスの汎用性が高まります。はかいこうせんメソッド、10万ボルトメソッドを
継承したポケモンの動作に加えて、それぞれ固有の攻撃メソッドを持ってます。「継承 + 独自のメソッドやプロパティ」を実装することで、継承したクラスに付加価値をつけることが出来ます。コンストラクタによる初期設定
各キャラクターは コンストラクタ により、身長、体重、体力などの初期設定が可能です。
オブジェクトを最初に生成する際に実行されるため、 初期設定 をするのに適しています。オブジェクト指向的に設計しない場合のデメリット
結論以下のようなことが挙げられます。
1. コードが見づらい
Pokemonクラスを継承せずに、毎回ステータスを記述しても結果は変わりませんが、コードが非常に長くなり、見づらいコードとなってしまいます。
2. 機能を増やすときの手間が増える
アップデートされた時にポケモンの数が大幅に追加することになッタと仮定します。
【ポケモンごとに Pokemon メソッドを記述していた場合】
新しいキャラクターには機能追加と Pokemon メソッドの記述が必要
【オブジェクト指向的な記述がされていた場合】
機能を追加するだけで完了。3. 修正漏れが起きやすい。
ポケモンの基本動作に、ポケモンセンターに行くと、状態異常、体力全回復する 「休む」機能をつけるのを忘れていました。
キャラクターごとに Pokemon メソッドを記述していた場合、一個一個に「休む」メソッドを記述し修正しなければいけませんが、
オブジェクト指向的に記述していれば、Pokemonクラスに「寝る」というメソッドを一回記述すれば修正完了です。