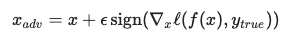- 投稿日:2020-11-18T19:01:42+09:00
TensorFlowの動作確認環境をDockerで構築する
やりたいこと
TensorFlowのDockerイメージをダウンロード
https://www.tensorflow.org/install/docker?hl=ja
して、コンテナを起動し、tensorflowの動作を確認したい。前提
- 任意のホストにDockerがインストール済であること。
- Dockerコマンドが使えること。
Dockerのインストール手順は
https://qiita.com/kenichiro-yamato/items/7e3cb21613784a27409d事前確認
バージョン
[root@docker ~]# docker -v Docker version 19.03.7, build 7141c199a2稼働中のコンテナ
[root@docker ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMESdocker pull でイメージを取得する
docker pull tensorflow/tensorflow結果
[root@docker ~]# docker pull tensorflow/tensorflow Using default tag: latest latest: Pulling from tensorflow/tensorflow 171857c49d0f: Pull complete 419640447d26: Pull complete 61e52f862619: Pull complete 40085aa86d3c: Pull complete b827fdfa00c7: Pull complete 134f84527676: Pull complete e1f30e7788ed: Pull complete a13925316d82: Pull complete 5decca4d86ff: Pull complete 70c56a3cd1fa: Pull complete Digest: sha256:c57fb9628d80872ece8640a22bd0153b2cc8d62d21d79f4d99c3b237a728b62e Status: Downloaded newer image for tensorflow/tensorflow:latest docker.io/tensorflow/tensorflow:latestイメージが取得できたことを確認
[root@docker ~]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE tensorflow/tensorflow latest 623195db36df 7 weeks ago 1.46GBdocker run でコンテナを起動する
メモリ指定、ポート指定、ホスト指定、共有ディレクトリ指定など、オプション指定は任意で変えてください。
docker run -m 4096m -p 80:80 -d --privileged -h yamato.host -i -t -v /root/share:/share:rw --name tensorflow_container1 tensorflow/tensorflowコンテナの起動を確認して接続する
[root@docker ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 62f578fc0279 tensorflow/tensorflow "/bin/bash" 11 seconds ago Up 10 seconds 0.0.0.0:80->80/tcp tensorflow_container1docker exec -it tensorflow_container1 /bin/bash
でtensorflow_container1に接続する。
[root@docker ~]# docker exec -it tensorflow_container1 /bin/bash ________ _______________ ___ __/__________________________________ ____/__ /________ __ __ / _ _ \_ __ \_ ___/ __ \_ ___/_ /_ __ /_ __ \_ | /| / / _ / / __/ / / /(__ )/ /_/ / / _ __/ _ / / /_/ /_ |/ |/ / /_/ \___//_/ /_//____/ \____//_/ /_/ /_/ \____/____/|__/接続成功。
初期状態の確認
既にpython3とpipが使える状態になっている。
root@yamato:~# python -V Python 3.6.9root@yamato:~# pip Usage: pip <command> [options]vimが入っていないのでインストールする。
apt-get updateしてから
apt-get install vimで、vimが使えるようになる。
pyファイルを作成して試す
vim test.py
print ("Hello World! I am Kenichiro Yamato")実行する。
python test.pyで
Hello World! I am Kenichiro Yamatoが表示されたらOK。
tensorflow のサンプルコードを試す
vi sample.py
import tensorflow as tf mnist = tf.keras.datasets.mnist (x_train, y_train),(x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation=tf.nn.relu), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ]) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) model.fit(x_train, y_train, epochs=5) model.evaluate(x_test, y_test)実行する。
python sample.pyワーニングやインフォメーションがいくつか出ているが、動作している模様。
2020-11-18 10:00:09.352555: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'libcudart.so.10.1'; dlerror: libcudart.so.10.1: cannot open shared object file: No such file or directory 2020-11-18 10:00:09.352579: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine. 2020-11-18 10:00:10.743602: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'libcuda.so.1'; dlerror: libcuda.so.1: cannot open shared object file: No such file or directory 2020-11-18 10:00:10.743630: W tensorflow/stream_executor/cuda/cuda_driver.cc:312] failed call to cuInit: UNKNOWN ERROR (303) 2020-11-18 10:00:10.743654: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:156] kernel driver does not appear to be running on this host (yamato.host): /proc/driver/nvidia/version does not exist 2020-11-18 10:00:10.743940: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN)to use the following CPU instructions in performance-critical operations: AVX2 To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags. 2020-11-18 10:00:10.752038: I tensorflow/core/platform/profile_utils/cpu_utils.cc:104] CPU Frequency: 3599995000 Hz 2020-11-18 10:00:10.752747: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x4e64770 initialized for platform Host (this does not guarantee that XLA will be used). Devices: 2020-11-18 10:00:10.752763: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version Epoch 1/5 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2193 - accuracy: 0.9347 Epoch 2/5 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0972 - accuracy: 0.9705 Epoch 3/5 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0676 - accuracy: 0.9789 Epoch 4/5 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0525 - accuracy: 0.9831 Epoch 5/5 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0423 - accuracy: 0.9862 313/313 [==============================] - 0s 1ms/step - loss: 0.0640 - accuracy: 0.9801
- 投稿日:2020-11-18T19:01:37+09:00
日英翻訳の作り方
日英翻訳の作り方
日英翻訳をtensorflowとkerasで実装していきます。
この記事の目次です。
1. 環境やデータセットの詳細
2. 基本的な流れ
3. データの前処理
4. モデル構築
5. 学習
6. 評価コードの詳細はgithubで公開していますので、参考にしてください。
Japanese-English_Translation
.pyinbで保存しているので、google colabで気軽に動かせるようになっています。
大昔に自然言語処理の勉強した際のコードを公開します。(少し整理したものを公開)お役に立てれば、幸いです。
環境やデータセットの詳細
ハードウェアの環境
gooble colabソフトウェアの環境
python3
tensorflow (version2.3.1)データセット
small_parallel_enjasmall_parallel_enjaは、田中コーパスからいくつかの文章を抽出した小さなデータセットです。
前処理がなされており、すごく使いやすいものになっています。
データセットを学習データと検証データ、テストデータの3つに分割しているので、分割する必要もありません。
リソースに余裕があるのでしたら、学習データと検証データを混ぜたものを学習データとして、交差検証を行っても良いのかもです。(GPUを複数台所持の方)基本的な流れ
以下の流れで進んでいきます。
1. データの前処理
2. モデル構築
3. 学習
4. 評価
まあ、普通ですねww
データの前処理
データの前処理は済んでるものを使用するので、結構楽です。
トークナイズは、tensorflowに組み込まれているkerasのAPIを使用します。
tf.keras.preprocessing.text.Tokenizer使い方は、結構簡単で、以下に例を示します。
tokenizer = tf.keras.preprocessing.text.Tokenizer(oov="<unk>") tokenizer.fit_on_texts(texts) sequences = tokenizer.texts_to_sequences(texts)tf.keras.preprocessing.text.Tokenizerのインスタンスを生成して、
そのインスタンスに使用する単語をfit_on_texts(texts)で教えてあげます。
これを行うことにより、ユニークな単語を内部で管理します。
その後、tokenizer.texts_to_sequences(texts)でそれぞれの文章を数値化すれば良いだけです。textsとは、テキストデータセットのことを指します。textsのフォーマットは、文字列のリストになっている必要があります。texts = ["I am Niwaka", "Hello !", .., "Wow !"]上のコードは、tf.keras.preprocessing.text.Tokenizerインスタンスに渡すtextsのフォーマット例です。
使い方は、
tf.keras.preprocessing.text.Tokenizer
上のリンクへ飛べば分かります。ミニバッチ化による学習を行うために、ミニバッチ内でのデータの形状が一致しないといけません。
しかし、自然言語データは一般的に可変長です。
そのため、他のデータセットと違い工夫しなければなりません。可変データを扱うには以下の2通りの方法が考えられます。
1.padding
2.バッチサイズを1にする(時系列長が数百レベルなら、こっちを使用するのかな?)ここでは、1のpaddingを使用します。
paddingとは、ミニバッチ内での最大時系列長がLだとすると、それに満たさないデータに対しては特殊な値を埋めることで長さをLにする手法のことです。tensorflowとkerasでは0が特殊な値として、設定されるようです。例えば、以下のような長さが統一されていないデータセットがあったとしましょう。
sequences = [ [12, 45], [3, 4, 7], [4], ]上のデータセットの最大長は3です。paddingを行うと以下のようになります。
padded_sequences = [ [12, 45, 0], [3, 4, 7], [4, 0, 0], ]tensorflowでは、textデータに対するpadding処理をtf.keras.preprocessing.sequence.pad_sequencesというAPIで提供しています。
使い方は、tf.keras.preprocessing.sequence.pad_sequencesに長さを統一したいデータセットを入力として与えるだけです。
padding引数は、後に0を埋めるか前に0を埋めるかの指定を行います。"post"を指定することで、あと埋めで0を埋めます。お好みで良いと思います。padded_sequences = tf.keras.preprocessing.sequence.pad_sequences(sequences, padding="post")これで、ミニバッチ化による学習を行うことができるようになりました。しかし、ここで問題があります。それは0をモデルがどう解釈するかという問題です。
できれば、0という特殊な値は無視できるようにしたいところですよね。でないと、可変長に対応できるRNNを使用する意味が薄れます。
tensorflowでは、Maskingと呼ばれる機能が用意されています。
Maskingとは、指定したステップ時の値を無視する機能のことです。これにより、可変長のデータをまとめて取り扱うことができます。(Maskingを使わずとも、可変長のデータを取り扱えますが、0という特殊な値もモデルに取り込まれることになります。そういうのは気持ち悪いので、避けたいです。)詳しくは以下のリンクへ飛んでください。リンク先では、tensorflowとkerasにおけるMakingとPaddingの使い方についての解説が詳細に書かれております。
Masking and padding with Kerastensorflowでは、Maskingは以下の方法で有効になります。
1.tf.keras.layers.Maskingを加える
2.tf.keras.layers.Embeddingの引数mask_zeroをTrueにする。
3.maskを利用するLayerに直接渡す。(これは愚直なやり方、動画などにはこれを使用するのかも)ここでは、2を使用します。
今回使用するモデルでは、Embeddingによって自動でmaskが生成され、そのmaskが次のレイヤーに自動的に伝搬していきます。
モデル構築
モデルには、Seq2Seqモデルを使用します。
Seq2Seqとは、
Sequenceデータを別の何かしらのSequenceデータに変換するモデルのことです。
ここでいうSequenceデータとは、時系列データのことです。Seq2Seqのインターフェースは、
変換後のsequence = Seq2Seq(変換前のsequence)です。
例えば、"私は学生です。"をSeq2Seqモデルに入力したとします。
"I am student ." = Seq2Seq("私は学生です。")Seq2Seqは、2つのモジュールで構成されています。
1つがEncoder、2つめがDecoderです。
EncoderによってSequenceデータをエンコードし、人間には理解できない特徴量を出力します。
Decoderにそれとstartトークンを入力し、別の何かしらのSequenceデータを得ます。
ここで、startトークンとはsequenceの始まりを意味する特別な単語です。以下にEncoderとDecoderのインターフェースを疑似言語で記述しました。
人間には理解できない特徴量 = Encoder(変換前のsequence) 変換後のsequence = Decoder(人間には理解できない特徴量、<start>トークン)それぞれのモジュールでは、RNNを使用しております。具体的な仕組みは
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
の最初の方を読めば分かるはずです。この記事は、attentionに関する記事なのですが、Seq2Seqの説明も書かれています。Seq2SeqではRNNを利用します。
RNNは、可変長データを取り扱うことができるので、自然言語を処理するのが得意です。加えて、各ステップで使用する重みは共有するので、パラメータの増加を抑えることができます。
ただし、あまりにも時系列長が長いデータは誤差逆伝播時に、勾配消失や勾配爆発につながるので注意ですね。
時系列長がたったの10でも、時間軸上に10層のレイヤーが展開されるのと同じことになります。
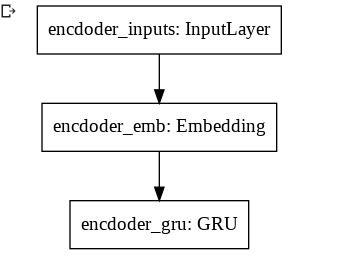
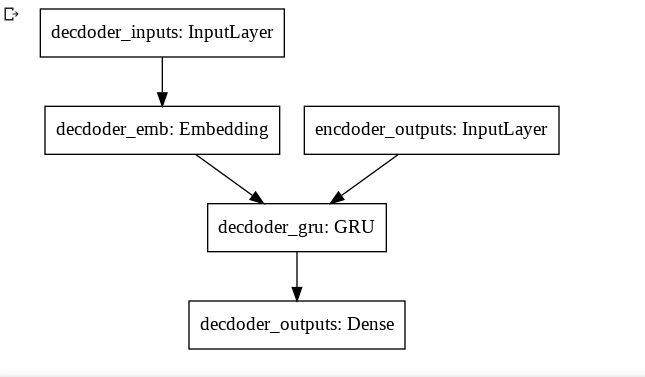
RNNにはGRUを採用しました。GRUは勾配消失を起こしづらいRNN系のモデルです。今回使用するdecoderとencoderのモデル図は以下です。
図1 encoder
図2 decoderEncoderとDecoderそれぞれでRNNを1つしか使用していないです。
データセットが小さいので、小さめのモデルにしました。tensorflowとkerasを用いたコードが以下になります。
The Functional APIを利用しています。
可変長データを表したい時は、tf.keras.InputのshapeにNoneと指定すると良いです。The Functional APIの使い方は、以下のリンクへ飛んでください。
The Functional API
以下は、モデル実装コードになります。modelとencoderとdecoderそれぞれ用意しています。
modelは、学習用に用意しました。model.fitで学習を行い得られたパラメータをencoderとdecoderに読み込んでいきます。学習時と推論時では、処理が異なります。def CreateEncoderModel(vocab_size): units = 128 emb_layer = tf.keras.layers.Embedding(vocab_size, units, mask_zero=True)#padding有効にするために、mask_zero=True gru_layer = tf.keras.layers.GRU(units) encoder_inputs = tf.keras.Input(shape=(None,)) outputs = emb_layer(encoder_inputs) outputs = gru_layer(outputs) encoder = tf.keras.Model(encoder_inputs, outputs) return encoder def CreateDecoderModel(vocab_size): units = 128 emb_layer = tf.keras.layers.Embedding(vocab_size, units, mask_zero=True)#padding有効にするために、mask_zero=True gru_layer = tf.keras.layers.GRU(units, return_sequences=True) dense_layer = tf.keras.layers.Dense(vocab_size, activation="softmax") decoder_inputs = tf.keras.Input(shape=(None,)) encoder_outputs = tf.keras.Input(shape=(None,)) outputs = emb_layer(decoder_inputs) outputs = gru_layer(outputs, initial_state=encoder_outputs) outputs = dense_layer(outputs) decoder = tf.keras.Model([decoder_inputs, encoder_outputs], outputs) return decoder def CreateModel(seed, ja_vocab_size, en_vocab_size): tf.random.set_seed(seed) encoder = CreateEncoderModel(ja_vocab_size) decoder = CreateDecoderModel(en_vocab_size) encoder_inputs = tf.keras.Input(shape=(None,)) decoder_inputs = tf.keras.Input(shape=(None,)) encoder_outputs = encoder(encoder_inputs) decoder_outputs = decoder([decoder_inputs, encoder_outputs]) model = tf.keras.Model([encoder_inputs, decoder_inputs], decoder_outputs) model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False), metrics=['accuracy']) return model, encoder, decoder学習
バッチサイズ32, 64, 128で探索してみます。
実験の設定を以下に示します。
1.RNNのunit数は128
2.重みの更新方法はAdam(学習率はデフォルトのまま)
3.epoch数は2
4.評価方法はBLEUエポックを2回で止め、2エポック目のモデルで、検証データに対する評価を行いました。
BLEUとは、翻訳の品質測定に使われる指標のことです。以下は学習コードです。
bleu_scores = [] batch_size_list = [32, 64, 128] for batch_size in batch_size_list: model, encoder, decoder = CreateModel(seed, len(ja_tokenizer.word_index)+1, len(en_tokenizer.word_index)+1) model.fit([train_ja_sequences, train_en_sequences[:, :-1]], train_en_sequences[:, 1:], batch_size=batch_size, epochs=2) model.save(str(batch_size)+"model.h5") encoder.load_weights(str(batch_size)+"model.h5", by_name=True) decoder.load_weights(str(batch_size)+"model.h5", by_name=True) bleu_score = Evaluate(valid_ja, valid_en, encoder, decoder) bleu_scores.append(bleu_score)Evaluate関数で、BLEUの測定を行なっています。(実装はgithubで公開しています。)
各バッチサイズを名前に用いて、モデル保存を行いました。Decode方法は、各ステップの最大確率となる単語を出力としました。
貪欲に単語を決めていきました。(貪欲法)
本当は、Beam Searchを使ったほうが良いです。Beam Searchは、貪欲法の条件を少し緩めた探索アルゴリズムになります。
貪欲に各ステップの単語を決めても、それが最適解になるかどうかは分からないので、Beam Searchを使用したほうがいいです。
Beam Searchは、以下の説明が参考になります。
C5W3L03 Beam Search
リンク先は動画になっているので、時間に余裕があるときに観ると良いです。kerasでは、loss値を求める際にmaskを適用しているのかどうか気になります。
適用されているという話を聞いたことがあるのですが、そこんところどうなっているのか実装を知らないので、よく分かりません。気持ち悪いと感じるならば、Neural machine translation with attentionのコスト関数の実装が参考になります。ただし、リンク先の実装はmodel.fitでしか学習を行なった経験しかない人にとっては結構難しいものになっていますので、注意してください。
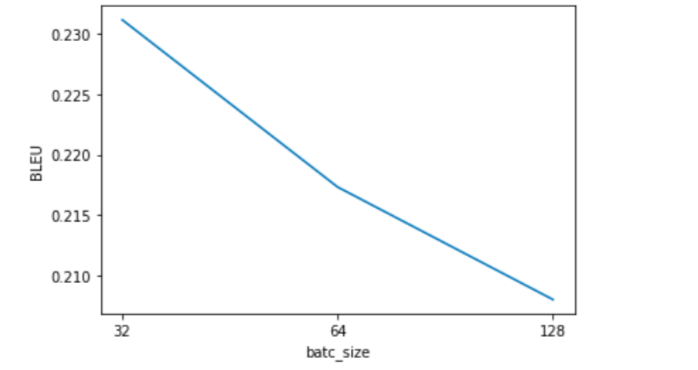
リンク先のコスト関数の実装は、maskするステップ時のコストを最終的なコストに計上しないように実装しています。実験結果をグラフにしました。
図3 実験結果画像が荒いですが、ご了承ください。
検証データに対する最も良いBLEUを得られたバッチサイズは32なので、32を使用して、再学習を行います。
図3を見る限り、バッチサイズを更に小さくすると、より良い結果が得られるかもです。
評価に入る前に、学習データと検証データを混ぜて、再学習しておきます。
再学習では、epoch数を10にしました。それ以外は同じです。train_and_valid_ja_sequences = tf.concat([train_ja_sequences, valid_ja_sequences], 0) train_and_valid_en_sequences = tf.concat([train_en_sequences, valid_en_sequences], 0) best_model, best_encoder, best_decoder = CreateModel(seed, len(ja_tokenizer.word_index)+1, len(en_tokenizer.word_index)+1) best_model.fit([train_and_valid_ja_sequences, train_and_valid_en_sequences[:, :-1]], train_and_valid_en_sequences[:, 1:], batch_size=32, epochs=10) best_model.save("best_model.h5")GPUを使用している場合、同じ結果が得られるとは限らないです。
評価
テストデータに対するBLEU0.19でした。(最大が1)
他と比較していないので分かりませんが、結構酷い結果だと思いますwwwテストデータに対する処理のコードは、以下になります。
best_encoder.load_weights("best_model.h5", by_name=True) best_decoderbest_decoder.load_weights("best_model.h5", by_name=True) bleu_score = Evaluate(test_ja, test_en, best_encoder, best_decoder) print("bleu on test_dataset:") print(bleu_score)素朴な疑問なのですが、BLEU評価方法はいくつか存在するようです。(smoothing_functionはいくつか存在するようです。)
統一されていなそうなのですが、そこのところ詳しい方教えてください。
統一されていないのでしたら、最も上手くいくsmoothing_functionでBLEUを測定すれば良いことになります…これはアリなのでしょうか?…最後に
精度を上げる方法をいくつか紹介して、この記事の終わりとします。
1.入力データを反転する
2.attentionをモデルに組み込む
3.stop_wordを用いる。
4.アンサンブル
5.層を深くする(その際、skip connectionを使うことを忘れないように)
6.Embedding層と全結合層の重みを共有する
7.Transformerにモデル変更
8.重みの初期値設定方法を変更ネットで検索すればいくらでも見つかりそうなものを列挙しました。使ったからといって、BLEUが向上するとは限りません。
興味があれば、Google先生に聞いてみてください。自然言語処理初心者なので、間違ったやり方などがありましたら、教えてくださると嬉しいです。
参考文献
1.small_parallel_enja
2.Masking and padding with Keras
3.The Functional API
4. Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
5.Neural machine translation with attention
6.C5W3L03 Beam Search
- 投稿日:2020-11-18T17:43:14+09:00
Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-build-q9rtk_fz/grpcio/ の対処法
やりたいこと
CentOS7+Python3.6.8の環境にて
pip3でtensorflowを入れてから、kerasを入れたい。現象
pip3 install --upgrade tensorflowを実行すると、
Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-build-q9rtk_fz/grpcio/が発生する。
対策
下記を実行する。
pip3 install --upgrade pip
pip3 install --upgrade pip WARNING: Running pip install with root privileges is generally not a good idea. Try `pip3 install --user` instead. Collecting pip Downloading https://files.pythonhosted.org/packages/cb/28/91f26bd088ce8e22169032100d4260614fc3da435025ff389ef1d396a433/pip-20.2.4-py2.py3-none-any.whl (1.5MB) 100% |################################| 1.5MB 1.3MB/s Installing collected packages: pip Successfully installed pip-20.2.4その後、
pip3 install --upgrade tensorflow
pip3 install --upgrade tensorflow WARNING: pip is being invoked by an old script wrapper. This will fail in a future version of pip. Please see https://github.com/pypa/pip/issues/5599 for advice on fixing the underlying issue. To avoid this problem you can invoke Python with '-m pip' instead of running pip directly. Collecting tensorflow Downloading tensorflow-2.3.1-cp36-cp36m-manylinux2010_x86_64.whl (320.4 MB) |################################| 320.4 MB 33 kB/s Collecting termcolor>=1.1.0 Using cached termcolor-1.1.0.tar.gz (3.9 kB) Collecting absl-py>=0.7.0 Using cached absl_py-0.11.0-py3-none-any.whl (127 kB) Collecting google-pasta>=0.1.8 Using cached google_pasta-0.2.0-py3-none-any.whl (57 kB) Collecting numpy<1.19.0,>=1.16.0 Downloading numpy-1.18.5-cp36-cp36m-manylinux1_x86_64.whl (20.1 MB) |################################| 20.1 MB 38.1 MB/s Collecting protobuf>=3.9.2 Using cached protobuf-3.14.0-cp36-cp36m-manylinux1_x86_64.whl (1.0 MB) Collecting h5py<2.11.0,>=2.10.0 Downloading h5py-2.10.0-cp36-cp36m-manylinux1_x86_64.whl (2.9 MB) |################################| 2.9 MB 85.8 MB/s Collecting tensorboard<3,>=2.3.0 Downloading tensorboard-2.4.0-py3-none-any.whl (10.6 MB) |################################| 10.6 MB 59.7 MB/s Collecting grpcio>=1.8.6 Downloading grpcio-1.33.2-cp36-cp36m-manylinux2014_x86_64.whl (3.8 MB) |################################| 3.8 MB 18.3 MB/s Collecting gast==0.3.3 Downloading gast-0.3.3-py2.py3-none-any.whl (9.7 kB) Collecting wheel>=0.26 Downloading wheel-0.35.1-py2.py3-none-any.whl (33 kB) Collecting wrapt>=1.11.1 Using cached wrapt-1.12.1.tar.gz (27 kB) Collecting six>=1.12.0 Using cached six-1.15.0-py2.py3-none-any.whl (10 kB) Collecting keras-preprocessing<1.2,>=1.1.1 Using cached Keras_Preprocessing-1.1.2-py2.py3-none-any.whl (42 kB) Collecting opt-einsum>=2.3.2 Downloading opt_einsum-3.3.0-py3-none-any.whl (65 kB) |################################| 65 kB 6.7 MB/s Collecting tensorflow-estimator<2.4.0,>=2.3.0 Downloading tensorflow_estimator-2.3.0-py2.py3-none-any.whl (459 kB) |################################| 459 kB 80.6 MB/s Collecting astunparse==1.6.3 Downloading astunparse-1.6.3-py2.py3-none-any.whl (12 kB) Collecting tensorboard-plugin-wit>=1.6.0 Downloading tensorboard_plugin_wit-1.7.0-py3-none-any.whl (779 kB) |################################| 779 kB 70.1 MB/s Collecting setuptools>=41.0.0 Downloading setuptools-50.3.2-py3-none-any.whl (785 kB) |################################| 785 kB 78.3 MB/s Collecting google-auth<2,>=1.6.3 Downloading google_auth-1.23.0-py2.py3-none-any.whl (114 kB) |################################| 114 kB 83.9 MB/s Collecting google-auth-oauthlib<0.5,>=0.4.1 Downloading google_auth_oauthlib-0.4.2-py2.py3-none-any.whl (18 kB) Collecting requests<3,>=2.21.0 Downloading requests-2.25.0-py2.py3-none-any.whl (61 kB) |################################| 61 kB 11.7 MB/s Collecting markdown>=2.6.8 Downloading Markdown-3.3.3-py3-none-any.whl (96 kB) |################################| 96 kB 8.6 MB/s Collecting werkzeug>=0.11.15 Downloading Werkzeug-1.0.1-py2.py3-none-any.whl (298 kB) |################################| 298 kB 71.2 MB/s Collecting pyasn1-modules>=0.2.1 Downloading pyasn1_modules-0.2.8-py2.py3-none-any.whl (155 kB) |################################| 155 kB 81.5 MB/s Collecting cachetools<5.0,>=2.0.0 Downloading cachetools-4.1.1-py3-none-any.whl (10 kB) Collecting rsa<5,>=3.1.4; python_version >= "3.5" Downloading rsa-4.6-py3-none-any.whl (47 kB) |################################| 47 kB 7.9 MB/s Collecting requests-oauthlib>=0.7.0 Downloading requests_oauthlib-1.3.0-py2.py3-none-any.whl (23 kB) Collecting idna<3,>=2.5 Downloading idna-2.10-py2.py3-none-any.whl (58 kB) |################################| 58 kB 9.1 MB/s Collecting urllib3<1.27,>=1.21.1 Downloading urllib3-1.26.2-py2.py3-none-any.whl (136 kB) |################################| 136 kB 87.1 MB/s Collecting certifi>=2017.4.17 Downloading certifi-2020.11.8-py2.py3-none-any.whl (155 kB) |################################| 155 kB 26.4 MB/s Collecting chardet<4,>=3.0.2 Downloading chardet-3.0.4-py2.py3-none-any.whl (133 kB) |################################| 133 kB 69.0 MB/s Collecting importlib-metadata; python_version < "3.8" Downloading importlib_metadata-2.0.0-py2.py3-none-any.whl (31 kB) Collecting pyasn1<0.5.0,>=0.4.6 Downloading pyasn1-0.4.8-py2.py3-none-any.whl (77 kB) |################################| 77 kB 10.4 MB/s Collecting oauthlib>=3.0.0 Downloading oauthlib-3.1.0-py2.py3-none-any.whl (147 kB) |################################| 147 kB 83.9 MB/s Collecting zipp>=0.5 Downloading zipp-3.4.0-py3-none-any.whl (5.2 kB) Using legacy 'setup.py install' for termcolor, since package 'wheel' is not installed. Using legacy 'setup.py install' for wrapt, since package 'wheel' is not installed. Installing collected packages: termcolor, six, absl-py, google-pasta, numpy, protobuf, h5py, tensorboard-plugin-wit, setuptools, pyasn1, pyasn1-modules, cachetools, rsa, google-auth, wheel, oauthlib, idna, urllib3, certifi, chardet, requests, requests-oauthlib, google-auth-oauthlib, zipp, importlib-metadata, markdown, werkzeug, grpcio, tensorboard, gast, wrapt, keras-preprocessing, opt-einsum, tensorflow-estimator, astunparse, tensorflow Running setup.py install for termcolor ... done Attempting uninstall: setuptools Found existing installation: setuptools 39.2.0 Uninstalling setuptools-39.2.0: Successfully uninstalled setuptools-39.2.0 Running setup.py install for wrapt ... done Successfully installed absl-py-0.11.0 astunparse-1.6.3 cachetools-4.1.1 certifi-2020.11.8 chardet-3.0.4 gast-0.3.3 google-auth-1.23.0 google-auth-oauthlib-0.4.2 google-pasta-0.2.0 grpcio-1.33.2 h5py-2.10.0 idna-2.10 importlib-metadata-2.0.0 keras-preprocessing-1.1.2 markdown-3.3.3 numpy-1.18.5 oauthlib-3.1.0 opt-einsum-3.3.0 protobuf-3.14.0 pyasn1-0.4.8 pyasn1-modules-0.2.8 requests-2.25.0 requests-oauthlib-1.3.0 rsa-4.6 setuptools-50.3.2 six-1.15.0 tensorboard-2.4.0 tensorboard-plugin-wit-1.7.0 tensorflow-2.3.1 tensorflow-estimator-2.3.0 termcolor-1.1.0 urllib3-1.26.2 werkzeug-1.0.1 wheel-0.35.1 wrapt-1.12.1 zipp-3.4.0 [root@creator ~]#で成功。
その後、
pip3 install keras
pip3 install keras WARNING: pip is being invoked by an old script wrapper. This will fail in a future version of pip. Please see https://github.com/pypa/pip/issues/5599 for advice on fixing the underlying issue. To avoid this problem you can invoke Python with '-m pip' instead of running pip directly. Collecting keras Downloading Keras-2.4.3-py2.py3-none-any.whl (36 kB) Collecting scipy>=0.14 Downloading scipy-1.5.4-cp36-cp36m-manylinux1_x86_64.whl (25.9 MB) |################################| 25.9 MB 20.8 MB/s Requirement already satisfied: numpy>=1.9.1 in /usr/local/lib64/python3.6/site-packages (from keras) (1.18.5) Requirement already satisfied: h5py in /usr/local/lib64/python3.6/site-packages (from keras) (2.10.0) Collecting pyyaml Downloading PyYAML-5.3.1.tar.gz (269 kB) |################################| 269 kB 71.6 MB/s Requirement already satisfied: six in /usr/local/lib/python3.6/site-packages (from h5py->keras) (1.15.0) Building wheels for collected packages: pyyaml Building wheel for pyyaml (setup.py) ... done Created wheel for pyyaml: filename=PyYAML-5.3.1-cp36-cp36m-linux_x86_64.whl size=44619 sha256=249c8446bb49aafbae06d7883b9e4e5331fcc9270ad65b5d2f7d97599566ce98 Stored in directory: /root/.cache/pip/wheels/e5/9d/ad/2ee53cf262cba1ffd8afe1487eef788ea3f260b7e6232a80fc Successfully built pyyaml Installing collected packages: scipy, pyyaml, keras Successfully installed keras-2.4.3 pyyaml-5.3.1 scipy-1.5.4も成功。
- 投稿日:2020-11-18T16:50:35+09:00
最適化アルゴリズムを単独実行で比較する(総合編)
はじめに
この記事では、Keras(Tensorflow)のOptimizerを単独実行させた実験結果を示すことにより、各種最適化アルゴリズムでのパラメーターの効果や、アルゴリズム間の比較を行う。
ここでは、これまで他の記事で扱ってきたアルゴリズム間での動作の違いを、同一グラフ上のアニメーションとして視覚化する。
ただし、AdadeltaとFtrlは特殊なので同時比較の対象としない。AMSgradはAdamとの違いが出なかったので省略した。SGD編
Adagrad/RMSprop/Adadelta編
Adam/Adamax/Nadam編
FTRL編実験方法
最適化のクラスを直接実行して、最適値に向かう様子をグラフにプロットして比較する。
具体的には、下記の内容。
- 初期値1.0、最適値0.0として、Optimiserのminimize()を直接実行し、ステップ毎に最適値に近づく様子を観察する。
- Keras使用。Google Colabで実行可な実験コードを最後に記載。
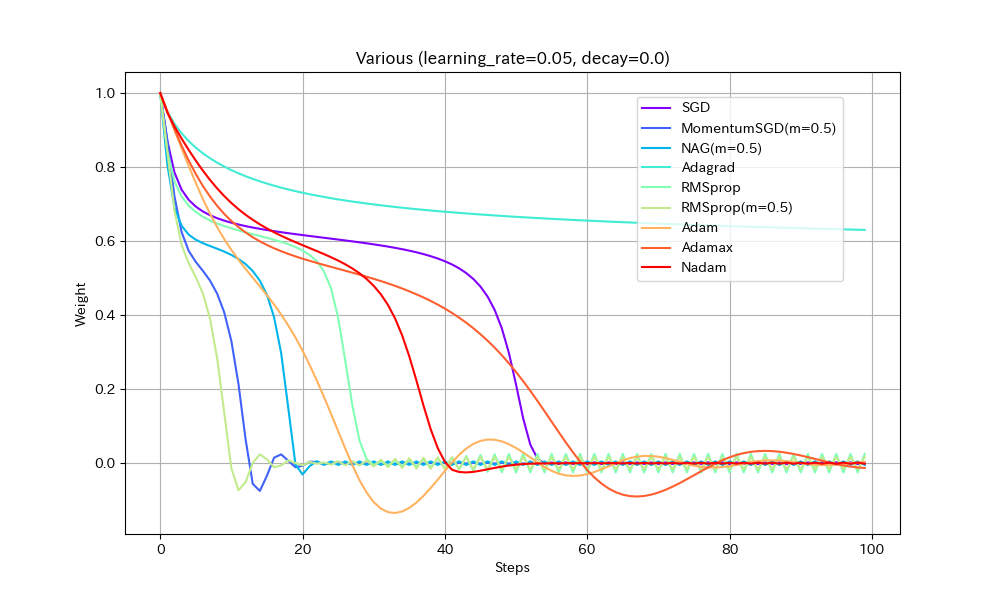
実験1. 途中に緩やかな区間がある場合
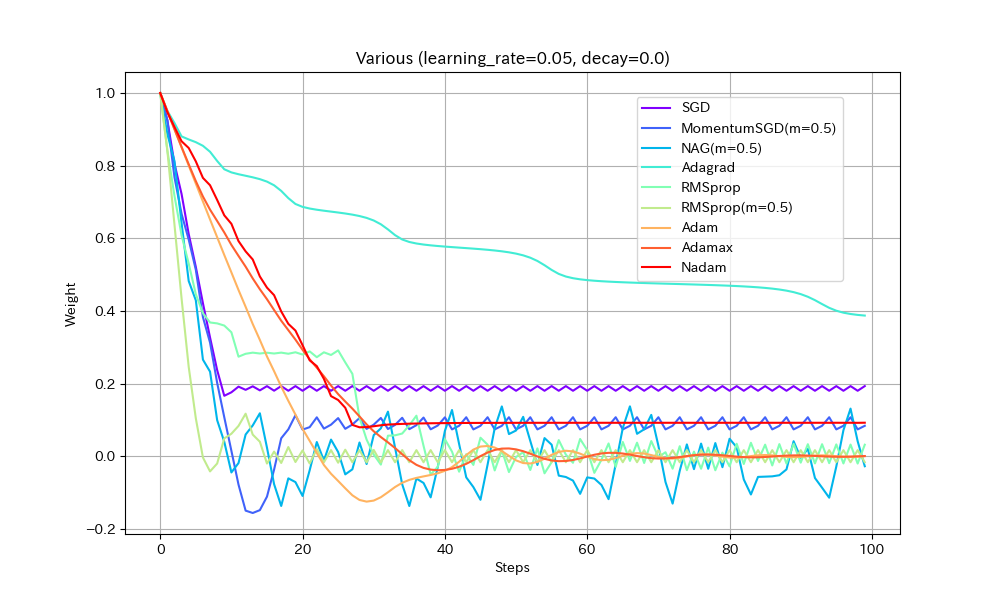
損失関数を「いったん下ったあと、途中平坦になり、再度急降下する」形にして動作を比べた。すべて同一の学習率にしてある。
Weight/Steps Loss/Weight
- 単純に最適値に到達するまでの早さで比べると、RMSprop(Momentum有)、MomentumSGD、NAGの順番で早く到達する。Momentumの加速効果が見て取れる。
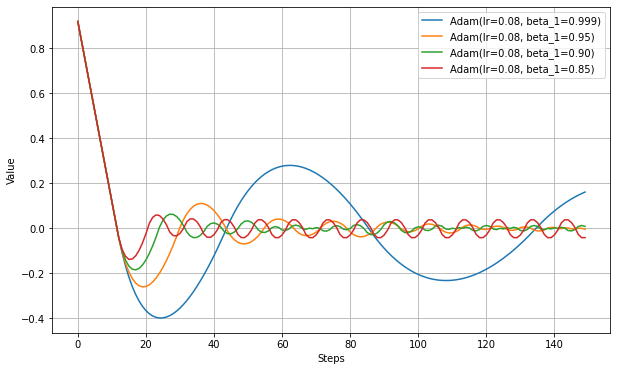
- NAGは単純なMomentumSGDよりも遅い。Nesterovでは減速も早くなるので、平坦な場所がくると急ブレーキがかかるようだ。NadamとAdamの比較でも同様の現象が見られる。
- Adamでは他のアルゴリズムより、最適値を通り過ぎた後に最も遠い地点まで進んでしまうようだ。この条件では勢いがつきすぎているようにも見えるが100step経過後には最適値にほぼ停止しているので、大きく問題視すべきことでは無いかもしれない。
- Adamとは違いNadamでは最適値で急ブレーキがかかるが、平坦区間で減速してしまっているので、この条件ではAdamに比べると学習の進みがかなり遅い。
- Adagradはこの条件では他のアルゴリズムより大幅に遅くなる。学習率を大きくとらないと最適値に到達できないだろう。
- Adagradを除くとAdamaxが最適値への到達が最も遅い。最適値を通り過ぎてからの振幅も大きく、あまりいいところが見られない。
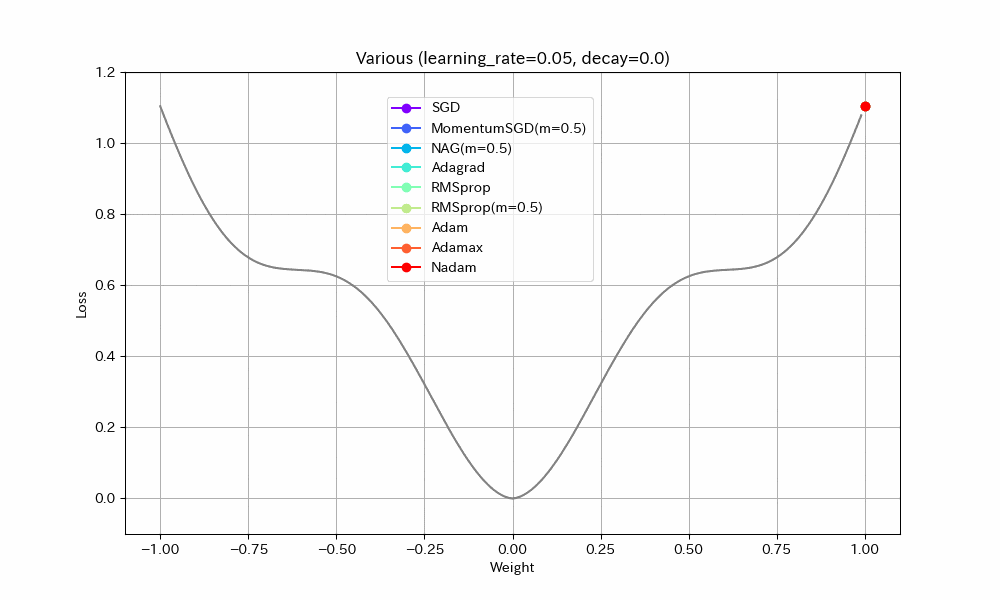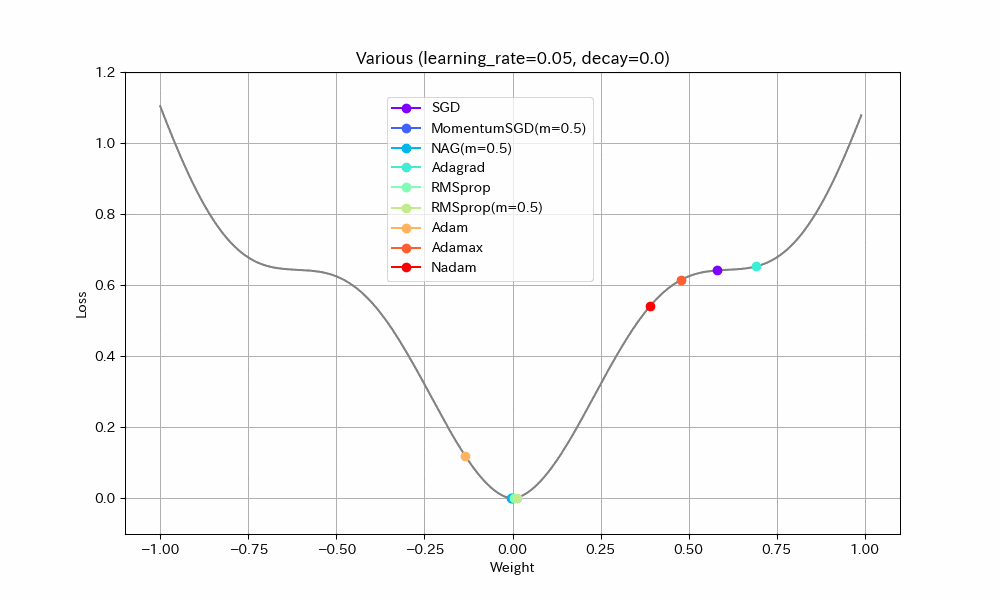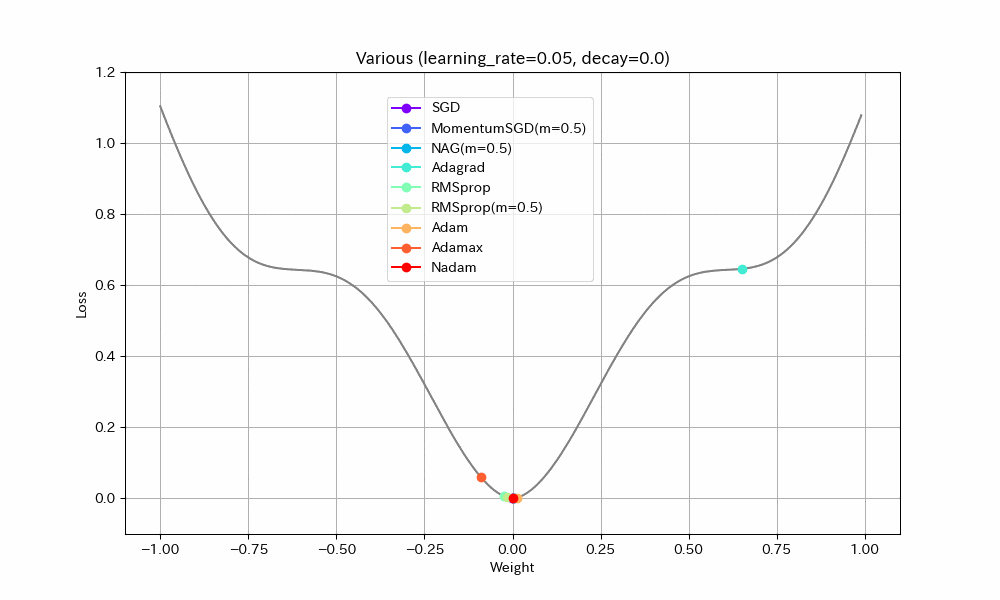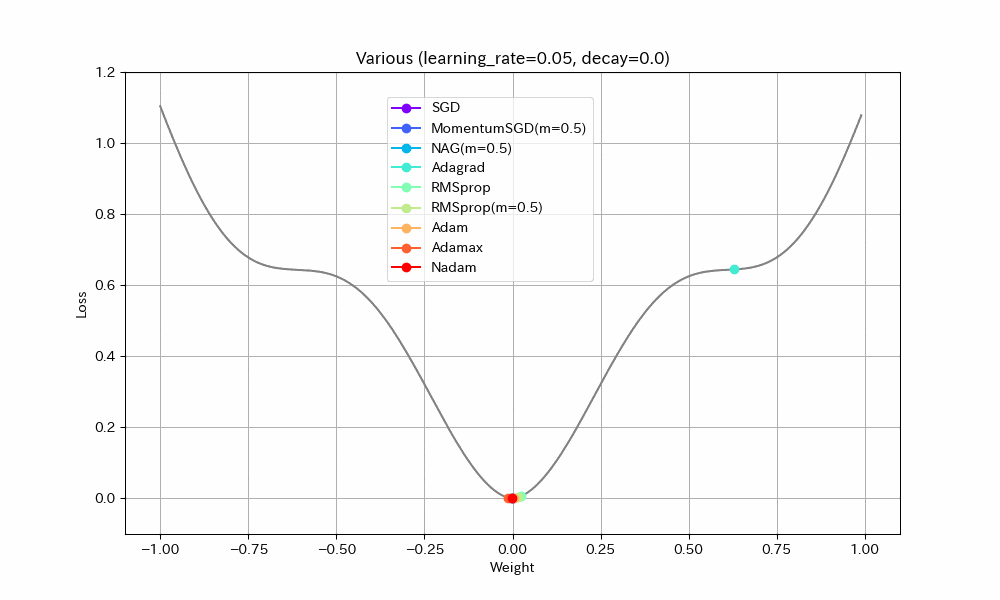
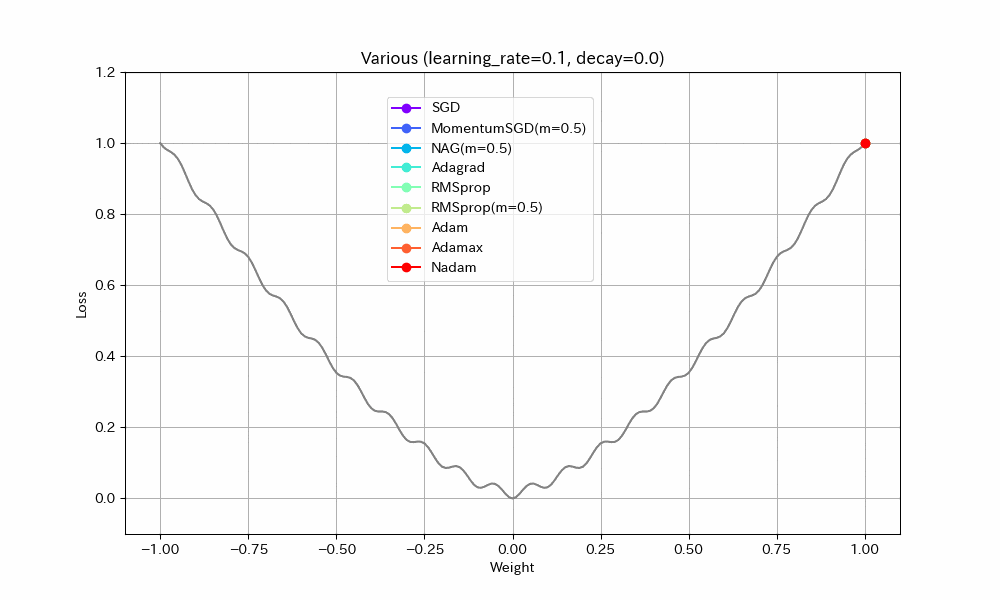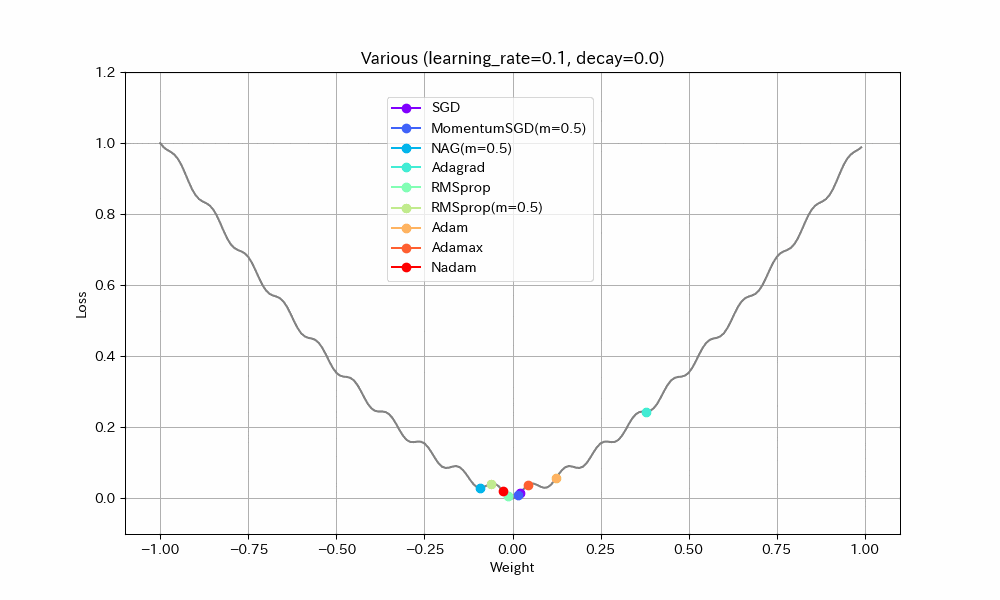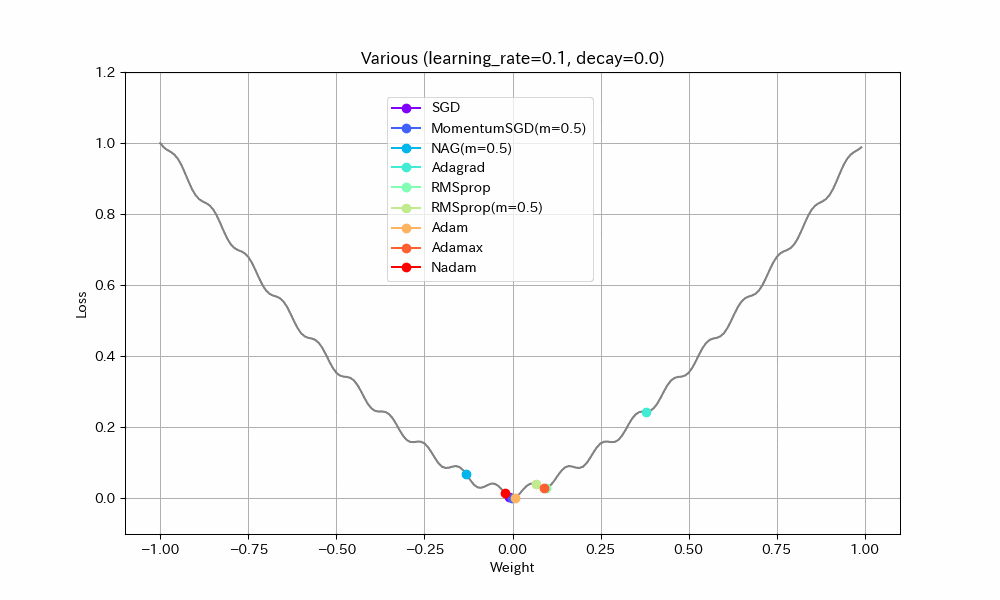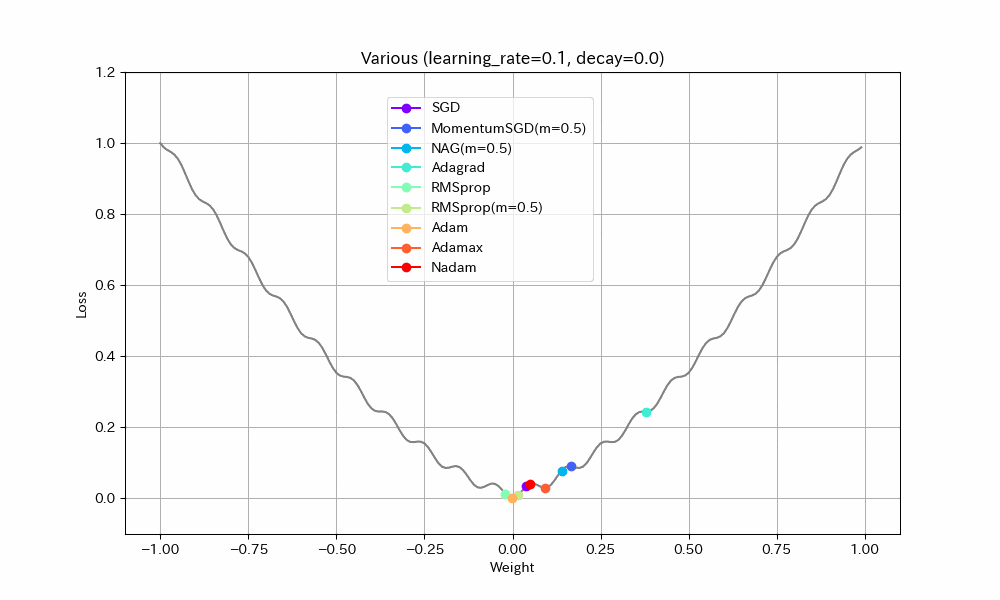
実験2. 局所最適解が複数存在する場合
損失関数を「局所最適解が複数存在する」形にして動作を比べた。損失関数以外は実験1と同じ。
Weight/Steps Loss/Weight
- SGD/Nadam/Adagradは途中で局所最適解にはまって、最適解までたどり着けていない。SGDとAdagradがはまるのは学習率が小さすぎたのだろう。Nadamは急減速できる特性が悪く作用したと考えられる。
- MomentumSGDは一度最適解を通り過ぎた後、反動で戻ってきた先で局所最適解にはまっている。
- RMSprop(Momentum有)が実験1同様、最速で最適解にたどり着き、正しく収束もできているが、RMSprop系の特性で振動が止まらない。
- NAGが最適値付近で大きく変動している。他の実験ではNesterov法は振動抑制効果がみられたが、場合によってはむしろ不安定になることがわかる。
- AdamとAdamaxは若干遅いが、きれいに最適解に収束している。
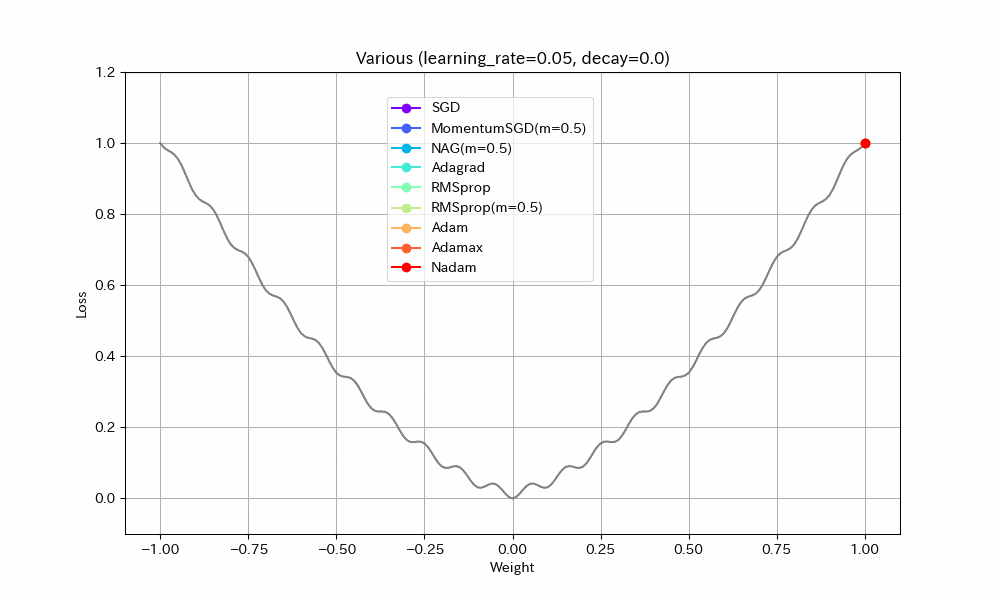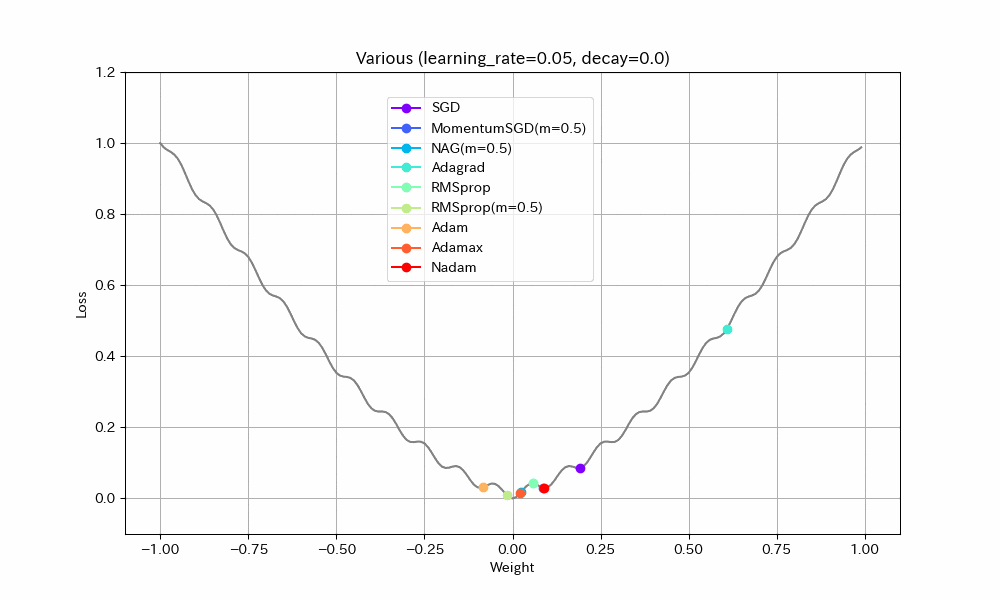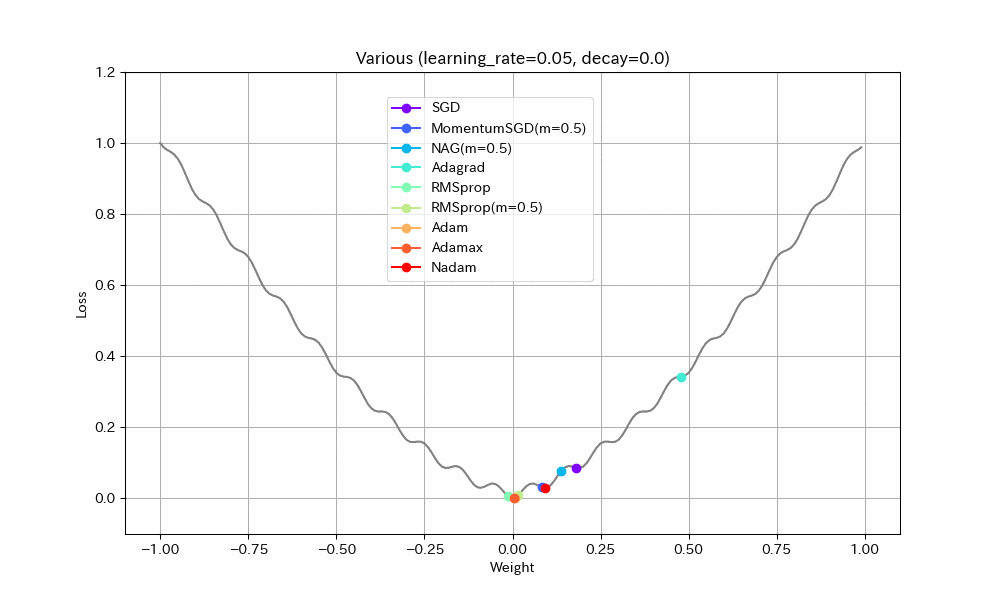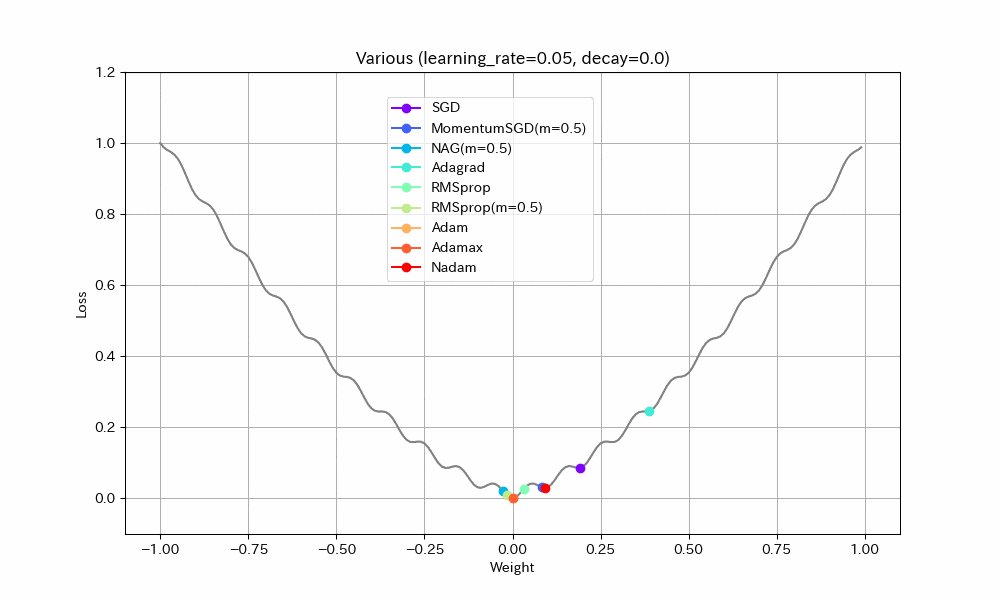
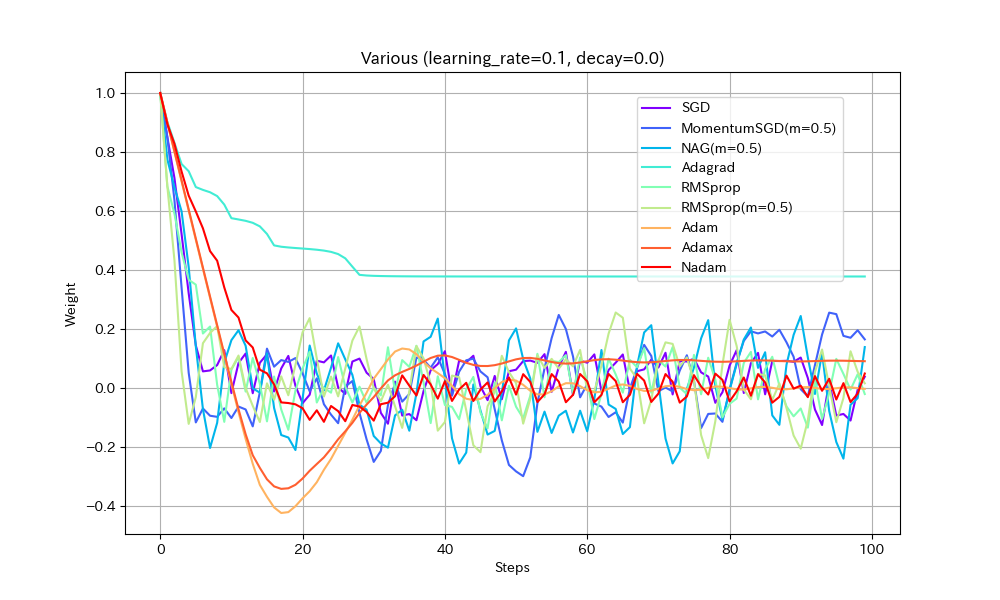
以下、学習率を2倍にした結果。
Weight/Steps Loss/Weight
- Adagrad以外は最適解まで到達している
- ほとんどのアルゴリズムで最適解付近の振動が激しくなっているが、Adamはうまく停止している。ただし、ある程度振動したほうが局所最適解から抜け出せる可能性が高くなるはずなので、Adamのように停止してしまったほうが本当に良いのかは、場合によると思われる。
実際の機械学習では、途中でOptimizerの学習率を一気に1/10下げることが良く行われる。学習率が小さすぎると最適解に到達できないが、大きすぎても収束しないことへの対応と考えられる。
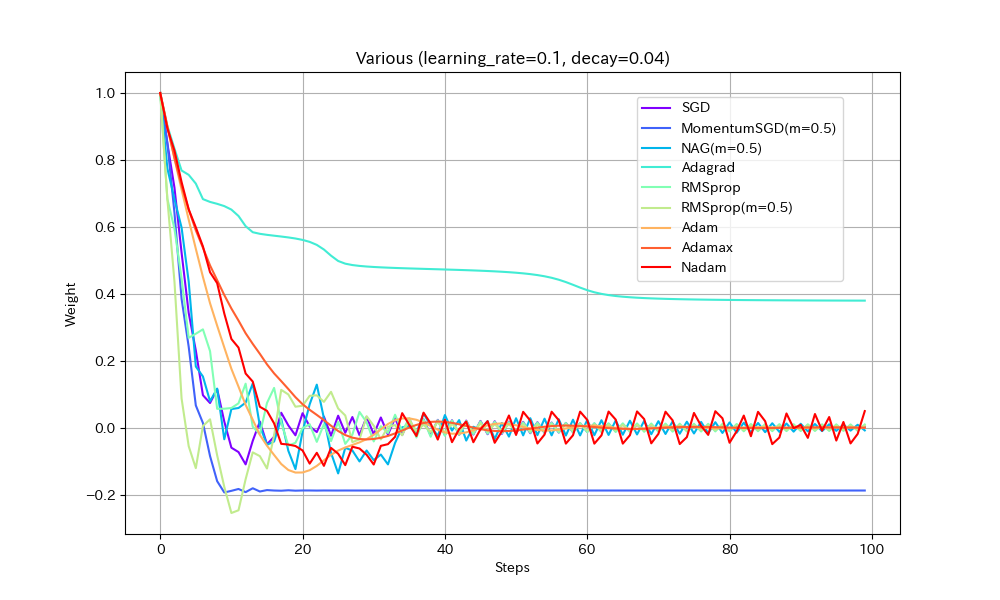
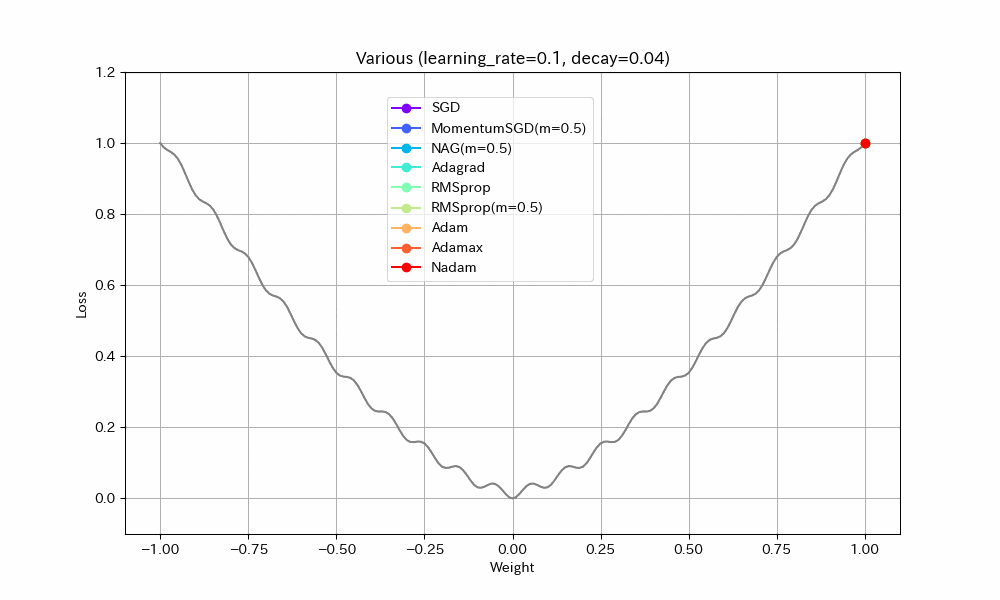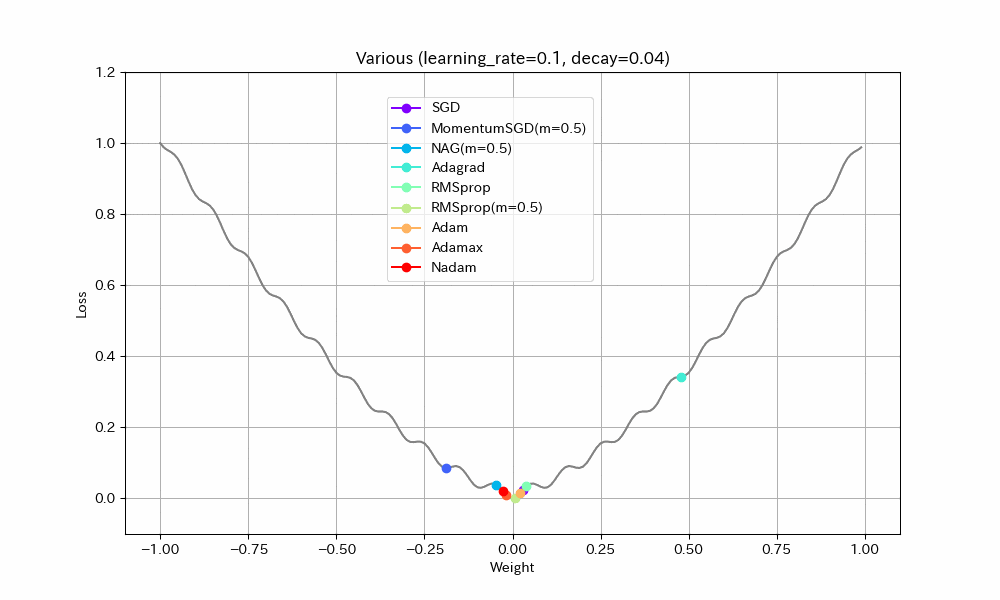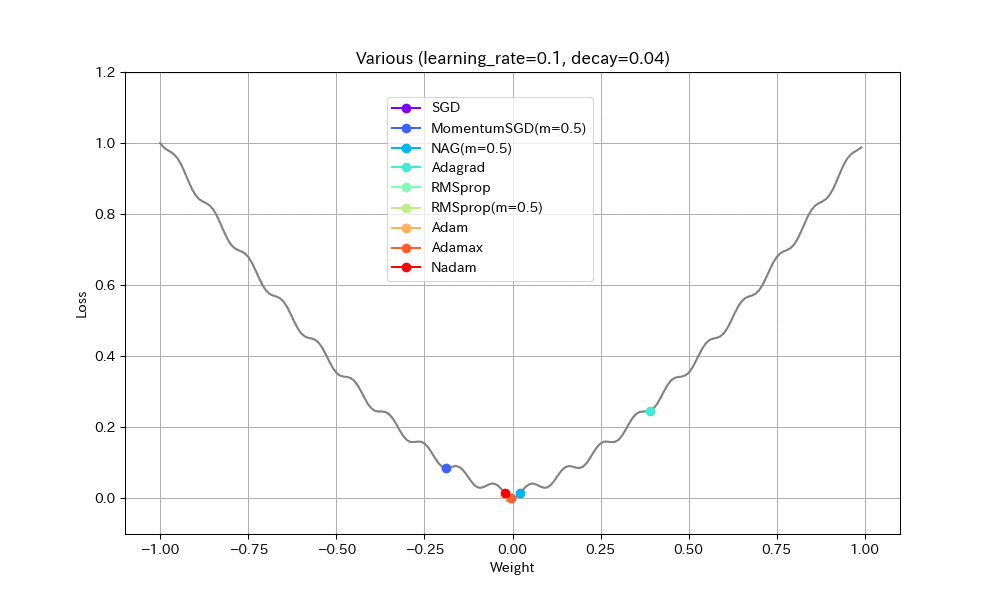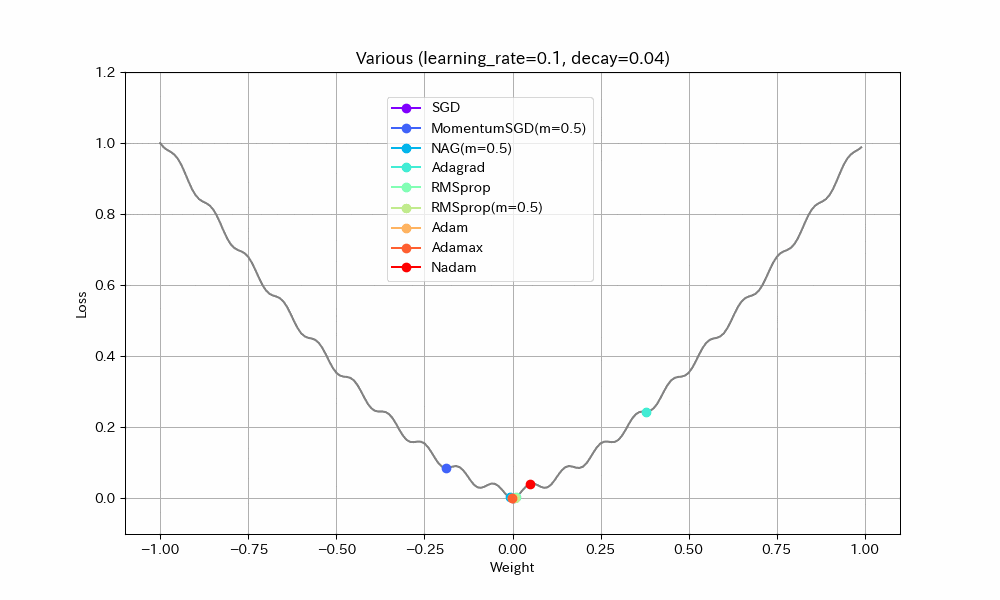
同様のことはDecayパラメータを使ってもできる(あまり使われることが無いようではあるが)。初期学習率0.1、Decay=0.04(100ステップで学習率0.05になるはず)という設定で実験する。
Weight/Steps Loss/Weight
- MomentumSGDとAdagrad以外は最適解で収束しているので、学習率を減らすことの良い効果が見えた。
- Nadamの振動が激しいが、これはNadamがDecayパラメータに対応していないためと思われる。
- MomentumSGDは最適解を行き過ぎた後で局所最適解につかまり戻れなくなっている。Decayの数値も気を付けて設定しなければならないことがわかる。この辺もDecayがあまり使われない原因かもしれない。
まとめ
各種アルゴリズムを同一条件で比較した。
学習率を同じ設定で比較するのが本当にフェアなのか、条件が単純すぎるのではないか、という疑問はあるが、それぞれの特色がある程度でたように思う。
以下、「非常に単純な条件下での実験」という前提での感想。
- MomentumSGD/RMSprop(Momentum有)/Adamが比較的良好な結果を出しているように思われる。
- 上記以外のアルゴリズムはあまり積極的に使用する理由が見つからないように思う。特に、NAG/NadamといったNesterov系は今一つ信頼できないような結果になったのは意外。
下記の実験コードを使えば、本記事に載せた以外の比較や、学習率等のパラメータを変更して実験を行えるので、興味のある方は各自実験してもらいたい。
実験コード
TestOptimizer.pyimport math import os import numpy as np import tensorflow as tf from tensorflow.keras.optimizers import SGD,RMSprop,Adagrad,Adadelta,Adam,Nadam,Adamax,Ftrl from IPython.display import HTML import matplotlib.pyplot as plt from matplotlib import animation from matplotlib import rc from matplotlib.animation import PillowWriter class LoopingPillowWriter(PillowWriter): def finish(self): self._frames[0].save( self._outfile, save_all=True, append_images=self._frames[1:], duration=int(1000 / self.fps), loop=0) def testOptims2(optims, lossFn='mae', total_steps=150, title=None): if lossFn == 'Abs': def loss(): return tf.abs(var1) elif lossFn == 'Square': def loss(): return var1**2 elif lossFn == 'Special': def loss(): return var1*(1010 if (i % 101) == 1 else -10) elif lossFn == 'Bumpy1': def loss(): return (tf.abs(var1)**1.5)+0.15*(tf.sin(var1*1.2*math.pi*2 - math.pi/2.0)+1.0) elif lossFn == 'Bumpy2': def loss(): return (tf.abs(var1)**1.5)+0.015*(tf.sin(var1*10*math.pi*2 - math.pi/2.0)+1.0) else: return w_list = [] loss_list = [] for label, optim in optims.items(): var1 = tf.Variable(1.0) w_buf = [] loss_buf = [] w_buf.append(var1.numpy()) loss_buf.append(loss()) for i in range(total_steps-1): optim.minimize(loss, [var1]).numpy() w_buf.append(var1.numpy()) loss_buf.append(loss()) w_list.append(w_buf) loss_list.append(loss_buf) loss_x_buf = [] loss_y_buf = [] for i in range(-100, 100): var1 = tf.Variable(i*0.01) loss_y_buf.append(loss()) loss_x_buf.append(i*0.01) cmap = plt.get_cmap("rainbow") coloring = [cmap(i) for i in np.linspace(0, 1, len(optims))] print('plotting history...') fig = plt.figure(figsize=(10, 6), facecolor="white",) ax = fig.add_subplot(111) steps = range(total_steps) for i, label in enumerate(optims.keys()): ax.plot(steps, w_list[i], color=coloring[i], label=label) fig.legend(bbox_to_anchor=(0.85, 0.85)) ax.set_xlabel('Steps') ax.set_ylabel('Weight') if title != None: ax.set_title(title) ax.grid() fig.savefig(lossFn+'_'+title+'.png') plt.show() print('making animation...') fig = plt.figure(figsize=(10, 6), facecolor="white",) ax = fig.add_subplot(111) ax.set_xlim((-1.1, 1.1)) ax.set_ylim((-0.1, 1.2)) if title != None: ax.set_title(title) images = [] loss_line, = ax.plot([], [], color='gray') images = [] for i, label in enumerate(optims.keys()): im, = ax.plot([], [], marker="o", color=coloring[i], label=label) images.append(im) def anim_ini(): loss_line.set_data(loss_x_buf, loss_y_buf) return (loss_line,) def anim_animate(i): for j, label in enumerate(optims.keys()): images[j].set_data(w_list[j][i], loss_list[j][i]) return images fig.legend(bbox_to_anchor=(0.6, 0.85)) ax.set_xlabel('Weight') ax.set_ylabel('Loss') ax.grid() interval = 100 anim = animation.FuncAnimation(fig, anim_animate, init_func=anim_ini, frames=total_steps, interval=interval, blit=False) anim.save(lossFn+'_'+title+'.gif', writer=LoopingPillowWriter(fps=1000.0/interval)) if 'COLAB_GPU' in os.environ.keys(): plt.close() rc('animation', html='jshtml') else: plt.show() return anim steps = 100 #@param {type: "number"} loss_type = "Bumpy1" #@param ["Abs", "Square", "Bumpy1","Bumpy2"] test_type = "Various" #@param ["SGD", "MomentumSGD", "NAG", "RMSprop", "RMSprop(2)","Adam", "Adamax", "Nadam","Adam vs AMSGrad vs Adamax vs Nadam","Adadelta","Various" ] learning_rate = 0.05 #@param {type: "number"} decay = 0.0 #@param {type: "number"} test_dict = {} test_dict['SGD'] = { 'SGD(lr/4, m=0.0)': SGD(learning_rate/4, momentum=0.0, decay=decay), 'SGD(lr/2, m=0.0)': SGD(learning_rate/2, momentum=0.0, decay=decay), 'SGD(lr, m=0.0)': SGD(learning_rate, momentum=0.0, decay=decay), 'SGD(lr*2, m=0.0)': SGD(learning_rate*2, momentum=0.0, decay=decay), 'SGD(lr*4, m=0.0)': SGD(learning_rate*4, momentum=0.0, decay=decay), } test_dict['MomentumSGD'] = { 'MomentumSGD(lr/4, m=0.5)': SGD(learning_rate/4, momentum=0.5, decay=decay), 'MomentumSGD(lr/2, m=0.5)': SGD(learning_rate/2, momentum=0.5, decay=decay), 'MomentumSGD(lr, m=0.5)': SGD(learning_rate, momentum=0.5, decay=decay), 'MomentumSGD(lr*2, m=0.5)': SGD(learning_rate*2, momentum=0.5, decay=decay), 'MomentumSGD(lr*4, m=0.5)': SGD(learning_rate*4, momentum=0.5, decay=decay), } test_dict['NAG'] = { 'NAG(lr/4, m=0.5)': SGD(learning_rate/4, momentum=0.5, decay=decay, nesterov=True), 'NAG(lr/2, m=0.5)': SGD(learning_rate/2, momentum=0.5, decay=decay, nesterov=True), 'NAG(lr, m=0.5)': SGD(learning_rate, momentum=0.5, decay=decay, nesterov=True), 'NAG(lr*2, m=0.5)': SGD(learning_rate*2, momentum=0.5, decay=decay, nesterov=True), 'NAG(lr*4, m=0.5)': SGD(learning_rate*4, momentum=0.5, decay=decay, nesterov=True), } test_dict['Adam'] = { 'Adam(lr/4)': Adam(learning_rate/4, decay=decay), 'Adam(lr/2)': Adam(learning_rate/2, decay=decay), 'Adam(lr)': Adam(learning_rate, decay=decay), 'Adam(lr*2)': Adam(learning_rate*2, decay=decay), 'Adam(lr*4)': Adam(learning_rate*4, decay=decay), } test_dict['Adamax'] = { 'Adamax(lr/4)': Adamax(learning_rate/4, decay=decay), 'Adamax(lr/2)': Adamax(learning_rate/2, decay=decay), 'Adamax(lr)': Adamax(learning_rate, decay=decay), 'Adamax(lr*2)': Adamax(learning_rate*2, decay=decay), 'Adamax(lr*4)': Adamax(learning_rate*4, decay=decay), } test_dict['Nadam'] = { 'Nadam(lr/4)': Nadam(learning_rate/4, decay=decay), 'Nadam(lr/2)': Nadam(learning_rate/2, decay=decay), 'Nadam(lr)': Nadam(learning_rate, decay=decay), 'Nadam(lr*2)': Nadam(learning_rate*2, decay=decay), 'Nadam(lr*4)': Nadam(learning_rate*4, decay=decay), } test_dict['Adam vs AMSGrad vs Adamax vs Nadam'] = { 'Adam': Adam(lr=learning_rate, decay=decay), 'AMSGrad': Adam(lr=learning_rate, amsgrad=True, decay=decay), 'Adamax': Adamax(lr=learning_rate, decay=decay), 'Nadam': Nadam(lr=learning_rate, decay=decay), } test_dict['RMSprop'] = { 'RMSprop(lr/4)': RMSprop(learning_rate/4, decay=decay), 'RMSprop(lr/2)': RMSprop(learning_rate/2, decay=decay), 'RMSprop(lr)': RMSprop(learning_rate, decay=decay), 'RMSprop(lr*2)': RMSprop(learning_rate*2, decay=decay), 'RMSprop(lr*4)': RMSprop(learning_rate*4, decay=decay), } test_dict['RMSprop(2)'] = { 'RMSprop(m=0.0)': RMSprop(learning_rate, decay=decay), 'RMSprop(m=0.5)': RMSprop(learning_rate, momentum=0.5, decay=decay), 'RMSprop(m=0.0,centered)': RMSprop(learning_rate, centered=True, decay=decay), 'RMSprop(m=0.5,centered)': RMSprop(learning_rate, momentum=0.5, centered=True, decay=decay), } test_dict['Adadelta'] = { 'Adadelta(lr/4)': Adadelta(learning_rate/4, decay=decay), 'Adadelta(lr/2)': Adadelta(learning_rate/2, decay=decay), 'Adadelta(lr)': Adadelta(learning_rate, decay=decay), 'Adadelta(lr*2)': Adadelta(learning_rate*2, decay=decay), 'Adadelta(lr*4)': Adadelta(learning_rate*4, decay=decay), } test_dict['Various'] = { 'SGD': SGD(learning_rate, momentum=0.0, decay=decay), 'MomentumSGD(m=0.5)': SGD(learning_rate, momentum=0.5, decay=decay), 'NAG(m=0.5)': SGD(learning_rate, momentum=0.5, nesterov=True, decay=decay), 'Adagrad': Adagrad(learning_rate, decay=decay), 'RMSprop': RMSprop(learning_rate, momentum=0.0, decay=decay), 'RMSprop(m=0.5)': RMSprop(learning_rate, momentum=0.5, decay=decay), 'Adam': Adam(learning_rate, decay=decay), 'Adamax': Adamax(learning_rate, decay=decay), 'Nadam': Nadam(learning_rate, decay=decay), } testOptims2( test_dict[test_type], total_steps=steps, lossFn=loss_type, title='{0} (learning_rate={1}, decay={2})'.format(test_type, learning_rate, decay) )参考
- 投稿日:2020-11-18T16:50:09+09:00
最適化アルゴリズムを単独実行で比較する(FTRL編)
はじめに
この記事では、実際のコードから翻訳した疑似コードを使って動作を紹介する。また、Keras(Tensorflow)のOptimizerを使用した実験結果を示すことにより、各種最適化アルゴリズムでのパラメーターの効果や、アルゴリズム間の比較を行う。
ここでは、FTRLを扱う。
SGD編
Adagrad/RMSprop/Adadelta編
Adam/Adamax/Nadam編
総合編実験方法
極簡単なネットワークを学習させ、学習過程をグラフにプロットして比較する。
具体的には、下記の内容。
- 初期値1.0、最適値0.0として、Optimiserのminimize()を直接実行し、ステップ毎に最適値に近づく様子を観察する。
- 損失関数は特に言及しない限り絶対値(MAE)を使用。場合によっては二乗(MSE)なども使用。
- Keras使用。Google Colabで実行可な実験コードを最後に記載。
Ftrl
FTRLは'Follow The (Prox-imally) Regularized Leader'の頭文字をとったもの。
広告で収益を上げるタイプのビジネスで重要な'ad Click–Through Rates'を予測するための研究で開発されたようだ。
TensorFlowやPyTorchで標準実装されているにも関わらず、あまり情報がない。ftrl.py
training_ops.cc
Tensorflow API Ftrl元論文
paperFtrlにおける設定可能なパラメーターは以下の通り。
Paramater Range Default Description lr float >= 0 0.001 Learning rate. learning_rate_power float < 0 -0.5 Controls how the learning rate decreases during training. Use zero for a fixed learning rate. initial_accumulator_value float > 0 0.1 The starting value for accumulators. l1_regularization_strength float >= 0 0.0 L1 Regularization Strength. l2_regularization_strength float >= 0 0.0 L2 Regularization Strength. l2_shrinkage_regularization_strength float >= 0 0.0 This differs from L2 above in that the L2 above is a stabilization penalty, whereas this L2 shrinkage is a magnitude penalty. When input is sparse shrinkage will only happen on the active weights. Web上にはFTRLの数式を紹介した記事があまりないようなので、元論文に載っている数式(だいぶ簡略化したが恐らく正しいはず)を記しておく。
Algorithm 1:Per-Coordinate FTRL-Proximal with L1 and L2 Regularization for Logistic Regression
\begin{align} & \sigma = \frac{1}{\alpha}(\sqrt{n_{t} + g_{t}^{2}} - \sqrt{n_{t}}) \\ & z_{t+1} = z_{t} + g_{t} - \sigma w_{t} \\ & n_{t+1} = n_{t} + g_{t}^{2} \\ & w_{t+1} = \left\{ \begin{array}{ll} - ( \frac{\beta+\sqrt{n_{t+1}}}{\alpha} + \lambda_{2})^{-1}(z_{t+1} - \textrm{sgn}(z_{t+1}) \lambda_{1}) & (\textrm{if } |z_{t+1}| > \lambda_{1} ) \\ 0 & ( \textrm{otherwise.}) \end{array} \right. \\ \end{align}なぜこれで学習ができるのかはよくわからない。
TensorFlow内ではおおむね以下のような処理になっているようだ。ftrl.pylr_pow = -self.lr_power nn = self.n + (grad**2) sigma = ((nn**lr_pow ) - (self.n**lr_pow )) / lr z = self.z + grad - (sigma * var); if abs(z)>l1: x = z - (l1 * sign(z)); y = ((nn**lr_pow )/lr) + (2*l2) var = -x / y else: var = 0 self.n = nn self.z = z元論文と若干違いがあるのが気になるが、lr_power=-0.5の場合は大体同じ結果になるはずだ。
数式中の$\alpha$がlrとなり学習率である。$\beta$は無視されている。
varが更新すべき重みで、これまで実験してきた他のアルゴリズムでは、「gradから、次のvarへの差分」を計算していたが、ここでは「gradとvarから、次のvarそのもの」を計算するかたちとなっている。
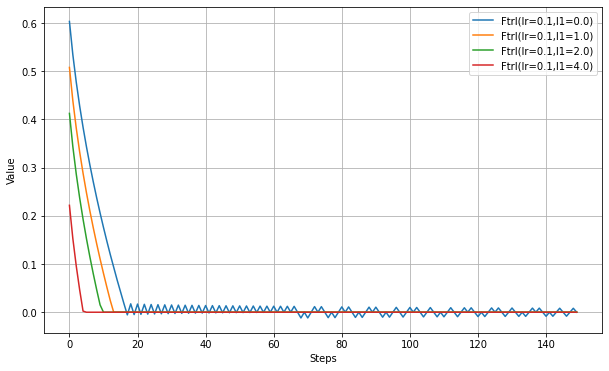
また、l1が設定されている場合は、条件によって重みが直接0になる場合が出てくる。ニューラルネットをスパース化させることが目的のようだ。
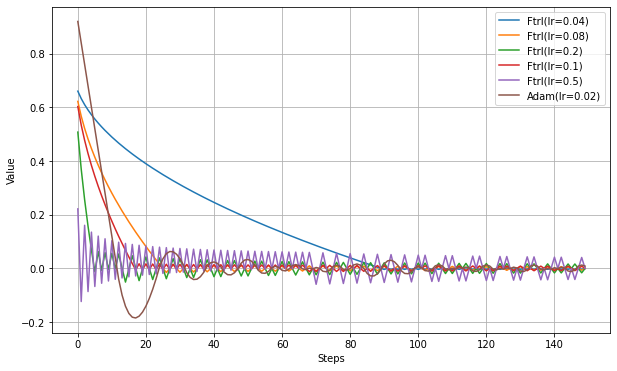
TensorFlowのコードを見ると、l2_shrinkage_regularization_strength を使う場合は少し違うアルゴリズムになるようだが、処理の内容は記載しない。以下、lrの設定実験。
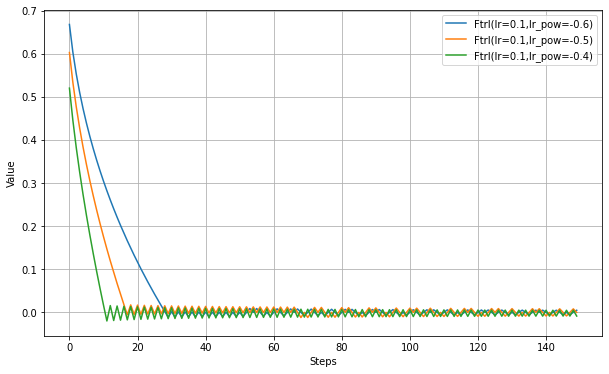
以下、lr_powerの設定実験。
以下、l1_regularization_strengthの設定実験。
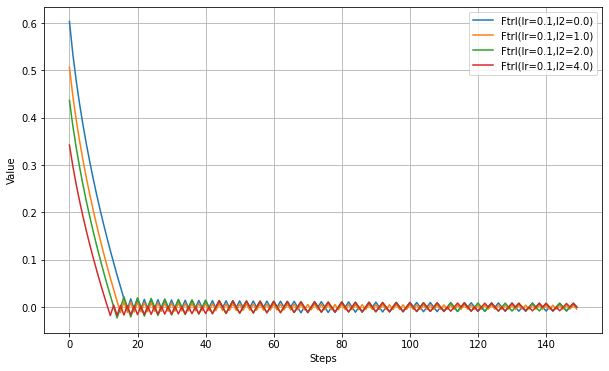
以下、l2_regularization_strengthの設定実験。
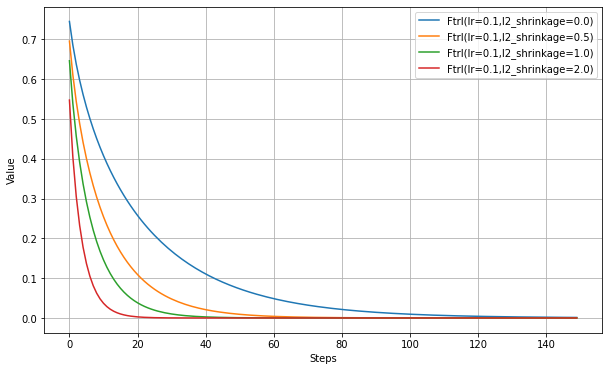
以下、l2_shrinkage_regularization_strengthの設定実験。
まとめ
特定の用途で使われるようだが、Web上の情報が他のアルゴリズムより少なく、結局どういうものかよくわからない。
実験結果は他のアルゴリズムと大差ないように見える。しかし、(ここには記載しないが)損失関数を少し変えると学習が進まなかったりしたので、使いどころが難しいという印象を持った。
実験コード
TestOptimizer.pyimport numpy as np import tensorflow as tf import matplotlib.pyplot as plt from tensorflow.keras.optimizers import SGD,RMSprop,Adagrad,Adadelta,Adam,Nadam,Adamax,Ftrl def testOptims(optims, lossFn='mae', total_steps=150): fig = plt.figure(figsize=(10,6),facecolor="white",) ax = fig.add_subplot(111) steps = range(total_steps) y = np.zeros(total_steps) if lossFn=='mae': loss = lambda: tf.abs(var1) elif lossFn=='mse': loss = lambda: var1**2 elif lossFn=='special': loss = lambda: var1*(1010 if (i % 101) == 1 else -10) for label, optim in optims.items(): var1 = tf.Variable(1.0) for i in range(total_steps): optim.minimize(loss, [var1]).numpy() y[i] = var1.numpy() ax.plot( steps, y, label=label ) ax.legend(bbox_to_anchor=(1.0,1.0)) ax.set_xlabel('Steps') ax.set_ylabel('Value') ax.grid() plt.show() print('Ftrl(lr,mae)') testOptims( { 'Ftrl(lr=0.04)': Ftrl(0.04), 'Ftrl(lr=0.08)': Ftrl(0.08), 'Ftrl(lr=0.2)': Ftrl(0.2), 'Ftrl(lr=0.1)': Ftrl(0.1), 'Ftrl(lr=0.5)': Ftrl(0.5), 'Adam(lr=0.02)': Adam(0.08), }, lossFn = 'mae' ) print('Ftrl(lr,mse)') testOptims( { 'Ftrl(lr=0.04)': Ftrl(0.04), 'Ftrl(lr=0.08)': Ftrl(0.08), 'Ftrl(lr=0.2)': Ftrl(0.2), 'Ftrl(lr=0.1)': Ftrl(0.1), 'Ftrl(lr=0.5)': Ftrl(0.5), 'Adam(lr=0.02)': Adam(0.08), }, lossFn = 'mse' ) print('Ftrl(learning_rate_power)') testOptims( { 'Ftrl(lr=0.1,lr_pow=-0.6)': Ftrl(0.1, learning_rate_power=-0.6), 'Ftrl(lr=0.1,lr_pow=-0.5)': Ftrl(0.1, learning_rate_power=-0.5), 'Ftrl(lr=0.1,lr_pow=-0.4)': Ftrl(0.1, learning_rate_power=-0.4), }, lossFn = 'mae' ) print('FTRL(l1_regularization_strength)') testOptims( { 'Ftrl(lr=0.1,l1=0.0)': Ftrl(0.1, l1_regularization_strength=0.0), 'Ftrl(lr=0.1,l1=1.0)': Ftrl(0.1, l1_regularization_strength=1.0), 'Ftrl(lr=0.1,l1=2.0)': Ftrl(0.1, l1_regularization_strength=2.0), 'Ftrl(lr=0.1,l1=4.0)': Ftrl(0.1, l1_regularization_strength=4.0), }, lossFn = 'mae' ) print('FTRL(l2_regularization_strength)') testOptims( { 'Ftrl(lr=0.1,l2=0.0)': Ftrl(0.1, l2_regularization_strength=0.0), 'Ftrl(lr=0.1,l2=1.0)': Ftrl(0.1, l2_regularization_strength=1.0), 'Ftrl(lr=0.1,l2=2.0)': Ftrl(0.1, l2_regularization_strength=2.0), 'Ftrl(lr=0.1,l2=4.0)': Ftrl(0.1, l2_regularization_strength=4.0), }, lossFn = 'mae' ) print('FTRL(l2_shrinkage)') testOptims( { 'Ftrl(lr=0.1,l2_shrinkage=0.0)': Ftrl(0.1, l2_shrinkage_regularization_strength=0.0), 'Ftrl(lr=0.1,l2_shrinkage=0.5)': Ftrl(0.1, l2_shrinkage_regularization_strength=0.5), 'Ftrl(lr=0.1,l2_shrinkage=1.0)': Ftrl(0.1, l2_shrinkage_regularization_strength=1.0), 'Ftrl(lr=0.1,l2_shrinkage=2.0)': Ftrl(0.1, l2_shrinkage_regularization_strength=2.0), }, lossFn = 'mse' )
- 投稿日:2020-11-18T16:49:38+09:00
最適化アルゴリズムを単独実行で比較する(Adam/Adamax/Nadam編)
はじめに
この記事では、数式は使わず、実際のコードから翻訳した疑似コードを使って動作を紹介する。また、Keras(Tensorflow)のOptimizerを使用した実験結果を示すことにより、各種最適化アルゴリズムでのパラメーターの効果や、アルゴリズム間の比較を行う。
ここでは、Adam/Adamax/Nadamを扱う。
SGD編
Adagrad/RMSprop/Adadelta編
FTRL編
総合編実験方法
極簡単なネットワークを学習させ、学習過程をグラフにプロットして比較する。
具体的には、下記の内容。
- 初期値1.0、最適値0.0として、Optimiserのminimize()を直接実行し、ステップ毎に最適値に近づく様子を観察する。
- 損失関数は特に言及しない限り絶対値(MAE)を使用。場合によっては二乗(MSE)なども使用。
- Keras使用。Google Colabで実行可な実験コードを最後に記載。
Adam
RMSpropの改良版。最もポピュラーなアルゴリズムの一つ。
RMSpropでは修正学習率に直接勾配を掛けた形になるが、Adamでは勾配も指数移動平均を使う。Keras実装は以下を参照した。
adam.py
training_ops.cc
TensorFlow API AdamAdamの論文。
Adam - A Method for Stochastic OptimizationAdamにおける設定可能なパラメーターは以下の通り。
Paramater Range Default Description lr float >= 0 0.001 Learning rate. beta_1 float, 0 < beta < 1 0.9 The exponential decay rate for the 1st moment estimates. beta_2 float, 0 < beta < 1 0.999 The exponential decay rate for the 2nd moment estimates. amsgrad Boolean False Whether to apply AMSGrad variant of this algorithm from the paper "On the Convergence of Adam and beyond" epsilon float >= 0 1e-8 A small constant for numerical stability. 内部処理を翻訳すると以下のようなコードになっている。
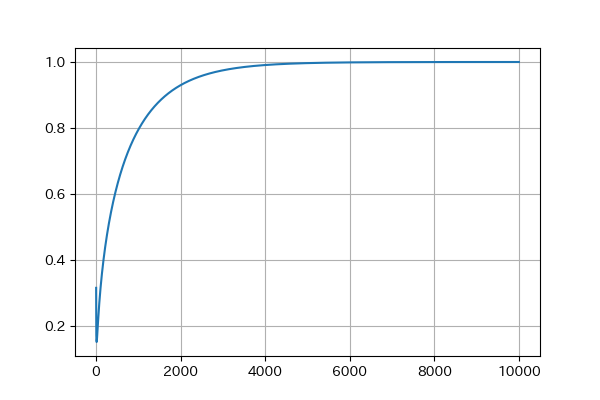
def get_step(grad): self.m = (self.beta_1 * self.m) + ((1. - self.beta_1) * grad) self.v = (self.beta_2 * self.v) + ((1. - self.beta_2) * (grad**2)) lr_t = lr * ((1. - (self.beta_2**iterations))**0.5) / (1. - (self.beta_1**iterations)) if amsgrad: self.vhat = max(self.vhat, self.v) v = -lr_t * self.m / ( (self.vhat**0.5)+self.epsilon ) else: v = -lr_t * self.m / ( (self.v**0.5)+self.epsilon ) return vコード上のlr_tは、本来は不偏推定量をとるために勾配(m)と二乗勾配(v)に掛ける補正係数を、そこだけ抜き出して学習率に掛けたものである。(最終的な結果は同じ)
lr_tはステップ数だけに依存して変化するので、ここだけグラフにしたものがこちら。(lr=1.0/beta_1=0.9/beta_2=0.999)
以下、学習率だけ設定した実験結果。
RMSpropよりも最適解近くでの振動が少ないように見える。
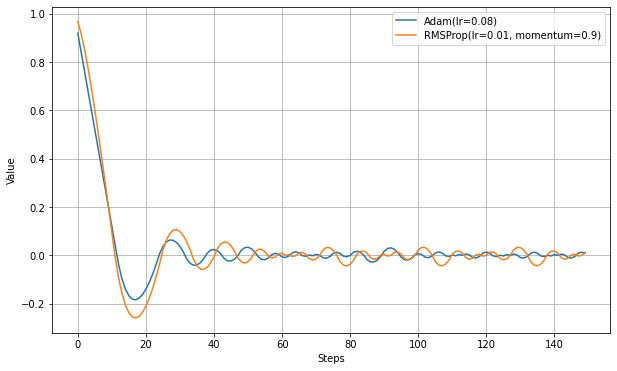
AdamはRMSpropにMomentumを導入したもの、という説明が良くされる。RMSpropにもmomentumの設定があるが、処理の内容は違う。以下は、同程度の学習速度を持つパラメータで比較した実験。
Adamのほうが最適値付近で振動が少ないようだ。
以下、beta_1を変更した実験結果。
以下、beta_2を変更した実験結果。(損失関数がMAEでは違いがなかったので、MSEの結果)
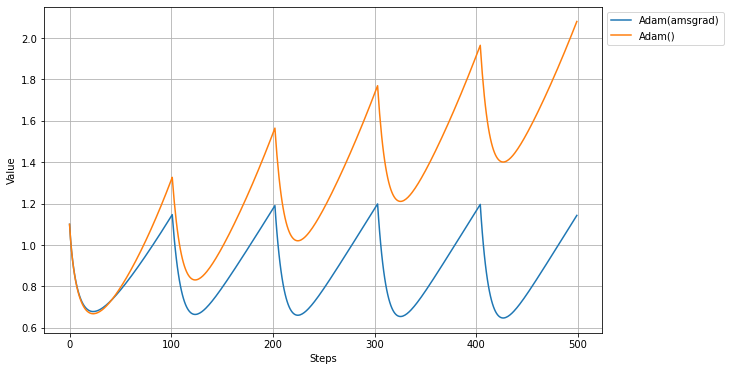
kerasではAdamでamsgradをTrueとするとAMSGradと呼ばれるアルゴリズムになる。過去の勾配の長期記憶を使うことにより、Adamでは収束できないような形の最適解での性能向上できるという。
AMSGradの論文。
ON THE CONVERGENCE OF ADAM AND BEYONDamsgrad=Trueとしても、これまで使用してきたMAEやMSEの損失関数では通常のAdamとの差は見られなかった。
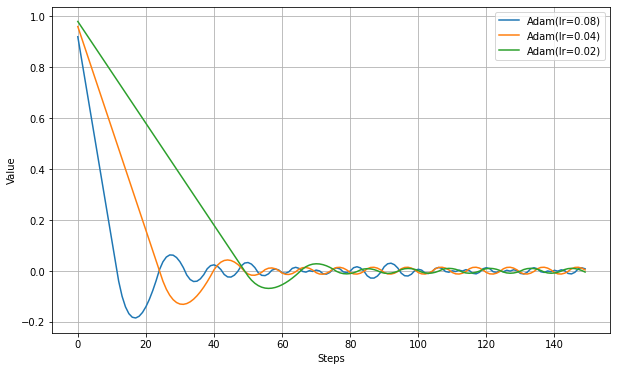
論文によると、AMSgradは'Adamでは収束できない条件があることへの改良版'ということで、その条件が例示されているので、その条件を再現して実験してみる。下記のような損失関数を用意してAdamとAMSgradで比較する。
loss = lambda: var1*(1010 if (i % 101) == 1 else -10)(i%101)==1の条件で(つまり101回に1回)、他とは逆方向の勾配が現れることになる。Adamではこの勾配をすぐ忘れてしまうので収束できない、とされている。
以下、実際にやってみた結果。(lr=0.1/beta_1=0.9/beta_2=0.99)
この条件では、AdamとAMSgradで大きな違いが出た。
Adamでは値がどんどん大きくなっていくが、AMSGradではほぼ同じ場所にとどまっている。
論文では-1が最適値とされているので、Adamよりは正確な値に近いように見える。Adamax
Adamの変形バージョン。
理論はともかく、二乗勾配が消えて勾配絶対値となり、過去の勾配の指数移動平均よりも大きな勾配が来た場合には、保持していた平均をクリアして最新の勾配絶対値に更新されるように見える。Keras実装は以下を参照した。
adamax.py
TensorFlow API AdamaxAdamの論文に同時記載。
Adam - A Method for Stochastic OptimizationAdaMaxにおける設定可能なパラメーターは以下の通り。
Paramater Range Default Description lr float >= 0 0.001 Learning rate. beta_1 float, 0 < beta < 1 0.9 The exponential decay rate for the 1st moment estimates. beta_2 float, 0 < beta < 1 0.999 The exponential decay rate for the exponentially weighted infinity norm. epsilon float >= 0 1e-7 A small constant for numerical stability. 以下、処理を翻訳したもの。
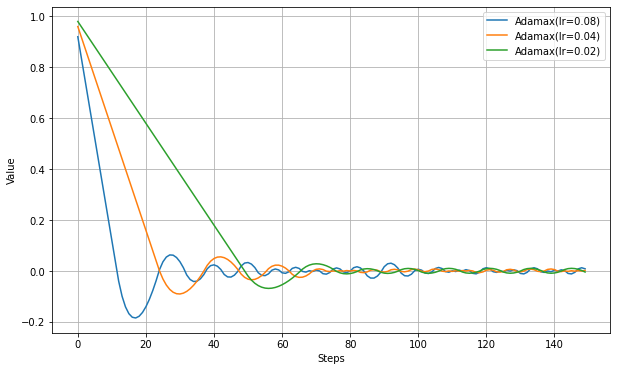
def get_step(grad): lr = self.lr * (1. / (1. + self.decay * iterations)) self.m = (self.beta_1 * self.m) + (1. - self.beta_1) * grad self.u = max(self.beta_2 * self.u, abs(grad)) lr_t = lr / (1. - (self.beta_1**t)) v = -lr_t * self.m / (self.u + self.epsilon) return v以下、学習率だけ設定した実験結果。
この実験ではAdamとの違いがよくわからなかった。
Nadam
AdamにSGDで採用されているNestrov加速法を適用したもの。
Keras実装は以下を参照した。
nadam.py
TensorFlow API NadamNadamの論文
Nadam reportNadamにおける設定可能なパラメーターは以下の通り。
Paramater Range Default Description lr float >= 0 0.001 Learning rate. beta_1 float, 0 < beta < 1 0.9 The exponential decay rate for the 1st moment estimates. beta_2 float, 0 < beta < 1 0.999 The exponential decay rate for the exponentially weighted infinity norm. epsilon float >= 0 1e-7 A small constant for numerical stability. 以下、処理を翻訳したもの。
def get_step(grad): t = iteration+1 momentum_cache_t = self.beta_1 * (1. - 0.5 * (pow(0.96, t * self.schedule_decay))) momentum_cache_t_1 = self.beta_1 * (1. - 0.5 * (pow(0.96, (t + 1) * self.schedule_decay))) m_schedule_new = self.m_schedule * momentum_cache_t m_schedule_next = m_schedule_new * momentum_cache_t_1 m_t = self.beta_1 * self.m + (1. - self.beta_1) * grad v_t = self.beta_2 * self.v + (1. - self.beta_2) * (g**2) g_prime = grad / (1. - m_schedule_new) m_t_prime = m_t / (1. - m_schedule_next) v_t_prime = v_t / (1. - (self.beta_2**t)) self.v = v_t self.m = m_t m_t_bar = (1. - momentum_cache_t) * g_prime + momentum_cache_t_1 * m_t_prime v = - self.lr * m_t_bar / ((v_t_prime**0.5) + self.epsilon) return vコードを見ただけではなにをやっているかよくわからないが、元論文にどうしてこうなるか書いてある模様。
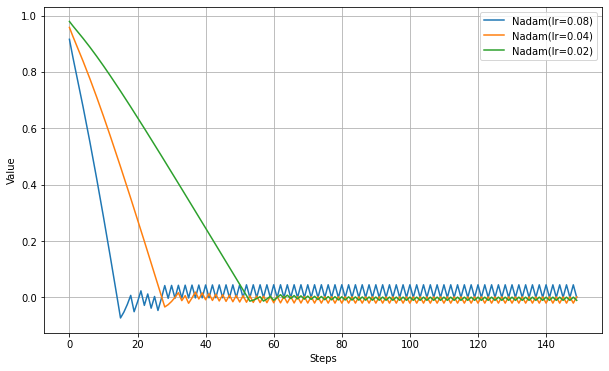
以下、学習率だけ設定した実験結果。
Adamに比べて最適値辺りのふるまいが大きく違う。NAGで見られたように振動抑制の効果が強いようだ。
RMSpropでは勾配が0に近くなると不安定にある現象が見られるので、Adam/Adamax/NadamでもMSEにして比較実験する。
RMSpropのように不安定になることは無いようだ。
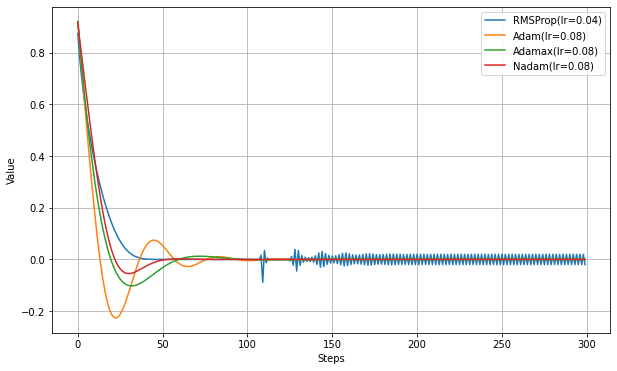
MAEではAdamaxとAdamの違いがあまりなかったが、MSEにするとはっきりした違いが出る。まとめ
- AdamはRMSpropと比較すると最適値付近できれいに収束するように見える。学習率を変化させても収束しやすいようで、この辺も人気の理由か。
- AMSgradはAdamの改良版だが、かなり特殊な勾配にしないと違いがはっきり表れなかった。
- AdamaxはAdamの派生版だが、Adamよりは最適値に向かう速度は若干遅いが、最適値付近での振動が穏やかになっているように見える。
- NadamはAdamにNesterovを適用したもので、Adamよりも最適値へ向かう速度は若干遅いが、最適値付近での振幅が少なくなっているように見える。ただし、MAEでは細かい振動が収まらない。
複雑な条件での比較は別記事で行うことにする。
参考
実験コード
TestOptimizer.pyimport numpy as np import tensorflow as tf import matplotlib.pyplot as plt from tensorflow.keras.optimizers import SGD,RMSprop,Adagrad,Adadelta,Adam,Nadam,Adamax,Ftrl def testOptims(optims, lossFn='mae', total_steps=150): fig = plt.figure(figsize=(10,6),facecolor="white",) ax = fig.add_subplot(111) steps = range(total_steps) y = np.zeros(total_steps) if lossFn=='mae': loss = lambda: tf.abs(var1) elif lossFn=='mse': loss = lambda: var1**2 elif lossFn=='special': loss = lambda: var1*(1010 if (i % 101) == 1 else -10) for label, optim in optims.items(): var1 = tf.Variable(1.0) for i in range(total_steps): optim.minimize(loss, [var1]).numpy() y[i] = var1.numpy() ax.plot( steps, y, label=label ) ax.legend(bbox_to_anchor=(1.0,1.0)) ax.set_xlabel('Steps') ax.set_ylabel('Value') ax.grid() plt.show() print('Adam(lr)') testOptims( { 'Adam(lr=0.08)': Adam(0.08), 'Adam(lr=0.04)': Adam(0.04), 'Adam(lr=0.02)': Adam(0.02), }, lossFn = 'mae' ) print('Adam(beta_1)') testOptims( { 'Adam(lr=0.08, beta_1=0.999)': Adam(0.08, beta_1=0.999), 'Adam(lr=0.08, beta_1=0.95)': Adam(0.08, beta_1=0.95), 'Adam(lr=0.08, beta_1=0.90)': Adam(0.08, beta_1=0.90), 'Adam(lr=0.08, beta_1=0.85)': Adam(0.08, beta_1=0.85), }, lossFn = 'mae' ) print('Adam(beta_2,mae)') testOptims( { 'Adam(lr=0.08, beta_2=0.999)': Adam(0.08, beta_2=0.999), 'Adam(lr=0.08, beta_2=0.95)': Adam(0.08, beta_2=0.95), 'Adam(lr=0.08, beta_2=0.90)': Adam(0.08, beta_2=0.90), 'Adam(lr=0.08, beta_2=0.85)': Adam(0.08, beta_2=0.85), }, lossFn = 'mae' ) print('Adam(beta_2,mse)') testOptims( { 'Adam(lr=0.08, beta_2=0.999)': Adam(0.08, beta_2=0.999), 'Adam(lr=0.08, beta_2=0.95)': Adam(0.08, beta_2=0.95), 'Adam(lr=0.08, beta_2=0.90)': Adam(0.08, beta_2=0.90), 'Adam(lr=0.08, beta_2=0.85)': Adam(0.08, beta_2=0.85), }, lossFn = 'mse' ) print('AMSGrad(mse)') testOptims( { 'Adam(lr=0.08)': Adam(0.08), 'Adam(lr=0.08,amsgrad)': Adam(0.08,amsgrad=True), }, lossFn = 'mse' ) print('AMSgrad(special)') testOptims( { 'Adam(amsgrad)': Adam(0.1, beta_1=0.9, beta_2=0.99, amsgrad=True), 'Adam()' : Adam(0.1, beta_1=0.9, beta_2=0.99, amsgrad=False), }, lossFn='special', total_steps=500 ) print('Adam vs RMSprop(mom)') testOptims( { 'Adam(lr=0.08)': Adam(0.08), 'RMSProp(lr=0.01, momentum=0.9)': RMSprop(0.01, momentum=0.9), }, lossFn = 'mae' ) print('Adamax(lr)') testOptims( { 'Adamax(lr=0.08)': Adamax(0.08), 'Adamax(lr=0.04)': Adamax(0.04), 'Adamax(lr=0.02)': Adamax(0.02), }, lossFn = 'mae' ) print('Nadam(lr)') testOptims( { 'Nadam(lr=0.08)': Nadam(0.08), 'Nadam(lr=0.04)': Nadam(0.04), 'Nadam(lr=0.02)': Nadam(0.02), }, lossFn = 'mae' ) print('MSE') testOptims( { 'RMSProp(lr=0.04)': RMSprop(0.04), 'Adam(lr=0.08)': Adam(0.08), 'Adamax(lr=0.08)': Adamax(0.08), 'Nadam(lr=0.08)': Nadam(0.08), }, lossFn = 'mse' , total_steps=300 )

- 投稿日:2020-11-18T16:49:07+09:00
最適化アルゴリズムを単独実行で比較する(Adagrad/RMSprop/Adadelta編)
はじめに
この記事では、数式は使わず、実際のコードから翻訳した疑似コードを使って動作を紹介する。また、Keras(TensorFlow)のOptimizerを使用した実験結果を示すことにより、各種最適化アルゴリズムでのパラメーターの効果や、アルゴリズム間の比較を行う。
ここでは、Adagrad/RMSprop/Adagradを扱う。
SGD編
Adam/Adamax/Nadam編
FTRL編
総合編実験方法
極簡単なネットワークを学習させ、学習過程をグラフにプロットして比較する。
具体的には、下記の内容。
- 初期値1.0、最適値0.0として、Optimiserのminimize()を直接実行し、ステップ毎に最適値に近づく様子を観察する。
- 損失関数は特に言及しない限り絶対値(MAE)を使用。場合によっては二乗(MSE)なども使用。
- Keras使用。Google Colabで実行可な実験コードを最後に記載。
Adagrad
MomenumSGDでは慣性項を導入することで学習を加速させた。
Adagradやその派生アルゴリズムは、基本的には学習率(勾配に掛ける係数)を適応的に変動させることで、学習を早めたり振動を抑える。Adagradの論文。
Adaptive Subgradient Methods for Online Learning and Stochastic OptimizationKeras実装は以下を参照した。
keras/optimizers.py
TensorFlow API AdagradAdagradにおける設定可能なパラメーターは以下の通り。
パラメーター 範囲 初期値 説明 learning_rate float >= 0 0.001 Learning rate. initial_accumulator_value float >= 0 0.1 Starting value for the accumulators epsilon float >= 0 1e-8 Fuzz factor. 内部処理を翻訳すると以下のようなコードになっている。
def get_step(grad): self.accumlator = self.accumlator + (grad**2) v = -lr * grad / ( (self.accumlator**0.5)+self.epsilon ) return vイテレーションごとにaccumelatorは確実に増加していく。lr / (accumulator**0.5)を修正学習率と解釈すれば、学習が進むと絶対に学習率が下がることになる。
SGDでもDecayを使えば学習率が下がるが、Adagradは実際の勾配をみて「適応的に学習率が減る」と解釈できる。
initial_accumulator_valueはaccumlatorの初期値。
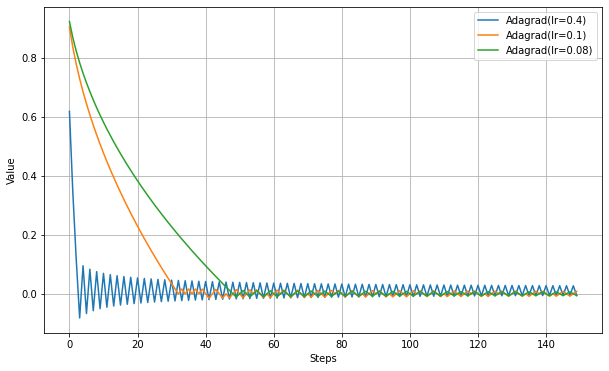
epsilonは勾配が非常に小さい場合に不安定になることを防ぐためのもの。以下、学習率の違いを見る実験。
最適値付近で振動するが、振幅が徐々に小さくなっていることがわかる。
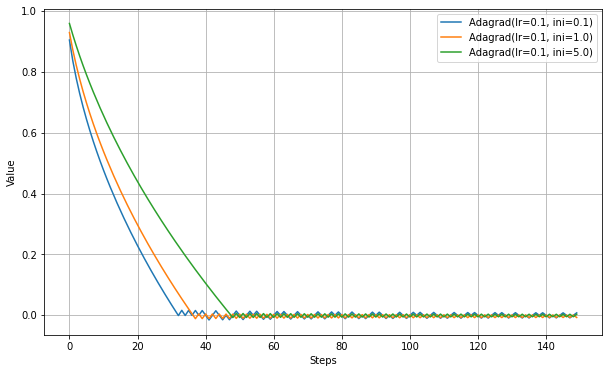
以下、initial_accumulator_valueの違いを見る実験。
initial_accumulator_valueを大きくすると、学習が遅くなる。これは修正学習率が最初から小さくなるためだろう。
RMSprop
Adagradでは、勾配が積算される一方なので、一度大きな勾配を経験するとその後の学習率が相対的に低くなりすぎる問題がある。実際の機械学習では勾配が0付近になる地点が複数あることが見込まれるので、最適解に到達する前に学習が止まってしまう可能性が高くなる。
「過去の勾配情報を忘却させていく」という手法でこの問題の緩和を目指したものがRMSpropとなる。
Adagradとの違いは、accumlatorの計算で単純に加算するのではなく、移動二乗平均平方根(moving RMS)としていることにある。これにより、学習が進むにつれて修正後の学習率が一方的に小さくなることを防ぐ。Keras実装は以下を参照した。
keras/optimizers.py
training_ops.cc
Tensorflow API RMSpropRMSpropの論文
rmsprop: Divide the gradient by a running average of its recent magnitudeRMSpropにおける設定可能なパラメーターは以下の通り。
Paramater Range Default Description lr float >= 0 0.001 Learning rate. rho float >= 0 0.9 Discounting factor for the history/coming gradient. momentum float >= 0 0.0 Momentum epsilon float >= 0 1e-8 A small constant for numerical stability. centered Boolean False If True, gradients are normalized by the estimated variance of the gradient; if False, by the uncentered second moment. Setting this to True may help with training, but is slightly more expensive in terms of computation and memory. 内部処理を翻訳すると以下のようなコードになっている。
def get_step(grad): self.accumlator = (self.rho*self.accumlator) + (1.0-self.rho)*(grad**2) if centered: self.mg = (self.rho*self.mg) + (1.0-self.rho)*grad denominator = self.accumlator - (self.mg**2) + epsilon else: denominator = self.accumlator + epsilon self.mom = self.mom*momentum + lr*grad/(denominator**0.5) v = -self.mom return vrhoは指数移動平均の係数で大きいほど過去の勾配を重要視する。
momentumはMomentumSGDで導入した慣性項と同じ機能。RMSpropの改良版であるAdamは「RMSpropにMomentumを追加したもの」と表現されることがあるようだが、こちらの実装はAdamとは別ものである。MomentumSGDとの関連でいえば、Adamよりもこちらのほうが素直に慣性項を追加した実装となっているように思われる。
centeredは「指数移動平均の中心値を補正するかどうか」、の設定と思われ、これはRMSpropGravesと呼ばれる改良版のようだ。Adagradとの差がわかりやすいようにmomentumとcenteredを抜くと以下のような処理。
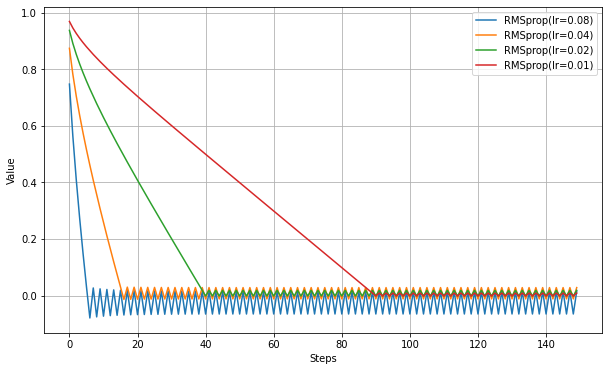
def get_step(grad): self.accumlator = (self.rho*self.accumlator) + (1.0-self.rho)*(grad**2) v = -lr * grad / ( (self.accumlator**0.5)+self.epsilon ) return v以下、lrだけ変更して実験。
Adagradと似たような動作になるが、Adagradでは振動は減衰していくことに比べると、RMSpropでは同様の減衰は見られない。指数移動平均により、古い勾配の寄与がなくなるため、一方的に減衰しなくなる効果が出ている。
以下、centeredをTrueにして実験(RMSpropGraves)。
学習が速くなっている。以下、momentumを設定して実験。
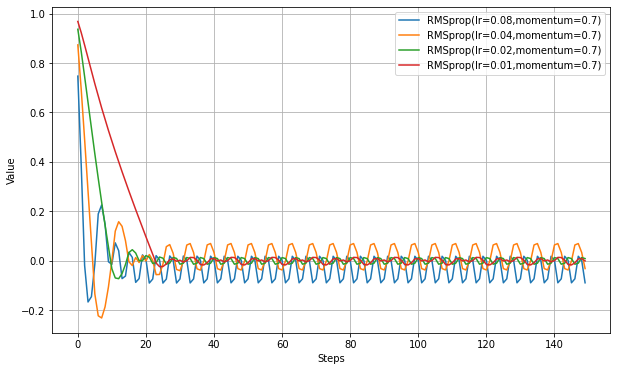
学習が速くなっている代わりに、最適値付近での振幅がやや増えているようだ。MomentumSGDと似ている。以下、rhoを変えた場合の違いの実験。
Adadelta
Adagradから派生したアルゴリズム。
RMSprop同様に、指数移動平均を使用して、過去の勾配を忘れる。違うところは、適応学習率の計算で過去のステップサイズの指数移動平均を掛けていることで、勾配が大きい場合と小さい場合の学習率の効果の差を軽減しているようだ。これにより学習率の設定が不要になった、と元論文では言っている模様。Keras実装は以下を参照した。
keras/optimizers.py
Tensorflow API AdadeltaAdadeltaの論文
Adadelta - an adaptive learning rate methodAdadeltaにおける設定可能なパラメーターは以下の通り。
Paramater Range Default Description lr float >= 0 0.001 Learning rate. rho float >= 0 0.95 The decay rate. epsilon float >= 0 1e-7 A constant epsilon used to better conditioning the grad update. decay float >= 0 0 Learning rate decay over each update. 内部処理を翻訳すると以下のようなコードになっている。
def get_step(grad): lr = self.lr * (1. / (1. + self.decay * iterations)) self.accumlator = (self.rho*self.accumlator) + (1.0-self.rho)*(grad**2) update = grad * (self.delta_accumulator+self.epsilon)**0.5) / ((self.accumlator+self.epsilon)**0.5) self.delta_accumulator = (self.rho*self.delta_accumulator) + (1.0-self.rho)*(update**2) v = -lr * update return vAdadeltaの特徴としてハイパーパラメータとしての学習率の調整が必要ない、と言われるが、実際にはlrが存在する。元論文と同じ設定にしたいならlr=1.0とせよ、とありこの場合は学習率を設定していないことにはなるかもしれない。
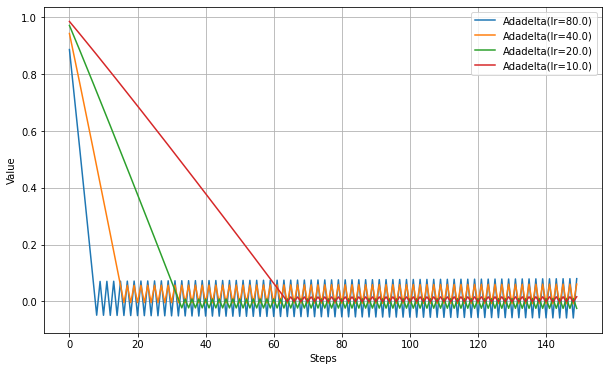
以下、lrを変えて実験。
他のアルゴリズムに比べlrに大幅に大きな値を設定しないと、同じ程度のステップ数では最適解に到達しない。少なくとも学習率の調整が必要な場合もあるということは言えそうだ。
Adadeltaには下記の注意書きがある。
According to section 4.3 ("Effective Learning rates"), near the end of training step sizes converge to 1 which is effectively a high learning rate which would cause divergence. This occurs only near the end of the training as gradients and step sizes are small, and the epsilon constant in the numerator and denominator dominate past gradients and parameter updates which converge the learning rate to 1.
学習の終わり付近で勾配が0に近づくとステップサイズが1に収束してしまうため、学習率が大きくなりすぎて発散する可能性がある、ということらしい。
損失関数がMAEでは勾配が0にならないので、MSEで実験する。RMSpropとAdagradの結果も載せる。
RMSpropが70step辺りで不安定になっている。これは分母が非常に小さくなって勾配の変化に敏感になっているためと思われる。
Adadeltaは220step辺りで発散が開始しているようだ。不安定になるまでのステップ数はRMSpropより長いので、より安定していると評価できるかもしれない。ただし発散はRMSpropより激しい。
Adagradにはこのような現象は見られない。まとめ
- Adagradは学習途中で学習率が減少しすぎて最適値に到達できない可能性がある。
- RMSpropはかなり高速に最適値へ向かう。Adagradと違い途中で学習率が一方的に減少することがないが、最適値付近での振動は止まらない。
- Keras/TensorFlowのRMSpropはmomentumとcenteredのパラメータがある。momentumを設定するとさらに高速になる。
- Adadeltaは学習率を他の最適化手法よりもかなり大きく設定しなければならない。また、最適値近くでは大きく発散する可能性がある。
条件が単純すぎたので、各アルゴリズムの違いが大きく出なかった可能性もある。もうすこし複雑な条件での比較は別記事で行うことにする。
参考
深層学習の最適化アルゴリズム
勾配降下法一覧 (2020)
RMSpropGravesについて自分なりに考えてみた
実験コード
TestOptimizer.pyimport numpy as np import tensorflow as tf import matplotlib.pyplot as plt from tensorflow.keras.optimizers import SGD,RMSprop,Adagrad,Adadelta,Adam def testOptims(optims, lossFn='mae', total_steps=150): fig = plt.figure(figsize=(10,6),facecolor="white",) ax = fig.add_subplot(111) steps = range(total_steps) y = np.zeros(total_steps) if lossFn=='mae': loss = lambda: tf.abs(var1) elif lossFn=='mse': loss = lambda: var1**2 for label, optim in optims.items(): var1 = tf.Variable(1.0) for i in range(total_steps): optim.minimize(loss, [var1]).numpy() y[i] = var1.numpy() ax.plot( steps, y, label=label ) ax.legend(bbox_to_anchor=(1.0,1.0)) ax.set_xlabel('Steps') ax.set_ylabel('Value') ax.grid() plt.show() print('Adagrad(lr)') testOptims( { 'Adagrad(lr=0.4)': Adagrad(0.4), 'Adagrad(lr=0.1)': Adagrad(0.1), 'Adagrad(lr=0.08)': Adagrad(0.08), }, lossFn = 'mae' , ) print('Adagrad(initial_accumulator_value)') testOptims( { 'Adagrad(lr=0.1, ini=0.1)': Adagrad(0.1, initial_accumulator_value=0.1), 'Adagrad(lr=0.1, ini=1.0)': Adagrad(0.1, initial_accumulator_value=1.0), 'Adagrad(lr=0.1, ini=5.0)': Adagrad(0.1, initial_accumulator_value=5.0), }, lossFn = 'mae', ) print('RMSprop(lr)') testOptims( { 'RMSprop(lr=0.08)': RMSprop(0.08), 'RMSprop(lr=0.04)': RMSprop(0.04), 'RMSprop(lr=0.02)': RMSprop(0.02), 'RMSprop(lr=0.01)': RMSprop(0.01), }, lossFn = 'mae', ) print('RMSprop(centered)') testOptims( { 'RMSprop(lr=0.08,centered)': RMSprop(0.08, centered=True), 'RMSprop(lr=0.04,centered)': RMSprop(0.04, centered=True), 'RMSprop(lr=0.02,centered)': RMSprop(0.02, centered=True), 'RMSprop(lr=0.01,centered)': RMSprop(0.01, centered=True), }, lossFn = 'mae', ) print('RMSprop(momentum)') testOptims( { 'RMSprop(lr=0.08,momentum=0.7)': RMSprop(0.08,momentum=0.7), 'RMSprop(lr=0.04,momentum=0.7)': RMSprop(0.04,momentum=0.7), 'RMSprop(lr=0.02,momentum=0.7)': RMSprop(0.02,momentum=0.7), 'RMSprop(lr=0.01,momentum=0.7)': RMSprop(0.01,momentum=0.7), }, lossFn = 'mae', ) print('RMSprop(rho)') testOptims( { 'RMSprop(lr=0.01, rho=0.95)': RMSprop(0.01, rho=0.95), 'RMSprop(lr=0.01, rho=0.9)': RMSprop(0.01, rho=0.90), 'RMSprop(lr=0.01, rho=0.8)': RMSprop(0.01, rho=0.80), }, lossFn = 'mae', ) print('Adadelta(lr)') testOptims( { 'Adadelta(lr=80.0)': Adadelta(80.0), 'Adadelta(lr=40.0)': Adadelta(40.0), 'Adadelta(lr=20.0)': Adadelta(20.0), 'Adadelta(lr=10.0)': Adadelta(10.0), }, lossFn = 'mae' ) print('RMSprop(mse)') testOptims( { 'RMSprop(lr=0.08)': RMSprop(0.08), 'Adadelta(lr=80.0)': Adadelta(80.0), 'Adagrad(lr=0.2)': Adagrad(0.2), }, lossFn = 'mse', total_steps=300 )



- 投稿日:2020-11-18T10:36:27+09:00
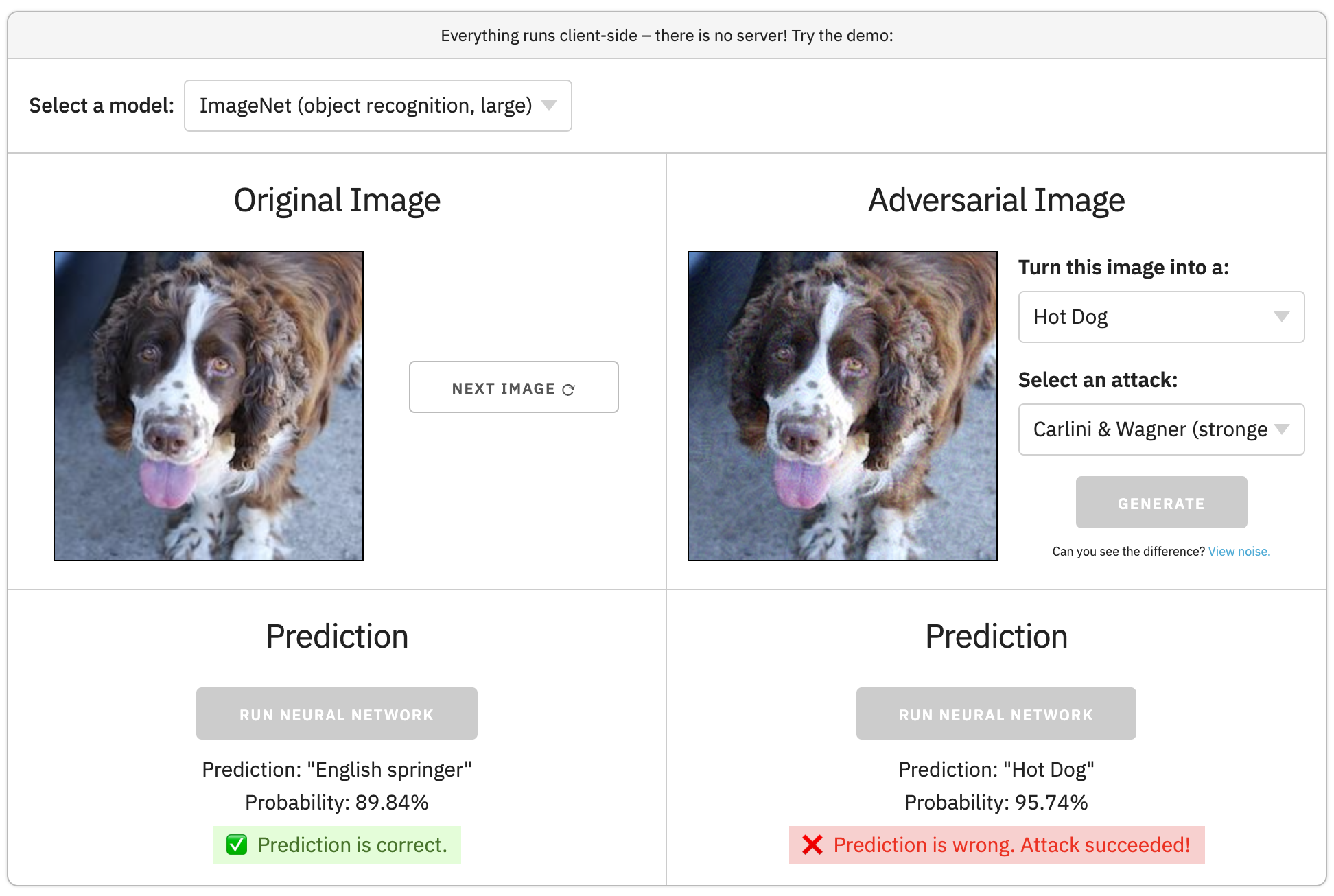
[English] Adversarial examples in your browser with TensorFlow.js
1. Introduction
In this article, I'll implement a simple adversarial attack in JavaScript.
Afterwards, you can play with more attacks in adversarial.js:
2. Background
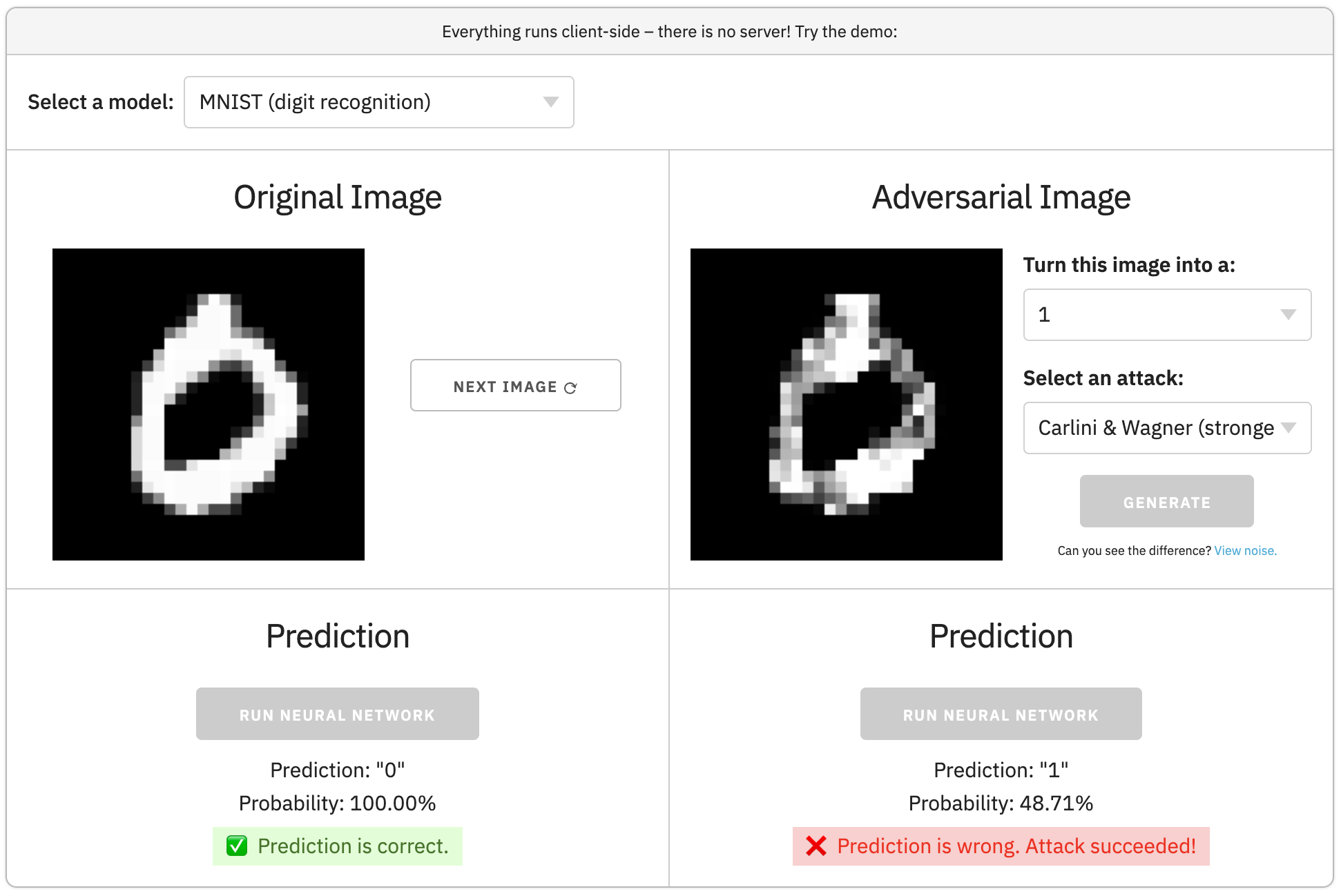
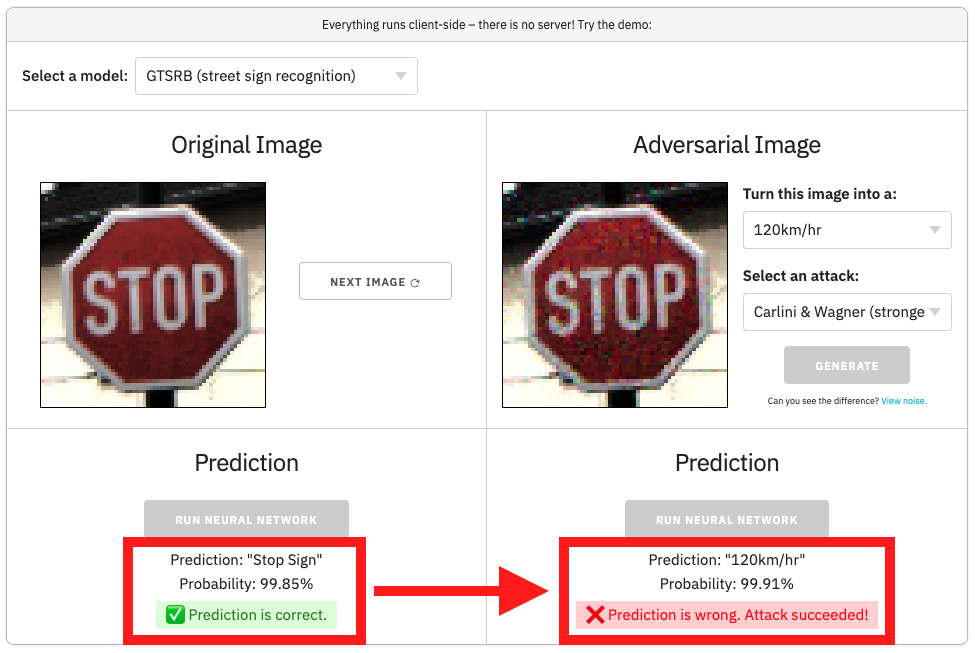
We start with a neural network image classifier, and a correctly classified image.
An adversarial example is the original image + a few changed pixels that cause an incorrect prediction.
In the example above, after changing a few pixels, we can force the neural network to think the "Stop" sign is a "120 km/hr" sign.Can you see the difference between the two images?
3. Implementation
So, how do we implement this?
In machine learning, we usually try to minimize the model's loss. However, to generate an adversarial example, we maximize the model's loss (with respect to the image).
Here's the maximization step, written in math:
This is called the FGSM attack. Now, let's implement it in JavaScript.Assume we've already loaded TensorFlow.js, the pre-trained
model, and several MNIST images indataset. (The full code is on CodePen.)The attack is just:
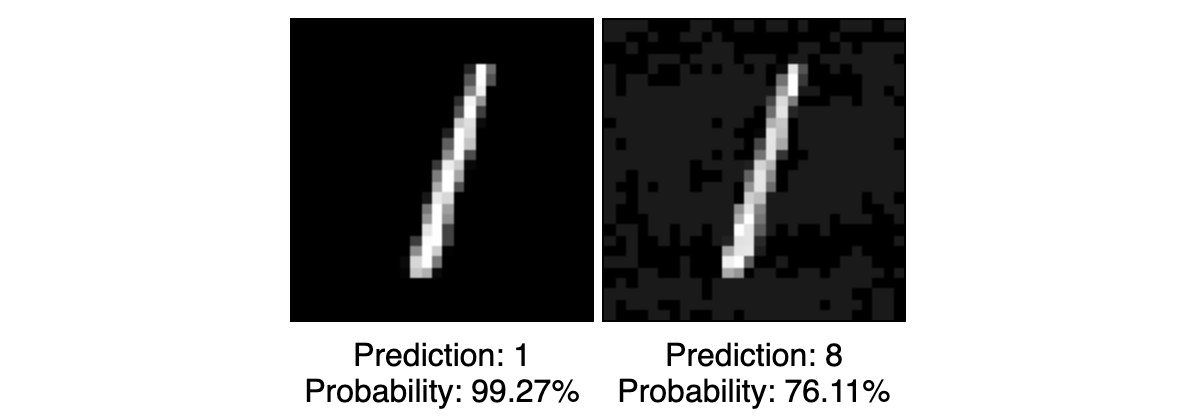
// Load one image and its label let img = dataset[1].xs; let lbl = dataset[1].ys; // Loss function that measures how close the image is to the original class (maximize this) function loss(input) { return tf.metrics.categoricalCrossentropy(lbl, model.predict(input)); } // Generate adversarial example with FGSM let grad = tf.grad(loss); let delta = tf.sign(grad(img)).mul(0.1); let aimg = img.add(delta).clipByValue(0, 1);Easy!
aimgis the adversarial image. Let's visualize it:// Draw the original and adversarial images tf.browser.toPixels(resize(img), origCanvas); tf.browser.toPixels(resize(aimg), advCanvas);And show the predictions:
// Make predictions on the original and adversarial images let origPred = model.predict(img).argMax(1).dataSync()[0]; let origProb = model.predict(img).max(1).dataSync()[0]; let advPred = model.predict(aimg).argMax(1).dataSync()[0]; let advProb = model.predict(aimg).max(1).dataSync()[0]; // Display predicted classes and probabilities origStatus.innerHTML = `Prediction: ${origPred}<br>Probability: ${(origProb * 100).toFixed(2)}%`; advStatus.innerHTML = `Prediction: ${advPred}<br>Probability: ${(advProb * 100).toFixed(2)}%`;We see that the attack succeeded!
(Full code on CodePen.)4. adversarial.js
In addition to FGSM, there are several more advanced attacks (e.g. BIM, JSMA, C&W).
All of these attacks are implemented in the adversarial.js library. It also has a web demo that generates adversarial examples in your browser.
Try it out!
See the code on GitHub:
5. Conclusion
If you have any questions, please comment below!
日本語に翻訳してくれたら、コメントしてください!