- 投稿日:2020-11-18T23:18:23+09:00
AtCoder:Python:サンプルテストをできるだけ自動化する。
AtCoderでコンテストの入力例をコピー→貼り付け→実行して合っているか確認していくのがめんどくさいのでできるだけ自動化したい。
でも自分でコーナーケースなどを作ってテストもしたいので自分で作成したケースも実行できるようにしたい。windowsでpythonはインストールされていれば以下に記載の手順を行えばできるようになる。
先にすべての手順を終えたあと、実際のコンテストでテストする際のやり方を説明する。
①サンプルダウンロードのプログラムを実行し、コンテスト名を入力(「abc123」など)
②入力例と出力例をダウンロード
③プログラムを書く
④実行して出力例と出力があっているか確認プログラムが行っていることの簡単な説明は以下。
①入力されたコンテスト名を受け取り
②pythonでコンテスト名からURLにアクセスしてhtmlから入力例と出力例を引っ張り出す。
③それぞれをtxtファイルに出力
④保存されたtxtファイルを引数としてプログラムを実行(windows batを使う)
⑤実行結果の出力と出力例を並べて表示導入方法と使い方を以下に記載。
【手順1】
コマンドプロンプトで
pip install requests
pip install BeautifulSoup
を入力してURL取得に使用するライブラリをインストールする。【手順2】
「Samples」、「Run」というフォルダを作る。(場所はどこでも良い)【手順3】
「Samples」フォルダの中にGetSample.pyというファイルを作り、以下を貼り付けGetSample.pyimport requests,os,glob from bs4 import BeautifulSoup def outtxt(pro): res=requests.get("https://atcoder.jp/contests/"+No+"/tasks/"+No+"_"+pro) soup=BeautifulSoup(res.text, 'html.parser') source=soup.find_all("pre") source=[str(source) for source in source] sample=[] for i in range(1,len(source)): if "<var>" in source[i]: break else: tmp=source[i] tmp=tmp.replace("<pre>","") tmp=tmp.replace("</pre>","") tmp=tmp.replace("\r\n","\n") sample.append(tmp) for i in range(0,len(sample),2): with open("Sample_Input_"+pro.upper()+"_"+str(i//2+1)+".txt", mode='w') as f: f.write(sample[i]) for i in range(1,len(sample),2): with open("Sample_Output_"+pro.upper()+"_"+str(i//2+1)+".txt", mode='w') as f: f.write(sample[i]) No=input() for file in glob.glob('*.txt'): os.remove(file) outtxt("a") outtxt("b") outtxt("c") outtxt("d") outtxt("e") outtxt("f")【手順4】
GetSample.pyをダブルクリックして実行。
→入力待でとまるので「abc123」などコンテスト名を入力。
→「Samples」フォルダの中に入力例と出力例のtxtファイルがだーっとできる。【手順5】
Runフォルダの中に「HandInput.txt」という空のtxtファイルを作る。【手順6】
Runフォルダの中に「Ans.py」をつくって以下を貼り付けAns.pyimport io,sys,os if len(sys.argv)>1: path=sys.argv[1] else: os.system('cls') path="HandInput.txt" try: with open(path) as f: INPUT=f.read() sys.stdin = io.StringIO(INPUT) except: print("指定されたファイルが見つかりません。") exit() # -------------------------------------------------------- # 以下に提出コードを記載【手順7】
「Run」フォルダの中に「SampleTest_A.bat」を作って以下を貼り付け
(「samplesフォルダのパス」のところはsamplesフォルダを作った場所のパスを書く(C:\Windows\・・・\Samplesみたいなやつ))SampleText_A.batecho off echo [Case1] Ans.py 「samplesフォルダのパス」\Sample_Input_A_1.txt type 「samplesフォルダのパス」\Sample_Output_A_1.txt echo [Case2] Ans.py 「samplesフォルダのパス」\Sample_Input_A_2.txt type 「samplesフォルダのパス」\Sample_Output_A_2.txt echo [Case3] Ans.py 「samplesフォルダのパス」\Sample_Input_A_3.txt type 「samplesフォルダのパス」\Sample_Output_A_3.txt echo [Case4] Ans.py 「samplesフォルダのパス」\Sample_Input_A_4.txt type 「samplesフォルダのパス」\Sample_Output_A_4.txt上と同じようにsampleTest_B.bat、sampleTest_C.bat、sampleTest_D.bat、sampleTest_E.bat、sampleTest_F.batを作る(batの中身のAと書かれているところをすべてB,C,D・・・に書き換える)
【手順8】
「Run」フォルダにSampleTest.pyを作って以下を貼り付け。
注意点としてpythonに直接フォルダのパスを書いてもエラーになるので、「samplesフォルダのパス」の部分はファイルパスの\を二重にすること。
(例 C\windows\・・・\Samples → C\\windows\\・・・\\Samples)SampleTest.pyimport os,sys os.system('cls') pro="A" os.system("「samplesフォルダのパス」\\SampleTest_"+pro+".bat")これで準備は終了。
【使用法】
まずAns.pyの「ここに提出コードを記載」の部分にコードを記載。
A問題ならSamplesTest.pyの「pro="A"」、B問題なら「pro="B"」にして実行。SamplesTest.py,出力例[Case1] 1 1 [Case2] 0 0 [Case3] 10 10 [Case4] 指定されたファイルが見つかりません。 指定されたファイルが見つかりません。サンプルの出力例と自分の答えがあっていればこんな感じになる。
上が自分の答え。下がサンプルの出力例。
見比べてあっていれば提出する。
自分で作ったサンプルを試したいなら入力をHandInput.txtに書いてAns.pyをそのまま実行する。まとめると、
「Run」フォルダの中は以下のようになっている。
Ans.py
GetSample.py
SampleTest.py
HandInput.txt「Samples」フォルダの中は以下のようになっている。
GetSample.py
SampleTest_A.bat
SampleTest_B.bat
SampleTest_C.bat
SampleTest_D.bat
SampleTest_E.bat
SampleTest_F.bat
「その他GetSample.pyを実行していればサンプルの入力(Sample_Input_A_1.txtなど)と出力(Sample_Output_A_1.txt)」GetSample.pyでatcoderの問題ページへアクセス→htmlファイルから入力例と出力例を取り出してテキストファイルに書き込み
Ans.pyの実行時に引数があればそれを入力として受け取り、なければHandInput.txtを入力として受け取りする。
SampleTest_A.batなどはAns.pyにGetSample.pyで出力したテキストファイルを引数として渡して実行するbat。
SampleTest.pyはSampleTest_A.batなどを実行するだけのプログラム(なくてもbatを直接叩けばテストはできるが全部VScode上でやりたかったのでつくっただけ)
- 投稿日:2020-11-18T22:52:11+09:00
LeetCodeに毎日挑戦してみた 1.Two Sum(Python、Go)
はじめに
無料英単語サイトE-tanを運営中の@ishishowです。
プログラマとしての能力を上げるために毎日leetcodeに取り組み、自分なりの解き方を挙げていきたいと思います。
Leetcodeとは
leetcode.com
ソフトウェア開発職のコーディング面接の練習といえばこれらしいです。
合計1500問以上のコーデイング問題が投稿されていて、実際の面接でも同じ問題が出されることは多いらしいとのことです。Go言語入門+アルゴリズム脳の強化のためにGolangとPythonで解いていこうと思います。(Pythonは弱弱だが経験あり)
1日目
Two Sum
- 問題内容(日本語訳)
整数の配列と整数が与えられた
nums場合target、合計がtarget。になるように2つの数値のインデックスを返します。各入力には**正確に*1つの解があると想定でき、同じ*要素を2回使用することはできません。
回答は任意の順序で返すことができます。
Example 1:
Input: nums = [2,7,11,15], target = 9 Output: [0,1] Output: Because nums[0] + nums[1] == 9, we return [0, 1].Example 2:
Input: nums = [3,2,4], target = 6 Output: [1,2]Example 3:
Input: nums = [3,3], target = 6 Output: [0,1]この問題は辞書型に値を代入していき、(Target - 値)が存在した時に処理を終えればよさそうでした。
ちなみに、私は最初に全探索でループ処理を二回で記述したのですが、RunTimeErrorになってしまい、解答を見ました。。。
Pythonのループ処理は遅い。。
- 解答コード
class Solution(object): def twoSum(self, nums, target): d = {} for i in range(len(nums)): if (target - nums[i]) in d: return [d[target - nums[i]],i] else: d[nums[i]] = i return 0
- 私の最初のコード(RunTimeErrorになる)
class Solution(object): def twoSum(self, nums, target): a = len(nums) for i in range(a): j = i+1 while j!=a: if nums[i] + nums[j] == target: return [i,j] j +=1 return 0エラーになったのでa=len(nums)にする苦し紛れの処理も虚しく、辞書型で書き直しました。。。
- Goでも書いてみます!
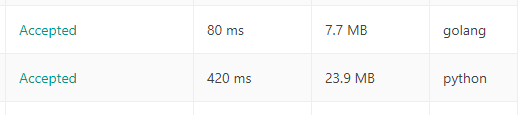
func twoSum(nums []int, target int) []int { m := make(map[int]int) for i, v := range nums { idx, ok := m[target-v] if ok { return []int{idx, i} } m[v] = i } return nil }Goだと実行時間が全然違いました!
※左からRunTime, Memory, 実効言語
- 自分メモ(Go)
makeを使う理由
Maps(連想配列)の初期値を指定しない場合、変数は
nil (nil マップ)に初期化されます。
nil マップは要素を格納することができず、要素を格納する場合はマップの初期化を行う必要があります。idx, ok := m[target-v]はその値があったらokにTrueが入る。
Goはarrayが固定長のため、スライスを使うことが多い。
Goの書き方が曖昧なので調べながらやっていますが、これをやり切ればかなりの実力が付きそうです!
参考にした記事
- 投稿日:2020-11-18T22:39:07+09:00
MLflow on Databricksを試してみた
動作環境
- 今回 lightGBMを利用するので、記事作成時点(2020年11月)で最新RuntimeのDatabricks 7.4MLを利用しています
追加の外部ライブラリをインストールしたい場合
- クラスターの
Librariesタブからインストールすることが可能です(7.4MLは既にlightGBMがインストール済み)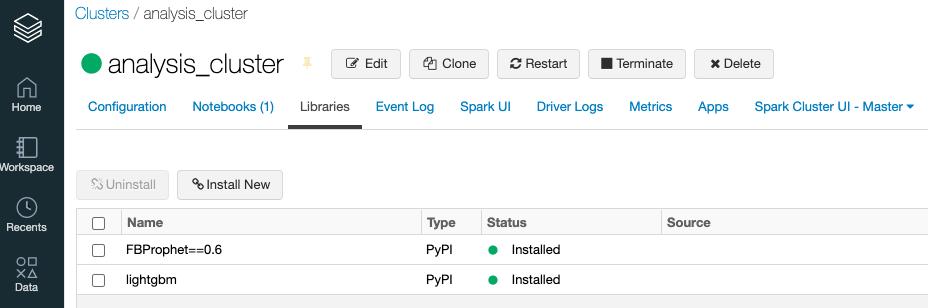
MLflow Trackingでモデルの評価をする
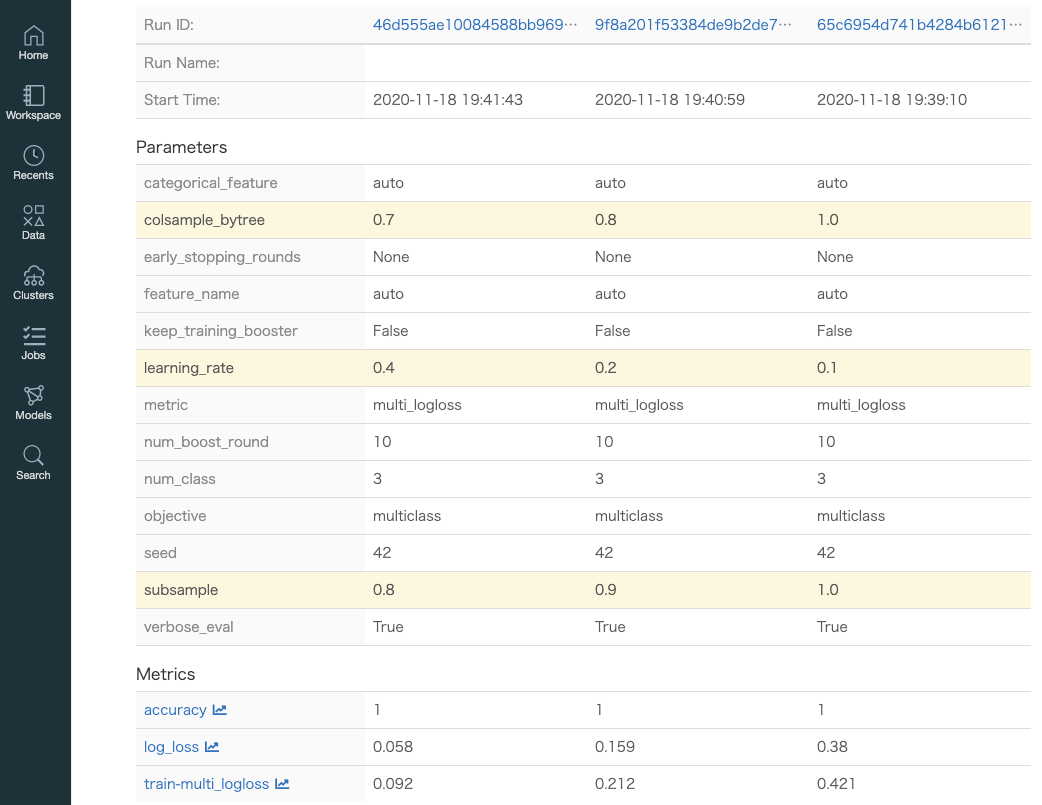
- irisデータセットをlightGBMで学習させてみる。Databricksクラスターを起動後、Notebook上で以下のサンプルコードを実行してみます
- 以下では、自動トラッキングの有効化(
mlflow.lightgbm.autolog())をしているため、自動的にパラメータとメトリックがトラッキングされます。from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, log_loss import lightgbm as lgb import mlflow import mlflow.lightgbm def train(learning_rate, colsample_bytree, subsample): # データ準備 iris = datasets.load_iris() X = iris.data y = iris.target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # lightgbmの形式にする train_set = lgb.Dataset(X_train, label=y_train) # 自動トラッキング mlflow.lightgbm.autolog() with mlflow.start_run(): # モデルを学習する params = { "objective": "multiclass", "num_class": 3, "learning_rate": learning_rate, "metric": "multi_logloss", "colsample_bytree": colsample_bytree, "subsample": subsample, "seed": 42, } model = lgb.train( params, train_set, num_boost_round=10, valid_sets=[train_set], valid_names=["train"] ) # モデルの評価 y_proba = model.predict(X_test) y_pred = y_proba.argmax(axis=1) loss = log_loss(y_test, y_proba) acc = accuracy_score(y_test, y_pred) # log metrics mlflow.log_metrics({"log_loss": loss, "accuracy": acc})
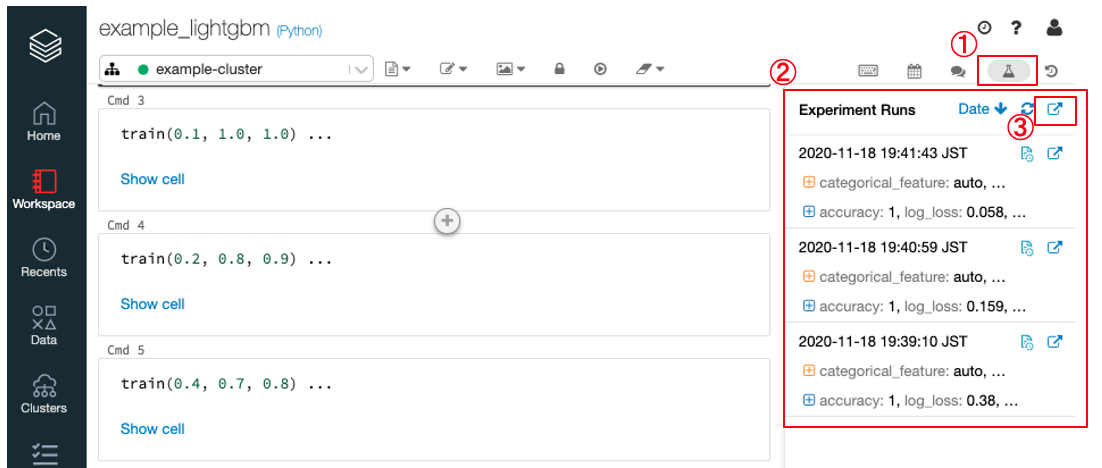
- 何回かパラメータを変更して実行してみます
train(0.1, 1.0, 1.0) train(0.2, 0.8, 0.9) train(0.4, 0.7, 0.8)
Notebookの右上の ①
Experimentアイコンをクリックすると実験結果②が表示されます
③のボタンをクリックすると実験結果一覧画面が表示されます
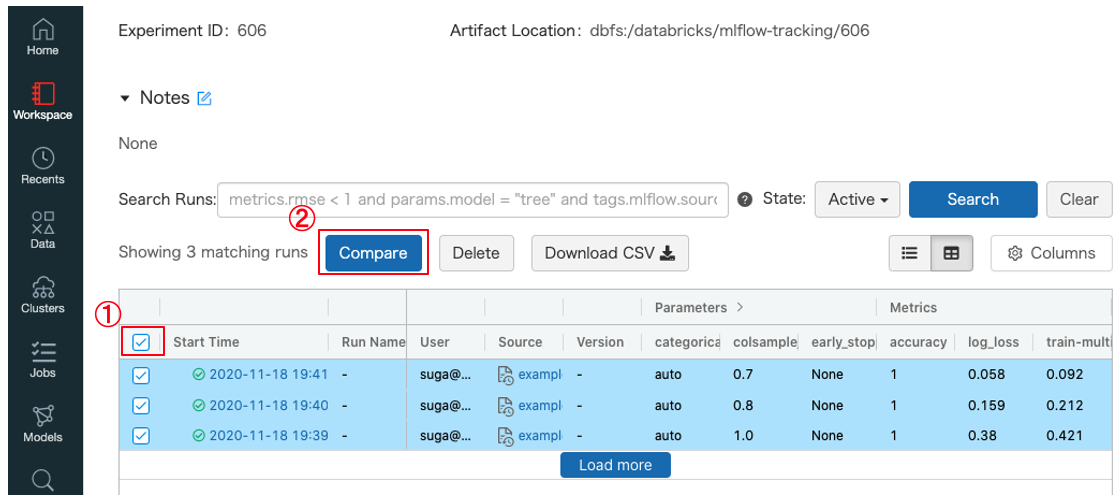
実験結果を全選択①して、
Compare②ボタンを押下すると実験結果の比較画面が表示されます(パラメータの差分と評価指標が一覧で比較することができる)
Model Registryにモデルを登録する
- MLflow Model Registry on Databricksは、モデルのバージョン、ステージ遷移(ステージングから本番への移行)、モデルの説明等をDatabricksのファイルシステム上で管理するモデルレジストリです
- 先ほどのモデル評価結果の比較画面のRunIDをクリックしてモデル詳細画面を表示します
Artifactsの中のRegister ModelボタンをクリックすることでModel Registryへ登録するこができます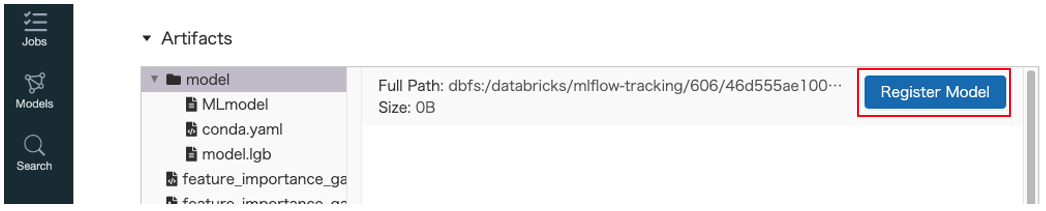
- 既存のモデル名を指定(version up)もしくは新規モデル名を入力します
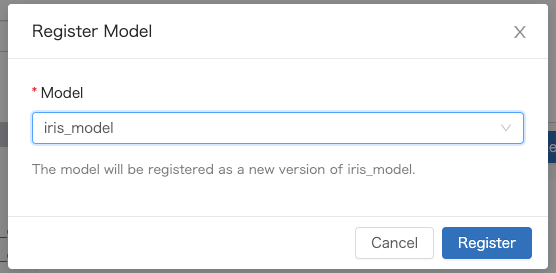
- 登録されたモデルは
Modelsタブから確認することができます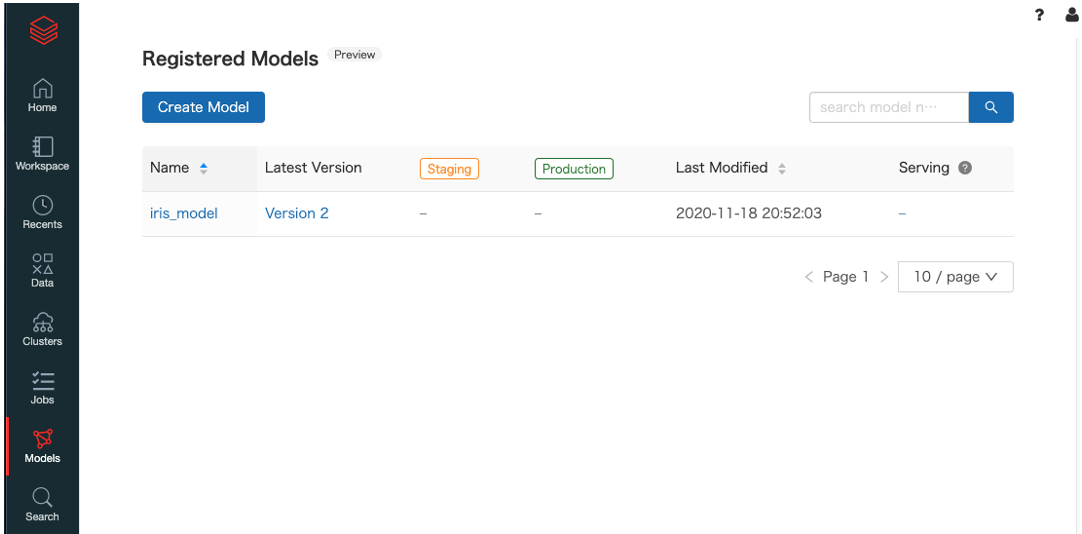
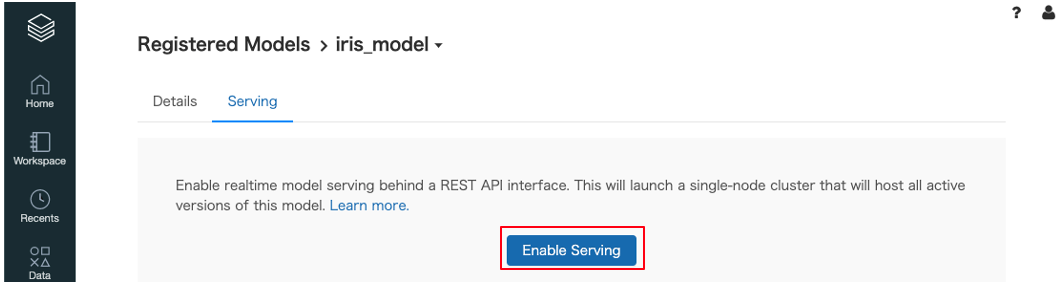
Model Servingを利用して推論APIを立ち上げる
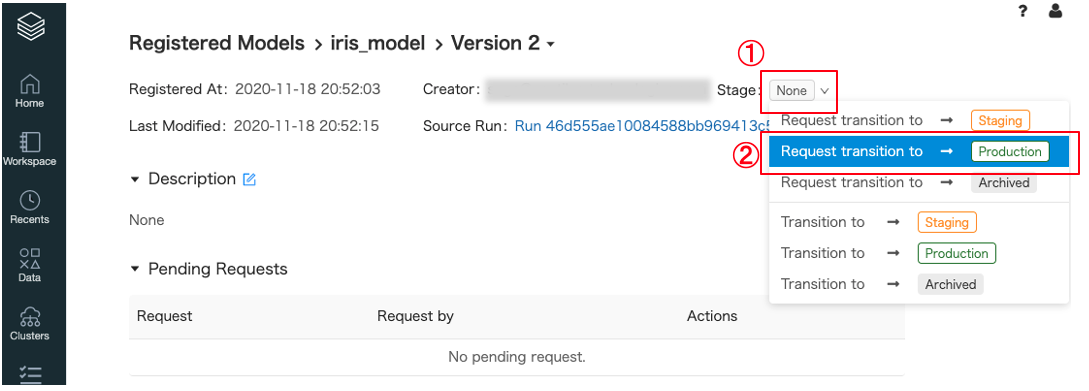
MLflow Model Servingは モデルレジストリのモデルに対して有効にすると固有の単一ノードクラスタを自動的に作成されて、RESTエンドポイントとして利用することができます。モデルレジストリのバージョンとステージに基づいて自動的にデプロイされますModelのステージを変更する
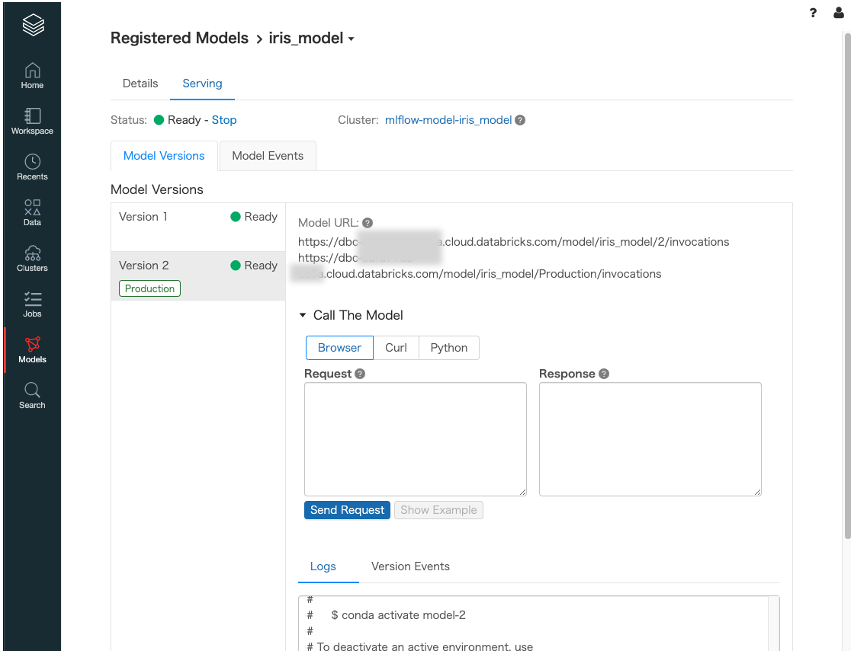
- 今回登録したモデルは
version 2、ステージはNoneとなっています。これからステージをProductionへ変更する要求をしますモデルレジストリ画面から
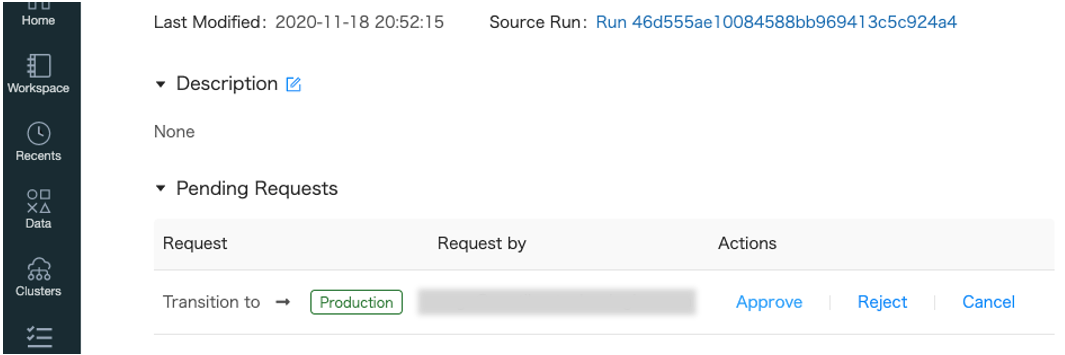
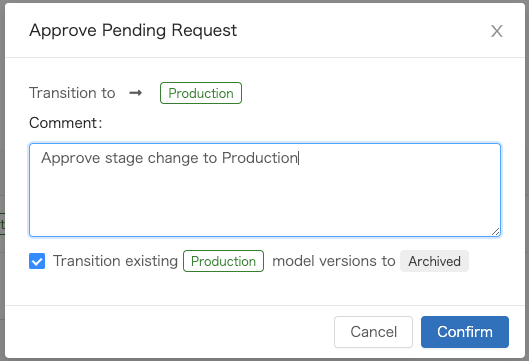
version 2のモデル詳細画面に遷移してStage: None①をクリックして、Request transition to -> Production②をクリックします
別のユーザーのモデル詳細画面ではステージ変更要求が表示されています
承認するとステージを変更することができます
Model Servingを有効にする
モデルレジストリのモデル詳細画面の
ServingタブからEnable Servingボタンをクリックすることで有効化することができます
しばらくするとモデルバージョン、ステージ毎にRESTエンドポイントが起動されたことを確認できます
クライアント側からAPIを利用する
クライアント側からAPIにアクセスするために、セキュリティトークンを払い出してもらう必要があります
- 管理者アカウントの
User Setting画面からAccess Tokensタブから作成することができます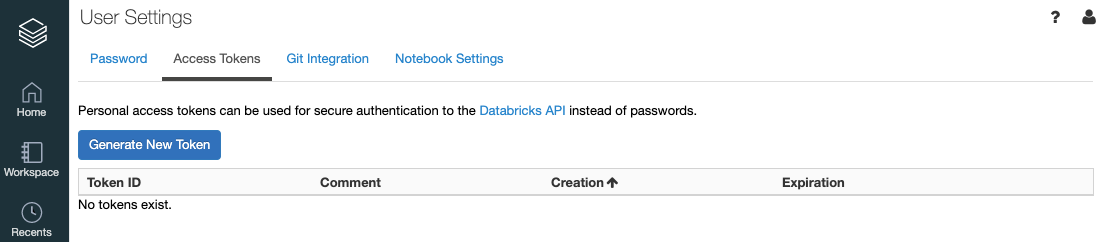
curlからAPIを利用してみます
export DATABRICKS_TOKEN={トークン} cat <<EOF > ./data.json [ { "sepal length(cm)": 4.6, "sepal width(cm)": 3.6, "petal length(cm)": 1, "petal width(cm)": 0.2 } ] EOF curl \ -u token:$DATABRICKS_TOKEN \ -H "Content-Type: application/json; format=pandas-records" \ -d@data.json \ https://dbc-xxxxxxxxxxxxx.cloud.databricks.com/model/iris_model/Production/invocations [[0.9877602676352799, 0.006085719008512947, 0.006154013356207185]]最後に
- 今回はMLflowをDatabricksのNotebook上から利用できる機能について解説をしてみました。まだまだ紹介できていない機能もあるので、次回まとめてみたいと思います。
- 投稿日:2020-11-18T22:35:23+09:00
【チョコプラ】悪い顔選手権のコメント欄から被害届を抽出する
はじめに
まずはこちらをご覧ください。
【企画】悪い顔選手権
https://www.youtube.com/watch?v=IEkLSfs1F68動作環境
- Python 3.6.8
- YouTube Data API ※使用前に登録が必要。
実装内容
コメント取得
- Youtube Data APIを使用してコメントとそれに対するリプライコメントを取得する。
- コメント以外の情報(コメントした人のID等)は取得しない。
被害届の判定条件
- 「長田①」「松尾2」のように、名前+数字(1~3)が入っている。
- 「~された」のように受動態になっている。
- ただし目撃情報も含みたいので「~いた」も含む。
ソースコード
get_youtube_comments.pyimport json import re import pandas as pd import requests API_KEY = '自分のAPIキーを入力する' VIDEO_ID = 'IEkLSfs1F68' def get_comment_info(api_key, video_id, page_token): comment_url = 'https://www.googleapis.com/youtube/v3/commentThreads' param = { 'key': api_key, 'videoId': video_id, 'part': 'replies, snippet', 'maxResults': '100', } if page_token: param['pageToken'] = page_token response = requests.get(comment_url, params=param) return response.json() def get_video_comments(api_key, video_id): comments = [] page_token = '' while page_token != None: resource = get_comment_info(api_key, video_id, page_token) for comment_thread in resource['items']: # コメント取得 comment = comment_thread['snippet']['topLevelComment']['snippet']['textDisplay'] comments.append(comment) if ('replies' in comment_thread) and ('comments' in comment_thread['replies']): for replies in comment_thread['replies']['comments']: # コメント取得 reply_comment = replies['snippet']['textDisplay'] comments.append(reply_comment) if 'nextPageToken' in resource: page_token = resource['nextPageToken'] else: page_token = None return comments # コメントのリストを取得 comments = get_video_comments(API_KEY, VIDEO_ID) # 改行タグの削除 comments = list(map(lambda x: re.sub('<br />', '', x), comments)) target_list = [] report_comment_list = [] for comment in comments: target = re.findall('[長田|松尾]+[1-31-3①②③]', comment) # 複数ある場合はユニーク値だけ取り出す target = list(set(target)) passive_words = re.findall('(れた|れました|いた|いました)', comment) if len(target) > 0 and len(passive_words) > 0: # 1コメントにtargetが複数ある場合はtargetごとにリストに追加する for t in target: target_list.append(t) report_comment_list.append(comment) df = pd.DataFrame({'target': target_list, 'comment': report_comment_list}) # ランダムに数件表示 df.sample(5, random_state=42)実行結果
print(df.shape) ->(178, 2)のべ178件の被害届が出されているようです。
target comment 19 松尾② あまりにも執拗に追いかけてくるので本当に恐怖でした。後ろに幼い子どもも乗せていたので、気が気... 45 長田① 長田①にパーカー盗まれた。 24 長田③ 長田③なお、以前から「神が私と手を取った」と近隣住民に対して話回っていたという情報が多数入っ... 30 松尾② 松尾②に、蟹96匹盗まれました。 67 松尾① 松尾①と長田②と松尾③にオレオレ詐欺されました。No.24が気になりますね。
まとめ
チョコプラはいいぞ~
参考リンク
参考にさせていただきました。ありがとうございました。
【Python】Youtube Data Apiを使ってコメントを全取得する
YouTube Data APIでコメントとチャンネル登録者を取得する
チョコレートプラネットチャンネル
- 投稿日:2020-11-18T22:21:54+09:00
2次元配列の動きを眺めるための関数を作った(Python)
はじめに
主に競プロにて、2次元配列の変化を観察したいときがあると思います。
DPとか、DPとか。1次元配列ならまだしも、2次元配列を逐次
ということで、2次元配列の変化をじーっと眺めるための関数を用意しました。完成品はこちら↓
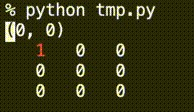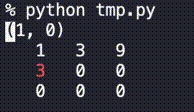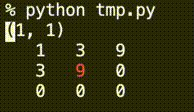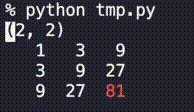
from time import sleep def print_2d_overwrite(list2d, val_width=5, sleep_sec=1.0, header=None, highlights=[]): res_str = f'{header}\n' if header is not None else '' for i, row in enumerate(list2d): for j, v in enumerate(row): v_str = str(v).rjust(val_width) if (i,j) in highlights: v_str = f'\033[31m{v_str}\033[0m' res_str += f' {v_str}' res_str += '\n' new_line_cnt = res_str.count('\n') res_str += f'\033[{new_line_cnt}A' print(res_str, end='') sleep(sleep_sec) # --- sample --- n = 3 list2d = [ [0]*n for _ in range(n)] for i in range(n): for j in range(n): list2d[i][j] = 3**(i+j) print_2d_overwrite(list2d, val_width=3, header=(i,j), highlights=[(i,j)])動作の様子は↓
ポイントは以下です。
- 標準出力を上書きする
- 値の長さ(表示桁)を揃える
- 文字列の色を変える
- sleepする(
time.sleep()するだけ)標準出力を上書きする
関連する記事 が昨日投稿されていてビックリ。
自分が実装の参考にした記事は こちら です。
これらの記事で解説は十分なので、今回は要点だけ説明。
\033[nAで、カーソルをn行上に移動できます。
表示したい2次元配列を文字列(res_str)に変換し、その中の 改行\nの個数を数え、文字列の最後に追加しています。f文字列を使うと楽。
end=''を忘れずに。new_line_cnt = res_str.count('\n') res_str += f'\033[{new_line_cnt}A' print(res_str, end='')値の長さ(表示桁)を揃える
こんな感じで長さが揃ってないと見にくい
3 5 345 235 -48 123 1 2 3ので、各要素の長さ(表示桁)を揃えたいです。
3 5 345 235 -48 123 1 2 3今回は、
str.rjust(n)を利用してこれを実現します。
文字列を右寄せにし、n文字に足りない分は第2引数で指定した文字で埋めます(何も指定しない場合はスペース埋め)。v_str = str(v).rjust(val_width)文字列の色を変更する
\033[31m色変したい文字列\033[0mでOKです。
30m~37mで色設定可能。31mは赤です。
(詳細は こちら)関数内で、
highlightsに指定された値の色を変更しています。こちらもf文字列を使うと楽。if (i,j) in highlights: v_str = f'\033[31m{v_str}\033[0m'おわりに
もしかしたらデバッグで使えるかもしれないので、競プロ用スニペットに加えておきました。
sleepの部分をキー入力にしたらもっと便利かもと思ったのですが、Macだとsudoしないとkeyboardが使えず面倒だったので、このままで。
- 投稿日:2020-11-18T22:21:54+09:00
2次元配列の動きを眺める関数を作った(Python)
はじめに
主に競プロにて、2次元配列の変化を観察したいときがあると思います。
DPとか、DPとか。1次元配列ならまだしも、2次元配列を逐次
ということで、2次元配列の変化をじーっと眺めるための関数を用意しました。完成品はこちら↓
from time import sleep def print_2d_overwrite(list2d, val_width=5, sleep_sec=1.0, header=None, highlights=[]): res_str = f'{header}\n' if header is not None else '' for i, row in enumerate(list2d): for j, v in enumerate(row): v_str = str(v).rjust(val_width) if (i,j) in highlights: v_str = f'\033[31m{v_str}\033[0m' res_str += f' {v_str}' res_str += '\n' new_line_cnt = res_str.count('\n') res_str += f'\033[{new_line_cnt}A' print(res_str, end='') sleep(sleep_sec) # --- sample --- n = 3 list2d = [ [0]*n for _ in range(n)] for i in range(n): for j in range(n): list2d[i][j] = 3**(i+j) print_2d_overwrite(list2d, val_width=3, header=(i,j), highlights=[(i,j)])動作の様子は↓
ポイントは以下です。
- 標準出力を上書きする
- 値の長さ(表示桁)を揃える
- 文字列の色を変える
- sleepする(
time.sleep()するだけ)標準出力を上書きする
関連する記事 が昨日投稿されていてビックリ。
自分が実装の参考にした記事は こちら です。
これらの記事で解説は十分なので、今回は要点だけ説明。
\033[nAで、カーソルをn行上に移動できます。
表示したい2次元配列を文字列(res_str)に変換し、その中の 改行\nの個数を数え、文字列の最後に追加しています。f文字列を使うと楽。
end=''を忘れずに。new_line_cnt = res_str.count('\n') res_str += f'\033[{new_line_cnt}A' print(res_str, end='')値の長さ(表示桁)を揃える
こんな感じで長さが揃ってないと見にくい
3 5 345 235 -48 123 1 2 3ので、各要素の長さ(表示桁)を揃えたいです。
3 5 345 235 -48 123 1 2 3今回は、
str.rjust(n)を利用してこれを実現します。
文字列を右寄せにし、n文字に足りない分は第2引数で指定した文字で埋めます(何も指定しない場合はスペース埋め)。v_str = str(v).rjust(val_width)文字列の色を変更する
\033[31m色変したい文字列\033[0mでOKです。
30m~37mで色設定可能。31mは赤です。
(詳細は こちら)関数内で、
highlightsに指定された値の色を変更しています。こちらもf文字列を使うと楽。if (i,j) in highlights: v_str = f'\033[31m{v_str}\033[0m'おわりに
もしかしたらデバッグで使えるかもしれないので、競プロ用スニペットに加えておきました。
sleepの部分をキー入力にしたらもっと便利かもと思ったのですが、Macだとsudoしないとkeyboardが使えず面倒だったので、このままで。
- 投稿日:2020-11-18T22:08:27+09:00
クラス内のProcessPoolExecutorにselfを渡してはいけない
環境
Python 3.7.4
Windows 10ProcessPoolExecutorが止まる
並列処理のためにProcessPoolExecutorを使用した際にエラーが発生しました。
以下がそのコードです。import concurrent import concurrent.futures class Process: def __init__(self): self.process_list = [] self.executor = concurrent.futures.ProcessPoolExecutor(max_workers=4) # self.executor = concurrent.futures.ThreadPoolExecutor(max_workers=4) # スレッド処理なら動く def _process(self, n): # 処理部 return 1 def start_process(self, n): # 実行部 self.process_list.append(self.executor.submit(self._process, n)) def get_result(self): # 結果取得 print("wait...") concurrent.futures.wait(self.process_list, return_when=concurrent.futures.FIRST_EXCEPTION) print("all processes were finished") res_list = [res.result() for res in self.process_list] print("got result") self.executor.shutdown(wait=True) print("shutdown") self.process_list = [] return res_list if __name__ == "__main__": process = Process() for i in range(10): process.start_process(i) result = process.get_result() print(result)このコードを実行すると、
res_list = [res.result() for res in self.process_list]の部分で、
TypeError: can't pickle _thread.RLock objectsというエラーが発生します。
ちなみに、ThreadPoolExecutorなら動きます。
解決方法
処理部を
def _process(self, n): # 処理部 return 1から
@staticmethod def _process(n): # 処理部 return 1に変更します。処理部で自身(self)の持つインスタンス変数を使用していた場合は引数に加えます。
また、自身のインスタンスメソッドを使用していた場合は、そのメソッドもselfを引数に取らないもの(staticmethod, classmethod等)に変更する必要があります。
ProcessPoolExecutorに渡すメソッドの引数にpickle化できないオブジェクト(ProcessPoolExecutor, queue.Queue, threading.Lock, threading.RLock等)を含むオブジェクトを渡さなければ大丈夫だと思います。
原因
この問題は、クラスのインスタンスにProcessPoolExecutor、つまりpickle化できないオブジェクトを含んでおり、それをインスタンスメソッドのself引数によってマルチプロセスに渡していることが原因です。
ProcessPoolExecutorのドキュメントによると、
ProcessPoolExecutor uses the multiprocessing module, which allows it to side-step the Global Interpreter Lock but also means that only picklable objects can be executed and returned.
(引用元: https://docs.python.org/ja/3/library/concurrent.futures.html#processpoolexecutor)と書いてあるように、pickle化可能なオブジェクトのみ実行&return可能だそうです。
そのため、インスタンスメソッドを用いない(引数にselfを取らないメソッドを用いる)ことで回避できます。
修正例
インスタンス変数を使っていた場合の修正例です。
self.calc,self.hogeがインスタンス変数です。""" インスタンス変数を使用していた場合 """ import concurrent import concurrent.futures class Calc: def __init__(self, a): self.a = a def calc(self, n): return self.a + n class Process: def __init__(self): self.process_list = [] self.executor = concurrent.futures.ProcessPoolExecutor(max_workers=4) # self.executor = concurrent.futures.ThreadPoolExecutor(max_workers=4) self.calc = Calc(10) # 処理を行うクラスのインスタンス self.hoge = 3 # インスタンス変数 def _process_bad(self, n): res = self.calc.calc(n) * self.hoge return res @staticmethod def _process(calc, n, hoge): res = calc.calc(n) * hoge return res def start_process(self, n): # 実行部 # self.process_list.append(self.executor.submit(self._process_bad, n)) # NG self.process_list.append(self.executor.submit(self._process, self.calc, n, self.hoge)) # OK def get_result(self): # 省略 if __name__ == "__main__": process = Process() for i in range(10): process.start_process(i) result = process.get_result() print(result)
_process_bad()のように書いていた場合は、_process()のようにメソッド内で使用する変数をすべて引数に渡す必要があります。また、
Calcクラスにもpickle化できないオブジェクトを含まないようにしなければなりません。ちなみにstaticmethodにする以外に、classmethodにしたりクラス外のメソッドを呼び出したりしても動きます。
# クラスメソッドにした例 @classmethod def _process(cls, calc, n, hoge): res = calc.calc(n) * hoge return resおわりに
私がこの問題に遭遇したときは以下のように、結果取得前にshutdownしていました。
def get_result(self): # 結果取得 self.executor.shutdown(wait=True) # 取得前にshutdown res_list = [res.result() for res in self.process_list] self.process_list = [] return res_listこうするとエラーメッセージが表示されないまま止まってしまいます。
また、pickle化できないものは戻り値にさえ入れなければ問題ないという勘違いもしており、しばらく原因がわかりませんでした。
エラーに苦しんで書いたマルチプロセス処理ですが、私がやりたかった処理ではマルチスレッドと大差ない実行時間となりました。
外部ライブラリを使う場合はマルチスレッド処理でも複数のCPUを使ってくれることがあるようです。
参考
[1] https://bugs.python.org/issue29423 (using concurrent.futures.ProcessPoolExecutor in class giving 'TypeError: can't pickle _thread.RLock objects' in 3.6, but not 3.5)
[2] https://qiita.com/walkure/items/2751b5b8932873e7a5bf (ProcessPoolExector.mapのfuncにlambda式を渡せない)
[3] https://qiita.com/kokumura/items/2e3afc1034d5aa7c6012 (concurrent.futures使い方メモ)
[4] https://docs.python.org/ja/3.6/library/concurrent.futures.html (17.4. concurrent.futures -- 並列タスク実行)
[5] https://qiita.com/walkure/items/2751b5b8932873e7a5bf (ProcessPoolExector.mapのfuncにlambda式を渡せない)
[6] https://qiita.com/kaitolucifer/items/e4ace07bd8e112388c75#4-concurrentfutures (Pythonのthreadingとmultiprocessingを完全理解)
- 投稿日:2020-11-18T21:12:19+09:00
Pandasの使い方2
1 この記事は
DataFrame型データの各種操作方法をメモする。
2 内容
2-1 Multi Index型 DataFrameのデータについて特定のindexのみのデータを表示する。
sample.pyimport pandas as pd import numpy as np idx = pd.IndexSlice #dataを定義する。 dat = [ [100,'2019-07-01','9997','740'], [100,'2019-07-02','9997','749'], [100,'2019-07-03','9997','757'], [200,'2019-07-01','9997','769'], [200,'2019-07-02','9997','762'], [200,'2019-07-03','9997','760'] ] #datをDataFrame型変数dfに格納する。 df = pd.DataFrame(dat,columns=["A","B","C","D"]) #A,B列をindexに指定する。 df=df.set_index(["A","B"]) print("dfを表示する","\n",df) #index=100のデータを抽出する。 df=df.loc[idx[100, :], :] print("dfからindex=100のデータを抽出する。","\n",df)実行結果
C D dfを表示する C D A B 100 2019-07-01 9997 740 2019-07-02 9997 749 2019-07-03 9997 757 200 2019-07-01 9997 769 2019-07-02 9997 762 2019-07-03 9997 760 dfからindex=100のデータを抽出する。 C D A B 100 2019-07-01 9997 740 2019-07-02 9997 749 2019-07-03 9997 757
- 投稿日:2020-11-18T20:03:27+09:00
Unfold関数について
Conv2D演算
2次元畳み込みの演算を考えた場合、入力$(Batch,H,W,C_{in})$、出力$(Batch,H,W,C_{out})$、カーネルサイズ$(3,3)$、畳み込みの重み$W=(3,3,C_{in},C_{out})$とすれば、
実質的にConv2D演算は
$matmul(x,W)=matmul((Batch,HW,9C_{in}), (9C_{in}, C_{out}))=(Batch,HW,C_{out})$
というmatmulの行列演算を考えることに等しいです。
ここで$c=matmul(a,b)$という行列演算において$a=(i,j,k,m),b=(m,n)$ならば$c=(i,j,k,n)$です。一方で入力$(Batch,H,W,C_{in})$に対して
x[:,0]=input[:,0:H-2,0:W-2,:] \\ x[:,1]=input[:,0:H-2,1:W-1,:] \\ x[:,2]=input[:,0:H-2,2:W-0,:] \\ x[:,3]=input[:,1:H-1,0:W-2,:] \\ x[:,4]=input[:,1:H-1,1:W-1,:] \\ x[:,5]=input[:,1:H-1,2:W-0,:] \\ x[:,6]=input[:,2:H-0,0:W-2,:] \\ x[:,7]=input[:,2:H-0,1:W-1,:] \\ x[:,8]=input[:,2:H-0,2:W-0,:]のような$(H,W)$から$(H-2,W-2)$の抜き出しを行い、行列演算の前に$(Batch,HW,9C_{in})$のような行列に変換する必要があります。このような行列変形は$im2col$と呼ばれます。この処理によって入力チャンネル数がカーネルサイズ総数倍になると考えることができます。また$im2col$処理自体には重みを持ちません。
def im2col(input_data, filter_h, filter_w, stride=1, pad=0): N, C, H, W = input_data.shape out_h = (H + 2*pad - filter_h)//stride + 1 out_w = (W + 2*pad - filter_w)//stride + 1 img = np.pad(input_data, [(0,0), (0,0), (pad, pad), (pad, pad)], 'constant') col = np.zeros((N, C, filter_h, filter_w, out_h, out_w)) for y in range(filter_h): y_max = y + stride*out_h for x in range(filter_w): x_max = x + stride*out_w col[:, :, y, x, :, :] = img[:, :, y:y_max:stride, x:x_max:stride] col = col.transpose(0, 4, 5, 1, 2, 3).reshape(N*out_h*out_w, -1) return colPytorchにおいてim2col関数はUnfold関数と呼ばれます。
従って、Conv2D=(im2col+matmul)=(Unfold+matmul)となっている筈です。本題は本当にそうなっているか確認してみました。PyTorchにおける比較
PyTorchはチャンネルファーストで入力$(Batch,C_{in},H,W)=(25,3,32,32)$、出力$(Batch,C_{out},H,W)=(25,16,30,30)$、カーネルサイズ$(3,3)$、重み$W=(C_{out}, 3×3×C_{in})=(16,27)$とします。
(Unfold+matmul)演算
import numpy as np import torch input = torch.tensor(np.random.rand(25,3,32,32)).float() weight = torch.tensor(np.random.rand(16,3,3,3)).float() weight2 = weight.reshape((16,27)) print('input.shape= ', input.shape) print('weight.shape= ', weight.shape) print('weight2.shape=', weight2.shape) x = torch.nn.Unfold(kernel_size=(3,3), stride=(1,1), padding=(0,0), dilation=(1,1))(input) output1 = torch.matmul(weight2, x).reshape((25,16,30,30)) print('x.shape= ', x.shape) print('output1.shape=', output1.shape) ----------------------------------------------------------- input.shape= torch.Size([25, 3, 32, 32]) weight.shape= torch.Size([16, 3, 3, 3]) weight2.shape= torch.Size([16, 27]) x.shape= torch.Size([25, 27, 900]) output1.shape= torch.Size([25, 16, 30, 30])ここでUnfold関数を入力にかけると$x=(25, 3×3×3, 30×30)=(25,27,900)$となり、$W=(16,27)$のとき、$matmul(W,x)=(25,16,30×30)$となります。
Conv2D演算
一方、入力$(Batch,C_{in},H,W)=(25,3,32,32)$、Conv2D関数の重みを$W=(16,3,3,3)$とした場合、出力を求めるコードは以下です。
conv1 = torch.nn.Conv2d(3, 16, kernel_size=3, bias=False) conv1.weight.data = weight output2 = conv1(input) print('conv1.weight.shape=', conv1.weight.shape) print('output2.shape= ', output2.shape) ----------------------------------------------------------- conv1.weight.shape= torch.Size([16, 3, 3, 3]) output2.shape= torch.Size([25, 16, 30, 30])これらから(Unfold+matmul)で求めたoutput1とConv2Dで求めたoutput2を比較すると値は完全に一致しました。従ってConv2D=(Unfold+matmul)と演算的には等価であるのが確認できました。
output1: tensor([[[[7.4075, 7.1269, 6.2595, ..., 6.9860, 6.5256, 7.3597], [6.4978, 7.3303, 6.7621, ..., 7.2054, 6.9357, 7.3798], [5.9309, 5.5016, 6.3321, ..., 5.7143, 7.0358, 6.8819], ..., [6.0168, 6.9415, 7.5508, ..., 5.4547, 4.7888, 6.0636], [5.0191, 7.0944, 7.0875, ..., 3.9413, 4.1925, 5.5689], [6.2448, 6.4813, 5.5424, ..., 4.2610, 5.8013, 5.3431]], ...... output2: tensor([[[[7.4075, 7.1269, 6.2595, ..., 6.9860, 6.5256, 7.3597], [6.4979, 7.3303, 6.7621, ..., 7.2054, 6.9357, 7.3798], [5.9309, 5.5016, 6.3321, ..., 5.7143, 7.0358, 6.8819], ..., [6.0168, 6.9415, 7.5508, ..., 5.4547, 4.7888, 6.0636], [5.0191, 7.0944, 7.0874, ..., 3.9413, 4.1925, 5.5689], [6.2448, 6.4813, 5.5424, ..., 4.2610, 5.8013, 5.3431]], ......Unfold関数の他の使い道
kernel_sizeとstrideが等しい時、Vision Transformerのパッチ分割に相当します。
まあ、別にパッチ分割はUnfold使わずともreshapeとtransposeで代用出来るんですが…。input = torch.tensor(np.random.rand(25,3,224,224)).float() x = torch.nn.Unfold(kernel_size=(14,14), stride=(14,14), padding=(0,0), dilation=(1,1))(input) ----------------------------------------------------------- input.shape= torch.Size([25, 3, 224, 224]) x.shape= torch.Size([25, 588, 256]) #(25,3*14*14,16*16)Vision Transformerが全くConv2Dを使っていないという話において、Attention重みとValueとの演算にmatmulが含まれるのでViTでもUnfold+matmulが結局Conv2D相当なのではと根拠のない妄想しました。
まとめ
Unfold関数はPytorchにおけるim2col関数であり、Conv2D=(Unfold+matmul)である。
またtensorflowではextract_image_patches関数である。
- 投稿日:2020-11-18T19:52:23+09:00
Djangoでフォロー機能を実装する
前段
SNS系アプリにほぼ必須のフォロー機能をDjangoで実装しました。
ライブラリ不使用の自前実装になります。
各自用途や要件に合わせてカスタマイズしてください。開発環境
- Django
- Python 3.8.5
- MySQL
- Visual Studio Code
※SQLite3でもほぼコード変更なしで書けます。
フォロー機能の具体的な要件
- フォローすることができる/解除もできる
- 自分自身をフォローすることはできない
- フォロー数、フォロワー数を確認できる
フォロワーの一覧表示などはここでは省きます。
必要最小限の機能要件を実装します。テーブル設計
テーブルを1つだけ作成して済ましてしまう方法もありますが、個人的にSQL文が冗長になったり、テーブル管理がしにくい印象を持ったので今回は2つ用意します。
follow_relationテーブル
データ 格納する情報 データ型 user_id フォローする側のユーザーID UUID followed_id フォローされる側のユーザーID UUID follow_countテーブル
データ 格納する情報 データ型 user_id ユーザーID UUID follow フォローしている数 INT followed フォローされている数 INT
follow_relationテーブルは、ユーザー間のフォロー状態の管理、follow_countテーブルはユーザーのフォロー数、フォロワー数の管理をしています。views.pyの編集
テーブルができたらさっそくフォロー機能を実装していきましょう。
フォロー機能のおおまかな流れは以下のようになります。ページのリクエスト ↓ followd_status関数にてフォロー状態を確認&表示 ↓ フォローボタンを押す ↓ follows関数がフォロー状態に応じて処理 ↓ 元のページにリダイレクトでは以下コードになります。
followed_status関数@login_required def followed_status(request, accesskey): # 省略 # 各自必要なパラメータを取得してください # データベースへの接続 connection = MySQLdb.connect( host='localhost', user='***', passwd='***', db='***', charset="utf8" ) # カーソルの取得 cursor = connection.cursor() # クエリのセット follow_relation = "SELECT COUNT(*) FROM follow_relation where user_id = UUID_TO_BIN(%s) and followed_id = UUID_TO_BIN(%s);" # クエリの実行 # user_id、followed_idは各自で取得 cursor.execute(follow_relation, (user_id, followed_id)) row_follow = cursor.fetchone() follows = row_follow[0] # ログインユーザーとページユーザーが同一人物か判定 # 同一人物ならフォローできないようにします if followed_id == user_id: followed_status_code = 1 else: followed_status_code = 2 # もしfollowsが0より大きかったらTrue # followsが0だったらFalseを返す followed = False if follows > 0 : followed = True return followed_status_code, followed必要なパラメータは各自別テーブルから引き出してください。
今回必要なのはフォローする側とされる側のIDのみです。
user_idがフォローする側、followed_idがフォローされる側です。
- ユーザー同士のIDを照合します
ステータスコードを付与して同一人物か判別します。
followed_status_code = 1なら自分自身(フォローできない)
followed_status_code = 2なら他人同士(フォローできる)になります。
- フォロー状態を確認します
TrueとFalseでフォロー状態を確認します。
Falseならまだフォローしていない
Trueなら既にフォローしているになります。
では、次にfollows関数を見ていきます。follows関数@login_required def followes(request, accesskey): # 省略 # 各自必要なパラメータを取得してください # データベースへの接続 connection = MySQLdb.connect( host='localhost', user='***', passwd='***', db='***', charset="utf8" ) # カーソルの取得 cursor = connection.cursor() # 共通クエリをセットしてください # ここで必要な情報を取得しておきます # 自分自身はフォローできないようにする if user_id == followed_id: followed = False # セッションにフォロー状態を保存します request.session['page_followed_status'] = followed else: if followed == False: # フォローするときの処理になります # クエリのセット # 新規フォロー関係の挿入 follow_reation = "INSERT INTO follow_relation (user_id, followed_id) values(UUID_TO_BIN(%s), UUID_TO_BIN(%s));" # フォローする側ユーザーのフォロー数を1つ増やす follow_update = "UPDATE follow_count SET follow = follow + 1 where user_id=UUID_TO_BIN(%s);" # フォローされる側ユーザーのフォロワー数を1つ増やす followed_update = "UPDATE follow_count SET followed = followed + 1 where user_id=UUID_TO_BIN(%s);" # クエリの実行 cursor.execute(follow_relation, (user_id, followed_id)) cursor.execute(follow_update, (user_id, )) cursor.execute(followed_update, (followed_id, )) # 接続を終了する cursor.close() connection.commit() connection.close() # フォローした状態にする followed = True request.session['page_followed_status'] = followed else: # フォローを外すときの処理になります # クエリのセット # フォロー関係の削除 follow_relation = "DELETE FROM follow_relation where user_id=UUID_TO_BIN(%s) and followed_id = UUID_TO_BIN(%s);" # フォローを外す側ユーザーのフォロー数を1つ減らす follow_update = "UPDATE follow_count SET follow = follow - 1 where user_id=UUID_TO_BIN(%s);" # フォローを外される側ページユーザーのフォロワー数を1つ減らす followed_update = "UPDATE follow_count SET followed = followed - 1 where user_id=UUID_TO_BIN(%s);" # クエリの実行 cursor.execute(sql_followrelation_delete, (user_id, followed_id)) cursor.execute(sql_follow_update, (user_id, )) cursor.execute(sql_followed_update, (followed_id, )) # 接続を終了する cursor.close() connection.commit() connection.close() # フォローしていない状態にする followed = False request.session['page_followed_status'] = followed return redirect('元のページ', accesskey)こちらはif文で分岐させてフォローするorフォロー解除の実際の処理をおこなっています。そして最後にフォローの状態を切り替えています。元のページにリダイレクトして終了です。(今回はAjaxなどを使用しないためページ遷移が生じています)
最後に表示用のviewを編集します。
result関数@login_required def result(request, accesskey): # 省略 # フォローの状態を把握する status = followed_status(request, accesskey) followed_status_code = status[0] followed = status[1] # フォローの状態をセッションに保存(一時的) request.session['page_followed_status'] = followed params = { # 省略 'page_followed_status': followed, 'page_followed_status_code': followed_status_code, } return render(request, 'result.html', params)該当箇所のみ記載しています。
followed_status関数を呼び出してフォロー状態を確認しています。
(followed_status関数では、ステータスコードとフォロー状態が返されます。)
そしてセッションに一時的に保存してます。urls.pyの編集
urls.pyurlpatterns = [ # 省略 path('元のページ', views.pages, name='各自で設定'), path('元のページ/follow/', views.follows, name="follows"), # 省略 ]テンプレートの編集
最後にテンプレートです。
result.html<!-- フォローボタンを追記 --> {% if page_followed_status_code is 2 %} {% if page_followed_status is False %} <p><a href="{% url 'follows' page_accesskey %}">フォローする</a></p> {% else %} <p><a href="{% url 'follows' page_accesskey %}">フォローをやめる</a></p> {% endif %} {% endif %}
ステータスコードが2の場合(自分自身でなく他人同士の場合)のみ表示されるようになっています。そしてフォロー状態が
Falseのとき「フォローする」、Trueのとき「フォローをやめる」と表示させるためif分岐させています。リンクが押されるとページ移動先でfollows関数が呼び出されフォロー処理をして、また元のページにリダイレクトされるような流れになってます。
最後に
自分なりにコードを改変して使ってみてください。
「いいね機能」もほぼ同様に実装することができます!
- 投稿日:2020-11-18T19:01:37+09:00
日英翻訳の作り方
日英翻訳の作り方
日英翻訳をtensorflowとkerasで実装していきます。
この記事の目次です。
1. 環境やデータセットの詳細
2. 基本的な流れ
3. データの前処理
4. モデル構築
5. 学習
6. 評価コードの詳細はgithubで公開していますので、参考にしてください。
Japanese-English_Translation
.pyinbで保存しているので、google colabで気軽に動かせるようになっています。
大昔に自然言語処理の勉強した際のコードを公開します。(少し整理したものを公開)お役に立てれば、幸いです。
環境やデータセットの詳細
ハードウェアの環境
gooble colabソフトウェアの環境
python3
tensorflow (version2.3.1)データセット
small_parallel_enjasmall_parallel_enjaは、田中コーパスからいくつかの文章を抽出した小さなデータセットです。
前処理がなされており、すごく使いやすいものになっています。基本的な流れ
以下の流れで進んでいきます。
1. データの前処理
2. モデル構築
3. 学習
4. 評価
まあ、普通ですねww
データの前処理
データの前処理は済んでるものを使用するので、結構楽です。
トークナイズは、tensorflowに組み込まれているkerasのAPIを使用します。
tf.keras.preprocessing.text.Tokenizer使い方は、結構簡単で、以下に例を示します。
tokenizer = tf.keras.preprocessing.text.Tokenizer(oov="<unk>") tokenizer.fit_on_texts(texts) sequences = tokenizer.texts_to_sequences(texts)tf.keras.preprocessing.text.Tokenizerのインスタンスを生成して、
そのインスタンスに使用する単語をfit_on_texts(texts)で教えてあげます。
これを行うことにより、ユニークな単語を内部で管理します。
その後、tokenizer.texts_to_sequences(texts)でそれぞれの文章を数値化すれば良いだけです。textsとは、テキストデータセットのことを指します。textsのフォーマットは、文字列のリストになっている必要があります。texts = ["I am Niwaka", "Hello!!", .., "Wow!!"]上のコードは、tf.keras.preprocessing.text.Tokenizerインスタンスに渡すtextsのフォーマット例です。
使い方は、
tf.keras.preprocessing.text.Tokenizer
上のリンクへ飛べば分かります。ミニバッチ化による勾配法を行うために、ミニバッチ内でのデータの形状が一致しないといけません。
しかし、自然言語データは一般的に可変長です。
そのため、他のデータセットと違い工夫しなければなりません。可変データを扱うには以下の2通りの方法が考えられます。
1.padding
2.バッチサイズを1にする(時系列長が数百レベルなら、こっちを使用するのかな?)ここでは、1のpaddingを使用します。
paddingとは、ミニバッチ内での最大時系列長がLだとすると、それに満たさないデータに対しては特殊な値を埋めることで長さをLにする手法のことです。tensorflowとkerasでは0が特殊な値として、設定されるようです。例えば、以下のような長さが統一されていないデータセットがあったとしましょう。
sequences = [ [12, 45], [3, 4, 7], [4], ]上のデータセットの最大長は3です。paddingを行うと以下のようになります。
padded_sequences = [ [12, 45, 0], [3, 4, 7], [4, 0, 0], ]tensorflowでは、textデータに対するpadding処理をtf.keras.preprocessing.sequence.pad_sequencesというAPIで提供しています。
使い方は、tf.keras.preprocessing.sequence.pad_sequencesに長さを統一したいデータセットを入力として与えるだけです。
padding引数は、後に0を埋めるか前に0を埋めるかの指定を行います。"post"を指定することで、あと埋めで0を埋めます。お好みで良いと思います。padded_sequences = tf.keras.preprocessing.sequence.pad_sequences(sequences, padding="post")これで、ミニバッチ化による学習を行うことができるようになりました。しかし、ここで問題があります。それは0をモデルがどう解釈するかという問題です。
できれば、0という特殊な値は無視できるようにしたいところですよね。でないと、可変長に対応できるRNNを使用する意味が薄れます。
tensorflowでは、Maskingと呼ばれる機能が用意されています。
Maskingとは、指定したステップ時の値を無視する機能のことです。これにより、可変長のデータをまとめて取り扱うことができます。(Maskingを使わずとも、可変長のデータを取り扱えますが、0という特殊な値もモデルに取り込まれることになります。そういうのは気持ち悪いので、避けたいです。)詳しくは以下のリンクへ飛んでください。リンク先では、tensorflowとkerasにおけるMakingとPaddingの使い方についての解説が詳細に書かれております。
Masking and padding with Kerastensorflowでは、Maskingは以下の方法で有効になります。
1.tf.keras.layers.Maskingを加える
2.tf.keras.layers.Embeddingの引数mask_zeroをTrueにする。
3.maskを利用するLayerに直接渡す。(これは愚直なやり方、動画などにはこれを使用するのかも)ここでは、2を使用します。
今回使用するモデルでは、Embeddingによって自動でmaskが生成され、そのmaskが次のレイヤーに自動的に伝搬していきます。
モデル構築
モデルには、Seq2Seqモデルを使用します。
Seq2Seqとは、
Sequenceデータを別の何かしらのSequenceデータに変換するモデルのことです。
ここでいうSequenceデータとは、時系列データのことです。Seq2Seqのインターフェースは、
変換後のsequence = Seq2Seq(変換前のsequence)です。
例えば、"私は学生です。"をSeq2Seqモデルに入力したとします。
"I am student ." = Seq2Seq("私は学生です。")Seq2Seqは、2つのモジュールで構成されています。
1つがEncoder、2つめがDecoderです。
EncoderによってSequenceデータをエンコードし、人間には理解できない特徴量を出力します。
Decoderにそれとstartトークンを入力し、別の何かしらのSequenceデータを得ます。
ここで、startトークンとはsequenceの始まりを意味する特別な単語です。以下にEncoderとDecoderのインターフェースを疑似言語で記述しました。
人間には理解できない特徴量 = Encoder(変換前のsequence) 変換後のsequence = Decoder(人間には理解できない特徴量、<start>トークン)それぞれのモジュールでは、RNNを使用しております。具体的な仕組みは
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
の最初の方を読めば分かるはずです。この記事は、attentionに関する記事なのですが、Seq2Seqの説明も書かれています。Seq2SeqではRNNを利用します。
RNNは、可変長データを取り扱うことができるので、自然言語を処理するのが得意です。加えて、各ステップで使用する重みは共有するので、パラメータの増加を抑えることができます。
ただし、あまりにも時系列長が長いデータは誤差逆伝播時に、勾配消失や勾配爆発につながるので注意ですね。
時系列長がたったの10でも、時間軸上に10層のレイヤーが展開されるのと同じことになります。
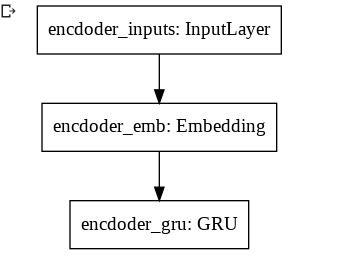
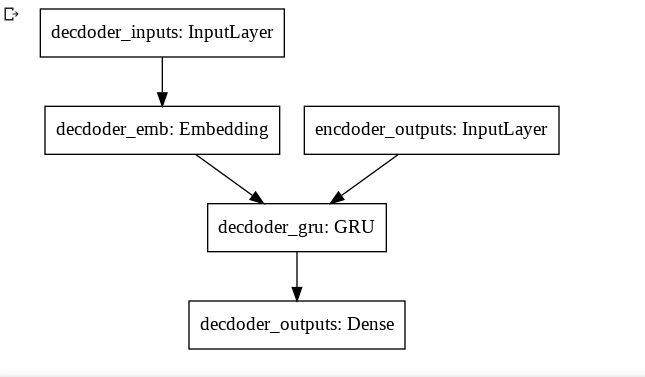
RNNにはGRUを採用しました。GRUは勾配消失を起こしづらいRNN系のモデルです。今回使用するdecoderとencoderのモデル図は以下です。
図1 encoder
図2 decoderEncoderとDecoderそれぞれでRNNを1つしか使用していないです。
データセットが小さいので、小さめのモデルにしました。tensorflowとkerasを用いたコードが以下になります。
The Functional APIを利用しています。
可変長データを表したい時は、tf.keras.InputのshapeにNoneと指定すると良いです。The Functional APIの使い方は、以下のリンクへ飛んでください。
The Functional API
以下は、モデル実装コードになります。modelとencoderとdecoderそれぞれ用意しています。
modelは、学習用に用意しました。model.fitで学習を行い得られたパラメータをencoderとdecoderに読み込んでいきます。学習時と推論時では、処理が異なります。def CreateEncoderModel(vocab_size): units = 128 emb_layer = tf.keras.layers.Embedding(vocab_size, units, mask_zero=True)#padding有効にするために、mask_zero=True gru_layer = tf.keras.layers.GRU(units) encoder_inputs = tf.keras.Input(shape=(None,)) outputs = emb_layer(encoder_inputs) outputs = gru_layer(outputs) encoder = tf.keras.Model(encoder_inputs, outputs) return encoder def CreateDecoderModel(vocab_size): units = 128 emb_layer = tf.keras.layers.Embedding(vocab_size, units, mask_zero=True)#padding有効にするために、mask_zero=True gru_layer = tf.keras.layers.GRU(units, return_sequences=True) dense_layer = tf.keras.layers.Dense(vocab_size, activation="softmax") decoder_inputs = tf.keras.Input(shape=(None,)) encoder_outputs = tf.keras.Input(shape=(None,)) outputs = emb_layer(decoder_inputs) outputs = gru_layer(outputs, initial_state=encoder_outputs) outputs = dense_layer(outputs) decoder = tf.keras.Model([decoder_inputs, encoder_outputs], outputs) return decoder def CreateModel(seed, ja_vocab_size, en_vocab_size): tf.random.set_seed(seed) encoder = CreateEncoderModel(ja_vocab_size) decoder = CreateDecoderModel(en_vocab_size) encoder_inputs = tf.keras.Input(shape=(None,)) decoder_inputs = tf.keras.Input(shape=(None,)) encoder_outputs = encoder(encoder_inputs) decoder_outputs = decoder([decoder_inputs, encoder_outputs]) model = tf.keras.Model([encoder_inputs, decoder_inputs], decoder_outputs) model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False), metrics=['accuracy']) return model, encoder, decoder学習
バッチサイズ32, 64, 128で探索してみます。
実験の設定を以下に示します。
1.RNNのunit数は128
2.重みの更新方法はAdam(学習率はデフォルトのまま)
3.epoch数は2
4.評価方法はBLEUエポックを2回で止め、2エポック目のモデルで、検証データに対する評価を行いました。
BLEUとは、翻訳の品質測定に使われる指標のことです。以下は学習コードです。
bleu_scores = [] batch_size_list = [32, 64, 128] for batch_size in batch_size_list: model, encoder, decoder = CreateModel(seed, len(ja_tokenizer.word_index)+1, len(en_tokenizer.word_index)+1) model.fit([train_ja_sequences, train_en_sequences[:, :-1]], train_en_sequences[:, 1:], batch_size=batch_size, epochs=2) model.save(str(batch_size)+"model.h5") encoder.load_weights(str(batch_size)+"model.h5", by_name=True) decoder.load_weights(str(batch_size)+"model.h5", by_name=True) bleu_score = Evaluate(valid_ja, valid_en, encoder, decoder) bleu_scores.append(bleu_score)Evaluate関数で、BLEUの測定を行なっています。(実装はgithubで公開しています。)
各バッチサイズを名前に用いて、モデル保存を行いました。Decode方法は、各ステップの最大確率となる単語を出力としました。
貪欲に単語を決めていきました。(貪欲法)
本当は、Beam Searchを使ったほうが良いです。Beam Searchは、貪欲法の条件を少し緩めた探索アルゴリズムになります。
貪欲に各ステップの単語を決めても、それが最適解になるかどうかは分からないので、Beam Searchを使用したほうがいいです。
Beam Searchは、以下の説明が参考になります。
C5W3L03 Beam Search
リンク先は動画になっているので、時間に余裕があるときに観ると良いです。kerasでは、loss値を求める際にmaskを適用しているのかどうか気になります。
適用されているという話を聞いたことがあるのですが、そこんところどうなっているのか実装を知らないので、よく分かりません。気持ち悪いと感じるならば、Neural machine translation with attentionのコスト関数の実装が参考になります。ただし、リンク先の実装はmodel.fitでしか学習を行なった経験しかない人にとっては結構難しいものになっていますので、注意してください。
リンク先のコスト関数の実装は、maskするステップ時のコストを最終的なコストに計上しないように実装しています。実験結果をグラフにしました。
図3 実験結果画像が荒いですが、ご了承ください。
検証データに対する最も良いBLEUを得られたバッチサイズは32なので、32を使用して、再学習を行います。
図3を見る限り、バッチサイズを更に小さくすると、より良い結果が得られるかもです。
評価に入る前に、学習データと検証データを混ぜて、再学習しておきます。
再学習では、epoch数を10にしました。それ以外は同じです。train_and_valid_ja_sequences = tf.concat([train_ja_sequences, valid_ja_sequences], 0) train_and_valid_en_sequences = tf.concat([train_en_sequences, valid_en_sequences], 0) best_model, best_encoder, best_decoder = CreateModel(seed, len(ja_tokenizer.word_index)+1, len(en_tokenizer.word_index)+1) best_model.fit([train_and_valid_ja_sequences, train_and_valid_en_sequences[:, :-1]], train_and_valid_en_sequences[:, 1:], batch_size=32, epochs=10) best_model.save("best_model.h5")GPUを使用している場合、同じ結果が得られるとは限らないです。
評価
テストデータに対するBLEU0.19でした。(最大が1)
他と比較していないので分かりませんが、結構酷い結果だと思いますwwwテストデータに対する処理のコードは、以下になります。
best_encoder.load_weights("best_model.h5", by_name=True) best_decoderbest_decoder.load_weights("best_model.h5", by_name=True) bleu_score = Evaluate(test_ja, test_en, best_encoder, best_decoder) print("bleu on test_dataset:") print(bleu_score)素朴な疑問なのですが、BLEU評価方法はいくつか存在するようです。(smoothing_functionはいくつか存在するようです。)
統一されていなそうなのですが、そこのところ詳しい方教えてください。
統一されていないのでしたら、最も上手くいくsmoothing_functionでBLEUを測定すれば良いことになります…これはアリなのでしょうか?…最後に
精度を上げる方法をいくつか紹介して、この記事の終わりとします。
1.入力データを反転する
2.attentionをモデルに組み込む
3.stop_wordを用いる。
4.アンサンブル
5.層を深くする(その際、skip connectionを使うことを忘れないように)
6.Embedding層と全結合層の重みを共有する
7.Transformerにモデル変更
8.重みの初期値設定方法を変更ネットで検索すればいくらでも見つかりそうなものを列挙しました。使ったからといって、BLEUが向上するとは限りません。
興味があれば、Google先生に聞いてみてください。自然言語処理初心者なので、間違ったやり方などがありましたら、教えてくださると嬉しいです。
参考文献
1.small_parallel_enja
2.Masking and padding with Keras
3.The Functional API
4. Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
5.Neural machine translation with attention
6.C5W3L03 Beam Search
- 投稿日:2020-11-18T18:12:47+09:00
Python: Pythonista 3 on iPadでUIを使ってみる
はじめに
最近出たばかりの、iPad Air 4 を買った。使用目的は主に手書きメモ作成なのだが、計算しながらメモを作成する場合も多い。手書きメモといってもテキストと数字だけなら、わざわざ手書きにしなくても、さっさとテキストエディタで打ち込めばいいのだが、説明図が必要となると、やはり手書きが便利である。計算が必要な場合には、これまでは iMac で Python を立ち上げて計算させながら iPad で手書きスケッチやメモを行っていたが、iPad があるのに iMac を立ち上げるのもなんかかっこ悪い、というかスマートでない。
そこで、最近はご無沙汰であったが、iPad mini 4 用に購入していた、Pythonista 3 を使ってみることにした。Pythonista 3 は、numpy および matplotlib を含んでおり、これらはほぼ間違いなく動く。scipy や pandas など、その他のライブラリは使えないと思ったほうが良い。このため、複雑な計算でも numpy と matplotlib のみを使っているコードなら実用性がある。また GUI も使えるらしいのだが、これまで自分で使ったことはないので、使用頻度の高い簡単な計算プログラムを、アプリ風にして iPad で使えるようにしてみた。(要はiPad Air 4を買って嬉しいので、これを使っていろいろなことをやろうという趣旨である)
やっていること
やっていることは Mac に入れている「急勾配水路の等水深を求めるプログラム」を Pythonista 用に書き換えて GUI で動くようにしたものである。
もとのコードは以下の「はてな」に投稿したものである。https://damyarou.hatenablog.com/entry/2020/10/23/073643
このプログラムは非線形方程式を解くため、Mac 用プログラムでは scipy を使っているが、Pythonista では scipy は使えないため、非線形方程式を解く二分法の部分は自前で書き換えている。
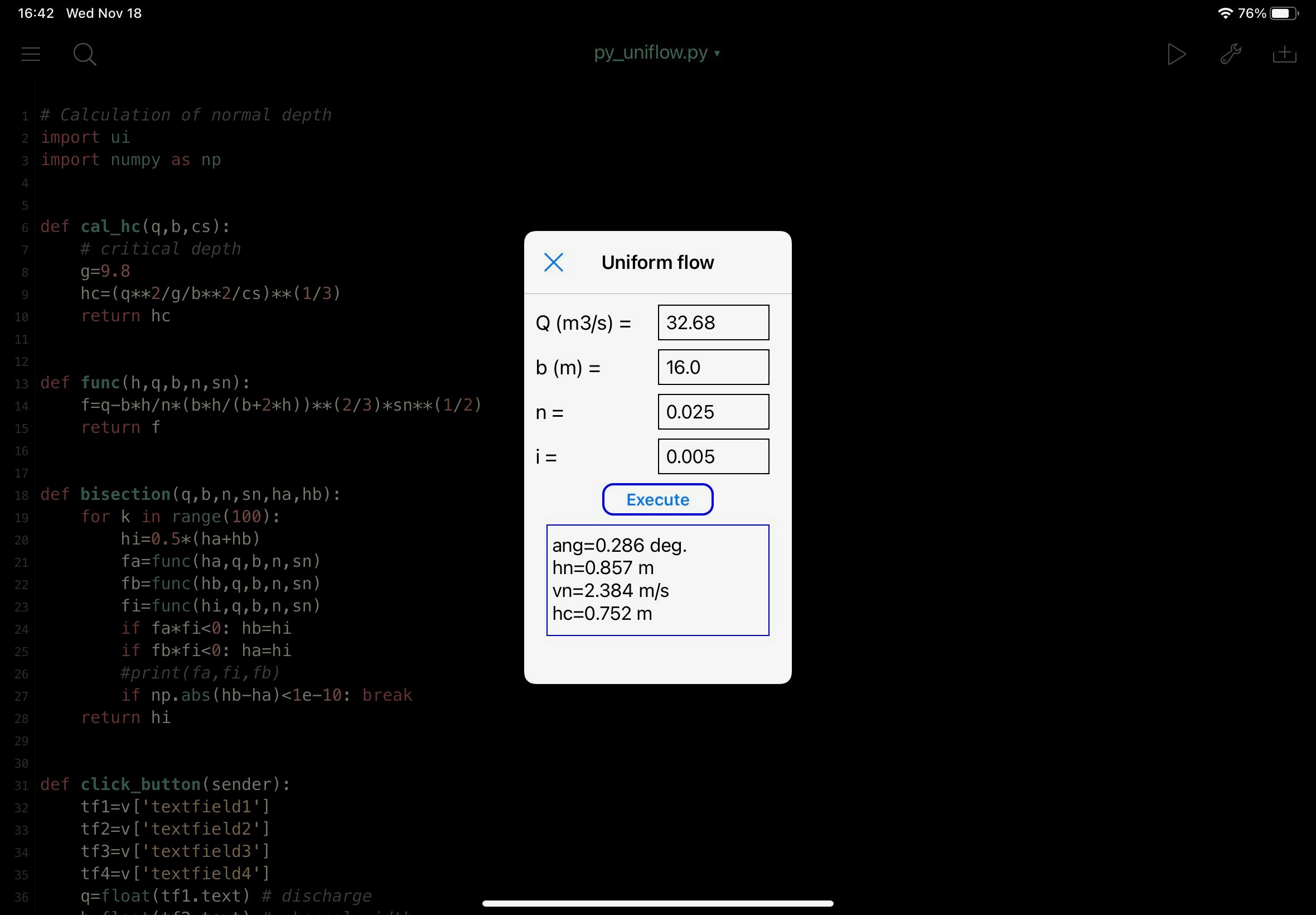
更に、ここからが自分にとって初めての挑戦であるが、アプリ風に GUI を使って仕上げてみた。実行結果は以下の写真のようになる。上側4個の四角にデータを入力し、
Executeというボタンを押すと結果が下側四角の中に示される。
プログラム作成に当たり以下のサイトを参考にさせていただいた。
Pythonista 3 では、UI プログラミングを指定すると、2つのファイルができる。下の写真では。
py_uniflow.pyとpy_uniflow.pyuiというファイルが確認できる。「xxx.py」はコードを書き込むプログラムで、「xxx.pyui」は、UI の配置や特性を定義するファイルである。
配置できるオブジェクトの一覧は、UIの配置と特性を定義する
py_uniflow.pyui上で、左上の四角で囲まれた+マークを押すと表示されるので、そこから使いたいものを選択する。
このプログラムでは、以下の4種類のオブジェクトを使っている。
- label
- textfield
- button
- textview
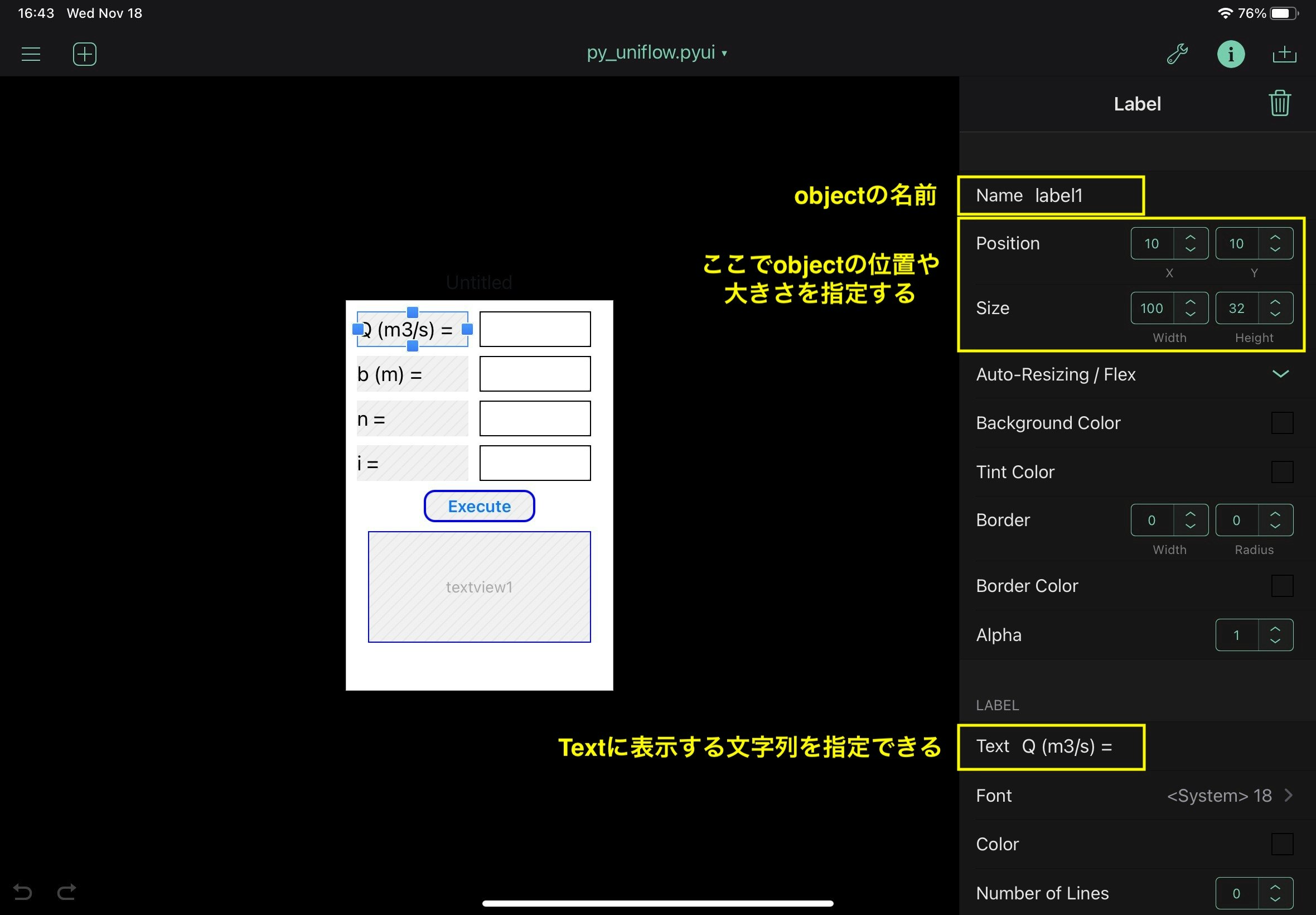
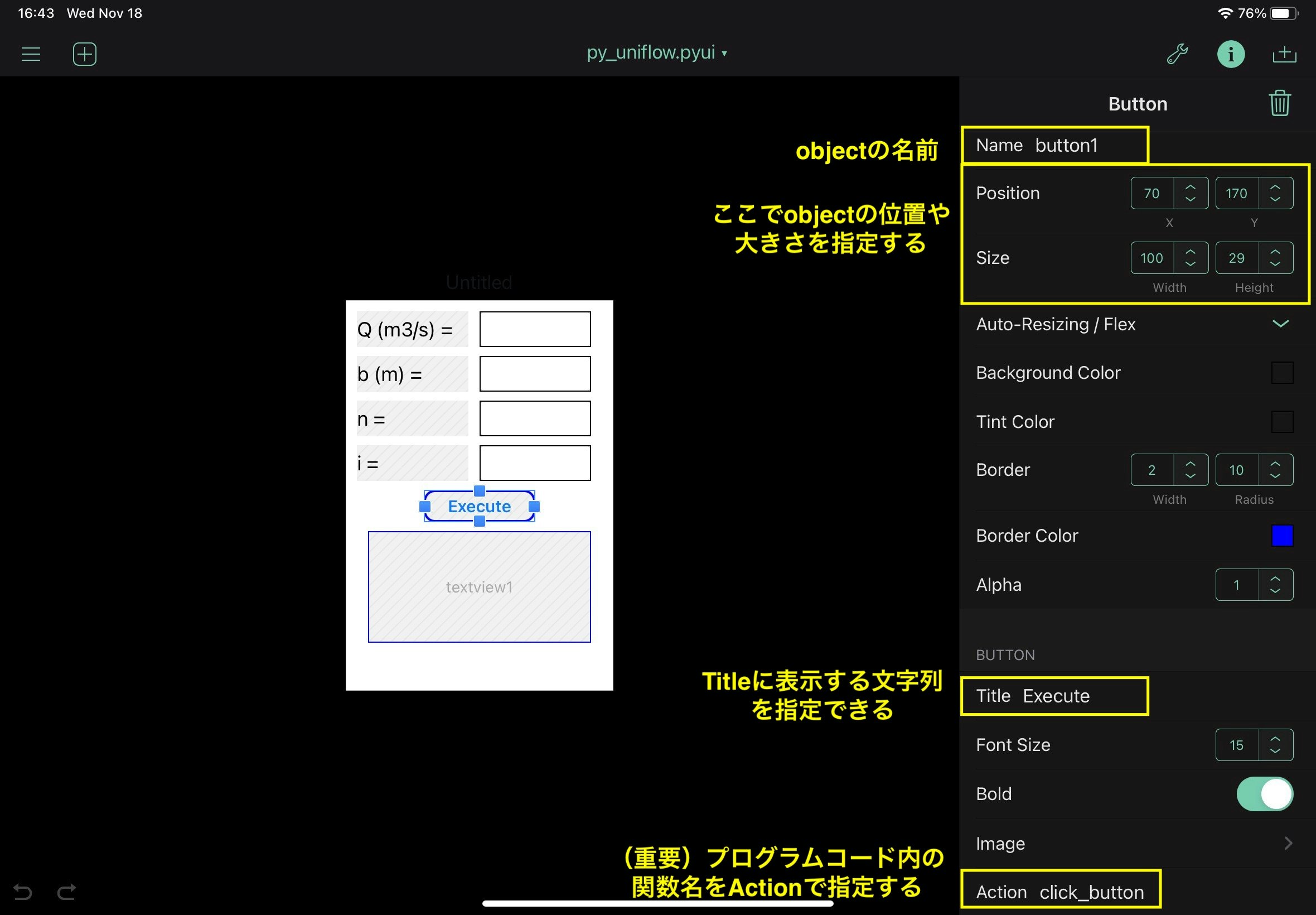
labelとbuttanについては、py_uniflow.pyuiの中で行っている、特性値指定箇所の写真を示しておく。
textfieldとtextviewは、位置と大きさを調整しているだけなので、写真は省略。
こんな感じでプログラムをiPad上で仕上げていく。
コード
py_uniflow.pyのコード全文は以下の通り。関数def click_buttonの中に主な処理は全て詰め込んである。# Calculation of normal depth import ui import numpy as np def cal_hc(q,b,cs): # critical depth g=9.8 hc=(q**2/g/b**2/cs)**(1/3) return hc def func(h,q,b,n,sn): f=q-b*h/n*(b*h/(b+2*h))**(2/3)*sn**(1/2) return f def bisection(q,b,n,sn,ha,hb): for k in range(100): hi=0.5*(ha+hb) fa=func(ha,q,b,n,sn) fb=func(hb,q,b,n,sn) fi=func(hi,q,b,n,sn) if fa*fi<0: hb=hi if fb*fi<0: ha=hi #print(fa,fi,fb) if np.abs(hb-ha)<1e-10: break return hi def click_button(sender): tf1=v['textfield1'] tf2=v['textfield2'] tf3=v['textfield3'] tf4=v['textfield4'] q=float(tf1.text) # discharge b=float(tf2.text) # channel width n=float(tf3.text) # Manning's roughness coefficient i=float(tf4.text) # invert gradient theta=np.arctan(i) sn=np.sin(theta) cs=np.cos(theta) ha=0.0 # lower initial value for bisection method hb=10.0 # upper initial value for bisection method hn=bisection(q,b,n,sn,ha,hb) vn=q/b/hn hc=cal_hc(q,b,cs) # hn: normal depth # vn: flow velocity # hc: critical depth tv=v['textview1'] ss='ang={0:.3f} deg.\n'.format(np.degrees(theta)) ss=ss+'hn={0:.3f} m\n'.format(hn) ss=ss+'vn={0:.3f} m/s\n'.format(vn) ss=ss+'hc={0:.3f} m'.format(hc) tv.text=ss v = ui.load_view() v.name='Uniform flow' v.present('sheet')以 上
- 投稿日:2020-11-18T17:48:47+09:00
IDWR速報データのインフルエンザ定点当たり報告数・都道府県別をスクレイピング
国立感染症研究所に同じデータのCSVがあるのでスクレイピング
from urllib.parse import urljoin import requests from bs4 import BeautifulSoup url = "https://www.niid.go.jp/niid/ja/data.html" headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko" } r = requests.get(url, headers=headers) r.raise_for_status() soup = BeautifulSoup(r.content, "html.parser") tag = soup.select_one( 'div.leading-0 > table > tbody > tr > td > p.body1 > a[href$="-teiten.csv"]' ) link = urljoin(url, tag.get("href")) import pandas as pd df = pd.read_csv( link, encoding="cp932", skiprows=3, index_col=0, header=0, usecols=[0, 1, 2], na_values="-", ) df1 = df[df.index.notna()]
- 投稿日:2020-11-18T15:16:20+09:00
Boto3でAWSのリソースを取得する時に作成したリソースだけ表示する
前提
AWSのリソースをBoto3で取得する時に、一部のリソースだと作った覚えのないリソースが含まれてしまうことがある。
これらはおそらくAWSが自動で作成したり、デフォルトで用意されているものだろう。
私の場合、スナップショット一覧を取得しようとしたら、AWSコンソール上では見たことないし、作った覚えがないリソースがあった。
以下がソースである。client = self.session.client('ec2') snapshots = client.describe_snapshots()対処方法
自身が作成したものだけを表示するためには
OwnerIdsを指定してあげれば良い。自分が作ったリソースを表示
client = self.session.client('ec2') snapshots = client.describe_snapshots(OwnerIds=['self'])ユーザIDを指定
client = self.session.client('ec2') snapshots = client.describe_snapshots(OwnerIds=['xxxxxxxxxxxx'])※ xxxxxxxxxxxx にユーザIDを指定
- 投稿日:2020-11-18T14:55:28+09:00
「ゼロから作るDeep Learning」自習メモ(その18)ワン!ニャン!Grad-CAM!
「ゼロから作るDeep Learning」(斎藤 康毅 著 オライリー・ジャパン刊)を読んでいる時に、参照したサイト等をメモしていきます。 その17 ←
Google Colaboratory 上で、本のスクリプトを Keras に置き換えて実行できることが確認できました。
で、
今度はKaggleの猫と犬のデータセットの判別をやらせてみることにしました。
自習メモその6の2でやったときは、正解率が60%で、あてずっぽうより少しマシ程度の結果。
このときは、データ作成時にメモリエラーが頻発したため、訓練データの数を減らしましたし、ニューラルネットはこの時点で理解できていた2層の全結合ネットだったので、1次元に変換したりしました。
自習メモその12では、畳み込みニューラルネットで処理してみましたが、メモリエラーでまともな学習ができず、正解率が50%と、あてずっぽうと同じレベル。今回はGoogle Colaboratory でメモリエラーを気にしないで、畳み込みニューラルネットに再挑戦して見ようかと思います。
Google Drive に写真をアップ
猫と犬のデータはそれぞれ400MBくらい、マイドライブの空き容量は数ギガあるので、容量の問題はありません。ただ、これをフォルダごとアップしようとすると、時間がかかりすぎて、タイムアウトになったりしました。1フォルダ12500個のファイルなので、ファイル数の問題なのかもしれませんが、犬フォルダは途中で止まったのに、猫フォルダは全部アップできたりして、原因がよくわかりません。時間がかかったから、という理由だと、回線が混んでいた、サーバーの負荷が高かったとか、その時々の事情によるでしょうから、ま、しょうがない。
colab画面を長い時間ほっておくとタイムアウトになる?
長時間スクリプトを実行させたままにして画面の操作をしないでいるとタイムアウトになるという話があったので、画像の形を整える処理は、犬と猫で分けて別々に退避してから、ひとつにまとめました。
自習メモその12でやったのと同じように画像を加工しましたが、自習メモその12は本のDeepConvNet用のデータだったので、channels_first (batch, channels, height, width) の形式になるようにtransposeで加工していました。Kerasは channels_last (batch, height, width, channels) 形式なので、transpose せずに保存しています。
前回作成したKeras版のDeepConvNetで学習させてみた
#入力データの準備 from google.colab import drive drive.mount('/content/drive') import os import pickle mnist_file = '/content/drive/My Drive/Colab Notebooks/deep_learning/dataset/catdog.pkl' with open(mnist_file, 'rb') as f: dataset = pickle.load(f) x_train = dataset['train_img'] / 255.0 #正規化している。 t_train = dataset['train_label'] x_test = dataset['test_img'] / 255.0 t_test = dataset['test_label'] print(x_train.shape)(23411, 80, 80, 3)
画像データは 0 ~ 255 の整数値ですが、これを255.0で除算して0.0~1.0 の範囲に収まるように変換しています。これをやると、学習の速度があがりました。
正規化していないと、エポックを5回やっても正解率60%になりませんでしたが、正規化してから学習させると4回目で60%を超えました。# TensorFlow と tf.keras のインポート import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers from keras.layers import Dense, Activation, Flatten, Conv2D, MaxPooling2D, Dropout # ヘルパーライブラリのインポート import numpy as np import matplotlib.pyplot as plt def create_model(input_shape, output_size, hidden_size): import numpy as np import matplotlib.pyplot as plt filter_num = 16 filter_size = 3 filter_stride = 1 filter_num2 = 32 filter_num3 = 64 pool_size_h=2 pool_size_w=2 pool_stride=2 model = keras.Sequential(name="DeepConvNet") model.add(keras.Input(shape=input_shape)) model.add(Conv2D(filter_num, filter_size, strides=filter_stride, padding="same", activation="relu", kernel_initializer='he_normal')) model.add(Conv2D(filter_num, filter_size, strides=filter_stride, padding="same", activation="relu", kernel_initializer='he_normal')) model.add(MaxPooling2D(pool_size=(pool_size_h, pool_size_w),strides=pool_stride)) model.add(Conv2D(filter_num2, filter_size, strides=filter_stride, padding="same", activation="relu", kernel_initializer='he_normal')) model.add(Conv2D(filter_num2, filter_size, strides=filter_stride, padding="same", activation="relu", kernel_initializer='he_normal')) model.add(MaxPooling2D(pool_size=(pool_size_h, pool_size_w),strides=pool_stride)) model.add(Conv2D(filter_num3, filter_size, strides=filter_stride, padding="same", activation="relu", kernel_initializer='he_normal')) model.add(Conv2D(filter_num3, filter_size, strides=filter_stride, padding="same", activation="relu", kernel_initializer='he_normal')) model.add(MaxPooling2D(pool_size=(pool_size_h, pool_size_w),strides=pool_stride)) model.add(keras.layers.Flatten()) model.add(Dense(hidden_size, activation="relu", kernel_initializer='he_normal')) model.add(Dropout(0.5)) model.add(Dense(output_size)) model.add(Dropout(0.5)) model.add(Activation("softmax")) #モデルのコンパイル model.compile(loss="sparse_categorical_crossentropy", optimizer="adam", metrics=["accuracy"]) return model input_shape=(80,80,3) output_size=2 hidden_size=100 model = create_model(input_shape, output_size, hidden_size) model.summary()Model: "DeepConvNet"
Layer (type) Output Shape Param #
conv2d (Conv2D) (None, 80, 80, 16) 448
conv2d_1 (Conv2D) (None, 80, 80, 16) 2320
max_pooling2d (MaxPooling2D) (None, 40, 40, 16) 0
conv2d_2 (Conv2D) (None, 40, 40, 32) 4640
conv2d_3 (Conv2D) (None, 40, 40, 32) 9248
max_pooling2d_1 (MaxPooling2 (None, 20, 20, 32) 0
conv2d_4 (Conv2D) (None, 20, 20, 64) 18496
conv2d_5 (Conv2D) (None, 20, 20, 64) 36928
max_pooling2d_2 (MaxPooling2 (None, 10, 10, 64) 0
flatten (Flatten) (None, 6400) 0
dense (Dense) (None, 100) 640100
dropout (Dropout) (None, 100) 0
dense_1 (Dense) (None, 2) 202
dropout_1 (Dropout) (None, 2) 0
activation (Activation) (None, 2) 0
Total params: 712,382
Trainable params: 712,382
Non-trainable params: 0input_shape と output_size 以外は、その17で作ったスクリプトと同じです。
model.fit(x_train, t_train, epochs=10, batch_size=128) test_loss, test_acc = model.evaluate(x_test, t_test, verbose=2)Epoch 1/10
195/195 [==============================] - 385s 2s/step - loss: 0.7018 - accuracy: 0.5456
Epoch 2/10
195/195 [==============================] - 385s 2s/step - loss: 0.6602 - accuracy: 0.5902
Epoch 3/10
195/195 [==============================] - 383s 2s/step - loss: 0.6178 - accuracy: 0.6464
Epoch 4/10
195/195 [==============================] - 383s 2s/step - loss: 0.5844 - accuracy: 0.6759
Epoch 5/10
195/195 [==============================] - 383s 2s/step - loss: 0.5399 - accuracy: 0.7090
Epoch 6/10
195/195 [==============================] - 383s 2s/step - loss: 0.5001 - accuracy: 0.7278
Epoch 7/10
195/195 [==============================] - 382s 2s/step - loss: 0.4676 - accuracy: 0.7513
Epoch 8/10
195/195 [==============================] - 382s 2s/step - loss: 0.4485 - accuracy: 0.7611
Epoch 9/10
195/195 [==============================] - 380s 2s/step - loss: 0.4295 - accuracy: 0.7713
Epoch 10/10
195/195 [==============================] - 382s 2s/step - loss: 0.4099 - accuracy: 0.7788
4/4 - 0s - loss: 0.3249 - accuracy: 0.8500正解率は85%。
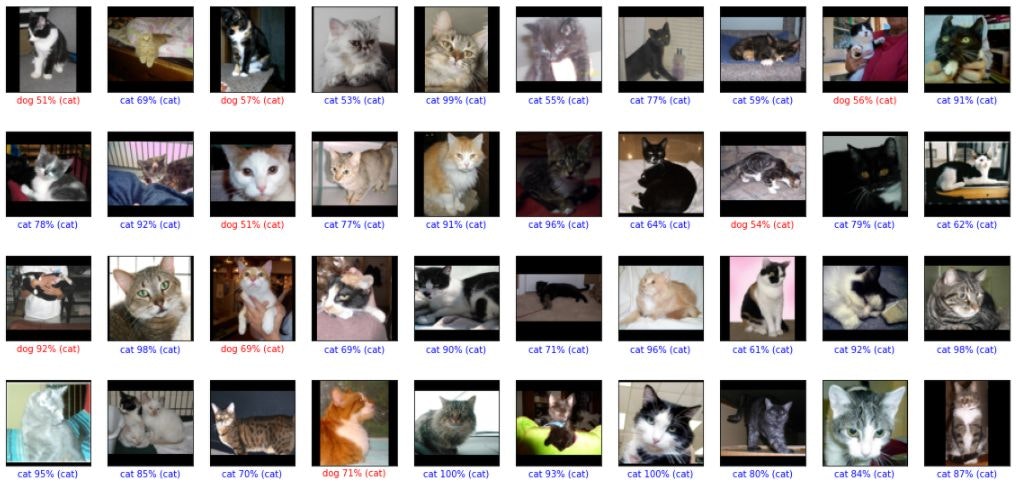
判定結果を表示してみました。#予測する predictions = model.predict(x_test) def plot_image(i, predictions_array, t_label, img): class_names = ['cat', 'dog'] predictions_array = predictions_array[i] img = img[i].reshape((80, 80, 3)) true_label = t_label[i] plt.grid(False) plt.xticks([]) plt.yticks([]) plt.imshow(img, cmap=plt.cm.binary) predicted_label = np.argmax(predictions_array) if predicted_label == true_label: color = 'blue' else: color = 'red' plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label], 100*np.max(predictions_array), class_names[true_label]), color=color) # X個のテスト画像、予測されたラベル、正解ラベルを表示します。 # 正しい予測は青で、間違った予測は赤で表示しています。 num_rows = 10 num_cols = 10 num_images = num_rows*num_cols plt.figure(figsize=(2*num_cols, 2.5*num_rows)) for i in range(num_images): plt.subplot(num_rows, num_cols, i+1) plot_image(i, predictions, t_test, x_test) plt.show()
猫を犬と間違えたのが9件、犬を猫と間違えたのが6件です。
顔が大きく真正面を向いている場合は間違いがないように見えます。横向きだったり、顔が小さいと間違えているのかもしれません。猫はみんな三角耳、多くの犬がたれ耳というのもポイントか?と言う事で
画像の何に注目して判定しているのかが知りたくなって、GRAD-CAMを使って見ることにしました。
Grad-CAM
Gradient-weighted Class Activation Mapping (Grad-CAM) 勾配加重クラス活性化マッピング手法と言うらしい。グラドキャムでいいのかな?
Grad 勾配と言うと、損失関数のところで出てきましたが、どうやら、勾配が大きくなるところが分類に最も影響する、ということのようです。
それ以上の追求はあきらめて、プログラムを動かして、結果だけ見てみようかと思います。Grad-CAM計算用のプログラムは、こちらを参考にしました。
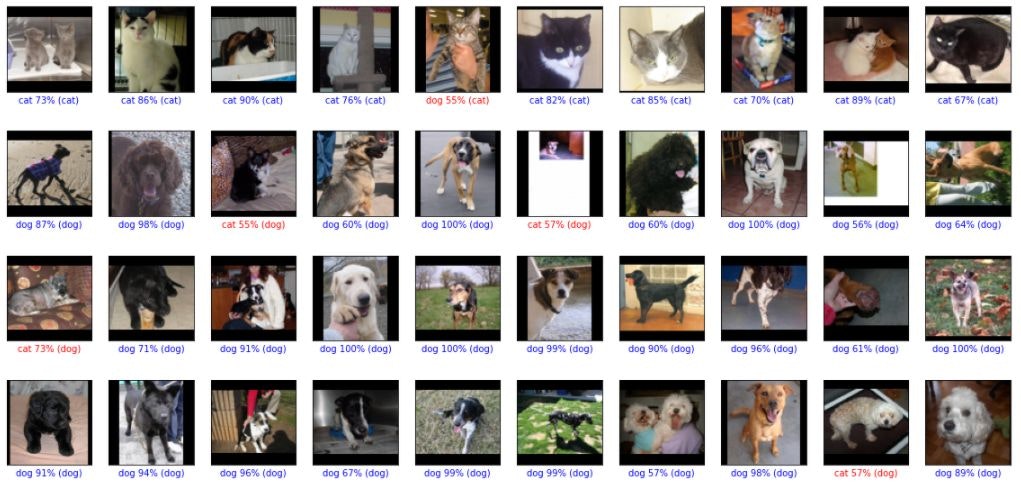
→kerasとtensorflowでGrad-CAMを実装してみたimport numpy as np import cv2 # Grad−CAM計算用 from tensorflow.keras import models import tensorflow as tf def grad_cam(input_model, x, layer_name, IMAGE_SIZE = (80, 80)): """ Args: input_model(object): モデルオブジェクト x(ndarray): 画像 layer_name(string): 畳み込み層の名前 Returns: output_image(ndarray): 元の画像に色付けした画像 """ # 画像の前処理 # 読み込む画像が1枚なため、次元を増やしておかないとmode.predictが出来ない X = np.expand_dims(x, axis=0) preprocessed_input = X.astype('float32') / 255.0 grad_model = models.Model([input_model.inputs], [input_model.get_layer(layer_name).output, input_model.output]) with tf.GradientTape() as tape: conv_outputs, predictions = grad_model(preprocessed_input) class_idx = np.argmax(predictions[0]) loss = predictions[:, class_idx] # 勾配を計算 output = conv_outputs[0] grads = tape.gradient(loss, conv_outputs)[0] gate_f = tf.cast(output > 0, 'float32') gate_r = tf.cast(grads > 0, 'float32') guided_grads = gate_f * gate_r * grads # 重みを平均化して、レイヤーの出力に乗じる weights = np.mean(guided_grads, axis=(0, 1)) cam = np.dot(output, weights) # 画像を元画像と同じ大きさにスケーリング cam = cv2.resize(cam, IMAGE_SIZE, cv2.INTER_LINEAR) # ReLUの代わり cam = np.maximum(cam, 0) # ヒートマップを計算 heatmap = cam / cam.max() # モノクロ画像に疑似的に色をつける jet_cam = cv2.applyColorMap(np.uint8(255.0*heatmap), cv2.COLORMAP_JET) # RGBに変換 rgb_cam = cv2.cvtColor(jet_cam, cv2.COLOR_BGR2RGB) # もとの画像に合成 output_image = (np.float32(rgb_cam) / 2 + x / 2 ) return output_image , rgb_camfrom keras.preprocessing.image import array_to_img, img_to_array, load_img predictions = model.predict(x_test) def hantei_hyouji(i, x_test, t_test, predictions, model): class_names = ['cat', 'dog'] x = x_test[i] true_label = t_test[i] predictions_array = predictions[i] predicted_label = np.argmax(predictions_array) IMAGE_SIZE = (80, 80) target_layer = 'conv2d_5' cam, heatmap = grad_cam(model, x, target_layer, IMAGE_SIZE) moto=array_to_img(x, scale=True) hantei=array_to_img(heatmap, scale=True) hyouji=array_to_img(cam, scale=True) print("{} {:2.0f}% ({})".format(class_names[predicted_label], 100*np.max(predictions_array), class_names[true_label])) row = 1 col = 3 plt.figure(figsize=(15,15)) plt.subplot(row, col, 1) plt.imshow(moto) plt.axis('off') plt.subplot(row, col, 2) plt.imshow(hantei) plt.axis('off') plt.subplot(row, col, 3) plt.axis('off') plt.imshow(hyouji) plt.show() return for i in range(100): hantei_hyouji(i, dataset['test_img'], t_test, predictions, model)で、結果は
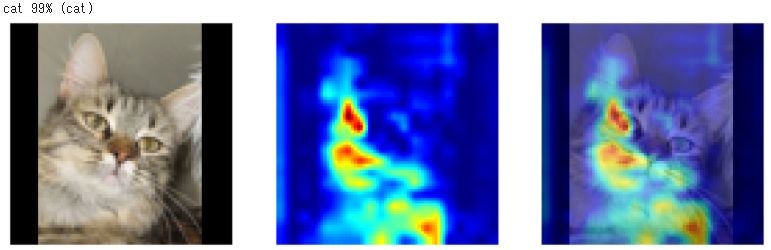
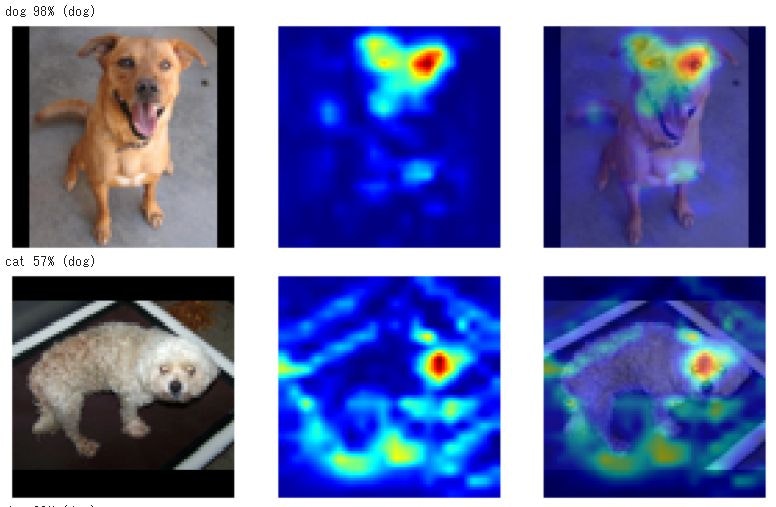
どうも、猫については耳とか目ではなく、体の模様とか、体のかたちとかを見ているような感じです。
犬のほうは、顔、特に鼻に注目しているようです。参考サイト
kerasとtensorflowでGrad-CAMを実装してみた




- 投稿日:2020-11-18T14:13:30+09:00
discord.pyのtimestampにはUTCを指定しなきゃいけないってお話
経緯
先日こんな質問を受けました。曰く、
embedのタイムスタンプが、何故か9時間先に進んだ時刻になってしまう
と。
ちょっと検証してみましょう。from datetime import datetime # 中略 embed = discord.Embed(title="hoge", description="fuga", timestamp=datetime.now()) await message.channel.send(embed=embed)
確かにおかしいですね
今回はこの件についてまとめてみました。解決法
解決法はいくつか在るので3つほど提示してみます。
UTCでの時間を取得する
datetime.utcnow Python公式ドキュメント
datetime.utcnowを用いてUTCでの時間を取得する方法です。
提示する方法の中で一番単純なのでこれをおすすめします。from datetime import datetime # 中略 embed = discord.Embed(title="hoge", description="fuga", timestamp=datetime.now())このコードを
- embed = discord.Embed(title="hoge", description="fuga", timestamp=datetime.now()) + embed = discord.Embed(title="hoge", description="fuga", timestamp=datetime.utcnow())このように変更すれば解決できます。(
timestamp=datetime.now()をtimestamp=datetime.utcnow()へ書き換えてください。)UTCでの時間を取得する(2)
datetime.now()は引数を指定しないとマシンのタイムゾーンでの現在時間を返しますが、タイムゾーンを指定して取得することもできます。
UTCの時間を渡してあげればいいので、引数にtimezone.utcを渡してあげましょう。from datetime import datetime, timezone # 中略 embed = discord.Embed(title="hoge", description="fuga", timestamp=datetime.now(timezone.utc)) await message.channel.send(embed=embed)こんな感じ。
手動で時間を引いてみる
datetime.timedelta Python公式ドキュメント
datetime.timedeltaを使えば特定の時間から、特定の時間前や時間後のdatetimeオブジェクトを取得することができます。
例えばJSTならUTCから9時間進んでいるため、datetime.nowからdatetime.timedelta(hours=9)を引いてやればUTCに変換できます。from datetime import datetime, timedelta #中略 JST_time = datetime.now() UTC_time = JST_time - timedelta(hours=9) embed = discord.Embed(title="hoge", description="fuga", timestamp=UTC_time) await message.channel.send(embed=embed)原因
現在のローカルな日時を返します。
と在るように、実行しているマシンのタイムゾーンでの現在時刻を返します。
しかしembedのtimestampは、UTCで時間が渡されることを想定しているようで、UTCをマシンのタイムゾーンに変換する処理をdiscordクライアント側が自動で行ってしまうようです。そのため、タイムスタンプが未来になってしまっていたという事ですね。
原因がわかれば解決は簡単です。最初に提示した方法を用いてみて、、、
よし、ok!最後に
今回は初めての試みとして、質問された内容を記事としてまとめてみました。
少しでもbot開発者の助けになったら幸いです。
- 投稿日:2020-11-18T14:10:27+09:00
SPSS Modelerのフィールド作成ノードをPythonで書き換える。時系列センサーデータからの特徴量抽出
SPSS Modelerで既存のデータから関数などを使ってデータを加工する「フィールド作成」ノードをつかって、時系列センサーデータから特徴量抽出を行います。そしてその処理をPythonのpandasで書き換えてみます。
SPSS Modelerでは様々なデータ加工を行うノードが用意されていますが、「フィールド作成」ノードはかなり汎用的な自由度の高いデータ加工を行うノードです。
加工のパターンは「派生」のリストから選べます。派生というとイメージがしにくいですがderiveという英語の翻訳で、元のデータから派生してつくる加工のパターンという意味になります。
個人的によく使う順に説明します。
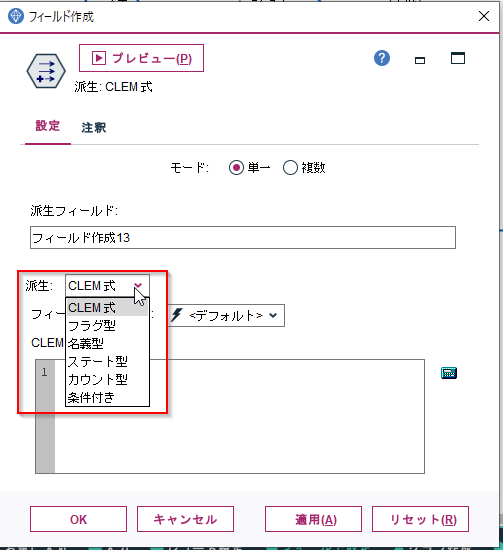
- CLEM式:四則演算や論理演算、関数をつかった加工。もっとも汎用的です
- 条件付き:IF文を作成して加工データを作ります
- フラグ型、名義型:IF文でフラグやカテゴリ型の変数を生成します
- カウント型:IF文などによって、累積値を生成します
- ステート型:IF文で状態の遷移から特徴量を生成します
いずれもレコードを上から順に処理します。特にカウント型やステート型ではレコードの処理順を意識することが必須になります。
汎用的なノードですのでさまざまな加工が考えられますが、今回は時系列のセンサーデータから特徴量を抽出する目的で利用してみます。
時系列のセンサーデータはそのままではあまり情報量がないため、有効な特徴量を加工してつくることが分析のカギになります。例えば「200Wを超えたらエラーになる」という単純な特徴がつかめれば簡単なのですが、実際にはそのセンサーの値がどう変化してきたか、例えば急激に電力量が上がっている、電力量が安定せずに増減をジグザグに繰り返しているなどの情報で分析しないと意味がある分析ができないことがほとんどです。
分析対象のデータは以下です。
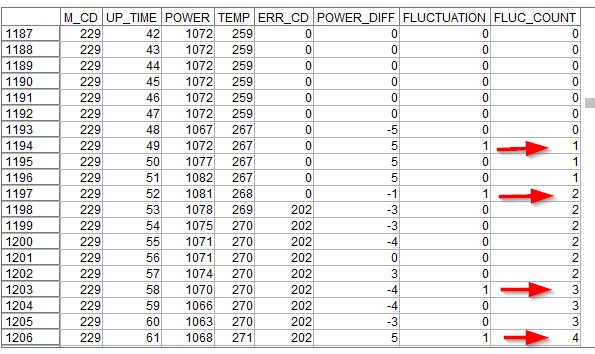
M_CD: マシンコード
UP_TIIME: 起動時間
POWER: 電力
TEMP: 温度
ERR_CD: エラーコード各マシンコードごとに起動時間にそって電力や温度の変化、そしてエラーがあればそれが時系列に記録されています。
今回はこのデータから以下のような特徴量を作ってみます。
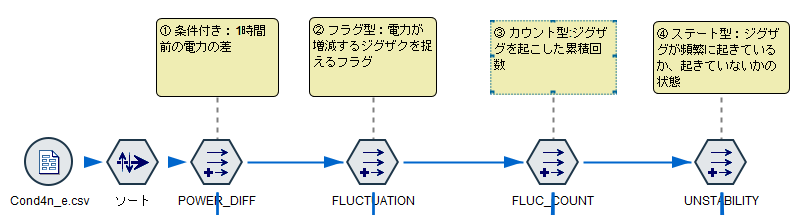
① 条件付き:1時間前の電力の差
② フラグ型:電力が増減するジグザクを捉えるフラグ
③ カウント型:ジグザグを起こした累積回数
④ ステート型:ジグザグが頻繁に起きているか、起きていないかの状態
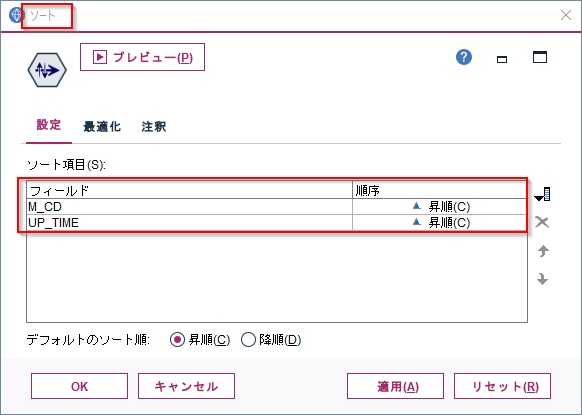
いずれもレコード順序が要な加工を行いますので、ソートノードをつかって各マシンコードと起動時間ごとにソートをしておきます。
1m.① 条件付き:1時間前の電力の差 Modeler版
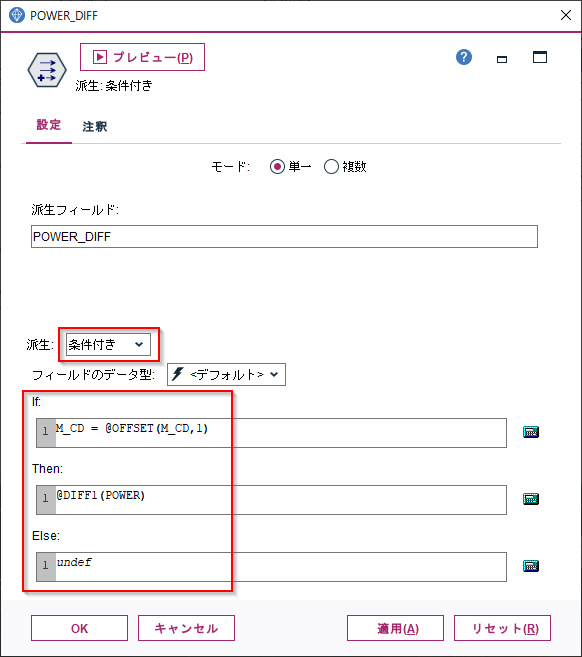
「1時間前の電力との差」の特徴量を作ってみます。
フィールド作成ノードで「派生:条件付き」に設定します。
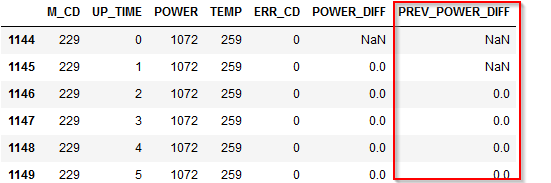
そうするとIF文の構造を表す入力項目がでてきます。実はIF文は「派生:CLEM式」でも書けるのですが、より可読性を高めるためには「派生:条件付き」を使うことをお勧めします。まずThen:に@DIFF1(POWER)を入力します。@DIFF1はCLEM関数というModelerのビルトイン関数で、一行前との差を計算するというものです。これで1時間前の電力との差が計算できます。
次にIf:にM_CD = @OFFSET(M_CD,1)、Else:にundefを設定します。
@OFFSETとはN行前の値を参照するという関数です。ここでは1行前を参照しています。undefはNULLを意味します。つまり前行のM_CDと同じ場合は@DIFF1(POWER)を計算し、前行のM_CDと異なる場合は、別のマシンの電力との差を計算しても意味がないので、NULLを入れるという意味になります。
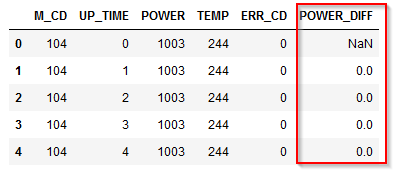
結果は以下のようになります。
POWER_DIFFという新しい派生列ができていて、前の行のPOWERから現在のPOWERを引いた値が入っています。930行目の例でいうと988W-991W=-3Wが入っています。また、941行目をみると$null$が入っています。これは940行目までがM_CD=204のマシンのデータで、941行目からがM_CD=209 のマシンのデータなので電力との差を計算しても意味がないのでNULLを入れています。
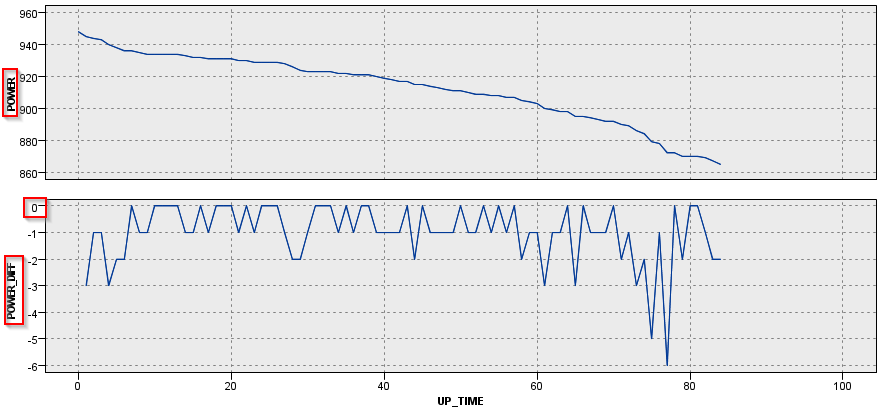
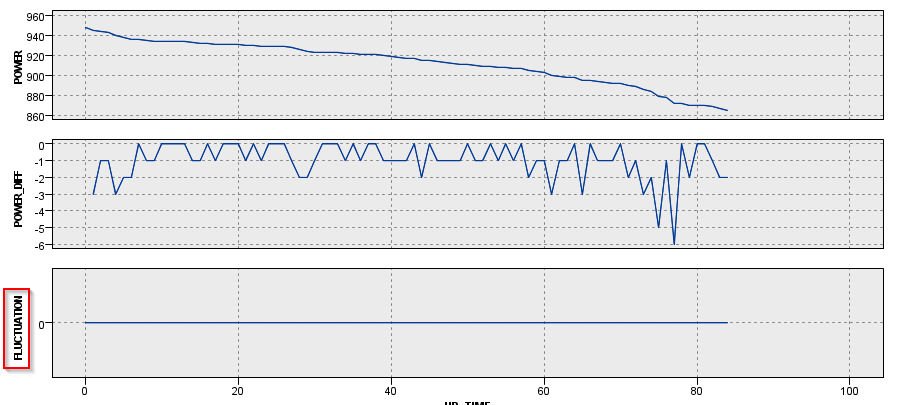
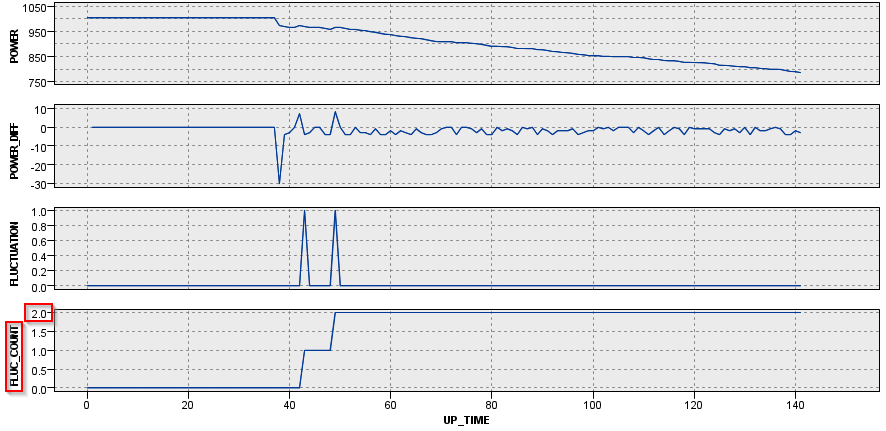
ちなみに時系列のグラフでM_CD = 1000とM_CD = 229の2台のマシンを見てみます。
M_CD = 1000は最初から単調に電力が-1W、-2W減少しており、一度も増えてはいません。最後の方で-5W、-6Wという比較的大きな減り方をしています。
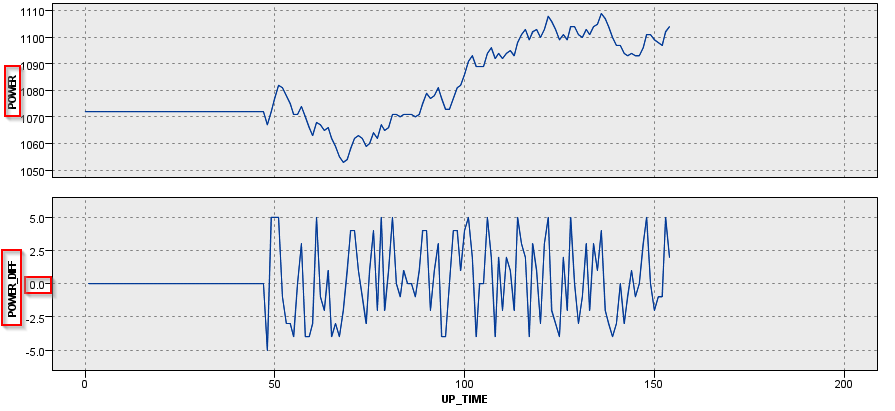
M_CD = 229の場合はかなりプラスの差もマイナスの差もあり、増減を繰り返していました。
1p.① 条件付き:1時間前の電力の差 pandas版
pandasではM_CDごとにグループ化してPOWERに対して、1時間前の計算をあらわすdiff(1)の計算を行ってdf['POWER_DIFF']という新しい列に入れています。
#1時間前の電力の差 df['POWER_DIFF'] = df.groupby(['M_CD'])['POWER'].diff(1)
2m.② フラグ型:電力が増減するジグザクを捉えるフラグ Modeler版
M_CD = 229のマシンのように電力が増減を繰り返すことは電源に何か問題があるかもしれません。「1時間前の電力の差」だけですとその単一の値(例:-5W)だけでは、電力の増減のジグザグを捉えることはできていません。
電力の差がプラスからマイナスに転じた、もしくはマイナスからプラスに転じたことを示す特徴量を作ります。フィールド作成ノードで「派生:フラグ型」に設定します。
フィールドのデータ型はここでは後で時系列グラフに表示したかったので連続型にし、真の場合1,偽の場合は0としました。単にフラグが欲しいだけであれば、データ型はフラグ型のままで構いません。
真となる条件に
POWER_DIFF * @OFFSET(POWER_DIFF,1) < 0
を設定します。「1時間前の電力の差」*1時間前の「1時間前の電力の差」を計算しマイナスになるかを判定しています。
プラスとマイナスの掛け算はマイナスになり、プラス同士やマイナス同士の場合の掛け算はプラスになります。ですので、符号が反転した場合に、つまりジグザグが起きた場合にフラグを立てています。
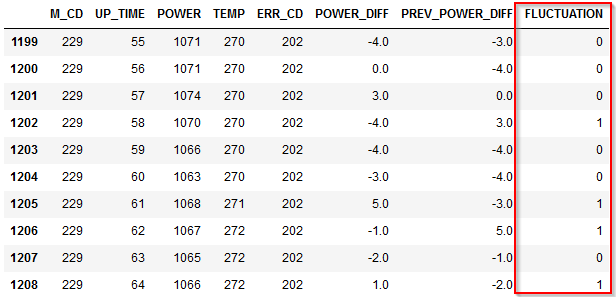
結果は以下のようになります。
FLUCTUATIONという新しい派生列ができていて、POWER_DIFFと前の行のPOWER_DIFFの符号が違う場合に1が入っています。
1195行目で言うと1時間前に5W増加し、この時間も5W増加していますので、単調に増えています。そのためフラグは0です。
一方で、
1197行目で言うと1時間前に5W増加していますが、この時間は-1Wと減少していますので、ジグザグが起きています。そのためフラグは1です。
グラフをみないとわからなかったジグザグの状況が1197行目の1レコードをみるだけでもわかるようになりました。
やはり時系列のグラフでM_CD = 1000とM_CD = 229の2台のマシンを見てみます。
M_CD = 1000は最初から単調に電力が減少しているので、ジグザグは起きていません。
M_CD = 229の場合は細かく増減を繰り返していることがよく分かります
2p.② フラグ型:電力が増減するジグザクを捉えるフラグ pandas版
pandasでジグザグを捉えるフラグをつくることはすこしややこしくなります。
まず1時間前のPOWER_DIFFの変数を作ります。
M_CDごとにグループ化してPOWER_DIFFに対して、1時間前の値をshift(1)で参照し、df['PREV_POWER_DIFF']という新しい列に入れています。#1時間前のPOWER_DIFFの列を追加 df['PREV_POWER_DIFF'] = df.groupby(['M_CD'])['POWER_DIFF'].shift(1)この列は最終的には不要なので、Modelerでは作成しなかった列ですが、pandasでは計算のために必要です。
次に関数func_fluctuationを定義します。この関数の中の以下のIF文で
if x.POWER_DIFF * x.PREV_POWER_DIFF < 0:
で「1時間前の電力の差」*1時間前の「1時間前の電力の差」を計算しマイナスになるかを判定しています。そしてこの関数を各行に対してlambdaで呼び出して、結果をdf['FLUCTUATION']という新しい列に入れています。
注意が必要なのはaxis=1としていることで、pandas.Seriesからpandas.DataFrameに変換していることです。#プラスとマイナスの反転判定をする関数 def func_fluctuation(x): if x.POWER_DIFF * x.PREV_POWER_DIFF < 0: return 1 else: return 0 #プラスとマイナスの反転判定をする関数を各行から呼び出し df['FLUCTUATION'] = df.apply(lambda x:func_fluctuation(x),axis=1)以下のように生成できました。
- 参考
- pandasで条件分岐(case when的な)によるデータ加工を網羅したい - Qiita
- https://qiita.com/Hyperion13fleet/items/98c31744e66ac1fc1e9f
3m.③ カウント型:ジグザグを起こした累積回数 Modeler版
M_CD = 229のマシンのようにジグザグが何度もある場合は電源に何か問題があるかもしれませんが、逆に数回のジグザクであれば問題ないと考えられるかもしれません。
起動後に累積でジグザグが何回発生したかという累積和の特徴量を作成してみます。フィールド作成ノードで「派生:カウント型」に設定します。
増分条件に
FLUCTUATION = 1
増分は1
を設定します。ジグザグが発生した時に1つカウントアップするという意味です。
また、リセット条件にはM_CD /= @OFFSET(M_CD,1)を設定し、マシンが変わったらカウンターを0に戻すという設定をしています。
結果は以下のようになります。
FLUC_COUNTという新しい派生列ができていて、FLUCTUATIONに1が入ると1つずつカウントアップされていきます。
1194行目をみると、FLUCTUATIONが発生しているのでFLUC_COUNTが1になります。
その後1197行までは1が維持されます。そして1197行でまたFLUCTUATIONが発生しているので、2に増えています。
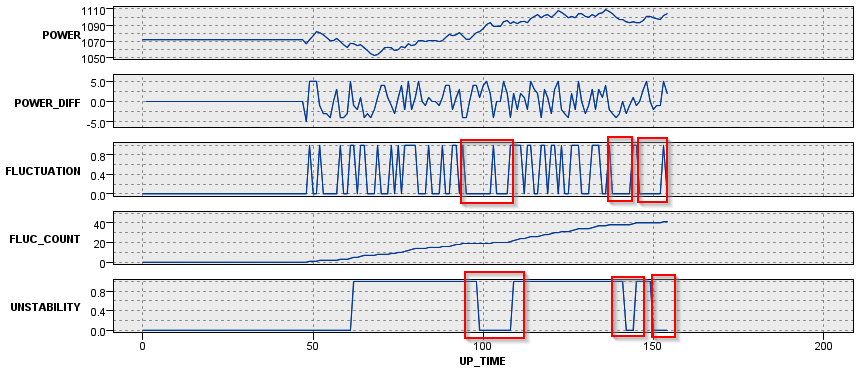
今度は時系列のグラフでM_CD = 104とM_CD = 229の2台のマシンを見てみます。
M_CD = 104は40時間過ぎに2回のジグザグがあり、その後は単調に電力が減少しています。なのでFLUC_COUNTは50時間後くらいからは2のままで保たれます。
M_CD = 229の場合はずっと細かく増減を繰り返して40回以上ジグザグ状態を繰り返していました。
3p.③ カウント型:ジグザグを起こした累積回数 pandas版
pandasでは累積和を計算するcumsum()という関数で計算をすることができます。
M_CDごとにグループ化してFLUCTUATIONの累積和をcumsum()で計算しdf['FLUC_COUNT']という新しい列に入れています。#ジグザグを起こした累積回数 df['FLUC_COUNT'] = df.groupby(['M_CD'])['FLUCTUATION'].cumsum()以下のように生成できました。
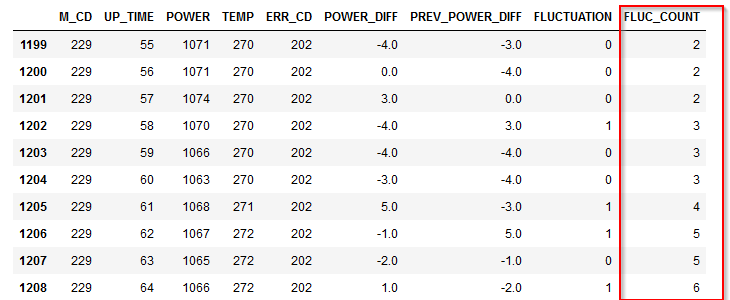
4m.④ ステート型:ジグザグが頻繁に起きているか、起きていないかの状態 Modeler版
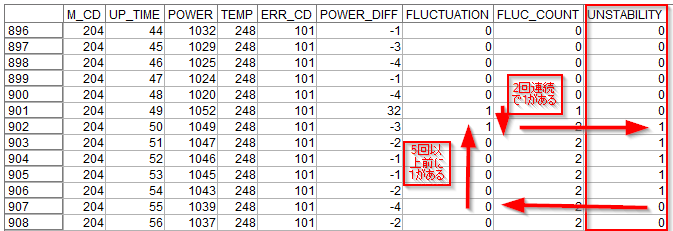
ジグザグの状態も多少の変動であれば大きな問題はないかもしれません。一方でジグザグが短期間で繰り返すようならその後ジグザグがおさまってもその影響は残るかもしれません。
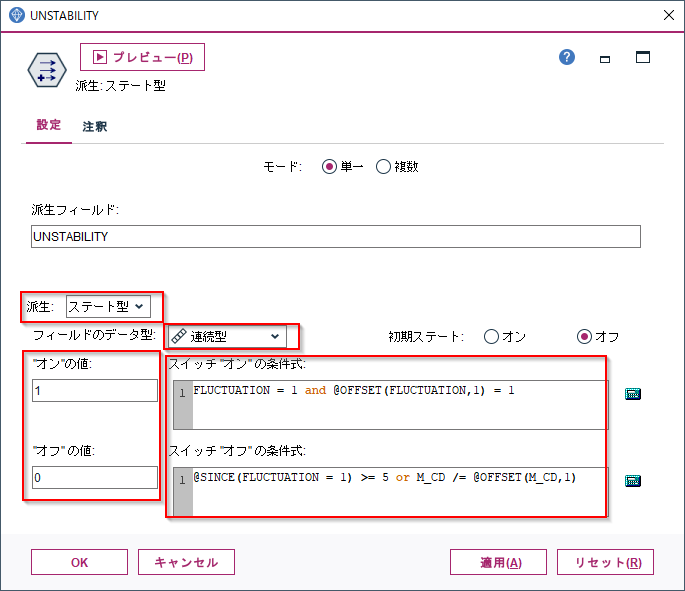
そういう複雑な状況を表現できるのが「派生:ステート型」になります。フィールド作成ノードで「派生:ステート型」に設定します。
フィールドのデータ型はここでは後で時系列グラフに表示したかったので連続型にし、”オン”の場合1,”オフ”の場合は0としました。単にフラグが欲しいだけであれば、データ型はフラグ型のままで構いません。
スイッチ”オン”の条件式に
FLUCTUATION = 1 and @OFFSET(FLUCTUATION,1) = 1
を設定します。
これはジグザグが起きていて、1時間前にもジグザグが起きたということを意味します。
つまり2時間連続でジグザグが起きたということです。次にスイッチ”オフ”の条件式に
@SINCE(FLUCTUATION = 1) >= 5 or M_CD /= @OFFSET(M_CD,1)
を設定します。
@SINCEは、引数として与えた式が成り立つのは何行前かという行数を数値を返します。@SINCE(FLUCTUATION = 1) >= 5 はジグザグが最後に起きたのが5行以上前ということを意味します。つまり逆に言うと、5時間以上連続でジグザグが起きていないので安定しているということを意味しています。またM_CD /= @OFFSET(M_CD,1)はリセット条件になっていて、マシンが変わったらステータスをオフに戻すという設定をしています。
フラグ型と似ているのですが、オンとオフの条件を非対称にできるのがステート型です。ここではジグザグの不安定な状況が2回続いたら、オンにして、一方で安定状態は5回続かないとオフに戻さないということをしています。
結果は以下のようになります。
UNSTABILITYという新しい派生列ができています。
まず902行目をみると、FLUCTUATIONに1が2レコード連続で入って1がたちます。ジグザグが2時間連続で続くことを不安定と判定したことになります。次に903行目から906行目までは、FLUCTUATIONは0で発生していませんが、UNSTABILITYは1のままです。
そして907行目で5レコード以上前にFLUCTUATIONが1だったので、つまり5レコード以上連続でFLUCTUATIONが0だったので、UNSTABILITYが0に戻りました。ジグザグが5時間以上発生しなかったので、安定したと判定したことになります。
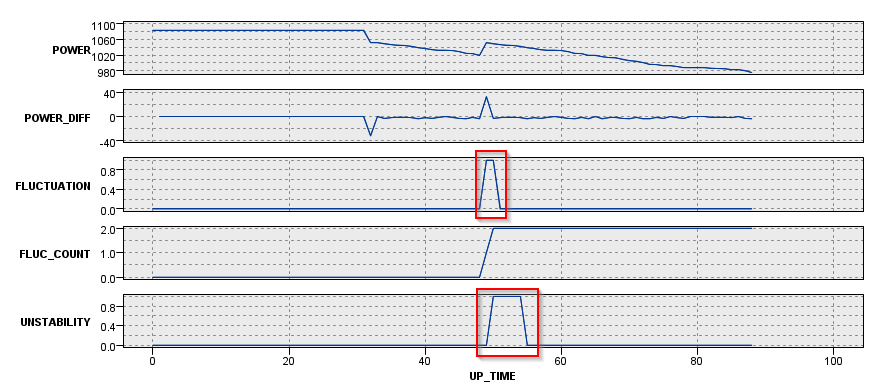
今度は時系列のグラフでM_CD = 204とM_CD = 229の2台のマシンを見てみます。
M_CD = 204は49時間過ぎに2回のジグザグがあり、その後は単調に電力が減少しています。なのでUNSTABILITYは一度1になった5時間後からは0のままで保たれます。
M_CD = 229の場合はずっと細かく増減を繰り返していて、UNSTABILITYは1である期間が長いのですが、5時間連続でジグザグがない状態が3回あり、その間はUNSTABILITYは0になっています。
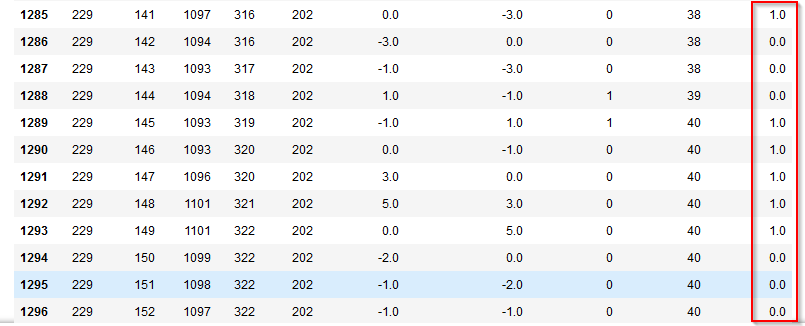
4p.④ ステート型:ジグザグが頻繁に起きているか、起きていないかの状態 pandas版
pandasではこのような複雑な条件を表現するのは難しいので、ループ処理でシリアルな処理を考えました。
#先頭行は安定の初期値 df.at[0, 'UNSTABILITY'] = 0 stable_seq_count = 0 #2行目(index=1)からループ処理 for index in range(1,len(df)): #既定は直前のステータスを保持する df.at[index, 'UNSTABILITY'] = df.at[index-1, 'UNSTABILITY'] #変動があった場合 if df.at[index, 'FLUCTUATION'] == 1 : #連続安定カウントを初期化 stable_seq_count = 0 #変動が2回続いた場合、不安定状態判定 if df.at[index-1, 'FLUCTUATION'] == 1: df.at[index, 'UNSTABILITY'] = 1 #変動がなかった場合、連続安定カウントをアップ elif df.at[index, 'FLUCTUATION'] == 0: stable_seq_count += 1 #連続安定カウントが5回以上続いた場合かマシンが別のマシンになった場合、安定状態判定 if stable_seq_count >= 5 or df.at[index, 'M_CD'] != df.at[index-1, 'M_CD']: df.at[index, 'UNSTABILITY'] = 0以下のように生成できました。
- 参考
- Python 3.x - データフレームの中の一個前の列を参照して、次の列の演算を行う Python,Pandas|teratail
- https://teratail.com/questions/64620
- Pythonのfor文によるループ処理(range, enumerate, zipなど) | note.nkmk.me
- https://note.nkmk.me/python-for-usage/
5. サンプル
サンプルは以下に置きました。
ストリーム
https://github.com/hkwd/200611Modeler2Python/raw/master/derive/derive3.str
notebook
https://github.com/hkwd/200611Modeler2Python/blob/master/derive/derive.ipynb
データ
https://raw.githubusercontent.com/hkwd/200611Modeler2Python/master/data/Cond4n_e.csv■テスト環境
Modeler 18.2.2
Windows 10 64bit
Python 3.6.9
pandas 0.24.16. 参考情報






- 投稿日:2020-11-18T13:58:34+09:00
Pytorchのdatasetについて説明してみた
動機
研究室でPytorchを使っている人がいるのでその方向けの説明用に
本題 - 「なぜdatasetが必要なのか」
- 深層学習の入力データはバッチごとであるため
- バカでかいデータを一気に扱うとメモリが死ぬので細かく扱えるdatasetが便利だから
- とにかくシャッフルとかも勝手にやってくれるから
簡易的なコードと説明
dataset.pyimport torch from sklearn.datasets import load_iris class Dataset(torch.utils.data.Dataset): def __init__(self, transform=None): self.iris = load_iris() #irisdatasetの読み込み self.data = self.iris['data'] self.label = self.iris['target'] self.datanum = len(self.label) #データの総数 self.transform = transform #データに対する特別な処理 def __len__(self): return self.datanum def __getitem__(self, index): data = self.data[index] label = self.label[index] if self.transform: data = self.transform(data) return data, label if __name__ == "__main__": batch_size = 20 dataset = Dataset() dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True) for data in dataloader: print("データ件数: " + str(len(data[0]))) print("data: {}".format(data[0])) print("レーベル件数: " + str(len(data[1]))) print("label: {}".format(data[1]) + "\n")以上がコードの全容です。
わかりやすくするために本当に最小限だけにしてます。initはクラスを定義した際の処理です。
今回はとても小さなデータなのでinit内で全部定義しちゃってますが、
もしとても大きなデータをストレージからイテレーションしたい場合はここでパスなどを指定し、getitemで順番にイテレーションするといい感じです。lenはデータの総数を返します。
getitemはindexで指定されたデータを返します。
Dataloaderでイテレーションする際は後述するバッチサイズ分だけデータをまとめて指定して返します。Dataloaderについて
第一引数にDatasetクラスのインスタンスであるdatasetを渡します。
第二引数や第三引数には、バッチサイズやshuffleをするか(True/False)を渡します。
特別な理由がない限りshuffleはTrueにしましょう。for 以外にもDataloaderをイテレーションする方法はありますが、ここではforを使います。
上記のプログラムを実行したのが以下です。データ件数: 20 data: tensor([[6.8000, 3.0000, 5.5000, 2.1000], [6.7000, 3.1000, 5.6000, 2.4000], [5.4000, 3.9000, 1.3000, 0.4000], [5.5000, 2.4000, 3.7000, 1.0000], [5.1000, 3.7000, 1.5000, 0.4000], [4.5000, 2.3000, 1.3000, 0.3000], [6.6000, 2.9000, 4.6000, 1.3000], [6.5000, 3.0000, 5.8000, 2.2000], [7.0000, 3.2000, 4.7000, 1.4000], [4.4000, 3.2000, 1.3000, 0.2000], [5.0000, 3.4000, 1.5000, 0.2000], [5.4000, 3.4000, 1.5000, 0.4000], [4.9000, 2.4000, 3.3000, 1.0000], [6.3000, 3.4000, 5.6000, 2.4000], [7.7000, 2.6000, 6.9000, 2.3000], [6.2000, 2.8000, 4.8000, 1.8000], [6.2000, 3.4000, 5.4000, 2.3000], [5.6000, 2.7000, 4.2000, 1.3000], [6.1000, 3.0000, 4.9000, 1.8000], [6.7000, 3.0000, 5.0000, 1.7000]], dtype=torch.float64) レーベル件数: 20 label: tensor([2, 2, 0, 1, 0, 0, 1, 2, 1, 0, 0, 0, 1, 2, 2, 2, 2, 1, 2, 1], dtype=torch.int32) ~~~~~途中省略~~~~~~ データ件数: 10 data: tensor([[4.8000, 3.4000, 1.6000, 0.2000], [6.1000, 2.8000, 4.7000, 1.2000], [5.1000, 3.8000, 1.9000, 0.4000], [6.7000, 3.3000, 5.7000, 2.1000], [6.4000, 2.9000, 4.3000, 1.3000], [7.4000, 2.8000, 6.1000, 1.9000], [6.4000, 3.2000, 5.3000, 2.3000], [5.0000, 3.3000, 1.4000, 0.2000], [5.0000, 3.2000, 1.2000, 0.2000], [5.8000, 2.7000, 4.1000, 1.0000]], dtype=torch.float64) レーベル件数: 10 label: tensor([0, 1, 0, 2, 1, 2, 2, 0, 0, 1], dtype=torch.int32)データもレーベルもバッチサイズとして定義した20ずつで正しく出力してくれています。
150/20はあまり10なのですがDataloaderでは、エラーなく10件出力してくれています。
特別な処理なしでこのように合わせてくれるのも便利な点です。最後に
簡単な例ですので別途質問があればコメントください。
誤りがあった場合もお願いします。
- 投稿日:2020-11-18T13:29:50+09:00
【素人の備考録】Raspberry Pi 3,Wordpress vs Raspberry Pi 3,python,Django
初めに・・・
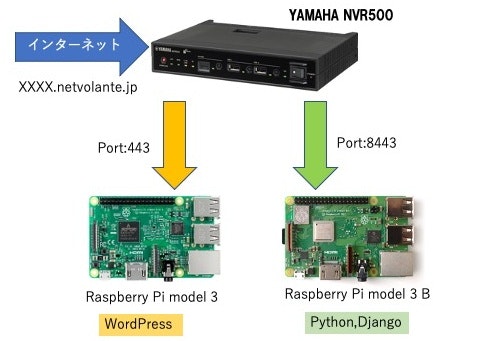
インフラエンジュニアとして20年以上働いています。
自分用のWebサーバをRaspberryPiで構築した時の備考録です。HomeLan環境機器
ルーター:YAMAHA NVR500
サーバ1:Raspberry Pi model 3
サーバ2:Raspberry Pi model 3B
DNS: ネットボランチDNSサービス XXXXXX.netvolante.jp
1.Raspberry Pi model 3、WordPress
サーバ構築について
色々なサイトを参考にして構築しました。稼働状況について
2016年5月から稼働しています。WordPressで構築しました。
ほぼ毎日、iPhoneよりWordPressアプリを使い画像、動画を投稿しています。
2020年11月にシステム更新を行い、自己証明書も設定しました。
投稿しているファイル(iPhone 12 pro Maxのカメラを使用)
画像ファイル jpg 約5MB
動画ファイル mov 約20MB 撮影時間約20秒システム概要について
確認日時:2020/11/3
Linux raspberrypi 4.9.35-v7
Wordpress 4.8 から 5.5.3-ja に更新
PHP 5.6.40-0+deb8u12 から PHP 7.4.11 に更新
mysql Ver 15.1 Distrib 10.1.47-MariaDB
Apache/2.4.25 (Raspbian)
SSH tcp port 443システム稼働中メモリ容量
pi@raspberrypi:/ $ free
total used free shared buff/cache available
Mem: 945512 204728 382040 26192 358744 654512
Swap: 0 0 0SDカード使用容量:64GB(2016年5月より)
pi@raspberrypi:/ $ df
ファイルシス 1K-ブロック 使用 使用可 使用% マウント位置
/dev/root 59460156 20191148 36825620 36% /
devtmpfs 468148 0 468148 0% /dev
tmpfs 472756 0 472756 0% /dev/shm
tmpfs 472756 6284 466472 2% /run
tmpfs 5120 4 5116 1% /run/lock
tmpfs 472756 0 472756 0% /sys/fs/cgroup
/dev/mmcblk0p1 61384 22256 39128 37% /boot
tmpfs 94548 0 94548 0% /run/user/10002.Raspberry Pi model 3B、python3.8.6など
サーバ構築について(下記サイトを参考にしました)
参考にしたサイト
MacでRaspberryPi入門
https://qiita.com/shippokun/items/9070fc58f69d8c063e44OSはミラーサイトより
https://www.raspbian.org/RaspbianMirrors
OS:2020-08-20-raspios-buster-arm64.img → 64bitを使用参考にしたサイト
さくらのVPSで、https対応かつDjango+uWSGI+nginxなアプリのログイン機能を実装してみた
https://qiita.com/ezmscrap/items/26b1897923db3665ac1c参考にしたサイト
『超入門』Djangoで作る初めてのウェブアプリケーション Part1(Pythonインストール)
https://note.com/takuya814/n/n5c156740b4ef参考にしたサイト
Django SQLite3からMySQLへの移行
https://qiita.com/ta2mi/items/0547de41d021d67ac3dc備考
OSを2020-08-20-raspios-buster-arm64.img(64ビット)にしてシステム構築時のトラブル等は
一切ありませんでした。
構築したアプリケーションで画像ファイルをiPhone,Safariより投稿できることを確認しました。システム概要について
確認日時:2020/11/18
Linux raspberrypi3b 5.4.72-v8+ #1356 SMP PREEMPT
Thu Oct 22 13:58:52 BST 2020 aarch64 GNU/Linux
PHP 7.3.19-1~deb10u1 (cli)
Python 3.8.6
mysql Ver 15.1 Distrib 10.3.25-MariaDB
nginx/1.14.2
Django version 3.1.3
SSH tcp port 8443システム稼働中メモリ容量
pi@raspberrypi3b:~$ free
total used free shared buff/cache available
Mem: 934396 317252 319736 6620 297408 552316
Swap: 102396 9472 92924SDカード128GB:使用容量
pi@raspberrypi3b:~$ df
ファイルシス 1K-ブロック 使用 使用可 使用% マウント位置
/dev/root 123588468 4192636 114327400 4% /
devtmpfs 335612 0 335612 0% /dev
tmpfs 467196 0 467196 0% /dev/shm
tmpfs 467196 12104 455092 3% /run
tmpfs 5120 4 5116 1% /run/lock
tmpfs 467196 0 467196 0% /sys/fs/cgroup
/dev/mmcblk0p1 258095 56073 202023 22% /boot
tmpfs 93436 0 93436 0% /run/user/1000後書き
各サイトを参考にして、サーバ構築をしました。pythonに興味があり、ブログサイトを構築となりましたが、今回は、検証用に構築し、自己証明書も設定しました。
pythonでの構築には機能の追加等多いに期待はできると思いますが
以前から稼働しているWordPressと比べて当然ながら手間がかかります。構築後の事を考えると仕事でブログサイトを構築となると運用管理面からWordPressになるでしょう。
インフラ関連の仕事をしてきて、オンプレミスでのサーバ構築が全てでしたが、AWSなどのウェブでのサーバ構築に興味があり、1年間の無料枠でEC2、EBS、mysqlでWordPress、VNCが短時間で構築出来ました。
時代の流れに流されないよう色々な情報取得には、このサイトが多いに役に立つと思います。
- 投稿日:2020-11-18T13:10:12+09:00
pandas自習メモ
install#install pip install pandas一次元のデータ構造体であるSeries。
Series# randomで作成 arr = np.random.randn(6) s1 = pd.Series(arr) # arangeで作成 arr2 = np.arange(6) s2 = pd.Series(arr2) # onesで作成 arr3 = np.ones(6) s3 = pd.Series(arr3) # zerosで作成 arr4 = np.zeros(6) s4 = pd.Series(arr4) # index指定 arr = np.random.randn(6) s5 = pd.Series(arr, index=["一月", "二月", "三月", "四月", "五月", "六月"]) #※indexは重複しても大丈夫 # 辞書で作成 dict_data = {"一月": 11, "二月": 13, "三月": 10, "四月": 14, "五月": 8, "六月": 10} s6 = pd.Series(dict_data) ############################################### #indexでデータ取得 s6[0] #keyでデータ取得 s3["一月"]二次元のデータ構造体であるDataFrame。
DataFrameimport pandas as pd import numpy as np #numpyで作成 arr = np.random.randn(20).reshape((4, 5)) df = pd.DataFrame(arr) # 行、列index指定 index = ["Q1", "Q2", "Q3", "Q4"] columns = ["A", "B", "C", "D", "E"] df = pd.DataFrame(arr, index=index, columns=columns) ################################################### # 使い方 #行取得 df.index #列取得 df.columns #データ取得 df.values #describe取得 df.describe() #count データの個数 #unique ユニークな(一意な)値の個数 #top 最も出現頻度の高い値(最頻値) #freq 最頻値の出現回数 #mean 平均値 #std 標準偏差 #min 最小値 #25% 1/4分位数 #50% 中央値 #75% 3/4分位数 #max 最大値 #sort #index並び替え df.sort_index(axis=0, ascending=False) #※axis:0行,1列 ascending:true昇順,false降順 #A列で降順 df.sort_values(axis=0, by="A", ascending=False) #Q3行で昇順 df.sort_values(axis=1, by="Q3", ascending=True) ############################################## #データ取得 #行データ取得 df.loc["Q3"] df.loc["Q1":"Q3"] df.iloc[0] df.iloc[0:3] #列データ取得 df.loc[:,"B"] df.loc["Q2","A":"C"] df.iloc[:, 0] df.iloc[0:2, 0:3] #行列データ取得 df.ix["Q0":"Q2", 1:3] ############################################ #空データ確認 df.isnull() #空データの行列削除 df.dropna(axis=0, how="any") #※axis:0行1列 how:"any"あれば削除,"all"全部nanなら削除 #空データを1にする df.fillna(value=1) ############################################# #データ結合 # concat方式 pd.concat([df1, df2, df3,...], axis=0 or 1, ignore_index=True, join="outer" or "inner", join_axes=[data1.index]) # df1 :DataFrame # axis:結合方向 # ignore_index:indexを並び替え(default:False) # join:outer直和 inner和集合 # join_axes:結合基準データ index1 = pd.date_range("2018-10-01", periods=4) df1 = pd.DataFrame(np.arange(20).reshape((4, 5)), index=index1, columns=list("ABCDE")) index2 = pd.date_range("2018-10-03", periods=3) df2 = pd.DataFrame(np.arange(12).reshape((3, 4)), index=index2, columns=list("DEFG")) # axis=0 垂直方向で結合 result = pd.concat([df1, df2], axis=0, sort=True) # axis=1 水平方向で結合 result2 = pd.concat([df1, df2], axis=1) # axis=0, join_axes=[df1.columns] result6 = pd.concat([df1, df2], axis=0, join_axes=[df1.columns], sort=False) # axis=1, join_axes=[df1.index] result7 = pd.concat([df1, df2], axis=1, join_axes=[df1.index], sort=False) #df1.append()方式 df1.append([df2, df2, df3,...], axis=0 or 1, ignore_index=True) result8 = df1.append(df2, ignore_index=True, sort=False) #pd.merge()方式 pd.merge(left, right, on=["key1", "key2"], how="inner" or "outer" or "left" or"right" indicator="説明") left = pd.DataFrame({ "key": ["A0", "A1", "A2", "A3"], "B": ["B0", "B1", "B2", "B3"], "C": ["C0", "C1", "C2", "C3"], }) right = pd.DataFrame({ "key": ["A0", "A1", "A2", "A3"], "D": ["B1", "B2", "B2", "B4"], "E": ["C2", "C1", "C5", "C2"] }) # "key"で結合 result9 = pd.merge(left, right, on="key") result10 = pd.merge(left, right, on=["key", "B"]) result11 = pd.merge(left, right, on=["key", "B"]) result12 = pd.merge(left, right, on=["key", "B"], how="left") result11 = pd.merge(left, right, on=["key", "B"], how="right") #how = left:leftを全部保留で結合 ################################################ #データのoutput left = pd.DataFrame({ "key": ["A0", "A1", "A2", "A3"], "B": ["B0", "B1", "B2", "B3"], "C": ["C0", "C1", "C2", "C3"], }) # csv left.to_csv("left_data.csv") # json left.to_json("left.json") #そのほか #to_json,to_excel,to_csv,to_clipboard, #to_dense,to_dict,to_feather,to_gbq, #to_hdf,to_html,to_latex,to_msgpack, #to_panel,to_parquet,to_pickle,to_records #to_sparse,to_sql,to_stata ######################################### #グラフ import matplotlib.pyplot as plt s = pd.Series(np.random.randn(1000)) result = s.cumsum() result.plot() plt.show()
- 投稿日:2020-11-18T11:57:27+09:00
Kernel Method with Python
はじめに
先日ゼミで福水健次先生のカーネル法入門の3章までを読みました。ゼミでは手書きだったので発表資料のまとめ直しと、カーネル法の簡単な紹介をできたらと思います。(細かい理論は置いといて、)最後にカーネル主成分分析をpythonで実装します。私の発表範囲が前半の正定値カーネルと最後の実装の部分だったので、途中大きく抜けてるところがありますが大きな問題はないと思います。
注意
・理論よりも雰囲気を重視します。
・番号がついてるものに関しては福水先生の本の番号と同じです。前提知識
・簡単な統計
・線形代数
・関数解析(ヒルベルト空間論)目次
・カーネル法の概要
・正定値カーネル
・再生核ヒルベルト空間
・カーネル主成分分析(Kernel PCA)
・カーネル正準相関分析(Kernel CCA) ←気が向いたら追記します。(なんでサポートベクタマシンやらないの?って思った方も多いかもしれませんが、ゼミがそこまでいかなかっただけです。時間があれば自分で読んでみようかなぁとは思ってます。)
カーネル法の概要
例として主成分分析を扱います。$m$次元のN個のデータ$X_1,...,X_N \in \chi=\mathbb{R}^m$に対し、単位ベクトル$u$を持ちいて射影した先$u^\mathsf{T}X$の分散がp番目に大きくなるような$u$を探します。これを第p主成分と呼び、$m$よりも少ない軸を取ることで次元圧縮やノイズ除去ができます。これを数式に書くと
\frac{1}{N}\sum_{i=1}^{N}\left\{u^{\mathsf{T}}X_{i}-\frac{1}{N}\left(\sum_{j=1}^{N}u^{\mathsf{T}}X_{j}\right)\right\}^{2}がp番目に大きくなるように$\|u\|=1$を満たすように動かすことになります。しかし、これでは線形的な計算しか行っていないので非線形な特徴抽出はできません。そこで非線形関数でデータ$X_i$を別の空間に送ることで非線形的な計算を行います。
上記の計算で核となるのは$u$と$X$の内積です。上記の例では$\mathbb{R}^m$上で考えていたので通常の内積$\langle u,X \rangle_{\mathbb{R}^m}=u^\mathsf{T}X$が定まっています。これはデータ$X_i$を非線形写像$\phi:\chi→H$で別の空間$H$に送ったとしても、その空間に内積が定まっていれば計算できるはずです。この場合は$u$と$X$の内積$\langle u,X \rangle_{\mathbb{R}^m}$を$f \in H$を$u$の代わりに用いて$\langle f,\phi(X) \rangle_H$として主成分分析を行えばいいということです。
つまり、線形演算のみで考えていた問題を写像$\phi$を用いて別の空間に飛ばし、その空間で元の問題を考えるのがカーネル法です。従来の手法では冪展開$(X,Y,Z ... )\rightarrow(X^2, Y^2, Z^2, XY...)$を用いて非線形演算を行うのが主流でしたが、時代の変化とともに扱うデータの次元が増え、計算量が膨大になってしまう問題がありました。カーネル法では特徴写像$\phi$で送られた空間の内積を効率よく計算するカーネル関数を利用することで、通常の問題と大差ない計算量で非線形演算を可能にしています。
以上より特徴写像$\phi$と空間$H$をうまく定めるのが現在の目標です。
正定値カーネル
データ空間を$\chi$として、特徴写像$\phi$を$\phi:\chi→H$と定義します。ここで$H$は内積$\langle・,・\rangle_H$をもつ内積空間です。
その内積はある関数$k(x,y)=\langle\phi(x),\phi(y)\rangle_H$で簡単に計算できると嬉しいはずです。こうすることで、(後述する具体例で扱いますが、)$\phi$と$H$の直接的な表現を考えることなく$k$のみの表示で表せ、さらに計算コストは$\phi$に依らないことがわかります。
ここでは正定値カーネルというものを定義し、それが満たす性質を考えます。
Def 正定値カーネル
関数$k:\chi×\chi→\mathbb{R}$が以下の2つの性質を満たすとき、$k$を$\chi$上の正定値カーネルとよぶ。
・対称性:任意の$x,y \in \chi$に対し、$k(x,y)= k(y,x)$
・正定値性:任意の$n \in \mathbb{N}, x_1...x_N \in \chi, c_1...c_N \in \mathbb{R}$に対し、$\sum_{i,j=1}^{n}c_ic_jk(x_i,x_j)\geq0$正定値性は対称性を仮定したうえで、$ij$成分が$k(x_i, x_j)$であるような$N×N$の正方行列の半正定値の定義と一致します。ここで正定値性と書いているのは、慣例から上記の定義を正定値性と呼んでいるからです。
Prop2.1
正定値カーネルに関して以下の性質が成り立ちます。
(1)$k(x,x)\geq0 \quad(\forall x \in \chi)$
(2)$|k(x,y)| \leq k(x,x)k(y,y) \quad(\forall x,y \in \chi)$
(3)$\chiの部分集合\Upsilonに対して、kの\Upsilon×\Upsilonの制限は\Upsilon上の正定値カーネルとなる。$proof(2)
A = \left(\begin{matrix} k(x,x) & k(x,y)\\k(x,y) & k(y,y) \end{matrix} \right)は半正定値対称行列で、固有値はすべて実数であり非負なので、対角化して行列式を考えると$det(A) \geq0$。また定義の通り行列式を計算しそれが非負である不等式を変形すればよい。
Prop2.2
正定値カーネルは以下の操作について閉じています。
$k_i$を正定値カーネルとします、
(1)$a,b \in \mathbb{R_{\geq0}}$に対して$ak_i+bk_j$
(2)$k_ik_j$
(3)$\lim_{n \to \infty}k_n$proof:(2)
$k_ik_j$が成分の$N×N$行列が半正定値であればよいので、$k_i,k_j$を成分とする2つの行列のアダマール積を考え、片方の行列を対角化して正定値性の定義式に代入する。Prop2.6
$Vを内積\langle・,・\rangle_V$を持つ内積空間とする。写像$\phi:\chi\rightarrow V , x\mapsto\phi(x)$が与えられたとき、$k(x,y)=\langle\phi(x),\phi(y)\rangle_V$は正定値カーネルとなる。
proof
正定値カーネルの定義に従い計算すればよい。特徴写像$\phi$はこのような性質を満たすようなものが望ましかったのでした。適当に$V$を定め写像を用意すれば正定値カーネル$k$によって簡単に計算できるはずです。しかし、実は$k$を定めると$V$は一意に定まり、前述したとおり$\phi$の直接的な表現は実際の計算では必要ないことから、正定値カーネル$k$を定めればよいことがわかります。
再生核ヒルベルト空間
ここでは正定値カーネル$k$とある性質を持った内積空間$H$が一対一に対応することを確認します。
Def 再生核ヒルベルト空間
内積空間$H$を完備化したものをヒルベルト空間と言います。$\chi$を集合として、$\chi$上の関数からなるヒルベルト空間$H$で以下の性質を満たすものを再生核ヒルベルト空間と呼ぶ。
・再生性:$\forall x \in \chi, \forall f \in H, \exists k_x \in H s.t. \langle f,k_x\rangle_H = f(x)$上の定義の$k_x \in H$に対して、$k(y,x) = k_x(y)$により定まるカーネル$k$を$H$の再生核と呼ぶ。
prop2.7
$\chi$上の再生核ヒルベルト空間$H$の再生核$k$は$\chi$上の正定値カーネルであり、$H$の再生核は一意。
proof
$k(x,y)=k_y(x)=\langle k_y, k_x\rangle_H = \langle k(・,y), k(・,x)\rangle_H$と変形できるので
$\sum_{i,j=1}^{n}c_ic_jk(x_i,x_j)\geq0$がわかる。
一意性は$k, \overline{k}$を$H$上の再生核としてそれぞれが再生核であることと対称性を用いると$k=\overline{k}$が示せる。prop2.8
$||k(・,x)||_H=\sqrt{k(x,x)} $
proof
左辺の2乗を再生性を用いて計算すればよい。prop2.11
集合$\chi$上の正定値カーネル$k$に対し、以下の3つの性質を満たす$\chi$上の再生核ヒルベルト空間が一意に存在する。
(1)$\forall x \in \chi, k(・,x) \in H$
(2)$k(・,x)(x \in \chi)$によって張られる部分空間(線形包)は$H$内で稠密
(3)$k$は$H$の再生核prop2.7とprop2.11を合わせると、正定値カーネルと再生核ヒルベルト空間が1対1に対応していることがわかる。
ここで特徴写像$\phi:\chi→H$を$x \mapsto k(・,x)$と定義すると、再生性を用いれば
\begin{align} &\begin{split} \langle\phi(x),\phi(y)\rangle_H &= \langle k(・,x), k(・,y)\rangle_H \\ &= \langle k_x, k_y \rangle_H \\ &= k_x(y) \\ &= k(y,x) \\ &= k(x,y) \end{split}\\ \end{align}となるので、計算したかった内積が正定値カーネル$k$で計算できることがわかりました。
ここで、正定値カーネルのよく使われる例をいくつか紹介します。
・線形カーネル(通常のユークリッド内積)
k_0(x,y) = x^\mathsf{T} y・指数型
k_E(x,y)=exp(\beta x^\mathsf{T} y) \ (\beta>0)・ガウスカーネル
k_G(x,y) =exp \left(-\frac{\|x-y\|^2}{2 \sigma^2} \right)カーネル主成分分析
簡単に理論の紹介を終えたので応用例です。
通常の主成分分析は、$u$によって射影されたときの分散を大きくなるような$||u||=1$を求めるというものでした。\frac{1}{N}\sum_{i=1}^{N}\left\{u^{\mathsf{T}}X_{i}-\frac{1}{N}\left(\sum_{j=1}^{N}u^{\mathsf{T}}X_{j}\right)\right\}^{2}カーネル主成分分析では特徴写像$\phi:\chi→H$を用いてデータ$X_i$を$H$上に飛ばし、$H$で内積$\langle・,・\rangle_H$を使って計算すれば非線形な特徴を捉えることができます。つまり以下の式を最大化する$f (||f||_H=1)$を求めることになります。
\frac{1}{N}\sum_{i=1}^{N}\left\{\langle f,\phi\left(X_{i}\right)\rangle_{H}\ -\ \frac{1}{N}\left(\sum_{j=1}^{N}\left\langle f,\ \phi\left(X_{j}\right)\right\rangle_H \right)\right\}^{2}$\tilde{\phi}(X_i)=\phi(X_i) - \frac{1}{N}\sum_{i=j}^{N}\phi(X_j)$と中心化すれば、
\frac{1}{N}\sum_{i=1}^{N}\left(\langle f,\ \tilde{\phi}\left(X_{i}\right)\rangle_{H} \right)^{2}を最大化するような$f$を考えればよいことがわかる。
$ ||f||_{H}=1$であるから、$f$は $\tilde{\phi} \left(X_{1}\right)...\tilde{\phi} \left(X_{N}\right)$で貼られる$H$の部分空間Span\left\{\tilde{\phi}\left(X_{1}\right),...,\tilde{\phi}\left(X_{N}\right)\right\} \subset Hの要素として考えてよい。したがって、
f = \sum_{i=1}^{N}\alpha_{i}\tilde{\phi}\left(X_{i}\right)と表せる。
つまり、さきほどの内積$\langle f, \tilde{\phi}(X_{i}) \rangle_H$は$\langle \tilde{\phi}(X_i), \tilde{\phi}(X_j) \rangle$の線形結合で表せ、$\tilde{\phi}$の中心化をとけば、$k(X_i,X_j)=\langle \phi(X_i), \phi(X_j) \rangle$であるから$k$の線形結合で表せ、係数も$\alpha$を使って表せる。したがって$\alpha$を求めることで$f$は$H$上の関数として定まり、最大化を達成できる。ここでは簡単のために
\tilde{k}(X_i,X_j)= \langle \tilde{\phi}(X_i), \tilde{\phi}(X_j) \rangle_Hと置き、$\tilde{k}(X_i,X_j)$を$ij$成分に持つ行列を$\tilde{K}$とする。これは中心化グラム行列と呼ばれる。
最大化するする問題は以下のように変形でき、一般化固有値問題に帰着できる。
\begin{align} &\begin{split} \frac{1}{N}\sum_{i=1}^{N}\left(\langle f,\ \tilde{\phi}\left(X_{i}\right)\rangle_{H} \right)^{2} &= \frac{1}{N}\sum_{i=1}^{N}\left\{\sum_{j=1}^{N}\alpha_j\tilde{k}(X_j,X_i)\right\}^{2}\\ &=\frac{1}{N}\sum_{i=1}^{N}\left\{\sum_{j=1}^{N}\sum_{k=1}^{N}\alpha_{j}\alpha_{k}\tilde{k}(X_j,X_i)\tilde{k}(X_k,X_i)\right\} \\ &= \frac{1}{N}\sum_{j=1}^{N}\sum_{k=1}^{N}\left\{\alpha_{j}\alpha_{k}\sum_{i=1}^{N}\tilde{k}(X_j,X_i)\tilde{k}(X_i,X_k)\right\}\\ &= \frac{1}{N}\sum_{j=1}^{N}\sum_{k=1}^{N}\left(\alpha_{j}\alpha_{k}\tilde{K}_{jk}^2\right)\\ &=\frac{1}{N}\alpha^\mathsf{T} \tilde{K}^2 \alpha\\ \end{split}\\ &\begin{split} ||f||_H &= \langle f, f \rangle \\ &= \langle \sum_{i=1}^{N}\alpha_{i}\tilde{\phi}\left(X_{i}\right), \sum_{j=1}^{N}\alpha_{j}\tilde{\phi}\left(X_{j}\right) \rangle \\ &= \sum_{i=1}^{N}\sum_{j=1}^{N}\alpha_i \alpha_j \langle \tilde{\phi}(X_i), \tilde{\phi}(X_j) \rangle \\ &= \alpha^\mathsf{T} \tilde{K} \alpha \end{split}\\ \end{align}以上より最大化問題は
\newcommand{\argmax}{\mathop{\rm arg~max}\limits} \argmax_{\alpha \in \mathbb{R}^N} \, \alpha^\mathsf{T} \tilde{K}^2 \alpha \ \ s.t. \ \alpha^\mathsf{T} \tilde{K} \alpha = 1$\tilde{K}$は半正定値対称行列であるから、固有値分解(対角化)すると、縦ベクトル$u^i$を$N$本並べたユニタリ行列$U$と対角行列$\Lambda=diag(\lambda_1,...,\lambda_N) \ (\lambda_1 \geq \lambda_2 \geq ...\geq \lambda_N \geq 0)$を用いて、
\tilde{K} = U \Lambda U^{*}と分解できる。$\tilde{K}^2 = U \Lambda^2 U^{*}$であるから、
\alpha^\mathsf{T} \tilde{K}^2 \alpha = \sum_{i=1}^{N} (\alpha^\mathsf{T} u^i)^2 \lambda_i^2したがって、$\lambda_1 \geq \lambda_2 \geq ...\geq \lambda_N \geq 0$を考えれば、p番目に大きくなる$\alpha$は$\alpha \parallel u^p$の時であり、長さは$\alpha^\mathsf{T} \tilde{K} \alpha=1$を満たすように調整すればよい。$\alpha = c_p u^p$と置けば、$u^i$はユニタリ行列の列ベクトルということに気を付けると、
\begin{align} &\begin{split} \alpha^\mathsf{T} \tilde{K} \alpha &= \sum_{i=1}^{N} (c_p u^{p^{\mathsf{T}}} u^i)^2 \lambda_i \\ &= c_p^2 \lambda_p \end{split}\\ \end{align}であるから、$c_p = \frac{1}{\sqrt{\lambda_p}}$である。
したがって分散をp番目に大きくする$f$(第p主軸)はf^p = \sum_{i=1}^{N}\frac{1}{\sqrt{\lambda_p}} u_i^p \tilde{\phi}(X_i)となり、データ$X_i$の第p主成分は
\begin{align} &\begin{split} \langle \tilde{\phi}(X_i), f^p \rangle_H &= \sum_{j=1}^N \frac{1}{\sqrt{\lambda_p}} u_j^p \langle \tilde{\phi}(X_i), \tilde{\phi}(X_j) \rangle_H \\ &= \sum_{j=1}^N \frac{1}{\sqrt{\lambda_p}} u_j^p \tilde{K}_{ij} \\ &= \sum_{j=1}^N \frac{1}{\sqrt{\lambda_p}} u_j^p \sum_{k=1}^N \lambda_k u_i^k u_j^k \\ &= \frac{1}{\sqrt{\lambda_p}} \sum_{k=1}^N \lambda_k u_i^k \sum_{j=1}^N u_j^p u_j^k \\ &= \frac{1}{\sqrt{\lambda_p}} \sum_{k=1}^N \lambda_k u_i^k \delta(p,k) \\ &= \sqrt{\lambda_p} u_i^p \end{split}\\ \end{align}つまり、$\tilde{k}(X_i,X_j)$を$ij$成分に持つ行列$\tilde{K}$を固有値分解したときの固有値とユニタリ行列がわかれば十分である。
以上をPythonを用いて実装する。データにはワインデータ(http://archive.ics.uci.edu/ml/datasets/Wine)
を利用する。
カーネル関数にはガウスカーネルを使うことにする。import numpy as np import matplotlib.pyplot as plt #データの読み込み wine = np.loadtxt("wine.csv", delimiter=",") N = wine.shape[0] #178 labels = np.copy(wine[:,0]).flatten() wine = wine[:, 1:] #標準化 mean = wine.mean(axis=0) wine -= mean std = wine.std(axis=0) wine /= std def kernel(x,y, σ=4): return np.exp(-((x-y)**2).sum() / (2*σ**2)) #中心化グラム行列Kの計算 K = np.zeros(shape=(N,N)) for i,j in np.ndindex(N,N): K[i,j] = kernel(wine[i,:], wine[j,:]) Q = np.identity(N) - np.full(shape=(N,N), fill_value=1/N) K_tilde = Q @ K @ Q #固有値分解 λs, us = np.linalg.eig(K_tilde) #固有値の大きい順に並べ替え λ_index = np.argsort(λs) D = np.zeros(shape=(N)) U = np.zeros(shape=(N,N)) for i, index in enumerate(λ_index[::-1]): D[i] = λs[index] U[:,i] = us[:,index] #データの第n主成分 X_1 = np.sqrt(D[0]) * U[:,0] X_2 = np.sqrt(D[1]) * U[:,1] #グラフの作成 clasters = dict([(i,[[],[]]) for i in range(1,4)]) for i,label in enumerate(labels): clasters[label][0].append(X_1[i]) clasters[label][1].append(X_2[i]) for label,marker in zip(range(1,4), ["+","s","o"]): plt.scatter(clasters[label][0], clasters[label][1], marker=marker) plt.show()
いい感じに分類できていることがわかります。
ちなみにカーネル関数の選び方でグラフの形が大きく変わります。同じガウスカーネルでもハイパーパラメータの設定によって変わるので、グリッドサーチみたいなことをしてもいいですね。参考文献
福水健次, カーネル法入門[正定値カーネルによるデータ解析], 朝倉書店, 2010年
- 投稿日:2020-11-18T11:26:51+09:00
streamlitで遊ぼう!
はじめに
この記事ではstreamlitでいくつかアプリケーションを作成し、streamlitに入門することを目的とします。
streamlitを用いて、プロトタイプアプリを簡単に作成できるようになれればと思います。repository: https://github.com/irisu-inwl/streamlit-tutorial
動作確認環境: windwos10, docker for windows
- この記事でやること

- streamlitでアプリケーションを作るために利用できそうなメソッド群の紹介
- 機械学習・データ分析アプリケーションのプロトタイプの作成
- この記事で取り扱わないこと

- 機械学習アルゴリズムの解説
- データサイエンス部分の解説
準備
streamlit環境をdockerで用意します。
docker build --tag streamlit-base . docker run -itd -p 8501:8501 --name streamlit-tutorial streamlit-basestreamlitでwidgeを配置する。
widgetを次のように簡単に書くことが出来、インタラクティブなアプリケーションを実装できます
ソース: https://github.com/irisu-inwl/streamlit-tutorial/blob/main/src/widget.py
- 環境準備
docker run -itd -p 8501:8501 -v <自分のsrcディレクトリ>:/opt/streamlit/src/ --name streamlit-tutorial streamlit-base streamlit run src/widget.py
localhost:8501にアクセスすることでアプリケーションを確認できます。デモ:
— いりす (@irisuinwl) November 18, 2020以下にコードで利用した細かい機能を紹介していきます。
チェックボックス
下記のコードでチェックボックスを配備できます。
st.checkboxメソッドの引数にラベル、返り値に状態が入ります。# checkbox checkbox_state = st.checkbox('Show text') if checkbox_state: st.write('checkbox enable')
ボタン
ボタンウィジェットを下記コードで配置します。
チェックボックス同様に、引数にラベル、返り値に状態が入ります。# button button_state = st.button('Say hello') if button_state: st.write('Why hello there') else: st.write('Goodbye')
セレクトボックス
セレクトボックスを
st.selectboxで配備できます。
第一引数にラベル、第二引数に選択する範囲を指定できます。# selectbox option = st.selectbox( 'select box:', [1, 2, 3] ) st.write('You selected: ', option)
インプットボックス
文字入力を行うインプットボックスを配置します。
# inputbox title = st.text_input('inputbox', 'おはよう') st.write('inputbox:', title)スライダー
スライダーを配置します。
# slider age = st.slider('How old are you?', 0, 130, 25) st.write("I'm ", age, 'years old')
ファイルアップロード
画像をドラッグアンドドロップしてアップロードする処理が
st.file_uploaderで可能となります。
下記処理で、画像がアップロードされればuploaded_fileが存在するのでifブロックに入ります。# file upload from PIL import Image import io uploaded_file = st.file_uploader('Choose a image file') if uploaded_file is not None: image = Image.open(uploaded_file) img_array = np.array(image) st.image( image, caption='upload images', use_column_width=True )
キャッシュ処理
streamlitではイベントが発火する度、コードを再実行します。
cf: https://docs.streamlit.io/en/stable/main_concepts.html#app-modelそのため、巨大なデータを読み込んだり、計算時間のかかる処理を実行すると、イベント発火のたびに描画に時間がかかってしまいます。
そこで、streamlitではキャッシュを利用することによって、処理を効率化します。
下記例では、waitを掛けるメソッドに対して、プログレスバーを表示する処理で、キャッシュを使った場合と使わなかった場合を見てます。import time import streamlit as st @st.cache def progress_cache(i): time.sleep(0.05) def progress_no_cache(i): time.sleep(0.05) def view_bar(func): # Add a placeholder latest_iteration = st.empty() bar = st.progress(0) for i in range(100): # Update the progress bar with each iteration. latest_iteration.text(f'Iteration {i+1}') bar.progress(i + 1) func(i) st.title('Cache example') st.write('Starting a long computation with cache...') view_bar(progress_cache) st.write('Starting a long computation without cache...') view_bar(progress_no_cache) st.write('...and now we\'re done!')— いりす (@irisuinwl) November 21, 2020データ可視化
ランダムデータやアイリスデータを使ってデータの可視化をしてみます。
ソース: https://github.com/irisu-inwl/streamlit-tutorial/blob/main/src/visualization.pydocker run -itd -p 8501:8501 -v <自分のsrcディレクトリ>:/opt/streamlit/src/ --name streamlit-tutorial streamlit-base streamlit run src/visualization.pyLinePlot
@st.cache def load_time_series_data(): """ ランダムに時系列データを生成する。 """ chart_data = pd.DataFrame( np.random.randn(20, 3), columns=['a', 'b', 'c'] ) return chart_data st.write('時系列データをline plot') chart_data = load_time_series_data() st.line_chart(chart_data)
DataFrame表示
DataFrameも
st.writeで画面描画することが出来ます。@st.cache def load_iris_data(): """ データ読み込み, cacheにして最適化を行う """ iris_data = load_iris() df = pd.DataFrame(iris_data.data, columns=iris_data.feature_names) labels = iris_data.target_names[iris_data.target] return df, labels st.write('### アイリスデータを見ていく') df, labels = load_iris_data() st.write('DataFrameの表示') st.write(df)
相関ヒートマップ
seabornやmatplotlibをwrapして表示できます。
def show_heatmap(df): """ 各特徴の相関ヒートマップをみる """ fig, ax = plt.subplots(figsize=(10,10)) sns.heatmap(df.corr(), annot=True, ax=ax) st.pyplot(fig) st.write('特徴ごとの相関のHeatMap表示') show_heatmap(df)
特徴とラベルごとに分布を出す
def show_distplot(df, labels): """ それぞれの特徴について、各ラベルごとの分布を見る """ for column in df.columns: st.write(f'- {column}') series = df[column] target_names = list(set(labels)) hist_data = [series[labels == name] for name in target_names] fig = ff.create_distplot( hist_data, target_names, bin_size=[.1, .25, .5]) st.plotly_chart(fig, use_container_width=True) st.write('ラベルごとの特徴の分布をみる') show_distplot(df, labels)
PCAで2次元にマッピング
@st.cache(allow_output_mutation=True) def fit_transform_pca(df): """ 主成分分析した結果の第二主成分ベクトルを可視化した結果を得る """ pca = PCA(n_components=2) X = pca.fit_transform(df) return X def show_scatter2d(X, labels): fig, ax = plt.subplots(figsize=(10,10)) target_names = list(set(labels)) for i, target in enumerate(target_names): X_ = X[labels == target] x = X_[:, 0] y = X_[:, 1] ax.scatter(x, y, cmap=[i]*len(X_), label=target) ax.legend() st.pyplot(fig) st.write('主成分分析をして、2次元にマッピングする') df_pca = fit_transform_pca(df) show_scatter2d(df_pca, labels)
画像分類アプリを作る
kerasのpretrainedモデルを使って、画像分類アプリを作ります。
コード: https://github.com/irisu-inwl/streamlit-tutorial/blob/main/src/image_clf.py
widget.pyで紹介したファイルアップロードを使い画像を読込、kerasのpretrained Xceptionモデルを読みだして予測するコードを以下のように書きます。
cf: https://keras.io/ja/applications/#xceptionst.set_option('deprecation.showfileUploaderEncoding', False) @st.cache(allow_output_mutation=True) def load_model(): """ Xceptionモデルをloadする。 """ model = Xception(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000) return model def preprocessing_image(image_pil_array: 'PIL.Image'): """ 予測するためにPIL.Imageで読み込んだarrayを加工する。 299×299にして、pixelを正規化 cf: https://keras.io/ja/applications/#xception """ image_pil_array = image_pil_array.convert('RGB') x = image.img_to_array(image_pil_array) x = np.expand_dims(x, axis=0) x = preprocess_input(x) return x model = load_model() st.title('画像分類器') st.write("pretrained modelを使って、アップロードした画像を分類します。") uploaded_file = st.file_uploader('Choose a image file') if uploaded_file is not None: image_pil_array = Image.open(uploaded_file) st.image( image_pil_array, caption='uploaded image', use_column_width=True ) x = preprocessing_image(image_pil_array) result = model.predict(x) predict_rank = decode_predictions(result, top=5)[0] st.write('機械学習モデルは画像を', predict_rank[0][1], 'と予測しました。') st.write('#### 予測確率@p5') df = pd.DataFrame(predict_rank, columns=['index', 'name', 'predict_proba']) st.write(df) df_chart = df[['name', 'predict_proba']].set_index('name') st.bar_chart(df_chart)また、モデルのdownloadをアプリ起動ごとするのは面倒なので、dockerfileにダウンロードスクリプトを仕込みます。
- download_model.py
from tensorflow.keras.applications.xception import Xception, preprocess_input, decode_predictions model = Xception(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)Dockerfileで呼び出し処理を書き、build時にモデルのダウンロードを行います。
RUN python src/download_model.py以下のようなアプリが出来上がりました。
— いりす (@irisuinwl) November 20, 2020時系列分析アプリを作る
Facebookの時系列分析ライブラリ
prophetと東京都COVID-19のデータを使い、東京都COVID-19感染者数を時系列分析するアプリを作ります。
モデルは、簡単に考えるため、SIモデル(SIRモデルからRを除いたもの)を用います、つまり、感染者総数をロジスティック曲線でfittingすることを考えます。モデルの学習と予測を行います。
dsに日付、yに値が入ったDataFrameに対して、fitで学習、predictで予測が出来ます。@st.cache(allow_output_mutation=True) def fit_and_forecast(df: 'pd.DataFrame', periods:int = 14): """ 与えられたDataFrameに対して、prophetのmodelと予測結果を返す """ model = Prophet(growth='logistic') model.fit(df) future = model.make_future_dataframe(periods=periods) future['cap'] = df.iloc[0].cap forecast = model.predict(future) return model, forecast df = load_data('data/data.json') st.write('### 直近の感染者数') st.write(df.tail()) prophet_df = df[['日付', '感染者総数']].rename(columns={'日付':'ds', '感染者総数':'y'}) prophet_df['cap'] = prophet_df.iloc[-1].y*1.5 model, forecast = fit_and_forecast(prophet_df)
- モデルの予測値と実測値、トレンドと季節変動、変化点の表示
学習・予測した結果とモデルの推定したトレンドや季節変動、変化点を表示します。
st.write('### モデルの予測結果と実測値') fig = plot_plotly(model, forecast) st.plotly_chart(fig, use_container_width=True) st.write('### トレンドと季節変動') fig = plot_components_plotly(model, forecast) st.plotly_chart(fig, use_container_width=True) st.write('### 変化点') fig = model.plot(forecast) add_changepoints_to_plot(fig.gca(), model, forecast) st.pyplot(fig)
おわり
以上になります。
streamlit便利! 最高! というお気持ちが伝われば良いかなーと。
コード中にバグや不備があったらコメントやissueお願いします
参考:
- https://docs.streamlit.io/en/stable/getting_started.html
- 公式チュートリアルが豊富なのでここを見ればほぼOKです。
- https://docs.streamlit.io/en/stable/api.html
- https://docs.streamlit.io/en/stable/caching.html
- streamlitを使った様々なキャッシュの利用方法が載ってます。
- https://facebook.github.io/prophet/docs/quick_start.html
- https://medium.com/katanaml/covid-19-growth-modeling-and-forecasting-with-prophet-2ff5ebd00c01
- prophetによるモデリングはこちらの記事を参考にしました。
- https://keras.io/ja/






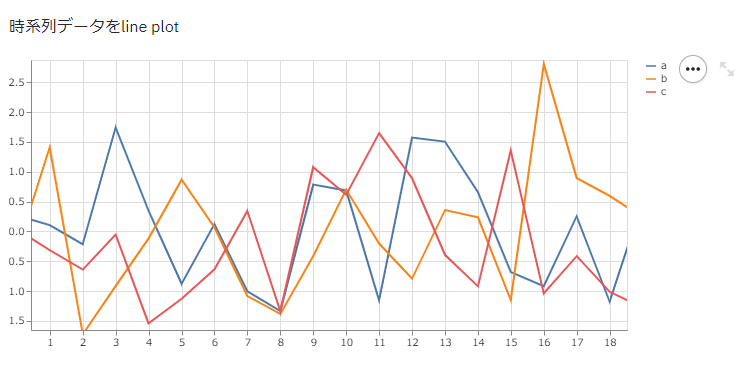
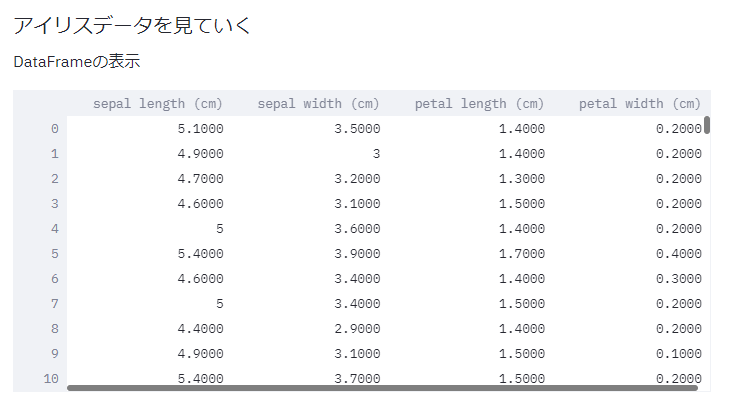
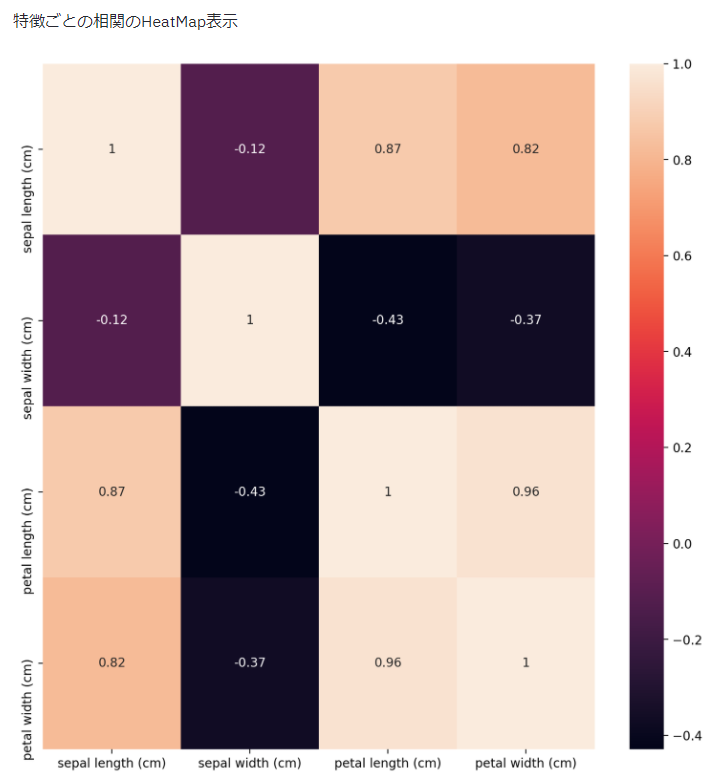
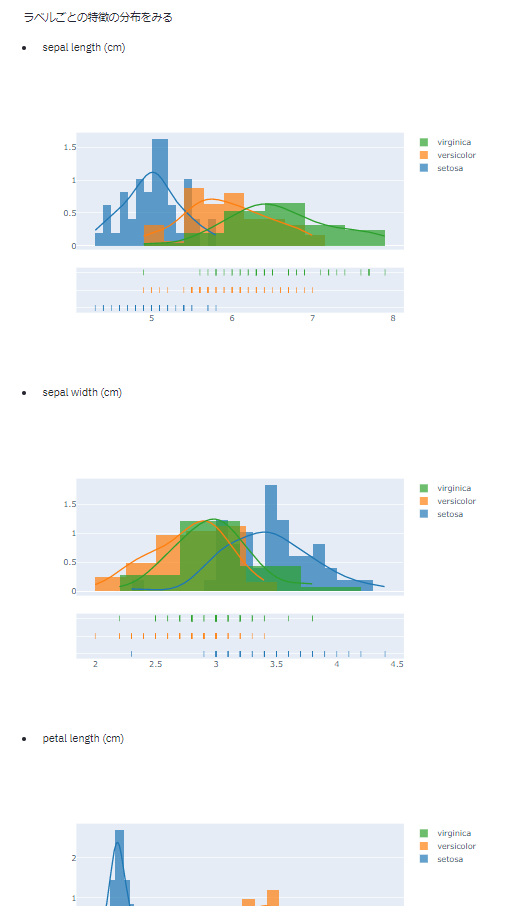
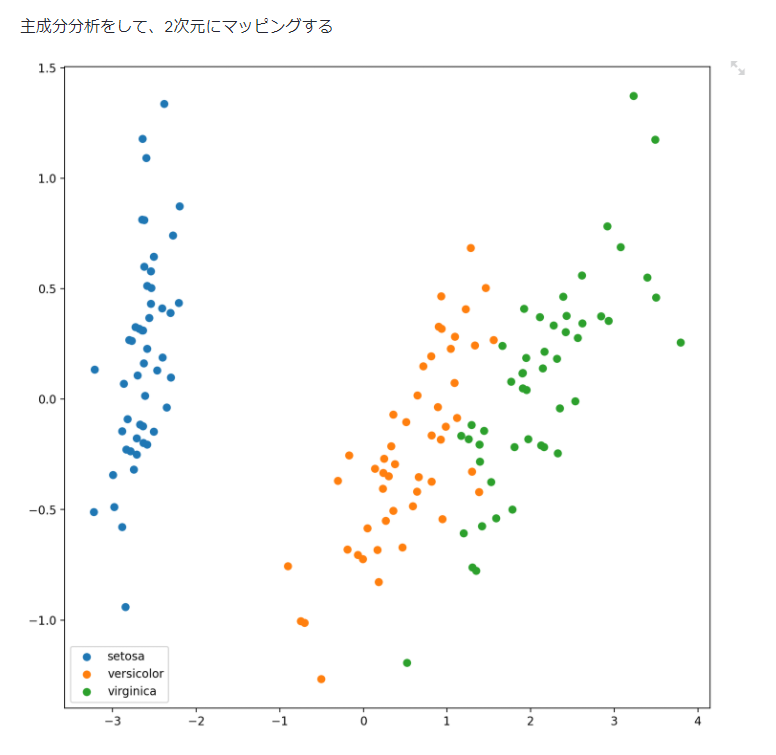
- 投稿日:2020-11-18T10:30:05+09:00
SPSS Modelerのレコード追加ノードをPythonで書き換える。
SPSS Modelerでデータを縦方向に追加するのが、レコード追加ノードです。
SQLでいうUNION ALLにあたる加工処理です。
これをPythonのpandasで書き換えてみます。0.元データ
以下の2つの時系列のセンサーデータをつかって行います。
似たデータ項目ですが、列名が違っていたり、片方にしかない列が含まれています。■データ1:Cond4n_e104.csv
M_CD: マシンコード
UP_TIIME: 稼働時間
POWER: 電力
TEMP: 温度
ERR_CD: エラーコード
■データ2:COND2n.csv
Time:稼働時間
Power:電力
Temperature:温度
Pressure:圧力
Uptime:起動時間
Status:状態コード
Outcome:エラーコード
1m.レコードの追加 Modeler版
データ1「Cond4n_e104.csv」の列に合わせて、データ2「COND2n.csv」を追加します。
まずフィルターノードを使って、データ2の列をデータ1の列名に合わせます。
次にレコード追加ノードを接続します。
M_CDに当たる列がデータ2のCOND2n.csvには存在しないのでNULLが入ります。
以下のようにデータ1にデータ2が追加されました。
ちなみにレコード追加ノードでは、フィールド一致基準のデフォルトは「名前」ですが、名前が違っていても、列位置を基準に追加することもできます。
また、追加するデータ2にしか含まれていないPressureなども追加したい場合はフィールド入力元で「すべてのデータセット」を選ぶと追加ができます。
さらにどちらのデータから来たかを示すタグ列をつけたりすることも可能です。1p.レコードの追加 pandas版
フィルターノードに当たる処理をrenameとdropを使って行います。renameでデータ1と列名をそろえ、dropで不要な列を削除します。
#データ2の列をデータ1の列名に合わせます。 df2_1=df2.rename(columns={'Time': 'UP_TIME', 'Power': 'POWER', 'Temperature': 'TEMP', 'Outcome': 'ERR_CD'})\ .drop(['Pressure','Uptime','Status'],axis=1) df2_1
次に、レコード追加ノードにあたるレコード追加処理を行います。
方法は二つあってappendとconcatがあります。
どちらでも結果は同じです。3つ以上のデータを結合する場合はconcatの書き方の方がわかりやすくてよいと思います。#appendを使う方法 df1.append(df2_1)#concatを使う方法 pd.concat([df1,df2_1])
- 参考
- pandas.DataFrame, Seriesの重複した行を抽出・削除 | note.nkmk.me
- https://note.nkmk.me/python-pandas-duplicated-drop-duplicates/
- pandas.DataFrame.append — pandas 1.1.4 documentation
- https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.append.html#pandas.DataFrame.append
2. サンプル
サンプルは以下に置きました。
ストリーム
https://github.com/hkwd/200611Modeler2Python/raw/master/append/append.str
notebook
https://github.com/hkwd/200611Modeler2Python/blob/master/append/append.ipynb
データ
https://raw.githubusercontent.com/hkwd/200611Modeler2Python/master/data/Cond4n_e104.csv
https://raw.githubusercontent.com/hkwd/200611Modeler2Python/master/data/COND2n.csv■テスト環境
Modeler 18.2.2
Windows 10 64bit
Python 3.7.9
pandas 1.0.54. 参考情報
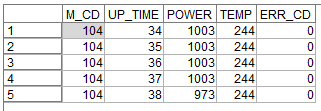
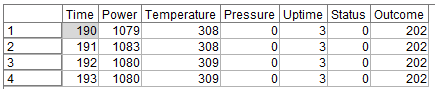
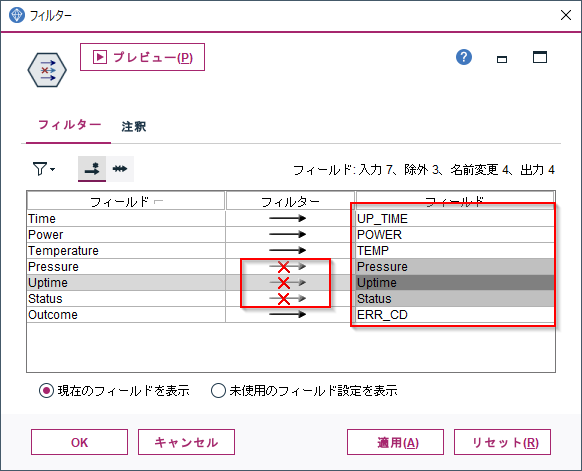
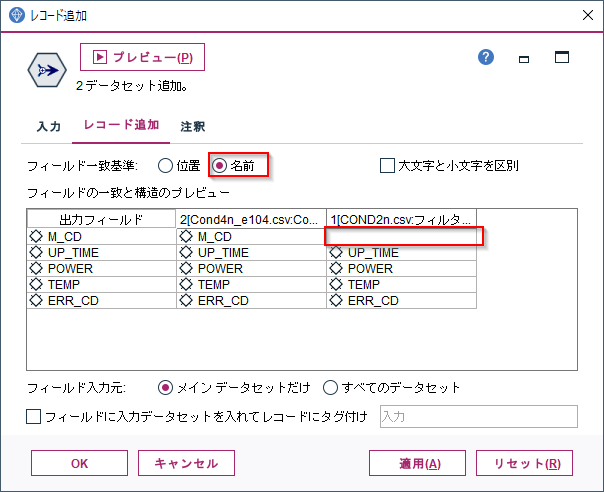
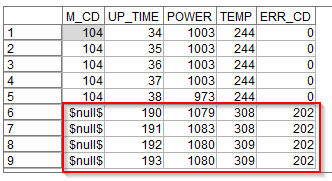
- 投稿日:2020-11-18T09:27:25+09:00
線形回帰・Ridge回帰・Lasso回帰の違い
■ はじめに
今回は、線形回帰・Ridge回帰・Lasso回帰における
各特徴と違いについて、記事をまとめさせていただきます。
■ モジュール・データの準備
import numpy as np import pandas as pd import matplotlib.pyplot as plt import mglearn from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.linear_model import Ridge, Lasso from sklearn.linear_model import RidgeCV from yellowbrick.regressor import AlphaSelectionmglearnとは、データの使用やプロットを視覚化するためのモジュールです。
今回は改良版のbostonデータセットを使用します。
元データと異なり、特徴量は104個となります。X, y = mglearn.datasets.load_extended_boston() X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) print('X:', X.shape) print('y:', y.shape) print('X_train:', X_train.shape) print('y_train:', y_train.shape) print('X_test:', X_test.shape) print('y_test:', y_test.shape) # X: (506, 104) # y: (506,) # X_train: (379, 104) # y_train: (379,) # X_test: (127, 104) # y_test: (127,)1. 線形回帰
lr = LinearRegression().fit(X_train, y_train) # 決定係数(回帰モデルの予測の正確さを測る指標) print('Train set score: {}'.format(lr.score(X_train, y_train))) print('Test set score: {}'.format(lr.score(X_test, y_test))) # Train set score: 0.9520519609032729 # Test set score: 0.6074721959665842scoreは、決定係数(回帰モデルの予測の正確さを測る指標)です。
線形回帰において、手元にある訓練データの予測の精度は高いですが
テストデータ(未知のデータ)に対しては、予測の精度が低くなる傾向があります。スポーツ(野球)に例えると、普段からストレートの球ばかり打つ練習をしていたために
本番の試合では、カーブの球に全く対応できなくなってしまうといった感じでしょうか。実務やKaggleでは、未知のデータに対する汎化性能(本番への対応力)が重要となるため
今回のデータの場合、線形回帰モデルは不向きであることが分かります。
2. Ridge回帰
先ほどのような、訓練データに適応しすぎて
テストデータへの汎化性能が落ちることを「過学習」といいます。これを防ぐために、Ridge回帰で正則化(パラメータ:alpha)を行います。
回帰係数(各特徴量の値)が大きくなったり、ばらつきがあると過学習が起こりやすくなりますが
パラメータのalphaを大きくすると、回帰係数は0に近づいていきます。ridge = Ridge(alpha=1).fit(X_train, y_train) print('Training set score: {}'.format(ridge.score(X_train, y_train))) print('Test set score: {}'.format(ridge.score(X_test, y_test))) # Training set score: 0.885796658517094 # Test set score: 0.7527683481744752訓練データへの適応は低下しますが、テストデータへの汎化性能は向上しました。
Ridge回帰のalphaはデフォルトで1となっているので、他の値でも試してみます。ridge10 = Ridge(alpha=10).fit(X_train, y_train) print('Training set score: {:.2f}'.format(ridge10.score(X_train, y_train))) print('Test set score: {:.2f}'.format(ridge10.score(X_test, y_test))) # Training set score: 0.79 # Test set score: 0.64alpha=1のときよりも、テストデータへの予測精度が低下しました。
ridge01 = Ridge(alpha=0.1).fit(X_train, y_train) print('Training set score: {}'.format(ridge.score(X_train, y_train))) print('Test set score: {}'.format(ridge.score(X_test, y_test))) # Training set score: 0.885796658517094 # Test set score: 0.7527683481744752こちらは、alpha=1のときと同じくらいの予測精度となります。
ここで、各回帰係数の大きさとばらつきについて
alpha=0.1, 1, 10の、3パターンを比較をしてみます。plt.plot(ridge10.coef_, 's', label='Ridge alpha=10') plt.plot(ridge.coef_, 's', label='Ridge alpha=1') plt.plot(ridge01.coef_, 's', label='Ridge alpah=0.1') plt.plot(lr.coef_, 'o', label='LinearRegression') plt.xlabel('Coefficient index') plt.ylabel('Coefficient magnitude') plt.hlines(0, 0, len(lr.coef_)) plt.ylim(-25, 25) plt.legend()
横軸:104個の特徴量
縦軸:モデルにおける各回帰係数の大きさalpha=0.1, 1のように、データにある程度のばらつきがあった方が、スコアは高いことが分かります。
しかし線形回帰のようにばらつきが大きすぎたり(過学習)、alpha=10のように正則化を強くしすぎてしまうと
決定係数のスコアは低くなってしまいます。先ほどはいくつかのalphaを代入してスコアの比較を行いましたが
最適なalphaについて、事前に調べる方法もあります。まずパラメータalphaについて、値の探索する範囲を設定し
RidgeCVで訓練データについて交差検証を実行、AlphaSelectionで最適な値を求めプロットします。alphas = np.logspace(-10, 1, 500) ridgeCV = RidgeCV(alphas = alphas) alpha_selection = AlphaSelection(ridgeCV) alpha_selection.fit(X_train, y_train) alpha_selection.show() plt.show()
これにより、今回のRidge回帰における最適なパラメータ(alpha)の値が分かりました。ridge0069 = Ridge(alpha=0.069).fit(X_train, y_train) print('Training set score: {}'.format(ridge.score(X_train, y_train))) print('Test set score: {}'.format(ridge.score(X_test, y_test))) # Training set score: 0.885796658517094 # Test set score: 0.7527683481744752実際に試してみると、alpha=0.1, 1の時と同じ、高いスコアとなりました。
次に、線形回帰とRidge回帰(alpha=1)の比較として、学習曲線をプロットしてみます。
mglearn.plots.plot_ridge_n_samples()
横軸:データサイズ(総数)
縦軸:決定係数線形回帰では過学習を起こしやすいため、訓練データのスコアは高いですが
テストデータにおいては、汎化性能がほぼゼロとなってしまっています。ただし、データサイズが十分にあれば
Ridge回帰と同程度の汎化性能を持つことが分かります。
3. Lasso回帰
Ridge回帰と同様に、係数が0に近づくように制約をかけますが
かけ方が少し異なり、Lasso回帰はいくつかの係数が完全にゼロとなります。Number of features used:使用した特徴量の数
lasso = Lasso().fit(X_train, y_train) print('Training set score: {:.2f}'.format(lasso.score(X_train, y_train))) print('Test set score: {:.2f}'.format(lasso.score(X_test, y_test))) print('Number of features used: {}'.format(np.sum(lasso.coef_ != 0))) # Training set score: 0.29 # Test set score: 0.21 # Number of features used: 4lasso001 = Lasso(alpha=0.01, max_iter=100000).fit(X_train, y_train) print('Traing set score: {:.2f}'.format(lasso001.score(X_train, y_train))) print('Test set score: {:.2f}'.format(lasso001.score(X_test, y_test))) print('Number of features used: {}'.format(np.sum(lasso001.coef_ != 0))) # Traing set score: 0.90 # Test set score: 0.77 # Number of features used: 33lasso00001 = Lasso(alpha=0.0001, max_iter=100000).fit(X_train, y_train) print('Training set score: {:.2f}'.format(lasso00001.score(X_train, y_train))) print('Test set score: {:.2f}'.format(lasso00001.score(X_test, y_test))) print('Number of features used: {}'.format(np.sum(lasso00001.coef_ != 0))) # Training set score: 0.95 # Test set score: 0.64 # Number of features used: 96重要度の低い特徴量が0になりやすいように設計された誤差関数をもとに
訓練を行い、実際に使用する特徴量を決定しています。今回の場合は、特徴量数が96個のように多かったり、4個のように少なすぎると
汎化性能が低くなっていることが分かります。Lasso(alpha=0.0001)とRidge(alpha=1)について
回帰係数の大きさとばらつきを比較してみます。plt.plot(lasso.coef_, 's', label='Lasso alpha=1') plt.plot(lasso001.coef_, '^', label='Lasso alpha=0.01') plt.plot(lasso00001.coef_, 'v', label='Lasso alpha=0.0001') plt.plot(ridge01.coef_, 'o', label='Ridge alpha=0.1') plt.legend(ncol=2, loc=(0, 1.05)) plt.ylim(-25, 25) plt.xlabel('Coefficient index') plt.ylabel('Coefficient magnitude')
横軸:104個の特徴量
縦軸:モデルにおける各回帰係数の大きさ上図を見ると、やはり係数のばらつきもある程度は必要であり
Lasso(alpha=0.0001)はRidge(alpha=1)と同程度散らばっているので
決定係数のスコアも近しいことが分かります。
■ 結論
線形回帰を考えるのであれば、まずはRidge回帰でモデリングをして
不要な特徴量などがあると分かれば、Lasso回帰を行ってみるのが良い。ElasticNet(RidgeとLassoの両方のパラメータを持つ)は精度では優れますが、調整に手間がかかります。
■ 参考文献
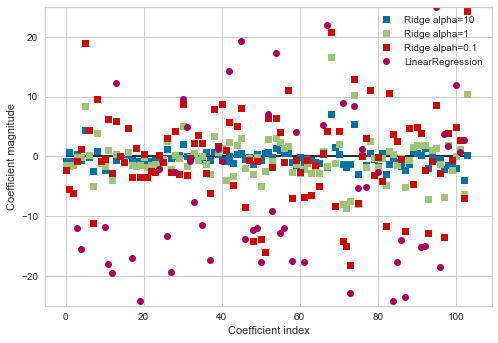
- 投稿日:2020-11-18T06:32:04+09:00
discord.py でよく躓くとこ(随時更新)
はじめに
これはteratailとかDiscord Bot Portal JPの質問に回答していって「こういうの多いなぁ」って感じたり、自分が躓いたとこを貼るだけのやつです。
discord.py公式のよくある質問とかを見てからこの記事を読むのをおすすめします。一般
Q. add_reactionがHTTPException吐く!ちゃんと
:thinking:って書いたのに!
A. add_reactionで標準の絵文字を使うには?みたいにUnicodeの絵文字を引数に渡す必要があります。
?みたいなのをもってくるのに1番手っ取り早い方法はDiscordで\を絵文字の前につけて送信する方法です。(\:thinking:みたいに書いて送信すると、Unicodeの絵文字が送信されるからそれをコピペ)
「絵文字をソースコードに書きたくない!」って人はR.Dannyのcharinfoとかで\U0001f914みたいなやつをもってくるとか、emojiライブラリのemoji.emojize(":thinking_face:", use_aliases=True)を使うとかしましょう。Q. TextChannel.history、チャンネルID指定したのにAttributeエラー吐く!なんで!?
A. チャンネルIDはそのままだとただのクソデカ数値(正確にはsnowflakeっていう特殊なやつだけど)です。
client.get_channel(チャンネルID)(bot.get_channel(チャンネルID)の人もいるかも)でTextChannelオブジェクトを持ってきましょう。
(変えたらAttributeError:'NoneType' object has no attribute〜を吐くときは、チャンネルIDが間違ってる可能性があります。)Embed
Q. timestampの時間ずれる!なんで!?
A. EmbedのtimestampはUTC指定です。
- datetime.datetime.now(datetime.timezone.utc)
- datetime.datetime.utcnow()
- datetime.timedelta(hours=9)をマイナスする(PCの時刻が日本なら)
でUTCになります。commandsフレームワーク
Q. コマンド動かない!ちゃんとon_message を使うとコマンドが動作しなくなります。どうしてですか。のやつ入れたのに! or process_commands入れたらグローバルチャット(とかあいさつとか)動かない!
A. グローバルチャット(とかあいさつとか)用とprocess_commands用でon_messageを2個おいてませんか?
最後に定義した方だけ実行されます。
process_commandsのon_messageを消して、
もう片方のon_messageにawait bot.process_commands(message)
(それかawait client.process_commands(message)みたいな)を書きましょう。Q. よくある質問の
bot.process_commands(message)入れたらNameError: name 'bot' is not defined出たんだけど!?
A. botではなくclientっていう名前の変数にcommands.Bot入れてませんか?(client = commands.Bot(色々))await client.process_commands(message)にしてみましょう。
coroutine関係
Q.
time.sleepしたらBot全体が止まるんだけど!
A.asyncio.sleepを使ってみましょう。import discord import asyncio # ← 重要 # ~~~~~ @client.event async def on_message(message): if message.author.bot: return # ~~~~~ if message.content == "起きろ": msg = await message.channel.send("(。-ω-)zzz") await asyncio.sleep(5) await msg.edit(content="(。゚ω゚) ハッ!")最後に
ここで解決できなくて、teratailで質問しようと思っているそこのあなた。
1つだけ覚えておいて欲しいことがあります。
「tracebackとコードを貼って。」
teratailが用意しているテンプレートを使えば回答率が結構上がります。(多分)
これを忘れないようにしておきましょう。最後まで読んでくれてありがとうございました。
もしここで解決したならLGTMしてね()
- 投稿日:2020-11-18T06:09:46+09:00
ヤフービジネスにSelenium Pythonでログインする
ヤフービジネスのIDとパスワード数百件。
はたしてこのエクセルリストのIDとパスワードでログインできるのでしょうか。
パスワードを変更してもエクセルのリストが更新されないこと多数。
そこで、スクレイピングでログイン確認をします。簡単かと思いきや少しはまったのでメモします。
結論
直接ログイン画面からログインしない。ヤフー内の別のページからログイン画面に遷移してログインする。
例えば
直接ログイン画面に遷移せず
https://business.yahoo.co.jp/
↓
https://login.bizmanager.yahoo.co.jp/login
の順番で遷移します。ヤフービジネスログイン画面のソースをみてみると多数のhidden項目があります。
この.crumbが空だとログインできない(何もおこらない)仕組みになっているようです。
なのでhiddenの.crubが空の状態で正しいIDとパスワードを入力しても、何もおこらないし、間違ったIDとパスワードを入力しても「IDとパスワードが違います」の画面すら表示されないのです。ヤフービジネスログイン画面 hiddenの.crumbに値なし<form method="post" action="/login.php" autocomplete="off" name="login_form" onsubmit="return checkMultipleSubmit();"> <input type="hidden" name="url" value="https://business.yahoo.co.jp/" data-rapid_p="1"> <input type="hidden" name="action" value="login" data-rapid_p="2"> <input type="hidden" name=".flow" value="" data-rapid_p="3"> <input type="hidden" name=".crumb" value="" data-rapid_p="4">https://business.yahoo.co.jp/
↓
https://login.bizmanager.yahoo.co.jp/login
の順番で遷移すると
hiddenの.crubに値が入力されています。ヤフービジネスhiddden.crumbにセッションの値が設定された後<form method="post" action="/login.php" autocomplete="off" name="login_form" onsubmit="return checkMultipleSubmit();"> <input type="hidden" name="url" value="https://business.yahoo.co.jp/" data-rapid_p="1"> <input type="hidden" name="action" value="login" data-rapid_p="2"> <input type="hidden" name=".flow" value="" data-rapid_p="3"> <input type="hidden" name=".crumb" value="dD14Q0R0ZkImc2s9eGlqMXh3dTRLcVJzM29KQ3pLMlIwaHNVcVZvLQ==" data-rapid_p="4">この状態になった後にログインすればスクレイピングでログインできるようになります。
環境
Windows10
Python3.8.3
Selenium
グーグルクローム・driverにクロームドライバーが設定されているものとします。
・あまりにも早く進むとブロックされてしまうかもしれないのであえてtime.sleepを入れています。from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC #直接ログイン画面に進まない driver.get("https://business.yahoo.co.jp/") driver.get("https://login.bizmanager.yahoo.co.jp/login.php") #確実にsendkeyするために関数を作成しました。 move_textbox_id(driver,"user_name","ここにID") move_textbox_id(driver,"password","ここにパスワード") #早く進みすぎてブロックされるといやなのでゆっくりと進みます。 time.sleep(1) element = driver.find_element_by_xpath("//*@id='bidlogin']/div/div/form/fieldset/div[3]/input") element.click() try: #ログアウトのリンクテキストを発見できたらログインOKにしました。 WebDriverWait(driver,8).until(EC.presence_of_element_located((By.LINK_TEXT, "ログアウト"))) except: #なにかしらの理由でログアウトリンクを発見できない場合の処理 def move_textbox_id(driver, id, atai): start = time.time() while driver.find_element_by_id(id).get_attribute('value')!=atai: driver.find_element_by_id(id).clear() time.sleep(1) #センドキーで値を入力する driver.find_element_by_id(id).send_keys(atai) time.sleep(1) if time.time()-start > 5 : return False return Trueただたんにログインするだけだから簡単かと思いきや大変でした。
とくにシークレットモードで操作している場合、直接ログイン画面からログインすると絶対にログインできないです。
確かにスクレイピングでなくて手作業でログインするときも1回目のログインははじかれてました。
コピペに全角でもまざっていたのかと思って気にもとめないでいましたが。
- 投稿日:2020-11-18T05:52:40+09:00
Pythonを使ってジャンケンをするプログラム
この記事では、
Pythonを使ってジャンケンをするプログラム
を書いていきます。求め方
1, Botの出す手をランダムで生成する。
2, あいこだった場合、もう一度繰り返す。
3, ジャンケンの結果を表示1, Botの出す手をランダムで生成する。
まずはBotの出す手をランダムで生成していきます。色々なやり方がありますが、今回はrandom.randint(0, 2)でやります。
これは、ランデムで範囲内の整数を生成できます。この整数をグー・チョキ・パーに当てはめていきます。
janken.pyimport random def janken(your_result): n = random.randint(0, 2) if n == 0: bot = "グー" elif n == 1: bot = "チョキ" else: bot = "パー"2, あいこだった場合、もう一度繰り返す。
次に、あいこだった時に、もう一度最初からやり直すように書いていきます。私は、もう一度関数を呼び出せば最初からやり直しできると考えました。
※このやり方は良く無いやり方かもしれないので、参考程度にお願いいたします。janken.pyif your_result == bot: j = input("あいこでしょ! > ") janken(j)3, ジャンケンの結果を表示
最後にジャンケンの結果を表示します。
あいこの場合は除かれているので、勝ちか負けのパターンを書いていきます。janken.pyif your_result == "グー": if bot == "パー": print("僕はパーをだしたよ。君の負けだよ。") elif bot == "チョキ": print("僕はチョキを出したよ。君の勝ちだよ。") elif your_result == "パー": if bot == "チョキ": print("僕はチョキを出したよ。君の負けだよ。") elif bot == "グー": print("僕はグーを出したよ。君の勝ちだよ。") elif your_result == "チョキ": if bot == "グー": print("僕はグーを出したよ。君の負けだよ。") elif bot == "パー": print("僕はパーをだしたよ。君の勝ちだよ。")最後に、出し手を取得してから関数を呼び出して終わりです。
全体像janken.pyimport random def janken(your_result): n = random.randint(0, 2) if n == 0: bot = "グー" elif n == 1: bot = "チョキ" else: bot = "パー" if your_result == bot: j = input("あいこでしょ! > ") janken(j) if your_result == "グー": if bot == "パー": print("僕はパーをだしたよ。君の負けだよ。") elif bot == "チョキ": print("僕はチョキを出したよ。君の勝ちだよ。") elif your_result == "パー": if bot == "チョキ": print("僕はチョキを出したよ。君の負けだよ。") elif bot == "グー": print("僕はグーを出したよ。君の勝ちだよ。") elif your_result == "チョキ": if bot == "グー": print("僕はグーを出したよ。君の負けだよ。") elif bot == "パー": print("僕はパーをだしたよ。君の勝ちだよ。") j = input("ジャンケンをするよ!グーかチョキかパーを入力してね。 > ") janken(j)実行結果
ジャンケンで先行後攻を決めるよ!グーかチョキかパーを入力してね。 > グー あいこでしょ! > グー 僕はパーをだしたよ。君の負けだよ。まとめ
今回は、
Pythonを使ってジャンケンをするプログラム
を書いていきました。あまりよろしくない文法等があるかもしてませんが、一応これで動作します。
比較的簡単なプログラムだと思うので、ご自身で改良してみてください!
ありがとうございました!
注意
この記事は、プログラミング初学者が書いており、内容に誤りがある場合がございます。
あしからずご了承願います。
また、誤りにお気づきの場合にはご指摘いただけると幸いです。
よろしくお願いいたします。
- 投稿日:2020-11-18T05:00:25+09:00
エラーと戦う
pythonで出たエラーに苦戦した話
この記事は検索下手な私が「ん?これってなんのこっちゃ」ってなった体験談ww
attribute error
AttributeError: module(object) ‘xxx’ has no attribute ‘yyy’このようなエラーが出ることがある..
今回私が起こしてしまったエラーは関数の返り値がオブジェクトの際、返り値を入れるオブジェクトの内容が変わってしまった時起きた...
sample.pyclass Person: def __init__(self, name:str, age:int): self.name = name self.age = age def renamed(person, pserson2): person.name = 'Kein' return person, ron bob = Person('Bob', 19) ron = Person('Ron', 23) kein = renamed(bob, ron) print(kein.name) print(kein.age) print(ron.name) print(ron.age)こんな感じで入れる変数の数が違った...
対処
sample.pyclass Person: def __init__(self, name:str, age:int): self.name = name self.age = age def renamed(person, pserson2): person.name = 'Kein' return person, ron bob = Person('Bob', 19) ron = Person('Ron', 23) kein, ron = renamed(bob, ron) print(kein.name) print(kein.age) print(ron.name) print(ron.age)ちゃんと返り値を入れようねってことだった、
自分のコードを見ればわかる話だが、エラ〜メッセージで対処しようとすると知識がないと苦戦するかも?
可読性の高いコードを書いていきたいものだ
- 投稿日:2020-11-18T01:01:43+09:00
ロジスティック回帰
本記事では、ロジスティック回帰の基本的な考え方と、pythonでの実践的なコードについて紹介していきます!
学生時代に勉強していたことについて、超わかりやすくまとめたつもりなので、初心者から普段コードをバリバリ書いている人まで、是非参考にしていただけたらと思います。ロジスティック回帰の基本的な考え方
ロジスティック回帰は、通常二値分類に利用される方法です。
ロジスティック回帰の考え方を説明するにあたり、例えば、有名なタイタニックの例を考えてみましょう。
n個の変数$(x_0,x_1,x_2,,x_n)$(タイタニックの例では、PassengerIDが)
math
X =
\begin{bmatrix}
x_0 \\
x_1 \\
x_2 \\
\vdots \\
x_n \\
\end{bmatrix}
W = \begin{bmatrix} β_0 \\ β_1 \\ β_2 \\ \vdots \\ β_n \\ \end{bmatrix}として、
Z=β_0+β_1x_1+β_2x_2+...+β_nx_n …① \\ = w^{T}Xこの場合、確率pを以下のように表すのがロジスティック回帰です。
p=\frac{1}{1+e^{-(β_0+β_1x_1+β_2x_2+...+β_nx_n)}} =\frac{1}{1+e^{-Z}} …②そして、求めたpに対して、
$$
y =
\begin{cases}
1 & x ≧ 0.5 \\
0 & x < 0.5
\end{cases}
$$のように、pが域値(ある一定のライン)を上回ったか否かで分類するのがロジスティック回帰の基本的な流れです。
①は、同値変形により、以下の式となります。
\log\frac{p}{1-p}=β_0+β_1x_1+β_2x_2+...+β_nx_n
- (参考) 同値変形 (分かる人は飛ばしてOKです) ②の右辺の分母と分子にe^Zをかけて、
p=\frac{e^Z}{1+e^Z}\\ ⇔e^Z=p(1+e^Z)\\ ⇔e^Z=\frac{p}{1-p}\\ ⇔\log\frac{p}{1-p}=Z=β_0+β_1x_1+β_2x_2+...+β_nx_n …③
③の左辺、つまり
\log\frac{p}{1-p}は、『対数オッズ』(もしくは『ロジット』)と呼ばれます。
ロジスティック回帰は、言い換えれば、与えられた因子x_1,x_2,x_3,...x_nに対し、目的変数pが③の式を満たすような最適なパラメータ
β_1,β_2,β_3,...β_nを求める計算となる訳です。
ところで、②の式は、グラフ化してみると以下のようになります。
グラフを見れば分かるように、入力値$Z$は、$-∞≦Z≦∞$を取るのに対し、出力値$y$は、$0<y<1$を取ります。重回帰分析との違い
重回帰分析が、基本的には残差の正規分析を仮定しているのと異なり、ロジスティック回帰は、誤差の分布に正規分布を仮定していないというのが便利なところです。
最尤法による最適パラメータの推定方法
では、最適パラメータはどのように求められるのでしょうか。
この章の計算部分は、まさにpythonでLogisticRegression()を使えば自動的に計算してくれる訳ではありますが、実際のビジネスで分析に利用するにあたり、『ライブラリを使って計算したらそうなったから、その仕組みは知らない』というのであればブラックボックス化してしまいます。最適パラメータ化には様々な方法がありますが、ここでは『ニュートン法』について紹介してみたいと思います。
上の①の式をもう一度見てみましょう。
p=\frac{1}{1+e^{-(β_0+β_1x_1+β_2x_2+...+β_nx_n)}} =\frac{1}{1+e^{-Z}} …②n個のデータセット(pと$x_0,x_1,...x_n$)
対数尤度関数は、
L(w)=log(\prod_{i = 0}^{n}p^Y(1-p)^{1-Y})\\\ ⇔L(w)=Y\sum_{i=0}^{n}log{p}+(1-Y)\sum_{i=0}^{n}log{(1-p)}\\\ ⇔L(w)=Y\sum_{i=0}^{n}log{\frac{1}{1+e^{-w^Tx}}}+(1-Y)\sum_{i=0}^{n}log{(1-\frac{1}{1+e^{-w^Tx}})}\\\これが最大となるような$w$を求めれば良い。
これは、$-L(w)$(=$E(w)$とする)が最小となる事と同義である。では、どのようにしたら$E(w)$が最小となるパラメータ$w$を見つけられるだろうか。
ここでは、初めに一定の$w^{(t)}$を暫定的におき、状況により$w^{(t+1)}←w^{(t)}-d^{(t)}$のように$w$を更新していく事で、最適な行列に近づけていく方法を考えよう。
では、どのようにして$d^{(t)}$を求めたら良いだろうか。
テイラー展開により、E(w+d)∼E(w)+\frac{δE(w)}{δw}d^{(t)}+\frac{1}{2}\frac{δ^2E(w)}{δwδw}{d^{(t)}}^2 …④これが最小となるようなd^{(t)}を求めれば良いから、これを$d^{(t)}$で偏微分して、
\frac{δE(w)}{δw}+\frac{δ^2E(w)}{δwδw}{d^{(t)}}=0 \\\ ⇔{d^{(t)}}=\left(\frac{δ^2E(w)}{δwδw}\right)^{-1}\frac{δE(w)}{δw}w^{(t+1)}←w^{(t)}-\left(\frac{δ^2E(w)}{δwδw}\right)^{-1}\frac{δE(w)}{δw} …⑤これがニュートン法である。
ここで、
\frac{δE(w)}{δp}=-\frac{δY\sum_{i=0}^{n}log{p}+(1-Y)\sum_{i=0}^{n}log{(1-p)}}{δp}\\\ =-\frac{Y}{p}+\frac{1-Y}{1-p} \\\ =\frac{p-Y}{p(1-p)}\frac{δp}{δw}=\frac{δ}{δw}\frac{1}{1+e^{-w^Tx}} \\\ =\frac{δ}{δw}(1+e^{-w^Tx})^{-1} \\\ =\frac{xe^{-w^Tx}}{(1+e^{-w^Tx})^2} \\\ =\frac{xe^{-w^Tx}}{(1+e^{-w^Tx})^2} \\\ =px(1-p)よって、
\frac{δE(w)}{δw}=\frac{p-Y}{p(1-p)}px(1-p)=x(p-Y) …⑥また、$E(w)$の2階微分は、
\frac{δ^2E(w)}{δwδw}=\frac{δ}{δw}x\left(\frac{1}{1+e^{-w^Tx}}-Y\right) \\\ =px^2(1-p) …⑦⑥⑦より、⑤に代入して、
w^{(t+1)}←w^{(t)}-\frac{1}{px^2(1-p)}x(p-Y) …⑧L(w+d)∼L(w)+L'(w)h以上を踏まえて、以下のようなアルゴリズムでパラメータの最適化が行われます。
- 初期パラメータ$w^{(0)}$を定める。
- 上記の方法により対数尤度関数を更新する。
- ⑧によりパラメータ$w$を更新する。
- 更新された$w$を元に、再び対数尤度関数の更新を始める。
- 対数尤度関数の更新に変化が無くなったら更新をストップする。この時の$w$が最適パラメータとなる。
ロジスティック回帰の応用例
以上、タイタニックの例を基に、ロジスティック回帰の数学的な考え方及び、pythonでの簡単なコードの書き方について説明しましたが、実際に、ロジスティック回帰は社会科学の様々な分野でも応用されています。
例えば、会計分野においては、企業の倒産リスクを調べるにあたり、営業利益率等のPL数値に加え、GC(Going Concern:継続企業の前提)に関する注記の有無を因子に入れて、倒産リスクをロジスティック回帰で分析する研究がなされています。


- 投稿日:2020-11-18T00:49:03+09:00
【Tips】pyenvでPython3系の3.5.3未満をインストールしようとしたときに発生するエラーへの対処
問題:Pythonインストールにおけるエラー
入力
pyenv install 3.4.8出力
Downloading Python-3.4.8.tar.xz... -> https://www.python.org/ftp/python/3.4.8/Python-3.4.8.tar.xz Installing Python-3.4.8... ERROR: The Python ssl extension was not compiled. Missing the OpenSSL lib? Please consult to the Wiki page to fix the problem. https://github.com/pyenv/pyenv/wiki/Common-build-problems BUILD FAILED (Ubuntu 18.04 using python-build 1.2.19-1-gece59ca8) Inspect or clean up the working tree at /tmp/python-build.20201118000548.3700 Results logged to /tmp/python-build.20201118000548.3700.log Last 10 log lines: (cd /home/【ユーザ名】/.anyenv/envs/pyenv/versions/3.4.8/share/man/man1; ln -s python3.4.1 python3.1) if test "xupgrade" != "xno" ; then \ case upgrade in \ upgrade) ensurepip="--upgrade" ;; \ install|*) ensurepip="" ;; \ esac; \ ./python -E -m ensurepip \ $ensurepip --root=/ ; \ fi Ignoring ensurepip failure: pip 9.0.1 requires SSL/TLS環境
- Ubuntu 18.04 LTS (Windows 10 2004 WSL1上環境)
- anyenv
- pyenv 1.2.19-1-gece59ca8
原因:OpenSSLの対応バージョン
Python3系のの3.5.2まではOpenSSLの1.1に未対応。
解決方法:OpenSSLのダウングレード
sudo apt install libssl1.0-dev pyenv install 3.4.8補足
1. 事後処理
OpenSSL1.0をインストールすることでOpenSSLがダウングレードしてしまう。
Pythonのインストールが無事終了したら以下を実行。sudo apt install libssl-dev2. Rubyの場合
Rubyにおいても2.4未満で同様の原因によるエラーが発生する。
くわしくはこちらの記事を参照。参考文献