- 投稿日:2020-10-28T23:41:02+09:00
networkxにおける条件に合う頂点の削除
課題
プログラム内で定義したグラフから条件に合う頂点を削除しよう!
今回の条件
- networkxを利用する
- グラフはプログラム内で定義する
- [次数が0の頂点]もしくは[次数が1の頂点とその頂点に接続する辺]を削除する。
最初に考えたプログラム
import networkx as nx import matplotlib.pyplot as plt G=nx.Graph() G.add_nodes_from([1,2,3,4,5,6,7,8,9,10]) G.add_edges_from([(1,2),(2,4),(3,2),(4,5),(6,10),(7,6),(8,6),(9,8),(10,8),(1,9),(8,1)]) #n=G.number_of_nodes() #[次数が0の頂点]もしくは[次数が1の頂点とその頂点に接続する辺]を削除する for v in G: #print(G.degree(v)) #print("v=",v) G_deg=G.degree(v) if G_deg==0 or G_deg==1: G.remove_node(v) #print("G_deg=",G_deg) #グラフの出力 nx.draw_networkx(G) plt.show()よしできたと思い実行してみました。
エラー
Traceback (most recent call last): File "kadai06d.py", line 10, in <module> for v in G: RuntimeError: dictionary changed size during iteration一筋縄ではいかず。。。
原因を探るためネットで調べてみました。原因1
まずエラーの意味は,「iterate しているオブジェクトを変更することはできない」というエラーだそうです。
つまり、for v in G:でループを回しながらの削除はできないということなのでしょうか。改良1
for v in G内で削除ができないのなら、条件にあう頂点をリストアップしてからfor v in Gの外で一気に削除してしまおうと考えました。改良1のプログラム
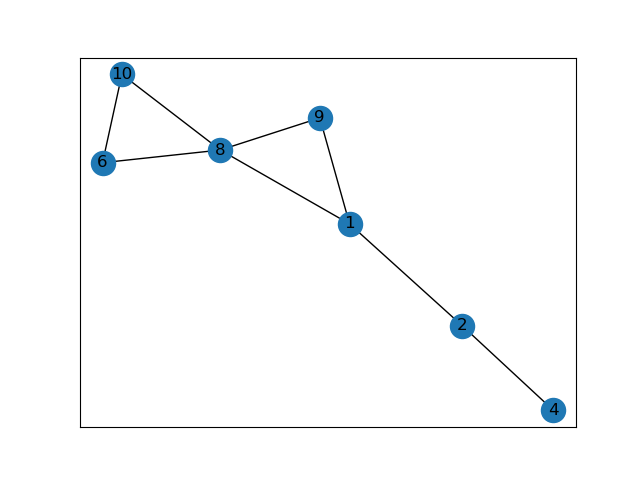
import networkx as nx import matplotlib.pyplot as plt G=nx.Graph() G.add_nodes_from([1,2,3,4,5,6,7,8,9,10]) G.add_edges_from([(1,2),(2,4),(3,2),(4,5),(6,10),(7,6),(8,6),(9,8),(10,8),(1,9),(8,1)]) node_be=G.number_of_nodes() #削除前の頂点数 edge_be=G.number_of_edges() #削除前の辺数 #[次数が0の頂点]もしくは[次数が1の頂点とその頂点に接続する辺]を削除する G_rem=[] #条件に合う頂点をリストアップする for v in G: G_deg=G.degree(v) #print("G_deg[",v,"]=",G_deg) if G_deg<=1: #print("v=",v) G_rem.append(v) #条件に合う頂点を削除する G.remove_nodes_from(G_rem) node_af=G.number_of_nodes() #削除後の頂点数 edge_af=G.number_of_edges() #削除後の辺数 #グラフの出力 nx.draw_networkx(G) plt.show()これで実行してみました。
実行したグラフ
\\次数が1の頂点が残っている///原因2
for v in G:で一回見ただけでvはどんどん大きくなって次数が1になってもスルーしてしまっているみたいです。つまり、一回やって終わりではだめで何回も見返さなくてはならないのです!改良2
for v in G:を何回も繰り返すために2重ループをしてみることにしました。
頂点数分だけ何回もforを回してみます。改良したプログラム
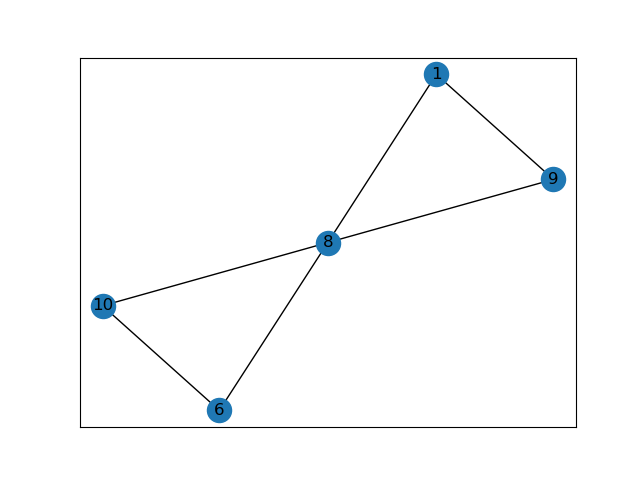
import networkx as nx import matplotlib.pyplot as plt G=nx.Graph() G.add_nodes_from([1,2,3,4,5,6,7,8,9,10]) G.add_edges_from([(1,2),(2,4),(3,2),(4,5),(6,10),(7,6),(8,6),(9,8),(10,8),(1,9),(8,1)]) node_be=G.number_of_nodes() #削除前の頂点数 edge_be=G.number_of_edges() #削除前の辺数 #[次数が0の頂点]もしくは[次数が1の頂点とその頂点に接続する辺]を削除する G_rem=[] #条件に合う頂点をリストアップする for i in range(node_be): for v in G: G_deg=G.degree(v) #print("G_deg[",v,"]=",G_deg) if G_deg<=1: #print("v=",v) G_rem.append(v) #条件に合う頂点を削除する G.remove_nodes_from(G_rem) node_af=G.number_of_nodes() #削除後の頂点数 edge_af=G.number_of_edges() #削除後の辺数 #グラフの出力 nx.draw_networkx(G) plt.savefig("output.png") plt.show()実行したグラフ
次数1の頂点はなくなりました!最後に
いろいろ段階を踏まなくては簡単に頂点が削除できないことがわかりました。
最後までありがとうございました。
- 投稿日:2020-10-28T23:16:34+09:00
【Python】アヤメの分類器を作ってみた【機械学習】
こちらの講座を参考にしながらアヤメの分類器を作ってみたので備忘録です。
[初心者必見!Pythonでニューラルネット・深層学習を完全攻略]環境
Mac OS Catalina 10.15.7
Spyder 4.1.4
Anaconda 3
Python 3.7.9
Keras 2.3.1やったこと
作成したコードです。
iris.pyfrom sklearn.datasets import load_iris#アヤメのデータを取得 iris = load_iris() from sklearn.model_selection import train_test_split as split #データセットを分けるツール X_train,X_test,y_train,y_test = split(iris.data, iris.target, train_size = 0.8) #データセット のうち80%を学習用、20%を実験用に分ける import keras #ニューラルネットの作成 #Dense:ニューラルネット定義クラス #Activateion:活性化関数クラス from keras.layers import Dense, Activation model = keras.models.Sequential()#モデルを作る入れ物を作成 model.add(Dense(units =32,input_dim = 4 )) #中間層32個、入力層4個 model.add(Activation('relu'))#活性化関数Relu model.add(Dense(units = 3))#出力層:3個 model.add(Activation('softmax'))#活性化関数softmax #コンパイル model.compile( loss = 'sparse_categorical_crossentropy', optimizer = 'sgd', metrics = ['accuracy']) #学習の実行 model.fit(X_train,y_train,epochs = 100)#100回繰り返し学習 #評価の実行 #テストデータの正答率をチェックする score = model.evaluate(X_test,y_test,batch_size = 1)#scoreにはloss(損失) ,accuracy(精度)のベクトルが入る #参考:https://aidiary.hatenablog.com/category/Keras?page=1478696865 accuracy = score[1] print('精度 ="',str(accuracy))#printで数値と文字列を組み合わせるには、数値をstr()で文 字列にする #参考:https://www.javadrive.jp/python/string/index9.html #1個のデータだけチェックする import numpy as np x = np.array([[5.1,3.5,1.4,0.2]])#X_trainと同じ形式の配列を作成 r = model.predict(x)#確率のベクトル print('ラベルごとの確率=',r) print('一番確率の高いラベル=',r.argmax())#argmax()はベクトルの中で一番大きいラベルを返す #データを出力する json_string = model.to_json() #モデルをインポートしたい場合 #from keras.models import model_fromjson #model = model_from_json/json_string) #学習パラメータの保存 #先にh5pyをインストールしておく model.save_weights('param.hdf5') #読み込むとき #model.load_weight('param.hdf5')実行結果
精度 =" 0.9666666388511658 ラベルごとの確率= [[0.9405338 0.05598015 0.00348606]] 一番確率の高いラベル= 0
- 投稿日:2020-10-28T23:14:48+09:00
ディレクトリごとにある画像らをPDF化させるCLIツールを作った
Github
https://github.com/ikota3/image_utilities
概要
自炊を快適に行うために,ディレクトリごとに格納されている画像らをそれぞれPDF化させるツールを作りました.
また,サブディレクトリも再帰的に見て作成を行います.動作確認はWindows10で行いました.
必要なもの
- Library
fireimg2pdf使い方
$ git clone https://github.com/ikota3/image_utilities $ cd image_utilities $ pip install -r requirements.txt $ python src/images_to_pdf.py convert -i "path/to/input" -o "path/to/output" -e "jpg,jpeg,png"実装内容
今回,CLIツールを作るために全て一から作るのは大変そうだと思い,前に話題になっていた fire というライブラリを使いました.
実際,すごく使いやすかったです.
コマンドを叩けるようにする
まずはコマンドを叩いて入力値を受け取れるよう,骨組みを作成します.
今回はクラスを作って,fireで呼び出すようにします.
fireはクラスのほかにも関数,モジュール,オブジェクト,他様々なものを呼び出すことが可能です.
詳しくは公式のドキュメントを参照ください.
https://github.com/google/python-fire/blob/master/docs/guide.mdimages_to_pdf.pyimport fire class PDFConverter(object): """Class for convert images to pdf.""" def __init__( self, input_dir: str = "", output_dir: str = "", extensions: Union[str, Tuple[str]] = None, force_write: bool = False, yes: bool = False ): """Initialize Args: input_dir (str): Input directory. Defaults to "". output_dir (str): Output directory. Defaults to "". extensions (Union[str, Tuple[str]]): Extensions. Defaults to None. force_write (bool): Flag for overwrite the converted pdf. Defaults to False. yes (bool): Flag for asking to execute or not. Defaults to False. """ self.input_dir: str = input_dir self.output_dir: str = output_dir if not extensions: extensions = ('jpg', 'png') self.extensions: Tuple[str] = extensions self.force_write: bool = force_write self.yes: bool = yes def convert(self): print("Hello World!") if __name__ == '__main__': fire.Fire(PDFConverter)ひとまずこれくらいで骨組みは完成です.
この状態でコマンドを打つと,Hello World!と出力されるはずです.$ python src/images_to_pdf.py convert Hello World!また,
input_dir = ""などの他のパラメータは,デフォルト値を設定していますが,これを設定せずにコマンド側で値を渡さなかったとき,fire側のエラーが発生します.値の渡し方は,
__init__で設定した引数の接頭辞の前にハイフンをつけたあとに,渡したい値を書くだけです.下記コマンドの渡し方は,書き方に違いはあれど結果は変わらないです.
$ # self.input_dirの例 $ python src/images_to_pdf.py convert -i "path/to/input" $ python src/images_to_pdf.py convert -i="path/to/input" $ python src/images_to_pdf.py convert --input_dir "path/to/input" $ python src/images_to_pdf.py convert --input_dir="path/to/input"また,つまづいた点としてリストを渡そうとしたときに戸惑いました.
$ # self.extensionsの例 $ python src/images_to_pdf.py convert -e jpg,png # OK $ python src/images_to_pdf.py convert -e "jpg,png" # OK $ python src/images_to_pdf.py convert -e "jpg, png" # OK $ python src/images_to_pdf.py convert -e jpg, png # NG入力値チェック
PDF化処理を行う前に,
isinstance()による型チェックと,指定したパスが存在するものか,等のチェックを行っています.images_to_pdf.pydef _input_is_valid(self) -> bool: """Validator for input. Returns: bool: True if is valid, False otherwise. """ is_valid = True # Check input_dir if not isinstance(self.input_dir, str) or \ not os.path.isdir(self.input_dir): print('[ERROR] You must type a valid directory for input directory.') is_valid = False # Check output_dir if not isinstance(self.output_dir, str) or \ not os.path.isdir(self.output_dir): print('[ERROR] You must type a valid directory for output directory.') is_valid = False # Check extensions if not isinstance(self.extensions, tuple) and \ not isinstance(self.extensions, str): print('[ERROR] You must type at least one extension.') is_valid = False # Check force_write if not isinstance(self.force_write, bool): print('[ERROR] You must just type -f flag. No need to type a parameter.') is_valid = False # Check yes if not isinstance(self.yes, bool): print('[ERROR] You must just type -y flag. No need to type a parameter.') is_valid = False return is_validディレクトリを走査し,画像を集め,PDF化
受け取った
input_dirのパスからディレクトリを走査するために,os.walk()というものを使っています.
https://docs.python.org/ja/3/library/os.html?highlight=os%20walk#os.walk以下のようにディレクトリを走査し,画像を集めていき,PDF化を行っています.
images_to_pdf.pydef convert(self): # 拡張子の接頭辞に . を加える extensions: Union[str | Tuple[str]] = None if isinstance(self.extensions, tuple): extensions = [] for extension in self.extensions: extensions.append(f'.{extension}') extensions = tuple(extensions) elif isinstance(self.extensions, str): extensions = tuple([f'.{self.extensions}']) # ディレクトリを走査し,それぞれのディレクトリにある画像らをPDFにする for current_dir, dirs, files in os.walk(self.input_dir): print(f'[INFO] Watching {current_dir}.') # 対象の画像があるパスを格納するリスト images = [] # filesはcurrent_dirにあるファイルのリスト # ソートは桁数が異なるものだと順番がおかしくなる(https://github.com/ikota3/image_utilities#note) # そのため,期待通りのものにするために関数を用意した(後述) for filename in sorted(files, key=natural_keys): if filename.endswith(extensions): path = os.path.join(current_dir, filename) images.append(path) # 走査した結果,画像がなかったとき if not images: print( f'[INFO] There are no {", ".join(self.extensions).upper()} files at {current_dir}.' ) continue pdf_filename = os.path.join( self.output_dir, f'{os.path.basename(current_dir)}.pdf' ) # -f パラメータがある時は,ファイルがあっても強制上書きを行う if self.force_write: with open(pdf_filename, 'wb') as f: f.write(img2pdf.convert(images)) print(f'[INFO] Created {pdf_filename}!') else: if os.path.exists(pdf_filename): print(f'[ERROR] {pdf_filename} already exist!') continue with open(pdf_filename, 'wb') as f: f.write(img2pdf.convert(images)) print(f'[INFO] Created {pdf_filename}!')ディレクトリにある画像を集めるとき,ソートがおかしくなり,順番が期待しているものではなかった時があったため,関数を用意しました.
また,以下のリンクを参考に作っています.
https://stackoverflow.com/questions/5967500/how-to-correctly-sort-a-string-with-a-number-insidesort_key.pyimport re from typing import Union, List def atoi(text: str) -> Union[int, str]: """Convert ascii to integer. Args: text (str): string. Returns: Union[int, str]: integer if number, string otherwise. """ return int(text) if text.isdigit() else text def natural_keys(text: str) -> Union[List[int], List[str]]: """Key for natural sorting Args: text (str): string Returns: Union[List[int], List[str]]: A list of mixed integer and strings. """ return [atoi(c) for c in re.split(r'(\d+)', text)]終わり
以前,CLIツールをライブラリを使わずに作ったことがありましたが,fireと比べてみると簡単に実装することができました!
皆さんもCLIツール,作ってみませんか?
- 投稿日:2020-10-28T23:10:02+09:00
Pythonから昔の学振DC申請書のWordファイル(.doc)を読んで操作してみる
モチベーション
とある大学事務の人から、科研費申請書をチェックするのが大変だという話を聞きました。現在は手で1部ずつ赤入れをしているそうです。
- 公募要領に沿って記入しているか
- 図や参考文献は適切に入っているか
- 業績リストは適切な形式になっているか
など、自動チェックツールがあると良さそうです。
Pythonで自動チェックツールを作れるといいですね! と思いつつ、すぐ作るのは荷が重いので、まずはPythonからのWordファイルの読み書きを試してみました。
科研費申請書に準じるサンプルとして、筆者が2011年6月に提出した日本学術振興会特別研究員(学振)DC2の申請書を読んでみました。学振についてよく知らない人は、身近な博士課程出身者に聞いてみると感情のこもった応答が返ってくるかもしれません。PythonからWordファイルってどうやって読むの?
Read from a word file in python
主にpython-docxとdocx2txtがあり、どちらも.docxファイルのみに対応しています。後述しますが、.docファイルを読む時は、antiwordによる.docxへの変換が必要になります。
docx2txtはヘッダ・フッタ・ハイパーリンクからもテキストを読み取れるということなので、今回は主にdocx2txtで試してみました。環境
- MacOS Mojave 10.14.5
- Anaconda 2020.02
- Python 3.7.6
- Jupyter Notebook 6.0.3
python-docxのインストール
bashpip install python-docxpython-docxはPython 3.4までしか対応していないようですが、Python 3.7で動くことは動きました。AnacondaにPython 3.4が入らないので、3.7のままにしました。
docx2txtのインストール
bashpip install docx2txtantiwordのインストール
後述しますが、サンプルとして読みたかったWordファイルが.docxではなく.doc形式でした。
python-docxで.doc形式のファイルは開けません。
Wordで開いて.docxとして保存するのはなんか負けたような気がするので、antiwordでの変換を試みました。apt-getでインストール:失敗
結論から言うと、Macでapt-getでのantiwordのインストールはできませんでした。
antiwordはapt-getで入れればいいのか、と思ってfinkを入れ、finkのインストール途中でJDKがないと言われてなぜかAdobe Flashplayerのダウンロードページに飛ばされたりしました(もちろんFlashplayerをインストールしても何も解決しませんでした)。bashsudo apt-get antiword出力結果E: Invalid operation antiwordbrewでインストール:成功
bashbrew install antiwordここを見てbrewコマンドを入れたら無事インストールできました。
bash(base) akpro:~ kageazusa$ antiword Name: antiword Purpose: Display MS-Word files Author: (C) 1998-2005 Adri van Os Version: 0.37 (21 Oct 2005) Status: GNU General Public License Usage: antiword [switches] wordfile1 [wordfile2 ...] Switches: [-f|-t|-a papersize|-p papersize|-x dtd][-m mapping][-w #][-i #][-Ls] -f formatted text output -t text output (default) -a <paper size name> Adobe PDF output -p <paper size name> PostScript output paper size like: a4, letter or legal -x <dtd> XML output like: db (DocBook) -m <mapping> character mapping file -w <width> in characters of text output -i <level> image level (PostScript only) -L use landscape mode (PostScript only) -r Show removed text -s Show hidden (by Word) text2005年のツールなんですね!
python-docxでの読み書きテスト
こちらの後半のコードをコピペしたら動き、Wordファイルの作成・読み取りができました。
Python 3.7で特に問題はないようです。
なお、こちらのコメント欄にあるコードをコピペして動かしてみたら、docx_simple_serviceは読み込めませんでした。たぶんPythonのバージョンによるものだと推定しています。errorModuleNotFoundError: No module named 'docx_simple_service'antiwordで.docファイルを.docxファイルに変換してdoc2txtで読む
いよいよサンプルを読んでみます。
サンプル
このような申請書を使います。最近はもうなくなった枠線が現役だった時代です。.docファイルなので、そのままではPythonで読めません。
最終版のWordファイルが発掘できなかったので、メール提出して事務チェックしてもらった最終よりちょっと前のバージョンを使います。
.docファイルの読み取り
こちらの回答にある関数ですぐ読めました。
pathの指定部分だけ微妙に変えてあります。
.docファイルをantiwordで.docxファイルに変換して読み、読んだ.docxファイルはすぐ消しています。pythonimport os, docx2txt def get_doc_text(filepath, file): if file.endswith('.docx'): text = docx2txt.process(file) return text elif file.endswith('.doc'): # converting .doc to .docx doc_file = os.path.join(filepath, file) docx_name = file + 'x' docx_file = os.path.join(filepath, docx_name) if not os.path.exists(docx_file): os.system('antiword ' + doc_file + ' > ' + docx_file) with open(docx_file) as f: text = f.read() os.remove(docx_file) #docx_file was just to read, so deleting else: # already a file with same name as doc exists having docx extension, # which means it is a different file, so we cant read it print('Info : file with same name of doc exists having docx extension, so we cant read it') text = '' return text読めました!
小見出しごとの内容を抽出してみる
読んだテキストを使って、小見出しごとの内容を抽出してみたいと思います。
今回の例では、小見出しは【】で括られています。【問題点】とか。テキストの整形
改行などを削除します。
pythongakushin = get_doc_text('./sample', '110624GakushinDraftKAGE2.1.doc') gakushin = gakushin.replace('\n', '').replace('|', '').replace('\u3000', '')
まだ連続スペースが残っているので、ここを見ながら削除します。pythonimport re # 連続スペースを削除して半角スペース1個にする gakushin = re.sub('[ ]+', ' ', gakushin)et al. と年号の間など、できればスペースが残ってほしいところもあるので、とりあえず半角スペース1つは残しました。厳密にやるならスペース全部削除した後にet al. とか & の周りだけ置換するのがよいと思います。
小見出しの抽出
【】で括られた部分を検索してみます。正規表現弱者なので、検索してここを参考にしたら動きました。
pythonre.findall('\【.+?\】', gakushin)出力結果['【背景】', '【問題点】', '【解決方策、研究目的、研究方法、特色と独創的な点】', '【研究経過1】', '【研究経過2】', '【これからの研究計画の背景】', '【問題点・解決すべき点】', '【着想に至った経緯】', '【2-1】', '【2-2】', '【査読あり】', '【口頭発表・査読なし】', '【ポスター発表・査読なし】', '【研究職を志望する動機】', '【目指す研究者像】', '【自己の長所等】', '【特に優れた学業成績,受賞歴】', '【特色ある学外活動】']小見出しが抽出できました!
小見出しの下の文章の抽出
小見出しを変数に格納して、小見出し自体を使ってテキスト
gakushinを分割してみます。pythonsubhead = re.findall('\【.+?\】', gakushin) text = gakushin split_result = [] for i in range(len(subhead)): new_text = text.split(subhead[i]) split_result.append(new_text[0]) text = new_text[1] # 最後の1回だけ[1]を入れる split_result.append(new_text[1])
文章を小見出しで分割してリスト化できました。要素数を調べてみます。pythonprint('小見出しの要素数', len(subhead)) print('分割した文章の要素数', len(split_result))出力結果小見出しの要素数 18 分割した文章の要素数 19小見出しの要素数+1 = 小見出しで分割した文章の要素数 となり、計算は合っているようです。
小見出しとその下の文章が合うように、pandas DataFrameに格納してみます。リストsplit_resultの最初の要素は捨てることになります。pythonimport pandas as pd df = pd.DataFrame([subhead, split_result[1:19]]).T df.columns = ['subhead', 'text']
小見出しとその下の文章が対応づけられました。文字数を数えてデータフレームに入れてみます。
pythondf['length'] = df.text.apply(len)
【2-2】という項目が特に長いようです。これだけ見ても【2-2】が何を表す見出しなのかはよくわかりません。研究計画っぽいですが、【1】がない理由は不明です。まとめ
Pythonから.docファイルを読み取り、テキストを操作することができました。
今後いろいろ試していきたいと思います。参考
- 特別研究員|日本学術振興会
- Read from a word file in python
- python-docx
- docx2txt
- Read .doc file with python
- Install antiword on Mac OSX
- Python で excel・wordの読み書き
- 【Python】【Word】【python-docx】python-docxを使ってPythonでワード文章のひな形を作成してみる
- 研究者、ツイッターで政治を動かす?
- Reading .doc file in Python using antiword in Windows (also .docx)
- 連続するスペースを削除して1つにするpythonのコード
- かっこで囲まれた文字を検索する







- 投稿日:2020-10-28T22:54:35+09:00
【Python】Tensorflow2.0がPython3.8に対応していなかったのでPythonをダウングレードした話
環境
Mac OS Catalina 10.15.7
Spyder 4.1.4
Anaconda 3
Python 3.8.3やったこと
TerminalでTensorflowをインストールしようとすると、下記のようなエラーが出ました。(2020/10/28現在)
(省略) UnsatisfiableError: The following specifications were found to be incompatible with the existing python installation in your environment: Specifications: - tensorflow -> python[version='2.7.*|3.7.*|3.6.*|3.5.*'] Your python: python=3.8 If python is on the left-most side of the chain, that's the version you've asked for. When python appears to the right, that indicates that the thing on the left is somehow not available for the python version you are constrained to. Note that conda will not change your python version to a different minor version unless you explicitly specify that. (省略)TensorflowのサポートしているPythonのバージョンは3.7までだけど、あなたのは3.8ですよ。と教えてくれています。
というわけでこちらの記事を参考にさせていただきながら、Python3.7の仮想環境を作りました。
[環境構築 Python]Anaconda NavigaterのEnviromentsにあるCreateボタンを押し、
Name:python37
Package:python3.7
で作成完了。
▶︎ボタンを押してTerminalを起動し、condaを更新# condaの更新 conda update --all conda update -n base condaそしてtensorflowをインストール
conda install tensorflowちなみに、condaとpipを混同するのはあまり素敵じゃないようです。
[condaとpip:混ぜるな危険]Spyderを起動して下記を入力して実行。無事importできました。
import tensorflow
- 投稿日:2020-10-28T22:43:10+09:00
Flaskで作るSNS Python基本編
初めに
Udemyの下記講座の受講記録
Python+FlaskでのWebアプリケーション開発講座!!~0からFlaskをマスターしてSNSを作成する~
https://www.udemy.com/course/flaskpythonweb/Pythonの基本文法編とFlaskを使ったアプリケーション作成に分けて記載する。
- 環境はAnacondaのdockerイメージで作成したコンテナ上で行う。
仮想環境構築
venvを使用してアプリケーション作成用の仮想環境を作成する。
1.仮想環境の作成
(base) root@e8cf64ce12e9:/home/venv/flaskenv# python -m venv flaskenv2.仮想環境起動
・起動した仮想環境名が行の頭に()付きで表示される。
(base) root@e8cf64ce12e9:/home/venv/flaskenv# source bin/activate (flaskenv) (base) root@e8cf64ce12e9:/home/venv/flaskenv#・停止
(flaskenv) (base) root@e8cf64ce12e9:/home/venv/flaskenv# deactivate (base) root@e8cf64ce12e9:/home/venv/flaskenv#Git登録
1.Githubでリポジトリを作成
省略
2.ローカルGitの登録とGithub連携
kekosh@kekosh-mbp flaskenv % git init Initialized empty Git repository in /Users/kekosh/work/docker/venv/flaskenv/.git/ kekosh@kekosh-mbp flaskenv % git add . kekosh@kekosh-mbp flaskenv % git commit -m 'first commit' kekosh@kekosh-mbp flaskenv % git remote add origin git@github.com:kekosh/flask-sns.git kekosh@kekosh-mbp flaskenv % git push -u origin masterGithubリポジトリ(「remote add ....」の先)変更する場合
kekosh@kekosh-mbp flaskenv % git remote rm originMacの注意点
Macの場合「.DS_Store」という隠しファイルが各ディレクトリに作成される。
これはGit管理するべきファイルではないため、コミット前にgitignoreに管理対象外として登録しておく。# Mac .DS_StoreすでにGithubに連携済みの場合は、.gitignoreに上記追加後、Gitのキャッシュを削除して
次回コミットから管理対象外となるようにする。kekosh@kekosh-mbp flaskenv % git rm -r --cached .Python
all (and条件の集合体)
複数の比較条件をtupleとしてまとめたものを引数に取る。すべての条件式がTrueの場合にTrue返す
>>> i = 0 >>> x = 'test' >>> if all((i<10, x =='test')): ... print('全部True') ... 全部Trueany (OR条件の集合体)
複数の比較条件をtupleとしてまとめたものを引数に取る。条件式のうち一つでもTrueの場合にTrue返す。
>>> i = 0 >>> x = 'any' >>> if any((i > 10, x == 'any' )): ... print('True含む') ... True含むenumerate (インデックスを同時取得する)
>>> list = ['taro','jiro','sabu','shiro'] >>> for i, v in enumerate(list): ... print(i, v) ... 0 taro 1 jiro 2 sabu 3 shirozip (2つの配列から同時に値を取得する)
>>> list_a = ['cat','dog','rabbit'] >>> list_b = ['mike','jhon','usa'] >>> for a, b in zip(list_a,list_b): ... print(a, b) ... cat mike dog jhon rabbit usaセイウチ演算子 (変数への代入と使用を同時実行する。python3.8以降)
省略
import traceback (エラーの詳細を取得する)
m = 100 n = input() try: result = m /int(n) print(result) except ZeroDivisionError as ze: import traceback traceback.print_exc() print('end')#結果 kekosh-mbp:flaskenv kekosh$ python main.py 0 Traceback (most recent call last): File "main.py", line 5, in <module> result = m /int(n) ZeroDivisionError: division by zero endtry ~ except ~ else ~ finally
- else:エラーが発生しなかった場合のみ実行する処理。ここで発生したExceptionはこれ以前のexceptではキャッチされない。
- finally:エラーの有無に関わらず必ず実行される処理。
try: #主な処理 except XXXXXX as e: #特定の例外発生時に実行する処理 except Exception e: #特定の処理を記載している例外以外のすべての例外発生時の処理 else: #例外が発生しなかった場合にのみ実行される処理 finally: #例外の有無に関わらず必ず実行される処理raise Exception (特定の例外を意図的に返す)
raise ZeroDivisionError('ゼロでは割り切れません')独自例外の作成
Exceptionクラスを継承したクラスを作成する。
#テンプレート class MyException(Exception) print('独自エラー発生')#実装例 class EvenDevideError(Exception): pass def main(): m = 10 n = int(input('入力:')) if n == 2: raise EvenDevideError('even number input') else: print('end') if __name__ == '__main__': main()#結果 kekosh-mbp:flaskenv kekosh$ python main.py 入力:2 Traceback (most recent call last): File "main.py", line 14, in <module> main() File "main.py", line 9, in main raise EvenDevideError('even number input') __main__.EvenDevideError: even number input可変長引数
- 可変長引数は引数の一番うしろに
- def func(arg1, *arg2): "*args2"に渡された引数はタプルとして関数に渡される。
- def func(arg1, arg2): "arg2"に渡された引数は辞書型として関数に渡される。
>>> def func_1(arg1, *arg2): ... print("arg1={}, *arg2={}".format(arg1, arg2)) ... >>> def func_2(arg1, **arg2): ... print("arg1={}, **arg2={}".format(arg1, arg2)) #値を複数渡した場合、"*"がついてない変数に前から一つずつ値をセットし、 #残った引数値はarg2にまとめてタプルとしてセットされる。 >>> func_1(1,2,3,4,5) arg1=1, *arg2=(2, 3, 4, 5) #"**"の場合は値を渡す時に辞書型変数と同じように"id=1"のような形式で #引数をセットする必要がある。 >>> func_2(1,2,3,4,5) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: func_2() takes 1 positional argument but 5 were given >>> >>> func_2(1, id=1, name='taro') arg1=1, **arg2={'id': 1, 'name': 'taro'}ジェネレータ関数
- yield val : 関数の処理を'yield'の箇所で停止し、呼び出し元にyieldの変数を返す。
- 'yield'以下の処理は'next(func)'として呼び出すことで実行される。
def generater(max): print('ジェネレーター作成') for i in range(max): #インスタンス作成時にyieldで処理が停止し、呼元にはyieldの変数を返す yield i print('yield実行') gen = generater(10) #next()にジェネレータ関数を渡すことで、yield以降の処理が実行される n = next(gen) print('n = {}'.format(n)) n = next(gen) print('n = {}'.format(n)) #next()ではなくループ処理で実行することも可能 for x in generater(10): print('x = {}'.format(x))ジェネレーター作成 n = 0 yield実行 n = 1
- next()関数の他にジェネレータ関数には以下のメソッドがある。
- send(val) : ジェネレータ関数内の'yield'を変数に代入している場合、その変数にvalの値を代入する。
def gengerator(max) #省略 for i in generator() x = yield i print(x) gen = generator(10) #yieldで処置を止めた後、yieldが格納されている変数にsend(val)のvalを格納する。 gen.send(100)
- generator.throw(err_value): 意図的にエラーを発生させる。
- generator.close(): yield処理の終了
サブジェネレータ
- yield from sub generator :ジェネレータ関数から別のジェネレータ関数を呼びだすことができる。
def sub_gen(): yield 'sub_generator' print('on sub_gen') return 'sub_gen' def main_gen(): yield 'main_generator' #yield from でサブジェネレータを呼びだす res = yield from sub_gen() print(res) return 'main_gen' gen = main_gen() print(next(gen)) print(next(gen)) print(next(gen))main_generator sub_generator on sub_gen sub_gen Traceback (most recent call last): File "d:/MyFile/arc/pyenv/py-outlook/app.py", line 17, in <module> print(next(gen)) StopIteration: main_gen
- 'yield from'でサブジェネレータを呼び出した場合も通常のジェネレータ同様、'yield val'のところで処理を停止し、呼び出し元にvalの値を返す。
- 次回実行(next()など)時には、処理を停止した'yield'の位置から続きの処理を実行する。
- 上記3つめのprint()の時点でジェネレータの処理は終了しているため、エラーが返される。
ジェネレータの用途
- ジェネレータはメモリ使用量削減のために利用する。
- List型変数を宣言して何万件ものデータを入れるとメモリ使用量が莫大となるが、ジェネレータを使ってList型変数を作成した場合、メモリ使用量が大幅に削減できる。
高階関数
- 関数を変数に代入すること。
- 高階関数の場合、変数に代入する際に関数には「()」をつけない。
def print_hello(func): print('hello') func('taro') return print_message def print_bye(name='someone'): print('good bye, {}'.format(name)) def print_message(): print('戻り値が関数') #pattern1. リストの要素として関数を格納 list = [1, 'test', print_bye, print_hello] #pattern1. 高階関数を実行する場合は、インデックスの後ろに「()」をつける list[2]() #pattern2. 関数の引数に関数を渡すパターン(戻り値も関数) var = print_hello(print_bye) var()#pattern1の結果 good bye, someone #pattern2の結果 hello good bye, taro 戻り値が関数lambda式
- 通常の関数(def)から関数名を除いて1行で定義する関数(無名関数)
- 無名関数 lambda 引数:返り値の処理
#if文のlambda式 def func(x): response = '' #通常のif文 if x > 5: response = 'large' else: response = 'small' return response #lambda形式 response = 'large' if x > 5 else 'small' return response x = int(input('入力:')) res = func(x) print(res)>>> func = lambda x,y,z : x*y*z if z > 10 else x*y >>> >>> func(1,2,3) 2 >>> func(1,2,15) 30再帰
- 関数内でその関数自身を実行すること。
>>> def fib(n): ... n = int(n) ... return n if n <= 2 else fib(n-1) + fib(n-2) >>> for i in range(1,10): ... print(fib(i)) ... 1 2 3 5 8 13 21 34 55リスト内包表記
- 変数名 = [式 for 変数 in リスト(if式) ]
- リスト型だけでなく、カッコを丸括弧で定義するとジェネレータになり、丸括弧の前に「tuple」をつけるとタプル形式の結果を返す。また、set型の場合はカッコを{}にする。
- リスト内包表記内で関数を実行し、その結果をリストの要素に設定することも可能
#リストを作成するリスト内包表記 >>> list_a = [x * 2 for x in range(1,10)] >>> print(list_a) [2, 4, 6, 8, 10, 12, 14, 16, 18] >>> >>> list_b = [x * 2 for x in range(1,10) if x % 2 == 0] >>> print(list_b) [4, 8, 12, 16] #タプル作成のリスト内包表記 >>> list_c = tuple(x for x in range(10)) >>> list_c (0, 1, 2, 3, 4, 5, 6, 7, 8, 9) >>> type(list_c) <class 'tuple'>デコレータ関数
- 複数の関数共通で実行したい処理をデコレータ関数として定義し、'@デコレータ関数名'として対象の関数の前に設置することで、デコレータ関数をセットされた関数を実行した際にデコレータ関数の処理が一緒に実行される。
#デコレータ関数を定義 def decorator(func): def wrapper(*args, **kwargs): print('*' * 30) #引数:func にはデコレータをセットした関数オブジェクトがセットされる。 func(*args, **kwargs) print('*' * 30) return wrapper #デコレータ関数の引数にデコレータをセットした関数がセットされて実行される。 @decorator def func_a(*args, **kwargs): print('func_aを実行') print(args) @decorator def func_b(*args, **kwargs): print('func_bを実行') print(kwargs) func_a(1,2,3) func_b(4,5,6,id=4,name='test')kekosh-mbp:flaskenv kekosh$ python decorator.py ****************************** func_aを実行 (1, 2, 3) ****************************** ****************************** func_bを実行 {'id': 4, 'name': 'test'} ******************************map関数
- map([関数], [関数に渡す変数]...)
- 第1引数に指定した関数の引数に、第2引数以降に指定したリスト型、辞書型などイテレート型の変数から要素を順次取得して処理した結果を返す。
#代表例:第2引数にリスト型 list_a = [1,2,3,4,5] map_a = map(lambda x: x*2, list_a) #map型オブジェクトの内容はfor文で確認する for x in map_a: print(x) #辞書型引数も使用可能 person = { 'name': 'Yamada' ,'age': '34' ,'country': 'Japan' } #関数部分はlambda式の記述も可能 map_b = map(lambda d : d+ ',' + person.get(d), person) for m in map_b: print(m) ''' 関数に複数引数を渡す場合、第1引数の関数にわたすイテレータ式変数間で 要素数が異なる場合は、最も要素数が少ないものに合わせてあまりは切り捨てる。 ''' list_x = ['apple','grape','lemon','peach'] dic_x = {'apple':'150','grape':'140','lemon':'110','peach':'180'} tuple_x = tuple(x for x in range(1,5)) def mapping(name,dic,count): fruit = name price = dic_x.get(fruit) return fruit + ':' + str(price) + ':' + str(count) map_c = map(mapping,list_x,dic_x,tuple_x) for mc in map_c: print(mc)2 4 6 8 10 name,Yamada age,34 country,Japan apple:150:1 grape:140:2 lemon:110:3 peach:180:4Class定義
#クラス定義のテンプレート class className: """クラスの機能を説明するコメント""" def methodName(self,...): #処理 #定義したクラスを使用するためにインスタンスを作成する instance = className()#<サンプル> #クラスの定義 class Car: country = 'japan' year = 2020 name = 'Prius' #クラスにメソッドを定義する場合、メソッドの第1引数は必ず「self」とすること。 def print_name(self): print('メソッド実行') print(self.name) my_Car = Car() print(my_Car.year) my_Car.print_name() #リスト型の1要素にクラス(インスタンス)を使用する list = ['apple', 'banana', Car()] list[2].print_name()クラス変数とインスタンス変数
クラス変数
- オブジェクト同士で共有可能な変数
- クラス直下に記載するアクセス方法
- クラス名.クラス変数名
- インスタンス名.__class__.クラス変数
※__class__を記載しない場合(インスタンス名.クラス名)に取得できるデータはクラス変数とは異なる(インスタンス変数が取得される)インスタンス変数
- インスタンスごとに別々に利用する変数
- メソッド内に記載するアクセス方法
インスタンス名.変数class SampleA(): #クラス変数 class_val = 'class val' def set_val(self): #インスタンス変数 self.instance_val = 'instance val' def print_val(self): print('クラス変数:{}'.format(self.class_val)) print('インスタンス変数:{}'.format(self.instance_val)) #インスタンス作成 instance_A = SampleA() #インスタンスメソッドの呼び出し instance_A.set_val() print(instance_A.instance_val) instance_A.print_val() #クラス変数の出力 print(SampleA.class_val) print(instance_A.__class__.class_val) print('---------------------') #クラスから新しいインスタンスを作成 instance_B = SampleA() instance_B.class_val = 'change' #クラス変数の値をインスタンスから変更した場合、別のインスタンスからクラス変数を参照した場合も #値が変わってしまうことに注意。 print('instance_Aのクラス変数:{}'.format(instance_A.__class__.class_val)) print('instance_Bのクラス変数:{}'.format(instance_B.__class__.class_val))instance val クラス変数:class val インスタンス変数 = instance val class val class val --------------------- instance_Aのクラス変数:class val instance_Bのクラス変数:class val kekosh-mbp:flaskenv kekosh$コンストラクタ
- インスタンス作成時に呼び出されるメソッド
class Sample: #コンストラクタ def __init__(self, msg, name=None): print('コンストラクタ実行') #インスタンス変数に引数の値を代入 self.msg = msg self.name = name def print_msg(self): print(self.msg) def print_name(self): print(self.name) inst_1 = Sample('hello', 'taro') inst_1.print_msg() inst_1.print_name()#インスタンス作成時にコンストラクタは自動的に実行される。 コンストラクタ実行 hello taroデストラクタ
- インスタンス削除時(利用終了時)に呼び出される処理
#デストラクタ def __del__(self): print('デストラクタが実行されました') print('name = {}'.format(self.name))# インスタンス処理終了時(del インスタンス名で削除した場合含む) デストラクタが実行されました name = taroメソッドの種類
インスタンスメソッド
- クラス内で定義したメソッドのうち、インスタンス作成後に利用可能となるメソッド。第1引数は必ずselfとなる。selfは自分自身を指す。
- インスタンスメソッドからクラスメソッド、スタティックメソッドを利用することは可能。クラスメソッド
インスタンス化せずに使用できるメソッド。メソッドの定義直上に「@classmethod」と記載し、第1引数を「cls」とする。
- クラス名.クラスメソッド名() でクラスメソッドを実行可能。
- cls はclass自身の意
- cls.クラス変数名 でクラス変数にアクセス可能。
- クラスメソッドではインスタンス変数にアクセスすることはできない。スタティックメソッド
- メソッド定義直上に「@staticmethod」と記載する。
- クラス変数もインスタンス変数もアクセスできない関数。class Human: class_name='Human' #コンストラクタ def __init__(self, name, age): self.name = name self.age = age #インスタンスメソッド def print_name_Age(self): print('インスタンスメソッド実行') print('name={}, age={}'.format(self.name, self.age)) #クラスメソッド @classmethod def print_class_name(cls, msg): print('クラスメソッド実行') print(cls.class_name) print(msg) #スタティックメソッド @staticmethod def print_msg(msg): print('スタティックメソッド実行') print(msg) #クラスメソッド Human.print_class_name('こんにちは') #インスタンスメソッド human =Human('taro', 18) human.print_name_Age() #スタティックメソッド human.print_msg('スタティック')クラスメソッド実行 Human こんにちは インスタンスメソッド実行 name=taro, age=18 スタティックメソッド実行 スタティック特殊メソッド
インスタンスにアクセスする際に特定の処理を実行すると呼び出されるメソッド
メソッド 概要 __str__(self) str(),print()を実行した際に呼び出され、文字列を返す __bool__(self) if文の比較処理をカスタマイズする __len__(self) len()の処理内容をカスタマイズする __eq__(self、other) インスタンスに対して==演算子を使用した場合に呼び出される __name__(self) クラスの名前を返す __hash__(self) 渡された値からハッシュ値を作成して返す 参考
公式ドキュメント
https://docs.python.org/ja/3.6/reference/datamodel.html#special-method-names@IT
https://www.atmarkit.co.jp/ait/articles/2002/18/news007.html#特殊メソッド class Human: #コンストラクタ def __init__(self, name, age, phone): self.name = name self.age = age self.phone = phone #特殊メソッド:print()した時に以下の処理結果で返す def __str__(self): return self.name + ":" + str(self.age) #特殊メソッド:「==」による比較処理の内容をカスタマイズ """ インスタンスを比較したときに、ageが異なってもnameとphoneが一致していれば Trueを返す。 """ def __eq__(self, args): return (self.name == args.name) and (self.phone == args.phone) man = Human('tanaka', 18, '090-9999-8888') print(man) woman = Human('tanaka', 20, '090-9999-8888') print(man == woman)#__str__の結果 tanaka:18 #__eq__を定義していない場合 False #__eq__を定義している場合 Trueここまでのまとめ
#独自例外 class CharaterAlreadyExistsException(Exception): pass class AllCharacters: ''' キャラクター情報管理用クラス ''' all_characters = [] alive_characters = [] dead_characters = [] @classmethod def character_append(cls,name): #同一名称は独自エラーを返す if name in cls.all_characters: raise CharaterAlreadyExistsException('既存のキャラクター名') cls.all_characters.append(name) cls.alive_characters.append(name) @classmethod def character_delete(cls,name): cls.dead_characters.append(name) cls.alive_characters.remove(name) class Character: def __init__(self,name,hp,offense,defense): #インスタンス作成時にコンストラクタ内でキャラ情報を登録 AllCharacters.character_append(name) self.name = name self.hp = hp self.offense = offense self.defense = defense def attack(self,enemy,critical=1): if self.hp <= 0: print('Character is Already dead.') return attack = self.offense - enemy.defense attack = 1 if attack <= 0 else attack enemy.hp -= (attack * critical) if enemy.hp <= 0: AllCharacters.character_delete(enemy.name) def critical(self, enemy): self.attack(enemy,2) #---- アプリケーション実行 ----- chara_A = Character('A',10,5,3) chara_B = Character('B',8,6,2) print(chara_B.hp) #chara_A.attack(chara_B) chara_A.critical(chara_B) print(chara_B.hp) print(AllCharacters.alive_characters) chara_A.critical(chara_B) print(AllCharacters.dead_characters) print(AllCharacters.alive_characters) chara_B.attack(chara_A)#実行結果 8 2 ['A', 'B'] ['B'] ['A'] Character is Already dead.クラスの継承
継承
- 別のクラスの性質を引き継ぐこと。
- 継承元をスーパークラス、継承先をサブクラスと呼ぶ。
- サブクラスはスーパークラスのプロパティとメソッドを引き継ぐことができる。ポリモフィズム
- 複数作成したサブクラスにおいて、同じ名称のメソッドではあるが処理内容が異なるメソッドを作成する。
- 呼び出す際に処理内容を気にせずに呼び出すことが可能な性質のことオーバーライド
- 親クラスで定義されたメソッドと同名のメソッドを定義することで、サブクラス独自の処理内容に書き換えること。オーバーロード
- 親クラスで定義されたメソッドと同名のメソッドをサブクラスで定義すること。このとき、引数、返り値を変更した場合はオーバーロードとなる。
- pythonではオーバーロードという機能はない。オーバーロードと同様の機能を実現したい場合は、予め対象のメソッドにデフォルト値Noneの引数を必要数定義しておくことによって引数の数の変更に対応したりすることができる。#親クラス class Person: def __init__(self, name, age): self.name = name self.age = age def greeting(self): print('hello, {}'.format(self.name)) def say_age(self): print('{} years old.'.format(self.age)) #Personクラスを継承 class Employee(Person): def __init__(self, name, age, number): #super()を使って親クラスのコンストラクタを呼び出す。 super().__init__(name, age) #親クラスのコンストラクタ呼出で下記プロパティの値はセットしているため、 #サブクラスではプロパティへの代入は省略可能 # self.name = name # self.age = age #numberはEmployeeクラスの独自要素なので別途代入処理 self.number = number def say_number(self): print('my number is {}'.format(self.number)) #親クラスのメソッドをオーバーライド def greeting(self): #親クラスの同名メソッドを実行 super().greeting() print('I\'m employee number = {}'.format(self.number)) #オーバーロード(pythonにはない機能。デフォルト引数で代用可能) # def greeting(self, age=None): # print('オーバーロード') man = Employee('Tanaka', 34, 12345) man.greeting() man.say_age()hello, Tanaka I'm employee number = 12345 34 years old.クラスの多重継承
多重継承
複数のクラスを親クラスとして継承することができる。class Class_A: def __init__(self, name): self.a_name = name def print_a(self): print('ClassA method running') print('a = {}'.format(self.a_name)) def print_hi(self): print('{}, hi'.format(self.name)) class Class_B: def __init__(self, name): self.b_name = name def print_b(self): print('ClassB method running') print('b = {}'.format(self.b_name)) def print_hi(self): print('{}, Hi!'.format(self.b_name)) #多重継承するサブクラス class NewClass(Class_A, Class_B): def __init__(self, a_name, b_name, name): Class_A.__init__(self, a_name) Class_B.__init__(self, b_name) self.name = name def print_new_name(self): print("name = {}".format(self.name)) def print_hi(self): Class_A.print_hi(self) Class_B.print_hi(self) print('New Class hi') sample = NewClass('A_Name','B_Name','New Class Name',) #継承したClassA、ClassBのメソッドを実行 sample.print_a() sample.print_b() #サブクラス独自のメソッドを実行 sample.print_new_name() #サブクラスからスーパークラスのメソッドを実行 sample.print_hi()ClassA method running a = A_Name ClassB method running b = B_Name name = New Class Name New Class Name, hi B_Name, Hi! New Class hiポリモフィズム
複数のサブクラスを作成した場合に同名のメソッドが必ず定義されていて実行できること?
抽象クラス
- そのクラス自身のインスタンスを作成しない(できない)、抽象メソッドを持つクラスで、スーパークラスとしてサブクラスが継承して使うためのクラス。
- 抽象クラスを作成する場合、メタクラスとしたabcライブラリの「ABCmeta」というメタクラスを抽象クラスの「metaclass」に設定する必要がある#抽象クラスのテンプレート from abc import ABCMeta, abstractmethod class Human(metaclass=ABCMeta) @abstractmethod def say_name(self, name): passabstractメソッド
- メソッドの直上に「@abstractmethod」と宣言して作成されるメソッド
- abstractメソッドを持つクラスをスーパークラスとした場合、サブクラスでは必ずabstractメソッドをオーバーライドしたメソッドを定義する必要がある。#抽象クラス from abc import ABCMeta, abstractmethod class Human(metaclass = ABCMeta): def __init__(self, name): self.name = name #抽象メソッド @abstractmethod def say_something(self): pass def say_name(self): print('my name is {}.'.format(self.name)) """ 以下のように抽象クラスを継承している場合、@abstractmethodとして宣言されている メソッドをオーバーライドしていない場合は、インスタンス作成時にエラーとなる。 class Woman(Human): pass エラー: TypeError: Can't instantiate abstract class Woman with abstract methods say_something """ class Woman(Human): def say_something(self): print('I\'m Lady.') class Man(Human): #オーバーライドで引数の種類を追加 def say_something(self, name='nameless', age='20'): print('I\'m Men.' + str(age)) #抽象クラス実行 # wm = Woman('Hanako') # me = Man("Yamada") # wm.say_something() # me.say_something('taro',12) #ポリモフィズム """ 実行するまでhumanインスタンスはManかWomanか決まっていないが 実行するインスタンスメソッドはどちらのクラスのインスタンスであっても問題なく 実行できる """ num = input('Please input 0 or 1: ') human = "" if num == '0': human = Woman(Human) elif num == '1': human = Man(Human) else: print('wrong number') human.say_something()-- 抽象クラス実行結果確認 -- I'm Lady. I'm Men.12 #0を入力した場合 -- ポリモフィズム実行結果 -- I'm Lady. #1を入力した場合 -- ポリモフィズム実行結果 -- I'm Men.20プライベート変数
- 外部からアクセスできない変数(pythonではアクセスする方法あり)
- クラスを経由してのアクセスは可能。ただしあまり使用することはない。
- 実際にプログラミングする場合は基本的にプライベート変数で定義すべき
__variable = "val"#private変数を呼び出そうとした場合 AttributeError: 'Human' object has no attribute '__name'#インスタンスからプライベート変数にアクセスする val = インスタンス._クラス名__nameカプセル化,setter,getter
Private変数を使用する場合、クラス外部からPrivate変数が見えないようにカプセル化する必要がある。
#getterの定義 def get_変数名(): 処理 #setterの定義 def set_変数名(); 処理 #getter,setterを呼び出すためのプロパティを作成 変数名 = property(get_変数名, set_変数名)-「変数名」の部分にはすべて共通の名称が入る。
<パターン1>
#カプセル化、getter、setter パターン1 class Human: def __init__(self,name,age): #private変数 self.__name = name self.__age = age def get_name(self, name): print('call getter [name]') return self.__name def set_name(self, name): print('call setter [name]') self.__name = name #propertyの作成(getter,setterの利用に必要) #外部からアクセスする際はpropertyを使用する。 name = property(get_name, set_name) def print_name(self): print(self.__name) human = Human('Tanaka', 20) #getter,setterを使用するときはプロパティを変数のように呼び出す human.name = 'Suzuki' human.print_name()<パターン2(こちらが主)>
#getter @property def val_name(self): return private変数 #setter @val_name.setter def val_name(self, val): self.__val = val#カプセル化、getter、setter パターン2 class Human: def __init__(self, name, age): self.__name = name self.__age = age #getterの定義 @property def name(self): print('call getter [name]') return self.__name @name.setter def name(self, name): print('call setter [name]') self.__name = name @property def age(self): print('call getter [age]') return self.__age @age.setter def age(self, age): print('call setter [age]') if age >= 5: print('4以下の値を入力してください。') return else: self.__age = age human = Human('taro', 24) human.name = 'goro' human.age = 5 print(human.name) print(human.age)ここまでのまとめ
#抽象メソッド用ライブラリ from abc import abstractmethod, ABCMeta #抽象クラス定義 class Animals(metaclass=ABCMeta): #カプセル化対応(private変数、getter、setter) def __init__(self, voice): self.__voice = voice @property def voice(self): return self.__voice @voice.setter def voice(self, voice): self.__voice = voice #抽象メソッド(サブクラスで必ずオーバーライドが必要) @abstractmethod def speak(self, voice): pass """ 以下サブクラスはAnimalsをスーパークラスとして継承しているため、 コンストラクタの処理、getter、setterは共通 """ class Dog(Animals): #self.voice はスーパークラスで定義したgetterの処理を利用している。 def speak(self): print(self.voice) class Cat(Animals): def speak(self): print(self.voice) class Sheep(Animals): def speak(self): print(self.voice) class Other(Animals): def speak(self): print(self.voice) #標準入力を取得 select = int(input('数値を入力してください: ')) if select == 1: #犬 animal = Dog("わん") elif select == 2: #猫 animal = Cat("にゃー") elif select == 3: #羊 animal = Sheep("メー") else: #その他 animal = Other("そんな動物はいない") animal.speak()ファイル入力
filepath = 'resources/test.txt' """ #open,closeを明示する(閉じ忘れ帽子のためにwithを使うほうが良い) f = open(filepath, mode='r') #読み取りモードでファイルを開く data = f.read() #ファイルの内容をすべて読み込み f.close() print(data) """ #open,closeを自動的に行う #encodingオプションで読み込むファイルの文字コードを指定 with open(filepath, mode='r', encoding='utf-8') as f: text = '' #一行だけ読み込む #print(f.readline()) #1行ずつ読み込む(配列として返す) for line in f.readlines(): text += line print(text)ファイル出力
filepath = 'resources/output.txt' """ #newlineオプションで改行文字を指定する。(デフォルト:\n) f = open(filepath, mode='w', encoding='utf-8', newline='\n') f.write('書き込みました') """ list_a = [ ['A','B','C'], ['あ','い','う'] ] #with構文を使った場合 mode:w は同名ファイルが存在する場合は上書きする。 with open(filepath, mode='w', encoding='utf-8', newline='\n') as f: f.writelines('\n'.join(list_a[0])) #追記モードでファイルを出力する。指定したファイルが存在しない場合は新規作成する。 with open(filepath, mode='a', encoding='utf-8', newline='\n') as f: f.writelines(list_a[1])withの使い方
with [class] as x: 処理withを記載している処理実行前に、指定したクラスに定義されている下記処理を実行する。
- __init__
- __ener__
また、クラスの処理終了時に下記の処理を実行する。
- __exit__
<使い所>
開始から終了までの処理が継続して行われている場合
- ファイル書き込み処理(ファイル開く→書き込み→閉じる)
- DBへのデータ書き込み(DB接続→データ登録→DB切断
class WithTest: """ 自作クラスをwithで使用可能なクラスにするためには、以下の3メソッドが実装されている必要がある。 """ def __init__(self, file): print('init called') self.__file = file def __enter__(self): print('enter called') self.__file = open(self.__file, mode='w', encoding='utf-8') return self def __exit__(self, exc_type, exc_val, traceback): print('exit caled') def write(self, msg): self.__file.write(msg) with WithTest('resources/output.txt') as wt: print('---withの中--') wt.write("書き込み")init called enter called ---withの中-- exit caled kekosh-mbp:flaskenv kekosh$
- 投稿日:2020-10-28T21:14:49+09:00
Pyxelの環境構築(Mac)
Pyxelというレトロゲームエンジンの環境構築手順についてまとめておきます。
Mac向けの解説となっています。
Pyxelとは
Pythonでレトロ風のゲームを開発することのできるゲームエンジンです。
githubで公開されているので詳しくはこちらを見てください。
https://github.com/kitao/pyxelPyxelの環境構築
この順番で説明していきます。
- Homebrewのインストール
- Python3のインストール
- Pyxelのインストール
手順1
Pyxelを使うためには、Python3のインストールが必要です。(Macに標準でインストールされているPythonはバージョンが古く、Pyxelが動作しません。)
そして、Python3をインストールするために、Homebrewを使うと便利ですのでインストールしていきます。まず、Mac標準のアプリケーションのターミナルを開いて、下のコードを入力して実行してください。
brew -v実行結果が下のようになった場合は、homebrewがすでにインストールされています。手順4に進んでください
Homebrew 2.5.5 Homebrew/homebrew-core実行結果が下のようになった場合はHomebrewがインストールされていません。手順2に進んでください。
command not found実行結果が下のようになった場合はHomebrewが正しくインストールされていません。手順3に進んでください。
Homebrew 2.5.5 Homebrew/homebrew-core N/A手順2
下のコードを実行してください。なにかウィンドウが出てきた場合、画面の指示にしたがってインストールしてください。
また、press RETURN ・・・ と表示された場合はEnterキーを、password: と表示されたら自分のパソコンのログインパスワードを入力してください。xcode-select --install終了したら、次に下のコードを実行してください。かなり時間がかかります。
先ほどと同じように、press RETURN ・・・ と表示された場合はEnterキーを、password: と表示されたら自分のパソコンのログインパスワードを入力してください。/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"終了したら、手順4に進んでください。
手順3
下のコードを実行してください。
brew update-reset終了したら、次に下のコードを実行してください。かなり時間がかかります。
press RETURN ・・・ と表示された場合はEnterキーを、password: と表示されたら自分のパソコンのログインパスワードを入力してください。brew doctor終了したら、手順4に進んでください。
手順4
Homebrewがインストールされたと思うので、次にPython3のインストールを進めていきます。
下のコードを実行してください。そこそこ時間がかかります。
brew install python3 gcc sdl2 sdl2_image gifsicle終了したら、手順5に進んでください。
手順5
Python3がインストールされたと思うので、最後にPyxelをインストールしていきます。
下のコードを実行してください。
pip3 install -U pyxelこれで、Pyxelでレトロゲームを作る準備は終了です!!!
まとめ
お疲れ様です!!
かなり時間がかかったと思いますが、これでPyxelを使えるようになっているはずです。
Pyxelの使い方についてはたくさん記事があると思うので各自調べてやってみてください!最後まで読んでいただきありがとうございました!
間違った内容がありましたらご指摘いただけると嬉しいです!参考
- 投稿日:2020-10-28T20:43:53+09:00
TypeError: unsupported operand type(s) for -: 'datetime.time' and 'datetime.time'となったときの対応方法
- 環境
- macOS Catalina バージョン10.15.7
- Python 3.8.5
- pandas 1.1.3
事象 : TypeError: unsupported operand type(s) for -: 'datetime.time' and 'datetime.time'
時間を引き算したら怒られた
Traceback (most recent call last): File "/Users/mananakai/tryPython/main.py", line 30, in calc_diff diff = end - start TypeError: unsupported operand type(s) for -: 'datetime.time' and 'datetime.time'def calc_diff(start, end): diff = end - start print(diff)原因 : datetime.timeとdatetime.dateはそのままじゃ計算できない
時間情報(datetime.time)、日付情報(datetime.date)だけでは計算できない。
計算には、日時情報(datetime.datetime)を使う。対応 : datetime.datetimeに変換して計算する
計算結果は、時刻間の差情報(datetime.timedelta)になる
def calc_diff(start, end): today = datetime.date.today() d_start = datetime.datetime.combine(today, start) d_end = datetime.datetime.combine(today, end) diff = d_end - d_start print(type(diff)) # >> <class 'datetime.timedelta'>
- 投稿日:2020-10-28T19:10:55+09:00
組合せ最適化で、書籍を平らに積んでみよう
背景
ノートPCでオンライン会議をしようとしています。
ノートPCの位置が低いので、カメラの角度が下からになっています。
急いでノートPCの高さを高くしたいのですが、手元で使えるのがいくつかの書籍しかないです。
ノートPCは書籍より大きいので、書籍を2列に積む必要があります。また、2列の書籍の高さが違うとバランスが悪いので、2列の書籍の高さは同じくらいにしたいです。問題
いくつかの書籍を2列に積んでなるべく高くしてください。
そのとき2列の書籍の高さの差は1ミリメートルまでにしてください。考え方
組合せ最適化を使って解きます。
手順としては、問題を定式化して、Pythonでモデルを作成してソルバーで解きます。
「最適化におけるPython」も参考にしてください。定式化
- 入力パラメーター
books:各書籍の高さlimit:2列の高さの差の上限- 変数
obj:2列の高さのうち低い方suml:左の列の高さsumr:右の列の高さvl:各書籍ごとに左の列に積むかどうか(0:積まない、1:積む)vr:各書籍ごとに右の列に積むかどうか(0:積まない、1:積む)- 目的関数:2列の高さのうち低い方を最大化
- 制約条件
objはsumlとsumrのうち小さい方(1)sumlは左の列の高さ(2)sumrは右の列の高さ(3)sumlとsumrの差がlimit以下(4)- 書籍は左右のどちらかにしか置けない(5)
Pythonで解いてみよう
入力パラメーターは、乱数で適当に作成します。
import random from ortoolpy import model_max, addvars, addbinvars, lpDot, value random.seed(1) books = [random.randint(10, 20) for _ in range(20)] # 本の厚さ(ミリメートル) limit = 1 # 左右の高さの差の許容値(ミリメートル) n = len(books) m = model_max() # 数理モデル obj, suml, sumr = addvars(3) # 低い方の高さ、左の高さ、右の高さ vl = addbinvars(n) # 左に本を置くか vr = addbinvars(n) # 右に本を置くか m += obj # 目的関数(なるべく高くする) m += obj <= suml # (1) m += obj <= sumr # (1) m += suml == lpDot(books, vl) # (2) m += sumr == lpDot(books, vr) # (3) m += suml - sumr <= limit # (4) m += sumr - suml <= limit # (4) for vli, vri in zip(vl, vr): m += vli + vri <= 1 # (5) m.solve() # ソルバーで求解 print(f'{m.status = }') print(f'{value(suml) = }') print(f'{value(sumr) = }') print(f'{[int(value(vli) - value(vri)) for vli, vri in zip(vl, vr)]}')
lpDot(X, Y)は、XとYの内積です。つまりlpDot(books, vl)は、左の列の高さになります。出力
m.status = 1 value(suml) = 149.0 value(sumr) = 148.0 [-1, -1, -1, 1, -1, 1, -1, 1, 1, 1, -1, 1, 1, 1, -1, -1, -1, 1, 1, -1]
m.status = 1は「最適解が得られている」という意味です。
value(X)は変数Xの値を取得します。
左の列の高さは149ミリメートル、右の列の高さは148ミリメートルで、差は1ミリメートルになっています。
最後のリストは、1が左の列に置いて、-1が右の列に置くことを表しています。余談
上記は0.1秒で計算できますが、
limitを0にすると、計算時間は24秒になります(240倍)。
このように、組合せ最適化では、ちょっとパラメーターが変わると計算時間が大きく変わることがあります。
limitを色々変えたいときは、「ビンパッキング問題の解き方」のような工夫が必要かもしれません。
- 投稿日:2020-10-28T18:14:23+09:00
自作クラスと既存のクラスの演算
- 投稿日:2020-10-28T17:51:49+09:00
UDPで通信開始して、TCPで送受信する
試しに書いたけど、使うことなさそうだったので、なんかの時用のメモ
UDPServer_and_TCPClient.py
#UDPサーバーと、TCPクライアントを実行する from socket import socket, AF_INET, SOCK_DGRAM, SOCK_STREAM #TCPで接続開始をして、データ送信する関数 def tcp_send(): with socket(AF_INET, SOCK_STREAM) as s: s.connect(('127.0.0.1', 50010)) while True: s.sendall(b'hello') #UDPサーバー udp_server = socket(AF_INET, SOCK_DGRAM) udp_server.bind(('', 8888)) while True: msg, address = udp_server.recvfrom(8192) if msg.decode('utf-8') == "tcp_start": #特定の文字列を受け取ったら、TCPクライアントを接続して送信 tcp_send() break udp_server.close()TCPServer_and_UDPClient.py
#TCPサーバーと、UDPクライアントを実行する from socket import socket, AF_INET, SOCK_DGRAM, SOCK_STREAM #UDP送信する関数 def udp_send(): udp_client = socket(AF_INET, SOCK_DGRAM) udp_client.sendto("tcp_start".encode(), ("127.0.0.1", 8888)) #TCPサーバーを作成 with socket(AF_INET, SOCK_STREAM) as tcp_server: tcp_server.bind(('127.0.0.1', 50010)) tcp_server.listen(1) #UDP送信 udp_send() while True: conn, addr = tcp_server.accept() with conn: while True: data = conn.recv(1024) print(data.decode('utf-8'))
- 投稿日:2020-10-28T17:19:26+09:00
AWS Lambda Layers作成から紐付けまでさらっと解説
はじめに
Pythonを扱う前提の記事です。
Layers(レイヤー)とは
ガイドによると
レイヤーは、ライブラリ、カスタムランタイム、またはその他の依存関係を含む ZIP アーカイブです。レイヤーを使用することで、関数のライブラリを使用することができます。
ライブラリのような共通で使用するモジュールをLayerにすることで、デプロイパッケージにライブラリを含める必要がなくなります。
つまり、Lambdaでサードパーティ製のライブラリやモジュールを使用する際に、Layerに格納して各Lambda関数から呼び出して使用するというような使い方ができます。注記
・Lambdaで一度に利用できるLayerは5つまで
・解凍後のデプロイパッケージのサイズ制限 250 MBディレクトリ構成
Lambda実行環境のパスは /opt ディレクトリとなるので、
Layerのディレクトリ構成としては /opt/python/Layer となります。レイヤー自体のパッケージ構成はこんな感じ。
python ├ layer.py (共通処理などコードも入れられます。common的に扱える) ├ Crypto (外部ライブラリその1) ├ psycopg2 (外部ライブラリその2) ├ sqlalchemy (外部ライブラリその3) …etcLayerの作成
ローカルで作成してみます。
ライブラリを場所指定でpip installする。
$ pip install pycryptodome -t .そしてzip
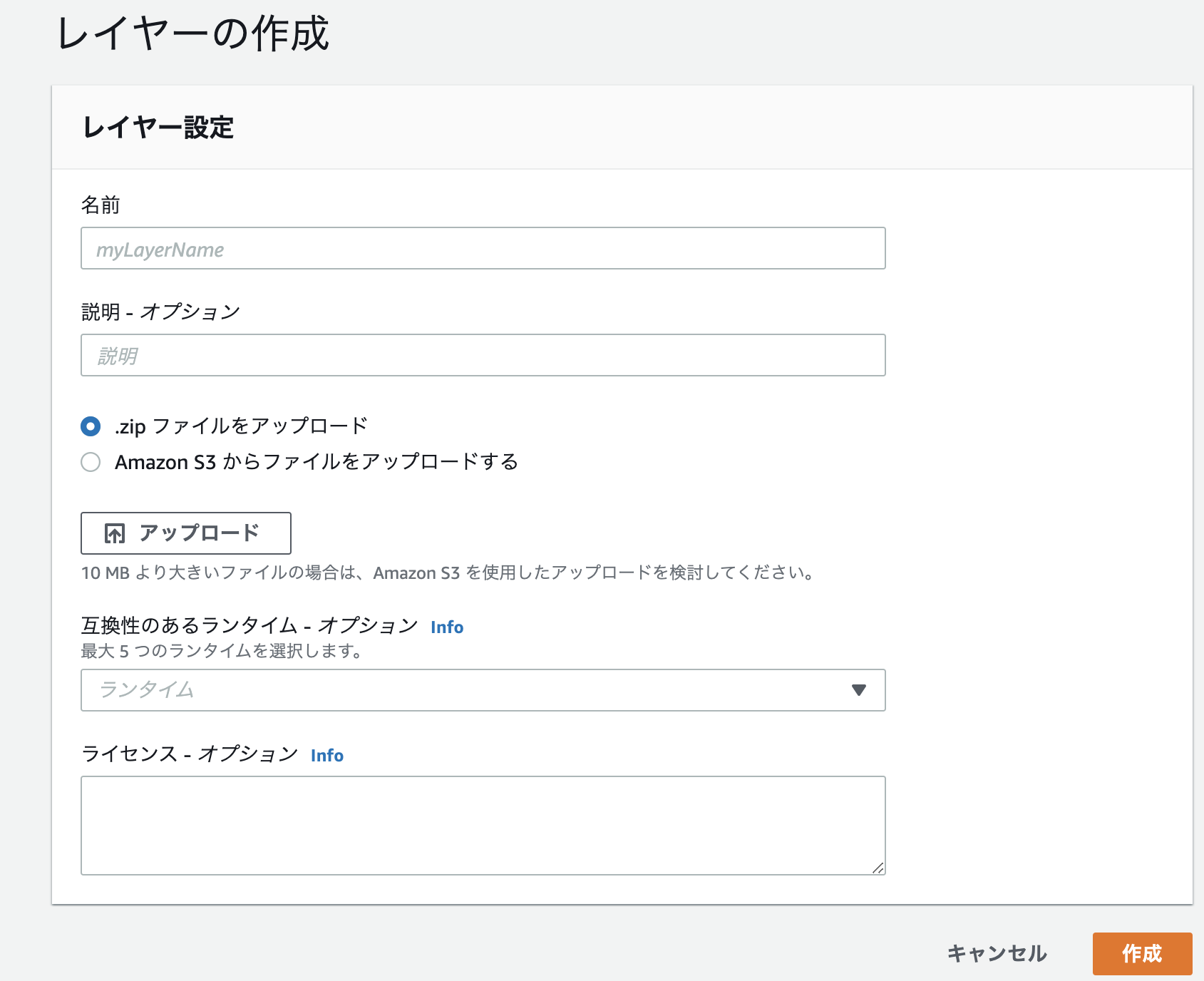
$ zip -r ../python .AWS上でLayerの作成を行います
上から順に
・名前(必須)
・説明(なくても可)
・アップロード(先ほど作成したzipを選択)
・互換性のあるランタイム - オプション(忘れがちになるので注意)
・ライセンス - オプション(なくても可)「作成」をクリックしLayerを作成します。
Lambda関数に紐付け
今度はLambda関数にLayerを紐付けます。
Layerを紐付けたいLambda関数から「デザイナー」を選択し、
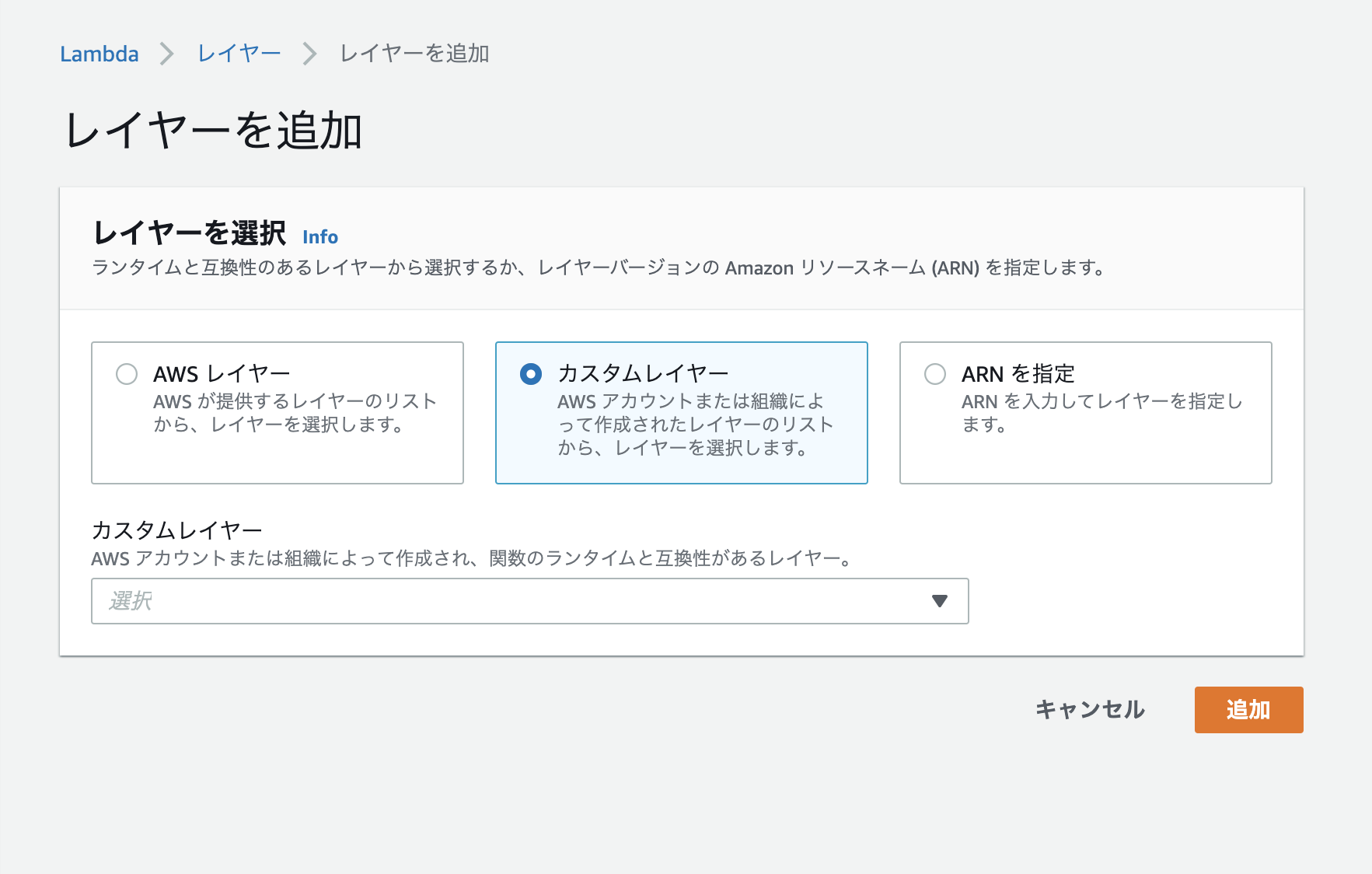
「レイヤーの追加」を選択。
「レイヤーの選択」から「カスタムレイヤー」をクリックし作成したLayerを選びます。
その後「バージョン」を設定し、「追加」をクリックして完了です。Lambdaから呼び出すときはimportして呼び出します。
import layerよくあるミス
・LambdaはAmazon Linux上で動作するので、
pip installした環境によっては実行エラーとなるライブラリもあります。・AWSにアップロードしたLayerはバージョンごとにダウンロードすることも出来ます。
そしてLayerが増えてくるとディレクトリで、こんな感じで管理することもあるかと思います。test_layer ├ python ├ layer.py ├ Cryptoこの場合、そのまま解凍し修正してzipしがちですが、
そのままzipすると親ディレクトリも圧縮してしまいアップロード後の展開時にディレクトリ階層とマッチしなくなるので
作成した時と同じく中身をzipしましょう。$ zip -r ../python .まとめ
Layerは上手く使えばLambda間でのコード共有など非常に便利です。
上手く活用していきましょう。参考
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/configuration-layers.html
- 投稿日:2020-10-28T17:04:20+09:00
Azureのサービス一覧を抽出する
業務で一覧表を作る必要が出たので作成。
なんでもかんでもExcelで一覧表作らせる文化、きらいだよ。スクレイピング方法については AWSサービス一覧(2019/03版)※2020/09/05更新 を参考にさせて頂きました。
Azure サービス一覧
AI + 機械学習
サービス名 説明 Anomaly Detector 異常検出機能をアプリに簡単に追加。 Azure Bot Service オンデマンドにスケーリングできるインテリジェントなサーバーレス ボット サービス Azure Cognitive Search モバイルおよび Web アプリ開発のための AI を活用したクラウド検索サービス Azure Databricks 迅速、簡単で協調型の Apache Spark ベースの分析プラットフォーム Azure Machine Learning 実験とモデル管理ができる、エンド ツー エンドのスケーラブルで信頼性の高いプラットフォームで、すべてのユーザーが AI を使えるようにします Azure Open Datasets 機械学習モデルの開発を加速させる選別されたオープン データセットをホストして共有するためのクラウド プラットフォーム Bing Autosuggest アプリの検索機能にインテリジェントな自動提案オプションを追加 Bing Custom Search 簡単に使用できる、広告なしの商用グレード検索ツールで、必要な検索結果の提供を実現 Bing Entity Search Web からエンティティ情報を特定して追加することで、優れたエクスペリエンスを提供 Bing Image Search 画像を検索してさまざまな情報を手に入れましょう Bing News Search ニュースを検索して包括的な結果を入手 Bing Spell Check アプリでのスペル ミスを検出して修正 Bing Video Search ビデオを検索して包括的な結果を入手 Bing Visual Search お好きなデバイスに魅力的な画像アプリケーションを作成するうえで役立つ豊富な分析情報を入手。 Bing Web Search 何十億もの Web ドキュメントからの詳細検索を強化 Azure Cognitive Services スマートな API 機能を追加して状況に合ったやり取りを実現 Computer Vision 画像から意思決定に役立つ情報を抽出 Content Moderator 画像、テキスト、ビデオを自動モデレート Custom Vision 貴社の最先端のコンピューター ビジョン モデルを、独自の用途向けに簡単にカスタマイズできます Data Science Virtual Machines AI 開発のためにあらかじめ構成されたリッチな環境 Face 写真に含まれる顔の検出、識別、分析、グループ化、タグ付け Form Recognizer フォームを解釈し、ドキュメントを抽出できる AI サービス Immersive Reader あらゆる年齢や能力のユーザーがテキストを読み理解できるようにサポート Kinect DK 高度な AI センサーと開発者キットを使用して、コンピューターによる視覚と音声のモデルを作成します Language Understanding ユーザーが入力したコマンドをアプリが理解できるようにする Microsoft Genomics ゲノム シーケンシングと研究の分析情報を強化する Personalizer パーソナライズされたユーザー エクスペリエンスを提供する AI サービス Project Bonsai プレビュー シミュレーションを使用したインテリジェントな産業用制御システムを作成するための機械教示サービス QnA Maker 情報から会話形式のナビゲーションしやすい回答を抽出 Speaker Recognition プレビュー 話者を認証して識別する Speech サービス機能 Speech to Text 読み上げられたオーディオをテキストに正確に変換する音声サービス機能 Speech Translation リアルタイムの音声翻訳をアプリに簡単に統合する Text Analytics センチメントとトピックを簡単に評価して、ユーザーが求めるものを理解 Text to Speech テキストをリアルな音声に変換する音声サービス機能 Translator シンプルな REST API 呼び出しで機械翻訳を簡単に実行 Video Indexer 動画の分析情報を解明 メトリクス アドバイザー プレビュー メトリクスを監視して問題を診断する AI サービス DevOps
サービス名 説明 Azure Artifacts パッケージの作成とホストを行い、チームで共有 Azure Boards チームの垣根を超えて作業を計画、追跡したり、作業に関する相談をしたりできます Azure DevOps チームがコードを共有し、作業を追跡し、ソフトウェアを出荷するためのサービス Azure DevTest Labs 再利用可能なテンプレートとアーティファクトを使用して環境を素早く構築 Azure Monitor アプリケーション、インフラストラクチャ、およびネットワークに対する完全な可観測性 Azure Pipelines どのようなプラットフォームやクラウドにも継続的にビルド、テスト、デプロイできます Azure Repos プロジェクトにクラウドでホストされた容量無制限のプライベート Git リポジトリを実現します Azure Test Plans 手動および探索的テストのツールキットを使い、自信をもってテスト、リリースを実施 DevOps tool integrations お気に入りの DevOps ツールで Azure を利用できます ID
サービス名 説明 Azure Active Directory オンプレミスのディレクトリを同期してシングル サインオンを実現 Azure Active Directory Domain Services ドメイン コントローラーを使用せずにドメインに Azure 仮想マシンを接続可能 Azure Information Protection いつでもどこでも、お客様の機密情報をより厳重に保護します Azure Active Directory 外部 ID コンシューマーの ID とアクセスの管理をクラウドで実行 Web
サービス名 説明 API Apps 簡単操作によるクラウド API の作成と利用 API Management API を開発者、パートナー、および従業員に、安全かつ大規模に発行する App Service Web およびモバイル向けのパワフルなクラウド アプリを短期間で作成 Azure Cognitive Search モバイルおよび Web アプリ開発のための AI を活用したクラウド検索サービス Azure Maps シンプルで安全な位置 API が、地理空間コンテキストをデータに提供します Azure SignalR Service リアルタイム Web 機能を簡単に追加 Azure Spring Cloud フル マネージドの Spring Cloud サービス、VMware と共同で作成および運用 Content Delivery Network グローバル展開によりセキュアで信頼性の高いコンテンツ配信を実現 Mobile Apps モバイル アプリ用のバックエンドを構築およびホストする Notification Hubs どのバックエンドからでもあらゆるプラットフォームへプッシュ通知を送信 Static Web Apps Preview A modern web app service that offers streamlined full-stack development from source code to global high availability Web App for Containers 業務に合わせてスケーリング可能なコンテナー化された Web アプリを簡単にデプロイして実行 Web Apps 大規模な基幹業務系 Web アプリを短時間に作成してデプロイします Azure Communication Services プレビュー Microsoft Teams で使用されているのと同じ安全なプラットフォームを使用して、リッチなコミュニケーション エクスペリエンスを構築 Windows Virtual Desktop
サービス名 説明 Windows Virtual Desktop Azure で提供される、最適な仮想デスクトップのエクスペリエンス コンテナー
サービス名 説明 API Apps 簡単操作によるクラウド API の作成と利用 Azure Functions サーバーレス コードを使用してイベントを処理 Azure Kubernetes Service (AKS) Kubernetes のデプロイ、管理、運用を簡略化する Azure Red Hat OpenShift Red Hat と連携して動作するフル マネージド OpenShift サービス Container Instances サーバーを管理することなく Azure でコンテナーを簡単に実行 Container Registry Azure でのデプロイの種類を問わず、さまざまなコンテナー イメージを保存、管理 Mobile Apps モバイル アプリ用のバックエンドを構築およびホストする Service Fabric Windows または Linux でのマイクロサービスの開発とコンテナーのオーケストレーション Web App for Containers 業務に合わせてスケーリング可能なコンテナー化された Web アプリを簡単にデプロイして実行 Web Apps 大規模な基幹業務系 Web アプリを短時間に作成してデプロイします コンピューティング
サービス名 説明 API Apps 簡単操作によるクラウド API の作成と利用 App Service Web およびモバイル向けのパワフルなクラウド アプリを短期間で作成 Azure CycleCloud あらゆる規模の HPC クラスターやビッグ コンピューティング クラスターを作成、管理、運用、最適化 Azure Dedicated Host Windows および Linux 用の Azure VM をホストする専用物理サーバー Azure Functions サーバーレス コードを使用してイベントを処理 Azure Kubernetes Service (AKS) Kubernetes のデプロイ、管理、運用を簡略化する Azure Spring Cloud フル マネージドの Spring Cloud サービス、VMware と共同で作成および運用 Azure VMware Solution Azure でネイティブに VMware ワークロードを実行 Batch クラウド規模のジョブ スケジュール設定とコンピューティング管理 Cloud Services 高可用性と無限の拡張性を備えたクラウド アプリケーションと API を作成 Container Instances サーバーを管理することなく Azure でコンテナーを簡単に実行 Linux Virtual Machines Ubuntu、Red Hat などでの仮想マシンのプロビジョニング Mobile Apps モバイル アプリ用のバックエンドを構築およびホストする Service Fabric Windows または Linux でのマイクロサービスの開発とコンテナーのオーケストレーション SQL Server on Virtual Machines エンタープライズ SQL Server アプリをクラウドでホストする Static Web Apps Preview A modern web app service that offers streamlined full-stack development from source code to global high availability Virtual Machine Scale Set 数千個の Linux および Windows 仮想マシンを管理およびスケールアップ可能 仮想マシン Windows と Linux の仮想マシンを数秒でプロビジョニング Web Apps 大規模な基幹業務系 Web アプリを短時間に作成してデプロイします Windows Virtual Desktop Azure で提供される、最適な仮想デスクトップのエクスペリエンス ストレージ
サービス名 説明 Archive Storage アクセスの頻度が非常に少ないデータを、業界随一の価格で保存する Avere vFXT for Azure ファイルベースのハイパフォーマンス ワークロードをクラウドで実行 Azure Backup データ保護を簡素化し、ランサムウェアから保護する Azure Data Lake Storage Azure Blob Storage 上に構築された、非常にスケーラブルで安全な Data Lake 機能 Azure Data Share ビッグ データを外部組織と共有するためのシンプルかつ安全なサービス File Storage 標準の SMB 3.0 プロトコルを使用するファイル共有 Azure FXT Edge Filer HPC 環境用のハイブリッド ストレージ最適化ソリューション Azure HPC Cache ハイパフォーマンス コンピューティング (HPC) 向けファイル キャッシュ Azure NetApp Files NetApp によって支えられたエンタープライズ グレードの Azure ファイル共有 Blob Storage REST ベースの、非構造化データ用オブジェクト ストレージ Data Box Azure やエッジ コンピューティングにデータを転送するためのアプライアンスとソリューション Disk Storage Azure Virtual Machines 用のハイパフォーマンスで高度に堅牢性のあるブロック ストレージ Queue Storage トラフィックに応じた効率的なスケーリングのアプリ ストレージ アカウント 耐久性があり、高度にスケーラブルな高可用性クラウド ストレージ Storage Explorer Azure Storage リソースの参照と通信 StorSimple エンタープライズ向けのハイブリッド クラウド ストレージ ソリューションでコストを削減 セキュリティ
サービス名 説明 Application Gateway (英語) 安全でスケーラブルな高可用性 Web フロント エンドを Azure で構築する Azure Active Directory オンプレミスのディレクトリを同期してシングル サインオンを実現 Azure Active Directory Domain Services ドメイン コントローラーを使用せずにドメインに Azure 仮想マシンを接続可能 Azure Defender ハイブリッド クラウド ワークロードの保護 Azure DDoS Protection お客様のアプリケーションを DDoS (分散型サービス拒否) 攻撃から保護します Azure Dedicated HSM クラウドで使用するハードウェア セキュリティ モジュールの管理 Azure Front Door セキュリティが強化されたスケーラブルなデリバリー ポイントによって、グローバルなマイクロサービスベースの Web アプリケーションに対応 Azure Information Protection いつでもどこでも、お客様の機密情報をより厳重に保護します Azure Sentinel クラウドネイティブの SIEM とインテリジェントなセキュリティ分析を連携させて会社を保護する Key Vault キーやその他のシークレットを保護し、制御を維持する Security Center セキュリティ管理を統合し、Advanced Threat Protection をハイブリッド クラウド ワークロード間で有効化 VPN Gateway 安全なクロスプレミス接続を確立する Web Application Firewall Web アプリを強力に保護するクラウドネイティブな Web アプリケーション ファイアウォール (WAF) サービス Azure Defender for IoT プレビュー アンマネージドおよびマネージド IoT/OT デバイスの両方に対する継続的な資産管理と脅威検出 データベース
サービス名 説明 Azure API for FHIR FHIR サービスを容易に作成およびデプロイしてヘルス データ ソリューションと相互運用性を手に入れる Azure Cache for Redis 優れたスループットと待機時間の短いデータ アクセスにより、アプリケーションを強化 Azure Cosmos DB あらゆるスケールに対応したオープン API を備えた、高速な NoSQL データベース Azure Database for MariaDB アプリ開発者向けのマネージド MariaDB データベース サービス Azure Database for MySQL アプリ開発者のためのマネージド MySQL データベース サービス Azure Database for PostgreSQL アプリ開発者のためのマネージド PostgreSQL データベース サービス Azure Database Migration Service オンプレミスからクラウドへのデータベースの移行を簡素化 Azure SQL 移行とアプリの最新化のための最新の SQL ファミリ Azure SQL Database クラウド内のインテリジェントなマネージド SQL Azure SQL Edge Azure Platform でプライベートにサービスを利用 Azure SQL Managed Instance クラウド内の常に最新のマネージド SQL インスタンス SQL Server on Virtual Machines エンタープライズ SQL Server アプリをクラウドでホストする Table Storage 半構造化データセットを使用した NoSQL キー値の保存 ネットワーク
サービス名 説明 Application Gateway (英語) 安全でスケーラブルな高可用性 Web フロント エンドを Azure で構築する Azure Bastion お客様の仮想マシンへのプライベートでフル マネージドの RDP および SSH アクセス Azure DDoS Protection お客様のアプリケーションを DDoS (分散型サービス拒否) 攻撃から保護します Azure DNS Azure で DNS ドメインをホストする Azure ExpressRoute Azure への専用プライベート ネットワーク ファイバー接続 Azure Firewall クラウドによる無制限のスケーラビリティ、ゼロ メンテナンス、高可用性をビルトインで備えたネイティブなファイアウォール機能 Azure Firewall Manager グローバルに分散されたソフトウェア定義境界のネットワーク セキュリティ ポリシーとルートを一元管理 Azure Front Door セキュリティが強化されたスケーラブルなデリバリー ポイントによって、グローバルなマイクロサービスベースの Web アプリケーションに対応 Azure Internet Analyzer プレビュー ネットワーク インフラストラクチャの変更が顧客のパフォーマンスに及ぼす影響をテストします。 Azure Private Link Azure プラットフォーム上でホストされたサービスにプライベート アクセス、データは Microsoft ネットワーク上に保持 Content Delivery Network グローバル展開によりセキュアで信頼性の高いコンテンツ配信を実現 Load Balancer アプリケーションに優れた可用性とネットワーク パフォーマンスを提供 Network Watcher (英語) ネットワーク パフォーマンスの監視と診断ソリューション Traffic Manager 高パフォーマンスと高可用性のために着信トラフィックをルーティングする Virtual Network プライベート ネットワークをプロビジョニング、オプションでオンプレミスのデータセンターに接続 Virtual WAN Azure を介して支店間接続を最適化し、自動化する VPN Gateway 安全なクロスプレミス接続を確立する Web Application Firewall Web アプリを強力に保護するクラウドネイティブな Web アプリケーション ファイアウォール (WAF) サービス Azure Orbital プレビュー Azure に接続された衛星地上局およびスケジューリングのサービスでデータの高速ダウンリンクを実現 ハイブリッド環境
サービス名 説明 Azure Active Directory オンプレミスのディレクトリを同期してシングル サインオンを実現 Azure Arc Azure のサービスと管理をどのインフラストラクチャでも利用できる Azure Database for PostgreSQL アプリ開発者のためのマネージド PostgreSQL データベース サービス Azure DevOps チームがコードを共有し、作業を追跡し、ソフトウェアを出荷するためのサービス Azure ExpressRoute Azure への専用プライベート ネットワーク ファイバー接続 Azure IoT Edge クラウドのインテリジェンスと分析をエッジ デバイスに拡張 Azure Sentinel クラウドネイティブの SIEM とインテリジェントなセキュリティ分析を連携させて会社を保護する Azure SQL Database クラウド内のインテリジェントなマネージド SQL Azure SQL Edge Azure Platform でプライベートにサービスを利用 Azure Stack 革新的なハイブリッド アプリケーションをクラウドの境界を越えて作成し、実行する Security Center セキュリティ管理を統合し、Advanced Threat Protection をハイブリッド クラウド ワークロード間で有効化 Azure Stack HCI プレビュー ハイパーコンバージド インフラストラクチャと Azure およびハイブリッド サービスを統合して、オンプレミスで仮想ワークロードを実行する Azure Stack Hub Azure Stack Hub は統合ハードウェア システムとして販売され、ソフトウェアは検証済みのハードウェアに事前インストールされています Azure Stack Edge Azure のコンピューティング、ストレージ、インテリジェンスをエッジにもたらす Azure マネージド デバイス ブロックチェーン
サービス名 説明 Azure Blockchain Service プレビュー コンソーシアム ブロックチェーン ネットワークの構築、管理、展開 Azure Blockchain Tokens Preview 台帳ベースのトークンを簡単に定義、作成、管理 Azure Blockchain Workbench Preview クラウド内でのブロックチェーン アプリの容易なプロトタイプ作成 Azure Cosmos DB あらゆるスケールに対応したオープン API を備えた、高速な NoSQL データベース Logic Apps コードを記述せずに、クラウド全体でデータのアクセスと使用を自動化する メディア
サービス名 説明 Azure Media Player 1 つのプレーヤーですべての再生ニーズに対応 Content Delivery Network グローバル展開によりセキュアで信頼性の高いコンテンツ配信を実現 Content Protection AES、PlayReady、Widevine、Fairplay を使用した安全なコンテンツ配信 Encoding クラウドの規模でスタジオ グレードのエンコード Live and On-demand Streaming ビジネス ニーズを満たすように規模を調整しながら事実上すべてのデバイスにコンテンツを配信 ライブ ビデオ分析 プレビュー お好みの AI を使用して、インテリジェントなビデオベースのアプリケーションを構築する Media Services 大規模にビデオおよびオーディオをエンコード、保存、ストリーミング Video Indexer 動画の分析情報を解明 モノのインターネット (IoT)
サービス名 説明 API Management API を開発者、パートナー、および従業員に、安全かつ大規模に発行する Azure Cosmos DB あらゆるスケールに対応したオープン API を備えた、高速な NoSQL データベース Azure Digital Twins プレビュー 次世代の IoT 空間インテリジェンス ソリューションを構築する Azure Functions サーバーレス コードを使用してイベントを処理 Azure IoT Central IoT ソリューションの作成を加速する Azure IoT Edge クラウドのインテリジェンスと分析をエッジ デバイスに拡張 Azure IoT Hub 莫大な数の IoT 資産を接続、監視、管理 Azure IoT ソリューション アクセラレータ テンプレートを使用して、一般的な IoT のシナリオ向けに自在にカスタマイズが可能なソリューションを作成 Azure Machine Learning 実験とモデル管理ができる、エンド ツー エンドのスケーラブルで信頼性の高いプラットフォームで、すべてのユーザーが AI を使えるようにします Azure Maps シンプルで安全な位置 API が、地理空間コンテキストをデータに提供します Azure RTOS 組み込み IoT の開発と接続を簡単に行う Azure Sphere シリコンからクラウドへ MCU 搭載デバイスを安全に接続 Azure SQL Edge Azure Platform でプライベートにサービスを利用 Azure Stream Analytics アプリケーションやデバイスからのデータの高速移動ストリームのリアルタイム分析 Azure Time Series Insights IoT デバイスから収集した時系列のデータを調査して分析 Event Grid 信頼性の高い大規模イベント配信の実現 Kinect DK 高度な AI センサーと開発者キットを使用して、コンピューターによる視覚と音声のモデルを作成します Logic Apps コードを記述せずに、クラウド全体でデータのアクセスと使用を自動化する Notification Hubs どのバックエンドからでもあらゆるプラットフォームへプッシュ通知を送信 Windows 10 IoT Core Services 長期の OS サポートと、デバイスの更新プログラムを管理し、デバイスの正常性を評価するためのサービス Azure Defender for IoT プレビュー アンマネージドおよびマネージド IoT/OT デバイスの両方に対する継続的な資産管理と脅威検出 モバイル
サービス名 説明 API Management API を開発者、パートナー、および従業員に、安全かつ大規模に発行する App Service Web およびモバイル向けのパワフルなクラウド アプリを短期間で作成 Azure Cognitive Search モバイルおよび Web アプリ開発のための AI を活用したクラウド検索サービス Azure Maps シンプルで安全な位置 API が、地理空間コンテキストをデータに提供します Azure Cognitive Services スマートな API 機能を追加して状況に合ったやり取りを実現 Notification Hubs どのバックエンドからでもあらゆるプラットフォームへプッシュ通知を送信 Spatial Anchors 空間認識機能を備えたマルチユーザー対応の複合現実エクスペリエンスを作成します Visual Studio App Center アプリの作成、テスト、リリース、監視をモバイルとデスクトップ アプリで継続的に行う Xamarin クラウドの機能を活用したモバイル アプリを迅速に作成 Azure Communication Services プレビュー Microsoft Teams で使用されているのと同じ安全なプラットフォームを使用して、リッチなコミュニケーション エクスペリエンスを構築 移行
サービス名 説明 Azure Database Migration Service オンプレミスからクラウドへのデータベースの移行を簡素化 Azure Migrate オンプレミスの VM を簡単に検出、評価して適切なサイズに調整し、Azure に移行 Azure Site Recovery 組み込みのディザスター リカバリー サービスを使用してビジネスを継続的に稼働する コスト管理と請求 クラウドへの支出を最適化しながら、クラウドの可能性を最大限に高める Data Box Azure やエッジ コンピューティングにデータを転送するためのアプライアンスとソリューション 開発者ツール
サービス名 説明 App Configuration アプリ構成用の高速でスケーラブルなパラメーター ストレージ Azure DevOps チームがコードを共有し、作業を追跡し、ソフトウェアを出荷するためのサービス Azure DevTest Labs 再利用可能なテンプレートとアーティファクトを使用して環境を素早く構築 Azure Lab Services クラスルーム、評価、開発とテストなどのシナリオ向けにラボをセットアップ Azure Pipelines どのようなプラットフォームやクラウドにも継続的にビルド、テスト、デプロイできます Developer tool integrations Eclipse、IntelliJ、Maven などの馴染み深い開発ツールで Azure を利用できます SDK 必要なコマンド ライン ツールと SDK を入手 Visual Studio クラウドでアプリケーションを開発するための強力かつ柔軟な環境 Visual Studio Code クラウド開発用の強力かつ軽量なコード エディター Visual Studio Codespaces プレビュー どこからでもアクセスできる、クラウドを利用した開発環境 管理とガバナンス
サービス名 説明 Automation プロセス自動化でクラウド管理を簡素化 Azure Advisor 個別化された Azure のベスト プラクティスを提示するリコメンデーション エンジン Azure Backup データ保護を簡素化し、ランサムウェアから保護する Azure Blueprints プレビュー 管理された環境の迅速で反復可能な作成の有効化 Azure Lighthouse 多くの顧客を正確に管理できるようにサービス プロバイダーを支援します Azure Managed Applications 各種クラウド サービスの管理を簡単に Azure Migrate オンプレミスの VM を簡単に検出、評価して適切なサイズに調整し、Azure に移行 Azure Mobile App いつでも、どこからでも Azure リソースに接続 Azure Monitor アプリケーション、インフラストラクチャ、およびネットワークに対する完全な可観測性 Azure Policy コーポレート ガバナンスと標準を Azure リソースに大規模に実装する Azure Resource Manager アプリのリソースの管理方法を簡素化する Azure Resource Manager テンプレート Resource Manager を使用してすべての Azure リソースにコードとしてのインフラストラクチャを提供する Azure Service Health Azure サービスの問題による影響が発生した場合に、パーソナライズされたガイダンスとサポートを受けられます Azure Site Recovery 組み込みのディザスター リカバリー サービスを使用してビジネスを継続的に稼働する Cloud Shell ブラウザーベースのシェルで Azure での管理を効率化 コスト管理と請求 クラウドへの支出を最適化しながら、クラウドの可能性を最大限に高める Log Analytics オンプレミスおよびクラウドのマシン データの収集、検索、および視覚化 Microsoft Azure Portal 単一の統合コンソールですべての Azure 製品をビルド、管理、監視する Network Watcher (英語) ネットワーク パフォーマンスの監視と診断ソリューション Traffic Manager 高パフォーマンスと高可用性のために着信トラフィックをルーティングする Azure Automanage プレビュー Windows Server 仮想マシンの管理を簡略化 Azure Resource Mover プレビュー Azure リージョン間で複数のリソースを移動する方法をシンプルに 統合
サービス名 説明 API Management API を開発者、パートナー、および従業員に、安全かつ大規模に発行する Azure API for FHIR FHIR サービスを容易に作成およびデプロイしてヘルス データ ソリューションと相互運用性を手に入れる Event Grid 信頼性の高い大規模イベント配信の実現 Logic Apps コードを記述せずに、クラウド全体でデータのアクセスと使用を自動化する Service Bus プライベートとパブリックのクラウド環境間での接続 複合現実
サービス名 説明 Azure Digital Twins プレビュー 次世代の IoT 空間インテリジェンス ソリューションを構築する Kinect DK 高度な AI センサーと開発者キットを使用して、コンピューターによる視覚と音声のモデルを作成します Remote Rendering プレビュー 高品質の対話型 3D コンテンツをレンダリングし、リアルタイムでデバイスにストリーミングします Spatial Anchors 空間認識機能を備えたマルチユーザー対応の複合現実エクスペリエンスを作成します 分析
サービス名 説明 Azure Analysis Services サービスとしてのエンタープライズ グレードの分析エンジン Azure Data Explorer 高速かつスケーラビリティの高いデータ探索サービス Azure Data Lake Storage Azure Blob Storage 上に構築された、非常にスケーラブルで安全な Data Lake 機能 Azure Data Share ビッグ データを外部組織と共有するためのシンプルかつ安全なサービス Azure Databricks 迅速、簡単で協調型の Apache Spark ベースの分析プラットフォーム Azure Stream Analytics アプリケーションやデバイスからのデータの高速移動ストリームのリアルタイム分析 Azure Synapse Analytics 制限のない分析サービスで分析情報を得るまでの時間を短縮する (旧称 SQL Data Warehouse) Data Catalog エンタープライズ データ アセットからより多くの価値を引き出す Data Factory エンタープライズでの利用に耐えうる大規模なハイブリッド データ統合を簡単に実現 Data Lake Analytics ビッグ データを簡単にする分散分析サービス Event Hubs 何百万ものデバイスから製品利用統計情報を受信 HDInsight クラウド Hadoop 、Spark、R Server、HBase、および Storm クラスターのプロビジョニング Log Analytics オンプレミスおよびクラウドのマシン データの収集、検索、および視覚化 Power BI Embedded 魅力的で完全対話式のデータの可視化をアプリに組み込む R Server for HDInsight 予測分析、機械学習、ビッグ データの統計モデリング スクレイピング用コード(python)
import requests from bs4 import BeautifulSoup import re import copy def parse_html(): url = 'https://azure.microsoft.com/ja-jp/services/' r = requests.get(url) soup = BeautifulSoup(r.content, 'lxml') groups = [] service = [] current_category = '' for div1 in soup.select('div#products-list'): for div2 in div1.select('div.row'): category = div2.select('h2.product-category') if not category: for div3 in div2.select('div.column.medium-6'): s = {} span = div3.select('span', limit=1) href = div3.select('a', limit=1) description = div3.select('p.text-body4', limit=1) if len(span) > 0 and len(href) > 0 and len(description) > 0: s['service_name'] = span[0].text.rstrip('\n') s['href'] = href[0].get('href').rstrip('\n') s['description'] = description[0].text.rstrip('\n') service.append(s) else: if current_category != category[0].text: if current_category == '': current_category = category[0].text elif len(service) > 0: group = {} tmp = copy.deepcopy(service) group['category_name'] = current_category group['service'] = tmp groups.append(group) current_category = category[0].text service.clear() if len(service) > 0: group = {} group['category_name'] = current_category group['service'] = service groups.append(group) return (groups) def print_markdown(services): base_url = 'https://azure.microsoft.com' for s in services: print('### %s' % (s['category_name'])) print() print('| サービス名 | 説明 |') print('| --- | --- |') for service in s['service']: name = service['service_name'] description = service['description'] if (service['href'].startswith('/')): href = base_url + service['href'] else: href = service['href'] print('| [%s](%s) | %s |' % (name, href, description)) print() print_markdown(parse_html())
参考サイト
- 投稿日:2020-10-28T16:33:13+09:00
YouTubeのプレイリストから音声をダウンロードするやつ
while trueで回してるけど賢い方法を知りたい
try...exceptで再実行させる方法が知りたい使うもの
- Python
- YouTube-dlc
YouTube-dlcはYouTube-dlからフォークされたpython製ツール
YouTube-dlの更新頻度が低かったことでフォークされた
YouTube-dlがDMCA takedown食らっているのでYouTube-dlcがおすすめ?実装
- YoutubeDLError はYouTube-dlのエラーすべての継承元
- download_optsのformatとpostprocessorsをいじれば動画とかもいける
import youtube_dlc import json import time import random import os playlist = "https://www.youtube.com/playlist?list=PL2DyWpzBLr6x_Y6XHp5w9qdgyiNCGHJv0" outputpath = "./output2" flat_list = { "extract_flat": True, } download_opts = { "format": "bestaudio/best", "outtmpl": outputpath + "/%(title)s.%(ext)s", "postprocessors": [ { "key": "FFmpegExtractAudio", "preferredcodec": "mp3", "preferredquality": "256", } ], } def wait_time(s, e): sleeptime = random.randrange(s, e) + random.random() print("wait for " + str(f"{sleeptime:.1f}")) time.sleep(sleeptime) if __name__ == "__main__": if not os.path.exists(outputpath): print("Make output directory --> " + outputpath) os.makedirs(outputpath) with youtube_dlc.YoutubeDL(flat_list) as ydl: try: info_dict = ydl.extract_info(playlist, download=False) except youtube_dlc.utils.YoutubeDLError: print("\nNot get playlist. Please Retry") exit(1) except: print("\nother error") exit(1) o = json.loads(json.dumps(info_dict, ensure_ascii=False)) urllist = [] for items in o["entries"]: urllist.append("https://www.youtube.com/watch?v=" + items["id"]) urlnum = len(urllist) print( "--------------------------------------------------------------\n" "\ndownload items " + str(urlnum) + "\n" "download start\n\n" "--------------------------------------------------------------" ) with youtube_dlc.YoutubeDL(download_opts) as ydl: i = 0 for url in urllist: while True: try: wait_time(10, 20) ydl.extract_info(url, download=True) except KeyboardInterrupt: print("\nKeyboardInterrupt") exit(1) except youtube_dlc.utils.YoutubeDLError: wait_time(10, 20) except: print("\nother error") exit(1) else: i += 1 print( "\n\nDownloaded Items " + str(i) + "/" + str(urlnum) + "\n\n" "--------------------------------------------------------------" ) break print("\nDownload complete\n")
- 投稿日:2020-10-28T16:14:02+09:00
MyCLI: MySQL、MariaDB、Perconaの自動補完機能を備えたコマンドラインインターフェース
MyCLIは、MySQL、MariaDB、Percona用の使いやすいコマンドラインインターフェイス(CLI)で、自動補完機能や構文ハイライト機能で開発のスピードアップを支援します。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
前提条件
MyCLIツールはPythonをベースにしているので、PIP経由でインストールする必要があります。pipとpython開発ライブラリがインストールされていることを確認してください。ECSインスタンスを正しくセットアップしていれば、以下の3行のコードを実行してMyCLIをインストールするだけです。
yum install python-pip yum -y install python-devel pip install mycliMyCLIの詳細
MyCLI の使い方がわからない場合は、以下に示すように、いつでも
—helpコマンドを実行して、その様々なオプションについて知ることができます。$ mycli --help Usage: mycli [OPTIONS] [DATABASE] Options: -h, --host TEXT Host address of the database. -P, --port INTEGER Port number to use for connection. Honors $MYSQL_TCP_PORT -u, --user TEXT User name to connect to the database. -S, --socket TEXT The socket file to use for connection. -p, --password TEXT Password to connect to the database --pass TEXT Password to connect to the database --ssl-ca PATH CA file in PEM format --ssl-capath TEXT CA directory --ssl-cert PATH X509 cert in PEM format --ssl-key PATH X509 key in PEM format --ssl-cipher TEXT SSL cipher to use --ssl-verify-server-cert Verify server's "Common Name" in its cert against hostname used when connecting. This option is disabled by default -v, --version Version of mycli. -D, --database TEXT Database to use. -R, --prompt TEXT Prompt format (Default: "\t \u@\h:\d> ") -l, --logfile FILENAME Log every query and its results to a file. --defaults-group-suffix TEXT Read config group with the specified suffix. --defaults-file PATH Only read default options from the given file --myclirc PATH Location of myclirc file. --auto-vertical-output Automatically switch to vertical output mode if the result is wider than the terminal width. -t, --table Display batch output in table format. --csv Display batch output in CSV format. --warn / --no-warn Warn before running a destructive query. --local-infile BOOLEAN Enable/disable LOAD DATA LOCAL INFILE. --login-path TEXT Read this path from the login file. -e, --execute TEXT Execute query to the database. --help Show this message and exit.使用例
以下のコマンドを実行して、ApsaraDB for RDSインスタンス上でMyCLIを実行するだけです。
$ mycli ®Ch{RDS DNS Alias} ®Cu{RDS User Name} -p{RDS Password}接続されると、デフォルトのCLIを使用するのと同じようにMyCLIを使用することができます。
続きを読むには
また、Alibaba Cloudでは、Alibaba Cloud CLI上で独自のコマンド自動補完機能を提供しています。詳細については、https://www.alibabacloud.com/help/doc-detail/29998.html をご覧ください。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ
- 投稿日:2020-10-28T15:43:30+09:00
【AtCoder】ABC128B - Guidebook
ソートの勉強になる問題です。
市名と点数を格納していくので、辞書かな?
→同じ市が複数あるので辞書は使えません。レストランの番号はリストのインデックスかな?
→並び替えるので、リストにレストランの番号を入れた方がいい。という訳で、リストに番号、市名、点数を入れていきます。
市名と点数の並び替えってどうやるの?
→l.sort(key=lambda x:x[1],x[2])キモは、市名は辞書順(昇順)だけれど、点数は降順という所。
解説の方には、点数を-1倍するとあって、なるほどなーと思いました。
第1キーは昇順、第2キーは降順にしたい場合は
キーに-をつければ降順になるという記事を見つけたので、
その方法を使ってみました。n=int(input()) l=[] for i in range(n): s,p=input().split() l.append([i+1,s,int(p)]) l.sort(key=lambda x:(x[1],-x[2])) for i in l: print(i[0])
- 投稿日:2020-10-28T15:33:33+09:00
〇〇env系ツールをanyenvで一括管理する
はじめに
この記事は フューチャーAdvent Calendar 2020 の20日目の記事です。
環境構築に便利な〇〇env系ツールを、もっと便利に扱える
anyenvに感動したので、ブログ化しました。開発言語のバージョン管理
複数プロジェクトに関わる場合、開発言語のバージョン管理は必須スキルです。
他の開発メンバーと利用バージョンを一致させなければ、フォーマッタ適用 → PRでの差分爆発が生じてレビュアーに袋叩きにされます。なので、各エンジニアはそれぞれの創意工夫により、開発言語のバージョン管理問題を解決しています。
私の場合、環境構築ポリシーとして
- ローカル環境への直ダウンロードは厳禁
- 環境構築は基本的にDockerを使うという方針を、ずっと貫いています。
...
スミマセン。強がりです。
貫けていませんでした。〇〇env の多用
コロナ影響で在宅勤務へ移行した結果、NWの問題によりDockerがうまく使えない状況が増え、仕方なく〇〇env系ツールの利用を開始しました。
インストールした〇〇env系ツールは
- PJ開発はメインでgoを使う → goenv
- 環境Aはpythonのみ動く → pyenv
- 環境Bはrubyのみ動く → rbenv
- AWSのMFA(多要素認証)でet-otpを使う → jenvというもので、開発作業で新しい言語が必要になるたびに、対応するツール1つ1つ追加していました。
これらは同じコマンド操作で設定可能なため、ストレスになるのはパッケージのダウンロード時間くらいだと思っていましたが、知らぬ間に開発環境汚染が進んでいました。
bash_profileが汚れていた
担当業務で Vue.js のコードに触れる機会があり、新たに
nodenvをインストールしようとしたところ
- 〇〇env系ツールの環境構築って、いっつも同じような環境変数を追加しているな
- bash_profileのメンテしてたっけ?ということに気づき、cat ~/.bash_profile すると、↓こんな感じになっていました
... # goenv export GOENV_ROOT=$HOME/.goenv export PATH=$GOENV_ROOT/bin:$PATH eval "$(goenv init -)" # pyenv export PYENV_ROOT="$HOME/.pyenv" export PATH="$PYENV_ROOT/bin:$PATH" eval "$(pyenv init -)" # jenv export JENV_ROOT=$HOME/.jenv export PATH="$HOME/.jenv/bin:$PATH" eval "$(jenv init -)" (rbenv, nodenv などの設定が続く...) ...あれ?
開発環境が汚れないよう注意していたはずなのに
所々で微妙な違いがあり、綺麗な状態とは言い難い...〇〇env系ツールが増えるごとに
bash_profileに追記し続けるのを止めたい...
anyenv が便利そう!
anyenvを使って綺麗にする
anyenv自体の説明前に、このツールを使うと何が綺麗になるか?から説明します。
すでにインストール済みのgoenv, pyenvなどはanyenv経由での再設定が必要になりますが、それを乗り越えれば、bash_profile に必要な
〇〇env系ツールの記述は、以下のみで十分となります。将来的に新しい 〇〇env が必要になった場合でも、bash_profile への追記は不要です。... # anyenv eval "$(anyenv init -)" ...goenv, jenvごとにPATHを設定 & initする煩わしい記述から解放され、かつ、操作方法は従来の〇〇env系コマンドを利用可能なので、開発環境汚染を少しでも減らしたいエンジニアであれば、このツールを使わない理由は無いと思います。
anyenvとは?
anyenv - All in one for **env
This is a simple wrapper for rbenv style environment managers. You don't have to git clone or modify your shell profile for each **env anymore if you install anyenv.
https://github.com/anyenv/anyenv#anyenv---all-in-one-for-env
端的に言うと、複数の〇〇envを一括管理できる便利ツールです。
執筆時点(2020.12.10)では、以下〇〇envパッケージがanyenvでは利用可能です。
有名どころは網羅しているので、多くの開発プロジェクトで導入可能だと思います。$ anyenv install -l Renv #R crenv #Crystal denv #D erlenv #Erlang exenv #Elixir goenv #Go hsenv #Haskell jenv #Java jlenv #Julia luaenv #Lua nodenv #Node.js phpenv #PHP plenv #Perl pyenv #Python rbenv #Ruby sbtenv #Sbt scalaenv #Scala swiftenv #Swift tfenv #terraform上記から欲しい言語をインストールすれば、あとはいつも通りの〇〇env操作コマンドで環境構築可能です。
anyenvのインストール手順
macの場合
Homebrewを利用します。
$ brew install anyenv $ echo 'eval "$(anyenv init -)"' >> ~/.bash_profile $ exec $SHELL -l $ anyenv install --init # enter "y"Linux環境の場合
GitHubから直接引っ張ってきます。
$ git clone https://github.com/anyenv/anyenv ~/.anyenv $ echo 'export PATH="$HOME/.anyenv/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(anyenv init -)"' >> ~/.bash_profile $ exec $SHELL -l $ anyenv install --init # enter "y"最後に
$ anyenv install 〇〇envで欲しいパッケージを取得すれば、これまで通りの〇〇envコマンドが利用できます。ex) node.jsのv15.0.1が欲しい場合
anyenvを利用し、nodenvを取得します。
$ anyenv install nodenv $ exec $SHELL -l $ anyenv versions nodenv: Warning: no Node detected on the system次は、nodenvでv15.0.1を取得します。
$ nodenv install 15.0.1 $ nodenv global(local) 15.0.1 $ node -v v15.0.1以上により、Node.js:v15.0.1 が利用可能となりました。
私の開発では goenv, pyenv, jenv, nodenv が必須なので、以下の設定を入れています。
$ anyenv versionsにより、各envの設定状況が一覧できます。$ anyenv versions goenv: system 1.XX.0 * 1.YY.0 (set by /Users/<username>/.anyenv/envs/goenv/version) jenv: system * XX.0 (set by /Users/<username>/.anyenv/envs/jenv/version) nodenv: system * XX.0 (set by /Users/<username>/.anyenv/envs/nodenv/version) pyenv: system XX.0 * YY.0 (set by /Users/<username>/.anyenv/envs/pyenv/version)anyenvインストール以前に設定したgoenvやpyenvの環境変数が残っている場合は、bash_profileから削除することも忘れないようご注意ください。
まとめ
- 環境変数、
echo 'export hogehoge"' >> ~/.bash_profileで追加したまま放置していませんか- 複数の〇〇env系ツールを使っているなら、anyenvの利用がオススメ
- anyenvでbash_profileがスッキリ
- 投稿日:2020-10-28T15:10:58+09:00
【Python】インスタンスをインスタンス変数でソートする方法
Pythonに限らず、プログラムを書いているとリスト(配列)や辞書をソートする機会はよくあります。そして、それらの方法はブログ記事などでたくさん紹介されています。
ただ、リストや辞書ほど頻度は多くありませんが、インスタンスのリストをインスタンス変数でソートしたいという事があります。例えば、次のような
Studentというクラスがあった場合に、studentsというインスタンスのリストをscoreでソートするというような場面です。class Student: def __init__(self, name, score): self.name = name self.score = score a = Student('Taro', 70) b = Student('Hanako', 90) c = Student('Jiro', 80) students = [a, b, c]このような場合、operator.attrgetter関数を使えば次のように数行(ほぼ一行)で書けます。
from operator import attrgetter students.sort(key=attrgetter('score')) for s in students: print(s.name, s.score)Taro 70 Jiro 80 Hanako 90降順にソートしたい場合は、次のように
sortメソッドの引数reverseをTrueにするだけです。from operator import attrgetter students.sort(key=attrgetter('score'), reverse=True) for s in students: print(s.name, s.score)Hanako 90 Jiro 80 Taro 70
- 投稿日:2020-10-28T14:26:50+09:00
Twitterのブロックを一斉に解除しようの巻
概要
- Twitter APIを利用して積もり積もったブロックを一斉に解除する
Twitter、楽しんでますか?
どうも、2010年くらいからTwitterやってるけどアカウント一回消したので2013年からやってるみたいに見えるけど割と古参なツイッタラーSotonoです。
Twitter、スマホの普及でインターネット人口が爆発的に増えてやってる人が無茶苦茶増えましたよね。
…まあその分目につくアカウントも爆発的に増えたのでブロック機能も大活躍〜って感じなのですが…ところでこれは宣伝なんですけども、趣味で作っている音楽の新曲を発表しました。
本筋とはちょっとしか関係ありませんが、どうぞ聴いてみてください。嫌なものに蓋をする行為としてのブロック
僕は以前、ワードで検索をかけて、引っかかったユーザーをすべてブロックするというスクリプトを制作した経験があります。 (記事にはしていませんが)
その目的は単純明快で、「 見たくないものに蓋をしたかった 」ということなんですね。
ただ、こちらから蓋をすると向こうからも見えなくなるといったデメリットがブロック機能にはございまして、
僕はこのスクリプトを使って100万人弱のアカウントをブロックしてきました。おふがお氏リスペクトかなにか?嫌なワードをミュートすればいいじゃんって話なんですが、実はワードミュート、活用してます。
じゃあなんでそんな数ブロックしたのかといいますと、「 そんなことを言ってるやつは他のことを言わせてもロクなことを言わない 」と思ったからなんですね。例えば話題Aが嫌いで、「そんな話題ききとうない!!」とワードミュートしてても、
その人が話題Bを発言しても似たようなニュアンスのことが多いんですね。
なので「話題A嫌じゃ!そんな事を言うやつは話題Bでも同じこと言う!!」とブロック、という感じです。
いわゆる先行ブロックと呼ばれる行為にあたります。ブロックの何がいけないの?
ところで、このブロックという行為、ひとつデメリットがあります。
それはもちろん、これですよね。
- 人を拒絶するため、見てもらえるコンテンツが見てもらえなくなる
これに尽きると思います。
ここでさっき宣伝した曲が出てくるんですが、もしかしたら「曲が伸びないのは、自分が100万弱の人間をブロックしているからなのでは?」
と思ったんですね。
Twitterのアクティブユーザーが予想で1億人いるとして、1%に満たない数字だとしても、100万人の人には届かない。これはいけない…
ブロック解除しなくちゃ…でも100万人もポチポチするの嫌じゃ…そうだ、APIでなんとかならないか!?
な り ま し た
では本題です。
Pythonを用いてTwitterのAPIを使ってブロックを全部解除していきましょう。
なんでPython?それしか使えないからだよまず用意するものはこちら。
Twitter API使用権限を用意する
このへんを参考に取得してください。
取得したものを、とりあえずわかりやすく
key.pyにぶちこんでおきましょう。key.pyAPI_KEY = 'hoge' API_SECRET = 'hoge' ACCESS_TOKEN = 'hoge' ACCESS_TOKEN_SECRET = 'hoge' def api(): # TwiterのAPIを使えるようにする api = OAuth1Session( API_KEY, API_SECRET, ACCESS_TOKEN, ACCESS_TOKEN_SECRET ) return apiこれで
key.api()を実行すると返り値としてTwitterのAPI使用権限が渡されます。実際にAPIを動かしてみよう
最終的にしたいことを箇条書きにするとこうなります。
- ブロックした人間のリストを取得する
- 片っ端からブロックを解除する
とりあえずスクリプトの名前はAPIの名前からとって
block_destroy.pyとしましょう。ブロックした人間のリストを取得する関数を作る
block_destroy.pyimport key import json def get_ids(): twitter = key.api_proc() url = 'https://api.twitter.com/1.1/blocks/ids.json' res = twitter.get(url) id_dict = json.loads(res.text) ids = id_dict['ids'] twitter.close() return ids解説1
https://api.twitter.com/1.1/blocks/ids.jsonをGETしてresを取得。これは、ブロックしたアカウントをidリストとして出力するようなAPIアドレス。
resの中にあるtextを引っ張り出す。textはjson形式なのでjson.loads()で辞書型に変換。- ほしいのは辞書ではなく配列なので、辞書に格納されている配列を
'ids'で取り出す。returnで関数の外へ引っ張り出す。 > ちなみにこれで取得できるアカウントの件数は一度に5000件。idをもとにブロックを解除する関数を作る
block_destroy.pyimport key def destroy(_id): twitter = key.api_proc() url = f'https://api.twitter.com/1.1/blocks/destroy.json' params = {'user_id': _id} twitter.post(url, params=params) twitter.close()解説2
https://api.twitter.com/1.1/blocks/destroy.jsonこれは、パラメーター付与してPOSTすると、そのアカウントのブロックを解除するAPIアドレス。
- 関数
destroyにユーザーのIDを渡すとブロックを解除するように作る。paramsでパラメーターを定義し、idをそこに付与する。- URLにパラメーターを付与してPOST、ブロックの解除が成立する。
ふたつの関数をつなぎ合わせる関数を作る
block_destroy.pyfrom tqdm import tqdm from multiprocessing import Pool def main(): ids = get_ids() if len(ids) == 0: exit() pool = Pool(processes=10) print('-' * 10) with tqdm(total=len(ids)) as t: for _ in pool.imap_unordered(destroy, ids): t.update(1) if __name__ == "__main__": while True: main()解説3
get_idsでアカウントIDを5000件取得。if…もしアカウントIDが0件だったらexit()処理を終了する。この処理を入れるのは、前述したとおり、一度に取得できるアカウントIDの個数が5000件のため。
next cursor?そんなの知らない!
poolでサブプロセスを起動して処理の並列化を行い、高速化を図る- ついでに
tqdmで進捗をわかりやすくするdestroy関数を実行し、idsの中身を順番に渡すことでブロック解除を行う- 以下ブロック件数0になるまで無限ループ
これでスッキリ全員ブロックできた
なんというか…清々しい気分だ… pic.twitter.com/kYaQJLezW2
— Sotono / 爪楊枝 (@_Sotono) October 28, 2020おわり。
参考
- 投稿日:2020-10-28T14:03:05+09:00
【AtCoder】ABC148-B 出力方法
問題自体は簡単ですが、出力方法を工夫すればコードが短くなります。
print()の引数に、end=""と付ければ改行されません。n=int(input()) s,t=input().split() for i in range(n): print(s[i]+t[i],end="")
- 投稿日:2020-10-28T14:03:05+09:00
【AtCoder】出力方法
出力方法を工夫してコードを短くできる問題をまとめました。
この方法を知らなかった時は、全てリストにして、"".join(リスト)にして~とめんどくさいことをしていました。ABC148-B
問題自体は簡単ですが、出力方法を工夫すればコードが短くなります。
print()の引数に、end=""と付ければ改行されません。n=int(input()) s,t=input().split() for i in range(n): print(s[i]+t[i],end="")ABC137-B
if文で最後の文字の後には改行を入れています(入れなくても通るのですが、コードの正しさ的に入れましょう)。
k,x=map(int, input().split()) for i in range(x-k+1,x+k): if i<x+k-1: print(i,end=" ") else: print(i)
- 投稿日:2020-10-28T13:20:27+09:00
Beautiful Soup 4を使ってPythonで基本的なヘッドレスウェブスクレイピング「ボット」を書く
この記事では、CentOS 7を使用したAlibaba Cloud Elastic Compute Service (ECS)上で、Beautiful Soup 4を使用してPythonで基本的なヘッドレスウェブスクレイピング "ボット "を作っていきます。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
アリババクラウドにCentOSインスタンスを設定する
このチュートリアルでは、CentOSを実行しているAlibaba Cloudインスタンスの起動に慣れている必要があります。ECSインスタンスの設定方法がわからない場合は、このチュートリアルをチェックしてください。すでに購入している場合は、このチュートリアルをチェックして、それに応じてサーバーを設定してください。
私はこのレッスンのためにCentOSのインスタンスをデプロイしました。このプロジェクトのためには、肥大化していない方が良いでしょう。このプロジェクトではGUI(Graphical User Interface)を使用しないので、基本的なターミナルのコマンドラインの知識があることをお勧めします。
ターミナルのコマンドラインからPython 3、PIP3、Nanoをインストール
特定のインスタンスのすべてをアップデートするのは、常に良いアイデアです。まず、すべてのパッケージを最新のバージョンにアップデートしましょう。
sudo yum update基本的なウェブスクレイピング "bot "にPythonを使う予定です。私はこの言語の比較的シンプルさやモジュールの多様性にも感心しています。特に、RequestsとBeautiful Soup 4モジュールを使用します。
通常はPython3がデフォルトでインストールされていますが、そうでない場合はPython3とPipをインストールします。まずはIUS(Inline with Upstream Stableの略)をインストールします。IUS はコミュニティプロジェクトで、Red Hat パッケージマネージャ (RPM) パッケージを提供しています。続いて、python36uとpipをインストールしていきます。
sudo yum install https://centos7.iuscommunity.org/ius-release.rpm sudo yum install python36u sudo yum install python36u-pipPipは、Pythonパッケージインデックスにあるようなソフトウェアパッケージをインストールして管理するためのパッケージ管理システムです。Pip は easy_install の代替です。
過去にpython36u-pipではなくpipのインストールで頭を悩ませたことがあるので、pipのインストールはPython2.7用、python36u-pipはPython3用であることに注意してください。
Nanoは基本的なテキストエディタで、このようなアプリケーションでは重宝します。それではNanoをインストールしてみましょう。
sudo yum install nanoPipを使ってPythonパッケージをインストールする
次に、今日使用するPythonパッケージであるRequestsとBeautiful Soup4をインストールする必要があります。
これらは PIP を通してインストールします。
pip36u install requests pip36u install beautifulsoup4Requests は、Requests .get メソッドを使ってウェブページに移動できるようにする Python モジュールです。
Requests を使うと、Python スクリプトを使ってプログラム的に HTTP/1.1 リクエストを送信することができます。URL にクエリ文字列を手動で追加したり、POST データをフォームエンコードしたりする必要はありません。Keep-alive と HTTP 接続プーリングは 100% 自動で行われます。今日はRequests .getメソッドを中心にWebページのソースを取得していきます。
Beautiful Soupは、HTMLやXMLファイルからデータを取り出すためのPythonライブラリです。お気に入りのパーサーと連携して、ナビゲート、検索、解析ツリーの変更などを簡単に行うことができます。
Beautiful Soup 4 を Python の標準の html.parer と一緒に使用して、Requests で取得する Web ページ ソースからのデータを解析して整理します。このチュートリアルでは、私たちはより人間の読みやすい方法で私たちのデータを整理するために美しいスープ「prettify」メソッドを使用します。
Python_apps というフォルダを作成します。そして、現在の作業ディレクトリをPython_appsに変更します。
mkdir Python_apps cd Python_appsPythonでヘッドレススクレイピングボットを書く
さて、いよいよお楽しみです。Pythonヘッドレススクレーパーボットを書くことができます。我々は、URLに移動し、ページのソースを取得するために要求を使用しています。その後、Beautiful Soup 4を使用して、HTMLソースを解析して半可読形式にします。これを行った後、解析したデータをインスタンス上のローカルファイルに保存します。それでは、作業に取り掛かりましょう。
ページソースを取得するために Requests を使用し、データを可読状態にフォーマットするために BeautifulSoup4 を使用します。そして、open() と write() の Python メソッドを使用して、ページデータをローカルのハードドライブに保存します。さあ、行ってみましょう。
Nano またはお好みのテキストエディタをターミナルで開き、"bot.py "という名前の新しいファイルを作成します。私は Nano が基本的なテキスト編集機能に完全に適していると感じています。
まず、インポートを追加します。
############################################################ IMPORTS import requests from bs4 import BeautifulSoup以下のコードでは、いくつかのグローバル変数を定義しています。
1、ユーザーの URL 入力
2、入力されたURLを取得するRequests.getメソッド
3、テキストデータを変数に保存するRequests.textメソッド####### REQUESTS TO GET PAGE : BS4 TO PARSE DATA #GLOBAL VARS ####### URL FOR SITE TO SCRAPE url = input("WHAT URL WOULD YOU LIKE TO SCRAPE? ") ####### REQUEST GET METHOD for URL r = requests.get("http://" + url) ####### DATA FROM REQUESTS.GET data = r.textさて、グローバル変数 "data" を BS4 オブジェクトに変換して、BS4 の prettify メソッドでフォーマットしてみましょう。
####### MAKE DATA VAR BS4 OBJECT source = BeautifulSoup(data, "html.parser") ####### USE BS4 PRETTIFY METHOD ON SOURCE VAR NEW VAR PRETTY_SOURCE pretty_source = source.prettify()これらの変数をローカルファイルと同様にターミナルで出力してみましょう。これは、実際にローカルファイルに書き込む前に、どのようなデータがローカルファイルに書き込まれるかを示してくれます。
print(source)最初に大きなテキストの塊でソースを取得します。これは人間が解読するのは非常に難しいので、フォーマットの手助けをBeautiful Soupに頼ることにします。そこで、Prettifyメソッドを呼び出して、データをより良く整理してみましょう。これで人間の読みやすさが格段に良くなります。そして、BS4のprettify()メソッドの後にソースを出力します。
print(pretty_source)コードを実行した後、この時点で端末には、入力されたページのHTMLソースのプレティファイドされたフォーマットが表示されているはずです。
さて、そのファイルをAlibaba Cloud ECSインスタンス上のローカルハードドライブに保存してみましょう。そのためには、まず書き込みモードでファイルを開く必要があります。
これを行うために、open()メソッドの第2引数に文字列 "w "を渡す。
####### OPEN SOURCE IN WRITE MODE WITH "W" TO VAR LOCAL_FILE ####### MAKE A NEW FILE local_file = open(url.strip("https://" + "http://") + "_scrapped.txt" , "w") ####### WRITE THE VAR PRETTY_SOUP TO FILE local_file.write(pretty_source) ### GET RID OF ENCODING ISSUES ########################################## #local_file.write(pretty_source.encode('utf-8')) ####### CLOSE FILE local_file.close()上記のコードブロックでは、先ほど入力したURLに"_scrapped.txt "を連結した名前のファイルを作成してオープンする変数を作成しています。openメソッドの第一引数はローカルディスク上のファイル名です。ファイル名から "HTTPS://"と "HTTP://"を取り除いています。これを取り除かないと、ファイル名は無効になります。第二引数は、この場合の書き込みの許可です。
そして、.writeメソッドに引数として "pretty_source "変数を渡して、変数 "local_file "に書き込みます。ローカルファイルに正しく印刷するために、テキストをUTF-8でエンコードする必要がある場合は、コメントアウトした行を使用します。そして、ローカルのテキストファイルを閉じます。
コードを実行してどうなるか見てみましょう。
python3.6 bot.pyスクラップするURLを入力するように言われます。https://www.wikipedia.org を試してみましょう。これで、特定のウェブサイトからのきちんとフォーマットされたソースコードが.txtファイルとしてローカルの作業ディレクトリに保存されました。
このプロジェクトの最終的なコードは以下のようになります。
print("*" * 30 ) print(""" # # SCRIPT TO SCRAPE AND PARSE DATA FROM # A USER INPUTTED URL. THEN SAVE THE PARSED # DATA TO THE LOCAL HARD DRIVE. """) print("*" * 30 ) ############################################################ IMPORTS import requests from bs4 import BeautifulSoup ####### REQUESTS TO GET PAGE : BS4 TO PARSE DATA #GLOBAL VARS ####### URL FOR SITE TO SCRAPE url = input("ENTER URL TO SCRAPE") ####### REQUEST GET METHOD for URL r = requests.get(url) ####### DATA FROM REQUESTS.GET data = r.text ####### MAKE DATA VAR BS4 OBJECT source = BeautifulSoup(data, "html.parser") ####### USE BS4 PRETTIFY METHOD ON SOURCE VAR NEW VAR PRETTY_SOURCE pretty_source = source.prettify() print(source) print(pretty_source) ####### OPEN SOURCE IN WRITE MODE WITH "W" TO VAR LOCAL_FILE ####### MAKE A NEW FILE local_file = open(url.strip("https://" + "http://") + "_scrapped.txt" , "w") ####### WRITE THE VAR PRETTY_SOUP TO FILE local_file.write(pretty_source) #local_file.write(pretty_source.decode('utf-8','ignore')) #local_file.write(pretty_source.encode('utf-8') ####### CLOSE FILE local_file.close()概要
CentOS 7を搭載したAlibaba Cloud Elastic Compute Service (ECS)インスタンス上に、Beautiful Soup 4を使ってPythonで基本的なヘッドレスWebスクレイピング「ボット」を構築する方法を学びました。Requestsを使って特定のウェブページのソースコードを取得し、Beautiful soup 4を使ってデータを解析し、最後にスクレイピングしたウェブページのソースコードをインスタンス上のローカルテキストファイルに保存しました。Beautiful soup 4モジュールを使って、人間が読みやすいようにテキストをフォーマットすることができます。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ
- 投稿日:2020-10-28T12:58:54+09:00
Dockerを使用してアプリケーションをコンテナー化する方法と、DockerComposeを使用して開発環境でアプリケーションを実行する方法
はじめに
Dockerは、最も人気のあるコンテナ化テクノロジーの1つです。使いやすく、開発者にとって使いやすいツールであり、他の同様のテクノロジーよりもスムーズで簡単に使用できるという利点があります。 2013年3月の最初のオープンソースリリース以来、Dockerは開発者や運用エンジニアから注目を集めています。 Docker Inc.によると、DockerユーザーはDocker Hubに1050億を超えるコンテナーをダウンロードし、580万のコンテナーをドッキングしました。このプロジェクトには、Githubに32Kを超えるスターが集まっています。
それ以来、Dockerが主流になり、10万を超えるサードパーティプロジェクトがこのテクノロジーを使用しており、コンテナ化スキルを持つ開発者の需要が高まっています。
このブログ記事では、Dockerを使用してアプリケーションをコンテナー化する方法と、DockerComposeを使用して開発環境でアプリケーションを実行する方法について説明します。 メインアプリとしてPythonAPIを使用します。
MetricFireの無料デモを予約して、Docker、Kubernetes、Pythonのセットアップを監視する方法を確認してください。
開発環境のセットアップ
開始する前に、いくつかの要件をインストールします。 ここではFlaskで開発されたミニPythonAPIを使用します。 FlaskはPythonフレームワークであり、APIのプロトタイプを迅速に作成するための優れた選択肢です。 私たちのアプリケーションはFlaskを使用して開発されます。 Pythonに慣れていない場合は、このAPIを作成する手順を以下に示します。
Python仮想環境を作成して、依存関係を他のシステム依存関係から分離しておくことから始めます。 その前に、人気のあるPythonパッケージマネージャーであるPIPが必要です。
インストールは非常に簡単です。次の2つのコマンドを実行する必要があります。
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py python get-pip.py参考までに、Python3がインストールされている必要があります。 次のように入力して、これを確認できます。
python --versionPIPをインストールした後、次のコマンドを使用して仮想環境をインストールします。
pip install virtualenv公式ガイドに従って、他のインストール方法を見つけることができます。 次に、仮想環境を作成する必要があるフォルダーのプロジェクトを作成し、それをアクティブ化します。 また、アプリ用のフォルダーとapp.pyというファイルを作成します。
mkdir app cd app python3 -m venv venv . venv/bin/activate mkdir code cd code touch app.py特定の都市の天気を表示する簡単なAPIを作成します。 たとえば、ロンドンの天気を表示したいとします。 ルートを使用してリクエストする必要があります:
/london/ukPIPを使用して「flask」および「requests」と呼ばれるPython依存関係をインストールする必要があります。 後でそれらを使用します:
pip install flask requests要件ファイルは次のようになります。
certifi==2019.9.11 chardet==3.0.4 Click==7.0 Flask==1.1.1 idna==2.8 itsdangerous==1.1.0 Jinja2==2.10.3 MarkupSafe==1.1.1 requests==2.22.0 urllib3==1.25.7 Werkzeug==0.16.0これはAPIの初期コードです。
from flask import Flask app = Flask(__name__) @app.route('/') def index(): return 'App Works!' if __name__ == '__main__': app.run(host="0.0.0.0", port=5000)テストするには、python app.pyを実行し、http://127.0.0.1:5000 /にアクセスする必要があります。 「AppWorks!」が表示されます。 Webページで。 openweathermap.orgのデータを使用するので、必ず同じWebサイトでアカウントを作成し、APIキーを生成してください。
次に、APIに特定の都市の気象データを表示させるための便利なコードを追加する必要があります。
@app.route('/<string:city>/<string:country>/') def weather_by_city(country, city): url = 'https://samples.openweathermap.org/data/2.5/weather' params = dict( q=city + "," + country, appid= API_KEY, ) response = requests.get(url=url, params=params) data = response.json() return data全体的なコードは次のようになります。
from flask import Flask import requests app = Flask(__name__) API_KEY = "b6907d289e10d714a6e88b30761fae22" @app.route('/') def index(): return 'App Works!' @app.route('/<string:city>/<string:country>/') def weather_by_city(country, city): url = 'https://samples.openweathermap.org/data/2.5/weather' params = dict( q=city + "," + country, appid= API_KEY, ) response = requests.get(url=url, params=params) data = response.json() return data if __name__ == '__main__': app.run(host="0.0.0.0", port=5000)127.0.0.1:5000/london/ukにアクセスすると、次のようなJSONが表示されるはずです。
{ "base": "stations", "clouds": { "all": 90 }, "cod": 200, "coord": { "lat": 51.51, "lon": -0.13 }, ...ミニAPIが機能しています。 Dockerを使用してコンテナ化しましょう。
Dockerを使用してアプリのコンテナーを作成
APIのコンテナを作成しましょう。 最初のステップは、Dockerfileを作成することです。 Dockerfileは、Dockerデーモンがイメージを構築するために従う必要のあるさまざまな手順と指示を含む有益なテキストファイルです。 イメージをビルドした後、コンテナを実行できるようになります。
Dockerfileは常にFROM命令で始まります。
FROM python:3 ENV PYTHONUNBUFFERED 1 RUN mkdir /app WORKDIR /app COPY requirements.txt /app RUN pip install --upgrade pip RUN pip install -r requirements.txt COPY . /app EXPOSE 5000 CMD [ "python", "app.py" ]上記のファイルでは、次のことを行いました。
- 「python:3」というベースイメージを使用
- また、PYTHONUNBUFFEREDを1に設定。PYTHONUNBUFFEREDを1に設定すると、ログメッセージをバッファリングする代わりにストリームにダンプできます。
- また、フォルダー/ appを作成し、それをworkdirとして設定
- 要件をコピーし、それを使用してすべての依存関係をインストール
- アプリケーションを構成するすべてのファイル、つまりapp.pyファイルをworkdirにコピー
- アプリがこのポートを使用するため、最終的にポート5000を公開し、app.pyを引数としてpythonコマンドを起動。 これにより、コンテナの起動時にAPIが起動します。
Dockerfileを作成したら、イメージ名と選択したタグを使用してDockerfileをビルドする必要があります。 この場合、名前として「weather」を使用し、タグとして「v1」を使用します。
docker build -t weather:v1 .Dockerfileとapp.pyファイルを含むフォルダー内からビルドしていることを確認してください。
コンテナをビルドした後、次を使用して実行できます。
docker run -dit --rm -p 5000:5000 --name weather weather:v1-dオプションを使用するため、コンテナーはバックグラウンドで実行されます。 コンテナは「weather」(-name weather)と呼ばれます。 ホストポート5000を公開されたコンテナポート5000にマッピングしたため、ポート5000でも到達可能です。
コンテナの作成を確認したい場合は、以下を使用できます。
docker ps次の出力と非常によく似た出力が表示されるはずです。
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 0e659e41d475 weather:v1 "python app.py" About a minute ago Up About a minute 0.0.0.0:5000->5000/tcp weatherこれでAPIをクエリできるようになります。 CURLを使用してテストしてみましょう。
curl http://0.0.0.0:5000/london/uk/最後のコマンドがJSONを返す必要がある場合:
{ "base": "stations", "clouds": { "all": 90 }, "cod": 200, "coord": { "lat": 51.51, "lon": -0.13 ... }開発のためのDockerComposeの使用
Docker Composeは、マルチコンテナーDockerアプリケーションを定義および実行するためにDockerInc。によって開発されたオープンソースツールです。 Docker Composeは、開発環境で使用することを目的としたツールでもあります。これにより、コンテナーを手動で再起動したり、変更のたびにイメージを再構築したりすることなく、コードの更新時にコンテナーを自動再ロードできます。 Dockerコンテナのみを使用して開発するComposeがないと、イライラするでしょう。
実装部分では、「docker-compose.yaml」ファイルを使用します。
これは、APIで使用している「docker-compose.yaml」ファイルです。
version: '3.6' services: weather: image: weather:v1 ports: - "5000:5000" volumes: - .:/app上記のファイルで、イメージ「weather:v1」を使用するようにサービス「weather」を構成したことがわかります。 ホストポート5000をコンテナポート5000にマップし、現在のフォルダをコンテナ内の「/ app」フォルダにマウントします。
イメージの代わりにDockerfileを使用することもできます。 すでにDockerfileがあるので、この場合はこれをお勧めします。
version: '3.6' services: weather: build: . ports: - "5000:5000" volumes: - .:/appここで、「docker-compose up」を実行してサービスの実行を開始するか、「docker-composeup--build」を実行してビルドしてから実行します。
まとめ
この投稿では、ミニPython API用のDockerコンテナーを作成する方法を確認し、DockerComposeを使用して開発環境を作成しました。 GoやRailsなどの別のプログラミング言語を使用している場合は、いくつかの小さな違いを除いて、通常は同じ手順に従います。 MetricFireの無料デモを予約して、MetricFireが監視環境に適合するかどうかを確認してください。

- 投稿日:2020-10-28T12:39:16+09:00
部分和と向き合ってみる
こんばんは。
お久しぶりです(*´ω`)今回のチャンレンジは、任意の要素を含んだ配列の中から
無作為に要素を選んで、合算します。
しかし、ただ合算すれば良いのではなく、
目標値になるように合算しなければなりません。例えば、合計が 20になるように配列の中から組み合わせを選んでください!!
っというものです。ややこい(;´・ω・)
かなり有名で基礎的な内容のようですが、
個人的には手こずりました(笑)いきなりですけど、
コードを載せちゃいます。Partial_sum.pydef solve(Nlist, target, i=0, sum=0): if i == len(Nlist): return sum == target if (solve(Nlist, target, i + 1, sum)): return True if (solve(Nlist, target, i + 1, sum + Nlist[i])): return True return False Nlist = [1,3,5,12,7] target = 11 print(solve(Nlist, target))思ったよりシンプルですが、動きは複雑です。
例えばですが、
最初はここだけ見ます。Partial_sum.py#ここから start!! Nlist = [1,3,5,12,7] target = 11 # ↓[1,3,4...] ↓ 11 print(solve(Nlist, target))solve の中に、Nlist と target を放り込みます。
イメージとしては、要素を含んだ配列と、目標となる合計値を
丸々投げて、あと宜しく!! ってするだけです。
では、solve の中を見ていきましょう。Partial_sum.py# iは現在地のイメージです。 # sum は現在の数値の合計値です。 # 現在地は 0, 合計値も 0 def solve(Nlist, target, i=0, sum=0): # Nlist の長さは 5 、最初は i == 0 なので Pass!! if i == len(Nlist): return sum == target # あれ?! if 文の中に更に solve があります。分けわからん!! # もう読むのを辞めよう(笑) if (solve(Nlist, target, i + 1, sum)):分からん、投げ出したいです(笑)。
ダメダメ!逃げちゃ。。
答えから言うと、if 文の中に再帰を設けている場合、
その再帰処理をやり切って ture or false を導きます。
これにより if 文の中に入るか否かを判断します。
んな、馬鹿な(笑)取りあえず出発しますか、
if の中にある solve(Nlist, target, i + 1, sum) の
先に何があるかを探す冒険に。では、順番に行きましょう( `ー´)ノ
i=0.pydef solve(Nlist, target, i=0, sum=0): #pass! if i == len(Nlist): return sum == target #if 文の条件文が True or False の何れか、ハッキリするまで再帰処理を続けます。 if (solve(Nlist, target, i + 1, sum)): return Truei=1.py#solve(Nlist,target,1(=0+1),0) で再帰処理に入りました。 def solve(Nlist, target, i=1, sum=0): #pass!! if i == len(Nlist): return sum == target # また再帰処理です。恐れず行きましょう!! if (solve(Nlist, target, i + 1, sum)): return Truei=2.py#solve(Nlist,target,2(=1+1),0) で再帰処理に入りました。 def solve(Nlist, target, i=2, sum=0): #pass!! if i == len(Nlist): return sum == target # また再帰処理です。恐れず行きましょう!! if (solve(Nlist, target, i + 1, sum)): return Truei=3.py#solve(Nlist,target,3(=2+1),0) で再帰処理に入りました。 def solve(Nlist, target, i=3, sum=0): #pass!! if i == len(Nlist): return sum == target # また再帰処理です。恐れず行きましょう!! if (solve(Nlist, target, i + 1, sum)): return Truei=4.py#solve(Nlist,target,4(=3+1),0) で再帰処理に入りました。 def solve(Nlist, target, i=4, sum=0): #pass!! if i == len(Nlist): return sum == target # また再帰処理です。恐れず行きましょう!! if (solve(Nlist, target, i + 1, sum)): return Truei=5.py#solve(Nlist,target,5(=4+1),0) で再帰処理に入りました。 def solve(Nlist, target, i=5, sum=0): #i == len(Nlist) == 5 でやっと、冒頭の if 文の中に入れます。 if i == len(Nlist): # でも残念、sum(0) != target(11)。False return sum == targetなるほど、i = 5 まで行きましたが結局 False でした。
その後、どうなるんでしょう。。
とりあえず i = 5 の結果は False だったので、
前の層である i = 4 に持ち帰ってみましょう。i=4.pydef solve(Nlist, target, i=4, sum=0): #pass!! if i == len(Nlist): return sum == target # if 分内の条件文は Flase でした。って事は、ここの if 文は pass です!! #次の if 文へ行きましょう!! if (solve(Nlist, target, i + 1, sum)): return True # ここでは i = 4 なので代入してみましょう # (solve(Nlist, target, 4 + 1, sum + Nlist[4])) # (solve(Nlist, target, 5 , 0 + 7 ) //Nlist = [1,3,5,12,7] if (solve(Nlist, target, i + 1, sum + Nlist[i])): return Trueはい、次の if 文に移ります。
新たな条件文で、再度 i = 5 の時を確かめてみましょう。i=5.py#solve(Nlist,target,5,7) で再帰処理に入りました。 def solve(Nlist, target, i=5, sum=7): #i == len(Nlist) == 5 , if 文の中に入れます。 if i == len(Nlist): # でも残念、sum(7) != target(11)。False return sum == targetここまでを図にすると以下のような形になると思います。
優秀な人は、頭でこれが出来るんでしょうけど、
自分はできなかったので、紙に書いたりして整理しました。
話を戻します、i = 4 までは何をしてもダメだったようです。
では、i = 3 に、この結果を報告しましょう。i=3.py#solve(Nlist,target,3(=2+1),0) で再帰処理に入りました。 def solve(Nlist, target, i=3, sum=0): #pass!! if i == len(Nlist): return sum == target #False なので pass !! #今までの処理からsum が 11 になることはありませんでした if (solve(Nlist, target, i + 1, sum)): return True # (solve(Nlist, target, 3 + 1, sum + Nlist[3])): //Nlist = [1,3,5,12,7] # (solve(Nlist, target, 4 , 0 + 12 )): # 上記の条件を以下に代入して、新たな if 分に突入!! if (solve(Nlist, target, i + 1, sum + Nlist[i])): return Truei=4.py#solve(Nlist,target,4(=3+1),12) で再帰処理に入りました。 def solve(Nlist, target, i=4, sum=12): #pass!! if i == len(Nlist): return sum == target # 再帰処理です。恐れず行きましょう!! if (solve(Nlist, target, i + 1, sum)): return Truei=5.py#solve(Nlist,target,5(=4+1),12) で再帰処理に入りました。 def solve(Nlist, target, i=5, sum=12): #i == len(Nlist) == 5 , if 文の中に入れます。 if i == len(Nlist): # でも残念、sum(12) != target(11)。False return sum == targetFalse でしたね、一つ戻って報告です。
i=4.py#solve(Nlist,target,4(=3+1),12) で再帰処理に入りました。 def solve(Nlist, target, i=4, sum=12): #pass!! if i == len(Nlist): return sum == target #False で Pass! if (solve(Nlist, target, i + 1, sum)): return True #Next↓ if (solve(Nlist, target, i + 1, sum + Nlist[i]))://Nlist = [1,3,5,12,7] return Truei=5.py#solve(Nlist,target,5(=4+1),12 + 7) で再帰処理に入りました。 def solve(Nlist, target, i=5, sum=19): #i == len(Nlist) == 5 , if 文の中に入れます。 if i == len(Nlist): # でも残念、sum(19) != target(11)。False return sum == target図にしてみます。
なんか、木構造見たいです(笑)
気の長い作業ですが、以下のポイントだけ抑えれば oK です。1.True, False が見えるまで if 文の条件文(再帰)は追っかけ続ける
2.True, False が見えたら、ひとつ前の層に戻り、solve 内の記述に沿い忠実に動作を追いかける偉そうに書いていますが、私は全く知らなかったので、
何をどう遷移しているか確認するために
以下のように pirnt を混ぜました。Partial_sum.pydef solve(Nlist, target, i=0, sum=0): print(f"i:{i},sum:{sum}") # 再帰処理中に、現在値を表示して分かりやすくする if i == len(Nlist): # 再帰処理は、冒頭に最下層に来た時の条件文を入れます。 # なので、この if 文に入った時が最下層と分かるコメントを print します print(f"Result:i={i},sum={sum}") print() # 次の処理とを区切るために改行しています return sum == target if (solve(Nlist, target, i + 1, sum)): return True if (solve(Nlist, target, i + 1, sum + Nlist[i])): return True return False Nlist = [1,3,5,12,7] target = 11 print(solve(Nlist, target))実行結果を見てみましょう!!
実行結果.pyi:0,sum:0 i:1,sum:0 i:2,sum:0 i:3,sum:0 i:4,sum:0 i:5,sum:0 Result:i=5,sum=0 #↑前述の図と比較してみてください。i, sum の変化が図と一致していません? #Result:i=5,sum=0 とあるように sum は 11 ではないので False を返します #返した後は i=4 の時に帰ります。 #帰ったあとは、そのまま次の IF 文に続きます。 #よって、次の表示は以下にある i = 5 の時の pirnt になります。 #理解できない人は前述のページに戻ってください。 i:5,sum:7 Result:i=5,sum=7 #↑sum(=7) != 11 なので False です。 #よって、i = 4 の時の 2 つの if 文は両方とも False となります。 #次は i = 3 の時の if 文に戻りますが、処理は後は前述と同じです。 i:4,sum:12 i:5,sum:12 Result:i=5,sum=12 i:5,sum:19 Result:i=5,sum=19 i:3,sum:5 i:4,sum:5 i:5,sum:5 Result:i=5,sum=5 i:5,sum:12 Result:i=5,sum=12 i:4,sum:17 i:5,sum:17 Result:i=5,sum=17 i:5,sum:24 Result:i=5,sum=24 i:2,sum:3 i:3,sum:3 i:4,sum:3 i:5,sum:3 Result:i=5,sum=3 i:5,sum:10 Result:i=5,sum=10 i:4,sum:15 i:5,sum:15 Result:i=5,sum=15 i:5,sum:22 Result:i=5,sum=22 i:3,sum:8 i:4,sum:8 i:5,sum:8 Result:i=5,sum=8 i:5,sum:15 Result:i=5,sum=15 i:4,sum:20 i:5,sum:20 Result:i=5,sum=20 i:5,sum:27 Result:i=5,sum=27 i:1,sum:1 i:2,sum:1 i:3,sum:1 i:4,sum:1 i:5,sum:1 Result:i=5,sum=1 i:5,sum:8 Result:i=5,sum=8 i:4,sum:13 i:5,sum:13 Result:i=5,sum=13 i:5,sum:20 Result:i=5,sum=20 i:3,sum:6 i:4,sum:6 i:5,sum:6 Result:i=5,sum=6 i:5,sum:13 Result:i=5,sum=13 i:4,sum:18 i:5,sum:18 Result:i=5,sum=18 i:5,sum:25 Result:i=5,sum=25 i:2,sum:4 i:3,sum:4 i:4,sum:4 i:5,sum:4 Result:i=5,sum=4 i:5,sum:11 Result:i=5,sum=11 True以上のように、遷移できない限界まで達した後に、
一つ戻り、また限界まで動作するような処理を繰り返す手法を深さ優先探索と言います。
資料には、比較的簡単に書けるって書いてありますが、
いやいや、初心者にはキッツイ!!( ゚Д゚)まだまだ先は長そうです(*´ω`)
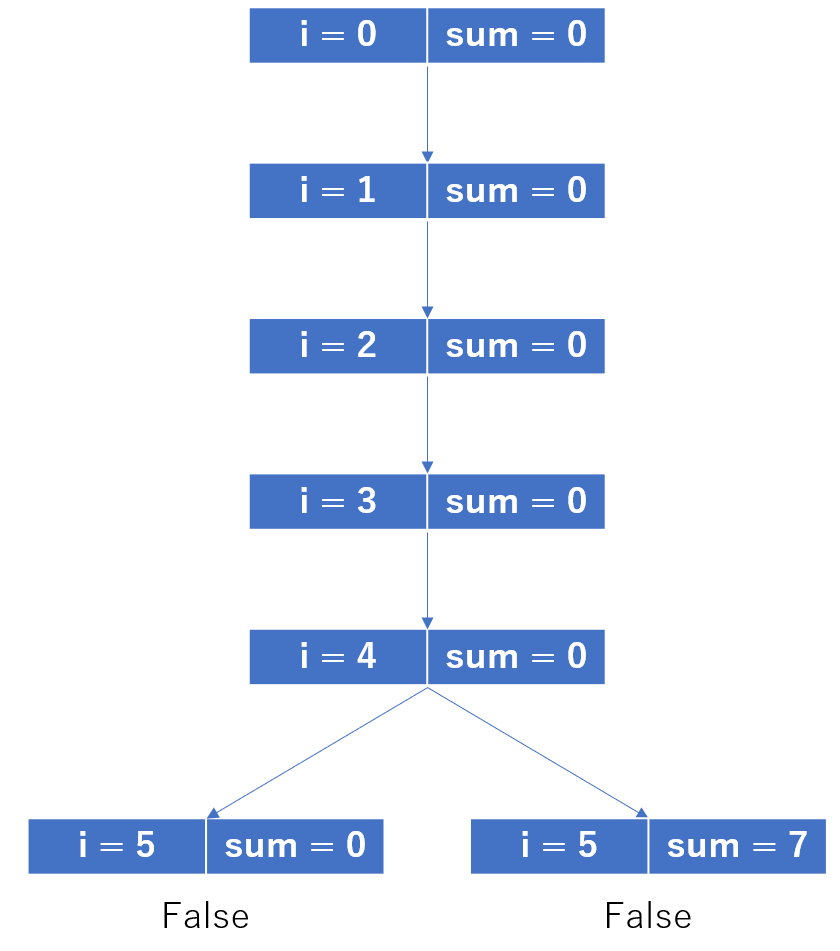
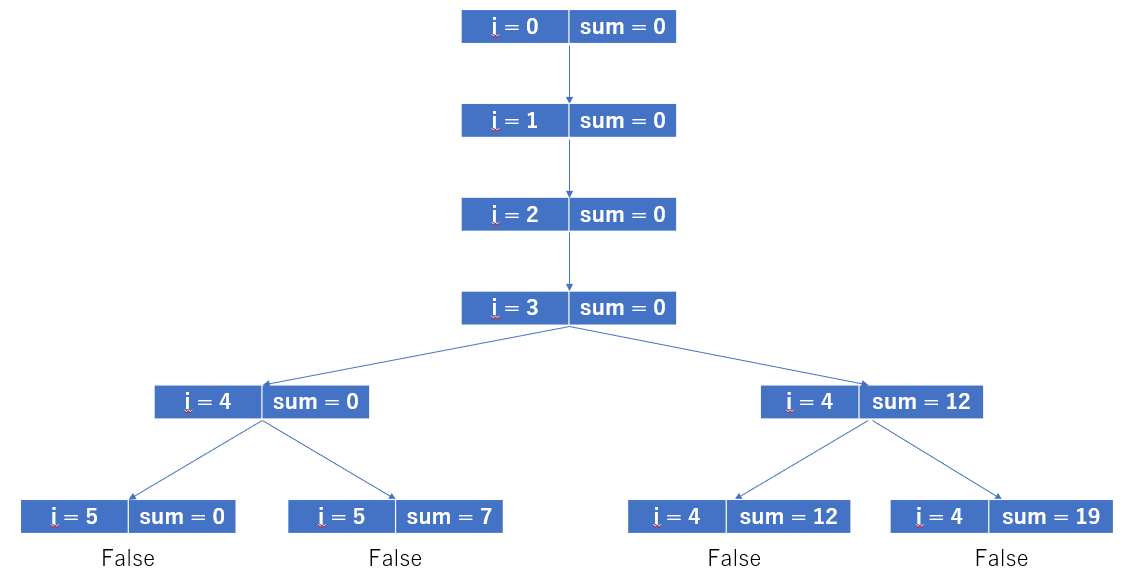
- 投稿日:2020-10-28T11:16:52+09:00
xml.etree.ElementTreeの使い方
Python 3.8.2
xml.etree.ElementTree --- ElementTree XML API
パース
ファイルから
import xml.etree.ElementTree as ET tree = ET.parse('country_data.xml') root = tree.getroot()文字列から
root = ET.fromstring(country_data_as_string)検索
タグで現在の要素の 直接の子要素 のみ検索
# Listが返ってくる list = root.findall('country'):タグで最初に見つかった要素だけ検索
elem = root.find('country'):XPath式で検索
root.findall("./country/neighbor")コンテンツと属性へのアクセス
コンテンツにアクセス
rank = country.find('rank').text属性にアクセス
# どちらでも country.get('name') country.attrib['name']子要素の生成
elem = ET.SubElement(root,'country') elem = ET.SubElement(root,'country', attrib={'name':'Liechtenstein'})子要素の削除
>>> for country in root.findall('country'): ... # using root.findall() to avoid removal during traversal ... rank = int(country.find('rank').text) ... if rank > 50: ... root.remove(country) ...出力
sys.stdoutに出力
ET.dump(root)ファイルに出力
- 改行されないので見にくい
tree = ET.ElementTree(root) tree.write('filename', encoding="utf-8", xml_declaration=True)改行付きでファイルに出力
import xml.dom.minidom as md document = md.parseString(ET.tostring(root, 'utf-8')) with open(fname,'w') as f: document.writexml(f, encoding='utf-8', newl='\n', indent='', addindent=' ')
- 投稿日:2020-10-28T11:07:40+09:00
Tkinter 相互関連があるCallbackをテストする2
最近忙しく、Markdownの書き方も少し忘れていたため、思い出す意味も込めて投稿。
下記相互関係のCallbackを使った場合に、複数のオブジェクトを関係を作ると
ソースが雑多となるため、ペアとしてまとめられるようにソース修正。
https://qiita.com/Nomisugi/items/8d11e0419091ac21866d (修正前のコード)MultiBinEditor.pyimport tkinter as tk class HexSpinbox(tk.Spinbox): def __init__(self, *args, **kwargs): self.var = tk.StringVar() self.bytenum = kwargs.pop('bytenum', 1) self.add_callback = None self.handle_obj = None max_val = 0x1<<(self.bytenum*8) super().__init__(*args, **kwargs, textvariable=self.var, from_=0,to=max_val, increment=1, command=self.callback ) def set(self, val): s = "0x{:0%dx}" % (self.bytenum*2) self.var.set(s.format(int(val))) def get(self): hstr = super().get() return int(hstr, 16) def callback(self): val = super().get() self.set(val) self.add_callback(val) if self.add_callback != None else None def setCallback_pair(self, obj): self.pair_obj = obj self.add_callback = self.handle def handle(self, val): self.set(val) self.pair_obj.set(val) def setCallback(self, func): self.add_callback = func class BinEditFrame(tk.Frame): def __init__(self, master): super().__init__(master) self.val = 0x00 self.bits = [] self.add_callback = None self.pair_obj = None for i in range(8): btn = tk.Button(self,text=str(i), relief='raised', command=self.callback(i)) btn.pack(sid='right') self.bits.append(btn) def callback(self, i): def push(): self.val ^= (1<<i) self.redraw() self.add_callback(self.val) if self.add_callback != None else None return push def redraw(self): #All Button Delete for bit in self.bits: bit.destroy() self.bits.clear() #All Button ReCreate for i in range(8): if (self.val & (1<<i) > 0): btn = tk.Button(self,text=str(i), relief='sunken', command=self.callback(i) ) else: btn = tk.Button(self,text=str(i), relief='raised', command=self.callback(i) ) btn.pack(sid='right') self.bits.append(btn) def setCallback(self, func): self.add_callback = func def setCallback_pair(self, obj): self.pair_obj = obj self.add_callback = self.handle def handle(self, val): self.set(val) self.pair_obj.set(val) def set(self, val): self.val = int(val) self.redraw() if __name__ == "__main__": print("BinHexEditor") win = tk.Tk() hx = HexSpinbox(win) hx.pack(side=tk.LEFT) be = BinEditFrame(win) be.pack(side=tk.LEFT) hx.setCallback_pair(be) be.setCallback_pair(hx) win.mainloop()外部にCallback関数を追加せずに、相互の数値を変更できる仕組みができました。
これを使って特殊バイナリエディタを作ってみます。
- 投稿日:2020-10-28T10:59:25+09:00
Pythonで型を極める?(型チェックをいつするべきか)
もともと以下の記事のコメントに書いていたのですが、コメントに書くには攻撃的すぎる内容だと思ったので、ここに移しました。
Pythonで型を極める【Python 3.9対応】宗教論争を引き起こすだけ、であろうことは承知の上での記事です。
最近、静的型付けの利点(というか、動的型付けの欠点?)がよく語られるようになってきて、TypeScript が隆盛したり、Pythonでも静的な型チェックができるようになっています。
ただ、個人的に、(とくに動的型付け言語に、後から追加された静的型チェック機能において)、「不要な型付け」(場合によっては、むしろ「有害にすら思える型付け」)をしているコードが増えているような気がしています。Pythonで型を極める【Python 3.9対応】
の記事で、def add(a, b): """引数を足した結果を返す""" return a + bに型を付けて
def add_type(a: int, b: int) -> int: """引数を足した結果を返す""" return a + bとする、という例が登場します。
しかしながら、この例では、型は書くべきではないと思います。
不必要に型を特定するのは良くないです。
この場合、a+bという演算に意味があるような型であればよいのであって、intに特定するのは「悪い」プログラミングスタイルだと思います。
もちろん、上記は、単なる例として出しているだけ、というのは理解していますが、それでも、この例は「例として不適切」だと考えます。intに特定するとどういったケースで不都合があるのでしょうか?
現実は理想論だけではすまない、というのをわかった上で、理想論として語れば、
具象型に対してではなくて、インタフェースに対してプログラミングするべき
だからです。
この例で言えば、
add関数は、「+演算子で加算できる」という性質(インタフェース)を備えた任意のオブジェクトに対して適用可能です。もちろん、個々の具体的な型によって、+演算子が実行する具体的な処理内容は異なりますが(ポリモーフィズム)、add関数は、+演算子という「インタフェース」に対してプログラミングしているわけで、+演算子の具体的な処理内容は関知していない(というか、+演算子の具体的な処理内容に依存してはいけない)わけです。この例で、具象型である
intに縛るべきではないです。そうしてしまうと、それこそ、後から、intではなくfloatに変えたくなったら、プログラム上のintというキーワードを全てfloatに置換しないといけない、みたいな作業が発生することになります。もっと言えば、
add関数の引数を数値に絞る必然性もないと思います。add関数の引数は、+演算子というインタフェースが定義されていればよいわけで、add関数に、strやlist、さらには、__add__特殊メソッドが定義された独自クラスを入力することは何の問題もないです。もっと正確に言えば、そもそも、add関数は+演算子を備える任意のオブジェクトに対してキチンと動作するように書かれているべきです。実は、最近、静的型付け言語の世界(とくにC++やRustなんかでは顕著ですが)では、可能な限り型指定はしない(コンパイラに自動で型推論させる)、あえて型指定する場合でも最大限Genericな型にする、というプログラミングスタイルが広がっています。
一方で、最近、Pythonで型指定をしているコードをちょくちょく見かけるようになったのですが、なぜこんな「不要な型指定」をするのか、と疑問に思うコードが多かったりします。
正直に言うと、「30年前のC++のコード」を見ているような気分になります。Pythonのプログラマーは、静的型付け言語の世界でのこの30年の試行錯誤(とその結果起ったパラダイムシフト)を、またゼロからやり直すつもりなのか?と思ったり。これを書くと宗教戦争を引き起こす可能性がかなりありますが、私の「偏見」では、Pythonで型指定したがるのは、Pythonが初めての言語の人たち(あるいは20〜30年前のC++やJavaの知識で止まっている人たち)であって、むしろ、最近、静的型付け言語からPythonに移ってきた人たちは、Pythonで型指定したがらない、という印象があります。
- 投稿日:2020-10-28T10:22:26+09:00
Codeforces Round #597 (Div. 2) バチャ復習(10/27)
今回の成績
今回の感想
Dが全く解けませんでした。
典型問題のようなので反省して次に生かしたいと思います。A問題
$a,b$が互いに素であることを判定すれば良いです。中国剰余定理を思い出せば良いだけです。
A.pyfrom math import gcd for _ in range(int(input())): a,b=map(int,input().split()) if gcd(a,b)==1: print("Finite") else: print("Infinite")B問題
下記の変数$r,p,s$が0以上で相手に勝てる手のみをまずは埋めていきます。勝てる手を埋めた時に半分以上で勝てる場合は残りの手を適当に決めてから出力すれば良いです。半分以上勝てない場合でも今の手の選び方が最大の選び方なので、NOを出力します。
実装は無心に行えば良いです。
B.pyfrom collections import deque for _ in range(int(input())): n=int(input()) r,p,s=map(int,input().split()) t=input() ans=["" for i in range(n)] w=0 for i in range(n): if t[i]=="R": if p>0: ans[i]="P" p-=1 w+=1 elif t[i]=="P": if s>0: ans[i]="S" s-=1 w+=1 else: if r>0: ans[i]="R" r-=1 w+=1 if w<-(-n//2): print("NO") else: ansp=deque() for i in range(r): ansp.append("R") for i in range(p): ansp.append("P") for i in range(s): ansp.append("S") for i in range(n): if ans[i]=="": ans[i]=ansp.popleft() print("YES") print("".join(ans))C問題
$10^9+7$で割るのを失念していました…。
このような文字列の数え上げの問題は順番を決めて数え上げるのが良いです。また、その際に状態をうまく設定することでDPにすることができます。つまり、以下のようなDPをおきます。
$dp[i]:=$($i$番目の文字(1-indexed)まで見た時にありうる文字列の総数)
初期化は$dp[0]=1,dp[1]=1$とすればよく、この時$i$番目の文字への遷移を考えて以下のようになります。
(1)$i$番目の文字が変換された文字ではない場合
$dp[i]+=dp[i-1]$
(2)$i$番目の文字が変換された文字の場合
$i-1$番目及び$i$番目の文字がいずれも$u$またはいずれも$n$であるという条件のもとで
$dp[i]+=dp[i-2]$以上の二つの遷移を考えて$10^9+7$で割り忘れなければ答えはでます。また、$w,m$は必ず$uu,nn$にそれぞれ変わるので、$w$または$m$が含まれる場合は0を出力する必要があります。
C.pymod=10**9+7 s=input() n=len(s) dp=[0]*(n+1) dp[0]=1 dp[1]=1 for i in range(2,n+1): dp[i]+=dp[i-1] dp[i]%=mod #print(s[i-2:i]) if s[i-2:i]=="uu" or s[i-2:i]=="nn": dp[i]+=dp[i-2] dp[i]%=mod #print(dp) if ("w" in s)or("m" in s): print(0) else: print(dp[n])D問題
最小全域木が見えないと解くのは不可能だと思います。僕は約9ヶ月前に一回解いただけだったので全く思いつきもしませんでした。しかし、今回でだいぶ整理されたので、次に出てきたら解ける気がします。
できるだけコストが小さくなるように都市間の辺を繋ぐか発電所を作るかしていきます。このとき、都市間の辺をつないだ時のコストの最小化を狙うので最小全域木の問題と捉えられます。また、発電所を作るコストについても新たな頂点(超頂点)を導入して元々の頂点との間の重み付きの辺を考えることで、最小全域木を解く問題に帰着することができます。
つまり、発電所の頂点を作って$i$番目の都市との間のコストを$c_i$としてやれば良いです。このようにすれば$n+1$の頂点における最小全域木を考えるだけで解を求まります。また、発電所のおいた都市及び繋いだ都市間の辺の情報も出力しますが、これはクラスカル法で辺を付け足す際の場合分けにより簡単に実装することができます。
上記で考察及び実装は良いのですが、クラスカル法で複数の異なる型の値を返したかったのでtupleを初めて使ったことにも触れようと思います。非常に使い心地が良いので今後も使っていこうと思います(documentはこちら)。
(✳︎)…最小全域木に関しては一応この記事にライブラリを載せました。
D.cc//デバッグ用オプション:-fsanitize=undefined,address //コンパイラ最適化 #pragma GCC optimize("Ofast") //インクルードなど #include<bits/stdc++.h> using namespace std; typedef long long ll; //マクロ //forループ //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる //FORAは範囲for文(使いにくかったら消す) #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) #define FORA(i,I) for(const auto& i:I) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() #define SIZE(x) ll(x.size()) //定数 #define INF 1000000000000 //10^12:∞ #define MOD 1000000007 //10^9+7:合同式の法 #define MAXR 100000 //10^5:配列の最大のrange //略記 #define PB push_back //挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 //以下、素集合と木は同じものを表す class UnionFind{ public: vector<ll> parent; //parent[i]はiの親 vector<ll> siz; //素集合のサイズを表す配列(1で初期化) map<ll,vector<ll>> group; //集合ごとに管理する(key:集合の代表元、value:集合の要素の配列) ll n; //要素数 //コンストラクタ UnionFind(ll n_):n(n_),parent(n_),siz(n_,1){ //全ての要素の根が自身であるとして初期化 for(ll i=0;i<n;i++){parent[i]=i;} } //データxの属する木の根を取得(経路圧縮も行う) ll root(ll x){ if(parent[x]==x) return x; return parent[x]=root(parent[x]);//代入式の値は代入した変数の値なので、経路圧縮できる } //xとyの木を併合 void unite(ll x,ll y){ ll rx=root(x);//xの根 ll ry=root(y);//yの根 if(rx==ry) return;//同じ木にある時 //小さい集合を大きい集合へと併合(ry→rxへ併合) if(siz[rx]<siz[ry]) swap(rx,ry); siz[rx]+=siz[ry]; parent[ry]=rx;//xとyが同じ木にない時はyの根ryをxの根rxにつける } //xとyが属する木が同じかを判定 bool same(ll x,ll y){ ll rx=root(x); ll ry=root(y); return rx==ry; } //xの素集合のサイズを取得 ll size(ll x){ return siz[root(x)]; } //素集合をそれぞれグループ化 void grouping(){ //経路圧縮を先に行う REP(i,n)root(i); //mapで管理する(デフォルト構築を利用) REP(i,n)group[parent[i]].PB(i); } //素集合系を削除して初期化 void clear(){ REP(i,n){parent[i]=i;} siz=vector<ll>(n,1); group.clear(); } }; //辺の構造体 struct Edge{ ll u,v,cost; //後ろにconstつける! bool operator<(const Edge& e) const {return this->cost<e.cost;} }; //クラスカル法 //ret:=最小全域木の重みの総和 //n:=頂点の総数 //計算量:=O(|E|log|V|) tuple<ll,vector<ll>,vector<pair<ll,ll>>> Kruskal(vector<Edge> &edges,ll n){ vector<ll> f1;vector<pair<ll,ll>> f2; sort(ALL(edges));//辺の重みの昇順 UnionFind uf=UnionFind(n); ll ret=0; FORA(e,edges){ //その辺を加える必要があるか(発電所or辺) if (!uf.same(e.u,e.v)){ uf.unite(e.u,e.v); ret+=e.cost; if(e.v==n-1){ f1.PB(e.u+1); }else{ f2.PB(MP(e.u+1,e.v+1)); } } } return {ret,f1,f2}; } signed main(){ //小数の桁数の出力指定 //cout<<fixed<<setprecision(10); //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); ll n;cin>>n; vector<pair<ll,ll>> xy(n);REP(i,n)cin>>xy[i].F>>xy[i].S; vector<ll> c(n);REP(i,n)cin>>c[i]; vector<ll> k(n);REP(i,n)cin>>k[i]; vector<Edge> edges; REP(i,n){ FOR(j,i+1,n-1){ edges.PB({i,j,(abs(xy[i].F-xy[j].F)+abs(xy[i].S-xy[j].S))*(k[i]+k[j])}); } } REP(i,n)edges.PB({i,n,c[i]}); tuple<ll,vector<ll>,vector<pair<ll,ll>>> t=Kruskal(edges,n+1); cout<<get<0>(t)<<endl; cout<<SIZE(get<1>(t))<<endl; REP(i,SIZE(get<1>(t))){ if(i==SIZE(get<1>(t))-1)cout<<get<1>(t)[i]<<endl; else cout<<get<1>(t)[i]<<" "; } cout<<SIZE(get<2>(t))<<endl; REP(i,SIZE(get<2>(t))){ cout<<get<2>(t)[i].F<<" "<<get<2>(t)[i].S<<endl; } }E問題
今回は飛ばします。
F問題
$a,b$のそれぞれで同時に桁DPを考え、上から$i$桁目を見た時に$l$に等しいか(①),$l$より大きく$r$より小さいか(②),$r$に等しいか(③)という3通りを考えようとしたら実装が破滅しました(遷移が$3 \times 3 \times 3$の27通りになるので)。
方針は合っていたのですが、$a=b=0$の時以外は$a\neq b$なので、$r$のMSBから順に考えれば$a$は①と②,$b$は②と③しか満たさないことがわかります。したがって、遷移が$2 \times 2 \times 3$通りになり、十分に書き下せる量に減らすことができます。
今回はupsolveしませんが、次見たときは解けるようになっていて欲しいです。よく考えたらコンテスト中にもっと集中して解けば良いだけの話ではあるので、反省しています。

- 投稿日:2020-10-28T10:21:58+09:00
Pythonで算出するVIFとExcelで算出するVIFが違う..??
PythonでVIF確認出来て超便利!
PythonでVIF(Variance Inflation Factor)を調べることができ、この結果を見ながら説明変数間の多重共線性を確認することができます。
一般的にVIF>10の場合は多重共線性が強いと判断できるとの事。from statsmodels.stats.outliers_influence import variance_inflation_factor df_all = pd.read_excel('train.xlsx',sheet_name="Sheet1") cols = df_all.select_dtypes(include=[np.number]).columns cols_x = cols[1:] data_x = df_all[cols_x] #vifを計算する vif = pd.DataFrame() vif["VIF Factor"] = [variance_inflation_factor(data_x.values, i) for i in range(data_x.shape[1])] #vif["features"] = data_x.columns #vifを計算結果を出力する print(vif) #vifをグラフ化する plt.plot(vif["VIF Factor"])こんな感じで結果が出ます。便利ですよね!
ところが、、Excelで算出したVIFと比較すると..
VIFが異なる結果で出てくることが発覚しました('Д')..!!
そもそもVIFは以下の式で求められます。
VIF = 1/(1-R2) # R2:決定係数説明変数の1つを目的変数と見立てたときに、残りの説明変数で重回帰分析した際に得られる決定係数R2を使用します。
感覚的に言えば、「残りの説明変数である1つの変数を上手に表現できるなら、その変数はいらなくない?」って事だと理解しています。
VIFが違うという事は、PythonとExcelでこのR2が異なるということになるので、一瞬パニックになりました。違いの原因は、切片を含むか否か..でした。
何故異なるか、その原因は説明変数に切片を含めるか否か、という事が判明しました。
Python側では、切片=0として処理
Excelで検討した際は、切片を特に指定しませんでした。Excelでも切片=0とするように設定したところVIFが一致することを確認できました。
↑ここにチェックを入れるかどうか皆さんに聞きたい..結局どっちが正しいのでしょうか?
- Pythonのstatsmodel使っておけば問題ないのでは?
- 切片は特に指定するべきではない?
- とにかくR2が最大になる組み合わせでVIFを評価するべきで、切片が0か否かは重要ではない?
- VIFはあくまで目安なので、特に気にする必要はない?
上記のようなことを考えているのですが、皆さんいかがでしょうか?
そもそもstatsmodelのVIF算出アルゴリズムがどうなっているのかも気になります..。ご意見やアドバイスがあれば是非、よろしくお願いします!!
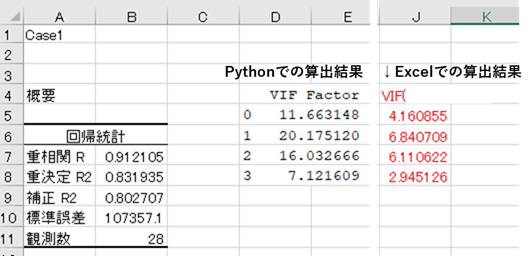
- 投稿日:2020-10-28T08:56:36+09:00
conditional GANの出力をクラス毎に保存する 〜PyTorchによるcGAN実装とともに〜
2回目の投稿です。
前回はPyTorchでDCGANの実装を行うとともに出力画像を1枚ずつ保存できるようにしました。今回はGANの出力を制御できるように改良したconditional GAN(条件付きGAN)の実装を行なっていきます。それと同時に前回同様、出力画像を1枚ずづ保存できるようにしていきます。
目的
conditional GANの実装を行い、出力を1枚ずつ保存する
conditional GAN
conditional GANは生成する画像を明示的に分けられるようにしたものです。訓練時に教師データのラベル情報も用いて訓練することでこれを可能にしました。
論文はこちら以下論文より
GeneratorとDiscriminatorの両方の入力にクラスラベルの情報を追加して学習を行う感じです。入力の形式が少し変わる感じですがGANの基本的な構造としては変わらないです。実装
実装に移っていきます。今回は前回実装したDCGANをベースとしたconditional GANの実装をしていきます。
実行環境
Google Colaboratory
モジュールのインポート&保存先の設定
まずはモジュールのインポートから
import argparse import os import numpy as np import torchvision.transforms as transforms from torchvision.utils import save_image from torch.utils.data import DataLoader from torchvision import datasets import torch.nn as nn import torch.nn.functional as F import torch img_save_path = 'images-C_dcgan' os.makedirs(img_save_path, exist_ok=True)コマンドライン&デフォルト値の設定
前回とほぼ同じです。
微妙な変更点としては、生成する画像サイズがMNISTデフォルトの28×28ではなく32×32になっています。parser = argparse.ArgumentParser() parser.add_argument('--n_epochs', type=int, default=200, help='number of epochs of training') parser.add_argument('--batch_size', type=int, default=64, help='size of the batches') parser.add_argument('--lr', type=float, default=0.0002, help='adam: learning rate') parser.add_argument('--beta1', type=float, default=0.5, help='adam: decay of first order momentum of gradient') parser.add_argument('--beta2', type=float, default=0.999, help='adam: decay of second order momentum of gradient') parser.add_argument('--n_cpu', type=int, default=8, help='number of cpu threads to use during batch generation') parser.add_argument('--latent_dim', type=int, default=100, help='dimensionality of the latent space') parser.add_argument('--n_classes', type=int, default=10, help='number of classes for dataset') parser.add_argument('--img_size', type=int, default=32, help='size of each image dimension') parser.add_argument('--channels', type=int, default=1, help='number of image channels') parser.add_argument('--sample_interval', type=int, default=400, help='interval between image sampling') args = parser.parse_args() #google colabの場合は args=parser.parse_args(args=[]) print(args) C,H,W = args.channels, args.img_size, args.img_size重みの設定
def weights_init_normal(m): classname = m.__class__.__name__ if classname.find('Conv') != -1: torch.nn.init.normal(m.weight, 0.0, 0.02) elif classname.find('BatchNorm2d') != -1: torch.nn.init.normal(m.weight, 1.0, 0.02) torch.nn.init.constant(m.bias, 0.0)Generator
Generatorの定義をしていきます。catで生成画像の情報とラベルの情報をくっつけて生成します。
class Generator(nn.Module): # initializers def __init__(self, d=128): super(Generator, self).__init__() self.deconv1_1 = nn.ConvTranspose2d(100, d*2, 4, 1, 0) self.deconv1_1_bn = nn.BatchNorm2d(d*2) self.deconv1_2 = nn.ConvTranspose2d(10, d*2, 4, 1, 0) self.deconv1_2_bn = nn.BatchNorm2d(d*2) self.deconv2 = nn.ConvTranspose2d(d*4, d*2, 4, 2, 1) self.deconv2_bn = nn.BatchNorm2d(d*2) self.deconv3 = nn.ConvTranspose2d(d*2, d, 4, 2, 1) self.deconv3_bn = nn.BatchNorm2d(d) self.deconv4 = nn.ConvTranspose2d(d, C, 4, 2, 1) # forward method def forward(self, input, label): x = F.relu(self.deconv1_1_bn(self.deconv1_1(input))) y = F.relu(self.deconv1_2_bn(self.deconv1_2(label))) x = torch.cat([x, y], 1) x = F.relu(self.deconv2_bn(self.deconv2(x))) x = F.relu(self.deconv3_bn(self.deconv3(x))) x = torch.tanh(self.deconv4(x)) return x前回はUpsampling+Conv2dでGeneratorを実装しました。今回は前回の方法ではなく、ConvTranspose2dを利用して実装を行っています。この違いについてはこちらの記事にまとめられているので気になる方はご覧ください。
Discriminator
Discriminatorの定義です。こちらもcatでラベル情報をくっつけています。
class Discriminator(nn.Module): # initializers def __init__(self, d=128): super(Discriminator, self).__init__() self.conv1_1 = nn.Conv2d(C, d//2, 4, 2, 1) self.conv1_2 = nn.Conv2d(10, d//2, 4, 2, 1) self.conv2 = nn.Conv2d(d, d*2, 4, 2, 1) self.conv2_bn = nn.BatchNorm2d(d*2) self.conv3 = nn.Conv2d(d*2, d*4, 4, 2, 1) self.conv3_bn = nn.BatchNorm2d(d*4) self.conv4 = nn.Conv2d(d * 4, 1, 4, 1, 0) def forward(self, input, label): x = F.leaky_relu(self.conv1_1(input), 0.2) y = F.leaky_relu(self.conv1_2(label), 0.2) x = torch.cat([x, y], 1) x = F.leaky_relu(self.conv2_bn(self.conv2(x)), 0.2) x = F.leaky_relu(self.conv3_bn(self.conv3(x)), 0.2) x = F.sigmoid(self.conv4(x)) return xLoss関数やネットワークの設定
Loss関数の定義や、重みの初期化、Generator・Discriminatorの初期化、Optimizerの設定を行います
# Loss function adversarial_loss = torch.nn.BCELoss() # Initialize Generator and discriminator generator = Generator() discriminator = Discriminator() if torch.cuda.is_available(): generator.cuda() discriminator.cuda() adversarial_loss.cuda() # Initialize weights generator.apply(weights_init_normal) discriminator.apply(weights_init_normal) # Optimizers optimizer_G = torch.optim.Adam(generator.parameters(), lr=args.lr, betas=(args.beta1, args.beta2)) optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=args.lr, betas=(args.beta1, args.beta2))Dataloaderの作成
Dataloaderを作成していきます。今回は32*32の大きさで画像を生成するので、画像の前処理の部分でMNISTの画像をリサイズしています。
# Configure data loader os.makedirs('./data', exist_ok=True) dataloader = torch.utils.data.DataLoader( datasets.MNIST('./data', train=True, download=True, transform=transforms.Compose([ transforms.Resize(args.img_size), transforms.ToTensor(), transforms.Normalize([0.5,], [0.5,]) ])), batch_size=args.batch_size, shuffle=True, drop_last=True) print('the data is ok')Training
GANのTrainingです。
for epoch in range(1, args.n_epochs+1): for i, (imgs, labels) in enumerate(dataloader): Batch_Size = args.batch_size N_Class = args.n_classes img_size = args.img_size # Adversarial ground truths valid = torch.ones(Batch_Size).cuda() fake = torch.zeros(Batch_Size).cuda() # Configure input real_imgs = imgs.type(torch.FloatTensor).cuda() real_y = torch.zeros(Batch_Size, N_Class) real_y = real_y.scatter_(1, labels.view(Batch_Size, 1), 1).view(Batch_Size, N_Class, 1, 1).contiguous() real_y = real_y.expand(-1, -1, img_size, img_size).cuda() # Sample noise and labels as generator input noise = torch.randn((Batch_Size, args.latent_dim,1,1)).cuda() gen_labels = (torch.rand(Batch_Size, 1) * N_Class).type(torch.LongTensor) gen_y = torch.zeros(Batch_Size, N_Class) gen_y = gen_y.scatter_(1, gen_labels.view(Batch_Size, 1), 1).view(Batch_Size, N_Class,1,1).cuda() # --------------------- # Train Discriminator # --------------------- optimizer_D.zero_grad() # Loss for real images d_real_loss = adversarial_loss(discriminator(real_imgs, real_y).squeeze(), valid) # Loss for fake images gen_imgs = generator(noise, gen_y) gen_y_for_D = gen_y.view(Batch_Size, N_Class, 1, 1).contiguous().expand(-1, -1, img_size, img_size) d_fake_loss = adversarial_loss(discriminator(gen_imgs.detach(),gen_y_for_D).squeeze(), fake) # Total discriminator loss d_loss = (d_real_loss + d_fake_loss) d_loss.backward() optimizer_D.step() # ----------------- # Train Generator # ----------------- optimizer_G.zero_grad() g_loss = adversarial_loss(discriminator(gen_imgs,gen_y_for_D).squeeze(), valid) g_loss.backward() optimizer_G.step() print ("[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]" % (epoch, args.n_epochs, i, len(dataloader), d_loss.data.cpu(), g_loss.data.cpu())) batches_done = epoch * len(dataloader) + i if epoch % 20 == 0: noise = torch.FloatTensor(np.random.normal(0, 1, (N_Class**2, args.latent_dim,1,1))).cuda() #fixed labels y_ = torch.LongTensor(np.array([num for num in range(N_Class)])).view(N_Class,1).expand(-1,N_Class).contiguous() y_fixed = torch.zeros(N_Class**2, N_Class) y_fixed = y_fixed.scatter_(1,y_.view(N_Class**2,1),1).view(N_Class**2, N_Class,1,1).cuda() with torch.no_grad(): gen_imgs = generator(noise, y_fixed).view(-1,C,H,W) save_image(gen_imgs.data, img_save_path + '/epoch:%d.png' % epoch, nrow=N_Class, normalize=True)実行結果
実行結果は以下のようになります。
生成画像がクラスごとに綺麗に並んでいるのがわかります。conditional GANではこのように生成する画像を制御することができます。クラス毎に画像を生成して保存する
前回同様、こちらも1枚ずつ画像を保存できるようにしていきます。
if epoch % 20 == 0: noise = torch.FloatTensor(np.random.normal(0, 1, (N_Class**2, args.latent_dim,1,1))).cuda() #fixed labels y_ = torch.LongTensor(np.array([num for num in range(N_Class)])).view(N_Class,1).expand(-1,N_Class).contiguous() y_fixed = torch.zeros(N_Class**2, N_Class) y_fixed = y_fixed.scatter_(1,y_.view(N_Class**2,1),1).view(N_Class**2, N_Class,1,1).cuda() with torch.no_grad(): gen_imgs = generator(noise, y_fixed).view(-1,C,H,W) save_image(gen_imgs.data, img_save_path + '/epoch:%d.png' % epoch, nrow=N_Class, normalize=True)ここの部分を
if epoch % 20 == 0: for l in range(10): #各クラス10枚ずつ保存する noise = torch.FloatTensor(np.random.normal(0, 1, (N_Class**2, args.latent_dim,1,1))).cuda() #fixed labels y_ = torch.LongTensor(np.array([num for num in range(N_Class)])).view(N_Class,1).expand(-1,N_Class).contiguous() y_fixed = torch.zeros(N_Class**2, N_Class) y_fixed = y_fixed.scatter_(1,y_.view(N_Class**2,1),1).view(N_Class**2, N_Class,1,1).cuda() for m in range() with torch.no_grad(): gen_imgs = generator(noise, y_fixed).view(-1,C,H,W) save_gen_imgs = gen_imgs[10*i] save_image(save_gen_imgs, img_save_path + '/epochs:%d/%d/epoch:%d-%d_%d.png' % (epoch, i, epoch,i, j), normalize=True)このように変更します。なおこのようにする場合は画像を保存するディレクトリ構造を変えておく必要があります。
images-C_dcgan ├── epochs:20 │ ├── 0 │ ├── 1 │ ├── 2 │ ├── 3 │ ├── 4 │ ├── 5 │ ├── 6 │ ├── 7 │ ├── 8 │ └── 9 │ . │ . │ . │ └── epochs:200 ├── 0 ├── 1 ├── 2 ├── 3 ├── 4 ├── 5 ├── 6 ├── 7 ├── 8 └── 920エポック毎に0~9のディレクトリがある状態です。
os.makedirsを使って一気に作成すると楽ですね。これで各クラス毎に画像が保存されるようになりました。まとめ
今回はDCGANに引き続きconditional GANを実装し、生成画像を1枚ずつ保存できるようにしました。今回は1番簡単な、GeneratorとDiscriminatorの両方の入力にラベル情報を付与する形でconditional GANを実装していきました。今現在、conditional GANを実装する上でデファクトスタンダードとなっているのは、Projection DiscriminatorやConditional Batch Normalizationといった技術です。ここら辺の技術はまだあまり理解していないので機会があれば実装しながら勉強していきたいと思います。