- 投稿日:2020-10-28T23:17:51+09:00
AWS ルートユーザARNがよくわからなかったので整理する
はじめに
こんにちは。たけじんです。
初めて記事を書いてみます。AWSに触れて1年のひよっこ?ですが、少しずつ勉強していきます。
最近、AWSをいじっていていたときに、
「ルートユーザのARN」が示すものがよくわからなくなってしまったので、整理して残しておきたいと思います。結論
ルートユーザのARNは、使用するポリシーやポリシー内のどこで使用されるかによって扱いが異なります。
通常は・・・
アカウント内のIAMエンティティを示します。IAMユーザ、IAMロールですね。
例外として・・・
AWS Organizationsにて、SCPで利用される場合、アカウントのルートユーザ自体を示します。
ルートユーザのARN
ルートユーザのARNは以下のように表されます。
arn:aws:iam::123456789012:rootルートユーザのARNの使用例
Principalの指定に使用する
例えば、IAMロールにスイッチロールする場合、IAMロールの信頼ポリシーでは、以下のようにスイッチ元のAWSアカウントを"Principal"に指定するかと思います。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::123456789012:root" }, "Action": "sts:AssumeRole" } ] }この場合は、アカウントID 123456789012のアカウント内のIAMユーザは、上記信頼ポリシーが設定されたIAMロールにスイッチロールすることができます。
PrincipalにルートユーザのARNが指定されており、ここでARNが示すものは「アカウントID 123456789012のアカウント内のIAMユーザ、ロール」です。余談ですが、ルートユーザはスイッチロールができません。
AWS アカウントのルートユーザー としてサインインすると、ロールを切り替えることはできません。IAM ユーザーとしてサインインしているときに、ロールを切り替えることができます。
あと、
ロールからロールへのスイッチは「ロールの連鎖(Role chaining)」と言うそうです。かっこいい。Principalの指定で使用されるケースとしては、IAMロールの信頼ポリシーで使用する以外にもS3バケットへのアクセス許可などがあります。
AWS Organizations SCPに使用する
Organizationsを利用している場合、SCPを利用することでルートユーザによる操作も制限することができます。
以下の例の場合、SCPとしてポリシーが適用されたアカウントのルートユーザはEC2に関する操作ができなくなります。{ "Version": "2012-10-17", "Statement": [ { "Sid": "RestrictEC2ForRoot", "Effect": "Deny", "Action": [ "ec2:*" ], "Resource": [ "*" ], "Condition": { "StringLike": { "aws:PrincipalArn": [ "arn:aws:iam::*:root" ] } } } ] }ConditionにてルートユーザのARNが指定されていますが、ここでARNが示すものは「アカウントのルートユーザのみ」です。
このように、ルートユーザのARNは使用されるされるポリシーによって扱いが異なっています。
なぜ異なるのか(想像)
あくまで想像ですが・・・
AWS Organizationsが登場するまでは、ルートユーザは制限なく何でもできるユーザであり、逆に制限をかけるという発想がなく、IAMエンティティをまとめて表現するためにルートのARNが利用されていたのではないでしょうか。
(Organizationsが登場したとき、僕はまだ社会人1年目でAWSの存在すら知らなかったです...)
ところが、Organizationsの登場によりルートユーザにも制限をかけたいシーンが出てきたために、SCPでは例外的にルートユーザを示すようになっているのではないかと思います。まとめ
ルートユーザのARNは使用されるにポリシーによって扱いが異なる、と言うお話でした!
初めてこのような記事を書くので、読みづらい部分が多いかと思いますが、どなたかのお役に立てれば幸いです。
- 投稿日:2020-10-28T23:17:51+09:00
AWS ルートユーザARNの扱いがよくわからなかったので整理する
はじめに
AWSのIAMポリシーをいじっていていたときに、「ルートユーザのARN」が示すものがよくわからなくなってしまったので、整理して残しておきたいと思います。
結論
ルートユーザのARNは、使用するポリシーやポリシー内のどこで使用されるかによって扱いが異なります。
通常は・・・
アカウント内のIAMエンティティを示します。IAMユーザ、IAMロールですね。
例外として・・・
AWS Organizationsにて、SCPで利用される場合、アカウントのルートユーザ自体を示します。
ルートユーザのARN
ルートユーザのARNは以下のように表されます。
arn:aws:iam::123456789012:rootルートユーザのARNの使用例
Principalの指定に使用する
例えば、IAMロールにスイッチロールする場合、IAMロールの信頼ポリシーでは、以下のようにスイッチ元のAWSアカウントを"Principal"に指定するかと思います。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::123456789012:root" }, "Action": "sts:AssumeRole" } ] }この場合は、アカウントID 123456789012のアカウント内のIAMユーザは、上記信頼ポリシーが設定されたIAMロールにスイッチロールすることができます。
PrincipalにルートユーザのARNが指定されており、ここでARNが示すものは「アカウントID 123456789012のアカウント内のIAMユーザ、ロール」です。余談ですが、ルートユーザはスイッチロールができません。
コンソールでのロールの切り替えに関する主要事項AWS アカウントのルートユーザー としてサインインすると、ロールを切り替えることはできません。IAM ユーザーとしてサインインしているときに、ロールを切り替えることができます。
あと、
ロールからロールへのスイッチは「ロールの連鎖(Role chaining)」と言うそうです。かっこいい。IAMロールの信頼ポリシーで使用する以外にも、Principalの指定で使用されるケースとしてはS3バケットへのアクセス許可などがあります。
追加条件付きでの複数のアカウントへのアクセス許可の付与AWS Organizations SCPに使用する
Organizationsを利用している場合、SCPを利用することでルートユーザによる操作も制限することができます。
以下の例の場合、SCPとしてポリシーが適用されたアカウントのルートユーザはEC2に関する操作ができなくなります。{ "Version": "2012-10-17", "Statement": [ { "Sid": "RestrictEC2ForRoot", "Effect": "Deny", "Action": [ "ec2:*" ], "Resource": [ "*" ], "Condition": { "StringLike": { "aws:PrincipalArn": [ "arn:aws:iam::*:root" ] } } } ] }ConditionにてルートユーザのARNが指定されていますが、ここでARNが示すものは「アカウントのルートユーザのみ」です。
このように、ルートユーザのARNは使用されるされるポリシーによって扱いが異なっています。
なぜ異なるのか(想像)
あくまで想像ですが・・・
AWS Organizationsが登場するまでは、ルートユーザは制限なく何でもできるユーザであり、逆に制限をかけるという発想がなく、IAMエンティティをまとめて表現するためにルートのARNが利用されていたのではないでしょうか。
(Organizationsが登場したとき、僕はまだ社会人1年目でAWSの存在すら知らなかったです...)
ところが、Organizationsの登場によりルートユーザにも制限をかけたいシーンが出てきたために、SCPでは例外的にルートユーザを示すようになっているのではないかと思います。まとめ
ルートユーザのARNは使用されるにポリシーによって扱いが異なる、と言うお話でした!
初めてこのような記事を書くので、読みづらい部分が多いかと思いますが、どなたかのお役に立てれば幸いです。
- 投稿日:2020-10-28T21:30:43+09:00
AWSにネットワークを構築する方法
はじめに
AWSはAmazon Web Servisesの略で、Amazonが提供しているクラウドサーバーのサービスです。
AWSへの理解度を高めるために、学んだことをアウトプットします。
今回はネットワークとの関係を記載します。今回の流れ
- VPCの作成
- サブネットの作成
- インターネットゲートウェイの作成
- ルートテーブルの作成
VPCの作成
VPCとは
AWSの中に自由なネットワークを作れる領域のこと。
VPCの作成手順
- AWSマネジメントコンソールでVPCページに行く
サービス検索にVPCと入力すると表示されます。
- リージョンの設定をする
リージョンを設定していない人は画面右上の自身のアカウント名の横にあるリージョンの設定を行います。
私はアジアパシフィック(東京)を選択しています。
- VPCを作成する
サイドバーのVPCをクリックし、右画面の「VPCの作成」をクリック、そして、VPCの設定画面に遷移します。
名前タグとIPv4 CIDRブロックの入力欄が出てくるので、好きなものを入力します。
IPv4 CIDRブロックは使用するIPアドレスの範囲です。
(意味が分からない方はこちらの記事をどうぞ。https://qiita.com/daisuke30x/items/2ef2233001c14f8076d3)今回は参考にしている書籍に倣って、「10.0.0.0/16」とします。
(つまり、10.0.0.0 ~ 10.0.255.255)作成したVPCのネットワーク空間は作成したユーザー以外からは見えない状態です。
サブネットの作成
サブネットとは
VPCを分割したネットワークのこと。
サブネットを作成する理由
①物理的な隔離
例えば、社内LANを構築する場合、1階と2階で別のサブネットに分けたいことが挙げられます。
どちらかのサブネットが障害を起こしても、もう片側には影響が出にくいというメリットがあります。②セキュリティ上の理由
例えば、以下の例があります。
「社内で経理部のネットワークだけは、他部署からアクセスできなくしたい」
「サーバー群だけ別のサブネットにし、そのサブネットとの通信を監視・一部のデータのみ通したい」
「インターネットに接続するサーバーだけを別のサブネットにし、社内LANから隔離したい」サブネットの作成手順
- サイドバーの「サブネット」をクリックし、右画面の「サブネットの作成」をクリックします。
- 名前タグに好きな名前を入力します。
- VPCに作成したものを入力、もしくは選択します。
- IPv4 CIDRブロックには割り当てるIPアドレスの範囲を指定します。
サブネットのIPアドレスはVPC領域の範囲の中で指定します。
今回、VPC領域10.0.0.0 ~ 10.0.255.255で設定しているため、その中の10.0.1.0 ~ 10.0.1.255を指定します。
つまり、「10.0.1.0/24」と入力します。
- 「作成」をクリックします。
インターネットゲートウェイの作成
インターネットゲートウェイとは
VPCとインターネットを接続するもの。
インターネットゲートウェイの作成手順
- サイドバーの「インターネットゲートウェイ」をクリックし、右画面の「インターネットゲートウェイの作成」をクリックします。
- 名前タグに好きな名前を入力します。(今回は名前を入れずに進みます。)
- 「インターネットゲートウェイの作成」をクリックします。
- 作成したインターネットゲートウェイにチェックを入れ、アクションボタンから「VPCにアタッチ」をクリックし、作成したVPCを入力後、「アタッチ」をクリックします。
(アタッチの作業によりインターネットゲートウェイとVPC領域を結びつけることができます。)
ルートテーブルの作成
ここではサブネットとインターネットとの接続をします。
ルートテーブルとは
データの送信先のIPアドレスの値により、どのネットワークにデータを流すか決めるもの。
流すべきネットワーク先はターゲットと呼ばれます。ルートテーブルの作成
- サイドバーの「ルートテーブル」をクリックし、右画面の「ルートテーブルの作成」をクリックします。
- 名前タグに好きな名前を入力します。
- 作成したVPCを入力か選択します。
- 「作成」をクリックします。
- 「サブネットの関連付け」をクリックします。
- 希望のサブネットにチェックを入れ、「保存」をクリックします。
- サブネットのデフォルトのゲートウェイの「ルート」タブをクリックし、「ルートの編集」ボタンをクリックします。
- 「ルートの追加」ボタンをクリックし、送信先に「0.0.0.0/0」と入力、ターゲットには作成したインターネットゲートウェイを選択、「ルートの保存」をクリックします。
設定できたかは、サブネットの「ルートテーブル」タブから確認できます。
参考
「Amazon Web Services 基礎からのネットワーク&サーバー構築」
著者:大澤文孝、玉川憲、片山暁雄、今井雄太最後に
本投稿が初学者の復習の一助となればと幸いです。
- 投稿日:2020-10-28T20:55:17+09:00
個人開発・スタートアップで採用すべき最強のアーキテクチャを考えた
結論
「アジリティ」「コスト最適化」「スモールな構成」「開発スピード」という観点でWebアプリケーションのアーキテクチャを考えてみました。
- ServerlessFrameworkを使い倒す
- フロントエンドはS3 hosting + CloudFrontで。SSRもLambda@Edgeでできます
- データベースはRDSは使わずにDynamoDBで
- APIは基本的にGraphQL。必要に応じてRESTも簡単に追加できるよ。
背景 アーキテクチャに絶対の正解はない
アーキテクチャには絶対の正解はありません。
なぜなら、プロダクトやフェーズによって求められる要件が異なり、それに適したアーキテクチャを考える必要があるからです。例えば、先日障害で証券取引が1日休場になった東証の高速取引システムは、安定性や信頼の要件に全振りをしていて、400台のサーバで負荷分散をしていたり業務系と運用系でネットワークを分けて障害の影響範囲を局所化するようなアーキテクチャになっています。
AWSやメルカリなどの成長企業では拡張性の要件が高く、イノベーションを起こし続けるために全体のアプリケーションに影響を与えずに新しいサービスを展開できるように、マイクロサービスアーキテクチャが採用されます。では個人開発やスタートアップはどんな要件が重視されるか考えてみます。
こちらにスタートアップが失敗する理由のランキングが掲載されています。スタートアップが失敗する理由ランキング
1位 市場ニーズがなかった
2位 資金の枯渇
3位 適切でないチーム構成
4位 競争力で負けた
5位 使いにくいプロダクトこれらはアーキテクチャで全て解決できる問題ではないですが、どんな要件が必要かが見えてきます。
1位 市場ニーズがなかった → 顧客の声に合わせて仕様を変化させていくアジリティ
2位 資金の枯渇 → コスト最適化
3位 適切でないチーム構成 → なるべく専門家を必要としないスモールな構成
4位 競争力で負けた → 開発スピードを高めて競合を抜き去る
5位 使いにくいプロダクト → 改善サイクルを高めるアジリティ個人開発/スタートアップに必要な要件は「アジリティ」「コスト最適化」「スモールな構成」「開発スピード」ではないかという仮説が立ちます。
この観点で技術要素を検討してみました。技術要素
背景にて、個人開発とスタートアップには「アジリティ」「コスト最適化」「スモールな構成」「開発スピード」が優れている技術要素を採用すべきだという検討を行いました。
この観点で私が優れていると思う技術要素を紹介していこうと思います。
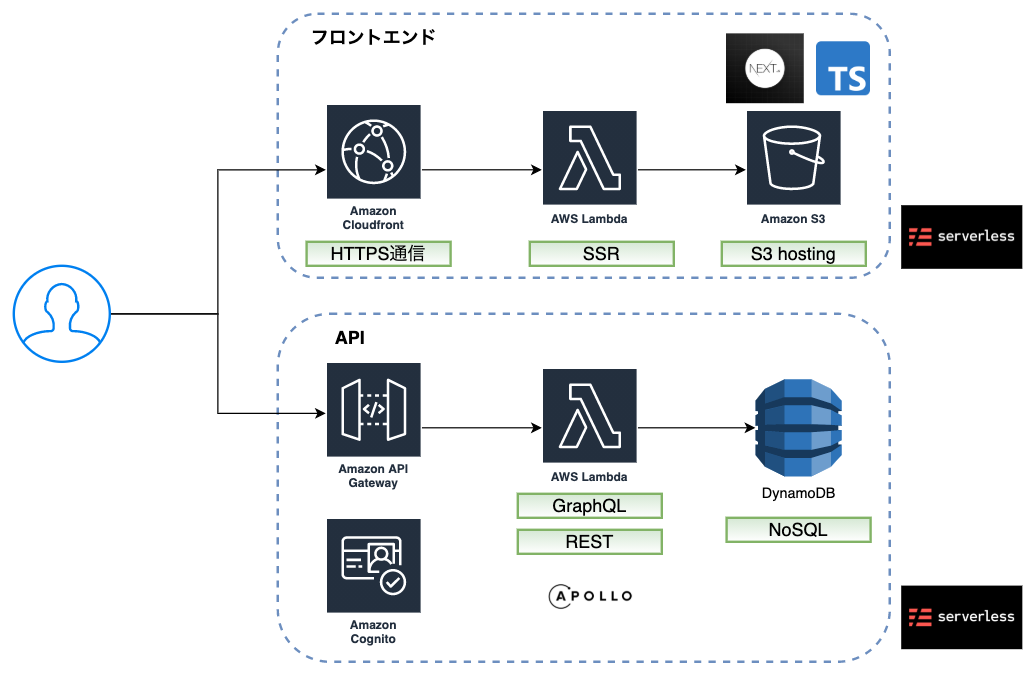
構成は「フロントエンド」「データベース」「バックエンド(API)」の3段階で説明していきます。フロントエンド
フロントエンドフレームワークの選定
フロントエンドフレームワークはReact,Vue,Angularの3大フレームがあります。
「開発スピード」「アジリティ」という観点で考えると、TypeScriptで型付けをすることが必須だと思います。入力補完の恩恵を受けつつ、どんなデータを受け渡せば良いかが一眼でわかることで開発効率をあげつつ、仕様変更でコードを変更した際のエラーチェックがコンパイル時にわかるためです。
そしてTypeScriptとの相性という観点ではReactが他の2つのフレームワークに比べて群を抜いているという印象で、フロントエンドフレームワークはReactを採用すべきだと思っています。
また、「開発速度」「スモールな構成」という観点で、私は素のReactを使うよりもNext.jsを使うことを推奨します。というのもNext.jsは、必要だが実装するのは面倒なことをNo Configで実現できるためです。具体的にいうとルーティングとSSR(SEO, SNSのOGPのため)です。
以上より、Next.js(TypeScript)がフロントエンドフレームワークとして推奨します。フロントエンドのデプロイ先
Next.jsのデプロイ先として真っ先に頭に浮かぶのは、vercel, Netlify, Herokuなどがあります。
これらは非常に楽にデプロイができて、基本無料で使えるため選択肢に入ってきます。
しかし無料枠には必ず機能的な制限があるため、スケールすることを前提にするならばできればAWSで構築したいところです。
S3 hosting + CloudFrontであればAWS無料枠で使えますし、無料枠がなくなってもほぼ無料です(S3は0.025USD/GB, CloudFrontは0.114 USD/1GB)。
vercel等のサービスで有料アカウントになると固定費がかかってきますが、AWSのこの構成であればonDemandな課金になるので、「コスト最適」という点でS3hosting + CloudFrontを推奨します。
ちなみにvercelの無料枠もほぼ無制限みたいなものなので、極端なスケールを前提としないのであればvercelも全然ありです。
フロントエンドのデプロイ先としてEC2やECSなどのサーバを使うことは「開発速度」「コスト最適化」という観点から論外かなと思っています。Next.jsのSSRはLambda@Edgeで行います。
この構成のデプロイはServerlessFrameworkを使うことで、No Configで簡単に行えます。
https://github.com/serverless-nextjs/serverless-next.jsデータベース
RDS vs DynamoDB
結論から言うと問答無用でDynamoDBを選択することを推奨します。
正確にいうとDynamoDBでは表現しきれないデータ構造や複雑すぎるアクセスパターンの場合はRDSにせざるをえないのですが、初期のフェーズではDynamoDBで作って無理が出てきたらRDSとの併用を考えるという形が良いと思います。
「コストの最適化」という観点からいうと、Dynamoは従量課金ができるのに対してRDSはインスタンスの起動時間で課金されます。またRDS+LambdaはRDS Proxyの導入を行わないといけません。 Aurora Serverlessもありますが、こちらはコールドスタートが致命的です。
「アジリティ」という観点からいうと、DynamoはNoSQLなのでスキーマが固定されず仕様の変更に柔軟に対応できますが、RDBはテーブル間の依存関係があるためテーブルを捨てにくくマイグレーションやSQLの作り直しが発生します。
「開発速度」という観点では、Dynamoはデータベース機能の管理が不要であることとGraphQLと相性が良いことで開発効率をあげることができます。DynamoDBの設計
DynamoDBを推奨しますが、RDBライクにDynamoDBを設計してしまうと確実に詰みます。DynamoDBはJoinができないため、Joinが必要のないようにテーブル設計をする必要があります。
RDBとNoSQLはテーブル設計のやり方が全く異なるので、ここに必ず最初学習コストをかけてください。お勧めのリンクを貼っておきます。
サーバーレスアプリケーション向きのDB設計ベストプラクティス
Amazon DynamoDBのデータモデリング
DynamoDB に合わせた NoSQL 設計バックエンド(API)
REST vs GraphQL
「アジリティ」「スモールな構成」「開発スピード」という観点でGraphQLを推奨します。
GraphQLは今まで持っていたバックエンドの責務をフロントエンドに移譲する側面があります。それによって、UIに変更が加えられるたびにAPI修正をする必要がなくなりアジリティが高まります。
またLambdaでREST APIを記述すると、エンドポイントの数だけLambdaを作ることになる(そうしない方法もあるが)が、GraphQLは単一エンドポイントなので「スモールな構成」を維持できます。
GraphQLはフロントエンドから利用する時に非常に扱いやすく、これは体感ですがRESTよりもフロントエンドの開発スピードは高くなっている気がします。とはいえ、RESTの方が向いている処理もあります。例えばファイルアップロードなどはGraphQLでやろうとするとひと工夫が必要です。そういう場合はRESTのエンドポイントを併用することは全く問題ありません。API Gatewayを間におくことで同じドメインで対応が可能です。
デプロイについて
API Gateway + Lambda(GraphQL) + Lambda(REST) + DynamoDB の構成のデプロイはServerlessFrameworkを使えば簡単に可能です。
こちらに各言語のテンプレートが用意されているので探してデプロイまでやってみてください。その手軽さに驚くと思います。
ちなみに自分はこちらのテンプレートをカスタマイズして使いやすいようにしてから使っています。認証認可について
認証認可はログイン機能などを実装する際はCognitoを活用します。開発スピードを意識すると自前実装しちゃった方が早い時もあったりしますが、セキュリティに関わるのでマネージドサービスを使った方がアンパイでしょう。
こちらもServerlessFrameworkで追加可能です。最終形
以上をまとめると上の図のような構成になりました。
まとめ
「アジリティ」「コスト最適化」「スモールな構成」「開発スピード」という観点でWebアプリケーションのアーキテクチャを考えてみました。
- ServerlessFrameworkを使い倒す
- フロントエンドはS3 hosting + CloudFrontで。SSRもLambda@Edgeでできます
- データベースはRDSは使わずにDynamoDBで
- APIは基本的にGraphQL。必要に応じてRESTも簡単に追加できるよ。
がポイントだと思います。
個人開発/スタートアップに関わる方々の参考になればと思います。
もし興味がある人がいれば自分のテンプレートも公開しようかなと思います。
ありがとうございました。
- 投稿日:2020-10-28T19:39:27+09:00
CloudFormationのスタックからリソースを外して、別のスタックにインポートする。
0.前段
リソース管理とリリース手順はなるべくシンプルなほうが望ましいのですが、複雑化してしまいがちです。
とある案件でAWSリソースの手動管理・複数のスタックによる管理の併存し、危険な香りがしたのでスタックの整理を実施しました。
作業内容は「IAMロール、API GW、lambdaを一つのスタックにまとめる」なのですが、その内容の一部、具体的には下記2点について主に記載します。
- CloudFormationのスタックからリソース(IAMロール、APIGW)を剥がす。
- CloudFormationで管理されていないリソース(IAMロール、API GW)を新しくスタックに追加する。
1.CloudFormationのスタックからリソースを剥がす。
既存のスタックからリソースを剥がします。
内容としては「IAMロールとAPI GWに削除保護を付与し、スタックを削除する。」になります。1-1.リソースに削除保護を付与する
CloudFormationを経由してリソースを作成した場合、cFnのスタックが作成されているはずです。
cFnのコンソールからリソースを剥がしたいスタックを選択します。
「スタックアクション」->「既存スタックの変更セットを作成」->「デザイナーでテンプレートを作成」と遷移してテンプレートを作成します。
残したいリソースに対して「DeletionPolicy」を付加します。template.yamlResources: SampleIamRole: Type: AWS::IAM::Role DeletionPolicy: RetainDeletionPolicyはリソースの削除保護に当たります。
作成したテンプレートを使ってスタック内のリソースに削除保護を付与します。
「スタックアクション」->「既存スタックの変更セットを作成」->「既存テンプレートを置き換える」と遷移して、先程作成したテンプレートを反映させます。
画面に従ってポチポチで変更セットが作成されるので、それを実行したらリソースへの削除保護の完了です。1-2.スタックを削除する。
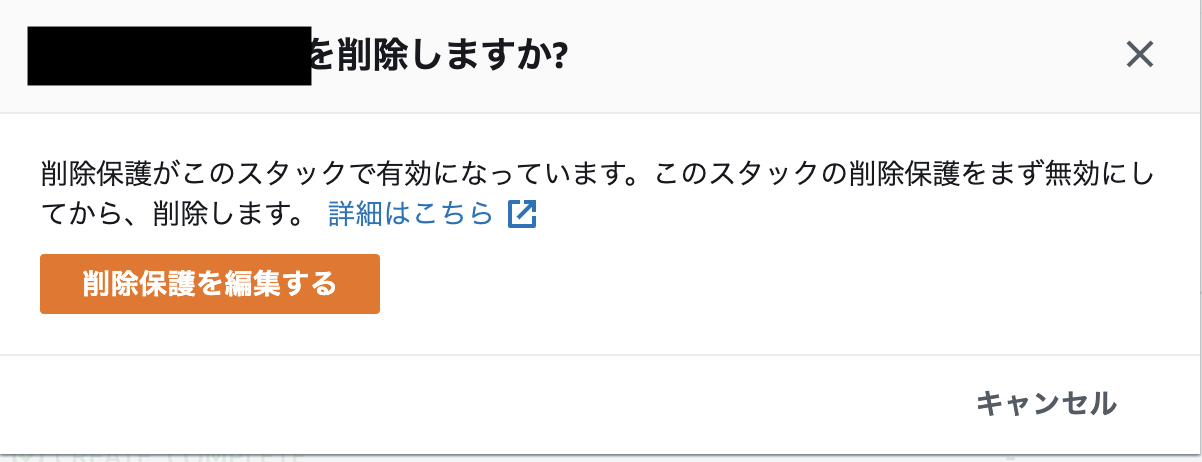
変更セットが反映されたらスタックを削除します。
cFnコンソール上で削除保護を設定している場合、削除保護を編集を要求されます。
ここでいう削除保護は、スタックそのものの削除保護であり、リソースの保護とは別物です。
ここの削除保護は無効にする必要があります。コンソール上で「DELETE_SKIPPED」と表示されていたら成功です。
削除保護漏れに気をつけて作業しましょう
参考:AWS CloudFormation スタックを削除したときにリソースの一部を保持する方法を教えてください。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/delete-cf-stack-retain-resources/API GWも同じように削除保護をつけた上でスタックを削除しました。
2.CloudFormationで管理されていないリソースを新しくスタックに追加する。
スタックからリソースを剥がしたので、これを別のスタックに移します。
内容としては「スタック上で管理されていないIAMロールとAPI GWをlambda用のスタックに移し替える」になります。2-1.準備するもの
- インポート先になるスタック
- インポート元のリソースとインポート先のリソースを一緒に記述したテンプレートファイル
- インポートするリソースの識別子
2-1-1.テンプレート作成時の注意
テンプレートはcFn用に作成したものになります。
1.インポート対象にするリソースにはRetentionPolicyをつける
RetentionPolicy: Retainをつけないとエラーが出ます。参考;既存のリソースをCloudFormation管理に取り込む リソースインポートの概要
https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/resource-import.html?icmpid=docs_cfn_console#resource-import-overview2.インポート先のリソースも記述が必要
インポート先のリソースが書かれていないと、その情報を加えるか削除するかしてくれという旨のエラーが出ました。3.空のスタックは作成できない
cFnではそもそも空のスタックを作成することができません。
しょうがないのでIAMロールを1つ作成してインポート先のスタックを作成しました。4.インポートがサポートされていないリソースがある
「Transform: AWS::Serverless-2016-10-31」を利用するリソースのインポートはサポートされていないようです。
参考:AWS CloudFormation の「このテンプレートにはインポートするリソースが含まれていません」というエラーを解決する方法を教えてください。(2020年6月26日作成)
https://aws.amazon.com/jp/premiumsupport/knowledge-center/cloudformation-template-resources-error/
他に、作業中に、明示にサポートしていないという表示がされたのは「AWS::ApiGateway::ApiKey」と「AWS::ApiGateway::GatewayResponse」でした。5.Outputsが設定されているテンプレートファイルは使えない
Outputsはインポート時には設定できないので消しておかないといけませんでした。2-1-2.インポートするリソースの識別子
今回はIAMロールとAPI GWをインポートしようと思っていました。識別子として必要になるパラメータは下記です。
AWSリソース 識別子 例 AWS::IAM::Role IAMロール名 lambda-exec-role AWS::ApiGateway::RestApi RestApiID hoge123fuga AWSコンポーネントによって変わってくるのでここは都度都度の確認になるかと思います。
2-2.インポート実行
上記のあれこれを経て、エラーは乗り越えたのでインポートしました。
インポート先のスタックをcFnコンソールから開いて、「スタックアクション」->「スタックへのリソースのインポート」からインポートを実施できます。
テンプレートは1-1で作成済みだったのでそれを流用しました。最低限実施したいと思っていた「AWS::IAM::Role」と「AWS::ApiGateway::RestApi」は実行できました。
下記だけだと全然結果わかりませんけど、目的のスタックにIAMロールとAPIを追加できています。
2-3.samでのデプロイ実行
「Transform: AWS::Serverless-2016-10-31」が記述が必要な内容は、インポートはできませんが、IAMロールとAPI GWをインポートしたスタックに対してsamを使ったlambdaのデプロイできました。
バラバラになっていたIAMロール、APIGW、lambdaのスタックを一つにまとめることができました。3.感想
便利は便利なのですが、感覚を掴むまではどうしてもエラーとの戦いになるのでそれなりに時間がかかります。
設計のミスでリソース管理がわやになっていたり、操作ミスによるスタックを削除してしまったりというのが主な出番に見えるので、使わずにすむならそのほうが幸せです。
強いて言えば、開発中であってもIDが変わったりDBやストレージに保存した内容を削除したくないといった場合が出番でしょうか。スタック削除ミスに関しては、スタックそのものへの削除保護があるのでそちらを有効にするのがいいと思います。X.余談
今回の作業のきっかけになったプロジェクトでは、IAM、lambda、API GWがそれぞれ別スタックで管理されていたものを一つにまとめました。
cFnのスタックの分割方法については諸説あるかと思います。cFnのベストプラクティスでは、多層アーキテクチャーとサービス指向アーキテクチャーに触れています。
参考:ライフサイクルと所有権によるスタックの整理
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/best-practices.html#organizingstacks単純に一つにまとめたのは2点理由があります。
1つは、すでにサービス単位で別れるようにリポジトリを分割できていてAWSコンポーネントの種類が少なかったからです。
もう1つは、samが「sam deploy」でsamconfig.tomlとtemplate.yamlを見てくれるシンプルな作りになっているのにいちいち--template-fileやら--config-fileやらのオプションを付けるのが嫌だったからです。
リソースの数によるテンプレートファイルの肥大化は避けられませんが、種類で圧迫されるわけではないのでまぁいいかなと。それよりデプロイ時のオペレーション数が増えたり、メンテされるかもわからないデプロイスクリプト書くほうが嫌だなと思った次第です。
なるべく自分で作るよりAWSに任せたいというタイプのエンジニアです。

- 投稿日:2020-10-28T19:36:37+09:00
AWS CloudFormationでS3エンドポイントを使用したS3バケットを構築しよう
はじめに
AWS CloudFormationを利用してVPC構築のテンプレートのサンプルです。
テンプレートの概要が分からない場合は、はじめてのAWS CloudFormationテンプレートを理解するを参考にしてください。
コードはGitHubにもあります。
今回は、akane というシステムの dev 環境を想定しています。
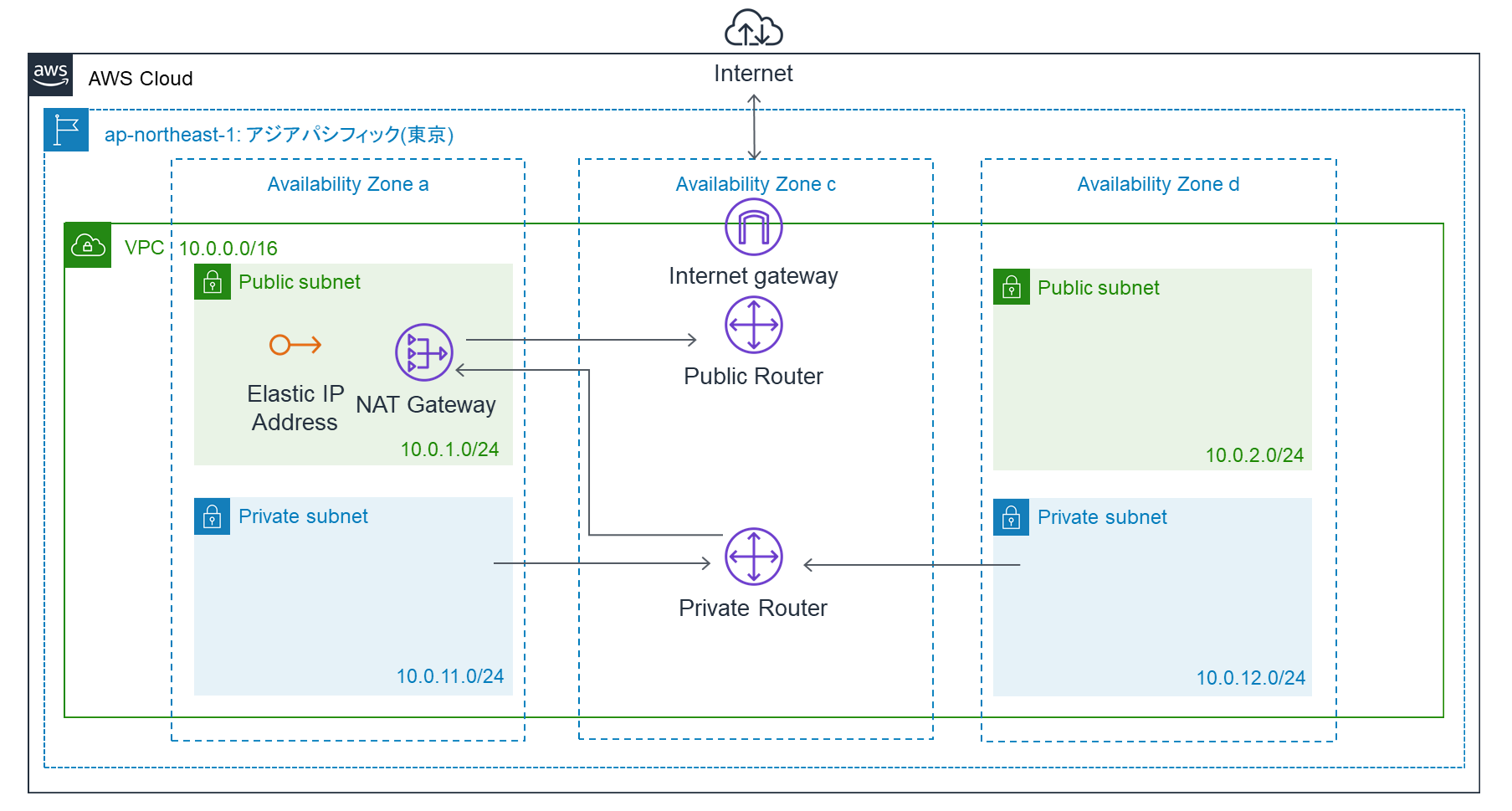
同じ構成で違う環境を作成する場合は、{環境名}-parameters.jsonを別途作成します。ディレクトリ構成akane (システム) ├─ network (スタック) | ├─ network.yml (CFnテンプレート) | └─ dev-parameters.json (dev 環境のパラメータ) └─ s3 (スタック) ├─ s3.yml (CFnテンプレート) └─ dev-parameters.json (dev 環境のパラメータ)AWS リソース構築内容
- networkスタック
- VPC (10.0.0.0/16)
- Publicサブネット1 (10.0.1.0/24)
- Publicサブネット2 (10.0.2.0/24)
- Privateサブネット1 (10.0.11.0/24)
- Privateサブネット2 (10.0.12.0/24)
- インターネットゲートウェイ
- Publicルートテーブル
- Elastic IP (NATゲートウェイ用)
- NATゲートウェイ
- Privateルートテーブル
- s3スタック
- s3バケット (akane-dev-album)
- バケットポリシー (s3:ListBucket, s3:GetObject, s3:PutObject)
- S3エンドポイント (インターフェイスエンドポイント: Publicルートテーブル, Privateルートテーブルに関連づける)
実行環境の準備
AWS CloudFormationを動かすためのAWS CLIの設定を参考にしてください。
AWS リソース構築手順
下記を実行してスタックを作成
./create.sh下記を実行してスタックを削除
./delete.shVPC構築テンプレート
1. networkスタック
network.ymlAWSTemplateFormatVersion: '2010-09-09' Description: Network For Akane # Metadata: Parameters: SystemName: Type: String AllowedPattern: '[a-zA-Z0-9-]*' EnvType: Description: Environment type. Type: String AllowedValues: [all, dev, stg, prod] ConstraintDescription: must specify all, dev, stg, or prod. VPCCidrBlock: Type: String AllowedPattern: (\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})/16 PublicSubnet1: Type: String AllowedPattern: (\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})/24 PublicSubnet2: Type: String AllowedPattern: (\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})/24 PrivateSubnet1: Type: String AllowedPattern: (\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})/24 PrivateSubnet2: Type: String AllowedPattern: (\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})/24 Mappings: AzMap: ap-northeast-1: 1st: ap-northeast-1a 2nd: ap-northeast-1c 3rd: ap-northeast-1d # Conditions # Transform Resources: # VPC作成 akaneVPC: Type: AWS::EC2::VPC Properties: CidrBlock: !Ref VPCCidrBlock EnableDnsSupport: true EnableDnsHostnames: true InstanceTenancy: default Tags: - Key: Name Value: !Sub - ${SystemName}-${EnvType}-vpc - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} - Key: SystemName Value: !Ref SystemName - Key: EnvType Value: !Ref EnvType ########################################################################### # Publicサブネット関連 ########################################################################### # Publicサブネット作成 akanePublicSubnet1: Type: AWS::EC2::Subnet Properties: VpcId: !Ref akaneVPC CidrBlock: !Ref PublicSubnet1 AvailabilityZone: !FindInMap [AzMap, !Ref 'AWS::Region', 1st] MapPublicIpOnLaunch: true Tags: - Key: Name Value: !Sub - ${SystemName}-${EnvType}-public-subnet1 - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} - Key: SystemName Value: !Ref SystemName - Key: EnvType Value: !Ref EnvType akanePublicSubnet2: Type: AWS::EC2::Subnet Properties: VpcId: !Ref akaneVPC CidrBlock: !Ref PublicSubnet2 AvailabilityZone: !FindInMap [AzMap, !Ref 'AWS::Region', 3rd] MapPublicIpOnLaunch: true Tags: - Key: Name Value: !Sub - ${SystemName}-${EnvType}-public-subnet2 - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} - Key: SystemName Value: !Ref SystemName - Key: EnvType Value: !Ref EnvType # インターネットゲートウェイ作成 akaneInternetGateway: Type: AWS::EC2::InternetGateway Properties: Tags: - Key: Name Value: !Sub - ${SystemName}-${EnvType}-igw - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} - Key: SystemName Value: !Ref SystemName - Key: EnvType Value: !Ref EnvType # インターネットゲートウェイをVPCにアタッチ akaneVPCGatewayAttachment: Type: AWS::EC2::VPCGatewayAttachment Properties: VpcId: !Ref akaneVPC InternetGatewayId: !Ref akaneInternetGateway # Publicルートテーブル作成 akanePublicRouteTable: Type: AWS::EC2::RouteTable Properties: VpcId: !Ref akaneVPC Tags: - Key: Name Value: !Sub - ${SystemName}-${EnvType}-public-route - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} - Key: SystemName Value: !Ref SystemName - Key: EnvType Value: !Ref EnvType # Publicルートテーブル サブネット関連付け akanePublicSubnetRouteTableAssociation1: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: !Ref akanePublicSubnet1 RouteTableId: !Ref akanePublicRouteTable akanePublicSubnetRouteTableAssociation2: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: !Ref akanePublicSubnet2 RouteTableId: !Ref akanePublicRouteTable # Publicルートテーブル ルートにインターネットゲートウェイを関連付ける akanePublicRoute: Type: AWS::EC2::Route Properties: RouteTableId: !Ref akanePublicRouteTable DestinationCidrBlock: 0.0.0.0/0 GatewayId: !Ref akaneInternetGateway ########################################################################### # Privateサブネット関連 ########################################################################### # Privateサブネット作成 akanePrivateSubnet1: Type: AWS::EC2::Subnet Properties: VpcId: !Ref akaneVPC CidrBlock: !Ref PrivateSubnet1 AvailabilityZone: !FindInMap [AzMap, !Ref 'AWS::Region', 1st] MapPublicIpOnLaunch: false Tags: - Key: Name Value: !Sub - ${SystemName}-${EnvType}-private-db-1 - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} - Key: SystemName Value: !Ref SystemName - Key: EnvType Value: !Ref EnvType akanePrivateSubnet2: Type: AWS::EC2::Subnet Properties: VpcId: !Ref akaneVPC CidrBlock: !Ref PrivateSubnet2 AvailabilityZone: !FindInMap [AzMap, !Ref 'AWS::Region', 3rd] MapPublicIpOnLaunch: false Tags: - Key: Name Value: !Sub - ${SystemName}-${EnvType}-private-db-2 - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} - Key: SystemName Value: !Ref SystemName - Key: EnvType Value: !Ref EnvType # Privateルートテーブル作成 akanePrivateRouteTable: Type: AWS::EC2::RouteTable Properties: VpcId: !Ref akaneVPC Tags: - Key: Name Value: !Sub - ${SystemName}-${EnvType}-private-route - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} - Key: SystemName Value: !Ref SystemName - Key: EnvType Value: !Ref EnvType # Privateルートテーブル サブネット関連付け akanePrivateSubnetRouteTableAssociation1: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: !Ref akanePrivateSubnet1 RouteTableId: !Ref akanePrivateRouteTable akanePrivateSubnetRouteTableAssociationWeb2: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: !Ref akanePrivateSubnet2 RouteTableId: !Ref akanePrivateRouteTable # NATゲートウェイ用ElasticIP作成 akaneNATGatewayEIP: Type: AWS::EC2::EIP Properties: Domain: vpc Tags: - Key: Name Value: !Sub - ${SystemName}-${EnvType}-natgw-eip - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} - Key: SystemName Value: !Ref SystemName - Key: EnvType Value: !Ref EnvType # NATゲートウェイ作成 akaneNATGateway: Type: AWS::EC2::NatGateway Properties: AllocationId: !GetAtt akaneNATGatewayEIP.AllocationId SubnetId: !Ref akanePrivateSubnet1 Tags: - Key: Name Value: !Sub - ${SystemName}-${EnvType}-natgw - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} - Key: SystemName Value: !Ref SystemName - Key: EnvType Value: !Ref EnvType # Privateルートテーブル ルートにNATゲートウェイを関連付ける akanePrivateRoute: Type: AWS::EC2::Route Properties: RouteTableId: !Ref akanePrivateRouteTable DestinationCidrBlock: 0.0.0.0/0 NatGatewayId: !Ref akaneNATGateway Outputs: akaneVPC: Value: !Ref akaneVPC Export: Name: !Sub - ${SystemName}-${EnvType}-vpc - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} akanePublicSubnet1: Value: !Ref akanePublicSubnet1 Export: Name: !Sub - ${SystemName}-${EnvType}-public-subnet1 - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} akanePublicSubnet2: Value: !Ref akanePublicSubnet2 Export: Name: !Sub - ${SystemName}-${EnvType}-public-subnet2 - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} akanePrivateSubnet1: Value: !Ref akanePrivateSubnet1 Export: Name: !Sub - ${SystemName}-${EnvType}-private-subnet1 - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} akanePrivateSubnet2: Value: !Ref akanePrivateSubnet2 Export: Name: !Sub - ${SystemName}-${EnvType}-private-subnet2 - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} akanePublicRouteTable: Value: !Ref akanePublicRouteTable Export: Name: !Sub - ${SystemName}-${EnvType}-public-route-table - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} akanePrivateRouteTable: Value: !Ref akanePrivateRouteTable Export: Name: !Sub - ${SystemName}-${EnvType}-private-route-table - {SystemName: !Ref SystemName, EnvType: !Ref EnvType}dev-parameters.json{ "Parameters": [ { "ParameterKey": "SystemName", "ParameterValue": "akane" }, { "ParameterKey": "EnvType", "ParameterValue": "dev" }, { "ParameterKey": "VPCCidrBlock", "ParameterValue": "10.0.0.0/16" }, { "ParameterKey": "PublicSubnet1", "ParameterValue": "10.0.1.0/24" }, { "ParameterKey": "PublicSubnet2", "ParameterValue": "10.0.2.0/24" }, { "ParameterKey": "PrivateSubnet1", "ParameterValue": "10.0.11.0/24" }, { "ParameterKey": "PrivateSubnet2", "ParameterValue": "10.0.12.0/24" } ] }2. s3スタック
s3.ymlAWSTemplateFormatVersion: '2010-09-09' Description: S3 For Akane # Metadata: Parameters: SystemName: Type: String AllowedPattern: '[a-zA-Z0-9-]*' EnvType: Description: Environment type. Type: String AllowedValues: [all, dev, stg, prod] ConstraintDescription: must specify all, dev, stg, or prod. BucketName: Type: String AllowedPattern: '[a-zA-Z0-9-]*' # Mappings # Conditions # Transform Resources: # バケット作成 akaneS3Bucket: Type: AWS::S3::Bucket Properties: BucketName: !Sub - ${SystemName}-${EnvType}-${BucketName} - {SystemName: !Ref SystemName, EnvType: !Ref EnvType, BucketName: !Ref BucketName} AccessControl: Private # BucketEncryption: # ServerSideEncryptionConfiguration: # - ServerSideEncryptionByDefault: # SSEAlgorithm: AES256 Tags: - Key: Name Value: !Sub - ${SystemName}-${EnvType}-s3 - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} - Key: SystemName Value: !Ref SystemName - Key: EnvType Value: !Ref EnvType # バケットポリシー作成 akaneS3BucketPolicy: Type: AWS::S3::BucketPolicy Properties: Bucket: !Ref akaneS3Bucket PolicyDocument: Statement: - Sid: !Sub - ${SystemName}-${EnvType}-${BucketName} - {SystemName: !Ref SystemName, EnvType: !Ref EnvType, BucketName: !Ref BucketName} Action: - s3:ListBucket - s3:GetObject - s3:PutObject Effect: Allow Resource: - !Join - '' - - 'arn:aws:s3:::' - !Ref akaneS3Bucket - !Join - '' - - 'arn:aws:s3:::' - !Ref akaneS3Bucket - /* Principal: '*' # VPCエンドポイント作成 akaneS3Endpoint: Type: AWS::EC2::VPCEndpoint Properties: PolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: '*' Action: - s3:* Resource: - !Join - '' - - 'arn:aws:s3:::' - !Ref akaneS3Bucket - !Join - '' - - 'arn:aws:s3:::' - !Ref akaneS3Bucket - /* - !Join - '' - - 'arn:aws:s3:::*' - !Ref AWS::Region - '.amazon.com/*' - !Join - '' - - 'arn:aws:s3:::*' - !Ref AWS::Region - '.amazon.com' RouteTableIds: - Fn::ImportValue: !Sub - ${SystemName}-${EnvType}-public-route-table - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} - Fn::ImportValue: !Sub - ${SystemName}-${EnvType}-private-route-table - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} ServiceName: !Sub com.amazonaws.${AWS::Region}.s3 VpcId: Fn::ImportValue: !Sub - ${SystemName}-${EnvType}-vpc - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} Outputs: akaneS3Bucket: Value: !Ref akaneS3Bucket Export: Name: !Sub - ${SystemName}-${EnvType}-bucket - {SystemName: !Ref SystemName, EnvType: !Ref EnvType}dev-parameters.json{ "Parameters": [ { "ParameterKey": "SystemName", "ParameterValue": "akane" }, { "ParameterKey": "EnvType", "ParameterValue": "dev" }, { "ParameterKey": "BucketName", "ParameterValue": "album" } ] }3. 実行ファイル
create.sh#!/bin/sh SYSTEM_NAME=akane ENV_TYPE=dev create_stack () { STACK_NAME=$1 aws cloudformation create-stack \ --stack-name ${SYSTEM_NAME}-${ENV_TYPE}-${STACK_NAME} \ --template-body file://./${SYSTEM_NAME}/${STACK_NAME}/${STACK_NAME}.yml \ --cli-input-json file://./${SYSTEM_NAME}/${STACK_NAME}/${ENV_TYPE}-parameters.json aws cloudformation wait stack-create-complete \ --stack-name ${SYSTEM_NAME}-${ENV_TYPE}-${STACK_NAME} } create_stack network create_stack s3delete.sh#!/bin/sh SYSTEM_NAME=akane ENV_TYPE=dev STACK_NAME=network delete_stack () { STACK_NAME=$1 aws cloudformation delete-stack \ --stack-name ${SYSTEM_NAME}-${ENV_TYPE}-${STACK_NAME} aws cloudformation wait stack-delete-complete \ --stack-name ${SYSTEM_NAME}-${ENV_TYPE}-${STACK_NAME} } delete_stack s3 delete_stack network
- 投稿日:2020-10-28T17:43:02+09:00
AWS Security JAM 2020に参加して(2020年10月参加)
本日はAWSが実施したイベント「AWS Security JAM 2020」に参加しました。
AWSの運営の方から「問題の内容に触れない範囲での感想はOK」との話がありましたので、問題内容は一切記載せずにイベント内容と感想についてアップしておこうと思います。
私としては、なかなか良いイベントであり、参加する意義があったと思っています!イベントの位置付け
まず、今回のイベントは「AWS Security Roadshow」の一環で開催されました。
「AWS Security Roadshow」は以下のようなイベントです。お客様が抱える様々なセキュリティに対する課題とその対応方法、実際のお客様のAWSのセキュリティサービス活用事例、今後必要となるセキュリティ対策、AWSのセキュリティの方向性などを包括的にご説明する予定です。企業・組織の中で、セキュリティやコンプライアンスに課題をお持ちの皆様(営業、マーケティング、開発や運用など)、セキュリティに関する意思決定に関わる管理職や役員の方、公共機関や金融機関のセキュリティ担当者など、AWSセキュリティの最新情報を知りたい方は是非ご参加ください。
そして、「AWS Security JAM」は以下の通りです。
AWS Security JAM は、権限管理、自動化、インシデントレスポンスなどに関連するサービスを利用して、参加者が各課題ごとに AWS 環境を適切に修正するゲーミング形式のイベントです。 参加者はオンライン上で提示されたセキュリティ上の課題に対して、実際の AWS マネジメントコンソールを利用し、ご自身の知識、経験を活用し、必要に応じて学習をしながら課題解決に取り組みます。 (提示される課題は re:Invent2019や過去にAWSのイベント(例: AWS Professional Services が実施したイベント)で出題された課題を含みます)
ゲーミング形式というのが面白そうだと思い参加することにしました。
開催日は10月28日(水)。
仕事しながらは無理…と判断し、「有給休暇」カードを切って自宅から参加することとしました。
参加方法
参加方法は「AWS Security JAM 2020」で申請するだけです。
後日案内のメールが届きます。
事前に実施しておく必要があるのは「AWS Jam」への登録のみ。
あとは開始前に接続する為のWebinarにアクセスするのみです。
WebinerでAWS JAMのセキュリティコードを教えてもらえるので、それを入力することで当日のイベント環境に接続します。
内 容
内容は以下の通りです。
13:00-13:30 Security JAMご紹介
13:30-16:00 Security JAM演習
16:00-16:30 クロージング<ルール>
・個人単位で9問の問題を解く速さを競う。
・ヒントが1問につき3つまで取得できるが、ヒントを空けるたびに減点される。
※なので、ヒントを空けずに回答すると高得点となる。ルールは上記の通りシンプルで、2時間30分の制限時間内で他の参加者と競うイベントなのです。以下のマップから問題を選択して1問ずつ解いていきます。問題は好きな問題から開始できます。それぞれの問題でAWSコンソール環境が準備されているので、その環境に対してセキュリティ対策を実施して、問題が解決したら完了となります。
問題内容については詳細は記載できませんが、基本的な内容から、最近開始されたサービスまで幅広くセキュリティ機能の知識が問われます。最初の方の問題は皆が解けますが、あとになるほど難易度が上がっていくわけです。
私は9問中4問くらいまではなんとか解けましたが、5問目くらいからヒント3つとも空けないと全然歯が立たなくなり…自分の実力が分かって勉強になりました(3つ目はほぼ答え・・・)。ヒント3つでも解けない場合はAWSの方に質問することも可能です。1問解らなくなり質問したのですが、親切に支援してもらって乗り切りました!もちろん、上位者は最終問題まで完了しており、すごいなぁと感嘆しました。
どれだけ実務経験を積んだら、この境地に至るのかなぁ・・・
問題NO 参加数 完了数 1 76 72 2 69 59 3 58 42 4 52 25 5 37 21 6 54 18 7 33 25 8 27 10 9 21 02 感想
時間制限ありで実力を競う形で面白いイベントだと思いました。
参加料無料ですし、問題も練られていて勉強になります。
そして他の方との実力差も感じることができて、また学習意欲が高まります。
こんな楽しいイベントを企画して頂いた運営の方々には感謝の気持ちでいっぱいです。
年休を取得して参加した甲斐がありました。毎年実施しているようなので、来年度もぜひ参加して、
自分の実力を試す機会にしたいと思いました。この記事を参照された方も、興味があれば次回参加することをお勧めします!


- 投稿日:2020-10-28T17:19:26+09:00
AWS Lambda Layers作成から紐付けまでさらっと解説
はじめに
Pythonを扱う前提の記事です。
Layers(レイヤー)とは
ガイドによると
レイヤーは、ライブラリ、カスタムランタイム、またはその他の依存関係を含む ZIP アーカイブです。レイヤーを使用することで、関数のライブラリを使用することができます。
ライブラリのような共通で使用するモジュールをLayerにすることで、デプロイパッケージにライブラリを含める必要がなくなります。
つまり、Lambdaでサードパーティ製のライブラリやモジュールを使用する際に、Layerに格納して各Lambda関数から呼び出して使用するというような使い方ができます。注記
・Lambdaで一度に利用できるLayerは5つまで
・解凍後のデプロイパッケージのサイズ制限 250 MBディレクトリ構成
Lambda実行環境のパスは /opt ディレクトリとなるので、
Layerのディレクトリ構成としては /opt/python/Layer となります。レイヤー自体のパッケージ構成はこんな感じ。
python ├ layer.py (共通処理などコードも入れられます。common的に扱える) ├ Crypto (外部ライブラリその1) ├ psycopg2 (外部ライブラリその2) ├ sqlalchemy (外部ライブラリその3) …etcLayerの作成
ローカルで作成してみます。
ライブラリを場所指定でpip installする。
$ pip install pycryptodome -t .そしてzip
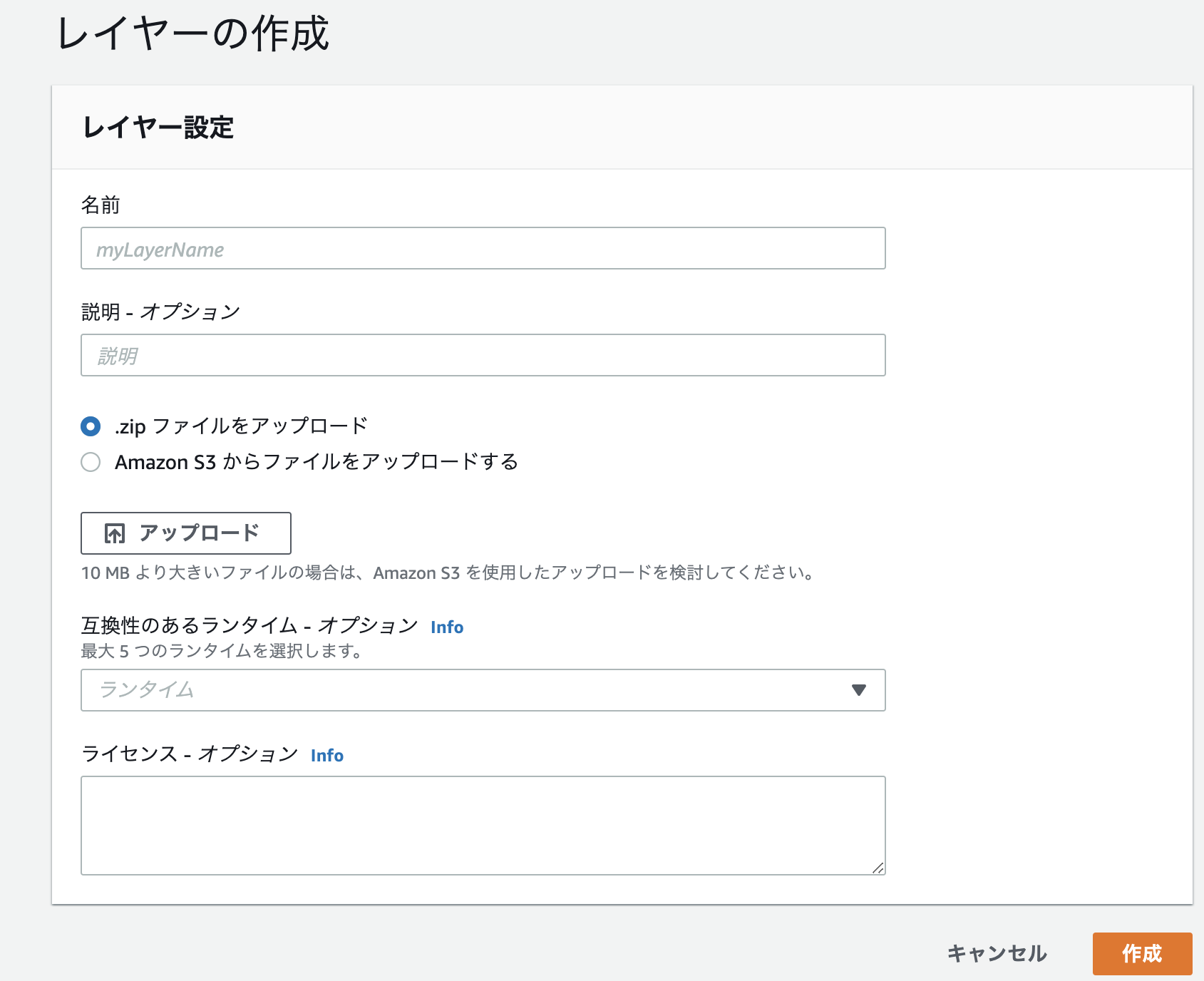
$ zip -r ../python .AWS上でLayerの作成を行います
上から順に
・名前(必須)
・説明(なくても可)
・アップロード(先ほど作成したzipを選択)
・互換性のあるランタイム - オプション(忘れがちになるので注意)
・ライセンス - オプション(なくても可)「作成」をクリックしLayerを作成します。
Lambda関数に紐付け
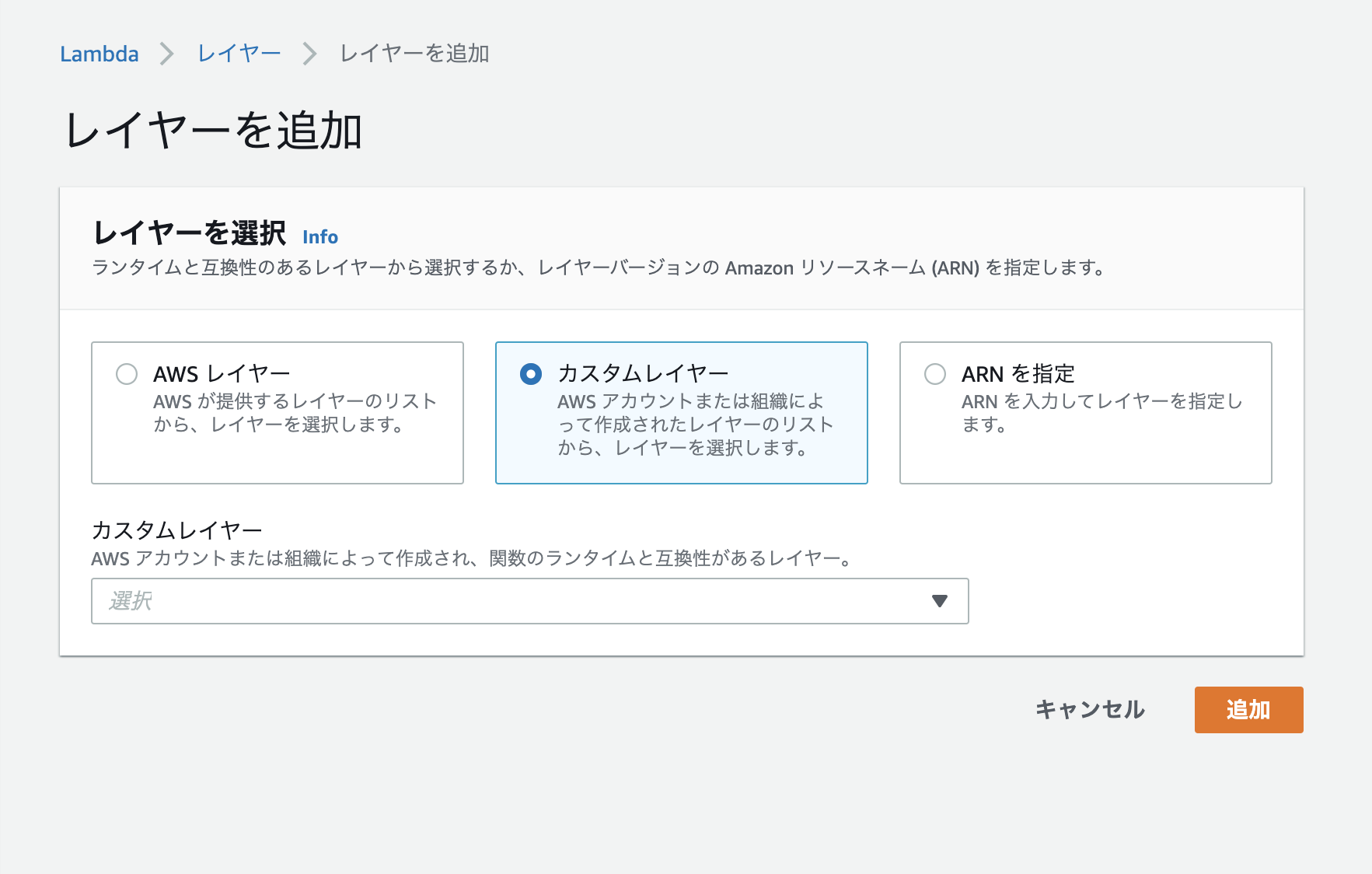
今度はLambda関数にLayerを紐付けます。
Layerを紐付けたいLambda関数から「デザイナー」を選択し、
「レイヤーの追加」を選択。
「レイヤーの選択」から「カスタムレイヤー」をクリックし作成したLayerを選びます。
その後「バージョン」を設定し、「追加」をクリックして完了です。Lambdaから呼び出すときはimportして呼び出します。
import layerよくあるミス
・LambdaはAmazon Linux上で動作するので、
pip installした環境によっては実行エラーとなるライブラリもあります。・AWSにアップロードしたLayerはバージョンごとにダウンロードすることも出来ます。
そしてLayerが増えてくるとディレクトリで、こんな感じで管理することもあるかと思います。test_layer ├ python ├ layer.py ├ Cryptoこの場合、そのまま解凍し修正してzipしがちですが、
そのままzipすると親ディレクトリも圧縮してしまいアップロード後の展開時にディレクトリ階層とマッチしなくなるので
作成した時と同じく中身をzipしましょう。$ zip -r ../python .まとめ
Layerは上手く使えばLambda間でのコード共有など非常に便利です。
上手く活用していきましょう。参考
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/configuration-layers.html
- 投稿日:2020-10-28T15:52:24+09:00
[AWS]S3への画像の保存
はじめに
herokuにアプリケーションをデプロイしましたが、画像ファイルがリンク切れになるため、S3に保存先を設定しました。
目次
1.バケットの作成
2.バケットポリシーの設定
3.画像がS3のバケットに保存されるように設定1. バケットの作成
バケットとはS3で実際にデータが格納される場所のことです。
上部の「サービス」をクリックして、「S3」をクリックします。
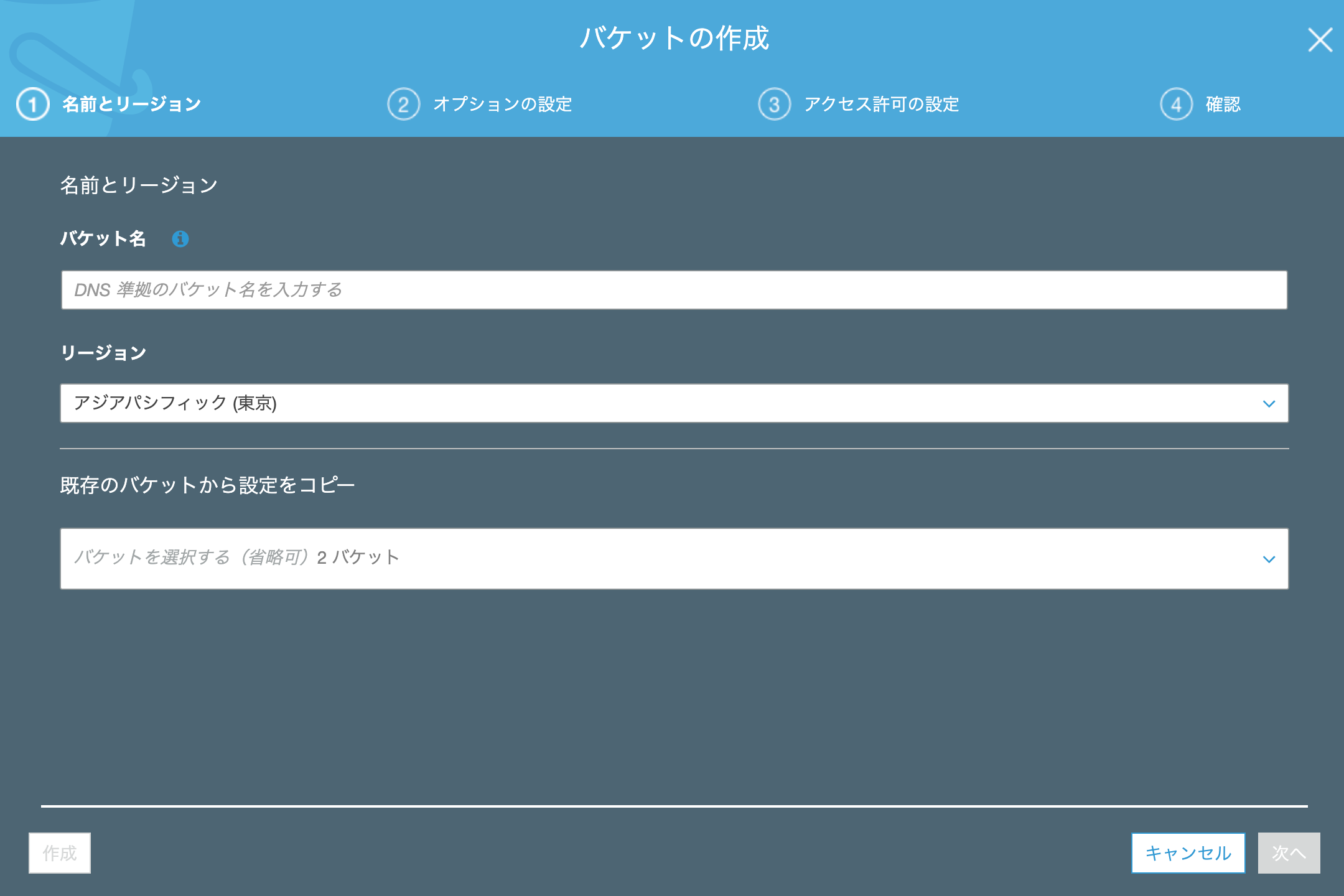
ページ遷移したら、「バケットを作成」をクリックします。次に「バケット名」を入力します。
「バケット名」は他のユーザーが作ったバケットと重複した名称は使うことができません。
「リージョン」は「アジアパシフィック(東京)」を選択しておきましょう。
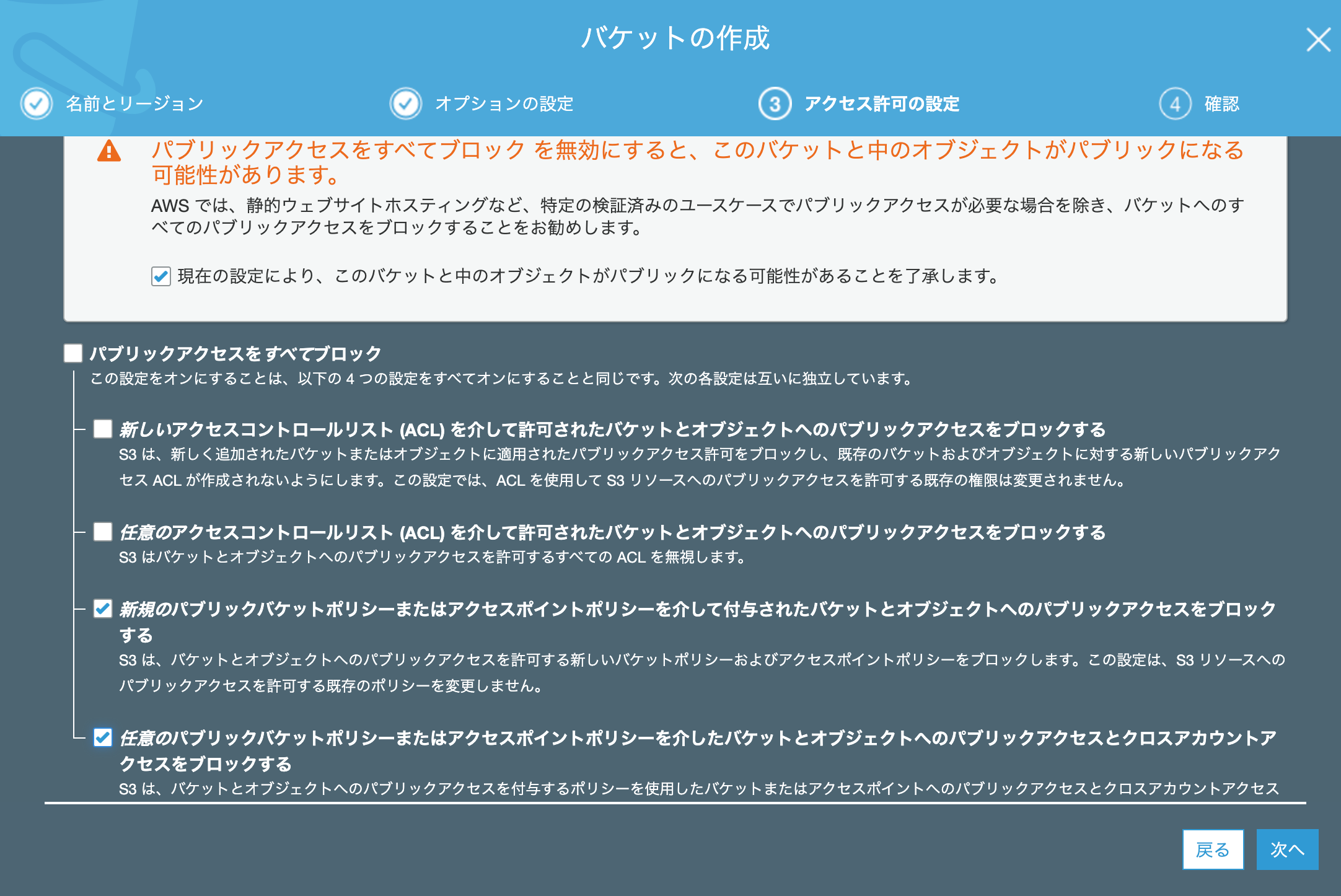
遷移後の画面では何も選択せずに「次へ」をクリックします。「パブリックアクセスをすべてブロック」のチェックを外します。
以下のように3箇所にチェックを入れ、「次へ」をクリックします。
画面遷移後、バケット作成の内容を確認し問題がなければ「バケットを作成」をクリックします。2. バケットポリシーの設定
バケットポリシーとは、どのようなアクセスに対してS3への保存やデータの読み取りを許可するか決められる仕組みです。
今回は「IAMユーザー」からのアクセスのみを許可するように設定します。まず、「IAMユーザー」の設定を確認します。
「サービス」をクリックし、「IAM」を検索します。
画面遷移後、「ユーザー」をクリックし、作成したユーザー名をクリックします。
ユーザーの情報が表示されるので、「ユーザーARN」をメモして保存しておきます。次に、バケットポリシーの設定を行います。
先ほどと同様に「ユーザー」をクリックし、「S3」を検索します。
作成したバケットをクリックします。
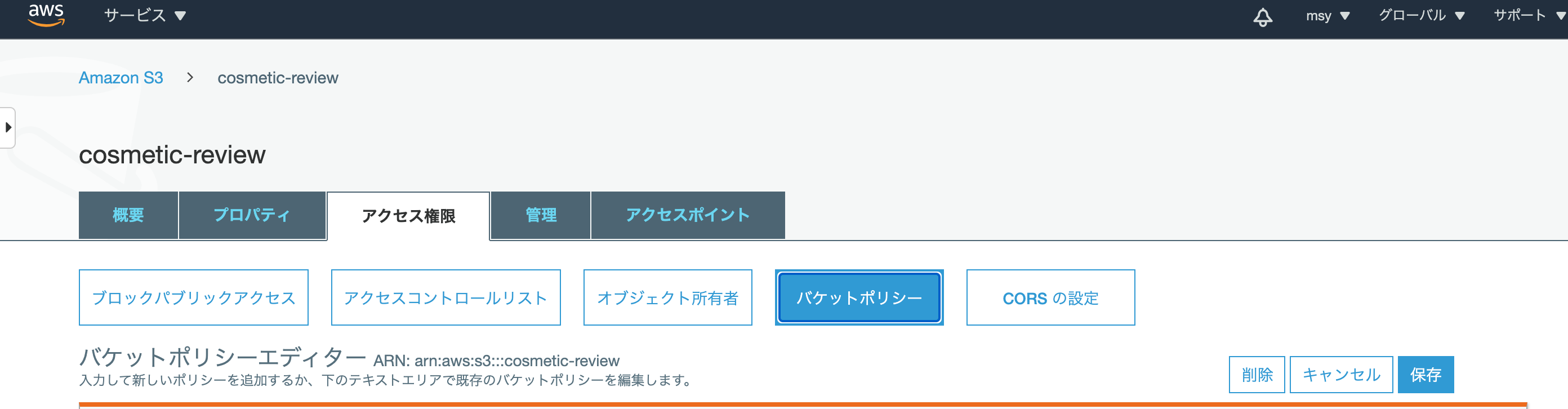
「アクセス権限」をクリックし、「バケットポリシー」をクリックします。
バケットポリシーエディターに以下を貼り付けます。バケットポリシー
{ "Version": "2012-10-17", "Id": "Policy1544152951996", "Statement": [ { "Sid": "Stmt1544152948221", "Effect": "Allow", "Principal": { "AWS": "①" }, "Action": "s3:*", "Resource": "arn:aws:s3:::②" } ] }先ほど保存しておいた「ユーザーARN」を①に、「作成したバケット名」を②に記述します。
「保存」をクリックし、「このバケットに対してパブリックアクセスの〜」と表示されていれば成功です。3. 画像がS3のバケットに保存されるように設定
ローカル環境からS3に画像を保存
必要なgemをインストール
S3を使用するために必要なgemをインストールします。
以下をgemfileの一番下に記述したらコマンドでbundle installを実行します。gemfilegem "aws-sdk-s3", require: false保存先を指定
現状画像の保存先はローカルに設定されているので、S3に保存されるように設定を変更します。
「:local」→「:amazon」に編集します。config/environments/development.rb~略~ config.active_storage.service = :amazon ~略~config/storage.ymltest: service: Disk root: <%= Rails.root.join("tmp/storage") %> local: service: Disk root: <%= Rails.root.join("storage") %> # 以下を追記します amazon: service: S3 access_key_id: <%= ENV['AWS_ACCESS_KEY_ID'] %> secret_access_key: <%= ENV['AWS_SECRET_ACCESS_KEY'] %> region: ap-northeast-1 bucket: ご自身のバケット名 ~略~「access_key_id」と「secret_access_key」は環境変数を読み込むための記述です。
環境変数の設定
ターミナルで以下のコマンドを実行します。
ターミナル
vim ~/.zshrc「i」を押します。
ターミナル
export AWS_ACCESS_KEY_ID="ここにCSVファイルのAccess key IDの値をコピー" export AWS_SECRET_ACCESS_KEY="ここにCSVファイルのSecret access keyの値をコピー"「escキー」→「:wq」の順で実行します。
ターミナルで以下を実行し、設定を反映させます。
ターミナル
source ~/.zshrcアプリケーションを操作し、S3に画像が保存されているか確認します。
本番環境(Heroku)からS3に画像を保存
保存先を指定
「:local」→「:amazon」に編集します。
config/environments/production.rb~略~ config.active_storage.service = :amazon ~略~Heroku上で環境変数を設定
ターミナルで以下を実行します。
ターミナル
heroku config:set AWS_ACCESS_KEY_ID="ここにCSVファイルの「Access key ID」の値をコピー"ターミナル
heroku config:set AWS_SECRET_ACCESS_KEY="ここにCSVファイルの「Secret access key」の値をコピー"「heroku config」コマンドで環境変数を確認します。
編集内容をHerokuに反映
変更をmasterブランチにマージします。
下記のコマンドで編集した内容をHerokuに反映させます。ターミナル
git push heroku master以下のコマンドを実行し、「Web URL」にアクセスしS3に画像が保存されるか確認します。
ターミナル
heroku apps:info
- 投稿日:2020-10-28T15:38:30+09:00
自宅サーバー(MariaDB+Java)から月額費用を抑えてAWS(DynamoDB+Python+PHP)に移行した話
初めまして、kagamikarasuと申します。
「SOLD OUT 2 市場情報サイト」の開発などを行っております。2020年8月頃から「市場情報サイト」の再開発を進めて9月にリプレース、
1ヶ月以上経過して落ち着いたので「市場情報サイト」について記事にしたいと思います。SOLD OUT 2 とは?
mu様が運営している「オンラインお店ごっこ」です。
https://so2.mutoys.com/チュートリアル
https://so2-docs.mutoys.com/common/tutorial.htmlアイテムを消費して新しいアイテムを手に入れて、それを元に新しい商品を作ったり販売したりします。
NPC向けに売ったり、ユーザーに向けて売ったり、イベントに参加したり、プレイスタイルは人それぞれです。SOLD OUT 2 市場情報サイトとは?
私(@kagamikarasu)が開発している市場情報サイトです。
https://market.kagamikarasu.net/mu様の方でAPIが公開されているので、それを利用して開発しました。
商品毎の価格/在庫推移や店舗毎の在庫減少数などをグラフ/表形式で把握する事ができます。エンドユーザーが出来る事は参照のみです。
なぜ再開発したのか?
自宅サーバー + Conoha(LB役割) + Java 1.8 + MySQL(後にMariaDB)で運用していたのですが、
開発が行いづらくなったので再開発をしました。Javaのゴタゴタだったり、証明書の取得やデプロイが面倒だったり、
データベースの肥大化、自宅サーバー(ただのPC/UPS無し)を辞めたかったりしたかったので....データベース肥大化との戦い
大きいテーブルでは10億レコード超えていました。
当初何も考えてなかったのでデータ量は考えていませんでした。明らかに遅くなっているのを感じたので、インデックスや検索条件を見直したりしたのですが、
焼け石に水状態だったので、ストレージを変更してIOPSを稼ぐことで解決しました。3年間でHDD→SSD→SSD(NVME)です。
NVMEとても速いです、甘えと言われたらそれまでですが、
ストレージ変更する際、移行が速すぎてコマンド打ち間違えたか?と疑うほどです。移行目標
- クラウド環境
- 開発/デプロイが容易
- 落ちても勝手に復帰する様に
- 月額費用は抑える
ちょうどSAAの勉強をしていたのでAWSを利用することにしました。
一番大きな問題が4番目の月額費用は抑えるです。何も考えずにRDS+EC2+ALBだと構成次第では、RDSでそれなりな金額になってしまうかと思います。
法人ならば何の事も無い金額ですが、個人(少なくとも私)ではとても辛いです('A'利用したサービス
※以下に記載するものについては、用法用量を守ってお使いください。
- DynamoDB(オンデマンド)
- SQS(標準キュー)
- Lambda(Python+Pandas) + CloudWatchEvent
- ECS(EC2spot+ECR+ALB)
- S3(HIVE+json形式)
- Route53
- API Gateway
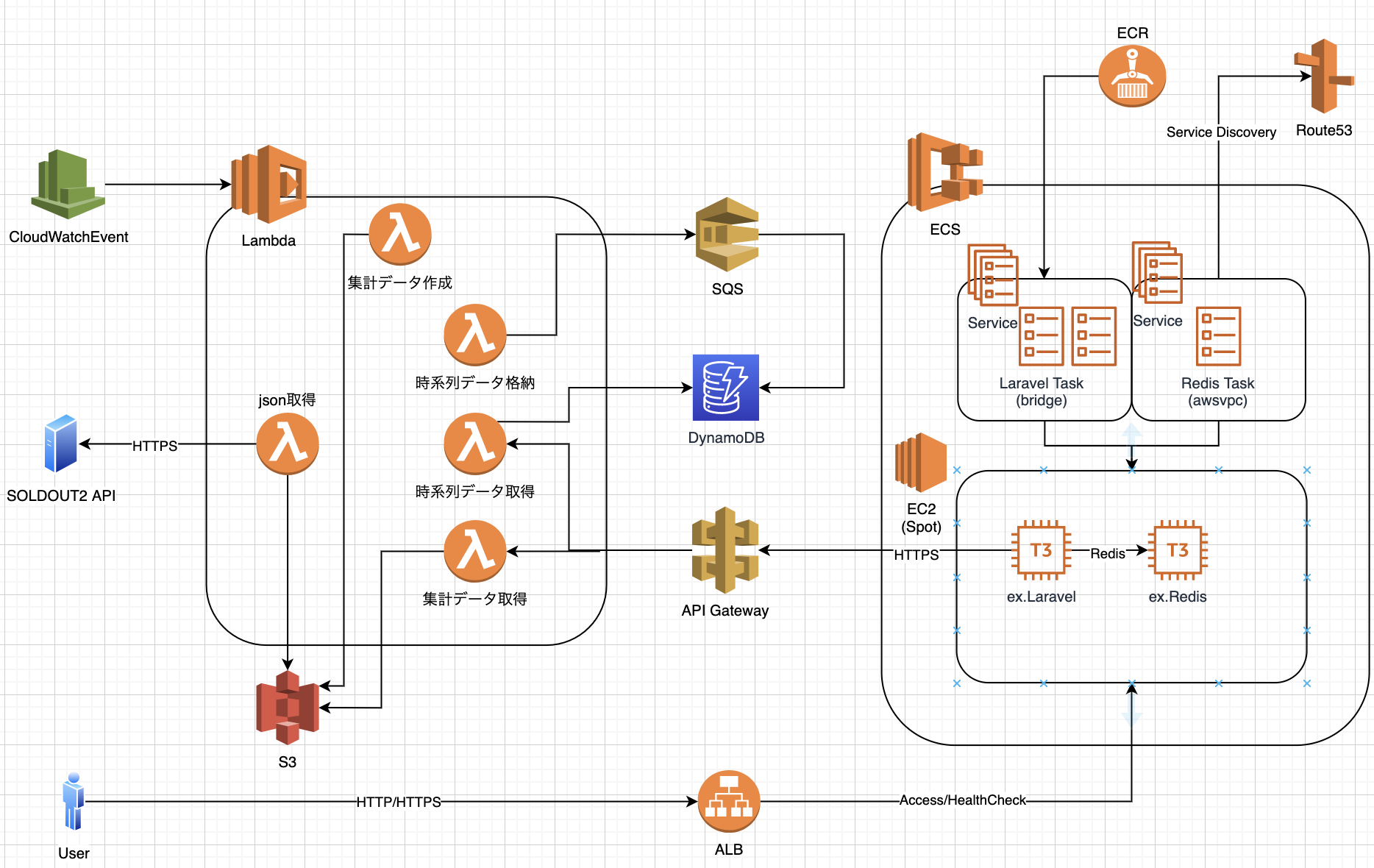
移行後構成図
DynamoDB
RDS(MariaDB)に移行するのが最も楽ですが、数百GBのデータを移行して運用するとそれだけで運用費が詰みます。
数百GB移行と書きましたが、移行データは全てHIVE形式+JSON形式でS3に移します。
必要に応じて後述するS3→Lambda→SQS→DyanamoDBを行います。DynamoDBの無料枠は記事記述時点で25GBの無料枠、オンデマンド25のWCU/RCU。
- 1WCUは1秒で最大1KBのデータを書き込み可能
- 1RCUは1秒で最大4KBのデータを読み込み可能
との事なので、1レコード辺りのデータは1KB内に抑えるのが望ましいです。
今回はテーブルを一つだけ使い5WCU/RCUを割り当てています。
市場情報サイトはアイテム単位で抽出する為、自ずとパーティションキーはitem_idになります。
時系列で持ちたいのでソートキーは登録日時のUNIX時間とします。移行前のデータベース(MariaDB)では、10分間隔の店舗単位(集計前)でデータを持っていましたが、
移行後のデータベース(DyanmoDB)では、3時間間隔のアイテム単位(集計済)でデータを持ちます。SQSも使っているので具体的な集計・格納手段は後述しますが、以下の図の様なWCU消費となります。
容量が25GBに収まっているうちはデータベースは無料で使い続ける事ができます。
SQS
次にSQSです。
キューイングという物は意識した事がありませんでしたがSAAを勉強しているうちに、これはとても良い物だと知りDynamoDBを組み合わせて使うことにしてみました。SQSの無料枠は100万件のリクエストです。
最初よく分かっていなかったのですが、送受信で2リクエスト使うことになります。
現状2000アイテムで見積もっているので、100万リクエストで抑える為に3時間単位にしています。
2000 * 8 * 30 * 2 = 96万件
SQSなので多少足が出ても大丈夫ですが、出来るだけ無料枠で抑えたいので3時間単位です。前述した通り、3時間毎に集計データをDynamoDBに格納しています。
アイテム単位で格納しますが、現状3時間毎に約2000アイテム格納する必要がありました。
もし1秒で2000アイテム格納するならば、1アイテム1KBとして2000WCU必要です。
月額$1000超えて破産してしまうので、今回はSQSとDynamoDBを組み合わせて書き込みタイミングをずらす様にします。具体的にはLambda(集計)→SQS→Lambda(SQS抽出/DynamoDB格納)→DynamoDBとなります。
FIFOである必要はないので、標準キューを利用します。最初SQSのLambdaトリガー便利と思っていたのですが、モニタリングしていると想定していない消費が発生しており、調べてみると以下のことが発生していました。
参考:https://encr.jp/blog/posts/20200326_morning/微々たる物ですが、ちょっと気持ち悪い感じがしたのでLambdaトリガーではなく、CloudWatchEventとLambdaで自前でSQSから取ってくる様にしました。
SQSの受信数は以下の様になりました。
CloudWatchEventでは1分単位でキューを見る様にして、Lambda側でキューの取得制限を設けて出来るだけキャパシティーオーバーしない様にしています。
Lambda
取得・集計は全てCloudWatchEvent+Lambdaに任せています。
Lambdaはリクエスト数と実行時間です。
無料枠は100万件のリクエストと40万GB秒となっています。
少なくとも、私の使い方で無料枠を超える事はありませんでした。
(無料枠の1割ちょっと位)執筆時点では以下の様な関数を作っています。
- マスタデータ取得(S3保存)
- 販売・注文データ取得(S3保存)
- 販売・注文データ集計(S3取得/保存・SQS)
- 人口データ取得(S3保存)
- 人口データ集計(S3取得/保存・SQS)
- API Gateway用レスポンス関数
- その他コンテンツ作成用関数
Python+Pandasを使っているので、集計周りが非常に楽です。
最初はforでゴリ押し出来ると思っていたのですがメモリで非常に辛くなったので、Pandasを利用しました。Serverless Frameworkを利用しているので、デプロイも楽になりました。
やっている事はCloudFormationと同じかと思いますので、API Gatewayに関する記述もしています。
※Admin権限が必要ですが、仕組み上これは致し方ないと思います...テスト・デプロイを繰り返していくと、バージョン管理している為か無駄が増えていきます。
「serverless-prune-plugin」を利用して自動削除すると良いかと思います。Lambdaに利用量は以下になります。
関数によって割り当てているメモリ量は異なりますが、128MB〜512MBにしています。
CloudWatchEvent
バッチ処理(定期処理)に使用しました。
EC2+cronやdigdagなど色々あると思いますが、Lambdaが使えるのでCloudWatchEventと組み合わせます。ある時バッチ動いていないなーと思ったら、GMTなんですよね...
言語設定を日本語にしているのでJSTだと油断していました...ECS(EC2)
次にECSについてですが、これがとても強力です。
ECR+ECS+ALB+Route53の組み合わせです。
- ECR - dockerイメージの保持
- ECS(Service->Task) - dockerコンテナの実行
- ALB - ECSタスク(dockerコンテナ)をターゲット
- Route 53 - ECSのサービスディスカバリを用いてdockerコンテナ間通信
Fargateでは無くEC2を使っています。(安いので...)
ECSとALBにより1つのEC2インスタンスで複数のタスク->dockerコンテナを動かすことが出来ます。これにより新しくインスタンスを更新や追加することなくデプロイする事ができます。(インスタンスのメモリ上限で無い限り)
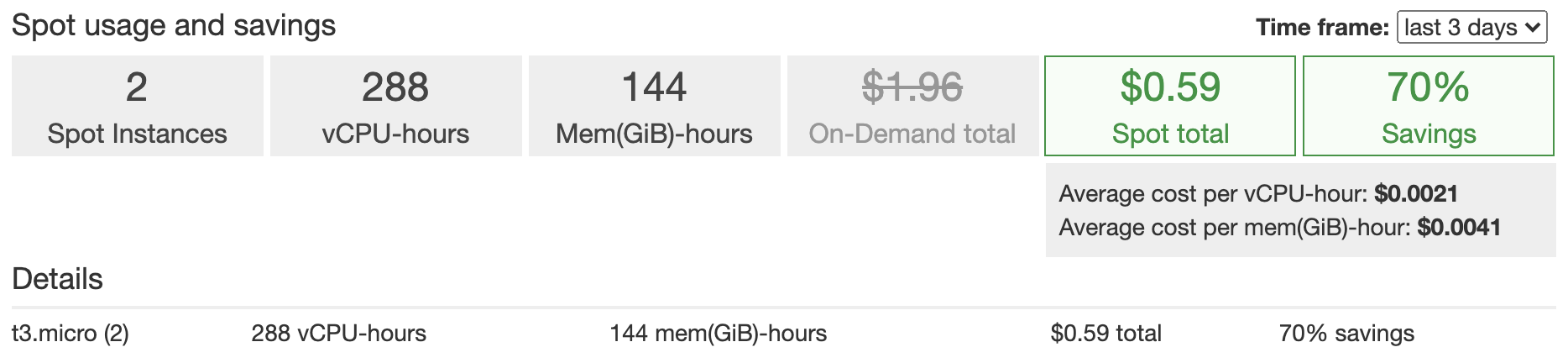
EC2インスタンスそのものの存在が薄くなります、dockerで動かしているのでSSHで接続する事自体ありません。またEC2はスポットインスタンスを利用しています。
これによりインスタンスタイプにもよりますが、オンデマンドインスタンスと比べて70%料金を削減する事ができました。
大幅に割引される代わりに、AWSからいつ中断されてもおかしく無い代物です。
もし落ちた場合、スポットフリートにより自動的に必要なインスタンスが補充され、ECSサービスにより必要なタスクが補充されます。
同時にALBによるヘルスチェックが働き、異常な物はターゲットから外され、正常な物はターゲットされるようになります。今回はt3.microインスタンスを利用しましたので、1時間辺り約1円それが2台で1ヶ月動かすと1440円程になります。
スポットインスタンスを利用していますので、場合にもよりますが今回は70%引きとして432円となります。ALB
先に述べた通り、ECSとの組み合わせの為に利用していますが、ACMによる証明書利用が可能です。
Let's Encryptに比べると非常に楽です、ポチポチボタン押すだけで終わるので。ただ、アクセス数などにもよりますが恐らく2000円程掛かってしまいます。
単一のサービスだけで使うならば個人利用は少々高いですが、ホストベースルーディングが可能な為、
複数のサービスを運用しているならば、ECSやACM、ルーティング、マネージドも考慮すると高い投資では無いと思います。また、Redisにてセッションを管理している為、スティッキーセッションはオフにしています。
オンにしていると突如EC2が落ちた際に、落ちたEC2の方にアクセスが行ってしまう為です。Route 53
ドメイン周りになります。
ちなみにドメインに関しては昨年位に「お名前.com」から「Route 53」に移管しました。
基本的に毎月50円位掛かっていました。それはさておき、ECSのサービスディスカバリという機能があります。
ECSにてコンテナ間で通信を実現するのは大変です。
(同一サーバの別コンテナは繋がるが、別サーバ同士やネットワークモードなどなど...)サービスディスカバリではECSで登録したサービスを内部ホストゾーンに自動登録/更新する事ができます。
ネットワークモードがawsvpcであればAレコードの登録が可能です。新しいホストゾーンが作成されるので新たに50円程掛かってしまいますが、自動でサービスと内部ドメインを紐付けてくれるのは非常に助かります。
サービス(タスク)が落ちてもECSが自動的に復帰、紐付けまで行ってくれます。今回の環境ではRedis(ElastiCacheではない)をECS内で立てている関係上、
アプリケーション側(別コンテナ)と通信する為に利用しています。
ElastiCache使えると良いのですが、コストが掛かるので....S3
S3では保存量、GET/PUTに対して課金が発生します。
今回のシステムではS3にマスタデータ、集計前/後データを格納しています。
PUTはシステム側でしか出来ないので出来るだけ発生していない様にしていますが、GETはユーザのタイミングによってしまう為、Redisを用いてEC2内でキャッシュしてGETが出来るだけ発生していない様にしています。
クローラー対策
通信にもお金が掛かります、微々たる物ですがサービスを組み合わせている程、影響が大きくなってくると思います。
特にALBでは新規接続等に対して課金があるので、無駄は通信は行いたくありません。
robots.txtで対応できる物はいいですが、ACLでインバウンド接続を切るのも手かと思います。約2ヶ月経って
スポットインスタンスを使ったので不安定になるかなーと思っていたのですが、一度も落ちた形跡が無いのが驚きでした。
リプレイスから数週間は新機能開発をしていたのですが、以前の環境と比べて飛躍的に開発が行いやすいです。特にDockerでの開発なので構築時点は多少大変ですが、以降はビルドしてタスクを更新するだけです。
Lambda側のPandasも非常に扱いやすく、一度仕組みが出来ると何でも出来そうな気がしてきます。
→基本的にはLambdaでデータ生成、LaravelでRedisに格納してユーザーに結果を返却。無料枠の使用量は月末前で以下の様になりました。
アカウント作成から1年以上経っているので、1年間の無料枠が無いと思っていたのですが、
free tierとなっており請求が発生していませんでした。
アカウント作成ではなく、初請求から1年とかだったりするのでしょうかね...?今後の展望
今回は取り敢えず移行したという感じです。
過去データはS3に全て保存してあるので、必要があればDynamoDBにいつでも反映できる状態になっています。
(過去データはあまり必要とされていない気がする....)設計周りばかりやっていたので、運用周りが疎かになっています。
例えばデプロイ作業は手動になっています。
追々、CircleCIとかCodeDeploy周りも組み合わせてみたいと思っていますが、一人で開発していると別にそんなに困っていないとかとか思ってしまいます。他にも監視周りも疎かです。
外形監視はやっておらず、SNSの設定も行っておりません。
最近気付いたのですが、botが大量アクセスしておりLCUを地味に消費していたのでrobots.txtとACLを設定しました。
ログはCloudWatchに出力しているので、気軽に解析できる様な環境は整えたいです。数値データを取り扱っているので、機械学習してみるのも面白いかと思っています。
実は少し触ったのですが(重回帰)、パラメータが多く手持ちのPCでは悲鳴を上げてしまいました('A'
Lambdaだと色々と厳しいから、インスタンスを立てて解析する感じになるのでしょうかね。最後に
一つ一つの内容は薄い物になってしまいましたが、もし機会があれば掘り下げて記事にしたいと思っています。
ここまで読んで頂きありがとうございました!




- 投稿日:2020-10-28T15:36:15+09:00
実践編!Amazon S3/Google Cloud Storage エンタープライズデータ保護のテクニック 後編
はじめに
前回は 実践編!Amazon S3/Google Cloud Storage エンタープライズデータ保護のテクニック 中編 として 3-2-1 ルールや制約、検証で分かった制限事項を説明してきました。今回はベストプラクティスやトラブルシューティングについて解説していきます!
総所有コスト(TCO)
NetBackup を使ってs3fs をバイパスする保護を実装するには次のコストを考慮する必要があります。
- クラウドに対して行われた API 要求の数
- データ転送コスト
- ストレージコスト
- クラウドでマシンをホストするコスト
- FETB(フロントエンドテラバイト)ないし、アラカルトのライセンス料金
通常はこれらの要因がコストに影響しますが、コストの要因は環境やクラウドプロバイダーによって異なります。s3fs は S3 互換ストレージへデータをアップロードあるいはダウンロードするために、クラウドプロバイダーによるコストがかかります。
ベストプラクティスと考慮事項
ベストプラクティスと考慮事項はこちらを参考にしてください。
• バックアップに使用する NetBackup メディアサーバーに S3バケットをマウントします。メディアサーバーが Linux 以外の場合は、別の NetBackup クライアントまたはメディアサーバーが必要です。
• パフォーマンスを向上させるにはアクセラレータを有効にします。アクセラレータはフルバックアップでも、変更時間に基づいてファイルの読み取りを回避します。基本的な考え方として、最初のバックアップと 2 番目のバックアップの間で 10% のファイルだけが変更された場合、2 番目のバックアップは最初のバックアップにかかった時間の10%程度です。
• バックアップではバケットをマウントしたままにします。バケットを再マウントするとinode 番号が変更されます。これはアクセラレータの最適化に影響します。NetBackup アクセラレータは、バックアップ間で inode のファイル数を比較し、ファイルが変更されたかどうかを判断します。しかし FUSEはファイルシステムのマウント中にiノードのファイル数を変更することができます(開いているファイルの場合は変更できません)。これにより、Accelerator はファイルが変更されたことを確認しバックアップを作成します。 これを回避するには s3fs でバケットをマウントしている間、FUSE の remember =-1 オプションを使用します。
詳細は以下を確認してください。
https://libfuse.github.io/doxygen/structfuse__config.html例えば以下のようなコマンドを発行します。
/usr/bin/s3fs <バケット名> /awsmount -o url=http://s3.amazonaws.com -o remember =-1• パフォーマンスを向上させるために複数のストリームを使用してデータをバックアップします。この場合、追加の帯域幅が必要になりメディアサーバーの CPU 消費が増加します。設定方法はこちらをご覧ください。
• アクセラレータと s3fs のキャッシュは同じデータを繰り返し読み取らないようにする代替手段です。アクセラレータを使用できない場合は、s3fs データキャッシュを有効にし、s3fs の use_cache パラメータを使います。これにより、s3fs はクラウドからではなくローカルキャッシュからデータを読み取ります。キャッシュされたコピーが使えるかどうかを理解するために、s3fs はファイルの変更時間とS3ストレージから返されたファイルチェックサムを比較します。これらのいずれかが変更された場合、s3fs はキャッシュを再ダウンロードして更新します。これは、連続バックアップで同じデータを読み取り続ける NetBackup のようなアプリケーションに適しています。 キャッシュを使用する場合は次の予防的措置を講じる必要があります。
- キャッシュを使用する場合、1047 に遭遇する可能性があります。
- ensure_diskfree パラメータが正しく設定されていることを確認してください。 設定されていない場合、キャッシュのために構成されたパーティション全体が占有されてしまうことに配慮します。
- キャッシュサイズがバックアップ対象のサイズより大きい場合はより良い性能が得られます。
- 設定済み (かつ使用可能な) キャッシュサイズは、少なくとも最も大きなオブジェクトと同等以上のサイズであることが期待されます。それ以外の場合は s3fs はスペースが使用可能になるのを待機するため、バックアップ処理をポーズします。
s3fs は設定されたキャッシュサイズを使い尽くすまでデータキャッシュをトリミングしません。 データキャッシュを定期的にトリミングするにはスクリプトを実行します。例えば以下のようなスクリプトを実行します。
https://github.com/s3fs-fuse/s3fs-fuse/blob/master/test/sample_delcache.sh
• NetBackup はファイルをバックアップするときにデフォルトでファイルのアクセス時間をバックアップ前の状態にリセットします。ただしこれは、s3fsファイルシステムの場合、S3 ストレージに対して HTTP PUTをコールする必要があることを意味します。特に多数のファイルがある場合にパフォーマンスに悪影響を及ぼします。
NetBackupでは、バックアップ後のアクセス時間を保持するためにファイルのアクセス時間をバックアップ前の値にリセットする機能を提供しています。詳細はこちらをご覧ください。このオプションはデフォルトで true ですが、オフにするとバックアップのパフォーマンスが向上します。
メモ:アクセラレータでポリシーを構成した場合、この構成は無視されます。
• ファイルのサイズよりもファイルの数がバックアップ時間に影響します。ファイル数が増えるとバックアップの処理が遅くなります。これは、s3fs がファイル (オブジェクト) メタデータを取得するために、より多くの HTTP コールを起動する必要があるためです。推奨事項の 1 つは、マルチストリーミングを使用することです。詳細はこちらを参照してください。
• s3fs マウントに復元すると、s3fs は並列スレッドを持つマルチパートリクエストとしてデータをアップロードします。同時実行についてはparallel_countパラメータ (既定値は 5)、各パーツのサイズ multipart_size パラメータ (デフォルトは 10 MB)を用いて制御します。
• データはクラウドから読み取られるため、メディアサーバーはクライアントがデータを送信するのを待つ必要があります。これにより、タイムアウトが発生する可能性があります。タイムアウトを避けるには、クライアントのリードタイムアウトにより大きな値を設定します。 詳細はこちらを参照してください。
• バックアップセレクションでALL_LOCAL_DRIVES ディレクティブを設定し、NFS をフォローする (Follow NFS) オプションをポリシー属性の設定に含めます。
トラブルシューティング
-curldogフラグを設定し、s3fs を実行すると S3 に対して行われたすべての curlリクエストの URL とヘッダーが出力されます。これは問題のトラブルシューティングに役立ちます。トラブルシューティングのために、これらのログを bpbkar と tar ログと突き合わせる必要があるケースがあります。
おわりに
いかがでしたでしょうか。アクセラレータもきちんと機能しますので、マージ処理不要の永久増分高速バックアップも期待できますね!ちなみに Azure BLOB の保護の技法についてはこちらで公開していますので、合わせてご参照ください!
商談のご相談はこちら
本稿からのお問合せをご記入の際には「コメント/通信欄」に#GWCのタグを必ずご記入ください。ご記入いただきました内容はベリタスのプライバシーポリシーに従って管理されます。
その他のリンク
【まとめ記事】ベリタステクノロジーズ 全記事へのリンク集もよろしくお願い致します!
- 投稿日:2020-10-28T14:35:00+09:00
AWSを使ったWordPress環境構築(冗長構成)
事前準備
構成はWebサーバ1台、DBサーバ1台です。
環境
環境 IP Webサーバ 10.0.1.1 DBサーバ 10.0.2.1 DBサーバの操作
- DBサーバに接続する。
直接SSHで接続するか、Webサーバを経由して接続してください。
MySQL Yum RepositoryからMySQL5.7をインストールする。
- Yumリポジトリの情報のインストール
$ sudo yum localinstall https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm
- MySQL8.0リポジトリを無効にし、MySQL5.7リポジトリを有効にする
$ sudo yum-config-manager --disable mysql80-community $ sudo yum-config-manager --enable mysql57-community #適用されているか確認 $ cat /etc/yum.repos.d/mysql-community.repo
- MySQLのインストール・起動
$ sudo yum install -y mysql-community-server $ sudo systemctl start mysqld
- MySQLの初期パスワードの確認
$ sudo cat /var/log/mysqld.log | grep root@localhost [Note] A temporary password is generated for root@localhost: 12桁の文字列
- MySQLのパスワード変更
$ mysqladmin -uroot -p password Enter password:古いパスワード New password:新しいパスワード Confirm new password:新しいパスワード #Warnigがでても変更はできています Warning: Since password will be sent to server in plain text, use ssl connection to ensure password safety.
- WordPress用のDB・ユーザーを作成する
$ mysql -uroot -p Enter password:設定したパスワード #WordPress用のユーザー作成 mysql> CREATE USER 'wordpress'@'localhost' IDENTIFIED BY 'wordpressユーザーのパスワード'; #WordPress用のDB作成 mysql> CREATE DATABASE `wordpress`; #DB権限を作成したユーザーに付与 mysql> GRANT ALL PRIVILEGES ON `wordpress`.* TO "wordpress"@"10.0.1.1"; #設定反映 mysql> FLUSH PRIVILEGES; mysql> EXIT;※サブネットマスクはワイルドカード方式を用いることで指定できる。
'10.0.1.%'Webサーバの操作
- WordPressのDBダンプを取得
$ sudo systemctl start mysqld $ mysqldump -uroot -p wordpress | gzip > wordpress.dump.gz Enter password: #WebサーバのMySQLの停止 $ sudo systemctl stop mysqld #ダンプをリストア $ zcat wordpress.dump.gz | mysql -h 10.0.2.1 -uwordpress -p wordpress
- WordPressの設定変更
# WordPessの設定を変更 $ sudo vim wordpress/wp-config.php /** WordPress のためのデータベース名 */ define( 'DB_NAME', 'wordpress' ); /** MySQL データベースのユーザー名 */ define( 'DB_USER', 'wordpress' ); /** MySQL データベースのパスワード */ define( 'DB_PASSWORD', 'パスワード' ); /** MySQL のホスト名 */ define( 'DB_HOST', '10.0.2.1' ); # サービスリロード $ sudo systemctl reload httpd
- 投稿日:2020-10-28T14:35:00+09:00
初心者がWordPress環境構築してみた(冗長構成)
事前準備
構成はWebサーバ1台、DBサーバ1台です。
環境
環境 IP Webサーバ 10.0.1.1 DBサーバ 10.0.2.1 DBサーバの操作
- DBサーバに接続する。
直接SSHで接続するか、Webサーバを経由して接続してください。
MySQL Yum RepositoryからMySQL5.7をインストールする。
- Yumリポジトリの情報のインストール
$ sudo yum localinstall https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm
- MySQL8.0リポジトリを無効にし、MySQL5.7リポジトリを有効にする
$ sudo yum-config-manager --disable mysql80-community $ sudo yum-config-manager --enable mysql57-community #適用されているか確認 $ cat /etc/yum.repos.d/mysql-community.repo
- MySQLのインストール・起動
$ sudo yum install -y mysql-community-server $ sudo systemctl start mysqld
- MySQLの初期パスワードの確認
$ sudo cat /var/log/mysqld.log | grep root@localhost [Note] A temporary password is generated for root@localhost: 12桁の文字列
- MySQLのパスワード変更
$ mysqladmin -uroot -p password Enter password:古いパスワード New password:新しいパスワード Confirm new password:新しいパスワード #Warnigがでても変更はできています Warning: Since password will be sent to server in plain text, use ssl connection to ensure password safety.
- WordPress用のDB・ユーザーを作成する
$ mysql -uroot -p Enter password:設定したパスワード #WordPress用のユーザー作成 mysql> CREATE USER 'wordpress'@'localhost' IDENTIFIED BY 'wordpressユーザーのパスワード'; #WordPress用のDB作成 mysql> CREATE DATABASE `wordpress`; #DB権限を作成したユーザーに付与 mysql> GRANT ALL PRIVILEGES ON `wordpress`.* TO "wordpress"@"10.0.1.1"; #設定反映 mysql> FLUSH PRIVILEGES; mysql> EXIT;※サブネットマスクはワイルドカード方式を用いることで指定できる。
'10.0.1.%'Webサーバの操作
- WordPressのDBダンプを取得
$ sudo systemctl start mysqld $ mysqldump -uroot -p wordpress | gzip > wordpress.dump.gz Enter password: #WebサーバのMySQLの停止 $ sudo systemctl stop mysqld #ダンプをリストア $ zcat wordpress.dump.gz | mysql -h 10.0.2.1 -uwordpress -p wordpress
- WordPressの設定変更
# WordPessの設定を変更 $ sudo vim wordpress/wp-config.php /** WordPress のためのデータベース名 */ define( 'DB_NAME', 'wordpress' ); /** MySQL データベースのユーザー名 */ define( 'DB_USER', 'wordpress' ); /** MySQL データベースのパスワード */ define( 'DB_PASSWORD', 'パスワード' ); /** MySQL のホスト名 */ define( 'DB_HOST', '10.0.2.1' ); # サービスリロード $ sudo systemctl reload httpd
- 投稿日:2020-10-28T10:43:38+09:00
AWS Cognito 構築手順
AWS Cognito 構築手順
世にたくさん出回っていますが、整理した手順です。
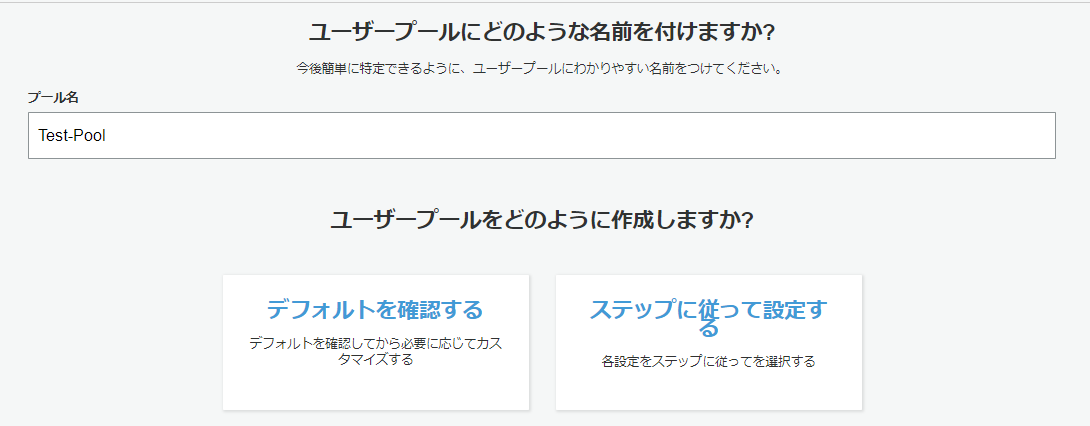
ユーザプールの作成
1. AWSサービスからCognitoを選択
2. ユーザプールを作成する。を選択
3. プール名を任意で決めて、「ステップに従って設定する」を指定。
4. 属性の設定
本設定は後から変更できないとのこと。
今回の設定では、下記とした。(用途によって適宜設定する)
- 認証時のユーザ名は「ユーザ名」(他にも任意のメールアドレスや電話番号が選択できるが、メールアドレスの場合、重複登録ができず動作確認しにくいため、今回はユーザ名にしておく)
- サインアップ時の入力必須項目は無しにしておく。(住所、電話番号、名前、誕生日や性別など指定できる)
5. ポリシーの設定
パスワードの強度は、最小8文字、数字、特殊文字、大文字、小文字を必要とする。(デフォルト)
管理者のみサインアップ許可(管理者以外のユーザにもサインアップの許可を与えることができる)
一時パスワードの有効期限7日間(デフォルト)
6. MFAの設定
MFA無効
アカウント回復の方法は、なし(他にも「Eメール」や「電話」が選択できる)
Cognitoに対するSMSメッセージの送信を許可するロールは作成しない(作成するとMFAを有効にする必要がある)
5. メッセージのカスタマイズ
SMSで送信するメッセージ内容のカスタマイズ。
今回は、デフォルトのまま。
6. タグ
現状、必要かわからず、必要あれば別途追加できそうなので、とりあえず未設定のまま。
7. デバイス設定
クライアントのデバイス記録の機能を使用するか選択します。
今回は”いいえ”を選択します。 機能を使用する場合はMFAの設定が必要になるようです。
8.アプリクライアントを指定
クライアント名の入力と「クライアントシークレットの生成」のチェックを外すす(※1)。
※1:クライアントシークレットの生成は、JavascriptのSDKが対応していないとのことでJavascriptでアプリを作るのであれば、必須
<備考>
「トークンの有効期限」のトークンとは更新トークンのことで、認証後、アクセストークンを背面で更新してくれる期間のこと。
「アクセストークン」はリソースへの更新権限を許可するためのトークン
「IDトークン」はその人がだれかを確認するためのトークン9. トリガ
認証時前や後に起動するLambdaが設定できる。
今のところ使用しないので設定しない。10. ユーザ登録
現時点では、ユーザ登録をWebアプリからしないので、AWSコンソールから手動でユーザ登録した。
[参考URL]

- 投稿日:2020-10-28T10:38:01+09:00
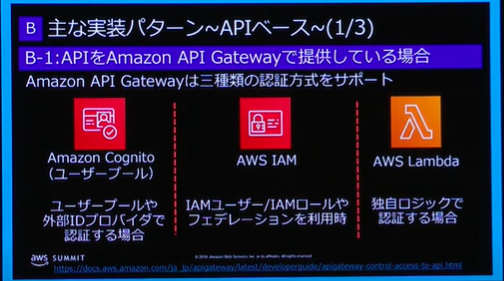
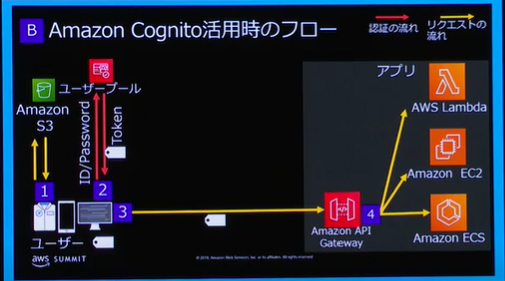
WebアプリからAWSユーザ認証する方法について
AWSユーザ認証の方法
概要
まず、Webアプリを作成する方法として、大きくは下記2種類ありますが、今回はS3にホスティングする方法でのユーザ認証の方法について、まとめます。
- EC2を使用する方法
- S3にホスティングする方法
S3にWebアプリをホスティングし、AWSに対してリクエストする構成としては、下図の通り。
ユーザ認証の方法
下記の3種類があるが、Cognitoを使用した認証が一般的に思う。
下記個別のメリット・デメリット
1. AWS Cognitoを使用する方法
AWSのサービスでユーザ名、パスワードを用いたユーザ管理をすることができる。
Googleアカウント、Facebookアカウントなどでの認証もできる。
[メリット]
- 独自のユーザ認証の仕組みを作成する必要がない。
- ユーザ名、メールアドレスなどで認証する仕組みを作れる
- 一時的なセキュリティ情報として認証できる(有効期限を設けることができる)ため、安全
[デメリット]
- 有料
→ただし、50,000ユーザ(月間アクティブユーザ)まで無料
2. AWS IAMを使用する方法
IAMと対応するアクセスキーとシークレットキーを発行してアクセスする方法。
[メリット]
- 独自のユーザ認証の仕組みを作成する必要がない。
[デメリット]
AWSがランダムで発行するアクセスキーとシークレットキーを使用する必要がある。
基本的に一般ユーザに配布して使用するものではなく、サーバサイドでの制御に使用するもの。
一時的なセキュリティ情報とならないため、危険。
3. Lambdaを使用する方法
独自のユーザ管理、認証の方法を構築する必要がある。
[メリット]
- 自由に作ることができる。
[デメリット]
- 認証の仕組みをすべて作成する必要がある。
Amazon Cognitoについて
概要
Amazon Cognito は、ウェブアプリケーションやモバイルアプリケーションの認証、許可、ユーザー管理をサポートするサービス。
Amazon Cognito の主な 2 つのコンポーネントは、ユーザープールと ID プールです。
1. ユーザプール
ログインを提供する機能。
- ユーザパスワード、メールアドレス、電話番号、カスタム属性などを格納可能 ユーザにまつわるデータベースのようなもの。
- 上記を利用して認証し、API Gatewayにアクセス可能なトークンを取得することができる。
2. IDプール
ユーザープールからユーザ認証成功時に発行されるトークンを使って、AWSのサービスに対するアクセス権を得ることができる機能のこと。
AWSのS3やDynamoDBなどのサービスに直接アクセスするときに使用する機能。
現時点ではAPI Gateway経由でのアクセスを想定しており、今回は使用しなくても良い想定。
3. アクセスの流れ
- S3からWebページを取得する。
- Cognitoを使用してユーザ認証を行う。
- 認証成功時に取得したトークンを使用してAPI GatewayへRequestし、情報を取得する。
4. 認証したユーザをAWS内で特定する方法について
Cognitoで認証時に取得できるトークンをBase64でデコードすると、ユーザ名などの情報を取得する事ができる。
API GatewayのREST APIコール時、上記トークンを使用するため、Lambdaでユーザ名を取得することができ、ユーザ名などのユーザ管理情報をDBなどに保持しておけば、ユーザ情報を特定することができると考える。
[参考URL]
・Cognitoについての概要
https://qiita.com/fjisdahgaiuerua/items/d420a2137e8d67e0a190・CognitoとIAMでの認証の違い
https://qiita.com/katekichi/items/dbf279077db6a7b597fc
https://www.skyarch.net/blog/?p=16856
https://dev.classmethod.jp/articles/lex_access_by_unauth_user_using_cognito/・Cognito QA
https://aws.amazon.com/jp/cognito/faqs/

- 投稿日:2020-10-28T09:35:18+09:00
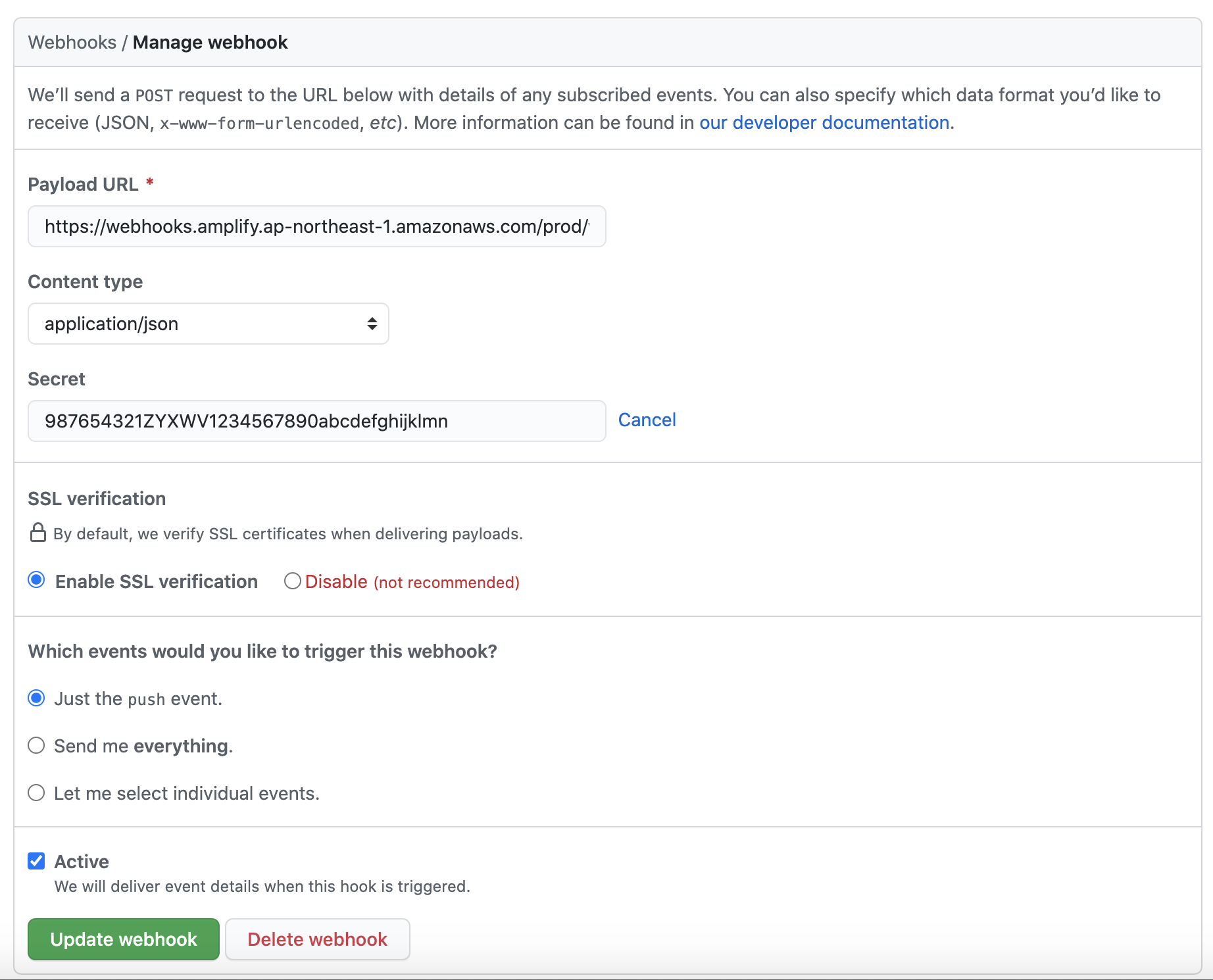
AWS Amplify ConsoleでGitHubのWebhookを手動で設定する
Amplify ConsoleのWebhookを手動で消して「マズい!」と思ったこと、ありますか?私はあります。
手動で再設定できるので、やってみましょう。手順
- WebhookのIDとTokenを払い出す。
- GitHubのリポジトリに登録する。
1. WebhookのIDとTokenを払い出す。
$ aws amplify create-webhook --app-id 12345678abcdef --branch-name master { "webhook": { "webhookArn": "arn:aws:amplify:ap-northeast-1:ACCOUNT_ID:apps/12345678abcdef/webhooks/********-9dc2-458c-b131-bb81bdfc96a7", "webhookId": "********-9dc2-458c-b131-bb81bdfc96a7", "webhookUrl": "https://webhooks.amplify.ap-northeast-1.amazonaws.com/prod/webhooks?id=********-9dc2-458c-b131-bb81bdfc96a7&token=987654321ZYXWV1234567890abcdefghijklmn", "branchName": "master", "createTime": "2020-10-28T09:14:00.000000+09:00", "updateTime": "2020-10-28T09:14:00.000000+09:00" } }2. GitHubのリポジトリに登録する。
ポイントは3点。
- Payload URLにはWebhookURLを登録する。&token以降は省いてもOK
- Content Typeは
application/json- SecretはTokenの値
以上です。tokenをSecretに設定するのが分かりづらいと思ったので記事にしました。
- 投稿日:2020-10-28T05:00:24+09:00
AWS AmplifyでPythonのFunctionをCI/CDするとbuildに失敗する問題の対処方法
題名の通り、AWS AmplifyでPythonのFunctionをCI/CDするとbuildに失敗する問題に遭遇しました。
結論(対処方法)
ビルド設定のamplify.ymlに以下を追記することでbuildを通すことができました。
version: 1 backend: phases: build: commands: # ここから追記 >>> - export BASE_PATH=$(pwd) - yum install -y gcc openssl-devel bzip2-devel libffi-devel python3.8-pip - cd /opt && wget https://www.python.org/ftp/python/3.8.2/Python-3.8.2.tgz - cd /opt && tar xzf Python-3.8.2.tgz - cd /opt/Python-3.8.2 && ./configure --enable-optimizations - cd /opt/Python-3.8.2 && make altinstall - pip3.8 install --user pipenv - ln -fs /usr/local/bin/python3.8 /usr/bin/python3 - ln -fs /usr/local/bin/pip3.8 /usr/bin/pip3 - cd $BASE_PATH # <<< ここまで追記 - '# Execute Amplify CLI with the helper script' - amplifyPush --simple発生した問題
CI/CDのビルドフェーズにて、下記のようにPython3.8以上が必要な旨が出力されています。
2020-10-27T19:21:49.678Z [INFO]: python3 found but version Python 3.7.4 is less than the minimum required version. You must have python >= 3.8 installed and available on your PATH as "python3". It can be installed from https://www.python.org/downloads You must have pipenv installed and available on your PATH as "pipenv". It can be installed by running "pip3 install --user pipenv". 2020-10-27T19:21:49.679Z [WARNING]: ✖ An error occurred when pushing the resources to the cloud ✖ There was an error initializing your environment. 2020-10-27T19:21:49.687Z [INFO]: init failed 2020-10-27T19:21:49.688Z [INFO]: Error: Missing required dependencies to package tatamifmmusiclibrary7312699f at buildResource (/root/.nvm/versions/node/v10.16.0/lib/node_modules/@aws-amplify/cli/node_modules/amplify-provider-awscloudformation/src/build-resources.js:30:11) at process._tickCallback (internal/process/next_tick.js:68:7) 2020-10-27T19:21:49.699Z [ERROR]: !!! Build failed 2020-10-27T19:21:49.699Z [ERROR]: !!! Non-Zero Exit Code detected 2020-10-27T19:21:49.699Z [INFO]: # Starting environment caching... 2020-10-27T19:21:49.700Z [INFO]: # Environment caching completed原因
Amplify CLIで
amplify add functionしてランタイムにPythonを選択すると、内部的にはPython 3.8が選択されるようです。
一方、CI/CDで使用するAmazon Linux2でインストールされるPythonは3.7.4のため、バージョンの不一致が起こってしまいます。解決のヒント
経験上、Amplifyの問題はGitHub Issueにあがっているケースが多いです。
本件も以下Issueにて既に議論がされていました。Amplify can't find Python3.8 on build phase of CI/CD #595
カスタムイメージを作成した人もいるようですが、あまり非公式なイメージは使いたくないので、多少buildに時間がかかってもPython 3.8をインストールしたほうが良いと判断しました。
いずれAmazon Linux2でインストールされるPythonのバージョンが上がると思うので、暫定対処で良いでしょう。
- 投稿日:2020-10-28T01:45:09+09:00
Amazon CloudWatch Logsにおける任意のログストリーム用のURLを動的に生成する
はじめに
CloudWatch Logsと言えば、AWSを使っている人は必ずと言っていいほどお世話になるログ管理のサービスです。
サービス自体はシンプルでとても便利なんですが、なぜかURLがちょっと特殊な作りになっていて、僕自身、任意のログストリーム用のURLを動的に生成しようとしたとき「ん?これどうなってんの・・・?」とはじめは戸惑いました。ちょっとしたTips程度ですが、同様のことで悩んでいる人がいるかもなので記事にしておきます。
CloudWatch LogsのURL構造はどうなっているか
URLは以下のようになっています。
ちなみにhoge-lambdaというLambdaを実行したときのログストリームのものです。https://ap-northeast-1.console.aws.amazon.com/cloudwatch/home?region=ap-northeast-1#logsV2:log-groups/log-group/$252Faws$252Flambda$252Fhoge-lambda/log-events/2020$252F10$252F27$252F$255B$2524LATEST$255D542bf48a98944249b069342e12861b99分かりやすくするために、以下のようにURLを分解してみます。
こうすると定型部分 + ロググループ名 + 定型部分 + ログストリーム名の構造になっていることが分かります。1. 定型部分 https://ap-northeast-1.console.aws.amazon.com/cloudwatch/home?region=ap-northeast-1#logsV2:log-groups/log-group/ 2. ロググループ名 $252Faws$252Flambda$252Fhoge-lambda 3. 定型部分 /log-events/ 4. ログストリーム名 2020$252F10$252F27$252F$255B$2524LATEST$255D542bf48a98944249b069342e12861b99ロググループ名・ログストリーム名はURLエンコードされている
次に、ロググループ名とログストリーム名に注目します。
コンソール画面から正しいロググループ名とログストリーム名を引っ張ってきてそれぞれを比較してみます。正しいロググループ名 /aws/lambda/hoge-lambda URLに含まれているロググループ名 $252Faws$252Flambda$252Fhoge-lambda正しいログストリーム名 2020/10/27/[$LATEST]542bf48a98944249b069342e12861b99 URLに含まれているログストリーム名 2020$252F10$252F27$252F$255B$2524LATEST$255D542bf48a98944249b069342e12861b99上記を見比べると、それぞれ以下のように変換されていることが分かりました。
しかし、この変換をするようなエンコード方式ってどんなだろう・・・となります。/ -> $252F [ -> $255B $ -> $2524 ] -> $255Dこれ、実はURLエンコードを2回実施されているんです。
途中経過も含めると以下のように変換されています。1発目 2発目 / -> %2F -> $252F [ -> %5B -> $255B $ -> %24 -> $2524 ] -> %5D -> $255Dつまり、CloudWatch Logsで使われているURLは以下のように作られていることが分かります。
URL構造
定型部分 + URLエンコードを2回実施したロググループ名 + 定型部分 + URLエンコードを2回実施したログストリーム名まとめ
ロググループ名とログストリーム名の部分のみをURLエンコード×2回実施すればいい、とだけ理解してもらえればOKです。
CloudWatch LogsのSubscription Filterなどを使ってログ監視などを実装する場合は、アラート通知する内容に生成したログストリーム用URLを埋め込んであげると、エラー発生時のログ確認が素早くできるようになるので個人的にオススメです。
- 投稿日:2020-10-28T01:45:09+09:00
Amazon CloudWatch Logsにおける任意のログストリームページのURLを動的に生成する
はじめに
CloudWatch Logsと言えば、AWSを使っている人は必ずと言っていいほどお世話になるログ管理のサービスです。
サービス自体はシンプルでとても便利なんですが、なぜかURLがちょっと特殊な作りになっていて、僕自身、任意のログストリームページのURLを動的に生成しようとしたとき「ん?これどうなってんの・・・?」とはじめは戸惑いました。ちょっとしたTips程度ですが、同様のことで悩んでいる人がいるかもなので記事にしておきます。
CloudWatch LogsのURL構造はどうなっているか
URLは以下のようになっています。
ちなみにhoge-lambdaというLambdaを実行したときのログストリームのものです。https://ap-northeast-1.console.aws.amazon.com/cloudwatch/home?region=ap-northeast-1#logsV2:log-groups/log-group/$252Faws$252Flambda$252Fhoge-lambda/log-events/2020$252F10$252F27$252F$255B$2524LATEST$255D542bf48a98944249b069342e12861b99分かりやすくするために、以下のようにURLを分解してみます。
こうすると定型部分 + ロググループ名 + 定型部分 + ログストリーム名の構造になっていることが分かります。1. 定型部分 https://ap-northeast-1.console.aws.amazon.com/cloudwatch/home?region=ap-northeast-1#logsV2:log-groups/log-group/ 2. ロググループ名 $252Faws$252Flambda$252Fhoge-lambda 3. 定型部分 /log-events/ 4. ログストリーム名 2020$252F10$252F27$252F$255B$2524LATEST$255D542bf48a98944249b069342e12861b99ロググループ名・ログストリーム名はURLエンコードされている
次に、ロググループ名とログストリーム名に注目します。
コンソール画面から正しいロググループ名とログストリーム名を引っ張ってきてそれぞれを比較してみます。正しいロググループ名 /aws/lambda/hoge-lambda URLに含まれているロググループ名 $252Faws$252Flambda$252Fhoge-lambda正しいログストリーム名 2020/10/27/[$LATEST]542bf48a98944249b069342e12861b99 URLに含まれているログストリーム名 2020$252F10$252F27$252F$255B$2524LATEST$255D542bf48a98944249b069342e12861b99上記を見比べると、それぞれ以下のように変換されていることが分かりました。
しかし、この変換をするようなエンコード方式ってどんなだろう・・・となります。/ -> $252F [ -> $255B $ -> $2524 ] -> $255Dこれ、実はURLエンコードを2回実施されているんです。
途中経過も含めると以下のように変換されています。1発目 2発目 / -> %2F -> $252F [ -> %5B -> $255B $ -> %24 -> $2524 ] -> %5D -> $255Dつまり、CloudWatch Logsで使われているURLは以下のように作られていることが分かります。
定型部分 + URLエンコードを2回実施したロググループ名 + 定型部分 + URLエンコードを2回実施したログストリーム名まとめ
重要なのは、ロググループ名とログストリーム名の部分のみをURLエンコード×2回実施すればいいという点だけです。
ここさえ抑えておけば、あとは定型部分と結合するだけで動的にURLが生成できるので簡単ですね。CloudWatch LogsのSubscription Filterなどを使ってログ監視を実装するのはよくあるユースケースかと思いますが、アラート通知する内容に生成したログストリームページのURLを埋め込んであげると、エラー発生時のログ確認が素早くできるようになるので個人的にオススメです。
- 投稿日:2020-10-28T01:00:05+09:00
AWSの主要なサービス概要
はじめに
追記:850点ほどでAWS認定クラウドプラクティショナー合格することができました。
AWSクラウドプラクティショナーの認定試験を受験するにあたり学んだサービスの概要をまとめました。
内容の構成に関しましてはAWS認定資格試験テキスト AWS認定 クラウドプラクティショナーを参考にさせていただきました。
AWSの基礎を学べる良書と感じました。AWS主要なサービス概要
AWSクラウドの概念
クラウドとは
インターネット経由でコンピューティング、データベース、ストレージ、アプリケーションをはじめとした様々なITリソースをオンデマンドで利用することのできるサービスの総称。
オンデマンド:従量課金のことで、実際に使った分の支払いをすること
クラウド (クラウドサービス) とは?クラウドの6つメリット
固定の償却コストが変動コストに
自前でデータセンターやサーバーを持つ場合(オンプレミス)には実物の購入や建物や冷却装置などの多額の投資を固定の償却コストとして扱う必要があったが、クラウドサービスを利用することで必要な時に必要な分だけ利用して支払う変動コストにすることができる。当然実物の購入費や施設の維持費も必要なくなる。
オンプレミス:サーバーなどを使用者が自前の施設などで管理する運用方式。略称は「オンプレ」スケールによる大きなコストメリット
数十万規模のユーザーがクラウドサービスを使用するため、規模の経済が働きオンプレよりも低い変動コストを実現することができる。
規模の経済:多くの企業が同じサービスを利用することで1企業あたりの支払うコストが低くなること
IntelがAWSに特化したIntel Xeon プロセッサを提供するくらい大規模なクラウドサービスであるキャパシティ予測が不要に
オンプレでは必要なキャパシティを事前に計算し用意しておく必要があったが、クラウドではリソースの増減を行うことができるので予測する必要がなくなった。
自前でサーバーを確保しておくことは多額のコストがかかり、使用していない時にもコストが発生するがクラウドでは必要な時にのみ使用することができるのでコストも抑えることができる。速度と迅速性の向上
クラウドではITリソースを必要な時に簡単に利用することができる。従来のオンプレミスではサーバーの用意に数週間の時間を要していたためクラウドを利用することで迅速に必要なものを揃えることができ、組織としての俊敏性が向上する。
アジリティと表現することもある。データセンターの運用保守投資が不要
オンプレではデータセンターを管理することに人員や、サーバーの設置・保守運用といった業務が発生していたがクラウドを利用することでそれらの業務をする必要がなくなるため企業はサービスの開発に専念することができる。
わずか数分で世界中にデプロイ
わずか数回クリックするだけで世界中にデプロイすることができる。
デプロイ:サービスをインターネットを通じてアクセスできるように世界に展開することクラウドのデメリット
オンプレと比較すると自社でサーバーを扱うことができないためカスタマイズ性が落ちることがあげられる。
また、クラウドにアクセスするにはオンライン環境が必須である。
クラウドサーバ導入における2つのデメリットWell-Architectedフレームワーク
AWS Well-Architectedホワイトペーパー
クラウドアーキテクトがアプリやワークロード向けに高い安全性、性能、障害耐性、効率化を備えたインフラを構築する際に役立つ。
いくつかの基本的な質問に答えると、自分のアーキテクチャがクラウドのベストプラクティスがどの程度実践できているかを知り、改善するためのガイダンスを得ることができる。Well-Architectedの5つの柱
運用上の優秀性
変更の自動化、イベントの対応、日常業務を管理するための標準化が含まれる。
セキュリティの柱
データの機密性と整合性、権限管理における権限の特定と管理、システムの保護、セキュリティイベントを検出する制御の確立などが含まれる。
信頼性の柱
障害から迅速に回復してユーザーの要求に応える。
分散システムの設計、復旧計画、変更の処理方法が含まれる。パフォーマンス効率の柱
ワークロードの要件に応じた適切なリソースタイプやサイズの選択、パフォーマンスのモニタリング、ビジネス要件の増大に応じて効率を維持するための情報に基づいた意思決定が含まれる。
コスト最適化の柱
費用が発生する箇所の把握と管理、最適で正しい数のリソースタイプの選択、時間経過に伴う支出の分析、過剰な出費を抑えながらのビジネスニーズに対応したスケーリングなどが含まれる。
Well-Architected Tool
概要
ワークロードの状態をレビューして、ベストプラクティスと比較することができる。
WAフレームワークをベースとしており、クラウドアーキテクトがアプリ向けに実装可能な安全で高いパフォーマンス、障害耐性を備えた、効率的なインフラ構築をサポートする目的で開発された。
利用するには、マネジメントコンソールでワークロードを定義し、5つの柱に沿った質問に解答するだけ。その後AW Toolから実績のあるベストプラクティスを使ったクラウド向けアーキテクチャの設計方法に関する計画が提示される。料金
無料
クラウドの種類
SaaS、Paas、IaaSとは
VDI(デスクトップ仮想化)とDaaSの違いとは
IaaS
Infrastructure as a Serviceの略
インフラをインターネット上のサービスとして提供する形態のこと。
Google Compute CloudやAmazon EC2が代表的なサービス。PaaS
Platform as a Serviceの略
ハードウェアやOSなどのプラットフォーム一式をインターネット上のサービスとして提供する形態のこと。
Google App EngineやMicrosoft Azureなどが代表的なサービス。SaaS
Software as a Serviceの略
これまではパッケージ商品として販売していたソフトウェアをインターネット経由で提供・利用する形態のこと。
Salesforceなどが代表的なサービス。DaaS
Desktop as a Serviceの略
クラウド上にあるデスクトップをインターネットを経由して提供・利用する形態のこと。
クライアント側の端末では画面の共有とマウスとキーの入力操作を行うだけなので、マシンの性能が低くても様々なサービスを利用できることからリモートワークに導入するために注目されている。クラウドのデプロイモデル
クラウド
完全にアプリケーションがクラウド上にデプロイされていて、アプリの全体がクラウド上で実行される。
ハイブリッド
クラウドベースのリソースと、クラウド上にはない既存のリソースとの間でインフラを接続する方法。
(クラウド+オンプレミスでの運用など)オンプレミス
リソースをオンプレミスでデプロイする方法。
AWSのセキュリティ
責任共有モデル
AWSはセキュリティを最優先事項と言い切っている。しかし、ユーザーの使い方次第ではセキュリティを維持することはできない。そのためAWSとユーザーでセキュリティを担う責任を共有する責任共有モデルを実施している。
これはAWSとユーザーで明確にセキュリティ維持の責任範囲を分けることで成り立っている。
初期段階ではAWSはクラウドの本体に責任を持ち、ユーザーはクラウドの中身に責任を持つ。しかし、AWSの提供するマネージドなサービスを利用することで、利用した部分はユーザーからAWSの責任範囲に移管される。AWSの責任範囲
ハードウェアやリージョン、アベイラビリティゾーン、エッジロケーションなどの物理的なものや、各種ソフトウェアの管理(アップデートやパッチなど)がAWSの担当。
仮想化を実現するハイパーバイザーもAWSの責任範囲。ユーザーの責任範囲
ゲストオペレーティングシステムの管理(アップデートやパッチのインストール)、関連するアプリケーションソフトウェアの管理やAWSより提供されるセキュリティグループファイアーウォールの設定などがあげられる。
AWSからセキュリティ対策のサービスが複数提供されているので活用していくことが望ましい。
各管理プレーンはユーザーの担当クラウドのセキュリティ
データの保護
ユーザーのプライバシー保護のため強力な安全策が用意されている。
全てのデータは安全性が非常に高いデータセンターに保存される。コンプライアンスの要件に準拠
インフラストラクチャの中で数多くのコンプライアンスプログラムを管理できる。
コンプライアンスの準拠に必要な要件は初めから達成されている。
例えば、自国のリージョンを使用することでデータの国内保持のコンプライアンスを達成することができる。コスト削減
ユーザーは独自のデータセンターなどを管理する費用を支払う必要もなく、AWSでは非常に高いレベルのセキュリティ対策を行ってくてるため、セキュリティにかける費用も抑えられる。
迅速なスケーリング
AWSクラウドの使用量に合わせてセキュリティをスケーリングできる。ビジネスの規模にかかわらずAWSインフラによってユーザーのデータが保護される。
MFA
多要素認証のことであり、通常のIDとパスワードの入力に加えて認証に必要な要素を追加することでセキュリティを強化することが目的。
例として、ワンタイムパスワードの追加入力や秘密の質問なあどと行った様々なものがある。
AWSはマネジメントコンソールへのログインに対してMFAの追加を強く推奨している。セキュリティのベストプラクティス
ユーザーが責任を担う部分のベストプラクティスとして4つの項目がある。
転送中のデータの保護
パスワードなどが暗号化されることなく送信されてしまわないように適切な通信プロトコルを使用すること。
脆弱性のある暗号化プロトコルの使用も避ける。蓄積データの保護
蓄積データの物理的な保護はAWSが行ってくれるが、運用の中でデータを出力する際にデータへのアクセス権限のない者がアクセスできてしまうことがある。その際に個人情報などを見られてしまわないようにデータの暗号化を行うことが望ましい。AWSではストレージやデータベースの暗号化オプションが存在するのでこれらを使用することも検討する。
AWS資格情報の保護
ルートアカウントを使用すると全ての権限が使用できてしまうので、ユーザーごとにIAMユーザーを作成して必要最低限の権限を与えて運用する。
アプリケーションの安全性の確保
クロスサイトスクリプティングやSQLインジェクションなどの攻撃に対する対策をしておく。
日頃から脆弱性に対する情報収集を行うことや、Amazon Inspectorを使用した脆弱性診断を行うことが望ましい。IAM
AWS Identity and Access Managementの略。
ユーザーのAWSクラウドリソースへのアクセス管理サービス。
ユーザーのグループ作成、管理やアクセス権を使用してリソースへのアクセス許可、拒否の設定を行える。
AWSサインアップ時に作成したアカウントはルートアカウントと呼ばれ、全ての権限を持っているため日常的に使用しないようにする。
そこで、IAMユーザーやIAMグループを作成することができる。
追加設定として日時の制限やアクセス元のIPアドレス、SSLを使用しているかどうか、MFA認証が行われているかなどの条件を追加することができる。
料金IAMグループ
IAMユーザーをグループでまとめることができる。
開発グループや運用グループなどでくくることで管理がしやすくなる。
作成された段階では何も権限がない状態になっている。
グループにユーザーを追加することで自動でそのユーザーにもグループと同じ権限が適用される。
複数のユーザーの権限管理を行えるので権限管理を行いやすい。
1000人以上いるような会社の各部門などで権限管理を行う際に重宝する。
グループをユニットと表現することもある。IAMユーザー
IAMユーザー毎にAWSの各種リソースに対するアクセス権を設定でき、IAMユーザーに対してAPIキーも作成できる。
作成された時には権限が何も与えられていない状態になっている。権限を追加する際には必要最低限の権限のみを付与する。
権限の許可と拒否が相反する際には拒否が優先される。
APIキーは1人のユーザーに2つまで発行できる。これはキーの入れ替えを行う際に2つないと一時的にAPIキーがない状態が生まれてしまうのを避けるため。IAMポリシー
AWSリソースヘのアクセス管理に利用するもの。
IAMアイデンティティまたはAWSリソースにアタッチする。
オペレーションの実行方法を問わずにアクションのアクセス許可を定義するもの。ポリシーが適用されたユーザーはそのリソーへのアクセスが可能となる。
料金は無料。
AWS IAM
IAMユーザーを作成したらポリシーを設定することでアクセス管理を行える。AWS管理ポリシー
AWSが用意している再利用可能なポリシー。複数のIAMユーザー、IAMグループ、IAMロール間で共有可能。
カスタマー管理ポリシー
ユーザーが作成した再利用可能なポリシー。複数のIAMユーザー、IAMグループ、IAMロール間で共有可能。
インラインポリシー
各IAMユーザー(IAMグループやIAMロール)専用にユーザーが個別作成するポリシー。
IAM ポリシーIAMロール
IAMロールを使用すると通常はリソースにアクセスしないユーザーやサービスへのアクセスを委任することができる。
一時的にセキュリティの認証を得ることができるロールを担うことができる。
IAMロールAWS Organizations
アカウントの作成を自動化できたり、アカウント単体毎ではなくまとめて請求を行うことができる。
まとめて請求することでS3の容量計算が変わったりと料金が節約できる場合がある。セキュリティグループ
1つ以上のインスタンスのトラフィックを制御する仮想ファイアウォール。
今までは中央集権的なファイアウォールを1つだけ外部ネットワークの前に置いていた、それぞれのノードの前に設置することがベストであったがコストの面と、サーバーを置くラックのスペース制限もありできなかった。しかし、クラウドでは各インスタンス毎に個別のファイアウォール設定を行えるセキュリティグループを用いることで実現できる。
セキュリティグループはその名前の通り、グループとして同目的のサーバー群に同じ設定を適用することもできる。
行える設定としては以下がある。
・許可ルールの指定が可能
・拒否ルールの指定は不可能
・インバウンドトラフィックとアウトバンドトラフィックのルールを個別に指定可能デフォルトの仕様
・セキュリティグループを新規作成する際にはインバウンドルールはない。
・ルールを追加するまで別のホストからインスタンスに送信されるインバウンドトラフィックは許可されない。
・デフォルトでは全てのアウトバンドトラフィックを許可するアウトバンドルールがある。
・セキュリティグループはステートフル。
・インスタンスからリクエストを送信する場合にはそのリクエストのレスポンストラフィックはインバウンドセキュリティグループルールに関わらず許可される。パワーユーザー
IAMユーザーの管理以外の全ての権限が有効になっているユーザーのこと。
ルートアカウント
AWSのアカウント作成時のアカウントをルートアカウントという。
ルートアカウントは全ての操作をすることができる権限の最も強いアカウントである。
業務での操作ではルートアカウントは使用せずに適切な権限のみを与えた別のユーザーを作成して利用する。
ユーザーは1アカウントの中で複数作成することができる。組織単位
組織単位のことをOUと呼ぶ
Organization Userサービスコントロールポリシー(SCP)
組織を管理するために使用できるポリシータイプのこと。
組織内の全てのアカウントの最大限使用できる権限を提供し、アカウントの組織のアクセスコントロールガイドラインに沿って活動することを確実にすることができる。
組織が一括請求のみを有効にしている時にはSCPは使用できない。インラインポリシー
ユーザーが自身で作成と管理をすることができるポリシー。
プリンシパルエンティティにアタッチすることができる。
プリンシパルエンティティ: (ユーザーまたはロール) を使用してリクエストを送信するユーザーまたはアプリケーション。 プリンシパルに関する情報には、プリンシパルがサインインに使用したエンティティに関連付けられたポリシーが含まれます。
プリンシパルエンティティカスタマー管理ポリシー
AWSアカウントで作成、管理できる。管理者権限を有しているユーザーまたはAWS側によって作成されて複数のIAMエンティティにアタッチすることができるポリシータイプ。
鍵の種類
IDとパスワード
マネジメントコンソールへのログインに使用される。
これらの管理はユーザーの責任。
MFAを使用することでセキュリティを強化できる。キーペア
EC2などのログインに使用するもの。キーペアは公開認証方式という認証方式である。
公開鍵と秘密鍵のペアで構成されており、サーバーやEC2インスタンスに公開鍵を設定しておき、アクセスするユーザーの秘密鍵と一致するかで認証する。
秘密鍵の管理はユーザーの責任で、紛失した際には鍵のリセットを行うことはできない。
利用者毎に秘密鍵を生成することが望ましく、誰がアクセスしたかの特定も容易になる。
利用者毎にキーペアを生成して公開鍵をサーバーに設定する。
公開鍵はパブリックキー、秘密鍵はプライベートキー(PEMキー)と呼ぶこともある。
パブリック暗号はパブリックキーを使用してデータを暗号化し、受信者はプライベートキーを使用してデータを複合すること。
複合化:暗号化されたデータを元に戻すことAPIキー
CLIやSDK、プログラム上で使用する際にはAPIキーを利用する。
APIキーはアクセスキーとシークレットアクセスキーのペアで構成される。AWS Shield
マネージド型の分散サービス妨害のDDoS攻撃の保護サービス。
DoS攻撃はトラフィックを増大させて、サーバーに負荷をかけることでサービスの利用を困難にさせたりダウンさせたりすることを目的とした攻撃のことである。それを複数のコンピューターをのっとりターゲットに対して一斉に行う攻撃をDDoS攻撃という。
AWS Shieldはアプリのダウンタイムとレイテンシーを最小限に抑える常時稼働の検出と自動インライン緩和策を提供している。
StandardとAdvancedの二つの種類がある。
AWS ShieldStandard
無料
一般的なDDoS攻撃から保護してくれる。
Amazon Cloud FrontやAmazon Route53と一緒に使用するとインフラを標的とした既知の攻撃から総合的に保護してくれる。Advanced
有料
攻撃の通知や分析、レポートの作成をDDoS Response Teamにアウトソーシングすることができる。
Advancedを利用するとAWS WAFサービスが無料かつ無制限に利用することができる。AWS WAF
WAFはWeb Application Firewallの略。
アプリの可用性の低下、セキュリティの侵害、リソースの過剰消費などの一般的なWebの脆弱性からアプリを保護するマネージド型のWebアプリケーションファイアーウォール。
SQLインジェクションやクロスサイトスクリプティング、定義した特定のトラフィックパターンを除外するWebセキュリティルールの作成などを行える。
料金は利用した分にだけ課金される。基本料金は無料。初期費用はなし。
しかし定義は最初から設定されているわけではないので、自分で設定する必要がある。サードパーティの提供するWebセキュリティルールを設定することも可能。
この料金は以下の3つできまる。
・Webアクセスコントロールリスト(Web ACL)数に基づく課金方式
・Web ACLごとに追加するルール数に基づく課金方式
・受け取るWebリクエスト数に基づく課金方式
AWS WAFはAmazon CloudFrontにデプロイでき、EC2上で動作するウェブサーバーやオリジンサーバーの手前に配置したApplication Load BalancerやAPIを使用するためのAmazon API GateWayに適用できる。
AWS WAFInspector
自動化されたセキュリティ評価サービスで、AWSにデプロイしたアプリのセキュリティとコンプライアンスを向上させることができる。
自動的にアプリを評価して、露出、脆弱性、ベストプラクティスからの逸脱がないかを確認できる。
評価のあとは重大性の順に結果を表示した詳細なリストが作成され、確認することができる。
評価はルールパッケージに沿って行われる。
料金使用した分にだけ支払う。料金は2つの基準があり、EC2インスタンスの数と、選択したルールパッケージのタイプによって料金が変わる。
Inspectorで診断が行えるものは以下。
・一般的な脆弱性や漏洩
・ネットワークセキュリティにおけるベストプラクティス
・認証におけるベストプラクティス
・OSのセキュリティにおけるベストプラクティス
・アプリケーションセキュリティにおけるベストプラクティス
・OCI DSS3.0アセスメント(クレジットカード会社の情報セキュリティ基準)
Amazon InspectorAWS Artifact
AWSのコンプライアンスレポートにアクセスできるセルフサービスポータル。
AWSの監査人が作成したレポート、認証、認定、その他のサードパーティによる認定にオンデマンドでアクセスできる。
AWSとの契約を確認、承認、管理できる。組織内の全てのアカウントにAWSの契約を適用できる。
AWSのセキュリティ管理環境の高い透明性を保つ。セキュリティとコンプライアンスを継続的にモニタリングして新しいレポートをすぐに確認できる。
料金は無料。
Service Organization Control(SOC)、Payment Card Industry(PCI)のレポートなどが取得可能。
AWS ArtifactネットワークACL
ネットワークアクセスコントロールリスト(ネットワークACL)は1つ以上のサブネットのインバウンドトラフィック(受信)とアウトバンドトラフィック(送信)を制御するファイアウォールとして動作するVPC用のセキュリティオプションレイヤー。
セキュリティの追加レイヤーをVPCに追加するにはsキュリティグループと同様のルールを指定したネットワークACLをセットアップできる。
セキュリティグループと似ているので注意。
ネットワークACLAWS Key Management Service (AWS KMS)
このサービスを使用すると暗号化キーを簡単に作成して管理し、幅広いAWSノサービスやアプリでの使用を制御できるようになる
セキュアで弾力性の高いサービスで、キーを保護するために検証済み、または検証段階のハードウェアセキュリティモジュールを使用する。
AWS CloudTrailと統合されており、全てのキーの使用ログを表示できるので規制及び、コンプライアンスの要求に応えることができる。
フルマネージド型である。(キーの使用権限などはユーザーだが、権限の実行、耐久性、物理的な部分はAWS)
マネジメントコンソール、またはSDK、CLIからキーの権限を簡単に作成、インポート、ローテーション、削除、管理できる。
料金は無料枠がありつつ、キーストレージやキーの使用量によって課金される。
AWS KMSAWS CloudHSM
クラウドベースのハードウェアセキュリティモジュール(HSM)。これによりクラウドで暗号化キーを簡単に生成して使用できるようになる。
FIPS 140-02レベル3認証ずみのHSMを使用して暗号化キーを管理できる。業界標準のAPIを使用してアプリケーションを柔軟に統合できる。
CloudHSMはハードウェアのプロビジョニング、ソフトウェアへのパッチ適用、効果養成、バックアップといった時間のかかる管理タスクを自動化する完全マネージメント型のサービスである。オンデマンドでキャパシティを追加及び削除することで簡単にスケールできる。前払いの必要はない。
料金はHSMを起動してから終了するまで各HSMごとに1時間単位で課金される。
AWS CloudHSMAmazon Guard Duty
悪意のある操作や、不正な操作を継続的にモニタリングすることで脅威を検知するサービスである。AWSのアカウントとワークロードを保護する。
VPCフローログmCloud Trailイベントログ、DNSログ、悪意のあるIPやドメインのリストを用いることで悪意を検知する。
AWS Organizationを使用して複数のアカウントにサポートを提供するので全てのアカウントにGuardDutyを適用させることができる。
料金は分析されたAWS CloudTrailのイベントの数、分析されたAmazonVPCフローログとDNSログデータの量に基づいている。
GuarDuty分析のためにこれらのログソースを有効化することへの追加料金はない。
Amazon GuardDutyAccess Advisor
IAMエンティティが最後にAWSサービスにアクセスした日付と時間を表示する機能のこと。
AWS CLIまたはSDKでIAMアクセスアドバイザーAPIを使用することで全アカウントのIAMアクセス権限の分析を自動化することができる。
IAMのアクセス管理などを支援することができる。AWSのテクノロジー
リージョン
現在は24のリージョンと1つのローカルリージョンがある。
リージョン内には2つ以上のアベイラビリティゾーンがある。
日本にいても東京リージョンしか選択できないわけではなく他のリージョンも選択できる。
複数のリージョンに完全に稼働する同じシステムを構築して災害時のダウンタイムを最小にするマルチサイトアクティブ-アクティブという構成も検討できる。
リージョンによってコストや使用されるサービスが異なることがある。
どのリージョンを選択するかには以下がある。
・保存するデータやシステムがそのリージョン地域の法律やシステムを所有している企業のガバナンス要件を満たしているか
・ユーザーや連携するデータに近いか
・必要なサービスが揃っているか
・コスト効率が良いか
マルチリージョンで展開することで99.99%以上の可用性を実現できる。
マルチAZでは1リージョンを丸ごと巻き込む災害があった際には99.99%以上の可用性は維持できない。ほぼ止まらないシステムを構築できるがその分コストがかかってしまう。アベイラビリティゾーン(AZ)
1リージョンには必ず2つ以上のAZがある。
複数のデータセンターから構成されている。
各AZは停電や災害が発生した際に同時に被害に合わない場所に構成されている。
事前に障害が発生することを見越した設計となっており、これはDesign for Failure(障害に備えた設計)と呼ばれている。
これらの設計がされていることから、AWSでは可用性、対障害性を持った運用を行うことができる。
同一リージョン内のAZは高速なプライベート光ファイバーネットワークにより数ミリ秒の低レイテンシー接続を実現している。
99%以上可用性を維持することはできない。
マルチAZでは1リージョンを丸ごと巻き込む災害があった際には99.99%以上の可用性は維持できない。エッジロケーション
全世界に200箇所以上存在する。
リージョンのない国にも設置されている。
エッジロケーションの用途としては以下2つ
・低レイテンシーなDNSクエリの実現
・コンテンツの低レイテンシー配信
Amazon Route53というDNSサービスがエッジロケーションで使用されており、低レイテンシーでDNSクエリを返すことができる。
CDNサービスであるAWS CloudFrontもエッジロケーションで使用されており低レイテンシーでコンテンツキャッシュを配信することができる。
Route53とCloudFrontはDDoS攻撃から保護するAWS Shield Standardの対象なのでエッジロケーションでサービスへの攻撃から保護することができる。その他
ユーザーからさらに近い位置にあるAWS LocalZone。
アプリに10ミリ秒未満のレイテンシーを実現するAWS Wavelength。
オンプレミスの施設でAWSを利用するAWS Outpostsのような色んなサービスがある。
エッジロケーションを使用することでユーザーに最も近い場所から低レイテンシーでサービスを提供することが可能となる。コンピューティングサービス
●
ネットワークサービス
●
API Gatewayストレージサービス
Amazon Elastic Block Store(EBS)
EC2インスタンスにアタッチして使用するブロックストレージボリューム。
以下の特徴がある。
・EC2のインスタンスのボリュームとして使用
・AZ内でレプリケートされる
・ボリュームタイプの変更が可能
・容量の変更が可能
・高い耐久性のスナップショット
・ボリュームの暗号化
・永続的ストレージ
別のリージョンにあるEBSからスナップショットを作成した場合にはそのリージョン内にスナップショットが作成される。
自動スナップショットをバックアップとして取得することが出来るが、初期状態では設定されていないので設定する必要がある。EC2インスタンスの追加ボリュームとして使用
EC2インスタンスのルートボリューム(ブートボリューム)または追加ボリュームとして使用する。
不要になればいつでも削除できる。AZ内でレプリケート
EBSは同じAZ内の複数サーバー間で自動的にレプリケートされる。
ハードウェアの障害が発生してもデータが失われることはない。ボリュームタイプの変更が可能
標準のSSD、プロビジョンドIOPS SSD、スループット最適化HDD、Cold HDDというボリュームタイプがある。
標準SSD(汎用SSD)の性能は最大でも16,000IOPSで、かつ一定の性能を約束するものではない、これを超える際にはプロビジョンドIOPSを検討する。
プロビジョンドIOPSは最小のIOPSを指定することができる。指定できる最大値は64,000。
SSDをほとんど使用せずにコストを節約したい場合にはスループット最適化HDDを、さらにアクセス頻度が低い場合にはCold HDDを検討する
後者2つはルートボリューム(ブートボリューム)として使用することはできない。追加ボリュームとしてのみ。
ボリュームタイプは使用を開始した後でも変更できる。
IOPS:1秒あたりにディスクが処理できるI/Oアクセスの数のこと容量の変更が可能
確保しているストレージ量に対して課金が発生する。
容量は使用を開始した後からでも変更できる。
そのため足りなくなってきたら容量を変更することが出来る。高い耐久性のスナップショット
EBSは同じAZ内で自動的にレプリケートされているがそのAZ自体が使えなくなった際にはEBSも使用できなくなってしまう。
EBSのスナップショットを作成するとS3の機能によりスナップショットが保存される。
S3はイレブンナインの耐久性なので、このスナップショットもイレブンナインの耐久性になっている。
スナップショットは複数のAZに自動的に冗長化される。ボリュームの暗号化
ボリュームを暗号化すると、作成したスナップショットも暗号化される
暗号化に関して追加の操作は必要ない。永続的ストレージ
EBSはインスタンスのホストとは異なるハードウェアで管理されている。インスタンスを一時停止して再度稼働させた際にもEBSで保存したデータは残っている。つまりインスタンスの状態に関係なく永続的にデータが残っている。
インスタンスストア
EBSに対してインスタンスのホストローカルのストレージを使用するのがインスタンスストア。
これはインスタンスが起動している時のみデータを保持している。
EC2を停止するとインスタンスストアのデータも消える。
インスタンスストアをルートボリュームとして起動出来るAMIもあるが、その際にはEC2は停止することができない。
インスタンス用のブロックレベルの一時ストレージを提供する。
ホストコンピュータに物理的にアタッチされたディスク上に存在する。
一時的で物理的にアタッチという点がポイント。
頻繁に変更される情報であるバッファ、キャッシュ、スクラッチデータ、その他の一時コンテンツなどのストレージに最適である。
Amazon EC2 インスタンスストアAmazon Simple Storage Service(S3)
●
Amazon Glacier
アクセス頻度が低いが長期保存したいデータの保存に向いている。
Amazon Elastic File System(EFS)
複数のEC2インスタンスからマウントして供用利用できるファイルストレージサービス。
LAN上にあるNASとして利用できる共有ファイルストレージ。
パブリックなインターネットからのアクセスができないようにして完全な内部向けのストレージとしてセキュリティを強化できる。
リージョンに設置されるサービス。
リージョン、AZ、VPC間でアクセスできる。
Direct ConectあるいはAWS VPNを介して複数のEC2インスタンスやオンプレミスサーバー間でファイルを共有できる。
フルマネージド型。
従量課金で、2種類のストレージタイプがある。
Amazon EFSAmazon Storage Gateway
オンプレミスアプリケーションとAWSのストtレージサービスをシームレスに接続して利用できるゲートウェイサービス。
オンプレミスから実質無制限のクラウドストレージへアクセスを提供することのできるハイブリッドクラウドストレージ。
ユースケースとしてオンプレミスのデータのバックアップをAmazon S3に作成することが可能となる。
従量課金で使用するストレージタイプと容量、リクエストの回数、AWS外に転送されるデータ量に基づいて課金される。
Amazon Storage GatewaySnowball
物理デバイスを使用してペタバイト級の大容量データ転送を行うことができるサービス。
オンプレミスからAWSヘデータを転送する目的で利用される。Snowmobile
エクサバイト級のデータを転送する際に使用する。
データベースサービス
RDS
RDSはAmazon Relational Database Serviceの略。
利用できるデータベースエンジンはAmazon Aurora、MySQL、PostgreSQL、MarinaDB、Oracle、Microsoft SQL Server。
RDSを使用することでインフラ管理から解放される。
デフォルトで7日間の自動バックアップが適用される。(0~35日間で設定できる)指定した時間にバックアップデータが作成される。
35日間を超えてバックアップデータを保存しておく場合には手動のスナップショットを作成できる。
自動バックアップも手動スナップショットもRDSのスナップショットインターフェイスからアクセスできるが実態はS3の機能を利用して保存している。
RDSのバックアップスナップショットの耐久性は非常に高い。
スナップショットの復元からインスタンスを起動できる。
データベースの単一障害点とならないように設計する必要がある。
RDSのマルチAZ配置をオンにするとAZを跨いだレプリケーションが自動的に行われる。マスターに障害が発生した際のフェイルオーバーも自動で行われる。
レプリケーション用のユーザー作成、レプリケーションそのものの設定、レプリケーションのための管理を行う必要はない。
マスターとスタンバイの間でレプリケーションが実行され、マスターに障害が発生した際にはスタンバイがマスターになる。
Amazon Aurora、MySQL、PostgreSQL、MarinaDBではリードレプリカを作成することができ、リードレプリカにより読み込みの負荷をマスターデータベースから軽減できる。
他のリージョンにリードレプリカを作成することもできる。これをクロスリージョンレプリカという。
垂直スケーリングを行える。
キャパシティは自動で向上させることができない。容量はスケーリングできる。
RDSはAZに設置されるサービスである。
オートスケーリングの設定はユーザー側でする必要がある。
ライトレプリカという読み込み機能をレプリケーションする機能はRDSにはない。
ホットスタンバイ:ホットスペアともいう。複数の同じ構成のものを用意しておいて障害発生時に本番系から待機系に切り替える方式のこと
コールドスタンバイ:同じ構成のものを用意しておくが、普段は停止しておき障害発生時に起動して切り替える方式のこと
Amazon RDSポイントタイムリカバリー
自動バックアップを設定している期間内であれば数秒までを指定して特定のインスタンスを復元できる。過去直近では5分前に戻せる。
このポイントタイムリカバリーはトランザクションログが保存されていることによって可能になっている。
RDSが起動したタイミングでトランザクションログは保存され始めている。Amazon Aurora
クラウドに最適化して設計されたリレーショナルデータベースエンジン。
MySQL、Postgreをそのまま移行させることが基本的には可能。
MySQLの5倍、PostgreSQLの3倍のスループットを実現する。
高速分散型リレーショナルデータベース。
マルチクラスター機能によって別AZにWriterのマスターをマルチ構成で生成できる。
リードレプリカは最大15個まで生成できる。
リードレプリカはマルチAZ構成させることができる。
リードレプリカは手動で増加させることが出来る。
バックアップが非常に強固。
スタンバイにアクセスできる。(リードレプリカがマスター昇格する)
ディスクの容量を見込みで確保しなくても自動で増加する。
Amazon AuroraDynamoDB
NoSQL型の高いパフォーマンスを持ったフルマネージド型のデータベースサービスである。
データベースサーバとしてのインスタンスを作成する必要はなくテーブル作成からスタートする。
最低限の設定ではテーブル名とプライマリーキーを決めれば使い始めることが出来る。
リージョンを選択して利用する。
アイテムと呼ばれるデータを保存すると自動で複数のAZで同期されて保存される。つまり最初からマルチAZ構成になっている。
データ容量は無制限である。
課金は使用しているデータ容量のみに課金される。
性能は自分で決めることができ、書き込みと読み込みのキャパシティユニットを設定する必要がある。
ユースケースはモバイル、IoT、大規模なWebシステムのバックエンド、サーバーレスアーキテクチャ、ジョブステータスの管理、セッション管理、クリックストリームデータなど様々。
DynamoDBは水平スケーリングが可能で大量のアクセスがあってもパフォーマンスを保ったまま処理が出来る。
しかし、厳密なトランザクションが必要な処理や複雑なクエリには向かない(銀行の振り込みなど)
SQLとは異なりキーさえあっていれば自由度の高いデータを保存することが可能。
セッションデータやメタデータの蓄積、ゲームの行動記録、IoTデータの蓄積及び解析に向いている。
JOSN形式のデータの保存、処理するドキュメント型のデータベースとして利用するのも向いている。JOSN形式ドキュメントからデータを取得、操作を高速に実行することができる。
マネジメントコンソールから1クリックするか、APIコール、CLIを利用して継続的バックアップを有効化しないと自動バックアップはされない。
全てのデータはSSDに保存される。
DynamoDB Streamsを有効化することでレプリケーションプロセスを管理することなく高速で大規模にスケールされたグローバルユーザーベースのアプリケーションを構築出来る。
Tagsなどの半構造化データの処理にも向いている。
キャパシティモードは以下を選択できる。
・オンデマンドは利用負荷が予測できない場合に選択するモード
・プロビジョニング済み(デフォルト)は利用負荷が予め予測できる場合にはプロビジョンンドスループットを選択する
SSD:Solid State Disc
半構造化:非構造化データにフレキシブルな構造を与えたもの(フレキシブル構造はNoSQLとも呼ばれる)Amazon DynamoDB Accelerator(DAX)
フルマネージド型の高可用性インメモリキャッシュでDynamoDBに特化している。
リクエストのレイテンシをミリ秒からマイクロ秒に短縮する機能である。
Amazon DynamoDBAmazon Redshift
高速でシンプルなデータウェアハウスサービス。
データの分析に使用する。
大規模のなデータ分析にも対応している。
ペタバイト級の構造化データと半構造化データを標準的なSQLを使用してクエリをすることが出来る。
クエリの結果をS3データレイクに保存することもできる。そうすることでAmazon EMR、Amazon Athena、Amazon SageMakerといった他の分析サービスを使用してさらに分析をすることが出来る。
Amazon RedshiftAmazon ElasticCache
インメモリデータストアサービス。
RDSやDynamoDBのクエリの結果をキャッシュに使用したりアプリのセッション情報を管理する用途で使われる。
高スループットかつ低レイテンシーなインメモリデータストアからデータを取得して大量のデータを扱うアプリケーションを構築したり、既存のアプリケーションのパフォーマンスを改善したりすることが可能。
ミリ秒未満の応答時間が必要な最も要求の厳しいアプリケーション向けに、完全マネージド型のRedisとMemcachedを提供する。
Amazon ElasticCacheAmazon Neptune
フルマネージドなグラフデータベースサービス。
関係性や相関情報を扱う。
SNS、レコメンデーションエンジン、経路案内、物流最適化などのアプリの機能に使用される。
Amazon NeptuneAmazon Kinesis
ストリーミングデータをリアルタイムで収集、処理、分析することが簡単になるサービス。
インサイトを適時に取得して新しい情報に迅速に対応することができる。
このサービスを利用すると機械学習、分析、その他のアプリに用いる動画、音声、アプリログ、ウェブサイトのクリックストリーム、IoTテレメトリデータをリアルタイムで取り込める。
データを受信するとすぐに処理及び分析を行うため、全てのデータを収集するのを待たずに処理を開始して直ちに応答することができる。
完全マネージド型。
Amazon KinesisAmazon Athena
インタラクティブなクエリサービス。
S3内のデータを標準のSQLを使用して簡単に分析できる。
サーバーレスである。
実行したクエリに対してのみ料金が発生する。
誰でもSQLのスキルを使って大型データセットを素早く簡単に分析することが出来る。
Amazon AthenaAmazon Managed Apache Cassandra Service(Amazon MCS)
スケーラブルで可用性の高い管理されたApache Cassandra互換データベースサービス。
キーと値や表示形式を含む大量の構造化データを保存、取得、管理することが出来る。
事実上の無制限のスループットとストレージで毎秒数千リクエストを処理できるアプリを構築可能になる。
サーバーレス。
従量課金。
Amazon MCSAWS Database Migration Service(AWS DMS)
データベースを短期間で安全にAWSに移行することが出来る。
移行中もデータベースは完全に使用できる状態に保たれているのでダウンタイムを最小限に保つことが出来る。
一般的に広く普及しているほとんどの商用データベース、オープンソース出たベースとの移行で使用できる。
異なるデータベース間でも移行することができる。(OracleからMySQLなど)
このサービスを使用するとデータの高可用性を維持しつつ継続的にレプリケートし、Amazon Redshift、Amazon S3にデータをストリーミングすることでペタバイト級のデータウェアハウスに統合できる。
移行先のスキーマ作成もSCT(Schema Conversion Tool)で自動作成できる。
Amazon Aurora、Amazon Redshift、Amazon DynamoDM、Amazon DocumentDBに移行する場合はDMSを6ヶ月間無料で利用できる。
AWS DMS管理サービス
Cloud Watch
各インスタンスの状況をモニタリングするサービス。
標準メトリクスというAWSが管理している範囲の情報をお客様側での追加設定なしで収集している。
メトリクスデータはダッシュボードで可視化出来る。
主な機能は以下。
・標準メトリクスの収集、可視化
・カスタムメトリクスの収集、可視化
・ログの収集
・アラーム
標準メトリクスはCPUの使用率やネットワークのステータス情報など。
標準メトリクスで取得できない情報はカスタムメトリクスとして取得することが出来る。このカスタムメトリクスはPutMetricDataAPIを使用して書き込むことが出来る。
CloudWatchへの書き込みを行うプログラムはCloudWatchエージェントとして提供されているのでEC2にインストールするだけで使用できる。
CloudWatch Logsを使用すると各ログを取得することができる。
ログの情報をEC2の外部に書き出すことでEC2をよりステートレスにできる。
ログとして書き出すことでオートスケーリングで終了させたインスタンスのログの解析を行うことができる。
このメトリクス値に対してアラームを設定することが出来る。
アラームに対して実行できる3つのアクション
・EC2の回復:EC2ホストに障害が発生した場合には自動で回復する。
・AutoScalingの実行:AutoScalingポリシーではCloudWatchアラームに基づいてスケールイン、スケールアウトのアクションを実行する。
・SNSへの通知:SNSで通知することでそのメッセージをEメールで送信したりLambdaへ渡すなどできる。これを利用して監視の仕組みを作成することができる。Lambdaへ渡すことでアラームの後の処理を自動化できる。
メトリクスの保存期間を過ぎたものは消去される。これ以上の期間使用したい場合にはS3などに保存する。CloudWatch Logsでは任意の保存期間を設定でき、消去しないこともできる。
CloudWatch Eventsは発生した運用上の変更を認識できる。これに対してアクションを実行することもできる。
CloudWatchはEC2へのアクセスログを取得できない。
Amazon CloudWatchCloud Trail
AWSアカウント内の全てのAPIの呼び出しを記録できる。つまりAWSアカウント内における全ての操作を記録できるということ。
監査や調査に使用することができる。
誰がいつどのアクションを実行したのかを確認できるので、コンプライアンス違反などを監視できる。
Cloud Watch Logsと統合することでログデータを検索したり、コンプライアンス違反のイベントを特定したり、インシデントの調査と監査の要求に対する応答を迅速化したりできる。
似たサービスにAWS Configがあり、こちらはリソースの変更を記録する。誰がいつ何を変更したのかを自動で記録できる。コンプライアンスや監査の要件には適さない部分もある。AWS Config
AWSリソースの設定を評価、監査、審査出来るサービス。リソースの設定が継続的にモニタリング及び記録されて望まれる設定の評価を自動的に実行出来る。
このサービスを利用するとAWSリソース間の設定や関連性の変更を確認し、詳細なリソース設定履歴を調べ、社内ガイドラインで指定された設定い対する全体的なコンプライアンスを確認できる。これによりコンプライアンス監査、セキュリティ分析、変更管理、運用上のトラブルシューティングを簡素化できる。
ルールから逸脱するものがあればSNSで通知することが出来る。
EC2のアクセスログは取得することができない。
誰がどのアクションを実行したのかは監視できない。
従量課金。
AWS ConfigAWS Systems Manager
AWSのインフラを可視化し制御するためのサービス。
このサービスを使用することで様々な運用データを確認でき、AWSリソース全体に関わる運用タスクを自動化出来る。
リソースをアプリごとにグループ化して運用データの表示を行える。これによりモニタリングやトラブルシューティングを行うことが出来る。
インフラを安全に運用、管理することが出来るようになります。
このサービスの一つであるOpsCenterを利用すると運用上の問題の確認、調査、解決を一元的に行うことが出来る。
AWS Systems ManagerCloudFormation
AWSの各リソースを含めた環境を自動生成、更新、管理できる。
Terraformと同様のサービス。
CloudFormationを利用することで同一のAWS環境を何度でも自動で構築できる。
自動プロビジョニングをコードを用いて行うことが出来る。
コードはAWS CodeCommitなどのリポジトリでバージョン管理出来る。Elastic Beanstalk
Webアプリの環境を簡単にAWSに構築するサービス。CloudFormationと似ているがテンプレートを作成する時間が必要なく、設定パラメータを提供することでApacheやNginx、IIS、各言語の実行環境も合わせて簡単に構築出来る。しかし、AWSの全てのサービスを網羅しているわけではなくWebアプリケーションやタスク実行環境を構築することに向いている。
アプリケーションの継続デプロイのための高性能な機能を有している。AWS Trusted Advisor
このサービスは環境の状態を自動的にチェックして回りベストプラクティスに対してどうだったかを示すアドバイスをレポートする。
チェック項目は以下の5点
・コスト最適化
・パフォーマンス
・セキュリティ
・フォールトレランス(耐障害性)
・サービス制限コスト最適化
見直すことでコストを最適化出来るという視点でアドバイスをレポートしてくれる
具体的にどれくらいコストが削減されるかも提示される。
主な項目として
・使用率の低いEC2インスタンス
使ってないのに起動していたり、過剰に高いスペックのインスタンスがある。これらは適切に運用することでコストを下げれる可能性がある。
他にもEBSやRedshiftも使用率をチェックされる。
アイドル状態についてはELB、RDS、elasticIPアドレスに対してもチェックされる。
・リザーブドインスタンスの最適化
リザーブドインスタンスの購入でコストが下がらないかチェックする。
購入済みのリザーブドインスタンスについては有効期限が切れる30日前からアラートの対象になるので購入し忘れの防止になる。
リザーブドインスタンスは継続更新はできず、新規購入することが求められる。パフォーマンス
・使用率の高いインスタンス
実装している処理に対してリソースが不足している可能性があるので、処理が最も早く終了するインスタンスへの切り替えを推奨することもある。
・セキュリティグループルールの増大
ルールが多いとそれだけトラフィックが制限されることになる50以上のルールがあるとパフォーマンスの低下に繋がる恐れがある。
このアラートが発生した場合にはルールをまとめられないか検討する必要がある。
対象のインスタンスにそれだけのポートを必要とする機能を多くインストールしていないか、インスタンスを分けることはできないかを検討する。
・コンテンツ配信の最適化
CloudFrontにキャッシュを持つことでS3から直接配信するよりもパフォーマンスが向上する。
キャッシュがどれだけ使用されているかを示すヒット率もチェックされる。セキュリティ
セキュリティリスクのある環境になっていないかをチェックする。
・S3バケットのアクセス許可
誰でもアクセス出来るバケットがないかをチェックする。
意図してそのように設定している場合ももちろんある。
こういう設定にしたい場合にはバケット全体を公開するのではなくその中に作ったオブジェクトのみを公開にすることで、誤って機密情報をバケットに公開するというリスクが避けれる。
・セキュリティグループの開かれたポート
リスクの高い特定のポートが許可されていないか、セキュリティグループをチェックする。
・パブリックなスナップショット
EBSやRDSのスナップショットは他の特定のアカウントに共有することも出来る、アカウントを特定せずに公開共有することも出来る。
誤って公開すると他の全てのAWSカウントと共有してしまうことになるので、必要なアカウントとの共有のみになるようにチェックする。
・ルートアカウントのMFAとIAMの使用
ルートアカウントを使用するのは危険なのでIAMを使用する。
また、MFAを設定することでセキュリティを強化出来る。
IAMパスワードポリシーが有効かされているかのチェックもある。フォールトレランス
障害耐性の低い状態でないかのチェックを行う。
・EBSのスナップショット
EBSのスナップショットが作成されていない、または最後に作成されてから時間が経っていないかをチェックする。
EBSボリュームはAZ内で複製されているがAZに障害が起こる可能性はある。EBSスナップショットを作成するとスナップショットはS3に保存されるので高い耐久性でデータが保持される。
・EC2、ELBの最適化
複数のAZでバランスよく配置されているかをチェックする。
ELBではクロスゾーン負荷分散やConnecting Draining(セッション完了を待ってから切り離す機能)が無効になっていないかチェックする。
・RDSのマルチAZ
マルチAZになっていないデータベースインスタンスがないかをチェックする。サービス制限
AWSアカウントを作成した最初の時点ではサービス制限がいくつかある。これはソフトリミットと呼ばれている。
これは誤った操作による意図しない請求を回避する。不正アクセスによる意図しない請求を回避するため。
インスタンスの最大数の制限などがある。制限を超えて使用する予定がある場合にはAWSに事前に申告しておく。Amazon Cognito
アプリケーションに素早く簡単にユーザーのサインアップ、サインイン、及びアクセスコントロール機能を追加することが出来る。
SNSアカウントなどを利用したサインインもサポートしている。
無料枠ありの従量課金制。
Amazon CognitoAmazon Simple Workflow Service(Amazon SWF)
クラウドのワークフロー管理アプリケーション。
デベロッパーが並行したステップ、または連続したステップがあるバックグラウンドジョブを構築、実行、スケールするのに役立つ。
クラウド内の完全マネージド型の状態トラッカー、及びタスクコーディネーターとしてみなすことができる。
Amazon SWFAWS リソースグループ
リソースグループツールを使用するとプロジェクトと使用するリソースに基づいて情報を整理、及び統合するカスタムツールを作成できる。
これを使用すると多数のリソース上のタスクを一度に管理及び自動化しやすくなる
AWS リソースグループAWS マネジメントコンソール
アカウントを登録することで使用できるGUIツール。
シンプルで直感的にAWSリソースにアクセスすることが出来る。
コマンドでアクセスできるのはAmazon CLI。請求と料金
サポートプラン
AWSには4つのサポートプランがあり、エスカレーションパス(問合せ先)を確保することができる。
ベーシックプラン
・AWSアアウントを作成した時に提供されている無料のサポートプラン
・技術サポートはAWSサービスの稼働状況をモニタリングしているヘルスチェックのみ
・Trusted Advisorは最低限必要な項目のみ開発サポートプラン
・29USDか使用料の3%のお大きい方
・技術サポートを作成できるユーザーは1ユーザーで時間帯は9:00~18:00
・構成要素についてのアーキテクトサポート
・Trusted Advisorは最低限必要な項目のみビジネスプラン
・100USDか使用料に応じた計算式の高い方
・技術サポートを作成できるユーザーは無制限で、時間帯は24時間
・アーキテクチャはユースケースのガイダンス
・Trusted Advisorは全項目
・サポートAPIが使用可能
・サードパーティソフトウェアのサポートエンタープライズプラン
・15,000USDか使用料金に応じた計算式の大きい方
・技術サポートを作成出来るユーザーは無制限で、時間帯は24時間
・アプリケーションのアーキテクトサポート
・Trusted Advisorは全項目
・サポートAPIが使用可能
・サードパーティソフトウェアのサポート
・テクニカルアカウントマネージャー(TAM)
・サポートコンシェルジュ
・ホワイトグローブケースルーティング
・管理ビジネス評価リザーブド購入の種類
・Elastic Chacheリザーブドノード
・DynamoDBリザーブドキャパシティ
・Redshiftリザーブドノード
・EC2リザーブドインスタンス
・RDSリザーブドインスタンス
のように様々な種類が存在する。請求ダッシュボード
どのサービスにいくらくらい使用しているのかを確認することができる。
コストエクスプローラー
何をどれだけ使っているのかを確認、分析に利用できるもの。
コスト配分タグ
AWSサービスにはタグをつけることが出来るサービスがあり、タグはキーと値で構成されている。
このタグをコスト分析のために有効化しておくことでコスト分析に利用できる。請求アラーム
CloudWatchでは請求金額もメトリクスの1つである。そのため、SNSと連携することで設定していた請求額を超えたりした際には通知をすることが出来る。請求アラームを設定することで意図しない請求や、使いすぎを防止できる。
AWS Badgets
設定予算を超えると予測される時にアラートを発信するサービスで、請求アラームと組み合わせて使用する。
一括請求
Qrganizationの一括請求を使用することで複数アカウントの請求を1つにまとめることが出来る。
一括請求により複数アカウントでリザーブドインスタンスが使用できるようになったり、複数アカウントの合計使用量でボリュームディスカウントを受けられる可能性もありメリットがある。AWS簡易見積もりツール
AWSでどれくらいのコストがかかるのかを事前に確認することができる。
マネジメントコンソールにログインしなくても使用することができる。
このサービスが今後終了が通知されている。
今後はAWS料金計算ツールを使用する。TCO計算ツール
AWSへの移行、導入を検討している際にオンプレミスで構築した場合とのコスト比較をレポートしてくれるサービス。
経営層などへのプレゼンテーションに利用できる。
マネジメントコンソールへログインしなくても使用することができる。AWSのコスト使用状況のレポート
サービス、料金、予約などに関するメタデータを含むAWSのコストと使用状況に関する最も包括的なデータを提供する。
使用状況のデータを日単位または時間単位で集計することも可能である。Pay as you go
使った分だけのライセンス料を払う課金方式。
その他サービス
AWS Server Migration Service(AWS SMS)
サーバーの移行を支援するサービス。
多数のオンプレミスのワークロードをAWSに移行するためのサービス。
クラウドへの移行プロセスの簡素化ができ、数回のクリックで移行を開始できる。
ダウンタイムを最小にすることができる。
追加料金なしで使用できるが移行プロセス中に使用されるS3バケット、EBSボリューム、データ転送、及び実行するEC2インスタンスに対しては標準料金がかかる。
AWS SMSAWS Application Discovery Service(AWS ADS)
オンプレミスデータセンターに関する情報を収集することにより、エンタープライズのお客様の移行プロジェクト計画を支援するサービス。
サーバーの設定データ、使用状況データ、動作データが収集され、提供される。これによりワークロードを把握することができる。
収集されたデータはAWS ADSのデータストアに暗号化形式で保存される。このデータを総所有コスト(TCO)の見積もりやAWSへの移行計画に使用できる。
このデータをAWS Migration HubというサーバーをAWSに移行し、移行する際の進捗を追跡できるサービスでも使用できる。
AWS ADSInfrastructure Event Management
エンタープライズプランのユーザー(追加料金を払うとビジネスプランのユーザーも可能)が利用できるプログラムで、アプリの起動、インフラの移行、マーケティングイベントなどの大規模なイベントなどの計画に利用できるサービス。
イベントの前に戦略的な計画の支援を受けたり、リアルタイムサポート得ることができる。
料金プランには様々なものがある。Amazon Simple Queue Service(Amazon SQS)
完全マネージド型のメッセージキューイングサービス。
マイクロサービス、分散システム、及びサーバーレスアプリケーションの切り離しとスケーリングが可能である。
コンポーネント間でメッセージを送信、保存、受信できる。メッセージが失われることなく他のサービスを利用可能にしておく必要もない。
プッシュ形式ではなくポーリング処理による通知である。
以下の2種類のメッセージキューを利用できる。
・標準キュー 最大限のスループットが得られ、配信順序はベストエフォート型で配信は少なくとも1回行われる。
・SQS FIFOキュー メッセージが送信される順序の通りに1回のみ処理されるように設計されている。
ポーリング処理:複数の機器やプログラムに対して順番に定期的に問合せを行い、一定の条件を満たした場合に送受信や処理を行う通信及び処理方式のこと
ベストエフォート型:最大限の結果が得られるように努力する。結果に関しての保証は行わないとする方式Amazon Simple Email Service(Amazon SES)
デベロッパーが任意のアプリでメールを送信できるようにする費用対効果の高い、柔軟でスケーラブルなメールサービスである。
このサービスを利用すると安全、グローバル、大規模にEメールを送信することができる。
配信可能性を最適化する。
使用例として取引Eメール、マーケティングEメール、Eメールの一斉送信があげられる。
料金はEC2からの利用した場合には月に62,000通までは無料。無料期間の有効期間はなし。
送信メールデータ、受信メールチャンク、EC2データ転送に関しては課金されるので注意。
Amazon SES不正使用対策チーム
AWSリソースが不正に利用されていた場合に報告するところ。
不正利用の種類としてはスパム、ポートスキャニング、DoS攻撃、侵入の試み、不快なコンテンツや著作権違反のコンテンツのポスティング、マルウェア攻撃などがあげられる。
ポートスキャニング:対象のコンピュータのTCPあるいはUDPのポートに接続を試みて、機能の停止や侵入などの攻撃に使えそうな脆弱性がないかを調べることAmazon Connect
音声とチャットのためのクラウドのコンタクトセンター。顧客サービスを低コストで提供できる。
事例としてコールセンターシステムの構築を行える。
Amazon ConnectAmazon Litesail
このサービスは単純なワークロードで、迅速なデプロイ及びAWSの使用するのに最適なサービスで小規模で始めることができる。
クラウドに慣れていない人でも簡単に扱えるように必要な物が最初から揃っているプランである。
ヴァーチャルプライベートサーバー(VPS)を提供する。
Amazon LitesailAmazon Workmail
既存のデスクトップ及びモバイルメールクライアントアプリをサポートする安全なビジネスメール及びカレンダーサービス。
マネージドである。
Outlookとの互換性がある。
Amazon WorkmailAmazon Simple Notification Service(Amazon SNS)
システム間通信とアプリの個人通信の両方に向けてのメッセージサービスを提供している。
疎結合化されたマイクロサービスアプリケーション間のメッセージングを可能にしている。
SMSやモバイルプッシュ、電子メールを介してユーザーと直接通信したりできる。
アプリの疎結合化ができる。
従量課金である。
フルマネージド型。
Amazon SNS
プッシュ方式とは:サーバーから能動的に情報を送信する通信方式
プル方式:クライアント側からの要求に基づいてサーバーが応答する場合にはプル型というAmazon EMR
オープンソースのツールを利用して膨大な量のデータを処理するための業界をリードするビッグデータのクラウドプラットフォーム。
使いやすく、伸縮性があり、低コスト、信頼性、セキュア、柔軟性といった特徴を持っている。
ビッグデータフレームワーク、クラスタープラットフォームと表現することもある。
Amazon EMR参考
主な学習は以下を参考にいたしました。
その他の参考資料は文中に記載させていただいております。
AWSホワイトペーパー
AWS各サービスの概要
AWS認定資格試験テキスト AWS認定 クラウドプラクティショナー
この問題だけで合格可能!AWS 認定クラウドプラクティショナー 模擬試験問題集(7回分455問)注意
サービスの内容は執筆当時のものです。また、個人が取りまとめたものになりますので公式のドキュメントとズレが生じている場合には公式ドキュメントが正しい内容になります。
- 投稿日:2020-10-28T00:12:36+09:00
AWS CloudFormationで2層ネットワークを構築しよう
はじめに
AWS CloudFormationを利用してVPC構築のテンプレートのサンプルです。
テンプレートの概要が分からない場合は、はじめてのAWS CloudFormationテンプレートを理解するを参考にしてください。
コードはGitHubにもあります。
今回は、akane というシステムの dev 環境を想定しています。
同じ構成で違う環境を作成する場合は、{環境名}-parameters.jsonを別途作成します。ディレクトリ構成akane (システム) └─ network (スタック) ├─ network.yml (CFnテンプレート) └─ dev-parameters.json (dev 環境のパラメータ)AWS リソース構築内容
- VPC (10.0.0.0/16)
- Publicサブネット1 (10.0.1.0/24)
- Publicサブネット2 (10.0.2.0/24)
- Privateサブネット1 (10.0.11.0/24)
- Privateサブネット2 (10.0.12.0/24)
- インターネットゲートウェイ
- Publicルートテーブル
- Elastic IP (NATゲートウェイ用)
- NATゲートウェイ
- Privateルートテーブル
AWS システム構成図
実行環境の準備
AWS CloudFormationを動かすためのAWS CLIの設定を参考にしてください。
AWS リソース構築手順
下記を実行してスタックを作成
./create.sh下記を実行してスタックを削除
./delete.shVPC構築テンプレート
1. networkスタック
network.ymlAWSTemplateFormatVersion: '2010-09-09' Description: Network For Akane # Metadata: Parameters: SystemName: Type: String AllowedPattern: '[a-zA-Z0-9-]*' EnvType: Description: Environment type. Type: String AllowedValues: [all, dev, stg, prod] ConstraintDescription: must specify all, dev, stg, or prod. VPCCidrBlock: Type: String AllowedPattern: (\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})/16 PublicSubnet1: Type: String AllowedPattern: (\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})/24 PublicSubnet2: Type: String AllowedPattern: (\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})/24 PrivateSubnet1: Type: String AllowedPattern: (\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})/24 PrivateSubnet2: Type: String AllowedPattern: (\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})/24 Mappings: AzMap: ap-northeast-1: 1st: ap-northeast-1a 2nd: ap-northeast-1c 3rd: ap-northeast-1d # Conditions # Transform Resources: # VPC作成 akaneVPC: Type: AWS::EC2::VPC Properties: CidrBlock: !Ref VPCCidrBlock EnableDnsSupport: true EnableDnsHostnames: true InstanceTenancy: default Tags: - Key: Name Value: !Sub - ${SystemName}-${EnvType}-vpc - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} - Key: SystemName Value: !Ref SystemName - Key: EnvType Value: !Ref EnvType ########################################################################### # Publicサブネット関連 ########################################################################### # Publicサブネット作成 akanePublicSubnet1: Type: AWS::EC2::Subnet Properties: VpcId: !Ref akaneVPC CidrBlock: !Ref PublicSubnet1 AvailabilityZone: !FindInMap [AzMap, !Ref 'AWS::Region', 1st] MapPublicIpOnLaunch: true Tags: - Key: Name Value: !Sub - ${SystemName}-${EnvType}-public-subnet1 - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} - Key: SystemName Value: !Ref SystemName - Key: EnvType Value: !Ref EnvType akanePublicSubnet2: Type: AWS::EC2::Subnet Properties: VpcId: !Ref akaneVPC CidrBlock: !Ref PublicSubnet2 AvailabilityZone: !FindInMap [AzMap, !Ref 'AWS::Region', 3rd] MapPublicIpOnLaunch: true Tags: - Key: Name Value: !Sub - ${SystemName}-${EnvType}-public-subnet2 - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} - Key: SystemName Value: !Ref SystemName - Key: EnvType Value: !Ref EnvType # インターネットゲートウェイ作成 akaneInternetGateway: Type: AWS::EC2::InternetGateway Properties: Tags: - Key: Name Value: !Sub - ${SystemName}-${EnvType}-igw - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} - Key: SystemName Value: !Ref SystemName - Key: EnvType Value: !Ref EnvType # インターネットゲートウェイをVPCにアタッチ akaneVPCGatewayAttachment: Type: AWS::EC2::VPCGatewayAttachment Properties: VpcId: !Ref akaneVPC InternetGatewayId: !Ref akaneInternetGateway # Publicルートテーブル作成 akanePublicRouteTable: Type: AWS::EC2::RouteTable Properties: VpcId: !Ref akaneVPC Tags: - Key: Name Value: !Sub - ${SystemName}-${EnvType}-public-route - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} - Key: SystemName Value: !Ref SystemName - Key: EnvType Value: !Ref EnvType # Publicルートテーブル サブネット関連付け akanePublicSubnetRouteTableAssociation1: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: !Ref akanePublicSubnet1 RouteTableId: !Ref akanePublicRouteTable akanePublicSubnetRouteTableAssociation2: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: !Ref akanePublicSubnet2 RouteTableId: !Ref akanePublicRouteTable # Publicルートテーブル ルートにインターネットゲートウェイを関連付ける akanePublicRoute: Type: AWS::EC2::Route Properties: RouteTableId: !Ref akanePublicRouteTable DestinationCidrBlock: 0.0.0.0/0 GatewayId: !Ref akaneInternetGateway ########################################################################### # Privateサブネット関連 ########################################################################### # Privateサブネット作成 akanePrivateSubnet1: Type: AWS::EC2::Subnet Properties: VpcId: !Ref akaneVPC CidrBlock: !Ref PrivateSubnet1 AvailabilityZone: !FindInMap [AzMap, !Ref 'AWS::Region', 1st] MapPublicIpOnLaunch: false Tags: - Key: Name Value: !Sub - ${SystemName}-${EnvType}-private-db-1 - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} - Key: SystemName Value: !Ref SystemName - Key: EnvType Value: !Ref EnvType akanePrivateSubnet2: Type: AWS::EC2::Subnet Properties: VpcId: !Ref akaneVPC CidrBlock: !Ref PrivateSubnet2 AvailabilityZone: !FindInMap [AzMap, !Ref 'AWS::Region', 3rd] MapPublicIpOnLaunch: false Tags: - Key: Name Value: !Sub - ${SystemName}-${EnvType}-private-db-2 - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} - Key: SystemName Value: !Ref SystemName - Key: EnvType Value: !Ref EnvType # Privateルートテーブル作成 akanePrivateRouteTable: Type: AWS::EC2::RouteTable Properties: VpcId: !Ref akaneVPC Tags: - Key: Name Value: !Sub - ${SystemName}-${EnvType}-private-route - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} - Key: SystemName Value: !Ref SystemName - Key: EnvType Value: !Ref EnvType # Privateルートテーブル サブネット関連付け akanePrivateSubnetRouteTableAssociation1: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: !Ref akanePrivateSubnet1 RouteTableId: !Ref akanePrivateRouteTable akanePrivateSubnetRouteTableAssociationWeb2: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: !Ref akanePrivateSubnet2 RouteTableId: !Ref akanePrivateRouteTable # NATゲートウェイ用ElasticIP作成 akaneNATGatewayEIP: Type: AWS::EC2::EIP Properties: Domain: vpc Tags: - Key: Name Value: !Sub - ${SystemName}-${EnvType}-natgw-eip - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} - Key: SystemName Value: !Ref SystemName - Key: EnvType Value: !Ref EnvType # NATゲートウェイ作成 akaneNATGateway: Type: AWS::EC2::NatGateway Properties: AllocationId: !GetAtt akaneNATGatewayEIP.AllocationId SubnetId: !Ref akanePrivateSubnet1 Tags: - Key: Name Value: !Sub - ${SystemName}-${EnvType}-natgw - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} - Key: SystemName Value: !Ref SystemName - Key: EnvType Value: !Ref EnvType # Privateルートテーブル ルートにNATゲートウェイを関連付ける akanePrivateRoute: Type: AWS::EC2::Route Properties: RouteTableId: !Ref akanePrivateRouteTable DestinationCidrBlock: 0.0.0.0/0 NatGatewayId: !Ref akaneNATGateway Outputs: akaneVPC: Value: !Ref akaneVPC Export: Name: !Sub - ${SystemName}-${EnvType}-vpc - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} akanePublicSubnet1: Value: !Ref akanePublicSubnet1 Export: Name: !Sub - ${SystemName}-${EnvType}-public-subnet1 - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} akanePublicSubnet2: Value: !Ref akanePublicSubnet2 Export: Name: !Sub - ${SystemName}-${EnvType}-public-subnet2 - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} akanePrivateSubnet1: Value: !Ref akanePrivateSubnet1 Export: Name: !Sub - ${SystemName}-${EnvType}-private-subnet1 - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} akanePrivateSubnet2: Value: !Ref akanePrivateSubnet2 Export: Name: !Sub - ${SystemName}-${EnvType}-private-subnet2 - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} akanePublicRouteTable: Value: !Ref akanePublicRouteTable Export: Name: !Sub - ${SystemName}-${EnvType}-public-route-table - {SystemName: !Ref SystemName, EnvType: !Ref EnvType} akanePrivateRouteTable: Value: !Ref akanePrivateRouteTable Export: Name: !Sub - ${SystemName}-${EnvType}-private-route-table - {SystemName: !Ref SystemName, EnvType: !Ref EnvType}dev-parameters.json{ "Parameters": [ { "ParameterKey": "SystemName", "ParameterValue": "akane" }, { "ParameterKey": "EnvType", "ParameterValue": "dev" }, { "ParameterKey": "VPCCidrBlock", "ParameterValue": "10.0.0.0/16" }, { "ParameterKey": "PublicSubnet1", "ParameterValue": "10.0.1.0/24" }, { "ParameterKey": "PublicSubnet2", "ParameterValue": "10.0.2.0/24" }, { "ParameterKey": "PrivateSubnet1", "ParameterValue": "10.0.11.0/24" }, { "ParameterKey": "PrivateSubnet2", "ParameterValue": "10.0.12.0/24" } ] }2. 実行ファイル
create.sh#!/bin/sh SYSTEM_NAME=akane ENV_TYPE=dev STACK_NAME=network aws cloudformation create-stack \ --stack-name ${SYSTEM_NAME}-${ENV_TYPE}-${STACK_NAME} \ --template-body file://./${SYSTEM_NAME}/${STACK_NAME}/${STACK_NAME}.yml \ --cli-input-json file://./${SYSTEM_NAME}/${STACK_NAME}/${ENV_TYPE}-parameters.jsondelete.sh#!/bin/sh SYSTEM_NAME=akane ENV_TYPE=dev STACK_NAME=network aws cloudformation delete-stack \ --stack-name ${SYSTEM_NAME}-${ENV_TYPE}-${STACK_NAME}