- 投稿日:2020-10-18T15:45:47+09:00
Pytorch、Tensorflowのいくつかのバージョンに対して(NVIDIA)GPUを使うための環境
目的
Pytorch、Tensorflowのいくつかのバージョンに対して(NVIDIA)GPUを使うための環境
に関する記事です。例えば、自力だけで何かをつくる場合には、Tensorflowの2.Xを使うとか、決めることもできるかもしれませんが、github等で示された(示されている)他の方の例を参照する場合など、まだまだ、Tensorflow1.Xを動作させることも多いはず。
同様に、Pytorchのバージョンもいろいろ。
それに対して、NVIDIAのCUDAの対応バージョンが狭い気がする。
しかも、10.0と10.1で違うとか、細かいことを言われると心が折れる。この記事前提:
- 複数の環境をうまく併設できる方は、この記事は関係ないと思います。
- ここでは、Windowsユーザ向けに記事を書いています。
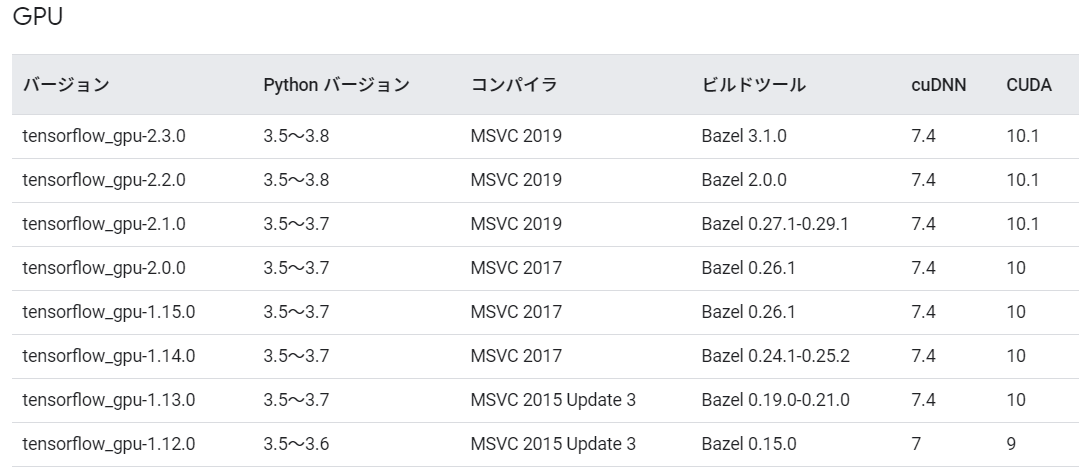
TensorflowとかPytorchで示されている組合せの推奨
Tensorflow
以下は、source_windowsとなっているとおり、Windowsに関する情報です。
https://www.tensorflow.org/install/source_windows?hl=ja
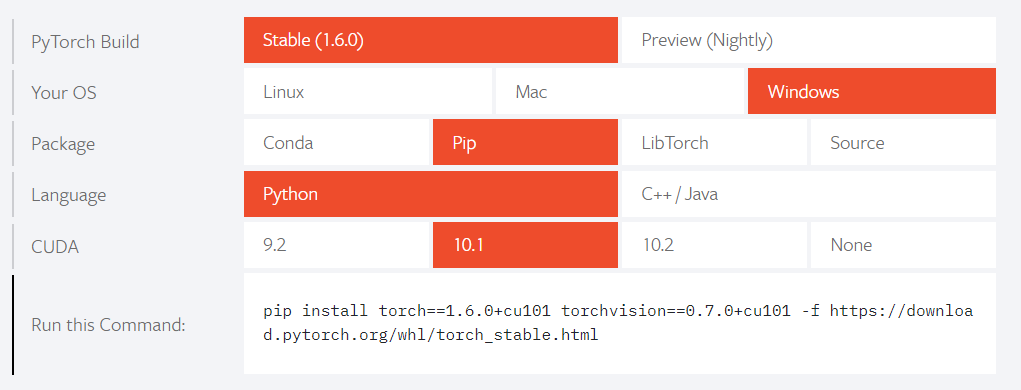
Pytorch
対策
(あまり、細かいことを気にされない方は、)
Tensorflowにて、1.X⇔2.X は、pip一発ということで許容するとして、
さて、GPU側をどうするかですが、
以下のように併設するでどうでしょう。C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1実際に使う側をPATHで優先的にみせる。
対策を整理すると、
- Tensorflowについては、1.X⇔2.X は、pip一発
- GPU(CUDA)は、複数を併設し、Pathでどちらを使うか切り替える。
(すみません、PytorchもTensorflowと同様であることを期待しています。あんまり、経験値なし。。。)
補足
cuDNNのバージョンの調べ方(ベターな方法)
以下の手順で調べられる感じ。
ヘッダファイルを調べる方法がよく示されているが、それでは、有効でないヘッダファイルを調べる可能性もあると思うので。手順は以下。
- 使おうとしているCUDAのバージョンにあったcupyをインストール
from cupy.cuda import cudnncudnn.getVersion()8004であることがわかる全然スマートではないが、ベターな気がします。
D:\_qiita>python -m pip install cupy-cuda101 Defaulting to user installation because normal site-packages is not writeable Requirement already satisfied: cupy-cuda101 in c:\users\XYZZZ\appdata\roaming\python\python37\site-packages (8.0.0) Requirement already satisfied: fastrlock>=0.3 in c:\program files (x86)\microsoft visual studio\shared\python37_64\lib\site-packages (from cupy-cuda101) (0.5) Requirement already satisfied: numpy>=1.15 in c:\users\XYZZZ\appdata\roaming\python\python37\site-packages (from cupy-cuda101) (1.17.2) D:\_qiita> D:\_qiita>python Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> from cupy.cuda import cudnn >>> cudnn.getVersion() 8004 >>>まとめ
自分の備忘のために、もう少し、情報を別途増やすつもりです。
- 投稿日:2020-10-18T00:06:06+09:00
画像のバッチを作成してImageDataGeneratorで水増しする
はじめに
ディープラーニングを用いた画像のセグメンテーション(塗り分け)のために、
- 大きい画像から小さい画像バッチの作成
- ImageDataGeneratorによるdata augmentation(データの水増し)
を行います。
環境はpython3.7、Tensorflow2.1.1を使用しています。画像データ
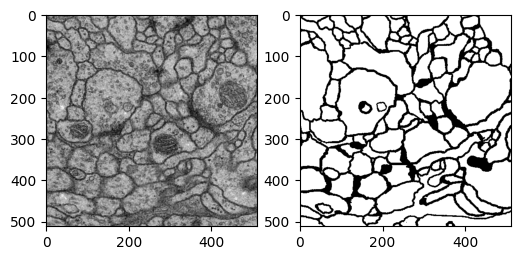
ISBI challenge 2012(Segmentation of neuronal structures in EM stacks)に載っている細胞の画像データを用いています。ホームページ上から登録を行うことで画像データをダウンロードできます。元の細胞画像と塗り分け済みのデータが入っています。このデータを基にして教師あり学習で自動的に塗り分けを行うために、学習データの整備をしていきます。
画像バッチの作成
オリジナルの画像データは(512, 512)のサイズになっています(上図)。この画像を(256, 256)のサイズに分割します。
まずはデータを読み込みます。from skimage import io import tensorflow as tf import glob dir_name = "./data/train" paths_train_img = glob.glob(dir_name + "/train_image*") paths_train_label = glob.glob(dir_name + "/train_label*") train_images = [] train_labels = [] for path in paths_train_img[:-5]: train_images.append(io.imread(path)/255.0) path = path.replace('image', 'labels') train_labels.append(io.imread(path)/255.0) train_images = train_images[..., tf.newaxis] train_labels = train_labels[..., tf.newaxis] # print(train_images.shape) # (25, 512, 512, 1)train_imagesにオリジナルの細胞画像、train_labelsに塗り分け済みのデータが入っています。画像はtrain_images[i]とtrain_labels[i]が対応づくようになっています。後でtensorflowで使うために、tf.newaxisを用いてaxisを一つ増やしてあります。
さて、画像を切り分けてバッチを作成します。そのためにtf.image.extract_patchesを使います。tf.image.extract_patchesに関しては公式ページは個人的には分かりにくかったですが、stackoverflowの記事は分かりやすかったです。
ksize_rows = 256 ksize_cols = 256 strides_rows = 256 strides_cols = 256 ksizes = [1, ksize_rows, ksize_cols, 1] strides = [1, strides_rows, strides_cols, 1] rates = [1, 1, 1, 1] padding='VALID' def make_patches(images): image_patches = tf.image.extract_patches(images, ksizes, strides, rates, padding) # image patchesは(25, 2, 2, 65536)の形状。 # 65536=256*256で(256, 256)サイズの画像が一次元的に格納されている。 patches = [] for patch in image_patches: for i in range(patch.shape[0]): for j in range(patch.shape[1]): patch2 = patch[i,j,:] patch2 = np.reshape(patch2, [ksize_rows, ksize_cols,1]) # (i,j) の位置の画像バッチを(256, 256)の形状にリシェイプ patches.append(patch2) patches = np.array(patches) return patches train_image_patches = make_patches(train_images) train_label_patches = make_patches(train_labels)上記のmake_patchesを使うことで画像が(256, 256)サイズのバッチ画像に切り分けられます。元の画像が(512, 512)のサイズ25枚だったので、train_image_patchesとtrain_label_imagesには(256, 256)のサイズの画像データがそれぞれ100枚入っています。
ImageDataGenratorによる画像の水増し
ImageDataGeneratorを用いてdata augmentationを行なっていきます。ImageDataGeneratorでは、画像の回転、ズーム、フリップなどの変換を用いて画像の水増しを行います。回転やズームなどの最大値を引数として渡します。また画像の前処理用の関数を与えて、各種変換の前に画像の前処理を行えます。下の例では、前処理としてガウシアンノイズを加えています。
from tensorflow.keras.preprocessing.image import ImageDataGenerator import skimage def add_noise(img): output_img = skimage.util.random_noise(img, var=0.01, clip=False) return np.array(output_img) SEED1 = 1 batch_size = 2 args={ "rotation_range":0.2, "width_shift_range":0.2, "height_shift_range":0.2, "zoom_range":0.2, "shear_range":0.2, "vertical_flip":True, "horizontal_flip":True, "fill_mode":"reflect", "preprocessing_function":add_noise } image_data_generator = ImageDataGenerator(**args ).flow(train_image_patches, batch_size=batch_size, seed=SEED1) args.pop("preprocessing_function") label_data_generator = ImageDataGenerator(**args ).flow(train_label_patches, batch_size=batch_size, seed=SEED1)塗り分け済みの正解データにはノイズを加えたくないため、argsからpreproccesing_functionを取り除いてlabel_data_generatorを作成しています。同じseedを用いてimage_data_generatorとlabel_data_genratorを作成することで、元画像と塗り分け済み画像が正しく対応するようにしています。
最後にまとめて一つのgeneratorにしておきます。
def my_image_mask_generator(image_data_generator, mask_data_generator): train_generator = zip(image_data_generator, mask_data_generator) for (img, mask) in train_generator: yield (img, mask) my_generator = my_image_mask_generator(image_data_generator, label_data_generator)実際に作成される画像データを見てみましょう。
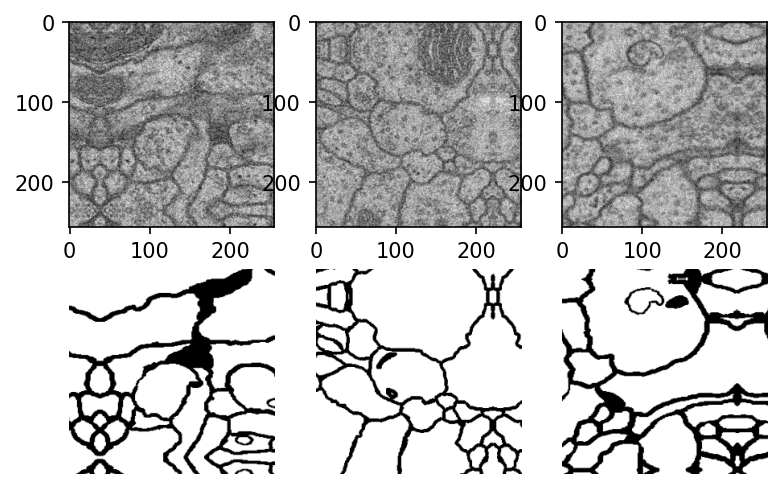
plt.figure(dpi=100) for i in range(3): img, mask = next(my_generator) plt.subplot(2, 3, i + 1) plt.imshow(img[0, :,:,0], cmap="gray") plt.subplot(2, 3, i + 4) plt.imshow(mask[0, :, :, 0], cmap="gray") plt.axis('off') plt.show()
オリジナルの細胞画像と塗り分け済み画像が正しく対応づけられた、画像バッチが作成されているのが見て取れます。また端の方で一部反射したような画像になっています。これはImageDataGeneratorで "fill_mode":"reflect"としたため、画像を平行移動した際に生じる空白をreflectモードで補完したためです。
まとめ
これで画像セグメンテーションのための、画像バッチ化とデータ水増しができました。次回はこの画像データを用いてディープラーニングを行なっていきます。
- 投稿日:2020-10-18T00:06:06+09:00
画像のパッチを作成してImageDataGeneratorで水増しする
はじめに
ディープラーニングを用いた画像のセグメンテーション(塗り分け)のために、
- 大きい画像から小さい画像パッチの作成
- ImageDataGeneratorによるdata augmentation(データの水増し)
を行います。
環境はpython3.7、Tensorflow2.1.1を使用しています。画像データ
ISBI challenge 2012(Segmentation of neuronal structures in EM stacks)に載っている細胞の画像データを用いています。ホームページ上から登録を行うことで画像データをダウンロードできます。元の細胞画像と塗り分け済みのデータが入っています。このデータを基にして教師あり学習で自動的に塗り分けを行うために、学習データの整備をしていきます。
画像パッチの作成
オリジナルの画像データは(512, 512)のサイズになっています(上図)。この画像を(256, 256)のサイズに分割します。
まずはデータを読み込みます。from skimage import io import tensorflow as tf import glob dir_name = "./data/train" paths_train_img = glob.glob(dir_name + "/train_image*") paths_train_label = glob.glob(dir_name + "/train_label*") train_images = [] train_labels = [] for path in paths_train_img[:-5]: train_images.append(io.imread(path)/255.0) path = path.replace('image', 'labels') train_labels.append(io.imread(path)/255.0) train_images = train_images[..., tf.newaxis] train_labels = train_labels[..., tf.newaxis] # print(train_images.shape) # (25, 512, 512, 1)train_imagesにオリジナルの細胞画像、train_labelsに塗り分け済みのデータが入っています。画像はtrain_images[i]とtrain_labels[i]が対応づくようになっています。後でtensorflowで使うために、tf.newaxisを用いてaxisを一つ増やしてあります。
さて、画像を切り分けてパッチを作成します。そのためにtf.image.extract_patchesを使います。tf.image.extract_patchesに関しては公式ページは個人的には分かりにくかったですが、stackoverflowの記事は分かりやすかったです。
ksize_rows = 256 ksize_cols = 256 strides_rows = 256 strides_cols = 256 ksizes = [1, ksize_rows, ksize_cols, 1] strides = [1, strides_rows, strides_cols, 1] rates = [1, 1, 1, 1] padding='VALID' def make_patches(images): image_patches = tf.image.extract_patches(images, ksizes, strides, rates, padding) # image patchesは(25, 2, 2, 65536)の形状。 # 65536=256*256で(256, 256)サイズの画像が一次元的に格納されている。 patches = [] for patch in image_patches: for i in range(patch.shape[0]): for j in range(patch.shape[1]): patch2 = patch[i,j,:] patch2 = np.reshape(patch2, [ksize_rows, ksize_cols,1]) # (i,j) の位置の画像パッチを(256, 256)の形状にリシェイプ patches.append(patch2) patches = np.array(patches) return patches train_image_patches = make_patches(train_images) train_label_patches = make_patches(train_labels)上記のmake_patchesを使うことで画像が(256, 256)サイズのパッチ画像に切り分けられます。元の画像が(512, 512)のサイズ25枚だったので、train_image_patchesとtrain_label_imagesには(256, 256)のサイズの画像データがそれぞれ100枚入っています。
ImageDataGenratorによる画像の水増し
ImageDataGeneratorを用いてdata augmentationを行なっていきます。ImageDataGeneratorでは、画像の回転、ズーム、フリップなどの変換を用いて画像の水増しを行います。回転やズームなどの最大値を引数として渡します。また画像の前処理用の関数を与えて、各種変換の前に画像の前処理を行えます。下の例では、前処理としてガウシアンノイズを加えています。
from tensorflow.keras.preprocessing.image import ImageDataGenerator import skimage def add_noise(img): output_img = skimage.util.random_noise(img, var=0.01, clip=False) return np.array(output_img) SEED1 = 1 batch_size = 2 args={ "rotation_range":0.2, "width_shift_range":0.2, "height_shift_range":0.2, "zoom_range":0.2, "shear_range":0.2, "vertical_flip":True, "horizontal_flip":True, "fill_mode":"reflect", "preprocessing_function":add_noise } image_data_generator = ImageDataGenerator(**args ).flow(train_image_patches, batch_size=batch_size, seed=SEED1) args.pop("preprocessing_function") label_data_generator = ImageDataGenerator(**args ).flow(train_label_patches, batch_size=batch_size, seed=SEED1)塗り分け済みの正解データにはノイズを加えたくないため、argsからpreproccesing_functionを取り除いてlabel_data_generatorを作成しています。同じseedを用いてimage_data_generatorとlabel_data_genratorを作成することで、元画像と塗り分け済み画像が正しく対応するようにしています。
最後にまとめて一つのgeneratorにしておきます。
def my_image_mask_generator(image_data_generator, mask_data_generator): train_generator = zip(image_data_generator, mask_data_generator) for (img, mask) in train_generator: yield (img, mask) my_generator = my_image_mask_generator(image_data_generator, label_data_generator)実際に作成される画像データを見てみましょう。
plt.figure(dpi=100) for i in range(3): img, mask = next(my_generator) plt.subplot(2, 3, i + 1) plt.imshow(img[0, :,:,0], cmap="gray") plt.subplot(2, 3, i + 4) plt.imshow(mask[0, :, :, 0], cmap="gray") plt.axis('off') plt.show()
オリジナルの細胞画像と塗り分け済み画像が正しく対応づけられた、画像パッチが作成されているのが見て取れます。また端の方で一部反射したような画像になっています。これはImageDataGeneratorで "fill_mode":"reflect"としたため、画像を平行移動した際に生じる空白をreflectモードで補完したためです。
まとめ
これで画像セグメンテーションのための、画像パッチ化とデータ水増しができました。次回はこの画像データを用いてディープラーニングを行なっていきます。