- 投稿日:2020-10-18T23:58:12+09:00
Rails Webpackerでエラー
はじめに
railsでwebアプリを作ろうと思ったがエラーが出た
環境:MacOS 10.15.7
Webアプリ作成
Railsガイドの通りに一番簡単なblogアプリを作成する
https://railsguides.jp/getting_started.html$ rails new blog$ cd blogエラーが出た
$ rails server => Booting Puma => Rails 6.0.3.4 application starting in development => Run `rails server --help` for more startup options Exiting (中略) Webpacker configuration file not found /Users/momoka/Desktop/ruby_on_rails/blog/config/webpacker.yml. Please run rails webpacker:install Error: No such file or directory @ rb_sysopen - /Users/momoka/Desktop/ruby_on_rails/blog/config/webpacker.yml (RuntimeError)Please run rails webpacker:installと書いてあるので、実行する
$ rails webpacker:install sh: node: command not found sh: nodejs: command not found Node.js not installed. Please download and install Node.js https://nodejs.org/en/download/Node.js インストールしてと言ってるのでする
$ brew install Node.jsもう一回webpackerをインストールしよう
$ rails webpacker:install Yarn not installed. Please download and install Yarn from https://yarnpkg.com/lang/en/docs/install/Yarnをインストールしろって言ってる()
$ brew install Yarn ==> Downloading https://yarnpkg.com/downloads/1.22.10/yarn-v1.22.10.tar.gz ==> Downloading from https://github-production-release-asset-2e65be.s3.amazonaws.com/49970642/30fd160 ######################################################################## 100.0% ? /usr/local/Cellar/yarn/1.22.10: 15 files, 5MB, built in 1 secondもう一回webpackerをインストールしよう
$ rails webpacker:install create config/webpacker.yml Copying webpack core config create config/webpack create config/webpack/development.js create config/webpack/environment.js create config/webpack/production.js create config/webpack/test.js Copying postcss.config.js to app root directory (中略) ├─ webpack-dev-middleware@3.7.2 ├─ webpack-dev-server@3.11.0 └─ ws@6.2.1 ✨ Done in 6.41s. Webpacker successfully installed ? ?やったーーーーーー

- 投稿日:2020-10-18T22:01:20+09:00
Ruby on Rails save時にrollbackする原因がわからないとき。
はじめに
今回はrailsでsave時にrollbackする原因がわからないときの対処について学習してきます。
現在ユーザーがメモを登録できるサイトを作成中。
今回やりたい事
fromから登録(note)を送ってDBに保存(ユーザーに紐づいた)してviewに表示させる苦戦したところ
登録した際にrollbackしてしまう。@note.save!と記述すると下記のエラーが出たので検索
ActiveRecord::RecordInvalid: Validation failed: User must exist
要約するとuserモデルに値が入ってなくてバリデーションで弾かれていたみたい
解決策
optional: trueを記載
note.rbclass Note < ApplicationRecord belongs_to :user,optional: true validates :title, presence: true validates :explanation, presence: true endoptional: trueとはなにか?
Railsのbelongs_toに指定できるoptional: trueとは?
belongs_toの外部キーのnilを許可するというもの参考
しかし、
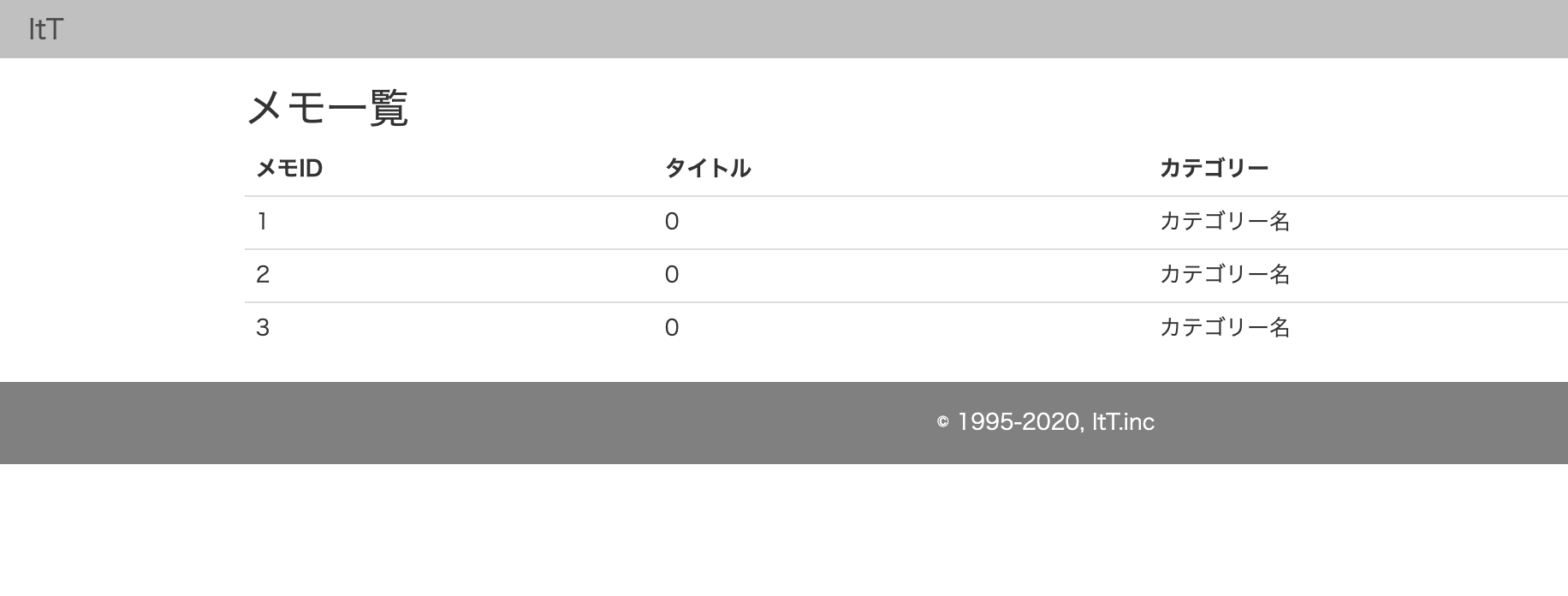
rollbackは解消されたが投稿したタイトルが全部0で表示されてしまいす。
原因
マイグレーションファイルのtitleのデータ型がintegerになっていたからでした。
text型に直してrails db:migration:resetをして解決!
- 投稿日:2020-10-18T20:50:33+09:00
[Rails]本番環境で画像が表示されないエラーについて
はじめに
ローカル環境ではしっかりと画像が表示されていたのに本番環境にデプロイすると画像が表示されなくなった時の対応。
環境
・Rails 6.0.3.
・Haml状況
以下の表記みたいにRailsのヘルパーメソッドの
image_tagを用いて画像をパス指定していてローカル環境ではうまく表示されていた。= image_tag "assets/material/icon/icon.png"しかし、いざデプロイすると画像が表示されなくなりました。(この表記もあやしいですが)
もちろん
scssファイルに記載しているbackground-imageも表記されませんでした(この対応ついては下の方に記載してます)原因
本番環境では、画像もコンパイルされ、画像ファイル名が変わりディレクトリも変わってしまいます!
本番環境とローカル環境での違いは、
パスが変わる(app/assets/images/icon.png => /assets/icon.png)
名前が変わる(icon.png => icon-xxx… .png) ※xxx… はdigest
これが変わってしまいます!対策
assets_path()というRailsのオプションを使用します。
これは便利で本番環境へデプロイしファイル名やディレクトリが変わってもそれに対応しているのでローカルも本番もこれ一つで対応できてしまいます!具体的には以下のように修正
= image_tag asset_path("assets/material/icon/icon.png")これでうまく行くと思いきや、、、、
ローカル環境でも表示されなくなりました。。。。ダメ元でデプロイしても結果は同じ(当然です)
asset_pathでもうまくいかない原因
asset_pathというオプションはapp/assets/imagesの直下にあるファイルに対応しているが、どうやらその先のディレクトリの中にあるファイルには対応していないみたいです。対応
ディレクトリで管理していた画像をすべて
app/assets/images直下へ移動し、表記も下記のように修正しました。= image_tag asset_path("icon.png")これでデプロイするとようやく画像が表示されました!!
まとめると
asset_pathというオプションを使うことと画像ファイルの場所をimages直下にすることが解決策でした。[scss]background-imageについて
こちらも以下のようにただ画像ファイルのパスを指定してもうまくいきませんでした。
background-image: url("main-image.jpg");対応
image-urlを使うとローカルでも本番環境でも対応してくれます。background-image:image-url("main-image.jpg");このように記述すると対応できます。
もちろん画像はapp/assets/images直下のものを指定ここで注意が必要なのは
:(コロン)の後はスペースを開けずに記述する点です。SCSSの記述はコロンのあとは大体半角スペースを開けて記述していたのでクセになってました。
なので誤っているとは知らずになかなか原因に辿り着けずにいました。これでデプロイすると正常に画像が表示されました!!
- 投稿日:2020-10-18T20:30:48+09:00
Nuxt.js × Rails APIモードでアプリケーションを作る
やりたいこと
Nuxt.jsでフロントを、RailsでAPIを作る
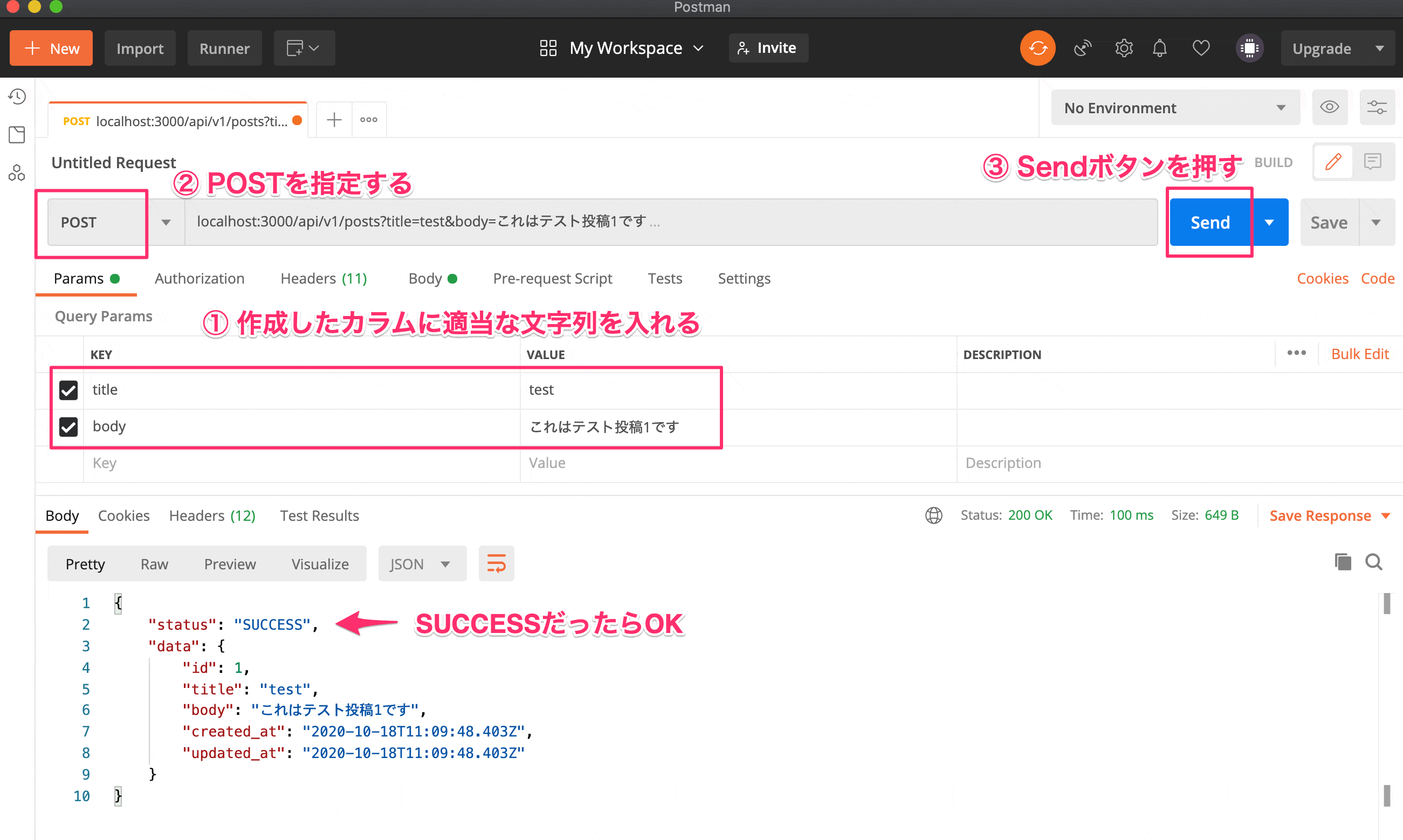
作成したAPIに対してPostmanで投稿をする
※ 次の記事でNuxt.js側からRailsのAPIを叩いてDBにデータを保存する方法を掲載します開発環境
ruby 2.6.5
Rails 6.0.3.4
node v14.7.0
yarn 1.22.4フロントをNuxt.jsで作る
- post-appというディレクトリの中に
appという名前でフロント用のアプリケーションを作る- Axiosはプロジェクト作成時にインストールするように選択する
// post-appというディレクトリを作る $ mkdir post-app $ cd post-app // nuxtでのアプリケーションを作る $ npx create-nuxt-app app // 各種設定を選択する ? Project name: (app) └ そのままEnterボタン押す ? Programming language: (Use arrow keys) ❯ JavaScript TypeScript └ JavaScriptを選択 ? Package manager: ❯ Yarn Npm └ Yarnを選択 ? UI framework: (Use arrow keys) ❯ None Ant Design Vue Bootstrap Vue Buefy Bulma Chakra UI Element Framevuerk iView Tachyons Tailwind CSS Vuesax Vuetify.js └ Noneを選択 ? Nuxt.js modules: ❯◉ Axios ◯ Progressive Web App (PWA) ◯ Content └ Axiosを選択(スペースキーを押す) ? Linting tools: (Press <space> to select, <a> to toggle all, <i> to invert selection) ❯◯ ESLint ◯ Prettier ◯ Lint staged files ◯ StyleLint └ そのままEnterボタン押す ? Testing framework: (Use arrow keys) ❯ None Jest AVA WebdriverIO └ そのままEnterボタン押す ? Rendering mode: Universal (SSR / SSG) ❯ Single Page App └ Single Page Appを選択 ? Deployment target: (Use arrow keys) ❯ Server (Node.js hosting) Static (Static/JAMStack hosting) └ Serverを選択 ? Development tools: ❯◉ jsconfig.json (Recommended for VS Code if you're not using typescript) ◯ Semantic Pull Requests └ jsconfig.jsonを選択(スペースキーを押す)nuxtのポート番号を8000番に変更する
公式より引用▼
app/nuxt.config.jsexport default { server: { port: 8000, // デフォルト: 3000 host: '0.0.0.0' // デフォルト: localhost } // その他の設定 }実際の記述▼
app/nuxt.config.jsserver: { port: 8000, },ローカルホストを立ち上げる
$ cd app $ yarn dev // 下記が表示されたらhttp://localhost:8000/でアクセス可能 │ Nuxt.js @ v2.14.7 │ │ │ │ ▸ Environment: development │ │ ▸ Rendering: client-side │ │ ▸ Target: server │ │ │ │ Listening: http://localhost:8000/RailsでAPIサーバーを作る
// APIモード、DBはMySQLでrailsアプリケーションを作る $ rails new api --api -d mysql // DBを作る $ rails db:create Created database 'api_development' Created database 'api_test'ModelとControllerを作る
// Post Modelを作る $ rails g model Post title:string body:text // migrateする $ rails db:migrate // apiディレクトリの中のv1ディレクトリの中にpostsコントローラーを作る // test用のディレクトリの自動生成をスキップする $ rails g controller api::v1::posts --skip-test-frameworkルーティングの設定
/api/v1/postsというルーティングを作るapi/config/routes.rbRails.application.routes.draw do namespace :api do namespace :v1 do resources :posts end end endPostsControllerを設定する
api/app/controllers/api/v1/posts_controller.rbclass Api::V1::PostsController < ApplicationController before_action :set_post, only: [:show, :update, :destroy] def index posts = Post.order(created_at: :desc) render json: { status: 'SUCCESS', message: 'Loaded posts', data: posts } end def show render json: { status: 'SUCCESS', message: 'Loaded the post', data: @post } end def create post = Post.new(post_params) if post.save render json: { status: 'SUCCESS', data: post } else render json: { status: 'ERROR', data: post.errors } end end def destroy @post.destroy render json: { status: 'SUCCESS', message: 'Deleted the post', data: @post } end def update if @post.update(post_params) render json: { status: 'SUCCESS', message: 'Updated the post', data: @post } else render json: { status: 'SUCCESS', message: 'Not updated', data: @post.errors } end end private def set_post @post = Post.find(params[:id]) end def post_params params.permit(:title, :body) end endPostmanを使って投稿してみる
Postman
使い方参考記事
- 下記のようになっていたらOK
Railsのコンソールで投稿できている確認する
// コンソールを立ち上げる $ rails c // 投稿を確認する irb(main):001:0> Post.first上記でPostmanと同じ内容が表示されていればOKです
※別の記事でNuxt.js側からデータを投稿する処理を実装します
- 投稿日:2020-10-18T20:22:08+09:00
RailsチュートリアルでCloud9の容量がいっぱいになったときの対処法
対処法
Railsのチュートリアルの公式から、対処法が記載されています。
ただ、私が本エラーに遭遇した時、Railsのチュートリアルが記載してる対処法を見つけられなかったので、アクセスの多いQiitaに投稿しておきます。RailsチュートリアルでCloud9の容量がいっぱいになったときの対処法
コメント
一人でも多く、本事象から抜け出して楽しくRailsチュートリアルを完走できることを祈ってます!
- 投稿日:2020-10-18T20:20:19+09:00
Docker でRails6とPostgreSQLの環境構築
Dockerで Rails6 + PostgreSQLで環境構築
自分の備忘録も兼ねてDockerでRails6 + PostgreSQLで環境構築のやり方を記事にして残しておきます。
今回はアプリ名をshopping_appとして作成していきます。作成する環境の各バージョン
- Ruby 2.7.2
- Rails 6.0.3
- PostgreSQL 13.0
ディレクトリ構造
. ├── Dockerfile ├── docker-compose.yml └── shopping_app ├── Gemfile └── Gemfile.lockDockerfileの作成
まずはDockerfileの作成をします。
FROM ruby:2.7.2 ENV LANG C.UTF-8 RUN curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | apt-key add - \ && echo "deb https://dl.yarnpkg.com/debian/ stable main" | tee /etc/apt/sources.list.d/yarn.list RUN apt-get update -qq && \ apt-get install -y build-essential \ libpq-dev \ nodejs \ postgresql-client yarn RUN mkdir /app RUN mkdir /app/shopping_app ENV APP_ROOT /app/shopping_app WORKDIR $APP_ROOT ADD ./shopping_app/Gemfile $APP_ROOT/Gemfile ADD ./shopping_app/Gemfile.lock $APP_ROOT/Gemfile.lock RUN bundle install ADD . $APP_ROOTdocker-compose.ymlの作成
docker-compose.ymlを作成します。今回はportを1501に設定しています。
version: '3' services: postgres: image: postgres ports: - "3306:3306" volumes: - ./tmp/db:/var/lib/postgresql/data #MacOSの場合 environment: POSTGRES_USER: 'admin' POSTGRES_PASSWORD: 'admin-pass' restart: always app: build: . image: rails container_name: 'app' command: bundle exec rails s -p 1501 -b '0.0.0.0' ports: - "1501:1501" environment: VIRTUAL_PORT: 80 volumes: - ./shopping_app:/app/shopping_app depends_on: - postgres restart: always volumes: app_postgre: external: trueGemfileの作成
source 'https://rubygems.org' gem 'rails', '6.0.3'Gemfile.lockは空のままでいいです。
コンテナをBuildしてappを作成
$ docker-compose run app rails new . --force --database=postgresql --skip-bundlewebpackerのinstall
docker-compose run app rails webpacker:installDatabaseの作成と設定
作成されたappのdatabase.ymlを設定します。
default: &default adapter: postgresql encoding: unicode # For details on connection pooling, see Rails configuration guide # https://guides.rubyonrails.org/configuring.html#database-pooling pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> # 以下を記述 user: admin password: admin-pass host: postgresimageをbuild
docker-compose buildDatabaseの作成
docker-compose run app rails db:create以上で構築完了です。
以下のコマンドでアプリを起動してdocker-compose uphttp://localhost:1501/
にアクセスすれば以下の画面に表示されます。
以上です。

- 投稿日:2020-10-18T19:49:37+09:00
[Rails]Userモデルの単体テストコード
はじめに
Rspecというgemを用いてテストコードを実装しました。
今回はユーザー登録機能の単体テストコードについて、正常系と異常系の挙動の確認を行いました。目次
1必要なgemの導入
2FactoryBotの記述
3テストコードの記述1. 必要なgemの導入
gemfileのgroup :development, :testの中に、以下を追記します。
その後、bundle installを実行します。gemfilegem 'pry-rails' gem 'rspec-rails' gem 'factory_bot_rails' gem 'faker'次に、Rspecを書くためのディレクトリを作成します。
ターミナル
rails g rpsec:install実行すると、以下のようにディレクトリとファイルが生成されます。
ターミナル
create .rspec create spec create spec/spec_helper.rb create spec/rails_helper.rbテストコードの結果をターミナル上で確認するための記述をします。
.rspec--format documentation2. FactoryBotの記述
FactoryBotとはインスタンスをまとめておくことができるgemです。
specディレクトリにfactoriesディレクトリを作成し、その中にuser.rbファイルを作成します。
user.rbを以下のように編集します。spec/factories/user.rbFactoryBot.define do factory :user do nickname { Faker::Name.last_name } email { Faker::Internet.free_email } password = Faker::Internet.password(min_length: 6) password { password } password_confirmation { password } end endFakerはランダムな値を生成するgemです。
3. テストコードの記述
spec/models/user_spec.rbを以下のように編集します。
spec/models/user_spec.rbrequire 'rails_helper' RSpec.describe User, type: :model do describe User do before do @user = FactoryBot.build(:user) end describe 'ユーザー新規登録' do context '新規登録がうまくいくとき' do it 'nicknameとemail、passwordとpassword_confirmationが存在すれば登録できること' do expect(@user).to be_valid end it 'passwordが6文字以上あれば登録できること' do @user.password = '123456' @user.password_confirmation = '123456' expect(@user).to be_valid end end context '新規登録がうまくいかないとき' do it 'nicknameが空では登録できないこと' do @user.nickname = nil @user.valid? expect(@user.errors.full_messages).to include('ニックネームを入力してください') end it 'emailが空では登録できないこと' do @user.email = nil @user.valid? expect(@user.errors.full_messages).to include('Eメールを入力してください') end it '重複したemailが存在する場合登録できないこと' do @user.save another_user = FactoryBot.build(:user, email: @user.email) another_user.valid? expect(another_user.errors.full_messages).to include('Eメールはすでに存在します') end it 'passwordが空では登録できないこと' do @user.password = nil @user.valid? expect(@user.errors.full_messages).to include('パスワードを入力してください') end it 'passwordが存在してもpassword_confirmationが空では登録できないこと' do @user.password_confirmation = '' @user.valid? expect(@user.errors.full_messages).to include('パスワード(確認用)とパスワードの入力が一致しません') end it 'passwordが5文字以下であれば登録できないこと' do @user.password = '12345' @user.password_confirmation = '12345' @user.valid? expect(@user.errors.full_messages).to include('パスワードは6文字以上で入力してください') end end end end end以下のコマンドでテストコードを実行します。
ターミナル
bundle exec rspec spec/models/user_spec.rb今回は、'rails-i18n’を用いているためエラーメッセージが日本語表記になっています。
pry-railsというgemを用いることで、テストコードの実行を途中で止め、エラーメッセージの確認を行なっています。参考リンク
https://github.com/rspec/rspec-rails
https://github.com/faker-ruby/faker
- 投稿日:2020-10-18T19:38:08+09:00
[Rails] 投稿一覧をカテゴリー別で表示する方法
前提
- Ruby 2.6.3
- Rails 5.2.4.4
- devise導入済(しなくてもいい)
- 基本的なページは完成している
- コントローラー名は今回gears
- gearモデルにはcategoryカラムが存在する
- 今回はログインユーザーにしか見えない投稿一覧なので、他ユーザーも閲覧できるようにしたい場合は
user_id: @user.idを省いてください。やり方
Controller
編集前
gears_controller.rbdef index @user = current_user @gear = Gear.where(user_id: @user.id) end編集後
gears_controller.rbdef index @user = current_user @gear1 = Gear.where(user_id: @user.id, category: "住居系") @gear2 = Gear.where(user_id: @user.id, category: "料理系") @gear3 = Gear.where(user_id: @user.id, category: "火周り系") @gear4 = Gear.where(user_id: @user.id, category: "その他") endView
index.html.erb<div class="category bg-success">住居系</div> <% @gear1.each do |gear| %> <div class="gear-index-item mb-20"> <% if gear.image.attached? %> <%= image_tag gear.image, class: "index-img" %> <% else %> <img class="index-img" src="<%= "/images/default_gear.jpg" %>" alt="Index image cap"> <% end %> <%= link_to(gear.name, "/gears/#{gear.id}") %> </div> <% end %> <div class="category bg-warning">料理系</div> <% @gear2.each do |gear| %> <div class="gear-index-item mb-20"> <% if gear.image.attached? %> <%= image_tag gear.image, class: "index-img" %> <% else %> <img class="index-img" src="<%= "/images/default_gear.jpg" %>" alt="Index image cap"> <% end %> <%= link_to(gear.name, "/gears/#{gear.id}") %> </div> <% end %> . . .それぞれeach文で繰り返し処理を行う。
結果
まとめ
whereメソッドを使えば簡単に特定カラムでまとめられる!

- 投稿日:2020-10-18T19:25:41+09:00
初心者がGitHubに自分のアプリを上げる方法
前提条件
Githubに登録していること
アプリがあること大きな流れ
①ワーキングツリーを作成
②インデックスにファイルを登録
③ローカルリポジトリにファイルを登録
④リモートリポジトリと接続
⑤リモートリポジトリにファイルを登録前提
GitHubにアップしたいファイルがあるフォルダにがカレントディレクトリであること
①ワーキングツリーを作成
git init
.gitが生成されていることを確認
ls -a②インデックスにファイルを登録
git add *
備考
*はワイルドカードで、カレントディレクトリにある全てのファイルをインデックスに登録している③ローカルリポジトリにファイルを登録
git commit -m 'test'
備考
-mはコミットに対してコメントを付ける機能でつけてもつけなくてもいいです。
確認
コミットされたことを確認
git log
Author: xxx
Date: Sun xxx xx 17:35:23 2020 +0900test
④リモートリポジトリと接続
git remote add origin https://github.com/xxxxxxxx/xxxxxxxx.git
備考
originはリモートリポジトリ名で、任意の名前をつけても良い。基本はorigin
https/://github.com/xxxxxxxx/xxxxxxxx.gitはリモートリポジトリURL。GitHubのウェブページでリポジトリを作成すると付与される。(多分リポジトリページにそれらしきものはある)
確認
git remote -v
備考
接続しているリモートリポジトリ先が表示される⑤リモートリポジトリにファイルを登録
git push origin master
備考
masterはブランチ名。デフォルトがmaster。
自分の今いるブランチを確認したい場合は以下コマンド
git branch --contains
確認
自分のGitHubのリポジトリページにアクセスしてアップロードされていることを確認
- 投稿日:2020-10-18T18:03:06+09:00
whereメソッドを使って別のモデルの値を参考に絞り込みを行う。
概要
whereメソッドを使った複数の条件の絞り込みを行ったのでまとめる。
やりたいこと
productモデルが作成された時間の直前に作成されたdeveloperモデルの情報を一つ取得したい。
前提条件
Product(製品)モデルとDeveloper(開発者)を作成。この2つのモデルは関連付けされていない。(ここはあえてです)
Developerモデルはどんな製品を作ったのかの情報(developed_product_number)を持っている。productには製品ナンバー(number)がついておりこの2つの値は等しい。
(だったら関連付けさせようよって話ですが今回はこの条件でいきます。)
同一の製品を作成した複数の開発者の中から製品ができる直前に作成された開発者の値を取得したい。実装
ではまず実際のコードを載せます。
product = Product.find(params[:id]) @Developer = Developer.where(developed_product_number: product.id).where('created_at < ?', product).order(created_at: :desc).limit(1)こんな感じです。解説いきます
product = Product.find(params[:id])対象となるproductのIDを取得して変数productに代入。
ここで変数@Developerに条件をつけて絞り込み検索をした値を入れます。@Developer = Developer.where(developed_product_number: product.id).where('created_at < ?', product).order(created_at: :desc).limit(1)部分的に分けます。
@Developer = Developer.where(developed_product_number: product.number)ここでは先程取得した変数productのidを取得しています。
次に値を絞り込みます。
where('created_at < ?', product).order(created_at: :desc).limit(1)ここでproductが作成された時間より前に作成された複数の開発者の情報取得し、降順から数えて1つ目の開発者の情報を取得しました。
かなり長くなってしまったのでここのコードはスコープなどに切り分ける必要がありますね。
- 投稿日:2020-10-18T17:14:09+09:00
データベースになくても、データとして扱える活動的なハッシュ
はじめに
アンケートなんかでよく見かける、都道府県をプルダウンから選択させる機能。、form_withメソッドを使用して投稿する機能をもたせることができる。しかし、その都道府県はテーブル上では数値で管理されている方が使い勝手がよい。数値で管理できるようにするには、予め、都道府県名とそれに紐づく数字を用意しておく必要がある。そのようなときに便利な機能が、ActiveHashである。
ActiveHashとは
基本的に変更することのないデータをモデル内に記入することで、データベースへ保存せずにデータを取り扱うことができるようになるGem。主に、ビューで、プルダウンメニューとして表示させたいときに使う。
公式ドキュメントはこちら
準備の流れ
1. Gemの記述
2. Gemをインストール
3. モデルを生成1. Gemの記述
ファイルのいちばん下の行でOK
Gemfilegem 'active_hash'2. Gemをインストール
% bundle install3. モデルを生成
% rails g model モデル名 --skip-migrationモデル名には、プルダウンメニューを一括りにするような名前が望ましい。
ex)野球、サッカー、テニス…
のようなプルダウンを作成する場合は、モデル名はsportとなる。
--skip-migrationオプションをつけることで、マイグレーションファイルを生成しなくなる。ActiveHashはデータベースに保存しないので、マイグレーションファイルを必要としない。以後、スポーツのプルダウンメニューを例に説明する。
記述から表示までの流れ
4. クラスを定義し継承する
5. プルダウンメニューの項目を記述
6. アソシエーションを記述
7. バリデーションを記述
8. プルダウンメニューを表示4. クラスを定義し継承する
「3. モデル生成」で作られたモデルを以下の記述に変更する。
app/models/sport.rbclass Sport < ActiveHash::Base self.data = [] endActiveHash::Baseを継承することで、ActiveRecordのメソッドが使用できる。
5. プルダウンメニューの項目を記述
プルダウンの中身は、配列にハッシュで入れる。
app/models/sport.rbclass Sport < ActiveHash::Base self.data = [ { id: 1, name: '---' }, { id: 2, name: 'Baseball' }, { id: 3, name: 'Soccer' }, { id: 4, name: 'Tennis' } ] end6. アソシエーションを記述
以下、すでに、別の投稿したものを保存するテーブルが存在する前提の説明。
app/models/post.rbclass Post < ApplicationRecord extend ActiveHash::Associations::ActiveRecordExtensions belongs_to_active_hash :sport end
extend ActiveHash::Associations::ActiveRecordExtensionsの記述によって、belongs_to_active_hashメソッドが使えるようになる。sportモデルにアソシエーションの記述の必要はない。
※通常のアソシエーションと記述が異なる点に注意
7. バリデーションを記述
app/models/post.rbclass Post < ApplicationRecord extend ActiveHash::Associations::ActiveRecordExtensions belongs_to_active_hash :sport validates :sport_id, presence: true #空の投稿を保存できない validates :sport_id, numericality: { other_than: 1 } #プルダウンの選択が「--」の時は保存できない end8. プルダウンメニューを表示
collection_selectメソッド
collection_select(保存されるカラム名, オブジェクトの配列, カラムに保存される項目, 選択肢に表示されるカラム名, オプション, htmlオプション)collection_select(:sport_id, Sport.all, :id, :name, {}, {class:"sport-select"})保存されるカラム名:テーブルのどのカラムに保存をするのか。
オブジェクトの配列:配列のハッシュ全て表示させる場合は、.allでOK
カラムに保存される項目:app/models/sport.rbの中で、id:としていた部分を、カラムに保存させたい
選択肢に表示されるカラム名:プルダウンでapp/models/sport.rbのname:としていた部分を表示させる
オプション:必要に応じて
htmlオプション:クラス名など最後に
とにかく、collection_selectメソッドの引数が多すぎて、混乱しそう…
- 投稿日:2020-10-18T16:16:25+09:00
【Rails】お気に入り登録とお気に入りした一覧を表示する巻
はじめに
ネットショッピングしてていいなと思った商品見つけたらお気に入り登録したことありますよね?
そのとき、画面が更新されずにお気に入りやいいねすると♡マークの色が変わったりしますよね。あとは、お気に入りした商品を一覧で確認できたらいいですよね。今回はその実装のメモ書きです。※出品や投稿機能(itemsテーブル)及びログイン機能(usersテーブル)が備わっていることを前提にお話を進めます。
実装の手順(同期編)
完成のイメージはクリックした時に画面の一部が更新されて数字のカウントが増えていく・・・みたいなイメージ。ついでに削除機能も搭載します。お気に入りに追加したものは一覧で確認できるページも作成しちゃいます。
まずは、itemsテーブルとusersテーブルの中間テーブルとして
likesテーブルを作成。↓追加するカラムとアソシエーションはこんな感じ↓
itemsテーブル
Column Type Options ===略===
※追加なし※Association
- has_many :likes
- has_many :liked_users, through: : likes, source: :user #お気に入一覧作りたい時使うが今回は使わない
likesテーブル #中間テーブル
Column Type Options item_id integer null: false user_id integer null: false Association
- belongs_to :item
- belongs_to :user
usersテーブル
Column Type Options ===略===
※追加なし※Association
- has_many :likes
- has_many :liked_items, through: :likes, source: :item #お気に入一覧作りたい時使うが今回は使わない
これにてDB設計は完了
つづいてモデルの作成。以下のコマンドをターミナルに入力rails g model likeテーブルを作成するためマイグレーションファイルを編集
2XXXXXXXXXXXX5_create_likes.rbclass CreateLikes < ActiveRecord::Migration[5.2] def change create_table :likes do |t| t.integer :item_id, null: false t.integer :user_id, null: false end end endからのrails db:migrateします。
そしたらモデルが生成されるのでアソシエーションを書いていきます。user.rbhas_many :likes #追加item.rubyhas_many :likes #追加like.rbclass Like < ApplicationRecord belongs_to :item belongs_to :user validates :user_id, presence: true validates :item_id, presence: true validates_uniqueness_of :item_id, scope: :user_id def self.like_method(item, user) Like.find_by(item_id: item.id, user_id: user.id) end endself.like_method(item, user)
ここでIF分の設定をしちゃいます。
likeテーブルにitem_idとuser_idに入ってるーーーって条件を設定します!
次にコントローラーを作成するため以下のコマンドを実行rails g controller likes無事にコントローラーが作成されたら、
・ビューファイル
・コントローラー
・ルーティング
それぞれ設定していきます。routes.rbーー略ーー resources :items, only: [:new, :create, :edit, :update, :show, :destroy] do resources :likes, only: [:create, :destroy] end ーー略ーー resources :users, only: [:show] do resources :likes, only: [:index] end ーー略ーーcreateとdestroyはitemsにネスト
indexはusersにネストlikes_controller.rbclass LikesController < ApplicationController before_action :set_item, only: [:create, :destroy] def index @items = Item.includes(:item_images).order("created_at DESC") end def create @like = Like.create(item_id: params[:item_id],user_id: current_user.id) redirect_to item_path(@item.id) end def destroy @like = Like.find_by(item_id: params[:item_id],user_id: current_user.id) @like.destroy redirect_to item_path(@item.id) end def set_item @item = Item.find(params[:item_id]) end endcreateとdestroyはビューファイルがないのでリダイレクトの設定が必要になります。
index.html.hamlーー略ーー - if user_signed_in? && Like.like_method(@item, current_user) .check_btn__like--add{data: {item_id: @item.id}} = link_to "/items/#{@item.id}/likes/:id" , method: :DELETE do = icon( "fa", "star") お気に入り = @item.likes.length - elsif user_signed_in? .check_btn__like{data: {item_id: @item.id}} = link_to "/items/#{@item.id}/likes", method: :POST do = icon( "fa", "star") お気に入り = @item.likes.length - else .check_btn__like = link_to new_user_session_path do = icon( "fa", "star") お気に入り = @item.likes.length ーー略ーーお気に入り登録する時の画面はこちら
index.html.haml.mypage_Wrapper %section.mypage_title お気に入り一覧 %section.like_Wrapper .like__box - @items.each do |item| - if user_signed_in? && Like.like_method(item, current_user) .like__box__product .like__image = link_to item_path(item.id) do = image_tag item.item_images[0].image.url .like__name = item.name %ul %li = item.price.to_s %li = "円" %li.like__tax = "(税込)" %li.like__icon = link_to "/items/#{item.id}/likes/:id" , method: :DELETE do = icon("fas", "star") .bottom_Wrapperこれが、お気に入りした商品一覧で表示するもの
like.scss.like_Wrapper { width: 100%; } .like__box { background-color:white; margin: 0 auto; width: 65%; display: flex; justify-content: center; flex-wrap: wrap; &__product { width: 180px; height: 90%; margin: 25px 2% 0; transition: all .3s ease-in-out; .like__image { width: 180px; height: 140px; margin-bottom: 3%; img{ width: 100%; height: 100%; object-fit: cover; } } .like__name { font-weight: bold; } ul{ display: flex; font-size: 16px; li{ font-weight: bold; } .like__tax { font-size: 10px; writing-mode: lr-tb; width: 30px; line-height: 30px; margin-left: 2%; margin-right: 24%; } .like__icon { i { font-size:1.1em; color: orange; } } } } &__product:hover { cursor: pointer; transform: scale(1.1, 1.1); } }一応、CSSも
ここまでの実装で同期した状態で実装できるかと思います!
いったんここまで、Ajaxを利用した非同期通信を実装するとよりリッチになるのでそのことを書いて行けたらいいなと・・・
それはまた後日・・・
参考
https://techtechmedia.com/favorite-function-rails/#i
https://qiita.com/naberina/items/c6b5c8d7756cb882fb20
https://qiita.com/hisamura333/items/e3ea6ae549eb09b7efb9
https://qiita.com/shh-nkmr/items/48fe53282253d682ecb0


- 投稿日:2020-10-18T14:54:05+09:00
オブジェクト指向まとめ
前置き
今更ながらオブジェクト指向の概要をまとめていく。私もオブジェクト指向を理解するのに苦しんだのでなるべく初学者にわかりやすく簡潔に書いていきます。
マサカリ上等ですのでコメントお待ちしております。1.オブジェクト
オブジェクトとは「対象」「物」という意味で、プログラミングではデータ処理の集まりのことを指している。
Rubyでいうならば、配列やHash、数字や文字列など全てのデータは(モノ)オブジェクトである2.オブジェクト指向
オブジェクト指向プログラミングとは、モノ(オブジェクト)の作成と操作として見る考え。
3.クラス(class)
クラス(class)はオブジェクト指向において、データと処理をひとまとめにした設計図のようなもの。
基本的にクラスを元にしてオブジェクトを生成することで使えるようになる4.プロパティ(property)
オブジェクトが持っているデータのことをプロパティ(属性)という。
5.メソッド(method)
オブジェクトが持っている処理のこと。人でいえば「走る、歩く、止まる」などのオブジェクトが何らかのアクションを起こす処理の事
def メソッドの名前 やりたい処理 end例えば「こんにちは」と呼びだすhelloメソッドを定義するのであれば
def hello puts 'こんにちは' end hello #=> こんにちはといった感じになる。
6.インスタンス(instance)
インスタンスとはクラスから生成されたオブジェクトの事。
インスタンス作成の際にはnewメソッドを使用します。class human def initialize(name) @name = name end def hello puts "こんにちは" end end human = human.new("徳川家康")ここで定義されているinitializeメソッドはインスタンスが生成された時に自動で実行されるメソッドです。
これでnameという属性に「徳川家康」という値がセットされました。humanクラスから生成されたhumanというインスタンスは徳川家康という固有の名前をもち、helloというメソッドを使うことができます。
この1行だけでこれだけの情報を持ったオブジェクトが作成できるのできます。7.カプセル化
オブジェクトが持つデータや処理のうち、別のオブジェクトから直接利用される必要のないものを隠すことを言い、利用する場合は外部から操作するために作られた処理を設けることを言う。先ほどのレーシングカーの例でも出てきた、オブジェクト指向の基本概念。
カプセル化にはpublicとprivateがあります。
publicに記述したメソッドなどは外部からのアクセスは可能だが、privateを指定すると、呼び出す際にエラーとなります。publicの場合
class human #public => 何も指定しなければrubyはデフォルトでpublicになる。基本的に省略可能。 def initialize(name) @name = name end def hello puts "こんにちは" end end human = human.new("徳川家康") puts human.name #=> 徳川家康が出力されるprivateの場合
class human private def initialize(name) @name = name end def hello puts "こんにちは" end end human = human.new("徳川家康") puts human.name #=> エラーが出力される8.継承
特定のオブジェクトの機能を引き継いで使う事。
似たようなオブジェクトを複数作る時に、全てのプロパティやメソッドをいちいちプログラミングするのは非常に手間が掛かるが、継承を使うことにより、同じ機能を実装できる。class Human def work puts '歩きました' end end #Humanクラスを継承 class IeyasuTokugawa < Human def unification puts "天下統一しました" end end IeyasuTokugawa = IeyasuTokugawa.new puts IeyasuTokugawa.unification #=> 天下統一しました puts IeyasuTokugawa.work #=>歩きましたクラスを継承した場合、クラス自体で定義されたメソッドの他に親クラスで定義されているメソッドも使用することが出来ます。先ほどの例で言えば「IeyasuTokugawa」クラスのオブジェクトは「unification」メソッドの他に親クラスの「work」メソッドも実行することが出来ます。
クラス内で定義されたメソッドだけではなく、スーパークラス(親クラス)で定義されているメソッドも実行できることが確認できます。
9.ポリモーフィズム
ポリモーフィズムとは(Polymorphism)とは、オブジェクト指向プログラミングにおける概念、手法の一つです。日本語で「多様性」とも言います。
異なるクラスに対し、同一のインターフェースが提供されていることを言います。クラスを使う側は、クラスの実態を意識せずにメソッドを呼び出せます。
class Human def speak(voice='') "#{self.name}: #{voice}" end end #継承 class NobunagaOda < Human def speak(voice='鳴かぬなら 殺してしまえ ホトトギス') super end end class IeyasuTokugawa < Human def speak(voice='水よく船を浮かべ 水よく船を覆す') super end end NobunagaOda = NobunagaOda.new NobunagaOda.name = '織田信長' IeyasuTokugawa = IeyasuTokugawa.new IeyasuTokugawa.name = '徳川家康' NobunagaOda.speak #=>織田信長: 鳴かぬなら 殺してしまえ ホトトギス IeyasuTokugawa.speak #=>徳川家康: 水よく船を浮かべ 水よく船を覆す同じspeakメソッドであっても、クラスでの定義に応じて挙動の変化することがわかりました。
10.オブジェクト指向のメリット・デメリット
メリット
1.プロブラムのメンテナンスがしやすくなる
・プログラムの一つ一つを小さなまとまりで考える事が出来る為、複雑なプログラムが減ります。改修による影響度が減り、メンテナンスがしやすくなります。
2.分業化ができる
・システムの規模が大きくなるほど、プログラムの実装は膨大になります。オブジェクト指向は平行で大人数での実装が可能の為生産性が上がります。また似た機能等を他に影響を与える事なく機能を実装することも可能です。
3.プログラムの品質が高くなる
・あらゆるところが部品化されている為に問題箇所の特定が容易です。まとまりのあるプログラムのためコードの可読性も高く直感的にわかりやすい。
デメリット
1.難易度が高く教育コストがかかる
・開発現場で活躍する為には付け焼き刃の知識では役に立たない。抽象的な概念が多く、しっかり理解する為にはそれなりに
現場経験が必要2.設計力が試される
・継承やポリモーフィズムなど便利な概念が使用できる代わりに、他のコードとの影響性や拡張性、共通化などより可読性高く品質を上げる為には設計力が必要不可欠。
最後に
私もまだまだ初学者のため技術力がありません。プログラムを書いている際に基本的概念は少なくとも頭に入れておくことが重要だと思います。他の初学者の皆さんも一緒に覚えていって欲しいと思います。
- 投稿日:2020-10-18T13:15:05+09:00
Gem paranoiaを使った論理削除
備忘録
今回自作アプリ作成の際に論理削除を用いたので備忘録として記録します。
プログラミング初心者のため間違いがあればご指摘お願いします!
今回はrails、MySQLを使い開発を進めています。論理削除とは
一般的な削除は物理削除と言い削除したらDB上からもデータが削除されます。
それに対し、論理削除とは一般的な削除とは違い、あたかも削除されたように見せてDBにはデータが残っている状態のことを言います。
削除履歴を表示したり、データの復元などにも使われます。ステップ1 Gemの導入
論理削除の手間を大幅にカットしてくれるGemのparanoiaを導入する。
Gemfileに記述しターミナルでbundle installgem 'rails_12factor'ステップ2 カラムを追加
論理削除をするとこちらのカラムに削除した日時が挿入され、削除フラグを立てる事ができます。
class AddDeletedAtToCategories < ActiveRecord::Migration[6.0] def change add_column :categories, :deleted_at, :datetime end end正しければ、$ rails db:migrateして下さい。
モデルに以下の記述をします。ステップ3 モデルを編集する
acts_as_paranoidまとめ
以上の設定でparanoiaを使った論理削除の設定が完了しました!
普通に実装しようとするとかなり大変だと思いますが、paranoiaを使う事で簡単に実装する事ができました!
プログラミング初心者の方の役に立てると幸いです。
- 投稿日:2020-10-18T13:14:54+09:00
#google-mapで検索が行えない。。
googlemapで住所検索を設定するまでの過程
↓こちらを参考にさせていただきました。誠にありがとうございます。
https://qiita.com/nagaseToya/items/e49977efb686ed05eadb起こったエラー名
this api key is not authorized to use this service or api
(サービスやAPI使うに当たって適切な権限を持っていませんよ)*意訳いろいろと調べてみて結果、、口を揃えて 「Geocoding API」が有効化されてないよ。。。という
*(Geocoding APIは住所位置を認証する権限、、みたいな)
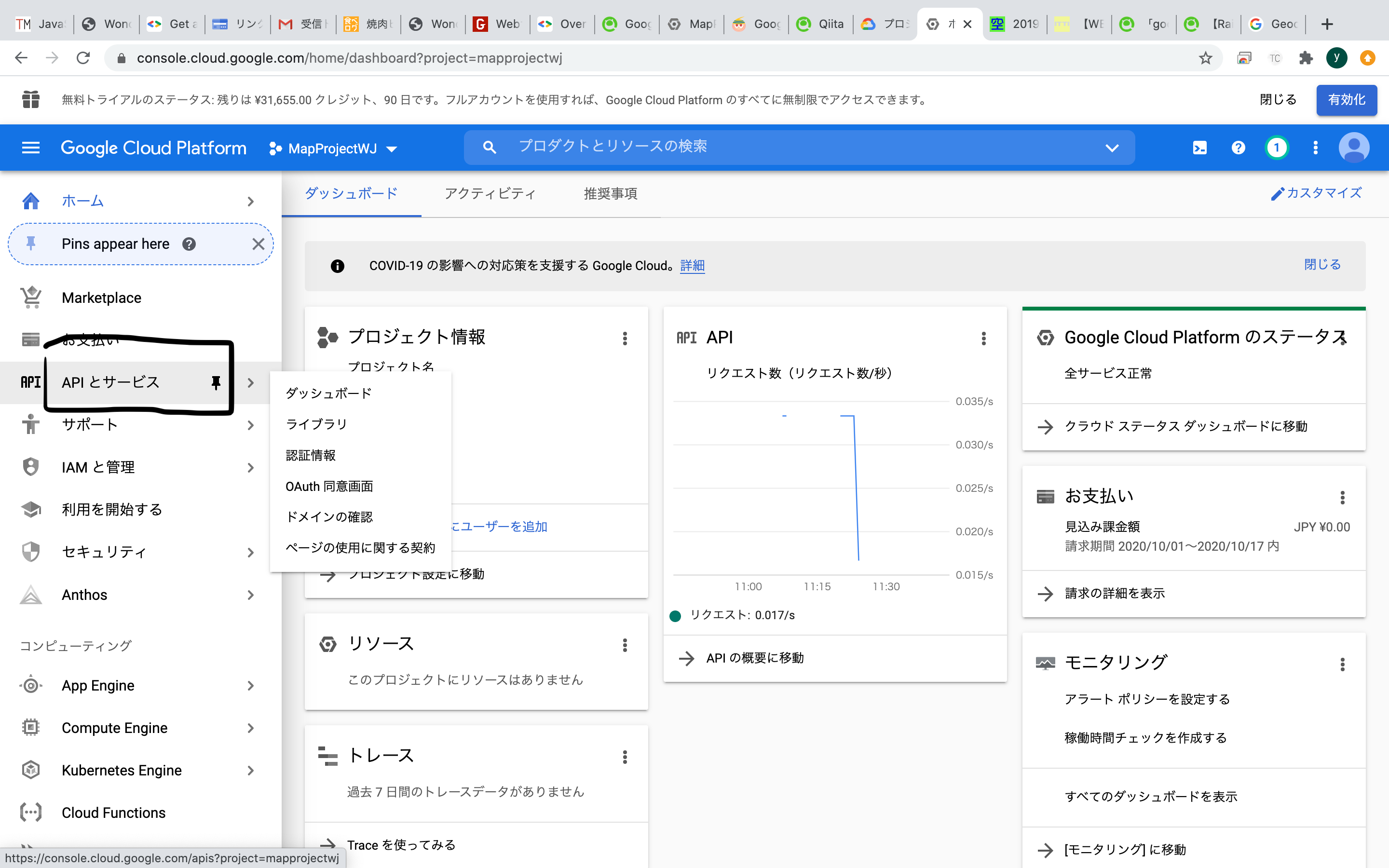
①まず左にあるリストから『APIとサービス』を選びましょう
②『認証情報』を選択
③指定されたAPIキーを選びましょう
④アプリケーションの制限を選択して保存
以上です。上の検索画面からGeocoding APIと調べると、Geocoding APIを有効にするという項目が出ますが
これをやってもうまくいかなかったので上記の手順を踏んでみてください!
以上ご一読ありがとうございました!


- 投稿日:2020-10-18T12:05:19+09:00
【0からAWSに挑戦】EC2とVPCを使ってRailsアプリをAWSにデプロイする part2
EC2とVPCを使ってRailsアプリをAWSにデプロイする part1
前回の続きです。
↓↓↓↓前回の記事はこちら↓↓↓↓↓
①EC2とVPCを使ってRailsアプリをAWSにデプロイする part1環境
・Ruby on Rails 6.0
・Ruby 2.6.6
・dbはmysqlを使用
・アプリケーションサーバはpumaを使用
・webサーバーはnginxを使用手順
前回は③までいきました。なので今回は④からやります
①VPCを作成
②VPC内にサブネットを作成
③インターネットゲートウェイ・セキュリティグループ・ルートテーブルの設定
④EC2を作成
⑤EC2にrails環境を構築、gitからアプリをpullする④EC2を作成
EC2の設定
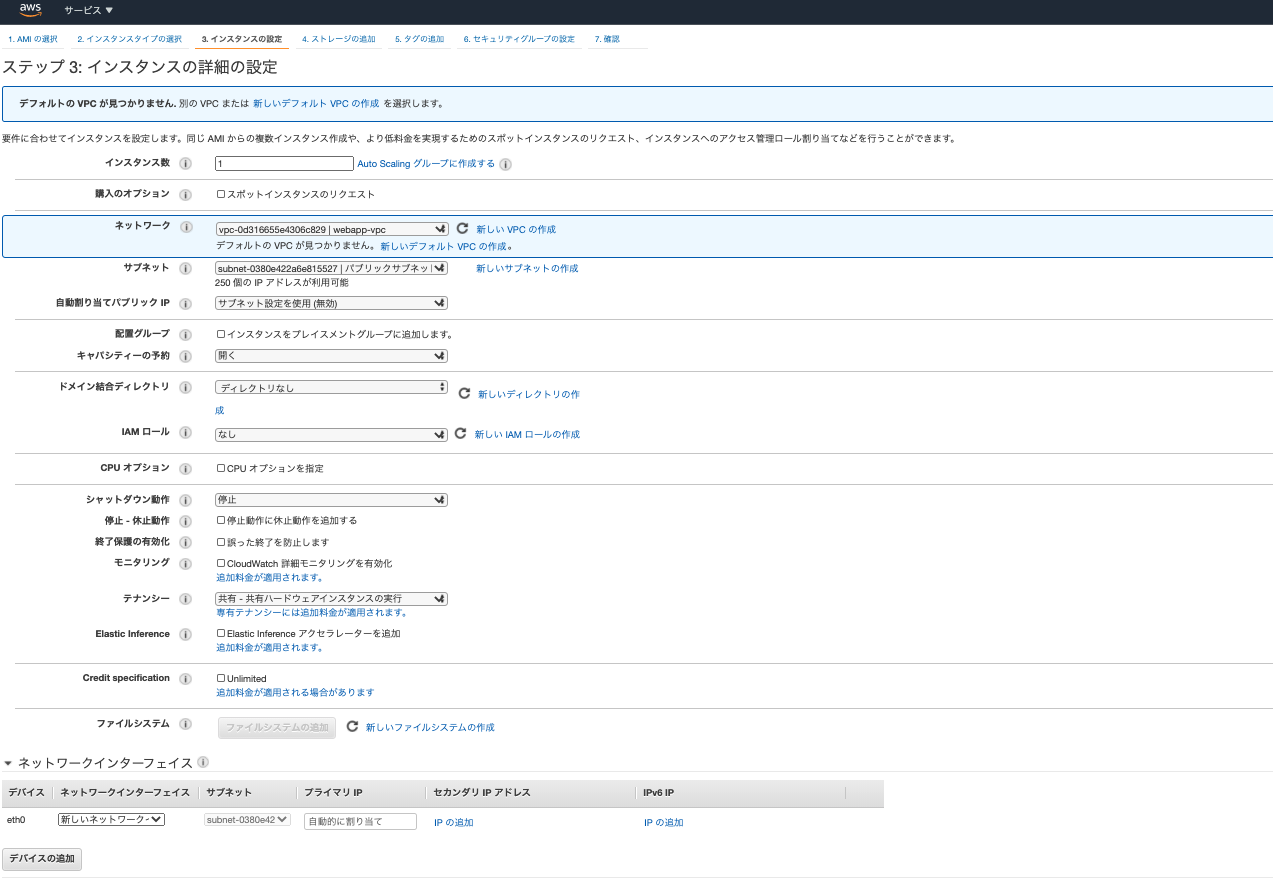
前回作成したサブネットの中にEC2(Elastic Compute Cloud)サーバーを構築しましょう。このEC2で作成した仮想サーバーにwebサーバーやアプリケーションを入れることで、デプロイができるようになります。
ではさっそくEC2を作成しましょう。まずはAWSのサービスメニューからEC2で検索します。そうしたらEC2の画面がでてきますので、左のサイドメニューからインスタンスを選択しましょう。(※ちなみにEC2で作成した仮想サーバーをインスタンスといいます。)
インスタンスを選択すると、右上にインスタンス起動のボタンがあるのでそれをクリックし、EC2の作成をはじめます。インスタンスの設定までには6ステップあるので順にみていきましょう。
1.最初のステップはAMIの設定です。簡単にいうとEC2上の仮想サーバーにどんなOSをいれるかです。ここは一番上のAmazonLinux2を選択します。
2.インスタンスタイプは無料枠のものがt2.microしかないのでそれを選択します。
3.インスタンスの詳細設定は少し量が多いですが、必要なところだけ抽出してみていきましょう。
- ネットワークは先程作成したVPCを選択してください
- サブネットも先程作成したサブネットを選択してください
- 自動割当パブリックは有効に設定します。これはインターネットからアクセスするのに必要な設定です
- ネットワークインターフェイスのプライマリIPを10.0.1.10に設定します。この設定はプライベートIPの設定です。サブネット(10.0.1.0/24)のなかの好きなIPアドレスにインスタンスを配置できます。
- 上記以外は空欄でOKです。4.ストレージの追加はそのままでOKです。無料枠が30Gまでなのでそれを超えなければストレージ上げても問題ないです。
5.タグの追加もそのままでOKです。ただ複数インスタンスを作る場合は、{キー:NAME,値:WEBサーバー}みたいに設定しておくと便利です。
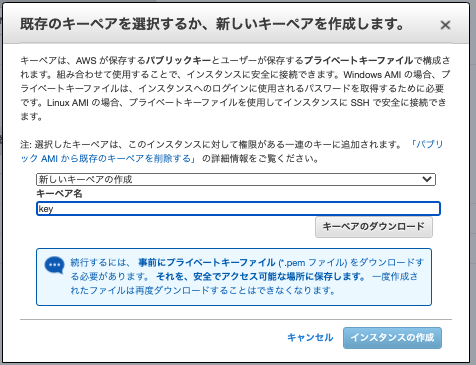
6.セキュリティグループは前記事で紹介しましたが、実はサーバー単位でも設定できます。もちろん前回サブネットに設定したセキュリティグループも適応できるので、今回は既存のセキュリティグループ(前記事で作成したもの)を使います。以上で設定は完了です。確認画面のあと、起動ボタンを押すとインスタンスが生成されます。また生成と同時に鍵が生成されます。新しいキーペアを作成し、ダウンロードしましょう。ダウンロードしたファイルはSSH通信の際に必要になるのでなくさない用にしてください。
ElasticIPの設定
現状でもEC2の起動は問題ありませんが、EC2を起動するたびにIPアドレスが変わってしまいます。そこでElasticIPというものを使って、IPアドレスを固定化しましょう。EC2の左サイドメニューからElasticIPを選択し、ElasticIPの割り当てをクリックしてください。その後設定画面に行きますが、設定はデフォルトのままでよいので、そのまま割当ボタンを押します。あとはElasticIPとEC2の関連付けが必要ですので、右上にあるアクションボタンからElasticIPの関連付けを選択し、先程作成したEC2を選んでください。
SSHで接続する
SSH(secure shell)とは簡単にいうとローカル(Macだとターミナル)からEC2サーバーを操作できるようにすることです。SSHに接続するには先程EC2の起動時に作成した鍵が必要です。ターミナルで下記の様に打つことでSSH接続ができます。
ターミナル#ホームディレクトリ user@usr ~ % ssh -i key.pem ec2-user@18.777.12.17
- 「ssh」の箇所でsshを使うことを宣言しています。
- 「-i」は秘密鍵ファイルを意味します。なので先程EC2作成と同時に生成したファイルを指定します。おそらく「(自分で設定した名前).pem」というファイルがダウンロードフォルダにあると思うので、それをホームディレクトリに移します。
- 「ec2-user」はEC2がデフォルトで用意しているユーザー名です。
- そのあとの数字はElasticIPです。 要約すると「先程作成した秘密鍵を使って指定したIPアドレスにec2-userというユーザー名でSSH接続します」という意味になります。以上でSSHログインできると思います。ログインできると下記の画面のようになります。
ターミナルLast login: Sat Oct 17 08:24:35 2020 from 210.28.31.150.dy.iij4u.or.jp __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ No packages needed for security; 1 packages available Run "sudo yum update" to apply all updates. [user@ip-10-0-1-10 ~]$また上記コマンド打った際に、鍵ファイルのパーミッションエラーが起こることがあります。これは鍵ファイルが他人にも閲覧できる状態のために起こるエラーです。下記コマンドで鍵ファイルの権限を変更しましょう。
ターミナルuser@usr ~ % chmod 400 key.pem上記のコマンドや権限に関しては、こちらの記事がわかりやすかったのでご参照ください。
これでEC2サーバーに入ることだできたので、あとはこの中に環境構築していくだけです。ちなみに自分はこのまま「ec2-user」で作業を進めたのですが、複数人で作業を行う場合などは作業用userを作ったほうがよいです。作業用ユーザー作成はこちらの記事に書いてあります。
※参照に書いていた「世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまで」にも書いてありますね。もしかしたら1人の場合も作成したほうがよいかもしれません。
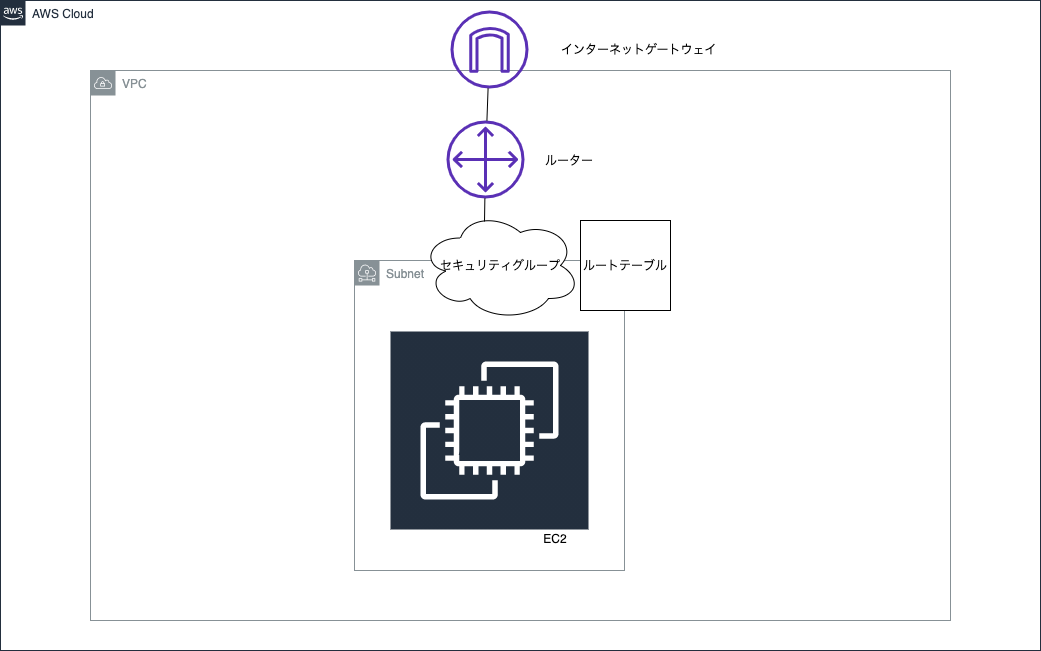
ちなみに現状の構成は下記のような感じです。
この記事で完結しようと思ったら環境構築が長くなりそうなので、一旦ここで切ります。
感想・まとめ
EC2の構築は結構簡単そうに見えて意外と時間を要しました。というのも最初から難しいことをやろうとしていたからです。具体的にはサブネットをDB用とWEBサーバー用に分割してEC2を踏み台サーバーにしてアクセスする方法やRDSやAWSのロードバランサーを使う方法を一気にやろうとしてました。そのためEC2構築あたりからぐちゃぐちゃしてしまい、無駄に時間を食ってしまいました。
このことから自分のような初学者は最初は無理せず、基本的で簡単な方法をまずこなすことを第一にし、その後で機能を積み重ねるというやり方を特に意識してやるべきかと実感しました。参考
「Amazon Web Services 基礎からのネットワーク&サーバー構築 改訂3版 著 大澤文孝,玉川憲,片山暁雄,今井雄太」
→おすすめの本です。AWSだけでなくネットワーク知識についても触れているので、初学者にとっては神技術書です。(下準備編)世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまで
→こちらもわかりやすくてよかったです。AWSの内容は「Amazon Web Services 基礎からのネットワーク&サーバー構築」とほとんど同じです。なのでこちらだけでAWSやってみるのもありかと思います。ただネットワーク知識が浅い人やインフラ初心者は最初に「Amazon Web Services 基礎からのネットワーク&サーバー構築」にやってネットワーク知識補充しながらやらないと苦労すると思います※本記事は上記2つを参考にさせていただきながら実装しています。
なので実装に関しては類似箇所も多いかと思いますが、WEBサーバーの種類・DBのバージョンなどの構成などはもちろん自分なりにアレンジしています。

- 投稿日:2020-10-18T11:51:17+09:00
Railsガイド(Action Controller の概要)を改めて読んで
5. セッション
Railsアプリケーションにはユーザーごとにセッションオブジェクトが生成され、前のリクエスト情報を継続して利用することができる。セッションは
ControllerとViewでのみ利用でき、少量のデータがセッションに保存される。
セッションの保存先としては、以下のようなストレージから選ぶことができる。
ActionDispatch::Session::CookieStore: すべてのセッションをクライアント側のブラウザのcookieに保存するActionDispatch::Session::CacheStore: データをRailsのキャッシュに保存するActionDispatch::Session::ActiveRecordStore: Active Recordを用いてデータベースに保存する (activerecord-session_store gemが必要)ActionDispatch::Session::MemCacheStore: データをmemcachedクラスタに保存する (この実装は古いのでCacheStoreを検討すべき)セッションは固有のIdを持っており、それを
cookieに保存します。セッションIDをURLで渡すことはセキュリティ上とても危険があるため、Railsではデフォルトで許可されていない。なので、セッションIDは必ずcookieで渡さなくてはならない。多くの
SessionStore(のセッションID)は、サーバー上のセッションデータを検索するために使用される。
ただしCookieStoreだけは、cookie自身にすべてのセッションデータを保存する(必要であればセッションIDも利用可能)。
RailsではCookieStoreがデフォルトで使われ、Railsでの推奨セッションストアとなっている。
CookieStoreの利点は、
- 非常に軽量な点
- 新規で利用する時の準備が全く不要な点
cookieデータは改竄防止のために暗号署名が与えられており、cookie自身も暗号化されているため、内容を他人に読目内容になっている。(改竄されたcookieはRailsが拒否してくれる)
CookieStoreには約4KBのデータを保存でき、容量はこれで十分。利用するセッションストアの種類に関わらず、セッションに大量のデータを保存することは好ましくない。ユーザーセッションに重要なデータが含まれていない場合や、セッションを長期保存する必要のない場合は
ActionDispatch::Session::CacheStoreを検討するとよい。
メリットは、Webアプリケーションに設定されているキャッシュ実装を利用して保存するため、既存のキャッシュインフラをそのまま利用することができる。よって、特段準備する必要がない。
デメリットは、セッションが短命なので、セッションがいつでも消える可能性がある点である。5-1. セッションにアクセスする
セッションへのアクセスは、コントローラ内の
sessionインスタンスメソッドを使って可能となる。セッションの値は、ハッシュに似たキー/値ペアを使って保存される。class ApplicationController < ActionController::Base private # キー付きのセッションに保存されたidでユーザーを検索する # :current_user_id はRailsアプリケーションでユーザーログインを扱う際の定番の方法。 # ログインするとセッション値が設定され、 # ログアウトするとセッション値が削除される。 <方法①> def current_user @current_user ||= session[:current_user_id] && User.find_by(id: session[:current_user_id]) end <方法②> def current_user if session[:current_user_id] @current_user ||= User.find_by(id: session[:current_user_id]) end end endセッションに何かを保存したければ、ハッシュのようにキーを割り当てる。
class LoginsController < ApplicationController # "Create" a login, aka "log the user in" def create if user = User.authenticate(params[:username], params[:password]) # セッションのuser idを保存し、 # 今後のリクエストで使えるようにする session[:current_user_id] = user.id redirect_to root_url end end endセッションからデータの一部を削除したい場合は、そのキーバリューペアを削除します。
class LoginsController < ApplicationController # ログインを削除する (=ログアウト) def destroy # セッションidからuser idを削除する session.delete(:current_user_id) # メモ化された現在のユーザーをクリアする @_current_user = nil redirect_to root_url end endセッション全体をリセットするにはreset_sessionを使う。
5-2. Flash
flashはセッションの中の特殊な部分で、リクエストごとにクリアされる。リクエスト直後のみ参照可能となる特徴を持っており、エラーメッセージをviewに渡したりする。
flashはハッシュとしてアクセスし、これをFlashHashインスタンスと呼ぶ。
例として、ログアウトする動作を扱ってみる。コントローラでflashを使うことで、次のリクエストで表示するメッセージを送信することができる。class LoginsController < ApplicationController def destroy session.delete(:current_user_id) flash[:notice] = "You have successfully logged out." redirect_to root_url end end
flashメッセージはリダイレクトの一部として割り当てることもできる。オプションとして:notice、:alertの他に、一般的な:flashも使用可能。redirect_to root_url, notice: "You have successfully logged out." redirect_to root_url, alert: "You're stuck here!" redirect_to root_url, flash: { referral_code: 1234 }6. Cookie
Webアプリケーションでは、
cookieと呼ばれる少量のデータをクライアント側(ブラウザ)に保存できる。HTTPは「ステートレス」なプロトコルなので、基本的にリクエストとリクエストの間には何の関連も持たないが、cookieを使うとリクエスト同士の間で (あるいはセッション同士の間であっても) このデータが保持されるようになる。Railsではcookiesメソッドを使ってcookieに簡単にアクセスできる。アクセス方法はセッションの場合とよく似ていて、ハッシュのように動作する。class CommentsController < ApplicationController def new # cookieにコメント作者名が残っていたらフィールドに自動入力する @comment = Comment.new(author: cookies[:commenter_name]) end def create @comment = Comment.new(params[:comment]) if @comment.save flash[:notice] = "Thanks for your comment!" if params[:remember_name] # コメント作者名を保存する cookies[:commenter_name] = @comment.author else # コメント作者名がcookieに残っていたら削除する cookies.delete(:commenter_name) end redirect_to @comment.article else render action: "new" end end endセッションを削除する場合はキーに
nilを指定することで削除しましたが、cookieを削除する場合はこの方法ではなく、cookies.delete(:key)を使用しなければならない。
Railsでは、機密データ保存のために署名済みcookie jarと暗号化cookie jarを利用することもできる。
- 署名済み
cookie jarでは、暗号化した署名をcookie値に追加することで、cookieの改竄を防ぐ。- 暗号化
cookie jarでは、署名の追加と共に、値自体を暗号化してエンドユーザーに読まれることのないようにしてくれる。これらの特殊な
cookieではシリアライザを使って値を文字列に変換して保存し、読み込み時に逆変換(deserialize)を行ってRubyオブジェクトに戻している。Rails.application.config.action_dispatch.cookies_serializer = :json新規アプリケーションのデフォルトシリアライザは
:jsonとなっている。
cookieには文字列や数字などの「単純なデータ」だけを保存することが推奨されている。cookieに複雑なオブジェクトを保存しなければならない場合は、後続のリクエストでcookieから値を読み出す場合の変換については自分で面倒を見る必要がある。
cookieセッションストアを使う場合、sessionやflashハッシュについても同様のことが該当する。7. XMLとJSONデータを出力する
ActionControllerのおかげで、XMLデータやJSONデータの出力 (レンダリング) は非常に簡単に行える。scaffoldを使って生成したコントローラは以下のようになっている。class UsersController < ApplicationController def index @users = User.all respond_to do |format| format.html # index.html.erb format.xml { render xml: @users } format.json { render json: @users } end end end上のコードでは、
render xml: @users.to_xmlではなくrender xml: @usersとなっていることにご注目。Railsは、オブジェクトがString型でない場合は自動的にto_xmlを呼んでくれる。
.to_xml配列またはハッシュをXML形式に変換するメソッド。
array.to_xml([オプション]) hassh.to_xml([オプション])8. フィルタ
フィルタは、コントローラにあるアクションの「直前 (before)」、「直後 (after)」、あるいは「直前と直後の両方 (around)」に実行されるメソッド。
フィルタは継承されるので、フィルタをApplicationControllerで設定すればアプリケーションのすべてのコントローラでフィルタが有効となる。
「before系」フィルタのよくある使われ方として、ユーザーがアクションを実行する前にログインを要求するというのがあります。このフィルタメソッドは以下のようになる。
class ApplicationController < ActionController::Base before_action :require_login private def require_login unless logged_in? flash[:error] = "You must be logged in to access this section" redirect_to new_login_url # halts request cycle end end endこのメソッドはエラーメッセージを
flashに保存し、ユーザーがログインしていない場合にはログインフォームにリダイレクトするというシンプルなものである。この例ではフィルタを
ApplicationControllerに追加したので、これを継承するすべてのコントローラが影響を受ける。つまり、アプリケーションのあらゆる機能についてログインが要求されることになる。当然だが、アプリケーションのあらゆる画面で認証を要求してしまうと、認証に必要なログイン画面まで表示できなくなるという困った事態になってしまうので、このようにすべてのコントローラやアクションでログイン要求を設定すべきではない。skip_before_actionメソッドを使えば、特定のアクションでフィルタをスキップすることが可能となる。class LoginsController < ApplicationController skip_before_action :require_login, only: [:new, :create] end上記のようにすることで、
LoginsControllerのnewアクションとcreateアクションをこれまでどおり認証不要にすることができる。特定のアクションについてだけフィルタをスキップしたい場合には:onlyオプションを使うことができる。逆に特定のアクションについてだけフィルタをスキップしたくない場合は:exceptオプションを使う。これらのオプションはフィルタの追加時にも使うことができるので、最初の場所で選択したアクションに対してだけ実行されるフィルタを追加することもできる。8-1.
afterフィルタとaroundフィルタ「before系」フィルタ以外に、アクションの実行後に実行されるフィルタや、実行前実行後の両方で実行されるフィルタを使うこともできる。
「after系」フィルタは「before系」フィルタと似ているが、「after系」フィルタの場合アクションは既に実行済みであり、クライアントに送信されようとしている応答データにアクセスできる点が「before系」フィルタとは異なる。当然ながら、「after系」フィルタをどのように書いても、アクションの実行が中断するようなことはない。ただし、「after系」フィルタは、アクションが成功した後にしか実行されず、リクエストサイクルの途中で例外が発生した場合は実行されないのでご注意する。
「around系」フィルタを使う場合は、フィルタ内のどこかで必ず
yieldを実行して、関連付けられたアクションを実行してやる義務が生じます。これはRackミドルウェアの動作と似ている。たとえば、何らかの変更に際して承認ワークフローがあるWebサイトを考えてみる。管理者はこれらの変更内容を簡単にプレビューし、トランザクション内で承認できるとする。
class ChangesController < ApplicationController around_action :wrap_in_transaction, only: :show private def wrap_in_transaction ActiveRecord::Base.transaction do begin yield ensure raise ActiveRecord::Rollback end end end end「around系」フィルタの場合、画面出力 (レンダリング) もその作業に含まれることにご注意する。特に上の例では、ビュー自身がデータベースから (スコープなどを使って) 読み出しを行うとすると、その読み出しはトランザクション内で行われ、データがプレビューに表示される。
あえて
yieldを実行せず、自分でレスポンスをビルドするという方法もある。この場合、アクションは実行されない。9. リクエストフォージェリからの保護
- 投稿日:2020-10-18T11:01:07+09:00
git add .した後にgit statusするとChanges not staged for commit:と出る時の対処法
内容
GitHubにcommitしようと思いgit add . をしてgit status で確認したところ、"Changes not staged for commit:"と出てうまく反映されてなかった
実際出たエラー内容
$ git add . $ git status On branch login Changes to be committed: (use "git reset HEAD <file>..." to unstage) modified: app/controllers/users_controller.rb modified: db/mysql/volumes/ib_logfile0 modified: db/mysql/volumes/ibdata1 modified: db/mysql/volumes/ibtmp1 modified: db/mysql/volumes/myapp_test/users.ibd modified: db/mysql/volumes/mysql/innodb_index_stats.ibd modified: db/mysql/volumes/mysql/innodb_table_stats.ibd modified: spec/requests/users_signup_spec.rb Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: db/mysql/volumes/ibdata1解決方法
このエラーの場合"db/mysql/volumes/ibdata1"がうまくステージされてないよと言われているので,ファイル名を指定してgit addコマンドを実行する
$ git add db/mysql/volumes/ibdata1 $ git status On branch login Changes to be committed: (use "git reset HEAD <file>..." to unstage) modified: app/controllers/users_controller.rb modified: db/mysql/volumes/ib_logfile0 modified: db/mysql/volumes/ibdata1 modified: db/mysql/volumes/ibtmp1 modified: db/mysql/volumes/myapp_test/users.ibd modified: db/mysql/volumes/mysql/innodb_index_stats.ibd modified: db/mysql/volumes/mysql/innodb_table_stats.ibd modified: spec/requests/users_signup_spec.rbちゃんと反映されました!
最後に
コミットはこまめに行うので、エラーが出たら焦らず対処していきたいです。
- 投稿日:2020-10-18T09:59:32+09:00
Rails Tutorial 拡張機能の返信機能を作ってみた(その2):modelの変更
Rails Tutorialをの第14章にある、返信機能を作る件で、前回の続きです。
コーディングの作業でやることを洗い出す
やる作業をおさらいして洗い出します。
・gitでbranchを作る
・testを作る
model、integrationmodelに列を追加
modelの列の追加はどうやってやるかテキストで探します。
9.1.1でmigrateで列を追加していたことが分かります。modelでreplyによる表示の有無をどう作るか考えます。改めて仕様を見ます。
@replyは受信者のフィードと送信者のフィードにのみ表示されるようにします。
表示する人で3つに分けて考えます。
1 送信者、2 受信者、3.第3者(送信者でも受信者でもない)1 送信者
自分がpostしたmicropostなので、今の機能でも表示されます。
2 受信者
受信者が送信者をフォローしている場合と、していない場合の2つが考えられます。
受信者が送信者をフォローしている場合は、今の機能でも表示されます。
受信者が送信者をフォローしていない場合は、今の機能では表示されません。
ここに機能を追加する必要があると分かります。機能は、in_reply_toと自分が等しければ表示するです。
メソッドuser.micrpostsで返すところに変更を加える と考えたのですが、うまくいかないです。
自分がpostしたわけではないからです。
送信者を選んでその人のmicropostを返すのではないです。誰がpostしたかにかかわらず、
in_reply_toと自分が等しいmicropostを全部表示する機能です。思いついたこととして、micropostが増えるとパフォーマンスに問題が出てくるリスクが高いです。対策としてindexをつける必要がありそうです。
主キーで検索するのではなく、代替キーで検索するリスクだと理解しました。どう作るかに戻り、この実装方法なら、送信者をフォローしているかどうかにかかわらず表示してくれるので、その場合分けは不要だと分かりました。
次に、どのメソッドに機能を追加するか考えます。
リスト14.46を見たところ、Userモデルのfeedメソッドがよさそうです。
whereで条件を指定できそうです。3 第3者
第3者が受信者のフィード画面を表示すると、replyが表示されません。
上記の仕様で機能を作ると、表示されてしまいます。
なので表示されないような機能を追加する必要があります。
in_reply_toと自分が等しくなければ表示しないようにすればいいです。
user.micrpostsメソッドで返すところに変更を加えればよいと初めは考えました。
受信者のところでfeedメソッドがよさそうと上記のとおり分かったので、同じメソッドがよさそうと直観的に感じました。条件となるSELECT文
14.3.2をもう一度読みます。
micropostsテーブルから、あるユーザー (つまり自分自身) がフォローしているユーザーに対応するidを持つマイクロポストをすべて選択 (select) することです
をもとに考え、micropostsテーブルから、自分が受信者であるreplyをすべて選択 (select) することです。
SELECT * FROM microposts WHERE user_id IN (<list of ids>) OR user_id = <user id> OR in_reply_to = <user id>とすればよいと考えます。
リスト14.44は
def feed Micropost.where("user_id IN (?) OR user_id = ? OR in_reply_to = ?", following_ids, id,id) endでよさそうです。
これで仕様は押さえられたと判断し、作っていくことにします。
ブランチ作成
いつものようにブランチを作成します。
ubuntu:~/environment/sample_app (master) $ git checkout -b reply-micropostmodelに列を追加
modelに列を追加する方法をテキストから探します。
6.3.1 「ハッシュ化されたパスワード」で列を追加していました。同様に作ります。ubuntu:~/environment/sample_app (reply-micropost) $ rails generate migration add_reply_to_microposts in_reply_to:integerdb/migrate/20201003003147_add_reply_to_microposts.rbclass AddReplyToMicroposts < ActiveRecord::Migration[5.1] def change add_column :microposts, :in_reply_to, :integer end endmodelのテストを作成
次はmodelのテストを作ります。
13.1.2 Micropostのバリデーション と同じく進めます。
どのmodelのテストをするのかですが、micropostに列を追加したので、micropostと考えます。reply の送信者、受信者を踏まえ、replyのmicropostを作ります。
replyをするとfeed画面に表示されるテストは、ingegrationテストで行うことにします。その前にmodelのtestで何をテストするかを考えます。
replyで追加するメソッドの機能をテストする、として、CRUDのうちupdate,deleteはなさそうなので、replyをcreate、read、の2つが必要です。コンソールでやってみます。
>> user2.microposts.create!(content: "test2", in_reply_to: 1 ) >> user2.microposts.create!(content: "test3", in_reply_to: 1 ) >> Micropost.where(in_reply_to: 1) Micropost Load (0.2ms) SELECT "microposts".* FROM "microposts" WHERE "microposts"."in_reply_to" = ? ORDER BY "microposts"."created_at" DESC LIMIT ? [["in_reply_to", 1], ["LIMIT", 11]] => #<ActiveRecord::Relation [#<Micropost id: 304, content: "test3", user_id: 30, created_at: "2020-10-03 02:37:38", updated_at: "2020-10-03 02:37:38", picture: nil, in_reply_to: 1>, #<Micropost id: 303, content: "test2", user_id: 30, created_at: "2020-10-03 02:18:35", updated_at: "2020-10-03 02:18:35", picture: nil, in_reply_to: 1>]>今あるメソッドで十分だとすると、modelでは機能を追加しないのでテストも必要なさそうですが、一応書いてみます。
test/models/micropost_test.rbtest "reply should be returned" do @reply_post = @reply_sender.microposts.create!(content: "reply test1", in_reply_to: @user.id) assert Micropost.where(in_reply_to: @user.id).include?(@reply_post) endintegrationテストを作成
modelのテストが出来たので、次にintegrationテストを作ります。
テスト内容は、replyを1件作り、受信者のfeed画面に表示されることです。その前に、変更をどこに加えるのか考えます。controllerに変更を加えるので、その結果のテストも作る必要があると考えました。
まずはintegrationテストからやります。
参考になりそうなテストを探し、following_test.rbがよさそうです。
また、postするところは、microposts_interface_test.rbを元にコピーします。test/integration/reply_test.rb REDtest "reply to user " do log_in_as(@user) content = "@reply #{@other.name} Cum aspermatur" post microposts_path, params: { micropost: {content: content }} log_in_as(@other) get root_path assert_not @other.following?(@user) #get root_path assert_match content, response.body #assert_match content, response.body endfeedを変更
replyを表示するようにfeedに変更を加えます。
まずテストデータを作ります。fixtureにデータを追加します。
test/fixtures/microposts.ymltonton: content: "@reply malory tonton is the name of the panda." created_at: <%= Time.zone.now %> user: michaelfeedのテストはどこでやるかですが、userモデルに変更をするのでmodelのテストと考えます。
test/models/user_test.rb REDtest "feed should have the reply posts" do michael = users(:michael) malory = users(:malory) reply_post = microposts(:tonton) assert michael.feed.include?(reply_post) assert malory.feed.include?(reply_post) puts reply_post.content end endfeedを変更します。
app/models/user.rbdef feed following_ids = "SELECT followed_id FROM relationships WHERE follower_id = :user_id" Micropost.where("user_id IN (#{following_ids}) OR user_id = :user_id OR in_reply_to = reply_id", user_id: id, reply_id: id ) endtonton: content: "@reply malory tonton is the name of the panda." created_at: <%= Time.zone.now %> user: michael in_reply_to: <%= User.find_by(name: "Malory Archer").id %>feedを変更したことで、他のテストがエラー
feedを変更したことで、他のテストがエラーになりました。エラーメッセージを見ます。
ubuntu:~/environment/sample_app (reply-micropost) $ rails test test/models/micropost_test.rb Running via Spring preloader in process 2886 Started with run options --seed 405 FAIL["test_order_should_be_most_recent_first", MicropostTest, 0.5243559590000189] test_order_should_be_most_recent_first#MicropostTest (0.52s) --- expected +++ actual @@ -1 +1 @@ -#<Micropost id: 941832919, content: "Writing a short test", user_id: 762146111, created_at: "2020-10-10 01:35:16", updated_at: "2020-10-10 01:35:17", picture: nil, in_reply_to: nil> +#<Micropost id: 981300582, content: "@reply malory tonton is the name of the panda.", user_id: 762146111, created_at: "2020-10-10 01:35:17", updated_at: "2020-10-10 01:35:17", picture: nil, in_reply_to: 659682706> test/models/micropost_test.rb:33:in `block in <class:MicropostTest>' 6/6: [===================================================================================================] 100% Time: 00:00:00, Time: 00:00:00テストデータに問題があるとエラーメッセージに出ています。投稿時刻が最新のテストデータをfixtureにmost_recentとして作っていたのに、tontonがそれより投稿時刻が新しくしてしまっていたのが原因と考えます。投稿時刻を最新にする必要はないので、tontonの投稿時刻を直します。
test/fixtures/microposts.yml 変更前tonton: content: "@reply malory tonton is the name of the panda." created_at: <%= Time.zone.now %> user: michaeltest/fixtures/microposts.yml 変更後tonton: content: "@reply malory tonton is the name of the panda." created_at: <%= 2.minutes.ago %> user: michael in_reply_to: <%= User.find_by(name: "Malory Archer").id %>無事直りました。
画面で表示して確認
@replyが書いてあるmicropostがページに表示されることを確かめます。
リスト 13.25:「サンプルデータにマイクロポストを追加する」を参考にサンプルトデータを作ります。db/seeds.rb# reply sender = users.first reciever = users.second reply_content = "@reply #{receiver.name} reply test" sender.microposts.create!(content: reply_content, in_reply_to: receiver.id )rails serverを上げて画面を表示すると、replyのmicropostが表示されていることが確かめられました。
所要時間
10/2から10/10までの7.0時間です。
- 投稿日:2020-10-18T09:02:53+09:00
【Rails】rails s が反応しない、止まらないときの対処法
たまにこの現象が起きるので、備忘としてメモ。
Rails始めたてで同じ状況に陥った方の助けになれば幸いです。事象
ローカルサーバーを立ち上げてchromeで動作確認しながらアプリ制作中…
不安定だなあと思って健気に待っていたら、localhost:3000のタブだけ止まっていることに気づく。
ターミナルでcontrol + cを試しても反応しない…なんだこれは…
強制終了するのも恐いしどうしたもんだろうか。
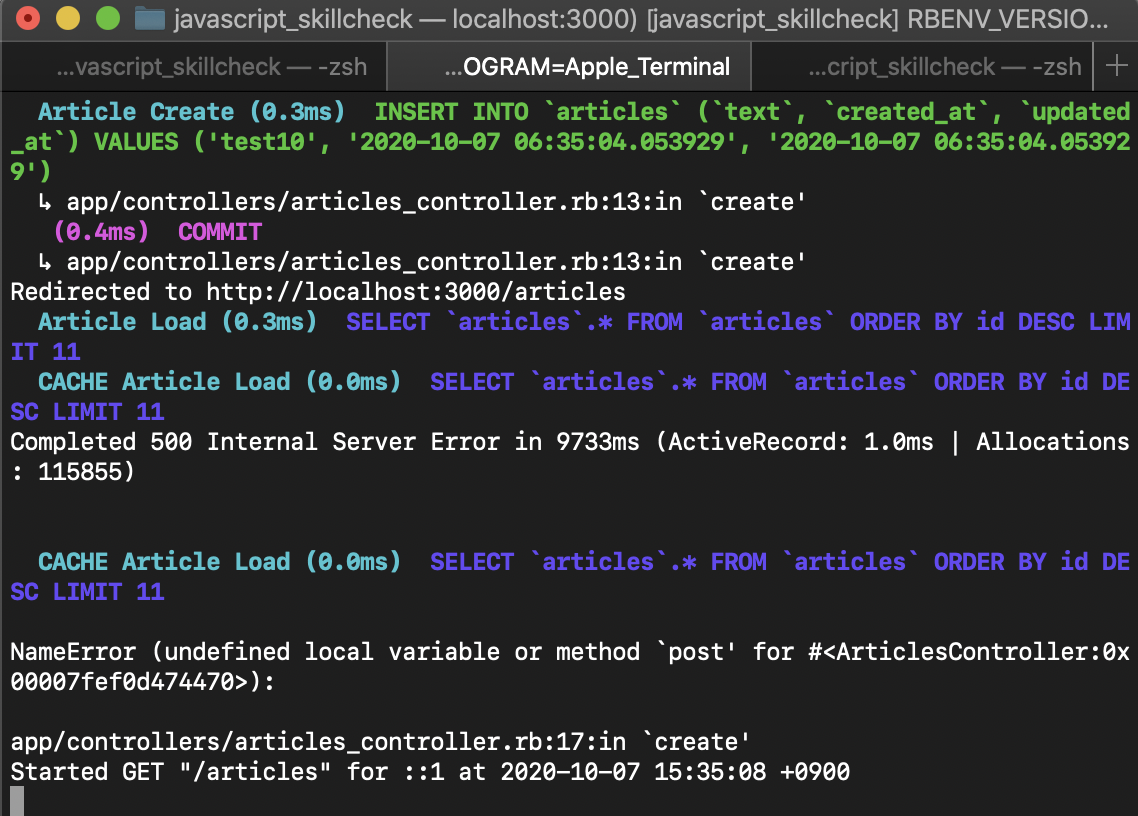
/articlesを読み込んでる図
対処法
- rubyのPIDを確認
- rubyのPIDを止める
1. rubyのPIDを確認する
lsofコマンドで、ポート番号3000で動いている処理を確認する。
↓lsof -i:3000の結果(実際はUSER以降の列にも出力があります)daikimorita@daikinoMacBook-Pro javascript_skillcheck % lsof -i:3000 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME Google xxxx localhost:55103->localhost:hbci (ESTABLISHED) ruby xxxxx localhost:hbci (LISTEN) ruby xxxxx localhost:hbci (LISTEN) ruby xxxxx localhost:hbci->localhost:54631 (CLOSE_WAIT) ruby xxxxx localhost:hbci->localhost:54636 (CLOSE_WAIT) ruby xxxxx localhost:hbci->localhost:54655 (CLOSE_WAIT) ruby xxxxx localhost:hbci->localhost:54656 (CLOSE_WAIT) ruby xxxxx localhost:hbci->localhost:54659 (CLOSE_WAIT) ruby xxxxx localhost:hbci->localhost:55103 (ESTABLISHED)rubyのPIDは xxxxx(数字が入ります) と表示されている。これを止めたい。
何行も出てるのは、私がcontrol + cを何度も押したせいです笑2. rubyのPIDを止める
下記のコマンドを実行します。
kill -9 xxxxx結果
「
rails sを実行しているターミナルのタブ」を見ると、killedの表示が出ていて、スタンバイ状態になってます。zsh: killedもう一度
rails sで立ち上げてみると、無事にchromeでページが表示されました。解決!参考記事
- 投稿日:2020-10-18T00:39:39+09:00
【Rails】画面からアップロードされたXMLファイルをHash型で読み込む方法
Rails(5系)を使ったアプリケーションで、画面からアップロードされたXMLファイルをHash型で読み込みたい場合の実装例です。
アップロードするXMLファイル
今回は検証用に以下のXMLファイルを使用
<?xml version="1.0" encoding="UTF-8"?> <items> <item>AAA</item> <item>BBB</item> <item>CCC</item> </items>html.erbの記述
適当にファイルとボタンタグを配置します。(デザイン・スタイルはお好みでどうぞ!)
<%= form_tag xxx_path, multipart: true do %> <label>XMLファイルの読み込み</label> <div class="row"> <div class="col-sm-2"> <%= file_field_tag :file, class: 'btn btn-primary' %> </div> </div> <div class="row"> <div class="col-sm-4"> <%= submit_tag '送信', class: 'btn btn-primary' %> </div> </div> <% end %>Controller.rbの記述
xml = REXML::Document.new(File.new(params[:file].path).read) xml_h = Hash.from_xml(xml.to_s)上記の結果以下のようなHash形式でファイルの中身を取得できます。
{"items"=>{"item"=>["AAA", "BBB", "CCC"]}}
- 投稿日:2020-10-18T00:11:38+09:00
Active StrageをRSpecでテスト
はじめに
Active Strageを使用し、画像投稿ができるアプリを制作中です。
その際のテストの書き方の例を紹介します。factories
FactoryBot.define do factory :post do ... trait :post_image do image { fixture_file_upload("app/assets/images/XXX.PNG") } end ...letを定義
let(定義名) { 定義の内容 } let(:post_image) { FactoryBot.create(:post_image) }使用する(例)
post = FactoryBot.create(:post,:post_image)参考にさせて頂いたサイト
https://qiita.com/maca12vel/items/ee4d16827f24f69080ae
https://shuttodev.hatenablog.com/entry/2019/09/04/015756
- 投稿日:2020-10-18T00:10:59+09:00
[Rails] ActiveStorageを使ってpostsにアバターを表示
やりたいこと
Posts#index(以下タイムライン)にアバターやユーザー名を表示したい
前提
devise導入
ActiveStorage導入
アバターをusersモデルに追加やり方
postsモデルに
:avatarのhas_one_attachedとuserインスタンスメソッドを追加post.rbclass Post < ApplicationRecord validates :content, {presence: true, length: {maximum: 140}} validates :user_id, {presence: true} has_one_attached :avatar def user return User.find_by(id: self.user_id) end endviewに.userを追加
index.html.erb<% @posts.each do |post| %> <div class="posts-index-item mb-20"> <div class="posts-index-user"> <!--avatar--> <div class="posts-index-img d-inline"> <% if post.user.avatar.attached? %> <%= image_tag post.user.avatar, class: "avatar-index rounded-circle mx-auto" %> <% else %> <img class="avatar-index rounded-circle mx-auto" src="<%= "/images/default_user.png" %>" alt="Userimage"> <% end %> </div> <!--username--> <div class="posts-index-username d-inline"> <%= link_to post.user.username, users_show_path %> </div> </div> <!--content--> <%= link_to(post.content, "/posts/#{post.id}") %> </div> <% end %>結果
まとめ
userメソッドによってparamsの使えないposts#indexでもUserモデルを扱える。
⇒post.user.avatarによりUserモデルに紐づいた:avatarを取り扱える
- 投稿日:2020-10-18T00:00:59+09:00
【0からAWSに挑戦】①EC2とVPCを使ってRailsアプリをAWSにデプロイする part1
背景
未経験から自社開発系企業の就職を目指します。良質なポートフォリオ作成のためAWSを勉強することにしました。
現状の知識レベルとしては、Ruby on railsを使って簡単なアプリケーション開発、gitを使ったバージョン管理、herokuを使ってデプロイできるレベルです。自分の忘備録かつ、同じくらいのレベルでこれからAWSに挑戦してみようと思っている方に向けて少しでも役に立てればと思います。
最終目標
AWSのEC2とVPCを使ってアプリケーションを本番環境で動かすことが目標です。
環境
・Ruby on Rails 6.0
・Ruby 2.6.6
・dbはmysqlを使用
・アプリケーションサーバはpumaを使用
・webサーバーはnginxを使用手順
今回は下記手順で進めたいと思います。
①VPCを作成
②VPC内にサブネットを作成
③インターネットゲートウェイ・セキュリティグループ・ルートテーブルの設定
④EC2を作成
⑤EC2にrails環境を構築、gitからアプリをpullするでは早速はじめましょう。
※大前提ですが、すでにAWSの登録は完了しているという前提で進めます。EC2とVPCを使ってRailsアプリをAWSにデプロイする part1
①VPCを作成
そもそもVPCとは何かというと、(Virtual Private Cloud)の略で、ユーザー専用のクラウド環境を作ることができるものです。VPCの領域を定義することで、そのVPC内で好きなようにネットワークを構成したり、サーバーを立ち上げることができます。
AWS内のサービスメニューで「VPC」と検索するとすぐ出てくると思います。検索したら左のメニューバーからVPCを選択し、VPCの作成を選びましょう。そうしたら下記画面が出てくるはずです。
※リージョンは「東京」を選択しています。リージョンとはデータセンター群のある地域のことで、右上のヘッダーから選択できます。
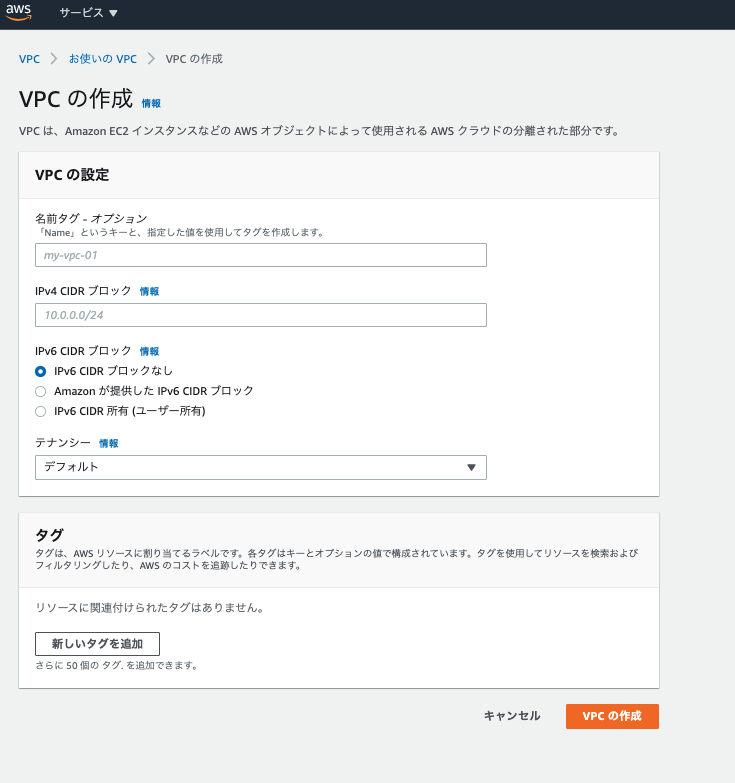
簡単に説明します
- 名前タグに関しては、vpcの名前の名前になるのでわかりやすい名前を設定しましょう。
- CIDRブロックとは、VPCのIPアドレスの範囲に関する設定です。VPCで使うのはプライベートIPですので、ある程度自由にIPの範囲を設定できます。入力欄に見本として「10.0.0.0/24」書かれていますが、「/24」の部分はCIDER表記になります。IPアドレスはネットワーク部とホスト部の2つ、合計32ビットで表記されます。CIDER表記の、「/24」はそのうちのネットワーク部の占めるビット数の割合です。ホスト部が多いほど任意に設定できる値が増えます。基本は「/24」か「/16]でよいでしょう。今回は「10.0.0.0/16」で進めます。
- その他はデフォルトのままで問題ありません。
これだけでVPC空間出来上がりです。
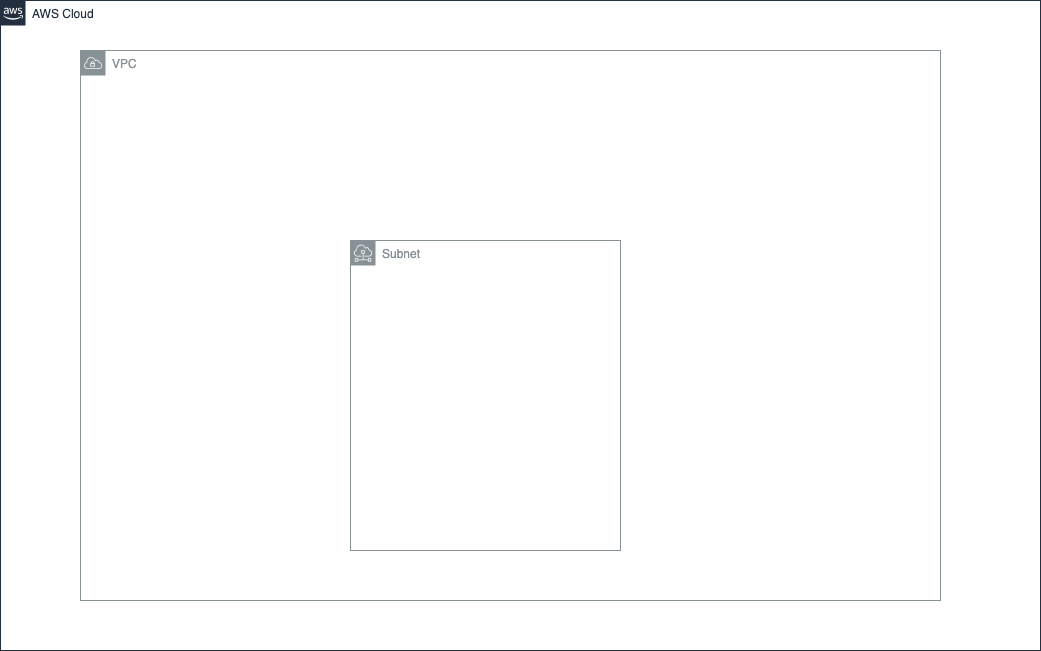
②VPC内にサブネットを作成
サブネットとはVPCのCIDRブロックを細分化したものです。もっと砕けていうと、VPCの内にいくつかの部屋を作るイメージです。例えばWEBサーバー用の部屋、データベース用の部屋みたいな感じです。通常VPCはサブネットを使って、細分化して運用します。下記のようなイメージです。
ではサブネットをつくりましょう。
左側のサイドメニューからサブネットを選択し、サブネットの作成をクリックしましょう。そうすると下記のような画面がでるはずです。
- 名前タグはサブネットの名前になります。わかりやすい名前をつけましょう。
- VPCは先程作ったVPC領域が選択できるようになっていると思うのでそれを選択してください。
- アベイラビリティゾーンとはリージョンの中に存在するデータセンターのことです。リージョンには複数のデータセンター(アベイラビリティゾーン)があります。今回で言えば東京リージョンのどのデータセンターを使うか指定します。ただ指定なしを選択すると勝手に適切なアベイラビリティゾーンを選択してくれるので、今回は指定なしでいきます。
- そして最後に再び、CIDRブロックがでてきましたが、これはVPC領域「10.0.0.0/16」の中のIPアドレスの範囲を指定します。今回は「10.0.1.0/24]を指定します。
以上でサブネットの構築は完了です。
③インターネットゲートウェイ・セキュリティグループ・ルートテーブルの設定
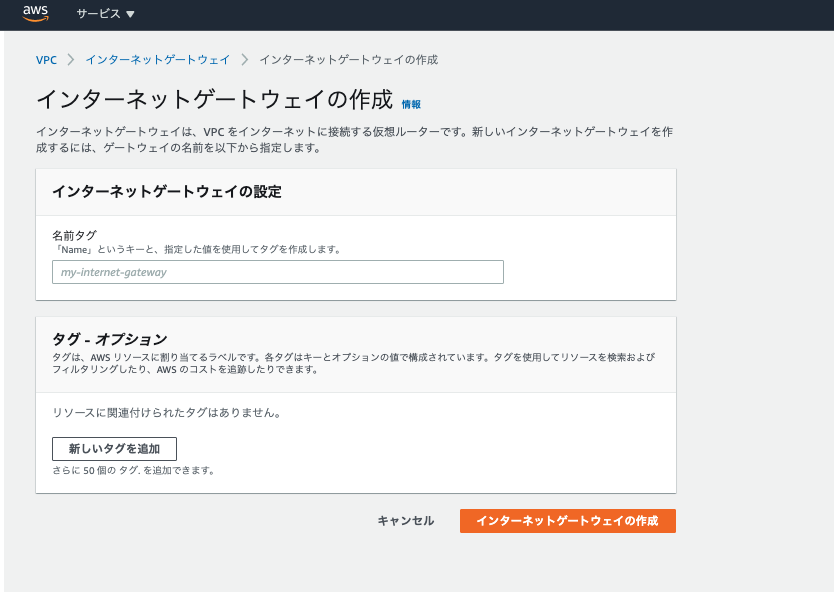
インターネットゲートウェイ
インターネットゲートウェイとはその名の通り、インターネットでやり取りするための出入り口です。VPCはプライベートな空間なので、VPC内でやり取りはできるものの、そのままではインターネットに接続できません。なのでインターネットでやり取りができるような設定が必要です。左側のサイドメニューからインターネットゲートウェイを選択しましょう
こちらは名前を設定するだけで大丈夫です。これでインターネットゲートウェイは作成できたのですが、この作成できたインターネットゲートウェイをVPCと結びつける必要があります。ただ紐付けは簡単です。作成後の画面の上の方にアクションボタンをクリック→VPCにアタッチをクリック→先程作成したVPCを選択→インターネットゲートウェイのアタッチ。
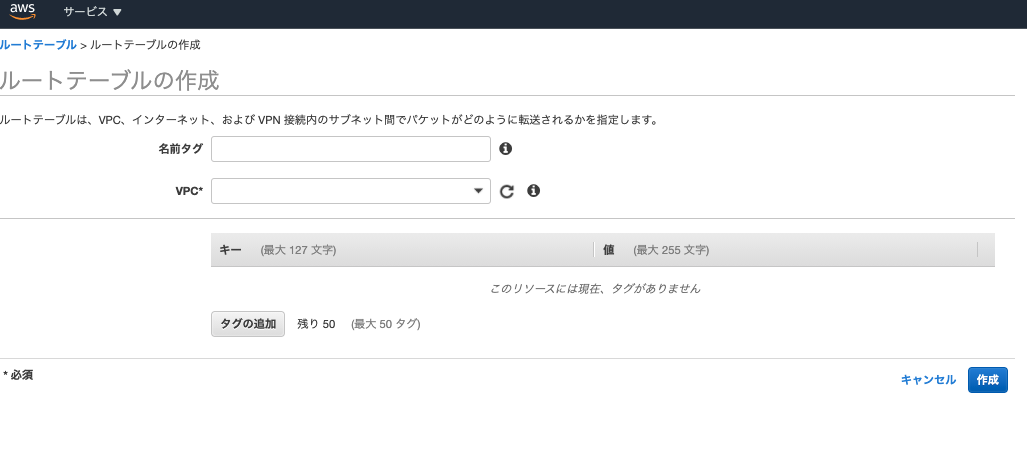
これで完了です。ルートテーブル
これはrails勉強した人なら、「AWS界のルーティング」といえばわかると思います。送られてきたデータはルートテーブルを基に振り分けられます。
もう少し具体的な内容で説明すると、インターネットで使われる「TCP/IP」(ネットワークをする際の規格・ルール)ではパケットという単位でデータのやりとりをします。そのパケットには宛先IPアドレスの情報が書かれています。その宛先IPアドレスを基にルーターが次々に宛先に近いネットワークへとパケットを転送することで、最終的に目的地までデータを届けることができるのです。逆にルーターが、どの宛先IPアドレスがきたときどこに転送すればいいかわからないと困りますよね。そこでルートテーブルに設定を記載するのです。すなわちルートテーブルとは、「どの宛先IPアドレスがきたとき、どこにデータを送るかを記したメモ」です。それではルートテーブル作成しましょう。左のサイドメニューからルートテーブルを選択しましょう。するとすでにルートテーブルが存在しています。実はサブネットを作成したときに、デフォルトのルートテーブルが作成されるのです。ちなみにデフォルトのルートテーブルの意味は「送信先(宛先IPアドレス)が10.0.0.0/16(VPC領域)であれば、ローカルのネットワークにデータを転送する」という意味になります。(下記参照)
ただこのままではインターネットと通信ができません。そこでインターネットゲートウェイへ転送する設定のルートテーブルを作成しましょう。ルートテーブル作成ボタンをクリックしてください。ここは名前を入力しと先ほど作ったVPCを選択して完了です。
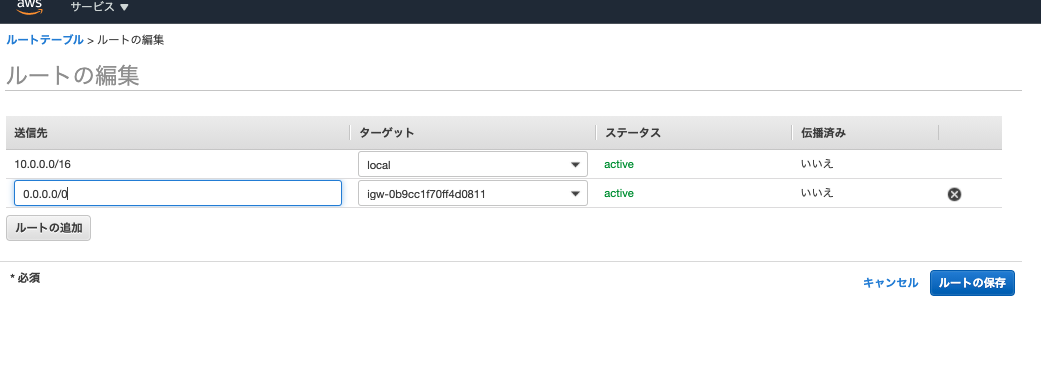
そして次に作成したルートテーブルの設定と先程作ったサブネットを紐付けが必要です。先程作ったルートテーブルを選択すると下の方にそのルートテーブルの詳細メニューが表示されます。まずはルートを選択しルートの追加ボタンを押しましょう。そして送信先を0.0.0.0/0にし、ターゲットをINTERNET GATEWAYにすればOKです。(INTERNET GATEWAYを選択するとidが勝手にでてきます)
次にサブネットの関連付けです。サブネットの関連付けを選択し、サブネットの関連付けの編集ボタンを押しましょう。先ほど作成したサブネットを選択肢完了です。
以上でインターネットと通信できるルートテーブルの設定が完了しました。セキュリティグループ
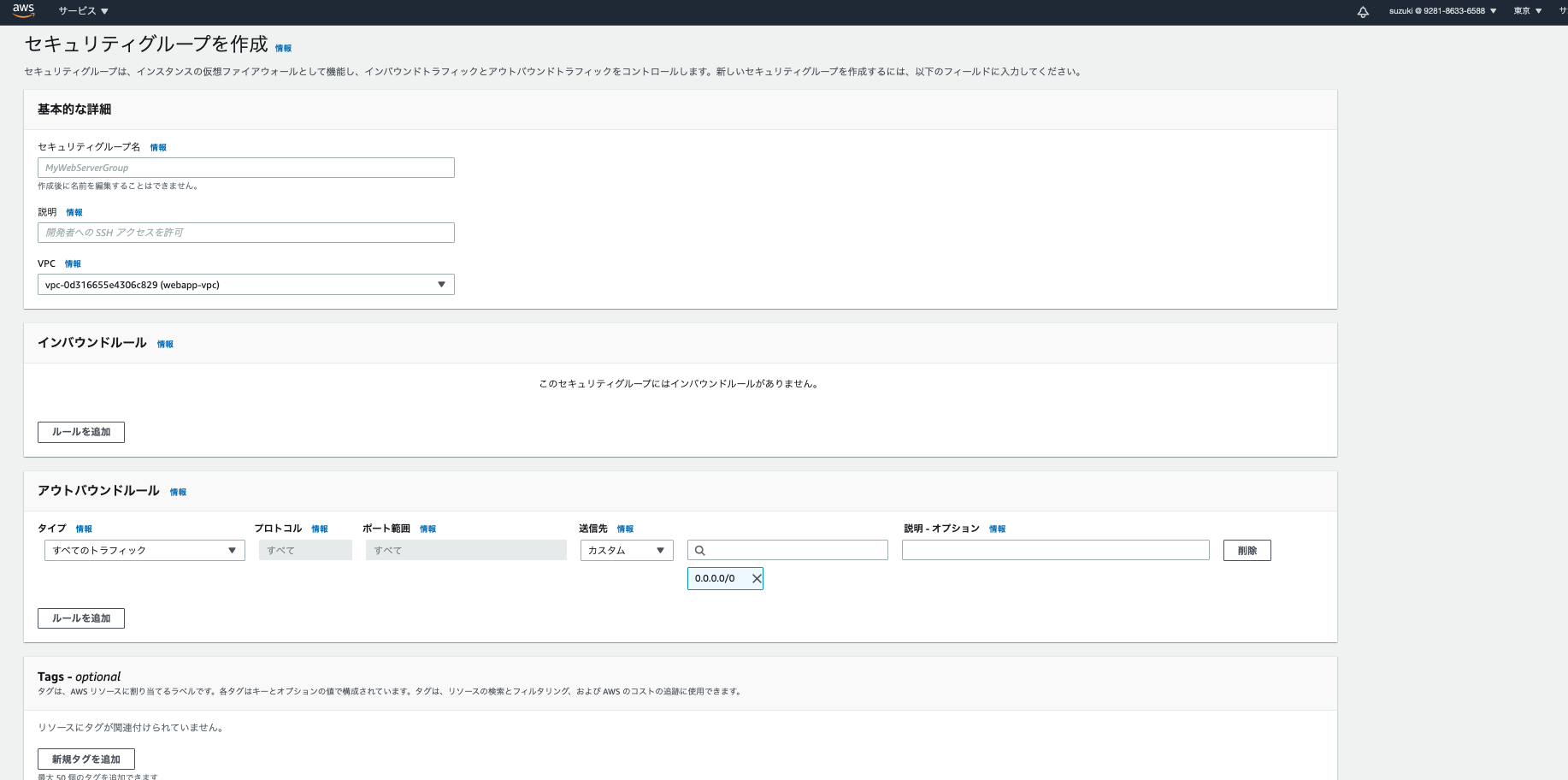
セキュリティグループはその名の通りセキュリティに関する設定です。通信の種類によって通信するか、拒否するかを設定できます。早速作成しましょう。左のサイドメニューからセキュリティグループを選択肢、セキュリティグループを作成を選択します。そうすると下記画面がでてくると思います。
- セキュリティグループ名・説明はわかりやすい名称を入れてください。
- VPCは先程作成したものを選択してください。
- インバウンドルールは簡単にいうと受信の設定です。ここには{タイプ:SSH 送信先:マイIP}、{タイプ:HTTP 送信先:任意の場所}を選択してください(※それ以外の欄は自動入力されます)。これでSSHとHTTPの通信が受信できるようになりました。
- アウトバウンドルールは簡単にいうと送信の設定です。ここはデフォルトのままでOKです
以上でセキュリティグループの設定完了です。
少し長くなってしまったので④と⑤は次回の記事に書きます。(④と⑤が重いので、、、、)
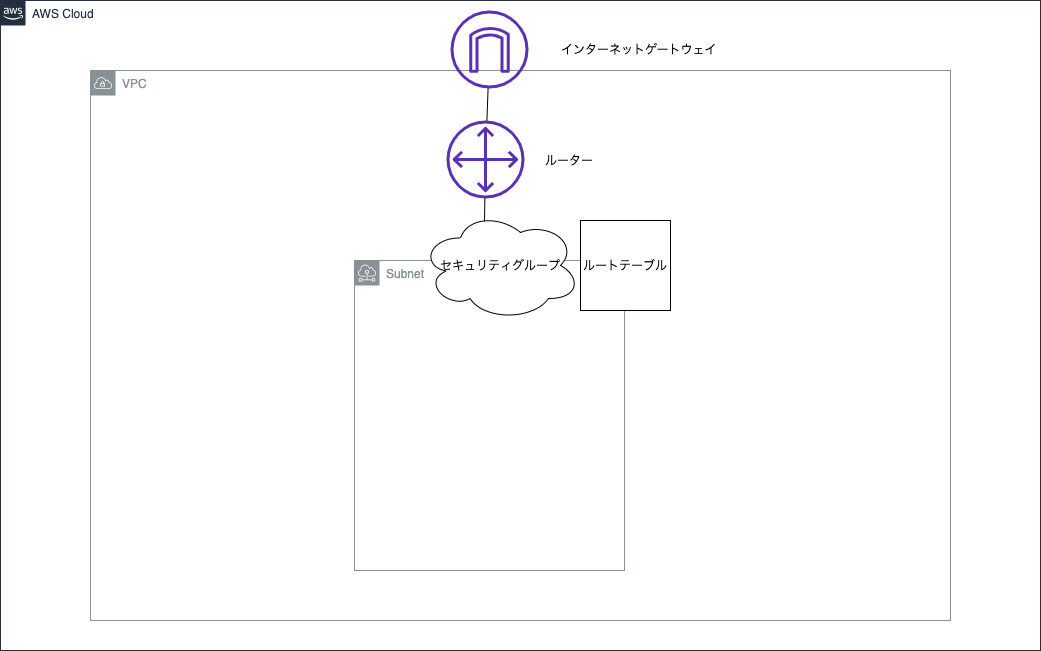
ここまででネットワークの構成は下記の用になっているはずです。※ヘタですいません
次回はサブネットの中にEC2を作成していきたいと思います。感想・まとめ
ここに関しては、「Amazon Web Services 基礎からのネットワーク&サーバー構築」という図書をみながらやった結果非常にスムーズにいきました。ネットワークの知識もつけたし、AWSでネットワークやサーバー構築する際の流れもなんとなくわかりました。ただネットワーク関連はまだ知識が浅いので別途勉強が必要だなとも思いました。
参考
「Amazon Web Services 基礎からのネットワーク&サーバー構築 改訂3版 著 大澤文孝,玉川憲,片山暁雄,今井雄太」
→おすすめの本です。AWSだけでなくネットワーク知識についても触れているので、初学者にとっては神技術書です。(下準備編)世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまで
→こちらもわかりやすくてよかったです。AWSの内容は「Amazon Web Services 基礎からのネットワーク&サーバー構築」とほとんど同じです。なのでこちらだけでAWSやってみるのもありかと思います。ただネットワーク知識が浅い人やインフラ初心者は最初に「Amazon Web Services 基礎からのネットワーク&サーバー構築」にやってネットワーク知識補充しながらやらないと苦労すると思います※本記事は上記2つを参考にさせていただきながら実装しています。
なので実装に関しては類似箇所も多いかと思いますが、WEBサーバーの種類・DBのバージョンなどの構成などはもちろん自分なりにアレンジしています。




- 投稿日:2020-10-18T00:00:59+09:00
【0からAWSに挑戦】EC2とVPCを使ってRailsアプリをAWSにデプロイする part1
背景
未経験から自社開発系企業の就職を目指します。良質なポートフォリオ作成のためAWSを勉強することにしました。
現状の知識レベルとしては、Ruby on railsを使って簡単なアプリケーション開発、gitを使ったバージョン管理、herokuを使ってデプロイできるレベルです。自分の忘備録かつ、同じくらいのレベルでこれからAWSに挑戦してみようと思っている方に向けて少しでも役に立てればと思います。
最終目標
AWSのEC2とVPCを使ってアプリケーションを本番環境で動かすことが目標です。
環境
・Ruby on Rails 6.0
・Ruby 2.6.6
・dbはmysqlを使用
・アプリケーションサーバはpumaを使用
・webサーバーはnginxを使用手順
今回は下記手順で進めたいと思います。
①VPCを作成
②VPC内にサブネットを作成
③インターネットゲートウェイ・セキュリティグループ・ルートテーブルの設定
④EC2を作成
⑤EC2にrails環境を構築、gitからアプリをpullするでは早速はじめましょう。
※大前提ですが、すでにAWSの登録は完了しているという前提で進めます。EC2とVPCを使ってRailsアプリをAWSにデプロイする part1
①VPCを作成
そもそもVPCとは何かというと、(Virtual Private Cloud)の略で、ユーザー専用のクラウド環境を作ることができるものです。VPCの領域を定義することで、そのVPC内で好きなようにネットワークを構成したり、サーバーを立ち上げることができます。
AWS内のサービスメニューで「VPC」と検索するとすぐ出てくると思います。検索したら左のメニューバーからVPCを選択し、VPCの作成を選びましょう。そうしたら下記画面が出てくるはずです。
※リージョンは「東京」を選択しています。リージョンとはデータセンター群のある地域のことで、右上のヘッダーから選択できます。
簡単に説明します
- 名前タグに関しては、vpcの名前の名前になるのでわかりやすい名前を設定しましょう。
- CIDRブロックとは、VPCのIPアドレスの範囲に関する設定です。VPCで使うのはプライベートIPですので、ある程度自由にIPの範囲を設定できます。入力欄に見本として「10.0.0.0/24」書かれていますが、「/24」の部分はCIDER表記になります。IPアドレスはネットワーク部とホスト部の2つ、合計32ビットで表記されます。CIDER表記の、「/24」はそのうちのネットワーク部の占めるビット数の割合です。ホスト部が多いほど任意に設定できる値が増えます。基本は「/24」か「/16]でよいでしょう。今回は「10.0.0.0/16」で進めます。
- その他はデフォルトのままで問題ありません。
これだけでVPC空間出来上がりです。
②VPC内にサブネットを作成
サブネットとはVPCのCIDRブロックを細分化したものです。もっと砕けていうと、VPCの内にいくつかの部屋を作るイメージです。例えばWEBサーバー用の部屋、データベース用の部屋みたいな感じです。通常VPCはサブネットを使って、細分化して運用します。下記のようなイメージです。
ではサブネットをつくりましょう。
左側のサイドメニューからサブネットを選択し、サブネットの作成をクリックしましょう。そうすると下記のような画面がでるはずです。
- 名前タグはサブネットの名前になります。わかりやすい名前をつけましょう。
- VPCは先程作ったVPC領域が選択できるようになっていると思うのでそれを選択してください。
- アベイラビリティゾーンとはリージョンの中に存在するデータセンターのことです。リージョンには複数のデータセンター(アベイラビリティゾーン)があります。今回で言えば東京リージョンのどのデータセンターを使うか指定します。ただ指定なしを選択すると勝手に適切なアベイラビリティゾーンを選択してくれるので、今回は指定なしでいきます。
- そして最後に再び、CIDRブロックがでてきましたが、これはVPC領域「10.0.0.0/16」の中のIPアドレスの範囲を指定します。今回は「10.0.1.0/24]を指定します。
以上でサブネットの構築は完了です。
③インターネットゲートウェイ・セキュリティグループ・ルートテーブルの設定
インターネットゲートウェイ
インターネットゲートウェイとはその名の通り、インターネットでやり取りするための出入り口です。VPCはプライベートな空間なので、VPC内でやり取りはできるものの、そのままではインターネットに接続できません。なのでインターネットでやり取りができるような設定が必要です。左側のサイドメニューからインターネットゲートウェイを選択しましょう
こちらは名前を設定するだけで大丈夫です。これでインターネットゲートウェイは作成できたのですが、この作成できたインターネットゲートウェイをVPCと結びつける必要があります。ただ紐付けは簡単です。作成後の画面の上の方にアクションボタンをクリック→VPCにアタッチをクリック→先程作成したVPCを選択→インターネットゲートウェイのアタッチ。
これで完了です。ルートテーブル
これはrails勉強した人なら、「AWS界のルーティング」といえばわかると思います。送られてきたデータはルートテーブルを基に振り分けられます。
もう少し具体的な内容で説明すると、インターネットで使われる「TCP/IP」(ネットワークをする際の規格・ルール)ではパケットという単位でデータのやりとりをします。そのパケットには宛先IPアドレスの情報が書かれています。その宛先IPアドレスを基にルーターが次々に宛先に近いネットワークへとパケットを転送することで、最終的に目的地までデータを届けることができるのです。逆にルーターが、どの宛先IPアドレスがきたときどこに転送すればいいかわからないと困りますよね。そこでルートテーブルに設定を記載するのです。すなわちルートテーブルとは、「どの宛先IPアドレスがきたとき、どこにデータを送るかを記したメモ」です。それではルートテーブル作成しましょう。左のサイドメニューからルートテーブルを選択しましょう。するとすでにルートテーブルが存在しています。実はサブネットを作成したときに、デフォルトのルートテーブルが作成されるのです。ちなみにデフォルトのルートテーブルの意味は「送信先(宛先IPアドレス)が10.0.0.0/16(VPC領域)であれば、ローカルのネットワークにデータを転送する」という意味になります。(下記参照)
ただこのままではインターネットと通信ができません。そこでインターネットゲートウェイへ転送する設定のルートテーブルを作成しましょう。ルートテーブル作成ボタンをクリックしてください。ここは名前を入力しと先ほど作ったVPCを選択して完了です。
そして次に作成したルートテーブルの設定と先程作ったサブネットを紐付けが必要です。先程作ったルートテーブルを選択すると下の方にそのルートテーブルの詳細メニューが表示されます。まずはルートを選択しルートの追加ボタンを押しましょう。そして送信先を0.0.0.0/0にし、ターゲットをINTERNET GATEWAYにすればOKです。(INTERNET GATEWAYを選択するとidが勝手にでてきます)
次にサブネットの関連付けです。サブネットの関連付けを選択し、サブネットの関連付けの編集ボタンを押しましょう。先ほど作成したサブネットを選択肢完了です。
以上でインターネットと通信できるルートテーブルの設定が完了しました。セキュリティグループ
セキュリティグループはその名の通りセキュリティに関する設定です。通信の種類によって通信するか、拒否するかを設定できます。早速作成しましょう。左のサイドメニューからセキュリティグループを選択肢、セキュリティグループを作成を選択します。そうすると下記画面がでてくると思います。
- セキュリティグループ名・説明はわかりやすい名称を入れてください。
- VPCは先程作成したものを選択してください。
- インバウンドルールは簡単にいうと受信の設定です。ここには{タイプ:SSH 送信先:マイIP}、{タイプ:HTTP 送信先:任意の場所}を選択してください(※それ以外の欄は自動入力されます)。これでSSHとHTTPの通信が受信できるようになりました。
- アウトバウンドルールは簡単にいうと送信の設定です。ここはデフォルトのままでOKです
以上でセキュリティグループの設定完了です。
少し長くなってしまったので④と⑤は次回の記事に書きます。(④と⑤が重いので、、、、)
ここまででネットワークの構成は下記の用になっているはずです。※ヘタですいません
次回はサブネットの中にEC2を作成していきたいと思います。感想・まとめ
ここに関しては、「Amazon Web Services 基礎からのネットワーク&サーバー構築」という図書をみながらやった結果非常にスムーズにいきました。ネットワークの知識もつけたし、AWSでネットワークやサーバー構築する際の流れもなんとなくわかりました。ただネットワーク関連はまだ知識が浅いので別途勉強が必要だなとも思いました。
参考
「Amazon Web Services 基礎からのネットワーク&サーバー構築 改訂3版 著 大澤文孝,玉川憲,片山暁雄,今井雄太」
→おすすめの本です。AWSだけでなくネットワーク知識についても触れているので、初学者にとっては神技術書です。(下準備編)世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまで
→こちらもわかりやすくてよかったです。AWSの内容は「Amazon Web Services 基礎からのネットワーク&サーバー構築」とほとんど同じです。なのでこちらだけでAWSやってみるのもありかと思います。ただネットワーク知識が浅い人やインフラ初心者は最初に「Amazon Web Services 基礎からのネットワーク&サーバー構築」にやってネットワーク知識補充しながらやらないと苦労すると思います※本記事は上記2つを参考にさせていただきながら実装しています。
なので実装に関しては類似箇所も多いかと思いますが、WEBサーバーの種類・DBのバージョンなどの構成などはもちろん自分なりにアレンジしています。
- 投稿日:2020-10-18T00:00:04+09:00
データベースの操作(SQL編)
データベースの操作 ~SQL編~
- SQLの使用方法を知る
- データベースの基本的な操作を理解
- テーブルの基本的な操作を理解
ターミナルでの使用方法
ターミナル# ホームディレクトリに戻る % cd # MySQLに接続 % mysql -u rootSequel Proでの使用方法
Sequel Proを使用してログインする際は、下記のように入力
ターミナルで以下のSQLを実行
ターミナルmysql> CREATE DATABASE sqltest;MySQLで以下のSQL文を実行
ターミナルmysql> SHOW DATABASES;データベースを削除
ターミナルmysql> DROP DATABASE sqltest;データベースを指定
データベースを作成して、選択
ターミナルmysql> CREATE DATABASE sqltest; Query OK, 1 row affected (0.00 sec)コマンドでテーブルを作成
ターミナルmysql> CREATE TABLE goods (id INT, name VARCHAR(255));作成したテーブルを表示
ターミナルmysql> SHOW TABLES;テーブルの構造を確認
ターミナルmysql> SHOW columns FROM goods;カラムを追加
ターミナルmysql> ALTER TABLE goods ADD (price int, zaiko int);カラムを変更
ターミナルmysql> ALTER TABLE goods CHANGE zaiko stock int;カラムを削除
ターミナルmysql> ALTER TABLE goods DROP stock;現場からは以上です!
