- 投稿日:2020-10-18T23:37:11+09:00
行政データや複数APIを使って写真サイトを立ち上げて学んだこと
経済産業省のプロジェクト「FIND/47」の写真(2次利用OK)を利用し、NTTのCotohaやGoogleのAPIを使用してランダムに国内風景写真を表示するサイトを作った。自分で言うのもアレだけど、個人開発の制作30時間で良い感じのサイトができた。
旅行好きのためのランダム風景写真サイト JP-ictures
どういうサイトかと言うと
サイトの訪問時・更新時におおよそ1000枚の写真から1枚をランダムで選択し、表示する。その写真の撮影場所のマップと関連するワードの解説を入れる。というシンプルなサイト。
旅行の行き先を探している人や直感で旅行に行こう!って人に向けたサイトであり、写真を見て旅行欲を刺激して広告収入を得れたら良いなー程度で作り上げた。暇つぶしにするのも最適。このサイト作成を通して伝えたいことは
- 開発期間の短縮のために利用できるAPIは利用すべし
- 行政関係は無料で使えるデータが多い
ということ。特に初心者に伝えたい。
開発期間の短縮のために利用できるAPIは利用しろ
個人開発は納期などの制限もなく伸び伸びとできるのがメリット。しかし、長期間ではモチベを保ちきれない。そのために目的に沿い利用できる企業・行政のシステムは利用した方が効率がいい。
このサイトでもNTTのCotohaとGoogle Map、国土地理院などのAPIを利用。(APIではないがDBPediaなども)これらのおかげで開発期間をかなり短縮できた。実際、上記に挙げたAPIはすでに使い方の解説や実例を紹介した記事もQiitaに多いため、手を出しやすい。開発期間の短縮と勉強にもなり、一石二鳥。
行政関係は無料で使えるデータが多い
サイトのメインで使用している写真の引用元であるFIND/47は経済産業省、上記に挙げた国土地理院も行政関係であり、無料で使えるデータやAPIが多い。
個人開発では資金にも限りがあるため、無料で使用可能なデータやシステムが多い行政関係はありがたい存在になる。(もちろん企業でも無料で提供しているものも多い。)以上が伝えたいこと。
最後に
個人開発エンジニアでWebサービスだと、相手の便利を追求するサービスが多い。だが、それはエンジニアとして当たり前のことであり、便利さを追求するのがエンジニアの極意だとも思っている。だからこそ、こんな息抜きにもなる暇つぶしサイトが一つぐらいあってもいいんじゃないか。と思って作った。
そのため、開発の息抜きにでも見てほしい。そして、使った感想やコメントなどがあったら是非ください。あともっとDjango仲間増えてほしい。
- 投稿日:2020-10-18T23:22:44+09:00
素因数分解でC言語、Java、Pythonのベンチマーク
Pythonの練習がてら、素因数分解を簡単なロジックで計算させるプログラムを作成してみました。ついでにC言語、Javaでも作成して処理速度を競わせてみたのでアップします。
プログラムは長くなるので結果から。
# C言語 $ ./a.exe 123456789 123456789 = 3 * 3 * 3607 * 3803 所要時間は2.884932秒です。 # Java >java -jar Factorization.jar 123456789 123456789 = 3803 * 3607 * 3 * 3 所要時間は1245ミリ秒です。 # Python3 >python factorization.py 123456789 123456789 = 3 * 3 * 3607 * 3803 所要時間は60.498295秒ですなんとJavaがトップ。
Pythonが遅いのは、Pythonをほとんど使ったことがない私が作ったプログラムがゴミなのでしょう^^;しかし、CよりJavaが早いかなぁ。というのが疑問だったので、環境を変えてみることに。Cの実行環境はCygwinを使用していたのですが、公平を期すために!? Linuxですべて動かしてみます。
使用したのはAWSのEC2です。Amazon Linux2 イメージで、ベンチマーク目的なのでちょっとリッチにt2.xlargeを使ってみました。(お金がかかるので終わったらすぐ削除;;)結果は以下の通り。
[ec2-user ~]$ #C言語 [ec2-user ~]$ ./a.out 123456789 123456789 = 3 * 3 * 3607 * 3803 所要時間は2.730501秒です。 [ec2-user ~]$ #Java [ec2-user ~]$ java -jar Factorization.jar 123456789 123456789 = 3803 * 3607 * 3 * 3 所要時間は828ミリ秒です。 [ec2-user ~]$ #Python [ec2-user ~]$ python3 factorization.py 123456789 123456789 = 3 * 3 * 3607 * 3803 所要時間は33.936324秒ですやはりJavaがトップです。Windowsに比べて一番早くなったのはPythonかな。
個人的にはC言語が一番速いかと思っていたのでちょっと意外な結果ですが、自分でキューを作成するより、JavaのArrayQueueクラスのほうが優秀ということなんでしょうね。。。以下に、使用したソースを掲載しておきます。
- C言語
#include <stdio.h> #include <stdlib.h> #include <sys/time.h> typedef unsigned long ulong_t; // 素因数を収集するキュー typedef struct _que { ulong_t prime; struct _que* next; } que_t; que_t* factrization(ulong_t); long getusec(); void main(int argc, char** argv){ ulong_t num; char* e; num = strtoul(argv[1], &e, 10); long before = getusec(); // 素因数分解を実行 que_t* q = factrization(num); long after = getusec(); // 結果を表示する printf("%d = %d", num, q->prime); while(q->next != NULL){ q = q->next; printf(" * %d", q->prime); } // 経過時間を表示する long spend = (after - before); long sec = spend / 1000000; long usec = spend % 1000000; printf("\n所要時間は%d.%d秒です。\n", sec, usec); } // 渡された自然数nを素数と自然数の積に分解する que_t* factrization(ulong_t n){ // 素数を計算するための行列 // (メモリ確保時に0埋めするため、0が入っている要素が素数候補) ulong_t* p = calloc((n+1), sizeof(ulong_t)); // 2から初めて、素数を割り出す for(int a = 2; a < (n/2); a++){ // すでに非素数と確定している数は飛ばす if(p[a] != 0){ continue; } // 素数の倍数を候補から外していく int b = 2; int m = a * b; while(m < n){ p[m] = -1; // 非0⇒素数ではない b++; m = a * b; } // nが倍数であるとき(非素数であるとき) if(n == m){ // n = a * b(aは素数) // printf("%d = %d * %d\n", n, a, b); // bについて再帰的に繰り返す que_t* f = factrization(b); // キューにaを入れる que_t* qa = malloc(sizeof(que_t)); qa->prime = a; // キューの先頭にaを追加する qa->next = f; // キューを返す return qa; } } // 最後まで言った場合nは素数 // キューを生成して返す que_t* qp = malloc(sizeof(que_t)); qp->prime = n; qp->next = NULL; free(p); return qp; } // 現在時刻(μ秒の取得) long getusec(){ struct timeval _time; gettimeofday(&_time, NULL); long sec = _time.tv_sec; sec *= 1000000; long usec = _time.tv_usec; return sec + usec; }
- Java
package example; import java.util.ArrayDeque; import java.util.Calendar; import java.util.Iterator; import java.util.Queue; import java.util.Scanner; /** * 素因数分解に挑戦する */ public class Factrization { public static void main(String[] args) { int num; num = Integer.parseInt(args[0]); // 分解した素因数を登録するキュー Queue<Integer> queue = new ArrayDeque<>(); Calendar before = Calendar.getInstance(); // 素因数分解を実行する queue = fact(num, queue); Calendar after = Calendar.getInstance(); // 結果を表示する Iterator<Integer> i = queue.iterator(); System.out.printf("%d = %d", num, i.next()); while (i.hasNext()) { System.out.printf(" * %d", i.next()); } System.out.println(); System.out.printf("所要時間は%dミリ秒です。\n", (after.getTimeInMillis() - before.getTimeInMillis())); } /** * 渡された自然数を素数と自然数の積に分解する */ static Queue<Integer> fact(int n, Queue<Integer> q) { // 素数の候補となる配列を定義。 // Javaでは生成時に0埋めされるので、0が入っている要素を素数の候補とする int[] p = new int[n + 1]; for (int a = 2; a < (n / 2); a++) { // 非素数と確定している場合は飛ばす if (p[a] != 0) { continue; } int b = 2; int m = a * b; while (m < n) { p[m] = -1; // 非0⇒素数でない要素 b++; m = a * b; } if (n == m) { // System.out.printf("%d = %d * %d\n", n, a, b); Queue<Integer> f = fact(b, q); f.add(a); return f; } } q.add(n); return q; } }
- Python
import sys import time # 素因数分解 def factrization(n): # 与えられた数値までの整数を定義する p = list(range(n+1)) # 2から初めて、倍数を削除する # 最大値の半分までやればOK for a in range(2,int(n/2)): # aが素数ではないことが決まっていたら次へ if p[a] == 0 : continue # 素数にかける数 b = 2 m = a * b # aの倍数(つまり素数ではない数)を0とする while m < n: p[m] = 0 b += 1 m = a * b # nがaの倍数であれば if m == n: # n=a*bが確定 # print('%d = %d * %d' % (n, a, b)) # bをさらに素因数分解する fact = factrization(b) # 確定したaは素数なので出力する return [a] + fact #nが0にならなかったらnが素数 return [n] # コマンドライン引数で自然数を渡す num = eval(sys.argv[1]) before = time.time() # 素因数分解を実行する f = factrization(num) after = time.time() # 実行結果を表示する print('%d = %d' % (num, f[0]), end='') for p in f[1:]: print(' * %d' % p, end='') print('\n所要時間は%f秒です' % (after - before))
- 投稿日:2020-10-18T22:22:06+09:00
Djangoチュートリアル(ブログアプリ作成)④ - ユニットテスト編
前回、Djangoチュートリアル(ブログアプリ作成)③ - 記事一覧表示編では管理サイトから作成した記事を一覧表示させるために、クラスベース汎用ビューを使いました。
このままアプリ内での記事作成、詳細、編集、削除といった CRUD 処理を追加したいところではありますが、グッとこらえてユニットテストを盛り込みましょう。
Django のテストについて
どんどん機能を追加していくのは楽しいですが、普段はテストを書いているでしょうか?
各種チュートリアルなどでDjangoの簡単なアプリを作れるようになった方でも、
少し自分なりにいじった時にエラーを引き起こしてしまう場合があるかと思います。
また、Djangoをrunserver等で起動した際には特にエラーが出力されなくても
実際に画面をブラウザ経由で動かした時にエラーに気づく場合もあるかと思います。いくつかの操作を手動でテストするという方法はもちろんありますが、毎回そういったことを行うのは無駄という他ありません。
そこで、Djangoの機能を用いてユニットテストを行うことを推奨します。
DjangoではUnitTestクラスを用いてテストを自動化することができるので、
最初にテスト用のコードだけ書いてしまえば後は何度も同じことをする必要はありません。テストの考えることは開発コードを考えるのと同じぐらい重要であり、
テストを作ってからアプリ動作のためのコードを書くという開発手法もあるぐらいです。これを機にテストを行えるようになり、あなたのテスト時間を節約してアプリ本体をより改善することに労力を費やしましょう。
フォルダ構成について
この時点では下記のようなフォルダ構成になっているはずです。
. ├── blog │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── migrations │ │ ├── 0001_initial.py │ │ └── __init__.py │ ├── models.py │ ├── tests.py # 注目 │ ├── urls.py │ └── views.py ├── db.sqlite3 ├── manage.py ├── mysite │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py └── templates └── blog ├── index.html └── post_list.htmlお気づきになられた方はいるかもしれませんが、blog ディレクトリ配下に tests.py というファイルが自動的に作成されています。
この tests.py の中に直接テストケースを作成していってもよいのですが、
model のテスト、view のテストとテストごとにファイルが分かれていた方が何かと管理しやすいので
下記のように tests ディレクトリを作成し、中にそれぞれ空ファイルを作成しておきましょう。
tests ディレクトリ内のファイルも実行されるように、中身はからの init.py ファイルも作成しておくのがポイントです。. ├── blog │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── migrations │ │ ├── 0001_initial.py │ │ └── __init__.py │ ├── models.py │ ├── tests # 追加 │ │ ├── __init__.py │ │ ├── test_models.py │ │ ├── test_urls.py │ │ └── test_views.py ......なお、モジュールの名前は「test」で始めないと Django が認識してくれないので注意してください。
テストの書き方
Django では Python標準のTestCaseクラス(unittest.TestCase)を拡張した、
Django独自のTestCaseクラス(django.test.TestCase)を使います。
このクラスではアサーションというメソッドを使うことができ、返り値が期待する値であるかどうかをチェックする機能があります。また、前述の通りテストモジュールは「test」という文字列で始まっている必要があるのと、
テストメソッドも「test」という文字列で始める必要があります(詳細は後述します)。このルールを守ることで Django がテストメソッドをプロジェクト内から探し出し、自動で実行してくれるようになります。
test_models.py
それではまずは model のテストから作成していきましょう。
おさらいですが、blog/models.py に記述されている Post model はこのようになっています。models.py... class Post(models.Model): title = models.CharField('タイトル', max_length=200) text = models.TextField('本文') date = models.DateTimeField('日付', default=timezone.now) def __str__(self): # Post モデルが直接呼び出された時に返す値を定義 return self.title # 記事タイトルを返すこの model に対して、今回は次の3ケースでテストしましょう。
1.初期状態では何も登録されていないこと
2.1つレコードを適当に作成すると、レコードが1つだけカウントされること
3.内容を指定してデータを保存し、すぐに取り出した時に保存した時と同じ値が返されることではまずひとつめからです。
test_models.py を開き、必要なモジュールを宣言します。
test_models.pyfrom django.test import TestCase from blog.models import Postそしてテストクラスを作っていくのですが、必ず TestCase を継承したクラスにします。
test_models.pyfrom django.test import TestCase from blog.models import Post class PostModelTests(TestCase):さて、この PostModelTest クラスの中にテストメソッドを書いていきます。
TestCase を継承したクラスの中で「test」で始めることで、
Django がそれはテストメソッドであることを自動で認識してくれます。
そのため、def の後は必ず test で始まるメソッド名を名付けましょう。test_models.pyfrom django.test import TestCase from blog.models import Post class PostModelTests(TestCase): def test_is_empty(self): """初期状態では何も登録されていないことをチェック""" saved_posts = Post.objects.all() self.assertEqual(saved_posts.count(), 0)saved_posts に現時点の Post model を格納し、
assertEqual でカウント数(記事数)が「0」となっていることを確認しています。さて、これで一つテストを行う準備が整いました。
早速これで一回実行していきましょう。テストの実行は、manage.py が置いてあるディレクトリ (mysite内) で下記のコマンドを実行します。
実行すると、命名規則に従ったテストメソッドを Django が探し出し、実行してくれます。(blog) bash-3.2$ python3 manage.py test Creating test database for alias 'default'... System check identified no issues (0 silenced). ..... ---------------------------------------------------------------------- Ran 1 tests in 0.009s OK一つのテストを実行し、エラーなく完了したことを意味しています。
ちなみに、先ほどは Post 内にデータが空 (=0) であることを確認しましたが、データが1つ存在していることを期待するようにしてみます。
test_models.py(一時的)from django.test import TestCase from blog.models import Post class PostModelTests(TestCase): def test_is_empty(self): """初期状態だけど1つはデータが存在しているかどうかをチェック (error が期待される)""" saved_posts = Post.objects.all() self.assertEqual(saved_posts.count(), 1)この時の test 実行結果は下記のようになっています。
(blog) bash-3.2$ python3 manage.py test Creating test database for alias 'default'... System check identified no issues (0 silenced). F ====================================================================== FAIL: test_is_empty (blog.tests.test_models.PostModelTests) 初期状態だけど1つはデータが存在しているかどうかをチェック (error が期待される) ---------------------------------------------------------------------- Traceback (most recent call last): File "/Users/masuyama/workspace/MyPython/MyDjango/blog/mysite/blog/tests/test_models.py", line 9, in test_is_empty self.assertEqual(saved_posts.count(), 1) AssertionError: 0 != 1 ---------------------------------------------------------------------- Ran 1 test in 0.002s FAILED (failures=1)AssertionError が出ており、期待される結果ではないためにテストは失敗していますね(実験としては成功です)。
Django のテストではデータベースへ一時的なデータの登録も create メソッドから実行できるので、
データを登録しないと確認できないような残りのテストも実行することができます。
下記に model のテストの書き方を載せておくので、参考にしてみてください。test_models.py(全文)from django.test import TestCase from blog.models import Post class PostModelTests(TestCase): def test_is_empty(self): """初期状態では何も登録されていないことをチェック""" saved_posts = Post.objects.all() self.assertEqual(saved_posts.count(), 0) def test_is_count_one(self): """1つレコードを適当に作成すると、レコードが1つだけカウントされることをテスト""" post = Post(title='test_title', text='test_text') post.save() saved_posts = Post.objects.all() self.assertEqual(saved_posts.count(), 1) def test_saving_and_retrieving_post(self): """内容を指定してデータを保存し、すぐに取り出した時に保存した時と同じ値が返されることをテスト""" post = Post() title = 'test_title_to_retrieve' text = 'test_text_to_retrieve' post.title = title post.text = text post.save() saved_posts = Post.objects.all() actual_post = saved_posts[0] self.assertEqual(actual_post.title, title) self.assertEqual(actual_post.text, text)test_urls.py
model 以外にも、urls.py に書いたルーティングがうまくいっているのかどうかを確認することもできます。
おさらいすると blog/urls.py はこのようになっていました。blog/urls.pyfrom django.urls import path from . import views app_name = 'blog' urlpatterns = [ path('', views.IndexView.as_view(), name='index'), path('list', views.PostListView.as_view(), name='list'), ]上記のルーティングでは /blog/ 以下に入力されるアドレスに従ったルーティングを設定しているので、
/blog/ 以下が ''(空欄) と 'list' であった時のテストをします。
それぞれのページへ view 経由でリダイレクトされた結果が期待されるものであるかどうかを、assertEqual を用いて比較してチェックします。test_urls.pyfrom django.test import TestCase from django.urls import reverse, resolve from ..views import IndexView, PostListView class TestUrls(TestCase): """index ページへのURLでアクセスする時のリダイレクトをテスト""" def test_post_index_url(self): view = resolve('/blog/') self.assertEqual(view.func.view_class, IndexView) """Post 一覧ページへのリダイレクトをテスト""" def test_post_list_url(self): view = resolve('/blog/list') self.assertEqual(view.func.view_class, PostListView)ここまでで一旦テストを実行しておきましょう。
※先ほど、データベースが空である状態のテストをしたときと比べると
データを登録するテストケースが増えているため
テスト用のデータベース作成、消去の処理がメッセージに出力されていることが分かります(blog) bash-3.2$ python3 manage.py test Creating test database for alias 'default'... System check identified no issues (0 silenced). ..... ---------------------------------------------------------------------- Ran 5 tests in 0.007s OK Destroying test database for alias 'default'...test_views.py
最後に view のテストも行いましょう。
views.py はこのようになっていました。
views.pyfrom django.views import generic from .models import Post # Postモデルをimport class IndexView(generic.TemplateView): template_name = 'blog/index.html' class PostListView(generic.ListView): # generic の ListViewクラスを継承 model = Post # 一覧表示させたいモデルを呼び出しIndexView のテストでは、GET メソッドでアクセスした時にステータスコード 200(=成功) が返されることを確認します。
test_views.pyfrom django.test import TestCase from django.urls import reverse from ..models import Post class IndexTests(TestCase): """IndexViewのテストクラス""" def test_get(self): """GET メソッドでアクセスしてステータスコード200を返されることを確認""" response = self.client.get(reverse('blog:index')) self.assertEqual(response.status_code, 200)何か view でメソッドを追加したときは、
どんなにテストを書く時間がなくてもこれだけは最低限テストケースとして作成する癖をつけましょう。ListView の方もテストをしていきます。
同じく 200 のステータスコードが返ってくることの確認はもちろん、
ここではデータ(記事)を2つ追加した後に記事一覧を表示させ、
登録した記事のタイトルがそれぞれが一覧に含まれていることを確認するテストを作成します。なお、ここで少し特殊なメソッドを使います。
テストメソッドは「test」で始めるように前述しましたがsetUpとtearDownというメソッドが存在します。setUpメソッドではテストケース内で使うデータの登録をし、
tearDownメソッドでは setUp メソッド内で登録したデータの削除を行えます。
(どちらも、どんなデータを登録するかは明示的に記述する必要があることには注意しましょう)同じテストケースの中で何回もデータの登録をするような処理を書くのは手間&テストに時間がかかる要因になるので、
共通する処理は一箇所にまとめてしまおうというものです。これらのメソッドを使い、test_views.py を作成するとこのようになります。
test_views.pyfrom django.test import TestCase from django.urls import reverse from ..models import Post class IndexTests(TestCase): """IndexViewのテストクラス""" def test_get(self): """GET メソッドでアクセスしてステータスコード200を返されることを確認""" response = self.client.get(reverse('blog:index')) self.assertEqual(response.status_code, 200) class PostListTests(TestCase): def setUp(self): """ テスト環境の準備用メソッド。名前は必ず「setUp」とすること。 同じテストクラス内で共通で使いたいデータがある場合にここで作成する。 """ post1 = Post.objects.create(title='title1', text='text1') post2 = Post.objects.create(title='title2', text='text2') def test_get(self): """GET メソッドでアクセスしてステータスコード200を返されることを確認""" response = self.client.get(reverse('blog:list')) self.assertEqual(response.status_code, 200) def test_get_2posts_by_list(self): """GET でアクセス時に、setUp メソッドで追加した 2件追加が返されることを確認""" response = self.client.get(reverse('blog:list')) self.assertEqual(response.status_code, 200) self.assertQuerysetEqual( # Postモデルでは __str__ の結果としてタイトルを返す設定なので、返されるタイトルが投稿通りになっているかを確認 response.context['post_list'], ['<Post: title1>', '<Post: title2>'], ordered = False # 順序は無視するよう指定 ) self.assertContains(response, 'title1') # html 内に post1 の title が含まれていることを確認 self.assertContains(response, 'title2') # html 内に post2 の title が含まれていることを確認 def tearDown(self): """ setUp で追加したデータを消す、掃除用メソッド。 create とはなっているがメソッド名を「tearDown」とすることで setUp と逆の処理を行ってくれる=消してくれる。 """ post1 = Post.objects.create(title='title1', text='text1') post2 = Post.objects.create(title='title2', text='text2')この状態でテストを実行すると model, url, view で合計 8 つのテストが実行されます。
(blog) bash-3.2$ python3 manage.py test Creating test database for alias 'default'... System check identified no issues (0 silenced). ........ ---------------------------------------------------------------------- Ran 8 tests in 0.183s OK Destroying test database for alias 'default'...これで、これまで書いたコードについてユニットテストを作成することができました。
他にも期待される template が呼び出されているかどうか等、
Django 独自のテスト方法を用いたテストで冗長的にチェックする方法もありますが
コードを書く前にテストを作成する癖をつけ、後々のチェックの手間を省くようにしていきましょう。次回はアプリ内で記事を作成できるようにします。
今回覚えたユニットテストを先に書く TDD (テスト駆動開発) スタイルでいきましょう。
- 投稿日:2020-10-18T21:24:31+09:00
会話の内容にあわせてBGMを自動選曲する
1.はじめに
Sonyとレッジが企画する第2弾となるAI開発コンテスト「Neural Network Console Challenge」に再挑戦。Audiostockの音声(BGM)データや書誌(曲の説明文)を解析して、自由課題「日常会話の内容にあわせてBGMを自動選曲するプレーヤーを作る」に取り組んでいきます。
Google Homeなどのスマートスピーカーが、部屋にいる人の会話内容にあわせてBGMを自動再生していくシステムを考えます(プライバシーの観点から実用化のハードルは高そうですが…)。2.実験環境&データ
・Google Colaboratory(python3)
・Neural Network Console(Windows版)
※参加に当たりクラウド版のGPU利用申請はしましたが、結局ローカル版で十分な処理量でしたので、アウトプットはWindows版での結果となりました
・学習用データ提供:Audiostock 約1万曲と書誌。書誌は以下のような一行説明とタグがついています。
作品No. データ名 一行説明 タグ 42554 audiostock_42554.wav オープニングに最適な曲です オープニング 42555 audiostock_42555.wav ボサノバな曲です ボサノバ 42556 audiostock_42556.wav ほのぼのとしたイージーリスニング コミカル コミカル,かわいい,温かい,ほのぼの,イージーリスニング 42557 audiostock_42557.wav 変拍子な曲です 変拍子 3.BGMの自動分類
BGMの音声データ(WAV)を使い、自動分類をするためのモデルをNNCを活用して作成します。時間の都合上、今回は3クラス分類ができるモデルを構築しました。
3-1.アノテーションと学習データ
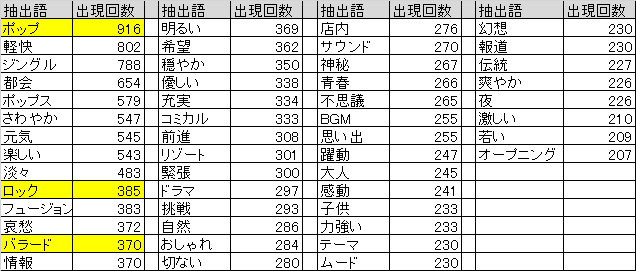
どのようなクラスを作ることが望ましいか調査するために、まず、テキストデータを統計的に分析できる「KHcoder」を使って、上記の「一行説明」に含まれる単語を調査。上位の結果は以下のようになりました。
これらの中から、実際にBGMを聞いてみつつ分類できそうな(テンポや音色などが違う)
"ロック", "ポップ", "バラード"のいづれかが含まれる曲を学習データにすることに。学習データ1468件、評価データ105件を作成しました。また、作成にあたり効果音のような音源(ジングル)は、曲の長さが短いので対象外としました。3-2.メル周波数ケプストラム係数に変換
BGMのWAVデータをメル周波数ケプストラム係数に変換し、40次元のベクトルに落とし込んでいきます(詳しくは割愛しますが、このページに詳しく書いてありました)。縦軸の音の高さ毎に平均を取り(1,40)の配列にして、学習用データとしました。
Wav_to_Mel.pyimport pandas as pd import numpy as np import librosa y, sr = librosa.load(file_name) #40次元で特徴量抽出 mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=40) #縦軸で平均を計算し、出力 S_A = np.mean(mfcc, axis = 1) np.savetxt(output_filename, S_A.reshape(1, -1), delimiter=',', fmt="%s")3-3.NNCで分類モデルを作る
NNCでベクトルを分類するモデルを学習させてました。CNNでの解法が一般的なようですが、様々なネットワークや活性化関数を試してみたところ、結局以下の設定が最も精度が高いという結果に。この辺は時間があれば、さらに実験を繰り返したいところです。
ちなみにNNCの利点でいうと、関数を変えてみるなどの試行錯誤がGUIが整備されているのですごい楽です。どのようなネットワークになっているかも直感的に分かりますし、Google Colabなどと比較した場合の魅力の一つだと思います。
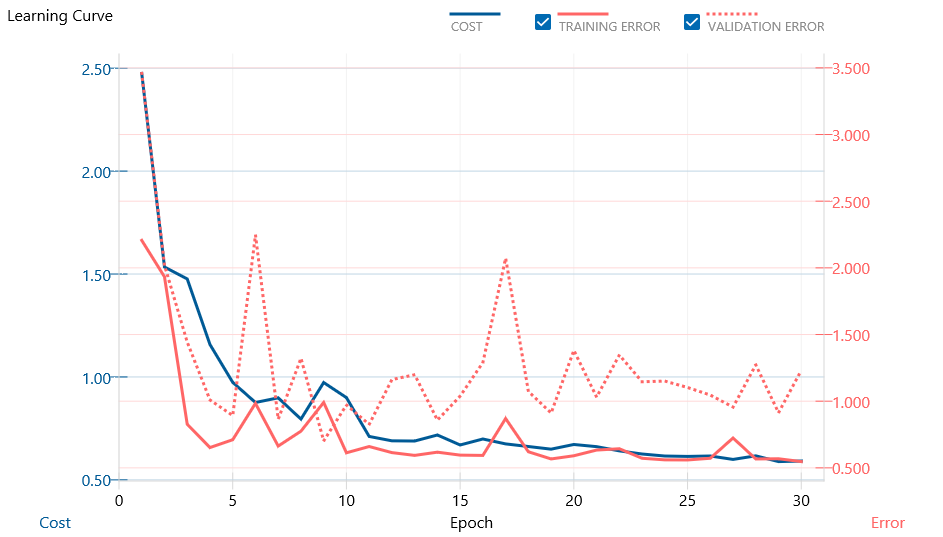
低次元のベクトルを学習させたので、今回はCPU(Windows版)で十分な処理量でしたが、ほぼ同設定で学習したクラウド版での学習結果も、一応Publishing予定。30エポック学習させ、学習曲線は以下のようになりました(Best Validationは9エポック目でした)。
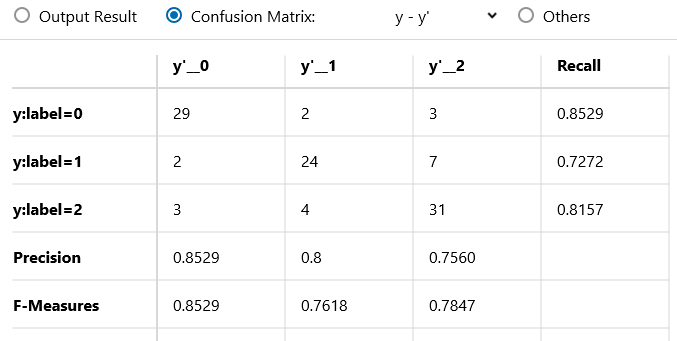
次に、作成したモデルを用い、テストデータで評価し、精度をはかってみます。
3分類問題とはいえ、Accuracyは0.8とある程度の特徴はとれていそうです。平均適合率も約8割以上となり、適したBGMを選曲するという課題に対しては価値のあるモデルとなっていそうです。4.日常会話を分析する
Bertの学習済みモデルを活用し、会話内容と近しいBGMを一行説明から選び出します。会話(テキスト)のベクトルを算出し、コサイン類似度で最も近い一行説明をもつBGMを選出します。まずはテキストベースで相応しいBGMを探し、その後は3.でつくったBGMを元にした分類に基づく選曲に繫げていきます。NNCでBERTの実装が思いつかなかったので、知見のあるGoogle colabとtransformersで処理しました(個人的にはNNCは画像分野は充実しているので、次は自然言語周りの強化をしてくれると仕事的にも嬉しいですね)。
Conversation_to_BGM.pyimport pandas as pd import numpy as np import torch import transformers from transformers import BertJapaneseTokenizer from tqdm import tqdm tqdm.pandas() class BertSequenceVectorizer: def __init__(self): self.device = 'cuda' if torch.cuda.is_available() else 'cpu' self.model_name = 'cl-tohoku/bert-base-japanese-whole-word-masking' self.tokenizer = BertJapaneseTokenizer.from_pretrained(self.model_name) self.bert_model = transformers.BertModel.from_pretrained(self.model_name) self.bert_model = self.bert_model.to(self.device) self.max_len = 128 def vectorize(self, sentence : str) -> np.array: inp = self.tokenizer.encode(sentence) len_inp = len(inp) if len_inp >= self.max_len: inputs = inp[:self.max_len] masks = [1] * self.max_len else: inputs = inp + [0] * (self.max_len - len_inp) masks = [1] * len_inp + [0] * (self.max_len - len_inp) inputs_tensor = torch.tensor([inputs], dtype=torch.long).to(self.device) masks_tensor = torch.tensor([masks], dtype=torch.long).to(self.device) seq_out, pooled_out = self.bert_model(inputs_tensor, masks_tensor) if torch.cuda.is_available(): return seq_out[0][0].cpu().detach().numpy() else: return seq_out[0][0].detach().numpy() if __name__ == '__main__': #元データの読み込み df_org = pd.read_csv('./drive/NNC/BGMデータ一覧.csv') #学習データにある曲のみに絞る df_org = df_org.dropna(subset=["一行説明"]) df_org = df_org[~df_org['一行説明'].str.contains("ジングル")] df_org = df_org[~df_org['タグ'].str.contains("ジングル")] df_org = df_org.head(5000) word = ["ロック", "ポップ", "バラード"] df = df_org.iloc[0:0] for w in word: df_detect = df_org[df_org["一行説明"].str.contains(w)] df = pd.concat([df, df_detect]) df = df.reset_index(drop=True) BSV = BertSequenceVectorizer() #書誌から特徴ベクトルを計算 df['text_feature'] = df['一行説明'].progress_apply(lambda x: BSV.vectorize(x)) #入力テキストから類似ベクトル(BGM)を探る nn = NearestNeighbors(metric='cosine') nn.fit(df["text_feature"].values.tolist()) vec = BSV.vectorize("おはよう。今日は良い天気だね。そうだね。一日晴れみたいだよ。") ##コサイン類似度を計算 dists, result = nn.kneighbors([vec], n_neighbors=1) print(df["データ名"][r], df["一行説明"][r]) ###出力結果 audiostock_45838.wav Name: データ名, dtype: object 188 忙しくも楽しいポップ/ロック Name: 一行説明, dtype: object5.実験
それでは想定される会話文を入力として、どのような曲が選ばれるか試してみます。最終的に選ばれるBGMは、学習、評価に用いず、かつ一行説明に"ロック"、"ポップ"、"バラード"という単語が含まれない300曲をランダムに選びにしました。全体像は図のようになります。
最終的に選び出す曲は、予測確率が高いものをNNCが出力するファイル「output_result.csv」から順に流すことにしました(NNCは学習時の評価と最終的な評価で異なるデータを設定できるんですね)。では様々なケースで選曲してみます。ケース1)
◆会話文:
おはよう。今日は良い天気だね。そうだね。一日晴れみたいだよ。
◆類似度が高い一行説明:
忙しくも楽しいポップ/ロック(audiostock_45838.wav)→ ラベル「ロック」
※説明内に「ポップ」もありますが、ラベルは「ロック」に分類しました
◆選曲結果:
・audiostock_44217 ハード&ヘヴィーなスポーツ系オープニング
・audiostock_44540 パワフルなハード・ブギー
・audiostock_46435 激闘マイナー・ファンク・メタル
・audiostock_43382 若さの暴走POP ROCK
・audiostock_44100 躍動感とスピード感の溢れる曲朝っぽい曲かどうかは置いておいて、「パワフル」、「躍動感」といった元気になりそうな曲を選ぶことができました!エレキギターを使ったメタル風の曲が選ばれる傾向にありそうです。
ケース2)
◆会話文:
週末は山梨でキャンプの予定。久々に湖畔で静かに過ごせるよ。だいぶ涼しくなってきたから気をつけて。
◆類似度が高い一行説明:
ふと遠い日の親の愛情を懐かしく思うポップ(audiostock_45997.wav)→ラベル「ポップ」
◆選曲結果:
・audiostock_45254 怪談話に背筋が凍る趣のある純邦楽
・audiostock_44771 恐怖のドキュメント・タッチのBGM
・audiostock_46760 旅情 懐かしい 哀愁 さびしい 黄昏
・audiostock_46657 さわやか 希望 ドライブ 軽快 前進
・audiostock_44331 南国カリブのほのぼのミュージック1、2曲目は明らかにまずい選択結果になってしまいましたが(怪談…)、4、5曲目は旅にぴったりのポップなBGMが選べています。また、3曲目の曲説明はもの悲しい雰囲気がありますが、タグに「ポップ」が入っているBGMで、実際に聞いてみるとそこまで暗い曲ではありませんでした。このことからもポップ調の曲を自動選択できる傾向はあると言えそうです。
ケース3)
◆会話文:
あのドラマ、感動モノって聞いたんだけど見た?。切なくて悲しい話。ラストは泣いたよ。
◆類似度が高い一行説明:
ウォーミングなバラード、ティーンの気持ち(audiostock_43810.wav)→ラベル「バラード」
◆選曲結果:
・audiostock_46013 瑞々しく神秘的でゆったりとした環境
・audiostock_44891 夜の星のリラクゼーション系アンビエント
・audiostock_44575 童話の世界が広がる優しいアンビ風サウンド
・audiostock_45599 ひんやりとした朝の雰囲気の神秘的な環境
・audiostock_45452 庭園に芸術的な気品漂う優美なクラシック神秘的でゆったりとしたバラード調の曲やクラシックといった静かなBGMをうまく抽出することができています。
3分類ともBGMの特徴量のみで自動選択しましたが、こちらがほぼ意図した通りの曲を抽出できていそうです!選択しなかった(予測した確率が低かった)BGMを見てみると、「バラエティ番組タイトルBGM」(audiostock_43840)、「ラテン風味のユーロ・ハウス調」(audiostock_42921)、「多国籍 アフリカ 神秘 紀行 おしゃれ」(audiostock_46146)などとなっており、適さないBGMの見分けもついているモデルとなっていることが確認できました。
6.まとめと考察
日常会話の内容に併せてBGMを自動選曲するプレーヤーを作る、という課題に対して、
- "ロック", "ポップ", "バラード"という3分類ができるモデルをNNCで構築。精度、適合率ともに80%を超えるモデルを作ることができた
- 自然言語モデルと組み合わせることで、BGMの自動選曲が実現できるスキーマを考案
- 最終的には曲の特徴から自動選曲するので、Audiostockの投稿者がこちらが意図する説明文やタグを付けなくとも、適したBGMを選び出すことができる
ということが実現できました。今回は計1600曲程度と学習データが小さいものでのモデル作成しかできませんでしたが、アノテーションとデータ数をさらに精査することで、精度の向上がさらに見込めたり、3つ以上の分類クラスも作れたりするはずです。BGMの特徴量の出し方にも研究の余地がさらにありそうです。
スマートスピーカーを想定したサービス提案でしたが、それに限らずSNSでタグやテキストから曲をつけて投稿したり、動画編集で字幕データからBGMを自動で選曲したりするなど、将来性のある提案になりそうです。7.参考文献



- 投稿日:2020-10-18T21:00:59+09:00
【Django】管理画面でのモデル名の複数形を修正する
Django モデル名
Djangoでは一般的に(?)モデル名を単数形の形で定義する。
そのため、管理サイトでは複数形の"s"が自動で付与されて表示される。ただ、カテゴリーモデルのCategoryをCategoriesにしてくれたり、
ニュース(お知らせ)モデルのNewsをNewsのままにしてくれる機能はない。これらは
CategorysとNewssになってしまいます。表示上の問題だと思うので、スルーしても差し支えないと思われますが
少し気になるので修正してみました。正しい表示に直してみる
モデルのMetaオプションで表示したい文字を指定すればOKです。
class Meta: verbose_name_plural = 'Categories'小文字でも良いみたいです。
class Meta: verbose_name_plural = 'categories'Categories
models.pyclass Category(models.Model): name = models.CharField(max_length=50) class Meta: verbose_name_plural = 'Categories' def __str__(self): return self.name終わりに
今回も備忘録。
誰かのお役に立てれば幸いです。
- 投稿日:2020-10-18T20:55:43+09:00
ルービックキューブロボットのソフトウェアをアップデートした 5. 機械操作(Python)
この記事はなに?
私は現在2x2x2ルービックキューブを解くロボットを開発中です。これはそのロボットのプログラムの解説記事集です。
かつてこちらの記事に代表される記事集を書きましたが、この時からソフトウェアが大幅にアップデートされたので新しいプログラムについて紹介しようと思います。該当するコードはこちらで公開しています。
関連する記事集
「ルービックキューブを解くロボットを作ろう!」
1. 概要編
2. アルゴリズム編
3. ソフトウェア編
4. ハードウェア編ルービックキューブロボットのソフトウェアをアップデートした
1. 基本関数
2. 事前計算
3. 解法探索
4. 状態認識
5. 機械操作(Python)(本記事)
6. 機械操作(Arduino)
7. 主要処理今回は機械操作(Python)編として、
controller.pyを紹介します。初期設定など
最初にシリアル通信やGPIOのセットアップをします。
ser_motor = [None, None] GPIO.setmode(GPIO.BCM) GPIO.setup(21,GPIO.IN) ser_motor[0] = serial.Serial('/dev/ttyUSB0', 115200, timeout=0.01, write_timeout=0) ser_motor[1] = serial.Serial('/dev/ttyUSB1', 115200, timeout=0.01, write_timeout=0)アクチュエータを動かすコマンドを送る
アクチュエータとはここではつまりモーターです。モーターは自作Arduino互換機に繋がれていて、Arduinoにコマンドを送ることでアクチュエータを動作させます。ここではコマンドを送る関数を紹介します。
''' アクチュエータを動かすコマンドを送る ''' ''' Send commands to move actuators ''' def move_actuator(num, arg1, arg2, arg3=None): if arg3 == None: com = str(arg1) + ' ' + str(arg2) else: com = str(arg1) + ' ' + str(arg2) + ' ' + str(arg3) ser_motor[num].write((com + '\n').encode())アクチュエータを動かすコマンドには2種類あって、これによって引数の数が違います。そこで
arg3 == Noneを使ってif文を書いています(なら関数を分ければ良いという話ではありますが)。パズルを掴む/離す
先程の関数を使って、パズルを掴む関数と離す関数を作りました。これは時々行う動作のため関数化してあります。
''' キューブを掴む ''' ''' Grab arms ''' def grab_p(): for i in range(2): for j in range(2): move_actuator(j, i, 1000) sleep(3) ''' キューブを離す ''' ''' Release arms ''' def release_p(): for i in range(2): for j in range(2): move_actuator(i, j, 2000)2台のArduino
iについて、それぞれに繋がれている2つのモーターjを動かします。1000や2000というのは、1000を送るとパズルを掴み、2000を送ると離すようにしてあるということです。
アームのキャリブレーション
アームはステッピングモーターで動かしているため、適宜位置を調整してやる必要があります。Arduinoにはホールセンサ(磁気センサ)がついていて、アームには磁石をつけてあります。これを使うことで位置調整を自動で行います。Pythonからはコマンドを送るだけで位置調整ができるようになっています。
''' アームのキャリブレーション ''' ''' Calibration arms ''' def calibration(): release_p() sleep(0.1) for i in range(2): for j in range(2): move_actuator(j, i, 0, 500)実際にロボットを解法通りに動かす
解法とその他定数を入力するとロボットを動かしてくれる関数です。
ロボットには非常停止ボタンがついていて、まずその処理が行われます。ちなみに非常停止ボタンはプルアップになっているのでコネクタが外れるだけでも動作が止まります。
そして初手以外を回す際にはパズルを持ち替え、順次モーターを回し、最大の回転数に比例した時間だけ休みます。最後に解くのにかかった時間を返します。
''' 実際にロボットを動かす ''' ''' Control robot ''' def controller(slp1, slp2, rpm, ratio, solution): strt_solv = time() for i, twist in enumerate(solution): # 非常停止ボタンを押すと止まる if GPIO.input(21) == GPIO.LOW: if bluetoothmode: client_socket.send('emergency\n') solvingtimevar.set('emergency stop') print('emergency stop') return # パズルの持ち替え if i != 0: grab = twist[0][0] % 2 for j in range(2): move_actuator(j, grab, 1000) sleep(slp1) for j in range(2): move_actuator(j, (grab + 1) % 2, 2000) sleep(slp2) max_turn = 0 for each_twist in twist: move_actuator(each_twist[0] // 2, each_twist[0] % 2, each_twist[1] * 90, rpm) max_turn = max(max_turn, abs(each_twist[1])) # パズルが回転するのを待つ slptim = 2 * 60 / rpm * max_turn * 90 / 360 * ratio sleep(slptim) solv_time = str(int((time() - strt_solv) * 1000) / 1000).ljust(5, '0') return solv_timeまとめ
今回は実際にロボットを動かす関数(と言ってもやっていることはコマンドを送ることですが)を解説しました。次はArduino側でコマンドを受け取ってからどうやってモーターを動かしているのかについて解説します。

- 投稿日:2020-10-18T20:50:58+09:00
Tkinterで日付セッターを実装する
ソースコードは以下になります。
import tkinter as tk from tkinter import ttk import datetime import calendar year_list = ['2020', '2021'] month_list = [str(date).zfill(2) for date in range(1, 13)] date_list = [str(date).zfill(2) for date in range(1, 32)] hours_list = [str(date).zfill(2) for date in range(24)] minutes_list = [str(date).zfill(2) for date in range(60)] seconds_list = [str(date).zfill(2) for date in range(60)] def change_date(): def inner(self): last_day = calendar.monthrange(int(cb_year.get()), int(cb_month.get()))[1] if int(cb_date.get()) > last_day: cb_date.set(str(last_day).zfill(2)) cb_date.config(values=[str(date).zfill(2) for date in range(1, last_day+1)]) # datetime形式で出力 # date = cb_year.get()+'-'+cb_month.get()+'-'+cb_date.get()+' '+cb_hours.get()+':'+cb_minutes.get()+':'+cb_seconds.get() # print("Date = ", date) return inner root = tk.Tk() root.title('Date Picker') cb_year = ttk.Combobox(root, values=year_list, width=5, state='readonly') cb_year.set(year_list[0]) cb_year.bind('<<ComboboxSelected>>', change_date()) cb_year.pack(side='left') label_slash = ttk.Label(root, text='/') label_slash.pack(side='left') cb_month = ttk.Combobox(root, values=month_list, width=5, state='readonly') cb_month.set(month_list[0]) cb_month.bind('<<ComboboxSelected>>', change_date()) cb_month.pack(side='left') label_slash = ttk.Label(root, text='/') label_slash.pack(side='left') cb_date = ttk.Combobox(root, values=date_list, width=5, state='readonly') cb_date.set(date_list[0]) cb_date.pack(side='left') label_space = ttk.Label(root, text=' ') label_space.pack(side='left') cb_hours = ttk.Combobox(root, values=hours_list, width=5, state='readonly') cb_hours.set(hours_list[0]) cb_hours.pack(side='left') label_colon = ttk.Label(root, text=':') label_colon.pack(side='left') cb_minutes = ttk.Combobox(root, values=minutes_list, width=5, state='readonly') cb_minutes.set(minutes_list[0]) cb_minutes.pack(side='left') label_colon = ttk.Label(root, text=':') label_colon.pack(side='left') cb_seconds = ttk.Combobox(root, values=seconds_list, width=5, state='readonly') cb_seconds.set(seconds_list[0]) cb_seconds.pack(side='left') root.mainloop()年や月による最終日の違いはcalenderモジュールで対応しました。
起動後は以下のような画面が出るので日時を選択できます。
最後まで読んでいただきありがとうございました。
またお会いしましょう。

- 投稿日:2020-10-18T19:33:09+09:00
git hubにpushしようとしたところ「fatal: The current branch develop/feature/discussion has no upstream branch.」と出てしまった場合の対応方法
怒られた
$ git pushでコードをgit hubにアップしようとしたところ、
fatal: The current branch develop/feature/discussion has no upstream branch.と怒られてしまいました。
これは、「githubが「知らんブランチなんやけど」と言っているようです。対応策
上流ブランチをあてがって上げればいいのですが、エラーの時にヒントを出してくれてます。
なので、そのまま
$ git push --set-upstream origin develop/feature/discussionとコードして、
$ git pushこれで、パスワード入力したらOKです。
Everything up-to-date

- 投稿日:2020-10-18T19:20:14+09:00
pythonで線形回帰やGLMが使えるStatsModelsの使い方メモ
StatsModels
線形回帰、ロジスティック回帰、一般化線形モデル、ARIMAモデル、自己相関関数の算出などの統計モデルがいろいろ使えるパッケージです。
API一覧
https://www.statsmodels.org/stable/api.html1. install
pipで入ります
https://www.statsmodels.org/stable/install.htmlterminalpip install statsmodels2. 線形回帰
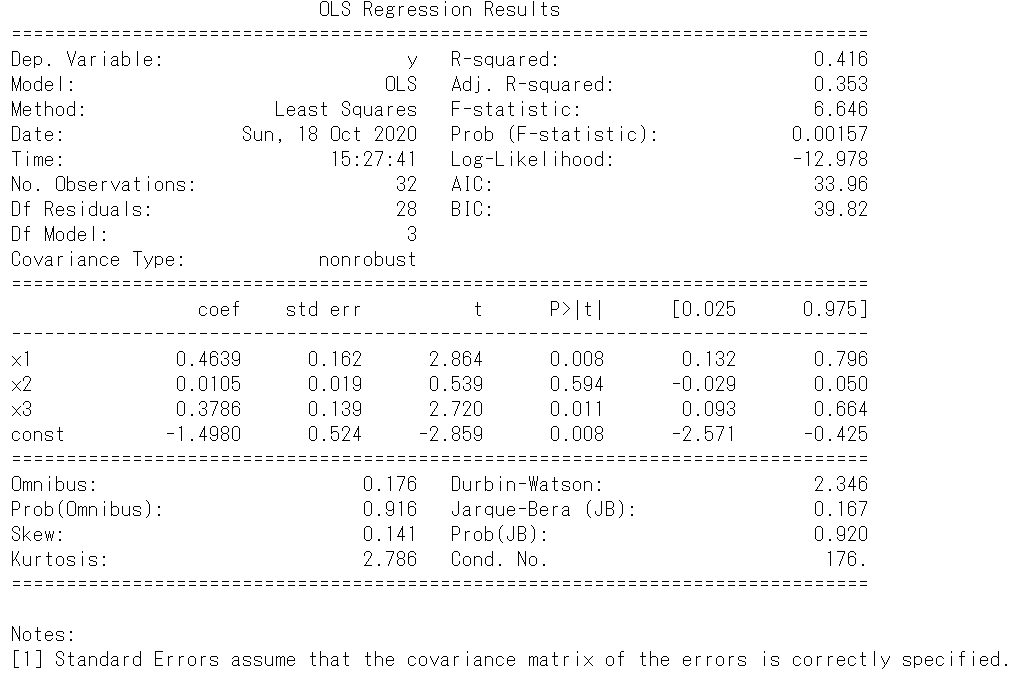
statsmodels.api.OLS()でordinary least squareによる線形回帰モデルを作成できます。xを変数のみで構成すればy切片なし、statsmodels.api.add_constant()でxに定数列を追加すればy切片ありでの回帰となります。
pythonimport numpy as np import statsmodels.api as sm spector_data = sm.datasets.spector.load(as_pandas=False) x = spector_data.exog xc = sm.add_constant(x, prepend=False) y = spector_data.endog print(xc.shape, y.shape) # Fit and summarize OLS model model = sm.OLS(y, xc) res = model.fit() print(res.summary())
それぞれの値を取り出すことも出来ますpython>>> res.params # 係数 array([ 0.46385168, 0.01049512, 0.37855479, -1.49801712]) >>> res.pvalues # P値 array([0.00784052, 0.59436148, 0.01108768, 0.00792932]) >>> res.aic, res.bic # 赤池情報量基準、ベイズ情報量基準 (33.95649234217083, 39.81943595336974) >>> res.bse # 標準誤差 array([0.16195635, 0.01948285, 0.13917274, 0.52388862]) >>> res.resid # 残差 array([ 0.05426921, -0.07340692, -0.27529932, 0.01762875, 0.42221284, -0.00701576, 0.03936941, -0.05363477, -0.16983152, 0.37535999, 0.06818476, -0.28335827, -0.39932119, 0.72348259, -0.41225249, 0.0276562 , -0.03995305, -0.01409045, -0.56914272, 0.39131297, -0.06696482, 0.14645583, -0.36800073, -0.78153024, 0.22554445, 0.52339378, 0.36858806, -0.37090458, 0.20600614, 0.0226678 , -0.53887544, 0.8114495 ])推定はpredict()です
pythonresult.predict(xc)resultarray([-0.05426921, 0.07340692, 0.27529932, -0.01762875, 0.57778716, 0.00701576, -0.03936941, 0.05363477, 0.16983152, 0.62464001, -0.06818476, 0.28335827, 0.39932119, 0.27651741, 0.41225249, -0.0276562 , 0.03995305, 0.01409045, 0.56914272, 0.60868703, 0.06696482, 0.85354417, 0.36800073, 0.78153024, 0.77445555, 0.47660622, 0.63141194, 0.37090458, 0.79399386, 0.9773322 , 0.53887544, 0.1885505 ])3. ロジスティック回帰
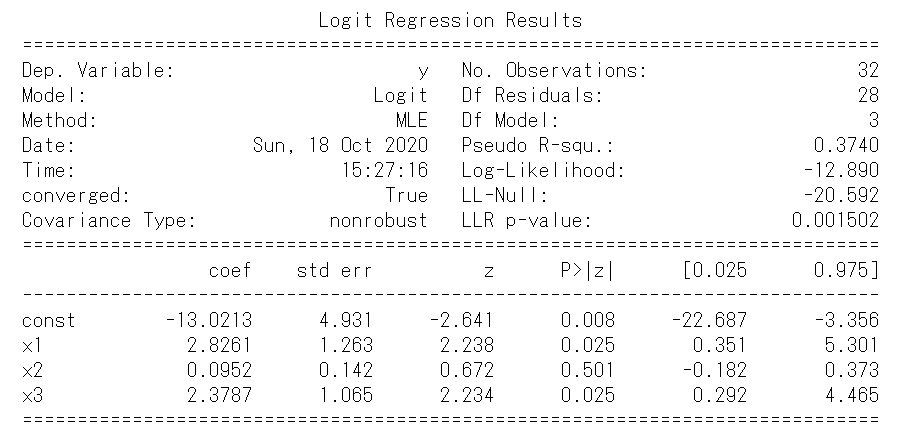
pythonimport numpy as np import matplotlib.pyplot as plt import statsmodels.api as sm # Load the data from Spector and Mazzeo (1980) spector_data = sm.datasets.spector.load() spector_data.exog = sm.add_constant(spector_data.exog) y = spector_data.endog x = spector_data.exog # Follow statsmodles ipython notebook model = sm.Logit(y, x) res = model.fit(disp=0) print(res.summary())
同様に諸々の値も取得できますpython>>> res.params array([-13.02134686, 2.82611259, 0.09515766, 2.37868766]) >>> res.pvalues array([0.00827746, 0.02523911, 0.50143424, 0.0254552 ]) >>> res.aic, res.bic (33.779268444262826, 39.642212055461734) >>> res.bse array([4.93132421, 1.26294108, 0.14155421, 1.06456425]) >>> res.resid_dev array([-0.23211021, -0.35027122, -0.64396264, -0.22909819, 1.06047795, -0.26638437, -0.23178275, -0.32537884, -0.48538752, 0.85555565, -0.22259715, -0.64918082, -0.88199929, 1.81326864, -0.94639849, -0.24758297, -0.3320177 , -0.28054444, -1.33513084, 0.91030269, -0.35592175, 0.44718924, -0.74400503, -1.95507406, 0.59395382, 1.20963752, 0.95233204, -0.85678568, 0.58707192, 0.33529199, -1.22731092, 2.09663887])python>>> res.predict(x) array([0.02657799, 0.05950125, 0.18725993, 0.02590164, 0.56989295, 0.03485827, 0.02650406, 0.051559 , 0.11112666, 0.69351131, 0.02447037, 0.18999744, 0.32223955, 0.19321116, 0.36098992, 0.03018375, 0.05362641, 0.03858834, 0.58987249, 0.66078584, 0.06137585, 0.90484727, 0.24177245, 0.85209089, 0.83829051, 0.48113304, 0.63542059, 0.30721866, 0.84170413, 0.94534025, 0.5291172 , 0.11103084])4. 一般化線形モデル
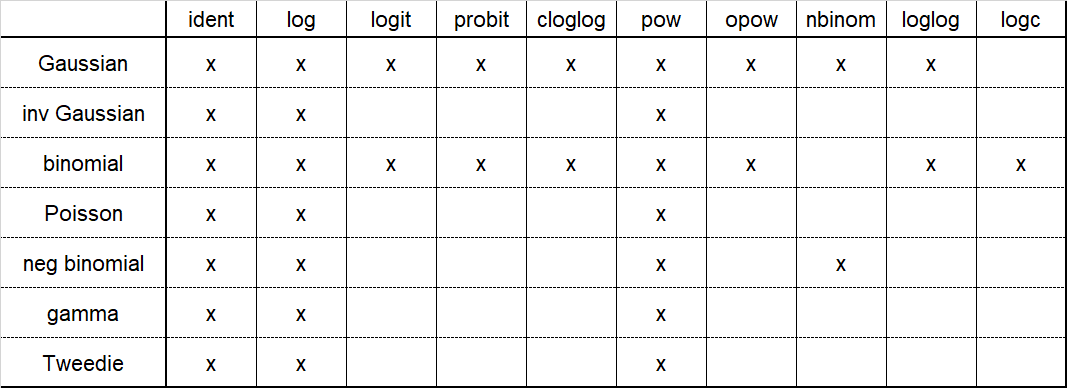
分布とリンク関数は以下の組み合わせから選びます
また、分布とリンク関数についての詳細は以下にまとまってます
https://www.statsmodels.org/stable/glm.html#familiessm.GLM()のfamily=sm.families.Gamma()の部分が分布とリンク関数を指定する部分です。下記ではガンマ分布でリンク関数が指定されていないのでデフォルトのinverseが使われますが、logを使う場合はsm.families.Gaussian(sm.families.links.log)のようにします。
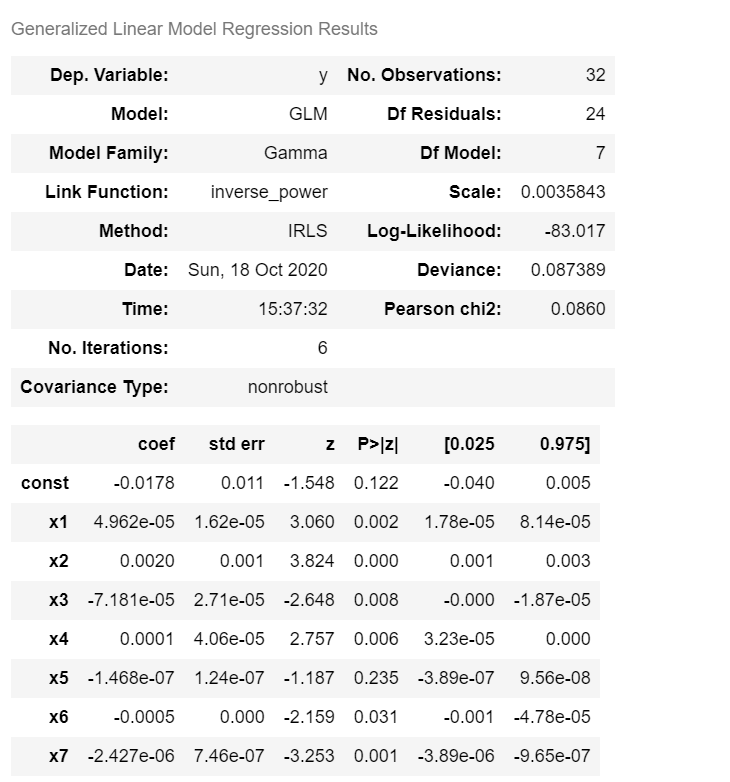
pythonimport statsmodels.api as sm data = sm.datasets.scotland.load(as_pandas=False) x = sm.add_constant(data.exog) y = data.endog model = sm.GLM(y, x, family=sm.families.Gamma()) res = model.fit() res.summary()
python>>> res.params [-1.77652703e-02 4.96176830e-05 2.03442259e-03 -7.18142874e-05 1.11852013e-04 -1.46751504e-07 -5.18683112e-04 -2.42717498e-06] >>> res.scale 0.003584283173493321 >>> res.deviance 0.08738851641699877 >>> res.pearson_chi2 0.08602279616383915 >>> res.llf -83.01720216107174python>>> res.predict(x) array([57.80431482, 53.2733447 , 50.56347993, 58.33003783, 70.46562169, 56.88801284, 66.81878401, 66.03410393, 57.92937473, 63.23216907, 53.9914785 , 61.28993391, 64.81036393, 63.47546816, 60.69696114, 74.83508176, 56.56991106, 72.01804172, 64.35676519, 52.02445881, 64.24933079, 71.15070332, 45.73479688, 54.93318588, 66.98031261, 52.02479973, 56.18413736, 58.12267471, 67.37947398, 60.49162862, 73.82609217, 69.61515621])
- 投稿日:2020-10-18T18:55:18+09:00
python startswith()
引数の文字列から始まっているか確認する
object.startswith(string)
object = 'あいうえお' string1 = 'あいう' string2 = 'いうえ' >>> print(object.startswith(string1)) True >>> print(object.startswith(string2)) False
- 投稿日:2020-10-18T18:27:42+09:00
実務で使えそうなPandas関連操作の自分用メモ
0. はじめに
最近、データサイエンス100本ノック(構造化データ加工編)を一通り解いてPandasの勉強をしました。
まずは答えを見ずにわからない箇所は自分で調べて全問解いた後、答え合わせをして勉強したのですが、今回の勉強を通じて、普段実務で使えそうだと思った処理を自分用にまとめました。※あくまで自分用のまとめですので、出力結果や説明は割愛しており、以下の順番も100本ノックの順と無関係です。模範解答にはない処理もあります。
1. データセットの読み込み〜前処理
ファイル入出力
# ファイル読み込み。文字コードはUTF-8、Tab区切り df = pd.read_csv('data/d.csv', header=0, encoding='utf-8', sep='\t')# ファイル書き込み。ヘッダーあり、文字コードはUTF-8、カンマ区切り df.to_csv('data/d.csv', header=True, encoding='utf-8', sep=',')# ファイル書き込み。ヘッダーなし、文字コードは文字コードはCP932、Tab区切り df.to_csv('data/d.csv', header=False, encoding='cp932', sep='\t')データフレームのコピー
df2 = df.copy()キーを使ったデータフレームの結合
pd.merge(df_receipt, df_store[['store_cd', 'store_name']], on='store_cd', how='inner') #inner:内部結合, left:左外部結合, right:右外部結合, outer:完全外部結合データフレームの連結
pd.concat([df1, df2], axis=1) #mergeと違い、リストで渡す。axis=0とすれば縦方向、axis=1とすれば横方向に結合される。データフレームの件数(行数)
len(df)ユニーク数
len(df['id'].unique())ユニークな要素の値とその出現回数
df['id'].value_counts()欠損値の処理
# 各列の欠損数の確認 df.isnull().sum()# 欠損値が一つでも含まれるレコードを削除 df.dropna()# fillnaは辞書型で一度に指定できる df.fillna({'price': mean(df['price']), 'cost': median(df['cost'])})重複の削除
#subsetで対象とする列を設定して重複削除 df.drop_duplicates(subset=['name', 'cd'], keep='first', inplace=True)列名の変更
# renameで任意の列名を変更 df.rename(columns={'ymd':'sales_date'}, inplace=True)# リストで直接書き換える df.columns = ['category', 'price', 'cost']型キャスト
# 文字列型に変換 df['sales_date'].astype(str)# True, Falseを1, 0に変換する (df['sales']>2000).astype(int)値の置換
code_dict = { 'A': 11, 'B': 22, 'C': 33, 'D': 44 } df['name'].replace(code_dict) #一致しないときはそのまま df['name'].map(code_dict) #一致しないときはNAN条件を満たす行にアクセスし、値を代入
df.loc[df['age10']=='60代', 'age10'] = '60代以上'条件を満たすか否かの0-1フラグを立てる
(df['sales'] != 0).apply(int) #salesが0でなければ1のフラグが立つ列に関数を適用して変換
# 四捨五入する df['price'].apply(lambda x: np.round(x))# 1.1倍して、小数点以下を切り捨てる df['price'].apply(lambda x: np.floor(x * 1.1))# 常用対数化(底=10)する df['sales'].apply(lambda x: math.log10(x))複数の列に関数を適用して変換
# 2つの列の月の差を出す df[['end_date', 'start_date']].apply(\ lambda x: relativedelta(x[0], x[1]).years * 12 + relativedelta(x[0], x[1]).months, axis=1)# 欠損値ならx[1](メジアン)。そうでなければそのまま df[['price', 'median_price']].apply(\ lambda x: np.round(x[1]) if np.isnan(x[0]) else x[0], axis=1)値を標準化(平均0、標準偏差1)
# 1行で書く場合 df['sales_ss'] = preprocessing.scale(df['sales'])from sklearn import preprocessing scaler = preprocessing.StandardScaler() scaler.fit(customer[['sales']]) customer['sales_ss'] = scaler.transform(customer[['sales']])値を正規化(最小値0、最大値1)
from sklearn import preprocessing scaler = preprocessing.MinMaxScaler() scaler.fit(customer[['sales']]) customer['sales_mm'] = scaler.transform(customer[['sales']])ダミー変数を作成
pd.get_dummies(df, columns=['cd']) # columnsを指定すると特定の列だけ適用でき、object型でなくてもダミー化できる文字列操作
# 先頭3文字の抽出 df['name'].str[0:3]# 文字列の連結 df['gender'].str.cat((df['age10']).astype(str)) # gender列とage10列の文字列を結合する数値条件による行の抽出
# queryメソッドによるデータ抽出。複数条件を指定するときにシンプルに書ける df[['sales_date', 'id', 'cd', 'quantity', 'amount']]\ .query('id == "XXXX" & (amount >= 1000 | quantity >=5)')# (参考)queryメソッドを使わない場合、条件が複雑だと煩雑になる target = (df['id']=="XXXX") & ((df['amount']>=1000) | (df['quantity']>=5)) df[target][['sales_date', 'id', 'cd', 'quantity', 'amount']]文字列条件による行の抽出
# "SASS" から始まる行を抽出 df['store'].str.startswith('SASS')# 1 で終わる行を抽出 df['id'].str.endswith('1')# 札幌 を含む行を抽出 df['address'].str.contains('札幌')# 正規表現を使った判定 df['cd'].str.contains('^[A-D]', regex=True) #A〜Dのいずれかから始まる df['cd'].str.contains('[1-9]$', regex=True) #1〜9のいずれかで終わる df['cd'].str.contains('^[A-D].*[1-9]$', regex=True) #A〜Dのいずれかから始まり、かつ、1〜9のいずれかで終わる df['tel'].str.contains('^[0-9]{3}-[0-9]{3}-[0-9]{4}', regex=True) #電話番号が3桁-3桁-4桁2. 集計
ソート
# sales列を基準に降順ソート df.sort_values('sales', ascending=True).head(10) #Falseにすれば昇順# 複数列を基準にソート。また各列それぞれ降順、昇順を指定できる df.sort_values(['sales', 'id'], ascending=[False, True])# sales が多い順(ascending=False)にランクを降る。method='min'とすると値が同じ時は同じ数字が振られる df['sales'].rank(method='min', ascending=False)groupbyによる集計
# 集計する列ごとに適用する集計関数を選ぶ df.groupby('id', as_index=False).agg({'amount':'sum', 'quantity':'sum'})# 1つの列に複数の集計を適用 df.groupby('id', as_index=False).agg({'ymd':['max', 'min']})# 任意の関数(ここではpd.Series.mode)を指定 df.groupby('id', as_index=False).agg({'cd': pd.Series.mode})# 無名関数lambdaを指定 df.groupby('id', as_index=False).agg({'amount': lambda x: np.var(x)})# agg関数を使わない書き方も可能 df.groupby('id', as_index=False).max()[['id', 'ymd']] df.groupby('id', as_index=False).sum()[['id', 'amount', 'quantity']]# (参考)groupbyによる最頻値(モード)を集計する場合agg関数を使う df.groupby('id', as_index=False).mode() #エラーが出るクロス集計
pd.pivot_table(df, index='age10', columns='gender', values='amount', aggfunc='sum') #index:表側, columns:表頭, values: 対象とする値, aggfunc: 集計方法)pd.pivot_table(sales, index='id', columns='year', values='amount', aggfunc='sum', margins=True) #margins=True とすれば、総計・小計を出せる4分位点の算出
df.quantile([0, 0.25, 0.5, 0.75, 1.0])[['amount']]3. 日時関連の処理
時間変数の変換
# 文字列 → datetime型 pd.to_datetime(df['str_date'])# エポック秒 → datetime型 pd.to_datetime(df['epoch'], unit='s')# datetime型 → エポック秒 df['date'].astype(np.int64) // 10**9※参考:https://stackoverflow.com/questions/15203623/convert-pandas-datetimeindex-to-unix-time
# datetime型 → 文字列 %Y:年4桁, %m:月2桁, %d:日2桁。 ※%大文字と小文字で意味が違うことに留意。たとえば%Mは分を意味する df['date'].dt.strftime('%Y%m%d')datitime変数から年・月・日の情報を取り出す
# 年情報を取り出す。monthで月、dayで日付を取り出せる t.dt.year# 0埋め2桁の文字列を得るにはstrftimeを使う t.dt.strftime('%d')時間変数の差分
# 日数差を出すときはdatetime型を単に引く df['end_date'] - df['start_date']# 月の差を出すときは、relativedeltaを使う relativedelta(x0, x1).years * 12 + relativedelta(x0, x1).months曜日の処理
# weekday関数で曜日を数字(月曜日からの日数)で出力 df['月曜からの経過日数'] = df['ymd'].apply(lambda x: x.weekday())# その日の週の月曜日の日付を得る df['当該週の月曜日'] = df['ymd'].apply(lambda x: x - relativedelta(days=x.weekday()))時系列の処理
# 1時点前との差分 df['sales'].diff(1)# 1時点前との変化率 df['sales'].pct_change(1)# 1時点前の値 df['sales'].shift(1)# 2時点前の値 df['sales'].shift(2)4. サンプリング
ランダムサンプリング
# ランダムで10%のデータをサンプリング df.sample(frac=0.1, random_state=5)# 性別(gender)の割合に基づきランダムに10%のデータを層化抽出 _, test = train_test_split(df, test_size=0.1, stratify=df['gender'], random_state=5)# 学習データとテストデータに8:2の割合で分割する df_train, df_test = train_test_split(df, test_size=0.2, random_state=5)# 1:1となるようにアンダーサンプリングする r = RandomUnderSampler(random_state=5) df_sample, _ = r.fit_sample(df, df['flag'])参考
勉強するにあたって、以下を参考にさせていただきました。ありがとうございました。
- データサイエンス100本ノック(構造化データ加工編)
- note.nkmk.me
- 投稿日:2020-10-18T18:22:00+09:00
Python isinstance
isinstance(object, classinfo)
objectの型がclassinfoにあっているかを返す
>>> print(isinstance(1, int)) True >>> print(isinstance(1, str)) False
- 投稿日:2020-10-18T18:16:40+09:00
python url設定 include 関数に関して
URLの設定でinclude は実際何してるんだろう?
include()を使用してPATHの設定を引きとれるとなっているが、実際何をしているんだろう
(参考)
mysite/urls.pyfrom django.contrib import admin from django.urls import include, path urlpatterns = [ path('polls/', include('polls.urls')), path('admin/', admin.site.urls), ]実際の関数内原文
def include(arg, namespace=None): app_name = None if isinstance(arg, tuple): # Callable returning a namespace hint. try: urlconf_module, app_name = arg except ValueError: if namespace: raise ImproperlyConfigured( 'Cannot override the namespace for a dynamic module that ' 'provides a namespace.' ) raise ImproperlyConfigured( 'Passing a %d-tuple to include() is not supported. Pass a ' '2-tuple containing the list of patterns and app_name, and ' 'provide the namespace argument to include() instead.' % len(arg) ) else: # No namespace hint - use manually provided namespace. urlconf_module = arg if isinstance(urlconf_module, str): urlconf_module = import_module(urlconf_module) patterns = getattr(urlconf_module, 'urlpatterns', urlconf_module) app_name = getattr(urlconf_module, 'app_name', app_name) if namespace and not app_name: raise ImproperlyConfigured( 'Specifying a namespace in include() without providing an app_name ' 'is not supported. Set the app_name attribute in the included ' 'module, or pass a 2-tuple containing the list of patterns and ' 'app_name instead.', ) namespace = namespace or app_name # Make sure the patterns can be iterated through (without this, some # testcases will break). if isinstance(patterns, (list, tuple)): for url_pattern in patterns: pattern = getattr(url_pattern, 'pattern', None) if isinstance(pattern, LocalePrefixPattern): raise ImproperlyConfigured( 'Using i18n_patterns in an included URLconf is not allowed.' ) return (urlconf_module, app_name, namespace)
- 投稿日:2020-10-18T17:22:30+09:00
ディープラーニングによる動画フレーム補間 Part1【Python】
大学でディープラーニングによる動画のフレーム補間を扱っており、その過程で試している実装をアウトプットします。
これからも動画のフレーム補間の実装の続きを投稿していくので、もしよければLGTM&フォローお願いします。今回やったことは、実際の動画フレームを用いて前後6フレームから中間1フレームを生成するネットワークの構築です。
実装環境
Google Colab
https://colab.research.google.com/notebooks/welcome.ipynb?hl=ja実装概要
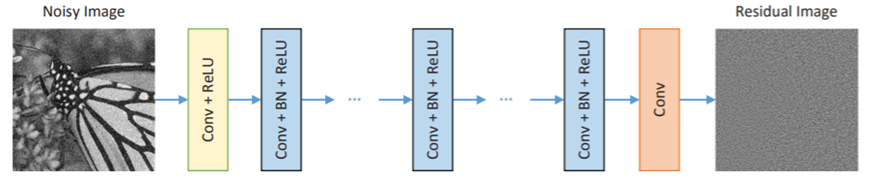
前後フレーム(前3・後3)から中間フレームを生成するディープラーニング。ネットワークはDnCNN[1]です。手近にこのネットワークがあったので使用しています。
([1] Kai Zhang, Wangmeng Zuo, Yunjin Chen, Deyu Meng, and Lei Zhang, “Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising”, https://arxiv.org/abs/1608.03981)
DnCNNのネットワークは次の通りです。本来はノイズ除去を目的としたものです。
入力について、フレームサイズは160*90、チャネル数は18チャネル(6フレーム*RBG)です。
出力について、フレームサイズは同様で、チャネル数は3チャネルです。青色の中間層のパラメータをいじりました。
層数15、カーネルサイズ3*3、チャネル数72となっています。
データセット
街を撮影したMOT17を使いました。
https://motchallenge.net/
セット数は、train 1320, test 1285 です。結果
1つ目の画像は、上から前2フレーム、生成した中間フレーム、後2フレームとなります。実際にはもう1フレームずつ入力がありますが、画像が小さくなってしまうので省略しました。
次の画像は、正解の中間フレームとの比較です。
前後に引っ張られていたり、色が変化していたりと、補間できているとは全然言えない結果ですね。
性能評価
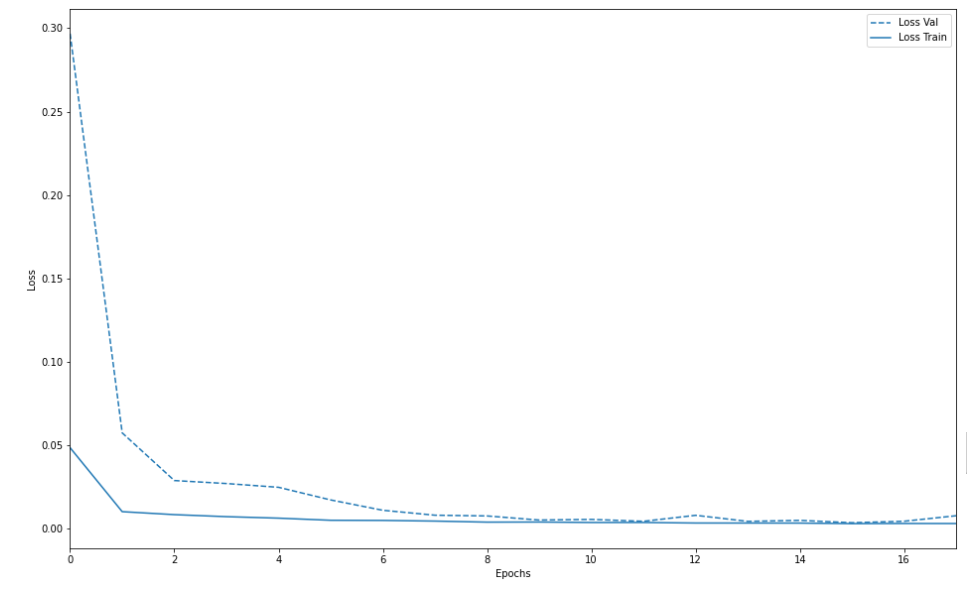
汎化性能のグラフはこちら。近い値を取っているので、ここは問題ないと思われる。
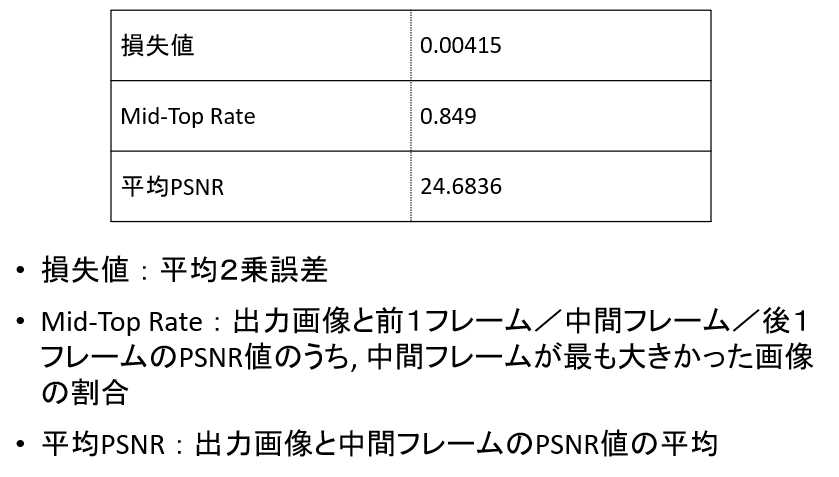
損失値等の数値データはこちら。
数値上、そこまで悪い値ではない印象です。以前に1画像をトリミングして疑似的なフレーム補間を行ったときの損失値と平均PSNRに近いです。しかし、これは前後画像がほぼ同じ画像であるためと思われます。mid-top rateは低くなっているので、ここを上げる必要があります。
考察
補間できていない理由として、
・データセット数の少なさ
・入力6フレームがうまく機能していない
・ネットワーク(DnCNN)の問題
の3点だと考えています。訓練・テストデータともに1300セットほどです。元の画像数は多いのですが、1セットで7フレーム消費するのでなかなか量が稼げないです。自作データセットを今作っている最中なので、データセット数に気を付けながら進めたいと思います。
入力6フレームはどうなのでしょうか。。どの論文見ても前後2フレームで補間を行っているので、このまま6フレームでやり続けてうまくいくのか心配です。比較のためにも2フレームに戻したほうがいいと思い始めました。
今後の方針
・自作データセットでセット数を増やす。
※ハイスピードカメラによるデータセット。このデータセットを使って精度が向上するかが研究の目的です。
・入力フレーム数を何枚にするか検証。
・別のネットワークでの検証。最後に
最後まで読んでいただきありがとうございました。
改善点等ありましたら遠慮なくご指摘ください。
これからもこの系統の投稿をしていくので、よければLGTM&フォローお願いします!



- 投稿日:2020-10-18T16:59:05+09:00
pythonを使ってMicrosoft Formsを自動送信する方法(Mac版)
はじめに
最近
アレの影響があり、私の置かれている状況ではMicrosoftFormsを毎朝早くまでに送信しなければいけなくなりました。それを「めんどくさいな」と考えた私はpythonのwebスクレイピングを習うついでにFormsの自動回答を実装することにしました。
1.作成環境
・macOS X Catalina 10.15.7
・chorme 86.0.4240.80
・Python 3.7.4
・Homebrew2.モジュールのインストール
コマンドプロントでseleniumをインストールします。
pip install seleniumHomebrewを用いてwebdriderをinstallします。Homebrewを入れていない場合はまずHomebrewを入れていください
brew install chormedriver3.コードの作成
seleniumにあるwebdriverをインポートする。
処理をして秒止めるsleepをインポートする。form_sendfrom selenium import webdriver from time import sleepselenium自体に処理を待つのモジュールがあるのですが試してみたところうまいことページ遷移後の動作がうまくいかなかったのでsleep()で動作を止めることになります。
下記の場合は10秒処理を止めます。sleep(10)ウェブブラウザを立ち上げurl = '***'の***にformsのURLを入れます。
form_sendbrowser = webdriver.Chrome() url = '***' browser.get(url)formsのURLをいれるとログイン画面に行くのでメールアドレスを入力するtext-boxの要素を調べます。
⌘ + option + i でデベロッパーツールを開き 左上にある下記マークを押すことで要素の指定ができます。
調べるとMicrosoft formsではi0116のidが使用されています。(変わっているかもしれませんので作成時にチェックをすることをお勧めします)
browser.find_element_by_id()を使用することでidから要素を指定できます。
.send_keys(email)でテキストボックスにemailを記入できます。emailは各自指定してください。
同じようにしてボタンのidを探します。.click()とすることでその要素をクリックします。form_sendbrowser.find_element_by_id('i0116').send_keys(email) browser.find_element_by_id('idSIButton9').click() sleep(3)同じようにしてパスワード画面とログイン維持確認画面入力します。
form_sendbrowser.find_element_by_id('i0118').send_keys(password) browser.find_element_by_id('idSIButton9').click() sleep(3) browser.find_element_by_id('idSIButton9').click() sleep(3)するとformsの回答画面に行きます。
formsの回答部分にはidが指定されていないためxpathを指定していきます。
・ラジオボタンを押したい場合
browser.find_elements_by_xpath("//input[@value='***']")[0].click()***には入力したいラジオボタンのvalueをデベロッパーツールで探して入力してください
・textboxを入力する場合
browser.find_elements_by_xpath("//input[@class='***']")[0].click()***には入力したいラジオボタンのclassをデベロッパーツールで探して入力してください
browser.find_elements_by_xpath()では指定したxpathにあてはまるものがリスト化されて取得されるため1つ目が[0]、2つ目が[1]、3つ目が[2]のようになっています。そのためtextboxの2つ目へ文字を入れたい場合は[0]が[1]になります。
入力が完了すれば送信ボタンを押すコードを入力します。
browser.find_element_by_xpath("//button[@title='送信']").click())最後にブラウザのタブを閉じて終了
browser.quit()全体のソースコード
from selenium import webdriver from time import sleep email = '各自入力' password = '各自入力' url = '各自入力' browser = webdriver.Chrome() browser.get(url) browser.find_element_by_id('i0116').send_keys(email) browser.find_element_by_id('idSIButton9').click() sleep(3) browser.find_element_by_id('i0118').send_keys(password) browser.find_element_by_id('idSIButton9').click() sleep(3) browser.find_element_by_id('idSIButton9').click() sleep(3) #formsに入力したい事柄で変化します。 browser.find_elements_by_xpath("//input[@value='各自入力']")[0].click() browser.find_elements_by_xpath("//input[@value='各自入力']")[0].click() sleep(3) browser.find_element_by_xpath("//button[@title='各自入力']").click() sleep(10) browser.quit()4.cronで時間を指定
レンタルサーバーを借りていない私はmacにあるcronを用いて自動実行します。
システム環境設定のセキュリティーとプライバシーの鍵を解除し+から
/usr/sbin/crnを選択し開きます。
ターミナルを開いて
crontab -eと入力します。
・毎日6時に実行する場合(*は全て実行するということです。)# 分 時間 日 月 曜日 python 保存されているディレクトリ(必ず絶対パスを入力) 0 6 * * * python form_sendcronはスリープ状態では実行されていないのでその前1分間だけスリープ解除する設定にします。
システム環境設定の省エネルギーからスケジュールを選択し時間を入力します。
(1日に何度も実行しその時だけ立ち上げたい時はpmsetを活用するといいでしょう)5.後書き
初めて記事を書きました。
記事を書くのは意外と根気が入りましたが理解度アップと暇つぶしには良かったと思います。
相当不純な動機でMicrosoft formsの自動回答を作成しましたが良いものに活用していただければ大変喜びます。
最後まで読んでいただきありがとうございました。
※Windows版は執筆されません。

- 投稿日:2020-10-18T16:55:09+09:00
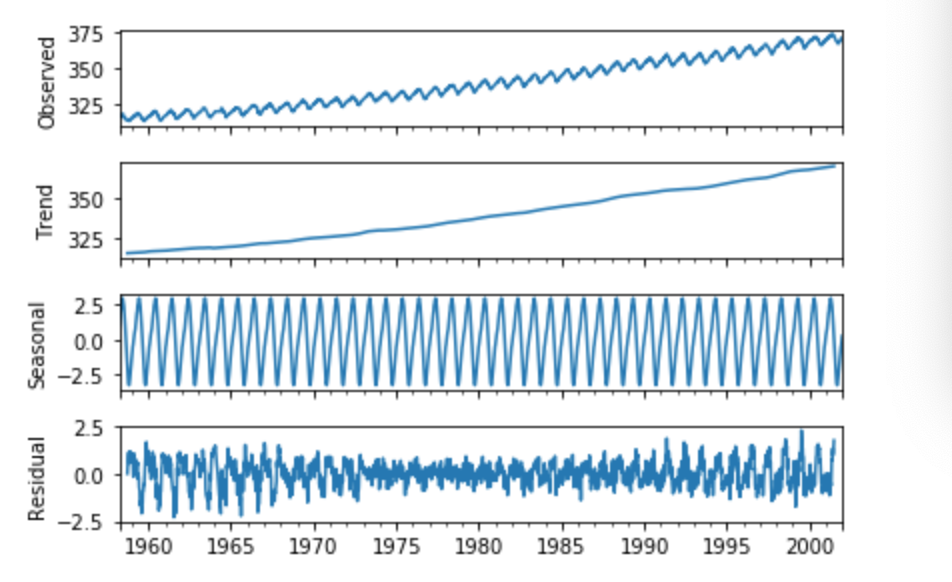
時系列分析3 時系列データの前処理
Aidemy 2020/10/29
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、時系列分析の3つ目の投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・時系列データをpandasで扱う
・時系列データを定常性にする方法時系列データをpandasで扱う
データの読み込みと表示
・SARIMAで時系列データを分析することが最終目標ではあるが、このとき渡すデータに対してはいくつかの前処理を行う必要がある。
・時系列データがCSVファイルで与えられている場合、読み込みは
pd.read_csv("ファイルパス") で行う。時間情報をインデックスに変換する
・時系列データの分析の際には、時間の情報(Hour,Monthなど)をインデックスに変換することで扱いやすくする。
・変換の手順は以下のようになる。
①index情報をpd.date_range("開始時","終了時",freq="間隔")で定義する。
②定義した情報を元のデータのインデックスに代入する。
③元のデータの時間情報を削除する。・①で入力する元のデータの開始時や終了時、間隔はdf.head()やdf.tail()で確認できる。
・また間隔に関しては、秒単位でデータが構成されている場合は「S」、分なら「min」、時間なら「H」、日なら「D」、月なら「M」を渡せば良い。・コード
・結果
データが定常性を持たないときの原因
・時系列データが定常性を持たないときの原因には、「トレンド」と「季節変動」があげられる。
・定常性があるときには期待値が一定であるはずだが、正のトレンドがあった場合期待値は上昇傾向にあると言うことになるので、定常性があるとは言えない。
・同様に、定常性があるときには自己相関係数が一定であるはずだが、季節変動のあるデータ、すなわち一年の中で一時期だけ値が急増急落するようなデータでは、自己相関係数が一定であるとは言えない。・このような場合は、トレンド、季節変動を取り除く変換を行えば定常性があるデータにすることができる。
・この定常化したデータでモデルを作成した後、再度トレンドや季節変動を合成して原系列のモデルを構築する。時系列データを定常性にする
トレンド、季節変動の除去
・トレンド、季節変動を除去し、定常性を持たせるには、以下の4つの方法が挙げられる。詳しくは後述。
・対数変換で変動の分散を一様にする
・移動平均を取ってトレンドを推定し、それを除去する
・階差系列に変換する(一般的)
・季節調整を行う対数変換
・「時系列分析1」で見た通り、対数変換を行えばデータの値の変化を穏やかにすることができる。
・これを利用すると、季節変動のような急激な値の変化があるデータに対して、自己共分散を一様にすることができる。すなわち、季節変動を除去することができる。
・しかし、この方法ではトレンドが除去できないので、対数変換の他にトレンドを除去する処理を行う必要がある。
・対数変換はnp.log(データ)で行える。・コード
・結果
移動平均
・移動平均とは、一定の区間の平均を取ると言うことを、区間を移動しながら行うことである。
・移動平均によって、元のデータの特徴を残しつつ、データを滑らかにすることができる。これにより、季節変動を除去し、トレンドを抽出することができる。
・例として、月ごとのデータに季節変動があるとき、12個の移動平均をとることで季節変動を除去できる。また、抽出したトレンドについても「(元の系列)-(移動平均)」で除去することができる。・移動平均は以下のように算出できる。
データ.rolling(window=移動平均の個数).mean()・コード(CO2濃度のデータ、51週間(1年間)ごとの移動平均をとる)
・結果
階差系列
・「時系列分析1」で見た通り、データを一つ前の値との差をとって扱うことを階差系列という。
・階差系列にすることで、トレンドと季節変動を除去することができる。簡単に行えるため、定常性を持たせるための最も一般的な方法である。
・階差系列を求めるにはデータ.diff()で求めることができる。
・一回階差系列を求めたものを一次階差系列といい、一次階差系列の階差系列を求めたものを二次階差系列という。・コード
・結果
季節調整
・「時系列分析1」で見た通り、季節調整済み系列にすることで、原系列からトレンドと季節変動を除去することができる。
・除去の仕組みとしては、「原系列=トレンド+季節変動+残差」というように原系列は分解できるが、これを「残差=原系列ー(トレンド+季節変動)」というように変換すると残差は原系列からトレンドと季節変動を除去したものになる。これを利用している。
・季節調整済み系列にするには、sm.tsa.seasonal_decompose(データ,freq=区間の指定)を行えば良い。・コード
・結果
まとめ
・時系列分析を行う前に、時系列データの時間情報をインデックスにしておく。
・時系列モデルに渡すデータは定常性がなければいけないので、定常性のないデータに関しては階差系列にするなどの前処理を行う必要がある。今回は以上です。最後まで読んでいただき、ありがとうございました。



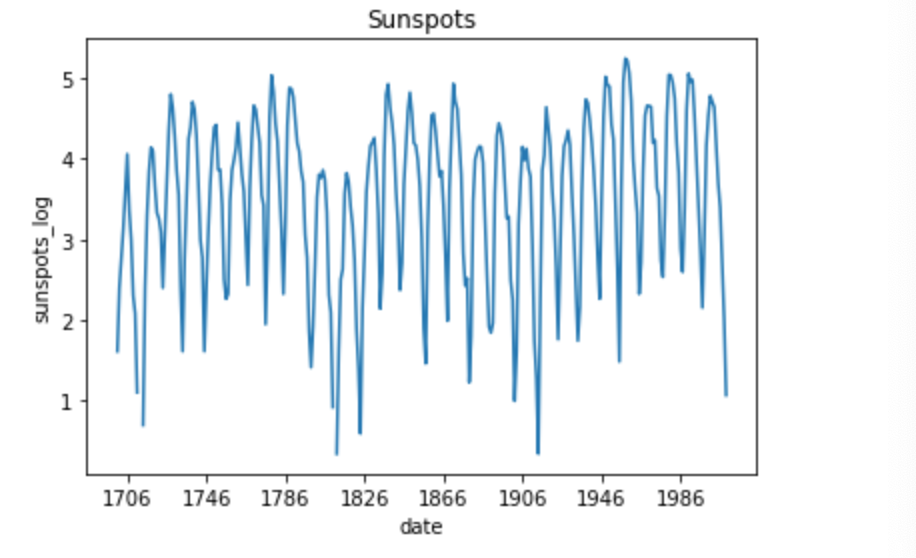

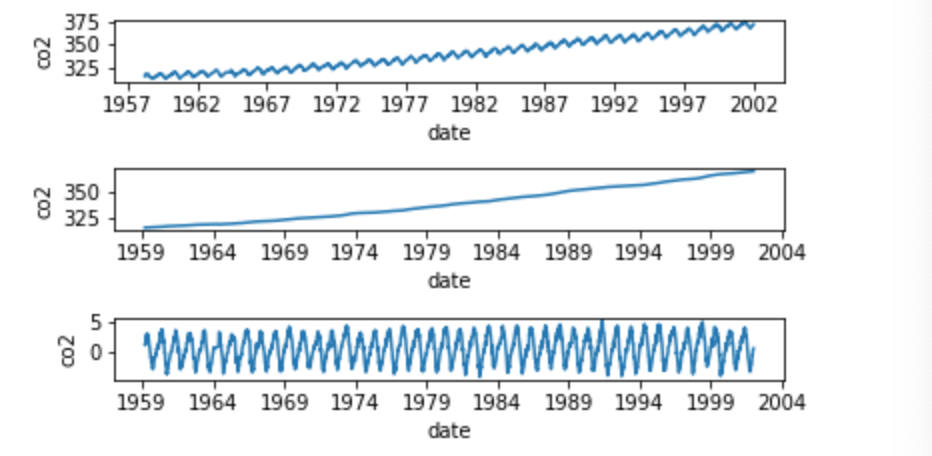

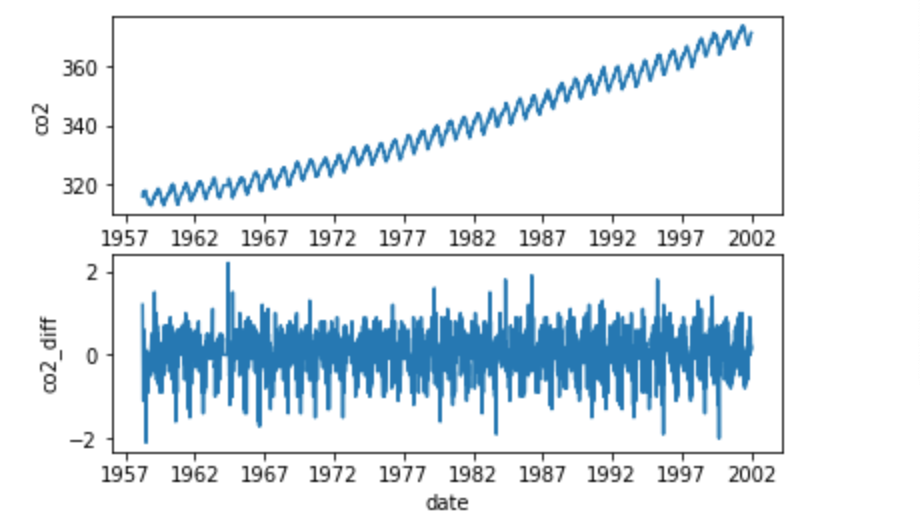

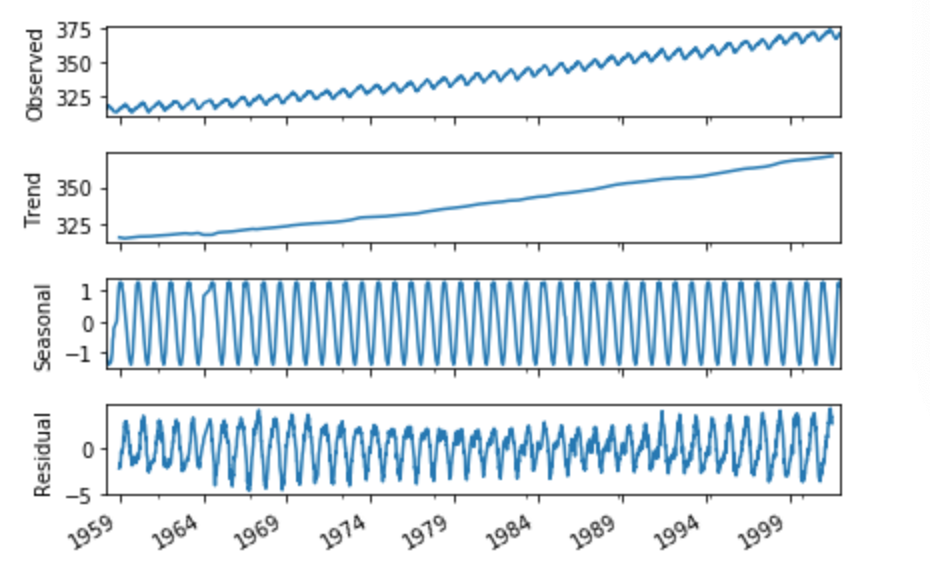
- 投稿日:2020-10-18T16:54:39+09:00
時系列分析2 定常性、ARMA・ARIMAモデル
Aidemy 2020/10/29
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、時系列分析の2つ目の投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・定常性について
・ARMA・ARIMAモデルについて定常性
定常性とは
・時系列データにおいて、「時間経過に依らず常に一定の値を軸に、同程度の幅で揺れて変化する」ものを定常性があると表現する。
・定常性があるかどうかは、データを一回可視化し、上記特徴を有しているかを目視で確認する必要がある。
・時系列分析においては、定常性のない時系列をそのまま扱うと無意味な相関(擬似相関)を検出してしまう恐れがあるため、定常性のある時系列に変換する必要がある。弱定常性/強定常性
・弱定常性とは、時系列データの期待値と自己共分散が常に一定であることを指す。
・期待値が一定であることから「常に一定の値が軸に」なっているといえ、自己共分散が一定である事から「同程度の幅で揺れて変化する」と言えるので、定常性がある状態だと言える。ホワイトノイズ
・ホワイトノイズとは、全ての時点で期待値が0で、分散が一定で、共分散が0であること(弱定常性)を表す。
・時系列モデルのパターンのうち、不規則変動(誤差)は数学的に表すのが難しいため、ホワイトノイズを用いて対応することになっている。ARMA/ARIMA/SARIMAモデル
ARMA/ARIMA/SARIMAモデルについて
・ARMA(アーマ)/ARIMA(アリマ)モデルは時系列分析を行う際に使われるモデルである。
・この二種類の発展型にSARIMA(サリマ)と言うモデルも存在し、最終的にはSARIMAモデルで時系列分析を行う。
・ARMA/ARIMAモデルは「AR」「MA」と言うモデルが組み合わされたモデルである。次項以降で詳しく説明する。
*これらのモデルを実際に構築するのは「時系列分析4」になるので、そちらを参照のこと。ARモデル
・ARモデルでは、ある時点kの時系列データ「yk」を、その一つ前の時点のデータ「yk-1」を使って表すことで自己相関が作られる。
・このように過去の値から回帰的にデータの値を推定するので、ARモデルは「自己回帰モデル」とも言われる。またこの時、過去のp個のデータを使って次のデータを予測する時,AR(p)と表す。MAモデル
・MAモデルでは、ある時点kの時系列データのうちホワイトノイズ「εk」をひとつ前のホワイトノイズ「εk-1」を使って表すことで自己相関が作られる。
・ホワイトノイズは不規則変動(誤差)を示すので、MAモデルは過去の誤差に影響されるモデルであると言える。またこの時、過去のq個の誤差を使って次のデータを予測する時、MA(q)と表す。ARMAモデル
・先述の通り、ARMAモデルはARモデルとMAモデルを組み合わせてできたモデルである。
・AR(p)とMA(q)を組み合わせたときはARMA(p,q)と表現される。ARIMAモデル
・ARIMAモデルとは、「原系列で渡されたデータを階差系列に変換するARMAモデル」のことである。
・原系列が渡されるARMAモデルは定常性のあるデータや過程でしか扱うことができないが、階差系列に変換するARIMAモデルでは定常性のないデータや過程も扱うことができる。・モデルがARMA(p,q)で、変換するときの階差がd(差分を取るのがd時点前)であるときはARIMA(p,d,q)と表す。
・このときの「p」を自己相関度、「d」を誘導、「q」を移動平均と言う。まとめ
・定常性のうち弱定常性は、時系列データの期待値と自己共分散が常に一定であることを指す。
・ホワイトノイズとは、全ての時点で期待値が0で、分散が一定で、共分散が0であることを表す。
・時系列分析を行う際に使われるモデルとして、ARMAモデルとARIMAモデルがある。これらのモデルはARモデルとMAモデルが組み合わされてできたものであり、ARIMAモデルの方ではデータが階差系列に変換されるので、定常性のないデータも扱うことができる。今回は以上です。最後まで読んでいただき、ありがとうございました。
- 投稿日:2020-10-18T16:54:15+09:00
時系列分析1 基礎編
Aidemy 2020/10/
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、次系列分析の1つ目の投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・時系列分析について
・時系列データの種類
・時系列データの統計量時系列分析について
時系列データとは
・時系列データとは、時間と共に値が変化するデータのことを指す。例えば、時間ごとの気温や売上高、株価などが当てはまる。
・特に、商品の売り上げ予測、来店者数の予測など、ビジネスにおいて重要な分析である。
・時系列分析は、pythonのStatsModelsを使って実装する。(復習)時系列データの表示
・時系列分析には、時系列データをグラフで図式化することが不可欠である。図式化にはMatplotlibを使う。以下で、今回出てくるpltの復習をする。
・グラフの作成:plt.plot(x,y)
・グラフの表示:plt.show()
・x軸の表示範囲を設定:plt.xlim([,]) (y軸ならylim)
・グラフのタイトル:plt.title("")
・x軸のタイトル:plt.xlabel("") (y軸ならylabel)時系列データのパターン
・時系列データには以下の3パターンがある。時系列データは、これら3パターンが組み合わさってできている。
・トレンド:長期的なデータの傾向。値が上昇していれば「正のトレンド」、減少していれば「負のトレンド」という。
・周期変動:時間経過に伴ってデータの値が上昇と下降を繰り返すこと。特に1年間の周期変動を季節変動という。
・不規則変動:時間経過にかかわらず、データの値が変動すること。モデリング
・モデリングとは、時系列データを定式化(モデルを構築)することである。
・このモデルを使って予測を行ったりデータ同士の関連を分析したりすることが時系列分析にあたる。時系列データの種類
・時系列データには、まず加工前のデータそのものである「原系列」がある。この原系列の性質を分析することが時系列分析の目的であるが、実際に分析するのは加工後のデータであることがほとんどである。
・加工後のデータには、「対数系列」「階差系列」「季節調整済み系列」などがある。以下ではそれぞれについて詳しく見ていく。対数系列
・時系列データのうち値の変動が大きいデータについて、その変化を穏やかなものにすることを対数変換と言い、対数変換を行ったデータのことを対数系列という。
・対数変換を行うには、以下を実行すれば良い。
np.log(DataFrameのデータ)階差系列
・時系列データのうち、一つ前の値との差をとって扱うことを階差系列という。
・階差系列に変換すると、トレンド(長期的な傾向)を取り除くことができる。
・トレンドを取り除くことで「時間経過にかかわらず全体を見ると時系列の値が変化しない」ということを示す定常過程にすることが可能になることがある。定常過程については後述する。・階差系列を行うには、以下を実行すれば良い。
DataFrameのデータ.diff()季節調整済み系列
・1年間の周期変動のことを季節変動といったが、季節変動のあるデータは、そのままでは「季節変動パターンではないデータの分析」が難しい。このような場合に対処するため、季節変動を取り除く処理をすることがあり、この加工を行なったデータのことを季節調整済み系列という。
・季節調整済み系列を行うには、以下を実行すれば良い。(smはstatsmodelsのこと)
sm.tsa.seasonal_decompose(データ)・コード
・結果
時系列データの統計量
期待値(平均)
・各時系列データの平均値を期待値(Expectation)という。
・平均値はnp.mean()で求めることができる。分散/標準偏差
・各時系列データが期待値からどのぐらいばらけているかを示した値が分散である。
・分散は(各データ - 期待値)^2で求められ、この平方根を標準偏差という。
・株、投資の世界では、標準時偏差がリスク計測の重要な指標になっている。自己共分散/自己相関係数
・自己共分散とは、同じデータ同士の別の時系列での共分散をさす。
・時系列がkだけ離れている時、k次の自己共分散といい、以下のように求められる。
(各データ - 期待値)(kだけ離れたデータ - 期待値)
・上記の式をkについての関数として見たものを自己共分散関数という。・この自己共分散を、異なる値との間でも比べられるように変換したものが自己相関係数である。
・自己相関係数は、過去の値とどれぐらい似ているかを表している。
・自己相関係数は以下のように求められる。
自己共分散 / (データの標準偏差)(kだけ離れたデータの標準偏差)_
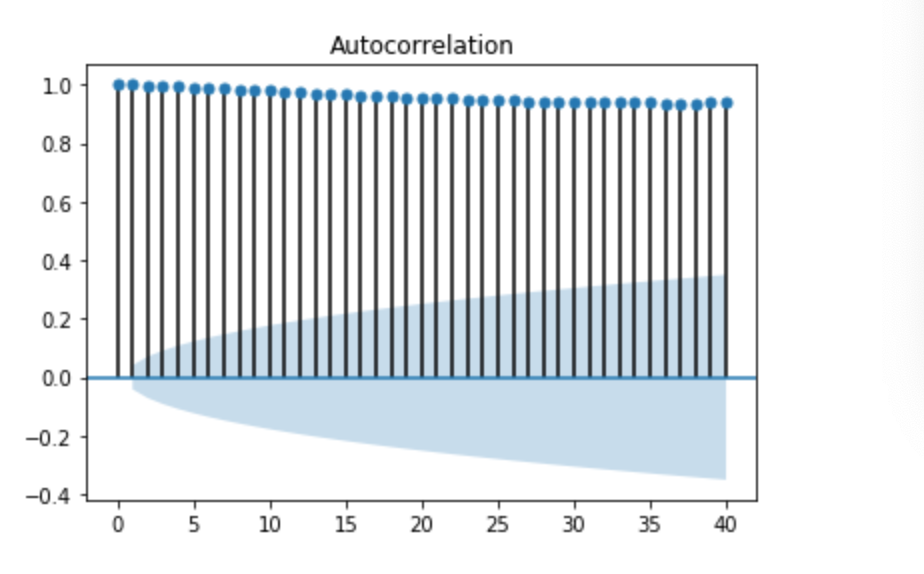
・上記の式をkについての関数として見たものを自己相関関数といい、これをグラフにしたものをコレログラムという。自己相関関数の出力
・自己相関関数は
sm.tsa.stattools.acf(データ,nlags)で表される。
・グラフ(コレログラム)は
sm.graphics.tsa.plot_acf(データ,lags)で表される。・引数である「lag」とは「ずらした時系列kの値」のことである。
・相関係数は1.0に近いほど正の相関が強く、-1.0に近いほど負の相関が強いと言える。・コード
・結果
まとめ
・時系列データとは、時間と共に値が変化するデータのことを言う。
・時系列データには3つのパターンがある。長期的な値の上昇下降の傾向が「トレンド」、時間経過に伴い値の上昇下降を繰り返すことが「周期変動」、時間経過にかかわらず値が変化することが「不規則変動」である。
・時系列分析の統計量には、期待値(平均)や分散、標準偏差などがある。また、これらを使って算出した自己共分散、自己相関係数があり、自己相関係数を算出することで、その時点でのデータの過去との類似性がわかる。今回は以上です。最後まで読んでいただき、ありがとうございました。


- 投稿日:2020-10-18T16:04:41+09:00
時系列データに対するクラスタリング k-shape法の実装【pythonによる教師なし学習 13章】
この記事でやること
- k-shapeによる時系列データの分類を実装
- データには心電図データを使用はじめに
時系列データの分類手法として、k-shape法 がよく用いられます。 この記事ではk-shape法を 用いて心電図データのクラスタリングを行います。
データやコードは「pythonによる教師なし学習」を参考にさせて頂いています。扱うデータ
カリフォルニア大学リバーサイド校の時系列データコレクション(UCR Time Series Classification Archive)を使います。
https://www.cs.ucr.edu/~eamonn/time_series_data/このなかのECG5000を用います。passwordは【attempttoclassify】です。
ライブラリのインポート
ここは参考本を引用しています。一部この記事では扱わないものも入っています。
colabで実行する場合がのインストールが必要です。
!pip install kshape !pip install tslearn'''Main''' import numpy as np import pandas as pd import os, time, re import pickle, gzip, datetime from os import listdir, walk from os.path import isfile, join '''Data Viz''' import matplotlib.pyplot as plt import seaborn as sns color = sns.color_palette() import matplotlib as mpl from mpl_toolkits.axes_grid1 import Grid %matplotlib inline '''Data Prep and Model Evaluation''' from sklearn import preprocessing as pp from sklearn.model_selection import train_test_split from sklearn.model_selection import StratifiedKFold from sklearn.metrics import log_loss, accuracy_score from sklearn.metrics import precision_recall_curve, average_precision_score from sklearn.metrics import roc_curve, auc, roc_auc_score, mean_squared_error from keras.utils import to_categorical from sklearn.metrics import adjusted_rand_score import random '''Algos''' from kshape.core import kshape, zscore import tslearn from tslearn.utils import to_time_series_dataset from tslearn.clustering import KShape, TimeSeriesScalerMeanVariance from tslearn.clustering import TimeSeriesKMeans import hdbscan sns.set("talk")データ読込
次にデータの読込です。時系列データが4000個あり、5個のクラスタに分類されるデータです。
# データ読込 current_path = os.getcwd() file = os.path.sep.join(["",'data', 'datasets', 'ucr_time_series_data', '']) #個人のフォルダに応じて書き換え data_train = np.loadtxt(current_path+file+ "ECG5000/ECG5000_TRAIN", delimiter=",") data_test = np.loadtxt(current_path+file+ "ECG5000/ECG5000_TEST", delimiter=",") data_joined = np.concatenate((data_train,data_test),axis=0) data_train, data_test = train_test_split(data_joined, test_size=0.20, random_state=2019) X_train = to_time_series_dataset(data_train[:, 1:]) y_train = data_train[:, 0].astype(np.int) X_test = to_time_series_dataset(data_test[:, 1:]) y_test = data_test[:, 0].astype(np.int) # データ構造の表示 print("Number of time series:", len(data_train)) print("Number of unique classes:", len(np.unique(data_train[:,0]))) print("Time series length:", len(data_train[0,1:])) # Calculate number of readings per class print("Number of time series in class 1.0:", len(data_train[data_train[:,0]==1.0])) print("Number of time series in class 2.0:", len(data_train[data_train[:,0]==2.0])) print("Number of time series in class 3.0:", len(data_train[data_train[:,0]==3.0])) print("Number of time series in class 4.0:", len(data_train[data_train[:,0]==4.0])) print("Number of time series in class 5.0:", len(data_train[data_train[:,0]==5.0])) """ Number of time series: 4000 Number of unique classes: 5 Time series length: 140 Number of time series in class 1.0: 2327 Number of time series in class 2.0: 1423 Number of time series in class 3.0: 75 Number of time series in class 4.0: 156 Number of time series in class 5.0: 19 """データの可視化
class1~5のデータを可視化します。素人がみてもいまいち違いがわかりませんね。
fig, ax = plt.subplots(5,5,figsize=[30,10],sharey=True) ax_f = ax.flatten() #class1~5のプロット df_train = pd.DataFrame(data_train) cnt = 0 for class_i in range(1,6): df_train_plot = df_train[df_train[0] == class_i] for i in range(0,5): ax_f[cnt].set_title("class: {}".format(class_i)) ax_f[cnt].plot(df_train_plot.iloc[i][1:]) cnt += 1
k-shapeによる分類
k-shapeの実装とその評価です。
評価には「調整ランド法」という手法を用いて1に近いほど、クラスタリングの精度が高いということになります。#k-shape ks = KShape(n_clusters=5,max_iter=100,n_init=100,verbose=0) ks.fit(X_train) #調整ランド法による評価 #実際のラベルとどのくらいあっているかを確かめる #1に近いほど予測クラスタリングがあっていることになる preds=ks.predict(X_train) ars = adjusted_rand_score(data_train[:,0],preds) print("train Adjusted Rand Index:",ars) preds_test=ks.predict(X_test) ars = adjusted_rand_score(data_test[:,0],preds) print("test Adjusted Rand Index:",ars) UCR Time Series Classification Archiveまた、クラスターごとのクラス分布を表示すると下記のようになります。
分布が偏っていることからまあまあうまくクラスタリングできていますね。ただ、数の少ない3,4,5が最も多いというような分け方にはなっていない点には注意が必要です。
# クラスター内部の分布可視化 preds_test = preds_test.reshape(1000,1) preds_test = np.hstack((preds_test,data_test[:,0].reshape(1000,1))) preds_test = pd.DataFrame(data=preds_test) preds_test = preds_test.rename(columns={0: 'prediction', 1: 'actual'}) counter = 0 for i in np.sort(preds_test.prediction.unique()): print("Predicted Cluster ", i) print(preds_test.actual[preds_test.prediction==i].value_counts()) print() cnt = preds_test.actual[preds_test.prediction==i] \ .value_counts().iloc[1:].sum() counter = counter + cnt print("Count of Non-Primary Points: ", counter) """ Predicted Cluster 0.0 2.0 29 4.0 2 1.0 2 3.0 2 5.0 1 Name: actual, dtype: int64 Predicted Cluster 1.0 2.0 270 4.0 14 3.0 8 1.0 2 5.0 1 Name: actual, dtype: int64 Predicted Cluster 2.0 1.0 553 4.0 16 2.0 9 3.0 7 Name: actual, dtype: int64 Predicted Cluster 3.0 2.0 35 1.0 5 4.0 5 5.0 3 3.0 3 Name: actual, dtype: int64 Predicted Cluster 4.0 1.0 30 4.0 1 3.0 1 2.0 1 Name: actual, dtype: int64 Count of Non-Primary Points: 83 """終わりに
この記事では時系列データのクラスタリング手法であるk-shapeの実装を行いました。k-meansを行うときとかなり似てますね。
信号処理や異常検知なんかに役立つと思います。参考になった方はLGTMなどしていただけると励みになります。

- 投稿日:2020-10-18T14:41:31+09:00
python 外部ファイル読みこみ
(サンプル ファイル名:urls.py)
from django.contrib import admin from django.urls import path, include urlpatterns = [ path('polls/', include('polls.urls')), path('admin/', admin.site.urls), ]単体関数呼び出し
from ファイル名 import 関数名複数関数呼び出し
from ファイル名 import 関数名, 関数名
- 投稿日:2020-10-18T14:14:22+09:00
ラズパイでサーボライブラリpiServoCtlを使う(ハードウェアPWM使用)
ここではRaspberryPi4でPython3.7を使用しました。
ホビー用サーボ(左からSG92R、SG90)ライブラリをインストールする
piServoCtlライブラリを使用します。
Github: https://github.com/naoto64/piServoCtl
以下のコマンドを打ってインストールできます。$ sudo pip3 install piServoCtl使い方
このライブラリは、pigpioを使用しているため、pigpiodを起動する必要があります。コマンド
sudo pigpiodを打つか、pigpiodを自動起動させておいてください。pigpiodの自動起動については、このサイトが参考になります。
https://hakengineer.xyz/2017/09/22/post-318/
サーボはSG92RやSG90を使用しましたが、他のサーボでも動くと思います。example.pyfrom piservo import Servo # piservoモジュールをインポート(piServoCtlと間違えないように) import time myservo = Servo(12) # GPIO12にサーボをつなぐ myservo.write(180) time.sleep(3) myservo.write(0) time.sleep(3) myservo.stop()このプログラムを実行すると、サーボが180度、0度の位置に動きます。ですが、0度付近でサーボがガタガタ動きます。サーボモータに若干のズレがあるようで、少し修正が必要なようです。
myservo = Servo(12, min_pulse=0.61, max_pulse=2.34)
myservo = Servo(12)の部分を上のように変更すると、ほぼ正確に動くようになりました。サーボは個体差があるようなので、サーボに合わせてmin_pulse, max_pulseの部分を適宜書き換えて下さい。実行結果
PythonのpiServoCtlライブラリでサーボを動かしてみた。#Python #Raspberry #ラズパイ #電子工作 #サーボ #Servohttps://t.co/VuUtBdYo1a pic.twitter.com/css7esWEjw
— naoto64 (@naoto64_2000) October 18, 2020

- 投稿日:2020-10-18T14:00:44+09:00
pythonユーザーへ権限付与からmakemigrations して migrate までの流れ整理
git hubでclone作成から、各人が手を動かすためのbranchを作るためにsqlへの記録が必要になりますが、今回はその記録までの流れと、ひっかかったので、そのトラブルシュートも記載します。
まずpythonユーザーへの権限付与はこちら
grant CREATE, DROP, SELECT, UPDATE, INSERT, DELETE, ALTER, REFERENCES, INDEX on saku202010.* to python@localhost;ですと、
そのあとにmakemigrationをします。
# python manage.py makemigrations register# python manage.py makemigrations shopこちらは各アプリケーションごとに行います。
順調かとおもいきやこんなエラーがでました。
no changes detected in app ','これは、データベースに変化はない。ってやつで、もうやらなくてもいい「ことがある」という意味です。
結論としては次のステップにいってOKです。yuota@MacBook-Pro-3 saku202010 % python3 manage.py migrateでmigrateを実行してもらうと、
できました!ということです。


- 投稿日:2020-10-18T12:49:44+09:00
AtCoder Beginner Contest 180 復習
今回の成績
今回の感想
まあまあの成績でした。今回のFは難しくて全く解ける気がしませんでした。解答を見て理解はしましたが応用できそうにないので、今回はupsolveしません。E問題は典型であることに終わってから気づきました。今まで解いたことのないパターンの典型だったので、よく復習しようとおもいます。
A問題
$n< a$のときは問題が不成立だと思ったのですが、制約より$n \geqq a$が成り立ちます。
A.pyn,a,b=map(int,input().split()) print(n-a+b)B問題
問題文の通りに実装するだけです。実は入力をそのまま絶対値に変換しても問題ないです。
B.pyn=input() x=list(map(lambda y:abs(int(y)),input().split())) print(sum(x),sum([i*i for i in x])**0.5,max(x))C問題
分配した際にシュークリームが余ってもいいと誤読して$[\frac{n}{k}]$の値の候補を求める問題だと勘違いしてました。
余らないように分配するので約数を列挙するだけです。
C.pydef m(): n=int(input()) d=[] for i in range(1,int(n**0.5)+1): if n%i==0: d+=[i] if i!=n//i:d+=[n//i] d.sort() return d for i in m():print(i)D問題
冷静に場合分けをするだけの問題ですが、2WAを出してしまいました…。結果的に1WAで済めば青パフォだったので悔しいです。
A倍するかBを足すかのいずれの選択かをします。前者と後者で最適な選択をしますが、前者が一度最適でなくなった場合はそれ以降は最適なのは常に後者となります。また、これは変化量を$\times A$と$+B$で比べればわかります。
よって、$x$をA倍するのが最適な場合($\leftrightarrow$$x$にBを足した値よりも$x$をA倍した値の方が小さい場合)、を考えます。このとき、$x\times A \leqq x+ B$を比較の条件式で使うのは当然ですが、$x <y$を満たすように条件を置くことも必要です。ループの中を丁寧に実装すれば、ループを抜けた後に$B$を足す計算も$ans+[\frac{y-x-1}{b}]$を求めるだけになります。
D.pyx,y,a,b=map(int,input().split()) ans=0 while True: if x*a<=x+b: if x*a>=y: print(ans) exit() else: ans+=1 x*=a else: #こっから+ #x*a>x+b #x<y break print(ans+(y-x-1)//b)E問題
典型問題だったようですが、解き終わった後に見るとそれもそうだなという気がします。
以下、コンテストの考察過程を記します。また、題意の三次元座標は$x$軸,$y$軸,$z$軸で張られるものとします。
まず、最大で$n=17$なので$n!$は間に合いません。$2^n$の問題でよくあるのが半分全列挙なので応用しようとしてできませんでした。次にコストの式を見てうまく決まるとことがないかを考えましたが、二頂点を結んだ時に$z$座標の大きい方から小さい方へと結ぶ方が良さそうということしかわかりません。ここで、制約を睨むと$2^{17}$なのでbitDPであれば通ることに気づきます。よって、到達した都市の集合を管理したDPを考えて以下のようになります。
$dp[i][j]:=$(部分集合$i$に含まれる都市には到達済みで都市$j$にいる時の最小のコストの和)
到達した都市の集合をbitで表したい場合はbitDPになるということさえ覚えていれば思いつける問題だと思います。また、この問題は有名なTSP(巡回セールスマン問題)の亜種になります。
ここで、DPの遷移の順序は状態$i$(整数)の小さい順序で行えばよく以下のようになります(✳︎)。初期化は$dp[1][0]=1$のみ行います。(ある$i$で都市$j$にいる時に都市$k$にいく遷移を考えます。$j=k$のときは考える必要がありません。また、$dist[j][k]$は$j$から$k$にいく際のコストです。)
$dp[i|(1<<k)][k]=min(dp[i|(1<<k)][k],dp[i][j]+dist(j,k))$
以上より、最終的に都市1に戻ってくることから$dp[1<<n-1][0]$が答えとなります。
(✳︎)…小さい順序でやって良いことの証明をします。すなわち、任意の移動の仕方が表現できることをここで示します。
$i$の状態から$j$→$k$へと移動するとき、状態は$i$→$i|(1<<k)$となります。つまり、bitwise orをとることで状態(を表す整数)は非減少です。よって、状態(を表す整数)の昇順で遷移(更新)していけば全ての移動の仕方を表現することができます。また、それぞれの状態$i$を頂点として遷移を有向辺と見た時にトポロジカルソートされていれば$i$の小さい方から更新することができ、bitDPではこれが成り立つので良いという解釈もできると思います。さらに、遷移で状態を表す整数が非減少というのは$i$より小さい$j$は$i$を包含しないと考えてもわかると思います。
[2020/10/18 追記]
上記の議論ではある都市から他の都市へと移動する時に他の都市を経由しない方が短いということを暗黙的に使っていますが、これは三角不等式がコストの式で成り立つことから示せます。また、他の都市を経由した方が短くなる場合は先にワーシャルフロイドで全都市間のコストを求めてから同様のbitDPを行えば良いです。
E.pyn=int(input()) tos=[list(map(int,input().split())) for i in range(n)] #1からjでのコスト def co(i,j): return abs(i[0]-j[0])+abs(i[1]-j[1])+max(0,j[2]-i[2]) inf=10**12 dp=[[inf for j in range(n)] for i in range(1<<n)] dp[1][0]=0 for i in range(1,1<<n): for j in range(n): #自身には戻らぬ for k in range(n): if j==k:continue dp[i|(1<<k)][k]=min(dp[i|(1<<k)][k],dp[i][j]+co(tos[j],tos[k])) ans=inf for i in range(n): ans=min(ans,dp[(1<<n)-1][i]+co(tos[i],tos[0])) print(ans)F問題
今回は解きません。

- 投稿日:2020-10-18T11:34:39+09:00
Django ViewではHttpメソッド名の関数を定義することができる(get, post, put,patch,delete...)
言いたいこと
Django ViewではHttpメソッドの関数が定義できます?
定義した関数にHttpメソッドで振り分けられます。
私はGETでしかできないものだと思っていました。views.pydef get(): # 処理 def post(): # 処理該当メソッドの呼び出し場所
該当メソッドの呼び出し場所は以下にあります。
from django.views.generic import View以下、メソッドの呼び出し場所の抜粋です。
django/views/generic/base.pyclass View: """ Intentionally simple parent class for all views. Only implements dispatch-by-method and simple sanity checking. """ http_method_names = ['get', 'post', 'put', 'patch', 'delete', 'head', 'options', 'trace'] # ここにdef __init__や def asViewメソッド類がありますが、 # 今回は関係ないので省略します def dispatch(self, request, *args, **kwargs): # Try to dispatch to the right method; if a method doesn't exist, # defer to the error handler. Also defer to the error handler if the # request method isn't on the approved list. if request.method.lower() in self.http_method_names: handler = getattr(self, request.method.lower(), self.http_method_not_allowed) else: handler = self.http_method_not_allowed return handler(request, *args, **kwargs)
def dispatchが今回の解説の要です。解説
1行目 - ifで分岐するが、基本は常にTrue
def dispatchにある、メソッド内の1行目を参照します。django/views/generic/base.pyclass View: def dispatch(self, request, *args, **kwargs): if request.method.lower() in self.http_method_names: # ←こいつの解説 handler = getattr(self, request.method.lower(), self.http_method_not_allowed)まず、
request.methodですね。
リクエストのメソッドを示しています。Djangoの公式ページには以下のような記述があります。
HttpRequest.method
リクエストに使われた HTTP メソッドを表す文字列です。必ず大文字になります。if request.method == 'GET': do_something() elif request.method == 'POST': do_something_else()すなわち、
request.methodにはHTTPメソッド名が入ることになります?
メソッド名は大文字で渡されています。例えば、以下のようなものですね。
'GET'
'POST'
'PUT'続きを読んでいきます。
django/views/generic/base.py(再掲)if request.method.lower() in self.http_method_names:これらを
.lower()で小文字にしています。ここまでで、
request.method.lower()が読み解けます。Httpメソッド名が小文字で入っている。ということですね。
Httpメソッド名が小文字で入っている。これを踏まえて続きを見ましょう。
self.http_method_namesがあります。
これは以下のような変数が定義されています。django/views/generic/base.pyhttp_method_names = ['get', 'post', 'put', 'patch', 'delete', 'head', 'options', 'trace']Httpメソッド名が羅列されています。
getもpostもありますね。django/views/generic/base.py(再掲)if request.method.lower() in self.http_method_names:よって、1行目if文の結論としては
Httpメソッド名の場合にTrueとなる。
という結果になります。
要は、いつでもif文をTrueを通過するという認識です。
http_method_namesから
'get'や'post'の記述を消せば、Falseになりますね。
ここらへんはカスタマイズ可能な作りになっているようです。2行目- 定義された関数を呼び出す
django/views/generic/base.pyclass View: def dispatch(self, request, *args, **kwargs): if request.method.lower() in self.http_method_names: handler = getattr(self, request.method.lower(), self.http_method_not_allowed) # ←こいつの解説
handler =の部分ですね。まず、
getattr()という関数があります。
これは、公式ページに以下のような解説があります。object の指名された属性の値を返します。 name は文字列でなくてはなりません。文字列がオブジェクトの属性の一つの名前であった場合、戻り値はその属性の値になります。例えば、 getattr(x, 'foobar') は x.foobar と等価です。指名された属性が存在しない場合、 default が与えられていればそれが返され、そうでない場合には AttributeError が送出されます。
組み込み関数 — Python 3.9.0 ドキュメント
https://docs.python.org/ja/3/library/functions.html#getattr重要な部分はこの行です。
例えば、 getattr(x, 'foobar') は x.foobar と等価です。
getattr(ターゲットオブジェクト名, ターゲット関数名)のように使っています。
以下は何を示すでしょうか。getattr(self, request.method.lower())
request.method.lower()は'get'や'post'等のHttpメソッドの小文字でした。これらを組み合わせると、例えば、以下のようになります。
self.get()
self.post()
selfは自身を表します。
すなわち、自身が持つ関数のことです。def get(): def post():これが
def get()やdef post()でメソッドを定義できる理由です。Httpメソッド名に関連する関数を呼び出しているのです。
したがって、Viewを継承する、もしくはViewを継承しているTemplateViewなどのクラスを継承していれば、
以下のようにHttpメソッドごとに関数を分けることができるのですね。?views.pyfrom django.views.generic import TemplateView class HogeView(TemplateView): # Viewを継承しているTemplateViewなどのクラスを継承 template_name = 'hoge.html' def get(): # httpメソッド名の関数(GET)が使える pass # お好きな処理 def post(): # httpメソッド名の関数(POST)が使える pass # お好きな処理結論
Django ViewではHttpメソッドの関数が定義できます?
views.pydef get(): # 処理 def post(): # 処理以上!
ここまで読んでいただき、ありがとうございました。
あとがき
Djangoの継承関係把握は難しいです。
便利なサイトを紹介しておきます。
Django View Classの継承関係が見れたり、継承したメソッドが参照できます。
ご参考まで。View -- Classy CBV
https://ccbv.co.uk/projects/Django/2.2/django.views.generic.base/View/

- 投稿日:2020-10-18T10:50:19+09:00
django 更新
- 投稿日:2020-10-18T09:51:47+09:00
GCPのCloud functionsをローカルでエミュレートする
Google Cloud Platformでバックエンドを構築するにあたり、デプロイするのに一分程度かかってしまうため、開発時はローカルでエミュレートする環境を構築するとスムーズです。Python環境でCloud Functionsをエミュレートする方法についてまとめます。
結論
main.pyにhelloという関数を作って置いて
main.pydef hello(request): request_json = request.get_json() if request.args and 'message' in request.args: return request.args.get('message')+'get' elif request_json and 'message' in request_json: return request_json['message']+'post' else: return f'Hello Worlds!'そのフォルダでターミナルを下記を打てばいいです。
terminal.functions-framework --target=helloportを指定するときは下記です。
terminal.functions-framework --target=hello --port=8081curlコマンド
デバッグ用のcurlコマンドです。
get.通信curl -X GET "localhost:8081/?message=Hi,get"post.通信curl -X POST -H "Content-Type: application/json" -d '{"message":"hi,post"}' localhost:8081/corsの設定について
main.pydef hello(request): request_json = request.get_json() headers = { 'Access-Control-Allow-Origin': '*', } """ headers = { 'Access-Control-Allow-Origin': 'https://example.com', } """ if request.args and 'message' in request.args: return (request.args.get('message')+'get', 200, headers) elif request_json and 'message' in request_json: return (request_json['message']+'post', 200, headers) else: return (f'Hello Worlds!', 200, headers)Deployment
うまくいったらGCPへデプロイします。
terminal.gcloud functions deploy hello \ --runtime python37 --trigger-http --allow-unauthenticatedhttps://cloud.google.com/functions/docs/quickstart
公式
https://github.com/GoogleCloudPlatform/functions-framework-python
応用例
実際は返り値はJSON形式になることが多いので、その場合です。
main.pyimport json def hello(request): request_json = request.get_json() headers = { 'Access-Control-Allow-Origin': 'http://localhost:8080', } """ headers = { 'Access-Control-Allow-Origin': 'https://example.com', } """ print('called') if request.args and 'message' in request.args: input = request.args.get('message') rtrn = {'output':'hi %s(get)'%(input)} return (json.dumps(rtrn), 200, headers) elif request_json and 'message' in request_json: input = request_json['message'] rtrn = {'output':'hi %s(post)'%(input)} return (json.dumps(rtrn), 200, headers) else: rtrn = {'output':'hi (no args)'} return (json.dumps(rtrn), 200, headers)標準モジュール以外の場合、requirement.txtを作成する必要がありますが、この場合はjsonだけなのでいらないです。
- 投稿日:2020-10-18T05:48:07+09:00
完全栄養マクドナルド食の線型計画による実装~もしマクドナルドだけで生活すると栄養バランスはどうなるのか?~
背景と概要
マクドナルドが大好きである。
しかし、ジャンクフード、健康に悪い、
などという話は以前よりよく見かける。では本当にマクドナルドを食べ続けると、
健康に悪いのだろうか?
マクドナルドだけで生活する場合本当に、
栄養の偏りやカロリー過剰などが発生するのだろうか?本稿は、マクドナルドだけで
一日に必要なすべての栄養素を摂取する食事
をする場合に、どのようなメニューを選ぶべきで、
その結果どのような栄養問題が生じるのか、
PuLPというPythonの線型計画ライブラリを用いて
研究した結果をまとめたものである。すなわち、マクドナルドだけで
完全栄養食としてのメニューを組み立てるには
何をどれだけ食べればいいの?
そしてその時何カロリーになるの? という
世の中の0.001%くらいの人が一度は疑問に
思ったことがある問題に対して解を与える。また、栄養食的な代表選手ということで、
牛乳の栄養素を含んだ上での五角形の形
になっていることで高名な
コーンフレーク(こちらも大好きである)を
メニューに加えた場合の考察も追加する。「無人島にマクドナルドだけ持って行っていい」と
言われた場合にとても役立つ研究であることを確信している。実装の基本方針
まず、マクドナルドの全メニューの
栄養情報については、
以下の公式サイトにて公開されている。https://www.mcdonalds.co.jp/products/nutrition_balance_check/
こちらのサイトでメニューを選び、
自分の性別・年齢・身体活動レベルを
入力することで、一日に必要な栄養素に対して、
どの程度満たすか?を確認することが可能だ。本研究は、つまりコレを、
一日分すべての栄養素を100%満たしつつ、
塩分は基準値以下となるように調整し、
かつカロリーは出来るだけ少なくする、
ようなメニュー選択の最適解を目指すことになる。一見難しそうな問題に見えるものの、
実は単純な線型計画の問題であり、
PythonのPuLPライブラリで一発で解決できる。一番工夫すべき点は、データや変数が多いために、
問題をうまくコードに落とすのが超面倒なこと。
「teriyaki-ba-ga」という変数とか、
「 VitaminC > 100」みたいな式を大量に書いていたら、
夢までも「たらったったったー」で
埋め尽くされるのは間違いない。
月見バーガーなどのメニュー追加にも
対応しにくくなってしまう。その点に留意しながら、以下のような段取りで研究を進める。
①線型計画問題とはなにか?
②PuLPの基本的な使い方を確認
③マクドナルドの公式サイトからデータを取得し、
Pythonで加工できるようにする
④一日に必要な栄養素=完全栄養食問題として、
コードを実装する。(うまく汎用的に作る)
⑤いくつか条件を変えながら結果を見て遊ぶ
⑥1メニュー1回まで制限にして遊ぶ
⑦コーンフレークをメニューに追加してさらに遊ぶ①線型計画問題とは?
- カロリー 栄養1 栄養2 栄養3 てりやき 20 25 10 15 ポテト 12 11 10 18 コーラ 15 13 16 25 必要栄養量 ★ここを最小に 300 200 100 ■問題:上記のような栄養表があるときに、
栄養素1~3の必要量を満たしつつ、
カロリーを最小にするような、
てりやき、ポテト、コーラの注文の仕方は何か?⇒答え:
てりやき×8、ポテト×1、コーラ×7
で 298カロリーこのように、何かの最適解を求める問題において、
目的関数(カロリー)や、制約条件(満たすべき栄養素)が
線型(二乗とかが出ない一次元の多項式)の不等式で
表現できる問題のことを、線型計画問題と言う。PythonではPuLPというライブラリが用意されており、
この問題をコードで記載するだけで
一発で最適解を求めることが出来る。②PuLPの基本的な使い方
PuLPの使い方を見てみる。
なお以降のコードも全てColaboratory上で実行を試している。PuLPのインストール方法
PuLPのインストールpip install pulpさきほどの例題を解くコードが以下。
一番基本的な使い方を見てみる。PuLPの一番基本的な使い方import pulp # !pip install pulp # 参考1:https://www.y-shinno.com/pulp-intro/ # 問題の定義 # 最小化か、最大化か、どちらかを指定する problem = pulp.LpProblem(name="マック", sense=pulp.LpMinimize) #problem = pulp.LpProblem(name="マック", sense=pulp.LpMaximize) # 変数の定義(※変数の指定は、pythonは日本語でもOK) # 物の個数を表現するため、0以上の整数である、と定義している てりやき = pulp.LpVariable(name = "てりやき", lowBound = 0, cat="Integer") ポテト = pulp.LpVariable(name = "ポテト", lowBound = 0, cat="Integer") コーラ = pulp.LpVariable(name = "コーラ", lowBound = 0, cat="Integer") # 目的関数(最小or最大にすべき関数) problem += 20 * てりやき + 12 * ポテト + 15 * コーラ # 制約条件の定義 # 書き方として、必ず、等号を入れて、<=.==,>= などの書き方にすること! problem += 25 * てりやき + 11 * ポテト + 13 * コーラ >= 300 problem += 10 * てりやき + 10 * ポテト + 16 * コーラ >= 200 problem += 15 * てりやき + 18 * ポテト + 25 * コーラ >= 100 # 問題を解く status = problem.solve() print(pulp.LpStatus[status]) #ステータスの全種類は、下記の通り。 #「Optimal」が、最適解が得られた、の意 # {-3: 'Undefined', # -2: 'Unbounded', # -1: 'Infeasible', # 0: 'Not Solved', # 1: 'Optimal'} # 結果表示 print("Result") print("てりやき:", てりやき.value()) print("ポテト:", ポテト.value()) print("コーラ:", コーラ.value())出力結果Optimal Result てりやき: 8.0 ポテト: 1.0 コーラ: 7.0一つ目の工夫のポイントは、
変数名を「日本語」にしている点。
Python3では変数名にアスキーコード以外も利用可能であり、
最初から日本語にしておくことで、
マクドナルドのメニューの商品名称を
そのまま変数名として扱うことが出来る。
逆にこうしないと、てりやきは「teriyaki」で・・・
みたいに、全メニューに英語名を付与して、
しかもそのマッピングを管理しないといけなくなる。
この時点で日が暮れてしまう。だが、変数を日本語にしただけでは、各栄養素ごとの式を
全て入力していくのは依然としてものすごく大変である。
他のメニューが追加されたときなどに、全ての
problem += 10 * てりやき + 10 * ポテト + 16 * コーラ >= 200
の式を更新していくのもヤバイことになる(語彙力不足)そこで、以下のように、
メニュー名や栄養素の値をリスト形式で扱えるようにする。
コードはだいぶ異なるが、結果や意味は全く同じである。
これで月見バーガーの季節になっても全く問題はない。PuLPの少し汎用的な書き方import pulp # !pip install pulp # 参考2:http://www.nct9.ne.jp/m_hiroi/light/pulp01.html # 問題の定義( # 最小化か、最大化か、どちらかを指定 problem = pulp.LpProblem(name="マック", sense=pulp.LpMinimize) #problem = pulp.LpProblem(name="マック", sense=pulp.LpMaximize) # データの定義 target_menu_list =["てりやき","ポテト","コーラ"] kcal =[20,12,15] eiyou1 =[25,11,13] eiyou2 =[10,10,16] eiyou3 =[15,18,25] # 変数の定義 # 変数の定義を、リスト内包表記で書く、かつ、変数名を動的に、リスト内のデータて定義 xs = [pulp.LpVariable('{}'.format(x), cat='Integer', lowBound=0) for x in target_menu_list] # 目的関数や制約条件を、行列の掛け算型で書く # 目的関数(最小or最大にすべき関数) problem += pulp.lpDot(kcal, xs) # 制約条件の定義 problem += pulp.lpDot(eiyou1, xs) >= 300 problem += pulp.lpDot(eiyou2, xs) >= 200 problem += pulp.lpDot(eiyou3, xs) >= 100 # 問題を解く status = problem.solve() print(pulp.LpStatus[status]) # 結果表示 print("Result") print("てりやき:", てりやき.value()) print("ポテト:", ポテト.value()) print("コーラ:", コーラ.value())ポイントは、行列の掛け算型で式を定義している点と、
てりやき、などの変数名を動的に名付けている点。つまり、
target_menu_list =["てりやき","ポテト","コーラ"]
⇒
target_menu_list =["てりやき","ポテト","コーラ","月見バーガー"]
のようにメニュー名のリストを更新してあげれば、
'{}'.format(x)の箇所で、変数名として使われて、
月見バーガーという変数が動的に生成される、というワケ。これらの工夫をしておかないと、
数行のデータで遊ぶ分には問題ないが、
マクドナルドの実データ数百行には全く対応出来ない。PuLPというライブラリがありながらも、
全人類の夢であった完全栄養マクドナルド食の検討が
今までなされてこなかった理由は、
普通に作ったらコードがヤバイことになるから、
が理由に違いない。きっとそうに違いない(反復法による強調)③マクドナルドのデータ入手&加工
先に挙げたマクドナルドの公式サイトから、
最新全メニューの栄養価一覧表を見ることが出来る。
バーガー、サイド、ドリンク、バリスタ、の4種類。
スクレイピングなどする必要もなく、
単純に4回コピペして、CSV形式で保存しよう。
※「-」のデータだけ、置換で「0」にしておく保存したCSVデータは、以下のようなコードで、
Pythonで辞書形式で読み出すことが出来る。マクドナルドデータの読み込みimport csv McDonaldsDict = {} with open('/content/drive/My Drive/MACD/マクドナルド栄養価一覧20201009_R.csv') as f: reader = csv.DictReader(f) # OrderedDict([('商品名', 'えびフィレオ'), ('重量g', '174'), ・・・が1行ごとに入っている # ※ジュース系などで、栄養価が「-」のものは0を置換済み for row in reader: # 'えびフィレオ' : OrderedDict([('商品名', 'えびフィレオ'), ('重量g', '174')・・・ の辞書形式に加工 McDonaldsDict[row["商品名"]] = row後で、対象の商品だけ選んで取り出す、
ということがしやすいように、
「商品名」をキーとした辞書形式にしておく。
(※辞書形式の中がさらに辞書型になっている二重辞書)また、1日に必要な栄養素についても、
データを参照して以下のように定義しておこう。
対象は、完全栄養マクドナルド食に興味がありそうな暇人たち
本研究の想定読者層に合わせてみた。必要な栄養素(例)#男性:30歳~49歳の1日に必要な栄養量。 #身体活動レベル1=生活の大部分が座位で、 # 静的な活動が中心の場合、で計算 # ただし、食塩相当量は、必要ではなく「以下」にすべき値 one_da_nutrition_dict ={ "エネルギーkcal" : 2300.0, "たんぱく質g" : 65.0 , "脂質g" : 63.9 , "炭水化物g" : 330.6 , "カルシウムmg" : 750.0 , "鉄mg" : 7.5 , "ビタミンAμg" : 900.0 , "ビタミンB1mg" : 1.4 , "ビタミンB2mg" : 1.6 , "ビタミンCmg" : 100.0 , "食物繊維g" : 21.0 , "食塩相当量g" : 7.5 , }④いよいよ完全栄養マクドナルド食
ここまでで全部の準備が出来た。
マクドナルドのメニューは多様であるが、
「ミルクも入れて完全な5角形」とか
「サラダや野菜ジュースで健康」というのは
典型的なマクドナルド感が薄いので、
まずは代表選手として主観ながら以下のメンバーを選出した。
- てりやきマックバーガー
- ハンバーガー
- チーズバーガー
- ダブルチーズバーガー
- 月見バーガー
- ビッグマック
- フィレオフィッシュ
- チキンマックナゲット 5ピース
- マックフライポテト(M)
- マックフライポテト(S)
- ケチャップ
- バーベキューソース
- コカ・コーラ(M)
- マックシェイク® バニラ(S)
- ミニッツメイド オレンジ(M)
この選択は大規模な宗教論争なることが予想されるため、
他神の信徒の方もいらっしゃるだろうが、一旦異論は認めない。
他宗派の方はぜひ選抜メンバーを変えてコードを追試してみてほしい。これらの組み合わせだけで、
一日に必要な栄養素を全て摂取し、
かつ塩分は基準値以下とする場合に、
最低何カロリーになるのだろうか!?さあ以下のコード一発にまとめたので、実行してみよう!!
完全栄養マクドナルド食の線型計画import pulp # 問題の定義 # 今回は、カロリーを最小化したいため、最初化で設定 problem = pulp.LpProblem(name="完全栄養マクドナルド食", sense=pulp.LpMinimize) import csv McDonaldsDict = {} with open('/content/drive/My Drive/MACD/マクドナルド栄養価一覧20201009_R.csv') as f: reader = csv.DictReader(f) # OrderedDict([('商品名', 'えびフィレオ'), ('重量g', '174'), ・・・が1行ごとに入っている # ※ジュース系などで、栄養価が「-」のものは0を置換済み for row in reader: # 'えびフィレオ' : OrderedDict([('商品名', 'えびフィレオ'), ('重量g', '174')・・・ の辞書形式に加工 McDonaldsDict[row["商品名"]] = row # 特定の栄養価のリストを取得する # 対象のtarget_menu_listに入っている順番に、その栄養価の値を取得。 def get_nutrition_val_list(nutrition_dict, target_menu_list, eiyou_name): result_list = [] for menu_name in target_menu_list: #栄養価を取得してfloatに置換 eiyou_val = nutrition_dict[menu_name][eiyou_name] result_list.append(float(eiyou_val)) return result_list # 品物 # ※カロリーの問題であるため、コカ・コーラ ゼロや爽健美茶など、 # カロリーが完全に0のものは除外しておくこと。 target_menu_list = [ "てりやきマックバーガー", "ハンバーガー", "チーズバーガー", "ダブルチーズバーガー", "月見バーガー", "ビッグマック", "フィレオフィッシュ", "チキンマックナゲット 5ピース", "マックフライポテト(M)", "マックフライポテト(S)", "ケチャップ", "バーベキューソース", # "スイートコーン", # "サイドサラダ", "コカ・コーラ(M)", "マックシェイク® バニラ(S)", "ミニッツメイド オレンジ(M)", # "ミルク", # "野菜生活100(M)", ] #男性:30歳~49歳の1日に必要な栄養量。 #身体活動レベル1=生活の大部分が座位で、 # 静的な活動が中心の場合、で計算 # ただし、食塩相当量は、必要ではなく「以下」にすべき値 one_da_nutrition_dict ={ "エネルギーkcal" : 2300.0, "たんぱく質g" : 65.0 , "脂質g" : 63.9 , "炭水化物g" : 330.6 , "カルシウムmg" : 750.0 , "鉄mg" : 7.5 , "ビタミンAμg" : 900.0 , "ビタミンB1mg" : 1.4 , "ビタミンB2mg" : 1.6 , "ビタミンCmg" : 100.0 , "食物繊維g" : 21.0 , "食塩相当量g" : 7.5 , } # 対象とする栄養素について、対象の商品リストごとの栄養価を、リスト形式で作成する eiyou_data={} for key in one_da_nutrition_dict.keys(): #keyに入っている栄養の名称(日本語)を、データのdictのkeyにする eiyou_data[key] = get_nutrition_val_list(McDonaldsDict, target_menu_list, key) # 変数の定義(※日本語の文字列をそのまま変数として利用) xs = [pulp.LpVariable('{}'.format(x), cat='Integer', lowBound=0) for x in target_menu_list] # 目的関数:エネルギーの最小化 problem += pulp.lpDot(eiyou_data["エネルギーkcal"], xs) # 制約条件:一日に必要な栄養量をそれぞれ満たすこと。 # 条件カスタマイズ&ON-OFFしやすいように、あえてループ外で記載。 # 食塩相当については、「以内」としている。解が存在するかどうか?は要注意。 problem += pulp.lpDot(eiyou_data["たんぱく質g"], xs) >= one_da_nutrition_dict["たんぱく質g"] problem += pulp.lpDot(eiyou_data["脂質g"], xs) >= one_da_nutrition_dict["脂質g"] problem += pulp.lpDot(eiyou_data["炭水化物g"], xs) >= one_da_nutrition_dict["炭水化物g"] problem += pulp.lpDot(eiyou_data["カルシウムmg"], xs) >= one_da_nutrition_dict["カルシウムmg"] problem += pulp.lpDot(eiyou_data["鉄mg"], xs) >= one_da_nutrition_dict["鉄mg"] problem += pulp.lpDot(eiyou_data["ビタミンAμg"], xs) >= one_da_nutrition_dict["ビタミンAμg"] problem += pulp.lpDot(eiyou_data["ビタミンB1mg"], xs) >= one_da_nutrition_dict["ビタミンB1mg"] problem += pulp.lpDot(eiyou_data["ビタミンB2mg"], xs) >= one_da_nutrition_dict["ビタミンB2mg"] problem += pulp.lpDot(eiyou_data["ビタミンCmg"], xs) >= one_da_nutrition_dict["ビタミンCmg"] problem += pulp.lpDot(eiyou_data["食物繊維g"], xs) >= one_da_nutrition_dict["食物繊維g"] problem += pulp.lpDot(eiyou_data["食塩相当量g"], xs) <= one_da_nutrition_dict["食塩相当量g"] #与えられた問題の内容を表示 print(problem) status = problem.solve() print("Status", pulp.LpStatus[status]) # ※「Optimal」であることを確認すること。 # 簡易結果表示 print([x.value() for x in xs]) print(problem.objective.value()) # 変数名ごとに表示 for x in xs: print(str(x) + " × "+ str(int(x.value())) ) # それぞれの栄養素がいくらになったのか、計算結果を表示 print("----結果----") for key in one_da_nutrition_dict.keys(): print(key + ": " + str(one_da_nutrition_dict[key]) +" に対し " + str(round(pulp.lpDot( eiyou_data[key], xs).value())) )上記を実行すると・・・
結果: 8035kcal
出力結果# 問題定義周りのログ出力は省略して記載 てりやきマックバーガー × 0 ハンバーガー × 0 チーズバーガー × 0 ダブルチーズバーガー × 1 月見バーガー × 2 ビッグマック × 0 フィレオフィッシュ × 0 チキンマックナゲット_5ピース × 0 マックフライポテト(M) × 0 マックフライポテト(S) × 0 ケチャップ × 2 バーベキューソース × 0 コカ・コーラ(M) × 0 マックシェイク®_バニラ(S) × 0 ミニッツメイド_オレンジ(M) × 46 ----結果---- エネルギーkcal: 2300.0 に対し 8035 たんぱく質g: 65.0 に対し 175 脂質g: 63.9 に対し 85 炭水化物g: 330.6 に対し 1654 カルシウムmg: 750.0 に対し 1526 鉄mg: 7.5 に対し 20 ビタミンAμg: 900.0 に対し 900 ビタミンB1mg: 1.4 に対し 12 ビタミンB2mg: 1.6 に対し 2 ビタミンCmg: 100.0 に対し 5433 食物繊維g: 21.0 に対し 38 食塩相当量g: 7.5 に対し 8 #補足;食塩は以下条件であり、roundで8になっている?実に、1日の必要量 2300kcalに対してなんと、
8035kcal も摂取することになる。
そして、
ダブルチーズバーガー × 1
月見バーガー × 2 を圧倒的に洗い流す、
46杯というミニッツメイド_オレンジの洪水。典型的なマクドナルド感の代表選手
のみに限定してしまうと
さすがにちょっとヤバイ感じ(語彙力)になってしまった。だが全国のマクドナルド・ファンの皆様、ご安心召されよ、
そもそもこのように選択肢が少ない状態で、
全栄養素を満たすように、という条件であるため、
8035kcalという結果になってしまっただけである。
より現実的な条件の場合も確認していきたい。ここまでの結果で終わってしまっては私としても、
夜な夜な、黄色と赤色のピエロによる闇討ちを
怖がらなくてはいけなくなってしまう。⑤いくつか条件を変えながら結果を見て遊ぶ
まずは「野菜もしっかり食べよう」の勅令に従って、
サラダ、スイートコーン、のコメントアウトを戻す。
また、ミルクや野菜生活もOKとしよう!結果: 1994kcal
野菜もしっかり食べようてりやきマックバーガー × 1 ハンバーガー × 0 チーズバーガー × 0 ダブルチーズバーガー × 0 月見バーガー × 0 ビッグマック × 0 フィレオフィッシュ × 0 チキンマックナゲット_5ピース × 0 マックフライポテト(M) × 0 マックフライポテト(S) × 2 ケチャップ × 0 バーベキューソース × 0 スイートコーン × 2 サイドサラダ × 95 コカ・コーラ(M) × 0 マックシェイク®_バニラ(S) × 0 ミニッツメイド_オレンジ(M) × 0 ミルク × 0 野菜生活100(M) × 0 ----結果---- エネルギーkcal: 2300.0 に対し 1994 たんぱく質g: 65.0 に対し 72 脂質g: 63.9 に対し 64 炭水化物g: 330.6 に対し 331 カルシウムmg: 750.0 に対し 1308 鉄mg: 7.5 に対し 22 ビタミンAμg: 900.0 に対し 2580 ビタミンB1mg: 1.4 に対し 3 ビタミンB2mg: 1.6 に対し 2 ビタミンCmg: 100.0 に対し 1454 食物繊維g: 21.0 に対し 87 食塩相当量g: 7.5 に対し 4基準値の2300kcalより少ない1994kcal。
しっかり栄養を取りながらダイエットが出来る。
実に健康的な結果が出て、しかも、
てりやきマックバーガー × 1
マックフライポテト(S) × 2
も食べることが出来るなんて!!と、思いきや、
サイドサラダ × 95 (絶句)こんなに野菜は食べられないですよねー!!
健康ジュースの通販番組のネタになりそうな量である。
やはりサイドサラダによる影響は大きすぎた。そこで、コーンフレーク方式を試す。
ミルクやジュース等の飲み物による補充はOKとする案。
サイドサラダ とスイートコーン だけ外そう。結果: 2933kcal
てりやきマックバーガー × 0 ハンバーガー × 0 チーズバーガー × 1 ダブルチーズバーガー × 0 月見バーガー × 1 ビッグマック × 0 フィレオフィッシュ × 0 チキンマックナゲット_5ピース × 0 マックフライポテト(M) × 2 マックフライポテト(S) × 2 ケチャップ × 0 バーベキューソース × 0 コカ・コーラ(M) × 0 マックシェイク®_バニラ(S) × 0 ミニッツメイド_オレンジ(M) × 2 ミルク × 3 野菜生活100(M) × 2 ----結果---- エネルギーkcal: 2300.0 に対し 2933 たんぱく質g: 65.0 に対し 81 脂質g: 63.9 に対し 125 炭水化物g: 330.6 に対し 371 カルシウムmg: 750.0 に対し 1013 鉄mg: 7.5 に対し 8 ビタミンAμg: 900.0 に対し 2018 ビタミンB1mg: 1.4 に対し 2 ビタミンB2mg: 1.6 に対し 2 ビタミンCmg: 100.0 に対し 311 食物繊維g: 21.0 に対し 21 食塩相当量g: 7.5 に対し 8チーズバーガー × 1
月見バーガー × 1
マックフライポテト(M) × 2
マックフライポテト(S) × 2
に、オレンジジュース、ミルク、野菜ジュースを数本ずつ。
ちょうどお昼と夜にバリューセットを頼む感じで、
2933kcalとちょっと超過しすぎだが、
これならばある程度現実に近い感じではないだろうか!?
(おそらく食物繊維か何かのためにポテトが多すぎるので、
少し別のメニュー等で食物繊維を摂取すればよい)これは、通常のポテト版のバリューセットの
飲み物を、オレンジジュース or ミルク or 野菜生活
にするだけで、栄養バランス的にはかなり理想的。
ということを示唆している。(食物繊維/鉄が少し不足)マクドナルド食は健康に良い!とまでは言えないものの、
そこまで悪い結果でもないだろう。この示唆に従って、試しに以下の組み合わせで
先述の公式サイトでの栄養表示を試してみた。
- チーズバーガー
- マックフライポテトM
- 野菜生活M
- ミルク
- ミニッツメイドオレンジM
画像出典:マクドナルド公式サイト > 私達の責任 > Our Food > 栄養バランスチェック
一食相当分で、およそどの栄養素も1日の40%ラインを超えているため、
バリューセットにミルクと果物ジュースを追加するだけで
こんなに理想的な食事になる!!みたいな宣伝が出来そうである。
脂質が過剰という説はある。
また、もしかしたらだいたいの食べ物はミルクと野菜ジュースで
補強すると"コーンフレーク五角形"を作れるのかもしれない。⑥1メニュー1回まで制限にして遊ぶ
さらにさらに、より現実的な解として、
どのメニューも最大1回まで注文できる場合
(つまり、サラダばかり95個も頼むのはNGとする)
で最適解を求めてみる。
対象のメニュー範囲も合わせて通常の全種類まで拡大する。コードを以下のように変えるだけ!
①(バリスタ以外の)全通常メニューを対象とする
②変数の定義時に、「最大値=1」の条件を追加するどのメニューも一回だけ注文可能な場合# バリスタメニューは抜く target_menu_list = [x for x in McDonaldsDict.keys() if McDonaldsDict[x]["区分"]!="バリスタ"] # 中略 # 変数の定義 upBound=1 が最大値1の条件 xs = [pulp.LpVariable('{}'.format(x), cat='Integer', lowBound=0, upBound=1) for x in target_menu_list]1回まで注文できる場合で結果を見てみよう!
結果: 2453kcal
エッグマックマフィン × 1 ストロベリージャム × 1 マックグリドル_ベーコンエッグ × 1 サイドサラダ × 1 シェアポテト × 1 スイートコーン × 1 サントリー黒烏龍茶#濃いめ × 1 プレミアムローストアイスコーヒー(L) × 1 プレミアムローストコーヒー(M) × 1 プレミアムローストコーヒー(S) × 1 ホットティー(ストレート)(M) × 1 マックシェイク®_チョコレート(S) × 1 ミニッツメイド_オレンジ(S) × 1 ミルク × 1 リキッドレモン × 1 野菜生活100(M) × 1 ----結果---- エネルギーkcal: 2300.0 に対し 2453 たんぱく質g: 65.0 に対し 67 脂質g: 63.9 に対し 95 炭水化物g: 330.6 に対し 331 カルシウムmg: 750.0 に対し 856 鉄mg: 7.5 に対し 8 ビタミンAμg: 900.0 に対し 1161 ビタミンB1mg: 1.4 に対し 1 ビタミンB2mg: 1.6 に対し 2 ビタミンCmg: 100.0 に対し 254 食物繊維g: 21.0 に対し 21 食塩相当量g: 7.5 に対し 8代表的なバーガー系が出なくなってしまったのが残念だが、
まあまあ現実的に注文できそうな解を得ることが出来た。
サラダ、スイートコーン、野菜生活、
ミルク、オレンジジュース、などの
前回からのエースは相変わらず選ばれている。
マックシェイク®_チョコレートが入っているのが意外な結果。⑦コーンフレークをメニューに追加してさらに遊ぶ
最後に、栄養バランス5角形の代表格、
コーンフロスティ(ケロッグ)のデータを追加してみる。
ケロッグの公式サイトから、コーンフロスティのデータを参照し、
以下のように個別にDictデータを作成。
元のデータに追加して実行するだけ。コーンフロスティのデータfrom collections import OrderedDict ## 牛乳無し版のコーンフロスティデータの追加 # 参考:https://www.kelloggs.jp/ja_JP/products/corn-frosties.html k_od = OrderedDict() k_od['商品名'] = "コーンフロスティ" k_od['重量g'] = 30.0 k_od['エネルギーkcal'] = 114.0 k_od['たんぱく質g'] = 1.7 #1.2~2.2 k_od['脂質g'] = 0.25 #0~0.5 k_od['炭水化物g'] = 26.9 #k_od['ナトリウムmg'] = #k_od['カリウムmg'] = k_od['カルシウムmg'] = 1.5 #0.5~2.5 #k_od['リンmg'] = k_od['鉄mg'] = 1.4 k_od['ビタミンAμg'] = 96 #53~139 k_od['ビタミンB1mg'] = 0.47 k_od['ビタミンB2mg'] = 0.42 #k_od['ナイアシンmg'] = k_od['ビタミンCmg'] = 15 #k_od['コレステロールmg'] = k_od['食物繊維g'] = 1.2 #0.4~2.0 k_od['食塩相当量g'] = 0.3 #k_od['区分'] = #追加コーンフロスティデータの追加 #McDonaldsDict["コーンフロスティ"] = k_od今回は、マクドナルドの代表選手に絞ったメニューで、
サラダ無し、飲み物有り版に、
コーンフロスティを選択肢として加えた版の結果をご紹介しよう。結果: 2544kcal
てりやきマックバーガー × 0 ハンバーガー × 2 チーズバーガー × 0 ダブルチーズバーガー × 0 月見バーガー × 0 ビッグマック × 0 フィレオフィッシュ × 0 チキンマックナゲット_5ピース × 0 マックフライポテト(M) × 2 コカ・コーラ(M) × 0 ミニッツメイド_オレンジ(M) × 0 ミルク × 3 野菜生活100(M) × 0 コーンフロスティ × 7 ----結果---- エネルギーkcal: 2300.0 に対し 2544 たんぱく質g: 65.0 に対し 68 脂質g: 63.9 に対し 85 炭水化物g: 330.6 に対し 381 カルシウムmg: 750.0 に対し 788 鉄mg: 7.5 に対し 14 ビタミンAμg: 900.0 に対し 940 ビタミンB1mg: 1.4 に対し 4 ビタミンB2mg: 1.6 に対し 4 ビタミンCmg: 100.0 に対し 145 食物繊維g: 21.0 に対し 21 食塩相当量g: 7.5 に対し 7コーンフロスティ × 7
ミルク × 3
で、コーンフロスティを選択肢に入れない場合には
2933kcalだったのが、2544kcalまで
摂取カロリーを減らすことが出来た。
さすがあのトラは伊達じゃない。が、一方でトラを追加した状態でも、
ハンバーガー × 2
マックフライポテト(M) × 2
とバリューセット勢が食い込んでいるのも、
マクドナルド側の優秀さも物語っている。すなわち、朝食にコーンフロスティ+ミルク、(
×7で結構沢山)
昼・夜それぞれバリューセット(ポテト)、という食生活でも、
そこそこの栄養バランスは保たれるようだ。総括と感想
完全栄養マクドナルド食について
今回の研究成果によって、
無人島にマクドナルドだけを持っていける場合に、
最適なメニューを注文できるようになった。バリューセットは、サイドをポテトにしても
意外といい感じの栄養バランスにはなるものの、
やはりサラダやスイートコーンを選ばない限り、
そこそこカロリーオーバーになってしまう。
「野菜もしっかり食べよう」また、飲み物として、
ミルク、野菜生活、オレンジジュース、
あたりが有用であると分かった。
野菜生活を追加した栄養バランスの5角形を作れば
黄色のピエロも、腕組みしたトラと戦えるのではないか?
サイドサラダも加えるとさらに戦力アップ。一方で、選択肢を超典型的なメニューだけに絞ると、
実に8000kcal以上 になってしまう。
好きなものばかり注文していると太る、
ということが分かった。(あたりまえ)サイドサラダとスイートコーンをOKにすれば、
一日に必要な栄養素を保ちつつ、
カロリーを基準値以下にすることが可能であったため、
結局、マクドナルドだけで生活する場合の指針としては、
バリューセット(ポテト)を注文しつつも、
サラダ、ミルク、野菜生活をより多く注文することで、
比較的健康的な栄養バランスの食事を維持可能となる。バランス良く食べようという、一見あたりまえの結論であるものの、
1店舗内の選択肢の組み合わせだけでコレが実現出来るのは、
結構エライことではないだろうか?
私からマクドナルドに改善を求めるとすれば、
ハッピーセットのメインの選択肢として、+100円くらいで
てりやきマックバーガーも選べるようにして欲しいこと、くらいである。
また、ぜひ本コード相当のツールを公式サイトにも組み込んで欲しい。
その際にはぜひ協力させていただきたい。線型計画のコードについて
当初、栄養素に関する計算は、
PuLPや線型計画の代表的な問題であり、
マクドナルド公式サイトにも
データが一覧形式で存在したため、
結構簡単に出来るかなーと思っていた。しかし、実データに適用しようとすると、
そのまま作るとヤバいコードになってしまう。
日本語名変数、動的な変数付け、行列での式定義、などなど、
PuLPのサンプルから変えないといけない箇所が多数発生し、
予想以上に様々な追加工夫を要した。最終的には、これらの工夫のおかげて、
様々にデータを入れ替えて遊ぶ研究を深めることができた。今回のコードは、CSVさえ作ればブラウザ上だけで、
コピペ1発で実行できる形にまとめているため、
興味がある方はぜひ追試し、
いろいろ条件を変えて考察してみてほしい。
Colaboratoryでできるため窓からでもリンゴからでも実行可能だ。マクドナルド公式サイトのメニューデータは、
日々更新されているようなので、結果は変わるかもしれない。
以上。本研究の結果が、
マクドナルドの門をくぐるたびに罪悪感を覚えるような、
信心の足りないマック信者たちへの救済の一助となれば幸いである。
エンジニア諸氏にはマック信者が多いと誰かが言っていた気がする
- 投稿日:2020-10-18T04:55:47+09:00
Python基礎③
Pythonの基礎知識③です。
自分の勉強メモです。
過度な期待はしないでください。関数
-関数とは、ある処理をまとめたプログラムの塊
-関数の作り方
関数の定義def 関数名(): # 行末にコロン 実行する処理 # インデントを揃える(半角スペース4つ分)例def hello(): # 行末にコロン print('Hello World') # インデントを揃える(半角スペース4つ分) hello() #出力結果 → Hello World
-引数
関数を呼び出す際に、関数に値を渡すことができ、その値を引数と言う引数を受け取る関数の定義def 関数名(仮引数): # 行末にコロン 実行する処理 # インデントを揃える(半角スペース4つ分)例def hello(name): # 行末にコロン print('Hello' + name) # インデントを揃える(半角スペース4つ分) hello('Aki') # Akiが、仮引数nameに代入される #出力結果 → Hello Aki
-スコープ
仮引数や関数の中で定義した変数は関数の中だけ使用できる例def hello(name): print(name) # 変数nameのスコープ内、関数内なので使用出来る print(name) # 変数nameのスコープ外、使えないのでエラー発生
-複数の引数
引数は左から順番に「第1引数、第2引数・・・」と呼ぶ例def hello(name, message): # 行末にコロン, 引数の間はコンマで区切る print('Hello' + name + message) # インデントを揃える(半角スペース4つ分) hello('Aki', '元気?') # Akiが、仮引数nameに、元気?が、仮引数messageに代入される #出力結果 → Hello Aki 元気?
-引数の初期値
引数には初期値を設定することもできる例def hello(name, message = 'おはよう!'): # 行末にコロン print(name + 'さん、' + message) # インデントを揃える(半角スペース4つ分) hello('Aki') # Akiが、仮引数nameに代入される #出力結果 → Akiさん、 おはよう!
-戻り値
処理結果のを呼び出し元に返す引数を受け取る関数の定義def 関数名(): # 行末にコロン return 戻り値 # 呼び出し元に返す例def validate(hand): if hand < 0 or hand > 2: return False # 呼び出し元に返す
-returnの性質
returnは戻り値を呼び出し元に返すだけでなく、関数内の処理を終了させる性質も持つ。
よって、return以降の関数の処理が実行される事はない。例def hello(name): if name == 'ゲスト': return '名前を教えてください' print(name + 'さん、ようこそ!') # return以降なので実行されない
-複数のreturn
条件分岐と組み合わせると複数のreturnを用いることが出来る例def hello(name): if name == 'ゲスト': return '名前を教えてください' print(name + 'さん、ようこそ!') print(hello(Aki))
モジュール
-モジュールとは、コードが書かれたファイルのこと
-import
importを使うことでモジュールを読み込むことが出来る
「import モジュール名」と書く事で読み込める
モジュール名はファイル名から拡張子(.py)を取り除いたもの例# ファイル名 → sample.py import sample
-モジュールの使い方
上記では、只ファイルを読み込んだだけで、中に書かれている事は実行されない
「モジュール名.関数名()」と書く事で、モジュール内に書かれている中見の実行をさせる事が出来る例# ファイル名 → sample.py # 関数名 → validate(hand) import sample if sample.validate(hand)-また,、Pythonには便利なモジュールが既にいくつか用意されています
「random」 = ランダムな値を生成するモジュール
「math」 = 複雑な演算の為のモジュール
「datetime」 = 日付や時間データを操作するモジュール
- 投稿日:2020-10-18T02:14:39+09:00
AtCoder Beginner Contest 180
A - box
C++#include<iostream> #include<vector> #include<algorithm> #include<iomanip> #include<utility> #include<iomanip> #include<map> #include<queue> #include<cmath> #include<cstdio> #define rep(i,n) for(int i=0; i<(n); ++i) #define pai 3.1415926535897932384 using namespace std; using ll =long long; using P = pair<int,int>; int main(int argc, const char * argv[]) { int n, a, b; cin >> n >> a >> b; cout << n - a + b << endl; return 0; }B - Various distances
Pythonimport math N = int(input()) X = list(map(int, input().split())) ans1 = 0 ans2 = 0 ans3 = 0 for i in range(0, N): X[i] = abs(X[i]); ans1 = ans1 + X[i]; ans2 = ans2 + X[i] * X[i]; print(ans1); print(math.sqrt(ans2)); print(max(X));C - Cream puff
C++#include<iostream> #include<vector> #include<algorithm> #include<iomanip> #include<utility> #include<iomanip> #include<map> #include<queue> #include<cmath> #include<cstdio> #define rep(i,n) for(int i=0; i<(n); ++i) #define pai 3.1415926535897932384 using namespace std; using ll =long long; using P = pair<int,int>; vector<ll> divisor(ll n) { vector<ll> ret; for (ll i = 1; i * i <= n; i++) { if (n % i == 0) { ret.push_back(i); if (i * i != n) ret.push_back(n / i); } } sort(ret.begin(), ret.end()); return ret; } int main(int argc, const char * argv[]) { ll N; cin >> N; vector<long long> Ans = divisor(N); rep(i, Ans.size()){ cout << Ans[i] << endl; } return 0; }D - Takahashi Unevolved
C++#include<iostream> #include<vector> #include<algorithm> #include<iomanip> #include<utility> #include<iomanip> #include<map> #include<queue> #include<cmath> #include<cstdio> #define rep(i,n) for(int i=0; i<(n); ++i) #define pai 3.1415926535897932384 #define ll_limit 2e18 using namespace std; using ll =long long; using P = pair<int,int>; int main(int argc, const char * argv[]) { ll X, Y, A, B; cin >> X >> Y >> A >> B; ll ans = 0; while((double)A*X<=2e18 && A*X<=A+B && A*X<Y){ X*=A; ans++; } cout << ans+(Y-1-X)/B << endl; return 0; }