- 投稿日:2020-10-18T22:41:47+09:00
MacでのPlantUMLを使ったアクティビティ図の書き方あれこれ①
アクティビティ図について
UMLでアクティビティ図を書く機会があったので復習がてら基本的な流れをメモしておこうと思い、例で考えながら各構成要素について書き残しておこうと思います。
アクティビティ図とは何ぞや?
処理と処理の順番を表現するために作られた表記法で、具体的な業務の流れを各人で共有し、足りないものはないか、もしくは余分な構成要素が存在しないかをお互いに認知するきっかけともなりうるので多くの開発現場で導入されています。
アルゴリズムなどの考え方もこのアクティビティ図で表現されることが多く、抽象的な流れを具体的なものに落とし込むことはITエンジニアとして重要な能力の一つでしょう。
それでそれで?どうやって記述するの?
今回はPlantUMLを使って記述します。
公式サイトに記述がある通り、PlantUML は、以下のようなダイアグラムを素早く作成するためのコンポーネントです。
- シーケンス図
- ユースケース図
- クラス図
- アクティビティ図(古い文法はこちら)
- コンポーネント図
- 状態遷移図(ステートマシン図)
- オブジェクト図
- 配置図
- タイミング図
以下のような、UML以外の図もサポートしてます。
- ワイヤーフレーム
- アーキテクチャ図
- 仕様及び記述言語 (SDL)
- Ditaa
- ガントチャート
- マインドマップ
- WBS図(作業分解図)
- AsciiMath や JLaTeXMath による、数学的記法
- ER図
引用:https://plantuml.com/ja/とある通り、様々な設計図やフロー図を素早く書けることから多くの人に使われています。
コードっぽく書けるというのが非常にありがたい点で、最初は特有の文法に慣れるのに時間がかかるかもしれませんが、慣れてしまえば非常に手早く書くことができるようになります。
導入
今回はVSCodeで使います。
環境的には以下を導入しましょう。実行環境
JDK
Javaを使えるようにしていないとそもそも使えないので以下のコマンドでインストール。
$ brew cask install adoptopenjdkgraphviz
シーケンス図とアクティビティ図 以外 のダイアグラムを使いたい場合は、Graphviz software をインストールする必要があるのでインストールしましょう。
$ brew install graphvizPlantUML
$ brew install plantumlVSCode
インストールし、拡張機能で'PlantUML'と検索すればでます。
インストールすればひとまずVSCodeの設定は終了です。
ちなみにVSCodeで
option+Dでリアルタイムで更新したUMLが描画されます。
便利。実例
例えば、100円両替機のアクティビティ図の例は以下のようになります。
これをPlantUMLで書くと以下のようになります。
MoneyChanger.wsd@startuml start :投入金の種類を判別する; if()then(1000円紙幣または500円硬貨) :100円硬貨を出す; else(それ以外) :投入金を戻す; endif stop @enduml以上の要素をそれぞれ分解して考えてみましょう。
まずは最初の
@startumlです。これは最後の要素の@endumlとセットで始点と終点を宣言しています。これがないと No ファイル名 Foundと表示されます。次に
startとstopです。
これは最初の●と最後の◉を表しています。
その次の:投入金の種類を判別する;ですが、アクティビティ図で何かしらの行動を表すアクションを表してます。
PlantUMLでは、:アクションとして表示したい行動;でアクションを表すことが出来ます。
次に
if()then(1000円紙幣または500円硬貨) :100円硬貨を出す; else(それ以外) :投入金を戻す; endifですが、分岐を表します。
thenの直後にifの条件を書き、その場合のアクションを直後に記入します。そして、分岐ということで
elseが必要です。
ちなみにifと同じ書き方でelifも書けますし、入れ子構造の分岐も書けます。
elseは直後に条件を記述し、あとはアクションを書くだけです。最後に分岐が終わったことを宣言するために
endifを書くと分岐が認識されます。ちなみに、最初の
ifの直後の()が空欄ですが、これは分岐の段階でのデシジョンノードに条件を記入する必要がないためで、必要であれば以下のように記入できます。@startuml start :投入金の種類を判別する; if(true)then(1000円紙幣または500円硬貨) :100円硬貨を出す; else(それ以外) :投入金を戻す; endif stop @endumlこうすると以下のようになります。
少し余談ですが、VSCodeの場合は
command+shift+Pでコマンドパレットを呼び出します。
コマンドパレットにPlantUMLを入力し、PlantUML:Export Current Diagramを選択すると指定した拡張子で出力されます。
便利な機能なので覚えくと良さげです。ここまでで基本的なアクションと分岐の書き方はまとめました。
次はループや細かいオブジェクトについての書き方を書いていきたいと思います。




- 投稿日:2020-10-18T22:39:31+09:00
【e-Taxソフト】⑥有価証券の内訳書を期末評価する
はじめに
税務(法人税法)ではなく、
会計(金融商品に関する会計基準、第64項)の規定で、
有価証券を帳簿価額ではなく時価で評価しなければならない。株価データ(決算期末の終値)が必要ですが、
Yahooファイナンスは(Webスクレイピング)禁止だし、
有料でデータを買うのもバカバカしいし、
国税庁は持ってるはずだけど公開してないようだし、
元ネタとしてJPX(東京証券取引所)から入手することとした。株式相場表があれば、有価証券と突合するだけ!
だけどこれ、PDFなんですよ。。
PDF:株式相場表:をCSV(テキスト)に変換しました。
※これが一番大変この記事が意味をなくす時が来ることを望む。
使い方
PDF:株式相場表:と言っても、
必要なのは「立会市場」だけ。
※PDFの右上「1-n」のページのみ抽出PDF変換.Rsource( file.path( なんとかディレクトリー,"PDF_株式相場表.R" ) ) f <- file.path( なんとかディレクトリー ,"stq_20200831.PDF" ) # ダウンロードした元ネタ 立会市場 <- 株式相場表.main( f )期末評価.R# ⑥有価証券の内訳書(i06_e)ができてる前提で残高行のみ抽出 帳簿価額 <- i06_e[ !is.na(i06_e[,6]) & i06_e[,6] != 0,c(4,5,6,8)] # ⑥有価証券の内訳書(帳簿価額)に時価カラムを追加する 有価証券 <- merge( 帳簿価額 ,立会市場[,c(1,11)] ,all.x=T ,by.x="種類=株式" ,by.y="コード=" ) # 目検 sapply( 有価証券 ,mode ) nrow(帳簿価額) ;nrow(有価証券) # 微調整 有価証券[,3] <- as.integer( 有価証券[,3] ) # (列3)数量 有価証券[,4] <- as.integer( 有価証券[,4] ) # (列4)帳簿価額 有価証券[,5] <- as.integer( gsub( "," ,"" ,有価証券[,5] ) ) # (列5)時価 # 期末評価額(列6)=数量(列3)*時価(列5) 有価証券 <- cbind( 有価証券 ,"期末評価額="=有価証券[,3] * 有価証券[,5] ) # 差額(列7)=期末評価額(列6)ー 帳簿価額(列4) 有価証券 <- cbind( 有価証券 ,"差額="=有価証券[,6] - 有価証券[,4] ) # 会計(評価益、その他有価証券差額など)に反映 sum( 有価証券[,4] ,na.rm=T) # 帳簿価額 sum( 有価証券[,6] ,na.rm=T) # 期末評価額 sum( 有価証券[,7] ,na.rm=T) # 差額PDF_株式相場表.R# pdfデータをインポートするため library( pdftools ) # install.packages( 'pdftools' ) 株式相場表.init <- function( n=1 ) { # 列数 df <- data.frame( matrix( NA ,0 ,16 ) ) # 列名 colnames( df ) <- c( "コード=" # 列1 ,"売買単位=" # 列2 ,"銘柄名=" # 列3 ,"午前.始値=" # 列4 ,"午前.高値=" # 列5 ,"午前.安値=" # 列6 ,"午前.終値=" # 列7 ,"午後.始値=" # 列8 ,"午後.高値=" # 列9 ,"午後.安値=" # 列10 ,"午後.終値=" # 列11 ,"最終気配=" # 列12 ,"前日比=" # 列13 ,"売買高加重平均価格=" # 列14 ,"売買高=" # 列15 ,"売買代金=" # 列16 ) switch( n , "1" = { # 普通取引 # print( sapply( df ,mode ) ) } , "2" = { } # 当日決済取引 , "3" = { } # 発行日決済取引 , "4" = { } # 立会外分売取引 , "5" = { } # ToSTNeT市場 , "6" = { } # 優先株等 , "7" = { } # , "8" = { } # 内国投信等 , "9" = { } # , "10" = { } # 外国株式 , "11" = { } # , "12" = { } # , "13" = { } # , "14" = { } # , "15" = { } # ToSTNeT市場 当日決済取引 ) return( df ) } print( c( "株式相場表.init()" ,株式相場表.init ) ) # y抽出 yn <- function( page ,y ) { # page:株価相場表の特定ページ # y:明細行の"y" r <- subset( page ,page[ ,"y"] == y ,select=c("x","text") ) o <- order( as.integer( r[,"x" ] ) ) r <- r[ o, ] return( r ) } print( c( "yn()" ,yn ) ) 株式相場表.page <- function( page ) { df_code <-subset( page ,page[ ,"x" ] == 74 ) # コード mei <- 株式相場表.init() if( nrow( df_code ) == 0 ) return( mei ) for( l in 1:nrow( df_code ) ) { n <- as.integer( df_code[ l,"y" ] ) r <- yn( page ,n ) mei[ l,1:2 ] <- r[1:2 ,2 ] mei[ l, 3 ] <- r[ 3 ,2 ] switch( nrow( r ) - 16 ,"1" = { mei[ l, 3] <- paste( r[ 3 ,2 ] ,r[ 4 ,2 ] ) } ,"2" = { mei[ l, 3] <- paste( r[ 3 ,2 ] ,r[ 4 ,2 ] ,r[ 5 ,2 ] ) } ,"3" = { print( r ) } ) mei[ l, 4:16] <- tail( r[ ,2 ] ,13 ) } return( mei ) } print( c( "株式相場表.page()" ,株式相場表.page ) ) 株式相場表.main <- function( f ,n="1-") { p <- pdf_info( f )$pages df <- pdf_data( f ) stack <- 株式相場表.init() for( i in 1:p ) { page <- sapply( df[[ i ]] ,"[" ) s2 <- subset( page ,page[,"y"] == 71 ,select="text")[ 2 , ] s3 <- subset( page ,page[,"y"] == 71 ,select="text")[ 3 , ] print( paste( "page =" ,i ,s2 ,s3 ) ) if( s2 != "1-") break r <- 株式相場表.page( page ) stack <- rbind( stack , r ) } return( stack ) } print( c( "株式相場表.main()" ,株式相場表.main ) ) #
元ネタ
JPX、よくあるご質問
Q5. 税金の申告に必要な過去の株価(終値)を知りたい。
https://www.jpx.co.jp/faq/stock_listed_company.html【お問合せの前に】
●過去1年以内の株価につきましては →「東京証券取引所日報」をご利用ください。
東京証券取引所日報
https://www.jpx.co.jp/markets/statistics-equities/daily/

- 投稿日:2020-10-18T20:36:34+09:00
gitに自動pushする方法
はじめに
私はAtCoderの過去問を解いたらそのソースコードをgithubにpushしています。
毎回同じコマンドを打つのはめんどくさいので、Macでlinux系のコマンドcrontabを使用してgit pushを自動化しました。crontabとは
決まった時間に自動的にコマンドを使用してくれるデーモンプロセスです。
crontab -eでコマンドの登録をします。分 時 日 月 曜日 コマンド * * * * * some_commands*はワイルドカードを意味しています。
例えば、以下のようにすると、毎日20時0分にechoしてくれます
分 時 日 月 曜日 コマンド 0 20 * * * echo "Hello World!"Macでの注意点
私はmacOS 10.15.5 catalinaを使用しているのですがこのままだとcrontabが動かないので、
フルディスクアクセスにcronを追加しましょう。
このサイトのやり方が参考になります。crontabにgit pushを登録
SSH のラッパースクリプト(git_ssh.sh)を作成します。
git_ssh.sh#!/bin/bash exec ssh -o IdentityFile=/path/to/id_git_rsa "$@"秘密鍵とシェルスクリプトのパーミッションを変更します。
こうすることで秘密鍵を利用して git push が実行されます。chmod 600 /path/to/id_git_rsa chmod 755 /path/to/git_ssh.sh
crontab -eを実行して以下のコマンドを書き込みます。crontab0 20 * * * cd /path/to/git_repository; export GIT_SSH=/path/to/git_ssh.sh; git add .; git commit -m "daily commit"; git push -u origin master;これで毎日20時0分にgit pushが実行されます。
実行されない場合
crontabが実行されてないと
ターミナルで
私は以下のようなエラーが出ました。
fatal: could not read Username for 'https://github.com': Device not configuredリポジトリのリモートURLがHTTPSになっていたのが問題っぽいです。
このコマンドを打ちましょう。git remote set-url origin git@github.com:username/repo.git私はこれでエラーが解決でき、無事にgit pushできました。
まとめ
crontabを利用してgit pushを自動化しました。皆さんも是非crontabを利用してみてください。
参考文献
https://qiita.com/ryusukefuda/items/878556158d8f1d3d887a
https://mac-ra.com/catalina-crontab/
http://tm.root-n.com/unix:command:git:cron_git_push
http://nyangryy.hatenablog.com/entry/2013/11/12/175408
- 投稿日:2020-10-18T19:36:05+09:00
Dockerfileの作り方(基礎)
はじめに
Dockerは多くのIT開発企業で導入されている環境構築を楽にする技術です。
DockerfileはDockerImageの設計図のようなものです。
Dockerfileを自身で作成することで構築したい環境のDocker imageを作成できます。Dockerfile、DockerImage、コンテナの関係
Dockerfile => DockerImage => コンテナ の順に作成します。
DockerImageの作成方法
Dockerfileが存在するディレクトリで docker build .コンテナの作成方法
docker run (DockerImage名 or ID)Dockerfileのインストラクション
- FROM
- RUN
- CMD
- ENTRYPOINT
- COPY
- ADD
- ENV
- WORKDIR
Dockerfile作成手順
FROM
ベースとなるイメージを決定するインストラクションです。
Dockerfileの最初に記述します。
FROMの後には基本的にOSを記述します。FROM OS(Docker imageから選ぶ) 例)FROM ubuntu:latest 例)FROM ruby:2.5RUN
FROMで記述したOSに対応するコマンドを実行するインストラクションです。
RUN毎にLayerが作成されます。(DockerImageは層を積み重ねていくように作成されます。)RUN OSに対応するコマンド 例)FROM ubuntu:latest RUN touch test => DockerImageにはubuntuのLayerにtouch testのLayerが追加で作成されます。 (testというファイルを作成するDockerImageを作成しています。) 例)FROM ubuntu:latest RUN apt-get update && apt-get install -y \ curl\ nginx => DockerImageにはubuntuのLayerにcurlとnginxという2つのパッケージをインストールするLayerが追加作成されます。 (apt-get updateはインストールするパッケージを新しいものにするために記述し、apt-get installはパッケージをインストールするために記述します。) (-yはインストール中にyesかnoかの質問をされても、全てyesとして進むために使用し、バックスラッシュはパッケージを見やすくするための改行のために使用しています。)DockerfileをbuildしてDockerImageを一度作成したものはキャッシュされるため、追加で下に下にとRUNを記述していくことでbuildの時間を少なくすることができます。
※ただし、Layerは少ない方が望ましいため、最終的には、例のように&&や、\を用いた記述のように、RUNの記述をまとめて、RUNを少なくするようにします。CMD
コンテナの実行コマンドを指定するインストラクション。
Dockerfileの最後に記述します。CMD OSに対応するコマンド 例)FROM ubuntu:latest RUN apt-get update && apt-get install -y \ curl\ nginx CMD ["/bin/bash"] => Dockerfileをbuildし、DockerImageを作成した後、docker runによりコンテナ作成・実行した際に、/bin/bashが実行されるようになります。ENTRYPOINT
CMDに近い役割を持つインストラクションです。
CMDはDockerImageを実行(docker run)する際に、コマンドを上書きできるものです。(例:docker run lsとすると上記CMD説明時の例ではbashではなく、lsが実行される。)
ENTRYPOINTを使うと、コマンドの上書きできなくなり、CMDはENTRYPOINTのオプションを記述する形となります。
ENTRYPOINT OSに対応するコマンド 例)FROM ubuntu:latest RUN apt-get update && apt-get install -y \ curl\ nginx ENTRYPOINT ["ls"] CMD ["--help"] => ENTRYPOINTにlsコマンドを記述することでdocker runの際にlsコマンド以外のコマンドが実行できなくなり、CMDはオプションの--helpが指定されています。COPY
Dockerfileの入っているディレクトリ(BuildContextと言います)の中にあるファイルをDockerImageにコピーするインストラクションです。
Copy BuildContext内のファイル名 例)FROM ubuntu:latest RUN mkdir /new_dir COPY test /new_dir CMD ["/bin/bash"] => Dockerfileをbuildした際、DockerImageに/new_dirというディレクトリを作成し、/new_dirにtestというファイルがコピーさせるLayerがutubtuのLayerに追加作成されます。 このDockerImageからコンテナを作成した際には、コンテナ内に/new_dirというディレクトリとtestというファイルが作成されています。ADD
COPYのコマンドと似ていて、同じくコピーができるインストラクションです。
ADDとCOPYとの違い
ADDは圧縮ファイルをコピーした際、コピーと解凍の両方を行います。
COPYは単純なコピーのみです。
圧縮ファイルをコピー・解凍する時にはADD、圧縮ファイルが関係ない単純なコピーにはCOPYを使います。Copy BuildContext内のファイル名 例)FROM ubuntu:latest ADD sample.tar / CMD ["/bin/bash"] => Dockerfileをbuildした際、DockerImageにsample.tarを/(ルート直下)にコピー・解凍するLayerを作成されます。 コンテナを作成した際に、コンテナのルート直下にsample.tarが解凍されたものが作成されています。ENV
環境変数を設定するインストラクションです。
ENV 環境変数 例)FROM ubuntu:latest ENV key1 value CMD ["/bin/bash"] => コンテナ作成時にkey1=valueという環境変数が設定されるDockerImageが作成されます。WORKDIR
インストラクションの実行ディレクトリを変更するインストラクションです。
WORKIDIR ディレクトリ 例)FROM ubuntu:latest RUN mkdir sample_folder WORKDIR /sample_folder RUN touch sample_file => sample_folderというディレクトリを作り、sample_folder内でsample_fileを作成するLayerとなります。 (WORKDIRを使ったことで、コンテナ内に作成した/sample_folderの中でRUNの実行ができます。)参考
Udemy
かめれおん講師 「米国AI開発者がゼロから教えるDocker講座」
有料ですが、初学者の私にも非常に理解しやすかったです。
最後に
本投稿が初学者の復習の一助となればと幸いです。
- 投稿日:2020-10-18T16:03:07+09:00
Javaを学んでいく過程の記録(環境構築:無償のJDKの導入まで)
1. はじめに
Androidアプリ作成のためJavaを独学で学んでみることにしました。
Kotlinは使用しません。学びながら、経過を書いていくので、間違いも多々あろうかと思います。
でも、失敗や勘違いも含めて、そういう経過を書き残しておきます。なお環境は、macで進めていきます。
まずは、環境構築からです。
今回は、無償で商用利用もできる「Adopt Open JDK」というものを導入することにしましたが、その選定の経緯を含めて作業内容を残しておきます。1-1. Javaは有償化された?
環境構築をしようとして、最初からつまづきました。
Javaは有償化されたとの記事がちらほらとあります。調べてみると、「Oracle JDK」というものが有償化されたのであって、Java自体は無償とのこと(詳しくは「Java有償化」って、どういうこと?~」を参照ください)。
なお、「有償となるのは商用利用する場合」であり、個人的な学習などであれば「Oracle JDK」も無償で使用できます。1-2. Oracle JDKとは
では、Oracle JDKとは何なのか。
以下「商用製品/Oracle JDKとは」からの引用です。Oracle JDK(オラクルジェーディーケー)とは通称であり、Oracle社が提供するJava言語用開発ツールキット「JDK(Java SE Development Kit)」を指します。
まあ、Oracle社が提供する「Java開発ツール」ということですね。
C言語で言うと、Visual Studio とか gcc のようなものなんでしょう、きっと。1-3. JDKとは
そして、JDK(Java SE Development Kit)とは何なのか。
これも、先ほどのサイトに、次のように書いてありました。「JDK」とは「Java SE Development Kit」の略称です。
JavaSEを利用してJava言語でプログラム開発を行う際に必要な開発用ソフトウェアをまとめたパッケージです。「コードエディタ」や「IDE(統合開発環境)」などは付属しておらず、Javaプログラム開発を始めるための最低限のソフトウェアのセットです。
JDKには以下のものが含まれます。
・コンパイラ
・デバッガ
・アーカイバ
・Javaプログラム実行環境(JRE) などまあ、コンパイラなどの「開発用のソフトウェアをまとめたもの」ということですね。
コンパイラについては、weblio辞書の「コンパイラ型言語」を参照してください。1-4. Java SEとは
JDKの説明に出てくる「Java SE」とは「Java Platform, Standard Edition」の略で、 Javaプラットフォームで使用されるAPIの集合体とのことです。
いまいちイメージが湧きませんが、今は、「まあ、そんなものか」と思っておきます。2. AdoptOpenJDKのインストール
以上で見たように、現在は、「Oracle JDK」は無償で商用利用はできません。
厳密には、バージョンにより無償利用も可能(下記参考サイト)ですが、ここでは詳しく書きません。●参考サイト
Java有償化とは?無償で利用できない?いや、できます。じゃあ、世の方々はどうしているのかと調べてみると、無償で商用利用もできる「Adopt Open JDK」というものがあるようで、これを使っている人が多いようです。
●参考サイト
Android Studioで別のOpenJDKプロバイダーによるJDKを使用する2-1. ダウンロード方法
結論として、無償で商用利用もできる「Adopt Open JDK」を使うことにしました。
次のURLからダウンロードできます。Adopt Open JDKのサイト:https://adoptopenjdk.net/
URLをクリックすると、
WindowsかMacかを自動的に判定してくれます。
私の環境は、macなので、Download for macOS x64と表示されています。
ダウンロードする前に、
1. Choose a Version(Javaのバージョン)と2. Choose a JVM(Java仮想マシン)の項目を選択する必要があります。バージョンの選択
ここでは、バージョンは
OpenJDK 11 (LTS)を選択しました。
LTSとは Long Term Support版のことで、長期間のサポートがされるバージョンとなります。
このLTSの最新版を使用すれば、おおよそ間違いないと思います。JVMの選択
ここでは、JVMは
HotSpotを選択しました。
JVMとは、Java仮想マシン(Java Virtual Machine)のことで、Javaプログラムを実行するために必要となるものとのことです。詳しくは分かりませんが、まあ、そんなものと考えておきます。
選択肢として、HotSpotとOpenJ9の2つがありますが、初心者の私にはさっぱりわかりません。
「AdoptOpenJDKを使う」というサイトをみると、Oracle Javaとの互換性を優先したければHotSpotを選択した方が良いようなので、ここは保守的にHotSpotとしておきました。あとは、青いボタンを押してダウンロードを開始します。
2-2. インストール方法
ダウンロードしたファイルをダブルクリックすると、インストーラーが立ち上がります。
あとは、画面の指示に従って進めれば問題なくインストールができました。インストールに際しては、Windows版の解説となりますが「AdoptOpenJDK11(JDK11)インストール手順<Windows向け>」というサイトを参考にしました。
3. インストール後の確認
ターミナルで
java -versionというコマンドを打ってJavaのバージョンを確認してみます。$ java -version openjdk version "11.0.8" 2020-07-14 OpenJDK Runtime Environment AdoptOpenJDK (build 11.0.8+10) OpenJDK 64-Bit Server VM AdoptOpenJDK (build 11.0.8+10, mixed mode)以上のように表示されれば、無事にJDKがインストールできたことになると思います。
4. おわりに
今ある解説が、ほとんどOracle JDKを使用するものであり、環境もWindowsの場合が多いので、macでAdopt Open JDKを使用する場合の過程を残しておくことにしました。
まだ、これで良かったかどうかの結果が見えないので、少しずつ記録を残していこうと思います。
- 投稿日:2020-10-18T16:03:07+09:00
Javaの環境構築(無償のJDKの導入まで)
1. はじめに
Androidアプリ作成のためJavaを独学で学んでみることにしました。
Kotlinは使用しません。学びながら、経過を書いていくので、間違いも多々あろうかと思います。
でも、失敗や勘違いも含めて、そういう経過を書き残しておきます。なお環境は、macで進めていきます。
まずは、環境構築からです。
今回は、無償で商用利用もできる「Adopt Open JDK」というものを導入することにしましたが、その選定の経緯を含めて作業内容を残しておきます。1-1. Javaは有償化された?
環境構築をしようとして、最初からつまづきました。
Javaは有償化されたとの記事がちらほらとあります。調べてみると、「Oracle JDK」というものが有償化されたのであって、Java自体は無償とのこと(詳しくは「Java有償化」って、どういうこと?~」を参照ください)。
なお、「有償となるのは商用利用する場合」であり、個人的な学習などであれば「Oracle JDK」も無償で使用できます。1-2. Oracle JDKとは
では、Oracle JDKとは何なのか。
以下「商用製品/Oracle JDKとは」からの引用です。Oracle JDK(オラクルジェーディーケー)とは通称であり、Oracle社が提供するJava言語用開発ツールキット「JDK(Java SE Development Kit)」を指します。
まあ、Oracle社が提供する「Java開発ツール」ということですね。
C言語で言うと、Visual Studio とか gcc のようなものなんでしょう、きっと。1-3. JDKとは
そして、JDK(Java SE Development Kit)とは何なのか。
これも、先ほどのサイトに、次のように書いてありました。「JDK」とは「Java SE Development Kit」の略称です。
JavaSEを利用してJava言語でプログラム開発を行う際に必要な開発用ソフトウェアをまとめたパッケージです。「コードエディタ」や「IDE(統合開発環境)」などは付属しておらず、Javaプログラム開発を始めるための最低限のソフトウェアのセットです。
JDKには以下のものが含まれます。
・コンパイラ
・デバッガ
・アーカイバ
・Javaプログラム実行環境(JRE) などまあ、コンパイラなどの「開発用のソフトウェアをまとめたもの」ということですね。
コンパイラについては、weblio辞書の「コンパイラ型言語」を参照してください。1-4. Java SEとは
JDKの説明に出てくる「Java SE」とは「Java Platform, Standard Edition」の略で、 Javaプラットフォームで使用されるAPIの集合体とのことです。
いまいちイメージが湧きませんが、今は、「まあ、そんなものか」と思っておきます。2. AdoptOpenJDKのインストール
以上で見たように、現在は、「Oracle JDK」は無償で商用利用はできません。
厳密には、バージョンにより無償利用も可能(下記参考サイト)ですが、ここでは詳しく書きません。●参考サイト
Java有償化とは?無償で利用できない?いや、できます。じゃあ、世の方々はどうしているのかと調べてみると、無償で商用利用もできる「Adopt Open JDK」というものがあるようで、これを使っている人が多いようです。
●参考サイト
Android Studioで別のOpenJDKプロバイダーによるJDKを使用する2-1. ダウンロード方法
結論として、無償で商用利用もできる「Adopt Open JDK」を使うことにしました。
次のURLからダウンロードできます。Adopt Open JDKのサイト:https://adoptopenjdk.net/
URLをクリックすると、
WindowsかMacかを自動的に判定してくれます。
私の環境は、macなので、Download for macOS x64と表示されています。
ダウンロードする前に、
1. Choose a Version(Javaのバージョン)と2. Choose a JVM(Java仮想マシン)の項目を選択する必要があります。バージョンの選択
ここでは、バージョンは
OpenJDK 11 (LTS)を選択しました。
LTSとは Long Term Support版のことで、長期間のサポートがされるバージョンとなります。
このLTSの最新版を使用すれば、おおよそ間違いないと思います。JVMの選択
ここでは、JVMは
HotSpotを選択しました。
JVMとは、Java仮想マシン(Java Virtual Machine)のことで、Javaプログラムを実行するために必要となるものとのことです。詳しくは分かりませんが、まあ、そんなものと考えておきます。
選択肢として、HotSpotとOpenJ9の2つがありますが、初心者の私にはさっぱりわかりません。
「AdoptOpenJDKを使う」というサイトをみると、Oracle Javaとの互換性を優先したければHotSpotを選択した方が良いようなので、ここは保守的にHotSpotとしておきました。あとは、青いボタンを押してダウンロードを開始します。
2-2. インストール方法
ダウンロードしたファイルをダブルクリックすると、インストーラーが立ち上がります。
あとは、画面の指示に従って進めれば問題なくインストールができました。インストールに際しては、Windows版の解説となりますが「AdoptOpenJDK11(JDK11)インストール手順<Windows向け>」というサイトを参考にしました。
3. インストール後の確認
ターミナルで
java -versionというコマンドを打ってJavaのバージョンを確認してみます。$ java -version openjdk version "11.0.8" 2020-07-14 OpenJDK Runtime Environment AdoptOpenJDK (build 11.0.8+10) OpenJDK 64-Bit Server VM AdoptOpenJDK (build 11.0.8+10, mixed mode)以上のように表示されれば、無事にJDKがインストールできたことになると思います。
4. おわりに
今ある解説が、ほとんどOracle JDKを使用するものであり、環境もWindowsの場合が多いので、macでAdopt Open JDKを使用する場合の過程を残しておくことにしました。
まだ、これで良かったかどうかの結果が見えないので、少しずつ記録を残していこうと思います。
- 投稿日:2020-10-18T16:03:07+09:00
【初心者】Javaの環境構築(Adopt Open JDKの導入まで)
1. はじめに
Androidアプリ作成のためJavaを知識ゼロから独学で学んでみることにしました。
Kotlinは使用しません。学びながら、経過を書いていくので、間違いも多々あろうかと思います。
でも、失敗や勘違いも含めて、そういう経過を書き残しておきます。なお環境は、macで進めていきます。
まずは、環境構築からです。
今回は、無償で商用利用もできる「Adopt Open JDK」というものを導入することにしましたが、その選定の経緯を含めて作業内容を残しておきます。1-1. Javaは有償化された?
環境構築をしようとして、最初からつまづきました。
Javaは有償化されたとの記事がちらほらとあります。調べてみると、「Oracle JDK」というものが有償化されたのであって、Java自体は無償とのこと(詳しくは「Java有償化」って、どういうこと?~」を参照ください)。
なお、「有償となるのは商用利用する場合」であり、個人的な学習などであれば「Oracle JDK」も無償で使用できます。1-2. Oracle JDKとは
では、Oracle JDKとは何なのか。
以下「商用製品/Oracle JDKとは」からの引用です。Oracle JDK(オラクルジェーディーケー)とは通称であり、Oracle社が提供するJava言語用開発ツールキット「JDK(Java SE Development Kit)」を指します。
まあ、Oracle社が提供する「Java開発ツール」ということですね。
C言語で言うと、Visual Studio とか gcc のようなものなんでしょう、きっと。1-3. JDKとは
そして、JDK(Java SE Development Kit)とは何なのか。
これも、先ほどのサイトに、次のように書いてありました。「JDK」とは「Java SE Development Kit」の略称です。
JavaSEを利用してJava言語でプログラム開発を行う際に必要な開発用ソフトウェアをまとめたパッケージです。「コードエディタ」や「IDE(統合開発環境)」などは付属しておらず、Javaプログラム開発を始めるための最低限のソフトウェアのセットです。
JDKには以下のものが含まれます。
・コンパイラ
・デバッガ
・アーカイバ
・Javaプログラム実行環境(JRE) などまあ、コンパイラなどの「開発用のソフトウェアをまとめたもの」ということですね。
コンパイラについては、weblio辞書の「コンパイラ型言語」を参照してください。1-4. Java SEとは
JDKの説明に出てくる「Java SE」とは「Java Platform, Standard Edition」の略で、 Javaプラットフォームで使用されるAPIの集合体とのことです。
いまいちイメージが湧きませんが、今は、「まあ、そんなものか」と思っておきます。2. AdoptOpenJDKのインストール
以上で見たように、現在は、「Oracle JDK」は無償で商用利用はできません。
厳密には、バージョンにより無償利用も可能(下記参考サイト)ですが、ここでは詳しく書きません。●参考サイト
Java有償化とは?無償で利用できない?いや、できます。じゃあ、世の方々はどうしているのかと調べてみると、無償で商用利用もできる「Adopt Open JDK」というものがあるようで、これを使っている人が多いようです。
●参考サイト
Android Studioで別のOpenJDKプロバイダーによるJDKを使用する2-1. ダウンロード方法
結論として、無償で商用利用もできる「Adopt Open JDK」を使うことにしました。
次のURLからダウンロードできます。Adopt Open JDKのサイト:https://adoptopenjdk.net/
URLをクリックすると、
WindowsかMacかを自動的に判定してくれます。
私の環境は、macなので、Download for macOS x64と表示されています。
ダウンロードする前に、
1. Choose a Version(Javaのバージョン)と2. Choose a JVM(Java仮想マシン)の項目を選択する必要があります。バージョンの選択
ここでは、バージョンは
OpenJDK 11 (LTS)を選択しました。
LTSとは Long Term Support版のことで、長期間のサポートがされるバージョンとなります。
このLTSの最新版を使用すれば、おおよそ間違いないと思います。JVMの選択
ここでは、JVMは
HotSpotを選択しました。
JVMとは、Java仮想マシン(Java Virtual Machine)のことで、Javaプログラムを実行するために必要となるものとのことです。詳しくは分かりませんが、まあ、そんなものと考えておきます。
選択肢として、HotSpotとOpenJ9の2つがありますが、初心者の私にはさっぱりわかりません。
「AdoptOpenJDKを使う」というサイトをみると、Oracle Javaとの互換性を優先したければHotSpotを選択した方が良いようなので、ここは保守的にHotSpotとしておきました。あとは、青いボタンを押してダウンロードを開始します。
2-2. インストール方法
ダウンロードしたファイルをダブルクリックすると、インストーラーが立ち上がります。
あとは、画面の指示に従って進めれば問題なくインストールができました。インストールに際しては、Windows版の解説となりますが「AdoptOpenJDK11(JDK11)インストール手順<Windows向け>」というサイトを参考にしました。
3. インストール後の確認
ターミナルで
java -versionというコマンドを打ってJavaのバージョンを確認してみます。$ java -version openjdk version "11.0.8" 2020-07-14 OpenJDK Runtime Environment AdoptOpenJDK (build 11.0.8+10) OpenJDK 64-Bit Server VM AdoptOpenJDK (build 11.0.8+10, mixed mode)以上のように表示されれば、無事にJDKがインストールできたことになると思います。
4. おわりに
今ある解説が、ほとんどOracle JDKを使用するものであり、環境もWindowsの場合が多いので、macでAdopt Open JDKを使用する場合の過程を残しておくことにしました。
まだ、これで良かったかどうかの結果が見えないので、少しずつ記録を残していこうと思います。
- 投稿日:2020-10-18T05:48:07+09:00
完全栄養マクドナルド食の線型計画による実装~もしマクドナルドだけで生活すると栄養バランスはどうなるのか?~
背景と概要
マクドナルドが大好きである。
しかし、ジャンクフード、健康に悪い、
などという話は以前よりよく見かける。では本当にマクドナルドを食べ続けると、
健康に悪いのだろうか?
マクドナルドだけで生活する場合本当に、
栄養の偏りやカロリー過剰などが発生するのだろうか?本稿は、マクドナルドだけで
一日に必要なすべての栄養素を摂取する食事
をする場合に、どのようなメニューを選ぶべきで、
その結果どのような栄養問題が生じるのか、
PuLPというPythonの線型計画ライブラリを用いて
研究した結果をまとめたものである。すなわち、マクドナルドだけで
完全栄養食としてのメニューを組み立てるには
何をどれだけ食べればいいの?
そしてその時何カロリーになるの? という
世の中の0.001%くらいの人が一度は疑問に
思ったことがある問題に対して解を与える。また、栄養食的な代表選手ということで、
牛乳の栄養素を含んだ上での五角形の形
になっていることで高名な
コーンフレーク(こちらも大好きである)を
メニューに加えた場合の考察も追加する。「無人島にマクドナルドだけ持って行っていい」と
言われた場合にとても役立つ研究であることを確信している。実装の基本方針
まず、マクドナルドの全メニューの
栄養情報については、
以下の公式サイトにて公開されている。https://www.mcdonalds.co.jp/products/nutrition_balance_check/
こちらのサイトでメニューを選び、
自分の性別・年齢・身体活動レベルを
入力することで、一日に必要な栄養素に対して、
どの程度満たすか?を確認することが可能だ。本研究は、つまりコレを、
一日分すべての栄養素を100%満たしつつ、
塩分は基準値以下となるように調整し、
かつカロリーは出来るだけ少なくする、
ようなメニュー選択の最適解を目指すことになる。一見難しそうな問題に見えるものの、
実は単純な線型計画の問題であり、
PythonのPuLPライブラリで一発で解決できる。一番工夫すべき点は、データや変数が多いために、
問題をうまくコードに落とすのが超面倒なこと。
「teriyaki-ba-ga」という変数とか、
「 VitaminC > 100」みたいな式を大量に書いていたら、
夢までも「たらったったったー」で
埋め尽くされるのは間違いない。
月見バーガーなどのメニュー追加にも
対応しにくくなってしまう。その点に留意しながら、以下のような段取りで研究を進める。
①線型計画問題とはなにか?
②PuLPの基本的な使い方を確認
③マクドナルドの公式サイトからデータを取得し、
Pythonで加工できるようにする
④一日に必要な栄養素=完全栄養食問題として、
コードを実装する。(うまく汎用的に作る)
⑤いくつか条件を変えながら結果を見て遊ぶ
⑥1メニュー1回まで制限にして遊ぶ
⑦コーンフレークをメニューに追加してさらに遊ぶ①線型計画問題とは?
- カロリー 栄養1 栄養2 栄養3 てりやき 20 25 10 15 ポテト 12 11 10 18 コーラ 15 13 16 25 必要栄養量 ★ここを最小に 300 200 100 ■問題:上記のような栄養表があるときに、
栄養素1~3の必要量を満たしつつ、
カロリーを最小にするような、
てりやき、ポテト、コーラの注文の仕方は何か?⇒答え:
てりやき×8、ポテト×1、コーラ×7
で 298カロリーこのように、何かの最適解を求める問題において、
目的関数(カロリー)や、制約条件(満たすべき栄養素)が
線型(二乗とかが出ない一次元の多項式)の不等式で
表現できる問題のことを、線型計画問題と言う。PythonではPuLPというライブラリが用意されており、
この問題をコードで記載するだけで
一発で最適解を求めることが出来る。②PuLPの基本的な使い方
PuLPの使い方を見てみる。
なお以降のコードも全てColaboratory上で実行を試している。PuLPのインストール方法
PuLPのインストールpip install pulpさきほどの例題を解くコードが以下。
一番基本的な使い方を見てみる。PuLPの一番基本的な使い方import pulp # !pip install pulp # 参考1:https://www.y-shinno.com/pulp-intro/ # 問題の定義 # 最小化か、最大化か、どちらかを指定する problem = pulp.LpProblem(name="マック", sense=pulp.LpMinimize) #problem = pulp.LpProblem(name="マック", sense=pulp.LpMaximize) # 変数の定義(※変数の指定は、pythonは日本語でもOK) # 物の個数を表現するため、0以上の整数である、と定義している てりやき = pulp.LpVariable(name = "てりやき", lowBound = 0, cat="Integer") ポテト = pulp.LpVariable(name = "ポテト", lowBound = 0, cat="Integer") コーラ = pulp.LpVariable(name = "コーラ", lowBound = 0, cat="Integer") # 目的関数(最小or最大にすべき関数) problem += 20 * てりやき + 12 * ポテト + 15 * コーラ # 制約条件の定義 # 書き方として、必ず、等号を入れて、<=.==,>= などの書き方にすること! problem += 25 * てりやき + 11 * ポテト + 13 * コーラ >= 300 problem += 10 * てりやき + 10 * ポテト + 16 * コーラ >= 200 problem += 15 * てりやき + 18 * ポテト + 25 * コーラ >= 100 # 問題を解く status = problem.solve() print(pulp.LpStatus[status]) #ステータスの全種類は、下記の通り。 #「Optimal」が、最適解が得られた、の意 # {-3: 'Undefined', # -2: 'Unbounded', # -1: 'Infeasible', # 0: 'Not Solved', # 1: 'Optimal'} # 結果表示 print("Result") print("てりやき:", てりやき.value()) print("ポテト:", ポテト.value()) print("コーラ:", コーラ.value())出力結果Optimal Result てりやき: 8.0 ポテト: 1.0 コーラ: 7.0一つ目の工夫のポイントは、
変数名を「日本語」にしている点。
Python3では変数名にアスキーコード以外も利用可能であり、
最初から日本語にしておくことで、
マクドナルドのメニューの商品名称を
そのまま変数名として扱うことが出来る。
逆にこうしないと、てりやきは「teriyaki」で・・・
みたいに、全メニューに英語名を付与して、
しかもそのマッピングを管理しないといけなくなる。
この時点で日が暮れてしまう。だが、変数を日本語にしただけでは、各栄養素ごとの式を
全て入力していくのは依然としてものすごく大変である。
他のメニューが追加されたときなどに、全ての
problem += 10 * てりやき + 10 * ポテト + 16 * コーラ >= 200
の式を更新していくのもヤバイことになる(語彙力不足)そこで、以下のように、
メニュー名や栄養素の値をリスト形式で扱えるようにする。
コードはだいぶ異なるが、結果や意味は全く同じである。
これで月見バーガーの季節になっても全く問題はない。PuLPの少し汎用的な書き方import pulp # !pip install pulp # 参考2:http://www.nct9.ne.jp/m_hiroi/light/pulp01.html # 問題の定義( # 最小化か、最大化か、どちらかを指定 problem = pulp.LpProblem(name="マック", sense=pulp.LpMinimize) #problem = pulp.LpProblem(name="マック", sense=pulp.LpMaximize) # データの定義 target_menu_list =["てりやき","ポテト","コーラ"] kcal =[20,12,15] eiyou1 =[25,11,13] eiyou2 =[10,10,16] eiyou3 =[15,18,25] # 変数の定義 # 変数の定義を、リスト内包表記で書く、かつ、変数名を動的に、リスト内のデータて定義 xs = [pulp.LpVariable('{}'.format(x), cat='Integer', lowBound=0) for x in target_menu_list] # 目的関数や制約条件を、行列の掛け算型で書く # 目的関数(最小or最大にすべき関数) problem += pulp.lpDot(kcal, xs) # 制約条件の定義 problem += pulp.lpDot(eiyou1, xs) >= 300 problem += pulp.lpDot(eiyou2, xs) >= 200 problem += pulp.lpDot(eiyou3, xs) >= 100 # 問題を解く status = problem.solve() print(pulp.LpStatus[status]) # 結果表示 print("Result") print("てりやき:", てりやき.value()) print("ポテト:", ポテト.value()) print("コーラ:", コーラ.value())ポイントは、行列の掛け算型で式を定義している点と、
てりやき、などの変数名を動的に名付けている点。つまり、
target_menu_list =["てりやき","ポテト","コーラ"]
⇒
target_menu_list =["てりやき","ポテト","コーラ","月見バーガー"]
のようにメニュー名のリストを更新してあげれば、
'{}'.format(x)の箇所で、変数名として使われて、
月見バーガーという変数が動的に生成される、というワケ。これらの工夫をしておかないと、
数行のデータで遊ぶ分には問題ないが、
マクドナルドの実データ数百行には全く対応出来ない。PuLPというライブラリがありながらも、
全人類の夢であった完全栄養マクドナルド食の検討が
今までなされてこなかった理由は、
普通に作ったらコードがヤバイことになるから、
が理由に違いない。きっとそうに違いない(反復法による強調)③マクドナルドのデータ入手&加工
先に挙げたマクドナルドの公式サイトから、
最新全メニューの栄養価一覧表を見ることが出来る。
バーガー、サイド、ドリンク、バリスタ、の4種類。
スクレイピングなどする必要もなく、
単純に4回コピペして、CSV形式で保存しよう。
※「-」のデータだけ、置換で「0」にしておく保存したCSVデータは、以下のようなコードで、
Pythonで辞書形式で読み出すことが出来る。マクドナルドデータの読み込みimport csv McDonaldsDict = {} with open('/content/drive/My Drive/MACD/マクドナルド栄養価一覧20201009_R.csv') as f: reader = csv.DictReader(f) # OrderedDict([('商品名', 'えびフィレオ'), ('重量g', '174'), ・・・が1行ごとに入っている # ※ジュース系などで、栄養価が「-」のものは0を置換済み for row in reader: # 'えびフィレオ' : OrderedDict([('商品名', 'えびフィレオ'), ('重量g', '174')・・・ の辞書形式に加工 McDonaldsDict[row["商品名"]] = row後で、対象の商品だけ選んで取り出す、
ということがしやすいように、
「商品名」をキーとした辞書形式にしておく。
(※辞書形式の中がさらに辞書型になっている二重辞書)また、1日に必要な栄養素についても、
データを参照して以下のように定義しておこう。
対象は、完全栄養マクドナルド食に興味がありそうな暇人たち
本研究の想定読者層に合わせてみた。必要な栄養素(例)#男性:30歳~49歳の1日に必要な栄養量。 #身体活動レベル1=生活の大部分が座位で、 # 静的な活動が中心の場合、で計算 # ただし、食塩相当量は、必要ではなく「以下」にすべき値 one_da_nutrition_dict ={ "エネルギーkcal" : 2300.0, "たんぱく質g" : 65.0 , "脂質g" : 63.9 , "炭水化物g" : 330.6 , "カルシウムmg" : 750.0 , "鉄mg" : 7.5 , "ビタミンAμg" : 900.0 , "ビタミンB1mg" : 1.4 , "ビタミンB2mg" : 1.6 , "ビタミンCmg" : 100.0 , "食物繊維g" : 21.0 , "食塩相当量g" : 7.5 , }④いよいよ完全栄養マクドナルド食
ここまでで全部の準備が出来た。
マクドナルドのメニューは多様であるが、
「ミルクも入れて完全な5角形」とか
「サラダや野菜ジュースで健康」というのは
典型的なマクドナルド感が薄いので、
まずは代表選手として主観ながら以下のメンバーを選出した。
- てりやきマックバーガー
- ハンバーガー
- チーズバーガー
- ダブルチーズバーガー
- 月見バーガー
- ビッグマック
- フィレオフィッシュ
- チキンマックナゲット 5ピース
- マックフライポテト(M)
- マックフライポテト(S)
- ケチャップ
- バーベキューソース
- コカ・コーラ(M)
- マックシェイク® バニラ(S)
- ミニッツメイド オレンジ(M)
この選択は大規模な宗教論争なることが予想されるため、
他神の信徒の方もいらっしゃるだろうが、一旦異論は認めない。
他宗派の方はぜひ選抜メンバーを変えてコードを追試してみてほしい。これらの組み合わせだけで、
一日に必要な栄養素を全て摂取し、
かつ塩分は基準値以下とする場合に、
最低何カロリーになるのだろうか!?さあ以下のコード一発にまとめたので、実行してみよう!!
完全栄養マクドナルド食の線型計画import pulp # 問題の定義 # 今回は、カロリーを最小化したいため、最初化で設定 problem = pulp.LpProblem(name="完全栄養マクドナルド食", sense=pulp.LpMinimize) import csv McDonaldsDict = {} with open('/content/drive/My Drive/MACD/マクドナルド栄養価一覧20201009_R.csv') as f: reader = csv.DictReader(f) # OrderedDict([('商品名', 'えびフィレオ'), ('重量g', '174'), ・・・が1行ごとに入っている # ※ジュース系などで、栄養価が「-」のものは0を置換済み for row in reader: # 'えびフィレオ' : OrderedDict([('商品名', 'えびフィレオ'), ('重量g', '174')・・・ の辞書形式に加工 McDonaldsDict[row["商品名"]] = row # 特定の栄養価のリストを取得する # 対象のtarget_menu_listに入っている順番に、その栄養価の値を取得。 def get_nutrition_val_list(nutrition_dict, target_menu_list, eiyou_name): result_list = [] for menu_name in target_menu_list: #栄養価を取得してfloatに置換 eiyou_val = nutrition_dict[menu_name][eiyou_name] result_list.append(float(eiyou_val)) return result_list # 品物 # ※カロリーの問題であるため、コカ・コーラ ゼロや爽健美茶など、 # カロリーが完全に0のものは除外しておくこと。 target_menu_list = [ "てりやきマックバーガー", "ハンバーガー", "チーズバーガー", "ダブルチーズバーガー", "月見バーガー", "ビッグマック", "フィレオフィッシュ", "チキンマックナゲット 5ピース", "マックフライポテト(M)", "マックフライポテト(S)", "ケチャップ", "バーベキューソース", # "スイートコーン", # "サイドサラダ", "コカ・コーラ(M)", "マックシェイク® バニラ(S)", "ミニッツメイド オレンジ(M)", # "ミルク", # "野菜生活100(M)", ] #男性:30歳~49歳の1日に必要な栄養量。 #身体活動レベル1=生活の大部分が座位で、 # 静的な活動が中心の場合、で計算 # ただし、食塩相当量は、必要ではなく「以下」にすべき値 one_da_nutrition_dict ={ "エネルギーkcal" : 2300.0, "たんぱく質g" : 65.0 , "脂質g" : 63.9 , "炭水化物g" : 330.6 , "カルシウムmg" : 750.0 , "鉄mg" : 7.5 , "ビタミンAμg" : 900.0 , "ビタミンB1mg" : 1.4 , "ビタミンB2mg" : 1.6 , "ビタミンCmg" : 100.0 , "食物繊維g" : 21.0 , "食塩相当量g" : 7.5 , } # 対象とする栄養素について、対象の商品リストごとの栄養価を、リスト形式で作成する eiyou_data={} for key in one_da_nutrition_dict.keys(): #keyに入っている栄養の名称(日本語)を、データのdictのkeyにする eiyou_data[key] = get_nutrition_val_list(McDonaldsDict, target_menu_list, key) # 変数の定義(※日本語の文字列をそのまま変数として利用) xs = [pulp.LpVariable('{}'.format(x), cat='Integer', lowBound=0) for x in target_menu_list] # 目的関数:エネルギーの最小化 problem += pulp.lpDot(eiyou_data["エネルギーkcal"], xs) # 制約条件:一日に必要な栄養量をそれぞれ満たすこと。 # 条件カスタマイズ&ON-OFFしやすいように、あえてループ外で記載。 # 食塩相当については、「以内」としている。解が存在するかどうか?は要注意。 problem += pulp.lpDot(eiyou_data["たんぱく質g"], xs) >= one_da_nutrition_dict["たんぱく質g"] problem += pulp.lpDot(eiyou_data["脂質g"], xs) >= one_da_nutrition_dict["脂質g"] problem += pulp.lpDot(eiyou_data["炭水化物g"], xs) >= one_da_nutrition_dict["炭水化物g"] problem += pulp.lpDot(eiyou_data["カルシウムmg"], xs) >= one_da_nutrition_dict["カルシウムmg"] problem += pulp.lpDot(eiyou_data["鉄mg"], xs) >= one_da_nutrition_dict["鉄mg"] problem += pulp.lpDot(eiyou_data["ビタミンAμg"], xs) >= one_da_nutrition_dict["ビタミンAμg"] problem += pulp.lpDot(eiyou_data["ビタミンB1mg"], xs) >= one_da_nutrition_dict["ビタミンB1mg"] problem += pulp.lpDot(eiyou_data["ビタミンB2mg"], xs) >= one_da_nutrition_dict["ビタミンB2mg"] problem += pulp.lpDot(eiyou_data["ビタミンCmg"], xs) >= one_da_nutrition_dict["ビタミンCmg"] problem += pulp.lpDot(eiyou_data["食物繊維g"], xs) >= one_da_nutrition_dict["食物繊維g"] problem += pulp.lpDot(eiyou_data["食塩相当量g"], xs) <= one_da_nutrition_dict["食塩相当量g"] #与えられた問題の内容を表示 print(problem) status = problem.solve() print("Status", pulp.LpStatus[status]) # ※「Optimal」であることを確認すること。 # 簡易結果表示 print([x.value() for x in xs]) print(problem.objective.value()) # 変数名ごとに表示 for x in xs: print(str(x) + " × "+ str(int(x.value())) ) # それぞれの栄養素がいくらになったのか、計算結果を表示 print("----結果----") for key in one_da_nutrition_dict.keys(): print(key + ": " + str(one_da_nutrition_dict[key]) +" に対し " + str(round(pulp.lpDot( eiyou_data[key], xs).value())) )上記を実行すると・・・
結果: 8035kcal
出力結果# 問題定義周りのログ出力は省略して記載 てりやきマックバーガー × 0 ハンバーガー × 0 チーズバーガー × 0 ダブルチーズバーガー × 1 月見バーガー × 2 ビッグマック × 0 フィレオフィッシュ × 0 チキンマックナゲット_5ピース × 0 マックフライポテト(M) × 0 マックフライポテト(S) × 0 ケチャップ × 2 バーベキューソース × 0 コカ・コーラ(M) × 0 マックシェイク®_バニラ(S) × 0 ミニッツメイド_オレンジ(M) × 46 ----結果---- エネルギーkcal: 2300.0 に対し 8035 たんぱく質g: 65.0 に対し 175 脂質g: 63.9 に対し 85 炭水化物g: 330.6 に対し 1654 カルシウムmg: 750.0 に対し 1526 鉄mg: 7.5 に対し 20 ビタミンAμg: 900.0 に対し 900 ビタミンB1mg: 1.4 に対し 12 ビタミンB2mg: 1.6 に対し 2 ビタミンCmg: 100.0 に対し 5433 食物繊維g: 21.0 に対し 38 食塩相当量g: 7.5 に対し 8 #補足;食塩は以下条件であり、roundで8になっている?実に、1日の必要量 2300kcalに対してなんと、
8035kcal も摂取することになる。
そして、
ダブルチーズバーガー × 1
月見バーガー × 2 を圧倒的に洗い流す、
46杯というミニッツメイド_オレンジの洪水。典型的なマクドナルド感の代表選手
のみに限定してしまうと
さすがにちょっとヤバイ感じ(語彙力)になってしまった。だが全国のマクドナルド・ファンの皆様、ご安心召されよ、
そもそもこのように選択肢が少ない状態で、
全栄養素を満たすように、という条件であるため、
8035kcalという結果になってしまっただけである。
より現実的な条件の場合も確認していきたい。ここまでの結果で終わってしまっては私としても、
夜な夜な、黄色と赤色のピエロによる闇討ちを
怖がらなくてはいけなくなってしまう。⑤いくつか条件を変えながら結果を見て遊ぶ
まずは「野菜もしっかり食べよう」の勅令に従って、
サラダ、スイートコーン、のコメントアウトを戻す。
また、ミルクや野菜生活もOKとしよう!結果: 1994kcal
野菜もしっかり食べようてりやきマックバーガー × 1 ハンバーガー × 0 チーズバーガー × 0 ダブルチーズバーガー × 0 月見バーガー × 0 ビッグマック × 0 フィレオフィッシュ × 0 チキンマックナゲット_5ピース × 0 マックフライポテト(M) × 0 マックフライポテト(S) × 2 ケチャップ × 0 バーベキューソース × 0 スイートコーン × 2 サイドサラダ × 95 コカ・コーラ(M) × 0 マックシェイク®_バニラ(S) × 0 ミニッツメイド_オレンジ(M) × 0 ミルク × 0 野菜生活100(M) × 0 ----結果---- エネルギーkcal: 2300.0 に対し 1994 たんぱく質g: 65.0 に対し 72 脂質g: 63.9 に対し 64 炭水化物g: 330.6 に対し 331 カルシウムmg: 750.0 に対し 1308 鉄mg: 7.5 に対し 22 ビタミンAμg: 900.0 に対し 2580 ビタミンB1mg: 1.4 に対し 3 ビタミンB2mg: 1.6 に対し 2 ビタミンCmg: 100.0 に対し 1454 食物繊維g: 21.0 に対し 87 食塩相当量g: 7.5 に対し 4基準値の2300kcalより少ない1994kcal。
しっかり栄養を取りながらダイエットが出来る。
実に健康的な結果が出て、しかも、
てりやきマックバーガー × 1
マックフライポテト(S) × 2
も食べることが出来るなんて!!と、思いきや、
サイドサラダ × 95 (絶句)こんなに野菜は食べられないですよねー!!
健康ジュースの通販番組のネタになりそうな量である。
やはりサイドサラダによる影響は大きすぎた。そこで、コーンフレーク方式を試す。
ミルクやジュース等の飲み物による補充はOKとする案。
サイドサラダ とスイートコーン だけ外そう。結果: 2933kcal
てりやきマックバーガー × 0 ハンバーガー × 0 チーズバーガー × 1 ダブルチーズバーガー × 0 月見バーガー × 1 ビッグマック × 0 フィレオフィッシュ × 0 チキンマックナゲット_5ピース × 0 マックフライポテト(M) × 2 マックフライポテト(S) × 2 ケチャップ × 0 バーベキューソース × 0 コカ・コーラ(M) × 0 マックシェイク®_バニラ(S) × 0 ミニッツメイド_オレンジ(M) × 2 ミルク × 3 野菜生活100(M) × 2 ----結果---- エネルギーkcal: 2300.0 に対し 2933 たんぱく質g: 65.0 に対し 81 脂質g: 63.9 に対し 125 炭水化物g: 330.6 に対し 371 カルシウムmg: 750.0 に対し 1013 鉄mg: 7.5 に対し 8 ビタミンAμg: 900.0 に対し 2018 ビタミンB1mg: 1.4 に対し 2 ビタミンB2mg: 1.6 に対し 2 ビタミンCmg: 100.0 に対し 311 食物繊維g: 21.0 に対し 21 食塩相当量g: 7.5 に対し 8チーズバーガー × 1
月見バーガー × 1
マックフライポテト(M) × 2
マックフライポテト(S) × 2
に、オレンジジュース、ミルク、野菜ジュースを数本ずつ。
ちょうどお昼と夜にバリューセットを頼む感じで、
2933kcalとちょっと超過しすぎだが、
これならばある程度現実に近い感じではないだろうか!?
(おそらく食物繊維か何かのためにポテトが多すぎるので、
少し別のメニュー等で食物繊維を摂取すればよい)これは、通常のポテト版のバリューセットの
飲み物を、オレンジジュース or ミルク or 野菜生活
にするだけで、栄養バランス的にはかなり理想的。
ということを示唆している。(食物繊維/鉄が少し不足)マクドナルド食は健康に良い!とまでは言えないものの、
そこまで悪い結果でもないだろう。この示唆に従って、試しに以下の組み合わせで
先述の公式サイトでの栄養表示を試してみた。
- チーズバーガー
- マックフライポテトM
- 野菜生活M
- ミルク
- ミニッツメイドオレンジM
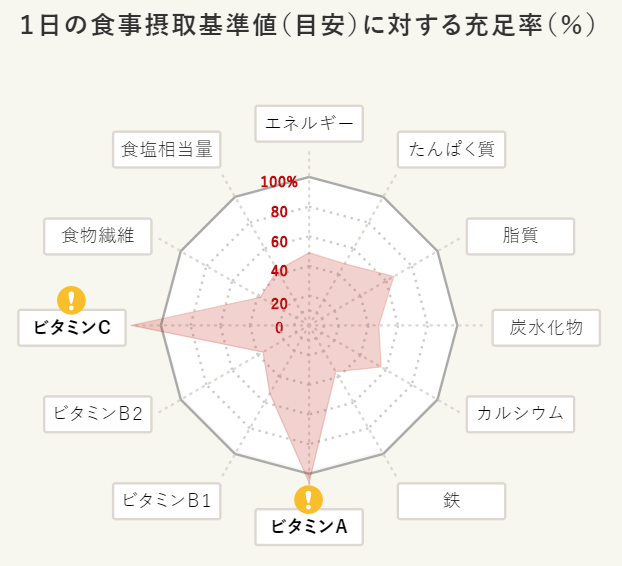
画像出典:マクドナルド公式サイト > 私達の責任 > Our Food > 栄養バランスチェック
一食相当分で、およそどの栄養素も1日の40%ラインを超えているため、
バリューセットにミルクと果物ジュースを追加するだけで
こんなに理想的な食事になる!!みたいな宣伝が出来そうである。
脂質が過剰という説はある。
また、もしかしたらだいたいの食べ物はミルクと野菜ジュースで
補強すると"コーンフレーク五角形"を作れるのかもしれない。⑥1メニュー1回まで制限にして遊ぶ
さらにさらに、より現実的な解として、
どのメニューも最大1回まで注文できる場合
(つまり、サラダばかり95個も頼むのはNGとする)
で最適解を求めてみる。
対象のメニュー範囲も合わせて通常の全種類まで拡大する。コードを以下のように変えるだけ!
①(バリスタ以外の)全通常メニューを対象とする
②変数の定義時に、「最大値=1」の条件を追加するどのメニューも一回だけ注文可能な場合# バリスタメニューは抜く target_menu_list = [x for x in McDonaldsDict.keys() if McDonaldsDict[x]["区分"]!="バリスタ"] # 中略 # 変数の定義 upBound=1 が最大値1の条件 xs = [pulp.LpVariable('{}'.format(x), cat='Integer', lowBound=0, upBound=1) for x in target_menu_list]1回まで注文できる場合で結果を見てみよう!
結果: 2453kcal
エッグマックマフィン × 1 ストロベリージャム × 1 マックグリドル_ベーコンエッグ × 1 サイドサラダ × 1 シェアポテト × 1 スイートコーン × 1 サントリー黒烏龍茶#濃いめ × 1 プレミアムローストアイスコーヒー(L) × 1 プレミアムローストコーヒー(M) × 1 プレミアムローストコーヒー(S) × 1 ホットティー(ストレート)(M) × 1 マックシェイク®_チョコレート(S) × 1 ミニッツメイド_オレンジ(S) × 1 ミルク × 1 リキッドレモン × 1 野菜生活100(M) × 1 ----結果---- エネルギーkcal: 2300.0 に対し 2453 たんぱく質g: 65.0 に対し 67 脂質g: 63.9 に対し 95 炭水化物g: 330.6 に対し 331 カルシウムmg: 750.0 に対し 856 鉄mg: 7.5 に対し 8 ビタミンAμg: 900.0 に対し 1161 ビタミンB1mg: 1.4 に対し 1 ビタミンB2mg: 1.6 に対し 2 ビタミンCmg: 100.0 に対し 254 食物繊維g: 21.0 に対し 21 食塩相当量g: 7.5 に対し 8代表的なバーガー系が出なくなってしまったのが残念だが、
まあまあ現実的に注文できそうな解を得ることが出来た。
サラダ、スイートコーン、野菜生活、
ミルク、オレンジジュース、などの
前回からのエースは相変わらず選ばれている。
マックシェイク®_チョコレートが入っているのが意外な結果。⑦コーンフレークをメニューに追加してさらに遊ぶ
最後に、栄養バランス5角形の代表格、
コーンフロスティ(ケロッグ)のデータを追加してみる。
ケロッグの公式サイトから、コーンフロスティのデータを参照し、
以下のように個別にDictデータを作成。
元のデータに追加して実行するだけ。コーンフロスティのデータfrom collections import OrderedDict ## 牛乳無し版のコーンフロスティデータの追加 # 参考:https://www.kelloggs.jp/ja_JP/products/corn-frosties.html k_od = OrderedDict() k_od['商品名'] = "コーンフロスティ" k_od['重量g'] = 30.0 k_od['エネルギーkcal'] = 114.0 k_od['たんぱく質g'] = 1.7 #1.2~2.2 k_od['脂質g'] = 0.25 #0~0.5 k_od['炭水化物g'] = 26.9 #k_od['ナトリウムmg'] = #k_od['カリウムmg'] = k_od['カルシウムmg'] = 1.5 #0.5~2.5 #k_od['リンmg'] = k_od['鉄mg'] = 1.4 k_od['ビタミンAμg'] = 96 #53~139 k_od['ビタミンB1mg'] = 0.47 k_od['ビタミンB2mg'] = 0.42 #k_od['ナイアシンmg'] = k_od['ビタミンCmg'] = 15 #k_od['コレステロールmg'] = k_od['食物繊維g'] = 1.2 #0.4~2.0 k_od['食塩相当量g'] = 0.3 #k_od['区分'] = #追加コーンフロスティデータの追加 #McDonaldsDict["コーンフロスティ"] = k_od今回は、マクドナルドの代表選手に絞ったメニューで、
サラダ無し、飲み物有り版に、
コーンフロスティを選択肢として加えた版の結果をご紹介しよう。結果: 2544kcal
てりやきマックバーガー × 0 ハンバーガー × 2 チーズバーガー × 0 ダブルチーズバーガー × 0 月見バーガー × 0 ビッグマック × 0 フィレオフィッシュ × 0 チキンマックナゲット_5ピース × 0 マックフライポテト(M) × 2 コカ・コーラ(M) × 0 ミニッツメイド_オレンジ(M) × 0 ミルク × 3 野菜生活100(M) × 0 コーンフロスティ × 7 ----結果---- エネルギーkcal: 2300.0 に対し 2544 たんぱく質g: 65.0 に対し 68 脂質g: 63.9 に対し 85 炭水化物g: 330.6 に対し 381 カルシウムmg: 750.0 に対し 788 鉄mg: 7.5 に対し 14 ビタミンAμg: 900.0 に対し 940 ビタミンB1mg: 1.4 に対し 4 ビタミンB2mg: 1.6 に対し 4 ビタミンCmg: 100.0 に対し 145 食物繊維g: 21.0 に対し 21 食塩相当量g: 7.5 に対し 7コーンフロスティ × 7
ミルク × 3
で、コーンフロスティを選択肢に入れない場合には
2933kcalだったのが、2544kcalまで
摂取カロリーを減らすことが出来た。
さすがあのトラは伊達じゃない。が、一方でトラを追加した状態でも、
ハンバーガー × 2
マックフライポテト(M) × 2
とバリューセット勢が食い込んでいるのも、
マクドナルド側の優秀さも物語っている。すなわち、朝食にコーンフロスティ+ミルク、(
×7で結構沢山)
昼・夜それぞれバリューセット(ポテト)、という食生活でも、
そこそこの栄養バランスは保たれるようだ。総括と感想
完全栄養マクドナルド食について
今回の研究成果によって、
無人島にマクドナルドだけを持っていける場合に、
最適なメニューを注文できるようになった。バリューセットは、サイドをポテトにしても
意外といい感じの栄養バランスにはなるものの、
やはりサラダやスイートコーンを選ばない限り、
そこそこカロリーオーバーになってしまう。
「野菜もしっかり食べよう」また、飲み物として、
ミルク、野菜生活、オレンジジュース、
あたりが有用であると分かった。
野菜生活を追加した栄養バランスの5角形を作れば
黄色のピエロも、腕組みしたトラと戦えるのではないか?
サイドサラダも加えるとさらに戦力アップ。一方で、選択肢を超典型的なメニューだけに絞ると、
実に8000kcal以上 になってしまう。
好きなものばかり注文していると太る、
ということが分かった。(あたりまえ)サイドサラダとスイートコーンをOKにすれば、
一日に必要な栄養素を保ちつつ、
カロリーを基準値以下にすることが可能であったため、
結局、マクドナルドだけで生活する場合の指針としては、
バリューセット(ポテト)を注文しつつも、
サラダ、ミルク、野菜生活をより多く注文することで、
比較的健康的な栄養バランスの食事を維持可能となる。バランス良く食べようという、一見あたりまえの結論であるものの、
1店舗内の選択肢の組み合わせだけでコレが実現出来るのは、
結構エライことではないだろうか?
私からマクドナルドに改善を求めるとすれば、
ハッピーセットのメインの選択肢として、+100円くらいで
てりやきマックバーガーも選べるようにして欲しいこと、くらいである。
また、ぜひ本コード相当のツールを公式サイトにも組み込んで欲しい。
その際にはぜひ協力させていただきたい。線型計画のコードについて
当初、栄養素に関する計算は、
PuLPや線型計画の代表的な問題であり、
マクドナルド公式サイトにも
データが一覧形式で存在したため、
結構簡単に出来るかなーと思っていた。しかし、実データに適用しようとすると、
そのまま作るとヤバいコードになってしまう。
日本語名変数、動的な変数付け、行列での式定義、などなど、
PuLPのサンプルから変えないといけない箇所が多数発生し、
予想以上に様々な追加工夫を要した。最終的には、これらの工夫のおかげて、
様々にデータを入れ替えて遊ぶ研究を深めることができた。今回のコードは、CSVさえ作ればブラウザ上だけで、
コピペ1発で実行できる形にまとめているため、
興味がある方はぜひ追試し、
いろいろ条件を変えて考察してみてほしい。
Colaboratoryでできるため窓からでもリンゴからでも実行可能だ。マクドナルド公式サイトのメニューデータは、
日々更新されているようなので、結果は変わるかもしれない。
以上。本研究の結果が、
マクドナルドの門をくぐるたびに罪悪感を覚えるような、
信心の足りないマック信者たちへの救済の一助となれば幸いである。
エンジニア諸氏にはマック信者が多いと誰かが言っていた気がする
- 投稿日:2020-10-18T01:11:12+09:00
futterのインストールからサンプルプログラムを動かすまで
目的
- モバイルアプリの開発を1つのコードで実装することを目的とし、そのためのツールとしてFlutterを使用することとした
- Flutterのインストールを行い、インストール後の確認としてサンプルプログラムを作成してiOSとAndroidの各シミューレタで動かす
環境
- OS:macOS Mojave(10.14.6)
- iOS向けのコマンドラインツール等はインストール済み(iOSの開発をした端末を使用)
- 動作確認はVSCodeを使用(インストール済み)
flutterのインストール
gitからclone
# 開発用フォルダへ移動 cd /Users/xxxx/develop # gitから取得 git clone https://github.com/flutter/flutter.gitflutterへパスを通す
# bash_profileへ設定追加 export PATH="\$PATH:`pwd`/flutter/bin" >> ~/.bash_profile # 設定を即時反映させる source ~/.bash_profile開発者ツールをダウンロード(任意)
flutter precache環境構築状況の確認
flutter doctorflutter doctorの結果に応じて必要なツールをインストール
- 表示されたメッセージの内容に合わせて設定していけばOK
- 解決しない場合は個別に調査
私の環境で足りなかった設定の追加
- android studio のセットアップ
- android studio のページからインストーラをダウンロードして実行
cocoapods のインストール
- インストールコマンドを実行
sudo gem install cocoapodsERROR: While executing gem ... (NoMethodError) undefined method `invoke_with_build_args' for nil:NilClass
- エラーになったので、エラーメッセージを調べてた結果rubyを入れ直し
rbenv uninstall 2.6.1 rbenv install 2.6.1
- インストールコマンドを再実行して問題なく終了することを確認
flutter doctorを実行 → android studio のtool chainのエラーが消えない[!] Android toolchain - develop for Android devices: is partially installed; more components are available. (Android SDK version 30.0.2)
- android studio からコマンドラインツールを追加インストール
- 次の
flutter doctorの実行でandroidのライセンス確認?のエラーが出ていたので、メッセージに合わせてコマンドを実行flutter doctor --android-licensesデバイスが見つからない
[!] Connected device ! No devices available
- android studio から仮想端末を起動
- android studio を起動
- 「Configure → AVD manager」
- 設定済みの端末があったので、そのまま再生ボタンのアイコンをクリックして実行
flutter doctorですべての問題が解決していることを確認Doctor summary (to see all details, run flutter doctor -v): [✓] Flutter (Channel master, 1.23.0-19.0.pre.83, on Mac OS X 10.14.6 18G6020 darwin-x64, locale ja-JP) [✓] Android toolchain - develop for Android devices (Android SDK version 30.0.2) [✓] Xcode - develop for iOS and macOS (Xcode 11.2.1) [✓] Android Studio (version 4.1) [✓] VS Code (version 1.48.0) [✓] Connected device (1 available)サンプルプロジェクトの作成、シミュレータでの動作確認
- 必要に応じてVSCodeの拡張機能を入れる、これらは入れておきましょう
- Flutter
- Dart
プロジェクトを作成
flutter create {project name}VSCodeで
lib/main.dartを開くiOSでの動作確認
- F5もしくはrun→start debuggingで実行
- シミュレータの選択肢が表示されるのでOSを選択
- iOSシミュレータ起動後、しばらく(数分程度)待つと起動します
- iOSとして動作することを確認
androidでの動作確認
- コマンドパレットから「Flutter: Select Device」を選択、androidのエミュレータを選択
- 選択したエミュレータ起動後、androidとして動作することを確認
参考
- 公式サイトのflutterのインストール手順(macOS)(https://flutter.dev/docs/get-started/install/macos)
- github(https://github.com/flutter/flutter)
- FlutterでHello worldを動かすまでの環境構築手順(iOS, Android)(https://qiita.com/unsoluble_sugar/items/deaa129fb289922c8634)
- 投稿日:2020-10-18T00:24:21+09:00
MacBookAirにpyenvをインストールし、pythonを切り替えて使うようにする
前書き
前記事に引き続き、まだmarkdown及びmacOS、CUI操作に慣れていないこともあり、
マナー違反もあるかもしれませんが、生暖かい優しさでコメントいただけると幸いです。
本当に初歩の初歩的な内容(メモ書き)となります。環境
macOS Catalina バージョン 10.15.7
ゴール
macにコマンドライン(ターミナル)でpyenvを入れ、
pyenv経由で複数pythonをインストールし、用途に応じて切り替えができるようにする。結論
少し引っかかったものの、
ターミナルの再起動によって問題なく完了できた。いざ、着手
と言いつつ、作業自体はすでに完了したので、初心者あるあるな部分で戸惑ってしまったので、
備忘録としてメモだけ残しておきます。基本的にはこちらのQiita記事を参考にさせていただきました。
わかりやすくて大変助かりました、ありがとうございました。。。本来は、ver3.xxのpythonが入ってしまえば個人的には問題なかったのですが、
pyenvは切り替えが自由にできるということが主な機能ということで、
試験的にデフォルトでmacに入っていたpython 2.7.16と、新規で使いたい3.9.0をpyenvでインストールしました。コマンドは以下です。
pyenv install 2.7.16 pyenv install 3.9.0以下のコマンドで、問題なく二つのバージョンのpythonがインストールされていることは確認でき、
pyenv versions次のコマンドで、デフォルトで使用するpythonのバージョンを指定したはずなのですが、
pyenv global 3.9.0python --version上記でバージョン確認しても、現行の2.7.16のままでした。。。
googleで解決策を探すと、このような記事が見つかりました。
こちらで解決できる!ワクワクしながら
/etc/pathsを確認しても、問題なさそう・・・何故なんだ、と悩むこと数分。
もしや、と思いターミナルを再起動。
問題なく切り替わっていました。
ぐぬぬ、、意外と見落としてしまいますね。
今後も気をつけます。