- 投稿日:2020-10-18T23:32:08+09:00
JavaScript 経験者が Java を学習する際の入門前メモ
知り合いの JavaScript 経験者が、Java を学びたいと言ってましたので、簡単な入門前メモをまとめてみました。
想定している読者
Web ブラウザで動作する、もしくは NodeJS 環境で動作する JavaScript コードを学んだことがある、もしくは書いたことがある方を想定しています。
きちんと学ぶにはJava入門書を読んだり、良質なコードを多く参照して真似したりすることが有効だと思います。ただ現時点で JavaScript の知識があるのであれば、Java との差分を確認してから学んだほうが理解が早まるのではないか?と思い、このメモをまとめてみました。
このメモが簡単すぎる、冗長すぎると感じる方は、素晴らしいまとめサイトである Java コード入門 をお勧めします。
開発環境
いまの時代、何らかの統合開発環境を利用することを想定しています。とりあえず想定しているのは、昔ながらの Eclipse (統合開発環境) です。入門本や記事は多くありますが、例えば以下のような記事はどうでしょう。
ただし事前に自分で学習する場合はともかく、仕事用のコードを書く方は、仕事先の環境を聞いて開発環境や、Java のバージョンなど合わせたほうが良いでしょう。
より手軽に試してみる
ちょっと Java コードを試したいだけであれば、オンライン上のサービスを利用するのもお手軽で良いです。
また Docker 環境があれば、Java 環境を含んだ Docker Image を実行することで、Java 開発環境をインストールせずに試すこともできますね。私も今年 docker-lambda を使うネタ とか VSCode + Codewindネタ (NodeJSですがJavaも可) とか投稿しているので、興味があれば参照してみてください。
ポイントとなる差分
コンパイラ言語
Java はコンパイラ言語、JavaScript はスクリプト言語とされています。これは確かにそうなのですが、以下の理由であまり気にしなくても良いとおもいます。
- JavaScript は js ファイルを直接実行する実装が多い
- それに対して Java は class ファイルにいったん変換(コンパイル)してから実行する実装が多く、それにひと間かかる
- ただし今どきの統合開発環境はこの「ひと手間」を勝手に実行してくれるので、開発者はあまり意識する必要はない
Java の場合は *.class という中間ファイルが実行時に自動で作成される、ぐらいの知識で十分だと思います。
更に最近の Java では *.java ファイルをそのまま実行できる (ように裏でこっそりコンパイルしてくれる) ので、もはやコンパイル言語かどうかも怪しいかも?です。コンパイル言語という出自から派生した、次の静的型付けだけ理解できれば大丈夫。
静的型付けと動的型付け
Java は静的な型付け言語で、動的な JavaScript とは異なります。型についてチェックが厳しいので、それを意識して書かないとエラーや警告が頻発して驚かされるでしょう。
TypeScript のような静的型付けのできる JavaScript 系言語の経験者は、このセクションはスキップしてOK。
動的型付けのほうが気楽に書けるので、個人的には好きです。が、仕事でコードを管理する場合など、大規模だったり、実装とテストを気楽に繰り返せない状況では、静的型付け言語のほうが結果として楽な気がしますね。
以下の記事がお勧めです。
- Java、C、C#、VB.netなどは「静的な型付け」
- JavaScript、Python、Rubyなどは「動的な型付け」
「静的~」は構造をコンパイル時にチェックする。「動的~」は構造を実行時にチェックする。
静的型付けのメリットはなんと言ってもコンパイルエラーが出ること。これに付きます。
これによって実行して初めてわかる問題をかなり減らすことができます。C言語のようにしょぼい型システムだと嬉しさなんてありませんが、JavaやScala, OCaml, Haskellなどだとかなり有用です。なお、紹介した記事を全部理解する必要はなく、ざっくり読んで「ふーん」とおおまかに感じるだけで良いとおもいます。学習が進んだ後で、もう一度読み返すことを前提として紹介しています。
オブジェクト指向
JavaScript にも オブジェクト指向 の概念は あります が、必須の知識ではなく、実はあまり意識しなくてもコードを書けたりします。
それに対して Java ではオブジェクト指向は根っことなる部分ですし、より複雑な仕組みがあります。
とりあえず入り口としては、継承、インターフェイス ぐらいを理解しておけば良さそうにおもわれます。特にインターフェイスは JavaScript にないもので、かつ、地味なところで、わりとお世話になっていたりします。
インターフェイスとは、ある特定の機能を実現するために必要なメソッドのシグニチャ(名前や引数、戻り値の型)だけを定義したものです。処理そのものは持ちません。
簡単に言えば、クラス定義から実行されるコード部分を省いたものです。つまりはそのクラスの外部仕様を定義するものの、実際の処理内容は記載されていません。C言語であればヘッダファイル(*.h)に相当するものです。
更に Java にはクラスとインターフェイスの中間のような抽象クラスもあり、「部分的にコードを省いた」クラスという感じです。
インターフェスや抽象クラスはそのままでは利用できず、継承(インターフェイスは実装)して、足りない処理コードを補ったクラスを定義する必要があります。と言うと難しそうですが、実は最初は、それほど気にしなくても大丈夫です。
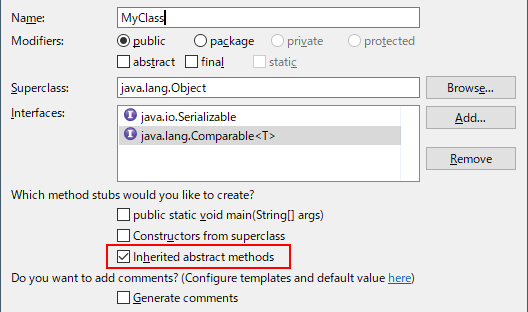
例えば Eclipse では、クラス新規作成時に、以下のようにメソッドの自動生成がデフォルトでチェック済みなので、コード実装がされていない関数(メソッド)があれば、自動的に定義部分も作成しておいてくれます。間違って消したり、実装し忘れがあっても、警告やエラーがしっかり出ますので、すぐわかります。
メソッドのオーバーロード
Java コードを読んでいると、同じ名前の関数(メソッド)が幾つも定義されていて、どれを呼んでいるのか迷子になることがあります。これは メソッドのオーバーロード によるものです。
Javaでは、「同じ名前で、引数の型、並びだけが異なる」メソッドを複数定義することもできます。これをメソッドのオーバーロードと言います。
JavaScript だと、単に関数名だけみて探せば良いのですが。Java の場合は同じ名前の関数(メソッド)が複数定義されている場合、それらのなかから引数の数や型(継承関係も含む)が一致するものを探さないといけません。
まあ統合開発環境だと、このあたりもチェックしたうえで参照元に移動できますので、それほどは困らないのですが。例えば Eclipse だと、関数を呼び出しているところで F3 キーを押すと、それを定義したコードに移動できます。
文字列の比較
Java 初心者が最初にひっかかる点が「文字コードの比較」ミスです。以下のような例が有名ですね。
String str1 = "123"; String str2 = "123"; String str3 = "12" + "3"; String str4 = "12"; str4 += "3"; System.out.println(str1 == str2); // true (1 System.out.println(str1 == str3); // true (2 System.out.println(str1 == str4); // false (3 System.out.println(str1.equals(str4)); // true (4JavaScript だと文字列の
==演算は値の比較になるので、上記は全部 true になります。Java だと基本的に
==は「同じオブジェクトかどうか」の判定になり、値の比較にはequalsメソッドを使用します。ここでやっかいなのが、(1 と (2 は多くの環境で
trueの結果になることで、バグ発生の原因となり得ます。これは Java コンパイル時の最適化による影響です。Java で文字列は immutable (イミュータブル/不変)なもので、プログラム実行中にその値は変わりません。であれば
"123"という同じ値の文字列であれば、内部的に「あれ、これ真面目に2個用意しなくても、1個用意して使いまわせばいいよね?」という最適化(手抜き)をします。その結果 (1 がtrueになります。更に最近の Java コンパイラは賢いので、
"12" + "3"という式がコード中に含まれると「あれ、これ結局 "123" という文字列を使いたいんだよね?」と察してしまい、勝手に式を"123"という結果に置き換えてしまいます。なのでその結果、(1 と同じ理由で (2 もtrueになります。なおこの結果は Java8 でのコンパイル結果です。その後のバージョンのもっと賢い Java コンパイラは (3 も
trueになる最適化をしてくれるかもしれませんねwというわけで、Java においては値の比較は
equalsという関数を使うこと、お忘れなく!また JavaScript にもある概念ですが、Java の ラッパークラス についても、一応は確認しておくと良いでしょう。
言語の拡張について
Java 言語は古い、化石のような存在である、といった印象をもつ方も居ると思います。Java は最新の言語仕様をわりと積極的に取り入れており、特に、JavaScript にどんどん影響されてきています。以下、個人的な感想も含みます。
JavaScript は Java の影響も強く受けているので、Java の子供みたいなものです。そして Java は JavaScript の良いところを順に実装してきています。順に機能が追加されているため Java のバージョンには注意が必要で、詳細は Javaバージョン履歴 を参照してください。
ただし Java は過去との互換性も重視しており、抜本的な構造改革は難しいので、かなり強引な実装になっている部分もあります。新機能を単に使う分には良いのですが、その実装部分に踏み込むとかなり難解な部分もあるので、細かな部分が気になっても、探求は学習が進んだあとに取っておくのをお勧めします。
実装の工夫例
Java にも 無名クラス があり、例えば以下のように利用できますが、
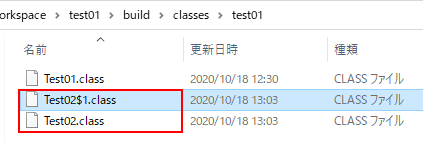
Test02import java.util.*; public class Test02 { public static void main(String[] args) { new Thread(new Runnable() { // ココ public void run(){ System.out.print("Runnable.run"); } }).start(); } }過去との互換性を維持するため、つまりは無名クラスなど知らない実行環境のため、コンパイル時には以下のような class ファイルが自動生成されています。コード上は無名クラスとして記述されていますが、実際には内部で名前(今回は Test02$1)が付与されているわけです。
※ 私も最初、この謎の class ファイル群はなんだろう?と不思議に思っていましたなお余談ですが JavaSE 8 からは新しい記述の ラムダ式 が使え、より JavaScript っぽい表記ができます。
Test02List<String> list = new ArrayList<>(Arrays.asList("aa", "bb")); list.replaceAll(str -> str.toUpperCase()); System.out.println(list); // [AA, BB]まだ馴染みの薄い拡張
上記のとおり Java 言語は拡張されてきていますが、まだ馴染みが薄いといいますか、わりと先進的な Java 開発の現場でないと見かけない要素もあります。
さきほどのラムダ式もそうですが、JavaScript では普通の書き方でも、Java 言語のなかで使用すると違和感が出てくることもあるでしょう。バージョンの関係で使えたとしても、です。既存のコードを読み、また先輩の開発者に聞いて、雰囲気をみて使いましょう。郷に入っては郷に従え、です。
個人的には ジェネリックス はもう普通に使われているケースが多く、使っていないのは、ものすごく古いコードだけだと思います。
アノテーション はかなり一般的になったと感じますが、独自アノテーションを定義するまで活用する例はまだ少ないと感じます。
Stream API は JavaScript だと多用する書き方ですが、Java のコードではまだあまり積極的に利用されていないように感じます。まあこれは、言語というよりライブラリ設計の話題な気もしますが…
※ これらは案件、現場によって大きく異なるので、繰り返しますがあくまで個人の感想です
ライブラリは大事
どの開発言語でもそうですが、言語ごとの差異はそれほど大きくなく、どちらかというと習得に時間がかかるのはライブラリの把握と上手な利用方法です。
Java は標準ライブラリがなかなか豊富です。まずか以下のような公式の API 仕様を参照してみましょう。とはいえ全部を読むのは難しいため、クラス利用時に詳細を確認しつつ、少しずつ理解の幅を広げていくのが良いでしょう。
- Java(tm) Platform, Standard Edition 8 API仕様
- Java® Platform, Standard Edition & Java Development Kit バージョン11 API仕様
java.lang が標準のライブラリで、設定しなくても最初から、自動的に読み込まれます。もし、ちゃんと読んでいくのであれば、最初はここからかな?
JavaScript の場合、NodeJS なら npm サイト で探せば、必要な機能はたいてい見つかるものです。Java の場合はまず Maven Repository を探すのが良いでしょう。各バージョンのコンパイル済みライブラリ(jar)ファイルの入手もできます。
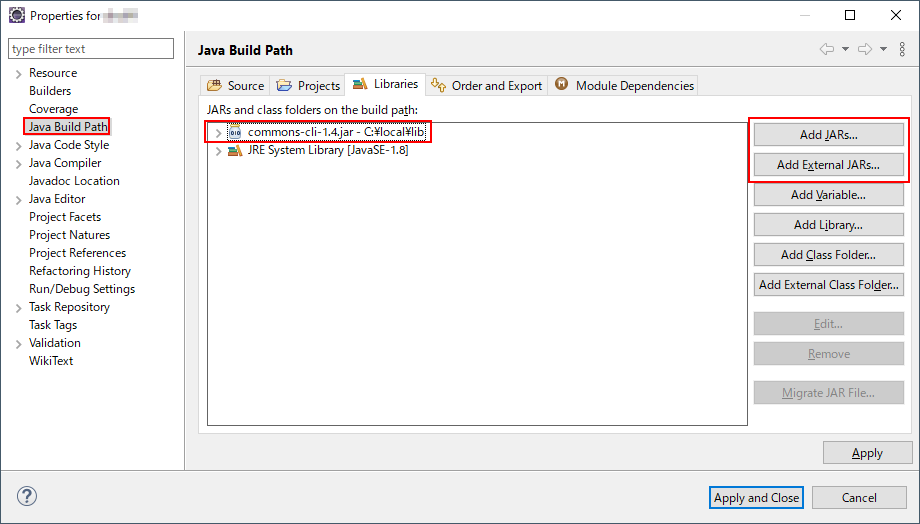
なお NodeJS の npm はダウンロードと設定を同時に実行してくれますが、Java の場合は Java 実行環境から見つかるようちゃんと配慮してあげる必要があります。コマンドラインで実行している場合はクラスパスを設定してあげるか、-cp もしくは -classpath オプションで配置した場所を明示する必要があります。Eclipse の場合はプロジェクトの Java Build Path 設定を確認して、見当たらなければ追加してあげましょう。
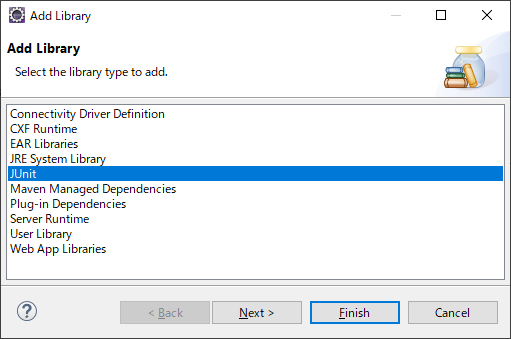
JUnit など有名どころは Eclipse 環境で既に用意されている場合もあるので、まず先に下の Add Library ボタンを押してみるのも良いかもしれません。
さあ学習を始めましょう
と、最初に気になりそうな点をざっと書いてみました。あとは実際に Java の学習を始めてください。個人的なお勧めは、やはり Java コード入門 サイトです。
プロググラミング自体がまだ不慣れで、より優しい入門書を読みたい場合には スッキリわかるJava入門 第3版 スッキリわかるシリーズ など良いかもしれません。
逆に自信のある方は上記の Web サイトなどで理解した後、資格取得も視野にいれ、バージョンにあわせて以下のような書籍で学習するのも良いかもしれません。
Enjoy!
以上、JavaScript 経験者へ、Java を学ぶ際に知っておいたほうが良さそうなことをまとめてみました。これから Java 言語に親しんでいく際の、敷居が少しでも下がったのであれば嬉しいです。
逆に、よけい混乱させてしまったのであれば、すみません。文章は読み飛ばし、ご紹介した各種リンク先だけでも、参照いただければと思います!
私自身は Java -> JavaScript と学んだ人なので、見落としなど多いとおもいます。記述もいいかげんだったり、まだ十分ではないと思いますが、気がついた点があったら修正・追記していきたいとおもいます。
それではまた!
- 投稿日:2020-10-18T23:22:44+09:00
素因数分解でC言語、Java、Pythonのベンチマーク
Pythonの練習がてら、素因数分解を簡単なロジックで計算させるプログラムを作成してみました。ついでにC言語、Javaでも作成して処理速度を競わせてみたのでアップします。
プログラムは長くなるので結果から。
# C言語 $ ./a.exe 123456789 123456789 = 3 * 3 * 3607 * 3803 所要時間は2.884932秒です。 # Java >java -jar Factorization.jar 123456789 123456789 = 3803 * 3607 * 3 * 3 所要時間は1245ミリ秒です。 # Python3 >python factorization.py 123456789 123456789 = 3 * 3 * 3607 * 3803 所要時間は60.498295秒ですなんとJavaがトップ。
Pythonが遅いのは、Pythonをほとんど使ったことがない私が作ったプログラムがゴミなのでしょう^^;しかし、CよりJavaが早いかなぁ。というのが疑問だったので、環境を変えてみることに。Cの実行環境はCygwinを使用していたのですが、公平を期すために!? Linuxですべて動かしてみます。
使用したのはAWSのEC2です。Amazon Linux2 イメージで、ベンチマーク目的なのでちょっとリッチにt2.xlargeを使ってみました。(お金がかかるので終わったらすぐ削除;;)結果は以下の通り。
[ec2-user ~]$ #C言語 [ec2-user ~]$ ./a.out 123456789 123456789 = 3 * 3 * 3607 * 3803 所要時間は2.730501秒です。 [ec2-user ~]$ #Java [ec2-user ~]$ java -jar Factorization.jar 123456789 123456789 = 3803 * 3607 * 3 * 3 所要時間は828ミリ秒です。 [ec2-user ~]$ #Python [ec2-user ~]$ python3 factorization.py 123456789 123456789 = 3 * 3 * 3607 * 3803 所要時間は33.936324秒ですやはりJavaがトップです。Windowsに比べて一番早くなったのはPythonかな。
個人的にはC言語が一番速いかと思っていたのでちょっと意外な結果ですが、自分でキューを作成するより、JavaのArrayQueueクラスのほうが優秀ということなんでしょうね。。。以下に、使用したソースを掲載しておきます。
- C言語
#include <stdio.h> #include <stdlib.h> #include <sys/time.h> typedef unsigned long ulong_t; // 素因数を収集するキュー typedef struct _que { ulong_t prime; struct _que* next; } que_t; que_t* factrization(ulong_t); long getusec(); void main(int argc, char** argv){ ulong_t num; char* e; num = strtoul(argv[1], &e, 10); long before = getusec(); // 素因数分解を実行 que_t* q = factrization(num); long after = getusec(); // 結果を表示する printf("%d = %d", num, q->prime); while(q->next != NULL){ q = q->next; printf(" * %d", q->prime); } // 経過時間を表示する long spend = (after - before); long sec = spend / 1000000; long usec = spend % 1000000; printf("\n所要時間は%d.%d秒です。\n", sec, usec); } // 渡された自然数nを素数と自然数の積に分解する que_t* factrization(ulong_t n){ // 素数を計算するための行列 // (メモリ確保時に0埋めするため、0が入っている要素が素数候補) ulong_t* p = calloc((n+1), sizeof(ulong_t)); // 2から初めて、素数を割り出す for(int a = 2; a < (n/2); a++){ // すでに非素数と確定している数は飛ばす if(p[a] != 0){ continue; } // 素数の倍数を候補から外していく int b = 2; int m = a * b; while(m < n){ p[m] = -1; // 非0⇒素数ではない b++; m = a * b; } // nが倍数であるとき(非素数であるとき) if(n == m){ // n = a * b(aは素数) // printf("%d = %d * %d\n", n, a, b); // bについて再帰的に繰り返す que_t* f = factrization(b); // キューにaを入れる que_t* qa = malloc(sizeof(que_t)); qa->prime = a; // キューの先頭にaを追加する qa->next = f; // キューを返す return qa; } } // 最後まで言った場合nは素数 // キューを生成して返す que_t* qp = malloc(sizeof(que_t)); qp->prime = n; qp->next = NULL; free(p); return qp; } // 現在時刻(μ秒の取得) long getusec(){ struct timeval _time; gettimeofday(&_time, NULL); long sec = _time.tv_sec; sec *= 1000000; long usec = _time.tv_usec; return sec + usec; }
- Java
package example; import java.util.ArrayDeque; import java.util.Calendar; import java.util.Iterator; import java.util.Queue; import java.util.Scanner; /** * 素因数分解に挑戦する */ public class Factrization { public static void main(String[] args) { int num; num = Integer.parseInt(args[0]); // 分解した素因数を登録するキュー Queue<Integer> queue = new ArrayDeque<>(); Calendar before = Calendar.getInstance(); // 素因数分解を実行する queue = fact(num, queue); Calendar after = Calendar.getInstance(); // 結果を表示する Iterator<Integer> i = queue.iterator(); System.out.printf("%d = %d", num, i.next()); while (i.hasNext()) { System.out.printf(" * %d", i.next()); } System.out.println(); System.out.printf("所要時間は%dミリ秒です。\n", (after.getTimeInMillis() - before.getTimeInMillis())); } /** * 渡された自然数を素数と自然数の積に分解する */ static Queue<Integer> fact(int n, Queue<Integer> q) { // 素数の候補となる配列を定義。 // Javaでは生成時に0埋めされるので、0が入っている要素を素数の候補とする int[] p = new int[n + 1]; for (int a = 2; a < (n / 2); a++) { // 非素数と確定している場合は飛ばす if (p[a] != 0) { continue; } int b = 2; int m = a * b; while (m < n) { p[m] = -1; // 非0⇒素数でない要素 b++; m = a * b; } if (n == m) { // System.out.printf("%d = %d * %d\n", n, a, b); Queue<Integer> f = fact(b, q); f.add(a); return f; } } q.add(n); return q; } }
- Python
import sys import time # 素因数分解 def factrization(n): # 与えられた数値までの整数を定義する p = list(range(n+1)) # 2から初めて、倍数を削除する # 最大値の半分までやればOK for a in range(2,int(n/2)): # aが素数ではないことが決まっていたら次へ if p[a] == 0 : continue # 素数にかける数 b = 2 m = a * b # aの倍数(つまり素数ではない数)を0とする while m < n: p[m] = 0 b += 1 m = a * b # nがaの倍数であれば if m == n: # n=a*bが確定 # print('%d = %d * %d' % (n, a, b)) # bをさらに素因数分解する fact = factrization(b) # 確定したaは素数なので出力する return [a] + fact #nが0にならなかったらnが素数 return [n] # コマンドライン引数で自然数を渡す num = eval(sys.argv[1]) before = time.time() # 素因数分解を実行する f = factrization(num) after = time.time() # 実行結果を表示する print('%d = %d' % (num, f[0]), end='') for p in f[1:]: print(' * %d' % p, end='') print('\n所要時間は%f秒です' % (after - before))
- 投稿日:2020-10-18T22:57:37+09:00
【Java】 文字列の一部を切り出すsubstringの使い方
開始位置を指定する場合
String.substring(int beginIndex)public class Main { public static void main(String[] args) { String sports = "soccer,baseball,basketball"; System.out.println(sports.substring(7)); } }実行結果
baseball,basketball開始、終了位置を指定する場合
String.substring(int beginIndex, int endIndex)public class Main { public static void main(String[] args) { String sports = "soccer,baseball,basketball"; System.out.println(sports.substring(7, 15)); } }実行結果
baseball参照
- 投稿日:2020-10-18T20:11:15+09:00
Java SE Bronze(1Z0-818)合格体験記
はじめに
Qiita初投稿になります。
今年の7月に開発実務未経験による転職を経て大阪の開発会社で働いてます。
本試験は、Javaの知識がどこまで身についているのか目に見える形として証明したかったというのと、Javaの基礎力向上を目的に資格試験にチャレンジしてみたという経緯です。私のスペック
- 元インフラ運用屋
- Java未経験(もちろん開発実務も経験ありません)
- 少しPHP触ったことがある
申込み注意点
- 申込みの手順がかなり複雑
- 試験名に注意
はじめに、"申込みの手順がかなり複雑"については、私が解説するよりも既にわかりやすい記事がありますので、こちらの記事を参照ください。
こちらの記事も試験を受ける上で大変参考になりましたので、共有致します。
続いて、"試験名に注意"に関してですが、既にご存知の方は大丈夫なのですが、「Java SE 7/8 Bronze(1Z0-814)」という試験は今年(2020年)の7/31に配信を終了しています。こちらのリンクから辿って頂けると確認できると思います。
後継版の試験名は「Java SE Bronze(1Z0-818)」なので、ご注意を。ピアソンVUEの検索窓にて1Z0-818だけでも検索でヒットします期間(学習時間)
- 2週間程度
- 平日6~9時間(その他業務もあり、多少のばらつきがあります)
- 休日5時間程度
- 合計:80時間~110時間程度
私の良くないところで、時間がある分怠けてしまいがちです。期限が迫ってきてようやく焦るようなダメ人間です。何事もはじめに期間を決めると良いかもしれませんね(自戒)
私からアドバイスとしては、平日も休日も一定の学習時間を確保できるのであれば、本試験は2週間(デキル方なら1週間みっちり)で十分です。
貴方が設定した期間から逆算して毎日コツコツ学習していきましょう!学習方法
- 参考書(紫本)
- 苦手分野をググって理解できるまで学習(Qiitaの記事など)
- 実際にコードを書いてデバッガ置いて処理を追う
上記3点のみです。
紫本を合計3周ほどしましたが、2周くらいに留めておいてネットでも違う書籍でも良いので、まだ解いたことのない問題を解くべきでした。
また、私の場合"オーバーロード・オーバーライド"や"for文のネスト"問題に苦戦していたので、問題に躓く度にググって、実際にコードを書いてデバッグしてプログラムの流れを理解するようにしていました。直前チェック
- JVM
クラスファイルを読み込む
クラスファイル内に書かれたバイトコードを解釈して実行(クラスファイルを実行すること)
メモリ管理
- 識別子
識別子(変数、メソッド、クラスなど、、)の1文字目は、英字(a~z, A~Z), ($), (_)のみ
2文字以降は数字も可能
文字数の制限はない
- char型
char型はUnicode(16ビット)で表現できる1文字であり、文字列と区別される
char型は符号なし整数(1とか5とか)を扱うことができる
char型にUnicode値を格納する場合は、シングルクォート(')で囲む
ダブルクォート(")で囲んだ場合は文字列となる
- 基本データ型のデフォルト値
整数値:0
浮動小数点型:0.0
boolean型:false
char型:¥u0000
参照型:null
- if文
if文では、処理する文が1行しかない場合、{}を省略してもよい
しかし、2行以上の処理を記述した場合は、条件式の結果に関係なく実行される
- switch文
switch文の式の結果は、データ型として, short, int, enum, char, Stringのいずれかの値である必要がある(問題のはじめに確認する方が良さそう)
- while文
while(false) と記述するとコンパイルエラーになる
- 拡張for文
変数宣言と参照変数名の変数のデータ型は合わせないとコンパイルエラーになる
変数宣言はfor文の中で宣言する必要がある。外で宣言するとコンパイルエラーになる
- コンストラクタ
コンストラクタ名はクラス名と同じ
すべてのアクセス修飾子を指定できる
戻り値, void, abstract, static, finalは指定不可
戻り値を指定するとコンストラクタではなくメソッドになるので注意
サブクラスに引き継がれない
- メンバ
インスタンスメンバはクラスがインスタンス化されると、格オブジェクトの中に個々の領域が確保される
staticメンバは複数インスタンス化されても一箇所で領域が確保される
- メンバ間アクセス
インスタンスメンバ -> staticメンバに直接アクセスはOK
staticメンバ -> インスタンスメンバに直接アクセスはNG
staticでアクセス場合は、インスタンス化する必要がある
- アクセス修飾子・修飾子
publicおよびデフォルト:クラス・コンストラクタ・変数・メソッド
protectedおよびprivate:コンストラクタ・変数・メソッド(抽象メソッドには使用不可。サブクラスでオーバーライドするため。)
ローカル変数や制御文(if, for):アクセス修飾子は指定できない
abstract修飾子:コンストラクタ・変数には使用不可
static修飾子:変数・メソッドのみ
- final修飾子
変数 -> 定数
メソッド -> サブクラス側でオーバーライドできなくなる
クラス -> 継承不可になる
コンストラクタ -> 使用できない
- publicなクラス
publicクラスは1ファイルにつき1つ
publicクラスを定義した場合、ファイル名も同じにする
- オーバーロード
メソッド名(コンストラクタ名)が同じ
引数の並び, 引数の型, 引数の数が異なることが条件
- オーバーライド
シグネチャ(メソッド名と引数リスト)が同じ
戻り値は同じか、その戻り値の型のサブクラスであればオーバーライドとみなされる
アクセス修飾子は、スーパークラスと同じか、それよりも公開範囲が広いものでなければならない
インスタンスメソッド(非staticメソッド)をstaticメソッドでオーバーライドすることはできない
- 継承
サブクラスで引き継ぐことができるのは変数, メソッド
コンストラクタは引き継がれない
Java言語は単一継承のみをサポートしているため、extendsキーワードの後に指定できるクラスは一つのみ
継承関係のあるクラス(サブクラス)をインスタンス化すると必ずスーパークラスのコンストラクタから実行してサブクラスのコンストラクタが実行される
サブクラス側で明示的に呼び出したいコンストラクタを指定しないと、暗黙的にスーパークラスの引数を持たないコンストラクタがsuper()で呼び出されてしまう
- 抽象クラス
抽象クラスを継承した抽象クラスはスーパークラスで定義されている抽象メソッドを実装(オーバーライド)しなくてもエラーにならない。しかし、継承先が具象クラスであれば実装する必要がある
インスタンス化できない
- インタフェース
インタフェース内で変数を宣言する際は、staticな定数public static finalになるため宣言と同時に初期化する必要がある
インタフェースを実装する際の抽象メソッドのオーバーライドには必ずpublicをつける必要がある
extendsとimplementsを併用する際は、extendsを先に記述する
抽象メソッドにstatic修飾子は付けられない
- パッケージ
パッケージ名を階層化する場合は、階層名をドット< . >で区切る
- パッケージ・コンパイル・実行
パッケージ内にあるソースファイルをコンパイルする際はバックスラッシュ< \ >繋ぎになる
実行する際はドット繋ぎになる
- パッケージ・public
自分が所属するパッケージ以外のクラスに自クラスの利用を許可するためには、許可するクラス名とメソッド名にpublicを付ける最後に一言
何とかここまで執筆できたことに安心しております。
執筆中に試験の事や、資格学習について思い返すことが何点かあったので最後にそれをお伝えして終了させて頂きます。
まず資格学習についてですが、
参考書を何周もして問題に慣れることも大切ですが、”問題を1分以下(理想は50秒)”で解けるようになっておくことの方が大切だと感じました(試験では1問1分ペースを要求されるので)。また、他の方も仰っているように”オーバーロード・オーバーライド”問題の理解度が合否に直結すると言っても過言ではありません。
試験本番についてですが、
本番は思っている以上に緊張感がエグいので、文章の読解力が普段よりも格段に落ちます(私は初めの5分くらいは緊張のあまり頭が回りませんでした(笑))そのため、緊張するなと言う方が難しいですが、なるべくリラックスして試験に望んでください。以上になります。
次はJava Silverですね。
- 投稿日:2020-10-18T19:05:45+09:00
[Java]HashMap,TreeMap,LinkedHashMapのセットした値の保持順
[Java]HashMap,TreeMap,LinkedHashMapのセットした値の保持順
Mapにはいくつか種類があるけど、格納した値がどの順番で保持されるか(どの順番で出力されるか)違いがある。よく見る(個人的に)Mapたちのそれをまとめた。
どのMapを使うかはこの特徴の違いで選ぶことが多い気がする。
HashMap TreeMap LinkedHashMap 順序不定 keyの昇順 登録順 以下、確認してみた。
test.javapublic static void main(String[] args) { final int key = 0; final int value = 1; HashMap<String,String> hashMap = new HashMap<String,String>(); TreeMap<String,String> treeMap = new TreeMap<String,String>(); LinkedHashMap<String,String> linkedHashMap = new LinkedHashMap<String,String>(); String[][] keyValue = {{"Japan","America","China","Korea","India"}, {"Tokyo","Washington D.C.","Beijing","Seoul","New Delhi"}}; for(int i = 0; i < keyValue[key].length; i++) { hashMap.put(keyValue[key][i], keyValue[value][i]); treeMap.put(keyValue[key][i], keyValue[value][i]); linkedHashMap.put(keyValue[key][i], keyValue[value][i]); } System.out.println("HashMap の結果を出力!"); for(String hashMapKey : hashMap.keySet()) { System.out.println( hashMapKey +" の首都は "+ hashMap.get(hashMapKey) + " です。"); } System.out.println(); System.out.println("TreeMap の結果を出力!"); for(String treeMapKey :treeMap.keySet()) { System.out.println( treeMapKey +" の首都は "+ treeMap.get(treeMapKey) + " です。"); } System.out.println(); System.out.println("LinkedHashMap の結果を出力!"); for(String linkedHashMapKey : linkedHashMap.keySet()) { System.out.println( linkedHashMapKey +" の首都は "+ linkedHashMap.get(linkedHashMapKey) + " です。"); } }実行結果HashMap の結果を出力! Japan の首都は Tokyo です。 China の首都は Beijing です。 America の首都は Washington D.C. です。 Korea の首都は Seoul です。 India の首都は New Delhi です。 TreeMap の結果を出力! America の首都は Washington D.C. です。 China の首都は Beijing です。 India の首都は New Delhi です。 Japan の首都は Tokyo です。 Korea の首都は Seoul です。 LinkedHashMap の結果を出力! Japan の首都は Tokyo です。 America の首都は Washington D.C. です。 China の首都は Beijing です。 Korea の首都は Seoul です。 India の首都は New Delhi です。よって、HashMapは順序不定、TreeMapはkeyの昇順(今回はアルファベットの昇順)、LinkedHashMapは登録順になっていることを確認した。
まぁでも毎回忘れちゃうんですよね。
- 投稿日:2020-10-18T18:14:20+09:00
[Java11]Google Cloud BuildからGoogle Cloud Functionsにデプロイする
前置き
GCP で Java を動かすには Google App Engine だと思っていたら、今年の春に Cloud Functions でも使えるようになっていました。
Google Cloud Functions が Java 11 に対応
※比較表にはまだ載っていない(2020/10/18時点)これは、Javaで作ったとある処理を Cloud Functions で動かした記録です。
環境
- 構成
- GitHub: ソース置き場
- Google Cloud Build: GitHubへのpushをトリガーにビルド&デプロイする
- Google Cloud Functions: アプリケーションを動かす
- trigger: HTTP リクエスト(Webhook)
- 言語
- Java11
- Gradle
- yaml
やったこと
1. CGPのプロジェクトでFunctionsを使えるようにする
Cloud Build も Cloud Functions も有効な請求先アカウントにリンクされていないと利用できません。
一応、課金を有効にしてもある程度は無料枠内で使うことができます。
(個人的に使う範囲ならおそらく大丈夫。最初はお試し枠もあるのでその期間なら安心)次に、APIとサービス > ライブラリからCloud Functions APIを有効にします。
2. GCPでCloud BuildとGitHubを連携させる
公式ドキュメントを参考に、自分のリポジトリと連携させます。
ビルドトリガーの作成と管理 | Cloud Build のドキュメント | Google Cloudイベントとソースの組み合わせで、どのブランチ/タグでいつ発動させるかを指定できます。
今回は、masterにpushしたときにだけ動かすようにしました。
(検証中は^test.*にして特定branchを対象にしました)
3. JavaをGoogle Cloud Functions で動く形にする
公式ドキュメントを参考に、関数の入り口となるクラスを作ります。
最初の関数: Java | Google Cloud Functions に関するドキュメント
response.setContentTypeは日本語を返さないなら不要だと思います。
今回はプレーンテキストで日本語を返す形にしたので設定しています。MessageFunction.javaimport com.google.cloud.functions.HttpFunction; import com.google.cloud.functions.HttpRequest; import com.google.cloud.functions.HttpResponse; public class MessageFunction implements HttpFunction { @Override public void service(HttpRequest request, HttpResponse response) throws Exception { response.setContentType("Content-Type: text/plain; charset=UTF-8"); if (request.getFirstQueryParameter("message").isEmpty()) { response.setStatusCode(400); response.getWriter().write("Query parameter 'message' is required"); return; } String message = request.getFirstQueryParameter("message").get(); if (message.length() == 0) { response.setStatusCode(400); response.getWriter().write("Query parameter 'message' is empty"); return; } response.getWriter().write(message); } }4. Cloud buildでJavaアプリケーションのビルド、デプロイをする
公式ドキュメントを参考に設定ファイルを用意します。
Java アプリケーションのビルド | Cloud Build のドキュメント | Google Cloud
Cloud Functions へのデプロイ | Cloud Build のドキュメント | Google Cloudこれだけあれば最低限Functionsにデプロイさせて動かせます。
cloudbuild.yamlsteps: - name: 'gcr.io/cloud-builders/gcloud' args: - functions - deploy - Function名を指定する - --region=リージョンを指定 - --source=. - --runtime=java11 - --entry-point=HttpFunctionを実装したクラスをFQCNで指定 - --trigger-http
- nameがステップの単位となり、順番に処理が進みます。
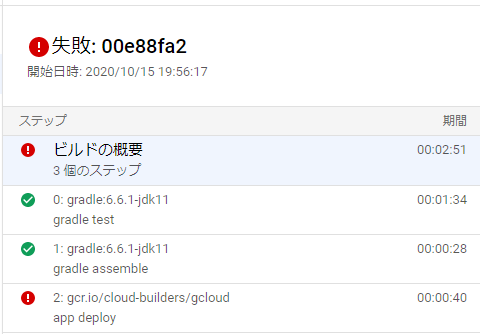
stepでエラーがあると、複数ステップあってもそこまでで処理が止まります。Javaのバージョン違いでビルドできなかったり、テスト失敗すると、ちゃんと履歴に「失敗」が表示され、履歴からログ詳細も確認できます。
画像は、デプロイ前にビルドが必要だと思っていたときの履歴です。
※App Engineへのデプロイも同様にyamlで設定できます。
App Engine へのデプロイ | Cloud Build のドキュメント | Google Cloud5. 確認
うまく動くとこんな感じです。
つまづき
Cloud Buildでgradleが動かない
gradleフォルダに含まれるファイルが必要でした。
ただ、そもそもgcloud functions deployすればOKだったので、これはデプロイとは別でgradleを実行したい場合にだけです。ERROR: (gcloud.functions.deploy) OperationError: code=3, message=Build failed: Error: Could not find or load main class org.gradle.wrapper.GradleWrapperMain Caused by: java.lang.ClassNotFoundException: org.gradle.wrapper.GradleWrapperMain; Error ID: 42fc8383 ERROR ERROR: build step 0 "gcr.io/cloud-builders/gcloud" failed: step exited with non-zero status: 1デプロイする権限が足りない
自動生成されるユーザーのままではだめでした。
(Cloud Buildで必ずしもFunctionsをデプロイするわけじゃないので当然といえば当然 ? )Cloud Build > 設定でCloud Functions開発者を有効にします。
その上でIAMと管理からCloud Buildに紐づけられているメンバに、サービス アカウント ユーザーの IAM ロール(roles/iam.serviceAccountUser)を割り当てます。
https://cloud.google.com/functions/docs/troubleshooting#role-actAsStep #1: Already have image (with digest): gcr.io/cloud-builders/gcloud Step #1: Created .gcloudignore file. See `gcloud topic gcloudignore` for details. Step #1: ERROR: (gcloud.functions.deploy) ResponseError: status=[403], code=[Forbidden], message=[Missing necessary permission iam.serviceAccounts.actAs for $MEMBER on the service account アカウント名. Step #1: Ensure that service account アカウント名 is a member of the project プロジェクト名, and then grant $MEMBER the role 'roles/iam.serviceAccountUser'. Step #1: You can do that by running 'gcloud iam service-accounts add-iam-policy-binding アカウント名 --member=$MEMBER --role=roles/iam.serviceAccountUser' Step #1: In case the member is a service account please use the prefix 'serviceAccount:' instead of 'user:'. Please visit https://cloud.google.com/functions/docs/troubleshooting for in-depth troubleshooting documentation.] Finished Step #1 ERROR ERROR: build step 1 "gcr.io/cloud-builders/gcloud" failed: step exited with non-zero status: 1メンバーを編集 > 別のロールを追加で追加するのですが、ID名の
roles/iam.serviceAccountUserではヒットしません…(日本語じゃなくて英語表記にしていれば大丈夫かも)。
また空白の違いも厳密に検索しているみたいなので、日本語名をコピーして検索する必要がありました。
公式ドキュメントの名称をコピーするか、IAMと管理 > ロールからはID名で検索できるのでそこからタイトルをコピーして検索します。作成されたトリガーのHTTPをコールしてもForbiddenになる
現在のFunctionsは、デフォルトで認証ありで作成されます。
ちゃんと認証してアクセスするか、認証なしでもコールできるように設定します。
IAM によるアクセス管理 | Google Cloud Functions に関するドキュメント > 認証されていない関数の呼び出しを許可するError: Forbidden Your client does not have permission to get URL /xxxxx from this server.ソースに書いた日本語が文字化けする
JavaファイルをUTF-8で書いていても、Cloud Buildした結果では文字化けが生じていました。
gradle を使っていたのですが、コンパイル時の文字コードにも UTF-8 を指定すると解消します。
(Cloud Buildのデフォルト文字コードなんなんだ…)
build.gradle(抜粋)tasks.withType(JavaCompile) { options.encoding = 'UTF-8' }感想
GCPの権限回りでかなり手こずりました。
でも、これでWebhook作れました
次はFunctions同士を連携させたい!




- 投稿日:2020-10-18T17:22:21+09:00
Dozer.mapperの使い方
Dozerとは
Javaのマッピングフレームワークの一つ。
Dozerは、あるオブジェクトから別のオブジェクトにデータをコピーするために再帰を使用するマッピングフレームワークです。フレームワークは、Bean間でプロパティをコピーできるだけでなく、異なるタイプ間で自動的に変換することもできます。Dozerのメリット
- クラス間のbeenの受け渡しを簡略化できる
- beenの受け渡し時に値、型の変換ができる
設定方法(環境)
Gradleプロジェクト
「build.gradle」ファイルに下記を記述
記述場所:dependencies
記述コード:implementation 'net.sf.dozer:dozer:5.5.1'Mavenプロジェクト(今回はこちらを主体に紹介していきます)
pom.xmlに下記を追記
<dependency> <groupId>net.sf.dozer</groupId> <artifactId>dozer</artifactId> <version>5.5.1</version> </dependency>application.contextに下記を追記することで書くマッピングxmlを読み込むことができる。
<bean class="org.dozer.spring.DozerBeanMapperFactoryBean"> <property name="mappingFiles" value="classpath*:/META-INF/dozer/**/*-mapping.xml" /><!-- (1) --> </bean>Dozerの使い方
まずDozer.mapperを利用した場合と利用していない場合のコードの記載を比べてみます。
Duzer.mapperなしinput.setId(context.getId()); input.setName(context.getName()); input.setTitle(context.getTitle()); input.setSubtitlle(context.getSubTitle()); input.setBusinessDate(context.getBusinessDate());Dozer.mapperありMapper mapper = new DozerBeanMapper(); mapper.map(context, input);一目で分かる通り、記述が大幅に省略されています。
今回はbeenの階層構造なしですが、それでも何度もgetter,setterを記載せずにすみ、値の写かえ漏れを防ぎます。概要も見たところで詳細に説明していく。
今回利用するbeenこれをServiceの呼び出しに必要なbeenにマッピングさせていく。
@Data public class ControllerContext { private int id; private String name; private String title; private String subTitle; private Date businessDate; }@Data public class ServiceContext { private int id; private String name; private String title; private String subtitlle; private Date businessDate; }コントローラのbeenに以下のように値を設定する。
その後Dozer.mapperにてマッピングを行う。ServiceContext input = new ServiceContext(); context.setId(2); context.setName("いいい"); context.setTitle("タイトル2"); context.setSubTitle("サブタイトル2"); context.setBusinessDate(DateUtils.addDays(new Date(), 1)); Mapper mapper = new DozerBeanMapper(); mapper.map(context, input); System.out.println(input);出力結果ServiceContext(id=2, name=いいい, title=タイトル2, subtitlle=サブタイトル, businessDate=Mon Oct 19 00:17:38 JST 2020)
メソッド 説明 mapper.map() 第一引数に変換元のbeen名、第二引数に変換後のbeen名を記述することで使用できる 正常にマッピングされていることがわかる。
このようにしてbeenマッピングの記述を省略し、簡潔にプログラムを書くことができる。フィールド名が異なる場合のマッピング
Dozerのデフォルト設定では、コピー元と先で名前が同じプロパティを自動的にコピーします。
名前が異なるプロパティをコピーするには、カスタムマッピングが必要になります。Dozerの設定はXMLとJava Configのいずれかで定義することができます。
使いたいほうを使ってもらえればOKですが、今回はXMLの場合の記述について記載します。初めのMavenプロジェクトの場合のセットアップを実施していれば、
resouce/META-INF/dozer配下の-mapping.xml形式のファイルがマッピング時に読み込まれるようになっています。マッピングXMLは以下のように記述します。
<?xml version="1.0" encoding="UTF-8"?> <mappings xmlns="http://dozer.sourceforge.net" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://dozer.sourceforge.net http://dozer.sourceforge.net/schema/beanmapping.xsd"> <!-- omitted --> <mapping> <class-a>com.example.mavenDemo.controller.ControllerForm</class-a> <class-b>com.example.mavenDemo.service.ServiceContext</class-b> <field> <a>controllerTitle</a> <b>title</b><!-- (1) --> </field> </mapping> <!-- omitted --> </mappings>
タグ 説明 class-a タグ内にコピー元のBeanの、完全修飾クラス名を指定する。 class-b タグ内にコピー先のBeanの、完全修飾クラス名を指定する。 a <field>タグ内の<a>タグ内にコピー元のBeanの、マッピング用のフィールド名を指定する。b <field>タグ内の<b>タグ内にclass-aに対応するコピー先のBeanの、マッピング用のフィールド名を指定する。上記のカスタムマッピングの設定により、フィールド名の違いを緩和してくれる。
データ型が違う場合のマッピング
データ型が異なる場合も既存のパターンであれば自動的に保管が行われます。
変換のパターンについては以下を参照してください。
Basic Property Mapping先ほど例としてあげたマッピングの
idをintにしたマッピング例を挙げてみる@Data public class ControllerForm { private String id; private String name; private String title; private String subTitle; private Date businessDate; }@Data public class ServiceContext { private int id; private String name; private String title; private String subTitle; private Date businessDate; }Mapper mapper = new DozerBeanMapper(); mapper.map(context, input);実行結果ServiceContext(id=2, name=いいい, title=タイトル2, subTitle=サブタイトル2, businessDate=Mon Oct 19 17:12:25 JST 2020)データ型が違う場合も正常にマッピングが行えていることがわかる。
参考
本記事ではDozerマッピングの触りの部分しか紹介することができなかった。
詳細については参考記事を参照してください。Javaマッピングフレームワークのパフォーマンス - Codeflow
Spring Boot キャンプ : Spring Boot + Dozer編
Dozerの使い方
- 投稿日:2020-10-18T16:17:45+09:00
JavaScriptをJavaで呼び出してみる
はじめに
今回は、Javaアプリケーション内でJavaScriptを使う方法を実践してみます。
JSPの中でJavaScriptを実践知る方法とJavaファイルの中で実践する方法の二つがあります。開発環境
eclipse
tomcat
javaJSPファイルでJSを実行
IndexServlet.java
index.jsp
main.js
を作成していきます。
このような階層となっています。
servlet.IndexServlet.javapackage servlet; import java.io.IOException; import javax.servlet.ServletException; import javax.servlet.annotation.WebServlet; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; /** * Servlet implementation class IndexServlet */ @WebServlet("/IndexServlet") public class IndexServlet extends HttpServlet { private static final long serialVersionUID = 1L; /** * @see HttpServlet#HttpServlet() */ public IndexServlet() { super(); // TODO Auto-generated constructor stub } /** * @see HttpServlet#doGet(HttpServletRequest request, HttpServletResponse response) */ protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { // TODO Auto-generated method stub response.getWriter().append("Served at: ").append(request.getContextPath()); } /** * @see HttpServlet#doPost(HttpServletRequest request, HttpServletResponse response) */ protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { // TODO Auto-generated method stub doGet(request, response); } }サーブレットはノータッチでOKです。(あくまでもJSPでJSを実行することが目的なので)
index.jsp<%@ page language="java" pageEncoding="UTF-8"%> <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>index</title> </head> <style> .box1 { width: 200px; height: 200px; background-color: #ccffcc; } .box2 { width: 200px; height: 200px; background-color: #ddd; } </style> <body> <h1>JSPでのJS実行確認</h1> <div class="box1">box1</div> <div class="box2">box2</div> <form action="IndexServlet" method="post"> ユーザID:<input type="text" name="user_id" id="user_id"> パスワード:<input type="password" name="pass" id="pass"> <input type="submit" value="ログイン" id="btn"> </form> <input type="button" value="パスワードをみる" id="passshow"> <script src="https://code.jquery.com/jquery-3.4.1.min.js"></script> <script src="main.js"></script> </body> </html>・クリックすると色が変わるボックス
・マウスホバーで色が変わるボックス
・ログインフォームのバリデーション
の三つを実装していきます。main.js/* ---------クリックした時の処理---------*/ $('.box1').on('click', (e) => { $(e.target).css({'background-color': 'skyblue' }); }); /* ------マウスをホバーした時の処理----------*/ const onMouseenter = (e) => { $(e.target).css({ 'background-color': '#ff9999', }); }; const onMouseleave = (e) => { $(e.target).css({ 'background-color': '#dddddd', }); }; $('.box2') .on('mouseenter', onMouseenter) .on('mouseleave', onMouseleave); /*-------- パスワードを見れるようにする--------------*/ $('#passshow').on('click', () => { $('#pass').attr('type', 'text'); }); /*----------ログイン時にバリデーションを設定する(空欄だった場合弾く)----------- */ $('#btn').on('click', (e) => { const id = $('#user_id').val(); const pass = $('#pass').val(); if(!id){ e.preventDefault(); console.log(id); alert('IDが空欄です'); } if(!pass){ e.preventDefault(); console.log(pass); alert('パスワードが空欄です'); } })以上のようにJSを実装することができた。
(HTMLの時と全く同じように実装することができた。)JavaファイルでJSを実行する
次に、JavaファイルのなかでJSを実行する方法の一つを紹介する。
解説は全てコード内にあるのでみていただければ。。。下記のコードは、オラクルのJavaドキュメントガイドの下記のページを解説した物になります。
https://docs.oracle.com/javase/jp/8/docs/technotes/guides/scripting/prog_guide/api.htmltest.javaimport java.io.File; import javax.script.Invocable; import javax.script.ScriptEngine; import javax.script.ScriptEngineManager; public class test { public static void main(String[] args) throws Exception{ //ScripteEnginManagerインスタンスを作成 ScriptEngineManager factory = new ScriptEngineManager(); //ScripteEngineManagerインスタンスのgetEngineByNameメソッドでJSのスクリプトエンジンを指定 ScriptEngine engine = factory.getEngineByName("JavaScript"); //JSエンジンの活用--------------------------------- //コンソールに表示・スクリプトをJS文として評価 engine.eval("print('Hello World')"); //文字ファイルを読み込むためのクラスjava.io.FileReaderを使うことでJSファイルごと実行できる //同じパッケージ同じ階層にある時 File file1 = new File("src/test.js"); engine.eval(new java.io.FileReader(file1)); //srcと同じ階層のresourcesフォルダにある時 File file2 = new File("resources/test.js"); engine.eval(new java.io.FileReader(file2)); //put(キー名, ソースコード)でキー名にソースコードを保存できる engine.put("file", file1); //getAbsolutePathで絶対パスを取得する・スクリプトをJS文として評価 engine.eval("print(file.getAbsolutePath())"); //変数に関数などを代入可能 String script1 = "function helle(name) { print('Hello' + name);}"; //変数名で呼び出し(engineに保存されている)・スクリプトをJS文として評価 engine.eval(script1); //engineに保存されている関数やメソッドを呼び出す。→関数などの実行ができる *invocable 呼び出し可能という意味 Invocable inv1 = (Invocable) engine; //今回は関数なのでinvokeFunction("呼び出される関数名", "引数")で実行できる inv1.invokeFunction("helle", "太郎"); //"obj"というオブジェクトを作成して、"obj"オブジェクトのメソッドも定義 String script2 = "var obj = new Object(); " + "obj.goodbye = function(name){print('Goodbye' + name + 'さん');}"; //engineに保存・スクリプトをJS文として評価 engine.eval(script2); //engineを呼び出し可能にする Invocable inv2 = (Invocable) engine; //呼び出したいメソッドを持つオブジェクトを取得する(扱えるようにする) Object obj1 = engine.get("obj"); //今回はメソッドなので、invokeMethod(オブジェクト名, "メソッド名", "引数")で実行 inv2.invokeMethod(obj1, "goodbye", "次郎"); //Runnableインターフェースのメソッドとしてスクリプト関数を扱うことができる・グローバルに使えるようになる //引数の無い関数生成 String script3 = "function run() { print('java.lang.Runnableインターフェースの呼び出し'); }"; //スクリプトをJS文として評価・呼び出し可能状態にする engine.eval(script3); Invocable inv3 = (Invocable) engine; //Runnable(インターフェース)を取得し、スクリプト関数(inv3)をメソッドr1として実装 Runnable r1 = inv3.getInterface(Runnable.class); //Threadオブジェクト(Runnableインターフェースが実装されている)にメソッドr1を渡すし作成 Thread th1 = new Thread(r1); //実行開始 th1.start(); //引数の無いメソッド生成 String script4 = "var obj = new Object();" + "obj.run = function() {print('Runnableメソッドの呼び出し');}"; //スクリプトとして評価 engine.eval(script4); //objをオブジェクトとして扱えるようにする Object obj2 = engine.get("obj"); //呼び出し可能にする Invocable inv4 = (Invocable) engine; //Runnable(インターフェース)を取得し、スクリプト関数(inv4)をメソッドr2として実装 Runnable r2 = inv4.getInterface(obj2, Runnable.class); //Threadオブジェクト(Runnableインターフェースが実装されている)にメソッドr1を渡し作成 Thread th2 = new Thread(r2); th2.start(); } }最後に
今回紹介したようにJavaとJSを組み合わせることができれば、より動的なページが作れそうですね。
- 投稿日:2020-10-18T15:44:46+09:00
【Effective Java】不必要なオブジェクトの生成を避ける
Effective Javaの独自解釈です。
第3版の項目6について、自分なりにコード書いたりして解釈してみました。概要
- どこでオブジェクトが生成されるかを意識する。
- 用意されているオブジェクトの存在を知る。
- 何度も同じ値で再利用されるようなオブジェクトは定数化する。
- ボクシングでオブジェクトが意図せず作成されることに注意する。
不必要にオブジェクトが生成される例と対策
String
String s = new String("hoge");このコードでは、まず
”hoge”という文字が入ったオブジェクトが作成され、次にnew String(“hoge”)で”hoge”という文字が入った別のオブジェクトが作成される。
要するに中身が同じオブジェクトが二重に生成されるのである。以下のようにすることで、オブジェクト生成を一回で済ませられる。String s = "hoge";Boolean
Booleanオブジェクトは実は以下のように、Stringオブジェクトを引数にすることで生成することができる。Boolean b = new Boolean("true");しかしそもそも
Booleanはnull,true,falseの三つの値しかとらない。Booleanクラスにはtrueとfalseのオブジェクトが定数の形で予め用意されている。Booleanクラスの一部
public static final Boolean TRUE = new Boolean(true); public static final Boolean FALSE = new Boolean(false);また、これらの定数を返す
valueOfメソッドも用意されている。public static Boolean valueOf(String s) { return parseBoolean(s) ? TRUE : FALSE; }ということで、以下のように
valueOfメソッドを利用してBooleanオブジェクトを宣言すれば、元々Booleanクラスで用意されているオブジェクトを参照し、あらたに生成する必要することがなくなる。Boolean b = Boolean.valuOf("true");メソッドが呼ばれる度に生成されるオブジェクト
以下の、文字列が正しいローマ数字であるか判定するメソッドを考える。
static boolean isRomanNumeral(String s) { return s.matches("^(?=.)M*(C[MD]|D?C{0,3})" + "(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$"); }
String.matchesは、内部的にPatternオブジェクトを生成しているので、このメソッドが呼ばれる度に新たなPatternオブジェクトが生成されてしまう。
予めPatternオブジェクトを定数として定義しておけば、Patternオブジェクト生成はクラス初期化時の一回で済ませることができる。public class RomanNumerals { private static final Pattern ROMAN = Pattern.compile( "^(?=.)M*(C[MD]|D?C{0,3})" + "(X[CL]|L?X{0,3})(I[XV]|V?I{0,3})$"); static boolean isRomanNumeral(String s) { return ROMAN.matcher(s).matches(); } }※
String.matchesは内部的にPatternオブジェクトを生成し、そのオブジェクトから.matcher(判定対象文字列).matches()を呼んでいるので、Patternオブジェクト生成部分が丸ごと省略された形となる。不必要なボクシング
以下のコードを考える。
private static long sum() { Long sum = 0L; for (long i = 0; i <= Integer.MAX_VALUE; i++) sum += 1; return sum; }
sum += 1は内部的にLong sum = sum + (Long)1のように毎回キャストされて演算されているので、毎回Longオブジェクトが生成されてしまう。
そもそもこのメソッドはsumがLong型である必要がないため、sumをlong型で宣言するだけで大幅に速度改善できる。
これはわかりやすい例だが、わざわざラッパークラスを使用する必要があるかどうかは常に意識すべきである(nullを取る必要性、シチュエーションがありえるかどうかなど)。注意
メソッドの引数のオブジェクトは、メソッド内部で状態を変更すべきではないという考えがある。今そのオブジェクトがどういう状態になっているかが見えにくく、バグ発生リスクが上がるからである。
よほどパフォーマンスが求めらていない限り、この場合はメソッド内で新たにオブジェクトを生成し、引数のオブジェクトの内容をコピーすることでバグ発生リスクの低減を優先すべきだと考える。
- 投稿日:2020-10-18T10:13:30+09:00
SpringBoot+MyBatis+MySQLの初歩
概要
これまでJdbcTemplateの使用経験しかなくMyBatisを使ったことがなかったので、SpringBoot + MyBatis + MySQLを使用してみた。
環境
- macOS Catalina 10.15.7
- Java11
- SpringBoot 2.3.4
- MySQL 8.0
- Gradle
やってみたこと
今回は本の情報がDBに登録されており、それを1件取得、全件表示することにします。
- データベースからID検索し表示
- 全件取得して一覧表示
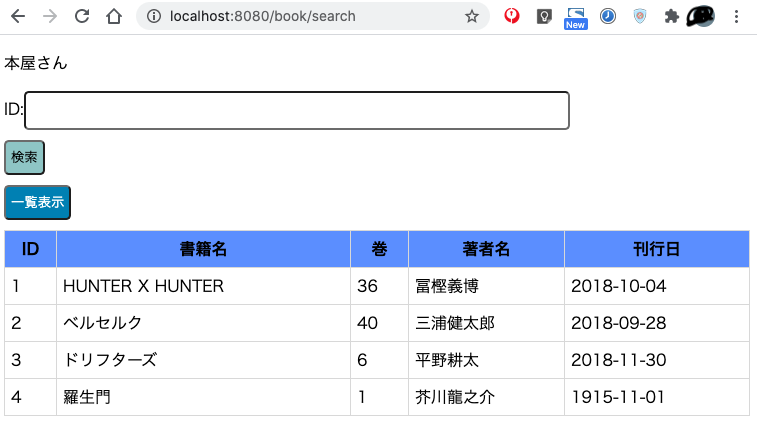
■初回アクセス時の画面
■1件検索(idをフォームに入力して検索を押下)
■全件表示(一覧表示を押下)
準備する各種クラス・設定ファイルたち
- build.gradle(こちらの依存関係にMyBatisを追加)
- DB関連:data.sql、schema.sql
- BookFormクラス(入力フォームからの値を受け取る)
- ビュー画面(Thymeleaf使用)
- Bookクラス(DBからの値を受け取るEntityクラス)
- BookDaoインタフェース(DBへ問合せを行うためのインタフェース)
- BookDao.xml(ここにSQLを記載。)
- BookServiceクラス(Daoクラスを呼び出す。)
- BookControllerクラス(ブラウザからのリクエストに応じたビューを返す。状況に応じてserviceクラスを呼び出す。)
なぜか、BookDaoはインタフェースを実装せずともBookServiceクラスから利用できる。裏側でごにょごにょ実装されてServiceクラスから利用できるようになっているらしい。
ディレクトリ構成
- MyBatisはマッピングファイル(XMLファイル)にSQLを書くやり方を採用(アノテーション内にSQLを書くやり方もあり)。マッピングファイルはresorces配下のDaoと同じ階層に配置することで、Dao利用時に自動で読み込んでくれる。
└── src ├── main │ ├── java │ │ └── com │ │ └── example │ │ └── demo │ │ ├── ServletInitializer.java │ │ ├── SpringTestApplication.java │ │ ├── controller │ │ │ └── BookController.java │ │ ├── dao │ │ │ └── BookDao.java │ │ ├── entity │ │ │ └── Book.java │ │ ├── form │ │ │ └── BookForm.java │ │ └── service │ │ └── BookService.java │ └── resources │ ├── application.properties │ ├── com │ │ └── example │ │ └── demo │ │ └── dao │ │ └── BookDao.xml │ ├── data.sql │ ├── schema.sql │ ├── static │ │ └── css │ │ └── style.css │ └── templates │ └── index.html └── test依存関係
dependencies { implementation 'org.springframework.boot:spring-boot-starter-thymeleaf' implementation 'org.springframework.boot:spring-boot-starter-web' implementation 'org.mybatis.spring.boot:mybatis-spring-boot-starter:2.1.3' compileOnly 'org.projectlombok:lombok' developmentOnly 'org.springframework.boot:spring-boot-devtools' runtimeOnly 'mysql:mysql-connector-java' annotationProcessor 'org.projectlombok:lombok' providedRuntime 'org.springframework.boot:spring-boot-starter-tomcat' testImplementation('org.springframework.boot:spring-boot-starter-test') { exclude group: 'org.junit.vintage', module: 'junit-vintage-engine' }DBの定義
まずはMySQLでデータベースを作っておく。今回の例でいうとlibrary。
CREATE DATABASE library;下記ファイルを用意すると、SpringBoot起動の度にテストデータを用意してくれる。
schema.sql--booktableがあれば削除 DROP TABLE IF EXISTS booktable; --booktableがなければ新しく作成 CREATE TABLE IF NOT EXISTS booktable( id INT AUTO_INCREMENT, book_name VARCHAR(50) NOT NULL, volume_num INT NOT NULL, author_name VARCHAR(50) NOT NULL, published_date DATE NOT NULL, PRIMARY KEY(id) );data.sql--本のリスト初期データ --idカラムはオートインクリメントなので不要 INSERT INTO booktable (book_name, volume_num,author_name,published_date) VALUES ( 'HUNTER X HUNTER',36,'冨樫義博','2018-10-04'), ( 'ベルセルク',40,'三浦健太郎','2018-09-28'), ( 'ドリフターズ',6,'平野耕太','2018-11-30'), ( '羅生門',1,'芥川龍之介','1915-11-01') ;設定ファイル(application.properties)
接続先に
?serverTimezone=JSTをつけないと上手くいかない。また、mybatis.configuration.map-underscore-to-camel-case=trueにより、DBのカラム名がスネークケースであってもJava側ではキャメルケースとして認識してくれる。### データベース接続設定 spring.datasource.url=jdbc:mysql://localhost:3306/library?serverTimezone=JST spring.datasource.username=root spring.datasource.password=password spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver ### スネークケースのDBカラム名をSpringのEntity側ではキャメルケースとして対応付けてくれる。 mybatis.configuration.map-underscore-to-camel-case=true ### 初期化を行うかの指定。 spring.datasource.initialization-mode=always各種クラス
Formクラス
今回は画面からはidのみ受け取るのでフィールドは1個。HTML側のinputタグ内name属性とフィールド名は一致させておく。lombokの機能により、@Dataでセッターゲッターは追記不要。フィールドの型はプリミティブ型の
intではなく、参照型(ラッパークラス)のIntegerにするのが良いらしい。ゼロとnullで区別がつくため。BookForm.javapackage com.example.demo.form; import lombok.Data; @Data public class BookForm { private Integer id; }Entityクラス
データベースから取得したデータをいったん格納するオブジェクト。Formクラスにも書いたが、型は参照型が良い。
Book.javapackage com.example.demo.entity; import java.time.LocalDate; import lombok.Data; @Data public class Book { private Integer id; private String bookName; private Integer volumeNum; private String authorName; private LocalDate publishedDate; }Daoインタフェースとマッピングファイル
MyBatisの場合は、インタフェースをつくり@MapperアノテーションをつけることでRepositoryクラスになる。1件検索のメソッドでは、単純に数値だけ渡すよりも、Entityクラス(Bookクラス)を介した方が、マッピングファイルの中で、Entityクラスの各フィールドを柔軟に参照できる。
BookDaopackage com.example.demo.dao; import java.util.List; import org.apache.ibatis.annotations.Mapper; import com.example.demo.entity.Book; @Mapper public interface BookDao { //1件検索 Book findById(Book book); //全件取得 List<Book> findAll(); }【XMLファイルについて】
- ファイル名は対応するDaoと同じにする。
- 配置場所はresorces配下のDaoインタフェースと同じ階層にする。
namespace属性にはDaoインタフェースの完全修飾クラス名を書く。select要素にSELECT文を書く。
id属性にはDaoインタフェースの対応するメソッド名を書く。resultType属性には検索結果をマッピングするクラス名を書く。今回はBookクラス。parameterType属性は今回省略。メソッドの引数の型を書くらしい。省略すると、自動で実際の引数の型が判定される。- 下記
findByIdでは、WHERE句でEntityクラス(Bookクラス)のidフィールドを参照している。BookDao.xml<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.example.demo.dao.BookDao"> <select id="findById" resultType="com.example.demo.entity.Book"> SELECT id, book_name, volume_num, author_name, published_date FROM booktable WHERE id = #{id} </select> <select id="findAll" resultType="com.example.demo.entity.Book"> SELECT id, book_name, volume_num, author_name, published_date FROM booktable </select> </mapper>Serviceクラス
Daoクラスでも書いたが、1件検索メソッドではEntityクラスのidフィールドに値をセットしている。全件取得はEntityクラスを要素にもつリストを返す。
package com.example.demo.service; import java.util.List; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; import com.example.demo.dao.BookDao; import com.example.demo.entity.Book; @Service public class BookService { @Autowired BookDao bookDao; //1件検索 public Book findById(Integer id) { Book book = new Book(); book.setId(id); return this.bookDao.findById(book); } //全件取得 public List<Book> getBookList(){ return this.bookDao.findAll(); } }Controllerクラス
下記では@GetMappingや@PostMappingを使いわけてません。
BookController.javapackage com.example.demo.controller; import java.util.List; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Controller; import org.springframework.ui.Model; import org.springframework.web.bind.annotation.RequestMapping; import com.example.demo.entity.Book; import com.example.demo.form.BookForm; import com.example.demo.service.BookService; @Controller @RequestMapping("/book") public class BookController { @Autowired BookService bookService; @RequestMapping("/search") public String index(BookForm bookForm, String showList, Model model) { //タイトル model.addAttribute("title", "本屋さん"); //bookform(formクラス)がnullじゃなかったら1件検索 if(bookForm.getId() != null) { Book book = bookService.findById(bookForm.getId()); model.addAttribute("book", book); } //一覧表示ボタンが押されると本一覧をmodelに登録。 if(showList != null) { List<Book> bookList = bookService.getBookList(); model.addAttribute("bookList", bookList); } return "index"; } }画面
th:ifでControllerのModelに登録したオブジェクトがnullかどうかで表示する内容が変わります。index.html<!DOCTYPE HTML> <html xmlns:th="http://www.thymeleaf.org"> <head> <title th:text="${title}">title</title> <link href="/css/style.css" rel="stylesheet"> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> </head> <body> <p>本屋さん</p> <form action="/book/search" method="post"> <label>ID:<input class="input" type="text" name="id"></label><br> <div><input class="search" type="submit" value="検索"/></div> </form> <form action="/book/search" method="post"> <div><input class="list" type="submit" name="showList" value="一覧表示"/></div> </form> <div th:if="${book} !=null" th:object="${book}"> <table> <tr> <th>ID</th> <th>書籍名</th> <th>巻</th> <th>著者名</th> <th>刊行日</th> </tr> <tr> <td th:text="*{id}">id</td> <td th:text="*{bookName}">書籍名</td> <td th:text="*{volumeNum}">巻</td> <td th:text="*{authorName}">著者名</td> <td th:text="*{publishedDate}">刊行日</td> </tr> </table> </div> <div th:if="${bookList} !=null"> <table> <tr> <th>ID</th> <th>書籍名</th> <th>巻</th> <th>著者名</th> <th>刊行日</th> </tr> <tr th:each="book:${bookList}" th:object="${book}"> <td th:text="*{id}">id</td> <td th:text="*{bookName}">書籍名</td> <td th:text="*{volumeNum}">巻</td> <td th:text="*{authorName}">著者名</td> <td th:text="*{publishedDate}">刊行日</td> </tr> </table> </div> </body> </html>CSSよく分かりません。タグを[type=" "]で区別できたり、table thとスペース区切りで子要素を指定できたりする、ということはわかりました。。。
style.css@charset "UTF-8"; input[type="text"]{ width:70%; border-radius: 5px; padding: 10px; } input[type="submit"].search{ border-radius: 5px; padding: 5px; margin-top: 10px; background-color:#99CCCC; } input[type="submit"].list{ border-radius: 5px; padding: 5px; margin-top: 10px; background-color: #008BBB; color:#FFFFFF } table{ width: 100%; margin-top: 10px; border-collapse: collapse; } table th, table td { border: 1px solid #ddd; padding: 6px; } table th { background-color: #6699FF; }

- 投稿日:2020-10-18T01:00:43+09:00
Encapsulation(カプセル化)復習
Encapsulation(カプセル化)とはなんだっけかな?
最近OOPの基本概念の1つであるカプセル化の理解が薄れていたので、めちゃくちゃ復習範囲狭めで自分の復習用で書きます。
カプセル化ってなんなの?とプログラミングしたことない彼女に聞かれた場合、
簡単に説明すると、薬のカプセルみたいに、外部から中にあるあの細かい粒たちを守ることw。と最初に言い、それからコードで説明するかも。
外部からオブジェクトに対するアクセスコントロールと自分は理解しています。(本当はもっとあるかもしれない。。)
コメントでアドバイスを頂き、自分の理解が間違っていたことに気付けました。アクセスコントロールはカプセル化をするための手段なので、カプセル化とは違いますね。
カプセル化の説明
カプセル化は、ソフトウェアを分割する際に、関係するデータとそのデータを必要する処理を1つにまとめ、無関係なものや関係性の低いものをクラスから排除することで「何のためのクラスなのか?」というクラスの目的を明確化するために行い、ほかのクラスに重複するデータや処理がない状態を目指すものです。
めちゃくちゃ簡単なコードで具体的に説明すると
Person.javapublic class Person { private int age; private String name; // クレジットカードの暗証番号 private int creditCardPinNum; public double weight = 69; public Person(int age, String name, int creditCardPinNum) { this.age = age; this.name = name; this.creditCardPinNum = creditCardPinNum; } // getter public String getName() { return name; } // setter public void changeName(String name) { this.name = name; } // 外部から年齢を読むことはできる getter public int getAge() { return age; } }注意:概念を復讐するため、自分なりの解釈になってます。
まず人って年齢変えれませんよね?10歳の人が”明日から20歳する”とはできません、
なので、Personクラスのageは変更できないようアクセスコントロールされています(メンバー変数をprivateにし、setterメソッドをなくしている)。
他人に自分の年齢は伝えることはできるので、getterはあります(嘘がつけるとかは今回無しで)。nameですが、人って名前は何回でも変更可能なので、Person クラスではsetterメソッド(changeName)が書かれています。
まとめ
カプセル化とは外部からのアクセスコントロール(情報隠蔽)
カプセル化は、ソフトウェアを分割する際に、関係するデータとそのデータを必要する処理を1つにまとめ、無関係なものや関係性の低いものをクラスから排除することで「何のためのクラスなのか?」というクラスの目的を明確化するために行い、ほかのクラスに重複するデータや処理がない状態を目指すものです。
- 投稿日:2020-10-18T00:40:45+09:00
Javaのバージョン違いによるオプション使用可否
先日普段と違うPCを使うシーンがありました。
入っているJavaのバージョンを確認しようとしたところ以下のようなエラーが。。Terminal$ java --version Unrecognized option: --version Error: Could not create the Java Virtual Machine. Error: A fatal exception has occurred. Program will exit.––versionのオプションは認識されていません?
Javaの仮想マシーンが作成できません??
致命的エラー???おかしいなぁと思い調べたところ、以下の記事を見つけました。
どうやらJDK9以降は ––vesion を使えるらしいですが、
JDK8以前は –version じゃないとダメらしいです。
ハイフン一つの違いで。。
Javaのバージョン確認をする際は、どのバージョンでも動く以下がベターですね◎Terminal$ java -version