- 投稿日:2020-10-13T23:55:24+09:00
GithubからのClone作成方法
Clone作成方法について手順を記載します。
まず、鍵を作成しましょう。
% ssh-keygen+---[RSA 3072]----+ | .o | | .o o | | + o o | | . o . . | | S . o.. | | ..o =.o o.= | |o .+..+.*...+ | |=oo.+++o.+o. | |*+o=BE. .oo. | +----[SHA256]-----+githubに鍵を登録する方法です。
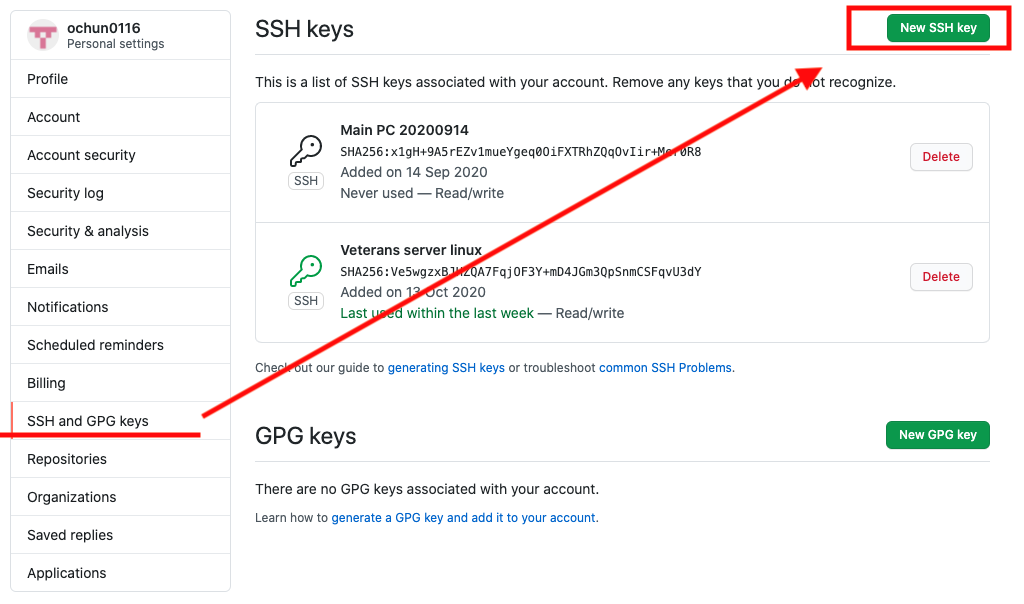
Githubに矢印通りに鍵を登録する
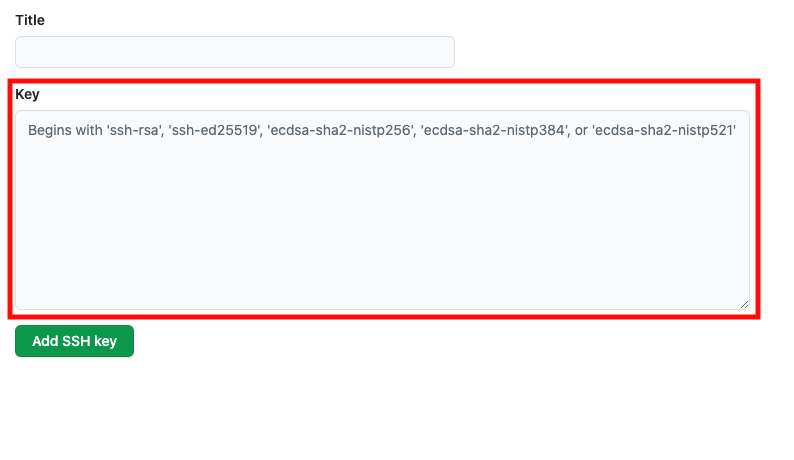
% ls ~/.ssh id_rsa id_rsa.pub known_hosts rsa_GitHub rsa_GitHub.pubと出るので、、、id_rsa.pubの中身をコピーします。
% vi ~/.ssh/id_rsa.pubエンターして、表示された中身を「key」のブランクボックスに入れる。
Add SSH KEYを発行する。
で登録完了。
ターミナルを開いて、以下コマンドを入力
% git clone git@github.com:ochun0116/saku202010.gitCloning into 'saku202010'... Enter passphrase for key '/Users/yuota/.ssh/id_rsa':パスワードを入力します。
(パスワードは入力しても反応しないので)入力が終わったらエンターをおします。remote: Enumerating objects: 8337, done. remote: Counting objects: 100% (8337/8337), done. remote: Compressing objects: 100% (5221/5221), done. remote: Total 8337 (delta 2045), reused 8337 (delta 2045), pack-reused 0 Receiving objects: 100% (8337/8337), 12.16 MiB | 5.62 MiB/s, done. Resolving deltas: 100% (2045/2045), done. Updating files: 100% (6155/6155), done.これで完了です!
クローンが作れていることを確認。

- 投稿日:2020-10-13T23:49:27+09:00
Mathmatics for ML
Linear Models
yハットを予測値、ベクトルw(=w1, w2..., wp)を係数(coef)、w0を切片(intercept)とする。
\hat{y}(w, x) = w_0 + w_1 x_1 + ... + w_p x_pOrdinary Least Squares
以下の残差平方和を最小とするような係数を見つける。なお、L2ノルムは普通のユークリッド距離を意味する。
\min_{w} || X w - y||_2^2sklearn
class sklearn.linear_model.LinearRegression(*, fit_intercept=True, normalize=False, copy_X=True, n_jobs=None)Implementation
Ridge Regression
損失関数として、L2ノルムの二乗の正則化項を加えたもの。係数の絶対値が抑えられ、過学習の予防となる。
\min_{w} || X w - y||_2^2 + \alpha ||w||_2^2sklearn
class sklearn.linear_model.Ridge(alpha=1.0, *, fit_intercept=True, normalize=False, copy_X=True, max_iter=None, tol=0.001, solver='auto', random_state=None)Lasso Regression
損失関数として、L1ノルム(マンハッタン距離)の正則化項を加えたもの。係数の一部を0にして特徴量の次元を削減できることがある。
\min_{w} { \frac{1}{2n_{\text{samples}}} ||X w - y||_2 ^ 2 + \alpha ||w||_1}Multi-task Lasso
Elastic-Net
L1ノルムとL2ノルムの和の正則化項を加える。ρ=0のときRidge回帰、ρ=1のときLasso回帰に帰着する。
\min_{w} { \frac{1}{2n_{\text{samples}}} ||X w - y||_2 ^ 2 + \alpha \rho ||w||_1 + \frac{\alpha(1-\rho)}{2} ||w||_2 ^ 2}Multi-task Elastic-Net
Least Angle Regression (LARS)
Orthogonal Matching Pursuit (OMP)
停止条件が付いている。
\underset{w}{\operatorname{arg\,min\,}} ||y - Xw||_2^2 \text{ subject to } ||w||_0 \leq n_{\text{nonzero\_coefs}}Bayesian Regression
p(y|X,w,\alpha) = \mathcal{N}(y|X w,\alpha)Logistic Regression
Regressionと言っときながらClassification。ベルヌーイ分布に従う変数の統計的回帰モデル。連結関数としてロジットを使用する。
K-nearest Neighbors / k近傍法
応用
映画・音楽・検索結果・ショッピングなどのユーザーの趣味を予測。類似したユーザーの好みに基づいて予測をするCollaborative Filteringや、過去にユーザーが好んだものに基づいて予測するContent-based Filtering等がある。
Q-Learning / Q学習
sを状態、aを行動、rを報酬としたとき、状態行動価値Q(s, a)の学習アルゴリズム。以下の式において、αは学習率、γは割引率を意味する。以下のようにして次々とαに従ってQ(st, at)を更新していく。更新先の状態st+1の最大Q値をγに従った分だけ採用する。
Q(s_t, a_t) \leftarrow (1-\alpha)Q(s_t, a_t) + \alpha(r_{t+1} + \gamma \max_{a_{t+1}}Q(s_{t+1}, a_{t+1}))\\ Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha(r_{t+1} + \gamma \max_{a_{t+1}}Q(s_{t+1}, a_{t+1}) - Q(s_t, a_t))Sarsa
Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha(r_{t+1} + \gamma Q(s_{t+1}, a_{t+1}) - Q(s_t, a_t))モンテカルロ法
Returns(s, a) \leftarrow append(Returns(s, a), r)\\ Q(s, a) \leftarrow average(Returns(s, a))
- 投稿日:2020-10-13T23:27:35+09:00
Chainerによる機械学習のためのPython学習メモ 7章 回帰分析
What
Chainerを利用して機械学習を学ぶにあたり、私自身が、気がついた点、リサーチした内容をまとめる記事になります。今回は、機械学習に必要な回帰分析を勉強します。
私の理解に基づいて記述しているため、間違っている場合があります。間違いは都度修正するつもりです、ご容赦ください。
単回帰分析と重回帰分析
回帰分析とは、データ群が与えれた時、どんなグラフから発生したデータでしょう?を求める分析。
単回帰は入出力が1体1の場合。
話変わるけど、いろんな現象が正規分布に従うのはなぜ?と思ったことを思い出した。
下記参考、正直まだ腹に落ちていないのでもう一度勉強しなおします。
https://goldninjass.hatenablog.com/entry/2016/04/04/152631データの前処理
という手法があるらしい。平均値が0になるようにデータセットを平行移動する処理のことらしい
単回帰分析
原理は最小二乗法。
重回帰分析
多変数の入力に対し、1出力を与える。基本的には単回帰分析の連立。解法が大学数学だから、演習問題くらい説いておいた方が良さげ。
Comment
数学の学習はここまで、大学で一度は聞いたことがあるというのが多かったため、スムーズに進んだ。
次回から、Pythonと数学を組み合わせていよいよ機械学習の習得に取り掛かります。
- 投稿日:2020-10-13T23:26:25+09:00
Pythonで正規表現
ソースコードは以下になります。
import re string = "0" result = re.fullmatch(r'0|1|2', string) if result: print("Match!") else: print("Not Match")実行結果は以下になります。
Match!最後まで読んでいただきありがとうございました。
またお会いしましょう。
- 投稿日:2020-10-13T23:20:19+09:00
[wxpython] wx.lib.plotの基本&時間軸を使用する方法
はじめに
初投稿です!よろしくお願い致します!
GUIの中にリアルタイムでグラフを描画する機会があり、その時のまとめです。
GUIはwxpythonを使用した為、同じwxモジュール内にあるwx.lib.plotを使用しました。
時間軸の記事を探すのに苦労したので参考になれば幸いです。環境
mac OS
python 3.8.5
wxpython 4.1.0インポート
import wx import wx.lib import wx.lib.plot as plot基本
wx.Frame -> wx.Panel -> plot.Canvasの順に配置していきます。
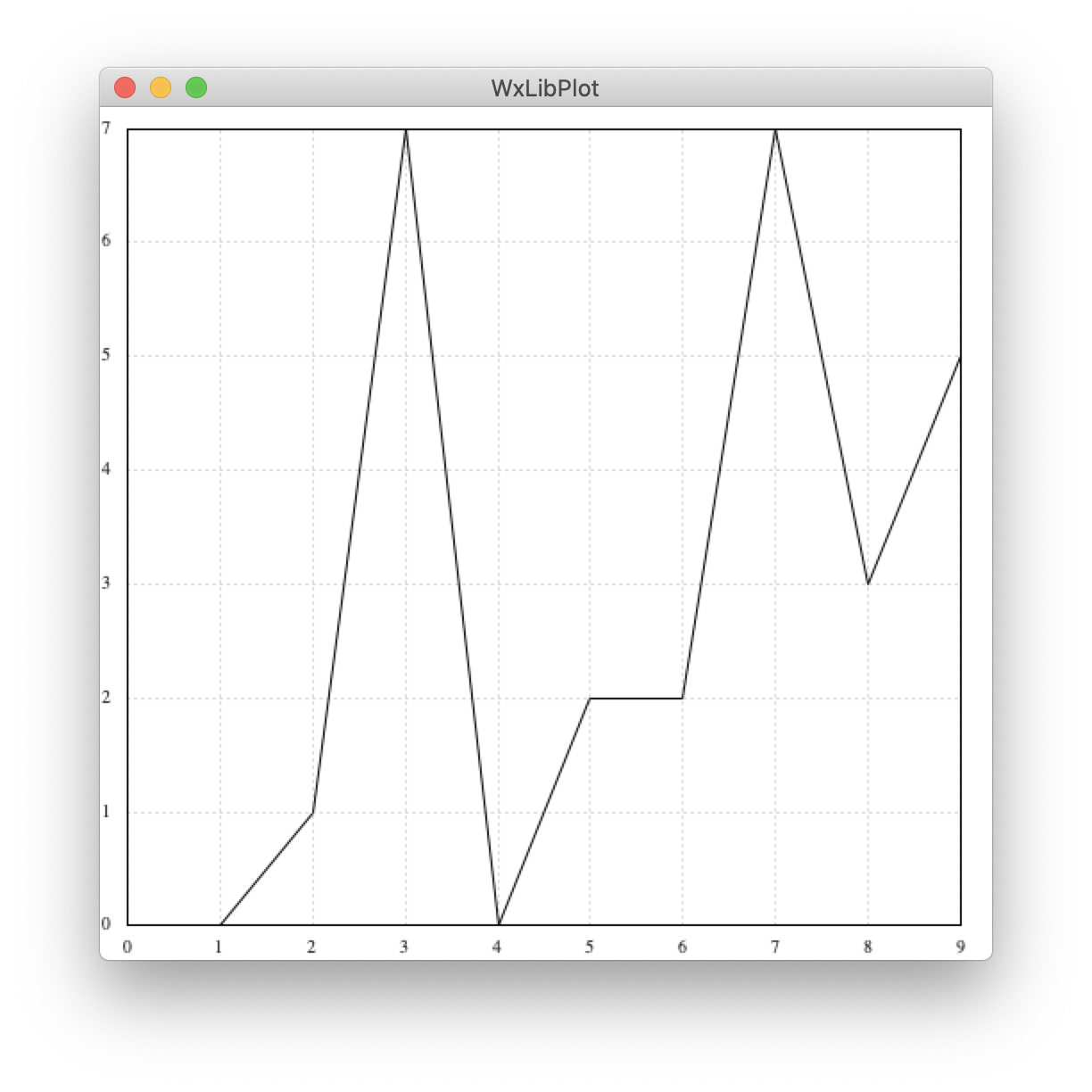
import wx import wx.lib import wx.lib.plot as plot # グラフ描画に使用 import random # 描画する値 x_val = list(range(10)) y_val = [random.randint(0, 10) for i in range(10)] # 0~10までのランダムな値10個 # [(x1, y1), (x2, y2),...(xn, yn)]という形式でグラフに渡すため変形 xy_val = list(zip(x_val, y_val)) class MainFrame(wx.Frame): def __init__(self, parent, id, title): wx.Frame.__init__(self, parent, id, title, size=(500, 500)) # panel作成 self.panel = wx.Panel(self, -1) # graph作成 self.plotter = plot.PlotCanvas(self, -1) # 表示する線を作成 & 描画 line = plot.PolyLine(xy_val) gc = plot.PlotGraphics([line]) self.plotter.Draw(gc) # sizer作成 & 設置 sizer = wx.GridSizer(1, 1, gap=(0, 0)) sizer.Add(self.plotter, flag=wx.EXPAND) self.SetSizer(sizer) # 画面中央にGUIを表示 self.Center() self.Show() def main(): app = wx.App() MainFrame(None, -1, 'WxLibPlot') app.MainLoop() if __name__ == '__main__': main()結果
レイアウト
グラフタイトル、凡例、ラベルの追加
ズーム or ドラッグ機能の有効化
フォントサイズ、線の色、太さを変更しますズームとドラッグは共存できない為、片方を有効にするともう片方は無効になります。
上記コードのself.plotter = plot.PlotCanvas(self, -1)下を下記に変更します。
self.plotter.enableLegend = True # 凡例表示をTrueにする self.plotter.fontSizeTitle = 18 # グラフタイトルの文字サイズを18にする(デフォルト=15) self.plotter.fontSizeLegend = 18 # 凡例の文字サイズを18にする(デフォルト=7) self.plotter.fontSizeAxis = 18 # xyラベル, 座標の文字サイズを18にする(デフォルト=10) # ズーム or ドラッグ機能を有効にする。どちらか片方しか有効にできない # self.plotter.enableZoom = True self.plotter.enableDrag = True # 表示する線を作成 & 描画() line = plot.PolyLine(xy_val, legend='sample', colour='red', width=4) # 凡例文字追加、線の色を赤、太さを4に変更 gc = plot.PlotGraphics([line], 'WxLibPlot', 'xaxis', 'yaxis') # グラフタイトル、xyラベル追加結果
ドラッグを有効にしています。
リアルタイム描画
wx.Timerを利用して1秒置きにランダムな値を取る折れ線グラフを描画します。
今回はプロットの開始、終了を制御するボタンを追加しています。import wx import wx.lib import wx.lib.plot as plot # グラフ描画に使用 import random class MainFrame(wx.Frame): def __init__(self, parent, id, title): wx.Frame.__init__(self, parent, id, title, size=(500, 500)) # panel作成 self.panel = wx.Panel(self, -1) # 測定開始、停止用ボタン self.start_button = wx.Button(self, -1, label='start') self.stop_button = wx.Button(self, -1, label='stop') # graph作成 self.plotter = plot.PlotCanvas(self, -1) # plot点の初期値 self.x_val = 0 self.xy_val = [] self.plotter.enableLegend = True # 凡例表示をTrueにする self.plotter.fontSizeTitle = 18 # グラフタイトルの文字サイズを18にする(デフォルト=15) self.plotter.fontSizeLegend = 18 # 凡例の文字サイズを18にする(デフォルト=7) self.plotter.fontSizeAxis = 18 # xyラベル, 座標の文字サイズを18にする(デフォルト=10) # ズーム or ドラッグ機能を有効にする。どちらか片方しか有効にできない # self.plotter.enableZoom = True # self.plotter.enableDrag = True # 表示する線を作成 & 描画() line = plot.PolyLine(self.xy_val, legend='sample', colour='red', width=2) # 凡例文字追加、線の色を赤、太さを4に変更 gc = plot.PlotGraphics([line], 'RealTimePlot', 'xaxis', 'yaxis') # グラフタイトル、xyラベル追加 self.plotter.Draw(gc) # フレームのタイマーを作成 self.timer = wx.Timer(self) # sizer作成 & 設置 sizer1 = wx.FlexGridSizer(2, 1, gap=(0, 0)) # 2行1列のグラフとsizer2を並べる用サイザー sizer2 = wx.GridSizer(1, 2, gap=(0, 0)) # 1行2列のボタンを並べる用サイザー sizer1.Add(self.plotter, flag=wx.EXPAND) # flag=wx.EXPAND: 幅、高さを最大まで伸ばす sizer1.Add(sizer2, flag=wx.ALIGN_RIGHT) # flag=wx.ALIGN_RIGHT: 右寄せに設置 sizer1.AddGrowableCol(0) # 1列目の幅を最大まで伸ばす sizer1.AddGrowableRow(0) # 1行目の高さを最大まで伸ばす # ボタンの設置 sizer2.Add(self.start_button) sizer2.Add(self.stop_button) self.SetSizer(sizer1) # イベント達 self.start_button.Bind(wx.EVT_BUTTON, self.graph_start) self.stop_button.Bind(wx.EVT_BUTTON, self.graph_stop) self.Bind(wx.EVT_TIMER, self.graph_plot) # 画面中央にGUIを表示 self.Center() self.Show() def graph_start(self, event): self.plotter.Clear() # グラフを初期化 self.x_val, self.xy_val = 0, [] # x_val, xy_valを初期化 self.timer.Start(1000) def graph_stop(self, event): self.timer.Stop() def graph_plot(self, event): y_val = random.randint(0, 100) self.xy_val.append((self.x_val, y_val)) line = plot.PolyLine(self.xy_val, legend='sample', colour='red', width=2) gc = plot.PlotGraphics([line], 'RealTimePlot', 'xaxis', 'yaxis') self.plotter.Draw(gc) self.x_val += 1 def main(): app = wx.App() MainFrame(None, -1, 'WxLibPlot') app.MainLoop() if __name__ == '__main__': main()結果
スタートボタンを押した後一度白くなるのはグラフを初期化しているからです。
xSpecという属性を変更することで描画方法が変わります
self.plotter.xSpec = 'auto' # or 'min', int, (min, max), 'none'
上から、'auto', 'min', int, (min, max)となります。'auto'がデフォルトです。
整数型を代入した場合、'min'と動作は同じですが、座標が固定されます。上の例では、グラフを4分割してその境界上に座標を表示しています。'none'はx軸、ラベルが消えるだけなので省略します。
時間軸表示
一番書きたかった個所です。早速ですが、コードと結果を記載します。
時間間隔は1秒にしています。import datetime as dt import random import wx import wx.lib import wx.lib.plot as plot class TimeAxisPlot(plot.PlotCanvas): def __init__(self, parent, id): plot.PlotCanvas.__init__(self, parent, id) # レイアウト関係を定義 self.enableLegend = True self.fontSizeLegend = 18 self.fontSizeAxis = 18 self.xSpec = 4 self.startDate = dt.datetime.now() self.data = [] line = plot.PolyLine(self.data, legend='sample', colour='red') gc = plot.PlotGraphics([line], 'TimeAxisPlot', 'time', 'yaxis') self.Draw(gc) def _xticks(self, *args): ticks = plot.PlotCanvas._xticks(self, *args) # ticks = [(プロット点, 表示する文字), (),...()] new_ticks = [] for tick in ticks: t = tick[0] time_value = self.startDate + dt.timedelta(seconds=t) time_value_str = time_value.strftime('%H:%M:%S') new_ticks.append([t, time_value_str]) # new_ticks = [(プロット点, 時刻), (),...()] # 表示する文字を時刻に変更 return new_ticks class MainFrame(wx.Frame): def __init__(self, parent, id, title): wx.Frame.__init__(self, parent, id, title, size=(500, 500)) # panel作成 self.panel = wx.Panel(self, -1) # 測定開始、停止用ボタン self.start_button = wx.Button(self, -1, label='start') self.stop_button = wx.Button(self, -1, label='stop') # graph作成 self.plotter = TimeAxisPlot(self, -1) # plot点の初期値 self.x_val = 0 self.xy_val = [] self.plotter.enableLegend = True # 凡例表示をTrueにする self.plotter.fontSizeTitle = 18 # グラフタイトルの文字サイズを18にする(デフォルト=15) self.plotter.fontSizeLegend = 18 # 凡例の文字サイズを18にする(デフォルト=7) self.plotter.fontSizeAxis = 18 # xyラベル, 座標の文字サイズを18にする(デフォルト=10) # 表示する線を作成 & 描画() line = plot.PolyLine(self.xy_val, legend='sample', colour='red', width=2) # 凡例文字追加、線の色を赤、太さを4に変更 gc = plot.PlotGraphics([line], 'RealTimePlot', 'xaxis', 'yaxis') # グラフタイトル、xyラベル追加 self.plotter.Draw(gc) # フレームのタイマーを作成 self.timer = wx.Timer(self) # sizer作成 & 設置 sizer1 = wx.FlexGridSizer(2, 1, gap=(0, 0)) # 2行1列のグラフとsizer2を並べる用サイザー sizer2 = wx.GridSizer(1, 2, gap=(0, 0)) # 1行2列のボタンを並べる用サイザー sizer1.Add(self.plotter, flag=wx.EXPAND) # flag=wx.EXPAND: 幅、高さを最大まで伸ばす sizer1.Add(sizer2, flag=wx.ALIGN_RIGHT) # flag=wx.ALIGN_RIGHT: 右寄せに設置 sizer1.AddGrowableCol(0) # 1列目の幅を最大まで伸ばす sizer1.AddGrowableRow(0) # 1行目の高さを最大まで伸ばす # ボタンの設置 sizer2.Add(self.start_button) sizer2.Add(self.stop_button) self.SetSizer(sizer1) # イベント達 self.start_button.Bind(wx.EVT_BUTTON, self.graph_start) self.stop_button.Bind(wx.EVT_BUTTON, self.graph_stop) self.Bind(wx.EVT_TIMER, self.graph_plot) # 画面中央にGUIを表示 self.Center() self.Show() def graph_start(self, event): self.plotter.Clear() # グラフを初期化 self.x_val, self.xy_val = 0, [] # x_val, xy_valを初期化 self.timer.Start(1000) def graph_stop(self, event): self.timer.Stop() def graph_plot(self, event): y_val = random.randint(0, 100) self.xy_val.append((self.x_val, y_val)) line = plot.PolyLine(self.xy_val, legend='sample', colour='red', width=2) gc = plot.PlotGraphics([line], 'RealTimePlot', 'xaxis', 'yaxis') self.plotter.Draw(gc) self.x_val += 1 def main(): app = wx.App() MainFrame(None, -1, 'TimeAxisPlot') app.MainLoop() if __name__ == '__main__': main()結果
plot.Canvasを継承して新しいクラスを作成、x軸座標のメソッドをオーバーライドします。
ここで、def _xticks(self, *args): ticks = plot.PlotCanvas._xticks(self, *args) # ex)ticks = [(0, '0.0'), (0.5, '0.5'), (1.0, '1.0'), (1.5, '1.5'), (2.0, '2.0')] # [(x座標(float)), (x座標に表示する文字(str))...]ticksは[(x座標(float)), (x座標に表示する文字(str))...]を返します。
この表示する文字を時刻に変更することで時間軸を作成しています。方法
座標と時刻のタプルを作り、空リストnew_ticksにappendする
ex)スタート時刻:0:00, ticks= [(0, '0.0'), (0.5, '0.5'), (1.0, '1.0'), (1.5, '1.5'), (2.0, '2.0')]の時for文1回目
1. tick = (0, '0.0')
2. t = 0
3. スタート時刻にt秒ずれた日付を作成、strに変形(=00:00)
4. (0, '00:00')をnew_ticksにappend
以下ループnew_ticks = [] for tick in ticks: # 取得したticksでループ # タプルの0番目(x座標点)を取得 t = tick[0] time_value = self.startDate + dt.timedelta(seconds=t) time_value_str = time_value.strftime('%H:%M:%S') new_ticks.append([t, time_value_str]) # new_ticks = [(プロット点, 時刻), (),...()] # 表示する文字を時刻に変更 return new_ticks最後に
読んで頂きありがとうございます。
実行中に気付いたのですが、描画速度の最速は0.05s程度でした。
これよりタイマーの間隔を短くしても実行速度に変化がなかったので注意が必要です。参考サイト
公式
wx.lib.plot — wxPython Phoenix 4.1.1a1 documentationリアルタイム描画の参考
wxPython:アニメーションとグラフ描画を同時描画する時間軸の参考
【備忘録】プロットの y 軸の目盛をカスタマイズ ─ wxPython
wxPython-users - wx.lib.plot custom labels?




- 投稿日:2020-10-13T22:57:38+09:00
Pythonで日時フォーマットを判定してUnixtimeに変換する
ソースコードは以下になります。
日時の変換の可否によって判定しています。import datetime def validate_datetime(date_str): try: date_obj = datetime.datetime.strptime(date_str, '%Y-%m-%d %H:%M:%S') except: print('Invalid Datetime Format') return False return date_obj def main(): date_str = '2020-10-13 22:47:57' result = validate_datetime(date_str) if result: print(int(result.timestamp())) if __name__ == '__main__': main()実行結果は以下になります。
1602596877最後まで読んでいただきありがとうございました。
またお会いしましょう。
- 投稿日:2020-10-13T22:25:23+09:00
【Udemy Python3入門+応用】 66. 独自例外の作成
※この記事はUdemyの
「現役シリコンバレーエンジニアが教えるPython3入門+応用+アメリカのシリコンバレー流コードスタイル」
の講座を受講した上での、自分用の授業ノートです。
講師の酒井潤さんから許可をいただいた上で公開しています。■独自例外の作成
◆raise
raise IndexError('test error')resultTraceback (most recent call last): File "/~~~", line 1, in <module> raise IndexError('test error') IndexError: test error
raiseを使うことで、指定したエラーを引き起こすことができる。
◆独自のエラーを作る
class UppercaseError(Exception): pass def check(): words = ['APPLE', 'orange', 'banana'] for word in words: if word.isupper(): raise UppercaseError(word) check()resultTraceback (most recent call last): File "/~~~", line 10, in <module> check() File "/~~~", line 8, in check raise UppercaseError(word) __main__.UppercaseError: APPLEこのように、プログラム内で自分で作ったエラーを発生させることができるようになる。
class UppercaseError(Exception): pass def check(): words = ['APPLE', 'orange', 'banana'] for word in words: if word.isupper(): raise UppercaseError(word) try: check() except: print('This is my fault. Go next.')resultThis is my fault. Go next.このようにしておくと、処理内でエラーが発生したときに、
「これはPythonのデフォルトのエラーではなくて、自分で作ったエラーが発生しているんだな」
と認識できるようになるため、開発で便利。
- 投稿日:2020-10-13T22:19:43+09:00
停まれ標識検知 可視化部分の開発part3 物体を検知した時にソケット通信を使って音声で知らせる
前回まで
前回は,socket通信を使って記録する部分までを書いていきました.今回はsocket通信をした後に音声を使ってお知らせする部分まで作っていきたいと思います.
※今回は正直あんまり中身がありません.ちなみに今回はスマホを検知した時に限定して書いています今回実装した機能
Yolov5上で物体を検知した時➡ソケット通信をする.➡ソケット通信を受けたときに音声を再生する.
※ただこれだけをやっています.本当は場合分けでこれが来たらこれっていうプログラムが書きたいなぁと思っているので次回以降書いていきたいと思っています.クライアント側
detect.pyif label1=="chair": print("椅子を検知しました.") with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s2: s2.connect(('127.0.0.1', 50007)) s2.sendall(b'isukenti') data = s2.recv(1024)※クライアント部分は前回同様です.
サーバ側server.pyfrom playsound import playsound import socket # AF = IPv4 という意味 # TCP/IP の場合は、SOCK_STREAM を使う with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s: # IPアドレスとポートを指定 s.bind(('127.0.0.1', 50007)) # 1 接続 s.listen(1) # connection するまで待つ while True: # 誰かがアクセスしてきたら、コネクションとアドレスを入れる conn, addr = s.accept() with conn: while True: # データを受け取る data = conn.recv(1024) if not data: break #print('data : {}, addr: {}'.format(data, addr)) conn.sendall(b'Received: ' + data) playsound('2.wav') # クライアントにデータを返す(b -> byte でないといけない)基本的には,playsound()を使って音声を再生しているだけです.
pip install playsound
音声作成はこちらを使っています.
https://w.atwiki.jp/softalk/次回へ
次回はもう少し中身のある話を書いていけたらいいなと思っていますが,実装したことはそのまま載せたいので中身がない記事になってしまうときもあります.ごめんなさい.
次回は,物体ごとに音声を場合分けするプログラムを書いていきたいなと考えていますのでよろしくお願いします.実際に動いている動画
- 投稿日:2020-10-13T22:06:33+09:00
【Udemy Python3入門+応用】 65. 例外処理
※この記事はUdemyの
「現役シリコンバレーエンジニアが教えるPython3入門+応用+アメリカのシリコンバレー流コードスタイル」
の講座を受講した上での、自分用の授業ノートです。
講師の酒井潤さんから許可をいただいた上で公開しています。■例外処理
◆基本
l = [0, 1, 2] i = 5 try: print(l[i]) except: print('Error!')resultError!
try:の中に書いたものを実行しようとし、それが何らかのエラーにより実行できなかった場合、
except:内の処理が実行される。
◆エラーの種類の指定
l = [0, 1, 2] del l try: print(l) except IndexError as ex: print('Error massage: {}'.format(ex)) except NameError as ex: print('Error massage: {}'.format(ex))resultError massage: name 'l' is not defined
IndexErrorだったらこの処理、
NameErrorだったらこの処理、といったようにエラーの種類の指定もできる。
◆finally:
l = [0, 1, 2] i = 5 try: print(l[i]) except: print('Error!') finally: print('clean up')resultError! clean up
finally:内に書いた処理は、tryが成功しようが、exceptとなろうが、必ず実行される。
l = [0, 1, 2] i = 5 try: print(l[i]) finally: print('clean up')resultclean up Traceback (most recent call last): File "/~~~", line 5, in <module> print(l[i]) IndexError: list index out of rangeしたがって、実際エラーが起きてしまった場合でも、
finally内の処理が先に実行され、その後エラーでプログラムが停止することになる。
◆else:
l = [0, 1, 2] try: print(l[0]) except: print('Error!') else: print('done')result0 done
else:を使うと、try:内の処理が成功した場合のみ、else:内の処理が実行される。
- 投稿日:2020-10-13T22:01:16+09:00
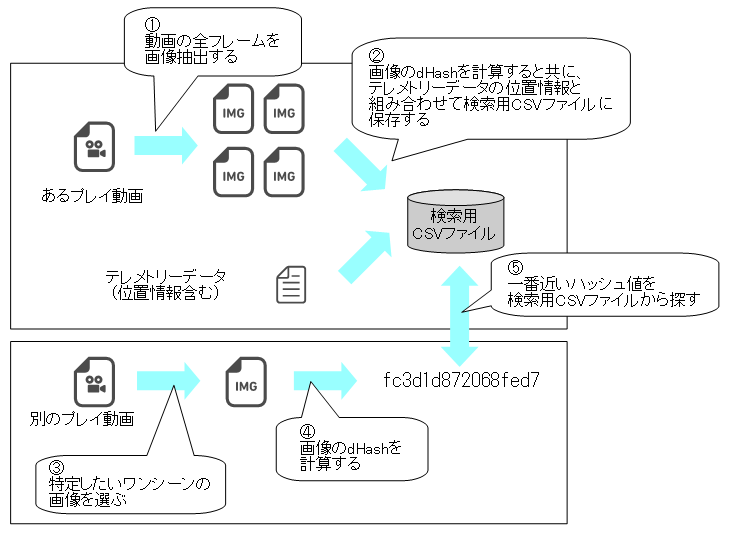
dHashを使ってレースゲームのワンシーンからコース上の位置を特定する
1. はじめに
類似画像検索アルゴリズムの一種に dHash というものがあります。アルゴリズムの中身は「Perceptual Hashを使って画像の類似度を計算してみる」を見ていただくのが分かり易いのですが、ざっくり以下のような特徴のある類似画像検索アルゴリズムだと私は理解しています。
- ハッシュ値計算が非常に高速
- 検索精度が比較的高く、特にfalse-positiveが少ない
- 対象画像に対してグレースケール変換した上でハッシュ値計算を行うため、多少の色彩のブレに強い
- 対象画像に対して9x8サイズの画像に縮小したうえでハッシュ値計算を行うため、多少の位置ズレに強い
そこで、この dHash を使って、レースゲーム Assetto Corsa のプレイのワンシーン(オンボード映像)からそのシーンがコース上のどの位置の画像なのかを特定することができるかを試してみました。
具体的には、以下のような流れになります。
①
まず、コースを1周するあるプレイ動画(オンボード映像)から全フレームを PNG 画像として抽出・保存します。②
保存した全フレームの画像に対して dHash のハッシュ値を計算します。また、プレイ動画撮影時に取得したテレメトリーデータからある時刻に車両がどの位置にあったか特定できるので、その位置情報と組み合わせて計算したハッシュ値を検索用CSVファイルに保存します。③
一方、別のプレイ動画からコース上の位置を特定したいワンシーンを選択します。④
選択したワンシーンの画像に対して dHash のハッシュ値を計算します。⑤
計算した dHash のハッシュ値に一番近いハッシュ値を持つ画像を検索用CSVファイルから検索します。検索でヒットした画像には②で位置情報を紐付けているので、その位置を選択したワンシーンのコース上の位置と見做します。レースゲームのワンシーンは、コース上近い位置にいても、プレイごとに若干通るラインに差が出るなどの理由で若干位置ズレが発生します。そういった差を吸収して、類似画像検索ができるかというのが今回のポイントになるかと思います。
2. 実装コード
今回は Python で上述の処理を実装します。
2-1. プレイ動画からのフレーム画像抽出
プレイ動画ファイル(mp4ファイル)から全フレームの画像を抽出するには今回は OpenCV を使いました。以下のページを参考にしています。
フレーム画像が「(フレーム番号).png」というファイル名で保存されます。
01_extract_frames.pyimport cv2 import sys def extract_frame(video_file, save_dir): capture = cv2.VideoCapture(video_file) frame_no = 0 while True: retval, frame = capture.read() if retval: cv2.imwrite(r'{}\{:06d}.png'.format(save_dir, frame_no), frame) frame_no = frame_no + 1 else: break if __name__ == '__main__': video_file = sys.argv[1] save_dir = sys.argv[2] extract_frame(video_file, save_dir)このスクリプトは③でも利用します。
2-2. dHashの計算と位置情報の紐付け
抽出したフレーム画像のうち、ある期間(特定の周回の部分)に該当する画像について、ImageHash パッケージの dhash 関数を用いて dHash のハッシュ値を計算します。加えて、以下のin-game Appスクリプトで取得したテレメトリーデータ(事前に該当部分だけを抽出)と紐付けを行い、検索用CSVファイルに出力します。
02_calc_dhash.pyfrom PIL import Image, ImageFilter import imagehash import csv import sys frame_width = 1280 frame_hight = 720 trim_lr = 140 trim_tb = 100 dhash_size = 8 def calc_dhash(frame_dir, frame_no_from, frame_no_to, telemetry_file, output_file): # テレメトリーデータファイルを読み込む position_data = [row for row in csv.reader(open(telemetry_file), delimiter = '\t')] writer = csv.writer(open(output_file, mode = 'w', newline='')) for i in range(frame_no_from, frame_no_to + 1): # 抽出したフレーム画像を読み込み、トリミングする(タイムなどが画像端に表示されているのを消すため) frame = Image.open(r'{}\{:06d}.png'.format(frame_dir, i)) trimed_frame = frame.crop(( trim_lr, trim_tb, frame_width - trim_lr, frame_hight - trim_tb)) # dHash 値の計算 dhash_value = str(imagehash.dhash(trimed_frame, hash_size = dhash_size)) # テレメトリーデータとの紐付け # 画像もテレメトリーも一定周期で出力されているため、単純に行数比例で紐付ける position_no = round((len(position_data) - 1) * (i - frame_no_from) / (frame_no_to - frame_no_from)) writer.writerow([ i, dhash_value, position_data[position_no][9], position_data[position_no][10] ]) if __name__ == '__main__': frame_dir = sys.argv[1] frame_no_from = int(sys.argv[2]) frame_no_to = int(sys.argv[3]) telemetry_file = sys.argv[4] output_file = sys.argv[5] calc_dhash(frame_dir, frame_no_from, frame_no_to, telemetry_file, output_file)このスクリプトの結果、以下のような(フレーム番号)、(ハッシュ値)、(メートル単位の2D座標位置)の情報がCSVファイルに出力されます。
731,070b126ee741c080,-520.11,139.89 732,070b126ee7c1c080,-520.47,139.90 733,070b126ee7c1c480,-520.84,139.92このスクリプトは④でも利用します。
2-3. 一番近いハッシュ値の探索
指定したハッシュ値に一番近いハッシュ値を持つ画像を2-2.で出力した検索用CSVファイルから検索します。
ハッシュ値同士の近さはハミング距離を用います。ハミング距離の算出には gmpy2 パッケージの popcount を利用しています(とても高速らしいので)。
03_match_frame.pyimport csv import gmpy2 import sys def match_frame(base_file, search_hash): base_data = [row for row in csv.reader(open(base_file))] min_distance = 64 min_line = None results = [] for base_line in base_data: distance = gmpy2.popcount( int(base_line[1], 16) ^ int(search_hash, 16) ) if distance < min_distance: min_distance = distance results = [base_line] elif distance == min_distance: results.append(base_line) print("Distance = {}".format(min_distance)) for min_line in results: print(min_line) if __name__ == '__main__': base_file = sys.argv[1] search_hash = sys.argv[2] match_frame(base_file, search_hash)以下のように、ハッシュ値が一番近い画像の情報と紐付いた位置情報を出力します。
(同じ距離の画像が複数ある場合は、全ての画像情報を表示します)> python.exe 03_match_frame.py dhash_TOYOTA_86.csv cdc9cebc688f3f47 Distance = 8 ['13330', 'c9cb4cb8688f3f7f', '-1415.73', '-58.39'] ['13331', 'c9eb4cbc688f3f7f', '-1415.39', '-58.44']3. 検索結果
今回は、ニュルブルクリンク北コース(全長20.81km)を TOYOTA 86 GT で走行したプレイ動画を全フレーム抽出⇒ハッシュ値計算を行い、BMW Z4 で走行した別のプレイ動画の幾つかのシーンの画像に近い画像を探してみます。
まずは有名どころの3つのコーナーの画像がちゃんと検索できるか確認してみます。
- Schwedenkreuz
検索に用いた画像 ヒットした画像 画像 ハッシュ値 ced06061edcf9f2d 0c90e064ed8f1f3d 位置情報 (-2388.29, 69.74) (-2416.50, 66.67) ハッシュ値の距離 = 10, 位置情報のズレ = 28.4m
dHash ではハッシュ値の距離が10以下だと同じ画像と見做すと言われているそうですが、ギリギリですね。画像の上でも、コーナーの形状は似ていますが、周りの木の位置は若干違っており、似ている or 似ていないを判断し辛いですね。
- Bergwerk
検索に用いた画像 ヒットした画像 画像 ハッシュ値 7c5450640c73198c 7c7c50642d361b0a 位置情報 (317.58, -121.52) (316.18, -121.45) ハッシュ値の距離 = 11, 位置情報のズレ = 1.4m
これは画像的にはかなり近いですね。ただ、ハッシュ値の距離は 11 と先ほどより大きくなっています。
- Karussell
検索に用いた画像 ヒットした画像 画像 ハッシュ値 665d1d056078cde6 665c1d856050da8d 位置情報 (2071.48, 77.01) (2071.23, 77.12) ハッシュ値の距離 = 13, 位置情報のズレ = 0.27m
車両の位置的にも非常に近く、画像もかなり似ているように見えますが、よく見ると若干向きが違いますね。ハッシュ値の距離は 13 と結構大きいです。
以上、有名どころの3か所のコーナーで試してみましたが、大体近い位置は特定できるようです。
その他、ランダムに選択した10か所のシーンで試してみましたが、以下のようになりました。
- 正しい位置のみがヒット:6件
- 正しい位置と誤った位置の両方がヒット:1件
- 誤った位置のみヒット:3件
誤った位置のみヒットしたケースを1件だけ以下に示します。
検索に用いた画像 ヒットした画像 画像 ハッシュ値 b7b630b24c1e1f1e b7b43839481e3f1f 位置情報 (1439.61, -18.69) (2059.41, 37.44) ハッシュ値の距離 = 9, 位置情報のズレ = 622.34m
左右の木の生い茂り方やコースの先が左カーブ or ストレートと結構違いがあるように見えるのですが、ハッシュ値の距離は 9 と比較的近いです。
ちなみに、本来ヒットしてほしい画像は以下です。
検索に用いた画像 ヒットした画像 ハッシュ値の差 = 13
ぱっと見は似た画像ですが、よく見るとずれており、その結果比較的大きい差になっているのかなと思います。
4. さいごに
本記事では、レースゲームのシーンをdHashで類似画像検索してみました。
有名どころのコーナーなど特徴的なシーンに関しては比較的精度は良いのですが、ランダムにシーンを選んでみると勝率7割といったところでした(確かめた件数が10件と少ない点は許してください)。
しっかりとした解釈ではなく、個人的な感想としては以下の感じです。
- dHashはハッシュ値の距離が10以下だと同じ画像と見做すそうですが、今回ではかなり似た画像でも8-15程度の距離が出ており、判断のしきい値は検討が必要かな。
- 人が見ると違う画像でも、8-10ぐらいの距離になっていることもあり、false-positive が少ないとは言い切れないような。(これは「人が見て違う」が人によって異なりそうな気もするので何とも言えないですが)
精度を向上させたいなら、以下のような方策も考えらるのではないかと思います。
- 一番近い画像だけではなく、ある程度近い範囲の画像を確認する。
- 検索する際に1シーンだけではなく前後のシーンも含めて検索する









- 投稿日:2020-10-13T21:32:55+09:00
pandasで欠損値nanじゃないデータを抽出する方法
- 環境
- macOS Catalina バージョン10.15.7
- Python 3.8.5
- pandas 1.1.3
抽出元のデータはこんなかんじ
df = pandas.read_csv('CSV.csv') print(df)出力名前 回数 開始 終了 0 ぽんすけ 1 9:00 18:00 1 ぽんすけ 2 18:00 NaN 2 ぽんすけ 3 9:00 13:00 3 ぽんすけ 4 NaN NaN 4 ぽんすけ 5 9:00 NaN 5 ぽんすけ 6 18:00 NaN 6 ぽんすけ 7 12:00 NaN 7 ぽんすけ 8 12:00 NaN 8 ぽんすけ 9 NaN 18:00 9 ぽんすけ 10 NaN NaN1つのカラムがNaNじゃないデータを抽出する
抽出したい
データ開始 終了 x NaN NaN o NaNじゃない NaN x NaN NaNじゃない o NaNじゃない NaNじゃない 方法# [開始]カラムがNaNのデータを削除する方法 print(df.dropna(subset=['開始'])) # [開始]カラムがNaNではないデータを抽出する方法 print(df[df['開始'].notna()]) # [開始]カラムがNaNではないデータを抽出する方法 print(df.query('開始.notna()', engine='python'))出力名前 回数 開始 終了 0 ぽんすけ 1 9:00 18:00 1 ぽんすけ 2 18:00 NaN 2 ぽんすけ 3 9:00 13:00 4 ぽんすけ 5 9:00 NaN 5 ぽんすけ 6 18:00 NaN 6 ぽんすけ 7 12:00 NaN 7 ぽんすけ 8 12:00 NaN2つのカラム両方NaNじゃないデータを抽出する
抽出したい
データ開始 終了 x NaN NaN x NaNじゃない NaN x NaN NaNじゃない o NaNじゃない NaNじゃない 方法# [開始]または[終了]カラムのどちらかがNaNのデータを削除する方法 print(df.dropna(subset=['開始', '終了'])) # [開始][終了]カラム両方がNaNではないデータを抽出する方法 print(df.query('開始.notna() & 終了.notna()', engine='python'))出力名前 回数 開始 終了 0 ぽんすけ 1 9:00 18:00 2 ぽんすけ 3 9:00 13:002つのカラムどっちかがNaNじゃないデータを抽出する
抽出したい
データ開始 終了 x NaN NaN o NaNじゃない NaN o NaN NaNじゃない o NaNじゃない NaNじゃない 方法# NaNを空文字にして[開始][終了]カラムをくっつけて空文字ではないデータを抽出する方法 print(df[df['開始'].str.cat(df['終了'], na_rep='') != '']) # [開始][終了]カラムどちらかがNaNではないデータを抽出する方法 print(df.query('開始.notna() | 終了.notna()', engine='python'))出力名前 回数 開始 終了 0 ぽんすけ 1 9:00 18:00 1 ぽんすけ 2 18:00 NaN 2 ぽんすけ 3 9:00 13:00 4 ぽんすけ 5 9:00 NaN 5 ぽんすけ 6 18:00 NaN 6 ぽんすけ 7 12:00 NaN 7 ぽんすけ 8 12:00 NaN 8 ぽんすけ 9 NaN 18:00「1つのカラムがNaNじゃない」&「1つのカラムがNaN」のデータを抽出する
抽出したい
データ開始 終了 x NaN NaN x NaNじゃない NaN o NaN NaNじゃない x NaNじゃない NaNじゃない 方法# [開始]カラムがNaNを抽出した後に[終了]カラムがNaNのデータを削除する方法 print(df[df['開始'].isna()].dropna(subset=['終了'])) # [開始]カラムがNaNではない かつ [終了]カラムがNaNのデータを抽出する方法 print(df.query('開始.isna() & 終了.notna()', engine='python'))出力名前 回数 開始 終了 8 ぽんすけ 9 NaN 18:00
- 投稿日:2020-10-13T20:35:37+09:00
Unalignable boolean Series provided as indexerとなったときの対応方法
事象 :
notnaでNaNではないインデックスでデータを抽出しようとしたら怒られた
- 環境
- macOS Catalina バージョン10.15.7
- Python 3.8.5
- pandas 1.1.3
import pandas if __name__ == '__main__': df = pandas.read_csv('CSV.csv') print(df[df.query('名前 == "ぽんすけ"')['開始'].notna()])エラーメッセージpandas.core.indexing.IndexingError: Unalignable boolean Series provided as indexer (index of the boolean Series and of the indexed object do not match).原因 : 不明
抽出しようとしているDataFrameのインデックス分のインデックスが
notnaの結果にないから?
誰か教えて欲しい。# 抽出しようとしているDataFrameのインデックスは0~39までの40ある print(df) # 名前 回数 開始 終了 # 0 ぽんすけ 1 9:00 18:00 # ...省略... # 39 ぽんすけ 10 NaN NaN # notnaの結果のインデックスは抜け番がいっぱいで10しかない print(df.query('名前 == "ぽんすけ"')['開始'].notna()) # 0 True # 2 True # 5 True # 11 True # 14 False # 21 True # 24 True # 29 False # 34 True # 39 False # Name: 開始, dtype: bool
notnaの結果のインデックスに合うDataFrameから抽出すればなんとかなりそう# notnaの結果のインデックスに合うDataFrame print(df.query('名前 == "ぽんすけ"')) # 名前 回数 開始 終了 # 0 ぽんすけ 1 9:00 18:00 # 2 ぽんすけ 3 9:00 13:00 # 5 ぽんすけ 7 12:00 NaN # 11 ぽんすけ 5 9:00 NaN # 14 ぽんすけ 4 NaN NaN # 21 ぽんすけ 2 18:00 NaN # 24 ぽんすけ 6 18:00 NaN # 29 ぽんすけ 9 NaN 18:00 # 34 ぽんすけ 8 12:00 NaN # 39 ぽんすけ 10 NaN NaN対応 : notnaの結果のインデックスに合うDataFrameから抽出する
import pandas if __name__ == '__main__': df = pandas.read_csv('CSV.csv') ponsuke = df.query('名前 == "ぽんすけ"') print(ponsuke[ponsuke['開始'].notna()])できた名前 回数 開始 終了 0 ぽんすけ 1 9:00 18:00 2 ぽんすけ 3 9:00 13:00 5 ぽんすけ 7 12:00 NaN 11 ぽんすけ 5 9:00 NaN 21 ぽんすけ 2 18:00 NaN 24 ぽんすけ 6 18:00 NaN 34 ぽんすけ 8 12:00 NaN
- 投稿日:2020-10-13T19:54:36+09:00
AWS LambdaでSlackに添付ファイルとして投稿(Python)
Amazon S3からファイルを取得してSlackに添付ファイルとして投稿するAWS Lambdaを作っていたが、AWS LambdaのPython環境にはrequestsモジュールが入っていなかったので苦戦した。
前提・環境
AWS Lambda Python環境
やりたかった事
- Amazon S3からファイルを取得する
- ファイルをSlackの
files.uploadAPIで添付ファイルとして投稿する(content typeはmultipart/form-dataを使う)できなかったこととその理由
Pythonでのファイルのアップロードは、
https://qiita.com/5zm/items/92cde9e043813e02eb68
や
https://www.it-swarm-ja.tech/ja/python/python%E3%81%A7%E3%83%AA%E3%82%AF%E3%82%A8%E3%82%B9%E3%83%88%E3%81%A8-multipart-formdata%E3%82%92%E9%80%81%E4%BF%A1%E3%81%99%E3%82%8B%E6%96%B9%E6%B3%95%EF%BC%9F/1069592211/
にあるように、requestsを使うのが定番。
しかしAWS LambdaのPython環境にはrequestsモジュールが入っていなかった。解決方法
- requestsの含まれるLambda Layerを使う
- requestsではなくurllib.requestを使う <- 採用
実装
urllib.requestを使うと言ってもmultipart form dataを作成する必要があるので以下のURLを参考にした。
https://necoyama3.hatenablog.com/entry/20150608/1434982490
この記事内に記載にあるencode_multipart_formdataメソッドはデータ部とファイル部をmultipart form dataの形式に変換してくれる。これを利用して以下のようにした。
## ポイント1: fileパラメータを除いたパラメータを定義する data = { 'token': <your token>, 'channels': <your channels>, 'initial_comment': key + 'を投稿します:eyes:', 'filename': key, 'filetype': 'webp' } url = "https://slack.com/api/files.upload" content = open('/tmp/' + key, 'rb').read() ## ポイント2: fileパラメータを定義する file = {'file': {'filename': key, 'content': content}} ## ポイント3: dataとfileをひとつのmultipart form dataに変換する content_type, body = encode_multipart_formdata(data, file) header = {'Content-Type': content_type} request = urllib.request.Request(url, body, header) response = urllib.request.urlopen(request)ポイントになるのは
1.data変数でSlack files.upload APIのfileパラメータを除いたパラメータを定義する
2.file変数でSlack files.upload APIのfileパラメータを定義する
3.encode_multipart_formdataメソッドでmultipart form dataに変換するの3点。
これでrequestsを使わずにAWS LambdaでSlackにファイルを投稿できるようになった。最後に
Lambda Layerを作るのとどちらが楽なんだろうか…?
- 投稿日:2020-10-13T19:09:33+09:00
Flask-AdminとFlask-LoginによるDB管理者画面の実装
はじめに
Flaskを使ったDjangoの管理者画面のようなものを実装するには、Flask-Adminというライブラリを使うと便利です。
しかしFlask-Adminをそのまま使うだけでは、パスワードを打つことなく(ログインすることなく)管理者画面に入ることができてしまい、セキュリティ上とても脆弱です。
この記事では、Flask-AdminとFlask-Loginを使用してログイン機能のついたDB管理者画面の実装を行っていきます。この記事は
参考元
- Introduction To Flask-Admin
- This example shows how to integrate Flask-Login authentication with Flask-Admin using the SQLAlchemy backend.
の情報量が若干少ないので、日本語でもう少し解説の情報を増やしてみた記事です。
英語のできる方や冗長な言い回しが苦手な方は、上記のリンクから参考元サイトを見ることができます。MVCについて
Model-View-Controllerモデルについてほんの少しで良いので知っておく必要があります。
なぜならこの記事でモデルとかコントローラーとかの単語を出すからです。
↓の記事とかが参考になると思います。
MVCモデルについて筆者の環境
Ubuntu20.04LTS MySQL 8.0.21 Python3.8.5 Flask==1.1.2 Flask-Admin==1.5.6 Flask-Login==0.5.0 Flask-SQLAlchemy==2.4.4 mysqlclient==2.0.1ソースコード全体
いきなりですが、お時間がない方用に最終的なソースコード全体をお見せします。
詳しい解説はこれ以降。from flask import Flask, abort, jsonify, render_template, request, redirect, url_for from wtforms import form, fields, validators import flask_admin as admin import flask_login as login from flask_admin.contrib import sqla from flask_admin import helpers, expose from flask_admin.contrib.sqla import ModelView from werkzeug.security import generate_password_hash, check_password_hash from flask_sqlalchemy import SQLAlchemy app = Flask(__name__) app.config['SQLALCHEMY_DATABASE_URI'] = "mysql://{user}:{password}@{host}/{db_name}".format(**{ 'user': os.environ['RDS_USER'], 'password': os.environ['RDS_PASS'], 'host': os.environ['RDS_HOST'], 'db_name': os.environ['RDS_DB_NAME'] }) app.config['SECRET_KEY'] = os.environ['FLASK_SECRET_KEY'] db = SQLAlchemy(app) class AdminUser(db.Model): id = db.Column(db.Integer, primary_key=True) login = db.Column(db.String(50), unique=True) password = db.Column(db.String(250)) @property def is_authenticated(self): return True @property def is_active(self): return True @property def is_anonymous(self): return False def get_id(self): return self.id def __unicode__(self): return self.username class LoginForm(form.Form): login = fields.StringField(validators=[validators.required()]) password = fields.PasswordField(validators=[validators.required()]) def validate_login(self, field): user = self.get_user() if user is None: raise validators.ValidationError('ユーザー名もしくはパスワードが違います。') if not check_password_hash(user.password, self.password.data): raise validators.ValidationError('ユーザー名もしくはパスワードが違います。') def get_user(self): return db.session.query(AdminUser).filter_by(login=self.login.data).first() class RegistrationForm(form.Form): login = fields.StringField(validators=[validators.required()]) password = fields.PasswordField(validators=[validators.required()]) def validate_login(self, field): if db.session.query(AdminUser).filter_by(login=self.login.data).count() > 0: raise validators.ValidationError('同じユーザー名が存在します。') def init_login(): login_manager = login.LoginManager() login_manager.init_app(app) @login_manager.user_loader def load_user(user_id): return db.session.query(AdminUser).get(user_id) class MyModelView(sqla.ModelView): def is_accessible(self): return login.current_user.is_authenticated class MyAdminIndexView(admin.AdminIndexView): @expose('/') def index(self): if not login.current_user.is_authenticated: return redirect(url_for('.login_view')) return super(MyAdminIndexView, self).index() @expose('/login/', methods=('GET', 'POST')) def login_view(self): form = LoginForm(request.form) if helpers.validate_form_on_submit(form): user = form.get_user() login.login_user(user) if login.current_user.is_authenticated: return redirect(url_for('.index')) link = '<p>アカウント未作成用 <a href="' + url_for('.register_view') + '">ここをクリック</a></p>' self._template_args['form'] = form self._template_args['link'] = link return super(MyAdminIndexView, self).index() @expose('/register/', methods=('GET', 'POST')) def register_view(self): form = RegistrationForm(request.form) if helpers.validate_form_on_submit(form): user = AdminUser() form.populate_obj(user) user.password = generate_password_hash(form.password.data) db.session.add(user) db.session.commit() login.login_user(user) return redirect(url_for('.index')) link = '<p>既にアカウントを持っている場合は <a href="' + url_for('.login_view') + '">ここをクリックしてログイン</a></p>' self._template_args['form'] = form self._template_args['link'] = link return super(MyAdminIndexView, self).index() @expose('/logout/') def logout_view(self): login.logout_user() return redirect(url_for('.index')) init_login() admin = admin.Admin(app, '管理者画面', index_view=MyAdminIndexView(), base_template='my_master.html') admin.add_view(MyModelView(AdminUser, db.session)) @app.route("/", methods=['GET']) def index(): return "Hello, World!" if __name__ == "__main__": app.run()DBに接続する
app = Flask(__name__) app.config['SQLALCHEMY_DATABASE_URI'] = "mysql://{user}:{password}@{host}/{db_name}".format(**{ 'user': os.environ['RDS_USER'], 'password': os.environ['RDS_PASS'], 'host': os.environ['RDS_HOST'], 'db_name': os.environ['RDS_DB_NAME'] }) app.config['SECRET_KEY'] = os.environ['FLASK_SECRET_KEY'] db = SQLAlchemy(app)ここの解説はインターネット上に日本語の記事も多いので省略します。
管理者アカウントのモデルを作成する
class AdminUser(db.Model): id = db.Column(db.Integer, primary_key=True) login = db.Column(db.String(50), unique=True) password = db.Column(db.String(250)) @property def is_authenticated(self): return True @property def is_active(self): return True @property def is_anonymous(self): return False def get_id(self): return self.id def __unicode__(self): return self.usernameloginはユーザー名のことです。
管理者画面にログインする際のユーザー名とパスワードを定義しています。
各メソッドにpropertyデコレータが付いてるのは、後にログイン処理を書いていくときにログイン済かどうかとかそういう情報を取得するためです。
propertyデコレータについて詳しく知りたい方は↓
プロパティコントローラーの作成
class LoginForm(form.Form): login = fields.StringField(validators=[validators.required()]) password = fields.PasswordField(validators=[validators.required()]) def validate_login(self, field): user = self.get_user() if user is None: raise validators.ValidationError('ユーザー名もしくはパスワードが違います。') if not check_password_hash(user.password, self.password.data): raise validators.ValidationError('ユーザー名もしくはパスワードが違います。') def get_user(self): return db.session.query(AdminUser).filter_by(login=self.login.data).first() class RegistrationForm(form.Form): login = fields.StringField(validators=[validators.required()]) password = fields.PasswordField(validators=[validators.required()]) def validate_login(self, field): if db.session.query(AdminUser).filter_by(login=self.login.data).count() > 0: raise validators.ValidationError('同じユーザー名が存在します。')ビュー(ログイン画面とか管理者アカウント登録画面)のフォームから入力を受けた際の処理を書いたコントローラーです。
ここで注目してほしいのは、LoginFormクラスにあるcheck_password_hash(user.password, self.password.data)です。これはハッシュ化されて保存してある本当のパスワードと、ログイン画面から入力された値をハッシュ化したものを、両者比較し一致したらTrueを返しれくれる便利なやつです。
推奨されないですが、もしDBにパスワードを平文で保存している時は条件式のところを
if user.password != self.password.data:に変更すると良いと思います。
ビューの作成
def init_login(): login_manager = login.LoginManager() login_manager.init_app(app) @login_manager.user_loader def load_user(user_id): return db.session.query(AdminUser).get(user_id) class MyModelView(sqla.ModelView): def is_accessible(self): return login.current_user.is_authenticated class MyAdminIndexView(admin.AdminIndexView): @expose('/') def index(self): if not login.current_user.is_authenticated: return redirect(url_for('.login_view')) return super(MyAdminIndexView, self).index() @expose('/login/', methods=('GET', 'POST')) def login_view(self): form = LoginForm(request.form) if helpers.validate_form_on_submit(form): user = form.get_user() login.login_user(user) if login.current_user.is_authenticated: return redirect(url_for('.index')) link = '<p>アカウント未作成用 <a href="' + url_for('.register_view') + '">ここをクリック</a></p>' self._template_args['form'] = form self._template_args['link'] = link return super(MyAdminIndexView, self).index() @expose('/register/', methods=('GET', 'POST')) def register_view(self): form = RegistrationForm(request.form) if helpers.validate_form_on_submit(form): user = AdminUser() form.populate_obj(user) user.password = generate_password_hash(form.password.data) db.session.add(user) db.session.commit() login.login_user(user) return redirect(url_for('.index')) link = '<p>既にアカウントを持っている場合は <a href="' + url_for('.login_view') + '">ここをクリックしてログイン</a></p>' self._template_args['form'] = form self._template_args['link'] = link return super(MyAdminIndexView, self).index() @expose('/logout/') def logout_view(self): login.logout_user() return redirect(url_for('.index')) init_login() admin = admin.Admin(app, '管理者画面', index_view=MyAdminIndexView(), base_template='my_master.html') admin.add_view(MyModelView(AdminUser, db.session))普通にFlaskでやる時と若干似てる感じですね。
ここで注目してほしいのはMyModelViewクラスです。
MyModelViewはsqla.ModelViewを継承し、is_accessibleメソッドをオーバライドしています。(する必要があるのです)
is_accessibleメソッドでは、ユーザーが既にログイン済みか否かを返しています。
is_accessibleメソッドをオーバライドするだけで、後のビュークラス(ここではMyAdminIndexViewクラス)でアクセス制御ルールを定義できるようになります。init_login() admin = admin.Admin(app, '管理者画面', index_view=MyAdminIndexView(), base_template='my_master.html') admin.add_view(MyModelView(AdminUser, db.session))で実際にどのモデルにおいてどのビュークラスを使用するかなどを定義しています。
HTMLを書く
HTMLがないと意味がないですね。
プロジェクトルートディレクトリにtemplatesディレクトリを作成し、以下のような構造でファイルやディレクトリを作ります。templates/ admin/ index.html my_master.html index.htmlmy_master.html
{% extends 'admin/base.html' %} {% block access_control %} {% if current_user.is_authenticated %} <div class="btn-group pull-right"> <a class="btn dropdown-toggle" data-toggle="dropdown" href="#"> <i class="icon-user"></i> {{ current_user.login }} <span class="caret"></span> </a> <ul class="dropdown-menu"> <li><a href="{{ url_for('admin.logout_view') }}">ログアウト</a></li> </ul> </div> {% endif %} {% endblock %}ログイン後の画面で、ユーザーIDのところを押されたらドロップダウンでログアウトボタンが出るようなやつです。
templates/index.html
<html> <body> <div> <a href="{{ url_for('admin.index') }}">Go to admin!</a> </div> </body> </html>インデックスページなんで何でも良いです。
適当に書いておきます。templates/admin/index.html
{% extends 'admin/master.html' %} {% block body %} {{ super() }} <div class="row-fluid"> <div> {% if current_user.is_authenticated %} <h1>Civichat管理者画面</h1> <p class="lead"> 認証済 </p> <p> データの管理はこちらの画面からできます。ログアウトしたい場合は/admin/logout にアクセスしてください。 </p> {% else %} <form method="POST" action=""> {{ form.hidden_tag() if form.hidden_tag }} {% for f in form if f.type != 'CSRFTokenField' %} <div> {{ f.label }} {{ f }} {% if f.errors %} <ul> {% for e in f.errors %} <li>{{ e }}</li> {% endfor %} </ul> {% endif %} </div> {% endfor %} <button class="btn" type="submit">完了</button> </form> {{ link | safe }} {% endif %} </div> <a class="btn btn-primary" href="/"><i class="icon-arrow-left icon-white"></i> 戻る</a> </div> {% endblock body %}ログイン後の管理者画面のインデックスページのようなものです。
パスワード認証に加えIP制限したい
そもそもログインフォームにたどり着く前にIPアドレスでアクセス制限したい、というニーズもあると思います。
↓の記事が参考になると思います。最後に
何か間違いがあったらコメントでご指摘頂ければ幸いです。
- 投稿日:2020-10-13T18:18:46+09:00
Djangoで要素の数を数えてテンプレートに出力する方法
はじめに
Djangoのテンプレート内で要素を全てカウントして「全何件」のように表示したい
結論
Django の組み込みテンプレートタグ(Built-in template tags and filters)
{{ value|length }} を使用する例)template.html<h3>本棚({{ books|length }})</h3>ブラウザーからは
と表示。Rubu on Rails では <%= Objects.all %> で表示できるのは知っていたが、Djangoの
組み込みタグというワードをしらないために意外と手間取った。参考文献
https://docs.djangoproject.com/ja/3.1/ref/templates/builtins/#ref-templates-builtins-filters

- 投稿日:2020-10-13T18:01:04+09:00
Draw LDheatmap in R or Python
In gwas study, we usually see a LDheatmap figure.
How to do it?
If you have the vcf file from plink, you can directly use the code below to achieve this goal.In python:
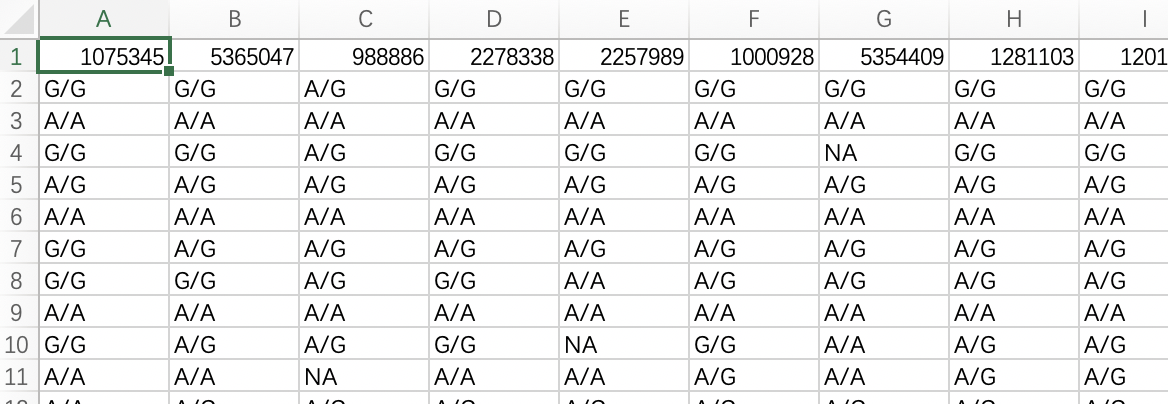
import re import os import argparse parser = argparse.ArgumentParser(description="Author: Peng Zhao ") parser.add_argument('-vcf', type=str,help="VCF file") parser.add_argument('-pos', type=str,help="Position of the SNPs") parser.add_argument('-chr', type=str,help="Names of chromosomes") parser.add_argument('-out', type=str,help="The prefix of the output file") args = parser.parse_args() vcf_name = args.vcf pos_name = args.pos chr_name = args.chr out_name = args.out inf = open(vcf_name,"r") inf2 = open(pos_name,"r") ouf = open("./scripts/temp/temp.vcf","w") chr_id = chr_name dict_1 = {} for line2 in inf2: line2 = line2.replace("\n","") li2 = re.split("\t| ",line2) dict_1[li2[0]] = "1" for line in inf: line = line.replace("\n","") li = re.split("\t| ",line) if li[0][:1] != "#": if li[0] == chr_id: if li[1] in dict_1: n = len(li) for i in range(9, n): if li[i] == "0/0": li[i] = str(li[3]) + "/" + str(li[3]) elif li[i] == "0/1": li[i] = str(li[3]) + "/" + str(li[4]) elif li[i] == "1/1": li[i] = str(li[4]) + "/" + str(li[4]) li[2] = str(li[0]) + "&" + str(li[1]) del li[0:2] del li[1:7] ouf.write("%s\n" % (li)) ouf.close() inf3 = open("./scripts/temp/temp.vcf","r") ouf3 = open("./scripts/temp/temp.replace.vcf","w") for line3 in inf3: line3 = line3.replace("\n","").replace(" ","").replace("[","").replace("\'","").replace(",","\t").replace("]","") ouf3.write("%s\n" % (line3)) ouf3.close() dos2unix_command = "dos2unix ./scripts/temp/temp.replace.vcf" rank_command = "awk \'{for(i=1;i<=NF;i=i+1){a[NR,i]=$i}}END{for(j=1;j<=NF;j++){str=a[1,j];for(i=2;i<=NR;i++){str=str \" \" a[i,j]}print str}}\' ./scripts/temp/temp.replace.vcf > ./scripts/temp/temp.replace.rank.vcf" plot_command = "Rscript ./scripts/LDplot.R" mv_command = "cp " + str(pos_name) + " ./scripts/temp/snp.pos.txt" mv_command1 = "cp ./scripts/temp/temp.replace.rank.vcf " + str(out_name) + ".snp.geno.txt" mv_command2 = "cp ./scripts/temp/snp.pos.txt " + str(out_name) + ".snp.pos.txt" mv_command3 = "mv ./scripts/temp/LDplot.pdf " + str(out_name) + ".pdf" rm_command = "rm ./scripts/temp/*" os.system(dos2unix_command) os.system(rank_command) os.system(mv_command) os.system(plot_command) os.system(mv_command1) os.system(mv_command2) os.system(mv_command3) os.system(rm_command)'In R:
suppressMessages(library("LDheatmap")) suppressMessages(library("genetics")) suppressMessages(library("grid")) library("LDheatmap") library("genetics") library("grid") setwd("./scripts/temp/") SNPdataSometimes the data we are dealing with is not from plink or tassel, here I provide one way to deal with them.
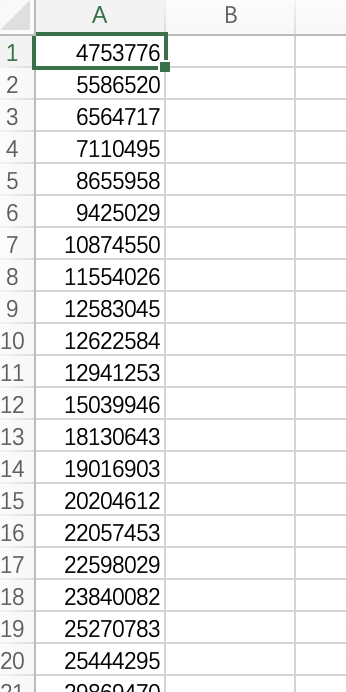
date should be in that structure
file1:
row1:SNP order
column: SNPs in each individualfile2:
The position of SNPs, in the same order of file1In R:
library("LDheatmap") library("genetics") SNPdata <- read.table("snp.geno.txt",header=T,sep="\t") SNPpos <- read.table("snp.pos.txt",header=F,sep="\t") num <- ncol(SNPdata) for(i in 1:num){ SNPdata[,i]<-as.genotype(SNPdata[,i]) } pos <- as.vector(unlist(SNPpos)) color.rgb <- colorRampPalette(rev(c("white","red")),space="rgb") LDheatmap(SNPdata,pos,color=color.rgb(20),flip=TRUE) library("grid") grid.edit(gPath("ldheatmap","heatMap","heatmap"),gp=gpar(col="white",lwd=8))
- 投稿日:2020-10-13T17:45:48+09:00
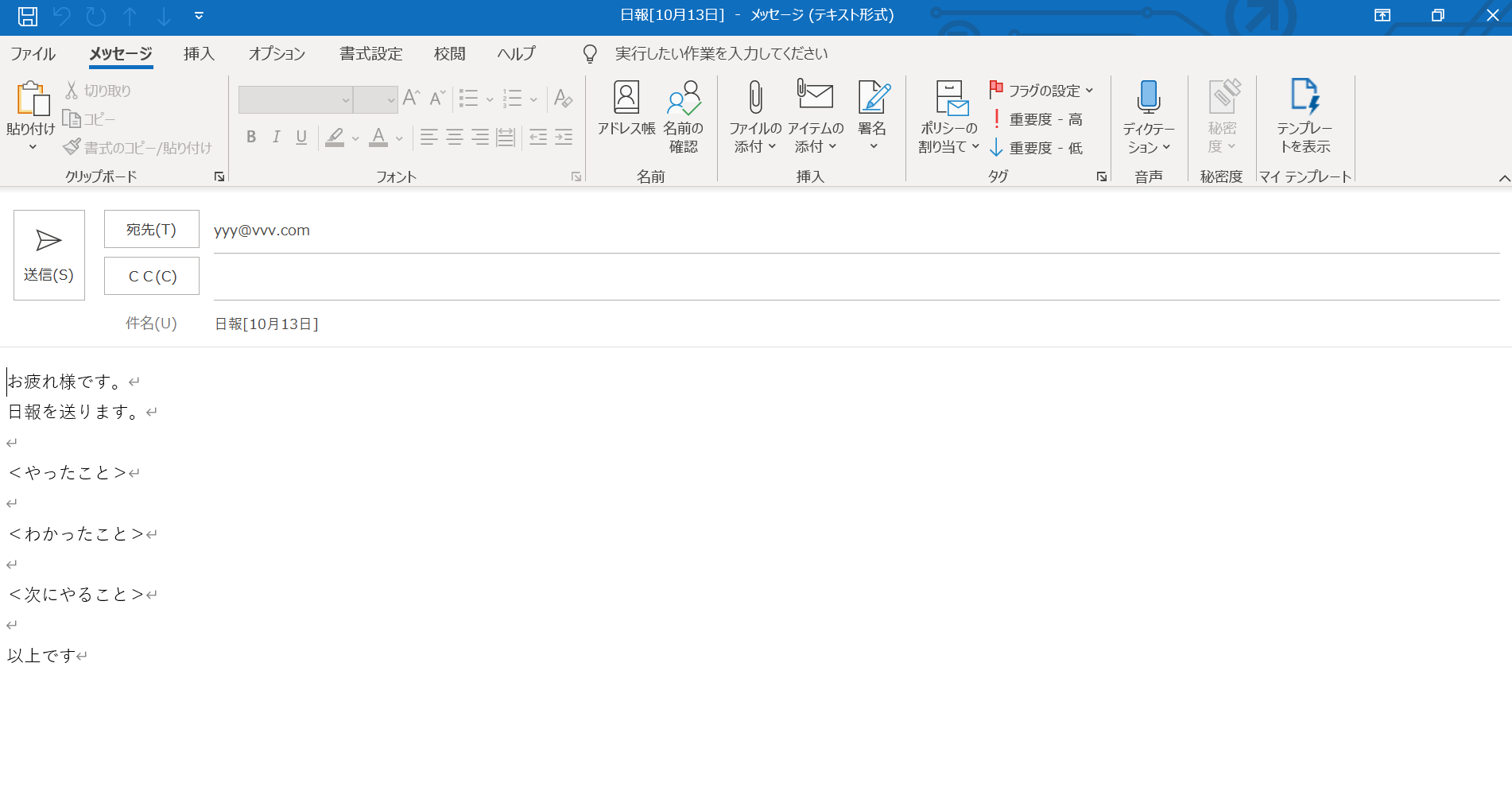
[Outlook]日報メールをPythonで自動作成してみた
概要
このサイトより、日報のテンプレートは作れるけど、
件名に今日の日付を自動で入れることができない!日報メールを自動作成してほしい!と思い、実行に移してみた
コード
import win32com.client import datetime # メール送信 object = win32com.client.Dispatch("Outlook.Application") mail = object.CreateItem(0) mail.BodyFormat = 1 # 宛先の設定 To,CC,Bcc mail.To = "yyy@vvv.com" # mail.cc = "yyy@vvv.com" # mail.Bcc = "yyy@vvv.com" # 今日の日付を取得 today = datetime.datetime.now() # メールの件名 mail.Subject = "日報[{}月{}日]".format(today.month,today.day) # メールの本文 mail.Body = """\ お疲れ様です。 日報を送ります。 <やったこと> <わかったこと> <次にやること> 以上です """ # 作成したメールの表示 mail.Display(True) # メール送信 # mail.Send()実行結果
- メールを作成することができた!
まとめ
日報メールを自動作成することができた!
参考
- 投稿日:2020-10-13T17:23:03+09:00
地域共通クーポン取扱店舗一覧のExcelファイルをスクレイピング
地域共通クーポン取扱店舗一覧のExcelファイルをスクレイピング
スクレイピング
import datetime import re from urllib.parse import urljoin import requests from bs4 import BeautifulSoup url = "https://biz.goto.jata-net.or.jp/couponlist.html" headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko" } r = requests.get(url, headers=headers) r.raise_for_status() soup = BeautifulSoup(r.content, "html.parser") area = {} for a in soup.select("section.download_couponlist div.button_area > a"): s = a.get("aria-label") m = re.search("地域共通クーポン取扱店舗一覧_(.+)((\d{4})年(\d{1,2})月(\d{1,2})日時点)", s) year, month, day = map(int, m.group(2, 3, 4)) area[m.group(1)] = { "link": urljoin(url, a.get("href")), "date": datetime.date(year, month, day), } areaデータラングリング
import pandas as pd # area.keys() # dict_keys(['北海道', '東北地方', '関東地方', '中部地方', '近畿地方', '中国地方', '四国地方', '九州・沖縄地方', '全国']) df0 = pd.read_excel(area["全国"]["link"]) df0["紙クーポン"] = df0["クーポン種別"].str.contains("紙", na=False).astype(int) df0["電子クーポン"] = df0["クーポン種別"].str.contains("電子", na=False).astype(int) industries = df0["業種"].str.split(".", expand=True).rename(columns={0: "業種コード", 1:"業種名"}) industries["業種コード"] = industries["業種コード"].astype(int) df1 = pd.concat([df0, industries], axis=1) pd.crosstab(df1["業種名"], df1["都道府県"])
業種名 三重県 京都府 佐賀県 兵庫県 北海道 千葉県 和歌山県 埼玉県 大分県 大阪府 奈良県 宮城県 宮崎県 富山県 山口県 山形県 山梨県 岐阜県 岡山県 岩手県 島根県 広島県 徳島県 愛媛県 愛知県 新潟県 東京都 栃木県 沖縄県 滋賀県 熊本県 石川県 神奈川県 福井県 福岡県 福島県 秋田県 群馬県 茨城県 長崎県 長野県 青森県 静岡県 香川県 高知県 鳥取県 鹿児島県 その他 476 762 143 906 1641 823 269 706 449 1114 207 420 164 378 281 363 338 461 257 334 220 496 120 189 1069 651 2446 502 569 253 320 495 1188 334 644 622 184 595 445 274 1216 187 1322 218 168 200 400 その他運送サービス 0 4 0 6 11 6 0 2 1 2 2 0 1 6 0 3 2 1 1 4 0 3 2 5 12 7 6 0 4 3 15 2 5 1 1 5 0 5 0 4 11 1 2 7 5 0 2 コンビニ・スーパー 619 896 200 1445 2566 1611 356 1772 448 2909 355 787 425 401 293 313 376 702 575 518 235 851 250 562 2552 660 5666 513 1139 494 587 436 2898 363 1403 489 394 511 767 371 688 593 1100 297 286 232 876 スポーツ 38 19 5 63 76 75 14 48 10 34 9 22 14 9 11 9 18 26 18 14 6 19 8 13 29 40 46 52 41 27 13 14 48 7 38 24 8 46 43 10 115 9 60 8 8 6 17 スポーツ観戦 0 0 1 0 2 0 0 0 0 0 0 1 0 0 3 0 0 0 0 0 0 0 0 0 0 0 32 0 0 0 0 0 0 0 0 0 0 0 2 0 0 1 0 0 0 0 0 フィットネス(スポーツジム等) 0 2 1 2 4 1 1 1 2 7 0 0 3 0 1 0 1 3 0 3 1 9 0 1 8 0 16 0 9 0 1 1 5 1 6 3 2 0 0 0 5 0 8 0 1 0 1 レンタカー 51 72 22 109 225 163 36 151 36 173 27 73 36 26 41 44 18 43 63 43 28 64 15 37 224 83 302 59 147 31 43 41 185 27 167 63 48 40 48 54 50 55 60 34 14 31 91 体験型アクティビティ 26 96 9 37 151 44 20 24 11 33 12 13 18 6 11 8 45 36 15 24 6 24 17 9 33 22 133 63 454 20 27 21 58 13 30 10 2 37 9 8 110 17 101 8 32 3 76 劇場、観覧場、映画館、演劇場 0 4 3 3 6 8 0 2 1 4 0 0 1 1 0 0 1 0 0 0 2 2 2 2 4 2 23 1 8 1 2 3 4 3 5 1 3 2 2 0 0 0 2 1 0 0 1 小売(お土産等) 764 1794 441 2116 2456 1341 280 1528 702 2874 393 1117 309 556 477 456 386 869 673 423 309 1001 270 450 2273 754 5273 637 886 602 645 849 2262 473 1918 682 356 636 596 545 1167 458 1554 390 300 197 651 文化施設(美術館、博物館等) 3 21 1 18 18 7 5 1 16 6 3 10 0 11 7 11 22 21 22 6 8 6 3 10 18 17 13 12 3 8 7 17 30 8 5 9 4 4 2 11 31 4 24 5 11 5 4 海上運送 9 8 1 5 14 4 5 1 5 8 0 7 0 3 3 0 0 0 5 1 3 36 2 7 6 5 12 0 25 5 3 1 3 1 8 0 2 0 0 14 2 11 13 18 7 1 14 物流(宅配等) 0 2 0 0 5 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 1 0 31 0 1 0 1 0 0 0 0 0 1 0 1 0 1 1 0 0 2 航空運送 0 1 0 0 4 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 2 0 0 1 0 0 0 1 0 2 0 0 15 0 0 0 0 0 0 0 0 0 0 0 0 2 観光施設(遊園地、動物園、温泉施設、観光農園等) 71 50 10 75 89 50 17 38 65 47 13 45 13 20 16 26 52 48 20 32 13 28 18 21 49 42 36 42 43 28 43 25 53 23 22 48 21 54 24 13 119 16 103 18 10 16 18 遊興施設(ネットカフェ、漫画喫茶等) 1 2 0 5 20 5 0 7 0 14 2 7 1 1 3 0 0 1 3 0 0 3 1 0 5 5 48 3 4 1 2 0 14 0 7 2 0 2 4 0 2 0 2 3 3 0 1 鉄道 8 26 0 14 5 12 8 7 0 17 1 44 0 32 2 21 4 18 9 31 1 6 9 14 94 49 59 8 19 8 6 9 28 5 43 31 14 10 27 5 53 17 69 29 8 2 8 飲食店(酒類提供あり) 275 728 41 312 576 487 51 195 63 884 124 103 40 132 163 54 74 218 115 53 43 328 47 57 719 227 1578 151 214 128 136 232 522 199 255 110 82 75 98 61 537 40 513 90 92 26 104 飲食店(酒類提供なし) 76 105 13 117 96 111 15 62 23 132 33 26 11 30 42 14 15 77 29 20 15 62 18 18 165 56 130 43 36 38 49 70 99 32 59 23 11 25 25 17 122 19 125 58 24 7 25
- 投稿日:2020-10-13T17:16:56+09:00
SFCの体育予約システム監視システムを作りたい(β版)
はじめに
この記事は慶應大学SFCの学生向けに書かれたものです。技術に関してはわかりやすい説明を心がけますが、体育システムそのものの説明等は省いていますのでその点をあらかじめご了承ください。
また、この記事を参照して作ったプログラムによって生じた被害等の責任は一切負いませんので、同じようなシステムを作る際は自己責任で制作してください。β版ですので無限に改善点がある状態で投稿しております。
目的
SFCの体育予約システムで受けたい授業に空きが発生した場合に素早く予約したい。
利用規約をよく読む
体育システム内に利用規約について記載されたページは存在しないが、慶應大学のサイト規約を参考に以下のことに注意する。
・サイト上の情報を外部一般に公開しない
・体育予約システムにリンクすることは自由だが、画像などのサイト要素の中にリンクを含むときは明示する.
・過度なアクセスはBAN対象となるため、常識の範囲内でリクエストする環境
・macOS Catalina 10.15.5
・python 3.8.0使用ライブラリ(リンク先は公式ドキュメント)
requests サーバー間のデータ転送を行うためのライブラリ。curlコマンドを使いやすくしたものという理解で良い
bs4 pythonのhtmlパーサー
lxml python用のHTML, XMLパーサー, bs4単体だとXpathが使えないため導入。Xpathを使わない場合は不要
Xpathの使い方がわからなくなった場合はこちらの記事を参照 →Xpathの使い方まとめ
pyyaml 秘匿情報をyaml形式で保存したため、それを読み込むためのライブラリ
time アクセス間隔を制御するために使う。
上記ライブラリはすべて pipでインストール可能であるため、各自未インストールのライブラリを
pip ~でインストールしてくださいその他
LINE Notify 自分のLINEアカウントに通知を送ることができる便利な公式API
LINE Notifyの準備
https://notify-bot.line.me/ja/
上記サイトから自身のLINEアカウントにログインし、右上のトグルをクリックしマイページに移動する
画面下部に下図のようなボタンがあるため、そこをクリックしてアクセストークンを入手する。
ソースコード
ファイル構成
・main.py (実行ファイル)
・secrets.yaml (秘匿情報をまとめておくファイル)main.pyimport requests import yaml from lxml import html from bs4 import BeautifulSoup import time # insecureRequestWarningがうるさいので消す import urllib3 from urllib3.exceptions import InsecureRequestWarning urllib3.disable_warnings(InsecureRequestWarning) # 秘匿情報を別ファイルから読み込む SECREATS = yaml.load(open('secrets.yaml').read(),Loader=yaml.SafeLoader) def checkTargetClass(targetClass: str): ''' ログインし、指定した授業に空きが有る場合、その授業の予約リンクを返す ''' PE_SYSTEM_URL = 'https://wellness.sfc.keio.ac.jp/v3/' # セッションを開始 session = requests.session() # ログイン login_info = { 'login':SECREATS['user'], 'password':SECREATS['pass'], 'submit':'login', 'page':'top', 'lang':'ja', 'mode':'login', 'semester':'20205' } # ログイン実行 res = session.post(PE_SYSTEM_URL, data=login_info, verify=False) res.raise_for_status() # エラーならここで例外を発生させる # Xpathで検索できる形式にパース soup_parsed_data = BeautifulSoup(res.text, 'html.parser') lxml_coverted_data = html.fromstring(str(soup_parsed_data)) # 予約ページリンク検出&移動 reservePageTag = lxml_coverted_data.xpath('//*[@id="sidenav"]/ul/li[4]/a') reservePageLink = reservePageTag[0].get('href') res = session.get(PE_SYSTEM_URL+reservePageLink) res.raise_for_status() # パース soup_parsed_data = BeautifulSoup(res.text, 'html.parser') lxml_coverted_data = html.fromstring(str(soup_parsed_data)) # 予約可能な授業一覧と予約確認ページリンクを取得 targetElemChunk = lxml_coverted_data.xpath('//*[@id="maincontents"]/div[6]/table/tbody/tr') classInfoList = [] for classInfoRow in targetElemChunk: className = classInfoRow[7].text reseveConfirmPageLink = classInfoRow[9].find('a').get('href') if targetClass in className: notify(className+PE_SYSTEM_URL+reseveConfirmPageLink) classInfo = [className, reseveConfirmPageLink] classInfoList.append(classInfo) def watch(): while True: checkTargetClass('食事学') time.sleep(1800) # 通知を送る def notify(message): LINE_NOTIFY_URL = 'https://notify-api.line.me/api/notify' TOKEN = SECREATS['notify-token'] headers = {'Authorization': f'Bearer {TOKEN}'} data = {'message': f'message: {message}'} requests.post(LINE_NOTIFY_URL, headers = headers, data = data) def main(): watch() if __name__ == "__main__": main()secrets.yamluser: 'ログインid' pass: 'パスワード' notify-token: 'LINE APIから発行されたトークン'使い方
コマンドラインから
python main.pyを実行し、そのまま永久放置改善点
・流石に永久放置は不便なのでサーバーにファイルを移転したい
・webアプリ化してGUIで操作したい
・アクセス頻度を1800秒おきに設定したが、もう少し間隔が短くてもいけるかも
・↑あるいはキャンセルが頻繁に発生するタイミングが特定できれば、その時間のみ頻繁にアクセスする方法で耐えれるかも

- 投稿日:2020-10-13T17:14:40+09:00
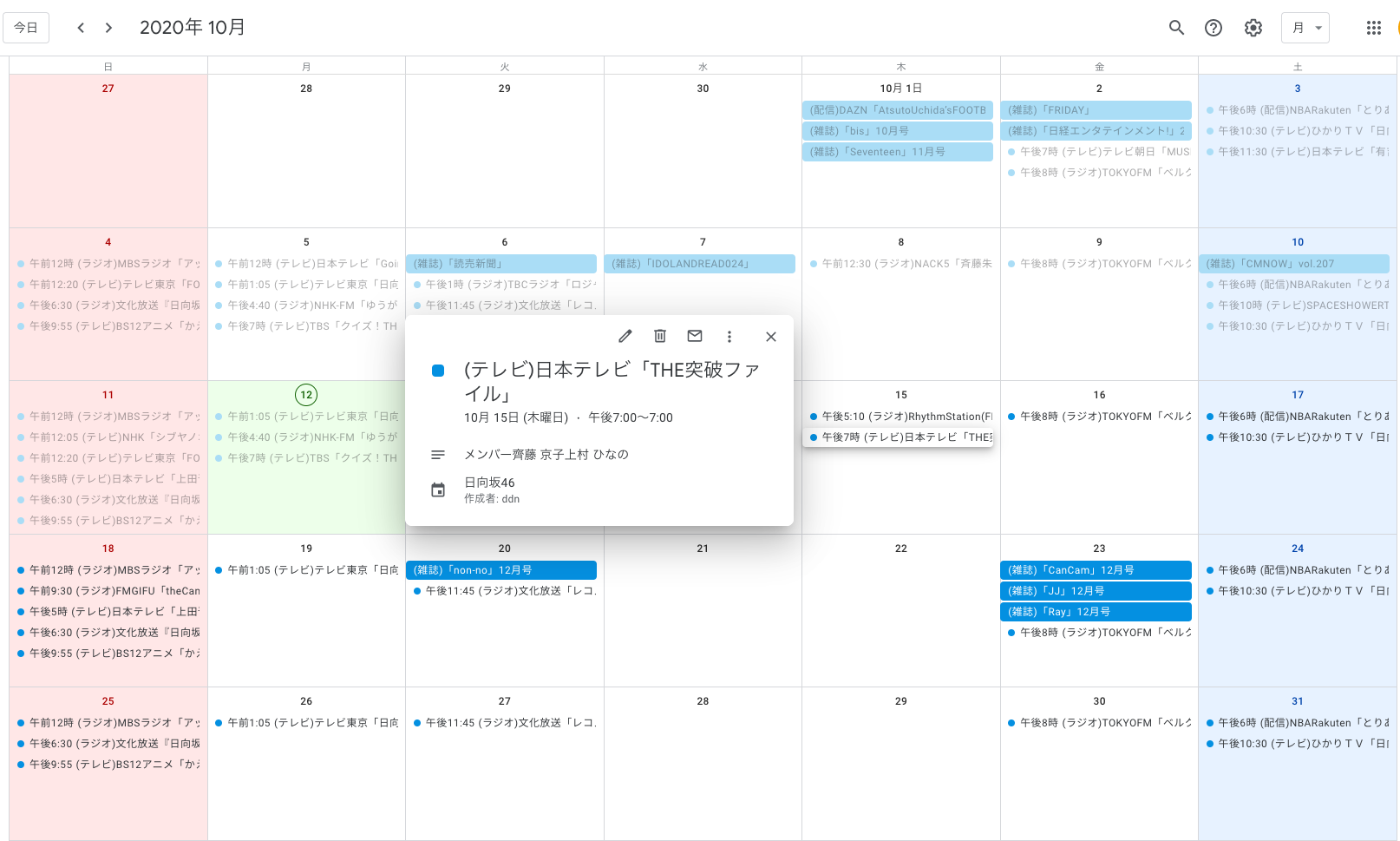
日向坂46のスケジュールをスクレイピングして、Google Calendarに反映させる
結論
codeに興味がなく、カレンダーの追加だけを行いたい方はこちらから。
Google Accountを持っていれば、すぐさま追加できます。本記事では、HPから情報を取得して、以下のようなカレンダーを自動生成することを目指します。
これにより、
- Google Calendarの通知をオンにすれば、彼女らの活動を見逃すことが無くなる
- 予め、活動予定が分かるため、他の予定を入れてしまい、見られなくなってしまうリスクを軽減できる
といったメリットがあります。背景
日向坂46は坂道グループの1つであり、「ハッピーオーラ」をモットーに活動されているグループです。
彼女らの「ビジュアル」はもちろん、「明るさ」・「どんなことにも一生懸命に取り組む姿勢」に惹かれる人は少なくなく、自分もその一人です。彼女らの活動を追うためには、HPでの「スケジュール」のページを確認するのが最も確実であるので、自分もよく拝見させていただいています。
ただ、
- どの日にどんな活動があるのかを確認するのに効率が悪い(スクロールしてその日の場所まで移動しなければならないため、パッと見ではわからない)
- 必ずしも、時系列順に記述されているわけではない(「22:00~」の予定の次の段落で「18:00~」の予定が記述されている場合がある)
という点が、個人的に不満でした。また、すでにこちらのサイト のカレンダーを導入することで、主要なイベントに関してカバーすることができますが、細かいイベント(固定化されていない不定期な活動)に関してはカバーされていないように見受けられました。
そこで、これらの不満を解消すべく、「自分のGoogle Calendarに、彼女らのスケジュールを反映させる」ことを実現しようと考えました。
実装
バージョン
- Python 3.7.3
- bs4==0.0.1
- python-dateutil==2.8.1
- google-api-python-client==1.10.0
- google-auth-httplib2==0.0.4
- google-auth-oauthlib==0.4.1
準備
Google APIを取得する必要があります。
手順としましては、こちらの記事がわかりやすいので、ご参照ください。また、定期実行を行いたい場合は、cronやHerokuを用いると良いです。
個人的にはローカルpcで実行する必要がないHerokuが好きなので、こちらを利用しています。
Herokuに関しましては、以前、自分のhatenaブログで使い方を説明しているので、よろしければそちらをご参照ください。手順
- HPにおけるスケジュールから必要な情報をスクレイピング
- Google Calendarに情報を反映させる
①HPから必要な情報をスクレイピング
イベント情報を取得する関数
取得する情報は、以下の4つです。
- カテゴリ
- イベント名
- 時間
- 出演メンバー
出演イベントは、同じ日に複数存在する場合があるので、
- 各日付ごとのイベントをまとめて取得(search_event_each_date)
- ある特定の日のイベントを取得(search_event_info)
- ある1つのイベントの細かい情報の取得(search_detail_info)
という流れで情報を取得します。
def search_event_each_date(year, month): url = ( f"https://www.hinatazaka46.com/s/official/media/list?ima=0000&dy={year}{month}" ) result = requests.get(url) soup = BeautifulSoup(result.content, features="lxml") events_each_date = soup.find_all("div", {"class": "p-schedule__list-group"}) time.sleep(3) # NOTE:サーバーへの負荷を解消 return events_each_date def search_event_info(event_each_date): event_date_text = remove_blank(event_each_date.contents[1].text)[ :-1 ] # NOTE:曜日以外の情報を取得 events_time = event_each_date.find_all("div", {"class": "c-schedule__time--list"}) events_name = event_each_date.find_all("p", {"class": "c-schedule__text"}) events_category = event_each_date.find_all( "div", {"class": "c-schedule__category category_media"} ) events_link = event_each_date.find_all("li", {"class": "p-schedule__item"}) return event_date_text, events_time, events_name, events_category, events_link def search_detail_info(event_name, event_category, event_time, event_link): event_name_text = remove_blank(event_name.text) event_category_text = remove_blank(event_category.text) event_time_text = remove_blank(event_time.text) event_link = event_link.find("a")["href"] active_members = search_active_member(event_link) return event_name_text, event_category_text, event_time_text, active_members def search_active_member(link): try: url = f"https://www.hinatazaka46.com{link}" result = requests.get(url) soup = BeautifulSoup(result.content, features="lxml") active_members = soup.find("div", {"class": "c-article__tag"}).text time.sleep(3) # NOTE:サーバー負荷の解消 except AttributeError: active_members = "" return active_members def remove_blank(text): text = text.replace("\n", "") text = text.replace(" ", "") return text時間に関する関数
特に時間に関しては、表記によって、
- 「24:20~25:00」といったように、次の日になってしまっている
- そもそも、日付の情報しかない
といった場合が存在するため、それらに対応した関数を用意します。def over24Hdatetime(year, month, day, times): """ 24H以上の時刻をdatetimeに変換する """ hour, minute = times.split(":")[:-1] # to minute minutes = int(hour) * 60 + int(minute) dt = datetime.datetime(year=int(year), month=int(month), day=int(day)) dt += datetime.timedelta(minutes=minutes) return dt.strftime("%Y-%m-%dT%H:%M:%S") def prepare_info_for_calendar( event_name_text, event_category_text, event_time_text, active_members ): event_title = f"({event_category_text}){event_name_text}" if event_time_text == "": event_start = f"{year}-{month}-{event_date_text}" event_end = f"{year}-{month}-{event_date_text}" is_date = True else: start, end = search_start_and_end_time(event_time_text) event_start = over24Hdatetime(year, month, event_date_text, start) event_end = over24Hdatetime(year, month, event_date_text, end) is_date = False return event_title, event_start, event_end, is_date②Google Calendarに情報を反映させる
大まかな手順は、以下の通りです。
- APIをもとに、インスタンスを生成
- 以前追加したイベントかどうかの判定
- イベントの追加
APIの設定
from googleapiclient.discovery import build from google_auth_oauthlib.flow import InstalledAppFlow from google.auth.transport.requests import Request def build_calendar_api(): SCOPES = ["https://www.googleapis.com/auth/calendar"] creds = None if os.path.exists("token.pickle"): with open("token.pickle", "rb") as token: creds = pickle.load(token) if not creds or not creds.valid: if creds and creds.expired and creds.refresh_token: creds.refresh(Request()) else: flow = InstalledAppFlow.from_client_secrets_file("credentials.json", SCOPES) creds = flow.run_local_server(port=0) with open("token.pickle", "wb") as token: pickle.dump(creds, token) service = build("calendar", "v3", credentials=creds) return service以前に追加したイベントかどうかの判定
追加する前に、「以前に追加したイベントであるかどうか」を判定するために、「イベント名-時刻」をもとに確認します。
そのためのリストを、search_events関数で取得します。def search_events(service, calendar_id, start): end_datetime = datetime.datetime.strptime(start, "%Y-%m-%d") + relativedelta( months=1 ) end = end_datetime.strftime("%Y-%m-%d") events_result = ( service.events() .list( calendarId=calendar_id, timeMin=start + "T00:00:00+09:00", # NOTE:+09:00とするのが肝。(UTCをJSTへ変換) timeMax=end + "T23:59:00+09:00", # NOTE;来月までをサーチ期間に。 ) .execute() ) events = events_result.get("items", []) if not events: return [] else: events_starttime = change_event_starttime_to_jst(events) return [ event["summary"] + "-" + event_starttime for event, event_starttime in zip(events, events_starttime) ] def change_event_starttime_to_jst(events): events_starttime = [] for event in events: if "date" in event["start"].keys(): events_starttime.append(event["start"]["date"]) else: str_event_uct_time = event["start"]["dateTime"] event_jst_time = datetime.datetime.strptime( str_event_uct_time, "%Y-%m-%dT%H:%M:%S+09:00" ) str_event_jst_time = event_jst_time.strftime("%Y-%m-%dT%H:%M:%S") events_starttime.append(str_event_jst_time) return events_starttimeイベントの追加
def add_date_schedule( event_name, event_category, event_time, event_link, previous_add_event_lists ): ( event_name_text, event_category_text, event_time_text, active_members, ) = search_detail_info(event_name, event_category, event_time, event_link) # カレンダーに反映させる情報の準備 (event_title, event_start, event_end, is_date,) = prepare_info_for_calendar( event_name_text, event_category_text, event_time_text, active_members, ) if ( f"{event_title}-{event_start}" in previous_add_event_lists ): # NOTE:同じ予定がすでに存在する場合はパス pass else: add_info_to_calendar( calendarId, event_title, event_start, event_end, active_members, is_date, ) def add_info_to_calendar(calendarId, summary, start, end, active_members, is_date): if is_date: event = { "summary": summary, "description": active_members, "start": {"date": start, "timeZone": "Japan",}, "end": {"date": end, "timeZone": "Japan",}, } else: event = { "summary": summary, "description": active_members, "start": {"dateTime": start, "timeZone": "Japan",}, "end": {"dateTime": end, "timeZone": "Japan",}, } event = service.events().insert(calendarId=calendarId, body=event,).execute()全文
今回は、今月から3ヶ月先までの予定をGoogle Calendarに反映させるようにしています。
calendarIdだけは、自分のカレンダーのidを設定する必要があります。import time import pickle import os.path import requests from bs4 import BeautifulSoup import datetime from dateutil.relativedelta import relativedelta from googleapiclient.discovery import build from google_auth_oauthlib.flow import InstalledAppFlow from google.auth.transport.requests import Request def build_calendar_api(): SCOPES = ["https://www.googleapis.com/auth/calendar"] creds = None if os.path.exists("token.pickle"): with open("token.pickle", "rb") as token: creds = pickle.load(token) if not creds or not creds.valid: if creds and creds.expired and creds.refresh_token: creds.refresh(Request()) else: flow = InstalledAppFlow.from_client_secrets_file("credentials.json", SCOPES) creds = flow.run_local_server(port=0) with open("token.pickle", "wb") as token: pickle.dump(creds, token) service = build("calendar", "v3", credentials=creds) return service def remove_blank(text): text = text.replace("\n", "") text = text.replace(" ", "") return text def search_event_each_date(year, month): url = ( f"https://www.hinatazaka46.com/s/official/media/list?ima=0000&dy={year}{month}" ) result = requests.get(url) soup = BeautifulSoup(result.content, features="lxml") events_each_date = soup.find_all("div", {"class": "p-schedule__list-group"}) time.sleep(3) # NOTE:サーバーへの負荷を解消 return events_each_date def search_start_and_end_time(event_time_text): has_end = event_time_text[-1] != "~" if has_end: start, end = event_time_text.split("~") else: start = event_time_text.split("~")[0] end = start start += ":00" end += ":00" return start, end def search_event_info(event_each_date): event_date_text = remove_blank(event_each_date.contents[1].text)[ :-1 ] # NOTE:曜日以外の情報を取得 events_time = event_each_date.find_all("div", {"class": "c-schedule__time--list"}) events_name = event_each_date.find_all("p", {"class": "c-schedule__text"}) events_category = event_each_date.find_all( "div", {"class": "c-schedule__category category_media"} ) events_link = event_each_date.find_all("li", {"class": "p-schedule__item"}) return event_date_text, events_time, events_name, events_category, events_link def search_detail_info(event_name, event_category, event_time, event_link): event_name_text = remove_blank(event_name.text) event_category_text = remove_blank(event_category.text) event_time_text = remove_blank(event_time.text) event_link = event_link.find("a")["href"] active_members = search_active_member(event_link) return event_name_text, event_category_text, event_time_text, active_members def search_active_member(link): try: url = f"https://www.hinatazaka46.com{link}" result = requests.get(url) soup = BeautifulSoup(result.content, features="lxml") active_members = soup.find("div", {"class": "c-article__tag"}).text time.sleep(3) # NOTE:サーバー負荷の解消 except AttributeError: active_members = "" return active_members def over24Hdatetime(year, month, day, times): """ 24H以上の時刻をdatetimeに変換する """ hour, minute = times.split(":")[:-1] # to minute minutes = int(hour) * 60 + int(minute) dt = datetime.datetime(year=int(year), month=int(month), day=int(day)) dt += datetime.timedelta(minutes=minutes) return dt.strftime("%Y-%m-%dT%H:%M:%S") def prepare_info_for_calendar( event_name_text, event_category_text, event_time_text, active_members ): event_title = f"({event_category_text}){event_name_text}" if event_time_text == "": event_start = f"{year}-{month}-{event_date_text}" event_end = f"{year}-{month}-{event_date_text}" is_date = True else: start, end = search_start_and_end_time(event_time_text) event_start = over24Hdatetime(year, month, event_date_text, start) event_end = over24Hdatetime(year, month, event_date_text, end) is_date = False return event_title, event_start, event_end, is_date def change_event_starttime_to_jst(events): events_starttime = [] for event in events: if "date" in event["start"].keys(): events_starttime.append(event["start"]["date"]) else: str_event_uct_time = event["start"]["dateTime"] event_jst_time = datetime.datetime.strptime( str_event_uct_time, "%Y-%m-%dT%H:%M:%S+09:00" ) str_event_jst_time = event_jst_time.strftime("%Y-%m-%dT%H:%M:%S") events_starttime.append(str_event_jst_time) return events_starttime def search_events(service, calendar_id, start): end_datetime = datetime.datetime.strptime(start, "%Y-%m-%d") + relativedelta( months=1 ) end = end_datetime.strftime("%Y-%m-%d") events_result = ( service.events() .list( calendarId=calendar_id, timeMin=start + "T00:00:00+09:00", # NOTE:+09:00とするのが肝。(UTCをJSTへ変換) timeMax=end + "T23:59:00+09:00", # NOTE;来月までをサーチ期間に。 ) .execute() ) events = events_result.get("items", []) if not events: return [] else: events_starttime = change_event_starttime_to_jst(events) return [ event["summary"] + "-" + event_starttime for event, event_starttime in zip(events, events_starttime) ] def add_date_schedule( event_name, event_category, event_time, event_link, previous_add_event_lists ): ( event_name_text, event_category_text, event_time_text, active_members, ) = search_detail_info(event_name, event_category, event_time, event_link) # カレンダーに反映させる情報の準備 (event_title, event_start, event_end, is_date,) = prepare_info_for_calendar( event_name_text, event_category_text, event_time_text, active_members, ) if ( f"{event_title}-{event_start}" in previous_add_event_lists ): # NOTE:同じ予定がすでに存在する場合はパス pass else: add_info_to_calendar( calendarId, event_title, event_start, event_end, active_members, is_date, ) def add_info_to_calendar(calendarId, summary, start, end, active_members, is_date): if is_date: event = { "summary": summary, "description": active_members, "start": {"date": start, "timeZone": "Japan",}, "end": {"date": end, "timeZone": "Japan",}, } else: event = { "summary": summary, "description": active_members, "start": {"dateTime": start, "timeZone": "Japan",}, "end": {"dateTime": end, "timeZone": "Japan",}, } event = service.events().insert(calendarId=calendarId, body=event,).execute() if __name__ == "__main__": # -------------------------step1:各種設定------------------------- # API系 calendarId = ( "〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜" # NOTE:自分のカレンダーID ) service = build_calendar_api() # サーチ範囲 num_search_month = 3 # NOTE;3ヶ月先の予定までカレンダーに反映 current_search_date = datetime.datetime.now() year = current_search_date.year month = current_search_date.month # -------------------------step2.各日付ごとの情報を取得------------------------- for _ in range(num_search_month): events_each_date = search_event_each_date(year, month) for event_each_date in events_each_date: # step3: 特定の日の予定を一括で取得 ( event_date_text, events_time, events_name, events_category, events_link, ) = search_event_info(event_each_date) event_date_text = "{:0=2}".format( int(event_date_text) ) # NOTE;2桁になるように0埋め(ex.0-> 01) start = f"{year}-{month}-{event_date_text}" previous_add_event_lists = search_events(service, calendarId, start) # step4: カレンダーへ情報を追加 for event_name, event_category, event_time, event_link in zip( events_name, events_category, events_time, events_link ): add_date_schedule( event_name, event_category, event_time, event_link, previous_add_event_lists, ) # step5:次の月へ current_search_date = current_search_date + relativedelta(months=1) year = current_search_date.year month = current_search_date.month最後に
本記事では、日向坂46のスケジュールをGoogle Calendarに反映させる方法を紹介しました。
これにより、
- Google Calendarの通知をオンにすれば、彼女らの活動を見逃すことが無くなる
- 予め、活動予定が分かるため、他の予定を入れてしまい、見られなくなってしまうリスクを軽減できる
といったメリットがあります。今回は、日向坂46にフォーカスをおきましたが、「①HPから必要な情報をスクレイピング」を変更すれば、②を使い回して、任意の方のスケジュールをGoogle Calendarに反映させることができます。
━━━━━━━━━━
もし日向坂46を知らない方は、これを気に興味を持ってみては如何でしょうか。
個人的には、毎週日曜日25:05〜からテレビ東京で放送されている、「日向坂で会いましょう」がオススメです。
アイドルとは思えない、バラエティ能力の高さに驚愕し、惹かれるはずです。
他にも、日向坂46 OFFICIAL YouTube CHANNELで曲から知ってみるのもいいと思います。また、完全に余談になりますが、僕の最近の推しは、松田好花さんで、笑顔がとても素敵な方です。
ひとつよしなに。参考サイト
Googleカレンダーの任意の予定をPythonで抽出する方法
【Python】Google Calendar APIを使ってGoogle Calendarの予定を取得・追加する
━━━━━━━━━━
日向坂46ホームページ

- 投稿日:2020-10-13T17:09:10+09:00
【初心者】【Python/Django】駆け出しWebエンジニアがDjangoチュートリアルをやってみた~その7~
今回はadminフォームをカスタマイズしていきます。
admin フォームのカスタマイズ
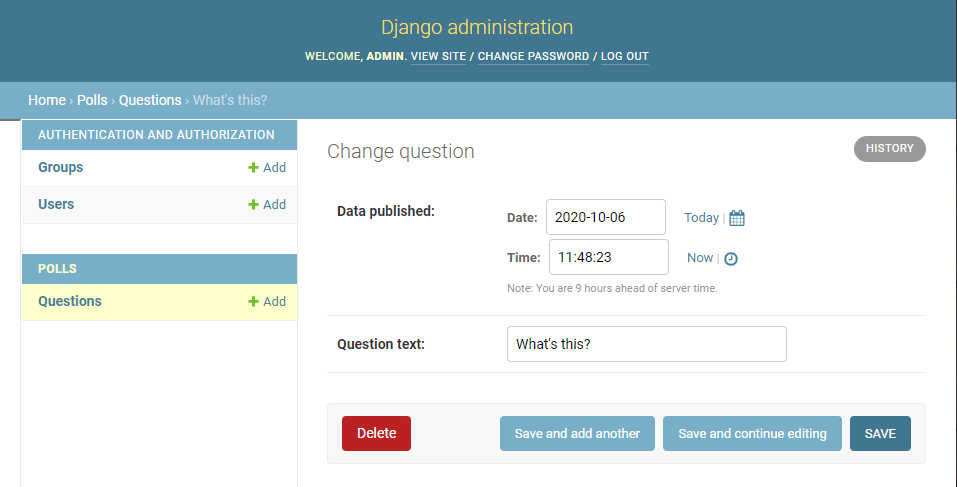
現在のadminフォームを確認していきます。
polls/admin.pyfrom django.contrib import admin # Register your models here. from .models import Question admin.site.register(Question)「http://127.0.0.1:8000/admin/polls/question/5/change/」にアクセスすると以下の表示がされます。
admin.pyを修正する①
adminフォームをカスタマイズするためにはadmin.pyを修正します。
QuestionAdminクラスを作成し、question_text、pub_dateの表示順序を変更します。
もともとはquestion_textの下にpub_dateでしたが、以下のコードではpub_dateの下にquestion_textとします。polls/admin.pyfrom django.contrib import admin # Register your models here. from .models import Question class QuestionAdmin(admin.ModelAdmin): fields = ['question_text', 'pub_date'] admin.site.register(Question, QuestionAdmin)
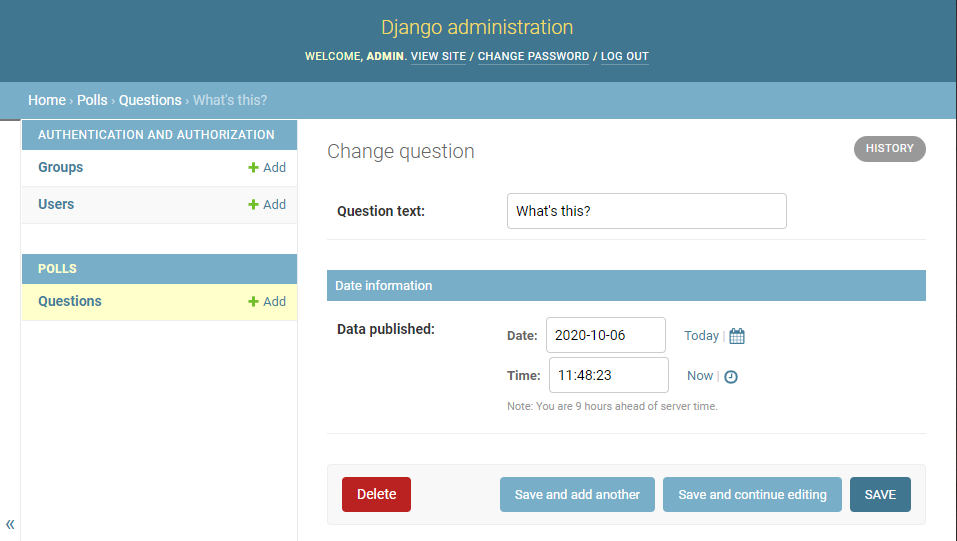
admin.pyを修正する②
polls/admin.pyclass QuestionAdmin(admin.ModelAdmin): fieldsets = [ (None, {'fields': ['question_text']}), ('Date information', {'fields': ['pub_date']}), ]
リレーションを張ったオブジェクトの追加
Questionが表示されることは確認できましたが、Questionに紐づくChoiceも同時に表示できないものでしょうか?
チュートリアルを進めていきます。polls/admin.pyfrom django.contrib import admin from .models import Question, Choice admin.site.register(Choice)Choiceが追加されました。
選択肢「The sky」に紐づく質問は選択肢を開かないと確認できません。
選択肢「The sky」は質問「What's this?」に紐づいていることが確認できます。
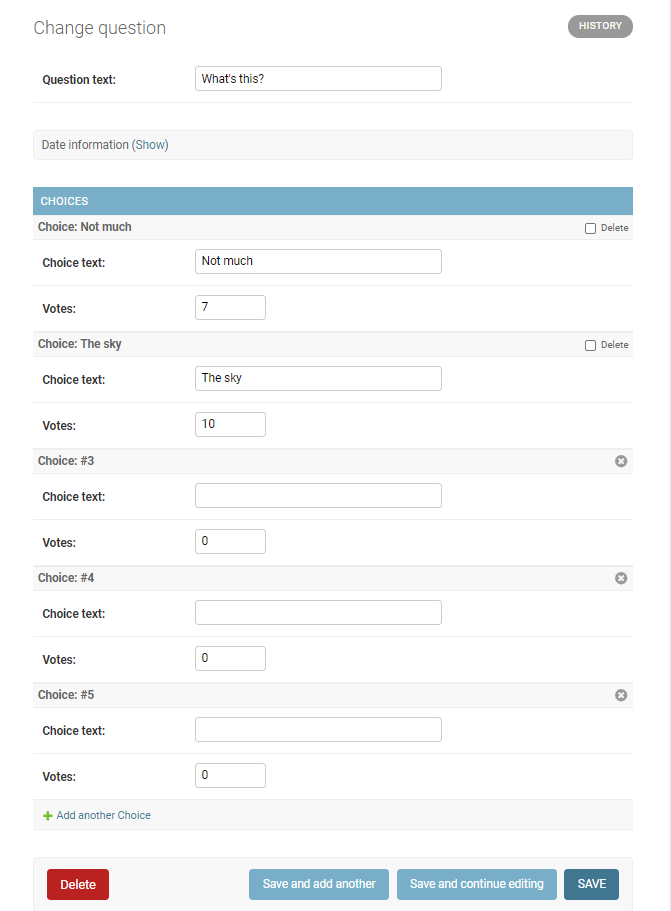
質問と選択肢を同時に表示します。
ChoiceInlineでは3つの空白のChoiceフィールドを表示すると指定しています。polls/admin.pyfrom django.contrib import admin # Register your models here. from .models import Question, Choice class ChoiceInline(admin.StackedInline): model = Choice extra = 3 class QuestionAdmin(admin.ModelAdmin): fieldsets = [ (None, {'fields': ['question_text']}), ('Date information', {'fields': ['pub_date'], 'classes': ['collapse']}), ] inlines = [ChoiceInline] admin.site.register(Question, QuestionAdmin)質問「What's this?」には選択肢「Not much」「The sky」があり、3つの空白選択肢欄が表示されています。
。
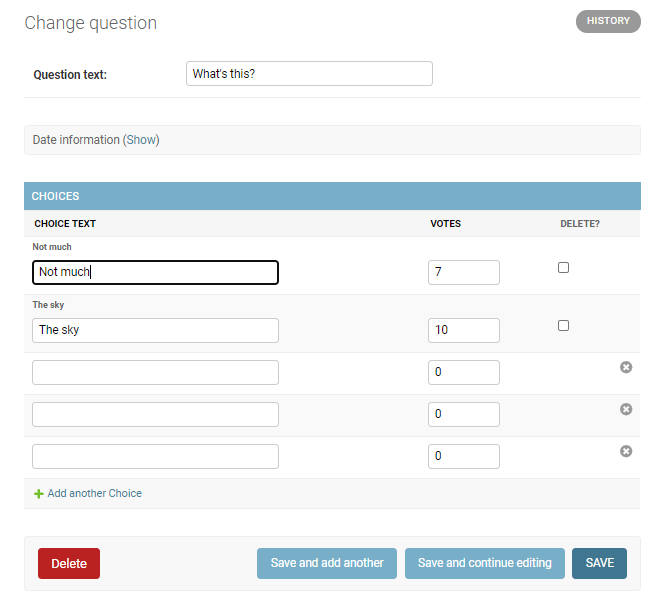
Choiceの表示が縦長になっているので、テーブル形式で表示するように修正しましょう。
polls/admin.pyclass ChoiceInline(admin.TabularInline):テーブル形式で表示され、すっきりしました。
管理サイトのチェンジリストページをカスタマイズする
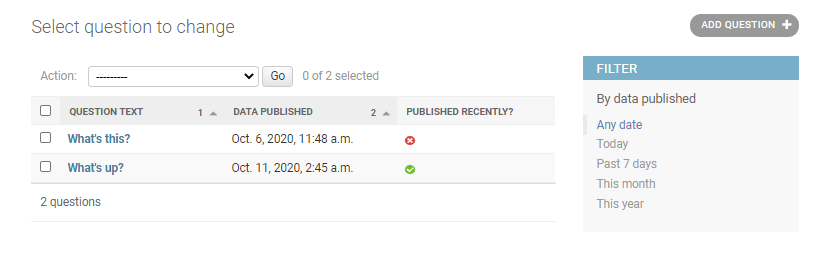
チェンジリストは「http://127.0.0.1:8000/admin/<アプリ名>/<クラス名>/」で表示される内容です。
polls/admin.pyclass QuestionAdmin(admin.ModelAdmin): fieldsets = [ (None, {'fields': ['question_text']}), ('Date information', {'fields': ['pub_date'], 'classes': ['collapse']}), ] inlines = [ChoiceInline] list_display = ('question_text', 'pub_date', 'was_published_recently')「http://127.0.0.1:8000/admin/polls/question/」を開きます。
今までは「QUESTION TEXT」カラムのみでしたが、新たに「DATA PUBLISHED」「PUBLISHED RECENTLY?」カラムが追加されました。「QUESTION TEXT」「DATA PUBLISHED」カラムは並び替えに対応しています。
一方で「PUBLISHED RECENTLY?」カラムは並び替えに対応していないのですが、理由はメソッドの戻り値を表示しているからです。
「PUBLISHED RECENTLY?」で絞り込みをするためにfilterを使いましょう。
polls/models.pyclass Question(models.Model): question_text = models.CharField(max_length=200) pub_date = models.DateTimeField('data published') def __str__(self): return self.question_text def was_published_recently(self): return timezone.now() - datetime.timedelta(days=1) <= self.pub_date <= timezone.now() was_published_recently.admin_order_field = 'pub_date' was_published_recently.boolean = True was_published_recently.short_description = 'Published recently?'list_filterを追加します。
class QuestionAdmin(admin.ModelAdmin): fieldsets = [ (None, {'fields': ['question_text']}), ('Date information', {'fields': ['pub_date'], 'classes': ['collapse']}), ] inlines = [ChoiceInline] list_display = ('question_text', 'pub_date', 'was_published_recently') list_filter = ['pub_date']サイドバーにfilterが表示されました。
「すべての期間 ("Any date")」「今日 ("Today")」「今週 ("Past 7 days")」「今月 ("This month")」「今年 ("This year")」で絞り込みできます。
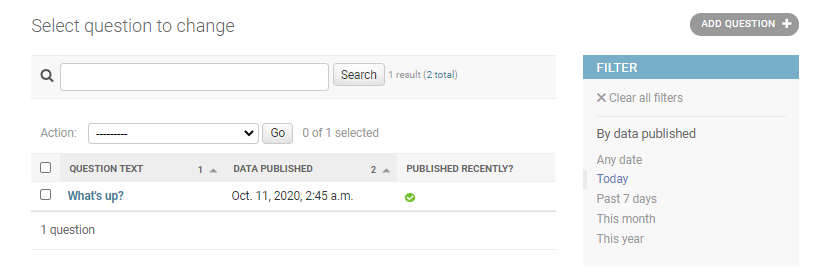
続いて検索窓を作成します。
polls/admin.pysearch_fields = ['question_text']画面上部に検索窓が表示されました。
以上で終了となります。ありがとうございました。



- 投稿日:2020-10-13T16:59:35+09:00
【python】import sys sys.argv の使い方
- 投稿日:2020-10-13T16:53:05+09:00
Windows 10にPython開発環境をインストールする
最終更新日
2020年10月13日
検証を行ったWindows 10のバージョンは下記です。
- Windows 10 Home 2004 19041.546
インストールするもののバージョンは下記です。
- Miniconda (Python 3.8版)
- PyCharm Community Edition 2020.2
この記事が古くなった場合、下記の手順は最新のインストール手順とは異なっている可能性があります。
Miniconda
インストール
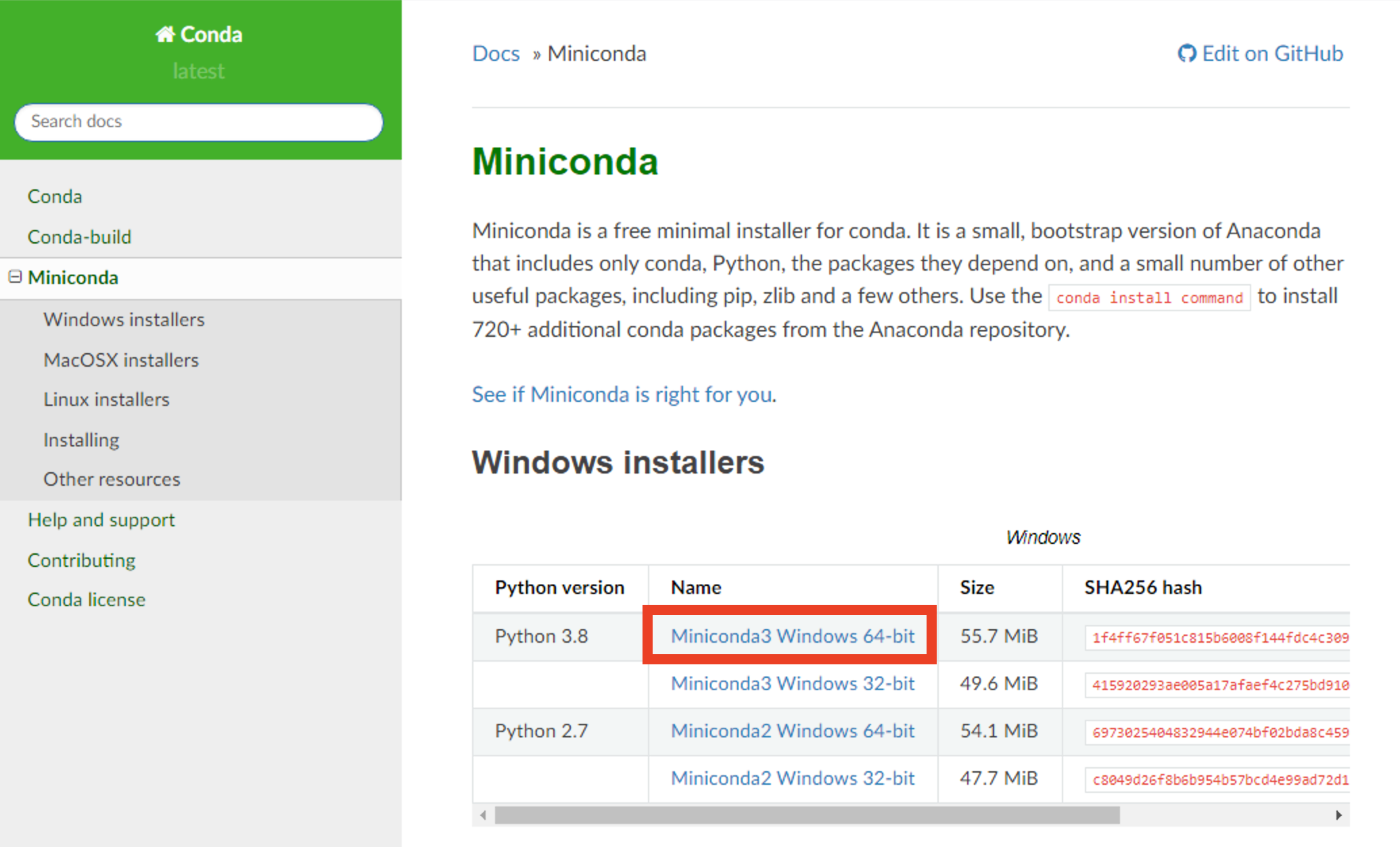
(1) https://docs.conda.io/en/latest/miniconda.html にアクセスしてください。
(2) [Python 3.8]の[Miniconda2 Windows 64-bit]をクリックしてください。
(3) ダウンロードしたEXEファイルをダブルクリックしてください。
(4) [Next]をクリックしてください。
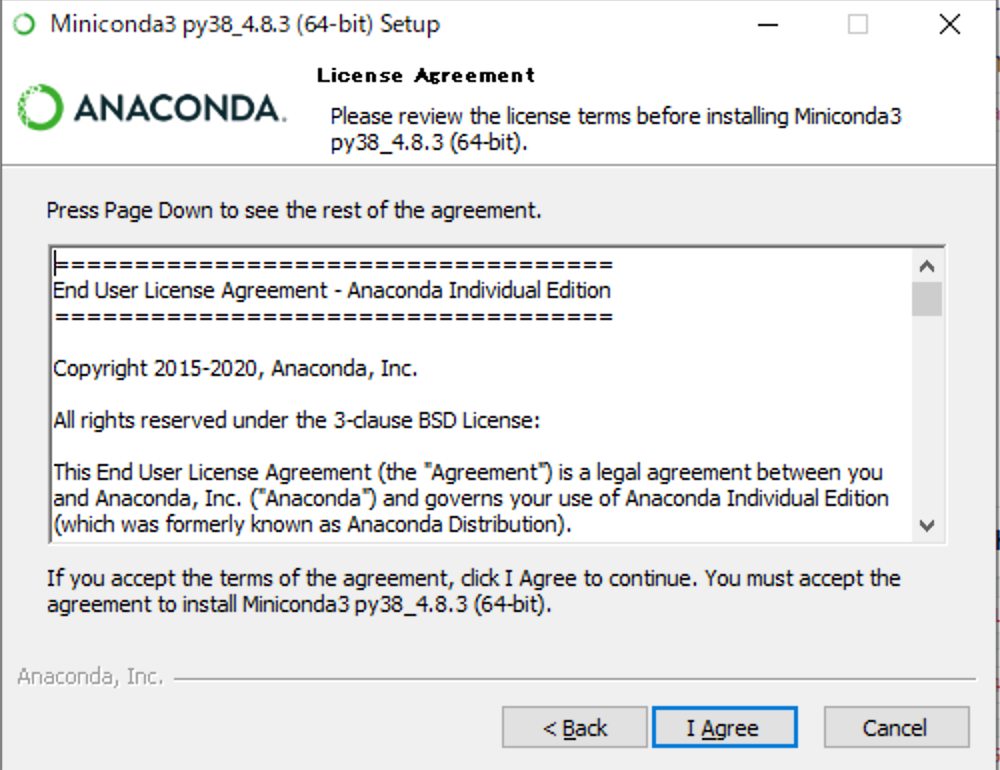
(5) [I Agree]をクリックしてください。
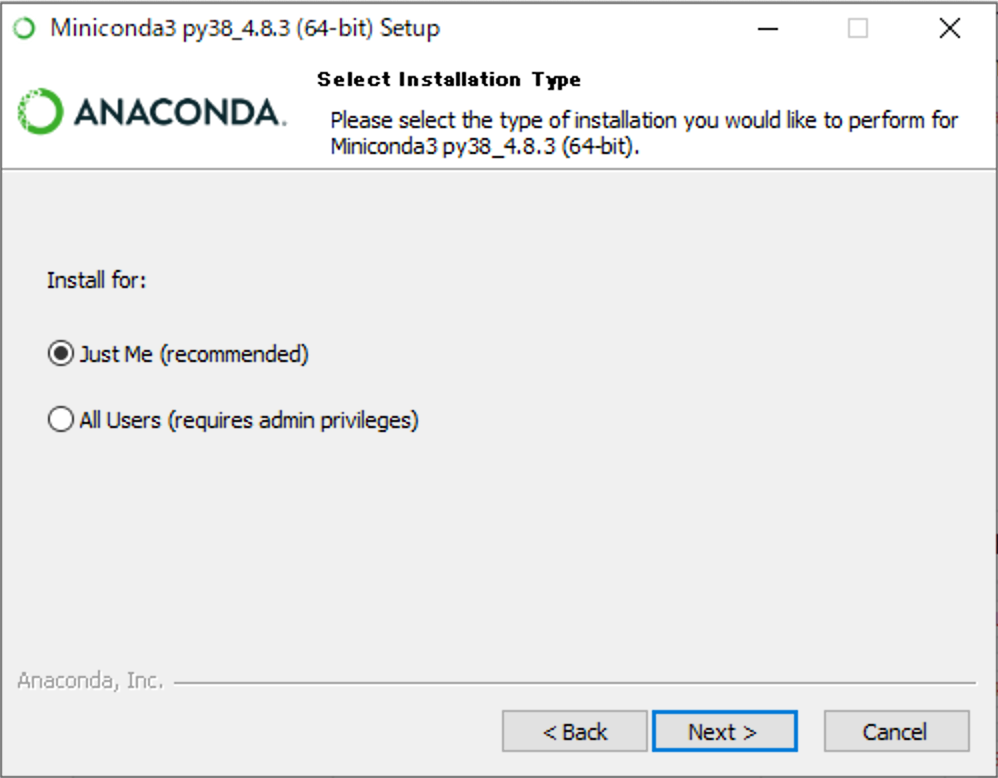
(6) 現在のユーザーのみにインストールする場合は[Just Me]を選択して、[Next]をクリックしてください。
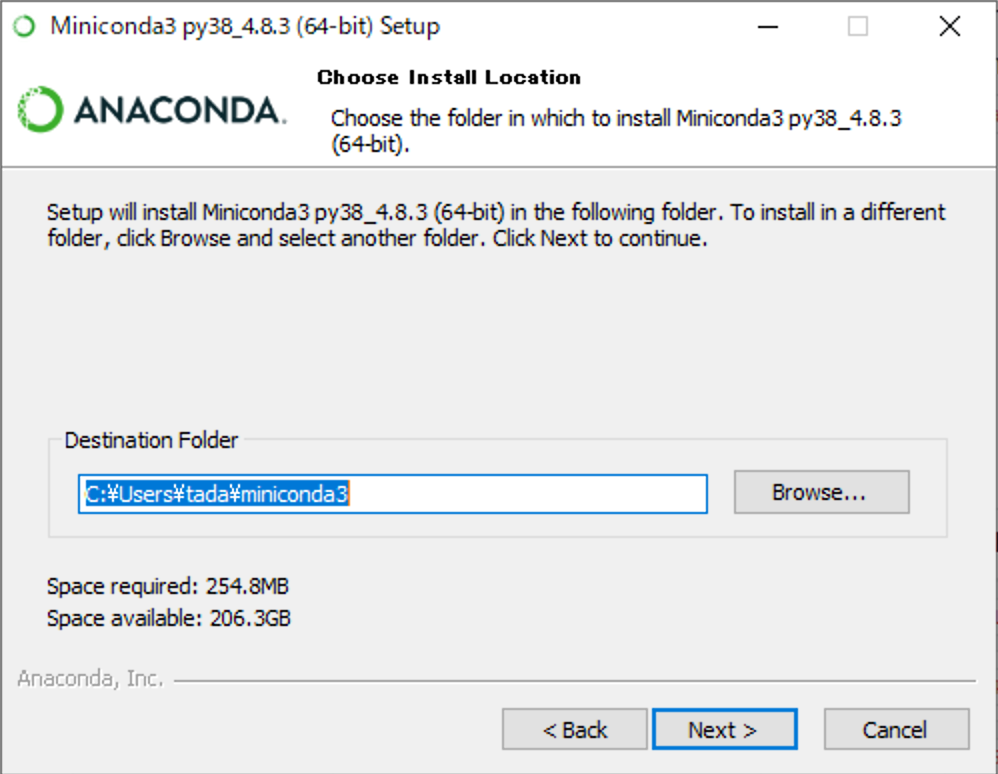
(7) [Next]をクリックしてください。
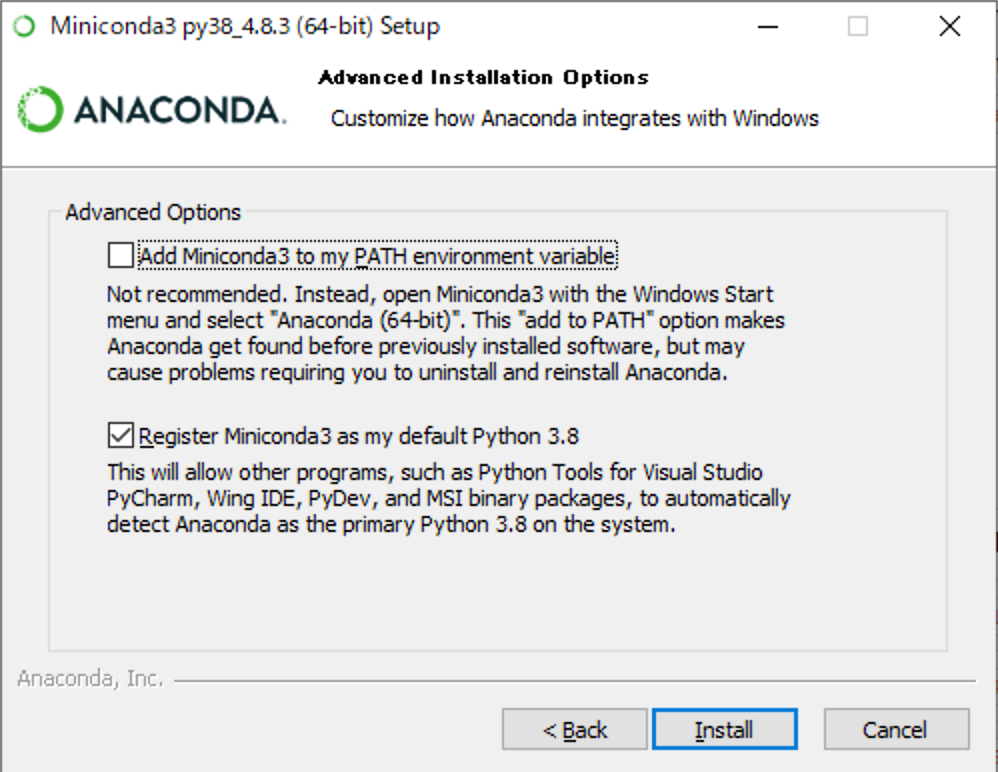
(8) [Install]をクリックしてください。
(9) [Next]をクリックしてください。
(10) チェックを全て外して、[Finish]をクリックしてください。
確認
(1) スタートメニューから[Anaconda Prompt]を起動してください。
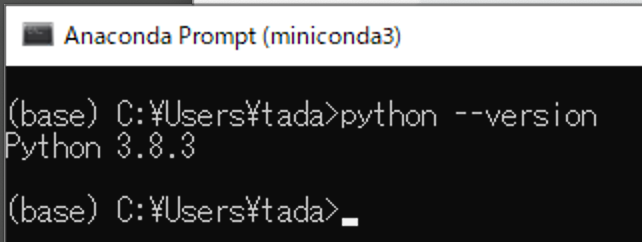
(2)
python --versionを実行してください。下記のように表示されれば成功です。
PyCharm
インストール
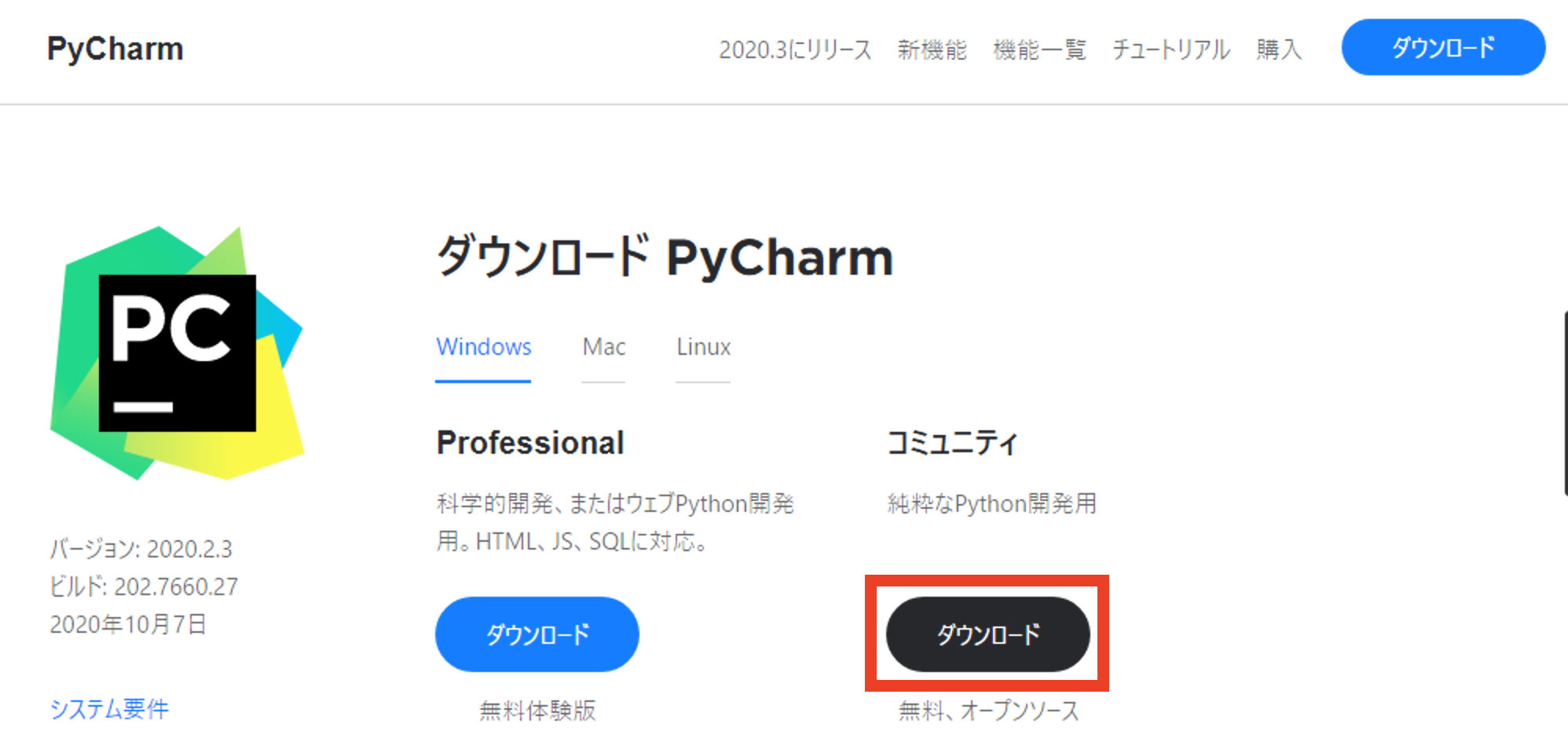
(1) https://www.jetbrains.com/ja-jp/pycharm/download/ にアクセスしてください。
(2) [コミュニティ]の[ダウンロード]ボタンをクリックしてください。
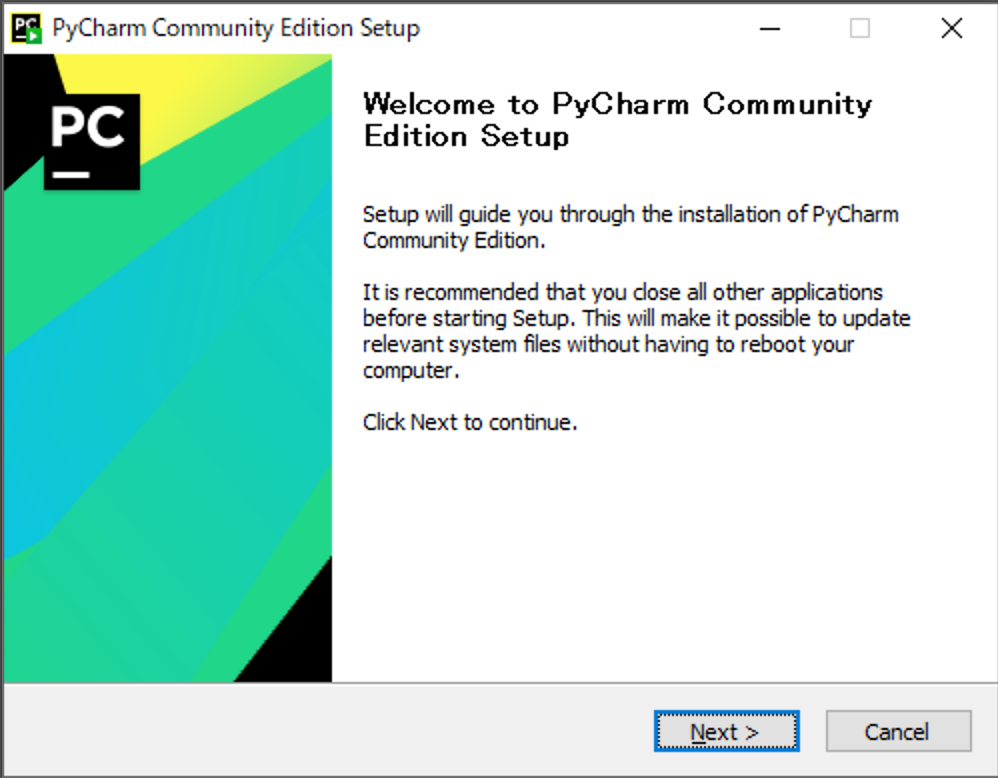
(3) ダウンロードしたEXEファイルをダブルクリックしてください。[ユーザーアカウント制御]が表示されたら[はい]をクリックしてください。
(4) [Next]をクリックしてください。
(5) [Next]をクリックしてください。
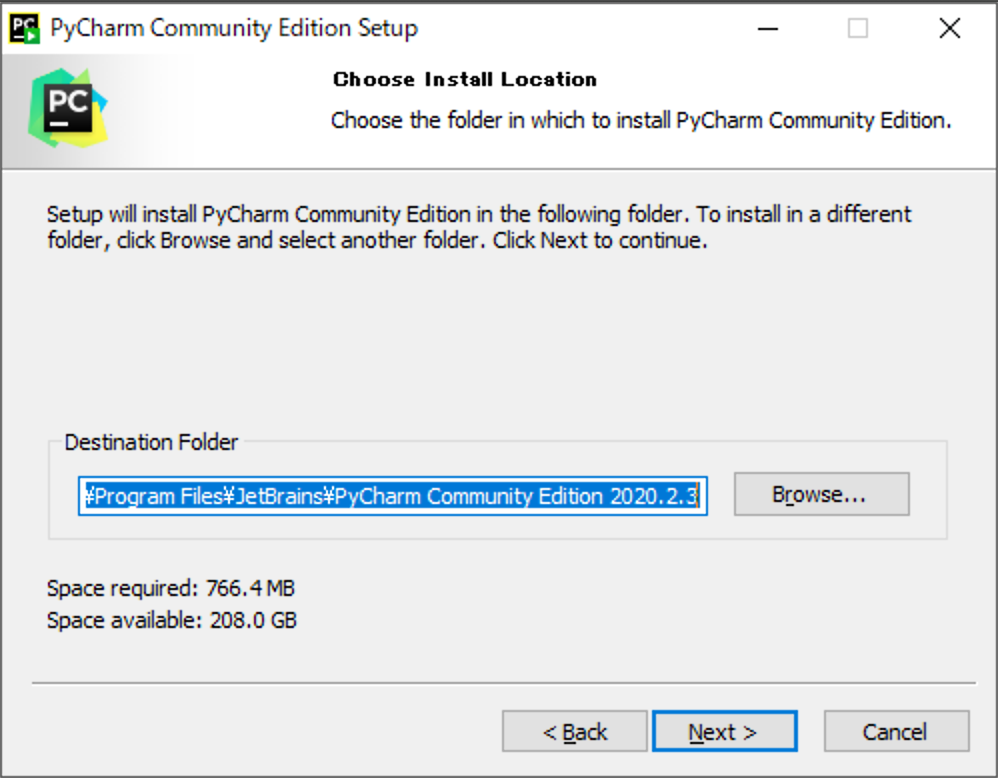
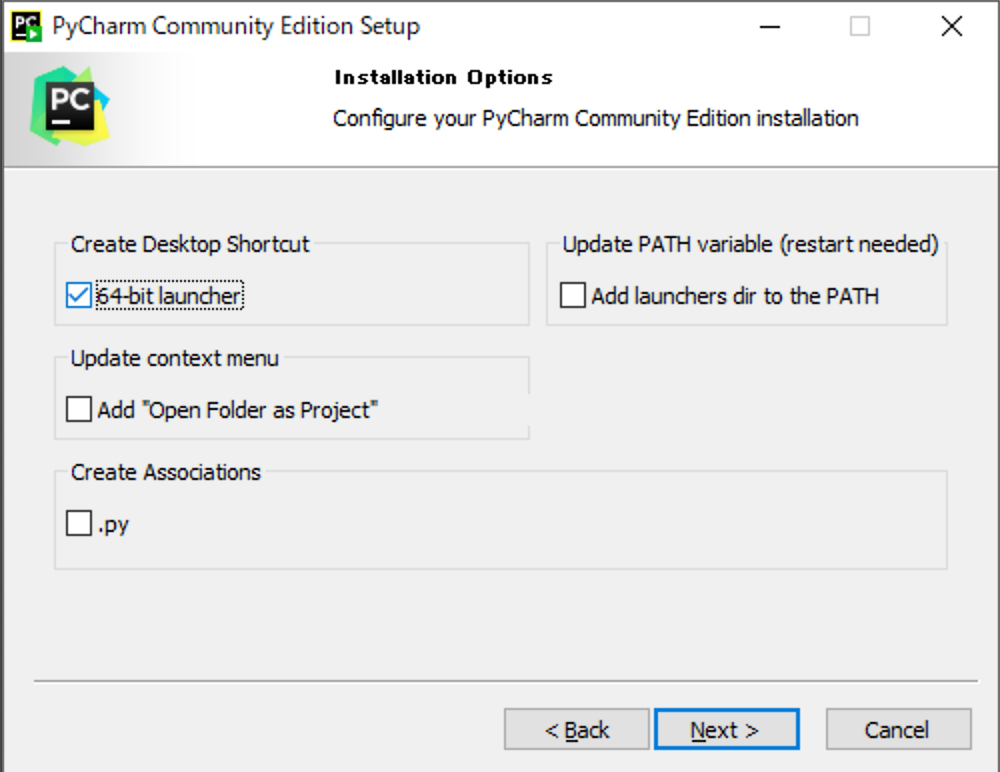
(6) [64-bit launcher]にチェックを入れて、[Next]をクリックしてください。
(7) [Install]をクリックしてください。
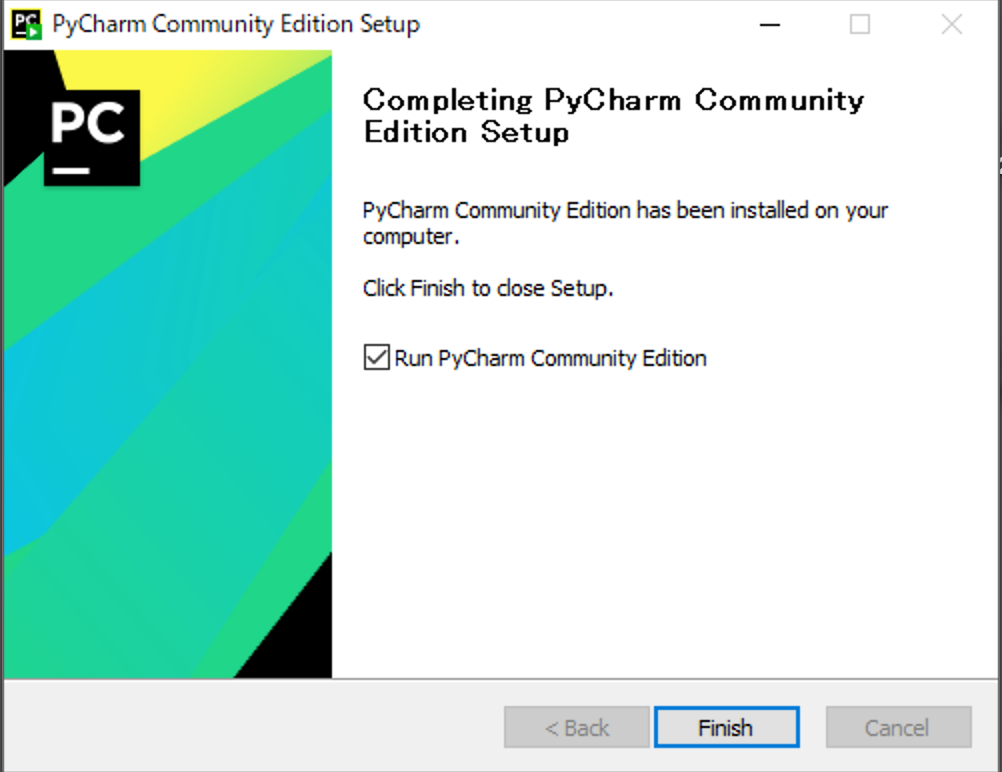
(8) [Run PyCharm Community Edition]にチェックを入れて、[Finish]をクリックしてください。
起動と初期設定
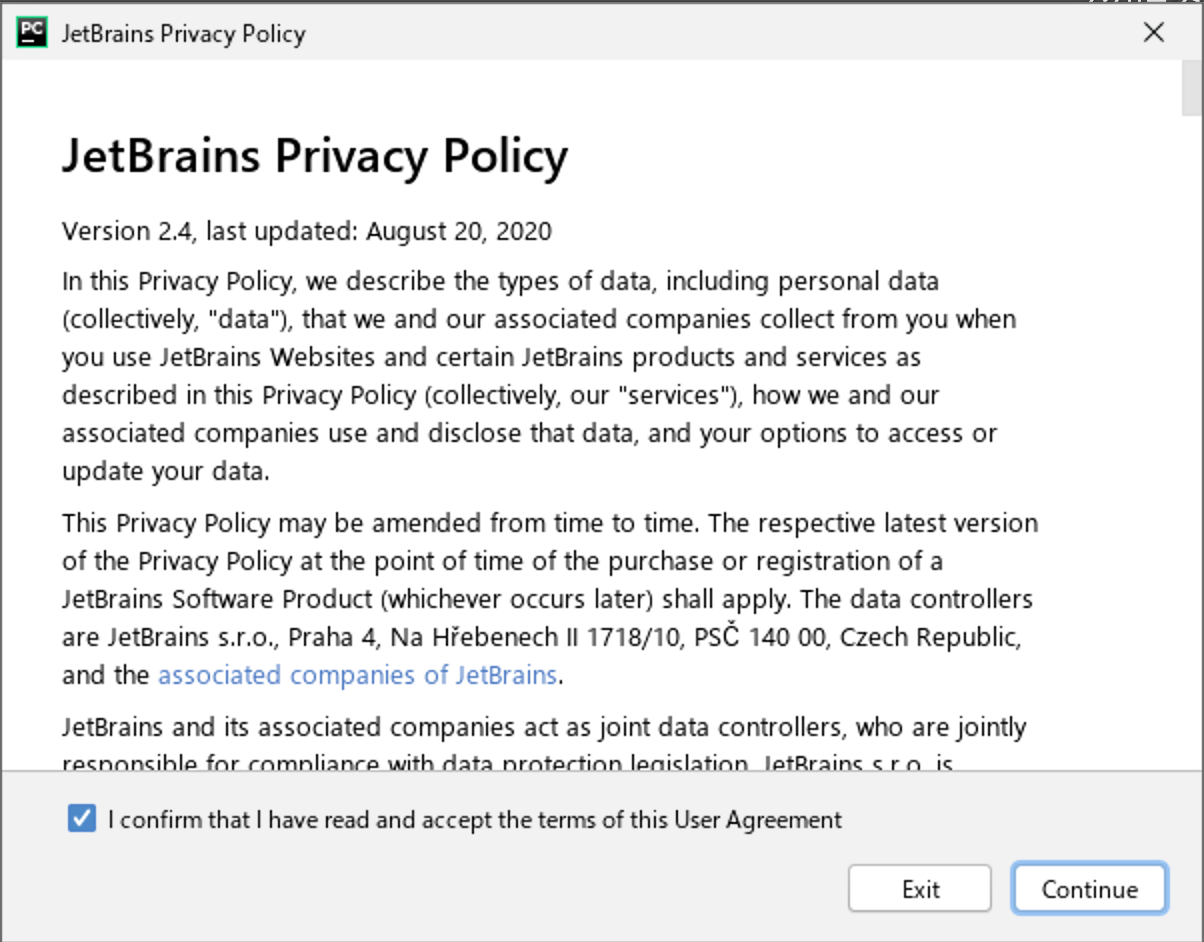
(1) [I confirm that I have read and accept the terms of this User Agreement]にチェックを入れて、[Continue]をクリックしてください。
インストールの最後で[Run PyCharm Community Edition]にチェックを入れなかった場合は、デスクトップのPyCharmアイコンをダブルクリックして起動してください。
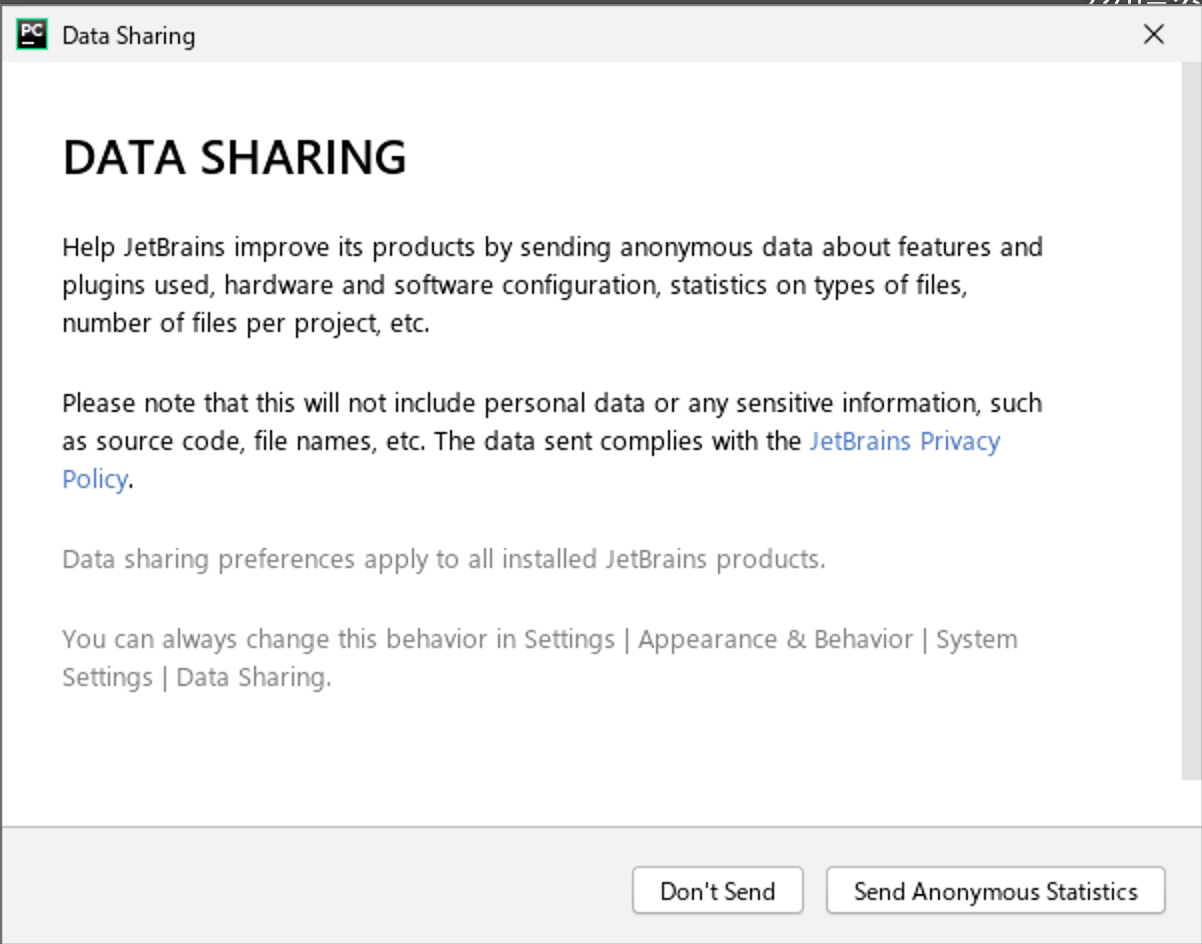
(2) JetBrains者への匿名での統計データ送信に同意する場合は[Send Anonymous Statistics]を、そうでない場合は[Don't Send]をクリックしてください。
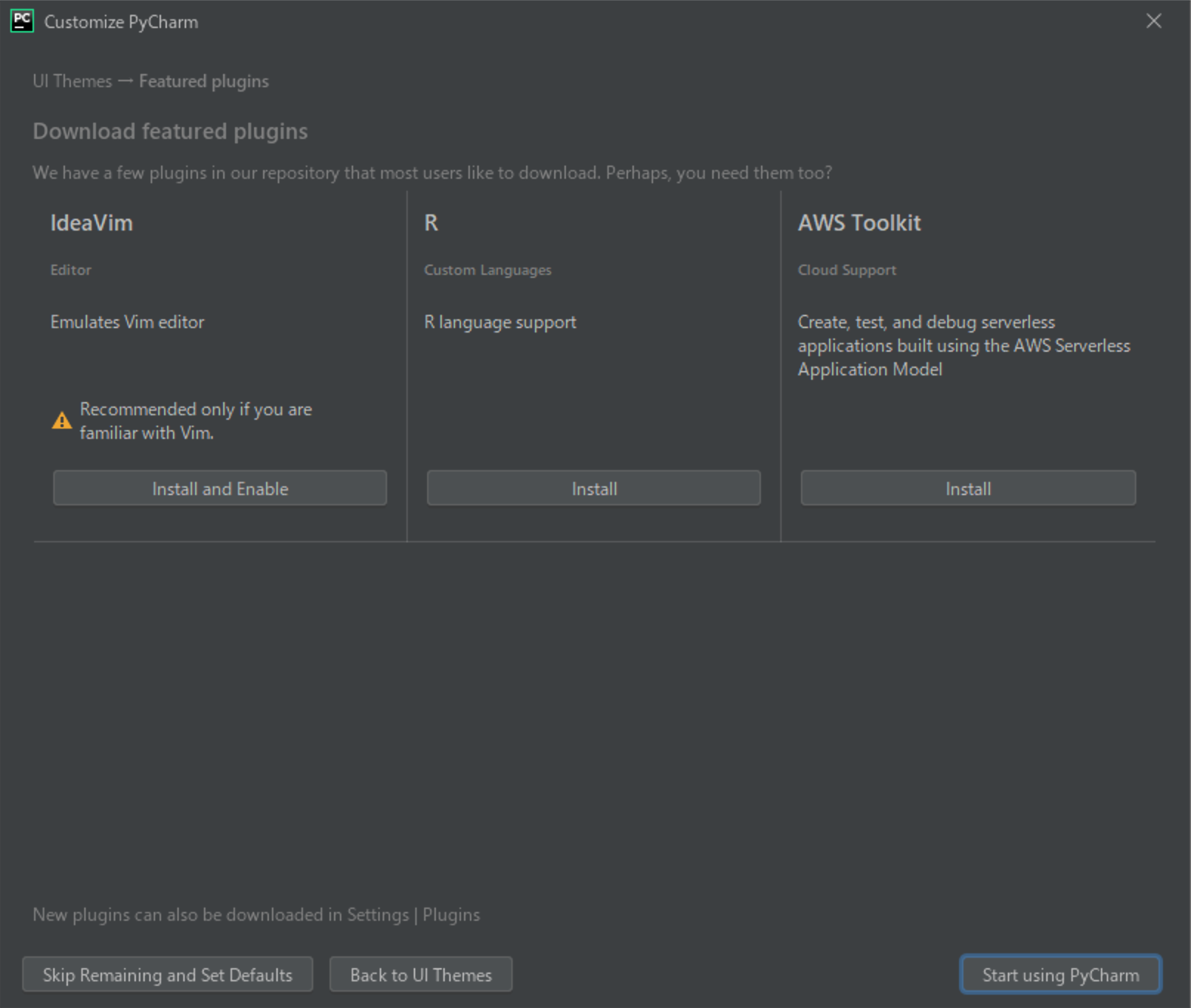
(3) [Darcula]・[Light]のどちらか好みのテーマを選択して、[Next: Featured plugins]をクリックしてください。
(4) そのまま[Start using PyCharm]をクリックしてください。
Pythonインタープリターと文字コードの設定
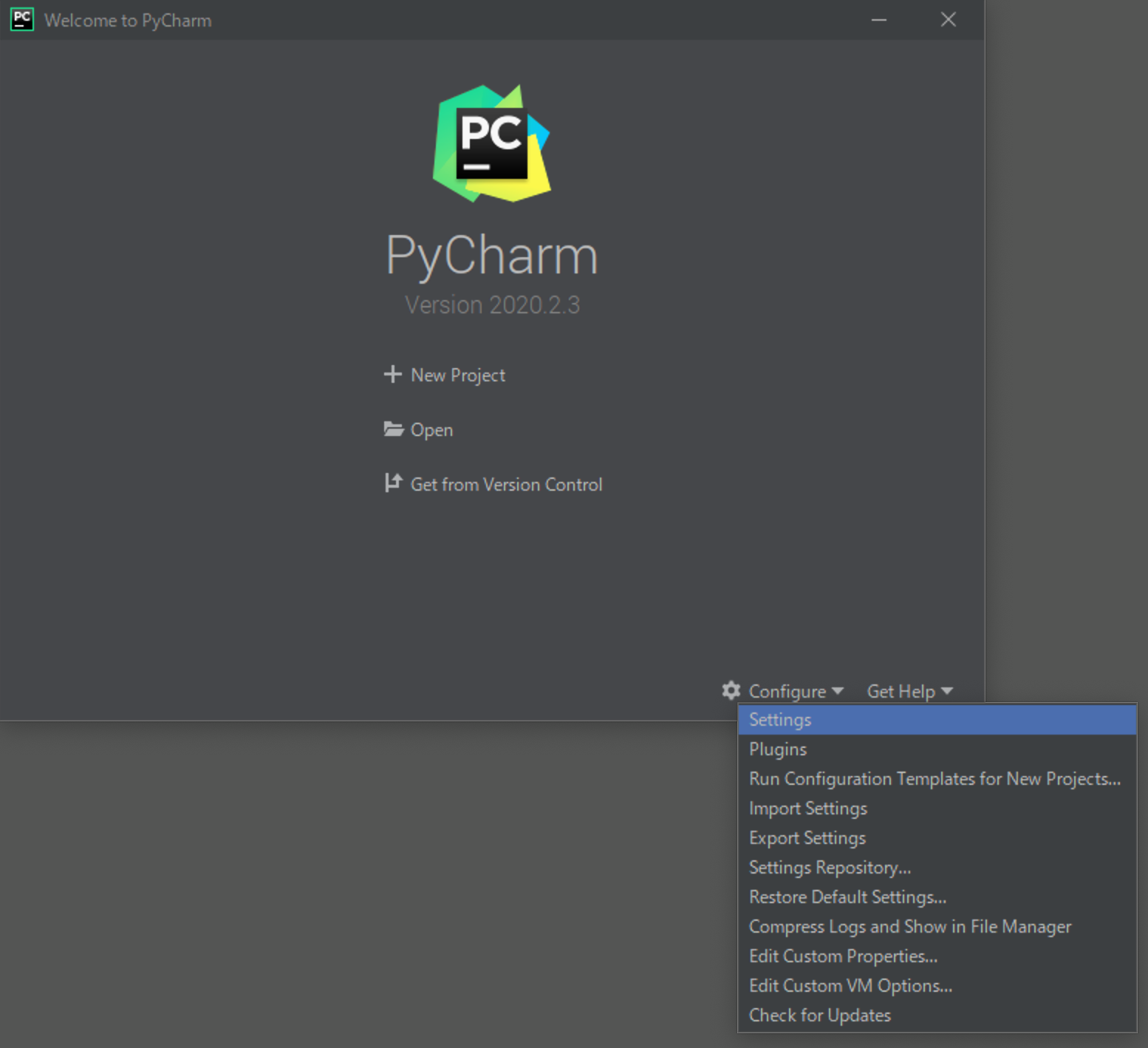
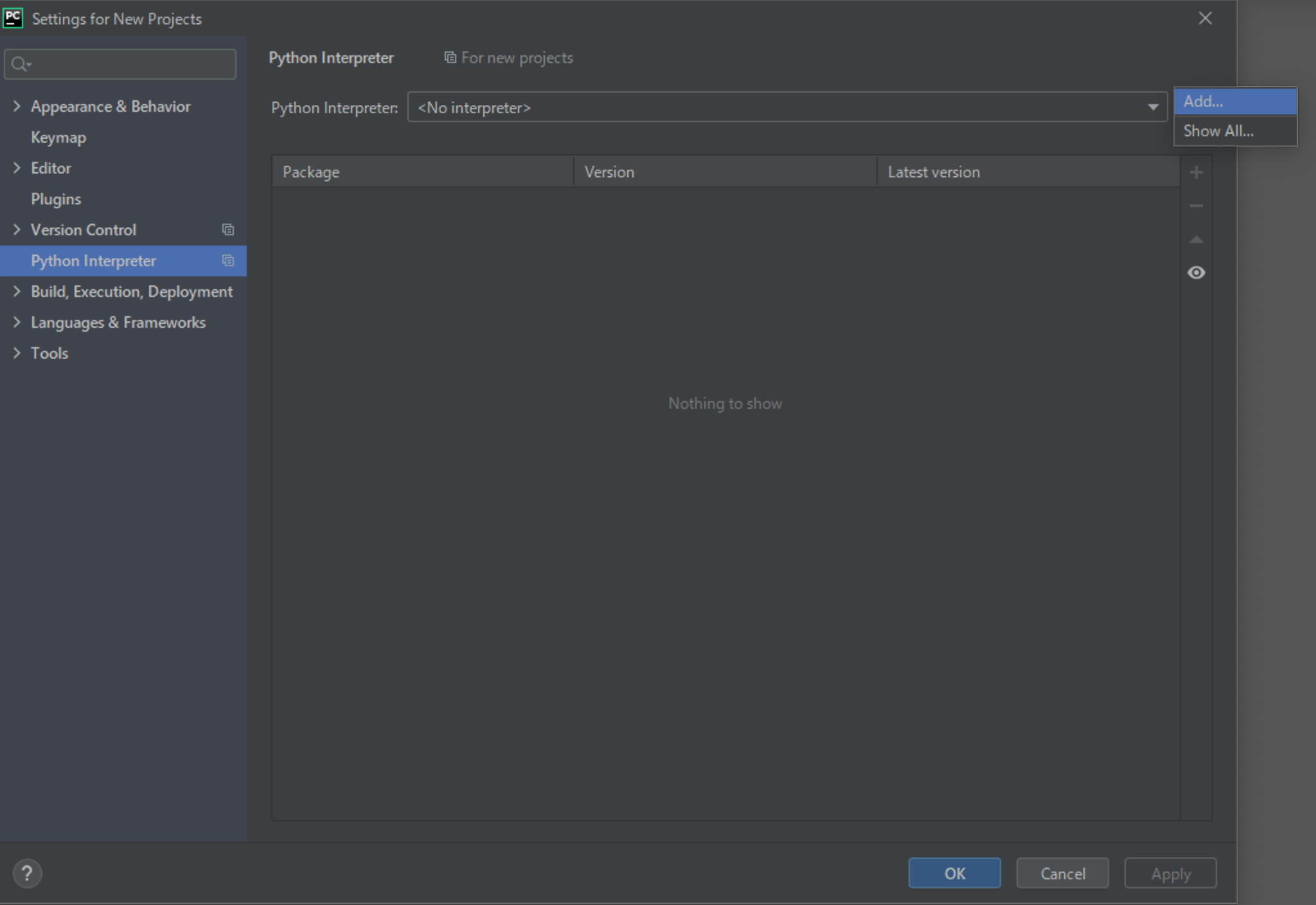
(1) [Configure]-[Settings]をクリックしてください。
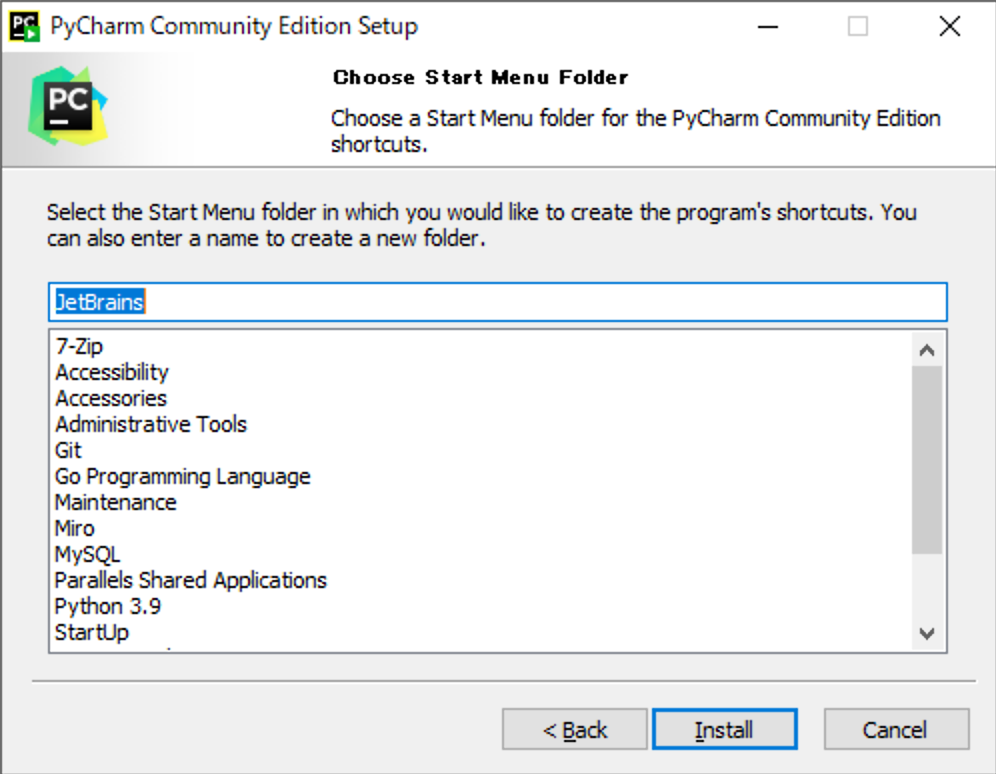
(2) 画面左のメニューから[Python Interpreter]を選択→画面右端の歯車アイコンをクリック→[Add...]をクリックしてください。
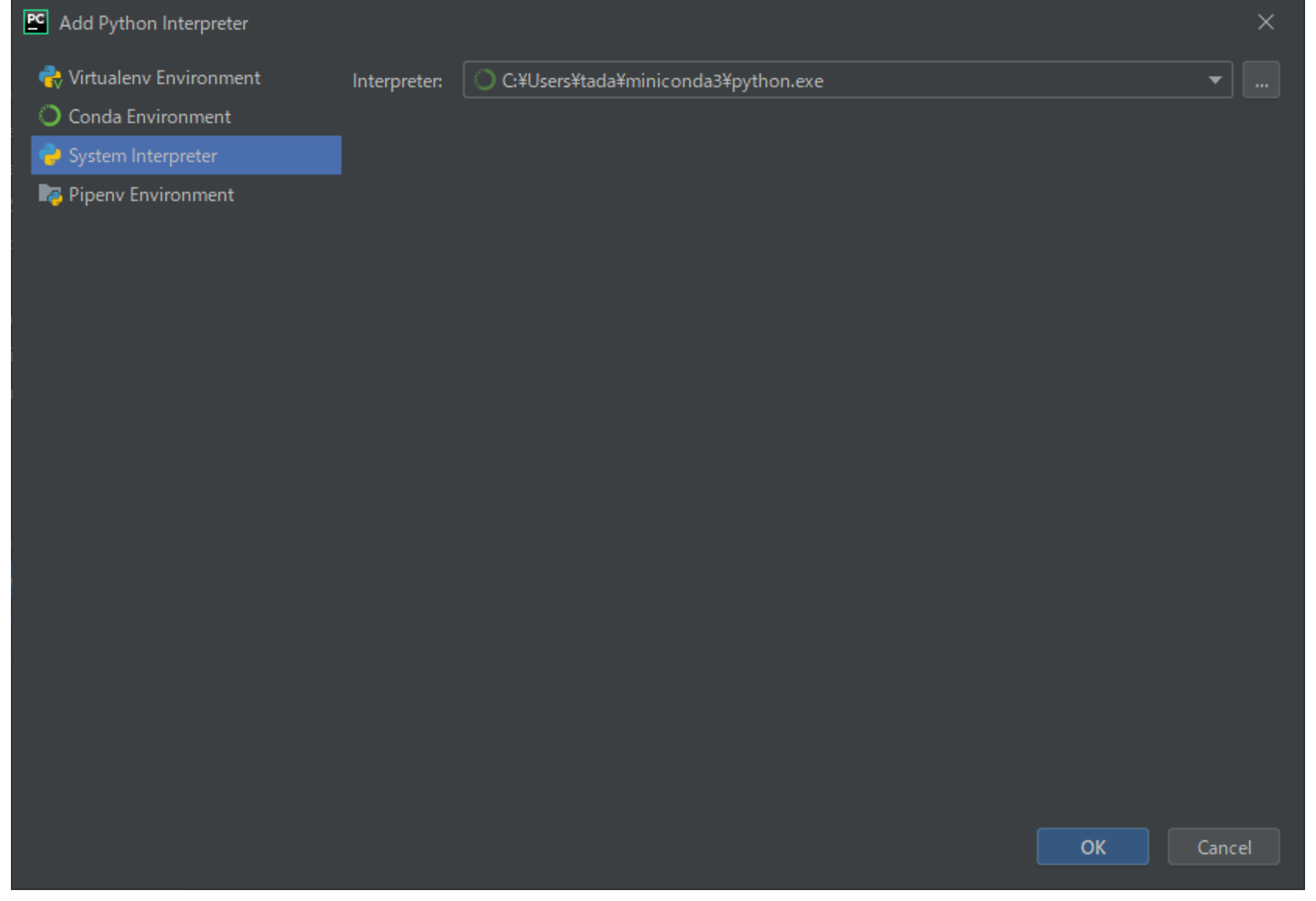
(3) 画面左のメニューから[System Interpreter]を選択→画面右側の[...]をクリックして「C:¥Users¥ユーザー名¥miniconda3¥python.exe」を選択して[OK]→[OK]をクリックしてください。
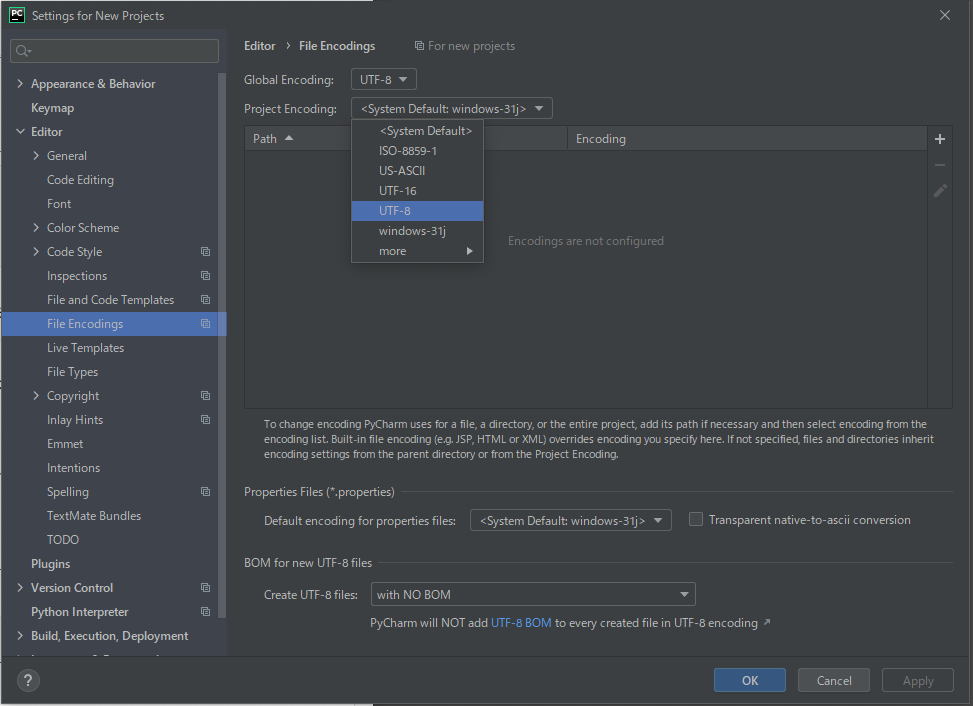
(6) [Editor]-[File Encodings]を選択→[Project Encoding]を[UTF-8]に変更してください。
(7) [OK]をクリックしてください。
PyCharmを好みに設定する(ここの手順は必須ではありません)
こちらの記事を参考にしてください。
IntelliJ IDEA(Java用IDE)の設定の説明ですが、PyCharmでも同様です。
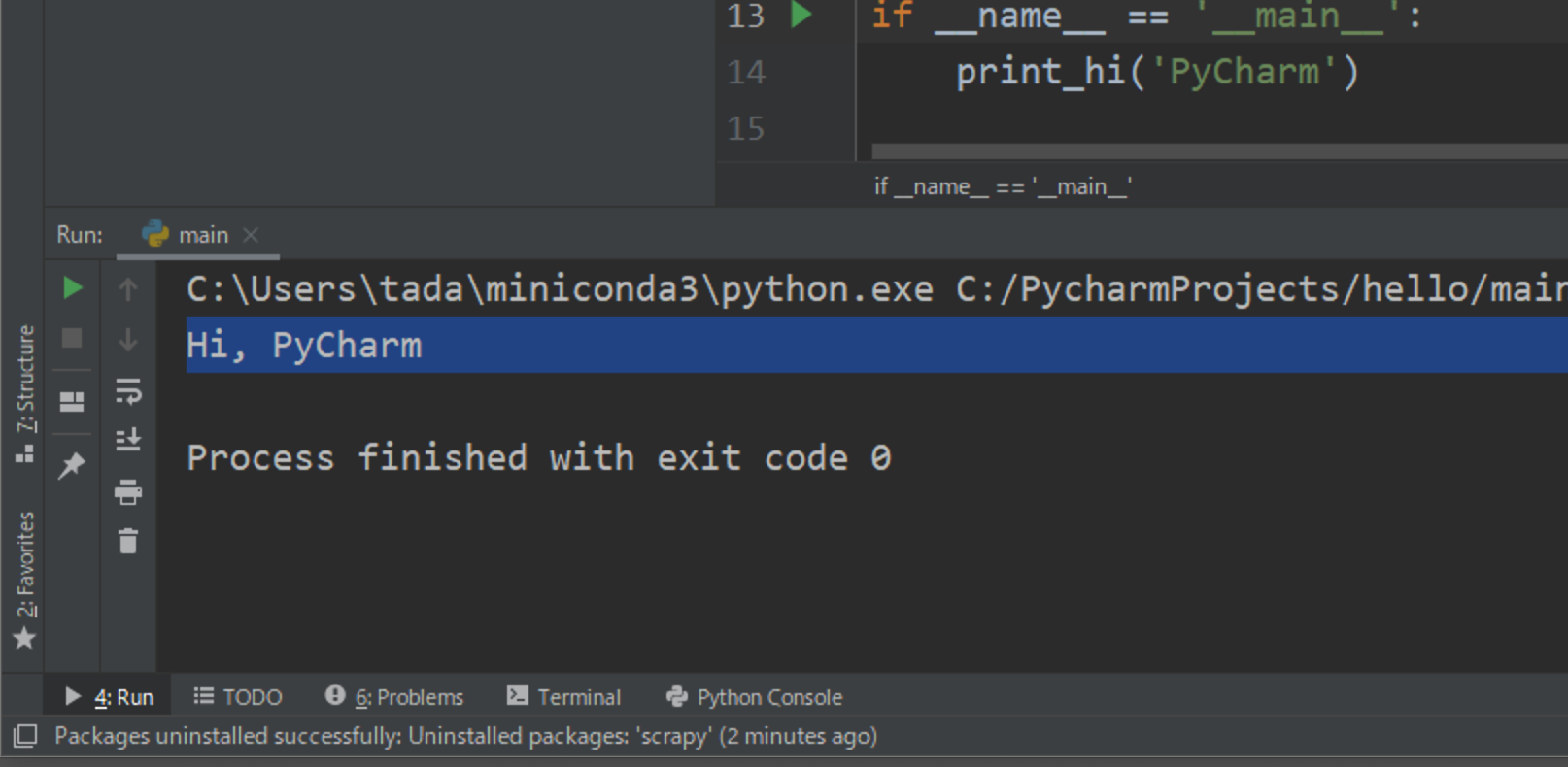
PyCharmでHello World
(1) [New Project]をクリックしてください。
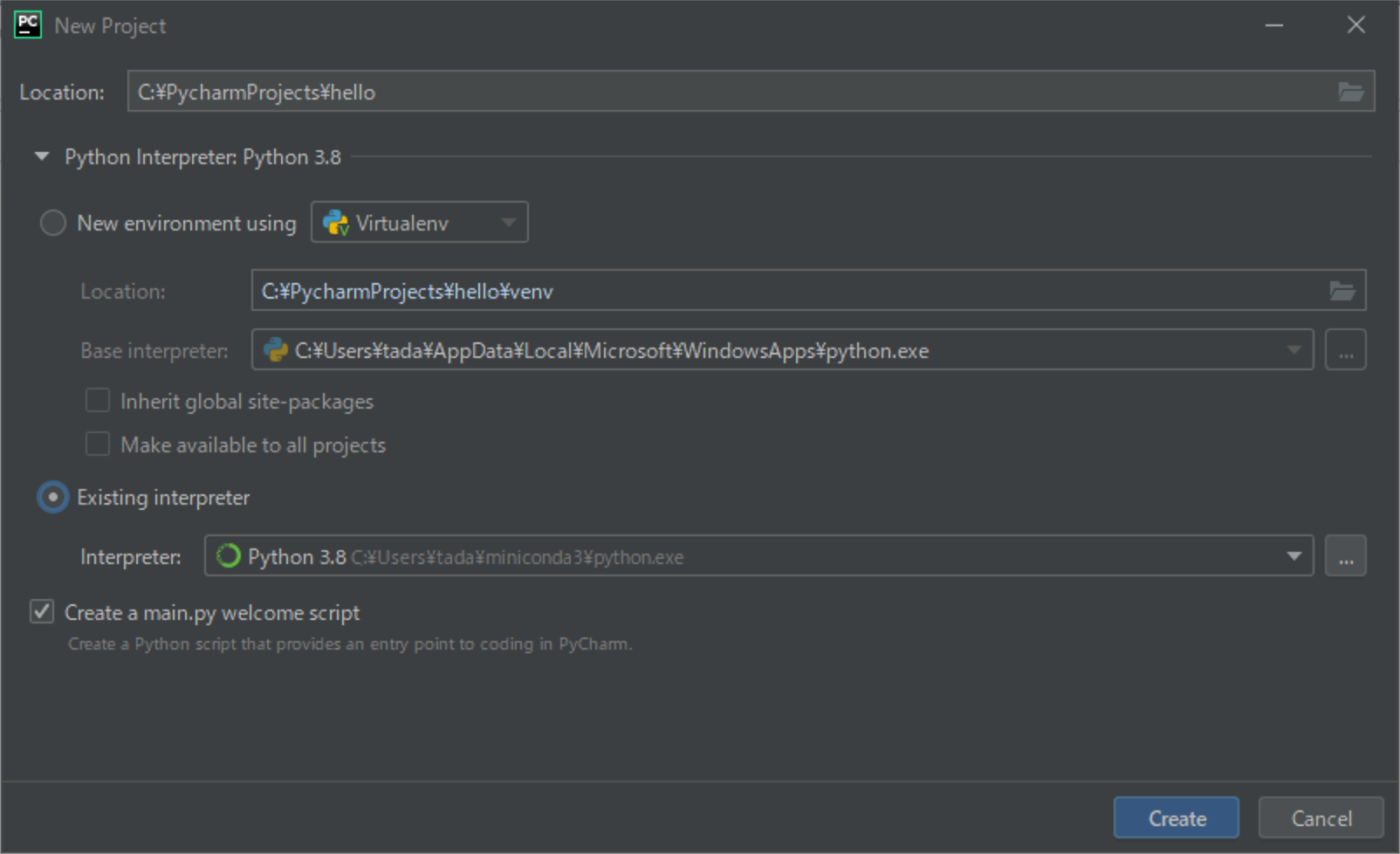
(2) [Location]に適当なパスを入力→[Existing interpreter]を選択→[Create a main.py welcome script]にチェックを入れて、[Create]をクリックしてください。
(3) [Don't show tips]にチェックを入れて、[Close]をクリックしてください。
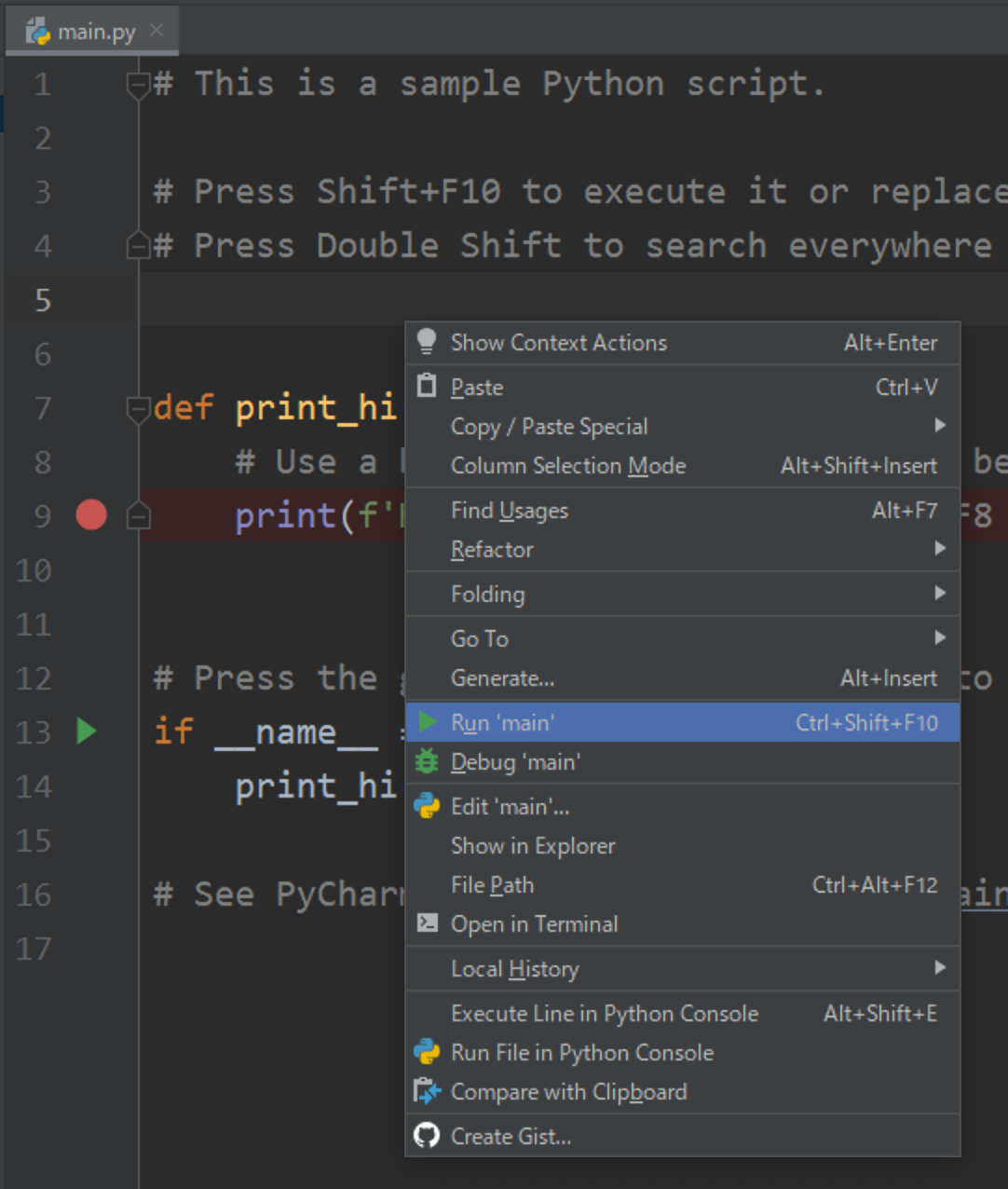
(4) main.py内で右クリックして、[Run 'main']をクリックしてください。
(5) [Hi, PyCharm]と表示されれば成功です。


- 投稿日:2020-10-13T16:46:59+09:00
初めてtensorflowやってみた
タイトル通り初めてtensorflowやってみて環境構築に四苦八苦したので書いてみました。
Qiita初めて書くので説明がうまくないかもですが、よろしくお願いします。構築した環境
私が構築した環境を大雑把に説明します。
- Windows10 Education 2004
- Anaconda3 2020.07 (Python3.83)
- tensorflow-gpu 2.30
- CPU : Ryzen7 1700
- GPU : GTX 1060 6GB
まずPythonの環境構築
Anaconda3 から下にあるGraphical Installerをダウンロード、OS,bitは環境に合わせて選択してください。
インストーラのガイドに従ってインストール、チェックなどはそのままでも大丈夫です。
インストールが終わったら、Anaconda prompt を起動
tensorflow-gpu 2.30 をインストールするために tensorflow pipガイド の下のリストから自分の環境に合わせたものをダウンロード
tensorflowのパッケージファイルをダウンロードしたら、
pip install --upgrade [ダウンロードしたファイル]とAnaconda prompt に入力してインストールNvidia GPU環境の構築
ここからはNvidia GPUを利用したい人向けです。
参考にさせていただいた記事のよるとtensorflow 2.3 はCUDA 10.1,cuDNN 7.6で動作するようです。私の環境でもこの組み合わせで動作しました。
tensorflow のバージョンに合わせてCUDA, cuDNN を導入してください。またtensorflowでGPUを使用するためにはメモリ使用量の設定をしないといけないようです。
そのために下記のコードをコードの先頭に記述します。pythonphysical_devices = tf.config.list_physical_devices('GPU') if len(physical_devices) > 0: for device in physical_devices: tf.config.experimental.set_memory_growth(device, True) print('{} memory growth: {}'.format(device, tf.config.experimental.get_memory_growth(device))) else: print("Not enough GPU hardware devices available")コードの記述はtensorflowのバージョンによって異なりますので、私が参考にさせていただいた記事をご参照ください。
tensorflowを試してみる
tensorflow のチュートリアルにあるニューラルネットワークを使った画像の分類をやってみます。
GPUで処理をするために先程のコードを追加しています。newralnet_demo.py# TensorFlow と tf.keras のインポート import tensorflow as tf from tensorflow import keras # ヘルパーライブラリのインポート import numpy as np import matplotlib.pyplot as plt # import os # os.environ['CUDA_VISIBLE_DEVICES'] = '-1' # print(tf.__version__) # GPU_settings physical_devices = tf.config.list_physical_devices('GPU') if len(physical_devices) > 0: for device in physical_devices: tf.config.experimental.set_memory_growth(device, True) print('{} memory growth: {}'.format( device, tf.config.experimental.get_memory_growth(device))) else: print("Not enough GPU hardware devices available") fashion_mnist = keras.datasets.fashion_mnist (train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data() class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot'] train_images.shape len(train_labels) train_labels test_images.shape len(test_labels) plt.figure() plt.imshow(train_images[0]) plt.colorbar() plt.grid(False) plt.show() train_images = train_images / 255.0 test_images = test_images / 255.0 plt.figure(figsize=(10, 10)) for i in range(25): plt.subplot(5, 5, i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(train_images[i], cmap=plt.cm.binary) plt.xlabel(class_names[train_labels[i]]) plt.show() model = keras.Sequential([ keras.layers.Flatten(input_shape=(28, 28)), keras.layers.Dense(128, activation='relu'), keras.layers.Dense(10, activation='softmax') ]) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) model.fit(train_images, train_labels, epochs=5) test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2) print('\nTest accuracy:', test_acc) predictions = model.predict(test_images) predictions[0] np.argmax(predictions[0]) test_labels[0] def plot_image(i, predictions_array, true_label, img): predictions_array, true_label, img = predictions_array[i], true_label[i], img[i] plt.grid(False) plt.xticks([]) plt.yticks([]) plt.imshow(img, cmap=plt.cm.binary) predicted_label = np.argmax(predictions_array) if predicted_label == true_label: color = 'blue' else: color = 'red' plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label], 100*np.max(predictions_array), class_names[true_label]), color=color) def plot_value_array(i, predictions_array, true_label): predictions_array, true_label = predictions_array[i], true_label[i] plt.grid(False) plt.xticks([]) plt.yticks([]) thisplot = plt.bar(range(10), predictions_array, color="#777777") plt.ylim([0, 1]) predicted_label = np.argmax(predictions_array) thisplot[predicted_label].set_color('red') thisplot[true_label].set_color('blue') i = 0 plt.figure(figsize=(6, 3)) plt.subplot(1, 2, 1) plot_image(i, predictions, test_labels, test_images) plt.subplot(1, 2, 2) plot_value_array(i, predictions, test_labels) plt.show() i = 12 plt.figure(figsize=(6, 3)) plt.subplot(1, 2, 1) plot_image(i, predictions, test_labels, test_images) plt.subplot(1, 2, 2) plot_value_array(i, predictions, test_labels) plt.show() # X個のテスト画像、予測されたラベル、正解ラベルを表示します。 # 正しい予測は青で、間違った予測は赤で表示しています。 num_rows = 5 num_cols = 3 num_images = num_rows*num_cols plt.figure(figsize=(2*2*num_cols, 2*num_rows)) for i in range(num_images): plt.subplot(num_rows, 2*num_cols, 2*i+1) plot_image(i, predictions, test_labels, test_images) plt.subplot(num_rows, 2*num_cols, 2*i+2) plot_value_array(i, predictions, test_labels) plt.show() # テスト用データセットから画像を1枚取り出す img = test_images[0] print(img.shape) # 画像を1枚だけのバッチのメンバーにする img = (np.expand_dims(img, 0)) print(img.shape) predictions_single = model.predict(img) print(predictions_single) plot_value_array(0, predictions_single, test_labels) _ = plt.xticks(range(10), class_names, rotation=45) np.argmax(predictions_single[0])処理がうまく行けば画像が分類されて一覧で表示されます。
参考にしたサイト
金子邦彦研究室様のwebサイトをかなり参考にさせていただきました。
とても参考になりました。ありがとうございます。




- 投稿日:2020-10-13T16:46:08+09:00
AWS Glueで自作関数のインポート
自作関数インポートでつまづく
AWS Glueで共通処理や複雑な関数を別ファイルに記述する際は単純なインポートができません。
といってもジョブの作成時にファイルのパスを追加するだけなのですが、ドキュメントの該当部分がわからなかったのでメモしておきますインポート方法
基本的には
AWS Glue での Python ライブラリの使用
のドキュメントを参考にすれば対応可能です。pythonファイルをzip化、S3にあげてスクリプトのパス設定が基本の流れとなっています。
今回は以下の簡単な2つの関数をインポートします。1関数1ファイルとなっています。
hello_world.pydef hello_world(name): return 'Hello World, ' + str(name)calcu.pydef sum(x, y): return x + yこの2つのファイルをzipでまとめて今回は適当に
lib.zipというzipファイルを作成しました。
このzipファイルをs3にあげます。
s3://example_backet/lib.zipというパスに配置したとします。
このパスをジョブの作成時または編集でPython ライブラリパスという選択肢に記載します。
仮に複数のzipファイルが存在する場合はカンマ区切りで記入します。
これでジョブ作成後はいつものようにimportが可能となります。
sample.pyfrom hello_world import hello_world from calcu import sum hoge = hello_world('hoge') sum = sum(1, 2)
- 投稿日:2020-10-13T16:30:04+09:00
django tutorialメモ
pythonのウェブフレームワークであるDjangoの公式チュートリアル
「はじめての Django アプリ作成」その1~5までのメモです。ほんとにただのメモです。
本家サイトはこちら
https://docs.djangoproject.com/ja/3.1/intro/tutorial01/1. インストール
python環境を作ってpipで入ります
terminalpip install django入ってるか確認してみます
terminal$ python -m django --version 3.1.2django 3.1.2が入ってるようです
2. Djangoプロジェクトを作る
django-admin startproject hogeを実行すると、プロジェクトに最低限必要なフォルダとファイルを自動作成してくれます。
terminaldjango-admin startproject mysite作成されるファイルは以下のような構成です
ディレクトリ構造mysite/ manage.py mysite/ __init__.py settings.py urls.py asgi.py wsgi.pyDBはpython標準のsqlite3になっています。
とりあえずこの状態でサンプルページを表示できるのでやってみましょう。manage.py runserverと実行すると開発用の簡易サーバーが起動します。
terminalpython manage.py runserver起動したサーバーはlocal hostの8000番ポートに待機するので以下のURLをブラウザで開くと見られます。
http://127.0.0.1:8000
なお、この簡易サーバーは開発中の利用だけを考えて作られているので「絶対に運用環境では使わないでください」と公式チュートリアルに書かれています。本番環境ではApacheなどを使って公開しましょう。
3. プロジェクト内にアプリケーションを作る
Djangoは複数のアプリケーションを連携して使えるようにしてくれています。以下のように実行すればアプリに最低限必要なファイルを自動生成してくれます。
terminalpython manage.py startapp pollsディレクトリ構造polls/ __init__.py admin.py apps.py migrations/ __init__.py models.py tests.py views.pyアプリはいくつでも作れるので、機能別に上手く分割すると生産性が上がりそうです。
4. pollsアプリのviewを作る
viewはviews.pyに書きます。
以下は/polls/index.htmlを読みに来たらhttpで「Hello, world. You're at the polls index.」と返すようなviewになります。
polls/views.pyfrom django.http import HttpResponse def index(request): return HttpResponse("Hello, world. You're at the polls index.")上記views.pyへの関連付けをurls.pyに書いていきます。
django.urls.path()に書くと関連付けてくれます。以下のように書くとmysite/urls.py → polls/urls.py → polls/views.pyの順で参照してpolls/views.py内のindex()を見つけてくれるようになります。
mysite/urls.pyfrom django.contrib import admin from django.urls import include, path urlpatterns = [ path('polls/', include('polls.urls')), path('admin/', admin.site.urls), ]polls/urls.pyfrom django.urls import path from . import views urlpatterns = [ path('', views.index, name='index'), ]これで関連付けできたので、簡易サーバーを起動して確認しましょう。
terminalpython manage.py runserverurlにpolls/views.pyに書いた内容が待機してくれます。
http://localhost:8000/polls/5. DBの変更
デフォルトではsqlite3を使うようになっていますので特にDBを設定しなくても出来るようになっています。本番ではpostgreSQLやmySQLに変更すると思いますのでその場合は以下を参照します。
https://docs.djangoproject.com/ja/3.1/intro/tutorial02/6. TIME_ZONEの設定
標準だとUTCで設定されています
mysite/setting.py変更前TIME_ZONE = 'UTC'日本標準時にする場合は以下のように変更します
mysite/setting.py変更後TIME_ZONE = 'Asia/Tokyo' USE_TZ = True7. migrateする
setting.pyの内容に基づいてDBを構築します
terminalpython manage.py migratedjangoはDBのデータをオブジェクトとして扱ってくれるのでデータのハンドリングが楽になるみたいです。(書いてる僕は現時点でよく分かってません。)
8. modelを作る
polls/models.pyimport datetime from django.db import models from django.utils import timezone class Question(models.Model): question_text = models.CharField(max_length=200) pub_date = models.DateTimeField('date published') def __str__(self): return self.question_text def was_published_recently(self): return self.pub_date >= timezone.now() - datetime.timedelta(days=1) class Choice(models.Model): question = models.ForeignKey(Question, on_delete=models.CASCADE) choice_text = models.CharField(max_length=200) votes = models.IntegerField(default=0) def __str__(self): return self.choice_textsetting.pyINSTALLED_APPS = [ 'polls.apps.PollsConfig', 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ]modelに変更があったことをdjangoに認識させます
terminalpython manage.py makemigrations polls9. django shellを使う
djangoは整理されたディレクトリ構造を強制することで生産性を高めるように作られていますが、ファイルの繋がりが複雑になりdjangoから関数を実行したときにどうなるか確認しにくいという問題があります。これを確認しやすいように用意されているのがdjango shellで、python manage.py shellで実行することが出来ます。
django_shell>>> from polls.models import Choice, Question >>> Question.objects.all() <QuerySet []>django_shell>>> from django.utils import timezone >>> q = Question(question_text="What's new?", pub_date=timezone.now()) >>> q.save()django_shell>>> q.id 1django_shell>>> q.question_text = "What's up?" >>> q.save()django_shell>>> Question.objects.all() <QuerySet [<Question: Question object (1)>]>django_shell>>> q.question_text >>> q.pub_date datetime.datetime(2012, 2, 26, 13, 0, 0, 775217, tzinfo=<UTC>)django_shellpython manage.py shell In [1]:django_shell>>> from polls.models import Choice, Question >>> Question.objects.all() <QuerySet [<Question: What's up?>]>django_shell>>> Question.objects.filter(id=1) <QuerySet [<Question: What's up?>]>django_shell>>> Question.objects.filter(question_text__startswith='What') <QuerySet [<Question: What's up?>]>django_shell>>> from django.utils import timezone >>> current_year = timezone.now().year >>> Question.objects.get(pub_date__year=current_year) <Question: What's up?>django_shell>>> Question.objects.get(id=2) Traceback (most recent call last): ... DoesNotExist: Question matching query does not exist.django_shell>>> Question.objects.get(pk=1) <Question: What's up?>django_shell>>> q = Question.objects.get(pk=1) >>> q.was_published_recently() Truedjango_shell>>> q = Question.objects.get(pk=1) >>> q.choice_set.all() <QuerySet []>django_shell>>> q.choice_set.create(choice_text='Not much', votes=0) >>> q.choice_set.create(choice_text='The sky', votes=0) >>> c = q.choice_set.create(choice_text='Just hacking again', votes=0) >>> c.question <Question: What's up?>django_shell>>> q.choice_set.all() <QuerySet [<Choice: Not much>, <Choice: The sky>, <Choice: Just hacking again>]>django_shell>>> q.choice_set.count() 3django_shell>>> Choice.objects.filter(question__pub_date__year=current_year) <QuerySet [<Choice: Not much>, <Choice: The sky>, <Choice: Just hacking again>]>django_shell>>> c = q.choice_set.filter(choice_text__startswith='Just hacking') >>> c.delete()10. 監理ユーザーを作る
djangoプロジェクト監理用のsuperuserを作ります。このsuperuserはdjango用なのでLinux OSのuserとは別になります。
django_shellpython manage.py createsuperuserIDとパスワードを入力すれば登録完了です。これによりadminページにログインできるようになるので簡易サーバーを起動してadminページにログインしましょう。
django_shellpython manage.py runserveradminページのURL
http://127.0.0.1:8000/admin/
ログインすると以下のように表示されます
11. adminページからアプリを編集する
polls/admin.pyfrom django.contrib import admin from .models import Question admin.site.register(Question)以下のようにpollsアプリの欄が追加されました
Questionsをクリックするとオブジェクト内の値を操作できます
shellから操作するよりこっちの方が分かりやすいので上手く使いたいですね。
12. Viewを足していく
はじめての Django アプリ作成、その3
https://docs.djangoproject.com/ja/3.1/intro/tutorial03/URLによって開くviewを変える
polls/views.pyfrom django.http import HttpResponse def index(request): return HttpResponse("Hello, world. You're at the polls index.") def detail(request, question_id): return HttpResponse("You're looking at question %s." % question_id) def results(request, question_id): response = "You're looking at the results of question %s." return HttpResponse(response % question_id) def vote(request, question_id): return HttpResponse("You're voting on question %s." % question_id)polls/urls.pyfrom django.urls import path from . import views urlpatterns = [ # ex: /polls/ path('', views.index, name='index'), # ex: /polls/5/ path('<int:question_id>/', views.detail, name='detail'), # ex: /polls/5/results/ path('<int:question_id>/results/', views.results, name='results'), # ex: /polls/5/vote/ path('<int:question_id>/vote/', views.vote, name='vote'), ]これでpython manage.py runserverして以下URLをブラウザで開くと、polls/views.pyのdetail(), results(), vote() がそれぞれ実行されます。
http://127.0.0.1:8000/polls/34/
http://127.0.0.1:8000/polls/34/results/
http://127.0.0.1:8000/polls/34/vote/インデックスページを作る
polls/views.pyのindex()を以下のように書き換えてQuestion.
polls/vies.pyfrom django.http import HttpResponse from .models import Question def index(request): latest_question_list = Question.objects.order_by('-pub_date')[:5] output = ', '.join([q.question_text for q in latest_question_list]) return HttpResponse(output) def detail(request, question_id): return HttpResponse("You're looking at question %s." % question_id) def results(request, question_id): response = "You're looking at the results of question %s." return HttpResponse(response % question_id) def vote(request, question_id): return HttpResponse("You're voting on question %s." % question_id)13. templateを作る
上記ではviews.pyに直接画面レイアウトを書き込んでしまっていますが、修正しやすいようにtemplateに記述を分けるようにしましょう。views.pyにloader.get_template('polls/index.html')を書いてtemplate/polls/index.htmlを読むようにします。
polls/views.pyfrom django.http import HttpResponse from django.template import loader from .models import Question def index(request): latest_question_list = Question.objects.order_by('-pub_date')[:5] template = loader.get_template('polls/index.html') context = { 'latest_question_list': latest_question_list, } return HttpResponse(template.render(context, request))polls/templates/polls/index.html{% if latest_question_list %} <ul> {% for question in latest_question_list %} <li><a href="/polls/{{ question.id }}/">{{ question.question_text }}</a></li> {% endfor %} </ul> {% else %} <p>No polls are available.</p> {% endif %}render
templateを読み込んでrenderするのをrender()で置き換えると短く書けますし、importするパッケージも少なくて済みます。
polls/views.pyfrom django.shortcuts import render from .models import Question def index(request): latest_question_list = Question.objects.order_by('-pub_date')[:5] context = {'latest_question_list': latest_question_list} return render(request, 'polls/index.html', context)14. 404エラー表示
try/exceptで例外になったときに404を出すようにします。
polls/views.pyfrom django.http import Http404 from django.shortcuts import render from .models import Question def index(request): latest_question_list = Question.objects.order_by('-pub_date')[:5] context = {'latest_question_list': latest_question_list} return render(request, 'polls/index.html', context) def detail(request, question_id): try: question = Question.objects.get(pk=question_id) except Question.DoesNotExist: raise Http404("Question does not exist") return render(request, 'polls/detail.html', {'question': question})get_object_or_404
いちいちtry/exceptするのは面倒なので、getして失敗したら404を返す関数であるget_object_or_404()に置き換えてみます
from django.shortcuts import get_object_or_404, render from .models import Question # ... def detail(request, question_id): question = get_object_or_404(Question, pk=question_id) return render(request, 'polls/detail.html', {'question': question})15. アプリの名前空間
polls/urls.pyのapp_nameを指定するとアプリの名前空間から参照できるようになります。これをやらないと別アプリに同じ名前のviewがあったときに動作が怪しくなりそうなので、忘れない内にview作るときに指定しておいた方が良いと思います。
polls/urls.pyfrom django.urls import path from . import views app_name = 'polls' urlpatterns = [ path('', views.index, name='index'), path('<int:question_id>/', views.detail, name='detail'), path('<int:question_id>/results/', views.results, name='results'), path('<int:question_id>/vote/', views.vote, name='vote'), ]これにより、viewの参照がdetailからpolls:detailに変更になります。他のviewも同様にpolls:hogeのように指定し直しましょう。
polls/templates/polls/index.html{% if latest_question_list %} <ul> {% for question in latest_question_list %} <li><a href="{% url 'polls:detail' question.id %}">{{ question.question_text }}</a></li> {% endfor %} </ul> {% else %} <p>No polls are available.</p> {% endif %}16. フォームを書く
はじめての Django アプリ作成、その4
https://docs.djangoproject.com/ja/3.1/intro/tutorial04/投票ボタンを追加します
polls/detail.html<h1>{{ question.question_text }}</h1> {% if error_message %}<p><strong>{{ error_message }}</strong></p>{% endif %} <form action="{% url 'polls:vote' question.id %}" method="post"> {% csrf_token %} {% for choice in question.choice_set.all %} <input type="radio" name="choice" id="choice{{ forloop.counter }}" value="{{ choice.id }}"> <label for="choice{{ forloop.counter }}">{{ choice.choice_text }}</label><br> {% endfor %} <input type="submit" value="Vote"> </form>こんな感じでボタンができます
http://127.0.0.1:8000/polls/1/
formのactionを「polls:voteのviewにpostする」にしてあるので、これに対応するviewを作ります。polls:voteのviewはpolls/urls.pyに以下のように書いてますのでpoll/views.pyに書いてやれば良いという事になります。
polls/urls.pypath('<int:question_id>/vote/', views.vote, name='vote'),choiceされている対象を1つ足して/polls/results/にリダイレクトするようにしてやります
polls/views.pyfrom django.http import HttpResponse, HttpResponseRedirect from django.shortcuts import get_object_or_404, render from django.urls import reverse from .models import Choice, Question def vote(request, question_id): question = get_object_or_404(Question, pk=question_id) try: selected_choice = question.choice_set.get(pk=request.POST['choice']) except (KeyError, Choice.DoesNotExist): # Redisplay the question voting form. return render(request, 'polls/detail.html', { 'question': question, 'error_message': "You didn't select a choice.", }) else: selected_choice.votes += 1 selected_choice.save() # Always return an HttpResponseRedirect after successfully dealing # with POST data. This prevents data from being posted twice if a # user hits the Back button. return HttpResponseRedirect(reverse('polls:results', args=(question.id,)))リダイレクトで呼ばれる/polls/results/のviewも書いてやります
from django.shortcuts import get_object_or_404, render def results(request, question_id): question = get_object_or_404(Question, pk=question_id) return render(request, 'polls/results.html', {'question': question})17. 汎用ビューを使う
汎用ビューを使うことで無駄な記述が減らせるようです。
polls/urls.pyfrom django.urls import path from . import views app_name = 'polls' urlpatterns = [ path('', views.IndexView.as_view(), name='index'), path('<int:pk>/', views.DetailView.as_view(), name='detail'), path('<int:pk>/results/', views.ResultsView.as_view(), name='results'), path('<int:question_id>/vote/', views.vote, name='vote'), ]polls/views.pyfrom django.http import HttpResponseRedirect from django.shortcuts import get_object_or_404, render from django.urls import reverse from django.views import generic from .models import Choice, Question class IndexView(generic.ListView): template_name = 'polls/index.html' context_object_name = 'latest_question_list' def get_queryset(self): """Return the last five published questions.""" return Question.objects.order_by('-pub_date')[:5] class DetailView(generic.DetailView): model = Question template_name = 'polls/detail.html' class ResultsView(generic.DetailView): model = Question template_name = 'polls/results.html'まだまだ続くんですが
https://docs.djangoproject.com/ja/3.1/intro/tutorial05/
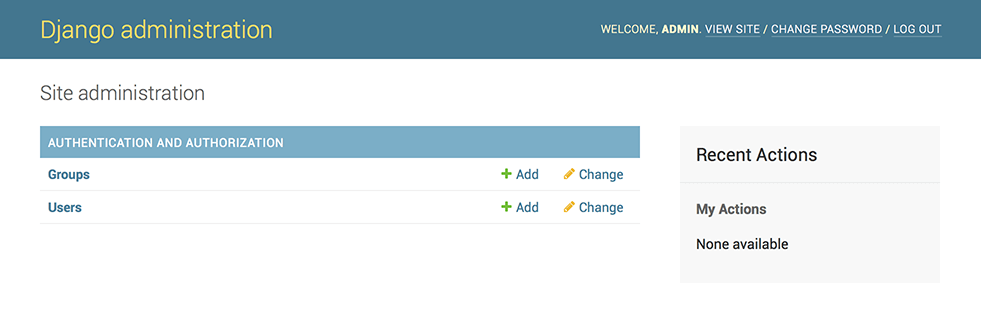
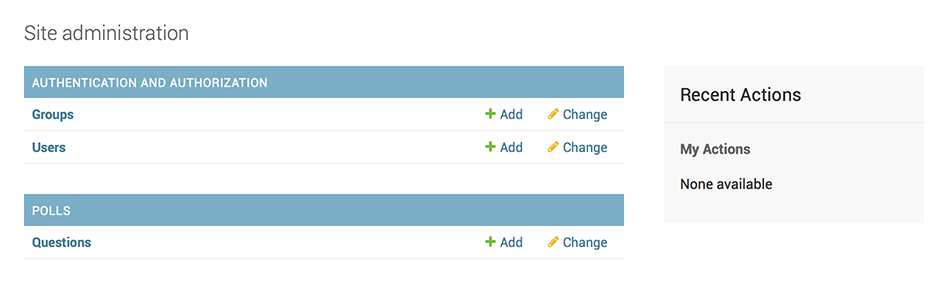
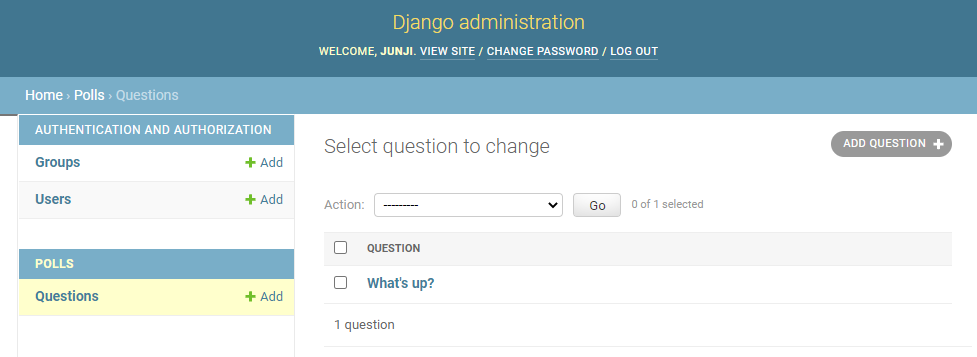

- 投稿日:2020-10-13T15:59:52+09:00
HHKB プログラミングコンテスト 2020 復習
今回の成績
今回の感想
二番目に良いパフォでしたが、目指しているのはここではないので悔しいです。D問題を飛ばしてE問題に移れた良いのですが、D問題は丁寧に考えれば解けたはずの問題なので悔しいです。
A問題
Yに等しい場合はupperメソッドで変換します。
A.pys,t=input(),input() if s=="Y": print(t.upper()) else: print(t)B問題
問題文の読解ができなくて焦りました。要約すれば、縦2マスまたは横2マスを選択した時にいずれのマスも散らかってないマスである場合の数を求める問題です。
縦2マスか横2マスを選択します。この時、反転させて考えれば縦2マスは横2マスとみなせるので元の行列の横2マスの判定と、反転させた行列の横2マスの判定をそれぞれ行って和を求めます。
B.pyh,w=map(int,input().split()) s=[list(input()) for i in range(h)] t=[["" for j in range(h)] for i in range(w)] for i in range(h): for j in range(w): t[j][i]=s[i][j] ans=0 for i in range(h): for j in range(w-1): if s[i][j]=="." and s[i][j+1]==".": ans+=1 for i in range(w): for j in range(h-1): if t[i][j]=="." and t[i][j+1]==".": ans+=1 print(ans)C問題
コドフォで良く出る$mex$を求める問題です。$i$番目までに出てきた数を保存する配列$check$と$i$番目の時点での解(出てきてない数の中の最小値)を$mi$を保持しておきます。
この時、$mi$は単調増加するので、$check[mi]!=0$のときは$check[mi]=0$となる$mi$が見つかるまでインクリメントをし、$check[mi]=0$のときは$mi$を出力すれば良いです。
(そこまで簡単だとは思わないのですが、多くの人が通していて驚きです。)
C.pyn=int(input()) p=list(map(int,input().split())) check=[0]*200001 mi=0 for i in range(n): check[p[i]]+=1 while True: if check[mi]>0: mi+=1 else: break print(mi)D問題
まず、赤い正方形と青い正方形を複数置くものだと誤読していました。赤い正方形と青い正方形は一つずつなので、片方を固定した時のもう片方の並べ方を求めて式変形により$O(1)$で求めることを考えます。ここで、(赤い正方形の一辺:A)$\geqq$(青い正方形の一辺:B)として赤い正方形を固定して青い正方形を動かすことを考えます。この時、赤い正方形は左下の角が$(i,j)\ (0 \leqq i <N-A,0 \leqq i <N-A)$にあるものとします。
すると、上記の赤,緑,黄色,青の長方形に青の正方形が入る場合の数を考えれば良いです。また、それぞれ四箇所の重なる部分に青の正方形が含まれる場合は引いて計算する必要があります。ここで、長方形の部分及び重なる部分はそれぞれ対称性より合計をとると等しいので、以下の赤の長方形から青の長方形を引いたものを四倍することで答えは求まります。
(1)赤の長方形について
青の正方形と青の正方形の横幅を考えれば、$B \leqq i \leqq N-A$が成り立ちます。この時、含まれる青の正方形の数は\begin{align} &\sum_{i,j}(N-B-1)(i-B+1)\\ &=(N-B-1)\sum_{i,j}(i-B+1)\\ &=(N-B-1)\sum_{j}(\sum_{i}(i-B+1))\\ &=(N-B-1)\sum_{j}(1,2,…,N-A-B+1)\\ &=(N-B-1)\sum_{j}\frac{(N-A-B+1)(N-A-B+2)}{2}\\ &=(N-B-1)(N-A+1)\frac{(N-A-B+1)(N-A-B+2)}{2}\\ \end{align}(2)青の長方形について
先ほどの$B \leqq i \leqq N-A$に加え、$B \leqq j \leqq N-A$も成り立ちます。この時、含まれる青の正方形の数は\begin{align} &\sum_{i,j}(j-B-1)(i-B+1)\\ &=\sum_{i}(i-B+1)\times \sum_{j}(j-B+1)\\ &=(\frac{(N-A-B+1)(N-A-B+2)}{2})^2\\ \end{align}上記の計算は$(j-B-1),(i-B+1)$とそれぞれ$i,j$に依存するので、和として分離することを用います。一方の項に$i,j$が含まれる場合は分離できないことに注意が必要です。
以上の(1)から(2)を引いたものを四倍して求めれば良いです。また、Pythonを使えば多倍長整数なのでオーバフローは気にしなくて大丈夫で、最後に$10^9+7$で割った余りを求めます。
D.pymod=10**9+7 for _ in range(int(input())): n,a,b=map(int,input().split()) if a<b: a,b=b,a x=(n-a-b+1)*(n-a-b+2)//2*(n-a+1)*(n-b+1)*4 y=((n-a-b+1)*(n-a-b+2)//2)**2*4 if a+b>n: print(0) continue print((x-y)%mod)E問題
本番でDからすぐに移れたので良かったです。実装もあまりバグらせずに素直にできたので良かったです。
まず、総和とあるので、照らされるマスが$2^k$通りのうち何回現れるかを考えます(総和は要素の回数に注目!)。ここで、あるマスに照明を置いた時に照らされるマスはそのマスから連続した散らかってないマスになります。ここで、いくつかのマスに照明をおいた時、複数の照明があるマスを照らす可能性があります。この時はそのマスを1回として解に加える必要があるので、そのマスを$x$個の照明が照らせると仮定してそのマスが照らされるマスとして何回現れるか考えました。ここで、$x$個のいずれかの照明がついていればそのマスは照らされます。よって、証明の置くマスの選び方が$2^k$通りでその$x$個のいずれのマスも選ばない選び方が$2^{k-x}$通りなので、少なくとも一つ選ぶ選び方は$2^k-2^{k-x}$通りです($\because$ 包除原理)。
よって、それぞれのマスについていくつのマスから照らされるかを求めて2乗の前計算も行うことで総和を$O(HW)$で求めることができます。ここで、あるマスを照らすマスは行または列を共有しており、行列を転置させれば同様なので、行を共有するマスのうちいくつのマスから照らされるかをまずは考えます。
ここで、ある行に$y$個だけ連続した散らかってないマスがあった時、そこに含まれる任意のマスについて行を共有して照らされるマスの数は$y$となります。したがって、itertoolsのgroupby関数(参照)を使って連続した散らかってないマスをまとめることで、$O(HW)$でそれぞれのマスでの$y$を求めることができます。同様に列を共有するマスのうちいくつのマスから照らされるかを求めて$y$と足し合わせた値から1を引くことで($\because$そのマスを二回カウントしている)それぞれのマスにおける$x$が求まります。
E.pymod=10**9+7 h,w=map(int,input().split()) s=[list(input()) for i in range(h)] k=0 for i in range(h): for j in range(w): if s[i][j]==".": k+=1 t=[["" for j in range(h)] for i in range(w)] for i in range(h): for j in range(w): t[j][i]=s[i][j] po=[0]*(k+1) po[0]=1 for i in range(1,k+1): po[i]=po[i-1]*2 po[i]%=mod #行でつながっている部分 from itertools import groupby check=[[0]*w for i in range(h)] for i in range(h): now=0 for key,group in groupby(s[i]): l=len(list(group)) if key=="#": now+=l else: for j in range(now,now+l): check[i][j]+=l now+=l for i in range(w): now=0 for key,group in groupby(t[i]): l=len(list(group)) if key=="#": now+=l else: for j in range(now,now+l): check[j][i]+=l now+=l ans=0 for i in range(h): for j in range(w): #print(k,k-check[i][j]) if check[i][j]!=0: ans+=(po[k]-po[k-check[i][j]+1]) ans%=mod print(ans)F問題
今回は飛ばします。

- 投稿日:2020-10-13T15:16:24+09:00
pyenvとvenvで仮想環境を構築する
Pythonの環境を構築することがあったので備忘録としてまとめておきます。
使用環境
Mac Catalina 10.15.6
仮想環境の構築に使うもの
仮想環境を構築する上でよく使われるものは
- pyenv
- venv
- virtualenv
- pipenv
- Anaconda
- Docker
など様々ありますが、今回は手軽にできる pyenv と venv で構築したいと思います。
ではそれぞれのインストール方法です。pyenv
pythonのバージョンを管理するツールです。
これひとつで Python 2系もPython 3系も同時に管理できる優れものです。pyenv のインストール方法
1. Homebrew からインストール
ターミナル.brew install pyenvHomebrewをインストールしていない場合は、
ターミナル./bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"で実行してHomebrewをインストールできます。
2. pyenv 用の .profile を作成
pyenv 用に PATH を通します。
自分のホームディレクトリ直下に .zshrc を作成して以下のように記述します。
ちなみにターミナル.cd pwdで自分のホームディレクトリがわかります。
/Users/ユーザー名/.zshrcexport PYENV_ROOT="$HOME/.pyenv" export PATH="$PYENV_ROOT/bin:$PATH" if command -v pyenv 1>/dev/null 2>&1; then eval "$(pyenv init -)" fiここまできたら一度ターミナルを閉じます。
もう一度立ち上げ、
ターミナル.pyenv -helpでエラーが起きなければ pyenv のインストールは完了です。
python のインストール
1.Python の確認
現在pyenvによってインストール可能なPythonのバージョンを確認してみます。
ターミナル.pyenv install --list羅列したバージョンの中から自分に合うものを選びます。
2. インストール
ターミナル.pyenv install [自分に合うバージョン] 例) pyenv install 3.8.53. 選択したPythonのバージョンをデフォルトに設定
正しくインストールされているか確認します。
ターミナル.pyenv versions system 3.8.5このように先ほどインストールしたものが表示されていればOKです。
では、インストールしたバージョンをデフォルトに設定します。ターミナル.pyenv global [自分に合うバージョン] 例) python global 3.8.5では確認します。
ターミナル.pyenv versions system * 3.8.5 (set by /Users/ユーザー名/.pyenv/version)このようにセットされていればOKです。
一応Pythonのバージョンを確認しておきます。
ターミナル.python -V 3.8.5このように変わっていれば完璧です。
また蛇足かもしれませんが、このままだと Jupyter などで使用できない場合があるので、pip をアップデートすることをお勧めします。
ターミナル.pip install --upgrade pipvenv (virtualenv)
venv と virtualenv はどちらも、 Python のモジュール・ライブラリをプロジェクト毎に管理することができるツールです。
ただし、Python 3系には venv が元々搭載されているのに対し、Python 2系は virtualenv をインストールする必要があります。
基本的な部分は変わらないので、今回はPython 3系に準じていきます。1. virtualenv のインストール (python 2系のみ)
ターミナル.pip install virtualenv2. プロジェクトに移動
ターミナル.cd path/to/プロジェクトこのように、仮想環境を適用したいプロジェクトの直下に作成するのが慣例のようです。
3. 仮想環境作成
ターミナル.※ Python 2系 virtualenv [作成する仮想環境名] ※ Python 3系 python -m venv [作成する仮想環境名]これで仮想環境が作成されました。
どうやら.venvで作成することが慣例のようです。4. 仮想環境をアクティベートする
仮想環境は持っているだけでは意味がありません。ドラクエの武器と同じです。
アクティベートはドラクエでいう装備です。
プロジェクト直下で以下のコマンドを行います。ターミナル.source [仮想環境名]/bin/activate もしくは . [仮想環境名]/bin/activate 例) . .venv/bin/activateこれでターミナルが
(仮想環境名): ~ 例) (.venv): ~ってなればアクティベートできています。
この状態で
pip installすると全て venv に蓄積されるので、ローカル環境は汚染されずにすみます。ちなみにディアクティベートは
ターミナル.deactivateでOKです。
- 投稿日:2020-10-13T13:14:42+09:00
AtCoder Regular Contest 105 復習
今回の成績
今回の感想
A,B問題しか解けず、B問題は後から嘘解法であったことが判明し、C問題をupsolveしようとしたら一部のケースのみWAとなって散々な目に合いました。C問題は貪欲法なので間違いが存在しうるのですが、どこが間違いなのか今もわからずしんどい気持ちになっています。
(しんどかったのですが、解法の通りに最長経路で解けました。詳しくは以下のC問題の解説を見てください。)
A問題
二つに分けて一致するかを考えます。この時、ある選び方をして選んだ数の合計が全体の合計のちょうど1/2になっていれば良いと考えれば良いです。
よって、$a+b,b+c,c+d,d+a,a+c,b+d,a,b,c,d$のいずれかがちょうど1/2になるかを判定すれば良いです。また、数を三つ選ぶ時は考える必要がありません。
A.pya,b,c,d=map(int,input().split()) cand=[a+b,b+c,c+d,d+a,a+c,b+d,a,b,c,d] s=sum([a,b,c,d]) if s%2==1: print("No") elif s//2 in cand: print("Yes") else: print("No")B問題
愚直にシミュレーションを行います。また、最終的に残る数は一つだけで同じ数には同じ操作を行うので、setで数を保存しておきます。最大の数と最小の数を選ぶので整列されているsetは好都合です。
コンテスト中にはテストケースが弱く通せましたが、この解法は嘘解法です。例えば、$1 \ 10^9$となる時に$10^9$回のsetへの挿入を行うからです。したがって、この操作がユークリッドの互除法であることに気づいて全体のgcdを取る解法が正答となります。また、シミュレーションの際に(最大値)-$x \times$(最小値)>0となる中で最大の$x$の分だけまとめてシミュレートして良いので、これを行えばおそらく高速に動作するはずです。
B.cc//デバッグ用オプション:-fsanitize=undefined,address //コンパイラ最適化 #pragma GCC optimize("Ofast") //インクルードなど #include<bits/stdc++.h> using namespace std; typedef long long ll; //マクロ //forループ //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる //FORAは範囲for文(使いにくかったら消す) #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) #define FORA(i,I) for(const auto& i:I) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() #define SIZE(x) ll(x.size()) //定数 #define INF 1000000000000 //10^12:∞ #define MOD 1000000007 //10^9+7:合同式の法 #define MAXR 100000 //10^5:配列の最大のrange //略記 #define PB push_back //挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 signed main(){ //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); ll n;cin>>n; set<ll> ans; REP(i,n){ ll a;cin>>a; ans.insert(a); } while(SIZE(ans)!=1){ ll l,r;l=*ans.begin();r=*--ans.end(); ans.erase(r); ans.insert(r-l); } cout<<*ans.begin()<<endl; }C問題
C問題は貪欲法でのACしようとしてできなかったので解説の最長経路を取り入れてプログラムを書きました。解説より計算量的には重いですが、枝刈りを入れて高速化しました。
まず、任意のラクダの並び順を試して$N!$通りです。さらに、それぞれの並び順について、それぞれのパーツを渡れる際に必要なラクダの間の距離を求めるのに、$O(M \times N^2)$です。したがって、計算量は$O(N! \times M \times N^2)$となり間に合わないので、うまく枝刈りなどを行うことにより高速化します(コンテスト中は諦めてしまいましたが、$10^{11}$くらいまでは定数倍高速化による非想定解法でも通ることがあるので、諦めずに取り組むようにします。)。
まず、上記の方針は、
①ラクダの並び順を定める($next$_$permutation$を使うだけ(参照))
②それぞれのパーツ($M$通り)があるラクダから始めてどのラクダ($N-1$通り)から載せることができないかを求める。という順番になります。
また、②で貪欲法を使うとコーナーケースを踏んでWAになってしまいます。ここでは、あるラクダから始めてどのラクダから載せることができないか(そのパーツの長さだけ離れていなければならない)という情報を辺とみなすことにより、最初のラクダから最後のラクダまでの最長経路を求めるという問題に帰着できれば良いです。
よって、$dp[i]:=$(最初のラクダから$i$番目のラクダまでの最長距離)としたDPを$next$_$permutation$のdo-while文の中で行えば良いです。あるパーツを選んだ時を遷移とみなしますが、ここでは詳細は省略します。
(以下で、定数倍高速化を行います。)
(確か、初めのパーツを減らす高速化をするだけで通すことができます。)(長さ,重さ)でパーツを管理して$a \geqq c$かつ$b \leqq d$となる$(a,b),(c,d)$が存在した時、$(a,b)$を満たしていれば$(c,d)$も成り立つので、任意のパーツ間で長さの大小と重さの大小が一致するようにパーツを減らすことができます。したがって、長さの昇順にパーツを並べて長さの大きいものから小さいものを見て上記が成り立つ場合は小さい方を使わないものとしてチェックをします。これを任意のパーツで行うので、全体の計算量は$O(M^2)$となります。また、一度チェックされたパーツについては探索を行う必要がないので枝刈りすることができます。
次に、重さが最大のラクダが端にない場合は端に置いたほうが良いので(証明はしていません)、最後のラクダを重さの最大のラクダで固定してよく$(N-1)!$通りのラクダの並び順のみ考えれば良いです。
また、パーツは重さの昇順($\leftrightarrow$長さの昇順)で並んでいるので、あるパーツがあるラクダから載せることができない時、次のパーツが載せられないラクダもそのラクダ以降となるので、尺取法のような計算量の節約をすることができます。
以上の定数倍高速化により、$O(N! \times M \times N^2)$を$O(M^2+(N-1)! \times N \times (M+N))$に落とすことができます。最悪ケースの$N=10,M=100000$を考えれば大体$10^{11}$→$10^{10}$に落とすことができています。また、$10^{10}$で枝刈りもしているので26msまで落とすことができました(2020/10/13時点で最速)。流石にここまで高速化できていれば、最悪のケースが入っていてもギリギリ通せそうな気がします。
C_fastest.cc#pragma GCC optimize("Ofast") #include<bits/stdc++.h> using namespace std; #define REP(i,n) for(int i=0;i<int(n);i++) #define REPD(i,n) for(int i=n-1;i>=0;i--) #define SIZE(x) int(x.size()) #define INF 2000000000 #define PB push_back #define F first #define S second int w[8]; pair<int,int> partsx[100000]; bool info[100000]; int n,m; vector<pair<int,int>> parts; inline int read(){ int x=0,w=0;char ch=0; while(!isdigit(ch)){w|=ch=='-';ch=getchar();} while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();} return w?-x:x; } signed main(){ n=read();m=read(); REP(i,n)w[i]=read(); sort(w,w+n); REP(i,m){partsx[i].F=read();partsx[i].S=read();} sort(partsx,partsx+m); int ma=INF; REP(i,m)ma=min(ma,partsx[i].S); if(ma<w[n-1]){ cout<<-1<<endl; return 0; } REP(i,m)info[i]=true; REPD(i,m){ if(!info[i])continue; REP(j,i){ if(partsx[i].S<=partsx[j].S){ info[j]=false; } } } REP(i,m)if(info[i])parts.PB(partsx[i]); m=SIZE(parts); int ans=INF; do{ vector<int> dp(n,0); REP(j,n-1){ int k=j;int check=w[k]; REP(i,m){ while(k!=n){ if(parts[i].S<check){ dp[k]=max(dp[j]+parts[i].F,dp[k]); break; } k++; check+=w[k]; } if(k==n){ dp[n-1]=max(dp[j],dp[n-1]); break; } } } ans=min(ans,dp[n-1]); }while(next_permutation(w,w+n-1)); cout<<ans<<endl; }D問題以降


- 投稿日:2020-10-13T12:19:00+09:00
データフレームからの条件要素抽出:Rの%in%は、PythonではDataFrame.isin()
Rユーザーの私がpythonを書く上で頻繁にど忘れしてしまう操作をメモしておく。
"R %in% in python"などと都度検索しても欲しい情報にすぐにたどり着けなかったため。特定の列が複数の要素のいずれかにマッチする行を抽出する
データフレーム: iris
特定の列名: Species
複数の要素: cond ("setosa"もしくは"virginica"のみ抽出)Rで%in%演算子を使って書ける操作は、
### R ### library(dplyr) cond <- c("setosa", "virginica") df <- iris %>% dplyr::filter(., Species %in% cond)Pandasだと.isin()で書ける。
### python ### ### iris データセット準備 import pandas as pd from sklearn import datasets iris_sk = datasets.load_iris() iris = pd.DataFrame(iris_sk.data, columns=iris_sk.feature_names) iris['Species'] = iris_sk.target_names[iris_sk.target] cond = ["setosa", "virginica"] df = iris[iris["Species"].isin(cond)]