- 投稿日:2020-10-13T22:08:22+09:00
Aurora PostgreSQLのスロークエリログをAmazon ESに取り込んでみた
はじめに
SQLクエリごとの応答時間や時系列での推移を可視化できるとアプリケーションの性能改善に繋がりますよね^^
本投稿は、Aurora PostgreSQLのスロークエリログをAmazon Elasticsearch Serviceに取り込んでみたという内容です。
【参考】
・ Amazon Auroraの特徴 PostgreSQL互換エディション利用環境
product version logstash (OSS版) 7.7.1 Java (Corretto) 11.0.8 OS(EC2) Amazon Linux2 (t3.small) AMI ID ami-03657b56516ab7912 Elasticsearch 7.7 (latest) PostgreSQL 11.6 Region us-east-2 ※投稿時点における最新版を採用しています。
【構成図】
- CloudWatch Logsに出力したAurora PostgreSQLのログをLogstashがInputしています。
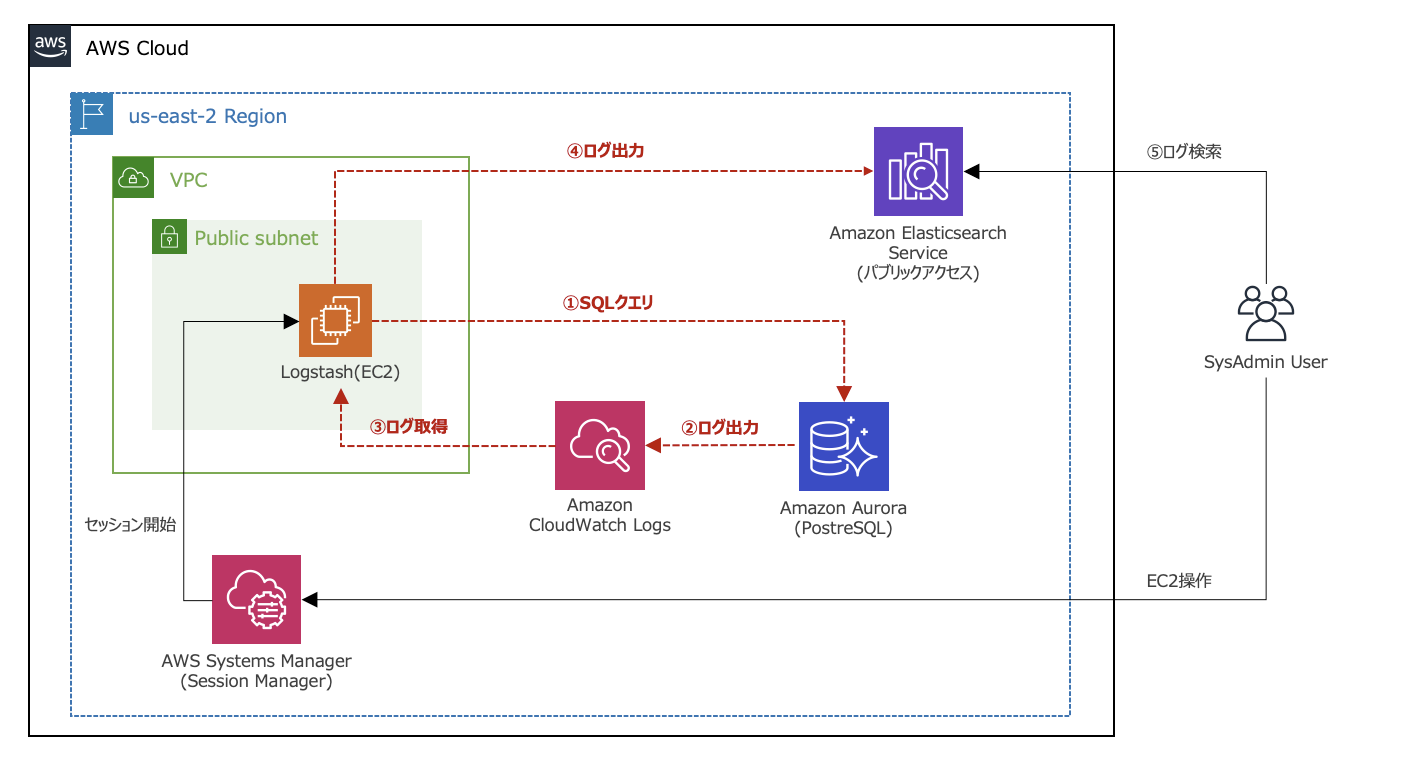
前提条件
- Elasticsearchへのログ出力にはElastic社のETLツールであるLogstashを利用しています。
- Logstashのバージョンは、Amazon Elasticsearch Serviceの最新バージョンに合わせています。
- Amazon Elasticsearch ServiceはOSS版のため、LogstashもOSS版としています。
- Amazon Elasticsearch Service(以下、Amazon ES)は、パブリックアクセスとしています。
(IPアドレスによるホワイトリスト制御でセキュリティを確保しています)- Aurora PostgreSQLのDBクラスタは事前に構築された状態としています。
【参考】
・ Logstashとは実施内容
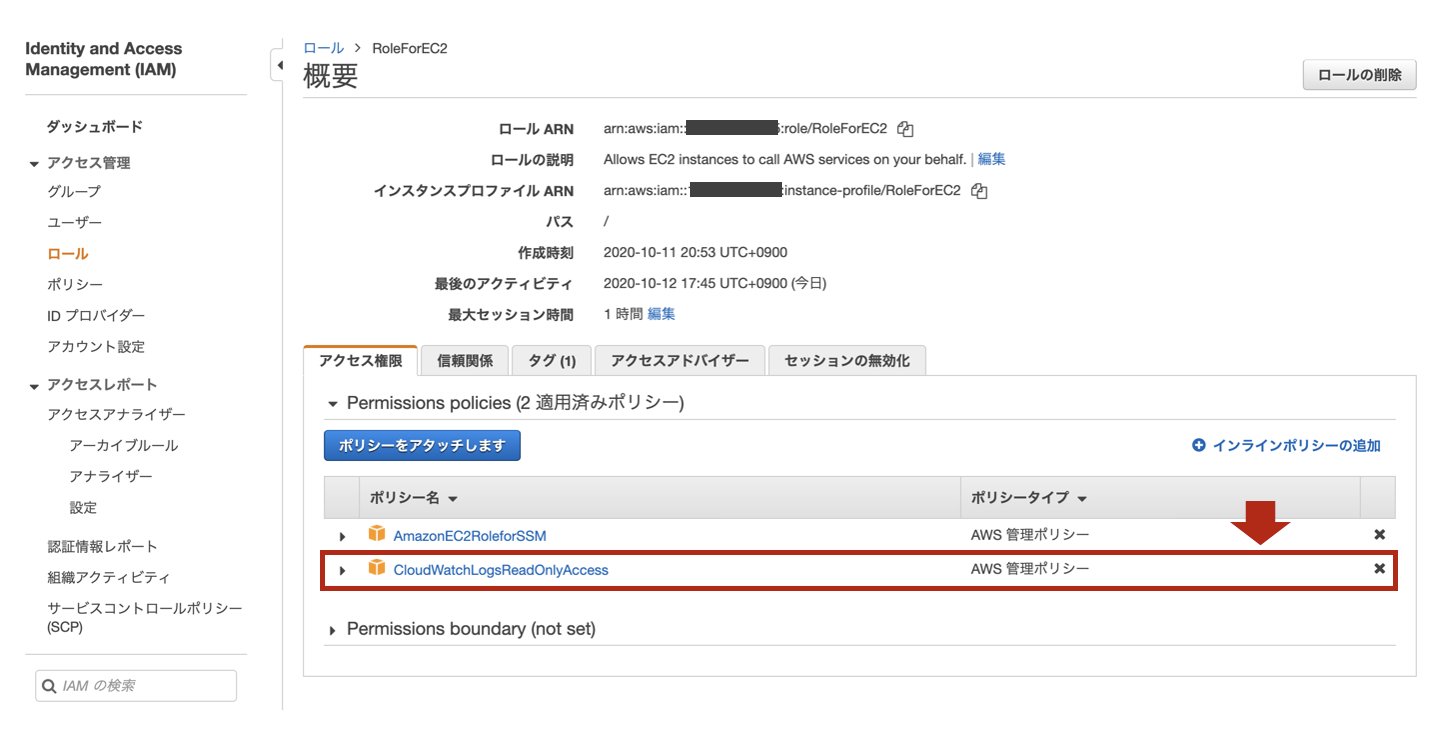
- IAM Role作成
- ログ記録の設定
- スロークエリログ出力設定
- スロークエリログの確認
- Amazon ESのドメイン作成
- Logstashの構築
- Kibanaでの各設定
1. IAM Role作成
- EC2として構築するLogstashに割り当てるIAM Roleを作成します。
- logatashのEC2に割り当てるIAM Roleとして
RoleForEC2というロールを作成し、
CloudWatchLogsReadOnlyAccessというIAM Policyを割り当てます。
CloudWatchLogsReadOnlyAccess{ "Version": "2012-10-17", "Statement": [ { "Action": [ "logs:Describe*", "logs:Get*", "logs:List*", "logs:StartQuery", "logs:StopQuery", "logs:TestMetricFilter", "logs:FilterLogEvents" ], "Effect": "Allow", "Resource": "*" } ] }2. ログ記録の設定
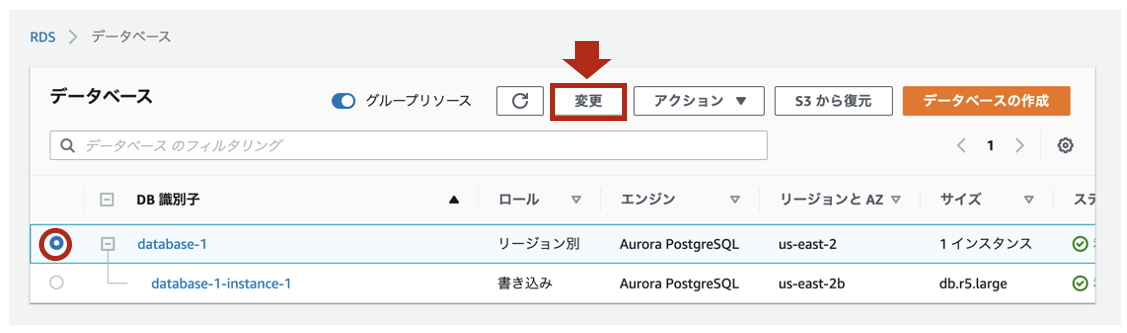
- [RDS] > [データベース]をクリックし、ログを出力したいDBクラスタ名をチェックします。[変更]をクリックします。
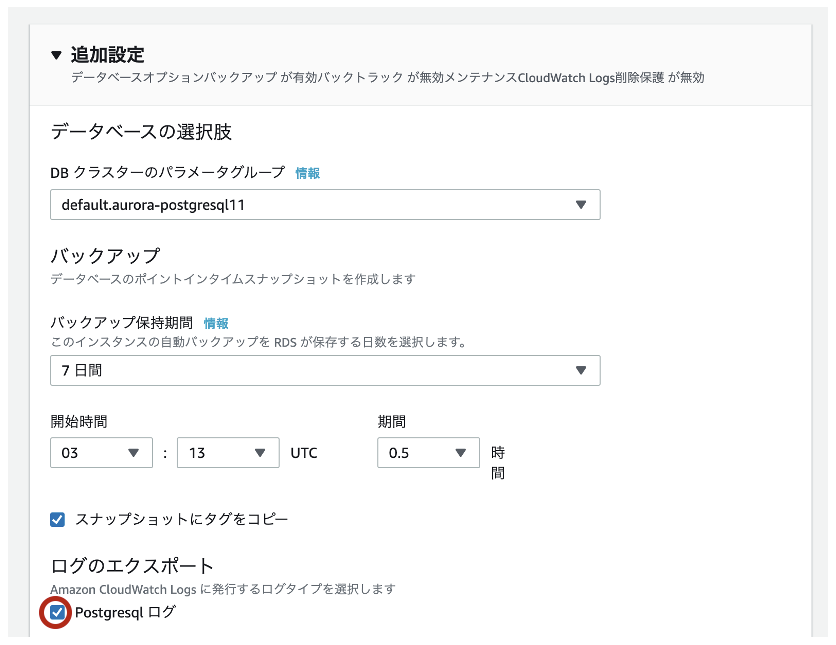
- [追加設定] > [ログのエクスポート]で
Postgresqlログにチェックを入れて保存します。
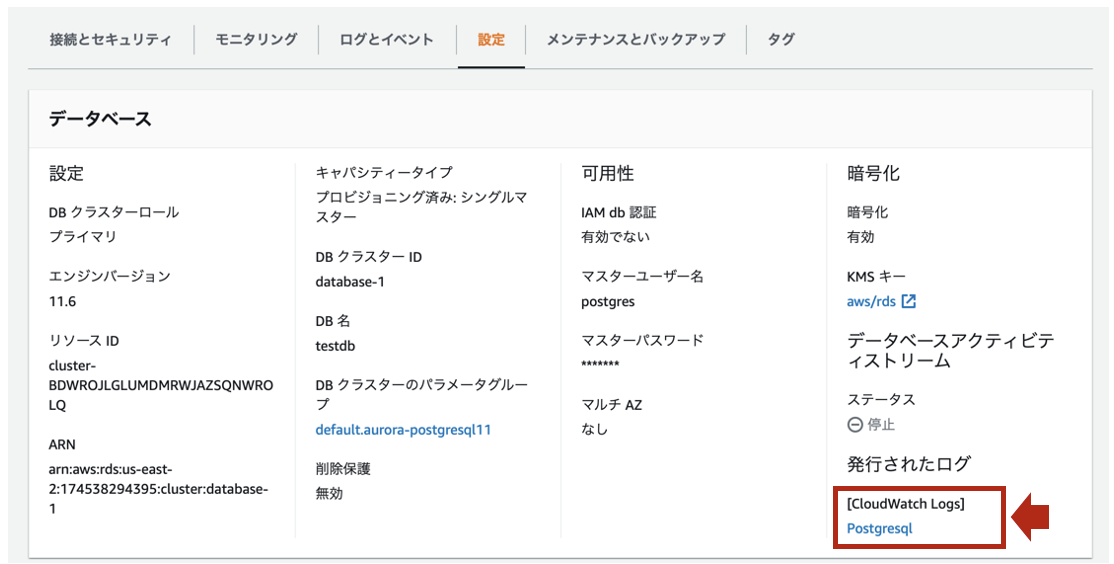
- [設定]タブで[CloudWatch Logs]が以下のようになっていれば、CloudWatch Logsのロググループが自動生成されてます。
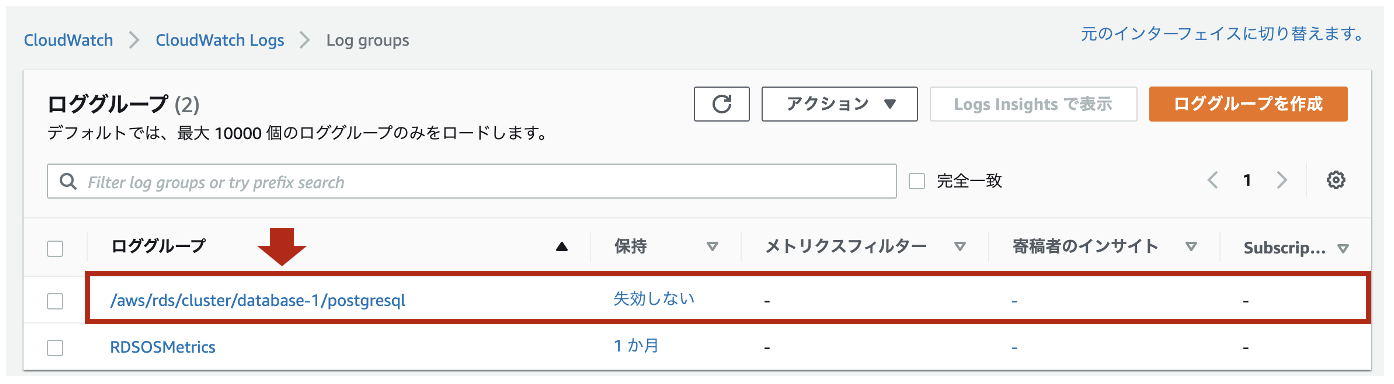
- [CloudWatch] > [ロググループ]をクリックし、
/aws/rds/cluster/<DBクラスタ名>/postgresqlというロググループであればOKです。
【参考】
・ Aurora PostgreSQLログの発行3. スロークエリログ出力設定
- PostgreSQLのログ記録をオンにした状態では、エラーログのみが記録されます。
※ 全般、スロークエリ、監査のログは追加設定が必要です。- パラメータグループで設定を追加しますが、DBインスタンスにアタッチされたデフォルトのパラメータグループは設定変更が出来ません。
- スロークエリログの出力設定のためのパラメータグループを以下の内容で作成します。
【パラメータグループの設定】
項目 値 パラメータグループファミリー aurora-postgresql11 タイプ DB Cluster Parameter Group グループ名 testpostgresql11-paramatergroup (任意) 説明 testpostgresql11 (任意)
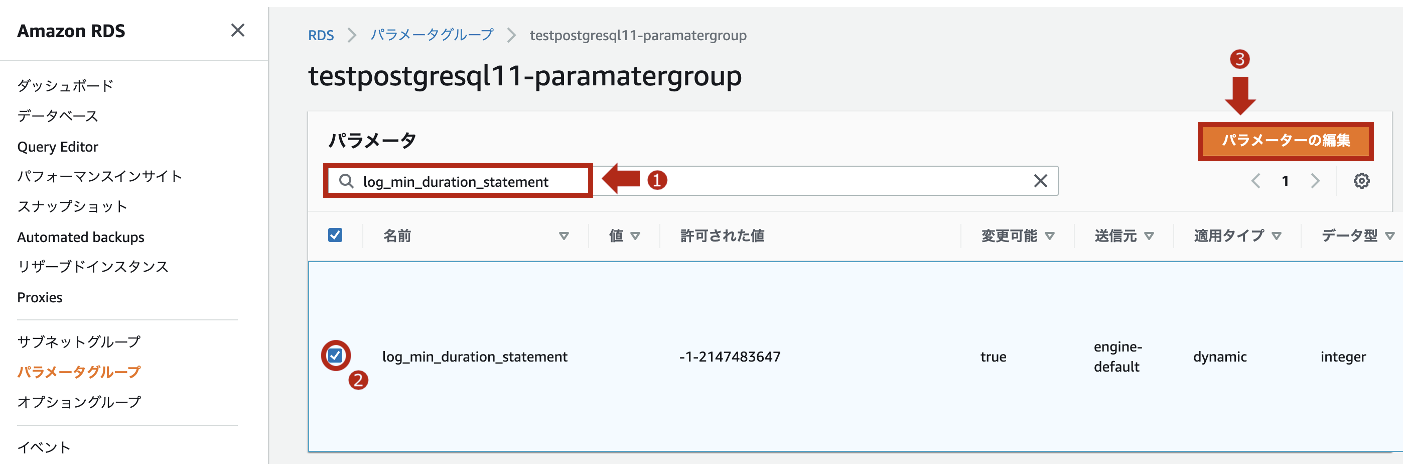
- 上記で作成したパラメータグループにて、
log_min_duration_statementのパラメータを編集します。
※ 設定した数値(ミリ秒)を閾値とし、クエリの応答時間が指定値を超えるとログに記録されます。(デフォルト無効です。)
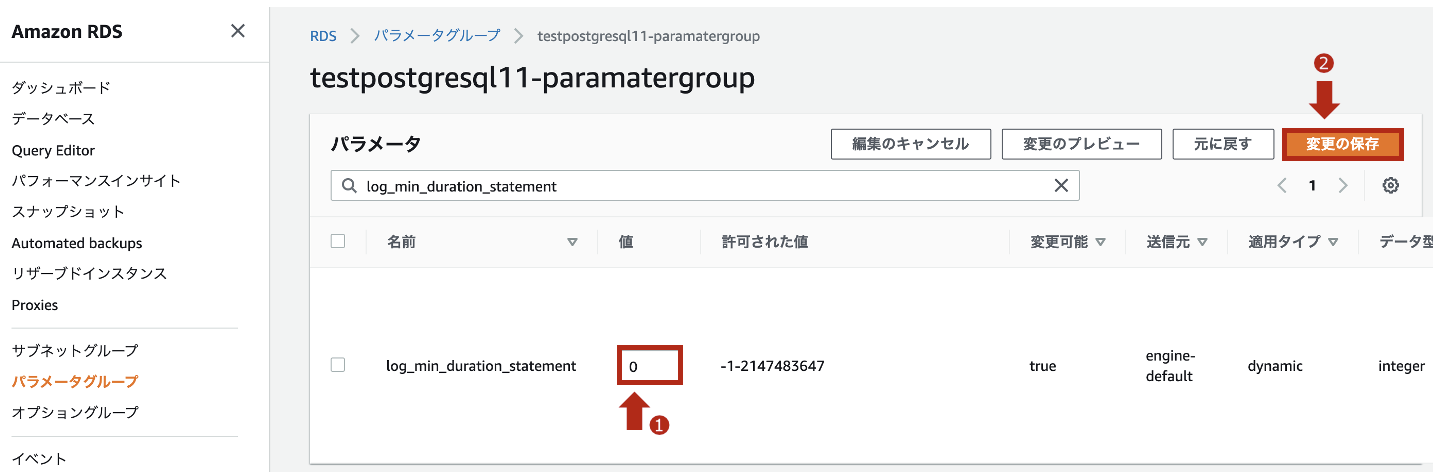
- 今回は、値に
0を設定して、保存します。
※ この場合、全てのクエリにおいて、応答時間が記録されます。どんなログが出るか見てましょう。
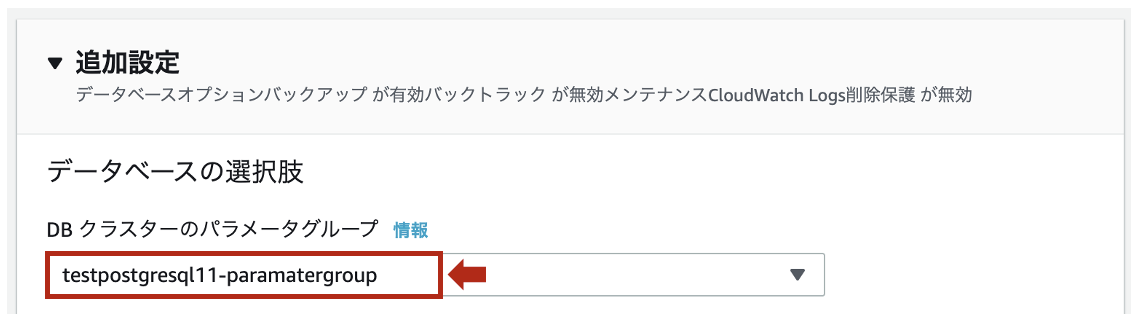
- 作成したパラメータグループを適用するDBクラスタ名をチェックし、[変更]をクリックします。
- [追加設定] > [DBクラスターのパラメータグループ]で作成したパラメータグループを指定します。
- [変更のスケジューリング]を
今すぐとして、[クラスターの変更]をクリックします。
※ 本番稼働中のDBクラスターで再起動を伴う変更を保留している場合は注意してください。【参考】
・ RDSのデフォルトパラメータグループを変更する
・ postgresql on RDSでスロークエリを出力する4. スロークエリログの確認
- [Systems Manager] > [Session Manager]からLogstash用のEC2に接続します。
- EC2から以下のコマンド操作でDBに接続し、testtableという名前のテーブルを作成します。
- 適当なデータ(name: guest01、text: test01)をINSERTし、その後SELECTでクエリします。
※ EC2からPostgreSQLにTCP5432で通信許可されている状態としています。sh-4.2$ psql -h [Auroraのエンドポイント] -U [マスターユーザ名] Password for user postgres: xxxxxxxxxxx(パスワード) psql (9.2.24, server 11.6) WARNING: psql version 9.2, server version 11.0. Some psql features might not work. SSL connection (cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256) Type "help" for help. postgres=> CREATE TABLE testtable (name VARCHAR(255), text VARCHAR(255)); postgres=> INSERT INTO testtable (name, text) values ('guest01', 'test01'); postgres=> SELECT * FROM testtable;
- [CloudWatch Logs]のロググループ配下のログストリームに以下のようなログが出力されます。(こちらがスロークエリログです。)
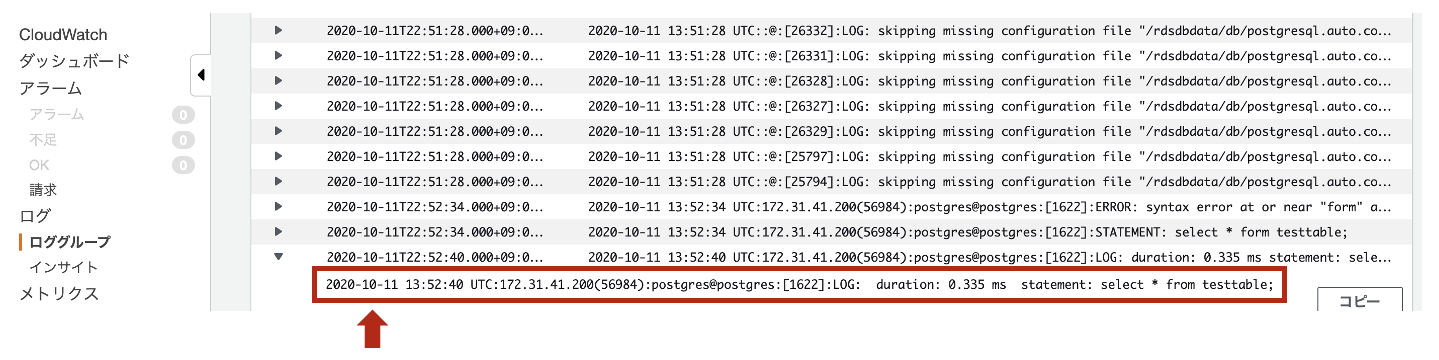
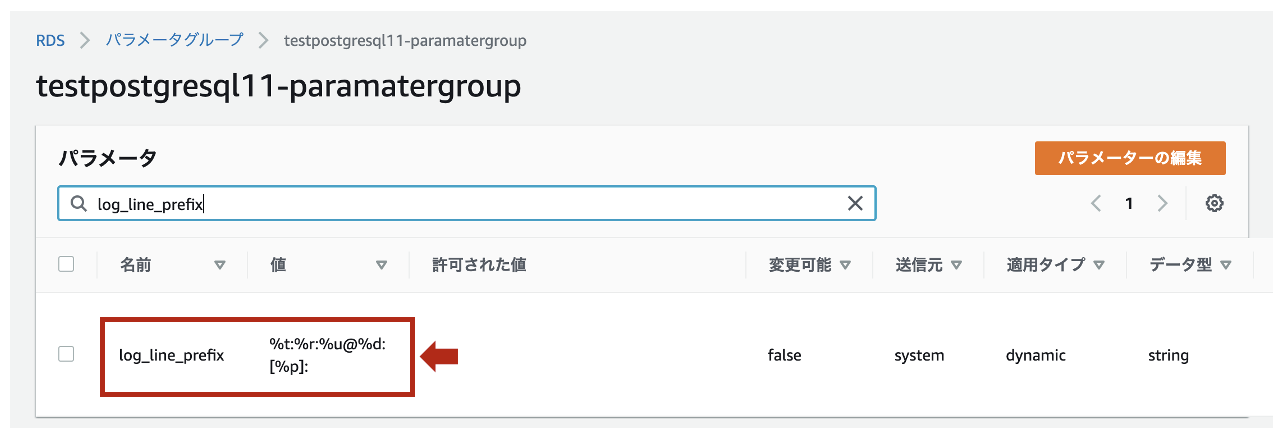
少し余談になりますが、デフォルトのログフォーマットは
log_line_prefixで%t:%r:%u@%d:[%p]:と定義されています。
【参考】
・ log_line_prefixの説明5. Amazon ESのドメイン作成
- 下記内容でAmazon ESのドメインを作成します。
項目 値 リージョン us-east-2 デプロイタイプ 開発およびテスト Elasticsearchのバージョン 7.7 (latest) Elasticsearchのドメイン test-es インスタンスタイプ t3.small.elasticsearch ノードの数 1 データノードのストレージタイプ EBS EBS ボリュームタイプ 汎用(SSD) EBS ボリュームサイズ 10 GiB 自動スナップショットの開始時間 00:00 UTC (デフォルト) ネットワークアクセス パブリックアクセス 細かいアクセスコントロールを有効化 無効 Amazon Cognito認証を有効化 無効 ドメインアクセスポリシー カスタムアクセスポリシー (IPv4アドレス) ドメインへのすべてのトラフィックにHTTPSを要求 有効 ノード間の暗号化 無効 保管時のデータの暗号化の有効化 無効 ※アクセスポリシーに追加するIPは、Amazon ESにアクセスする自宅IPとLogstashのIPになります。
ドメインアクセスポリシー{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "*" }, "Action": "es:*", "Resource": "arn:aws:es:us-east-2:<AWSアカウント>:domain/test-es/*", "Condition": { "IpAddress": { "aws:SourceIp": [ "<自宅IP>/32", "<LogstasのEIP>/32" ] } } } ] }6. Logstashの構築
Logstashの構築手順は、Amazon Corretto 11で構築するLogstashになります。
スロークエリログは、正規表現パターンを使って以下のようなフィールドと値にパースします。
フィールド 値(サンプル) データ型 タイムスタンプ 2020-10-11 13:52:40 日付型 タイムゾーン UTC 文字列型 (keyword) IPアドレス 172.31.41.200 IP型 ポート番号 56984 文字列型 (keyword) ユーザ名 postgres 文字列型 (keyword) データベース名 postgres 文字列型 (keyword) プロセスID 1622 文字列型 (keyword) ログレベル LOG 文字列型 (keyword) クエリ応答時間 0.335 数値型 (float) クエリ文 select * from testtable; 文字列型 (keyword)
- Grokパターン(
/etc/logstash/grok_patterns/aurora-postgresql-slowlog)を保存するディレクトリを作成します。$ sudo mkdir /etc/logstash/grok_patterns $ sudo vi /etc/logstash/grok_patterns/aurora-postgresql-slowlog
- 下記の内容を上記のGrokパターンファイルに記述します。
aurora-postgresql-slowlog### PosgreSQL slowLog POSTGRESQL_SLOWLOG %{TIMESTAMP_ISO8601:timestamp} %{TZ:timezone}:%{IP:ipaddress}\(%{NUMBER:src_port}\):%{WORD:username}@%{WORD:database}:\[%{NUMBER:process_id}\]:%{WORD:log_level}:\s*duration: %{NUMBER:duration} ms\s*statement: %{GREEDYDATA:statement}
- 下記のパイプライン構成ファイル(
/etc/logstash/conf.d/logstash.conf)を作成します。
(このタイミングではLogstashのプロセスは起動しません)$ sudo vi /etc/logstash/conf.d/logstash.conf
- 下記の内容を上記のパイプライン構成ファイルに記述します。
logstash.confinput { cloudwatch_logs { log_group => [ "/aws/rds/cluster/database-1/postgresql" ] region => "us-east-2" interval => 5 sincedb_path => "/etc/logstash/aurora-postgre-cwl_sincedb" } } filter { if "duration:" in [message] { ### 読み込むGrok Patternファイルを"patterns_dir"で指定 grok { patterns_dir => [ "/etc/logstash/grok_patterns" ] match => { "message" => "%{POSTGRESQL_SLOWLOG}" } } ### dateフィールドから@timestampを抽出 date { match => [ "timestamp", "yyyy-MM-dd HH:mm:ss" ] timezone => "UTC" target => "@timestamp" } ### @timstampから日本時間を抽出 ruby { code => "event.set('[@metadata][local_time]',event.get('[@timestamp]').time.localtime.strftime('%Y-%m-%d'))" } ### document_idに利用する一意のIDを作成 fingerprint { source => "message" target => "[@metadata][fingerprint]" method => "MURMUR3" } ### デフォルトの型がstringのため、フィールド定義で定義した型に変換 mutate { ### typeフィールドを追加 add_field => { "type" => "aurora-postgre-slowlog-cwl" } ### 不要なフィールドを削除 remove_field => [ "timestamp", "timezone" ] } } } output { if "duration:" in [message] { ### 出力先のAmazonESのIndexを指定 elasticsearch { hosts => [ "https://search-test-es-xxxxxxxxxxxxxxxxxxxxxx.us-east-2.es.amazonaws.com:443" ] index => "%{type}-%{[@metadata][local_time]}" document_id => "%{[@metadata][fingerprint]}" ilm_enabled => false } } }【参考】
・ Logstashの実践的な説明
・ cloudwatch-logs input
・ grok filter
・ date filter
・ ruby filter
・ fingerprint filter
・ mutate filter
・ elasticsearch output7. Kibanaでの各設定
Amazon ESの
KibanaのURLをクリックします。
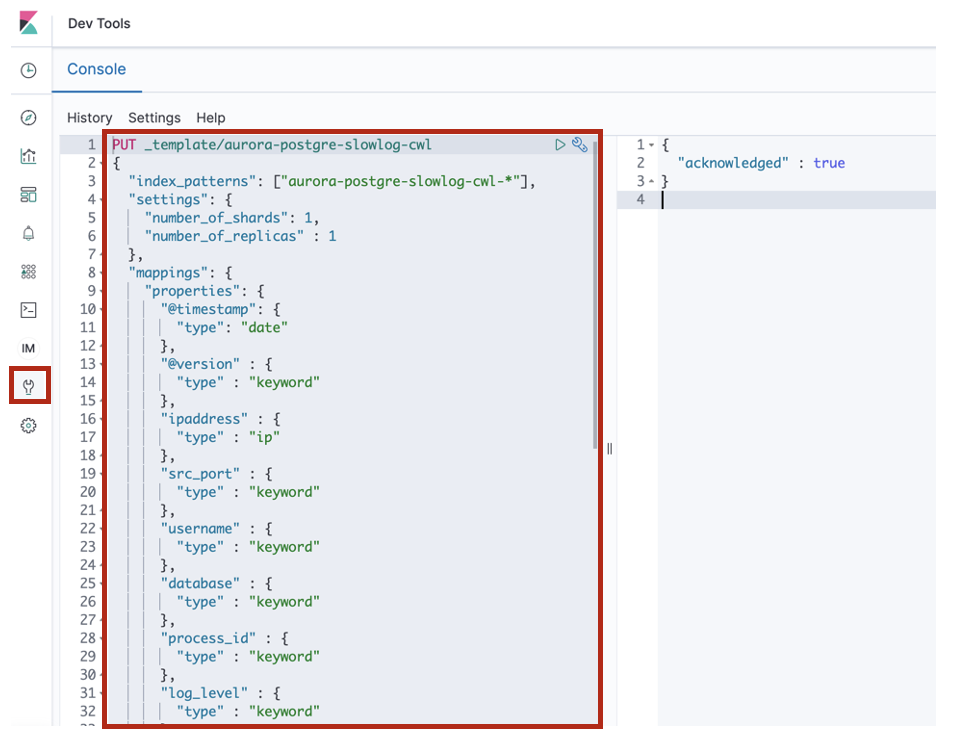
[Dev Tools]のConsoleからAurora PostgreSQLのスロークエリログのIndex Templateを追加します。
上記で張り付けたIndex Templateは以下の通りです。
index_templete_aurora-postgre-slowlog-cwlPUT _template/aurora-postgre-slowlog-cwl { "index_patterns": ["aurora-postgre-slowlog-cwl-*"], "settings": { "number_of_shards": 1, "number_of_replicas" : 1 }, "mappings": { "properties": { "@timestamp": { "type": "date" }, "@version" : { "type" : "keyword" }, "ipaddress" : { "type" : "ip" }, "src_port" : { "type" : "keyword" }, "username" : { "type" : "keyword" }, "database" : { "type" : "keyword" }, "process_id" : { "type" : "keyword" }, "log_level" : { "type" : "keyword" }, "duration" : { "type" : "float" }, "statement" : { "type" : "keyword" }, "type" : { "type" : "keyword" }, "tags" : { "type" : "keyword" }, "message" : { "type" : "text" }, "cloudwatch_logs" : { "properties" : { "event_id" : { "type" : "keyword" }, "ingestion_time" : { "type" : "date" }, "log_group" : { "type" : "keyword" }, "log_stream" : { "type" : "keyword" } } } } } }※ durationは応答時間(ミリ秒)が入るフィールドなので、float型とします。
- Logstashを起動します。
logstash_start$ sudo systemctl start logstash $ sudo systemctl status logstash ● logstash.service - logstash Loaded: loaded (/etc/systemd/system/logstash.service; disabled; vendor preset: disabled) Active: active (running) since Sun 2020-02-23 17:11:21 UTC; 4min 42s ago Main PID: 32168 (java) CGroup: /system.slice/logstash.service └─32168 /bin/java -Xms1g -Xmx1g -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -Djava.awt.h... Feb 23 17:12:00 ip-172-31-37-204.ec2.internal logstash[32168]: [2020-02-23T17:12:00,242][INFO ][logstash.outputs.elasticsearch][main] New Elastic...:443"]} Feb 23 17:12:00 ip-172-31-37-204.ec2.internal logstash[32168]: [2020-02-23T17:12:00,282][INFO ][logstash.filters.geoip ][main] Using geoip data....mmdb"} Feb 23 17:12:00 ip-172-31-37-204.ec2.internal logstash[32168]: [2020-02-23T17:12:00,332][INFO ][logstash.outputs.elasticsearch][main] Using defau...emplate Feb 23 17:12:00 ip-172-31-37-204.ec2.internal logstash[32168]: [2020-02-23T17:12:00,396][INFO ][logstash.outputs.elasticsearch][main] Attempting ...field"= Feb 23 17:12:00 ip-172-31-37-204.ec2.internal logstash[32168]: [2020-02-23T17:12:00,460][WARN ][org.logstash.instrument.metrics.gauge.LazyDelegatingGaug... Feb 23 17:12:00 ip-172-31-37-204.ec2.internal logstash[32168]: [2020-02-23T17:12:00,467][INFO ][logstash.javapipeline ][main] Starting pipeline {:pip... Feb 23 17:12:01 ip-172-31-37-204.ec2.internal logstash[32168]: [2020-02-23T17:12:01,418][INFO ][logstash.javapipeline ][main] Pipeline started..."main"} Feb 23 17:12:01 ip-172-31-37-204.ec2.internal logstash[32168]: [2020-02-23T17:12:01,497][INFO ][logstash.agent ] Pipelines running {:co...es=>[]} Feb 23 17:12:01 ip-172-31-37-204.ec2.internal logstash[32168]: [2020-02-23T17:12:01,736][INFO ][logstash.agent ] Successfully started L...=>9600} Feb 23 17:12:14 ip-172-31-37-204.ec2.internal logstash[32168]: /usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-filter-fingerprint-3.2...recated Hint: Some lines were ellipsized, use -l to show in full.
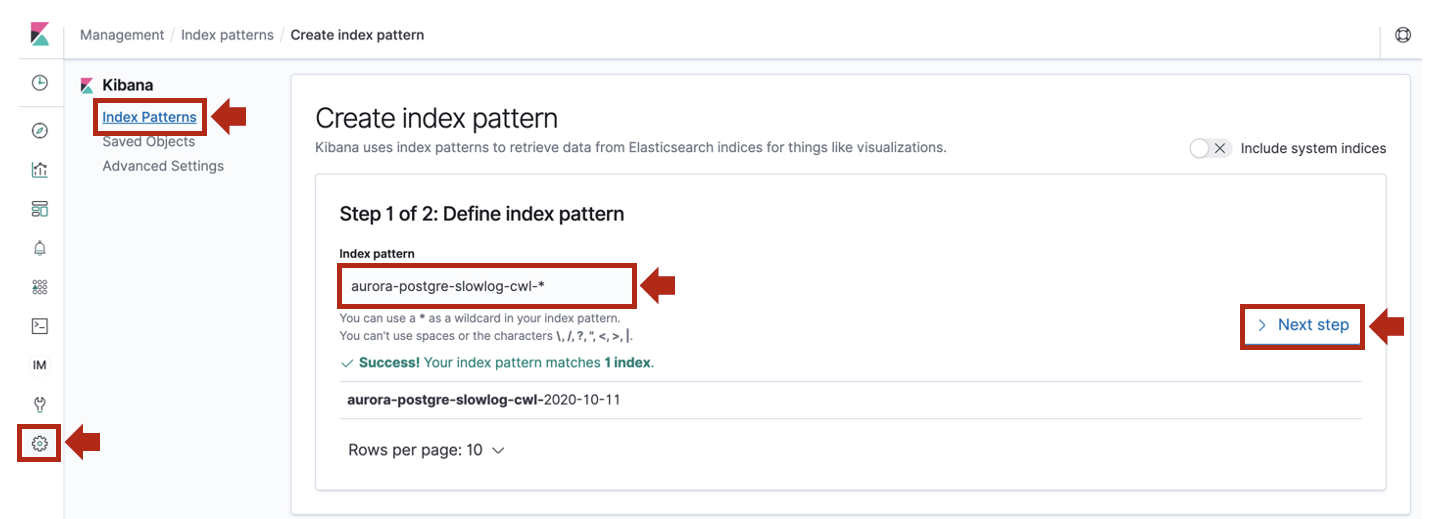
- Kibanaの [Management] > [Index Patterns]で
Create index patternをクリックします。
aurora-postgre-slowlog-cwl-*という名前でIndex Patternを作成します。
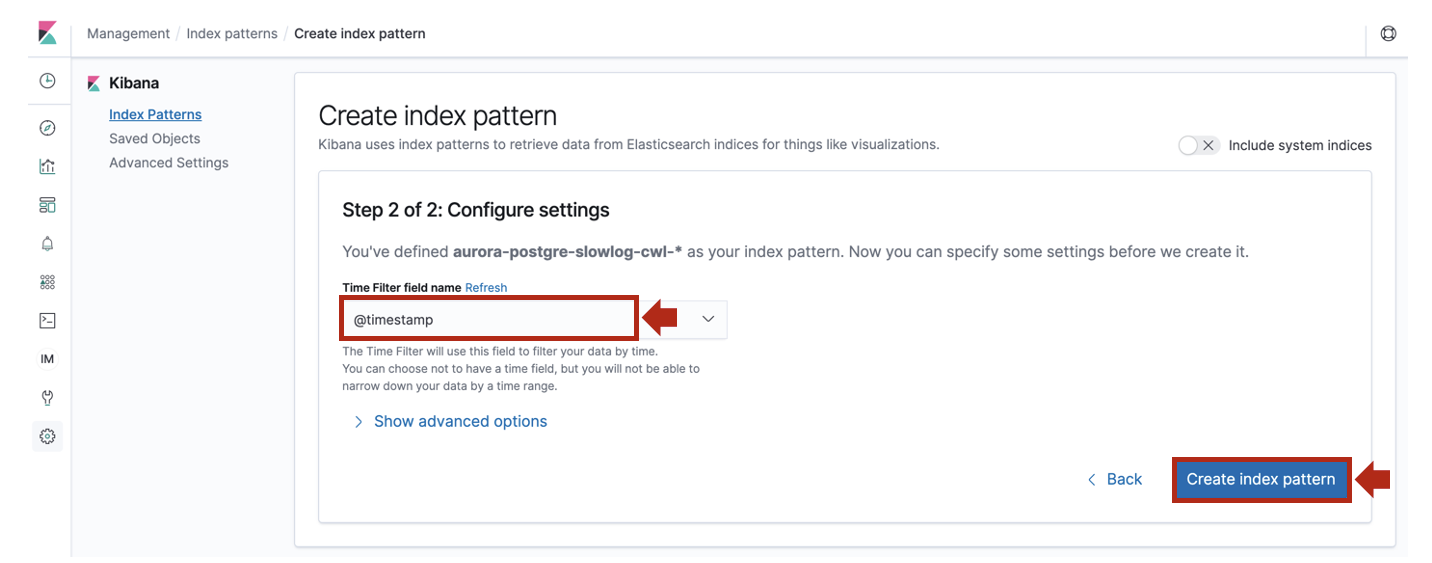
@timestampを指定します。
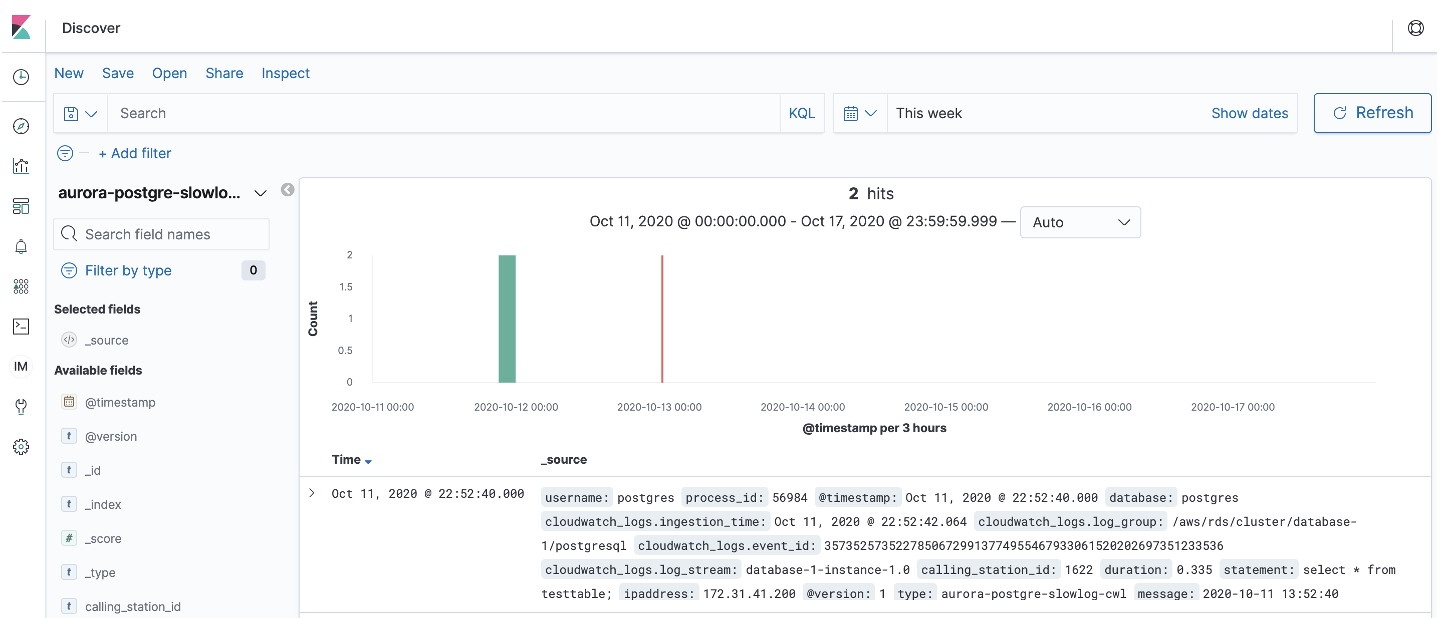
[Discover]を開き、Index Patternに
aurora-postgre-slowlog-cwl-*を指定します。デフォルトでは直近15分間のログが表示されます。表示されていればOKです。
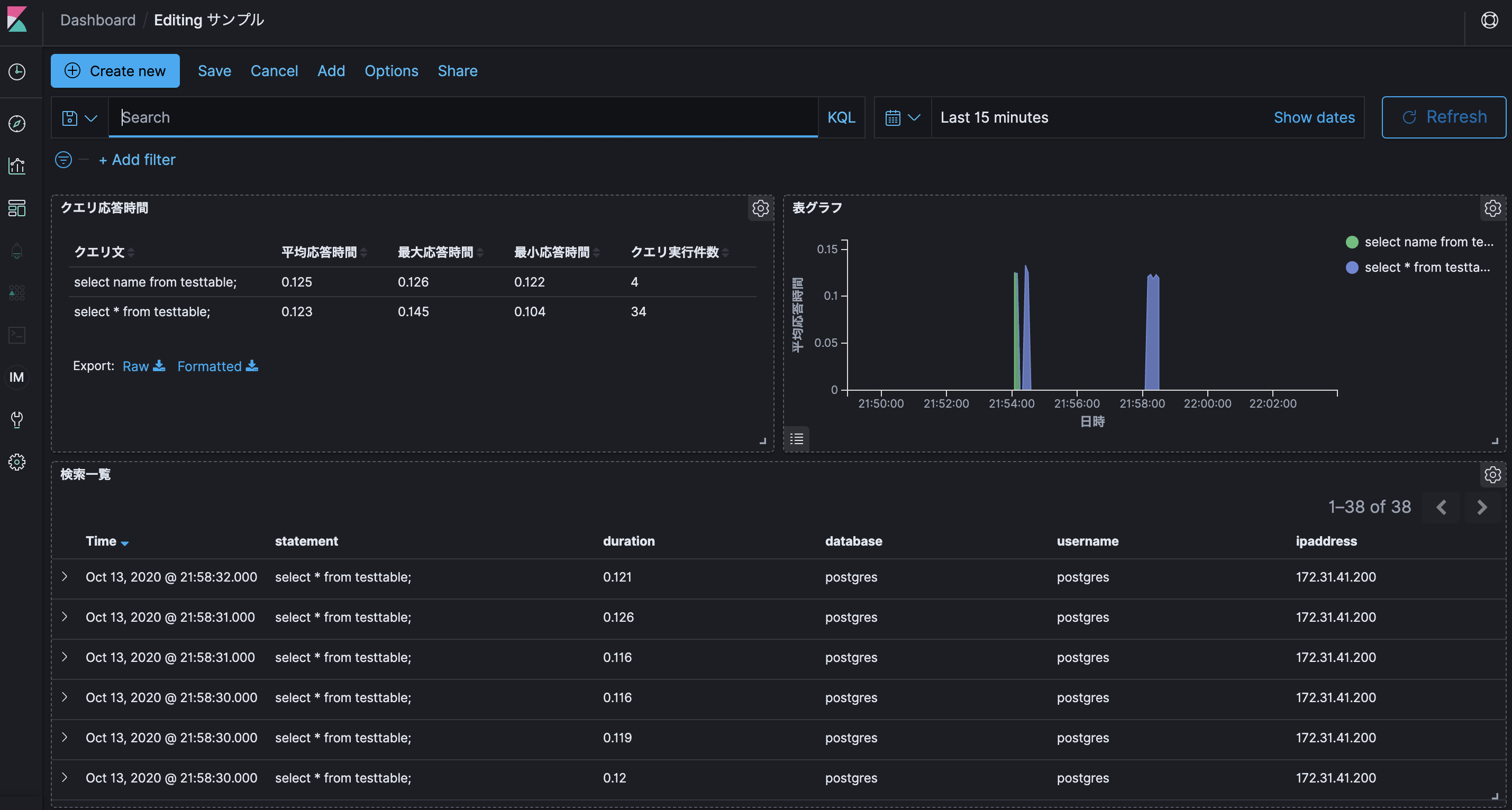
取り込んだログは以下のような感じです。
aurora-postgre-slowlog_sample{ "_index": "aurora-postgre-slowlog-cwl-2020-10-11", "_type": "_doc", "_id": "711173058", "_version": 2, "_score": null, "_source": { "src_port": "56984", "ipaddress": "172.31.41.200", "database": "postgres", "cloudwatch_logs": { "event_id": "35735257352278506729913774955467933061520202697351233536", "log_group": "/aws/rds/cluster/database-1/postgresql", "ingestion_time": "2020-10-11T13:52:42.064Z", "log_stream": "database-1-instance-1.0" }, "@timestamp": "2020-10-11T13:52:40.000Z", "process_id": "1622", "duration": "0.335", "@version": "1", "log_level": "LOG", "username": "postgres", "type": "aurora-postgre-slowlog-cwl", "message": "2020-10-11 13:52:40 UTC:172.31.41.200(56984):postgres@postgres:[1622]:LOG: duration: 0.335 ms statement: select * from testtable;", "statement": "select * from testtable;" }, "fields": { "cloudwatch_logs.ingestion_time": [ "2020-10-11T13:52:42.064Z" ], "@timestamp": [ "2020-10-11T13:52:40.000Z" ] }, "sort": [ 1602424360000 ] }まとめ
いかがでしたでしょうか?
冒頭のダッシュボードの作り方が全然出てこないじゃないか!?
というコメントがありそうですが、Kibanaでのダッシュボードは創意工夫溢れるものなので
取り込んだログをアドホックに分析し、それぞれの環境に合わせて素敵なダッシュボードを
作って頂けると幸いです^-^以下のようなサンプルデータを取り込んでみて色々と試してみるのも良いかと思います!
【参考】
・ PostgreSQLサンプルデータ
- 投稿日:2020-10-13T19:57:13+09:00
【AWS初学者用】AWS セキュリティグループとネットワークACLの違い
本記事について
本記事はAWS初学者の私が学習していく中でわからない単語や概要をなるべくわかりやすい様にまとめたものです。
もし誤りなどありましたらコメントにてお知らせいただけるとありがたいです。セキュリティグループ
セキュリティグループとはEC2インスタンスなどに適用することができるファイアウォール機能です。
EC2インスタンスから出る通信(往路)をアウトバウンド、EC2インスタンスに入る通信(復路)をインバウンドと呼びます。
セキュリティグループのデフォルトの設定値はアウトバウンドは全て許可、インバウンドは全て拒否になっています。「去るもの追わず、来るもの拒む」という状態です!付け入る隙がないですね...
そしてセキュリティグループはインスタンスに対し複数適用する事が可能で、ステートフルな制御をします。
(※ステートフルについては私自身こんがらがってしまったので後ほど図で解説します。)ネットワークACL
ネットワークACLはサブネットに適用する事ができるファイアウォール機能です。
セキュリティグループと同じ様にアウトバウンド通信・インバウンド通信にルールを適用します。ネットワークACLは主にサブネット間の通信の制御に用いられます。
セキュリティグループとの違いとして「1つのサブネットに1つのネットワークスACLを設定可能」、「デフォルトの設定値は全て許可」、「ステートレスな制御」が挙げられます。「ステートフル」と「ステートレス」
ステーツフルとステートレスの違いはどの視点から見るかによって変わってるらしく、私も調べてみましたが決定的な記事が見つけられなかったです。
まあしかし、どの様な動きをするのか分かっていれば言葉の意味などはさほど問題ない!と言い聞かせました...
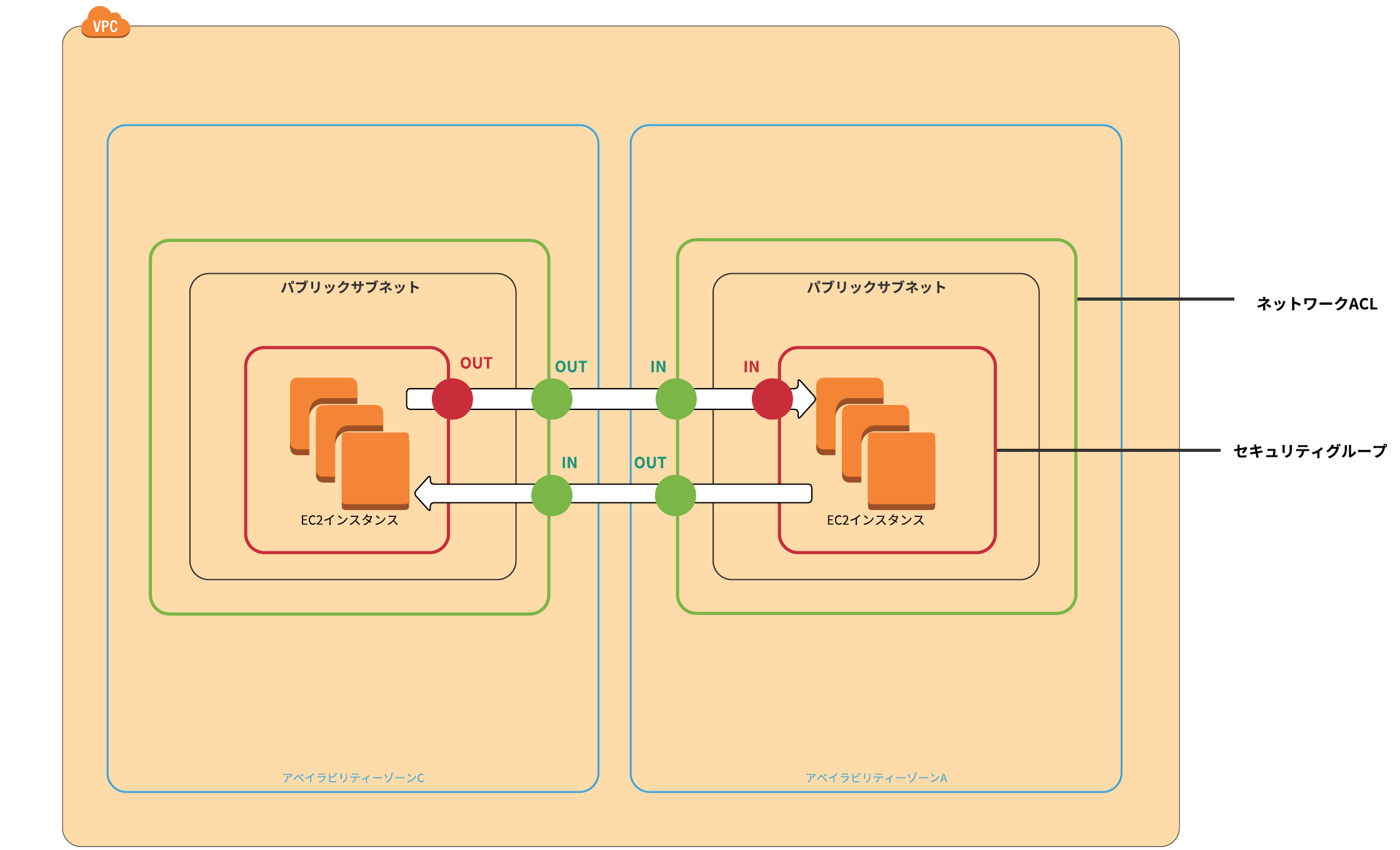
とりあえず自分がわかりやすい様に図にしてみました。
緑の枠がネットワークACLで、赤の枠がセキュリティグループです。
緑の丸はネットワークACLでの制御が適用された事を表し、赤い丸はセキュリティグループでの制御が適用されたことを表しています。この図でわかることは往路でセキュリティグループの制御が適用されたら、復路では制御にかかわらず通信は許可されています。
逆にネットワークACLでは往路と復路両方に制御が適用されています。これらをまとめると往路と復路で制御のルールが同じ(往路が許可されたら復路も許可!)なのがステートフル!
往路と復路で制御のルールを変える事ができるのがステートレス!とは言ってもこれは私なりの解釈なので気になる方は自分で調べてみてください。
項目 セキュリティグループ ネットワークACL 選択範囲 インスタンス サブネット デフォルト設定 IN : 拒否 OUT : 許可 全て許可 ステータス ステートフル ステートレス まとめ
それぞれの違いはいくつかありましたが大きな違いとしてはステートフルとステートレスの部分とインスタンスに適用かサブネットに適用かなのではないでしょうか?
もっとわかりやすい説明があったらぜひとも教えて頂きたいです...
- 投稿日:2020-10-13T19:42:22+09:00
azure VMでsudoersファイルのsyntaxエラーを起こしちゃったときの対処法
ある時、Azure VMで
sudo lsしたらsudo: parse errorエラーがどうやら/etc/sudoers.d/user(sudoersファイル)の修正ミスでsyntax errorとなっていてsudoできなくなっていました・・・
対処法
# ブラウザからログイン az login az vm run-command invoke -g [リソースグループ名] -n [VM名] --command-id RunShellScript --scripts "rm -rf /etc/sudoers.d/user"あとは必要に応じておかしくなる前の
/etc/sudoers.d/userを復元してください。
sudoersファイルを編集できる権限が消えちゃったときはVMコンソール-パスワードのリセットから復旧用のユーザを作成して作業すると良さそうです。感想
とっても簡単でビックリ。
AWSで同じ問題が発生した際(どちらも私がやったんじゃないよ・・・)はdiskを別のVMにマウントしなおしてゴニョゴニョしたんですが、Azureはそれよりもさらに簡単に対応できました。
- 投稿日:2020-10-13T18:02:39+09:00
【妄想】最強のWordPressインフラを考えてみる。
とりあえず夢詰め込んでみる。
・コンテンツ容量≒ディスク容量を考えなくていい
・DB容量を考えなくていい
・DBのリソースマネジメントしなくていい
・DBのメンテナンスしなくていい
・スパイクトラフィックもヘビートラフィックも捌ける
・訪問ユーザーが少ない時は最低限のコストに自動的に変動ワガママ過ぎじゃない?
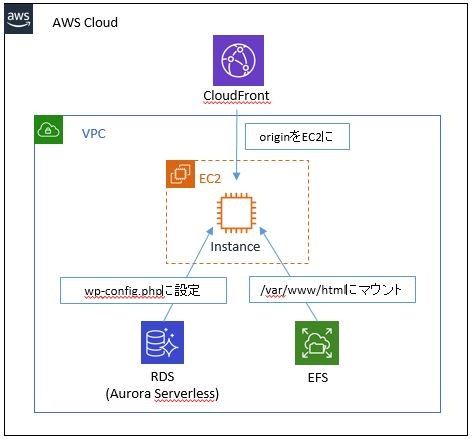
とりあえず夢構成かんがえてみた
OSはAmazon Linux2想定。EC2やらWordPressインストールやら
↓見て。
【超初心者向け】WordPressをAmazon EC2インスタンスにインストールする一点。今回DBはRDSを利用するので、wp-config.php内の以下項目をAurora Serverlessのホスト名に変更する。
/** MySQL のホスト名 */ define('DB_HOST', 'xxxxxx.cluster-yyyyyyyyyyyy.ap-northeast-1.rds.amazonaws.com')Cloudfront設定
↓見て。
WordPressサイトをCloudFrontで配信するWordPressの設定画面で間違えてCloudfrontのホスト名ではなく、
独自ドメインを登録してしまった時に解決策を探してた時に見つけた記事。
ちょうどCloudfrontの設定も書いてくれてた。ってか、一回間違えたらWEBからアクセス出来なくなる上に、
完全復旧には設定ファイルどころかDBも書き換えなきゃならないって罠過ぎん?????EFSの設定メモ
マウントヘルパーをインストール → マウント → ちゃんと付いてるかチェック
$sudo yum update $sudo yum install -y amazon-efs-utils $sudo mount -t efs fs-123456:/ /var/www/html $df -h所感
WordPressの設定で色々と蹴躓いたけど、それ以外は何の問題も発生せずに構築出来て拍子抜けした。
問題無くサイトも編集できるし、費用は本当に最低限で済むし最強では…?
出来れば誰も見てない時はAurora Serverlessが落ちてくれれば言うことなしだけど、
なんかずっと起動してて料金が発生してた。
ちゃんと5分アイドル状態なら落ちる設定になってたはずなんだけど不思議…。
これは要検証しておきたい。まぁでも、何にせよこれでCloudformation組んだらWordPress環境これで良くねってなりそう。
Aurora Serverlessが高いなーって思ったら、Cloudfront+EC2+EFSだけでも十分いけそうだし。20201014追記
Aurora Serverless単体で起動して試してみたところ、
きっちりキャパシティユニットが0になって停止していたのを、
WordPressにDB設定した途端にCPU使用率が10~15%使用しっぱなしになり、
アイドル状態にならなくなりました。普段WordPressを利用されている方には当たり前なのかもしれませんが、
WordPressってDBサーバーのリソース常時使ってるんですね…。となると、最低でも1ACU分($72.00/month)は必要になってくるのね。。
それでも、Multi-AZとかリードレプリカを使う構成よりもコストメリットはありそうですが。
- 投稿日:2020-10-13T15:06:26+09:00
【AWS初学者用】AWS VPCとは?
本記事について
本記事はAWS初学者の私が学習していく中でわからない単語や概要をなるべくわかりやすい様にまとめたものです。
もし誤りなどありましたらコメントにてお知らせいただけるとありがたいです。AWS ネットワーク図
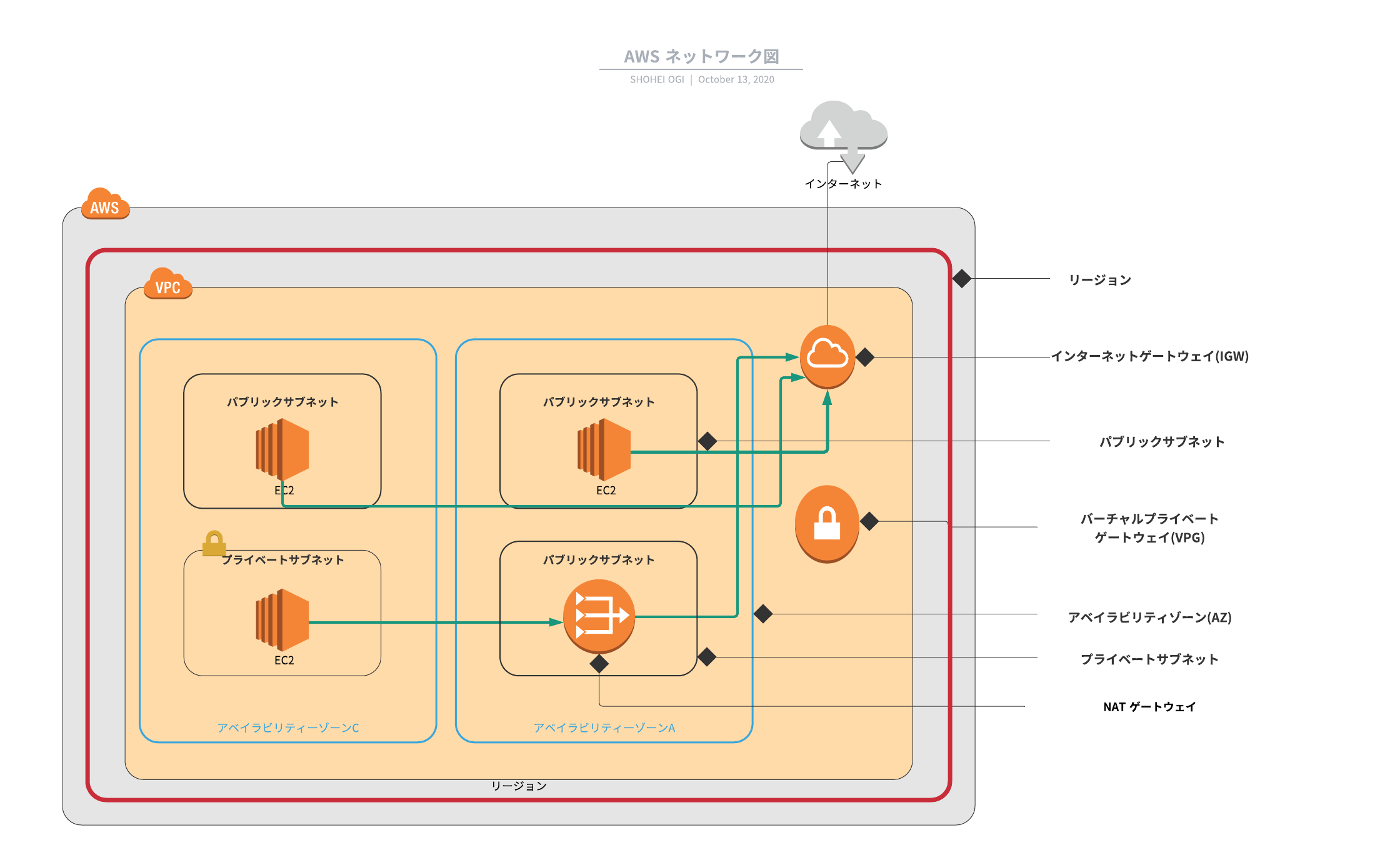
VPCとは何か?の前にAWSのネットワーク図を簡単ではありますが作成しました。(見辛くてすみません..)
VPCの中身はたくさんあってとても覚えづらいですね。理解するのに時間かかりそうですが、VPCはAWSサービスを利用する上でとても大切なのでしっかり学習します!
VPC(Virtual Private Cloud)
VPCは名前の通り、AWS上にプライベートなネットワーク空間を作成できるサービスです。
通常、AWS上のハードウェアやインフラストラクチャは全ユーザーに共有された状態ですが、VPCを利用することでユーザーごとにプライベートネットワークを構築できます。VPCを利用する上で欠かせない物がたくさんあるのでまとめていきます。
サブネット
サブネットとはネットワークを分割した小さなネットワークで、VPCには1つ以上のサブネットは存在します。
サブネットはAZ(アベイラビリティゾーン)を指定する必要があります。(AZについては過去の記事で紹介してます。https://qiita.com/petite_amelie/items/ae20ae046bf9a198abde)
サブネットには2種類存在し、パブリックサブネットとプライベートサブネットが存在します。パブリックサブネット
パブリクサブネットは外のネットワークと直接つながっているサブネットです。
プライベートサブネット
プライベートサブネットは外のネットワークと直接つなげることができないサブネットです
基本的にWEBサービスを開発する場合は外部からの攻撃を受ける可能性を考えて、プライベートサブネットにリソースを置くことが望ましいみたいです。
インターネットゲートウェイ(IGW)
インターネットゲートウェイとはVPC内から外のネットワークへ繋ぐための通路の様な役割を持っています。
インターネットゲートウェイをVPCにアタッチすることで、VPCないのシステムはインターネットへアクセスできます。NATゲートウェイ
NATゲートウェイはプライベートサブネットから外のネットワークへ繋ぐための役割を持っています。
先ほど「インターネットゲートウェイは外のネットワークへ繋ぐ役割を持っている」と言いましたが、プライベートサブネットは直接IGWには繋げません。なのでNATゲートウェイを利用して、IGWに接続し外のネットワークにアクセスします。
この一連の流れは「ネットワーク図」の緑の矢印が表しています。NATゲートウェイを利用せずにプライベートサブネットを外のネットワークへ繋ぐことも可能みたいです。その場合はNATインスタンスというEC2インスタンスを利用して接続するとのことです。
バーチャルプライベートゲートウェイ(VPゲートウェイ)
バーチャルプライベートゲートウェイはオンプレミス環境に接続する際に利用されます。
IGWはインターネットへ、VPゲートウェイはオンプレミス環境へ繋ぐということですね。VPCエンドポイント
VPCエンドポイントはゲートウェイ型とインターフェイス型があり、どちらもAWSのサービスへインターネットを経由せずにプライベート接続を可能とするアクセスポイントみたいです。
VPCピアリング接続
VPCピアリング接続は異なるVPC間を接続するサービスです。
通常、VPCはプライベートネットワークなので異なるVPC間の接続はできませんが、VPCピアリングを使えば可能になるとのことです。まとめ
AWS初学者の私からすると、とてもハードな内容でしたがAWSを利用する上では欠かせない内容とのことだったのでがんばりました...
もし理解が間違っているところあればご指摘頂けると幸いです!
- 投稿日:2020-10-13T14:43:36+09:00
クラウドストレージに保管されたバックアップデータをAWS移行に利用しませんか?【CloudCatalyst編】
はじめに
以前、「NetBackup CloudCatalyst for AWS入門」で、CloudCatalystについて解説を行いました。
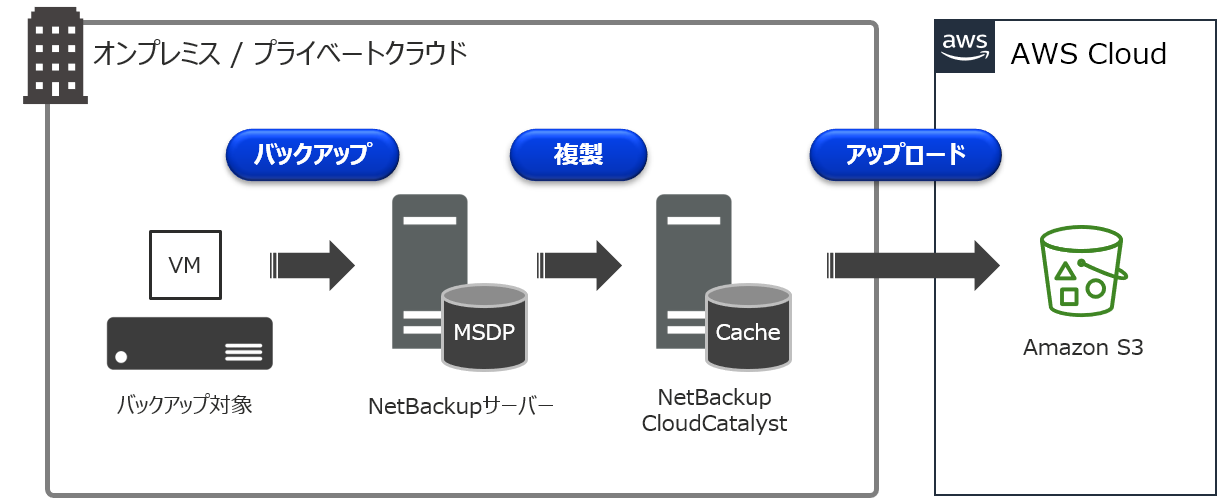
CloudCatalystの詳細については、こちらのまとめ記事をご参照下さい。CloudCatalystでは、重複排除されたバックアップデータをAmazon S3などのクラウドストレージに保管することが可能です。
通常、クラウドストレージに保管されたバックアップデータは、オンプレミスに存在するNetBackupサーバーでバックアップ/リストアなどの操作を行うことになります。オンプレミスではなく、クラウド上にNetBackupサーバーを構築することで、このクラウドストレージに保管されているバックアップデータを共有することが可能で、この機能を「Image sharing」と呼んでいます。
ちなみに、NetBackup 8.2でも同様の機能があり、その頃は「Automated disaster recovery」という名称でした。このImage sharingを利用することで、オンプレミス側で取得したVMwareの仮想マシンバックアップ(VADPバックアップ)を、AWSのAMIに変換して、Amazon EC2インスタンスとして起動させるといった使い方が出来ます!
今回は、Image sharing用NetBackupサーバーの構築手順からEC2インスタンス作成までの手順についてお伝えしたいと思います。【 備考:MSDP-Cloudについて 】
重複排除されたバックアップデータをクラウドストレージに複製するには、上述の通り、別途、CloudCatalystサーバーを準備して頂く必要がありました。NetBackup 8.3からMSDP-Cloudという新機能が追加されたのですが、このMSDP-Cloudを利用することで、重複排除およびクラウドストレージへの複製が、1台のメディアサーバーで構成することが可能となりました。(CloudCatalystとは別機能)
MSDP-CloudのサポートOSは、現状、RHELとCentOSになりますが、細かなバージョンや制限事項などは、マニュアルやSCLをご確認下さい。このMSDP-Cloudについては、別記事でご紹介させて頂きます。
Image sharing設定手順
注意事項
今回、ご紹介する手順はあくまで一例となります。
必ず、マニュアルやHardware and Cloud Storage Compatibility Listを参照し、Image sharingの詳細・制限事項について確認するようにして下さい。
- Veritas NetBackup Deduplication Guide - About image sharing in cloud using CloudCatalyst
- Hardware and Cloud Storage Compatibility List
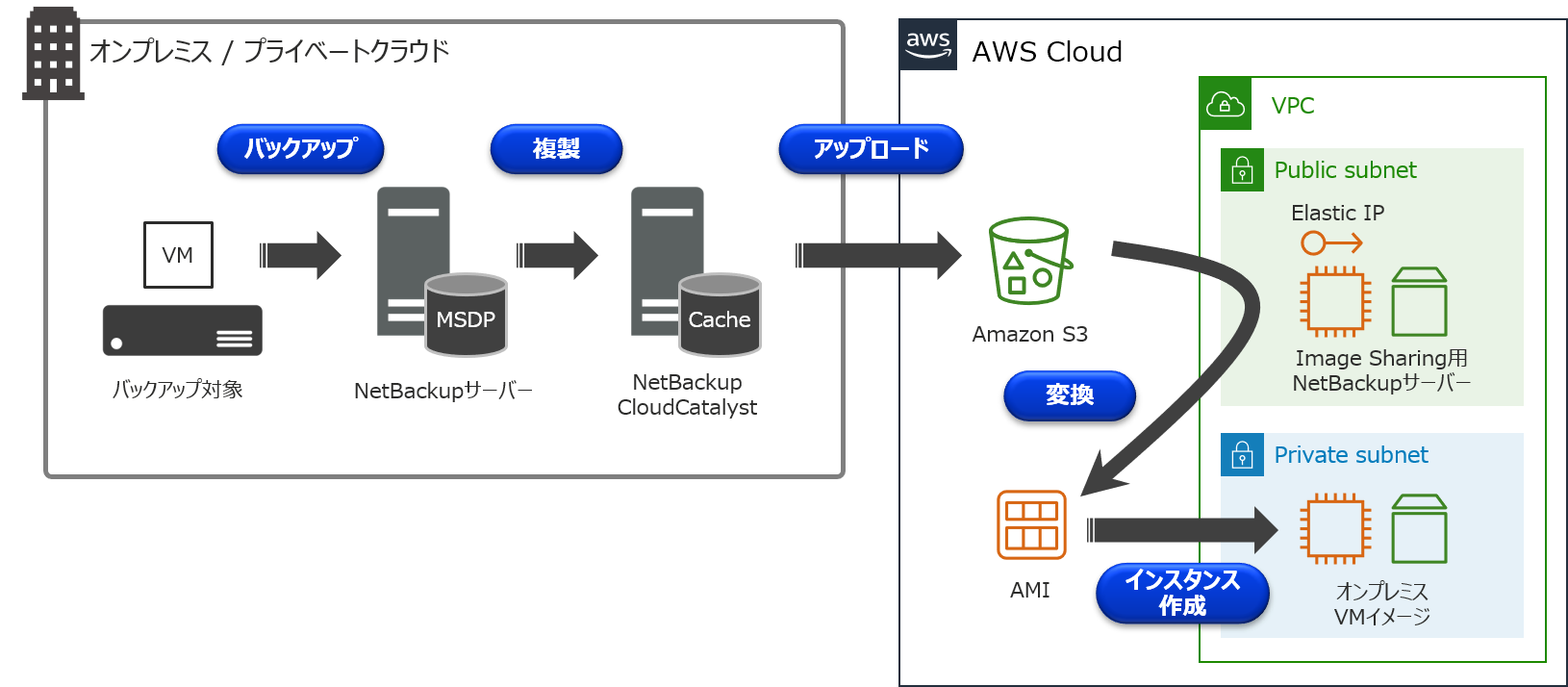
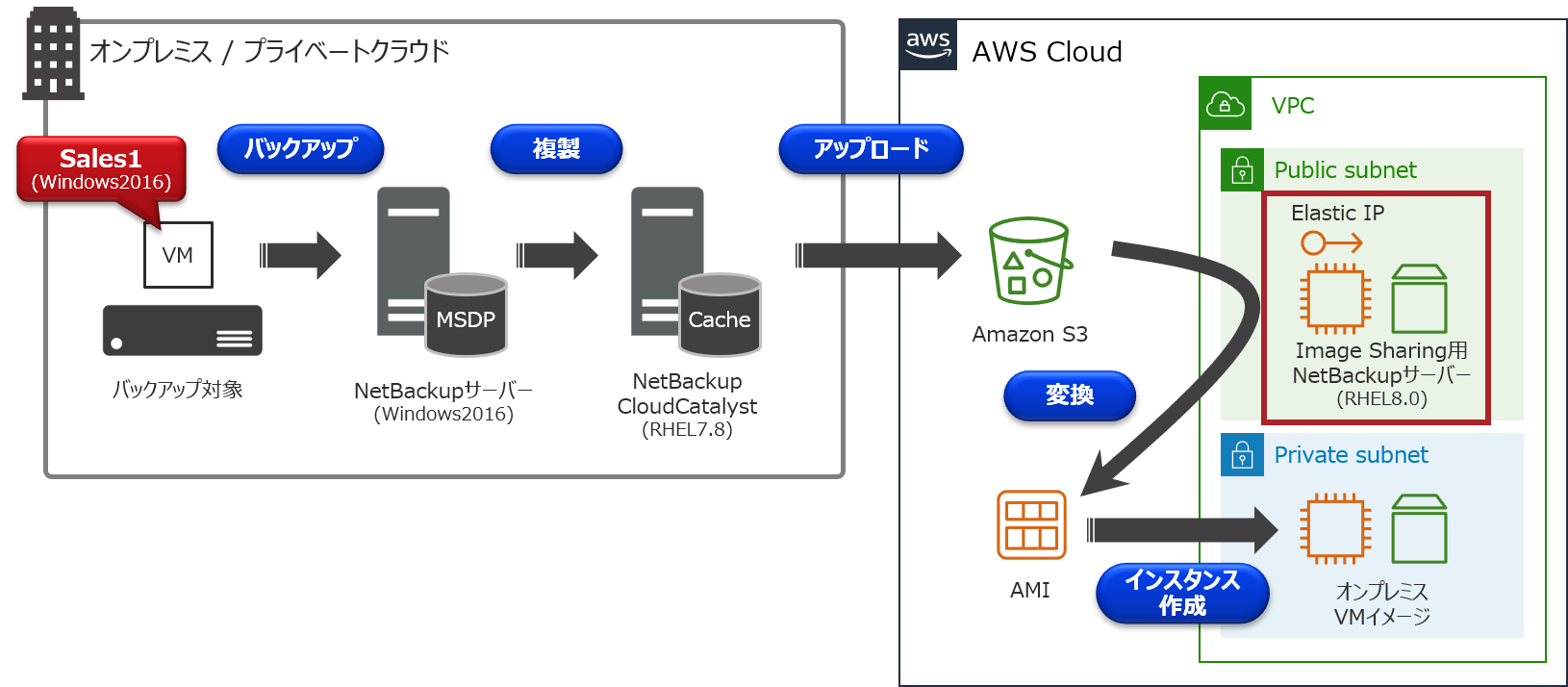
環境について
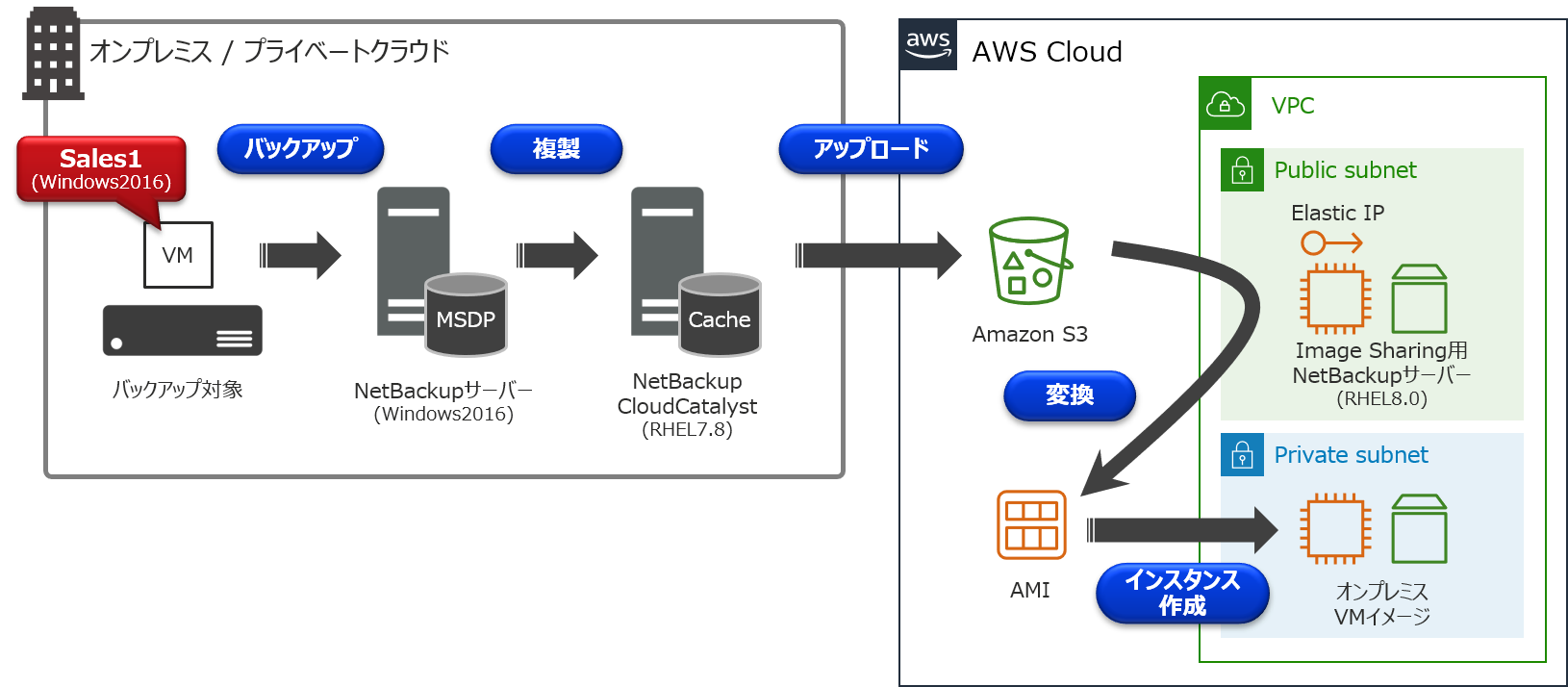
今回は以下のCloudCatalyst環境を例に、オンプレミスにあるVMware仮想マシンの「Sales1」を、EC2インスタンスとして起動するまでの手順について説明を行います。
- オンプレミス側
- バックアップ対象(VMware仮想マシン)
- ホスト名:Sales1
- Windows 2016
- 80GB HDD:Thin Provision(実使用量 12GB)
- NetBackupサーバー(マスターサーバー 兼 メディアサーバー)
- Windows 2016
- NetBackup 8.3
- NetBackup CloudCatalystサーバー
- RHEL 7.8
- NetBackup 8.3
- AWS側
- Image Sharing用NetBackupサーバー
- Elastic IPアドレス付与
- RHEL 8.0
- NetBackup 8.3
手順の流れ
①オンプレミス側でVADPバックアップを取得
②AWS側でEC2インスタンスを構築
③NetBackup 8.3のインストール
④Image sharing用NetBackupサーバーの構成
⑤Amazon S3に保存されているバックアップデータの確認
⑥バックアップデータをAMIに変換
⑦AMIからAmazon EC2インスタンスを起動詳細手順
①オンプレミス側でVADPバックアップを取得
オンプレミス側で「Sales1」のVADPバックアップを取得します。
CloudCatalystの構築やバックアップ手順などは、まとめ記事をご参照下さい。なお、NetBackupの管理コンソールですが、現時点では、日本語化パッチが出ていないため、メニューが英語表記となっておりますが、後日、提供される日本語化パッチを適用することで、メニューの日本語化が可能です。
一点、注意事項として、移行元の仮想マシンのファームウェアタイプは「BIOS」にして下さい。
「UEFI」の場合、AMI変換時に失敗しますので、ご注意下さい。②AWS側でEC2インスタンスを構築
Image Sharing用NetBackupサーバーを構築するため、AWS側でEC2インスタンスを構築します。
OSは、RHEL7.3 から RHEL8.0までがサポートされています。
また、以下の設定を実施するようにして下さい。
- セキュリティグループでHTTPSポート:443を有効にします。
- ホスト名を外部のFQDNに変更します。
# hostname ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com
- /etc/hostsファイルを編集します。外部IPアドレス/内部IPアドレス、どちらも外部ホスト名で登録します。
# cat /etc/hosts 18.180.xxx.xxx ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com 192.168.20.238 ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com
- /etc/resolv.confを編集します。内部ドメインの前に外部ドメインを検索するように変更します。
# cat /etc/resolv.conf search ap-northeast-1.compute.amazonaws.com ap-northeast-1.compute.internal nameserver 192.168.0.2
- Python 2.x系がインストールされていることを確認します。もし、インストールされていない場合、Python 2.x系を導入して下さい。
# which python /usr/bin/python # python -V Python 2.7.16③NetBackup 8.3のインストール
NetBackup8.3のインストールガイドに従って、マスターサーバーとしてインストールを行います。
また、NetBackupのサーバー名は先ほど設定したホスト名にして下さい。④Image sharing用NetBackupサーバーの構成
Image sharing用NetBackupサーバーの構成を行います。
ims_system_config.pyスクリプトを実行することで、Image sharingの構成が可能です。今回は、アクセスキー、シークレットアクセスキーを用いて実行しています。
もし、リージョンが異なるといったエラーが発生する場合は、「-r」オプションを付与して、Amazon S3のリージョンを指定して実行してみて下さい。構成完了までに10分ほど掛かります。
【実行コマンド】 # python /usr/openv/pdde/pdag/scripts/ims_system_config.py -k <AWS_access_key> -s <AWS_secret_access_key> -b <name_S3_bucket> -r <bucket_region> 【実行例】 # python /usr/openv/pdde/pdag/scripts/ims_system_config.py -k ***** -s ***** -b vrts-cloudcatalyst-test001 -r ap-northeast-1 *****************************IMPORTANT TIPS!********************************* Ensure that the hostname "ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com" is in the FQDN format. If the hostname is not in the FQDN format, the webservice might fail. Enter Y to continue or any other key to reset:Y INFO - Confirm hostname same to FQDN INFO - Begin checking the KMS encryption status in the cloud storage... WARNING - KMS encryption is disabled in the cloud storage. Disaster recovery will not use the KMS mode. INFO - Completed checking the KMS encryption status in the cloud storage. INFO - Begin syncing up sys inodes... INFO - Completed syncing up sys inodes. INFO - Begin configuring web service... INFO - Completed configuring web service. INFO - Begin creating storage server... INFO - [CMD]:/usr/openv/netbackup/bin/admincmd/csconfig cldinstance -as -in amazon.com -sts ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com -ssl 2 INFO - [CMD]:/usr/openv/netbackup/bin/admincmd/nbdevconfig -creatests -storage_server ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com -stype PureDisk_amazon_rawd -media_server ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com -st 9 INFO - [CMD]:/usr/openv/volmgr/bin/tpconfig -dsh -stype PureDisk_amazon_rawd INFO - [CMD]:/usr/openv/volmgr/bin/tpconfig -add -storage_server ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com -stype PureDisk_amazon_rawd -sts_user_id xxx INFO - [CMD]:/usr/openv/netbackup/bin/admincmd/nbdevconfig -getconfig -stype PureDisk_amazon_rawd -storage_server ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com INFO - [CMD]:/usr/openv/netbackup/bin/admincmd/nbdevconfig -setconfig -stype PureDisk_amazon_rawd -storage_server ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com -configlist /tmp/imagesharing_sts_config.txt INFO - [CMD]:/usr/openv/netbackup/bin/admincmd/nbdevconfig -previewdv -storage_server ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com -stype PureDisk_amazon_rawd -media_server ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com -dv vrts-cloudcatalyst-test001 -dvlist /tmp/imagesharing_dvlist.txt INFO - [CMD]:/usr/openv/netbackup/bin/admincmd/nbdevconfig -createdv -storage_server ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com -stype PureDisk_amazon_rawd -dv vrts-cloudcatalyst-test001 -config 'region:ap-northeast-1' INFO - [CMD]:/usr/openv/netbackup/bin/admincmd/nbdevconfig -createdp -storage_servers ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com -stype PureDisk_amazon_rawd -dp amazon_dp -dvlist /tmp/imagesharing_dvlist.txt INFO - [CMD]:/usr/openv/netbackup/bin/admincmd/bpstuadd -label amazon_dp_stu -odo 0 -dt 6 -dp amazon_dp -nodevhost -cj 20 -mfs 51200 INFO - Completed creating storage server. INFO - Begin verifying web service... INFO - [CMD]:/usr/openv/pdde/vpfs/bin/vpfs_config.sh --create_spws_self_signed_certs --storagepath /storage/storage --hostname ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com --upgrade INFO - [CMD]:/usr/openv/pdde/vpfs/bin/nb_admin_tasks --get_self_cert INFO - Completed verifying web service.⑤Amazon S3に保存されているバックアップデータの確認
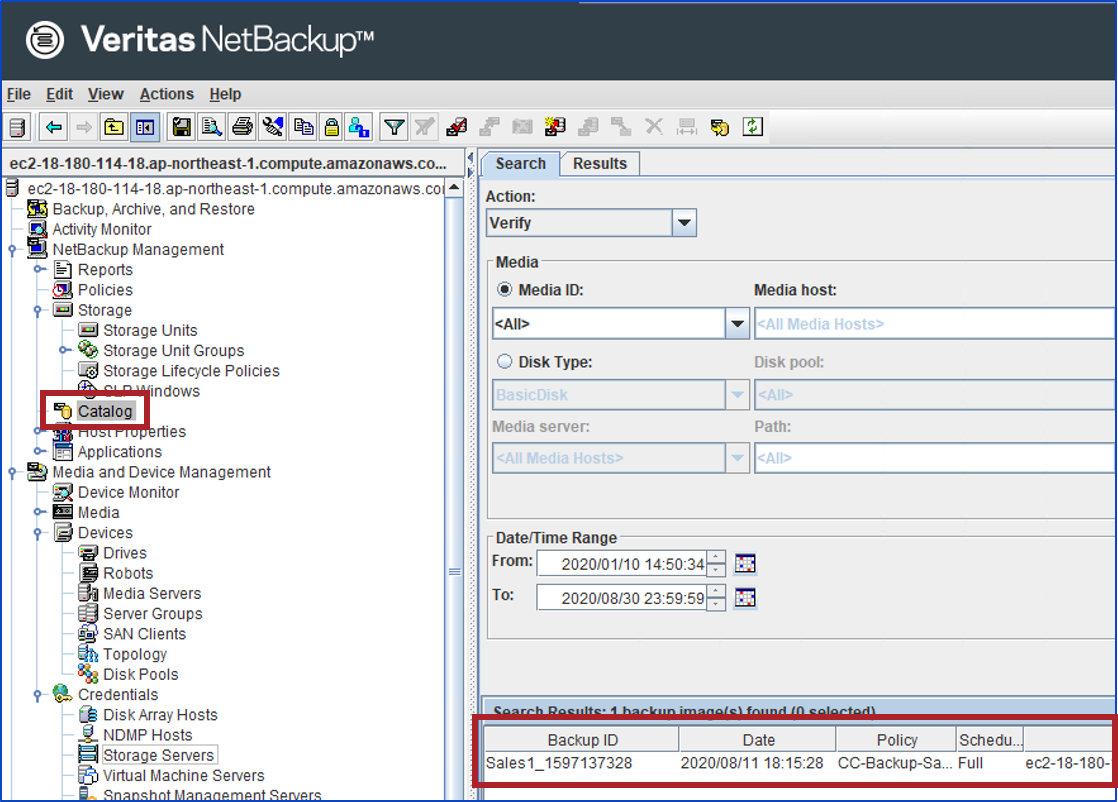
④のスクリプトが正常完了すれば、Amazon S3に保管されているバックアップデータを確認することが出来ます!
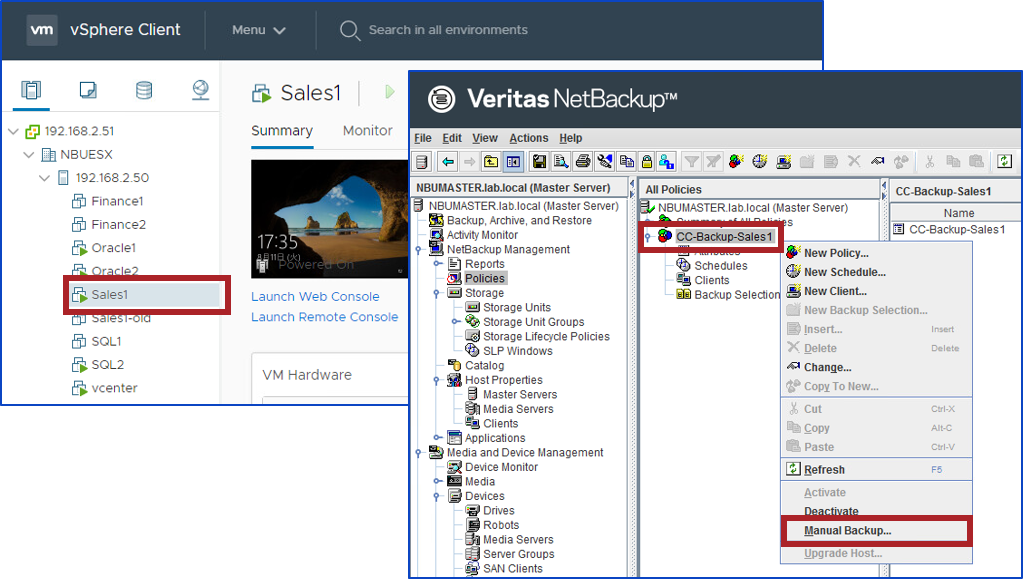
では、実際にSales1が表示されるかを確認してみましょう。まず、NetBackupにログインします。
もし、パスワードに特殊文字を用いている場合、シングルクォーテーション「'」で囲んで下さい。【実行コマンド】 # /usr/openv/netbackup/bin/admincmd/nbimageshare --login <username> <password> 【実行例】 # /usr/openv/netbackup/bin/admincmd/nbimageshare -login root 'PASSWORD' Login successful.Amazon S3に保管されているバックアップデータを確認してみます。
【実行コマンド】 # /usr/openv/netbackup/bin/admincmd/nbimageshare -listimage 【実行例】 # /usr/openv/netbackup/bin/admincmd/nbimageshare -listimage { "meta": { "pagination": { "count": 1, "last": 0, "next": 0, "limit": 0, "offset": 0, "prev": 0, "first": 0 } }, "data": [ { "attributes": { "backupTime": 1597137328, "resumeNumber": 1, "importStatus": "NotImported", "copyNumber": 2, "client": "Sales1", "policyType": "VMware", "policy": "CC-Backup-Sales1", "backupID": "Sales1_1597137328", "scheduleType": "Full" }, "type": "cloudImages", "id": "0" } ] }無事、オンプレミスでバックアップしたSales1が、AWS側にあるNetBackupから確認出来ました!!!
⑥バックアップデータをAMIに変換
無事にバックアップデータが確認出来ましたので、Sales1をAMIに変換したいと思います。
まず、NetBackupにバックアップイメージのインポートを行います。
⑤で出力された値を、引数として渡します。★注意事項★
マニュアルでは、オプションが「--singleimport」となっていますが、正しくは「--single-import」(singleとimportの間にハイフンが入る)となりますので、ご注意下さい。【実行コマンド】 # /usr/openv/netbackup/bin/admincmd/nbimageshare --single-import <client> <policy> <backupID> 【実行例】 # /usr/openv/netbackup/bin/admincmd/nbimageshare --single-import Sales1 CC-Backup-Sales1 Sales1_1597137328 { "type": "importResponse", "id": "6", "attributes": { "images": [ { "status": "0", "policy": "CC-Backup-Sales1", "backupID": "Sales1_1597137328" } ] } }bpdbjobsコマンドで、ジョブの実行状態が分かります。
StateがDoneで、Status 0で終了することを確認します。# /usr/openv/netbackup/bin/admincmd/bpdbjobs JobID Type State Status Policy Schedule Client Dest Media Svr Active PID FATPipe 6 Import Done 0 CC-Backup-Sales1 Sales1 ec2-18-180-xxx-xxx.ap-northeast-1.compute.amazonaws.com 22437ちなみに、リモート管理コンソールなどで、NetBackupサーバーに接続し、カタログ検索を行うと、バックアップ情報が表示されることを確認することが出来ます。(こちらのリモート管理コンソールも、①での説明と同様、後日、提供される日本語化パッチを適用することで、メニューの日本語化が可能です)
これで、準備万端です!
以下のコマンドを実行して、Sales1のAMI変換を行います。★注意事項★
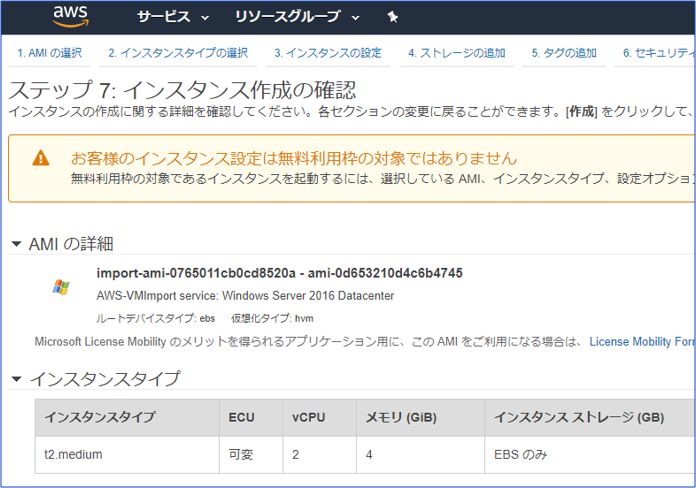
マニュアルでは、オプションが「--recovervm」となっていますが、正しくは「--recover-vm」(recoverとvmの間にハイフンが入る)となりますので、ご注意下さい。【実行コマンド】 # /usr/openv/netbackup/bin/admincmd/nbimageshare --recover-vm <client> <policy> <backupID> 【実行例】 # /usr/openv/netbackup/bin/admincmd/nbimageshare --recover-vm Sales1 CC-Backup-Sales1 Sales1_1597137328 { "type": "recoverEc2Response", "id": "7", "attributes": { "status": "0", "policy": "CC-Backup-Sales1", "backupId": "Sales1_1597137328" } }上記コマンド実行後、バックアップデータがAMIに変換され、AWS管理コンソールから確認することが可能です。
なお、AMI変換までに少し時間が掛かります。
今回の環境の場合、上記ジョブが完了するのに27分25秒の時間が掛かりました。⑦AMIからAmazon EC2インスタンスを起動
AWS管理コンソールにログインし、Sales1のAMIが登録されていることを確認します。
無事に登録されてますね!ここまで来れば、バックアップデータのAMI変換は無事に終わっていますので、EC2インスタンスとして正常に起動するかを確認します。
【EC2インスタンスの作成画面】
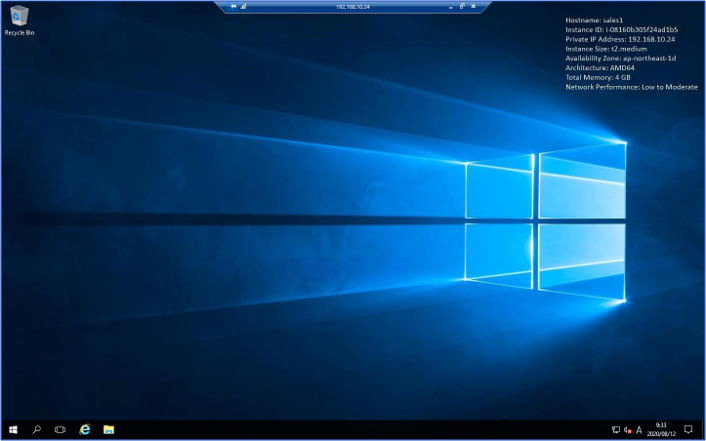
【Sales1のデスクトップ画面】
AWS上で無事にSales1インスタンスが起動していますね!
この後は環境に合わせて、アプリの動作確認などを実施して下さい。おわりに
いかがでしたでしょうか?
思いのほか、簡単にAWSへ移行することが実感頂けたのではないでしょうか。AWSへの移行は様々な方法がありますが、今回ご紹介した方法であれば、既存環境に手を加える必要はありません。
そのため、既存環境への影響を与えることなく、安全にAWSへの移行が可能です。有事の際のバックアップだけではなく、AWS移行にもバックアップを是非ご活用下さい!
商談のご相談はこちら
本稿からのお問合せをご記入の際には「コメント/通信欄」に#GWCのタグを必ずご記入ください。
ご記入いただきました内容はベリタスのプライバシーポリシーに従って管理されます。その他のリンク
【まとめ記事】ベリタステクノロジーズ 全記事へのリンク集もよろしくお願い致します!

- 投稿日:2020-10-13T10:26:47+09:00
AWSアカウントにつけられるエイリアス(別名)の命名規則
AWSのマネジメントコンソールにサインインするときに入力する「12桁の数字」ことAWSアカウントID、これには「自社名 (または他のわかりやすい識別子)」をエイリアス(別名)として設定することができます。設定はマネジメントコンソールからでもAWS CLIからでも可能です。
ただし完全に任意のエイリアスを付けられるわけではありません。マネジメントコンソールでの表示からすると、以下の制約があるようです。
- 28文字以内
- 使用できる文字は英子文字、数字、
-(ハイフン)だけ- すでに使われているエイリアスは使用不可(おそらく世界中でユニークであることが必要)
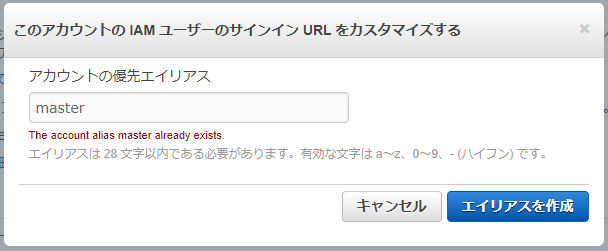
ユニークな文字列(まだ使われていないエイリアス)かどうかは、以下のようなサインインURLを試してみればわかりそうです。
https://your_account_id.signin.aws.amazon.com/console/「your_account_id」に、例えば以下のURLのうち、1つ目のいかにも使われていそうな
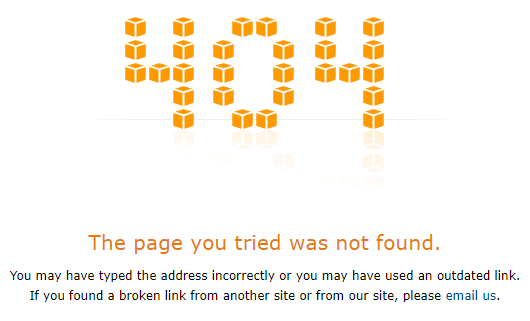
masterを入れたURLにアクセスしてみるとサインイン画面が表示されます。つまりmasterというエイリアスは存在する、すでに使われてるということです。しかしでたらめな文字列grauysdsrosvlxgd094ueを入れたほうは404 not foundになります(いまのところ)。これはエイリアスとしておそらく使われていない文字列です。
- https://master.signin.aws.amazon.com/console/
- https://grauysdsrosvlxgd094ue.signin.aws.amazon.com/console/
AWSアカウントを識別できないといけないので重複不可だろう、URLに使われるので文字種制限があるだろう、つまり「AWS S3バケットの命名規則」みたいな感じだろうと思っていましたが、文字列長が短くピリオドが使えないなどもう少し厳しいですね。
エイリアスの命名規則などを公式ドキュメントでうまく探せなかったので、メモでした。
参考
- 投稿日:2020-10-13T01:22:22+09:00
AWS DynamoDBにCSVファイルをインポートする方法
DynamoDBへのCSVファイルインポートはコンソールからは出来ないので、DQLを使った簡単な方法を明記します。
環境
Mac OSX
$ pip --version pip 20.1.1 from /usr/local/var/pyenv/versions/3.7.7/lib/python3.7/site- packages/pip (python 3.7) $ python --version 3.7.7まずPC内に以下のコマンド仮想環境を作ります。
$ python -m venv venv次に、その仮想環境に入ります。( ドット[ . ]のあとは半角スペース区切ってください。
$ . venv/bin/activate次にDQLをインストールします。
$ pip3 install dql環境変数を設定
以下のコマンドで AWS 認証情報のプロファイル (saml) とリージョン (東京) を環境変数に設定できます:export AWS_PROFILE=saml export AWS_REGION=ap-northeast-1Windows の場合は代わりに以下のコマンドを使ってください:
set AWS_PROFILE=saml set AWS_REGION=ap-northeast-1dql ツールを利用
以上の設定が終われば、dql コマンドを叩いてコマンドラインインターフェイスを開きます
$ dql ap-northeast-1>あとは、SQL文を入力していくんですが、
その前に
opt allow_select_scan trueを入力して、全件スキャンできるようにしておきます。それ以降は自由にSQL文を実行してください。
例としては、SELECT * FROM test_teble SAVE test.csvといった感じですね。SELECT * FROM {テーブル名} SAVE {ファイル名}にすると指定したテーブルから全件、指定したファイル名でローカル(コマンド実行ディレクトリ)にファイルが保存されます。