- 投稿日:2020-10-13T22:54:27+09:00
Electron上でVulkanを動かすことに成功しました(しかも現実的な範疇で)
この話の続きです。
https://qiita.com/nanikore55554/items/4ad9fca5d23f2c459f98
要約すると「Electron上でVulkanは動かせたけど、遅すぎて10fpsも出せませんでした。」という話です。
で、今回はなんとか現実的な範疇にまでプログラムを軽くする方法はないかと考え、実際にやってみた結果です。
1. そもそも何故重いのか?
前回も話しましたが、生の画像データ(RGBAのデータがそのまま入ってるconst char*型のデータ)からJpegへの変換が重すぎる事が原因です。とすれば、この部分をなくせば軽くなるはずです。
2. 生の画像データをElectron上で表示する方法
だが、ここで問題があります。Electron(正確にはウェブブラウザ)には生の画像を表示する方法がありません。これがあったからわざわざJpegへデータを変換していたのです。
しかし、回避方法があります。前回も触れたWebGLで表示する方法です。WebGLはUint8Array型のデータをテクスチャとして扱う事ができます。生の画像データを毎フレームごとにテクスチャにして表示すれば一々Jpegで変換する事なく表示する事ができるはずです。
3. 実際にやってみた方法
下記のQiitaにあるソースコードを参考にして作成しました。
https://qiita.com/aa_debdeb/items/4a95646e284987946019
このソースコードを改造して作成したソースを一部抜粋します。
sample.jssetInterval(() => { //Vulkan部分を実際に表示する関数 bar.main_loop(); //Vulkanで生成した画像をスクリーンショットとして撮る関数 bar.make_ss(); gl.clearColor(0.0, 0.0, 0.0, 1.0); //bar.send_raw_imageはスクリーンショットをjs側に送信する関数 pixels = new Uint8Array(bar.send_raw_image().buffer.slice(0, texWidth*texHeight*4)); texture = gl.createTexture(); gl.bindTexture(gl.TEXTURE_2D, texture); //texWidthは横幅、texHeightは縦幅 gl.texImage2D(gl.TEXTURE_2D, 0, gl.RGBA, texWidth, texHeight, 0, gl.RGBA, gl.UNSIGNED_BYTE, pixels); gl.texParameteri(gl.TEXTURE_2D, gl.TEXTURE_MAG_FILTER, gl.LINEAR); gl.texParameteri(gl.TEXTURE_2D, gl.TEXTURE_MIN_FILTER, gl.LINEAR); gl.bindTexture(gl.TEXTURE_2D, null); gl.clear(gl.COLOR_BUFFER_BIT); //シェーダを用意する関数 gl.useProgram(program); gl.activeTexture(gl.TEXTURE0); gl.bindTexture(gl.TEXTURE_2D, texture); gl.uniform1i(uniforms['u_texture'], 0); gl.drawArrays(gl.TRIANGLES, 0, 6); },32);4. 結果
普通に30fpsが出ました。それどころか、60fpsも余裕で出来ます。
前回、10fpsも出なかった事を考えれば大きな進化です。
しかし、CPUへの負担は大きく、30fpsで8%、60fpsで20%以上CPUのリソースが使われました。
負担となっているのは
pixels = new Uint8Array(bar.send_raw_image().buffer.slice(0, texWidth*texHeight*4));
の部分です。ここをnew Uint8Array(texWidth*texHeight*4)にしたらCPUの負担が一気に1%以下へ減りました。この部分をどうにかすれば、もっとElectronでVulkanを動かす事が現実的になると考えられます。5. もっと早くする方法がある?
実はもっと早く出来るかもしれない方法があります。前に述べたNVJpegを使ってエンコードし、Electronで表示する方法です。また試していませんが、libjpeg-turboを使うより早いらしいです。ただし、NVIDIA製のGPUでしか動かない(Electron最大の武器であるクロスプラットフォームが無くなる)という致命的な欠点があるので使って意味があるかどうかは微妙なところです。(どうも調べたら思ったより速度が上がるわけでも無さそうですし)
まぁ、Electronじゃないけど「HTMLで作るアプリは非常に作りやすい」という点だけに着目して専用のプラットフォームだけで動くHTML製ネイティブアプリを動かしている製品もありますけどね。あの携帯型ゲーム機とかゲーム機とかゲーム機とかな。
(詳しく知りたい人は「任○堂 react.js」と検索すると幸せになれるよ)。6. 前回触れなかったこと
実はVulkanだとスクリーンショットを撮るプログラムが非常に軽い。
本来、スクリーンショットを撮るというのはCPUの負担の大きいものです。
一回だけ撮るのなら問題有りませんが、毎フレームごとに撮るとなるとかなり負担は相当増大します。しかし、今回のプログラムでは非常に軽かったです。これを生かせばもっとヘンテコで有用なプログラムを作れるかもしれません。
最後に分かった事
1.やっぱりWebGLは凄いと思う
2.ただ、ここまで来たら何かきっかけがあればWebGPUはそんなに必要ないのかも?
3.各ウェブブラウザは生データの画像も表示できるようにすべきだと思う
- 投稿日:2020-10-13T22:49:42+09:00
TypeScriptでExpress環境を構築してみた
TypeScript/Express環境でローカルサーバを立て、Hello Worldを出力したい。
私自身はReact内で多少TypeScript触ってみた程度ですが、TypeScriptをこれから勉強する人の最初の一歩目を共に歩んでいければなと思います。
環境
npm: 6.14.X node: 14.13.X npx: 6.14.Xプロジェクトの作成
$ mkdir ts-app $ cd ts-app $ npm init -y
- 作業ディレクトリを作成し、移動します。
- そのディレクトリ内でnpm initとコマンドを打つことで、このディレクトリをnpmの管理下に置くということになります。
- lsコマンドでディレクトリ内を確認すると、package.jsonというファイルが作られていることを確認できるかと思います。
必要なパッケージのインストール
$ npm install --save typescript express
- TypeScriptとExpressをインストールします。
- package.jsonをみればバージョンの確認などができます。
- 私の環境では以下のようになりました。
- "express": "^4.17.1",
- "typescript": "^4.0.3"
TypeScriptが使える環境にする
$npx tsc --init
- 上記のコマンドを入力後lsコマンドを打てば、tsconfig.jsonというファイルが作られたことを確認できるかと思います。
※ typescriptをグローバルインストールしていれば
tsc --initのコマンド入力でも同様の結果が得られます。私の場合はグローバルにインストールしてあるtypescriptと作業ディレクトリ内のtypescriptでのバージョン差異が起こらないように上のコマンドで実施しています。tsconfig.jsonを編集
新たに作られたtsconfig.jsonを見てみます。
{ "compilerOptions": { /* Visit https://aka.ms/tsconfig.json to read more about this file */ /* Basic Options */ // "incremental": true, /* Enable incremental compilation */ "target": "es5", /* Specify ECMAScript target version: 'ES3' (default), 'ES5', 'ES2015', 'ES2016', 'ES2017', 'ES2018', 'ES2019', 'ES2020', or 'ESNEXT'. */ "module": "commonjs", /* Specify module code generation: 'none', 'commonjs', 'amd', 'system', 'umd', 'es2015', 'es2020', or 'ESNext'. */ // "lib": [], /* Specify library files to be included in the compilation. */ // "allowJs": true, /* Allow javascript files to be compiled. */ // "checkJs": true, /* Report errors in .js files. */ // "jsx": "preserve", /* Specify JSX code generation: 'preserve', 'react-native', or 'react'. */ // "declaration": true, /* Generates corresponding '.d.ts' file. */ // "declarationMap": true, /* Generates a sourcemap for each corresponding '.d.ts' file. */ // "sourceMap": true, /* Generates corresponding '.map' file. */ // "outFile": "./", /* Concatenate and emit output to single file. */ // "outDir": "./", /* Redirect output structure to the directory. */ // "rootDir": "./", /* Specify the root directory of input files. Use to control the output directory structure with --outDir. */ // "composite": true, /* Enable project compilation */ // "tsBuildInfoFile": "./", /* Specify file to store incremental compilation information */ // "removeComments": true, /* Do not emit comments to output. */ // "noEmit": true, /* Do not emit outputs. */ // "importHelpers": true, /* Import emit helpers from 'tslib'. */ // "downlevelIteration": true, /* Provide full support for iterables in 'for-of', spread, and destructuring when targeting 'ES5' or 'ES3'. */ // "isolatedModules": true, /* Transpile each file as a separate module (similar to 'ts.transpileModule'). */ /* Strict Type-Checking Options */ "strict": true, /* Enable all strict type-checking options. */ // "noImplicitAny": true, /* Raise error on expressions and declarations with an implied 'any' type. */ // "strictNullChecks": true, /* Enable strict null checks. */ // "strictFunctionTypes": true, /* Enable strict checking of function types. */ // "strictBindCallApply": true, /* Enable strict 'bind', 'call', and 'apply' methods on functions. */ // "strictPropertyInitialization": true, /* Enable strict checking of property initialization in classes. */ // "noImplicitThis": true, /* Raise error on 'this' expressions with an implied 'any' type. */ // "alwaysStrict": true, /* Parse in strict mode and emit "use strict" for each source file. */ /* Additional Checks */ // "noUnusedLocals": true, /* Report errors on unused locals. */ // "noUnusedParameters": true, /* Report errors on unused parameters. */ // "noImplicitReturns": true, /* Report error when not all code paths in function return a value. */ // "noFallthroughCasesInSwitch": true, /* Report errors for fallthrough cases in switch statement. */ /* Module Resolution Options */ // "moduleResolution": "node", /* Specify module resolution strategy: 'node' (Node.js) or 'classic' (TypeScript pre-1.6). */ // "baseUrl": "./", /* Base directory to resolve non-absolute module names. */ // "paths": {}, /* A series of entries which re-map imports to lookup locations relative to the 'baseUrl'. */ // "rootDirs": [], /* List of root folders whose combined content represents the structure of the project at runtime. */ // "typeRoots": [], /* List of folders to include type definitions from. */ // "types": [], /* Type declaration files to be included in compilation. */ // "allowSyntheticDefaultImports": true, /* Allow default imports from modules with no default export. This does not affect code emit, just typechecking. */ "esModuleInterop": true, /* Enables emit interoperability between CommonJS and ES Modules via creation of namespace objects for all imports. Implies 'allowSyntheticDefaultImports'. */ // "preserveSymlinks": true, /* Do not resolve the real path of symlinks. */ // "allowUmdGlobalAccess": true, /* Allow accessing UMD globals from modules. */ /* Source Map Options */ // "sourceRoot": "", /* Specify the location where debugger should locate TypeScript files instead of source locations. */ // "mapRoot": "", /* Specify the location where debugger should locate map files instead of generated locations. */ // "inlineSourceMap": true, /* Emit a single file with source maps instead of having a separate file. */ // "inlineSources": true, /* Emit the source alongside the sourcemaps within a single file; requires '--inlineSourceMap' or '--sourceMap' to be set. */ /* Experimental Options */ // "experimentalDecorators": true, /* Enables experimental support for ES7 decorators. */ // "emitDecoratorMetadata": true, /* Enables experimental support for emitting type metadata for decorators. */ /* Advanced Options */ "skipLibCheck": true, /* Skip type checking of declaration files. */ "forceConsistentCasingInFileNames": true /* Disallow inconsistently-cased references to the same file. */ } }どうやらいろいろな設定が書かれていてコメントアウトされているようです。。
今回は最低限必要な箇所だけコメントアウトし、必要に応じて編集していきます。
- 9行目の"allowJs" →コメントアウトを外す
- 17行目の"outDir" →コメントアウトを外し、
"outDir": "./dist",に変更- 18行目の"rootDir" →コメントアウトを外し、
"rootDir": "./app",に変更これで一通りの設定は終了です。
それでは実際にTypeScriptでコードを書いてJavaScriptにコンパイルしてみます。
ファイル作成
- TypeScriptを書くappディレクトリと、コンパイル時にJavaScriptが作られるdistディレクトリを作成し、app.tsファイルを作成します。
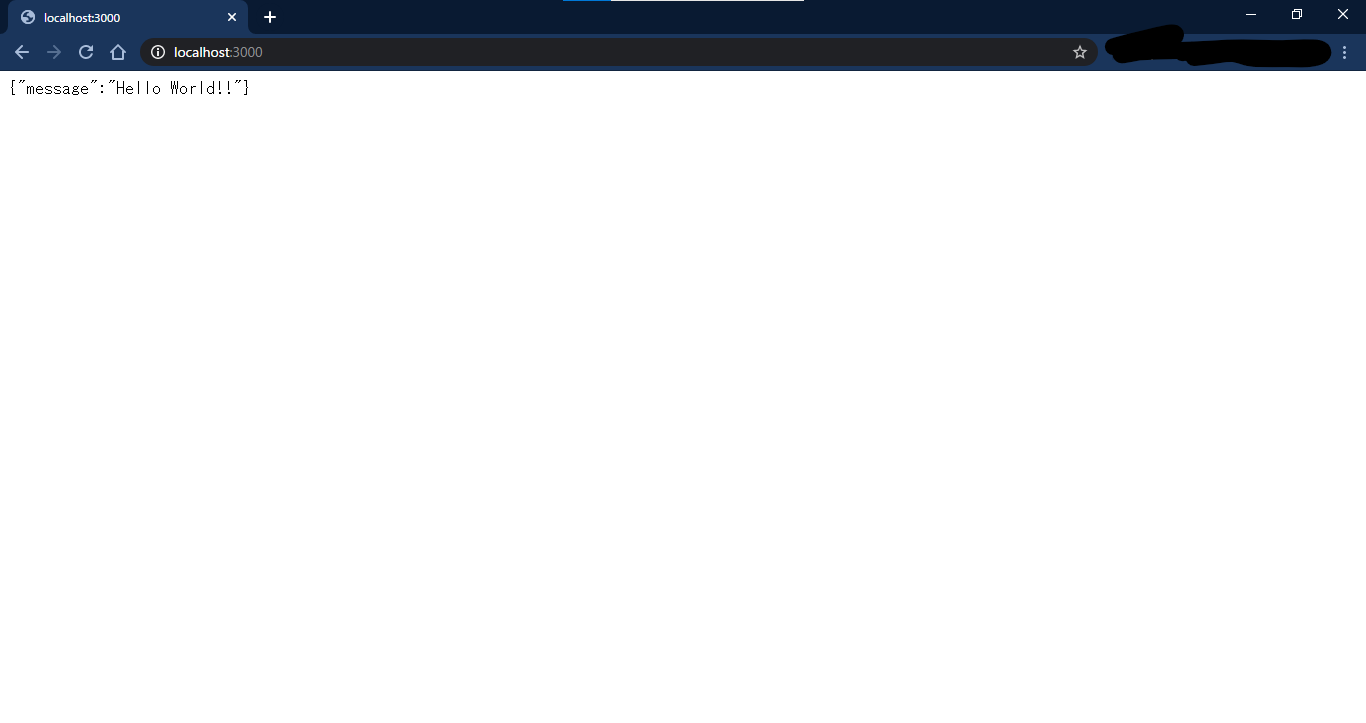
$ mkdir app dist $ touch app/app.tsapp.ts(app.js)の内容としては、localhost:3000にサーバを立て、ブラウザでアクセスすると"{ "message": "Hello World!!" }"というjson形式の文字列が参照できる画面が表示できるようになります。
app.tsimport express from 'express'; const app = express(); app.get('/', (req, res) => { res.json({ "message": "Hello World!!" }); }); app.listen(3000);この状態だと1行目の"express"のところでエラーになるかと思います。
VSCodeの場合カーソルを合わせるとエラーの内容が表示されるので見てると、モジュール 'express' の宣言ファイルが見つかりませんでした。となっているのでexpressの型定義ファイルをインストールします。$ npm install --save-dev @types/expressエラーが消えたのでコンパイルしていきます。
JavaScriptへのコンパイル
$ npx tscこのコマンドを入力すると、distディレクトリ内にapp.jsが作られます。
tsconfig.jsonの"outDir"に指定したディレクトリに作られるのです。watchモード
$ npx tsc --watchこのコマンドを使えばtsファイルが変更されるたびにコンパイルされるようになります。
ctr + C でwatchモードから抜けられます。サーバを立てる
$ node dist/app.jsこのコマンドでapp.jsに指定してあるポートでサーバが立ち上がります。
今回は3000ですので、http://localhost:3000 にブラウザでアクセスしてみると、
上手くいきました!
最後に
最後まで読んでいただきまして誠にありがとうございます!
これからTypeScriptでたくさんコードを書いていきたいと思っております。
この記事の内容で、ここ違うよなどの箇所があればバンバン突っ込んでいただけますと幸いでございます!
- 投稿日:2020-10-13T20:23:03+09:00
Google Spread Sheet のデータを毎分チェックし、変更があったら Firestore に保存する(Node.js)
TL;DR
タイトルから全てを察した方はこちらで十分かと思います。
import * as functions from "firebase-functions"; import admin from "firebase-admin"; import { google, sheets_v4 } from "googleapis"; // 公開関数 export const checkSpreadSheet = functions .region("asia-northeast2") .pubsub.schedule("every 1 minutes") .onRun(async () => { const sheetId = "スプレッドシートのID" const ranges = [ { sheet: "シート", start: "A1", end:"B1" } ]; const sheetData = await getSpreadSheetData(sheetId, ranges); const modifiedTime = await getModifiedTime(sheetId); await store(modifiedTime, sheetData); }); // 引数用定義 export interface SpreadSheetRange { sheet: string; start: string; end: string; } // シートの情報を取得 async function getSpreadSheetData( id: string, params: SpreadSheetRange[] ): Promise<sheets_v4.Schema$Spreadsheet> { const auth = await google.auth.getClient({ scopes: ["https://www.googleapis.com/auth/spreadsheets"] }); const sheets = google.sheets("v4"); const spreadsheetId = id; const ranges: string[] = []; for (const r of params) { ranges.push(`${r.sheet}!${r.start}:${r.end}`); } const res = await sheets.spreadsheets.get({ auth, spreadsheetId, ranges, includeGridData: true }); return res.data; } // 更新日取得 async function getModifiedTime(fileId: string): Promise<string> { const auth = await google.auth.getClient({ scopes: ["https://www.googleapis.com/auth/drive"] }); const d = google.drive("v3"); const res = await d.files.get({ auth, fileId, fields: "modifiedTime" }); return res.data.modifiedTime as string; } // firestore に保存 async function store( modifiedTime: string, data: sheets_v4.Schema$Spreadsheet ): Promise<void> { if (data.sheets) { const f = admin .firestore() .collection("spreadsheet") .doc(data.spreadsheetId as string); const ss = await f.get(); const ssdata = ss.data(); if (ssdata && ssdata.lastUpdate === modifiedTime) { return; } const d = ssdata ? ssdata : {}; d.lastUpdate = modifiedTime; const items: string[] = []; for (const s of data.sheets) { if (!s.data) continue; for (const col of s.data) { if (!col.rowData) continue; for (const row of col.rowData) { if (row.values && row.values.length !== 0) { items.push(row.values[0].formattedValue as string); } } } } d.items = items; await f.set(d); } }Google Spread Sheet を簡易 CMS として使う
ウェブサイトを作っていると、「この部分は更新できるようにしたい!」と言われる事が良くあります。
大がかりなものであればCMSを入れて対応するのが良いと思うのですが、「お知らせだけ」とか、「トップページの文言だけ」が対象だった場合は、そのためだけにCMSを入れるのはためらいますし、かといって自分でCRADのUIを作るのは面倒です。僕はそういった場合に
Google Spread Sheetを使用して簡易的なCMSとしてしまう事が多いです。
以前はこのライブラリを介して、リクエストの度に直接Google Sheets APIを叩いていました。https://www.npmjs.com/package/google-spreadsheet
懸念
ただ、
Google Sheets API自体に下記の制限があります。https://developers.google.com/sheets/api/limits
- プロジェクト毎に 500リクエスト / 100秒
- ユーザー毎に 100リクエスト / 100秒
小規模の案件であれば問題にならなそうですが、少し規模が大きくなると不安になってくる数字です。
何より、webという不特定多数のユーザーからアクセスされる環境の中、制限を下回る確実な補償がない以上「場合によっては制限を超えるかもしれない」という懸念を抱えながら運用しなければいけません。Google Spread Sheet + Cloud Functions + Firestore
そこで、今回
- Google Spread Sheet のデータを
- Cloud Functions で1分毎に更新チェックして
- 変更があれば Firestore に保存する
という方法を採ってみたので、記事として共有しようと思います。
サービスアカウントを取得する / APIを有効にする
こちらの記事を参考に、サービスアカウントの情報を取得します。
https://qiita.com/m_norii/items/63cc8f5eb91a3fc5505f
今回は更新日時を取得するために Google Drive API も使用するので、 Google Sheets API と合わせて有効にしておいてください。
必要な機能を実装する
ここから実際にコードを書いていきますが、順を追って説明していこうと思います。
また、全編を通してTypeScriptで記述しています。Firebase を初期化
この辺りはやり方も流儀も色々なので、ここでは詳しく触れません。
公式ドキュメントの通りにするのが一番シンプルかなと思います。https://firebase.google.com/docs/functions/get-started?hl=ja
依存パッケージのインストール
初期化が終わったら、今回必要な依存パッケージを入れます。
npm i -S googleapis firebase-adminスプレッドシートの情報を取得
importは省略
// 引数用の定義 export interface SpreadSheetRange { sheet: string; start: string; end: string; } // シートの情報を取得 async function getSpreadSheetData( id: string, params: SpreadSheetRange[] ): Promise<sheets_v4.Schema$Spreadsheet> { const auth = await google.auth.getClient({ scopes: ["https://www.googleapis.com/auth/spreadsheets"] }); const sheets = google.sheets("v4"); const spreadsheetId = id; const ranges: string[] = []; for (const r of params) { ranges.push(`${r.sheet}!${r.start}:${r.end}`); } const res = await sheets.spreadsheets.get({ auth, spreadsheetId, ranges, includeGridData: true }); return res.data; }
getSpreadSheetDataが本体で、SpreadSheetRangeはその引数のための定義になります。
sheetで指定したシートの内容を、startで指定したセルから、endで指定したセルまで読み込みます。また、引数を配列で取っている通り、複数のシートから同時にデータの取得ができます。基本的には素直に
Google Sheets APIを呼び出しており、戻り値もAPIが返したデータそのままです。
呼び出しは以下のようになります。const sheetData = await getSpreadSheetData("対象のスプレッドシートID", [ { sheet: "シート", start: "A1", end:"B1" } ]);返り値は
Schema$Spreadsheetになります。
定義は以下にソースがありますが、VSCode等でインテリセンスを見た方が早いと思います。https://github.com/googleapis/google-api-nodejs-client/blob/master/src/apis/sheets/v4.ts#L3972
更新日を取得
importは省略
// 更新日取得 async function getModifiedTime(fileId: string): Promise<string> { const auth = await google.auth.getClient({ scopes: ["https://www.googleapis.com/auth/drive"] }); const d = google.drive("v3"); const res = await d.files.get({ auth, fileId, fields: "modifiedTime" }); return res.data.modifiedTime as string; }
Google Sheets APIだけでスプレッドシート自体の最終更新日が分かれば良かったのですが、僕にはその方法が見つけられなかったので、Drive APIを使用してドキュメント自体の更新日を取得しています。
ここで、fieldsになにも指定しないと最低限の情報しか取得できなかったので、ご注意ください。使い方は、説明するまでもありませんが以下の通りです。
const modifiedTime = await getModifiedTime("対象のスプレッドシートID");Firestore に保存
importは省略
// firestore に保存 async function store( modifiedTime: string, data: sheets_v4.Schema$Spreadsheet ): Promise<void> { if (data.sheets) { const f = admin .firestore() .collection("spreadsheet") .doc(data.spreadsheetId as string); const ss = await f.get(); const ssdata = ss.data(); if (ssdata && ssdata.lastUpdate === modifiedTime) { return; } const d = ssdata ? ssdata : {}; d.lastUpdate = modifiedTime; const items: string[] = []; for (const s of data.sheets) { if (!s.data) continue; for (const col of s.data) { if (!col.rowData) continue; for (const row of col.rowData) { if (row.values && row.values.length !== 0) { items.push(row.values[0].formattedValue as string); } } } } d.items = items; await f.set(d); } }最初に更新日判定をしていて、更新日が同じだった場合は何も処理をしないようにしています。
それ以降の部分は、スプレッドシートがどういったフォーマットで書かれているかの仕様次第になるので、ケースによって最適解は大きく異なってくると思います。
今回は指定の列にあるテキストだけを拾ってくれば良い仕様だったので、スプレッドシートIDを用いてドキュメントを作り、その中のArrayにデータを入れるような作りになっています。前に出てきた2つの関数と合わせて使う事しか想定していないので、呼び出し方は割愛します。
Cloud Functions に登録する
前章で書いた機能を合わせ、以下のようなコードで今回の目的が達成できます。
const sheetId = "スプレッドシートのID" const ranges = [ { sheet: "シート", start: "A1", end:"B1" } ]; const sheetData = await getSpreadSheetData(sheetId, ranges); const modifiedTime = await getModifiedTime(sheetId); await store(modifiedTime, sheetData);これを、Cloud Functions に登録できる形にすると
export const checkSpreadSheet = functions .region("asia-northeast2") .pubsub.schedule("every 1 minutes") .onRun(async () => { const sheetId = "スプレッドシートのID" const ranges = [ { sheet: "シート", start: "A1", end:"B1" } ]; const sheetData = await getSpreadSheetData(sheetId, ranges); const modifiedTime = await getModifiedTime(sheetId); await store(modifiedTime, sheetData); });このような形になります。
ここまでの全ての定義を1つのファイルに書き、importを足すと冒頭のコードになります。regionやscheduleその他定数は要件に合わせて変更して下さい。終わりに
今後も良く使いそうだったので、自分用のメモも兼ねて今回まとめてみました。
ざっとググってみても同じような考えの方はたくさんいらっしゃるので、これが何番煎じの記事かは分かりませんが、同じような事をしようとしている人の労力を少しでも減らせれば幸いです。
- 投稿日:2020-10-13T19:43:18+09:00
paralleldots APIをnode経由で使用してみた [感情分析編]
はじめに
paralleldots AI APIというテキストから感情を分析するAPIがあるので、Nodeをプロキシとして利用し、このAPIを使ってみました。
環境
・ node version : v12.18.3
・ npm version : 6.14.6URIと機能
Path HTTPメソッド 機能 /api/v1/emotion POST 入力テキストの全体的な感情と各感情ラベル(Happy、Sad、Angry、Excited、Bored、Fear)の信頼スコアを含むjson応答を返します。 使用したparalleldots AI API
paralleldots AI APIとは??
開発者向けの包括的なドキュメント分類およびAPIのセットです。10億を超えるドキュメントでトレーニングされており、感情分析や感情検出などを提供しているそう。今回は、paralleldots AI APIの[/v4/emotion]こちらを使用していきます。
設定できるパラメータ
名前 詳細 Required Type text 分析したい文章を入力します。 Yes string/array api_key Api key Yes string lang_code 言語コード Yes string ・ ただ、今回は、nodeでプロキシしているので、プロキシサーバ側で[api_key]及び[lang_code]は設定しています。
構成
package.json{ "name": "node_poc", "version": "1.0.0", "description": "paralleldots AI API", "main": "app.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "author": "", "license": "ISC", "dependencies": { "axios": "^0.20.0", "express": "^4.17.1" } }app.jsconst express = require("express"); const app = express(); const axios = require('axios'); const server = app.listen(9000, function(){ console.log("Node.js is listening to PORT:" + server.address().port); }); app.post("/api/v1/emotion", function(req, res, next){ let params = new URLSearchParams(); params.append("api_key", '××××××××××××××××××××××××××××'); params.append("lang_code", 'en'); params.append("text", req.query.text); try { axios.post('https://apis.paralleldots.com/v4/emotion', params) .then((response) => { res.send(response.data) }) } catch (error) { console.error(error); } });Response
今回は、requestを日本語で行おうと思ったのですが、[lang_code]を英語以外を使用したい場合は、無料枠では使用できない為、仕方なく英語で行いました。
textには、
Be careful about reading health books. You may die of a misprint.
日本語訳にすると、[健康系の本を読むときは注意しなさい。ミスプリントのせいであなたは死ぬかもしれない。]
という意味です。笑Requestは、Postmanを使用しました。(curlより見やすい為)
・ 実際のResponse
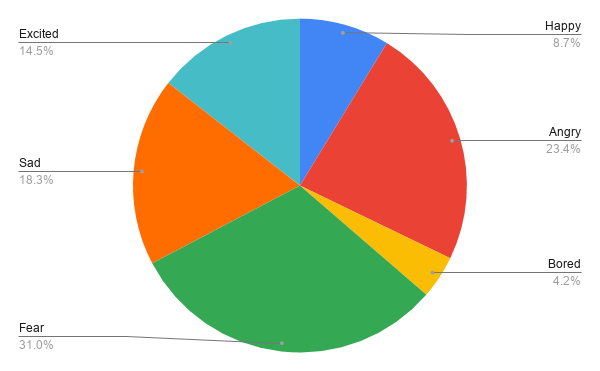
{ "emotion": { "Happy": 0.0872024649, "Angry": 0.2344884125, "Bored": 0.0416403769, "Fear": 0.3095755387, "Sad": 0.1825278824, "Excited": 0.1445653247 } }結果
やはり、死ぬかもしれないという恐怖を入れ込んだ文章を送ったため、Fearが一番結果の数値として高いことが分かります。
精度的にどうなのかは、個人の感性に依存しそうですが、、参照
- 投稿日:2020-10-13T19:43:18+09:00
paralleldots APIをnode経由で使用してみた (感情分析編)
はじめに
paralleldots AI APIというテキストから感情を分析するAPIがあるので、Nodeをプロキシとして利用し、このAPIを使ってみました。
環境
・ node version : v12.18.3
・ npm version : 6.14.6URIと機能
Path HTTPメソッド 機能 /api/v1/emotion POST 入力テキストの全体的な感情と各感情ラベル(Happy、Sad、Angry、Excited、Bored、Fear)の信頼スコアを含むjson応答を返します。 使用したparalleldots AI API
paralleldots AI APIとは??
開発者向けの包括的なドキュメント分類およびAPIのセットです。10億を超えるドキュメントでトレーニングされており、感情分析や感情検出などを提供しているそう。今回は、paralleldots AI APIの[/v4/emotion]こちらを使用していきます。
設定できるパラメータ
名前 詳細 Required Type text 分析したい文章を入力します。 Yes string/array api_key Api key Yes string lang_code 言語コード Yes string ・ ただ、今回は、nodeでプロキシしているので、プロキシサーバ側で[api_key]及び[lang_code]は設定しています。
構成
package.json{ "name": "node_poc", "version": "1.0.0", "description": "paralleldots AI API", "main": "app.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "author": "", "license": "ISC", "dependencies": { "axios": "^0.20.0", "express": "^4.17.1" } }app.jsconst express = require("express"); const app = express(); const axios = require('axios'); const server = app.listen(9000, function(){ console.log("Node.js is listening to PORT:" + server.address().port); }); app.post("/api/v1/emotion", function(req, res, next){ let params = new URLSearchParams(); params.append("api_key", '××××××××××××××××××××××××××××'); params.append("lang_code", 'en'); params.append("text", req.query.text); try { axios.post('https://apis.paralleldots.com/v4/emotion', params) .then((response) => { res.send(response.data) }) } catch (error) { console.error(error); } });Response
今回は、requestを日本語で行おうと思ったのですが、[lang_code]を英語以外を使用したい場合は、無料枠では使用できない為、仕方なく英語で行いました。
textには、
Be careful about reading health books. You may die of a misprint.
日本語訳にすると、[健康系の本を読むときは注意しなさい。ミスプリントのせいであなたは死ぬかもしれない。]
という意味です。笑Requestは、Postmanを使用しました。(curlより見やすい為)
・ 実際のResponse
{ "emotion": { "Happy": 0.0872024649, "Angry": 0.2344884125, "Bored": 0.0416403769, "Fear": 0.3095755387, "Sad": 0.1825278824, "Excited": 0.1445653247 } }結果
やはり、死ぬかもしれないという恐怖を入れ込んだ文章を送ったため、Fearが一番結果の数値として高いことが分かります。
精度的にどうなのかは、個人の感性に依存しそうですが、、参照
- 投稿日:2020-10-13T00:26:27+09:00
LINEボットでゲームブック、回想シーンを追加
前回の投稿( LINEボットでゲームブックを作った、ついでにシナリオエディタ作ったので完成 )の続きです。
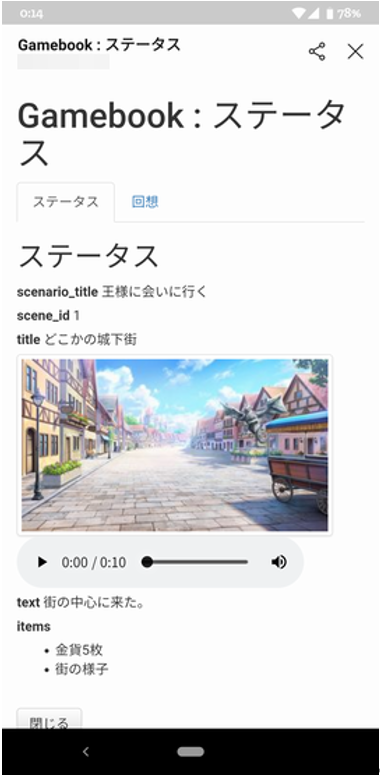
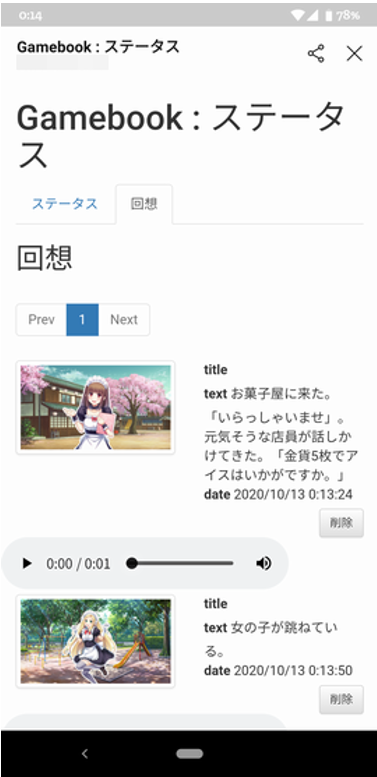
LINEボットでゲームブックを作りましたが、かのTyranoScriptを参考に、回想シーンを付けてみました。
気に入った画像があるページで、「記憶」 と言うと、その時の画像や音声を覚えておいてくれるので、いつでも見返せるようになります。
今回も、GitHubに上げています。poruruba/LinebotGamebook
https://github.com/poruruba/LinebotGamebook回想シーンを思い出すために、LIFFアプリを追加します。
こんな感じの画面が、LINEアプリ内に表示されます。
LIFFアプリの登録
LIFFアプリは、スマホのLINEアプリの中で起動できるWebページです。
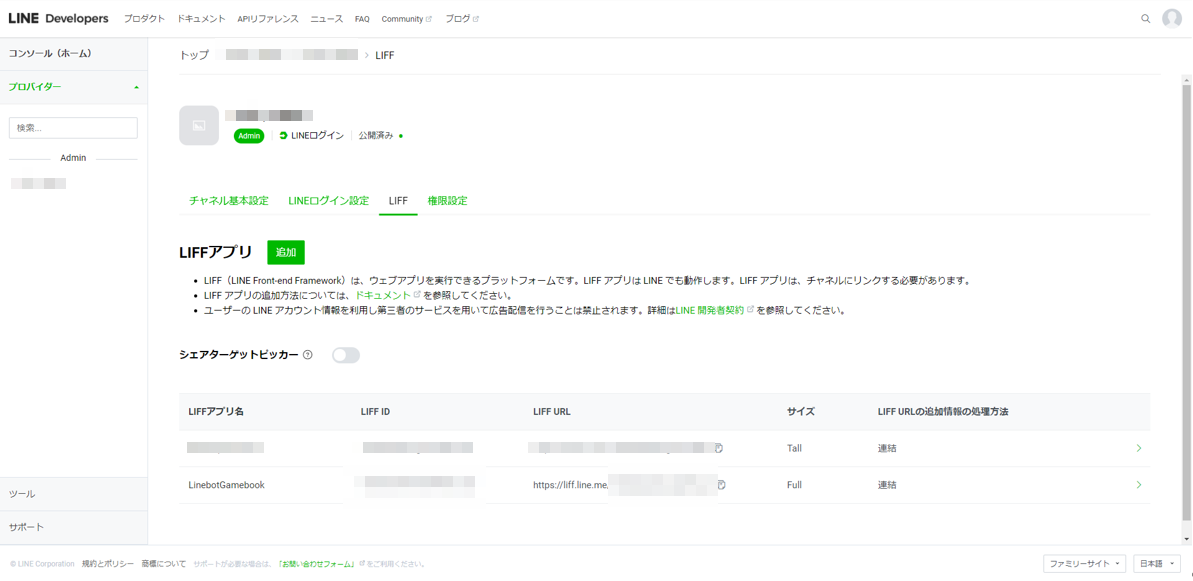
ユーザにログインを気にさせずにWebページを表示させられるのがよいです。LINE Developersより、LINEログインチャネルを作成し、LIFFタブを選択して、LIFFアプリの「追加」ボタンを押下すれば登録できます。
LIFFアプリ名には適当な名前を入力し、エンドポイントURLには、立ち上げたサーバのURLを以下のようにして入力します。
https://【サーバのURL】/gamebook/liff/index.html
そうすると、LIFF IDが払い出されます。これを覚えておきます。ついでに、このチャネルのチャネルIDも覚えておきます。
※ちなみに、以前はMessaging APIでLIFFが登録できていたのですが、最近はだめになったようです。(その影響で、liff.sendMessages()が呼び出せなくなっているような。。。)
あとは、上記のURLに表示させたいWebページを作ればよいです。
このページにユーザに飛んでもらうためには、チャットで「"https://liff.line.me/" + LIFF_ID」という感じのURLをクリックしてもらえばよいです。LIFFアプリとサーバの連携
LIFFアプリは通常のSPAのWebページです。
以下のjavascriptライブラリを取り込みます。public/gamebook/liff/index.html<script charset="utf-8" src="https://static.line-scdn.net/liff/edge/2/sdk.js"></script>LIFFアプリのJavascriptでは、Webページが起動した直後に、以下を呼び出します。
public/gamebook/liff/js/start.jsawait liff.init({ liffId: LIFF_ID }); this.id_token = liff.getIDToken();LIFF_IDは先ほど取得したものです。
そして、このid_tokenを立ち上げたサーバに渡します。public/gamebook/liff/js/start.jsvar param = { id_token: this.id_token, cmd: 'get' }; var json = await do_post(status_url, param );(参考) liff.init()、liff.getIDToken()
https://developers.line.biz/ja/reference/liff/#initialize-liff-app
https://developers.line.biz/ja/reference/liff/#get-id-tokenサーバ側では、IDトークンを検証してLINEユーザIDを判別して、シナリオの状態を取り出し、jsonとして戻してくれるようにサーバ側を実装しました。
サーバ側の処理
サーバ側ではIDトークンをLINEサーバに渡して正しさを確認すると、ユーザの情報が取得できます。ブラウザから取得したIDトークンと、先ほどメモっておいたチャネルIDを使います。
api/controllers/linebot/index.jsvar json = await do_post_urlencoded('https://api.line.me/oauth2/v2.1/verify', { id_token: body.id_token, client_id: LINE_CHANNEL_ID } ); var userId = json.sub;(参考) LIFFアプリおよびサーバーでユーザー情報を使用する
https://developers.line.biz/ja/docs/liff/using-user-profile/userIdがわかったので、DBまたはファイルから状態を取得し、以降の処理でクライアントに返してあげています。
あとは、ソースコードを見ていただければ!!
補足
LIFFアプリは、ChromeではなくLINEアプリの中で起動するのでJavascriptのデバッグがつらいです。
その場合には、以下の部分のコメントアウトを解除してください。consoleが見れます。public/gamebook/liff/js/start.js//var vConsole = new VConsole();Tencent/vConsole
https://github.com/Tencent/vConsole以上