- 投稿日:2020-09-27T23:35:10+09:00
PythonでYouTubeのコメントを取得
YouTubeのAPIを使って、動画のコメントを取得します。YouTubeのAPIについては割愛します。
やり方
getYouTubeComments.pyimport requests import json URL = 'https://www.googleapis.com/youtube/v3/' # ここにAPI KEYを入力 API_KEY = 'API KEYを入力' def print_video_comment(video_id, next_page_token): params = { 'key': API_KEY, 'part': 'snippet', 'videoId': video_id, 'order': 'relevance', 'textFormat': 'plaintext', 'maxResults': 100, } if next_page_token is not None: params['pageToken'] = next_page_token response = requests.get(URL + 'commentThreads', params=params) resource = response.json() for comment_info in resource['items']: # コメント text = comment_info['snippet']['topLevelComment']['snippet']['textDisplay'] # グッド数 like_cnt = comment_info['snippet']['topLevelComment']['snippet']['likeCount'] # 返信数 reply_cnt = comment_info['snippet']['totalReplyCount'] print('{}\t{}\t{}'.format(text.replace('\n', ' '), like_cnt, reply_cnt)) if 'nextPageToken' in resource: print_video_comment(video_id, resource["nextPageToken"]) # ここにVideo IDを入力 video_id = 'Video IDを入力' print_video_comment(video_id, None)実行結果の例
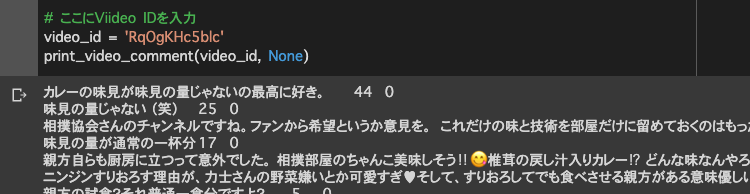
日本相撲協会公式チャンネル「高崎親方の料理の鉄人~出羽海部屋ちゃんこ~」の動画コメントを取得すると、下記のようになります。Google Colaboratoryで実行しています。
出力結果は、コメント、グッド数、返信数の順です。
参考
下記の記事を参考にしました。ありがとうございました。
- https://qiita.com/Doarakko/items/191209bf14cf5d76fa6f
- 投稿日:2020-09-27T21:30:12+09:00
Tensorflowが動かない!
新しいノートPCに機械学習環境を一からセットアップして
いざ動かそう!って時に動かなかった…色々と調べてみると結構設定がめんどくさかったです。
経験者からすればなんて事はないと思いますが
初心者だとなかなかハードル高い現象でしたので
メモ書きとして残します。PC環境
OS:Windows10 home 64bit
環境:Anaconda Navigator
Jupiter Notebook
GPU:Nvidia GTX1650初期設定
普通にAnaconda Navigatorをインストール
この辺りは多くの情報がありますのでさほど難しくなかったです。GPU用のCUDAやcuDNNのセットアップも実施していますが
そこは割愛します。(別途メモ書き予定)仮想環境作成
仮想環境を作成して作成した環境からコマンドプロンプトを立ち上げて必要分をインストール
pip install tensorflowやpip install keras等々のCNN作成に必要な物を
セットアップしました。現象
自分で真似して作ったプログラム
CNNによる学習データ
こいつのライブラリ関係を走らせてみるとエラー発生。cnn.ipynbimport keras from keras.utils import np_utils from keras.models import Sequential from keras.layers.convolutional import MaxPooling2D from keras.layers import Activation, Conv2D, Flatten, Dense,Dropout from sklearn.model_selection import train_test_split from keras.optimizers import SGD, Adadelta, Adagrad, Adam, Adamax, RMSprop, Nadam from PIL import Image import numpy as np import glob import matplotlib.pyplot as plt import time import osエラーとしては
Using TensorFlow backend.
ERROR:root:Internal Python error in the inspect module.
Below is the traceback from this internal error.文献としては結構出ていましたが具体的にどうしたのかを読み解くのに時間が掛かりました。
参考としてはGithubのエラー報告を見て四苦八苦しました。結果
Microsoftが配布しているVisual Studio 2015、2017 および 2019の再頒布プログラムが
インストールされていない為、動作する事が出来なかったようです。Pythonからこの世界に入ると他の言語に触れることがないので
C++がないといかんなんて知らなかったです。Microsoftサポートから
再頒布可能パッケージなる物をダウンロードしてインストールしたら動きました。まとめ
こういう世界はやり方が多数あるので
動けば正解と思いますが、初学者から見るとやはりどの手順が正解なのかを求めてしまいがち
1つ1つトライ&エラーしかないですがそれにしてもわかりにくいと思う今日この頃です。せめて残しているメモ書き位は自分自身でも振り返った時に混乱しない様に
分かりやすい手順を残さなければと思ったり思わなかったり…以上です。
- 投稿日:2020-09-27T21:21:25+09:00
pythonのクライアントアプリから AWS Batch起動方法
概要
前回作成したLambdaから実行する処理を流用してクライアントアプリから起動するように設定します。
準備
- AWS Batchは前々回のものをそのまま使います。AWS BatchのジョブさえできていればいいのでCodeCommitなどはこのためだけに準備しなくても大丈夫です。
- バッチを実行できるIAMユーザを作成します。
- AWS CLIをインストールして
aws_access_key_idaws_secret_access_keyDefault regionを設定します。
- このあたりの手順は公式 などを参考にしてください。
- クライアントアプリを作成する場合は
pyinstallerを以下のコマンドでインストールします。
pip install pyinstallerクライアントアプリの用意
- tkinterを使用して作成します。
- JOB_NAME はジョブ定義の名称
- JOB_DEFINITION はジョブ定義のジョブ定義ARN
- JOB_QUEUE はジョブキューのキューARN
XXXXXXXXXXの部分はAWSのアカウントIDを設定します。commandの部分に引数をリスト形式でenvironmentには環境変数を辞書形式 name,valeの辞書をリスト形式で設定します。- ソースは以下になります。
- ログ用のクラスはこちらを参照
長いので折りたたんでます
from utils.logger import LoggerObj import sys import os import requests import tkinter from datetime import datetime import boto3 from tkinter import * from tkinter import messagebox from tkinter import filedialog from tkinter import ttk from tkinter.ttk import * import threading from tkinter import messagebox from tkinter import filedialog from tkinter import Button,ttk,StringVar from selenium import webdriver from functools import partial root= tkinter.Tk() EXECUTE_LIST=['処理A','処理B','処理C'] class PythonGui(): def __init__(self): self.lock = threading.Lock() self.inputText=StringVar() self.progressMsg=StringVar() self.progressBar=None self.progressMsgBox=None self.progressStatusBar=None self.progressValue=None def init(self): pass # 初期設定後の動作 def preparation(self,logfilename): self._executer=partial(self.execute,logfilename) def progressSequence(self,msg,sequenceValue=0): self.progressMsg.set(msg) self.progressValue=self.progressValue+sequenceValue self.progressStatusBar.configure(value=self.progressValue) def quite(self): if messagebox.askokcancel('終了確認','処理を終了しますか?'): if self.lock.acquire(blocking=FALSE): pass else: messagebox.showinfo('終了確認','ブラウザ起動中はブラウザを閉じてください。') self.lock.release() root.quit() else: pass def execute(self,logfilename): logObj=LoggerObj() log=logObj.createLog(logfilename) log.info('処理開始') executeType=EXECUTE_LIST.index(self.combo.get()) nowDate=datetime.now().strftime('%Y%m%d%H%M%S') inputVal=self.inputText.get() client = boto3.client('batch') JOB_NAME = 'pandas-envtest' JOB_QUEUE = "arn:aws:batch:ap-northeast-1:XXXXXXXXXX:job-queue/first-run-job-queue" JOB_DEFINITION = "arn:aws:batch:ap-northeast-1:XXXXXXXXXX:job-definition/pandas-envtest:1" response = client.submit_job( jobName = JOB_NAME, jobQueue = JOB_QUEUE, jobDefinition = JOB_DEFINITION, containerOverrides={ 'command': [ inputVal,nowDate,str(executeType) ], 'environment': [ { 'name': 'TEST', 'value': 'abcd' } ] } ) self.progressMsgBox.after(10,self.progressSequence('処理実行中',sequenceValue=50)) root.update_idletasks() self.progressBar.stop() self.progressMsgBox.after(10,self.progressSequence('登録処理完了',sequenceValue=50)) root.update_idletasks() log.info('処理終了') self.lock.release() def doExecute(self): if self.lock.acquire(blocking=FALSE): if messagebox.askokcancel('実行前確認','処理を実行しますか?'): self.progressValue=0 self.progressStatusBar.configure(value=self.progressValue) self.progressBar.configure(maximum=10,value=0) self.progressBar.start(100) th = threading.Thread(target=self._executer) th.start() else: self.lock.release() else: messagebox.showwarning('エラー','処理実行中です') def progressMsgSet(self,msg): self.progressMsg.set(msg) def progressStart(self): self.progressBar.start(100) def main(self): root.title("Python GUI") content = ttk.Frame(root) frame = ttk.Frame(content, relief="sunken", width=300, height=500) title = ttk.Label(content, text="Python GUI") content.grid(column=0, row=0) title.grid(column=0, row=0, columnspan=4) fileLabel=ttk.Label(content,text="処理番号") pulldownLabel=ttk.Label(content,text="処理内容") fileInput=ttk.Entry(content,textvariable=self.inputText,width=23) self.inputText.set('A01') # コンボボックスの作成(rootに配置,リストの値を編集不可(readonly)に設定) self.combo = ttk.Combobox(content, state='readonly') # リストの値を設定 self.combo["values"] = tuple(EXECUTE_LIST) # デフォルトの値を食費(index=0)に設定 self.combo.current(0) labelStyle=ttk.Style() labelStyle.configure('PL.TLabel',font=('Helvetica',10,'bold'),background='white',foreground='red') self.progressMsgBox=ttk.Label(content,textvariable=self.progressMsg,width=70,style='PL.TLabel') self.progressMsg.set('処理待機中') self.progressBar=ttk.Progressbar(content,orient=HORIZONTAL,length=140,mode='indeterminate') self.progressBar.configure(maximum=10,value=0) self.progressStatusBar=ttk.Progressbar(content,orient=HORIZONTAL,length=140,mode='determinate') executeButton=ttk.Button(content,text='実行',command=self.doExecute) quiteButton=ttk.Button(content,text='終了',command=self.quite) fileLabel.grid(column=1, row=1,sticky='w') fileInput.grid(column=2, row=1) pulldownLabel.grid(column=1, row=2,sticky='w') # コンボボックスの配置 self.combo.grid(column=2, row=2) executeButton.grid(column=1, row=6,columnspan=2,sticky='we') quiteButton.grid(column=1, row=12,columnspan=2,sticky='we') root.mainloop() if __name__ == "__main__": pythonGui=PythonGui() pythonGui.preparation('log') pythonGui.main()
処理内容については以下のようになります。
- main
- 実行時に呼ばれる関数です。画面を作成する処理をこちらに記載しています。
- テキストエリアの初期値やコンボボックスの内容なども作成しています。
- doExecute
- 実行ボタンを押下したときに呼び出される処理です。
- thread を使用して 二重起動を防止しています。
- execute
- 実際にAWS Batchを呼び出す処理です。
- boto3.client を呼び出すところで
aws_access_key_idaws_secret_access_keyDefault regionを受け取る形にすればAWS CLIのインストールなどは不要になります。ソースを実行しても確認ができますが、クライアントアプリとして使う場合は以下のコマンドでexeを作成します。 ソースのファイル名を
pythonGui.pyとした場合以下のようになります。
- pyinstaller pythonGui.py --onefile
exeファイル実行すると以下のようクライアントアプリとして起動します。
AWS Batchの方の実行結果については前回と同様になるので割愛。
- 投稿日:2020-09-27T20:59:49+09:00
Pythonによる素数判定
pythonを使った100以下の素数判定を3種類のやり方で実装してみました。
また、それぞれかかった時間も表示しました。① print以外の組み込み関数を使わない(timeは除く)
import time n = 2 t1 = time.time() while n <= 100: div = 0 m = 1 while m <= n: if n % m == 0: div += 1 m += 1 if div == 2: print(n) n += 1 time = time.time() - t1 print("time:{}".format(time))実行結果
2
3
5
7
11
13
17
19
23
29
31
37
41
43
47
53
59
61
67
71
73
79
83
89
97
0.007971048355102539② 1つずつ確認していく方法
import time def ma(n): sosu_list = [] t1 = time.time() for n in range(2,n + 1): div = 0 for m in range(1,n + 1): if n % m == 0: div = div + 1 if div == 2: sosu_list.append(n) print(sosu_list) t1 = time.time() ma(100) time = time.time() - t1 print("time:{}".format(time))実行結果
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]
time:0.0027151107788085938③ エラトステネスの篩
import time def eratosu(n): sosu_list = [] false = [] for i in range(2,n+1): if i not in false: sosu_list.append(i) for j in range(i*i,n+1,i): false.append(j) return sosu_list t1 = time.time() print(eratosu(100)) time = time.time() - t1 print("time:{}".format(time))実行結果
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]
time:0.0005650520324707031①,②はtimeを比較すると基本的にあまり大きく変わりませんでした。ただ、②の方法は時々③に近いスピードが出ていて安定しませんでした。それに比べて③のプログラムはこの中で最も高速であるという結果が得られました。エラトステネスのふるいというアルゴリズムなのですが、とても効率的で計算量が少なかったためでしょう(wikiを参考にしたのでリンクを貼っておきます)
同じ結果を出力するプログラムでも、違う考え方で実装してみるのは考え方が深まって楽しいのでこれからも続けていきたいですね。
- 投稿日:2020-09-27T20:51:51+09:00
PyTorch+GPUをDockerで実装
はじめに
最近やっとDockerを使い始めました。
Dockerを使えば、いろんなPCでお手軽に深層学習できます。環境(ホスト)
OS:Ubuntu 20.04
GPU:NVIDIA GeForce GTX 1080GPUドライバをインストール
まず、ホストでGPUが使える環境にします。
$ nvidia-smi ですでにドライバがインストールされていれば、ここはスルーでいいです。
インストールの一例なので、参考までに$ sudo add-apt-repository ppa:graphics-drivers/ppa $ sudo apt update $ sudo apt install ubuntu-drivers-common $ sudo apt dist-upgrade $ sudo reboot (再起動) $ sudo ubuntu-drivers autoinstall $ sudo reboot (再起動)$ nvidia-smiで Driverのバージョンやメモリの使用状況などが出ればOK!
Dockerをインストール
これは公式ホームページ (https://docs.docker.com/engine/install/ubuntu/) をそのまま実行
$ sudo apt-get update $ sudo apt-get install \ apt-transport-https \ ca-certificates \ curl \ gnupg-agent \ software-properties-common $ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - $ sudo add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable" $ sudo apt-get update $ sudo apt-get install docker-ce docker-ce-cli containerd.io$ sudo docker run hello-world で動作確認
Nvidia Container Toolkitをインストール
DockerでCUDAを使うために必要(だと思われます。)
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#
https://github.com/NVIDIA/nvidia-docker/issues/1186$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID) $ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - $ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list $ sudo apt-get update $ sudo apt-get install -y nvidia-container-toolkit $ sudo systemctl restart dockerDockerfile
Dockerfileには仮想環境をどのようにするかを記述します。
1行目の FROM の部分でベースの環境を変更できます。(Ubuntu や CUDA のバージョンや cudnn の有無など)
nvidia/cuda の DockerHub を調べるといろいろ出てきます。(https://hub.docker.com/r/nvidia/cuda/tags)
また RUN の3行目で Python のライブラリを選択できます。DockerfileFROM nvidia/cuda:11.0-devel-ubuntu20.04 RUN apt-get update RUN apt-get install -y python3 python3-pip RUN pip3 install torch torchvision WORKDIR /work COPY train.py /work/ ENV LIBRARY_PATH /usr/local/cuda/lib64/stubs深層学習のスクリプト
先ほど作成した Dockerfile と同じディレクトリに train.py を実装します。
train.py は深層学習の Hello World! といえる MNIST というデータで学習します。
(引用:https://github.com/pytorch/examples/blob/master/mnist/main.py)train.pyfrom __future__ import print_function import argparse import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torchvision import datasets, transforms from torch.optim.lr_scheduler import StepLR class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 32, 3, 1) self.conv2 = nn.Conv2d(32, 64, 3, 1) self.dropout1 = nn.Dropout2d(0.25) self.dropout2 = nn.Dropout2d(0.5) self.fc1 = nn.Linear(9216, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.conv1(x) x = F.relu(x) x = self.conv2(x) x = F.relu(x) x = F.max_pool2d(x, 2) x = self.dropout1(x) x = torch.flatten(x, 1) x = self.fc1(x) x = F.relu(x) x = self.dropout2(x) x = self.fc2(x) output = F.log_softmax(x, dim=1) return output def train(args, model, device, train_loader, optimizer, epoch): model.train() for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = F.nll_loss(output, target) loss.backward() optimizer.step() if batch_idx % args.log_interval == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item())) if args.dry_run: break def test(model, device, test_loader): model.eval() test_loss = 0 correct = 0 with torch.no_grad(): for data, target in test_loader: data, target = data.to(device), target.to(device) output = model(data) test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability correct += pred.eq(target.view_as(pred)).sum().item() test_loss /= len(test_loader.dataset) print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( test_loss, correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset))) def main(): # Training settings parser = argparse.ArgumentParser(description='PyTorch MNIST Example') parser.add_argument('--batch-size', type=int, default=64, metavar='N', help='input batch size for training (default: 64)') parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N', help='input batch size for testing (default: 1000)') parser.add_argument('--epochs', type=int, default=14, metavar='N', help='number of epochs to train (default: 14)') parser.add_argument('--lr', type=float, default=1.0, metavar='LR', help='learning rate (default: 1.0)') parser.add_argument('--gamma', type=float, default=0.7, metavar='M', help='Learning rate step gamma (default: 0.7)') parser.add_argument('--no-cuda', action='store_true', default=False, help='disables CUDA training') parser.add_argument('--dry-run', action='store_true', default=False, help='quickly check a single pass') parser.add_argument('--seed', type=int, default=1, metavar='S', help='random seed (default: 1)') parser.add_argument('--log-interval', type=int, default=10, metavar='N', help='how many batches to wait before logging training status') parser.add_argument('--save-model', action='store_true', default=False, help='For Saving the current Model') args = parser.parse_args() use_cuda = not args.no_cuda and torch.cuda.is_available() torch.manual_seed(args.seed) device = torch.device("cuda" if use_cuda else "cpu") kwargs = {'batch_size': args.batch_size} if use_cuda: kwargs.update({'num_workers': 1, 'pin_memory': True, 'shuffle': True}, ) transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ]) dataset1 = datasets.MNIST('../data', train=True, download=True, transform=transform) dataset2 = datasets.MNIST('../data', train=False, transform=transform) train_loader = torch.utils.data.DataLoader(dataset1,**kwargs) test_loader = torch.utils.data.DataLoader(dataset2, **kwargs) model = Net().to(device) optimizer = optim.Adadelta(model.parameters(), lr=args.lr) scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma) for epoch in range(1, args.epochs + 1): train(args, model, device, train_loader, optimizer, epoch) test(model, device, test_loader) scheduler.step() if args.save_model: torch.save(model.state_dict(), "mnist_cnn.pt") if __name__ == '__main__': main()とりあえず実行して、動作確認
Dockerfile をビルドして、仮想環境を作り、動かします。
train.py を実行中に $ nvidia-smi でGPUが使われてるか確認できます。$ sudo docker build -t [コンテナ名] . $ sudo docker run -it --gpus all [コンテナ名] /bin/bash ----以下コンテナ内で----- $ python3 train.py最後に
今回は PyTorch で仮想環境を作成しましたが、Dockerfile の中身を変更することで、
その他の深層学習ライブラリも使えると思います。
また、学習データが膨大な場合などは、docker のコマンドで学習データを仮想環境にマウントすることもできます。
それにしても、Dockerって便利ですね(笑)
- 投稿日:2020-09-27T19:59:49+09:00
SenseHAT でプログラミング教育用ゲーム
で、またゲームを作ったので投稿します。楽しくなってきた。
最近流行りの、子供向けプログラミング教育用ゲームを作ってみました。
指定された場所へ移動するための経路を指示(プログラミング)するというあれです。
橙から青へ移動します。が、動かすだけだと縦横一直線になるので、障害物(緑)もつけてみた。こっちは完全に逐次処理なので、イベントハンドラは使っていません。
ただ、慣性で動かす、というのはアリかも。一応、小学生の娘は気に入ってくれた。ヨカッタ。
これでプログラミング学習ができるかは未検証。。
from sense_hat import SenseHat from time import sleep from random import randint sense = SenseHat() sense.clear() red = (255, 0, 0) blue = (0, 0, 255) yellow=(255,255,0) purple=(128,0,128) green=(0,255,0) indigg=(75,0,130) orange=(255,128,0) black=(0,0,0) sense.set_rotation(0) num_disturbs = 20 # スタートブロック(橙)をランダム設定 row_init=randint(0, 7) col_init=randint(0, 7) color_init=orange sense.set_pixel(col_init, row_init, color_init) # ゴールブロック(青)をランダム設定 row_target = randint(0, 7) col_target = randint(0, 7) # ゴールがスタート位置と同じにならないようにする while row_target == row_init and col_target == col_init: row_target = randint(0, 7) col_target = randint(0, 7) color_target = blue sense.set_pixel(col_target, row_target, color_target) # 妨害ブロックをランダム設定 disturbs = list() for i in range(0,num_disturbs): while True: row = randint(0, 7) col = randint(0, 7) if row == row_init and col == col_init: continue if row == row_target and col == col_target: continue duplicated = False for j in disturbs: if col == j[0] and row == j[1]: duplicated = True break if duplicated: continue disturbs.append((col, row)) break color_disturb = green for i in disturbs: sense.set_pixel(i[0], i[1], color_disturb) # 移動方向をプログラミング # 中ボタンで完了 commands = list() set_com=True while set_com: for event in sense.stick.get_events(): if event.action == "pressed": if event.direction == "middle": set_com = False else: commands.append(str(event.direction)) row=row_init col=col_init color=red # プログラミングした通りに、スタートブロックから動かす(赤) for com in commands: sense.set_pixel(col, row, black) sense.set_pixel(col_init, row_init, color_init) if com == "up": row = row - 1 elif com == "down": row = row + 1 elif com == "left": col = col - 1 elif com == "right": col = col + 1 elif com == "middle": row = row_init col = col_init if row > 7: row = 7 if row < 0: row = 0 if col > 7: col = 7 if col < 0: col = 0 sense.set_pixel(col, row, color) sleep(0.5) disturbed = False for i in disturbs: if col == i[0] and row == i[1]: disturbed = True break if disturbed: break # 成否を判定 if row == row_target and col == col_target: sense.show_letter("O") else: sense.show_letter("X") sleep(3) sense.clear()

- 投稿日:2020-09-27T19:51:01+09:00
Pythonでフォルダ内の~.xlsxの中身をHTMLに出力する
やりたいこと
フォルダ内に大量にExcelで作ったファイルがありどれがどれかわからないようになったときに「一つずつ調べるのはだるいな」という気持ちになりません?
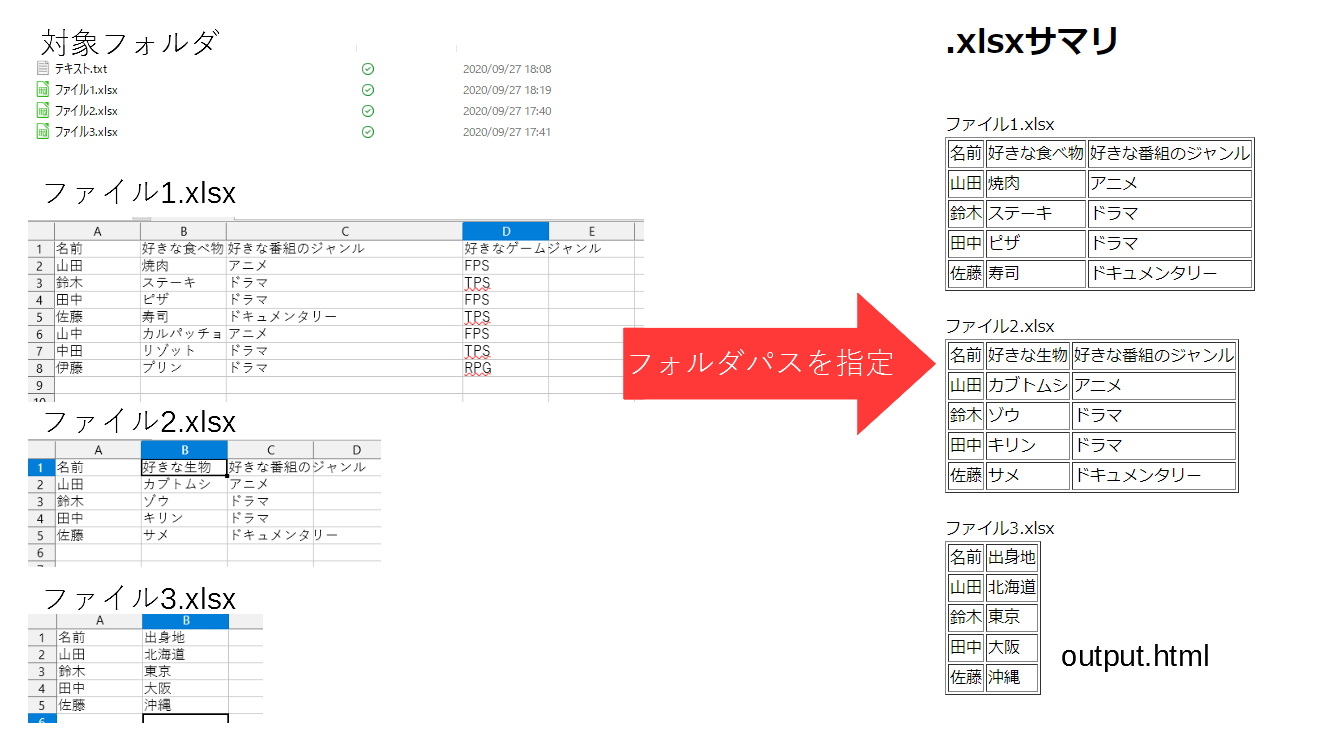
そこでフォルダ内の~.xlsxのファイルすべての頭のほうだけHTMLにして出力してやります。
これで探しているファイルがどれかわかって手間も多少は省けるはず…
利用するライブラリなど
Windows 10上でPython 3.8で実行しています。
- os
- フォルダ移動のために利用
- glob
- フォルダ内のファイルを調べるために利用
- io
- ファイルへの書き込みのために利用
- pandas
- .xlsxの読み込み・HTMLへの変換
- webbrowser
- 出力したHTMLをブラウザで開くために利用
ソースコード
ソースコードは以下の通りです。
import glob import io import os import webbrowser import pandas as pd folder = input('フォルダパスを入力してください\n') os.chdir(folder) files_in_folder = [i.lstrip('.\\') for i in glob.glob("./*")] xlsx_in_folder = [i for i in files_in_folder if i.endswith('.xlsx')] # .xlsx終わりだけ残す with io.StringIO() as s: s.write('<!DOCTYPE html>\n<html lang="jp">\n<head>\n\t<meta ' 'charset="UTF-8">\n\t<title>.xlsxサマリ</title>\n</head>\n<body>\n') s.write('<h1>.xlsxサマリ</h1>\n') # .xlsxを読み込んで頭5行・頭3列をhtmlにしたものを出力--ここから for i in xlsx_in_folder: s.write('<br>\n') s.write(i) # ファイル名 s.write(pd.read_excel(i, header=None, usecols=[0, 1, 2]).head().to_html(header=None, index=None)) # .xlsxを読み込んで頭5行・頭3列をhtmlにしたものを出力--ここまで s.write('</body>\n</html>') output = s.getvalue() with open("output.html", mode='w', encoding='utf-8') as f: f.write(output) webbrowser.open("output.html")出力
こんな感じでHTMLが出力され、既定のブラウザで開かれます。

- 投稿日:2020-09-27T18:15:43+09:00
主要4社のクラウド音声認識精度の比較
Amazon, Google, IBM, Microsoftの音声認識精度を比較してみました
- 今回使用した音声データは私の研究に関するミーティング(大学院でのゼミ)をAirPodsで録音したものを使用しています.ミーティングの参加者は3~5人です.音声には個人情報も含まれるため公開することはできませんのでご了承ください.
- データ量:300発言(約27分)
- 音声の質は生活音やノイズがかなり含まれています.音声の質としては良くないです(CSJなどの音声認識用コーパスに比べて)
- Googleなどの音声認識精度は論文に掲載されているようにかなり良い精度(日本語でもWER一桁)です.
- 研究用の質の良い音声を使用しているので精度がかなり良い
- 日常生活での音声に対してはどの程度の認識精度なのかはあまり報告されていない
- 今回は日常生活の中の音声をどれだけの精度で認識できるのかを調べてみました.加えて,研究に関する音声なので専門用語も多く含まれます.どれだけ専門用語に対応しているのかも気になるところです.
- Amazon, Google, IBM, Microsoftの音声認識サービスを使用という記事に書くAPIの使い方をまとめてあるのでよかったら参考にしてください.
認識精度比較
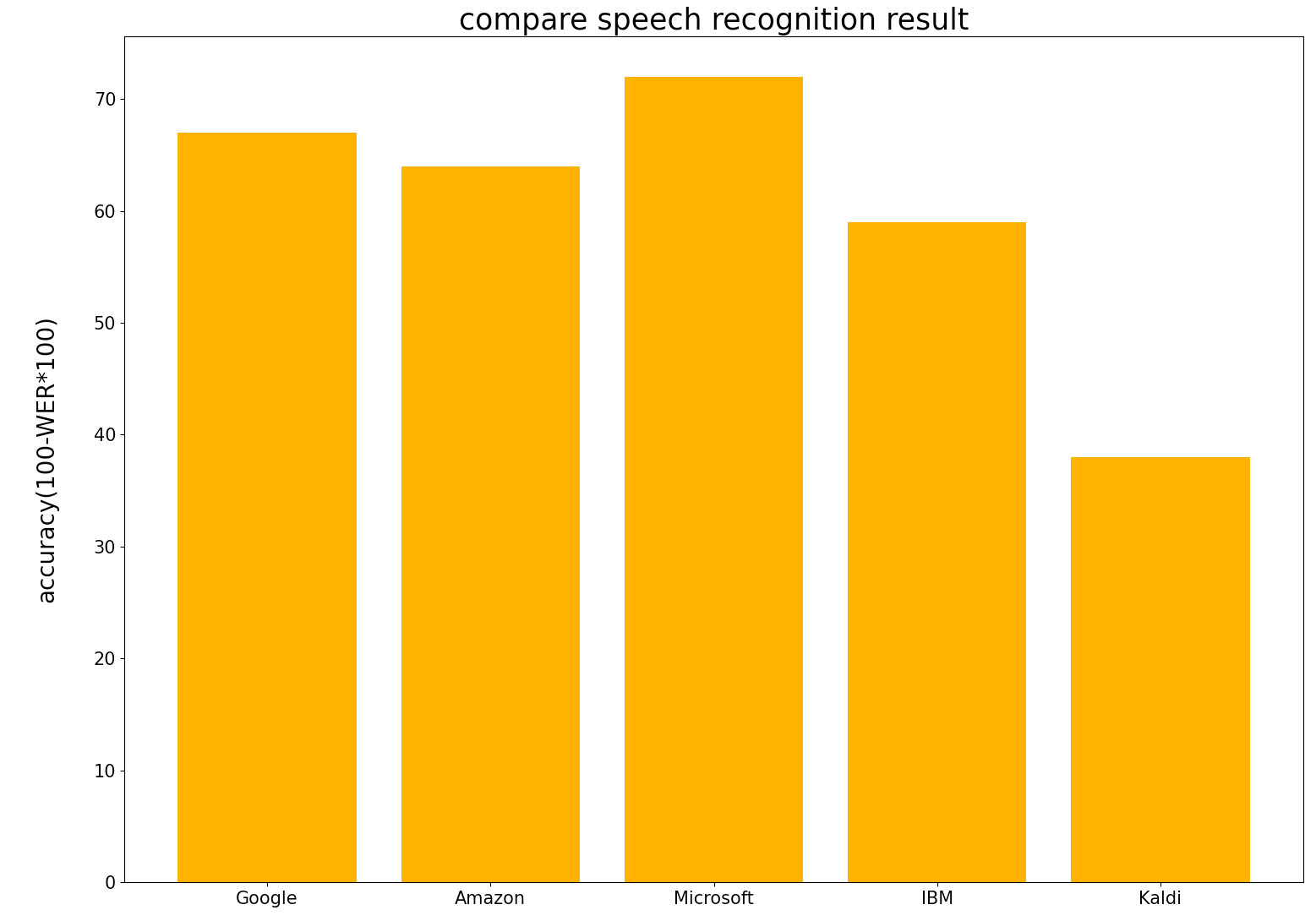
- Amazon, Google, IBM, Microsoftに加えて,Kaldi(CSJ,JNS,S-JNAS,CEJCで学習)での認識精度も載せておきます.
GCP WER: 0.3344722854973424 CER: 0.2765527007889945 AWS WER: 0.36209150326797385 CER: 0.2218905472636816 Azure WER: 0.28109824430332464 CER: 0.21596337579617833 Watson WER: 0.4107744107744108 CER: 0.29126794258373206 Kaldi WER: 0.616504854368932 CER: 0.47915630285543725
結果からMicrosoftが最も高精度であることがわかりました.Googleが一番良いと思っていたのですが違いました.WERを見ると一番良いMicrosoftでも28%程度であることがわかります.音声の質が良ければWER1桁まで良くなりますが,日常生活の音声ように生活音やノイズの多い環境ではここまで精度が落ちてしまうことがわかりました.しかし,Kaldiは悲惨であることから,GoogleやMicrosoftなどの音声認識器はある程度のノイズに対応できていると思います.
一応認識結果の一つを載せておきます
正解文: 近 さ っていう の を 計算 できる ので これ を 使い まし た で 打撃 音 を それぞれ マテリアル ごと に えと 距離行列 に し て さっき の こういう 感じ で 濃度 で 表す っていう の を やり まし た で この 二次元 の マップ に 置き換える っていう の も 一応 やっ て み た ん です けど なんか やる こと に すごい Google: 近 さ っていう の は 計算 できる ので これ を 使い まし た でも 打撃 音 を それぞれ マテリアル ごと に 距離行列 に し て さっき の こういう 感じ に なり まし た この 2次元 の マップ に 置き換える っていう の も 一応 やっ て み た ん です けど なんか やる こと に すごい Amazon: 近 さ って いう の を 計算 できる ので これ を 使い まし た で で も 打撃 音 を それぞれ マテリアル ごと に と 距離 行列 に し て さっき の こういう 感じ で ノード で 表わす って いう の が あり ます で この 人間 の マップ に 置き換える って いう の も 一応 やっ ! て み た ん です けど 何 か やる こと に 凄い Microsoft: 近 さ っていう の を 計算 できる ので これ を 使い まし た ね でも 打撃 音 を それぞれ マテリアル ごと に と 距離行列 に し て さっき の こういう 感じ で 飲ん で 表す っていう の が あり まし た で この 2次元 の マップ に 置き換える っていう の も 1 応 やっ て み た ん です けど なんか やる こと に すごい IBM:司 って いう の を 計算 できる ので これ を 使い まし た で でも 打撃 音 を それぞれ マテリアル 毎 に 時計 に 行列 に し て さっき の こういう 感じ な の で 表す って 言え ない です ここ の 人間 の マップ に 置き換える って いう の も 一応 やっ て み た ん です けど 何 か やる こと に 凄い Kaldi: 近 さ っていう の 5 日 計算 できる の で は これ を 使う まし た て ない ので 打撃 音 を それぞれ マテリアル ごと に 除去 林業 率 に対して 7 さっき の 声 感じ 子 ノード で 表す ッティ 名前 話し 下 4 9 2 次元 の の 特に 置き換える っていう の を 一 度 やっ 受け身 た ん です けど 何 か やる こと に 都合 よい
- 投稿日:2020-09-27T18:15:23+09:00
主要4社のクラウド音声認識サービスの使い方
Amazon, Google, IBM, Microsoftの音声認識サービスを使用
各社の音声認識サービスのAPIの名称です(呼び方は人によって違いますが間違っていたらすいません)
- Amazon:
- Transcribe
- Google:
- Cloud Speech-to-Text
- IBM:
- Watson Speech-to-Text
- Microsoft:
- Azure Speech-to-Text
Speech-to-TextというAPIを探せば見つかるはずです.AmazonだけはTranscribeと呼ばれていますが...
本記事では各APIを使うための準備(アカウント登録など諸々)は済ませてある前提の内容です
アカウント登録の方法は,検索すればわかりやすく説明してくれているサイトがあるので頑張って登録してみてくださいAmazon Transcribe の使い方
まず,認識させたい音声ファイルをS3というAWSのクラウドストレージの置く必要があります.
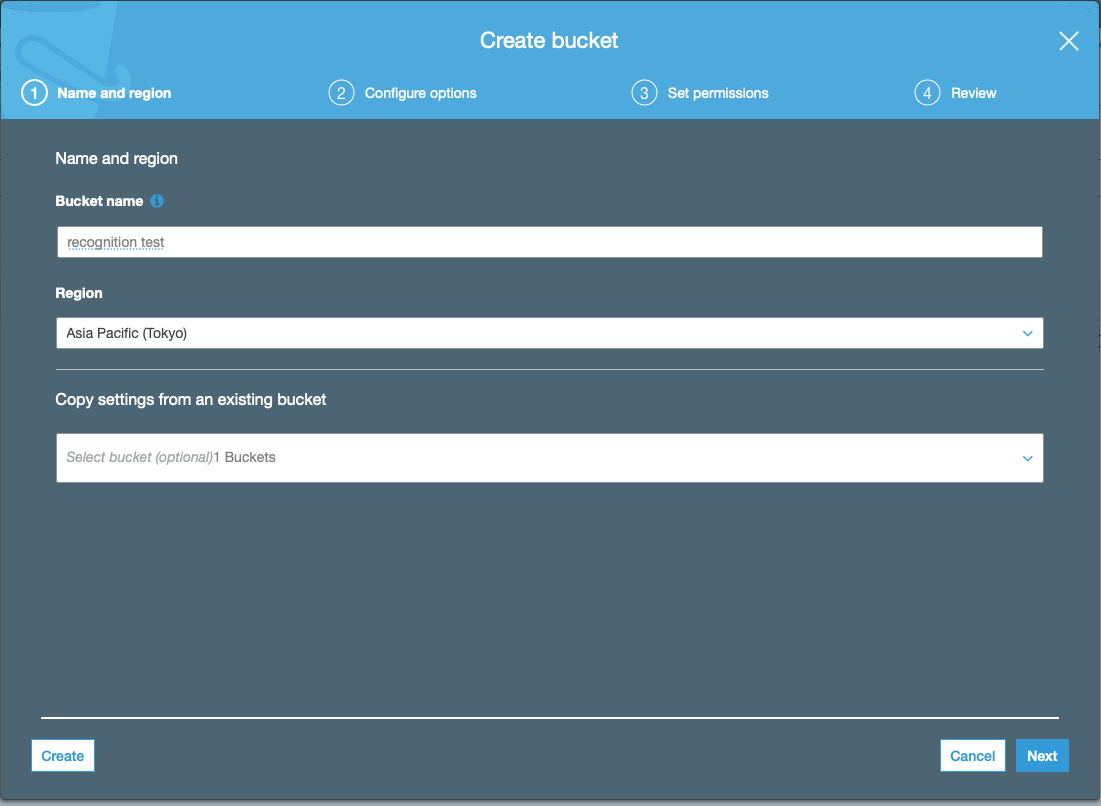
- S3のページの左上辺りにあるCreate bucketをクリックしてバケットを作成します.バケット名はなんでもいいです.地域(region)はtokyoにしておきました.
- Bucket name: recognitiontest(なんでも良い)
- Region: Asia Pacific(Tokyo)
- バケットを作成したら,作成したバケットに音声ファイルをアップロードすれば準備完了です.左上辺りにUploadというボタンがあるので,クリックすればアップロードできます.フォルダを作成して複数の音声ファイルをまとめることもできるのでお好みでやってください.
それでは認識を開始していきますが,APIを叩く前にAPIのアクセスキーなどの環境変数を通しておく必要があります.
% export AWS_SECRET_ACCESS_KEY=[自分のAWS_SECRET_ACCESS_KEY] % export AWS_ACCESS_KEY_ID=[自分のAWS_ACCESS_KEY_ID] % export AWS_DEFAULT_REGION=ap-northeast-1 % source ~/.zshrc
- あとはAPIを叩くだけです.サンプルプログラムを載せておきます.
recognize.pyfrom __future__ import print_function import os,sys import time import boto3 import glob from pprint import pprint import re import requests import json def extract_url(response): ''' apiのレスポンスから書き起こしを保存しているS3のurl情報を抽出 ''' p = re.compile(r'(?:\{\'TranscriptFileUri\':[ ]\')(.*?)(?:\'\}\,)') url = re.findall(p,str(response))[0] return url def get_json_result(url): ''' クラウドからjson形式の認識結果を含む情報をダウンロード ''' try: r = requests.get(url) return str(r.text) except requests.exceptions.RequestException as err: print(err) def extract_recognition_result(_json): ''' 認識結果を含むjsonから認識結果のみを抽出 ''' json_dict = json.loads(_json) recognized_result = json_dict['results']['transcripts'][0]['transcript'] return recognized_result def main(): # 作業用ディレクトリ _dir = '/Users/RecognitionTest' # 認識結果保存用ディレクトリ(AWSというディレクトリを事前に作成しておきます.このディレクトリ内にAPIからのレスポンス情報や書き起こし結果が保存されます) recognition_result = _dir+'/AWS' # 認識させたい音声ファイル名が記載されたテキストファイル speech_fname_file = _dir+'/speech_fname.txt' # 認識させたい音声ファイル名をリストへ格納 speech_fname_list = [] with open(speech_fname_file,'r') as f: path = f.readline() while path: speech_fname_list.append(path.strip()) path = f.readline() status_file = recognition_result+'/status.txt' json_file = recognition_result+'/json_response.txt' recog_result = recognition_result+'/recognition_result.txt' # 認識結果保存用ファイル with open(status_file,'w') as status_out: for speech_fname in speech_fname_list: transcribe = boto3.client('transcribe') job_name = str(speech_fname) # 音声ファイル名(必ずしも音声ファイル名である必要はなくなんでも良い) job_uri = f'https://[バケット名].s3-ap-northeast-1.amazonaws.com/{job_name}' # Bucket name -> recongnitiontest transcribe.start_transcription_job( TranscriptionJobName=job_name, Media={'MediaFileUri': job_uri}, MediaFormat='wav', LanguageCode='ja-JP' ) while True: # status: レスポンス情報(認識結果が保存されているS3クラウドのURLを含む) status = transcribe.get_transcription_job(TranscriptionJobName=job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) status_out.write(f'{speech_fname} {status}\n') with open(status_file,'r') as status_in, open(json_file,'w') as json_out, open(recog_result,'w') as result: status_list = status_in.readlines() client = boto3.client('transcribe') for status in status_list: job_name = status.strip().split(' ')[0] response = client.get_transcription_job(TranscriptionJobName=job_name) url = extract_url(response) _json = get_json_result(url) recog_text = extract_recognition_result(_json) json_out.write(f'{job_name} {_json}\n') result.write(f'{job_name} {recog_text}\n') if __name__ == "__main__": main()
- speech_fname.txtには認識させたい音声ファイル名が記載されたテキストファイルです.S3のバケットに置いた音声ファイル名と同じでなければなりません.以下に例を載せておきます.5つの別々の音声ファイルを認識させたい場合の例です.この音声ファイル名と同じ音声ファイルをS3クラウドストレージに置いておけば大丈夫です.
speech_fname.txtspeech_data1.wav speech_data2.wav speech_data3.wav speech_data4.wav speech_data5.wav
- APIのアクセスキーなどの環境変数を設定して,speech_fname.txtを用意できたならば,recognize.pyを実行すれば認識が開始されます.
- 認識結果は
/Users/RecognitionTest/GCP/recognition_result.txtに書き込まれています.
- Amazon Transcribeでも確認可能
Google Cloud Speech-to-Text の使い方
- Amazon Transcribeとは違い,認識させたい音声をクラウドに置く必要はありません.
- ローカルにある音声を認識可能
- 認識させたい音声ファイルのパスを記載したテキストファイルを用意しておく
- 以下のサンプルプログラムではspeech_data_path.txt
- IBM Watson, Microsoft Azure でも同様のものを使用
- それではまずAPIキーを環境変数を通しておきます.APIキーの情報はjsonファイルに記載されています.このjsonファイルはGCPのコンソールからダウンロードしておく必要があります.ナビゲーションメニューのAPIとサービスへ行けばjson形式の認証情報をダウンロードできます.
% export GOOGLE_APPLICATION_CREDENTIALS="[jsonファイルへのpath]" % source ~/.zshrc
- あとはAPIを叩くだけです.サンプルプログラムを載せておきます.
recognize.pyimport io import glob import os import shutil from google.cloud import speech_v1p1beta1 from google.cloud.speech_v1p1beta1 import enums def main(): client = speech_v1p1beta1.SpeechClient() # 作業用ディレクトリ _dir = '/Users/RecognitionTest' # 認識結果保存用ディレクトリ recognition_result = _dir+'/GCP' # 認識させたい音声ファイルへのパスが記載されたテキストファイル speech_data_path_file = _dir+'/speech_data_path.txt' # 認識させたい音声ファイルのパスをリストへ格納 speech_path_list = [] with open(speech_data_path_file,'r') as f: path = f.readline() while path: speech_path_list.append(path.strip()) path = f.readline() recog_result_fname = recognition_result+'/recognition_result.txt' # 認識結果保存用ファイル with open(recog_result_fname,'w') as recog_result: for speech_path in speech_path_list: # 音声ファイル名取得(認識結果を書き込むファイル名に使用) speech_file_name = speech_path.split('/')[-1].split('.')[0] # 音声ファイル名を認識結果書き込み用ファイル名にする # The use case of the audio, e.g. PHONE_CALL, DISCUSSION, PRESENTATION, et al. interaction_type = enums.RecognitionMetadata.InteractionType.DISCUSSION # The kind of device used to capture the audio recording_device_type = enums.RecognitionMetadata.RecordingDeviceType.RECORDING_DEVICE_TYPE_UNSPECIFIED # The device used to make the recording. # Arbitrary string, e.g. 'Pixel XL', 'VoIP', 'Cardioid Microphone', or other # value. recording_device_name = "MR" metadata = { "interaction_type": interaction_type, "recording_device_type": recording_device_type, "recording_device_name": recording_device_name, } # The language of the supplied audio. Even though additional languages are # provided by alternative_language_codes, a primary language is still required. language_code = "ja-JP" # 言語を日本語に設定 config = {"metadata": metadata, "language_code": language_code} with io.open(speech_path, "rb") as f: content = f.read() audio = {"content": content} # 認識開始 response = client.recognize(config, audio) # 認識結果の保存と表示 for result in response.results: # First alternative is the most probable result alternative = result.alternatives[0] print(u"Transcript: {}".format(alternative.transcript)) recog_result.write(u"{} {}".format(speech_file_name,alternative.transcript)+'\n') if __name__ == "__main__": main()
- 認識結果は
/Users/RecognitionTest/GCP/recognition_result.txtに書き込まれています.IBM Watson Speech-to-Text の使い方
- 使い方はGoogle Gloud Speech-to-Text とほぼ同じです.
- ただしAPIキーなどをプログラム内に記述する点が異なります.Google, Amazonでは環境変数として設定していました.
- APIキーとエンドポイントのURLを取得しておく必要があります.
- サンプルプログラムです
- [自分のAPIキー]と[エンドポイントのURL]は置き換えてください
- エンドポイントは"jp-tok"を指定した方がいいです.
recognize.pyimport os,sys import glob import re import json from os.path import join, dirname from ibm_watson import SpeechToTextV1 from ibm_watson.websocket import RecognizeCallback, AudioSource from ibm_cloud_sdk_core.authenticators import IAMAuthenticator from pprint import pprint import shutil import jaconv def extract_recognition_result(_json): recognized_result = [] json_dict = json.loads(_json) try: transcript = json_dict['results'][0]['alternatives'][0]['transcript'].split(' ') except: return ' ' # 言い淀み単語はカタカナ表記なので,平仮名表記に変換 for word in transcript: if 'D_' in word: recognized_result.append(jaconv.kata2hira(word)) else: recognized_result.append(word) recognized_result = ' '.join(recognized_result) recognized_result = recognized_result.replace('D_','') #言い淀みは'D_'で表現されているので削除する return str(recognized_result) def main(): # 作業用ディレクトリ _dir = '/Users/RecognitionTest' # 認識結果保存用ディレクトリ recognition_result = _dir+'/Watson' # 認識させたい音声ファイルへのパスが記載されたテキストファイル speech_data_path_file = _dir+'/speech_data_path.txt' # 認識させたい音声ファイルのパスをリストへ格納 speech_path_list = [] with open(speech_data_path_file,'r') as f: path = f.readline() while path: speech_path_list.append(path.strip()) path = f.readline() # jsonファイル(認識結果)格納ディレクトリ json_result_dir = recognition_result+'/json_result' for speech_path in speech_path_list: # 音声ファイル名取得(認識結果を書き込むファイル名に使用) speech_file_name = speech_path.split('/')[-1].split('.')[0] with open(f'{json_result_dir}/{speech_file_name}.json','w') as json_out: # set apikey authenticator = IAMAuthenticator('[自分のAPIキー]') service = SpeechToTextV1(authenticator=authenticator) # set endpoint url service.set_service_url('[エンドポイントのURL]') lang = 'ja-JP_BroadbandModel' # 言語を日本語に設定 with open(speech_path,'rb') as audio_file: result_json = service.recognize(audio=audio_file, content_type='audio/wav', timestamps=True, model=lang, word_confidence=True, end_of_phrase_silence_time=30.0) result_json = result_json.get_result() # json形式の認識結果を取得しているので,json_resultX.jsonに書き込み result = json.dumps(result_json, indent=2, ensure_ascii=False) json_out.write(result) json_file_list = glob.glob(json_result_dir+'/*.json') recog_result_file = recognition_result+'/recognition_result.txt' with open(recog_result_file,'w') as result: for json_file in json_file_list: with open(json_file,'r') as _json: print(json_file) speech_file_name = json_file.strip().split('/')[-1].split('.')[0] #保存したjson_resultX.jsonから認識結果のみを抽出 recog_result = extract_recognition_result(_json.read()) result.write(f'{speech_file_name} {recog_result}\n') if __name__ == "__main__": main()
- Watsonはデフォルトでは,言い淀み部分に"D_"を追記しています.サンプルプログラムではこの部分を除去しています.あと,言い淀み単語はカタカナ表記となっていますが,私は平仮名表記が必要であったので変換しています.
- 認識結果は
/Users/RecognitionTest/GCP/recognition_result.txtに書き込まれています.Microsoft Azure Speech-to-Text の使い方
- AzureはIBM Watsonと同様にプログラム内にAPIキー(speech_key)とregionを記述します
- speech_key: [自分のspeech_key] を書き換えてください
- service_region:japaneast としました
recognize.pyimport time import wave import glob import re import os try: import azure.cognitiveservices.speech as speechsdk except ImportError: print(""" Importing the Speech SDK for Python failed. Refer to https://docs.microsoft.com/azure/cognitive-services/speech-service/quickstart-python for installation instructions. """) import sys sys.exit(1) # Set up the subscription info for the Speech Service: # Replace with your own subscription key and service region (e.g., "westus"). # サービス地域(service_region)を東日本(japaneast)に設定 # speech_key -> Azureのマイページで確認 speech_key, service_region = "[自分のspeech_key]", "japaneast" # Specify the path to an audio file containing speech (mono WAV / PCM with a sampling rate of 16 # kHz). def main(): """performs continuous speech recognition with input from an audio file""" # <SpeechContinuousRecognitionWithFile> # 作業用ディレクトリ _dir = '/Users/RecognitionTest' # 認識結果保存用ディレクトリ recognition_result = _dir+'/Azure' # 認識させたい音声ファイルへのパスが記載されたテキストファイル speech_data_path_file = _dir+'/speech_data_path.txt' # 認識させたい音声ファイルのパスをリストへ格納 speech_path_list = [] with open(speech_data_path_file,'r') as f: path = f.readline() while path: speech_path_list.append(path.strip()) path = f.readline() #認識結果書き込み用ファイル作成(pre_result.txtには認識結果以外の情報も書き込まれる) with open(f'{recognition_result}/pre_result.txt','w') as recog_result: for speech_path in speech_path_list: speech_file_name = speech_path.split('/')[-1].split('.')[0] # 音声ファイル名を認識結果書き込み用ファイル名に使用 speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region) audio_config = speechsdk.audio.AudioConfig(filename=speech_path) speech_config.speech_recognition_language="ja-JP" # 言語を日本語に設定 profanity_option = speechsdk.ProfanityOption(2) # 不適切発言処理 0->隠す, 1->削除, 2->含む speech_config.set_profanity(profanity_option=profanity_option) # profanity_optionを変更 speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config) done = False def stop_cb(evt): """callback that signals to stop continuous recognition upon receiving an event `evt`""" print('CLOSING on {}'.format(evt)) nonlocal done done = True # Connect callbacks to the events fired by the speech recognizer speech_recognizer.recognizing.connect(lambda evt: print('RECOGNIZING: {}'.format(evt))) #認識結果の書き込み speech_recognizer.recognized.connect(lambda evt: recog_result.write('{} RECOGNIZED: {}'.format(speech_file_name,evt)+'\n')) speech_recognizer.session_started.connect(lambda evt: print('SESSION STARTED: {}'.format(evt))) speech_recognizer.session_stopped.connect(lambda evt: print('SESSION STOPPED {}'.format(evt))) speech_recognizer.canceled.connect(lambda evt: print('CANCELED {}'.format(evt))) # stop continuous recognition on either session stopped or canceled events speech_recognizer.session_stopped.connect(stop_cb) speech_recognizer.canceled.connect(stop_cb) # Start continuous speech recognition speech_recognizer.start_continuous_recognition() while not done: time.sleep(.5) speech_recognizer.stop_continuous_recognition() # </SpeechContinuousRecognitionWithFile> def fix_recognition_result(): ''' - pre_result.txtは以下のような形式の認識結果である - [SPEECH FILE NAME] RECOGNIZED: SpeechRecognitionEventArgs(session_id=XXX, result=SpeechRecognitionResult(result_id=YYY, text="[認識結果]", reason=ResultReason.RecognizedSpeech)) - [SPEECH FILE NAME]と[認識結果]の部分のみを抽出 ''' # 認識結果ファイル pre_result = '/Users/kamiken/speech_recognition_data/Cloud_Speech_to_Text/Compare4Kaldi/Compare_Test1/Azure/pre_result.txt' # 認識結果以外の情報(パラメータなど)を削除 with open(pre_result,'r') as pre, open(pre_result.replace('pre_',''),'w') as result: lines = pre.readlines() for line in lines: split_line = line.strip().split(' ') speech_file_name = split_line[0] text = str(re.findall('text=\"(.*)\",',' '.join(split_line[1:]))[0])+'\n' result.write(f'{speech_file_name} {text}') if __name__ == "__main__": main() fix_recognition_result()
- Azureは親切なことに,Fワードなど不適切な発言を「***」のようにアスタリスクで隠してくれます.私はWERを算出しないといけなかったので,サンプルプログラムでは全て表示させるような設定にしてあります.
- profanity_option = speechsdk.ProfanityOption(2)
- 引数は0(不適切発言をアスタリスクで隠す), 1(削除する), 2(隠しも削除もしない)のいずれかです
- 認識結果は
/Users/RecognitionTest/GCP/recognition_result.txtに書き込まれています.
- 投稿日:2020-09-27T18:04:46+09:00
ゼロから始めるDjango(part:2)
前回
参考文献
はじめての Django アプリ作成、その2 | Django ドキュメント | Django
DataBaseの設定
mysite/setting.py
- jangoの設定をいろいろ書いてあるPythonモジュール
- データベースのサポートなどもデフォルトで入っている
INSTALLED_APPS
アプリケーションの重要部分の設定。詳細は以下
-django.contrib.admin- 管理(admin)サイト
-django.contrib.auth- 認証システム
-django.contrib.contenttypes- コンテンツタイプフレームワーク
-django.contrib.sessions- セッションフレームワーク
-django.contrib.messages- メッセージフレームワーク
-django.contrib.staticfiles- 静的ファイルの管理フレームワークテーブルの作成
データベースのテーブル作成は以下のコマンドで行う。
python manage.py migrate-
migrateコマンドは上記のINSTALLED_APPSの設定を参照し`mysite/setting.py'ファイルのデータベース設定に従って必要なすべてのデータベースを作成する。
- コマンドラインクライアントでテーブルの中身を表示することが可能
- \dt (PostgreSQL
- SHOW TABLES; (MySQL)
- .schema (SQLite)
- SELECT TABLE_NAME FROM USER_TABLES; (Oracle)データベースモデルを生成
from django.db import models class Question(models.Model): question_text = models.CharField(max_length=200) pub_date = models.DateTimeField('date published') class Choice(models.Model): question = models.ForeignKey(Question, on_delete=models.CASCADE) choice_text = models.CharField(max_length=200) votes = models.IntegerField(default=0)
- QuestionとChoiceのモデル二つを生成している
- どちらもmodelsクラスのサブクラス
個々のクラスはモデルのデータベースフィールを表現している
CharFiledやIntegerFieldなどでどのようなデータ型を記憶させるかを指定している
models.CharField(max_length=200)やmodels.IntegerField(default=0)のように条件や初期値も指定可能ForeignKey(外部キー)で
Questionとリレーションシップを定義している。アプリケーションをプロジェクトに反映
- アプリケーションをプロジェクトに含めるには
setting.py'のINSTALLED_APPS`に設定を追加する- アプリケーション(今回はPolls)内の
apps.py内に記載されているクラスをINSTALLED_APPSに設定するINSTALLED_APPS = [ 'polls.apps.PollsConfig', 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ]モデルの変更を反映させる
下記コードを実行するとDjangoに変更があったことをマイグレーションの形で保存する
python manage.py makemigrations polls
- マイグレーション:Djangoがモデル(データベーススキーマ)の変更を保存する方法。
python manage.py checkプロジェクトに問題がないかを確認するコマンド
モデルのテーブルを作成したら、migrateを再度実行しモデルのテーブルをデータベースに作成する
モデルの変更を実施する3ステップ
- モデルを変更する
- マイグレーション作成のためにpython manage.py makemigrationsを実行
- データベースにこれらの変更を適用するためpython manage.py migrateを実行
マイグレーションの作成と適用のコマンドが分かれているのはなぜ?
- マイグレーションをバリデーション管理システムにコミットしアプリとともに配布するため
- 開発の容易化
- ほかの開発者や本番環境にとって使いやすいものになるため
データベースAPIの利便性の向上
シェル内で
>>> Question.objects.all()とすると
以下のように出力される。
<QuerySet [<Question: Question object (1)>]>
これだとデータベースのテーブルがどうなっているかわからないそのため`str'メソッドをQuestionとChoiceの両方に追加する
from django.db import models class Question(models.Model): # ... def __str__(self): return self.question_text class Choice(models.Model): # ... def __str__(self): return self.choice_text
- シェルでの表示の利便性以外にもdjangoの自動生成adminのオブジェクトの表現として使用される
- そのためstr()メソッドをモデルに追加することは重要
polls/models.pyfrom django.db import models from django.utils import timezone class Question(models.Model): # ... def was_published_recently(self): return self.pub_date >= timezone.now() - datetime.timedelta(days=1)管理ユーザを作成する
python manage.py createsuperuseradmin上で編集可能にする
from django.contrib import admin from .models import Question admin.site.register(Question)
- 投稿日:2020-09-27T17:52:47+09:00
FlaskでApschedulerが2回実行されるのを修正する
app.run()を
app.run(use_reloader=False)に変更
- 投稿日:2020-09-27T17:49:29+09:00
変数を渡すタイプのPythonのデコレータについての考察
Pythonで開発をしていると、関数の前後に共通処理を挟みたくなるケースが良くあるかと思います。その場合に良く使われるのはデコレータ(関数の上の行にアノテーションを付けるやつ)ではないでしょうか。この記事では、デコレータの基本的な使い方と、後半では変数を渡せるタイプのデコレータについて考察してみたいと思います。
※本記事の動作検証には、Pythonのバージョン3.7.3を使用しています。
一番シンプルなデコレータは、以下のような実装です。
def decorator(func): def decorated(*args, **kwargs): print('decorated 開始') func(*args, **kwargs) print('decorated 終了') return decoratedこのデコレータを実際に使う場合には以下のようにします。
@decorator def sample(name): print('{}が動作しました。'.format(name))このデコレートされたsample関数を実行すると、以下のようにprint出力される事から
期待通りにsample関数の前後に処理を挟めている事が分かります。decorated 開始 sampleが動作しました。 decorated 終了何故このような動作になるかと言うと、@はシンタックスシュガーで
実は以下のコードと等価だからです。def sample(name): print('{}が動作しました。'.format(name)) # @decoratorと等価 sample = decorator(sample)
ここまでは比較的分かりやすいのですが、変数を渡せるタイプのデコレータを理解しようとした時に、つまづくケースが多いのではないかと思います。
※以下に、変数を渡せるタイプのデコレータの実装例を記載します。def annotation(param): print('annotation 開始') def decorator(func): print('decorator 開始') print('param:{}'.format(param)) def decorated(*args, **kwargs): print('decorated 開始') print('param:{}'.format(param)) func(*args, **kwargs) print('decorated 終了') print('decorator 終了') return decorated print('annotation 終了') return decorator先ほどのシンタックスシュガー(@)の動きを考えると、最上位の関数(annotation)の引数は関数じゃないといけないのではないか?と思いがちですが、実際に下記のコードは正常に動作します。
print('アノテーション付きの関数を定義') @annotation(param=999) def sample(name): print('{}が動作しました。'.format(name)) print('アノテーション付きの関数を実行') sample('sample')以下にprint出力を記載
アノテーション付きの関数を定義 annotation 開始 annotation 終了 decorator 開始 param:999 decorator 終了 アノテーション付きの関数を実行 decorated 開始 param:999 sampleが動作しました。 decorated 終了上記のprint出力を見ると、annotation関数終了後に呼び出されているdecorator関数の中から
annotation関数の引数であるparamが参照出来ています。
何故このような挙動になるのかと言うと、関数が参照出来る変数は関数を定義した時に決まるので、annotation関数内で定義されたdecorator関数は、annotation関数の引数であるparamを参照する事が出来るからです。
※このようなオブジェクトの事をクロージャと言います。
同様に、decorated関数もクロージャになっている為、paramとfuncを参照する事が出来ます。また、print出力の内容を考察すると、変数を渡せるタイプのデコレータのシンタックスシュガー(@)は、以下と等価だと考えられます。
def sample(name): print('{}が動作しました。'.format(name)) # @annotation(param=999)と等価 sample = annotation(param=999)(sample)
参考資料
- 投稿日:2020-09-27T17:22:16+09:00
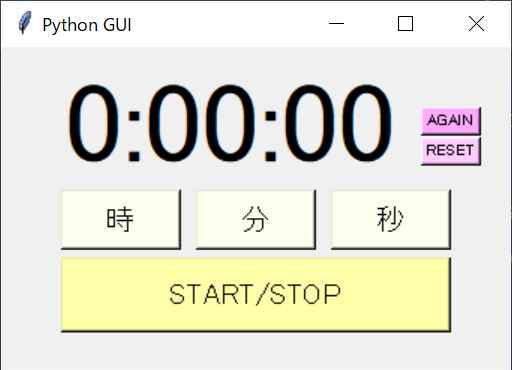
pythonでtkinterを使ってストップウォッチを作ってみた
tkinterでストップウォッチを作ってみました
構成
├── stop_watch.bat ├── code │ └── main.py └── sound └── 適当な音楽ファイル.mp3本体
main.pyimport os import time import pickle import tkinter as tk import tkinter.font as tk_font import threading from pygame import mixer class StopWatch: def __init__(self): self.prev_path = '../prev.pickle' self.sound_path = '../sound/適当な音楽ファイル.mp3' self.time_value = self.load_pickle(self.prev_path) if self.time_value is None: self.time_value = 0 self.starting_time_value = self.time_value w0 = 40 y0 = 60 y02 = y0 -20 w1 = 80 h1 = 40 wspace = 10 w2 = w1 * 3 + wspace * 2 h2 = 50 x1 = 40 x2 = x1 + w1 + wspace x3 = x2 + w1 + wspace x0 = x3 + 60 y1 = 10 y2 = 95 y3 = 140 size1 = 56 bg1 = '#ffffee' bg2 = '#ffffaa' bg0 = '#ffccff' bg02 = '#ffaaff' self.root = tk.Tk() self.enable_count_down = False self.root.title("Python GUI") self.root.geometry("340x215") self.time_text = tk.StringVar() self.time_label = tk.Label(self.root, textvariable=self.time_text, font=tk_font.Font(size=size1)) self.time_label.place(x=x1, y=y1) button_up_1_hour = tk.Button(text="時", command=self.plus_1_hour, font=tk.font.Font(size=14), bg=bg1) button_up_1_hour.place(x=x1, y=y2, width=w1, height=h1) button_up_1_min = tk.Button(text="分", command=self.plus_1_min, font=tk.font.Font(size=14), bg=bg1) button_up_1_min.place(x=x2, y=y2, width=w1, height=h1) button_up_1_sec = tk.Button(text="秒", command=self.plus_1_sec, font=tk.font.Font(size=14), bg=bg1) button_up_1_sec.place(x=x3, y=y2, width=w1, height=h1) button_start = tk.Button(text="START/STOP", command=self.start_stop, font=tk.font.Font(size=14), bg=bg2) button_start.place(x=x1, y=y3, width=w2, height=h2) button_reset = tk.Button(text="RESET", command=self.reset, font=tk.font.Font(size=8), bg=bg0) button_reset.place(x=x0, y=y0, width=w0) button_again = tk.Button(text="AGAIN", command=self.again, font=tk.font.Font(size=8), bg=bg02) button_again.place(x=x0, y=y02, width=w0) thread = threading.Thread(target=self.count_down) thread.start() self.update() self.root.mainloop() def plus_1_hour(self): self.time_value += 60 * 60 self.update() def plus_1_min(self): self.time_value += 60 self.update() def plus_1_sec(self): self.time_value += 1 self.update() def reset(self): self.time_value = 0 self.enable_count_down = False self.update() def again(self): self.time_value = self.starting_time_value self.enable_count_down = False self.update() def sound(self): mixer.init() mixer.music.load(self.sound_path) mixer.music.play(1) def count_down(self): while True: if self.time_value > 0 and self.enable_count_down: self.time_value -= 1 self.update() if self.time_value <= 0 and self.enable_count_down: self.time_value = 0 self.enable_count_down = False self.update() self.sound() time.sleep(1) def start_stop(self): self.starting_time_value = self.time_value self.enable_count_down = not self.enable_count_down @staticmethod def sec_to_hms(sec): minutes, sec = divmod(sec, 60) hour, minutes = divmod(minutes, 60) return '{}:{:0>2}:{:0>2}'.format(hour, minutes, sec) def update(self): hms = self.sec_to_hms(self.time_value) self.time_text.set(hms) self.save_pickle(self.time_value, self.prev_path) @staticmethod def save_pickle(model, model_path, protocol=4): with open(model_path, mode='wb') as f: if protocol is None: pickle.dump(model, f) else: pickle.dump(model, f, protocol=protocol) @staticmethod def load_pickle(path): if os.path.exists(path): try: with open(path, mode='rb') as f: obj = pickle.load(f) return obj except EOFError as e: print('load_pickle():', e) return None else: print('NOT FOUND load_pickle():', path) return None if __name__ == '__main__': StopWatch()stop_watch.pyを呼び出すバッチファイル
バッチファイルなりシェルスクリプトなりを作っておけば便利です
stop_watch.batstart C:/Users/ユーザー名/Anaconda3/envs/conda環境名/pythonw.exe ./code/main.py
- 投稿日:2020-09-27T16:50:22+09:00
OpenCVでスプライトを回転させる #2 ~cv2.warpAffine()を使いこなす~
はじめに
前回の記事「OpenCVでスプライトを回転させる」は夏休みに完成させることができず、週末も使って何とか一区切りさせた。
ところが、アップした翌日にはもう新たなアイデアが浮かんできた。やはり誘惑が多い環境はよろしくない。勉強をするにはもっと厳しい環境に身を置かなくては。職場とか。cv2.warpAffine()の詳細
前回割愛した、
cv2.warpAffine()の必須でない引数に興味深いものがあった。
参考記事 : OpenCVで画像上に別の画像を描画する
- src 元画像。必須。
- M 2*3の変換行列。必須。
- dsize 出力画像サイズを
(width, height)のタプルで指定する。必須。- dst 背景(元画像の外)画像。サイズはdsizeと同じである必要がある。
- flags 画像補完の方法。デフォ値は
cv2.INTER_LINEAR。他にcv2.INTER_NEARESTなど。- borderMode 背景(元画像の外)の処理方法。デフォ値は
cv2.BORDER_CONSTANT。- borderValue
borderMode=cv2.BORDER_CONSTANTの際の色。デフォ値は0。後述。事前に元画像を小加工する
画像処理の結果をわかりやすくするため、ちょっとした関数を作っておく。最小限の部分しか記載しないので注意。
def makeSampleImg(img4): # RGBA4チャンネル画像を持ってくる h, w = img.shape[:2] # 周囲に色を付けるだけでなくA=255(不透明)にするのがミソ cv2.rectangle(img, (0,0), (w-1,h-1), (0,0,255,255), 1) return img img_origin = cv2.imread(filename, -1) # RGBA画像 img4 = makeSampleImg(img_origin) img3 = img4[:, :, :3] # A要素をなくしRGB画像にする
元画像 小加工 3チャンネル化 背景を単色で塗りつぶす
borderMode=cv2.BORDER_CONSTANTで背景を単色にする。borderModeのデフォ値はこれなのでわざわざ記載する必要はない。
いくつか試してみる。背景色を指定M = cv2.getRotationMatrix2D((w/2,h/2), 30, 1) img_rot31 = cv2.warpAffine(img3, M, (w, h), borderValue=(255,255,0)) # 前景RGB、背景RGB img_rot32 = cv2.warpAffine(img3, M, (w, h), borderValue=(255,255,0,0)) # 前景RGB、背景RGBA(A成分=0) img_rot33 = cv2.warpAffine(img3, M, (w, h)) # 前景RGB、背景指定なし img_rot41 = cv2.warpAffine(img4, M, (w, h), borderValue=(255,255,0)) # 前景RGBA、背景RGB img_rot42 = cv2.warpAffine(img4, M, (w, h), borderValue=(255,255,0,0)) # 前景RGBA、背景RGBA(A成分=0) img_rot43 = cv2.warpAffine(img4, M, (w, h)) # 前景RGBA、背景指定なし img_rot44 = cv2.warpAffine(img4, M, (w, h), borderValue=(255,255,0,255)) # 前景RGBA、背景RGBA(A成分あり)前景がRGB画像の場合、背景色としてRGBAの4チャンネルを指定してもA成分は無視される(img_rot32)。
borderValueを指定しないと背景が黒になる(img_rot33、というかデフォの演算)が、背景色が(0,0,0)になると理解すべき。
img_rot31 img_rot32 img_rot33 前景がRGBA画像の場合、背景色としてRGBの3チャンネルを指定しても出力結果はRGBAの4チャンネルとなる。このとき付与されたA成分は
0。Aは透明度ではなく不透明度なので、これが0ということはRGB…じゃなかったBGR値が定義されていても結果として透明になる(img_rot41)。borderValueを指定しない場合も背景が透明になる(img_rot43)が、こちらも背景色が(0,0,0,0)になると考えれば理解しやすい。
もちろんA成分に0でない値を設定すればちゃんと色が付く(img_rot44)。
img_rot41 img_rot42 img_rot43 img_rot44 背景として画像を設定する
borderMode=cv2.BORDER_TRANSPARENTとするとdstで背景画像を指定することができる。
OpenCVではよくある話だが、cv2.warpAffine()するとdstで指定した背景画像は加工されてしまう。元画像を保持する必要があるときはdst=back.copy()としておく必要がある。TRANSPARENTだから透明になるのだな、だったら
dstを指定しなければ透明背景になるのかな、と期待したのだが、そう簡単にはいかなかった。Oh! なんだかイクラを食べたくなってきたぞ。背景画像を指定back = cv2.imread(back_name) # 前景画像と同サイズのRGB画像 back4 = cv2.cvtColor(back, cv2.COLOR_BGR2BGRA) # RGBA画像にする A成分は0ではなく255になる M = cv2.getRotationMatrix2D((w/2,h/2), 30, 1) img_rot35 = cv2.warpAffine(img3, M, (w, h), borderMode=cv2.BORDER_TRANSPARENT, dst=back.copy()) # 前景RGB、背景RGB img_rot36 = cv2.warpAffine(img3, M, (w, h), borderMode=cv2.BORDER_TRANSPARENT, dst=back4.copy()) # 前景RGB、背景RGBA img_rot37 = cv2.warpAffine(img3, M, (w, h), borderMode=cv2.BORDER_TRANSPARENT) # 前景RGB、背景指定なし img_rot45 = cv2.warpAffine(img4, M, (w, h), borderMode=cv2.BORDER_TRANSPARENT, dst=back.copy()) # 前景RGBA、背景RGB img_rot46 = cv2.warpAffine(img4, M, (w, h), borderMode=cv2.BORDER_TRANSPARENT, dst=back4.copy()) # 前景RGBA、背景RGBA img_rot47 = cv2.warpAffine(img4, M, (w, h), borderMode=cv2.BORDER_TRANSPARENT) # 前景RGBA、背景指定なし前景背景ともにRGB画像(img_rot35)で想定通りの挙動となった。
RGB前景で背景画像を指定しなかった場合、実行するたびに結果が変わってしまった(img_rot37)。
numpyには初期化されていない配列を作るnumpy.empty()という関数がある。ここでも同様の仕様で背景画像(というかnumpy配列)が作られているのだろう。
RGB前景でRGBA背景を指定したimg_rot36でゴミあり黒背景になってしまった理由はよくわからない。
img_rot35 img_rot36 img_rot37その1 img_rot37その2 前景背景ともにRGBA画像(img_rot46)は想定通りとはいえ、残念な結果でもある。前景の透明部分で背景を表示してくれたら嬉しかったのだが、そもそもアフィン変換はそういうものではないのだから仕方がない。
RGBA前景にRGB背景を指定したimg_rot45とRGBA前景で背景画像を指定しなかったimg_rot47は背景が透明になった。いずれもA要素に0が付与されたためと思われる。要するに、想定外の使い方はしないほうが賢明だというありきたりな結論となった。
img_rot45 img_rot46 img_rot47 スプライトに活用する
以上、先人の記事を参考に、画像の上に透明を含むRGBA画像を貼ることを考えたのだが、結論としては無理だった。
とはいえ、背景画像からはみ出てもエラーにならない仕様は魅力的だ。そこで、これまでやってきたマスク手法とアフィン変換を組み合わせることにした。
そしたら…できてしまった、超簡単に。外接四角形がどうとかROIがどうとか、面倒なのがまったくなしで。ソースimport cv2 def makeSampleImg(img4): h, w = img4.shape[:2] cv2.rectangle(img4, (0,0), (w-1,h-1), (0,0,255,255), 1) return img4 def putSprite_Affine(back, front4, pos, angle=0, center=(0,0)): x, y = pos front3 = front4[:, :, :3] mask1 = front4[:, :, 3] mask3 = 255- cv2.merge((mask1, mask1, mask1)) bh, bw = back.shape[:2] M = cv2.getRotationMatrix2D(center, angle, 1) M[0][2] += x M[1][2] += y front_rot = cv2.warpAffine(front3, M, (bw,bh)) mask_rot = cv2.warpAffine(mask3, M, (bw,bh), borderValue=(255,255,255)) tmp = cv2.bitwise_and(back, mask_rot) result = cv2.bitwise_or(tmp, front_rot) return result if __name__ == "__main__": filename_front = "uchuhikoushi.png" filename_back = "space.jpg" img_front = cv2.imread(filename_front, -1) img_front = makeSampleImg(img_front) # RGBA画像に枠をつける(必須ではない) img_back = cv2.imread(filename_back) pos = [(0, 50), (300,200), (400,400), (500,-50), (-100,1000)] # 画像を置く左上座標 xc, yc = 140, 60 # 前景画像の回転中心 angle = 0 while True: img = img_back.copy() for x,y in pos: img = putSprite_Affine(img, img_front, (x,y), angle, (xc,yc)) # 正しく描写されていることを確認する(必須ではない) cv2.circle(img, (x,y), 5, (0,255,0), -1) # 前景画像の左上にマーク cv2.circle(img, (x+xc,y+yc), 5, (0,0,255), -1) # 回転中心にマーク cv2.putText(img, f"angle={angle}", (10,440), cv2.FONT_HERSHEY_SIMPLEX, 1, (0,0,255), 2) cv2.imshow("putSprite_Affine", img) key = cv2.waitKey(1) & 0xFF if key == ord("q"): break angle = (angle + 30) % 360 cv2.destroyAllWindows()欠点といえば、背景画像全体に対しマスク画像とRGB画像をアフィン変換しているので計算量が無駄に大きい(「オーバーヘッドが大きい」というらしい)ことが挙げられる。
描写途中のfront_rot 描写途中のmask_rot 結果 ここでは前回のアニメGIFを載せるが、実際は赤枠付きのキャラが回転する。 
これが実行スピードにどう影響するか、今度確認してみよう。
終わりに
まだ終わりません。


















- 投稿日:2020-09-27T16:44:44+09:00
(Python)100万ハンド分析してみた〜AAの回数を推定してみた〜
閲覧いただき、ありがとうございます。
pbirdyellowです。今回はAAの出現回数を100万ハンドから推定してみました。
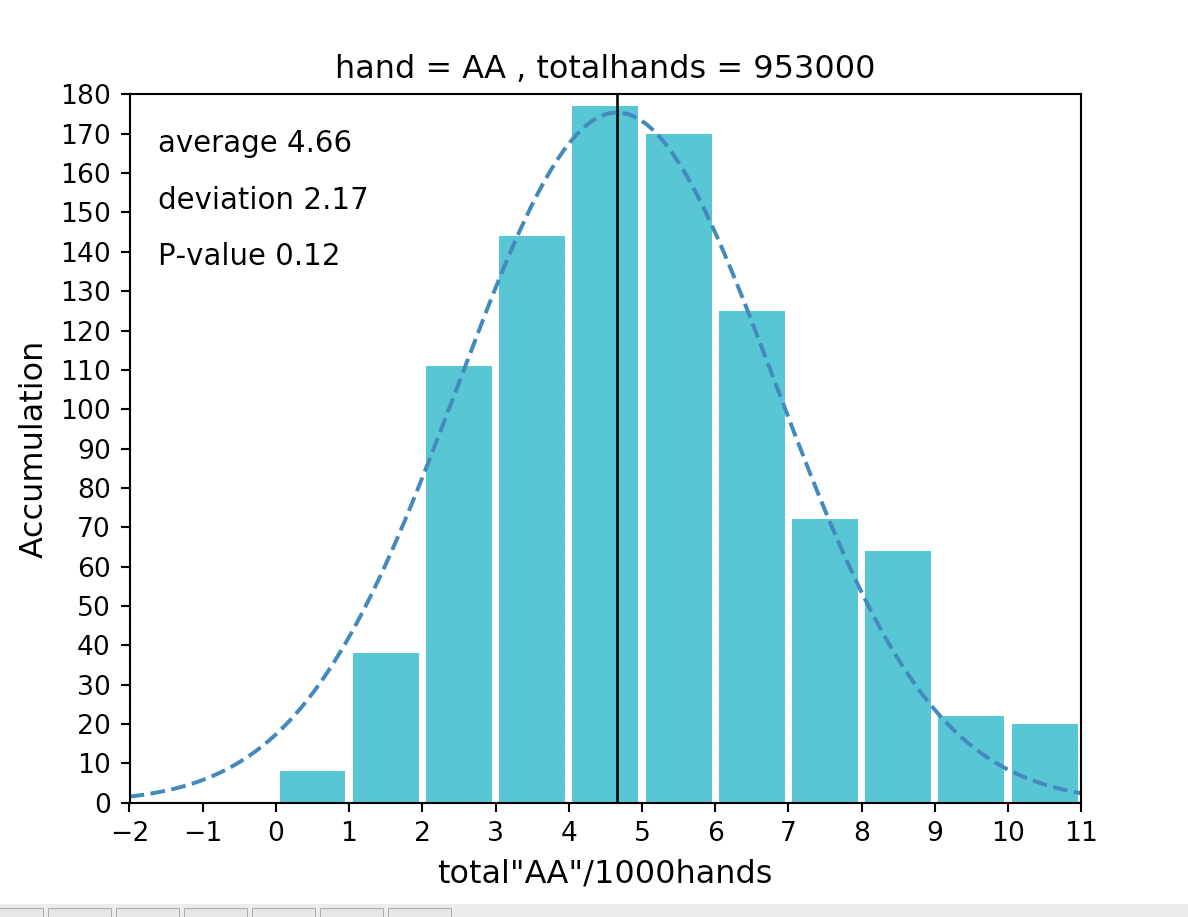
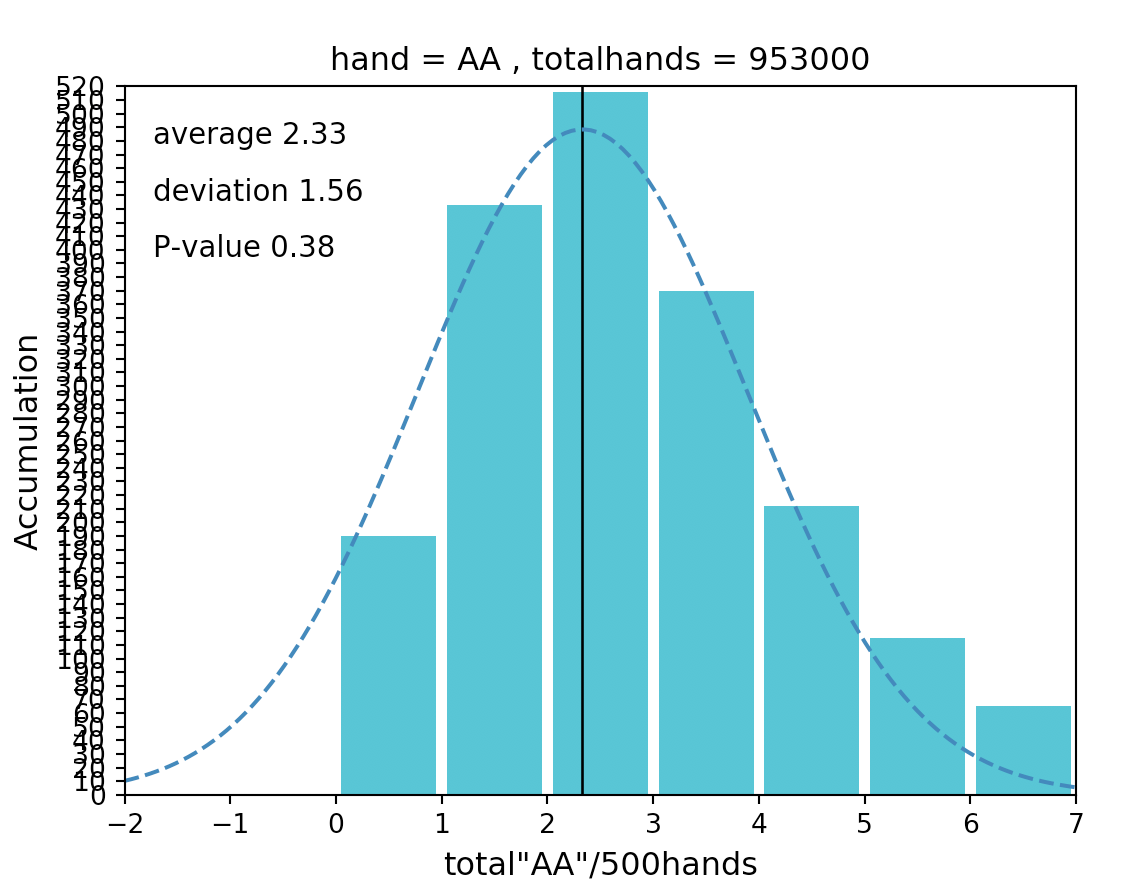
具体的には、今後プレーするであろう未知の2000ハンドに対して、AAがどれくらいの確率でどのくらい出現するのか推定します。
推定の手順は以下となります。①ハンドを集計してヒストグラムを作成する
②集計したハンドに正規性があるかを検定する
③平均値、標準偏差値を求める
④AAの出現回数を精度95%で推定する上記の内容や以降登場する専門用語については、下記の書籍がすごく分かりやすいので載せておきます。
・「完全独習 統計学入門 Kindle版」 小島 寛之 (著)
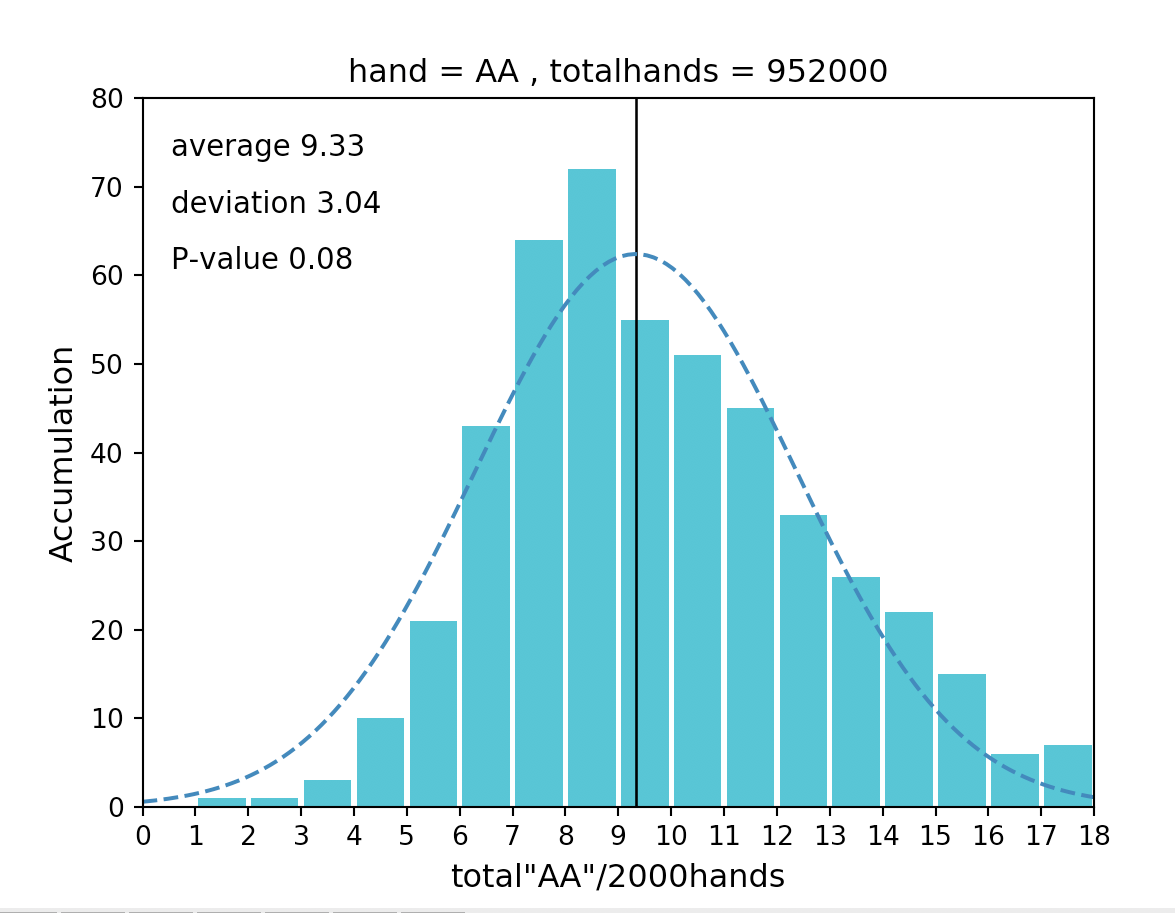
https://amzn.to/3mSPpqf以下が結論をまとめたヒストグラムになります。
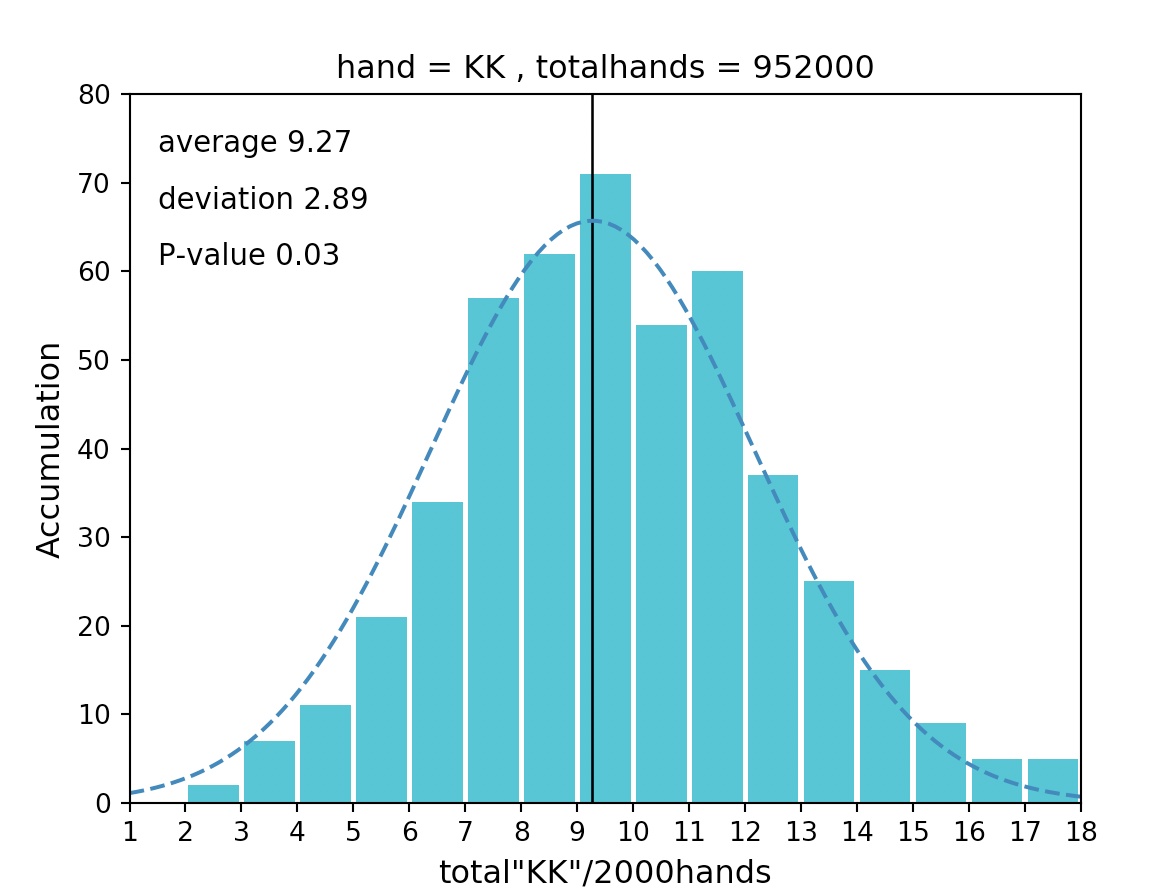
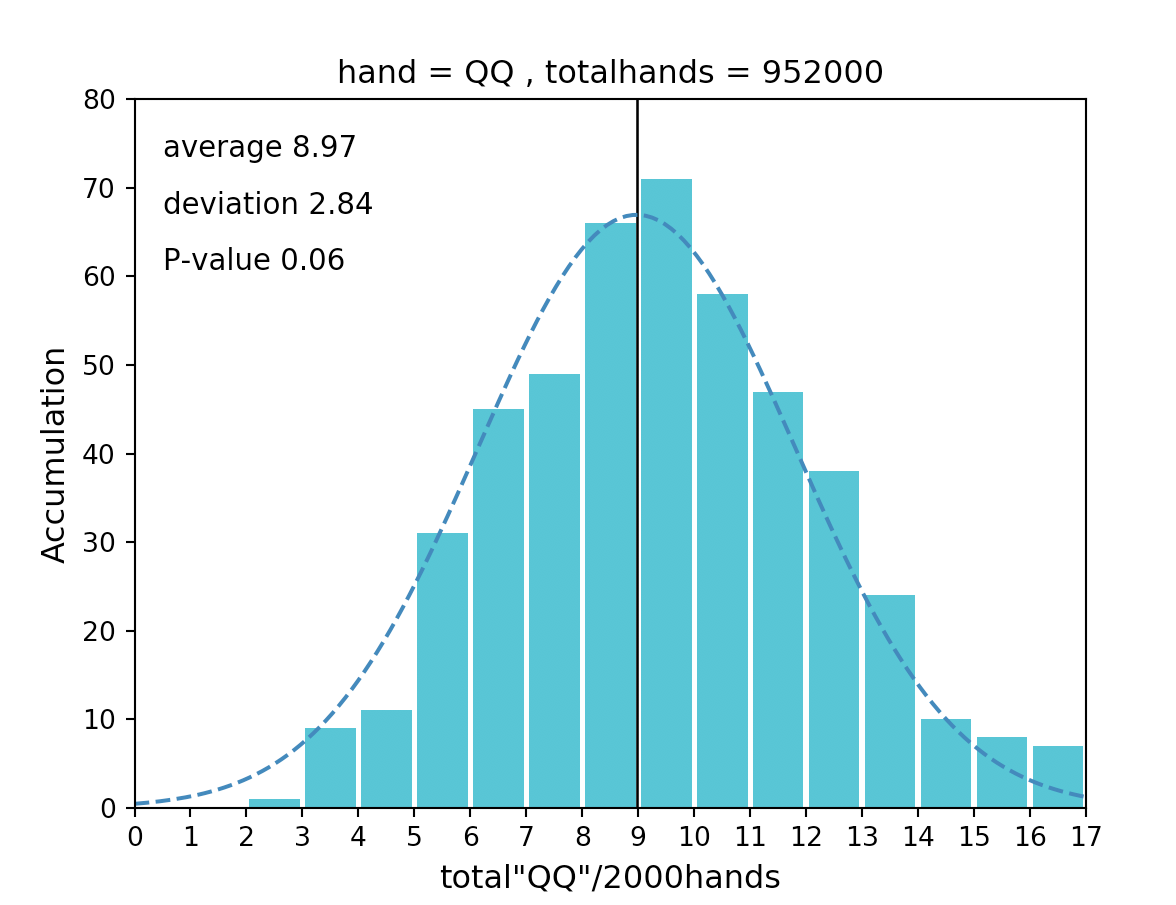
本記事のヒストグラムでは、縦軸は積算値、横軸は2000ハンドでAAが出現した回数を表しています。
■ヒストグラムとは
ヒストグラムとは、簡単に言うと「集計したデータを積み上げたグラフ」です。
上図を例にすると
・2000ハンド毎にAAが出現した回数が8回(横軸)であった事が、100万ハンドの中では72回(縦軸)あった
・2000ハンド毎にAAが出現した回数が2回(横軸)であった事が、100万ハンドの中では1回(縦軸)あった
などとなります。■SW検定とは
正規性かどうかの検定方法は様々ありますが、今回はSW検定と言うものを使います。
SW検定とは集計したデータの、そもそものデータ群(=母集団)に正規性があるかを検証する手法です。
正規性があると様々な法則が使えます。そしてそれらの法則を用いてAAの出現回数を推定する事が可能です。またSW検定ではp値を用いて正規性を判断します。
p値とは母集団に正規性があると仮定した場合、母集団からランダムにデータを選んで分布させた時、集計したデータのように分布する確率を表した値です。
一般的に、分布する確率が5%未満であった場合、それはあまりにも低すぎるので、そもそも母集団には正規性のもつ規則がない(=母集団には正規性がない)と判断されます。
上図ではp値(P-value)が0.08>0.05(=5%)なのでギリギリ正規性があると言えます。■平均値と標準偏差値
上図の
・average→平均(μ)
・deviation→標準偏差(σ)
が該当します。■精度95%の推定方法
集計したデータの平均値をμ、標準偏差値をσとすると
95%の確率で「μ-1.96σ≦x≦μ+1.96σ」内にAAの出現回数が収まります。なので「2000ハンドプレーするとAAは95%の確率で3.37回以上、15.29回以下の回数出現する」
ことになります。あくまで100万ハンドのデータを元に推定しているので上記の推定値には多少の誤差があります。
データが増え、平均値や標準偏差値が母平均値や母標準偏差値に近づくと推定値も正確な値となります。
※しかしこの数値は神のみぞ知る値になりますちなみにKKの場合だと以下となります。
P-value=0.03<0.05 なので仮定が棄却されて母集団には正規性がないと言うことになります。
この場合、集計したデータにも正規性はないので精度95%の推定算出はできません。
しかし、ハンド数がもっと増えるとP-valueの値は大きくなり正規性があるデータになると思います。
QQの場合だと正規性があり「2000ハンドプレーするとQQは95%の確率で3.40回以上、14.54回以下の回数出現する」 となります。
ところで、なんでKKには正規性ないねん。AAとかQQのヒストグラムと何が違うんや!
と仰る方もいらっしゃると思います。・・・仰るとおりです!!!
これはp値が境界ギリギリの数値周辺で推定しているのが悪いです。
2000ハンドごとを1000ハンドごとに変えるなどすれば、この問題は解消されます。
しかしこれはこれで問題で、横軸の数値は0以上しかとらないので、きちんとした分析ができなくなってしまいます・・・
要は100万ハンドでは少なすぎるということです笑
とはいえこのような複雑な計算がPythonだと一瞬でできるので本当に便利です。
ソースコードを置いておくので、是非みなさまも活用してみてください!!実のところ、SW検定の中身はあまりよく分かってないです。
Pythonではたった一行で計算できてしまうので、どういう数値が得られるのか分かっても計算過程は中々身につかないものです。
実例も交えて説明されている書籍等がありましたら、是非教えていただけると嬉しいです!以下がソースコードになります。
プログラムは完全初心者なので、より良いコードの書き方等ありましたら是非ご指摘ください!!pokermain.pyfrom holdcards import Holdcards from plotgraph import Plotgraph import os import glob import re path='ここにパスを記述' hand = "AA" #調べたいハンドを記述 count = 2000 #調べたいハンド毎を記述 num = lambda val : int(re.sub("\\D", "", val)) filelist = sorted(glob.glob(os.path.join(path,"*.txt"),recursive=True),key = num) totcards = [] graphdata = [] countdata = [] counthands = [] for item in filelist: print(item) with open(item) as f: data = f.readlines() card = Holdcards() h_cards = card.find_holdcards(data) totcards += h_cards i = 0 while len(totcards[count*i:count*(i+1)]) == count: graphdata.append(totcards[count*i:count*(i+1)]) i += 1 for item in graphdata: countdata.append(item.count(hand)) graph= Plotgraph() graph.writehist(countdata,hand,count,len(graphdata)*count) #SW検定-正規化holdcards.pyclass Holdcards: def __init__(self): self.trump={"A":"14","K":"13","Q":"12","J":"11","T":"10","9":"9","8":"8","7":"7","6":"6","5":"5","4":"4","3":"3","2":"2"} self.r_trump={"14":"A","13":"K","12":"Q","11":"J","10":"T","9":"9","8":"8","7":"7","6":"6","5":"5","4":"4","3":"3","2":"2"} self.hands = 0 self.tothands = 0 self.handlist = [] def find_holdcards(self,data): holdcards = [] for item in data: if 'Dealt to' in item: item = item[-7:-2] if item[1] == item[4]: if int(self.trump.get(item[0])) > int(self.trump.get(item[3])): item = item[0] + item[3] + 's' else: item = item[3] + item[0] + 's' else: if int(self.trump.get(item[0])) > int(self.trump.get(item[3])): item = item[0] + item[3] + 'o' elif item[0] == item[3]: item = item[0] + item[3] else: item = item[3] + item[0] + 'o' holdcards.append(item) return holdcardsplotgraph.pyimport numpy as np import pandas as pd import scipy.stats as st import math import matplotlib.pyplot as plt import matplotlib.ticker as ticker import matplotlib.transforms as ts class Plotgraph: def __init__(self): pass def writehist(self,countdata,hand,count,tothands):# 平均mu、標準偏差sig、正規乱数の個数n df = pd.DataFrame( {'p1':countdata} ) target = 'p1' # データフレームのなかでプロット対象とする列 # (1) 統計処理 mu = round(df[target].mean(),2) # 平均 sig = round(df[target].std(ddof=0),2)# 標準偏差:ddof(自由度)=0 print(f'■ 平均:{df[target].mean():.2f}、標準偏差:{df[target].std(ddof=0):.2f}') ci1, ci2 = (None, None) # グラフ描画パラメータ x_min = round(mu - 3*sig) x_max = round(mu + 3*sig) # プロットする点数範囲(下限と上限) j = 10 # Y軸(度数)刻み幅 k = 1 # 階級 bins = int((x_max - x_min)/k) # 区間の数 (x_max-x_min)/k (100-40)/5->12 d = 0.001 #ここから描画処理 plt.figure(dpi=96) plt.xlim(x_min,x_max) hist_data = plt.hist(df[target], bins=bins, color='tab:cyan', range=(x_min, x_max), rwidth=0.9) n = len(hist_data[0]) # 標本の大きさ plt.title("hand = "+hand+" , totalhands = "+str(tothands)) # (2) ヒストグラムの描画 plt.gca().set_xticks(np.arange(x_min,x_max-k+d, k)) # 正規性の検定(有意水準5%) _, p = st.shapiro(hist_data[0]) print(hist_data[0]) print(st.shapiro(hist_data[0])) if p >= 0.05 : print(f' - p={p:.2f} ( p>=0.05 ) であり母集団には正規性があると言える') U2 = df[target].var(ddof=1) # 母集団の分散推定値(不偏分散) print(U2) DF = n-1 # 自由度 SE = math.sqrt(U2/n) # 標準誤差 print(SE) ci1,ci2 = st.t.interval( alpha=0.95, loc=mu, scale=SE, df=DF ) else: print(f' ※ p={p:.2f} ( p<0.05 ) であり母集団には正規性があるとは言えない') # (3) 正規分布を仮定した近似曲線 sig = df[target].std(ddof=1) # 不偏標準偏差:ddof(自由度)=1 nx = np.linspace(x_min, x_max+d, 150) # 150分割 ny = st.norm.pdf(nx,mu,sig) * k * len(df[target]) plt.plot( nx , ny, color='tab:blue', linewidth=1.5, linestyle='--') # (4) X軸 目盛・ラベル設定 plt.xlabel('total"'+str(hand)+'"/'+str(count)+'hands',fontsize=12) plt.gca().set_xticks(np.arange(x_min,x_max+d, k)) # (5) Y軸 目盛・ラベル設定 y_max = max(hist_data[0].max(), st.norm.pdf(mu,mu,sig) * k * len(df[target])) y_max = int(((y_max//j)+1)*j) # 最大度数よりも大きい j の最小倍数 plt.ylim(0,y_max) plt.gca().set_yticks( range(0,y_max+1,j) ) plt.ylabel('Accumulation',fontsize=12) # (6) 平均点と標準偏差のテキスト出力 tx = 0.03 # 文字出力位置調整用 ty = 0.91 # 文字出力位置調整用 tt = 0.08 # 文字出力位置調整用 tp = dict( horizontalalignment='left',verticalalignment='bottom', transform=plt.gca().transAxes, fontsize=11 ) plt.text( tx, ty, f'average {mu:.2f}', **tp) plt.text( tx, ty-tt, f'deviation {sig:.2f}', **tp) plt.text( tx, ty-tt-tt, f'P-value {p:.2f}', **tp) plt.vlines( mu, 0, y_max, color='black', linewidth=1 ) plt.show()
- 投稿日:2020-09-27T16:37:17+09:00
AWS Cloud9でオウム返しLINE Botを作る
はじめに
AWS Cloud9 の
SAM Localを使い、オウム返しするLINE Botを作るメモ構成図
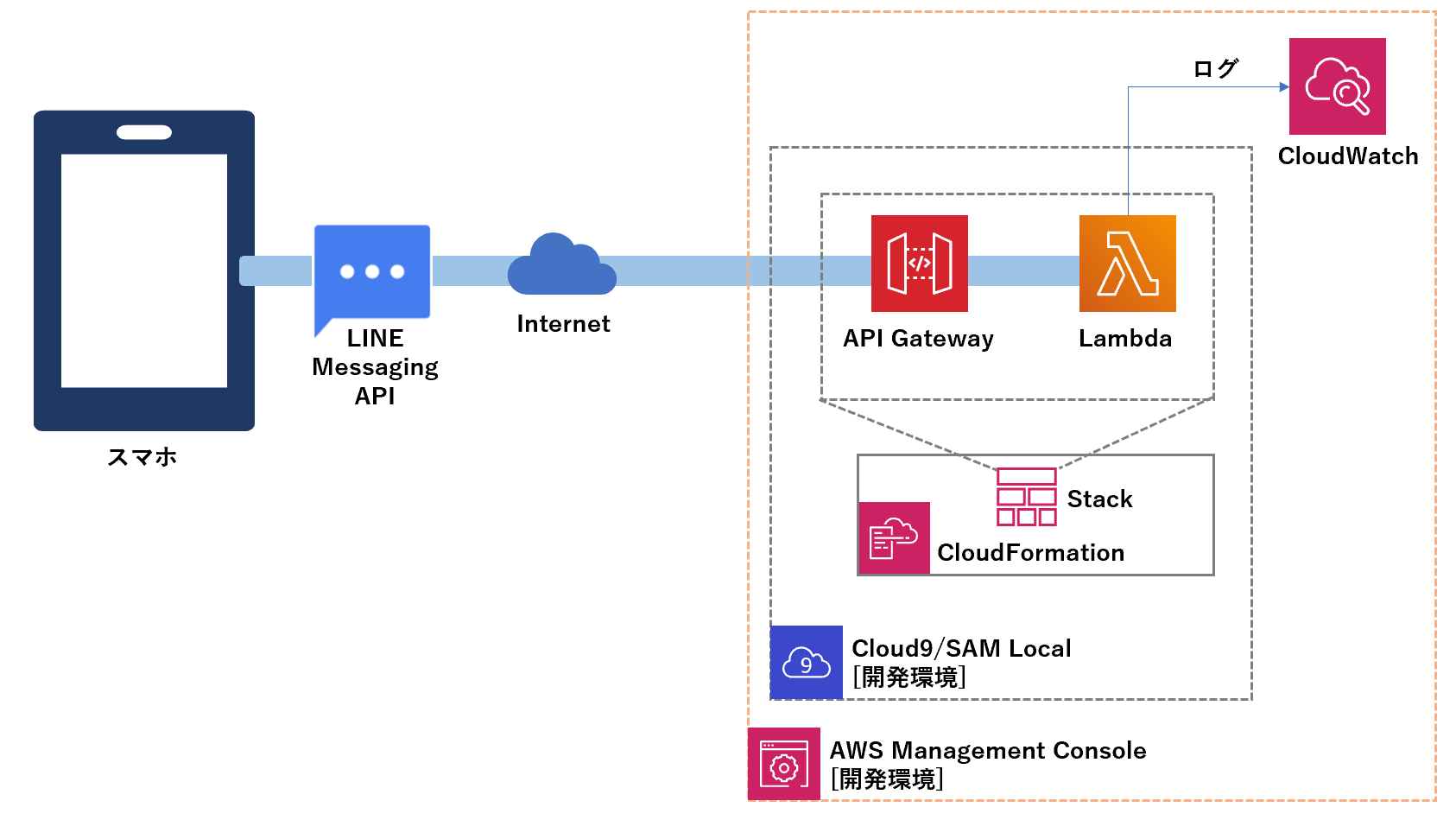
こんなの作ります。
手順の概要
- [LINE Developers] プロバイダー作成
- [LINE Developers] 作成したプロバイダーにチャネルを設定
- [LINE Developers] 作成したチャネルで2つの情報を取得
- チャネルアクセストークン
- チャネルシークレット
- [AWS] Cloud9環境を用意する(東京リージョン: ap-northeast-1)
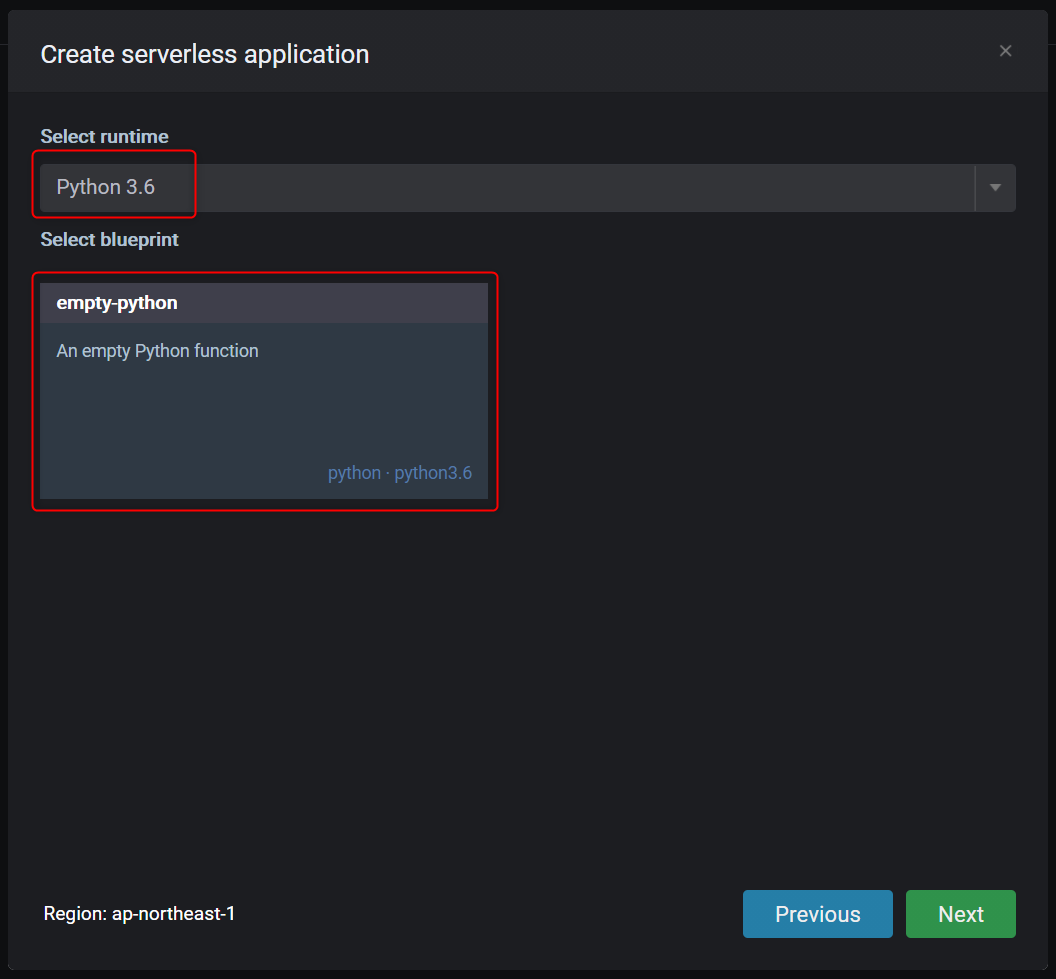
- [AWS-Cloud9] Lambdaを作成する
- Function name
- Application name
- [AWS] Lambdaスクリプト更新
- [AWS] Lambdaに環境変数を設定
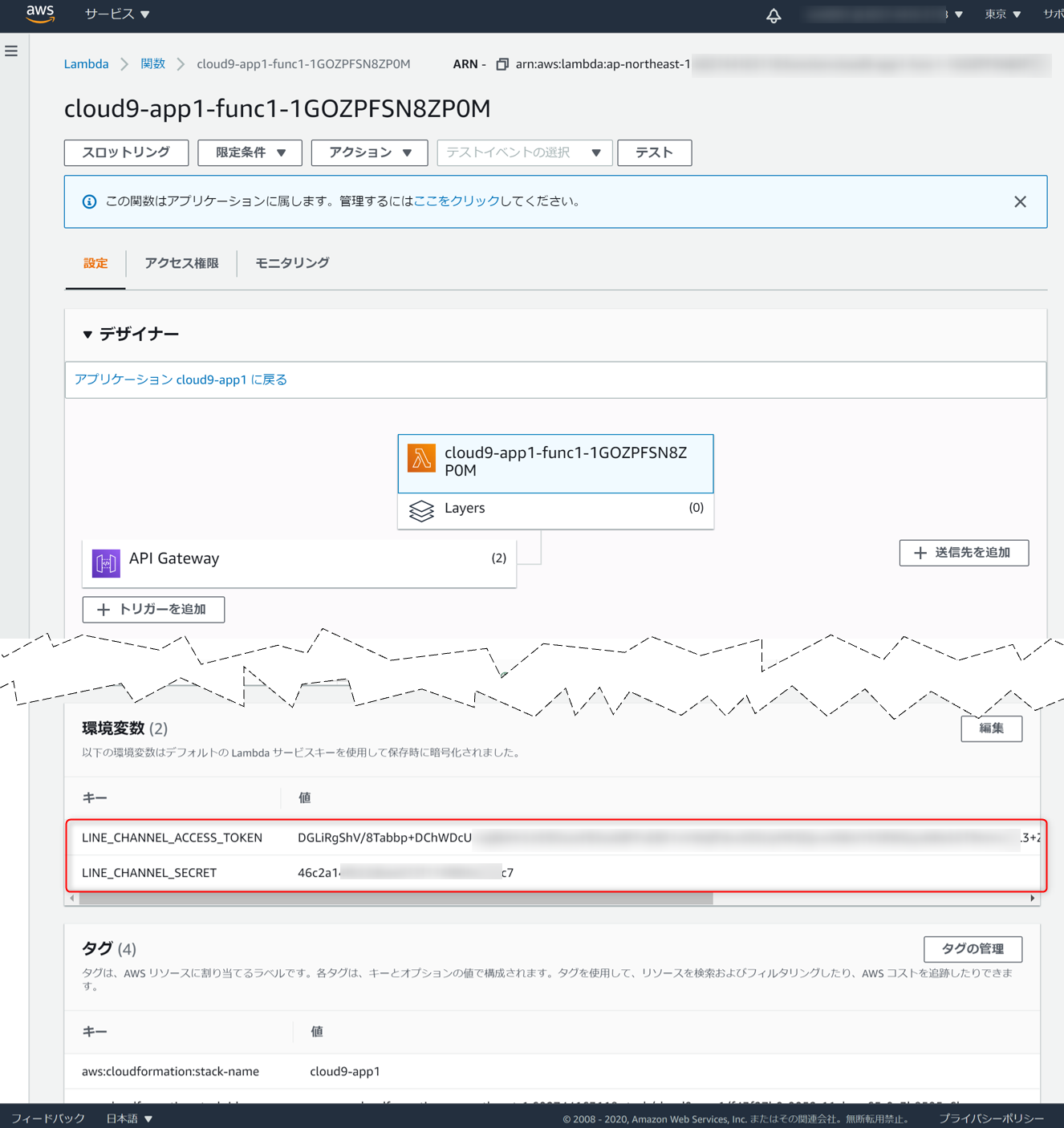
- LINE_CHANNEL_SECRET (チャネルシークレット)
- LINE_CHANNEL_ACCESS_TOKEN (チャネルアクセストークン)
- [AWS] API GatewayのURL呼び出し を確認
- [LINE Developers] チャネルの設定更新
- Webhook URL (← API GatewayのURL呼び出し)
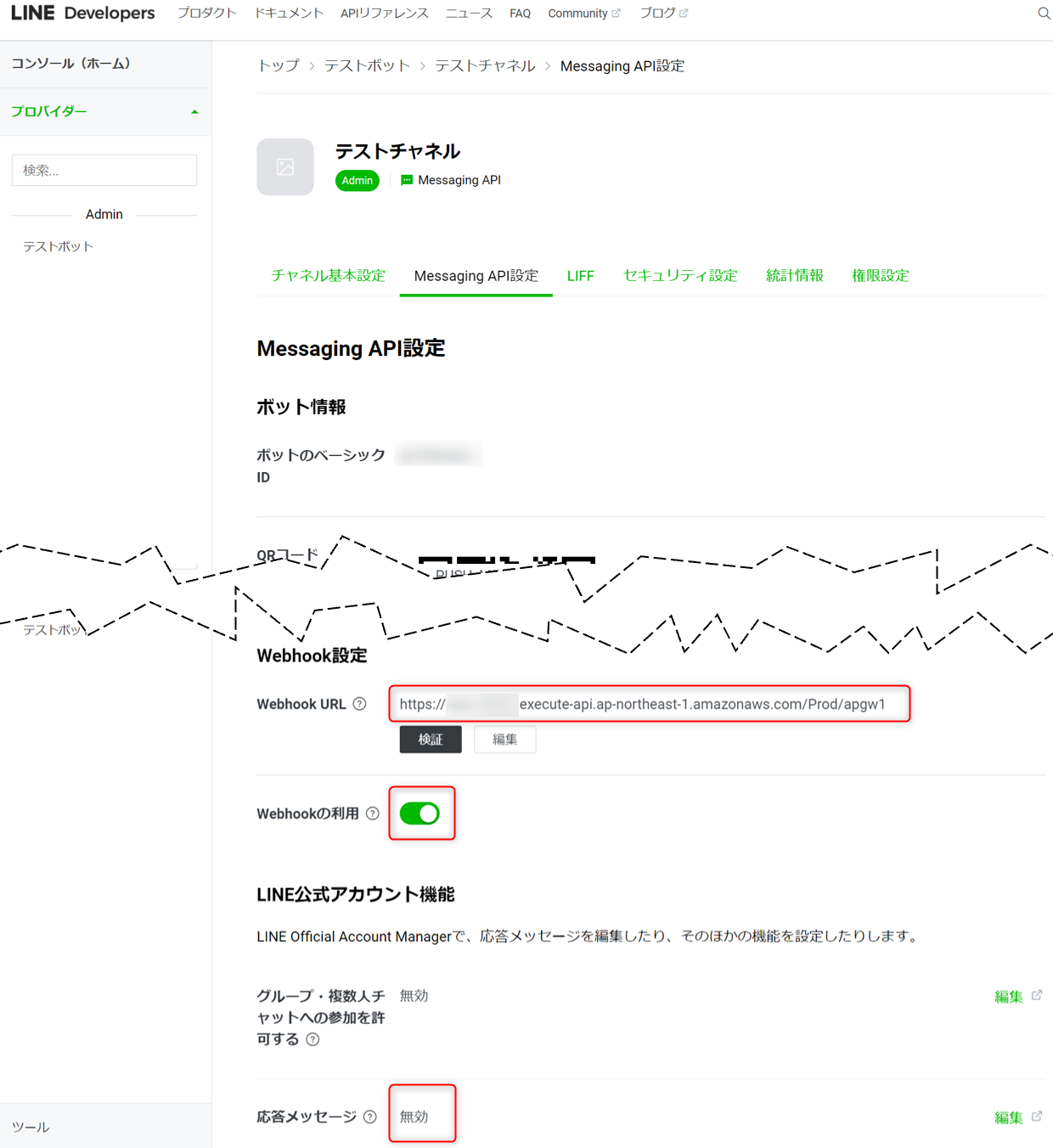
- Webhookの利用 無効->有効
- 応答メッセージ 有効->無効
参考
- LINE Messaging API × AWS Lambdaによる簡易応答システム #2-appx1: 署名検証
- 主にLambdaスクリプトを参考にさせて頂きました。
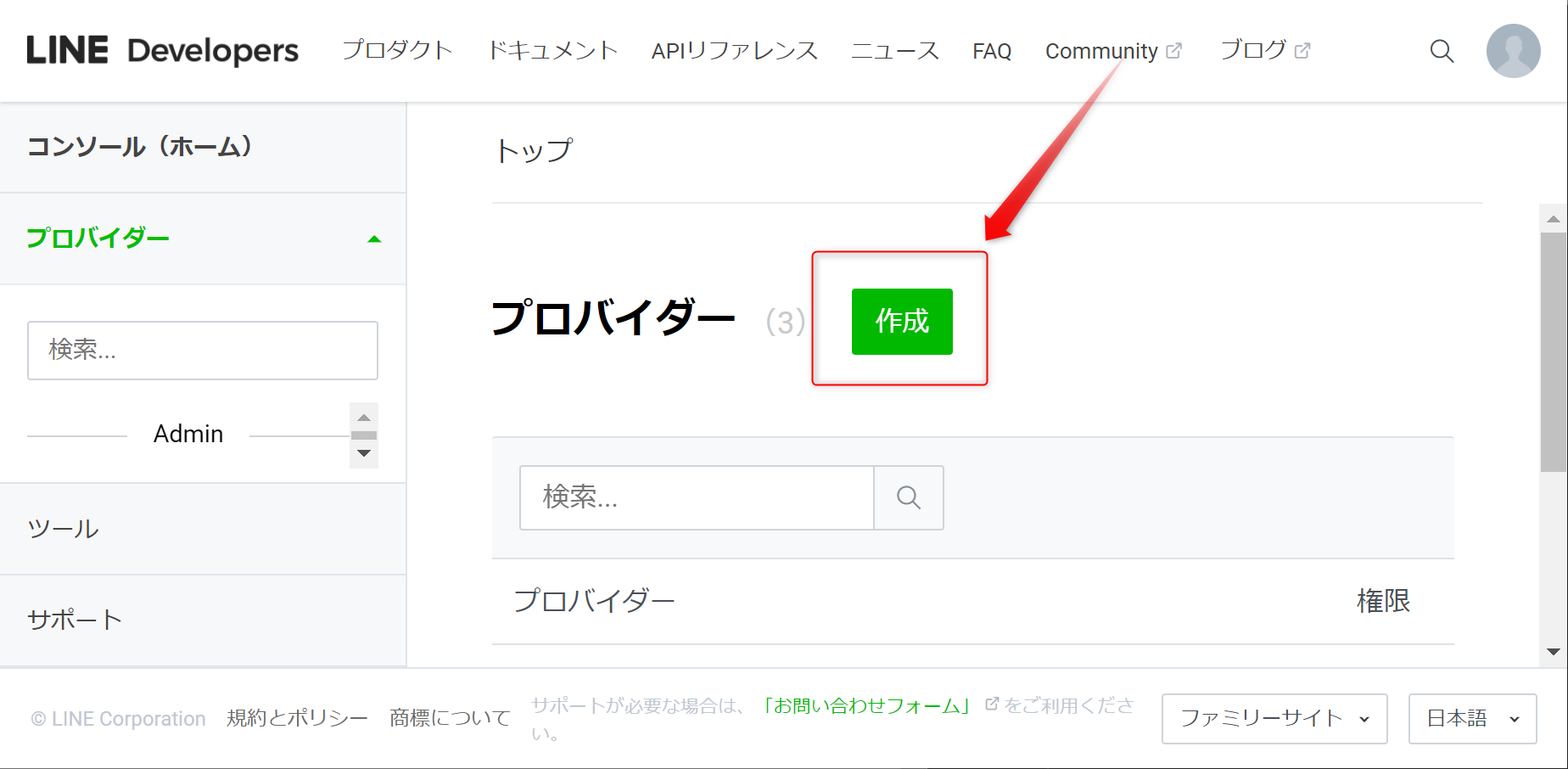
1.[LINE Developers] プロバイダー作成
LINE Developersでプロバイダーを作成します。
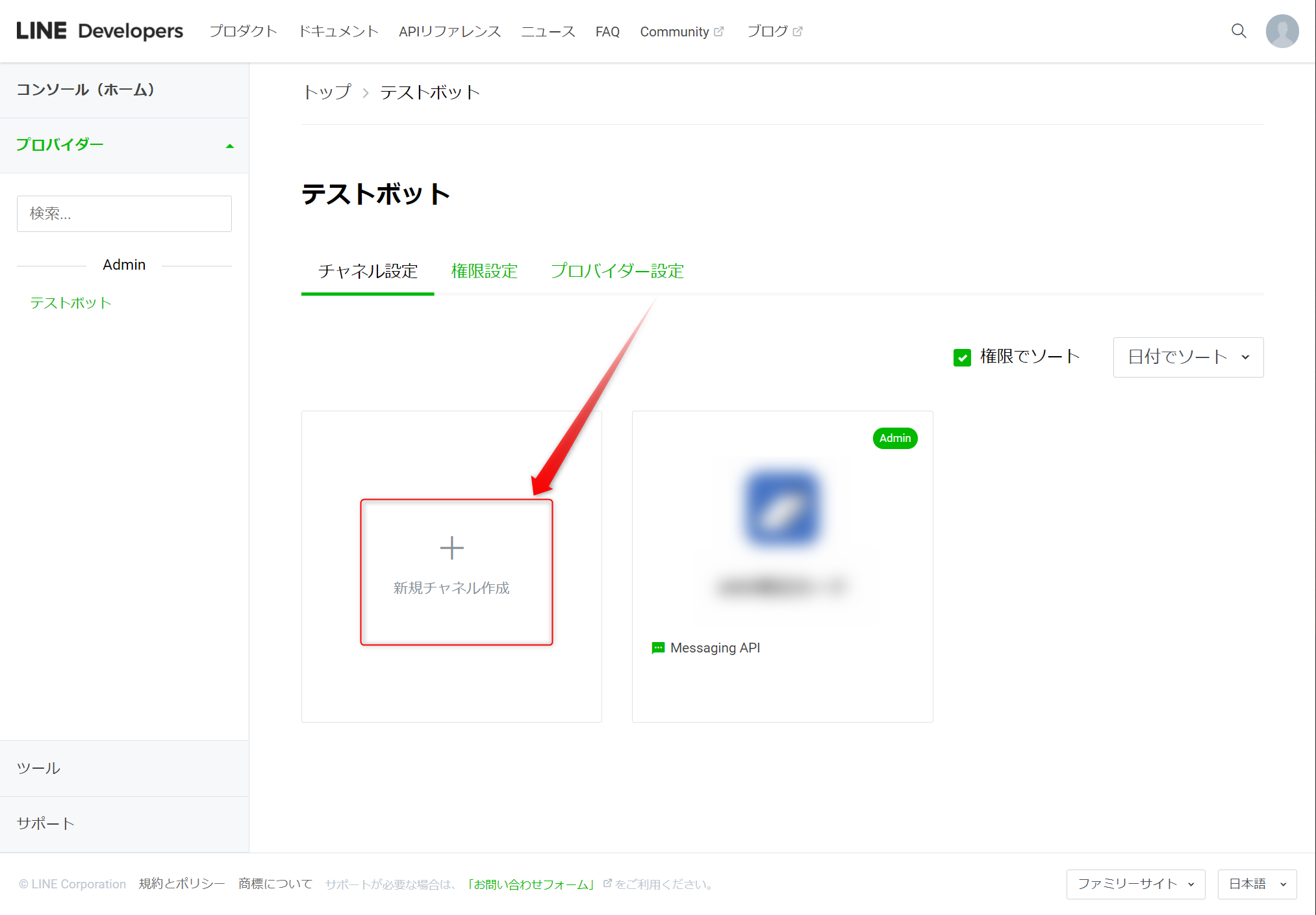
2.[LINE Developers] 作成したプロバイダーにチャネルを設定
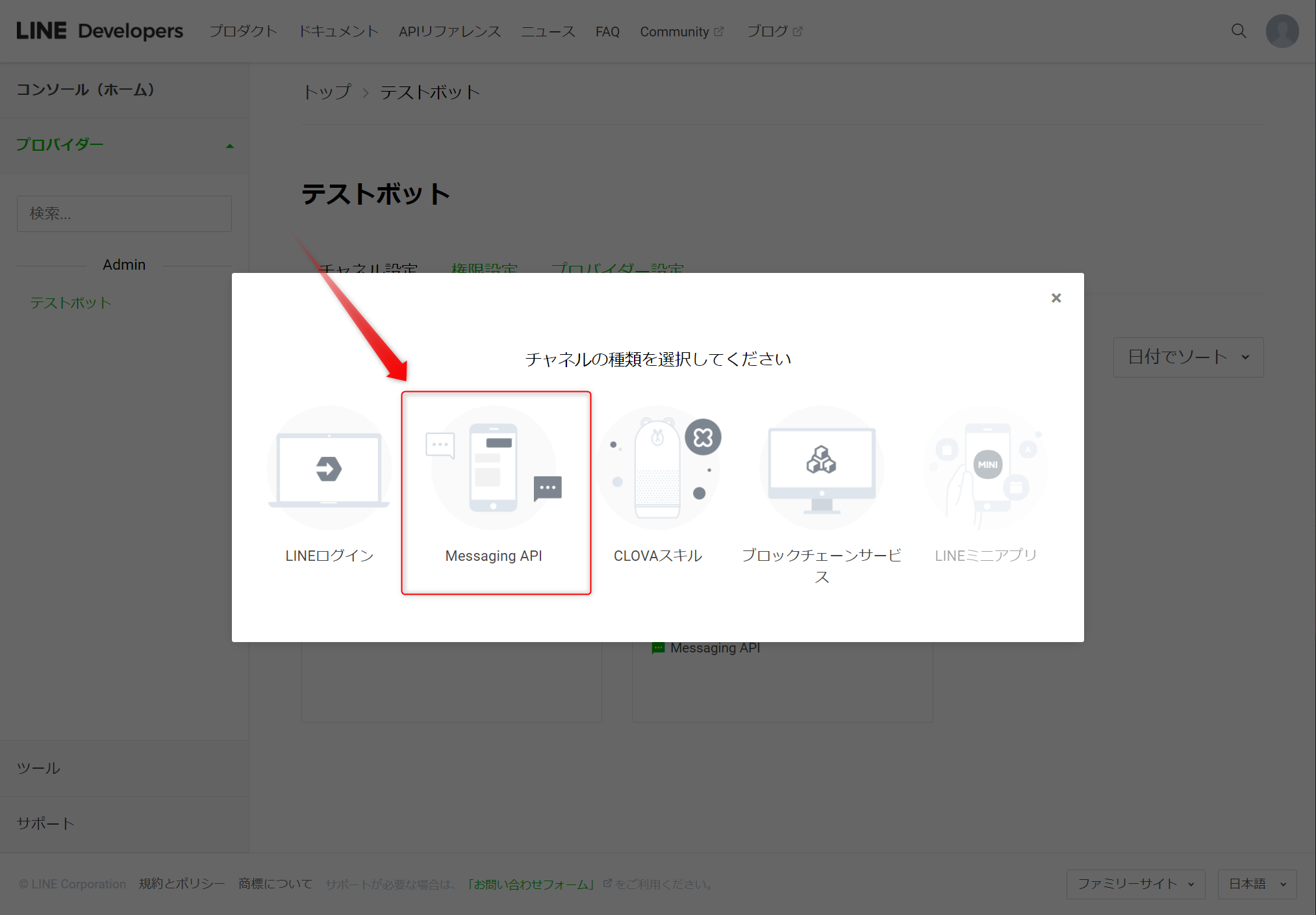
先ほど作成したプロバイダーにチャネルを設定します。
Messaging APIを選択します。
3.[LINE Developers] 作成したチャネルで2つの情報を取得
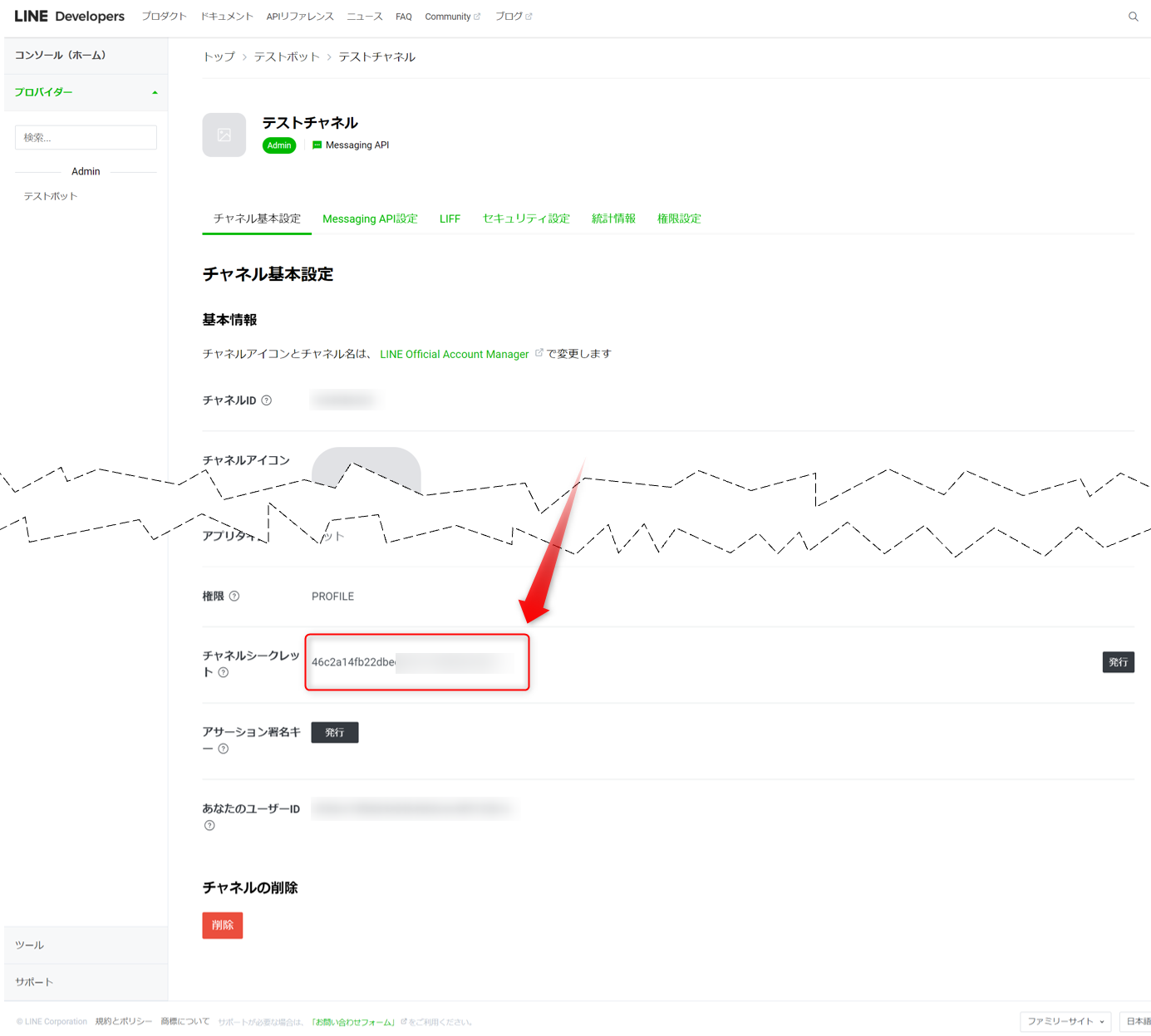
チャネルシークレット、チャネルアクセストークンの情報を取得します。
チャネルシークレットの情報
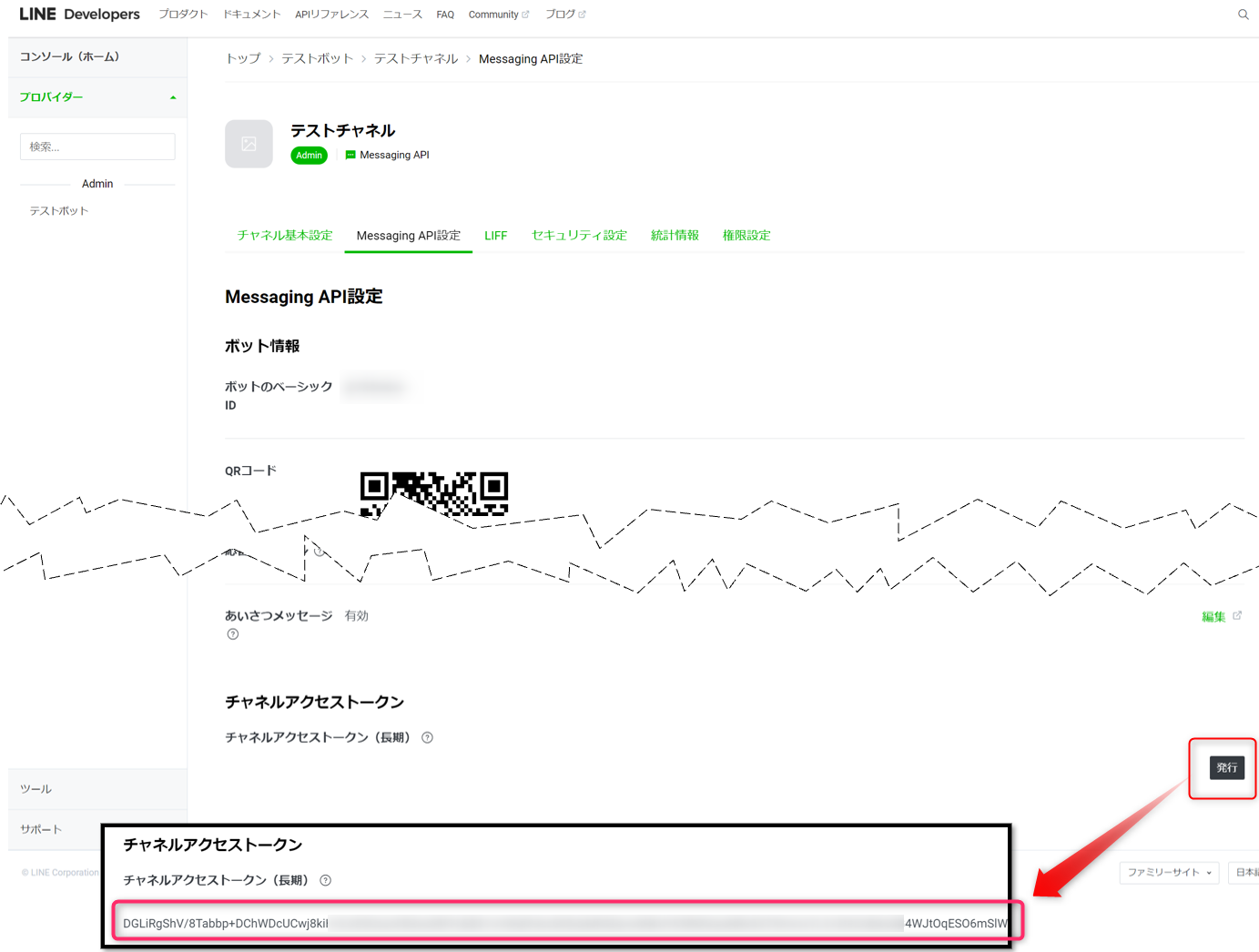
チャネルアクセストークンの情報は、発行ボタンをクリックします。
4.[AWS] Cloud9環境を用意する
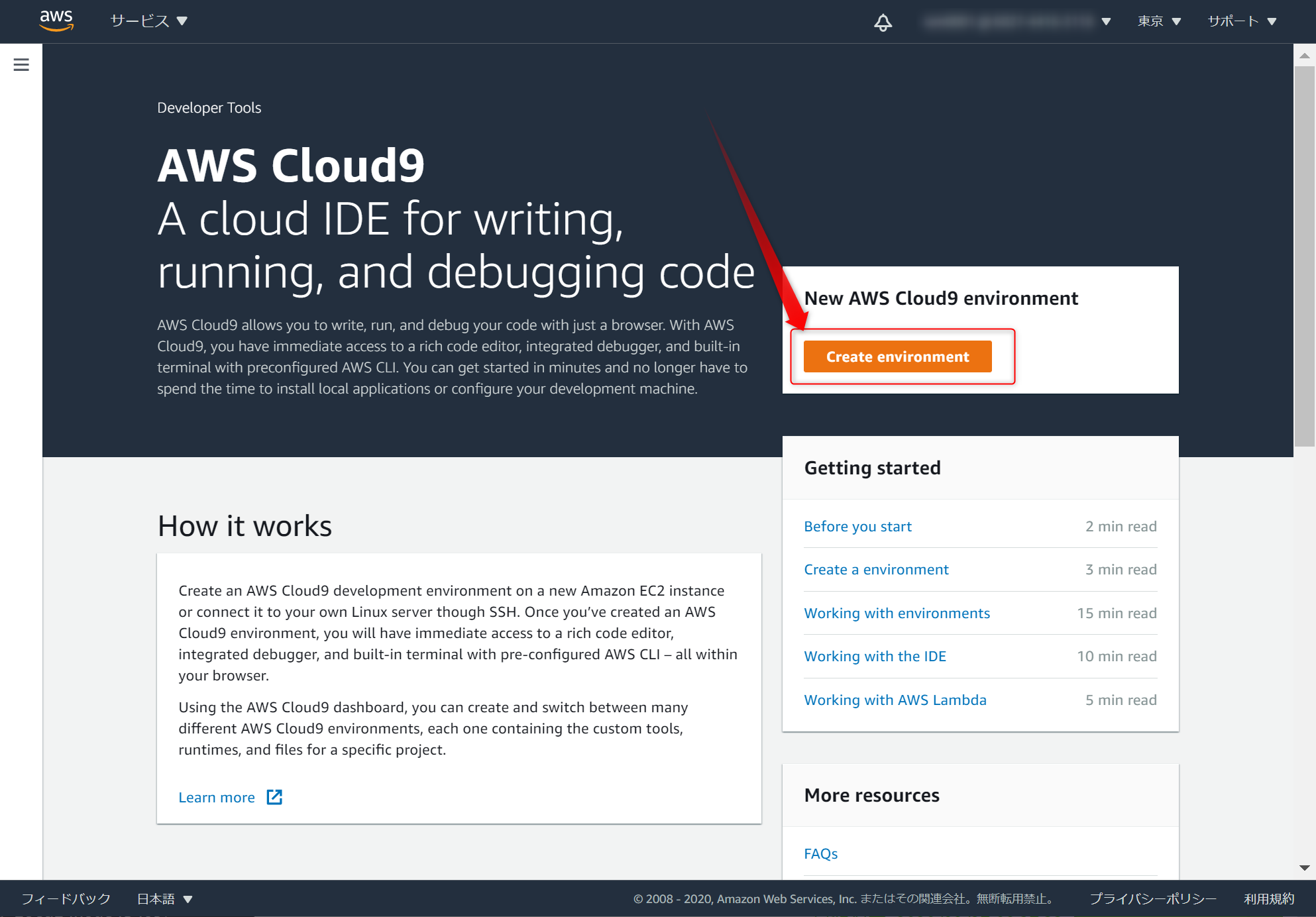
AWSコンソールで、Cloud9を作ります。東京リージョン(ap-northeast-1)で作成しました。
5.[AWS-Cloud9] Lambdaを作成する
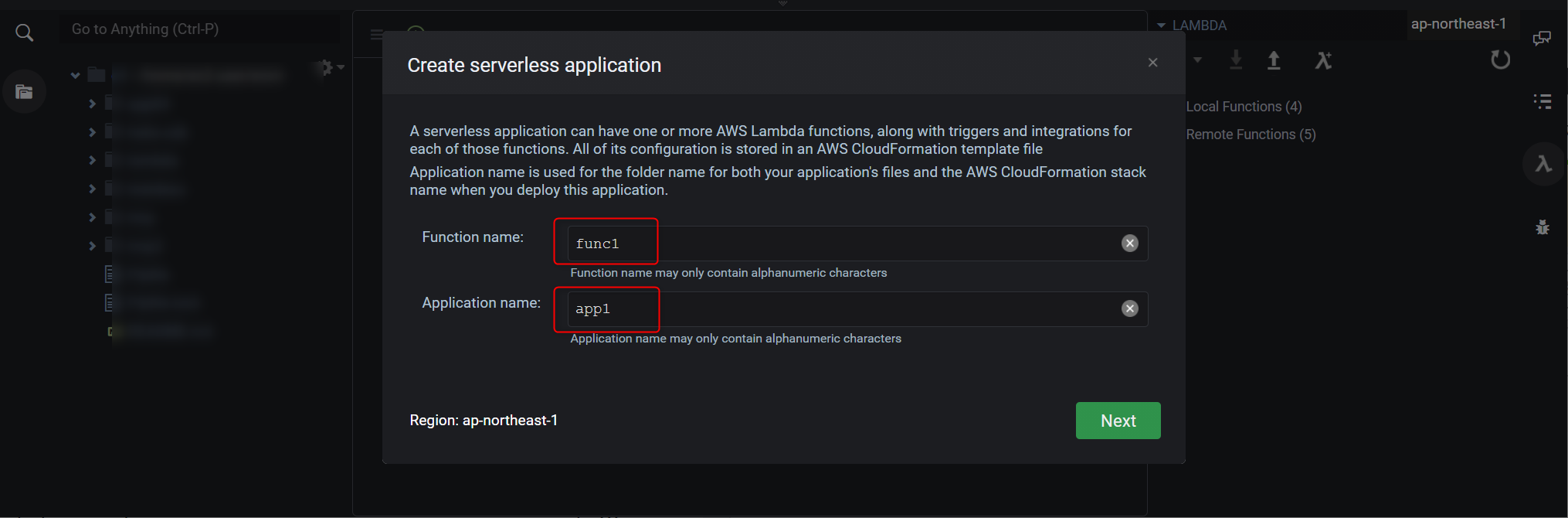
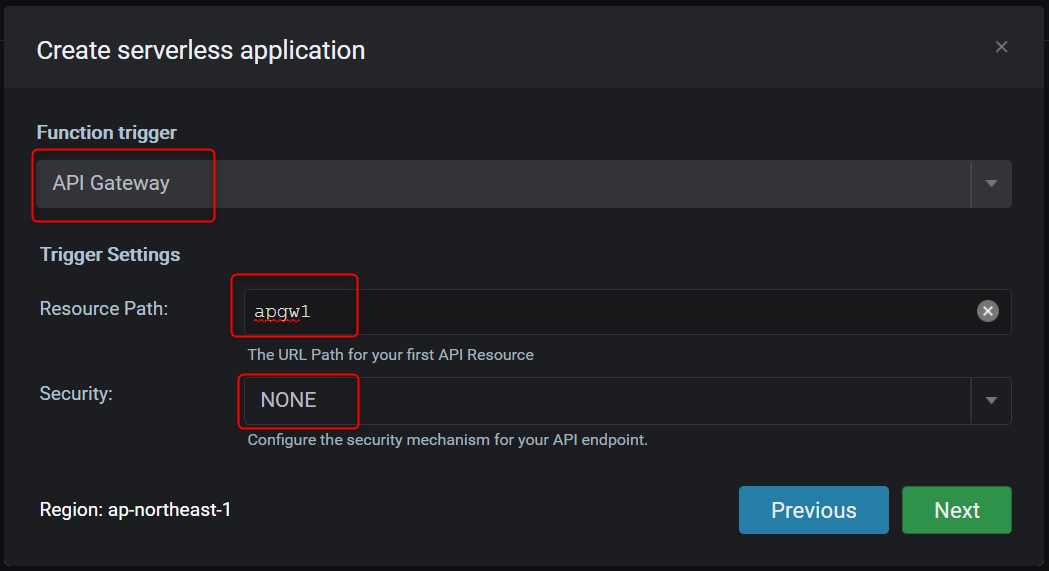
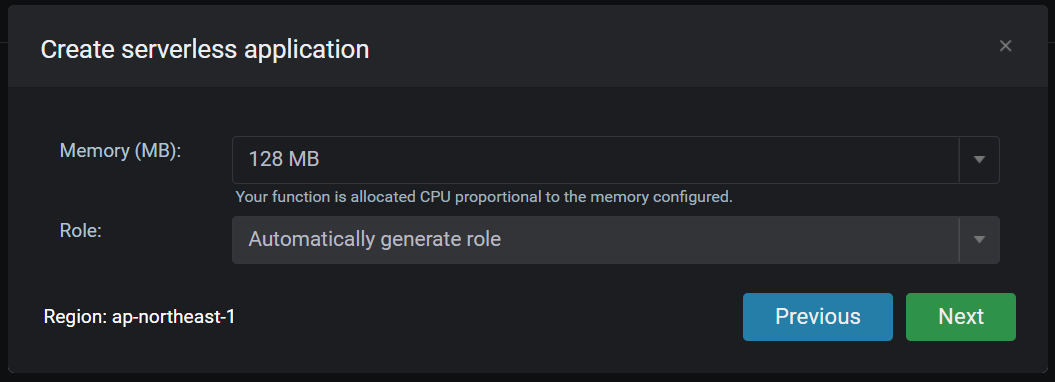
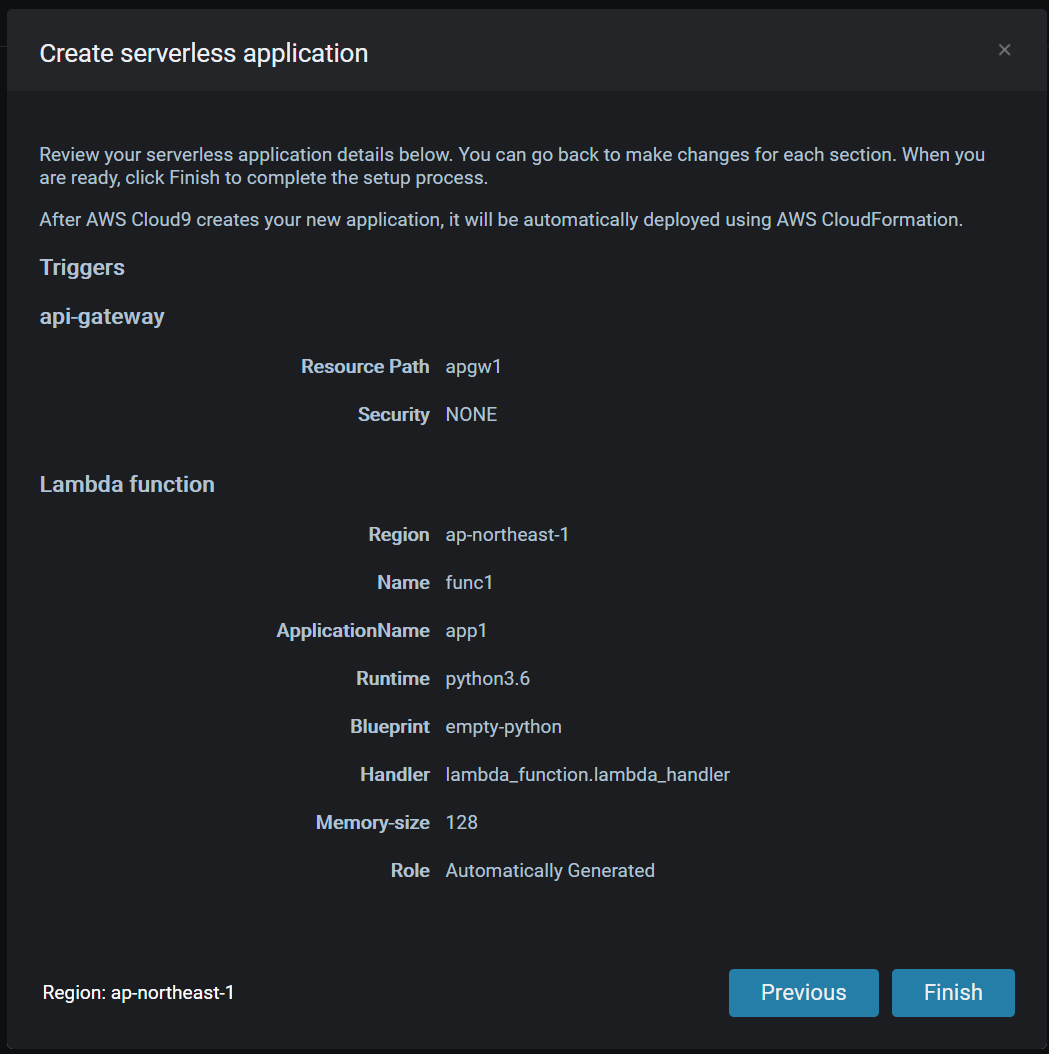
SAM Localを使いLambdaを作成します。Cloud9の右側にある
λ->λ+とクリックし、新規作成します。
赤枠の欄に、任意の文字列を設定し
Nextボタンをクリック
Pythonを選択しました。
API Gatewayもまとめて作成します。
デフォルト設定にしました。
Finishボタンをクリックすると作成が開始されます。
作成が完了すると、このような画面になります。
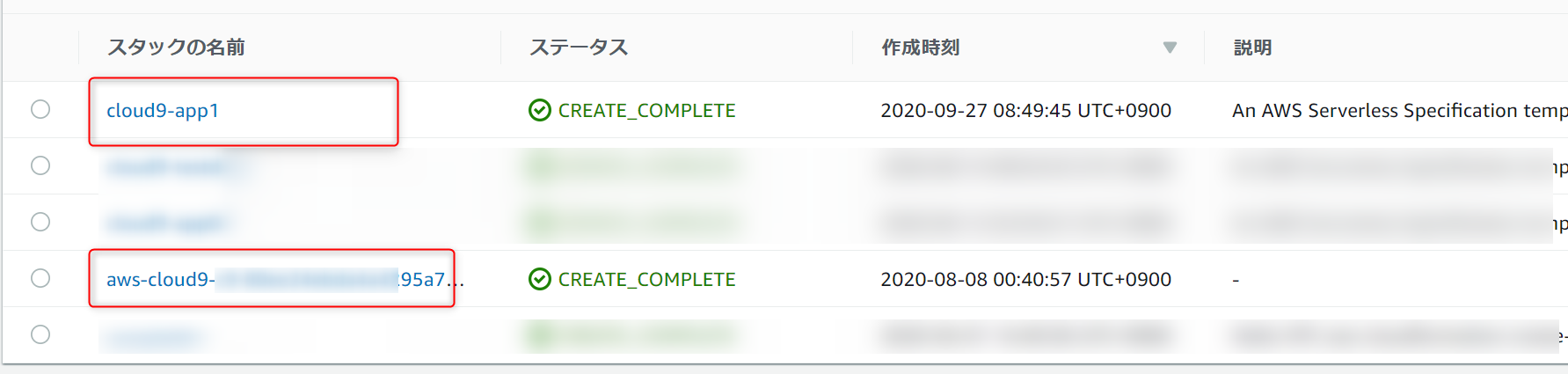
※余談※ [AWS] 作成したAWSリソース確認
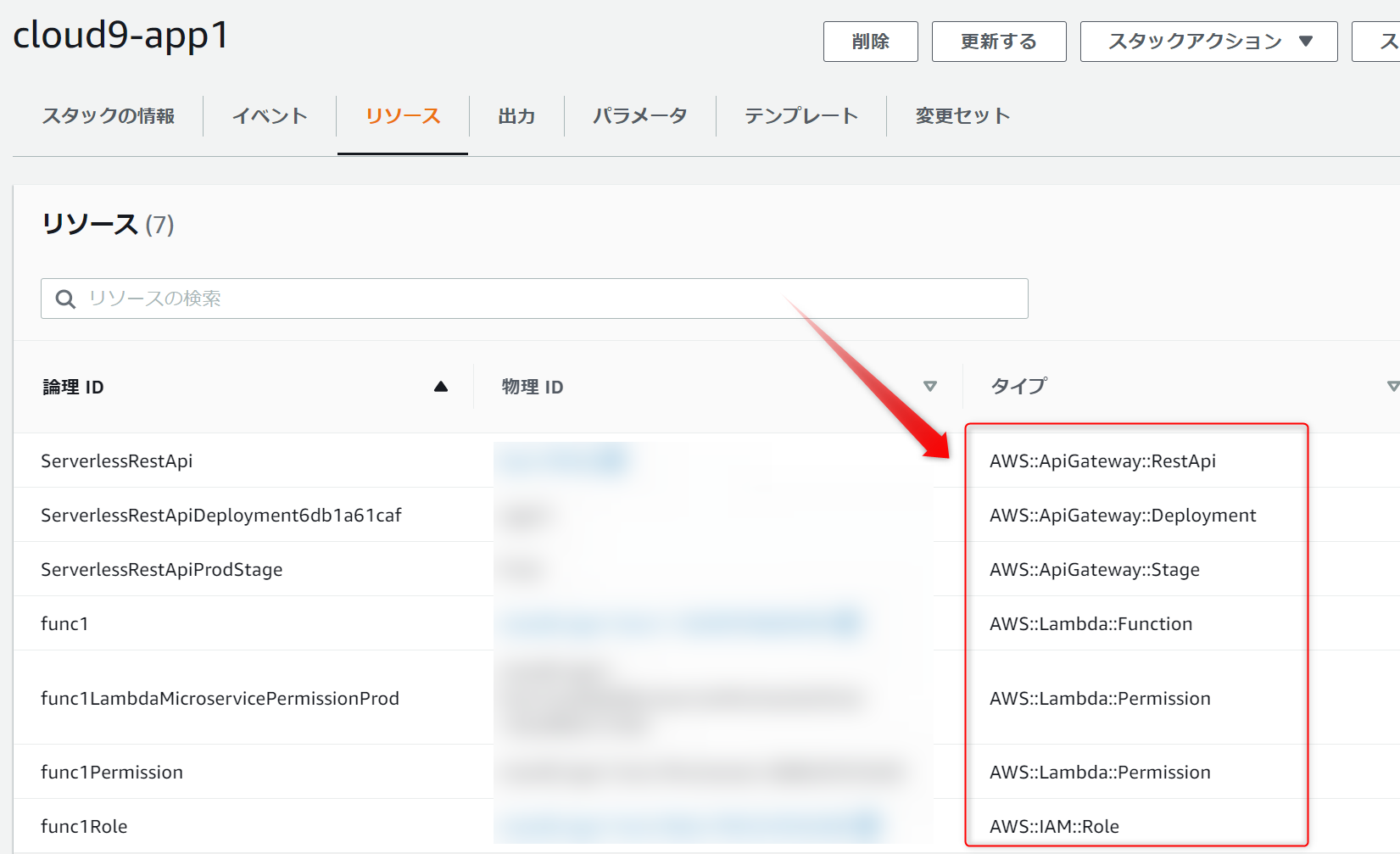
これまでで作成したAWSリソースは、CloudFormationスタックで確認できます。2つのスタックが作られていて、最初のスタック(aws-cluod9-xxx)は、Cloud9を作成したときのスタック、次のスタック(cloud9-app1)は、Lambdaを作ったときのスタックです。
Lambdaを作ったときのスタックのリソースタブで作成されたAWSリソースを確認できます。
6.[AWS] Lambdaスクリプト更新
今あるLambdaスクリプトを全て削除し、以下のスクリプトをコピーします。
Lambdaスクリプト# 環境変数 # LINE_CHANNEL_SECRET チャネルシークレット # LINE_CHANNEL_ACCESS_TOKEN チャネルアクセストークン import json import os import logging import urllib.request import base64 import hashlib import hmac # ログ出力の準備 logger = logging.getLogger() logger.setLevel(logging.INFO) def lambda_handler(event, context): # リクエスト内容をログ出力 logger.info(event) ### # 環境変数からLINEチャネルシークレットを取得 channel_secret = os.environ['LINE_CHANNEL_SECRET'] # LINEチャネルシークレットを鍵として、HMAC-SHA256アルゴリズムを使用してリクエストボディのハッシュ値を算出 hash = hmac.new(channel_secret.encode('utf-8'), event['body'].encode('utf-8'), hashlib.sha256).digest() # ハッシュ値をBase64エンコード signature = base64.b64encode(hash) # X-Line-Signatureを取得 xLineSignature = event['headers']['X-Line-Signature'].encode('utf-8') # 署名の一致を検証し、不一致の場合はログ出力 if xLineSignature != signature: logger.info('署名の不一致') return { 'statusCode': 200, 'body': json.dumps('署名が正しくないみたいだよ。') } ### # 1. Webhookイベントの内容を抽出 body = json.loads(event['body']) for event in body['events']: # 応答用のメッセージオブジェクトのリストを定義 messages = [] # 2. Webhookイベントタイプがmessageであり、 if event['type'] == 'message': # 3. メッセージタイプがtextの場合に、 if event['message']['type'] == 'text': # 4. 受信したテキストの内容をメッセージオブジェクトとする messages.append({ 'type': 'text', 'text': event['message']['text'] }) # 応答メッセージのリクエスト情報を定義 url = 'https://api.line.me/v2/bot/message/reply' headers = { 'Content-Type': 'application/json', # 環境変数からLINEチャネルアクセストークンを取得 'Authorization': 'Bearer ' + os.environ['LINE_CHANNEL_ACCESS_TOKEN'] } data = { # 応答用トークンとメッセージオブジェクトを設定 'replyToken': event['replyToken'], 'messages': messages } request = urllib.request.Request(url, data = json.dumps(data).encode('utf-8'), method = 'POST', headers = headers) with urllib.request.urlopen(request) as response: # レスポンス内容をログ出力 logger.info(response.read().decode("utf-8")) return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') }lambdaスクリプトを更新したら、デプロイボタン(上向きの矢印アイコン)でデプロイします。
7.[AWS] Lambdaに環境変数を設定
AWSコンソールでLambdaを開き、LINE Developersで作成したチャネルの
チャネルシークレットとチャネルアクセストークンを環境変数として設定します。
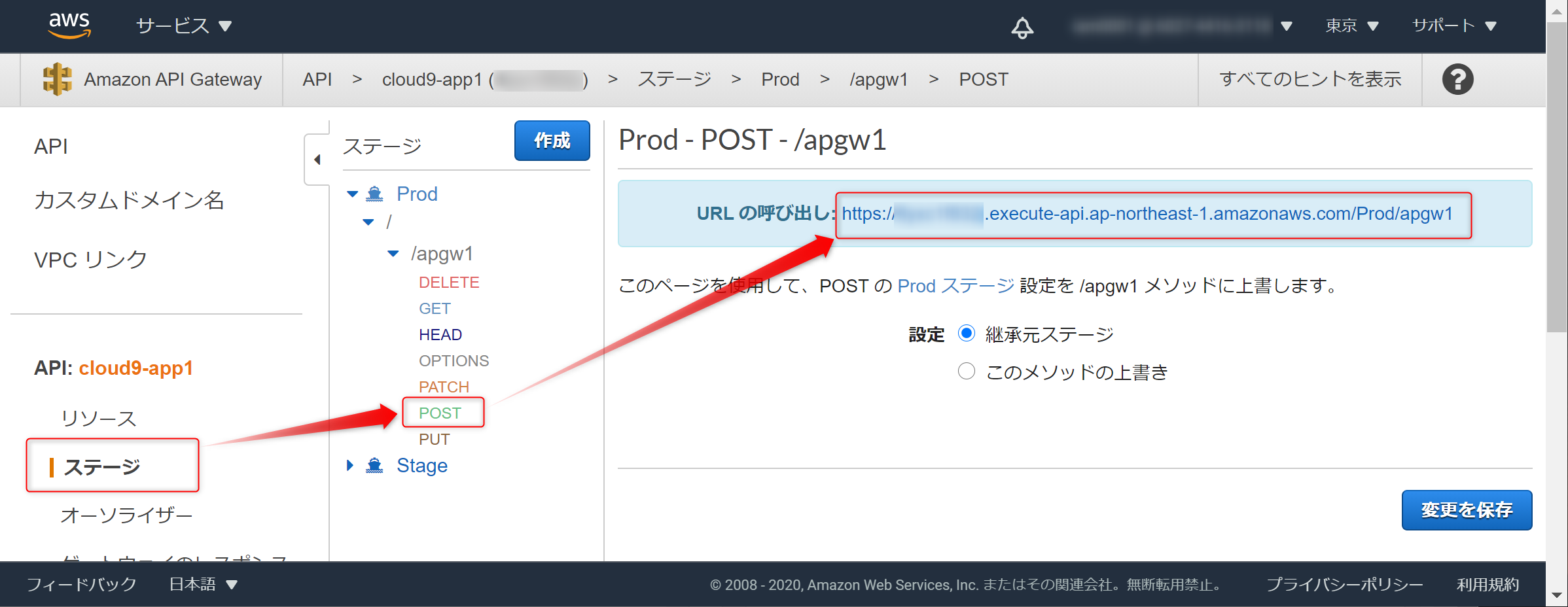
8.[AWS] API GatewayのURL呼び出しを確認
API GatewayのURL呼び出しを確認します。
9.[LINE Developers] チャネルの設定更新
さきほど確認した
API GatewayのURL呼び出しをLINE Developersで作成したチャネルのWebhook URLとして設定とWebhookの利用を有効にします。さらに、応答メッセージを無効にします。
これで『オウム返しのLINE Bot』の設定が完了です。
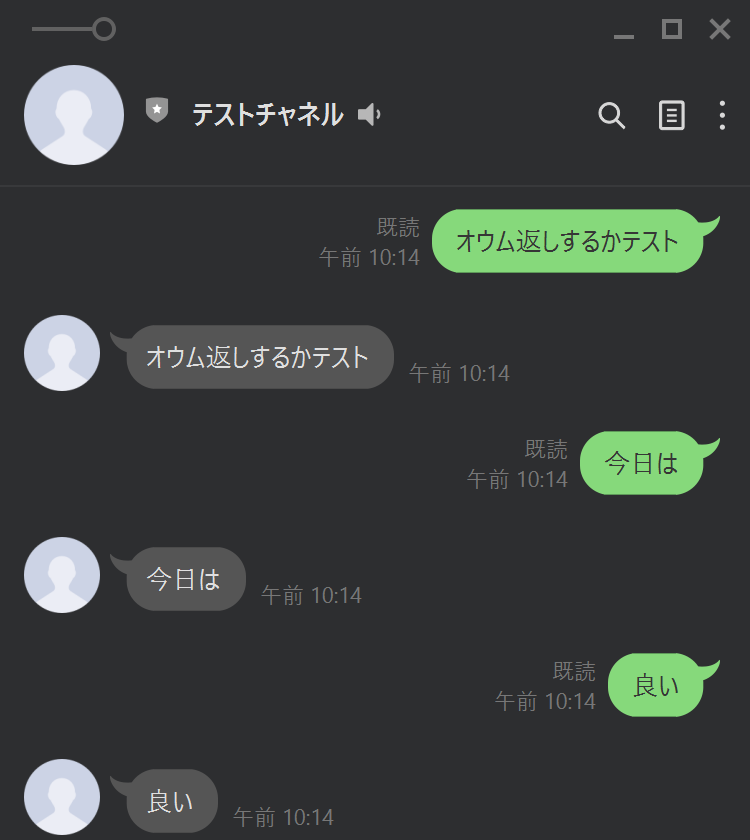
[LINE Bot] 動作確認
作成したチャネルをQRコードから友達登録し、オウム返しするか確認します。
このように、オウム返しをすれば成功
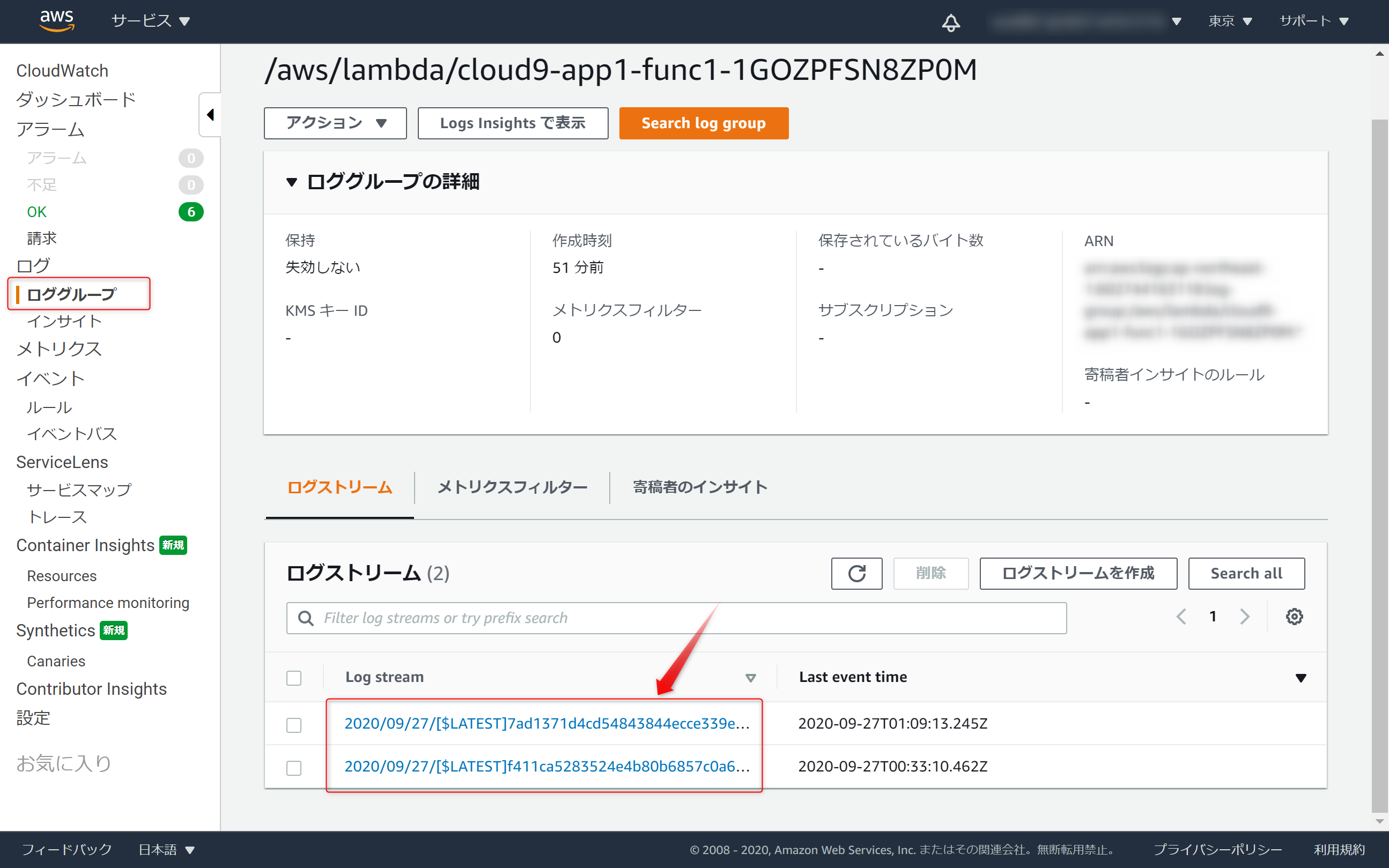
※補足※ [AWS] うまく動かないとき
CloudWatchのロググループでエラーが発生していないか確認するといいことあるかも
今回は、これでおわり


- 投稿日:2020-09-27T16:22:00+09:00
[cx_Oracle入門](第17回) 日付型のハンドリング
連載目次
検証環境
- Oracle Cloud利用
- Oracle Linux 7.7 (VM.Standard2.1)
- Python 3.8
- cx_Oracle 8.0
- Oracle Database 19.5 (ATP, 1OCPU)
- Oracle Instant Client 18.5
事前準備
下記テーブルの作成を実施してください。
sample17.sqlcreate table sample17( col_date date , col_ts timestamp(9) , col_tz timestamp(9) with time zone );DATE型の基本ハンドリング
第6回や第9回でも解説していますが、DATE型に対応するPythonの型はdatetime.datetimeになります。
DATE型に関しては、datetime.datetimeと受け渡しさせることで、普通にDBとのやり取りが可能です。
また、datetime.datetimeはマイクロ秒までの値をハンドリングできますが、DATE型は秒までしかハンドリングできないため、秒未満の値は切り捨てられます。
以下サンプルと実行結果です。
SELECT時に1日進めた値を取得して、異なる値を参照していることがわかるようにしています。sample17a.pyimport cx_Oracle import datetime USERID = "admin" PASSWORD = "FooBar" DESTINATION = "atp1_low" SQL1 = "insert into sample17(col_date) values(:now)" SQL2 = "select col_date + 1 from sample17" sys_date = datetime.datetime.now() print("APの値 :", sys_date) with cx_Oracle.connect(USERID, PASSWORD, DESTINATION) as conn: with conn.cursor() as cur: cur.execute("truncate table sample17") cur.execute(SQL1, [sys_date]) conn.commit() val = cur.execute(SQL2).fetchone()[0] print("DBの値 :", val.strftime("%Y-%m-%d %H:%M:%S.%f"))$ python sample17a.py APの値 : 2020-09-26 10:48:02.605423 DBの値 : 2020-09-27 10:48:02.000000TIMESTAMP型の基本ハンドリング
DATE型と同様、TIMESTAMP型も対応するPythonの型はdatetime.datetimeになります。
だたし、INSERTに関してはDATE型に比べて追加コーディングが必要です。
DATE型と同じコーディングだと、DATE型と同様に扱われてしまい、秒未満の値が切り捨てられてしまいます。
現時点では、
- Prepared Statementを使用する
- Cursor.setinputsizes()で該当するバインド変数がcx_Oracle.DB_TYPE_TIMESTAMPのサイズであることを指定する
- SQLを実行する
という記述が必要です。
以下サンプルと実行結果です。
なお、1日進めるSQL文がDATE型と異なりINTERVALを使用しているのは、「+ 1」だとDATE型にキャストされてしまい、秒未満の値が切り捨てられるためです。sample17b.pyimport cx_Oracle import datetime USERID = "admin" PASSWORD = "FooBar" DESTINATION = "atp1_low" SQL1 = "insert into sample17(col_ts) values(:now)" SQL2 = "select col_ts + interval '1' day from sample17" sys_date = datetime.datetime.now() print("APの値 :", sys_date) with cx_Oracle.connect(USERID, PASSWORD, DESTINATION) as conn: with conn.cursor() as cur: cur.execute("truncate table sample17") cur.prepare(SQL1) cur.setinputsizes(now=cx_Oracle.DB_TYPE_TIMESTAMP) cur.execute(None, {"now":sys_date}) conn.commit() val = cur.execute(SQL2).fetchone()[0] print("DBの値 :", val.strftime("%Y-%m-%d %H:%M:%S.%f"))$ python sample17b.py APの値 : 2020-09-26 23:51:27.832640 DBの値 : 2020-09-27 23:51:27.832640TIMESTAMP WITH TIME ZONE型、TIMESTAMP WITH LOCAL TIME ZONE型の基本ハンドリング
これらのデータ型は、TIMESTAMP型と同様のコーディングでハンドリングできます。
Cursor.setinputsizes()で指定する型を、それぞれcx_Oracle.DB_TYPE_TIMESTAMP_TZ、cx_Oracle.DB_TYPE_TIMESTAMP_LTZにしてください。
ただし、執筆時点ではnativeではなくawareなdatetimeを定義することで更新は行えますが、SELECTの場合、nativeなdatetimeで受けてしまうためにタイムゾーンの情報が落ちてしまいます。マニュアルを確認する限りでは、残念ながらCurosr.var()を使用してもawareなdatetimeで受ける設定はない模様です。
ですのでこれらのデータ型を使用する場合、cx_Oracleによるタイムゾーンの差異の吸収に期待せず、PythonもしくはSQLにてタイムゾーンの差異を意識したコーディング(自分でタイムゾーンの差異を計算する)を行うか、文字列(例えばISO 8601形式)を介してPythonとSQLの間を受け渡すようにしてください。
以下はISO 8601形式の日付文字列を使用した場合のサンプルです。sample17c.pyimport cx_Oracle import datetime USERID = "admin" PASSWORD = "FooBar" DESTINATION = "atp1_low" SQL1 = "insert into sample17(col_tz) values(to_utc_timestamp_tz(:now))" SQL2 = f"select to_char(col_tz + interval '1' day, 'YYYY-MM-DD\"T\"HH24:MI:SS.ff6\"Z\"') from sample17" sys_date = datetime.datetime.utcnow().replace(tzinfo=datetime.timezone.utc).isoformat() print("APの値 :", sys_date) with cx_Oracle.connect(USERID, PASSWORD, DESTINATION) as conn: with conn.cursor() as cur: cur.execute("truncate table sample17") cur.execute(SQL1, [sys_date]) conn.commit() val = cur.execute(SQL2).fetchone()[0] print("DBの値 :", val)$ python sample17c.py APの値 : 2020-09-27T07:05:42.948348+00:00 DBの値 : 2020-09-28T07:05:42.948348Z
- 投稿日:2020-09-27T16:13:47+09:00
全国医療AIコンテスト 2020 1st place solution
0.はじめに
大阪大学AI & Machine learning Society(AIMS)主催、全国医療AIコンテスト 2020という医療テーブルデータコンペで優勝(1st place, top 6%)したので、解法を投稿します。
今までの記事をご覧いただいている方はご存知かもしれませんが、僕は画像データ専門でやっているので、テーブルデータのコンペはあまり得意ではありません。
間違っている所、合理的でない部分もあるかと思いますがご了承ください。また、本記事は基本的にはコンペに参加された方に対して書いています。具体的な列名・特徴量について説明はありませんので、そういった部分は読み飛ばして頂いて構いません。(手法的な部分に関しては、ある程度詳しく説明しています!)
同様に、プライベートなコンペであったことから、参加者以外のコンペサイトへのアクセスは出来ませんので、ご了承ください。
1.コンペについて
1-1.コンペ概要
コンペはCOVID-19罹患者の死亡予測に関するテーブルデータコンペです。
与えられた死亡につながると考えられるリスク要因(所在地、肺炎の有無、年齢など)に対してのデータ分析を行い、モデルを作成、提出します。
コンペ期間は2日(9/26 14:00頃 ~ 9/27 12:00)と非常に短期のものとなっており、どれだけ高速に推論と実装、最適化を行えるかが鍵となりました。
また、コンペ参加は学生限定となっていました。1-2.評価指標
評価指標はROC曲線下面積です。この評価指標に関しては既に下記記事にて説明済みですので、省略します。
メラノーマコンペ-ROC曲線下面積1-3.データセット
データセットはシンプルに
・train.csv
・test.csv
・sample_submission.csv
の3つから成っています。trainで学習、testを予測、sample_submissionの形式で提出となります。データ内容については、以下のようなものがありました。
・患者の住所(詳細)
・年齢
・病院の所在
・患者の出身地
・患者が治療を受けた施設
・他のCOVID患者と接触歴があるか
・PCR検査結果
・肺炎
・発症日
・入院日 (受診日)
・挿管
・入院or外来
・慢性腎不全、糖尿病、高血圧、心血管疾患、ぜんそく、その他基礎疾患の有無test.csvを予測した結果が実際にLeaderBoardに反映されるコンペ(Code Competitionではない)ので、testデータとして与えられる量が多く、Pseudo Labelingなどの手法が有効になると考えられました。
2.EDA
一切する必要がありませんでした。というのも、コンペ運営のAkiyama氏がEDAとbaselineを兼ね備えたnotebookをコンペ開始時に公開しており、殆ど必要な情報は全て揃いました。
特に、LightGBMのfeature_importanceのスコアまで載っており、もう後はモデルを実装するだけ、という状態でした。
非常に分かりやすいデータ分析で、すぐにモデル実装に取り掛かることができました。3.理論
理論では、今回僕の解法の鍵となった手法に関して説明していきます。
3-1. Target Encoding
target encodingとは、カテゴリ変数において、"そのカテゴリの正解ラベルの平均値"自体を特徴量にする手法です。
正解ラベルそのものを間接的に特徴量として用いるため、リークに注意が必要であり、実装も結構面倒です。
今回この手法が必要になった理由は、477のカテゴリを持つ"place_patient_live2"というカテゴリ変数が存在したからです。通常、NNでカテゴリ変数を用いる場合OneHotEncodingによって処理しますが(GBDTにおいてはカテゴリ変数はそのまま使用できます)、477の列を作成し、そのうち1つだけが意味を持っているとなると、多くの列が無駄な特徴量となってしまうことが分かります(=疎な行列)
そこで、target encodingを用いることによって大幅に列数を減らし(477→1)、効率よく学習を行えるようにする必要がありました。
実際に、OneHotEncodingで学習した場合と、target encodingで学習した場合、僕のモデルでは後者の方が精度が大幅に良かったです。3-2. Pseudo Labeling
Pseudo Labelingは半教師あり学習手法の1つです。trainingデータのみではなく、testデータも学習することにより、精度の向上を目指します。まず、通常のモデルでtrainingデータを学習、testデータを評価し、予測値を出しますが、この予測値をそのままtestデータのラベルとして使ってしまい、もう一度0からtraining+testデータでの学習を行います。
これによって、trainingの予測結果がある程度正しければ、testデータの分の多様性を獲得することが出来ます。
この手法を用いる場合には、testデータが十分に与えられている必要があり、Code Competitionのようなtestデータが殆ど与えられないコンペにおいては使用できません。また、使用するテストデータの量にも気をつける必要があり、およそtrain:test = 2:1となるような量を用いるのが良いと言われています。この手法を用いることによって、単体のモデルの精度としては、
* Public LB 0.96696→0.96733
と、大幅な精度の向上を達成しました。今回は実際には、NNモデルとLGBMモデルのアンサンブルの出力結果をtestデータのラベルとして用いました。
4.検証
4-1.方針
元々、このコンペが始まる前に、テーブルデータであろうということはおおよそ見当はついていたので、EDA→LightGBMによるベースラインの作成→特徴量のWeight抽出→NN実装、の流れで行こう!と考えていたのですが、コンペ開始時点で、運営のAkiyama氏によるEDAとLightGBMによる実装、特徴量のWeightまで公開されていたので、もうあんまりやることがない…という状態でした。(1から実装するのを楽しみにしていたので、コンペ経験者側としてはちょっと残念…)
ということで、LightGBMによる精度はおおよそ分かったので、Pytorchによる線形モデルの実装をベースラインとして行いました。
(とりあえずLightGBMのまま、特徴量の作成に取り掛かる、という方針も考えられましたが、Feature Engineeringに関する知識があまり無い為、いきなりNNの作成に取り掛かりました。)4-2.使用する特徴量の選択と使い方
使用する特徴量は既に公開されているLGBMモデルのものを殆ど全部使いました。
それぞれ適応する特徴量の作成手法が異なるので、ざっくりとベースラインで使用したものを以下に記述します。・Standardization
標準化。平均0,分散1にスケーリングする。standard_cols = [ "age", "entry_-_symptom_date", "entry_date_count", "date_symptoms", "entry_date", ]・Onehot Encoding
カテゴリ変数の処理。カテゴリの数だけ列を作成し、その列だけ1,他を0とする。onehot_cols = [ "place_hospital", "place_patient_birth", "type_hospital", "contact_other_covid", "test_result", "pneumonia", "intubed", "patient_type", "chronic_renal_failure", "diabetes", "icu", "obesity", "immunosuppression", "sex", "other_disease", "pregnancy", "hypertension", "cardiovascular", "asthma", "tobacco", "copd", ]・Target Encoding
そのカテゴリ全体の正解ラベルの平均を特徴量として用いる手法
target_E_cols = ["place_patient_live2"]・日付に関するデータ
まず、日付として与えられるデータ(2020/09/26)を連続な値として考えられるデータ(例:9/26を0とした場合、9/27 : 1, 9/28 : 2)に変更します。その後、最大値を1,最小値を0としたmin_max_encodingを行います。4-3.ベースライン
name : medcon2020_tachyon_baseline about : simple NN baseline model : Liner Model batch : 32 epoch : 20 criterion : BCEWithLogitsLoss optimizer : Adam init_lr : 1e-2 scheduler: CosineAnnealingLR data : plane preprocess : OnehotEncoding,Standardization,Target Encoding train_test_split : StratifiedKFold, k=5 Public LB : 0.965754-4.LightGBMモデル
特徴量はAkiyama氏のFeature Engineering結果をそのまま用い、Optunaをかけることによりパラメータチューニングを行いました。
結果、Akiyama氏のbaseline : Public LB0.96636 Optunaを用いたモデル : Public LB0.96635と殆ど同じ結果が出たため、このbaselineは相当完成されたモデルであったことが伺えます。
但し、パラメータとしてはある程度異なるモデルなので、アンサンブル効果(多様性によって精度が向上すること)はある程度期待できます。4-5.アンサンブル提出
4-2のベースラインのパラメータを調整し、ある程度精度が出るようになってから、まずNNモデル1つと、Akiyama氏のbaselineモデルをAverage Ensemblingしたものを提出してみました。
※Public LB
NN単体 : 0.96696 LGBM単体 : 0.96636 Average Ensembling : 0.96738思ってもみない精度の向上です。NNとGBDTのアルゴリズムが全く異なるため、大幅にスコアが上がったと考えられます。
当時、ブッチギリ1位になりました。4-6.Pseudo Labeling
2日目(最終日)に、3.理論で説明したPseudo Labelingを実装しました。もっと手っ取り早く精度を上げる手法が存在したのかもしれませんが、僕にはこれしか思い浮かびませんでした…。
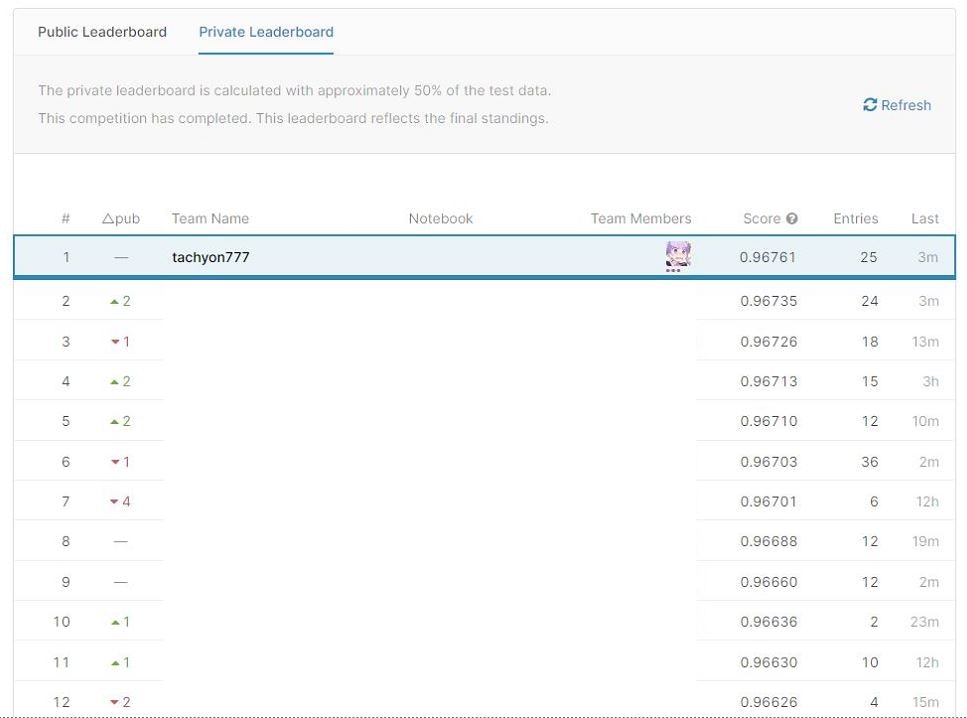
Pseudo Labeling実装前Average Ensembling Score : Private : 0.96753 Public : 0.96761
Pseudo Labeling実装後Average Ensembling Score : Private : 0.96761 Public : 0.96768結局、この2つを最終submissionに選びました。結果、後者が優勝モデルとなりました。
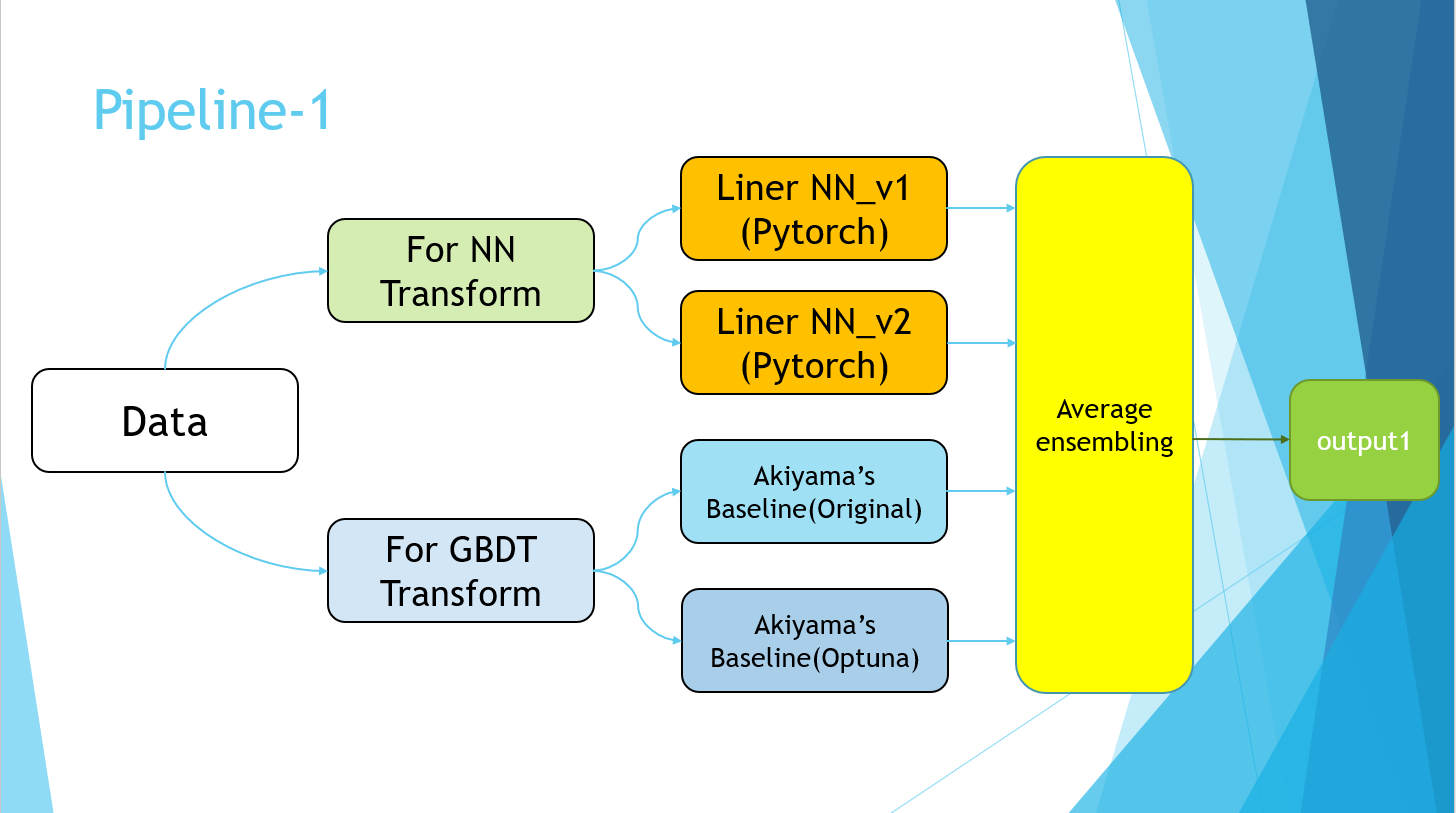
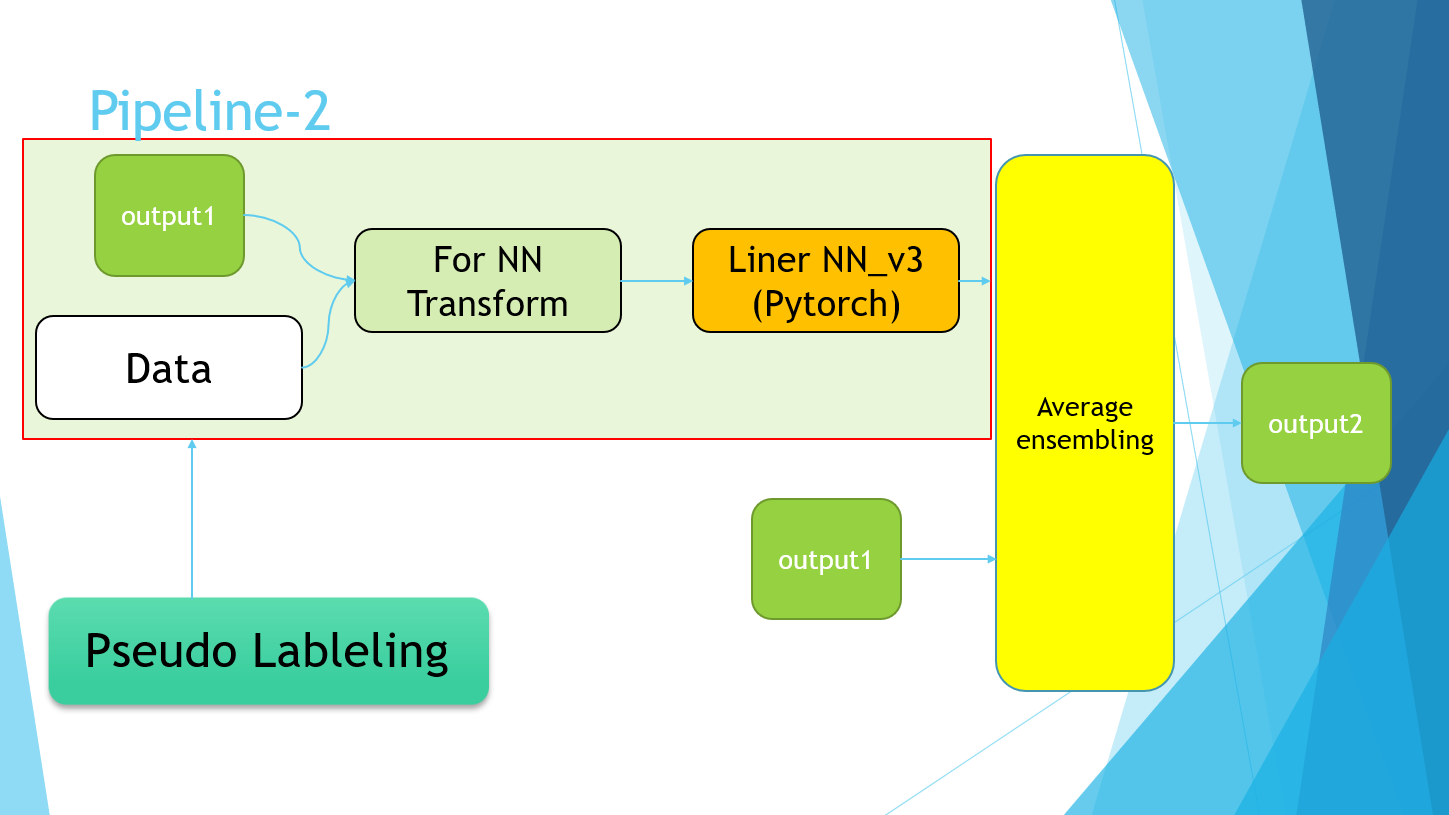
4-7.Pipeline
PowerPointのスライドで恐縮ですが、最終的に以下のようなパイプラインで完成しました。
Pipeline-2の部分は、単純にPseudo Labelingの実装を指しています。
最終的に、Pipeline-1の4モデルと、Pipeline-2のPseudo Labelingデータを用いて学習を行ったモデルの平均値を取りました。5.結果
優勝しました。(今までの人生で、優勝したことなんてあったかな…?)
手法に関しても、自分の中では申し分ないほどやりきったという感じで、達成感があります。
2日目はずっと1位にいて抜かされないか心配だったので、嬉しいと言うよりもホッとした気持ちが大きかったです…6.考察
今回はプライベートなコンテストというのもあり、他の方の解法を上げるのは控えさせていただきます。
他に試したかったこととしては、上位から
・特徴量の作成
・catboost
・NNモデルのハイパーパラメータ調整
という感じです。
実際にkaggleでこのデータでコンペが開かれたとなれば、僕のスコアも銅メダル以下になるでしょうから、まだまだ改善の余地はあると思われます。7.終わりに
大阪大学AI & Machine learning Society(AIMS)を始めとした主催者の皆様、一日目の発表者の皆様、コンテスト参加者の皆様、大変お疲れさまでした!
僕の解法が少しでも参考になれば幸いです。8.参考文献
1.門脇大輔 阪田隆司 保坂桂佑 平松雄司 Kaggleで勝つ データ分析の技術 技術評論社 2019
- 投稿日:2020-09-27T15:52:03+09:00
pythonを使った自動更新プログラムについて
質問をご覧頂きありがとうございます。
初歩的な質問でしたらすみません。
下記APIを使用し、10秒毎に価格が切り替わる仕組みを作りたいです。
どうすればブラウザ上で動く物が作れるでしょうか?
回答よろしくお願いします。import requests
bitflyer BTC
res = requests.get('https://api.bitflyer.jp/v1/ticker?product_code=BTC_JPY')
jsonData = res.json()
print('bitFlyer = ' + "¥{:,.0f}".format(jsonData["ltp"]))Zaif BTC
res = requests.get('https://api.zaif.jp/api/1/ticker/btc_jpy')
jsonData = res.json()
print('Zaif = ' + "¥{:,.0f}".format(jsonData["last"]))coincheck BTC
res = requests.get('https://coincheck.com/api/ticker')
jsonData = res.json()
print('coincheck = ' + "¥{:,.0f}".format(jsonData["last"]))
- 投稿日:2020-09-27T15:51:54+09:00
Pythonによる画像処理100本ノック#8 Maxプーリング
はじめに
どうも、らむです。
今回は画像をグリッド分割する手法であるプーリング処理の中でも、領域中の最大値を代表値とするMaxプーリングについて実装します。8本目:Maxプーリング
前回説明したプーリングとは、画像を固定長の領域にグリッド分割し、その領域内の値を全てある値にする処理です。この処理を施すことで画像はモザイク状になります。
Maxプーリングでは領域内の画素値の最大値で領域内を埋めます。
平均プーリングとMaxプーリングの違いは平均値を用いるか最大値を用いるかという点のみです。ソースコード
maxPooling.pyimport numpy as np import cv2 import matplotlib.pyplot as plt def maxPooling(img,k): dst = img.copy() w,h,c = img.shape # 中心画素から両端画素までの長さ size = k // 2 # プーリング処理 for x in range(size, w, k): for y in range(size, h, k): dst[x-size:x+size,y-size:y+size,0] = np.max(img[x-size:x+size,y-size:y+size,0]) dst[x-size:x+size,y-size:y+size,1] = np.max(img[x-size:x+size,y-size:y+size,1]) dst[x-size:x+size,y-size:y+size,2] = np.max(img[x-size:x+size,y-size:y+size,2]) return dst # 画像読込 img = cv2.imread('image.jpg') # Maxプーリング # 第2引数は領域長 img = maxPooling(img,40) # 画像保存 cv2.imwrite('result.jpg', img) # 画像表示 plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) plt.show()


画像左は入力画像、画像中央は前回の平均プーリング、画像右は今回の出力画像です。
上手くモザイク状の画像になっていることが分かりますね。また、輝度の高い最大値を使っているだけあって画像全体が平均プーリングよりも明るくなっています。おわりに
もし、質問がある方がいらっしゃれば気軽にどうぞ。
imori_imoriさんのGithubに公式の解答が載っているので是非そちらも確認してみてください。
それから、pythonは初心者なので間違っているところがあっても優しく指摘してあげてください。

- 投稿日:2020-09-27T15:49:13+09:00
教師あり/なし学習でおさえておくべき項目軽くまとめてみる
備忘録も兼ねて、「教師あり学習」と「教師なし学習」について、概要・利用するクラス・事例・キーワードと、学習する上で参考になったサイトについてまとめておきます。
『教師あり学習』
めちゃザックリ:特徴を表すデータと対応する答えのデータを与えて学習させることで予測モデルを作る。予測には分類問題と回帰問題がある。
各手法
①線形回帰
あらゆる直線のうち、損失関数(誤差関数)の値が最も小さくなるパラメータを求める。
- 利用するクラス:
sklearn.linear_model.LinearRegression- 事例:来客数と売上高の関係 など
- キーワード:単回帰、重回帰、多項式回帰、非線形回帰
- 参考サイト:scikit-learn で線形回帰 (単回帰分析・重回帰分析)
②ロジスティック回帰
二値分類のアルゴリズムで、分類問題に適用される。
- 利用するクラス:
sklearn.linear_model.LogisticRegression- 事例:営業訪問回数・満足度と売上の関係 など
- キーワード:シグモイド関数、交差エントロピー誤差関数
- 参考サイト:scikit-learnのロジスティック回帰でiris(アヤメ)の分類
③SVM(線形)
決定境界(直線)がデータから離れるように学習するアルゴリズムで、分類と回帰のどちらにでも使える。
- 利用するクラス:
sklearn.svm.SVC- 事例:テキスト分類、数字認識 など
- キーワード:ハードマージン、ソフトマージン
- 参考サイト:サポートベクターマシン(SVM)とは?〜基本からPython実装まで〜
④SVM(カーネル法)
カーネル関数により実空間のデータを超平面で分離できる空間に写像してから、データ集合を分離する。
- 利用するクラス:
sklearn.svm.SVC- 事例:色情報からの品種識別 など
- キーワード:カーネル関数(シグモイドカーネル、多項カーネル、RBF[放射基底関数]カーネル)
- 参考サイト:【Python】各種カーネル関数を使ってサポートベクターマシンを実装する【irisデータセット】
⑤ナイーブベイズ
特徴量がそれぞれ独立であるという仮定のもとで、データがあるラベルである確率を計算する。
- 利用するクラス:
sklearn.naive_bayes.MultinomialNB(他にGaussianNB、GaussianNBなど)- 事例:迷惑メール判定 など
- キーワード:スムージング
- 参考サイト:scikit-learn によるナイーブベイズ分類器
⑥ランダムフォレスト
多様性のある複数の決定木から出力を集め、多数決で分類の結果を出す。
- 利用するクラス:
sklearn.ensemble.RandomForestClassifier- 事例:行動履歴や属性による分類
- キーワード:ジニ係数、ブートストラップ法
- 参考サイト:[入門]初心者の初心者による初心者のための決定木分析
⑦ニューラルネットワーク
入力と出力の間に中間層を挟むことで、複雑な決定境界を学習する。
- 利用するクラス:
sklearn.neural_network.MLPClassifier- 事例:画像認識、音声認識
- キーワード:単純パーセプトロン、活性化関数、アーリーストッピング
- 参考サイト:自分でニューラルネットワークを作ろう
⑧k近傍法
入力データの近傍k個の分類の多数決により判定を行う。
- 利用するクラス:
sklearn.neighbors.KNeighborsClassifier- 参考サイト:機械学習 〜 K−近傍法 〜
評価方法
- a. 分類問題の場合
- a-1. 混同行列
利用するクラス:sklearn.metrics.confusion_matrix- a-2. 正解率
利用するクラス:sklearn.metrics.accuracy_score- a-3. 適合率
利用するクラス:sklearn.metrics.precision_score- a-4. 再現率
利用するクラス:sklearn.metrics.recall_score- a-5. F値
利用するクラス:sklearn.metrics.f1_score- a-6. ROC-AUC
利用するクラス:sklearn.metrics.roc_curve
参考サイト:
scikit-learnで混同行列を生成、適合率・再現率・F1値などを算出
scikit-learnでROC曲線とそのAUCを算出
- b. 回帰問題の場合
- b-1. 平均二乗誤差
利用するクラス:sklearn.metrics.mean_squared_error- b-2. 平均絶対誤差
利用するクラス:sklearn.metrics.mean_absolute_error- b-3. 決定係数
利用するクラス:sklearn.metrics.r2_score
参考サイト:scikit-learn で回帰モデルの結果を評価する
過学習を防ぐ方法
- a. ハイパーパラメータ
- a-1. グリッドサーチ
利用するクラス:sklearn.grid_search.GridSearchCV- a-2. ランダムサーチ
利用するクラス:sklearn.grid_search.RandomizedSearchCV
参考サイト:scikit-learnでモデルのハイパーパラメータチューニングをしよう!
- b. データ(学習データ&検証データ)の分割
- b-1. ホールドアウト法
利用するクラス:sklearn.model_selection.train_test_split- b-2. クロスバリデーション法
利用するクラス:sklearn.model_selection.cross_val_scoresklearn.model_selection.KFold- b-3. リーブワンアウト法
利用するクラス:sklearn.model_selection.LeaveOneOut参考サイト:機械学習、ディープラーニングでの学習データとテストデータの分割手法について
- c. 正則化
- c-1. リッジ回帰
利用するクラス:sklearn.linear_model.Ridge- c-2. ロッソ回帰
利用するクラス:sklearn.linear_model.Lasso
参考サイト:最短でリッジ回帰とラッソ回帰を説明(機械学習の学習 #3)
『教師なし学習』
めちゃザックリ:教師あり学習と異なり、目的変数は存在しない。ここでは特徴データに対し、別の形への変形や、部分集合を見つけることで、その構造を抽出する。手法に、次元削減とクラスタリングがある。
①主成分分析(PCA)
多数の量的説明変数を、より少ない指標や合成変数に要約し、データの変数を削減する。
- 利用するクラス:
sklearn.decomposition.PCA- キーワード:分散共分散行列、固有値問題、累積寄与率
- 参考サイト:主成分分析と固有値問題
②K平均法(K-means法)
データを与えられたクラスタ数に分類し、似たもの同士グループに分ける。
- 利用するクラス:
sklearn.cluster.KMeans- 事例:マーケティングデータ分析、画像分類
- キーワード:クラスタ内平方和、エルボー法、シルエット分析、k-means++、k-medoids法
- 参考サイト:k-meansの最適なクラスター数を調べる方法
③潜在意味解析(LSA)
文章データで、特徴量を単語数から潜在トピック数に削減することで、単語と文章の類似度を求める。
- 利用するクラス:
sklearn.decomposition.TruncatedSVD- キーワード:特異値分解、トピックモデル、tf-idf
- 参考サイト:機械学習 潜在意味解析 理論編
④非負値行列因子分解(NMF)
入出力データの値が全て非負という性質をもつ次元削減手法。
- 利用するクラス:
sklearn.decomposition.NMF- 事例:リコメンド、テキストマイニング
- 参考サイト:非負値行列因子分解(NMF)をふわっと理解する
⑤潜在的ディリクレ配分法(LDA)
文書内の単語からトピックを作成し、文書がどのトピックで構成されているかを求める。
- 利用するクラス:
sklearn.decomposition.LatentDirichletAllocation- 事例:自然言語処理
- キーワード:トピックモデル、ディリクレ分布
- 参考サイト:トピックモデル(LDA)で初学者に分かりづらいポイントについての解説
⑥混合ガウス分布(GMM)
複数のガウス分布の線型結合によりクラスタリングを行う。
- 利用するクラス:
sklearn.mixture.GaussianMixture- キーワード:ガウス分布
⑦局所線形埋め込み(LLE)
非線形なデータに対して、次元削減を行う。
- 利用するクラス:
sklearn.manifold.LocallyLinearEmbedding⑧t分布型確率的近傍埋め込み法(t-SNE)
高次元データを二次元か三次元に次元削減する方法で、データの可視化などに利用される。
- 利用するクラス:
sklearn.manifold.TSNE
- 投稿日:2020-09-27T15:49:13+09:00
教師あり/なし学習でおさえておくべきことを軽くまとめてみた
備忘録も兼ねて、「教師あり学習」と「教師なし学習」について、概要・利用するクラス・事例・キーワードと、学習する上で参考になったサイトについてまとめておきます。
『教師あり学習』
めちゃザックリ:特徴を表すデータと対応する答えのデータを与えて学習させることで予測モデルを作る。予測には分類問題と回帰問題がある。
各手法
①線形回帰
あらゆる直線のうち、損失関数(誤差関数)の値が最も小さくなるパラメータを求める。
- 利用するクラス:
sklearn.linear_model.LinearRegression- 事例:来客数と売上高の関係 など
- キーワード:単回帰、重回帰、多項式回帰、非線形回帰
- 参考サイト:scikit-learn で線形回帰 (単回帰分析・重回帰分析)
②ロジスティック回帰
二値分類のアルゴリズムで、分類問題に適用される。
- 利用するクラス:
sklearn.linear_model.LogisticRegression- 事例:営業訪問回数・満足度と売上の関係 など
- キーワード:シグモイド関数、交差エントロピー誤差関数
- 参考サイト:scikit-learnのロジスティック回帰でiris(アヤメ)の分類
③SVM(線形)
決定境界(直線)がデータから離れるように学習するアルゴリズムで、分類と回帰のどちらにでも使える。
- 利用するクラス:
sklearn.svm.SVC- 事例:テキスト分類、数字認識 など
- キーワード:ハードマージン、ソフトマージン
- 参考サイト:サポートベクターマシン(SVM)とは?〜基本からPython実装まで〜
④SVM(カーネル法)
カーネル関数により実空間のデータを超平面で分離できる空間に写像してから、データ集合を分離する。
- 利用するクラス:
sklearn.svm.SVC- 事例:色情報からの品種識別 など
- キーワード:カーネル関数(シグモイドカーネル、多項カーネル、RBF[放射基底関数]カーネル)
- 参考サイト:【Python】各種カーネル関数を使ってサポートベクターマシンを実装する【irisデータセット】
⑤ナイーブベイズ
特徴量がそれぞれ独立であるという仮定のもとで、データがあるラベルである確率を計算する。
- 利用するクラス:
sklearn.naive_bayes.MultinomialNB(他にGaussianNB、GaussianNBなど)- 事例:迷惑メール判定 など
- キーワード:スムージング
- 参考サイト:scikit-learn によるナイーブベイズ分類器
⑥ランダムフォレスト
多様性のある複数の決定木から出力を集め、多数決で分類の結果を出す。
- 利用するクラス:
sklearn.ensemble.RandomForestClassifier- 事例:行動履歴や属性による分類
- キーワード:ジニ係数、ブートストラップ法
- 参考サイト:[入門]初心者の初心者による初心者のための決定木分析
⑦ニューラルネットワーク
入力と出力の間に中間層を挟むことで、複雑な決定境界を学習する。
- 利用するクラス:
sklearn.neural_network.MLPClassifier- 事例:画像認識、音声認識
- キーワード:単純パーセプトロン、活性化関数、アーリーストッピング
- 参考サイト:自分でニューラルネットワークを作ろう
⑧k近傍法
入力データの近傍k個の分類の多数決により判定を行う。
- 利用するクラス:
sklearn.neighbors.KNeighborsClassifier- 参考サイト:機械学習 〜 K−近傍法 〜
評価方法
- a. 分類問題の場合
- a-1. 混同行列
利用するクラス:sklearn.metrics.confusion_matrix- a-2. 正解率
利用するクラス:sklearn.metrics.accuracy_score- a-3. 適合率
利用するクラス:sklearn.metrics.precision_score- a-4. 再現率
利用するクラス:sklearn.metrics.recall_score- a-5. F値
利用するクラス:sklearn.metrics.f1_score- a-6. ROC-AUC
利用するクラス:sklearn.metrics.roc_curve
参考サイト:
scikit-learnで混同行列を生成、適合率・再現率・F1値などを算出
scikit-learnでROC曲線とそのAUCを算出
- b. 回帰問題の場合
- b-1. 平均二乗誤差
利用するクラス:sklearn.metrics.mean_squared_error- b-2. 平均絶対誤差
利用するクラス:sklearn.metrics.mean_absolute_error- b-3. 決定係数
利用するクラス:sklearn.metrics.r2_score
参考サイト:scikit-learn で回帰モデルの結果を評価する
過学習を防ぐ方法
- a. ハイパーパラメータ
- a-1. グリッドサーチ
利用するクラス:sklearn.grid_search.GridSearchCV- a-2. ランダムサーチ
利用するクラス:sklearn.grid_search.RandomizedSearchCV
参考サイト:scikit-learnでモデルのハイパーパラメータチューニングをしよう!
- b. データ(学習データ&検証データ)の分割
- b-1. ホールドアウト法
利用するクラス:sklearn.model_selection.train_test_split- b-2. クロスバリデーション法
利用するクラス:sklearn.model_selection.cross_val_scoresklearn.model_selection.KFold- b-3. リーブワンアウト法
利用するクラス:sklearn.model_selection.LeaveOneOut参考サイト:機械学習、ディープラーニングでの学習データとテストデータの分割手法について
- c. 正則化
- c-1. リッジ回帰
利用するクラス:sklearn.linear_model.Ridge- c-2. ロッソ回帰
利用するクラス:sklearn.linear_model.Lasso
参考サイト:最短でリッジ回帰とラッソ回帰を説明(機械学習の学習 #3)
『教師なし学習』
めちゃザックリ:教師あり学習と異なり、目的変数は存在しない。ここでは特徴データに対し、別の形への変形や、部分集合を見つけることで、その構造を抽出する。手法に、次元削減とクラスタリングがある。
①主成分分析(PCA)
多数の量的説明変数を、より少ない指標や合成変数に要約し、データの変数を削減する。
- 利用するクラス:
sklearn.decomposition.PCA- キーワード:分散共分散行列、固有値問題、累積寄与率
- 参考サイト:主成分分析と固有値問題
②K平均法(K-means法)
データを与えられたクラスタ数に分類し、似たもの同士グループに分ける。
- 利用するクラス:
sklearn.cluster.KMeans- 事例:マーケティングデータ分析、画像分類
- キーワード:クラスタ内平方和、エルボー法、シルエット分析、k-means++、k-medoids法
- 参考サイト:k-meansの最適なクラスター数を調べる方法
③潜在意味解析(LSA)
文章データで、特徴量を単語数から潜在トピック数に削減することで、単語と文章の類似度を求める。
- 利用するクラス:
sklearn.decomposition.TruncatedSVD- キーワード:特異値分解、トピックモデル、tf-idf
- 参考サイト:機械学習 潜在意味解析 理論編
④非負値行列因子分解(NMF)
入出力データの値が全て非負という性質をもつ次元削減手法。
- 利用するクラス:
sklearn.decomposition.NMF- 事例:リコメンド、テキストマイニング
- 参考サイト:非負値行列因子分解(NMF)をふわっと理解する
⑤潜在的ディリクレ配分法(LDA)
文書内の単語からトピックを作成し、文書がどのトピックで構成されているかを求める。
- 利用するクラス:
sklearn.decomposition.LatentDirichletAllocation- 事例:自然言語処理
- キーワード:トピックモデル、ディリクレ分布
- 参考サイト:トピックモデル(LDA)で初学者に分かりづらいポイントについての解説
⑥混合ガウス分布(GMM)
複数のガウス分布の線型結合によりクラスタリングを行う。
- 利用するクラス:
sklearn.mixture.GaussianMixture- キーワード:ガウス分布
⑦局所線形埋め込み(LLE)
非線形なデータに対して、次元削減を行う。
- 利用するクラス:
sklearn.manifold.LocallyLinearEmbedding⑧t分布型確率的近傍埋め込み法(t-SNE)
高次元データを二次元か三次元に次元削減する方法で、データの可視化などに利用される。
- 利用するクラス:
sklearn.manifold.TSNE
- 投稿日:2020-09-27T15:39:53+09:00
Cisco Guest ShellをAPIサーバにしてPostmanから操作してみた
はじめに
Cisco Guest Shellは、ホストデバイス(IOS-XE)とは分離されたLinuxベースのコンテナ環境で、Python等を利用してIOS-XE設定を自動制御可能です。
今回は、Python Webフレームワーク「Flask」を用いてGuest Shell上でAPIサーバを構築し、Postmanからshowコマンド結果の取得、インターフェース設定変更を行ってみました。CSR1000V セットアップ
IOS-XE
IOS-XE側で仮想インターフェース
VirtualPortGroup0(192.168.30.1)を作成し、Guest Shellのアドレス(192.168.30.2)と関連付けを行い、外部からGuest Shellへのアクセスを可能としています。
環境依存のため割愛しますが、インターネットアクセスのため、Guest ShellのアドレスをGigabitEthernet1のアドレスに変換するPAT設定も行っています。設定ConfigRouter(config)#iox Router(config)#ip http server Router(config)#interface GigabitEthernet1 Router(config-if)# ip address 192.168.100.196 255.255.255.0 Router(config-if)# exit Router(config)#interface VirtualPortGroup0 Router(config-if)# ip address 192.168.30.1 255.255.255.0 Router(config-if)# exit Router(config)#app-hosting appid guestshell Router(config-app-hosting)# app-vnic gateway0 virtualportgroup 0 guest-interface 0 Router(config-app-hosting-gateway0)# guest-ipaddress 192.168.30.2 netmask 255.255.255.0 Router(config-app-hosting-gateway0)# app-default-gateway 192.168.30.1 guest-interface 0 Router(config-app-hosting)# name-server0 192.168.100.1 Router(config-app-hosting)# end Router#guestshell enable確認コマンドRouter#show iox-service IOx Infrastructure Summary: --------------------------- IOx service (CAF) 1.10.0.1 : Running IOx service (HA) : Not Supported IOx service (IOxman) : Running IOx service (Sec storage) : Not Supported Libvirtd 1.3.4 : Running Router#show app-hosting list App id State --------------------------------------------------------- guestshell RUNNINGGuest Shell
デフォルト設定をそのまま使用。
Router#guestshell [guestshell@guestshell ~]$ sudo ifconfig eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.30.2 netmask 255.255.255.0 broadcast 192.168.30.255 (省略) [guestshell@guestshell ~]$ netstat -nr Kernel IP routing table Destination Gateway Genmask Flags MSS Window irtt Iface 0.0.0.0 192.168.30.1 0.0.0.0 UG 0 0 0 eth0 192.168.30.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0Pythonパッケージのインストール
プリインストールされているPython2.7.5を使用し、Flaskと、showコマンドのパーサーテンプレートntc_templatesをインストールしました。
[guestshell@guestshell ~]$ python -V Python 2.7.5 [guestshell@guestshell ~]$ pip -V pip 20.2.3 from /usr/lib/python2.7/site-packages/pip (python 2.7) [guestshell@guestshell ~]$ pip install flask [guestshell@guestshell ~]$ pip install ntc_templatesHTTP GETでshowコマンド結果を取得
Pythonコード
Guest Shellのホームディレクトリ直下にapi.pyを作成しました。
[guestshell@guestshell ~]$ pwd /home/guestshell [guestshell@guestshell ~]$ touch api.py処理の大まかな流れは以下の通りです。
- 実行のトリガーは、APIクライアントからURI
http://<Guest ShellのIPアドレス>/show/<コマンド名を_を繋いだもの>宛てのHTTP GET- 関数
getCommand()を実行- URI末尾の'_'を' '(スペース)に変換し、showコマンドを生成
- プリインストールされているCisco CLI Pythonモジュールでshowコマンドを実行
- 出力結果をNTC-templates/TextFSMでパースしてJSONで返す
- 途中で失敗した場合はエラーメッセージをJSONで返す
また外部からアクセスするために、
app.run()の引数としてhost='0.0.0.0'を指定しています。api.pyfrom flask import Flask, jsonify, request from cli import configurep, cli from ntc_templates.parse import parse_output app = Flask(__name__) @app.route("/show/<command>", methods=["GET"]) def getCommand(command): cmd = "show " + command.replace("_", " ") try: sh_output = cli(cmd) sh_output_parsed = parse_output(platform="cisco_ios", command=cmd, data=sh_output) return jsonify(sh_output_parsed) except: return jsonify([{"result": "Fail to parse the output"}]) if __name__ == '__main__': app.run(debug=False, host='0.0.0.0', port=8080)Python実行/APIサーバ起動
[guestshell@guestshell ~]$ python api.py * Serving Flask app "api" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: off * Running on http://0.0.0.0:8080/ (Press CTRL+C to quit)PostmanからHTTP GET
Postmanからshowコマンド
show ip interface briefの結果を取得する例です。
GETで以下の通りURIを入力します。末尾がip_int_briefと省略されていますが、NTC-templates側で許容された省略形であれば問題なくパース可能です。
HTTP POSTでインターフェース設定変更
Pythonコード
上記のapi.pyにコードを追加しました。処理の大まかな流れは以下の通りです。
- 実行のトリガーは、APIクライアントからURI
http://<Guest ShellのIPアドレス>/set/interface宛てのHTTP POST。Body内にインタフェースの設定パラメータをJSON形式で記載。- 関数
setInterface()を実行- 設定パラメータに従いCLIコマンドを生成
- Cisco CLI Pythonモジュールで設定変更と設定保存を実施
- 成功した場合は、SuccessメッセージをJSONで返す
編集後、再度Python実行/APIサーバ起動を行います。
api.py(追加分)@app.route("/set/interface", methods=["POST"]) def setInterface(): interface_cmd = "interface " + request.json['interface'] if 'state' in request.json: if request.json['state'] == "enabled": state_cmd = "no shutdown" elif request.json['state'] == "disabled": state_cmd = "shutdown" else: state_cmd = "" if 'description' in request.json: description_cmd = "description " + request.json['description'] else: description_cmd = "" if 'address' in request.json: address_cmd = "ip address " + request.json['address'] + " " + request.json['netmask'] else: address_cmd = "" configurep([interface_cmd, state_cmd, description_cmd, address_cmd, "end"]) cli("write") return jsonify([{"result": "Success"}])PostmanからHTTP POST
Postmanから
GigabitEthernet2のDescription、IPアドレスの設定と、ポート開放を行う例です。POSTで以下の通りURIを入力し、HeaderでContent-Typeを
application/jsonに指定します。
Bodyに設定パラメータを記載します。下記の内、インターフェース名
interfaceは必須ですが、その他の開放/閉塞state、Descriptiondescription、IPアドレスaddress/netmaskの指定は任意です。
Sendボタンをクリックし、成功した場合は以下メッセージが表示されます。
api.py実行中のターミナル画面からも、設定状況が確認できます。
192.168.100.100 - - [27/Sep/2020 05:59:20] "POST /set/interface HTTP/1.1" 200 - Line 1 SUCCESS: interface GigabitEthernet2 Line 2 SUCCESS: no shutdown Line 3 SUCCESS: description TEST Line 4 SUCCESS: ip address 10.1.1.1 255.255.255.0 Line 5 SUCCESS: endIOS-XE側でも問題なく設定変更、保存が行われていました。
Router#sh conf | begin interface GigabitEthernet2 interface GigabitEthernet2 description TEST ip address 10.1.1.1 255.255.255.0 negotiation auto no mop enabled no mop sysid最後に
簡単な例ですが、無事Guest ShellでAPIサーバが構築出来ました。ただし、Guest Shellは認証無しでデバイスのshowコマンド実行/設定変更が出来てしまうので、セキュリティや証跡管理の観点で課題はあるかもしれません。
また今回の用途であれば、Guest ShellのようなOn-Box形式ではなく、Ansibleのような外部ツールを使ってOff-Boxで制御するのがベターかも知れません。



- 投稿日:2020-09-27T15:02:37+09:00
Evernote SDK for Python 3 を使ってノート情報を取得する
概要
- Evernote SDK for Python 3 を使って Evernote のノート情報を取得する
- 環境: Python 3.8.5 + Evernote SDK for Python 3 (evernote3 パッケージ) 1.25.14 + macOS catalina
Evernote SDK for Python 3 について
現時点 (2020年9月27日現在) ではまだテスト的なものとなっており、Python 用の公式 SDK は Python 3 をサポートしていないとのこと。
GitHub - evernote/evernote-sdk-python3: Testing the Evernote Cloud API for Python 3
This is a test SDK! The official Evernote SDK for Python doesn't support Python 3 yet; this repository is an experiment as we try to migrate.
This SDK contains wrapper code used to call the Evernote Cloud API from Python.
API Reference は All Thrift declarations にあるが、Python 用のものではないのでソースコードの該当箇所も合わせて確認したほうが良いかもしれない。
- evernote-sdk-python3/client.py at master · evernote/evernote-sdk-python3 · GitHub
- evernote-sdk-python3/NoteStore.py at master · evernote/evernote-sdk-python3 · GitHub
- evernote-sdk-python3/ttypes.py at master · evernote/evernote-sdk-python3 · GitHub
ライブラリのインストール
Evernote SDK for Python 3 をインストールする。
$ pip install evernote3==1.25.14oauth2 もインストールする必要がある (依存関係で自動的にインストールされないため)。
$ pip install oauth2ノート情報を取得するサンプルコード
from datetime import datetime, timezone, timedelta # Evernote SDK for Python 3 を使う from evernote.api.client import EvernoteClient from evernote.edam.notestore.ttypes import NoteFilter, NotesMetadataResultSpec # evernote.api.client.EvernoteClient を初期化 client = EvernoteClient( token = 'YOUR_AUTH_ACCESS_TOKEN', # アクセストークンを指定 sandbox = False # Sandbox ではなく Production 環境を使う場合は明示的に False を指定 ) # evernote.api.client.Store を取得 store = client.get_note_store() # ノートブック evernote.edam.type.ttypes.Notebook のリストを取得 notebook_list = store.listNotebooks() print(f'ノートブックの数: {len(notebook_list)}') # evernote.edam.type.ttypes.Notebook を取り出す for notebook in notebook_list: print(f'ノートブック名: {notebook.name}') # 取得するノートの条件を指定 filter = NoteFilter() filter.notebookGuid = notebook.guid # ノートブックの GUID を指定 # NoteMetadata に含めるフィールドを設定 spec = NotesMetadataResultSpec() spec.includeTitle = True spec.includeCreated = True spec.includeAttributes = True # ノートのメタデータのリスト evernote.edam.notestore.ttypes.NotesMetadataList を取得 notes_metadata_list = store.findNotesMetadata( filter, 0, # offset 条件にヒットした一覧から取得したいインデックス位置を指定 1, # maxNotes 取得するノート数の最大値。今回は最大で1つだけ取得する spec) print(f'ノートブックに含まれるノートの数: {notes_metadata_list.totalNotes}') # evernote.edam.notestore.ttypes.NoteMetadata を取り出す for note_meta_data in notes_metadata_list.notes: print(f' ノートのタイトル: {note_meta_data.title}') # evernote.edam.type.ttypes.Note を取得 note = store.getNote( note_meta_data.guid, # ノートの GUID を指定 True, # withContent True, # withResourcesData True, # withResourcesRecognition True) # withResourcesAlternateData print(f' タイトル: {note.title}') print(f' 作成日時: {datetime.fromtimestamp(note.created / 1000, timezone(timedelta(hours=9)))}') print(f' 内容(XHTML): {note.content[0:64]}') # 長いので先頭64文字だけ取り出す # メモに埋め込まれていたり添付されているメディアファイル情報を取り出す if note.resources is not None: # evernote.edam.type.ttypes.Resource を取り出す for resource in note.resources: print(f' 添付データファイル名: {resource.attributes.fileName}') print(f' データタイプ: {resource.mime}')サンプルの実行例
サンプルコードを my_notes.py というファイル名で保存して実行。
$ python my_notes.py ノートブックの数: 4 ノートブック名: Todoist ノートブックに含まれるノートの数: 6 ノートのタイトル: Completed Todoist Tasks タイトル: Completed Todoist Tasks 作成日時: 2017-09-02 09:43:19+09:00 内容(XHTML): <?xml version="1.0" encoding="UTF-8"?><!DOCTYPE en-note SYSTEM " ノートブック名: 音声データ ノートブックに含まれるノートの数: 5 ノートのタイトル: 五十音メッセージ タイトル: 五十音メッセージ 作成日時: 2016-08-14 20:03:58+09:00 内容(XHTML): <?xml version="1.0" encoding="UTF-8" standalone="no"?><!DOCTYPE 添付データファイル名: あいうえお.m4a データタイプ: audio/x-m4a ノートブック名: webclip ノートブックに含まれるノートの数: 2 ノートのタイトル: サンプルページ タイトル: サンプルページ 作成日時: 2015-03-19 17:34:03+09:00 内容(XHTML): <?xml version="1.0" encoding="UTF-8" standalone="no"?><!DOCTYPE 添付データファイル名: None データタイプ: image/jpeg 添付データファイル名: None データタイプ: image/png ノートブック名: 技術系資料置場 ノートブックに含まれるノートの数: 15 ノートのタイトル: ハッカソン資料 タイトル: ハッカソン資料 作成日時: 2018-02-23 15:26:58+09:00 内容(XHTML): <?xml version="1.0" encoding="UTF-8" standalone="no"?><!DOCTYPE 添付データファイル名: IMG_2741.HEIC データタイプ: image/jpeg 添付データファイル名: IMG_2618.HEIC データタイプ: image/jpeg参考資料
- Home - Evernote Developers
- Evernote Cloud API — Python Quick-start Guide - Evernote Developers
- evernote3 · PyPI
- GitHub - evernote/evernote-sdk-python3: Testing the Evernote Cloud API for Python 3
- API Reference (All Thrift declarations) - Evernote Developers
- Developer Tokens - Evernote Developers
- Get an Auth Token - Evernote Developers
- EvernoteのAPIを使ってみる - kkobayashi_a’s blog
- Pythonで使って覚えるEvernote API (1/6):CodeZine(コードジン)
- 投稿日:2020-09-27T14:29:06+09:00
Unicode Decode Eroorでpip installできないのを手動で直す
はじめに
Windows10、Anaconda環境でpip install markovifyを実行するとこんなエラーが出た
UnicodeDecodeError: 'cp932' codec can't decode byte 0x94 in position 8016: illegal multibyte sequence
原因
WindowsがCP932(Shift_JIS)でエンコードされていないファイルをCP932に変換してるっぽい
解決策
僕の場合はmarkovifyのソースファイルを落としてsetup.pyを修正することで解決しました
具体的には、READMEの読み込みに失敗しているのが原因なので
with open(os.path.join(HERE, 'README.md')) as f:これを
with open(os.path.join(HERE, 'README.md'),encoding='utf-8') as f:こうして
python setup.py installを実行して無事にインストールできました。やったね。
- 投稿日:2020-09-27T13:46:31+09:00
シンプルな API に CleanArchitecture を段階的に適用し、CleanArchitectureが具体的に「どんな変更に強いのか」をコードベースで理解してみる
目次
Part1: ベースとなるシンプルな API を作成する
Part2: Frameworks & Drivers 層: Web の登場
Part3: Enterprise Business Rules 層 & Application Business Rules 層の登場
Part4: Interface Adapters 層: Controllers の登場
Part5: ~番外編~ DTOの活用
Part6: Interface Adapters 層: Presenter の登場
Part7: Frameworks & Drivers 層: DB と Interface Adapters 層: Gateways の登場
Part8: Enterprise Business Rules 層: Entity & Value Object の採用
Part9: テスト可能~まとめ
なぜこの記事を書くか
最近、技術的にチャレンジさせてもらえるプロジェクトにアサインさせてもらえたので、CleanArchitectureを採用してみました。
採用した際に学んだことを、改めて言語化しておきたいなと思ったのと、
実装していたとき、各レイヤーが解決する課題が、コードベースで解説されている記事があったら捗ったなと思ったので、
この記事を書くことにしました。
どのような構成で記事を書くか
前述しましたが、現在CleanArchitectureについて世の中に公開されている記事は、
下記の2部構成であることが多いなと個人的に思っています。
- CleanArchitectureで作った成果物のコードはこんな感じです。
- 〇〇のコードは〇〇レイヤーに対応していて、〇〇レイヤーはこういう役割をしています。
「CleanArchitectureが具体的にどういう変更に強いのか」 をイメージするにあたり、
冒頭から既に完成された成果物のコードを提示する構成ではなく、
- 既存の成果物が仕様変更の際に抱える課題を、段階的に解決していく
- 最終的に
CleanArchitectureの構成になっているという構成にしようと思います。
各Partのストーリーについて
今回記事内で明らかにしたいことは、
「CleanArchitectureが具体的にどういう変更に強いのか」
です。
なので、記事内では、下記のような展開で、CleanArchitectureを適用していきます。
1. 既存の成果物に対して、「○○を追加・変更して欲しい」等の仕様変更依頼を受ける
2. 既存の成果物の設計で、仕様変更依頼に対応する際に、どのような懸念点があるかを、コードベースで明示する
3. 仕様変更依頼に対して、どのような設計になっていたら、懸念点がなく仕様変更できたかを、コードベースで明示する
4. 設計の変化によって、どのような仕様変更に耐えうるようになったかをまとめる
それでは早速始めていきます。
Part1: ベースとなるシンプルな API を作成する
Part1では、以降のPartの解説のベースとなるAPIを作成します。
作成する際に、
このAPIを、仕様変更を想定せず、意図的にモノリシックなものとなるように実装を進めるように意識してみました。
意図的にモノリシックにすることで、CleanArchitecture を適用した際、設計のメリットを可視化しやすくする狙いがあります。
段階的にファイルが責務ごとに分割され、結合が除々に疎になっていく様子を、以降のPartで観察しましょう。
CleanArchitectureを段階的に適用する最初の成果物
今回は
POSTリクエストを受けて、メモを保存する
GETリクエストを受けて、保存したメモを参照する
だけのメモ API を用意します。
実装
Webアプリケーションフレームワーク Flask を採用して、シンプルな api を作成します。
1. エンドポイントを用意する
要件を再掲しますが、今回作成する api は、
- POSTリクエストを受けて、メモを保存する
- GETリクエストを受けて、保存したメモを参照する
です。
要件を満たす実装では、
memo_idをプライマリーキーとして、memoを扱うこととします。まず上記 2 点の処理を実行するエンドポイントを用意します。
Flaskを用いて、POSTリクエストを受けて、メモを保存する ためのエンドポイントを用意します。
from flask import Flask, request app = Flask(__name__) @app.route('/memo/<int:memo_id>', methods=['POST']) def post(memo_id: int) -> str: # リクエストから値を取得する memo: str = request.form["memo"] pass同様に、GETリクエストを受けて、保存したメモを参照する ためのエンドポイントを用意します。
@app.route('/memo/<int:memo_id>') def get(memo_id: int) -> str: pass2. DB とメモのやりとりをする部分を用意する
では、このエンドポイントに、メモを保存する DB とのやりとりを記載していきます。
今回は保存する db として、mysql を採用しています。
まず、
memo_idでmemoの有無を確認するための関数を用意します。from mysql import connector # DB接続用の設定 config = { 'user': 'root', 'password': 'password', 'host': 'mysql', 'database': 'test_database', 'autocommit': True } def exist(memo_id: int) -> bool: # DBクライアントを作成する conn = connector.connect(**config) cursor = conn.cursor() # memo_idがあるかどうか確認する query = "SELECT EXISTS(SELECT * FROM test_table WHERE memo_id = %s)" cursor.execute(query, [memo_id]) result: tuple = cursor.fetchone() # DBクライアントをcloseする cursor.close() conn.close() # 検索結果が1件あるかどうかで存在を確認する if result[0] == 1: return True else: return False次に、POSTリクエストを受けて、メモを保存する 処理を、作成したエンドポイントに追記します。
from flask import Flask, request, jsonify from mysql import connector from werkzeug.exceptions import Conflict app = Flask(__name__) @app.route('/memo/<int:memo_id>', methods=['POST']) def post(memo_id: int) -> str: # 指定されたidがあるかどうか確認する is_exist: bool = exist(memo_id) if is_exist: raise Conflict(f'memo_id [{memo_id}] is already registered.') # リクエストから値を取得する memo: str = request.form["memo"] # DBクライアントを作成する conn = connector.connect(**config) cursor = conn.cursor() # memoを保存する query = "INSERT INTO test_table (memo_id, memo) VALUES (%s, %s)" cursor.execute(query, (memo_id, memo)) # DBクライアントをcloseする cursor.close() conn.close() return jsonify( { "message": "saved." } )
次に、GETリクエストを受けて、外部のDBに保存したメモを参照する 処理を実装します。
from werkzeug.exceptions import NotFound @app.route('/memo/<int:memo_id>') def get(memo_id: int) -> str: # 指定されたidがあるかどうか確認する is_exist: bool = exist(memo_id) if not is_exist: raise NotFound(f'memo_id [{memo_id}] is not registered yet.') # DBクライアントを作成する conn = connector.connect(**config) cursor = conn.cursor() # memo_idで検索を実行する query = "SELECT * FROM test_table WHERE memo_id = %s" cursor.execute(query, [memo_id]) result: tuple = cursor.fetchone() # DBクライアントをcloseする cursor.close() conn.close() return jsonify( { "message": f'memo : [{result[1]}]' } )次に、エラーハンドラを設定します。
from http import HTTPStatus from flask import make_response @app.errorhandler(NotFound) def handle_404(err): json = jsonify( { "message": err.description } ) return make_response(json, HTTPStatus.NOT_FOUND) @app.errorhandler(Conflict) def handle_409(err): json = jsonify( { "message": err.description } ) return make_response(json, HTTPStatus.CONFLICT)
3. appを起動
最後に、これまでに生成した各routerを付与した、
appを起動する処理を,ファイル内に記載します。if __name__ == '__main__': app.run(debug=True, host='0.0.0.0')4. 最終的なコード
main.py
from http import HTTPStatus from flask import Flask, request, jsonify, make_response from mysql import connector from werkzeug.exceptions import Conflict, NotFound app = Flask(__name__) # DB接続用の設定 config = { 'user': 'root', 'password': 'password', 'host': 'mysql', 'database': 'test_database', 'autocommit': True } def exist(memo_id: int) -> bool: # DBクライアントを作成する conn = connector.connect(**config) cursor = conn.cursor() # memo_idがあるかどうか確認する query = "SELECT EXISTS(SELECT * FROM test_table WHERE memo_id = %s)" cursor.execute(query, [memo_id]) result: tuple = cursor.fetchone() # DBクライアントをcloseする cursor.close() conn.close() # 検索結果が1件あるかどうかで存在を確認する if result[0] == 1: return True else: return False @app.route('/memo/<int:memo_id>') def get(memo_id: int) -> str: # 指定されたidがあるかどうか確認する is_exist: bool = exist(memo_id) if not is_exist: raise NotFound(f'memo_id [{memo_id}] is not registered yet.') # DBクライアントを作成する conn = connector.connect(**config) cursor = conn.cursor() # memo_idで検索を実行する query = "SELECT * FROM test_table WHERE memo_id = %s" cursor.execute(query, [memo_id]) result: tuple = cursor.fetchone() # DBクライアントをcloseする cursor.close() conn.close() return jsonify( { "message": f'memo : [{result[1]}]' } ) @app.route('/memo/<int:memo_id>', methods=['POST']) def post(memo_id: int) -> str: # 指定されたidがあるかどうか確認する is_exist: bool = exist(memo_id) if is_exist: raise Conflict(f'memo_id [{memo_id}] is already registered.') # リクエストから値を取得する memo: str = request.form["memo"] # DBクライアントを作成する conn = connector.connect(**config) cursor = conn.cursor() # memoを保存する query = "INSERT INTO test_table (memo_id, memo) VALUES (%s, %s)" cursor.execute(query, (memo_id, memo)) # DBクライアントをcloseする cursor.close() conn.close() return jsonify( { "message": "saved." } ) @app.errorhandler(NotFound) def handle_404(err): json = jsonify( { "message": err.description } ) return make_response(json, HTTPStatus.NOT_FOUND) @app.errorhandler(Conflict) def handle_409(err): json = jsonify( { "message": err.description } ) return make_response(json, HTTPStatus.CONFLICT) if __name__ == '__main__': app.run(debug=True, host='0.0.0.0')※ リクエスト単位でconnectionを張るのはあまりイケてないのですが、設計をわかりやすく説明できるよう、敢えてこのような形としています。この点は後ほど、話の展開の中できちんと回収します。
Part1を終えて
これで、下記 2 点 を実行する API が用意できました。
- POSTリクエストを受けて、メモを保存する
- GETリクエストを受けて、保存したメモを参照する
以降の記事では、各 part ごとに、container環境も含めすべてのコードを下記のリポジトリに格納してるので、
手元で動かしてみたい方は下記を参照してみてください。Part1: https://github.com/y-tomimoto/CleanArchitecture/tree/master/part1
次のPartから、このAPIに対しての仕様変更依頼を仮定し、CleanArchitectureを段階的に適用していきましょう。
- 投稿日:2020-09-27T13:46:31+09:00
[CleanArchitecture with Python] シンプルな API に CleanArchitecture を段階的に適用し、CleanArchitectureが具体的に「どんな変更に強いのか」をコードベースで理解してみる
Pythonを用いたCleanArchitectureの最終的なサンプルコードはこちら: https://github.com/y-tomimoto/CleanArchitecture/tree/master/part9
app ├── application_business_rules │ ├── __init__.py │ ├── boundary │ │ ├── __init__.py │ │ ├── input_port │ │ │ ├── __init__.py │ │ │ └── memo_input_port.py │ │ └── output_port │ │ ├── __init__.py │ │ └── memo_output_port.py │ └── memo_handle_interactor.py ├── enterprise_business_rules │ ├── __init__.py │ ├── dto │ │ ├── __init__.py │ │ ├── input_memo_dto.py │ │ └── output_memo_dto.py │ ├── entity │ │ ├── __init__.py │ │ └── memo.py │ ├── memo_data.py │ └── value_object │ ├── __init__.py │ └── memo_author.py ├── frameworks_and_drivers │ ├── __init__.py │ ├── db │ │ ├── __init__.py │ │ ├── mysql.py │ │ └── postgres.py │ └── web │ ├── __init__.py │ ├── fastapi_router.py │ └── flask_router.py ├── interface_adapters │ ├── __init__.py │ ├── controller │ │ ├── __init__.py │ │ └── flask_controller.py │ ├── gataways │ │ ├── __init__.py │ │ └── memo_repository_gateway.py │ └── presenter │ ├── __init__.py │ ├── ad_presenter.py │ └── default_presenter.py └── main.pyまとめ: 採用するレイヤーごとに、どのように変更に強くなるのか
CleanArchitectureを段階的に適用して得られた各メリットを提示
Part2: Frameworks & Drivers 層: Web の登場
採用したい各Webアプリケーションフレームワークを、Frameworks & Drivers 層: Web に切り出し、本来アプリケーションに期待する処理を
MemoHandlerに切り出したことで、
採用したい router を、main.pyで呼び出すだけで、アプリケーションに本来期待する処理である、memo_handler.pyに手を入れることなく、フレームワークを柔軟に変更 できる設計としました。この設計では、CleanArchitecture のルールの 1 つ、フレームワーク独立 が実現されています。
クリーンアーキテクチャ(The Clean Architecture翻訳) :https://blog.tai2.net/the_clean_architecture.html
フレームワーク独立: アーキテクチャは、機能満載のソフトウェアのライブラリが手に入ることには依存しない。これは、そういったフレームワークを道具として使うことを可能にし、システムをフレームワークの限定された制約に押し込めなければならないようなことにはさせない。
Part3: Enterprise Business Rules 層 & Application Business Rules 層の登場
アプリケーションに本来期待する処理が記載された
memo_handler.pyを
- Enterprise Business Rules
- Application Business Rules
に分割しました。
これにより、
memo_handler.pyを、
1. アプリケーションにおける原則的な処理と、
2. それらを活用してアプリケーションの仕様を満たす流動的な処理に分割することで、アプリケーションの仕様変更の際、既存の原則的な処理に影響を与えず、仕様を柔軟に修正・拡張できる設計になりました。
Part4: Interface Adapters 層: Controllers の登場
Interface Adapters 層の Controller を活用することによって、
更新頻度の高い、『外部からのリクエスト形式』を、実際の処理に適した形式に変更するという部分を、
フレームワークから切り出すことができました。これにより、アプリケーションで受け入れることのできるリクエストの形式を変更する際、
既存のWebアプリケーションフレームワークや、ビジネスルールを考慮せずに、コードの修正を行うことができるような設計になりました。Part5: ~番外編~ DTOの活用
DTOを採用することで、レイヤー間のデータアクセスを円滑にすると同時に、
アプリケーションで扱うデータ構造が変化した際に、各レイヤーへの影響を最小限に抑えられるような設計になりました。Part6: Interface Adapters 層: Presenter の登場
Presenter の実装に加えて、OutputPort の実装も行いました。
これにより、UIを変更する際、既存のWebアプリケーションフレームワークや、ビジネスルールを考慮せず、UIのみ を独立して変更できる設計になりました。
このPresenterの導入により、CleanArchitecture のルール、UI独立が達成されています。
クリーンアーキテクチャ(The Clean Architecture翻訳) :https://blog.tai2.net/the_clean_architecture.html
UIは、容易に変更できる。システムの残りの部分を変更する必要はない。たとえば、ウェブUIは、ビジネスルールの変更なしに、コンソールUIと置き換えられる。
Part7: Frameworks & Drivers 層: DB と Interface Adapters 層: Gateways の登場
DBレイヤーにDBを実装し、Gatawaysを採用しました、
これにより、DBの変更を行う際、各レイヤーを考慮せずに、DBを切り替えることのできる設計となっています。
これより、CleanArchitecture のルール、データベース独立が達成されています。
クリーンアーキテクチャ(The Clean Architecture翻訳) :https://blog.tai2.net/the_clean_architecture.html
データベース独立。OracleあるいはSQL Serverを、Mongo, BigTable, CoucheDBあるいは他のものと交換することができる。ビジネスルールは、データベースに拘束されない。
Part8: Enterprise Business Rules 層: Entity & Value Object の採用
データベースと同構造のオブジェクト、Entityを用いて、DBとのやりとりを行い、
秘匿性の高いプロパティを隠蔽するために、各Business Rules内でDTOを採用する設計にしました。これにより、各Business Rules で、秘匿性を持つプロパティを意識せず、DB上の値を扱うことができる設計となりました。
また、各プロパティのvalidate・加工処理を、ValueObjectを採用して、Entityから独立させました。
これにより、Entityを新たに生成・変更する場合に、各Entity内で特定のプロパティを意識した実装をしなくても良くなりました。なぜこの記事を書くか
最近、技術的にチャレンジさせてもらえるプロジェクトにアサインさせてもらえたので、CleanArchitectureを採用してみました。
採用した際に学んだことを、改めて言語化しておきたいなと思ったのと、
実装していたとき、各レイヤーが解決する課題が、コードベースで解説されている記事があったら捗ったなと思ったので、
この記事を書くことにしました。
どのような構成で記事を書くか
前述しましたが、現在CleanArchitectureについて世の中に公開されている記事は、
下記の2部構成であることが多いなと個人的に思っています。
- CleanArchitectureで作った成果物のコードはこんな感じです。
- 〇〇のコードは〇〇レイヤーに対応していて、〇〇レイヤーはこういう役割をしています。
「CleanArchitectureが具体的にどういう変更に強いのか」 をイメージするにあたり、
冒頭から既に完成された成果物のコードを提示する構成ではなく、
- 既存の成果物が仕様変更の際に抱える課題を、段階的に解決していく
- 最終的に
CleanArchitectureの構成になっているという構成にしようと思います。
各Partのストーリーについて
今回記事内で明らかにしたいことは、
「CleanArchitectureが具体的にどういう変更に強いのか」
です。
なので、記事内では、下記のような展開で、CleanArchitectureを適用していきます。
1. 既存の成果物に対して、「○○を追加・変更して欲しい」等の仕様変更依頼を受ける
2. 既存の成果物の設計で、仕様変更依頼に対応する際に、どのような懸念点があるかを、コードベースで明示する
3. 仕様変更依頼に対して、どのような設計になっていたら、懸念点がなく仕様変更できたかを、コードベースで明示する
4. 設計の変化によって、どのような仕様変更に耐えうるようになったかをまとめる
それでは早速始めていきます。
目次
Part1: ベースとなるシンプルな API を作成する
Part2: Frameworks & Drivers 層: Web の登場
Part3: Enterprise Business Rules 層 & Application Business Rules 層の登場
Part4: Interface Adapters 層: Controllers の登場
Part5: ~番外編~ DTOの活用
Part6: Interface Adapters 層: Presenter の登場
Part7: Frameworks & Drivers 層: DB と Interface Adapters 層: Gateways の登場
Part8: Enterprise Business Rules 層: Entity & Value Object の採用
Part9: テスト可能~まとめ
Part1: ベースとなるシンプルな API を作成する
Part1では、以降のPartの解説のベースとなるAPIを作成します。
作成する際に、
このAPIを、仕様変更を想定せず、意図的にモノリシックなものとなるように実装を進めるように意識してみました。
意図的にモノリシックにすることで、CleanArchitecture を適用した際、設計のメリットを可視化しやすくする狙いがあります。
段階的にファイルが責務ごとに分割され、結合が除々に疎になっていく様子を、以降のPartで観察しましょう。
CleanArchitectureを段階的に適用する最初の成果物
今回は
POSTリクエストを受けて、メモを保存する
GETリクエストを受けて、保存したメモを参照する
だけのメモ API を用意します。
実装
Webアプリケーションフレームワーク Flask を採用して、シンプルな api を作成します。
1. エンドポイントを用意する
要件を再掲しますが、今回作成する api は、
- POSTリクエストを受けて、メモを保存する
- GETリクエストを受けて、保存したメモを参照する
です。
要件を満たす実装では、
memo_idをプライマリーキーとして、memoを扱うこととします。まず上記 2 点の処理を実行するエンドポイントを用意します。
Flaskを用いて、POSTリクエストを受けて、メモを保存する ためのエンドポイントを用意します。
from flask import Flask, request app = Flask(__name__) @app.route('/memo/<int:memo_id>', methods=['POST']) def post(memo_id: int) -> str: # リクエストから値を取得する memo: str = request.form["memo"] pass同様に、GETリクエストを受けて、保存したメモを参照する ためのエンドポイントを用意します。
@app.route('/memo/<int:memo_id>') def get(memo_id: int) -> str: pass2. DB とメモのやりとりをする部分を用意する
では、このエンドポイントに、メモを保存する DB とのやりとりを記載していきます。
今回は保存する db として、mysql を採用しています。
まず、
memo_idでmemoの有無を確認するための関数を用意します。from mysql import connector # DB接続用の設定 config = { 'user': 'root', 'password': 'password', 'host': 'mysql', 'database': 'test_database', 'autocommit': True } def exist(memo_id: int) -> bool: # DBクライアントを作成する conn = connector.connect(**config) cursor = conn.cursor() # memo_idがあるかどうか確認する query = "SELECT EXISTS(SELECT * FROM test_table WHERE memo_id = %s)" cursor.execute(query, [memo_id]) result: tuple = cursor.fetchone() # DBクライアントをcloseする cursor.close() conn.close() # 検索結果が1件あるかどうかで存在を確認する if result[0] == 1: return True else: return False次に、POSTリクエストを受けて、メモを保存する 処理を、作成したエンドポイントに追記します。
from flask import Flask, request, jsonify from mysql import connector from werkzeug.exceptions import Conflict app = Flask(__name__) @app.route('/memo/<int:memo_id>', methods=['POST']) def post(memo_id: int) -> str: # 指定されたidがあるかどうか確認する is_exist: bool = exist(memo_id) if is_exist: raise Conflict(f'memo_id [{memo_id}] is already registered.') # リクエストから値を取得する memo: str = request.form["memo"] # DBクライアントを作成する conn = connector.connect(**config) cursor = conn.cursor() # memoを保存する query = "INSERT INTO test_table (memo_id, memo) VALUES (%s, %s)" cursor.execute(query, (memo_id, memo)) # DBクライアントをcloseする cursor.close() conn.close() return jsonify( { "message": "saved." } )
次に、GETリクエストを受けて、外部のDBに保存したメモを参照する 処理を実装します。
from werkzeug.exceptions import NotFound @app.route('/memo/<int:memo_id>') def get(memo_id: int) -> str: # 指定されたidがあるかどうか確認する is_exist: bool = exist(memo_id) if not is_exist: raise NotFound(f'memo_id [{memo_id}] is not registered yet.') # DBクライアントを作成する conn = connector.connect(**config) cursor = conn.cursor() # memo_idで検索を実行する query = "SELECT * FROM test_table WHERE memo_id = %s" cursor.execute(query, [memo_id]) result: tuple = cursor.fetchone() # DBクライアントをcloseする cursor.close() conn.close() return jsonify( { "message": f'memo : [{result[1]}]' } )次に、エラーハンドラを設定します。
from http import HTTPStatus from flask import make_response @app.errorhandler(NotFound) def handle_404(err): json = jsonify( { "message": err.description } ) return make_response(json, HTTPStatus.NOT_FOUND) @app.errorhandler(Conflict) def handle_409(err): json = jsonify( { "message": err.description } ) return make_response(json, HTTPStatus.CONFLICT)
3. appを起動
最後に、これまでに生成した各routerを付与した、
appを起動する処理を,ファイル内に記載します。if __name__ == '__main__': app.run(debug=True, host='0.0.0.0')4. 最終的なコード
main.py
from http import HTTPStatus from flask import Flask, request, jsonify, make_response from mysql import connector from werkzeug.exceptions import Conflict, NotFound app = Flask(__name__) # DB接続用の設定 config = { 'user': 'root', 'password': 'password', 'host': 'mysql', 'database': 'test_database', 'autocommit': True } def exist(memo_id: int) -> bool: # DBクライアントを作成する conn = connector.connect(**config) cursor = conn.cursor() # memo_idがあるかどうか確認する query = "SELECT EXISTS(SELECT * FROM test_table WHERE memo_id = %s)" cursor.execute(query, [memo_id]) result: tuple = cursor.fetchone() # DBクライアントをcloseする cursor.close() conn.close() # 検索結果が1件あるかどうかで存在を確認する if result[0] == 1: return True else: return False @app.route('/memo/<int:memo_id>') def get(memo_id: int) -> str: # 指定されたidがあるかどうか確認する is_exist: bool = exist(memo_id) if not is_exist: raise NotFound(f'memo_id [{memo_id}] is not registered yet.') # DBクライアントを作成する conn = connector.connect(**config) cursor = conn.cursor() # memo_idで検索を実行する query = "SELECT * FROM test_table WHERE memo_id = %s" cursor.execute(query, [memo_id]) result: tuple = cursor.fetchone() # DBクライアントをcloseする cursor.close() conn.close() return jsonify( { "message": f'memo : [{result[1]}]' } ) @app.route('/memo/<int:memo_id>', methods=['POST']) def post(memo_id: int) -> str: # 指定されたidがあるかどうか確認する is_exist: bool = exist(memo_id) if is_exist: raise Conflict(f'memo_id [{memo_id}] is already registered.') # リクエストから値を取得する memo: str = request.form["memo"] # DBクライアントを作成する conn = connector.connect(**config) cursor = conn.cursor() # memoを保存する query = "INSERT INTO test_table (memo_id, memo) VALUES (%s, %s)" cursor.execute(query, (memo_id, memo)) # DBクライアントをcloseする cursor.close() conn.close() return jsonify( { "message": "saved." } ) @app.errorhandler(NotFound) def handle_404(err): json = jsonify( { "message": err.description } ) return make_response(json, HTTPStatus.NOT_FOUND) @app.errorhandler(Conflict) def handle_409(err): json = jsonify( { "message": err.description } ) return make_response(json, HTTPStatus.CONFLICT) if __name__ == '__main__': app.run(debug=True, host='0.0.0.0')※ リクエスト単位でconnectionを張るのはあまりイケてないのですが、設計をわかりやすく説明できるよう、敢えてこのような形としています。この点は後ほど、話の展開の中できちんと回収します。
Part1を終えて
これで、下記 2 点 を実行する API が用意できました。
- POSTリクエストを受けて、メモを保存する
- GETリクエストを受けて、保存したメモを参照する
以降の記事では、各 part ごとに、container環境も含めすべてのコードを下記のリポジトリに格納してるので、
手元で動かしてみたい方は下記を参照してみてください。Part1: https://github.com/y-tomimoto/CleanArchitecture/tree/master/part1
次のPartから、このAPIに対しての仕様変更依頼を仮定し、CleanArchitectureを段階的に適用していきましょう。
- 投稿日:2020-09-27T13:45:01+09:00
Frameworks & Drivers 層: Webの登場
前回のPart1では、なるべくモノリシックに、
POSTリクエストを受けて、メモを保存する
GETリクエストを受けて、保存したメモを参照する
だけのメモ API を用意しました。
この記事では、前回の章で作成した下記のコードをベースとして解説を進めています。
1. 成果物に対して、仕様変更依頼を受ける
Part1 で作成した 『Flaskフレームワークを用いて作成したAPI』 に対して、とある仕様変更依頼を受けました。
「webアプリケーションフレームワークに Flask ではなく FastAPI を採用しよう。」
Part1では、この仕様変更依頼を想定して、仕様変更に強い設計を考えてみましょう。
フレームワークを交換したいケースに遭遇したことはあまりありませんが、導入として分かりやすい事例かと思い、採用してみました。
余談として、筆者の直近の体験になりますが、市況の変化により、急遽とあるWebアプリケーションのResponse Headerに、
特定のHeaderを付与したいという状況がありました。しかし、そのHeader属性は近年追加されたものであったため、当時採用していたWebアプリケーションフレームワークが、
そのHeader属性をサポートしておらず、Webアプリケーションフレームワーク自体の変更を迫られたというケースはありました。
(結局カスタムヘッダーに、Headerを生で書いて対応し、事なきを得ましたが、、、)2. 現在の設計のままで仕様変更依頼に対応する際の懸念点
さて、話を戻します。
現在は、
main.py内に、下記の処理がまとめて記載されています。
- フレームワークによりリクエストを受け付ける
- アプリケーションに本来期待する処理を実行する(メモの取得・保存)
main.py : TODO urlを記載する
現状の設計で変更を加える場合のコーディング
現在の設計で、採用するフレームワークを変更するとなると、どのような作業が発生するでしょうか?
フレームワークをFlaskからFastAPIに変更しようとした場合、
既存のmain.pyに下記のような修正を加えることになるでしょう。
- フレームワークによって構成されたルーターを書き換える
- レスポンスの形式を書き変える
- エラーハンドラを書き換える
- app の起動方法を書き変える
現在の設計のままで、既存の
main.pyに実際の修正を加えると、下記のようになるかと思います。main.py
from http import HTTPStatus - from flask import Flask, request, jsonify, make_response + from fastapi import FastAPI, Form, Response + import uvicorn from mysql import connector - app = Flask(__name__) + app = FastAPI() # DB接続用の設定 config = { ... } def exist(memo_id: int) -> bool: ... - @app.route('/memo/<int:memo_id>') + @app.get('/memo/{memo_id}') def get(memo_id: int) -> str: ... - return jsonify( - { - "message": f'memo : [{result[1]}]' - } - ) + return JSONResponse( + content={"message": f'memo : [{result[1]}]' + ) - @app.route('/memo/<int:memo_id>', methods=['POST']) + @app.post('/memo/{memo_id}') - def post(memo_id: int) -> str: + async def post(memo_id: int, memo: str = Form(...)) -> str: ... - return jsonify( - { - "message": "saved." - } - ) + return JSONResponse( + content={"message": "saved."} + ) - @app.errorhandler(NotFound) - def handle_404(err): - json = jsonify( - { - "message": err.description - } - ) - return make_response(json, HTTPStatus.NOT_FOUND) + @app.exception_handler(NotFound) + async def handle_404(request: Request, exc: NotFound): + return JSONResponse( + status_code=HTTPStatus.NOT_FOUND, + content={"message": exc.description}, + ) - @app.errorhandler(Conflict) - def handle_409(err): - json = jsonify( - { - "message": err.description - } - ) - return make_response(json, HTTPStatus.CONFLICT) + @app.exception_handler(Conflict) + async def handle_409(request: Request, exc: Conflict): + return JSONResponse( + status_code=HTTPStatus.CONFLICT, + content={"message": exc.description}, + ) if __name__ == '__main__': - app.run(debug=True, host='0.0.0.0') # DELETE + uvicorn.run(app=fastapi_app, host="0.0.0.0", port=5000) # NEWこのように力技で仕様変更することは可能ではありますが、いくつか懸念点があります。
現状の設計で変更を加える場合のコーディングの懸念点
この修正では、
main.py内の、フレームワークに関するコード を修正しています。しかし、
main.py内には、フレームワークに関するコードのみならず、アプリケーションに本来期待する、メモを取得・保存する処理 も記載されています。※ 複数の役割を一同に持つ
main.pyはSingle Responsibility Principle:単一責任の原則を満たしていないといえます。Single Responsibility Principle:単一責任の原則: https://note.com/erukiti/n/n67b323d1f7c5
この際、アプリケーションに本来期待する「メモを取得・保存する処理」に対して、誤って不必要な変更を加えてしまう かもしれません。
既に動作しているコードに対して、誤って不具合を引き起こすのではないか? と考えながら、修正を施すという状況は、なるべく避けたいです。
今回の例では、エンドポイントは 2 つのみですが、これが大規模なサービスで、複数のエンドポイントがある場合、この懸念はより大きなものとなるでしょう。
※ これは、SOLID 原則のうち、
Open/closed principle:オープン/クロースドの原則に反しているもと言えます。オープン/クロースドの原則は、変更が発生した場合に既存のコードには修正を加えずに、新しくコードを追加するとする原則です。今回のケースでは、新たにフレームワークを追加するにあたり、既存のコードに対する修正が多く発生しています。Open/closed principle:オープン/クロースドの原則: https://medium.com/eureka-engineering/go-open-closed-principle-977f1b5d3db0
3. 依頼に対して、どのような設計だったら、スムーズに仕様変更できたかを、CleanArchitecture ベースで考えてみる
i. 設計上の懸念点を再整理
懸念点 : 正常に動作している既存のコードに、不必要な変更を加えてしまう可能性がある
ⅱ. どのような設計になっていれば、懸念点を回避して仕様変更できたか
今回の懸念点は、
main.py内に、フレームワークのみならず、アプリケーションに本来期待する メモを取得・保存する処理もまとめられていることに起因しています。そのため、今回の懸念点は、
main.pyを、フレームワーク と、アプリケーションに本来期待する処理 に分割すると解消されそうです。
コードを役割ごとに分割した設計になっていれば、修正の影響範囲を、その役割の中だけに留めることができそうです。
ⅲ. 理想の設計を、CleanArchitecture で解釈した場合
main.pyには、
- flask フレームワークでリクエストを受け取る
- メモを保存する or メモを取得する
という 2 つの処理があります。
CleanArchitecture よりの言葉で、上記を言い換えると、
- Web アプリケーションフレームワーク
- アプリケーションに本来期待する機能
です。
CleanArchitecture で解釈するにあたり、下記の図では、
1について、Web (Frameworks & Drivers 層の一部)と表せそうです。
2については、アプリケーションに本来期待する機能ということなので、Application Business Rules 層か、Enterprise Business Rules 層のいづれかに該当しそうですが、ここでは一旦メモを保存する or メモを取得するという機能を形容して、MemoHandler として扱いましょう。と表わせそうです。
TODO : 図を挿入
では、
main.pyを Frameworks & Drivers 層: Web と MemoHandler に分割してみましょう。ⅳ. 実際のコーディング
main.pyからは、Frameworks & Drivers 層: Web の router を呼び出し、
各 router から、memo_handler.pyを呼び出すような設計にします。この設計にすることで、フレームワークを変更する場合には、
main.pyで呼び出すフレームワークを変更するのみで、
既存の処理であるmemo_handler.py自体に手を加えないので、誤って既存の処理が変更されることはありません。ツリー図
. ├── memo_handler.py └── frameworks_and_drivers └── web ├── fastapi_router.py └── flask_router.pyFrameworks & Drivers 層
frameworks_and_drivers/web/fastapi_router.py
from fastapi import FastAPI, Form, Request from fastapi.responses import JSONResponse from werkzeug.exceptions import Conflict, NotFound from memo_handler import MemoHandler from http import HTTPStatus app = FastAPI() @app.get('/memo/{memo_id}') def get(memo_id: int) -> str: return JSONResponse( content={"message": MemoHandler().get(memo_id)} ) @app.post('/memo/{memo_id}') async def post(memo_id: int, memo: str = Form(...)) -> str: return JSONResponse( content={"message": MemoHandler().save(memo_id, memo)} ) @app.exception_handler(NotFound) async def handle_404(request: Request, exc: NotFound): return JSONResponse( status_code=HTTPStatus.NOT_FOUND, content={"message": exc.description}, ) @app.exception_handler(Conflict) async def handle_409(request: Request, exc: Conflict): return JSONResponse( status_code=HTTPStatus.CONFLICT, content={"message": exc.description}, )frameworks_and_drivers/web/flask_router.py
from flask import Flask, request , jsonify , make_response from werkzeug.exceptions import Conflict,NotFound from http import HTTPStatus from memo_handler import MemoHandler app = Flask(__name__) @app.route('/memo/<int:memo_id>') def get(memo_id: int) -> str: return jsonify( { "message": MemoHandler().get(memo_id) } ) @app.route('/memo/<int:memo_id>', methods=['POST']) def post(memo_id: int) -> str: memo: str = request.form["memo"] return jsonify( { "message": MemoHandler().save(memo_id, memo) } ) @app.errorhandler(NotFound) def handle_404(err): json = jsonify( { "message": err.description } ) return make_response(json,HTTPStatus.NOT_FOUND) @app.errorhandler(Conflict) def handle_409(err): json = jsonify( { "message": err.description } ) return make_response(json, HTTPStatus.CONFLICT)MemoHandler
memo_handler.py
from mysql import connector from werkzeug.exceptions import Conflict, NotFound # sqlクライアント用のconfig config = { 'user': 'root', 'password': 'password', 'host': 'mysql', 'database': 'test_database', 'autocommit': True } class MemoHandler: def exist(self, memo_id: int): # DBクライアントを作成する conn = connector.connect(**config) cursor = conn.cursor() # memo_idがあるかどうか確認する query = "SELECT EXISTS(SELECT * FROM test_table WHERE memo_id = %s)" cursor.execute(query, [memo_id]) result: tuple = cursor.fetchone() # DBクライアントをcloseする cursor.close() conn.close() # 検索結果が1件あるかどうかで存在を確認する if result[0] == 1: return True else: return False def get(self, memo_id: int): # 指定されたidがあるかどうか確認する is_exist: bool = self.exist(memo_id) if not is_exist: raise NotFound(f'memo_id [{memo_id}] is not registered yet.') # DBクライアントを作成する conn = connector.connect(**config) cursor = conn.cursor() # memo_idで検索を実行する query = "SELECT * FROM test_table WHERE memo_id = %s" cursor.execute(query, [memo_id]) result: tuple = cursor.fetchone() # DBクライアントをcloseする cursor.close() conn.close() return f'memo : [{result[1]}]' def save(self, memo_id: int, memo: str): # 指定されたidがあるかどうか確認する is_exist: bool = self.exist(memo_id) if is_exist: raise Conflict(f'memo_id [{memo_id}] is already registered.') # DBクライアントを作成する conn = connector.connect(**config) cursor = conn.cursor() # memoを保存する query = "INSERT INTO test_table (memo_id, memo) VALUES (%s, %s)" cursor.execute(query, (memo_id, memo)) # DBクライアントをcloseする cursor.close() conn.close() return "saved."main.py
main.py上で採用するフレームワークを切り替えます。main.py
import uvicorn from frameworks_and_drivers.flask_router import app as fastapi_app from frameworks_and_drivers.flask_router import app as flask_app --- # フレームワークとしてflaskを採用する場合 flask_app.run(debug=True, host='0.0.0.0') --- # フレームワークとしてfast_apiを採用する場合 uvicorn.run(app=fastapi_app, host="0.0.0.0",port=5000)4. 設計の変化によって、どのような仕様変更に耐えうるようになったか?
各フレームワークを、Frameworks & Drivers 層: Web に切り出し、本来アプリケーションに期待する処理を
MemoHandlerに切り出したことで、
採用したい router を、main.pyで呼び出すだけで、アプリケーションに本来期待する処理である、memo_handler.pyに手を入れることなく、フレームワークを柔軟に変更 することができました。この設計では、CleanArchitecture のルールの 1 つ、フレームワーク独立 が実現されています。
クリーンアーキテクチャ(The Clean Architecture翻訳) :https://blog.tai2.net/the_clean_architecture.html
フレームワーク独立: アーキテクチャは、機能満載のソフトウェアのライブラリが手に入ることには依存しない。これは、そういったフレームワークを道具として使うことを可能にし、システムをフレームワークの限定された制約に押し込めなければならないようなことにはさせない。
- 投稿日:2020-09-27T13:45:01+09:00
[CleanArchitecture with Python] Frameworks & Drivers 層: Webの登場
前回のPart1では、なるべくモノリシックに、
POSTリクエストを受けて、メモを保存する
GETリクエストを受けて、保存したメモを参照する
だけのメモ API を用意しました。
この記事では、前回の章で作成した下記のコードをベースとして解説を進めています。
1. 成果物に対して、仕様変更依頼を受ける
Part1 で作成した 『Flaskフレームワークを用いて作成したAPI』 に対して、とある仕様変更依頼を受けました。
「webアプリケーションフレームワークに Flask ではなく FastAPI を採用しよう。」
Part1では、この仕様変更依頼を想定して、仕様変更に強い設計を考えてみましょう。
フレームワークを交換したいケースに遭遇したことはあまりありませんが、導入として分かりやすい事例かと思い、採用してみました。
余談として、筆者の直近の体験になりますが、市況の変化により、急遽とあるWebアプリケーションのResponse Headerに、
特定のHeaderを付与したいという状況がありました。しかし、そのHeader属性は近年追加されたものであったため、当時採用していたWebアプリケーションフレームワークが、
そのHeader属性をサポートしておらず、Webアプリケーションフレームワーク自体の変更を迫られたというケースはありました。
(結局カスタムヘッダーに、Headerを生で書いて対応し、事なきを得ましたが、、、)2. 現在の設計のままで仕様変更依頼に対応する際の懸念点
さて、話を戻します。
現在は、
main.py内に、下記の処理がまとめて記載されています。
- フレームワークによりリクエストを受け付ける
- アプリケーションに本来期待する処理を実行する(メモの取得・保存)
main.py : TODO urlを記載する
現状の設計で変更を加える場合のコーディング
現在の設計で、採用するフレームワークを変更するとなると、どのような作業が発生するでしょうか?
フレームワークをFlaskからFastAPIに変更しようとした場合、
既存のmain.pyに下記のような修正を加えることになるでしょう。
- フレームワークによって構成されたルーターを書き換える
- レスポンスの形式を書き変える
- エラーハンドラを書き換える
- app の起動方法を書き変える
現在の設計のままで、既存の
main.pyに実際の修正を加えると、下記のようになるかと思います。main.py
from http import HTTPStatus - from flask import Flask, request, jsonify, make_response + from fastapi import FastAPI, Form, Response + import uvicorn from mysql import connector - app = Flask(__name__) + app = FastAPI() # DB接続用の設定 config = { ... } def exist(memo_id: int) -> bool: ... - @app.route('/memo/<int:memo_id>') + @app.get('/memo/{memo_id}') def get(memo_id: int) -> str: ... - return jsonify( - { - "message": f'memo : [{result[1]}]' - } - ) + return JSONResponse( + content={"message": f'memo : [{result[1]}]' + ) - @app.route('/memo/<int:memo_id>', methods=['POST']) + @app.post('/memo/{memo_id}') - def post(memo_id: int) -> str: + async def post(memo_id: int, memo: str = Form(...)) -> str: ... - return jsonify( - { - "message": "saved." - } - ) + return JSONResponse( + content={"message": "saved."} + ) - @app.errorhandler(NotFound) - def handle_404(err): - json = jsonify( - { - "message": err.description - } - ) - return make_response(json, HTTPStatus.NOT_FOUND) + @app.exception_handler(NotFound) + async def handle_404(request: Request, exc: NotFound): + return JSONResponse( + status_code=HTTPStatus.NOT_FOUND, + content={"message": exc.description}, + ) - @app.errorhandler(Conflict) - def handle_409(err): - json = jsonify( - { - "message": err.description - } - ) - return make_response(json, HTTPStatus.CONFLICT) + @app.exception_handler(Conflict) + async def handle_409(request: Request, exc: Conflict): + return JSONResponse( + status_code=HTTPStatus.CONFLICT, + content={"message": exc.description}, + ) if __name__ == '__main__': - app.run(debug=True, host='0.0.0.0') # DELETE + uvicorn.run(app=fastapi_app, host="0.0.0.0", port=5000) # NEWこのように力技で仕様変更することは可能ではありますが、いくつか懸念点があります。
現状の設計で変更を加える場合のコーディングの懸念点
この修正では、
main.py内の、フレームワークに関するコード を修正しています。しかし、
main.py内には、フレームワークに関するコードのみならず、アプリケーションに本来期待する、メモを取得・保存する処理 も記載されています。※ 複数の役割を一同に持つ
main.pyはSingle Responsibility Principle:単一責任の原則を満たしていないといえます。Single Responsibility Principle:単一責任の原則: https://note.com/erukiti/n/n67b323d1f7c5
この際、アプリケーションに本来期待する「メモを取得・保存する処理」に対して、誤って不必要な変更を加えてしまう かもしれません。
既に動作しているコードに対して、誤って不具合を引き起こすのではないか? と考えながら、修正を施すという状況は、なるべく避けたいです。
今回の例では、エンドポイントは 2 つのみですが、これが大規模なサービスで、複数のエンドポイントがある場合、この懸念はより大きなものとなるでしょう。
※ これは、SOLID 原則のうち、
Open/closed principle:オープン/クロースドの原則に反しているもと言えます。オープン/クロースドの原則は、変更が発生した場合に既存のコードには修正を加えずに、新しくコードを追加するとする原則です。今回のケースでは、新たにフレームワークを追加するにあたり、既存のコードに対する修正が多く発生しています。Open/closed principle:オープン/クロースドの原則: https://medium.com/eureka-engineering/go-open-closed-principle-977f1b5d3db0
3. 依頼に対して、どのような設計だったら、スムーズに仕様変更できたかを、CleanArchitecture ベースで考えてみる
i. 設計上の懸念点を再整理
懸念点 : 正常に動作している既存のコードに、不必要な変更を加えてしまう可能性がある
ⅱ. どのような設計になっていれば、懸念点を回避して仕様変更できたか
今回の懸念点は、
main.py内に、フレームワークのみならず、アプリケーションに本来期待する メモを取得・保存する処理もまとめられていることに起因しています。そのため、今回の懸念点は、
main.pyを、フレームワーク と、アプリケーションに本来期待する処理 に分割すると解消されそうです。
コードを役割ごとに分割した設計になっていれば、修正の影響範囲を、その役割の中だけに留めることができそうです。
ⅲ. 理想の設計を、CleanArchitecture で解釈した場合
main.pyには、
- flask フレームワークでリクエストを受け取る
- メモを保存する or メモを取得する
という 2 つの処理があります。
CleanArchitecture よりの言葉で、上記を言い換えると、
- Web アプリケーションフレームワーク
- アプリケーションに本来期待する機能
です。
CleanArchitecture で解釈するにあたり、下記の図では、
1について、Web (Frameworks & Drivers 層の一部)と表せそうです。
2については、アプリケーションに本来期待する機能ということなので、Application Business Rules 層か、Enterprise Business Rules 層のいづれかに該当しそうですが、ここでは一旦メモを保存する or メモを取得するという機能を形容して、MemoHandler として扱いましょう。と表わせそうです。
TODO : 図を挿入
では、
main.pyを Frameworks & Drivers 層: Web と MemoHandler に分割してみましょう。ⅳ. 実際のコーディング
main.pyからは、Frameworks & Drivers 層: Web の router を呼び出し、
各 router から、memo_handler.pyを呼び出すような設計にします。この設計にすることで、フレームワークを変更する場合には、
main.pyで呼び出すフレームワークを変更するのみで、
既存の処理であるmemo_handler.py自体に手を加えないので、誤って既存の処理が変更されることはありません。ツリー図
. ├── memo_handler.py └── frameworks_and_drivers └── web ├── fastapi_router.py └── flask_router.pyFrameworks & Drivers 層
frameworks_and_drivers/web/fastapi_router.py
from fastapi import FastAPI, Form, Request from fastapi.responses import JSONResponse from werkzeug.exceptions import Conflict, NotFound from memo_handler import MemoHandler from http import HTTPStatus app = FastAPI() @app.get('/memo/{memo_id}') def get(memo_id: int) -> str: return JSONResponse( content={"message": MemoHandler().get(memo_id)} ) @app.post('/memo/{memo_id}') async def post(memo_id: int, memo: str = Form(...)) -> str: return JSONResponse( content={"message": MemoHandler().save(memo_id, memo)} ) @app.exception_handler(NotFound) async def handle_404(request: Request, exc: NotFound): return JSONResponse( status_code=HTTPStatus.NOT_FOUND, content={"message": exc.description}, ) @app.exception_handler(Conflict) async def handle_409(request: Request, exc: Conflict): return JSONResponse( status_code=HTTPStatus.CONFLICT, content={"message": exc.description}, )frameworks_and_drivers/web/flask_router.py
from flask import Flask, request , jsonify , make_response from werkzeug.exceptions import Conflict,NotFound from http import HTTPStatus from memo_handler import MemoHandler app = Flask(__name__) @app.route('/memo/<int:memo_id>') def get(memo_id: int) -> str: return jsonify( { "message": MemoHandler().get(memo_id) } ) @app.route('/memo/<int:memo_id>', methods=['POST']) def post(memo_id: int) -> str: memo: str = request.form["memo"] return jsonify( { "message": MemoHandler().save(memo_id, memo) } ) @app.errorhandler(NotFound) def handle_404(err): json = jsonify( { "message": err.description } ) return make_response(json,HTTPStatus.NOT_FOUND) @app.errorhandler(Conflict) def handle_409(err): json = jsonify( { "message": err.description } ) return make_response(json, HTTPStatus.CONFLICT)MemoHandler
memo_handler.py
from mysql import connector from werkzeug.exceptions import Conflict, NotFound # sqlクライアント用のconfig config = { 'user': 'root', 'password': 'password', 'host': 'mysql', 'database': 'test_database', 'autocommit': True } class MemoHandler: def exist(self, memo_id: int): # DBクライアントを作成する conn = connector.connect(**config) cursor = conn.cursor() # memo_idがあるかどうか確認する query = "SELECT EXISTS(SELECT * FROM test_table WHERE memo_id = %s)" cursor.execute(query, [memo_id]) result: tuple = cursor.fetchone() # DBクライアントをcloseする cursor.close() conn.close() # 検索結果が1件あるかどうかで存在を確認する if result[0] == 1: return True else: return False def get(self, memo_id: int): # 指定されたidがあるかどうか確認する is_exist: bool = self.exist(memo_id) if not is_exist: raise NotFound(f'memo_id [{memo_id}] is not registered yet.') # DBクライアントを作成する conn = connector.connect(**config) cursor = conn.cursor() # memo_idで検索を実行する query = "SELECT * FROM test_table WHERE memo_id = %s" cursor.execute(query, [memo_id]) result: tuple = cursor.fetchone() # DBクライアントをcloseする cursor.close() conn.close() return f'memo : [{result[1]}]' def save(self, memo_id: int, memo: str): # 指定されたidがあるかどうか確認する is_exist: bool = self.exist(memo_id) if is_exist: raise Conflict(f'memo_id [{memo_id}] is already registered.') # DBクライアントを作成する conn = connector.connect(**config) cursor = conn.cursor() # memoを保存する query = "INSERT INTO test_table (memo_id, memo) VALUES (%s, %s)" cursor.execute(query, (memo_id, memo)) # DBクライアントをcloseする cursor.close() conn.close() return "saved."main.py
main.py上で採用するフレームワークを切り替えます。main.py
import uvicorn from frameworks_and_drivers.flask_router import app as fastapi_app from frameworks_and_drivers.flask_router import app as flask_app --- # フレームワークとしてflaskを採用する場合 flask_app.run(debug=True, host='0.0.0.0') --- # フレームワークとしてfast_apiを採用する場合 uvicorn.run(app=fastapi_app, host="0.0.0.0",port=5000)4. 設計の変化によって、どのような仕様変更に耐えうるようになったか?
各フレームワークを、Frameworks & Drivers 層: Web に切り出し、本来アプリケーションに期待する処理を
MemoHandlerに切り出したことで、
採用したい router を、main.pyで呼び出すだけで、アプリケーションに本来期待する処理である、memo_handler.pyに手を入れることなく、フレームワークを柔軟に変更 することができました。この設計では、CleanArchitecture のルールの 1 つ、フレームワーク独立 が実現されています。
クリーンアーキテクチャ(The Clean Architecture翻訳) :https://blog.tai2.net/the_clean_architecture.html
フレームワーク独立: アーキテクチャは、機能満載のソフトウェアのライブラリが手に入ることには依存しない。これは、そういったフレームワークを道具として使うことを可能にし、システムをフレームワークの限定された制約に押し込めなければならないようなことにはさせない。
- 投稿日:2020-09-27T13:45:01+09:00
[CleanArchitecture with Python] Part2: Frameworks & Drivers 層: Webの登場
前回のPart1では、なるべくモノリシックに、
POSTリクエストを受けて、メモを保存する
GETリクエストを受けて、保存したメモを参照する
だけのメモ API を用意しました。
この記事では、前回の章で作成した下記のコードをベースとして解説を進めています。
1. 成果物に対して、仕様変更依頼を受ける
Part1 で作成した 『Flaskフレームワークを用いて作成したAPI』 に対して、とある仕様変更依頼を受けました。
「webアプリケーションフレームワークに Flask ではなく FastAPI を採用しよう。」
Part1では、この仕様変更依頼を想定して、仕様変更に強い設計を考えてみましょう。
フレームワークを交換したいケースに遭遇したことはあまりありませんが、導入として分かりやすい事例かと思い、採用してみました。
余談として、筆者の直近の体験になりますが、市況の変化により、急遽とあるWebアプリケーションのResponse Headerに、
特定のHeaderを付与したいという状況がありました。しかし、そのHeader属性は近年追加されたものであったため、当時採用していたWebアプリケーションフレームワークが、
そのHeader属性をサポートしておらず、Webアプリケーションフレームワーク自体の変更を迫られたというケースはありました。
(結局カスタムヘッダーに、Headerを生で書いて対応し、事なきを得ましたが、、、)2. 現在の設計のままで仕様変更依頼に対応する際の懸念点
さて、話を戻します。
現在は、
main.py内に、下記の処理がまとめて記載されています。
- フレームワークによりリクエストを受け付ける
- アプリケーションに本来期待する処理を実行する(メモの取得・保存)
main.py : https://github.com/y-tomimoto/CleanArchitecture/blob/master/part1/app/main.py
現状の設計で変更を加える場合のコーディング
現在の設計で、採用するフレームワークを変更するとなると、どのような作業が発生するでしょうか?
フレームワークをFlaskからFastAPIに変更しようとした場合、
既存のmain.pyに下記のような修正を加えることになるでしょう。
- フレームワークによって構成されたルーターを書き換える
- レスポンスの形式を書き変える
- エラーハンドラを書き換える
- app の起動方法を書き変える
現在の設計のままで、既存の
main.pyに実際の修正を加えると、下記のようになるかと思います。main.py
from http import HTTPStatus - from flask import Flask, request, jsonify, make_response + from fastapi import FastAPI, Form, Response + import uvicorn from mysql import connector - app = Flask(__name__) + app = FastAPI() # DB接続用の設定 config = { ... } def exist(memo_id: int) -> bool: ... - @app.route('/memo/<int:memo_id>') + @app.get('/memo/{memo_id}') def get(memo_id: int) -> str: ... - return jsonify( - { - "message": f'memo : [{result[1]}]' - } - ) + return JSONResponse( + content={"message": f'memo : [{result[1]}]' + ) - @app.route('/memo/<int:memo_id>', methods=['POST']) + @app.post('/memo/{memo_id}') - def post(memo_id: int) -> str: + async def post(memo_id: int, memo: str = Form(...)) -> str: ... - return jsonify( - { - "message": "saved." - } - ) + return JSONResponse( + content={"message": "saved."} + ) - @app.errorhandler(NotFound) - def handle_404(err): - json = jsonify( - { - "message": err.description - } - ) - return make_response(json, HTTPStatus.NOT_FOUND) + @app.exception_handler(NotFound) + async def handle_404(request: Request, exc: NotFound): + return JSONResponse( + status_code=HTTPStatus.NOT_FOUND, + content={"message": exc.description}, + ) - @app.errorhandler(Conflict) - def handle_409(err): - json = jsonify( - { - "message": err.description - } - ) - return make_response(json, HTTPStatus.CONFLICT) + @app.exception_handler(Conflict) + async def handle_409(request: Request, exc: Conflict): + return JSONResponse( + status_code=HTTPStatus.CONFLICT, + content={"message": exc.description}, + ) if __name__ == '__main__': - app.run(debug=True, host='0.0.0.0') # DELETE + uvicorn.run(app=fastapi_app, host="0.0.0.0", port=5000) # NEWこのように力技で仕様変更することは可能ではありますが、いくつか懸念点があります。
現状の設計で変更を加える場合のコーディングの懸念点
この修正では、
main.py内の、フレームワークに関するコード を修正しています。しかし、
main.py内には、フレームワークに関するコードのみならず、アプリケーションに本来期待する、メモを取得・保存する処理 も記載されています。※ 複数の役割を一同に持つ
main.pyはSingle Responsibility Principle:単一責任の原則を満たしていないといえます。Single Responsibility Principle:単一責任の原則: https://note.com/erukiti/n/n67b323d1f7c5
この際、アプリケーションに本来期待する「メモを取得・保存する処理」に対して、誤って不必要な変更を加えてしまう かもしれません。
既に動作しているコードに対して、誤って不具合を引き起こすのではないか? と考えながら、修正を施すという状況は、なるべく避けたいです。
今回の例では、エンドポイントは 2 つのみですが、これが大規模なサービスで、複数のエンドポイントがある場合、この懸念はより大きなものとなるでしょう。
※ これは、SOLID 原則のうち、
Open/closed principle:オープン/クロースドの原則に反しているもと言えます。オープン/クロースドの原則は、変更が発生した場合に既存のコードには修正を加えずに、新しくコードを追加するとする原則です。今回のケースでは、新たにフレームワークを追加するにあたり、既存のコードに対する修正が多く発生しています。Open/closed principle:オープン/クロースドの原則: https://medium.com/eureka-engineering/go-open-closed-principle-977f1b5d3db0
3. 依頼に対して、どのような設計だったら、スムーズに仕様変更できたかを、CleanArchitecture ベースで考えてみる
i. 設計上の懸念点を再整理
懸念点 : 正常に動作している既存のコードに、不必要な変更を加えてしまう可能性がある
ⅱ. どのような設計になっていれば、懸念点を回避して仕様変更できたか
今回の懸念点は、
main.py内に、フレームワークのみならず、アプリケーションに本来期待する メモを取得・保存する処理もまとめられていることに起因しています。そのため、今回の懸念点は、
main.pyを、フレームワーク と、アプリケーションに本来期待する処理 に分割すると解消されそうです。
コードを役割ごとに分割した設計になっていれば、修正の影響範囲を、その役割の中だけに留めることができそうです。
ⅲ. 理想の設計を、CleanArchitecture で解釈した場合
main.pyには、
- flask フレームワークでリクエストを受け取る
- メモを保存する or メモを取得する
という 2 つの処理があります。
CleanArchitecture よりの言葉で、上記を言い換えると、
- Web アプリケーションフレームワーク
- アプリケーションに本来期待する機能
です。
CleanArchitecture で解釈するにあたり、下記の図では、
1について、Web (Frameworks & Drivers 層の一部)と表せそうです。
2については、アプリケーションに本来期待する機能ということなので、Application Business Rules 層か、Enterprise Business Rules 層のいづれかに該当しそうですが、ここでは一旦メモを保存する or メモを取得するという機能を形容して、MemoHandler として扱いましょう。と表わせそうです。
では、
main.pyを Frameworks & Drivers 層: Web と MemoHandler に分割してみましょう。ⅳ. 実際のコーディング
main.pyからは、Frameworks & Drivers 層: Web の router を呼び出し、
各 router から、memo_handler.pyを呼び出すような設計にします。この設計にすることで、フレームワークを変更する場合には、
main.pyで呼び出すフレームワークを変更するのみで、
既存の処理であるmemo_handler.py自体に手を加えないので、誤って既存の処理が変更されることはありません。ツリー図
. ├── memo_handler.py └── frameworks_and_drivers └── web ├── fastapi_router.py └── flask_router.pyFrameworks & Drivers 層
frameworks_and_drivers/web/fastapi_router.py
from fastapi import FastAPI, Form, Request from fastapi.responses import JSONResponse from werkzeug.exceptions import Conflict, NotFound from memo_handler import MemoHandler from http import HTTPStatus app = FastAPI() @app.get('/memo/{memo_id}') def get(memo_id: int) -> str: return JSONResponse( content={"message": MemoHandler().get(memo_id)} ) @app.post('/memo/{memo_id}') async def post(memo_id: int, memo: str = Form(...)) -> str: return JSONResponse( content={"message": MemoHandler().save(memo_id, memo)} ) @app.exception_handler(NotFound) async def handle_404(request: Request, exc: NotFound): return JSONResponse( status_code=HTTPStatus.NOT_FOUND, content={"message": exc.description}, ) @app.exception_handler(Conflict) async def handle_409(request: Request, exc: Conflict): return JSONResponse( status_code=HTTPStatus.CONFLICT, content={"message": exc.description}, )frameworks_and_drivers/web/flask_router.py
from flask import Flask, request , jsonify , make_response from werkzeug.exceptions import Conflict,NotFound from http import HTTPStatus from memo_handler import MemoHandler app = Flask(__name__) @app.route('/memo/<int:memo_id>') def get(memo_id: int) -> str: return jsonify( { "message": MemoHandler().get(memo_id) } ) @app.route('/memo/<int:memo_id>', methods=['POST']) def post(memo_id: int) -> str: memo: str = request.form["memo"] return jsonify( { "message": MemoHandler().save(memo_id, memo) } ) @app.errorhandler(NotFound) def handle_404(err): json = jsonify( { "message": err.description } ) return make_response(json,HTTPStatus.NOT_FOUND) @app.errorhandler(Conflict) def handle_409(err): json = jsonify( { "message": err.description } ) return make_response(json, HTTPStatus.CONFLICT)MemoHandler
memo_handler.py
from mysql import connector from werkzeug.exceptions import Conflict, NotFound # sqlクライアント用のconfig config = { 'user': 'root', 'password': 'password', 'host': 'mysql', 'database': 'test_database', 'autocommit': True } class MemoHandler: def exist(self, memo_id: int): # DBクライアントを作成する conn = connector.connect(**config) cursor = conn.cursor() # memo_idがあるかどうか確認する query = "SELECT EXISTS(SELECT * FROM test_table WHERE memo_id = %s)" cursor.execute(query, [memo_id]) result: tuple = cursor.fetchone() # DBクライアントをcloseする cursor.close() conn.close() # 検索結果が1件あるかどうかで存在を確認する if result[0] == 1: return True else: return False def get(self, memo_id: int): # 指定されたidがあるかどうか確認する is_exist: bool = self.exist(memo_id) if not is_exist: raise NotFound(f'memo_id [{memo_id}] is not registered yet.') # DBクライアントを作成する conn = connector.connect(**config) cursor = conn.cursor() # memo_idで検索を実行する query = "SELECT * FROM test_table WHERE memo_id = %s" cursor.execute(query, [memo_id]) result: tuple = cursor.fetchone() # DBクライアントをcloseする cursor.close() conn.close() return f'memo : [{result[1]}]' def save(self, memo_id: int, memo: str): # 指定されたidがあるかどうか確認する is_exist: bool = self.exist(memo_id) if is_exist: raise Conflict(f'memo_id [{memo_id}] is already registered.') # DBクライアントを作成する conn = connector.connect(**config) cursor = conn.cursor() # memoを保存する query = "INSERT INTO test_table (memo_id, memo) VALUES (%s, %s)" cursor.execute(query, (memo_id, memo)) # DBクライアントをcloseする cursor.close() conn.close() return "saved."main.py
main.py上で採用するフレームワークを切り替えます。main.py
import uvicorn from frameworks_and_drivers.flask_router import app as fastapi_app from frameworks_and_drivers.flask_router import app as flask_app --- # フレームワークとしてflaskを採用する場合 flask_app.run(debug=True, host='0.0.0.0') --- # フレームワークとしてfast_apiを採用する場合 uvicorn.run(app=fastapi_app, host="0.0.0.0",port=5000)4. 設計の変化によって、どのような仕様変更に耐えうるようになったか?
最終的なコードはこちらです。: https://github.com/y-tomimoto/CleanArchitecture/blob/master/part2
各フレームワークを、Frameworks & Drivers 層: Web に切り出し、本来アプリケーションに期待する処理を
MemoHandlerに切り出したことで、
採用したい router を、main.pyで呼び出すだけで、アプリケーションに本来期待する処理である、memo_handler.pyに手を入れることなく、フレームワークを柔軟に変更 することができました。
この設計では、CleanArchitecture のルールの 1 つ、フレームワーク独立 が実現されています。
クリーンアーキテクチャ(The Clean Architecture翻訳) :https://blog.tai2.net/the_clean_architecture.html
フレームワーク独立: アーキテクチャは、機能満載のソフトウェアのライブラリが手に入ることには依存しない。これは、そういったフレームワークを道具として使うことを可能にし、システムをフレームワークの限定された制約に押し込めなければならないようなことにはさせない。