- 投稿日:2020-09-27T22:18:47+09:00
DockerのBASIC認証で作成した証明書と秘密鍵をAWS ALBで使用する方法
初めに
以下の手順に沿って進めます。
1. dockerがインストールされたAmazon LinuxにBASIC認証を作成する
2. BASIC認証で発行された秘密鍵と証明書を使用してALBを起動する用語や認識など間違いがありましたら教えていただけると幸いです。
手順1 BASIC認証作成
まず初めにopenssl.cnfの253行目subjectAltNameをインスタンスのプライベートアドレスに書き換えます。
[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ sudoedit /etc/pki/tls/openssl.cnf以下は書き換えた後、
catで表示させたものです。[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ cat -n /etc/pki/tls/openssl.cnf | head -n 255 | tail -n 5 251 252 # Include email address in subject alt name: another PKIX recommendation 253 subjectAltName=IP:xxx.xxx.xxx.xxx 254 # Copy issuer details 255 # issuerAltName=issuer:copyその後、以下のディレクトリを作ります。
[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ mkdir certs上記ディレクトリに上記証明書(domain.crt)、秘密鍵(domain.key)を作成します。
Enter PEM pass phrase:パスフレーズの入力を求められます。
Verifying - Enter PEM pass phrase:2度目の入力が求められます。同じ値を入力します。
なお、このパスフレーズは以降使用しません。[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ openssl req -newkey rsa:2048 -keyout certs/domain.key -x509 -days 365 -out certs/domain.crt Generating a 2048 bit RSA private key ........................................................................................+++ ........+++ writing new private key to 'certs/domain.key' Enter PEM pass phrase: Verifying - Enter PEM pass phrase:以下はすべて空白でエンターを押します。
Country Name (2 letter code) [XX]: State or Province Name (full name) []: Locality Name (eg, city) [Default City]: Organization Name (eg, company) [Default Company Ltd]: Organizational Unit Name (eg, section) []: Common Name (eg, your name or your server's hostname) []: Email Address []:以下ではcertsディレクトリに移動しパスフレーズを削除します。
これをしないと次のエラーによりdockerの起動に失敗します。msg="tls: failed to parse private key"
Enter pass phrase for domain.key:では先ほどのパスフレーズを入力します。[ec2-user@ip-xxx-xxx-xxx-xxx certs]$ openssl rsa -in domain.key -out new.key Enter pass phrase for domain.key: writing RSA key証明書をコピーします。
[ec2-user@ip-xxx-xxx-xxx-xxx certs]$ sudo cp certs/domain.crt /etc/pki/ca-trust/source/anchors/xxx.xxx.xxx.xxx.crt再起動を行います。
[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ sudo update-ca-trust enable [ec2-user@ip-xxx-xxx-xxx-xxx ~]$ sudo update-ca-trust [ec2-user@ip-xxx-xxx-xxx-xxx ~]$ sudo service docker restartパスワードを作成します。
username、passwordにそれぞれユーザー名、パスワードを入力します。[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ docker run --entrypoint htpasswd registry:2.6.2 -Bbn username password > auth/htpasswdプライベートレジストリ用のコンテナを起動します。
[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ docker run -d -p 5000:5000 \ --restart=always \ --name registry \ -v `pwd`/auth:/auth \ -v `pwd`/certs:/certs \ -e "REGISTRY_AUTH=htpasswd" \ -e "REGISTRY_AUTH_HTPASSWD_REALM=Registry Realm" \ -e "REGISTRY_AUTH_HTPASSWD_PATH=/auth/htpasswd" \ -e "REGISTRY_HTTP_TLS_CERTIFICATE=/certs/domain.crt" \ -e "REGISTRY_HTTP_TLS_KEY=/certs/new.key" \ registry:2.6.2ログインできることを確認します。
[ec2-user@ip-xxx-xxx-xxx-xxx certs]$ docker login https://xxx.xxx.xxx.xxx:5000 Username: testuser Password: WARNING! Your password will be stored unencrypted in /home/ec2-user/.docker/config.json. Configure a credential helper to remove this warning. See https://docs.docker.com/engine/reference/commandline/login/#credentials-store Login Succeeded手順2 ALBを起動する
aws-cliを使用してログインします。
以下のアクセスキーXXXやシークレットアクセスキーYYYとなっている部分は、
IAM→ユーザーをクリック→認証情報をクリック で確認できます。[ec2-user@ip-xxx-xxx-xxx-xxx certs]$ aws configure AWS Access Key ID [None]: XXX AWS Secret Access Key [None]: YYY Default region name [None]: ap-northeast-1 Default output format [None]: jsoncertsディレクトリに移動しIAMに証明書をアップロードします。
my-secret-sertは証明書の名前になります。[ec2-user@ip-xxx-xxx-xxx-xxx certs]$ aws iam upload-server-certificate --server-certificate-name my-server-cert \ --certificate-body file://domain.crt --private-key file://new.keyALBはVPC内にサブネットが2つ必要です。それらを作り終えたらEC2のコンソール画面に移動し、ロードバランサーをクリックします。
ALBを選択します。
HTTPSを選択します。
VPCの選択では先ほど作成したVPC、サブネットを選択します。
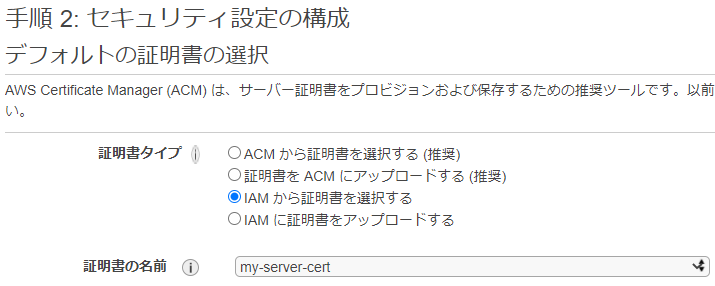
デフォルトの証明書の選択では、アップロードした証明書を選択します。
ルーティングの設定を以下のように行います。
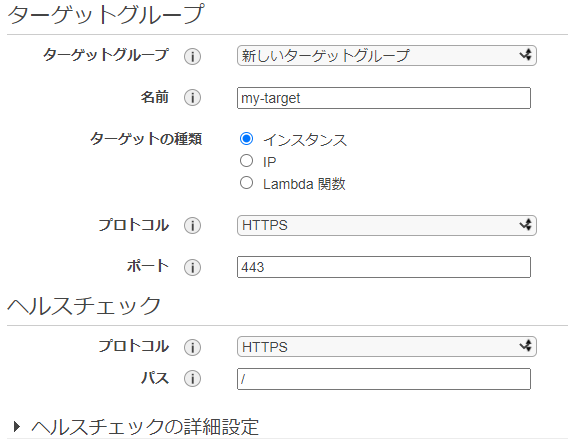
ターゲットの登録では、選択したサブネット内のEC2をターゲットグループに登録できます。
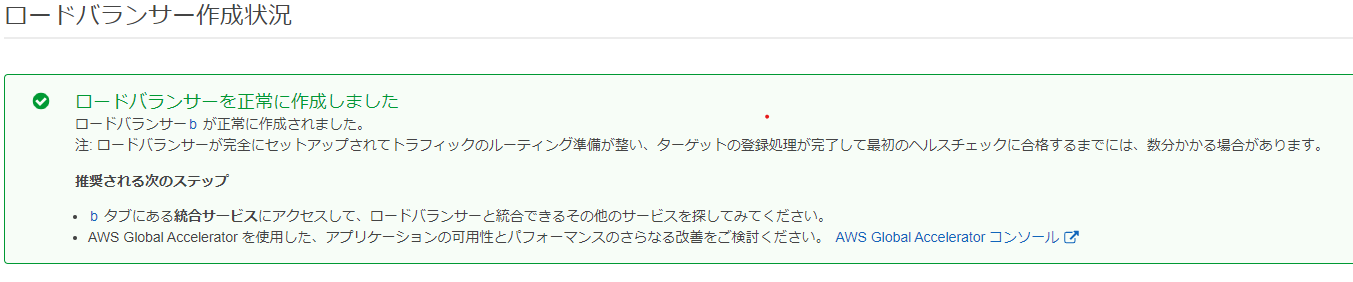
以下のメッセージにより正常に作成されたかどうかを確認します。
参考記事
- OpenSSL でサーバ証明書の作成
https://rfs.jp/server/setting/ssl-openssl.html- 四苦八苦しながらELBにSSL証明書をアップロードした話
https://www.simpline.co.jp/tech/%E5%9B%9B%E8%8B%A6%E5%85%AB%E8%8B%A6%E3%81%97%E3%81%AA%E3%81%8C%E3%82%89elb%E3%81%ABssl%E8%A8%BC%E6%98%8E%E6%9B%B8%E3%82%92%E3%82%A2%E3%83%83%E3%83%97%E3%83%AD%E3%83%BC%E3%83%89%E3%81%97%E3%81%9F/


- 投稿日:2020-09-27T21:21:25+09:00
pythonのクライアントアプリから AWS Batch起動方法
概要
前回作成したLambdaから実行する処理を流用してクライアントアプリから起動するように設定します。
準備
- AWS Batchは前々回のものをそのまま使います。AWS BatchのジョブさえできていればいいのでCodeCommitなどはこのためだけに準備しなくても大丈夫です。
- バッチを実行できるIAMユーザを作成します。
- AWS CLIをインストールして
aws_access_key_idaws_secret_access_keyDefault regionを設定します。
- このあたりの手順は公式 などを参考にしてください。
- クライアントアプリを作成する場合は
pyinstallerを以下のコマンドでインストールします。
pip install pyinstallerクライアントアプリの用意
- tkinterを使用して作成します。
- JOB_NAME はジョブ定義の名称
- JOB_DEFINITION はジョブ定義のジョブ定義ARN
- JOB_QUEUE はジョブキューのキューARN
XXXXXXXXXXの部分はAWSのアカウントIDを設定します。commandの部分に引数をリスト形式でenvironmentには環境変数を辞書形式 name,valeの辞書をリスト形式で設定します。- ソースは以下になります。
- ログ用のクラスはこちらを参照
長いので折りたたんでます
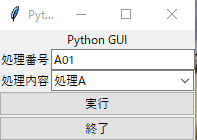
from utils.logger import LoggerObj import sys import os import requests import tkinter from datetime import datetime import boto3 from tkinter import * from tkinter import messagebox from tkinter import filedialog from tkinter import ttk from tkinter.ttk import * import threading from tkinter import messagebox from tkinter import filedialog from tkinter import Button,ttk,StringVar from selenium import webdriver from functools import partial root= tkinter.Tk() EXECUTE_LIST=['処理A','処理B','処理C'] class PythonGui(): def __init__(self): self.lock = threading.Lock() self.inputText=StringVar() self.progressMsg=StringVar() self.progressBar=None self.progressMsgBox=None self.progressStatusBar=None self.progressValue=None def init(self): pass # 初期設定後の動作 def preparation(self,logfilename): self._executer=partial(self.execute,logfilename) def progressSequence(self,msg,sequenceValue=0): self.progressMsg.set(msg) self.progressValue=self.progressValue+sequenceValue self.progressStatusBar.configure(value=self.progressValue) def quite(self): if messagebox.askokcancel('終了確認','処理を終了しますか?'): if self.lock.acquire(blocking=FALSE): pass else: messagebox.showinfo('終了確認','ブラウザ起動中はブラウザを閉じてください。') self.lock.release() root.quit() else: pass def execute(self,logfilename): logObj=LoggerObj() log=logObj.createLog(logfilename) log.info('処理開始') executeType=EXECUTE_LIST.index(self.combo.get()) nowDate=datetime.now().strftime('%Y%m%d%H%M%S') inputVal=self.inputText.get() client = boto3.client('batch') JOB_NAME = 'pandas-envtest' JOB_QUEUE = "arn:aws:batch:ap-northeast-1:XXXXXXXXXX:job-queue/first-run-job-queue" JOB_DEFINITION = "arn:aws:batch:ap-northeast-1:XXXXXXXXXX:job-definition/pandas-envtest:1" response = client.submit_job( jobName = JOB_NAME, jobQueue = JOB_QUEUE, jobDefinition = JOB_DEFINITION, containerOverrides={ 'command': [ inputVal,nowDate,str(executeType) ], 'environment': [ { 'name': 'TEST', 'value': 'abcd' } ] } ) self.progressMsgBox.after(10,self.progressSequence('処理実行中',sequenceValue=50)) root.update_idletasks() self.progressBar.stop() self.progressMsgBox.after(10,self.progressSequence('登録処理完了',sequenceValue=50)) root.update_idletasks() log.info('処理終了') self.lock.release() def doExecute(self): if self.lock.acquire(blocking=FALSE): if messagebox.askokcancel('実行前確認','処理を実行しますか?'): self.progressValue=0 self.progressStatusBar.configure(value=self.progressValue) self.progressBar.configure(maximum=10,value=0) self.progressBar.start(100) th = threading.Thread(target=self._executer) th.start() else: self.lock.release() else: messagebox.showwarning('エラー','処理実行中です') def progressMsgSet(self,msg): self.progressMsg.set(msg) def progressStart(self): self.progressBar.start(100) def main(self): root.title("Python GUI") content = ttk.Frame(root) frame = ttk.Frame(content, relief="sunken", width=300, height=500) title = ttk.Label(content, text="Python GUI") content.grid(column=0, row=0) title.grid(column=0, row=0, columnspan=4) fileLabel=ttk.Label(content,text="処理番号") pulldownLabel=ttk.Label(content,text="処理内容") fileInput=ttk.Entry(content,textvariable=self.inputText,width=23) self.inputText.set('A01') # コンボボックスの作成(rootに配置,リストの値を編集不可(readonly)に設定) self.combo = ttk.Combobox(content, state='readonly') # リストの値を設定 self.combo["values"] = tuple(EXECUTE_LIST) # デフォルトの値を食費(index=0)に設定 self.combo.current(0) labelStyle=ttk.Style() labelStyle.configure('PL.TLabel',font=('Helvetica',10,'bold'),background='white',foreground='red') self.progressMsgBox=ttk.Label(content,textvariable=self.progressMsg,width=70,style='PL.TLabel') self.progressMsg.set('処理待機中') self.progressBar=ttk.Progressbar(content,orient=HORIZONTAL,length=140,mode='indeterminate') self.progressBar.configure(maximum=10,value=0) self.progressStatusBar=ttk.Progressbar(content,orient=HORIZONTAL,length=140,mode='determinate') executeButton=ttk.Button(content,text='実行',command=self.doExecute) quiteButton=ttk.Button(content,text='終了',command=self.quite) fileLabel.grid(column=1, row=1,sticky='w') fileInput.grid(column=2, row=1) pulldownLabel.grid(column=1, row=2,sticky='w') # コンボボックスの配置 self.combo.grid(column=2, row=2) executeButton.grid(column=1, row=6,columnspan=2,sticky='we') quiteButton.grid(column=1, row=12,columnspan=2,sticky='we') root.mainloop() if __name__ == "__main__": pythonGui=PythonGui() pythonGui.preparation('log') pythonGui.main()
処理内容については以下のようになります。
- main
- 実行時に呼ばれる関数です。画面を作成する処理をこちらに記載しています。
- テキストエリアの初期値やコンボボックスの内容なども作成しています。
- doExecute
- 実行ボタンを押下したときに呼び出される処理です。
- thread を使用して 二重起動を防止しています。
- execute
- 実際にAWS Batchを呼び出す処理です。
- boto3.client を呼び出すところで
aws_access_key_idaws_secret_access_keyDefault regionを受け取る形にすればAWS CLIのインストールなどは不要になります。ソースを実行しても確認ができますが、クライアントアプリとして使う場合は以下のコマンドでexeを作成します。 ソースのファイル名を
pythonGui.pyとした場合以下のようになります。
- pyinstaller pythonGui.py --onefile
exeファイル実行すると以下のようクライアントアプリとして起動します。
AWS Batchの方の実行結果については前回と同様になるので割愛。
- 投稿日:2020-09-27T18:15:43+09:00
主要4社のクラウド音声認識精度の比較
Amazon, Google, IBM, Microsoftの音声認識精度を比較してみました
- 今回使用した音声データは私の研究に関するミーティング(大学院でのゼミ)をAirPodsで録音したものを使用しています.ミーティングの参加者は3~5人です.音声には個人情報も含まれるため公開することはできませんのでご了承ください.
- データ量:300発言(約27分)
- 音声の質は生活音やノイズがかなり含まれています.音声の質としては良くないです(CSJなどの音声認識用コーパスに比べて)
- Googleなどの音声認識精度は論文に掲載されているようにかなり良い精度(日本語でもWER一桁)です.
- 研究用の質の良い音声を使用しているので精度がかなり良い
- 日常生活での音声に対してはどの程度の認識精度なのかはあまり報告されていない
- 今回は日常生活の中の音声をどれだけの精度で認識できるのかを調べてみました.加えて,研究に関する音声なので専門用語も多く含まれます.どれだけ専門用語に対応しているのかも気になるところです.
- Amazon, Google, IBM, Microsoftの音声認識サービスを使用という記事に書くAPIの使い方をまとめてあるのでよかったら参考にしてください.
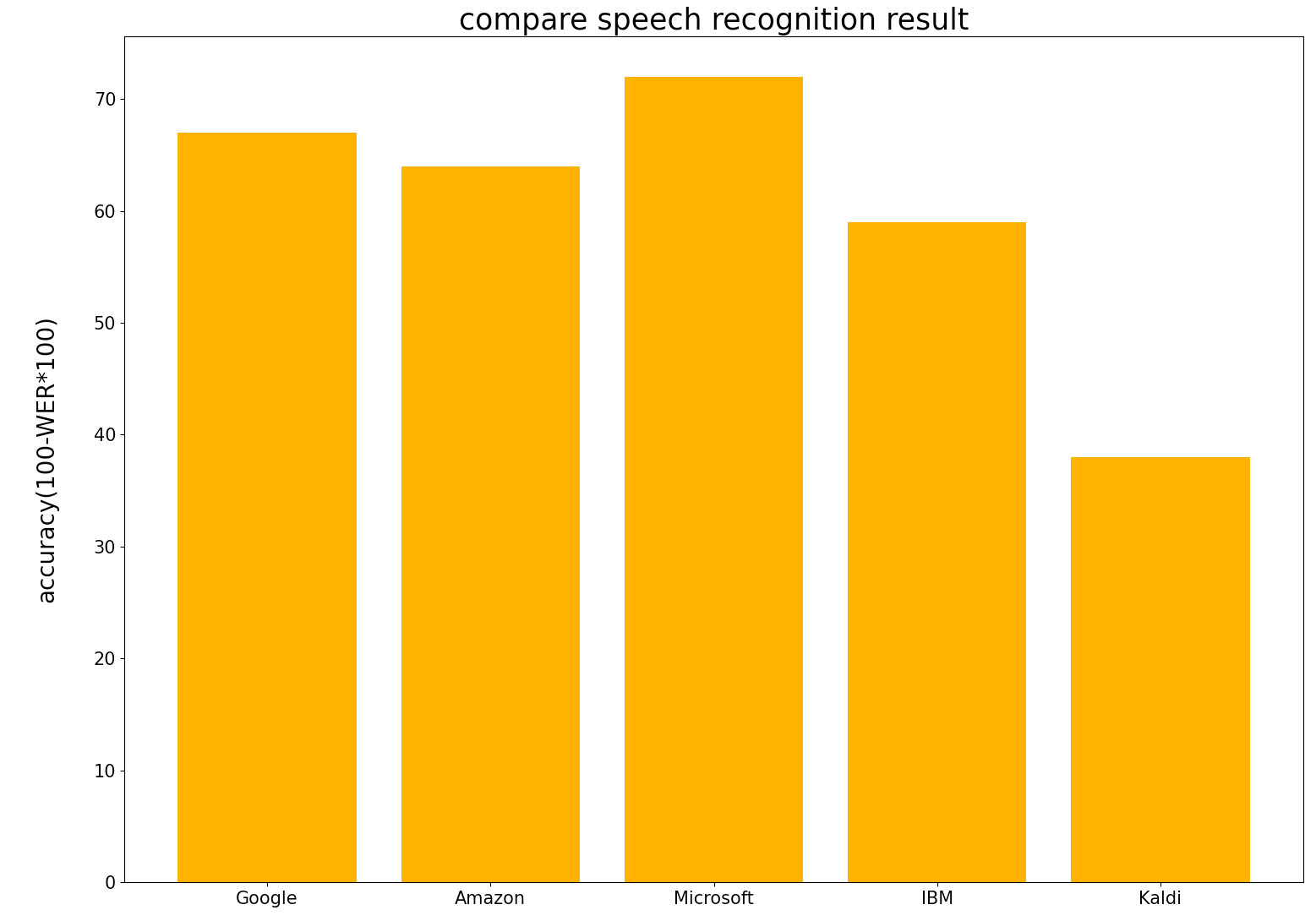
認識精度比較
- Amazon, Google, IBM, Microsoftに加えて,Kaldi(CSJ,JNS,S-JNAS,CEJCで学習)での認識精度も載せておきます.
GCP WER: 0.3344722854973424 CER: 0.2765527007889945 AWS WER: 0.36209150326797385 CER: 0.2218905472636816 Azure WER: 0.28109824430332464 CER: 0.21596337579617833 Watson WER: 0.4107744107744108 CER: 0.29126794258373206 Kaldi WER: 0.616504854368932 CER: 0.47915630285543725
結果からMicrosoftが最も高精度であることがわかりました.Googleが一番良いと思っていたのですが違いました.WERを見ると一番良いMicrosoftでも28%程度であることがわかります.音声の質が良ければWER1桁まで良くなりますが,日常生活の音声ように生活音やノイズの多い環境ではここまで精度が落ちてしまうことがわかりました.しかし,Kaldiは悲惨であることから,GoogleやMicrosoftなどの音声認識器はある程度のノイズに対応できていると思います.
一応認識結果の一つを載せておきます
正解文: 近 さ っていう の を 計算 できる ので これ を 使い まし た で 打撃 音 を それぞれ マテリアル ごと に えと 距離行列 に し て さっき の こういう 感じ で 濃度 で 表す っていう の を やり まし た で この 二次元 の マップ に 置き換える っていう の も 一応 やっ て み た ん です けど なんか やる こと に すごい Google: 近 さ っていう の は 計算 できる ので これ を 使い まし た でも 打撃 音 を それぞれ マテリアル ごと に 距離行列 に し て さっき の こういう 感じ に なり まし た この 2次元 の マップ に 置き換える っていう の も 一応 やっ て み た ん です けど なんか やる こと に すごい Amazon: 近 さ って いう の を 計算 できる ので これ を 使い まし た で で も 打撃 音 を それぞれ マテリアル ごと に と 距離 行列 に し て さっき の こういう 感じ で ノード で 表わす って いう の が あり ます で この 人間 の マップ に 置き換える って いう の も 一応 やっ ! て み た ん です けど 何 か やる こと に 凄い Microsoft: 近 さ っていう の を 計算 できる ので これ を 使い まし た ね でも 打撃 音 を それぞれ マテリアル ごと に と 距離行列 に し て さっき の こういう 感じ で 飲ん で 表す っていう の が あり まし た で この 2次元 の マップ に 置き換える っていう の も 1 応 やっ て み た ん です けど なんか やる こと に すごい IBM:司 って いう の を 計算 できる ので これ を 使い まし た で でも 打撃 音 を それぞれ マテリアル 毎 に 時計 に 行列 に し て さっき の こういう 感じ な の で 表す って 言え ない です ここ の 人間 の マップ に 置き換える って いう の も 一応 やっ て み た ん です けど 何 か やる こと に 凄い Kaldi: 近 さ っていう の 5 日 計算 できる の で は これ を 使う まし た て ない ので 打撃 音 を それぞれ マテリアル ごと に 除去 林業 率 に対して 7 さっき の 声 感じ 子 ノード で 表す ッティ 名前 話し 下 4 9 2 次元 の の 特に 置き換える っていう の を 一 度 やっ 受け身 た ん です けど 何 か やる こと に 都合 よい
- 投稿日:2020-09-27T18:15:23+09:00
主要4社のクラウド音声認識サービスの使い方
Amazon, Google, IBM, Microsoftの音声認識サービスを使用
各社の音声認識サービスのAPIの名称です(呼び方は人によって違いますが間違っていたらすいません)
- Amazon:
- Transcribe
- Google:
- Cloud Speech-to-Text
- IBM:
- Watson Speech-to-Text
- Microsoft:
- Azure Speech-to-Text
Speech-to-TextというAPIを探せば見つかるはずです.AmazonだけはTranscribeと呼ばれていますが...
本記事では各APIを使うための準備(アカウント登録など諸々)は済ませてある前提の内容です
アカウント登録の方法は,検索すればわかりやすく説明してくれているサイトがあるので頑張って登録してみてくださいAmazon Transcribe の使い方
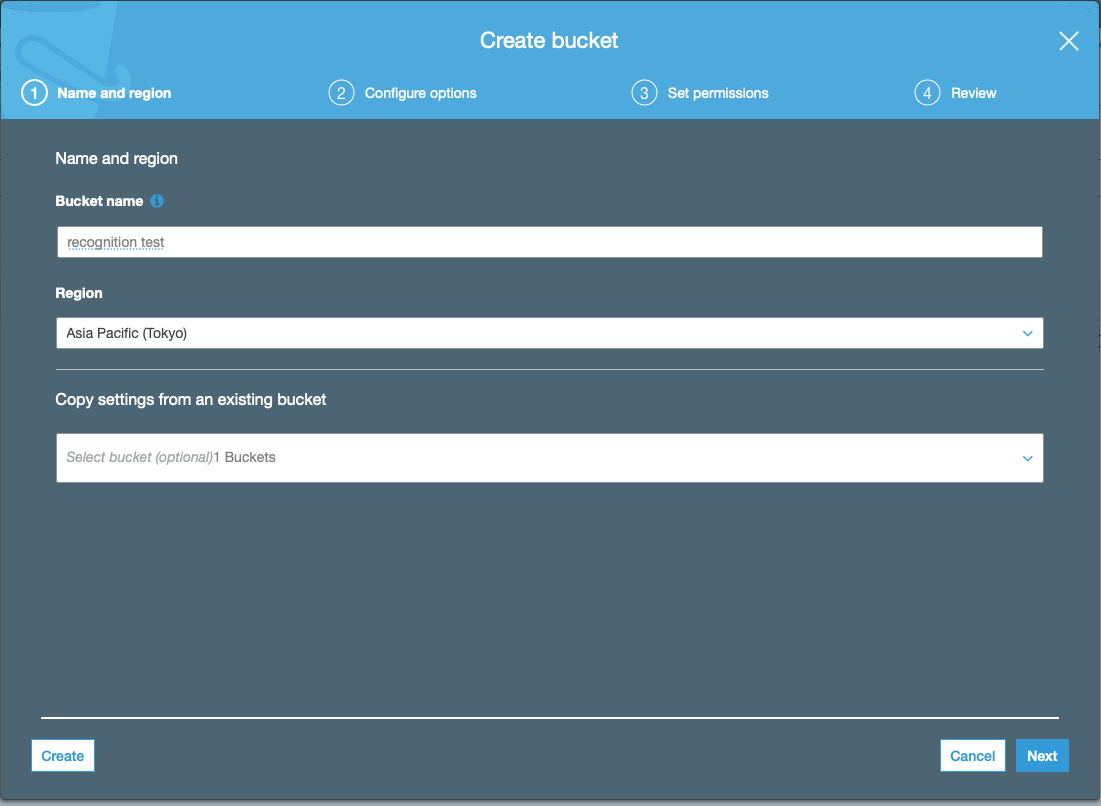
まず,認識させたい音声ファイルをS3というAWSのクラウドストレージの置く必要があります.
- S3のページの左上辺りにあるCreate bucketをクリックしてバケットを作成します.バケット名はなんでもいいです.地域(region)はtokyoにしておきました.
- Bucket name: recognitiontest(なんでも良い)
- Region: Asia Pacific(Tokyo)
- バケットを作成したら,作成したバケットに音声ファイルをアップロードすれば準備完了です.左上辺りにUploadというボタンがあるので,クリックすればアップロードできます.フォルダを作成して複数の音声ファイルをまとめることもできるのでお好みでやってください.
それでは認識を開始していきますが,APIを叩く前にAPIのアクセスキーなどの環境変数を通しておく必要があります.
% export AWS_SECRET_ACCESS_KEY=[自分のAWS_SECRET_ACCESS_KEY] % export AWS_ACCESS_KEY_ID=[自分のAWS_ACCESS_KEY_ID] % export AWS_DEFAULT_REGION=ap-northeast-1 % source ~/.zshrc
- あとはAPIを叩くだけです.サンプルプログラムを載せておきます.
recognize.pyfrom __future__ import print_function import os,sys import time import boto3 import glob from pprint import pprint import re import requests import json def extract_url(response): ''' apiのレスポンスから書き起こしを保存しているS3のurl情報を抽出 ''' p = re.compile(r'(?:\{\'TranscriptFileUri\':[ ]\')(.*?)(?:\'\}\,)') url = re.findall(p,str(response))[0] return url def get_json_result(url): ''' クラウドからjson形式の認識結果を含む情報をダウンロード ''' try: r = requests.get(url) return str(r.text) except requests.exceptions.RequestException as err: print(err) def extract_recognition_result(_json): ''' 認識結果を含むjsonから認識結果のみを抽出 ''' json_dict = json.loads(_json) recognized_result = json_dict['results']['transcripts'][0]['transcript'] return recognized_result def main(): # 作業用ディレクトリ _dir = '/Users/RecognitionTest' # 認識結果保存用ディレクトリ(AWSというディレクトリを事前に作成しておきます.このディレクトリ内にAPIからのレスポンス情報や書き起こし結果が保存されます) recognition_result = _dir+'/AWS' # 認識させたい音声ファイル名が記載されたテキストファイル speech_fname_file = _dir+'/speech_fname.txt' # 認識させたい音声ファイル名をリストへ格納 speech_fname_list = [] with open(speech_fname_file,'r') as f: path = f.readline() while path: speech_fname_list.append(path.strip()) path = f.readline() status_file = recognition_result+'/status.txt' json_file = recognition_result+'/json_response.txt' recog_result = recognition_result+'/recognition_result.txt' # 認識結果保存用ファイル with open(status_file,'w') as status_out: for speech_fname in speech_fname_list: transcribe = boto3.client('transcribe') job_name = str(speech_fname) # 音声ファイル名(必ずしも音声ファイル名である必要はなくなんでも良い) job_uri = f'https://[バケット名].s3-ap-northeast-1.amazonaws.com/{job_name}' # Bucket name -> recongnitiontest transcribe.start_transcription_job( TranscriptionJobName=job_name, Media={'MediaFileUri': job_uri}, MediaFormat='wav', LanguageCode='ja-JP' ) while True: # status: レスポンス情報(認識結果が保存されているS3クラウドのURLを含む) status = transcribe.get_transcription_job(TranscriptionJobName=job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) status_out.write(f'{speech_fname} {status}\n') with open(status_file,'r') as status_in, open(json_file,'w') as json_out, open(recog_result,'w') as result: status_list = status_in.readlines() client = boto3.client('transcribe') for status in status_list: job_name = status.strip().split(' ')[0] response = client.get_transcription_job(TranscriptionJobName=job_name) url = extract_url(response) _json = get_json_result(url) recog_text = extract_recognition_result(_json) json_out.write(f'{job_name} {_json}\n') result.write(f'{job_name} {recog_text}\n') if __name__ == "__main__": main()
- speech_fname.txtには認識させたい音声ファイル名が記載されたテキストファイルです.S3のバケットに置いた音声ファイル名と同じでなければなりません.以下に例を載せておきます.5つの別々の音声ファイルを認識させたい場合の例です.この音声ファイル名と同じ音声ファイルをS3クラウドストレージに置いておけば大丈夫です.
speech_fname.txtspeech_data1.wav speech_data2.wav speech_data3.wav speech_data4.wav speech_data5.wav
- APIのアクセスキーなどの環境変数を設定して,speech_fname.txtを用意できたならば,recognize.pyを実行すれば認識が開始されます.
- 認識結果は
/Users/RecognitionTest/GCP/recognition_result.txtに書き込まれています.
- Amazon Transcribeでも確認可能
Google Cloud Speech-to-Text の使い方
- Amazon Transcribeとは違い,認識させたい音声をクラウドに置く必要はありません.
- ローカルにある音声を認識可能
- 認識させたい音声ファイルのパスを記載したテキストファイルを用意しておく
- 以下のサンプルプログラムではspeech_data_path.txt
- IBM Watson, Microsoft Azure でも同様のものを使用
- それではまずAPIキーを環境変数を通しておきます.APIキーの情報はjsonファイルに記載されています.このjsonファイルはGCPのコンソールからダウンロードしておく必要があります.ナビゲーションメニューのAPIとサービスへ行けばjson形式の認証情報をダウンロードできます.
% export GOOGLE_APPLICATION_CREDENTIALS="[jsonファイルへのpath]" % source ~/.zshrc
- あとはAPIを叩くだけです.サンプルプログラムを載せておきます.
recognize.pyimport io import glob import os import shutil from google.cloud import speech_v1p1beta1 from google.cloud.speech_v1p1beta1 import enums def main(): client = speech_v1p1beta1.SpeechClient() # 作業用ディレクトリ _dir = '/Users/RecognitionTest' # 認識結果保存用ディレクトリ recognition_result = _dir+'/GCP' # 認識させたい音声ファイルへのパスが記載されたテキストファイル speech_data_path_file = _dir+'/speech_data_path.txt' # 認識させたい音声ファイルのパスをリストへ格納 speech_path_list = [] with open(speech_data_path_file,'r') as f: path = f.readline() while path: speech_path_list.append(path.strip()) path = f.readline() recog_result_fname = recognition_result+'/recognition_result.txt' # 認識結果保存用ファイル with open(recog_result_fname,'w') as recog_result: for speech_path in speech_path_list: # 音声ファイル名取得(認識結果を書き込むファイル名に使用) speech_file_name = speech_path.split('/')[-1].split('.')[0] # 音声ファイル名を認識結果書き込み用ファイル名にする # The use case of the audio, e.g. PHONE_CALL, DISCUSSION, PRESENTATION, et al. interaction_type = enums.RecognitionMetadata.InteractionType.DISCUSSION # The kind of device used to capture the audio recording_device_type = enums.RecognitionMetadata.RecordingDeviceType.RECORDING_DEVICE_TYPE_UNSPECIFIED # The device used to make the recording. # Arbitrary string, e.g. 'Pixel XL', 'VoIP', 'Cardioid Microphone', or other # value. recording_device_name = "MR" metadata = { "interaction_type": interaction_type, "recording_device_type": recording_device_type, "recording_device_name": recording_device_name, } # The language of the supplied audio. Even though additional languages are # provided by alternative_language_codes, a primary language is still required. language_code = "ja-JP" # 言語を日本語に設定 config = {"metadata": metadata, "language_code": language_code} with io.open(speech_path, "rb") as f: content = f.read() audio = {"content": content} # 認識開始 response = client.recognize(config, audio) # 認識結果の保存と表示 for result in response.results: # First alternative is the most probable result alternative = result.alternatives[0] print(u"Transcript: {}".format(alternative.transcript)) recog_result.write(u"{} {}".format(speech_file_name,alternative.transcript)+'\n') if __name__ == "__main__": main()
- 認識結果は
/Users/RecognitionTest/GCP/recognition_result.txtに書き込まれています.IBM Watson Speech-to-Text の使い方
- 使い方はGoogle Gloud Speech-to-Text とほぼ同じです.
- ただしAPIキーなどをプログラム内に記述する点が異なります.Google, Amazonでは環境変数として設定していました.
- APIキーとエンドポイントのURLを取得しておく必要があります.
- サンプルプログラムです
- [自分のAPIキー]と[エンドポイントのURL]は置き換えてください
- エンドポイントは"jp-tok"を指定した方がいいです.
recognize.pyimport os,sys import glob import re import json from os.path import join, dirname from ibm_watson import SpeechToTextV1 from ibm_watson.websocket import RecognizeCallback, AudioSource from ibm_cloud_sdk_core.authenticators import IAMAuthenticator from pprint import pprint import shutil import jaconv def extract_recognition_result(_json): recognized_result = [] json_dict = json.loads(_json) try: transcript = json_dict['results'][0]['alternatives'][0]['transcript'].split(' ') except: return ' ' # 言い淀み単語はカタカナ表記なので,平仮名表記に変換 for word in transcript: if 'D_' in word: recognized_result.append(jaconv.kata2hira(word)) else: recognized_result.append(word) recognized_result = ' '.join(recognized_result) recognized_result = recognized_result.replace('D_','') #言い淀みは'D_'で表現されているので削除する return str(recognized_result) def main(): # 作業用ディレクトリ _dir = '/Users/RecognitionTest' # 認識結果保存用ディレクトリ recognition_result = _dir+'/Watson' # 認識させたい音声ファイルへのパスが記載されたテキストファイル speech_data_path_file = _dir+'/speech_data_path.txt' # 認識させたい音声ファイルのパスをリストへ格納 speech_path_list = [] with open(speech_data_path_file,'r') as f: path = f.readline() while path: speech_path_list.append(path.strip()) path = f.readline() # jsonファイル(認識結果)格納ディレクトリ json_result_dir = recognition_result+'/json_result' for speech_path in speech_path_list: # 音声ファイル名取得(認識結果を書き込むファイル名に使用) speech_file_name = speech_path.split('/')[-1].split('.')[0] with open(f'{json_result_dir}/{speech_file_name}.json','w') as json_out: # set apikey authenticator = IAMAuthenticator('[自分のAPIキー]') service = SpeechToTextV1(authenticator=authenticator) # set endpoint url service.set_service_url('[エンドポイントのURL]') lang = 'ja-JP_BroadbandModel' # 言語を日本語に設定 with open(speech_path,'rb') as audio_file: result_json = service.recognize(audio=audio_file, content_type='audio/wav', timestamps=True, model=lang, word_confidence=True, end_of_phrase_silence_time=30.0) result_json = result_json.get_result() # json形式の認識結果を取得しているので,json_resultX.jsonに書き込み result = json.dumps(result_json, indent=2, ensure_ascii=False) json_out.write(result) json_file_list = glob.glob(json_result_dir+'/*.json') recog_result_file = recognition_result+'/recognition_result.txt' with open(recog_result_file,'w') as result: for json_file in json_file_list: with open(json_file,'r') as _json: print(json_file) speech_file_name = json_file.strip().split('/')[-1].split('.')[0] #保存したjson_resultX.jsonから認識結果のみを抽出 recog_result = extract_recognition_result(_json.read()) result.write(f'{speech_file_name} {recog_result}\n') if __name__ == "__main__": main()
- Watsonはデフォルトでは,言い淀み部分に"D_"を追記しています.サンプルプログラムではこの部分を除去しています.あと,言い淀み単語はカタカナ表記となっていますが,私は平仮名表記が必要であったので変換しています.
- 認識結果は
/Users/RecognitionTest/GCP/recognition_result.txtに書き込まれています.Microsoft Azure Speech-to-Text の使い方
- AzureはIBM Watsonと同様にプログラム内にAPIキー(speech_key)とregionを記述します
- speech_key: [自分のspeech_key] を書き換えてください
- service_region:japaneast としました
recognize.pyimport time import wave import glob import re import os try: import azure.cognitiveservices.speech as speechsdk except ImportError: print(""" Importing the Speech SDK for Python failed. Refer to https://docs.microsoft.com/azure/cognitive-services/speech-service/quickstart-python for installation instructions. """) import sys sys.exit(1) # Set up the subscription info for the Speech Service: # Replace with your own subscription key and service region (e.g., "westus"). # サービス地域(service_region)を東日本(japaneast)に設定 # speech_key -> Azureのマイページで確認 speech_key, service_region = "[自分のspeech_key]", "japaneast" # Specify the path to an audio file containing speech (mono WAV / PCM with a sampling rate of 16 # kHz). def main(): """performs continuous speech recognition with input from an audio file""" # <SpeechContinuousRecognitionWithFile> # 作業用ディレクトリ _dir = '/Users/RecognitionTest' # 認識結果保存用ディレクトリ recognition_result = _dir+'/Azure' # 認識させたい音声ファイルへのパスが記載されたテキストファイル speech_data_path_file = _dir+'/speech_data_path.txt' # 認識させたい音声ファイルのパスをリストへ格納 speech_path_list = [] with open(speech_data_path_file,'r') as f: path = f.readline() while path: speech_path_list.append(path.strip()) path = f.readline() #認識結果書き込み用ファイル作成(pre_result.txtには認識結果以外の情報も書き込まれる) with open(f'{recognition_result}/pre_result.txt','w') as recog_result: for speech_path in speech_path_list: speech_file_name = speech_path.split('/')[-1].split('.')[0] # 音声ファイル名を認識結果書き込み用ファイル名に使用 speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region) audio_config = speechsdk.audio.AudioConfig(filename=speech_path) speech_config.speech_recognition_language="ja-JP" # 言語を日本語に設定 profanity_option = speechsdk.ProfanityOption(2) # 不適切発言処理 0->隠す, 1->削除, 2->含む speech_config.set_profanity(profanity_option=profanity_option) # profanity_optionを変更 speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config) done = False def stop_cb(evt): """callback that signals to stop continuous recognition upon receiving an event `evt`""" print('CLOSING on {}'.format(evt)) nonlocal done done = True # Connect callbacks to the events fired by the speech recognizer speech_recognizer.recognizing.connect(lambda evt: print('RECOGNIZING: {}'.format(evt))) #認識結果の書き込み speech_recognizer.recognized.connect(lambda evt: recog_result.write('{} RECOGNIZED: {}'.format(speech_file_name,evt)+'\n')) speech_recognizer.session_started.connect(lambda evt: print('SESSION STARTED: {}'.format(evt))) speech_recognizer.session_stopped.connect(lambda evt: print('SESSION STOPPED {}'.format(evt))) speech_recognizer.canceled.connect(lambda evt: print('CANCELED {}'.format(evt))) # stop continuous recognition on either session stopped or canceled events speech_recognizer.session_stopped.connect(stop_cb) speech_recognizer.canceled.connect(stop_cb) # Start continuous speech recognition speech_recognizer.start_continuous_recognition() while not done: time.sleep(.5) speech_recognizer.stop_continuous_recognition() # </SpeechContinuousRecognitionWithFile> def fix_recognition_result(): ''' - pre_result.txtは以下のような形式の認識結果である - [SPEECH FILE NAME] RECOGNIZED: SpeechRecognitionEventArgs(session_id=XXX, result=SpeechRecognitionResult(result_id=YYY, text="[認識結果]", reason=ResultReason.RecognizedSpeech)) - [SPEECH FILE NAME]と[認識結果]の部分のみを抽出 ''' # 認識結果ファイル pre_result = '/Users/kamiken/speech_recognition_data/Cloud_Speech_to_Text/Compare4Kaldi/Compare_Test1/Azure/pre_result.txt' # 認識結果以外の情報(パラメータなど)を削除 with open(pre_result,'r') as pre, open(pre_result.replace('pre_',''),'w') as result: lines = pre.readlines() for line in lines: split_line = line.strip().split(' ') speech_file_name = split_line[0] text = str(re.findall('text=\"(.*)\",',' '.join(split_line[1:]))[0])+'\n' result.write(f'{speech_file_name} {text}') if __name__ == "__main__": main() fix_recognition_result()
- Azureは親切なことに,Fワードなど不適切な発言を「***」のようにアスタリスクで隠してくれます.私はWERを算出しないといけなかったので,サンプルプログラムでは全て表示させるような設定にしてあります.
- profanity_option = speechsdk.ProfanityOption(2)
- 引数は0(不適切発言をアスタリスクで隠す), 1(削除する), 2(隠しも削除もしない)のいずれかです
- 認識結果は
/Users/RecognitionTest/GCP/recognition_result.txtに書き込まれています.
- 投稿日:2020-09-27T16:49:31+09:00
AmplifyとGraphQLではじめるサーバレスWebアプリのチーム開発体験記
はじめに、この記事の目的
少し前にAmplifyとGraphQLを使って、少人数で完全サーバレスなWebアプリを開発する機会がありました。
誰かの参考になるか分かりませんが、既に消えかけている当時の記憶が完全に消えないうちに、
慣れ親しんでいるRESTではなく、Amplify/GraphQLを使ってみて感じた技術・チーム開発観点での気付きをメモしておこうと思います。いろいろと特殊な制約があり、最終的には少し複雑な構成になりましたが、そこは割愛して、ざっくりTODOアプリ的なものだと思って、読んでいただければと思います。
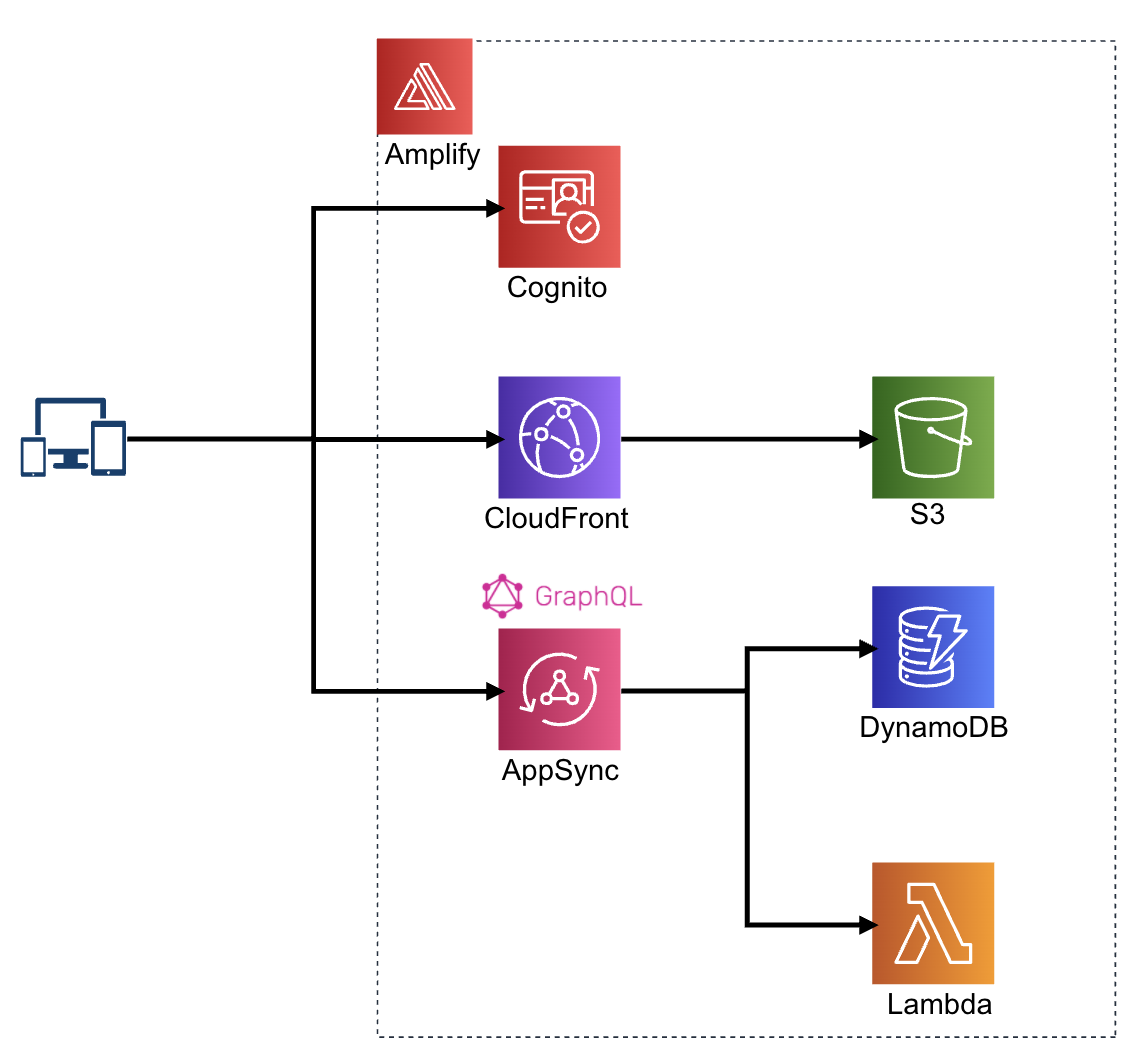
ざっくり構成
だいたいこのような構成のWebアプリを作りました。極めて標準的な構成です。
そもそも、なんでAmplify?
いろいろな選択肢がある中で、当時なぜAmplifyを使うことになったのかですが、
短納期リリース かつ 少人数開発 という制約があったので、以下の観点を意識していました。
※ とりあえず使ってみたい!というのも大きかったかも。
- 期待1: ユーザーに価値を届ける機能開発に時間を使いたい
- 認証, WebSocket, バックエンドAPI, データベース, ... 等の機能開発をする上で必要なベースが比較的簡単に作れる。
- 期待2: スケーラビリティ、運用/保守のしやすさ
- マネージドサービスをうまく利用することでユーザー数の増加や、運用/保守の手間を軽減できる。
- 期待3: 複数環境を簡単に作りたい
- 開発/テスト/商用環境といったように用途別の環境を簡単に作れる。
結論としては、Amplifyの機能をうまく使うことで、
上記の三つの期待は実現できました
なので、個人的にはおすすめ!です。これ以降は、開発の中で感じた便利なこと、困ったことを中心に書いていこうと思います。
実際やってみての気付き、Tips
自動的にフルスタックエンジニアになれます
schema.graphqlに以下のような記述をして、
amplify pushすると、DynamoDBのテーブルやresolverやAPIが作成されます。同時にAPIの呼び出しに使う標準的なQueryも作成されるので、Query/Mutation/Subscriptionがすぐに実行できます。簡単ですね。type Blog @model { id: ID! name: String! posts: [Post] @connection(name: "BlogPosts") } type Post @model { id: ID! title: String! blog: Blog @connection(name: "BlogPosts") comments: [Comment] @connection(name: "PostComments") } type Comment @model { id: ID! content: String post: Post @connection(name: "PostComments") }また、
@model,@connection,@auth,@function,@key, ... といったDirectiveが用意されているので、バックエンド側の基本的な設定もこのSchema.graphqlの中で完結することができます。※ただし、細かい設定は記述できないので、CloudFormation側で頑張る必要があります。
つまり、このschemaを書くことが、認証設定やデータベース作成やAPI作成をしていることと同じになります。
あとは、フロントエンドの開発をしてしまえば、フルスタックエンジニアの出来上がりです。他にも、DynamoDB StreamにLambdaを紐付けるのも
amplify add functionを実行した時に以下のように設定するだけで済みます。? What event source do you want to associate with Lambda trigger? Amazon DynamoDB Stream ? Choose the graphql @model(s) Blogフロントエンド、バックエンド共に TypeScriptで開発できる
少人数チームという制約もあり、できる限り利用する言語/技術は限定したいと思っていました。
そのため、今回はフロントもバックもTypeScriptで統一しました。
上記のフルスタックエンジニアの話にも関わりますが、誰でもどのレイヤーでも触れると
ユーザーストーリーを上から順番に着手していけることもあり、メンバーの意識が自然とユーザー価値に向けられるのも良い点でした!あと、
amplify pushしてできるsrc/API.tsやsrc/graphql/xxx.ts等のファイルをフロントだけでなくamplify add functionで追加したLambdaでも型を参照したくなると思います。
その時は.graphqlconfig.ymlを下記のように修正してあげると、Lambda側でも利用できるようになります。そうすることで、Lambda側も生成された型を使って開発できるようになるので、補完も効いて、開発効率が向上すると思います。projects: xxx: schemaPath: src/graphql/schema.json includes: - src/graphql/**/*.ts excludes: - ./amplify/** extensions: amplify: codeGenTarget: typescript generatedFileName: src/API.ts docsFilePath: src/graphql yyy(←関数名): schemaPath: src/graphql/schema.json includes: - src/graphql/**/*.ts excludes: - ./amplify/** extensions: amplify: codeGenTarget: typescript generatedFileName: amplify/backend/function/yyy/ts/API.ts # 任意のパスを設定してください docsFilePath: amplify/backend/function/yyy/ts/graphql # 任意のパスを設定してくださいMultiple Environmentで開発者ごとに専用環境を作成できる
Amplifyには、複数の環境を管理するためのMultiple Environmentという機能があります。
公式ドキュメントにも記載されているように、開発/テスト/本番環境ごとに環境を作ることができます。
Dev環境の中でも、Dev1,Dev2,...といったように、エンジニアごとに独自の環境を用意して利用できるため、
気軽にいろいろ試せて、環境が壊れても他のエンジニアに影響も与えないため、自由に開発できました。
環境を切り替える場合も、amplify env checkout 環境名を実行するだけで、簡単です。CI/CDではAmplify Headlessモードを使う!
amplify はコマンドラインの実行が対話式であるため、CI/CD上で自動実行する時に困ります。
そのような場合には、Amplify Headlessモードを使いましょう。--yes flag The --yes flag, or its alias -y, suppresses command line prompts if defaults are available, and uses the defaults in command execution.ドキュメントに記載されている通り、--yesをつけることで、全てデフォルトで進めることができます。
ただし、ここで気をつけておかないといけないことは、--yesをつけると、バックエンド側の変更処理が強制的に実行されるということです。例えば、amplify pull --yesを実行した場合でも、強制的にCloudFormationスタックの変更処理が実行されるということです。その場合は、以下のように実行することで対話式で聞かれる内容をコマンドに渡すことができます。AMPLIFY="{\ \"projectName\":\"app\",\ \"envName\":\"環境名\",\ \"appId\":\"アプリケーションID\",\ \"defaultEditor\":\"code\"\ }" AWSCLOUDFORMATIONCONFIG="{\ \"configLevel\":\"project\",\ \"useProfile\":true,\ \"profileName\":\"default\"\ }" PROVIDERS="{\ \"awscloudformation\":$AWSCLOUDFORMATIONCONFIG\ }" FRONTENDCONFIG="{\ \"SourceDir\":\"src\",\ \"DistributionDir\":\"dist\",\ \"BuildCommand\":\"yarn generate\",\ \"StartCommand\":\"yarn start\"\ }" FRONTEND="{\ \"frontend\":\"javascript\",\ \"framework\":\"vue\",\ \"config\":$FRONTENDCONFIG\ }" amplify pull \ --amplify $AMPLIFY \ --frontend "$FRONTEND" \ --providers $PROVIDERSこの設定でも、対話を0にすることができなかった(2020年9月時点)ので、expectコマンドを利用して回避しました。
最終的には、CodeBuildで複数のAWSアカウントへCI/CDできるようになりました。結局CloudFormation
今まではAmplifyを使うことで、今まではコードを頑張って書かないといけなかったことがコマンドラインでいくつか設定するだけで
簡単になって便利!という話をしてきましたが、一度触ったことがある人は知っている通り、実際は裏でCloudFormationテンプレートが作成されています。そのため、対話式のコマンドラインで設定できなかったり、schema.graphqlで表現しきれない部分は、CloudFormationテンプレートを編集して、細かい設定をすることになります。一つ例を書いてみます。
LambdaをVPC内に入れたい
例えば、以下のように
team-provider-info.jsonやCloudFormationテンプレートを編集することで、実現できます。team-provider-info.json"Env名": { ... "categories": { "function": { "関数名": { "vpcSecurityGroupIds": [ "セキュリティグループID" ], "vpcSubnetIds": [ "サブネットID", "サブネットID" ] }, }, ... } }xxx-cloudformation-template.json"LambdaFunction": { ... "Properties": { ... "VpcConfig": { "SecurityGroupIds": { "Ref": "vpcSecurityGroupIds" }, "SubnetIds": { "Ref": "vpcSubnetIds" } }, ... },他にもDynamoDBテーブルのバックアップの設定をしたい場合も、
"DynamoDBEnablePointInTimeRecovery": "true"のような設定を入れることで実現できます。基本的には同じ方針で、ほとんどのことは設定できました。チーム開発をしてみて
冒頭の
ユーザーに価値を届ける機能開発に時間を使いたいに関わることですが、Amplifyの利用で、バックエンド側の構築にかける時間が減ったこともあり、一つのユーザーストーリー(機能)を一人で開発することのハードルが下がったと思います。それによって、フロントエンドエンジニアとバックエンドエンジニアに分けた場合に生じていたコミュニケーションコストが減り、比較はできていないですが、結果としてベロシティも向上したのではと思います。
また、マネージドサービスかつサーバレスな構成になっているため、運用/保守について、リリース前もそうですがリリース後に必要な作業も減り、機能開発に集中できている感覚はあります。
ただ、フロントエンド、バックエンドのコードの密結合化が進むため、プロジェクトが大規模になったり、人数が増えた場合は、違った工夫が必要になりそうだなーと感じています。終わりに
- 基本的にはAmplifyの良いところベースで書いてきました。ただ、フレームワークというのは使い始めは、細かいところでつまづくことも多いと思います。ただ、もし興味があるのなら、軽めの開発で試してみるのが良いのではと思います。
- GraphQLについても書きたいことがあったのですが、
疲れた長くなってきたので、また次回にしようと思います。参考記事

- 投稿日:2020-09-27T16:25:11+09:00
docker centosでpython3をインストールする方法
はじめに
この記事ではAWSのAmazon Linux2を使用して次のことを実行します。
1. dockerのインストール
2. docker imageであるcentosを起動する
3. 2で起動したコンテナ内でpython3をインストール1. dockerのインストール
まず以下のようにyumのアップデートを行います。
[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ sudo yum update -y次にdockerをインストールします。
[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ sudo amazon-linux-extras install docker -yインストールが完了したら、docker daemonを起動します。
[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ sudo service docker startec2-userをdockerグループに追加します。
これは必須ではないですが、以降sudoなしでdockerコマンドが使用できます。[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ sudo usermod -a -G docker ec2-user上記コマンドを実行したら、一度ターミナルを閉じます。その後再度接続し直します。
2. centosを起動する
まず
runコマンドによってコンテナを起動します。イメージのプルがされていない場合、プルをしてから起動することができます。
オプション-itにより、起動したコンテナの中に入ることができます。
(・・・は表示されるメッセージを省略して書いています)[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ docker run -it centos ・ ・ ・ [root@xxx /]#3. コンテナ内でpython3をインストール
[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ yum install python3 -y以下のように
python3コマンドを入力することで対話モードになり、インストールされたことがわかります。[root@xxx /]# python3 Python 3.6.8 (default, Apr 16 2020, 01:36:27) [GCC 8.3.1 20191121 (Red Hat 8.3.1-5)] on linux Type "help", "copyright", "credits" or "license" for more information. >>>インストール後は
pip3コマンドを使用し、必要なパッケージのインストールを行うことができます。
次のコマンドでaws-cliのバージョン1をインストールしています。[root@xxx /]# pip3 install awscli参考記事
- AWS 公式サイト https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/docker-basics.html
- CentOS7 に pip と awscli をインストール https://rriifftt.hatenablog.com/entry/2015/10/28/142043
- 投稿日:2020-09-27T15:36:09+09:00
【QuickSight】CLIでの分析作成
参考文献
https://docs.aws.amazon.com/cli/latest/reference/quicksight/create-data-source.html
結論
現時点(2020年9月27日)では分析作成までの全ての工程をCLIで実現できない。
具体的にいうと、分析を作成することはできるが、分析内のビジュアル(一番の肝)が作成できないため、ビジュアルはGUIで作成する必要がある。現時点での分析作成までのフロー
- データソースの作製
create-data-source
- データセットの作成
create-data-set
- 分析の作成
create-analysisここまでがCLIでできること。
この先、分析内でビジュアルを作成したい場合はGUIでポチポチしてください…ちなみにcreate-analysisコマンドも最近しれっと追加された(2020年8月ごろ)ので、
ビジュアル作成のコマンドも近々追加されることに期待。今後、コマンド内の細かい設定事項について書こうと思います。
- 投稿日:2020-09-27T14:57:30+09:00
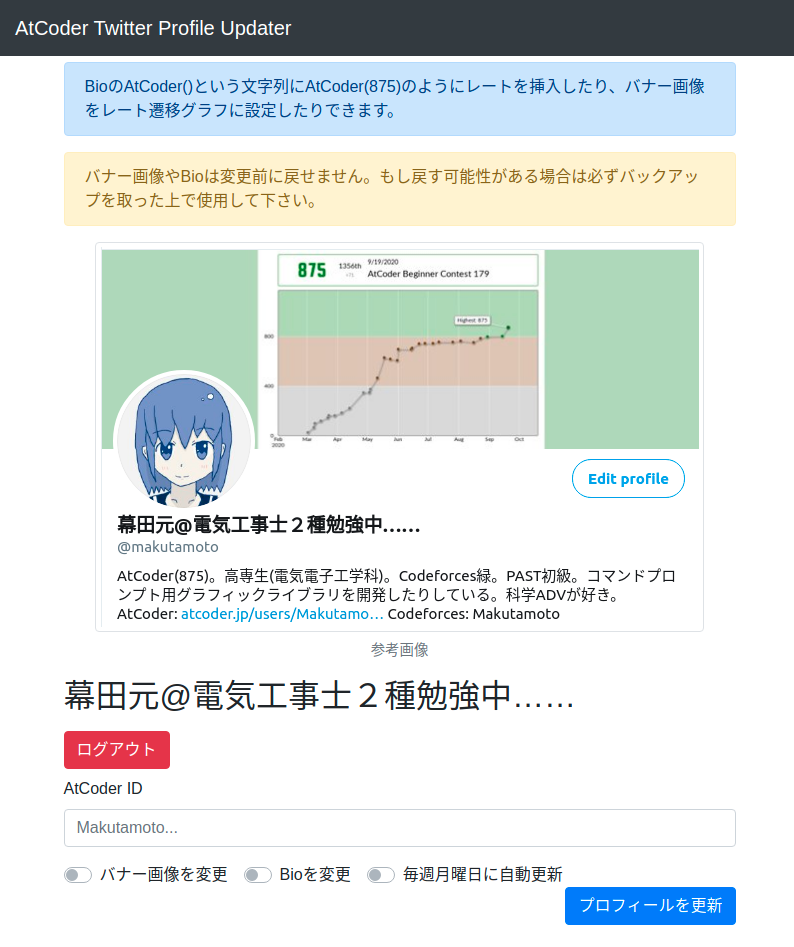
AtCoderのレートでTwitterのプロフィールを自動でアップデートしてくれるWebアプリ、AtCoder Twitter Profile Updaterを作った話。
はじめに
Twitterで競プロアカウントを運営している方でBioにAtCoderのレートを入れていたりバナー画像をレート遷移グラフに設定している人、それなりにいると思います。
いちいち新しい情報に更新するの面倒ではないですか?
今回はそういう方のためにバナー画像とBioの更新を自動化するツールを作ってみました。作ったもの ? AtCoder Twitter Profile Updater
GitHub ? makutamoto/atcoder-twitter-profile-updaterどんなアプリ?
Twitter認証をしてAtCoderIDを入力するとAtCoderから情報をとってきて自動でプロフィールを更新してくれます。
自動更新を有効にすると毎週月曜日(大体土日にコンテストがあるので月曜日にしました)に自動でデータを更新してくれます。技術解説
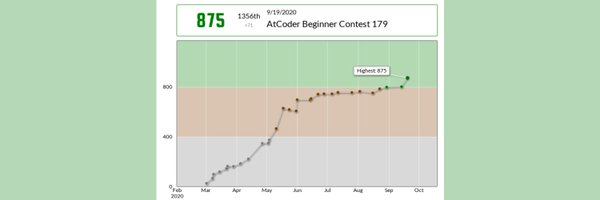
レートとレート遷移グラフの取得
このWebアプリは上の画像のようにレート遷移グラフを自動取得します。
これはPuppeteerを用いて実現しました。
Puppeteerはいわゆるヘッドレスブラウザというもので、Chromiumをバックグラウンドで起動してページ遷移などの操作やデータ取得、スクショ撮影などをすることができます。
ブラウザをまるまる起動するので重いですが、正確な描画ができるのが特徴です。
Lambdaに日本語フォントが入っていないため、企業コンのタイトルが文字化けするのがたまに傷ですが。(そのうち直します)
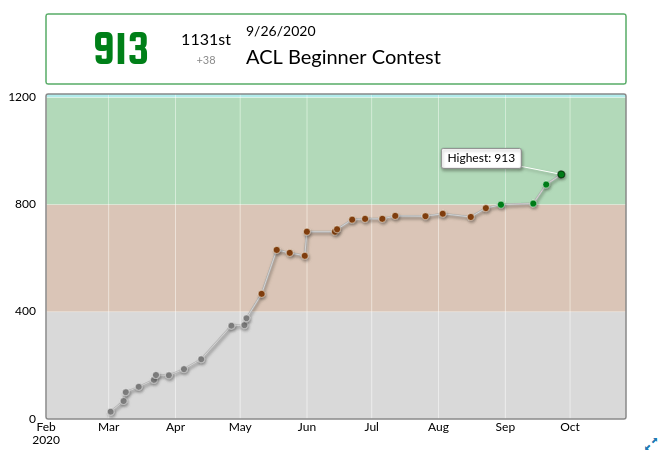
Puppeteerを使ってAtCoderのユーザーページを切り出すと、上のような画像が得られます。
Twitterのバナー画像は1500x500じゃないと勝手に切り取られるので、スケールをして余った背景はそれぞれのレートの色で塗りつぶしています。
このアイデアはこのページを参考にしました。ちなみに、スケールと塗りつぶしの画像加工はJimpを使っています。
他のライブラリのほうが速いのですが、部分的にネイティブコードが含まれていてLambdaで動くか不安でした。
そのため、全てJavaScriptで書かれているJimpを採用しています。またレート取得についてですが、レート情報もユーザーページに含まれているため、そこから引っこ抜きました。
Bioの更新
Bioの「AtCoder(レート)」という部分文字列を置換するために正規表現を使いました。
具体的な実装はこんな感じです。newBio = bio.replace(/AtCoder\(\d*?\)/g, `AtCoder(${rating})`);フロントエンド
フロントエンドはNext.jsで、React Bootstrapを使って実装しました。
特記することは特にありませんが、Vercelで簡単にデプロイできるので推しです。バックエンド
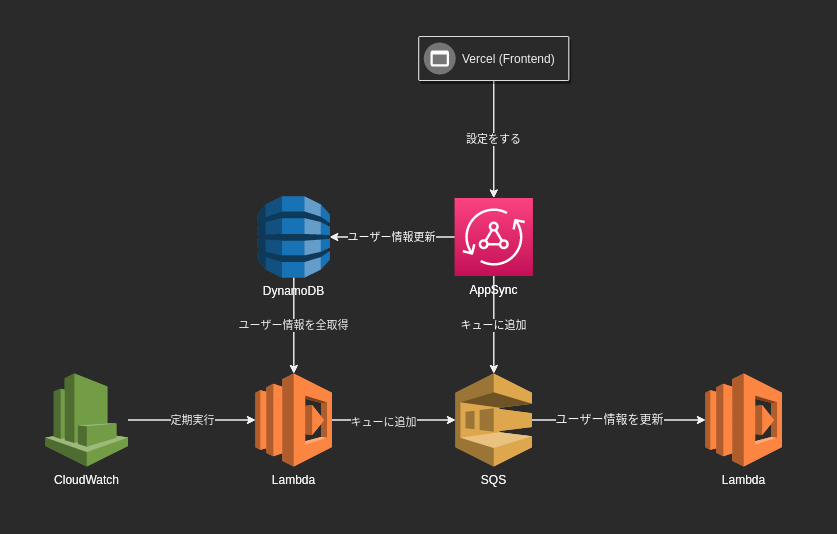
今回、はじめてAWSを使ってみました。
構成をGitで管理するためにAWS CDKを使っています。
これはクラウド構成をTypescriptなどのプログラミング言語で記述できるもので、IDEの補間が使えたりクラウド資源をコンポーネント化したりできるので今回便利に使わせていただきました。具体的な構成は図を作っておいたのでそちらを見て下さい。
感想
制作に4日ほどかかりました。
特に苦労したのはAppSync関係のセッティングですかね。(Apache Velocityがうまく書けなかった……)
ただ、習得すれば大きな武器になると思うので精進します!
- 投稿日:2020-09-27T14:56:26+09:00
AWS Summit Onlineのちょっとしたメモ②
AWS Summit Onlineのメモ
AWS Summit Onlineの気になったセッションを視聴してのちょっとしたメモになります。
・AWS のサービスを使ったオンプレミスからのデータベース移行
◆AWSにデータベースを移⾏する際のパターンと移⾏⽅法
パターン1:Re-Host
オンプレミスのデータベースをなるべく環境を変えずにAWSに移行すること
移行に対するリスクが小さい
パターン2:Re-Architecture
オンプレミスからAWSへの移行に合わせてアーキテクチャの変更をする
例:ORACLEからPostgreSQLへ変更をすることができる
エンジンの変更を行うので移行の際は検証をしっかりと行う必要がある
パターン3:(Re-Host or Re-Platform) & Re-Architecture
AWSへの移行の際はエンジンを変えずに、AWS上でエンジンを変更する
移⾏の流れとAWSで提供するDB移⾏サービス
Schema Conversion Tool(SCT)
Assessment(移行難易度の調査)
Schema conversion(スキーマの移行)
Code conversion(SQL、プロシージャーの移行)
Database Migration Service(DMS)
Data migration(データの移行)
Validation(データ移行の整合性をテスト)◆SCT/DMSの概要
Schema Conversion Tool
データベースのスキーマを変換するツール
ORACLE、MySQLなど様々なデータベースに対応しているDatabase Migration Service
データベースの中に格納されているデータをマイグレーションするサービス
ダウンタイムを最小化したデータ移行が可能
S3、Neptune、Kinesisなどのデータベース以外にも適応可能◆SCT/DMSを活⽤したデータベース移⾏の具体例
オンプレミスのORACLEからAurora PostgreSQLへの移行
SCTでAssessment、Schema conversion、Code conversionの3ステップを行う
DMSでData migration、Validationを行う
SCTはオンプレミス側の端末にインストールしてデータベースに接続する
DMSはAWS側にインスタンス作成
AWS側のネットワークからオンプレミス側のデータベースに接続するので、
VPNやDirect Connectなどのセキュアな接続環境が必要になるSCTによるデータベースの移⾏評価
グラフィカルなアセスメントレポートを出力可能
自動変換ができる割合や人の手でやらなければいけない割合が出力されるDatabase Migration Playbook
AWSがデータベース移行のベストプラクティスをまとめたものSCTによるスキーマ、コード変換
SCTで移行後のパフォーマンスが出るかは担保していないのでテストを行う必要ありDMSを使ったデータ移⾏⼿順のイメージ
DMSインスタンスを作成
DMSインスタンスからソースへ接続、ターゲットのデータベースへも接続する。接続する情報の事をエンドポイントと呼ぶ
エンドポイントを使用して移行タスクを設定
Full Load:ある断面のデータを最初から最後まで移行する
Full Load + CDC:移行中にソースで発生する更新データも移行する
CDCのみ:ある時点からの差分のみ移行する
移⾏タスクのモニタリング
正しくタスクが動いているのか、ソース側で発生した更新データをどのくらいの遅延でレプリケーションできているかレプリケーションインスタンスの作成は適切なインスタンスクラス、ストレージ容量を指定する
DMSを使った最⼩限のダウンタイムのデータ移⾏
1.初期データ移⾏(Full Load)
2.オンプレミスのデータ更新(CDC)
3.トランザクションログを参照し適応
4.オンプレミスに向いているアプリケーションの停止
5.差分データが無くなることをDMSで確認
6.差分データが適用された段階でアプリケーション再開
4~6が最小限のダウンタイムDMSのデータ検証機能
DMSの場合はデータのValidationはオプション
データのValidationと移行は非同期・パケットの気持ちになって辿る Amazon VPC のルーティング
◆VPCの主要な概念
AWSの各種サービスはリージョンというデータセンタークラスタで提供されている
日本には東京リージョン、大阪ローカルリージョンがある
リージョンの中にはアベイラビリティゾーン(AZ)というデータセンタクラスタがある
AZは電源、ネットワークが独立しているので障害発生時に他のAZに影響が無いようにしている
⾼可⽤性のためにマルチAZ構成を推奨しているVPC
リージョンの中でAZを跨いで構成できる独立したプライベートネットワーク領域サブネット
VPCの中にルーティングポリシー単位で定義
AZ単位で作成ルートテーブル
VPCやサブネットでデフォルトで動作しているルータの経路情報を登録している
EC2インスタンスから見るとデフォルトゲートウェイとして見えるVPCには様々なゲートウェイがある(Internet Gateway,NAT Gateway,Virtual Private gateway,AWS Transit Gatewayなど)
AWSの方で冗長化しているので使う側は考える必要が無い◆オンプレミスネットワークとの⽐較で理解するVPC
VPCを作ると→オンプレミスではDNSサーバを設定した状態に近い
サブネットを作ると→オンプレミスではVLANやL2ネットワークを作ることに近い
EC2を作ると→オンプレミスではスイッチにサーバを接続してOSをインストールした状態に近い◆VPC通信の実際
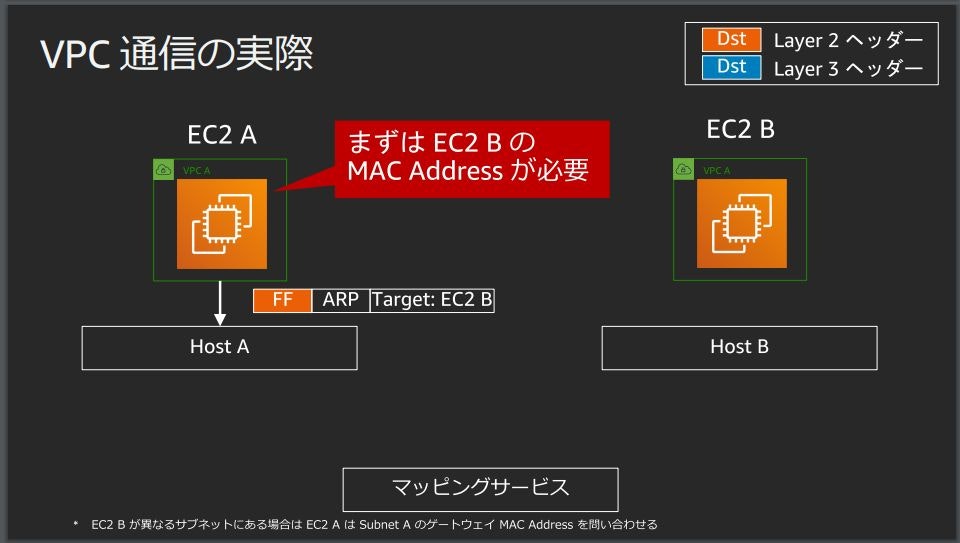
EC2 AからEC2 Bに対してHTTPアクセスする場合
EC2 BのMACアドレスを知るためにEC2 AからブロードキャストでARPが飛ぶ
Host Aはマッピングサービスという外部のWebサービスへの問い合わせに変換
マッピングサービスからEC2 BのMACアドレスとHost BのIPアドレスが返ってくる
返ってきた結果をARP ReplyとしてEC2 Aに渡す
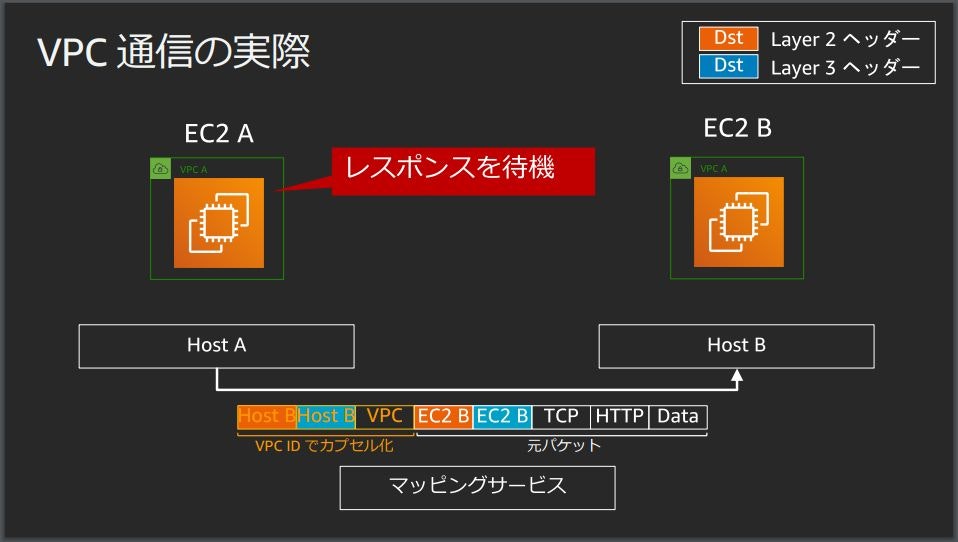
EC2 Aは実際に送りたいデータパケットを構成してEC2 Bに送る
Host AからHost Bにパケットを投げる際に元のパケットに対してVPC IDでカプセル化を行う
VPC内の通信では正規のインスタンスからの通信かどうかValidationしている
Host Bはマッピングサービスに正規のインスタンスかどうか問い合わせている
問い合わせの結果から問題が無ければカプセル化を解いてEC2 Bにパケットを渡す
普段は意識する必要のない通信
VPCの上ではL2/L3の通信が行われている◆VPCの全体像
EC2インスタンスを収容するホスト群Edge
Internet Gateway,Virtual Private Gateway,VPC Endpoint(Gateway)などをホストしているHyperplane
NAT Gateway,Transit Gateway,VPC Endpoint(Gateway)などをホストしている◆クラウドネットワークを設計するときは
主な設計パターン
VPC←→インターネット
VPC←→オンプレミス
VPC←→VPC
の3パターン
ルータの役割を果たすコンポーネントがどこにあるか、どういった経路を持っているかを考える◆パケットの気持ちで辿り設計を考えてみましょう
1.VPC内からNAT GWを介してInternetにアクセス
パブリックサブネットにNAT GWを配置、EC2インスタンスをプライベートサブネットに配置
EC2は自分のサブネットの外にあるものはとにかくデフォルトゲートウェイに投げる
プライベートサブネットのルートテーブルにパケットを投げる
プライベートサブネットのルートテーブルにはNAT GW宛のルーティングを書いておく必要がある
ルートテーブルに従ってNAT GWにパケットを投げる
パケットを受け取ったNAT GWはパブリックサブネットのルートテーブルにパケットを投げる
(NAT GWはルーティングを行わない)
パブリックサブネットのルートテーブルはInternet GW宛のルーティングを書いておく必要がある
ルートテーブルに従ってInternet GWにパケットを投げる
Internet GWはAWSが管理しているのでそれ以降の経路はユーザ側で確認できない(する必要が無い)2.VPC内からVGWを介してオンプレミスにアクセス
AWS Direct Connect
専用線や閉域網を使用して自社とAWSを接続するサービス
Direct Connect Locationを介して接続する
BGPを使用して経路交換をしているEC2インスタンスはルートテーブルにパケットを投げる
ルートテーブルには宛先がオンプレミスのサーバのIPアドレスはVGWにパケットを投げるルーティングを書いておく
ルートテーブルに従ってVGWにパケットを投げる
VGWにパケットが届くとVGWの経路情報に載っているBGPで通知されたオンプレミスのカスタマーゲートウェイに投げる
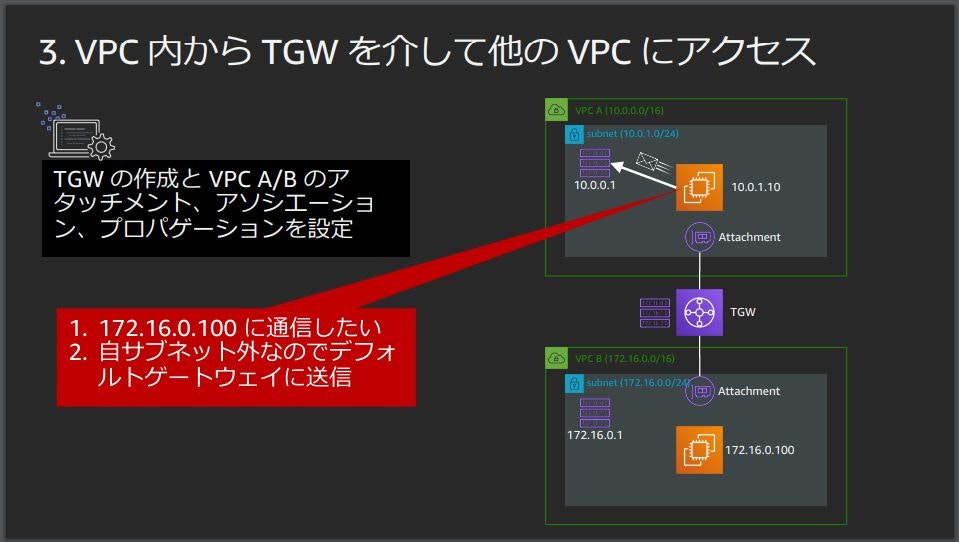
カスタマーゲートウェイにパケットが届いた後はAWSとは無関係な普通のルーティング3.VPC内からTGWを介して他のVPCにアクセス
Transit Gateway(TGW)
Transit Gatewayを作成するとデフォルトで1つのルートテーブルができる
必要に応じて複数のルートテーブルをホストできる
VRFのように1つのルータで複数のルーティングテーブルを持たせているイメージ
VPCと接続する際はAttachmentを作成
アソシエーションという設定でVPCの外に出るアウトバウンドの通信を制御
Attachmentから外に出るときにどのルートテーブルを使うかを指定できる
プロパゲーションという設定でインバウンドの通信を制御
EC2 Aからサブネットのルートテーブルへパケットを投げる
ルートテーブルには宛先がVPC BのCIDRはTGWに投げるルーティングを書いておく
ルートテーブルに従ってTGWにパケットを投げる
パケットはAttachmentを介してTGWに届く
TGWはアソシエーションの設定に従ってルートテーブルを選択
プロパゲーションの設定でVPC Bへの経路が登録されているルートテーブルを選択する◆まとめ
AWSのルーティングに必要な知識はオンプレミスと同じ
ルータの場所やパケットの動きを理解しておく
オンプレミスとは違い可用性やスケーラビリティの設計はクラウドに任せられる
- 投稿日:2020-09-27T13:06:39+09:00
TerraformでAmazon API Gatewayを構築する(アクセスログ詳細編)
はじめに
API Gateway+Terraform記事第3弾。
前回の記事でカスタムアクセスログについてさらっと触れたが、今回はログフォーマット関連でもう少し掘り下げてみる。アクセスログに出せるもの
以下のドキュメントを参照しよう。
【AWS公式】API Gateway での REST API の CloudWatch ログ記録の設定
【AWS公式】API Gateway マッピングテンプレートとアクセスのログ記録の変数リファレンスAPI Gatewayのドキュメントは結構散らかっていて、後者のページではあたかも色々なものをログに出せそうに見えるが、実際には前者のページに記載の通り、$context 変数のものだけしか出力できない。
例えば、ヘッダやパスパラメータやBodyで指定されるようなパラメータについては、出力できないため、あくまでもHTTPサーバとしてのアクセスログといった位置づけだろう。
※統合リクエストでAWSサービスとも統合できるのに、アプリケーションサーバ的なログが出せないのはちょっといただけないのだが……ログ出力の方法
前回の記事にも書いた通り、カスタムアクセスログについては、Terraformの
aws_api_gateway_stageでaccess_log_settingsを指定してあげることで出力可能だ。CloudWatch Logsの作成や、ログ書き込みのためのロール設定等は前回を参照してほしい。なお、ログフォーマットには、CLF、JSON、XML、CSVが設定可能だが、CloudWatch Logs Insightsで使えることを考えると、JSONが良いだろうということで、今回はJSONで書いている(後でJSON→CSV変換であれば色々な手段で簡単にできるし)。
今回の記事では、簡単な Mock 統合を作成し、そこの prod ステージに対して以下の設定をした。
resource "aws_api_gateway_stage" "prod" { stage_name = "prod" rest_api_id = aws_api_gateway_rest_api.my.id deployment_id = aws_api_gateway_deployment.dev_to_prod.id access_log_settings { destination_arn = aws_cloudwatch_log_group.apigateway_accesslog.arn format = replace(file("${path.module}/logformat.json"), "\n", "") } }format には直接書き込んでも良いが、色々と書きだしたい場合はファイルを分けた方が良いだろう。
replace() 関数を入れているのは、JSONを複数行にするとエラーになるためだ(API Gatewayの仕様)。
ファイルに '\' を入れても良いのだが、可読性を上げるために、ファイルは普通のJSON形式にして、Terraformに食わせるときに変換している。実際の出力
実際に設定した際の出力を確認していってみよう。
なお、全部一気にまとめて出力しようとしたら、ログフォーマット設定は最大で 3,000Byte までしか指定できないらしいので、まとめて出力することはできないようだ。実運用する際は、必要なものをピックアップしよう。なお、値が
"-"のものは、今回の単純な Mock のAPIでは使っていない機能によるものなので、実際には利用シーンに合わせた値が設定されるはずである。例に記載されているもの
フォーマットでの指定
{ "requestId": "$context.requestId", "ip": "$context.identity.sourceIp", "caller": "$context.identity.caller", "user": "$context.identity.user", "requestTime": "$context.requestTime", "httpMethod": "$context.httpMethod", "resourcePath": "$context.resourcePath", "status": "$context.status", "protocol": "$context.protocol", "responseLength": "$context.responseLength" }ログ出力内容
{ "requestId": "feee42ea-1b14-4f99-ad2a-5c0e17b01d5c", "ip": "xxx.xxx.xxx.xxx", "caller": "-", "user": "-", "requestTime": "26/Sep/2020:13:10:33 +0000", "httpMethod": "GET", "resourcePath": "/employee", "status": "200", "protocol": "HTTP/1.1", "responseLength": "0",共通的なコンテキスト変数
フォーマットでの指定
{ "account_id": "$context.accountId", "api_id": "$context.apiId", "authorizer_claims_property": "$context.authorizer.claims.property", "authorizer_principal_id": "$context.authorizer.principalId", "authorizer_property": "$context.authorizer.property", "aws_endpoint_request_id": "$context.awsEndpointRequestId", "domain_name": "$context.domainName", "domain_prefix": "$context.domainPrefix", "error_message": "$context.error.message", "error_message_string": "$context.error.messageString", "error_response_type": "$context.error.responseType", "error_validation_error_string": "$context.error.validationErrorString", "extended_request_id": "$context.extendedRequestId", "identity_account_id": "$context.identity.accountId", "identity_api_key": "$context.identity.apiKey", "identity_api_key_id": "$context.identity.apiKeyId", "identity_cognito_authentication_provider": "$context.identity.cognitoAuthenticationProvider", "identity_cognito_authentication_type": "$context.identity.cognitoAuthenticationType", "identity_cognito_identity_id": "$context.identity.cognitoIdentityId", "identity_cognito_identity_pool_id": "$context.identity.cognitoIdentityPoolId", "identity_principal_org_id": "$context.identity.principalOrgId", "identity_client_cert_client_cert_pem": "$context.identity.clientCert.clientCertPem", "identity_client_cert_subject_d_n": "$context.identity.clientCert.subjectDN", "identity_client_cert_issuer_d_n": "$context.identity.clientCert.issuerDN", "identity_client_cert_serial_number": "$context.identity.clientCert.serialNumber", "identity_client_cert_validity_not_before": "$context.identity.clientCert.validity.notBefore", "identity_client_cert_validity_not_after": "$context.identity.clientCert.validity.notAfter", "identity_user_agent": "$context.identity.userAgent", "identity_user_arn": "$context.identity.userArn", "path": "$context.path", "request_override_header_header_name": "$context.requestOverride.header.header_name", "request_override_path_path_name": "$context.requestOverride.path.path_name", "request_override_querystring_querystring_name": "$context.requestOverride.querystring.querystring_name", "response_override_header_header_name": "$context.responseOverride.header.header_name", "response_override_status": "$context.responseOverride.status", "request_time_epoch": "$context.requestTimeEpoch", "resource_id": "$context.resourceId", "stage": "$context.stage", "waf_response_code": "$context.wafResponseCode", "webacl_arn": "$context.webaclArn", "xray_trace_id": "$context.xrayTraceId" }ログ出力内容
{ "account_id": "xxxxxxxxxxxx", "api_id": "xxxxxxxxxx", "authorizer_claims_property": "-", "authorizer_principal_id": "-", "authorizer_property": "-", "aws_endpoint_request_id": "-", "domain_name": "xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com", "domain_prefix": "xxxxxxxxxx", "error_message": "-", "error_message_string": "-", "error_response_type": "-", "error_validation_error_string": "-", "extended_request_id": "TeaXkGWhNjMFVjw=", "identity_account_id": "-", "identity_api_key": "-", "identity_api_key_id": "-", "identity_cognito_authentication_provider": "-", "identity_cognito_authentication_type": "-", "identity_cognito_identity_id": "-", "identity_cognito_identity_pool_id": "-", "identity_principal_org_id": "-", "identity_client_cert_client_cert_pem": "-", "identity_client_cert_subject_d_n": "-", "identity_client_cert_issuer_d_n": "-", "identity_client_cert_serial_number": "-", "identity_client_cert_validity_not_before": "-", "identity_client_cert_validity_not_after": "-", "identity_user_agent": "curl/7.61.1", "identity_user_arn": "-", "path": "/prod/employee", "request_override_header_header_name": "-", "request_override_path_path_name": "-", "request_override_querystring_querystring_name": "-", "response_override_header_header_name": "-", "response_override_status": "-", "request_time_epoch": "1601126133567", "resource_id": "xxxxxx", "stage": "prod", "waf_response_code": "-", "webacl_arn": "-", "xray_trace_id": "-" }アクセスログのみのコンテキスト変数
フォーマットでの指定
{ "authorize_error": "$context.authorize.error", "authorize_latency": "$context.authorize.latency", "authorize_status": "$context.authorize.status", "authorizer_error": "$context.authorizer.error", "authorizer_integration_latency": "$context.authorizer.integrationLatency", "authorizer_integration_status": "$context.authorizer.integrationStatus", "authorizer_latency": "$context.authorizer.latency", "authorizer_request_id": "$context.authorizer.requestId", "authorizer_status": "$context.authorizer.status", "authenticate_error": "$context.authenticate.error", "authenticate_latency": "$context.authenticate.latency", "authenticate_status": "$context.authenticate.status", "integration_error": "$context.integration.error", "integration_integration_status": "$context.integration.integrationStatus", "integration_latency1": "$context.integration.latency", "integration_request_id": "$context.integration.requestId", "integration_status1": "$context.integration.status", "integration_error_message": "$context.integrationErrorMessage", "integration_latency2": "$context.integrationLatency", "integration_status2": "$context.integrationStatus", "response_latency": "$context.responseLatency", "waf_error": "$context.waf.error", "waf_latency": "$context.waf.latency", "waf_status": "$context.waf.status" }ログ出力内容
{ "authorize_error": "-", "authorize_latency": "-", "authorize_status": "-", "authorizer_error": "-", "authorizer_integration_latency": "-", "authorizer_integration_status": "-", "authorizer_latency": "-", "authorizer_request_id": "-", "authorizer_status": "-", "authenticate_error": "-", "authenticate_latency": "-", "authenticate_status": "-", "integration_error": "-", "integration_integration_status": "200", "integration_latency1": "0", "integration_request_id": "-", "integration_status1": "-", "integration_error_message": "-", "integration_latency2": "0", "integration_status2": "200", "response_latency": "3", "waf_error": "-", "waf_latency": "-", "waf_status": "-" }
- 投稿日:2020-09-27T11:06:18+09:00
AWS Linux2にAWS CLI バージョン2をインストールする方法
はじめに
AWS CLI バージョン2をインストールする方法について書きます。
AWS Linux2には初めからAWS CLI バージョン1があります。
[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ aws --version aws-cli/1.18.107 Python/2.7.18 Linux/4.14.193-149.317.amzn2.x86_64 botocore/1.17.31手順
以下の2つを行います。
1. AWS CLI バージョン2のインストール
2. AWS CLI バージョン1の削除AWS CLI バージョン2のインストール
以下のコマンドでインストールファイルをダウンロードします。
curlコマンドでインストーラをリクエストし、オプション -o "ファイル名"で指定したファイル名にリクエスト結果を書き込みます。[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
lsコマンドを使用してファイルが作成されたかを確認することできます。[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ ls awscliv2.zip次に作成したzipファイルを、
unzipコマンドを使用して解凍します。
・・・は表示されるメッセージを省略しています。[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ unzip awscliv2.zip Archive: awscliv2.zip creating: aws/ creating: aws/dist/ inflating: aws/README.md ・ ・ ・解凍後は以下のようにawsディレクトリが作成されます。
[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ ls aws awscliv2.zip~/aws/install がインストールプログラムなので、管理者権限でこれを実行します。
[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ sudo ./aws/install You can now run: /usr/local/bin/aws --versionインストールを確認します。
aws-cli/の後に、2が表示されていればバージョン2がインストールされています。[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ /usr/local/bin/aws --version aws-cli/2.0.52 Python/3.7.3 Linux/4.14.193-149.317.amzn2.x86_64 exe/x86_64.amzn.2AWS CLI バージョン1の削除
インストール直後は、
/usr/local/bin/awsのように絶対パスで指定しなければバージョン2が使用でない状態です。
相対パスawsではバージョン1が呼び出されます。[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ aws --version aws-cli/1.18.107 Python/2.7.18 Linux/4.14.193-149.317.amzn2.x86_64 botocore/1.17.31バージョン1の
awsコマンドは相対パスで呼び出せるので、環境変数に入っています。[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ echo $PATH /usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/ec2-user/.local/bin:/home/ec2-user/bin以下のように
~/usr/binにバージョン1が入っています。
lsコマンドでディレクトリ内のディレクトリ・ファイルを表示し、grep '検索したい文字列' で検索したいディレクトリ・ファイルを表示させることができます。[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ ls /usr/bin/ | grep 'aws' aws aws_completerこれらを
rmコマンドで削除します。[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ sudo rm -f /usr/bin/aws /usr/bin/aws_completerこれにより
awsコマンドは、/usr/local/bin/awsを参照するようになります。[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ aws --version aws-cli/2.0.52 Python/3.7.3 Linux/4.14.193-149.317.amzn2.x86_64 exe/x86_64.amzn.2参考記事
AWS 公式サイト
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/install-cliv2-linux.html
- 投稿日:2020-09-27T08:34:55+09:00
CodeBuildでAssumeRoleを利用してクロスアカウントのリソースにアクセスする
はじめに
CodeBuildでビルドを行う際に別アカウントのリソースにアクセスするケースがありました。そのため、AssumeRoleを利用して別アカウントのリソースにアクセスするように設定したので、その方法を紹介します。
要件
アカウントAのCodeBuildからアカウントBのリソースにアクセスする。
設定
AssumeRoleを利用するためにRoleの設定とCodeBuildでAssumeRoleの認証情報を環境変数にエクスポートを行います。
Roleの設定
アカウントAのCodeBuild用Role
CodeBuild用Roleにsts:assumeRoleのアクセス許可を追加して、AssumeRole操作を許可します。
ResourceはアカウントBのリソースを操作するRoleを指定します。{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "sts:AssumeRole", "Resource": "arn:aws:iam::アカウントAのID:role/crossaccess-from-accountA" } ] }アカウントBのリソース用Role
IAM Roleに『crossaccess-from-accountA』を作成します。
信頼されたエンティティの種類で『別のAWSアカウント』を選択、アカウントAのIDを指定しアクセスするリソースへの必要なポリシーをアタッチします。buildspec.ymlの設定
アカウントAのCodeBuildからアカウントBのリソースにアクセスするためにAssumeRoleの認証情報を環境変数にエクスポートします。
以下のようにbuildspec.ymlのpre_buildフェーズにコマンドを記述します。pre_build: commands: - credentials=$(aws sts assume-role --role-arn ${ASSUME_ROLE_ARN} --role-session-name "RoleSessionFromCodeBuild" | jq .Credentials) - export AWS_ACCESS_KEY_ID=$(echo ${credentials} | jq -r .AccessKeyId) - export AWS_SECRET_ACCESS_KEY=$(echo ${credentials} | jq -r .SecretAccessKey) - export AWS_SESSION_TOKEN=$(echo ${credentials} | jq -r .SessionToken)AssumeRoleの認証情報を環境変数にエクスポート後のcommandsセクションに、アカウントBのリソースにアクセスするコマンドを記述します。
まとめ
上記の設定後にアカウントAのCodeBuildでビルドを行うと、アカウントBのリソースにアクセスすることができました!
AssumeRoleを利用する際にIAMRoleの設定は行いますが、CodeBuildでAssumeRoleを利用する際に認証情報を環境変数にエクスポートするところでハマったので勉強になりました。
- 投稿日:2020-09-27T03:50:44+09:00
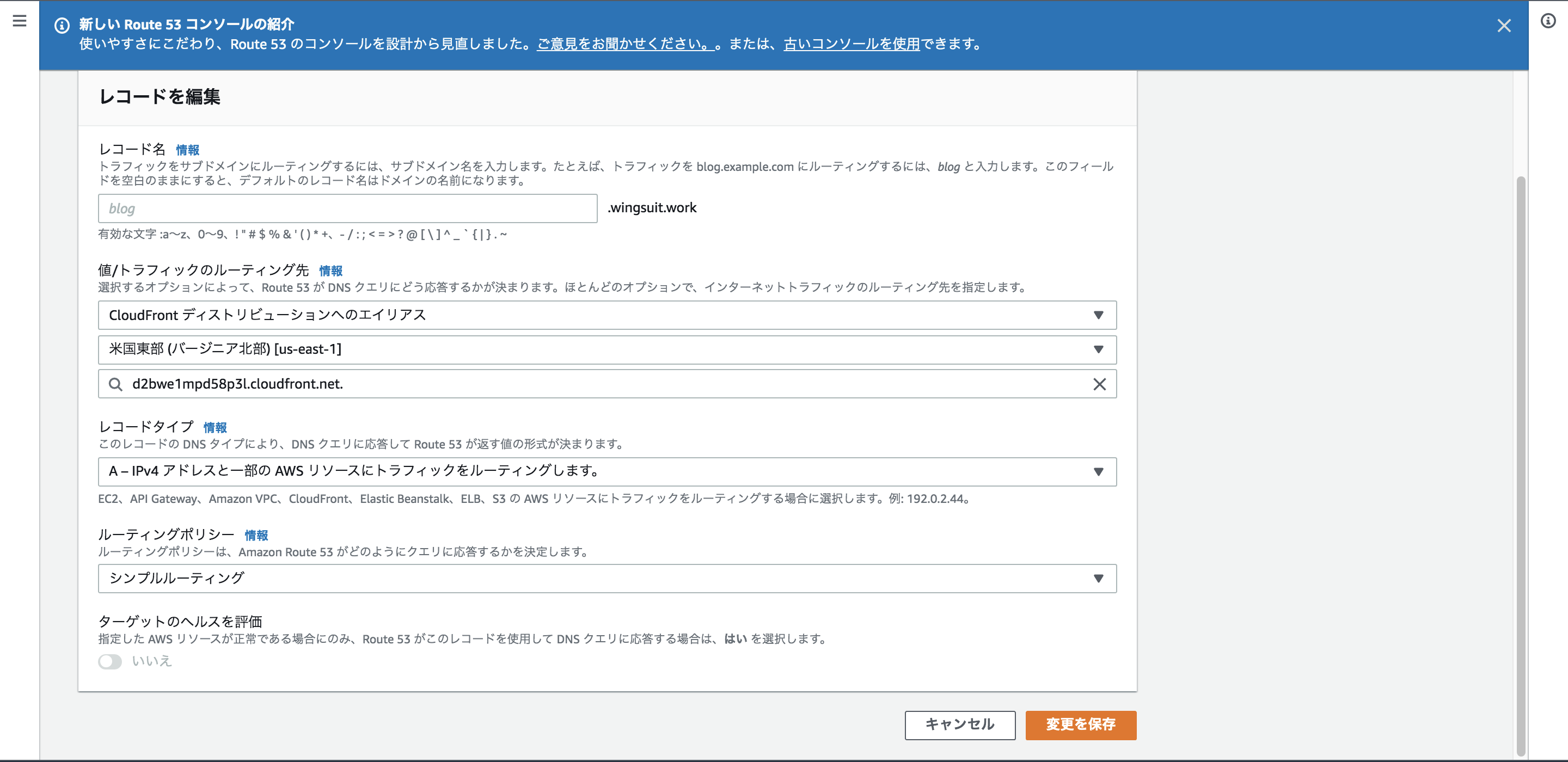
Well Architected Frameworkを意識して自分なりにアーキテクチャ設計・構築をしてみた。<Route53、ACM編>
HTTPS化
ACM
事前にドメインを取得して、Route53にホストゾーンの作成を行っています。
注意
ALBで利用する証明書はALBのあるリージョンで、Cloudfrontで利用する証明書は必ず「バージニア北部」で取得して下さい。それではマネジメントコンソールの「Certificate Manager」から証明書の発行を行います。
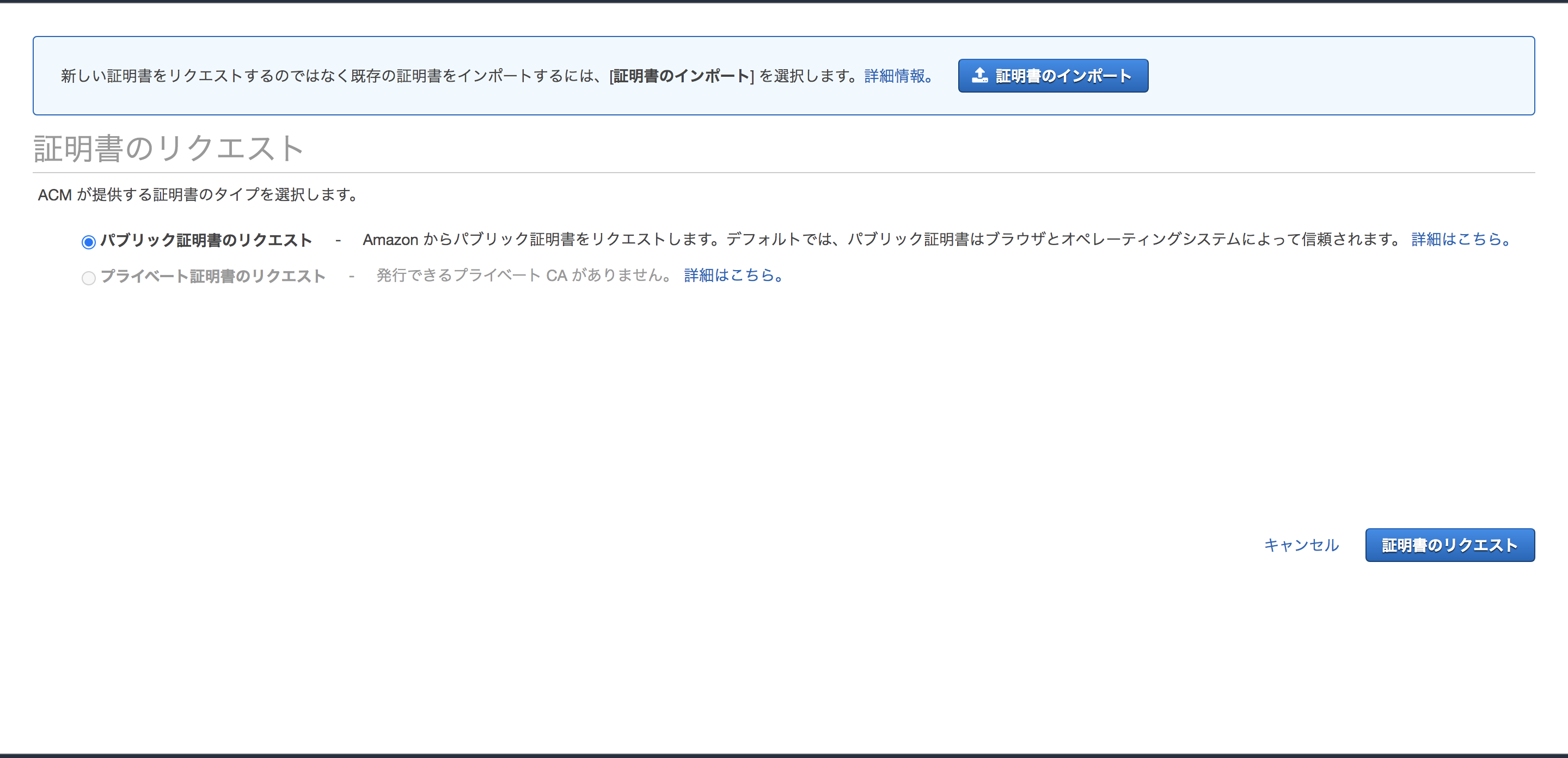
今回は一般的な用途ですので、「パブリック証明書のリクエスト」を選択して下さい。
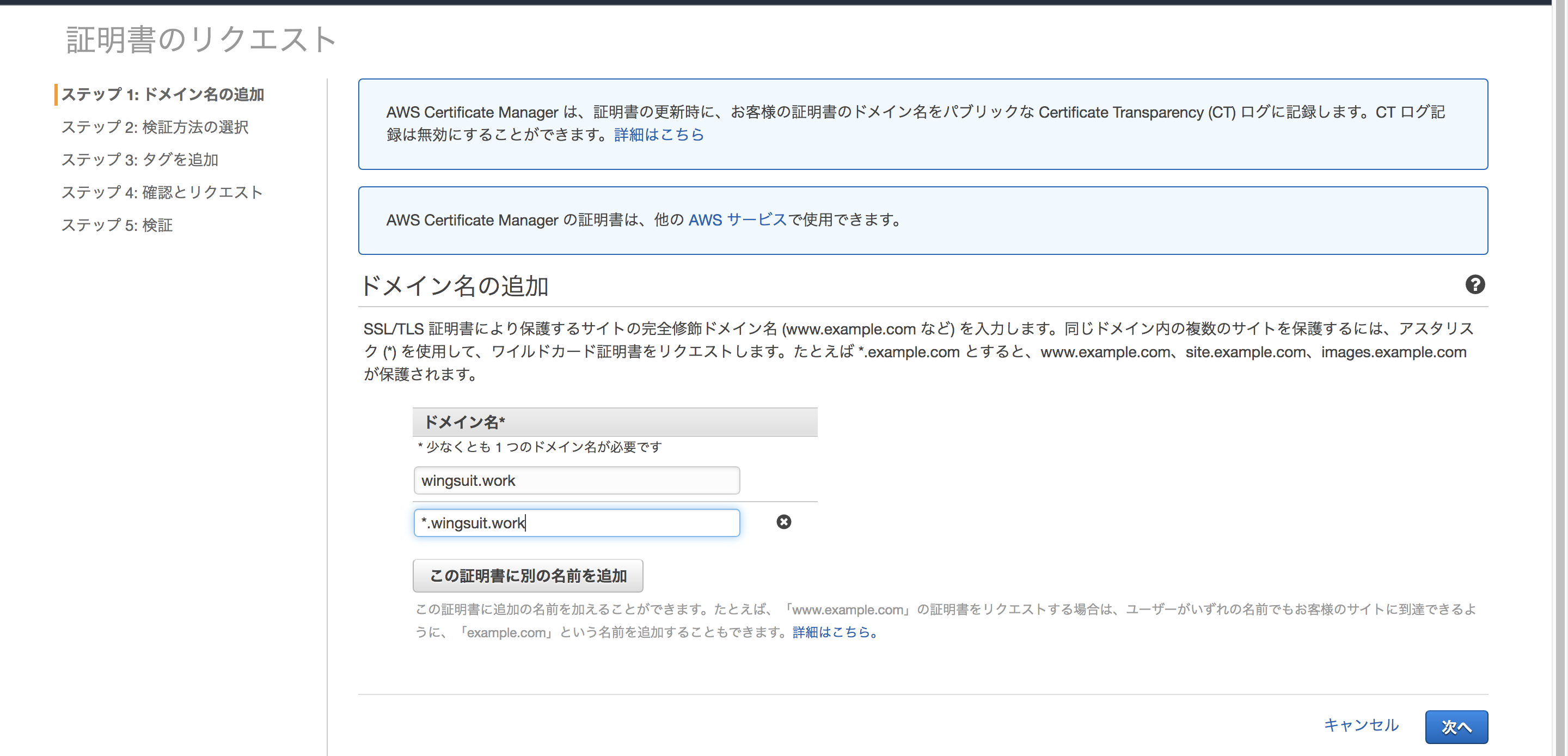
ドメイン名の登録を行います。
この時、複数のドメインを追加することも可能です。
また、「*.example.com」のようにワイルドカードで追加することも可能ですので、サブドメインを使うのであれば、追加しても良いでしょう。「*.example.com」で発行を行った場合、「example.com」は適用されないので、別で登録する必要があります。
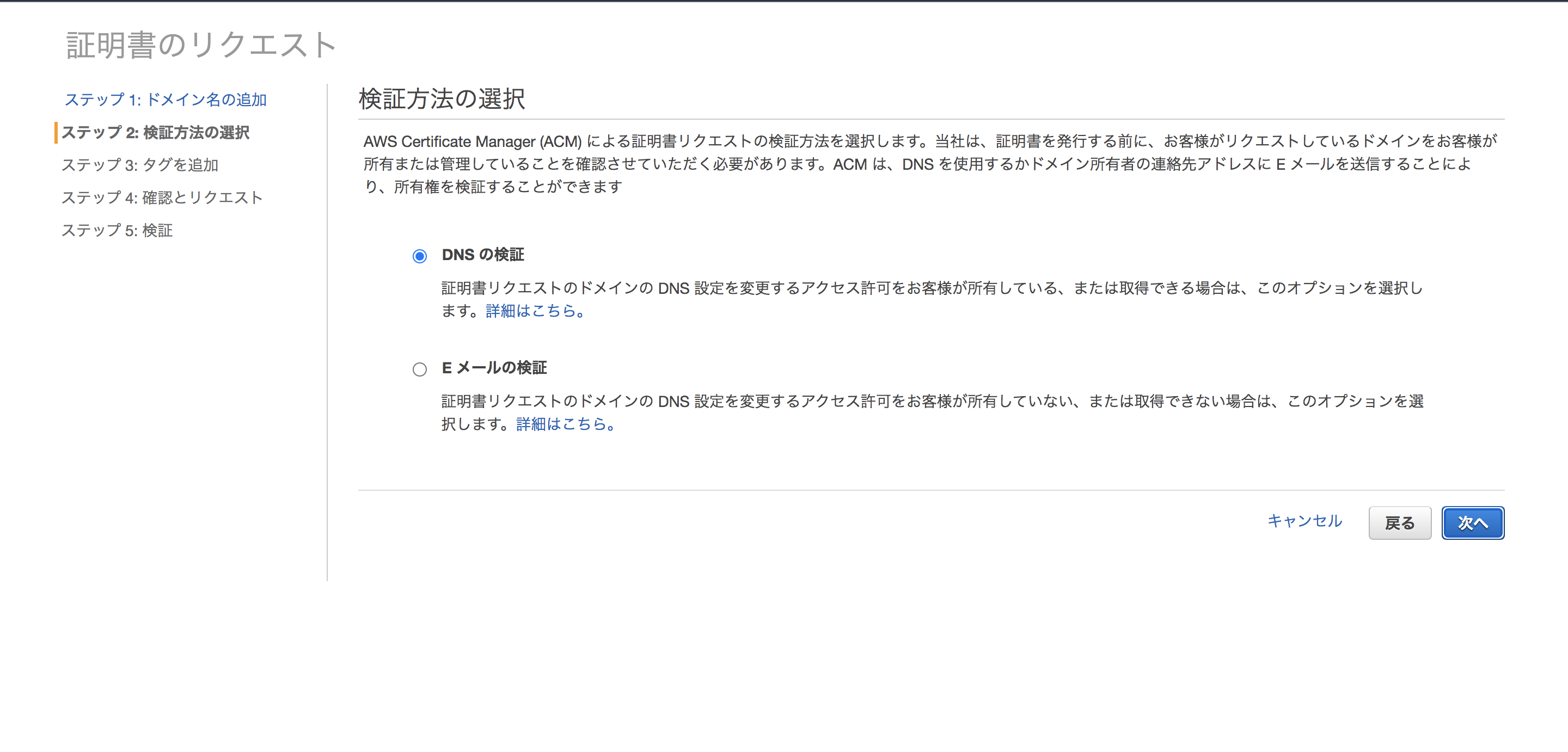
今回は「DNSの検証」を選択します。
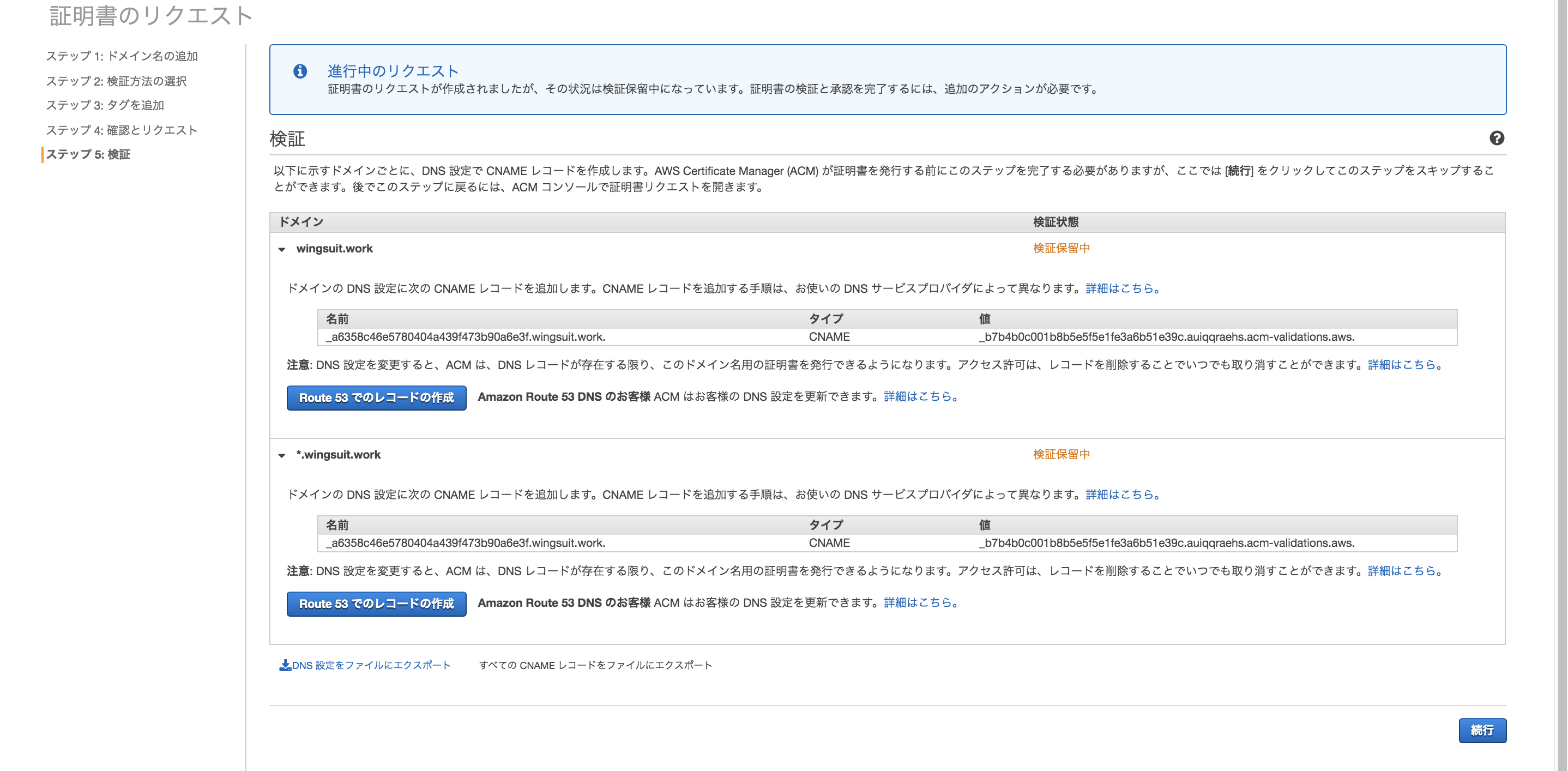
「Route53でのレコードの作成」をクリックすると、ACMが自動でCNAMEのレコードを追加してくれます。
検証に少し時間がかかるので、今のうちにALB用の証明書も発行しておきます。
状況が「発行済み」になれば完了です。
Cloudfrontでカスタムドメイン(デフォルト以外のドメイン)を使用する場合はALBでのHTTPS化も必要です。
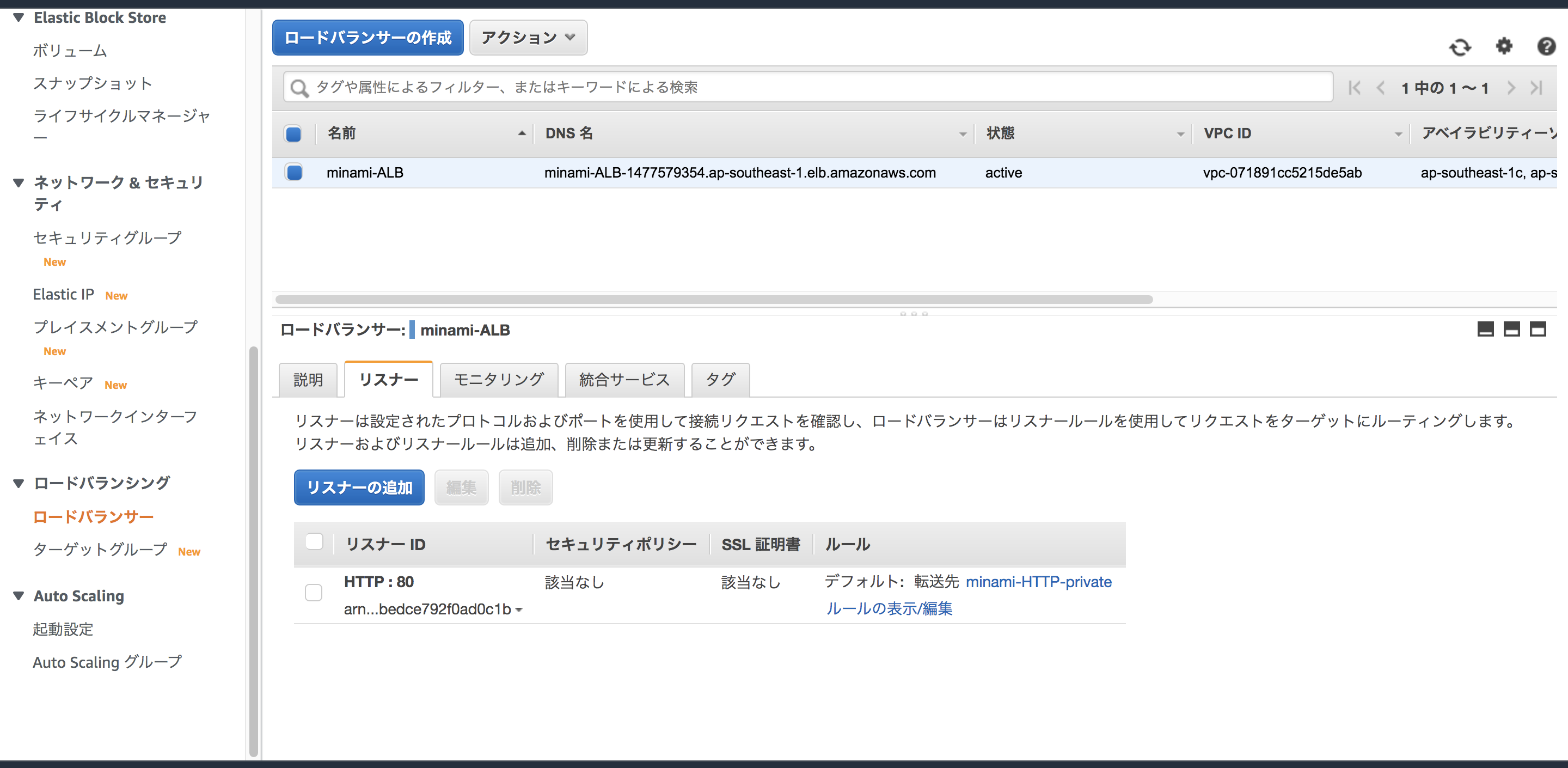
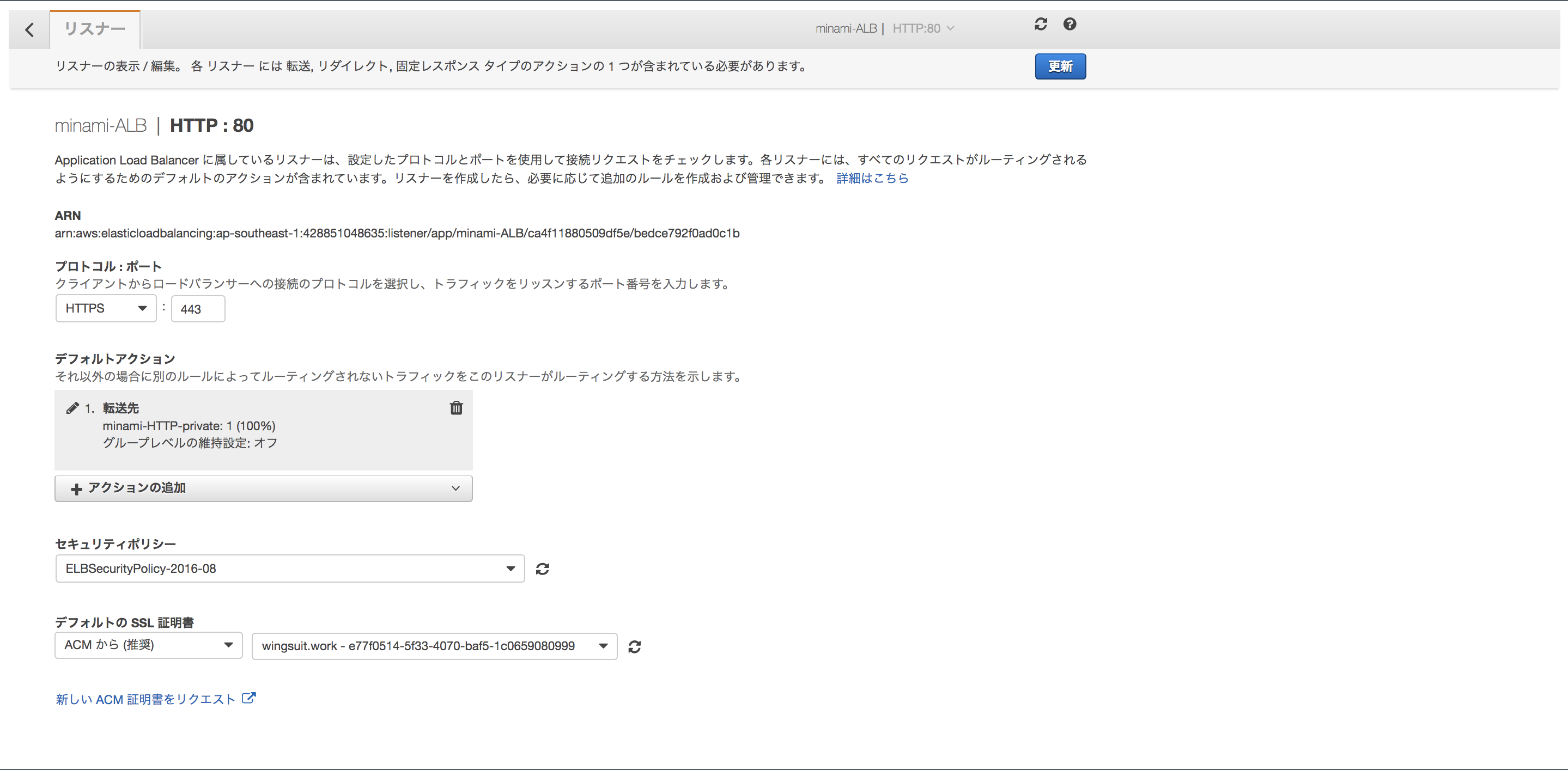
まずはALBのHTTPS化を行いましょう。リスナーを「HTTPS」→「HTTPS」に変更します。
リスナーを選択して「編集」に進んで下さい。
「プロトコル:ポート」→「HTTPS:443」に変更
「デフォルトのSSL証明書」から先ほど作成した証明書を選択をして下さい。
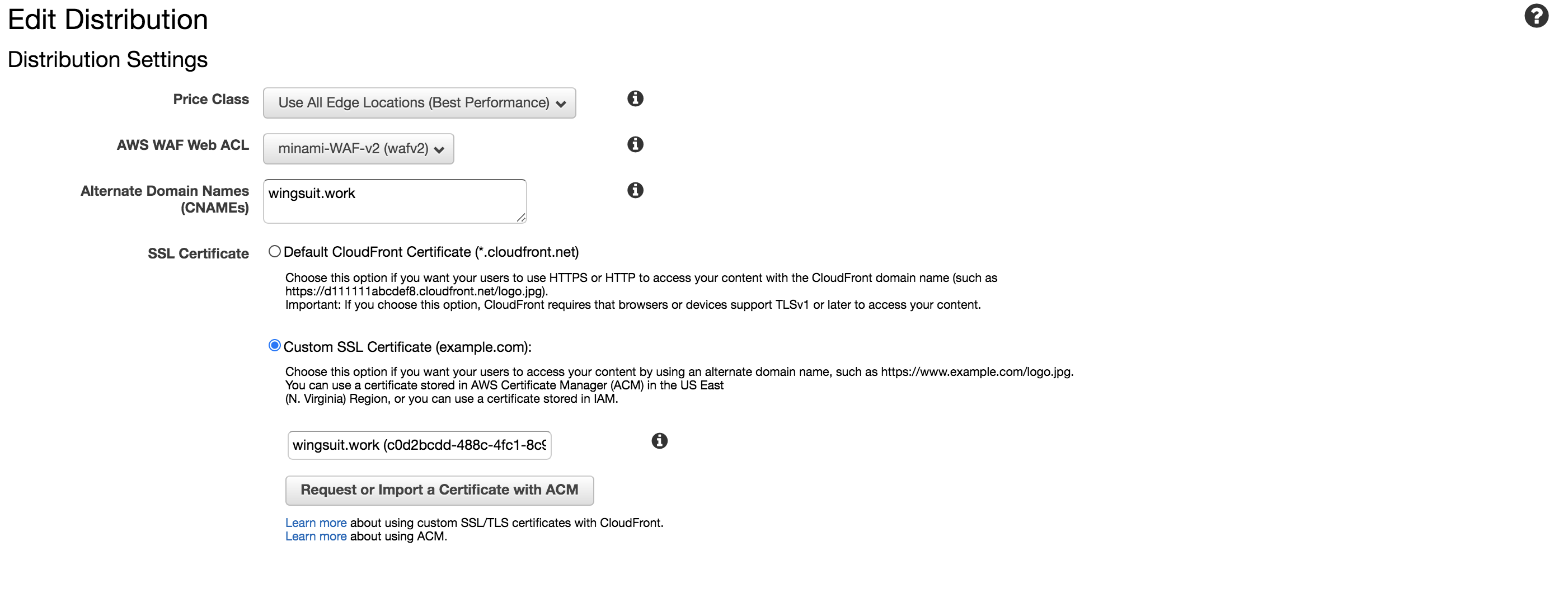
次にCloudfront側でのHTTPS化を行います。
「Distribution」の設定から
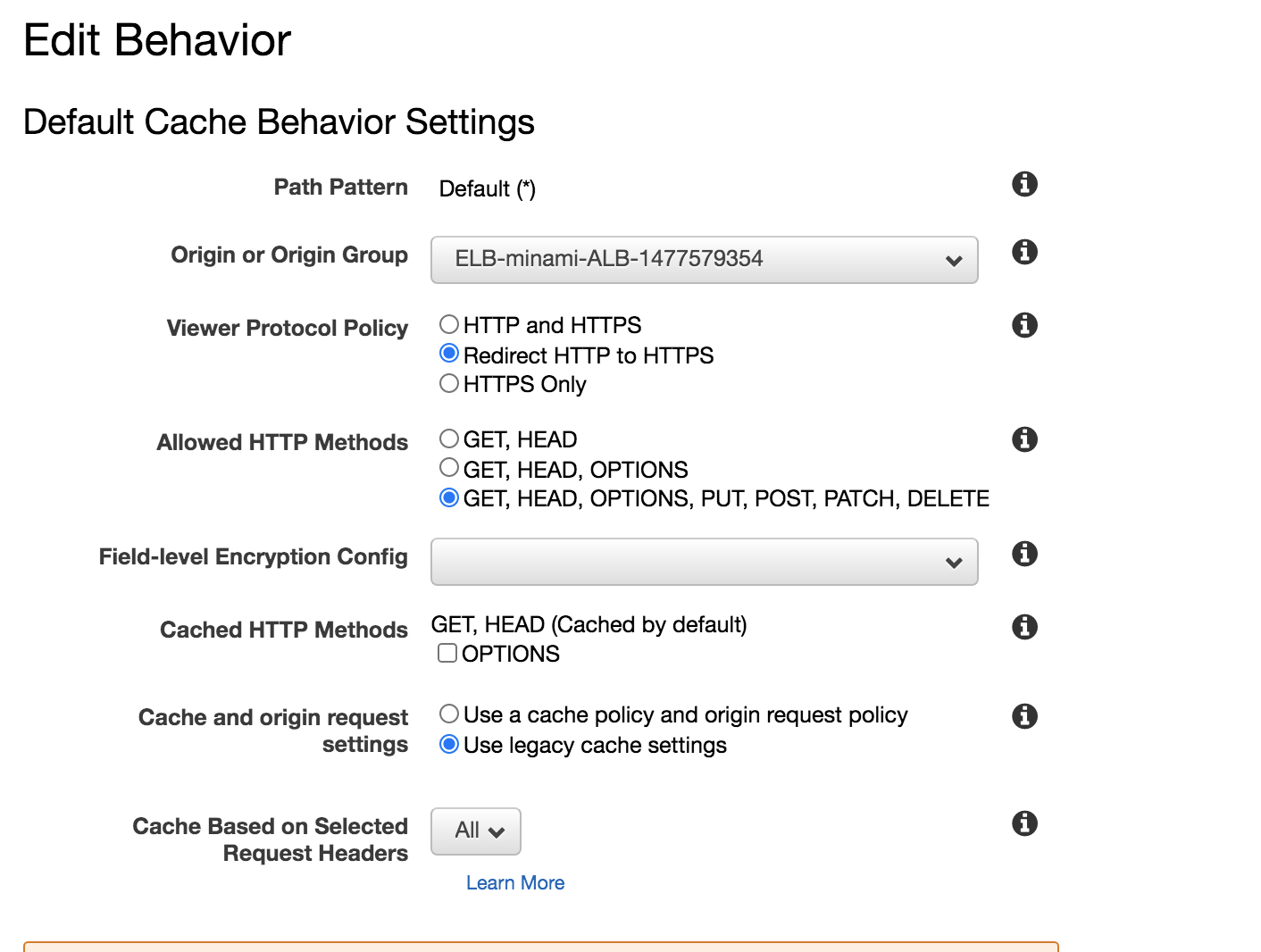
設定 項目 Alternate Domain Names ドメイン名 SSL Certificate 先ほど作成したCloudfront用の証明書 を設定します。
また、Behaviorの設定の
設定 項目 Viewer Protocol Policy Redirect HTTP to HTTPS を設定することで、Cloudfront側でリダイレクトの設定を行うことができます。
補足
Cloudfrontを使わない場合はALBのリダイレクト機能を設定することで同じようなことができます。
最後に、「Route53」にてレコードの追加を行えばHTTPS化の完成です。
Route53
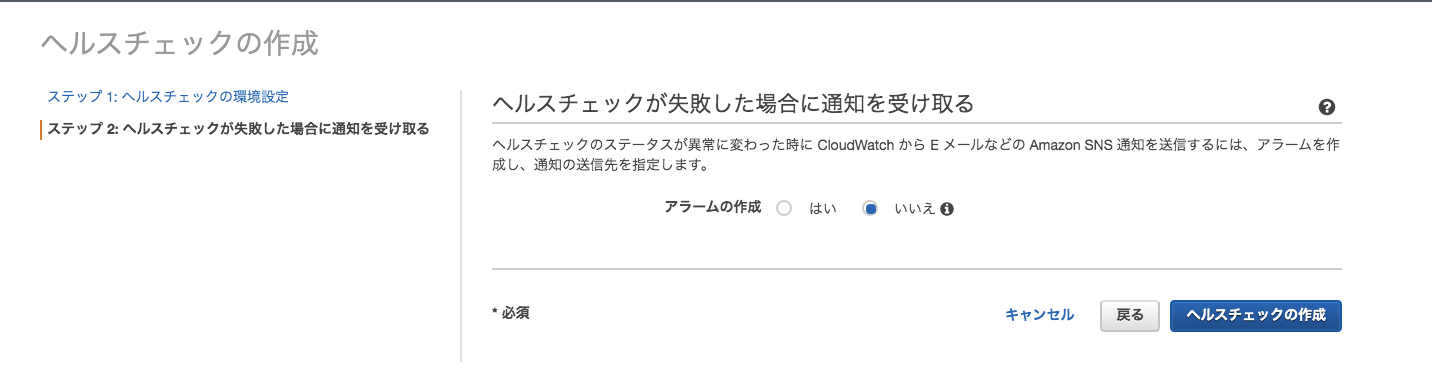
ヘルスチェックの有効化
Route53のヘルスチェックは3種類あります。
ヘルスチェックの種類
エンドポイントをモニタリングするヘルスチェック
- IPアドレス OR ドメイン名 に対してTCP接続を確立しようと試み、正常かどうかを判断する。
他のヘルスチェック (算出したヘルスチェック) を監視するヘルスチェック
- 「エンドポイントをモニタリングするヘルスチェック」を複数使用し、AND、ORで制御可能なヘルスチェック
CloudWatch アラームをモニタリングするヘルスチェック
- Cloudwatchを利用したヘルスチェック
- ユースケースとしてはDynamoDBへのスロットル読み込みイベント数や正常に機能していると推測される ELBの数などの CloudWatch メトリクスのステータスをモニタリングして判断を行う みたいな使い方が出来ます。
フェイルオーバーを実装する為にヘルスチェックを関連付ける場合は基本的には「エンドポイント」で作成すればいいかと思います。
SNS通知が利用できるので、Chatbotを利用して簡単にSlackBotも作れそうですね
これに関しては、後ほど作成を行います。
Route53でのヘルスチェックでもレイテンシーも追加の設定で確認できますが、より詳しいサービスの監視を行いたい場合はCloudwatch Syntheticを利用するといいでしょう。
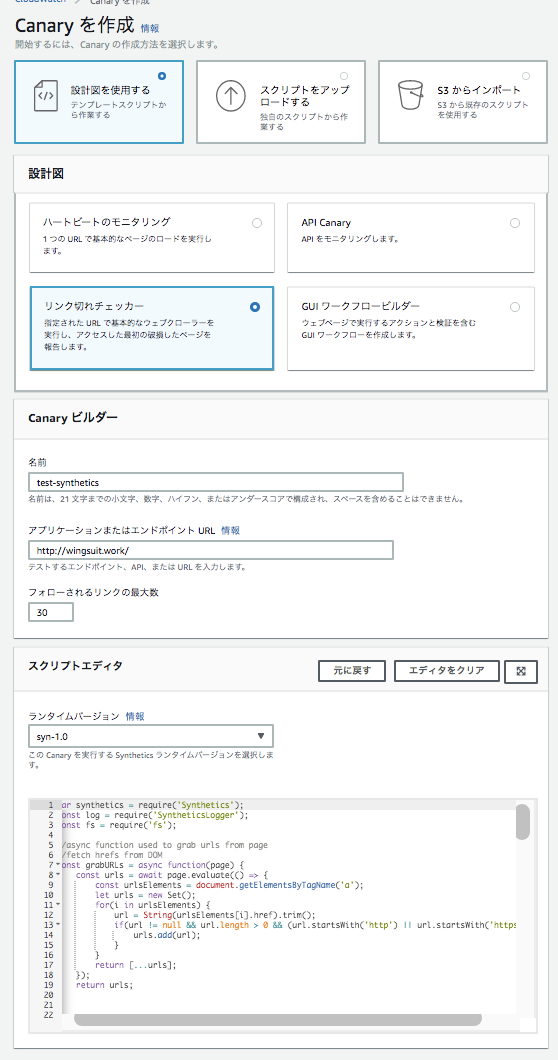
Cloudwatch Syntheticsを用いてサービス状況を監視
CloudwatchSyntheticsというサービスの概要は知っていましたが、触るのは今回が初めてでした。
設定はこんな感じでエンドポイントの URL を指定すると、その下の Canary Builder に監視内容を設定するコードが生成されるっぽいです。(現時点ではPythonは指定出来ない...)
ハートビートのモニタリング
URLをチェックしてくれるAPI Canary
そのまま APIバージョンリンク切れチェッカー
いろんなパスまで見てくれるGUIワークフロービルダー
ページ内での色々なアクションを監視してくれるっぽい
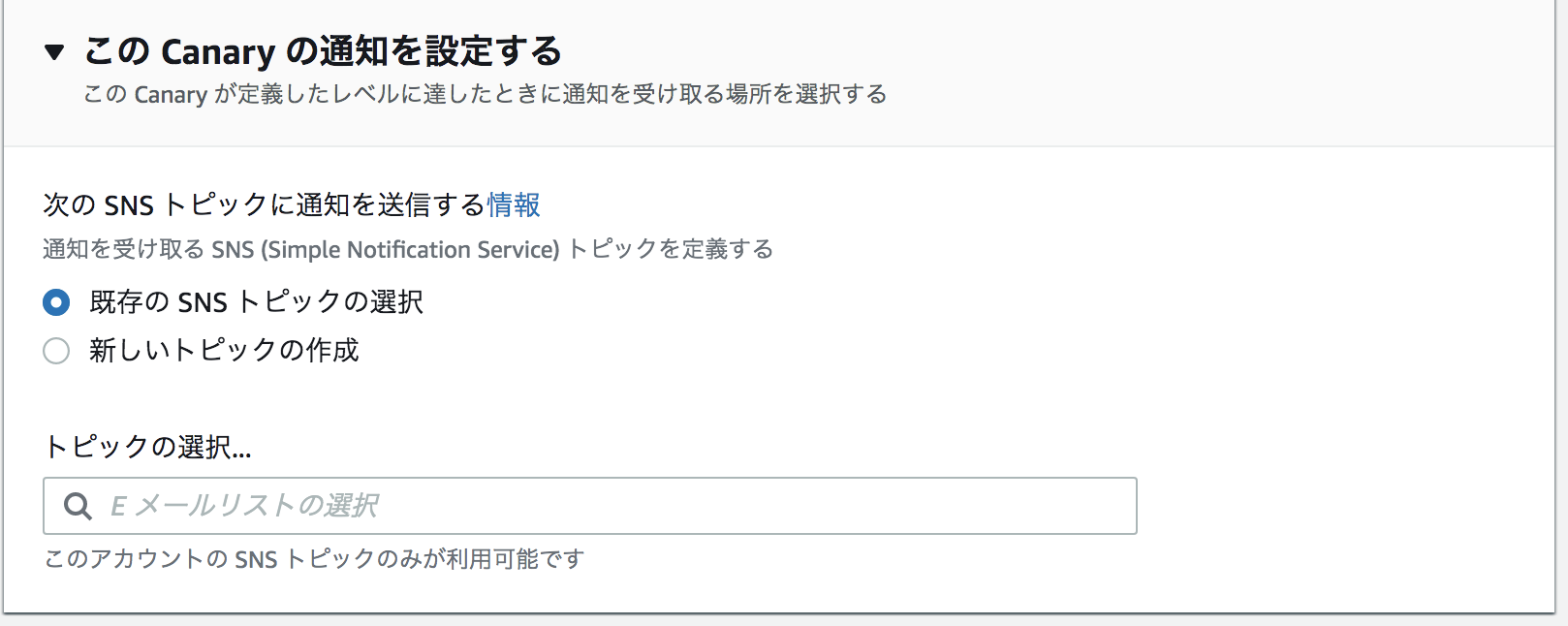
SNSトピックと関連付け出来るので、Slackへの通知も簡単そうですね
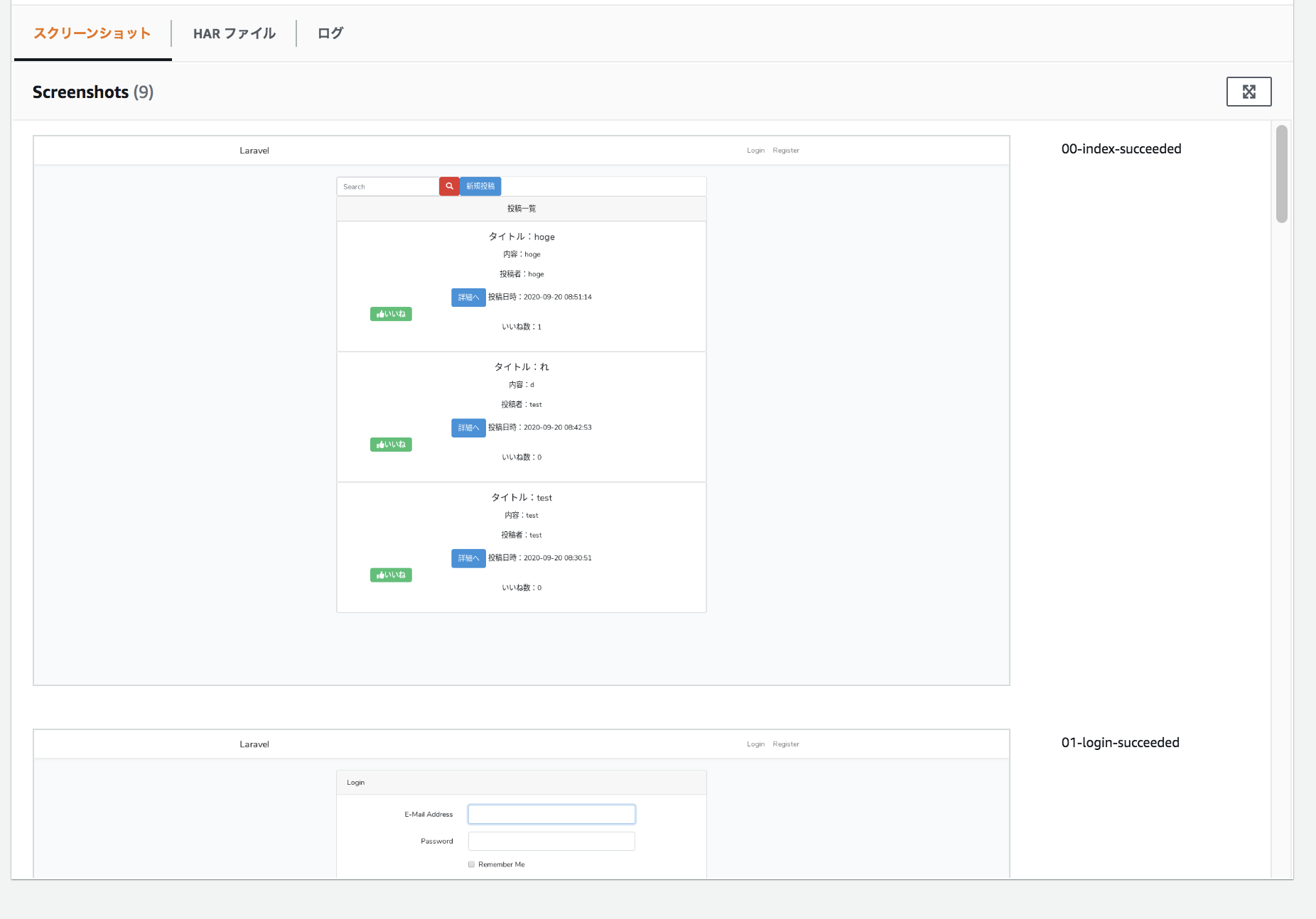
ログと一緒にスクリーンショットも保存してくれるのは面白いです
レスポンスタイムも
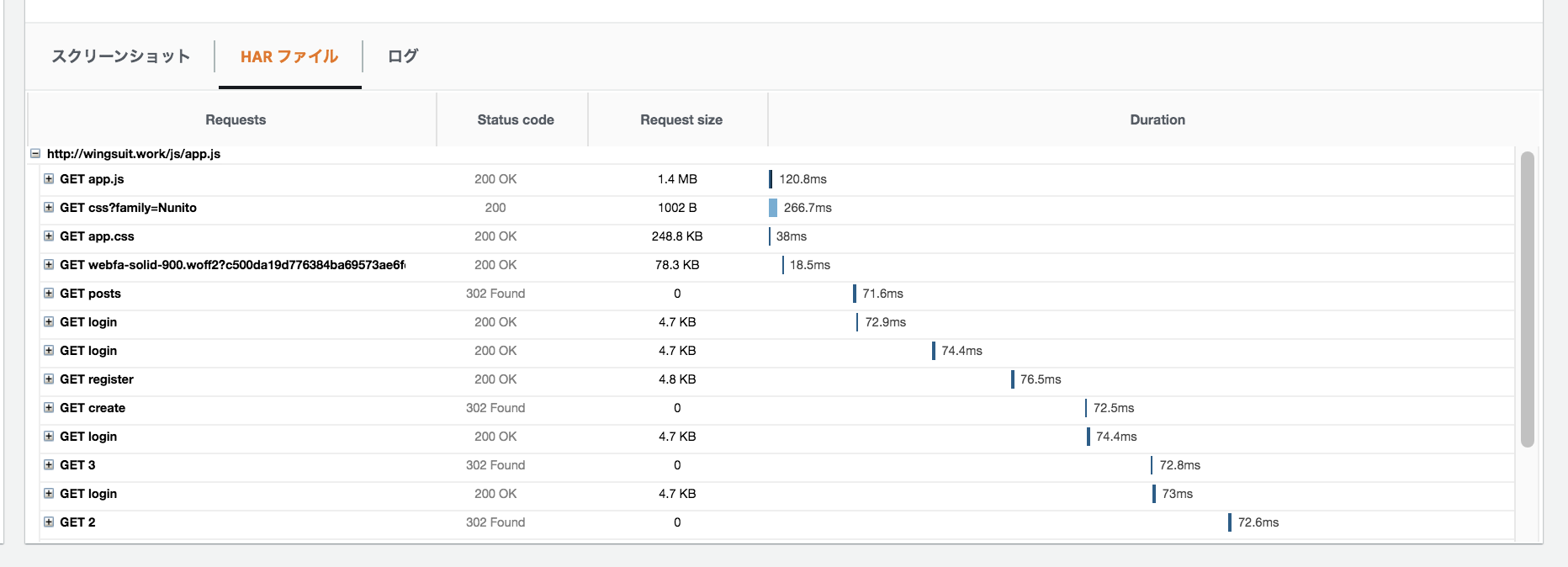
ログも
Cloudwatchアラームで異常時のアラートを設定する事もできます(レスポンスタイムでアラートなど)
Syntheticsの利点として一番大きいのは「圧倒的安さ!」かと思います。
1時間に1回実行する設定でもたったの約100円/月!!!Datadogでもsyntheticsモニタリングありますけど、$12/月ですね。
また、AWS Lambda + Amazon S3 + Amazon CloudWatch Alarms を使ってるサービスなので、とてもわかりやすいです。それでいてとても柔軟な設定ができるので結構使えそうな気がします。
最後に


- 投稿日:2020-09-27T01:41:21+09:00
AWS Linux2でpython3をインストールする方法
yumでインストール
以下のようにyumでインストールします。
sudoは管理者権限でコマンドを実行します。
python3のインストールはこれだけです。[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ sudo yum install python3 -yオプション -y は、以下のようなメッセージにすべてyで答えるために付けます。
Is this ok [y/d/N]:モジュールのインストール
モジュールのインストールにはpip3コマンドを使用します。
オプション -V でpip3のバージョンを確認できます。[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ pip3 -V pip 9.0.3 from /usr/lib/python3.7/site-packages (python 3.7)ここではpandasをインストールしたいとします。(pandasをインストールしたいモジュールに置き換えてください)
・・・の部分は、表示されるメッセージを省略しています。[ec2-user@ip-xxx-xxx-xxx-xxx ~]$ sudo pip3 install pandas WARNING: Running pip install with root privileges is generally not a good idea. Try `pip3 install --user` instead. Collecting pandas ・ ・ ・ Installing collected packages: pytz, numpy, six, python-dateutil, pandas Successfully installed numpy-1.19.2 pandas-1.1.2 python-dateutil-2.8.1 pytz-2020.1 six-1.15.0参考文献
AWS 公式ホームページ
https://aws.amazon.com/jp/premiumsupport/knowledge-center/ec2-linux-python3-boto3/
- 投稿日:2020-09-27T00:49:41+09:00
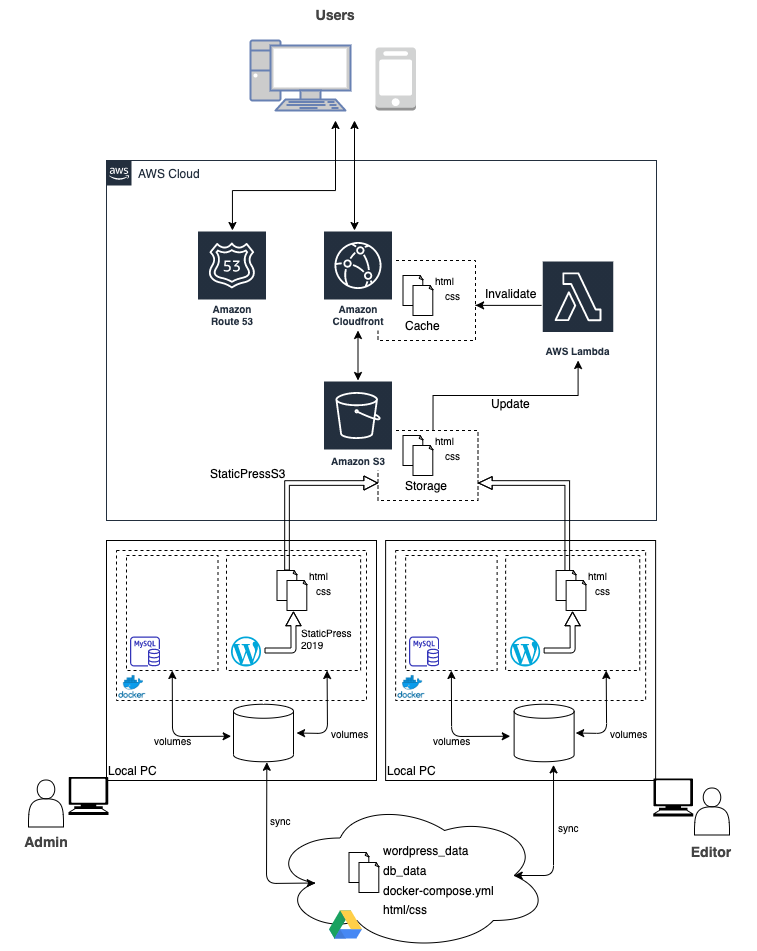
レンタルサーバのWordPressをAWS(S3+CloudFront)に移行した話
背景
Webライターを営む妻からある日受けた相談。
レンタルサーバ(エックスサーバ)とWordPressでブログを運営しているが、サーバとかよくわからないから教えてほしい、というかそのままサーバ管理をやってほしいと。
良いネタが見つかった愛する妻を助けるため興味の赴くままに頑張った結果、気付いたら爆速かつ低コストなブログが出来あがっていました。以下実際のブログなのでよければご覧ください!
https://urichiki.com/システム構成
概要
コンセプトとしては、WordPressをWebサーバとして運用するのではなく、WordPressで作成したコンテンツを静的化(html/css)し、Amazon S3に配置することでサーバレス化することを基本方針としています。
アイデア自体は目新しいものではなくすでに色々な記事で紹介されているので、構築手順や細かい説明は割愛して、簡単に各技術の導入背景等を説明していきます。
技術的な興味を持っていただいた方や、私と同じように静的化したブログ環境を構築したいと考えている方の参考になれば幸いです。構成図
AWS
S3
ストレージサービス。このブログの中心部分です。
https://aws.amazon.com/jp/s3/単純なストレージサービスとしてファイルを保存するだけでなく、保存したファイルをWebホスティングさせることも出来ます。ここでは、Wordpressを静的化したhtml/cssファイル等を配置し、S3からWebホスティングさせることを基本方針としています。
CloudFront
CDN(Contents Delivery Network)サービス。
https://aws.amazon.com/jp/cloudfront/CloudFrontを利用することで世界中に配置されているエッジサーバ経由でオリジンサーバ(今回だとS3)にアクセスが行われ、取得したコンテンツがエッジサーバにキャッシュされます。ネットワーク的に最寄りのエッジサーバ経由でアクセスが行われ、かつキャッシュが有効な間はオリジンサーバへアクセスすることなくコンテンツが取得出来るため、オリジンサーバへのリクエストを大幅に削減することが出来ます。
また、今回はCloudFrontを利用することでHTTPS化にも対応しました。Route 53
DNSサービス。
https://aws.amazon.com/jp/route53/元々エックスドメイン(エックスサーバのDNSサービス)で管理されていたドメイン(urichiki.com)を、AWSで一元管理するためにRoute 53に管理を移行しました。
Lambda
サーバーレスコンピューティングサービス。
https://aws.amazon.com/jp/lambda/S3に最新記事をアップしても、CloudFrontに古い記事がキャッシュされている間は最新記事が反映されません。この時間差を無くすため、S3に記事がアップされたイベントを検知し、キャッシュの無効化を自動で行うようLambda関数を作成しました。
WordPress
Docker
WordPress自体はdocker-composeを利用し、MySQLとWordPressのコンテナをlocalhost上に立ち上げる構成としました。
コンテナ再起動時に作成した内容が消えてしまわないよう、volumesという設定を利用してコンテナ側ディレクトリをホスト側へマウントさせることで永続化しています。
https://qiita.com/tomokei5634/items/75d2501cfb968d0cfab5また作成したデータはストレージサービス(ここではGoogle Drive)を利用して同期することで、複数のPCからでも擬似的にWordPressを同じように編集出来るようにしました。
ただし、複数のPCで同時にWordPressを編集した場合に競合してバグる恐れもあるので、編集作業自体は同時には実施しないよう注意する必要があります。今回は、ブログの編集者が私以外には妻だけで、口頭コミュニケーションで充分回避可能なので簡易的にこの構成としましたが、複数人数で編集を行う必要がある場合は普通にサーバを準備した方が無難かと思います。補足)
当初はEC2にWordpressを配置しようと考えていましたが、以下の理由からDockerでlocalhostにWordpressを立ち上げる構成に変更しました。
- EC2はインスタンスの起動時間に応じて課金される。月1,000円以上のランニングがかかってしまうため、ランニングを抑えるためには毎回インスタンスの起動、停止をしないといけない。
- Wordpressのメイン編集者が妻なので、AWSコンソールに入ってEC2インスタンスの起動と停止を毎回させるのは手間
StaticPress
ブログの静的化はStaticPressというプラグインを利用。S3への転送はStaticPressS3というプラグインで、静的化と同時に自動でS3へ転送されるようにしました。
以下参考記事です。
https://qiita.com/Ichiro_Tsuji/items/c6a52ec0ee95ead42f68その他
S3上ではコード実行が出来ないため、Wordpressの動的コンテンツ(コメント機能、ブログ内検索、お問い合わせフォーム等)は利用出来ません。
ここではブログ内検索だけはGoogleカスタム検索を入れて代替し、それ以外の機能は元々使ってなかったようなので特に対応はしませんでした。
なお、CloudFrontからLambda関数を呼び出すなどすれば、動的コンテンツ提供も可能です。コスト
旧レンタルサーバ(エックスサーバ)
サーバレンタル費用:1,000円/月
ドメイン更新料:1,650円/年現在(AWS)
Route53のHostZone利用料:$0.50(約52円)/月
ドメイン移行費用:$12(約1,254円) ※初期費用のみ
ドメイン更新料:$12(約1,254円)/年AWSの無料利用期間中のため、現状月のランニング費用は約50円だけです。
無料期間が終わってかつ多少アクセスが増えても、200〜300円/月以内には収まる試算。メリット/デメリット
メリット
- とにかく速い
- ランニングコストが安い。アクセスが少ないうちはほぼノーコスト
- 静的ファイルをS3経由で提供するだけなので、セキュリティ問題とほぼ無縁。特にWordPressの脆弱性との戦いをしなくて良くなる
- もしアクセスが集中してもブログがダウンすることはまず無い
デメリット
- 動的コンテンツの提供が難しい ※Googleカスタム検索などである程度代替は可能
- 構築に手間がかかり、知識も必要
- S3へのアップロードに時間がかかる
まとめ
当初はちょっと設定をイジったり他のサーバに移行するぐらいのつもりでしたが、興味の赴くままに色々試していたら気づけばこの構成に。。。不思議ですね。
だいぶ寄り道しながら調べながら構築したので結構時間がかかってしまいましたが、結果それなりのものが出来たかなと思ってます。
妻も中身はよくわかってないみたいですが大変満足してくれたようです。余談
StaticPress プラグイン
StaticPressが、wp-admin配下等の静的サイトとしては不要なページまでファイル出力する仕様になっていたため、対処としてプラグインのソースコードを修正して不要なファイルが出力対象外になるようにしました。
ただ、プラグインのアップデートをするとこの修正が上書きされてしまうので、この手段はあまり好ましい手段では無かったかなと思います。
静的化プラグインは他にもいくつか選択肢があるみたいなので、安易にプラグインに手を加えてしまう前に他のプラグインを試してみるべきでした。PageSpeed Insights
体感的にはかなり爆速になったのですが、PageSpeed Insightsで見てみたところスコアがモバイル30点台、パソコン60点台と悲惨な点数に。。。
どうやらGoogleAdsenseがスコアに大きく影響する模様。
GoogleAdsenseの自動広告をマニュアル設定に変更したり、他にもWordPress側でプラグインや設定変更を少し試してみましたが、多少改善してパソコンは90点前後になったもののモバイルは50点前後止まり。
明らかに広告だけ遅延して表示されますが記事は爆速で表示されるので、ユーザの体感的には全く問題無いだろうということで時間との兼ね合いでここは諦めることに。悔しいのでそのうちどこかで再チャレンジしようと思います。
- 投稿日:2020-09-27T00:32:15+09:00
え、CloudFormationでdynamoDBを作成するときは全カラムをプライマリー・ソートキーにしなきゃいけないんですか!?
結論
そんなことはないです。
背景
こんな感じのテーブルを作ろうとしました。
- 主キー:UserId(型:String)
- カラム :Name(型:String)
なので、以下のようなテンプレートを用意しました。
AWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: 'sam-dynamo Sample SAM Template for sam-dynamo ' Globals: Function: Timeout: 3 Resources: UserTable: Type: AWS::DynamoDB::Table Properties: AttributeDefinitions: - AttributeName: UserId AttributeType: S - AttributeName: Name AttributeType: S KeySchema: - AttributeName: UserId KeyType: HASH TableName: User ProvisionedThroughput: ReadCapacityUnits: 5 WriteCapacityUnits: 5 StreamSpecification: StreamViewType: NEW_IMAGEこのテンプレートを実行したところ、以下のようなエラーがでました。
One or more parameter values were invalid: Number of attributes in KeySchema does not exactly match number of attributes defined in AttributeDefinitionsなんで?
先程のエラーは、「
KeySchemaのattributesの数と、AttributeDefinitionsのattributesの数が違うぞ」という内容です。
確かに公式ドキュメントにはこのように書かれています。Specifies the attributes that make up the primary key for the table. The attributes in the KeySchema property must also be defined in the AttributeDefinitions property.「
KeySchemaにあるやつはAttributeDefinitionsにもある必要があるぞ」とのことです。
ただ、そうなると、「じゃあ最初からキーとして利用しないカラムにも属性(この場合ソートキー)を付ける必要がある?」という思考になり、大分困惑しました。DynamoDB is schemaless (except the key schema)
そこで調べたところ、以下のような記述がありました1。
DynamoDB is schemaless (except the key schema) That is to say, you do need to specify the key schema (attribute name and type) when you create the table. Well, you don't need to specify any non-key attributes. You can put an item with any attribute later (must include the keys of course).そういえば、DynamoDBは必要なカラムはあとから追加できましたね…
つまり、「テーブル作成時はキーとして利用するカラムのみを作成し、それ以外はあとから追加する」のが正しい利用方法ということですね。終わりに
ちゃんと理解してる人からすれば何を当然、というようなことでしょうが、これまでMySQLしか触ってなかった自分にとって、「テーブル作成時は必要なカラムをすべて作成すべき」という認識だったので、大分ハマりました。
同様の問題に直面した方、今一度そのカラムはキーとして利用するか考えたほうが良さそうです。
参考
- 投稿日:2020-09-27T00:13:54+09:00
Instance Metadata Service Version 2 (IMDSv2):インスタンスメタデータサービスv2の設定と挙動確認
Instance Metadata Service Version 2 (IMDSv2):インスタンスメタデータサービスv2の設定と挙動確認の作業メモ
本記事の内容
- Instance Metadataとは
- Instance Metadata Service Version 2 を使う理由
- AWS-CLI実行環境準備
- 既存インスタンスのIMDSv2強制設定
- IMDSv2強制設定時の挙動確認
1. Instance Metadataとは
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/ec2-instance-metadata.html
インスタンスメタデータは、インスタンスに関するデータで、実行中のインスタンスを設定または管理するために使用します。インスタンスメタデータは、ホスト名、イベント、およびセキュリティグループなどのカテゴリに分けられます。
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/configuring-instance-metadata-service.html
次のいずれかのメソッドを使って、実行中のインスタンスからインスタンスメタデータにアクセスできます。
- インスタンスメタデータサービスバージョン 1 (IMDSv1) – リクエスト/レスポンスメソッド
- インスタンスメタデータサービスバージョン 2 (IMDSv2) – セッション志向メソッド
インスタンスメタデータサービスバージョン 2 の仕組み
IMDSv2は、セッション志向リクエストを使用します。セッション志向リクエストを使用して、セッション期間 (1 秒~6 時間) を定義するセッショントークンを作成します。指定した期間中、それ以降のリクエストに同じセッショントークンを使用できます。指定した期間が期限切れになった後、将来のリクエストに使用する新しいセッショントークンを作成する必要があります。
2. Instance Metadata Service Version 2 を使う理由
2019年7月29、米金融大手のCapital Oneにて不正アクセスにより、1億人以上の個人情報が漏洩。
Information on the Capital One Cyber Incident
https://www.capitalone.com/facts2019/情報漏洩の原因は以下の通り
- 攻撃者がWAFを経由してEC2のインスタンスメタデータにアクセスし、IAM Roleの認証情報(S3へのアクセス)を取得。
- IMDSv1は、メタデータへの接続に認証は行われない。
- 取得したIAM Roleの認証情報を利用し、Capital OneのS3にアクセスし、情報を取得。
一方、IMDSv2は、メタデータへのアクセスに、事前に取得したTokenを必須とする。
IMDSv2の使い方と、セキュリティ面でのメリットは以下の通り。使い方
- PUTリクエストを使って、6 時間 (21,600 秒) のセッショントークンを作成する
- セッショントークンヘッダーをTOKENという名前の変数に保管する
- トークンを使って最上位メタデータアイテムをリクエストする
メリット
- ほとんどのWAFはPUTリクエストを許容していない為、WAFを経由した外部からのアクセスが成功する可能性が低い。
- メタデータレスポンスのホップリミットを短くし複数ホストを経由した取得を防止できる。(1に設定すれば、CapitalOneで発生したような、WAFを経由したメタデータ取得を阻止できる)
- PUTリクエストは、X-Forwarded-Forヘッダーが含まれている場合、拒否する。(プロキシサーバでは、通常X-Forwarded-Forヘッダーを付与する)
3. AWS-CLI実行環境準備
インスタンス構築/設定変更のコマンドを発行するためのAWS-CLI実行用インスタンス(cli_instance)を準備
cli_instance環境(AWS-CLI発行元環境情報)[root@ip-10-0-0-74 ~]# cat /etc/system-release Amazon Linux release 2 (Karoo) [root@ip-10-0-0-74 ~]# [root@ip-10-0-0-74 ~]# uname -a Linux ip-10-0-0-74.ap-northeast-1.compute.internal 4.14.193-149.317.amzn2.x86_64 #1 SMP Thu Sep 3 19:04:44 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux [root@ip-10-0-0-74 ~]# [root@ip-10-0-0-74 ~]# aws --version aws-cli/1.18.107 Python/2.7.18 Linux/4.14.193-149.317.amzn2.x86_64 botocore/1.17.31 [root@ip-10-0-0-74 ~]# [root@ip-10-0-0-74 ~]# curl http://169.254.169.254/latest/meta-data/instance-type/ t3.small [root@ip-10-0-0-74 ~]#IMDSv2稼働確認用インスタンス「test_instance」構築
cli_instance環境(run-instances実行)[root@ip-10-0-0-74 ~]# aws ec2 run-instances \ > --image-id ami-0ce107ae7af2e92b5 \ > --instance-type t2.nano \ > --key-name key_file \ > --monitoring Enabled=false \ > --placement AvailabilityZone=ap-northeast-1a \ > --subnet-id subnet-03d74b8d6ab6c39f2 \ > --associate-public-ip-address \ > --security-group-ids sg-0a00ecb871bb15fb3 \ > --tag-specifications 'ResourceType=instance,Tags=[{Key=Name,Value=test_instance}]'構築したインスタンス(test_instance)デフォルトのインスタンスメタデータ設定の確認
cli_instance環境(describe-instances実行)[root@ip-10-0-0-74 ~]# aws ec2 describe-instances \ > --filters "Name=tag:Name,Values=test_instance" \ > --query Reservations[*].Instances[*].[MetadataOptions] [ [ [ { "State": "applied", "HttpEndpoint": "enabled", "HttpTokens": "optional", "HttpPutResponseHopLimit": 1 } ] ] ] [root@ip-10-0-0-74 ~]#
"HttpTokens": "optional" -> IMDSv1/IMDSv2が両方利用可能
"HttpTokens": "required" -> IMDSv2のみ利用可能(IMDSv2の強制化)"HttpTokens": "optional"状態での挙動確認(IMDSv1/IMDSv2が両方利用可能)
以下は新規に構築した「test_instance」環境上で実行test_instance環境(IMDSv1実行)[root@ip-10-0-0-68 ~]# curl http://169.254.169.254/latest/meta-data/ ami-id ami-launch-index ami-manifest-path block-device-mapping/ events/ hostname identity-credentials/ instance-action instance-id instance-life-cycle instance-type local-hostname local-ipv4 mac metrics/ network/ placement/ profile public-hostname public-ipv4 public-keys/ reservation-id security-groups services/ [root@ip-10-0-0-68 ~]#test_instance環境(IMDSv2実行)[root@ip-10-0-0-68 ~]# TOKEN=`curl -X PUT "http://169.254.169.254/latest/api/token" -H "X-aws-ec2-metadata-token-ttl-seconds: 21600"` && curl -H "X-aws-ec2-metadata-token: $TOKEN" -v http://169.254.169.254/latest/meta-data/ % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 56 100 56 0 0 9333 0 --:--:-- --:--:-- --:--:-- 11200 * Trying 169.254.169.254... * TCP_NODELAY set * Connected to 169.254.169.254 (169.254.169.254) port 80 (#0) > GET /latest/meta-data/ HTTP/1.1 > Host: 169.254.169.254 > User-Agent: curl/7.61.1 > Accept: */* > X-aws-ec2-metadata-token: AQAAAO6n081baEIWdrfpILhc9Egt4kTm0HSpUftcYqvJSR-NKewL6A== > * HTTP 1.0, assume close after body < HTTP/1.0 200 OK < Accept-Ranges: bytes < Content-Length: 313 < Content-Type: text/plain < Date: Sat, 26 Sep 2020 14:45:29 GMT < Last-Modified: Sat, 26 Sep 2020 14:28:58 GMT < X-Aws-Ec2-Metadata-Token-Ttl-Seconds: 21600 < Connection: close < Server: EC2ws < ami-id ami-launch-index ami-manifest-path block-device-mapping/ events/ hostname identity-credentials/ instance-action instance-id instance-life-cycle instance-type local-hostname local-ipv4 mac metrics/ network/ placement/ profile public-hostname public-ipv4 public-keys/ reservation-id security-groups * Closing connection 0 services/ [root@ip-10-0-0-68 ~]#4. 既存インスタンスのIMDSv2強制設定
以下はAWS-CLI実行環境「cli_instance」環境上で実行cli_instance環境[root@ip-10-0-0-74 ~]# # test_instanceのインスタンスID取得 [root@ip-10-0-0-74 ~]# aws ec2 describe-instances \ > --filters "Name=tag:Name,Values=test_instance" \ > --query Reservations[*].Instances[*].[InstanceId] [ [ [ "i-034109c70aaa4b055" ] ] ] [root@ip-10-0-0-74 ~]# [root@ip-10-0-0-74 ~]# # IMDSv2強制設定の実行("HttpTokens": "required") [root@ip-10-0-0-74 ~]# aws ec2 modify-instance-metadata-options \ > --instance-id i-034109c70aaa4b055 \ > --http-tokens required \ > --http-put-response-hop-limit 1 \ > --http-endpoint enabled { "InstanceId": "i-034109c70aaa4b055", "InstanceMetadataOptions": { "State": "pending", "HttpEndpoint": "enabled", "HttpTokens": "required", "HttpPutResponseHopLimit": 1 } } [root@ip-10-0-0-74 ~]#5. IMDSv2強制設定時の挙動確認
"HttpTokens": "required"状態での挙動確認(IMDSv2のみ利用可能(IMDSv2の強制化))
以下は新規に構築した「test_instance」環境上で実行test_instance環境(IMDSv1実行)[root@ip-10-0-0-68 ~]# curl http://169.254.169.254/latest/meta-data/ <?xml version="1.0" encoding="iso-8859-1"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en"> <head> <title>401 - Unauthorized</title> </head> <body> <h1>401 - Unauthorized</h1> </body> </html> [root@ip-10-0-0-68 ~]#
IMDSv2強制化されているため、IMDSv1の方法では取得できないtest_instance環境(IMDSv2実行)[root@ip-10-0-0-68 ~]# TOKEN=`curl -X PUT "http://169.254.169.254/latest/api/token" -H "X-aws-ec2-metadata-token-ttl-seconds: 21600"` && curl -H "X-aws-ec2-metadata-token: $TOKEN" -v http://169.254.169.254/latest/meta-data/ % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 56 100 56 0 0 9333 0 --:--:-- --:--:-- --:--:-- 11200 * Trying 169.254.169.254... * TCP_NODELAY set * Connected to 169.254.169.254 (169.254.169.254) port 80 (#0) > GET /latest/meta-data/ HTTP/1.1 > Host: 169.254.169.254 > User-Agent: curl/7.61.1 > Accept: */* > X-aws-ec2-metadata-token: AQAAAO6n081aj7u-yzdFHoD8zll2ZKiNfVS79OXp1qJDwgzw7-96gA== > * HTTP 1.0, assume close after body < HTTP/1.0 200 OK < Accept-Ranges: bytes < Content-Length: 313 < Content-Type: text/plain < Date: Sat, 26 Sep 2020 15:01:45 GMT < Last-Modified: Sat, 26 Sep 2020 14:28:58 GMT < X-Aws-Ec2-Metadata-Token-Ttl-Seconds: 21600 < Connection: close < Server: EC2ws < ami-id ami-launch-index ami-manifest-path block-device-mapping/ events/ hostname identity-credentials/ instance-action instance-id instance-life-cycle instance-type local-hostname local-ipv4 mac metrics/ network/ placement/ profile public-hostname public-ipv4 public-keys/ reservation-id security-groups * Closing connection 0 services/ [root@ip-10-0-0-68 ~]#