- 投稿日:2020-09-24T23:13:38+09:00
リングバッファのBit演算化(高速化)
経緯
リングバッファを使用する際に余剰を使用してインデックスを計算していた。職場のプログラマの方に「ビット演算でもできるよ」と教えてもらったのでここにメモしておく。
Code(Python)
ring_buffer.py# coding:utf-8 ''' Ring Bufferがビット演算で早くなるか実験 ''' import time import numpy as np def main(): ring_buff = np.array([i for i in range(1024)]) #余剰演算ver start = time.time() for cnt in range(102400): index = cnt % 1024 ring_buff[index] = cnt elapsed_time = time.time() - start print ("余剰ver :{0}".format(elapsed_time) + "[sec]") #bit演算ver start = time.time() for cnt in range(102400): index = cnt & 0b1000000000 ring_buff[index] = cnt elapsed_time = time.time() - start print ("bit ver :{0}".format(elapsed_time) + "[sec]") if __name__ == '__main__': main()
- 投稿日:2020-09-24T22:19:55+09:00
二点を固定した円の最小二乗法による近似
直線と同じように、最小二乗法を用いて点P1,P2, ... ,Pnから円を近似することができます。一般的な手法は他の記事を参照してもらうことにして、ここでは始点P1と終点Pnを必ず通り、かつ誤差が小さくなるような円を求めます。また、そのような関数をpython(numpy)で実装してみます。
方針
直線と同様に、各点に対して理論値と測定値の差(残差)を求め、それらの平方和を小さくするような値を求めます。
一般に円を表すためには中心座標$(x,y)$、半径$r$の3つのパラメータが必要ですが、2点$P_1,P_n$を通る円の中心は必ずこの2点の垂直二等分線上にあります。中心が決まれば半径も決まりますから、今回求めるパラメータは一つにできます。
方法
円の中心と半径をベクトルを用いてパラメータ表示し……などとやっても不可能ではないですが、計算が煩雑になってしまうので、別の方法を取ります。ひとまず$P_1(-a,0),P_n(a,0)$の場合を考えましょう。このとき、中心はy軸上の点$(0,y_0)$、半径$r^2 = y_0^2+a^2$となり、求める円の方程式は
x^2+y^2-2yy_0-a^2=0となります。この$y_0$を求めます。
各点に対する残差は、各点から中心までの距離と半径の差ですが、計算の簡単のためにあらかじめ自乗してから差を取ったものを考えます。つまり各点の残差は上の式に$(x_k,y_k)$を代入して
x_k^2+y_k^2-2y_ky_0-a^2です。これの平方和、すなわち
\sum \{ x_k^2+y_k^2-2y_ky_0-a^2 \} ^2を最小にするような$y_0$を求めます。この式は$y_0$の二次関数ですから、$y_0$の偏微分を0とおいて$y_0$を求めます。
\begin{align} \sum -4y_k( x_k^2+y_k^2-2y_ky_0-a^2 ) &= 0 \\ \sum x_k^2y_k+\sum y_k^3-2y_0\sum y_k^2-a^2\sum y_k &= 0 \\ \end{align}よって$y_0$は以下です。
y_0 = \frac{\sum x_k^2y_k+\sum y_k^3-a^2\sum y_k}{2\sum y_k^2}座標変換
さて、これを任意の点群に対して適用するには、点群に対して点$P_1(x_1,y_1)$が$(-a,0)$へ、点$P_n(x_n,y_n)$が$(a,0)$へ移るような変換をしないといけません。そのためには、
①$P_1$と$P_n$の中点$P_c$が原点に移るような平行移動を行う
②$P_1$と$P_n$がx軸上に移るような回転を行うの2ステップが必要です。細かい計算は省きますが、次の変換を行えばいいことがわかります。
\left( \begin{array}{c} x' \\ y' \end{array} \right) = -\frac{1}{a}\left( \begin{array}{cc} x_1-x_c & -(y_1-y_c)\\ y_1-y_c & x_1-x_c \end{array} \right) \left( \begin{array}{c} x-x_c \\ y-y_c \end{array} \right)ただし、$x_c,y_c$は$P_c$の座標、$a$は$|P_1P_c|$です。
この変換をすべての点に行ってから近似を行い、逆変換すれば中心・半径が求まります。実装
pythonで実装してみました。
def approxByArc(points): start = points[0] end = points[-1] sample = points[1:-1] midpoint = (start + end) /2 start2 = start - midpoint a = np.linalg.norm(start2) x = start2[0] y = start2[1] rotateMatrix = np.array([[x,y],[-y,x]]) * -1 / a def conversion(point): point = point - midpoint p = np.array([[point[0]], [point[1]]]) p = rotateMatrix @ p p = np.array([p[0][0],p[1][0]]) return p sample = np.apply_along_axis(conversion, 1, sample) xs = np.array([i[0] for i in sample]) ys = np.array([i[1] for i in sample]) p1 = np.sum(xs*xs*ys) p2 = np.sum(ys*ys*ys) p3 = np.sum(ys) * a * a p4 = np.sum(ys*ys) * 2 y0 = (p1+p2-p3)/p4 center = np.array([[0],[y0]]) center = np.linalg.inv(rotateMatrix) @ center center = np.array([center[0][0], center[1][0]]) center = center + midpoint radius = np.linalg.norm(center - start) return center,radiusちゃんと動くか試してみましょう。
points = [] points.append([60,50]) n = 40 for i in range(1,n): angle = math.pi / n * i radius = 10 + random.uniform(-0.4,0.4) x = 50 + radius * math.cos(angle) y = 50 + radius * math.sin(angle) points.append([x,y]) points.append([40,50]) r,c = approxByArc(np.array(points)) print(r) print(c)[50. 49.99319584] 10.00000231483068うまくいきました。
おわりに
単純な座標に変換してから計算する方法はプログラムがわかりやすくなる反面、手計算には向きません。ですが、このような複雑なステップを手計算する人はいないので大丈夫です。たぶん。
- 投稿日:2020-09-24T21:30:39+09:00
2020年で最も需要のあるプログラミング言語
本記事はMost in-demand programming languages in 2020の日本語訳です。翻訳元に報告していますが、もし苦情が来たら消します。
翻訳は不慣れなので変なところもあると思いますが、ご容赦ください。
ソフトウェア開発業界は絶えず変化しており、それは開発者の能力に対する企業のニーズも変化していることを意味します。そのため、あなたが想像できるように、Webアプリケーション、ゲーム、アルゴリズムなどのあらゆる側面の開発をカバーするために、選択できるプログラミング言語はたくさんあります。その上で、私たちは2020年で最も需要のあるプログラミング言語とその主な特徴について触れます。
- JavaScript (回答者の71%がこのスキルに関する求職者を探している)
- Java (57%)
- C# (53%)
- Python (51%)
- PHP (40%)
- Ruby (15%)
2020年で最も需要のあるプログラミング言語JavaScript
JavaScriptが2020年で最も需要のあるプログラミング言語リストのトップであることは全く不思議ではありません。
今日では何らかの方法でJavaScriptを使用することなしに開発者になることは不可能です。調査の回答者の71%以上がJavaScriptでコードを書ける開発者を探しており、JavaScriptが最も人気のあるプログラミング言語のうちの一つであることが想像できます。また、JavaScriptはWebにおける偏在性と私たちのインターネットへの重い依存のため、非常に人気があります。Twitter、Facebook、YouTubeなどの最も人気のあるサイトの多くは、JavaScriptを使ってインタラクティブなWebページを生成したり、コンテンツを動的にユーザに表示したりしています。
JavaScriptはコア言語があり、追加の開発ツールによって柔軟性が保たれています。JavaScriptは寛大で柔軟な構文を持ち、全てのメジャーなブラウザで動作するため、初学者にとって最も簡単なプログラミング言語の一つです。今日、JavaScriptは世界中で広く使用されているプログラミング言語であり、あらゆるところで動作します:コンテナ、マイクロコントローラ、モバイル端末、クラウド、ブラウザ、サーバなど。
主な特徴
- JavaScriptはここ数年で大規模な現代化と徹底的な点検を経てきました。ES5、ES6といったJavaScriptのメジャーなリリースはいくつかのモダンな機能が追加され、今日のJavaScriptは過去10年間のJavaScriptとは完全に別物です
- Node.jsのおかげでJavaScriptはイベント駆動なプログラミングを提供し、特にI/Oの複雑なタスクに適しています。今日では、Node.jsとJavaScriptは、サーバとモバイル端末を含めてほとんど全てのプラットフォームで動作します
- JavaScriptはブラウザプログラミングにおいて、議論の余地のない王様です。今日、Web開発は主にVue.js、Angular、ReactといったJavaScriptベースのSPAフレームワークによって支配されています
Java
Javaは2020年で最も需要のあるプログラミング言語リストで2位の座を手にしています。
Javaは、ビジネスでは最も人気のモバイルコンピューティングプラットフォームであるAndroidのネイティブ言語であることから人気のあるプログラミング言語です。
Javaは過去数年の間に、非常にユーザに優しいモダンな言語にビジネスの一部を奪われました。
Javaは欠陥の改善に取り組んでおり、GraalVMアクションを介してクラウドにフィットさせる努力をしています。Javaはまだエンタープライズではナンバーワンのプログラミング言語です。Javaは誕生してからずっとトップクラスの需要があるプログラミング言語です。大企業の多数がバックエンドWebシステムやデスクトップアプリケーションのためにJavaを使っているため、もし開発者がJavaを知っていれば、その開発者は継続的に需要が高い状態になるでしょう。Javaは静的型付けの言語で、そのためバグが少なく、メンテナンスを速く行えて管理しやすいです。
主な特徴
- Javaはマルチパラダイムを提供し、強力で、多機能で、柔軟な学習曲線と高い生産性を持つインタプリタ型のプログラミング言語です
- Javaは厳格な後方互換性を持ち、これはビジネスアプリケーションにとって重要な要件です。JavaではScalaやPythonのようなメジャーな破壊的変更が取り入れられたことはありません。その結果、Javaはいまだにビジネスにとってナンバーワンの選択肢です
- JavaのランタイムであるJVMはソフトウェア工学の結晶で、ビジネスにおいて最高の仮想マシンの一つです。何年もの技術革新とエンジニアリングの職人技により、JVMは素晴らしい機能と性能をJavaに提供します。JVMはいくつかの優秀なガベージコレクションもJavaに提供しています
C#
C言語は、移植性と、AppleやMicrosoftのような巨大なIT企業から早期に採用されたことのおかげで最も古くて最も人気のあるプログラミング言語のうちの一つとなった言語です。1
C-sharpとしても知られるC#は、2000年にMicrosoftによって開発された言語のスピンオフです。C#はオブジェクト指向言語で、アクションの代わりにオブジェクトを中心に、ロジックの代わりにデータを中心に構築されます。C#の特徴はJavaと似ており、Windowsのデスクトップアプリケーションとゲームを開発するのに特に有効です。しかし、C#はWebアプリケーションとモバイルアプリケーションを開発するのにも使えます。C#はC++のようなC派生の言語に似た構文を使っており、あなたがCファミリーの中の別の言語から来たのであれば簡単に習得できます。C#は銀行のトランザクション処理のような大企業のアプリケーションの開発にしばしば使われます。C#は人気のUnityゲームエンジンを使った2Dや3Dのビデオゲームを作るために推奨される言語です。今日では、C#はWindowsプラットフォームにおいてだけでなくLinuxプラットフォームやiOS/Androidプラットフォームでも幅広く使用される、マルチパラダイムな言語です。
主な特徴
- C#はプラットフォーム非依存でもあり、Linux、Windows、モバイル端末で動作します
- Microsoftの後ろ盾があり、長年に渡り業界にいるC#はライブラリとフレームワークの大きなエコシステムがあります。ASP.NETはWebアプリケーション開発に使われます(主にWindows上での)
- 開発者体験という面では、C#はJavaよりはるかに優れています
DevSkillerでテストされた言語トップ5Python
Pythonはおそらくこのリストの中で最もユーザに優しいプログラミング言語です。Pythonの構文は明確で、直感的で、ほとんど英語だとよく言われ、初学者にとって本当に良い選択肢です。Pythonは高レベルで、汎用性が高く、Webアプリケーションやデータ解析、アルゴリズムの開発などに使われます。Pythonは、科学計算やエンジニアリング、数学といったフィールドで頻繁に使われるSciPyやNumPyのようなパッケージも持っています。
Pythonはスクレイピングにしばしば使われ、PHPでコーディングするのに何時間もかかるものが、Pythonだと数分しかかかりません。Pythonは、あなたの時間を消費する日々のタスクを含む特定の作業を自動化するためにも使うことができます。もしバックエンドのWeb開発の例に興味があれば、オープンソースの(Pythonで書かれた)Djangoフレームワークは人気で、学ぶのが簡単で、多機能です。そしてJavaのように、Pythonには多様なアプリケーションがあり、あなたのユースケースのために最も良いプログラミング言語を選択する時に、多様で強力な選択肢となります。今日、Pythonは広く行き渡り、ソフトウェア開発の多くの分野で使用され、そしてその勢いが衰えるようには見えません。
主な特徴
- Pythonには非常に活発なコミュニティとサポートがあります。たとえあなたがデータサイエンス、業務アプリケーション、AIのどれで働いているのだとしても、常に十分なPythonの組織2やフレームワークが見つかります
- Pythonには第一級のC++/Cとの統合機能があり、CPU負荷の高いタスクをシームレスにC++/Cにオフロードすることができます。Pythonは、SciPy、Pandas、NumPyなど、統計、Scikit-Learn3、数学、および計算科学のための素晴らしいツールセットも提供します。 結論として、Pythonは機械学習/ディープラーニング/データサイエンスの状況やその他の科学的な領域を支配しています
- Pythonのウリはその言語設計にあります。それは生産性が高く、エレガントで、シンプルで、その上強力です。Pythonは開発者経験という面で黄金律を設定し、Julia、Goといったモダンな言語に対して多大な影響を与えました
PHP
たとえ多くの論争があるとしても、PHPは2020年で最も需要のあるプログラミング言語リストに入っています。
PHPは幅広く使用されているオープンソースの汎用スクリプト言語で、典型的にはWebアプリケーション開発に適しています。たとえ以前ほどではないとしても、PHPは依然として世界中で最も用いられているプログラミング言語のうちの一つです。PHPはFacebookやYahoo!といった多数の大きな会社によって使用されています。PHPは汎用的で、動的な、基本的にはサーバサイドのWebアプリケーションの開発のために使用されているプログラミング言語です。
PHPはJavaScriptのような新しいWeb言語が実現するまでずっと、ほとんど全てのモダンなWebサイトを構築可能にしました。いくつかの調査によると、PHPがWebの3分の1を支えているとのことです。たとえPHPが以前ほどは注目されていないとしても、PHPは今後何年にもわたって進化を継続し、最も人気のあるプログラミング言語のうちの一つとしての地位を維持するでしょう。
主な特徴
- 多くの大きな会社がPHPを使用しており、そのための素晴らしいツールのサポートに繋がっています
- PHPはWebアプリケーション開発に過去25年4に渡って使用されており、強力で安定したPHPフレームワークが数多く市場に存在します
- PHPは非常に生産性が高いサーバサイドWeb開発プログラミング言語のうちの一つです。結果として、Webアプリケーションを素早く開発するために、IT業界で広く使われています。最も有名なSNSの一つであるFacebookはPHPで開発されました
アメリカにおけるPHPバージョンの人気調査Ruby
特に、Rubyは人気のあるRuby on Rails Webアプリケーションフレームワークのための基盤として使われます。RubyはC言語で実装され、ガベージコレクタがあります。Rubyは90年代半ばに作られましたが、ここ10年ほどの間に人気を獲得しました。Rubyは非常に動的で、オブジェクト指向言語で、プログラマーが使うための様々な機能を持っています。Rubyの経験が6年以上ある開発者は、現在の採用状況では2倍の面接依頼を受けることが期待できます。
Twitter、Shopify、そして多くのスタートアップがいずれかの段階でRuby on Railsを使ってWebサイトを構築しています。Rubyはまた、素晴らしいハイテク企業との関連性のために選び出すには本当に良い言語です。5
Pythonのように、Rubyは開発者の生産性と幸福を非常に重視しています。Rubyは新しい開発者にとって学習曲線がフラットになる非常に優れた言語でもあります。主な特徴
- RubyはTwitter、GitHub、Airbnbのような最大級のソフトウェアプロジェクトで使われ、そして素晴らしいツールとフレームワークの支援があります
- Rubyそれ自体は破壊的ではありませんが、RubyのWeb開発フレームワークであるRuby on Railsはおそらく最も破壊的で、影響力のあるサーバサイドWeb開発フレームワークです
- Rubyはプログラミング言語の最高の機能のうちのいくつかをうまく利用してきました: 簡潔さ、動的、ガベージコレクタのあるオブジェクト指向、そして関数型です



- 投稿日:2020-09-24T21:02:37+09:00
k-means法を使用したクラスタリングによるデータ分析(python)(【高等学校情報科 情報Ⅱ】教員研修用教材)
はじめに
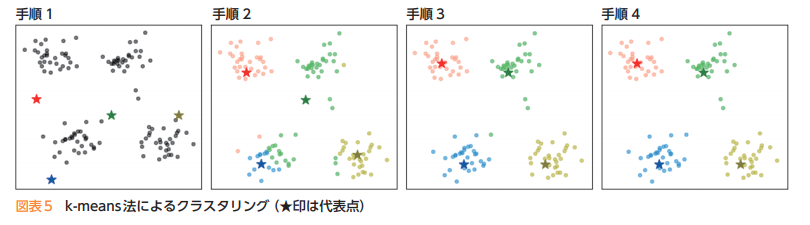
非階層型クラスタリングの手法の一つに、k-means法(k平均法)があります。
教材の「第3章 情報とデータサイエンス 後半 学習16.クラスタリングによる分類」の記述がわかりやすいので引用します。k-means法では,次の手順によってクラスタリングする。
1) あらかじめ分割するクラスタ数を決めておき,ランダムに代表点(セントロイド)を決める。
2) データと各代表点の距離を求め,最も近い代表点のクラスタに分類する。
3) クラスタごとの平均を求め,新しい代表点とする。
4) 代表点の位置が変わっていたら2に戻る。変化がなければ分類終了となる。
1)によりランダムに代表点を決めることによって,結果が大きく異なり,適切なクラスタリングとな
らない場合もある。何回か繰り返して分析をしたり,k-means++法を用いたりすることにより改善することができる。1’)データの中からランダムに一つの代表点を選び,その点からの距離の2乗に比例した確率で残りの代表点を選ぶ。
教材のクラスタリングについての説明が書かれている箇所「第3章 情報とデータサイエンス 後半 学習16.クラスタリングによる分類」では、すでにpythonによる実装例にて解説されてあります。
今回は「第5章 情報と情報技術を活用した問題発見・解決の探究 , 巻末 活動例3.データを活用するための情報技術の活用」内で、Rで書かれている実装例をpythonに置き換えることで、k-means法を使用したクラスタリングによるデータ分析について確認していきたいと思います。教材
高等学校情報科「情報Ⅱ」教員研修用教材(本編):文部科学省
第5章 情報と情報技術を活用した問題発見・解決の探究 , 巻末 (PDF:4.1MB)環境
ipython
Colaboratory - Google Colab教材内で取り上げる箇所
活動例3 データを活用するための情報技術の活用
pythonでの実装例と結果
分析を行う前に
今回、教材ではグラフプロットの際に日本語を使っております。
そのため、あらかじめグラフプロット(matplotlib)で日本語を使用できるように設定する必要があります。!apt-get -y install fonts-ipafont-gothic !ls -ll /root/.cache/matplotlib/: -rw-r--r-- 1 root root 46443 Sep 18 20:45 fontList.json -rw-r--r-- 1 root root 29337 Sep 18 20:25 fontlist-v310.json drwxr-xr-x 2 root root 4096 Sep 18 20:25 tex.cachelsコマンドの情報をもとに、古いフォントキャッシュのfontlist-v310.jsonを削除します。
# キャッシュを削除する。 !rm /root/.cache/matplotlib/fontlist-v310.json # 消すべきcache !ls -ll /root/.cache/matplotlib/# キャッシュを削除する。 !rm /root/.cache/matplotlib/fontlist-v310.json # 消すべきcache !ls -ll /root/.cache/matplotlib/ここで、google colabのランタイムのりスタートを行います。
次に、matplotlibで日本語が使えるように設定します。import matplotlib #日本語表示 matplotlib.rcParams['font.family'] = "IPAGothic"前処理
「学校における教育の情報化の実態等に関する調査」として、以下のExcelデータをダウンロードします。
「都道府県別『コンピュータの設置状況』及び『インターネット接続状況』の実態(高等学校)」
教材同様に、最初にpythonで分析をする前に、Excel上でデータクリーニングを行います。
整理・整形を行ったデータは以下としました。行った処理は以下のとおりです。
- 不必要なヘッダー,フッターの削除
- 不必要な項目の削除
- データをCSV形式にするため桁区切りのカンマの除去
- 項目名を作業しやすいように英字に変更
- データの各項目は,pref(都道府県別),school(学校数),student(児童生徒数),room(普通教室数),PC(学習者用PC総台数),spp(学習者用PC1台当たりの児童生徒数),prj(普通教室の大型提示装置整備率),lan(普通教室の校内LAN整備率),wlan(普通教室の無線LAN整備率)
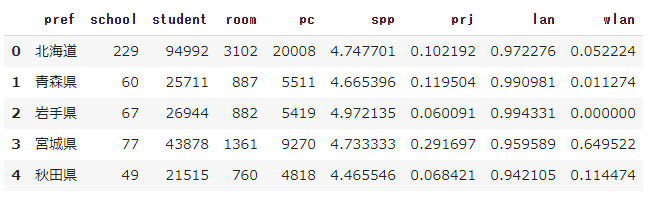
これらにもとづいて、データを読み込みを行います。
import pandas as pd from IPython.display import display pc = pd.read_csv('/content/pc_sjis.csv', encoding='shift_jis') display(pc.head())
教材では、以下のようになっています。
教材では、学習者用PC総台数を読み込むべきところを教育用PC総台数が読み込んでいる誤りがあるようです。
データの分析、可視化
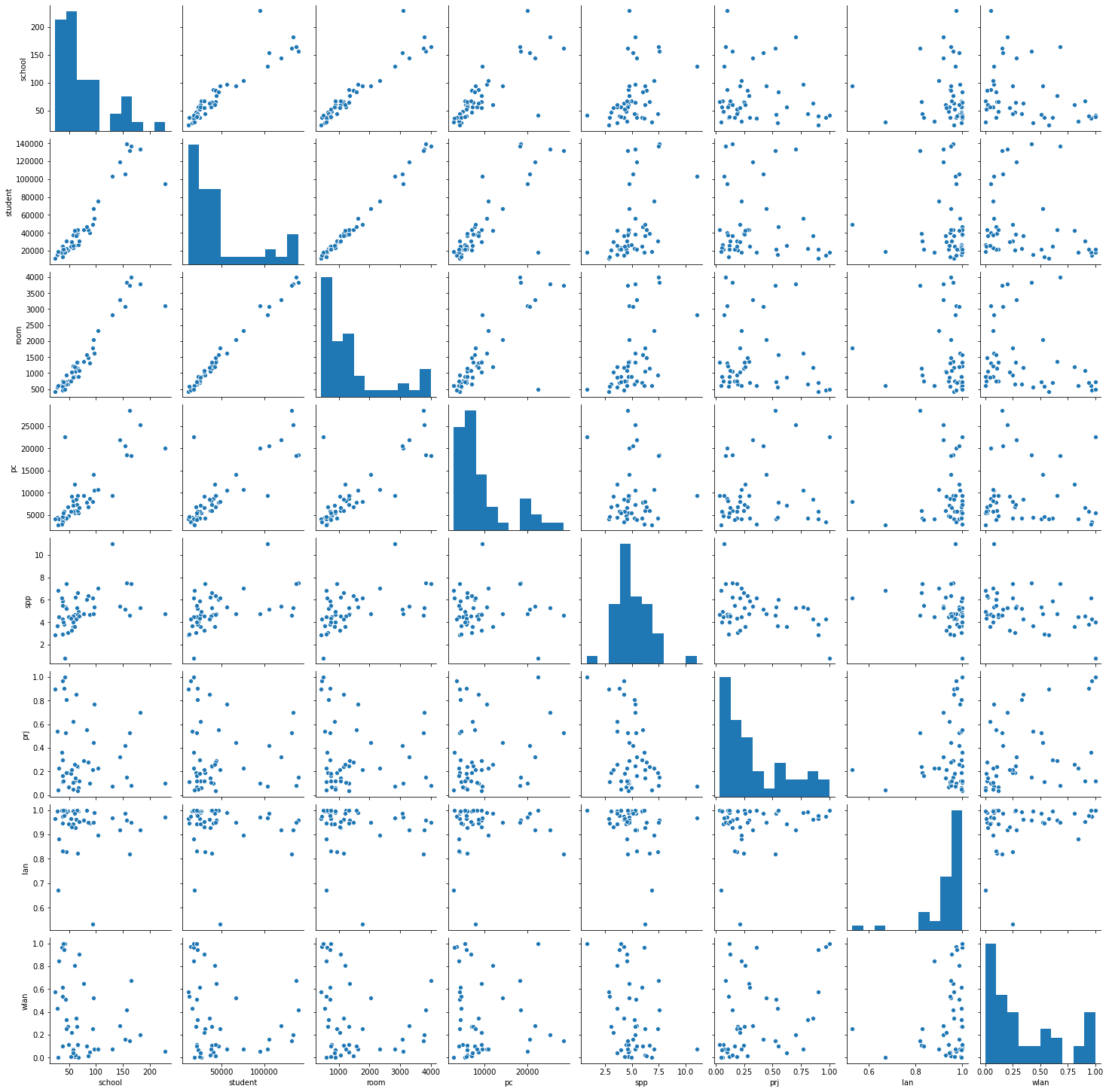
どのような傾向が読み取れるかを把握するため、まず散布図行列を表示してみます。
今回は、seabornモジュールを使ってみます。import seaborn as sns pg = sns.pairplot(pc) print(type(pg))
教材より、
生徒数と教室数のように直線傾向が明確に見えるものは,「情報Ⅰ」で学んだ相関係数や単回帰分析などの対象になる。今回は,直線傾向を見るのではないので,wlan(無線LAN)とspp(PC1台当たりの生徒数)を対象に考えてみよう。
とあるのでwlan(無線LAN)とspp(PC1台当たりの生徒数)の値を取り出し、スケーリングを行う。
具体的には、標準化を行いました。
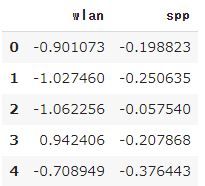
from sklearn.preprocessing import StandardScaler # 値の抽出(wlan spp) pc_ws = pc[['wlan', 'spp']] # 標準化(StandardScalerを使用したやり方) std_sc = StandardScaler() std_sc.fit(pc_ws) pcs = std_sc.transform(pc_ws) pcs_df = pd.DataFrame(pcs, columns = pc_ws.columns) display(pcs_df.head())
扱うデータの種類が別々なので、教科書と同じように標準化を行っております。
標準化については、過去の記事が参考になります。
https://qiita.com/ereyester/items/b78b22a76a8f50006880次にモデルの作成と分類を行います。
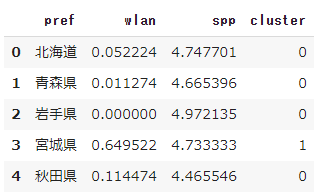
from sklearn.cluster import KMeans #モデルの作成 km = KMeans(init='random', n_clusters=2 , random_state=0) #予測 pc_cluster = km.fit_predict(pcs_df) cluster_df = pd.DataFrame(pc_cluster, columns=['cluster']) # 値の抽出(pref wlan spp cluster) pcs_cluster_df = pd.concat([pc[['pref', 'wlan', 'spp']], cluster_df], axis=1) display(pcs_cluster_df.head())
結果を散布図で確認したいと思います。
import matplotlib.pyplot as plt import numpy as np import seaborn as sns _, ax = plt.subplots(figsize=(5, 5), dpi=200) sns.scatterplot(data=pcs_cluster_df, x="wlan", y="spp", hue="cluster", ax=ax) for k, v in pcs_cluster_df.iterrows(): ax.annotate(v['pref'],xy=(v['wlan'],v['spp']),size=5) plt.show()
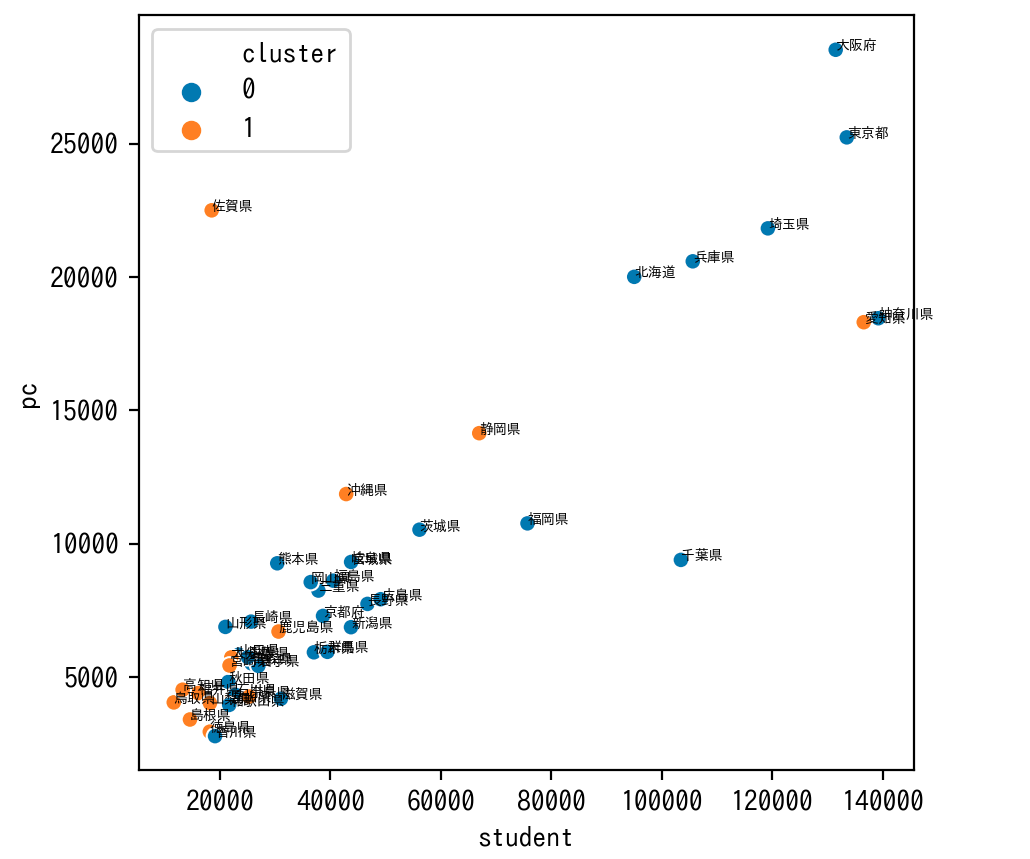
全体的に無線LAN(wlan)を情報をもとにして分類しているように見えます。
また、千葉県や佐賀県は群の中心から外れているように見えます。さらに分析
次は明らかな正の相関関係が読み取れる生徒数と学習用PCの台数のグラフについて、先ほどのクラスタで色分けしてグラフをプロットしてみます。
# 値の抽出(pref student pc cluster) pcs_cluster2_df = pd.concat([pc[['pref', 'student', 'pc']], cluster_df], axis=1) _, ax2 = plt.subplots(figsize=(5, 5), dpi=200) sns.scatterplot(data=pcs_cluster2_df, x="student", y="pc", hue="cluster", ax=ax2) for k, v in pcs_cluster2_df.iterrows(): ax2.annotate(v['pref'],xy=(v['student'],v['pc']),size=5) plt.show()
student(生徒数)に対するPC(学習者用PC総台数)の割合が大きいとwlan(普通教室の無線LAN整備率)の整備率の高いグループになる傾向があり、そうでないとwlan(普通教室の無線LAN整備率)の整備率の低いグループにある傾向があるようにみえます。
佐賀県はstudent(生徒数)に対するPC(学習者用PC総台数)の割合がとても大きく、逆に千葉県はstudent(生徒数)に対するPC(学習者用PC総台数)の割合がとても小さいなどの特徴が見てとれます。ソースコード
https://gist.github.com/ereyester/ce9370e3022f05f4d7548a8ccaed33cc

- 投稿日:2020-09-24T19:33:22+09:00
Codeforces Round #481 (Div. 3) バチャ復習(9/24)
今回の成績
今回の感想
今回はあまりバグらせずに通すことができました。良い傾向なので、引き続き頑張りたいと思います。
一部詰まる部分はありましたが今回のような安定したムーブが毎回できることを目標に頑張りたいです。
A問題
数列の右側から見て同じ数が二回現れないように取ってくれば良いです。したがって、数列の右側から数を見ていき、どの数が現れたかをsetの$s$に保存します。この時、$s$に含まれていない場合は答えで出力する配列
ansに挿入し、含まれている場合は次の数を見ます。A.pyn=int(input()) a=list(map(int,input().split()))[::-1] s={a[0]} ans=[str(a[0])] for i in range(1,n): if a[i] not in s: s.add(a[i]) ans.append(str(a[i])) print(len(ans)) print(" ".join(ans[::-1]))B問題
文字列は以下のように$x$が連続している部分と連続してない部分に分けることができます。
この$x$が連続している部分の長さ$l$をそれぞれ2以下にすることができれば題意を満たします。また、これに必要な削除の最小回数は$min(0,l-2)$で求められるので、$x$がどれだけ連続するかをそれぞれチエックします。ここで、$x$の連続する部分についてはgroupby関数を使えば以下のように簡単に求めることができます。
B.pyfrom itertools import groupby n=int(input()) s=[] for i in groupby(input(),lambda x:x=="x"): s.append(list(i[1])) #s=list(groupby(input(),lambda x:x=="x")) ans=0 for i in s: if i[0]=="x": ans+=max(0,len(i)-2) print(ans)C問題
全ての寮に対しての部屋番号からそれぞれの寮の番号と寮内での部屋番号を復元する問題です。とりあえず、番号がどうなっているかを把握するために全ての寮に対しての部屋番号を以下のように書き出しました。
また、それぞれの寮の部屋番号が最も小さい部屋に注目すると、$1 \rightarrow 1+a_1\rightarrow 1+a_1+a_2 \rightarrow … \rightarrow 1+a_1+a_2+…+a_{n-1}$と累積和になっているので、これを配列$s$として保存しておきます。この時、与えられた部屋番号を$b_i$とすれば、どの寮にいるかは配列$s$内で$b_i$以下で最大の要素のインデックスに対応します($bisect$_$right$)。また、その寮内での部屋番号は$b_i$から先ほど求めた最大の要素との差を考えれば良いだけです。
上記を任意の$i$に対して行えば$O(m \log{n})$でこの問題を解くことができます。
C.pyn,m=map(int,input().split()) a=list(map(int,input().split())) b=list(map(int,input().split())) from itertools import accumulate s=list(accumulate([1]+a))[:-1] from bisect import bisect_right #print(s) ans=[] for i in range(m): c=bisect_right(s,b[i])-1 #print(c) ans.append(str(c+1)+" "+str(b[i]-s[c]+1)) for i in range(m): print(ans[i])D問題
やることの見えていた問題ではありますが自分的にはかなり早くコードの実装をできたので、最近のバチャの成果を少しだけ感じました。
貪欲に考えると自由度が高いので、どこかを固定して考えようと思いました。この時、自分は両端を固定して考えることにしました。この時、$a[0],a[n-1]$の両端は$-1,0,+1$のいずれかの変化しかせず合計9通りの場合が存在します。
よって、両端の変化をさせた元での操作回数を返す関数$check$を定義することを以下では考えます。まず、変化後の$a[0],a[n-1]$に対して題意のように等差数列にするには$abs(a[n-1]-a[0])$が$n-1$の倍数であることが必要です($n-1$の倍数でない場合は$inf$を返します。)。この時の公差は$\frac{a[n-1]-a[0]}{n-1}$になります。したがって、$a[1]-a[0],a[2]-a[1],…,a[n-1]-a[n-2]$が全て$\frac{a[n-1]-a[0]}{n-1}$となるかどうかを前から貪欲に調べていきます。この時、$+1,-1$のいずれかの変化をして$\frac{a[n-1]-a[0]}{n-1}$となる場合はその変化を貪欲に行い、変える操作をカウントします。また、$+1,0,-1$のいずれの変化でも公差が$\frac{a[n-1]-a[0]}{n-1}$とならない要素があった場合はその時点で$inf$を返します。また、上記の判定をいずれもクリアした場合はカウントした操作の回数を返します。
以上より、9通りのそれぞれの場合の操作回数を求めることができ、最小値を出力します。また、最小値が$inf$になる場合は条件を満たさないので、-1を出力します。
また、自分の実装だと両端での操作回数を数えないミスが発生しうるので注意が必要です。さらに、場合分けが面倒だと思ったので、$n=1,2$の場合は先に0を出力しておきました。加えて、公差が負の場合にミスをしそうだと感じたので、その場合は反転して公差を非負にするようにしました。
D.pyn=int(input()) b=list(map(int,input().split())) if n==1 or n==2: print(0) exit() inf=10**12 #x,yはchangeの量(0,-1,+1),9通り def check(x,y): global b,n ret=0 if x!=0: ret+=1 if y!=0: ret+=1 a=[i for i in b] a[0]+=x a[n-1]+=y #昇順に if a[n-1]<a[0]: a=a[::-1] if (a[n-1]-a[0])%(n-1)!=0: return inf d=(a[n-1]-a[0])//(n-1) for i in range(n-1): if a[i+1]-a[i]==d: pass elif a[i+1]-a[i]==d+1: a[i+1]-=1 ret+=1 elif a[i+1]-a[i]==d-1: a[i+1]+=1 ret+=1 else: return inf return ret ans=inf for i in range(-1,2): for j in range(-1,2): ans=min(ans,check(i,j)) #print(i,j,check(i,j)) if ans==inf: print(-1) else: print(ans)E問題
考え忘れていたケースがあって2WAを出したので反省しています。冷静に考えれば少なくとも1WAに抑えられていたはずです。
まずは、どんな値であれば成り立つのかを考えるために、初めに$x$だけの人を載せていたとして条件を考えます。この時、$i$番目のバス停で人数の変化は$a_i$なので、それぞれのバス停を通過した後に$x+a_0,x+a_0+a_1,…,x+a_0+a_1+…+a_{n-1}$だけの人が乗っています。よって、これらが全て0以上$w$以下になれば良い(✳︎)ことがわかります。よって、$a_0,a_0+a_1,…,a_0+a_1+…+a_{n-1}$を累積和で求め、この中の最大値と最小値をそれぞれ$u,d$とします。ここで、$x+u \leqq w$かつ$x+d \geqq 0$を満たしていれば任意のバス停を通過した時に(✳︎)を満たします(最大値と最小値のみに注目!)。また、$0 \leqq x \leqq w$も満たす必要があります(これを忘れていたために2WAでした、勿体ないです。)。したがって、$x+u \leqq w$かつ$x+d \geqq 0$かつ$0 \leqq x \leqq w$を満たすので、これを全てマージすれば$max(0,-d) \leqq x \leqq min(w,w-u)$を満たすような整数$x$の個数を求めればよく、共通部分がない場合も考慮すれば$min(0,min(w,w-u)-max(0,-d)+1)$となります。
(上記ではまとまった考察ができており実装も簡潔ですが、コンテスト中は汚い実装と考察になってしまいました。反省です。)
E.pyn,w=map(int,input().split()) a=list(map(int,input().split())) from itertools import accumulate b=list(accumulate(a)) u,d=max(b),min(b) print(max(0,min(w,w-u)-max(0,-d)+1))E2.py#コンテスト中の実装 n,w=map(int,input().split()) a=list(map(int,input().split())) from itertools import accumulate b=list(accumulate(a)) u,d=max(b),min(b) if u-d>w: print(0) exit() if u>w: print(0) exit() ran=[max(0,-d),min(w,w-u)] if ran[1]<ran[0]: print(0) exit() print(ran[1]-ran[0]+1)F問題
初めに誤読しかけたので危なかったです。まず、問題設定として、$a,b$の二人がいた時に$r_a>r_b$かつ$a,b$が口論をしていなければ$a$は$b$のメンターをすることができます。
ここで、一つ目の条件のみであれば、$r$の値を昇順に持つことで$bisect$_$left$でインデックスを取ってきて簡単に求められます(大小は昇順で並べて数える!)。また、一つ目の条件を考えた後に二つ目の条件を加えると、一つの条件を満たしながら口論している人を除くとすれば良いこともわかります。
よって、$i$番目の人($r_i$)がメンターをできる相手の人数は、(①$r_i$よりスキルが低い人の人数)-(②$r_i$よりスキルが低いが口論をしている人の人数)となります。また、$check[i]:=$($i$番目の人が口論している中で$r_i$よりスキルが低い人の人数)、$p:=$(それぞれの人が持つスキルを順に並べた配列)とおけば、$check$は口論する人の組を受け取った時点で数えられ、$p$も入力を並べ替えるだけです。よって、①は$bisect$_$left(p,r_i)$をした際のインデックス(0-indexed)が相当し、②は$check[i]$が相当します。
以上より、$i$を順に動かして答えを配列$ans$に格納し、最終的に答えとして出力します。また、計算量は$O(k+n \log{n})$です。
F.pyn,k=map(int,input().split()) r=list(map(int,input().split())) check=[0]*n for i in range(k): x,y=map(int,input().split()) x-=1 y-=1 if r[x]>r[y]: check[x]+=1 if r[y]>r[x]: check[y]+=1 from bisect import bisect_left ans=[0]*n p=sorted(r) for i in range(n): b=bisect_left(p,r[i]) ans[i]=str(b-check[i]) print(" ".join(ans))G問題
計算量に余裕がありすぎたのと問題文が長いので勘繰ってしまいましたが、実装をするだけで拍子抜けしました。また、実装をするだけだったにもかかわらず30分程度解くのにかかってしまったので、半分くらいの時間で通せるように努力したいです。
まず、見落としがちな点を問題文から抜粋すると以下の二つになります。
・複数の試験を一日に受け取ることはできないが、問題の制約上そのような入力はない
・準備は連続している必要はないこの時、最も試験日の近い試験から準備する貪欲法で行けるのではないかと思いました。遠い試験日を先に順に準備する際のメリットがないので、この貪欲法は正しいです。また、これは遠い試験日を先に準備したとしてもそれよりも近い試験日の準備と入れ替えられることからも示せます。よって、以下ではこの貪欲法を実装します。
まず、以下の四つのデータ構造を用意します。それぞれが必要な理由は後述します。また、①と②を初期化する必要がありますが、これは入力を受け取った後に簡単に処理できるので説明は省きます。
①配列$exams[i]:=$($i$日目に準備を始められる試験の(試験日,必要な準備日数)を保持した配列)
②配列$ind[i]:=$($i$日目が試験日の試験の入力での受け取り順,ただし試験日がない場合は-1)
③配列$ans[i]:=$($i$日目の出力すべき答え)
④集合$cand:=$(準備のできる試験の(試験日,必要な準備日数)を保持した配列)まず、試験日の近い試験から準備をするために試験日の昇順で保持する④を用意します。これにより、それぞれの日では$cand$の最小の要素から順に準備していけば良いです。また、$i$日目に新たに準備を始められる試験が増えます。これは、①を用意すれば、$cand$に$exams[i]$の中身をすべて挿入するだけです。次に、その日が試験日である場合は準備ができないので、$ans[i]$を$m+1$にして次の日を考えます。これは、②を用意しておけば$ind[i]$が-1かどうかで判定することができ、$ind[i]$が-1でない場合は次の操作を考えます。
以上の判定を行った元で準備を行うことを考えますが、$cand$が空である可能性があります。この際は準備が行えないので$ans[i]=0$として次の日を考えます。そして、準備を行います。準備を行う際、見れば良いのは$cand$の最小の試験のみです(コンテスト中には気づかなかったため若干実装量が増えました。)。また、その試験の試験日がすでに過ぎている場合は準備が間に合ってないので、-1を出力してプログラムを終了します。それ以外の場合はその試験の対策をすればよく$ans[i]$にはその試験の入力での受け取り順を$ind$を用いて代入します。また、その試験の対策を行ってもまだ準備が必要な場合は$cand$から削除した後に必要な準備日数を-1して再度挿入します。
以上を全ての日で行った後に$ans$を出力すれば良いですが、まだ$cand$に要素が残っている可能性を考慮しなければなりません。この場合は準備が間に合ってない試験があるのと同義なので-1を出力します。それ以外の場合については試験の準備が全ての試験について間に合っているので$ans$を出力します。
(下記のコードは無駄のないように実装してあり上記の考察も無駄のないようにしていますが、コンテスト中はもう少し条件分岐などが多く間違いうるコードでした。反射神経で動くのも良いですが、もう少し考察を深めてから実装した方が良いかもしれません。)
G.cc//デバッグ用オプション:-fsanitize=undefined,address //コンパイラ最適化 #pragma GCC optimize("Ofast") //インクルードなど #include<bits/stdc++.h> using namespace std; typedef long long ll; //マクロ //forループ //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる //FORAは範囲for文(使いにくかったら消す) #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) #define FORA(i,I) for(const auto& i:I) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() #define SIZE(x) ll(x.size()) //定数 #define INF 1000000000000 //10^12:∞ #define MOD 1000000007 //10^9+7:合同式の法 #define MAXR 100000 //10^5:配列の最大のrange //略記 #define PB push_back //挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 signed main(){ //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); ll n,m;cin>>n>>m; vector<vector<ll>> exams(n); //準備できた日に対して vector<vector<pair<ll,ll>>> preparation(n); //試験日に対してのind vector<ll> ind(n,-1); REP(i,m){ ll s,d,c;cin>>s>>d>>c; exams[i]={s-1,d-1,c}; ind[d-1]=i; preparation[s-1].PB(MP(d-1,c)); } vector<ll> ans(n,-1); set<pair<ll,ll>> cand; REP(i,n){ REP(j,SIZE(preparation[i])){ cand.insert(preparation[i][j]); } if(ind[i]!=-1){ ans[i]=m+1; continue; } if(SIZE(cand)==0){ ans[i]=0; continue; } auto j=cand.begin(); while(j!=cand.end()){ if(j->S==0){ j=cand.erase(j); }else{ if(j->F<i){ cout<<-1<<endl; return 0; } ans[i]=ind[j->F]+1; pair<ll,ll> p=*j;p.S-=1; cand.erase(j); if(p.S!=0){ cand.insert(p); } break; } } if(ans[i]==-1)ans[i]=0; } if(SIZE(cand)==0){ REP(i,n){ if(i==n-1)cout<<ans[i]<<endl; else cout<<ans[i]<<" "; } }else{ auto j=cand.begin(); while(j!=cand.end()){ if(j->S!=0){ cout<<-1<<endl; return 0; } } REP(i,n){ if(i==n-1)cout<<ans[i]<<endl; else cout<<ans[i]<<" "; } } }



- 投稿日:2020-09-24T19:29:50+09:00
Kerasの使い方~簡単なモデル生成からCNNまで~
この記事でやること
ディープラーニングでは、使用するバックエンドによって実装手順がことなる。そのため、公式のドキュメントを読み込んだり、解説している参考書などを参照しながら使い方を学んでいく。この記事ではその使い方の流れを説明している。
kerasを使った場合の実装手順
1.訓練データを定義する
2.入力値を目的値にマッピングする複数の層からなるネットワークを定義する。
3.損失関数、オプティマイザ、監視する指標を選択することで学習プロセスを設定する。
4.モデルのfitメソッドを呼び出すことで、訓練データを繰り返し学習する。
kerasのpython環境の構築
anaconda上に新しい仮想環境を作り、tensorflow及びkerasをインストールする。今後は作った環境の上で実行していく。anaconda prompt上で以下を実行する。
conda create -n keras_env python=3.6 #仮想環境の作成 conda activate keras_env #環境の切り替え conda install tensorflow==1.12.0 conda isntall keras==2.2.4具体的な手順
データセットの読み込み
from keras.datasets import imdb (train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)データの前処理
データのベクトル化
ニューラルネットワークの入力値と目的値はすべて浮動小数点のデータのテンソルでなければならない。音声、画像、テキストなど、処理しなければならないデータがどのようなものであったとしても、まずそれらをテンソルに変換する必要がある。
クラス分類のラベルをベクトル化するにはone-hotエンコーディングを行う。from keras.utils.np_utils import to_categorical one_hot_train_labels = to_categorical(train_labels) one_hot_test_labels = to_categorical(test_labels)データの正規化
画像データは0~255の範囲のグレースケール値を表す整数としてエンコードされている。このデータをニューラルネットワークに供給するためには、float32型でキャストしてから255で割ることで0~1の範囲の浮動小数点に変換する。
ネットワークに範囲の異なる特徴量を供給するのはどう考えても問題である。そこで範囲を同じにするために正規化を行う。特徴量の平均値を引き、標準偏差で割るという処理を行う。そうすると、特徴量の中心が0になり、標準偏差が1になる。モデルの定義
各層ごとに活性化関数とニューロン数を設定する。順伝播させたい順に
add()で追加していけば良い。from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(16, activation='relu', input_shape=(10000,))) model.add(layers.Dense(16, activation='relu')) model.add(layers.Dense(1, activation='sigmoid')) model.add(Dense(200)) model.add(Activation("relu"))モデルのコンパイル
オプティマイザと損失関数を選択する。以下の場合は文字列で指定しているが、これが可能なのはkerasの一部としてパッケージ化されているためである。
model.compile(optimizer='rmsprop',#文字指定 loss='binary_crossentropy', metrics=['accuracy'])オプティマイザのパラメータ引数を指定したい場合は以下のようにオプティマイザクラスのインスタンスを指定して、メソッドを呼び出す。
from keras import optimizers model.compile(optimizer=optimizers.RMSprop(lr=0.001),#メソッド指定 loss='binary_crossentropy', metrics=['accuracy'])独自の損失関数や指標関数を使用したい場合は、lossパラメータか、metricsパラメータに引数として関数オブジェクトを指定する。
from keras import losses from keras import metrics model.compile(optimizer=optimizers.RMSprop(lr=0.001), loss=losses.binary_crossentropy, metrics=[metrics.binary_accuracy])検証データセット(validating data set)の設定
全く新しいデータでモデルを訓練するときに正解率を監視するには、もとの訓練データセットから取り分けておいたサンプルを使って検証データセットを作成する。以下では10000個のサンプルを取り出す場合。
x_val = x_train[:10000] #検証データの取り出し partial_x_train = x_train[10000:] # y_val = y_train[:10000] #正解検証データの取り出し partial_y_train = y_train[10000:]k分割交差検証
データの数が少ないと検証データはかなり小さなものになってしまう。結果として、検証と訓練にどのデータ点を選択したかによって検証スコアが大きく変化することになるかもしれない。つまり、検証データセットの分割方法によっては、検証スコアの分散が高くなり、過学習に陥ってしまう。それを防ぐ最適な方法がk分割交差検証である。詳しくは説明しないので、調べてみてほしい。
モデルの訓練
8のミニバッチで20エポックの訓練を行う。xは訓練データyは正解データであることが多い。
取り分けておいた10000サンプルでの損失値と正解率を監視する。検証データはvalidation_dataパラメータに引数として渡す。history = model.fit(partial_x_train, partial_y_train, epochs=20, batch_size=8, validation_data=(x_val, y_val))fitメソッドは1エポックごとに訓練した出力と、検証データの出力を辞書型で返す。今回は
historyオブジェクトに保存している。以下のコードを実行するとhistory_dict = history.history history_dict.keys()dict_keys(['val_acc', 'acc', 'val_loss', 'loss'])
となる。訓練データと検証データでの損失値をプロット
損失値をmatplotlibを使ってプロットする。
historyオブジェクトに訓練の記録がされているのでここから呼び出す。この結果を元にしてハイパーパラメータを調整する。import matplotlib.pyplot as plt acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs = range(1, len(acc) + 1) # "bo" is for "blue dot" plt.plot(epochs, loss, 'bo', label='Training loss') # b is for "solid blue line" plt.plot(epochs, val_loss, 'b', label='Validation loss') plt.title('Training and validation loss') plt.xlabel('Epochs') plt.ylabel('Loss') plt.legend() plt.show()CNNで画像認識する場合の手順
画像のコピー
訓練画像(train)を保存するフォルダと検証画像(validation)を保存するフォルダを作り、学習に使うために集めた画像をコピーして振り分ける。検証データの画像枚数はかんで決めるが、だいたい全画像数のの20%~40%で調整するといいだろう。後の前処理の工程で出てくる
flow_from_directory()のフォルダパスにここで作ったフォルダのパスを指定する。CNNのインスタンス化
from keras import layers from keras import models model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1))) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(Dense(2)) model.add(Activation("softmax"))CNNの入力テンソルの形状は(image_height,image_width,image_channels)だ。第3引数は画像のチャンネル数である。RGB画像の場合はチャンネル数が3になる。
Conv2D(出力特徴の深さ,フィルタサイズ)padding='same'の引数を指定すると出力の幅と高さが入力と同じになるようにパディングする。
ちなみにmodel.summary()で作成したモデルを確認できる。
画像分類の場合、最終層はDense(全結合層)にし、引数には分類するクラス数を指定する。出力は判定の確率になるので損失関数はsoftmaxを選択する。モデルのコンパイル
損失関数とオプティマイザの設定。
from keras import optimizers model.compile(loss='binary_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4), metrics=['acc'])データの前処理
データをCNNに供給するには、その前に浮動小数点型のテンソルとして適切に処理しておく必要がある。手順は以下の通り、
1.画像ファイルを読み込む
2.JPEGファイルの内容をRGBのピクセルグリッドにデコードする。
3.これらのピクセルを浮動小数点型のテンソルに変換する。
4.ピクセル(0~255)の尺度に取り直し、[0,1]の範囲の値にする。
kerasには、上記の手順を自動的に処理するユーティリティが用意されている。ImageDataGeneratorクラスを利用すれば、ディスク上の画像ファイルを前処理されたテンソルのバッチに自動的に変換できるpythonジェネレータをセットできる。ImageDataGeneratorを使ってディレクトリから画像を読み込む
from keras.preprocessing.image import ImageDataGenerator # All images will be rescaled by 1./255 train_datagen = ImageDataGenerator(rescale=1./255) test_datagen = ImageDataGenerator(rescale=1./255) train_generator = train_datagen.flow_from_directory( # This is the target directory train_dir, # All images will be resized to 150x150 target_size=(150, 150), batch_size=20, # Since we use binary_crossentropy loss, we need binary labels class_mode='binary') validation_generator = test_datagen.flow_from_directory( validation_dir, target_size=(150, 150), batch_size=20, class_mode='binary')モデルの訓練
モデルを訓練させるには
fit_generator()関数を利用する。
steps_per_epochは1エポックで進行するステップ数。validation_stepsは1エポックの中で何枚ずつ画像を検証するかを表す。history = model.fit_generator( train_generator, steps_per_epoch=10, epochs=30, validation_data=validation_generator, validation_steps=5)ネットワークの保存
訓練を終えたネットワークのパラメータを保存するには
save()関数を利用する。kerasでは.h5という拡張子のファイルで保存される。h5ファイルを呼び出せば次回以降はこのパラメータで画像の予測をさせることができる。model.save('cats_and_dogs_small_1.h5')正解率のプロット
import matplotlib.pyplot as plt acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs = range(len(acc)) plt.plot(epochs, acc, 'bo', label='Training acc') plt.plot(epochs, val_acc, 'b', label='Validation acc') plt.title('Training and validation accuracy') plt.legend() plt.figure() plt.plot(epochs, loss, 'bo', label='Training loss') plt.plot(epochs, val_loss, 'b', label='Validation loss') plt.title('Training and validation loss') plt.legend() plt.show()保存したネットワークでの推定
model = models.Sequential()にしていた部分を以下のように変えるだけ。load_modelの引数には保存したネットワークファイルのパスを指定する。
学習済みネットワークを使うので、学習のときにあったadd()系は不要。学習したモデルがそのまま読み込まれる。model=keras.models.load_model('cats_and_dogs_small_1.h5')参考
https://qiita.com/GushiSnow/items/8c946208de0d6a4e31e7#%E5%85%B7%E4%BD%93%E7%9A%84%E3%81%AA%E5%AE%9F%E8%A3%85%E4%BE%8B
https://qiita.com/tsunaki/items/608ff3cd941d82cd656b
https://qiita.com/tomo_20180402/items/e8c55bdca648f4877188
https://ymgsapo.com/2019/02/28/keras-dog-and-cat/
- 投稿日:2020-09-24T18:55:15+09:00
OpenCVによるごく単純な間違い探し
知り合いが画像の差分を見比べるプログラムが必要だといっていたのでPythonとOpenCVで組んでみた。要はOpenCVを用いた間違い探しだが、画像同士でいっさいのズレがないことが条件となるので、実務的なアレには向かないかもしれない。よりロバストな間違い探しが必要な方はこの記事などを参考にした方がいいかも。実装はこの記事の方法のが10倍ぐらい軽いと思うけど……。
結果
以下のような画像が出力される。
(画像はWikipediaより引用)ソースコード
import cv2 import matplotlib.pyplot as plt img1 = cv2.imread('img1.png') img1 = cv2.cvtColor(img1,cv2.COLOR_BGR2RGB) img1 = img1/255 img2 = cv2.imread('img2.png') img2 = cv2.cvtColor(img2,cv2.COLOR_BGR2RGB) img2 = img2/255 dif = cv2.absdiff(img1,img2) dif[dif>0] = 1 fig,axs = plt.subplots(2,2) ar = axs.ravel() ar[0].imshow(img1) ar[1].imshow(img2) ar[2].imshow(img1*dif*0.8 + img1*0.2) ar[3].imshow(img2*dif*0.8 + img2*0.2) plt.show()本質的な処理はOpenCVによる数行で済むが、matplotlibで表示するための下処理でけっこう行数がかかっている。要は
cv2.absdiffで差分画像がとれるので、それをマスクとして利用している。diffそのままだとRGBチャンネルそれぞれに対して差分を取っているので、dif[dif>0] = 1という操作によりマスクにする。思ったよりも手間取った点としては、OpenCVの画像データは
int型とfloat型の両方とも取れるようになっており、普段は便利なのだが今回はそのせいでマスクが上手くいかなかった。結果、画像を読み込んだ時点で/255して強制的にfloatにキャストしている。

- 投稿日:2020-09-24T18:33:32+09:00
組み合わせ爆発ハラスメントの処方箋
プログラミング初学者向けの内容です。
今のところ Golang, Ruby, Python, JavaScript, TypeScript による処方箋のみ掲載しています。ある日のこと
知人「店長からさぁ、
『うちはメニューの数が少ないから、
コンビ・メニュー作ることにした』『とりあえず、
今あるメニューを組み合わせて、
単品から全部入りまで
すべての組み合わせのリスト作ってくれ!』って、言われたんだけど…」
俺「え? それって、
???があるとしたら、
↓みたいなやつ?」1:?
2:?
3:? ?
4:?
5:? ?
6:? ?
7:? ? ?知人「そう。そう。それ!それ!」
俺「作れるけど、、
きっとものすごい数になるよ。
単品メニューって何種類くらいあんの?」知人「20種類くらいかなぁ。。
物好きな店長でしょ?!
めんどくせぇ。。」俺「…」
俺「あのさぁ、、
面倒くさいとかの次元じゃないんだけど。。」俺「0.1 mm 厚の紙を 26 回折ったら
富士山より高くなるって知ってる?」\begin{align} 0.1mm\times2^{26} &= 6,710,886.4 mm\\ &\fallingdotseq 6.7 km \end{align}知人「あ、なんか聞いたことあるかも。。」
俺「それと同じなんだけど、、」
\begin{align} 2^{20} - 1 &= 1,048,575 通り\\ &\fallingdotseq 105万通り \end{align}俺「105万通りは、
さすがにメニュー充実しすぎだろ(笑)」知人「へ〜、そんなになるんだぁ!」
俺「…」
Golang による処方箋
取り急ぎ Golang で書いてみます。
menu.gopackage main import ( "flag" "fmt" "strings" ) func comball(in []string) [][]string { n := 1 << len(in) out := make([][]string, n) for i := 0; i < n; i++ { ss := make([]string, 0, len(in)) for j := 0; j < len(in); j++ { if 1<<j&i != 0 { ss = append(ss, in[j]) } } out[i] = ss } return out } func main() { flag.Parse() args := flag.Args() for i, ss := range comball(args) { fmt.Printf("%d:%s\n", i, strings.Join(ss, " ")) } }Go のバージョンです。
version$ go version go version go1.15.2 linux/amd64実行してみます。
実行$ go run menu.go ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? > menu.txtGolang はコンパイルも実行も速くていいですね。
Generics をサポートしていないので string 型専用の関数になってしまい、そこが残念ポイントですが、LL のような感覚で気軽にいろいろ試せます。
(Generics は来年サポートされるようですね)プログラムは標準出力へ書き出すようにしましたが、そのまま出力するとたぶん大変なことになるので menu.txt という名前のファイルへリダイレクトしました。
ファイルの先頭を見てみます。
ファイルの先頭$ head menu.txt 0: 1:? 2:? 3:? ? 4:? 5:? ? 6:? ? 7:? ? ? 8:? 9:? ?最初の行に「なし」を出すようにしてます。
今度は末尾を見てみます。
ファイルの末尾$ tail menu.txt 1048566:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048567:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048568:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048569:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048570:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048571:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048572:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048573:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048574:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048575:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ?1行目の「なし」を除いて、ちゃんと 104 万 8,575 行あります。
ファイルサイズが 56.4 MiB もありますが、、(笑)
(圧縮して 4 Mib くらい)
ひとまず、これで大丈夫そうです。あと、 Golang はサクッとクロスコンパイルしてシングルバイナリが作れるのがいいですね!
とりあえず、AMD64 互換 の linux と Mac と Windows 用を用意して持ち帰ってもらうことにました。build.shGOOS=linux GOARCH=amd64 go build -o ./linux-amd64/menu menu.go GOOS=darwin GOARCH=amd64 go build -o ./darwin-amd64/menu menu.go GOOS=windows GOARCH=amd64 go build -o ./windows-amd64/menu.exe menu.goでも、、
せっかくプログラムを書いてあげたのに、結局、彼は「店長に怒られそう…」という理由で、これを使ってくれませんでした。
遠い昔を思い出す
知人は採用してくれませんでしたが、これってテストデータの生成(フラグの組み合わせとか)にも応用できますよ。
昔、入社 1 年目のとき、まるで野球部の球拾いのごとくテスターをやらされた日々を思い出します。
ある日、明確なテスト仕様書もない中で、先輩 SE から無茶振りされました。
「可能な組み合わせを全部テストするなんて当たり前なの!お前バカなの!?」
と怒鳴られました。
遠い昔のことなので、細かいことはあまり良く覚えてませんが、同期の仲間と計算してみると、1 個 1 分でやったとしても、寝ずにやって何十年かかるとか、そんな途方もないオーダーでした。
現実的な解が思い浮かばなかったので、もっと上の先輩に相談しました。
すると、即答で「バカは相手にしなくていいから(笑)!」と言ってくれ、あっさりとこの問題は解決してしまいました。今考えると完全にパワハラでした。
2〜3日、真剣に悩みましたから(笑)無茶ぶりした先輩 SE はその後しばらくして会社を辞めていきました。
でも、マシンが高速化し自動テストがあたりまえになった現代では、当時できなかったいろんなことができるようになりました。
あのとき、もし今の環境が手元にあったら、この程度の簡単な処方箋であっさりと解決していたのかも。。
そう考えると感慨深いものがあります。先輩 SE が後輩を馬鹿呼ばわりすることもなく、彼がさらに上の先輩から馬鹿呼ばわりされることもなかったかもしれません。
ということで、他の言語の例もいくつか載せておきます。
Ruby で調合する
Ruby はあまり書いたことがないので、らしいコードじゃないかもしれません。
プログラムをみる
menu.rbdef comb(arr) out = [] n = 1 << arr.size n.times do |i| a = [] arr.size.times do |j| if 1 << j & i != 0 a << arr[j] end end out << a end out end comb(ARGV).each.with_index(0) do |a, i| puts i.to_s + ":" + a.join(" ") end実行$ ruby --version ruby 2.7.0p0 (2019-12-25 revision 647ee6f091) [x86_64-linux] $ ruby menu.rb ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? > menu.txt $ tail menu.txt 1048566:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048567:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048568:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048569:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048570:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048571:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048572:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048573:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048574:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048575:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ?まあ、Ruby の場合は組み込み関数を使えば、↓これでもいけますね。
出力順が違いますけど。。menu2.rbdef comball(arr) out = [[]] arr.each_with_index { |s, i| out += arr.combination(i+1).to_a } out end comball(ARGV).each.with_index(0) do |a, i| puts i.to_s + ":" + a.join(" ") endRuby って、書く順番がなんか他の言語と違いますよね。
この感覚が気持ちよくて好きです。。Python で調合する
プログラムをみる
menu.pyimport sys def comball(arr): out = [] n = 1 << len(arr) for i in range(n): a = [] for j in range(len(arr)): if 1 << j & i != 0: a.append(arr[j]) out.append(a) return out arr = sys.argv arr.pop(0) for i, a in enumerate(comball(arr)): s = ' '.join(a) print('{0}:{1}'.format(i, s))実行$ python3 --version Python 3.6.8 $ python3 menu.py ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? > menu.txt $ tail menu.txt 1048566:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048567:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048568:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048569:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048570:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048571:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048572:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048573:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048574:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048575:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ?end や } が必要ない分、関数本体が短く書けますね。
JavaScript で調合する
プログラムをみる
menu.jsfunction comball(arr) { const out = [] const n = 1 << arr.length for (let i = 0; i < n; i++) { const a = [] for (let j = 0; j < arr.length; j++) { if ((1 << j & i) != 0) { a.push(arr[j]) } } out.push(a) } return out } const arr = process.argv.slice(2) comball(arr).forEach((a, i) => console.log(i + ":" + a.join(" ")) )実行$ node --version v12.16.1 $ node menu.js ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? > menu.txt $ tail menu.txt 1048566:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048567:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048568:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048569:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048570:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048571:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048572:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048573:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048574:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048575:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ?JavaScript って & より != の方が演算子の優先順位が高いんですよね。
だから括弧が付いてます。
なんか理由があるんですかね。。TypeScript で調合する
プログラムをみる
menu.tsfunction comball<T>(arr: T[]): T[][] { const out: T[][] = [] const n = 1 << arr.length for (let i = 0; i < n; i++) { const a: T[] = [] for (let j = 0; j < arr.length; j++) { if ((1 << j & i) != 0) { a.push(arr[j]) } } out.push(a) } return out } const arr: string[] = process.argv.slice(2) comball(arr).forEach((a, i) => console.log(i + ":" + a.join(" ")) )実行$ npx ts-node --version v8.10.1 $ npx ts-node menu.ts ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? > menu.txt $ tail menu.txt 1048566:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048567:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048568:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048569:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048570:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048571:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048572:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048573:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048574:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ? 1048575:? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ☕ ?TypeScript は関数シグネチャを見れば何をしそうか分かるところが良いですね。
あと、Generics 使っています。
でも、トランスパイルが遅いところが玉に瑕です。あとがき
本稿で扱ったプログラミング言語は演算子の使い方もほとんど同じなので、みんな似たコードになりましたが、それでも言語の個性が出ている部分もあって面白かったです。
後で他の言語も追記するかもしれません。
要望があればプログラムの解説も付けるかもしれません。あと、各言語のエキスパートの方で、もっとカッコいい書き方を知ってるよ! という人は是非教えてください。
それでは!
- 投稿日:2020-09-24T17:46:21+09:00
Github ActionsでDockerイメージをpullしてtestを行うJobを作成してみる手順
今回はPythonのプロジェクトのリポジトリを
Github Actionsでpytestをdocker-composeのイメージ上で行う為の練習を行ったのでそのメモを記載します。前提条件
- Github の packages のトークンを作成しておく。
- docker login しておく。
- Github の 任意のリポジトリに
Secretsをpackages操作可能なトークン番号を登録しておく。
(私の環境ではGHCR_IO_TOKENという名前で登録している。)フォルダ構成
repository/ # リポジトリディレクトリ ├ .github/ │ ├ workflows/ │ │ └ sample.yml # Github actionsのファイル ├ project/ │ ├ sample/ #(説明省略) │ │ ├ __init__.py │ │ └ add.py │ └ test/ #(説明省略) │ ├ __init__.py │ └ test_add.py ├ docker-compose.yml # 後ほど詳細記載 ├ Dockerfile # 適当なPythonイメージ(説明省略) └ requirements.txt # 適当なパッケージを記載(今回はpytestのみ記載している)手順
- docker-compose.ymlにimageを
ghcr.io指定したイメージ名を記載する。docker-compose upでイメージを作成後、docker-compose pushしてイメージをPushする- github actionsのファイルで pull して pytestを行う!
イメージをghcr.ioに上げる。
以下のようにイメージを指定する。
docker-compose.ymlservices: python: build: . #image: ghcr.io/Githubのユーザー名/リポジトリ名/イメージ名:タグ名 image: ghcr.io/n-jun-k2/sample-actions/python:v1ローカルでイメージを作成し、Pushする。
# とりあえずいつもの様にイメージを作成 docker-compose up -d # イメージをPush docker-compose pushGithub Actions のCIファイルについて
...は適当に変えてください。
チェックアウトしてログインしてpullしてpytestを行っています。.github/workflows/sample.ymlname: ... on: ... jobs: ...: name: ... runs-on: ubuntu-20.04 steps: - name: Checkout # チェックアウトして uses: actions/checkout@v2 - name: Login to Docker # docker login して uses: docker/login-action@v1 with: registry: ghcr.io username: ${{ github.repository_owner }} password: ${{ secrets.GHCR_IO_TOKEN }} - name: Set up Docker # pull してイメージを立ち上げ run: | docker pull ghcr.io/n-jun-k2/sample-actions/python:v1 docker-compose up -d - name: Run test # pytestを行う。 run: docker-compose exec -T python pytestこのCIファイルでdocker-composeイメージ上でpytestが行われる。
注意すべき点は、以下の
-Tのオプションを入れ忘れないように!エラーになっちゃうよdocker-compose exec -T python pytest
- 投稿日:2020-09-24T17:29:22+09:00
【Python】多次元配列に値を代入するときの注意点
やりたかったこと
動的計画法に関する問題で,初期化した2次元配列(dp)に対して,ある数字(60)を代入しようとしていた.
[問題] Atcoder EDPC C-Vacation(https://atcoder.jp/contests/dp/tasks/dp_c)
以下のようなコードを書いていた.
dp=[[0,0,0]]*5 print(dp) #出力 [[0,0,0],[0,0,0],[0,0,0],[0,0,0],[0,0,0]] a=[10,40,70] dp[0]=a print(dp) #出力 [[10,40,70],[0,0,0],[0,0,0],[0,0,0],[0,0,0]] # 以下が問題のコード####### dp[0][1]=60 print(dp) #出力 [[10,40,70],[0,60,0],[0,60,0],[0,60,0],[0,60,0]]本当はdp[0][1]の所だけに60を代入したかった.(以下)
print(dp) #出力 [[10,40,70],[0,60,0],[0,0,0],[0,0,0],[0,0,0]]原因
以下のようにリストを初期化してしまうと,要素であるリストが全て同じオブジェクトとして生成されてしまう.(以下)
# ダメな例1 dp=[[0,0,0]]*5 # ダメな例2 dp=[[0]*3]*5解決法
以下のように,「内包表記」 でリストを初期化すれば,全て異なるオブジェクトとして生成できる.
dp=[[0]*3 for i in range(5)] dp[0][1]=60 print(dp) #出力 [[10,40,70],[0,60,0],[0,0,0],[0,0,0],[0,0,0]]numpyなら楽にできる
import numpy as np dp=np.zeros((5,3)) dp[0,1]=60 print(dp) #出力 array([[ 0., 0., 0.],[ 0., 60., 0.],[ 0., 0., 0.],[ 0., 0., 0.],[ 0., 0., 0.]])まとめ
list型で多次元配列を初期化するなら,内包表記を使う.
ただし,numpyで初期化する方が楽.参考
- 投稿日:2020-09-24T16:34:31+09:00
時系列解析 実装詰まったところ -備忘録-
前提
問題点1
ARモデルをAICによって決定する
# importは通常通りの実装 model = ar_model.AR(y) for i in range(20): results = model.fit(maxlag=i+1)では、以下のエラーが発生する
RuntimeError: Model has been fit using maxlag=1, method=cmle, ic=None, trend=c. These cannot be changed in subsequent calls to `fit`. Instead, use a new instance of AR.試したこと
コード
model = ar_model.AR(y) results = model.fit(maxlag=1) print(results.aic) results = model.fit(maxlag=2) print(results.aic)出力結果
10.623349835083612 --------------------------------------------------------------------------- RuntimeError Traceback (most recent call last) <ipython-input-30-956416629a7e> in <module> 2 results = model.fit(maxlag=1) 3 print(results.aic) ----> 4 results = model.fit(maxlag=2) 5 print(results.aic) /opt/conda/envs/timeseries/lib/python3.8/site-packages/statsmodels/tsa/ar_model.py in fit(self, maxlag, method, ic, trend, transparams, start_params, solver, maxiter, full_output, disp, callback, **kwargs) 1349 fit_params = (maxlag, method, ic, trend) 1350 if self._fit_params is not None and self._fit_params != fit_params: -> 1351 raise RuntimeError(REPEATED_FIT_ERROR.format(*self._fit_params)) 1352 if maxlag is None: 1353 maxlag = int(round(12 * (nobs / 100.0) ** (1 / 4.0))) RuntimeError: Model has been fit using maxlag=1, method=cmle, ic=None, trend=c. These cannot be changed in subsequent calls to `fit`. Instead, use a new instance of AR.解決策1
コード
for i in range(20): model = ar_model.AR(y_diff) results = model.fit(maxlag=i+1) print(f'lag = {i + 1}\taic : {results.aic}')期待通りの結果が得られる
- 投稿日:2020-09-24T16:19:06+09:00
pyenvからインストールしたpythonでimport tkinterができなかった備忘録(masOS)
前書き
この投稿が二つ目の記事投稿になるN高生です。
この記事はpyenvからインストールしたpythonでimport tkinterができなかったのでそれをできるようにする対処法を書きます。
ほぼ備忘録ですが。。。
例によって、いろんなサイトを参考にしたのでそこのところご了承いただけると幸いです。動作環境
macOS Mojave(10.14.6)
python 3.7.0
pip 20.2.3
Homebrew 2.5.2ことの発端
pyenvからインストールしたpythonでimport tkinterをするとimport errorが出た。
(記事を投稿すると思っていなかったのでコードをメモしていない...)調べてみると
macOS(Mojave)でNo module named ‘_tkinter’を解決する(pyenv , Python3.x)
という今回の症状と酷似した内容の記事が見つかったためひとまずこちらを参考に進めてみた。解決に向けて試行錯誤
まずpyenvでインストールしたpythonをアンインストールしないといけないらしいので
解決に向けた準備#pipでインストールしたものをバックアップ $ pip freeze > pip.txt #アンインストール $ pyenv uninstall 3.7.0 #もしHomebrewからtcl-tkをインストールしている場合は削除 $ brew uninstall tcl-tkここまで準備ができたら次は
ActiveTclというサイトから8.5系をインストールしましょう。これがインストールできたらもう一度pyenvからpythonをインストールします。
私は3.7.0をインストールしました。この際、ここのコードに書いてある文を一文づつコピーしてターミナルに入れてください。
(筆者は最初インストールコマンドしか入れてなくて、あとあと苦労してます)$ CFLAGS="-I$(brew --prefix readline)/include -I$(brew --prefix openssl)/include -I$(xcrun --show-sdk-path)/usr/include" \ $ LDFLAGS="-L$(brew --prefix readline)/lib -L$(brew --prefix openssl)/lib" \ $ PYTHON_CONFIGURE_OPTS=--enable-unicode=ucs2 \ $ pyenv install 3.7.0 $ pyenv global 3.7.0ここで人によっては.bash_profileをいじる可能性があります。
(私はいじらなくても大丈夫でした)ひとまず解決...?
さあこれでなおったかな?と思いREPLで試してみました。
エラー出てない!!!
これで開発に取りかかれる!と思って次の一文を打つとあれ...
今度はRuntime errorが出てきました...なんてこった...解決に向けて試行錯誤(2回目)
ということで今度はこのエラーを解決するために色々調べてみた。
このgithubがどのサイトをみても参考にされていたので一度、目を通してみたが筆者は初心者なので正直あまりよくわからなかった。(わかる人ならこれで解決できると思います)そこで別のサイトを探し、
macOS Catalina 10.15.1のpyenv環境でtkinterを利用するための設定(python 3.7.x系)という日本語で書かれたサイトが出てきたのでこちらを参考に進めた。解決に向けた準備(2回目)#pipのバックアップを忘れずに行う $ pyenv uninstall 3.7.0 #brewからtcl-tkをインストール $ brew install tcl-tk次にpython-buildを書き換えます。しかしこのファイルはFinderで開いても見つからないので次のコマンドをターミナルに入れます。
open /usr/localこうすることで、自動的にFinderが開き、ファイルが表示されます。私かここからpython-buildを探しました。
python-buildの場所
(私の環境の場合)
/Cellar/pyenv/plugins/python-build/bin/python-guild
にあり、その770行目あたりに$CONFIGURE_OPTS ${!PACKAGE_CONFIGURE_OPTS} "${!PACKAGE_CONFIGURE_OPTS_ARRAY}" || return 1と記載されている欄を
$CONFIGURE_OPTS --with-tcltk-includes='-I/usr/local/opt/tcl-tk/include' --with-tcltk-libs='-L/usr/local/opt/tcl-tk/lib -ltcl8.6 -ltk8.6' ${!PACKAGE_CONFIGURE_OPTS} "${!PACKAGE_CONFIGURE_OPTS_ARRAY}" || return 1と置き換える。
これのあと、改めてpythonをインストールする。$ pyenv install 3.7.0さて、REPLで再度試してみよう。
今度こそ治った!
今回はエラーも出ず、ファイルを実行した際もエラーが出ませんでした。これにて一件落着。
今回もなかなか大変だった。
また記事を書く機会があれば書きます。

- 投稿日:2020-09-24T16:00:25+09:00
IQ Botのカスタムロジック:Split応用(テーブルに対して適用する、エラー制御を入れる)
IQ Botで扱うSplitについての基本は、こちらの記事に記載しています。
上記はフィールドに対するSplitのみに触れており、エラー制御なども組み込んでいないロジックだったので、ここでもう少し踏み込んで紹介します。
Splitをテーブルに適用するロジック
例えば、フィールドであれば
field_value = field_value.split("銀行")[0]と定義するロジックをフィールドに対して適用するとどうなるかというと、こんなかんじです。スプリットをテーブルに対して適用する場合#抽象化した関数の定義 def func_split(value, splitter, index): x = value if splitter in value: y = x.split(splitter) if (len(x) + 1) >= index: x = y[index] return x #関数の適用 df['列名'] = df['列名'].apply(func_split, splitter="銀行", index=0)上記の「抽象化した関数」には、単純なスプリットだけでなく、「もとの文字列の中にそもそも『銀行』の文字が含まれているか」「splitした結果のリストに、指定したindexが存在しうるか」というチェックの処理も含まれています。
さらに、上記のチェックが否であれば、スプリット前の値をそのまま返す、という処理になっています。
なので厳密には
field_value = field_value.split("銀行")[0]と単純に同じ、というわけではないのですが、実務で利用するときはこんな考慮を組み込むのが通常かと思います。関数をフィールドに対して適用する
えっ? そのエラー制御、フィールドに対しても組み込んだ方がいいんじゃないの? と思ったそこのあなた。
おっしゃるとおりです。
その場合は、上記のfunc_splitを当該フィールドのカスタムロジック欄に設定した上で、以下のように関数を適用します。スプリット(エラー制御あり)をフィールドに対して適用する場合#関数の適用 field_value = func_split(field_value, "銀行", 0)以上!
いかがでしたか?
ご質問がある方は、この記事にコメントをお寄せいただくか、TwitterのDMにてご連絡ください。
※ 上記は毎日チェックできているわけではないため、回答に時間がかかる場合があります。
IQぼっちをリアルにご存じの方は、仕事用のメールに質問をください。
- 投稿日:2020-09-24T15:48:17+09:00
データサイエンスのためのpython講座_使えるテクニック
python
・setはリストの重複を覗く際に使う。
・座標を商(行)と余り(列)で表現可能。
・shift+tabで関数のreference確認。
・_に最後に実行した戻り値が入っている。
numpy
・np.uint8(unsigned,integet,8bit)
0~255
画像データ等で利用。・np.float32
機械学習に使うデータを保存するときに使う。・np.float64
モデルの学習時に利用。・np.expand_dims
ndarrayの次元を増やす。・np.squeeze
ndarrayの次元を減らす。・flattern
arrayを1次元にする。・np.arrange(start,stop,step)
rangeと一緒。・np.linspace(start,stop,num)
startからstopの数字をnumの数に区切ったリストを作成。・np.logspace(start,stop,num,base=10)
startからstopの数字をnumの数に区切った数でbaseの累乗を計算。・np.zeros(),np.ones(),np.eyes()
要素が全て0、要素が全て1、対角要素が全て1。・np.random.rand()
0~1の数字をランダムで指定。・np.random.seed()
乱数を生成。・np.random.randn()
標準正規分布(平均0、分散1)から値を生成。・np.random.normal(平均、標準偏差)
正規分布(平均、標準偏差)から値を生成。・np.random.randint(low,high)
low以上、high以下でランダムに値を生成。
lowだけの場合はlow未満。・np.random.choice(list)
指定したリストからランダムな値を取得。・argmax(),argmin()
最大値、最小値のindexを取得。・中央値と平均の違い
中央値・・・並び替えが必要なため計算に時間がかかる。外れ値に強い。・time.time()
時間を計測。・68-95-99.7ルール
平均から標準偏差±1,2,3にデータが含まれる確率(正規分布)。・np.clip(array,min,max)
min以下はminに、max以上はmaxに変換。・np.where(条件、true,false)
条件に対してTrueであればtrueに指定の値、Falseであればfalseに指定の値に変換。・.all().any()
条件に対して全てTrueか、1つでもTrueか判定。・np.unique(array,return_count=True)
uniqueな要素とそれぞれのcountを返す。・np.bincount()
0,1,2,3・・・のcountを返す。・np.concatenate()
arrayを連結。・np.stack()
新しいaxisを生成して連結。
axis=-1を利用することが多い。・np.transpose()、.T
転置。・np.save(path,array),np.load(path)
arrayの保存、ロード。・np.save(path,dictionary).np.load(path,allow_pickle=True)[()]
辞書の保存、ロード。pandas
・pd.set_options("display.max_columns(rows)",num)
表示する行、列の数を指定。・.describe()
数字の統計量を表示。・.columns()
カラムのリストを表示。・inplace=True
元のデータフレームを更新。・reset_index(drop=True)
再度indexを割り振る。
元のindexを上書き。・set_index(カラム名)
指定したカラムをindexにする。・dropna(subset=[カラム名])
指定したカラムがnanの行を削除。・df[np.isnan(df["columns"])],df[df["columns"].isna()]
指定したカラムがnanの行を取得。・df.groupby("columns").統計量
指定したカラムでgroup byした統計量を表示。・pd.concat(df1,df2,axis)
指定したaxis(軸)の方向にデータフレームを結合。・df1.merge(df2,how,on,right_on,left_on,suffixies)
指定した結合方法,キーにてデータフレームを結合。・unique()
ユニークな値のみを取得。・nunique()
ユニークな値の数を取得。・value_counts()
それぞれの値にいくつのレコードがあるかを取得。・sort_values(by)
指定したカラムにてデータをソート。・apply(関数)
関数を各行に適用。・iterrows()
indexとseriesを返すイテレーションを生成。matplotlib
・%matplotlib inline
jupyter上で描画可。・plt.plot(x,y)
x軸,y軸にグラフを描画。・plt.x(y)label()
ラベルを表示。・plt.title()
タイトルを表示。・plt.legend()
判例を表示。・plt.x(y)ticks
指定したticksを表示。・plt.subplot(行、列、インデックス)
行、列、インデックスを指定して複数グラフを描画。・plt.figure()
fig=plt.figure()
ax1=fig.add_subplot(行、列、インデックス)・plt.subplots(行、列)
fig,axes=plt.subplots(行、列)
axes[0].plot(x,y)・plt.scatter(),plt.hist(),plt.bar(),plt.boxplot()
散布図、ヒストグラム、棒グラフ、箱ひげ図を描画。
plt["columns"].value_count().plot(kind="bar")seaborn
・sns.distplot(array,norm_hist,kde)
ヒストグラムを表示。
デフォルトで確率密度関数をKDEにて表示。・カーネル密度推定(KDE)
確率密度関数を推定する一つの手法。・sns.jointplot()
2変数の散布図を表示。
各ヒストグラムも表示。
kind="reg"で回帰直線を表示。・sns.pairplot()
全ての数値項目の散布図を表示。
hueで色分け。・sns.barplot(x=カテゴリカル変数、y=数値項目、data=df)
xのyの平均値を棒グラフで表示。
95%信頼区間を表示。・sns.countplot(x)
指定した変数の件数を表示。・sns.boxplot(x,y)
指定した変数の箱ひげ図を表示。・sns.violinplot(x,y)
指定した変数の分布密度を表示。・sns.swarmplot(x,y)
指定した変数の実際の分布を表示。・corr()
相関係数を表示。・sns.heatmap(df.corr(),annot=True,cmap="coolwarm")
相関表のヒートマップを表示。・sns.set(context,style,palette)
seabornのスタイルを変更。OpenCV
・cv2.imread()
画像ファイルをndarrayで読み込み。・plt.imshow()
ndarrayを画像として表示。
BGRで表示。・cv2.cvtColor(im,cv2.COLOR_BGR2RGB)
BGRからRGBに変換。・cv2.imwraight()
ndarrayを画像として保存。・Binarization(2値化)
①閾値を指定して2値化
cv2.threshold(ndarray,閾値,255,CV2.THRESH_BINARY)
②大津の2値化
cv2.threshold(ndarray,閾値,255,CV2.THRESH_BINARY+CV2.THRESH_OTSH)
閾値を自動で設定。
線形判別分析法(LDA)を画像に適用。
③Adaptive Thresholding
cv2.adaptiveThreshold(ndarray,255,cv2.ADAPTIE_THRESH_MEAN_C,CV2.THRESH_BINARY,サイズ、定数)
指定した範囲内の平均輝度値の平均から定数を引いたものを閾値として使用。glob
ファイルパスのリストを取得。
os&pathlib
・Path
パスオブジェクトを作成。
イテレーターとして利用。・os.path.split()
headとtailに分解。・os.path.join()
フォルダパスとファイル名を連結。・os.path.exists()
ファイルまたはディレクトリの存在を確認。・os.makedirs()
フォルダを作成。tqdm
・tqdm(イテレーター、total=len(df))
プログレスバーを表示。nibabel
・nib.load()
ニフティーのimageを取得。・get_fdata()
画像のndarrayを取得。multiprocessing
・map(func,iter)
iterにfuncを適用したiterを返す。・cpu_count()
使用できるCPUの物理コア数を確認。・Pool.map()、Pool.imap()
並列処理にてmap関数を適用。
map()はリストを、imap()はiterを返す。・Pool.imap_unordered()
処理の終わり次第返す。・zip()
複数のイテラブルオブジェクトの要素をタプルで返す。・p.close()、p.join()
並列処理を終了。・%load_ext autoreload,%autoreload 2
他ファイルの変更を反映。
・rollaxis(array,axis,start)
指定したaxisをstartで指定した位置に入れ込む。
- 投稿日:2020-09-24T15:24:17+09:00
[Python: UnicodeDecodeError] CSV読み込み時のエラー解決策の1つ
はじめに
最近、Android端末でセンサデータを収集し、それをPythonをもちいてJSON形式からCSV形式に変換してデータ整形をする、なんて機会がとても多くなってきました。
そこで、とあるエラーに嵌ってしまったので、備忘録としてメモを残しておきます。
発生したエラー
UnicodeDecodeError: '***' codec can't decode byte 0x* in position **:
このエラーをみると、CSVに何かおかしな文字が混ざってしまっているのか、それとも下記のコードに不備があるのかと思いました。
しかし、今回に限ってはそうではありませんでした。with open(path, encoding="***")該当するコードスニペット
dir = os.getcwd() + "/" + folder files = os.listdir(dir)このコードは、とあるフォルダに存在するファイルをリスト形式で返すことができるものです。
このコードを使って、大量のJSONファイルやCSVファイルをリスト形式で扱おうとしておりました。原因
.が先頭についているファイル、いわゆる隠れファイルがリストに含まれてしまうことが原因でした。
自環境の場合、「.DS_Store」がリストに含まれていました。さいごに
もし同じようなエラー(沼)に嵌ってしまった方がいれば、隠しファイルなど”本来扱いたくないファイル”を誤って読み込んでいないか確認することをおすすめします。
- 投稿日:2020-09-24T15:23:03+09:00
IQ Bot カスタムロジック(Python):差し替え処理をループで効率化
除外処理、置換処理に関するループを使った効率化を立て続けに解説してきましたが、すごく似たパターンで「差し替え」についてもループで効率化する方法を解説します。
「差し替え」とは?
これはプログラミング用語じゃないです。
こちらの記事で紹介しているような、「ある文字列が含まれていたら、別の文字列に置き換える」という処理です。置換の応用ですね。
「差し替え」をループで使う場面は?
たとえば「請求書の明細に略称で書かれてくる部門名を正式名称にしたい」とか、「注文書の明細に略称で書かれてくる商品名を正式名称にしたい」とか、そんな場面が該当すると思います。
ズバリ、やりかた!(フィールド項目編)
差し替え@フィールド項目sashikae_list = (("これが含まれていたら1","これに差し替えてね1"), ("これが含まれていたら2","これに差し替えてね2"), ("これが含まれていたら3","これに差し替えてね3")) for i in sashikae_list: if i[0] in field_value: field_value = i[1]解説は置換編のこのあたりを参照してください。ほぼ同じ仕組みです。
ズバリ、やりかた!(テーブル編)
差し替え@テーブルsashikae_list = (("これが含まれていたら1","これに差し替えてね1"), ("これが含まれていたら2","これに差し替えてね2"), ("これが含まれていたら3","これに差し替えてね3")) def table_sashikae(x,y): for i in y: if i[0] in x: x = i[1] return x df['列名'] = df['列名'].apply(table_sashikae,y=sasihkae_list)以上!
いかがでしたか?
今回は、仕組みとしては差し替えの処理を、置換のループと同じ構造で処理しているだけなので、あまり解説を厚くしていません。
ご質問がある方は、この記事にコメントをお寄せいただくか、TwitterのDMにてご連絡ください。
※ 上記は毎日チェックできているわけではないため、回答に時間がかかる場合があります。
IQぼっちをリアルにご存じの方は、仕事用のメールに質問をください。
- 投稿日:2020-09-24T15:06:31+09:00
爆速PythonフレームワークFastAPIをMySQLに繋いでRESTfulなAPIを作成してみた。
FastAPI とは?
FastAPIとはpython3.6以上を対象とした、APIを作成するためのモダンで処理速度が爆速なフレームワークです。
主な特徴としては
速さ: 非常にハイパフォーマンス。NodeJSやGoに匹敵する処理速度を誇る(StarletteとPydanticのおかげもあり)。Pythonの数あるフレームワークのうち最も処理速度が速いフレームワークの一つ。
コードの簡素化: コードの書く速度を約2~3倍から上昇させる。(*)
バグの少なさ: 約40%ほどの人為的コードバグを減らすことが可能。(*)
直感的に書ける: エディターのサポートも充実、補完も効きます。デバッグにかかる時間を減らすことが可能。
簡単: 簡単に書け、理解しやすいように設計されている。ドキュメント読むのに時間がたくさんかかる心配もない。
短い: コードの重複を避けることができる。渡す引数を変えるだけで様々な機能を提供する関数を備えている。
堅実: 本番環境でも開発環境と差異のないコードを使える。
Swaggerの提供: 作成したAPIはデフォルトで備えているSwaggerをもとに自動でドキュメント化され、各処理を実行できる。
(*)FastAPI制作チーム調べ、だそうです。
とりあえずサーバーを立ち上げてみる
「コードは言葉より物を言う」と言うことで、早速使っていきたいと思います。
まずは適当にフォルダを作り
mkdir fastapi-practice必要なパッケージをインストールします。
pip install fastapi sqlalchemy uvicorn mysqlclientグローバルインストールが嫌な方はpoetryなどを使ってインストールしてください(このあとでどのみちpoetry使います)。
FastAPIを動かすために必要な以下のファイルを作成します
touch main.pyそして以下の様にコードを記述していきます。
main.pyfrom fastapi import FastAPI from starlette.requests import Request app = FastAPI() def index(request: Request): return {'Hello': 'World'} app.add_api_route('/', index)なんとこれだけでサーバーが立ち上がってしまいます。
uvicorn main:appと打つだけでサーバーが立ち上がったはずです。
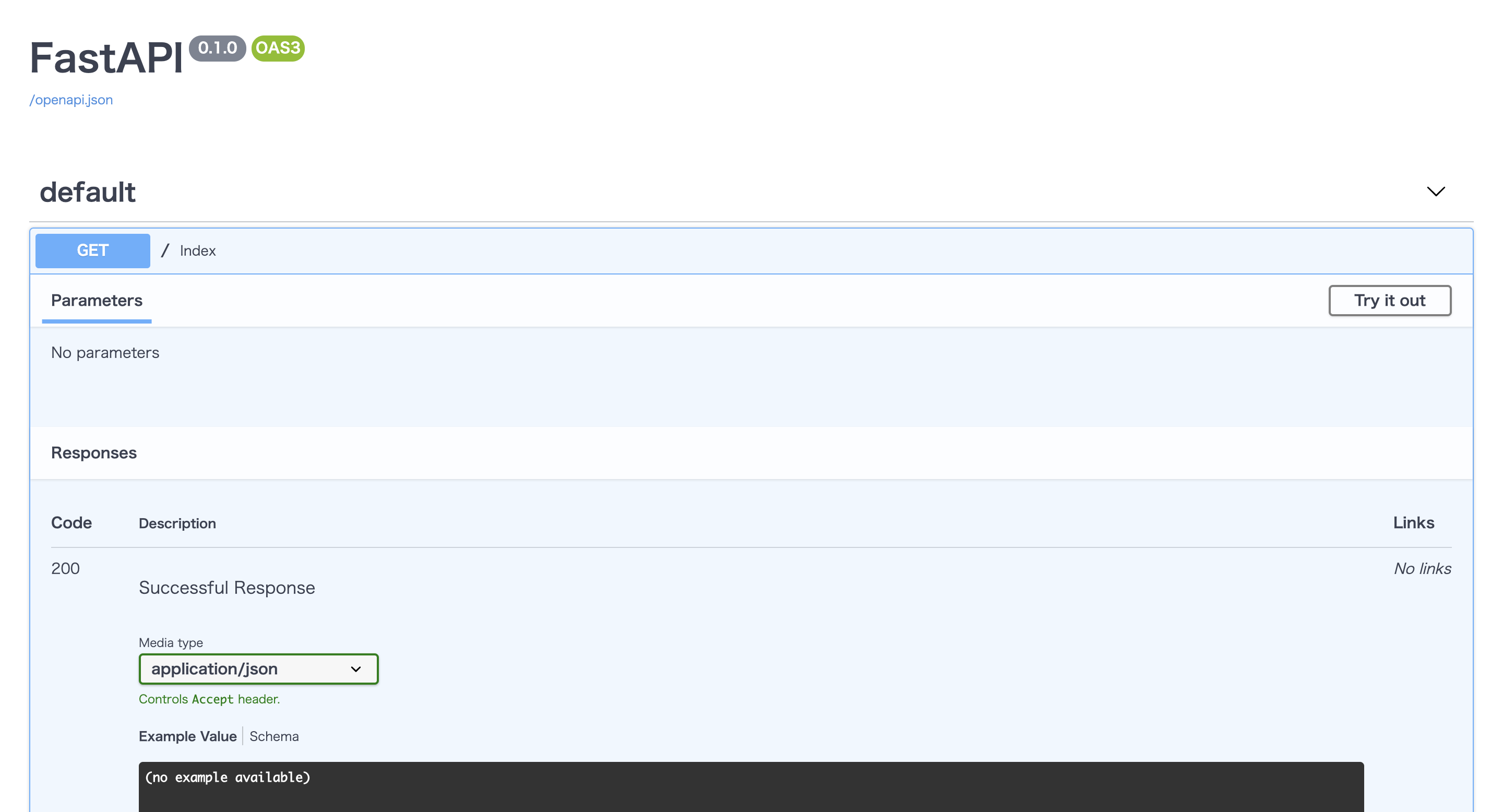
http://localhost:8000/
をブラウザで表示してみると{"Hello":"World"}と表示されているはずです。爆速ですね、FastAPI。
しかもSwaggerによりAPIの仕様も自動で作成されています!!(驚き!)
http://localhost:8000/docs
を表示してみてください。お洒落なUIで仕様書が作られているはずです。タブを開いて
Try it outのボタンを押すと実際にリクエストを送り、レスポンスを確認することだってできてしまいます!(感動!!)
ちなみに
http://localhost:8000/redoc
も自動で作られておりさらに詳細なドキュメントを簡単に作ることもできてしまいます!(凄すぎ!!!)実際に使ってみる (docker環境構築編)
それではリアルケースを想定したFastAPI + MySQLでRESTfulなAPIを作成してみましょう。
FastAPIはdockerで簡単に環境構築できるのでmysqlとFastAPIをそれぞれ今時っぽくコンテナ内で動かし、通信させる様にしてみます。
まずはフォルダ内にdocker-compose.ymlとdocker-sync.yml, Dockerfileを作成します。
touch docker-compose.yml docker-sync.yml Dockerfiledockerの詳しい使い方の説明はここでは省きますが、Dockerfileにコンテナを作成するための情報、docker-compose.ymlに作成されたコンテナ上で走らせるコマンド、docker-sync.ymlでローカルの開発環境とdockerコンテナ内のファイルをリアルタイムで同期するためにコードをつらつらと書いていきます。
docker-syncの使い方は他の方が書いてくださった以下の様な記事が参考になるかと思うので読んでみてください。
docker-syncは使わなくてもできますが、同期速度を爆速!にするために私は使ってます。https://qiita.com/Satoshi_Numasawa/items/278a143aa41735e1b0da
それではDockerfileからコードを書いていきます。
DockerfileFROM python:3.8-alpine RUN apk --update-cache add python3-dev mariadb-dev gcc make build-base libffi-dev libressl-dev WORKDIR /app RUN pip install poetryパッケージ管理にはpoetryを使います。
パッケージ管理にはpipenvやpyflowなどもあるのでここは好みですかね...?https://qiita.com/sk217/items/43c994640f4843a18dbe
こちらの記事に各パッケージマネージャーが分かりやすくまとめられています。
気になる方は是非一読してみてください。続いてdocker-sync.yml
docker-sync.ymlversion: "2" options: verbose: true syncs: fastapi-practice-sync: src: "." notify_terminal: true sync_strategy: "native_osx" sync_userid: "1000" sync_excludes: [".git", ".gitignore", ".venv"]そしてdocker-compose.ymlです
docker-compose.ymlversion: "3" services: db: image: mysql:latest command: --default-authentication-plugin=mysql_native_password restart: always environment: MYSQL_DATABASE: fastapi_practice_development MYSQL_USER: root MYSQL_PASSWORD: "password" MYSQL_ROOT_PASSWORD: "password" ports: - "3306:4306" volumes: - mysql_data:/var/lib/mysql fastapi: build: context: . dockerfile: "./Dockerfile" command: sh -c "poetry install && poetry run uvicorn main:app --reload --host 0.0.0.0 --port 8000" ports: - "8000:8000" depends_on: - db volumes: - fastapi-sync:/app:nocopy - poetry_data:/root/.cache/pypoetry/ volumes: mysql_data: poetry_data: fastapi-sync: external: truedocker-compose.ymlでミソなのが永続化するデータとその場かぎりのデータをうまく使い分けることです。
永続化しないデータはdocker-compose downするたびにリセットされてしまいます。今回のケースだとmysql内のデータ、poetryでインストールしたパッケージは永続化させ、コンテナを立ち上げる度にmysql内のデータが空になったりパッケージをダウンロードしなくていい様にします。
また書いていくコードはdocker-syncを使って同期させたいのでfastapi-practice-sync:/app:nocopyを記述して勝手に同期されるのを防ぎます。MySQLもdockerから最新のイメージをpullして構築していきます。
ここまででdockerのセットアップは終了です。
実際に使ってみる(FastAPI設定編)
まずはFastAPIに必要なパッケージをインストールするpoetryのセットアップです。
poetry initをターミナルで叩きます。
そうすると対話形式でセットアップが始まりますのでyesかnoを連打しましょう。(基本デフォルトの設定で問題ないのでEnter連打でも問題ない...と思います)そうすると
pyproject.tomlというファイルが作成されたかと思います。ここにパッケージの依存情報が追記されていくのでpoetryを使ってFastAPIを立ち上げるのに必要なパッケージをインストールしていきましょう。
poetry add fastapi sqlalchemy uvicorn mysqlclientこちらを入力しパッケージのインストールが終わるのを待ちます。
終了したら、pyproject.tomlを開いてみるとインストールされたパッケージの情報が記載されていることがわかります。pyproject.toml[tool.poetry] name = "fastapi-practice" version = "0.1.0" description = "" authors = ["Your Name <you@example.com>"] [tool.poetry.dependencies] python = "^3.8" fastapi = "^0.61.1" sqlalchemy = "^1.3.19" uvicorn = "^0.11.8" [tool.poetry.dev-dependencies] [build-system] requires = ["poetry>=0.12"] build-backend = "poetry.masonry.api"そうしたらあとは
docker-compose buildを打ち、イメージをビルドしてdocker-sync-stack startを入力するだけです!*
docker-sync-stack startはdocker-sync startとdocker-compose upを同時に実行するコマンドです。ログもよしなに出してくれるので便利です。新たにパッケージをインストールする際は、まずはローカルで
poetry addでパッケージをインストールしてdockerコンテナを再起動させればコンテナ内にも同期されるはずです!マイグレーションをする
お次はDB(MySQL)と連携させていきます。
今回はCRUDの勉強といえばTodoリストの作成!なのでTodoテーブルを定義しマイグレーションをかけていくことにします。
Todos Table
column datatype id integer title string content string done boolean この様な構成のテーブルをマイグレーションしていきます。
まずはデータベースを定義するファイルを作り
touch db.py以下の内容を書き込んでいきます。
db.pyfrom sqlalchemy import Boolean, Column, ForeignKey, Integer, String, create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import relationship, sessionmaker, scoped_session user_name = "root" password = "password" host = "db" database_name = "fastapi_practice_development" DATABASE = f'mysql://{user_name}:{password}@{host}/{database_name}' engine = create_engine( DATABASE, encoding="utf-8", echo=True ) Base = declarative_base() SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine) class Todo(Base): __tablename__ = 'todos' id = Column(Integer, primary_key=True, autoincrement=True) title = Column(String(30), nullable=False) content = Column(String(300), nullable=False) done = Column(Boolean, default=False) def get_db(): db = SessionLocal() try: yield db finally: db.close() def main(): Base.metadata.drop_all(bind=engine) Base.metadata.create_all(bind=engine) if __name__ == "__main__": main()FastAPIはsqlalchemyというPythonの中で最もよく利用されるORM(Object-Relation Mapping)の一つを使ってデータベースとPythonのオブジェクトを関連付けるのが主流みたいです。
これを書いたらdockerのコンテナ内に入り、マイグレーションをかけていきます。
docker-sync-stack startでコンテナを立ち上げ同期モードにし、
docker container lsで立ち上がっているコンテナリストをみます。
そしたら、docker exec -it {コンテナ名} shを叩き、コンテナの中に入ります。
そして、以下のコマンドでマイグレーションをかけていきます。poetry run python db.pyそうすると無事マイグレーションが走りテーブル作成に成功したのではないでしょうか!
そしたら次はCRUD処理をFastAPIで書いていきます。
FastAPIでCRUD処理を書こう
拡張性を意識してFastAPIに内蔵されているinclude_routerという機能を使い、ファイルを分割していきます。
mkdir routersと打ち、
touch routers/todo.pyというファイルを作ります。
こちらにCRUD処理を書いていきます。routers/todo.pyfrom fastapi import Depends, APIRouter from sqlalchemy.orm import Session from starlette.requests import Request from pydantic import BaseModel from db import Todo, engine, get_db router = APIRouter() class TodoCreate(BaseModel): title: str content: str done: bool class TodoUpdate(BaseModel): title: str content: str done: bool @router.get("/") def read_todos(db: Session = Depends(get_db)): todos = db.query(Todo).all() return todos @router.get("/{todo_id}") def read_todo_by_todo_id(todo_id: int, db: Session = Depends(get_db)): todo = db.query(Todo).filter(Todo.id == todo_id).first() return todo @router.post("/") async def create_todo(todo: TodoCreate, db: Session = Depends(get_db)): db_todo = Todo(title=todo.title, content=todo.content, done=todo.done) db.add(db_todo) db.commit() @router.put("/{todo_id}") async def update_todo(todo_id: int, todo: TodoUpdate, db: Session = Depends(get_db)): db_todo = db.query(Todo).filter(Todo.id == todo_id).first() db_todo.title = todo.title db_todo.content = todo.content db_todo.done = todo.done db.commit() @router.delete("/{todo_id}") async def delete_todo(todo_id: int, db: Session = Depends(get_db)): db_todo = db.query(Todo).filter(Todo.id == todo_id).first() db.delete(db_todo) db.commit()この様にしてざっとCRUD操作を書いていきました。
@routerの後にリクエスト名を書き、動作対象のURLを書くだけです。そしたらこちらを読み込める様に
main.pyも編集していきます。main.pyfrom fastapi import FastAPI from routers import todos app = FastAPI() app.include_router( todos.router, prefix="/todos", tags=["todos"], responses={404: {"description": "Not found"}}, )prefixはurlのパスを作ってくれます。tagsはdocsを見やすい様グルーピング化してくれます。
そうして
http://localhost:8000/docs
に接続すると以下の様になっているはずです!
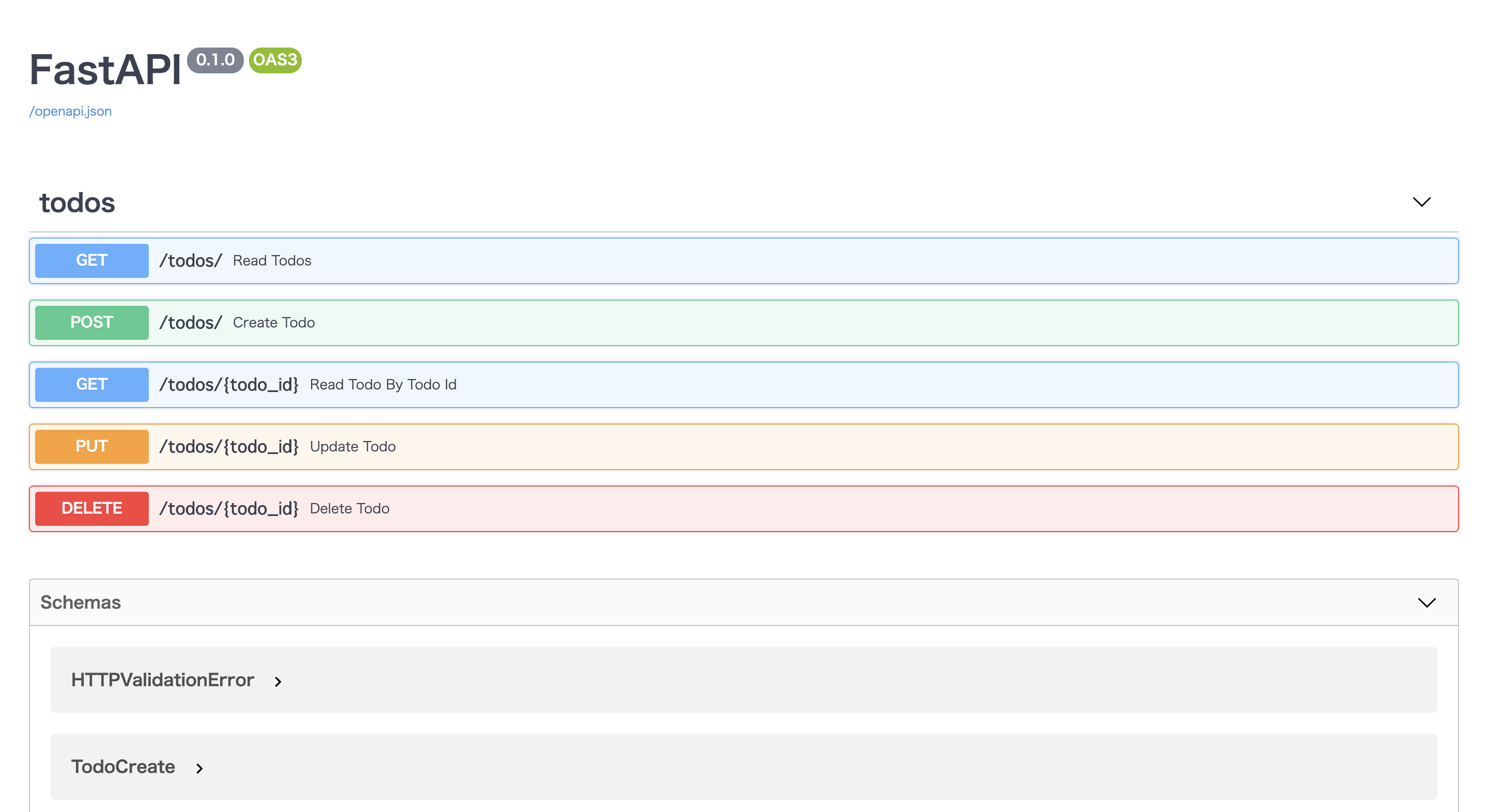
タブを開いてポチポチボタンを押してCRUD処理を試してみてください!
このままだとフロントエンドから呼ぶ際CORSエラーが起きるので別アプリから呼ぶ際は以下のCORSの処理を追記してみてください。
main.py# 追記 from starlette.middleware.cors import CORSMiddleware app.add_middleware( CORSMiddleware, allow_origins=["*"], allow_credentials=True, allow_methods=["*"], allow_headers=["*"], )まとめ
FastAPIいかがだったでしょうか?
こんなにも少ないコード量でAPIが作成できてしまうのがとても魅力的ですね。
Pythonでマイクロサービスを作成する際とても相性が良さそうです。Qiita初投稿だったため何か分かりづらい点あったら質問くださいませ!
これからはなるべくQiitaにもアウトプットしていきたい...です(頑張る

- 投稿日:2020-09-24T14:28:01+09:00
IQ Bot カスタムロジック(Python):置換処理をループで効率化
こちらの記事で、IQ Botにおける除外処理のループを使った効率化について説明しています。
除外は置換の一種なので、基本的に考え方は同じなのですが、たぶんコーディング的に若干置換の方が難易度が高い気がしたのでこちらに切り出しました。
どんなときに役立つ? ~置換編~
置換をループで処理するケースで、一番よく出会うのは「半角カナの揃え」です。
IQ Botに内蔵されているOCRエンジンのひとつであるABBYYは、半角カナの読みにやや弱い傾向があります。半角を全角で読んでしまう(あるいはその逆)だけであれば、Bot Storeに出ている日本語の半角⇔全角変換アクションでRPA側で補正すればいいのですが、「ガ」を「カ"」(カ+ダブルクォーテーション)のように読んでしまうケースがあり、これはまともにRPAでやるよりPythonでやった方が早いと思います。
(RPAでもPythonは書けますが)
除外と置換の違い
除外と置換の違いは、フィールド項目のロジックで見てみると以下のとおりです。
除外と置換の違い#これが除外 field_value = field_value.replace("除外する文字列","") #これが置換 field_value = field_value.replace("置換前の文字列","置換後の文字列")基本の文法は「置換」の方で、除外は置換でいう「置換後の文字列」を
""(=空の文字列)にすることで除外を実現している、という仕組みです。除外の場合は、置換後の文字列が常に
""で固定だったので、複数にわたる要素は"除外する文字列"(=置換前の文字列)だけでした。
なので、ループを回す対象のシーケンスは一次配列の構造でOKでした。一方、置換の場合は置換の前後がともに複数にわたるので、置換前・置換後をセットでシーケンスに入れる必要があります。
二次配列の構造です。これが難易度UPポイント。
でも安心してください。
はいてま……いえ、ちゃんと解説します。ズバリ、やりかた(置換の場合)
以下の構造で、置換処理のできあがりです。
置換処理の考え方replace_list = (("置換前の文字列1","置換後の文字列1"), ("置換前の文字列2","置換後の文字列2"), ("置換前の文字列3","置換後の文字列3")) for i in replace_list: field_value = field_value.replace(i[0],i[1])
replace_listは、タプルの中にタプルが入っている、つまり二次配列の構造になっていますね。forループの中の
iには、1回目の処理のときは("置換前の文字列1","置換後の文字列1")、2回目の処理のときは("置換前の文字列2","置換後の文字列2")というふうに、子のタプルが入ります。その
iからインデックス0(i[0]/置換前)と1(i[1]/置換後)の要素をそれぞれ取り出して、replaceの引数に渡しているという仕組みです。半角カナの揃え処理
ちなみに冒頭で例に挙げた半角カナの補正ロジックはこんなイメージです。
半角カナに対する置換処理replace_list = (('カ"','ガ'),('キ"','ギ'),('ク"','グ'),('ケ"','ゲ'),('コ"','ゴ'), ('サ"','ザ'),('シ"','ジ'),('ス"','ズ'),('セ"','ゼ'),('ソ"','ゾ'), ('タ"','ダ'),('チ"','ヂ'),('ツ"','ヅ'),('テ"','デ'),('ト"','ド'), ('ハ"','バ'),('ヒ"','ビ'),('フ"','ブ'),('ヘ"','べ'),('ホ"','ボ'), ('ハ°','パ'),('ヒ°','ピ'),('フ°','プ'),('ヘ°','ペ'),('ホ°','ポ')) for i in replace_list: field_value = field_value.replace(i[0],i[1])濁点は
"(ダブルクオーテーション)、半濁点は°(度)と読まれることを前提に、全角カナに揃えるという処理です。実際は、濁点や半濁点の読まれ方はもう少し揺れる場合が多いです。
OCRの結果を見つつ、通常の置換処理で、濁点や半濁点の読み取り結果を統一してあげてからこちらの処理をかけると効率がよいです。
テーブルの場合は?(置換編)
テーブルの場合は、forループの中身をテーブル用に変えればいいので、以下のとおりで動くはず。
置換処理(テーブルの場合)replace_list = (("置換前の文字列1","置換後の文字列1"), ("置換前の文字列2","置換後の文字列2"), ("置換前の文字列3","置換後の文字列3")) for i in replace_list: df['列名'] = df['列名'].str.replace(i[0],i[1])でも上記はあまり美しくない……気がするのは私だけですか?
私だったらこうします。
置換処理(テーブルの場合)replace_list = (("置換前の文字列1","置換後の文字列1"), ("置換前の文字列2","置換後の文字列2"), ("置換前の文字列3","置換後の文字列3")) def table_replace(x,y): for i in y: x = x.y(i[0],i[1]) return x df['列名'] = df['列名'].apply(table_replace,y=replace_list)こうしておくと、
- 置換したい文字列の組み合わせは同じだが、違う列に適用したいとき
- 列によって、置換したい文字列の組み合わせを変えたいとき
などに柔軟に対応が可能になります。
置換処理(テーブルの場合)replace_listA = (("置換前の文字列1","置換後の文字列1"), ("置換前の文字列2","置換後の文字列2"), ("置換前の文字列3","置換後の文字列3")) replace_listB = (("置換前の文字列a","置換後の文字列a"), ("置換前の文字列b","置換後の文字列b"), ("置換前の文字列c","置換後の文字列c")) def table_replace(x,y): for i in y: x = x.y(i[0],i[1]) return x df['列名1'] = df['列名1'].apply(table_replace,y=replace_listA) df['列名1'] = df['列名1'].apply(table_replace,y=replace_listB) df['列名2'] = df['列名2'].apply(table_replace,y=replace_listA) df['列名3'] = df['列名3'].apply(table_replace,y=replace_listB)という要領です。
列名1には
replace_listAとreplace_listBによる置換を両方適用し、
列名2にはreplace_listAによる置換だけを適用し、
列名3にはreplace_listBによる置換だけを適用した例です。以上!
うーんどうでしょう、難しかったですかね。
ご質問がある方は、この記事にコメントをお寄せいただくか、TwitterのDMにてご連絡ください。
※ 上記は毎日チェックできているわけではないため、回答に時間がかかる場合があります。
IQぼっちをリアルにご存じの方は、仕事用のメールに質問をください。
- 投稿日:2020-09-24T13:48:56+09:00
IQ Bot カスタムロジック(Python):除外処理をループで効率化
IQ Bot のカスタムロジックの中で、一番よく使う処理はなんといっても「置換」です。
不要な文字や記号の「除外」も「置換」の一種なので、カスタムロジックの使用ケースの8~9割がこれといっても過言ではないです。置換・除外の基本的なやりかたはこちらの記事で紹介していますが、今日はそんな置換の中で、「除外」の処理をループを使って効率化するやり方を紹介します。
どんなときに役立つ? (除外編)
印刷のかすれなどにより、取得項目に余計な記号が混じってしまうとしましょう。
「どこでも商事」が「どこでも商事.」(最後にドットが入っている)になってしまう場合は、こんなかんじで除外します。
通常の置換(除外)field_value = field_value.replace(".","")上記はノイズが1種類(ドット)だけだったのでよかったですが、「ど*こ;で',も:商!事.」のようにたくさんの種類のノイズが混じってしまう場合はどうすればいいでしょうか?
まともにやると以下のようになります。
通常の置換(除外)field_value = field_value.replace("*","") field_value = field_value.replace(";","") field_value = field_value.replace("'","") field_value = field_value.replace(",","") field_value = field_value.replace(":","") field_value = field_value.replace("!","") field_value = field_value.replace(".","")もし、他に「#」というノイズも除外したい!と思ったら、
field_value = field_value.replace("#","")というロジックを追加します。これでも間違いではないのですが、もうちょっと少ないロジックで書けますよ、というのが今回のおはなしです。
ズバリ、やりかたはこうだ! (除外編)
上記とまったく同じことが、以下のコードでできます。
ループを使って除外を効率化ignore_list = ("*",";","'",",",":","!",".") for i in ignore_list: field_value = field_value.replace(i,"")もし、上記でさらに「#」というノイズも除外したい!と思ったら、
ignore_listの最後に#の要素を加えるだけです。
ignore_list = ("*",";","'",",",":","!",".","#")ということですね。
最後の"#"が追加された要素です。ループを使った除外の解説
Pythonがシーケンスに対してループをかけるときの基本的な文法がこちらです。
シーケンスって何じゃ? と思った方はこちらの記事(外部リンク)を参照してください。
さらに初心者向けの説明はこちら。
リンク先ではシーケンスの一種である「リスト」について説明していますが、「リスト」以外にもいろんな種類のロッカーがあるんだな~くらいに思っていてください。ちなみに上記のコードの
ignore_listはタプルという型のシーケンスです。で、以下がそのタプルの中身の要素に対して、ひとつひとつ処理をかけていくループです。
#以降が、各行でやっていることの説明です。ループを使って除外を効率化for i in ignore_list: #ignore_listの要素のひとつひとつを、iという変数に入れて順番に処理してね field_value = field_value.replace(i,"") #field_valueの中のiを除外して、field_valueに代入してねテーブルの場合は? (除外編)
ループを使った効率化は、テーブルに対しても適用可能です。
テーブルの場合は、for文の中身をテーブル用の文法に変えて以下のように処理することもできますが……
ループを使って除外を効率化(テーブルの場合)ignore_list = ("除外したい文字1","除外したい文字2","除外したい文字3") for i in ignore_list: df['列名'] = df['列名'].str.replace(i,"")美しいのは以下だと思います。
ループを使って除外を効率化(テーブルの場合)ignore_list = ("除外したい文字1","除外したい文字2","除外したい文字3") def table_ignore(x,y): for i in y: x = x.y(i,"") return x df['列名'] = df['列名'].apply(table_replace,y=ignore_list)一見、下の方がコード量が多く見えますが、除外したい文字列のセットが複数できる場合や、それらの組み合わせを自在に複数の列に適用したい場合などに、下の方が柔軟性があります。
以上!
いかがでしたか?
常に初心者の味方がモットーの筆者ですが、今日のはさすがにプログラミング初心者向けの記事ではなかったかなという気がしています。ご質問がある方は、この記事にコメントをお寄せいただくか、TwitterのDMにてご連絡ください。
※ 上記は毎日チェックできているわけではないため、回答に時間がかかる場合があります。
IQぼっちをリアルにご存じの方は、仕事用のメールに質問をください。
- 投稿日:2020-09-24T12:31:12+09:00
SBI FXのAPI
FXでの自動取引をするために、SBIで使用できるAPIに関してまとめます。
なお、公式に公開されているAPIではないため、予告なく変更される可能性があります。
内容の正確性に関しては一切保証しません。Chartの取得
https://trade.sbifxt.co.jp/api_fxt/HttpApi/ChartCache.aspx
メソッド
POST
パラメータ
パタメータ名 意味 例 CURID 通過ペア USDJPY TIMESCALE 時間足の設定(0⇒1分足など) 0 COUNT 取得する足の数(上限未調査2000?) 100 DEVICE PCWebFXAUTO(固定でいい) PCWebFXAUTO GUID ChartCache_[16進数8桁]-[16進数*4桁]-[16進数*4桁]-[16進数4桁]-[16進数*12桁] ChartCache_94ddb1fa-d951-cf2a-09db-9cd005480950 取得結果
各行
時間,ASK/BID中央値,ASK,BID
足の情報は OCHL の順レートの取得
https://trade.sbifxt.co.jp/api_fxt/HttpApi/Rate.aspx
メソッド
GET
パラメータ
パタメータ名 必須/任意 意味 例 DEVICE 必須(多分) PCWebFXAUTO(固定でいい) PCWebFXAUTO GUID 必須(多分) Rate_[16進数8桁]-[16進数*4桁]-[16進数*4桁]-[16進数4桁]-[16進数*12桁] Rate_94ddb1fa-d951-cf2a-09db-9cd005480950 _ 任意 取得対象の日時(JSの(new Date).getTime()の結果) 1600919253978 取得結果
各行
通過ペア,通過ペア名,OCHL,???,???,???,対象となる数量(FROM),対象となる数量(TO),対象となる数量(FROM),売SWAP,買SWAP,日時
- 投稿日:2020-09-24T11:53:14+09:00
1つの配列に 2 つのスタックを Python で実装してみる
こんにちは、
初投稿から1晩経ちました。
196view 有難うございます。特に嬉しかったのはコメント頂いたことです。
@shiracamus さん有難うございます。
嬉しかったです。サンプルのコードまで頂いて。
また改めて頂いたヒントで考える機会を設けたいと思います。表題の件ですがどっかで、
聞いたことのある質問ですよね?
はい、チャレンジしちゃいました(笑)。色々な指摘を頂きそうですが、
一旦は、先日の記述スタイルでやってみます。
いやいや、スタックって何 !? って人は
https://qiita.com/AKpirion/items/f3d5b51ab2ee9080e9c6
か、他の有識者の記事を参考願います。
いきなり全貌を書いちゃいます。stack_x2.pyclass top: class full(Exception): pass class empty(Exception): pass def sel_ptr(self,sel): if sel == 0: self.ptr = self.ptr0 else: self.ptr = self.ptr1 return self.ptr def bak_ptr(self,sel): if sel == 0: self.ptr0 = self.ptr else: self.ptr1 = self.ptr def __init__(self,capacity:int = 8): self.str = [None] * capacity self.capa = capacity/2 self.ptr0 = 0 self.ptr1 = 4 self.ptr = 0 def push(self,value,sel): top.sel_ptr(self,sel) if (self.ptr >= self.capa and sel==0) or (self.ptr >= self.capa*2 and sel==1): raise top.full self.str[self.ptr] = value print(self.str) self.ptr += 1 top.bak_ptr(self,sel) def pop(self,sel): if sel == 0: self.ptr = self.ptr0 else: self.ptr = self.ptr1 if self.ptr <= 4*sel: raise top.empty self.ptr -= 1 if sel == 0: self.ptr0 = self.ptr print(f"ptr0 = {self.ptr0}") else: self.ptr1 = self.ptr print(f"ptr1 = {self.ptr1} ") return self.str[self.ptr] test = top() while True: num = int(input("select 1.push , 2.pop : ")) if num == 1 : s = int(input("enter data: ")) sel = int(input("select str: ")) try: test.push(s,sel) except test.full: print("full!") elif num == 2: sel = int(input("select str: ")) try: x = test.pop(sel) print(x) except test.empty: print("empty!") else: breakすいません、前提条件を伝えるのを忘れていました。
str: データを格納する箱
capa: str の深さ。なので、何個までデータを詰め込めるか。。です
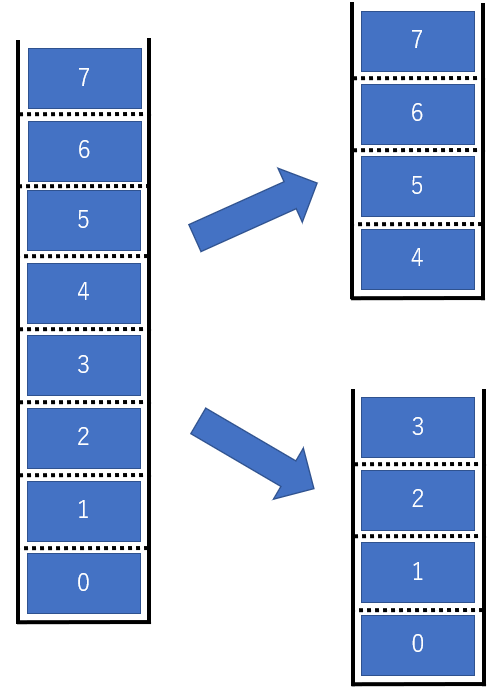
ptr : ポインタです。str の何処にデータをPush し、どこから Pop するかを意味します。今回は capa = 8 としました。
以下のイメージでやってみようと思います。
図の左側にあるように取り急ぎ、従来通り箱を1 つ作ります。
あとは、0 <= ptr <= 3 の領域と 4 <= ptr <= 7 の領域で分けて
スタックにしてあげます。見えます、見えます、皆さんの?マーク。
やり方は色々あると思いますが、
私は単に ptr を 2 つ用意(ptr0,ptr1)して、
0 <= ptr0 <= 3, 4 <= ptr1 <= 7 となるように
書き換えればいいのでは?っと解釈しました。じゃあ、おっさん、何したん!?
ってなると思いますので、順を追って見ていきましょう。stack_x2.pydef __init__(self,capacity:int = 8): self.str = [None] * capacity self.capa = capacity/2 # 箱を二分割 self.ptr0 = 0 # ポインタ 1つ目:0 <= ptr0 <= 3 で動作だから初期値 0 self.ptr1 = 4 # ポインタ 2つ目:4 <= ptr1 <= 7 で動作だから初期値 4 self.ptr = 0 # ptr0 or ptr1 を選択後、ptr に代入してスタック処理へ基本的には、Push/Pop を選択するときに、
どっちの箱に格納するか選択するようにします。
やり方としては self.ptr に ptr0 or ptr1 いずれか選択したほうを代入し、
今まで通り、self.ptr で push/pop するイメージです。
では、Push 行ってみましょう。まず ptr に ptr0,ptr1 のどちらを代入するか決めます。
sel を使って、sel == 0 の時、ptr = ptr0、sel == 1 の時、ptr = ptr1 とします。
それが以下の記述です、前述の記述から抜き取ってみました。stackx2.pydef sel_ptr(self,sel): if sel == 0: self.ptr = self.ptr0 else: self.ptr = self.ptr1 return self.ptr大丈夫そうですね。次は実際に Push をする本体です。
stackx2.pydef push(self,value,sel): top.sel_ptr(self,sel) if (self.ptr >= self.capa and sel==0) or (self.ptr >= self.capa*2 and sel==1): raise top.full self.str[self.ptr] = value print(self.str) self.ptr += 1 top.bak_ptr(self,sel)ptr を ptr0 or ptr1 の どちらかを代入した後は、
選択した 1つ目or2つ目の箱が、 Full か否かを
if 文でチェックする必要があります。
抜き出してみます。stackx2.py#sel == 0 で一つ目の箱を選択した場合 #sel == 0 で一つ目の箱を選択した場合 if (self.ptr >= self.capa and sel==0) or (self.ptr >= self.capa*2 and sel==1):Full か否かを確認出来たら、
従来通り、Push します。ここで終わりと思いきや、ちょっと Time!
Push は ptr をインクリメントしなくてはいけないので、
Push の処理が終わった後に ptr0 or ptr1 にインクリメントした情報を
アップデートしてあげないとスタックになりません。そのため、Push 処理の最後には以下を追加してあげる必要があります。
記述では top.bak_ptr(self,sel) っとありますが、やっていることは
以下の処理です。stackx2.pydef bak_ptr(self,sel): if sel == 0: self.ptr0 = self.ptr else: self.ptr1 = self.ptr最後は Pop です。
Push と、それほど変わりません。
ptr の選択 => Empty の有無を確認 => ptr の Update => return value です。stackx2.pydef pop(self,sel): if sel == 0: self.ptr = self.ptr0 else: self.ptr = self.ptr1 if self.ptr <= 4*sel: raise top.empty self.ptr -= 1 if sel == 0: self.ptr0 = self.ptr print(f"ptr0 = {self.ptr0}") else: self.ptr1 = self.ptr print(f"ptr1 = {self.ptr1} ") return self.str[self.ptr]いかがだったでしょうか。
Pop の記述に関する説明は省いてしまいましたが、
Push が分かれば何とかなるかと(笑)感触としては、Full / Empty を判断する条件を ptr0 ver , ptr1 ver と
条件分けしてあげることが出来れば、従来のスタックの記述を流用することで
乗り切れるのかなっと思いました。説明が雑!, 足りない!,分かりにくい!
しかも間違ってるよ、色々!!大変申し訳ありません。
コメント頂ければ修正、追記します。m(_ _)m
- 投稿日:2020-09-24T10:59:56+09:00
Blue Prism で Object の仕様書を自動生成する
はじめに
Blue Prism では、Object というアプリケーションを実際に操作する部品と、Process というビジネスロジックをかく部品のレイヤーが分かれていて、再利用性を高める仕組みになっています。
チーム内で Object の再利用を進めるには、「どういう Object があるのか」というドキュメントを作ってメンテナンスする必要がありますが、手で作ったりメンテナンスするのは辛かったり、Objectの内容がアップデートされているのに追従できなかったり、という問題が生じる可能性があります。この記事では、そうした重要な Object に関するドキュメント(Blue Prism 用語でいうところの ODI : Object Design Instruction)を自動で生成しよう、という話を扱います。
「Object Inventory」 というVBOがある! が動かない。。。
Ditigal Exchange に 「Object Inventory」 という VBO があるのですが、文字列のトリムが英語前提になっていたり、謎の Excel エラー(
Exception : HRESULT からの例外:0x800A03EC)が出たりして、うまく動きませんでした。。。ただ、そのヘルプページに下記の記述がありました。
This asset is a business object that uses the output from the BP command line /getbod function to create a list of all business objects, pages, descriptions, inputs and outputs.AutomateC.exe に
/getbodというスイッチがあるということは、ヘルプのコマンドラインオプションにも書かれていないです。。。/listprocesses と /getbod というスイッチ
先の「Object Inventory」VBOを覗いてみると、
/listprocessesスイッチで Process と Object の一覧を取得し、それぞれについて/getbodを呼んでいるようです。対象が Process だと、Could not find Business Objectという文字列がかえってくるので、それらは処理対象から外す、という流れのようです。
/getbodスイッチは実在した!python で実装してみる
拙いスクリプトですが、動作します。ご参考になれば幸いです。(Python 3.7.4で検証しました)
listprocesses したものについて、順次 getbod したものをテキストファイルに保存する
""" Blue Prism に接続するためのパラメーターを BP_USERNAME, BP_PASSWORD, BP_DBCONNAME 環境変数に設定して実行してください。 BP_USERNAME : ユーザー名 BP_PASSWORD : パスワード BP_DBCONNAME : 接続名 """ import delegator from pathlib import Path import logging import os logging.basicConfig(level=logging.DEBUG) logger = logging.getLogger(__name__) bp_username = os.environ["BP_USERNAME"] bp_password = os.environ["BP_PASSWORD"] bp_dbconname = os.environ["BP_DBCONNAME"] LISTPROCESSES_CMD = '"C:\Program Files\Blue Prism Limited\Blue Prism Automate\AutomateC.exe" /user {bp_username} {bp_password} /dbconname {bp_dbconname} /listprocesses' command = LISTPROCESSES_CMD.format( bp_username=bp_username, bp_password=bp_password, bp_dbconname=bp_dbconname ) context = delegator.run(command) object_list = context.out object_names = object_list.splitlines() logger.info(object_names) GETBOD_CMD = '"C:\Program Files\Blue Prism Limited\Blue Prism Automate\AutomateC.exe" /user {bp_username} {bp_password} /dbconname {bp_dbconname} /getbod "{object_name}"' for object_name in object_names: command = GETBOD_CMD.format( bp_username=bp_username, bp_password=bp_password, bp_dbconname=bp_dbconname, object_name=object_name, ) context = delegator.run(command) description = context.out if ( len(description.splitlines()) <= 1 ): # Process は説明が "XXというビジネスオブジェクトが見つかりませんでした" という1行だけ出力される logger.info("{} is not a object".format(object_name)) continue # ファイル名に slash がはいっているとファイルを作成できなくなるので置換 description_file_name = object_name.replace("/", "_") + ".txt" with open(Path("output_descriptions") / description_file_name, "w") as f: f.write(context.out)getbod したテキストファイルを markdown にして保存する
もっと簡単にパースできるライブラリなどあったらどなたか教えてください。。。
from typing import List, Optional from dataclasses import dataclass, field import re import enum import logging from pathlib import Path logger = logging.getLogger(__name__) logging.basicConfig(level=logging.DEBUG) @dataclass class VBOActionDescription: """ VBO の各アクションの情報を保持するクラス """ action_name: str description: str = "" pre_condition: str = "" post_condition: str = "" input_params: List[str] = field(default_factory=list) output_params: List[str] = field(default_factory=list) def as_markdown(self) -> str: """ Markdown 形式で表現する """ _md = ( "###{action_name}\n" "{description}\n" "\n" "####事前条件\n" "{pre_condition}\n" "\n" "####事後条件\n" "{post_condition}\n" "\n" "####入力パラメーター\n" "{input_params}\n" "\n" "####出力パラメーター\n" "{output_params}\n" "\n" ) input_params_md = ("\n").join( ["* {}".format(input_param) for input_param in self.input_params] ) output_params_md = ("\n").join( ["* {}".format(output_param) for output_param in self.output_params] ) out = _md.format( action_name=self.action_name, description=self.description, pre_condition=self.pre_condition, post_condition=self.post_condition, input_params=input_params_md, output_params=output_params_md, ) return out class VBODescription: """ VBO の情報を保持するクラス。VBOActionDescription のリストを小として持つ """ def __init__( self, object_name: str, description: Optional[str] = "", mode: str = "", actions: Optional[List[VBOActionDescription]] = None, ): self.object_name = object_name self.description = description self.mode = mode self.actions = actions def as_markdown(self) -> str: """ Markdown 形式で表現する """ _md = ( "#{object_name}\n" "{description}\n" "\n" "##動作モード\n" "{mode}\n" "\n" "##アクション\n" ) out = _md.format( object_name=self.object_name, description=self.description, mode=self.mode ) if self.actions: out = out + ("\n").join([action.as_markdown() for action in self.actions]) return out class DescriptionOfWhat(enum.Enum): """ VBO の説明文をパースする際に、「どの部分を読んでいるか」という情報が必要になったため設けた Enum """ business_object = "Business Object" action = "Action" pre_condition = "Pre Conditiion" post_condition = "Post Conditiion" def classify_line(line: str): """ 行の分類を行う """ line = line.strip() # =ビジネスオブジェクト - Utility - File Management= <=左のような行にマッチ match = re.search("^=(?P<content>[^=]*)=$", line) if match: return {"type": "object name", "content": match.groupdict()["content"]} # このビジネスオブジェクトの実行モードは「background」です <=左のような行にマッチ match = re.search("^このビジネスオブジェクトの実行モードは「(?P<mode>[^」]+)」です", line) if match: return {"type": "mode", "content": match.groupdict()["mode"]} # ==Append to Text File== <=左のような行にマッチ match = re.search("^==(?P<content>[^=]*)==$", line) if match: return {"type": "action name", "content": match.groupdict()["content"]} # ===前提条件=== <=左のような行にマッチ match = re.search("^===(?P<content>[^=]*)===$", line) if match: content = match.groupdict()["content"] if content == "前提条件": # Blue Prism側の翻訳が変。。。 return {"type": "pre condition", "content": content} if content == "エンドポイント": # Blue Prism側の翻訳が変。。。 return {"type": "post condition", "content": content} # それ以外 return {"type": "action attribute", "content": content} # *入力:File Path (テキスト) - Full path to the file to get the file size <=左のような行にマッチ match = re.search("^\*入力:(?P<content>.*)$", line) if match: return {"type": "input parameter", "content": match.groupdict()["content"]} # *出力:File Path (テキスト) - Full path to the file to get the file size <=左のような行にマッチ match = re.search("^\*出力:(?P<content>.*)$", line) if match: return {"type": "output parameter", "content": match.groupdict()["content"]} # それ以外の行 return {"type": "article", "content": line} def append_action_to_vbo_description(latest_action, vbo_description): actions = vbo_description.actions if actions: vbo_description.actions.append(latest_action) else: vbo_description.actions = [ latest_action, ] return vbo_description def convert_to_markdown(bod_description_filepath) -> str: """ Markdown に変換する処理の本体 """ vbo_description = None with open(bod_description_filepath, "r", encoding="shift_jis", newline="\r\n") as f: previous_line_type: Optional[DescriptionOfWhat] = None # いまどの内容を読んでいるか、を保持する。 latest_action = None for line in f: line_class = classify_line(line) if line_class["type"] == "object name": vbo_description = VBODescription(line_class["content"]) previous_line_type = DescriptionOfWhat.business_object continue if line_class["type"] == "mode": assert vbo_description, "実行モードが正しい位置で記述されていません" vbo_description.mode = line_class["content"] continue if line_class["type"] == "article": assert vbo_description, "正しいフォーマットで記述されていません" if previous_line_type == DescriptionOfWhat.business_object: vbo_description.description += line_class["content"] continue if previous_line_type == DescriptionOfWhat.action: assert latest_action, "正しいフォーマットで記述されていません" latest_action.description += line_class["content"] continue if previous_line_type == DescriptionOfWhat.pre_condition: assert latest_action, "正しいフォーマットで記述されていません" latest_action.pre_condition += line_class["content"] continue if previous_line_type == DescriptionOfWhat.post_condition: assert latest_action, "正しいフォーマットで記述されていません" latest_action.post_condition += line_class["content"] continue if line_class["type"] == "action name": assert vbo_description, "正しいフォーマットで記述されていません" if latest_action: vbo_description = append_action_to_vbo_description( latest_action, vbo_description ) latest_action = VBOActionDescription(line_class["content"]) previous_line_type = DescriptionOfWhat.action continue if line_class["type"] == "input parameter": assert vbo_description and latest_action, "正しいフォーマットで記述されていません" latest_action.input_params.append(line_class["content"]) continue if line_class["type"] == "output parameter": assert vbo_description and latest_action, "正しいフォーマットで記述されていません" latest_action.output_params.append(line_class["content"]) continue if line_class["type"] == "pre condition": assert vbo_description and latest_action, "正しいフォーマットで記述されていません" previous_line_type = DescriptionOfWhat.pre_condition continue if line_class["type"] == "post condition": assert vbo_description and latest_action, "正しいフォーマットで記述されていません" previous_line_type = DescriptionOfWhat.post_condition continue # debug logger.debug("line: {}".format(line.strip())) if latest_action: logger.debug("latest_action: {}".format(latest_action.as_markdown())) else: # 最後に残っている latest_action を回収 if latest_action: vbo_description = append_action_to_vbo_description( latest_action, vbo_description ) assert vbo_description, "正しいフォーマットで記述されていません" return vbo_description.as_markdown() if __name__ == "__main__": descriptions_folder = Path("output_descriptions") for description_file in descriptions_folder.glob("*.txt"): with open(descriptions_folder / (description_file.stem + ".md"), "w") as md_f: md_f.write(convert_to_markdown(description_file))参考URL
- 投稿日:2020-09-24T10:58:34+09:00
写真から3Dモデルを作る方法を思いついた その05面の削減
どーもKsukeです。
写真から3Dモデルを作る方法を思いついたその05で、面の削減をやっていきます。
その4はこちらhttps://qiita.com/Ksuke/items/144c06f128b015b001dd※注意※
この記事は思いついて試した事の末路を載せているだけなので、唐突なネタやBad Endで終わる可能性があります。やってみる
手順
1.面の削減・・・今回はこれだけです(調べて実装するのに苦労した割にやりたいことが1メソッドに収まったから記事の文字数がいつも以上に少ないのは秘密)。
ところどころにあるコードは、最後にまとめたものを載せてあります。2か所にしかソースがないですが、一応いつも通り最後にも載せてあります。1.面の削減
面の削減は、blenderの機能を利用して行います。どのような機能かというと、Blenderのオブジェクトモードで利用できるmodifierのうちのDecimateという機能です。いくつかパラメータを指定して実行すると、面の数を減らしてくれます。おまけで、面を減らした結果使われなくなった頂点の削除も行っています。
面の削減#面の数を減らす関数 def faceReduction(obj,modifierName="faceReductionDecimate"): # 変更オブジェクトをアクティブに変更する bpy.context.view_layer.objects.active = obj #オブジェクトモードに移行 bpy.ops.object.mode_set(mode='OBJECT', toggle=False) #modifierの、面削減のやつを追加 bpy.ops.object.modifier_add(type='DECIMATE') #名前を付けとく bpy.context.object.modifiers["Decimate"].name = modifierName #削減方法を指定 bpy.context.object.modifiers[modifierName].decimate_type = "COLLAPSE" #削減率を指定 bpy.context.object.modifiers[modifierName].ratio = 0.05 #Decimateを実行する bpy.ops.object.modifier_apply(modifier = modifierName) # 編集モードに移行する bpy.ops.object.mode_set(mode='EDIT', toggle=False) #接続がない頂点を削除 bpy.ops.mesh.delete_loose() #オブジェクト追加(前回までは確認用でしかオブジェクトの追加をしていなかったので) me,obj = addObj(coords=coords,faces=faces,name = "porigon",offset=[-50,-50,-50]) #面の削減 faceReduction(obj)動作確認
最後にコードが問題なく動くか、それと今回は面と頂点がどのくらい削減されたかも確認してみます。
1.オブジェクトの表示
こんな感じにオブジェクトが表示されていれば成功。
見るからに面と頂点も減ってます。2.面と頂点の削減数
表示・削減の後にこんな感じのコードを追加して、削減前と後の面と頂点の数を表示します。
頂点と面の数確認用#面の削減前の確認用オブジェクト追加 originMe,originObj = addObj(coords=coords,faces=faces,name = "originPorigon",offset=[-50,-50,-50]) #削減の後のオブジェクトを、各データを操作しやすい形式に変換 bm=bmesh.from_edit_mesh(obj.data) #再度編集モードに移行する bpy.ops.object.mode_set(mode='EDIT', toggle=False) #削減の前のオブジェクトを、各データを操作しやすい形式に変換 originBm=bmesh.from_edit_mesh(originObj.data) #2つのオブジェクトの面と頂点の数を表示 print("originObj:") print(" vertsLen:{}".format(len(originBm.verts))) print(" facesLen:{}".format(len(originBm.faces))) print() print("faceReductedObj:") print(" vertsLen:{}".format(len(bm.verts))) print(" facesLen:{}".format(len(bm.faces))) print()出力結果はこんな感じに。
originObj: vertsLen:13279 facesLen:26590 faceReductedObj: vertsLen:594 facesLen:1328大体1/20程度になってますね。元のオブジェクトのデータ量多すぎ。。。
次は?
やっとそれっぽくなりましたが、色がなくてさみしいので画像(モデルの生成に使ったやつ)をテクスチャとして張り付けてみようと思います。
コードまとめ
前回のコードの後ろに追加すれば動くはずです。
関数編
コードまとめ(関数編)#面の数を減らす関数 def faceReduction(obj,modifierName="faceReductionDecimate"): # 変更オブジェクトをアクティブに変更する bpy.context.view_layer.objects.active = obj #オブジェクトモードに移行 bpy.ops.object.mode_set(mode='OBJECT', toggle=False) #modifierの、面削減のやつを追加 bpy.ops.object.modifier_add(type='DECIMATE') #名前を付けとく bpy.context.object.modifiers["Decimate"].name = modifierName #削減方法を指定 bpy.context.object.modifiers[modifierName].decimate_type = "COLLAPSE" #削減率を指定 bpy.context.object.modifiers[modifierName].ratio = 0.05 #Decimateを実行する bpy.ops.object.modifier_apply(modifier = modifierName) # 編集モードに移行する bpy.ops.object.mode_set(mode='EDIT', toggle=False) #接続がない頂点を削除 bpy.ops.mesh.delete_loose()実行コード編
コードまとめ(実行コード編)#オブジェクト追加 me,obj = addObj(coords=coords,faces=faces,name = "porigon",offset=[-50,-50,-50]) #面の削減 faceReduction(obj) print("step05:face reduction success\n") #以下確認表示用(メインの流れと関係ないので、次の回では多分消えてる) #面の削減前の確認用オブジェクト追加 originMe,originObj = addObj(coords=coords,faces=faces,name = "originPorigon",offset=[-50,-50,-50]) #削減の後のオブジェクトを、各データを操作しやすい形式に変換 bm=bmesh.from_edit_mesh(obj.data) #再度編集モードに移行する bpy.ops.object.mode_set(mode='EDIT', toggle=False) #削減の前のオブジェクトを、各データを操作しやすい形式に変換 originBm=bmesh.from_edit_mesh(originObj.data) #2つのオブジェクトの面と頂点の数を表示 print("originObj:") print(" vertsLen:{}".format(len(originBm.verts))) print(" facesLen:{}".format(len(originBm.faces))) print() print("faceReductedObj:") print(" vertsLen:{}".format(len(bm.verts))) print(" facesLen:{}".format(len(bm.faces))) print()
- 投稿日:2020-09-24T10:55:01+09:00
Databricksでフォルダ名やNotebook名に日本語を使うと困る場合がある
先に結論
フォルダ名やNotebook名に日本語を使用した場合、dbutils.notebook.run を使って他のNotebookを呼ぶとエラーになるケースがある
どういうことか
次のようなフォルダ構成のNotebookがあります
/Users/xxx@yyy.jp |-MyNotebook |-Myノートブック |-MyNotebookCaller |-MyNotebookコーラー |-テスト |-MyNotebook |-MyNotebookCallerこのうち、以下のケースに当てはまる場合、dbutils.notebook.run を使った別Notebookの呼び出しに失敗しました
- 呼び出し元Notebookの名前に
日本語を使用した場合
- /Users/xxx@yyy.jp/
MyNotebookコーラー- 呼び出し元Notebookの格納フォルダの名前に
日本語を使用した場合
- /Users/xxx@yyy.jp/
テスト/MyNotebookCallerなお以下のケースの場合は問題なく呼び出しに成功しました
- 呼び出し先Notebookの名前に
日本語を使用した場合
- /Users/xxx@yyy.jp/
Myノートブック- 呼び出し先Notebookの格納フォルダの名前に
日本語を使用した場合
- /Users/xxx@yyy.jp/
テスト/MyNotebook検証
各Notebookの説明
MyNotebookCallerもしくはMyNotebookコーラーからMyNotebookにパラメータを渡して呼び出して、MyNotebookでは受け取ったパラメータを/Users/xxx@yyy.jp/MyNotebook
dbutils.widgets.text("param1", "111") dbutils.widgets.text("param2", "222") print("param1:{},param2:{}".format(dbutils.widgets.get("param1"), dbutils.widgets.get("param2")))/Users/xxx@yyy.jp/Myノートブック
#/Users/xxx@yyy.jp/MyNotebookと同じ/Users/xxx@yyy.jp/MyNotebookCaller
#Cmd1 同一フォルダのMyNotebookを呼ぶ dbutils.notebook.run( "./MyNotebook", 60, { "param1": "val1", "param2": "val2" } ) #Cmd2 同一フォルダのMyノートブックを呼ぶ dbutils.notebook.run( "./Myノートブック", 60, { "param1": "val1", "param2": "val2" } ) #Cmd3 テストフォルダのMyNotebookを呼ぶ dbutils.notebook.run( "./テスト/MyNotebook", 60, { "param1": "val1", "param2": "val2" } )/Users/xxx@yyy.jp/MyNotebookコーラー
#/Users/xxx@yyy.jp/MyNotebookCallerと同じ/Users/xxx@yyy.jp/テスト/MyNotebook
#/Users/xxx@yyy.jp/MyNotebookと同じ/Users/xxx@yyy.jp/テスト/MyNotebookCaller
#Cmd1 同一フォルダのMyNotebookを呼ぶ dbutils.notebook.run( "./MyNotebook", 60, { "param1": "val1", "param2": "val2" } ) #Cmd2 一つ上のフォルダのMyNotebookを呼ぶ dbutils.notebook.run( "../MyNotebook", 60, { "param1": "val1", "param2": "val2" } )検証① 呼び出し元Notebookの名前に
日本語を使用した場合/Users/xxx@yyy.jp/
MyNotebookコーラーから同一フォルダのMyNotebookを呼んでみますCmd1 同一フォルダのMyNotebookを呼ぶdbutils.notebook.run( "./MyNotebook", 60, { "param1": "val1", "param2": "val2" } )結果として
WorkflowExceptionが発生しました。
ラテン文字(ASCII文字セット)以外の文字である日本語を使ったことでエラーが返ってきたようです。com.databricks.WorkflowException: com.databricks.common.client.DatabricksServiceHttpClientException: INVALID_PARAMETER_VALUE: Only Latin1 (ASCII) characters are currently supported. Any international characters must be removed or replaced in workflow_context一応テストフォルダのMyNotebookを呼んでみても、
Cmd2 テストフォルダのMyNotebookを呼ぶdbutils.notebook.run( "./テスト/MyNotebook", 60, { "param1": "val1", "param2": "val2" } )こちらも同様に
WorkflowExceptionが発生しましたcom.databricks.WorkflowException: com.databricks.common.client.DatabricksServiceHttpClientException: INVALID_PARAMETER_VALUE: Only Latin1 (ASCII) characters are currently supported. Any international characters must be removed or replaced in workflow_context検証② 呼び出し元Notebookの格納フォルダの名前に
日本語を使用した場合/Users/xxx@yyy.jp/
テスト/MyNotebookCallerから同一フォルダのMyNotebookを呼んでみますCmd1 同一フォルダのMyNotebookを呼ぶdbutils.notebook.run( "./MyNotebook", 60, { "param1": "val1", "param2": "val2" } )こちらも結果として
WorkflowExceptionが発生しましたcom.databricks.WorkflowException: com.databricks.common.client.DatabricksServiceHttpClientException: INVALID_PARAMETER_VALUE: Only Latin1 (ASCII) characters are currently supported. Any international characters must be removed or replaced in workflow_context検証③ 呼び出し先Notebookの名前に
日本語を使用した場合/Users/xxx@yyy.jp/MyNotebookCallerから/Users/xxx@yyy.jp/
Myノートブックを呼んでみますCmd2 同一フォルダのMyノートブックを呼ぶdbutils.notebook.run( "./Myノートブック", 60, { "param1": "val1", "param2": "val2" } )呼び出し先のNotebook名に日本語が使われているにもかかわらず処理が正常終了しました。
渡したパラメータもちゃんと出力されているようです。param1:val1,param2:val2検証④ 呼び出し先Notebookの格納フォルダの名前に
日本語を使用した場合/Users/xxx@yyy.jp/MyNotebookCallerから/Users/xxx@yyy.jp/
テスト/MyNotebookを呼んでみますCmd3 テストフォルダのMyNotebookを呼ぶdbutils.notebook.run( "./テスト/MyNotebook", 60, { "param1": "val1", "param2": "val2" } )呼び出し先のNotebookのフォルダ名に日本語が使われているにもかかわらず処理が正常終了しました。
渡したパラメータもちゃんと出力されているようです。param1:val1,param2:val2まとめ
フォルダ名やNotebook名に日本語を使う場合は気をつけましょう
- 投稿日:2020-09-24T10:49:14+09:00
Djangoでメディアファイルを表示する話
Djangoでメディアファイルを表示するにはどうしたらいいのか
まずWebサービスでファイル登録を受け付けるにはだいたいこんな感じになります。
ファイル登録
↓
ファイル表示特にDjangoはファイルフィールド、というファイル保存専用のクラスや、
アップロードフォームや、モデルというクラスがあるので
結構簡単にできると思います。アップロード側は書くのがめんどくさいので、公式のドキュメントでもおkかも。(ファイルのアップロード)
大まかに書くとこんな感じ
Djangoでサポートしてるクラス 機能 ファイルフィールド リクエストからファイル情報を受け取り、バイナリデータをディレクトリに、DBにファイルアドレスを記録する アップロードフォーム モデル(Javaで言うエンティティ)のフィールドに値をセットする モデル モデル(Javaで言うエンティティ)のフィールドを持つ。Djangoのモデルには標準でORM機能がついており、常にDBとフィールドはマイグレーションされて同期されている。さらにモデルにはSave()メソッドが搭載されている。自動永続性ユニット(´・ω・`) まず、メディアファイルを設定するには、
メディアファイルに関するルートディレクトリを設定します。サーバーの設定。DjangoとNginxの設定
いつもの感じでsetting.pyを設定します。
setting.pyBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) MEDIA_ROOT = os.path.join(BASE_DIR, 'media') # ← これ追加 MEDIA_URL = '/media/'BASE_DIRがsetting.pyから二つ上、つまり、manage.pyのあるアプリのルートディレクトリ。という意味ですね。
なので、メディアファイルのルートディレクトリを、manage.pyと同じディレクトリにあるmediaディレクトリに設定しています。
そして、メディアファイルにアクセスするURLを/media/に設定しています。実はこの状態だとDjango側がOKでもアクセスを受けるNginx側が
「ファイルが大きすぎる!」とかエラーを出したりするので。大きな画像ファイルを送るよ。という設定を書かないといけません。
設定ファイルを開きましょう% sudo vim /etc/nginx/conf.d/site.conf $Ubuntuの場合のNginxの設定の場所。CentOS派は別のファイルで試してねsite.confserver { listen 80; listen [::]:80; server_name sample; client_max_body_size 20M; #追加。リクエスト送信の最大サイズを20Mバイトにします location /static { alias /home/あなたの設定したユーザーネーム/アプリのルート/static; } location /media { #追加。メディアファイルとURLを設定します alias /home/あなたの設定したユーザーネーム/アプリのルート/media; } location / { proxy_pass http://127.0.0.1:8000; } proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_set_header X-Forwarded-Proto $scheme; }こんな感じで、locationとDjangoのメディアルートが同じ場所を示すようにしましょう
(^-^)これで、サーバー設定は完了です!
アップロード機能の使い方
めんどくさいので端折って説明(´・ω・`)
ファイルフィールドはこんな感じでモデルに組み込んで使います。fileModel.pyfrom django.core.validators import FileExtensionValidator from django.db import models ''' 画像モデル @author Nozawa ''' class Picture(models.Model): id = models.BigAutoField(primary_key=True,unique=True) name = models.CharField(max_length=200) image = models.FileField(upload_to='upload_pict/%Y/%m/%d/', verbose_name='アップロード画像', validators=[FileExtensionValidator(['jpg','png','gif', ])], ) #upload_toで保存先ディレクトリを選択 validatorsで拡張子を選択。 verbose_nameで管理画面での表示の仕方を設定します uploader = models.CharField(max_length=200) uploadDate = models.DateField() updateDate = models.DateField() deleteFlg = models.BooleanField() def __str__(self): return '<Picture:id' + str(self.id) + ', ' + \ self.name + '(' + str(self.uploader) + ')>'アップロードフォームはこんな感じでつかいます。
PictUploadForm.py''' 画像アップロード用モデルフォーム ''' class PictUploadForm(forms.ModelForm): class Meta: model = Picture fields = ['name', 'image']pictureService.pydef createPicutre(self, request): pict:PictUploadForm = PictUploadForm(request.POST, request.FILES, instance=pictObj) pict.errors if pict.is_valid(): # 値が正しいか確認(バリデーション) pict.save() # 値をDBへの登録実は、アップロードフォームは、本来のファイルアップロードの書き方を省略する機能です。
アップロードフォームは、モデルのインスタンスとリクエストを入れることで、
モデルに自動的に値を設定してくれる便利クラスなのです!本来は公式ドキュメントにある通り、こんな書き方をします
sample.pyinstance = ModelWithFileField(file_field=request.FILES['file']) #コンストラクタにフィールド名を指定して設定している instance.save()最後に、アップロード側の表示画面になります
UploadView.pyclass UploadView(TemplateView): #初期化処理 def __init__(self): self.params = { 'form': PictUploadForm.PictUploadForm(), } # 画像フォームを表示する def get(self, request): # 画像オブジェクトを代入 return render(request, 'memFrame/アップロード画面.html', self.params)アップロード画面.html<form action="{% url 'pictUpload' %}" method="post" enctype="multipart/form-data"> <!--マルチパートを設定して、ファイルアップロードを準備--> {% csrf_token %} {{ form.name }} {{ form.image }} <tr> <td> <input type="submit" value="画像をアップロード!"/> </td> </tr> </form>表示機能の使い方
ViewingView.pyclass ViewingView(TemplateView): #画像サービスクラス pictService:PictService = PictService.PictService() # 画像フォームを表示する def get(self, request): # 画像オブジェクトを代入 pictList:list = self.pictService.findAll() self.params = { 'picts':pictList, } print(pictList) return render(request, 'myapplication/表示画面.html', self.params)表示画面.html{% for pict in picts %} <h2>{{ pict.name }}</h2> <img src='{{pict.image.url}}' width=200> #ファイルフィールドのURLをイメージタグに指定する {% endfor %}結果
アップロード画像を表示することが出来ましたヾ(。>﹏<。)ノ゙✧*。


- 投稿日:2020-09-24T10:48:02+09:00
深層学習入門 ~畳み込みとプーリング編~
対象者
前回の記事はこちら
前回まででDNN(Deep Neural Network)は完成です。
(レイヤーマネージャの使い方も含めて別の記事でDNNで遊ぶ予定です)
ここでは画像認識へ向けてCNN(Convolutional Neural Network)を作成していきます。
ここで用いるim2col関数とcol2im関数は、こちらとこちらで紹介しています。目次
畳み込み層
画像認識に多大な恩恵を与えるのが畳み込みという処理です。導入としては、画像などの位置関係が重要だと思われるデータに対して、単純にニューラルネットワークに1次元に平滑化して流すのはせっかくの位置関係という重要な情報を捨てるようなものなのでもったいない、みたいな感じです。
入力の次元を維持したまま、つまり位置関係などの重要な情報を維持したままニューラルネットワークにデータを流すのが畳み込み層の役割です。
畳み込み層はこのフィルタが普通のレイヤでの重みに相当しています。あとはこのgifの通りに動作するコードを書けばいいわけですが、実はそのまま実装するととても実用に耐えない激重コードになってしまいます。
というのも、簡略化してこのgifの部分を実装するとImage = I_h×I_wの配列 Filter = F_h×F_wの配列 Output = O_h×O_wの配列 for h in range(O_h): h_lim = h + F_h for w in range(O_w): w_lim = w + F_w Output[h, w] = Image[h:h_lim, w:w_lim] * Filterのようになり、二重ループでnumpy配列にアクセスして入力の該当箇所に要素積を施していき、その結果を出力に保存していく、みたいなことをすることになります。
しかもこのループ、ここでは二重ループですが実際の入力は4次元ですので四重ループになってしまいます。すると簡単にループ回数が急増することは想像に難くないでしょう。
numpyにはfor文でアクセスすると遅くなるという仕様があるため、できるだけループでのアクセスは避けたいものです。そこで活躍するのがim2col関数です。
先のgifはa = 1W + 2X + 5Y + 6Z \\ b = 2W + 3X + 6Y + 7Z \\ c = 3W + 4X + 7Y + 8Z \\ d = 5W + 6X + 9Y + 10Z \\ e = 6W + 7X + 10Y + 11Z \\ f = 7W + 8X + 11Y + 12Z \\ g = 9W + 10X + 13Y + 14Z \\ h = 10W + 11X + 14Y + 15Z \\ i = 11W + 12X + 15Y + 16Zという感じとなっていますが、これを行列積で表すと
\left( \begin{array}{c} a \\ b \\ c \\ d \\ e \\ f \\ g \\ h \\ i \end{array} \right)^{\top} = \left( \begin{array}{cccc} W & X & Y & Z \end{array} \right) \left( \begin{array}{ccccccccc} 1 & 2 & 3 & 5 & 6 & 7 & 9 & 10 & 11 \\ 2 & 3 & 4 & 6 & 7 & 8 & 10 & 11 & 12 \\ 5 & 6 & 7 & 9 & 10 & 11 & 13 & 14 & 15 \\ 6 & 7 & 8 & 10 & 11 & 12 & 14 & 15 & 16 \end{array} \right)となります。
im2col関数は入力画像やフィルタをこんな感じの行列に変換するための関数になります。詳しくはこちらで解説しています。
さて、このim2col関数を用いることで前述の問題はだいぶ解消されます。が、もちろんim2col関数を用いると元の入力などの形状とは異なるためこのままでは誤差逆伝播法での学習が進められません。ということで逆の動作を行うcol2im関数を逆伝播時に噛ませる必要があります。詳しくはこちらで解説しています。ここまでで簡単に畳み込み層の概要を説明しましたので、その設計図を示しておきます。
畳み込み層順伝播
順伝播から見ていきましょう。関係のある部分は下図のカラー部分です。
動作的には
- 入力画像を
im2col関数に投げる- 返り値とフィルタ(を変形したもの)とを行列積計算する。
- 2.の出力とバイアスとを足し算
- 活性化関数を通す
基本動作は通常のニューラルネットワークの順伝播と同じです。違うのはその前に
im2col関数を挟むことくらいですね。
詳しく見ていきましょう。
まず畳み込み演算は以下の図のようになります。
バイアスは省いています。
入力はバッチサイズ$B$、チャンネル数$C$、画像サイズ$(I_h, I_w)$のテンソルです。
フィルタは各チャンネルごとに$M$枚存在しており、入力と同じチャンネル数を持ち、フィルタサイズ$(F_h, F_w)$のテンソルです。
入力の各チャンネルに対応するチャンネルのフィルタを全てのバッチデータに対してフィルタリングを行い、結果として$(B, M, O_h, O_w)$という形状を持つテンソルができます。この処理を具体的にどう行うかを見ていきます。
入力及びフィルタを以下の図の通りに処理します。
これにより4次元テンソルを2次元に落とし込むことができたため、行列積を行うことができるようになります。
この出力にバイアス(形状は$(M, 1)$の2次元行列)を加えます。この時、numpyのブロードキャスト機能を用いて全ての列に同じ値を加算します。
その後この出力を変形、次元入れ替えすることで求める出力テンソルにします。
この出力テンソルを活性化関数に投げれば畳み込み層の順伝播の完了です。畳み込み層逆伝播
続いて逆伝播です。関係している部分は下図のカラー部分です。
動作としては
- 出力の勾配と活性化関数の微分の要素積をとる
- 一つはバイアスの勾配として利用する
im2col関数を通した入力画像との行列積をとったものはフィルタの勾配として利用する- フィルタとの行列積をとったものは
col2im関数を通して入力の勾配として利用するという感じです。
詳しく見ていきましょう。
伝播してきた勾配は$(B, M, O_h, O_w)$のテンソルです。まずは順伝播の時とは逆順にこの勾配を変形します。
フィルタへの勾配は勾配と入力の行列積で計算されます。
得られた結果は2次元行列であるため、これを変形することでフィルタと同じ形状の4次元テンソルへ揃えます。
バイアスへの勾配について、順伝播の際に全ての列に同じ値を加算したことが鍵になります。同じ値をいくつかの要素に加算することが示すのは、以下の図のような形状のネットワークと同等である、ということです。
(数は適当です)
このため、$axis=1$つまり列方向からそれぞれ1つのバイアスに向けて逆伝播が行われるため、それらを足し合わせたものがバイアスへの勾配となります。
入力への勾配はフィルタと勾配の行列積で計算されます。
計算結果のテンソルを見てみるとわかるかと思いますが、形状が順伝播の時に入力テンソルをim2col関数に投げた結果と同じとなっています。そのため、逆の操作を行うcol2im関数にこれを投げることで入力への勾配テンソルが形成されます。
これで畳み込み層の逆伝播は完了です。畳み込み層学習
さて、フィルタの変形は実は毎回行う必要がありません。最初に1回行うだけで良いです。その理由は「フィルタは毎回同じ変形をするのでわざわざ繰り返し行う必要がない」ためです。
フィルタは最初に変形したあとそのまま、ということは逆伝播で計算したフィルタへの勾配も変形する必要はありません。
そんなこんなで、畳み込み層の学習は通常のレイヤと同じ形になります。
畳み込み層実装
ということで実装します。ただし
BaseLayerを継承させるために少しの工夫が必要です。
conv.py
conv.pyimport numpy as np class ConvLayer(BaseLayer): def __init__(self, *, I_shape=None, F_shape=None, stride=1, pad="same", name="", wb_width=5e-2, act="ReLU", opt="Adam", act_dic={}, opt_dic={}, **kwds): self.name = name if I_shape is None: raise KeyError("Input shape is None.") if F_shape is None: raise KeyError("Filter shape is None.") if len(I_shape) == 2: C, I_h, I_w = 1, *I_shape else: C, I_h, I_w = I_shape self.I_shape = (C, I_h, I_w) if len(F_shape) == 2: M, F_h, F_w = 1, *F_shape else: M, F_h, F_w = F_shape self.F_shape = (M, C, F_h, F_w) if isinstance(stride, tuple): stride_ud, stride_lr = stride else: stride_ud = stride stride_lr = stride self.stride = (stride_ud, stride_lr) if isinstance(pad, tuple): pad_ud, pad_lr = pad elif isinstance(pad, int): pad_ud = pad pad_lr = pad elif pad == "same": pad_ud = 0.5*((I_h - 1)*stride_ud - I_h + F_h) pad_lr = 0.5*((I_w - 1)*stride_lr - I_w + F_w) self.pad = (pad_ud, pad_lr) O_h = get_O_shape(I_h, F_h, stride_ud, pad_ud) O_w = get_O_shape(I_w, F_w, stride_lr, pad_lr) self.O_shape = (M, O_h, O_w) self.n = np.prod(self.O_shape) # フィルタとバイアスを設定 self.w = wb_width*np.random.randn(*self.F_shape).reshape(M, -1).T self.b = wb_width*np.random.randn(M) # 活性化関数(クラス)を取得 self.act = get_act(act, **act_dic) # 最適化子(クラス)を取得 self.opt = get_opt(opt, **opt_dic) def forward(self, x): B = x.shape[0] M, O_h, O_w = self.O_shape x, _, self.pad_state = im2col(x, self.F_shape, stride=self.stride, pad=self.pad) super().forward(x.T) return self.y.reshape(B, O_h, O_w, M).transpose(0, 3, 1, 2) def backward(self, grad): B = grad.shape[0] I_shape = B, *self.I_shape M, O_h, O_w = self.O_shape grad = grad.transpose(0, 2, 3, 1).reshape(-1, M) super().backward(grad) self.grad_x = col2im(self.grad_x.T, I_shape, self.O_shape, stride=self.stride, pad=self.pad_state) return self.grad_xどのあたりを工夫しているのか説明していきます。
工夫せずに、先ほどまでで説明した通りに実装すると以下のようになります。
工夫なしver.
conv.pyimport numpy as np class ConvLayer(BaseLayer): def __init__(self, *, I_shape=None, F_shape=None, stride=1, pad="same", name="", wb_width=5e-2, act="ReLU", opt="Adam", act_dic={}, opt_dic={}, **kwds): self.name = name if I_shape is None: raise KeyError("Input shape is None.") if F_shape is None: raise KeyError("Filter shape is None.") if len(I_shape) == 2: C, I_h, I_w = 1, *I_shape else: C, I_h, I_w = I_shape self.I_shape = (C, I_h, I_w) if len(F_shape) == 2: M, F_h, F_w = 1, *F_shape else: M, F_h, F_w = F_shape self.F_shape = (M, C, F_h, F_w) _, O_shape, self.pad_state = im2col(np.zeros((1, *self.I_shape)), self.F_shape, stride=stride, pad=pad) self.O_shape = (M, *O_shape) self.stride = stride self.n = np.prod(self.O_shape) # フィルタとバイアスを設定 self.w = wb_width*np.random.randn(*self.F_shape).reshape(M, -1) self.b = wb_width*np.random.randn(M, 1) # 活性化関数(クラス)を取得 self.act = get_act(act, **act_dic) # 最適化子(クラス)を取得 self.opt = get_opt(opt, **opt_dic) def forward(self, x): B = x.shape[0] M, O_h, O_w = self.O_shape self.x, _, self.pad_state = im2col(x, self.F_shape, stride=self.stride, pad=self.pad) self.u = self.w@self.x + self.b self.u = self.u.reshape(M, B, O_h, O_w).transpose(1, 0, 2, 3) self.y = self.act.forward(self.u) return self.y def backward(self, grad): B = grad.shape[0] I_shape = B, *self.I_shape _, O_h, O_w = self.O_shape dact = grad*self.act.backward(self.u, self.y) dact = dact.transpose(1, 0, 2, 3).reshape(M, -1) self.grad_w = dact@self.x.T self.grad_b = np.sum(dact, axis=1).reshape(M, 1) self.grad_x = self.w.T@dact self.grad_x = col2im(self.grad_x, I_shape, self.O_shape, stride=self.stride, pad=self.pad_state) return self.grad_x
BaseLayerとの差異を、コードを省略しながら細かく見ていきます。
注目部分 BaseLayer形状 ConvLayer形状 w randn(prev, n) $(prev, n)$ randn(*F_shape).reshape(M, -1) $(M, CF_hF_w)$ b randn(n) $(n, )$ randn(M, 1) $(M, 1)$ x - $(B, prev)$ im2col(x) $(CF_hF_w, BO_hO_w)$ u x@w + b $(B, prev)@(prev, n)+(n)=(B, n)$ w@x + b $(M, CF_hF_w)@(CF_hF_w, BO_hO_w)+(M, 1)=(M, BO_hO_w)$ u - - u.reshape(M, B, O_h, O_w).transpose(1, 0, 2, 3) $(B, M, O_h, O_w)$ y act.forward(u) $(B, n)$ act.forward(u) $(B, M, O_h, O_w)$ grad - $(B, n)$ - $(B, M, O_h, O_w)$ dact grad*act.backward(u, y) $(B, n)$ grad*act.backward(u, y) $(B, M, O_h, O_w)$ dact - - dact.transpose(1, 0, 2, 3).reshape(M, -1) $(M, BO_hO_w)$ grad_w x.T@dact $(prev, B)@(B, n)=(prev, n)$ dact@x.T $(M, BO_hO_w)@(BO_hO_w, CF_hF_w)=(M, CF_hF_w)$ grad_b sum(dact, axis=0) $(n)$ sum(dact, axis=1).reshape(M, 1) $(M, 1)$ grad_x dact@w.T $(B, n)@(n, prev)=(B, prev)$ w.T@dact $(CF_hF_w, M)@(M, BO_hO_w)=(CF_hF_w, BO_hO_w)$ grad_x - - col2im(grad_x) $(B, C, I_h, I_w)$ まずは順伝播を揃えましょう。
順伝播の最も異なる点はuの計算ですね。\boldsymbol{x}@\boldsymbol{w} + \boldsymbol{b} \quad \Leftrightarrow \quad \boldsymbol{w}@\boldsymbol{x} + \boldsymbol{b}行列積は$\boldsymbol{w}@\boldsymbol{x} = \boldsymbol{x}^{\top}@\boldsymbol{w}^{\top}$とすることで順番を逆にすることができるため、
\begin{align} \boldsymbol{x} &\leftarrow \textrm{im2col}(\boldsymbol{x})^{\top} = (BO_hO_w, CF_hF_w) \\ \boldsymbol{w} &\leftarrow \boldsymbol{w}^{\top} = (CF_hF_w, M) \\ \boldsymbol{b} & \leftarrow (M, ) \end{align}のようにしておくことで順伝播の数式と揃えることが可能です。また、バイアスについても
numpyのブロードキャスト機能を有効にするために$(M, 1)$とわざわざ2次元行列としていたのを1次元配列にすることができます。
このように順伝播を変更すると\boldsymbol{x}@\boldsymbol{w} + \boldsymbol{b} = (BO_hO_w, CF_hF_w)@(CF_hF_w, M) + (M) = (BO_hO_w, M)と計算されるので、
BaseLayerのforwardで計算したあと、次の層への伝播をself.y.reshape(B, O_h, O_w, M).transpose(0, 3, 1, 2)とすることで$(B, M, O_h, O_w)$と変形することができます。
また、工夫した方のコードを見るとreturn文で上述の変形をして流していますが、これによりuとyの形状が$(BO_hO_w, M)$のままとなります。これはこのままで大丈夫です。続いて逆伝播です。勾配
gradは$(B, M, O_h, O_w)$となっており、このままではgrad*act.backward(u, y)の要素積計算ができません。\boldsymbol{grad} \otimes \textrm{act.backward}(\boldsymbol{u}, \boldsymbol{y}) = (B, M, O_h, O_w) \otimes (BO_hO_w, M)ということで
gradを変形して揃えましょう.
grad.transpose(0, 2, 3, 1).reshape(-1, M)とすればOKですね。
この後はBaseLayerのbackwardに投げれば\begin{array}[cccc] d\boldsymbol{dact} &= \boldsymbol{grad} \otimes \textrm{act.backward}(\boldsymbol{u}, \boldsymbol{y}) &= (BO_hO_w, M) & \\ \boldsymbol{grad_w} &= \boldsymbol{x}^{\top}@\boldsymbol{dact} &= (CF_hF_w, BO_hO_w)@(BO_hO_w, M) &= (CF_hF_w, M)\\ \boldsymbol{grad_b} &= \textrm{sum}(\boldsymbol{dact}, \textrm{axis}=0) &= (M, ) & \\ \boldsymbol{grad_x} &= \boldsymbol{dact}@\boldsymbol{w}^{\top} &= (BO_hO_w, M)@(M, CF_hF_w) &= (BO_hO_w, CF_hF_w) \end{array}となるので
\boldsymbol{grad_x} \leftarrow \textrm{col2im}(\boldsymbol{grad_x}^{\top}) = (B, C, I_h, I_w)とすればOKです。
BaseLayerのupdate関数については前述の通り変更する必要がありません。
よって、これで畳み込み層の完成です。プーリング層
続いてプーリング層です。まずプーリング層とは、入力画像の中から重要だと思われる情報のみを抜き出してデータサイズを小さくするレイヤです。この場合の重要な情報というのは、大抵の場合は最大値だったり平均値だったりします。
また、これを実装する際には畳み込み層と同様にim2col関数やcol2im関数を利用することで高速かつ効率的になります。
プーリング層の設計図は次のような感じとなります。
プーリング層順伝播
順伝播を見てみます。関係しているのはカラー部分です。
動作としては
- 入力画像を
im2col関数に投げる- 返り値の形状を取得する
- 返り値から最大値とそのインデックスを取得する
- 出力画像の形状に再構成する
という感じです。逆伝播のためにいくつか保持しておくべきものがありますね。
詳しく見ていきます。目標とする動作は下図の通りです。
まず、入力テンソルをim2col関数に投げて2次元行列に変換します。
さらにこの2次元行列を変形します。
このような縦長な行列に変形した後は列方向に和を取り、最後に変形と次元入れ替えを行えば出力の完成です。
また、列和を取る前に最大値のインデックスを取得しておく必要があります。プーリング層逆伝播
続いて逆伝播です。関係しているのは数のカラー部分ですね。
動作としては
- 出力画像の勾配を変形する
- 入力画像を
im2col関数に投げた時の返り値と同じ形状の空の行列を生成する- 生成した空の行列の、元の返り値の最大値があったインデックスに勾配情報を配置する
col2im関数に投げるという感じです。ちょっと言葉だけでは動作が分かりにくいですね…以下のような感じです。
プーリング層学習
設計図にないのでお分かりかと思いますが、プーリング層に学習すべきパラメータは存在しません。ということで学習することもありません。
プーリング層実装
プーリング層の説明は畳み込み層と比べて随分簡単でしたね。実装もそこまで複雑なことはしません。
pool.py
pool.pyimport numpy as np class PoolingLayer(BaseLayer): def __init__(self, *, I_shape=None, pool=1, pad=0, name="", **kwds): self.name = name if I_shape is None: raise KeyError("Input shape is None.") if len(I_shape) == 2: C, I_h, I_w = 1, *I_shape else: C, I_h, I_w = I_shape self.I_shape = (C, I_h, I_w) _, O_shape, self.pad_state = im2col(np.zeros((1, *self.I_shape)), (pool, pool), stride=pool, pad=pad) self.O_shape = (C, *O_shape) self.n = np.prod(self.O_shape) self.pool = pool self.F_shape = (pool, pool) def forward(self, x): B = x.shape[0] C, O_h, O_w = self.O_shape self.x, _, self.pad_state = im2col(x, self.F_shape, stride=self.pool, pad=self.pad_state) self.x = self.x.T.reshape(B*O_h*O_w*C, -1) self.max_index = np.argmax(self.x, axis=1) self.y = np.max(self.x, axis=1).reshape(B, O_h, O_w, C).transpose(0, 3, 1, 2) return self.y def backward(self, grad): B = grad.shape[0] I_shape = B, *self.I_shape C, O_h, O_w = self.O_shape grad = grad.transpose(0, 2, 3, 1).reshape(-1, 1) self.grad_x = np.zeros((grad.size, self.pool*self.pool)) self.grad_x[:, self.max_index] = grad self.grad_x = self.grad_x.reshape(B*O_h*O_w, C*self.pool*self.pool).T self.grad_x = col2im(self.grad_x, I_shape, self.O_shape, stride=self.pool, pad=self.pad_state) return self.grad_x def update(self, **kwds): passおわりに
CNNの実験コード組んでみたら上手く動かず、ずっと調査してました...結論から言うと畳み込み層もプーリング層も問題なく、活性化関数が問題だったんですけどね泣笑
活性化関数一覧の方の実装も変更してあります。
次回記事で実験コードを載せます。LayerManagerクラスなども結構変更してたりします。深層学習シリーズ
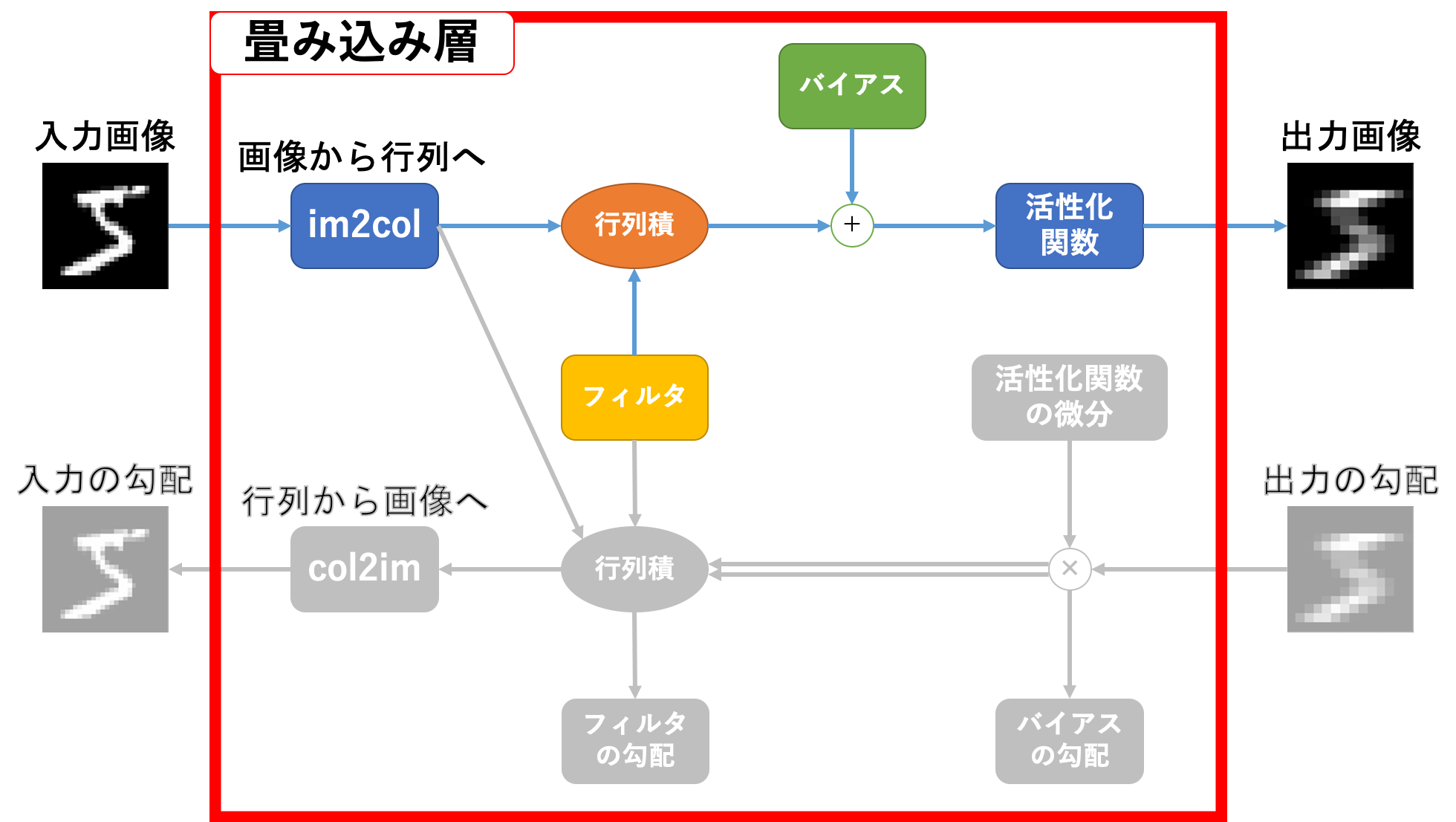
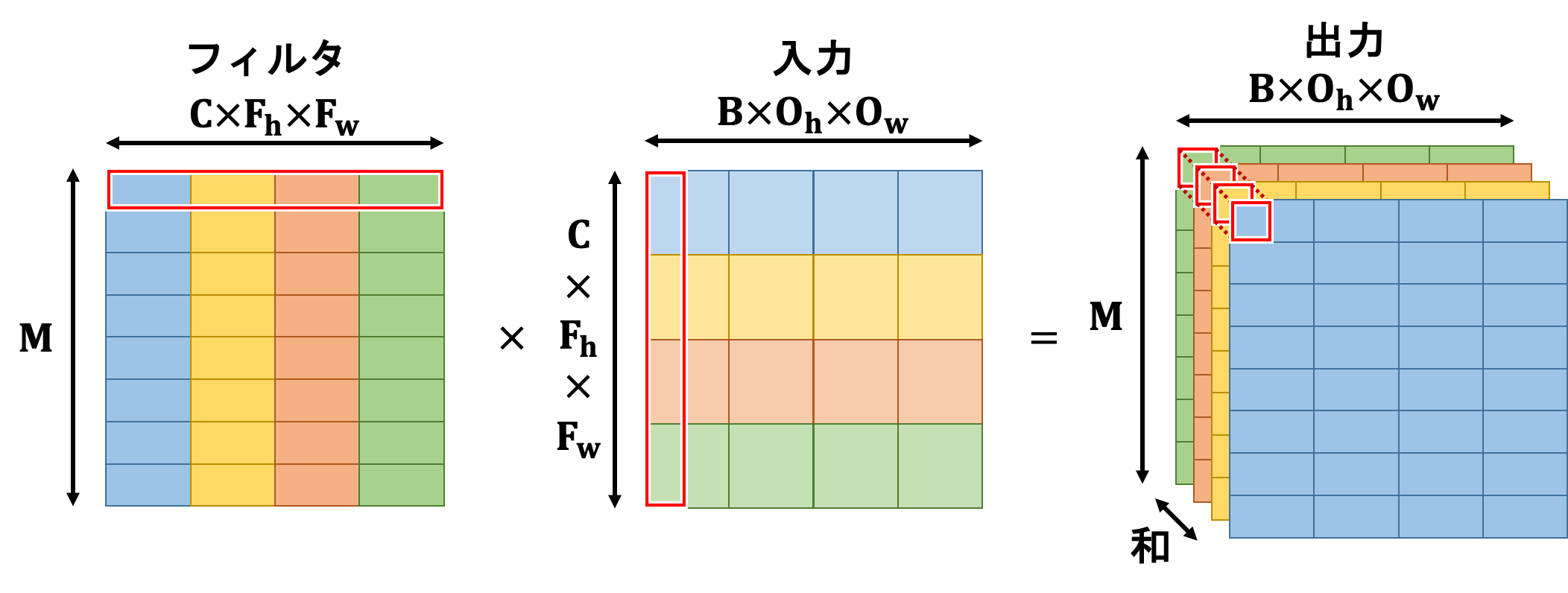
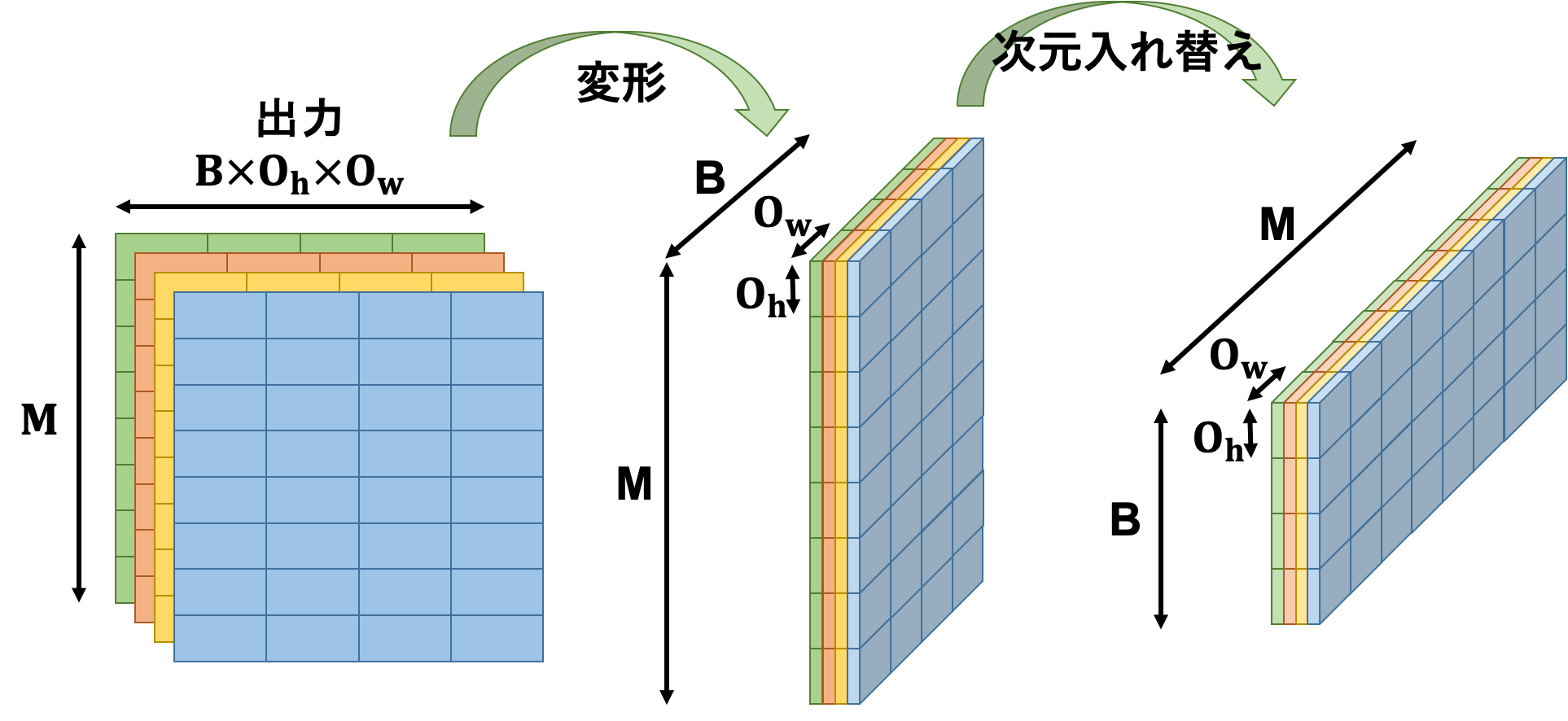
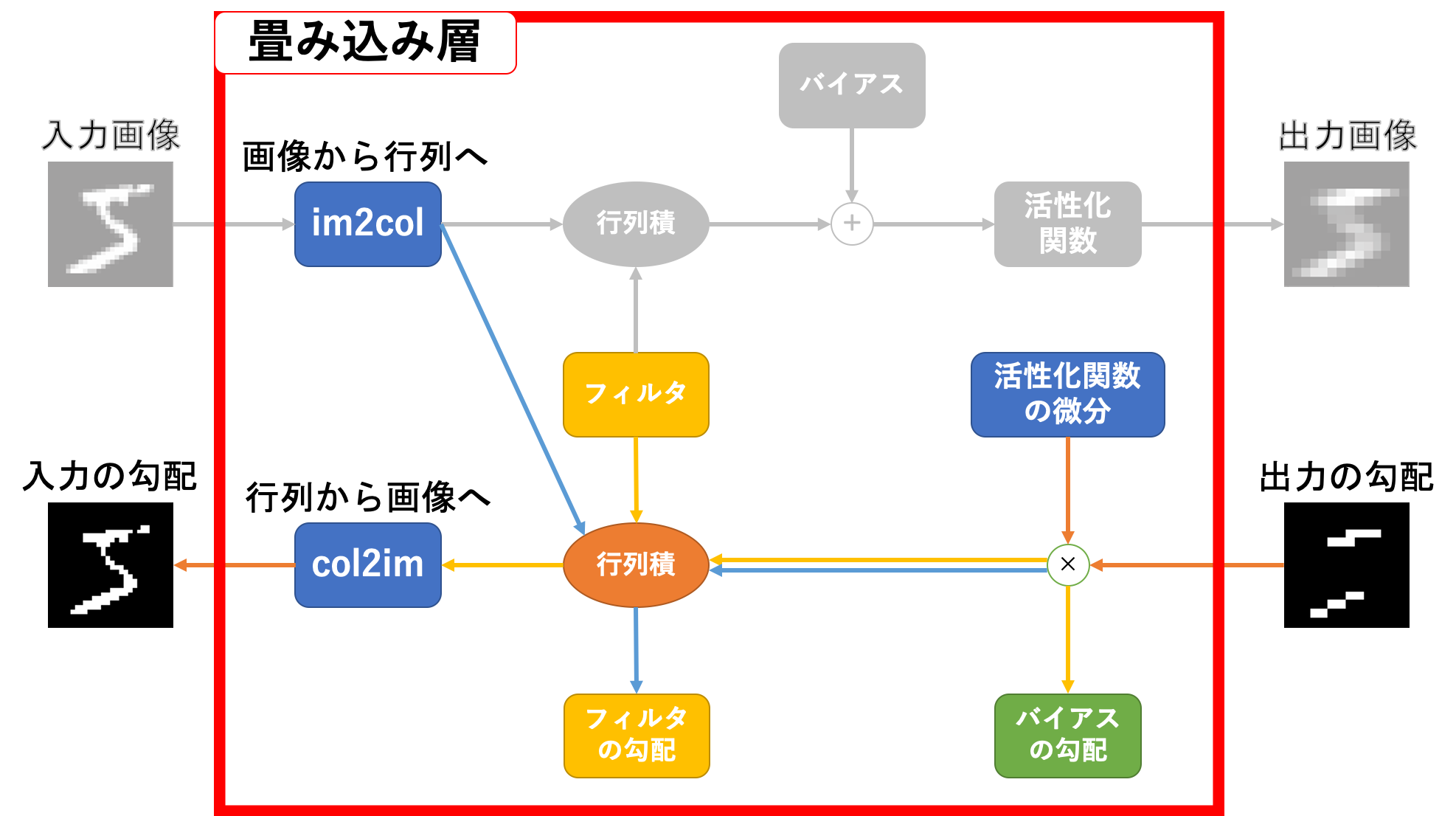
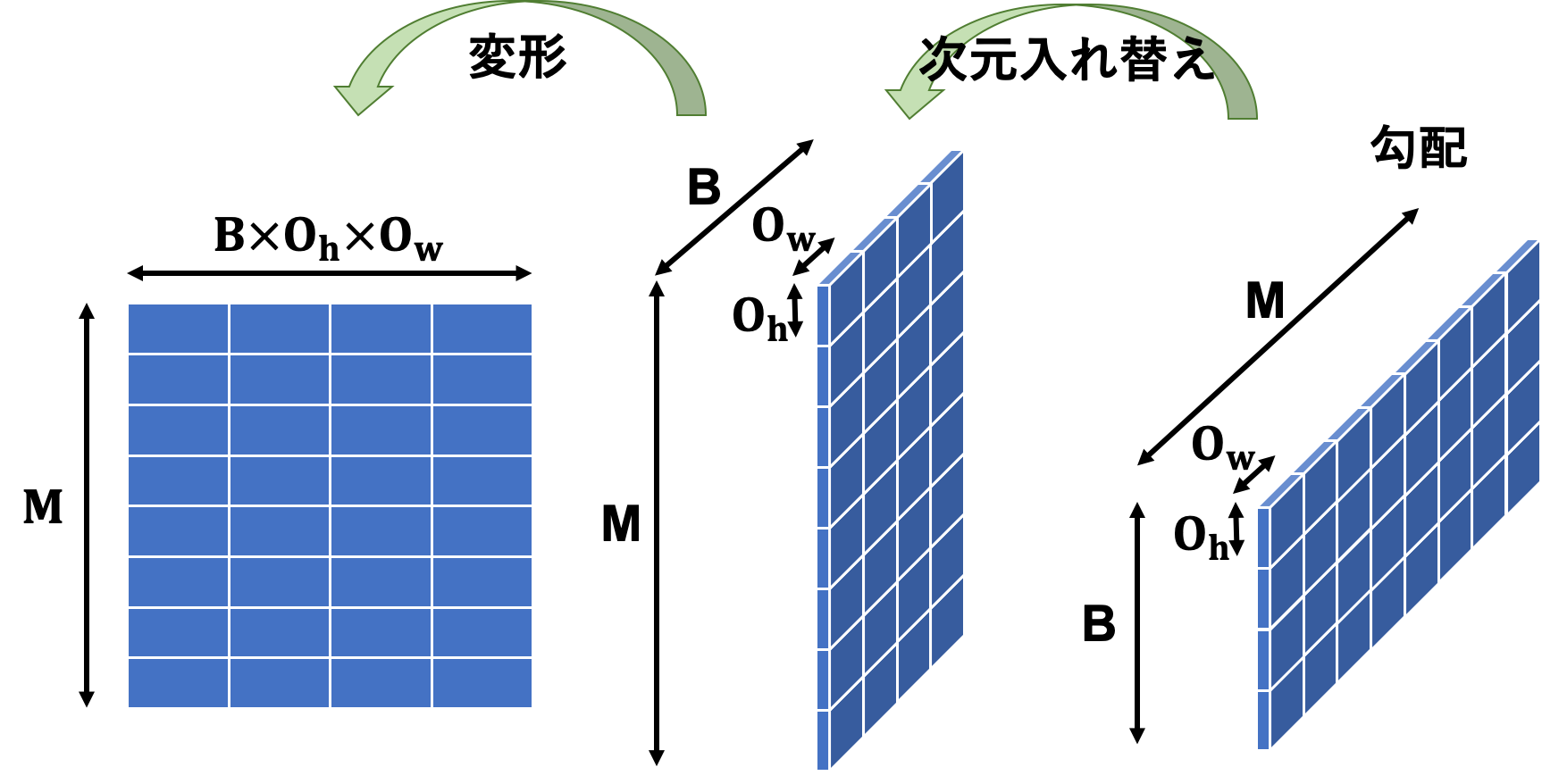
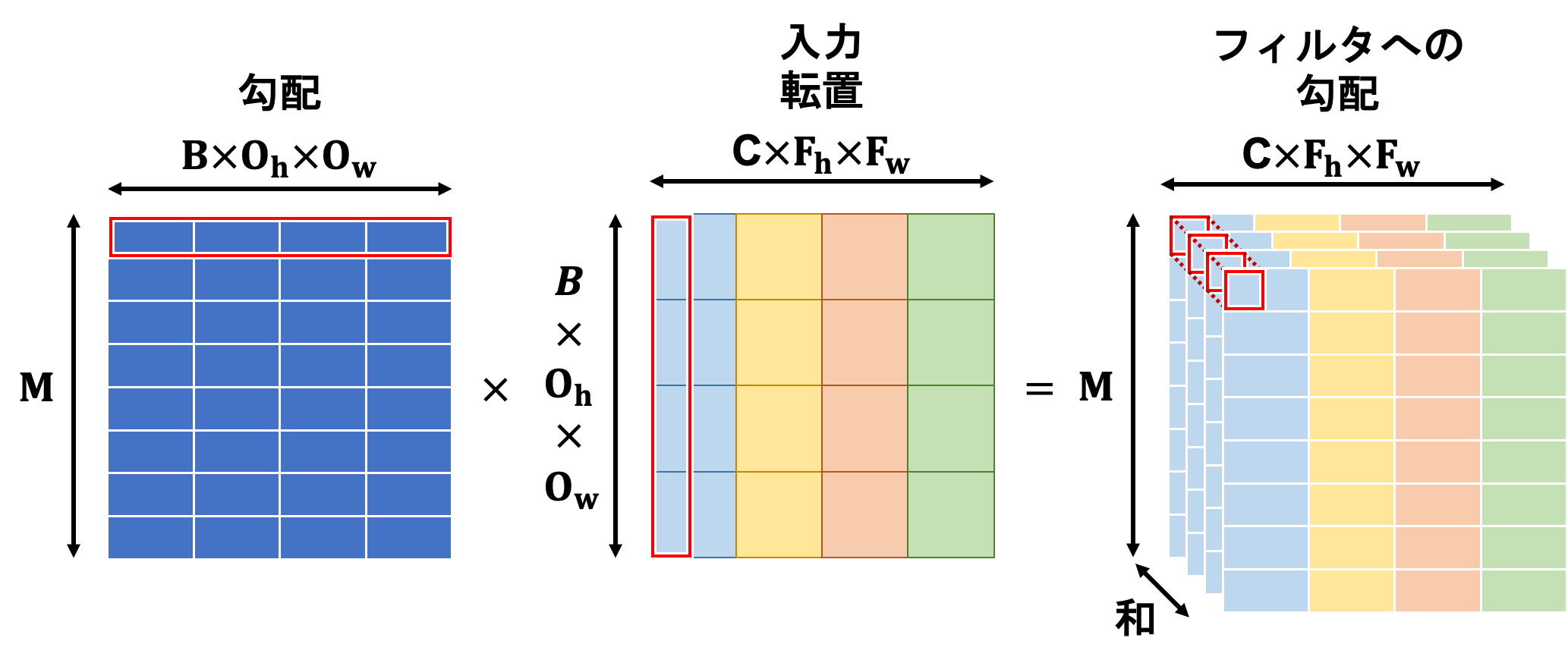
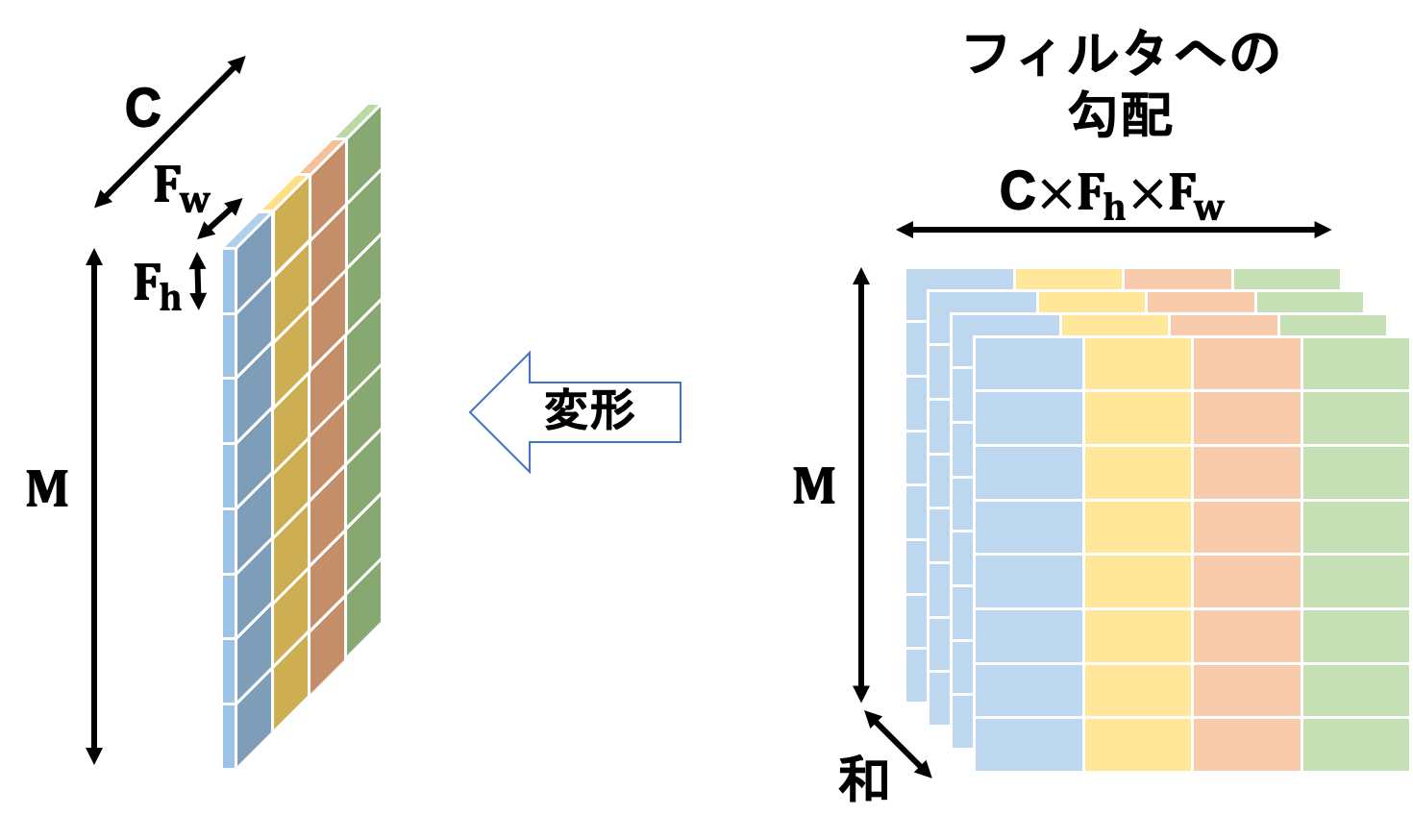

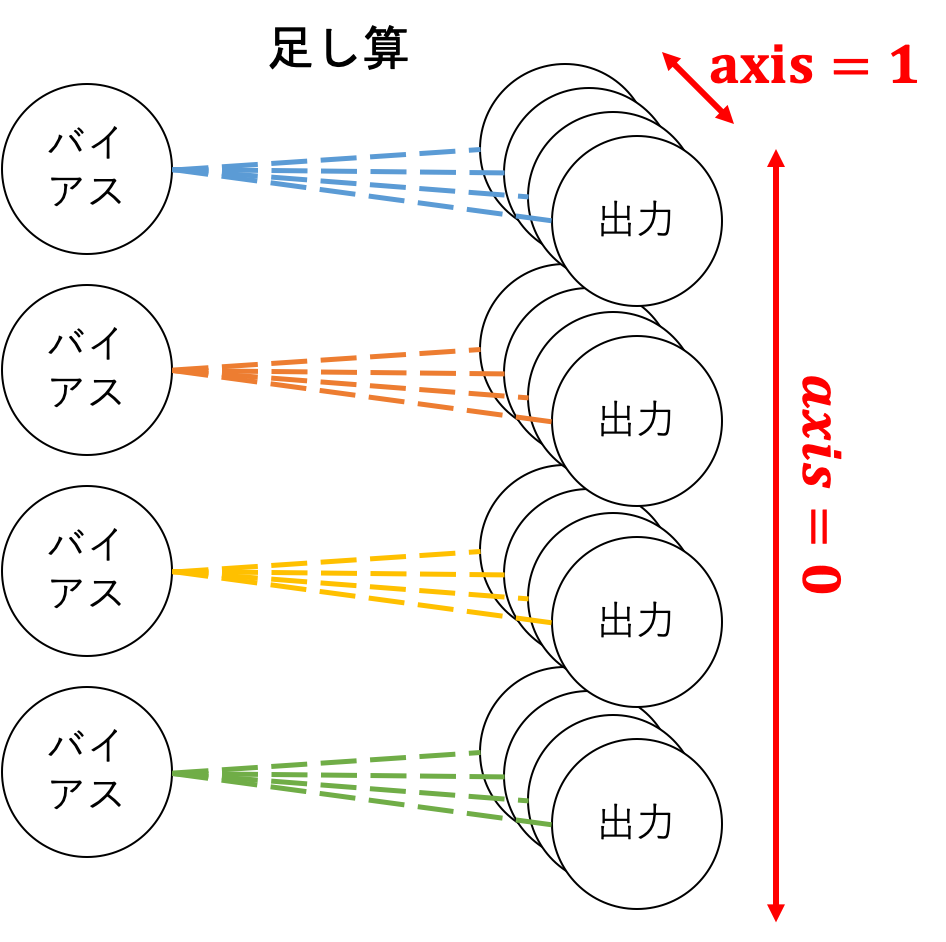
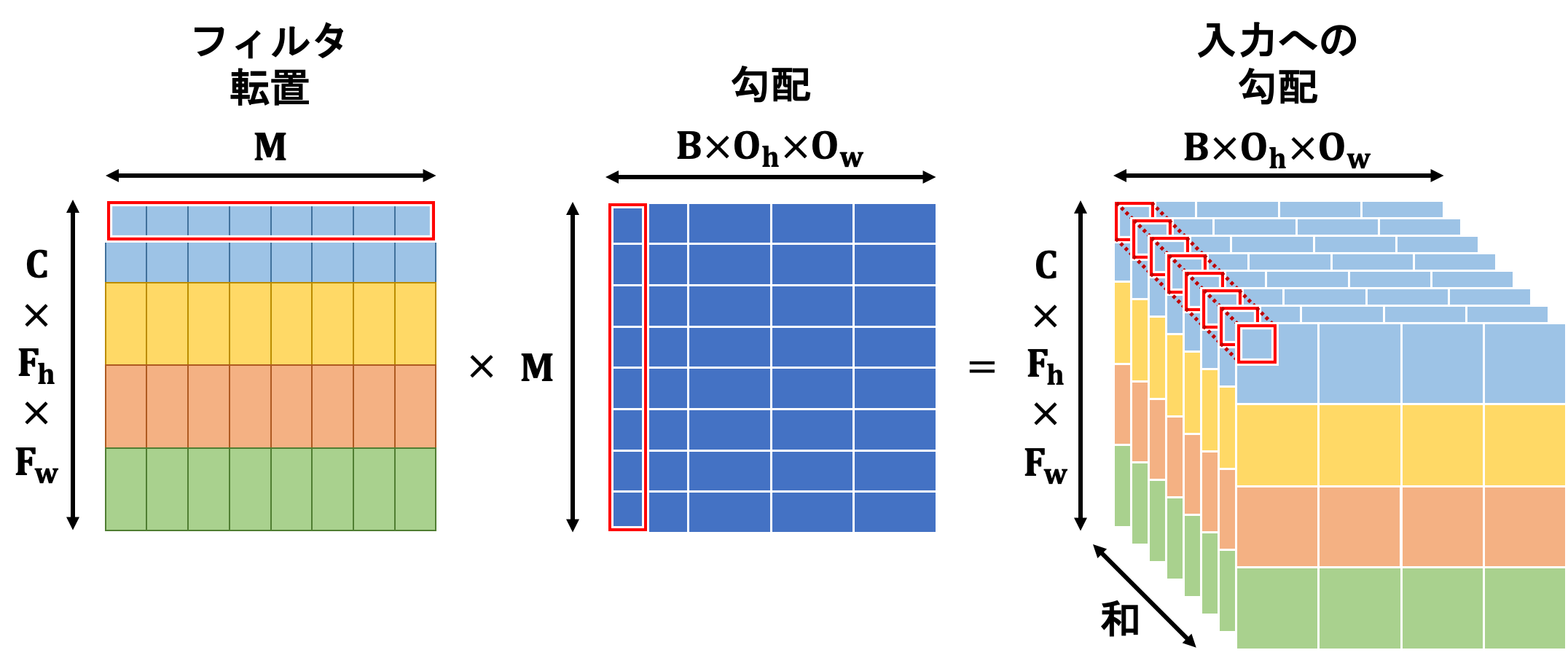
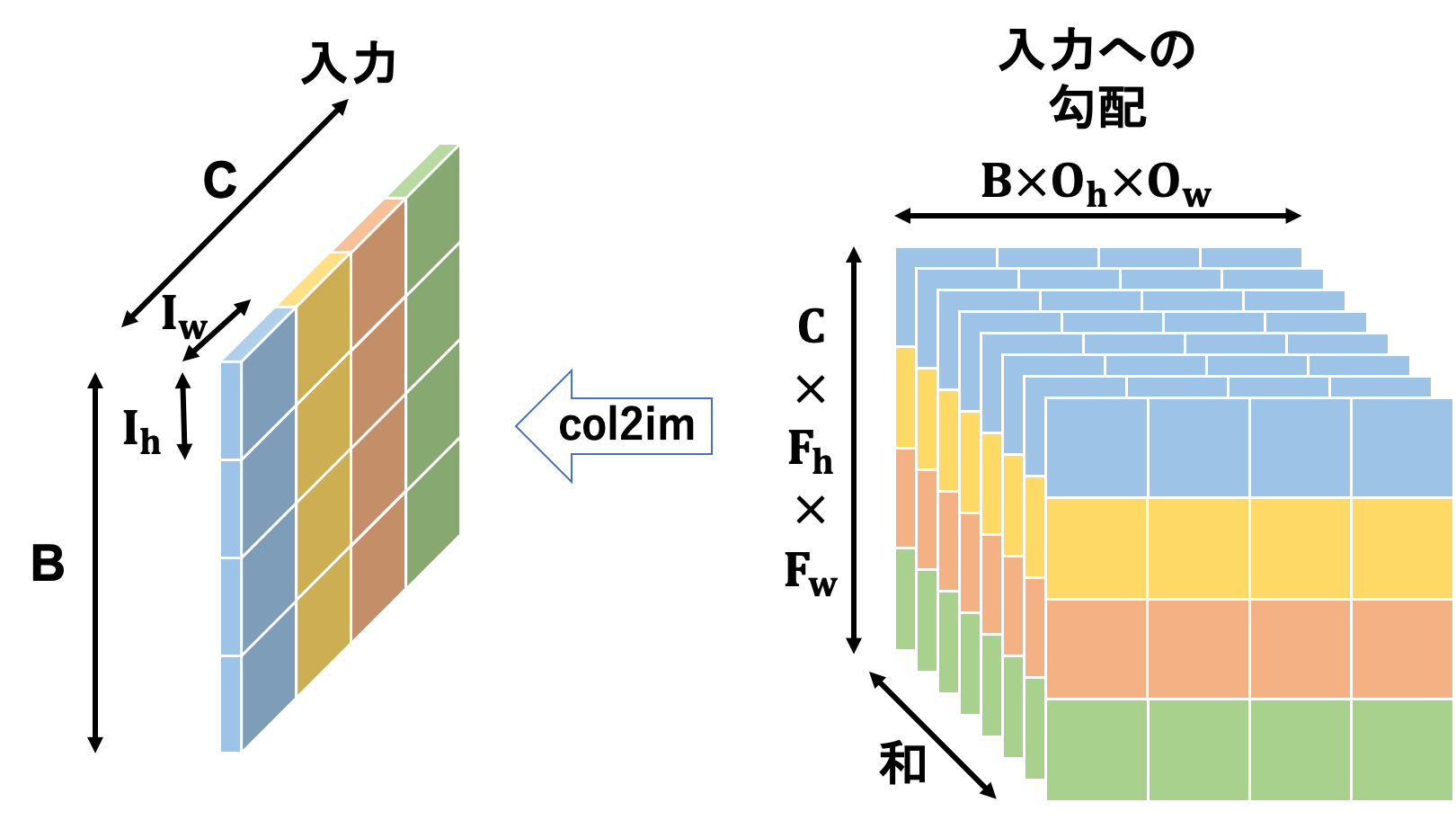
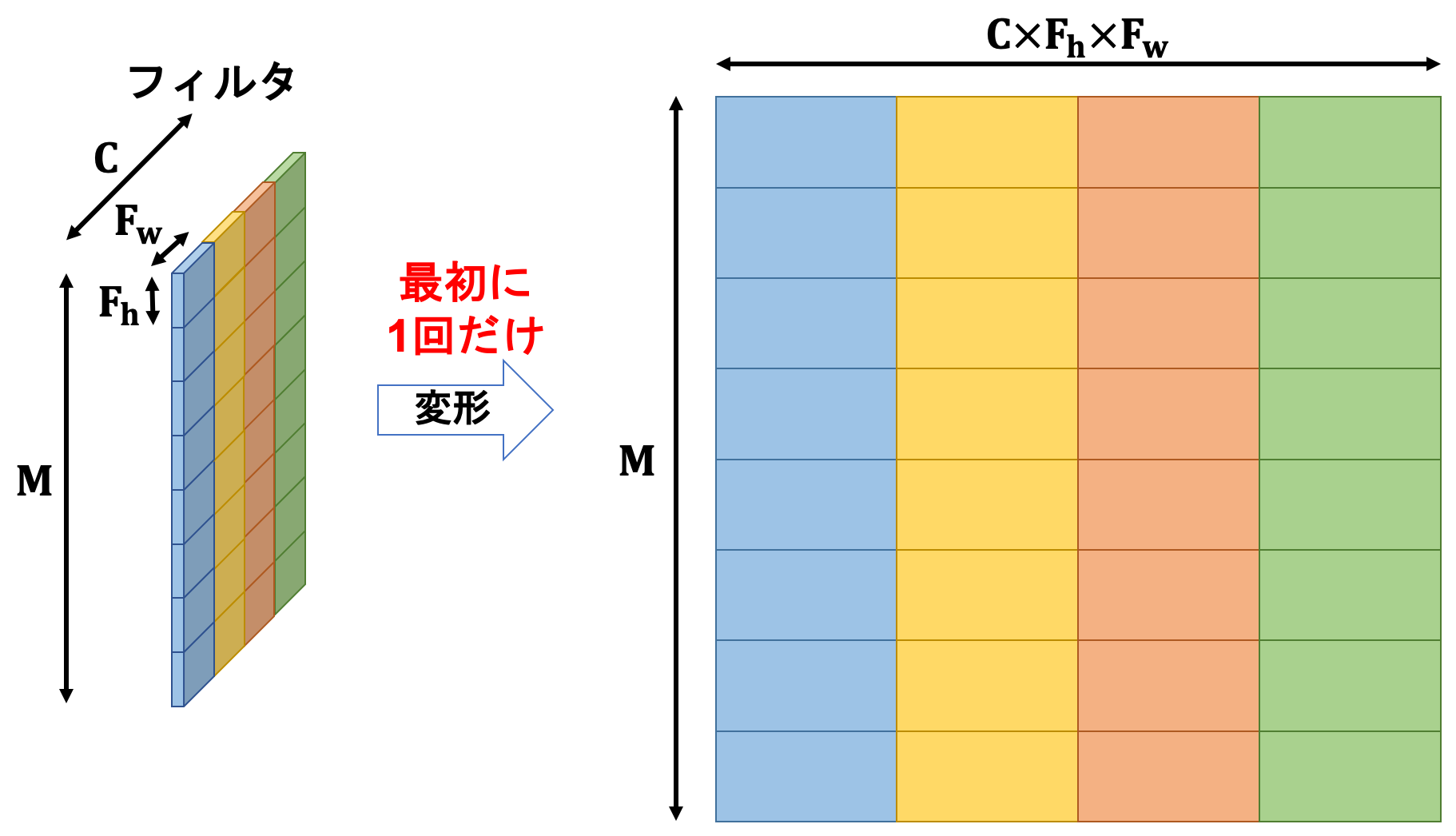
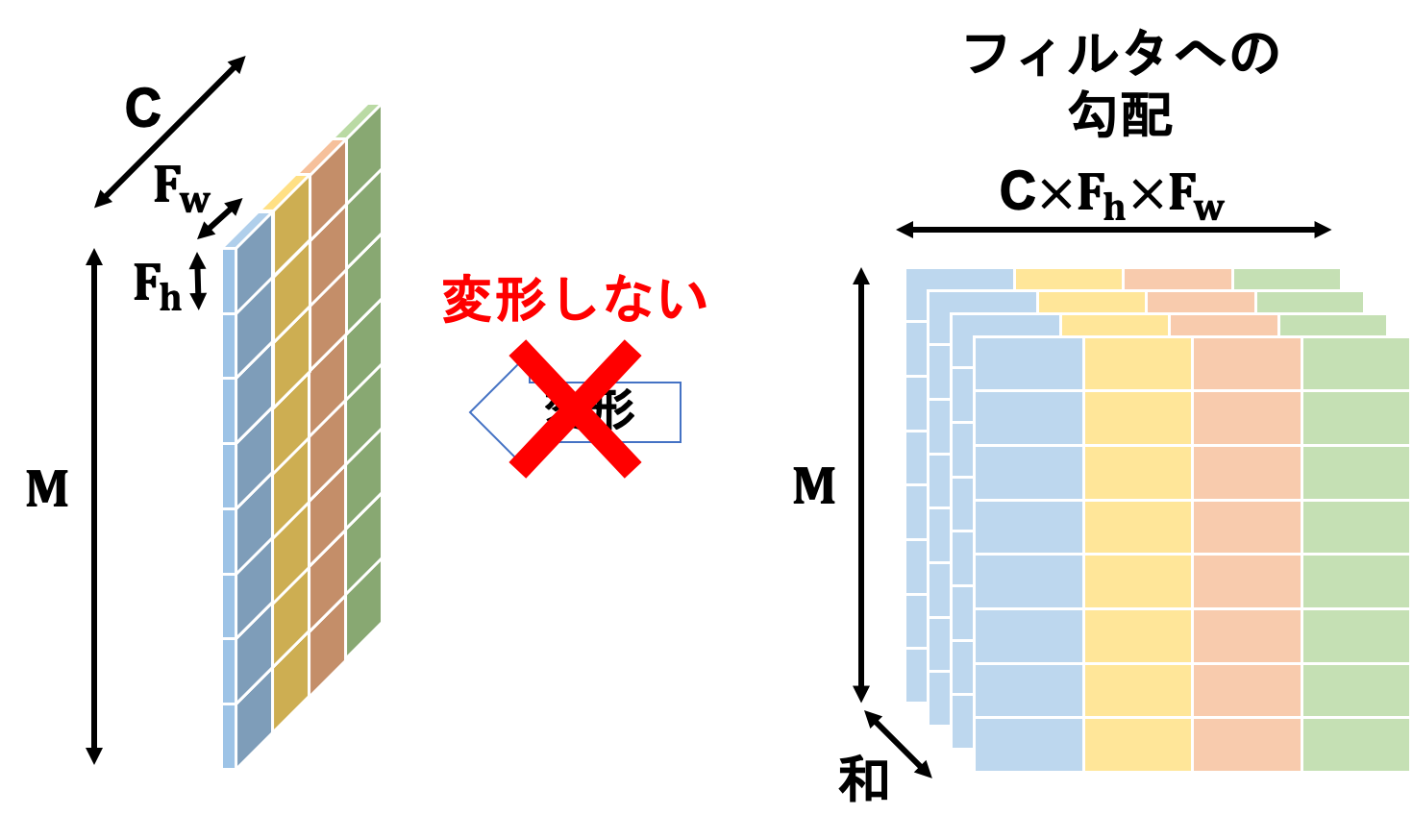
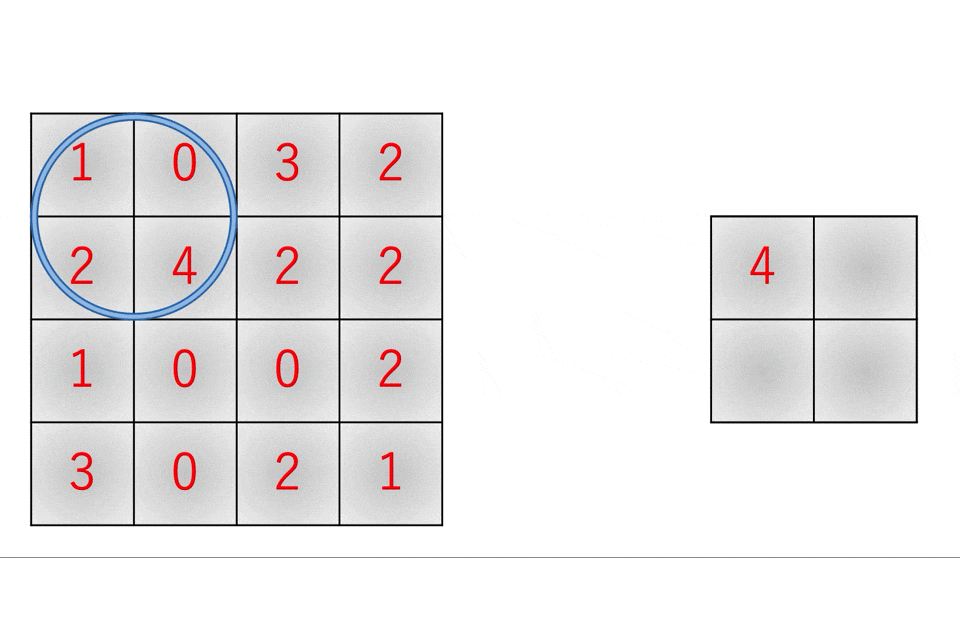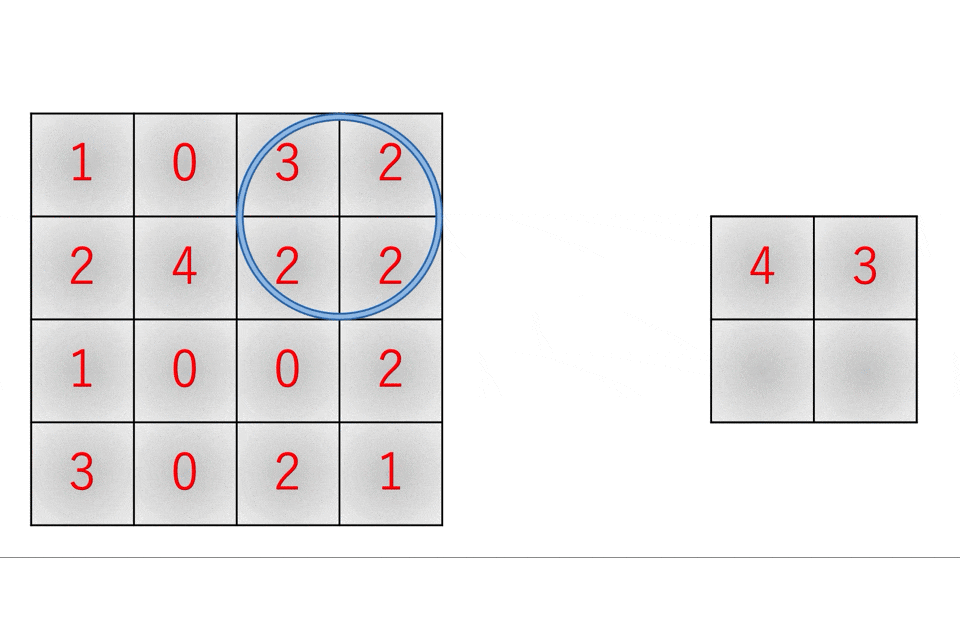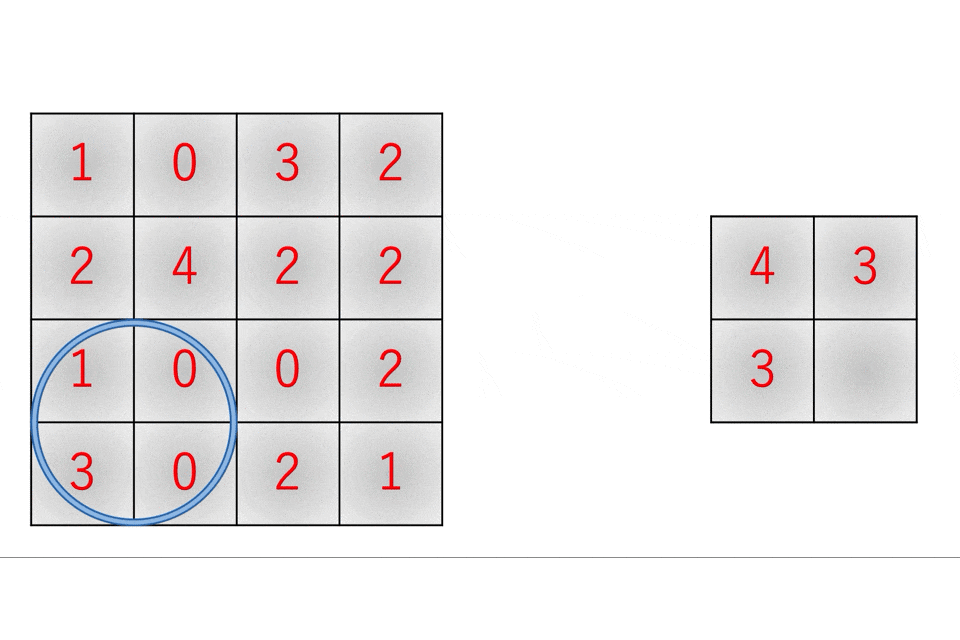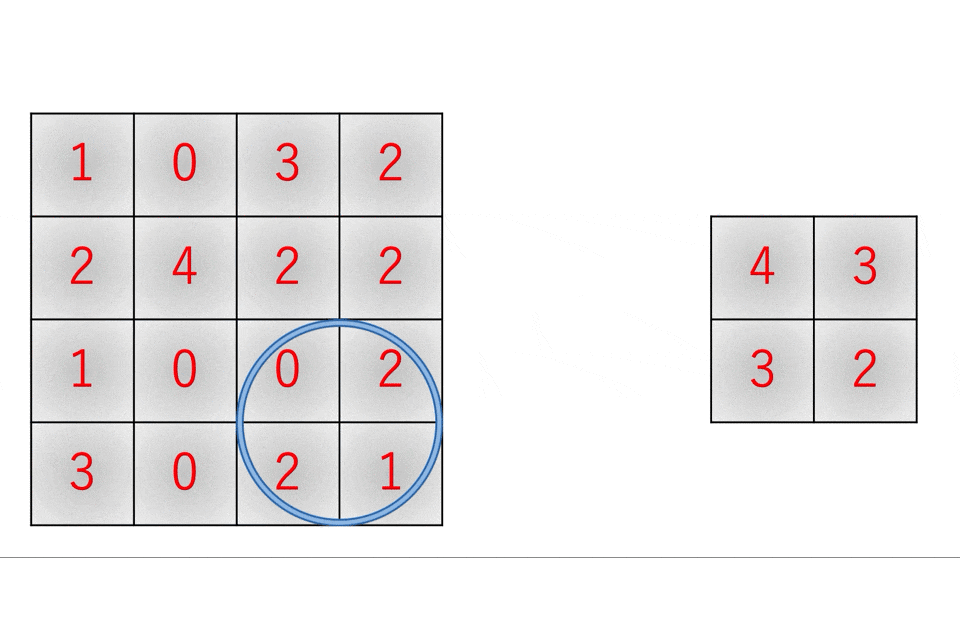

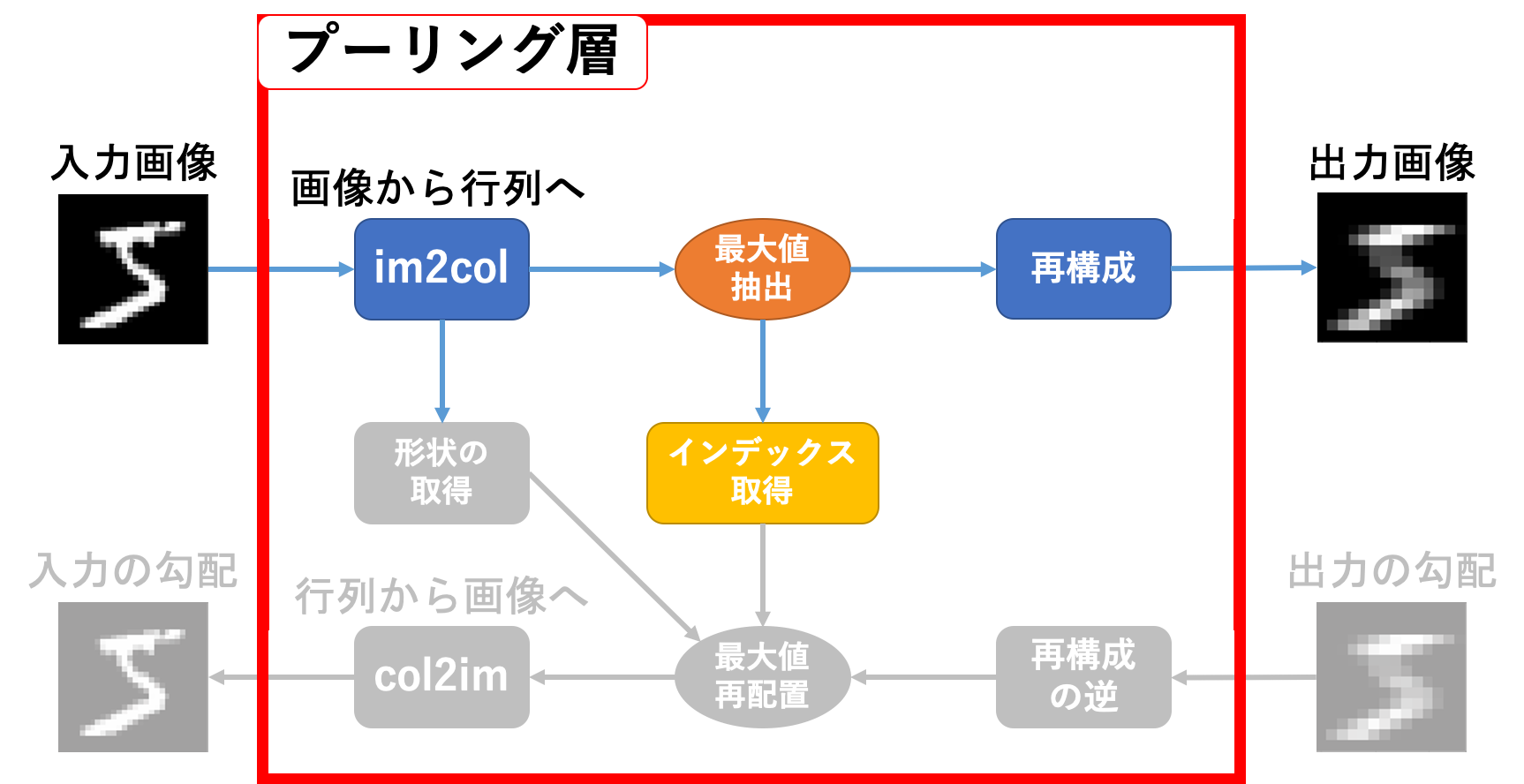

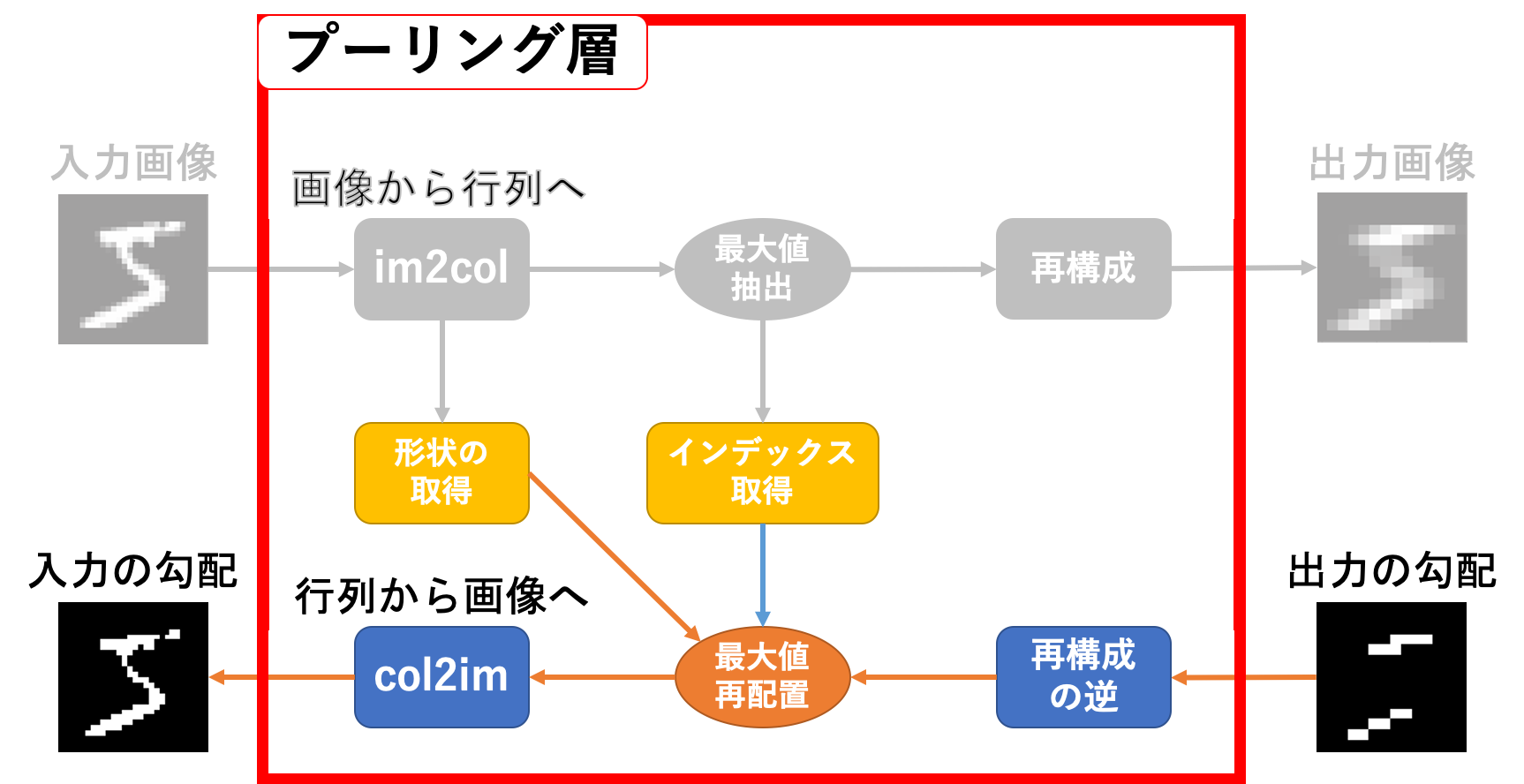
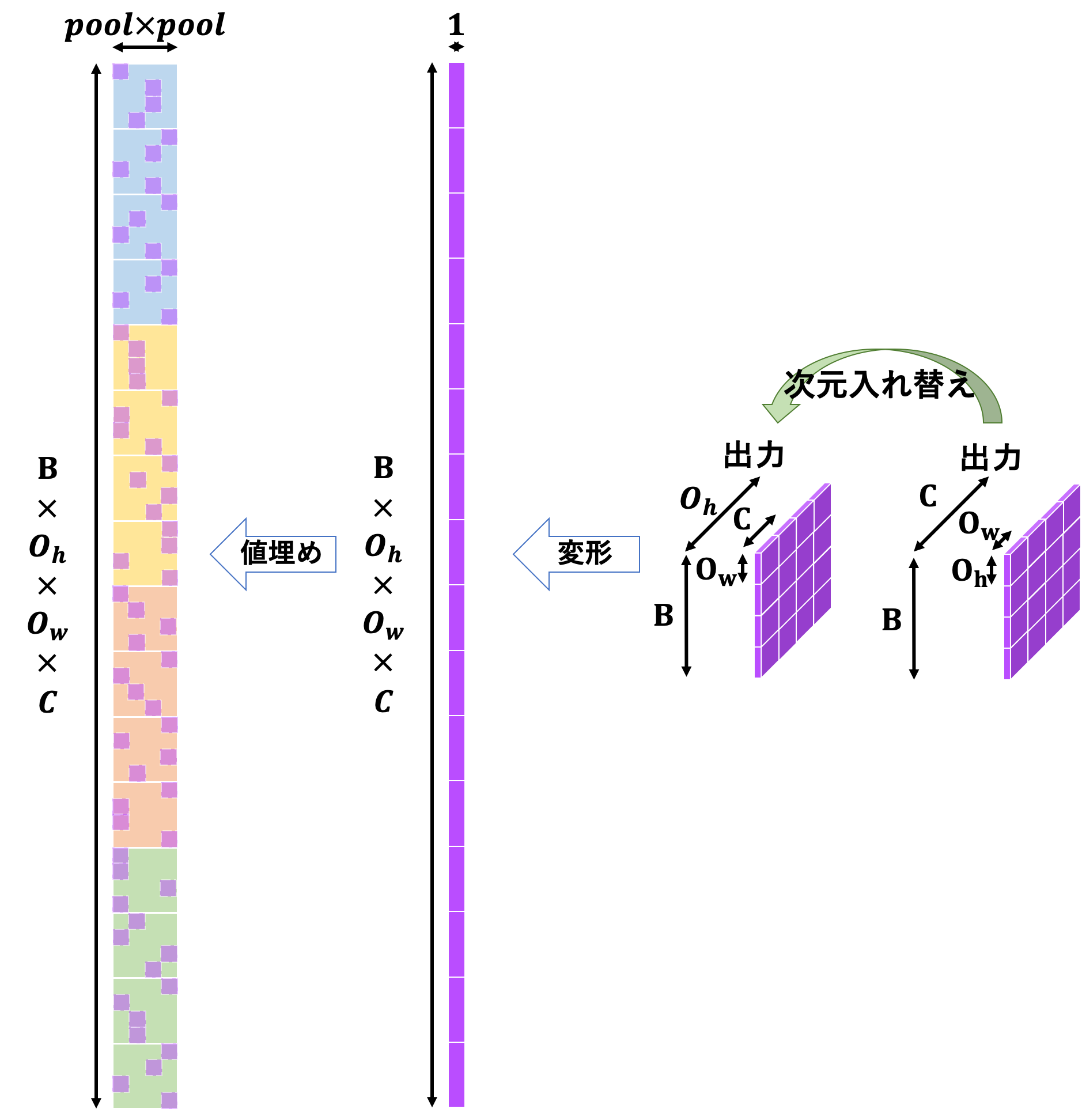
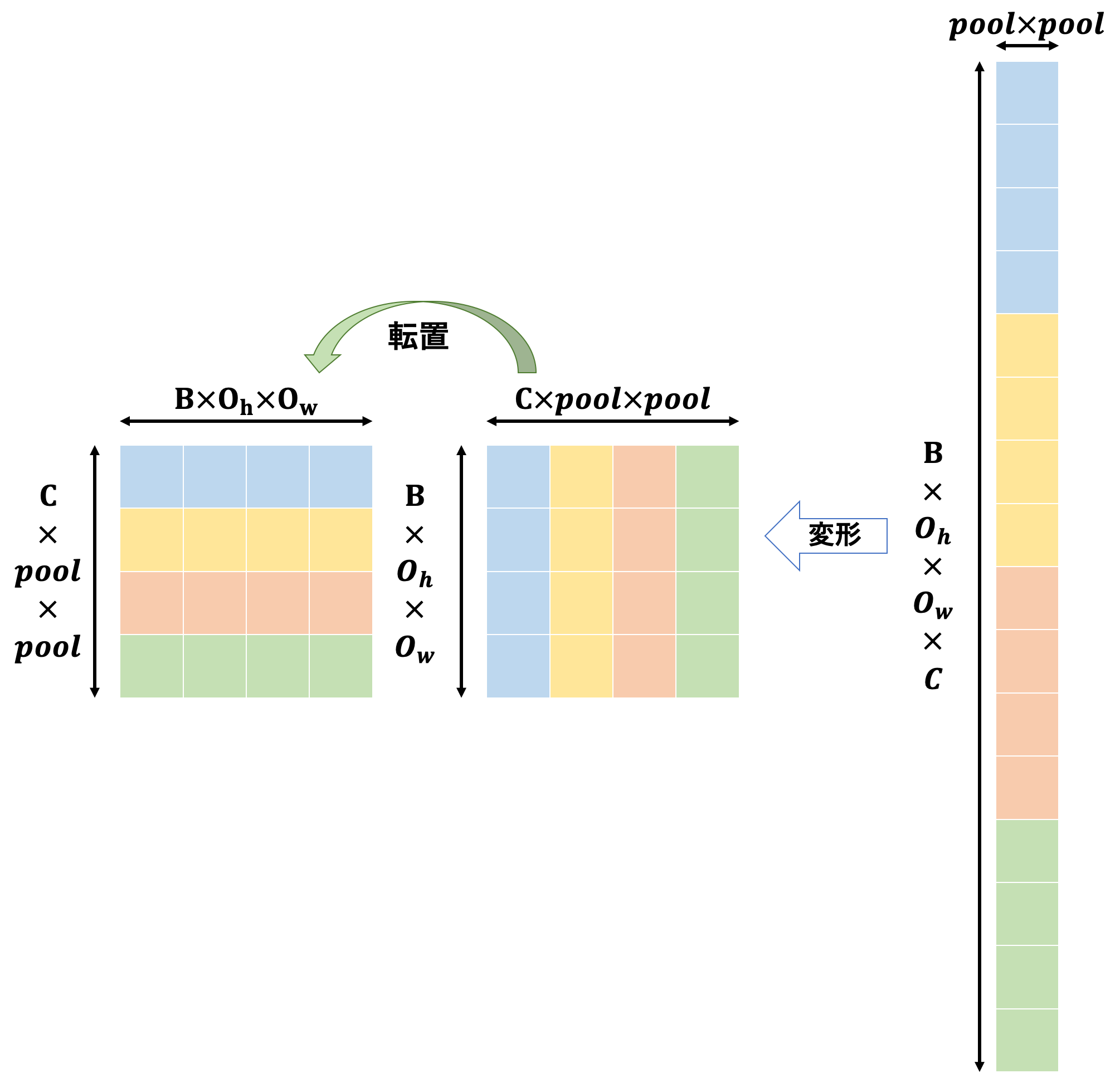
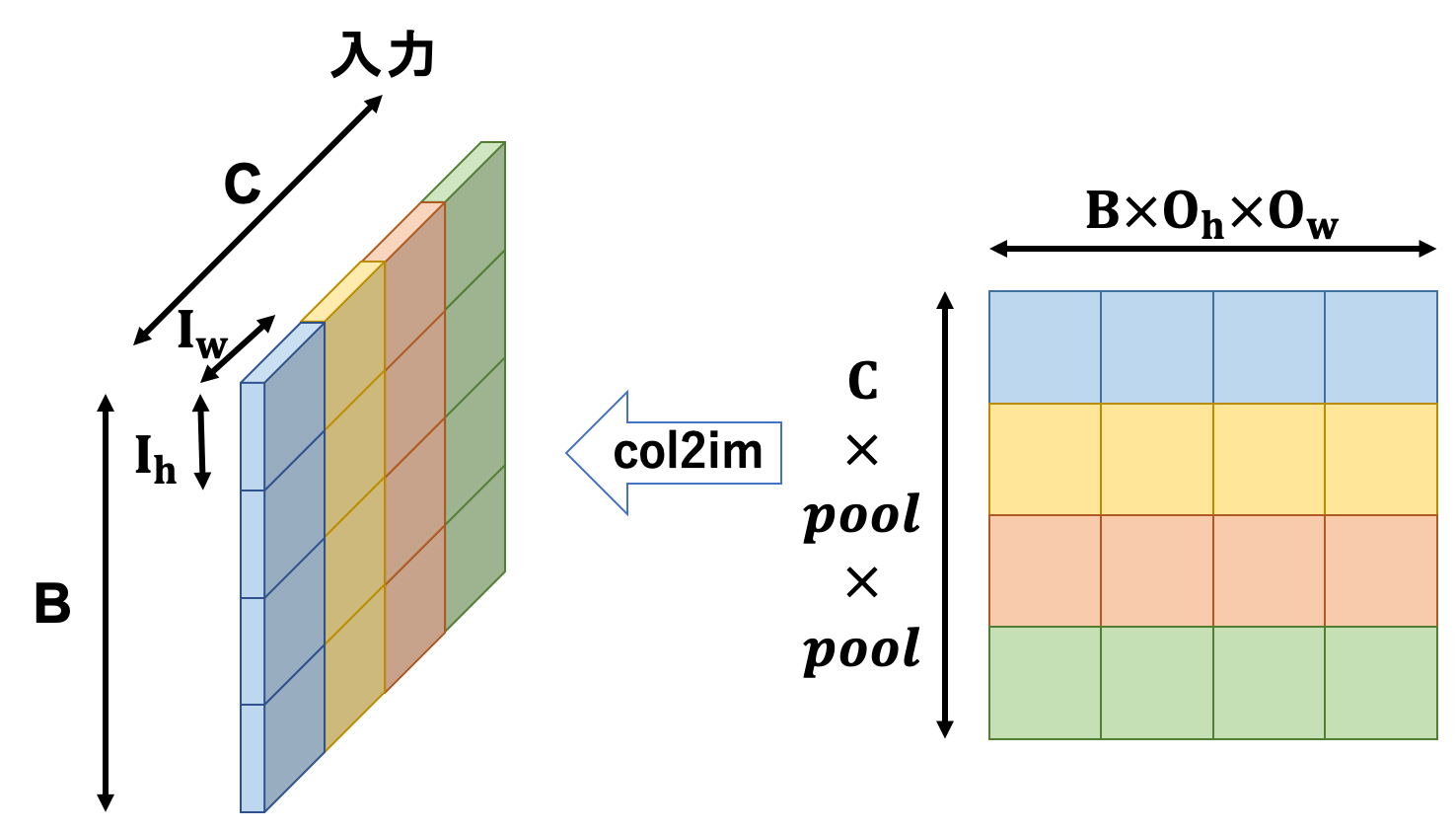
- 投稿日:2020-09-24T10:35:56+09:00
教師あり学習1 教師あり学習(分類)の基礎
Aidemy 2020/9/24
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、教師あり学習の一つ目の投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・教師あり学習の概要
・教師あり学習(分類)の種類教師あり学習(分類)について
教師あり学習(分類)とは
・前提として、教師あり学習とは「学習データと正解(教師)データを与えて正解するまで思考する方法」であり、これを通じて未知のデータを予測するのが目的。
・教師あり学習は「分類問題」と「回帰問題」に分けられる。今回は分類問題について見ていく。
・分類問題とは、「カテゴリ別に分けてあるデータを学習し、未知のデータのカテゴリ(離散値)を予測する」物をいう。例えば、「0〜9の手書き文字認識」「画像に写っているものの識別」「文章の著者予測」「顔写真の男女識別」などが挙げられる。・分類問題は「二項分類」「多項分類」に分けられる。
・二項分類は、男女認識のように、一方のグループに属しているかいないかで分類するもの。クラス間を直線で識別できる場合もある(線形分類)。
・多項分類は、数字の認識のように、分類できるクラスが多数あるもの。機械学習の流れ
・データの前処理→アルゴリズムの選択→モデルの学習→モデルによる予測
・教師あり学習(分類)では、アルゴリズムの選択で「分類アルゴリズム」を選択する。
データを作成する
・分類に適したデータを作成するには、make_classification()メソッドをインポートして使う。
・X,y = make_classification(n_samples=データの個数,n_classes=クラス数(デフォ値:2),n_features=特徴量,n_redundant=余分な特徴量,random_state=乱数のseed)
*変数Xはデータそのものを、yはクラスのラベルを格納する。
*特徴量とは、クラスを分ける特徴になりうるものの個数のことである。男女認識の例で言えば、「髪の長さ」「身長」「肩幅」を特徴として分けた時、実際の分類で使う物を前者2つとした場合、n_featuresは2,n_redundantは1となる。from sklearn.datasets import make_classification #データ数50、クラス数3、特徴量2、余分な特徴量1、seed0のデータを作成 X,y=make_classification(n_samples=50,n_classes=3,n_features=2,n_redundant=1,random_state=0)サンプルデータの取得
・scikit-learnライブラリ(sklearn)に用意されているサンプルデータセットを呼び出すことができる。
#アヤメのサンプルであるIrisデータを呼び出す。 #モジュールのインポート(Irisデータを取得するためのdataset,ホールドアウト法を使うためのtrain_test_splitをsklearnからインポート) from sklearn import datasets from sklearn.model_serection import train_test_split import numpy as np #Irisデータを取得 iris=datasets.load_iris() #トレーニングデータとテストデータに分ける(ホールドアウト法:testの割合30%) X=iris.data[:,[0,2]] #Irisの特徴量のうち、0、2列目(「がくの長さ」「花びらの長さ」) #(=学習データ) y=iris.target #Irisのクラスラベル(=正解の品種が書かれた教師データ) train_X,test_X,train_y,test_y = train_test_split(X,y,test_size=0.3,random_state=0)モデルの構築
・学習し、予測するもののことをモデルという。scikit-learnによって、Ruby on Railsのように用意されたモデルを呼び出して、それに学習や予測を行わせることができる。
・モデルの作成: モデル()
・学習: モデル名.fit(train学習データ,train教師データ)
・予測: モデル名.predict(データ)#LogisticRegression(ロジスティック回帰)というモデルをインポートする。 from sklearn.liner_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.datasets import make_classification #データの作成(データ数50、2クラス、特徴量3)とtrainとtestに分類 X,y = make_classification(n_samples=50,n_classes=2,n_features=3,n_redundant=0,random_state=0) train_X,test_X,train_y,test_y = train_test_split(X,y,random_state=0) #モデルの作成、学習、予測 model = LogisticRegression(random_state=0) model.fit(train_X,train_y) pred_y = model.predict(test_X) print(pred_y) #[1 1 0 0 0 0 0 0 0 0 0 1 0 0 0 1 1 1 0 0 0 0 1 1 1] print(test_y) #[1 1 0 0 0 0 0 0 0 0 0 1 0 0 0 1 1 1 0 1 1 0 1 1 1]分類のやり方(クラス間の境界線を作る)
今回扱う六種類
・ロジスティック回帰:境界線が直線→線形分類のみ。汎化能力が低い。
・線形SVM:境界線が直線→線形分類のみ。汎化能力が高い。学習・予測が遅い。
・非線形SVM:非線形分類を線形分類に直して、線形SVMとして処理する。
・決定木:データの要素ごとにクラスを決定。外れ値に左右されにくい。線形分類のみ。汎化されない。
・ランダムフォレスト:ランダムなデータに決定木を用いてクラスを決定。非線形分類も可能。
・k-NN:予測データと類似している教師データを抽出し、最も多かったクラスを予測結果として出力する。学習コストが0。高い予測精度。データ量が増えると低速化。ロジスティック回帰
・境界線が直線なので、線形分類のみ扱える。境界線がデータに寄り添ってしまうため汎化能力が低い。
・モデル作成はLogisticRegression()で行い、学習はfit()、予測はpredict()で行う。詳しくは前々項参照。正解率が知りたい時はmodel.score(pred_y,test_y)で行う。・ここでは、モデルの予測結果をグラフ(散布図)に表し、色分けして可視化する。
・(復習)散布図の作成:plt.scatter(x軸のデータ,y軸のデータ,c=[リスト],marker="マーカーの種類",cmap="色系統")
・下記に出てくるnp.meshgrid(x,y)は、座標(x,y)を行列に変換して渡す関数。#グラフを作るためのpltと、座標を取得するためのnpをインポート import matplotlib.pyplot as plt import numpy as np #plt.scatterで散布図の作成(学習データXの0列目をx軸、1列目をy軸とする) plt.scatter(X[:,0],X[:,1],c=y,marker=".",cmap=matplotlib.cm.get_cmap(name="cool"),alpha=1.0) #この次に指定するx軸(x1)、y軸(x2)の範囲指定 x1_min,x1_max = X[:,0].min()-1, X[:,0].max()+1 x2_min,x2_max = X[:,1].min()-1, X[:,1].max()+1 #np.meshgridで、グラフを0.02ずつ区切った箇所のx1、x2の交点のx座標をxx1、y座標をxx2に格納(np.arrange(最小値,最大値,間隔)) xx1,xx2 = np.meshgrid(np.arange(x1_min,x1_max,0.02),np.arange(x2_min,x2_max,0.02)) #座標(xx1,xx2)の配列に対してmodelで予測し、plt.comtourfでその結果を描画 Z=model.predict(np.array([xx1.ravel(),xx2.ravel()]).T).reshape((xx1.shape)) plt.contourf(xx1,xx2,Z,alpha=0.4,cmap=matplotlib.cm.get_cmap(name="Wistia")) #グラフの範囲、タイトル、ラベル名、グリッドの設定をして出力 plt.xlim(xx1.min(), xx1.max()) plt.ylim(xx2.min(), xx2.max()) plt.title("classification data using LogisticRegression") plt.xlabel("Sepal length") plt.ylabel("Petal length") plt.grid(True) plt.show()線形SVM
・境界線が直線→線形分類のみ。汎化能力が高い。学習・予測が遅い。
・SVMとは「サポートベクターマシン」のこと。サポートベクターは他クラスと距離が近いデータのことで、これらの距離が最も遠くなるように境界線が引かれるので、汎化されやすい。・線形SVMはLinearSVC()で実装できる。それ以外については、ロジスティック回帰と同様に実装できる。
非線形SVM
・非線形分類を線形分類に直して、線形SVMとして処理する。
・線形SVMに直すには「カーネル関数」を使う。
・非線形SVMは、from sklearn.svm import SVCでインポートしたSVC()を使う。それ以外はロジスティック回帰と同じ。決定木
・データの要素ごとにクラスを決定する。外れ値に左右されにくい。線形分類のみ。汎化されない。
・from sklearn.tree import DecisionTreeClassifierでインポートしたDecisionTreeClassifier()を使う。ランダムフォレスト
・ランダムなデータの決定木を複数作成し、それぞれ分類した結果のうち最も多数だったクラスを結果として出力する。アンサンブル学習の一つでもある。非線形分類も可能。
・from sklearn.ensemble import RandomForestClassifierでインポートしたRandomForestClassifier()を使う。k-NN
・予測データと類似している教師データをk個抽出し、最も多かったクラスを予測結果として出力する。学習コストが0。高い予測精度。データ量が増えると精度ダウンand低速化。
・from sklearn.neighbors import KNeighborsClassifierでインポートしたKNeighborsClassifier()を使う。まとめ
・教師あり学習(分類)とは、データを学習させ、そのデータに基づいて分類を予測するものである。
・分類に適したデータを作成するには、make_classification()メソッドをインポートして使う。
・データを作成せずとも、scikit-learnライブラリ(sklearn)に用意されているサンプルデータセットを呼び出して使うことができる。(ex)アヤメのデータIris)
・学習し、境界線を予測するモデルには、ロジスティック回帰,線形SVM,非線形SVM,決定木,ランダムフォレスト,k-NNがあり、それぞれに特徴がある。今回は以上です。ここまで読んでくださり、ありがとうございます。
- 投稿日:2020-09-24T10:15:36+09:00
conda-forgeからインストールする
condaでconda-forgeからインストールする
conda install -c conda-forge asammdf# 優先順位を一番上で追加する conda config --get channels conda-forge # 優先順位を一番下で追加する conda config --append channels conda-forge
- 投稿日:2020-09-24T10:06:29+09:00
dict型,list型,tuple型の違いと共通点
dict型 list型 tuple型とは?
dict型
辞書を扱う型です。
{}を使い、{キー1:値1,キー2:値2,キー3:値3}list型
リストと呼ばれる可変な配列を扱う型
[]を使い、[値1,値2,値3]tuple型
タプルという不変な配列を扱う型
()を使い、(値1,値2,値3)要素を追加する
- dict型
a={"apple":1,"orange":2,"book":3} a["ball"]=4 #要素を追加する print(a)実行結果a={"apple":1,"orange":2,"book":3,"ball":4}
- list型
append()を使うa=["apple","orange","book"] a.append("ball") #要素を追加する print(a)実行結果a=["apple","orange","book","ball"]
- tuple型
要素を追加することはできない。要素を削除する
削除方法はdict型,list型は同じです。
tuple型は要素を削除できません。
代表的なものは以下の2つです。
- pop()
dict型a={"apple":1,"orange":2,"book":3} a.pop("apple") print(a)実行結果a={"orange":2,"book":3}list型a=["apple","orange","book"] a.pop("0") print(a)実行結果["orange","book"]
- del
dict型a={"apple":1,"orange":2,"book":3} del a["apple"] print(a)実行結果{"orange":2,"book":3}list型a=["apple","orange","book"] del a[0] print(a)実行結果["orange","book"]
- 投稿日:2020-09-24T08:41:20+09:00
【Python】nlplotで企業特徴を把握できたら最&高じゃないですか?
きっかけ
現在、SEOライティングツールを開発する株式会社EXIDEAで、データ分析のインターンをしています。勤め始めて4ヶ月経ちましたが、コロナの影響で社内の方とまだ一度も面識がありません。が、定期的なオンライン飲み会やデイリーミーティングでどういった特徴を持った方が多いのか?ようやくわかってきました。また、最近の月次ミーティングで「採用」という言葉をよく耳にします。ベンチャー企業に限らず、Wantedlyを利用して採用活動に力を入れている企業は多いのではないでしょうか?この記事では、Wantedlyに投稿したストーリー記事を自然言語の可視化を手軽にできるようにしたパッケージnlplotを使用して、応募者に伝えたい企業特徴や想いを再認識しようというストーリーになります。
Githubにソースコードを公開していますので、よかったらどうぞ。
https://github.com/yuuuusuke1997/Article_analysis環境
・macOS
・Python 3.7.6
・Jupyter Notebook
・zshシェルストーリーの流れ
- データの収集(スクレイピング)
- 形態素解析(MeCab)
- 可視化(nlplot)
1. データの収集(スクレイピング)
1-1.スクレイピングの流れ
今回のスクレイピングは、以下のようにwebページを遷移して自社の全記事のみを取得していきます。スクレイピングするにあたり、Wantedlyさんに事前に許可をいただいた上で実施させていただきます。予めご了承いただけますようお願いいたします。
1-2. 事前準備
Wantedlyのwebページはページ下部までスクロールすることで次の記事が読み込まれます。そのため、ブラウザ操作を自動化するSeleniumを必要最低限の箇所で使用し、データの取得を行います。ブラウザを操作するには、お使いのブラウザに対応したdriverの用意とSeleniumライブラリをインストールする必要があります。私は、Google Chromeを愛用しているのでこちらからChromeDriverをダウンロードし、下記のディレクトリに配置しました。なお、Users配下の*はご自身のユーザー名に適宜変更してください。
$ cd /Users/*/documents/nlplot $ ls article_analysis.ipynb chromedriver post_articles.csv user_dic.csvSeleniumライブラリはpipでインストールします。
$ pip install seleniumSeleniumの導入から操作方法まで詳しく知りたい方は、こちらの記事が参考になるかと思います。準備が整ったので、実際にスクレイピングしていきます。
1-3. ソースコード
article_analysis.ipynbimport json import re import time import pandas as pd import requests from bs4 import BeautifulSoup as bs4 from selenium import webdriver base_url = 'https://www.wantedly.com' def scrape_path(url): """ ストーリー一覧ページからスペース詳細ページのURLを取得 Parameters -------------- url: str ストーリー一覧ページのURL Returns ---------- path_list: list of str スペース詳細ページのURLを格納したリスト """ path_list = [] response = requests.get(url) soup = bs4(response.text, 'lxml') time.sleep(3) # <script data-placeholder-key="wtd-ssr-placeholder"> の中身を取得 # json文字で、先頭の'//'を除去するため.string[3:] feeds = soup.find('script', {'data-placeholder-key': 'wtd-ssr-placeholder'}).string[3:] feed = json.loads(feeds) # {'body'}の'spaces'を取得 feed_spaces = feed['body'][list(feed['body'].keys())[0]]['spaces'] for i in feed_spaces: space_path = base_url + i['post_space_path'] path_list.append(space_path) return path_list path_list = scrape_path('https://www.wantedly.com/companies/exidea/feed') def scrape_url(path_list): """ スペース詳細ページからストーリー詳細ページのURLを取得 Parameters -------------- path_list: list of str スペース詳細ページのURLを格納したリスト Returns ---------- url_list: list of str ストーリー詳細ページのURLを格納したリスト """ url_list = [] # chromeを起動(chromedriverはこのファイルと同じディレクトリに配置) driver = webdriver.Chrome('chromedriver') for feed_path in path_list: driver.get(feed_path) # ページ下部までスクロールして、これ以上スクロールできなくなったらプログラム終了 # スクロール前の高さ last_height = driver.execute_script("return document.body.scrollHeight") while True: # ページ下部までスクロール driver.execute_script('window.scrollTo(0, document.body.scrollHeight);') # Seleniumの処理が速すぎて、新たなページを読み込めないので強制待機 time.sleep(3) # スクロール後の高さ new_height = driver.execute_script("return document.body.scrollHeight") # last_heightがnew_heightの高さと一致するまでスクロール if new_height == last_height: break else: last_height = new_height continue soup = bs4(driver.page_source, 'lxml') time.sleep(3) # <div class="post-space-item" >の要素を取得 post_space = soup.find_all('div', class_='post-content') for post in post_space: # <"post-space-item">の<a>要素を取得 url = base_url + post.a.get('href') url_list.append(url) url_list = list(set(url_list)) # webページを閉じる driver.close() return url_list url_list = scrape_url(path_list) def get_text(url_list, wrong_name, correct_name): """ ストーリー詳細ページからテキストを取得 Parameters -------------- url_list: list of str ストーリー詳細ページのURLを格納したリスト wrong_name: str 間違った社名 correct_name: str 正しい社名 Returns ---------- text_list: list of str ストーリーを格納したリスト """ text_list = [] for url in url_list: response = requests.get(url) soup = bs4(response.text, 'lxml') time.sleep(3) # <section class="article-description" data-post-id="○○○○○○">の中の<p>要素を全取得 articles = soup.find('section', class_='article-description').find_all('p') for article in articles: # 区切り文字で分割 for text in re.split('[\n!?!?。]', article.text): # 前処理 replaced_text = text.lower() # 小文字変換 replaced_text = re.sub(wrong_name, correct_name, replaced_text) # 社名を大文字に変換 replaced_text = re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+', '', replaced_text) # URLを除去 replaced_text = re.sub('[0-9]', '', replaced_text) # 数字を除外 replaced_text = re.sub('[,:;-~%()]', '', replaced_text) # 記号を半角スペースに置き換え replaced_text = re.sub('[、:;・〜%()※「」【】(笑)]', '', replaced_text) # 記号を半角スペースに置き換え replaced_text = re.sub(' ', '', replaced_text) # \u3000を除去 text_list.append(replaced_text) text_list = [x for x in text_list if x != ''] return text_list text_list = get_text(url_list, 'exidea', 'EXIDEA')取得したテキストはCSVファイルに保存します。
nlplot_articles.ipynbdf_text = pd.DataFrame(text_list, columns=['text']) df_text.to_csv('post_articles.csv', index=False)
2. 形態素解析(MeCab)
2-1. 形態素解析までの流れ
- MeCab本体のインストールと環境設定
- IPA辞書の追加
- NEologd辞書の追加
- ユーザー辞書の作成
- ようやく解析
2-1. 少しばかり休憩
ここからMeCabのインストールや諸々の準備に入るのですが、思った以上に上手くいかず心が折れるので、モチベーションアップに繋がれば幸いです。
そもそも、なんでこんなめんどくさい作業をするんだ。$ brew install mecabと叩けば一発で済むだろうと思う方も、もしかしたらいらっしゃるかもしれません。が、nlplotで形態素解析した結果を思い通りに出すためには、会社特有の事業部名や社内ワードを固有名詞として、文字コードをUTF-8でユーザー辞書に登録する必要があります。私は楽をしたくbrewでインストールした結果、文字コードがEUC-JPになってしまい、二度手間を踏むハメになりました。そのため、出力結果にこだわりたい方は、これから行う方法を是非試してみてください。一旦、手軽に試してみたいという方は、下記を参考にbrewでインストールしてみてください。
*追記
brewで文字コードを指定する方法をご存知の方がいらっしゃいましたら、コメント欄にてご教授いただけますと幸甚です。2-2. MeCab本体のインストールと環境設定
MeCab公式サイトから、curlコマンドでMeCab本体とIPA辞書をダウンロードします。なお、今回はローカル環境にインストールします。まずはMeCab本体のインストールです。
# ローカル環境にmecab本体のインストール先ディレクトリを作成 $ mkdir /Users/*/opt/mecab $ cd /Users/*/opt/mecab # カレントディレクトリに-oオプションでファイル名を指定してダウンロード $ curl -Lo mecab-0.996.tar.gz 'https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7cENtOXlicTFaRUE' # ソースコードファイルを解凍 $ tar zxfv mecab-0.996.tar.gz $ cd mecab-0.996 # 文字コードをUTF-8に指定してコンパイルできるかチェック $ ./configure --prefix=/Users/*/opt/mecab --with-charset=utf-8 # configureで作成されたMakefileをコンパイル $ make # インストール前に正常に作動するかチェック $ make check # makeでコンパイルされたバイナリファイルを/Users/*/opt/mecabにインストール $ make install Doneconfigure, make, make installって何と疑問に思う方は、こちらが参考になるかと思います。
インストールできたので、mecabコマンドを実行できるようにpathを通していきます。
# シェルの種類を確認 $ echo $SHELL /bin/zsh # .zshrcにパスを追加 $ echo 'export PATH=/Users/*/opt/mecab/bin:$PATH' >> ~/.zshrc """ 注意: ログインシェルによって、最後の(~/.zshrc)を変更 例) $ echo 'export PATH=/Users/*/opt/mecab/bin:$PATH' >> ~/.bash_profile """ # シェルの設定を反映 $ source ~/.zshrc # パスが通ったか確認 $ which mecab /Users/*/opt/mecab/bin/mecab Done参考記事: PATHを通すとは?
2-3. IPA辞書の追加
# 起点となるディレクトリに移動 $ cd /Users/*/opt/mecab # カレントディレクトリに-oオプションでファイル名を指定してダウンロード $ curl -Lo mecab-ipadic-2.7.0-20070801.tar.gz 'https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7MWVlSDBCSXZMTXM' # ソースコードファイルを解凍 $ tar zxfv mecab-ipadic-2.7.0-20070801.tar.gz $ cd mecab-ipadic-2.7.0-20070801 # 文字コードをUTF-8に指定してコンパイルできるかチェック $ ./configure --prefix=/Users/*/opt/mecab --with-charset=utf-8 # configureで作成されたMakefileをコンパイル $ make # makeでコンパイルされたバイナリファイルを/Users/*/opt/mecabにインストール $ make install Done # 文字コードの確認 # 文字コードがEUC-JPの場合、UTF-8に変更 $ mecab -P | grep config-charset config-charset: EUC-JP # 設定ファイルを検索 $ find /Users -name dicrc /Users/*/opt/mecab/mecab-ipadic-2.7.0-20070801/dicrc $ vim /Users/*/opt/mecab/mecab-ipadic-2.7.0-20070801/dicrc 【変更前】config-charset = EUC-JP 【変更後】config-charset = UTF-8 $ mecab おれは人間をやめるぞ!ジョジョーッ おれ 名詞,代名詞,一般,*,*,*,おれ,オレ,オレ は 助詞,係助詞,*,*,*,*,は,ハ,ワ 人間 名詞,一般,*,*,*,*,人間,ニンゲン,ニンゲン を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ やめる 動詞,自立,*,*,一段,基本形,やめる,ヤメル,ヤメル ぞ 助詞,終助詞,*,*,*,*,ぞ,ゾ,ゾ ! 記号,一般,*,*,*,*,!,!,! ジョジョーッ 名詞,固有名詞,組織,*,*,*,* EOS # IPA辞書のディレクトリ確認 $ find /Users -name ipadic /Users/*/opt/mecab/lib/mecab/dic/ipadic2-3. NEologd辞書の追加
# 起点となるディレクトリに移動 cd /Users/*/opt/mecab # ソースコードをgithubからダウンロード $ git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git $ cd mecab-ipadic-neologd # 実行して結果を確認する画面で「yes」と入力 $ ./bin/install-mecab-ipadic-neologd -n Done # 文字コードの確認 # 文字コードがEUC-JPの場合、UTF-8に変更 $ mecab -d /Users/*/opt/mecab/lib/mecab/dic/mecab-ipadic-neologd -P | grep config-charset config-charset: EUC-JP # 設定ファイルを検索 $ find /Users -name dicrc /Users/*/opt/mecab/lib/mecab/dic/mecab-ipadic-neologd/dicrc $ vim /Users/*/opt/mecab/lib/mecab/dic/mecab-ipadic-neologd/dicrc 【変更前】config-charset = EUC-JP 【変更後】config-charset = UTF-8 # NEologd辞書のディレクトリ確認 $ find /Users -name mecab-ipadic-neologd /Users/*/opt/mecab/lib/mecab/dic/mecab-ipadic-neologd $ echo “おれは人間をやめるぞ!ジョジョーッ | mecab -d /Users/*/opt/mecab/lib/mecab/dic/mecab-ipadic-neologd “ 記号,括弧開,*,*,*,*,“,“,“ おれは人間をやめるぞ! 名詞,固有名詞,一般,*,*,*,おれは人間をやめるぞ!,オレハニンゲンヲヤメルゾ,オレワニンゲンオヤメルゾ ジョジョーッ 名詞,一般,*,*,*,*,* EOSGithub公式: mecab-ipadic-neologd
# 最後にpython3でmecabを使用できるようにpip $ pip install mecab-python32-4. ユーザー辞書の作成
ユーザー辞書は、システム辞書で対応できなかった単語をユーザー自身が意味を与え作成します。
まずは、追加したい単語をフォーマットに従ってcsvファイルを作成します。一度可視化して、気になった単語があればcsvファイルに単語を追加してみてください。
""" フォーマット 表層形,左文脈ID,右文脈ID,コスト,品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用型,活用形,原形,読み,発音 """ # csvファイル作成 $ echo 'インターン生,-1,-1,1,名詞,一般,*,*,*,*,*,*,*,インターンセイ'"\n"'コアバリュー,-1,-1,1,名詞,一般,*,*,*,*,*,*,*,コアバリュー'"\n"'ミートアップ,-1,-1,1,名詞,一般,*,*,*,*,*,*,*,ミートアップ' > /Users/*/Documents/nlplot/user_dic.csv # csvファイルの文字コードを確認 $ file /Users/*/Documents/nlplot/user_dic.csv /users/*/documents/nlplot/user_dic.csv: UTF-8 Unicode text次に、作成したcsvファイルをユーザ辞書にコンパイルします。
# ユーザー辞書の保存先ディレクトリを作成 $ mkdir /Users/*/opt/mecab/lib/mecab/dic/userdic """ -d システム辞書があるディレクトリ -u ユーザ-辞書の保存先 -f CSVファイルの文字コード -t ユーザ辞書の文字コード/csvファイルの保存先 """ # ユーザー辞書を作成 /Users/*/opt/mecab/libexec/mecab/mecab-dict-index \ -d /Users/*/opt/mecab/lib/mecab/dic/mecab-ipadic-neologd \ -u /Users/*/opt/mecab/lib/mecab/dic/userdic/userdic.dic \ -f utf-8 -t utf-8 /Users/*/Documents/nlplot/user_dic.csv # userdic.dicができていることを確認 $ find /Users -name userdic.dic /Users/*/opt/mecab/lib/mecab/dic/userdic/userdic.dicmecabのインストールからユーザー辞書の作成まで完了したので、形態素解析に移ります。
参考記事: 単語の追加方法
2-5. ようやく解析
まずは、スクレイピング時に作成したcsvファイルを読み込みます。
nlplot_articles.ipynbdf = pd.read_csv('post_articles.csv') df.head()
nlplotでは、文章を単語単位で出力したいので、名詞で形態素解析を行います。
article_analysis.ipynbimport MeCab def download_slothlib(): """ SlothLibを読み込み、ストップワードを作成 Returns ---------- slothlib_stopwords: list of str ストップワードを格納したリスト """ slothlib_path = 'http://svn.sourceforge.jp/svnroot/slothlib/CSharp/Version1/SlothLib/NLP/Filter/StopWord/word/Japanese.txt' response = requests.get(slothlib_path) soup = bs4(response.content, 'html.parser') slothlib_stopwords = [line.strip() for line in soup] slothlib_stopwords = slothlib_stopwords[0].split('\r\n') slothlib_stopwords = [x for x in slothlib_stopwords if x != ''] return slothlib_stopwords stopwords = download_slothlib() def add_stopwords(): """ stopwordsにストップワードを追加 Returns ---------- stopwords: list of str ストップワードを格納したリスト """ add_words = ['ご覧', '社', '是非', 'ぜひ', 'お話', '弊社', '人間', 'いただき', '記事', '以外', 'ん', 'の', 'め', 'さ', 'こう'] stopwords.extend(add_words) return stopwords stopwords = add_stopwords() def tokenize_text(text): """ 形態素解析をして名詞のみを抽出 Parameters -------------- text: str dataframeに格納したテキスト Returns ---------- nons_list: list of str 形態素解析して名詞のみを格納したリスト """ # ユーザー辞書とneologd辞書が保存されたディレクトリを指定 tagger = MeCab.Tagger('-d /Users/*/opt/mecab/lib/mecab/dic/mecab-ipadic-neologd -u /Users/*/opt/mecab/lib/mecab/dic/userdic/userdic.dic') node = tagger.parseToNode(text) nons_list = [] while node: if node.feature.split(',')[0] in ['名詞'] and node.surface not in stopwords: nons_list.append(node.surface) node = node.next return nons_list df['words'] = df['text'].apply(tokenize_text)article_analysis.ipynbdf.head()
3. 可視化(nlplot)
3-1. 事前準備
$ pip install nlplot3-2. uni-gram
nlplot_articles.ipynbimport nlplot npt = nlplot.NLPlot(df, taget_col='words') # top_nで頻出上位2単語, min_freqで頻出下位単語を指定 # 上位2単語: ['会社', '仕事'] stopwords = npt.get_stopword(top_n=2, min_freq=0) npt.bar_ngram( title='uni-gram', xaxis_label='word_count', yaxis_label='word', ngram=1, top_n=50, stopwords=stopwords, save=True )
3-3. bi-gram
nlplot_articles.ipynbnpt.bar_ngram( title='bi-gram', xaxis_label='word_count', yaxis_label='word', ngram=2, top_n=50, stopwords=stopwords, save=True )
3-4. tri-gram
nlplot_articles.ipynbnpt.bar_ngram( title='tri-gram', xaxis_label='word_count', yaxis_label='word', ngram=3, top_n=50, stopwords=stopwords, save=True )
3-5. tree map
nlplot_articles.ipynbnpt.treemap( title='tree map', ngram=1, stopwords=stopwords, width=1200, height=800, save=True )
3-6. wordcloud
nlplot_articles.ipynbnpt.wordcloud( stopwords=stopwords, max_words=100, max_font_size=100, colormap='tab20_r', save=True )
3-7. 共起ネットワーク
nlplot_articles.ipynbnpt.build_graph(stopwords=stopwords, min_edge_frequency=13) display( npt.node_df, npt.node_df.shape, npt.edge_df, npt.edge_df.shape ) npt.co_network( title='All sentiment Co-occurrence network', color_palette='hls', save=True )
3-8. sunburst chart
nlplot_articles.ipynbnpt.sunburst( title='All sentiment sunburst chart', colorscale=True, color_continuous_scale='Oryel', width=800, height=600, save=True )
参考記事: 自然言語を簡単に可視化・分析できるライブラリ「nlplot」を公開しました
まとめ
今回の記事で、前処理の重要性を再認識することができました。というのも、nlplotを試してみたいという気持ちで始めたのですが、前処理せずに可視化すると悲惨な結果になったからです。その甲斐あって、mecabインストール時やユーザー辞書の作成でLinux周辺の知識を学べたことが一番の収穫だったと思います。知識として身につけるより、実際に手を動かすという基本的なこと怠らないように今後の学習に活かしていきます。
長くなりましたが、ここまで読んでくださりありがとうございます。誤っている箇所がございましたら、コメントでご指摘頂けると大変嬉しいです。