- 投稿日:2020-09-24T20:34:43+09:00
【実務未経験】AWS認定ソリューションアーキテクトアソシエイトに2週間で合格しました。
2020年9月にAWS認定ソリューションアーキテクトアソシエイト(SAA-C02)に合格したので、
合格までの勉強方法を合格体験記みたいな感じでメモしておきます。筆者について
現在、大学3年生(情報系の学科)で勉強を始めた時はAWSの使用経験はありませんでした。
ただ、8月末にAWS認定クラウドプラクティショナー(CLF)に合格していましたので、広くかなり浅くAWSの知識がある状態で勉強をスタートしました。
受けた経緯
AWSに興味があったので、学習の一つの目標としてクラウドプラクティショナーを取得。思ったよりもスコアが高かったので、「SAAも行けるんじゃないか?」と調子に乗って受けることにしました。
勉強方法
・これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)
【オススメ!】
・【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)まずは、おなじみのudemy教材です。
月に2回くらいセールをやっているのでその時に買いました。(定価はちょっと高すぎかも)僕はほとんどこの模擬試験問題集の方で合格したといっても過言ではないのでオススメです。
・AWS認定資格試験テキスト AWS認定 ソリューションアーキテクト-アソシエイトクラウドプラクティショナーの時と違って、SAAは本が何冊か出版されていましたが、クラウドプラクティショナーでお世話になった本のSAA版を購入しました。
ただ、先に言ってしまうと本は試験勉強中には読み切っていません。
これもおなじみBlackBeltです。
模擬試験をやってみてから、EC2、S3、EBSなどの主要なサービスで理解が浅いなと思うものはPDFを読むか、YouTubeを見ましょう。
僕はS3だけ見ました。勉強の流れ
2週間で合格とタイトルに書きましたが、最初の1週間はすごいだらけてしまいました。
実は1週間で試験をうけるつもりだったのですが、受かる気が全くしなかったので試験日を変更して、1週間延ばしています。
・最初の1週間
最初の1週間は本とudemyの突破講座(ハンズオン)を同時進行でやりました。
ただ、前述した通り、かなりだらけてしまったので、本は半分しか読めていなかったですし、ハンズオンはVPCまで(大体3割)くらいまでしか終わりませんでした。
ただ、ハンズオンはゆっくり丁寧にやっていたので、EC2とVPCの問題には結構強くなっていました。
ハンズオンは余裕をもってゆっくり丁寧にやるとかなり力が付くと思います!・残り1週間
ハンズオンと本はもう諦めた!!
とにかく時間がないので、ハンズオンは試験が終わってからやりますと誓って、udemyのハンズオン講座の最後についている模擬問題と、udemyの390問の模擬問題をとにかく解きました。
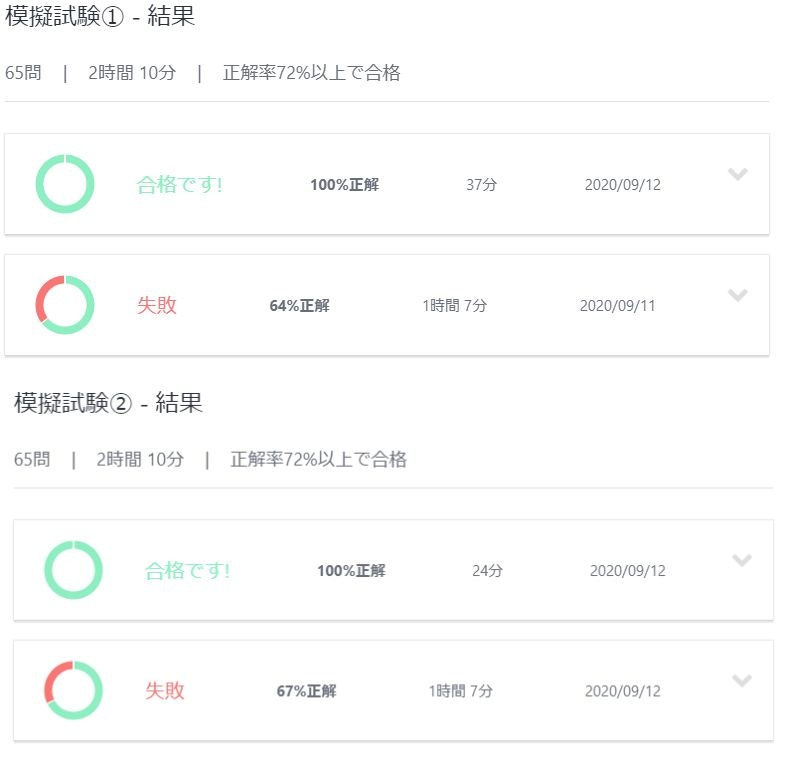
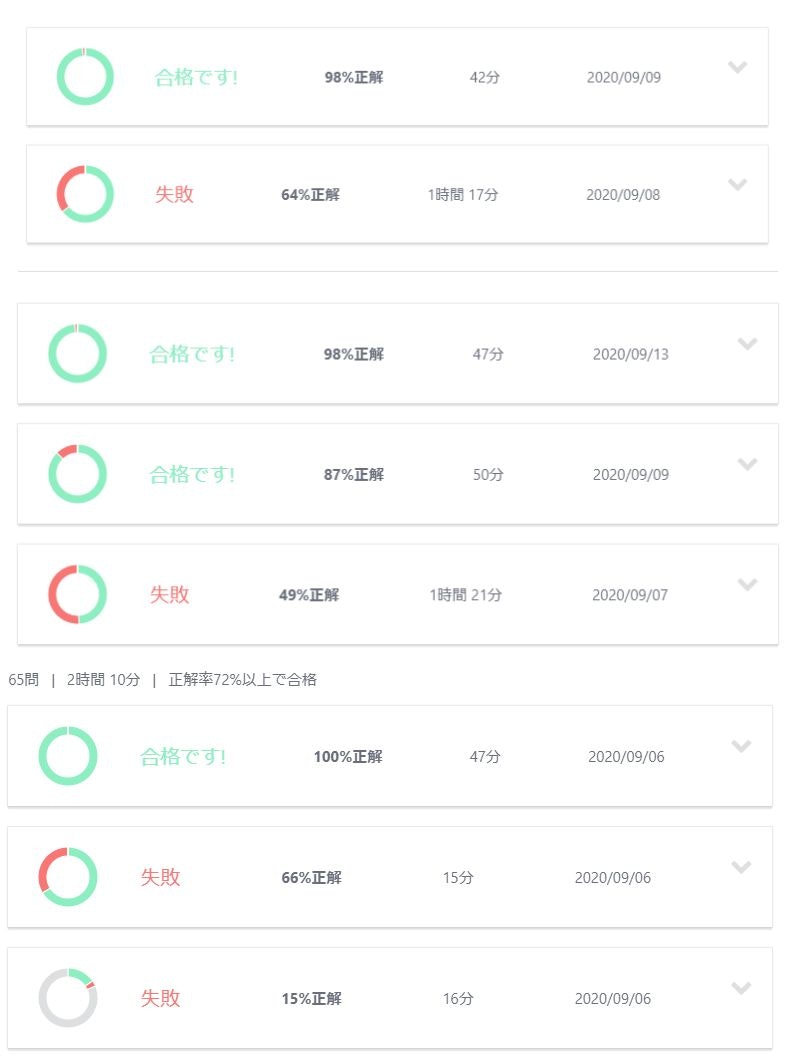
問題を解くよりも解説を読んで理解することに時間をかけました。どんな仕上がりだったのか、参考までに模擬試験のスコアを張っておきます。
【ハンズオンの模擬1と模擬2】
【模擬試験1、2、3】
【模擬試験4、5、6】
正直、結構ズタボロな感じですが、udemyの模擬問題は難しくできてるから、、、
と自分に言い聞かせつつ解説の理解をとにかく深めました。プラスでS3のblackbeltを見たのと、クラウドプラクティショナーの特典で、
公式の模擬問題が無料で受けられたので受けました。(スコアは75%でした)試験当日
試験はピアソンVUEで受験しました。
ピアソンVUEの試験当日の流れなどはこちらで解説していますので、ぜひ読んでみてください。問題1周目は迷った問題にチェックを付けて、
2周目は全体を復習しつつ、チェックを付けたところに時間をかけました。
諦めない心の持ち主なので試験終了6秒前まで見直しをしていましたが、
チェックを20個くらい付けていたので、2週目は50問目くらいまでしか見直しが終わらず
「落ちたかなー、、」と思いながら最後のアンケートをポチポチ、、、、最後に合否が出るのは知っていたのであまり期待しないで見てみると、
まさかの、「合格」。
小さくガッツポーズをして席を立ちました。試験結果
ご察しの通りギリギリ合格です(アブナー)後2問くらい間違えてたら不合格だったので、
最後の6秒まで諦めなくてよかったです(笑)おわりに
udemyのハンズオンをやり残していますが、Route53やCloudFrontについてはAWS認定SysOpsアドミニストレーターアソシエイト(SOA)の勉強の時に使います。
ただ、資格勉強ばかりしていても、意味がないので、一旦資格は置いておいてAWSを使って何か作ってみようかなと考えています。
![Inkedb5afe439faef972991362fca126f2d13[1]_LI.jpg](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F693048%2F7391500c-8123-13b5-f7c2-0781c5a07624.jpeg?ixlib=rb-1.2.2&auto=format&gif-q=60&q=75&s=6a28cb9198f85bb80760746ac78b1065)
- 投稿日:2020-09-24T18:50:41+09:00
【AWS】インフラ未経験の無職がAWSのSAAとDVAに受かったので、勉強法を振り返る
【概要】
AWSの下記の資格試験に合格したので、使用した勉強教材を振り返ります。
・ソリューションアーキテクト-アソシエイト(SAA)
・デベロッパー-アソシエイト(DVA)
【目次】
・使用教材
・勉強方法
・勉強時に気をつけること
・最後に【使用教材】
使用した主なサイト、教材は下記の4つ
①Udemy
②YouTube
③参考書(1冊)
④ Qwiklabs【勉強方法】
①Udemy
ソリューションアーキテクト-アソシエイト(SAA)の場合
『AWS:はじめてのAmazon Web Services』
https://www.udemy.com/course/aws-for-beginner/『これだけでOK! AWS 認定ソリューションアーキテクト
– アソシエイト試験突破講座(SAA-C02試験対応版)』
https://www.udemy.com/course/aws-associate/『AWS:ゼロから実践するAmazon Web Services。
手を動かしながらインフラの基礎を習得』
https://www.udemy.com/course/aws-and-infra/『【SAA-C02版】AWS 認定ソリューションアーキテクト
アソシエイト模擬試験問題集(6回分390問)』
https://www.udemy.com/course/aws-knan/デベロッパー-アソシエイト(DVA)の場合
『Amazon Web Service マスターコース VPC編』
https://www.udemy.com/course/amazon-web-service-vpc/『Amazon Web Service マスターコース EC2編』
https://www.udemy.com/course/amazon-web-service-ec2/『AWS 認定デベロッパー アソシエイト模擬試験問題集(5回分325問)』
https://www.udemy.com/course/aws-31955/《コメント》
■SAAとDVAの各模擬試験問題集は購入した方が良いと思います。
問題集を解いているときに意味が分からない単語はサイトで調べましょう。
問題集の回答を理解せずにそのまま覚えるのはNG!!
→実際の試験では角度を変えて、質問されるため。
■講座は、数時間のものから数十時間のものまであるので、
自身の性格に合わせて取る講座を選ぶと良いです。
短い講座のものを複数終わらせた方が勉強のモチベーションが上がるのか、それとも、
手ごたえがあるものを1講座終わらせて達成感を得た方がモチベーションが上がるのか、
自身の性格に合わせて講座を選択しましょう。■Udemyでは頻繁にセールが行われているので、
購入する際は、セールの時を見計らって購入すると良いです。
(90%近く割引されることが頻繁にあります。)②YouTube
『AWS Black Belt Online Seminar』
https://www.youtube.com/playlist?list=PLzWGOASvSx6FIwIC2X1nObr1KcMCBBlqY『AWS サービス別資料』
https://aws.amazon.com/jp/aws-jp-introduction/aws-jp-webinar-service-cut/『くろかわこうへい【渋谷で働いてたクラウドエンジニアTV】』
https://www.youtube.com/channel/UCX30pfp4p82rIiSJmBygADw/playlists《コメント》
■不明点をサイトで調べて、
そのサイト内で分からない所が出てきたらまた調べるといったような、
ツギハギな勉強ではなく、
体系的に、かつ無料で勉強できることが良いと思います。③テキスト
『AWS認定アソシエイト3資格対策
~ソリューションアーキテクト、デベロッパー、SysOpsアドミニストレーター~』
https://www.amazon.co.jp/dp/B07TT1N73K/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1《コメント》
■ソリューションアーキテクトとデベロッパーの資格を両方取得予定でしたので、
この本にしました。■ソリューションアーキテクトの資格取得のみが目的であれば、
別のソリューションアーキテクト専用の本の方が良いと思います。④ Qwiklabs
『Qwiklabs』
https://www.qwiklabs.com/?locale=ja《コメント》
■AWSのサービスをハンズオンを通して学べます。■Udemyの講座内で学習しても、サービスの説明、紹介だけで終わる講義もありましたので、
Qwiklabsで追加で勉強しました。
(無料のものだけ受講して、有料であれば、受講をあきらめましたが。。)【勉強時に気をつけること】
気を付けることは下記2点
①自分に合った勉強法を確立する
私の場合、テキストを読み込むことが苦手だったり、
先に知識を頭に入れておきたいといった性格だったりする為、
テキストを読んで「目から情報を得て理解する」のではなく、
動画視聴によって「耳から情報を得て理解する」ようにしました。②ハンズオンを通して体験、体感する
意味も分からず覚えている単語は、必ず単語を理解して覚えましょう。
問題集を解いているときに意味が分からない単語はサイトで調べます。
問題集の回答を理解せずに覚えるのはNGです!!
>実際の試験では角度を変えて、質問されるためです。【最後に】
■「〇時間の学習時間で資格取得しました」という記事を良く拝見しますが、
IT知識の有無、インフラの実務経験の有無、経験年数など、
前提が全く異なるので、これは気にしなくて良いと思います。。
自分のペースで頑張りましょう。■下記の資格取得のため引き続き、勉強し8冠を目指していきたい。。
・AWS 認定セキュリティ-専門知識
・AWS 認定 高度なネットワーキング-専門知識
・AWS 認定ビッグデータ-専門知識
・AWS 認定 機械学習-専門知識
・DevOpsエンジニア-プロフェッショナル
・ソリューションアーキテクト-プロフェッショナル■無職だと、受験料負担も報奨金もないのがつらいですね。。。
先行投資と考えて、就職先探して、投資分回収したいです。。■今回は勉強方法を纏めましたが、
今後は資格取得のための
・各サービスの解説
・似ているサービスの比較
・頻出テーマ解説
の記事をあげる予定です。
フォローして待っていただけると嬉しいです!

- 投稿日:2020-09-24T17:52:38+09:00
AWS SageMakerで既存のendpointを呼び出す
概要
SageMakerでendpointを立ち上げ、他のnotebookなどで使用したい場合の指定方法を示す。
コード
引数にendpoint_nameを指定する。
endpoint_nameはAWSコンソール->SageMaker->推論->エンドポイントで確認できる。MxNet
import sagemaker predictor = sagemaker.mxnet.model.MXNetPredictor(endpoint_name="mxnet-training-*")PyTorch
import sagemaker predictor = sagemaker.pytorch.model.PyTorchPredictor(endpoint_name="pytorch-training-*")おわりに
notebookが落ちてしまった場合や新しいnotebookで使うことができるようになります。
- 投稿日:2020-09-24T17:42:17+09:00
AWSのアカウントを作ろう
AWSアカウントの作成は公式ドキュメントにも書いてあります。
ただ、入力が必要な情報が幾つかあったので、まとめてみました。まず準備するもの
作成する際に以下の情報が必要になります。
ここでの注意点としては、氏名や住所を入力する際に日本語ではなく英語表記です。
# 準備物 1 メールアドレス 2 利用者氏名 3 クレジットカード 4 連絡先住所 5 連絡先電話番号 6 請求先住所・電話番号(※) (※)連絡先と請求先が違う場合には必要です。
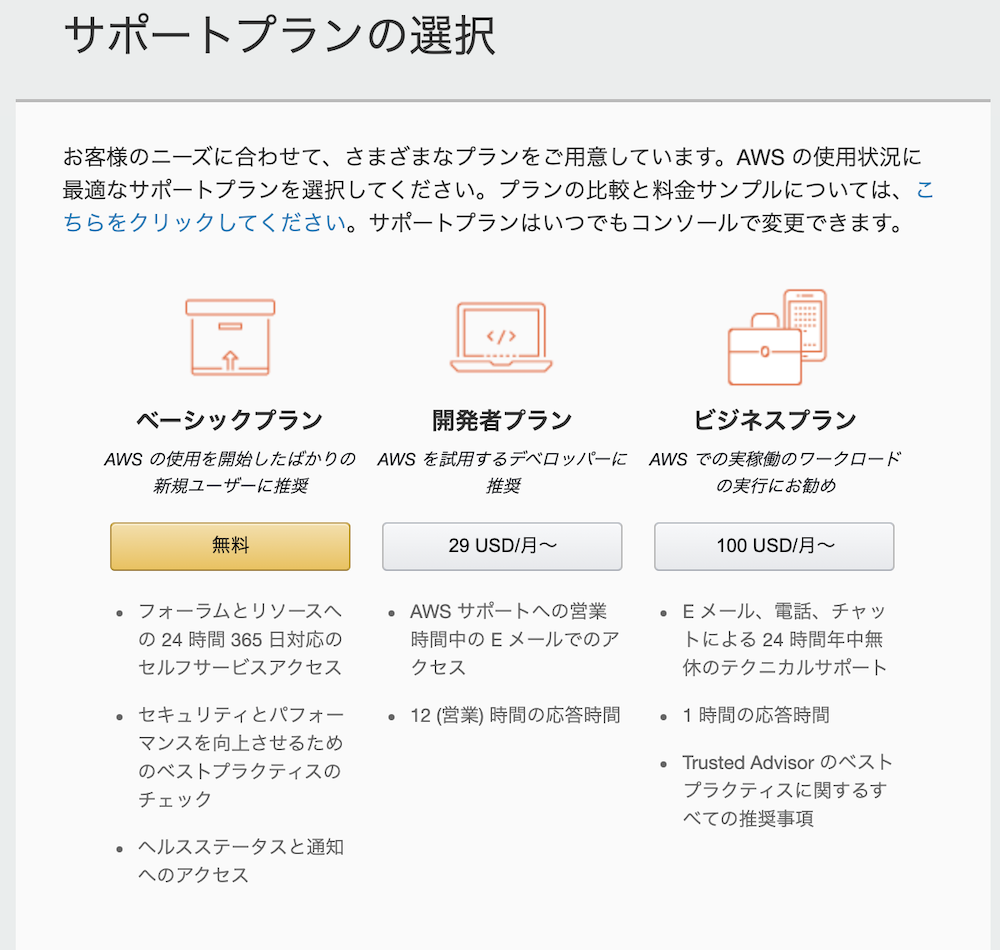
AWSアカウントのサポートプラン
アカウントには、サポートの充実度に応じて4種類のプランがあります。
今回作成するのは、ベーシックプランです。
プラン 概要 ベーシック 技術的なサポートはなく、自分でドキュメントなどを確認するがある基本無料のプラン 開発者 Eメールでの技術サポートが受けれるプラン。各種サービスの検証やテストにおすすめ ビジネス 24x365でクラウドエンジニアからのサポートが受けれるプラン エンタープライズ 24x365であり、ビジネスクリティカルな事象の際に即時対応のサポートが受けれるプラン 作成の手順
ここで登録する情報は、AWSアカウント作成後にマイアカウントのページから修正することが可能です。
1. AWSアカウント作成ページへアクセス
AWSアカウント作成のページへアクセスしてください。
2. AWSアカウントの作成
- ここではメールアドレスとパスワード、AWSアカウント名を登録します。
- パスワードは、8文字以上で3種類以上の文字種が混在する必要があります。
- AWSアカウント名は、例えばプロジェクトの名前だったり、個人で検証利用する場合には個人名を入力したりします。こちらは後から変更可能な名称です。
- AWSアカウントは、AWSアカウント番号という12桁の数字列で管理されます。このAWSアカウント名は、その番号のエイリアス的な位置づけです。
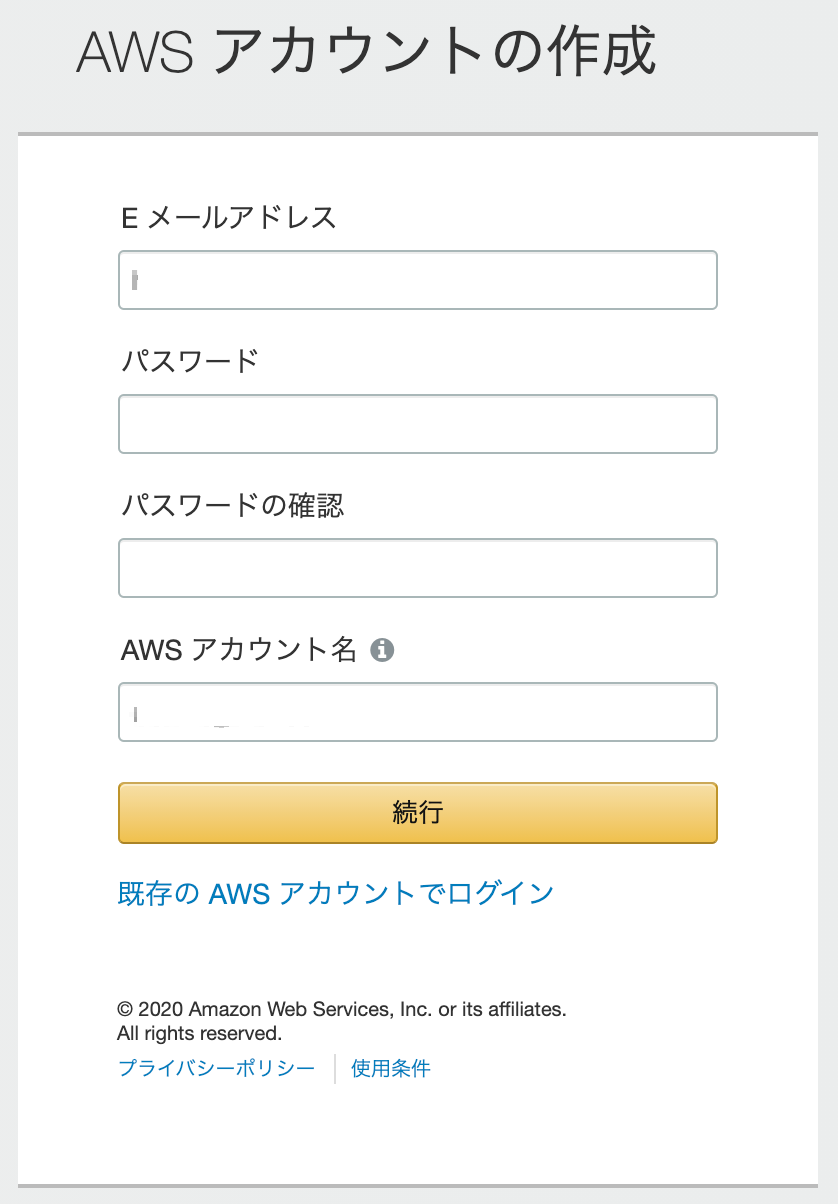
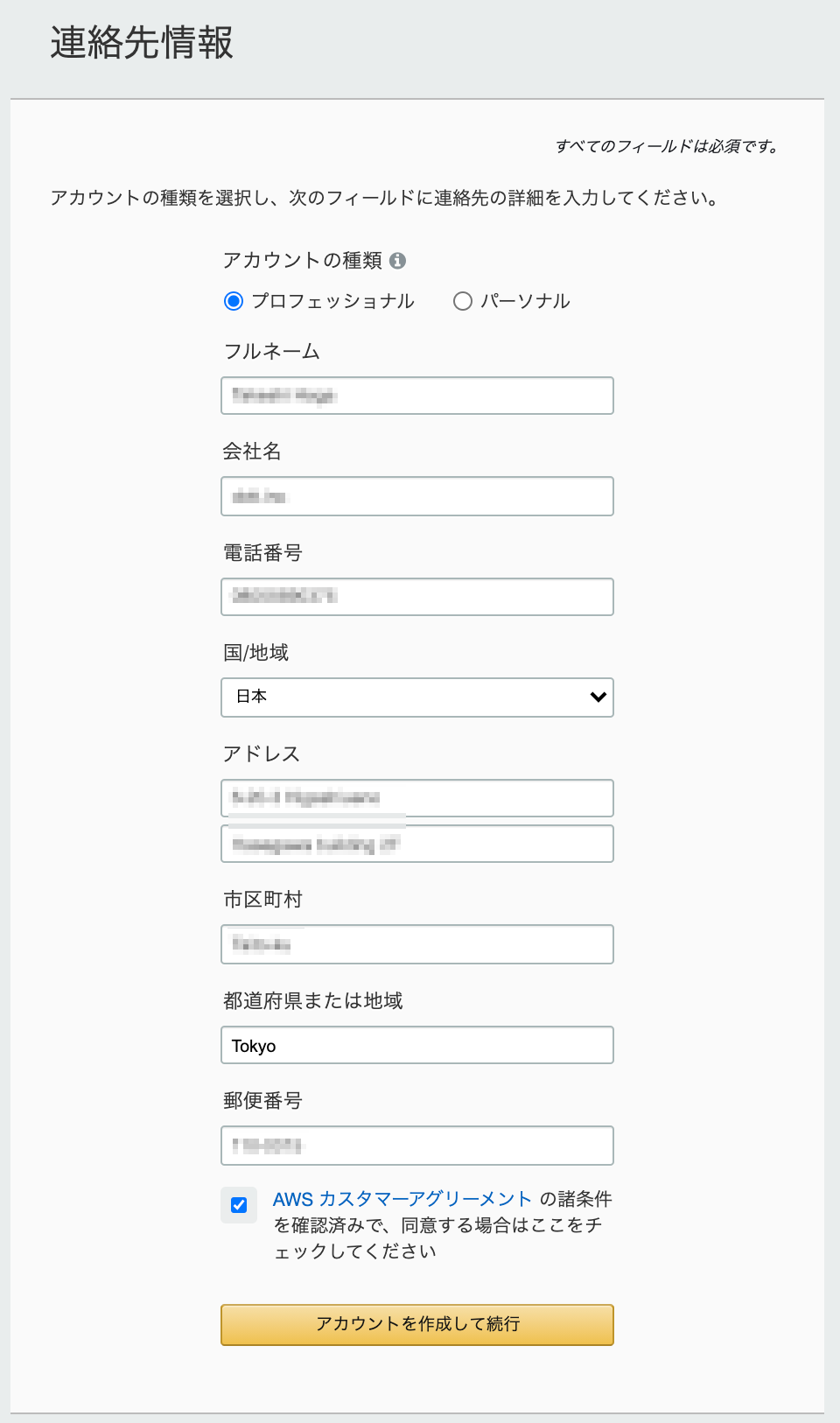
3. 連絡先情報
- アカウントの種類でプロフェッショナル/パーソナルとありますが、仕事利用か個人利用かと読み替えて選択してもらえれば良いと思います。
- 選択によって会社名になったり、個人名になったりします。
- 氏名や住所を入力する際に日本語ではなく、英語表記する必要があります。
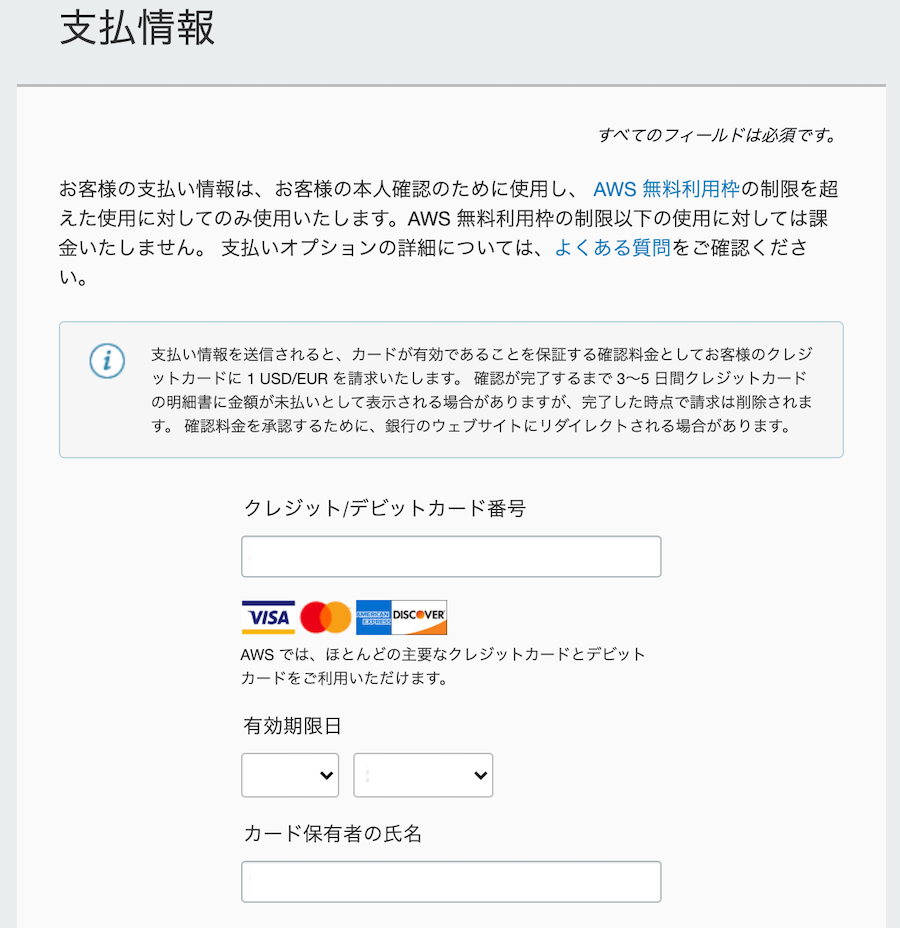
4. 支払情報
- 無料枠内で利用したい場合でもクレジットカード情報を入力する必要があります。
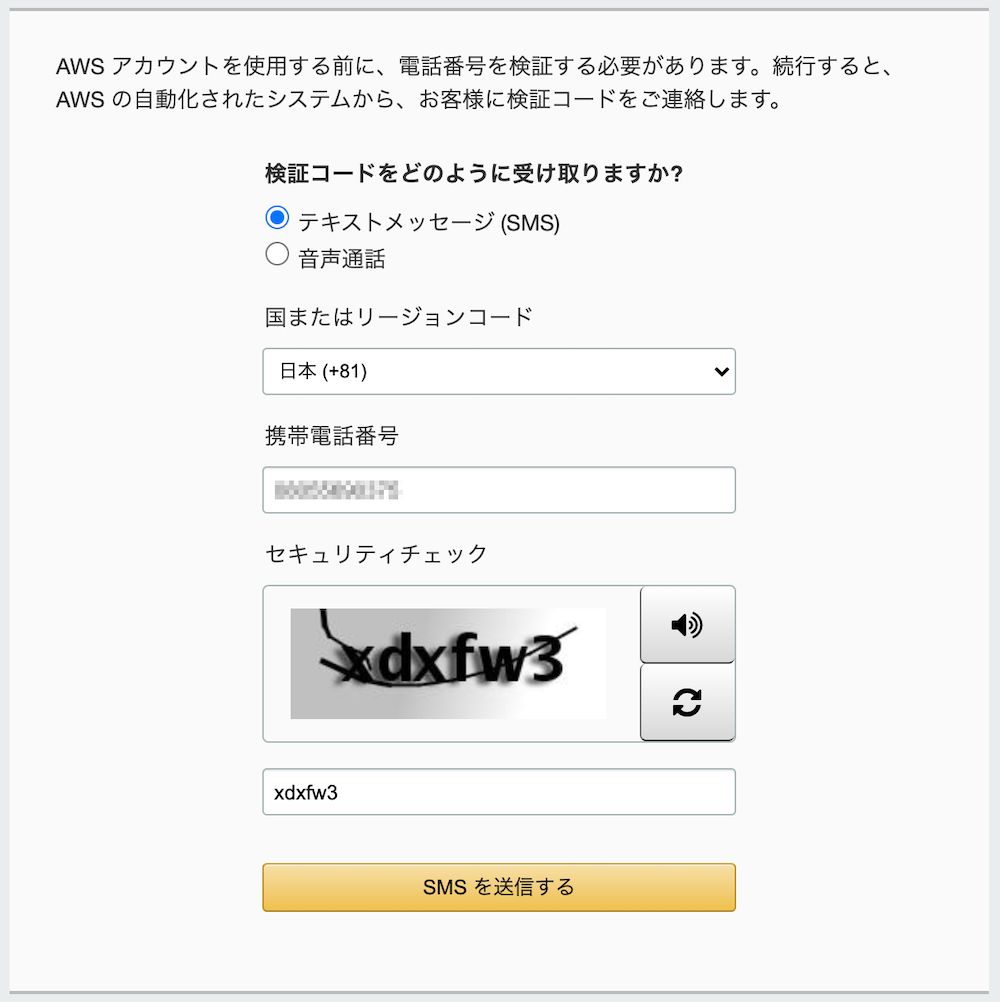
5. SMS認証
- 本人確認のため、SMS認証が必要になっています。
6. サポートプランの選択
- 前述で説明したサポートプランを選択する必要があります。
7. AWSアカウント作成完了
8. ルートアカウントでAWSコンソールへアクセスする
補足
AWS公式の作成の流れ
AWSアカウントの作成の流れが詳しく書いてあります。
* AWS アカウント作成の流れAWSアカウントを作成後にやるべきこと
- ルートアカウントでのアクセスは危険。
- ルートアカウントは、すべての操作ができるAdministrator権限です。
- ルートアカウントで日頃からログインし、システムを運用することはおすすめしません。
- AWS IAMにて操作権限を有したユーザーを作成しましょう。
- ルートアカウントへ多要素認証を設定する
- ハードウェアMFAが推奨されていますが、最低限バーチャルMFAを設定しましょう。
- 請求アラートを有効化しましょう
- EC2を立ち上げっぱなしで思わぬ請求を受けることがあるので必ず有効化し、被害が小さいうちに気づくようにしましょう。
- できれば、AWS Lambdaなどで日々の利用料をSlackへ通知する仕組みの導入をおすすめします。
- 投稿日:2020-09-24T16:33:19+09:00
EC2インスタンスのボリューム拡張をダウンタイムなしで実施した話
EC2インスタンスのボリューム拡張をダウンタイムなしで実施した話
お久しぶりです
多忙であまり書けてませんでした。
弊社で利用しているjenkinsサーバー(AWS EC2インスタンス)にて、アタッチしているEBSの空き容量がカツカツになってきたので拡張したいと思います。参考にしたのはこちら
前準備
前準備というよりは確認ですね。
## ブロックデバイスを表示するコマンド $ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT abcdn1 259:0 0 150G 0 disk ├─abcdn1p1 259:1 0 150G 0 part / └─abcdn1p128 259:2 0 1M 0 part ## 対象のデバイス ## 150GBしかない状態 $ df -h | grep abcdn1 /dev/abcdn1p1 150G 125G 26G 83% /ほんとカツカツ。
不要なジョブの削除などを行って対応してましたが、ボチボチしんどくなってきたのでストレージ拡張を提案した次第です。「ダウンタイムなし」とは言ったものの、流石にバックアップは取りたい。
- 対象インスタンスにSSHログインし、dockerなどを停止
- AWSのコンソールにて、対象のEC2インスタンスを停止
- ルートデバイスとして表示されている「/dev/xvda」のスナップショット作成開始
- 2,3分で完了
- 対象インスタンスを起動
- SSHログイン後、dockerなどを起動し各種サービスを手動で起動
とりあえずスナップショットは取得しました。
ちなみに業務時間中のお昼休みに作業を行ったので、$$誰も利用していない = 利用されてないからダウンしていない$$
ってことにしておきます。
集計バッチとかは、当日であればいつ動作しても支障がないように組んであるので問題ありませんでした。
EBSのサイズ拡張
- AWSコンソールにて
- EC2→インスタンス→対象インスタンスを選択
- [説明]→ルートデバイスに表示されているEBS IDからデバイスを開く
- アクション→ボリュームの変更→サイズを変更
- デバイスの容量拡張開始 → 完了まで1時間ほどかかりました
150GB → 500GBへの拡張で約1時間ほど要しました。
想定よりも長かったです。## 「abcdn1」デバイスの容量が500GBになったが、 ## パーティションの容量はまだ150GBのまま $ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT abcdn1 259:0 0 500G 0 disk ├─abcdn1p1 259:1 0 150G 0 part / └─abcdn1p128 259:2 0 1M 0 partデバイスの容量は増やしたのでパーティションの領域を拡張
## ルートボリューム「abcdn1」の「abcdn1p1」パーティションを拡張 $ sudo growpart /dev/abcdn1 1 CHANGED: partition=1 start=4096 old: size=314568671 end=314572767 new: size=1048571871,end=1048575967 ## 「abcdn1p1」パーティションが拡張された $ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT abcdn1 259:0 0 500G 0 disk ├─abcdn1p1 259:1 0 500G 0 part / └─abcdn1p128 259:2 0 1M 0 part ## しかし、まだストレージ自体は150GBしかない状態 $ df -h | grep abcdn1 /dev/abcdn1p1 150G 125G 26G 83% /ファイルシステムの拡張を行わないといけない模様。
## 「/dev/abcdn1p1」のファイルシステムを拡張 $ sudo xfs_growfs /dev/abcdn1p1 data blocks changed from 39321083 to 131071483 ## 正常に認識されました $ df -h | grep abcdn1 /dev/abcdn1p1 500G 125G 376G 25% /docker、及びdocker-composeが動作している状態でもEBSの拡張ができました。
とはいえ保険としてバックアップは必要で、バックアップ時にはインスタンス停止させるんですけども。
- 投稿日:2020-09-24T15:48:26+09:00
未経験者が自社開発企業に就職するためのREADME書き方
はじめに
こんにちは!
先月、無事にエンジニアデビューした1年目の者です。
私は某プログラミングスクールに3ヶ月間お世話になり、卒業後、3週間で自社開発企業に転職することができました。
この経験を生かして、私が意識してきたことを伝えていければと思います。まず、前提として転職では見せ方が最も重要だと考えています。
例えば、職務経歴書、面接対策、wantedlyのプロフィールなどなど、、
この記事では、その中でも重要なことの一つである、ポートフォリオの見せ方について共有します。記事の対象者
・未経験からエンジニア転職を考えていて、ポートフォリオを作成している方
・ポートフォリオのREADMEにて書く内容で迷っている方ポートフォリオの見せ方とは
エンジニアの方々は、忙しいので、書類選考の段階で、ソースを細かく見たりサイトを触って見たりしてくれるとは限りません。
ここで活躍するのが、READMEです。
私は、多くの転職成功された方々のREADMEを見て、自分なりの最適解を見つけました。
共通点は、端的でわかりやすく、視覚的に訴えていることでした。
この共通点からREADMEを使ってわかりやすく、視覚的に伝えられるようにすることが大事だと思います。
この記事では内容についてフォーカスしているので、書き方については他の方の記事を参考にしてください。READMEの構成
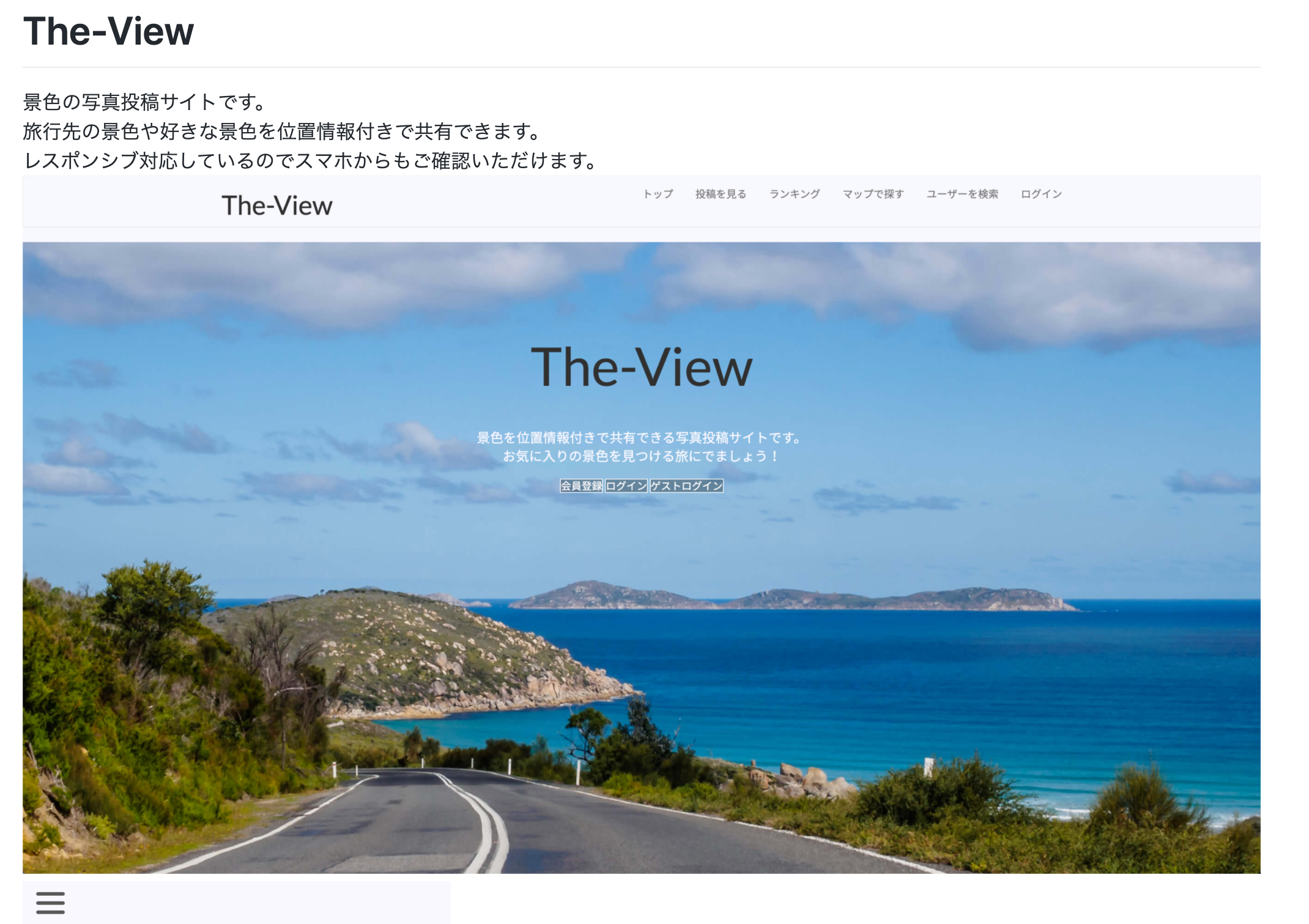
⬇️私の転職活動時に使用していたREADMEを元に説明していきます。
https://github.com/sora-uzu/The-View/blob/master/README.md書くことは、主に4つです。
1, タイトルと概要、URL
2, 使用技術
3, AWS(インフラ)構成図
4, 機能、非機能一覧1, タイトルと概要、URL
まずは、タイトル、URLはそのままの意味なので、概要について説明します。
概要は、以下の3点を一言で書いてください。
・どういうサイトか
・何ができるのか
・アピールポイントこれがかけたら、あとはサイトの分かりやすい画像を載せます。
載せ方は、癖があるので、
github readme 画像
などでググってください。
2, 使用技術
ここには、使用言語や、インフラ周りで使用しているサービスを書きます。
バージョンも書いていると良いです。
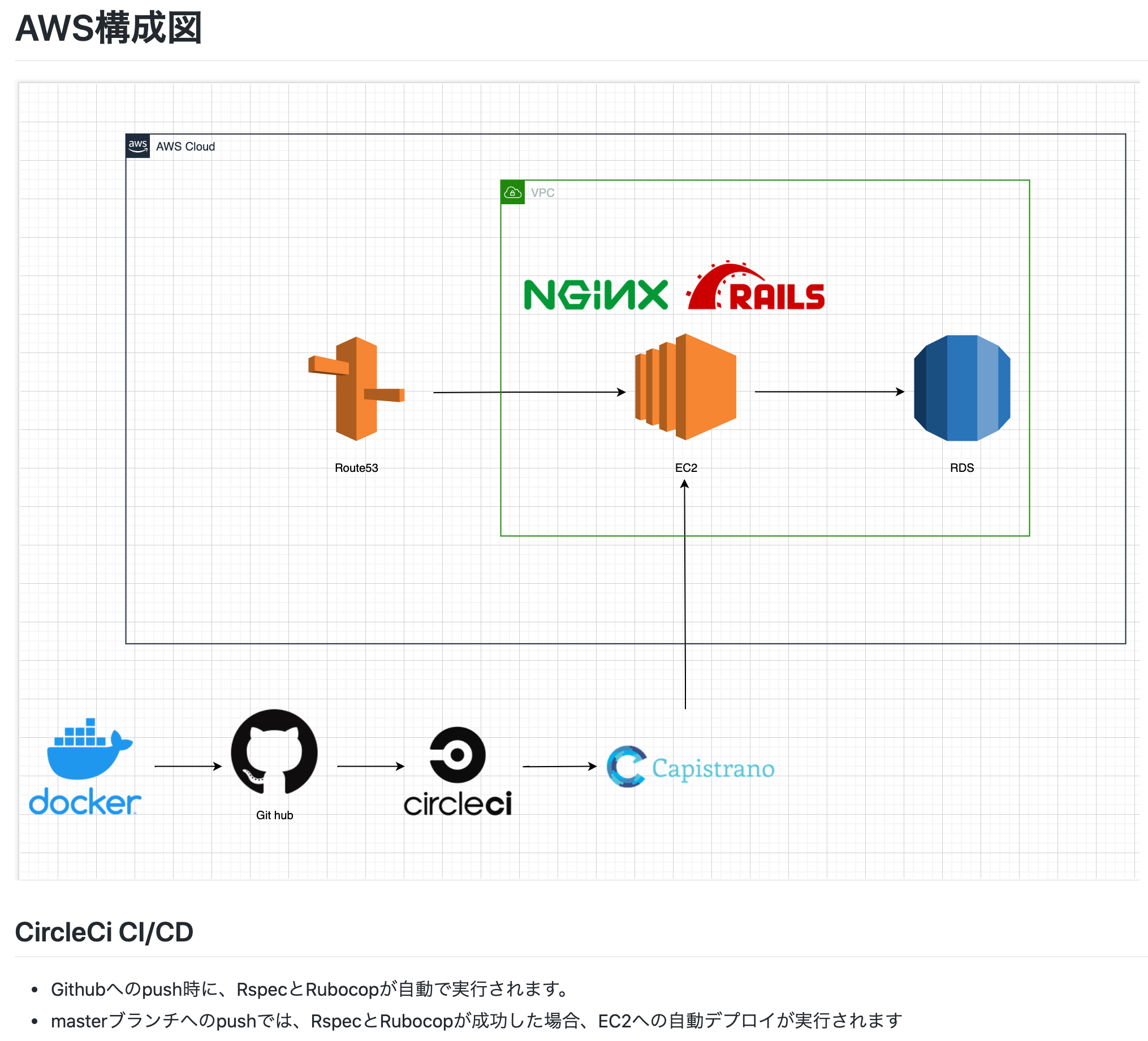
3, AWS(インフラ)構成図
インフラ周りで力を入れている方や、AWSを使っている方は、draw.ioを使ってインフラ構成図を作成してください。
各サービスの画像は、ググると公式サイトなどから転載可能な画像が取得できます。
インフラ周りでアピールポイントがあればここに記載すると良いと思います。
私の場合は、CircleCIでやっていることを書いています。
4, 機能、非機能一覧
機能と使用したgemを記載します。細かく書くというよりは、主な機能とそれに付随した機能を簡単に書いてください。
次に、非機能一覧では、なにでテストをしたか、何のテストをどのファイルで行っているかを書いてください。
最後に
以上が私が転職活動時にReadmeにおいて意識していたポイントです。私自身も多くの方のポートフォリオを参考にこういった構成になったので、皆さんも一つの参考にしていただけると嬉しいです。
ご覧いただきありがとうございました!会社の紹介
私は現在、株式会社ダイアログという物流×ITの会社に勤務しております。
2020年9月現在、エンジニアの募集はしていませんが、他にも様々な職種を募集しているので、Wantedlyのページをご覧ください。


- 投稿日:2020-09-24T15:04:32+09:00
AWS Perspectiveを使ってリソースの構成図を可視化してみた。
AWS Perspectiveとは
つい最近発表された、AWS Perspectiveですが、AWSアカウントのリソース構成を逆算してくれて
web UI(CloudFormationデザイナーみたいな)で可視化できるというソリューションのようです。
CloudFormationのテンプレートが用意されているのでデプロイするだけで使えるようになります。構築済みのアーキテクチャを可視化できるのは結構おもしろそうだし、役に立つ場面も多そう!
利用する際の注意点(コスト)
CloudFormationでソリューションをデプロイするので、ソリューション自体の料金がかかります。
・AWS Perspective deployment guide
このガイドによると、\$0.79/hr or $535.85/mthくらいのコストがかかるようです。
ちょっと使ってみたいくらいの方は、使用後すぐにソリューション削除した方が良いと思います。筆者はちゃんと削除された事を確認せずに寝たら\$15請求されちゃいました(汗)
使うための準備
デプロイやインポートの時間を含めると30分以上は準備にかかってしまうと思います。
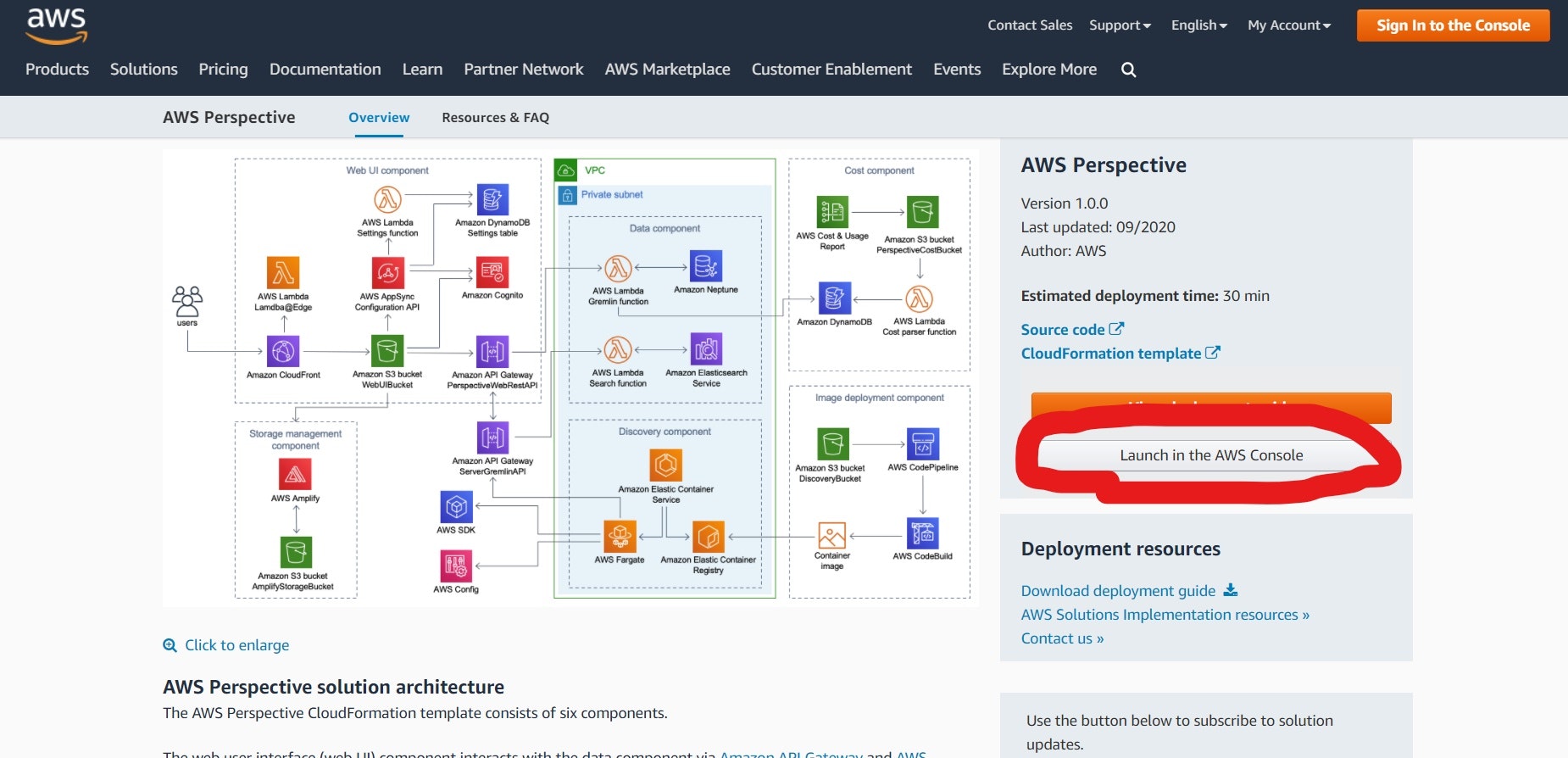
・CloudFormationテンプレートを使ってPerspectiveをデプロイする
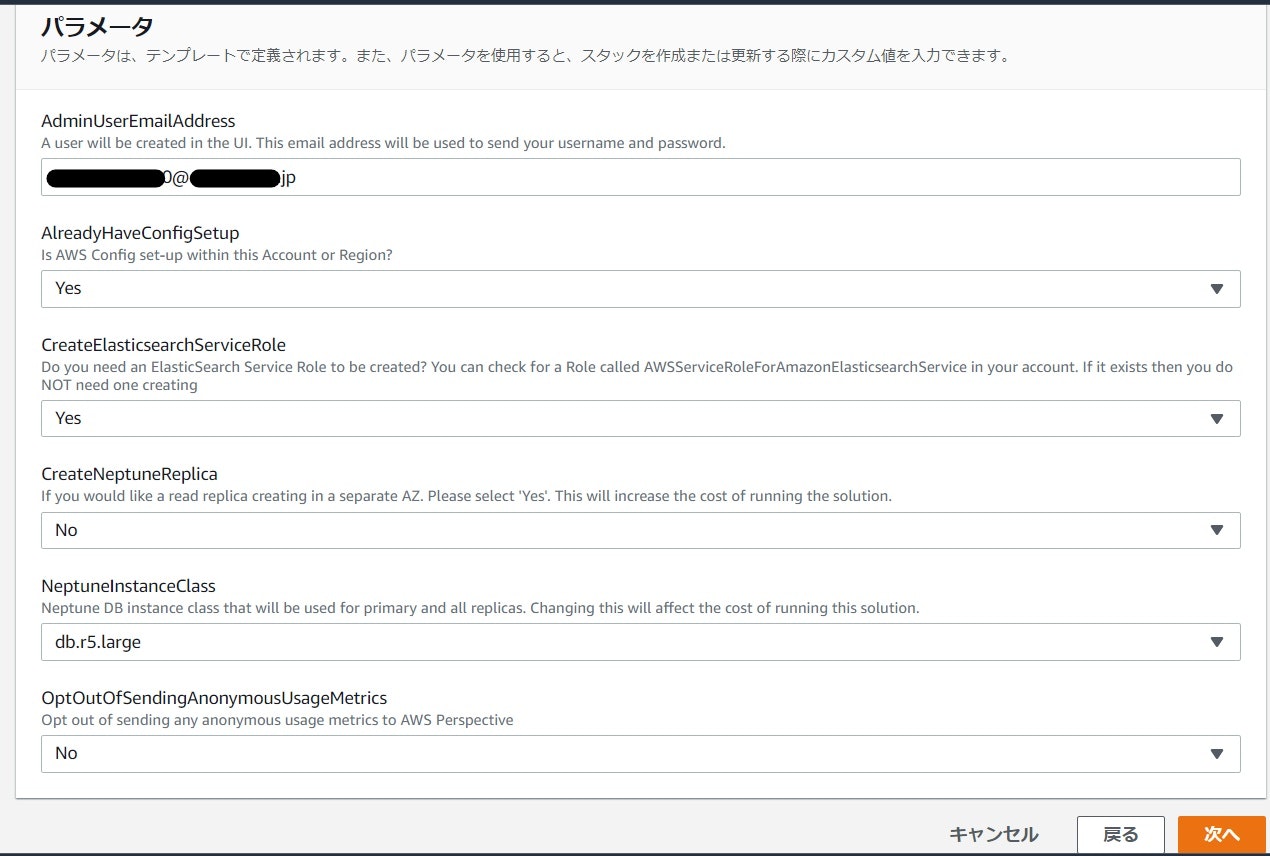
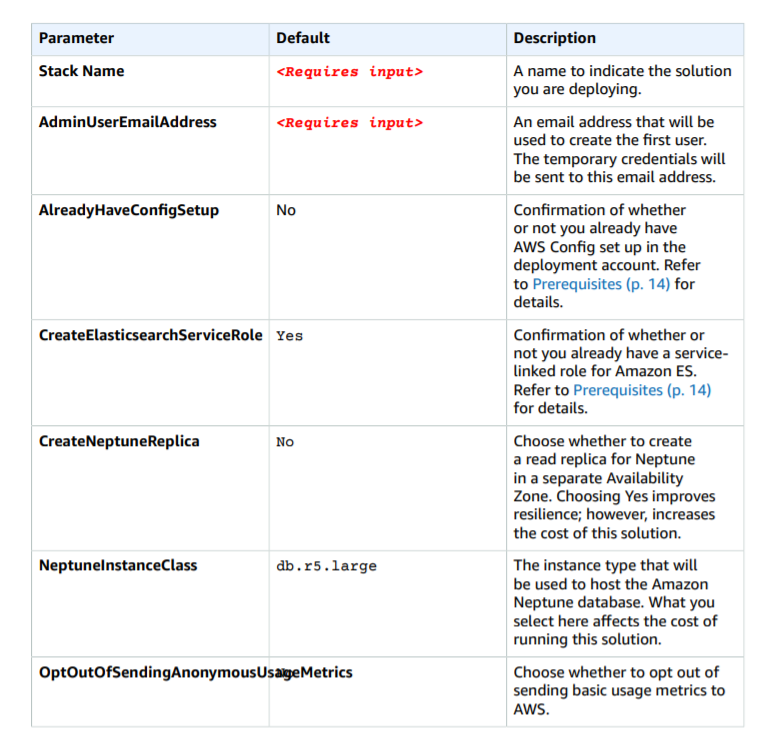
AWS公式のAWS Perspectiveサイトを開いて少し下にスクロールしたら右側に「Launch in the AWS console」という灰色のボタンがありますのでクリックします。
CloudFormationのスタック作成画面に行ったらまず、リージョンを東京に変更します。
スタックの作成画面はデフォルトのまま「次へ」をクリックします。
・「AdminUserEmailAddress」欄にメールアドレスを入力します。ここで入力したメールアドレスにログインに必要なIDとパスワードが送られてきます。
・「AlreadyHaveConfigSetup」はConfigの設定を特にしていなければ「NO」にします。(筆者は予め設定してあったのでYesになっています。)
一応、下に公式ガイドも貼っておきます。
この通りに設定していただければ大丈夫です。
それ以外はデフォルト設定でスタックの作成をクリックします。
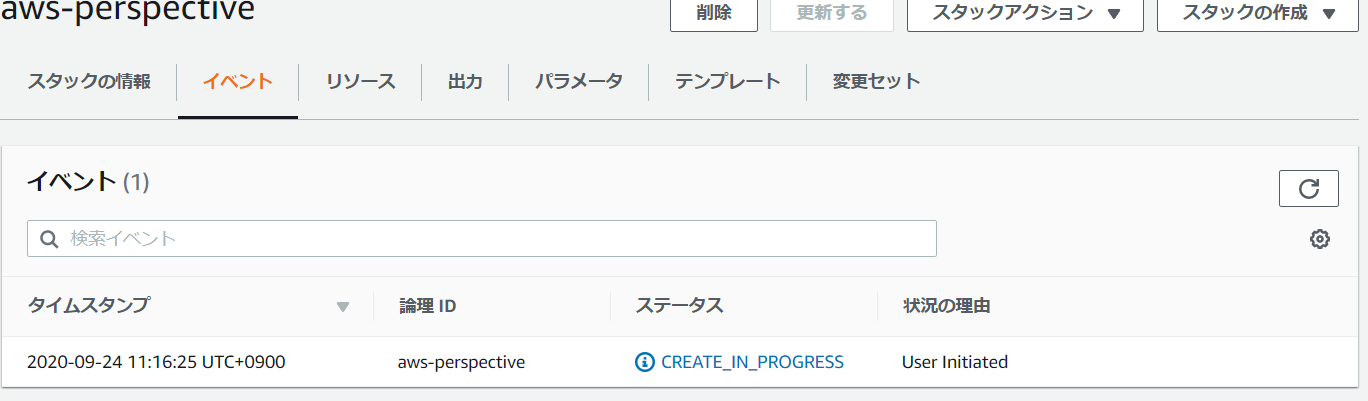
「CREATE_IN_PROGRESS」になるので、「CREATE_COMPLETE」になるまで待ちます。作成には20分くらいかかります。
待っている間に、先ほど登録したメールアドレスにメールが届いているか確認しておいてください。
そのメールに記載されているIDとパスワードでログインすることになります。・デプロイが完了したらログインする
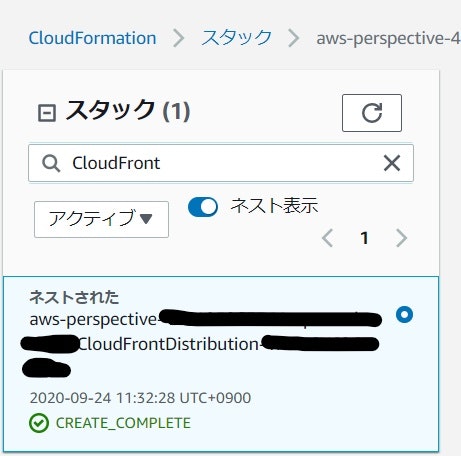
「CREATE_COMPLETE」になったらスタックの検索バーに「CloudFront」と入力して出てきたCloudFrontDistributionスタックをクリックします。
スタックの「出力」タブをクリックするとURLが出力されていますので、クリックするとログイン画面に飛びます。
先ほどのメールに記載されているログインIDとパスワードでログインし、パスワードの再設定と、メールアドレス認証を行います。認証が終わり「Getting Started」の画面になったら「Import」をクリックします。
インポート完了まで15分くらいかかります。これでAWS Perspectiveが使える状態になりました!
実際に使ってみる
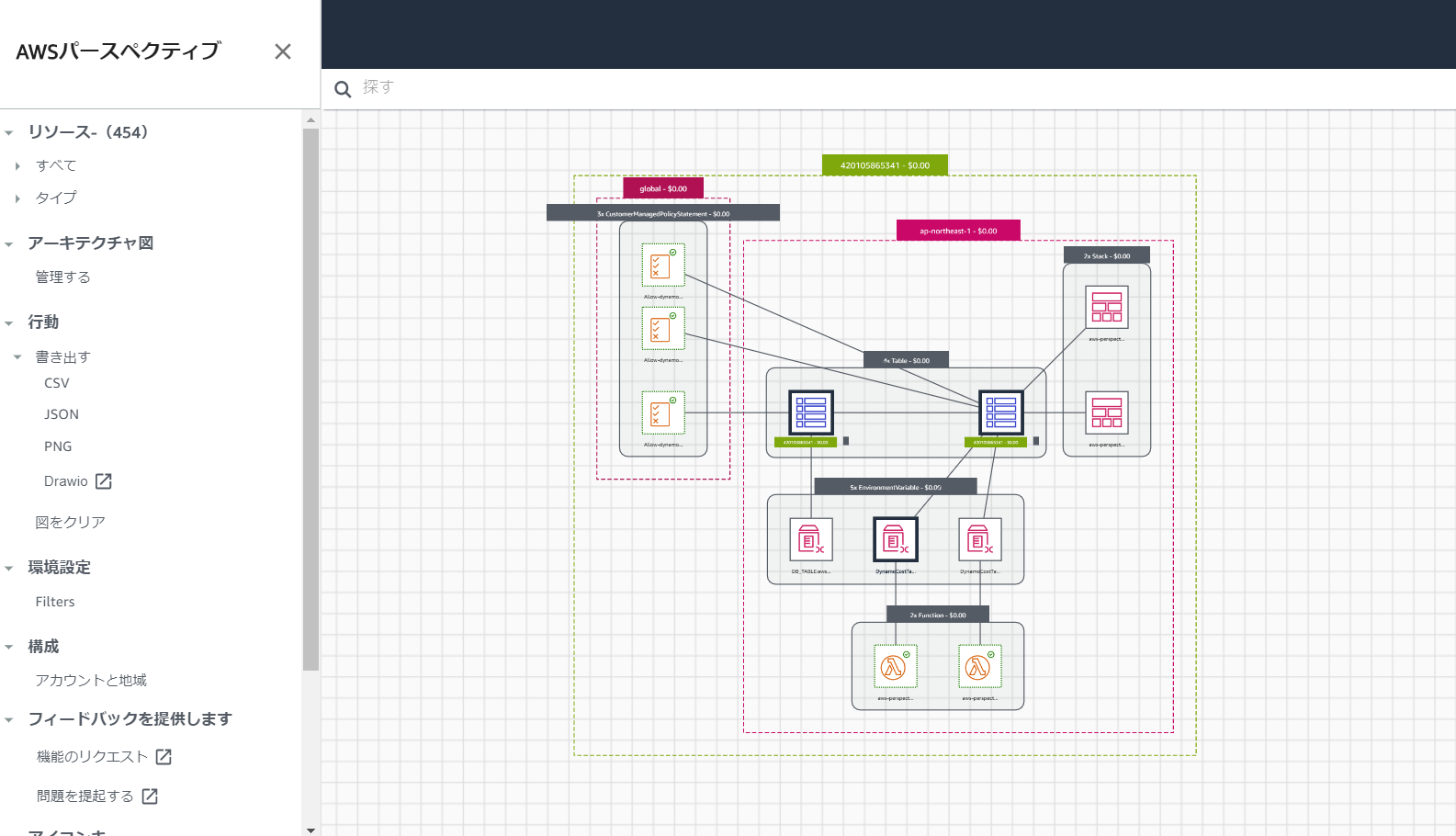
自分で作ったアーキテクチャも表示できますが、
試しにAWS PerspectiveのコンポーネントのLambdaとDynamoDBを表示させて、見やすいように移動させてみました。
見やすいようにリソース少なめで表示してみましたが、もっと表示させることもできます。web UIなので直感で操作できて結構楽しいです。
コストが細かく表示されているところが結構使えそうだなと思ったポイントです!
CSVやJSON、PNG、draw.ioとしてもエクスポートできるみたいですね!人によるかもしれませんが、少しだけ操作しずらい部分もあったので、アップデートに期待です。
最後に注意点
最初の利用する際の注意点でも上げましたが、ソリューション自体の料金で1時間約0.8ドルくらいかかるので、使い終わったら「aws-perspective」というスタックを削除することをおすすめします。
このスタックを削除することでCloudFromationで作成したリソースをクリーンアップできます。

- 投稿日:2020-09-24T14:50:38+09:00
【AWS SOA】S3バケットのパブリックアクセスに関する監視の備忘録
はじめに
AWS SOAの問題集の中で、S3の不正アクセス対策に関する問題が出題された。回答として必要以上にアクセス制限を設けずに、セキュリティ対策を行う方法として、AWS Configを使用して、パプリックアクセス可能なS3バケットが作成された際、監視をする方法が挙げられる。今回はその内容について簡単にまとめたい。
概要
AWS Configのルールを使用して、どのバケットが読み取りまたは書き込みのパブリックアクセスを許可されているのかを、迅速に特定することができる。またS3バケットのパブリックアクセスが可能となった場合、通知するようにAWS Configを設定することも可能。
方法
AWS Config>ルールを開く。ルールを追加を選択する。
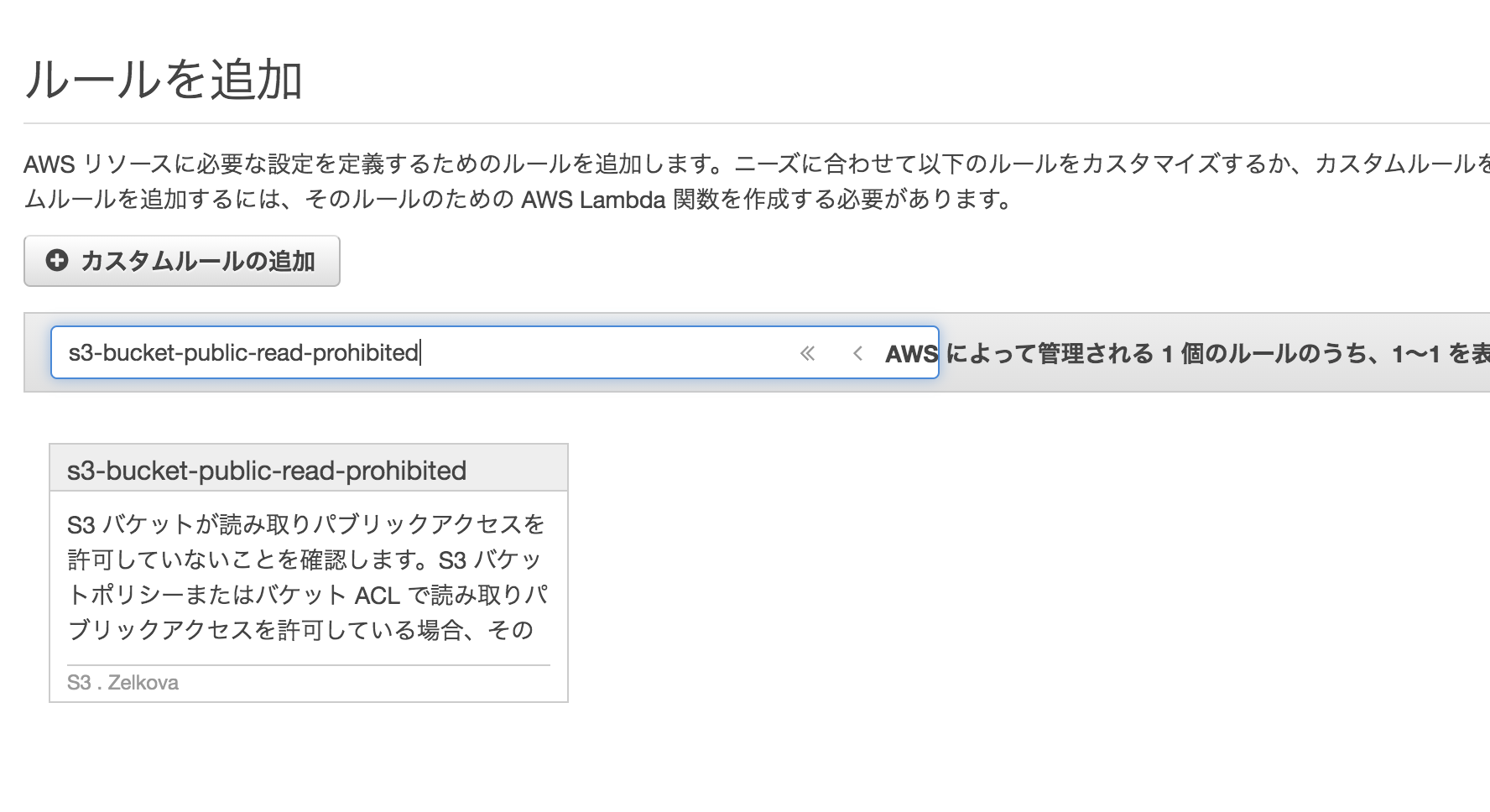
検索バーに「s3-bucket-public-read-prohibited」を入力して、「s3-bucket-public-read-prohibited」を選択する。
下にスクロールして、保存を選択する。
評価が数分で完了し、s3-bucket-public-read-prohibitedルールで非準拠のフラグが付いているS3バケット(インターネットからのパブリック書き込みアクセスまたはパブリック読み取りアクセスを許可しているバケット)を確認する。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/flag-buckets-aws-config/
- 投稿日:2020-09-24T14:21:59+09:00
AWS CloudFormation で「Property Name cannot be empty.」がでた時にやったこと
はじめに
これは新規の pipeline を CloudFormation で作成することになり物凄く困った時のメモです。
結論
Cloudformation のリファレンスを地道に1つずつ必須を調べました。
(足りなかったのは OutputArtifacts と InputArtifacts の Name)
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/aws-resource-codepipeline-pipeline.html経緯
ローカルに立てた former2 で既存のパイプラインをテンプレート化して、新しくスタックで作ろうとした時にエラーが表示され失敗してしまいました。
- CloudFormationは初めて利用したので 「Properties のどこかの Name の変数が空になってるのかな?」 と解釈していろいろ試しましたが解決しませんでした。
- 次に"Property Name cannot be empty."で検索しましたがまったくよい検索結果は得られませんでした。
- それからチュートリアルを読んでみたり、 変数をOutputs に表示しようとしたり、いろいろな所をコメントアウトして動作させてみましたところ 「Property Stage cannot be empty.」 と表示され「必須項目のどこかの Name が無い」と言う事に気付けました。
- そこからは CloudFormation のpipelineのリファレンスを見て必須項目を1つ1つ確認して OutputArtifacts と InputArtifacts に Nameが無いことにたどりつき、無事にスタックを作成することができました。
おわりに
テンプレートリファレンス、すごい、だいじ
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/template-reference.html(あと英語力をもうちょっとなんとか……)

- 投稿日:2020-09-24T10:36:20+09:00
AWSクレデンシャル情報取得のベストプラクティス(AWS SDK for Go)
はじめに
ECS(Fargate)でAWS SDK for Goを使ってAWSサービスを操作した際に、最初は勢いで作ったものの本当にこれでいいんだっけ?とモヤモヤしたことがあったので、クレデンシャル情報取得の優先順位とベストプラクティスについてまとめます。
結論
いきなりですが、下記がベストプラクティスとされる優先順位です。
詳細について後述します。1. ECSでアプリを実行している場合、タスクロール 2. EC2でアプリを実行している場合、EC2のIAMロール 3. 認証情報ファイル 4. 環境変数Sessionの生成
まず、AWSサービスを使うためのsessionを生成します。
今回はリージョンのみ指定しています。sess, err := session.NewSession(&aws.Config{ Region: aws.String("ap-northeast-1")}, )クレデンシャル情報取得の優先順位
上記のようにクレデンシャル情報の指定がない場合、以下の優先順位で認証情報を取得します。
1. 環境変数 2. 認証情報ファイル 3. EC2でアプリを実行している場合、EC2のIAMロール 4. ECSでアプリを実行している場合、タスクロールそれぞれの取得方法についての詳細です。
1.環境変数から認証情報を取得
開発作業中にローカル環境(macを想定)やAWS上のEC2インスタンスなどでまずはどの環境でもサクッと動かしたい時に有用です。
$ export AWS_ACCESS_KEY_ID=XXXXXXXXXXXXXXXXXXXX $ export AWS_SECRET_ACCESS_KEY=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX2.認証情報ファイル
credentialsのことです。AWS CLIや他の言語のAWS SDKで利用されるもの同じです。
aws configureコマンドで作成するとデフォルトで~/.aws/credentialsに作成されます。
クレデンシャル情報について何も指定しない場合は[default]の情報を取得します。[default] aws_access_key_id = XXXXXXXXXXXXXXXXXXXX aws_secret_access_key = XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX3.EC2 IAMロール
IAMロールを利用することで、EC2インスタンスの一時的なセキュリティ認証情報でAWSサービスの呼び出しを行うことができます。
クレデンシャル情報をさらすことも、手元でファイルを保管することなく、EC2インスタンスへのクレデンシャル情報の配布および管理を安全に行うことができます。
4.ECS タスクロール
タスクロールを利用することで、ECSタスク上で動作するアプリが一時的なセキュリティ認証情報でAWSサービスの呼び出しを行うことができます。
EC2 IAMロールと同様にクレデンシャル情報を安全に配布・管理できます。
また、タスクの実行IAMロールという似たような名前のロールがありますが、こちらはタスクがECRからのコンテナイメージのプルや、コンテナログをCloudWatchに発行を行うために必要なものです。タスクロールとは異なります。
[まとめ]クレデンシャル情報取得のベストプラクティス
環境変数にクレデンシャル情報を設定してしまえばローカル環境でもAWS上の環境でも動作はしますが、アクセスキーやシークレットアクセスキーが流出するリスクがあります。
認証情報ファイルも同様です。最終的にAWS上の環境にデプロイするのであればIAMロール or タスクロールがベストプラクティスです。
以下、ベストプラクティスとされる優先順位です。1. ECSでアプリを実行している場合、タスクロール 2. EC2でアプリを実行している場合、EC2のIAMロール 3. 認証情報ファイル 4. 環境変数参考
- https://docs.aws.amazon.com/sdk-for-go/v1/developer-guide/configuring-sdk.html
- https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/task-iam-roles.html
- https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/task_execution_IAM_role.html
- https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/iam-roles-for-amazon-ec2.html


- 投稿日:2020-09-24T09:11:59+09:00
Amazon S3で静的ホスティングしているWebサイトをHTTPS化する
最近、AWSを少し触っていて、Amazon S3の静的ホスティング機能を使ってWebサイトを作ってCognitoでログイン機能を付けてみたりして遊んでいたのですが、
これちょっと恥ずかしい!
Chromeだとわざわざ保護されていないことを晒上げてくれます!やったー!(笑)
でも、今時SSL化されてないWebページの方が珍しいですし、やってみようという事で筆者もhttps化(SSL化)してみることにしました。はじめに
この記事では、AWS Certificate Manager(以下「ACM」)とAmazon CloudFrontを利用してSSL証明書を発行・設定して、https接続できるようにしてみます。
Amazon S3で静的ホスティングをしていて、Amazon Route 53で独自ドメインを管理してルーティングしている事を前提にしています。(説明のためにドメイン名はexample.comとして書いていきます。)
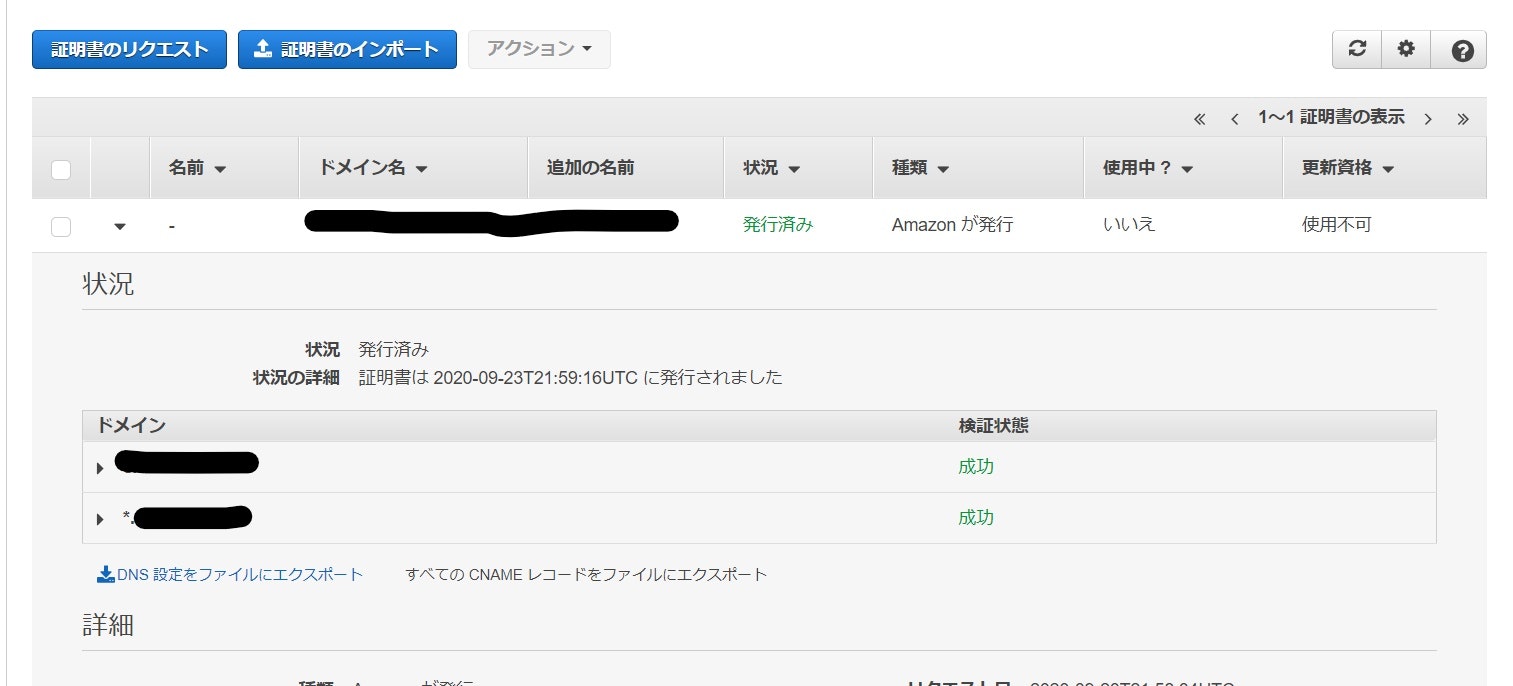
まずはACMでSSL証明書を発行する
・注意点
いきなりですが注意点です!
ACMで証明書を発行する前にAWSマネジメントコンソールの右上からリージョンを [米国東部 (バージニア北部)us-east-1] に変更してください!!
ACMで発行した証明書をCloudFrontで使用するには、 「米国東部 (バージニア北部)[us-east-1]」リー
ジョンで証明書を発行する必要があるようです。・実際に証明書を発行
AWSマネジメントコンソールで「Certificate Manager」を選択します。
・ACMが開いたら証明書のプロビジョニングの「今すぐ始める」をクリック
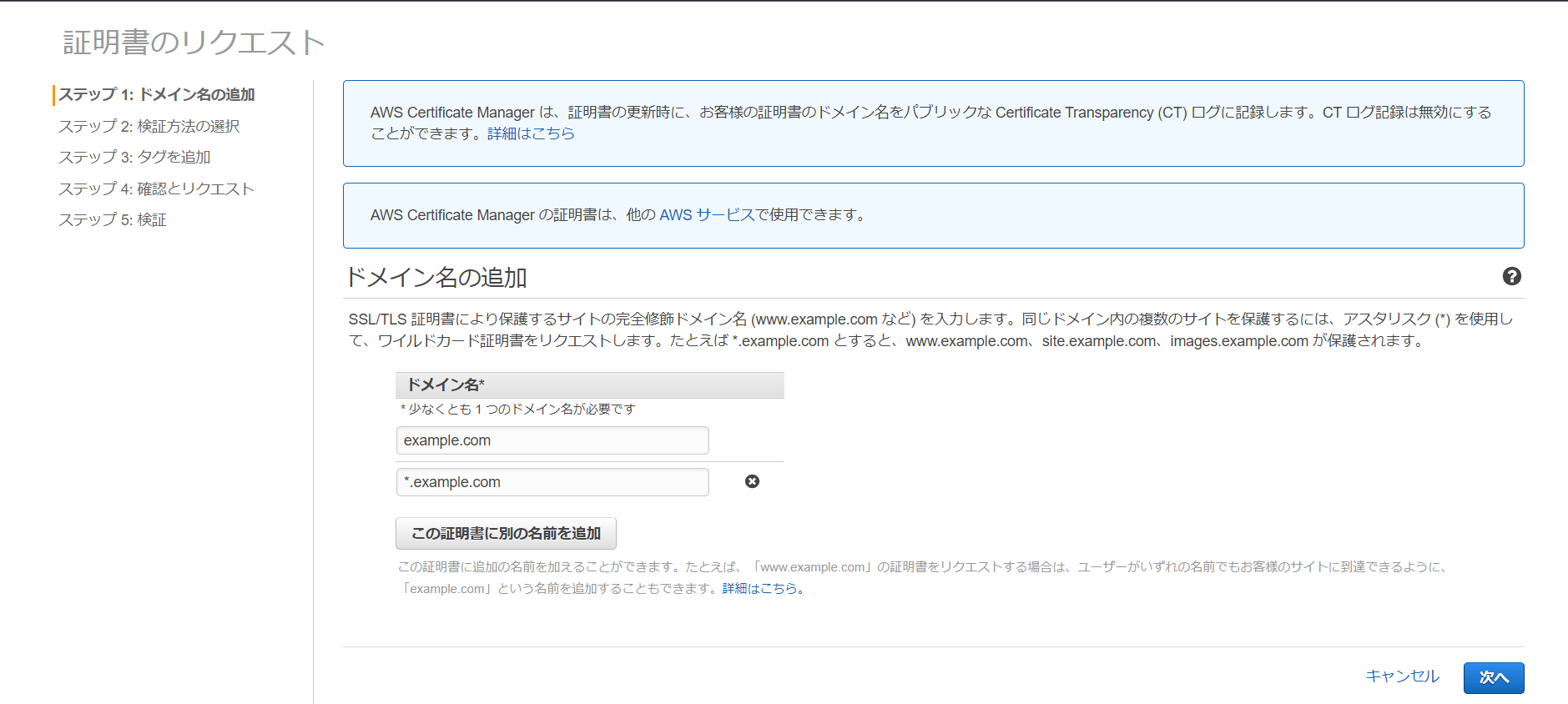
証明書のリクエストという画面になりますので、パブリック証明書のリクエストにチェックがついていることを確認して、証明書のリクエストをクリック。
・ドメイン名の追加でexample.comと*.example.comと入力して次へをクリック。
・DNSの検証にチェックが入っていることを確認して次へをクリック
タグを設定する方は設定していただいて、確定とリクエストをクリックします。
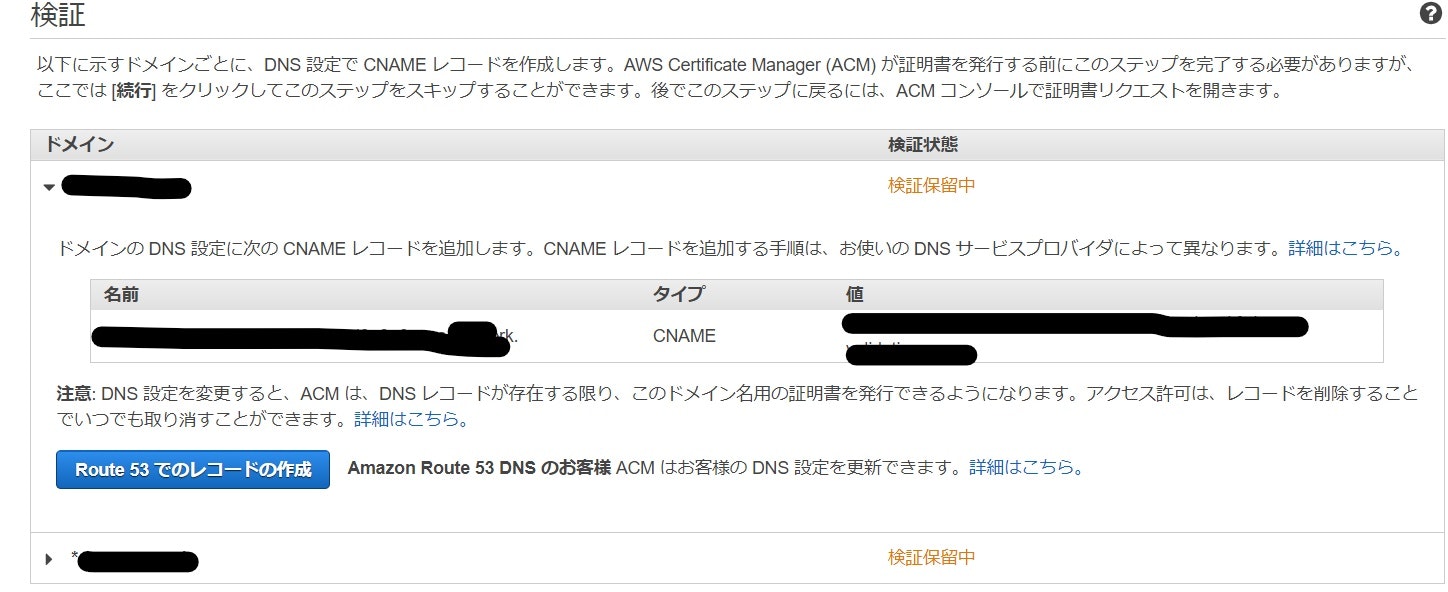
検証保留中になっていると思います。
次に、▶マークのドロップダウンボックスを選択して
「Route 53でのレコード作成」という青のボタンをクリックします。(両方のドメインでRoute 53のレコード作成を行ってください)
しばらくすると発行済みになるのでこれでSSL証明書の発行は完了です。
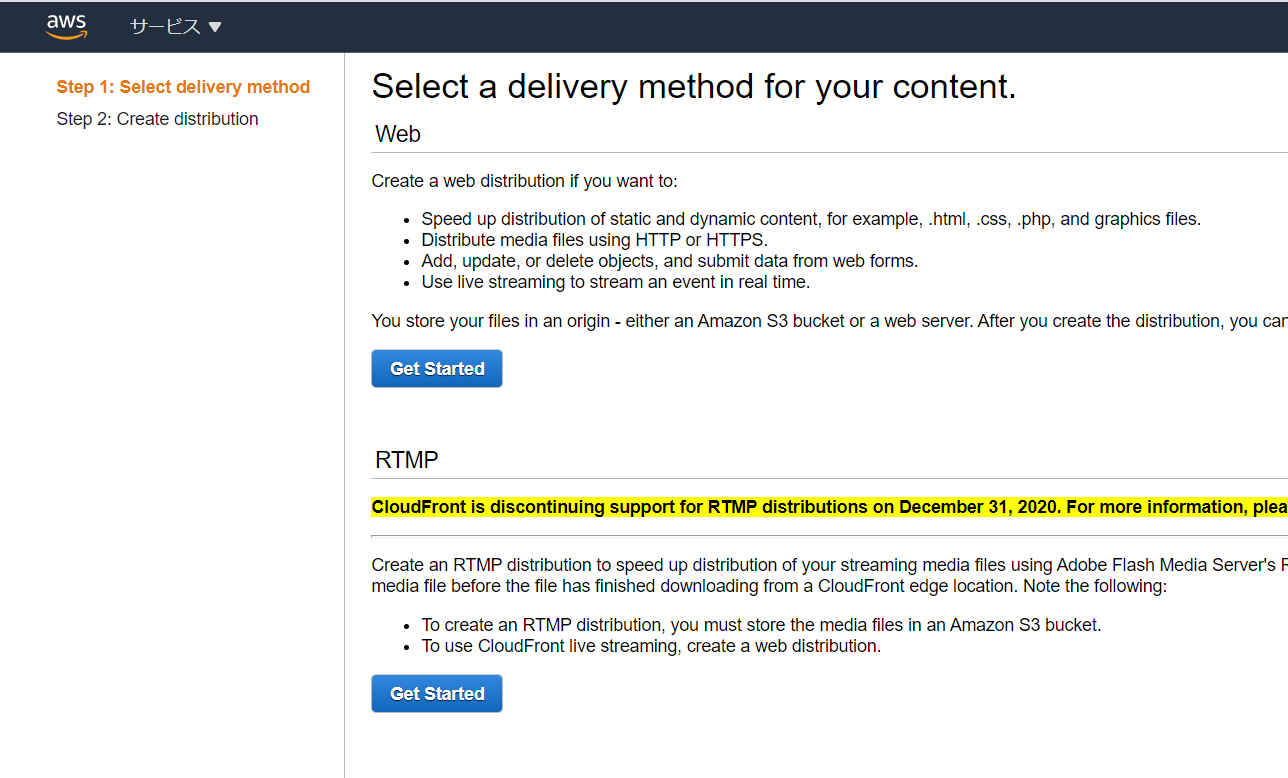
CloudFrontのディストリビューションに証明書を設定する
AWSマネジメントコンソールで「CloudFront」を選択します。
・「Distributions」タブの「Create Distribution」という青のボタンをクリック。
「Web」の「Get Started」をクリック。・変更箇所のみ説明
以下は変更する欄のみを画像付きで説明しますので、説明していない欄はデフォルトで大丈夫です。
・「Origin Domain Name」欄をクリックするとプルダウンメニューがでるので、静的ホスティングに使っているエンドポイントのS3を選択。
・「Viewer Protocol Policy」欄の「Redirect HTTP to HTTPS」をチェック
ここにチェックを入れておくとhttpへ接続しようとしても自動的にhttpsにリダイレクトしてくれます。
筆者は最初やった時にチェックを忘れていて直すのにRoute 53をいじったりしてしまってまあまあ時間がかかりました(汗)
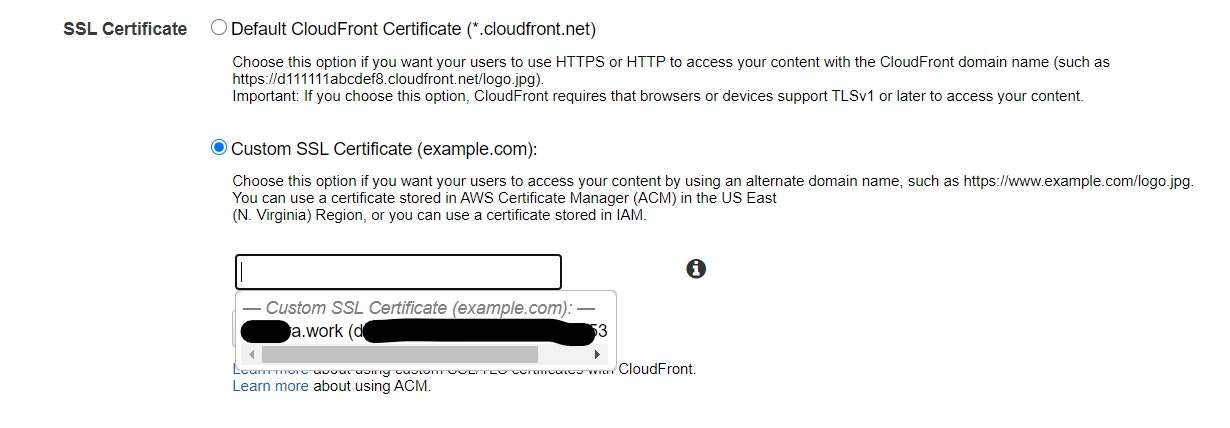
・「Alternate Domain Names(CNAMEs)」欄にドメイン名を入力。
・「SSL Certificate」欄の「Custom SSL Certificate(example.com):」欄にチェックをつけてACMで発行したSSL証明書を選択。
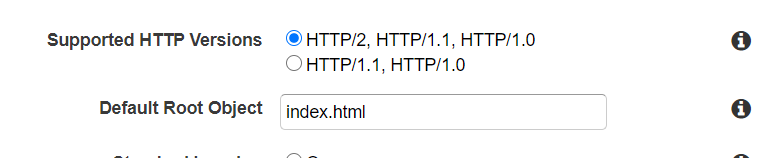
・最後に、「Default Root Object」欄にS3で静的ホスティングを有効にする際にインデックスドキュメントとして設定したファイル名を入力します。
設定直後は「Status」が「In Progress」ですが、しばらくすると「Deployed」に変わります。
これでCloudFrontに証明書を設定することが出来ました。
Route 53のレコードを設定
ここまで来たら最後に、S3に向いているRoute 53のルーティング先をCloudFrontへ変更するだけです。
まずは、AWSマネジメントコンソールで「Route 53」を選択します。
ホストゾーンタブをクリックしてドメイン名を選択します。
Aレコードにチェックボックスをつけて編集をクリック。
「値/トラフィックのルーティング先」欄を「CloudFrontディストリビューションへのエイリアス」「米国東部(バージニア北部)[us-east-1]」に変更し、ディストリビューションの選択から作成したディストリビューションを選択して「変更を保存」をクリックします。
これでACMで証明書を発行して、CloudFrontに設定、Route 53のルーティング先をCloudFrontに変更することができました!動作確認
いざchromeにドメイン名を入力!
えいちてぃーてぃーぴーえす!!!!
ついにあの忌々しい「保護されていない通信」の表記とおさらばです!!おわりに
S3で静的ホスティングしているサイトをhttps化(SSL化)してみましたが、意外と簡単にできちゃうんですね。
最近SAA(AWS認定ソリューションアーキテクトアソシエイト)を受けて無事合格できました。
その合格体験記とかもいずれ書ければなと思っています。











- 投稿日:2020-09-24T09:11:59+09:00
S3で静的ホスティングしているWebサイトをHTTPS化する
最近、AWSを少し触っていて、Amazon S3の静的ホスティング機能を使ってWebサイトを作ってCognitoでログイン機能を付けてみたりして遊んでいたのですが、
これちょっと恥ずかしい!
Chromeだとわざわざ保護されていないことを晒上げてくれます!やったー!(笑)
でも、今時SSL化されてないWebページの方が珍しいですし、S3でホストしているWebサイトをhttps化(SSL化)してみることにしました。はじめに
この記事では、AWS Certificate Manager(以下「ACM」)とAmazon CloudFrontを利用してSSL証明書を発行・設定して、https接続できるようにしてみます。
Amazon S3で静的ホスティングをしていて、Amazon Route 53で独自ドメインを管理してルーティングしている事を前提にしています。(説明のためにドメイン名はexample.comとして書いていきます。)
まずはACMでSSL証明書を発行する
・注意点
いきなりですが注意点です!
ACMで証明書を発行する前にAWSマネジメントコンソールの右上からリージョンを [米国東部 (バージニア北部)us-east-1] に変更してください!!
ACMで発行した証明書をCloudFrontで使用するには、 「米国東部 (バージニア北部)[us-east-1]」リージョンで証明書を発行する必要があるようです。
・実際に証明書を発行
AWSマネジメントコンソールで「Certificate Manager」を選択します。
・ACMが開いたら証明書のプロビジョニングの「今すぐ始める」をクリック
証明書のリクエストという画面になりますので、パブリック証明書のリクエストにチェックがついていることを確認して、証明書のリクエストをクリック。
・ドメイン名の追加でexample.comと*.example.comと入力して次へをクリック。
・DNSの検証にチェックが入っていることを確認して次へをクリック
タグを設定する方は設定していただいて、確定とリクエストをクリックします。
検証保留中になっていると思います。
次に、▶マークのドロップダウンボックスを選択して
「Route 53でのレコード作成」という青のボタンをクリックします。(両方のドメインでRoute 53のレコード作成を行ってください)
しばらくすると発行済みになるのでこれでSSL証明書の発行は完了です。
CloudFrontのディストリビューションに証明書を設定する
AWSマネジメントコンソールで「CloudFront」を選択します。
・「Distributions」タブの「Create Distribution」という青のボタンをクリック。
「Web」の「Get Started」をクリック。・変更箇所のみ説明
以下は変更する欄のみを画像付きで説明しますので、説明していない欄はデフォルトで大丈夫です。
・「Origin Domain Name」欄をクリックするとプルダウンメニューがでるので、静的ホスティングに使っているエンドポイントのS3を選択。
・「Viewer Protocol Policy」欄の「Redirect HTTP to HTTPS」をチェック
ここにチェックを入れておくとhttpへ接続しようとしても自動的にhttpsにリダイレクトしてくれます。
筆者は最初やった時にチェックを忘れていて直すのにRoute 53をいじったりしてしまってまあまあ時間がかかりました(汗)
・「Alternate Domain Names(CNAMEs)」欄にドメイン名を入力。
・「SSL Certificate」欄の「Custom SSL Certificate(example.com):」欄にチェックをつけてACMで発行したSSL証明書を選択。
・最後に、「Default Root Object」欄にS3で静的ホスティングを有効にする際にインデックスドキュメントとして設定したファイル名を入力します。
設定直後は「Status」が「In Progress」ですが、しばらくすると「Deployed」に変わります。
これでCloudFrontに証明書を設定することが出来ました。
Route 53のレコードを設定
ここまで来たら最後に、S3に向いているRoute 53のルーティング先をCloudFrontへ変更するだけです。
まずは、AWSマネジメントコンソールで「Route 53」を選択します。
ホストゾーンタブをクリックしてドメイン名を選択します。
Aレコードにチェックボックスをつけて編集をクリック。
「値/トラフィックのルーティング先」欄を「CloudFrontディストリビューションへのエイリアス」「米国東部(バージニア北部)[us-east-1]」に変更し、ディストリビューションの選択から作成したディストリビューションを選択して「変更を保存」をクリックします。
これでACMで証明書を発行して、CloudFrontに設定、Route 53のルーティング先をCloudFrontに変更することができました!動作確認
いざchromeにドメイン名を入力!
えいちてぃーてぃーぴーえす!!!!
ついにあの忌々しい「保護されていない通信」の表記とおさらばです!!おわりに
S3で静的ホスティングしているサイトをhttps化(SSL化)してみましたが、意外と簡単にできちゃうんですね。
最近SAA(AWS認定ソリューションアーキテクトアソシエイト)を受けて無事合格できました。
その合格体験記とかもいずれ書ければなと思っています。
- 投稿日:2020-09-24T09:07:08+09:00
SQSとmessage queingのメモ書き
MessageQueueとは
端的にいうと異なるソフトウェアでデータの通信を行うため使う機構です。
一般的なRESTAPIの構造だと、requestをしたらresponseが返るまで処理が行えません。そのため非同期の処理を行うことはできません。
なので、ソフトウェア間の通信を一旦 MQに格納して、双方の任意のタイミングで送受信を行えるようにするのがMQの思想です。
(AWSサイトより引用)SQS
Amazonが提供しているMessageQueueのサービスで二つのタイプからMQを構築することができます。
standard
性能を重要視した代わりに、順番の保証を捨てたMQです。
無限に近いスループットを持っていますが、
その代わりに、値を重複して返したり、順番もずれちゃう可能性があるため
冪等性を持った処理などに向いている種類です。FIFO
一般的なデータ構造のキューに基づいたMQです。
FIFOに基づいているため、順番は保証されますが、速度に限界があります。スループットは1秒間に3000程ですが、順番の保証と必ず1度しか値を返さないという保証があるため、処理の順番が大事な場合に向いてます。
MQが使えるケース
- 画像の加工など非常に重い処理を並列で行いたい場合
- 画像などを一旦MQに格納して同時にAWSのlambdaなどで加工を噛ませる。
- 画像が必要になったタイミングでGETで取得してもらう。
- バッチ処理を数で行いたい場合
- 処理に必要なデータをMQに書き込んで行き、規定数に到達したらバッチを走らせるという構成。

- 投稿日:2020-09-24T08:56:00+09:00
ICSアプローチに基づくドメイン駆動設計の戦略的設計
ドメイン駆動設計の戦略的設計では、主にマイクロサービス形式によるサービス指向アーキテクチャ(SOA)を使用したクラウドを使用した分散型システムを使用する。
海外ではマイクロサービスの設計の失敗事例が数多くあり、設計思想に何らかの欠陥があるのではないかと考えた。
事例を研究した結果、アメリカ式のドメイン駆動設計の戦略的設計に問題があるという結論に達した。
アメリカ式のドメイン駆動設計の戦略的設計は、テクノジーに偏重した高スペック重視の設計方法。
スペックを高めるために、クラウド上の外部サービスを使用した結果、設計が複雑化し、サービスが追加されるほど複雑化が加速し、分散システムが破綻する。
マイクロサービス形式による分散型システムにはシンプルで簡易な設計思想が必要である。
そこで、ロシア式のドメイン駆動設計の戦略的設計であるICSアプローチを使用する方法を紹介したいと思う。ICSアプローチ
ICSアプローチとは
ICSアプローチとはInformation(情報)、Cyber(サイバー)、Synergy(相乗)の3つの概念を統括したロシア式ドメイン駆動設計による戦略的設計。
ICSアプローチでは以下の3つの機能に焦点を当てている。
・目標に基づくシステムの監視によるエラー検知
・検知したエラーの報告
・メディアへ情報を投射する反射環境の構築なぜICSアプローチを推奨するのか
ICSアプローチをお勧めしている理由は、「よい商品を売る」よりも「良い商品を売っているという情報」のほうが強力だから。
「世論」の著書であるウォルターリップマンは以下のように論じている。
「人々は、主観的で偏見があり、必然的に世界の精神的イメージが省略された疑似環境を構築します。
ある程度、誰の疑似環境もフィクションです。人々は同じ世界に住んでいるが、彼らは異なる世界で考え、感じている」。新聞、TVなどのメディアを通してステレオタイプと呼ばれる疑似環境が構築される。
商品などは物質的な限界が存在する。
しかし、情報は物質的な限界はPCのデータ量に左右され、情報を投射することにって人々にステレオタイプを作成し、行動パターンを操作することができる。
そして、SNS、動画サイトの増加によって、情報を投射できる環境は増加している。ドメイン駆動設計の戦略的設計に求められているのはシステムの安定稼働と、システム連結による相乗効果である。
ロシア式のICSアプローチは設計思想がシンプルかつ高スペックなクラウドシステムを使用しなくも実現することができる。分散システムに必要な情報保護
分散システムは情報化によって業務の縦割りを一つのシステムに統合する。
情報が人間の体内の血液のように循環することによって、全てのシステムが正常に稼働する。
そのため、分散システムにおいて情報の保護が最優先に置かれる。
情報の保護を優先するために以下のような設計手法に焦点になる。
・情報の暗号化通信
・情報の共通データ構造の設定
・設定されたデータの書式チェック
分散システムはRestApiによるメッセージ駆動による通信方式になるため、暗号通信によってメッセージ駆動が実現される。ICSアプローチの機能
ICSアプローチの以下の機能が必要である
・通信に使用する情報モデルの作成
・情報モデルを合成し、情報モデルを組み合わせた情報構造体モデルの作成
・情報構造体モデルのプロパティに設定された値の意味を解釈する解釈機能
・異なるコンテキスト間で通信を行うために接続先URL、ユーザー、パスワードを設定する通信先設定インターフェース機能
・SNS、動画サイトなどへイベント情報を投射するための通知機能間接アプローチに基づく情報投射
間接アプローチとは
間接アプローチ戦略とは正面衝突を避け、間接的に相手を無力化・減衰させる戦略。
第一次世界大戦後、リデル・ハートによって提唱された。
現代では間接アプローチが重要。
なぜならSNS、動画サイトの登場でユーザー間の反射的反応によってシナジー(相乗)が発生するため。ハードパワー + ソフトパワーを融合させた心理的威嚇
手段には2つの方法が存在する。
・ハードパワーとは組織の資源 and 人材 and 経済活動を組み合わせて実行される長期持続の力。
・ソフトパワーは商品開発 or イベント企画によって発生する短期の力。ソフトパワーは認知 + 解釈 + 影響の3つの過程を得て共感が広がる。
間接アプローチ戦略はハードパワー + ソフトパワーを組み合わせた心理的威嚇である。
動画、SNSへソフトパワーを投射し、ハードパワーと結びつけることが重要である。間接アプローチの原則
積極的側面
・目的を手段に適合させよ
・目的を常に念頭に置け
・最小予期線を選択せよ
・最小抵抗線を利用せよ
・代替目標のある作戦線を選択せよ
・状況に対する柔軟性のある、計画および配置を心がけよ消極的側面
・敵が防御態勢を整えている間は攻撃するな
・一度失敗した作戦線で再攻撃をするな顧客のターゲティング方法と投射するイベントの内容について
顧客の要求は、顧客を取り巻いている外部環境によって発生する。
顧客の外部環境を分析、特定し、顧客の行動パターンの該当するイベントを情報媒体に投射することが重要である。
顧客の外部環境は以下の階層で分析することができる。・顧客を取りまく外部環境の階層
地理・・・住んでいる場所
文化・・・所属している文化、カレンダーから文化の種類を特定
職業・・・職業の違いによって発生する価値観に焦点をあてる
コミュニティ・・・ユーザーが所属しているコミニュティによって生じる行動パターン
経済・・・経済活動によって生じる行動パターン情報媒体へ投射するイベントは以下の2種類を用意する
・ネガティブフィードバック・・・顧客が損だと感じるイベント。
・ポジティブフィードバック・・・顧客が得だと感じるイベント。重要なのは顧客の意識決定のOODAループに入ることである。
OODAループは、観察(Observe)- 情勢への適応(Orient)- 意思決定(Decide)- 行動(Act)のループである。
観察(Observe)- 情勢への適応(Orient)の意識決定へ侵入することで、ソフトパワーを認知 + 解釈 + 影響の過程を得て拡大し、シナジー(相乗)が発生する結論
最終的に目指すべきドメイン駆動設計の方法とはロシア式 +アメリカ式 のハイブリッドアプローチ。
ロシア式で戦略的設計を行い、アメリカ式でアプリ内開発を行う。
アプリ内開発をアメリカの設計方式で行えば、複雑な設計もアプリ内で完結するためシステム全体には広がらない。
ICSアプローチに基づくとドメイン駆動設計のコアドメインとサブドメインの境界線も明確になる。
・コアドメイン・・・資材発注、販売、在庫管理など組織の経済活動を担当する業務
・サブドメイン・・・システム間のエラー検出、エラー通知、別メディアへの情報投射
ロシア式 +アメリカ式のドメイン駆動設計の設計方式はお互いを補完しあう関係にある設計方式である。
- 投稿日:2020-09-24T08:28:08+09:00
AWSクレデンシャル情報取得のベストプラクティス(AWS SDK for Go)
はじめに
ECS(Fargate)でAWS SDK for Goを使ってAWSサービスを操作した際に、最初は勢いで作ったものの本当にこれでいいんだっけ?とモヤモヤしたことがあったので、クレデンシャル情報取得の優先順位とベストプラクティスについてまとめます。
結論
いきなりですが、下記がベストプラクティスとされる優先順位です。
詳細について後述します。1. ECSでアプリを実行している場合、タスクロール 2. EC2でアプリを実行している場合、EC2のIAMロール 3. 認証情報ファイル 4. 環境変数Sessionの生成
まず、AWSサービスを使うためのsessionを生成します。
今回はリージョンのみ指定しています。sess, err := session.NewSession(&aws.Config{ Region: aws.String("ap-northeast-1")}, )クレデンシャル情報取得の優先順位
上記のようにクレデンシャル情報の指定がない場合、以下の優先順位で認証情報を取得します。
1. 環境変数 2. 認証情報ファイル 3. EC2でアプリを実行している場合、EC2のIAMロール 4. ECSでアプリを実行している場合、タスクロールそれぞれの取得方法についての詳細です。
1.環境変数から認証情報を取得
開発作業中にローカル環境(macを想定)やAWS上のEC2インスタンスなどでまずはどの環境でもサクッと動かしたい時に有用です。
$ export AWS_ACCESS_KEY_ID=XXXXXXXXXXXXXXXXXXXX $ export AWS_SECRET_ACCESS_KEY=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX2.認証情報ファイル
credentialsのことです。AWS CLIや他の言語のAWS SDKで利用されるもの同じです。
aws configureコマンドで作成するとデフォルトで~/.aws/credentialsに作成されます。
クレデンシャル情報について何も指定しない場合は[default]の情報を取得します。[default] aws_access_key_id = XXXXXXXXXXXXXXXXXXXX aws_secret_access_key = XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX3.EC2 IAMロール
IAMロールを利用することで、EC2インスタンスの一時的なセキュリティ認証情報でAWSサービスの呼び出しを行うことができます。
クレデンシャル情報をさらすことも、手元でファイルを保管することなく、EC2インスタンスへのクレデンシャル情報の配布および管理を安全に行うことができます。
4.ECS タスクロール
タスクロールを利用することで、ECSタスク上で動作するアプリが一時的なセキュリティ認証情報でAWSサービスの呼び出しを行うことができます。
EC2 IAMロールと同様にクレデンシャル情報を安全に配布・管理できます。
また、タスクの実行IAMロールという似たような名前のロールがありますが、こちらはタスクがECRからのコンテナイメージのプルや、コンテナログをCloudWatchに発行を行うために必要なものです。タスクロールとは異なります。
クレデンシャル情報取得のベストプラクティス
環境変数にクレデンシャル情報を設定してしまえばローカル環境でもAWS上の環境でも動作はしますが、アクセスキーやシークレットアクセスキーが流出するリスクがあります。
認証情報ファイルも同様です。最終的にAWS上の環境にデプロイするのであればIAMロール or タスクロールがベストプラクティスです。
以下、ベストプラクティスとされる優先順位です。1. ECSでアプリを実行している場合、タスクロール 2. EC2でアプリを実行している場合、EC2のIAMロール 3. 認証情報ファイル 4. 環境変数参考
- https://docs.aws.amazon.com/sdk-for-go/v1/developer-guide/configuring-sdk.html
- https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/task-iam-roles.html
- https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/task_execution_IAM_role.html
- https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/iam-roles-for-amazon-ec2.html
- 投稿日:2020-09-24T07:21:50+09:00
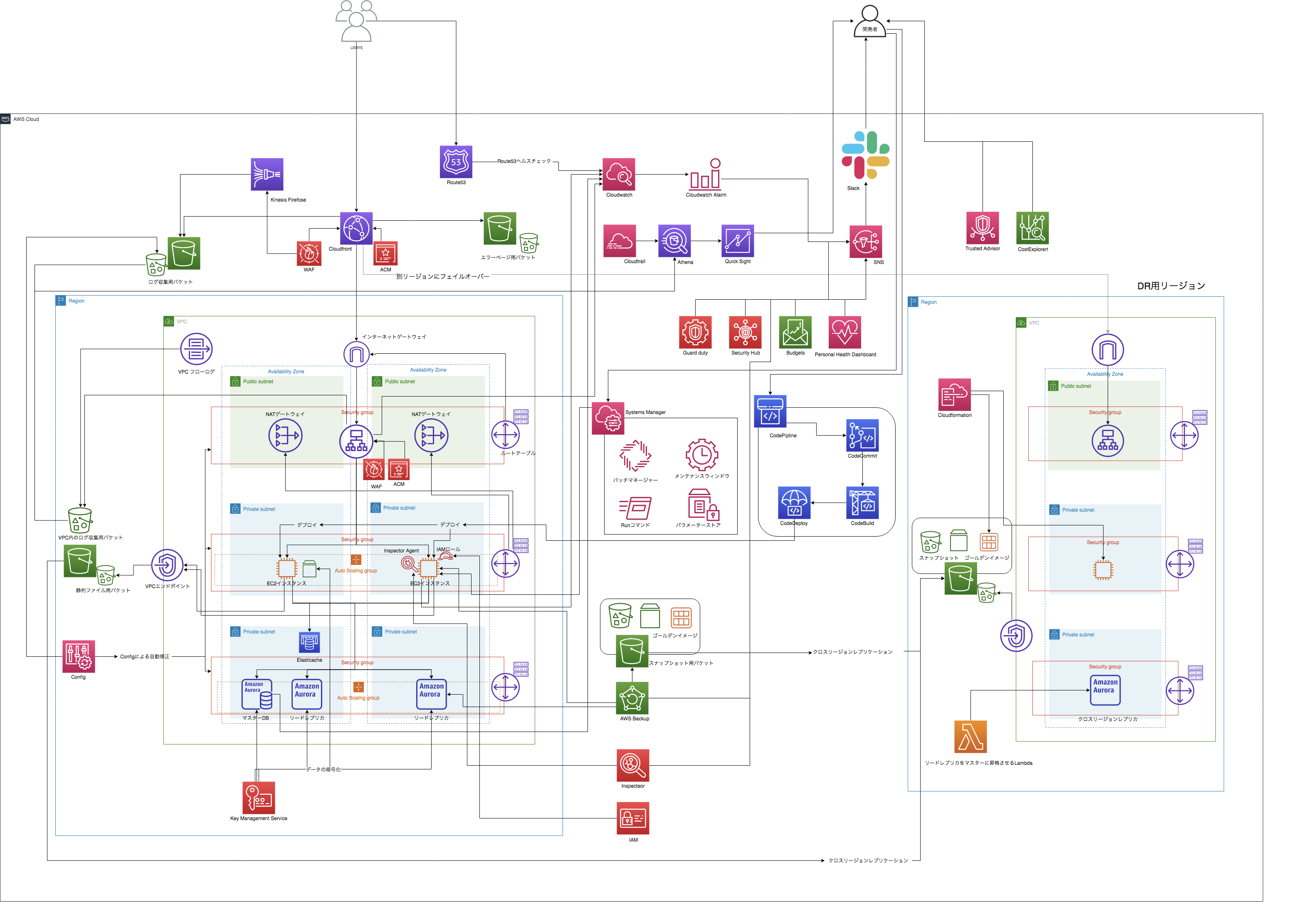
未経験者がWell Architected Frameworkを意識して自分なりにアーキテクチャ設計・構築をしてみた。<VPC、ELB編>
はじめに
この記事は、実務未経験者がロールプレイング形式でアーキテクチャの設計、構築を行うといった記事です。
よろしければ<準備編><アーキテクチャ設計編>もご覧くださいませ。前回までのあらすじ
前回は問題点を洗い出し、具体的な改善案を提案、アーキテクチャの設計を行いました。
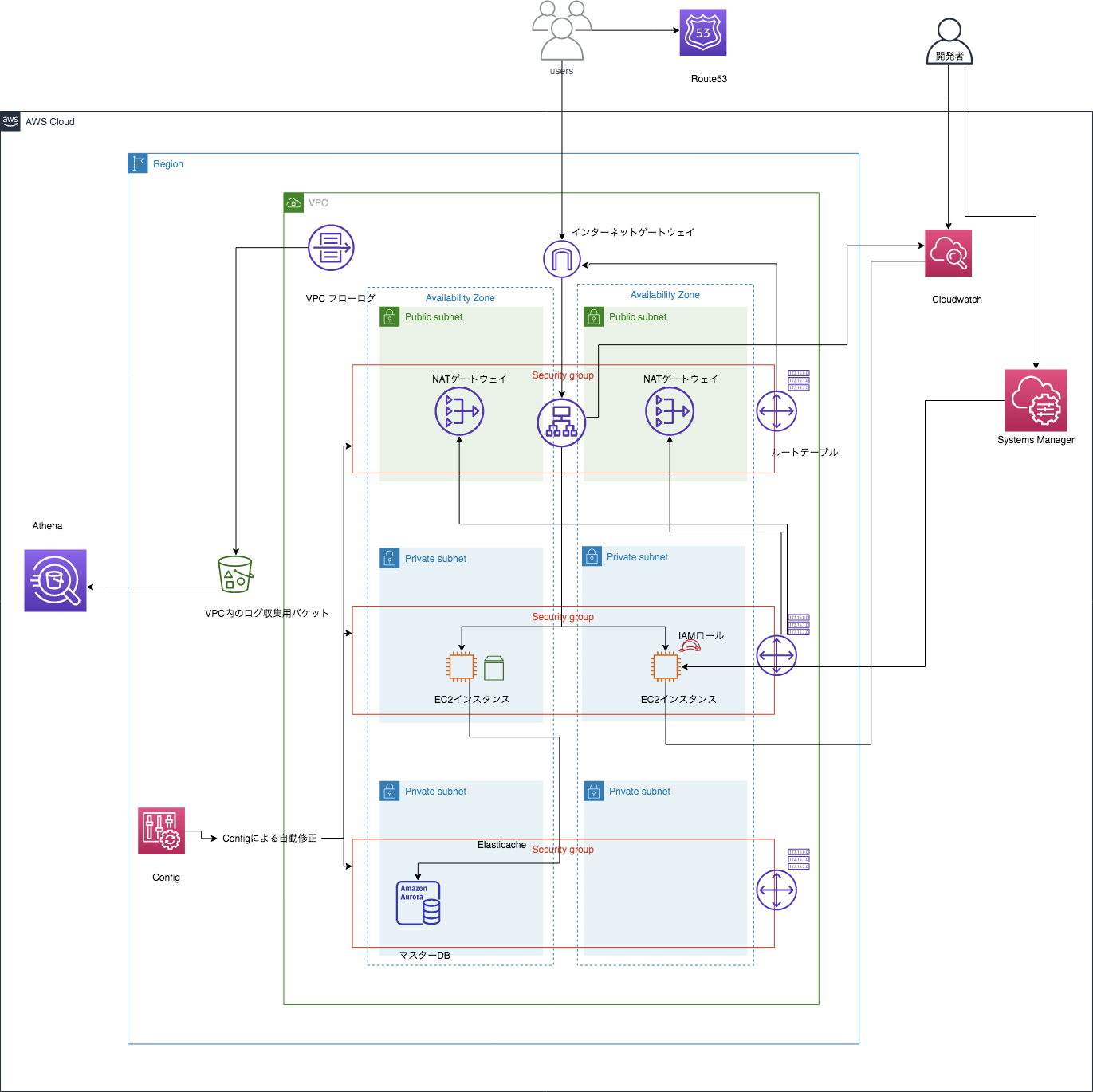
今現在のアーキテクチャはこれですので、どんどん構築していきます!
構築編
今回はVPCとALBの実装を行なっていきます。
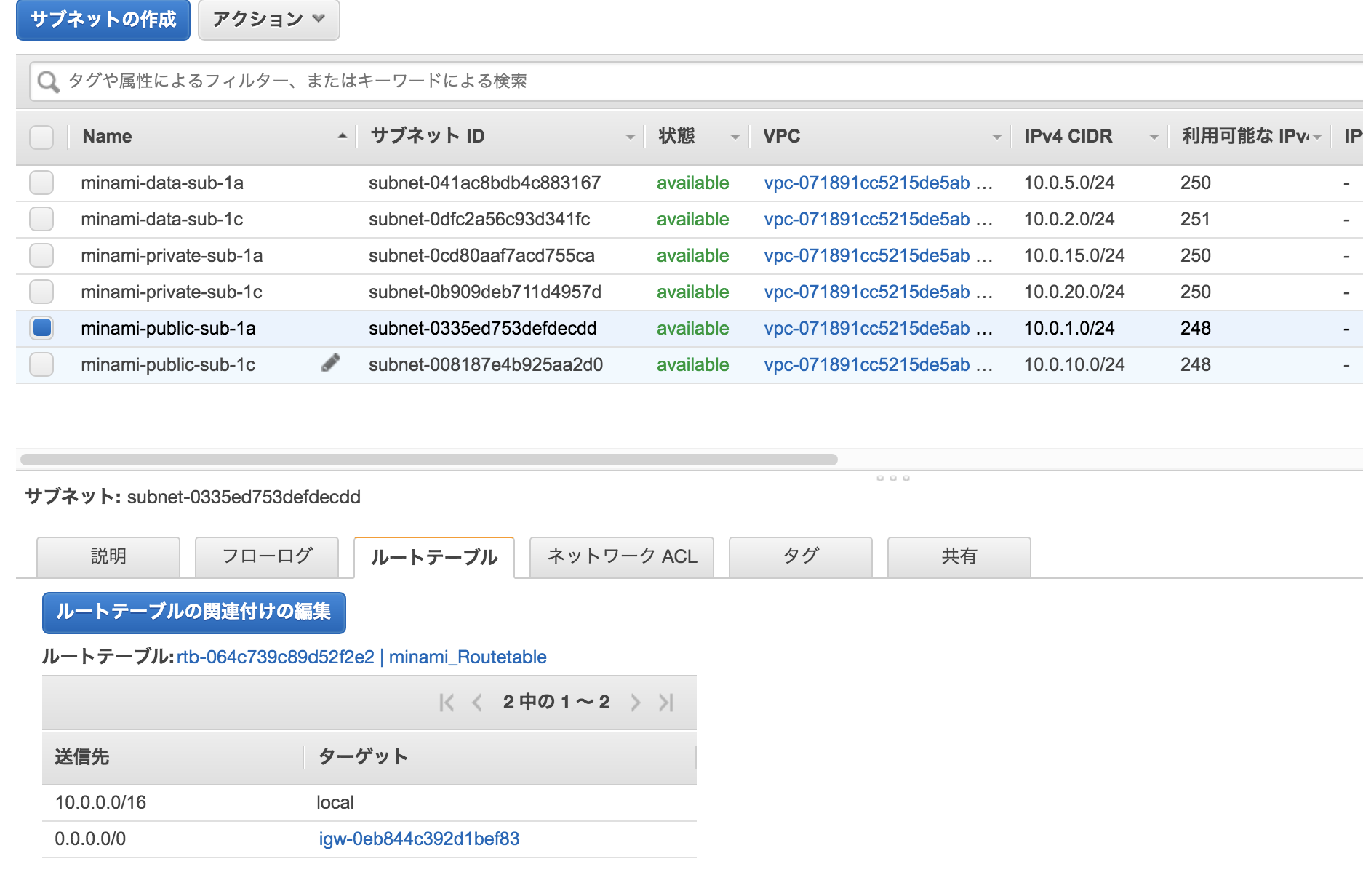
VPC / 通信の範囲に応じてSubnetを作成
セキュリテイ向上の為にもWebサーバーをプライベートサブネットに移行します。
また、WEBサーバーとデータベースのセキュリティグループを細かく分けて設定したいで、サブネットも分けてみました。今回は以下の3種類のサブネットを作成します。
publicサブネット
- NATゲートウェイ、ELB設置用のサブネット
privateサブネット(WEBサーバー用)
- メインのWEBサーバー設置用サブネット
privateサブネット(RDS用)
- RDS設置用サブネット
- ElastiCacheを追加する際はここのサブネットに配置
publicサブネットとprivateサブネット(RDS用)は前回作成したサブネットをそのまま使用できるので、privateサブネット(WEBサーバー用)を各AZに作成しました。
一応Nameタグも変更しておきましょう!
6つのサブネットの作成が完了したので、WEBサーバーを移行します。
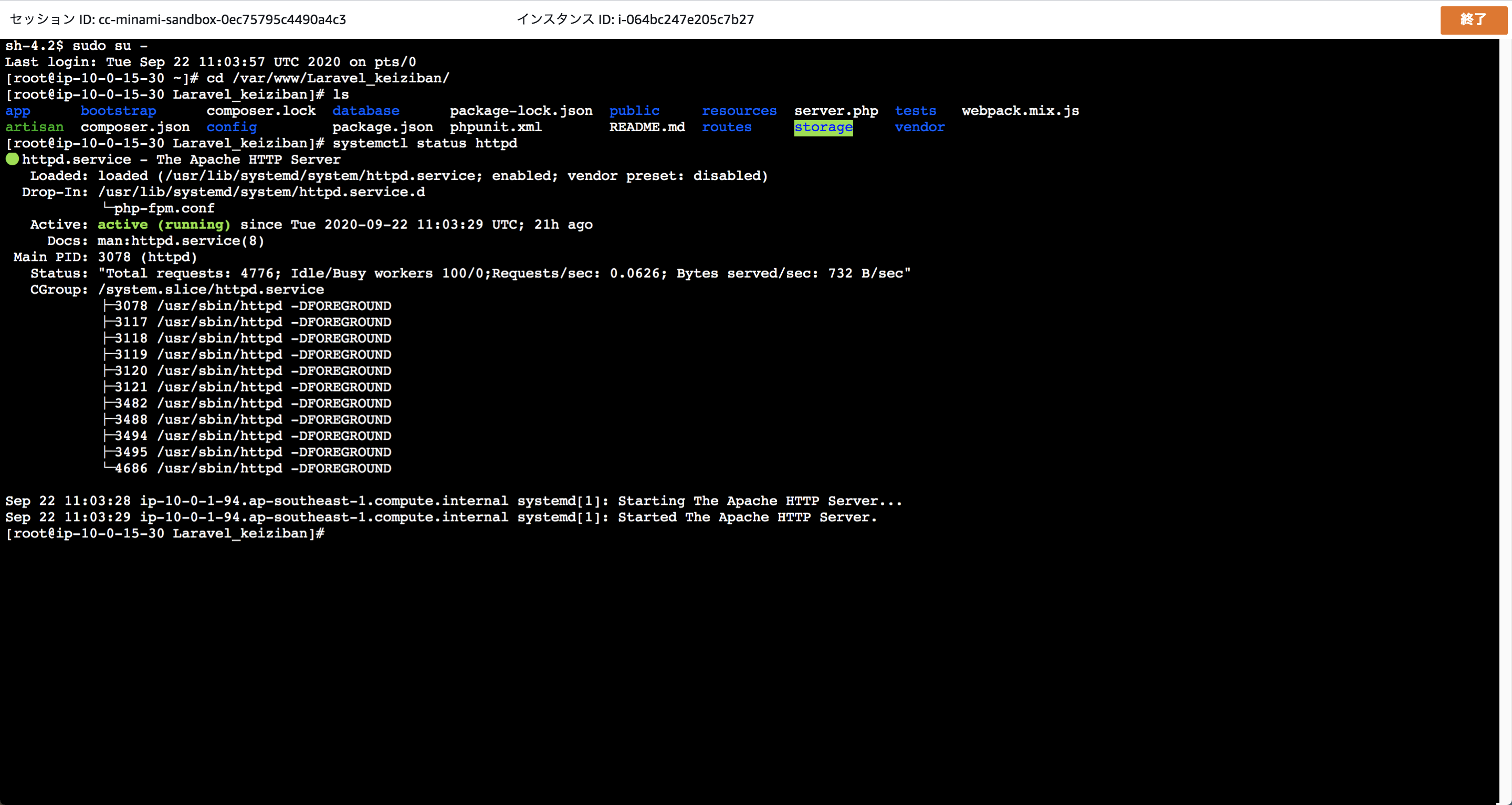
最新のゴールデンイメージ(AMI)を作成後、インスタンスの起動を行います。Systems Manager / Session Managerを用いてSSHログインを行う
今回はWEBサーバーをプライベートサブネットに設置します。
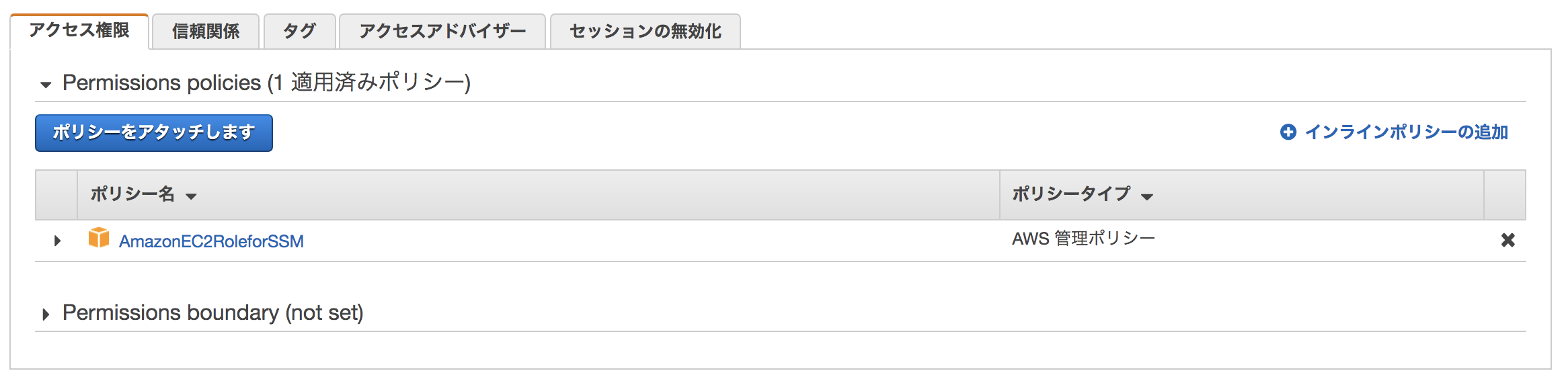
SSH接続を行う為に、SSM用のIAMロールを作成しましょう。
IAMの「ロールの作成」→ユースケースから「EC2」を選択→ポリシーは「AmazonEC2RoleforSSM」を選択してください。
こちらのIAMロールをEC2に関連付けると、SSMのセッションマネージャーでSSH接続することが出来ます。
SSHキーも無しで大丈夫ですので、紛失の心配もありません。
(SSMを使用しない方法であれば、踏み台サーバーを設置する方法もありますが、冗長化や管理がめんどくさいのでマネージドサービスに任せましょう!)
一応、セッションマネージャーを利用してSSH接続の確認も行なってみます!
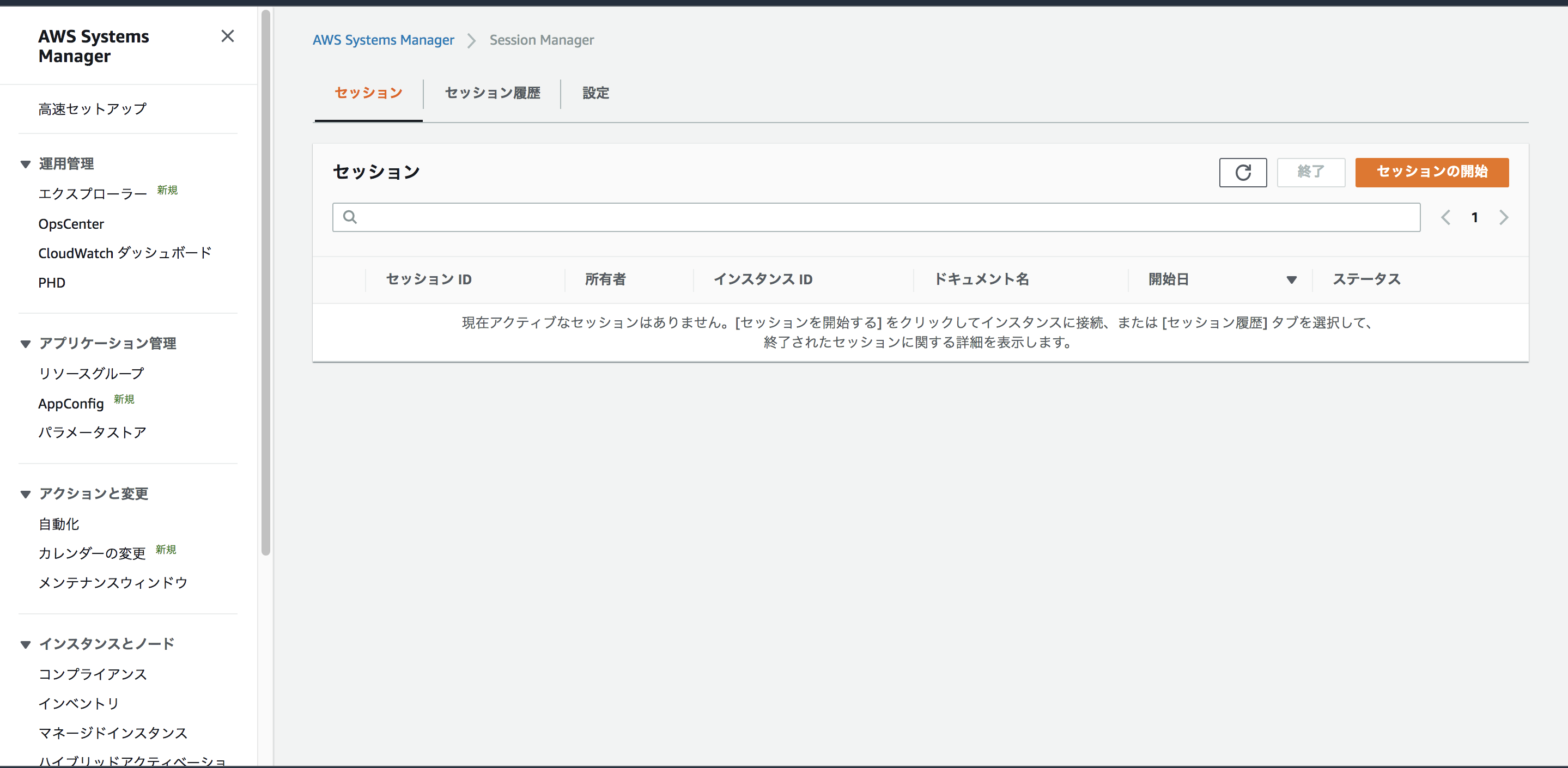
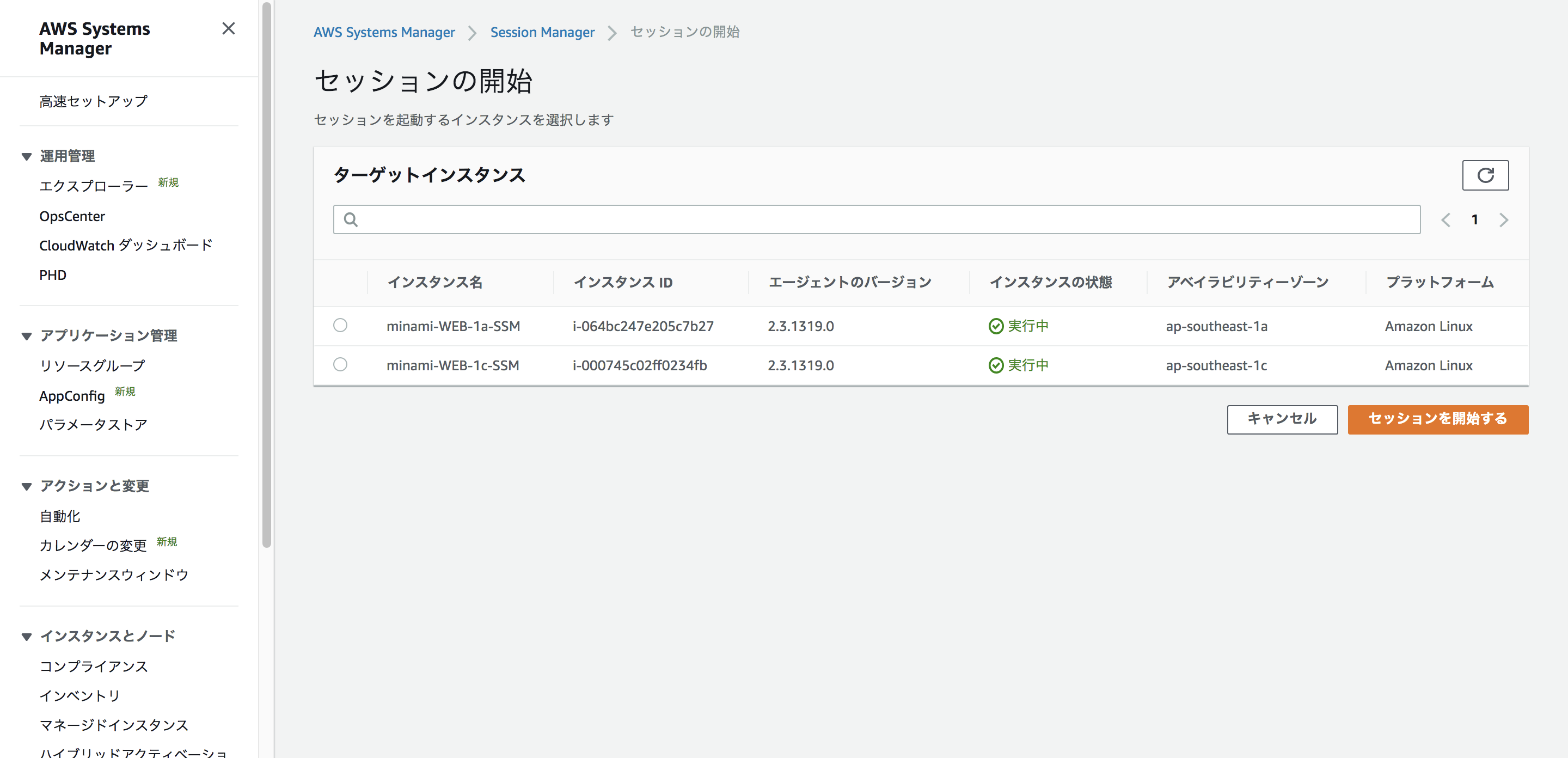
Systems Managerからセッションマネージャーを選択
セッションの開始を選択
接続したいインスタンスを指定して、「セッションを開始する」
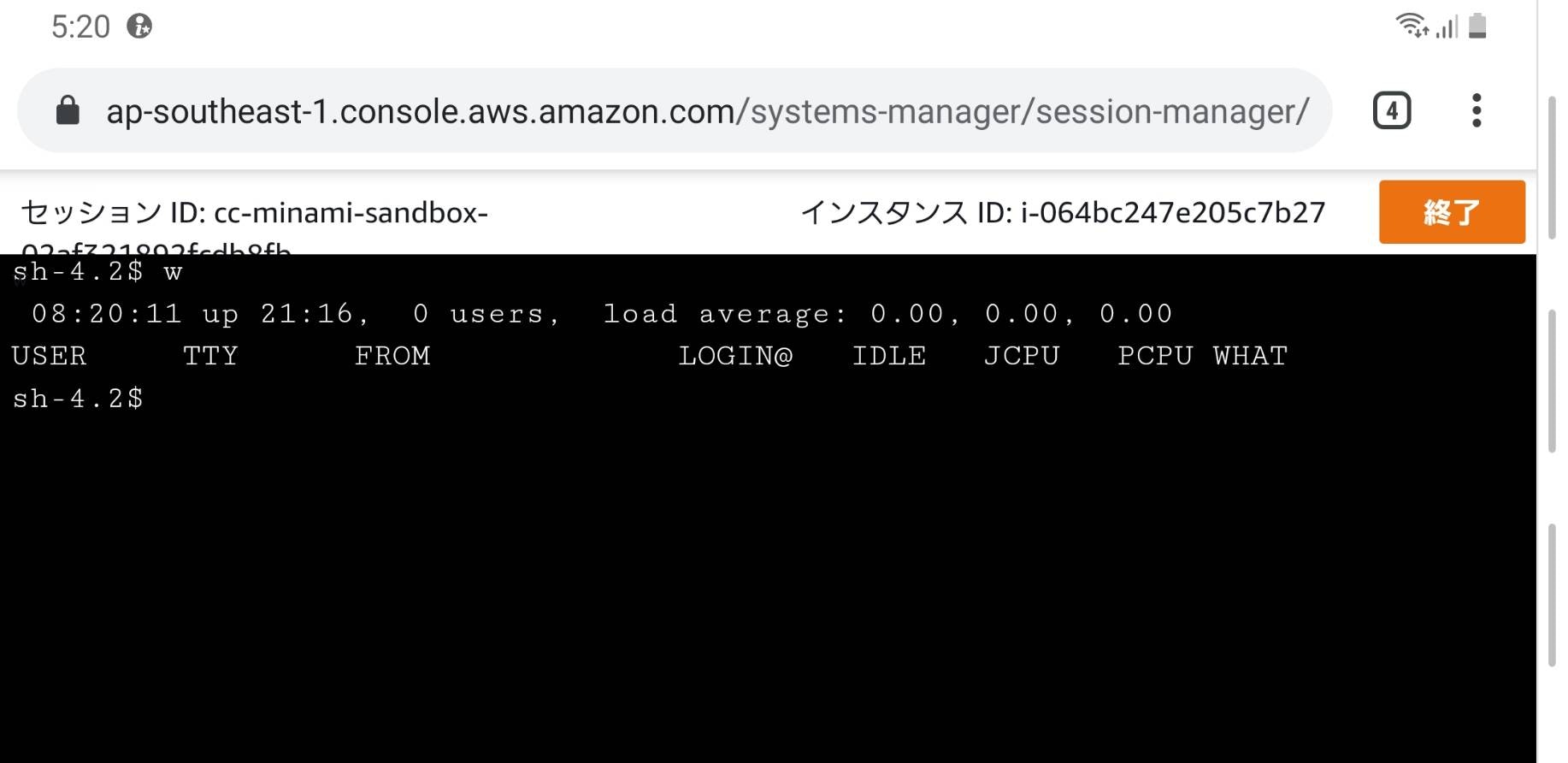
普通にコマンドを実行出来ますのでオススメです!(もちろん、スマートフォンやタブレットでもアクセス可能です!)
スマートフォンでもSSH接続してみました。
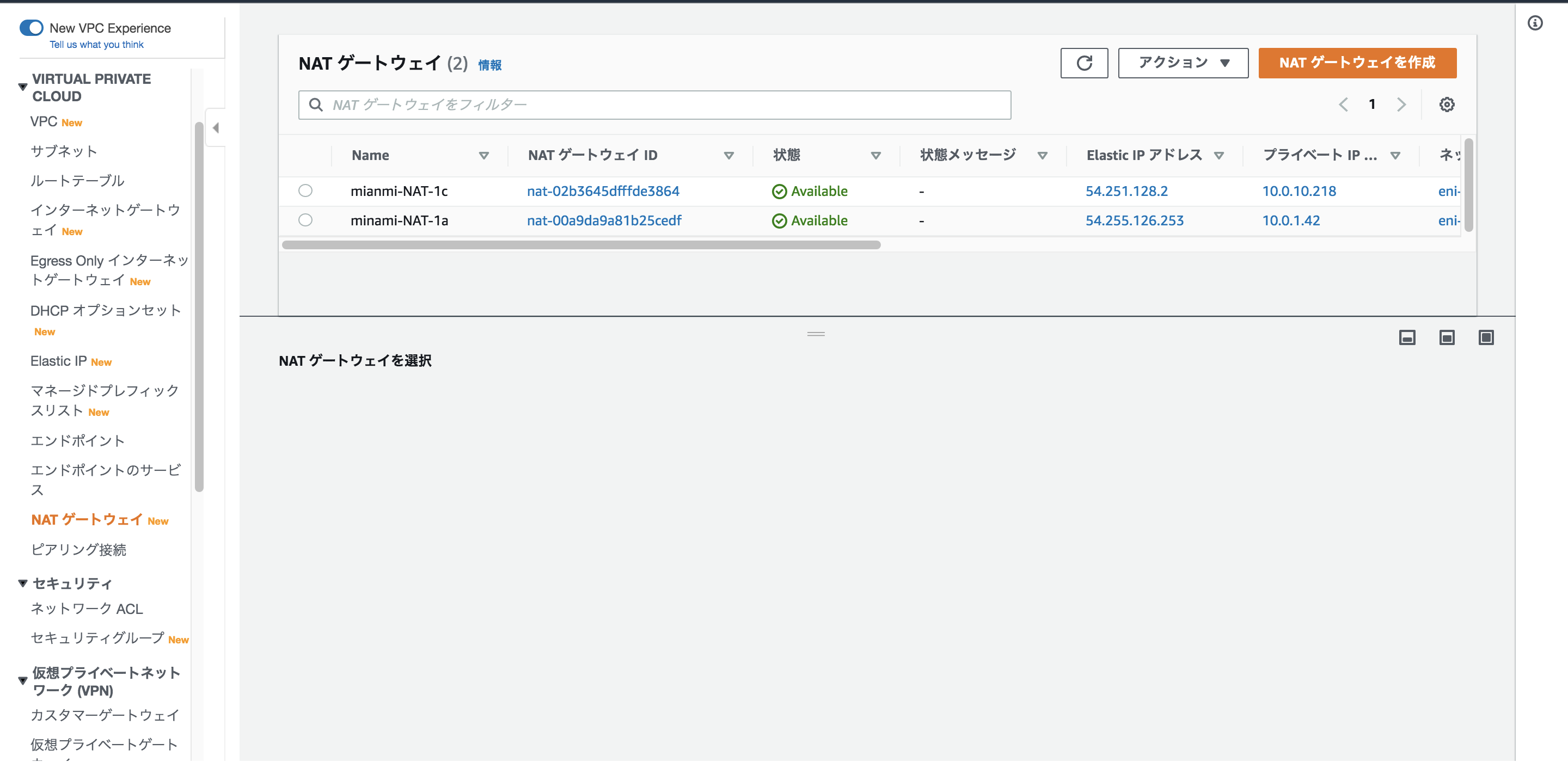
VPC / NAT Gatewayの作成、Route Tableの定義
Privateサブネットからインターネットへアクセスする時に必要となる要素です。
冗長化の為に、各AZに配置します。Routeテーブルは
publicサブネット
→インターネットゲートウェイprivateサブネット(WEBサーバー用)
→冗長化の為に同じAZのNATゲートウェイにルーティングprivateサブネット(RDS用)
RDSを利用しているので、一旦VPC内のルーティングのみに設定しました。
サクッとNATゲートウェイを作成して、ルーティングも設定しましょう
ALB / ターゲットグループの作成
前回までは、テストの為にRoute53の複数値ルーティングを使用していましたが、今後の拡張性も考えて(WAF,AutoScalingの導入など)ALBを実装していきます。
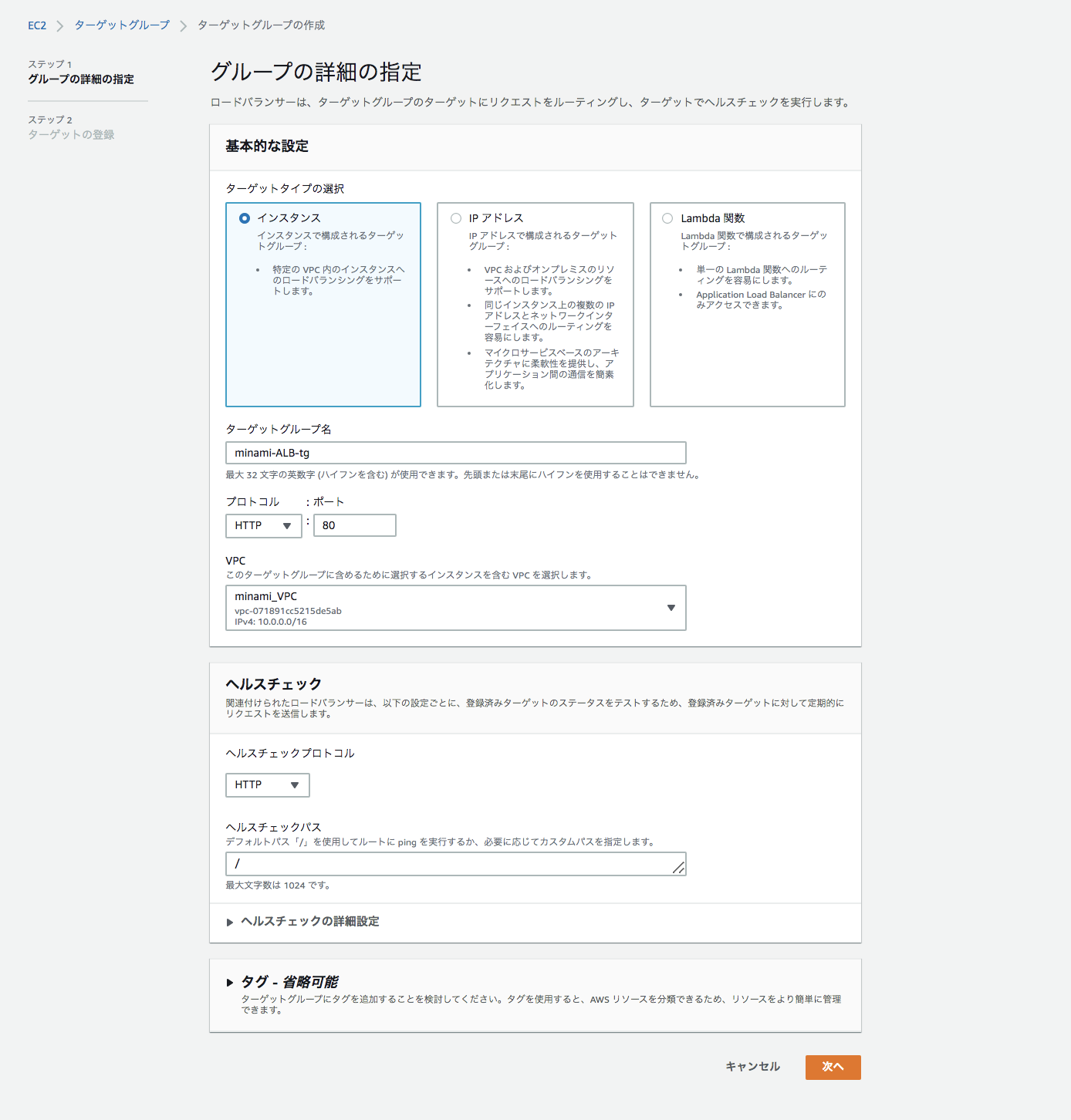
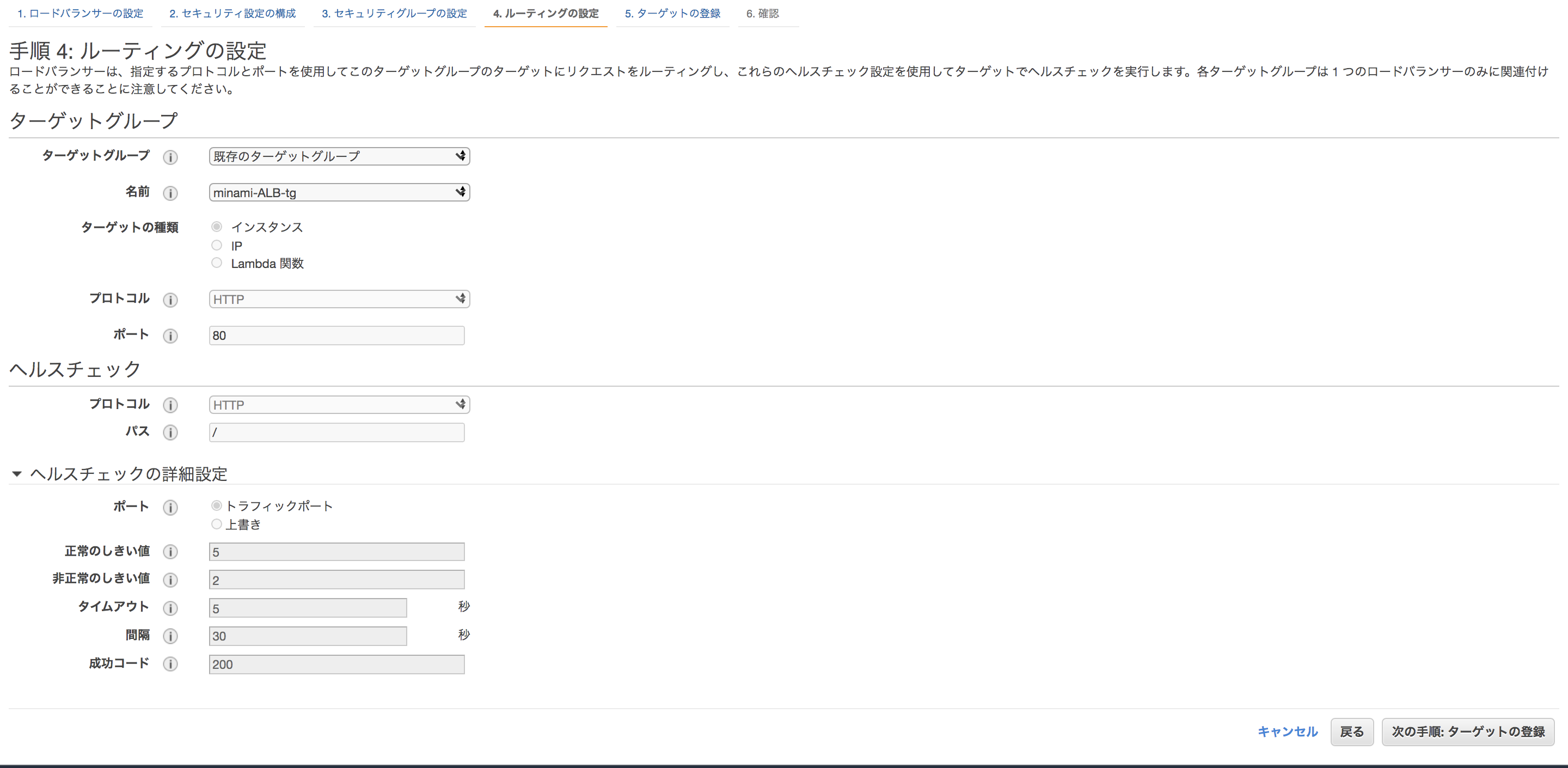
まずはターゲットグループを作成していきます
マネジメントコンソールの「EC2」→「ターゲットグループ」から作成します。
HTTPS化をする場合はプロトコルをHTTPSにしてください。
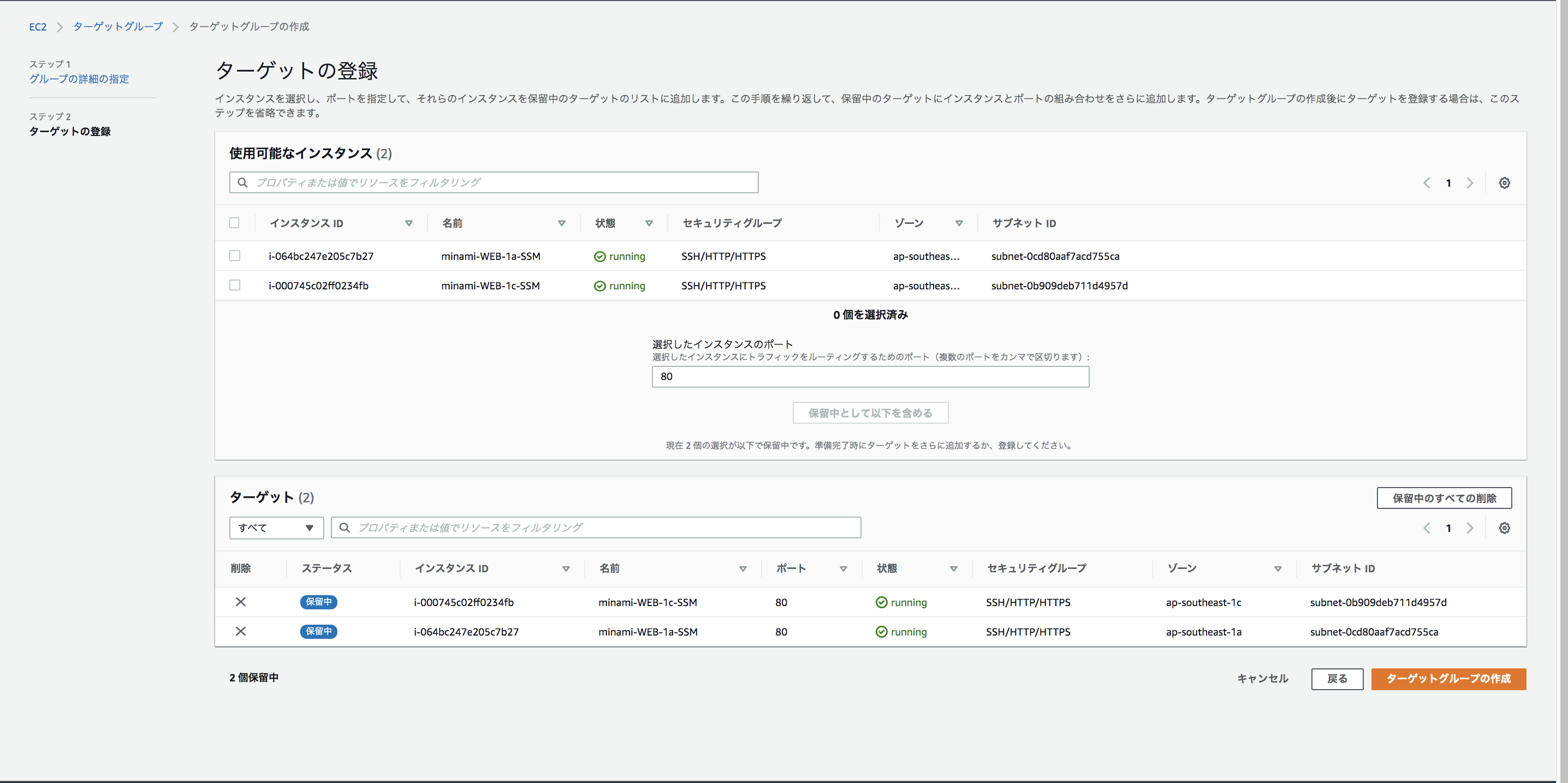
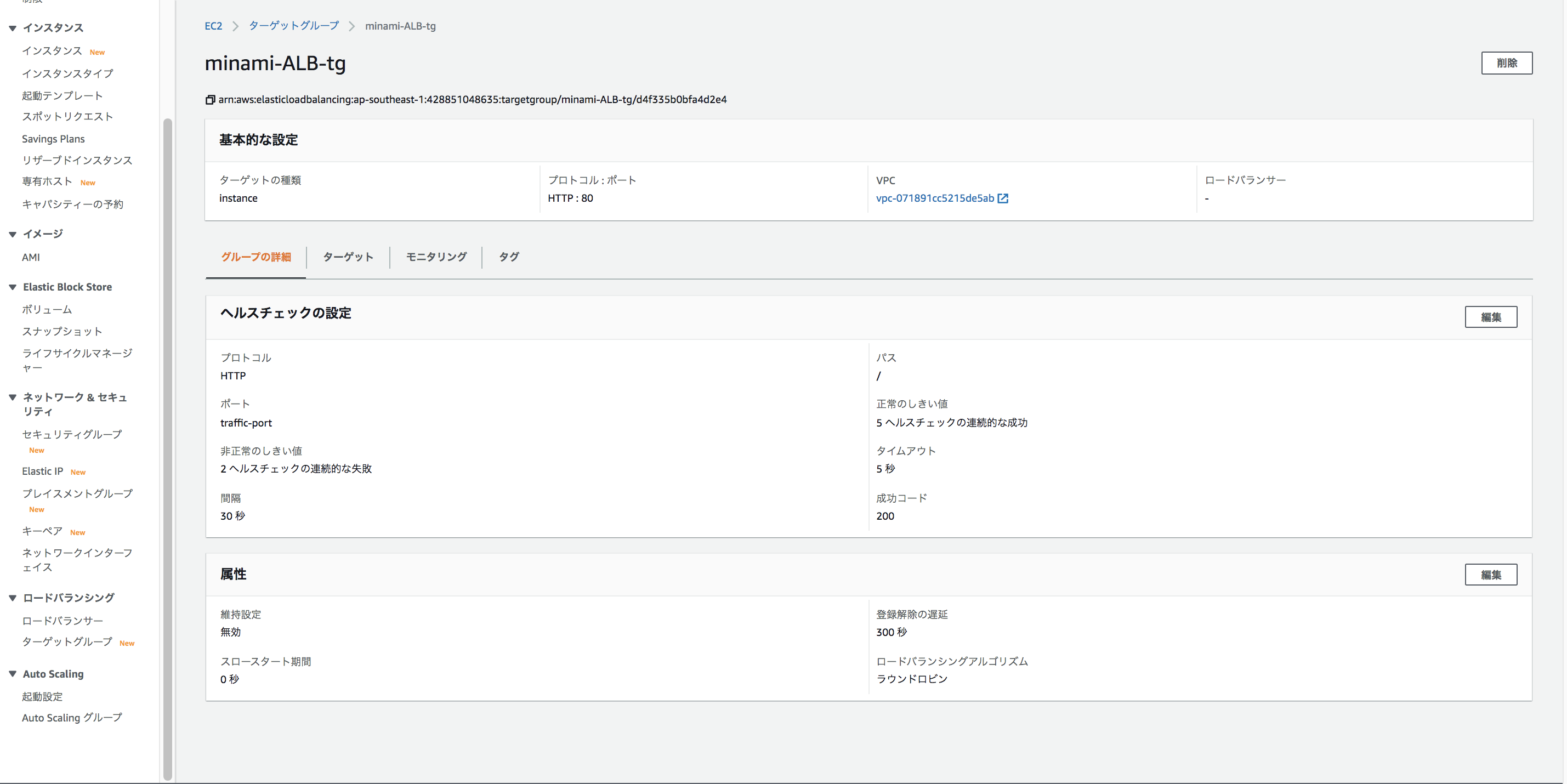
ヘルスチェックはプロトコルと、実際にチェックを行うパスを指定することが出来ます。インスタンスを指定して、ターゲットグループを作成しましょう。
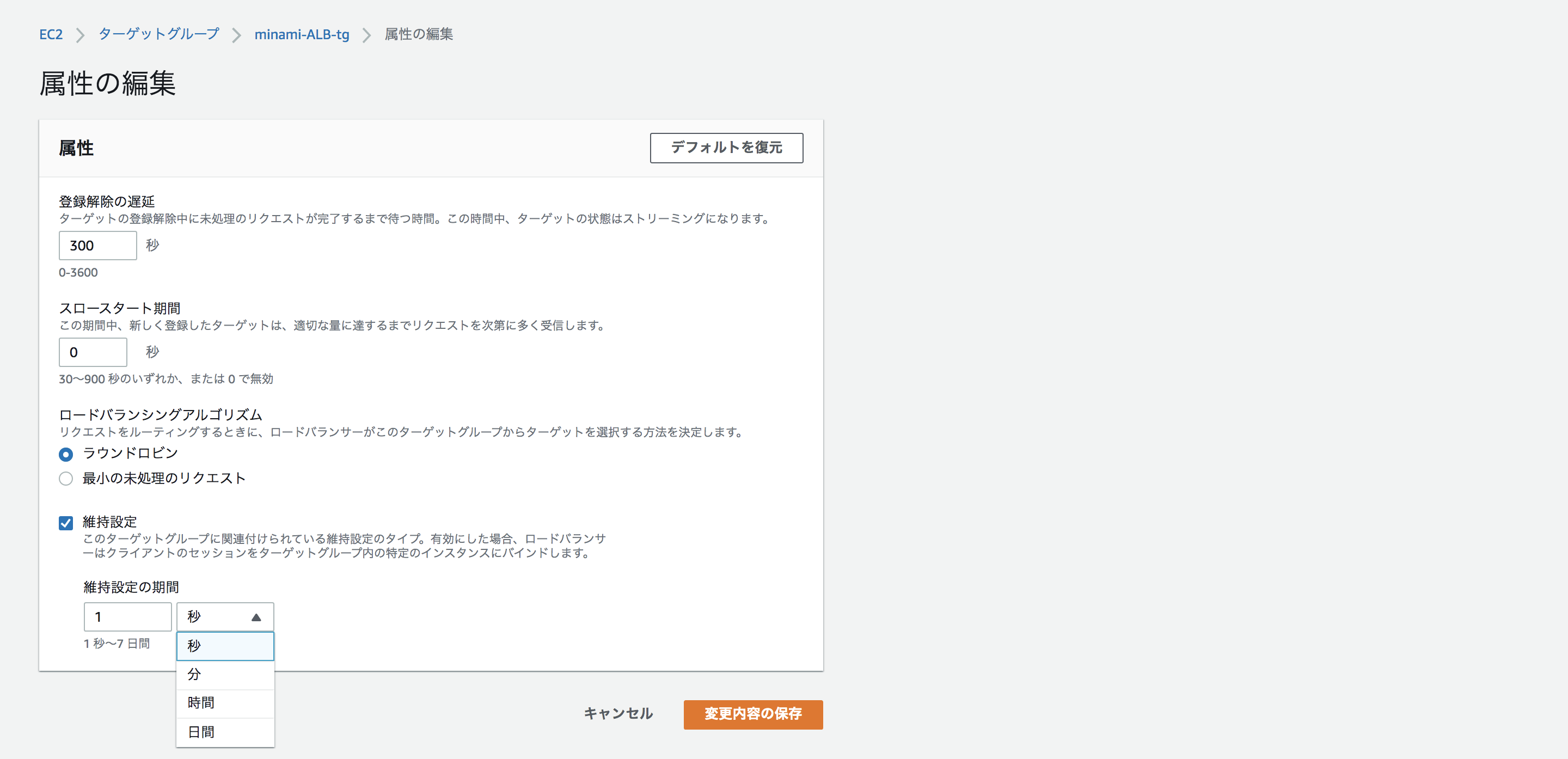
ステッキーセッションの設定を行いたい場合は「属性」の方から設定することも出来ます。
「維持設定」を選択すると、1秒から〜7日間まで指定することができます。
ALB / ALBの作成
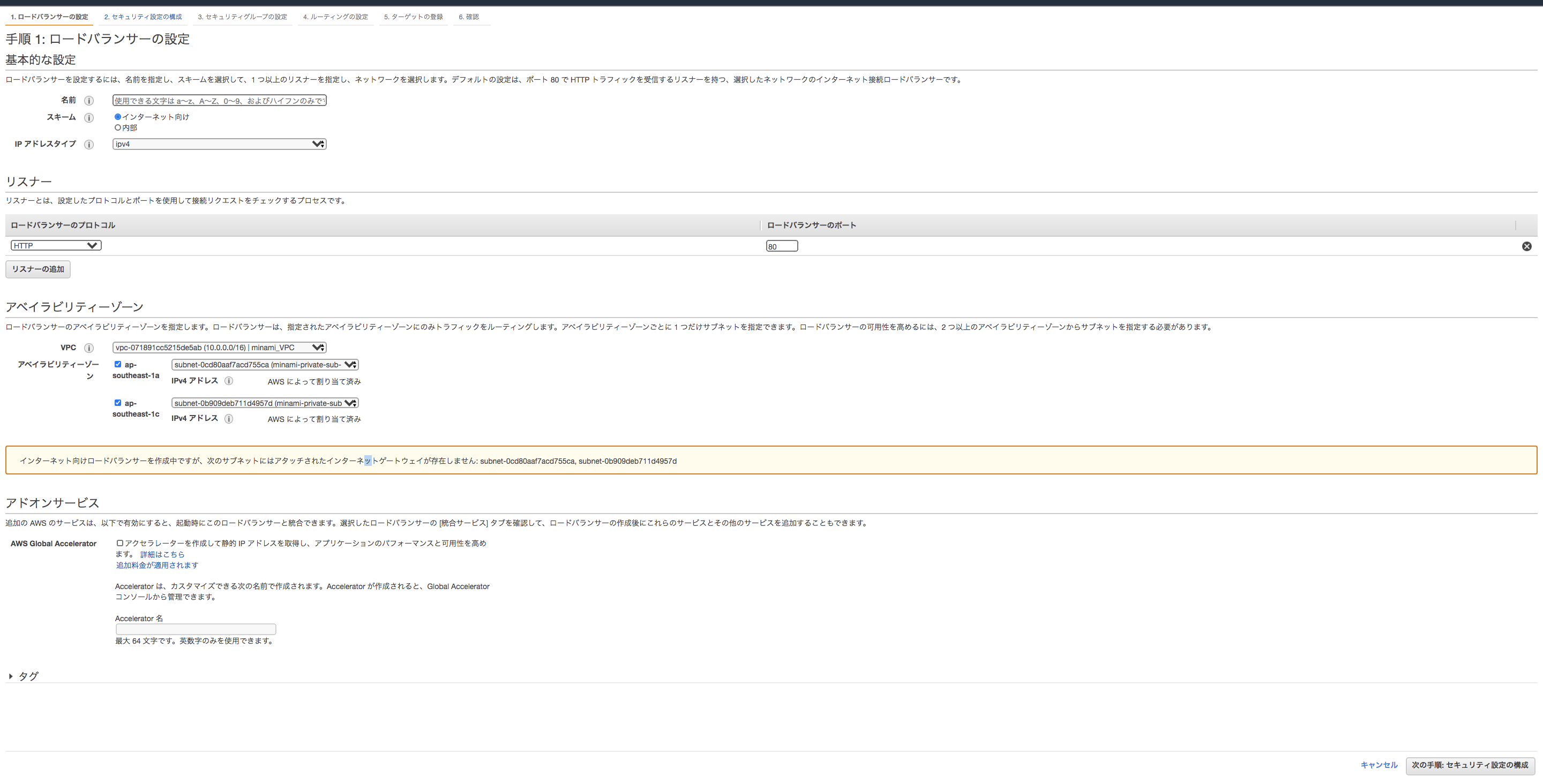
ターゲットグループの設定が終わったので、ロードバランサーを作成していきます。
今回はALBを選択しました。
HTTPS化をしたい場合は、「リスナー」からHTTPSを選択してください
VPCとサブネットの指定も行います。「アドオンサービス」の「AWS Global Accelerator」を設定するとパフォーマンスが上がりますが、追加料金も掛かるので一旦スルーしておきます。
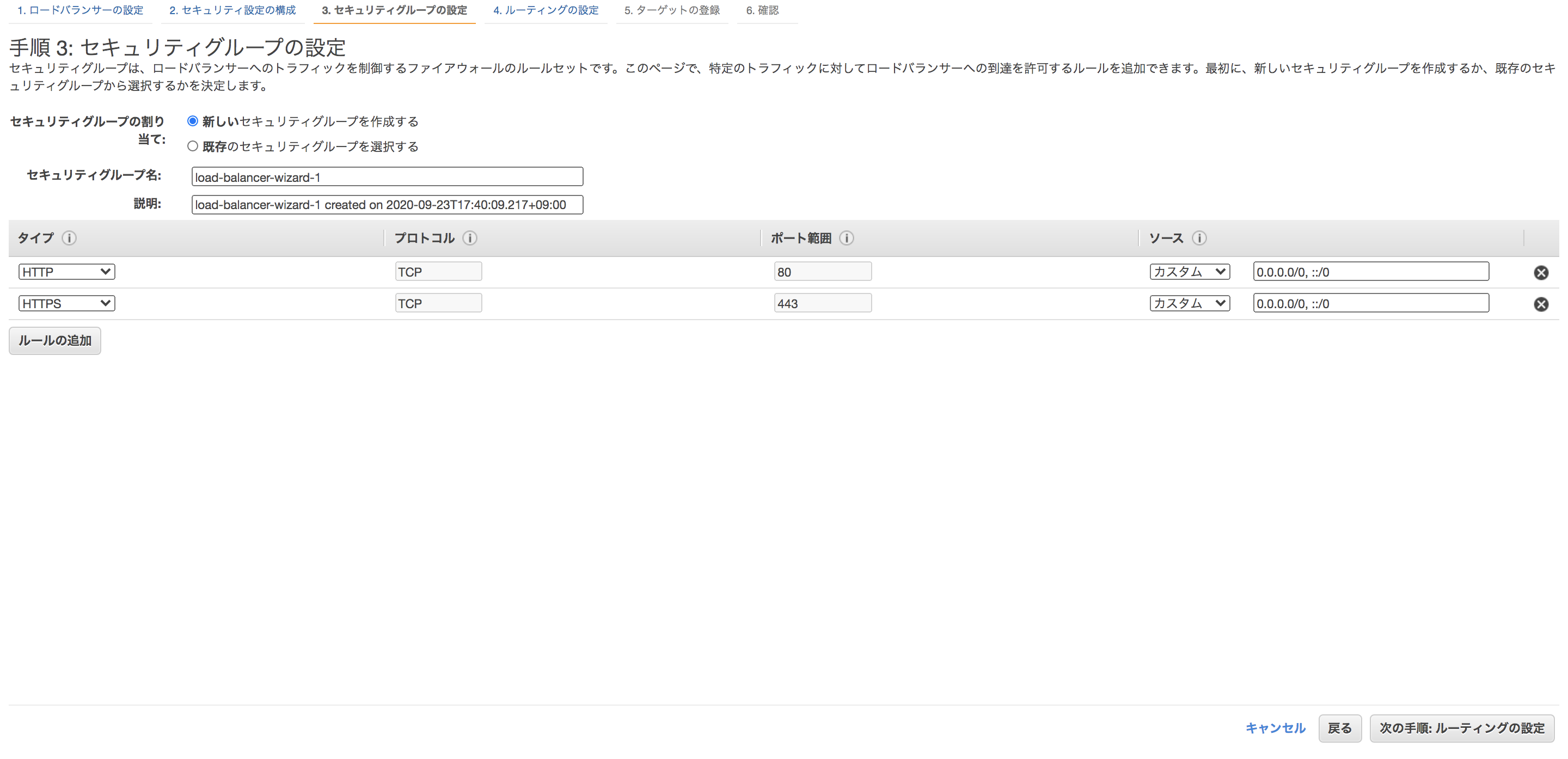
セキュリティグループを選択しましょう。
ALBに関しては0.0.0.0/0のフルオープンでも問題ないでしょう
ルーティングの設定で、先ほど作成したターゲットグループを指定してください。
そのまま「作成」まで進むと、ALBの完成です。
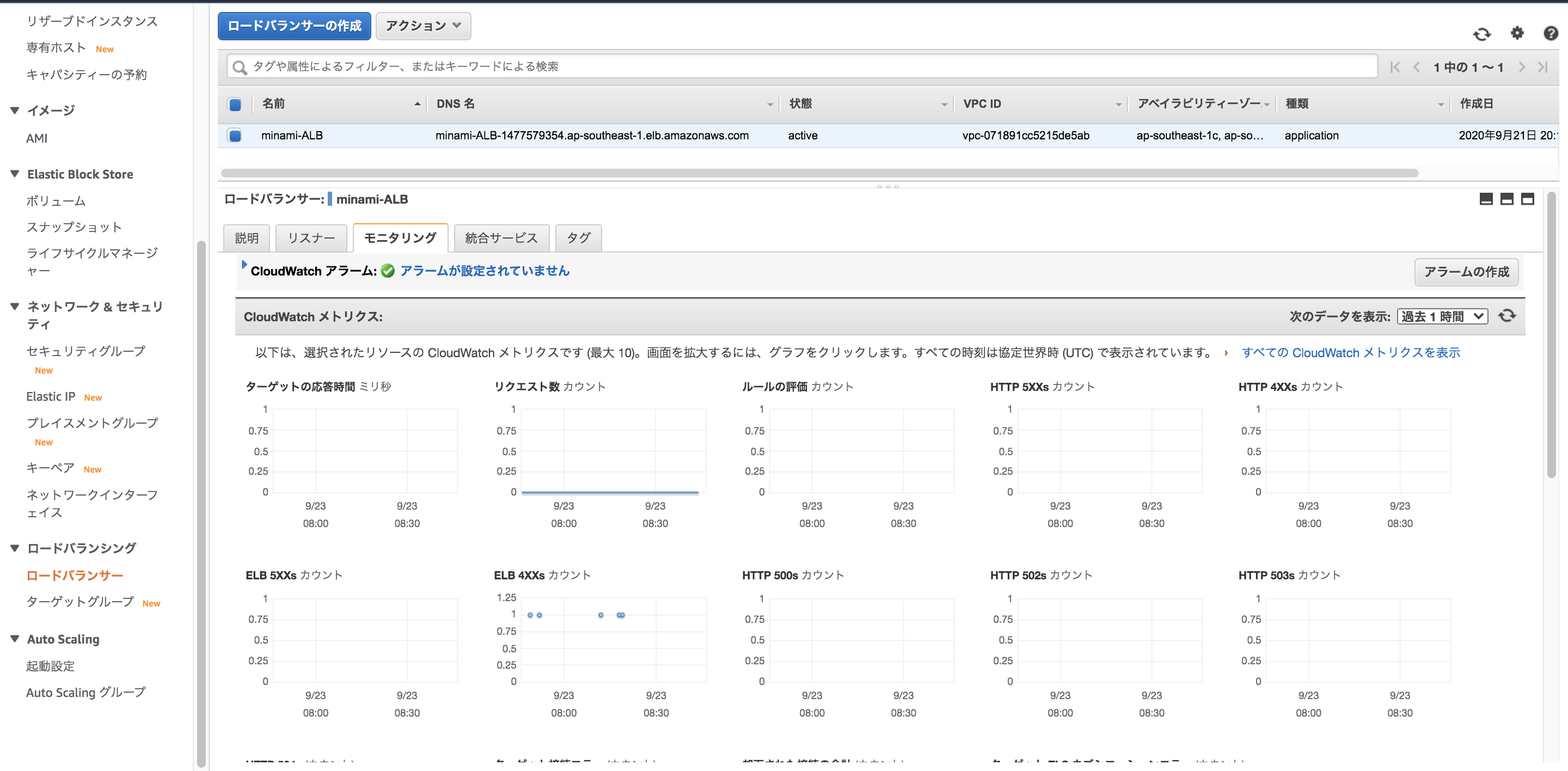
一応DNS名からアクセス出来るかの確認もしましょうCloudwatch / ELBのメトリクスを監視
ELBの監視については、モニタリングのタブからメトリクスの確認が出来ます。
Cloudwatchアラームも設定可能ですので、閾値を設定してサーバーダウンを通知することも可能です
主なメトリクスについて確認します。
こちらの記事が分かりやすいので確認しておきましょう
https://dev.classmethod.jp/articles/elb-and-cloudwatch-metrics-in-depth/
- ELBがバックエンドのステータスコードをそのまま返す場合(HTTPCode_Backend_*)
- 2XX~5XXまであります
- 主にバックエンド側でのエラー
- ELBが独自の判断によりステータスコードを返す場合(HTTPCode_ELB_*)
- 2XX~5XXまであります
- ELB側でのエラー
- RequestCount
- リクエストの合計値です。
- HTTPCode_Backend_*の合計がRequestCount
- SurgeQueueLength
- ELBで処理出来ず、待機中のリクエスト
- 基本的に0を目指しましょう(ELBのキャパシティを確認できますね)
- SpilloverCount
- ELBのキャパシティ(surge queue)を完全に超えてELBがエラーを返した数になります
ターゲットグループで確認出来るメトリクスもあります。
- HealthyHostCount
- ELBから見た正常なEC2インスタンス数の数
- UnHealthyHostCount
- ELBから見た異常なEC2インスタンス数の数
具体例を挙げてみます
2つのEC2インスタンスがあると仮定します。
2つとも正常な場合は
HealthyHostCount→2
UnHealthyHostCount→02つのインスタンスのサービスが停止している場合は
HealthyHostCount→0
UnHealthyHostCount→2EC2自体が停止した場合に関しては注意が必要です。
2つのEC2インスタンスが停止している場合
HealthyHostCount→No Data
UnHealthyHostCount→No Dataとなってしまいます。
ですので、「ロードバランシング対象サービスに異常がある場合」にも「EC2自体が停止した場合」にもどちらでもCloudWatchアラームを発報させるには、CloudWatchアラームの設定で、
- ステータスがALARM(閾値を上回った場合、以下の設定ではHealthyHostsが1以下になった場合)
- ステータスがINSUFFICIENT(データが不足している場合)
のどちらもアクション対象として設定してあげる必要があります。
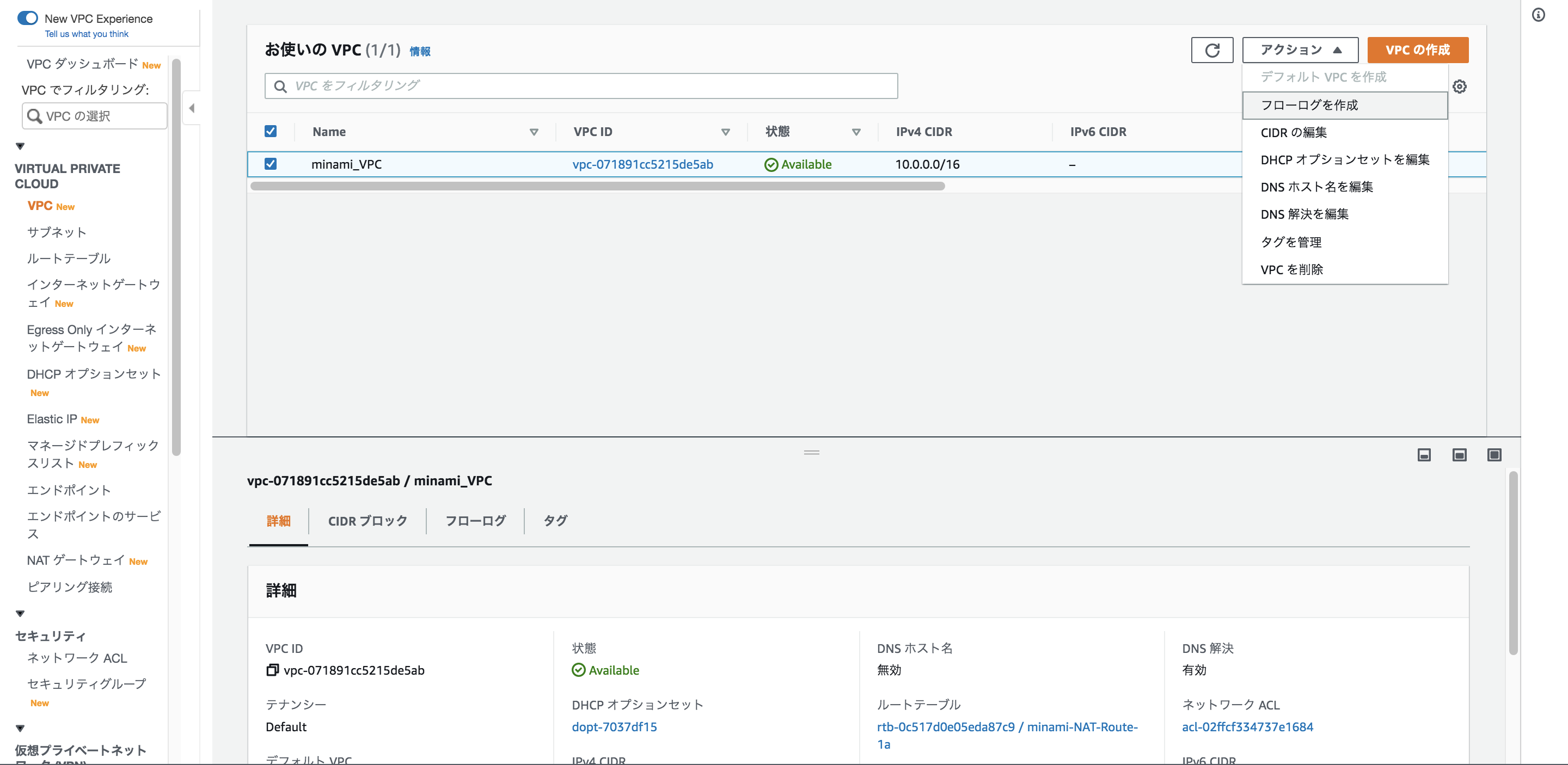
VPC / VPC FlowLogの作成、S3にログの収集、Athenaによる分析を行う
事前にVPCフローログの出力先となるS3バケットを作成しておきます(今後のログ収集における出力先をこちらのバケットに設定しておくと、その後の分析等が楽になります。)
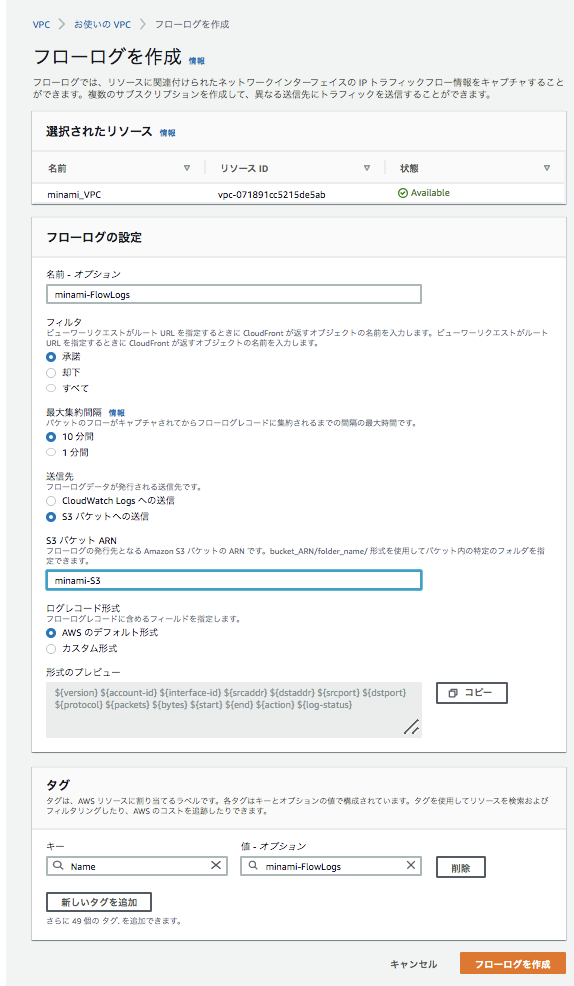
マネジメントコンソールの「VPC」→「アクション」→「フローログの作成」から作成画面に進んでください
VPCフローログはCloudwatchLogs、S3で出力先を選ぶことが出来ますが、「Athenaで一括管理を行いたい」、「コスト」の観点からS3を出力先として指定します。
その他の設定はデフォルトのままでも大丈夫でしょう。
S3への出力を確認してみましょう
ログ自体は圧縮されたファイルで、尚且つめちゃくちゃ見にくいです。
普通はAthanaなどで分析、閲覧を行います。
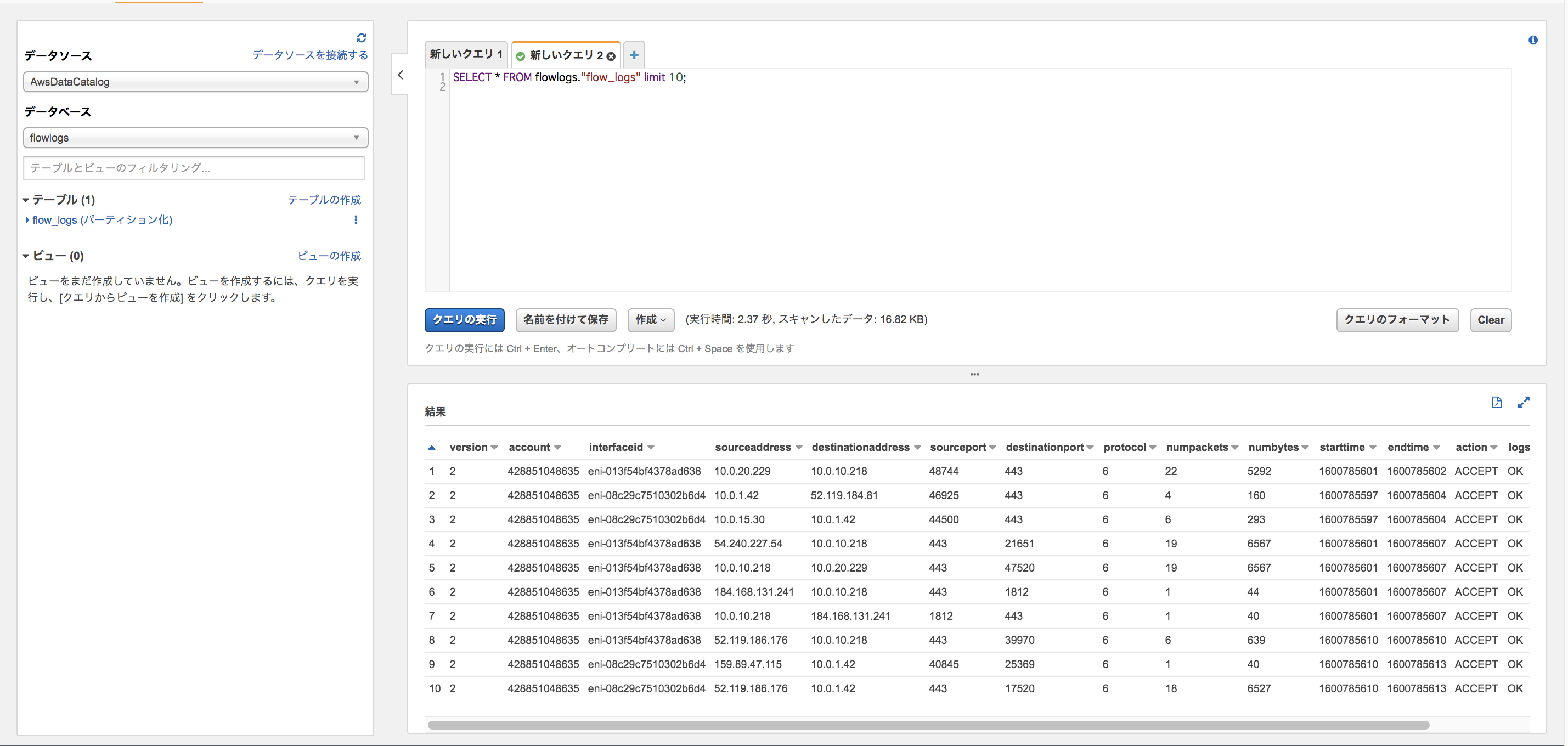
実際にAthenaを使って見てみましょう!
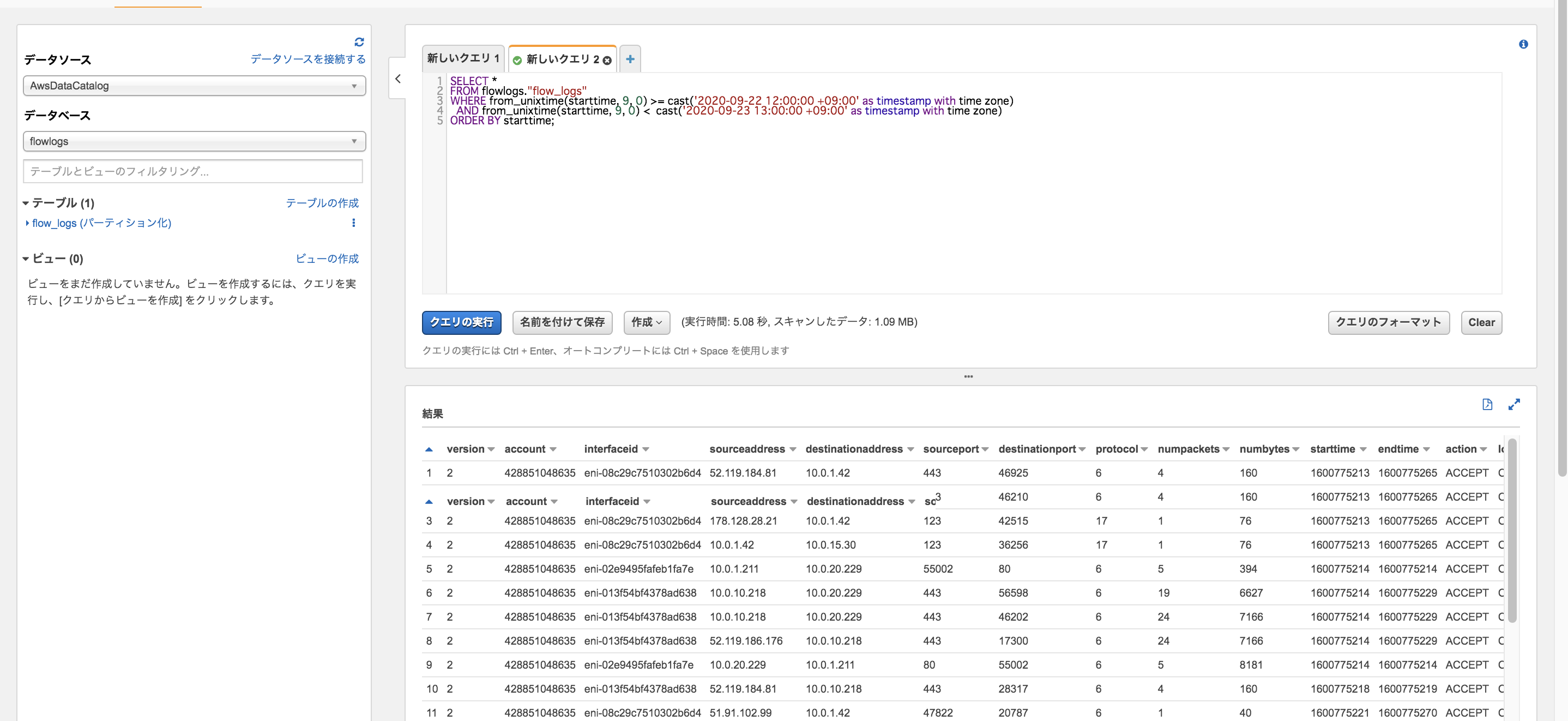
Athenaでファイルを閲覧するには
「データベースの作成」→「外部テーブルの作成」→「テーブルにデータを取り込む」→「好きなクエリを実行する」
の流れとなります。
一応デフォルトのデータベースを利用して「外部テーブルの作成」→「好きなクエリを実行する」の方法でも出来ますが、デフォルトのデータベースにテーブルが乱立するのでちゃんとサービスごとにデータベースを作成しましょう。データベースの作成
CREATE DATABASE お好きなデータベース名;外部テーブルの作成
CREATE EXTERNAL TABLE IF NOT EXISTS 先ほど作成したデータベース ( version int, account string, interfaceid string, sourceaddress string, destinationaddress string, sourceport int, destinationport int, protocol int, numpackets int, numbytes bigint, starttime int, endtime int, action string, logstatus string ) PARTITIONED BY (dt string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' LOCATION 'ログが置かれているバケットのアドレス 例s3://vpc-flow-logs/AWSLogs/123456789012/vpcflowlogs/ap-northeast-1/' TBLPROPERTIES ("skip.header.line.count"="1");テーブルにデータを取り込む
ALTER TABLE 先ほど作成したデータベース ADD PARTITION (dt='2020-03-17') location 'ログが置かれているバケットのアドレス 例s3://vpc-flow-logs/AWSLogs/123456789012/vpcflowlogs/ap-northeast-1/';完了したら、好きなクエリを入力しましょう。
10件表示させてみた↓
SELECT * FROM flowlogs."flow_logs" WHERE from_unixtime(starttime, 9, 0) >= cast('2020-09-22 12:00:00 +09:00' as timestamp with time zone) AND from_unixtime(starttime, 9, 0) < cast('2020-09-23 12:00:00 +09:00' as timestamp with time zone) ORDER BY starttime;WHERE、ORDER BYも使えるのでかなり便利ですね!(S3 SelectはORDER BY出来なかったりしますね)
VPC / Security Groupで必要最小限のアクセスのみを許可
基本的に、ネットワークにアクセスさせるリソース以外のセキュリティグループは最小限にしましょう。
例えば、ELBはフルオープンにせざるを得ないとしても、EC2のセキュリティグループは、ELBのみに制限する などです。セキュリティグループはアクセス元として、IPアドレス以外にもアクセス元のリソースに関連付けられているセキュリティグループを指定することもできます。
管理も楽ですし、セキュリティグループをソースとして指定する方法をオススメします。ちなみに補足としてネットワークACLによるアクセス制御も出来ますが、NACLはステートレスである為に一時ポートを考慮する必要があり、管理が大変です。
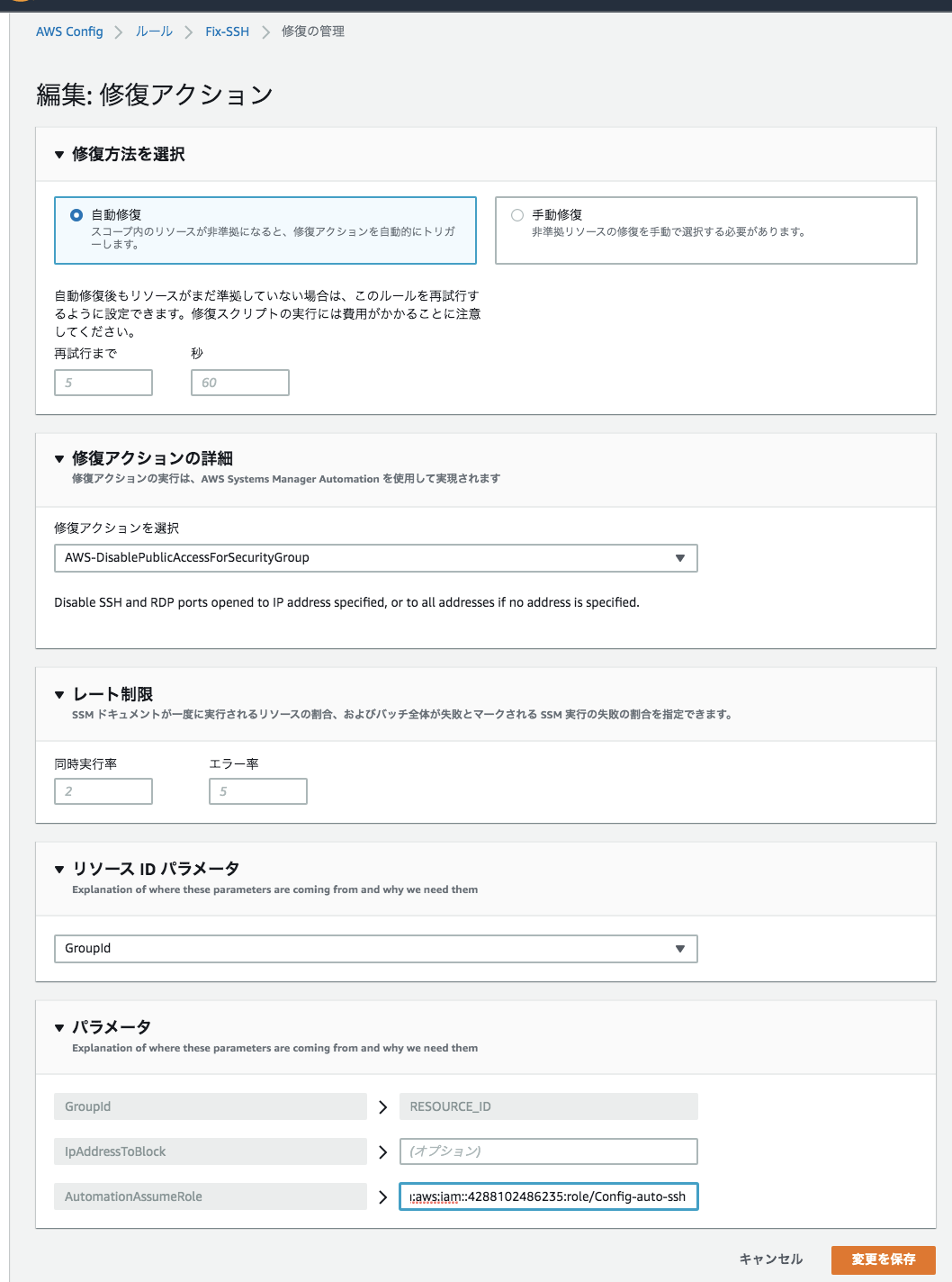
Config / セキュリティグループのSSH全開放をAWS Configによる自動修復によって修正する
よくやってしまいますが、SSHの全開放(0.0.0.0/0)もあまり好ましくありません。
今回はSystems Managerを使用しておりますので、WEBサーバーのセキュリティグループでSSHポートを開くことは無いと思いますが、AWS Config Rulesでコンプライアンスに非準拠となった時に自動修復が出来るようになりましたので、実装してみようと思います。仕組みとしては
「ConfigがSSHの全開放を検知」→「Systems ManagerのAutomationによって修正」
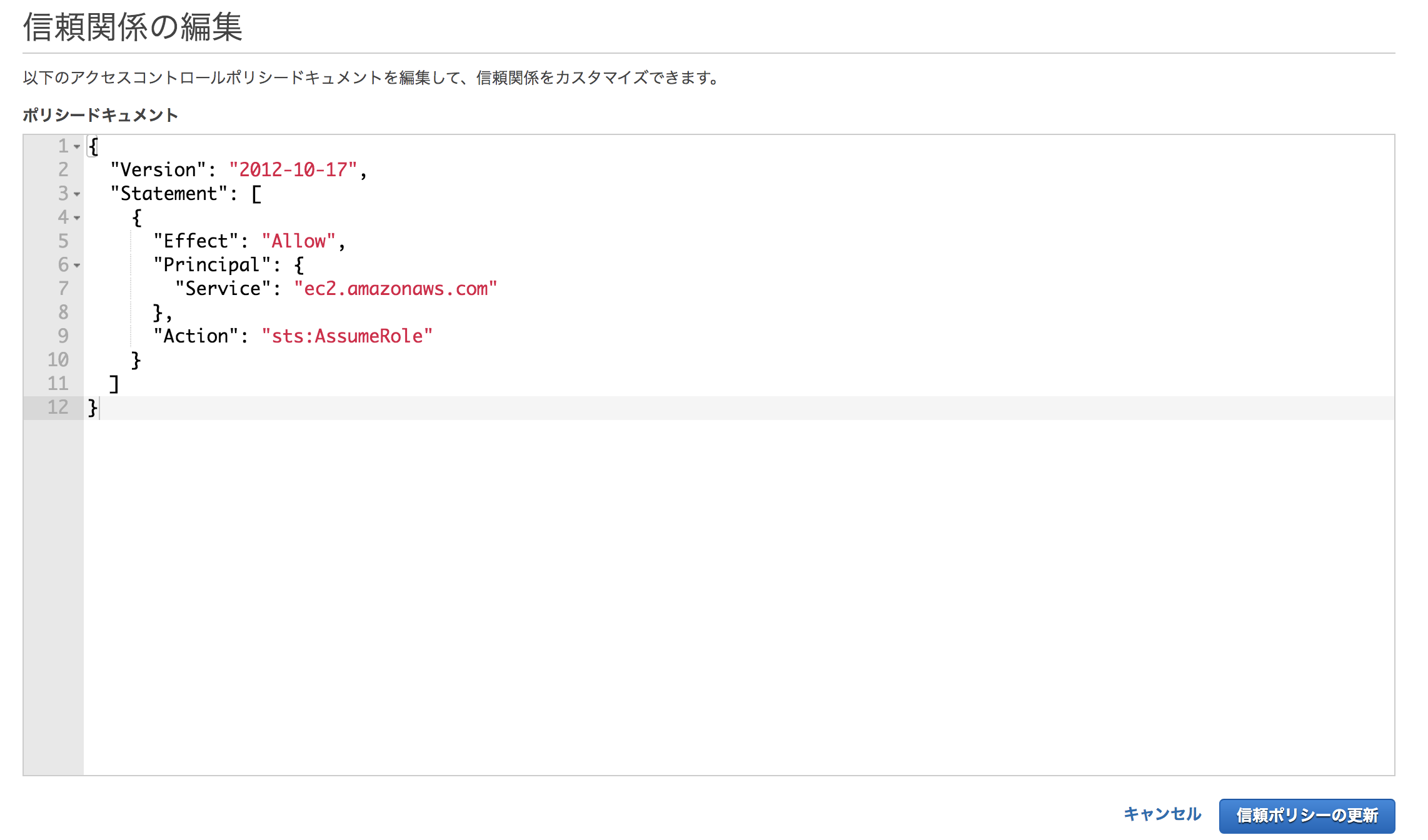
という流れになっております。Config側でAutomationは起動してくれるので、SSM用のIAMロールを作成するだけで出来ます。IAMロールを作成する前に今回必要なIAMポリシーを作成します。
「ポリシーの作成」からJSON形式を指定して、こちらのポリシーを作成して下さい。{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "ec2:RevokeSecurityGroupIngress", "Resource": "*" } ] }ビジュアルエディタの場合はサービスとしてSSMではなくEC2を選択してください。アクションは「RevokeSecurityGroupIngress」です。
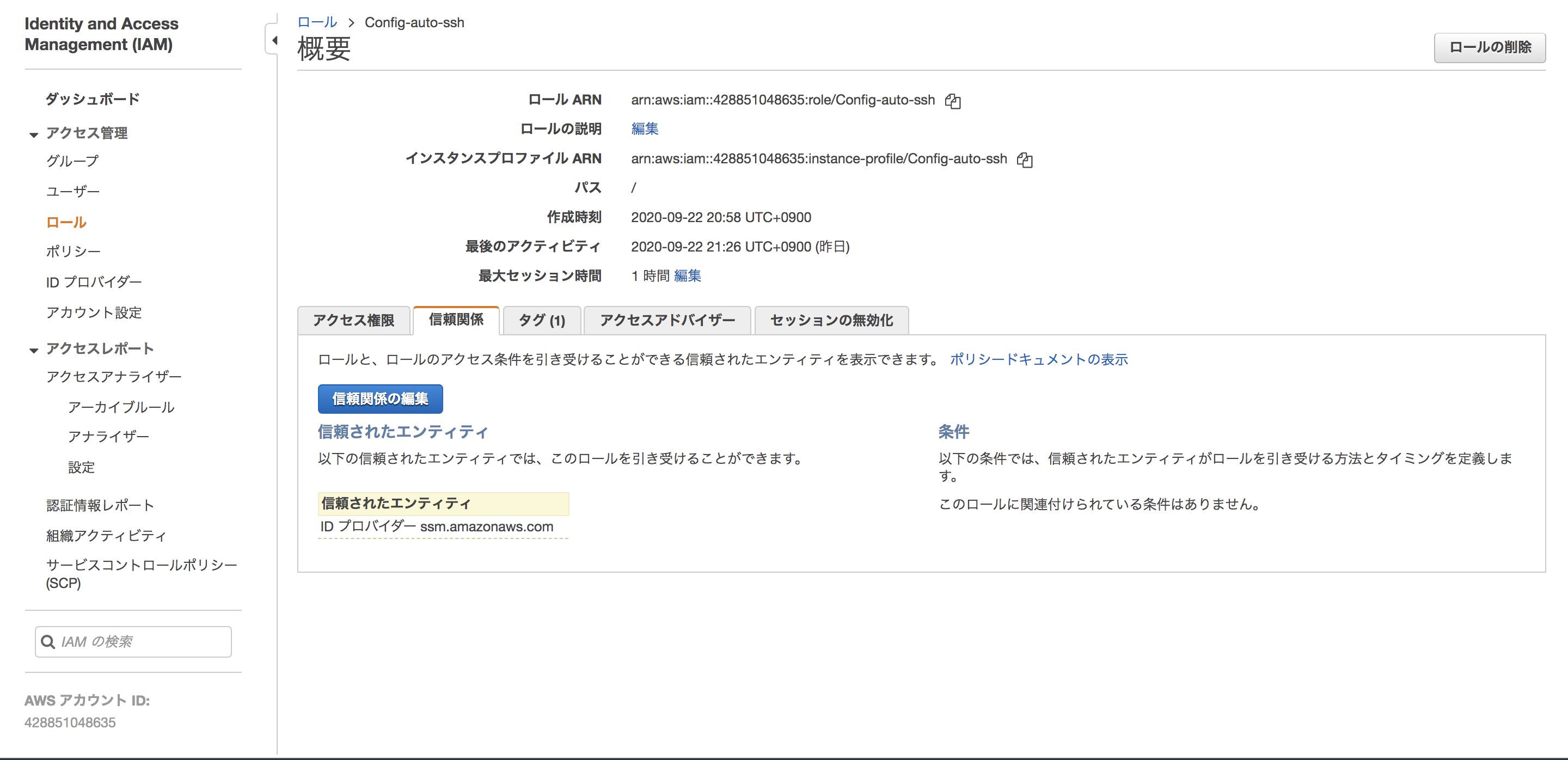
IAMロールを作成後、Configの設定でIAMロールを関連づけるので、ARNをコピーしておきましょう。
また、作成時にはサービスでEC2を選択して作成しましたが、SSMから利用するロールのため「信頼関係」からec2.amazonaws.comをssm.amazonaws.comに変更します。
この手法はちょいちょい使いますので、覚えておくと良いでしょう
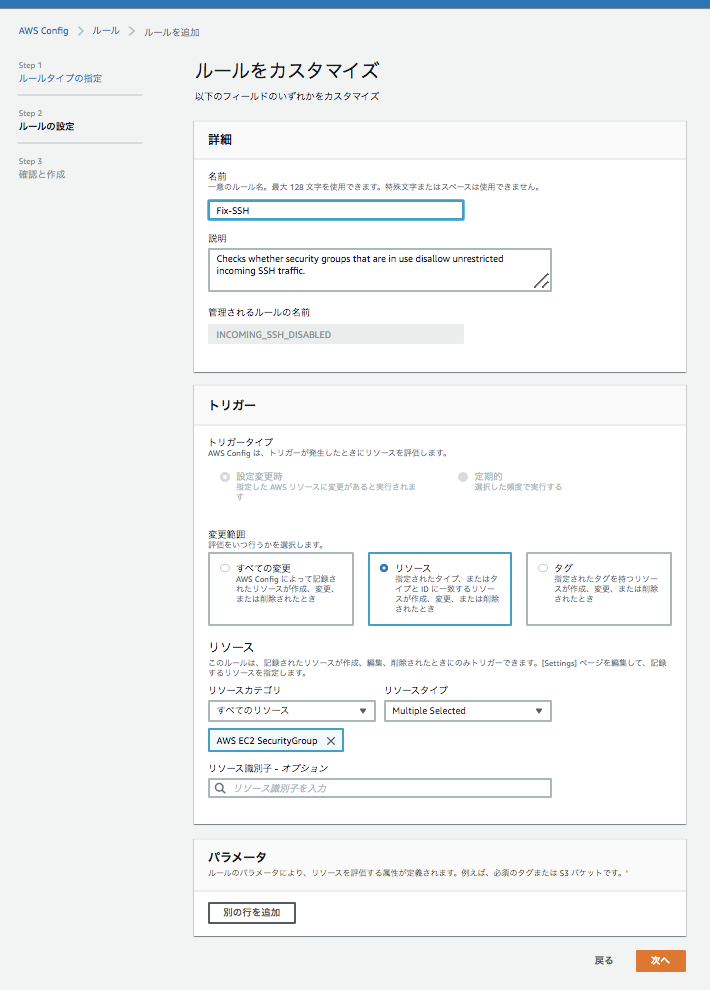
Configの「ルールの追加」からルールを作成していきます。
マネージドルールの検索欄から「restricted-ssh」を指定して下さい。
リソースは「AWS EC2 SecurityGroup」を指定します。
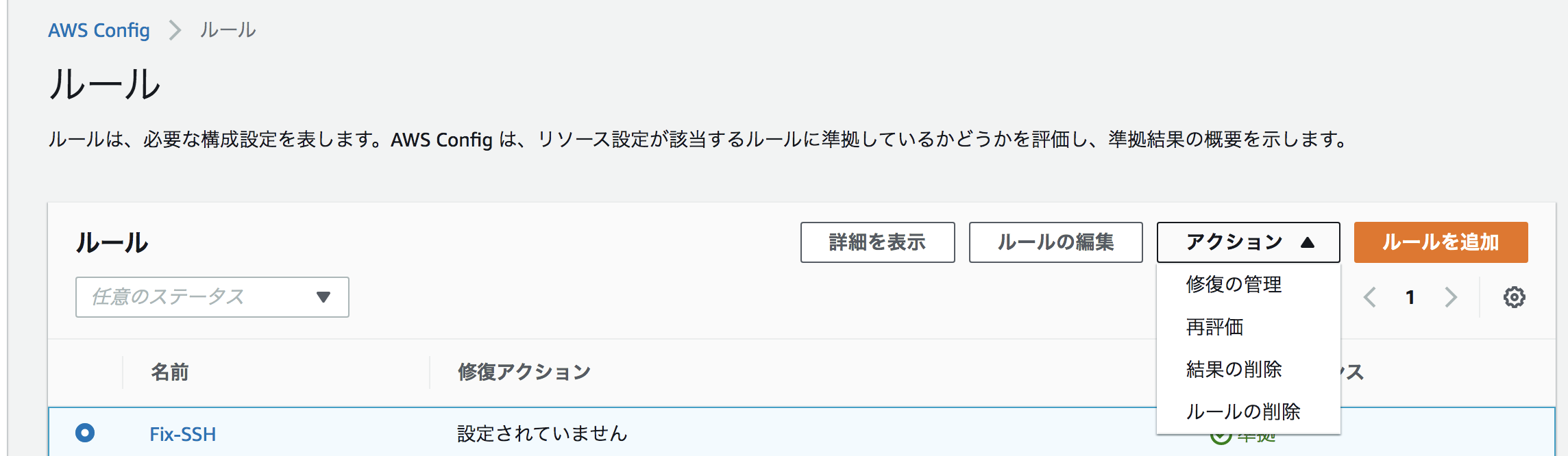
ルールの作成が完了したら、「アクション」→「修復の管理」を選択します。
修復アクションは「AWS-DisablePublicAccessForSecurityGroup」を選択。
リソースIDパラメーターは「GroupID」を選択して、先ほど作成したIAMロールのARNを入力したら完成です!
「restricted-ssh」以外にも様々なマネージドルールがありますし、カスタムルールも作成可能ですので
「コンプライアンスに非準拠を検知」→「自動修復」のパターンが色々出来そうですね!最後に
現時点でのアーキテクチャはこんな感じです。
前回はWA別で改善案をまとめていましたが、実際の構築はサービスごとで行うので、サービス別の改善案をまとめておきます
ACM
- CloudFront、ALBに証明書の関連付けを行いHTTPS化を行う
VPC
通信の範囲に応じてSubnetを作成NAT Gatewayの作成、Route Tableを定義するセキュリティグループを用いて必要最小限のアクセスのみを許可するVPC FlowLogの作成、S3にログの収集、Athenaによる分析を行うELB(ALB)
ELBのメトリクスを監視- ELBのアクセスログをS3に収集、Athenaによる分析分析を行う
ターゲットグループの作成ALBの作成- AutoScalingの有効化(検討)
- AutoHealingの有効化(検討)
Config
セキュリティグループのSSH全開放をAWS Configによる自動修復によって修正するCloudFront
- ディストリビューションの作成
- 特定地域からのアクセスをブロックする
- CloudFrontからのアクセスのみを許可(オリジンへの直接アクセスを禁止)
- カスタムエラーレスポンスとしてSorry Pageを実装
- CloudFrontのアクセスログをS3に収集、Athenaによる分析を行う
- Cloudfrontのメトリクスを監視
AWS WAF
- WebACLの作成
KMS
- EBSのボリュームを暗号化
IAM
- IAMロールの管理、リソースへの適用
AWS Backup
- RDSのスナップショット
- EBSのスナップショット
- ゴールデンイメージの管理
- バックアップイベントをSlackに通知
Cloudwatch
- Cloudwatch Syntheticsを用いてサービス状況を監視
- AutoRecoveryの有効化(検討)
Personal Health Dashboard
- AWSの障害をSlackに通知
Trusted Advisor
- セキュリティの現状、不要なリソースの確認を行う
Security Hub /
- Security Standardの有効化
- Slackに通知を行う
GuardDuty /
- Slackに通知を行う
EC2
- ログの正当性を担保する為にTime Sync Serviceで時刻同期を行う
- EC2インスタンスのメトリクスを監視
- CloudWatch Agentのインストール
CloudWatch Logs
- ログの収集、ロググループの作成
- メトリクスフィルタによるログの監視
- CloudWatch Logs Insightsによるログの分析
Kinesis Firehose
- AWS WAFのログの収集
Systems Manager
- SSM Agentのインストール
- Patch Managerを用いたパッチの自動化
- RunCommand、State Managerを用いた再起動、メンテナンスの自動化
Session Managerを用いてSSHログインを行うを用いてSSHログインを行う- Session Managerの操作ログの収集
- Parameter Storeを用いてデータベースへの接続情報を保存、管理
Cost Explorer
- コスト分配タグの設定
- CostExplorerを用いて、コストを確認
IAM(Organization)
- リソースに対して、コスト管理の為のタグ付けの強制
Budgets
- 予算を設定し、コストの管理を行う
- Slackへの通知
RDS
- リードレプリカの配置
- MySQLをAuroraMySQLに移行
- クラスターエンドポイント、リーダーエンドポイントの実装(検討)
- 容量のスケーリングの有効化
- 通信の暗号化
- イベントサブスクリプションによるRDSのイベントを通知
- クロスリージョンレプリカの配置
- Lambdaを用いてマスターDBへの昇格を制御
- RDSのデータを暗号化
- RDSのメトリクスを監視
ElastiCache
- Auroraと併用し、クエリ結果をキャッシング
Inspector
- 脆弱性を評価
- Slackに通知を行う
S3
- サーバー間でのファイルの共有が可能、コスト、可用性、耐障害性の観点から静的ファイルの保管をS3で行う
Route53
- ヘルスチェックの有効化
- フェイルオーバールーティングの実装
Cloudformation
- 別リージョンにスタックをコピー
- AMIのマッピング
Code3兄弟
- Code3兄弟を用いたCI/CDパイプラインの構築
参考
「セキュリティグループのSSH全開放をAWS Configで自動修復したら3分くらいで直ったからみんな使ってほしい件」
https://dev.classmethod.jp/articles/auto-recovery-restricted-ssh-without-lambda/「VPCフローログをAmazon Athenaで分析する」
https://dev.classmethod.jp/articles/vpc-flow-logs-athena/「ELB + CloudWatchアラームを使ったEC2サービス監視プラクティス」
https://dev.classmethod.jp/articles/elb-using-cloudwatch-alarm/「ELBの挙動とCloudWatchメトリクスの読み方を徹底的に理解する」
https://dev.classmethod.jp/articles/elb-and-cloudwatch-metrics-in-depth/






- 投稿日:2020-09-24T04:17:01+09:00
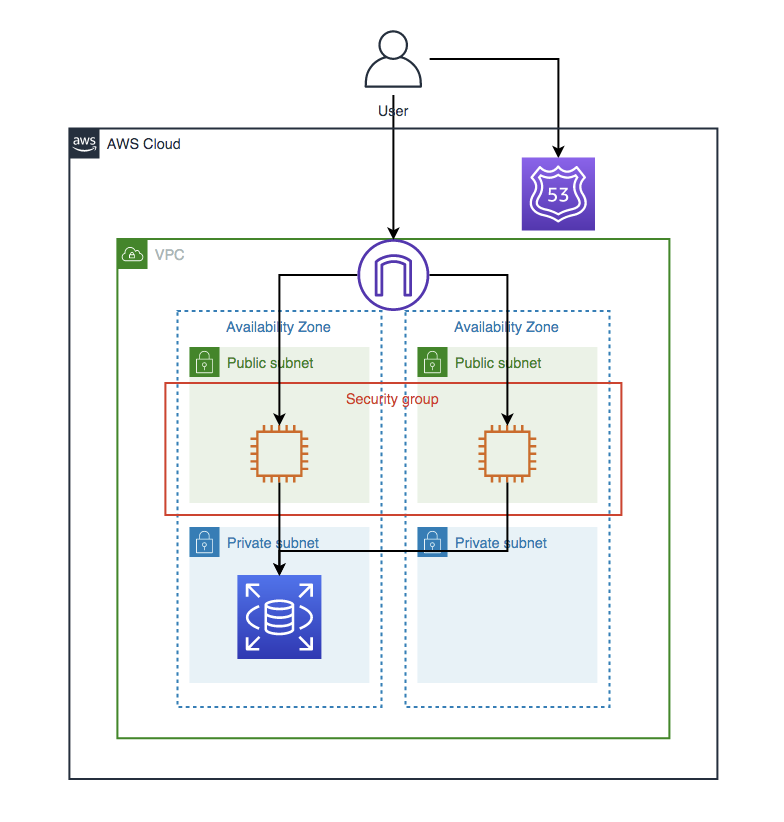
未経験の学生がWell Architected Frameworkを意識して自分なりにアーキテクチャ設計・構築をしてみた。<アーキテクチャ設計編>
はじめに
この記事は、実務未経験の大学生がロールプレイング形式でアーキテクチャの設計、構築を行うといった記事です。
よろしければ<準備編>もご覧くださいませ。前提条件の確認(ロールプレイング中)
- インフラエンジニアは4人
- 4人でインフラの構築、運用を行なっていかなければならない
- 自動化が重要
- 構築までの期間は1ヶ月
問題点
現環境の構築に携わったエンジニアにヒアリングを行い、現環境の問題点を整理しました。
Well-Architected フレームワークを元にアーキテクチャを考えた時に、現時点でのアーキテクチャでは以下の様な問題点が挙げられます。セキュリティ
- 通信にSSLが適用されていない
- セキュリティグループが適切に設定されていない(全てがフルオープンになっている)
- DDos等の一般的なセキュリティ対策を行なっていない
- データの暗号化が行われていない
- リソースに対する権限管理が曖昧である
- DBの接続情報など、設定ファイルにハードコーディングされている
信頼性
- 静的ファイルの保存先がEBSになっている
- 各リソースのスケーリングが行われていない
- 障害復旧の手順が決まっていない
運用の優秀性
- リソースの監視が行われていない
- ログの収集、分析を行なっていない
- デプロイが手動で行われている
- パッチ適用、メンテナンスが手動で行われている
コスト最適化
- リソースのコストを把握出来ない
パフォーマンス
- DBのキャパシティ、パフォーマンスに対する懸念がある
改善案
以上の問題点より、具体的な改善案を提案しました。
以下具体的な改善案です。
セキュリティ
通信にSSLが適用されていない
- ACM
- CloudFront、ALBへの関連付けを行いHTTPS化
セキュリティグループが適切に設定されていない(全てがフルオープンになっている)
VPC
- 通信の範囲に応じてSubnetを作成、Route Tableを定義する
- セキュリティグループを用いて必要最小限のアクセスのみを許可する
Systems Manager
- Session Managerを用いてSSHログインを行う
Config
- セキュリティグループのSSH全開放をAWS Configによる自動修復を行う
DDos等の一般的なセキュリティ対策を行なっていない
CloudFront
- ディストリビューションの作成
- 特定地域からのアクセスをブロックする
- CloudFrontからのアクセスのみを許可(オリジンへの直接アクセスを禁止)
Inspector
- 脆弱性を評価
AWS WAF
- WebACLの作成
データの暗号化が行われていない
RDS
- 通信の暗号化
KMS
- RDSのデータを暗号化
- EBSのボリュームを暗号化
リソースに対する権限管理が曖昧である
- IAM
- IAMロールの管理、リソースへの適用
DBの接続情報など、設定ファイルにハードコーディングされている
- Systems Manager
- Parameter Storeを用いてデータベースへの接続情報を保存、管理
信頼性
静的ファイルの保存先がEBSになっている
- S3
- 静的ファイルの保管をS3で行う
- サーバー間でのファイルの共有が可能、コスト、可用性、耐障害性の観点から
各リソースのスケーリングが行われていない
ALB
- ターゲットグループの作成
- ALBの作成
- AutoScalingの有効化(検討)
- AutoHealingの有効化(検討)
Cloudwatch
- AutoRecoveryの有効化(検討)
障害復旧の手順が決まっていない
フェイルオーバー
- Route53
- ヘルスチェックの有効化
- フェイルオーバールーティングの実装
- CloudFront
- カスタムエラーレスポンスとしてSorry Pageを実装
DRとしてパイロットライト
- RDS
- クロスリージョンレプリカの配置
- Lambdaを用いてマスターDBへの昇格を制御
- Cloudformation
- 別リージョンにスタックをコピー
- AMIのマッピング
スナップショット、AMIの管理
- AWS Backup
- RDSのスナップショット
- EBSのスナップショット
- ゴールデンイメージの管理
- バックアップイベントの通知
運用の優秀性
リソースの監視体制が不十分
Cloudwatch
- RDSのメトリクスを監視
- EC2インスタンスのメトリクスを監視
- CloudWatch Agentのインストール
- ELBのメトリクスを監視
- Cloudfrontのメトリクスを監視
- Cloudwatch Syntheticsを用いてサービス状況を監視
Personal Health Dashboard
- AWSの障害を通知
RDS
- イベントサブスクリプションによるイベントの通知
Trusted Advisor
- セキュリティの現状、不要なリソースの確認
Security Hub /
- Security Standardの有効化
- Slackに通知
GuardDuty /
- Slackに通知
ログの収集、分析を行なっていない
S3/Athena
- VPC FlowLogの作成、ログの収集、Athena分析
- CloudFrontのアクセスログの収集、Athena分析
- ELBのアクセスログの収集、Athenaによる分析
Systems Manager
- Session Managerの操作ログの収集
EC2
- Time Sync Serviceで時刻同期
CloudWatch Logs
- ログの収集、ロググループの作成
- メトリクスフィルタによるログの監視
- CloudWatch Logs Insightsによるログの分析
Kinesis Firehose
- AWS WAFのログの収集
デプロイが手動で行われている
- Code3兄弟
- Code3兄弟を用いたCI/CDパイプラインの構築
パッチ適用が手動
- Systems Manager
- SSM Agentのインストール
- Patch Managerを用いたパッチの自動化
- RunCommand、State Managerを用いた再起動の自動化
コスト最適化
リソースのコストを把握出来ない
Cost Explorer
- コスト分配タグの設定
- CostExplorerを用いて、コストを確認
IAM(Organization)
- リソースに対して、コスト管理の為のタグ付けの強制
Budgets
- 予算を設定し、コストの管理を行う
パフォーマンス
DBのキャパシティ、パフォーマンスに対する懸念がある
RDS
- リードレプリカの配置
- MySQLをAuroraMySQLに移行
- クラスターエンドポイント、リーダーエンドポイントの実装(検討)
- 容量のスケーリングの有効化
ElastiCache
- Auroraと併用し、クエリ結果をキャッシング
感想
アーキテクチャの設計が完了しました!
あとはこれを構築するだけです (...だけ?)アーキテクチャ図に3時間はかかっております
- 投稿日:2020-09-24T04:17:01+09:00
未経験者がWell Architected Frameworkを意識して自分なりにアーキテクチャ設計・構築をしてみた。<アーキテクチャ設計編>
はじめに
この記事は、実務未経験の大学生がロールプレイング形式でアーキテクチャの設計、構築を行うといった記事です。
よろしければ<準備編>もご覧くださいませ。前提条件の確認(ロールプレイング中)
- インフラエンジニアは4人
- 4人でインフラの構築、運用を行なっていかなければならない
- 自動化が重要
- 構築までの期間は1ヶ月
問題点
現環境の構築に携わったエンジニアにヒアリングを行い、現環境の問題点を整理しました。
Well-Architected フレームワークを元にアーキテクチャを考えた時に、現時点でのアーキテクチャでは以下の様な問題点が挙げられます。セキュリティ
- 通信にSSLが適用されていない
- セキュリティグループが適切に設定されていない(全てがフルオープンになっている)
- DDos等の一般的なセキュリティ対策を行なっていない
- データの暗号化が行われていない
- リソースに対する権限管理が曖昧である
- DBの接続情報など、設定ファイルにハードコーディングされている
信頼性
- 静的ファイルの保存先がEBSになっている
- 各リソースのスケーリングが行われていない
- 障害復旧の手順が決まっていない
運用の優秀性
- リソースの監視が行われていない
- ログの収集、分析を行なっていない
- デプロイが手動で行われている
- パッチ適用、メンテナンスが手動で行われている
コスト最適化
- リソースのコストを把握出来ない
パフォーマンス
- DBのキャパシティ、パフォーマンスに対する懸念がある
改善案
以上の問題点より、具体的な改善案を提案しました。
以下具体的な改善案です。
セキュリティ
通信にSSLが適用されていない
- ACM
- CloudFront、ALBに証明書の関連付けを行いHTTPS化を行う
セキュリティグループが適切に設定されていない(全てがフルオープンになっている)
VPC
- 通信の範囲に応じてSubnetを作成
- NAT Gatewayの作成、Route Tableを定義する
- セキュリティグループを用いて必要最小限のアクセスのみを許可する
Systems Manager
- Session Managerを用いてSSHログインを行う
Config
- セキュリティグループのSSH全開放をAWS Configによる自動修復によって修正する
DDos等の一般的なセキュリティ対策を行なっていない
CloudFront
- ディストリビューションの作成
- 特定地域からのアクセスをブロックする
- CloudFrontからのアクセスのみを許可(オリジンへの直接アクセスを禁止)
Inspector
- 脆弱性を評価
- Slackに通知を行う
AWS WAF
- WebACLの作成
データの暗号化が行われていない
RDS
- 通信の暗号化
KMS
- RDSのデータを暗号化
- EBSのボリュームを暗号化
リソースに対する権限管理が曖昧である
- IAM
- IAMロールの管理、リソースへの適用
DBの接続情報など、設定ファイルにハードコーディングされている
- Systems Manager
- Parameter Storeを用いてデータベースへの接続情報を保存、管理
信頼性
静的ファイルの保存先がEBSになっている
- S3
- サーバー間でのファイルの共有が可能、コスト、可用性、耐障害性の観点から静的ファイルの保管をS3で行う
各リソースのスケーリングが行われていない
ALB
- ターゲットグループの作成
- ALBの作成
- AutoScalingの有効化(検討)
- AutoHealingの有効化(検討)
Cloudwatch
- AutoRecoveryの有効化(検討)
障害復旧の手順が決まっていない
フェイルオーバー
- Route53
- ヘルスチェックの有効化
- フェイルオーバールーティングの実装
- CloudFront
- カスタムエラーレスポンスとしてSorry Pageを実装
DRとしてパイロットライト
- RDS
- クロスリージョンレプリカの配置
- Lambdaを用いてマスターDBへの昇格を制御
- Cloudformation
- 別リージョンにスタックをコピー
- AMIのマッピング
スナップショット、AMIの管理
- AWS Backup
- RDSのスナップショット
- EBSのスナップショット
- ゴールデンイメージの管理
- バックアップイベントをSlackに通知
運用の優秀性
リソースの監視体制が不十分
Cloudwatch
- RDSのメトリクスを監視
- EC2インスタンスのメトリクスを監視
- CloudWatch Agentのインストール
- ELBのメトリクスを監視
- Cloudfrontのメトリクスを監視
- Cloudwatch Syntheticsを用いてサービス状況を監視
Personal Health Dashboard
- AWSの障害をSlackに通知
RDS
- イベントサブスクリプションによるRDSのイベントを通知
Trusted Advisor
- セキュリティの現状、不要なリソースの確認を行う
Security Hub /
- Security Standardの有効化
- Slackに通知を行う
GuardDuty /
- Slackに通知を行う
ログの収集、分析を行なっていない
S3/Athena
- VPC FlowLogの作成、S3にログの収集、Athenaによる分析を行う
- CloudFrontのアクセスログをS3に収集、Athenaによる分析を行う
- ELBのアクセスログをS3に収集、Athenaによる分析分析を行う
Systems Manager
- Session Managerの操作ログの収集
EC2
- ログの正当性を担保する為にTime Sync Serviceで時刻同期を行う
CloudWatch Logs
- ログの収集、ロググループの作成
- メトリクスフィルタによるログの監視
- CloudWatch Logs Insightsによるログの分析
Kinesis Firehose
- AWS WAFのログの収集
デプロイが手動で行われている
- Code3兄弟
- Code3兄弟を用いたCI/CDパイプラインの構築
パッチ適用が手動
- Systems Manager
- SSM Agentのインストール
- Patch Managerを用いたパッチの自動化
- RunCommand、State Managerを用いた再起動、メンテナンスの自動化
コスト最適化
リソースのコストを把握出来ない
Cost Explorer
- コスト分配タグの設定
- CostExplorerを用いて、コストを確認
IAM(Organization)
- リソースに対して、コスト管理の為のタグ付けの強制
Budgets
- 予算を設定し、コストの管理を行う
- Slackへの通知
パフォーマンス
DBのキャパシティ、パフォーマンスに対する懸念がある
RDS
- リードレプリカの配置
- MySQLをAuroraMySQLに移行
- クラスターエンドポイント、リーダーエンドポイントの実装(検討)
- 容量のスケーリングの有効化
ElastiCache
- Auroraと併用し、クエリ結果をキャッシング
感想
アーキテクチャの設計が完了しました!
あとはこれを構築するだけです (...だけ?)アーキテクチャ図に3時間はかかっております
- 投稿日:2020-09-24T01:02:42+09:00
Laravel Envoy+CircleCIでEC2にデプロイ
概要
Laravel EnvoyとCircleCIを利用して、EC2にデプロイするということを試してみました。
https://laravel.com/docs/8.x/envoy
GithubのmasterブランチにマージされたらEC2上の本番サーバに、developブランチにマージされたらステージングサーバにデプロイされる想定です。前提
設定
- AWS上に本番環境(production)とステージング環境(staging)がEIPが割り当てられたEC2として存在する
- EC2からgit pull可能
- Githubでmasterとdevelopのブランチが存在するリポジトリ
- Githubのリポジトリにpushした際CircleCIが実行されるよう連携済み
バージョン
PHP: 7.4.7
Laravel Envoy: 2.3.1手順
Laravel Envoyの設定
$ composer require laravel/envoy今回簡易的に以下のようにEnvoy.blade.phpを作成します。
Envoy.blade.php@servers(['production' => 'ec2-user@xx.xx.xx.xx', 'staging' => 'ec2-user@yy.yy.yy.yy']) @setup $docRoot = '/var/www/html'; @endsetup @story('deploy') git @endstory @task('git', ['on' => $server]) cd {{ $docRoot }} git pull origin {{ $branch }} @endtask @finished echo "${server}へデプロイしました!"; @endfinishedCircleCIからEC2にデプロイするための設定
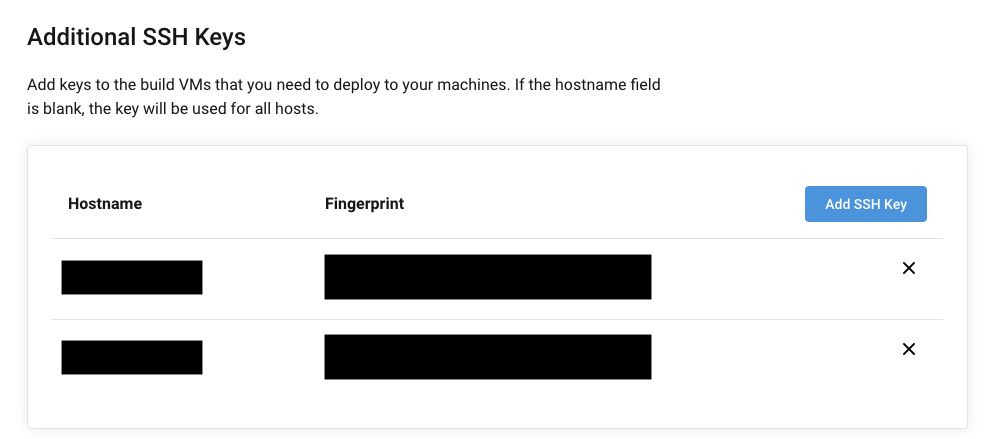
CircleCIからEC2にSSHするための設定
CircleCIのプロジェクトの設定ページから
SSH Keys>Additional SSH Keysへ進み、「Add SSH Key」で各サーバへSSH接続するための秘密鍵を登録します。HostnameにEIP、Private Keyに秘密鍵を入力します。
登録するとFingerprintが表示されているので、これを控えておきます。
EC2作成時に生成されるキーペアを用いる場合は不要ですが、新しく鍵を生成した場合は下記のようにして、公開鍵を~/.ssh/authorized_keysに追記しておく必要があります。$ cat id_rsa.pub >> authorized_keys環境変数の登録
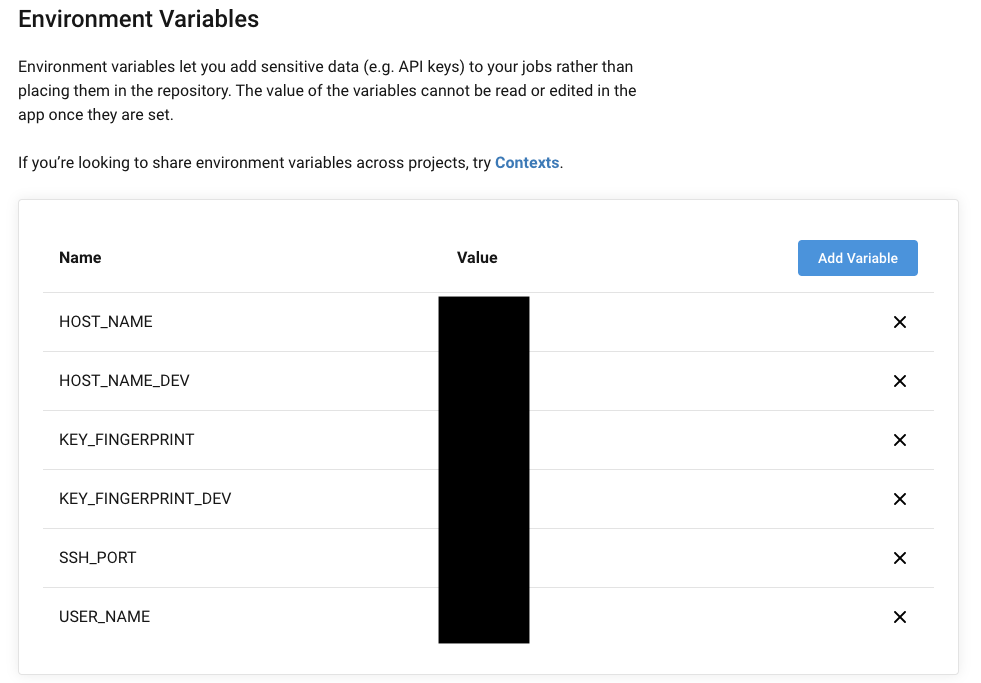
CircleCIのプロジェクトの設定ページから
Environment Variablesへ進み、「Add Variable」で必要な環境変数を登録します。今回は本番/ステージングサーバのEIP、先程作成されたFingerprint、ユーザー名、SSHのポート番号を登録しています。
configの設定
.circleci/config.ymlversion: 2 jobs: build: docker: - image: circleci/php:7.4-apache - image: circleci/postgres:11-alpine environment: POSTGRES_DB: default_test POSTGRES_USER: postgres POSTGRES_PASSWORD: postgres steps: - checkout ##### 〜〜中略〜〜 ##### # ---------------------------------------------------------------------------- # Deploy - add_ssh_keys: fingerprints: - "${KEY_FINGERPRINT}" - "${KEY_FINGERPRINT_DEV}" - run: name: Start ssh-keyscan command: ssh-keyscan -p ${SSH_PORT} ${HOST_NAME} >> ~/.ssh/known_hosts - run: name: Start ssh-keyscan(dev) command: ssh-keyscan -p ${SSH_PORT} ${HOST_NAME_DEV} >> ~/.ssh/known_hosts - run: name: Deploy to EC2 server command: | if [ "${CIRCLE_BRANCH}" == "master" ]; then ./vendor/bin/envoy run deploy --server=production --branch=master elif [ "${CIRCLE_BRANCH}" == "develop" ]; then ./vendor/bin/envoy run deploy --server=staging --branch=develop fi動作確認
masterでもdevelopでもないブランチにpush
デプロイは実行されずに終了している。
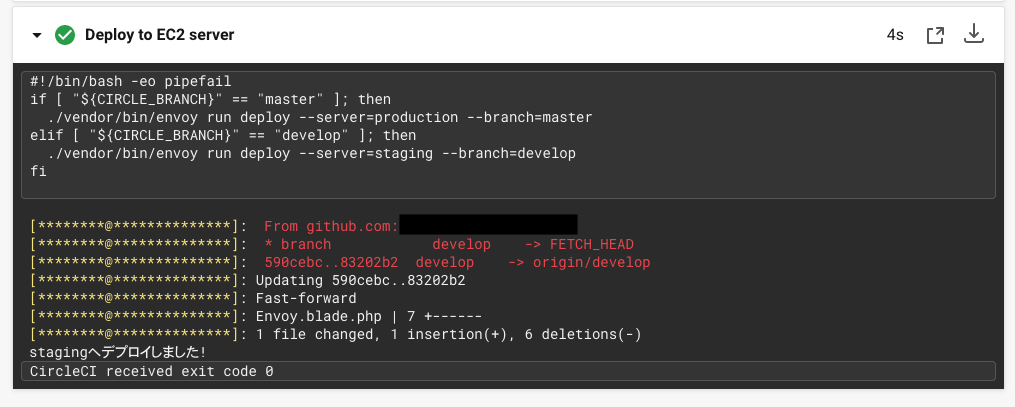
developにマージ
developブランチをpullしている。
masterにマージ
masterブランチをpullしている。
所感
関係ないブランチにも不要な処理が入ってしまうのはイマイチだった気がします。
もっと良いやり方ありましたら是非教えていただけたらと。参照

- 投稿日:2020-09-24T00:04:54+09:00
Chalice を使って AWS Lambda 上に Flask/Bottle のようにWebアプリケーションを構築する
はじめに
小規模なWebアプリケーションを作成する場合、Pythonでは Flask や Bottle を利用できる。
これらのフレームワークは「どのURLに対して」「どのプログラムを動かす」といった対応を Python のデコレータで対応させることで実現できる。
例えば、以下の Flask アプリケーションでは/にHTTPアクセスした時にHello, World!を返すWebサーバーを実装しており、ルーティング・レスポンス応答が非常に分かりやすい。Flaskの公式ページから引用# https://flask.palletsprojects.com/en/1.1.x/quickstart/ from flask import Flask app = Flask(__name__) @app.route('/') def hello_world(): return 'Hello, World!'さて、これらの Web アプリケーションは開発用途でローカルで動かす場合はすんなりと動いてくれる。
しかし、本番稼働として別のサーバーで稼働させようとした場合、アクセス可能なサーバーを調達したり、nginx+uwsgi/gunicornなどのミドルウェアを稼働させる必要があったりと、開発完了から本番稼働までに準備するものが多い印象である。
特にサーバーに関してはランニングコスト(実費)がかかったり、動作させているミドルウェアがダウンしてサービスが提供できていないことへの対処、ディスクフルなどアプリケーションとは別にちゃんとサーバーが正常に動いているかを考える必要がある、更にはOSやミドルウェアのセキュリティサポート期間切れへの対応などがあったりと、可能であればそもそもサーバーを使いたくない、という考えがある。
こういったモチベーションから、
- Pythonを使って Flask/Bottle のように簡単な記述でWebアプリケーションが作成できる
- サーバーを管理せずとも上記のWebアプリケーションを運用できる
という2点が解決できないかと考え、結果として AWS Lambda 用のマイクロフレームワーク Chalice を利用することでこれが実現できたので、このやり方を紹介する。
TL; DR
- Chalice のレスポンスで
text/htmlを利用する- ローカルでのテストには静的ファイルを返すローカル用の route を実装する
- 色々なコンテンツを返す場合は local に nginx を立ててプロキシする方法も視野に入れる
- HTML form からの POST を受け取れるような設定を Chalice の
@app.routeで行う必要がある- CloudFront を使って、静的ファイルは S3 Originへ、それ以外は Chalice でデプロイした API Gateway へと流す
- API Gatewayの場合、必ず
https://<FQDN>/<STAGE>/としてアクセスすることになるが、CloudFrontのOrigin Pathを使うことでトップレベルアクセス (https://<FQDN>/) をしても特定ステージの API Gateway の/へとアクセス可能になる利用サービスとインフラ構成図
この記事ではAWSで利用可能な多くのリソースを扱う。
- API Gateway + AWS Lambda (Chalice による自動化)
- CloudFront (サイトアクセスの最初に利用するエンドポイント)
- Amazon S3 (image/css/js などの静的ファイルの配置場所)
- Route 53 (独自ドメインの割当て)
- Certificate Manager (CloudFront で利用するSSL証明書の発行・管理)
それぞれのサービスの基本的な設定や使い方などはこの記事では行わない。
これらの関係を図示すると、以下のようになる。
Webアプリケーションの実装
そこそこコードの量が多くなったので、Gtihub にコード全体をデプロイしている。
https://github.com/t-kigi/chalice-lambda-webserver-example
コードは適時引用するが、全体の流れはこのリポジトリを参照の事。
利用したバージョンなど
開発環境は Ubuntu 18.04.
$ pipenv --version pipenv, version 2018.11.26 $ pipenv run chalice --version chalice 1.20.0, python 3.8.2, linux 5.4.0-48-genericWebアプリケーション開発に必要なChaliceの設定
1. レスポンス対応
Chaliceのセットアップなどは前に記事を書いているのでそちらを参照。 なお、今回は
chalice new-project serverとしてプロジェクトを作成している。Chalice は API 用途で使うことをデフォルトの挙動としているので、特に何も設定しない場合は
application/jsonのレスポンスが返ってくる。 しかし、Webアプリケーションとしてブラウザなどで表示可能なページを返す場合、text/htmlのレスポンスを返すとよい。
そのためにはレスポンスヘッダの ContentType をtext/htmlに設定してやる必要がある。 上記 Flask の例を Chalice で実現する場合、以下のようなコードになる。Flaskの例をChaliceで書き直した場合(app.py)from chalice import Chalice, Response app = Chalice(app_name='server') @app.route('/') def index(): return Response( status_code=200, headers={'Content-Type': 'text/html'}, body='Hello, World!')2. テンプレートエンジンの導入
さて、これだけ設定してやれば body に書かれた内容を
text/htmlでクライアント側に返してくれる。
つまり、テンプレートエンジンを使ってページを作成し、その最終結果を body に流してやることでテンプレートエンジンを利用したWebアプリケーションと同じことができる。
ここではテンプレートエンジンとしてjinja2を利用しているが、もし別のテンプレートエンジンを使いたければそれでも構わない。今回は以下のディレクトリ構成とした (必要な部分のみ抜粋)
. ├── app.py # Chalice のエントリーポイント └── chalicelib # deploy するファイルは全部 chalicelib の下に置く必要がある ├── __init__.py ├── common.py # 共通項目他を別のモジュールから呼び出すために配置 ├── template.py # chalicelib/templates からテンプレートをロードする関数など └── templates # この下にテンプレートを置く ├── index.tpl └── search.tplchalicelib/common.py(抜粋)# 複数ファイルで共有される Chalice オブジェクト app = Chalice(app_name='server') # プロジェクトが配置されているディレクトリのパス chalicelib_dir = os.path.dirname(__file__) project_dir = os.path.dirname(chalicelib_dir)chalicelib/templates以下のテンプレートファイルを取得できる設定(template.py)import os from jinja2 import Environment, FileSystemLoader, select_autoescape from chalicelib.common import project_dir template_path = os.path.join(project_dir, 'chalicelib/templates') loader = FileSystemLoader([template_path]) jinja2_env = Environment( loader=loader, autoescape=select_autoescape(['html', 'xml'])) def get(template_path): ''' テンプレートを取得 ''' return jinja2_env.get_template(template_path)
app.pyからchalicelib/templates/index.tplを読み込む例は以下の通り。app.pyfrom chalicelib import template from chalicelib.common import app def html_render(template_path, **params): ''' HTMLのレンダリングレスポンスを返す ''' tpl = template.get(template_path) return Response( status_code=200, headers={'Content-Type': 'text/html'}, body=tpl.render(**params)) @app.route('/') def index(): ''' トップページを返す ''' return html_render('index.tpl')3. ローカルでの検証
ローカル環境での検証には
chalice localコマンドを使う。
ただ、個人的にはローカル環境とデプロイ後の環境で違う設定をしたいことが多々あるので、ローカル検証用にlocalステージを作成することをオススメする。 local ステージを作成しておくとと、例えば
- localステージでのみ profile を使って AWS リソースにアクセスする(本番時はIAM Roleを使うのでProfileは利用しない)
- localステージでのみ有効な route を定義する
といったことを実現できる
localステージの作成のために、
.chalice/config.jsonのstagesにlocalスコープを書き加える。{ "version": "2.0", "app_name": "server", "stages": { "dev": { "api_gateway_stage": "v1" }, "local": { "environment_variables": { "STAGE": "local" } } } }これを書き加えた後、
chalice local --stage localとして起動する(既に稼働している場合は一度プロセスを停止して再起動)。 これで--stage localとして実行した場合にのみSTAGEという環境変数がlocalという値で定義されるようになる。4. 静的ファイルのレスポンス対応
開発で利用する主な用途の静的ファイルには、画像、CSS、JavaScriptのコードがある。 そこで、これらを配置するパスを決め、そこへのアクセス時にはそれらのファイルを読み込んで返すこととする。
これらのファイルは最終的にS3にアップロードし、Lambdaのアップロードの中には含めたくないためchalicelibの外に配置している。 用意したディレクトリ構造は以下の通り。静的ファイルの説明に必要な部分のみ抜粋. ├── server │ ├── app.py │ ├── chalicelib │ │ ├── __init__.py │ │ ├── common.py │ │ └── staticfiles.py │ └── static -> ../static └── static ├── css │ └── style.css ├── images │ ├── sample.png │ └── sub │ └── sample.jpg └── js └── index.js
chalice local --stage localでサーバーを実行するとlocalhost:8000にサーバーが立つ。 そのため、ここではhttp://localhost:8000/images/sample.pngにアクセスすることでstatic/images/sample.pngを取得できるような設定としたい。
これを実現するためにchalicelib/staticfiles.pyを用意した。chalicelib/staticfiles.py#!/usr/bin/python # -*- coding: utf-8 -*- ''' chalice local で動作する static file を返す実装です。 本番では CloudFront -> S3 へのパスで対処する内容となるため、 開発時にのみ利用することを想定しています。 ''' import os from chalice import Response from chalice import NotFoundError from chalicelib.common import app, project_dir def static_filepath(directory, file, subdirs=[]): ''' ローカルサーバーで static file のパスを生成して返す ''' pathes = [f for f in ([directory] + subdirs + [file]) if f is not None] filepath = os.path.join(*pathes) localpath = os.path.join(project_dir, 'static', filepath) return (f'/{filepath}', localpath) def static_content_type(filepath): ''' static file 用の Content-Type を返す ''' (_, suffix) = os.path.splitext(filepath.lower()) if suffix in ['.png', '.ico']: return 'image/png' if suffix in ['.jpg', '.jpeg']: return 'image/jpeg' if suffix in ['.css']: return 'text/css' if suffix in ['.js']: return 'text/javascript' return 'application/json' def load_static(access, filepath, binary=False): ''' static file の読み込み ''' try: with open(filepath, 'rb' if binary else 'r') as fp: data = fp.read() return Response( body=data, status_code=200, headers={'Content-Type': static_content_type(filepath)}) except Exception: raise NotFoundError(access) @app.route('/favicon.ico', content_types=["*/*"]) def favicon(): (access, filepath) = static_filepath(None, 'favicon.ico') return load_static(access, filepath, binary=True) @app.route('/images/{file}', content_types=["*/*"]) @app.route('/images/{dir1}/{file}', content_types=["*/*"]) def images(dir1=None, file=None): ''' ローカル環境用画像ファイルレスポンス (Lambdaにデプロイするとパスの都合で動かないのでCloudFrontでS3に流す) ''' (access, filepath) = static_filepath('images', file, [dir1]) return load_static(access, filepath, binary=True) @app.route('/css/{file}', content_types=["*/*"]) @app.route('/css/{dir1}/{file}', content_types=["*/*"]) def css(dir1=None, file=None): ''' ローカル環境用CSSファイルレスポンス (Lambdaにデプロイするとパスの都合で動かないのでCloudFrontでS3に流す) ''' (access, filepath) = static_filepath('css', file, [dir1]) return load_static(access, filepath) @app.route('/js/{file}', content_types=["*/*"]) @app.route('/js/{dir1}/{file}', content_types=["*/*"]) def js(dir1=None, file=None): ''' ローカル環境用JSファイルレスポンス (Lambdaにデプロイするとパスの都合で動かないのでCloudFrontでS3に流す) ''' (access, filepath) = static_filepath('js', file, [dir1]) return load_static(access, filepath)特定パスの時のみ、
static以下のファイルを読み込んでそのレスポンスを返す機能を持ったモジュールである。 これを local ステージの時のみ有効にするには、app.py(抜粋)import os stage = os.environ.get('STAGE', 'dev') if stage == 'local': # ローカル時のみ活用 from chalicelib import staticfiles # noqaとして
staticfilesを読み込んでやれば良い (# noqaは@app.routeに紐付けるためにモジュールをロードしているが、app.pyでは直接使ってない警告がでるため)。この状態で
http://localhost:8000にアクセスして、画像/CSS/JSがちゃんと適用されていれば静的リソースの読み込みは成功である。$ pipenv run chalice local --stage local Serving on http://127.0.0.1:8000 127.0.0.1 - - [23/Sep/2020 17:56:13] "GET / HTTP/1.1" 200 - 127.0.0.1 - - [23/Sep/2020 17:56:14] "GET /css/style.css HTTP/1.1" 200 - 127.0.0.1 - - [23/Sep/2020 17:56:14] "GET /images/sample.png HTTP/1.1" 200 - 127.0.0.1 - - [23/Sep/2020 17:56:14] "GET /js/index.js HTTP/1.1" 200 -
http://localhost:8000に Chrome でアクセスして表示される画面は以下の通り。
これだけあれば簡易的な検証はローカル上で完結可能になる。
参考. nginxでの対処
上記パスを逐一追加していく方法は拡張子が増えたり対象パスが増えていくと、その都度追加していくのは現実的ではない。
そういった場合はローカルに nginx を立てて、特定パスのみ root をstaticとするような location を書いた server 設定を利用すればよい。 その後 http://localhost/ でアクセス・検証を続ければよい。
この記事では nginx の利用方法などは説明しないが、複雑になってくる場合はこちらの導入を検討しても良いため、参考として紹介しておく。nginx.confの具体例location / { # 通常アクセスはこちら proxy_pass http://localhost:8000; } location ~ ^/(images|css|js)/ { # static リソースは固定パスから取得 root (プロジェクトパス)/static; }5. form からの POST の対応
ブラウザのformからPOSTを行う場合、Content-Type が
application/x-www-form-urlencodedやmultipart/form-dataとして送られる。
Chalice側ではデフォルトだとこれを受け付けないようになっているので、対応メソッドの content_types でこれらを受け取れるようにする必要がある。chalicelib/common.pypost_content_types = [ 'application/x-www-form-urlencoded', 'multipart/form-data' ] def post_params(): ''' post メソッドに送られたパラメータを dict で返します ''' def to_s(s): try: return s.decode() except Exception: return s # str 型に変換して返す body = app.current_request.raw_body parsed = dict(parse.parse_qsl(body)) return {to_s(k): to_s(v) for (k, v) in parsed.items()}app.py@app.route('/search', methods=['POST'], content_types=common.post_content_types) def search(): ''' 検索する ''' params = common.post_params() # パラメータを dict の形で取得するChalice のデプロイと動作確認
Programmic Access が可能な権限の広いIAMを入手しているのであれば、
chalice deployコマンド一つでアプリケーションをデプロイ可能となる。
一方、そうではない場合、あるいはCI/CDツールなどを利用する場合はchalice packageコマンドを使って CloudFormation でデプロイ可能なツールキットを作成すればよい。
具体例は以下の通り。--profileや--regionなどを省略しているので、適時追加すること。chalice_packageの利用例BUCKET=<CloudFormation用のリソースをアップロードするS3バケットを指定> # CloudFormationでのデプロイ方式に変換 $ pipenv run chalice package build $ cd build # Package化してS3にアップロード $ aws cloudformation package --template-file sam.json \ --s3-bucket ${BUCKET} --output-template-file chalice-webapp.yml # CloudFormationでデプロイ $ aws cloudformation deploy --template-file chalice-webapp.yml --stack-name <STACK名> --capabilities CAPABILITY_IAM今回は
chalice deployコマンドでデプロイした結果を使う。--stageを指定していないので、ここではdevステージの設定が使われる(同様に--region,--profileは省略)。$ pipenv run chalice deploy Creating deployment package. Reusing existing deployment package. Creating IAM role: server-dev Creating lambda function: server-dev Creating Rest API Resources deployed: - Lambda ARN: arn:aws:lambda:ap-northeast-1:***********:function:server-dev - Rest API URL: https://**********.execute-api.ap-northeast-1.amazonaws.com/v1/デプロイしたURLにアクセスすることでちゃんと
text/htmlが返ってくる。$ curl https://**********.execute-api.ap-northeast-1.amazonaws.com/v1/ <!DOCTYPE html> <html lang="ja"> <head> <title>HELLO</title> <meta charset="UTF-8"> <link rel="stylesheet" href="/css/style.css"> </head> <body> <h1>Lambda Web Hosting</h1> <p>バックエンドとして AWS Lambda + Chalice (Python) で Flask/Bottle っぽく動かして見るサンプルです。</p> <h2>Load Static Files</h2> <p>h1タグに別のファイル /css/style.css から読み取られたスタイルが当たっています。</p> <p>画像は以下の通りです。</p> <img src="/images/sample.png"/><br> <p>JavaScriptも読み込まれています。</p> <span id="counter">0</span><br> <button id="button" type="button">カウンター (ボタンを押すと数値を加算します)</button> <h2>Form Post</h2> <p>内部で持っているデータベースモックから一致するものを取得します。</p> <form method="POST" action="/search"> <label>検索キーワード: </label> <input type="text" name="keyword" value="" /> <br> <button type="submit">検索</button> </form> <script src="/js/index.js"></script> </body> </html>静的ファイルを S3 Bucket にデプロイ
どこかに一つS3バケットを作成し、ここのコンテンツをCloudFrontから参照できるようにする。
今回はsample-bucket.t-kigi.netバケットを用意した。
これは例えばawscliを使って以下のように一括アップロード・更新ができる。# 静的ファイルのrootに移動 cd static # ファイルを全部コピー $ aws s3 sync . s3://sample-bucket.t-kigi.net/ upload: css/style.css to s3://sample-bucket.t-kigi.net/css/style.css upload: js/index.js to s3://sample-bucket.t-kigi.net/js/index.js upload: ./favicon.ico to s3://sample-bucket.t-kigi.net/favicon.ico upload: images/sub/sample.jpg to s3://sample-bucket.t-kigi.net/images/sub/sample.jpg upload: images/sample.png to s3://sample-bucket.t-kigi.net/images/sample.pngCloudFront の設定
ウェブサイトのアクセス元としてCloudFrontのDistributionを立てるために以下の設定を行う。 なお、全てManaged Consoleで実施する手順となる。
- Certification Manager で us-east-1 に 対象ドメインのSSL証明書を作成する
- CloudFrontはリージョン指定がないので、利用するリソースは全て us-east-1 に作成する必要がある
- 今回はRoute53で管理しているホストゾーンのドメインに管理者であることを証明するレコードを追加することで証明書を有効化&自動更新するようにしている
Create Distribution>Webを選択してディストリビューションを作成し、以下を設定
- Origin Domain Name に API Gateway の FQDN を入力する (例:
**********.execute-api.ap-northeast-1.amazonaws.com)
- 補足: URIを張り付ければここと次のOrigin Pathは適切な値に設定してくれる
- トップページアクセスのために Origin Path に API Gateway のステージを入れる (例:
/v1)- Viewer Protocol Policyを
Redirect HTTP to HTTPSとする (API GatewayはHTTPSのみ受け付けるため)- Allowed HTTP Methods はWebアプリケーションサーバーとして全てのメソッドを受け入れるために。"GET, HEAD, OPTIONS, PUT, POST, PATCH, DELETE" を指定する
- Cache and origin request settings には Cache Policy として "Managed-CachingDisabled" を指定する (この段階ではCDNをキャッシュサーバーとして使う設定にはしない)
- Distribution Settings の Alternate Domain Names に事前に準備したドメインのFQDN (ここでは
lambdasite.t-kigi.net) を指定- SSL Certificate に事前に作成した SSL 証明書を指定
- 証明書を作成した直後だと選択肢に出てこないことがあるので、その場合はしばらく待つ
- それでも出てこない場合は作成したリージョンが us-east-1 であるかをもう一度チェック
- Default Root Object には 何も記入しない
- ここに書いてるとデフォルトアクセス時に関係ないURLのリクエストをAPI Gatewayに流してしまいトップページへのアクセスに失敗してしまう
- それ以外の項目はデフォルト or 自分の都合の良いように決定
- Distribution が作成された後、IDを選択して
Origins and Origin Groupsタブを選択
- Create Origin で事前に準備した静的ファイル用のS3バケットを追加
- Origin Path は未入力のまま (バケットのトップ = URLのトップとする)
- Restrict Bucket Access を Yes とする
- Create a New Identity を選択してCDNからS3にアクセスする新しい権限を作成する
- Grant Read Permissions on Bucket で "Yes, Update Bucket Policy" でバケットポリシーを更新する
Behaviorsタブを開き、Create Behavior で特定パスのオリジンを指定する
/images/*,/css/*,/js/*,/favicon.icoへのアクセスをS3 Originへと向ける (下記画像参照)- Allowed HTTP Methods は GET/HEAD で良い (あるいは適切に設定)
以上の手順を行い、CloudFront の状態が Deployed になるまで待つ。 大体10~20分程度かかる。
サンプルサイト
以上のデプロイを行ったサンプルサイトは以下の通り。
この手順で CloudFront の
/は API Gateway の/v1/へと転送されるので、サイトトップレベルのアクセスを捌けるようになる。
なお、/v1->/v1へとそのまま転送したい場合はオリジン設定のOrigin Pathに何も入力しなければよい。デフォルトのLambdaの同時実行数は1000なので、CDNのキャッシュと合わせれば、かなりの同時アクセスを捌けると想定できる。
お値段比較
NOTE: 各料金は2020/09/23の記事執筆時点で ap-northeast-1 (東京) リージョンのものを参考にした
AWSで(1年)無料枠とされている t2.micro を立てっぱなしにした場合の30日(一カ月)の料金は
- インスタンス稼働代金: 10.944USD =
(0.0152USD/hour * 24 hours * 30 days)- Amazon Linux2 AMI に付随する最小の EBS Volume (8GB) 代金: 0.96USD =
(0.12USD/month * 8)- その他、AWS外へのデータ転送量 (0.114USD/GB)
となり、小規模なシステムであればおよそ1200~1300円程度となる (記事執筆時現在)。
AWSアカウントを作成してから12カ月のうちは無料となるが、これを超えた場合、あるいは1企業内で複数アカウントを作成して紐づけた場合は無料枠は消失してしまう(経験談)。
ただし、これは冗長性を考慮しないシステムであり、インスタンスがダウンした場合は手動で対処することが前提である。
冗長化させようと思った場合、サーバーを2台(以上)用意したり、ALBを前段に置く (月額+約20USD) 必要があるなど、地味にコスト面での問題が出てくる。一方、AWS Lambda を使う場合であれば、
- 1 か月ごとに 100 万件の無料リクエスト、および 40 万 GB-秒のコンピューティング時間は(アカウントを作ってからの期限に関係なく)無料
- アプリケーションを128MBのメモリで動かすのであれば、約37日
(40万GB-秒÷0.125GB=320万秒)分の累計Lambda稼働時間が1か月あたり無料- 100万件以上のリクエストがあっても、次の100万件あたり 0.2 USD
- S3の料金は 100万リクエスト(GET)で 0.37USD、1GB保持あたり 0.025USD/month という低料金
- データ転送量はCloudFrontを通しても同じ (AWS外へのデータ転送量 (0.114USD/GB))
- それ以外にもAPI Gateway, Route 53など、細々した料金は発生する
といった形で、アクセス頻度の少ないサーバーであれば 1~2USDぐらいもあれば十分運用することが可能になるだろう。
単純比較でも大きな利点があるが、更に「ここで利用するAWSの各サービスは冗長化されている」というのも特筆すべき事項である。
秒間数万リクエストといったデータを全てLambdaで捌くのは厳しいかもしれないが、CloudFrontのキャッシュとAWS Lambdaの並列実行性を利用すれば、秒間数百リクエスト程度のサービスなら特に工夫せずとも十分捌ききれる可能性はある。
欠点を挙げるとすれば、Lambdaの仕組みとしてアクセスがない場合の初回立ち上がりにやや時間がかかることもあり、レスポンス時間が安定しないことがあるかもしれない。完全な静的サイトやSPAの場合
単なる静的コンテンツのみで構成されるウェブサイトであれば CloudFront - S3 だけで実現できる。
さらに言えばS3に各種静的コンテンツを置いて、API GatewayでAPIを提供し、CloudFrontで一部パスを直接API GatewayにつなげてCORSを気にしないようなSPA (Single Page Application) にするというのがよりモダンな使い方ではあると思う。ただ、今回はバックエンドでやり取りしたデータを使ってテンプレートエンジンを動かしたいという要件があったため AWS Lambda をデフォルトオリジンとしてそっちに通信を流すような設計を考えたという経緯がある。
まとめ
Chalice + AWS Lambda + AWSの各種リソースを利用して Serverless だが Flask/Bottle のようにWebアプリケーションを実装し、実際の運用環境に乗せる方法を紹介した。
ただ、結果的に様々なAWSのサービスを利用することで1つのサービスを構築するため、特に知識がない状態でこの記事を見ても理解が難しいものになってしまったとは思う。しかし、サーバーを管理しないWebアプリケーションを作る、という意味では「最終的にはコーディングに集中できる環境を作っている」とも言える。 サーバーを管理しないためにサーバーや各インフラのことを理解するというのも遠回りに感じるかもしれないが、この時代であれば学んで損はないと個人的には考えている。
記事の範囲外の発展内容
ここで紹介したプロジェクトをベースに
- アプリケーション側でデータストアとしてDynamoDBを利用する
- RDBを使うにはそれなりに制約があるので、Lambda - DynamoDB の組での実装を覚える教材に良いのではないか
- CloudFront の利用による効率的キャッシュの運用
- 今回はAPIのキャッシュはOFF、静的リソースのキャッシュはONにしている
- CDNのキャッシュはサイトの作りや設定次第で他利用者の情報流出の原因になったりするので、本番で利用する場合はパスとキャッシュの関係をよくよく考え、テストして使う事
- 認証機構の仕組みの導入
- 今はAPI GatewayのURIに直接アクセスしてもレスポンスが返ってくる
- API Gateway に API Key を導入したり、 Lambdaのヘッダで X-Forwarded-For による接続元IPアドレスを判定することで接続制限を実装できる
- CloudFront の 署名付きCookieを使うことでより制限のあるサイトを構築できる
- IDaaS が別にあるなら Chalice の Authorizer の仕組みを使ってもよい
- Python以外の言語でWebアプリケーションを実装する
- Chaliceのサポート部分を自分の好きな言語・フレームワークで書きかえればそれだけで同じことができる
などの点を導入していくことで、より実際の運用に耐えうる環境を構築することができる。


