- 投稿日:2020-09-24T22:51:09+09:00
JSFで文字列のリストをカンマ区切りの文字列で出力する方法
- 環境
- CentOS Linux release 7.8.2003 (Core)
- openjdk version "11.0.7" 2020-04-14 LTS
- JSF 2.3.9
方法1 : Beabでカンマ区切りの文字列用にGettrを作る
参考 : Javaでカンマ区切りで文字列連結するいくつかの方法 - Qiita
xhtml<!--省略--> <h5>文字列のリストをカンマ区切りの文字列で出力する</h5> <h:outputText value="#{sampleBean.commaDelimitedString}" /> <!--省略-->SampleBean.java// 省略 /** 文字列のリスト. */ @Getter private List<String> strings = Arrays.asList("文字列の", "リストを", "カンマ区切りで", "表示したい。"); /** * 文字列のリストをカンマ区切りの文字列として取得する. * @return カンマ区切りの文字列 */ public String getCommaDelimitedString() { return this.strings.stream().collect(Collectors.joining(",")); } // 省略方法2 : xhtmlで
ui:repeatするxhtml<!--省略--> <ui:repeat var="string" value="#{sampleBean.strings}" varStatus="index"> <h:outputText value="#{string}" /> <ui:fragment rendered="#{!index.last}">,</ui:fragment> </ui:repeat> <!--省略-->SampleBean.java// 省略 /** 文字列のリスト. */ @Getter private List<String> strings = Arrays.asList("文字列の", "リストを", "カンマ区切りで", "表示したい。"); // 省略

- 投稿日:2020-09-24T22:49:03+09:00
Oracleの機械学習OSS「Tribuo」を試してみた
はじめに
先日、OracleがJavaによる機械学習ライブラリーをオープンソースで公開したというニュースを目にしたので、軽く触ってみました。
- CodeZineニュース - Oracle、Javaによる機械学習ライブラリ「Tribuo」をオープンソースで公開
- マイナビニュース - Oracle、Java機械学習ライブラリ「Tribuo」を発表
これを見ると、機械学習の一般的なアルゴリズムに加えてXGBoostなども使えるようです。
特徴
公式サイトのトップページには以下の3つの特徴が挙げられています。
来歴(Provenance):Tribuoのモデル、データセット、評価には来歴があるため、それらを作成するために使用されたパラメーター、データの変換方法、ファイルなどが正確に追跡できる(※)。
型安全:Javaを使用しており、本番環境ではなくコンパイル時にミスを発見できる。
相互運用可能:XGBoostやTensorflowなどの一般的な機械学習ライブラリーへのインターフェイスを提供。ONNXモデル交換フォーマットをサポートしており、他のパッケージや言語(scikit-learnなど)で構築されたモデルをデプロイできる。
※:「Provenance」とは、モデルやデータセットがどのようにつくられたのかを示す情報のことです。訳が「来歴」で適切かどうかは分かりません。
とりあえず動かす
アヤメを分類するチュートリアルがあったので、まずはこれを試してみます。このチュートリアルでは、4つの特徴(がくと花弁の長さ・幅)を持つアヤメのデータを学習して、3種類(versicolor、virginica、setosa)に分類するモデルを作成して予測します。
以下のようにIntelliJでMavenプロジェクトを作成して、
pom.xmlに以下を追加します。<dependencies> <dependency> <groupId>org.tribuo</groupId> <artifactId>tribuo-all</artifactId> <version>4.0.0</version> <type>pom</type> </dependency> </dependencies>分類するアイリスの花のデータをダウンロードして、
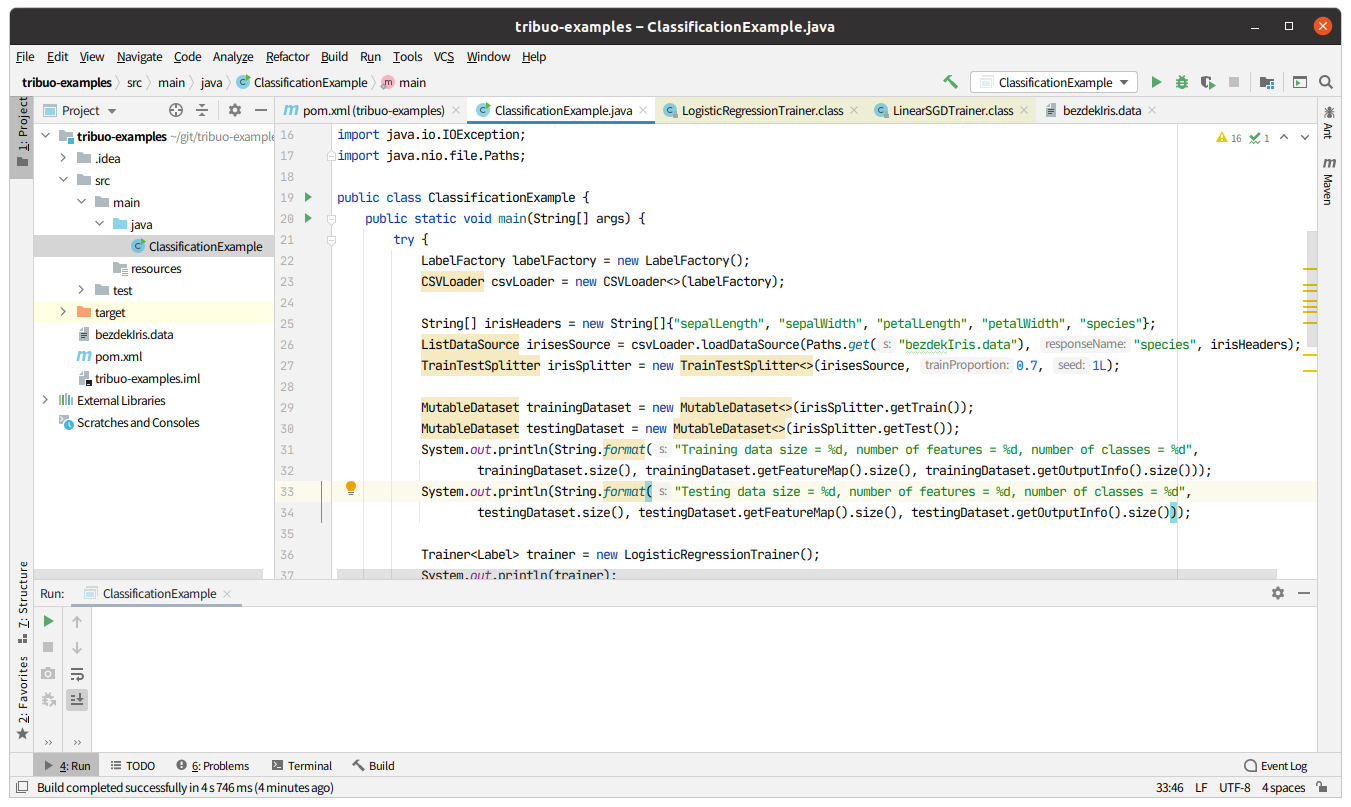
wget https://archive.ics.uci.edu/ml/machine-learning-databases/iris/bezdekIris.dataあとは、チュートリアルにある通り、クラスを作成すると、ディレクトリー構成は以下のようになります。
作成したサンプルプロジェクトは私のGitHubにアップロードしておくので、ソースコードの詳細を見たい方はこちらを参照下さい。
では、さっそく実行。ところが...チュートリアルの通りに実装したはずなのに、なぜかエラーが...
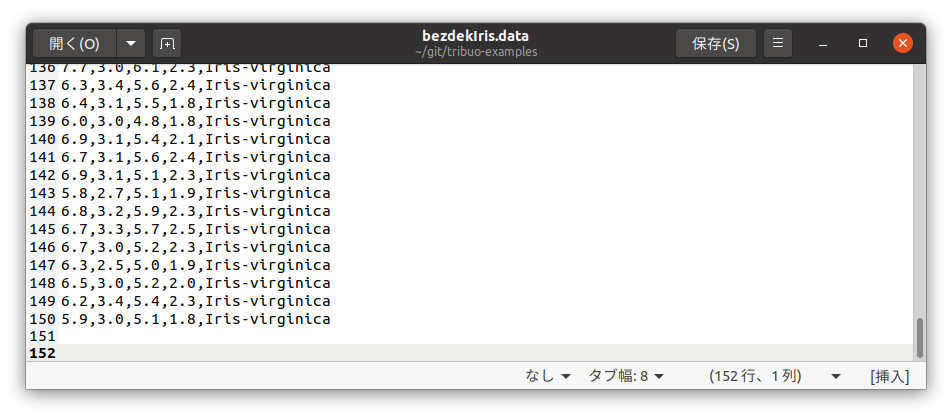
Exception in thread "main" java.lang.IllegalArgumentException: On row 151 headers has 5 elements, current line has 1 elements. at org.tribuo.data.csv.CSVIterator.zip(CSVIterator.java:168) at org.tribuo.data.csv.CSVIterator.getRow(CSVIterator.java:188) at org.tribuo.data.columnar.ColumnarIterator.hasNext(ColumnarIterator.java:114) at org.tribuo.data.csv.CSVLoader.innerLoadFromCSV(CSVLoader.java:249) at org.tribuo.data.csv.CSVLoader.loadDataSource(CSVLoader.java:238) at org.tribuo.data.csv.CSVLoader.loadDataSource(CSVLoader.java:209) at org.tribuo.data.csv.CSVLoader.loadDataSource(CSVLoader.java:161) at ClassificationExample.main(ClassificationExample.java:21) Process finished with exit code 1エラーメッセージに「
On row 151 …」とあるので、データファイルの151行目を確認してみると、データファイルの最終行に改行のみの1行がありました...
「そんなことでこけるなよ」と思いつつ空行を削除して、再び実行。今度は成功で、結果は検証用データの45件中44件が正解。正解率は97.8%でした。
Class n tp fn fp recall prec f1 Iris-versicolor 16 16 0 1 1.000 0.941 0.970 Iris-virginica 15 14 1 0 0.933 1.000 0.966 Iris-setosa 14 14 0 0 1.000 1.000 1.000 Total 45 44 1 1 Accuracy 0.978 Micro Average 0.978 0.978 0.978 Macro Average 0.978 0.980 0.978 Balanced Error Rate 0.022 Iris-versicolor Iris-virginica Iris-setosa Iris-versicolor 16 0 0 Iris-virginica 1 14 0 Iris-setosa 0 0 14ソースコードの解説
チュートリアルを読めばわかりますが、簡単にソースコードも解説しておきます。
作成したクラスは
main()メソッドを持つ1クラスだけです。多クラス分類に必要なクラスなどをいくつかimportしています。import org.tribuo.classification.Label; import org.tribuo.classification.LabelFactory; ...(略)... public class ClassificationExample { public static void main(String[] args) throws IOException {ダウンロードしたデータファイルを
CSVLoaderで読み込んで、ListDataSourceというクラスでデータを保持します。LabelFactory labelFactory = new LabelFactory(); CSVLoader csvLoader = new CSVLoader<>(labelFactory); String[] irisHeaders = new String[]{"sepalLength", "sepalWidth", "petalLength", "petalWidth", "species"}; ListDataSource irisesSource = csvLoader.loadDataSource(Paths.get("bezdekIris.data"), "species", irisHeaders);このデータを7:3で学習用のデータと検証用のデータに分けます。
TrainTestSplitter irisSplitter = new TrainTestSplitter<>(irisesSource, 0.7, 1L); MutableDataset trainingDataset = new MutableDataset<>(irisSplitter.getTrain()); MutableDataset testingDataset = new MutableDataset<>(irisSplitter.getTest());
LogisticRegressionTrainerを使用すると、ロジスティック回帰で学習できます。Trainer<Label> trainer = new LogisticRegressionTrainer(); Model<Label> irisModel = trainer.train(trainingDataset);クラスの
LogisticRegressionTrainer.toString()メソッドを呼び出すことで、以下のように使用しているハイパーパラメーターの値が分かります。LinearSGDTrainer(objective=LogMulticlass,optimiser=AdaGrad(initialLearningRate=1.0,epsilon=0.1,initialValue=0.0),epochs=5,minibatchSize=1,seed=12345)
LabelEvaluator.evaluate()で検証用のデータがどの程度正しいか評価します。LabelEvaluator evaluator = new LabelEvaluator(); LabelEvaluation evaluation = evaluator.evaluate(irisModel, testingDataset);評価した結果は
LabelEvaluationクラスのtoString()メソッドを呼び出すことで分かります。また、混同行列はgetConfusionMatrix()メソッドを呼び出すことで分かります。System.out.println(evaluation); System.out.println(evaluation.getConfusionMatrix());以上でモデルの学習と評価は終わりですが、チュートリアルには前述した「来歴(Provenance)」の取得方法も記載されています。
ModelProvenance provenance = irisModel.getProvenance(); System.out.println(ProvenanceUtil.formattedProvenanceString(provenance.getDatasetProvenance().getSourceProvenance()));このコードの出力は以下のようになります。
TrainTestSplitter( class-name = org.tribuo.evaluation.TrainTestSplitter source = CSVLoader( class-name = org.tribuo.data.csv.CSVLoader outputFactory = LabelFactory( class-name = org.tribuo.classification.LabelFactory ) response-name = species separator = , quote = " path = file:/home/tamura/git/tribuo-examples/bezdekIris.data file-modified-time = 2020-09-24T09:05:30+09:00 resource-hash = 36F668D1CBC29A8C2C1128C5D2F0D400FA04ED4DC62D12246F44CE9360360CC0 ) train-proportion = 0.7 seed = 1 size = 150 is-train = true )どのファイルを読み込んで、どのように学習用データと検証用データに分割したか、などが分かるようです。
応用
少しだけソースコードを追加・修正して、動作確認してみたいと思います。
通常、精度の高いモデルができたら、そのモデルを使って未知のデータの予測を行います。Tribuoでは
Model.predict()で予測ができ、その結果Predictionオブジェクトが返されます。このオブジェクトには、次のようにどの種類のアヤメであるかを示す確率が含まれています。
- Iris-versicolor: 90.1%
- Iris-virginica: 9.5%
- Iris-setosa: 0.4%
「では予測してみましょう」と言いたいところですが、未知のデータが無いので、検証用のデータをこのメソッドに与えてみます。以下のような実装をすることで、検証用データの予測が誤った行を特定できます。
List<Example> data = testingDataset.getData(); // 検証用のデータ for (Example<Label> testingData : data) { Prediction<Label> predict = irisModel.predict(testingData); // 検証用のデータを1件ずつ予測 String expectedResult = testingData.getOutput().getLabel(); // 正答 String predictResult = predict.getOutput().getLabel(); // 予測した結果 if (!predictResult.equals(expectedResult)) { System.out.println("Expected result : " + expectedResult); System.out.println("Predicted result: " + predictResult); System.out.println(predict.getOutputScores()); } }この出力結果は、以下のようになります。
Expected result : Iris-virginica Predicted result: Iris-versicolor {Iris-versicolor=(Iris-versicolor,0.5732799760841581), Iris-virginica=(Iris-virginica,0.42629863727592165), Iris-setosa=(Iris-setosa,4.213866399202189E-4)}誤った答えである「virginica」を57.3%、正しい答えである「versicolor」を42.6%と判定しているので、予測失敗した1件も惜しかったと言えます。
次に、前述のXGBoostを使用してみます。これは、
TrainerをLogisticRegressionTrainerからXGBoostClassificationTrainerに変更するだけで良さそうです(もちろんimportも必要ですが)。// Trainer<Label> trainer = new LogisticRegressionTrainer(); Trainer<Label> trainer = new XGBoostClassificationTrainer(2);コンストラクターに与えた
2は決定木の本数で、ここでは最小値の2を与えました。結果は変わらず、正解率は97.8%でした。
ビルドする
ただ、使うだけでなく、バグを修正したり機能追加したい方のためにビルドも方法も書いておきます。
Tribuoのビルドには、Java 8以降かつMaven 3.5以降が必要なので、まずはそれを確認しておきます。
$ mvn -version Apache Maven 3.6.3 Maven home: /usr/share/maven Java version: 1.8.0_265, vendor: Private Build, runtime: /usr/lib/jvm/java-8-openjdk-amd64/jre Default locale: ja_JP, platform encoding: UTF-8 OS name: "linux", version: "5.4.0-47-generic", arch: "amd64", family: "unix"ちなみにこの記事ではOSにUbuntu 20.04を使用しています。ビルドは、
mvn clean packageを実行するだけです。$ mvn clean package ・・・(略)・・・ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 03:54 min [INFO] Finished at: 2020-09-23T16:17:34+09:00 [INFO] ------------------------------------------------------------------------ビルドは4分弱で終了し、350MBほどのディスク容量が追加されました。以前、Deeplearning4jを試したことがありますが、それと比較するとはるかに軽量です(Deeplearning4jは数時間のビルド完了後に数十GB空き容量が無くなっていました)。
感想
軽く触ってみたり、ソースコードを眺めた感想は、「Javaとしては手軽だけど、機能不足」な印象を受けました。正直、「Pythonであれば、もっと簡単にいろいろなことができるのに」と思ってしまいました。
まだまだこれからなのかもしれませんが、この分野は淘汰のスピードが速いのでこの先も生き残れるのかは少し疑問です。このライブラリーを使用する明確な理由があればいいのですが...(Pythonのライブラリーで学習されたモデルをTribuoを使ってJavaプログラムから使用できるようなので、そういった用途はあるかもしれません)。今後の展開に期待したいです。
参考


- 投稿日:2020-09-24T22:41:32+09:00
SpigotをVSCodeで書く
SpigotをVSCodeで書く
マイクラのプラグインを作りたい。でもEclipseは使いたくない、VSCodeを使わせろって人向けにSpigotMC公式wiki を雑に日本語訳したものです。
多少の意訳および自分の環境1でうまくいかなかった部分を動くように変更が入っていることをご了承ください。前提条件
- VSCodeに java Extension packがインストールされていること。
- OpenJDKが入っていること。(java Extension packがOpenJDKを必要としています。)
- Apache Mavenも必要です。
- 基本的なjavaの知識を持っていること。
- プラグインのgroupID、packageのために使用可能なインターネットドメイン、もしくはメールアドレスの一部など一意な名前を用意できること。
ワークスペースの準備
VSCoedeでワークスペースを作成し、設定を行います。
ウインドウメニューから、もしくはdefault.code-workspaceを編集することで設定は変更することが出来る。files.autoGuestEncoding:
チェックボックスにチェックをつける。2files.encoding:
utf8を指定する。java.home:
OpenJDKの絶対パス指定する。java.jdt.ls.vmargs:
Java Language Serverを起動するための追加のJava VM引数を設定します。
"-Dfile.encoding=UTF-8"に設定する。2javac-linter.javac:
実行可能なjavacを設定します。
javacの引数に"-Dfile.encoding=UTF-8"を指定する。2最終的に"default.code-workspace"は下のようになっているはずです。
{ "folders": [ { "path": "." } ], "settings": { "files.autoGuessEncoding": true, "files.encoding": "utf8", "java.home": "C:\\openjdk-1.8.0", "java.jdt.ls.vmargs": "-Dfile.encoding=UTF-8", "javac-linter.javac": "javac -Dfile.encoding=UTF-8" } }空のプラグインの作成
ワークスペースのディレクトリを右クリックして"Generate from Maven Archetype"をクリックする。
VSCodeのウインドウの上部に表示されるメニューから"maven-archetype-quickstart"クリックする。3
バージョンの選択画面が出る場合は最新(2.0)を選べばよい。
エクスプローラが開くのでワークスペースを選択する。ターミナルでプロジェクトの設定をいくつか尋ねられる。
groupId:
package名を入力
artifactId:
バージョン番号を除いたプラグインの名前を入力
version:
プラグインのバージョン番号を入力。なにも入力せずにEnterを押すと"1.0-SNAPSHOT"になる。
package:
そのままEnterキーを押してデフォルトを使用することを推奨。デフォルトではgroupIdになる。その後、MavenからMavenプロジェクトの設定の確認を求められる。
それで正しいのならY、もしくはEnterを押すことで確定する。
"BUILD SUCCESS"という文がターミナルに出てきたら、pluginのディレクトリからpom.xmlを開き、下記のように編集する。Note:下記はgroupIdを“dev.cibmc.spigot.blankplugin”にした場合である
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>dev.cibmc.spigot.blankplugin</groupId> <artifactId>BlankPlugin</artifactId> <version>1.0-SNAPSHOT</version> <packaging>jar</packaging> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> </properties> <repositories> <repository> <id>spigot-repo</id> <url>https://hub.spigotmc.org/nexus/content/repositories/snapshots/</url> </repository> </repositories> <dependencies> <dependency> <groupId>org.spigotmc</groupId> <artifactId>spigot-api</artifactId> <version>1.12.2-R0.1-SNAPSHOT</version> <scope>provided</scope> </dependency> </dependencies> <build> <sourceDirectory>${project.basedir}/src/main/java</sourceDirectory> <resources> <resource> <directory>${project.basedir}/src/main/resources</directory> <includes> <include>plugin.yml</include> </includes> </resource> </resources> </build> </project>もちろん、SpigotAPIのバージョンは変更することが出来る。
[projectBaseDir]/src/main にresourcesディレクトリを作成し、その中にplugin.ymlを作成する。
下記はplugin.ymlの例である。main: dev.cibmc.spigot.blankplugin.App name: BlankPlugin version: 0.1
ここは元の記事にはない部分
ただし自分の環境1ではversinの内容はダブルクォートで囲む必要があり、api及びapi-versionという項目が必要になった。
apiはマインクラフトのバージョン(例1.16.2)、api-versionはSpigotのAPIのバージョン(例1.16)を指定する。よって、以下のようにすることで正常に動作する。(バージョン1.16.2の場合)
main: dev.cibmc.spigot.blankplugin.App name: BlankPlugin version: "0.1" api: 1.16.2 api-version: 1.16
この時点でワークスペースのディレクトリツリーは以下のようになっているはず。
BlankPlugin
┣ src
┃ ┣ main
┃ ┃ ┣ java
┃ ┃ ┃ ┗ dev
┃ ┃ ┃ ┗ cibmc
┃ ┃ ┃ ┗ spigot
┃ ┃ ┃ ┗ blankplugin
┃ ┃ ┃ ┗ App.java
┃ ┃ ┗ resources
┃ ┃ ┗ plugin.yml
┃ ┗ test
┣ target
┗ pom.xmlMAVENパネルから"BrankPlugin"を右クリックし、メニューから"install"を選択する。
ターミナルに"BUILD SUCCESS"が表示されたことを確認する。Note:例として用意したgroupIdである"dev.cibmc.spigot.blankplugin"はあなたがプラグインを作成するときはあなた自身のgroupIdに変更すること。
Note 2:もし、あなたがメインクラスの名前でAPPを使いたくないのならば、ファイルをリネームし、クラス名を変更し、plugin.ymlでのmainの定義を変更すること。
blank pluginを作成
前章で作成したディレクトリでApp.javaファイルを開く。(もしくはファイルをリネームしていればそのファイル)
下記は例のコードである。package dev.cibmc.spigot.blankplugin; import org.bukkit.plugin.java.JavaPlugin; public class App extends JavaPlugin { @Override public void onEnable() { getLogger().info("Hello, SpigotMC!"); } @Override public void onDisable() { getLogger().info("See you again, SpigotMC!"); } }"Classpath is incomplete. Only syntax errors will be reported."がVSCodeの右下に表示されるときは、MAVENパネルから"BrankPlugin"を右クリックして、メニューから"custom goals ..."を選択する。
その後、VSCodeウインドウの上部の入力欄に"eclipse:eclipse"を入力してEnterキーを押す。最後にMAVENパネルから"BrankPlugin"を右クリックして"install"をもう一度選択する。
ビルドが成功するとtargetディレクトリにSpigotプラグインが生成されている。blank pluginを実行する
作成したプラグインをpluginディレクトリにコピーし、サーバーを起動する。
すると、下のようなサーバーログが表示される。[HH:MM:SS] [Server thread/INFO]: [BlankPlugin] Enabling BlankPlugin v1.0-SNAPSHOT [HH:MM:SS] [Server thread/INFO]: [BlankPlugin] Hello, SpigotMC!コンソールでstopコマンドを実行すると、下のようなログが表示される。
[HH:MM:SS] [Server thread/INFO]: [BlankPlugin] Disabling BlankPlugin v1.0-SNAPSHOT [HH:MM:SS] [Server thread/INFO]: [BlankPlugin] See you again, SpigotMC!参考文献
SpigotMC公式wiki(https://www.spigotmc.org/wiki/creating-a-blank-spigot-plugin-in-vs-code/)
- 投稿日:2020-09-24T22:39:07+09:00
SpigotをVSCodeで書く
SpigotをVSCodeで書く
マイクラのプラグインを作りたい。でもEclipseは使いたくない、VSCodeを使わせろって人向けにSpigotMC公式wiki を雑に日本語訳したものです。
多少の意訳および自分の環境1でうまくいかなかった部分を動くように変更が入っていることをご了承ください。前提条件
- VSCodeに java Extension packがインストールされていること。
- OpenJDKが入っていること。(java Extension packがOpenJDKを必要としています。)
- Apache Mavenも必要です。
- 基本的なjavaの知識を持っていること。
- プラグインのgroupID、packageのために使用可能なインターネットドメイン、もしくはメールアドレスの一部など一意な名前を用意できること。
ワークスペースの準備
VSCoedeでワークスペースを作成し、設定を行います。
ウインドウメニューから、もしくはdefault.code-workspaceを編集することで設定は変更することが出来る。files.autoGuestEncoding:
チェックボックスにチェックをつける。2files.encoding:
utf8を指定する。java.home:
OpenJDKの絶対パス指定する。java.jdt.ls.vmargs:
Java Language Serverを起動するための追加のJava VM引数を設定します。
"-Dfile.encoding=UTF-8"に設定する。2javac-linter.javac:
実行可能なjavacを設定します。
javacの引数に"-Dfile.encoding=UTF-8"を指定する。2最終的に"default.code-workspace"は下のようになっているはずです。
{ "folders": [ { "path": "." } ], "settings": { "files.autoGuessEncoding": true, "files.encoding": "utf8", "java.home": "C:\\openjdk-1.8.0", "java.jdt.ls.vmargs": "-Dfile.encoding=UTF-8", "javac-linter.javac": "javac -Dfile.encoding=UTF-8" } }空のプラグインの作成
ワークスペースのディレクトリを右クリックして"Generate from Maven Archetype"をクリックする。
VSCodeのウインドウの上部に表示されるメニューから"maven-archetype-quickstart"クリックする。3
バージョンの選択画面が出る場合は最新(2.0)を選べばよい。
エクスプローラが開くのでワークスペースを選択する。ターミナルでプロジェクトの設定をいくつか尋ねられる。
groupId:
package名を入力
artifactId:
バージョン番号を除いたプラグインの名前を入力
version:
プラグインのバージョン番号を入力。なにも入力せずにEnterを押すと"1.0-SNAPSHOT"になる。
package:
そのままEnterキーを押してデフォルトを使用することを推奨。デフォルトではgroupIdになる。その後、MavenからMavenプロジェクトの設定の確認を求められる。
それで正しいのならY、もしくはEnterを押すことで確定する。
"BUILD SUCCESS"という文がターミナルに出てきたら、pluginのディレクトリからpom.xmlを開き、下記のように編集する。Note:下記はgroupIdを“dev.cibmc.spigot.blankplugin”にした場合である
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>dev.cibmc.spigot.blankplugin</groupId> <artifactId>BlankPlugin</artifactId> <version>1.0-SNAPSHOT</version> <packaging>jar</packaging> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> </properties> <repositories> <repository> <id>spigot-repo</id> <url>https://hub.spigotmc.org/nexus/content/repositories/snapshots/</url> </repository> </repositories> <dependencies> <dependency> <groupId>org.spigotmc</groupId> <artifactId>spigot-api</artifactId> <version>1.12.2-R0.1-SNAPSHOT</version> <scope>provided</scope> </dependency> </dependencies> <build> <sourceDirectory>${project.basedir}/src/main/java</sourceDirectory> <resources> <resource> <directory>${project.basedir}/src/main/resources</directory> <includes> <include>plugin.yml</include> </includes> </resource> </resources> </build> </project>もちろん、SpigotAPIのバージョンは変更することが出来る。
[projectBaseDir]/src/main にresourcesディレクトリを作成し、その中にplugin.ymlを作成する。
下記はplugin.ymlの例である。main: dev.cibmc.spigot.blankplugin.App name: BlankPlugin version: 0.1ただし自分の環境1ではversinの内容はダブルクォートで囲む必要があり、api及びapi-versionという項目が必要になった。
apiはマインクラフトのバージョン(例1.16.2)、api-versionnはマイクラのメジャーバージョン(例1.16)を指定する。
メジャーバージョンって言い方あってるのだろうか
よって、以下のようにすることで正常に動作する。(バージョン1.16.2の場合)main: dev.cibmc.spigot.blankplugin.App name: BlankPlugin version: "0.1" api: 1.16.2 api-version: 1.16この時点でワークスペースのディレクトリツリーは以下のようになっているはず。
BlankPlugin
┣ src
┃ ┣ main
┃ ┃ ┣ java
┃ ┃ ┃ ┗ dev
┃ ┃ ┃ ┗ cibmc
┃ ┃ ┃ ┗ spigot
┃ ┃ ┃ ┗ blankplugin
┃ ┃ ┃ ┗ App.java
┃ ┃ ┗ resources
┃ ┃ ┗ plugin.yml
┃ ┗ test
┣ target
┗ pom.xmlMAVENパネルから"BrankPlugin"を右クリックし、メニューから"install"を選択する。
ターミナルに"BUILD SUCCESS"が表示されたことを確認する。Note:例として用意したgroupIdである"dev.cibmc.spigot.blankplugin"はあなたがプラグインを作成するときはあなた自身のgroupIdに変更すること。
Note 2:もし、あなたがメインクラスの名前でAPPを使いたくないのならば、ファイルをリネームし、クラス名を変更し、plugin.ymlでのmainの定義を変更すること。
Create blank plugin
前章で作成したディレクトリでApp.javaファイルを開く。(もしくはファイルをリネームしていればそのファイル)
下記は例のコードである。package dev.cibmc.spigot.blankplugin; import org.bukkit.plugin.java.JavaPlugin; public class App extends JavaPlugin { @Override public void onEnable() { getLogger().info("Hello, SpigotMC!"); } @Override public void onDisable() { getLogger().info("See you again, SpigotMC!"); } }"Classpath is incomplete. Only syntax errors will be reported."がVSCodeの右下に表示されるときは、MAVENパネルから"BrankPlugin"を右クリックして、メニューから"custom goals ..."を選択する。
その後、VSCodeウインドウの上部の入力欄に"eclipse:eclipse"を入力してEnterキーを押す。最後にMAVENパネルから"BrankPlugin"を右クリックして"install"をもう一度選択する。
ビルドが成功するとtargetディレクトリにSpigotプラグインが生成されている。Running your blank plugin
作成したプラグインをpluginディレクトリにコピーし、サーバーを起動する。
すると、下のようなサーバーログが表示される。[HH:MM:SS] [Server thread/INFO]: [BlankPlugin] Enabling BlankPlugin v1.0-SNAPSHOT [HH:MM:SS] [Server thread/INFO]: [BlankPlugin] Hello, SpigotMC!コンソールでstopコマンドを実行すると、下のようなログが表示される。
[HH:MM:SS] [Server thread/INFO]: [BlankPlugin] Disabling BlankPlugin v1.0-SNAPSHOT [HH:MM:SS] [Server thread/INFO]: [BlankPlugin] See you again, SpigotMC!
- 投稿日:2020-09-24T21:30:39+09:00
2020年で最も需要のあるプログラミング言語
本記事はMost in-demand programming languages in 2020の日本語訳です。翻訳元に報告していますが、もし苦情が来たら消します。
翻訳は不慣れなので変なところもあると思いますが、ご容赦ください。
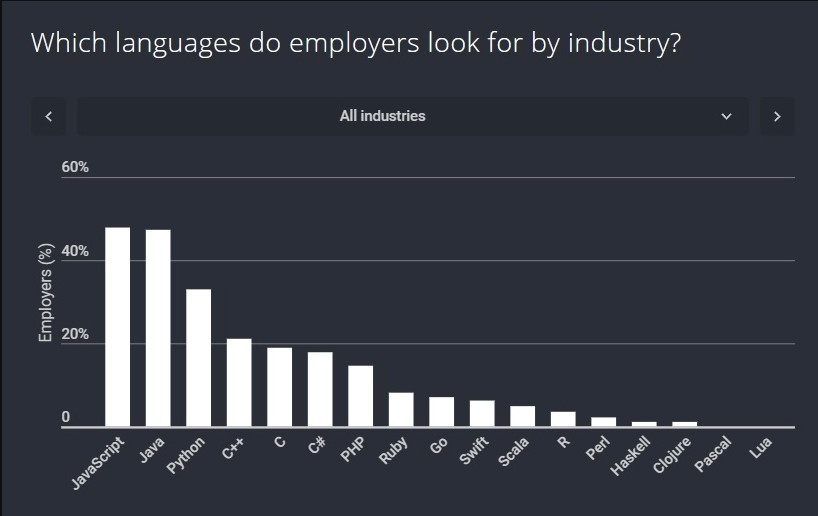
ソフトウェア開発業界は絶えず変化しており、それは開発者の能力に対する企業のニーズも変化していることを意味します。そのため、あなたが想像できるように、Webアプリケーション、ゲーム、アルゴリズムなどのあらゆる側面の開発をカバーするために、選択できるプログラミング言語はたくさんあります。その上で、私たちは2020年で最も需要のあるプログラミング言語とその主な特徴について触れます。
- JavaScript (回答者の71%がこのスキルに関する求職者を探している)
- Java (57%)
- C# (53%)
- Python (51%)
- PHP (40%)
- Ruby (15%)
2020年で最も需要のあるプログラミング言語JavaScript
JavaScriptが2020年で最も需要のあるプログラミング言語リストのトップであることは全く不思議ではありません。
今日では何らかの方法でJavaScriptを使用することなしに開発者になることは不可能です。調査の回答者の71%以上がJavaScriptでコードを書ける開発者を探しており、JavaScriptが最も人気のあるプログラミング言語のうちの一つであることが想像できます。また、JavaScriptはWebにおける遍在性と私たちのインターネットへの重い依存のため、非常に人気があります。Twitter、Facebook、YouTubeなどの最も人気のあるサイトの多くは、JavaScriptを使ってインタラクティブなWebページを生成したり、コンテンツを動的にユーザに表示したりしています。
JavaScriptはコア言語があり、追加の開発ツールによって柔軟性が保たれています。JavaScriptは寛大で柔軟な構文を持ち、全てのメジャーなブラウザで動作するため、初学者にとって最も簡単なプログラミング言語の一つです。今日、JavaScriptは世界中で広く使用されているプログラミング言語であり、あらゆるところで動作します:コンテナ、マイクロコントローラ、モバイル端末、クラウド、ブラウザ、サーバなど。
主な特徴
- JavaScriptはここ数年で大規模な現代化と徹底的な点検を経てきました。ES5、ES6といったJavaScriptのメジャーなリリースではいくつかのモダンな機能が追加され、今日のJavaScriptは10年前のJavaScriptとは完全に別物です
- Node.jsのおかげでJavaScriptはイベント駆動なプログラミングを提供し、特にI/Oの複雑なタスクに適しています。今日では、Node.jsとJavaScriptは、サーバとモバイル端末を含めてほとんど全てのプラットフォームで動作します
- JavaScriptはブラウザプログラミングにおいて、議論の余地のない王様です。今日、Web開発は主にVue.js、Angular、ReactといったJavaScriptベースのSPAフレームワークによって支配されています
Java
Javaは2020年で最も需要のあるプログラミング言語リストで2位の座を手にしています。
Javaは、ビジネスでは最も人気のモバイルコンピューティングプラットフォームであるAndroidのネイティブ言語であることから人気のあるプログラミング言語です。
Javaは過去数年の間に、非常にユーザに優しいモダンな言語にビジネスの一部を奪われました。
Javaは欠陥の改善に取り組んでおり、GraalVMアクションを介してクラウドにフィットさせる努力をしています。Javaはまだエンタープライズではナンバーワンのプログラミング言語です。Javaは誕生してからずっとトップクラスの需要があるプログラミング言語です。大企業の多数がバックエンドWebシステムやデスクトップアプリケーションのためにJavaを使っているため、もし開発者がJavaを知っていれば、その開発者は継続的に需要が高い状態になるでしょう。Javaは静的型付けの言語で、そのためバグが少なく、メンテナンスを速く行えて管理しやすいです。
主な特徴
- Javaはマルチパラダイムを提供し、強力で、多機能で、柔軟な学習曲線と高い生産性を持つインタプリタ型のプログラミング言語です
- Javaは厳格な後方互換性を持ち、これはビジネスアプリケーションにとって重要な要件です。JavaではScalaやPythonのようなメジャーな破壊的変更が取り入れられたことはありません。その結果、Javaはいまだにビジネスにとってナンバーワンの選択肢です
- JavaのランタイムであるJVMはソフトウェア工学の結晶で、ビジネスにおいて最高の仮想マシンの一つです。何年もの技術革新とエンジニアリングの職人技により、JVMは素晴らしい機能と性能をJavaに提供します。JVMはいくつかの優秀なガベージコレクションもJavaに提供しています
C#
C言語1は、移植性と、AppleやMicrosoftのような巨大なIT企業から早期に採用されたことのおかげで最も古くて最も人気のあるプログラミング言語のうちの一つとなった言語です。
C-sharpとしても知られるC#は、2000年にMicrosoftによって開発された、C言語のスピンオフです。C#はオブジェクト指向言語で、アクションの代わりにオブジェクトを中心に、ロジックの代わりにデータを中心に構築されます。C#の特徴はJavaと似ており、Windowsのデスクトップアプリケーションとゲームを開発するのに特に有効です。しかし、C#はWebアプリケーションとモバイルアプリケーションを開発するのにも使えます。C#はC++のようなC派生の言語に似た構文を使っており、あなたがCファミリーの中の別の言語から来たのであれば簡単に習得できます。C#は銀行のトランザクション処理のような大企業のアプリケーションの開発にしばしば使われます。C#は人気のUnityゲームエンジンを使った2Dや3Dのビデオゲームを作るために推奨される言語です。今日では、C#はWindowsプラットフォームにおいてだけでなくLinuxプラットフォームやiOS/Androidプラットフォームでも幅広く使用される、マルチパラダイムな言語です。
主な特徴
- C#はプラットフォーム非依存でもあり、Linux、Windows、モバイル端末で動作します
- Microsoftの後ろ盾があり、長年に渡り業界にいるC#はライブラリとフレームワークの大きなエコシステムがあります。ASP.NETはWebアプリケーション開発に使われます(主にWindows上での)
- 開発者体験という面では、C#はJavaよりはるかに優れています
DevSkillerでテストされた言語トップ5Python
Pythonはおそらくこのリストの中で最もユーザに優しいプログラミング言語です。Pythonの構文は明確で、直感的で、ほとんど英語だとよく言われ、初学者にとって本当に良い選択肢です。Pythonは高レベルで、汎用性が高く、Webアプリケーションやデータ解析、アルゴリズムの開発などに使われます。Pythonは、科学計算やエンジニアリング、数学といったフィールドで頻繁に使われるSciPyやNumPyのようなパッケージも持っています。
Pythonはスクレイピングにしばしば使われ、PHPでコーディングするのに何時間もかかるものが、Pythonだと数分しかかかりません。Pythonは、あなたの時間を消費する日々のタスクを含む特定の作業を自動化するためにも使うことができます。もしバックエンドのWeb開発の例に興味があれば、オープンソースの(Pythonで書かれた)Djangoフレームワークは人気で、学ぶのが簡単で、多機能です。そしてJavaのように、Pythonには多様なアプリケーションがあり、あなたのユースケースのために最も良いプログラミング言語を選択する時に、多様で強力な選択肢となります。今日、Pythonは広く行き渡り、ソフトウェア開発の多くの分野で使用され、そしてその勢いが衰えるようには見えません。
主な特徴
- Pythonには非常に活発なコミュニティとサポートがあります。たとえあなたがデータサイエンス、業務アプリケーション、AIのどれで働いているのだとしても、常に十分なPythonの組織2やフレームワークが見つかります
- Pythonには第一級のC++/Cとの統合機能があり、CPU負荷の高いタスクをシームレスにC++/Cにオフロードすることができます。Pythonは、SciPy、Pandas、NumPyなど、統計、Scikit-Learn3、数学、および計算科学のための素晴らしいツールセットも提供します。 結論として、Pythonは機械学習/ディープラーニング/データサイエンスの状況やその他の科学的な領域を支配しています
- Pythonのウリはその言語設計にあります。それは生産性が高く、エレガントで、シンプルで、その上強力です。Pythonは開発者経験という面で黄金律を設定し、Julia、Goといったモダンな言語に対して多大な影響を与えました
PHP
たとえ多くの論争があるとしても、PHPは2020年で最も需要のあるプログラミング言語リストに入っています。
PHPは幅広く使用されているオープンソースの汎用スクリプト言語で、典型的にはWebアプリケーション開発に適しています。たとえ以前ほどではないとしても、PHPは依然として世界中で最も用いられているプログラミング言語のうちの一つです。PHPはFacebookやYahoo!といった多数の大きな会社によって使用されています。PHPは汎用的で、動的な、基本的にはサーバサイドのWebアプリケーションの開発のために使用されているプログラミング言語です。
PHPはJavaScriptのような新しいWeb言語が実現するまでずっと、ほとんど全てのモダンなWebサイトを構築可能にしました。いくつかの調査によると、PHPがWebの3分の1を支えているとのことです。たとえPHPが以前ほどは注目されていないとしても、PHPは今後何年にもわたって進化を継続し、最も人気のあるプログラミング言語のうちの一つとしての地位を維持するでしょう。
主な特徴
- 多くの大きな会社がPHPを使用しており、そのための素晴らしいツールのサポートに繋がっています
- PHPはWebアプリケーション開発に過去25年4に渡って使用されており、強力で安定したPHPフレームワークが数多く市場に存在します
- PHPは非常に生産性が高いサーバサイドWeb開発プログラミング言語のうちの一つです。結果として、Webアプリケーションを素早く開発するために、IT業界で広く使われています。最も有名なSNSの一つであるFacebookはPHPで開発されました
アメリカにおけるPHPバージョンの人気調査Ruby
特に、Rubyは人気のあるRuby on Rails Webアプリケーションフレームワークのための基盤として使われます。RubyはC言語で実装され、ガベージコレクタがあります。Rubyは90年代半ばに作られましたが、ここ10年ほどの間に人気を獲得しました。Rubyは非常に動的で、オブジェクト指向言語で、プログラマーが使うための様々な機能を持っています。Rubyの経験が6年以上ある開発者は、現在の採用状況では2倍の面接依頼を受けることが期待できます。
Twitter、Shopify、そして多くのスタートアップがいずれかの段階でRuby on Railsを使ってWebサイトを構築しています。Rubyはまた、素晴らしいハイテク企業との関連性のために選び出すには本当に良い言語です。5
Pythonのように、Rubyは開発者の生産性と幸福を非常に重視しています。Rubyは新しい開発者にとって学習曲線がフラットになる非常に優れた言語でもあります。主な特徴
- RubyはTwitter、GitHub、Airbnbのような最大級のソフトウェアプロジェクトで使われ、そして素晴らしいツールとフレームワークの支援があります
- Rubyそれ自体は破壊的ではありませんが、RubyのWeb開発フレームワークであるRuby on Railsはおそらく最も破壊的で、影響力のあるサーバサイドWeb開発フレームワークです
- Rubyはプログラミング言語の最高の機能のうちのいくつかをうまく利用してきました: 簡潔さ、動的、ガベージコレクタのあるオブジェクト指向、そして関数型です



- 投稿日:2020-09-24T16:26:12+09:00
【Java】二次元配列を拡張for文で回す方法
拡張for文
for(型 変数名: 配列){ }:の右の配列を左の変数に代入しながらループを回すという手法を組み合わせて二次元配列を展開するにはどうしたら良いか、一瞬迷ったのと、PHPのように
foreach($datas as $key => $value){ for($i = 0; $i < count($value); i++){ $value[i] = 0; } }foreachを使うことも思い浮かべたけど、javaでは別のオブジェクトを生成しないといけないみたいなので、なんとかしたいなと思いました。
拡張forを2回書けば済む話
public class Control { public static void main(String[] args) { int[][] datas = { {0,0,0,0,0,0,0,0,0,0,0}, {0,0,0,0,0,1,1,1,1,1,0}, {0,0,0,0,0,0,1,1,1,1,0}, {0,0,0,0,0,1,1,1,1,1,0}, {0,0,0,0,1,1,1,1,1,1,0}, {0,0,0,1,1,1,1,1,0,1,0}, {0,0,1,1,1,1,1,0,0,0,0}, {0,0,0,1,1,1,0,0,0,0,0}, {0,0,0,0,1,0,0,0,0,0,0}, {0,0,0,0,0,0,0,0,0,0,0}, }; for(int[] data : datas ) { for(int value : data) { if(value == 0) { System.out.print(" "); } else { System.out.print("* "); } } System.out.println(""); // 入れ子になっている配列の展開が終わったら改行 } } }実行結果* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *別に悩むほどのことでもなかったけど、foreachが別のオブジェクトを生成しないと使えないという点は少し不便に感じたし、「それも覚えないといけないのか」と思うとちょっとびっくりしたので、メモ書きとして残しておきます。
- 投稿日:2020-09-24T15:52:06+09:00
[Java] PDF閲覧設定
日頃PDFファイルを閲覧する場合、「フルスクリーンモードにするか、メニューバー/ツールバーを非表示にするか、またドキュメントのページレイアウトをどうのように設定するかなど・・・」という個人的な習慣によってプリファレンスを設定しますよね。今日、本文ではFree Spire.PDF for Javaを通してこれらのプリファレンス設定を実現させる方法を紹介します。
JARパッケージのインポート
方法1: Free Spire.PDF for Javaをダウンロードして解凍したら、libフォルダーのSpire.Pdf.jarパッケージを依存関係としてJavaアプリケーションにインポートします。方法2: Mavenリポジトリから直接にJARパッケージをインストールしたら、pom.xmlファイルを次のように構成します。
<repositories> <repository> <id>com.e-iceblue</id> <name>e-iceblue</name> <url>http://repo.e-iceblue.com/nexus/content/groups/public/</url> </repository> </repositories> <dependencies> <dependency> <groupId>e-iceblue</groupId> <artifactId>spire.pdf.free</artifactId> <version>2.6.3</version> </dependency> </dependencies>Javaコード
import com.spire.pdf.*; public class ViewerPreference { public static void main(String[] args) { //PDFドキュメントをロードします PdfDocument pdf = new PdfDocument(); pdf.loadFromFile("test2.pdf"); //ウィンドウを中央に配置します pdf.getViewerPreferences().setCenterWindow(true); //タイトルを非表示にします pdf.getViewerPreferences().setDisplayTitle(false); //ウィンドウサイズに合わせます pdf.getViewerPreferences().setFitWindow(true); //メニューバーを非表示します pdf.getViewerPreferences().setHideMenubar(true); //ツールバーを非表示します pdf.getViewerPreferences().setHideToolbar(true); //2列で表示するようにページを設定します pdf.getViewerPreferences().setPageLayout(PdfPageLayout.Two_Column_Left); //全画面表示にします //pdf.getViewerPreferences().setPageMode(PdfPageMode.Full_Screen); //印刷ズームを設定する //pdf.getViewerPreferences().setPrintScaling(PrintScalingMode.App_Default); //ドキュメントを保存します pdf.saveToFile("viewer.pdf"); //閉じます pdf.close(); } }
- 投稿日:2020-09-24T13:33:19+09:00
Dagger Hiltを踏まえたテストのプラクティス
Dagger HiltというGoogleがAndroid開発において推奨するDIライブラリ(JVM言語であれば使える)のこちらのドキュメントについてです。
https://dagger.dev/hilt/testing-philosophy
結構良いテストについて個人的に刺さる概念があったので、書いておきます。
またシンプルな部分以外のHiltの良いところが分かる気がします。
Dagger Hiltを踏まえたテストのプラクティスについて書かれている。
Dagger HiltのAPIや機能は何が良いテストを作るかの暗黙の哲学に基づいて作られている。ただ、良いテストというのが万人に受け入れられているわけではいので、Hiltチームにおいてのテストの哲学を明らかにするためのドキュメントとなる。何をテストするのか
Hiltは外部の"ユーザーからの観点でテストする"ことを推奨する。外部のユーザーとはたくさんの意味がある。本当のユーザーも指すし、クラスやAPIの利用者も指す。
大切なところは"実装の詳細を表現してはいけない"ということ。内部の実装に依存したテスト、例えば内部のメソッドに依存したテストを書くとテストが壊れやすくなる。internalなメソッドの名前が変わっても、良いテストは何も変更する必要がない。今のテストを壊す要因はユーザーに見える変更があったときのみになる。実際の依存関係を利用する
Hiltのテストの哲学はすべてのクラスがそれぞれテストを書くことを強制しない。実際にはそのようなルールは"ユーザーからの観点でテストする"という原則に違反する。テストは書きやすく、実行しやすくするために、必要なだけ小さくする。(高速、リソースを大量に消費しないなど)
他に違いがないのであれば、テストは以下のことを、この順番で優先する
- 依存関係の実際のコードを利用する
- ライブラリが提供する標準のFakeを利用する
- 最後の手段としてMockを利用する
しかし、これにはトレードオフがある。
- テストに置いての本物の依存関係をインスタンス化するセットアップはボイラープレートになりやすく、繰り返しになりやすい。
- バックエンドのサーバーを立ち上げる必要があるなど、パフォーマンスのトレードオフが存在する。
Hiltは最初の問題を解決する。(詳細は以下)パフォーマンスについては問題になることはあるが、ほとんどの場合では問題にならない。I/Oで依存関係がある場合のみ問題になる可能性がある。パフォーマンスを大幅に低下させることなく、実際の依存関係を利用して便利かつ堅牢に利用できる場合は、実際の依存関係を利用する必要がある。これによってテストで大きな悪い影響がある場合は、Hiltはそのバインディングを交換する方法を提供する。
より多くの実際の依存関係を使うことの大きなアドバンテージ
- 実際の依存関係は本当の問題を補足しやすい。モックのように古いまま残されたりしない。
- "ユーザーからの観点でテスト"と組み合わせることで、同じカバレッジでもっと少ないテストの量で書くことができる。
- テストが壊れることが、FakeやMockの設定ミスによる問題による問題の代わりに、実際の問題を指し示す (そして、逆に言えばテストがパスすることはコードがちゃんと動くことを意味する)
- "ユーザーからの観点でテスト"と"実際の依存関係を使う"は相性が良い。依存関係を入れ替えないため。
もし本当の依存関係が使えないのであれば、次にライブラリが提供する標準のFakeを使う。ライブラリの作者や堅牢なカバレッジで提供されることによってメンテされているのであれば、標準のFakeはMockより良い。これらの理由によりMockは最終手段となる。
HiltとDI、そしてTest
これらの基礎によって、"HiltとDI、そしてTest"に入る。"実際の依存関係を使う"についてのDagger Hiltの答えはTestでDI/Daggerを使うことである。これはもっと実際に近い、なぜならプロダクションで行われるようにオブジェクトが作られるため。これはテストがプロダクションコードより壊れにくいことを意味し、実際のオブジェクトを使いやすくする。実際、
@Injectのコンストラクタがある場合は、Mockを作って入れるより、Daggerを使うほうが簡単で少ないコードにできる。残念なことにHiltを利用しないでこのようなテストを行うことは、ボイラープレートとDaggerの設定の作業により、これまでは困難だった。しかしHiltはボイラープレートコードを生成し、FakeやMockが必要なときにテストに違った設定をセットアップできる。Hiltを使えばこの問題はDaggerでテストを作成することの妨げにならず、実際の依存関係を簡単に利用できる。
実際にどうやってHiltがTestで依存関係を置き換えるかはこちらに書いてあります。 https://qiita.com/takahirom/items/3231edf2a430569b3e9d#testing
他の解決策の欠点
ユニットテストでDaggerを使わない方法はとてもよくある方法である。これは残念なことに大きな欠点があるが、HiltなしでDaggerを利用することの難しさを考えると理解できる。
例えば、Fooクラスをテストしようとする。class Foo @Inject constructor(bar: Bar) { }このケースでDaggerを使わない場合は単にコンストラクタを呼び出すだけ。一見これはとてもシンプルで理解できる、しかしFooのコンストラクタにBarを適応し始めると崩壊し始める。
テストでの直接のインスタンス化はMockを使うことを促進する
以前話した"実際の依存関係を使う"によって、本物のBarクラスをできるだけ使うべき。しかし、どのようにすれば良いだろうか?テストでFooクラスをテストで使うには、これは実際は再起になる: 自分でインスタンス化する必要があるので、Barもインスタンス化する必要があり、Barに依存関係を持っている場合、同様にそれらをインスタンス化する必要がある。深くなりすぎないようにするために、テストのスピードやパフォーマンスのためではなく、たくさんの壊れやすいボイラープレートコードはメンテナンスの問題を起こすため、FakeやMockを使い始める必要がある。これはFakeやMockを使い始めるには良い理由ではない。そして今これをすることを余儀なくされている。
以前に議論したように標準のFakeを利用する方法では、直接のインスタンス化をするメンテナンスの負荷を減らすことができる。しかし、必ずしもシンプルではない。(省略: 同様にFakeBarがClockに依存して、、などFakeも依存関係を管理しなくてはいけなくなる。)これは通常、開発者をMockを使うことを促進する。Mockは依存関係のチェーンによる問題を解決するが、静かに古いままのこされ残されたり、実際のバグを見つけるという全体的な目的でテストを役立たなくするという重大な欠点がある。テスト作成者以外は誰もMockの動作チェックをしないため、時間が経過するとテストが有用なシナリオをテストしなくなる可能性がかなりある。
テストでの直接のインスタンス化は実装の詳細を表現する
直接のインスタンス化は"実装の詳細を表現してはいけない"というプラクティスを破る。なぜなら、その依存関係の詳細のコンストラクタを呼ぶため。Barが
@Inject construcotrがついている場合、Fooが実装の詳細をリファクタしたりする場合があるので、Barに依存することを知る必要はない。
この点について説明すると、Foo(Bar, Baz)のようにFooがBarやBazといった依存関係を持っていたときに、Daggerではこのパラメーターの順番を変えても何も起こらない。しかし、直接インスタンス化していた場合はテストを変更する必要がある。同様に新しい@Injectクラスやオプショナルバインディングを追加する場合もプロダクションでは変更する必要がないが、テストでは変更が必要になる。まとめ
Hiltは実際の依存関係を使って簡単にテストを書くために、DaggerをテストでHiltを使うデメリットを治すように設計されている。Hiltを使ったテストはこれらの哲学に従う場合、全般的に良い体験になる。
- 投稿日:2020-09-24T12:31:06+09:00
【Eclipse使用】作成中のワークスペースを他のPCに移す際の注意
備忘録と共有
プログラミング初心者の私が、Eclipseを使用してJavaでWebアプリケーションを作っていた時の事。
ワークスペース→プロジェクトを作成し、色々コードを書いていたのですが、違うPCで作業をしなくてはならなくなったため、ワークスペースごとコピーして別の端末に移して作業をしようとした際に起こった困った事。次のようなエラーが出てしまいました
下部のマーカータブで、①javaのビルドパスの問題、②ファセット・プロジェクトの問題が出ています。
前提・考察
Eclipseでは、ワークスペースの設定はワークスペースごとに.metadataファイルに保存される。
ワークスペースごとコピーして違う環境にデータを移した時に、移動先のEclipseと設定ファイルとの間で、上手く設定の受け渡しが出来なかったのか、上記のエラーがでてしまったのだと考えます。
最初に作業したPCで設定したパースペクティブやテーマの設定も、初期化されてしまいました。
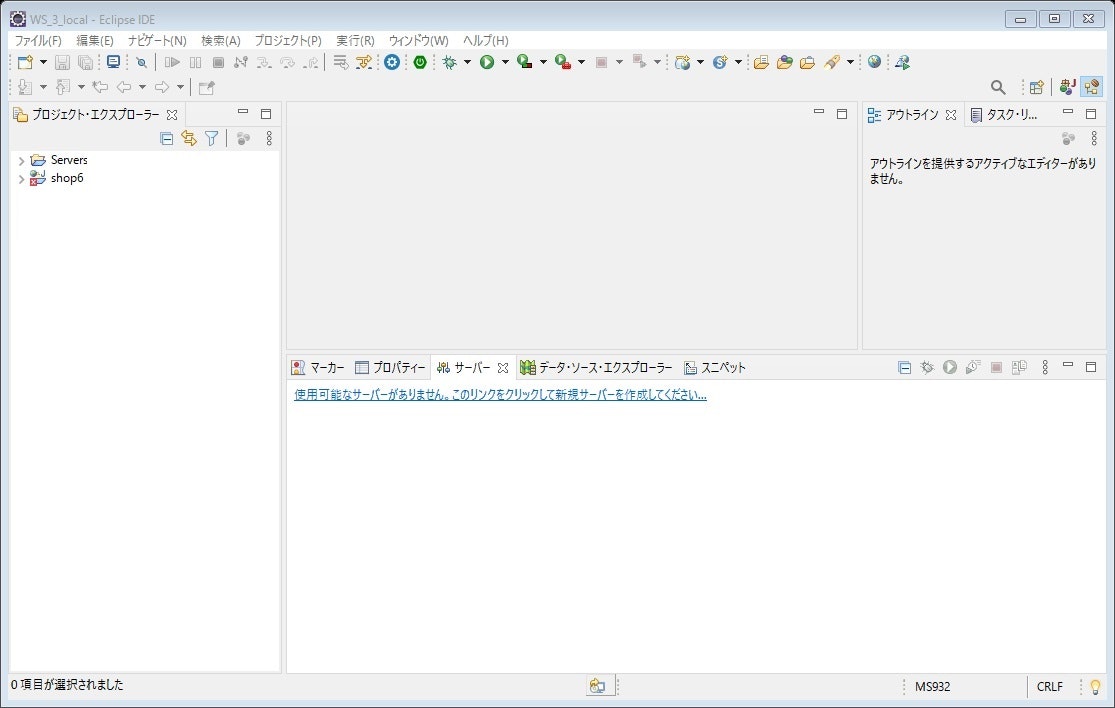
プロジェクトは読み込まれていない状態で、サーバーは作成されていない状態です。プロジェクトはインポートメニューから、「既存のプロジェクトをワークスペースへ」でインポートしましたが、
ワークスペースの設定と、プロジェクトごとの設定が、うまくうまくリンクしなかったのではないか。プロジェクトのプロパティを見てみる
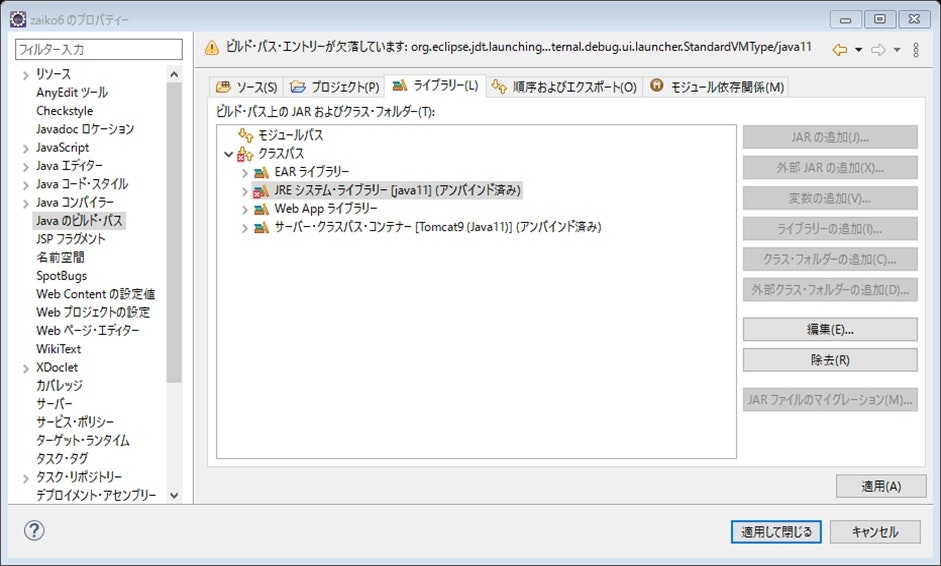
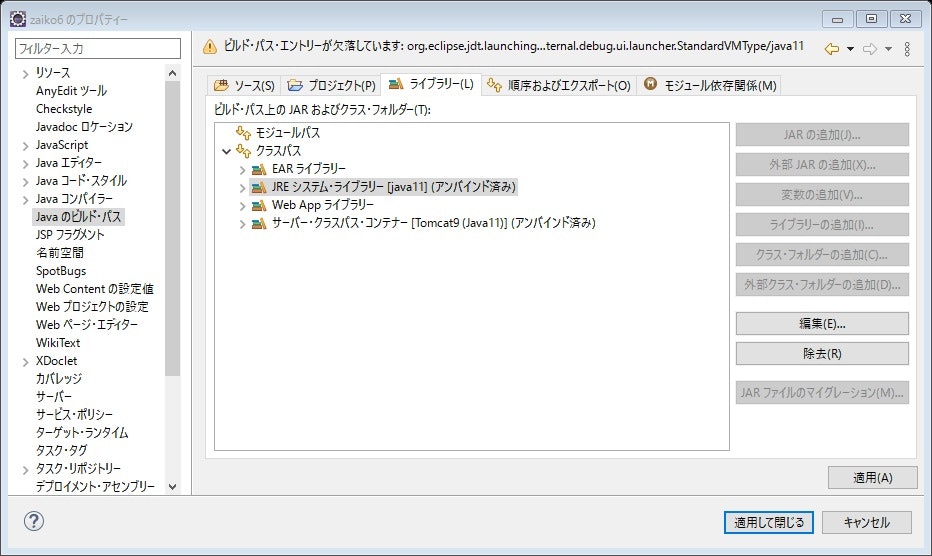
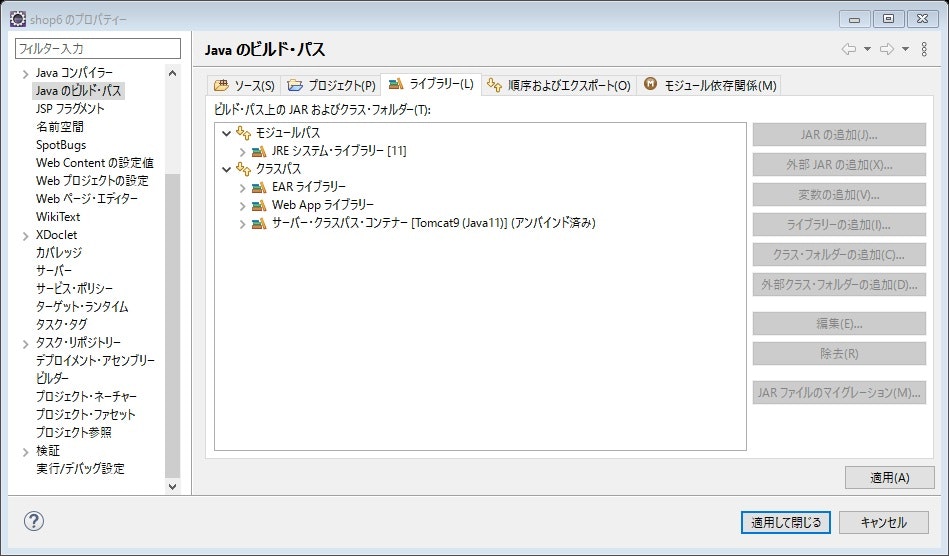
この状態で、インポートしたプロジェクトを右クリック>プロパティから、Javaのビルドパスを開くと、《JREシステム・ライブラリー》がアンバインド済みとなっています。
また、《サーバ・クラスパス・コンテナ》も同じくアンバインド済みです。
これは、プロジェクトの設定は、前のPCからのものが引き継がれているが、ワークスペースのそれとは違っているということなのでしょうか。JREシステム・ライブラリから解決する
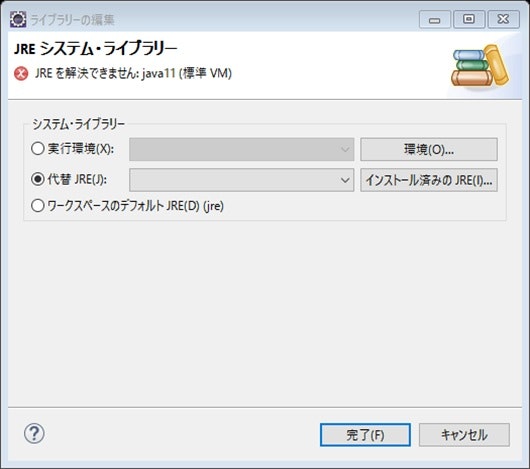
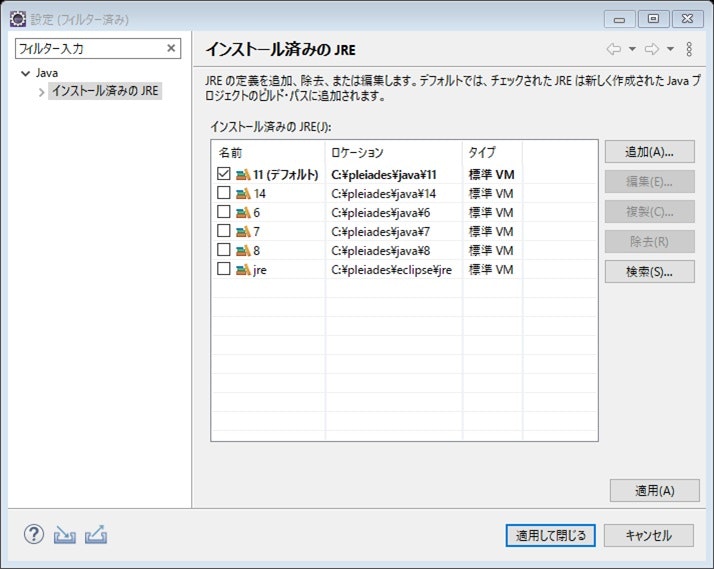
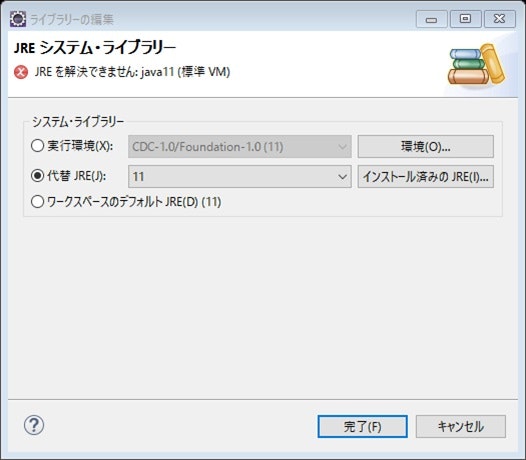
JREシステム・ライブラリを選択した状態で、編集をクリックすると、下の画面が表示される。
↑インストール済みのJREをクリック
↑検索をクリック
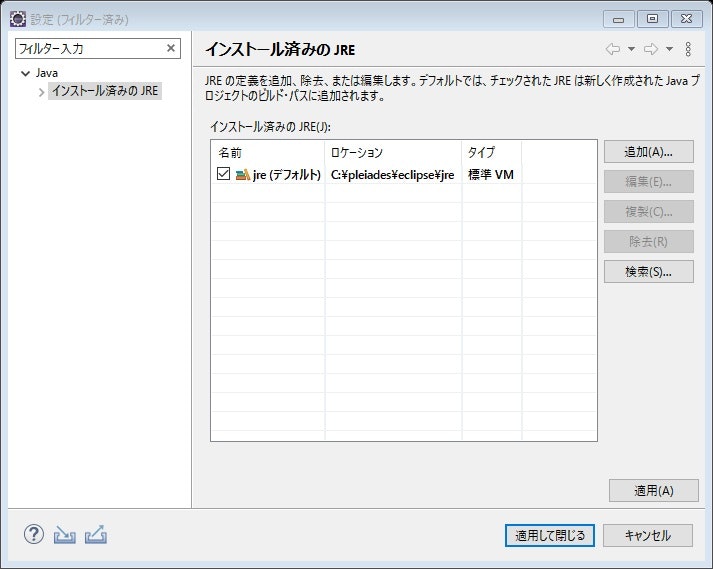
↑JREがインストールされているフォルダを選択すると、自動的に検索・追加を行ってくれる
↑インストール済みのJREに検索したものが追加された。
移行前のPCではjava11だったため、11を選択してデフォルトに設定しておく。
↑画面を戻ると、代替の欄で追加したJREを選択することが出来るようになっているので、11にしておく。
↑すると、最初に表示されていた×が消えました。
なぜか、適用して閉じ、また開くと×が付いているので、再度インストール済みのJREから指定のバージョンを選択する作業をすると、×とアンバインド済みの表示が消え、モジュールパスの方に移動した。(下の画像)
次に、サーバ・クラスパス・コンテナーを解決する
今回は、ワークスペースを開いた段階でサーバが作成されていなかった状態なので、サーバを作成する。
下部の、「使用可能なサーバがありません。このリンクをクリックして新規サーバを作成してください」をクリック。
今回はTomcat9だったので、それを選択する(次の画像の左窓)。
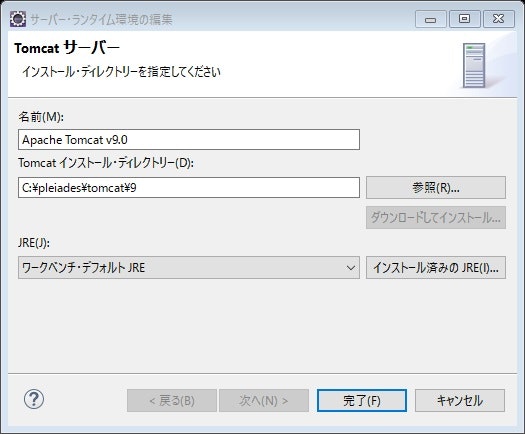
また、注意しないといけないのが、サーバー名の下の、サーバ・ランタイム環境の設定である。
サーバ・ランタイム環境の右下の「ランタイム環境の構成」をクリックすると、画像の右窓がでてくるので、Apache Tomcatの名前の箇所を選択する。すると、右側の編集ボタンが選択できるようになるので、クリックする。
すると、次のように現在選択されているサーバ・ランタイムの環境が表示される
↑Tomcatのインストールディレクトリの確認と、先ほど解決したJREシステム・ライブラリの設定と紐づいていないといけない。
ここでは、先ほどすでにJava11をデフォルトJREに設定してある為、JREの欄はワークベンチ・デフォルトJREで問題ない。もし違うJREが選択されていたら、直すか、最初の新規サーバの定義の窓から、「追加...」をクリックして設定する。
確認
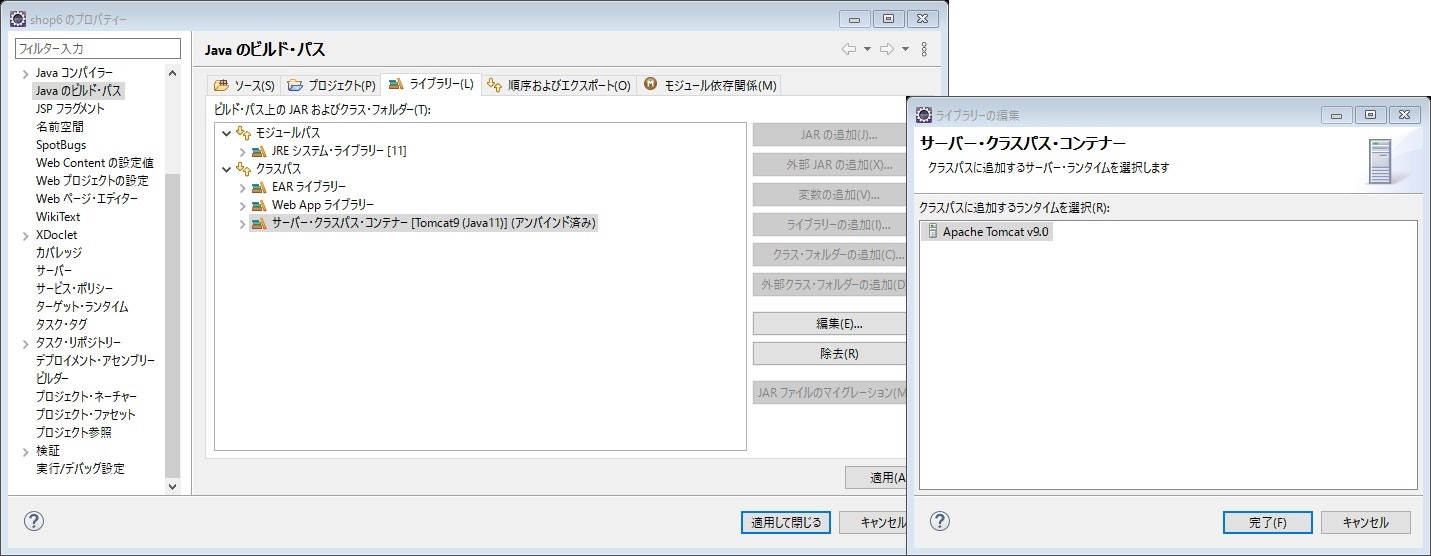
プロジェクトを右クリック>Javaのビルドパスを再度開き、ライブラリータブをみると、サーバ・クラスパス・コンテナがアンバインド済みになっているが、ここを選択した状態で、右側の編集ボタンをクリックする。
すると、下の画像の右側の窓がでるので、先ほど設定したランタイム(他の設定を作成していれば、それも表示される)を選択する。
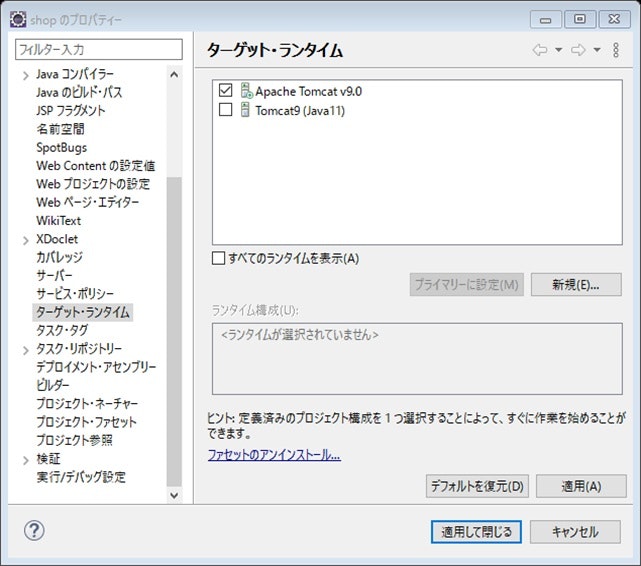
↓最後に、プロジェクトのプロパティまで画面を戻り、ターゲット・ランタイムの項目をクリックすると、ランタイム一覧が表示されるので、ここも、先ほど設定したランタイムにチェックが入るようにする。
(私の場合は違うところにチェックが入っていた)
これで、適用して閉じれば、全てのエラーが消えました。
(文字コードや、警告/エラーで個別の設定をしている場合は、それは別で設定し直さないといけません)もしかすると
もしかすると、これが一番重要かもしれませんが。
ワークスペースごと違う環境にフォルダを移動するには、エクスポート/インポートを使用するべきなのかもしれません。
「ワークスペースごと」と言いましたが、正確には、「ワークスペース(の設定)を」です。エクスポート
◆ファイル>エクスポート
開いたエクスポートウィザードで、一般>設定→次へ「すべてエクスポート」にチェックが入った状態で、宛先設定ファイルからエクスポート先のフォルダ名・ファイル名を指定して完了をクリックすると、指定した場所に.epfファイルが出来ています。(このファイルにはプロジェクトは含まれていません)
インポート
インポートする際は、
まず、Eclipseを起動する時には何かしらのワークスペースを開くと思いますが、そこに、先ほどエクスポートしたワークスペースの設定(.epf)を読み込むといったイメージです。
プロジェクト自体は、出来上がったワークスペースに、インポートする形で読み込んで使用します。
インポートする際に、読み込んだプロジェクトをワークスペースにコピーする設定もあったと思いますので、必要に応じて選択する必要があります。◆ファイル>インポート
開いたインポートウィザードで、一般>設定→次へすべてインポートにチェックが入った状態で、完了
最後になりますが
長々と呼んで頂き、ありがとうございました。
プログラミングに関しても、Eclipse使用歴に関しても短い為、理解がまだ浅い部分はありますが、問題は時間が掛かっても1つひとつ解決していきたいと思っています。


- 投稿日:2020-09-24T03:14:51+09:00
Javaの配列について
Java 配列
Javaの配列について学習しましたので、配列のメリットや使用例などアウトプットしていきます。
変数が持つ不便さと配列のメリット
今回は、点数管理プログラムを用いて変数と配列の使い方の比較をし、配列を使うメリットを解説します。
変数を使ったプログラム
testpublic class Main { public static void main(String[] args) { int sansu = 20; int kokugo = 30; int rika = 40; int eigo = 50; int syakai = 80; int sum = sansu + kokugo + rika + eigo + syakai; int avg = sum / 5; System.out.println("合計点:" + sum); System.out.println("平均点:" + avg); } }実行結果
合計点:220 平均点:44これでも、問題はないが不便なことが2点ある。
- 科目が増えると面倒で冗長なコードになる
- まとめて処理できない
配列を使ったプログラム
testpublic class Main { public static void main(String[] args) { int[] scores = {20, 30, 40, 50, 80}; int sum = scores[0] + scores[1] + scores[2] + scores[3] + scores[4]; int avg = sum / scores.length; System.out.println("合計点:" + sum); System.out.println("平均点:" + avg); } }実行結果
合計点:220 平均点:44実行結果はどちらも一緒だが、配列を使った方がコードがスッキリしてるし、手間的にもいくらかマシ。
こんな感じで配列を使うメリットを分かった(?)ところで一つひとつ解説していきます。配列とは
同一種類の複数データを並び順で格納するデータ。
また、並び順のことを添え字とよび、0から始まる決まりになっている。
配列を使ったプログラムで言うと、20点の科目が0番の要素となる。配列の書き方
配列を作成するには2Stepが必要。
Step1 配列の宣言
要素の型[] 配列の変数名int[] scores;Step2 要素の作成と代入
scores = new int[5];newはnew演算子と呼ばれ、指定された方の要素を[]内に指定された数だけ作成できる。
Step1とStep2を同時に行うこともできる
int[] scores = new int[5];配列の要素数の取得
int num = scores.length;