- 投稿日:2020-09-24T18:08:00+09:00
相関サブクエリの練習
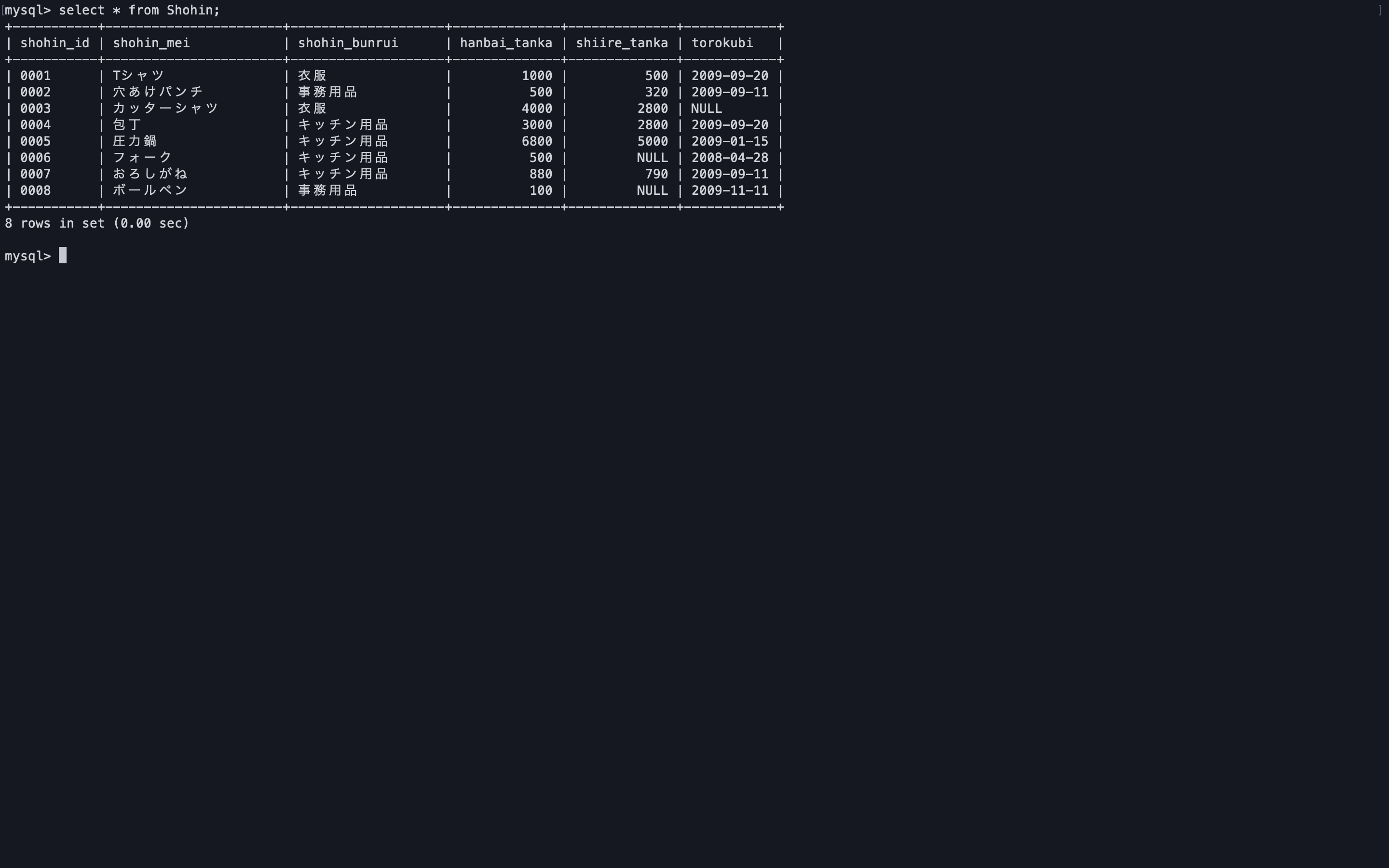
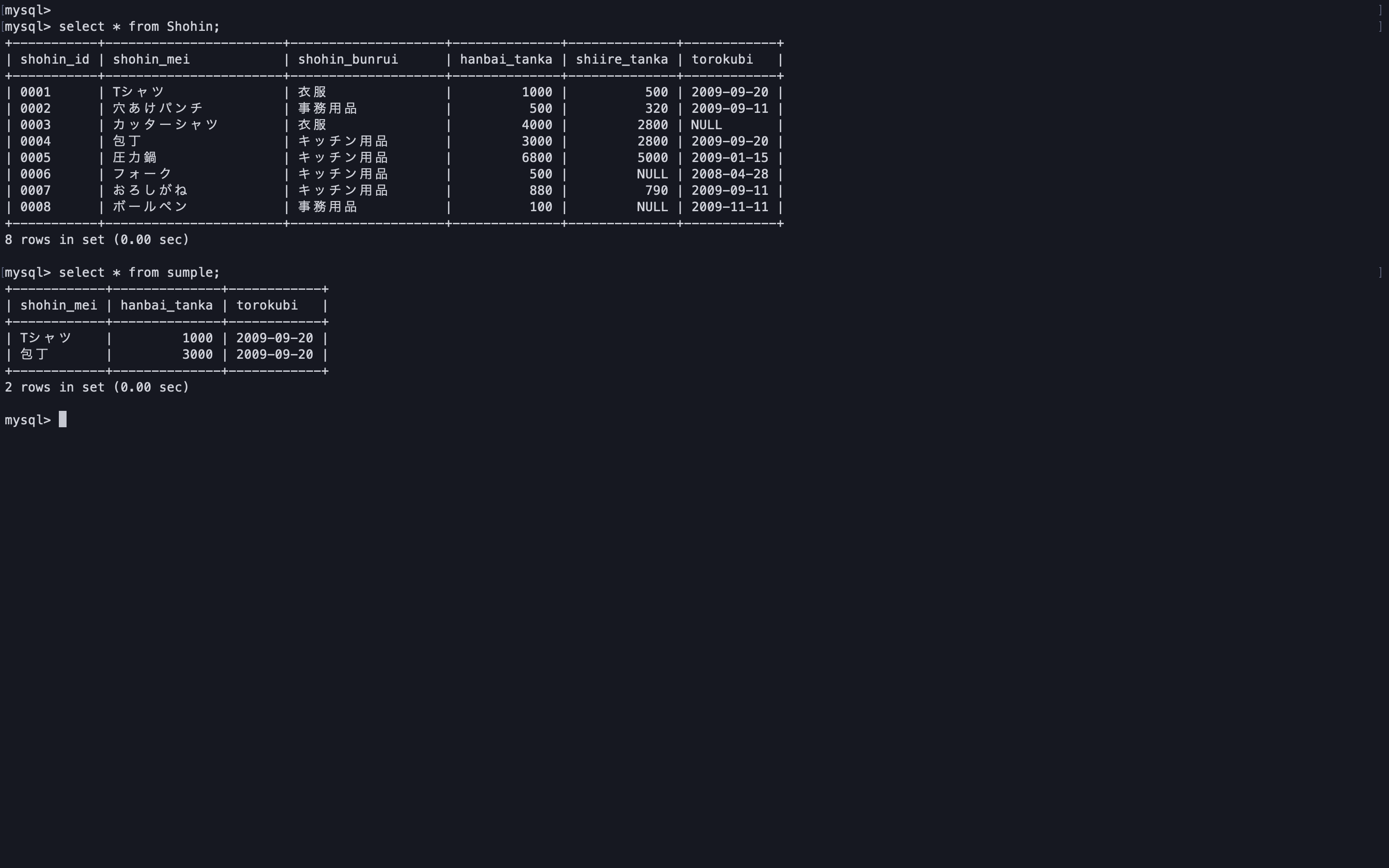
以下の画像のテーブルを使用する。
商品分類ごとに平均販売単価より高い商品を商品分類グループから抽出する。
まずは商品分類ごとの平均単価を出してみる。
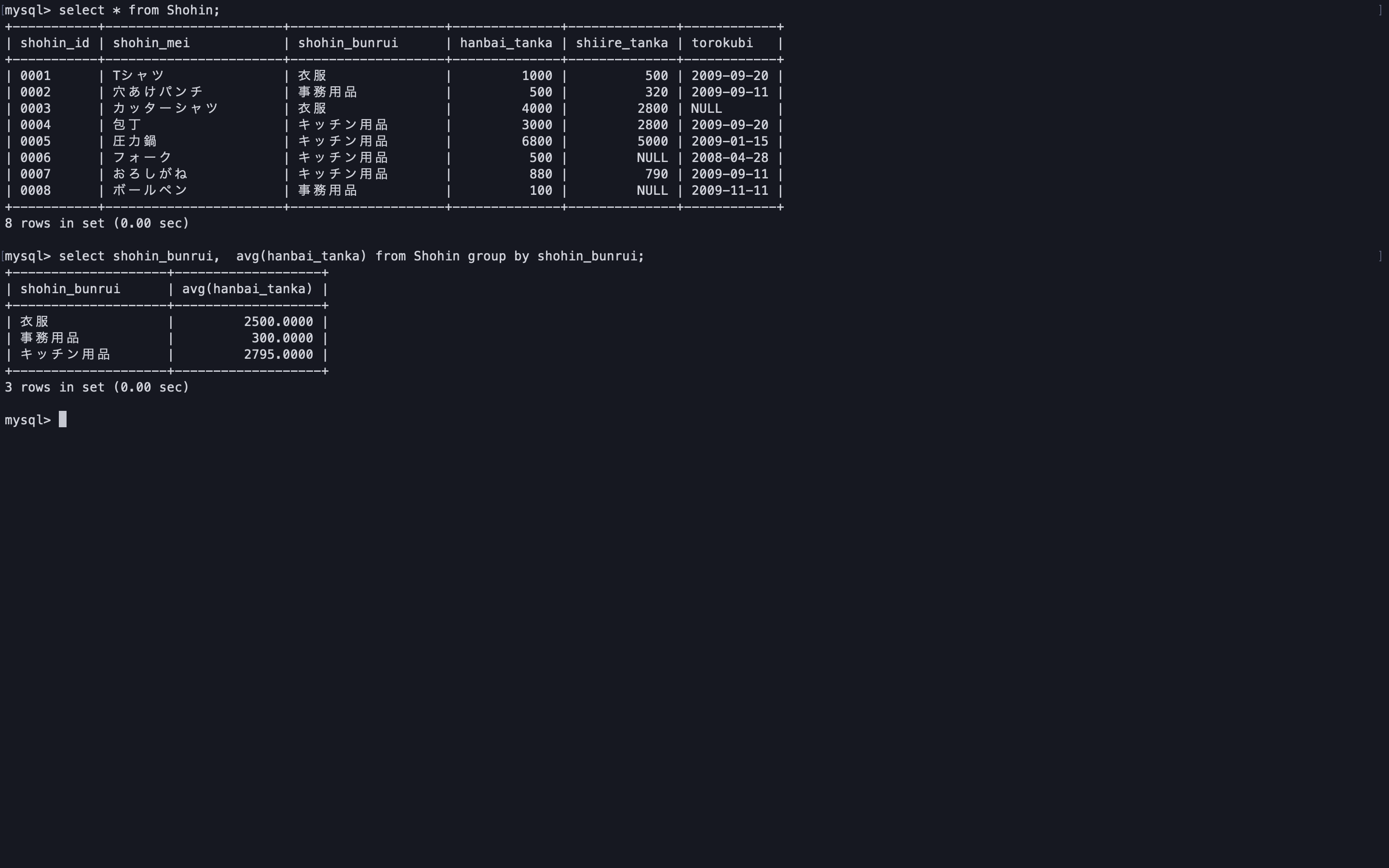
select shohin_bunrui, avg(hanbai_tanka) from Shohin group by shohin_bunrui;
相関サブクエリを使って抽出を行う。
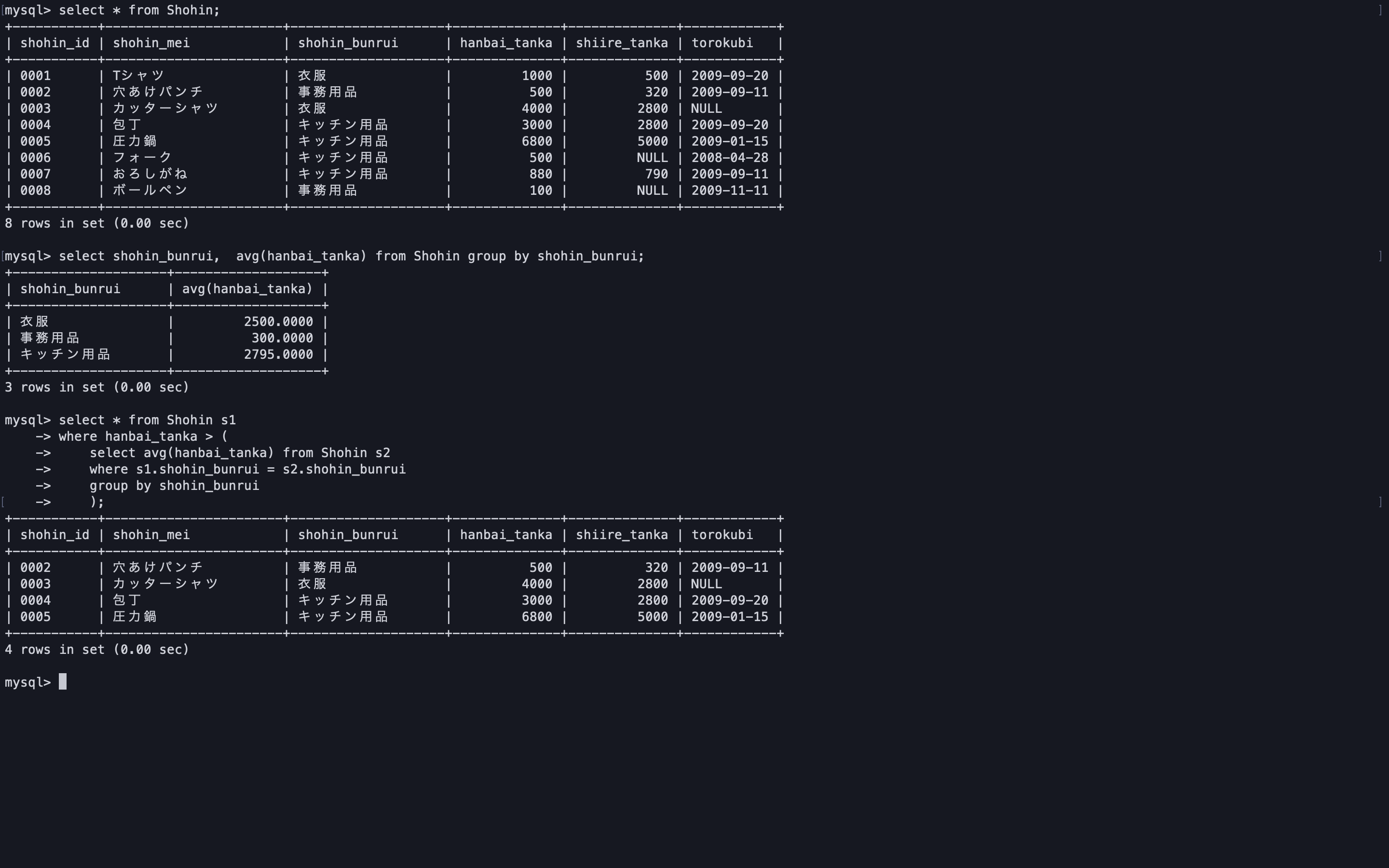
select * from Shohin s1 where hanbai_tanka > ( select avg(hanbai_tanka) from Shohin s2 where s1.shohin_bunrui = s2.shohin_bunrui group by shohin_bunrui );
相関サブクエリはテーブル全体ではなく、
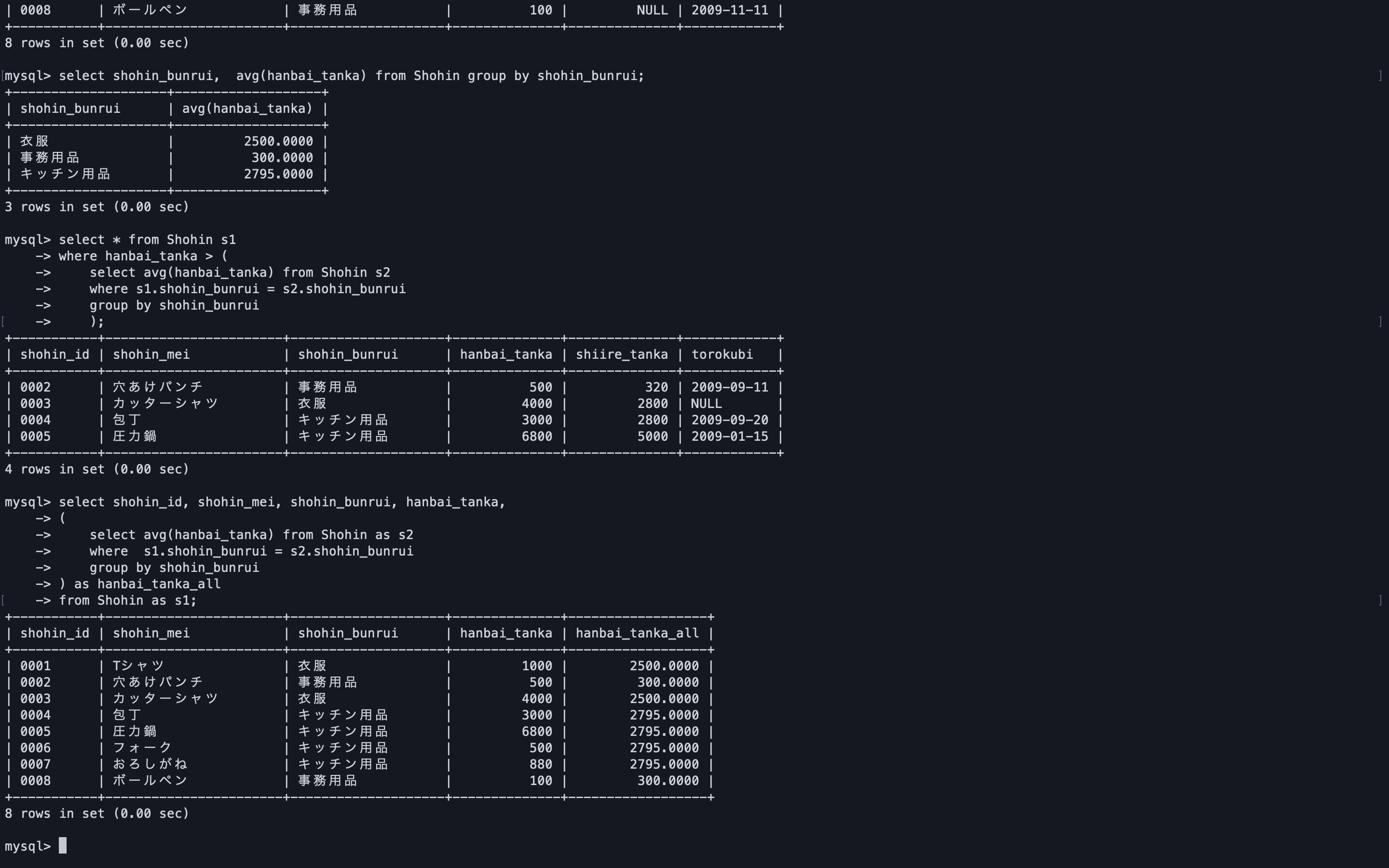
テーブルの一部のレコード集合に限定した比較をしたい場合に使用するようだ。次は商品分類ごとの平均単価列を抽出してみる。
select shohin_id, shohin_mei, shohin_bunrui, hanbai_tanka, ( select avg(hanbai_tanka) from Shohin as s2 where s1.shohin_bunrui = s2.shohin_bunrui group by shohin_bunrui ) as hanbai_tanka_all from Shohin as s1;
こちらを参考にさせていただきました。
SQL 第2版 ゼロからはじめるデータベース操作
- 投稿日:2020-09-24T17:03:16+09:00
MySQLでビューを扱う
ビューとは
SQLの観点から見ると、テーブルとビューは同じもの。
2つの違いはテーブルの中には実際のデータが保存され、
ビューの中にはselect文が保存されている点。
ビュー自体はデータを持たない。ビューを作成する
以下のようなテーブルがある状態。
create view ~でビューの作成を行う。
--- whereで条件をつけているがここはもちろん無くても実行可能 create view sumple as select shohin_mei, hanbai_tanka, torokubi from Shohin where hanbai_tanka >= 1000 and torokubi = '2009-09-20';作成したビューを検索する。
以下のSQLを実行した場合、
1.最初にビューに定義されたselectが実行される。
2.1の結果に対し、ビューをfrom句に指定したselect文が実行される。
ビューに対する検索では2つ以上のselect文が実行される、select * from sumple;
ビューを削除する
drop view ビュー名で削除
drop view sumple;こちらを参考にさせていただきました。
SQL 第2版 ゼロからはじめるデータベース操作

- 投稿日:2020-09-24T15:45:06+09:00
MySQLのインデックス,クエリの実行フロー,Explainの見方まとめ
この記事は何?
エンジニア歴2年の私が持っているMySQLに関する知見のアウトプットです。
間違った理解をしている部分があれば優しくご指摘頂けると助かります。
この記事で話すこと
MySQLのインデックス
- インデックスとは何か
- 作るとどうなるのか
- クラスタインデックス、セカンダリインデックスとは何か
SELECTクエリの実行フロー
SQLチューニング
- Explainの見方
- MySQL Workbentchの見方
- Extraフィールドに頻出するものの解説(Using filesort など)
MySQLのインデックス
インデックスとは何か
インデックスとは、本で言う「索引」です。
とよく言われますがもっと具体的に言うと
「b+treeという木構造で造られたデータ構造」です。
SELECTクエリを高速にするために作ります。
b+treeとは?
木構造のデータ構造の1つ。
ブロック単位のランダムアクセスが可能な補助記憶装置(HDDなど)上に木構造を実装するののに適していおり、MySQLなどのRDBMS(Relational Database Mnnagement System)のインデックスはこの構造で実装されることが多いです。木構造の種類
- 二分探索木
- 平衡木
- AVL木
- etc...
他にも色々ありますが、とりあえず木構造の1つということだけ理解しておけばOKです。
b+treeの特徴
- 計算量が少ないので探索が高速
二分探索木の計算量は O(n), 対してb+treeの計算量は O(logn)
つまりデータ量が増えても計算量が大きく上昇しないので大量データの保存に向いている。
- リーフノード間が繋がっているので範囲検索に強い
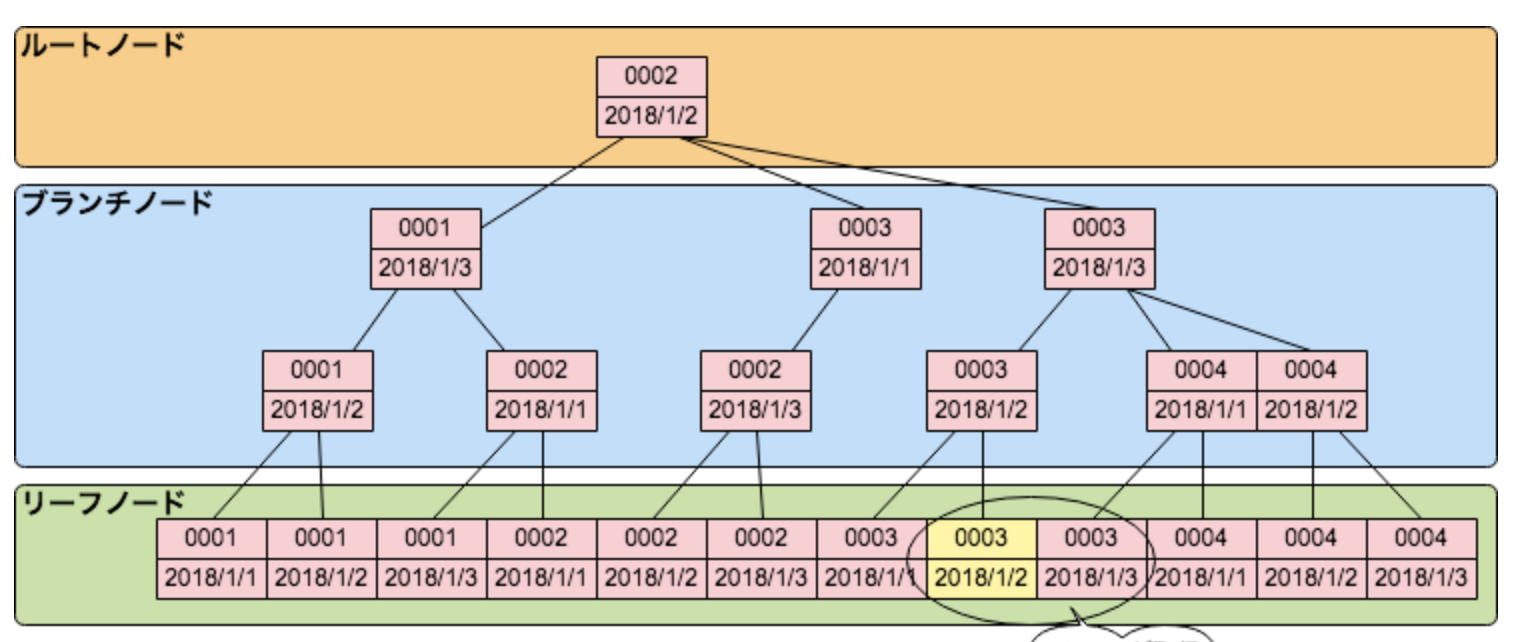
B+treeがBtreeと違う点はリーフノードにもブランチノードと同じ情報が入る事とリーフノードに次のリーフのポインタが入る事になります。これらの対応をする事で範囲検索やorder by、group by等の対応がしやすくなります。
引用元:https://devblog.thebase.in/entry/2018/12/09/110000例を上げて説明します。
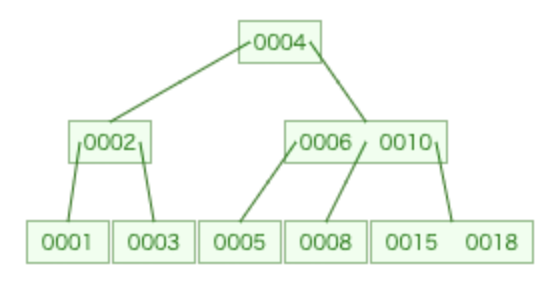
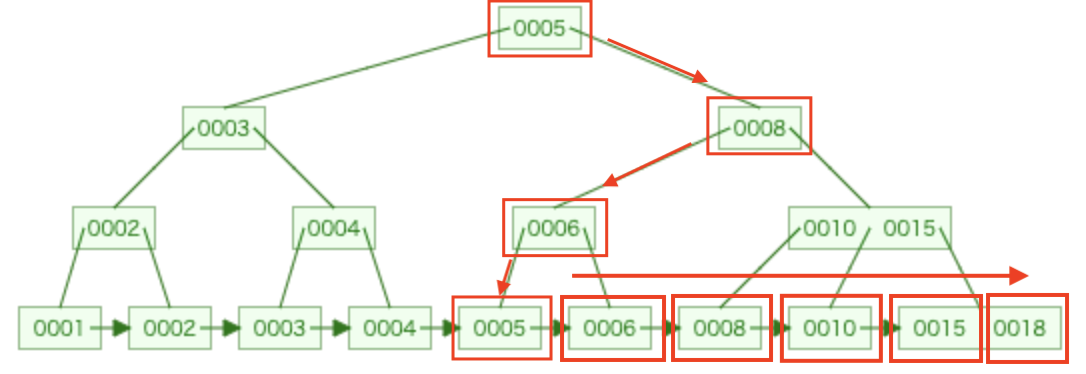
以下は[1,2,3,4,5,6,8,10,15,18]の値をもつnumberというカラムに対してインデックスを作成した場合のbtreeとb+treeです。
btree
b+tree
引用元に書いてある通り、b+treeの場合はリーフノードにもブランチノードと同じ情報が入っていることが分かります。
そしてリーフノードは昇順にソートされているので一つのリーフノードに辿り着いた後、右側を順番に取得していけることが分かります。例えば select * from テーブル名 where number > 5 というクエリがあった場合、b+treeは赤枠の5のリーフノードに辿り着いてそこから右に進んでリーフノードを取得していくことができます。
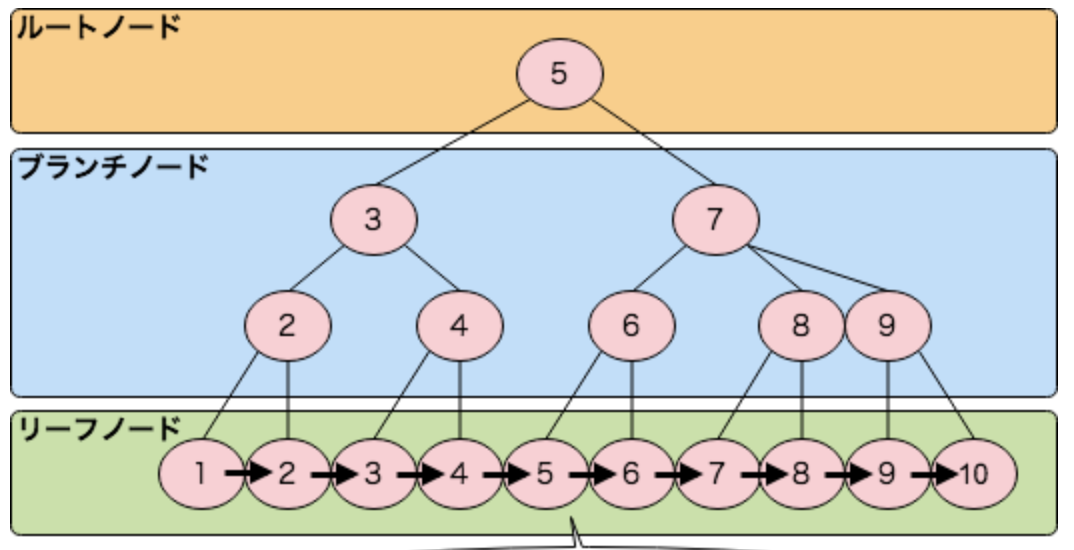
インデックスの構造
- ルートノード
- ブランチノード
- リーフノード
の3層で構成されています。
b+treeの構造
引用元:https://devblog.thebase.in/entry/2018/12/09/110000b+treeの複合インデックスの構造
引用元:https://devblog.thebase.in/entry/2018/12/09/110000インデックスはどう作られるのか?
余力があれば見ておくといいと思います。
正直自分も完全には理解してないですが、以下の記事で雰囲気は掴めました。
参考: https://www.atmarkit.co.jp/fcoding/articles/delphi/05/delphi05a.html以下のサイトは実際にbtreeやb+treeを作ってみることができます。
参考: https://www.cs.usfca.edu/~galles/visualization/BTree.html
参考: https://www.cs.usfca.edu/~galles/visualization/BPlusTree.htmlインデックスを作るとどうなる?
メリット
- SELECTクエリの実行時間が早くなるデメリット
- レコードを追加する度にインデックスのデータも増えるのでHDDの空きが減るどうして早くなる?
前提として、テーブルのレコードは補助記憶装置であるHDDのディスク、正確にはブロックに格納されています。
もしインデックスが何もない場合は、ディスクにアクセスしてブロックからレコードを読み取りにいきます。
そしてブロックを読み取るにはディスクを回して時期ヘッドを移動させて...という機械的な動作が必要にります。
だから遅いです。
そこでインデックスの出番。
インデックスを作るとブロックへのアクセスを減らすことができるので高速になります。
詳しくはこちら(YottaGin)を見てみてください。
クラスタインデックス、セカンダリインデックスって何?
MySQLのインデックスにはクラスタインデックスとセカンダリインデックスの2種類がある。
自分達が alter table add index などで追加するインデックスはセカンダリインデックスにあたる。
クラスタインデックスは意識せずとも勝手に作られてる。クラスタインデックス
クラスタインデックス = 主キー(PrimarilyKey,PKと呼ばれることもある)のインデックス。
クラスタインデックスのリーフノードには行データが格納されている。
クラスタインデックスを参照してレコードを取得する場合、ディスクを読み取りにいかないので高速。セカンダリインデックス
セカンダリインデックスのリーフノードにはカラムの値と主キーが格納されている。
セカンダリインデックスを参照する場合、リーフノードの主キーをもとにクラスタインデックスからレコードを取得する。SELECTクエリの実行フロー
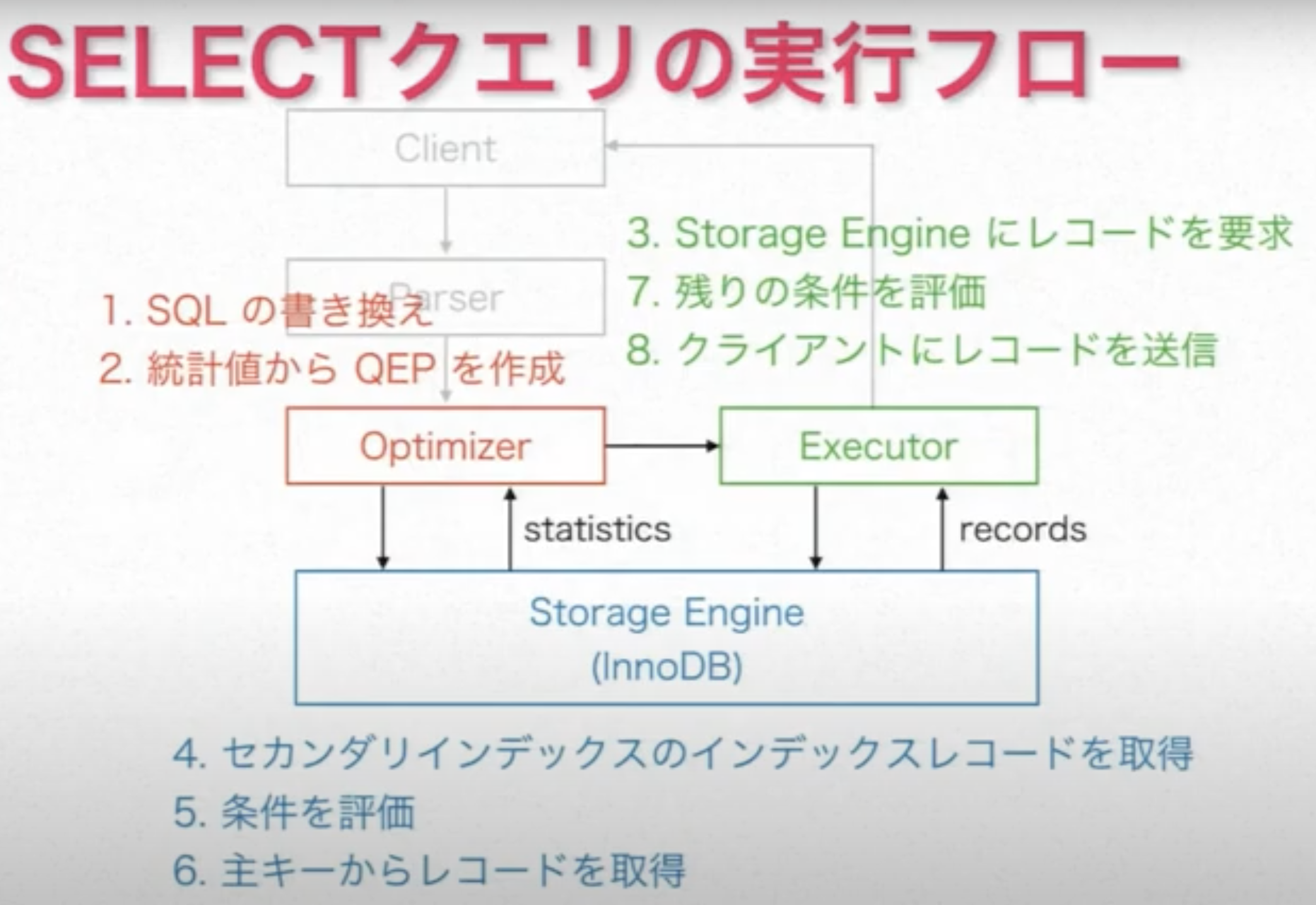
こちらの動画で出てくる図が分かりやすいです。
引用元:https://www.youtube.com/watch?v=R-48tlyAsCk&list=LLbomO5q85jBmGmGIZ-rnREg&index=1
簡単に解説します。(動画だと 15:15 ~ )
- まずMySQLクライアントからSQLを発行する
- パーサーがSQLを解析してAST(Abustracted Stracture Tree)と呼ばれるコンピュータが扱い易い形式に変換し、オプティマイザに渡します
- オプティマイザがASTと統計情報(ストレージエンジンから受取る)から実行計画(QEP:Query Execution Plan)を立てて、エグゼキュータに渡す
- エグゼキュータはストレージエンジンにレコードを要求する
- 利用できるインデックスがある場合、ストレージエンジンはセカンダリインデックスからインデックスレコード(リーフノードに格納されているカラム値と主キーのことだと思う)を取得する
- インデックスレコードのデータでwhere句の条件を評価できるなら評価する(Using Index Condition)
- 6で絞り込んで残ったインデックスレコードの主キーを用いてクラスタインデックスからレコードを取得する => ここで取得した数がexplainのrowsに表示される
- エグゼキュータで先ほど評価しきれなかったwhereの条件式を評価(Using where) => ここで絞り込めた割合がexplainのfilteredに表示される
- 必要に応じてJOINしたりソートしたりLIMITを適用したりする(Using Temporary や Using Filesort が出現する) => LIMITはソートが終わった後に評価される
- クライアントにレコードを返す
SQLチューニング
explainで表示される各フィールドの解説
それぞれの項目が何を示しているのかまとめておく
id
idはSELECTに付けられた番号である。じつは、MySQLはJOINをひとつの単位として実行するようにできている。idはそのクエリの実行単位を識別するものである。したがって、JOINしか行われていないこのようなクエリではidは常に1となる。
引用元:奥野幹也. 詳解MySQL 5.7 止まらぬ進化に乗り遅れないためのテクニカルガイド (Japanese Edition) (Kindle の位置No.2713-2719). Kindle 版.正直私はまだ説明できるほど理解できてないので、引用だけに止めておきます。
select_type
select_typeは、このテーブルがどのような文脈でアクセスされるかを示す。JOINの場合、select_typeは常にSIMPLEである。言葉の意味から考えると少しおかしいが、どれだけ複雑なJOINをしてもSIMPLEになる。一方、JOIN以外のもの、つまりサブクエリやUNIONがあるとidとselect_typeが変化する。2以上のidが出現するし、select_typeにもSIMPLE以外のものが表示される。
引用:奥野幹也. 詳解MySQL 5.7 止まらぬ進化に乗り遅れないためのテクニカルガイド (Japanese Edition) (Kindle の位置No.2719-2731). Kindle 版.正直私も理解できてないので、引用だけに止めておきます。
table
どのテーブルへアクセスするかを表している
type
アクセスタイプを表している
参考: http://nippondanji.blogspot.com/2009/03/mysqlexplain.htmlpossible_keys
オプティマイザが利用可能なインデックスの名前が表示される
この中から1つ選ばれて実際に使われるkey
実際に使われたインデックスの名前が表示される
key_len
key_lenフィールドは、選択されたインデックスの長さである。そんなに重要なフィールドではないが、インデックスが長すぎるのも非効率なので、たまには気にしてほしい。
引用元:奥野幹也. 詳解MySQL 5.7 止まらぬ進化に乗り遅れないためのテクニカルガイド (Japanese Edition) (Kindle の位置No.2778-2779). Kindle 版.正直私も理解できてないので、引用だけに止めておきます。
ref
条件式のキーとの比較で使われた値が表示される(const,テーブル名.カラム名,etc)
rows
ストレージエンジンから取得したレコードの数
filtered
エグゼキュータでwhere句を評価して残った割合が表示される
Extra
Usingfilesortなどが発生しているとここに表示される
詳しくは後述しますMySQL Workbenchのススメ
explainの表形式ってちょっと見辛いし、実行フローが掴みづらいですよね。
そんな方達におすすめなのがMySQL Workbenchです。MySQLWorkbentchの機能の一つにビジュアルExplainという機能があります。
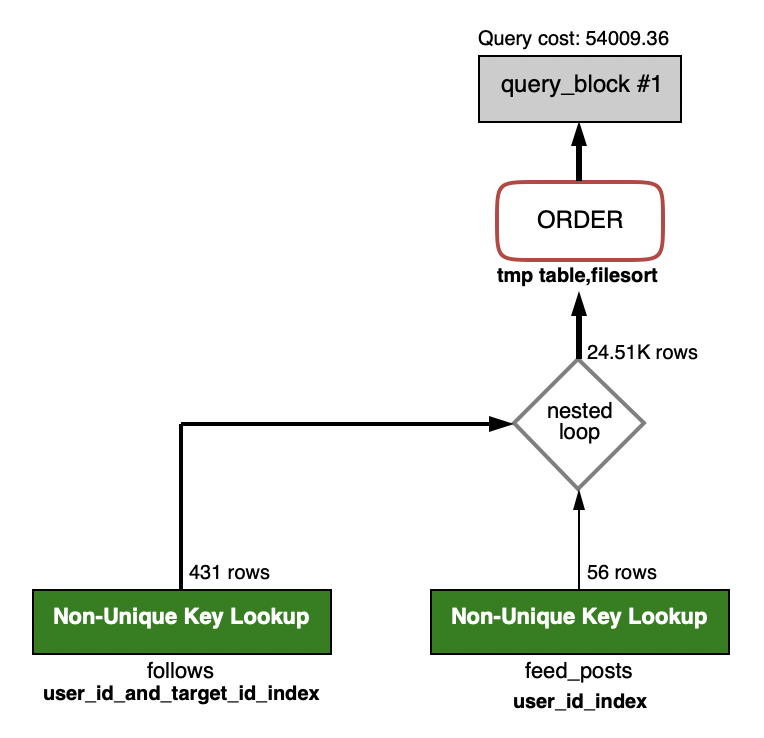
これを使うと図として実行計画を見ることができます。SELECT feed_posts.* FROM feed_posts INNER JOIN (SELECT * FROM follows WHERE user_id = 640925) as f ON feed_posts.user_id = f.target_id ORDER BY feed_posts.created_at DESC LIMIT 250;
例えば上図だと、最初にfollowsテーブルからレコードを取得して、その後feed_postsをJOIN(Nested Loop Join)した後のテーブルでソートしていることが分かります。
上手で何が行われているのか簡単に解説します。
1.followsテーブルからuser_id_and_target_id_indexを参照して431行を取得
2.取得したfollowsのレコード1行ずつに対してfeed_postsのレコードをNested Loop Joinする。followsレコードのtarget_idがfeed_postsのuser_idと一致したものをTemporaryTableとして保持しておく。
56rowsというのはfollowsレコード1件につき平均56行のfeed_postsが取得されるということを表してる。(のだと思います、ちょっと自信ないです。)
この56rowsというのは統計情報から判断しているので必ずも実際の数と等しいという訳ではありません。
例えばWHERE user_id = 640925 の値を変えても56rowsは変わらないです。3.JOINした結果 24.51kのレコードを持つ一時テーブルが作られる
4.一時テーブルのfeed_posts.created_atでソートするExplainの項目に頻繁に出る項目
それぞれ内部的にどんな処理が起こっているのかまとめておく。
Using Index
クエリをインデックスの走査だけで完遂できる時、つまりカバリングインデックスの時に出る
Using Filesort
ソートをインデックスで解決できず、エグゼキュータがソートを行った時に表示される
JOINしたテーブルでソートする場合は一時テーブルが作られるのでUsing Temporary Using Filesort2つセットで表示されるUsing Index Condition
where句による絞り込みをストレージエンジンで行った時に表示される
ストレージエンジンで評価できなかった条件はいつも通りエグゼキュータが行うおわりに
だんだん疲れてきて説明が雑になってしまった気がします。
体力ある時にもっと分かりやすく明確に書くのでお許しを。この記事が初学者の参考になると嬉しいです。
参考サイト
いろんなサイトを参考に勉強させてもらいました。
marusource https://blog.h13i32maru.jp/entry/2012/07/01/000000
atmarkIT https://www.atmarkit.co.jp/fcoding/articles/delphi/05/delphi05a.html
かえるの井戸端雑記 http://frogwell.hatenablog.jp/entry/2017/06/18/222312
USE THE INDEX LUKE! https://use-the-index-luke.com/ja/sql/anatomy/the-leaf-nodes
Crape Diem https://christina04.hatenablog.com/entry/2017/05/17/190000
YottaGin https://yottagin.com/?p=4855
Qiira https://qiita.com/jooohn1234/items/6c765e87fc0a16f078b3
- 投稿日:2020-09-24T15:06:31+09:00
爆速PythonフレームワークFastAPIをMySQLに繋いでRESTfulなAPIを作成してみた。
FastAPI とは?
FastAPIとはpython3.6以上を対象とした、APIを作成するためのモダンで処理速度が爆速なフレームワークです。
主な特徴としては
速さ: 非常にハイパフォーマンス。NodeJSやGoに匹敵する処理速度を誇る(StarletteとPydanticのおかげもあり)。Pythonの数あるフレームワークのうち最も処理速度が速いフレームワークの一つ。
コードの簡素化: コードの書く速度を約2~3倍から上昇させる。(*)
バグの少なさ: 約40%ほどの人為的コードバグを減らすことが可能。(*)
直感的に書ける: エディターのサポートも充実、補完も効きます。デバッグにかかる時間を減らすことが可能。
簡単: 簡単に書け、理解しやすいように設計されている。ドキュメント読むのに時間がたくさんかかる心配もない。
短い: コードの重複を避けることができる。渡す引数を変えるだけで様々な機能を提供する関数を備えている。
堅実: 本番環境でも開発環境と差異のないコードを使える。
Swaggerの提供: 作成したAPIはデフォルトで備えているSwaggerをもとに自動でドキュメント化され、各処理を実行できる。
(*)FastAPI制作チーム調べ、だそうです。
とりあえずサーバーを立ち上げてみる
「コードは言葉より物を言う」と言うことで、早速使っていきたいと思います。
まずは適当にフォルダを作り
mkdir fastapi-practice必要なパッケージをインストールします。
pip install fastapi sqlalchemy uvicorn mysqlclientグローバルインストールが嫌な方はpoetryなどを使ってインストールしてください(このあとでどのみちpoetry使います)。
FastAPIを動かすために必要な以下のファイルを作成します
touch main.pyそして以下の様にコードを記述していきます。
main.pyfrom fastapi import FastAPI from starlette.requests import Request app = FastAPI() def index(request: Request): return {'Hello': 'World'} app.add_api_route('/', index)なんとこれだけでサーバーが立ち上がってしまいます。
uvicorn main:appと打つだけでサーバーが立ち上がったはずです。
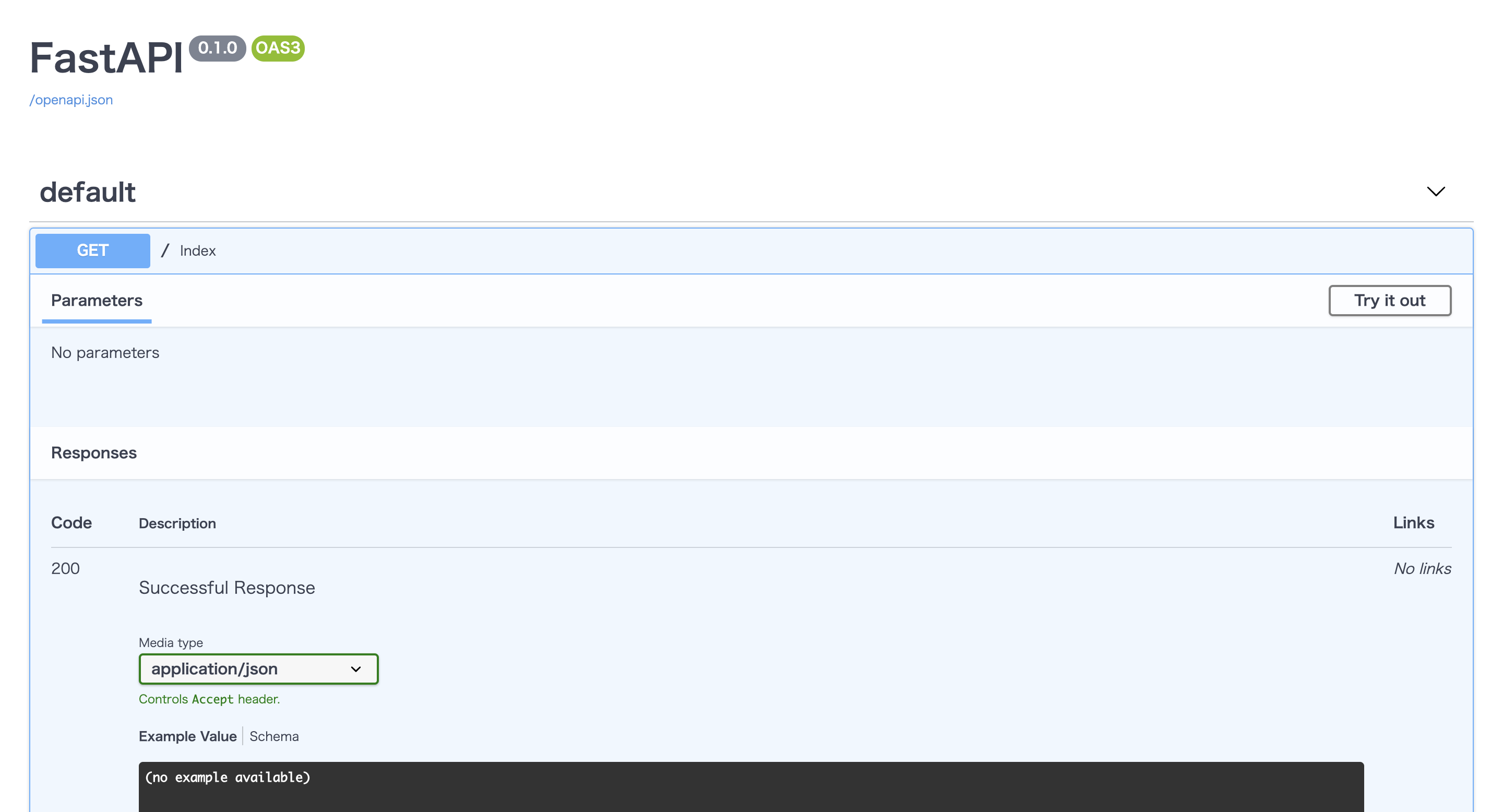
http://localhost:8000/
をブラウザで表示してみると{"Hello":"World"}と表示されているはずです。爆速ですね、FastAPI。
しかもSwaggerによりAPIの仕様も自動で作成されています!!(驚き!)
http://localhost:8000/docs
を表示してみてください。お洒落なUIで仕様書が作られているはずです。タブを開いて
Try it outのボタンを押すと実際にリクエストを送り、レスポンスを確認することだってできてしまいます!(感動!!)
ちなみに
http://localhost:8000/redoc
も自動で作られておりさらに詳細なドキュメントを簡単に作ることもできてしまいます!(凄すぎ!!!)実際に使ってみる (docker環境構築編)
それではリアルケースを想定したFastAPI + MySQLでRESTfulなAPIを作成してみましょう。
FastAPIはdockerで簡単に環境構築できるのでmysqlとFastAPIをそれぞれ今時っぽくコンテナ内で動かし、通信させる様にしてみます。
まずはフォルダ内にdocker-compose.ymlとdocker-sync.yml, Dockerfileを作成します。
touch docker-compose.yml docker-sync.yml Dockerfiledockerの詳しい使い方の説明はここでは省きますが、Dockerfileにコンテナを作成するための情報、docker-compose.ymlに作成されたコンテナ上で走らせるコマンド、docker-sync.ymlでローカルの開発環境とdockerコンテナ内のファイルをリアルタイムで同期するためにコードをつらつらと書いていきます。
docker-syncの使い方は他の方が書いてくださった以下の様な記事が参考になるかと思うので読んでみてください。
docker-syncは使わなくてもできますが、同期速度を爆速!にするために私は使ってます。https://qiita.com/Satoshi_Numasawa/items/278a143aa41735e1b0da
それではDockerfileからコードを書いていきます。
DockerfileFROM python:3.8-alpine RUN apk --update-cache add python3-dev mariadb-dev gcc make build-base libffi-dev libressl-dev WORKDIR /app RUN pip install poetryパッケージ管理にはpoetryを使います。
パッケージ管理にはpipenvやpyflowなどもあるのでここは好みですかね...?https://qiita.com/sk217/items/43c994640f4843a18dbe
こちらの記事に各パッケージマネージャーが分かりやすくまとめられています。
気になる方は是非一読してみてください。続いてdocker-sync.yml
docker-sync.ymlversion: "2" options: verbose: true syncs: fastapi-practice-sync: src: "." notify_terminal: true sync_strategy: "native_osx" sync_userid: "1000" sync_excludes: [".git", ".gitignore", ".venv"]そしてdocker-compose.ymlです
docker-compose.ymlversion: "3" services: db: image: mysql:latest command: --default-authentication-plugin=mysql_native_password restart: always environment: MYSQL_DATABASE: fastapi_practice_development MYSQL_USER: root MYSQL_PASSWORD: "password" MYSQL_ROOT_PASSWORD: "password" ports: - "3306:4306" volumes: - mysql_data:/var/lib/mysql fastapi: build: context: . dockerfile: "./Dockerfile" command: sh -c "poetry install && poetry run uvicorn main:app --reload --host 0.0.0.0 --port 8000" ports: - "8000:8000" depends_on: - db volumes: - fastapi-sync:/app:nocopy - poetry_data:/root/.cache/pypoetry/ volumes: mysql_data: poetry_data: fastapi-sync: external: truedocker-compose.ymlでミソなのが永続化するデータとその場かぎりのデータをうまく使い分けることです。
永続化しないデータはdocker-compose downするたびにリセットされてしまいます。今回のケースだとmysql内のデータ、poetryでインストールしたパッケージは永続化させ、コンテナを立ち上げる度にmysql内のデータが空になったりパッケージをダウンロードしなくていい様にします。
また書いていくコードはdocker-syncを使って同期させたいのでfastapi-practice-sync:/app:nocopyを記述して勝手に同期されるのを防ぎます。MySQLもdockerから最新のイメージをpullして構築していきます。
ここまででdockerのセットアップは終了です。
実際に使ってみる(FastAPI設定編)
まずはFastAPIに必要なパッケージをインストールするpoetryのセットアップです。
poetry initをターミナルで叩きます。
そうすると対話形式でセットアップが始まりますのでyesかnoを連打しましょう。(基本デフォルトの設定で問題ないのでEnter連打でも問題ない...と思います)そうすると
pyproject.tomlというファイルが作成されたかと思います。ここにパッケージの依存情報が追記されていくのでpoetryを使ってFastAPIを立ち上げるのに必要なパッケージをインストールしていきましょう。
poetry add fastapi sqlalchemy uvicorn mysqlclientこちらを入力しパッケージのインストールが終わるのを待ちます。
終了したら、pyproject.tomlを開いてみるとインストールされたパッケージの情報が記載されていることがわかります。pyproject.toml[tool.poetry] name = "fastapi-practice" version = "0.1.0" description = "" authors = ["Your Name <you@example.com>"] [tool.poetry.dependencies] python = "^3.8" fastapi = "^0.61.1" sqlalchemy = "^1.3.19" uvicorn = "^0.11.8" [tool.poetry.dev-dependencies] [build-system] requires = ["poetry>=0.12"] build-backend = "poetry.masonry.api"そうしたらあとは
docker-compose buildを打ち、イメージをビルドしてdocker-sync-stack startを入力するだけです!*
docker-sync-stack startはdocker-sync startとdocker-compose upを同時に実行するコマンドです。ログもよしなに出してくれるので便利です。新たにパッケージをインストールする際は、まずはローカルで
poetry addでパッケージをインストールしてdockerコンテナを再起動させればコンテナ内にも同期されるはずです!マイグレーションをする
お次はDB(MySQL)と連携させていきます。
今回はCRUDの勉強といえばTodoリストの作成!なのでTodoテーブルを定義しマイグレーションをかけていくことにします。
Todos Table
column datatype id integer title string content string done boolean この様な構成のテーブルをマイグレーションしていきます。
まずはデータベースを定義するファイルを作り
touch db.py以下の内容を書き込んでいきます。
db.pyfrom sqlalchemy import Boolean, Column, ForeignKey, Integer, String, create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import relationship, sessionmaker, scoped_session user_name = "root" password = "password" host = "db" database_name = "fastapi_practice_development" DATABASE = f'mysql://{user_name}:{password}@{host}/{database_name}' engine = create_engine( DATABASE, encoding="utf-8", echo=True ) Base = declarative_base() SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine) class Todo(Base): __tablename__ = 'todos' id = Column(Integer, primary_key=True, autoincrement=True) title = Column(String(30), nullable=False) content = Column(String(300), nullable=False) done = Column(Boolean, default=False) def get_db(): db = SessionLocal() try: yield db finally: db.close() def main(): Base.metadata.drop_all(bind=engine) Base.metadata.create_all(bind=engine) if __name__ == "__main__": main()FastAPIはsqlalchemyというPythonの中で最もよく利用されるORM(Object-Relation Mapping)の一つを使ってデータベースとPythonのオブジェクトを関連付けるのが主流みたいです。
これを書いたらdockerのコンテナ内に入り、マイグレーションをかけていきます。
docker-sync-stack startでコンテナを立ち上げ同期モードにし、
docker container lsで立ち上がっているコンテナリストをみます。
そしたら、docker exec -it {コンテナ名} shを叩き、コンテナの中に入ります。
そして、以下のコマンドでマイグレーションをかけていきます。poetry run python db.pyそうすると無事マイグレーションが走りテーブル作成に成功したのではないでしょうか!
そしたら次はCRUD処理をFastAPIで書いていきます。
FastAPIでCRUD処理を書こう
拡張性を意識してFastAPIに内蔵されているinclude_routerという機能を使い、ファイルを分割していきます。
mkdir routersと打ち、
touch routers/todo.pyというファイルを作ります。
こちらにCRUD処理を書いていきます。routers/todo.pyfrom fastapi import Depends, APIRouter from sqlalchemy.orm import Session from starlette.requests import Request from pydantic import BaseModel from db import Todo, engine, get_db router = APIRouter() class TodoCreate(BaseModel): title: str content: str done: bool class TodoUpdate(BaseModel): title: str content: str done: bool @router.get("/") def read_todos(db: Session = Depends(get_db)): todos = db.query(Todo).all() return todos @router.get("/{todo_id}") def read_todo_by_todo_id(todo_id: int, db: Session = Depends(get_db)): todo = db.query(Todo).filter(Todo.id == todo_id).first() return todo @router.post("/") def create_todo(todo: TodoCreate, db: Session = Depends(get_db)): db_todo = Todo(title=todo.title, content=todo.content, done=todo.done) db.add(db_todo) db.commit() @router.put("/{todo_id}") def update_todo(todo_id: int, todo: TodoUpdate, db: Session = Depends(get_db)): db_todo = db.query(Todo).filter(Todo.id == todo_id).first() db_todo.title = todo.title db_todo.content = todo.content db_todo.done = todo.done db.commit() @router.delete("/{todo_id}") def delete_todo(todo_id: int, db: Session = Depends(get_db)): db_todo = db.query(Todo).filter(Todo.id == todo_id).first() db.delete(db_todo) db.commit()この様にしてざっとCRUD操作を書いていきました。
@routerの後にリクエスト名を書き、動作対象のURLを書くだけです。そしたらこちらを読み込める様に
main.pyも編集していきます。main.pyfrom fastapi import FastAPI from routers import todos app = FastAPI() app.include_router( todos.router, prefix="/todos", tags=["todos"], responses={404: {"description": "Not found"}}, )prefixはurlのパスを作ってくれます。tagsはdocsを見やすい様グルーピング化してくれます。
そうして
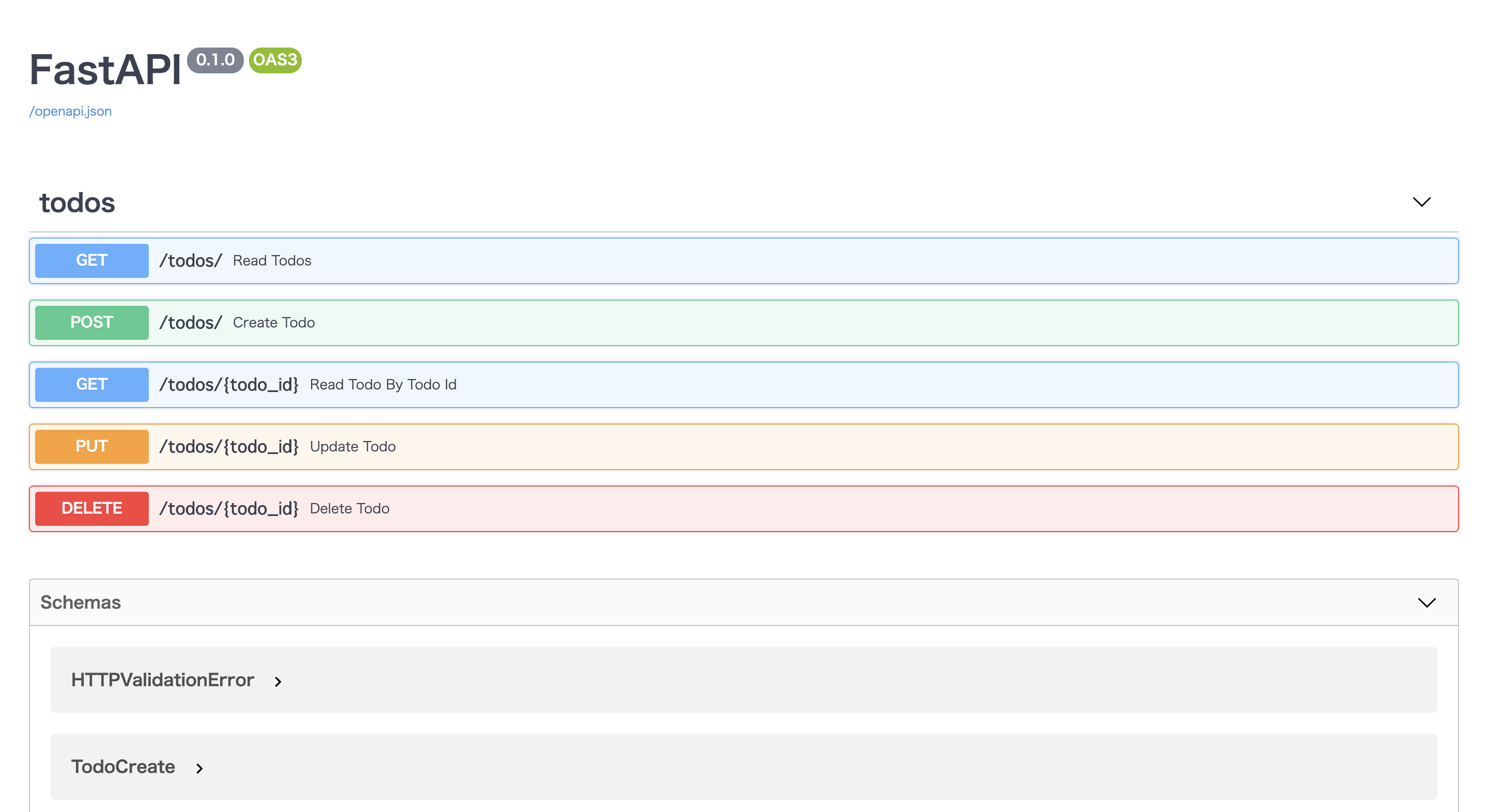
http://localhost:8000/docs
に接続すると以下の様になっているはずです!
タブを開いてポチポチボタンを押してCRUD処理を試してみてください!
このままだとフロントエンドから呼ぶ際CORSエラーが起きるので別アプリから呼ぶ際は以下のCORSの処理を追記してみてください。
main.py# 追記 from starlette.middleware.cors import CORSMiddleware app.add_middleware( CORSMiddleware, allow_origins=["*"], allow_credentials=True, allow_methods=["*"], allow_headers=["*"], )まとめ
FastAPIいかがだったでしょうか?
こんなにも少ないコード量でAPIが作成できてしまうのがとても魅力的ですね。
Pythonでマイクロサービスを作成する際とても相性が良さそうです。Qiita初投稿だったため何か分かりづらい点あったら質問くださいませ!
これからはなるべくQiitaにもアウトプットしていきたい...です(頑張る

- 投稿日:2020-09-24T13:00:25+09:00
LaravelDB.com~操作方法と勘所を書いた〜(2020/09/24メジャーアップデートに対応)
◇LaravelDB.com ?
Laravelのデータベース設計(ER図)するだけで、Migrationファイルがポンって作成できるFreeの「 テーブル設計&Migration作成 」 ツールです。
メイン機能
- Migrationの自動生成
- チームメンバーとの共有可能
- CRUDコード(β版)の自動生成
- CRUDコード(β版)でのValidation自動生成(テーブル設計に合わせて自動で生成)
用途
用途は開発者によってバラバラですね。
・Migrationのみ使う(ほとんどの人はここですかね)
・CRUDファイル全部(数%くらいの人)
・コード生成後、一部(Validationとか)をコピーして使う(結構な割合でいます)
・テーブル設計の共有(Team開発では使ってるようです)◇操作方法(マニュアル)
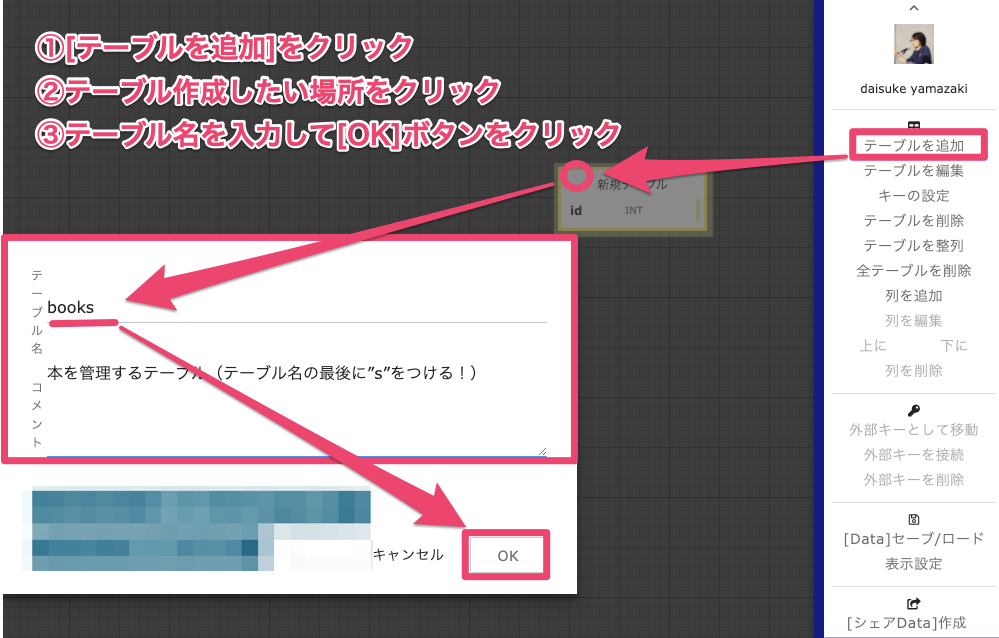
1.テーブル作成
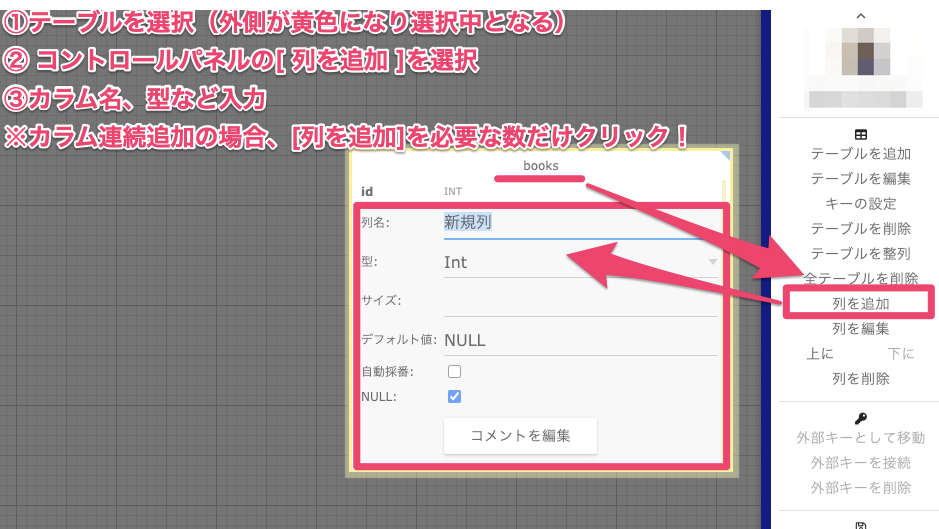
2.カラム作成
※使いやすくするポイント!! 「列を追加」ボタンを連打で必要な数だけ先に作ると便利!!
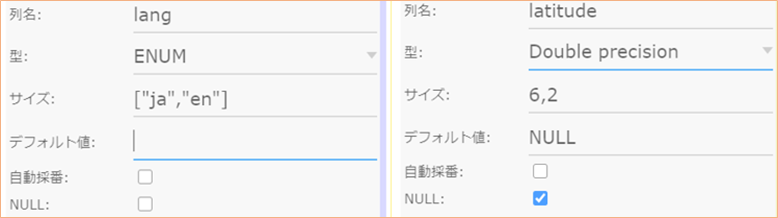
3.2020-09-24アップデートから使用可能
「 ENUM, UNSIGNED ] に対応、新規プロジェクトより表示されるようになります
以下はENUM、Doubleの入力してる例です。
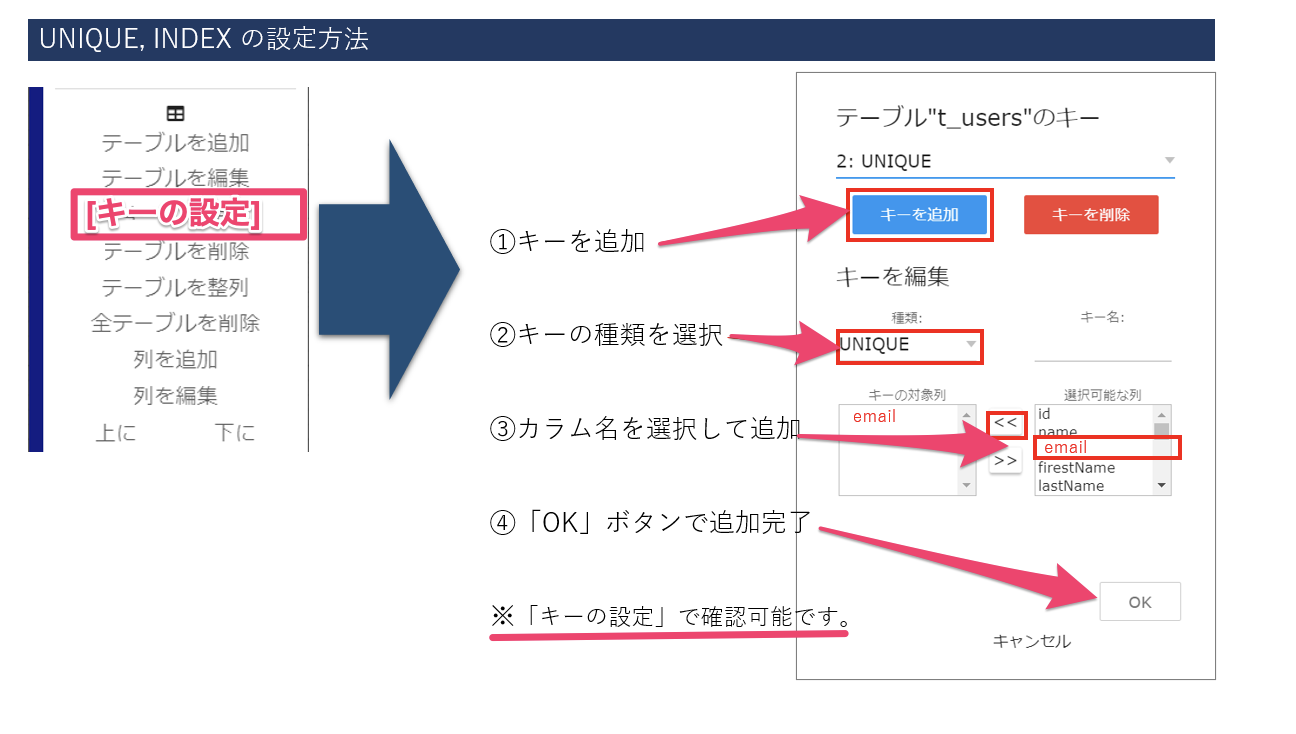
「 UNIQUE, INDEX ] に対応、新規プロジェクトより表示されるようになります
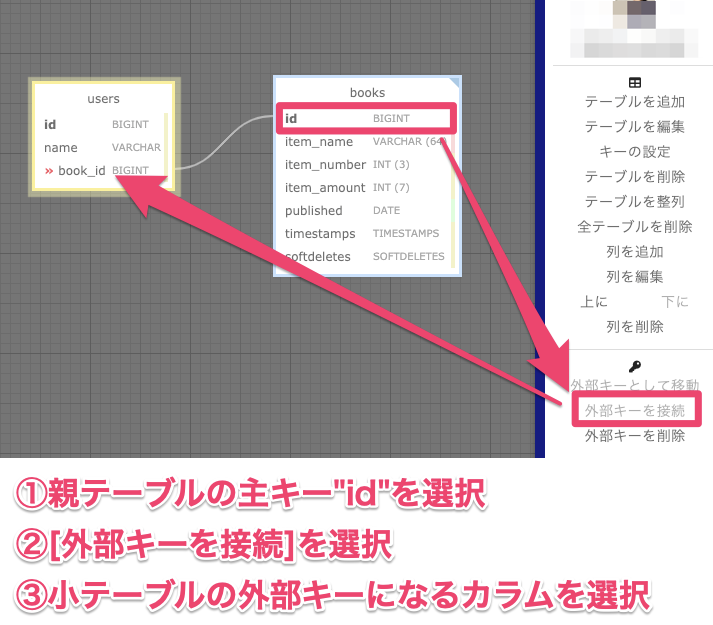
外部キーの設定
外部キー制約を使用する場合( ※1対他、多対多などを分ける機能は無い)
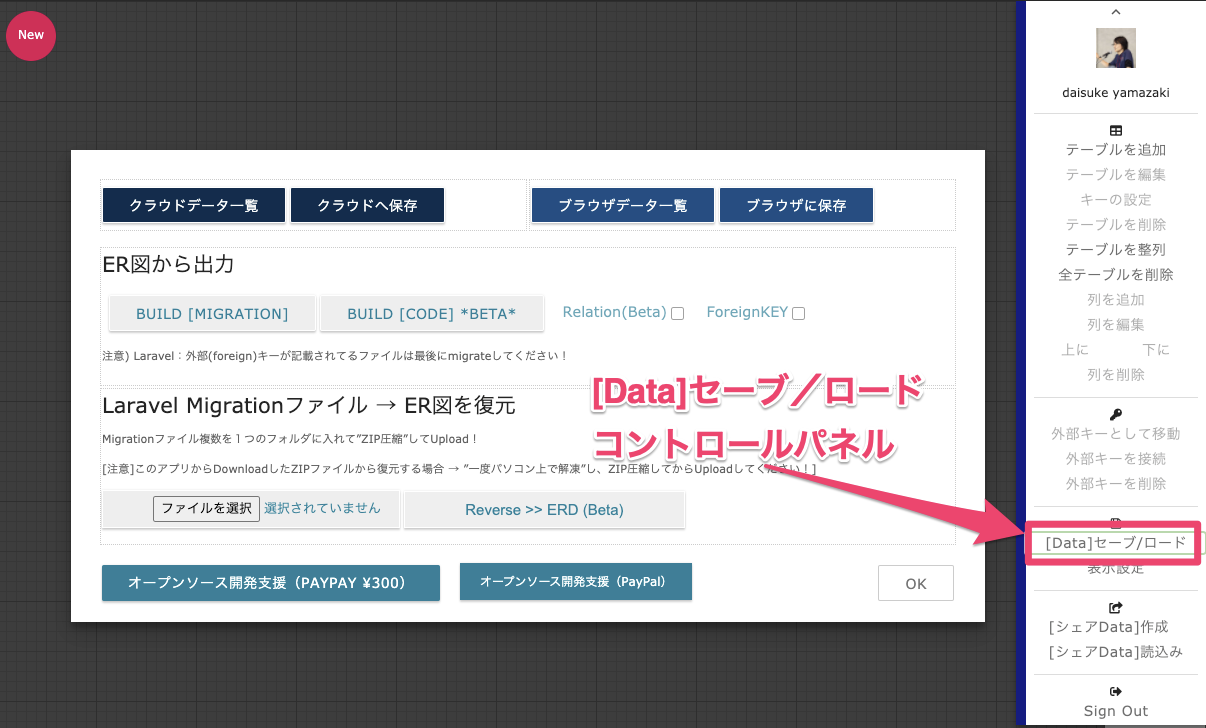
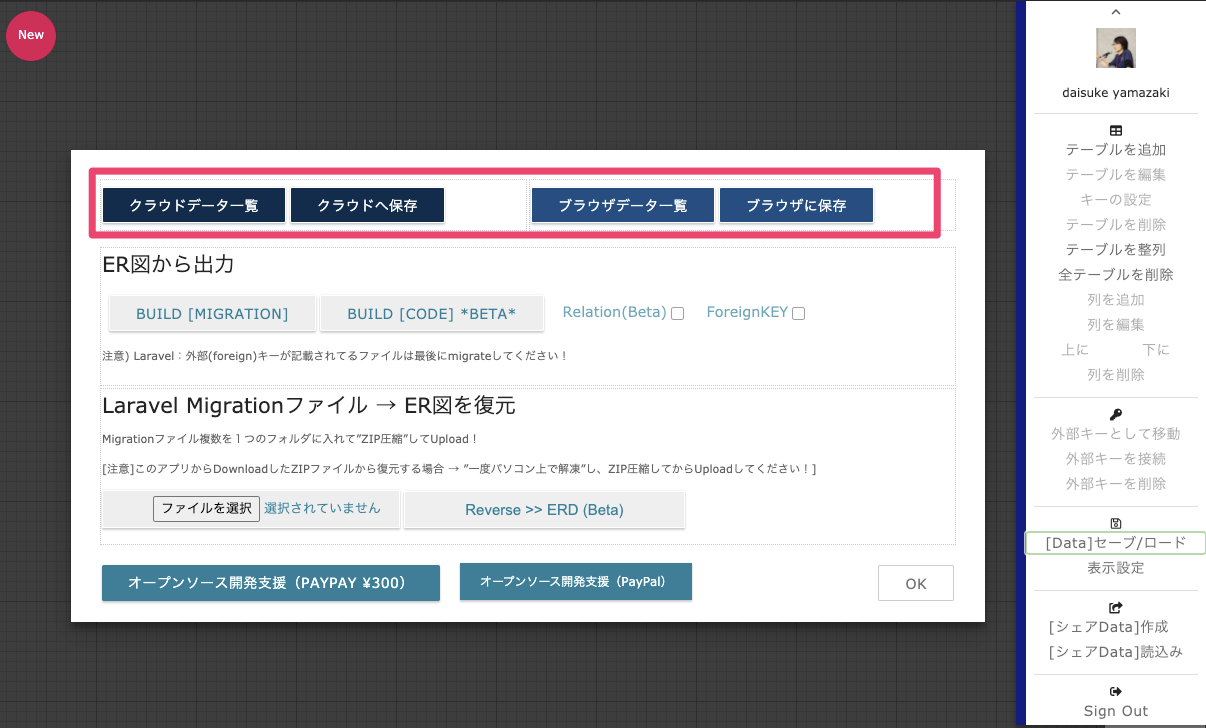
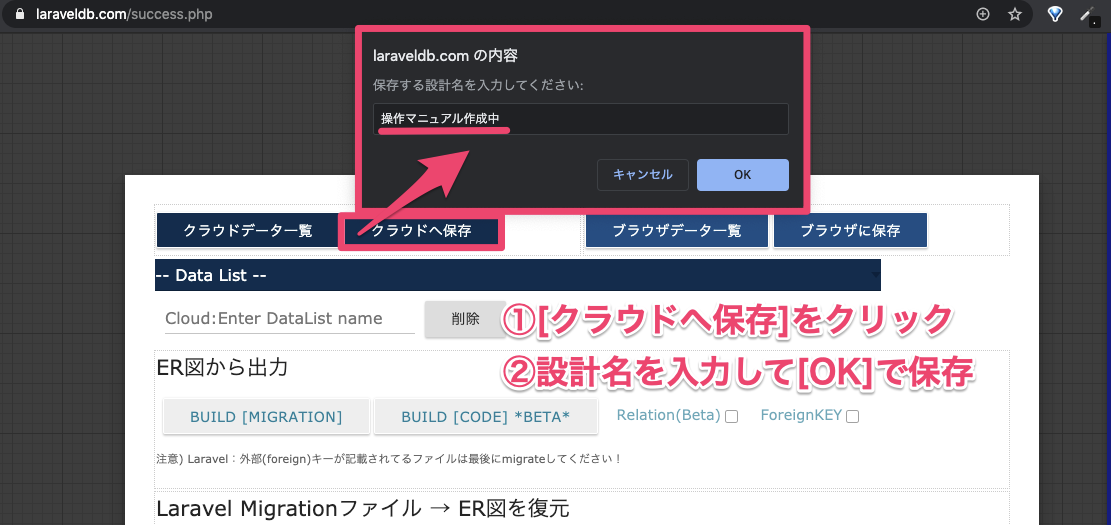
4.ER図の保存
コントロールパネル[Data:セーブ/ロード]から移動します。
「クラウドに保存」or「ブラウザに保存」を選択できます。
この例では「クラウドに保存」を選択。
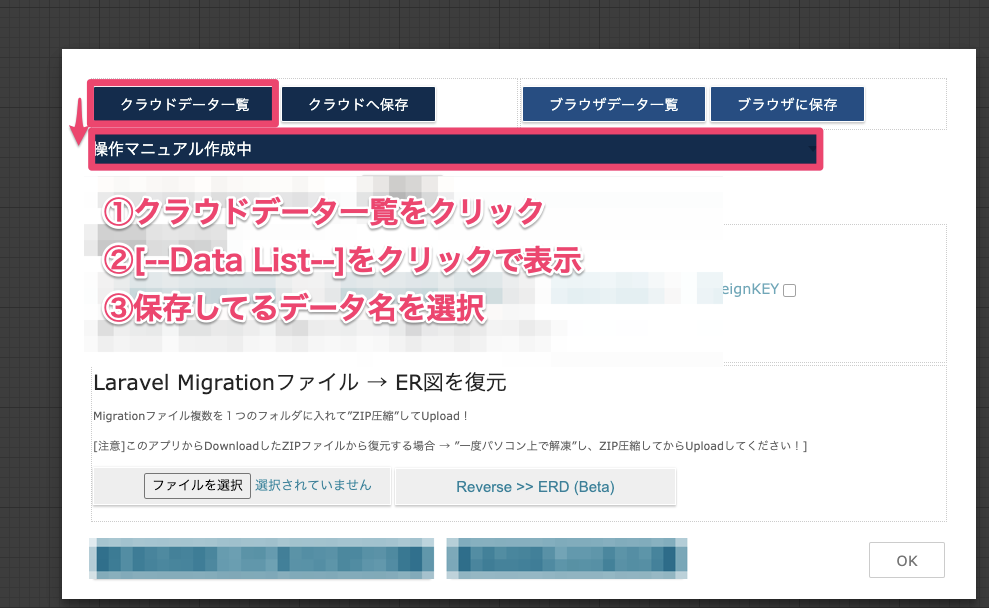
Save/Load機能 機能詳細 クラウドへ保存 アカウントに紐づきクラウドに保存します。 クラウドデータ一覧 保存したクラウド側のデータ一覧 ブラウザに保存 使用中のブラウザ「LocalStorage」に一時保存 ブラウザデータ一覧 localStorageに保存したデータ一覧
上記の「データ一覧」選択後、「 -- Data List -- 」の選択肢が表示されます。
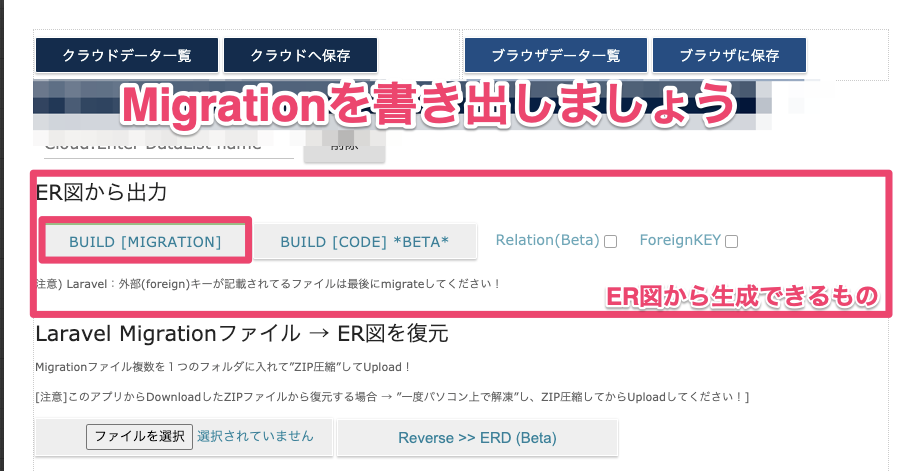
そこに表示されるデータ項目を選択するとER図を復元します。5.Migrationを生成
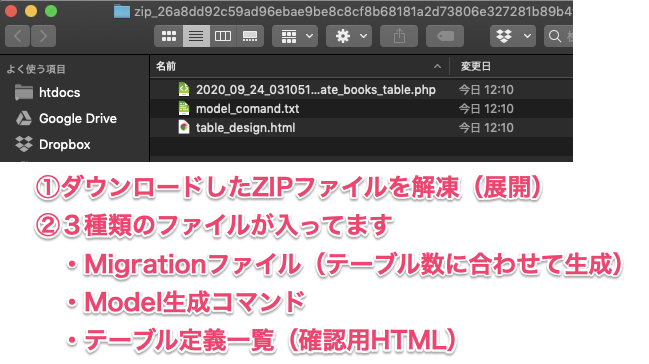
[ER図から出力]内のBuild [Migration]ボタンをクリックしてダウンロードします!
Zipファイルを解凍してダウンロードファイルを確認。
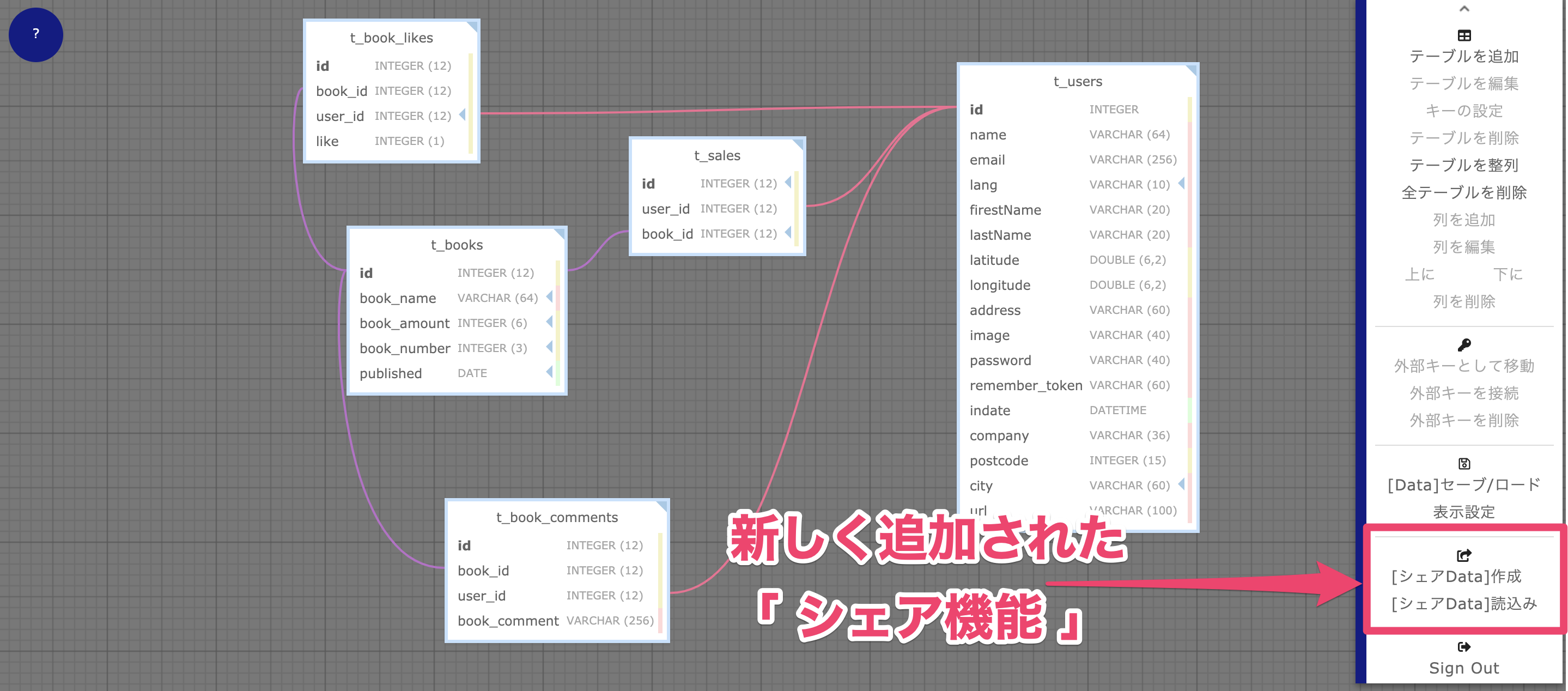
【ER図をTeamでシェア】
テーブル設計をシェアする機能のことです。
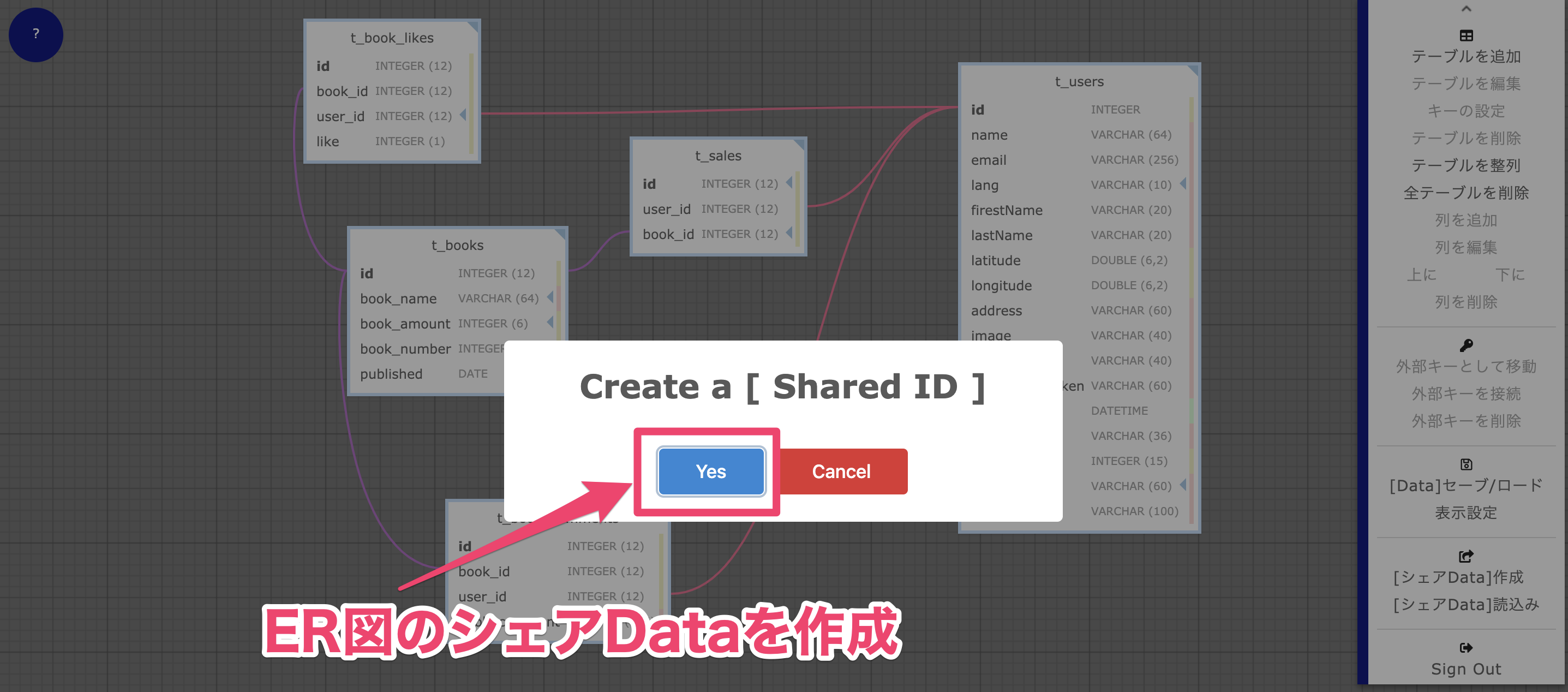
1 [送信側:シェアData]作成
見せたい相手にIDを渡しておいて、変更があれば「Create a [Share ID]」ボタンを押すと毎度データ更新されることを知っておきましょう!2 [送信側:シェアData] IDをコピー
ここでコピーしたIDを相手に知らせます。
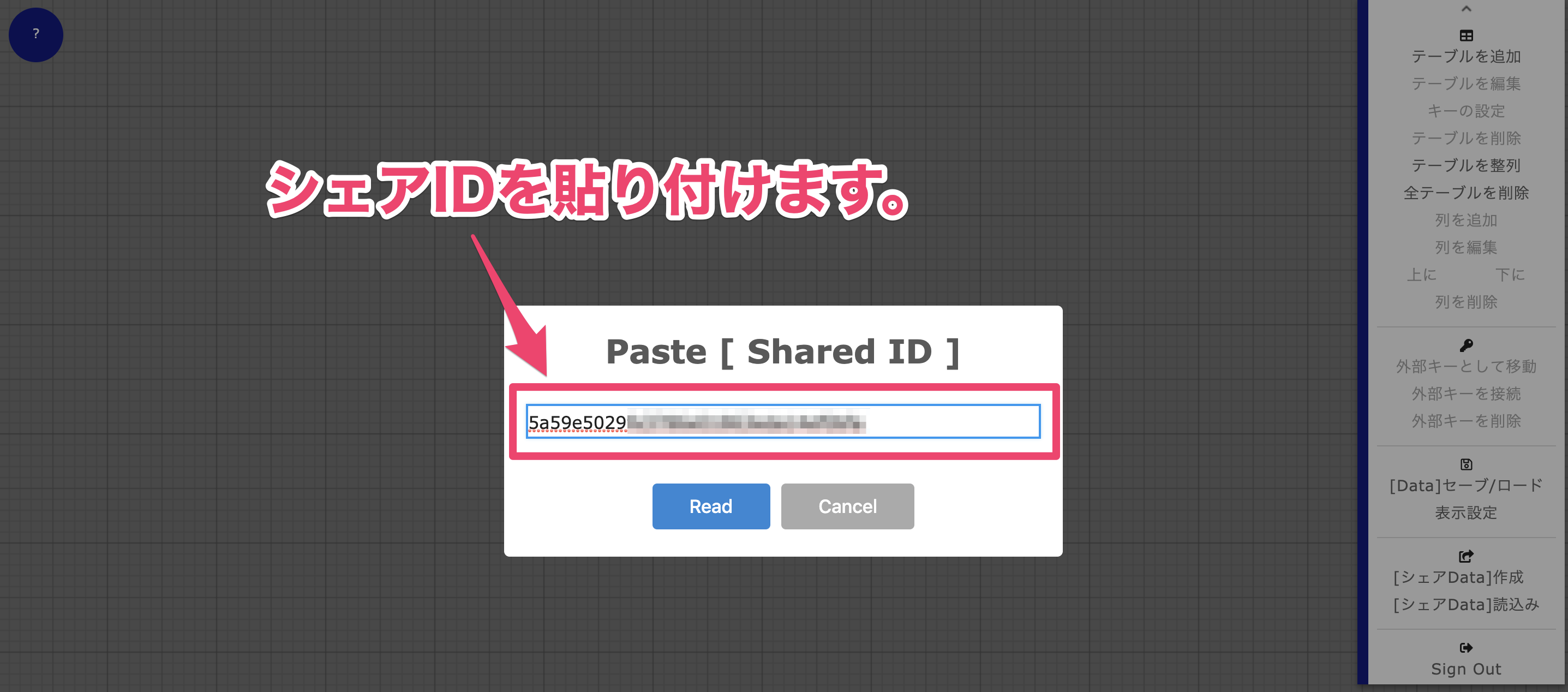
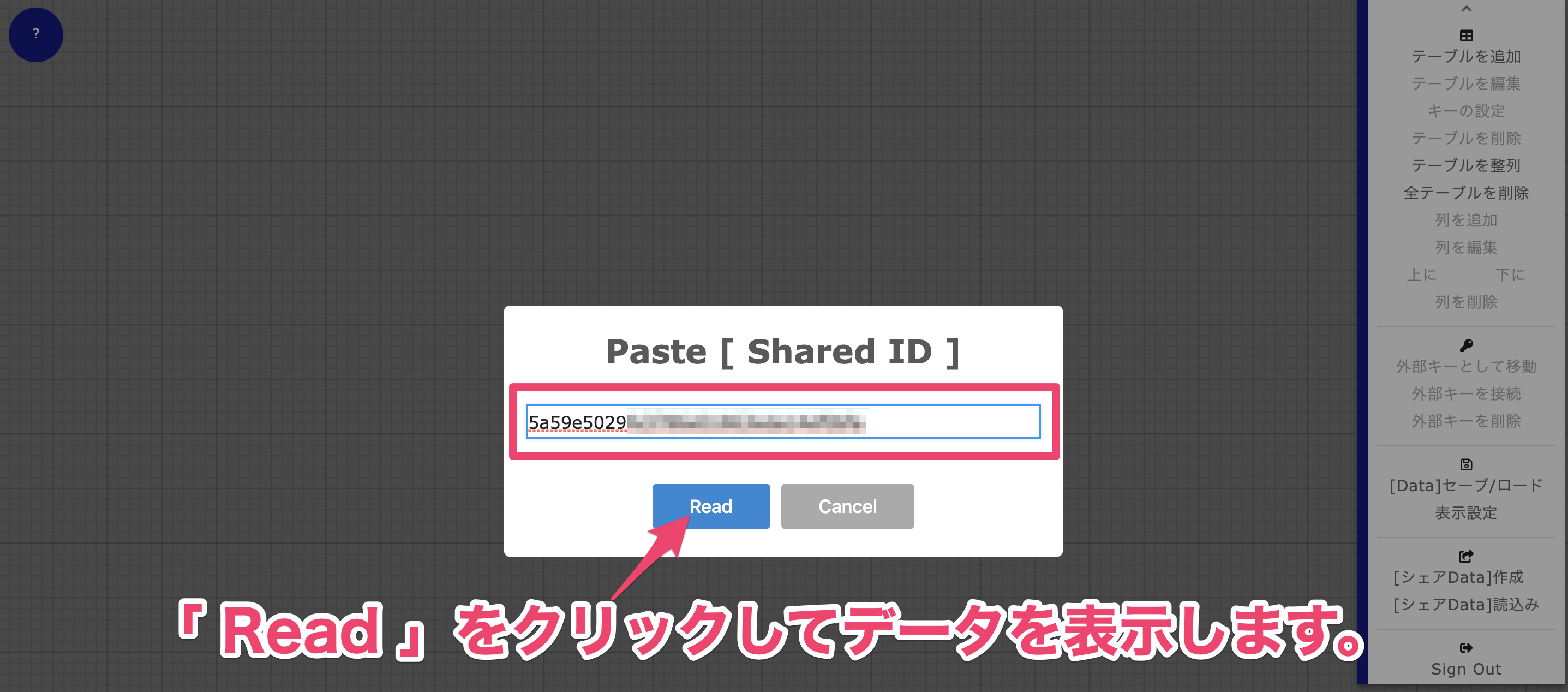
3 [受信側:シェアData]読み込み
相手は送られてきた[シェアData]IDを貼り付けます。
4 「Read」ボタンをクリックしてデータを受信表示しましょう。
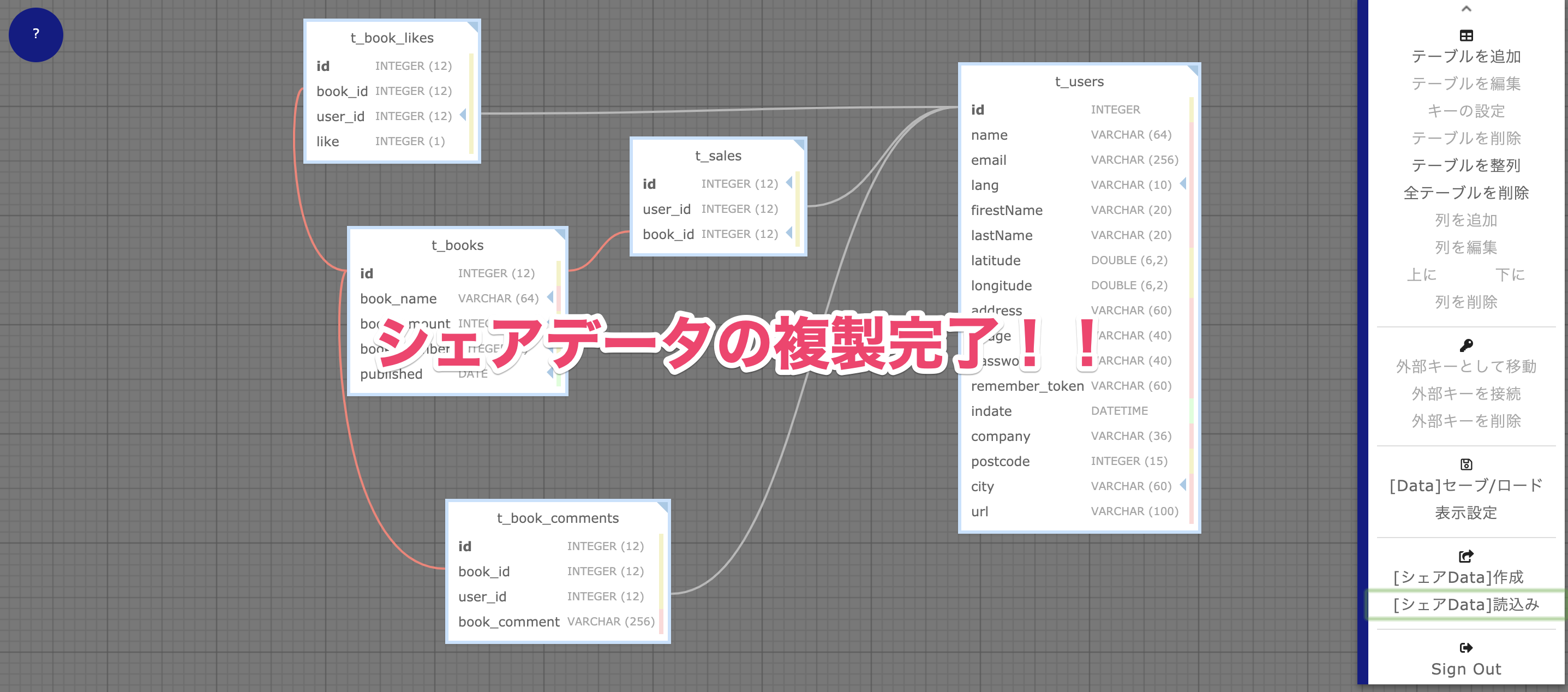
3.シェアデータの複製が完了!!
受信側にデータが入りました!受信側もそのデータを活用できるようになります。
チーム・メンタリング等のケースでも利用可能です。
※受信後は「別名を付けて保存しておくと良いでしょう!」◇ β版のCRUD/リレーションを使用したい場合(まだまだ開発段階の未知の機能)
<重要>この機能はテーブル名の末尾に「s」が無いとうまく動作しません。
※ENUMは必須・未入力のみ出力。
※intは型・必須・未入力のみ出力、sizeが未対応。
※2020-09-24Migrtion機能にアップデートが入ったので、β版機能に影響があるかもしれません。
まずは、複数のテーブルを簡単に作り「外部キーの接続」をして準備してください!!
その後、右メニュー「 [Data]セーブ/ロード 」クリックすると以下画面が表示されます。
BUILD [CRUD CODE] をクリック!!CRUD ファイル一式が生成されます
【ポイント】
Relation(Beta)にチェックを入れておくとリレーションします。
BUILD [MIGRATION] でもリレーション(QueryBuilder)がコメントで生成されますよ。
【このツールでのリレーションのポイント】
- JOINしてるテーブルの全ての項目を最初は表示します(同項目名が存在する場合、片方のみ表示します)。
- CRUDのコードが生成されたら、仕様に合わせてHTMLテーブルの項目を削除してください。
- リレーションは上記画像のように「チェック」を入れないと生成しないようにしています(Beta版のため)。
- Controller内にコードが生成されてますので、確認しておくと良いでしょう!
- 外部キーはこのツールでは非推奨としています(理由:Migrationの実行順序が重要でエラーになりやすい為)
プロトタイプ(ベースになるコードを生成してくれる)には十分すぎる機能ですね。
◇Validation → テーブル設計に合わせて生成
Validationって地味に面倒ですよね、完璧では内容ですが、少しの手直しで使用できるなら便利そうです!!
例でざっくりテーブルをER図で書いてみました。
以下"t_gsusers"テーブルを中心に見ていきます。
生成されたコントローラーのcreate(),edit()にはこういったvalidationが挿入されます。
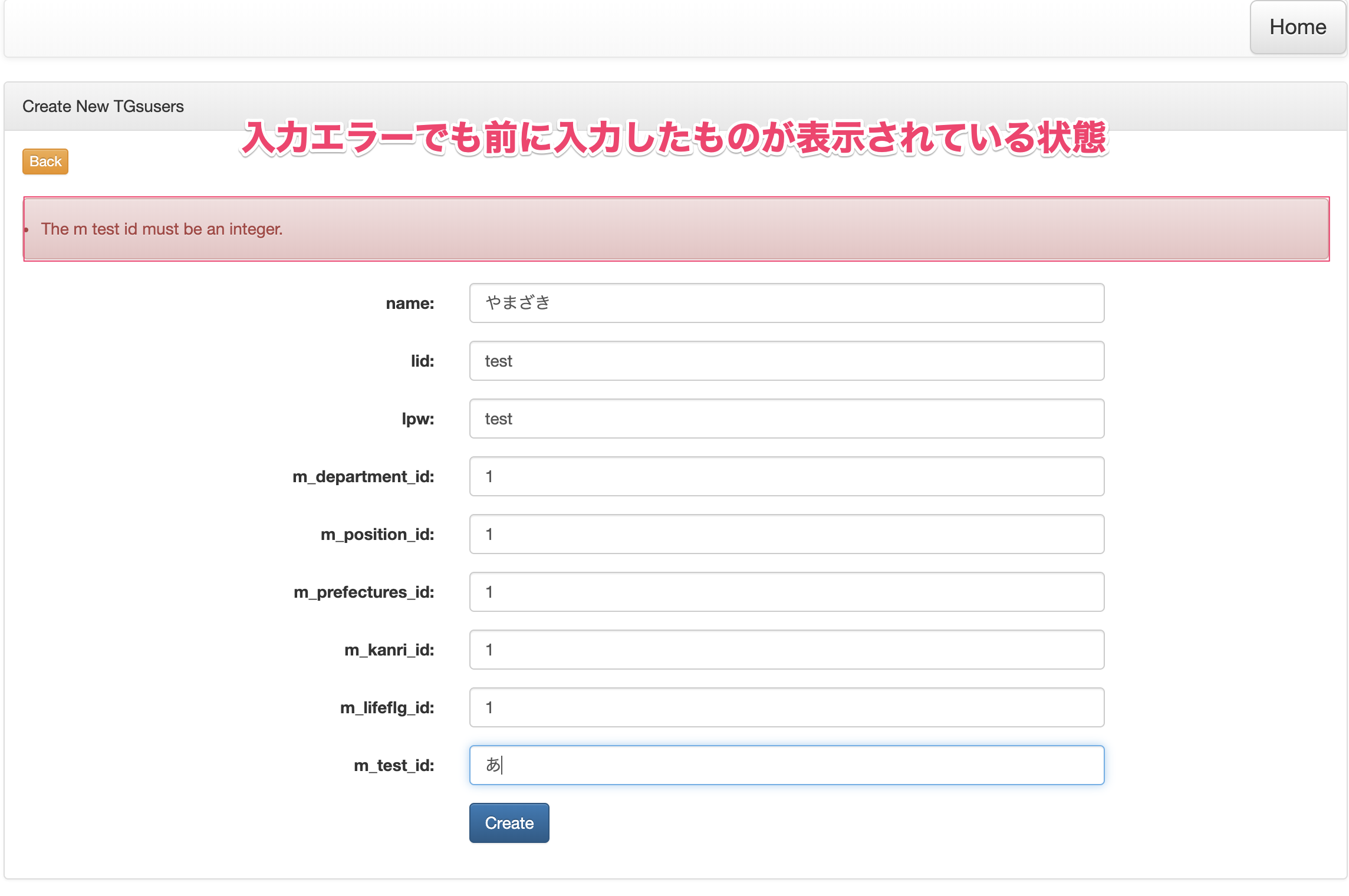
TGsusersController$this->validate($request, [ "name" => "required|max:128", //string('name',128) "lid" => "required|max:128", //string('lid',128) "lpw" => "required|max:128", //string('lpw',128) "m_department_id" => "required|integer", //integer('m_department_id') "m_position_id" => "required|integer", //integer('m_position_id') "m_prefectures_id" => "required|integer", //integer('m_prefectures_id') "m_kanri_id" => "required|integer", //integer('m_kanri_id') "m_lifeflg_id" => "required|integer", //integer('m_lifeflg_id') "m_test_id" => "required|integer", //integer('m_test_id') ]);{{old('name')}} → 入力項目を補完(CRUD:β版を使用した場合に生成されます)
validationで未入力等ではじかれた場合、入力した文字を消さずに表示します。
ベータ版のCRUD/リレーションの利用シーン
上記のようにβ版ではありますが、全てを利用するというよりは、コードを生成して、必要な部分だけ使うのも良いと思います。(実際にそういったケースを耳にしました〜)
◇LaravelDB.com 対応カラム一覧
tinyIncrements
mediumIncrements
smallIncrements
bigIncrements
increments
mediumInteger
smallInteger
bigInteger
tinyInteger
integer
unsignedInteger (2020-09-24対応)
unsignedTinyInteger (2020-09-24対応)
unsignedSmallInteger (2020-09-24対応)
unsignedMediumInteger (2020-09-24対応)
unsignedBigInteger (2020-09-24対応)
decimal
double
float
enum (2020-09-24対応)
geometryCollection
geometry
jsonb
json
char
longText
mediumText
text
multiLineString
lineString
string
multiPoint
multiPolygon
point
polygon
binary
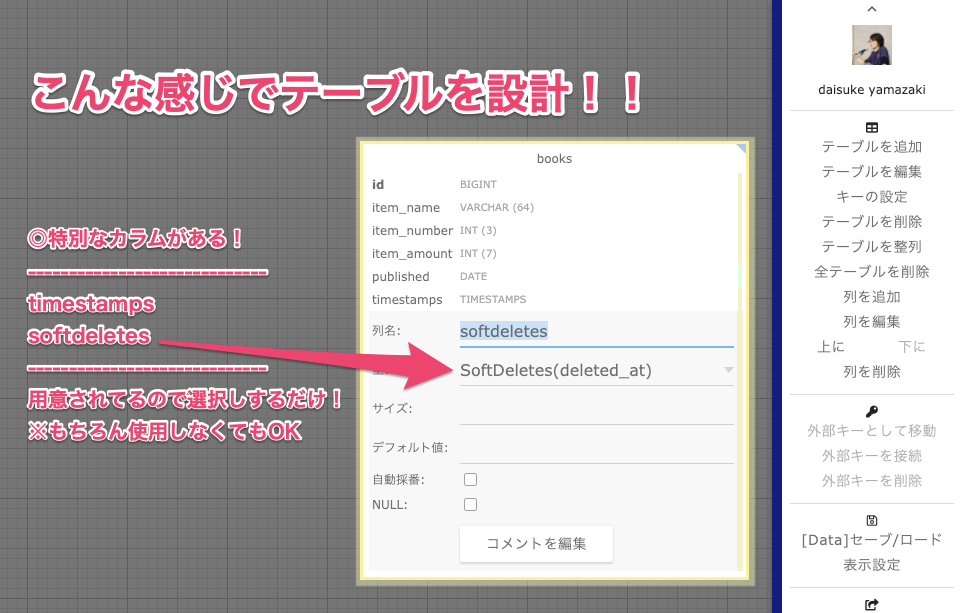
nullableTimestamps
timestamps (2020-09-24対応)
softDeletes (2020-09-24対応)
dateTime
timestamp
time
year
date◇そもそも、なんで作ったの?
私は学校でプログラミング(サービスを作る基本)を教えていて、テーブル設計している学生がその場にいて
「テーブル設計して、そこからMigrationファイル作成して、コードをイチから書いて・・・」普通の作業ではあるんですが、何故か「その時は疑問を感じました」、ER図書いたらMigrationファイル生成したら便利だよね~。
何割かの開発者は喜んでくれるのでは?と思ったのがキッカケでした。
特に「テーブル設計は保存可能」なので、前回作ったテーブル設計から新しい設計を複製できるのは嬉しい機能です。設計してMigration or CRUDコード書き出してができるので、「設計して→コード書いて」という往復作業が無くなるので、是非使ってほしいと思います。今後の展開
2020-09-24以降からは「Migration」を軸にアップデートしていきます
なぜ、↑そう思ったか?
良かれと思った機能が意外に余計だった。。。よくあるパターンですね。
テーブル名に"t_","m_"とかトランザクション・マスターテーブルなどがテーブル名で分かるようにした場合に、自動で「timestamps」「softDeletes」などを挿入する機能が逆に「解りにくくさせていた」という事があります。今回のアップデートで廃止いしたのでご安心ください(余計なことはしません(^^))。
やはりシンプルがベストなんですよね。今はいかに「シンプルにするか」だけ考えてアップデートを考えています。
※必要な機能はどうやって複雑にせずに追加するか?など、悩みが楽しくてしょうがありません。
※CRUD(β版)機能のアップデートはどうなるか未定(Laravel7までは動作確認ずみ)
※Laravel8移行のLTSの仕様で検討予定ですかね~~~かなり変わってるように思ったので。◇LaravelDB.com サイト
◇Twitterアカウント
以上



- 投稿日:2020-09-24T13:00:25+09:00
LaravelDB.com~操作方法と勘所を書いた〜2020/09/24メジャーアップデート版
◇LaravelDB.com ?
Laravelのデータベース設計(ER図)するだけで、Migrationファイルがポンって作成できるFreeの「 テーブル設計&Migration作成 」 ツールです。
メイン機能
- Migrationの自動生成
- チームメンバーとの共有可能
- CRUDコード(β版)の自動生成
- CRUDコード(β版)でのValidation自動生成(テーブル設計に合わせて自動で生成)
用途
用途は開発者によってバラバラですね。
・Migrationのみ使う(ほとんどの人はここですかね)
・CRUDファイル全部(数%くらいの人)
・コード生成後、一部(Validationとか)をコピーして使う(結構な割合でいます)
・テーブル設計の共有(Team開発では使ってるようです)◇操作方法(マニュアル)
1.テーブル作成
2.カラム作成
※使いやすくするポイント!! 「列を追加」ボタンを連打で必要な数だけ先に作ると便利!!
3.2020-09-24アップデートから使用可能
「 ENUM, UNSIGNED ] に対応、新規プロジェクトより表示されるようになります
以下はENUM、Doubleの入力してる例です。
「 UNIQUE, INDEX ] に対応、新規プロジェクトより表示されるようになります
外部キーの設定
外部キー制約を使用する場合( ※1対他、多対多などを分ける機能は無い)
4.ER図の保存
コントロールパネル[Data:セーブ/ロード]から移動します。
「クラウドに保存」or「ブラウザに保存」を選択できます。
この例では「クラウドに保存」を選択。
Save/Load機能 機能詳細 クラウドへ保存 アカウントに紐づきクラウドに保存します。 クラウドデータ一覧 保存したクラウド側のデータ一覧 ブラウザに保存 使用中のブラウザ「LocalStorage」に一時保存 ブラウザデータ一覧 localStorageに保存したデータ一覧
上記の「データ一覧」選択後、「 -- Data List -- 」の選択肢が表示されます。
そこに表示されるデータ項目を選択するとER図を復元します。5.Migrationを生成
[ER図から出力]内のBuild [Migration]ボタンをクリックしてダウンロードします!
Zipファイルを解凍してダウンロードファイルを確認。
【ER図をTeamでシェア】
テーブル設計をシェアする機能のことです。
1 [送信側:シェアData]作成
見せたい相手にIDを渡しておいて、変更があれば「Create a [Share ID]」ボタンを押すと毎度データ更新されることを知っておきましょう!2 [送信側:シェアData] IDをコピー
ここでコピーしたIDを相手に知らせます。
3 [受信側:シェアData]読み込み
相手は送られてきた[シェアData]IDを貼り付けます。
4 「Read」ボタンをクリックしてデータを受信表示しましょう。
3.シェアデータの複製が完了!!
受信側にデータが入りました!受信側もそのデータを活用できるようになります。
チーム・メンタリング等のケースでも利用可能です。
※受信後は「別名を付けて保存しておくと良いでしょう!」◇ β版のCRUD/リレーションを使用したい場合(まだまだ開発段階の未知の機能)
<重要>この機能はテーブル名の末尾に「s」が無いとうまく動作しません。
※ENUMは必須・未入力のみ出力。
※intは型・必須・未入力のみ出力、sizeが未対応。
※2020-09-24Migrtion機能にアップデートが入ったので、β版機能に影響があるかもしれません。
まずは、複数のテーブルを簡単に作り「外部キーの接続」をして準備してください!!
その後、右メニュー「 [Data]セーブ/ロード 」クリックすると以下画面が表示されます。
BUILD [CRUD CODE] をクリック!!CRUD ファイル一式が生成されます
【ポイント】
Relation(Beta)にチェックを入れておくとリレーションします。
BUILD [MIGRATION] でもリレーション(QueryBuilder)がコメントで生成されますよ。
【このツールでのリレーションのポイント】
- JOINしてるテーブルの全ての項目を最初は表示します(同項目名が存在する場合、片方のみ表示します)。
- CRUDのコードが生成されたら、仕様に合わせてHTMLテーブルの項目を削除してください。
- リレーションは上記画像のように「チェック」を入れないと生成しないようにしています(Beta版のため)。
- Controller内にコードが生成されてますので、確認しておくと良いでしょう!
- 外部キーはこのツールでは非推奨としています(理由:Migrationの実行順序が重要でエラーになりやすい為)
◇Validation → テーブル設計に合わせて生成
Validationって地味に面倒ですよね、完璧では内容ですが、少しの手直しで使用できるなら便利そうです!!
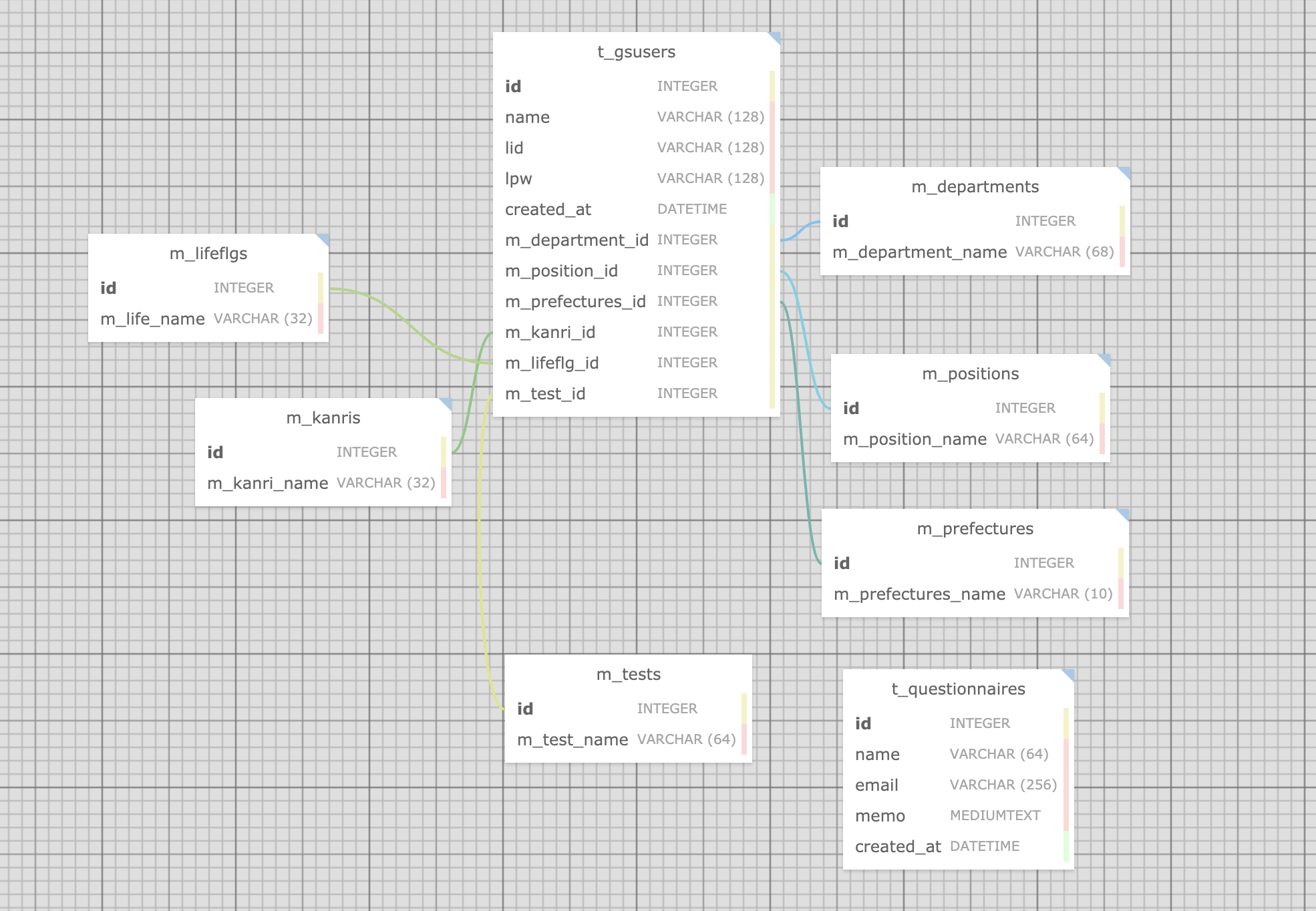
例でざっくりテーブルをER図で書いてみました。
以下"t_gsusers"テーブルを中心に見ていきます。
生成されたコントローラーのcreate(),edit()にはこういったvalidationが挿入されます。
TGsusersController$this->validate($request, [ "name" => "required|max:128", //string('name',128) "lid" => "required|max:128", //string('lid',128) "lpw" => "required|max:128", //string('lpw',128) "m_department_id" => "required|integer", //integer('m_department_id') "m_position_id" => "required|integer", //integer('m_position_id') "m_prefectures_id" => "required|integer", //integer('m_prefectures_id') "m_kanri_id" => "required|integer", //integer('m_kanri_id') "m_lifeflg_id" => "required|integer", //integer('m_lifeflg_id') "m_test_id" => "required|integer", //integer('m_test_id') ]);{{old('name')}} → 入力項目を補完(CRUD:β版を使用した場合に生成されます)
validationで未入力等ではじかれた場合、入力した文字を消さずに表示します。
ベータ版のCRUD/リレーションの利用シーン
上記のようにβ版ではありますが、全てを利用するというよりは、コードを生成して、必要な部分だけ使うのも良いと思います。(実際にそういったケースを耳にしました〜)
◇LaravelDB.com 対応カラム一覧
tinyIncrements
mediumIncrements
smallIncrements
bigIncrements
increments
mediumInteger
smallInteger
bigInteger
tinyInteger
integer
unsignedInteger (2020-09-24対応)
unsignedTinyInteger (2020-09-24対応)
unsignedSmallInteger (2020-09-24対応)
unsignedMediumInteger (2020-09-24対応)
unsignedBigInteger (2020-09-24対応)
decimal
double
float
enum (2020-09-24対応)
geometryCollection
geometry
jsonb
json
char
longText
mediumText
text
multiLineString
lineString
string
multiPoint
multiPolygon
point
polygon
binary
nullableTimestamps
timestamps (2020-09-24対応)
softDeletes (2020-09-24対応)
dateTime
timestamp
time
year
date◇そもそも、なんで作ったの?
私は学校でプログラミング(サービスを作る基本)を教えていて、テーブル設計している学生がその場にいて
「テーブル設計して、そこからMigrationファイル作成して、コードをイチから書いて・・・」普通の作業ではあるんですが、何故か「その時は疑問を感じました」、ER図書いたらMigrationファイル生成したら便利だよね~。
何割かの開発者は喜んでくれるのでは?と思ったのがキッカケでした。
特に「テーブル設計は保存可能」なので、前回作ったテーブル設計から新しい設計を複製できるのは嬉しい機能です。設計してMigration or CRUDコード書き出してができるので、「設計して→コード書いて」という往復作業が無くなるので、是非使ってほしいと思います。今後の展開
2020-09-24以降からは「Migration」を軸にアップデートしていきます
なぜ、↑そう思ったか?
良かれと思った機能が意外に余計だった。。。よくあるパターンですね。
テーブル名に"t_","m_"とかトランザクション・マスターテーブルなどがテーブル名で分かるようにした場合に、自動で「timestamps」「softDeletes」などを挿入する機能が逆に「解りにくくさせていた」という事があります。今回のアップデートで廃止いしたのでご安心ください(余計なことはしません(^^))。
やはりシンプルがベストなんですよね。今はいかに「シンプルにするか」だけ考えてアップデートを考えています。
※必要な機能はどうやって複雑にせずに追加するか?など、悩みが楽しくてしょうがありません。
※CRUD(β版)機能のアップデートはどうなるか未定(Laravel7までは動作確認ずみ)
※Laravel8移行のLTSの仕様で検討予定ですかね~~~かなり変わってるように思ったので。◇LaravelDB.com サイト
◇Twitterアカウント
以上
- 投稿日:2020-09-24T13:00:25+09:00
LaravelDB.com~操作方法と勘所を書いた〜(基本操作編)
◇LaravelDB.com ?
Laravelのデータベース設計(ER図)するだけで、Migrationファイルがポンって作成できるFreeの「 テーブル設計&Migration作成 」 ツールです。
メイン機能
- Migrationの自動生成
- チームメンバーとの共有可能
- CRUDコード(β版)の自動生成
- CRUDコード(β版)でのValidation自動生成(テーブル設計に合わせて自動で生成)
利用について
個人/プログラミング学習者: 無料
企業/商用利用:paypal等の寄付・ウイッシュリストでの寄付用途
用途は開発者によってバラバラですね。
・Migrationのみ使う(ほとんどの人はここですかね)
・CRUDファイル全部(数%くらいの人)
・コード生成後、一部(Validationとか)をコピーして使う(結構な割合でいます)
・テーブル設計の共有(Team開発では使ってるようです)◇操作方法(マニュアル)
1.テーブル作成
2.カラム作成
※使いやすくするポイント!! 「列を追加」ボタンを連打で必要な数だけ先に作ると便利!!
3.2020-09-24アップデートから使用可能
「 ENUM, UNSIGNED ] に対応、新規プロジェクトより表示されるようになります
以下はENUM、Doubleの入力してる例です。
「 UNIQUE, INDEX ] に対応、新規プロジェクトより表示されるようになります
外部キーの設定
外部キー制約を使用する場合( ※1対他、多対多などを分ける機能は無い)
4.ER図の保存
コントロールパネル[Data:セーブ/ロード]から移動します。
「クラウドに保存」or「ブラウザに保存」を選択できます。
この例では「クラウドに保存」を選択。
Save/Load機能 機能詳細 クラウドへ保存 アカウントに紐づきクラウドに保存します。 クラウドデータ一覧 保存したクラウド側のデータ一覧 ブラウザに保存 使用中のブラウザ「LocalStorage」に一時保存 ブラウザデータ一覧 localStorageに保存したデータ一覧
上記の「データ一覧」選択後、「 -- Data List -- 」の選択肢が表示されます。
そこに表示されるデータ項目を選択するとER図を復元します。5.Migrationを生成
[ER図から出力]内のBuild [Migration]ボタンをクリックしてダウンロードします!
Zipファイルを解凍してダウンロードファイルを確認。
【ER図をTeamでシェア】
テーブル設計をシェアする機能のことです。
1 [送信側:シェアData]作成
見せたい相手にIDを渡しておいて、変更があれば「Create a [Share ID]」ボタンを押すと毎度データ更新されることを知っておきましょう!2 [送信側:シェアData] IDをコピー
ここでコピーしたIDを相手に知らせます。
3 [受信側:シェアData]読み込み
相手は送られてきた[シェアData]IDを貼り付けます。
4 「Read」ボタンをクリックしてデータを受信表示しましょう。
3.シェアデータの複製が完了!!
受信側にデータが入りました!受信側もそのデータを活用できるようになります。
チーム・メンタリング等のケースでも利用可能です。
※受信後は「別名を付けて保存しておくと良いでしょう!」◇ リバースエンジニアリング(Migration → ER図)
フォルダにMigrationファイル(Schema::createのみ)一式集めZip圧縮したファイルをアップロードすることで、ER図へ変換(リバース)することが可能です。
Migrationファイル一式をZIP圧縮 → [ Reverse >>> ERD ]ボタンでアップロード
アップロード完了するとER図が表示されます。
Migration(ZIPファイルに一式纏めて) 機能詳細 [ Reverse >>> ERD ] Migrationファイル一式をフォルダに入れて、ZIP圧縮したファイルをアップロード 1.注意
以下Migrationファイル 「 Schema::create 」のみ現在は可能
※ Schema::create以外は対応検討中Schema::create("テーブル名", function (Blueprint $table) {...}2.注意
「LaravelDB.com」からZIPファイルをダウンロードしたファイルをそのままアップロードは出来ません。必ず、一度解凍したものをZIP圧縮しなおしてuploadしてください。◇ β版のCRUD/リレーションを使用したい場合(まだまだ開発段階の未知の機能)
<重要>この機能はテーブル名の末尾に「s」が無いとうまく動作しません。
※ENUMは必須・未入力のみ出力。
※intは型・必須・未入力のみ出力、sizeが未対応。
※2020-09-24Migrtion機能にアップデートが入ったので、β版機能に影響があるかもしれません。
まずは、複数のテーブルを簡単に作り「外部キーの接続」をして準備してください!!
その後、右メニュー「 [Data]セーブ/ロード 」クリックすると以下画面が表示されます。
BUILD [CRUD CODE] をクリック!!CRUD ファイル一式が生成されます
【ポイント】
Relation(Beta)にチェックを入れておくとリレーションします。
BUILD [MIGRATION] でもリレーション(QueryBuilder)がコメントで生成されますよ。
【このツールでのリレーションのポイント】
- JOINしてるテーブルの全ての項目を最初は表示します(同項目名が存在する場合、片方のみ表示します)。
- CRUDのコードが生成されたら、仕様に合わせてHTMLテーブルの項目を削除してください。
- リレーションは上記画像のように「チェック」を入れないと生成しないようにしています(Beta版のため)。
- Controller内にコードが生成されてますので、確認しておくと良いでしょう!
- 外部キーはこのツールでは非推奨としています(理由:Migrationの実行順序が重要でエラーになりやすい為)
◇Validation → テーブル設計に合わせて生成
Validationって地味に面倒ですよね、完璧では内容ですが、少しの手直しで使用できるなら便利そうです!!
例でざっくりテーブルをER図で書いてみました。
以下"t_gsusers"テーブルを中心に見ていきます。
生成されたコントローラーのcreate(),edit()にはこういったvalidationが挿入されます。
TGsusersController$this->validate($request, [ "name" => "required|max:128", //string('name',128) "lid" => "required|max:128", //string('lid',128) "lpw" => "required|max:128", //string('lpw',128) "m_department_id" => "required|integer", //integer('m_department_id') "m_position_id" => "required|integer", //integer('m_position_id') "m_prefectures_id" => "required|integer", //integer('m_prefectures_id') "m_kanri_id" => "required|integer", //integer('m_kanri_id') "m_lifeflg_id" => "required|integer", //integer('m_lifeflg_id') "m_test_id" => "required|integer", //integer('m_test_id') ]);{{old('name')}} → 入力項目を補完(CRUD:β版を使用した場合に生成されます)
validationで未入力等ではじかれた場合、入力した文字を消さずに表示します。
ベータ版のCRUD/リレーションの利用シーン
上記のようにβ版ではありますが、全てを利用するというよりは、コードを生成して、必要な部分だけ使うのも良いと思います。(実際にそういったケースを耳にしました〜)
◇LaravelDB.com 対応カラム一覧
tinyIncrements
mediumIncrements
smallIncrements
bigIncrements
increments
mediumInteger
smallInteger
bigInteger
tinyInteger
integer
unsignedInteger (2020-09-24対応)
unsignedTinyInteger (2020-09-24対応)
unsignedSmallInteger (2020-09-24対応)
unsignedMediumInteger (2020-09-24対応)
unsignedBigInteger (2020-09-24対応)
decimal
double
float
enum (2020-09-24対応)
geometryCollection
geometry
jsonb
json
char
longText
mediumText
text
multiLineString
lineString
string
multiPoint
multiPolygon
point
polygon
binary
nullableTimestamps
timestamps (2020-09-24対応)
softDeletes (2020-09-24対応)
dateTime
timestamp
time
year
date◇そもそも、なんで作ったの?
私は学校でプログラミング(サービスを作る基本)を教えていて、テーブル設計している学生がその場にいて
「テーブル設計して、そこからMigrationファイル作成して、コードをイチから書いて・・・」普通の作業ではあるんですが、何故か「その時は疑問を感じました」、ER図書いたらMigrationファイル生成したら便利だよね~。
何割かの開発者は喜んでくれるのでは?と思ったのがキッカケでした。
特に「テーブル設計は保存可能」なので、前回作ったテーブル設計から新しい設計を複製できるのは嬉しい機能です。設計してMigration or CRUDコード書き出してができるので、「設計して→コード書いて」という往復作業が無くなるので、是非使ってほしいと思います。今後の展開
2020-09-24以降からは「Migration」を軸にアップデートしていきます
なぜ、↑そう思ったか?
良かれと思った機能が意外に余計だった。。。よくあるパターンですね。
テーブル名に"t_","m_"とかトランザクション・マスターテーブルなどがテーブル名で分かるようにした場合に、自動で「timestamps」「softDeletes」などを挿入する機能が逆に「解りにくくさせていた」という事があります。今回のアップデートで廃止いしたのでご安心ください(余計なことはしません(^^))。
やはりシンプルがベストなんですよね。今はいかに「シンプルにするか」だけ考えてアップデートを考えています。
※必要な機能はどうやって複雑にせずに追加するか?など、悩みが楽しくてしょうがありません。
※CRUD(β版)機能のアップデートはどうなるか未定(Laravel7までは動作確認ずみ)
※Laravel8移行のLTSの仕様で検討予定ですかね~~~かなり変わってるように思ったので。◇LaravelDB.com サイト
◇Twitterアカウント
以上

- 投稿日:2020-09-24T09:31:20+09:00
SQL の DISTINCT を使うサンプル
概要
- SQL の DISTINCT を使うサンプルを書く
- 環境: MySQL Ver 8.0.21 for osx10.15 on x86_64 (Homebrew)
DISTINCT とは
指定したカラムにおいて重複するデータを取り除いて出力することができる機能。
DISTINCT(UNIQUE)...テーブルに同じデータ行がある場合、重複を取り除いた1件のみを返す。
MySQL :: MySQL 5.6 リファレンスマニュアル :: 13.2.9 SELECT 構文
ALL および DISTINCT オプションは、重複した行を返すかどうかを指定します。ALL (デフォルト) は、重複を含め、一致するすべての行を返すように指定します。DISTINCT は、重複した行の結果セットからの削除を指定します。両方のオプションを指定するとエラーになります。
サンプルデータを準備
買ったお菓子テーブルを作成。
mysql> CREATE TABLE katta_okashi ( -> number INTEGER, -> name VARCHAR(128), -> okashi VARCHAR(128), -> price INTEGER -> ); Query OK, 0 rows affected (0.02 sec)買ったお菓子データを追加。
mysql> INSERT INTO katta_okashi VALUES -> (1, 'Alice', 'candy', 100), -> (2, 'Alice', 'candy', 50), -> (3, 'Alice', 'cookie', 30), -> (4, 'Bob', 'chocolate', 200), -> (5, 'Bob', 'chocolate', 20), -> (6, 'Bob', 'cookie', 20); Query OK, 6 rows affected (0.03 sec) Records: 6 Duplicates: 0 Warnings: 0買ったお菓子データ一覧を出力。
mysql> select * from katta_okashi; +--------+-------+-----------+-------+ | number | name | okashi | price | +--------+-------+-----------+-------+ | 1 | Alice | candy | 100 | | 2 | Alice | candy | 50 | | 3 | Alice | cookie | 30 | | 4 | Bob | chocolate | 200 | | 5 | Bob | chocolate | 20 | | 6 | Bob | cookie | 20 | +--------+-------+-----------+-------+ 6 rows in set (0.00 sec)カラムを指定して重複行をまとめる
カラムにて一意となるデータになるように重複したデータを取り除いて出力できる。
name には何パターンのデータが入っているか。
mysql> select distinct name from katta_okashi; +-------+ | name | +-------+ | Alice | | Bob | +-------+ 2 rows in set (0.01 sec)okashi には何パターンのデータが入っているか。
mysql> select distinct okashi from katta_okashi; +-----------+ | okashi | +-----------+ | candy | | cookie | | chocolate | +-----------+ 3 rows in set (0.00 sec)複数カラムを指定して重複行をまとめる
複数カラムで一意となるデータ (組み合わせパターン分) が出力される。
mysql> select distinct name, okashi from katta_okashi; +-------+-----------+ | name | okashi | +-------+-----------+ | Alice | candy | | Alice | cookie | | Bob | chocolate | | Bob | cookie | +-------+-----------+ 4 rows in set (0.00 sec)カラム内の一意なデータのカウント
name が何種類あるか。
mysql> select count(distinct name) from katta_okashi; +----------------------+ | count(distinct name) | +----------------------+ | 2 | +----------------------+ 1 row in set (0.00 sec)okashi が何種類あるか。
mysql> select count(distinct okashi) from katta_okashi; +------------------------+ | count(distinct okashi) | +------------------------+ | 3 | +------------------------+ 1 row in set (0.01 sec)複数カラム name と count の組み合わせが何パターンあるか。
mysql> select count(distinct name, okashi) from katta_okashi; +------------------------------+ | count(distinct name, okashi) | +------------------------------+ | 4 | +------------------------------+ 1 row in set (0.02 sec)ORDER BY と組み合わせる
カラム内で一意となるデータを並び替えてから出力できる。
mysql> select distinct name from katta_okashi order by name desc; +-------+ | name | +-------+ | Bob | | Alice | +-------+ 2 rows in set (0.01 sec)参考資料