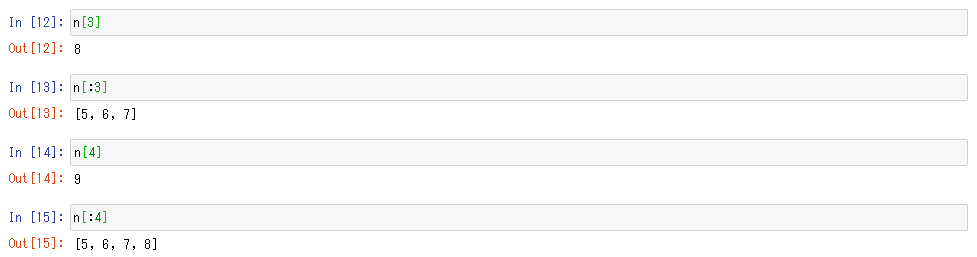
layer filters size input output
0 conv 32 3 x 3 / 1 608 x 608 x 3 ->608 x 608 x 32 0.639 BFLOPs
1 conv 64 3 x 3 / 2 608 x 608 x 32 ->304 x 304 x 64 3.407 BFLOPs
2 conv 32 1 x 1 / 1 304 x 304 x 64 ->304 x 304 x 32 0.379 BFLOPs
3 conv 64 3 x 3 / 1 304 x 304 x 32 ->304 x 304 x 64 3.407 BFLOPs
:
103 conv 128 1 x 1 / 1 76 x 76 x 256 ->76 x 76 x 128 0.379 BFLOPs
104 conv 256 3 x 3 / 1 76 x 76 x 128 ->76 x 76 x 256 3.407 BFLOPs
105 conv 255 1 x 1 / 1 76 x 76 x 256 ->76 x 76 x 255 0.754 BFLOPs
106 yolo
Loading weights from yolov3.weights...Done!
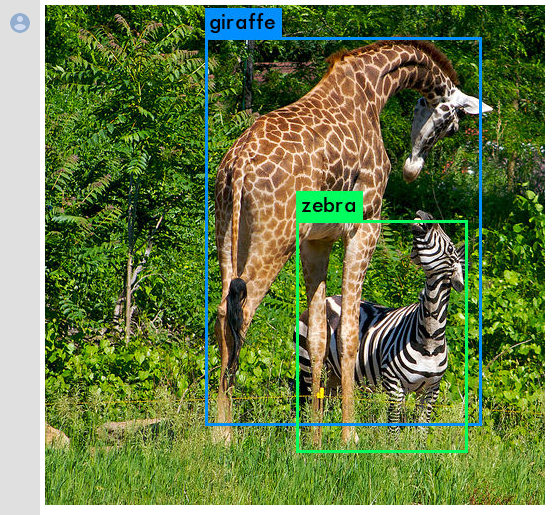
data/giraffe.jpg: Predicted in 19.677707 seconds.
giraffe: 98%
zebra: 98%
File "C:\programing\project\hoge\main.py", line 33, in _init_load
self.store = JsonStore('test.json', )
File "C:\Users\user\AppData\Local\Programs\Python\Python38\lib\site-packages\kivy\storage\jsonstore.py", line 29, in __init__
super(JsonStore, self).__init__(**kwargs)
File "C:\Users\user\AppData\Local\Programs\Python\Python38\lib\site-packages\kivy\storage\__init__.py", line 134, in __init__
self.store_load()
File "C:\Users\user\AppData\Local\Programs\Python\Python38\lib\site-packages\kivy\storage\jsonstore.py", line 43, in store_load
data = fd.read()
UnicodeDecodeError: 'cp932' codec can't decode byte 0x82 in position 85: illegal multibyte sequence
・画像を作成するには、np.array()関数(NumPyの行列を作る関数)を使う。また、range()を変数なしで多重ループさせて、縦横のピクセル情報(順番は青緑赤)を設定する。 ・np.array([[[B,G,Rの値]for _ in range(横のサイズ)] for_ in range(縦のサイズ)],dtype="uint8")
*uint8型とは、int型の中でも0〜255の値しか取らないもの。
・画像の保存はcv2.imwrite("ファイル名",画像)で行う。
・画像を作成するには、np.array()関数(NumPyの行列を作る関数)を使う。また、range()を変数なしで多重ループさせて、縦横のピクセル情報(順番は青緑赤)を設定する。 ・np.array([[[B,G,Rの値]for _ in range(横のサイズ)] for_ in range(縦のサイズ)],dtype="uint8")
*uint8型とは、int型の中でも0〜255の値しか取らないもの。
・画像の保存はcv2.imwrite("ファイル名",画像)で行う。
importquip# access to the quip
client=quip.QuipClient(access_token=<access_token>)# Get your thread_id from the URL of your document
user=client.get_authenticated_user()starred=client.get_folder(user["starred_folder_id"])# get the spreadsheet
spreadsheet=client.get_second_spreadsheet(thread_id=<thread_id>)parsedSpreadsheet=client.parse_spreadsheet_contents(spreadsheet)
スプレット形式のデータを取得できるのでデータフレームに落とし込む
quip_analysis.py
# create the dataframe
counter=0spreadsheetData=[]colNames=[]forrowsinparsedSpreadsheet["rows"]:cells=rows["cells"]rowData=[]forkey,valueincells.items():ifcounter==0:colNames.append(key)rowData.append(value['content'])spreadsheetData.append(rowData)counter+=1l=pd.DataFrame(spreadsheetData,columns=colNames)
#jupyter --versionTraceback (most recent call last):
File "/root/.pyenv/versions/anaconda3-5.3.1/bin/jupyter", line 7, in <module> from jupyter_core.command import main
ModuleNotFoundError: No module named 'jupyter_core'
一度conda からjupyter をインストールしてみる.
jupyterのインストール
#conda install jupyter
すると,以下のようなエラーが出力されてインストールが完了しない.
jupyterインストール時のエラー
failed with initial frozen solve. Retrying with flexible solve.
Solving environment: - 強制終了
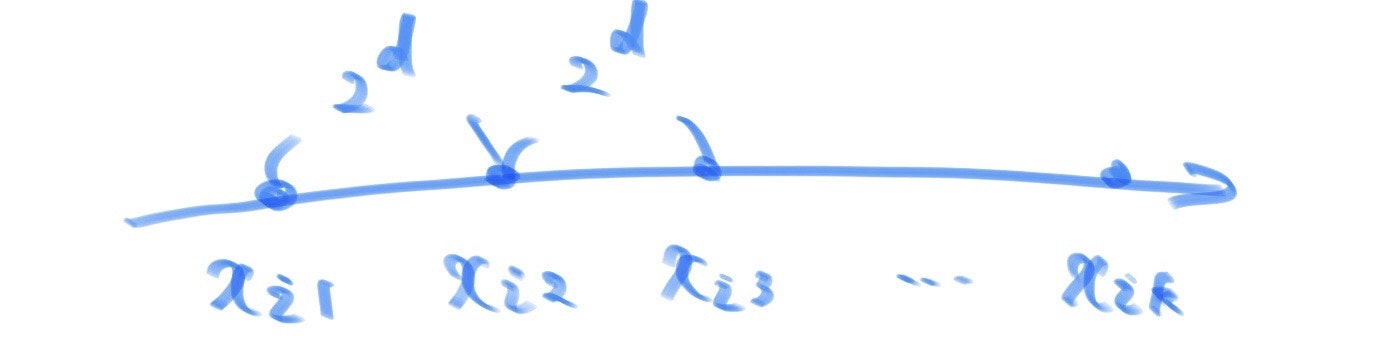
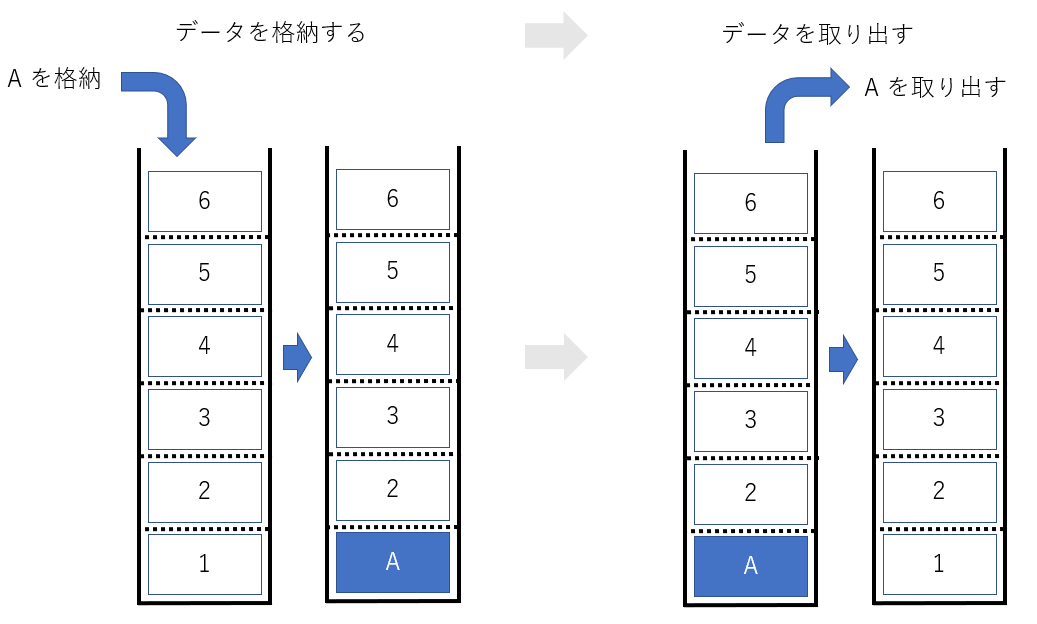
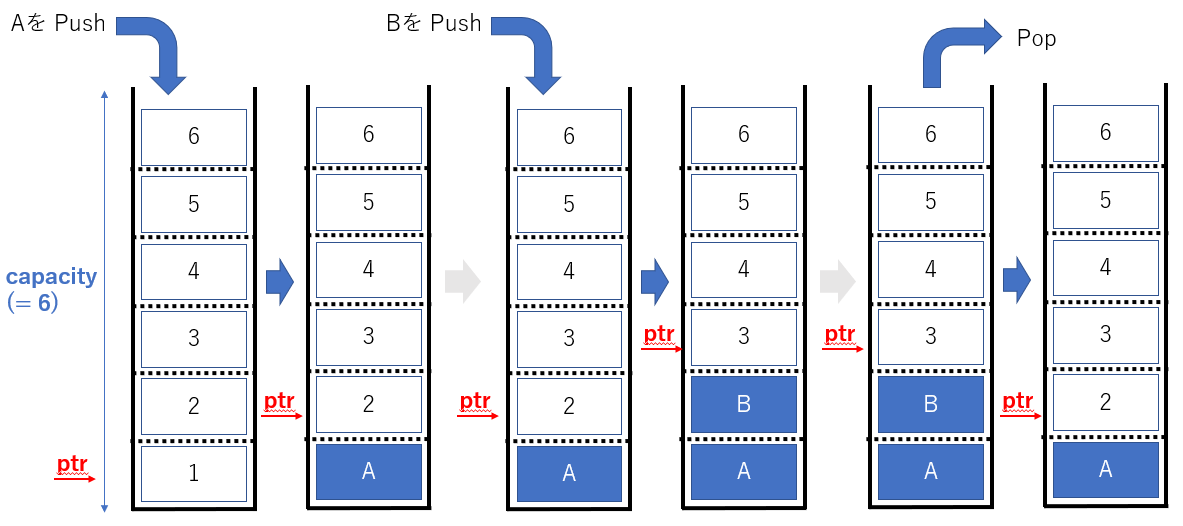
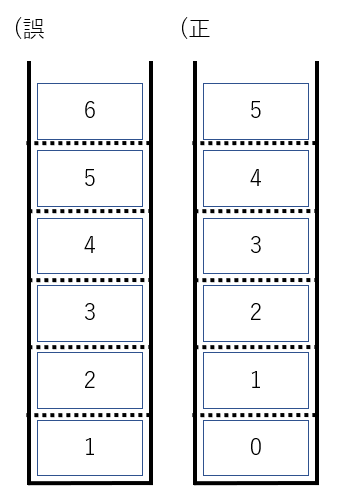
まずは、箱を空にして、A を格納した後に、取り出してみましょう。
A を格納して、取り出したら、元の空の状態に戻りました。
簡単ですね。
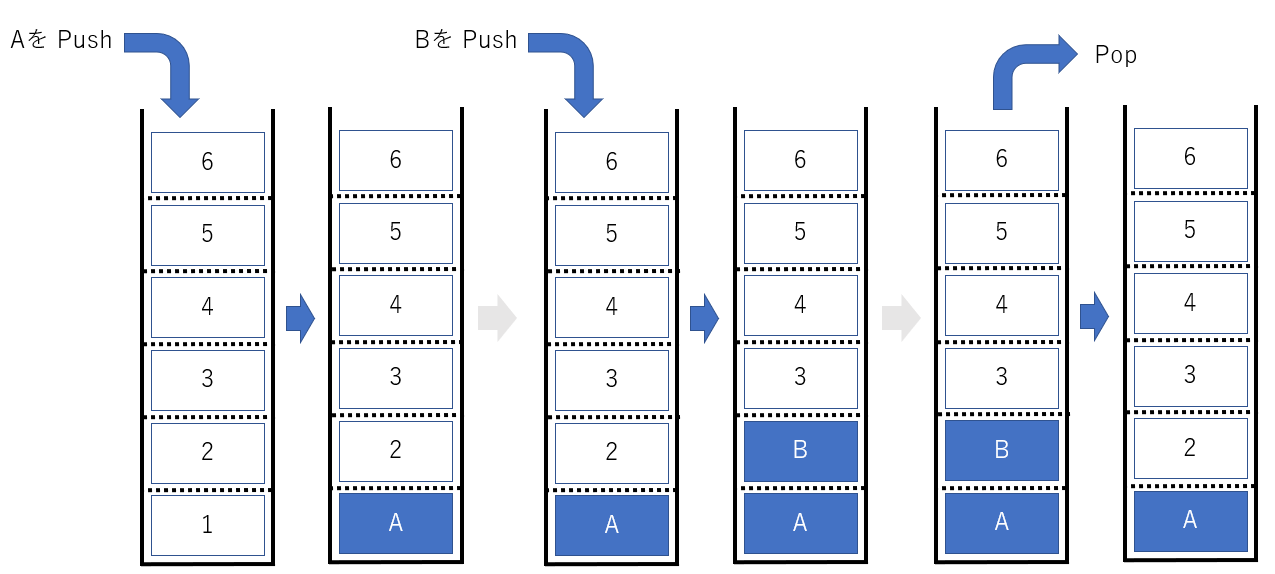
ではデータの格納を Push , 取り出しを Pop と命名したうえで、
データの Push / Pop を動きをもう少し図にしてみました。
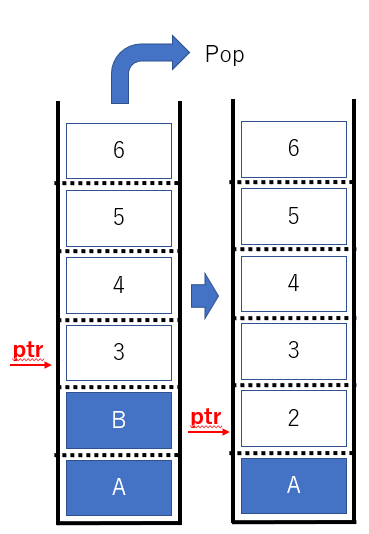
A , B を Push し、最後に pop してみました。最後に箱に残るのは A ですよね。
このようにして、最後に Push したデータを最初に Pop するスタックの動きをイメージできるようになりました。
wget http://ftp.tsukuba.wide.ad.jp/software/gcc/releases/gcc-10.2.0/gcc-10.2.0.tar.gz
tar zxvf gcc-10.2.0.tar.gz
cd gcc-10.2.0
./contrib/download_prerequisites
mkdir build
cd build
../configure --enable-languages=c,c++ --prefix=/usr/local --disable-bootstrap --disable-multilib
make > /dev/null
sudo make install all