- 投稿日:2020-09-23T21:00:00+09:00
【MySQL】試しにデータベースを作って色々いじってみた。
なんで書いたの?
MySQLについて学習した内容をアウトプットする目的で、適当なデータベースを作って(DBeaverなどは使わず)ターミナル上でコマンド操作して色々いじってみました。
※見て頂くと検討つくと思うのですが、私は乃木坂46・日向坂46のファンです。が、ここで作ったものは架空のものですので、その点お含み置きください。
目次
- AWSのRDSでMySQLサーバーを立ち上げる
- AWS公式ドキュメントを元に、RDSで起動中のMySQLサーバーに管理者としてログイン
- 下記内容をいじってみる
<具体的には>
- DBの作成
- DBの表示
- 使用するデータベースを選択
- テーブルの作成
- テーブルへレコードを挿入
- テーブルを表示
- テーブル名/インデックス名/カラム名を追加・変更
- 新しいカラムを追加した後に、追加したカラムを消去する
- 真偽値と登録日時をカラムとして追加してみる
- 後から主キー(Primary-key)を設定する
- AUTO_INCREMENTを追加する
1. AWSのRDSでMySQLサーバーを立ち上げる
やったことはざっと下記の通り。
- 無料枠でMySQLのDBを作成
- マスタユーザー(=管理者)の認証情報を入力(ユーザー名とパスワード)
- どのVPC(仮想ネットワーク)でRDSを実行させるか設定
- セキュリティグループで、「インバウンドのルールの編集」で、タイプ -> MySQL/Aurora、プロトコル -> TCP、ポート範囲 -> 3306、ソース -> 任意の場所,0.0.0.0/0, ::/0で設定(学習用のため任意の場所で設定)
2. AWS公式ドキュメントを元に、RDSで起動中のMySQLサーバーに管理者としてログイン
公式ドキュメントの「MySQL クライアントからの接続」を参照し、適切なエンドポイントと、MySQLマスタユーザー(=管理者)でコマンド操作
mysql -h <endpoint> -P 3306 -u <mymasteruser> -pすると、パスワードが求められるので、入力しログイン成功!
USER:~ user$ mysql -h ****.rds.amazonaws.com -P 3306 -u admin -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 29 Server version: 8.0.20 Source distribution Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>3.下記のコマンドを試しにやってみる
DBの作成
mysql> CREATE DATABASE HINATAZAKA_DB; Query OK, 1 row affected (0.06 sec)DBの表示
mysql> SHOW DATABASES; +--------------------+ | Database | +--------------------+ | HINATAZAKA_DB | | NOGIZAKA_DB | | information_schema | | mysql | | performance_schema | | testdb | +--------------------+ 6 rows in set (0.05 sec)使用するデータベースを選択
※この操作を入れないと、テーブル・カラムを操作する時に
DBの名前.処理内容といちいち書かないといけないのは面倒だと思い、調べてやってみた。mysql> USE NOGIZAKA_DB; Database changed mysql> USE testdb ; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changedテーブルの作成
mysql> CREATE TABLE blogs ( id int, name varchar(10)); Query OK, 0 rows affected (0.07 sec)テーブルへレコードを挿入
mysql> INSERT INTO blogs (id ,name) VALUES -> (1,"KAKI"), -> (2,"ASYU"), -> (3,"MATYU"); Query OK, 3 rows affected (0.06 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> SELECT * FROM blogs; +------+-------+ | id | name | +------+-------+ | 1 | KAKI | | 2 | ASYU | | 3 | MATYU | +------+-------+ 3 rows in set (0.06 sec)テーブルを表示
mysql> SHOW columns FROM blogs; +---------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+-------------+------+-----+---------+-------+ | id | int | YES | | NULL | | | name | varchar(10) | YES | | NULL | | | watcher | int | YES | | NULL | | +---------+-------------+------+-----+---------+-------+テーブル名/インデックス名/カラム名を追加・変更
mysql> ALTER TABLE blogs ADD watcher int; Query OK, 0 rows affected (0.07 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> SHOW columns FROM blogs; +---------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+-------------+------+-----+---------+-------+ | id | int | YES | | NULL | | | name | varchar(10) | YES | | NULL | | | watcher | int | YES | | NULL | | +---------+-------------+------+-----+---------+-------+ 3 rows in set (0.05 sec)新しいカラムを追加した後に、追加したカラムを消去する
mysql> ALTER TABLE blogs ADD comments varchar(10); Query OK, 0 rows affected (0.07 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> SHOW columns FROM blogs; +----------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +----------+-------------+------+-----+---------+-------+ | id | int | YES | | NULL | | | name | varchar(10) | YES | | NULL | | | watcher | int | YES | | NULL | | | comments | varchar(10) | YES | | NULL | | +----------+-------------+------+-----+---------+-------+ 4 rows in set (0.05 sec) mysql> ALTER TABLE blogs drop comments; Query OK, 0 rows affected (0.09 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> SHOW columns FROM blogs; +---------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+-------------+------+-----+---------+-------+ | id | int | YES | | NULL | | | name | varchar(10) | YES | | NULL | | | watcher | int | YES | | NULL | | +---------+-------------+------+-----+---------+-------+ 3 rows in set (0.05 sec)真偽値と登録日時をカラムとして追加してみる
mysql> ALTER TABLE blogs ADD is_draft BOOL; Query OK, 0 rows affected (0.13 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> ALTER TABLE blogs ADD created DATETIME; Query OK, 0 rows affected (1.07 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> SHOW columns FROM blogs; +----------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +----------+-------------+------+-----+---------+-------+ | id | int | YES | | NULL | | | name | varchar(10) | YES | | NULL | | | watcher | int | YES | | NULL | | | is_draft | tinyint(1) | YES | | NULL | | | created | datetime | YES | | NULL | | +----------+-------------+------+-----+---------+-------+ 5 rows in set (0.04 sec) mysql> INSERT INTO blogs (id,name,watcher,is_draft,created) VALUES (5,"YUTTAN",40,TRUE,2020-10-10); Query OK, 1 row affected, 1 warning (0.05 sec) mysql> SELECT * FROM blogs; +----+--------+---------+----------+---------------------+ | id | name | watcher | is_draft | created | +----+--------+---------+----------+---------------------+ | 1 | KAKI | NULL | NULL | NULL | | 2 | ASYU | NULL | NULL | NULL | | 3 | MATYU | NULL | NULL | NULL | | 5 | YUTTAN | 40 | 1 | 0000-00-00 00:00:00 | +----+--------+---------+----------+---------------------+ 4 rows in set (0.04 sec)後から主キー(Primary-key)を設定する
mysql> ALTER TABLE blogs ADD PRIMARY KEY(id); Query OK, 3 rows affected (0.08 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> SHOW columns FROM blogs; +----------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +----------+-------------+------+-----+---------+-------+ | id | int | NO | PRI | NULL | | | name | varchar(10) | YES | | NULL | | | watcher | int | YES | | NULL | | | is_draft | tinyint(1) | YES | | NULL | | | created | datetime | YES | | NULL | | +----------+-------------+------+-----+---------+-------+ 5 rows in set (0.03 sec)AUTO_INCREMENTを追加する
mysql> ALTER TABLE blogs MODIFY id INT AUTO_INCREMENT ; Query OK, 3 rows affected (0.16 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> SHOW columns FROM blogs; +----------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +----------+-------------+------+-----+---------+----------------+ | id | int | NO | PRI | NULL | auto_increment | | name | varchar(10) | YES | | NULL | | | watcher | int | YES | | NULL | | | is_draft | tinyint(1) | YES | | NULL | | | created | datetime | YES | | NULL | | +----------+-------------+------+-----+---------+----------------+ 5 rows in set (0.04 sec)最後に
DBeaver・MySQLWorkbenchなどDBクライアントを使うと圧倒的に早くSQLを書き、挙動もすぐに確認できるメリットを痛感しました。ただ、全然書いたことがない人が、いきなりそれに手を出すと、エラーに対して適切に原因を調査して書き直すというスキルが身につきにくいかな??と感じました。
もっともっとやれることがたくさんあります(集計関数・結合など)が、その部分も一通り学習できたタイミングでアウトプットとして載せていけたらと思います^^
参考
MySQL データベースエンジンを実行している DB インスタンスに接続する:MySQL クライアントからの接続
MariaDB データベースエンジンを実行している DB インスタンスへの接続
- 投稿日:2020-09-23T19:43:02+09:00
PDOを接続とプリペアドステートメント説明
PDOの接続方法
僕はmysqliに比べて、分かりづらかったので、PDOの接続の仕方を書いてみました。
<?php try { $pdo = new PDO("mysql:dbname=データベース名; host=localhost; charset=utf8mb4", "ユーザー名", "パスワード"); $pdo->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION); echo "接続完了"; } catch (PDOException $e) { exit(); echo "接続失敗"; } ?>プリペアドステートメントについて
プリペアドステートメントって、初めは分かりづらいですよね。
プリペアドステートメントとは、SQL文を最初に用意しておいて、その後はクエリ内のパラメータの値だけを変更してクエリを実行できる機能のことです。
この機能を利用することでクエリの解析やコンパイル等にかかる時間は最初の一回だけで良くなり、より高速に実行することができます。
また、SQLインジェクション対策に必要なパラメータのエスケープ処理も自動で行ってくれるため、安全かつ効率の良い開発が出来ます。プリペアドステートメントを利用してクエリを実行する流れ
PDOオブジェクトの作成
↓
prepareメソッドでSQL文をセット
↓
bindValue or bindParamでパラメータに値をセット
↓
executeメソッドでクエリを実行
↓
fetch or fetchAllメソッドで結果を配列で取得INSERTだとこんな感じで使います。
$stmt = $pdo -> prepare("INSERT INTO blog (title, text) VALUES (:title, :text)"); $stmt->bindParam(":title", $_POST['title'], PDO::PARAM_STR); $stmt->bindParam(":text", $_POST['text'], PDO::PARAM_STR); $stmt->execute();参考にしたサイト
PDO prepare プリペアドステートメントの使い方
- 投稿日:2020-09-23T18:39:13+09:00
MySQLの基本的な関数
COUNT関数
行数を取得することができる。
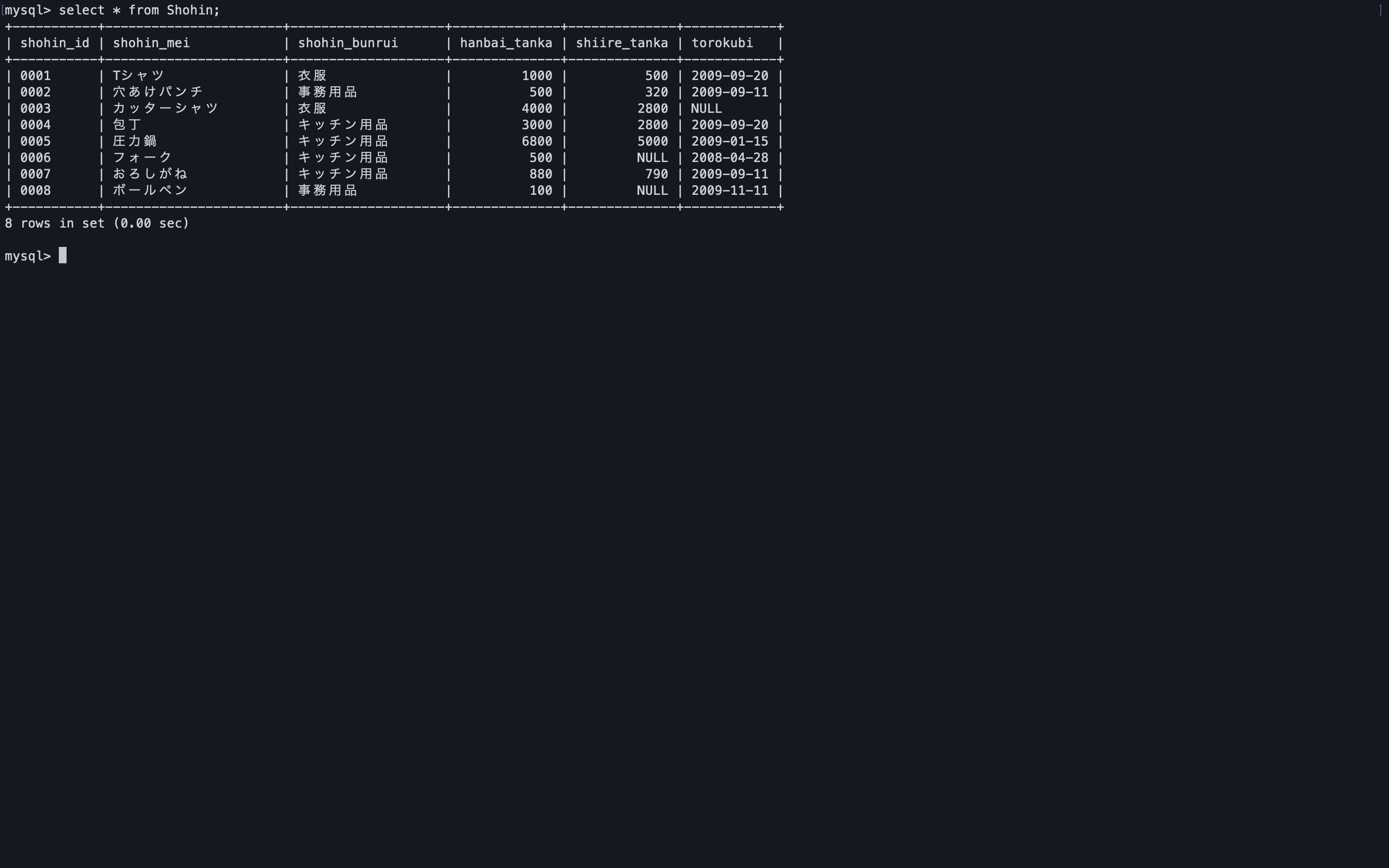
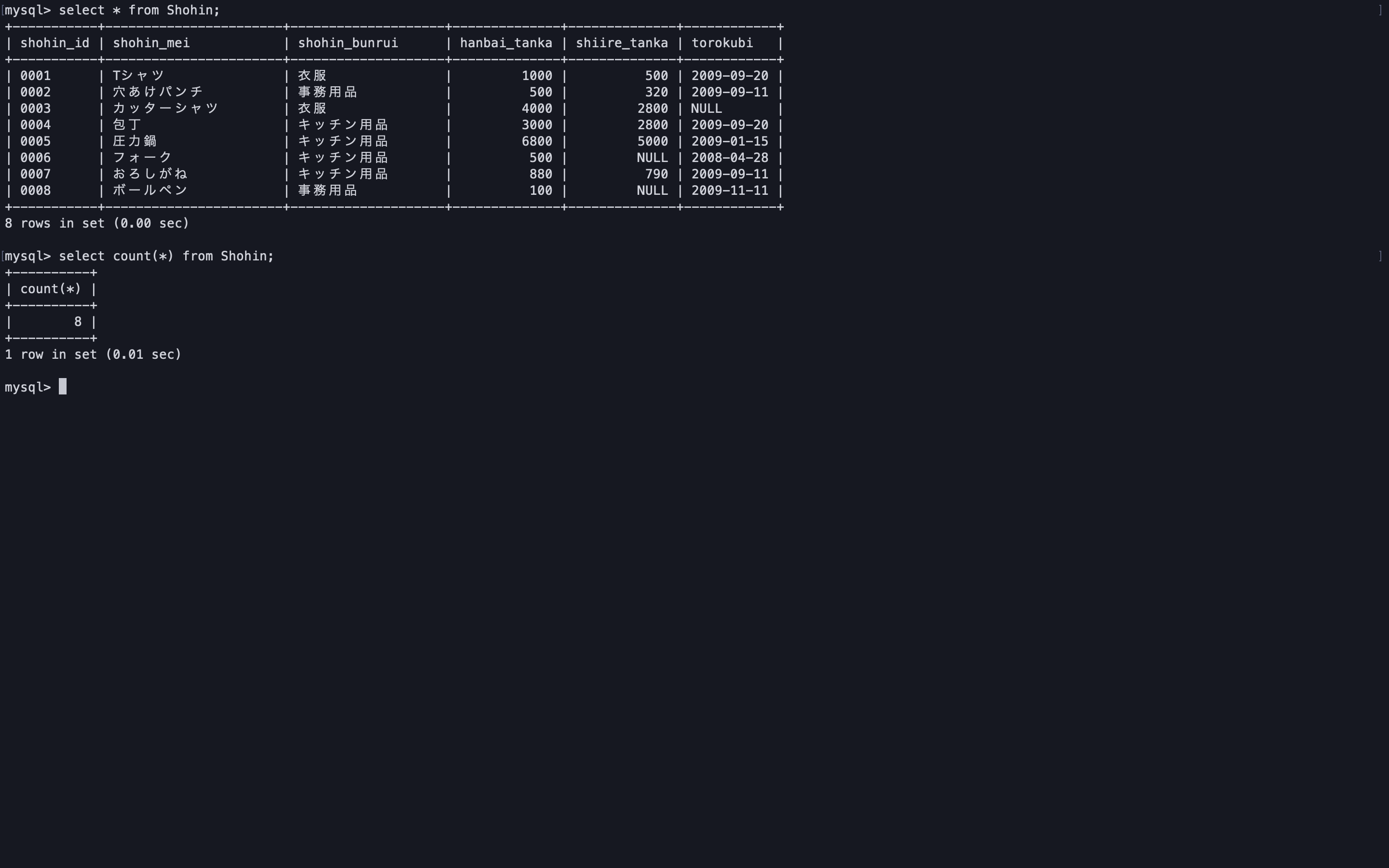
-- count関数の引数に*を渡した場合、nullのレコードもカウントされる select count(*) from Shohin;
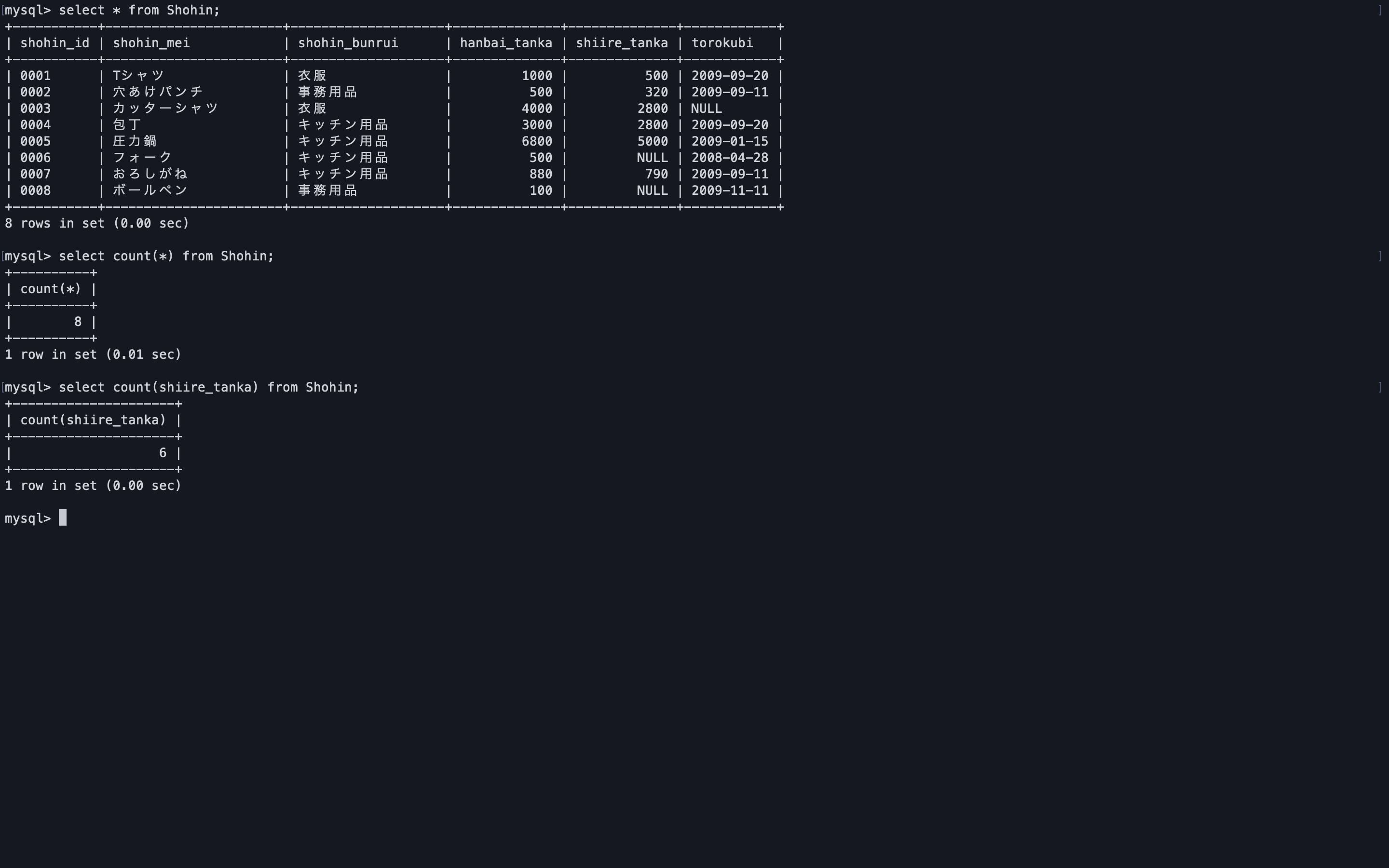
-- 引数で列名を渡した場合、対象の列がnullのレコードはカウントされない select count(shiire_tanka) from Shohin;
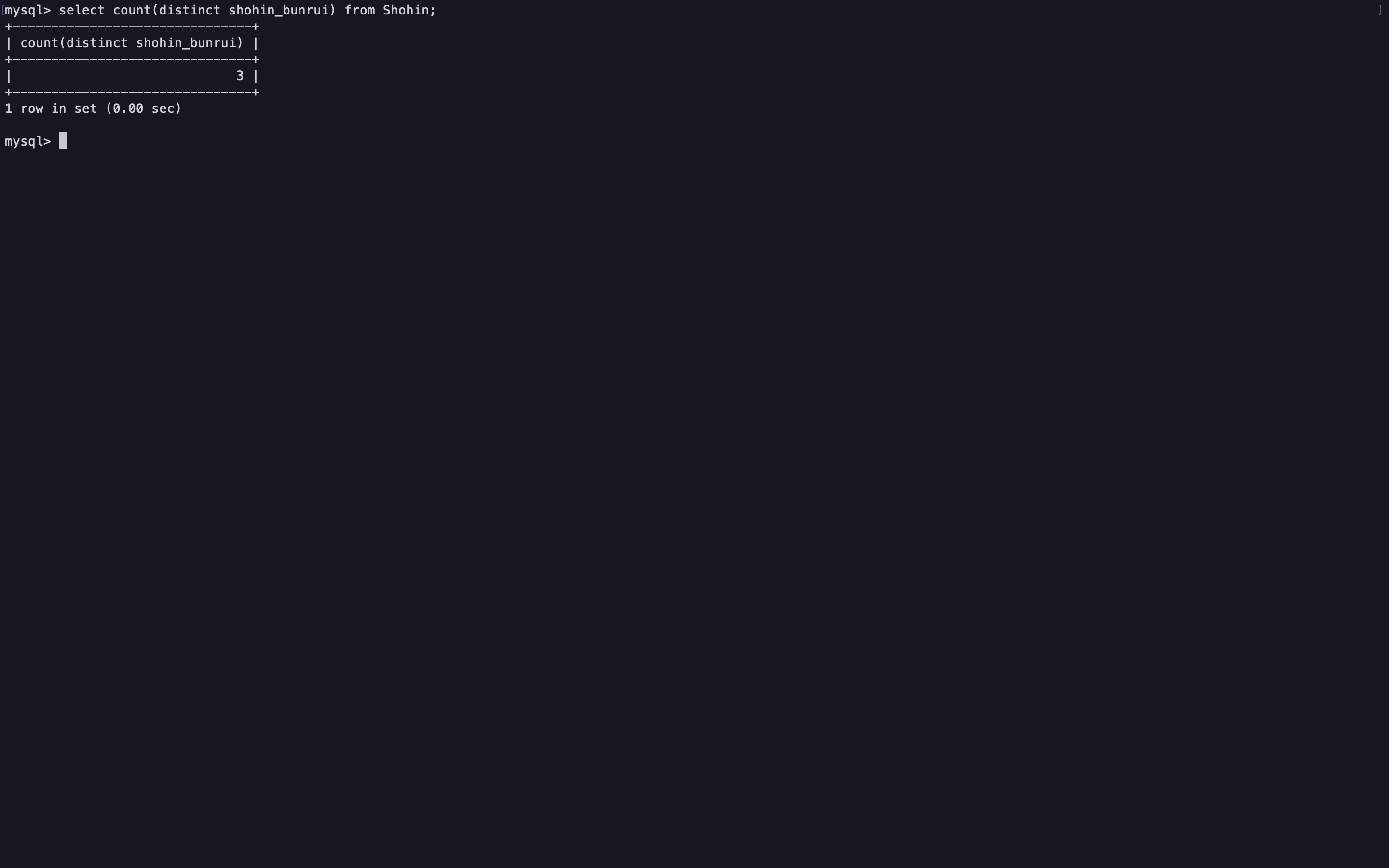
重複を除いてカウントしたい場合、distinctを使用する。
select count(distinct shohin_bunrui) from Shohin;
SUM関数
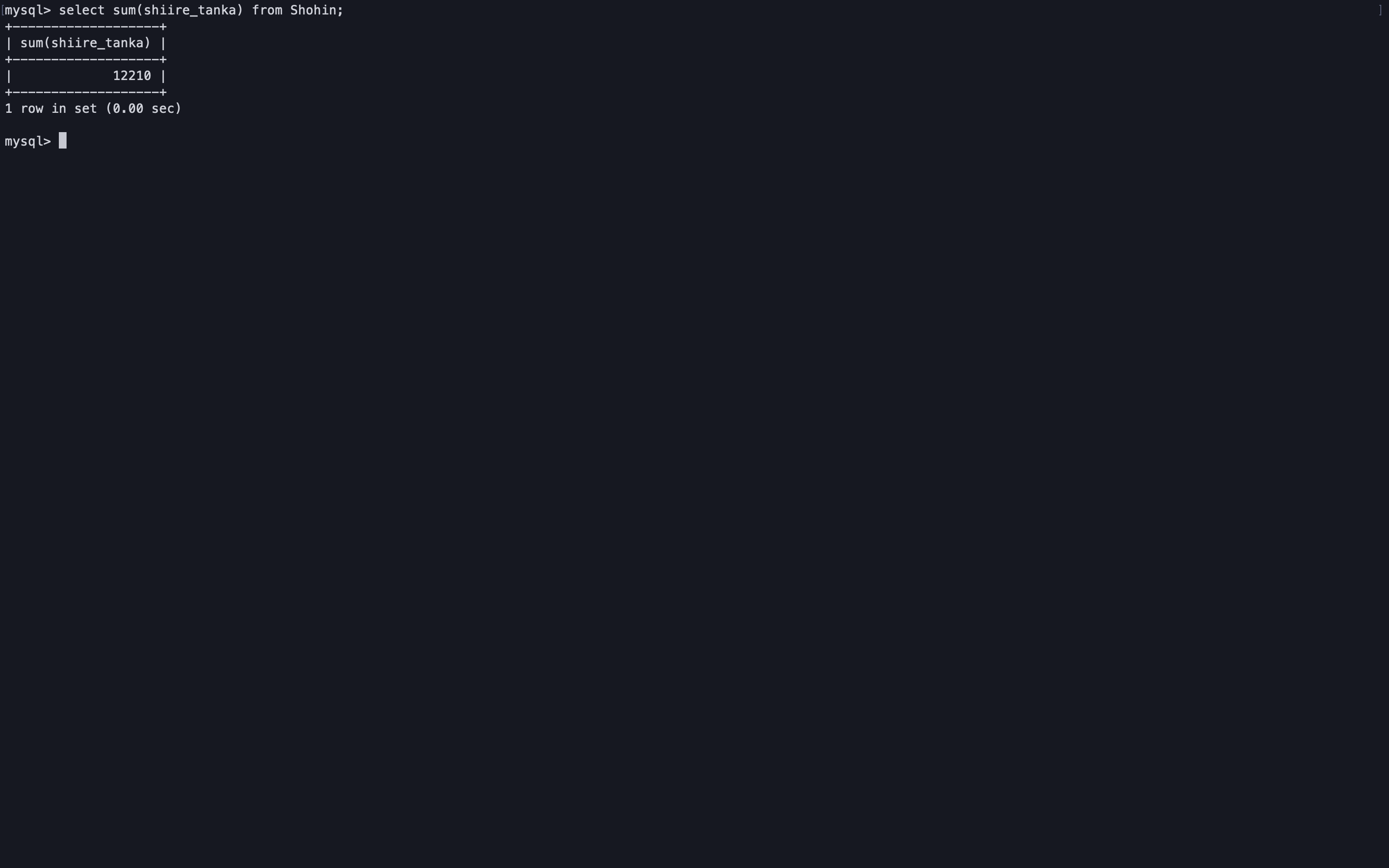
合計を取得することができる。
また、集約関数は引数に列名をとった場合、計算前にnullを除外する。
※count(*)は例外的にnullを除外しないselect sum(shiire_tanka) from Shohin;
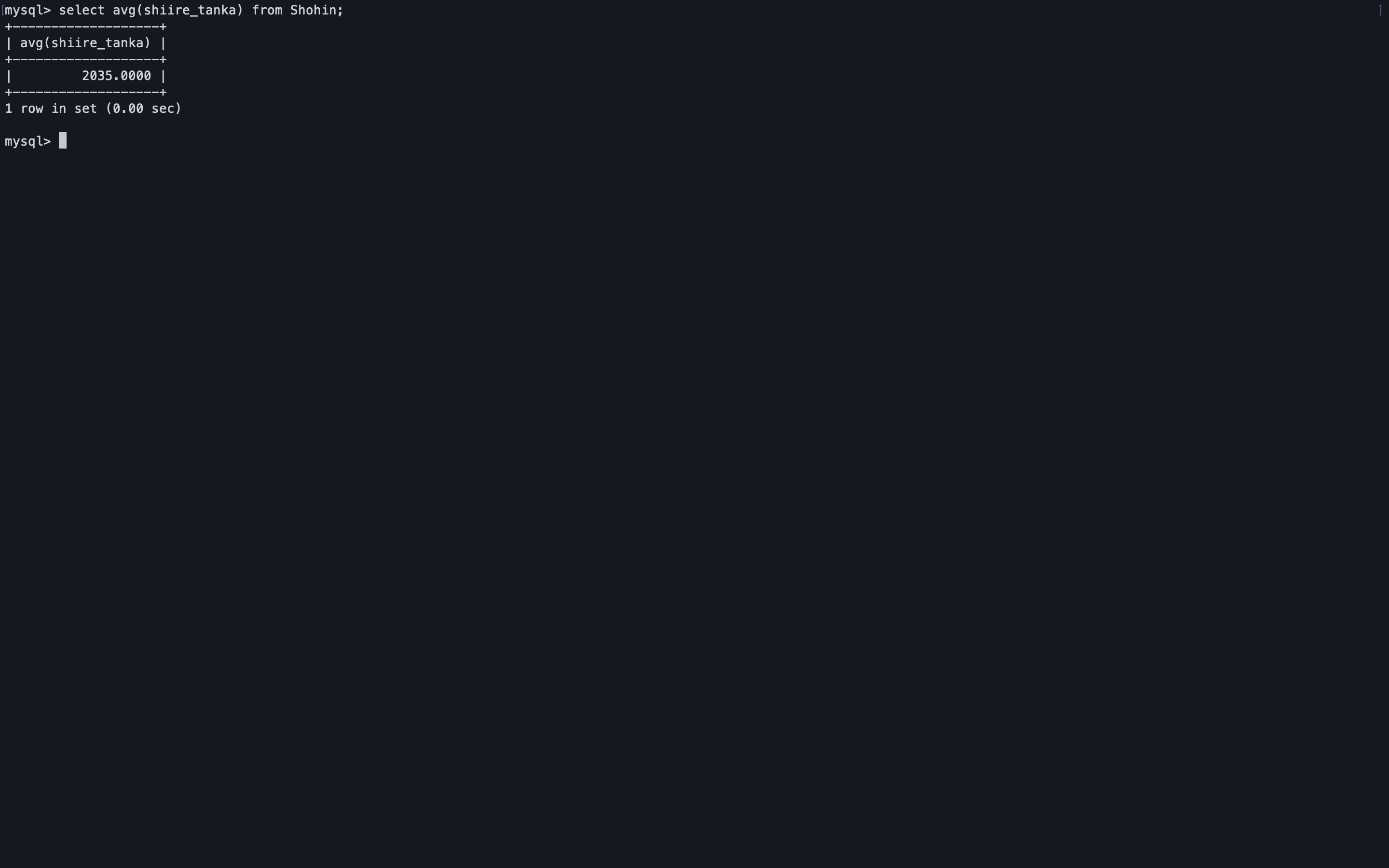
AVG関数
平均値を取得することができる。
select avg(shiire_tanka) from Shohin;
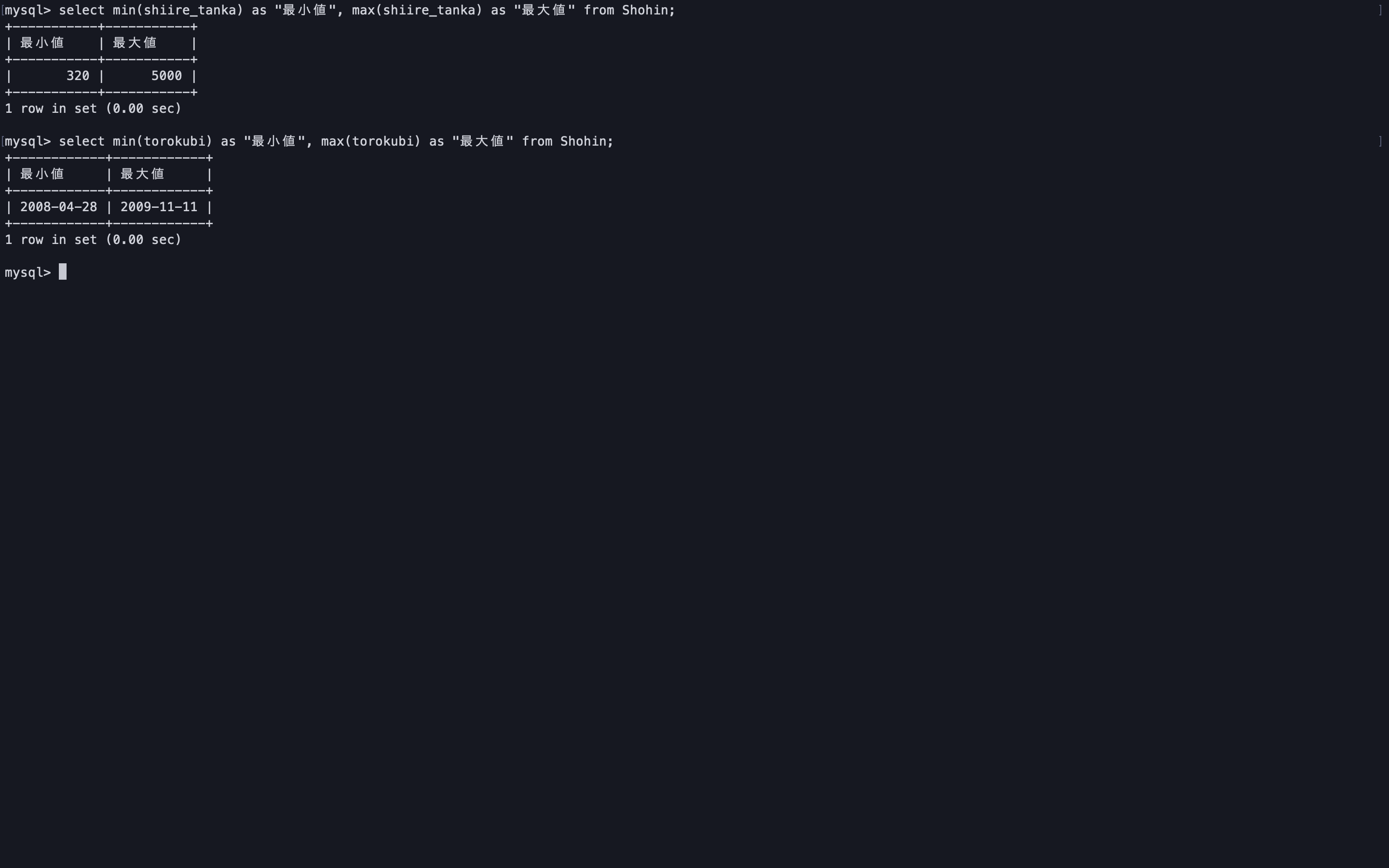
MAX関数、MIN関数
最大値、最小値を取得することができる。
構文はSUM関数、AVG関数と同じだが、
SUM関数、AVG関数は数値型の列に対してのみ使用できる点に対し、
MAX関数、MIN関数は原則的にどのような型の列にも使用できる。-- 数値型の列を指定 select min(shiire_tanka) as "最小値", max(shiire_tanka) as "最大値" from Shohin; -- 日付型の列を指定 select min(torokubi) as "最小値", max(torokubi) as "最大値" from Shohin;
- 投稿日:2020-09-23T18:15:56+09:00
FlaskでSQLiteからMySQLへ書き換えてみた
FlaskのチュートリアルではSQLiteを用いて掲示板アプリを作られていると思いますが、デプロイする際にMySQLに書き換える必要があったため書き換えたのでそれをここにも残しておこうと思います。
schema.sqlの書き換え
schema.sqlDROP TABLE IF EXISTS user; DROP TABLE IF EXISTS post; CREATE TABLE user ( id INTEGER PRIMARY KEY AUTOINCREMENT, username TEXT UNIQUE NOT NULL, password TEXT NOT NULL ); CREATE TABLE post ( id INTEGER PRIMARY KEY AUTOINCREMENT, author_id INTEGER NOT NULL, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, title TEXT NOT NULL, body TEXT NOT NULL, FOREIGN KEY (author_id) REFERENCES user (id) );db_mysql.pyimport MySQLdb import os def mysql(): # 接続する # ローカルでのDB用 conn = MySQLdb.connect( unix_socket = '/Applications/MAMP/tmp/mysql/mysql.sock', user='root', passwd='root', host='localhost', db='flask', charset='utf8' ) return conn def create_table(): conn = mysql() # カーソルを取得する cur = conn.cursor(MySQLdb.cursors.DictCursor) user_drop = "DROP TABLE IF EXISTS user" post_drop = "DROP TABLE IF EXISTS post" cur.execute(user_drop) cur.execute(post_drop) # テーブルの作成 user_table = """ CREATE TABLE user ( id INTEGER AUTO_INCREMENT, password TEXT NOT NULL, username VARCHAR(10) UNIQUE, PRIMARY KEY (id) ) """ cur.execute(user_table) post_table = """ CREATE TABLE post ( id INTEGER AUTO_INCREMENT, author_id INTEGER NOT NULL, created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, title TEXT NOT NULL, body TEXT NOT NULL, PRIMARY KEY (id) ) """ cur.execute(post_table) cur.close conn.closeschema.sqlにはSQLiteでテーブル作成のコードが書かれています。それをdb_mysql.pyにMySQLで書き換えました。MySQLdbを使うため下記コマンドを打つ必要があります。
$ pip3 install mysqlclientdb.pyの書き換え
db.pyを少し書き換えました。flask init-dbコマンドをするとdb_mysql.pyのcreate_table関数が実行されテーブル作成が行われます。
db.pyimport click from flask import current_app, g from flask.cli import with_appcontext from . import db_mysql def close_db(e=None): db = g.pop('db', None) if db is not None: db.close() def init_db_mysql(): db_mysql.create_table() @click.command('init-db') @with_appcontext def init_db_command(): """Clear the existing data and create new tables.""" init_db_mysql() click.echo('Initialized the database.') def init_app(app): app.teardown_appcontext(close_db) app.cli.add_command(init_db_command)以上でテーブルの書き換えが完了したので、あとはデータを入れたり取ってくるコードを書き換える必要がありますね。全部書くのはあれなんで一部抜粋です。
blog.pyの書き換え
blog.pyconn = db_mysql.mysql() db = conn.cursor(MySQLdb.cursors.DictCursor) db.execute( 'SELECT *' ' FROM post' ' WHERE post.id = %s', (post_id,) ) posts = db.fetchone()connでDB接続、dbで操作準備、db.executeで操作、db.fetchoneで取り出す。
以上がsqliteからMySQLに書き換える流れです。
まとめ
若干SQLiteとMySQLでは書き方が違うので多少戸惑った点があったのですが、慣れてしまえば大丈夫でした。間違い等ありましたらご指摘して頂けると幸いです。
- 投稿日:2020-09-23T17:52:21+09:00
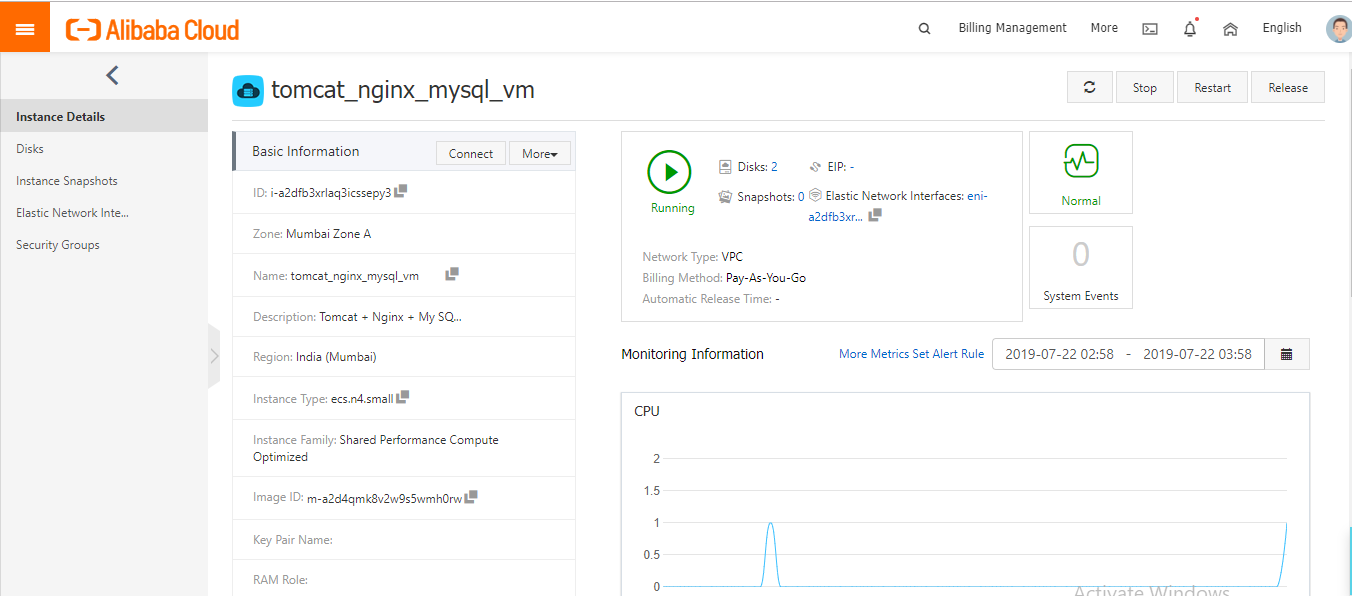
AnsibleとJenkinsを使用してTomcat、Java、MySQLからなるイメージをデプロイ
このチュートリアルでは、AnsibleとJenkinsを使用して、Tomcat、Java、MySQLで構成されたイメージをAlibaba Cloud上にデプロイします。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
前提条件
- 最低でも1台のJenkinsサーバが必要です(マスターのみまたはマスター/スレーブ設定の場合)。
そして、Jenkinsサーバのマスター/スレーブ(エージェント)環境を設定したら、サーバの状態を確認してエージェントが正常に稼働していることを確認します。特に私のセットアップでは、マスターノードをJenkinsサーバとして、エージェントマシンをAnsible用に使用しています。ご希望であれば、マスター自体にAnsibleをインストールすることで、1台だけのマシンを持つことも可能です。
- その後、マスターマシンとエージェントマシンにAnsible Toolをインストールします。
2.Ansibleを導入します。Ansibleは、ITオートメーションのための強力なツールであり、ターゲット環境をプロビジョニングし、その上でアプリケーションをデプロイするためにCI/CDプロセスで使用することができます。しかし、Ansibleはメンテナンスが面倒で、長期的にはスクリプトを再利用してしまうことを知っておいてください。
Ansible がインストールされている集中管理された場所から、異なるサーバ/環境にまたがって同じタスクを実行する場合に役立ちます。Ansible は完全にエージェントレスであるため、Chefや Puppet のような他の IaC (Infrastructure-as-Code) ツールと比較して優位性があります。Ansible を使用すると、クライアントシステムにエージェントをインストールする必要がなく、クライアントとサーバ間の SSH 通信によって自動化が行われます。指定した地域に何百ものインスタンスがあれば、すべての自動化が容易になります。AnsibleのプレイブックはYAML/YML言語で書かれています。Ansibleになると、以下のような知識も必要になってきます。
- Control node:Ansible がインストールされており、管理しているサーバーを担当するマシン
- Inventory:プレイブック内のコマンド、モジュール、タスクが動作するホストとホストグループを定義するファイル。このファイルは、Ansible 環境とプラグインに応じて多くの形式のいずれかになります。プロジェクト固有のインベントリファイルを別の場所に作成するために使用します。
- Playbook:Ansible の設定、デプロイメント、オーケストレーション言語の一部。リモートシステムに適用させたいポリシーや、一連のステップを記述することができます。
Ansible と Ansible Alicloud モジュールのインストール
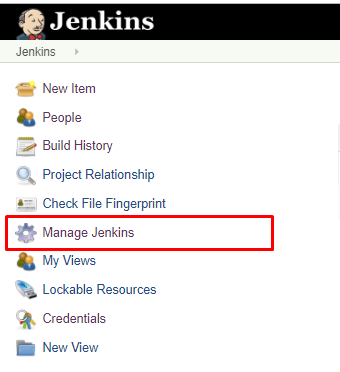
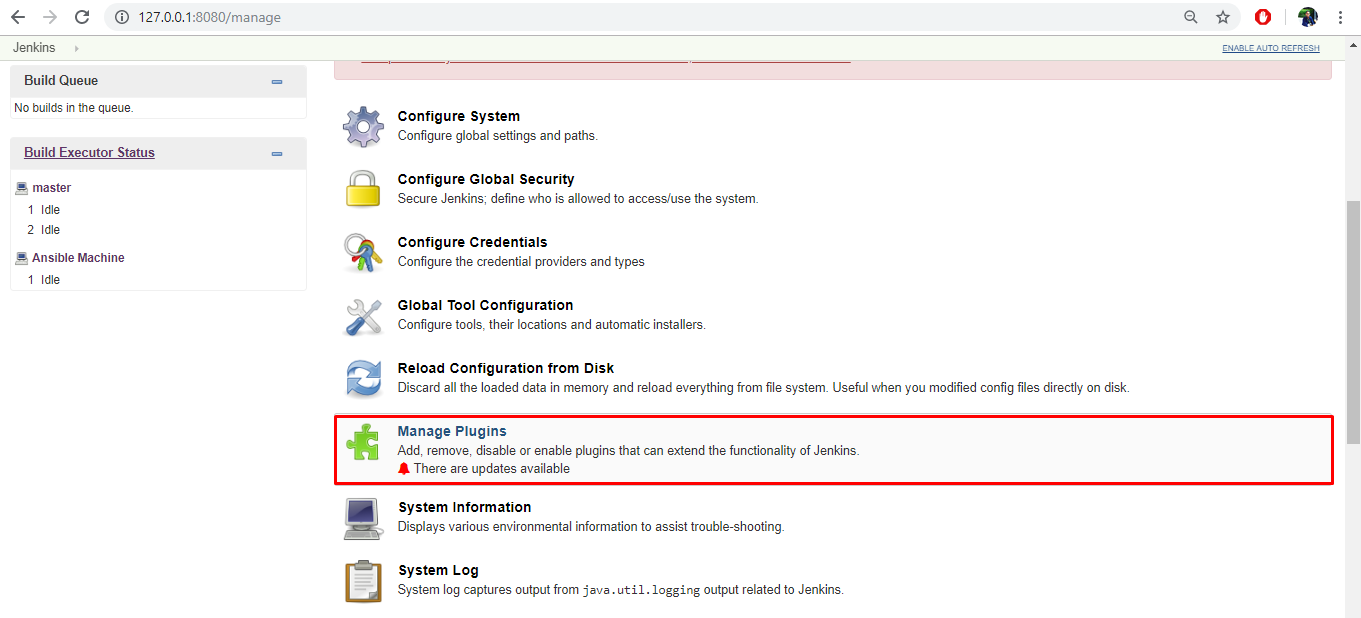
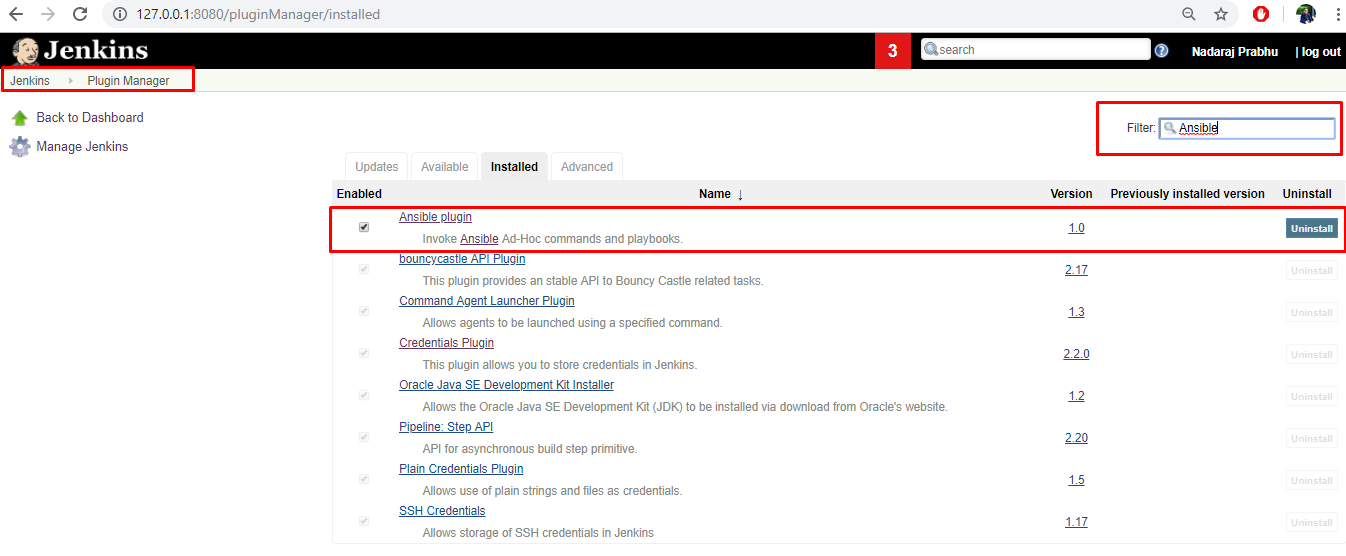
まず、JenkinsにAnsibleプラグインをインストールします。そのためには、以下の手順に従います。
- ダッシュボードのManage Jenkinsをクリックします。
- プラグインの管理をクリックして、ページの右上にある検索バーで Ansible プラグインを探します。
- Ansible を選択して、Download now をクリックし、再起動後にインストールします。
注意: このチュートリアルで行っている現在のセットアップには必要のない Ansible Tower はインストールしないでください。
Jenkins に Ansible プラグインをインストールしたら、次は Client/Agent マシンに Ansible をインストールする手順に進みます。
クライアント/エージェントマシンにAnsibleをインストール
Alibaba Ansibleモジュールは頻繁に更新されているので、最新版はGitHubのリンクを参照することをお勧めします。
- エージェントマシンでターミナルウィンドウを開き、以下のコマンドを実行します。
- CentOS 7.4を使用している場合は、このコマンドを使用すると良いでしょう。
sudo yum check-update; sudo yum install -y gcc libffi-devel python-devel openssl-devel epel-release sudo yum install -y python-pip python-wheel
- Ubuntu 16.04 LTSを使用している場合は、このコマンドを使用します。
sudo apt-get update && sudo apt-get install -y libssl-dev libffi-dev python-dev python-pip
- 次のコマンドを入力して、必要なパッケージAnsible for Alibabaをインストールします。
sudo pip install ansible sudo pip install ansible_alicloud sudo pip install ansible_alicloud_module_utilsAnsibleプレイブックを設定
アリババECSをプロビジョニングするためのAnsibleのプレイブックスクリプトをこちらに作成してみました。ソースコードをフォークして、環境に合わせてパラメータの値を変更することができます。
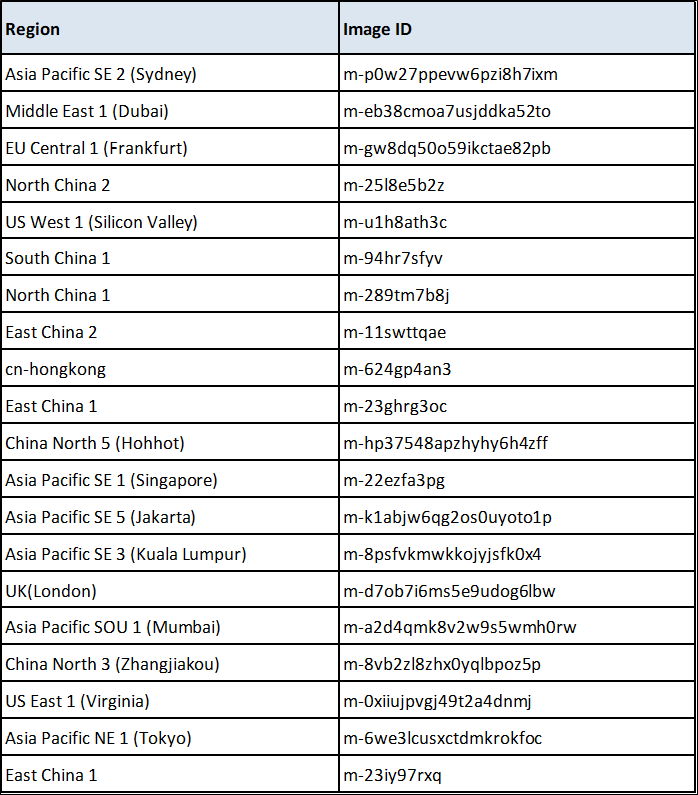
alicloud_access_key: <Alibaba Access Key> alicloud_secret_key: <Alibaba Secret Key> alicloud_region: <Alibaba Region for your resource> e.g. - ap-south-1 alicloud_zone: <Alibaba Zone for your resource> e.g. ap-south-1a password: <New VM Password> image: "m-a2d4qmk8v2w9s5wmh0rw"注:私はZhuyunが提供するAlibaba Application Stacksからイメージをインポートしています。こちらでご確認ください。Linux、Nginx、MySQL、Jdk-Tomcat(Nginx1.6-jdk1.7-tomcat7-mysql5.5-vsFTPd2.2.2)で構成されています。
アクセスキーとシークレットの生成
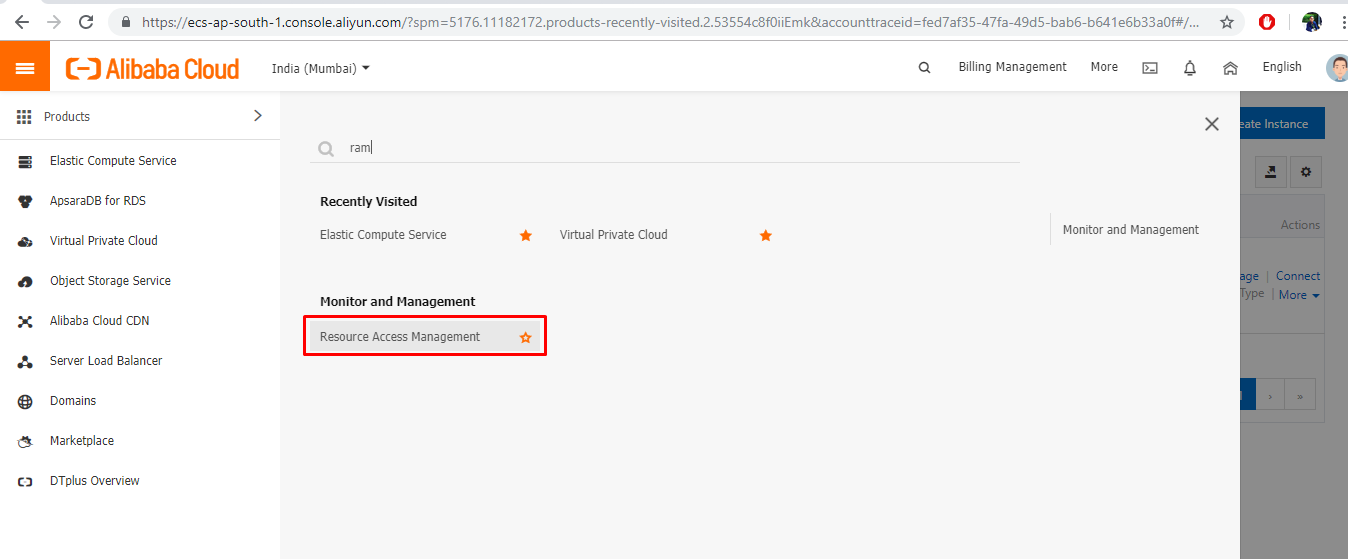
さて、アクセスキーとシークレットを生成する時が来ました。これを行うには、以下の手順に従ってください。
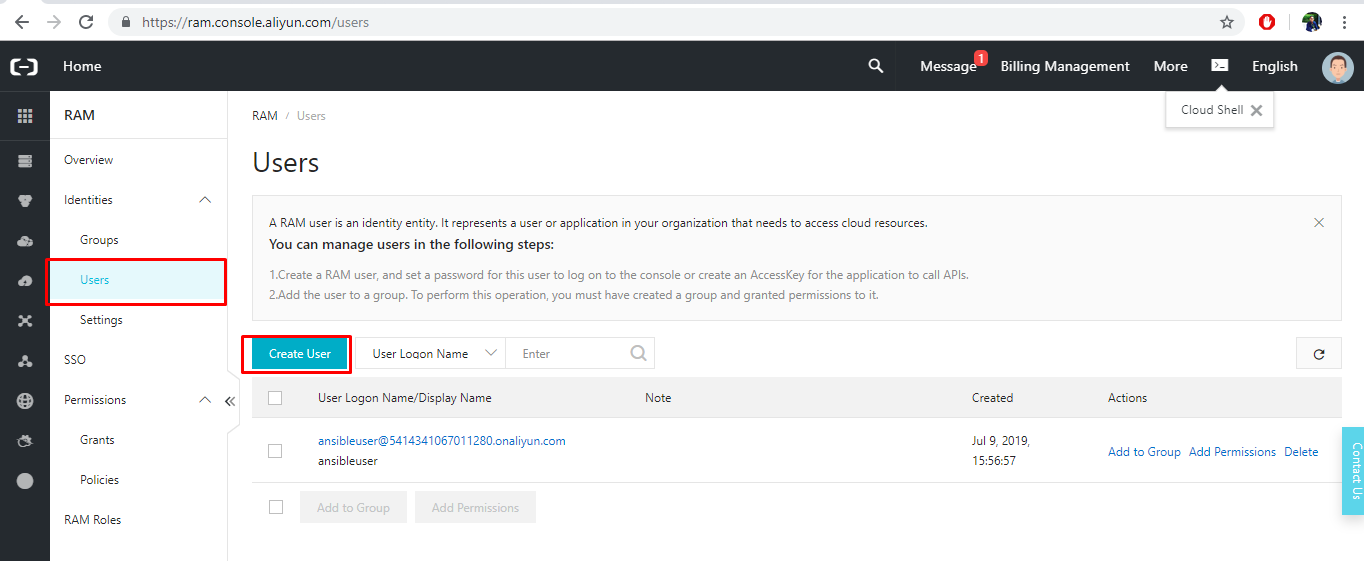
アクセスキーとシークレットキーを取得するには、Alibaba Cloudコンソールにアクセスして、製品メニューからリソースアクセス管理(RAM)を選択します。
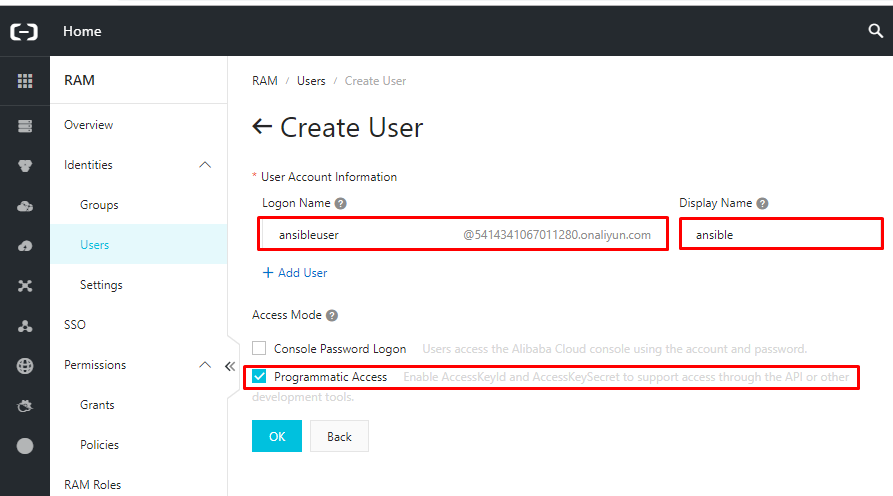
- 左側のナビゲーションペインで[ユーザー]オプションをクリックし、[ユーザーの作成]を選択します。
- 新しいユーザーを作成し、ログイン名と表示名を入力します。次に、[アクセスモード]で、[プログラムアクセス]にチェックを入れます。このユーザーに Console Password Logon アクセスを提供する必要はありません。
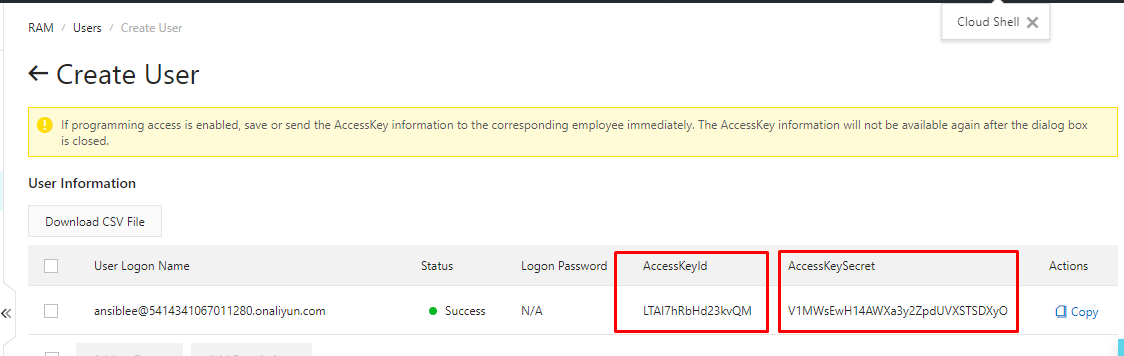
- プレイブックの
alicloud_access_keyとalicloud_secret_keyの値となるAccessKeyIdとAccessKeySecretをコピーします。注意:ダイアログボックスを閉じると、AccessKey情報は再び利用できなくなります。したがって、ダイアログボックスを閉じる前にこの情報をコピーして保存しておくことが重要です。
- VPC、V-Switchs、セキュリティグループ、またはECSインスタンスのようなリソースをプロビジョニングするための適切な権限を提供します。私はAdministratorAccessを提供していますが、これはAlibaba Cloudのサービスやリソースへのフルアクセスを提供するために起こることです。
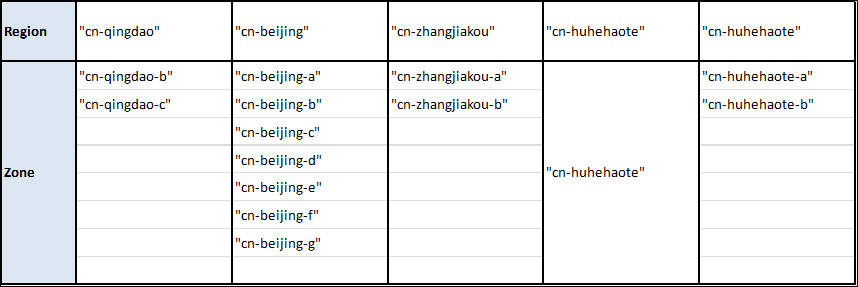
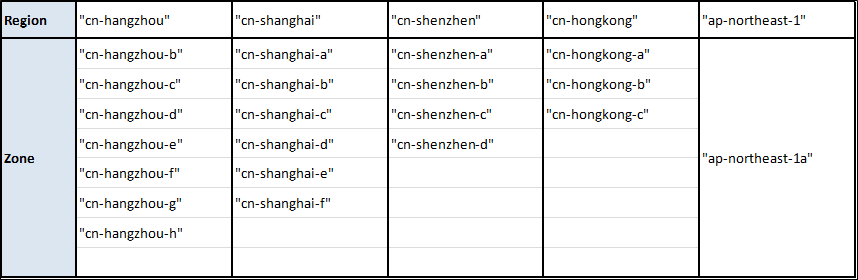
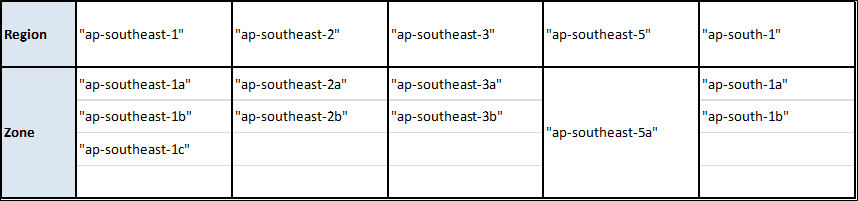
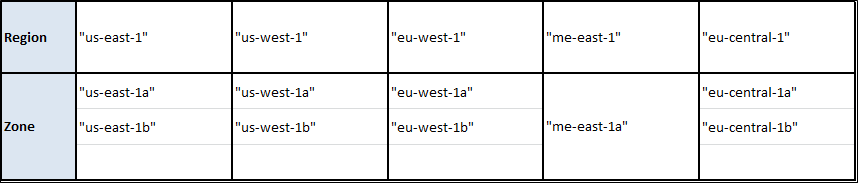
アリババクラウドの地域とゾーン
注)1.
- 完全なリストを取得するには、Alibaba CloudのCLIツールを使用することができます。JSONの壁を吐き出してくれるので、*nix上にいてjqツールが利用できるのも便利です。以上のことを考えると、必要なのはこの短いシェルスクリプトだけです。
#!/usr/bin/env bash for region in $( aliyun ecs DescribeRegions | jq '.Regions.Region[].RegionId' ) do echo $region reg=$( echo $region | sed s/\"//g ) echo '---' for zone in $( aliyun ecs DescribeZones --RegionId $reg | jq '.Zones.Zone[].ZoneId' | sort ) do echo $zone done echo '' done
- 以下の地域・ゾーンにリソースを提供したい場合は、こちらのリンクから実名登録を行ってください。
alicloud_region: cn-beijing alicloud_zone: cn-beijing-a以下に各リージョンのイメージIDを示します(Linux, Nginx, MySQL, Jdk-Tomcatイメージの場合)。もちろん、地域に応じてイメージIDを変更する必要があります。
Jenkinsジョブを使用してAlibaba VMを作成してデプロイする
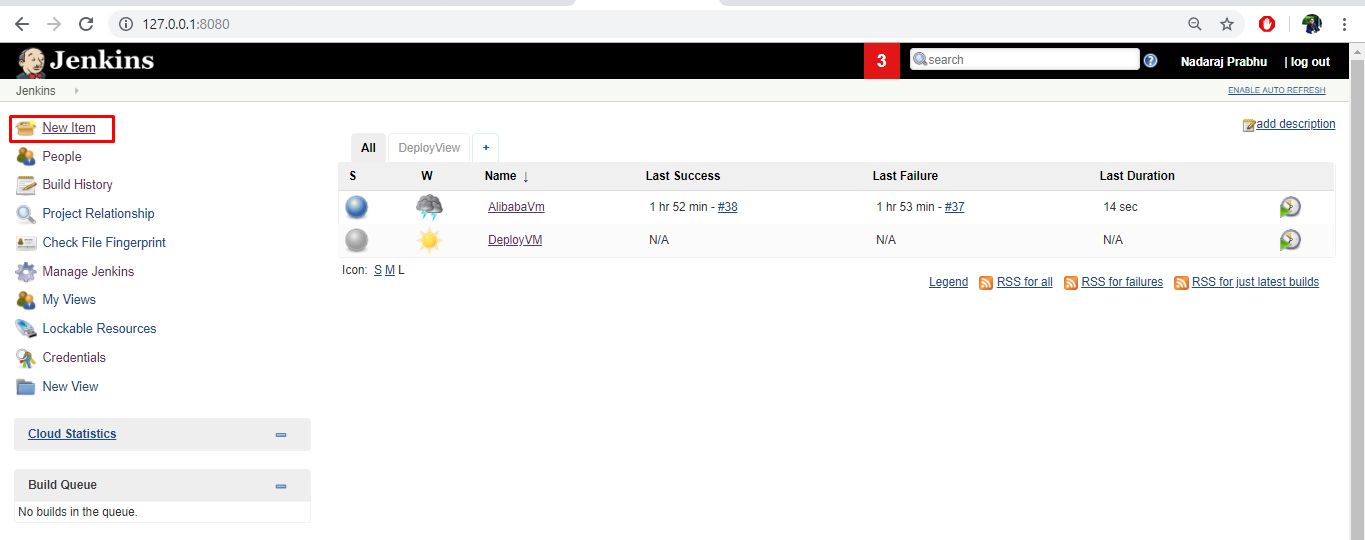
Jenkinsジョブを使用してAlibaba VMを作成してデプロイするには、以下の手順に従います。
- Jenkinsダッシュボードから、New Itemを選択します。
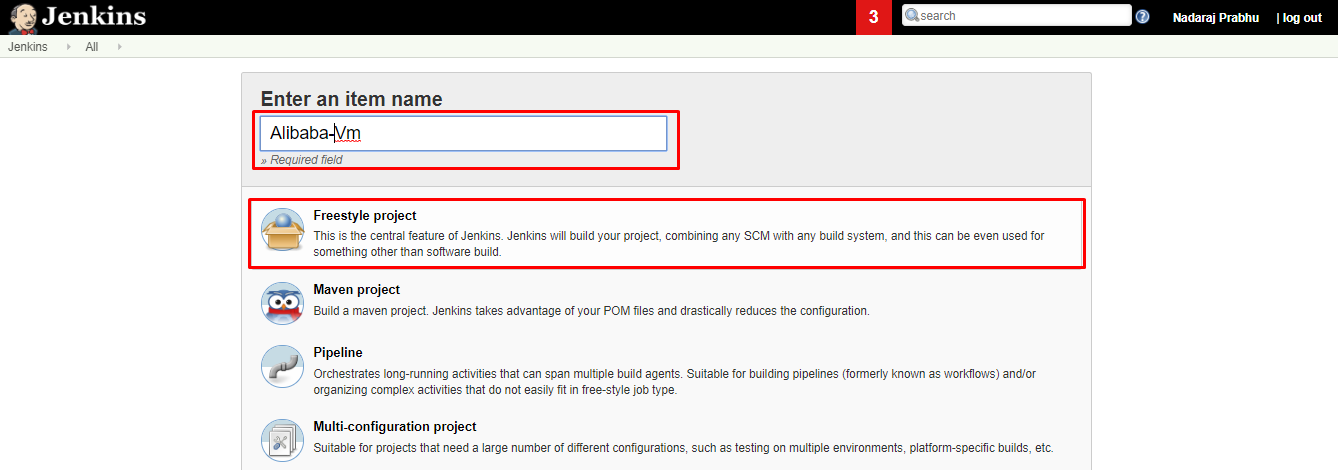
- 名前を入力し、「Freestyle project」を選択し、「OK」をクリックします。
- (オプション) 一般の下に、参考のために簡単な説明を記載してください。
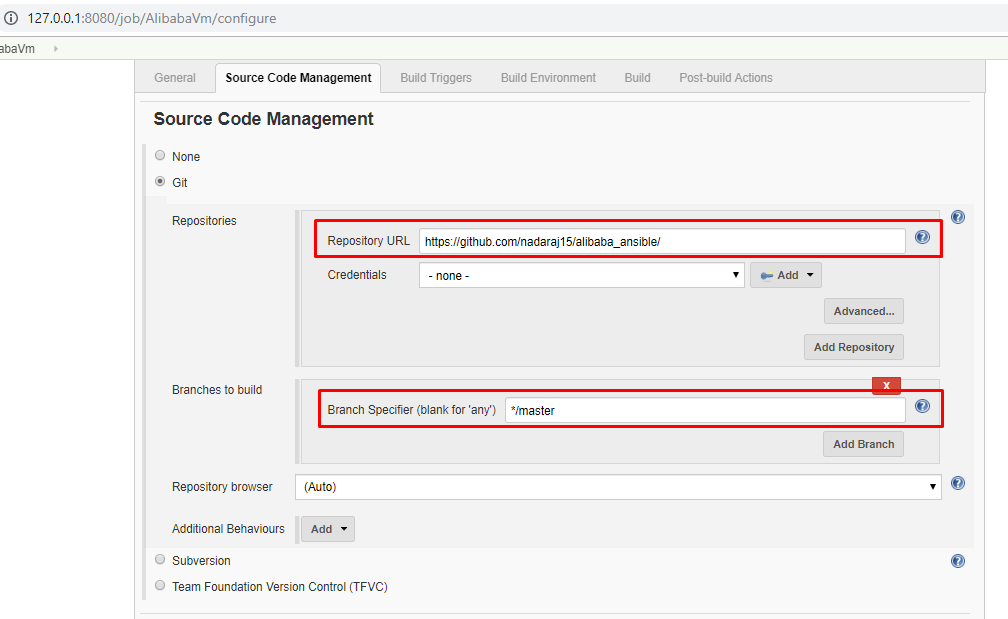
- 上部のソースコード管理(SCM)タブを選択するか、スクロールダウンして以下の情報を入力します。
SCM: - Git
リポジトリのURL:- GitHubのリンクにパラメータを変更したもの
例:https://github.com/nadaraj15/alibaba_ansible/
資格情報:- なし (パブリックリポジトリなので、プライベートの場合は Jenkins に資格情報を保存)
ブランチ指定子 ( 'any' の場合は空白): - */master
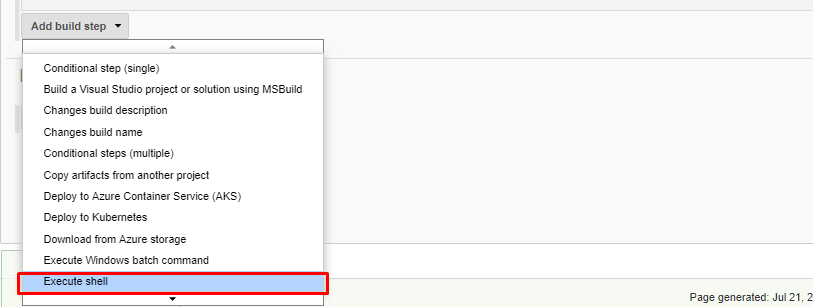
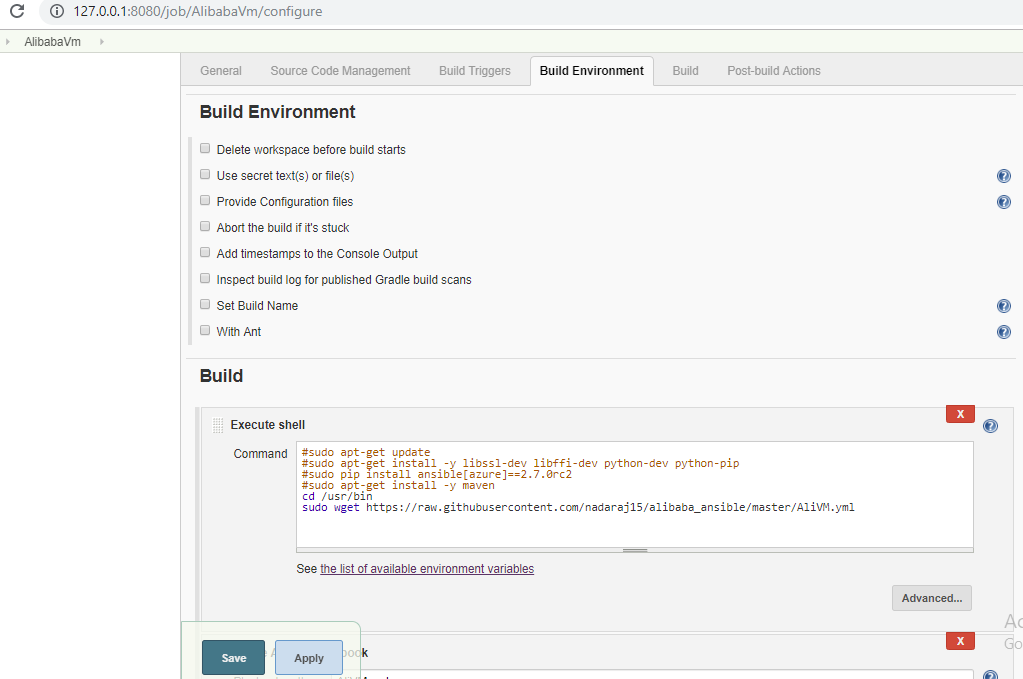
- 次に、ビルドトリガーはとりあえずスキップして、ビルド環境に移動します。新しいプロジェクトを作成する際には、いくつかの設定が用意されています。この設定ページでは、スクリプトを実行するなどの余分なアクションを実行するためのビルドステップを追加するオプションもあります。というよりも、シェルスクリプトを実行して、GitHubからAnsible Playbookファイルをダウンロードします。以下のコマンドを使用します。
sudo apt-get update (Optional) sudo apt-get install -y libssl-dev libffi-dev python-dev python-pip (Optional) sudo pip install ansible[azure]==2.7.0rc2 (Optional) sudo apt-get install -y maven (Optional) cd /usr/bin sudo wget https://raw.githubusercontent.com/nadaraj15/alibaba_ansible/master/AliVM.yml
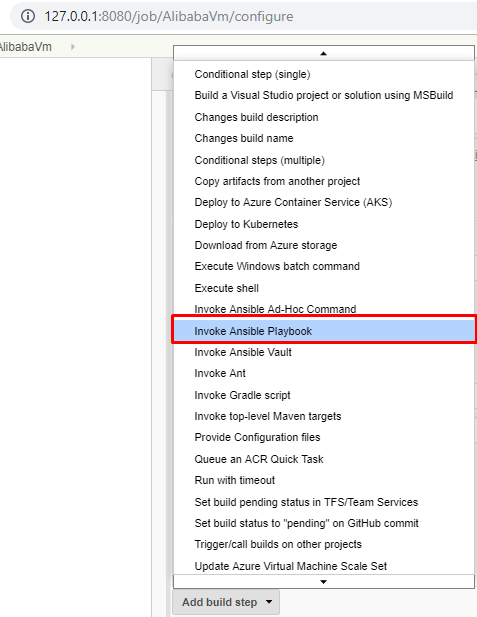
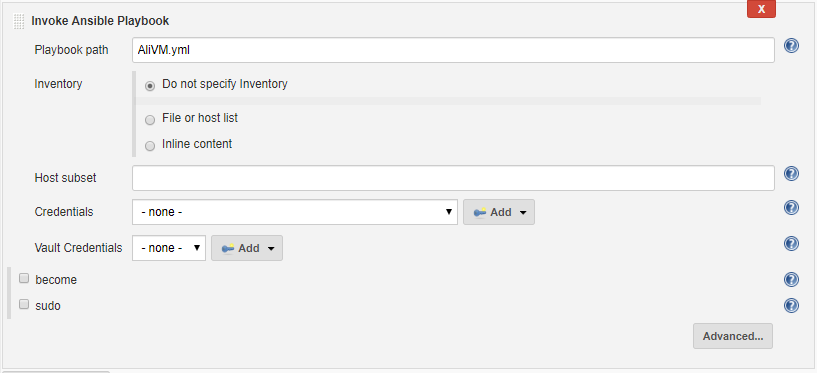
- ビルドステップを追加して ansible playbook を起動したいと思います。このステップは ansible playbook を実行します。以下の情報を入力します。
- Playbook path: - AliVM.yml (プレイブック名)
- Inventory: - 「Inventoryを指定しない」を選択
- Credentials:- 「なし」を選択します(デプロイメントファイルに資格情報を埋め込んでいるので、環境変数として資格情報を渡すことができます)
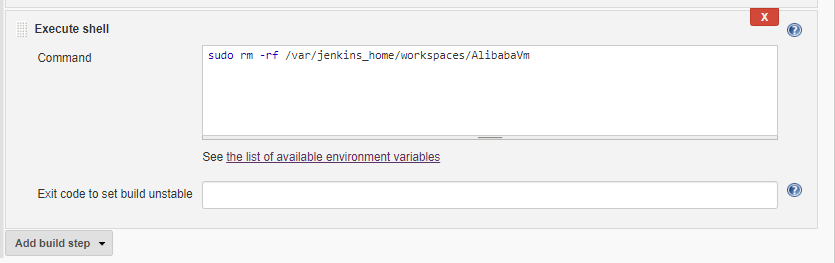
- デプロイ後のワークスペースをクリーンアップし、以下のコマンドでシェルスクリプトの実行ステップを追加します。
注意:
jenkins_homeがあなたの場所である場合、デフォルトのパスは/var/jenkins_homeに設定されています。しかし、カスタムの場所がある場合は、その代わりにその場所を使用することができます。sudo rm -rf /var/jenkins_home/workspaces/<workspace_name>
- 必要に応じてポストビルトアクションを追加します。最後に、すべてのステップが設定されたら、保存をクリックします。
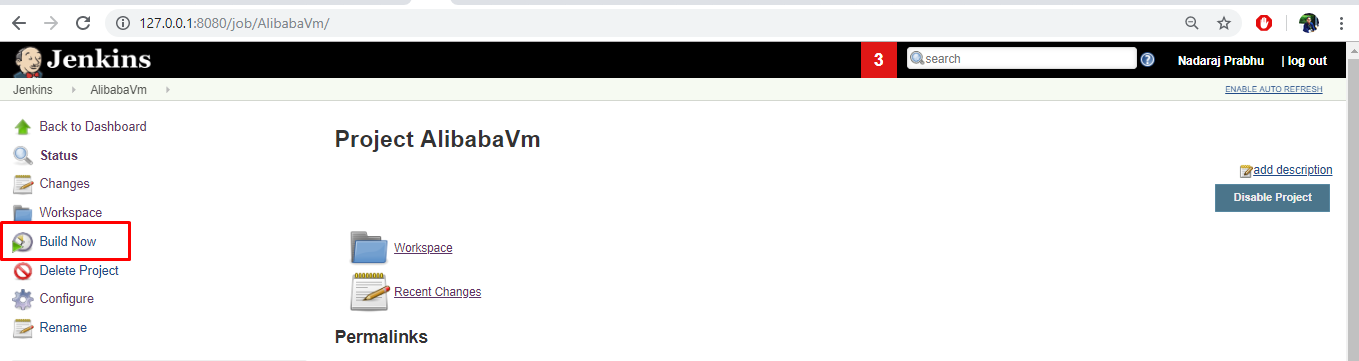
- Jenkinsプロジェクトダッシュボードに移動し、「Build now」をクリックして手動でビルドをトリガーします。
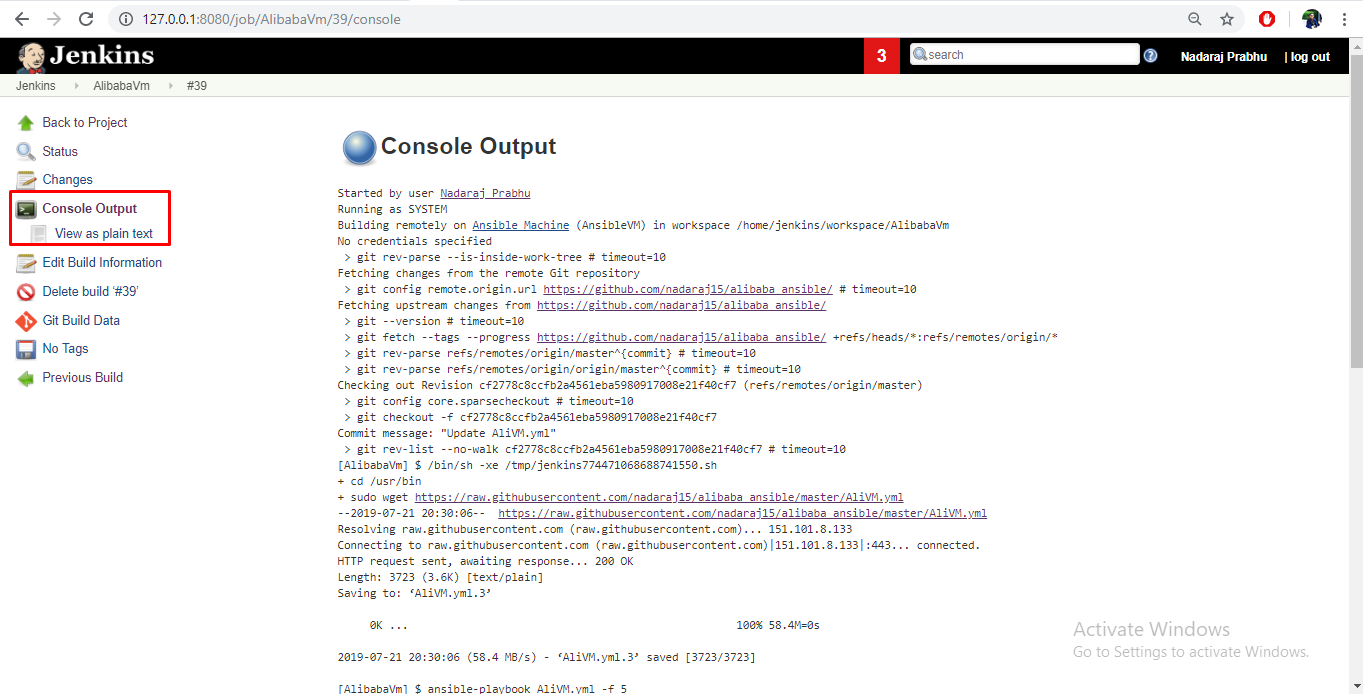
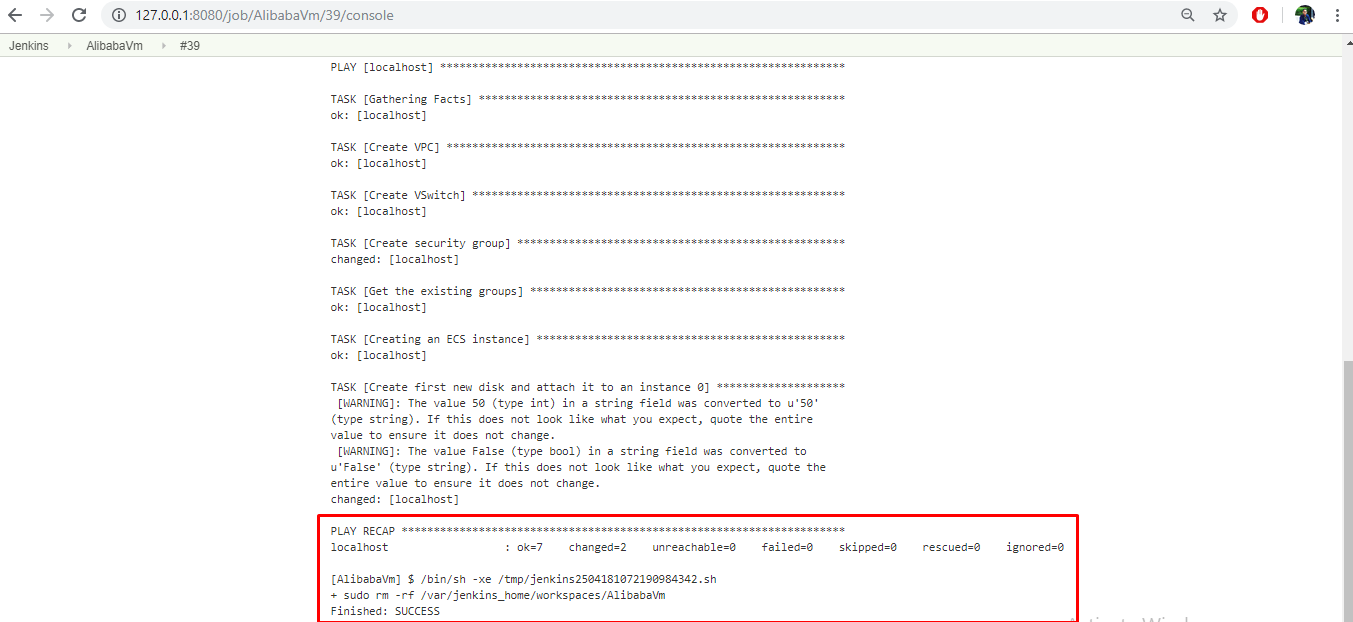
- コンソール出力に移動して、トリガーされたビルドステータスを確認します。すべてのリソースが正常にプロビジョニングされると、出力に成功ステータスが表示されます。
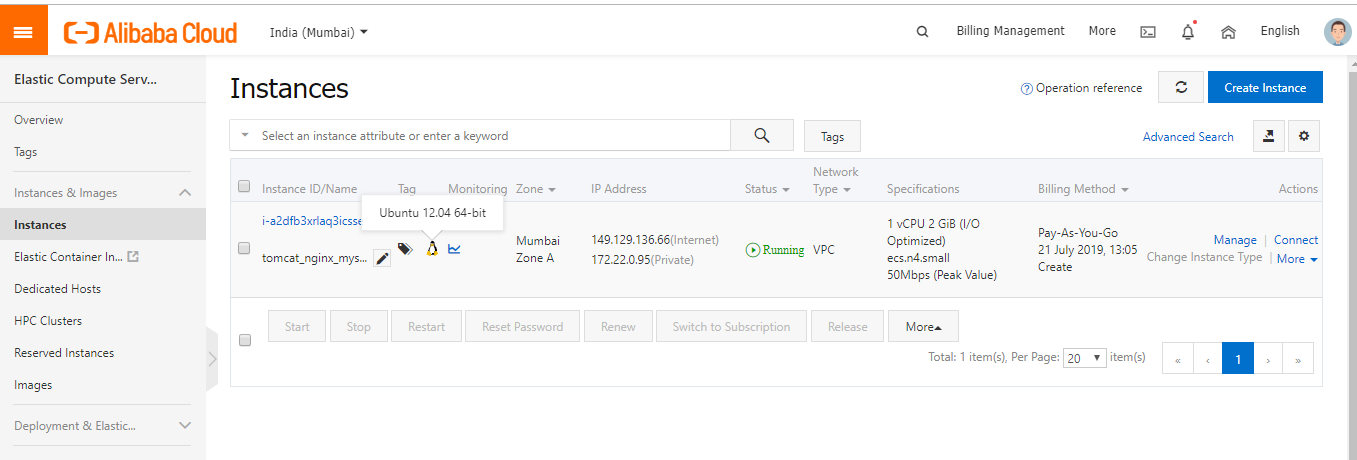
- Alibaba Consoleに移動して、プロビジョニングされたAlibaba ECSと構成を確認します。
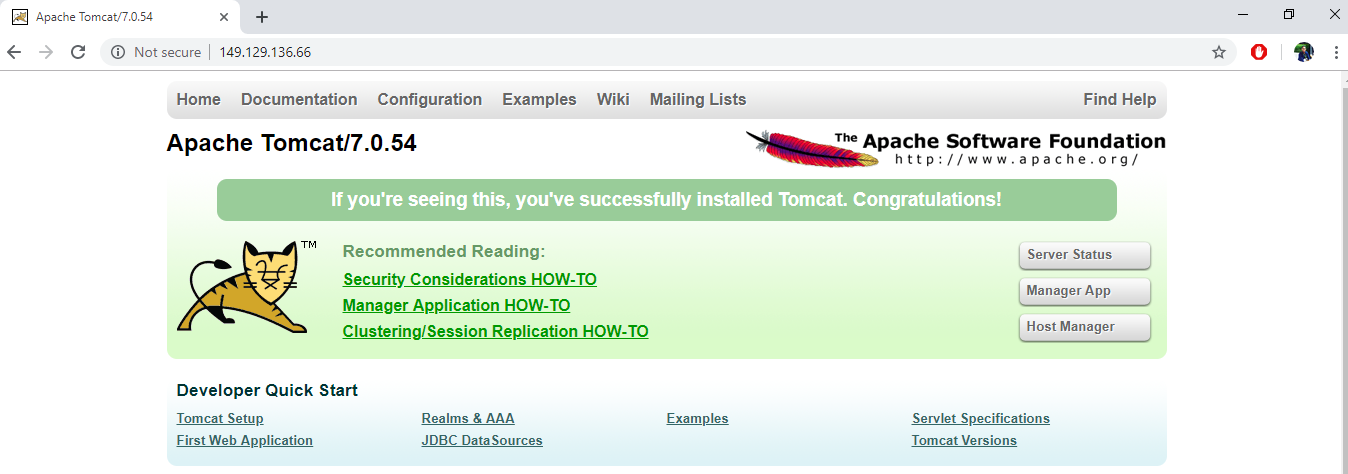
これで、Tomcat、Java、MySQLがインストールされたインスタンスをデプロイしました。ブラウザに対応するパブリックIPアドレスを入力すると、VMのパブリックIPの80番ポートを通してウェブサーバが公開されているので、Apache Tomcatのページが動作しているのが確認できます。
参考文献
1、https://www.alibabacloud.com/blog/ci%2Fcd-with-jenkins---part-1%3A-install-jenkins-on-ubuntu_593717
2、https://www.alibabacloud.com/blog/continuous-integration-with-jenkins-on-alibaba-cloud_594512
3、https://www.alibabacloud.com/blog/594449
4、https://github.com/alibaba/ansible-provider
5、https://mohitgoyal.co/2017/02/14/add-linux-slave-node-in-the-jenkins/
6、https://marketplace.alibabacloud.com/products/56728001/Tomcat_Nginx_My_SQL_Stack_Package_on_Ubuntu-cmjj011399.html?innerSource=search#product-detailsアリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ
- 投稿日:2020-09-23T16:58:36+09:00
MySQLのselectの基本操作
あるテーブルの全ての列を出力する
-- *で全ての列を指定することができる select * from Shohin;あるテーブルの特定の列を出力する
-- select句の後に対象の列名を記述する -- また、複数ある場合はカンマで区切る select shohin_id, shohin_mei, shiire_tanka from Shohin;別名をつける
ASを使用する。
日本語をつけることもできるが、その場合ダブルクォーテーションで囲む必要がある。select shohin_id as ID, shohin_mei as "商品名", shiire_tanka as "仕入単価" from Shohin;重複を除く
distinctを使用する。
nullについても、1つの種類として扱われる。select distinct shohin_bunrui from Shohin;複数列の前にdistinctを記述した場合、
複数行の組み合わせが全く同じ行が1つにまとめられる。-- 以下の場合、shohin_bunrui、torokubiの組み合わせが同じもののみが1つにまとめられる。 -- 例えばshohin_bunruiの値が同じでも、torokubiの値が同じでなければ1つにまとめられない。 -- distinctは先頭の前にしか書くことができない。 -- そのため、distinct shohin_bunrui, distinct torokubiとは書けない。 select distinct shohin_bunrui, torokubi from Shohin;条件の指定
whereを使用することで検索条件を指定することができる。
select * from Shohin where shohin_bunrui = "衣服";
- 投稿日:2020-09-23T16:34:19+09:00
MySQLのデータベース、テーブルの作成と削除、行の追加
データベース作成
create database shop;データベース一覧
show databases;データベース削除
drop database shop;テーブル作成
create table Shohin ( shohin_id varchar(4) not null primary key, shohin_mei varchar(100) not null, shohin_bunrui varchar(32) not null, hanbai_tanka int, shiire_tanka int, torokubi DATE );テーブル一覧
show tables;テーブル削除
drop table Shohin;データ追加
insertの後のintoは省略可能。
また、全てのカラムに対してデータを登録する場合、カラム名の指定を省略可能。-- into,カラム名を省略したバージョン insert Shohin values ('0001', 'Tシャツ', '衣服', 1000, 500, '2009-09-20'); -- 特定のカラムのみデータを登録する場合、valuesの前に対象のカラムを記述する -- 指定されていないカラムについてはnullが入る insert Shohin (shohin_id, shohin_mei, shohin_bunrui) values ('9999', '技術書', '経験値');データ削除
delete from Shohin where shohin_id = 9999;
- 投稿日:2020-09-23T04:24:28+09:00
anacondaでmysql-connector-pythonがインストール出来ない対処
状況
pythonを学習するにあたりanacondaを使用しているが、データベースを使用するためにインストールしようとしたが、エラーが出た
% conda install mysql-connector-python Collecting package metadata (current_repodata.json): done Solving environment: failed with initial frozen solve. Retrying with flexible solve. Solving environment: failed with repodata from current_repodata.json, will retry with next repodata source. Collecting package metadata (repodata.json): done Solving environment: failed with initial frozen solve. Retrying with flexible solve. Solving environment: \ Found conflicts! Looking for incompatible packages. This can take several minutes. Press CTRL-C to abort. failed UnsatisfiableError: The following specifications were found to be incompatible with the existing python installation in your environment: Specifications: - mysql-connector-python -> python[version='>=2.7,<2.8.0a0|>=3.7,<3.8.0a0|>=3.6,<3.7.0a0|>=3.5,<3.6.0a0'] Your python: python=3.8 If python is on the left-most side of the chain, that's the version you've asked for. When python appears to the right, that indicates that the thing on the left is somehow not available for the python version you are constrained to. Note that conda will not change your python version to a different minor version unless you explicitly specify that.詳しくはわからないが、互換性がない?バージョンの指定が必要?などが言われているような気がする。
エラーの内容が詳しくわかる方がいるのなら教えてください。対処法
conda install -c conda-forge mysql-connector-python
Anacondaはパッケージが少ないため、conda-forgeというチャンネルからinstallした。
pipでもインストール出来そうだが、anacondaとpipを混ぜるのは危険という記事を複数見つけたため、今回は使用しなかった。
(conda > conda-forge > pipの順で探してみるといい気がする。)一言
conda search mysql-connector-pythonを実行したときにpkgs/main channelにあるよ!的なことがわかったから、これを入力してもインストールできるのかもしれないコマンド実行時に複数のパッケージのインストールがされると表示されたが、これがmysql-connector-pythonの使用に必須の物なのか疑問