- 投稿日:2020-09-23T17:57:16+09:00
アリババのオープンソースのトラブルシューティングツール 「Archas 」
この記事では、アリババのオープンソースのトラブルシューティングツール「Archas」の概要と主な機能、そして今日から使い始められる方法を紹介します。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
Arthasの全機能とは
この記事を書いている時点ではバージョン3.1.1ですが、現在のバージョンのArthasの主要な機能を見てみましょう。Arthasは以下のことができます。
- クラスがロードされているかどうかのチェック
- クラスを逆コンパイルしてコードが期待通りに動作していることを確認します。
- クラスローダの統計情報とメソッドの呼び出し情報 (関連するパラメータ、リターンオブジェクト、スローされた例外を含む) を表示します。
- 指定されたメソッド呼び出しのスタックトレースをチェック
- 遅い呼び出しを追跡するためにメソッドの呼び出しをトレースする
- メソッド呼び出しの統計情報(秒当たりのクエリ、応答時間、成功率など)を監視します。
- システムメトリクス、スレッドの状態、CPU 使用率、ガーベージコレクション統計などの項目を監視します。
- コマンドラインとブラウザインタフェースを使用したローカルおよびリモートデバッグのためのtelnetとWebソケットをサポート
- Javaa開発キット6+をサポート
- Linux、MacOS、Windowsをサポート このページでは、アーサスのリリース情報を全て記載しています。
Arthasのインストールと実行
Arthasは、Linux、MacOS、Windowsを含む主要なオペレーティングシステムのほとんどで動作します。Arthas のセットアップを始める前に、Java Virtual Machine 6 以降がシステムにインストールされていることを確認する必要があります。一般的に言えば、Arthasは単一の実行可能なJarファイルで構成されていて、Arthasのランナーであるarthas-bootという名前です。
arthas-boostをダウンロードするには、以下のコマンドを使用します。
wget https://alibaba.github.io/arthas/arthas-boot.jarその後、以下のコマンドでArthasを管理します。
- 実行:
java -jar arthas-boot.jar- ヘルプの取得:
java -jar arthas-boot.jar -hArthasとArthasコマンドの使い方
Arthas のヘルプコマンド (
-h) から、診断ツールの特定の機能を有効にしたり、対処したりするための多くのオプションがあることがわかります。ここでは、よく使われるであろう興味深いオプションをいくつか紹介します。
--target-IP:ターゲットの Java 仮想マシンがネットワーク上の特定の IP アドレスにある場合、デフォルトは 127.0.0.0.1 (ローカルホスト) です。--telnet-port:対象の Java 仮想マシンが telnet ポートをリッスンします。デフォルトのポートは3658です。--http-port: 対象となる Java 仮想マシンのリッスンする HTTP ポート。対象の Java 仮想マシンがリッスンする HTTP ポート。デフォルトのポートは 8563 です。--use-version: 対象となるJava仮想マシンのバージョンを指定します。Arthas の特別なバージョンを使用します。--use-http: アイテムのダウンロードに HTTP を使用することを強制します。デフォルトではHTTPSが使用されます。—verbose: デバッグ情報をより多く表示するためにコードを冗長にします。デバッグ情報をより多く表示するために、コードをより冗長します。ターミナルコンソールの使用
Arthas が起動して起動したら、Enter をクリックして Arthas に飛び込むことができます。次に、Arthasに関連付けられたコマンドラインインターフェースを使って、Arthasサーバーに追加のコマンドを入力します。ここでは、この記事で紹介している例では、ローカルマシンなので
--target-ipを指定していません。以下はターミナルがどのように見えるかの例です。
ヘルプを入力してEnterキーをクリックすると、内部プロンプトから追加のヘルプを受け取ることができます。現在のマシンの結果は以下の通りです。
$ help NAME DESCRIPTION help Display Arthas Help keymap Display all the available keymap for the specified connection. sc Search all the classes loaded by JVM sm Search the method of classes loaded by JVM classloader Show classloader info jad Decompile class getstatic Show the static field of a class monitor Monitor method execution statistics, e.g. total/success/failure count, average rt, fail rate, etc. stack Display the stack trace for the specified class and method thread Display thread info, thread stack trace Trace the execution time of specified method invocation. watch Display the input/output parameter, return object, and thrown exception of specified method invocation tt Time Tunnel jvm Display the target JVM information ognl Execute ognl expression. mc Memory compiler, compiles java files into bytecode and class files in memory. redefine Redefine classes. @see Instrumentation#redefineClasses(ClassDefinition...) dashboard Overview of target jvm's thread, memory, gc, vm, tomcat info. dump Dump class byte array from JVM options View and change various Arthas options cls Clear the screen reset Reset all the enhanced classes version Display Arthas version shutdown Shutdown Arthas server and exit the console session Display current session information sysprop Display, and change the system properties. sysenv Display the system env. history Display command history cat Concatenate and print files pwd Return working directory name上記の結果から、Arthasの本番診断に役立ついくつかの追加コマンドを簡単に見つけることができます。では、以下の行でそのいくつかを見てみましょう。
まず、ダッシュボードコマンドがあります。これは、以下の画像に示すように、現在のJava仮想マシンのスレッド、CPU使用量、メモリ使用量、コンピュータアーキテクチャ、オペレーティングシステムの概要を、いくつかの追加情報とともにリアルタイムで提供します。
次に、classloader コマンドはクラスの読み込み情報を表示するために使用されます。他にも、すべてのクラスのインスタンスを完全にリストアップする(
-l)や、クラスローダの階層を表示する(-t)などのオプションがあります。また、クラスをデコンパイルするための素晴らしいツールである jad コマンドもあります。どのように動作するかというと、本番環境で実行されている正確なクラスコードを見つけることができるので、実行されているコードが実際にオンラインで実行したいコードであることを確認することができます。これは比較的簡単なコマンドで、ここに示されているクラス名に続きます:
jad java.lang.String。このコマンドの結果、コンソールにStringクラスがデコンパイルされていることになります。クラスのソース・コードのみをデコンパイルして、指定した場所のファイルに保存するより高度な方法は、次のようになります:
jad -source-only java.lang.String > /tmp/String.java。このため、ここでは-source-onlyを使用して、デコンパイルされたクラスの先頭からいくつかの特定のクラス・ローダと場所の記述を削除しています。getstatic コマンドは、クラスの静的フィールド値を表示するために使用されます。そのための構文は次のようになります。
getstatic package.to.Class staticFieldName.。そしてもう一つの例:getstatic java.lang.String serialVersionUIDは、以下のように文字列のシリアル・バージョン UID 値を表示します。
jvmコマンドは、Java仮想マシンの全結果を表示するために使用されます。次に、scは、JVMがロードしたすべてのクラスを検索クラスとして読み込むことができます。これは、クラスのロードの問題を検出するのに便利です。
これに続いて、
-dオプションは、検索されたクラスに関連する特定の情報を出力します。これらの情報は、それがどのようなクラスであるかを判断するために使用することができます。例えば、それがインターフェイスなのか、アノテーションなのか、列挙なのかを判断することができます。java.lang.Stringチェックの結果を、-dオプションを指定した場合としなかった場合の画像を以下に示します。
scはワイルドカード文字もサポートしており、特定の一致するクラスを含むすべてのクラスを表示するなど、より多くの結果を表示するのに役立ちます。これは以下のような構文で行うことができます:sc String*. 以下の出力例を参照してください。
smは検索メソッドの略で、ロードされたクラスのメソッドを検索してコンソールに表示するために使用されます。d オプションは、修飾子、アノテーション、パラメータ、戻り値の型、例外などの単一のメソッド情報を検索する際に特に便利です。その他の例
また、以下のコマンドを使用することもできます。
- sm java.lang.String - sm -d java.lang.String toStringどれにしても、次のような結果になります。
次に、現在のJVM環境変数をコンソールに表示できるsysenvを使用することもできます。また、以下のスクリーンショットのように、keymapコマンドを実行して現在のキーマップを印刷することもできます。
他にもよく使うコマンドに
threadがありますが、これは以下のように、すべてのJavaスレッド情報を1つのテーブルに表示するために使うことができます。
特定のスレッドのスタックを表示するには、例えば
thread 40のように、対応するスレッド ID を持つコマンドを実行するだけです。別の例として、thread -n 3を使うことでスタックトレースを詳細に表示して、最も使用頻度の高いスレッドの上位 3 つをリストアップすることもできますし、代わりにthread –bを使ってすべてのブロッキングスレッドを見つけてリストアップすることもできます。これらがどのように動作するかについての詳細な情報はこのドキュメントをチェックしてください。次に watch があります。これはクラスのメソッドの戻り値、例外、パラメータを監視します。watchコマンドを使った例を考えてみましょう。以下のように実行したとします。
watch package.to.*Controller * '{params, returnObj, throwExp}'上記では、1つ目のパラメータはワイルドカードをサポートしているクラス名で、2つ目のパラメータはメソッドです。これもたまたまワイルドカードの使用をサポートしています。このコマンドは全体として、リアルタイムでパラメータを表示し、任意のコントローラメソッドが呼び出された場合、または呼び出された場合にオブジェクトと例外を返します。このコマンドはデバッグにかなり便利です。
注意点としては、以下のようなものがあります。
*Controllerは UserController, BillingController, AuthController, IndexController などとマッチします。- watch コマンドは
-eオプションをサポートしており、例外をスローするリクエストのみを検出します。Arthas-demo プロジェクトを使用する際の他の良い例はドキュメントからアクセスできます。
コンソールインターフェイスでは、Arthas はオートコンプリート機能をサポートしています。また、Tab キーをクリックするだけで、最初に入力した単語に応じて、いくつかの異なるクラスのパッケージ間を移動して、より多くの提案を得ることができます。
下の画像は .string と入力したときに表示されるオートコンプリートの提案を示しています。
traceコマンドは、指定されたメソッド呼び出しの実行時間をトレースします。これは、最初のレベルのメソッド呼び出しのみがトレースされ、ディープトレースは行われないので、Javaアプリケーションにあるかもしれないパフォーマンス上の欠陥を判断するのに役立ちます。
次のように考えてみましょう:
trace package.to.Class method '#cost > 50’。このメソッドは、時間コストが50ms以上になると、クラスメソッド関数の実行をトレースして表示します。次に、stackコマンドは、現在のメソッドの完全な呼び出しスタックを表示します。1つのメソッドが呼ばれることはわかっていても、どのコードパスが実行されるのか、いつそのメソッドが呼ばれるのかについては全くわからないことがよくあります。これがスタックコマンドの目的です。これはtraceのような構文で、フィルタリングもサポートしており、例としてコストをミリ秒単位で表示します。
通常、コマンドラインインターフェースで方向矢印(左、右、上、下)を押すと、以前に実行したコマンドのリストをスクロールします。
shutdownコマンドは Arthas サーバーを完全にシャットダウンしてコンソールを終了するために使用されます。ArthasのWebコンソール
Arthasを操作するための最もポピュラーな方法の一つは、この記事で紹介してきたようにターミナルコマンドを使って操作することです。しかし、Arthasを操作するもう一つの方法は、もちろんブラウザのWebコンソールを使うことです。
ArthasのWebコンソールはWebソケットを使ってArthasのサーバーと通信し、
http://server_ip_address:8563/でアクセスすることができます。ローカルにデプロイした場合、アドレスは127.0.0.0.1になります。ウェブインターフェースは以下のようになっています。
ウェブコンソールのトップメニューから、サーバーのIPアドレスとポートを記入するだけで、他のArthasサーバーに接続できることがわかります。後日、さらに調査することで、より安全性の高いものにすることができます。
まとめ
この記事では、Arthasのインストール方法や起動方法など、Arthasについて詳しく説明しています。また、Arthasのコマンドラインインターフェースを使ってJVMスレッドを診断するためのコマンドを実行する方法についても学びました。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ











- 投稿日:2020-09-23T17:52:21+09:00
AnsibleとJenkinsを使用してTomcat、Java、MySQLからなるイメージをデプロイ
このチュートリアルでは、AnsibleとJenkinsを使用して、Tomcat、Java、MySQLで構成されたイメージをAlibaba Cloud上にデプロイします。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
前提条件
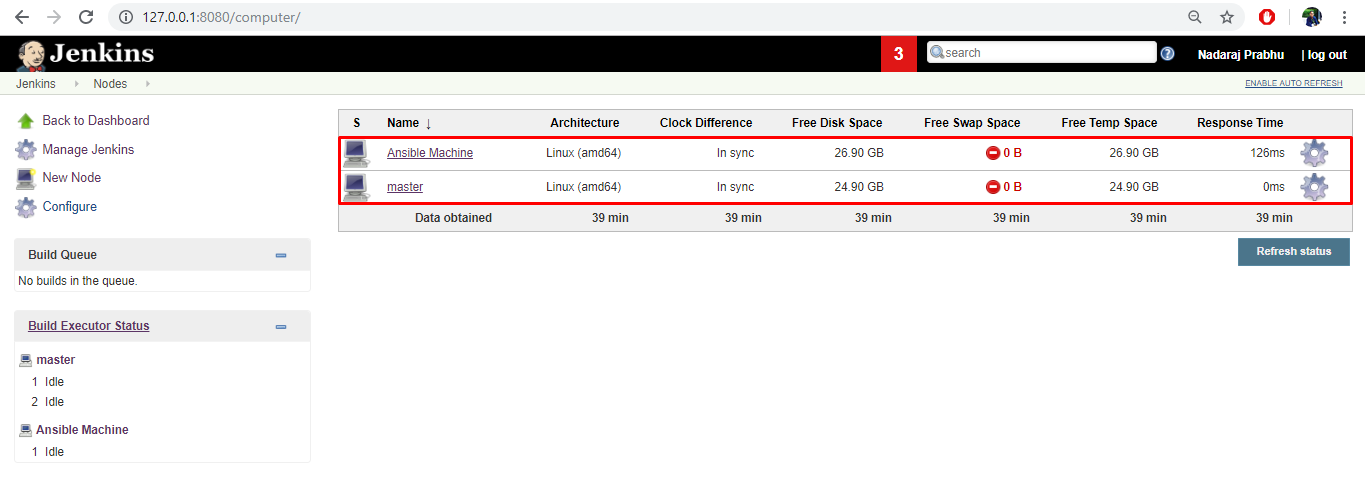
- 最低でも1台のJenkinsサーバが必要です(マスターのみまたはマスター/スレーブ設定の場合)。
そして、Jenkinsサーバのマスター/スレーブ(エージェント)環境を設定したら、サーバの状態を確認してエージェントが正常に稼働していることを確認します。特に私のセットアップでは、マスターノードをJenkinsサーバとして、エージェントマシンをAnsible用に使用しています。ご希望であれば、マスター自体にAnsibleをインストールすることで、1台だけのマシンを持つことも可能です。
- その後、マスターマシンとエージェントマシンにAnsible Toolをインストールします。
2.Ansibleを導入します。Ansibleは、ITオートメーションのための強力なツールであり、ターゲット環境をプロビジョニングし、その上でアプリケーションをデプロイするためにCI/CDプロセスで使用することができます。しかし、Ansibleはメンテナンスが面倒で、長期的にはスクリプトを再利用してしまうことを知っておいてください。
Ansible がインストールされている集中管理された場所から、異なるサーバ/環境にまたがって同じタスクを実行する場合に役立ちます。Ansible は完全にエージェントレスであるため、Chefや Puppet のような他の IaC (Infrastructure-as-Code) ツールと比較して優位性があります。Ansible を使用すると、クライアントシステムにエージェントをインストールする必要がなく、クライアントとサーバ間の SSH 通信によって自動化が行われます。指定した地域に何百ものインスタンスがあれば、すべての自動化が容易になります。AnsibleのプレイブックはYAML/YML言語で書かれています。Ansibleになると、以下のような知識も必要になってきます。
- Control node:Ansible がインストールされており、管理しているサーバーを担当するマシン
- Inventory:プレイブック内のコマンド、モジュール、タスクが動作するホストとホストグループを定義するファイル。このファイルは、Ansible 環境とプラグインに応じて多くの形式のいずれかになります。プロジェクト固有のインベントリファイルを別の場所に作成するために使用します。
- Playbook:Ansible の設定、デプロイメント、オーケストレーション言語の一部。リモートシステムに適用させたいポリシーや、一連のステップを記述することができます。
Ansible と Ansible Alicloud モジュールのインストール
まず、JenkinsにAnsibleプラグインをインストールします。そのためには、以下の手順に従います。
- ダッシュボードのManage Jenkinsをクリックします。
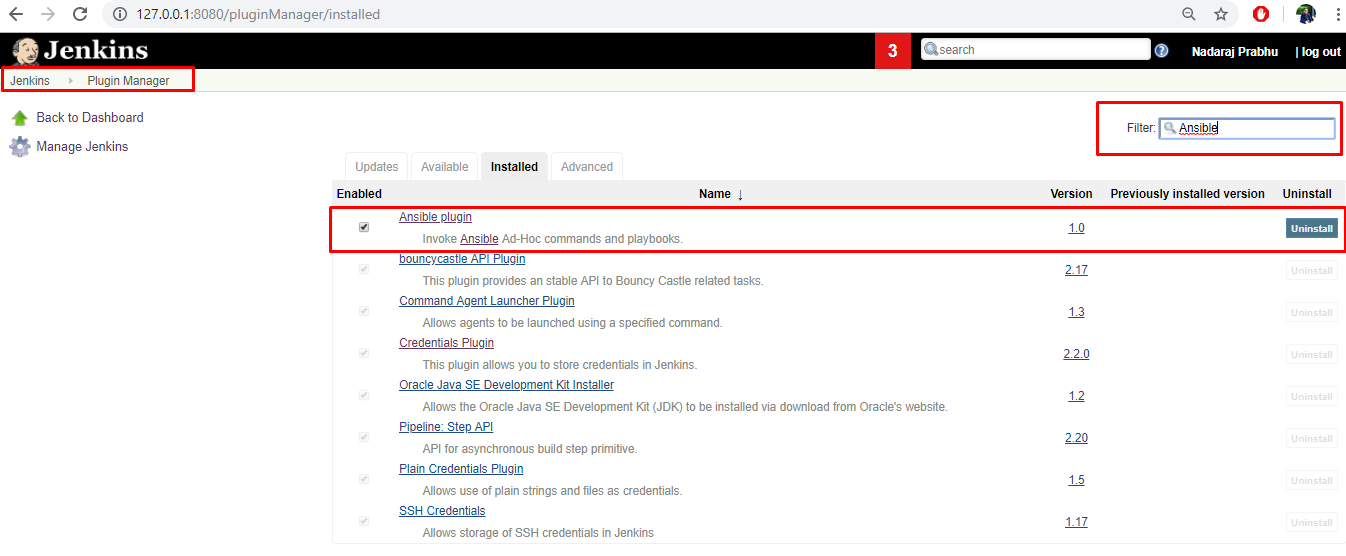
- プラグインの管理をクリックして、ページの右上にある検索バーで Ansible プラグインを探します。
- Ansible を選択して、Download now をクリックし、再起動後にインストールします。
注意: このチュートリアルで行っている現在のセットアップには必要のない Ansible Tower はインストールしないでください。
Jenkins に Ansible プラグインをインストールしたら、次は Client/Agent マシンに Ansible をインストールする手順に進みます。
クライアント/エージェントマシンにAnsibleをインストール
Alibaba Ansibleモジュールは頻繁に更新されているので、最新版はGitHubのリンクを参照することをお勧めします。
- エージェントマシンでターミナルウィンドウを開き、以下のコマンドを実行します。
- CentOS 7.4を使用している場合は、このコマンドを使用すると良いでしょう。
sudo yum check-update; sudo yum install -y gcc libffi-devel python-devel openssl-devel epel-release sudo yum install -y python-pip python-wheel
- Ubuntu 16.04 LTSを使用している場合は、このコマンドを使用します。
sudo apt-get update && sudo apt-get install -y libssl-dev libffi-dev python-dev python-pip
- 次のコマンドを入力して、必要なパッケージAnsible for Alibabaをインストールします。
sudo pip install ansible sudo pip install ansible_alicloud sudo pip install ansible_alicloud_module_utilsAnsibleプレイブックを設定
アリババECSをプロビジョニングするためのAnsibleのプレイブックスクリプトをこちらに作成してみました。ソースコードをフォークして、環境に合わせてパラメータの値を変更することができます。
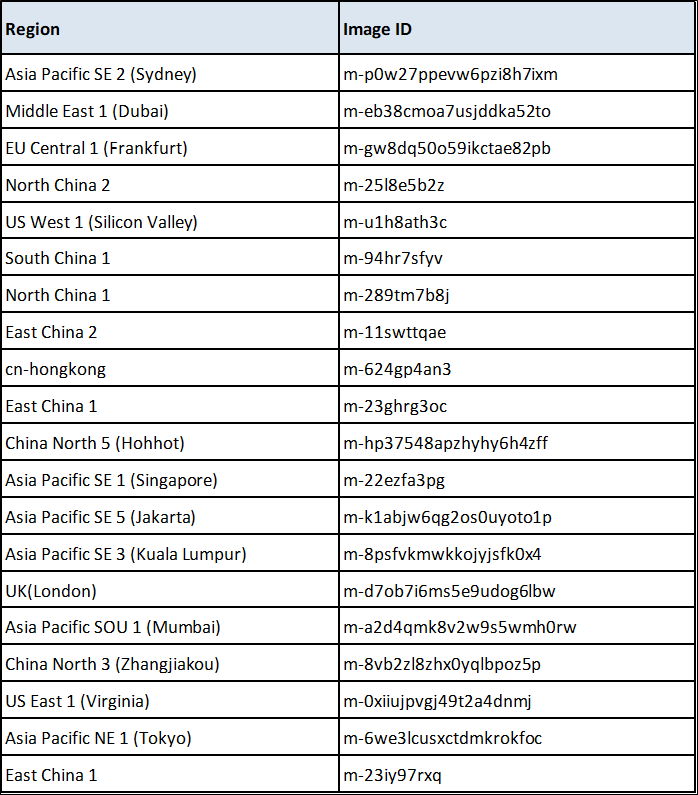
alicloud_access_key: <Alibaba Access Key> alicloud_secret_key: <Alibaba Secret Key> alicloud_region: <Alibaba Region for your resource> e.g. - ap-south-1 alicloud_zone: <Alibaba Zone for your resource> e.g. ap-south-1a password: <New VM Password> image: "m-a2d4qmk8v2w9s5wmh0rw"注:私はZhuyunが提供するAlibaba Application Stacksからイメージをインポートしています。こちらでご確認ください。Linux、Nginx、MySQL、Jdk-Tomcat(Nginx1.6-jdk1.7-tomcat7-mysql5.5-vsFTPd2.2.2)で構成されています。
アクセスキーとシークレットの生成
さて、アクセスキーとシークレットを生成する時が来ました。これを行うには、以下の手順に従ってください。
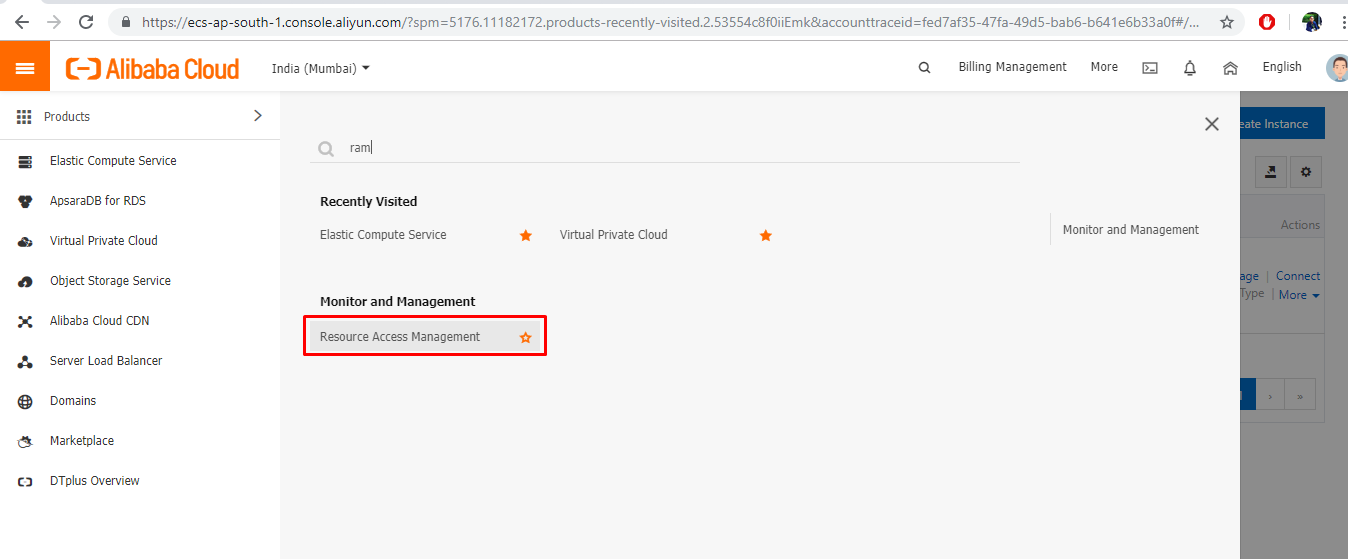
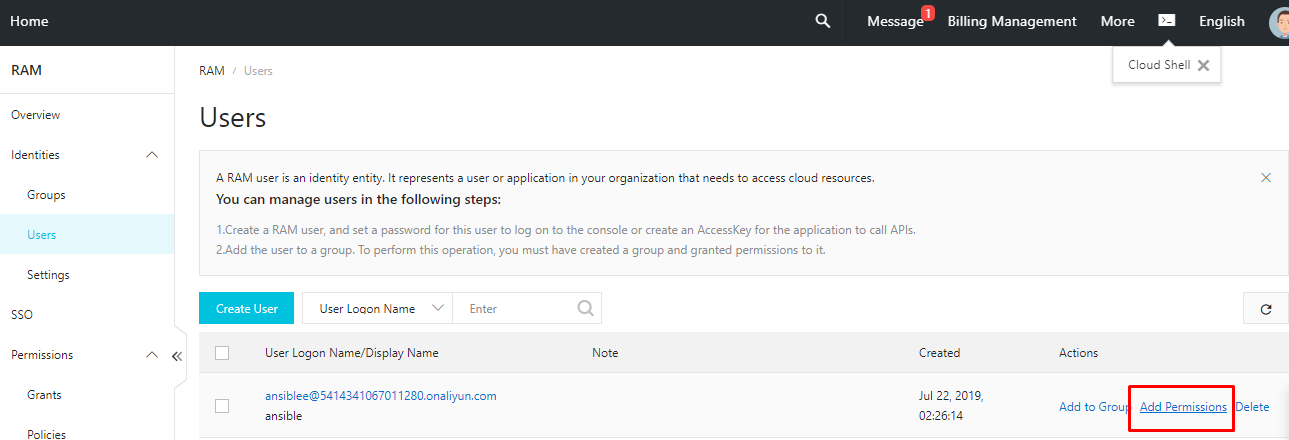
アクセスキーとシークレットキーを取得するには、Alibaba Cloudコンソールにアクセスして、製品メニューからリソースアクセス管理(RAM)を選択します。
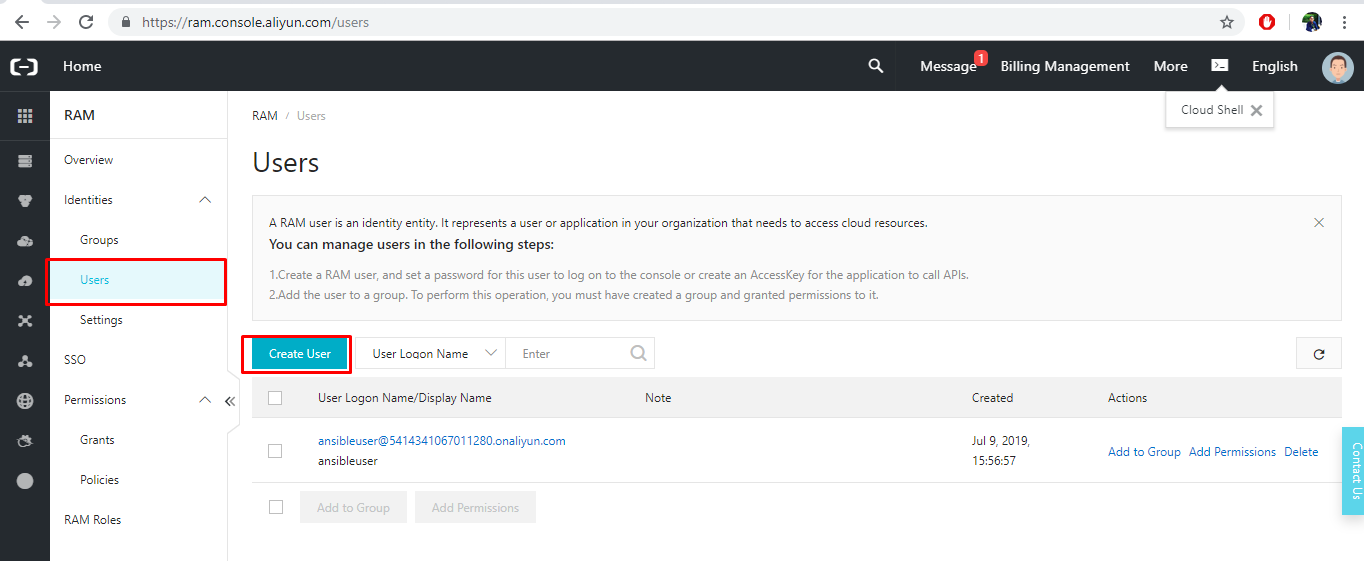
- 左側のナビゲーションペインで[ユーザー]オプションをクリックし、[ユーザーの作成]を選択します。
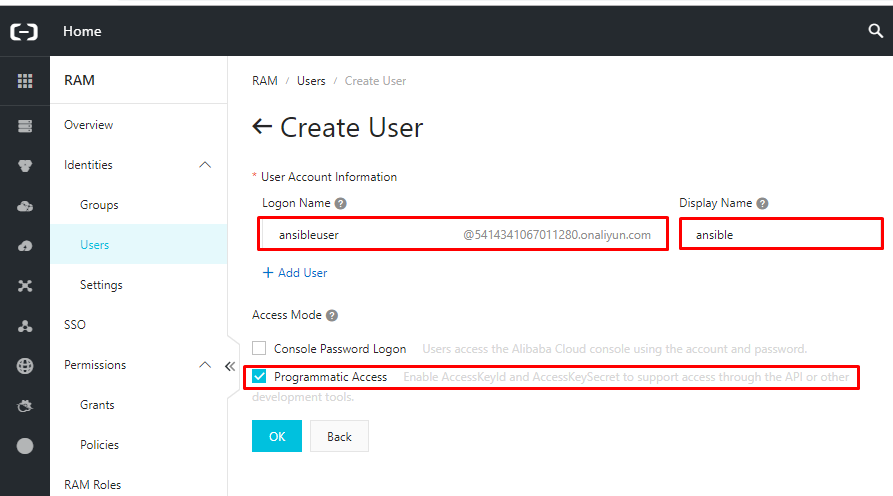
- 新しいユーザーを作成し、ログイン名と表示名を入力します。次に、[アクセスモード]で、[プログラムアクセス]にチェックを入れます。このユーザーに Console Password Logon アクセスを提供する必要はありません。
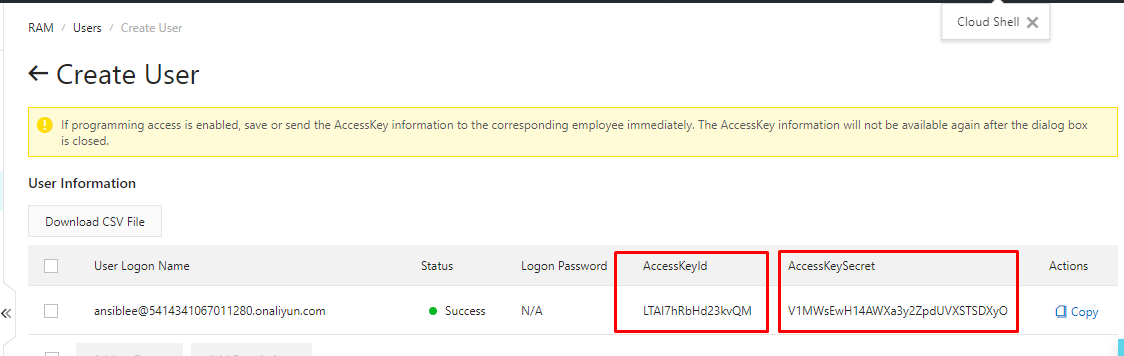
- プレイブックの
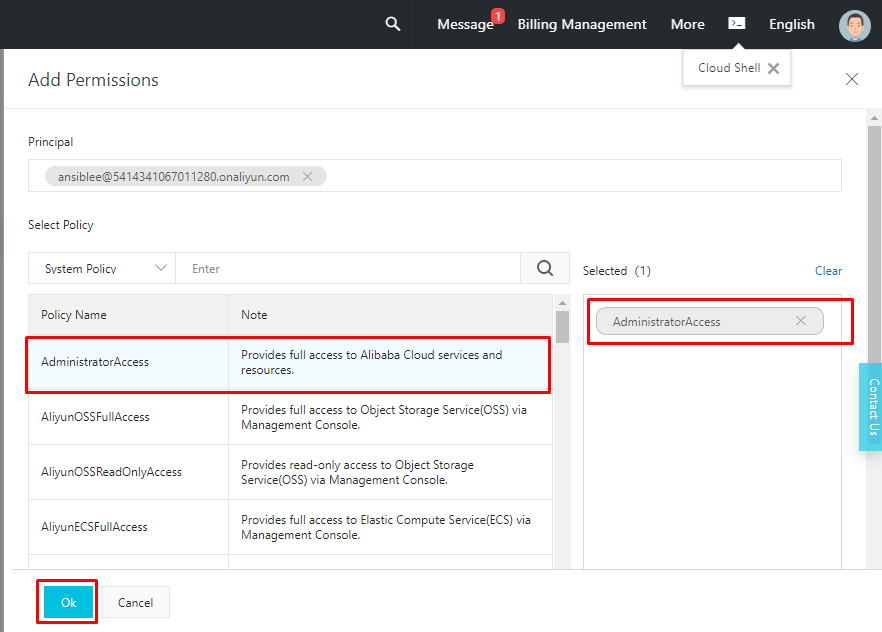
alicloud_access_keyとalicloud_secret_keyの値となるAccessKeyIdとAccessKeySecretをコピーします。注意:ダイアログボックスを閉じると、AccessKey情報は再び利用できなくなります。したがって、ダイアログボックスを閉じる前にこの情報をコピーして保存しておくことが重要です。
- VPC、V-Switchs、セキュリティグループ、またはECSインスタンスのようなリソースをプロビジョニングするための適切な権限を提供します。私はAdministratorAccessを提供していますが、これはAlibaba Cloudのサービスやリソースへのフルアクセスを提供するために起こることです。
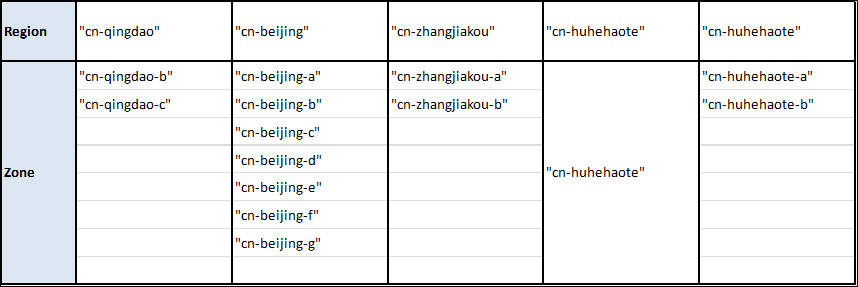
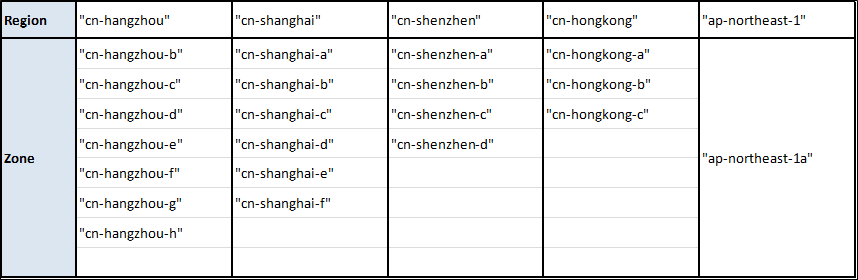
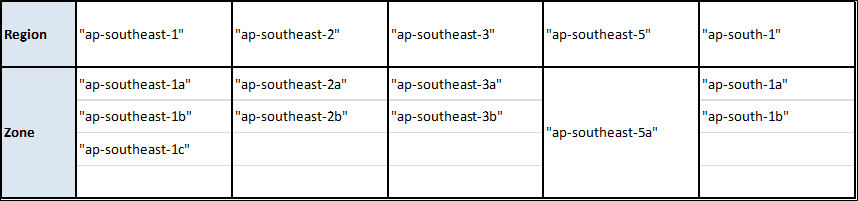
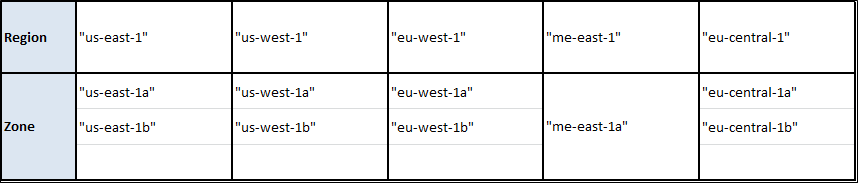
アリババクラウドの地域とゾーン
注)1.
- 完全なリストを取得するには、Alibaba CloudのCLIツールを使用することができます。JSONの壁を吐き出してくれるので、*nix上にいてjqツールが利用できるのも便利です。以上のことを考えると、必要なのはこの短いシェルスクリプトだけです。
#!/usr/bin/env bash for region in $( aliyun ecs DescribeRegions | jq '.Regions.Region[].RegionId' ) do echo $region reg=$( echo $region | sed s/\"//g ) echo '---' for zone in $( aliyun ecs DescribeZones --RegionId $reg | jq '.Zones.Zone[].ZoneId' | sort ) do echo $zone done echo '' done
- 以下の地域・ゾーンにリソースを提供したい場合は、こちらのリンクから実名登録を行ってください。
alicloud_region: cn-beijing alicloud_zone: cn-beijing-a以下に各リージョンのイメージIDを示します(Linux, Nginx, MySQL, Jdk-Tomcatイメージの場合)。もちろん、地域に応じてイメージIDを変更する必要があります。
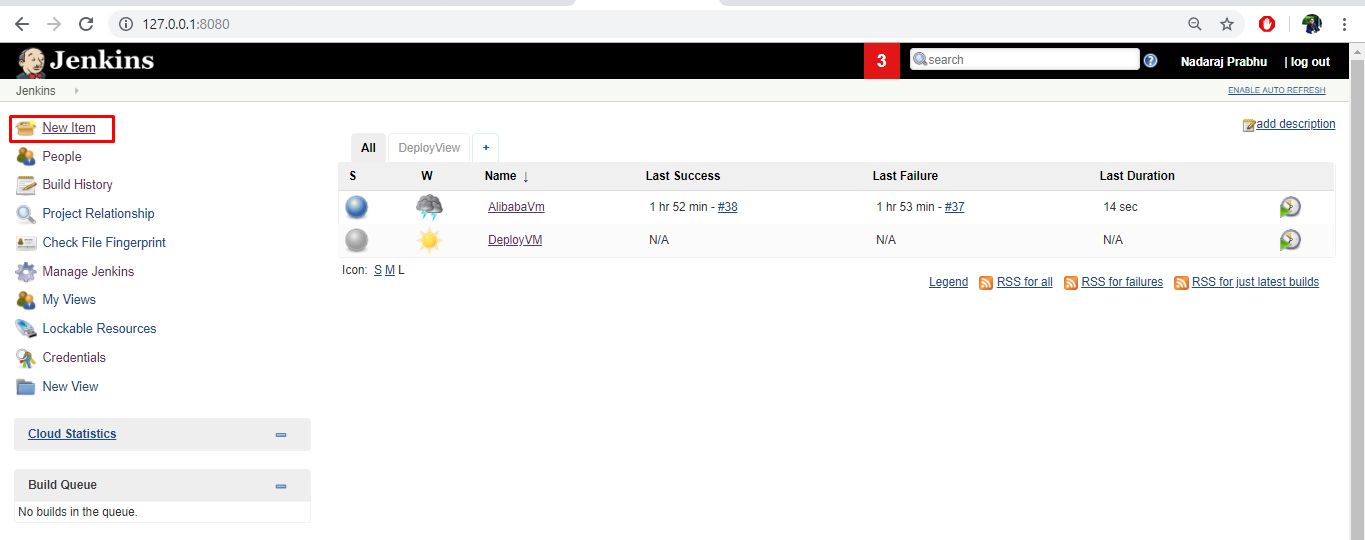
Jenkinsジョブを使用してAlibaba VMを作成してデプロイする
Jenkinsジョブを使用してAlibaba VMを作成してデプロイするには、以下の手順に従います。
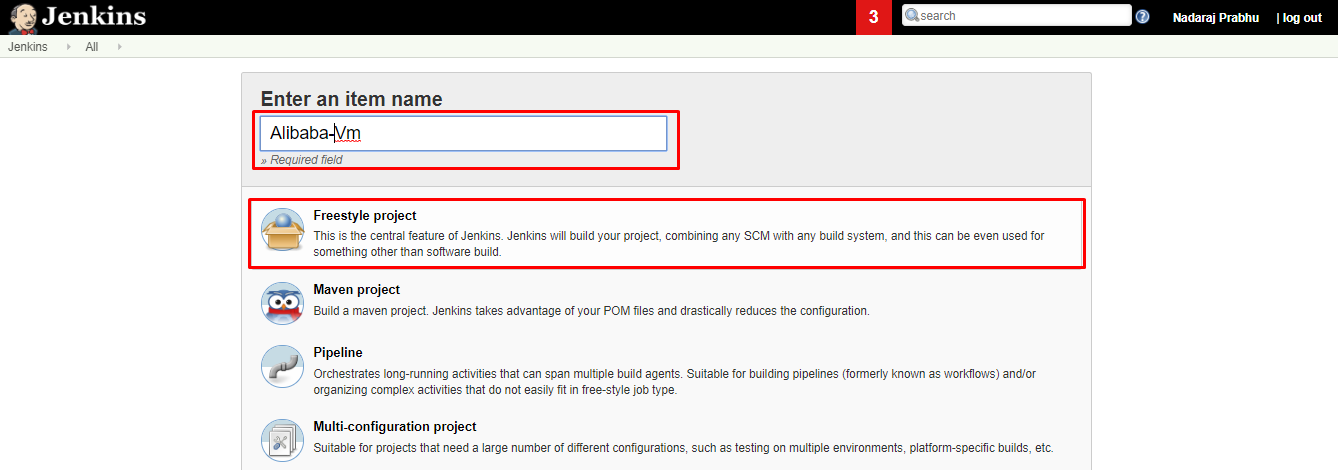
- Jenkinsダッシュボードから、New Itemを選択します。
- 名前を入力し、「Freestyle project」を選択し、「OK」をクリックします。
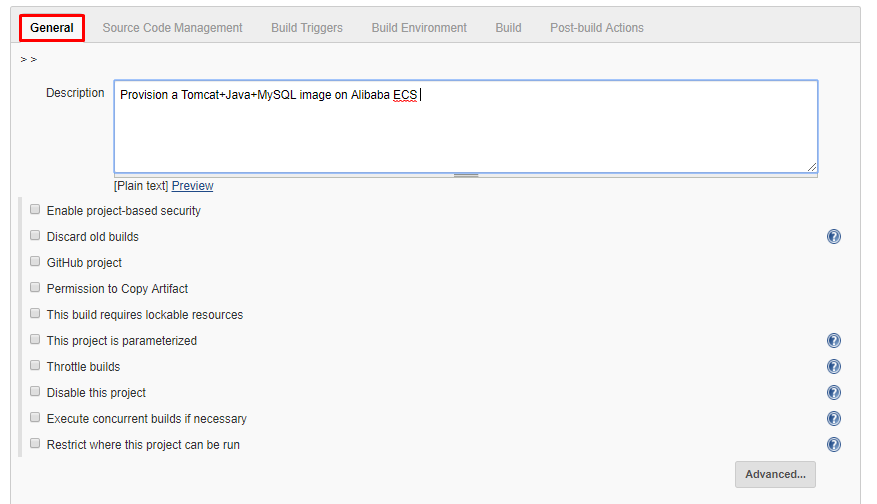
- (オプション) 一般の下に、参考のために簡単な説明を記載してください。
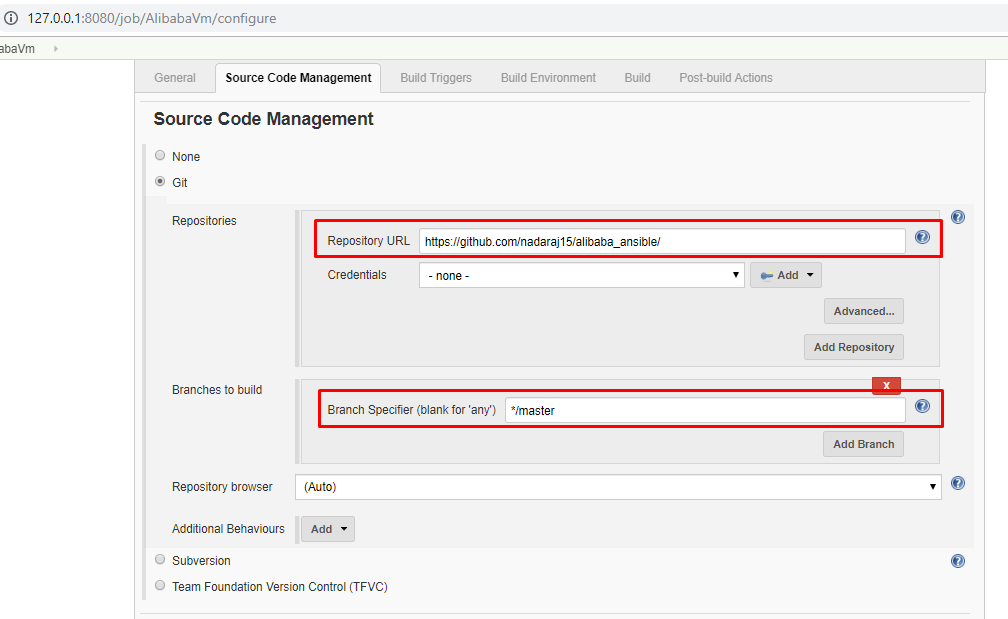
- 上部のソースコード管理(SCM)タブを選択するか、スクロールダウンして以下の情報を入力します。
SCM: - Git
リポジトリのURL:- GitHubのリンクにパラメータを変更したもの
例:https://github.com/nadaraj15/alibaba_ansible/
資格情報:- なし (パブリックリポジトリなので、プライベートの場合は Jenkins に資格情報を保存)
ブランチ指定子 ( 'any' の場合は空白): - */master
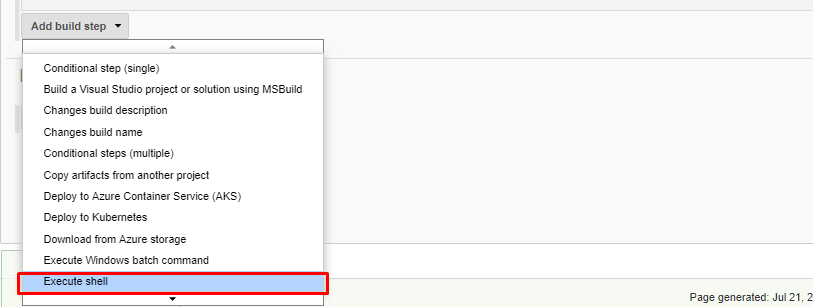
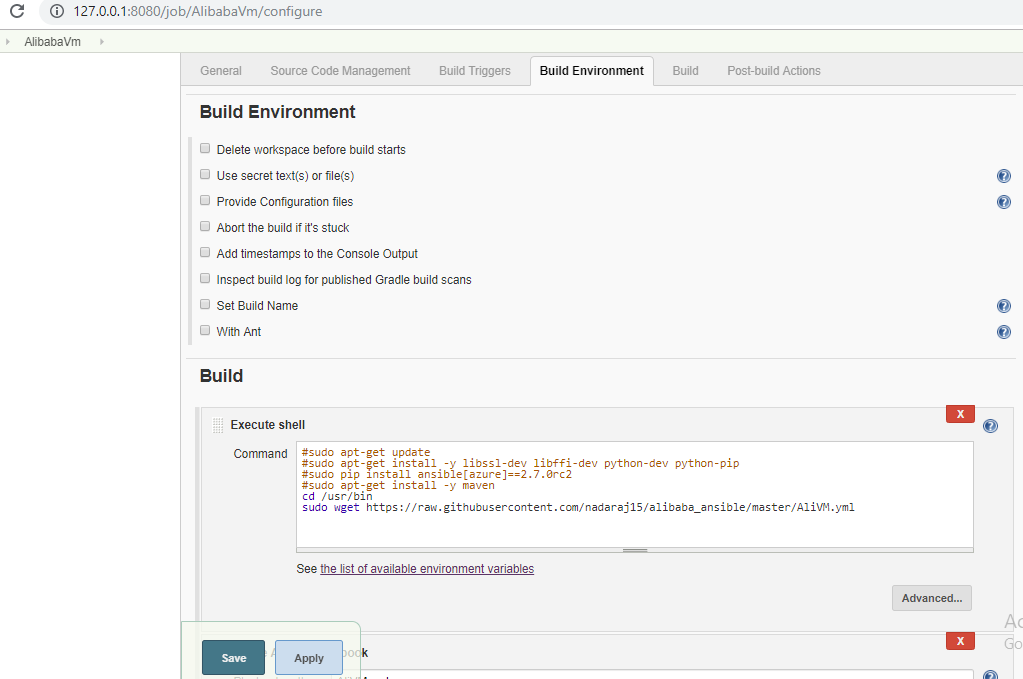
- 次に、ビルドトリガーはとりあえずスキップして、ビルド環境に移動します。新しいプロジェクトを作成する際には、いくつかの設定が用意されています。この設定ページでは、スクリプトを実行するなどの余分なアクションを実行するためのビルドステップを追加するオプションもあります。というよりも、シェルスクリプトを実行して、GitHubからAnsible Playbookファイルをダウンロードします。以下のコマンドを使用します。
sudo apt-get update (Optional) sudo apt-get install -y libssl-dev libffi-dev python-dev python-pip (Optional) sudo pip install ansible[azure]==2.7.0rc2 (Optional) sudo apt-get install -y maven (Optional) cd /usr/bin sudo wget https://raw.githubusercontent.com/nadaraj15/alibaba_ansible/master/AliVM.yml
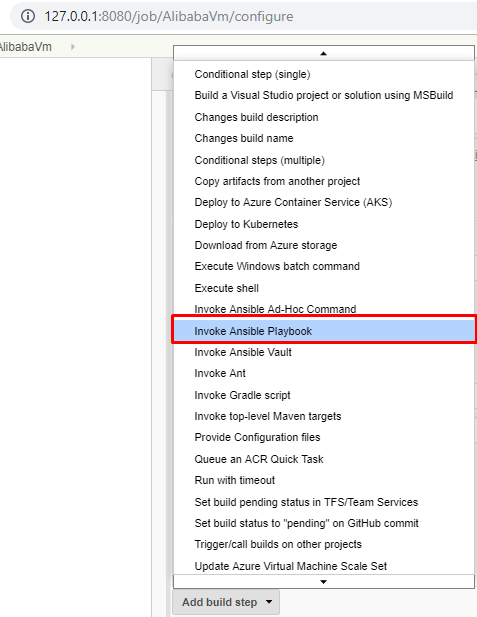
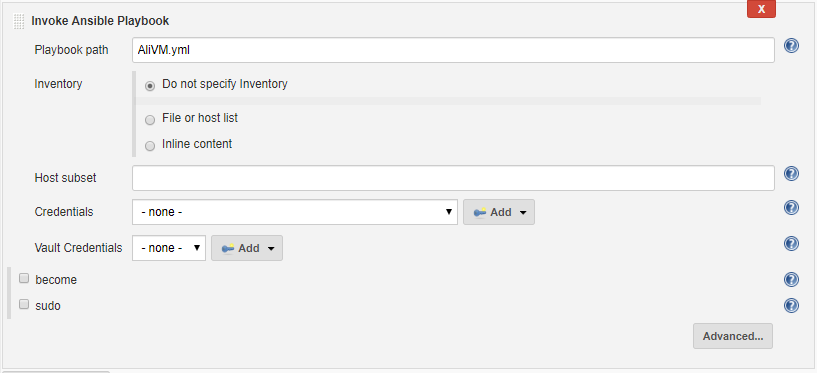
- ビルドステップを追加して ansible playbook を起動したいと思います。このステップは ansible playbook を実行します。以下の情報を入力します。
- Playbook path: - AliVM.yml (プレイブック名)
- Inventory: - 「Inventoryを指定しない」を選択
- Credentials:- 「なし」を選択します(デプロイメントファイルに資格情報を埋め込んでいるので、環境変数として資格情報を渡すことができます)
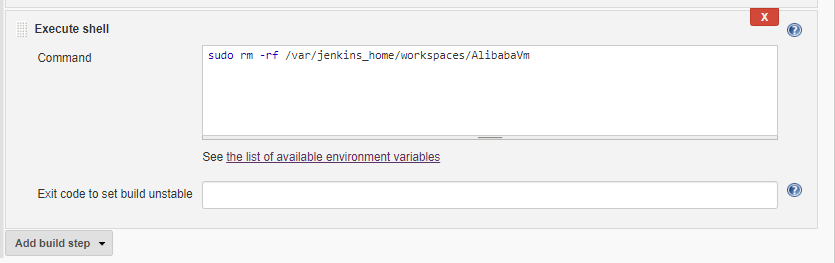
- デプロイ後のワークスペースをクリーンアップし、以下のコマンドでシェルスクリプトの実行ステップを追加します。
注意:
jenkins_homeがあなたの場所である場合、デフォルトのパスは/var/jenkins_homeに設定されています。しかし、カスタムの場所がある場合は、その代わりにその場所を使用することができます。sudo rm -rf /var/jenkins_home/workspaces/<workspace_name>
- 必要に応じてポストビルトアクションを追加します。最後に、すべてのステップが設定されたら、保存をクリックします。
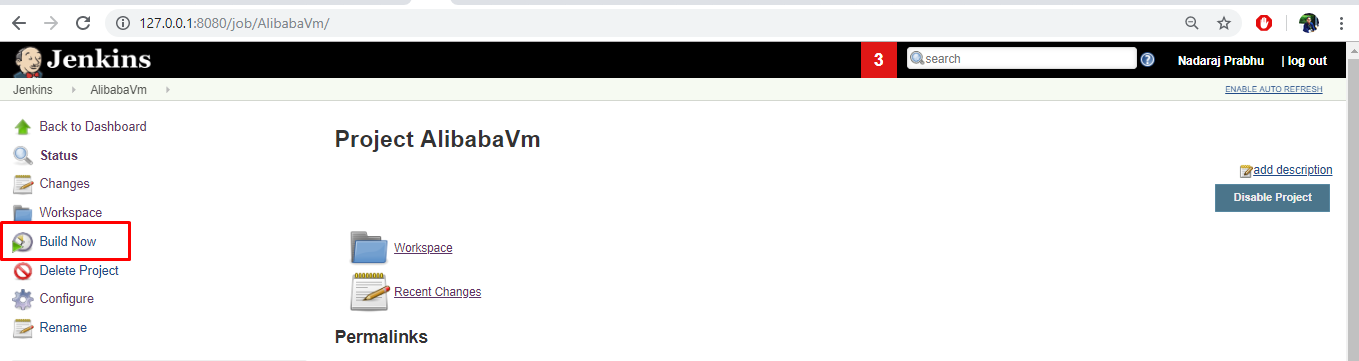
- Jenkinsプロジェクトダッシュボードに移動し、「Build now」をクリックして手動でビルドをトリガーします。
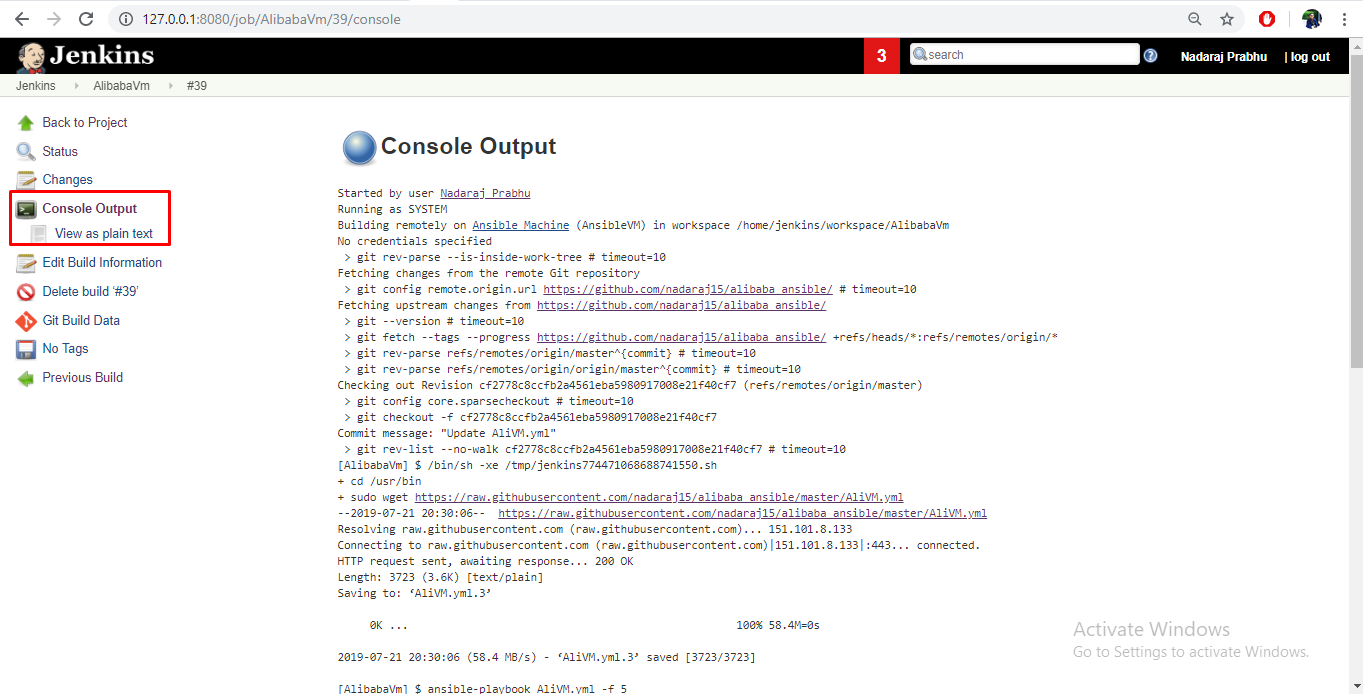
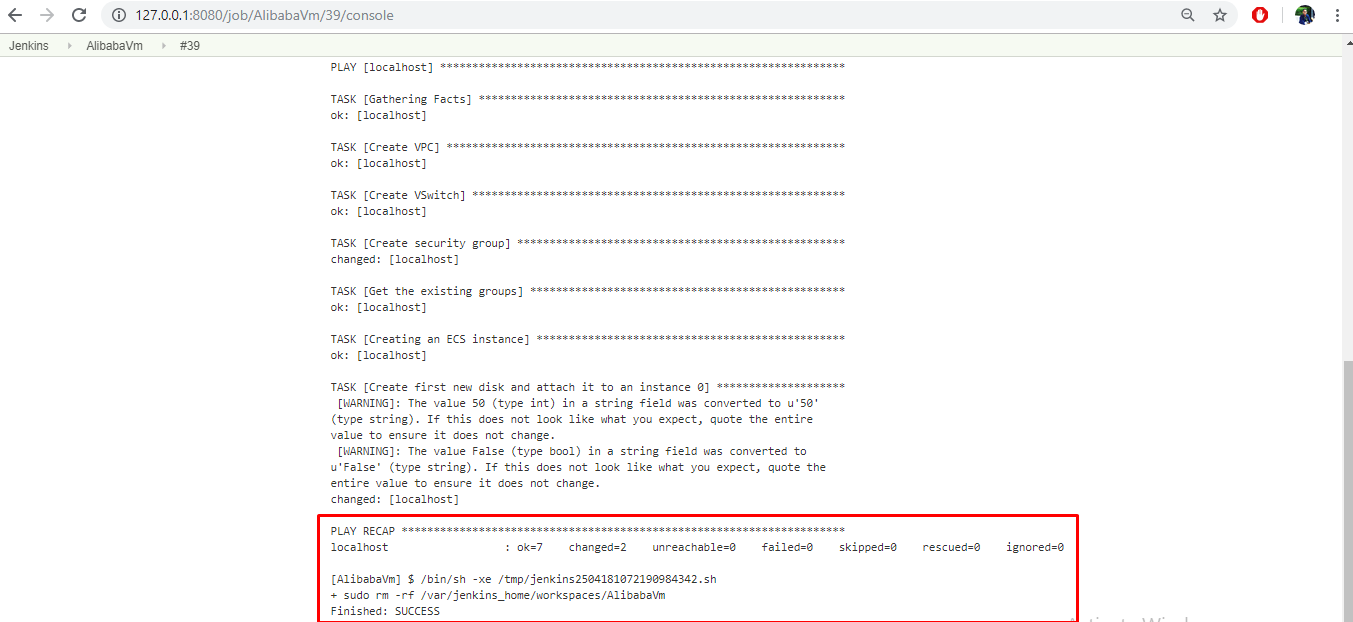
- コンソール出力に移動して、トリガーされたビルドステータスを確認します。すべてのリソースが正常にプロビジョニングされると、出力に成功ステータスが表示されます。
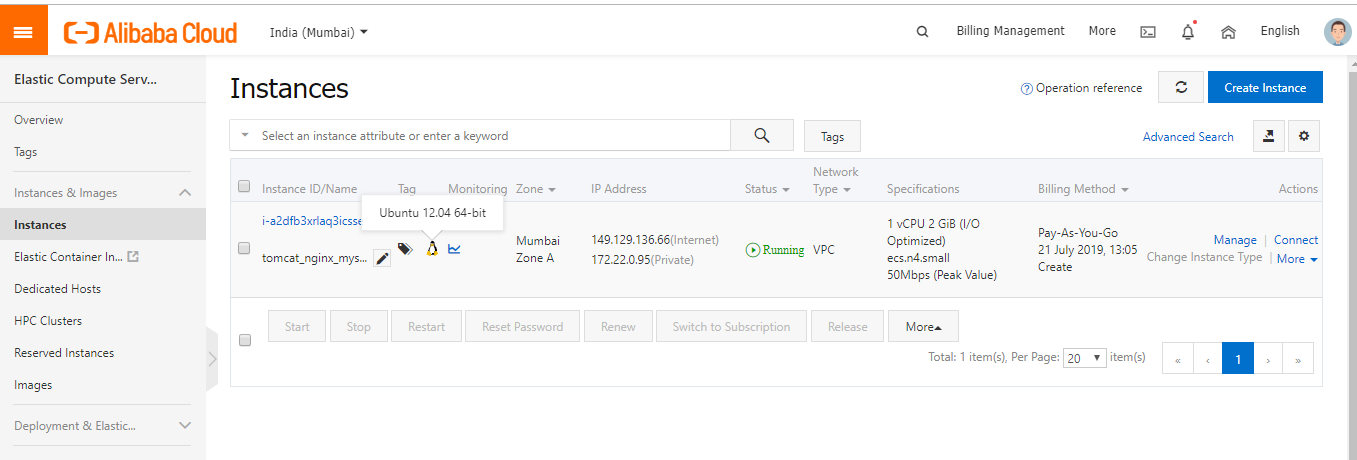
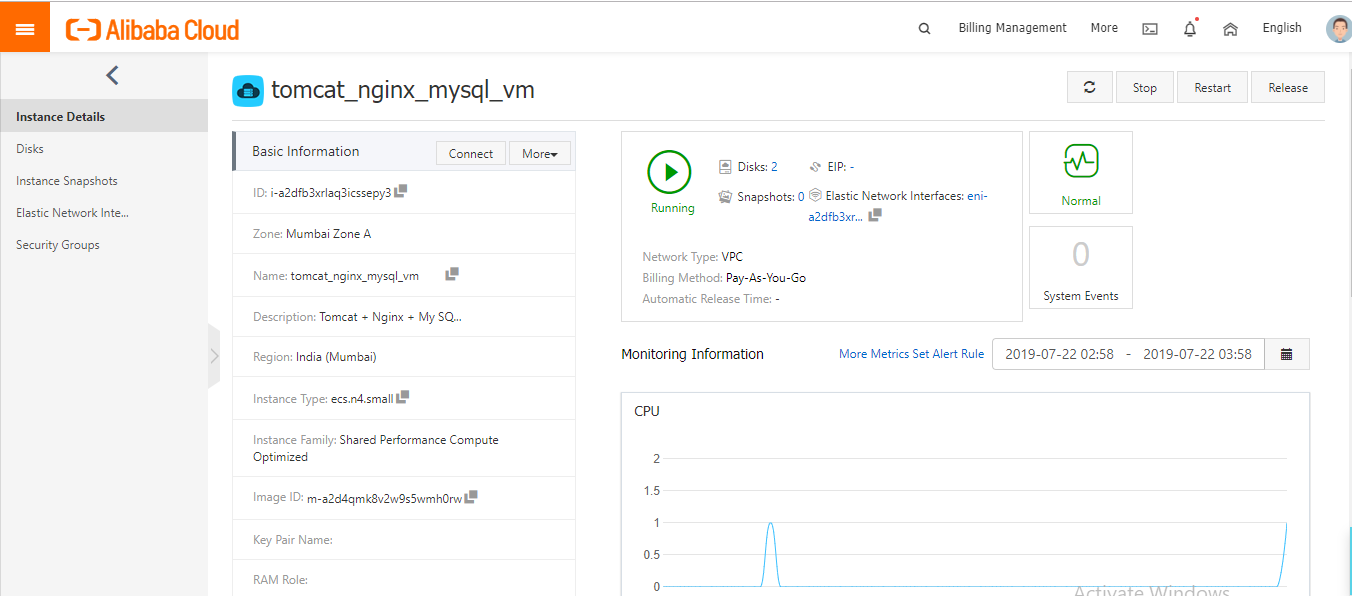
- Alibaba Consoleに移動して、プロビジョニングされたAlibaba ECSと構成を確認します。
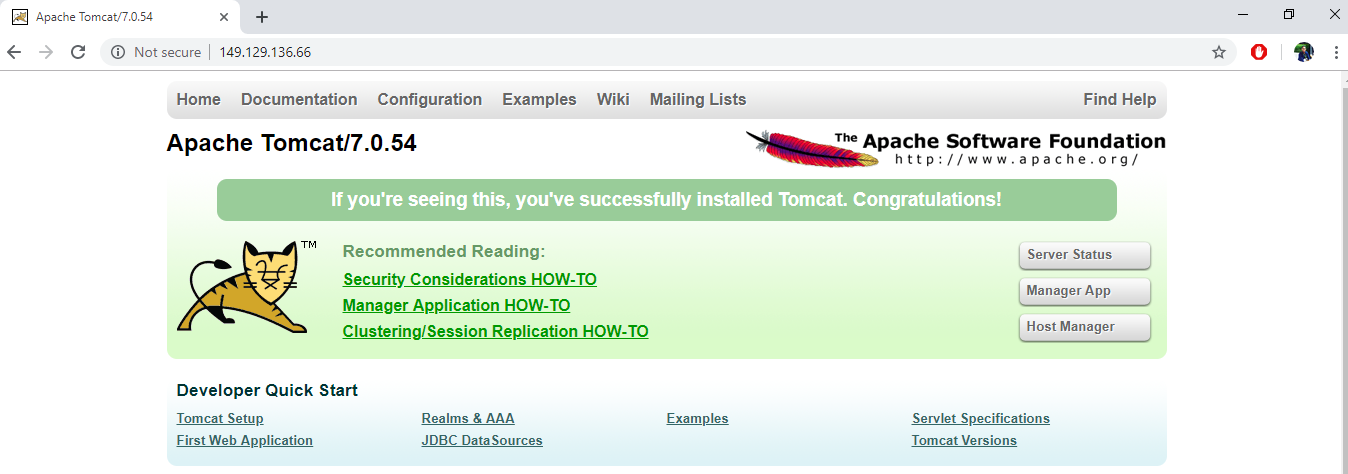
これで、Tomcat、Java、MySQLがインストールされたインスタンスをデプロイしました。ブラウザに対応するパブリックIPアドレスを入力すると、VMのパブリックIPの80番ポートを通してウェブサーバが公開されているので、Apache Tomcatのページが動作しているのが確認できます。
参考文献
1、https://www.alibabacloud.com/blog/ci%2Fcd-with-jenkins---part-1%3A-install-jenkins-on-ubuntu_593717
2、https://www.alibabacloud.com/blog/continuous-integration-with-jenkins-on-alibaba-cloud_594512
3、https://www.alibabacloud.com/blog/594449
4、https://github.com/alibaba/ansible-provider
5、https://mohitgoyal.co/2017/02/14/add-linux-slave-node-in-the-jenkins/
6、https://marketplace.alibabacloud.com/products/56728001/Tomcat_Nginx_My_SQL_Stack_Package_on_Ubuntu-cmjj011399.html?innerSource=search#product-detailsアリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ
- 投稿日:2020-09-23T17:35:05+09:00
Ubuntu 18.04にWildFlyをインストールする方法
WildFly は、Java で書かれ、Red Hat によって開発されたフリーのオープンソースでクロスプラットフォームなアプリケーションです。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
必要条件
- Ubuntu 18.04デスクトップがインストールされた新鮮なAlibaba Cloudインスタンス。
- インスタンスにrootパスワードが設定されています。
Alibaba Cloud ECSインスタンスを起動
新しいECSインスタンスを作成し、少なくとも4GB RAMを搭載したオペレーティングシステムとしてUbuntu 18.04を選択し、rootユーザーとしてインスタンスに接続します。
Ubuntu 18.04デスクトップインスタンスにログインしたら、以下のコマンドを実行して、ベースシステムを最新の利用可能なパッケージで更新します。
apt-get update -yアカウントが利用できるようになったら、非rootユーザーでログインして開始します。
Javaのインストール
WildFlyを使用するには、サーバにJavaバージョン8がインストールされている必要があります。デフォルトでは、Ubuntu 18.04のデフォルトリポジトリではJava 8は利用できません。そのため、同社の公式サイトからダウンロードする必要があります。
Java 8をダウンロードしたら、/usr/lib/jvmディレクトリに解凍します。
mkdir /usr/lib/jvm/ tar -zxvf jdk-8u221-linux-x64.tar.gz -C /usr/lib/jvm/次に、以下のコマンドでJavaのデフォルトバージョンを設定します。
update-alternatives --install /usr/bin/java java /usr/lib/jvm/jdk1.8.0_221/bin/java 1次に、以下のコマンドでJavaを検証します。
java -version出力:
java version "1.8.0_221" Java(TM) SE Runtime Environment (build 1.8.0_221-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.221-b11, mixed mode)WildFly のインストール
WildFlyをインストールする前に、WildFly用のユーザーとグループを作成する必要があります。以下のコマンドで作成できます。
groupadd -r wildfly useradd -r -g wildfly -d /opt/wildfly -s /sbin/nologin wildfly次に、以下のコマンドで最新版のWildFlyをダウンロードします。
wget https://download.jboss.org/wildfly/17.0.1.Final/wildfly-17.0.1.Final.zipダウンロードしたら、ダウンロードしたファイルを解凍し、以下のコマンドで
/opt/wildflyディレクトリに移動します。unzip wildfly-17.0.1.Final.zip mv wildfly-17.0.1.Final /opt/wildfly次に、以下のコマンドでワイルドフライのディレクトリに適切な権限を与えます。
chown -RH wildfly: /opt/wildflyWildFly用のSystemdファイルの設定
WildFlyの設定に必要なファイルをコピーします。
次にWildFlyの設定ファイルを/etc/directoryにコピーします。
mkdir -p /etc/wildfly cp /opt/wildfly/docs/contrib/scripts/systemd/wildfly.conf /etc/wildfly/次に、WildFly launch.shファイルを/opt/wildfly/bin/ディレクトリに移動します。
cp /opt/wildfly/docs/contrib/scripts/systemd/launch.sh /opt/wildfly/bin/ sh -c 'chmod +x /opt/wildfly/bin/*.sh'次に、以下のコマンドでWildFlyのsystemdファイルをコピーします。
cp /opt/wildfly/docs/contrib/scripts/systemd/wildfly.service /etc/systemd/system/以下のコマンドで設定ファイルをリロードします。
systemctl daemon-reload次に、WildFlyサービスを起動し、以下のコマンドで起動時に起動できるようにします。
systemctl start wildfly systemctl enable wildflyこれで、以下のコマンドでWildFlyの状態を確認できるようになりました。
systemctl status wildfly出力:
● wildfly.service - The WildFly Application Server Loaded: loaded (/etc/systemd/system/wildfly.service; disabled; vendor preset: enabled) Active: active (running) since Sat 2019-08-03 09:10:00 UTC; 7s ago Main PID: 15938 (launch.sh) Tasks: 52 (limit: 1098) CGroup: /system.slice/wildfly.service ├─15938 /bin/bash /opt/wildfly/bin/launch.sh standalone standalone.xml 0.0.0.0 ├─15943 /bin/sh /opt/wildfly/bin/standalone.sh -c standalone.xml -b 0.0.0.0 └─16003 java -D[Standalone] -server -Xms64m -Xmx512m -XX:MetaspaceSize=96M -XX:MaxMetaspaceSize=256m -Djava.net.preferIPv4Stack=true Aug 03 09:10:00 hitesh systemd[1]: Started The WildFly Application Server.WildFly認証の設定
次に、WildFlyの管理コンソールにアクセスするための管理者ユーザーを作成する必要があります。以下のコマンドで追加することができます。
/opt/wildfly/bin/add-user.sh以下のような出力が表示されるはずです。
What type of user do you wish to add? a) Management User (mgmt-users.properties) b) Application User (application-users.properties) (a): a Enter the details of the new user to add. Using realm 'ManagementRealm' as discovered from the existing property files. Username : letscloud Password recommendations are listed below. To modify these restrictions edit the add-user.properties configuration file. - The password should be different from the username - The password should not be one of the following restricted values {root, admin, administrator} - The password should contain at least 8 characters, 1 alphabetic character(s), 1 digit(s), 1 non-alphanumeric symbol(s) Password : Re-enter Password : What groups do you want this user to belong to? (Please enter a comma separated list, or leave blank for none)[ ]: About to add user 'letscloud' for realm 'ManagementRealm' Is this correct yes/no? yes Added user 'letscloud' to file '/opt/wildfly/standalone/configuration/mgmt-users.properties' Added user 'letscloud' to file '/opt/wildfly/domain/configuration/mgmt-users.properties' Added user 'letscloud' with groups to file '/opt/wildfly/standalone/configuration/mgmt-groups.properties' Added user 'letscloud' with groups to file '/opt/wildfly/domain/configuration/mgmt-groups.properties' Is this new user going to be used for one AS process to connect to another AS process? e.g. for a slave host controller connecting to the master or for a Remoting connection for server to server EJB calls. yes/no? yes To represent the user add the following to the server-identities definition <secret value="YWRtaW5AMTIz" />リモートロケーションからアクセスするためのWildFlyの設定
デフォルトでは、WildFly は localhost からしかアクセスできません。そのため、リモートからアクセスできるように WildFly を設定する必要があります。これは /etc/wildfly/wildfly.conf ファイルを編集することで行うことができます。
nano /etc/wildfly/wildfly.conf次の行を追加します。
WILDFLY_CONSOLE_BIND=0.0.0.0保存してファイルを閉じます。その後、/opt/wildfly/bin/launch.shファイルを開きます。
nano /opt/wildfly/bin/launch.sh以下のようにファイルを変更します。
if [ "x$WILDFLY_HOME" = "x" ]; then WILDFLY_HOME="/opt/wildfly" fi if [[ "$1" == "domain" ]]; then $WILDFLY_HOME/bin/domain.sh -c $2 -b $3 -bmanagement $4 else $WILDFLY_HOME/bin/standalone.sh -c $2 -b $3 -bmanagement $4 fiファイルを保存して閉じます。The, /etc/systemd/system/wildfly.serviceファイルを開きます。
nano /etc/systemd/system/wildfly.service次のように変更してください。
[Unit] Description=The WildFly Application Server After=syslog.target network.target Before=httpd.service [Service] Environment=LAUNCH_JBOSS_IN_BACKGROUND=1 EnvironmentFile=-/etc/wildfly/wildfly.conf User=wildfly LimitNOFILE=102642 PIDFile=/var/run/wildfly/wildfly.pid ExecStart=/opt/wildfly/bin/launch.sh $WILDFLY_MODE $WILDFLY_CONFIG $WILDFLY_BIND $WILDFLY_CONSOLE_BIND StandardOutput=null [Install] WantedBy=multi-user.target保存してファイルを閉じます。
次に、/var/run/wildflyディレクトリを作成し、正しいパーミッションを設定します。
mkdir /var/run/wildfly/ chown wildfly:wildfly /var/run/wildfly/最後に、systemd デーモンをリロードし、変更が有効になるようにサービスを再起動します。
systemctl daemon-reload systemctl restart wildflyWidFlyウェブコンソールへのアクセス
今、あなたのWebブラウザを開き、URLを入力してください http://your-server-ip:9990/console。次のページにリダイレクトされます。
ユーザー名とパスワードを入力します。次に、[Sign IN] ボタンをクリックします。以下のページにWildFlyのデフォルトダッシュボードが表示されるはずです。
結論
おめでとうございます!これでWidFlyがインストールされ、すぐに使えるようになりました。これでWidFlyがインストールされ、すぐに使えるようになりました。詳細はこちらをご覧ください: https://wildfly.org/
このガイドにご協力いただいた Hosting Canada の CTO、Gary Stevens 氏に感謝します。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ


- 投稿日:2020-09-23T14:20:56+09:00
【自分用メモ】BufferedReaderを使用したファイルの読み込み
FileReaderは一文字ずつ読み込むメソッド。
これをBufferingFilterを使用して、処理効率を上げよう!package practice1; import java.io.BufferedReader; import java.io.FileReader; import java.io.IOException; public class Read { public static void main(String[] args) { //FileReader=1文字ずつ読み込む動き //BufferedReader=一定数読んでため込んで、たまったら放出(普通は一行ずつ) FileReader fr=null; BufferedReader br=null; //finallyメソッドでclose処理ができるように、tryメソッドの外側で宣言。 //もしtryメソッド内で宣言してfinallyメソッドでclose()しようとするとローカル変数重複になる。 try { fr=new FileReader("c:\\work\\filetest.txt"); //あらかじめc:に作っておいたworkフォルダにfiletestファイルを作って以下の処理で使用 br=new BufferedReader(fr); //読み込み と ためこみ放出 の機能を組み合わせ! String brLine=br.readLine(); //brLineに代入することで、1文読んだ後に正しく出力できる。 while(brLine!=null) { System.out.println(brLine); brLine=br.readLine(); } }catch(IOException e) { e.printStackTrace(); // //エラーの詳細を、コンソールに赤文字で表示させるクラス //System.out.println("読み書きのエラーが発生しました"); }finally { //try-catchブロックがどう動いたとしても最後に必ず実行するfinallyメソッド if(br!=null) { try { br.close(); }catch(IOException e) {}//中身はカラでもいいし、エラーメッセージを出力してもいい } if(fr!=null) { try { fr.close(); }catch(IOException e) {}//中身はカラでもいいし、エラーメッセージを出力してもいい } } } }
- 投稿日:2020-09-23T14:11:43+09:00
GCPのDataFlowを簡単に触ってみた記録
Intro
Google Cloud Dataflowを触ることがあったので、備忘も兼ねてどんな感じだったか記録を残す。
Google Cloud Dataflowって?
簡単に言うと、ストリーミングデータやらの操作・管理を取り持ってくれるGCPのサービスです。
今回はPubSubで受けたデータをDataFlowを介してCloudStrageに配置しようと思います。
ログやトラッキングデータのような物が不特定多数postされ、それを保持したり後の分析に利用するようなケースを想定しています。1.Pub/Subにトピックを作成
Pub/Subってまたストレートな名前ですが、こちらもGCPのサービスです。所謂メッセージングというかキューというか。
今回のデータの始点、ある意味トリガーとなります。
とりあえず普通にGUIのコンソールから名前をつけるだけです。2.CloudStorageにバケット用意
今回の終点となる場所を用意しておきます。
新たにバケットを作るか、既存であれば任意のフォルダを用意してください。
一時ファイルを配置するフォルダも合わせて用意しておきましょう(後述)。3.DataFlowをテンプレートから作成
ここまで準備できると、あとは画面からポチポチしていくだけでできてしまいます。
というのも、DataFlowには利用頻度の高いユースケースに合わせて、テンプレートが用意されているので、
適宜選んで、必要な設定をするだけである程度動くものができてしまいます。「テンプレートからジョブを作成」リンクから作成画面にいったら、ジョブ名、リージョンを選択します。
そしてテンプレートを選択。
今回は「Pub/Sub to Text Files on Cloud Strage」(そのまま!)を選びます。
その他必須パラメータを設定する上でのポイントとしては、
- Pub/SubのTopic名は"projects〜"から始まるものにすること(トピックの詳細ページでコピーできるもの)。
- Output Directoryは日付フォーマットが使える。"gs://foo-bucket/bar-folder/YYYY/MM/DD"とかしておくとYMDのところは日付に応じて自動でフォルダを割り振ってくれる。
- "一時的なロケーション"を指定する必要あり。(まぁ、任意のバケットに適当に/tmpとか作っておけば取りえあず大丈夫かと)
4.TopicにPublishしてみる
以上までで、一通りの設定は完了。
ジョブを実行して、PubSubからメッセージをパブリッシュしてしばらくすると、CloudStorageにファイルができています。
中身にはパブリッシュしたメッセージが!
因みに、デフォルトは5分間でたまったメッセージが、それぞれ改行された上で1ファイルとしてCloudStorageに吐かれる模様。備考・感想
- そういえばsubscriptionを作っていません。通常、Topicに対してSubscriptionがあってPubSubが構成されるのですが、今回はジョブを作成した時点で自動でsubscriptionが作られていたようです。
- 既存テンプレート以外の構成は、適宜テンプレートの実装を行う必要があります。ただし、githubにテンプレートのリポジトリがあるので、それをベースにカスタマイズすることが可能(ソースはJavaかPython)。
- 最終的にはBigQueryも絡めてやってみたいが、今回の感触でそれも難しくなさそうな感じ。

- 投稿日:2020-09-23T13:57:25+09:00
【自分用メモ】BufferedWriterを使用したファイルの書き込み
FileWriterは一文字ずつ書き込むメソッド。
これをBufferingFilterを使用して、処理効率を上げよう!package practice1; import java.io.BufferedWriter; import java.io.FileWriter; import java.io.IOException; public class Write { public static void main(String[] args) { FileWriter fw=null; BufferedWriter bw=null; try { //cドライブには事前にworkファイル作成しておく fw=new FileWriter("c:\\work\\filetest.txt",true); //workフォルダにfiletestファイルを生成。もしあればそれを使用する bw=new BufferedWriter(fw); /*行ごとに書き込むために、「ため込んで一定量ずつ放出する」Bufferedメソッドをつくり、 FileWriter(書き込むメソッド)と組み合わせる*/ bw.write("abcdefg"); //書き込み。行単位で書き込めるのはBufferedメソッドのおかげ。 bw.newLine(); //改行処理 bw.write("1234567890"); bw.newLine(); bw.write("1 2 3 4 5 6 7 8 9 0"); bw.flush(); //強制的に「今書き込め!」と命令するメソッド }catch(IOException e){ e.printStackTrace(); //エラーの詳細を、コンソールに赤文字で表示させるメソッド //System.out.println("ファイル書き込みエラーです"); /* try-catch間でエラーが起こっても起きなくても * fileをcloseできるようにfiallyメソッド使う↓*/ }finally { if(bw!=null) { try { bw.close(); }catch(IOException e) {}//中身はカラでもいいし、なんらかのエラーメッセージを出力してもok } if(fw!=null) { try { fw.close(); }catch(IOException e) {} } } } }
- 投稿日:2020-09-23T12:49:07+09:00
【JavaとSQLをつなぐJDBCについて】
はじめに
JavaとSQLをつなぐJDBC(Java Database Connectivity)の実装が難しかったので備忘録として残します。
開発環境
・OS
Windows10
・エディタ
Ecripse
・Java
OpenJDK 8
・SQL
MySQL1,JDBCとは
JDBC(Java Database Connectivity) はJavaとRDを接続しJavaから操作するためのAPIです。
JDBCという概念を利用してJavaからSQLへデータを登録、更新、削除したり、SQLからデータを取り出したり出来ます。
DBにはOracle、MySQL、SQLServer等様々な種類がありそれぞれDBへ接続する方法も、DBの種類によって
変わってきますが、JDBC経由でDBに接続するとDB毎の個性をほとんど気にせずアクセスできるようになります。JDBCの歴史等わかりやすい記事があったので載せておきます。
https://data.wingarc.com/what-is-api-160842,実装
実装にあたり下記手順でJDBCを実装していきます。
①JDBCのドライバのロード
②SQLとの接続の確立
③SQL文の送信
④実行結果の取得
⑤接続の解除2-①
①JDBCのドライバのロード
Class.forNameメソッドを使ってドライバをロード (Classオブジェクトをメモリ上に生成 )します。
・Javaのバイトコードファイル(拡張子がclassファイル)をロードするためのメソッド。
・引数としてクラスを表す文字列(パッケージ名.クラス名)を指定します。
・ロードに失敗するとClassNotFoundExceptionが発生するため、
使用の際はtry~catchする必要があります。
後々変数として使えるように最初にフィールドで変数を宣言しておきます。MessageDao.javapublic class MessageDao { //接続に必要な変数を宣言 private static final String DRIVER_NAME = "oracle.jdbc.driver.OracleDriver"; private static final String JDBC_URL = "jdbc:oracle:thin:@localhost:1521:ORCL"; private static final String USER_ID = "imuser"; private static final String USER_PASS = "impass"; MessageDao (){ // JDBCドライバのロード try { Class.forName(DRIVER_NAME); } catch (ClassNotFoundException e) { e.printStackTrace(); } } }この状態で動かしてしまうとjava.lang.ClassNotFonudExceptionエラーがおきます。
JavaアプリケーションからDBアクセスをするには、
まずベンダーから提供される RDBMS専用のJDBCドライバを入手しなければいけません。
また、入手したJDBCドライバをJavaプログラムから使用できるようにするための設定が必要です。
JDBCドライバはOracle社のサイトからダウンロードできます。
https://www.oracle.com/technetwork/database/features/jdbc/jdbc-drivers-12c-download-1958347.htmダウンロード完了後、「ojdbc8.jar」というファイルがあるのでそれがJDBCドライバです。
「ojdbc8.jar」をC:あたりに配置します。JDBCドライバをJavaプログラムから使用できるようにするには、ビルド・パスへの追加が必要なので、以下の手順で実施します。
1.Eclipseのプロジェクト上で右クリック。
2.[プロパティ] → [Java のビルド・パス] → [ライブラリー]
3.[外部Jar の追加]を押下し、C:のojdbc8.jar ファイルを選択する。
4.[適用して閉じる]を押下する。実行を押して例外が発生しなければJDBCドライバのロードに成功しています。
2-②
②SQLとの接続の確立
DriverManagerクラスのメソッドgetConnection()を作成して、データベースへの接続を確立します。データベースを指すように、接続URL、DBユーザー名およびDBパスワードを更新します。
MessageDao.javapublic class MessageDao { //接続に必要な変数を宣言 private static final String DRIVER_NAME = "oracle.jdbc.driver.OracleDriver"; private static final String JDBC_URL = "jdbc:oracle:thin:@localhost:1521:ORCL"; private static final String USER_ID = "imuser"; private static final String USER_PASS = "impass"; MessageDao (){ // JDBCドライバのロード try { Class.forName(DRIVER_NAME); } catch (ClassNotFoundException e) { e.printStackTrace(); } } public ArrayList<MessageDto> select() { ArrayList<MessageDto> list = new ArrayList<>(); // コネクションクラスの宣言 Connection con = null; // ステートメントクラスの宣言 PreparedStatement ps = null; // リザルトセットクラスの宣言 ResultSet rs = null; // データベースにアクセス try { // データベースとの接続の確立を行う。 con = DriverManager.getConnection(JDBC_URL, USER_ID, USER_PASS); } } }DriverManagerクラスとは、
・JDBCドライバマネージャのクラスです。JDBCドライバにアクセスしてRDBMSを操作するための様々な機能が提供されていて、
getConnectionメソッドでRDBMSに接続し、接続に成功した場合は、DB接続に関する情報を有するConnectionオブジェクトを戻り値として返します。
引数にDBへの接続情報(接続先DB、ユーザーID、パスワード)を指定することで接続が実行されます。後でSQLから抽出した結果を格納するために使用する箱を、
ArrayList list = new ArrayList<>();
でMessageDto型のArrayListをlistとして空の箱を生成しておきます。2-③
③SQL文の送信
Statement系オブジェクトのexecuteQueryメソッドやexecuteUpdateメソッドでSQL文を実行するようRDBに依頼します。MessageDao.javapublic class MessageDao { //接続に必要な変数を宣言 private static final String DRIVER_NAME = "oracle.jdbc.driver.OracleDriver"; private static final String JDBC_URL = "jdbc:oracle:thin:@localhost:1521:ORCL"; private static final String USER_ID = "imuser"; private static final String USER_PASS = "impass"; MessageDao (){ // JDBCドライバのロード try { Class.forName(DRIVER_NAME); } catch (ClassNotFoundException e) { e.printStackTrace(); } } public int insert(MessageDto dto) { // コネクションクラスの宣言 Connection con = null; // ステートメントクラスの宣言 PreparedStatement ps = null; // 処理結果(件数)用変数 int result = 0; // データベースにアクセス try { // データベースとの接続の確立を行う。 con = DriverManager.getConnection(JDBC_URL, USER_ID, USER_PASS); //SQL文の生成(SELECT文) StringBuilder builder = new StringBuilder(); //SQL文のSELECT *で全件取得 builder.append("SELECT *"); builder.append("FROM "); builder.append(" MESSAGE_BOARD "); builder.append("ORDER BY "); builder.append(" ID DESC "); // ステートメントクラスにSQL文を格納 ps = con.prepareStatement(builder.toString()); } } }StringBuilder型のbuilderを変数として宣言してるのはappendメソッドで文字列同士の結合を行うためです。文字列同士の結合は"+演算子"でも可能ですが、StringBuilderのappendメソッドを使用した方がプログラムの処理スピードが早くなるためStringBuilder型の変数を宣言してappendメソッドを使用して結合しています。
2-④
④実行結果の取得
ResultSetオブジェクトを使用して送信したSELECT文の抽出結果のデータを取得します。
MessageDao.javapublic class MessageDao { //接続に必要な変数を宣言 private static final String DRIVER_NAME = "oracle.jdbc.driver.OracleDriver"; private static final String JDBC_URL = "jdbc:oracle:thin:@localhost:1521:ORCL"; private static final String USER_ID = "imuser"; private static final String USER_PASS = "impass"; MessageDao (){ // JDBCドライバのロード try { Class.forName(DRIVER_NAME); } catch (ClassNotFoundException e) { e.printStackTrace(); } } public int insert(MessageDto dto) { // コネクションクラスの宣言 Connection con = null; // ステートメントクラスの宣言 PreparedStatement ps = null; // 処理結果(件数)用変数 int result = 0; // データベースにアクセス try { // データベースとの接続の確立を行う。 con = DriverManager.getConnection(JDBC_URL, USER_ID, USER_PASS); //SQL文の生成(SELECT文) StringBuilder builder = new StringBuilder(); //SQL文のSELECT *で全件取得 builder.append("SELECT *"); builder.append("FROM "); builder.append(" MESSAGE_BOARD "); builder.append("ORDER BY "); builder.append(" ID DESC "); // ステートメントクラスにSQL文を格納 ps = con.prepareStatement(builder.toString()); // SQLを実行して取得結果をリザルトセット(rs)に格納 rs = ps.executeQuery(); while (rs.next()) { // 取得結果を格納するDtoをインスタンス化 MessageDto dto = new MessageDto(); // dtoに取得結果を格納 dto.setId (rs.getInt("id")); dto.setName (rs.getString("name")); dto.setMessage (rs.getString("message")); dto.setCreatedAt(rs.getTimestamp("created_at")); // Dtoに格納された1レコード分のデータをリストに詰める list.add(dto); } } } }ResultSetオブジェクトはStatement系クラスが持つexecuteQueryメソッドの戻り値として受け取る
ことができるオブジェクトで、送信したSELECT文の抽出結果のデータがrsに格納されています。
SQLから受け取った実行結果をループで回して1レコードずつ取得することができます。
セット完了後先ほど生成した空のlistにセットした値をaddします。2-⑤
⑤接続の解除
データベースへのアクセスが終了したら明示的に接続を解除する必要があるため、Connectionオブジェクト、Statement系オブジェクト、ResultSetオブジェクト、それぞれでcloseメソッドを使用して接続を解除(クローズ)します。
※接続をクローズしないと接続された状態が続くことになり、開発中は問題が顕在化されないですが運用を開始して思わぬアクセス数やデータ量が多くなってくると負荷がかかり初めて問題が発生するという事態に繋がる可能性があります。 必ずクローズする処理を書くようにします 。
MessageDao.javapublic ArrayList<MessageDto> select() { ArrayList<MessageDto> list = new ArrayList<>(); // コネクションクラスの宣言 Connection con = null; // ステートメントクラスの宣言 PreparedStatement ps = null; // リザルトセットクラスの宣言 ResultSet rs = null; // データベースにアクセス try { // データベースとの接続を行う con = DriverManager.getConnection(JDBC_URL, USER_ID, USER_PASS); StringBuilder builder = new StringBuilder(); builder.append("SELECT "); builder.append(" id "); builder.append(" ,name "); builder.append(" ,message "); builder.append(" ,created_at "); builder.append("FROM "); builder.append(" message_board "); builder.append("ORDER BY "); builder.append(" ID DESC "); // ステートメントクラスにSQL文を格納 ps = con.prepareStatement(builder.toString()); // SQLを実行して取得結果をリザルトセットに格納 rs = ps.executeQuery(); // リザルトセットから1レコードずつデータを取り出す while (rs.next()) { // 取得結果を格納するDtoをインスタンス化 MessageDto dto = new MessageDto(); // Dtoに取得結果を格納 dto.setId (rs.getInt("id")); dto.setName (rs.getString("name")); dto.setMessage (rs.getString("message")); dto.setCreatedAt(rs.getTimestamp("created_at")); // Dtoに格納された1レコード分のデータをリストに詰める list.add(dto); } } catch (SQLException e) { e.printStackTrace(); } finally { try { if (rs != null) { rs.close(); } if (ps != null) { ps.close(); } if (con != null) { con.close(); } } catch (SQLException e) { e.printStackTrace(); } } // 呼び出し元に取得結果を返却 return list; }以上でJDBCの実装が完了です。
SQLの追加、更新、削除は接続の書き方が少し変わるのでそのあたりと、JDBCテンプレートについてもまとめていこうと思います。
今後JDBCの実装をする方に少しでも参考になれば幸いです。参考文献
・https://docs.oracle.com/cd/E96517_01/tdpjd/creating-java-bean-implementation-jdbc-connection.html
・https://data.wingarc.com/what-is-api-16084
- 投稿日:2020-09-23T12:16:44+09:00
【Java】JSON 通信 with jackson
java で json の通信を行う (jackson を利用)
環境
- windows10
- eclipse:2020-06 (4.16.0)
- jackson
- java 1.8
例によって忘備録です・・・
順序
- Dto 生成
- jackson を使って Dto -> json に変換
- HttpURLConnection を使って通信
- 結果取得
Dto 生成
public class SampleDto implements Serializable { private static final long serialVersionUID = 1L; // ちゃんと生成した方が良さげ private int id; private String mail; public int getId() { return id; } public void setId(int id) { this.id = id; } public String getMail() { return mail; } public void setMail(String mail) { this.mail = mail; } }Dto -> json 変換
protected String createJson4Sample(SampleDto dto) { ObjectMapper mapper = new ObjectMapper(); try { return mapper.writerWithDefaultPrettyPrinter().writeValueAsString(dto); } catch (JsonProcessingException e) { StringWriter sw = new StringWriter(); e.printStackTrace(new PrintWriter(sw)); log.error(sw.toString()); return null; } }通信
protected String requestJson(String method, String json, String urlPath, String charset, String bearer) { HttpURLConnection con = null; if (StringUtils.isEmpty(charset)) { charset = StringUtils.lowerCase(StandardCharsets.UTF_8.name()); } String body = ""; try { URL url = new URL(urlPath); con = (HttpURLConnection)url.openConnection(); con.setRequestMethod(method); con.setUseCaches(false); con.setDoOutput(true); con.setRequestProperty("Content-Type", "application/json; charset=" + charset); if (StringUtils.isNotEmpty(bearer)) { con.setRequestProperty("Authorization", "Bearer "+bearer); } OutputStreamWriter out = new OutputStreamWriter(new BufferedOutputStream(con.getOutputStream())); out.write(json); out.close(); BufferedReader in = new BufferedReader(new InputStreamReader(con.getInputStream())); String line = in.readLine(); while (line != null) { body = body + line; line = in.readLine(); } } catch (Exception e) { StringWriter sw = new StringWriter(); e.printStackTrace(new PrintWriter(sw)); log.error(sw.toString()); return null; } finally { if (con != null) { con.disconnect(); } } return body; }結果取得
protected boolean checkResponseJson(String response) { ObjectMapper mapper = new ObjectMapper(); try { if (StringUtils.isEmpty(response)) { return false; } JsonNode root = mapper.readTree(response); String success = root.get("success").asText(); String id = root.get("id").asText(); log.info("Response:" + id + ":" + success); if (!"OK".equalsIgnoreCase(success)) { return false; } } catch (Exception e) { StringWriter sw = new StringWriter(); e.printStackTrace(new PrintWriter(sw)); log.error(sw.toString()); return false; } return true; }以上、お疲れさまでした!
- 投稿日:2020-09-23T01:38:09+09:00
開発未経験エンジニアのための開発業務に携わるためのプロジェクト
概要
未経験のエンジニアの方でどうやったら開発に業務に携われることができるかご相談を受けました。相談に対して回答していく中で2人で一緒に何か作っていこうという話になり、それ自体をプロジェクトとして発足しました。
最初に結論から申し上げるとこのプロジェクトの取り組みによって無事に開発現場が決まりました。継続的に活動を続けていくことで1つの成果となり、それらの記録として残すためQiitaの記事としてまとめようと思いました。
なぜプロジェクトとして発足したのか?
今回の場合は未経験のエンジニアの方で目標設定も定めづらそうなイメージがありました。こちらから提案してもよいのですが、できるだけご自身の目標にあったテーマを一緒に考えてモノづくりを取り組むようにしました。
また取り組む際の考え方も一緒に共有できればと考えました。もちろんペアプログラミングなどで技術的なことは共有はしますが、技術だけでなく解決に至るまでの考え方を一緒に共有し、エンジニアとしてお互いに考える力を伸ばすことを大切にしました。
開発手法だけでなく問題に対する解決方法など総合的に取り組むためにプロジェクトとして発足しました。
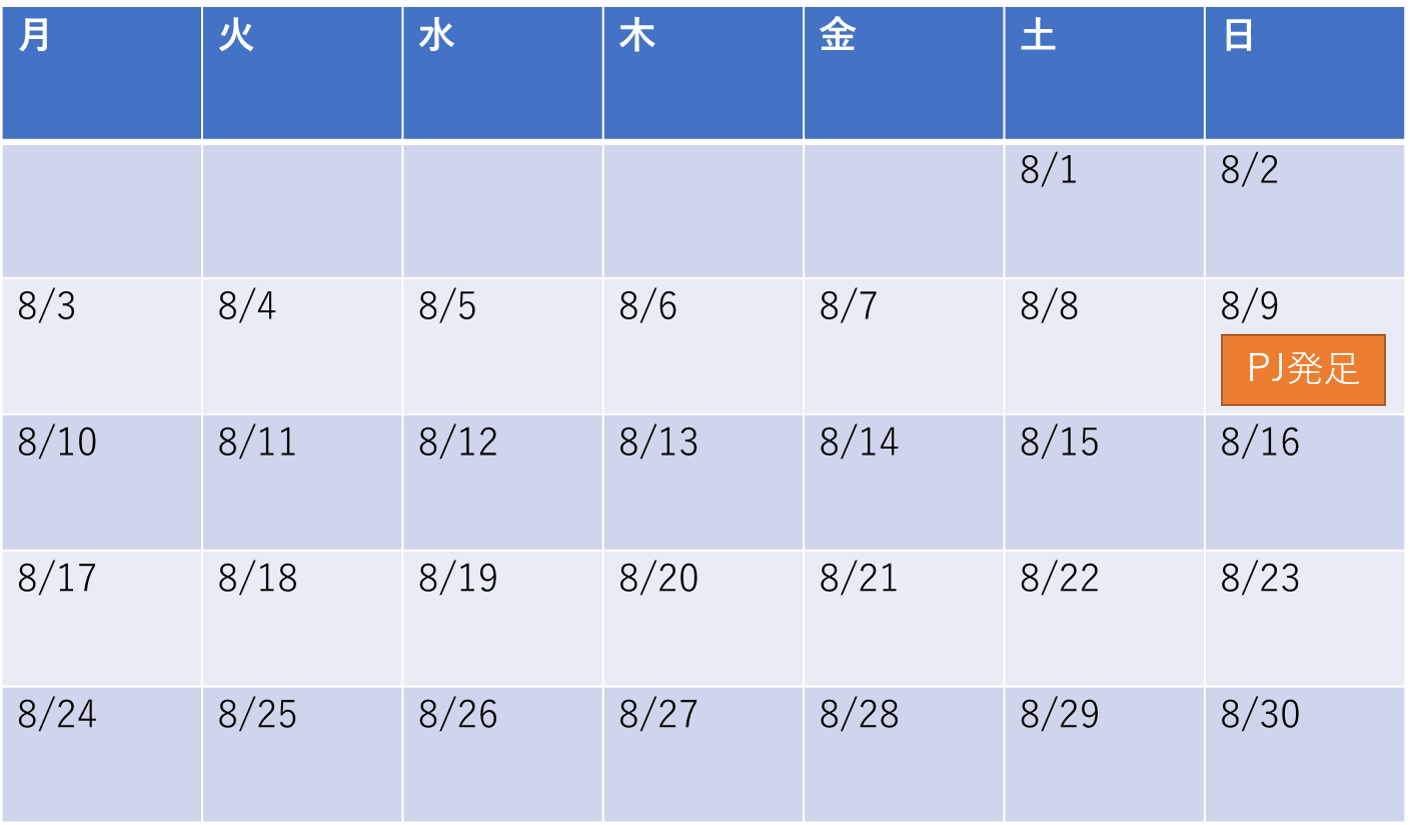
8/9(水):インセプションデッキの作成
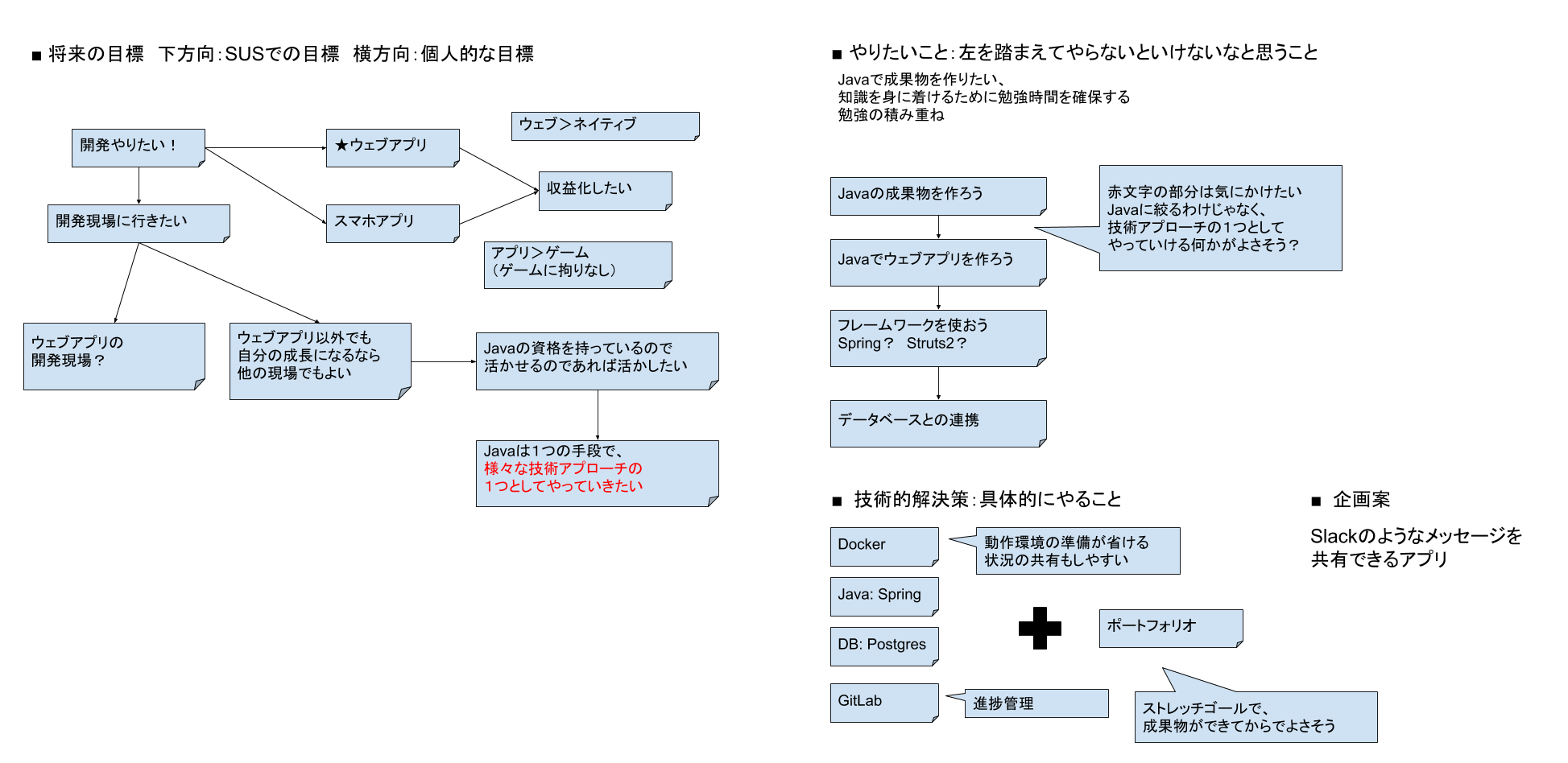
まずはプロジェクトとして目標の設定や何をやるべきか方向を定めるため、
Google Drawingでインセプションデッキを作成しました。
実際には2人だけのプロジェクトになるため、できるかぎり未経験のエンジニアの方にアウトプットしてもらえるようにテーマを考えて、2人が同じ方向を向けるように準備します。
インセプションデッキの流れ
将来の目標設定
まずは将来の目標をブレストで出していただきました。直近の目標や今後どうしていきたいのか理想像などを書き出してもらい、それらを整理して紐づけることでアプローチ方法を探っていきます。
目標設定からのやりたいこと・やらないといけないこと
「Javaの成果物を作ろう」ということから更に必要なことを相談しながら案を出し合いながらチャレンジすべき内容を決めていきました。
技術的解決策:具体的にやること
具体的に使用する技術を記載しています。
Javaの資格をお持ちとのことでJavaを活かすためにSpringを中心にDockerを使ったコンテナを用いたサービスを作ることになりました。またエンジニアとしてどういったことをPRすべきか伝えるために、ポートフォリオの作成もやることとして設定しました。
ただしポートフォリオはストレッチゴールで成果物ができてから取り組むことにしました。
伝えたかったこと
2人で同じ問題に対して考えて整理することで具体的なやることまで導くことができました。この考えるということ自体が開発における業務でも必要になる場合があると思っています。
自分で解決案を提案してみたり、その提案を他の人と相談しつつよりよい行動に移すことで、1人のエンジニアが組織として動くことができそうです。
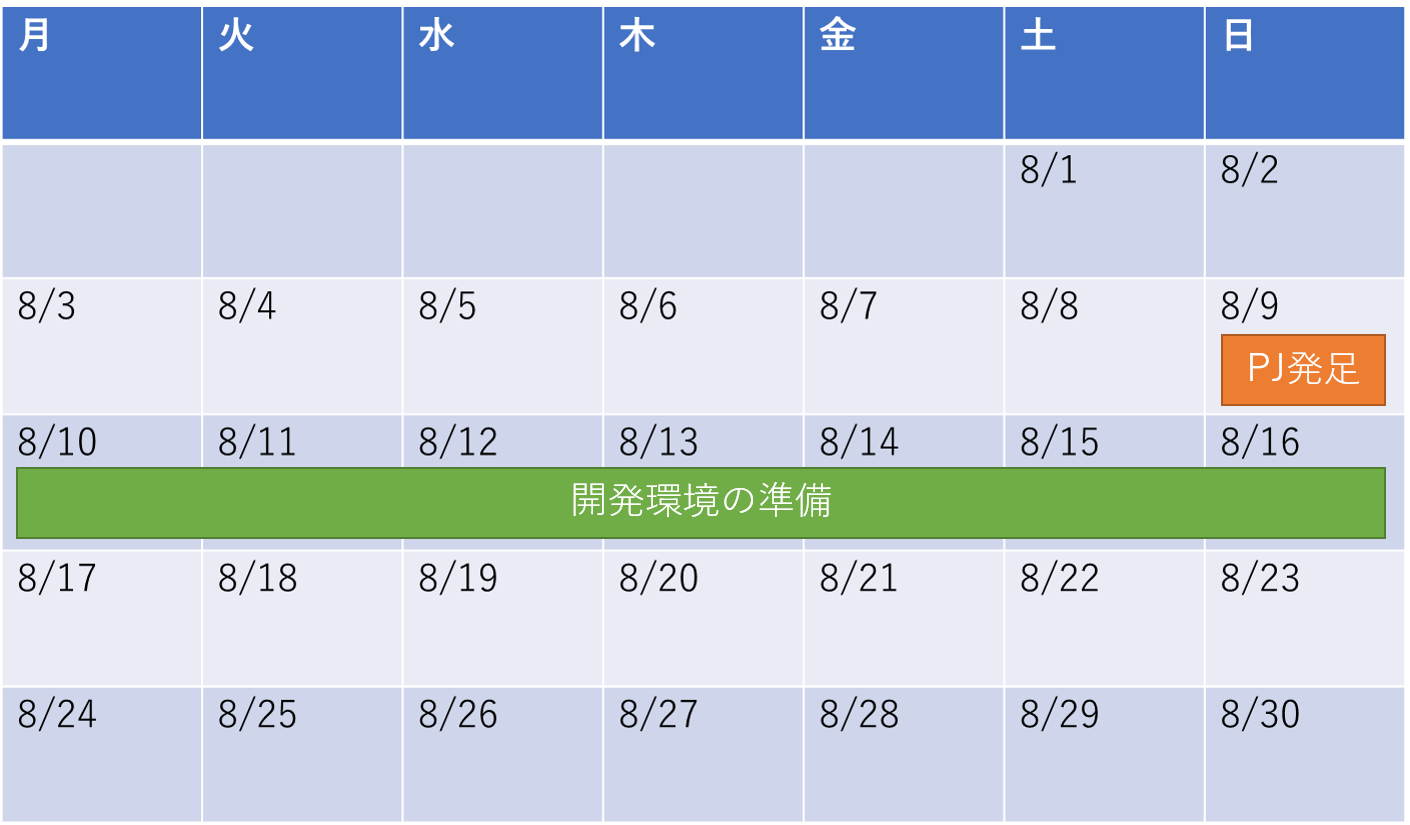
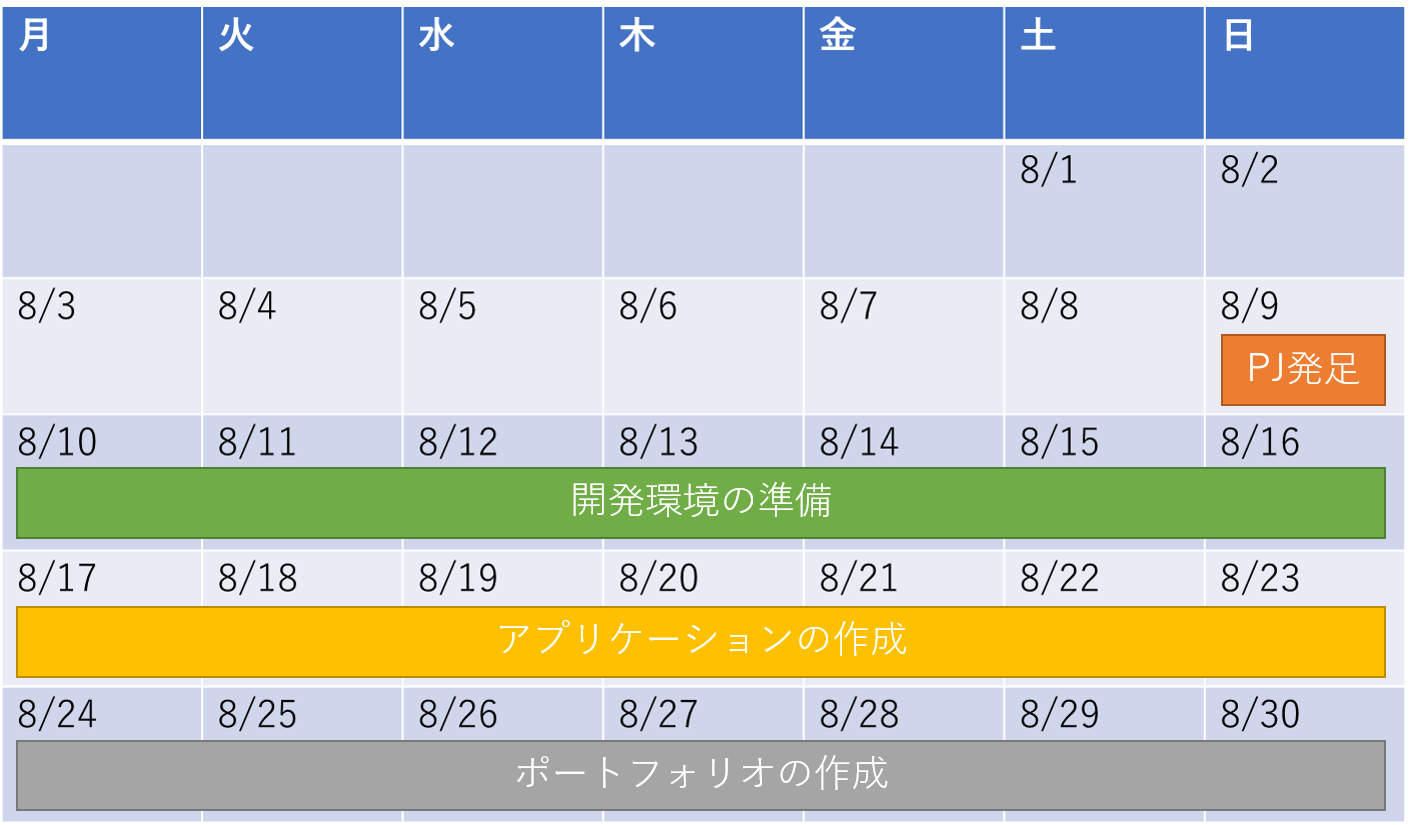
8/10(月)~8/16(日):開発環境の構築
8/10(月)以降から21:00~24:00にかけてペアプログラミングで作業しました。まずは開発環境の構築で
docker-composeを使ってSpringの基盤を準備しました。ここらへんの知識はペアプログラミングで全体の構成などを伝えながらメリットとデメリットを共有しました。
Springについてはeclipseでガッチリ環境を作ってもよかったのですが、コンテナ化してどこでも動かせるようにしました。
eclipseの場合で環境がおかしくなった場合はお互いの環境で再現できないことも考えられたため、コンテナですぐに環境を構築できるように進めました。なお、課題管理などは
GitLabを使用してIssueとして管理しMerge Requestも使うようにしました。開発からある程度は経過していますが以下の場所で公開されています。https://gitlab.com/vorwort.k/yasuda-spring
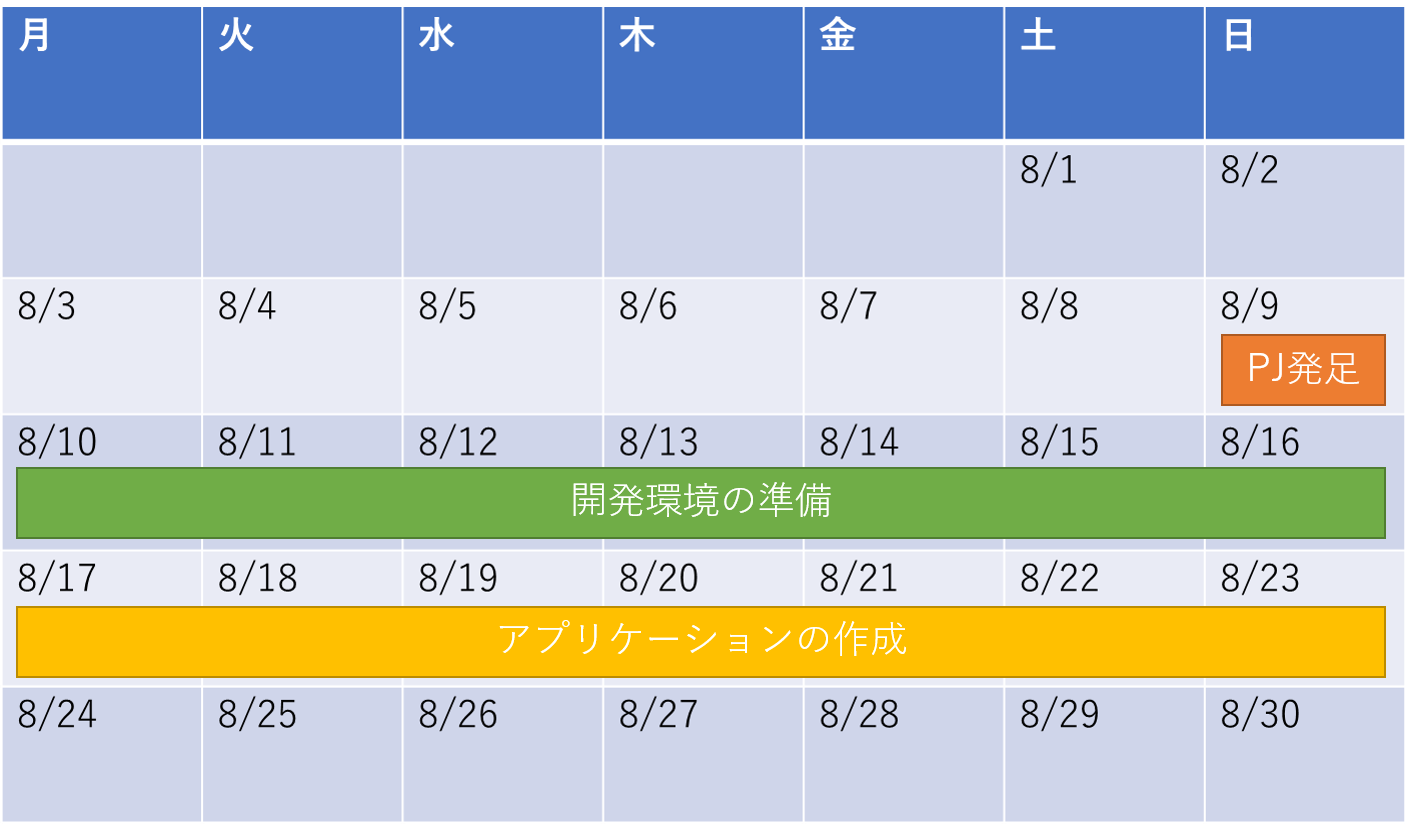
8/17(月)~8/23(日):サービスの構築
インセプションデッキでできるだけシンプルなモノを作ることになっています。今回はチャットアプリのようなモノを作っていきます。
実際に開発を進める上で
Springのコンテナをわざわざ起動しなおす必要があったり開発の手間が掛かっていました。
そういった手間もできるだけ改善するように取り組み、今回の場合ではソースのディレクトリとSpringのコンテナの中を同期させ、Gradleで自動的に再ビルドするように対応しました。そのようなナレッジはプロジェクトのReadme.mdに追記して記録するようにしました。開発や業務において問題に感じていることを改善することで今後のパフォーマンスに大きく影響するため、自分なりに何かアイデアがあれば話してみて取り組むと喜ばれることを共有しました。
週末にはおおよそのチャットアプリが完成したため週末に振り返りを行い、ポートフォリオの作成の準備を進めました。
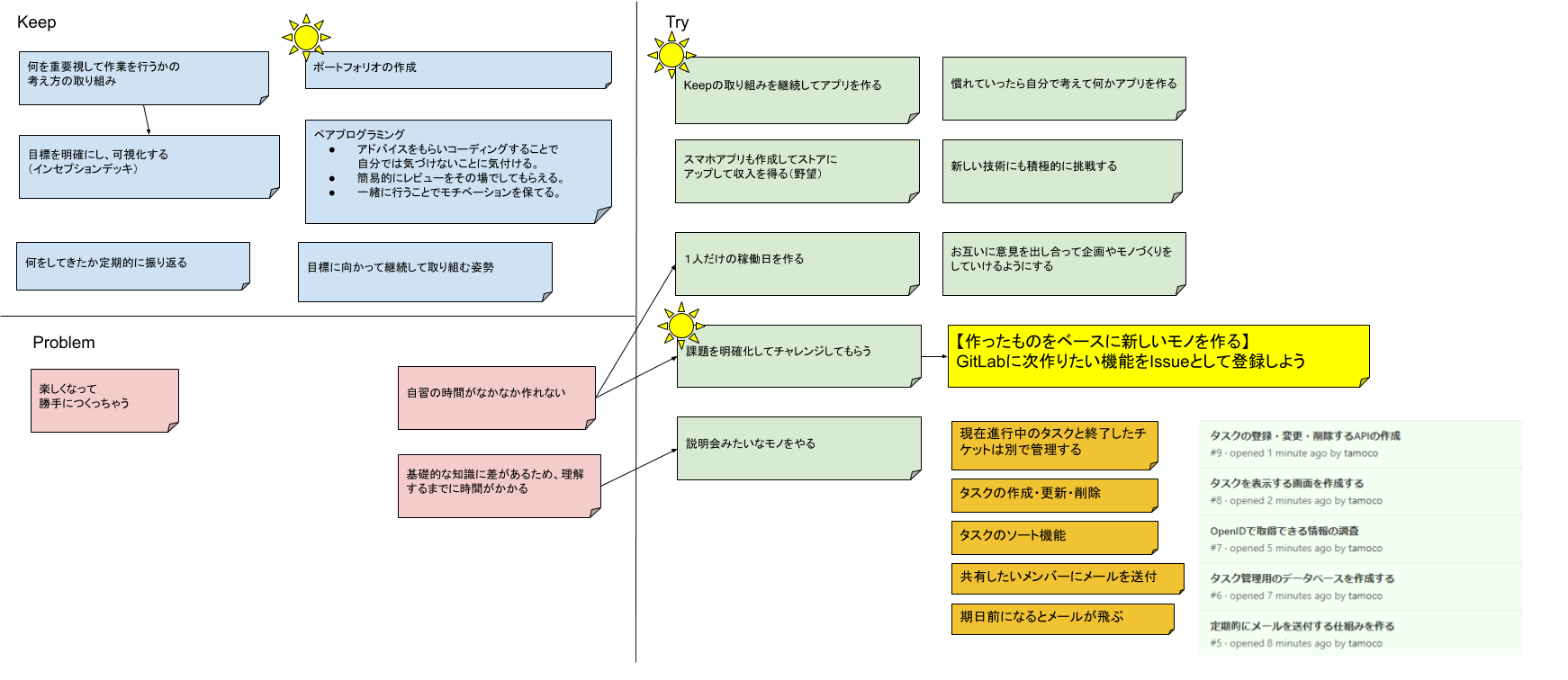
8/23(日):振り返り
振り返りは
KPTで行いました。ここでProblemとしてあがったのがペアプロでドライバーが変わったときに楽しくなってガツガツ勝手につくっちゃうことがあったので注意が必要だと思いました。
あと全体の構成などを共有する際に理解するのに時間が掛かっているようで、ゆっくりと消化する時間は必要だなと感じています。
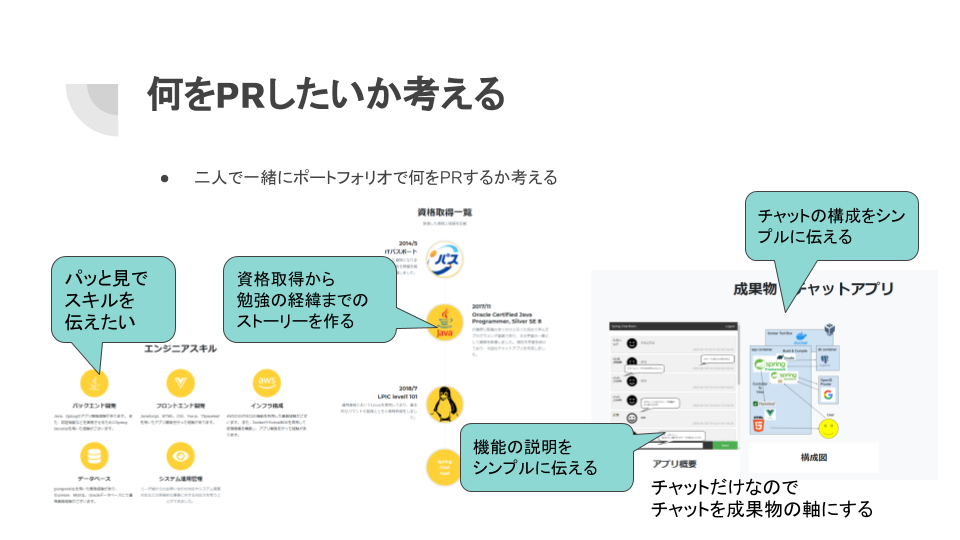
ポートフォリオを作成しようということなり、振り返りとは別に実際に学んだことを書き出してもらうことにしました。ポートフォリオの材料にできればと考えて書き出してもらいました。
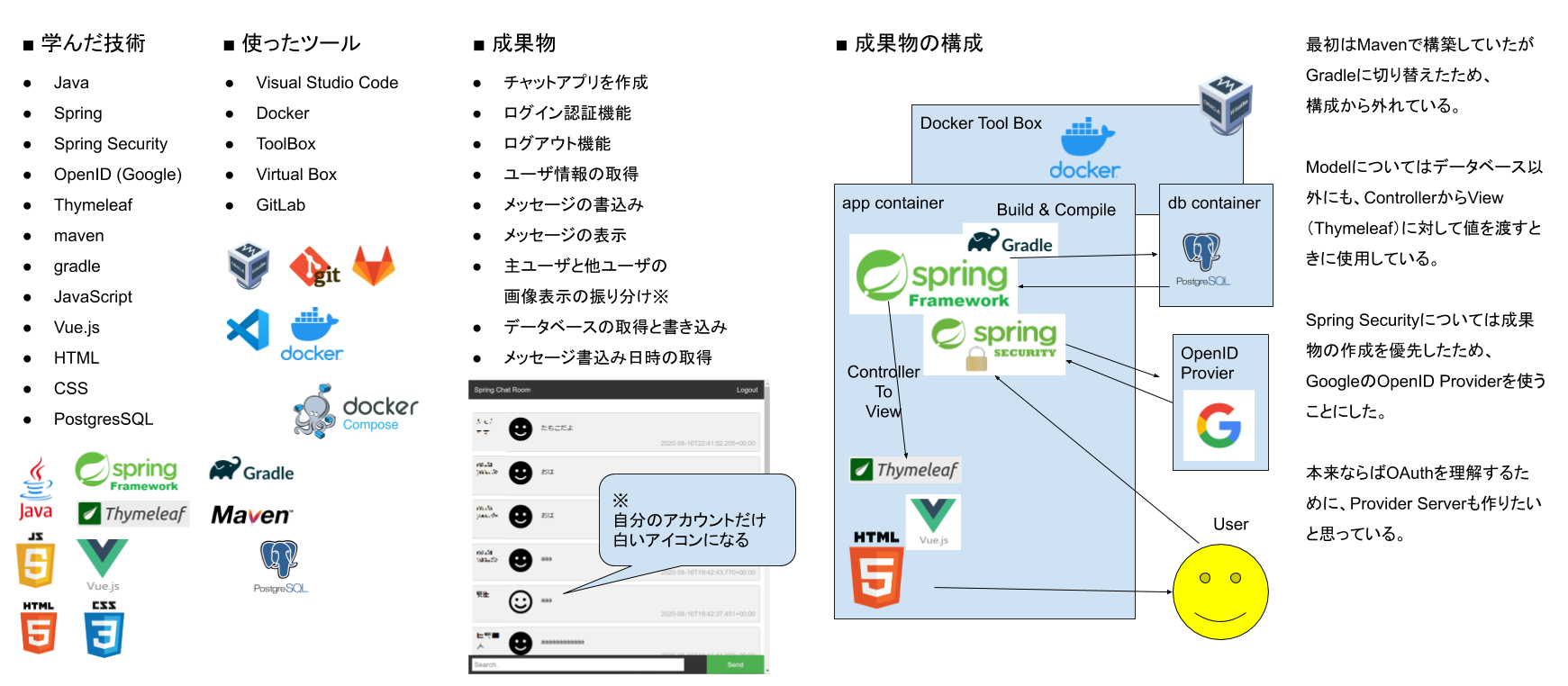
学んだことを整理する
上記の全体の構成などに理解するのに苦労しているようなので、これまで学んだ技術などを書き出してもらい整理してもらいました。今回はシンプルなチャットアプリサービスですが、実際に使った技術はいろいろとあることがわかります。
上記の図があるだけでポートフォリオができるまでの間、成果物に関する全体構成や学んでいる技術を伝えることができます。来週からポートフォリオの作成に入りますが、作成している期間も企業にPRするための資料として利用できます。
ここでポートフォリオの作成がストレッチゴールに設定したことが効いてきそうです。
8/24(月)~8/30(日):ポートフォリオの作成
上記の学んだことを整理した図を元にポートフォリオを作成します。ここで大事なのは自分で作成して自分で説明できるモノを作り上げることです。人と相談していろいろとコンテンツを入れることはできますが、面談などで自分の口で説明できるポートフォリオでないと、自分の武器にならないので注意が必要です。
作成していただいたポートフォリオ
https://yasu-portfolio.netlify.app/
2人で効果的なポートフォリオを考える
基本的には中身については1人で考えてもらい改善点などはアイデア程度でお伝えしました。またアイデアもできるだけ複数案出して自分で選んでもらうようにしました。この手法自体もポートフォリオを作った経緯として別の資料として作成しました。
総評
2人でプロジェクトとして発足してやり切ることがよかったと思います。まずはインセプションデッキで同じ方向を向くことで、やりたいことなどのすれ違いなどがなくなりました。また定期的にペアプロの時間を設けることで考え方なども共有できることがお互いの成長につながったと思います。自分としては相手に伝える上で伝え方などが難しく、できるだけ具体例などを用いて説明するように工夫しました。
一緒に2人で考えるということは2人で同じ問題に取り組むことになるので、その解決におけるプロセスの経験は何事にも代えがたいモノになったと思います。
今回は無事にポートフォリオの作成まで達成することができ、それによって無事に開発の現場が決まったということもお伺いしました。特にSESの営業担当からポートフォリオがあるだけでPRしやすいのは事実で、エンジニアが事前に準備できる武器としては有効だと思います。
9月は9月で上記のプロジェクトを継承して別のプロジェクトとして継続しております。こちらの内容については別の記事で投稿しようと思います。

- 投稿日:2020-09-23T01:38:09+09:00
開発未経験のエンジニアでも開発業務に就くことができたプロジェクト
概要
未経験のエンジニアの方でどうやったら開発に業務に携われることができるかご相談を受けました。相談に対して回答していく中で2人で一緒に何か作っていこうという話になり、それ自体をプロジェクトとして発足しました。
最初に結論から申し上げるとこのプロジェクトの取り組みによって無事に開発業務が決まりました。継続的に活動を続けていくことで1つの成果となり、それらの記録として残すためQiitaの記事としてまとめようと思いました。
なぜプロジェクトとして発足したのか?
今回の場合は未経験のエンジニアの方で目標設定も定めづらそうなイメージがありました。こちらから提案してもよいのですが、できるだけご自身の目標にあったテーマを一緒に考えてモノづくりを取り組むようにしました。
また取り組む際の考え方も一緒に共有できればと考えました。もちろんペアプログラミングなどで技術的なことは共有はしますが、技術だけでなく解決に至るまでの考え方を一緒に共有し、エンジニアとしてお互いに考える力を伸ばすことを大切にしました。
開発手法だけでなく問題に対する解決方法など総合的に取り組むためにプロジェクトとして発足しました。
8/9(水):インセプションデッキの作成
まずはプロジェクトとして目標の設定や何をやるべきか方向を定めるため、
Google Drawingでインセプションデッキを作成しました。
実際には2人だけのプロジェクトになるため、できるかぎり未経験のエンジニアの方にアウトプットしてもらえるようにテーマを考えて、2人が同じ方向を向けるように準備します。
インセプションデッキの流れ
将来の目標設定
まずは将来の目標をブレストで出していただきました。直近の目標や今後どうしていきたいのか理想像などを書き出してもらい、それらを整理して紐づけることでアプローチ方法を探っていきます。
目標設定からのやりたいこと・やらないといけないこと
「Javaの成果物を作ろう」ということから更に必要なことを相談しながら案を出し合いながらチャレンジすべき内容を決めていきました。
技術的解決策:具体的にやること
具体的に使用する技術を記載しています。
Javaの資格をお持ちとのことでJavaを活かすためにSpringを中心にDockerを使ったコンテナを用いたサービスを作ることになりました。またエンジニアとしてどういったことをPRすべきか伝えるために、ポートフォリオの作成もやることとして設定しました。
ただしポートフォリオはストレッチゴールで成果物ができてから取り組むことにしました。
伝えたかったこと
2人で同じ問題に対して考えて整理することで具体的なやることまで導くことができました。この考えるということ自体が開発における業務でも必要になる場合があると思っています。
自分で解決案を提案してみたり、その提案を他の人と相談しつつよりよい行動に移すことで、1人のエンジニアが組織として動くことができそうです。
8/10(月)~8/16(日):開発環境の構築
8/10(月)以降から21:00~24:00にかけてペアプログラミングで作業しました。まずは開発環境の構築で
docker-composeを使ってSpringの基盤を準備しました。ここらへんの知識はペアプログラミングで全体の構成などを伝えながらメリットとデメリットを共有しました。
Springについてはeclipseでガッチリ環境を作ってもよかったのですが、コンテナ化してどこでも動かせるようにしました。
eclipseの場合で環境がおかしくなった場合はお互いの環境で再現できないことも考えられたため、コンテナですぐに環境を構築できるように進めました。なお、課題管理などは
GitLabを使用してIssueとして管理しMerge Requestも使うようにしました。開発からある程度は経過していますが以下の場所で公開されています。https://gitlab.com/vorwort.k/yasuda-spring
8/17(月)~8/23(日):サービスの構築
インセプションデッキでできるだけシンプルなモノを作ることになっています。今回はチャットアプリのようなモノを作っていきます。
実際に開発を進める上で
Springのコンテナをわざわざ起動しなおす必要があったり開発の手間が掛かっていました。
そういった手間もできるだけ改善するように取り組み、今回の場合ではソースのディレクトリとSpringのコンテナの中を同期させ、Gradleで自動的に再ビルドするように対応しました。そのようなナレッジはプロジェクトのReadme.mdに追記して記録するようにしました。開発や業務において問題に感じていることを改善することで今後のパフォーマンスに大きく影響するため、自分なりに何かアイデアがあれば話してみて取り組むと喜ばれることを共有しました。
週末にはおおよそのチャットアプリが完成したため週末に振り返りを行い、ポートフォリオの作成の準備を進めました。
8/23(日):振り返り
振り返りは
KPTで行いました。ここでProblemとしてあがったのがペアプロでドライバーが変わったときに楽しくなってガツガツ勝手につくっちゃうことがあったので注意が必要だと思いました。
あと全体の構成などを共有する際に理解するのに時間が掛かっているようで、ゆっくりと消化する時間は必要だなと感じています。
ポートフォリオを作成しようということなり、振り返りとは別に実際に学んだことを書き出してもらうことにしました。ポートフォリオの材料にできればと考えて書き出してもらいました。
学んだことを整理する
上記の全体の構成などに理解するのに苦労しているようなので、これまで学んだ技術などを書き出してもらい整理してもらいました。今回はシンプルなチャットアプリサービスですが、実際に使った技術はいろいろとあることがわかります。
上記の図があるだけでポートフォリオができるまでの間、成果物に関する全体構成や学んでいる技術を伝えることができます。来週からポートフォリオの作成に入りますが、作成している期間も企業にPRするための資料として利用できます。
ここでポートフォリオの作成がストレッチゴールに設定したことが効いてきそうです。
8/24(月)~8/30(日):ポートフォリオの作成
上記の学んだことを整理した図を元にポートフォリオを作成します。ここで大事なのは自分で作成して自分で説明できるモノを作り上げることです。人と相談していろいろとコンテンツを入れることはできますが、面談などで自分の口で説明できるポートフォリオでないと、自分の武器にならないので注意が必要です。
作成していただいたポートフォリオ
https://yasu-portfolio.netlify.app/
2人で効果的なポートフォリオを考える
基本的には中身については1人で考えてもらい改善点などはアイデア程度でお伝えしました。またアイデアもできるだけ複数案出して自分で選んでもらうようにしました。この手法自体もポートフォリオを作った経緯として別の資料として作成しました。
総評
2人でプロジェクトとして発足してやり切ることがよかったと思います。まずはインセプションデッキで同じ方向を向くことで、やりたいことなどのすれ違いなどがなくなりました。また定期的にペアプロの時間を設けることで考え方なども共有できることがお互いの成長につながったと思います。自分としては相手に伝える上で伝え方などが難しく、できるだけ具体例などを用いて説明するように工夫しました。
一緒に2人で考えるということは2人で同じ問題に取り組むことになるので、その解決におけるプロセスの経験は何事にも代えがたいモノになったと思います。
今回は無事にポートフォリオの作成まで達成することができ、それによって無事に開発の現場が決まったということもお伺いしました。特にSESの営業担当からポートフォリオがあるだけでPRしやすいのは事実で、エンジニアが事前に準備できる武器としては有効だと思います。
9月は9月で上記のプロジェクトを継承して別のプロジェクトとして継続しております。こちらの内容については別の記事で投稿しようと思います。
- 投稿日:2020-09-23T01:38:09+09:00
開発未経験のエンジニアでも開発業務に就くことができるプロジェクト
概要
未経験のエンジニアの方でどうやったら開発に業務に携われることができるかご相談を受けました。相談に対して回答していく中で2人で一緒に何か作っていこうという話になり、それ自体をプロジェクトとして発足しました。
最初に結論から申し上げるとこのプロジェクトの取り組みによって無事に開発業務が決まりました。継続的に活動を続けていくことで1つの成果となり、それらの記録として残すためQiitaの記事としてまとめようと思いました。
なぜプロジェクトとして発足したのか?
今回の場合は未経験のエンジニアの方で目標設定も定めづらそうなイメージがありました。こちらから提案してもよいのですが、できるだけご自身の目標にあったテーマを一緒に考えてモノづくりを取り組むようにしました。
また取り組む際の考え方も一緒に共有できればと考えました。もちろんペアプログラミングなどで技術的なことは共有はしますが、技術だけでなく解決に至るまでの考え方を一緒に共有し、エンジニアとしてお互いに考える力を伸ばすことを大切にしました。
開発手法だけでなく問題に対する解決方法など総合的に取り組むためにプロジェクトとして発足しました。
8/9(水):インセプションデッキの作成
まずはプロジェクトとして目標の設定や何をやるべきか方向を定めるため、
Google Drawingでインセプションデッキを作成しました。
実際には2人だけのプロジェクトになるため、できるかぎり未経験のエンジニアの方にアウトプットしてもらえるようにテーマを考えて、2人が同じ方向を向けるように準備します。
インセプションデッキの流れ
将来の目標設定
まずは将来の目標をブレストで出していただきました。直近の目標や今後どうしていきたいのか理想像などを書き出してもらい、それらを整理して紐づけることでアプローチ方法を探っていきます。
目標設定からのやりたいこと・やらないといけないこと
「Javaの成果物を作ろう」ということから更に必要なことを相談しながら案を出し合いながらチャレンジすべき内容を決めていきました。
技術的解決策:具体的にやること
具体的に使用する技術を記載しています。
Javaの資格をお持ちとのことでJavaを活かすためにSpringを中心にDockerを使ったコンテナを用いたサービスを作ることになりました。またエンジニアとしてどういったことをPRすべきか伝えるために、ポートフォリオの作成もやることとして設定しました。
ただしポートフォリオはストレッチゴールで成果物ができてから取り組むことにしました。
伝えたかったこと
2人で同じ問題に対して考えて整理することで具体的なやることまで導くことができました。この考えるということ自体が開発における業務でも必要になる場合があると思っています。
自分で解決案を提案してみたり、その提案を他の人と相談しつつよりよい行動に移すことで、1人のエンジニアが組織として動くことができそうです。
8/10(月)~8/16(日):開発環境の構築
8/10(月)以降から21:00~24:00にかけてペアプログラミングで作業しました。まずは開発環境の構築で
docker-composeを使ってSpringの基盤を準備しました。ここらへんの知識はペアプログラミングで全体の構成などを伝えながらメリットとデメリットを共有しました。
Springについてはeclipseでガッチリ環境を作ってもよかったのですが、コンテナ化してどこでも動かせるようにしました。
eclipseの場合で環境がおかしくなった場合はお互いの環境で再現できないことも考えられたため、コンテナですぐに環境を構築できるように進めました。なお、課題管理などは
GitLabを使用してIssueとして管理しMerge Requestも使うようにしました。開発からある程度は経過していますが以下の場所で公開されています。https://gitlab.com/vorwort.k/yasuda-spring
8/17(月)~8/23(日):アプリケーションの作成
インセプションデッキでできるだけシンプルなモノを作ることになっています。今回はチャットアプリのようなモノを作っていきます。
実際に開発を進める上で
Springのコンテナをわざわざ起動しなおす必要があったり開発の手間が掛かっていました。
そういった手間もできるだけ改善するように取り組み、今回の場合ではソースのディレクトリとSpringのコンテナの中を同期させ、Gradleで自動的に再ビルドするように対応しました。そのようなナレッジはプロジェクトのReadme.mdに追記して記録するようにしました。開発や業務において問題に感じていることを改善することで今後のパフォーマンスに大きく影響するため、自分なりに何かアイデアがあれば話してみて取り組むと喜ばれることを共有しました。
週末にはおおよそのチャットアプリが完成したため週末に振り返りを行い、ポートフォリオの作成の準備を進めました。
8/23(日):振り返り
振り返りは
KPTで行いました。ここでProblemとしてあがったのがペアプロでドライバーが変わったときに楽しくなってガツガツ勝手につくっちゃうことがあったので注意が必要だと思いました。
あと全体の構成などを共有する際に理解するのに時間が掛かっているようで、ゆっくりと消化する時間は必要だなと感じています。
ポートフォリオを作成しようということなり、振り返りとは別に実際に学んだことを書き出してもらうことにしました。ポートフォリオの材料にできればと考えて書き出してもらいました。
学んだことを整理する
上記の全体の構成などに理解するのに苦労しているようなので、これまで学んだ技術などを書き出してもらい整理してもらいました。今回はシンプルなチャットアプリサービスですが、実際に使った技術はいろいろとあることがわかります。
上記の図があるだけでポートフォリオができるまでの間、成果物に関する全体構成や学んでいる技術を伝えることができます。来週からポートフォリオの作成に入りますが、作成している期間も企業にPRするための資料として利用できます。
ここでポートフォリオの作成がストレッチゴールに設定したことが効いてきそうです。
8/24(月)~8/30(日):ポートフォリオの作成
上記の学んだことを整理した図を元にポートフォリオを作成します。ここで大事なのは自分で作成して自分で説明できるモノを作り上げることです。人と相談していろいろとコンテンツを入れることはできますが、面談などで自分の口で説明できるポートフォリオでないと、自分の武器にならないので注意が必要です。
作成していただいたポートフォリオ
https://yasu-portfolio.netlify.app/
2人で効果的なポートフォリオを考える
基本的には中身については1人で考えてもらい改善点などはアイデア程度でお伝えしました。またアイデアもできるだけ複数案出して自分で選んでもらうようにしました。この手法自体もポートフォリオを作った経緯として別の資料として作成しました。
総評
2人でプロジェクトとして発足してやり切ることがよかったと思います。まずはインセプションデッキで同じ方向を向くことで、やりたいことなどのすれ違いなどがなくなりました。また定期的にペアプロの時間を設けることで考え方なども共有できることがお互いの成長につながったと思います。自分としては相手に伝える上で伝え方などが難しく、できるだけ具体例などを用いて説明するように工夫しました。
一緒に2人で考えるということは2人で同じ問題に取り組むことになるので、その解決におけるプロセスの経験は何事にも代えがたいモノになったと思います。
今回は無事にポートフォリオの作成まで達成することができ、それによって無事に開発の現場が決まったということもお伺いしました。特にSESの営業担当からポートフォリオがあるだけでPRしやすいのは事実で、エンジニアが事前に準備できる武器としては有効だと思います。
9月は9月で上記のプロジェクトを継承して別のプロジェクトとして継続しております。こちらの内容については別の記事で投稿しようと思います。