- 投稿日:2020-09-23T23:45:37+09:00
CloudWatchでよく使うドキュメント
CloudWatch設定作成時にドキュメントを探すのが手間なのでざっくりした作成の流れと共にまとめます。
サーバーで CloudWatch エージェントをインストールして実行する
ドキュメントに従って、任意のディレクトリにダウンロードをしてインストールを行います。
インストールが完了すると、以下ディレクトリが作成されます。
/opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.dインストールが失敗する場合は以下を確認
①インスタンスにロール「CloudWatchAgentServerRole」が割り当てられているか
②プロファイルが設定されているかウィザードを使用して CloudWatch エージェント設定ファイルを作成する
ウィザードを使用して、対話式に設定を行えます。
sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-config-wizard手動作成も可能。
ログ設定部分
"file_path": "ログのパス", "log_group_name": "任意の名前", "log_stream_name": "{instance_id}"configが完成したら、Agent起動
/opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m ec2 -c file:/opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.d/config.json -s↑ コマンドの file: 以降は先ほど作成したconfigのパスを指定
※メモリ監視等入れる場合はcollectdを要求される場合があり↓
yum -y install collectd ll /usr/share/collectd/types.dbサービス確認
systemctl status amazon-cloudwatch-agent.serviceAgentの起動を確認したら、
コンソールでログが送られている事を確認する。
CloudWatch>ログ>ロググループCloudWatch エージェントのトラブルシューティング
記事の途中にある「CloudWatch エージェントファイルとロケーション」にファイルの場所等が載っていて便利
- 投稿日:2020-09-23T23:41:03+09:00
AWS VPC Traffic Mirroring ~ demo
VPCトラフィクミラーリングでネットワークトラフィックを検査する。
EC2を2インスタンス使用して、片方のネットワーク利用をもう片方でモニタする。
概要についての簡単な説明は↓を参考にさせていただきました。
【初心者】AWS VPC Traffic Mirroring を使ってみる1.CloudFormationによる環境準備
AWSTemplateFormatVersion: '2010-09-09' Description: 'For making 2 of Amazon Linux (EC2) on a VPC. ' Mappings: AWSInstanceType2Arch: t3.medium: Arch: HVM64 t3.micro: Arch: HVM64 t3.small: Arch: HVM64 AWSRegionArch2AMI: ap-northeast-1: HVM64: ami-0a1c2ec61571737db us-east-1: HVM64: ami-0a887e401f7654935 us-west-2: HVM64: ami-0e8c04af2729ff1bb Outputs: AZ01: Description: Availability Zone of the Client EC2 instance 01 Value: !Join - '' - - !GetAtt 'ClientInstance.AvailabilityZone' AZ02: Description: Availability Zone of the Client EC2 instance 02 Value: !Join - '' - - !GetAtt 'ClientInstance2.AvailabilityZone' IP01: Description: Client EC2 IPaddress 01 Value: !Join - '' - - !GetAtt 'ClientInstance.PublicIp' IP02: Description: Client EC2 IPaddress 02 Value: !Join - '' - - !GetAtt 'ClientInstance2.PublicIp' Parameters: InstanceType: AllowedValues: - t3.micro - t3.small - t3.medium ConstraintDescription: must be a valid EC2 instance type. Default: t3.small Description: Amazon Linux instance type Type: String SSHLocation: AllowedPattern: (\d{1,3})\.(\d{1,3})\.(\d{1,3})\.(\d{1,3})/(\d{1,2}) ConstraintDescription: must be a valid IP CIDR range of the form x.x.x.x/x. Default: '0.0.0.0/0' Description: ' The IP address range that can be used to SSH to the EC2 instances' MaxLength: '18' MinLength: '9' Type: String Resources: AttachGateway: Properties: InternetGatewayId: !Ref 'InternetGateway' VpcId: !Ref 'ClientVPC' Type: AWS::EC2::VPCGatewayAttachment ClientInstance: Properties: ImageId: !FindInMap - AWSRegionArch2AMI - !Ref 'AWS::Region' - !FindInMap - AWSInstanceType2Arch - !Ref 'InstanceType' - Arch InstanceType: !Ref 'InstanceType' NetworkInterfaces: - AssociatePublicIpAddress: 'true' DeleteOnTermination: 'true' DeviceIndex: '0' GroupSet: - !Ref 'InstanceSecurityGroup' SubnetId: !Ref 'ClientSubnet' Tags: - Key: Application Value: !Ref 'AWS::StackId' - Key: Name Value: Client01 - Key: Workshop Value: TrafficMirroring UserData: !Base64 Fn::Join: - '' - - "#!/bin/bash -xe\n" - "yum update -y\n" - "amazon-linux-extras install -y epel\n" - "yum install -y nc\n" - "\n" Type: AWS::EC2::Instance ClientInstance2: Properties: ImageId: !FindInMap - AWSRegionArch2AMI - !Ref 'AWS::Region' - !FindInMap - AWSInstanceType2Arch - !Ref 'InstanceType' - Arch InstanceType: !Ref 'InstanceType' NetworkInterfaces: - AssociatePublicIpAddress: 'true' DeleteOnTermination: 'true' DeviceIndex: '0' GroupSet: - !Ref 'InstanceSecurityGroup' SubnetId: !Ref 'ClientSubnet' Tags: - Key: Application Value: !Ref 'AWS::StackId' - Key: Name Value: Client02 - Key: Workshop Value: TrafficMirroring UserData: !Base64 Fn::Join: - '' - - "#!/bin/bash -xe\n" - "yum update -y\n" - "amazon-linux-extras install -y epel\n" - "yum install -y wireshark\n" - "\n" Type: AWS::EC2::Instance ClientSubnet: Properties: AvailabilityZone: ap-northeast-1c CidrBlock: 10.100.0.0/24 MapPublicIpOnLaunch: 'true' Tags: - Key: Application Value: !Ref 'AWS::StackId' - Key: Name Value: ClientPublic VpcId: !Ref 'ClientVPC' Type: AWS::EC2::Subnet ClientVPC: Properties: CidrBlock: 10.100.0.0/16 EnableDnsHostnames: 'true' EnableDnsSupport: 'true' Tags: - Key: Application Value: !Ref 'AWS::StackId' - Key: Name Value: ClientVPC Type: AWS::EC2::VPC InboundAllAclEntry: Properties: CidrBlock: 10.100.0.0/16 Egress: 'false' NetworkAclId: !Ref 'NetworkAcl' Protocol: '-1' RuleAction: allow RuleNumber: '120' Type: AWS::EC2::NetworkAclEntry InboundResponsePortsNetworkAclEntry: Properties: CidrBlock: '0.0.0.0/0' Egress: 'false' NetworkAclId: !Ref 'NetworkAcl' PortRange: From: '1024' To: '65535' Protocol: '6' RuleAction: allow RuleNumber: '102' Type: AWS::EC2::NetworkAclEntry InboundSSHNetworkAclEntry: Properties: CidrBlock: '0.0.0.0/0' Egress: 'false' NetworkAclId: !Ref 'NetworkAcl' PortRange: From: '22' To: '22' Protocol: '6' RuleAction: allow RuleNumber: '101' Type: AWS::EC2::NetworkAclEntry InstanceSecurityGroup: Properties: GroupDescription: Enable SSH access via port 22 SecurityGroupIngress: - CidrIp: !Ref 'SSHLocation' FromPort: '22' IpProtocol: tcp ToPort: '22' - CidrIp: 10.100.0.0/16 IpProtocol: '-1' VpcId: !Ref 'ClientVPC' Type: AWS::EC2::SecurityGroup InternetGateway: Properties: Tags: - Key: Application Value: !Ref 'AWS::StackId' Type: AWS::EC2::InternetGateway NetworkAcl: Properties: Tags: - Key: Application Value: !Ref 'AWS::StackId' VpcId: !Ref 'ClientVPC' Type: AWS::EC2::NetworkAcl OutBoundRDPNetworkAclEntry: Properties: CidrBlock: '0.0.0.0/0' Egress: 'true' NetworkAclId: !Ref 'NetworkAcl' Protocol: '-1' RuleAction: allow RuleNumber: '100' Type: AWS::EC2::NetworkAclEntry Route: DependsOn: AttachGateway Properties: DestinationCidrBlock: '0.0.0.0/0' GatewayId: !Ref 'InternetGateway' RouteTableId: !Ref 'RouteTable' Type: AWS::EC2::Route RouteTable: Properties: Tags: - Key: Application Value: !Ref 'AWS::StackId' VpcId: !Ref 'ClientVPC' Type: AWS::EC2::RouteTable SubnetNetworkAclAssociation: Properties: NetworkAclId: !Ref 'NetworkAcl' SubnetId: !Ref 'ClientSubnet' Type: AWS::EC2::SubnetNetworkAclAssociation SubnetRouteTableAssociation: Properties: RouteTableId: !Ref 'RouteTable' SubnetId: !Ref 'ClientSubnet' Type: AWS::EC2::SubnetRouteTableAssociation2.SSMによる環境準備
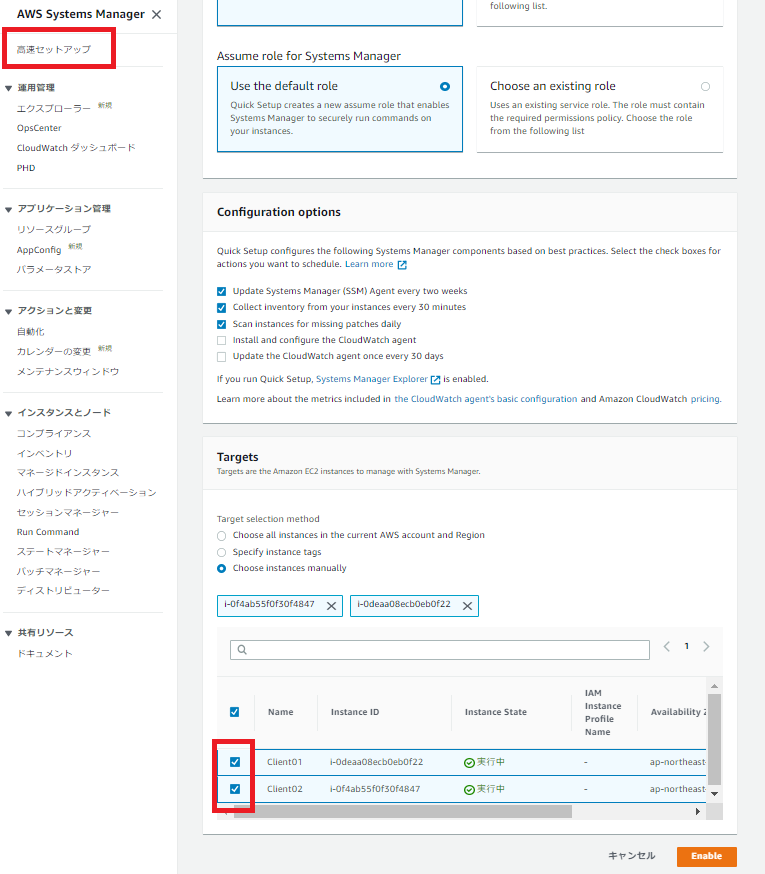
SSMには高速セットアップ機能があります。これを使ってインスタンスのSSM設定の自動構成します。
[新機能] Systems Manager Quick Setup ですばやく設定可能になりました!
3.トラフィックミラーリングの設定
2つのEC2が記録作成されているはずなので、ネットワークインターフェース eth0の情報を記録しておく。
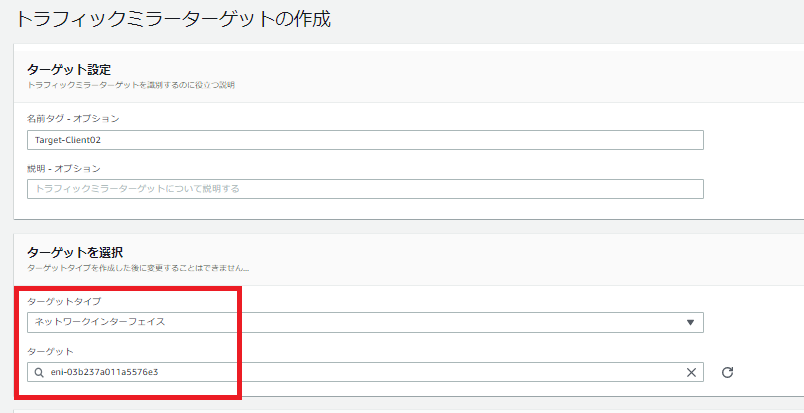
「ターゲットをミラーリングする」
「ターゲットタイプ:ネットワークインタフェース」で、先に記憶しておいたClient02のENIを選択する。
「フィルターをミラーリングする」
「インバウンド」「アウトバウンド」ルールを次のようにする。
「セッションをミラーリングする」
ミラーソースとして、Client01のENI、ミラーターゲットとして、「ターゲットをミラーリングする」で作ったものを指定。
フィルタはどのパケットをミラーリングするかであり、「フィルターをミラーリングする」で作ったものを指定。
4.EC2でパケットモニタリングする
Client02で、トラフィックミラーリングでコピーされたパケットを確認しながら、Client01を操作する。
client01curl checkip.amazonaws.comclient02sudo tcpdump -i eth0 -n port 4789 cpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes 14:26:56.151185 IP 10.100.0.223.65431 > 10.100.0.177.4789: VXLAN, flags [I] (0x08), vni 7348185 IP 18.209.184.162.http > 10.100.0.223.33962: Flags [S.], seq 2590301871, ack 2020809952, win 26847, options [mss 1460,sackOK,TS val 3553538939 ecr 284377333,nop,wscale 8], length 0 14:26:56.320805 IP 10.100.0.223.65431 > 10.100.0.177.4789: VXLAN, flags [I] (0x08), vni 7348185 IP 18.209.184.162.http > 10.100.0.223.33962: Flags [.], ack 86, win 115, options [nop,nop,TS val 3553539139 ecr 284377503], length 0 14:26:56.321122 IP 10.100.0.223.65431 > 10.100.0.177.4789: VXLAN, flags [I] (0x08), vni 7348185 IP 18.209.184.162.http > 10.100.0.223.33962: Flags [P.], seq 1:141, ack 86, win 115, options [nop,nop,TS val 3553539139 ecr 284377503], length 140: HTTP: HTTP/1.1 200 OK 14:26:56.491205 IP 10.100.0.223.65431 > 10.100.0.177.4789: VXLAN, flags [I] (0x08), vni 7348185 IP 18.209.184.162.http > 10.100.0.223.33962: Flags [F.], seq 141, ack 87, win 115, options [nop,nop,TS val 3553539310 ecr 284377672], length 0 4 packets captured 4 packets received by filter 0 packets dropped by kernel


- 投稿日:2020-09-23T23:37:43+09:00
Google Cloud Certified - Professional Cloud Architect に合格しました
資格取得に向けて
昨日 (2020/09/22)、タイトルの通り Google Cloud Certified - Professional Cloud Architect を取得しました
勉強期間は約 2 ヶ月ですこの嬉しさを忘れないうちにこれから受けようと思っている方に自分なりにアドバイスなどを残します
かっこいい…
想定する読者
- Google Cloud Certified - Professional Cloud Architect を受けようと思っている
- AWS Certified Solutions Architect – Associate を取って次、何を受けようか悩んでいる
本人スペック
- 今年 3 月に AWS Certified Solutions Architect – Associate を取得
- GCP の経験は昨年、PJ で GCE と Pub/Sub、IoT Core あたりを半年程触っていた程度
- 今年に入ってからの業務はもっぱらオンプレのインフラ屋さん
取ろうと思ったきっかけ
上でも書きましたが昨年、PJ で少し GCP を触っていました
ある時、「そういえば去年触ってた GCP、実はあんまりよく分からずにやってたな」と思い AWS の違いも含めてここは一度体系的に学んでおこうと思ったのがきっかけ
あと、正直これが自分の中で一番大きいですが最近の業務があまり楽しくなかったのでその欲求不満(?)的なものをどこかにぶつけたかったというのがあります
モチベーション
やると決めたら先に受験日を決めてしまう
まじでこれ大事、受験料まで払ってしまえばもう逃げられないから勉強するしかない
落ちたら 2 万無駄になると思うとめっちゃやる気でる勉強法
とりあえずやれることは色々やったのでご紹介します
公式ドキュメント
個人的に役立ったものをいくつか紹介します
- 『 1 行でわかる Google Cloud Platform』公開
- AWS プロフェッショナルのための Google Cloud
- [Cloud OnAir] Google Cloud とつなぐ色々な方法 〜 つなぐ方法をゼロからご紹介します〜
- [Cloud OnAir] BigQuery の仕組みからベストプラクティスまでのご紹介
- [Cloud OnAir] Bigtable に迫る!基本機能も含めユースケースまで丸ごと紹介
Cloud OnAir は通勤中の電車などで暇つぶしがてらいろいろ見ておくといいと思います
また、公式ドキュメントではありませんがメルカリの開発者ブログも公式には載っていない Tips が多くありそこから気付く点もあるのでおすすめです
例えばこれ、 メルペイでのSpannerとの戦いの日々
書籍
今回読んだのは以下になります
この中でどれか 1 冊だけ買うとしたら 2. の GCP の教科書をおすすめしますが、できれば 1. のエンタープライズ設計ガイドでざっくりと概要をつかんでから読んだ方がいいかと思います
GCP の教科書コンテナ編は、読んでおくに越したことはありませんが今回の資格取得に限っては別に読まなくてなんとかなります
ただ、内容としてはとても学ぶ点が多くあったので業務で GKE を扱うことになったら一度読み返すつもりです
Udemy
Udemy で GCP の日本語コースは皆無です
ここは腹を括って英語コースを受講しましょう、意外となんとかなります上記のコースは、解説も割と丁寧に書かれています
勉強していると自分では結局どこが大事なのかわからなくなったりするので問題を解いて第三者の視点で重要なポイントをおさえるといいです最後に
GCP は AWS と比べるとどうしても日本語の書籍などが少なく、勉強手段に困るかと思います
なんとなくクラウドを学びたくて、 AWS / GCP で悩んでいるならまずは AWS から勉強をすることをおすすめします
日本語書籍いっぱいだし、パブリッククラウドといえばやっぱり AWS が最初に上がるだろうしね!!
GCP の説明をするときに AWS の同等サービスと比較しながら解説するドキュメントも多いから AWS から勉強した方が効率的と思う

- 投稿日:2020-09-23T22:21:27+09:00
AWS EC2 起動テンプレートのユーザーデータを使用して Pytorch用 jupyter notebook の自動起動設定をする
はじめに
EC2の起動テンプレートにスクリプトを書いておくと、インスタンス作成時に自動的にスクリプトが実行されます。
Deep Learning AMI (Ubuntu 18.04) Version 34.0 - ami-0302aadfa73a0d917を使用し、ディープラーニングが実行できるjupyter notebookを自動で起動する設定をします。手順
起動テンプレート設定画面を開きます。
起動テンプレートを作成を選択。高度な詳細を開く。
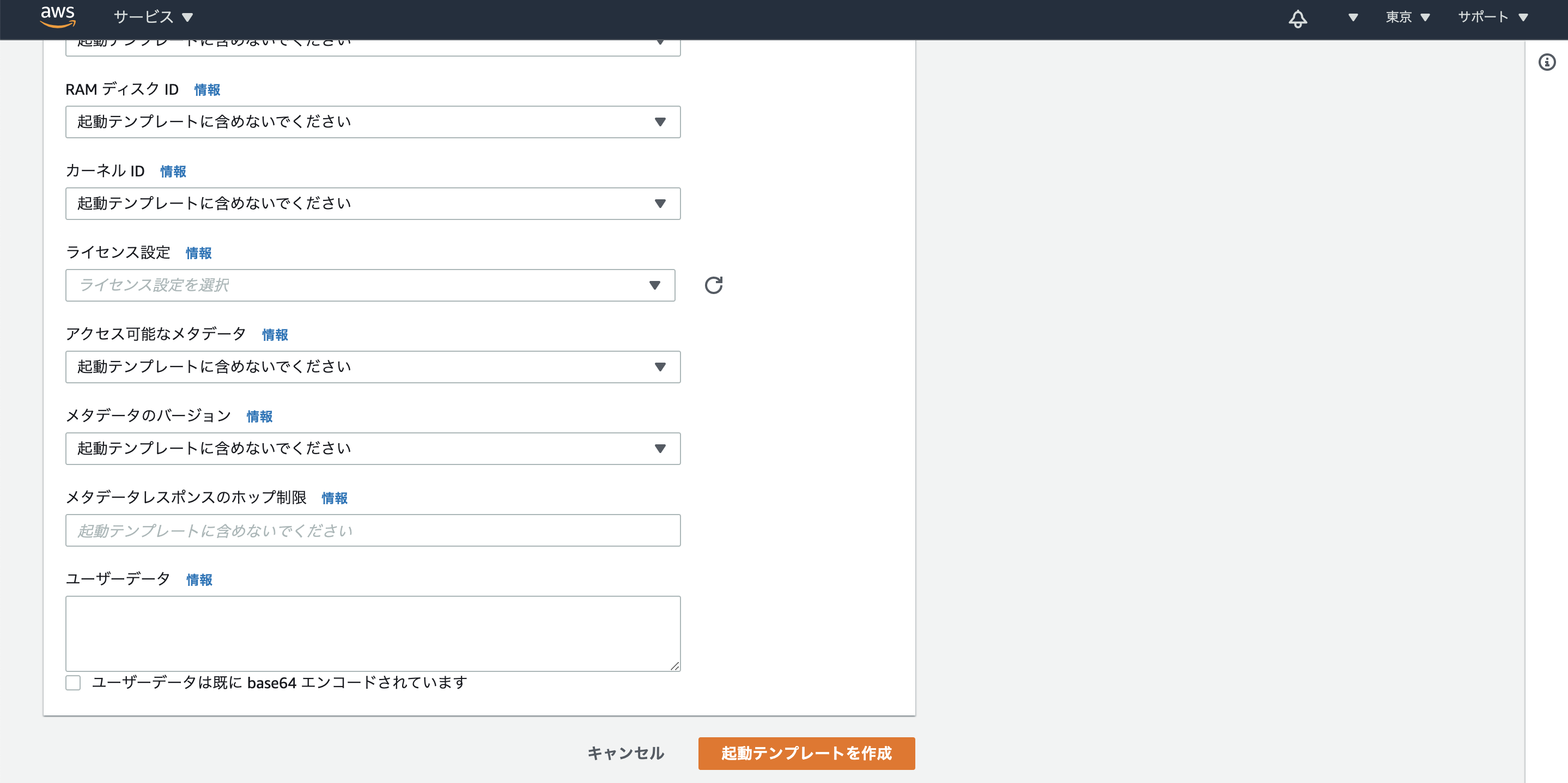
ユーザーデータに下記のスクリプトを貼り付け。
#!/bin/bash # write conf cat << EOF > /home/ubuntu/.jupyter/jupyter_notebook_config.py c = get_config() c.NotebookApp.ip = '0.0.0.0' c.NotebookApp.open_browser = False c.NotebookApp.port = 8080 c.NotebookApp.token = '' EOF chown ubuntu:ubuntu /home/ubuntu/.jupyter/jupyter_notebook_config.py # set auto start echo "/home/ubuntu/anaconda3/envs/pytorch_p36/bin/jupyter-notebook" > /home/ubuntu/start_jupyter.sh chmod 755 /home/ubuntu/start_jupyter.sh chown ubuntu:ubuntu /home/ubuntu/start_jupyter.sh bash -c 'cat > /etc/rc.local' << EOF #!/bin/sh # DLAMI Configurations /opt/dlami/start/dlami_start # jupyter su - ubuntu /home/ubuntu/start_jupyter.sh & exit 0 EOF # reboot shutdown -r now設定の意味はJupyter事始めを読めば分かると思います。
ユーザーデータの実行ログは
/var/log/cloud-init-output.logに出力されます。
Deep Learning AMI (Ubuntu 18.04) Version 34.0 - ami-0302aadfa73a0d917を前提にしているので、AMIを変えてOSやanaconda環境が変わると修正が必要になります。

- 投稿日:2020-09-23T20:20:01+09:00
Auto Scaling で追加したEC2 インスタンスにパブリックIPを割り振る
小ネタです。AWSコンソールから設定する方法について書きます。
困っていたこと
Auto Scaling で追加したEC2 インスタンスに
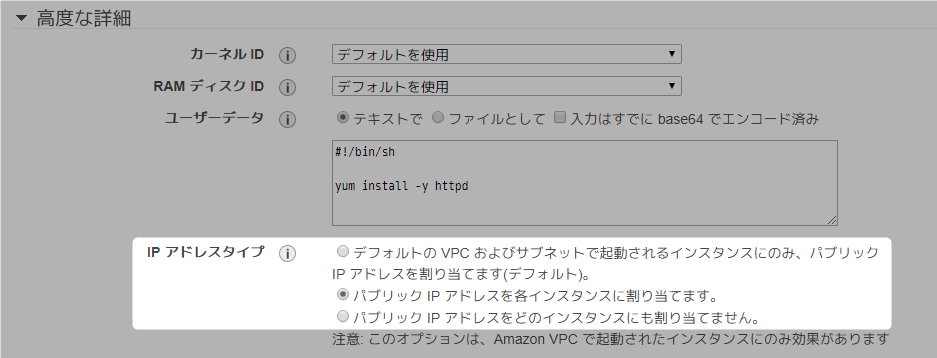
パブリック IPv4 アドレスが割り振られない。いろいろ調べたところ、Auto Scaling > [高度な詳細] > [IPアドレスタイプ] で設定できそうなのに、AWSコンソール上に見当たらなくて困っていました。
画像引用:AWS勉強会(3) / Auto Scalingチュートリアル - Qiita解決策
Auto Scaling グループに紐づくサブネットの
パブリック IPv4 アドレスの自動割り当てをはいにする
▼ 詳細
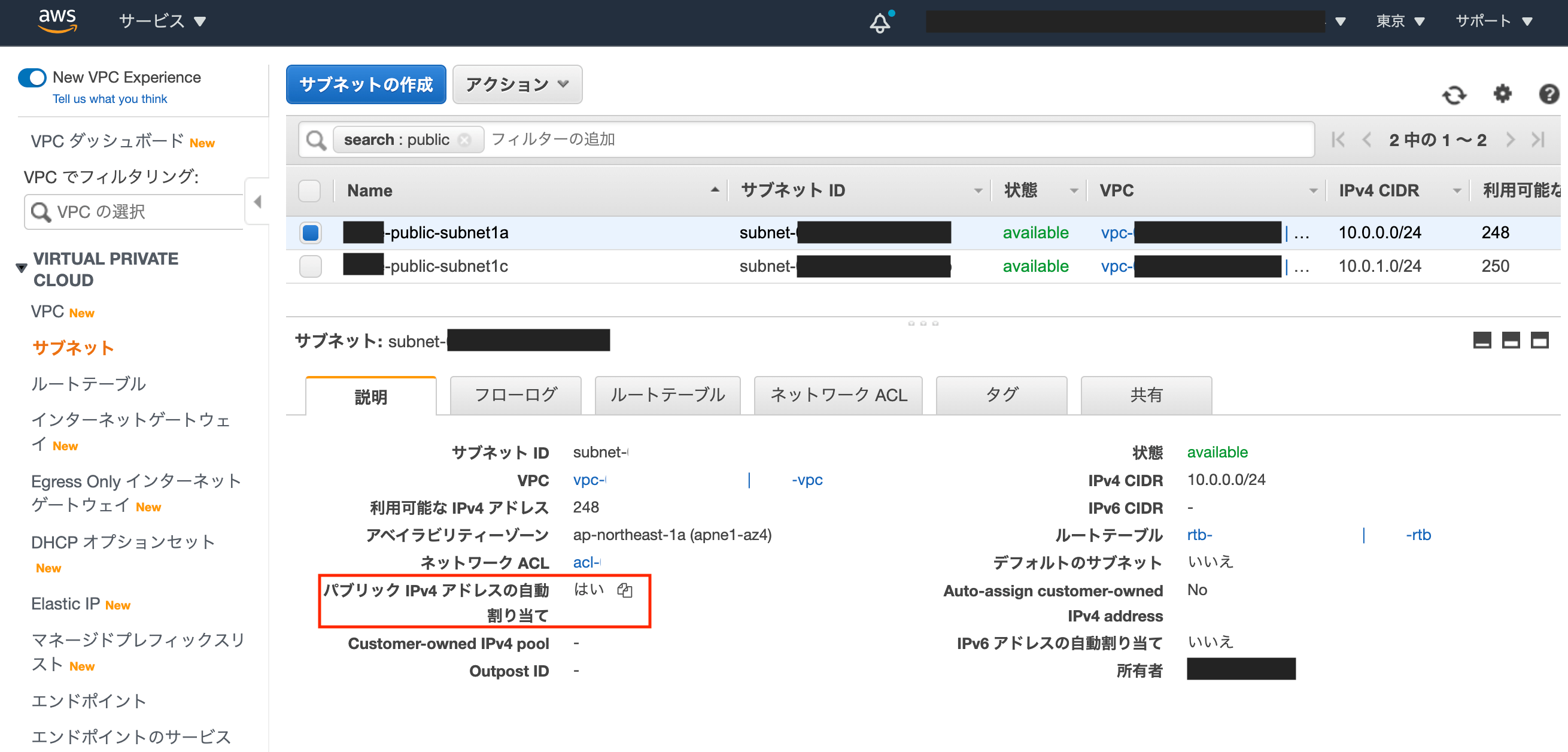
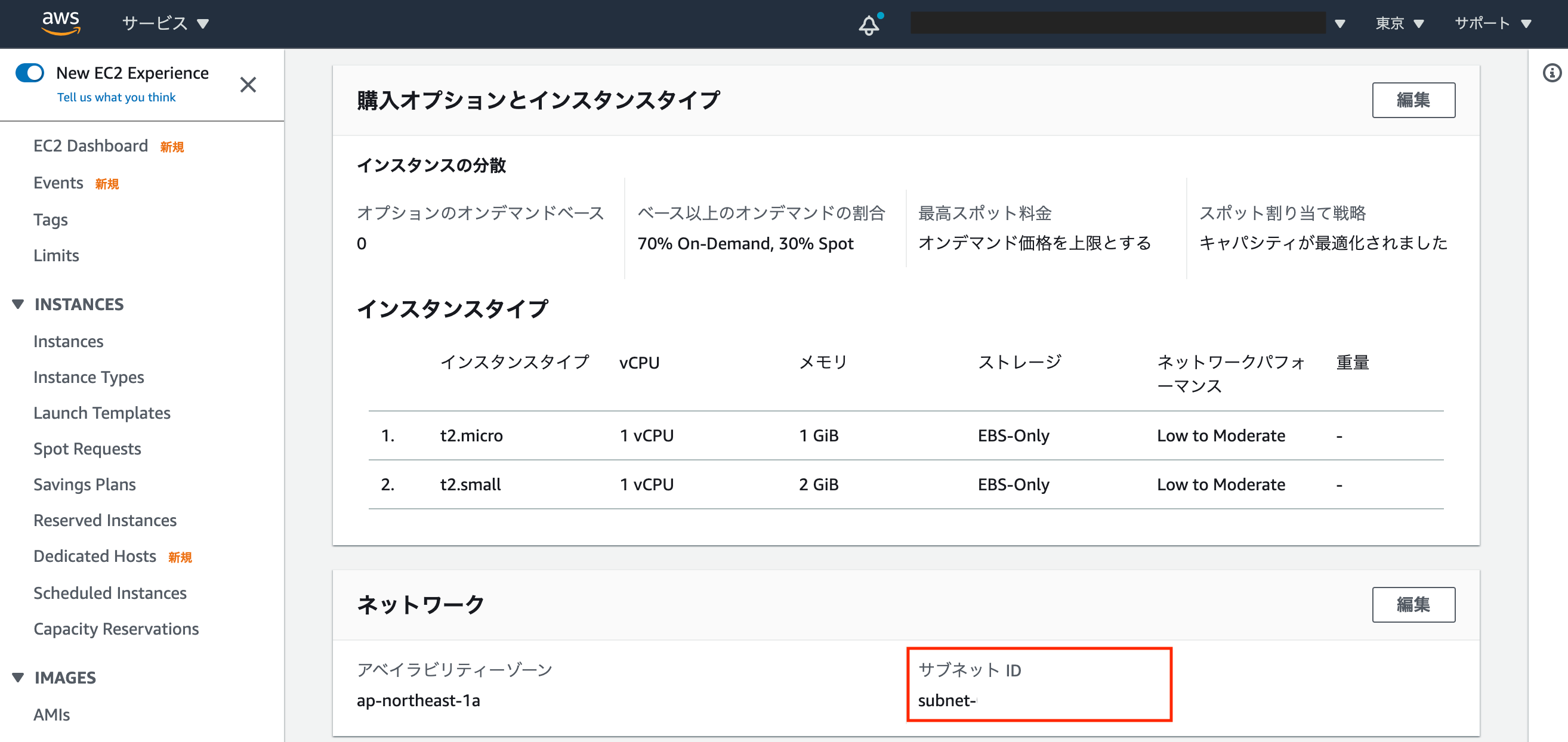
① Auto Scaling グループに紐づくサブネットがなんなのか確認する
1. [EC2] > [Auto Scaling グループ] で対象のAuto Scaling グループの名前をクリック
2. ネットワークのサブネットIDを控える
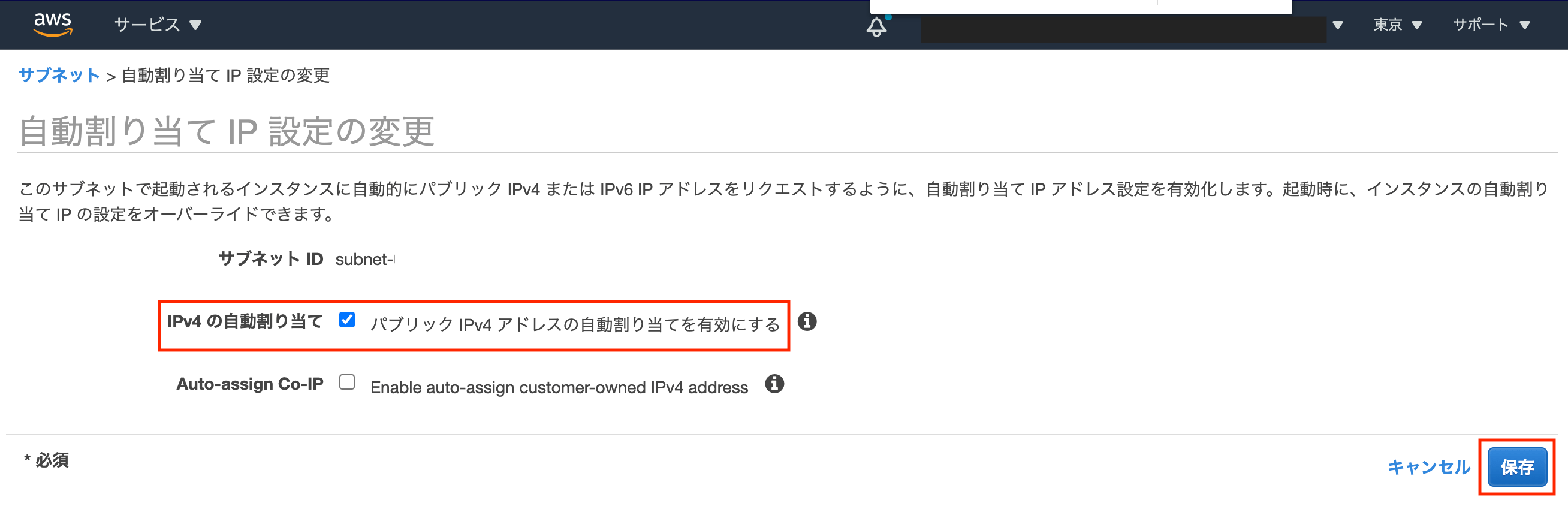
② サブネットの
パブリック IPv4 アドレスの自動割り当てを変更する
1. [VPC] > [サブネット] をクリック
2. 対象のサブネットIDを選択し、[アクション] > [自動割り当てIP設定の変更] をクリック
3.パブリック IPv4 アドレスの自動割り当てを有効にするにチェックを入れ、[保存] をクリック
余談 (なぜこれを解決したかったのか)
Auto Scaling で追加したEC2 インスタンスに自動でEIPを割り当てる、ということをやりたかったです。
上記を実施するためには、パブリックIPが付与されている必要がありました。以下の記事のおかげでEIPの自動割り当てをすることができました。圧倒的感謝
- 投稿日:2020-09-23T20:20:01+09:00
Auto Scaling で追加したEC2 インスタンスにパブリックIP を割り振る
小ネタです。AWSコンソールから設定する方法について書きます。
困っていたこと
Auto Scaling で追加したEC2 インスタンスに
パブリック IPv4 アドレスが割り振られない。いろいろ調べたところ、Auto Scaling > [高度な詳細] > [IPアドレスタイプ] で設定できそうなのに、AWSコンソール上に見当たらなくて困っていました。
画像引用:AWS勉強会(3) / Auto Scalingチュートリアル - Qiita解決策
Auto Scaling グループに紐づくサブネットの
パブリック IPv4 アドレスの自動割り当てをはいにする
▼ 詳細
① Auto Scaling グループに紐づくサブネットがなんなのか確認する
1. [EC2] > [Auto Scaling グループ] で対象のAuto Scaling グループの名前をクリック
2. ネットワークのサブネットIDを控える
② サブネットの
パブリック IPv4 アドレスの自動割り当てを変更する
1. [VPC] > [サブネット] をクリック
2. 対象のサブネットIDを選択し、[アクション] > [自動割り当てIP設定の変更] をクリック
3.パブリック IPv4 アドレスの自動割り当てを有効にするにチェックを入れ、[保存] をクリック
余談 (なぜこれを解決したかったのか)
Auto Scaling で追加したEC2 インスタンスに自動でEIPを割り当てる、ということをやりたかったです。
上記を実施するためには、パブリックIPが付与されている必要がありました。以下の記事のおかげでEIPの自動割り当てをすることができました。圧倒的感謝
- 投稿日:2020-09-23T15:51:23+09:00
【解説】ポートフォリオ(NotePro)
URL
概要
デバイス内に散らばった情報を一つにまとめることできるWEBアプリケーション
制作背景
日頃から私自身で困っていたことを解決したいという考えから作成いたしました。
1.以前Twitterいいねした投稿がいいねしすぎてすぐに見つからない 2.YouTubeでためになったことをスクショしたはいいものの、フォルダのどこにあるのかすぐに見つからない 3.参照リンクもまとめたい 4.某投稿サイトなどはあるが何かによりすぎて気軽な投稿はできそうにない雰囲気がある 5.まとめたものにいいねをもらいたい!!!!1.以前Twitterいいねした投稿がいいねしすぎてすぐに見つからない
Twitterでは気軽にいいねができすぎて、本当に必要な時、いいねした投稿が見つからないことが皆さんも結構あるのではないでしょうか。
また、Twitterアカウント自体複数持っている方も結構いるのではないでしょうか。そうなると尚更、見つかりずらくなります。
noteとしてまとめる時間はかかるものの、
各アカウントのいいね欄を探しに行く時間を考えたら圧倒的に時間削減できると考えたので作ろうと考えました。2.YouTubeでためになったことをスクショしたはいいものの、フォルダのどこにあるのかすぐに見つからない
私自身結構な頻度でスクショを撮ります。
動画を見ている際、コメントで出てくるところを撮ったりするのですがフォルダには日常生活で撮影した写真などもあり「あの時スクショした画像どこかな?」と探すことが結構な頻度であります。
なのでこういったことも解決できたらいいなと考えておりました。3.参照リンクもまとめたい
いいねしたツイート、スクリーンショットなどで、
参照元のリンクやページ内にある別サイトのリンクなども「まとめて管理できないかなあ」と考えておりました。4.某投稿サイトなどはあるが何かによりすぎて気軽な投稿はできそうにない雰囲気がある
某緑(これ)のやつだったりなどいろいろありますが、
私生活の豆知識なども一緒に投稿できる雰囲気ではないので、
もう少しラフで気軽に投稿できるWEBサービスが欲しかったのです。5.まとめたものにいいねをもらいたい!!!!
単にnoteの作成であればeveronteやiPhoneのメモなどで事足ります。
ですが、投稿するならまとめたものにいいねとかもらいたいと考えておりました。
しかし、SNSぽくしてしまうと、最近では悲しい事件が起きたりしているで
SNSの使い方、モラルなどが強く必要となり、noteツールにそういうことまではもたせたくないと考えていたりしてました。
なのでSNSのいいところだけを取り、誹謗中傷などはないけど、程よく承認欲求も満たされるものを作ろうじゃないか!という上記の理由から今回のNoteProを作成いたしました。
機能
リッチテキストによる投稿 idのtoken化 タグ機能 Twitterログイン機能 CSVのエクスポート機能 投稿に対するいいね ゴミ箱機能 プロフィールの画像設定リッチテキストによる投稿
・summernoteを使用し制作
※日本語の解説などがあまりなく結構時間とられました。idのtoken化
・user_idやpost_idを乱数保存
皆さんが良く利用するサービスでもuser/12(id)/edit上記みたいな簡単なIDで表示されているのはあまりないですよね。
簡単なIDにしてしまうと簡単に推測できてしまい悪用されかねないので
乱数(いろいろ種類がある)でトークン化して保守化しました。タグ機能
・投稿にタグを紐づけることができる
Twitterログイン機能
・Twitterからのログインをすることができる
CSVのエクスポート機能
・自分の投稿のみSCVで吐き出すことが可能
投稿に対するいいね
・他ユーザーのいいと思った投稿にいいねができる
ゴミ箱機能
・不要投稿はゴミ箱に入れることができる
プロフィールの画像設定
・アイコンの設定ができる
追加実装予定
使用技術
・言語:Ruby2.5.7
・フレームワーク:Ruby on Rails5.2.4.3
・テスト:RSpec
・フロント:slim(BEM)、Sass、JavaScript(jQuery)、Bootstrap4
・インフラ:AWS(VPC | ELB | EC2 | SES | Route53 )
・ソースコード管理:GitHub
・その他:Capistranoによる自動デプロイ環境
開発環境
Vagrant 2.2.4
SQLite 3.7.17本番環境
MySQL2 5.5.62
Nginx 1.16.1
Puma使用したgem
gem 'faker' gem 'pry-byebug' gem 'rubocop-airbnb' gem 'slim-rails' gem 'devise' gem 'summernote-rails', '~> 0.8.10.0' gem 'omniauth' gem 'omniauth-twitter' gem 'google-analytics-rails' gem 'meta-tags' gem 'aws-ses' gem "refile" gem 'rails-i18n' gem 'kaminari', '~> 1.2.1'なるべく少なくとは思いつつ想定より多くなってしまいました、、
NotePro作成するにあたり定義したものたち
- 投稿日:2020-09-23T15:51:23+09:00
ポートフォリオ(NotePro)の解説
URL
概要
デバイス内に散らばった情報を一つにまとめることできるWEBアプリケーション
制作背景
日頃から私自身で困っていたことを解決したいという考えから作成いたしました。
1.以前Twitterいいねした投稿がいいねしすぎてすぐに見つからない 2.YouTubeでためになったことをスクショしたはいいものの、フォルダのどこにあるのかすぐに見つからない 3.どうせなら参照リンクもまとめたい 4.某投稿サイトなどはあるが何かによりすぎて気軽な投稿はできそうにない雰囲気がある 5.まとめたものにいいねをもらいたい!!!!1.以前Twitterいいねした投稿がいいねしすぎてすぐに見つからない
Twitterでは気軽にいいねができすぎて、本当に必要な時、いいねした投稿が見つからないことが皆さんも結構あるのではないでしょうか。
また、Twitterアカウント自体複数持っている方も結構いるのではないでしょうか。そうなると尚更、見つかりずらくなります。
noteとしてまとめる時間はかかるものの、
各アカウントのいいね欄を探しに行く時間を考えたら圧倒的に時間削減できると考えたので作ろうと考えました。2.YouTubeでためになったことをスクショしたはいいものの、フォルダのどこにあるのかすぐに見つからない
私自身結構な頻度でスクショを撮ります。
動画を見ている際、コメントで出てくるところを撮ったりするのですがフォルダには日常生活で撮影した写真などもあり「あの時スクショした画像どこかな?」と探すことが結構な頻度であります。
なのでこういったことも解決できたらいいなと考えておりました。3.どうせなら参照リンクもまとめたい
いいねしたツイート、スクリーンショットなどで、
どうせなら参照元のリンクやページ内にある別サイトのリンクなども「まとめて管理できないかなあ」と考えておりました。4.某投稿サイトなどはあるが何かによりすぎて気軽な投稿はできそうにない雰囲気がある
某緑(これ)のやつだったりなどいろいろありますが、
私生活の豆知識なども一緒に投稿できる雰囲気ではないので、
もう少しラフで気軽に投稿できるWEBサービスが欲しかったのです。5.まとめたものにいいねをもらいたい!!!!
単にnoteの作成であればeveronteやiPhoneのメモなどで事足ります。
ですが、どうせならまとめたものにいいねとかもらいたいと考えておりました。
しかし、SNSぽくしてしまうと、最近では悲しい事件が起きたりしているで
SNSの使い方、モラルなどが強く必要となり、noteツールにそういうことまではもたせたくないと考えていたりしてました。
なのでSNSのいいところだけを取り、誹謗中傷などはないけど、程よく承認欲求も満たされるものを作ろうじゃないか!という上記の理由から今回のNoteProを作成いたしました。
機能
リッチテキストによる投稿 タグ機能 Twitterログイン機能 CSVのエクスポート機能 投稿に対するいいね ゴミ箱機能 プロフィールの画像設定リッチテキストによる投稿
・summernoteを使用し制作
※日本語の解説などがあまりなく結構時間とられました。タグ機能
・投稿にタグを紐づけることができる
Twitterログイン機能
・Twitterからのログインをすることができる
CSVのエクスポート機能
・自分の投稿のみSCVで吐き出すことが可能
投稿に対するいいね
・他ユーザーのいいと思った投稿にいいねができる
ゴミ箱機能
・不要投稿はゴミ箱に入れることができる
プロフィールの画像設定
・アイコンの設定ができる
追加実装予定
使用技術
・言語:Ruby2.5.7
・フレームワーク:Ruby on Rails5.2.4.3
・テスト:RSpec
・フロント:slim(BEM)、Sass、JavaScript(jQuery)、Bootstrap4
・インフラ:AWS(VPC | ELB | EC2 | SES | Route53 )
・ソースコード管理:GitHub
・その他:Capistranoによる自動デプロイ環境
開発環境
Vagrant 2.2.4
SQLite 3.7.17本番環境
MySQL2 5.5.62
Nginx 1.16.1
Puma使用したgem
gem 'faker' gem 'pry-byebug' gem 'rubocop-airbnb' gem 'slim-rails' gem 'devise' gem 'summernote-rails', '~> 0.8.10.0' gem 'omniauth' gem 'omniauth-twitter' gem 'google-analytics-rails' gem 'meta-tags' gem 'aws-ses' gem "refile" gem 'rails-i18n' gem 'kaminari', '~> 1.2.1'なるべく少なくとは思いつつ想定より多くなってしまいました、、
- 投稿日:2020-09-23T15:37:09+09:00
Glue+AthenaでMySQLとDynamoDBのデータをJOIN+分析する
目標
サーバーレス技術やマイクロサービスが台頭している昨今、DBをサービスごとに分けるケースが多くなってきています。
本記事では、RDBとDynamoDBの両方を活用しているあなたが、分析レポートを作成するケースを想定します。
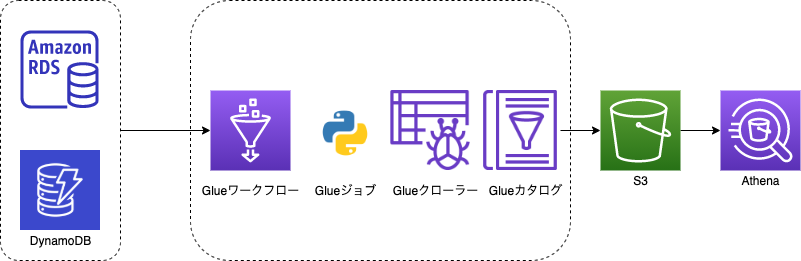
AWSを使ってETLし、両DBのデータをAthenaによりクエリするサンプルを作成していきます。構成図
データはRDSとDynamoDBに存在することが前提となります。
Glueの機能のみでS3へparquet化したデータをETLします。
AthenaでRDSのデータとDynamoDBのデータをクエリでJOINします。
Glueの作成
それではAWSリソースをTerraformで作成するサンプルをみてみましょう。
ジョブの作成
共通
Glue用のIAMロールを作成します。
Glue、S3、DynamoDBのアクセス権限を与えておきます。resource "aws_iam_role" "glue_role" { name = "AWSGlueServiceRole-Sample" assume_role_policy = data.aws_iam_policy_document.glue_assume_role.json } data "aws_iam_policy_document" "glue_assume_role" { statement { actions = ["sts:AssumeRole"] principals { identifiers = ["glue.amazonaws.com"] type = "Service" } } } resource "aws_iam_role_policy_attachment" "glue_policy-1" { policy_arn = "arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole" role = aws_iam_role.glue_role.name } resource "aws_iam_role_policy_attachment" "glue_policy-2" { policy_arn = "arn:aws:iam::aws:policy/AmazonS3FullAccess" role = aws_iam_role.glue_role.name } resource "aws_iam_role_policy_attachment" "glue_policy-3" { policy_arn = "arn:aws:iam::aws:policy/AmazonDynamoDBReadOnlyAccess" role = aws_iam_role.glue_role.name }続いてS3バケットです。
こちらのバケットにDBのデータを格納し、クローリングしてAthena検索できるようにします。resource "aws_s3_bucket" "results" { bucket = "hogehoge-XXX" acl = "private" } output "data-logs-bucket-name" { value = aws_s3_bucket.results.bucket }MySQL
続いてジョブの作成です。
ジョブはPython(Spark)で作成します。
aws-glue-scripts-${var.aws_account_id}-ap-northeast-1/にPythonファイルを配置することとします。variable "aws_account_id" {} resource "aws_glue_job" "mysql_job" { name = "mysql_job" role_arn = aws_iam_role.glue_role.arn command { script_location = "s3://aws-glue-scripts-${var.aws_account_id}-ap-northeast-1/mysql_job.py" python_version = 3 } connections = ["mysql_job"] glue_version = "2.0" number_of_workers = 10 worker_type = "G.1X" default_arguments = { "--bucket" = aws_s3_bucket.results.bucket "--continuous-log-logGroup" = "/aws-glue/jobs/output" "--enable-continuous-cloudwatch-log" = "true" "--enable-continuous-log-filter" = "true" "--enable-metrics" = "" "--job-language" = "python" "--job-bookmark-option" = "job-bookmark-disable" "--TempDir" = "s3://aws-glue-temporary-${var.aws_account_id}-ap-northeast-1/" } }以下に注目してください。
DBへの接続は別途AWSコンソールより行なうこととしています。
DBのパスワードなどをTerraform上に記録することを防ぐための対応です。
(SecretsManagerの活用や、ジョブの引数などで工夫しても可能です)connections = ["mysql_job"]Pythonのジョブは以下とします。
JDBC接続を確立し、1テーブルごとにS3へparquet化しています。
こちらのファイルはaws-glue-scripts-${var.aws_account_id}-ap-northeast-1/mysql_job.pyに配置しましょう。mysql_job.pyimport sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job arg_keys = ['JOB_NAME', 'bucket'] args = getResolvedOptions(sys.argv, arg_keys) (job_name, bucket) = [args[k] for k in arg_keys] # 以下の接続情報は直接入力やジョブの引数、もしくはSecretsManagerやParameterStore等の活用で指定する db_host = "" # Todo db_user = "" # Todo db_password = "" # Todo db_schema = "" # Todo db_port = "" # Todo jdbc_url = "jdbc:mysql://" + db_host + ":" + db_port + "/" + db_schema sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session target_tables = [ 'users', 'shops', ] for table_name in target_tables: data_path = "s3://" + bucket + "/" + table_name ds = glueContext.create_dynamic_frame_from_options('mysql', connection_options={ "url": jdbc_url, "user": db_user, "password": db_password, "dbtable": table_name }) glueContext.write_dynamic_frame.from_options( frame=ds, connection_type="s3", connection_options={ "path": data_path }, format="parquet" )DynamoDB
DynamoDBのジョブも同様に作成します。
resource "aws_glue_job" "dynamodb_job" { name = "dynamodb_job" role_arn = aws_iam_role.glue_role.arn command { script_location = "s3://aws-glue-scripts-${var.aws_account_id}-ap-northeast-1/dynamodb_job.py" python_version = 3 } glue_version = "2.0" number_of_workers = 10 worker_type = "G.1X" default_arguments = { "--bucket" = aws_s3_bucket.results.bucket "--continuous-log-logGroup" = "/aws-glue/jobs/output" "--enable-continuous-cloudwatch-log" = "true" "--enable-continuous-log-filter" = "true" "--enable-metrics" = "" "--job-language" = "python" "--job-bookmark-option" = "job-bookmark-disable" "--TempDir" = "s3://aws-glue-temporary-${var.aws_account_id}-ap-northeast-1/" } }こちらのファイルは
aws-glue-scripts-${var.aws_account_id}-ap-northeast-1/dynamodb_job.pyに配置しましょう。dynamodb_job.pyimport sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job arg_keys = ['JOB_NAME', 'bucket'] args = getResolvedOptions(sys.argv, arg_keys) (job_nam, bucket) = [args[k] for k in arg_keys] sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(job_name, args) target_tables = [ 'PurchaseHistories' ] for table_name in target_tables: data_path = "s3://" + bucket_root + "/" + table_name ds = glueContext.create_dynamic_frame_from_options('dynamodb', connection_options={ "dynamodb.region": "ap-northeast-1", "dynamodb.input.tableName": table_name, "dynamodb.splits": "72" }) glueContext.write_dynamic_frame.from_options( frame=ds, connection_type="s3", connection_options={ "path": data_path }, format="parquet" ) job.commit()クローラーの作成
続いてTerraformでGlueクローラーを作成しましょう。
ジョブによりS3に蓄積されたデータを、Glueデータカタログとして認識させるためのものです。
カタログとして認識させることでAthenaでクエリできるようになります。resource "aws_glue_crawler" "sample_crawler" { database_name = aws_glue_catalog_database.sample.name name = "sample_crawler" role = aws_iam_role.glue_role.arn s3_target { path = "s3://${aws_s3_bucket.results.bucket}/" } } resource "aws_glue_catalog_database" "sample" { name = "sample" }ワークフローの作成
続いてGlueワークフローを定義します。
ジョブ→クローラーと実行するようにスケジューリングを組むことが可能です。
毎日深夜01:00(JST)に実行するように定義してみましょう。resource "aws_glue_workflow" "sample_workflow" { name = "sample_workflow" } resource "aws_glue_trigger" "trigger" { name = "sample_workflow_start" schedule = "cron(0 16 * * ? *)" // UTC type = "SCHEDULED" workflow_name = aws_glue_workflow.sample_workflow.name actions { job_name = aws_glue_job.mysql_job.name } actions { job_name = aws_glue_job.dynamodb_job.name } } resource "aws_glue_trigger" "job_complete_trigger-0" { name = "sample_workflow_job_complete" type = "CONDITIONAL" workflow_name = aws_glue_workflow.sample_workflow.name actions { crawler_name = aws_glue_crawler.sample_crawler.name } predicate { conditions { job_name = aws_glue_job.mysql_job.name state = "SUCCEEDED" } conditions { job_name = aws_glue_job.dynamodb_job.name state = "SUCCEEDED" } } }以下の内容に注目してください。
actions { crawler_name = aws_glue_crawler.sample_crawler.name } predicate { conditions { job_name = aws_glue_job.mysql_job.name state = "SUCCEEDED" } conditions { job_name = aws_glue_job.dynamodb_job.name state = "SUCCEEDED" } }こちらの記述は、
mysql_jobとdynamodb_jobが完了した後、sample_crawlerを実行するという流れになっています。
Glueワークフローを使用することで、簡易的にETLの流れを定義することができました。Athenaによるクエリ
クローラーでカタログを作成できれば、Athenaで検索することができるようになります。
MySQLのデータとDynamoDBのデータをJOINできることを確認しましょう。
- 投稿日:2020-09-23T15:03:03+09:00
AWS認定SysOpsアドミニストレータ(SOA)を取得しました
AWS認定SysOpsアドミニストレータ アソシエイト(SOA)を受験し無事合格しました。
資格取得までに参考にしたものを投稿します。
私のAWSの知識
クラウドプラクティショナーに合格しました。
https://qiita.com/gdtypk/items/fa87750ec9278eb0db9aソリューションアーキテクトに合格しました。
https://qiita.com/gdtypk/items/52d96a5af0a05f06ebc4デベロッパーアソシエイトに合格しました。
https://qiita.com/gdtypk/items/4cfcf3c74b9faf3893aa業務では、EC2,RDS,Lambda,S3を軽く触っている程度になります。
やったこと
2週間、業務終了後の1時間を使って勉強していました。
試験範囲の確認
https://aws.amazon.com/jp/certification/certified-sysops-admin-associate/
AWS WEB問題集をこなす
以前、ダイヤモンドプランで登録していたので、そのまま利用できました。
こちらの問題集を1周しました。
分からなかった問題は、メモを残しました。
試験の過去問などが無いため、こちらのサービスは重宝します。
Black Beltを見る
試験を受けての感想
アソシエイトレベルの試験を全て合格できて良かったです。
この試験は、業務で全く扱うことのないものばかりだったので、
かなり勉強が大変でした・・。その他、勉強中に重要そうと思ったまとめ
SNS
- CloudWatchにログを1分おきに送信はできない。
EC2
- S3ベースのAMI=インスタンスストアボリューム
- インスタンスのステータス
- システムステータス:AWS側の問題。再起動し、別ホストで起動。
- インスタンスステータス:客側の問題。原因を調査する。
- EBSのスナップショット数の上限は10万
- プレイスメントグループ
- スプレッド:それぞれ異なるハードウェアに配置される
- クラスター:同じホストに配置
- 暗号化が対応できるのは、AES-NIを対応する
- AMIの作成に必要なもの
- X.509証明書と対応するプライベートキー
- アクセスをELBからのみにしたい場合、ポート8080のセキュリティグループをELBのものを指定する
- EBSのボリュームサイズを変更したら、どうする? EC2に接続し、CLIで拡張対応を行う。
- スナップショット:増分バックアップで、インスタンスを停止せず、リアルタイム保存 (推奨は停止して、一貫性を持たせる)
- ディスク使用量、メモリ使用量はカスタムメトリクス
- InstanceLimitExceeded:同時実行のインスタンス数の制限
- InsufficientInstanceCapacity:インスタンス容量の制限
EFS
- 途中で暗号化の変更はできない
Organizations
- サービスコントロールで各アカウントの権限を設定できる
WAF
- ELBだと、ALBにしか使えない
CloudFormation
StackSets:vpcを複数アカウント,複数リージョン
https://dev.classmethod.jp/articles/cloudformation-stacksets-all-region/再利用したいなら、パラメータ
リージョンで使い回すならマッピング
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/mappings-section-structure.htmlDeletionPolicy属性:削除前にスナップショット
変更セット:変更を反映する前に、検証することができる。
テンプレートセクション(Description,Resourcesとか)
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/template-anatomy.html#template-anatomy-sectionsテンプレートの中にLambdaのリンクを貼り、起動させることができる。
WaitConditionHandle:外部ソースから完了の連絡を受けるまで、他のリソース作成を中止
DependsOn:依存関係を記述する
OnFailure:スタック作成に失敗した時の動作(DO_NOTHING,DELETEなど)
ROLLBACK_COMPLETE:スタック作成が失敗。削除操作だけできる
ドリフト検出:手動で変更された箇所を検出
CloudFront
- CDN
- エンドユーザの近い場所
- コスト効率化
- 特定の国をブロックすることも可能
CloudTrail
- AWS APIコール全てを記録
- S3に自動的にログを保存
VPC
- デュアルスタック:iPv4とiPv6のアクセスを両立
- Egress-Only、NATインスタンスのIPv6(書き方::/0)
- S3のバケットポリシーで、特定のVPCエンドポイントを指定可能
- VPC内のパブリックサブネット内のインスタンスがネット接続できないのは、パブリックIPやElasticIPが付与されていないことがある。 https://aws.amazon.com/jp/premiumsupport/knowledge-center/instance-vpc-troubleshoot/
- VPC内で立ち上げたEC2インスタンスにはデフォルトのセキュリティグループが当てられる。 これは、同じセキュリティグループ間のインバウンドを許可し、アウトバウンドは全て許可
特別な理由があって、NATインスタンスを使うことがある。水平スケーリングもできる。
プライベートサブネットと、AWSサービスを通信するときは、NATではなく、VPCエンドポイントを使う。ネットワークを介さない。
VPCエンドポイント
- ゲートウェイエンドポイント:S3とDynamoDBにのみ
- インターフェイスエンドポイントPrivateLink:その他サービスと、プライベートネットで接続
S3
- ボールトロック:削除、変更を防止
- MFAデリート:CLIでデリートする時、認証番号を一緒に送る必要あり
- オブジェクトが見つからない。アクセスできない時は、400系エラー
- 暗号化について
- SSE-S3:S3が暗号化キーを管理
- SSE-KMS:KMSが管理するキー
- SSE-C:お客さんが管理するキー
- CSE:クライアントサイド暗号化
- S3に画像アップする際は、費用がいらない。
- バケットポリシーはオブジェクト単位では定義できない。
- 不正アクセスを見つける S3のアクセスログ記録を残し、Athenaで403系エラーを照会する
- 分析 ストレージクラスの分析とかができる。(ストレージ最適化)
Auto Scaling
- 立ち上げたインスタンスのメトリクスが取れないのは、ウォームアップ中
- デフォルト設定の場合、EC2を閉じる順番は、AZ毎の数を比較する
- 異常なインスタンスを落としたい時は、ELBヘルスチェックを使用するように、AutoScalingグループを設定する
- 最小数,最大数,希望数:現時点で希望するインスタンス数
- AutoScalingを削除する時は、グループのインスタンスを全て削除し、希望容量を0にする。
RDS
- 5分以内のポイント・イン・タイム・リカバリ。バックアップの作成
- マスタをリードレプリカに反映する時のラグReplicaLag
- SQL serverだけミラーリング機能がある
- セキュリティグループが変更されたら通知することができる。 https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/USER_Events.html
Artifact
- コンプライアンスレポートをダウンロードできる
クロスアカウントクロスリージョンダッシュボード
- 複数のリージョンの情報を表示
- 単一リージョン全てのEC2インスタンスの統計を取るには、詳細モニタリングが必要
CloudWatch
- Dimensions:メトリクスに付与できるタグみたいなもの(EC2のインスタンスIDとか)
- アラームの3種類
- OK:定義したしきい値を下回っている
- NG:定義したしきい値を上回っている
- INSUFFICIENT_DATA:データが不足している
- どれが標準なのか、カスタムなのかを確認(ディスク使用量、メモリ使用量)
- メトリクスの種類
- 標準メトリクス:5分単位(無料)
- 詳細メトリクス:1分単位(有料)
- 高解像度メトリクス:1秒単位(有料)
- 複数のリージョンにまたがるメトリクスの取得は詳細モニタリング
- 既存のアラーム名変更不可
- アラームの評価期間数に各評価期間の長さをかけた値が1日を超えてはいけない
snowball
- 現在は、snowball Edgeになっている。
- Storage Optimized:大容量のもの
- Compute Optimized:保存前に分析が必要なもの
- リージョンをまたいでデータを移動できない。S3のクロスリージョン使う
- https://aws.amazon.com/jp/snowball/faqs/#General
Aurora
- 読み取りエンドポイント:自動で使えるレプリカにアクセス
- クラスタエンドポイント:プライマリDBにアクセス
- インスタンスエンドポイント:特定のDBにアクセス
Direct Connect
- ゲートウェイを設置すれば、複数リージョンもいける
SSL
- 1つのインスタンスに複数のSSLを実装するときは、IPを複数割り当てる
ELB
- NLBは、IPアドレスのホワイトリストを登録できる
- ELBはリージョンをまたげないので、Route53を使用する
- ELBの種類
- ALB:柔軟性,HTTPヘッダーを受け取る。
- NLB:TCPで受け取り,ラウンドロビン,ステートレスウェブサーバーにルーティング
- CLB:何らかの評価を行い、ルーティングする時に使用
- CLBへアクセスすると、spilloverの値が高い。SurgeQueueLengthの値を監視する。
- CLBでさばききれなかったアクセス管理
- SurgeQueueLength:溜まってる数。1024超えるとアクセス拒否
- SpilloverCount:拒否された数
- Spillover Count:ロードバランサの容量を過剰してしまった数
- 500エラー
- 正常なインスタンスが存在しない。
- レート制限にかかっている
- (インスタンスからは何も返ってこない)
- ロードバランサはヘッダーを変更せずにバックエンドにリクエストを転送 (X-Forwardedは標準ではない)
Storage Gateway
- S3をオンプレミス環境と接続するための仕組み
- ボリュームゲートウェイ
- キャッシュ型:プライマリはs3に。頻繁に使うものはキャッシュでローカルに保存
- 保管型:ローカルに保存
- iscsiプロトコルを使用可能
- テーブゲートウェイ:バックアップ向け。glacier等に保存
Route53
- エイリアスレコード:cloud frontやs3にトラフィックを向けられる
- DNS
- ドメイン名を振る
- ヘルスチェックやレイテンシーなどで、ルーティング
- 特定の国を別のソーリーページに飛ばすとかができる
Personal Health Dashboard
- 異常があった時、通知もできる
Systems Manager(Patch Manager)
- EC2インスタンスに対して、パッチを当てられる。
- OSのパッチ適用をまとめてできる。
AWS Config
- 現在のシステムステータスやリソース構成を把握
- 構成履歴を管理
- 設定変更のモニタリング
- S3にパブリック・アクセス可能なバケットが作成されたら通知できる
- Rule:全てのインスタンスのセキュリティグループをテスト
SQS
- キューはデフォルトで4日間保持
Trusted Advisor
- サービス(クォーター)の制限,セキュリティ,コスト,耐障害性,パフォーマンス
大きい順
リージョン→アベイラビリティーゾーン→エッジ
インフラのコード管理
- Elastic BeansTalk:簡易的にデプロイ可能
- CloudFormation:ほぼ全てのAWSリソース管理可能
- OpsWorks:EC2など、特定のリソースを細かく指定(sheff,puppet)
EMR
- ビックデータの分析
AD Connector, AWS Managed Microsoft AD
- Active Directoryのユーザに対してAWSマネジメントコンソールへのアクセス権の認可が行える。
- オンプレのActive DirectoryユーザがAWSコンソールへのアクセス権を付与するには、
- VPNを作成,AD Connectorを使用 もしくは
- Managed Microsoft ADの間に既存の信頼関係を使用する
GuardDuty
- AWS環境やAWSアカウントに対する攻撃を検知する。
- 脅威リストと信頼済みIPリストを設定できる。(マスターアカウントのみ)
- ルールは無効にしたり、削除はできないがアーカイブすることによって通知を発生しないようにできる
QuickSight
- BIツール
Data Lifecycle Manager
- EBSのバックアップの作成・保持・削除の自動化
ElastiCache
- CurrConnections:Redisに接続している数(リードレプリカ除く)
Single Sign-On(SSO)
- AWSアカウントとビジネスアプリのアクセスを一元管理
- SAMLを使用
- ロールを割り当てる

- 投稿日:2020-09-23T11:45:40+09:00
Amazon SES経由のバウンスメールをCakephp3のWebアプリで受け取る際にハマったポイント
こんにちは、テックデザインカンパニーのマイロプスでエンジニアをしています後河内です。
以前、こちらに、Amazon SES経由のバウンスメールをWebアプリで受け取るという記事を書きました。
こちらの記事ではCakePHP2でのバウンスメールの受け取り方法を書かせていただきましたが、同様のことをCakePHP3のWebアプリで実施する必要が別の案件で実施したいという要望が出てきました。
当初はCakePHP2で一度実装したことなので、CakePHP3でも簡単にできると思ったのですが、その実装の中でハマった点がありましたので、備忘録もかねてそのことについて書いていきます。バウンス情報をWEBアプリにPOSTするところまでは、以前の記事、Amazon SES経由のバウンスメールをWebアプリで受け取るの『SNSでバウンス情報をPOSTする』と特に変わりありません。
以前との違いは、POSTされた情報の受け取り方になります。
POSTされた情報を受け取るために前回はCakePHP2でREST APIの実装をしましたが、今回はCakePHP3でREST APIの実装が必要になりました。CakePHP3でREST API
POSTされた情報を受け取るためのCakePHP3でのREST APIについては、以下の公式サイトの文書を参考にしました。
POSTされた情報を受け取るためにやらなければいけないことは大きく二つあります。
1.config/routes.phpでREST API用のルーティングの設定
2.データを受け取るコントローラhogehogeController.phpにaddファンクションの準備config/routes.phpでREST API用のルーティングの設定
ルーティングの設定は非常に簡単に終わりました。
公式の文書を参考にし、以下の2行を追加しただけです。config/routes.phpRouter::scope('/', function ($routes) { // 3.5.0 より前は `extensions()` を使用 $routes->setExtensions(['json']); $routes->resources('Recipes'); });データを受け取るコントローラhogehogeController.phpにaddファンクションの準備
ルーティングの設定を行い、下記のようなURLにPOSTすると
https://hogehoge.jp/hogehoge/hogehogeController.phpのaddファンクションが呼ばれることになります
また公式の文書によると
REST アプリケーションの場合、様々なフォーマットのデータを扱います。 CakePHP では、 RequestHandlerComponent クラスが助けてくれます。 デフォルトでは、POST や PUT で送られてくる JSON/XML の入力データはデコードされ、 配列に変換されてから $this->request->getData() に格納されます
とのことでしたので、jsonデータであれば$this->request->getData()にデータが自動で格納されていることになり、その中身からバウンスメールのメールアドレス情報を抜き取れると考えました。
そのため、当初は以下のようなコードでPOSTデータを扱おうと考えていました。hogehogeController.phppublic function add() { if ($this->request->is('post')) { $this->data=$this->request->getData(); } }しかし実際には、$this->request->getData()の中身は空っぽでした。
Amazon SNS メッセージおよびJSON形式を見る限り下のようなjson情報を送ってるので、json情報は自動格納されるのではないかと、悩みました。
POST / HTTP/1.1 x-amz-sns-message-type: SubscriptionConfirmation x-amz-sns-message-id: 165545c9-2a5c-472c-8df2-7ff2be2b3b1b x-amz-sns-topic-arn: arn:aws:sns:us-west-2:123456789012:MyTopic Content-Length: 1336 Content-Type: text/plain; charset=UTF-8 Host: myhost.example.com Connection: Keep-Alive User-Agent: Amazon Simple Notification Service Agent { "Type" : "SubscriptionConfirmation", "MessageId" : "165545c9-2a5c-472c-8df2-7ff2be2b3b1b", "Token" : "2336412f37...", "TopicArn" : "arn:aws:sns:us-west-2:123456789012:MyTopic", "Message" : "You have chosen to subscribe to the topic arn:aws:sns:us-west-2:123456789012:MyTopic.\nTo confirm the subscription, visit the SubscribeURL included in this message.", "SubscribeURL" : "https://sns.us-west-2.amazonaws.com/?Action=ConfirmSubscription&TopicArn=arn:aws:sns:us-west-2:123456789012:MyTopic&Token=2336412f37...", "Timestamp" : "2012-04-26T20:45:04.751Z", "SignatureVersion" : "1", "Signature" : "EXAMPLEpH+DcEwjAPg8O9mY8dReBSwksfg2S7WKQcikcNKWLQjwu6A4VbeS0QHVCkhRS7fUQvi2egU3N858fiTDN6bkkOxYDVrY0Ad8L10Hs3zH81mtnPk5uvvolIC1CXGu43obcgFxeL3khZl8IKvO61GWB6jI9b5+gLPoBc1Q=", "SigningCertURL" : "https://sns.us-west-2.amazonaws.com/SimpleNotificationService-f3ecfb7224c7233fe7bb5f59f96de52f.pem" }いろいろ調査し、実験していく中でわかったことは、CakePHP3は、POSTされた情報のヘッダー情報のコンテンツタイプをみてjsonかどうか判断しているようでした。今回SNSからPOSTされる情報のヘッダー情報のコンテンツタイプはContent-Type: text/plainだっためjsonと判定してなかったようです。
Content-Type: application/jsonにして同じようなデータをPOSTしたところ、$this->request->getData()に情報が自動格納されました。ただし、SNSからPOSTされる情報のヘッダー情報はこちらで変えることはできないので、json以外の情報の受け取り方を調査したところ、
$this->request->input()
で扱えることがわかりました。
$this->request->input()内のデータをjson_decode関数で配列化することで、バウンスメールのメールアドレス情報を抜き取ることができました。以下にPOSTされた情報を受け取り、バウンスメールのメールアドレス部分を抜き取るコードを記載します。
(なお最初にPOST先としての認証が必要ですが、最初にPOSTされたデータの中身を確認し、SubscribeURLに手動でアクセスという形で認証をおこなっています。)hogehogeController.phppublic function add() { if ($this->request->is('post')) { $this->data=json_decode($this->request->input(),true); //受け取ったJSON情報からバウンスメールのメールアドレス部分を抜き取る if(isset($this->data['Message'])){ $this->bounce=json_decode($this->data['Message'],true); //バウンスされたメールアドレス $mailaddress = $this->bounce['bounce']['bouncedRecipients'][0]['emailAddress']; } }今回のハマりポイント
- CakePHP3のREST APIは、POSTされる情報のヘッダー情報のコンテンツタイプをみてjsonかどうか判断している
- Amazon SNSでPOSTされる情報のヘッダー情報のコンテンツタイプはContent-Type:application/jsonではなくContent-Type:text/plain
すでにCakePHP4が出てますが、こちらでも同様のことが必要になったらまたハマりそうな気がしています。
また新たな問題点等やノウハウが見つかりましたら、別の記事として書いていけたらなと思っております。
- 投稿日:2020-09-23T09:16:03+09:00
TerraformでRDS→Glue→Redshift構築
TerraformでRDS→Glue→Redshift構築
前提
AWS CLI使えるぜ
Terraform使えるぜ出来上がるもの
VPC
IAM
RDS
Redshift
Glue
※クローラーの実行、JOBの作成はGUIからやる想定ネットワーク
vpc.tfresource "aws_vpc" "vpc_glue_test" { cidr_block = "10.0.0.0/16" instance_tenancy = "default" enable_dns_support = true enable_dns_hostnames = true tags = { Name = "vpc_glue_test" } } resource "aws_route_table" "route_table_glue_test" { vpc_id = aws_vpc.vpc_glue_test.id tags = { Name = "route_table_glue_test" } } resource "aws_route_table_association" "route_association1_glue_test" { subnet_id = aws_subnet.subnet1_glue_test.id route_table_id = aws_route_table.route_table_glue_test.id } resource "aws_route_table_association" "route_association2_glue_test" { subnet_id = aws_subnet.subnet2_glue_test.id route_table_id = aws_route_table.route_table_glue_test.id } resource "aws_subnet" "subnet1_glue_test" { vpc_id = aws_vpc.vpc_glue_test.id availability_zone = "ap-northeast-1a" cidr_block = "10.0.1.0/24" tags = { Name = "subnet1_glue_test" } } resource "aws_subnet" "subnet2_glue_test" { vpc_id = aws_vpc.vpc_glue_test.id availability_zone = "ap-northeast-1c" cidr_block = "10.0.2.0/24" tags = { Name = "subnet2_glue_test" } } resource "aws_security_group" "securty_group_glue_test" { name = "securty_group_glue_test" vpc_id = aws_vpc.vpc_glue_test.id ingress { from_port = 0 to_port = 65535 protocol = "tcp" self = true } egress { from_port = 0 to_port = 65535 protocol = "tcp" self = true } tags = { Name = "securty_group_glue_test" } } resource "aws_vpc_endpoint" "vpc_endpoint_glue_test" { vpc_id = aws_vpc.vpc_glue_test.id service_name = "com.amazonaws.ap-northeast-1.s3" tags = { Environment = "vpc_endpoint_glue_test" } route_table_ids = [ aws_route_table.route_table_glue_test.id ] }セキュリティグループ
Glueのクローラーが這い回る用のセキュリティグループです。
インバウンドとアウトバウンドを「自己参照」で全てのTCPを許可します。自己参照のセキュリティグループ:
同セキュリティグループ内に属する者だけがすり抜けられます。参考URL:
https://dev.classmethod.jp/articles/getting-started-aws-glue-access-data-stores-settings/サブネット
2つあるのは、RDSを立てる際に2つ以上指定しないといけないからです。
エンドポイント
Glueのクローラーが潜る用のS3フルアクセスのエンドポイントです。
潜る先がS3ではなくRDSやRedShiftであってもS3フルアクセスです。余談:
知識不足で推測の域を出ませんが、RDS等のDBもデータの保持自体はS3を使用しているはず。
以前、AWS大規模障害で1つのAZしか落ちてないのにマルチAZの冗長構成Webサーバが
軒並み落ちていたのは、「ELB」も土台は「EC2」だったというオチでした。
サーバレスだってサーバはあるんですね)IAM
iam.tfresource "aws_iam_instance_profile" "role_profile_glue_test" { name = "instance_role" role = aws_iam_role.role_glue_test.name } resource "aws_iam_role" "role_glue_test" { name = "role_glue_test" assume_role_policy = <<-EOF { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "glue.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } EOF } resource "aws_iam_role_policy" "role_policy_glue_test" { name = "role_policy_glue_test" role = aws_iam_role.role_glue_test.id policy = <<-EOF { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "glue:*", "s3:GetBucketLocation", "s3:ListBucket", "s3:ListAllMyBuckets", "s3:GetBucketAcl", "ec2:DescribeVpcEndpoints", "ec2:DescribeRouteTables", "ec2:CreateNetworkInterface", "ec2:DeleteNetworkInterface", "ec2:DescribeNetworkInterfaces", "ec2:DescribeSecurityGroups", "ec2:DescribeSubnets", "ec2:DescribeVpcAttribute", "iam:ListRolePolicies", "iam:GetRole", "iam:GetRolePolicy", "cloudwatch:PutMetricData" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "s3:CreateBucket" ], "Resource": [ "arn:aws:s3:::aws-glue-*" ] }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:PutObject", "s3:DeleteObject" ], "Resource": [ "arn:aws:s3:::aws-glue-*/*", "arn:aws:s3:::*/*aws-glue-*/*" ] }, { "Effect": "Allow", "Action": [ "s3:GetObject" ], "Resource": [ "arn:aws:s3:::crawler-public*", "arn:aws:s3:::aws-glue-*" ] }, { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": [ "arn:aws:logs:*:*:/aws-glue/*" ] }, { "Effect": "Allow", "Action": [ "ec2:CreateTags", "ec2:DeleteTags" ], "Condition": { "ForAllValues:StringEquals": { "aws:TagKeys": [ "aws-glue-service-resource" ] } }, "Resource": [ "arn:aws:ec2:*:*:network-interface/*", "arn:aws:ec2:*:*:security-group/*", "arn:aws:ec2:*:*:instance/*" ] }, { "Effect": "Allow", "Action": "s3:*", "Resource": "*" } ] } EOF }信頼されたエンティティ
Glueが徘徊する用に必要なので"Principal"はGlueです。
「IAM/ロール/<ロール名>/信頼関係/ポリシードキュメントの表示」で閲覧可能です。ポリシー
「AWSGlueServiceRole」と「AmazonS3FullAccess」をアタッチします。
RDS
rds.tfresource "aws_db_subnet_group" "rds_subnet_glue_test" { name = "rds_subnet_glue_test" subnet_ids = ["${aws_subnet.subnet1_glue_test.id}", "${aws_subnet.subnet2_glue_test.id}"] tags = { Name = "subnet_glue_test" } } resource "aws_db_instance" "rds_glue_test" { identifier = "rds-glue-test" allocated_storage = 20 storage_type = "gp2" engine = "postgres" engine_version = "11.5" instance_class = "db.t3.micro" name = "testdb" username = "testuser" password = "testpassword" vpc_security_group_ids = ["${aws_security_group.securty_group_glue_test.id}"] db_subnet_group_name = aws_db_subnet_group.rds_subnet_glue_test.id skip_final_snapshot = true }サブネット
指定したいのはVPC。VPCを指定したいために"aws_db_subnet_group"を指定しています。
セキュリティグループ
VPC内に作った自己参照セキュリティグループ内に配置します。
skip_final_snapshot
これtrueにしておかないとデストロイに手間取りました。
本番DBであればfalseでいいかと思います。RedShift
redshift.tfresource "aws_redshift_subnet_group" "redshift_subnet_glue_test" { name = "redshift-subnet-glue-test" subnet_ids = ["${aws_subnet.subnet1_glue_test.id}", "${aws_subnet.subnet2_glue_test.id}"] tags = { environment = "subnet_glue_test" } } resource "aws_redshift_cluster" "redshift_glue_test" { cluster_identifier = "redshift-glue-test" database_name = "testdwh" master_username = "testuser" master_password = "Test2020" node_type = "dc1.large" cluster_type = "single-node" publicly_accessible = false skip_final_snapshot = true cluster_subnet_group_name = aws_redshift_subnet_group.redshift_subnet_glue_test.name vpc_security_group_ids = ["${aws_security_group.securty_group_glue_test.id}"] }サブネット/セキュリティグループ/skip_final_snapshot
やりたいことはRDSと同じ。
Glue
glue.tfresource "aws_glue_catalog_database" "database_glue_test" { name = "database_glue_test" } resource "aws_glue_connection" "rds_connection_glue_test" { connection_properties = { JDBC_CONNECTION_URL = "jdbc:postgresql://${aws_db_instance.rds_glue_test.endpoint}/testdb" PASSWORD = "testpassword" USERNAME = "testuser" } name = "rds_connection_glue_test" physical_connection_requirements { availability_zone = aws_subnet.subnet1_glue_test.availability_zone security_group_id_list = [aws_security_group.securty_group_glue_test.id] subnet_id = aws_subnet.subnet1_glue_test.id } } resource "aws_glue_connection" "redshift_connection_glue_test" { connection_properties = { JDBC_CONNECTION_URL = "jdbc:postgresql://${aws_redshift_cluster.redshift_glue_test.endpoint}/testdwh" PASSWORD = "Test2020" USERNAME = "testuser" } name = "redshift_connection_glue_test" physical_connection_requirements { availability_zone = aws_subnet.subnet1_glue_test.availability_zone security_group_id_list = [aws_security_group.securty_group_glue_test.id] subnet_id = aws_subnet.subnet1_glue_test.id } } resource "aws_glue_crawler" "crawler_glue_test" { database_name = aws_glue_catalog_database.database_glue_test.name name = "database_glue_test" role = aws_iam_role.role_glue_test.arn jdbc_target { connection_name = aws_glue_connection.rds_connection_glue_test.name path = "testdb/%" } }データベース
"aws_glue_catalog_database" で箱だけ作るイメージです。
コネクション
"aws_glue_connection"でJDBC接続の設定を入れてあげます。
クローラー
どこに潜ってデータカタログを作成するかを記述しています。
最後に
あとはGUIでクローラの実行してあげれば
RDS内のテーブルメタデータをひっぱてきてくれる。
- 投稿日:2020-09-23T01:16:21+09:00
NUXTJS公式のS3とCloudFrontを使用してAWSへデプロイするには?をdocker-composeで実行する
はじめに
公式ドキュメント内の
AWS: S3 バケットと CloudFront Distribution の設定をdocker-composeで簡単にデプロイする方法をまとめたいと思います。(公式ドキュメント)S3 と CloudFront を使用して AWS へデプロイするには?
AWS(S3,CloudFront)の設定についてはこちらを参考に作成してください。
1.ファイル構成
nuxtapp/docker-compose.yml nuxtapp/Dockerfile nuxtapp/deploy.sh nuxtapp/gulpfile.js※
deploy.shとgulpfile.jsは公式の手順通り作成してください。2.Docker化に必要なファイル準備
DockerfileFROM node:12.18.3-alpine3.9 RUN apk add --no-cache openssh bash python make RUN npm install -g gulp RUN npm install --save-dev gulp gulp-awspublish gulp-cloudfront-invalidate-aws-publish concurrent-transformdocker-compose.ymlversion: '3' services: node: &app_base build: . # tty: true working_dir: /var/www volumes: - .:/var/www environment: PORT: 3000 HOST: 0.0.0.0 install: <<: *app_base command: npm ci dev: <<: *app_base ports: - "3000:3000" command: npm run dev generate: <<: *app_base command: npm run generate dev_static: image: httpd volumes: - ./dist:/usr/local/apache2/htdocs/ ports: - "80:80" s3deploy: <<: *app_base command: ./deploy.sh
docker-compose.ymlはこちらの記事をyarnからnpmに変更し、コンテナに手動でインストールしていた手順をDockerfileで準備したものです。3.使用方法
各コンテナは必要に応じで
docker-compose.ymlに定義してください。アプリの開発環境起動
$ docker-compose up devコンテナ内部で
npm run devを実行します。静的ファイル生成
$ docker-compose up generateコンテナ内部で
npm run generateを実行します。
出力結果はデフォルトだとnuxtapp/distに出力されます。出力された静的ファイルのローカルでの動作確認
$ docker-compose up dev_staticローカルでTomcatコンテナでdistを公開します。
http://localhostにアクセスするとアプリを確認できます。デプロイ
$ docker-compose up s3deployコンテナ内で
deploy.shを実行します。公式の手順の成功イメージ通りになれば完了です。
- 投稿日:2020-09-23T00:56:28+09:00
AWS ECS Fargateにシンプルなアプリをデプロイする
概要
シンプルなGo言語アプリケーションを、AWSのECS Fargateにデプロイする手順を紹介します。Fargateって最近聞くけど試したこと無い、これから試してみたい、という人向けの内容です。
また、Goでなくともにもコンテナ化できれば、同じ手順で構築できると思います。※この記事は、2020/9月時点のコンソールを元に書かれています。
環境
- Go言語 1.14.3
- Mac OS X 10.15.4
- AWS CLIは設定済み
ECS Fargateとは
まずECS(Elastic Container Service)は、AWSが提供するコンテナオーケストレーションのサービスです。ECSはAWSの他サービスとも連携しやすく、インストールや管理等が不要である点から、既にAWSを活用しているチームやスモールスタートしたいチームに向いていると言えます。コンテナオーケストレーションはKubernetes(k8s)が有名ですが、k8sの学習コストや定期的なバージョンアップ運用などが気になる場合には、ECSも選択肢になるでしょう。
ECSではコンテナが動く環境(サーバ)も当然必要となりますが、以下2種類の環境を取ることができます。
環境 特徴 ECS on EC2 ・自前のEC2インスタンスを立ててECSを稼働させる方式。
・EC2の細かなパラメータ設定等ができる。
・EC2のパッチ当てやスケーリング等は利用者側で行う必要がある。ECS on Fargate ・実行環境の管理をAWS側で行う方式。
・EC2のパッチ当てやスケーリング等がAWSによって行われるマネージドなサービス。
・EC2の細かなパラメータ設定等はできない。上記の通り、FargateではEC2を立てる必要が無くサーバインフラの管理やOS設計などが不要になるため、運用負荷が非常に減ります。今回は、そのFargateを使ってアプリをデプロイします。
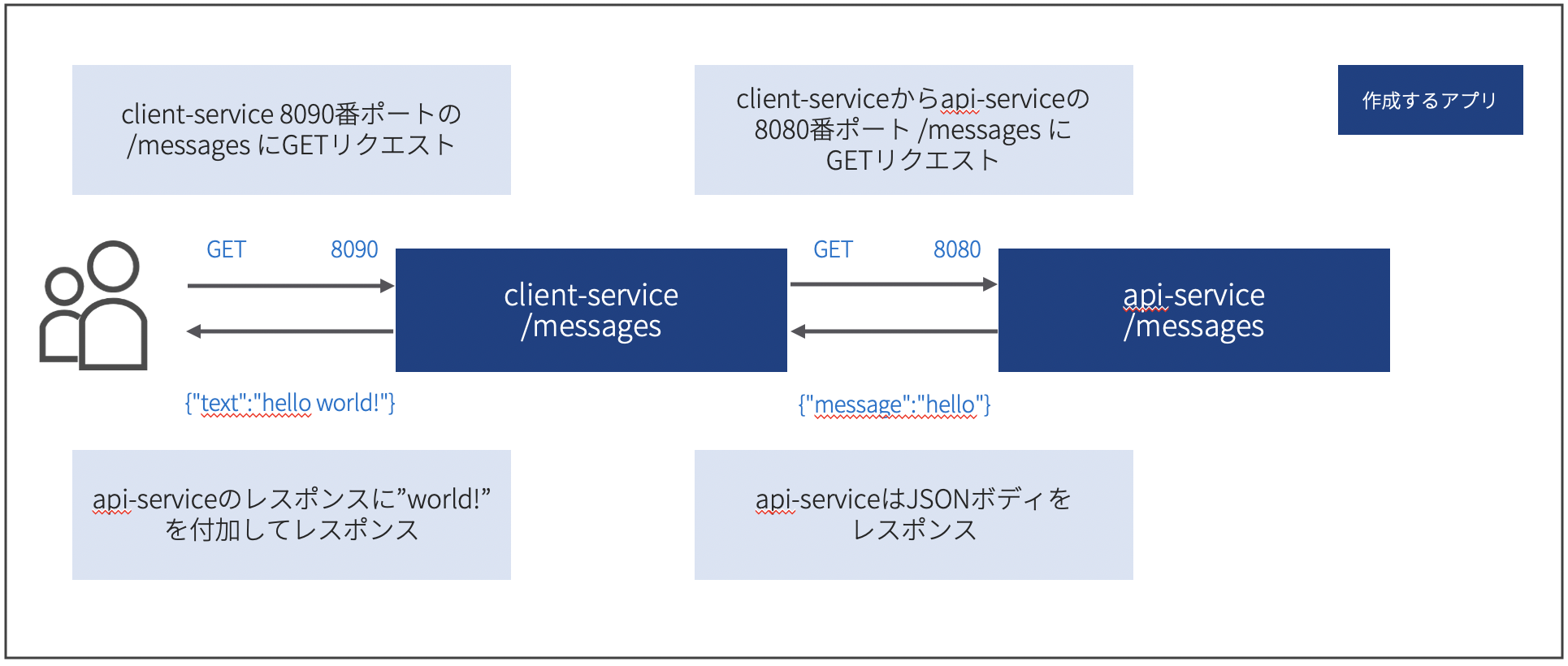
0. 構築するアプリ
アプリのイメージ図は以下の通りです。
試しにローカルでclient-service, api-serviceのそれぞれを実行すると、以下のようなレスポンスが得られます。ローカルでのリクエスト# api-serviceへのリクエスト $ curl http://localhost:8080/messages {"message":"hello"} # client-serviceへのリクエスト $ curl http://localhost:8090/messages {"text":"hello world!"}ディレクトリ構成
├── api-service │ ├── docker │ │ └── Dockerfile │ ├── exe │ │ └── api-service │ └── src │ └── api-service.go └── client-service ├── docker │ └── Dockerfile ├── exe │ └── client-service └── src └── client-service.goソース
api-service/src/api-service.gopackage main import ( "github.com/gin-gonic/gin" ) func main() { r := gin.Default() r.GET("/messages", func(c *gin.Context) { c.JSON(200, gin.H{ "message": "hello", }) }) r.Run(":8080") }client-service/src/client-service.gopackage main import ( "encoding/json" "fmt" "net/http" "os" "github.com/gin-gonic/gin" ) // 環境変数からAPIサービスのエンドポイント取得 var ( ApiServiceURL = os.Getenv("API_SERVICE_URL") ApiServicePort = os.Getenv("API_SERVICE_PORT") ApiResource = os.Getenv("API_RESOURCE") ) type Messages struct { Message string `json:"message"` } type ResponseBody struct { Text string `json:"text"` } func WrapperFunc(fn func(c *gin.Context)) gin.HandlerFunc { return func(c *gin.Context) { fn(c) } } // APIサービスにリクエストしてレスポンス作成 func CreateResponse(c *gin.Context) { url := ApiServiceURL + ":" + ApiServicePort + "/" + ApiResource resp, _ := http.Get(url) defer resp.Body.Close() var message Messages err := json.NewDecoder(resp.Body).Decode(&message) if err != nil { fmt.Println(err) } returnValue := message.Message + " world!" response := ResponseBody{ Text: returnValue, } c.JSON(200, response) } func main() { r := gin.Default() r.GET("/messages", WrapperFunc(CreateResponse)) r.Run(":8090") }api-serviceは、ginでAPIを実行しているだけです。
client-serviceは、ginでAPIを実行+api-serviceへのリクエストという2つの処理を行っています。api-service/docker/Dockerfile# STEP 1 FROM golang:alpine as builder RUN apk update && apk add --no-cache ca-certificates && update-ca-certificates WORKDIR $GOPATH/bin/ COPY ./exe/api-service ./api-service # STEP 2 FROM scratch COPY --from=builder /etc/ssl/certs/ca-certificates.crt /etc/ssl/certs/ COPY --from=builder /go/bin/api-service /go/bin/api-service ENTRYPOINT ["/go/bin/api-service"]client-service/docker/Dockerfile# STEP 1 FROM golang:alpine as builder RUN apk update && apk add --no-cache ca-certificates && update-ca-certificates WORKDIR $GOPATH/bin/ COPY ./exe/client-service ./client-service # STEP 2 build a small image FROM scratch COPY --from=builder /etc/ssl/certs/ca-certificates.crt /etc/ssl/certs/ COPY --from=builder /go/bin/client-service /go/bin/client-service ENTRYPOINT ["/go/bin/client-service"]Dockerfileはscratchイメージをマルチステージビルドで作成しています。ただ、今回はSSL通信はしないため通常のイメージでも問題ありません。なお、Goのbuild時には
GOOS=linuxを指定することを忘れないよう注意しましょう。Goのbuild例$ GOOS=linux go build client-service.go先述の通り、同様のコンテナイメージを作れれば他の言語でも問題ありません。
このアプリをECS Fargate上で動かしていきます。1. ECRにpush
ECSでコンテナを利用するため、AWSのコンテナレジストリサービスであるECRにコンテナイメージをpushします。
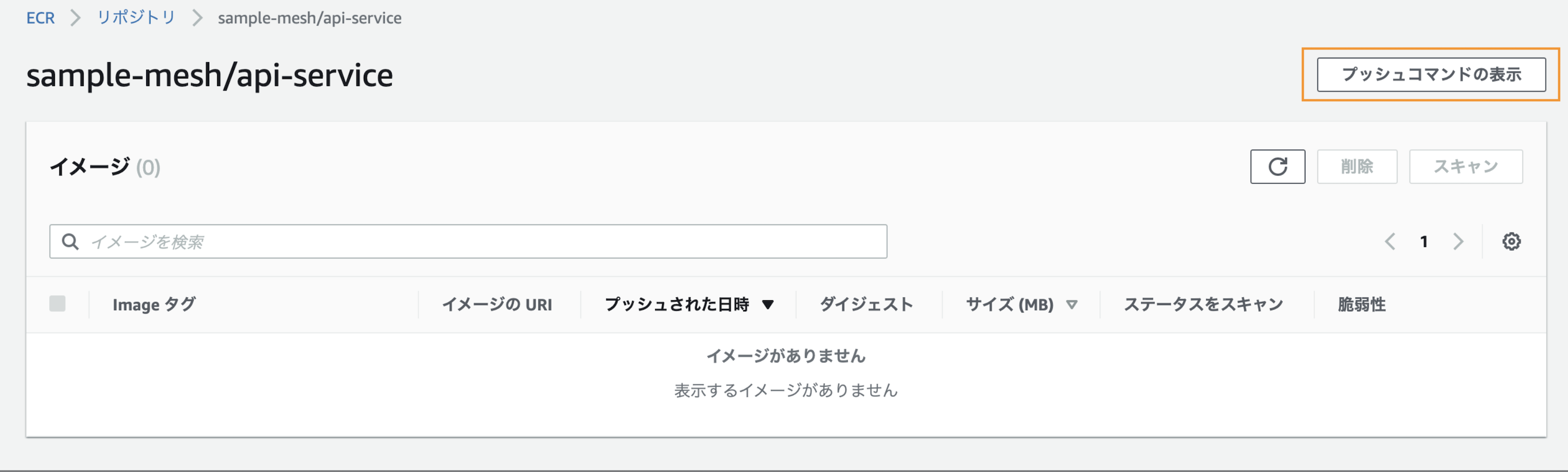
まずはECRのコンソールからリポジトリを作成します。任意の名前なので、ここではsample-mesh/api-serviceという名前です。
作成されたリポジトリを開き、右上を押してプッシュコマンドを表示します。
以下のようなコマンド例が表示されます。意味は、コンソールに表示されています。pushコマンド例$ aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin <account-id>.dkr.ecr.ap-northeast-1.amazonaws.com # docker build -t sample-mesh/api-service . # 今回のフォルダ構成だとDockerfileのパスが異なり上記コマンドはエラーになるため、パスを指定して実行します。 $ docker build -t sample-mesh/api-service -f ./docker/Dockerfile . # ----------------- $ docker tag sample-mesh/api-service:latest <account-id>.dkr.ecr.ap-northeast-1.amazonaws.com/sample-mesh/api-service:latest $ docker push <account-id>.dkr.ecr.ap-northeast-1.amazonaws.com/sample-mesh/api-service:latestもし、複数AWSアカウント等でAWSプロファイルを複数設定している場合、
aws ecr get-login-password~でエラーが出る場合がある場合があります。その場合、使用するプロファイルを指定することで解消できるので、以下のコマンドを実行します。$ export AWS_DEFAULT_PROFILE="プロファイル名" $ export AWS_PROFILE="プロファイル名"pushが上手くいくとECRのコンソールからもpushされたイメージが確認できます。これをECSで利用する全てのイメージ(今回で言えば、api-serviceとclient-serviceの2つ)について行います。
2. ECSの設定
次にECSの設定に入ります。クラスター、タスク定義、サービスの順に構築していきます。
1. クラスターの作成
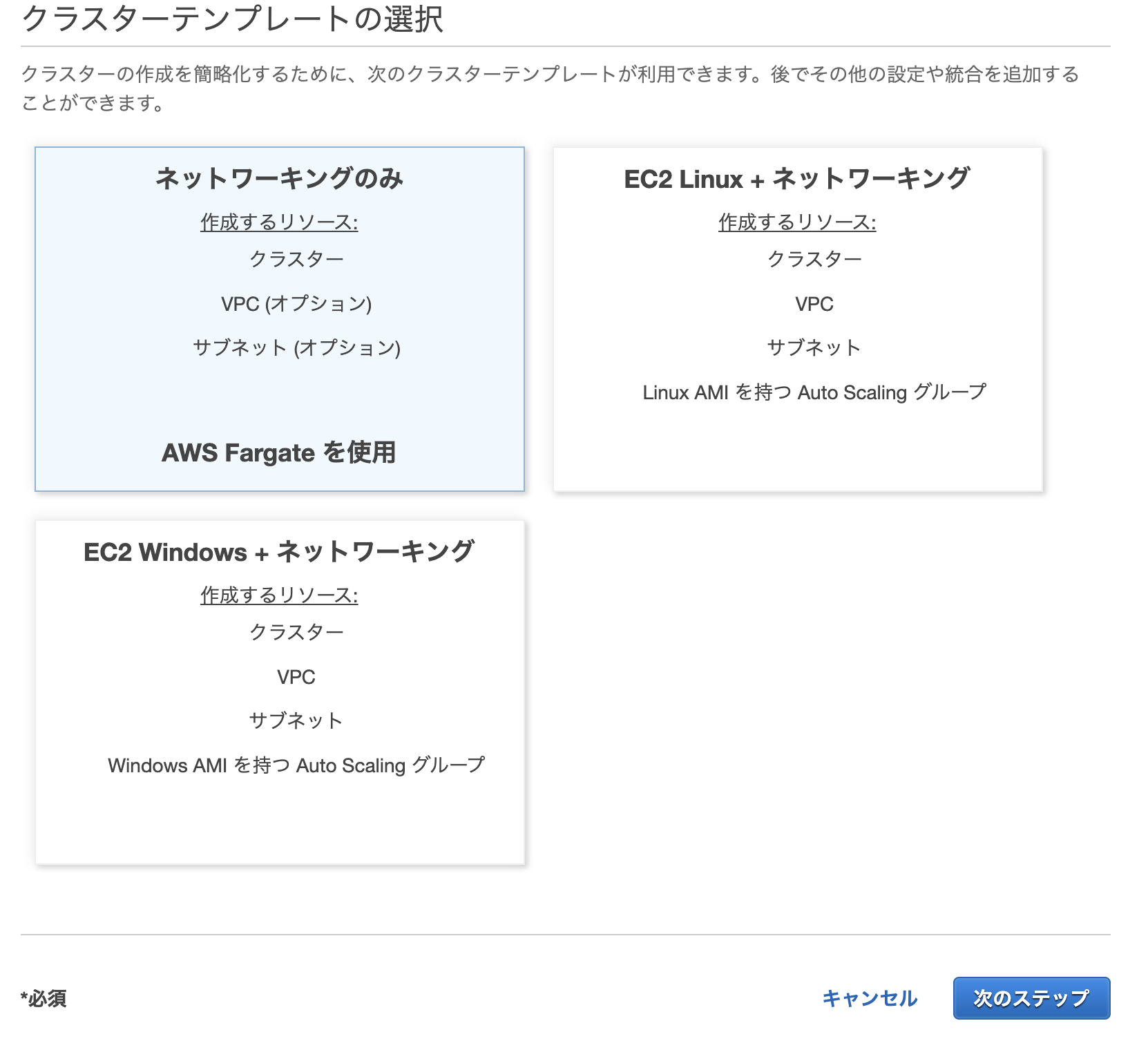
クラスターはECSが管理対象とする論理的なグループです。コンソールから「クラスターの作成」を選択します。
続いて、「ネットワーキングのみ」を選択して次のステップへ進みます。これがFargateを利用する上で必要になります。
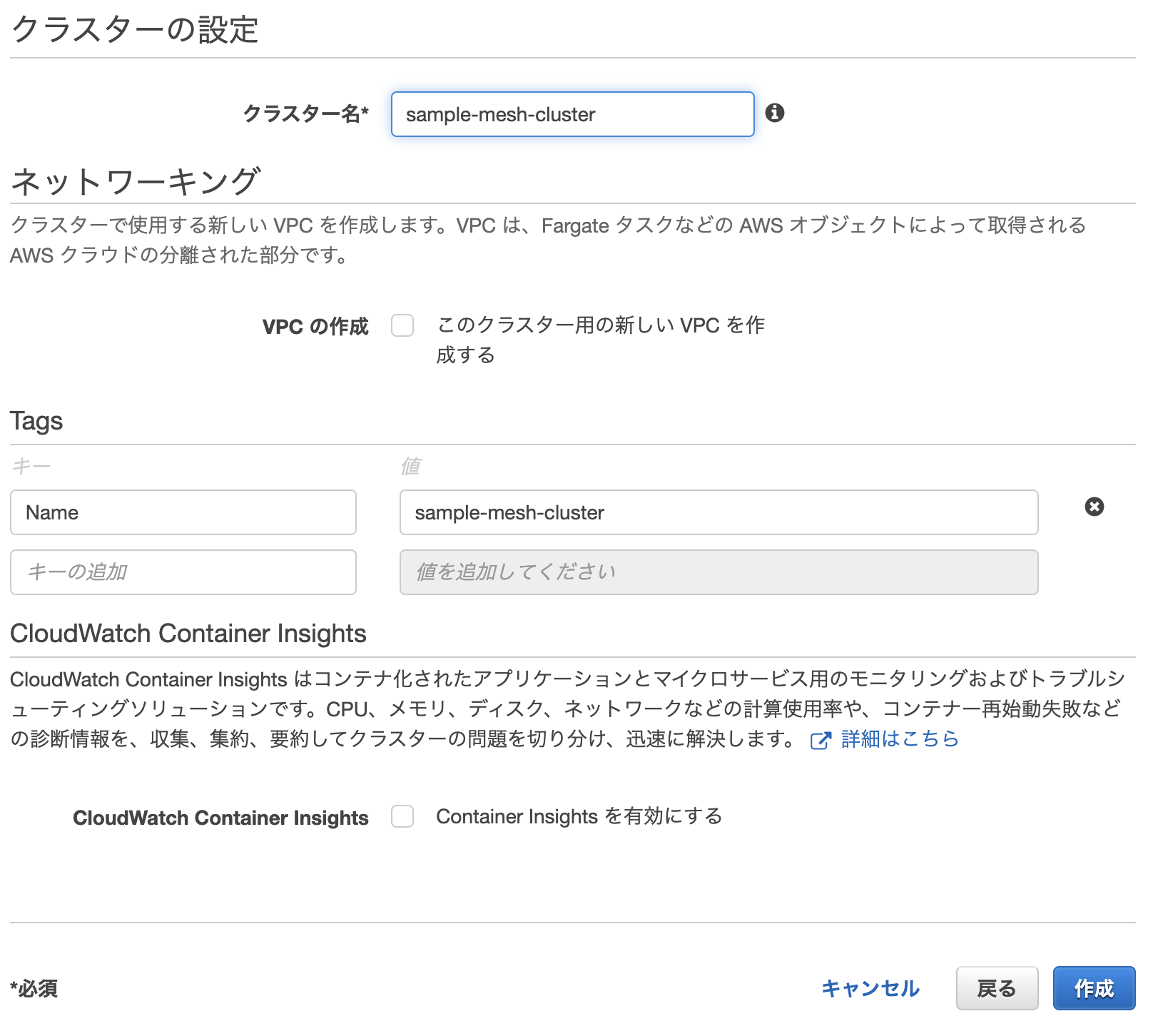
クラスター名を任意で指定します。タグはお好みでかまいません。
また、クラスター用にVPCを作成する場合には、VPCの作成にチェックを入れましょう。(今回は既にあるVPCを利用)
「作成」を押すとクラスターが作成されます。この時点では、論理的なグループを作成しただけです。
2. タスク定義の作成
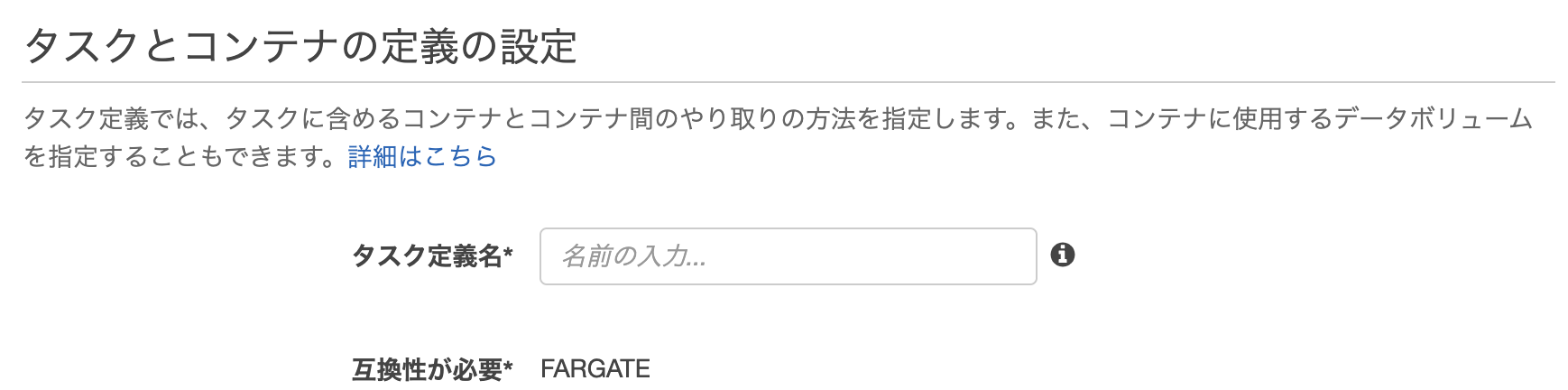
タスク定義では、実際に動作するコンテナのイメージや割り当てるIAMロール、環境変数などを定義します。同じくコンソールから「新しいタスク定義」を押します。
Fargateを選択した後、タスク定義の入力画面に移ります。
画面から入力しても良いのですが、結構手間になりますし入力ミスも気になります。ECSではJSONによる設定の登録が可能なので、今回はJSONで登録します。画面半ばくらいにある「JSONによる設定」を選択します。
実際に登録するJSONの内容は以下の通りです。account-idの部分は各自のアカウントIDに置き換える必要があります。ECSタスク定義(api-service){ "family": "api-apl", "taskRoleArn": "arn:aws:iam::<account-id>:role/ecsTaskExecutionRole", "executionRoleArn": "arn:aws:iam::<account-id>:role/ecsTaskExecutionRole", "networkMode": "awsvpc", "containerDefinitions": [ { "name": "api-endpoint", "image": "<account-id>.dkr.ecr.ap-northeast-1.amazonaws.com/sample-mesh/api-service:latest", "portMappings": [ { "containerPort": 8080, "protocol": "tcp" } ], "essential": true, "environment": [ ], "ulimits": [ { "name": "msgqueue", "softLimit": 0, "hardLimit": 0 } ], "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-create-group": true, "awslogs-group": "/ecs/sample-mesh", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "api-service" } } } ], "requiresCompatibilities": [ "FARGATE" ], "memory": "512", "cpu": "256", "tags": [ { "key": "Name", "value": "api-service" } ] }ECSタスク定義(api-service){ "family": "client-apl", "taskRoleArn": "arn:aws:iam::<account-id>:role/ecsTaskExecutionRole", "executionRoleArn": "arn:aws:iam::<account-id>:role/ecsTaskExecutionRole", "networkMode": "awsvpc", "containerDefinitions": [ { "name": "client-endpoint", "image": "<account-id>.dkr.ecr.ap-northeast-1.amazonaws.com/sample-mesh/client-service:latest", "portMappings": [ { "containerPort": 8090, "protocol": "tcp" } ], "essential": true, "environment": [ { "name": "API_SERVICE_URL", "value": "http://api-service.sample-mesh.local" }, { "name": "API_SERVICE_PORT", "value": "8080" }, { "name": "API_RESOURCE", "value": "messages" } ], "ulimits": [ { "name": "msgqueue", "softLimit": 0, "hardLimit": 0 } ], "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-create-group": true, "awslogs-group": "/ecs/sample-mesh", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "client-service" } } } ], "requiresCompatibilities": [ "FARGATE" ], "memory": "512", "cpu": "256", "tags": [ { "key": "Name", "value": "client-service" } ] }詳細は、AWS公式のタスク定義パラメータに一覧がありますが、主要なパラメータを紹介していきます。
パラメータ コンソールでの名前 概要 taskRoleArn タスクロール タスクが処理を行う際に利用するIAMロール。例えば、DynamoDBにアクセスする処理がある場合には、DynamoDBにアクセス可能なIAMポリシーの適用が必要
今回は特にAWSサービスを利用しないため権限が無くても問題無い。選択できるecsTaskExecutionRoleを利用executionRoleArn タスクの実行IAMロール ECS自体が利用するIAMロール。ECRからのイメージのpullやCloudWatchへのログ書き込みを行う。
今回はデフォルトで用意されたecsTaskExecutionRoleを利用containerDefinitions コンテナの定義 コンテナに対するパラメータ群 image イメージ コンテナレジストリのURIを指定。今回は、ECRにpushしたイメージのこと。 portMappings ポートマッピング アプリで利用するポート番号。今回は8080と8090。
このポート番号はアプリで利用する番号と後続で設定するセキュリティグループと合わせる必要がある。environment 環境変数 コンテナに渡す環境変数。今回の場合、client-serviceに渡す環境変数を設定
APIサービスのURLには、Cloud Mapで作成される名前検出名を設定(後述)logConfiguration ログ設定 logDriverにawslogsを指定することで、コンテナ内の標準出力がCloudWatch Logsに出力される。またawslogs-create-groupをtrueにすることで、ロググループが以下の名前で自動作成される。
・ロググループ: \$awslogs-group
・ログストリーム: \$awslogs-stream-prefix/\$name/IDこれを貼り付けて保存するとコンソール上にも反映されます。反映された後「作成」を押すとタスク定義が作成されます。
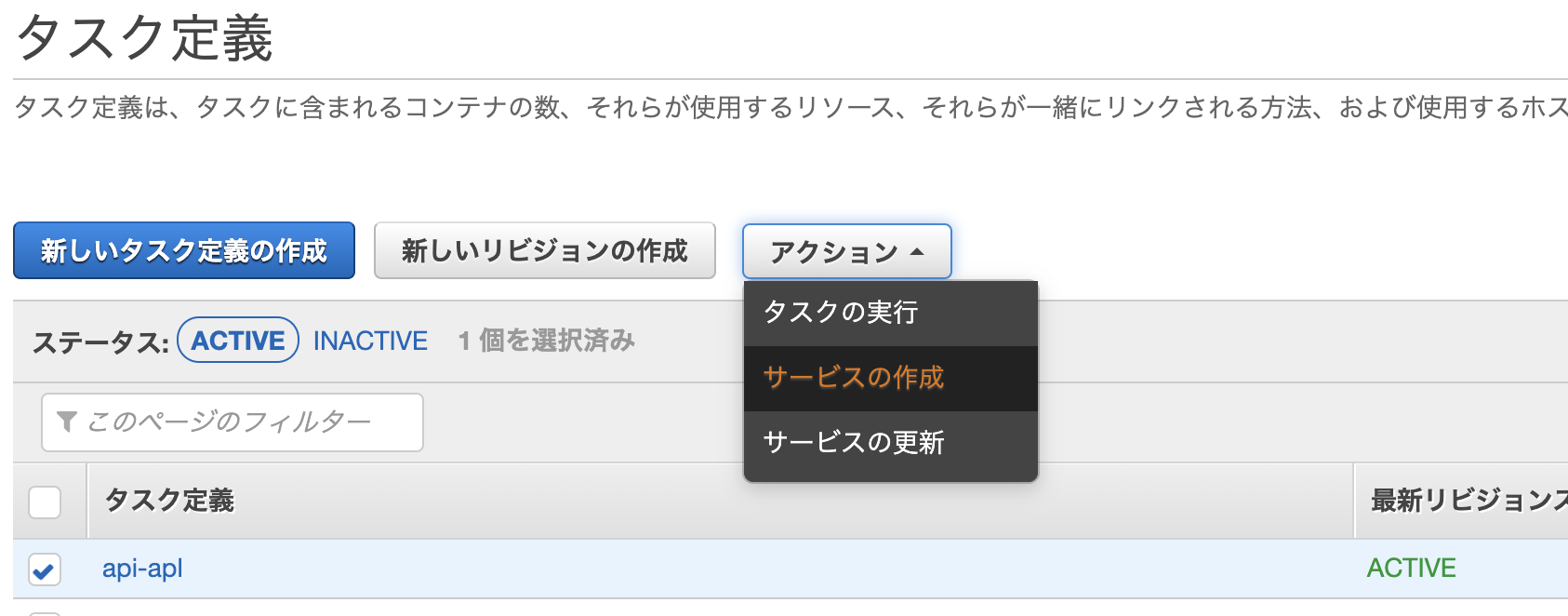
この時点で、タスク定義が作成されますが、まだコンテナは実行されません。3. サービスの作成
作成したタスク定義を使って、クラスター内でコンテナを実行させます。これがサービスとなります。
タスク定義から、アクション>サービスの作成と進みます。
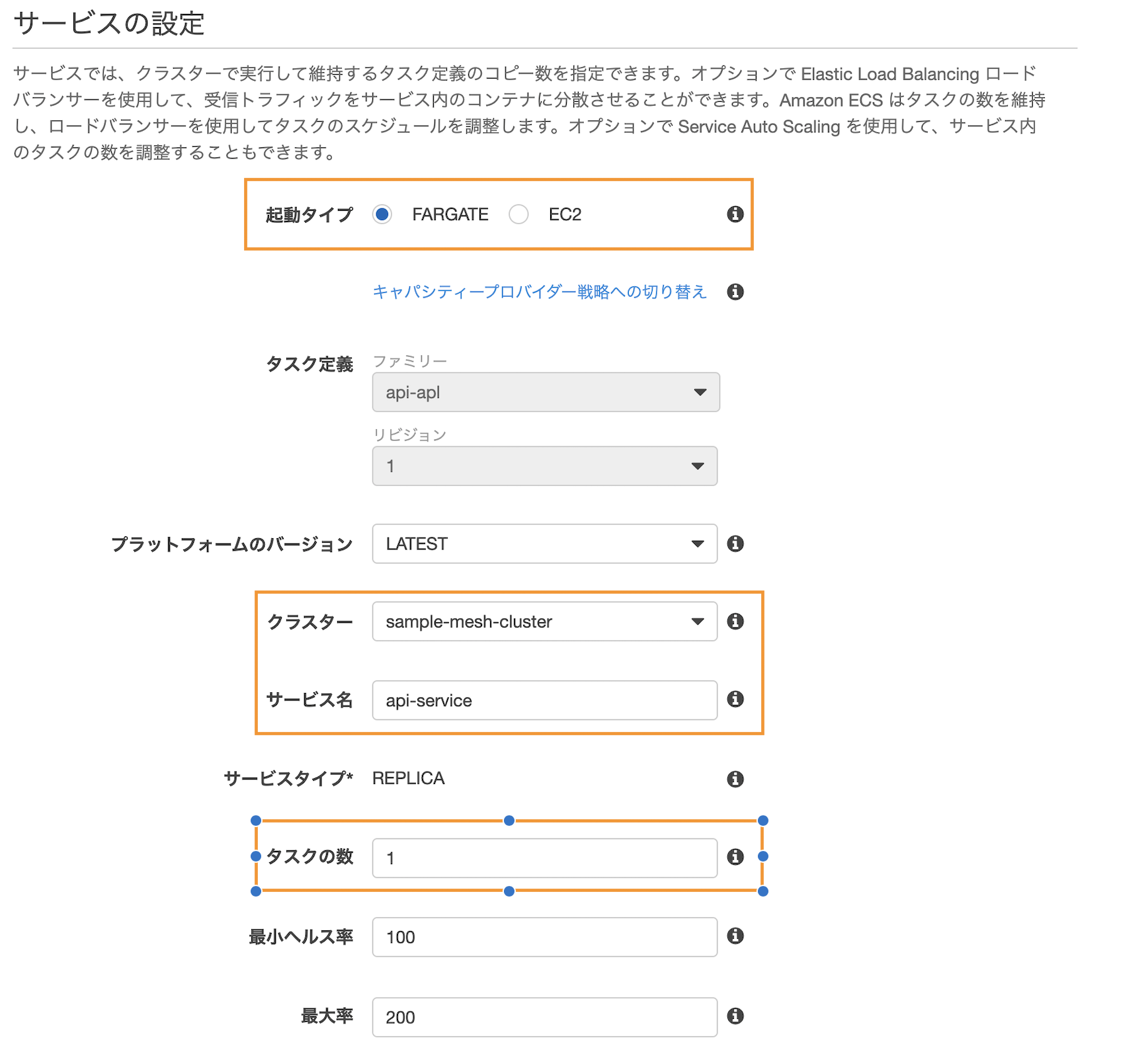
サービスの設定では、起動タイプにFARGATE, クラスターにはさきほど作成したものを選択、サービス名は任意、タスクの数はひとまず1を入力します。画面下部にあるデプロイメントタイプは「ローリングアップデート」で問題ありません。
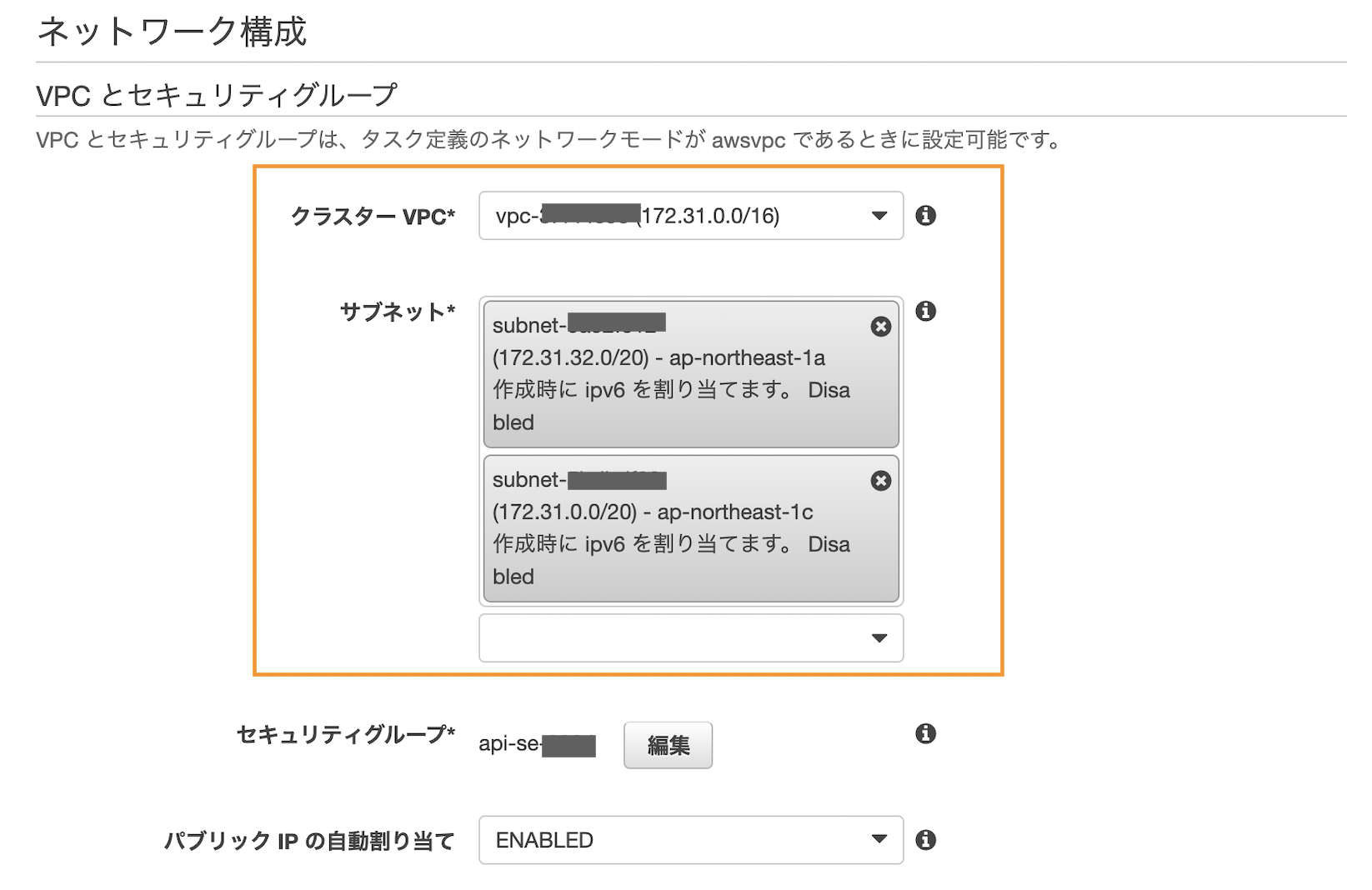
次のステップに進みます。ネットワーク構成からVPCとサブネットを選択します。
また、セキュリティグループは「編集」から利用するポートを許可します。今回の場合、8080, 8090を利用しているのでそれぞれ許可します。ECS(というかAWS全体的に)で上手く接続できない場合、ここの設定が誤っているパターンやIAMロールの設定ミスが非常に多いです[APIサービス側のセキュリティグループ設定例]
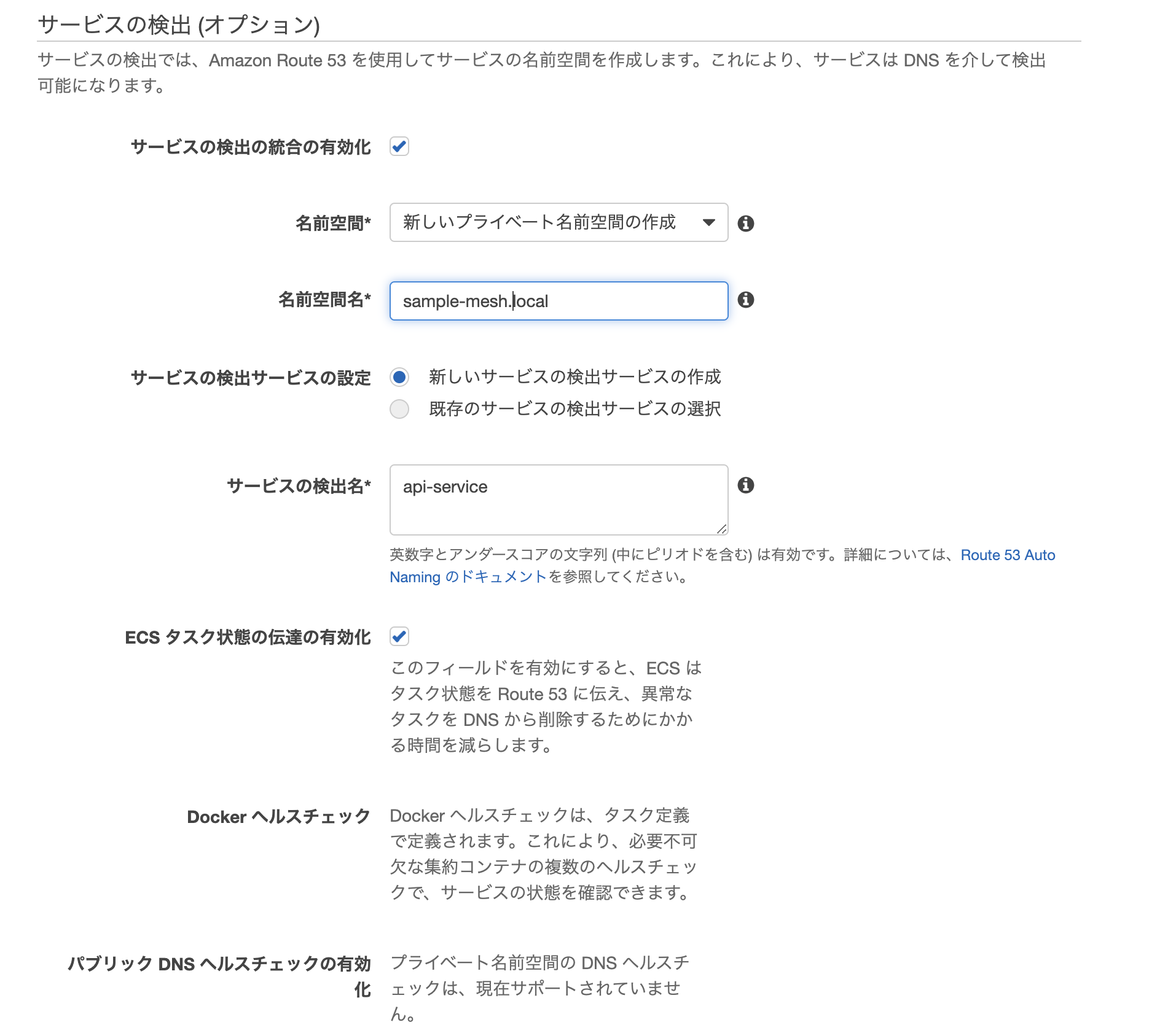
その後、api-serviceの設定時のみサービスの検出でチェックを入れて有効化します。ここで、名前空間名に
sample-mesh.local、サービス検出名にapi-serviceを設定します。
これにより、AWSの別サービスであるCloud Mapが設定され、別のサービスからapi-serviceにapi-service.sample-mesh.localという名前でアクセスすることが可能になります。さきほど、タスク定義でclient-serviceの環境変数に設定した値はこれのことです。
client-serviceは名前解決不要のため、サービスの検出にチェックを入れる必要はありません。
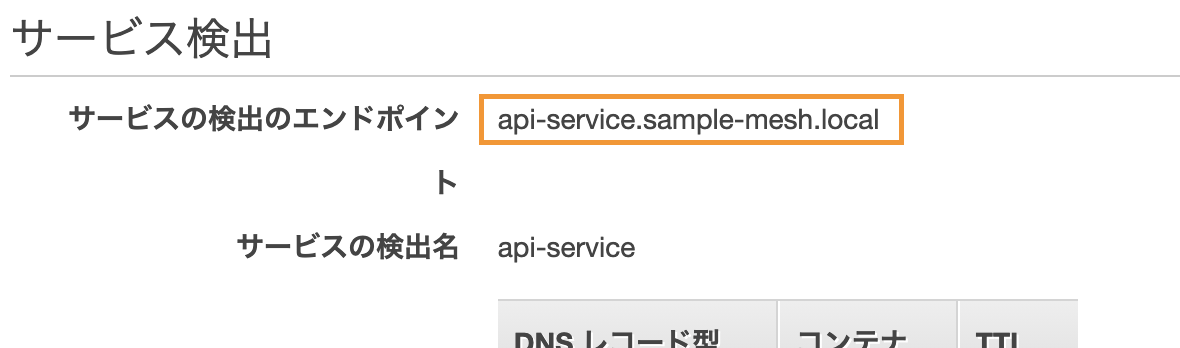
検出名は、サービスの作成後に以下の通りコンソールからも確認できます。先にapi-serviceから作成すると良いと思います。
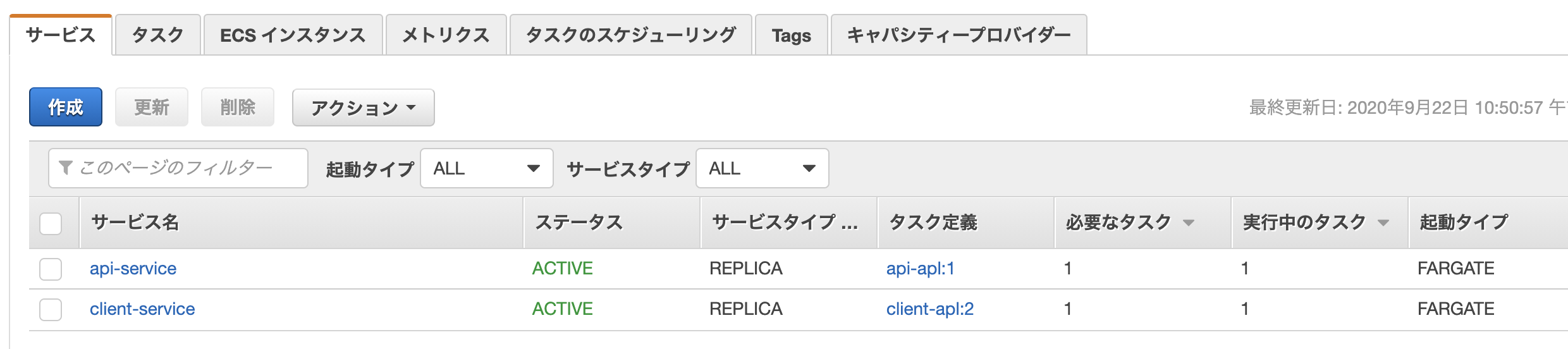
その他の設定はデフォルトで次のステップへ進んでいき、最後に「サービスの作成」を押すとサービスが作成されます。正常に作成が終わると、以下の通り2つのサービスが作成され「実行中のタスク」が1になります。
クラスター>タスクタブ>詳細のネットワーク欄に、割り当てられたパブリックIPアドレスが表示されます。(タスクごとにIPアドレスが割り当てられます。)試しにリクエストするとレスポンスが返ってきます。
※デプロイ先がパブリックサブネットである場合です。apiサービスへのリクエスト$ curl http://XXX.XXX.XXX.XXX:8080/messages {"message":"hello"}clientサービスへのリクエスト$ curl http://XXX.XXX.XXX.XXX:8090/messages {"text":"hello world!"}以上で、Fargateで起動するアプリケーションのデプロイと疎通が終わりました。
4. 片付け
放置しておくと時間で課金されるため、作成したものを削除していきます。
※今回の構成はセキュリティ的にも緩めなので、その点からもすぐに削除することをおすすめします。クラスターの削除
ECSのコンソールから作成したクラスターを選び、画面右上にある「クラスターの削除」を押して「delete me」を入力します。たまに、削除に失敗した旨のメッセージが出ることがありますが、その場合でもサービスはちゃんと削除されてたりします。失敗したら、もう一度「クラスターの削除」を押せばクラスターは削除されます。
※それでも失敗する場合は、サービスから削除していきましょう。
Cloud Mapの削除
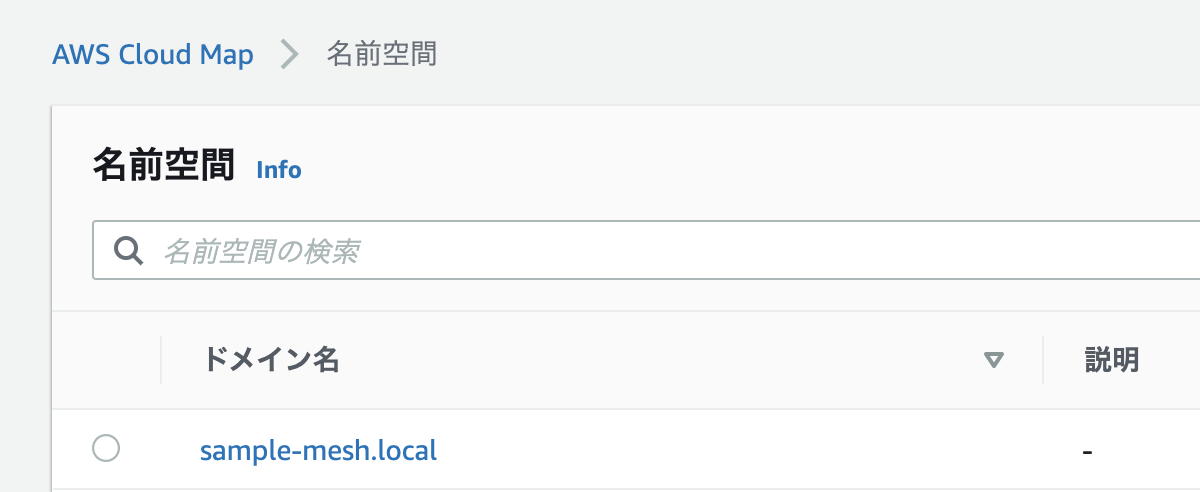
api-serviceの名前検出で利用したCloud Mapも削除しておく必要があります。「AWS Cloud Map」のコンソールに移動すると、以下の通りさきほど作成した名前空間が作成されています。
sample-mesh.localを選択して進むとapi-serviceがサービスの一覧にあるので削除します。サービスを削除すると名前空間の削除が可能になるため、名前空間の画面に戻ってsample-mesh.localを削除します。ECRの削除
ECRのコンソールから作成したリポジトリを開き削除します。対象は、api-serviceとclient-serviceの2つです。
余談ですが、ECRはコンテナのイメージサイズが大きいほど課金額も上がります。今回、GoのScratchイメージで構築していますが、この場合コンテナサイズが10数MBとかになります。そのため、課金額も非常に安くなります。
こういった理由から、Go以外の言語も含めてコンテナのサイズを小さくすることが重要と言えます。5. 実践的な構成に向けて
今回、できる限りシンプルな構成で作成しましたが、本番適用を考えると以下のような構成も最低限必要になります。
プライベートサブネットでの構築
- 今回両方のサービスをパブリックサブネットで構築していますが、インターネットと通信しないようなサービスはセキュリティ的にプライベートサブネットに配置されるべきです。少なくともapi-serviceはプライベートサブネットに置く必要があります。
- この場合、セキュリティグループで、api-serviceに対するアクセス元をclient-serviceのVPCに限定する、等の設定も必要です。
ELBでのロードバランシング/HTTPS化
- タスク数1で作成しましたが、実際は複数のタスクによる処理分散が行われることが多いです。そのため、ELBを設定して負荷分散を行ったりDNSでアクセスするほうが望ましいです。
- また、インターネットと繋ぐ場合、本来セキュリティ的にHTTPS化は必須ですので、ELBとACMなどを統合してSSL通信できるように設定します。
終わりに
思いのほか長くなってしまいましたが、ECS Fargateの構築手順をまとめてみました。ECSは最近新しい機能や改善が次々と行われるサービスのため、非常に面白いなと個人的には感じています。今後のアップデート等にも期待しましょう。
もし手順ミスなどありましたら、ご指摘いただけるとありがたいです!