- 投稿日:2020-07-15T22:46:29+09:00
ラズパイカメラでTensorflowによる手書き文字認識&結果をLED表示
作るもの
ラズパイのような軽量なデバイスで、ディープラーニングを動かすプロトタイプを作ってみる。
手書き文字 → カメラ → ラズパイ(Tensorflowで処理)→ 8x8 LED(結果表示)
ラズパイにTensorflow環境を構築する
https://www.tensorflow.org/install/pip?hl=ja#raspberry-pi_1
今回は仮想環境ではなく普通にインストール。$ sudo apt update $ sudo apt install python3-dev python3-pip $ sudo apt install libatlas-base-dev # required for numpy $ pip3 install --user --upgrade tensorflow # install in $HOMEMNISTデータを学習しモデルを保存
MNISTデータとは、
learnNum.py[githubリンク]
プログラムを動かす
MacのDocker環境だと動いていたが、ラズパイに作った環境だと下記修正が必要になった。
# h5pyがないエラーが出たのでインストール ImportError: `save_model` requires h5py. $ sudo apt-get install python3-h5py # tf.image.decode_image だと怒られたので、下記に変更。 tf.image.decode_jpeg # np.expand_dims だと怒られたので、下記に変更。 tf.expand_dims #steps引数の指定が必要だと怒られた。 ValueError: When using data tensors as input to a model, you should specify the `steps` argument. predictions = new_model.predict(img_expand, steps=1)MNISTモデルの読み込み
predictNum.pymnist = keras.datasets.mnist (train_images, train_labels), (test_images, test_labels) = mnist.load_data()テスト画像を食わせてみる。
「3」と認識し、動作確認は成功。
[githubリンク]カメラ画像の取得
predictNum.pyimport picamera camera = picamera.PiCamera() camera.capture('image.jpg')画像を切り取り黒背景化する
predictNum.py# 画像の読み込み img_path = "./image.jpg" img_raw = tf.io.read_file(img_path) img_tensor = tf.image.decode_jpeg(img_raw) img_crop = tf.image.crop_to_bounding_box(img_tensor, 0, 300, 620, 620) #切り取り img_rot = tf.image.rot90(img_crop, k=2) #180度回転 img_inv = tf.bitwise.invert(img_rot) #白黒反転 img_final = tf.image.resize(img_inv, [28, 28]) img_final = img_final/255.0 # 次元をそろえる img_gray = tf.image.rgb_to_grayscale(img_final) img_squeeze = tf.squeeze(img_gray) img_expand = (tf.expand_dims(img_squeeze,0))これだけだと画像のコントラストがはっきりせず正しく判定されない。
Pillowで画像を前処理する
コントラストを強くし、明るくしてみる。
predictNum.pyfrom PIL import Image from PIL import ImageEnhance filename = 'image.jpg' img = Image.open(filename) con1 = img.convert('L') con2 = ImageEnhance.Contrast(con1) con3 = con2.enhance(3.0) con4 = ImageEnhance.Brightness(con3) con5 = con4.enhance(3.0) con5.save('./image_con.jpg', quality=95)いけた!!
8x8LEDに結果を表示する
http://asamomiji.jp/contents/how-to-use-adafruit-8x8-mini-led-matrix-for-raspberry-pi
Adafruit公式のライブラリを使用する。
led.pyfrom PIL import Image from PIL import ImageDraw from PIL import ImageFont from Adafruit_LED_Backpack import Matrix8x8 display = Matrix8x8.Matrix8x8() display.begin() display.clear() image = Image.new('1', (8, 8)) draw = ImageDraw.Draw(image) font = ImageFont.load_default() draw.text((1, -1), '8', font=font, fill=255) display.set_image(image) display.write_display()注意点は、結果は数値でなく文字列で入力すること。


- 投稿日:2020-07-15T22:46:29+09:00
ラズパイカメラで手書き文字認識&結果をLED表示
ラズパイにTensorflow環境を構築する
https://www.tensorflow.org/install/pip?hl=ja#raspberry-pi_1
環境チェック
h5pyがないエラー。
ImportError: `save_model` requires h5py. $ sudo apt-get install python3-h5py # h5pyをインストールテストプログラムを動かす
MacのDocker環境だと動いていたが、ラズパイに作った環境だと下記修正が必要になった。
tf.image.decode_image だと怒られた。下記に。 tf.image.decode_jpeg np.expand_dims だと怒られた。下記に。 tf.expand_dims ValueError: When using data tensors as input to a model, you should specify the `steps` argument. #steps引数の指定が必要だと怒られた。 predictions = new_model.predict(img_expand, steps=1)MNISTの読み込み
predictNum.pymnist = keras.datasets.mnist (train_images, train_labels), (test_images, test_labels) = mnist.load_data()
「3」と認識し、動作確認は成功。カメラ画像の取得
predictNum.pyimport picamera camera = picamera.PiCamera() camera.capture('image.jpg')画像を切り取り黒背景化する
predictNum.py# 画像の読み込み img_path = "./image.jpg" img_raw = tf.io.read_file(img_path) img_tensor = tf.image.decode_jpeg(img_raw) img_crop = tf.image.crop_to_bounding_box(img_tensor, 0, 300, 620, 620) #切り取り img_rot = tf.image.rot90(img_crop, k=2) #180度回転 img_inv = tf.bitwise.invert(img_rot) #白黒反転 img_final = tf.image.resize(img_inv, [28, 28]) img_final = img_final/255.0 # 次元をそろえる img_gray = tf.image.rgb_to_grayscale(img_final) img_squeeze = tf.squeeze(img_gray) img_expand = (tf.expand_dims(img_squeeze,0))これだけだと画像のコントラストがはっきりせず正しく判定されない。
Pillowで画像を前処理する
コントラスト強く、明るくしてみる。
predictNum.pyfrom PIL import Image from PIL import ImageEnhance filename = 'image.jpg' img = Image.open(filename) con1 = img.convert('L') con2 = ImageEnhance.Contrast(con1) con3 = con2.enhance(3.0) con4 = ImageEnhance.Brightness(con3) con5 = con4.enhance(3.0) con5.save('./image_con.jpg', quality=95)いけた!!
8x8LEDに結果を表示する
http://asamomiji.jp/contents/how-to-use-adafruit-8x8-mini-led-matrix-for-raspberry-pi
led.pyfrom PIL import Image from PIL import ImageDraw from PIL import ImageFont from Adafruit_LED_Backpack import Matrix8x8 display = Matrix8x8.Matrix8x8() display.begin() display.clear() image = Image.new('1', (8, 8)) draw = ImageDraw.Draw(image) font = ImageFont.load_default() draw.text((1, -1), '8', font=font, fill=255) display.set_image(image) display.write_display()注意点は、結果は数値でなく文字列で入力すること。
- 投稿日:2020-07-15T22:36:52+09:00
Docker+anaconda上でtensorflowを動かしてみる
はじめに
新しくPCを購入したのでDockerを使用してpythonの環境構築してCNNを動かしてみました。
Dockerはほぼ初心者なのでこれを機に勉強していこうと思います。
今回の流れとしては
1.Docker上で公式のanaconda3イメージを取得する
2.anaconda3イメージを基にコンテナを作成
3.anaconda3にtensorflowを導入する
4.JupyterNoteookをブラウザから開く
5.Dockerのメモリを増やす
6.tensorflowを使用してCNNを構築する
となっています。環境
MacOS Catalina version 10.15.5
Docker version 19.03.8
1.Docker上で公式のanaconda3イメージを取得する
anacondaとは、データサイエンスをする方には必須なパッケージが一通り揃っているオープンソースのプラットフォームです。
こちらは公式からanaconda3のイメージがあるのでありがたく使っていきます。https://hub.docker.com/r/continuumio/anaconda3/
それでは、Dockerを起動してAnaconda3のイメージを取得します。
% docker pull continuumio/anaconda3 Using default tag: latest latest: Pulling from continuumio/anaconda3 68ced04f60ab: Pull complete 57047f2400d7: Pull complete 8b26dd278326: Pull complete Digest: sha256:6502693fd278ba962af34c756ed9a9f0c3b6236a62f1e1fecb41f60c3f536d3c Status: Downloaded newer image for continuumio/anaconda3:latest docker.io/continuumio/anaconda3:latest
pullはDockerイメージを取得するコマンドです。2.anaconda3イメージを基にコンテナを作成
次にコンテナを作成していきます。
% docker run --name anaconda -it -p 8888:8888 -v /Users/xxxx/docker/anaconda:/home continuumio/anaconda3 /bin/bash (base) root@xxxx:/# conda list各コマンド、オプションの意味は以下です。
run: コンテナを生成します。
--name [名前]: コンテナの名前を設定します。
-it: コンテナ内を操作できます。
-p [ホスト側のポート番号:コンテナのポート番号]: コンテナのポートをホスト側にバインドします。
-v [ホスト側のディレクトリ:コンテナ側のディレクトリ]: ホスト側のディレクトリをコンテナ内に
マウントします。
3.anaconda3にtensorflowを導入する
anaconda3に事前からインストールされているパッケージを確認してみます。
base) root@xxxx:/# conda list # packages in environment at /opt/conda: # # Name Version Build Channel _ipyw_jlab_nb_ext_conf 0.1.0 py37_0 _libgcc_mutex 0.1 main alabaster 0.7.12 py37_0 anaconda 2020.02 py37_0 anaconda-client 1.7.2 py37_0 anaconda-navigator 1.9.12 py37_0 anaconda-project 0.8.4 py_0 argh 0.26.2 py37_0 asn1crypto 1.3.0 py37_0 astroid 2.3.3 py37_0 astropy 4.0 py37h7b6447c_0 atomicwrites 1.3.0 py37_1 attrs 19.3.0 py_0 . . . yaml 0.1.7 had09818_2 yapf 0.28.0 py_0 zeromq 4.3.1 he6710b0_3 zict 1.0.0 py_0 zipp 2.2.0 py_0 zlib 1.2.11 h7b6447c_3 zstd 1.3.7 h0b5b093_0anaconda3のコンテナに入っているので
dockerコマンドは使えません。
anaconda terminalで使用できるconda listでパッケージを見ます。
anaconda3はtensorflowが最初からインストールされていないので、conda installを用いて
tensorflowとその周辺のパッケージをインストールしてきます。base) root@xxxx:/# conda install tensorflow4.JupyterNotebookをブラウザから開く
大学時代に愛用していたJupyterNotebookをブラウザから開けるようにします。
base) root@xxxx:/# jupyter notebook --port 8888 --ip=0.0.0.0 --allow-root . . . To access the notebook, open this file in a browser: file:///root/.local/share/jupyter/runtime/nbserver-12-open.html Or copy and paste one of these URLs: http://81127b992594:8888/?token=22ab4d7b42e6629eb76dad08af9c8e6b1d5b59e0f0050f73 or http://127.0.0.1:8888/?token=22ab4d7b42e6629eb76dad08af9c8e6b1d5b59e0f0050f73
末尾のURLをブラウザに入力するとJupyterNotebookが起動します。
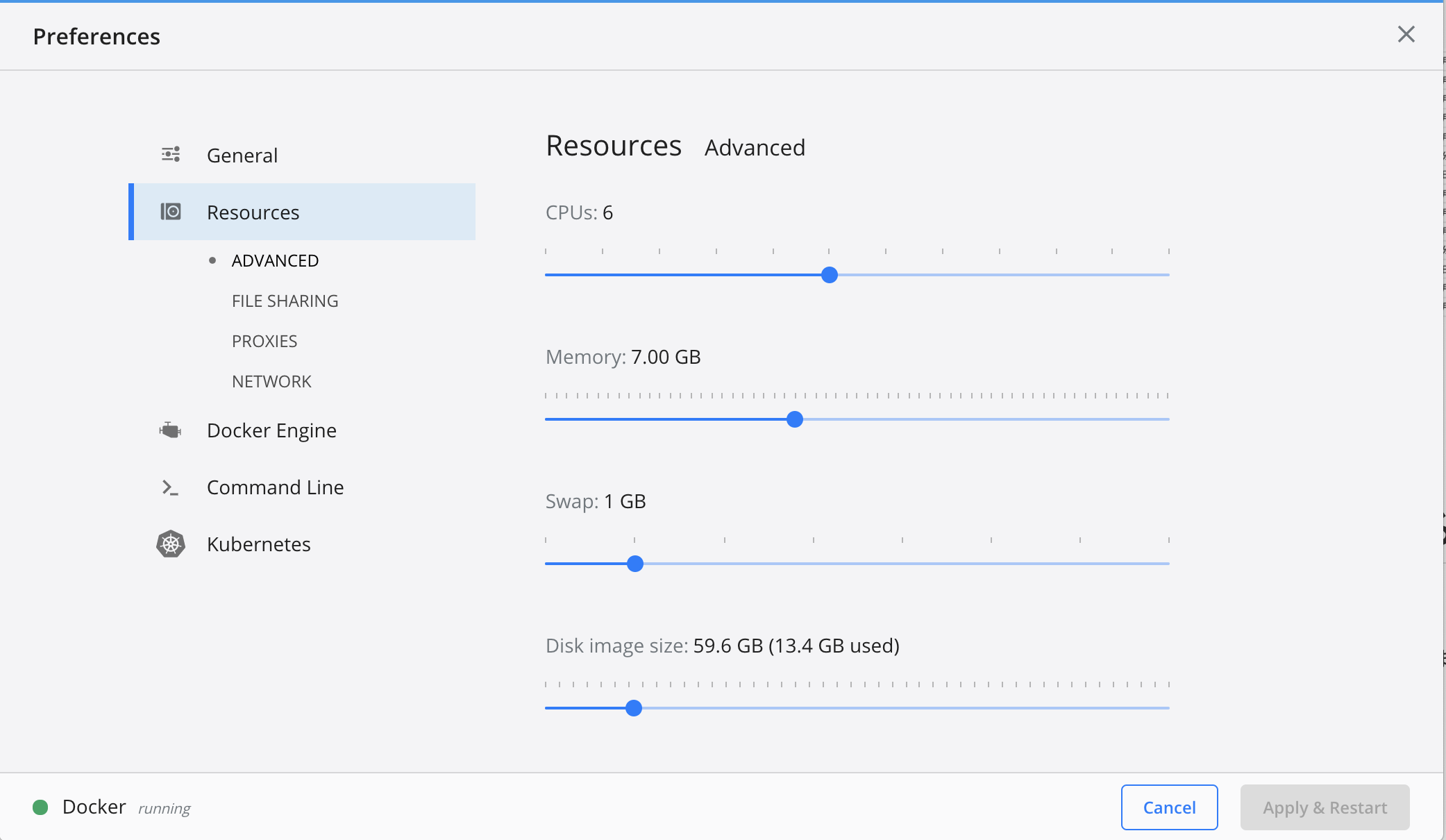
5.Dockerのメモリを増やす
CNNを構築する前にDockerはデフォルトではメモリが2Gまでしか使用できないので、CNNで学習させようとするとオーバーフローします。なので7Gまで使用できるように設定を変更していきます。
1. デスクトップの上部にあるDockerアイコンをクリック
2. Preferenceをクリック
3. Resourcesのタブをクリック
4. Memoryを7Gにする
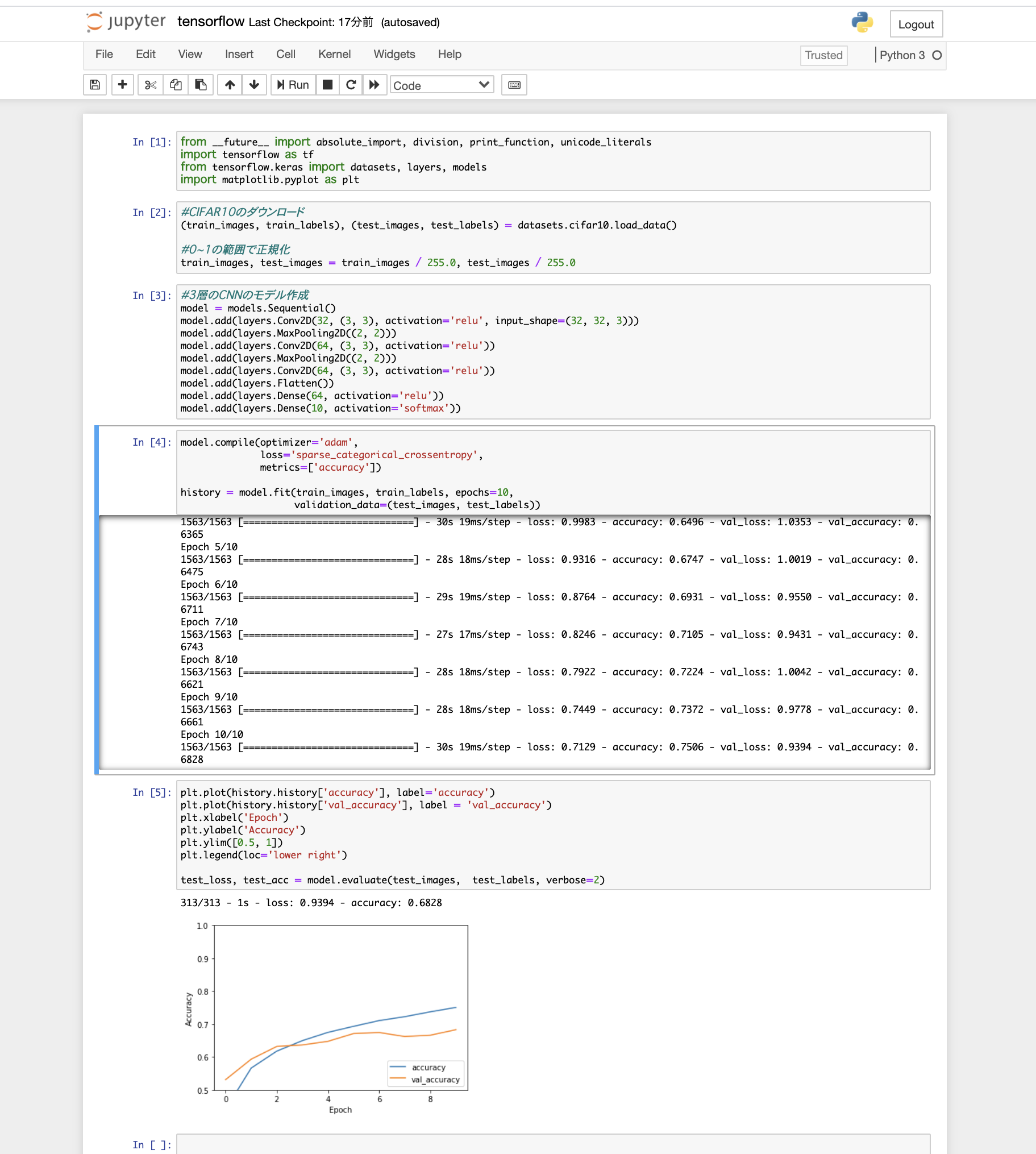
6.tensorflowを使用してCNNを構築する
最後にCNNを構築していきます。データセットは定番のCIFAR10をダウンロードし、3層の畳み込み層、最適化はadam法、損失関数はクロスエントロピー誤差を使用する至ってシンプルな構築でいきます。
tensorflowを問題なくインポートできて、メモリもオーバーフローしなかったのでこれで環境構築終了です!終わりに
Dockerを軽い気持ちで触ってみましたが、奥が深すぎて沼にハマりそうでした...
anaconda3にtensorflowを導入かつJupyterNotebookを開くという、おそらくDocker経験者なら簡単なことにかなり難航しました。Dockerはやっておいて損はないので積極的に使っていきたいです。
とりあえずtensorflowを動かすことができる環境を構築することができたので、これから色々深層学習についてこの環境で試していこうと思います。
- 投稿日:2020-07-15T21:02:35+09:00
Tensorflow・kerasでCNNを構築して画像分類してみる(実装編3)
前回の記事「Tensorflow・kerasでCNNを構築して画像分類してみる(実装編2)」では、実際にCNNの構築を進めました。畳み込み層とプーリング層を重ねたところまで進めています。
今回は、全結合層の追加や訓練データを利用した訓練を進めたいと思います。前提/環境
前提となる環境とバージョンは下記となります。
・Anaconda3
・Python3.7.7
・pip 20.0
・TensorFlow 2.0.0この記事ではJupyter Notebookでプログラムを進めていきます。コードの部分をJupyter Notebookにコピー&ペーストし実行することで同様の結果が得られるようにしています。
前回までは層を組み合わせ下記のようなCNNの構築をすすめました。
実装 その3 ネットワーク構築(全結合層の追加)
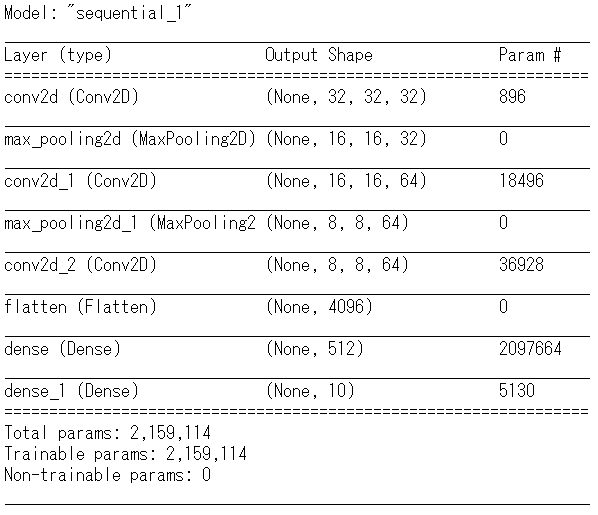
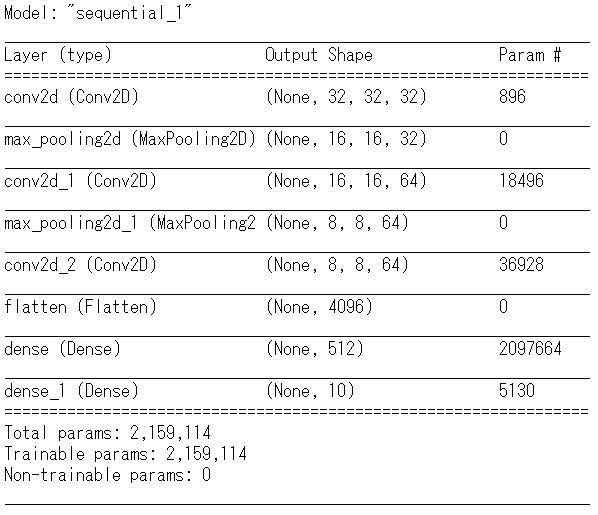
前回のsummaryの結果、最終的な層で出力される行列は(None,8,8,64)の四次元の配列の状態です。全結合層2次元の配列に変換しなければ扱えないので、モデルの追加の前処理を行います。
codefrom tensorflow.keras.layers import Flatten #2次元への変形 model.add(Flatten()) #変化形したあとの形状を確認 model.output_shape結果
(None, 4096)変換処理は終了しました。ここから全結合層を追加します。全結合層は順伝播型ニューラルネットワークの構築でも利用したDenseレイヤーを用います。
codefrom tensorflow.keras.layers import Dense model.add(Dense(units=512, activation='relu')) model.add(Dense(units=10, activation='softmax'))Denesレイヤー追加時に引数を設定しています。unitsは出力する次元の数を表します。ここでは512の出力する数として指定しています。
activationはそれぞれのユニットの出力時に利用する活性化関数を指定するものです。今回はreluという関数を指定します。
input_shapeは入力される行列の形状をしていしますが、2層目以降でkerasが自動的に判断するので省略しています。さらに出力層を追加します。こちらもDenseレイヤーを用います。順伝播型ニューラルネットワークの例でもありましたが、最終的に多クラス分類の問題です。ここではSoftmaxを活性化関数として分類することになります。
ここまでモデルを構築しました。ここからはモデルで実際に訓練をする前に最終的な構造を見ましょう。
codemodel.summary()結果
実装 その4 モデルの訓練
まずは構築したモデルのコンパイルをします。
codemodel.compile( optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'] )各引数について意味合いは下記となります。
- optimizer
- optimizerを指定することで最適化が可能です。今回はAdam(Adaptive Moment Estimation)を設定しています。
- loss
- lossは損失関数を選択します。ここでは交差エントロピーを利用します。kerasではcategorical_crossentropyなどいくつか指定ができます。
- metrics
- 評価関数の指定をするものです。ここではaccuracyを選択しています。評価関数も種類がありますので最適なものを利用しましょう。
次にコンパイルをしたので訓練を進めましょう。
codemodel.fit( x_train, y_train, batch_size=32, epochs=5, validation_split=0.2 )今回も訓練ではデータすべてを使うわけではありません、データセットの内50000枚を利用します。残りの10000枚のデータは未知のデータへの検証や予測のために利用します。
fit関数を用いるにあたり引数を指定しています。順伝播型ニューラルネットワークの構築と同様です。それぞれは下記の意味合いです。
- x_train
- 訓練データの画像の行列に対応します。
- y_train
- 訓練データのラベルに対応する行列に対応します。
- batch_size
- 整数またはNoneを指定します。動作としては設定したサンプル数ごとに勾配の更新を行います。指定しなければデフォルトで32で更新します。機械学習の原理として与えられた関数の傾き(勾配)を計算して、勾配の傾きが大きいほうへパラメーターをずらしていきます。この動きに対する指定となります。
- epochs
- 整数で,モデルを訓練するエポック数を指定します。
- validation_sprit
- 訓練データ全体を訓練にのみ利用するのではなく、一部を訓練中の検証用データとして用いる場合に設定します。kerasでは0から1までの浮動小数点数で指定します。この設定値は訓練データの中で検証データとして使う割合を示します。この記事では0.2を定していますが、訓練に使われるのは全体の8割、残りの2割は検証用データとして利用するということになります。ここで設定した検証データは訓練には利用されません。
結果
Train on 40000 samples, validate on 10000 samples
Epoch 1/5
40000/40000 [==============================] - 100s 3ms/sample - loss: 1.3853 - accuracy: 0.4956 - val_loss: 1.1217 - val_accuracy: 0.6030
Epoch 2/5
40000/40000 [==============================] - 104s 3ms/sample - loss: 0.9602 - accuracy: 0.6611 - val_loss: 0.9125 - val_accuracy: 0.6740
Epoch 3/5
40000/40000 [==============================] - 111s 3ms/sample - loss: 0.7617 - accuracy: 0.7332 - val_loss: 0.8462 - val_accuracy: 0.7027
Epoch 4/5
40000/40000 [==============================] - 110s 3ms/sample - loss: 0.6038 - accuracy: 0.7872 - val_loss: 0.8243 - val_accuracy: 0.7248
Epoch 5/5
40000/40000 [==============================] - 111s 3ms/sample - loss: 0.4530 - accuracy: 0.8400 - val_loss: 0.9037 - val_accuracy: 0.7179結果の意味合いの再復習となりますがloss、accuracy、val_loss、val_accuracyそれぞれの意味合いは下記になります。
- loss
- 訓練データを用いた場合の損失関数の値。損失関数の値が減少することが望ましい
- accuracy
- 訓練データに対しての分類精度(正解率)この値が高くなることが望ましい。
- val_loss
- 訓練データの一部を検証用データとして利用した場合に得られる。検証用データ(未知のデータ)に対する損失関数の値
- val_accuracy
- 訓練データの一部を検証用データとして利用した場合に得られる。検証用データ(未知のデータ)に対する正解率
今回はエポック数を5として実行しました。訓練の結果、lossは減少し、accuracyは向上しています。ただし検証用データでの評価分ではval_loss、val_accuracyとも一定の範囲内に落ち着いており精度が向上しているなどの結果は得られていません。
精度向上を目指して
結果として検証用データ(未知のデータ)に対する性能が低いという点をさらに改善できないかと思います。まず精度を向上する観点から訓練のエポック数を5から10に増やすという方向で検証しました。結果としては以下のように改善しないものでした。
結果(エポック8からエポック10の結果を抜粋)
Epoch 8/10
40000/40000 [==============================] - 104s 3ms/sample - loss: 0.0810 - accuracy: 0.9724 - val_loss: 1.8332 - val_accuracy: 0.7144
Epoch 9/10
40000/40000 [==============================] - 104s 3ms/sample - loss: 0.0641 - accuracy: 0.9795 - val_loss: 1.9246 - val_accuracy: 0.7138
Epoch 10/10
40000/40000 [==============================] - 106s 3ms/sample - loss: 0.0744 - accuracy: 0.9755 - val_loss: 1.9128 - val_accuracy: 0.7176訓練データの訓練用のデータに対しての精度は向上していますが、val_loss、val_accuracyに至っては改善していないどころか悪化しています。この結果からモデルに対して改善する必要があると考えられます。
改善点 その1
現状のモデルの構造をもう一度確認します。
ここで改善する点を考えてみました。
1.最初のConv2d層の後にmax_pooling2d層を設けているが、この段階で特徴マップが1/2になってしまっている。畳み込み層の出力数が少ない=つまり特徴量抽出が少ない上にプーリングの処理を行っているので精度が下がるのではないか?(上流で絞っているのでそれ以降は精度がそれほど上がらないのでと考えました。なので最初のConv2d層の後にさらに畳み込み層を追加するということで精度が上がらないかと考えました。
codemodel.add( Conv2D( filters=64, kernel_size=(3,3), strides=(1,1), padding='same', activation='relu' ) )結果
Train on 40000 samples, validate on 10000 samples
Epoch 1/5
40000/40000 [==============================] - 247s 6ms/sample - loss: 1.3414 - accuracy: 0.5145 - val_loss: 1.0411 - val_accuracy: 0.6298
Epoch 2/5
40000/40000 [==============================] - 259s 6ms/sample - loss: 0.8765 - accuracy: 0.6918 - val_loss: 0.8250 - val_accuracy: 0.7126
Epoch 3/5
40000/40000 [==============================] - 258s 6ms/sample - loss: 0.6652 - accuracy: 0.7649 - val_loss: 0.7685 - val_accuracy: 0.7396
Epoch 4/5
40000/40000 [==============================] - 246s 6ms/sample - loss: 0.4960 - accuracy: 0.8256 - val_loss: 0.7721 - val_accuracy: 0.7479
Epoch 5/5
40000/40000 [==============================] - 255s 6ms/sample - loss: 0.3358 - accuracy: 0.8830 - val_loss: 0.8837 - val_accuracy: 0.73815エポックで訓練を行ってみました。結果としては最終的な部分でlossが減少し、accurasyが向上し、val_loss、val_accurasyも微小ながら改善しています。(改善されたと言い切れる幅なのかというところはありますが)
エポック数を単純に増加させると過学習が起きているように思えます。過学習は訓練データに最適化されているが、評価データではloss、accuracyが改善されない状態です。つまり訓練データにのみ最適な状態で、未知のデータに対する汎化性能に問題があるといえます。この実験から、モデルの層を重ねる、あるいは改善するということで進めることが効果があるといえると思います。
データセットの評価用での分類、予測精度では図っていませんので正しいとは言い切れないですが、訓練段階でこういった点をみながら改善するということが重要だと思います。評価用データを用いた分類・予測
モデルの正解率の評価
codetest_loss, test_acc = model.evaluate(x_test, y_test, verbose=0) print('\nTest accuracy:', test_acc)結果
Test accuracy: 0.7293結果を評価すると、訓練データに対するaccuracyに比べ少々ですが減少しています。これは順伝播型ニューラルネットワークでも見られましたが想定範囲内です。
モデルを使い予測してみる
codepredictions = model.predict(x_test) predictions[0]結果
array([1.09461966e-04, 3.75682830e-05, 4.33398100e-06, 9.63908672e-01,
1.67364931e-08, 3.37889567e-02, 1.49343337e-04, 1.14129936e-04,
1.68450316e-03, 2.03081756e-04], dtype=float32)codenp.argmax(predictions[0])結果
3結果を見ると、cat(猫)と判定したようです。
まとめ
この記事で作成したCNNでは7割の正解率になりました。簡単な実装で7割まで結果を得られるというのはすごいことだと思いました。
ただ、7割を超え、精度を9割を目指すとなると、さらなる層の追加、最適化の手法やテクニックを必要とします。
単にエポック数を増やすと過学習となるので、モデル構造の改善が必要というのがわかりました。次回は最適化や精度向上のテクニックを書きたいと思います。

- 投稿日:2020-07-15T01:32:13+09:00
MagentaのMusicVAEで音楽データ学習時間を改善するためのプログラム
本記事はすでにMagentaの実践を行っている方に向けて書かれています。
Magnetaをご存じない方、実践した事がない方には何が書いてあるのか訳のわからない内容になると思いますのでご注意ください。MusicVAEの概要とその問題点
Googleの音楽機械学習ライブラリMagenta。
そのMagentaの多彩な音楽生成モデルの中でも3パート(メロディ、ベース、ドラム)のバンド演奏の様な高度な生成を可能にするのがMusicVAEです。MusicVAEは、Magentaの中でももっとも高度なモデルの一つですが、その分プログラムも複雑で、生成、学習とも、時間がかかります。
特に学習には非常に時間がかかり、大規模データだと数日かかっても終わらない、、、などという事も多々ありました。
このあまりに時間がかかる学習時間について、実はユーザーからGoogleに問い合わせや要望も寄せられており、Magneta開発チームの責任者の方も、プログラム的に問題があるボトルネックな箇所だ、と認める発言をしていました。
ただし同時に、オープンソースのプロジェクトであるMagentaにおいて、そう言った要望に応える改善を、早急に、頻繁に行う事は難しいという旨の発言もしています。
MusicVAEの学習時間を劇的に改善?preprocess_tfrecorf.py
しかし、抜本的なプログラムの見直しはない代わりに、代替案として、対策用のPythonスクリプトファイルを急遽作成してリリースしてくれています。
preprocess_tfrecord.py
です。
このPythonスクリプトファイルが何を行うのでしょうか?
コード内のコメントには以下の様に記述されていました。r”””Beam job to preprocess a TFRecord of NoteSequences for training a MusicVAE. Splits a TFRecord of NoteSequences (as prepared by convert_to_note_sequences) into individual examples using the DataConverter in the given config, outputting the resulting unique sequences in a new TFRecord file. The ID field of each new NoteSequence will contain a comma-separated list of the original NoteSequence(s) it was extracted from.日本語で概略を書くと
大規模な学習用のNotesequence TF Recordデータを、任意の設定に合わせ、Data Converterを使用し , (カンマ)で区切られ、個別にIDが割り振られた小さなデータに分割。
その小さなデータの集まりを、全く新しいTF Recordデータとして作成する。という前処理を行う様です。単にデータを少ない固まりに分割と聞くと、バッチサイズの変更では?とも思いますが、これまでバッチサイズを変えても学習時間の改善は見れられませんでした。
しかしこの分割されたTF Recordデータは、学習時間の改善に寄与するとの事ですので、学習の際に行われる(時間のかかるボトルネックな)作業を排除する事ができる処理なのでしょう。
学習時間改善!実行コマンド解説
実行には、Magentaの開発環境を構築する必要があります。
サンプルコマンドを見てみましょう。
(preprocess_tfrecord.pyサンプルコマンド)python -m magenta.models.music_vae.preprocess_tfrecord \ --input_tfrecord=/path/to/tfrecords/train.tfrecord \ --output_tfrecord=/path/to/tfrecords/train-$CONFIG.tfrecord \ --output_shards=10 \ --config=$CONFIG \ --alsologtostderrの様に実行します。
input_tfrecordにはご自身のTF Recordデータを渡してください。
pathやconfigは各自の設定に合わせて変更してください。
output_shardsは分割されるTF Recordデータの各データサイズでしょうか?その他のコマンドオプション
サンプルコマンド以外にも色々な指定を行えるオプションがあります。
サンプルコマンドで使用したものも合わせてどんなオプションが使用できるか?
tf.flagsで記述された部分のコードを見てみましょう。(preprocess_tfrecord.pyから抜粋)flags.DEFINE_string( ‘input_tfrecord’, None, ‘Filepattern matching input TFRecord file(s).’) #変換するTF Recordファイル flags.DEFINE_string( ‘output_tfrecord’, None, ‘The prefx for the output TFRecord file(s).’) #出力するTF Recordファイル flags.DEFINE_integer( ‘output_shards’, 32, ‘The number of output shards.’) #出力するTF Recordファイルの分割数? flags.DEFINE_string( ‘config’, None, ‘The name of the model config to use.’) #使用するMusicVAEの設定 flags.DEFINE_bool( ‘enable_filtering’, True, ‘If True, enables max_total_time, max_num_notes, min_velocities, ‘ ‘min_metric_positions, is_drum, and drums_only flags.’) #Trueならこれ以下のオプションを有効にする flags.DEFINE_integer( ‘max_total_time’, 1800, ‘NoteSequences longer than this (in seconds) will be skipped.’) #NoteSequenceの最大時間(指定数以上はスキップ) flags.DEFINE_integer( ‘max_num_notes’, 10000, ‘NoteSequences with more than this many notes will be skipped.’) #NoteSequenceの最大音数(指定数以上はスキップ) flags.DEFINE_integer( ‘min_velocities’, 1, ‘NoteSequences with fewer unique velocities than this will be skipped.’) #最小ベロシティ(指定数以下はスキップ) flags.DEFINE_integer( ‘min_metric_positions’, 1, ‘NoteSequences with fewer unique metric positions between quarter notes ‘ ‘than this will be skipped.’) #細かいタイミングにある音符をスキップ flags.DEFINE_bool( ‘is_drum’, None, ‘If None, filtering will consider drums and non-drums. If True, only drums ‘ ‘will be considered. If False, only non-drums will be considered.’) #TrueならDrum音だけを取り扱う。Falseならドラム音以外だけを取り扱う flags.DEFINE_bool( ‘drums_only’, False, ‘If True, NoteSequences with non-drum instruments will be skipped.’) #Trueならドラム音ではない音はスキップ flags.DEFINE_list( ‘pipeline_options’, ‘–runner=DirectRunner’, ‘A comma-separated list of command line arguments to be used as options ‘ ‘for the Beam Pipeline.’) #パイプラインオプション実行コマンドにオプションとして例えば
--is_drum=Trueの様に記述し実行できます。
最後に
MusicVAEは、これまで学習時間が非常に長いのが欠点でした、、、
まだこのpreprocess_tfrecord,pyは試していませんが、もし改善するなら、そしてできれば劇的に改善するなら、MusicVAEで試したい学習と生成はたくさんあります。学習時間の改善なども今後レポートしたいと思います。
楽しみにしていてください。