- 投稿日:2020-07-15T23:59:22+09:00
ゼロから始めるLeetCode Day87 「 1512. Number of Good Pairs」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
どうやら多くのエンジニアはその対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイトであり、海外のテックカンパニーでのキャリアを積みたい方にとっては避けては通れない道である。
と、仰々しく書いてみましたが、私は今のところそういった面接を受ける予定はありません。
ただ、ITエンジニアとして人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
Python3で解いています。
前回
ゼロから始めるLeetCode Day86 「33. Search in Rotated Sorted Array」Twitterやってます。
技術ブログ始めました!!
技術はLeetCode、Django、Nuxt、あたりについて書くと思います。こちらの方が更新は早いので、よければブクマよろしくお願いいたします!問題
1512. Number of Good Pairs
難易度はEasy。問題としては、整数の配列
numsが与えられます。
nums[i] == nums[j]でi < jの場合,ペア(i,j)を有効とし、有効であるペアの数を返すアルゴリズムを設計してください。Example 1:
Input: nums = [1,2,3,1,1,3]
Output: 4
Explanation: There are 4 good pairs (0,3), (0,4), (3,4), (2,5) 0-indexed.Example 2:
Input: nums = [1,1,1,1]
Output: 6
Explanation: Each pair in the array are good.Example 3:
Input: nums = [1,2,3]
Output: 0解法
class Solution: def numIdenticalPairs(self, nums: List[int]) -> int: ans,dic = 0,{} for i,j in enumerate(nums): if j in dic: ans += dic[j] dic[j] += 1 else: dic[j] = 1 return ans # Runtime: 32 ms, faster than 100.00% of Python3 online submissions for Number of Good Pairs. # Memory Usage: 13.6 MB, less than 100.00% of Python3 online submissions for Number of Good Pairs.
dicで要素を管理して、はい終わり!
速度や容量的にもかなりいいものがかけたのではないでしょうか(自画自賛)。
急いで書いたので深い解説、とまではいきませんが他にもCounterを使ったり、pointerを二つ使って書いたりもできるとは思います。
その解答をかけるようであれば、ぜひdisucussに投稿してみてください。では今回はここまで。
お疲れ様でした。
- 投稿日:2020-07-15T23:22:42+09:00
DjangoでAPIを作る
はじめに
やあみんな!こんにちは、こんばんは、あるいはおやすみなさい!
どうも僕です。Takurintonです。
今回はDjangoでAPI作ってそれを叩くみたいなことします。
背景としては、弊学のとある科目でそんな感じのことしないと実装できない問題があったのでちょっくらやってやるかって感じです。
まあ無知の状態からだったのでだいぶキツかったです。自由課題なので完全に自爆なんですけどね( ;∀;)前提条件
所要時間
全体の所要時間の合計としてはググる時間も含めて6時間くらいでした。目安までにどうぞ。
背景
もともと業務委託で作らせてもらっていたECサイトをまんま改造して作りました。でも更新してる最中のサイトをぶち壊してはいけないので、別で環境をDockerに作って、docker-composeで仮想環境をエイヤ!ってしてやろうかなとか思って簡単にですが作りました。
Dockerって使っても使わなくてもデータベースくらいしか変更点ないと思うので、そこら辺は省略します(細かいことは個人ブログでそのうち書きます)環境
OS macOS Chatalina version 10.15.4 言語 Python, Java フレームワーク Django REST framework 使用技術
Django REST framework全体のリンクはこちら
作る!!!
構成
もともとデータベースやらロジックはしっかりしてあったので、そこらへんの整備は必要ありませんでした。
今回作成するAPIでは注文情報を取得します。
イメージとして
- ユーザーのメアド
- 注文した店舗
- 注文した商品の値段と写真のリスト
- 合計金額
- 希望お届け時間
あたりを取得したいのでそれに合わせて実装しました。
これに関連したデータベースは以下のようになっています。
models.pyclass CustomUserManager(UserManager): use_in_migrations = True def _create_user(self, email, password=None, zip_code=None, address1=None, address2=None, address3=None, **extra_fields): if not email: raise ValueError('メールは必須で被りなし') email = self.normalize_email(email) user = self.model(email=email, **extra_fields) user.set_password(password) phone_number_regex = RegexValidator(regex=r'^[0-9]+$', message = ("Tel Number must be entered in the format: '09012345678'. Up to 15 digits allowed.")) phone_number = models.CharField(validators=[phone_number_regex], max_length=15, verbose_name='電話番号') zip_code = models.CharField(max_length=8) address1 = models.CharField(max_length=40) address2 = models.CharField(max_length=40) address3 = models.CharField(max_length=40, blank=True) user.save(using=self._db) return email def create_user(self, request_data, **kwargs): if not request_data['email']: raise ValueError('Users must have an email address.') user = self.model( email=request_data['email'], first_name=request_data['first_name'], last_name=request_data['last_name'], # password=request_data['password'], zip_code=request_data['zip_code'], address1=request_data['address1'], address2=request_data['address2'], address3=request_data['address3'], ) user.set_password(request_data['password']) user.save(using=self._db) return user def create_superuser(self, email, phone_number=None, password=None, zip_code=None, address1=None, address2=None, address3=None, **extra_fields): extra_fields.setdefault('is_staff', True) extra_fields.setdefault('is_superuser', True) if extra_fields.get('is_staff') is not True: raise ValueError('Superuser must have is_staff=True.') if extra_fields.get('is_superuser') is not True: raise ValueError('Superuser must have is_superuser=True.') return self._create_user(email, password, **extra_fields) class User(AbstractBaseUser, PermissionsMixin): #username = models.CharField(_('username'), max_length=20, unique=True) email = models.EmailField(_('email address'), unique=True) first_name = models.CharField(_('first name'), max_length=30) last_name = models.CharField(_('last name'), max_length=150) zip_code = models.CharField(max_length=8) address1 = models.CharField(max_length=40) address2 = models.CharField(max_length=40) address3 = models.CharField(max_length=40, blank=True) phone_number_regex = RegexValidator(regex=r'^[0-9]+$', message = ("Tel Number must be entered in the format: '09012345678'. Up to 15 digits allowed.")) phone_number = models.CharField(validators=[phone_number_regex], max_length=15, verbose_name='電話番号', null=True, blank=True) is_staff = models.BooleanField( _('staff status'), default=False, help_text=_( 'Designates whether the user can log into this admin site.'), ) is_active = models.BooleanField( _('active'), default=True, help_text=_( 'Designates whether this user should be treated as active. ' 'Unselect this instead of deleting accounts.' ), ) date_joined = models.DateTimeField(_('date joined'), default=timezone.now) objects = CustomUserManager() EMAIL_FIELD = 'email' USERNAME_FIELD = 'email' REQUIRED_FIELDS = [] def user_has_perm(self, user, perm, obj): return _user_has_perm(user, perm, obj) def has_perm(self, perm ,obj=None): return _user_has_perm(self, perm, obj=obj) def has_module_perms(self, app_label): return self.is_staff def get_short_name(self): return self.first_name class Meta: # db_table = 'api_user' swappable = 'AUTH_USER_MODEL' class Company(models.Model): name = models.CharField(max_length=255) introduction = models.TextField(max_length=65536) postal_code = models.CharField(max_length=8) company_image = models.ImageField() homepage = models.CharField(max_length=255, null=True, blank=True) images = models.BooleanField(verbose_name='', default=False) place = models.CharField(max_length=255) def __str__(self): return str(self.name) class Product(models.Model): company = models.ForeignKey(Company, on_delete=models.CASCADE) name = models.CharField(max_length=255) contents = models.CharField(max_length=255) category = models.ForeignKey(Category, on_delete=models.CASCADE) product_image = models.ImageField() option = models.CharField(max_length=255, null=True, blank=True, default=None) price = models.IntegerField() def __str__(self): return str(self.name) class Cart(models.Model): cart_id = models.IntegerField(null=True, blank=True) user = models.ForeignKey(User, on_delete=models.CASCADE, blank=True, null=True) is_active = models.BooleanField(default=True) pub_date = models.DateTimeField(null=True, blank=True) def __str__(self): return str(self.cart_id) class UserInfomation(models.Model): cart = models.ForeignKey(Cart, on_delete=models.CASCADE, blank=True, null=True) user = models.ForeignKey(User, on_delete=models.CASCADE, blank=True, null=True) day = models.CharField(max_length=255, default=None) time = models.CharField(null=True, blank=True, max_length=255, default=None) status = models.BooleanField(default=False, null=True, blank=True) total = models.IntegerField(null=True) remark = models.TextField(max_length=65535, null=True, blank=True) pub_date = models.DateTimeField(default=now) def __str__(self): return str(self.user) class OrderItems(models.Model): user = models.ForeignKey(UserInfomation, on_delete=models.CASCADE) cart = models.ForeignKey(Cart, on_delete=models.CASCADE, blank=True, null=True) item = models.ForeignKey(Product, on_delete=models.CASCADE, blank=True, null=True) number = models.IntegerField(null=True) price = models.IntegerField(null=True) total = models.IntegerField(null=True)
- Userテーブルはカスタムユーザーモデルを拡張しています
- それぞれのパーミションを取得するための関数をいくつか定義しています
- companyはproductと1対多になっています
- userはcartと1対多になっていますが、アクティブなカートは1つだけになります
- UserInfomationには確定した注文が入っています
- OrderItemsにはUserの情報が入っています
他にもテーブルはあるのですが、今回はこれだけあればできるので省略します。
作っていく
準備
まずrestframeworkをインストールしていない方はインストールします。
pip install djangorestframework次にsettings.pyに以下の設定を追加します。
settings.py... INSTALLED_APPS = [ ... 'rest_framework', ] ... JWT_AUTH = { 'JWT_VERIFY_EXPIRATION': False, # tokenの永続化 'JWT_AUTH_HEADER_PREFIX': 'JWT', } REST_FRAMEWORK = { 'DEFAULT_PERMISSION_CLASSES': ( 'rest_framework.permissions.IsAuthenticated', ), 'DEFAULT_AUTHENTICATION_CLASSES': ( 'rest_framework_jwt.authentication.JSONWebTokenAuthentication', ), 'NON_FIELD_ERRORS_KEY': 'detail', 'TEST_REQUEST_DEFAULT_FORMAT': 'json', 'DEFAULT_FILTER_BACKENDS': ( 'django_filters.rest_framework.DjangoFilterBackend', ), }ログイン機能
ここでは既に存在するユーザーにログインする機能を作成します。
今回は全てのリクエストに認証をかけます。ログイン中のユーザーのみ操作を可能にするのでここは必須です。
まずはエンドポイントを作成します。project_name/urls.pyfrom django.conf.urls import url from rest_framework_jwt.views import obtain_jwt_token urlpatterns = [ url(r'^login_/', obtain_jwt_token), ..., ]このエンドポイントを追加することでログイン機能が完成します。
あくまでデータベースを構築している前提です。obtain_jwt_tokenというのは、このエンドポイントにアクセスした時に認証用のトークンを返してくれるようにします。既存のユーザーでログインしてみたいと思います。
実験段階ではipythonを使っていきます(楽だから)In [1]: import requests In [2]: import json In [3]: data = {'email': 'hogehoge@gmail.com', 'password': 'hogehoge'} In [4]: r = requests.post('localhost:8000/login_/', data=data) In [5]: print(r.json()) Out[5]: {'token': 'eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjo5LCJ1c2VybmFtZSI6ImIxODA2NDI5QGdtYWlsLmNvbSIsImV4cCI6MTU5NDc5OTMwNCwiZW1haWwiOiJiMTgwNjQyOUBnbWFpbC5jb20ifQ.Torhy69ZyKMOOxQUUv3Ebn9V6wqSwUlsQUD5IPUaDJA'}こんな感じで長めのJSONが返ってきます。
この時の注意点としては、Pythonには辞書をJSONに変換してくれるjson.dumps(dict)というようなものがありますが、それをやるとエラーになります。ここで渡すのはあくまでもdict型のデータになります。また、この返ってきたトークンは後々使うので大切にしておいてください。
ログイン時に使うデータとしては、主キーであるメールアドレスとパスワードになっています。なんだかわからない人はmodels.pyのコードを読んでみてください。余談ですが、Pythonのrequestsではdataにbody、headersにヘッダーを入れることができます。
r.json()にすることでレスポンスをdict型に変換し、使いやすい形に変換することができます。
requestsとjsonはだいぶ密です。密です。密です。カスタムJSON
次は自分用にカスタマイズしたJSONを返していきます。
個人的にはここでつまづきました。最初はSerializerとGeneric viewsを使って実装する方がいいと思っていたのですが、どうやらこれではカスタムのJSON(これらを使うと任意の単一テーブルに存在するフィールドのものしか返せない)を返すことができないようなので、やり方を変更しました。
今のやり方にたどり着くまでにだいぶ時間がかかってしまったのでそこが反省です。カスタムのJSONを返したい場合にはシリアライザーなどはいらないらしいので、直接views.pyに記述していきます。
エンドポイントはurls.pyに記述します。urls.pyfrom django.urls import path from . import views urlpatterns = [ ... path('get_shop_view', views.ShopView.as_view()), #これを追加 ]views.pyfrom django.http import HttpResponse from rest_framework import generics class ShopView(generics.ListCreateAPIView): # list(self, request, *args, **kwargs) を使うことでカスタムJSONを生成することができるようになる def list(self, request, *args, **kwargs): # 最終的に返すJSONのリスト return_list = list() try: user_info = UserInfomation.objects.all() # 購入経験のある全てのユーザーを取得 for i in user_info: order = OrderItems.objects.filter(user=i) # ユーザーを指定 shop = order[0].item.company.name # 会社を指定 # 商品一覧を取得 order_items = dict() for i in order: order_items[i.item.name] = { 'price': i.item.price, # 値段 'images': str(i.item.product_image) # 画像のURL } total = sum([i.total for i in order]) #合計金額。リスト内包で生成したリストの合計を出す date_time_ = UserInfomation.objects.get(cart=i.cart) date_time = date_time_.day + date_time_.time # 希望お届け時間を取得 # 全体のリストにこれらのデータを入れる return_list.append( { 'user': str(i.user), # ユーザーのメアド 'shop': shop, # 注文した店舗 'order': order_items, # 注文した商品一覧 'total': total, # 合計金額 'datetime': date_time, # 希望お届け時間 } ) # エラーが出たら空のリストを返す except: pass return Response( return_list )ここまで作成してから先ほど作成したエンドポイントに今度はgetリクエストを投げてみます
In [1]: {'Content-Type': 'application/json', 'Authorization': 'JWT eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjo5LCJ1c2VybmFtZSI6ImIxODA2NDI5QGdtYWlsLmNvbSIsImV4cCI6MTU5NDc5OTMwNCwiZW1haWwiOiJiMTgwNjQyOUBnbWFpbC5jb20ifQ.Torhy69ZyKMOOxQUUv3Ebn9V6wqSwUlsQUD5IPUaDJA'} In[2]: order_list = requests.get('http://localhost:8000/get_shop_view', headers=headers) In [3]: order_list.json() Out[3]: [{'user': 'hogehoge@gmail.com', 'shop': '店舗B', 'order': {'ハンバーグ': {'price': 1000, 'images': 'IMG_4145_ykxb9h'}}, 'total': 1000, 'datetime': '2020年7月14日今すぐ'}, {'user': 'hogehoge@gmail.com', 'shop': '店舗B', 'order': {'ハンバーグ': {'price': 1000, 'images': 'IMG_4145_ykxb9h'}, 'カレー': {'price': 2, 'images': '11967451898714_y6tgch'}}, 'total': 2002, 'datetime': '2020年7月14日今すぐ'}, {'user': 'fugafuga@gmail.com', 'shop': '店舗B', 'order': {'シチュー': {'price': 11111, 'images': 'IMG_4900_oyb5ny'}, 'ハンバーグ': {'price': 1000, 'images': 'IMG_4145_ykxb9h'}, 'コーヒー': {'price': 199, 'images': '54490_jawqyl'}, 'カレー': {'price': 2, 'images': '11967451898714_y6tgch'}, 'パンケーキ': {'price': 100, 'images': 'tweet_p7chgi'}, 'Takurinton': {'price': 100, 'images': 'npyl13'}}, 'total': 24220, 'datetime': '2020年7月16日今すぐ'}]これは僕が事前にカートにホイホイ突っ込んでおいたやつですが、無事に返ってきました!!!
嬉しい〜!!!ここまで5時間45分くらいかかった。。。Javaで叩いてみる
レポートはJavaなのでJavaでも叩けるようになりたいなと思ってググってみたら意外と簡単でした。気難しい言語だと思ってたのでちょっと嬉しい。。。笑笑
Test.javaimport java.net.URI; import java.net.http.HttpClient; import java.net.http.HttpRequest; import java.net.http.HttpResponse; import java.net.http.HttpResponse.BodyHandler; import java.nio.charset.StandardCharsets; public class Test{ public static void main(String[] args){ try { HttpRequest request = HttpRequest .newBuilder(URI.create("http://localhost:8000/get_shop_view")) .header("Content-Type", "application/json") .header("Authorization", "JWT eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjo5LCJ1c2VybmFtZSI6ImIxODA2NDI5QGdtYWlsLmNvbSIsImV4cCI6MTU5NDc5OTMwNCwiZW1haWwiOiJiMTgwNjQyOUBnbWFpbC5jb20ifQ.Torhy69ZyKMOOxQUUv3Ebn9V6wqSwUlsQUD5IPUaDJA") .GET() .build(); BodyHandler<String> bodyHandler = HttpResponse.BodyHandlers.ofString(StandardCharsets.UTF_8); HttpResponse<String> response = HttpClient.newBuilder().build().send(request, bodyHandler); String body = response.body(); System.out.println(body); } catch (Exception e) { e.printStackTrace(); } } }相変わらずコードは長いですが、許容範囲内です。
HttpRequestにじゃんじゃか書いていくスタンスみたいです。ヘッダーのトークンは先ほど取得したものを同じものを利用することができます。
なんかあまり深く理解できてないけど、、、。コンパイルして実行します。
(base) Hogehoge:working takurinton$ javac Test.java (base) Hogehoge:working takurinton$ java Test [{'user': 'hogehoge@gmail.com', 'shop': '店舗B', 'order': {'ハンバーグ': {'price': 1000, 'images': 'IMG_4145_ykxb9h'}}, 'total': 1000, 'datetime': '2020年7月14日今すぐ'}, {'user': 'hogehoge@gmail.com', 'shop': '店舗B', 'order': {'ハンバーグ': {'price': 1000, 'images': 'IMG_4145_ykxb9h'}, 'カレー': {'price': 2, 'images': '11967451898714_y6tgch'}}, 'total': 2002, 'datetime': '2020年7月14日今すぐ'}, {'user': 'fugafuga@gmail.com', 'shop': '店舗B', 'order': {'シチュー': {'price': 11111, 'images': 'IMG_4900_oyb5ny'}, 'ハンバーグ': {'price': 1000, 'images': 'IMG_4145_ykxb9h'}, 'コーヒー': {'price': 199, 'images': '54490_jawqyl'}, 'カレー': {'price': 2, 'images': '11967451898714_y6tgch'}, 'パンケーキ': {'price': 100, 'images': 'tweet_p7chgi'}, 'Takurinton': {'price': 100, 'images': 'npyl13'}}, 'total': 24220, 'datetime': '2020年7月16日今すぐ'}]無事返ってきます。ReactとかVueだとブラウザの関係でもっとめんどくさくなるのですが、Javaならコマンドラインで完結するので簡単でした。
まとめ
実はここに書いたもの意外にユーザー作成、ユーザーの情報取得、お店の情報取得、お店が持ってる商品一覧などなど、、、たくさん作ってあります。
ここら辺は1つのテーブルに依存する部分が多いので、カスタムよりもフィールドを指定して作る方が速かったりするので使い分けが重要ってことですね。
Java触ると疲れちゃうので今日はここら辺にしておきます。笑笑また、6時間くらいで実装することができましたが、これをまだどんどんいじって行かないといけないので長い旅になりそうです。
コロナウイルスによるオンライン授業で課題ばっかり出て大変!テストはやるんかい!とか思ってる大学生の皆さん!一緒にコロナウイルスに負けないくらい勉強してこの状況を乗り越えましょう!あと2週間頑張るぞ〜!!
- 投稿日:2020-07-15T23:17:00+09:00
herokuでプリコネの文字を解読するtwitterアプリ作った(失敗)
リンク
本アプリ
https://twitter.com/priconeAIリポジトリ
https://github.com/misogihagi/priconne-AI感想
herokuでtesseract使おうとするとlibpngでエラーでて環境整えるまでめんどくさかった。
ゲームとかアニメとかに使われている文字は丸く配置されていたり、手書きだったりして本当にちゃんとしたやつを作るとなると時間がかかりそう。
そもそも自分で読めないものを読ませようとするのが間違っていたのかも
- 投稿日:2020-07-15T22:36:52+09:00
Docker+anaconda上でtensorflowを動かしてみる
はじめに
新しくPCを購入したのでDockerを使用してpythonの環境構築してCNNを動かしてみました。
Dockerはほぼ初心者なのでこれを機に勉強していこうと思います。
今回の流れとしては
1.Docker上で公式のanaconda3イメージを取得する
2.anaconda3イメージを基にコンテナを作成
3.anaconda3にtensorflowを導入する
4.JupyterNoteookをブラウザから開く
5.Dockerのメモリを増やす
6.tensorflowを使用してCNNを構築する
となっています。環境
MacOS Catalina version 10.15.5
Docker version 19.03.8
1.Docker上で公式のanaconda3イメージを取得する
anacondaとは、データサイエンスをする方には必須なパッケージが一通り揃っているオープンソースのプラットフォームです。
こちらは公式からanaconda3のイメージがあるのでありがたく使っていきます。https://hub.docker.com/r/continuumio/anaconda3/
それでは、Dockerを起動してAnaconda3のイメージを取得します。
% docker pull continuumio/anaconda3 Using default tag: latest latest: Pulling from continuumio/anaconda3 68ced04f60ab: Pull complete 57047f2400d7: Pull complete 8b26dd278326: Pull complete Digest: sha256:6502693fd278ba962af34c756ed9a9f0c3b6236a62f1e1fecb41f60c3f536d3c Status: Downloaded newer image for continuumio/anaconda3:latest docker.io/continuumio/anaconda3:latest
pullはDockerイメージを取得するコマンドです。2.anaconda3イメージを基にコンテナを作成
次にコンテナを作成していきます。
% docker run --name anaconda -it -p 8888:8888 -v /Users/xxxx/docker/anaconda:/home continuumio/anaconda3 /bin/bash (base) root@xxxx:/# conda list各コマンド、オプションの意味は以下です。
run: コンテナを生成します。
--name [名前]: コンテナの名前を設定します。
-it: コンテナ内を操作できます。
-p [ホスト側のポート番号:コンテナのポート番号]: コンテナのポートをホスト側にバインドします。
-v [ホスト側のディレクトリ:コンテナ側のディレクトリ]: ホスト側のディレクトリをコンテナ内に
マウントします。
3.anaconda3にtensorflowを導入する
anaconda3に事前からインストールされているパッケージを確認してみます。
base) root@xxxx:/# conda list # packages in environment at /opt/conda: # # Name Version Build Channel _ipyw_jlab_nb_ext_conf 0.1.0 py37_0 _libgcc_mutex 0.1 main alabaster 0.7.12 py37_0 anaconda 2020.02 py37_0 anaconda-client 1.7.2 py37_0 anaconda-navigator 1.9.12 py37_0 anaconda-project 0.8.4 py_0 argh 0.26.2 py37_0 asn1crypto 1.3.0 py37_0 astroid 2.3.3 py37_0 astropy 4.0 py37h7b6447c_0 atomicwrites 1.3.0 py37_1 attrs 19.3.0 py_0 . . . yaml 0.1.7 had09818_2 yapf 0.28.0 py_0 zeromq 4.3.1 he6710b0_3 zict 1.0.0 py_0 zipp 2.2.0 py_0 zlib 1.2.11 h7b6447c_3 zstd 1.3.7 h0b5b093_0anaconda3のコンテナに入っているので
dockerコマンドは使えません。
anaconda terminalで使用できるconda listでパッケージを見ます。
anaconda3はtensorflowが最初からインストールされていないので、conda installを用いて
tensorflowとその周辺のパッケージをインストールしてきます。base) root@xxxx:/# conda install tensorflow4.JupyterNotebookをブラウザから開く
大学時代に愛用していたJupyterNotebookをブラウザから開けるようにします。
base) root@xxxx:/# jupyter notebook --port 8888 --ip=0.0.0.0 --allow-root . . . To access the notebook, open this file in a browser: file:///root/.local/share/jupyter/runtime/nbserver-12-open.html Or copy and paste one of these URLs: http://81127b992594:8888/?token=22ab4d7b42e6629eb76dad08af9c8e6b1d5b59e0f0050f73 or http://127.0.0.1:8888/?token=22ab4d7b42e6629eb76dad08af9c8e6b1d5b59e0f0050f73
末尾のURLをブラウザに入力するとJupyterNotebookが起動します。
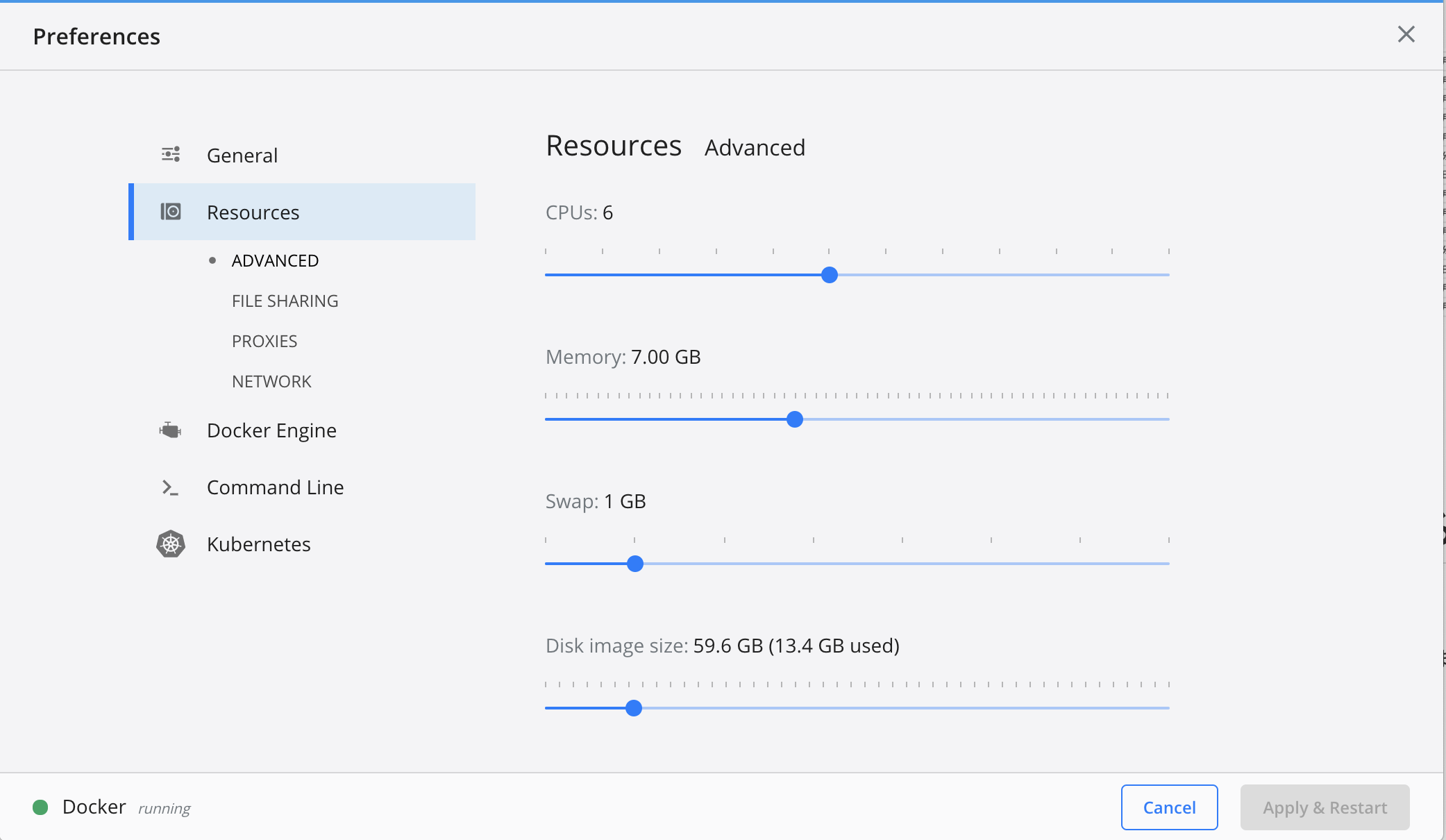
5.Dockerのメモリを増やす
CNNを構築する前にDockerはデフォルトではメモリが2Gまでしか使用できないので、CNNで学習させようとするとオーバーフローします。なので7Gまで使用できるように設定を変更していきます。
1. デスクトップの上部にあるDockerアイコンをクリック
2. Preferenceをクリック
3. Resourcesのタブをクリック
4. Memoryを7Gにする
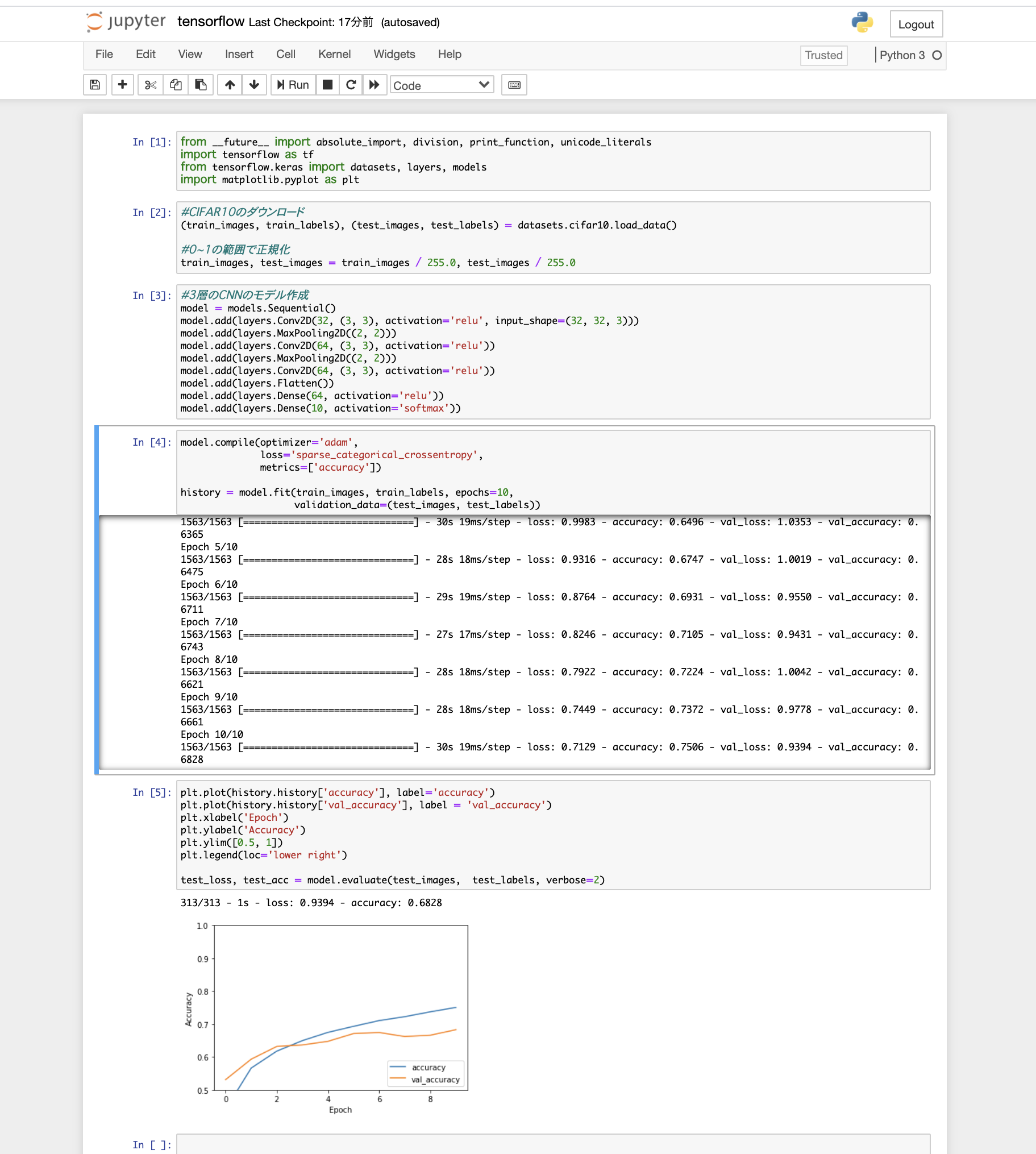
6.tensorflowを使用してCNNを構築する
最後にCNNを構築していきます。データセットは定番のCIFAR10をダウンロードし、3層の畳み込み層、最適化はadam法、損失関数はクロスエントロピー誤差を使用する至ってシンプルな構築でいきます。
tensorflowを問題なくインポートできて、メモリもオーバーフローしなかったのでこれで環境構築終了です!終わりに
Dockerを軽い気持ちで触ってみましたが、奥が深すぎて沼にハマりそうでした...
anaconda3にtensorflowを導入かつJupyterNotebookを開くという、おそらくDocker経験者なら簡単なことにかなり難航しました。Dockerはやっておいて損はないので積極的に使っていきたいです。
とりあえずtensorflowを動かすことができる環境を構築することができたので、これから色々深層学習についてこの環境で試していこうと思います。
- 投稿日:2020-07-15T22:07:29+09:00
Google Cloud Buildのステータスバッジを自動生成する
はじめに
GitHub ActionsやCircleCIを使ったことがある人が Google Cloud Build を触って思うこと・・・。
ステータスのバッジが付けられない!!調べてみると似たようなこと思っている方はいるようで「ビルドの結果からバッジを自動で作成する」的なものはOSSで何個か見つけたのですが、どうにもかゆいところに手が届かない感じで使いにくい・・・。
ということで、自分で作ってみました。こんな感じにREADMEにバッジを表示できます。
以下一連のシステムを構築するまでのまとめです。
結構長めなので話とかどうでもいいからさっさと試してみたい!という方は こちら へどうぞ。Google Cloud Buildとは
CI/CDを実現するためのマネージドサービスです(CI/CDってなんぞや?という方はググってください・・・)。
GitHub Actions 、 AWS CodeBuild 、 CircleCI なんかが親戚にあたります。
マネージドでないサービスも挙げると Jenkins や GitLab CI/CD が有名どころかと。
・・・ここら辺の名前を知っている方は、それらのGoogle版だと思ってもらえれば間違いありません。で、例えばGitHub Actionsの場合 こんな感じ にビルドステータスのバッジを生成してくれるのですが、どうもGoogle Cloud Buildにはこの機能がないっぽい(ドキュメントあさったけど見つけられなかったです・・・)。
CI/CDでビルドやテスト、デプロイが自動化できるのはいいことですが、最終的に開発者にフィードバックが来ないというのは困りものですよね。
もちろんコンソールから結果は確認できますが、いちいちコンソール開くのもダルいですし、作業していてよく目につくリポジトリのREADMEに、バッジとして貼っておきたいと思うのは、自然な感覚だと思います。バッジがないなら作ればいいじゃない!
その前に一応探してみた
プログラマなら自作すればいいじゃん!って思考に至りますよね。
でもまぁその前に、一応似たようなものが無いか調べてみたところそれっぽいものが見つかりました。なんとなくやりたいことは実現できてそうな感じですが、いくつか問題点がありました。
問題1:固定のバッジしか生成できない
バッジのメッセージ部分がビルドのステータスによって固定なのは分かりますが、ラベルの部分は動的に変更したくないですか?
例えば[test|success]や[deploy|success]みたいな感じです。
既存のものだとバッジのラベル部分が固定になるので、実際には使いづらいような気がします。問題2:ブランチに対して複数のバッジが発行できない
上の問題とからみますが、既存のものだとリポジトリのブランチの単位でバッジが保存されるため、例えば開発環境用のブランチで、テストとデプロイ用のビルドを回している場合、それら2つのバッジは保存できないことになります(既存のものはブランチに対して1つしかバッジが発行できないので、ラベル部分が固定だったと考えられます)。
その他にも、静的解析や脆弱性試験などブランチに対して様々なビルドを設定していることは十分ありえますし、実際Cloud Buildではそのような設定ができるので、この制限はかなり痛いです・・・。問題3:テンプレートとなるバッジの用意および配置の作業が面倒
スクリプトで用意しておけなくもないですが、できることなら避けたいですよね。
導入のための作業はなるだけ単純にしておきたいです。要件定義
既存のものを使うのは難しいと判断したので、以上のことも踏まえてこんな感じのものを目指しました(太字が改善部分です)。
- バッジの ラベル部分は設定によって動的に変えられる ようにする。
- バッジのメッセージ部分はビルドのステータスによって切り替わるようにする。
- リポジトリ/ブランチに対して 複数のバッジを生成・保存できる ようにする。
- バッジは完全に動的に生成 し、テンプレート等の事前準備は不要にする。
- システム構築にはマネージドなサービスを使い、極力メンテナンスが不要になるようにする。
- なるべくお金がかからない構成にする(←大事)。
システム構成
全体の流れは既存のプロダクトを参考にさせてもらいました。
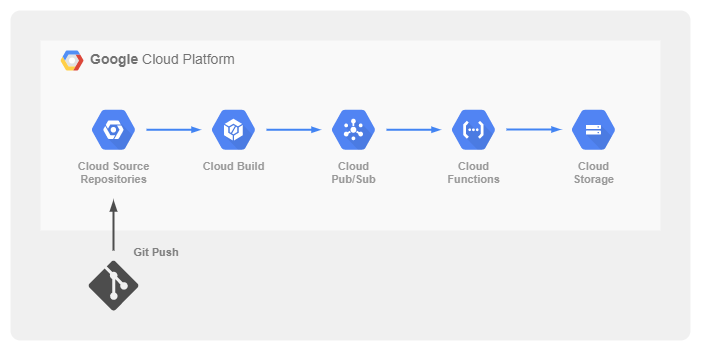
GCP上では、Cloud Source Repository、Cloud Build、Cloud Pub/Sub、Cloud Functions、Cloud Storageを連携させます(Cloud Source Repositoryの部分は代わりにGitHubでも大丈夫です)。リポジトリにPushすると、それをトリガにCloud Buildが実行されます。
Cloud Buildの実行に合わせて、Cloud Pub/Subへメッセージが送信されます。
Cloud Pub/Subのメッセージをトリガに、Cloud Functionsが発火し、Cloud Functions内でバッジの画像を生成し、それをCloud Storageへ保存するという流れです。全てマネージドのサービスを利用しているのでメンテナンスも不要ですし、各サービスとも無料枠があったり課金も使った分だけなのでお財布にも優しいです。
実際に作っていきます
Cloud Functionsによるバッジ(SVG画像)の生成
Cloud Functionsですが、自分がPythonistaなのでPythonで作るのは確定事項・・・。
で、Cloud Functions内でバッジを動的に生成したいので、SVG形式の画像を作成できるライブラリとかいろいろ探してみましたが、最終的にもっとヤバい pybadges というものを見つけました。
こちら名前の通りバッジを生成できるライブラリで、正にやりたかったことそのもの!
ありがたく使わせてもらいます。使い方はいたってシンプル。
さすがPython、簡単すぎてバカになりそう・・・。$ pip install pybadgesfrom pybadges import badge # バッジを生成する、これだけ・・・。 svg_image = badge(left_text="build", right_text="success", right_color="green") print(svg_image[:64]) # '<svg xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.'バッジの動的生成の部分についてはこれにて解決ですね!
Cloud Functionsからのバッジの保存
バッジを保存するためにCloud FunctionsからCloud Storageを操作する必要があります。
これは 公式のクライアントライブラリ があるので、それを使えば一瞬で終わりですね。$ pip install google-cloud-storagefrom google.cloud import storage # 普通にCloud Functions上で実行する分には、認証情報などの指定は不要です。 gcs_client = storage.Client() bucket = gcs_client.bucket("your-bucket-name") blob = bucket.blob("any/path/badge.svg") # キャッシュの設定を明示的に行わないと、公開コンテンツの場合1時間キャッシュされます・・・。 blob.cache_control = "max-age=60, s-maxage=60" # ファイルでなくても文字列をそのまま保存できるらしい。 # コンテンツタイプを指定しないと、外からアクセスした際に画像ではなくただのテキストファイルになるので注意! blob.upload_from_string(svg_image, content_type="image/svg+xml")バッジの保存についてもこれで問題なさそうです。
リポジトリの接続とCloud Buildの設定
メインの処理部分の目処がついたので、システムの設定周りを準備していきたいと思います。
とりあえず、GitHubなどの外部のサービスを使っている場合はリポジトリを接続したり、Cloud Buildの設定をする必要がありますが、ここら辺については割愛します。
冒頭にCloud Buildに関する説明は入れましたが、一応Cloud Build使ったことがある方(もしくは触ったことなくてもドキュメント見れば使えるレベルのGCPユーザ)を対象としているので、既にリポジトリの接続やビルドの設定はしてある前提で先に進みます。システムを構築するにあたり、ここで確認しておく必要があるのはCloud Buildのトリガについてです。
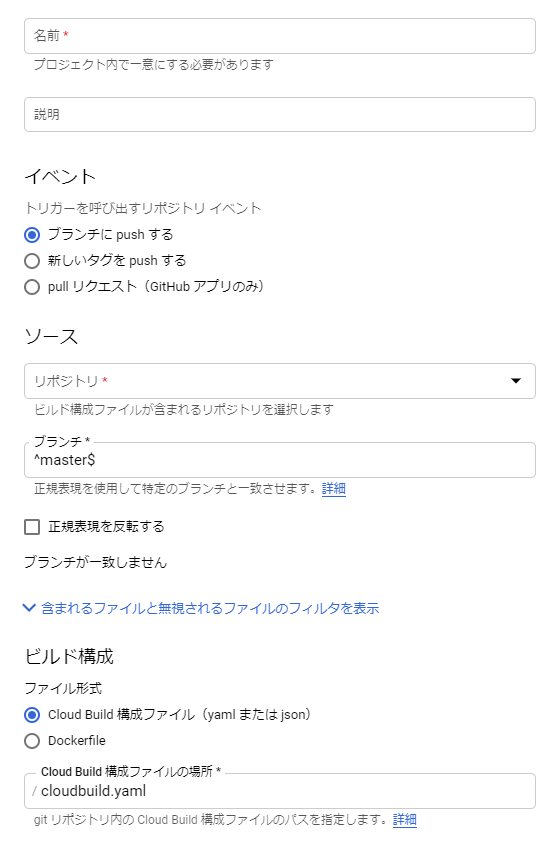
Cloud Buildのトリガ
Cloud Buildではトリガというものを設定してビルドを自動化します。
こちらはトリガの設定画面の抜粋です。
トリガにはビルドの処理を定義した構成ファイル(俗に言う
cloudbuild.yaml)が1つ設定されます。
このビルドの処理の結果をバッジとして生成します。トリガはリポジトリに対して設定しますが、リポジトリに対してトリガは複数設定可能です(1対多の関係)。
つまり、テストやデプロイなど、複数のビルドが設定できるということです。例:リポジトリとトリガの関係リポジトリ | +-- テストのトリガ | +-- 負荷試験のトリガ | +-- デプロイのトリガそして、トリガが実行された際の対象のブランチも同時に設定しますが、正規表現になっていることからも分かるようにトリガに対してブランチは複数設定可能です(1対多の関係)。
つまり、一つのトリガで開発環境や本番環境など異なる環境に対するビルドが設定できるということです。例:リポジトリとトリガとブランチの関係リポジトリ | +-- テストのトリガ | | | +-- masterブランチ | | | +-- developブランチ | +-- 負荷試験のトリガ | | | +-- developブランチ | +-- デプロイのトリガ | +-- masterブランチ | +-- developブランチこの仕様を把握すれば、自ずとビルド結果のバッジをどのような階層で保存すべきかが見えてきますね。
Cloud Pub/Subのトピック
Cloud Buildの実行をトリガにCloud Functionsが実行できれば良いのですが、それはできないのでCloud Pub/Subを経由させます(GCPのサービスは大体そんな感じです)。
というわけで、Cloud Buildの実行をトリガにCloud Pub/Subへメッセージを送信する必要があるのですが、これは特に作業いりません!
ドキュメント にある通り、実はCloud Buildからの通知はCloud Pub/Subを有効にした段階でGCP側で勝手に設定されています。Cloud Build がビルド更新メッセージを公開する Pub/Sub トピックは
cloud-buildsです。Pub/Sub API を有効にすると、cloud-buildsトピックが自動的に作成されます。ということで
cloud-buildsというトピックが既に利用できるので、これをCloud Functions発火のトリガとして設定しましょう。Cloud Storageのバケット作成
バッジの保存先であるバケットを用意しておきます。
GUIでポチポチしても良いですが、コマンドでサクッと作れます。$ export BUCKET_NAME='your-bucket-name' $ gsutil mb -c standard -l us-central1 gs://${BUCKET_NAME} $ gsutil iam ch allUsers:objectViewer gs://${BUCKET_NAME}リージョンは
asia-northeast1とかでも大丈夫ですがus-central1にすると 無料枠 が適用されます!
少しでも安く済ませたい方にはオススメです。3つ目のコマンドは全ユーザに対してバケットの読み取り権限を付与しています。
これをしないとREADME上にバッジをペタペタしても外から見れません・・・。バケットの準備については以上です。
Cloud Functionsの作成
cloud-buildsトピックをトリガに発火するCloud Functionsを作成します。
Cloud Pub/Subから受け取ったメッセージはJSON形式で取り出せるため、Cloud Buildに関する情報はそこから頑張って抽出します。・・・で、出来上がったものがこちらです。
1/3くらいはコメントやログ出力なのでコードの量ほど複雑ではないはずです。requirements.txtgoogle-cloud-storage pybadgesmain.py"""Cloud Build Badge Cloud Buildの情報からバッジを生成し、GCSへ保存する。 GCSのバケットは予め作成し、環境変数 `_CLOUD_BUILD_BADGE_BUCKET` にバケット名を設定しておくこと。 """ import base64 from collections import defaultdict import dataclasses import json import logging import os import sys from typing import List, Optional, overload from google.cloud import storage import pybadges @dataclasses.dataclass(frozen=True) class Build: """ビルドの情報。 Parameters ---------- status : str ステータス。 trigger : str トリガID。 repository : str, optional リポジトリ名。 branch : str, optional ブランチ名。 """ status: str trigger: str repository: Optional[str] = None branch: Optional[str] = None @dataclasses.dataclass(frozen=True) class Badge: """バッジオブジェクト。 Parameters ---------- label : str ラベル。 message : str メッセージ。 color : str 16進数カラーコード。 logo : str, optional Data URI形式のロゴ画像。 """ label: str message: str color: str logo: Optional[str] = None def to_svg(self) -> str: """SVG形式のバッジを生成する。 Returns ------- str SVG形式の画像データ。 """ return pybadges.badge( logo=self.logo, left_text=self.label, right_text=self.message, right_color=self.color ) def entry_point(event, context): """エントリポイント。""" try: return execute(event, context) except Exception as e: logging.error(e) sys.exit(1) def execute(event, context): """メイン処理。""" # Pub/Subのメッセージを取得する。 pubsub_msg = base64.b64decode(event["data"]).decode("utf-8") pubsub_msg_dict = json.loads(pubsub_msg) # 関係ないステータスの場合は抜ける。 build = parse_build_info(pubsub_msg_dict) if build.status not in { "WORKING", "SUCCESS", "FAILURE", "CANCELLED", "TIMEOUT", "FAILED" }: return # ログを出力する。 if not build.repository: logging.info("Unknown repository.") if not build.branch: logging.info("Unknown branch.") # 保存先のGCSバケットが設定されていることを確認する。 bucket_name = get_config("_CLOUD_BUILD_BADGE_BUCKET", pubsub_msg_dict) if not bucket_name: RuntimeError( "Bucket name is not set. Set the value to the environment variable '_CLOUD_BUILD_BADGE_BUCKET'." ) # バッジを生成し、GCSへ保存する。 badge = create_badge(pubsub_msg_dict) exported_badges = export_badge_to_gcs(badge, bucket_name, build) # ログを出力する。 for url in exported_badges: logging.info(f"Uploaded badge to '{url}'.") def parse_build_info(msg: dict) -> Build: """Cloud Buildの情報から必要なデータを取り出す。 Parameters ---------- msg : dict Pub/Subから受け取ったメッセージ。 Returns ------- Build Pub/Subのメッセージをパースしたデータ。 """ status = msg["status"] trigger = msg["buildTriggerId"] # ビルドの定義ファイル自体が壊れていた場合など、情報が取得できない場合がある。 repository, branch = None, None if "substitutions" in msg: repository = msg["substitutions"].get("REPO_NAME") branch = msg["substitutions"].get("BRANCH_NAME") return Build( status=status, trigger=trigger, repository=repository, branch=branch ) def create_badge(msg: dict) -> Badge: """バッジを生成する。 Parameters ---------- msg : dict Pub/Subから受け取ったメッセージ。 Returns ------- Badge ビルドのステータスを示すバッジ。 """ status = msg["status"] label = get_config("_CLOUD_BUILD_BADGE_LABEL", msg, default="build") logo = get_config("_CLOUD_BUILD_BADGE_LOGO", msg) status_to_color = defaultdict(lambda: "#9f9f9f") status_to_color["WORKING"] = "#dfb317" status_to_color["SUCCESS"] = "#44cc11" status_to_color["FAILURE"] = "#e05d44" return Badge( label=label, message=status.lower(), color=status_to_color[status], logo=logo ) def export_badge_to_gcs(badge: Badge, bucket_name: str, build: Build) -> List[str]: """バッジをGCSに保存する。 Parameters ---------- badge : Badge バッジ。 bucket_name : str バケット名。 build : Build ビルドの情報。 Returns ------- list of str GCSに保存したバッジのURLを格納したリスト。 """ def upload(path: str) -> None: bucket = gcs_client.get_bucket(bucket_name) blob = bucket.blob(path) blob.cache_control = "max-age=60, s-maxage=60" blob.upload_from_string(badge.to_svg(), content_type="image/svg+xml") def to_url(path: str) -> str: return f"https://storage.googleapis.com/{bucket_name}/{path}" uploaded = [] gcs_client = storage.Client() location = f"triggers/{build.trigger}/badge.svg" upload(location) uploaded.append(to_url(location)) if not build.repository or not build.branch: return uploaded branch = build.branch.replace("/", "_") # スラッシュは使えないので置換する。 location = f"repositories/{build.repository}/triggers/{build.trigger}/branches/{branch}/badge.svg" upload(location) uploaded.append(to_url(location)) return uploaded @overload def get_config(key: str, msg: dict) -> Optional[str]: ... @overload def get_config(key: str, msg: dict, default: None) -> Optional[str]: ... @overload def get_config(key: str, msg: dict, default: str) -> str: ... def get_config(key, msg, default=None): """設定値を取得する。 Parameters ---------- key : str 設定値取得のためのキー。 msg : dict Pub/Subから受け取ったメッセージ。 default : str, optional 設定値が存在しなかった際のデフォルト値。 Returns ------- str 設定値(存在しない場合は `None` もしくは `default` に指定した値)。 """ value = None if "substitutions" in msg: value = msg["substitutions"].get(key) if not value: value = os.getenv(key) if not value: value = default return valueデプロイはこちらもコマンドで行なえます。
なお、リージョンがus-central1なのは保存先のバケットと近い方が効率いいかなぁ・・・というちょっとした配慮です。$ export FUNCTION_NAME='any-function-name' $ export BUCKET_NAME='your-bucket-name' $ gcloud functions deploy ${FUNCTION_NAME} \ --runtime python37 \ --entry-point entry_point \ --trigger-topic cloud-builds \ --region us-central1 \ --set-env-vars _CLOUD_BUILD_BADGE_BUCKET=${BUCKET_NAME}以上で準備は完了です。
あとはCloud Buildを実行すればバッジが自動で生成されます。使い方について
対象となるビルドの指定
不要です!
プロジェクト内で走る全てのビルドに対して自動でバッジが作成されます(逆に言うと特定のビルドを除外したりはできません・・・)。
どんどんビルドを回してガンガンバッジを作りましょう!バッジの種類
ビルドのステータス に合わせてこんなバッジがほぼリアルタイムに生成されます。
種類はステータスごとに全部で6つです。
- ビルド中:working
- ビルドの成功:success
- ビルドの失敗:failure
- ビルドのキャンセル:cancelled
- ビルドのタイムアウト:timeout
- ステップのタイムアウト:failed
バッジの参照
同じバッジを2箇所に保存しており、それぞれ下記のURLで参照できます。
バッジの参照https://storage.googleapis.com/BUCKET/triggers/TRIGGER/badge.svg https://storage.googleapis.com/BUCKET/repositories/REPOSITORY/triggers/TRIGGER/branches/BRANCH/badge.svg
BUCKET:Cloud Storageのバケット名。TRIGGER:Cloud BuildのトリガID。REPOSITORY:ビルド対象のリポジトリ名。BRANCH:ビルド対象のブランチ名。最初は下の長い方の保存先だけで十分かなと考えていたのですが、ビルドの失敗具合によってはCloud Functions内でリポジトリ名やブランチ名が取得できない場合がありました(ビルドの構成ファイル自体のシンタックスエラーとか)。
そこで最低限情報が取れて、かつ一意のビルドを示す場所ということで上のパターンでも保存しました。
巨大なプロジェクトなど、環境ごとに複数のGCPプロジェクトが用意されていることも実際多いと思うので(自分が参加しているチームのプロジェクトがそんな感じです)、ビルドトリガの単位で保存しておけば実用性も損なわれないかなという感じです。例:リポジトリとトリガとブランチの関係(巨大なプロジェクトの場合)本番環境用のプロジェクト | +-- リポジトリ | +-- テストのトリガ | | | +-- masterブランチ | +-- デプロイのトリガ | +-- masterブランチ 開発環境用のプロジェクト | +-- リポジトリ | +-- テストのトリガ | | | +-- developブランチ | +-- 負荷試験のトリガ | | | +-- developブランチ | +-- デプロイのトリガ | +-- developブランチということで、トリガに対してブランチが1つしか設定されていない場合はこちらを参照ください。
https://storage.googleapis.com/BUCKET/triggers/TRIGGER/badge.svg対して、トリガに対して複数のブランチが設定されている場合はこちらを参照ください(ビルドの転け方によってはリポジトリ名・ブランチ名が取ってこれないので更新されない場合ありです・・・)。
https://storage.googleapis.com/BUCKET/repositories/REPOSITORY/triggers/TRIGGER/branches/BRANCH/badge.svgラベルのカスタマイズ
自分で言うのもあれですが、個人的にはかなり便利だなぁと思う機能です。
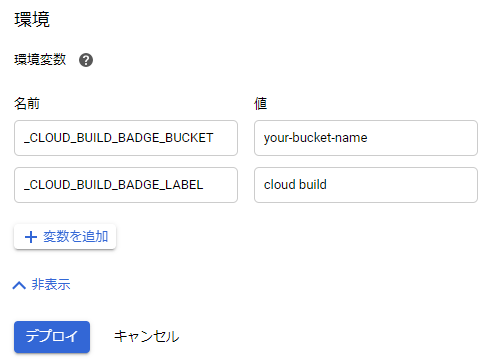
バッジのラベル部分を自由かつ簡単にカスタマイズできます。例えば「build」じゃなくて「cloud build」をデフォルトにしたいという場合は、Cloud Functionsの環境変数に
_CLOUD_BUILD_BADGE_LABELを設定してください。
さらに、Cloud Buildがテストやデプロイなど明確なタスクを持っていて「test」や「deploy」というラベルにしたいという場合は、Cloud Buildのトリガの環境変数に
_CLOUD_BUILD_BADGE_LABELを設定してください。
もしくはcloudbuild.yaml内のsubstitutions句に設定しても構いません。cloudbuild.yamlsubstitutions: _CLOUD_BUILD_BADGE_LABEL: deploy・・・さらにさらに、ロゴとか入れたいなぁという場合は
_CLOUD_BUILD_BADGE_LOGOにData URI形式の画像を設定できます!
本当はデフォルトでCloud Buildのロゴ付けたいなと思ったんですが、なんか権利関係の問題とかいろいろありそうなので、ロゴ出したい方は自分でカスタマイズしてください・・・。
ちなみに、アーキテクチャ図用ですが公式が アイコンセット 出してくれています。で、カスタマイズを施すとこんな感じになります。
これはもはや公式のバッジですね・・・。
まとめ
GCPのサービスを使ってCloud Buildのステータスバッジを自動生成するシステムを構築できました。
GitHub に置いておくので、同じようにCloud Buildのバッジをペタペタ貼りたい方がいたらぜひ使ってみてください。
それでは良きCI/CDライフを!

- 投稿日:2020-07-15T22:00:17+09:00
初心者がQiitaのタグ情報を取得しTOP10を可視化し考察する。
目的
2020/7/14現在のQiitaのタグランキング(TOP10)の記事数とフォロワー数の相関性を調べたい。
2020/7/14現在のタグランキング
ランキング タグ 記事数 フォロワー数 1位 Python 43447 79118 2位 JavaScript 35443 77167 3位 Ruby 28098 42793 4位 Rails 24287 29232 5位 PHP 20276 47787 6位 AWS 19735 8584 7位 iOS 16253 38170 8位 Java 15026 50361 9位 Docker 14948 7636 10位 Swift 14702 7268 環境
node v14.5.0
axios 0.19.2コード
app11.jsconst axios = require("axios"); async function main() { let response = await axios.get("https://qiita.com/api/v2/tags?page=1&per_page=20&sort=count"); for (let i = 0; i < 10; i++) { console.log('タグ: %s' ,response.data[i].id); console.log('記事の数: %d' ,response.data[i].items_count); console.log('フォロワー数: %d' ,response.data[i].followers_count); console.log(''); } } main();実行結果
タグ: Python 記事の数: 43447 フォロワー数: 79118 タグ: JavaScript 記事の数: 35443 フォロワー数: 77167 タグ: Ruby 記事の数: 28098 フォロワー数: 42793 タグ: Rails 記事の数: 24287 フォロワー数: 29232 タグ: PHP 記事の数: 20274 フォロワー数: 47787 タグ: AWS 記事の数: 19735 フォロワー数: 8584 タグ: iOS 記事の数: 16253 フォロワー数: 38170 タグ: Java 記事の数: 15206 フォロワー数: 50361 タグ: Docker 記事の数: 14948 フォロワー数: 7636 タグ: Swift 記事の数: 14701 フォロワー数: 7268結果
csvで出力しようしましたが、今回のトライではうまくできず・・・
テキストドキュメントにコピペし,(カンマ)へ置換をし不必要な部分は削除しました。Jupyter Notebookで可視化
最近まで勉強していたJupyter Notebookでチャートを作成しました。
ライブラリとCSVを読み込み、コードを実行。
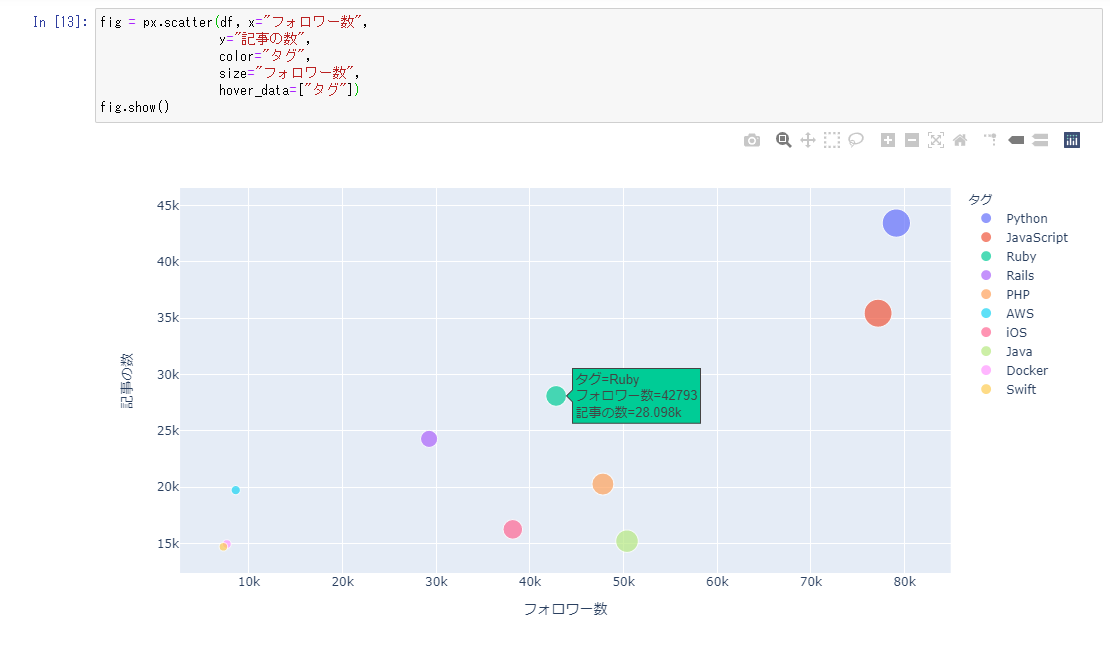
考察
- 今回グラフから読み取れるのは、PythonとJavaScriptの人気が非常に高い。
- Pythonは、AI、IoTなどの分野で活用され、人気が高まってる?私もRaspberrypiを使うようになりPythonに興味を持った。
- フォロワー数に対する記事数はPythonが多い、Pythonの記事は書きやすい技術が多い?またJavaを見るとフォロワー数は多いが、記事数は少なめ、なぜ??
今後
- JavaScriptにもグラフを書けるChart.jsやECharts.jsというライブラリがあるようなので、次回はそちらで可視化をしてみたい。
- 今回は私の考察のみだが、なぜこの2つが人気が高いのか、掘り下げてる。
- 投稿日:2020-07-15T21:20:46+09:00
Pythonでどうしてもsettings.iniを読み込めないエラーが生じた
この記事の内容
あるPCで動いていたコードが違うPCで動かないことがありました。
原因は相対パスを上手く読み込んでいないことが原因のようでしたので、備忘として解決策を記載します。
なお、現時点で解決策がうまくいく理由がわからないため、理解ができた段階で記事を更新する予定です。目次
1.背景
2.事象の整理
3.解決策
4.解決策が上手くいく理由1. 背景
とある簡単なアプリケーション作成のために書いたコードが1,000行超え始めたところから、1ページのpythonファイルにコードを書くことに限界を感じ始めましたので、処理
を分割し、複数のpythonファイルに分けて管理をすることとしました。
ログイン情報等の初期値についてはsettings.iniファイルを作成し、settings.pyからconfigparserを使って読み込むこととしました。
また、アップデート管理をするためにgithubも先日使い始めました。
初めてのことが重なり、わからないこともたくさん出てきたので備忘として記録を残します。2. 事象の整理
メインPCで作成したRepositoryをgitからサブPCにクローンを作成したときに、なぜかうまくいかない箇所がいくつかありました。
特に理由がわからなかったのが、相対パスで参照していたsettings.iniをsettings.pyから読み込めない点でした。メインPCでは下記のコードで問題なく動いていました。
settings.pyimport configparser conf = configparser.ConfigParser() conf.read('./settings.ini') # プロファイルパス PROFILE_PATH = conf['driver']['PROFILE_PATH'] # saleceforce Saleceforce_ID = conf['saleceforce']['Saleceforce_ID'] Saleceforce_PASS = conf['saleceforce']['Saleceforce_PASS'] Saleceforce_ADDRESS = conf['saleceforce']['Saleceforce_ADDRESS']しかし、これをサブPCで動かすと下記のエラーが生じます。どうやら
'./settings.ini'をうまく読み込めていないということがわかりました。raise KeyError(key) KeyError: 'driver'3. 解決策
こちらについては下記のように書き直してやるとうまくいきます。
settings.pyimport configparser import os conf = configparser.ConfigParser() path = os.path.join(os.path.dirname(__file__), 'settings.ini') conf.read(path, 'UTF-8') # プロファイルパス PROFILE_PATH = conf['driver']['PROFILE_PATH'] # saleceforce Saleceforce_ID = conf['saleceforce']['Saleceforce_ID'] Saleceforce_PASS = conf['saleceforce']['Saleceforce_PASS'] Saleceforce_ADDRESS = conf['saleceforce']['Saleceforce_ADDRESS']相対パスだとうまく読み込めないので、実行ファイルのディレクトリを
os.path.dirname(__file__)で読み込んで直接指定してやると上手くいきました。
違う環境でコードを実行するときはこっちのほうがいいのかもしれないです。4. 解決策が上手くいく理由
理由がわかりません。
自分の中で理解ができたら更新します。
- 投稿日:2020-07-15T20:40:31+09:00
【Python】初心者向け勉強会議事録(7/15)
7/15 21:00~ ZOOMにて開催
アジェンダ
- そういえばBool型って?
- while文
- break文
- 雑談
そういえばBool型ってなんだっけ
Bool型には
TrueとFalseがある。普段使ってるオブジェクトの型を確認するには
typeメソッドを使う。Try:普段使ってるオブジェクトが何の型か再確認してみよう。
解答例
Exampleprint(type(1)) # => <class 'int'> print(type('hogehoge')) # => <class 'str'> print(type(False)) # => <class 'bool'> print(type(Ture)) # => <class 'bool'>普段何気なく使っているif文の条件式。その中身は基本Bool型になってる。つまり条件を作るときは、式がちゃんとBool型になるか気を付けよう。
hoge = True if hoge: print('hogeの中身はTure') else: print('hogeの中身はFalse') # => hogeの中身はTureちなみに条件式によく使う
==とか>とかorみたいな演算子もBool型で返ってくる。a = 0 b = 1 print(a == b) # => False print(a < b) # => True print(a == b or a < b) # => Trueここまでは基本といえば基本だけど、「条件式はBool型」ってわかってるだけで、すでに勉強したif文やこれから勉強するwhile文が理解しやすくなりそうだったのでアジェンダに追加してみた。
応用として、trueと1,falseと0は等価なので
print(True == 1) print(False == 0)は、どちらも
Trueを返す。なぜこうなるかは調べてみてね。while文
while文は、繰り返し処理に使う基本的な構文。
while 条件式: 条件がTureの時に繰り返す処理例えば「1~10を出力」する場合
i = 1 # ループ変数とか言われる。カウントするために用意する while i <= 10: print(f'数値は {i}') i += 1 # 1ずつ加算してる。これがないと条件がずっとTureで無限ループになっちゃうTry:2の0乗から2の10乗を出力してみよう。(0乗はどんな数値でも1になる)
解答例
Examplei = 0 while i <=10: print(2 ** i) # ** 演算子で乗数をもとめる i += 1break文
break文は、繰り返し処理から抜け出すときに使う。
i = 0 while 1: print(i) if i > 2: break i += 1 # => 0 # => 1 # => 2 # => 3Try:「exit」と入力されるまで「文字を入力してください」と出力するプログラムを作ってみよう。ちなみになぜ
while 1:で無限ループになる?Bool型の話に遡ってみよう解答例
Examplewhile 1: str = input('文字を入力してください >> ') if str == 'exit': break雑談
- 投稿日:2020-07-15T20:18:43+09:00
某テーマパークのチケットをpythonで入手するプログラミング#1
背景
昨今の感染症拡大の影響からチケットに予約が必要になってしまったテーマパーク!
今やチケットを手に入れるには1日中パソコンやスマホと睨めっこをしてURLを連打しなくては夢のパスポートを手に入れることができなくなってしまった。そこで昔挫折したスクレイピングを練習するいい機会だと思い、スクレイピングを利用してできるだけ楽にパスポートを入手しようという試みである。
行う内容
こちらのサイトでいかに夢の国のパスポートを手に入れることが難しいかがわかると思う。
初めの関門はネットで調べて出てくるURLではアクセス過多により現在ページを開ませんというページに飛んでしまうことである。
まずここを乗り越えることを今回の目標としてこのURLに毎秒アクセスし、アクセスができたときに自分のメールアドレスに今つながりやすいということで連絡を入れるプログラムを実装する。
環境
python3上で動かす。
依存ライブラリはすべてpip3でインストールできるはずなのでまだインストールできていないようであれば$pip3 install hogeで環境は整うはずである。
実装
main.pyimport requests from bs4 import BeautifulSoup import time import gmail for i in range(100000): urlName = "https://reserve.tokyodisneyresort.jp/ticket/search/" url = requests.get(urlName) soup = BeautifulSoup(url.content, "html.parser") title = soup.find("h1").text print(i) if(title!="東京ディズニーリゾートからのお知らせ"): print("SUCEED!") gmail.send() print(soup)#全情報出力 break print("FAILURE") time.sleep(1)gmailというライブラリは存在せず後述する。ここで流れを確認する。
まず長いまたは無限のループ内にリンクにアクセスし、そのタイトルが「某テーマパークからのお知らせ」となっていた場合アクセス失敗なのでやり直し、ほかのタイトルになっていた場合アクセス成功なのでgmailを送信し、そのサイトのHTML情報をすべて吐いて終了というものである。ここで将来的に全自動化まで行いたいのでHTML情報を標準出力している。
次にgmailを送るスクリプトを書く。
gmail.pyimport smtplib from email.mime.text import MIMEText from email.utils import formatdate def send(): FROM_ADRESS = "メールを送る側のメアド" PASSWORD = "メール送る側のパスワード" TO_ADRESS = "メール受け取る側のパスワード" smtpobj = smtplib.SMTP('smtp.gmail.com', 587) smtpobj.ehlo() smtpobj.starttls() smtpobj.ehlo() smtpobj.login(FROM_ADRESS, PASSWORD) #メールの内容を記述 msg = MIMEText('https://reserve.tokyodisneyresort.jp/ticket/search/') msg['Subject'] = 'EASY TO ACCESS NOW!' msg['From'] = FROM_ADRESS msg['To'] = TO_ADRESS msg['Date'] = formatdate() smtpobj.sendmail(FROM_ADRESS,TO_ADRESS,msg.as_string()) smtpobj.close()必要最低限のコードでsend()を読んだ時にチケット購入のURLを送ることができるように実装した。
ここで注意しなくてはならないのがGmailのデフォルトの設定でメールを送る側が安全性の低いアプリからのアクセスを許可しておかないとgmail.send()は動かないということである。
設定を予め許可に変えてから動かさなくてはならない(デフォルトでは許可になっていない)動かし方
コードをすべてコピペしてmain.py,gmail.pyという名前で同じディレクトリ内に保存すれば
$python3 main.pyで実行されるはずである。
今後
今回のプログラムによって得られたHTML情報を用いて購入まで全自動で行うことを目標としてこれからpythonでのスクレイピングを勉強していきたいと思う。
- 投稿日:2020-07-15T20:18:43+09:00
某テーマパークのチケットをpythonで入手する
背景
昨今の感染症拡大の影響からチケットに予約が必要になってしまったテーマパーク!
今や1日中パソコンやスマホと睨めっこをしてURLを連打しなくては夢のパスポートを手に入れることができなくなってしまった。そこで昔挫折したスクレイピングを練習するいい機会だと思い、スクレイピングを利用してできるだけ楽にパスポートを入手しようと試みた。
行う内容
こちらのサイトでいかに夢の国のパスポートを手に入れることが難しいかがわかると思う。
初めの関門はネットで調べて出てくるURLではアクセス過多により現在ページを開ませんというページに飛んでしまうことである。
まずここを乗り越えることを今回の目標としてこのURLに毎秒アクセスし、アクセスができたときに自分のメールアドレスに今つながりやすいということで連絡を入れるプログラムを実装する。
環境
python3上で動かす。
依存ライブラリはすべてpip3でインストールできるはずなのでまだインストールできていないようであれば$pip3 install hogeで環境は整うはずである。
実装
main.pyimport requests from bs4 import BeautifulSoup import time import gmail for i in range(100000): urlName = "https://reserve.tokyodisneyresort.jp/ticket/search/" url = requests.get(urlName) soup = BeautifulSoup(url.content, "html.parser") title = soup.find("h1").text print(i) if(title!="東京ディズニーリゾートからのお知らせ"): print("SUCEED!") gmail.send() print(soup)#全情報出力 break print("FAILURE") time.sleep(1)gmailは後述するスクリプトなのでinstallは不要である。
ここで流れを確認する。
まず長いまたは無限のループ内にリンクにアクセスし、そのタイトルが「某テーマパークからのお知らせ」となっていた場合アクセス失敗なのでやり直し、ほかのタイトルになっていた場合アクセス成功なのでgmailを送信し、そのサイトのHTML情報をすべて吐いて終了というものである。ここで将来的に全自動化まで行いたいのでHTML情報を標準出力している。
次にgmailを送るスクリプトを書く。
gmail.pyimport smtplib from email.mime.text import MIMEText from email.utils import formatdate def send(): FROM_ADRESS = "メールを送る側のメアド" PASSWORD = "メール送る側のパスワード" TO_ADRESS = "メール受け取る側のメアド" smtpobj = smtplib.SMTP('smtp.gmail.com', 587) smtpobj.ehlo() smtpobj.starttls() smtpobj.ehlo() smtpobj.login(FROM_ADRESS, PASSWORD) #メールの内容を記述 msg = MIMEText('https://reserve.tokyodisneyresort.jp/ticket/search/') msg['Subject'] = 'EASY TO ACCESS NOW!' msg['From'] = FROM_ADRESS msg['To'] = TO_ADRESS msg['Date'] = formatdate() smtpobj.sendmail(FROM_ADRESS,TO_ADRESS,msg.as_string()) smtpobj.close()必要最低限のコードでsend()を読んだ時にチケット購入のURLを送ることができるように実装した。
ここで注意しなくてはならないのがGmailのセキュリティ設定でメールを送る側が安全性の低いアプリからのアクセスを許可しておかないとgmail.send()は動かないということである。
設定を予め許可に変えてから動かさなくてはならない(デフォルトでは許可になっていない)動かし方
コードをすべてコピペしてmain.py,gmail.pyという名前で同じディレクトリ内に保存すれば
$python3 main.pyで実行されるはずである。
今後
今回のプログラムによって得られたHTML情報を用いて購入まで全自動で行うことを目標としてこれからpythonでのスクレイピングを勉強していきたいと思う。
- 投稿日:2020-07-15T20:05:56+09:00
Pythonでは`+++`も`+++++`も`++++++++`も許される
バズっているようなので相乗りします。
C/C++ では+++は許される
JavaScriptで+++は許されない+ ++は許されるPythonでは
++も+++も++++++++++も許されます!a = 1 b = 2 print(a+b) # OK print(a++b) # OK print(a+++b) # OK # ... print(a+++++++++++++++b) # OKすなわち、
+を繋げてどんなに長い「演算子」をつくったとしても動きます。上でつくった「演算子」は、前置演算子としても使えます。
上でつくった「演算子」は2項演算子ですが、同様に前置演算子バージョンもあります。
a = 1 print(+a) # OK print(++a) # OK print(+++a) # OK # ... print(+++++++++++++++a) # OK
-----でもよい。
+が嫌いな方は、-を使って「演算子」を構成してもよいでしょう。a = 1 b = 2 print(a-b) # OK print(a--b) # OK print(a---b) # OK # ... print(a---------------b) # OKもちろん、前置演算子バージョンも使えます。
また、+と-を適宜まぜあわせて使ってもいいです。(+---+-+++-+のように)用途
ソースコードの区切り
print("first") print("second") print("third") 0-+-+-+-+-+-+-0 print("100 times")JavaScriptだとダメ
Javascriptの場合、以下のように3文字以上の「演算子」はエラーとなる可能性が高いです。
let a = 1 console.log(+++a) // NG console.log(a+++) // NG console.log(++-a) // NGただし、以下はOKです。
let a = 1, b = 2 console.log(-++a) // OK console.log(+-+a) // OK console.log(a++-b) // OK console.log(a-++b) // OK console.log(a++-++b) // OKなぜダメなの?
PythonとJavaScript (or C)の違いは、インクリメント演算子
++が定義されているかどうかです。例えば+++++という「演算子」がある場合は演算子を最小一致で切り出していくので、+++++という3つの演算子に分割されます。
++演算子は右側(or 左側)が左辺値(変数)でなければならないため、エラーとなります。思ったこと。
インクリメンタル演算子がある言語の場合、大体どれも同じ挙動をしますね。https://t.co/7RRNSuFLBk
— yasuo_ozu (@yasuo_ozu) July 14, 2020※
++が存在しない言語でも、Luaの場合は++のようにつなげて書くと++のように分割されず、エラーになるようです
- 投稿日:2020-07-15T19:31:07+09:00
新しいMacに綺麗にPython環境を構築し、Jupter Notebookを導入する方法
0. はじめに
Macの機種変更をしたのでローカルのJupterNotebookを使うために環境構築をした際のメモです。
0-1. 前提事項
Macは標準でPython2.xが導入されています。ただ、Python3.xを扱いたいので、まずはPython3.xを導入します。
(Python2.xは他のアプリ等で使われる可能性もあるので、綺麗に残しておきます。)
また、個人の環境なので、そこまで必要ないのかもしれませんが、venvをつかって環境を分離します。venvを使うと、導入パッケージを複数独立して切り分けることが出来ます。(Python 3.3からは標準で導入されています。)
pyenvをつかった、Python2.xとPython3.xの切り分けは実施しません。0-2. 導入ステップ
1.1. Homebrewのインストール
1.2. Python3のインストール
1.3. pipのアップデート
1.4. venvの環境設定
1.5. 必要そうなライブラリのインストール
1.6. Jupyter Notebookのインストール1. 導入
ここらからが導入ステップです。
1.1. Homebrewのインストール
導入方法をこちらを確認ください。
1.2. Python3のインストール
ターミナル$ brew install python31.3. pipのアップデート
ターミナル$ pip3 install --upgrade setuptools $ pip3 install --upgrade pippipはPythonで使用されるパッケージマネージャーです。Python3のインストール時に同時に導入されます。Python3.xなのでpip3です。Permission系のエラーが出た場合は、Sudoをつけて実行してみてください。
1.4. venvの環境設定
ターミナル$ cd [導入ディレクトリ] $ python3 -m venv [環境名]これにより、[導入ディレクトリ]に[環境名]のフォルダが作成され、その下位に必要なコンポーネントが導入されます。
下記のコマンドによりvenvが有効化されます。ターミナルに(env)が追加されます。終了する場合は、「deactive」とコマンドして下さい。ターミナル$ . [環境名]/bin/activate $ deactivate1.5. 必要そうなライブラリのインストール
Jupterで必要そうなPythonのライブラリをインストールします。
ターミナル$ pip install numpy $ pip install scipy $ pip install scikit-learn $ pip install Pillow $ pip install pandas $ pip install matplotlib1.6. Jupyter Notebookのインストール
ターミナル$ pip install jupyter2.Jupter Notebookの起動
ターミナル$ jupyter notebook3.おまけ(Jupyterthemesを用いた見た目の変更)
標準の設定は白ベースで、個人的にはフォントサイズも少し小さいのであまり好みではありません。Jupyterthemesという見た目を変えるパッケージを導入します。
ターミナル$ pip install jupyterthemes $ pip install --upgrade jupyterthemesお好みのテーマを設定します。テーマの詳細はご自身で調べて下さい。
ターミナルjt -t oceans16私の設定です。
ターミナルjt -t oceans16 -T -N -ofs 9 -f inconsolata -tfs 10 -cellw 80% -tfs 9以上です。
- 投稿日:2020-07-15T19:22:10+09:00
python使うけどclassはよくわからん、のでチュートリアルする
pythonは使うけどclassとかよくわからん。
でもpytorchにclassが頻出なので勉強する必要がある。同じような立場の人が心理障壁を下げるために使っていただけたらと思う。
正しい理解は公式ドキュメント9:classを参照してください。
とりあえず関数「def」
処理したい操作に名前と引数を指定することができる。
def kakezan(a, b): return a*b kakezan(9, 9)81実行結果は次のようにして変数に保存できる。
times99 = kakezan(9, 9)classについて一番かんたんな構造で考える
ただの情報の値の入った箱と考える
class keisan: num1=1 num2=2クラスの中の情報をドット記号を使って取り出すことができる。
keisan.num1引数とイコールで結ぶと、情報の入った箱を移し替えるようなイメージで扱える
box1 = keisan() box1<__main__.keisan at 0x7f5e03896b38>クラスの名前が出力される
box1.num1中身をドットで取り出すことができる。
box1というオブジェクトの変数を書き換える
box1.num1=10 box1.num110コンストラクタ
オブジェクトが生成される時に必ず実行されるメソッド(class内の関数)のこと
class keisan: num1=1 num2=2 def __init__(self): print('必ず表示される') box3 = keisan()classを変数に入れるとコンストラクタ部分が実行される
必ず表示される上記のselfは必ず書くおまじないである
selfがさしている対象は上記であればbox3
今は処理が何もないが、必ずなにか引数を入れなさい。という指示にも使えるclass keisan: num1=1 num2=2 def __init__(self,name1,age1): print('一人目の名前は' + name1 + 'で年齢は' + str(age1) + 'です。これは毎回表示されます。') box4 = keisan()--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-7-df434c06b06e> in <module>() 7 'で年齢は' + str(age1) + 'です。これは毎回表示されます。') 8 ----> 9 box4 = keisan() TypeError: __init__() missing 2 required positional arguments: 'name1' and 'age1'なにも入れないとprintが実行できないからエラーになる。
box4 = keisan(name1='Mike',age1=19)一人目の名前はMikeで年齢は19です。これは毎回表示されます。表示処理しておわり。
このままでは入力したものが取り出せない。
box4.name1--------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-9-53236fb457a0> in <module>() ----> 1 box4.name1 AttributeError: 'keisan' object has no attribute 'name1'エラーになる
保存したければ引数をつくっておくclass keisan: num1=1 num2=2 def __init__(self,name1,age1): self.name1=name1 self.age1=age1 print('一人目の名前は'+name1+'で年齢は'+str(age1)+'です。これは毎回表示されます。') box5 = keisan('Rachel',22) box5.name1Rachelとりだせた。
引数は無いけど決まった処理を行いたい時
class keisan: num1=1 num2=2 def __init__(self,val1): self.val1=val1 def plus10(self): self.val1 +=10 box6 = keisan(val1=15) box6.val115クラス内のplus10メソッドを使う
box6.plus10() box6.val125クラス内のオブジェクトを変更するメソッド
引数はselfでなくclsにする
class keisan: num2=2 def __init__(self,val1): self.val1=val1 def plus10(self): self.val1 +=10 def plus5(cls): cls.num2 +=5 box7 = keisan(val1=22) box7.num22classのnum2を変更するメソッドのplus5を実行する
box7.plus5() box7.num27クラス内のnum2が変更できた
お作法 変えてほしくない
classを設計して他人にコードを公開する時、設計上変更してほしくない部分は「_」記号を付ける。
class keisan: def __init__(self,val1,val2): self._val1=val1 #変えてほしくない self.val2=val2 #変えてもいい box9 = keisan(10,20) print(box9._val1) print(box9.val2)10 20box9._val1 = 30 box9._val130変えられちゃうんですけどね
もうちょっと変えてほしくない気持ちを強くする
class keisan: def __init__(self,val1,val2): self.__val1=val1 #変えてほしくない気持ちを強く self.val2=val2 #変えてもいい box10 = keisan(10,20) box10.__val1--------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-15-68ebfca72338> in <module>() 6 7 box10 = keisan(10,20) ----> 8 box10.__val1 AttributeError: 'keisan' object has no attribute '__val1'エラーになる
確認できなくなった。どうしても触りたいときは「_クラス名」を間に挟む
クラス名の確認
print(type(box10))<class '__main__.keisan'>クラス名はkeisanと確認できる
box10._keisan__val110確認できた。
_が一つよりも隠せた。名前空間がよくわからないけど
名前空間とは名前からオブジェクトへの対応付けに関係する概念
モジュール1番(機能のまとまり。関数のまとまりをイメージ)の中にある関数1がある。
おなじ名前の関数は、別のモジュールの中で定義されていたらなば、同じ名前でも別物として扱える
このような関数は異なった名前空間の関数の名前であり、関係は持たないらしいので確かめる
class cs1: def __init__(self,val1): self.val1=val1 def cal1(self,val2): self.kekka = self.val1 * val2 class cs2: def __init__(self,val1): self.val1=val1 def cal1(self,val2): self.kekka = self.val1 + val2 class1 = cs1(10) class1.cal1(15) print(class1.kekka) class2 = cs2(10) class2.cal1(15) print(class2.kekka)150 25同じ関数の名前でも別のclassのメソッドであれば別処理が行われる。
以上
- 投稿日:2020-07-15T19:02:39+09:00
PULSEで顔画像を毛穴や質感が分かるくらいの高画質に変換する
1.はじめに
皆さんは、低解像度の画像を高解像度の画像に変換したいと思ったことはありませんか。2020年6月デューク大は従来8倍が最大であった高解像度変換を64倍にまで引き上げる PULSE という手法を発表しました。これにより、目元も口元もハッキリしないモザイクの様な顔画像が毛穴や質感が分かるくらいの高画質に変換できます。
今回は、Githubで公開されているソースコードを試してみた結果をご紹介します。なお、コードは Google Colab で作成し Github に上げてありますので、自分でやってみたい方は、この「リンク」をクリックし表示されたシートの先頭にある「Colab on Web」ボタンをクリックすると動かせます。
2.アルゴリズム
アルゴリズムは、学習済みGANモデルを使って「ある高解像度画像から低解像度変換した画像」を生成し、これと「低解像度の画像」との差をロスとして、ロスを最小化する様な高解像度画像を求めるというものです。気になるのは、学習済みGANモデルを使っているので、学習に使った画像は上手く高解像度変換できると思いますが、学習に使っていない画像も上手く行くのかということです。
ということで今回は、色々な顔画像からわざと低解像度画像(32×32ピクセル)を作り、これをどの程度正確に高解像度変換(1024×1024ピクセル)できるのか見て行きたいと思います。最適化回数(steps)は1000とします。
3.学習済みの顔画像(FFHQデータセット)
PULSEで使われている学習済みGANモデルはStyleGANです。従って、学習にはFFHQデータセットが使われており、この顔画像は少なくとも上手く行くはずです。それでは、FFHQデータセットから3つの画像を取り出してやってみます。
Low Resolution は低解像度画像(32×32)、High Resolution はそれを高解像度変換した画像(1024×1024)、Real はLow Resolution を作成した元画像です。従って、High Resolution が Real にどれだけ近づいているかで高解像度変換の精度が分かります。当たり前ですが学習済み画像では、問題なく高解像度変換できています。
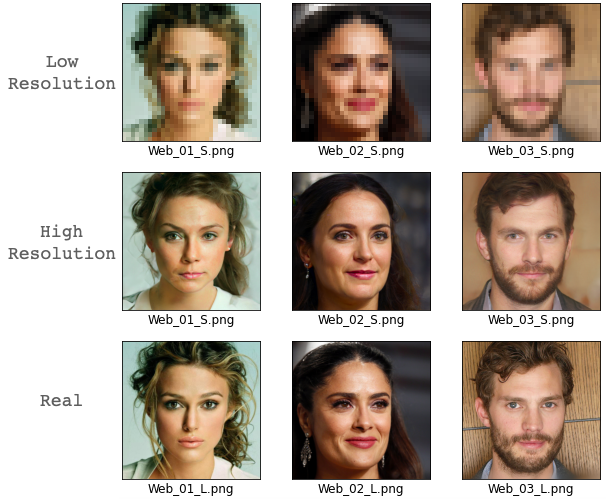
4.未学習の顔画像(外国人)
それでは、未学習の顔画像(外国人)ではどうでしょうか。Web検索で取得した3人の外国人の顔画像でやってみます。
ほほー、外国人なら学習に使っていない顔画像でも、上手く行くようです。5.未学習の顔画像(日本人)
それでは、未学習の顔画像(日本人)ではどうでしょうか。Web検索で取得した3人の日本人の顔画像でやってみます。確か、FFHQデータセットには、あまり日本人は居なかったようなので、どうなるでしょうか。
思ったらより良い出来です。High Resolution の方が Real に比べて、目がちょっと違うのと顔のシワが多い様に思いますが、まあまあではないでしょうか。最適化回数(steps)を増やすと、もう少し改善されるようです。
6.現実場面を想定したテスト
さて、今までは高画質画像をわざと32×32ピクセルに縮小して、それを高画質画像に変換するテストを行って来ましたが、現実場面でやりたいのは初めから低画質である画像を高画質に変換したいわけです。ここでは、そのテストをやってみます。
元乃木坂46の初代キャプテン桜井玲香のWekipediaには、冒頭にこんな画像があります。
画像サイズは 190×253ピクセルで、顔の部分だけだと90×90ピクセルくらいでしょうか。それでは、この画像から顔画像を切り取り高画質変換してみます。最適化回数(steps)はガッツリ6000でやってみます。
おっ! これ、結構いけてると思いませんか。
7.まとめ
予想を超える高画質変換が可能なことに驚きました。考えてみれば、32×32ピクセルの画像は、1024次元のベクトルと同じ情報量を持っているわけで、そこには高画質画像を引き出すためのポテンシャルは十分あるわけですね。
それにしても、デューク大面白いことを考えました。従来の方法とは全く違うPULSEという手法、興味深いです。






- 投稿日:2020-07-15T18:36:13+09:00
「Anvil」を使ってみた。
Python勉強して、Djangoのチュートリアルも一通り済ませたところで、「Anvil」というWebアプリが作成できるプラットフォームの話題が耳に入ってきたので、さらっと触ってみましたので、感想です。
※技術的な情報はほぼありません。すみません。一応、「Start Here」の3つのチュートリアルは済ませました。総計で4~5時間程度と思います。
Anvil/Learn Centre/Start Here
良い点
- 比較的、単純なユーザーインターフェース。
- 感覚としては、ExcelでVBAアプリを作成するのに近いかと思います。
- コード(ロジック)とデザイン(ビュー)が完全分離されていてわかりやすい。
- 好みや慣れもあると思いますが、HTMLにコード埋め込んだりすると「読みにくいな~」とか思ってしまうので。
- 基本的な機能の利用はブラウザ上で完結する。
- 開発環境を手元に作る必要がないので、始めるのが簡単です。
- 外部データの取り込み(データベースへのアクセスなど)もできるので、まだ試していませんが、ローカルPC上のデータとかクラウド上のデータベースとも繋げそうです。
- 無料プランでも作成したWebアプリの公開が可能。
- URLが固定、など制限はありますが、万人に使ってもらうようなアプリ(サイト)を作るのでなければ問題ないと思います。
- Pythonの基本的な記述方法が理解できていれば、OK。
- 一応、HTMLやCSSの直書きもできるようですが、画面デザインはドラッグアンドドロップとプロパティの設定でほぼほぼ完結するので、HTML/CSSを知らなくてもそれっぽい画面が作れます。
- 同様にデータベースを扱う際にもSQLの知識などは不要です。とはいえ、Pythonでデータベース上のデータを扱う方法については多少かじっておく方が理解は早いと思います。
悪い点
- チュートリアル&ドキュメントなどすべて英語。
- 中学生レベルの英文法とブラウザの翻訳拡張機能である程度どうにかなりますが、苦手意識があるとちょっと辛いです。
- 動画や、キャプチャ画面が多いので、英語読めなくてもなんとなくできてしまうかもしれません。
- お勧めできる人
- HTML/CSSで画面デザインができない/苦手な人。
- Pythonを勉強して、Pythonで何かできないかな?、と模索中の人。
- プログラミング勉強中で「何か動く」と楽しい人。
がっつり使い込む使い方もできそうですが、そうでもない人でも扱いやすそうに感じたので、日々の事務作業の効率化や、プログラミングの勉強、など間口は広いように思いました。
以上、乱文失礼いたしました。
- 投稿日:2020-07-15T18:02:16+09:00
都道府県別コロナ陽性者数を可視化
概要
東洋経済オンラインさんが、新型コロナウイルス国内感染の状況を可視化するページを公開しています。
ありがたいことに使用しているデータをこちらに公開してくださっていますので、pythonのjapanmapを使って都道府県別にプロットしてみました。結果
直接qiitaに貼れなかったので、twitterにあげたものを。
こちら(https://t.co/dJ6lpgGr9c)からデータをいただいて、日毎の都道府県別コロナ検査陽性者数をjapanmap(https://t.co/sGthVkJ6Kn)を使って可視化してみた。
— 侵略済スペース毛玉 (@space_kedama) July 15, 2020
ソースコードをこちら(https://t.co/0Bi7JyJs1Q)におくので、間違いがあったら指摘お願いします。 pic.twitter.com/2gJeHbHyOT積算の都道府県別コロナ検査陽性者数も載せとく。
— 侵略済スペース毛玉 (@space_kedama) July 15, 2020
日本中が白に染まっていく。 pic.twitter.com/BEKvZXTXGkソースコード
plot_pref.py#japanmap: https://qiita.com/SaitoTsutomu/items/6d17889ba47357e44131 import matplotlib.pyplot as plt import matplotlib.animation as animation import pandas as pd import japanmap def plot_pref(df_data, cmap): cmap_ = plt.get_cmap(cmap) #norm = plt.Normalize(vmin=df_data.min(), vmax=df_data.max()) norm = plt.Normalize(vmin=df_data.min(), vmax=50) fcol = lambda x: '#' + bytes(cmap_(norm(x), bytes=True)[:3]).hex() sm = plt.cm.ScalarMappable(norm=norm, cmap=cmap_) sm._A = [] im = plt.imshow(japanmap.picture(df_data.apply(fcol))) plt.xticks(color="None") plt.yticks(color="None") return sm, im def make_gif_integral(cmap='inferno'): df = pd.read_csv('./prefectures.csv') df_data_yrs = df['year'] df_data_mth = df['month'] df_data_day = df['date'] with open('./prefectures.csv') as f: lines = f.readlines() fig = plt.figure() ims = [] cnt = 0 for ii in range(len(df) // 47): start_i = ii * 47 goal_i = start_i + 47 tmp_lines = lines[0] + '"","","","","","","","",""\n' for li in lines[start_i+1:goal_i+1]: tmp_lines += li with open('./tmp.csv', 'w') as f: f.write(tmp_lines) pl_df = pd.read_csv('./tmp.csv') df_data = pl_df['testedPositive'] sm, im = plot_pref(df_data, cmap) title = '{}/{}/{}'.format(df_data_yrs[start_i], df_data_mth[start_i], df_data_day[start_i]) title = plt.text(s=title, x=300, y=0, ha='center', va='bottom', fontsize='large') if cnt == 0: plt.colorbar(sm) cnt += 1 ims.append([im]+[title]) #cb.remove() ani = animation.ArtistAnimation(fig, ims, interval=400, repeat_delay=5000) ani.save('./integral.gif', writer='imagemagick') def make_gif_daily(cmap='inferno'): df = pd.read_csv('./prefectures.csv') df_data_yrs = df['year'] df_data_mth = df['month'] df_data_day = df['date'] with open('./prefectures.csv') as f: lines = f.readlines() fig = plt.figure() ims = [] cnt = 0 tmp_lines_ = '' for ii in range(len(df) // 47): if ii == 0: pass else: start_i = ii * 47 goal_i = start_i + 47 tmp_lines = lines[0] + '"","","","","","","","",""\n' for jj in range(len(lines)): if start_i < jj <= goal_i: now_line_sp = lines[jj].split(',') pre_line_sp = lines[jj-47].split(',') if now_line_sp[3] != pre_line_sp[3]: print(now_line_sp[3], pre_line_sp[3]) new_line = now_line_sp new_line[5] = str(int(now_line_sp[5]) - int(pre_line_sp[5])) tmp_lines += ','.join(new_line) with open('./tmp.csv', 'w') as f: f.write(tmp_lines) tmp_lines_ += tmp_lines pl_df = pd.read_csv('./tmp.csv') df_data = pl_df['testedPositive'] sm, im = plot_pref(df_data, cmap) title = '{}/{}/{}'.format(df_data_yrs[start_i], df_data_mth[start_i], df_data_day[start_i]) title = plt.text(s=title, x=300, y=0, ha='center', va='bottom', fontsize='large') if cnt == 0: plt.colorbar(sm) cnt += 1 ims.append([im]+[title]) #cb.remove() with open('./daily_data.csv', 'w') as f: f.write(tmp_lines_) ani = animation.ArtistAnimation(fig, ims, interval=400, repeat_delay=5000) ani.save('./daily.gif', writer='imagemagick') if __name__ == '__main__': make_gif_integral() make_gif_daily()
- 投稿日:2020-07-15T16:43:49+09:00
Python 可変引数定義されたクラスを継承するときの覚書
PythonのGUI(Tkinter)を使ってプログラムを書いていると、GUI Class継承する場合に
もれなく可変引数も継承されます。
しかし、継承先のClassで引数を追加すると、継承元でエラーが発生して使いづらい状況です。例えば、TkinterのCheckbuttonは初期値を設定する事ができません。
初期値を設定できるようなCheckbuttonを作った際の覚書。普通に記述すると、下記のようになります。
NormalCheckboxcv = tk.BooleanVar() cb = tk.Checkbutton(self, parent, variable=cv) cv.set(True) #初期値設定しかし、私はこういう風に書きたい。
ShimplCheckboxcb = tk.Checkbutton(self, parent, check=True)そこで、tk.Checkbuttonを継承して、SimpleCheckを作ってみます
SimpleCheckbox.py# Initial value = check=True or False class SimpleCheck(tk.Checkbutton): def __init__(self, parent, *args, **kw): self.flag = kw.pop('check') self.var = tk.BooleanVar() if self.flag: self.var.set(True) self.txt = kw["text"] tk.Checkbutton.__init__(self, parent, *args, **kw, variable=self.var) def get(self): return self.var.get()しかし、このコードには問題があります。
それは、引数"check"を指定しなければエラーが発生するという問題ですmainloopif __name__ == '__main__': app = tk.Tk() sc1 = SimpleCheck(app, check=True, text="hoge") sc1.pack() sc2 = SimpleCheck(app) sc2.pack() print(sc1.getText()) print(sc1.cget('text'))#same result app.mainloop()errorTraceback (most recent call last): File "arg_test.py", line 24, in <module> sc2 = SimpleCheck(app) File "arg_test.py", line 7, in __init__ self.flag = kw.pop('check') KeyError: 'check'そこで可変引数を使った継承における、引数の取り出し方法を覚書として示す。
三項演算子を使った場合、"pass"を使うとエラーが出るようです。SimpleCheck.pyimport tkinter as tk # Check value :check=True or False (Default False) # Label text :text=Keword class SimpleCheck(tk.Checkbutton): def __init__(self, parent, *args, **kw): self.flag = kw.pop('check') if('check' in kw) else False self.txt = kw['text'] if('text' in kw) else "" self.var = tk.BooleanVar() if self.flag: self.var.set(True) tk.Checkbutton.__init__(self, parent, *args, **kw, variable=self.var) def get(self): return self.var.get() def getText(self): return self.txt if __name__ == '__main__': app = tk.Tk() sc1 = SimpleCheck(app, check=True, text="hoge") sc1.pack() sc2 = SimpleCheck(app) sc2.pack() print(sc1.getText()) print(sc1.cget('text'))#same result app.mainloop()追記@shiracamusさんからアドバイス頂きまして
三項演算子を使わなくてもDicのpop第二引数で初期値を設定できるようです。
アドバイスありがとうございました。diffdef __init__(self, parent, *args, **kw): self.flag = kw.pop('check', False) self.txt = kw['text'] if('text' in kw) else ""
- 投稿日:2020-07-15T15:45:38+09:00
Deep Learningを用いた株価予測 [データ入手編]
はじめに
どうにか工夫して、Deep Learningを使った株価予測をやってみたいと考えてこの記事を書くことにしました。
この記事では、株価予測に使うデータを「yahoo finance」からプログラムでダウンロードしてくることを目的に書いています。ちなみに、どういったモデルで株価を予測するのかについてはまだ未定で、これから考えて行きたいと思っています。いいアイディアがやオススメの手法がある方は教えていただけるとありがたいです。
では、やっていきたいと思います。
対象データ
今回の入手先は、「yahoo finance」です。
対象は、カブサポから上場銘柄一覧のcsvファイルがダウンロードできるので、その中の東証一部に絞ってデータを取ってきたいと思います。ダウンロードできる期間は、2010〜現在までです。
コード
stock_data.pyimport requests import io import re import pandas as pd cols = ['Id', 'Date', 'Open', 'High', 'Low', 'Close', 'Adj_Close', 'Volume'] stock_data = pd.DataFrame(columns=cols) code_list = pd.read_csv('stock_code_list.csv') # カブサポから入手したファイル code_list = code_list[code_list['市場名'] == '東証1部']['銘柄コード'] for code in code_list: url = 'https://query1.finance.yahoo.com/v7/finance/download/{}.T?period1=1262304000&period2=1589241600&interval=1d&events=history'.format(code) res = requests.get(url) if res.status_code != 200: print('NotFound:', code) else: stock = pd.read_csv(io.StringIO(res.text)) stock['Id'] = code stock_data = pd.concat([stock_data, stock], ignore_index=True, sort=False, keys=cols) print('OK:', code)これで、ダウンロードできました。
データサイズは約500万行ありました。おわりに
これでデータを入手できたので、次は予測アプローチを考えて行きたいと思います。
個人的には、ただ翌日の株価が上がるか下がるかとかではなく、もっと個人投資家向けに
上昇トレンドや下降トレンドを検知するようなプログラムができたらなと考えています。
また、定性データも加えられたら精度も上がるかもと考えています。いいアイディアがあればください、、、
こんな感じで、ちょこちょこ書いていきたいと思います。
- 投稿日:2020-07-15T15:23:00+09:00
Pythonのmatplotlibで一刻も早く画像を並べて表示したいという人へ
ソースコード
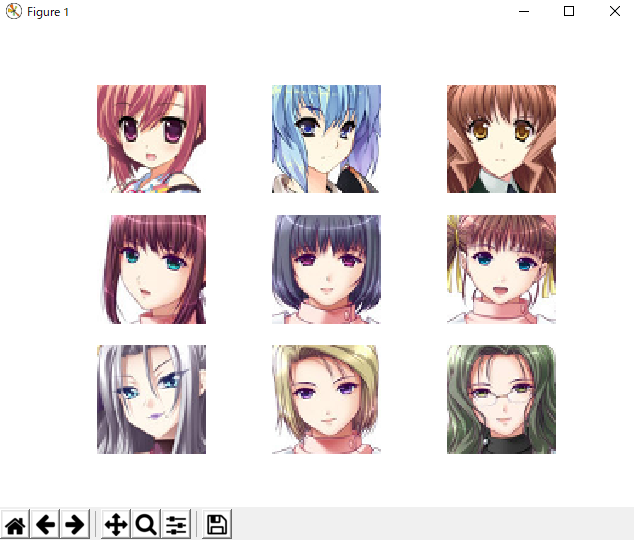
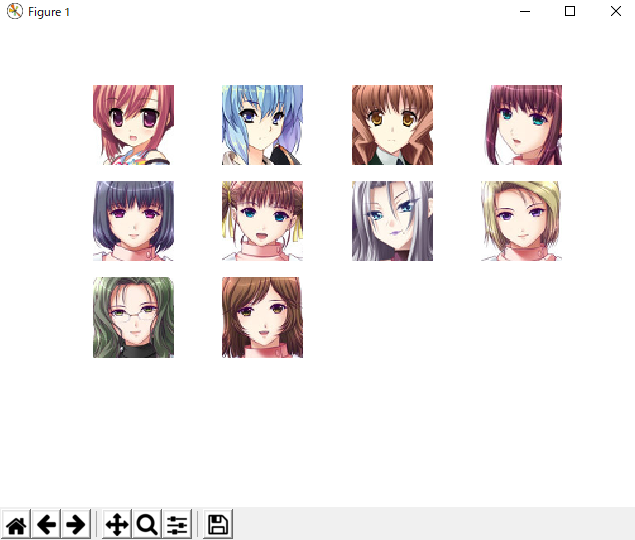
import matplotlib.pyplot as plt import cv2 import os root = "./data" #画像があるフォルダ。適宜変えてください lsdir = os.listdir(root) imgs = [] for l in lsdir: target = os.path.join(root,l) img = cv2.imread(target) img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB) #pyplotで表示するために色変換 imgs.append(img) shownumber = 10 #画像を並べる数 showaxis = 1 while(showaxis*showaxis < shownumber): showaxis += 1 cnt = 0 while(1): #limit = 30 #if cnt >= limit: # break fig,axs = plt.subplots(showaxis,showaxis) ar = axs.ravel() for i in range(showaxis*showaxis): ar[i].axis('off') if i < shownumber: ar[i].imshow(imgs[cnt]) cnt += 1 plt.show()表示結果
shownumber = 9
shownumber = 10
なぜこの記事を書いたか
- 画像表示をする度に
matplotlibについてぐぐっている気がするので、自分の中の定石を定めたかった- rowとcolumnを指定するのが微妙にめんどくさいため、表示数を指定するだけで動作するコードにしたかった
- そのようなソースコードがすぐにヒットするページを作りたかった
コードの説明
- フォルダを指定して
cv2.imreadで読み込み、imgsという配列にする。- OpenCVはBGR形式で読み込むため、
cv2.cvtColorでRGB形式に変換- 表示数
shownumberを指定したら、それを満たす最小の二乗数を求めて、1辺をshowaxisとする。while(showaxis*showaxis < shownumber): showaxis += 1
plt.subplotsで行と列がそれぞれshowaxisの数だけあるグラフを用意axsは縦位置と横位置を指定するのがめんどくさいため、axs.ravel()で一連の配列にする- 1ループごとに
shownumberの数だけ、imshowとaxis('off')で画像表示imgsが尽きるまでループを回し続けるコードの構成上、最終的には確実に範囲外参照エラーを起こすので注意。一応脱出処理をコメントで書いてます。
- 投稿日:2020-07-15T13:22:32+09:00
Spotify APIを使って好きな歌手(SHISHAMO)を分析してみた
はじめに
データ分析を勉強しているので自分の好きな物を分析してみようと考えたところ、SHISHAMOに行き着きました。どう分析してみようかとQiitaをみていたところ面白い記事を見つけました。
どうやら、Spotifyには曲ごとに属性データなるものがあるらしいです、SHISHAMOファンとしてはSHISHAMOの属性データにどのような特徴があるのか気になるところです。そこでSpotifyの属性データを使ってSHISAMOを分析してみました。
手順
Spotify APIの詳細な解説は他の人に任せて、具体的な手順を簡単に説明しておきます。
1.認証作業
import spotipy import pandas as pd client_id = 'client_id' client_secret = 'client_secret' client_credentials_manager = spotipy.oauth2.SpotifyClientCredentials(client_id, client_secret) spotify = spotipy.Spotify(client_credentials_manager=client_credentials_manager)spotify for developersからcliend_idとclient_secretを発行します。こちらの記事を参考に行いました。
2.データ収集
albums = spotify.artist_albums(artist_id, album_type=None, country=None, limit=20, offset=0) df = pd.DataFrame() for i in range(len(albums['items'])): album_url = albums['items'][i]['external_urls']['spotify'] album_name = albums['items'][i]['name'] album_truck = spotify.album_tracks(album_url)['items'] for j in range(len(album_truck)): truck_name = album_truck[j]['name'] truck_url = album_truck[j]['external_urls']['spotify'] truck = spotify.audio_features(truck_url)[0] tmp = pd.DataFrame(truck,index=['1',]).iloc[:,:11] tmp['album_name'] = album_name tmp['truck_name'] = truck_name df = df.append(tmp)artist_idは以下のようにSpotifyのwebplayerから取得できました。ちなみにこの背景の絵はボーカルの方が描いています、とても上手で可愛らしいですね。
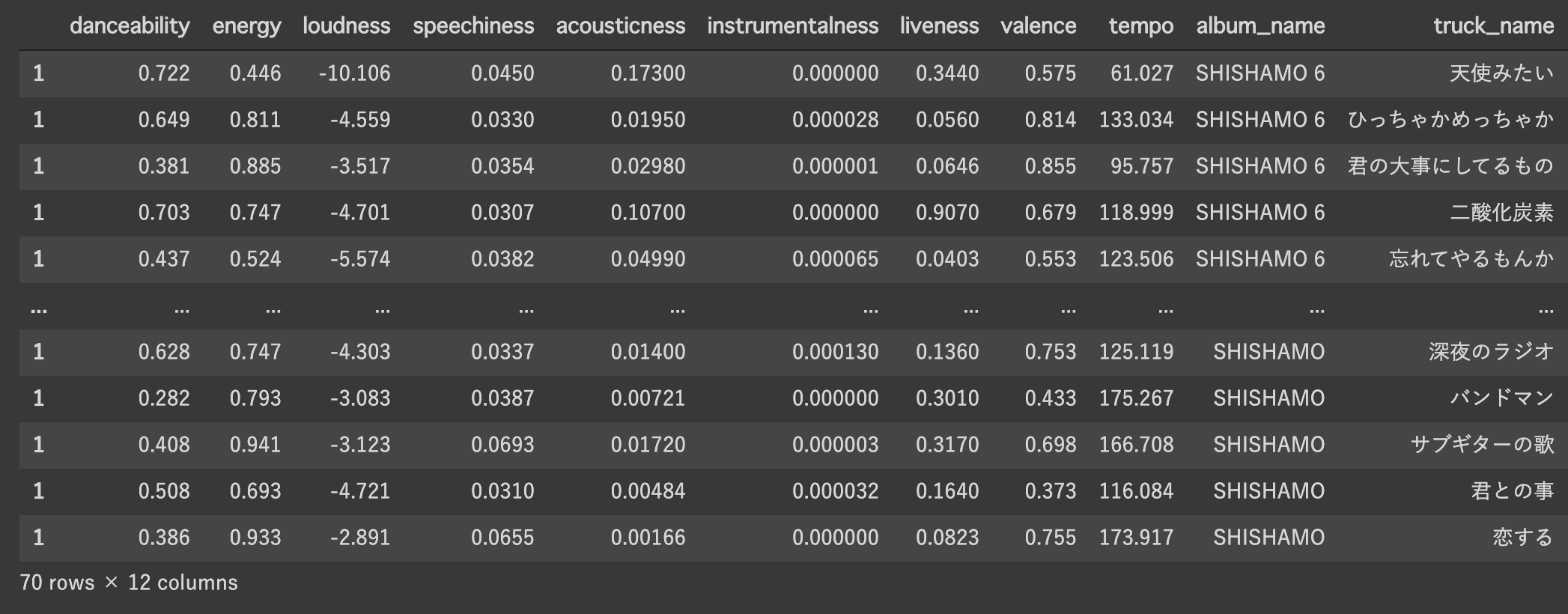
こんな感じで以下のようなデータを取得できました。
とても可愛らしい曲名が並んでいますね、またその曲を表す特徴量として11変数がSpotify上で与えられています、こちらがSpotifyの曲ごとの属性データです。この詳細についてはこちらの記事を参考にしてください。曲のテンポであったり、音圧、インスト感などがあるみたいです。
3.データ分析
今回はUmapを用いた次元圧縮&可視化による分析を行いました、Umapの詳細についてはこちらの記事を参考にしてみてください。PCAと同様にクラスタリングに適した低次元空間に射影するためのアルゴリズムと考えていただければ良いかと思っています(詳細は私も理解しきれていません)。
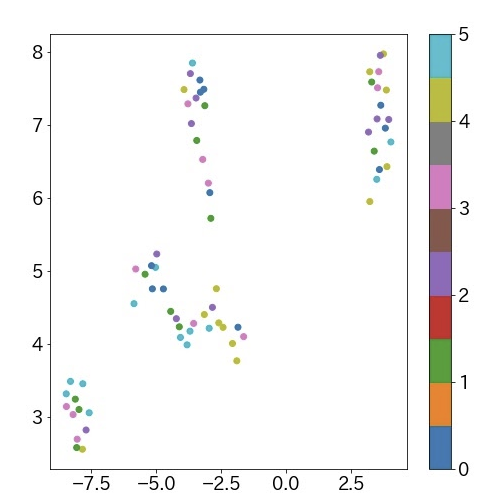
こちらがUmapを用いて、SHISHAMO1~6の全アルバムの曲データを二次元にプロットした結果になります。
なんとなく4グループあるように見えますね。きれいにクラスタリングされたので、この結果に対して
1. アルバムごとの特徴はあるのか?
2. 人気曲の特徴はあるのか?
3. 自分の好きな曲に特徴はあるのか?
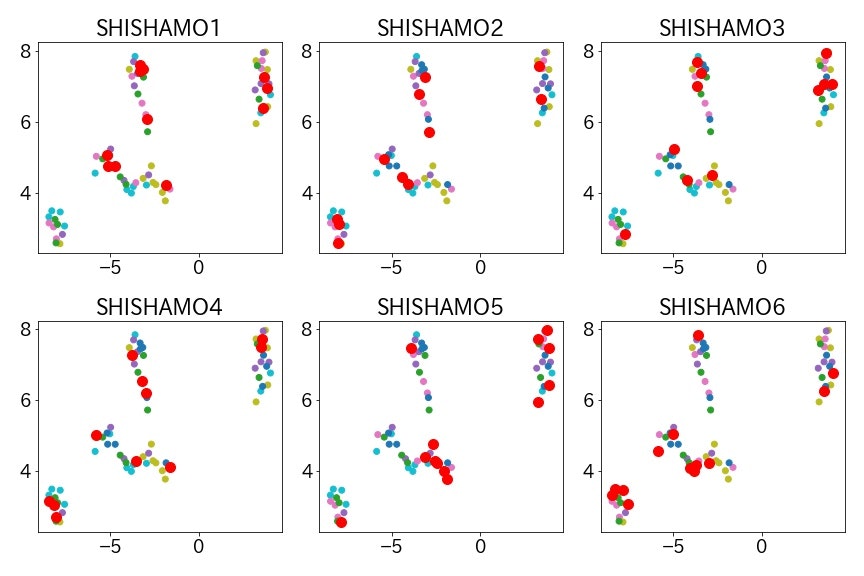
の三点についてみてみました。1.アルバムごとに特徴はあるのか?
アルバムごとに赤丸でプロットしたグラフです。
グラフ左下のグループに属する曲が1stアルバムにはなかったことがわかりました、曲の振り幅の広がるSHISHAMOの成長が感じ取れますね。またアルバムごとにバランスよく各グループの曲を収録されていることがわかります。バラードだけのアルバムとか嫌ですよね、流石です。2.人気曲の特徴はあるのか?
人気曲には特徴があるのかについて分析してみました。SHISHAMOの人気曲については判断が難しいので独断で知名度の高そうな4曲を選びました。
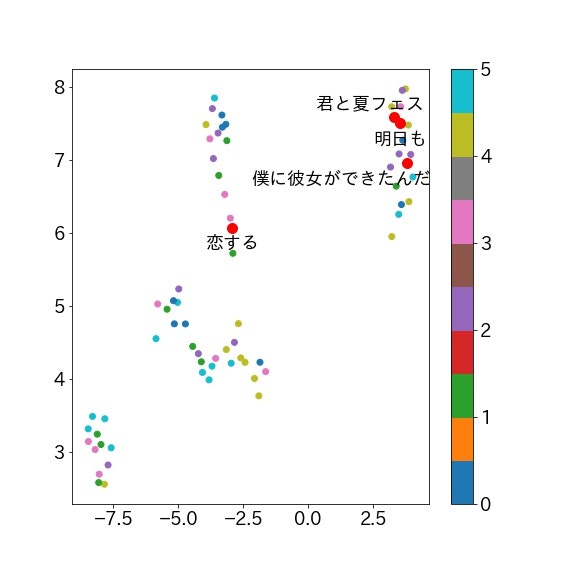
「明日も」「君と夏フェス」「恋する」「僕に彼女ができたんだ」です、ファンの方なら納得していただけると思います。聴いたことのない方は聴いてみてください。
右上に集まっている気がします、アップテンポな曲が多いからですかね?二大有名な曲の「明日も」「君と夏フェス」がかなり近くて驚きました。「恋する」はライブの締めで演奏することの多いアップテンポな曲で、「君と夏フェス」と同じクラスターかと思っていたので意外でした。
3. 自分の好きな曲に特徴はあるのか?
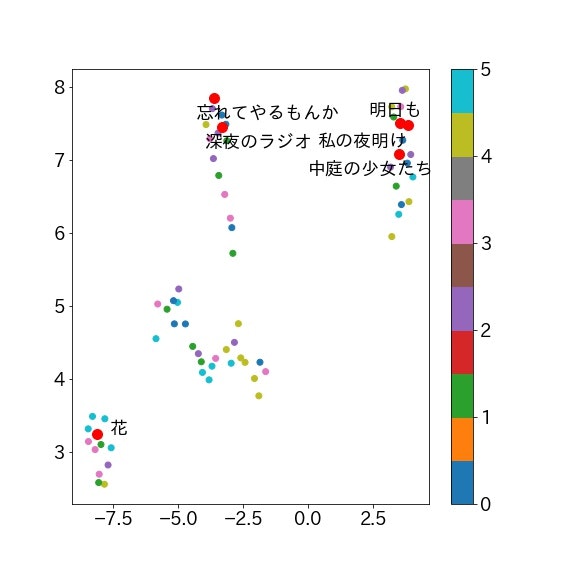
自分の好きな曲に特徴があるのか分析してみました。どの曲も大好きで優劣がつかないので各アルバムから1曲ずつ選びました。
「深夜のラジオ」「花」「中庭の少女たち」「明日も」「私の夜明け」「忘れてやるもんか」の6曲です、自分のなかでは振り幅のある選曲のつもりです。
これまた右上に集まっている気がします、「花」だけ完全に分離していますね。「私の夜明け」という曲は「明日も」とは雰囲気が異なり、暗い雰囲気もある曲なのですが右上に来ています。私自身はそんなに似ていないと思っていたのですが、似た曲なのかもしれませんね。最後に
売れている曲や自分の好きな曲が意外に偏っていて驚きました。今回は自分の好きな歌手で分析を行いましたが、好きな曲はあるが他の曲をあまり知らないアーティストで同様の分析を行い自分へのおすすめ曲を探してみるとかやっても面白いかなと思いました。同じアーティストでもハマる曲とハマらない曲はあると思うのでそういうのが分類できたら楽しそうですね。
補足
PCAにおける各主成分の寄与率をみてました。
第一主成分がほとんどテンポ、第二主成分がほとんどキーで決まっていることがわかります。Umapの二軸とは完全に一致するものではありませんが、似たものをみている可能性は高いと思います。分析の最後にこれをみて少しがっかりしました。。
- 投稿日:2020-07-15T10:30:55+09:00
Titanicでつまづいても大丈夫!超初心者向けKaggle攻略法をご紹介
Kaggle始めてみたけどTitanicの時点でよくわからない!
Kaggleに登録してTitanicでのチュートリアルを見たものの何をやってるかよくわからない方もいますよね。
また、Titanicがある程度できるようになっても他の分析の時どう活かしていければいいかわかりづらいのも事実。
そこで今回はKaggleでTitanicに取り組むレベルの人でもKaggleでどのようなステップを踏めばいいかを解説していきます。
この記事ではTitanicではなくPythonのライブラリで入っているアヤメのデータセットを使用し品種を分類していきます。
それではまず、必要なライブラリとデータをインポートするところからお伝えしていきます。
必要なライブラリとデータをインポート
KaggleでTitanicをやる場合もその先の問題に取り組む場合もまずは必要な道具を揃えていく必要があります。
これを行わないとせっかくコードを書いてもエラーが出てしまうので注意が必要です。
import numpy as np import pandas as pd from pandas import DataFrame, Series #numpyは計算、pandasはデータの加工で使用。 from sklearn.datasets import load_iris #もともとあるデータを拝借 from sklearn import datasets #データをpandasで使えるようにする from sklearn.model_selection import train_test_split #データを分割するのに使う from sklearn.linear_model import LogisticRegression #機械学習で今回はこれを使う import matplotlib.pyplot as plt import seaborn as sns #どちらも図にするのに使うここで各ライブラリがどう使われているか触れていきます。
numpyはデータの計算、pandasは読み込んだデータの加工に使われます。
sklearnには自由に使えるデータセットが入っていたり機械学習の手法などが揃えられています。
ここではアヤメの特徴と品種名が記載されたデータを読み込んでいます。
また、そのデータをpandasで使えるようにするものやデータを分割するのに必要なものも読み込んでいます。
データの分割については後程説明していきます。
matplotlibやseabornは与えられたデータを図表にし可視化させるために使われています。
データを眺めるだけではわからないことや次の作戦を考えるヒントになることもあります。
データの全体像を見て欠損値がないか確かめる
ライブラリを読み込んだので今回使うアヤメのデータを見ていきましょう。
iris = load_iris()#アヤメのデータを読み込み df = pd.DataFrame(iris.data, columns=iris.feature_names)#データをデータフレームで見られるようにする df.head()#データの冒頭だけ見る df.describe()#データの全体像を見るデータの冒頭
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) 0 5.1 3.5 1.4 0.2 1 4.9 3.0 1.4 0.2 2 4.7 3.2 1.3 0.2 3 4.6 3.1 1.5 0.2 4 5.0 3.6 1.4 0.2 データの全体像
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) count 150.000000 150.000000 150.000000 150.000000 mean 5.843333 3.057333 3.758000 1.199333 std 0.828066 0.435866 1.765298 0.762238 min 4.300000 2.000000 1.000000 0.100000 25% 5.100000 2.800000 1.600000 0.300000 50% 5.800000 3.000000 4.350000 1.300000 75% 6.400000 3.300000 5.100000 1.800000 max 7.900000 4.400000 6.900000 2.500000 データを読み込み冒頭部分と概観を出してみました。
ここで書かれているSepal Lengthはがく片の長さ、Sepal Widthはがく片の幅、Petal Lengthは花びらの長さ、Petal Widthは花びらの幅になります。
ここにある情報がアヤメの品種を特徴づけるものであり「特徴量」と言います。
このデータは全部で150のデータがあり品種は三種類あります。
しかしここではより簡単にするため二種類に絞っていきます。
df = df[:100]ここから「欠損値」といいデータに抜けているところがないか見ていきます。
ここで何か勉強の参考書をイメージしてみましょう。
私達は参考書を見ている時何か誤植やよく見えない箇所があってもなんとなく頭の中で補って理解することはできます。
しかしプログラムは入力された情報を「そのまま認識する」のでエラーが表示されてしまいます。
そのため最初の段階でそれがないか確認しておく必要があるのです。
df.isnull().sum() sepal length (cm) 0 sepal width (cm) 0 petal length (cm) 0 petal width (cm) 0 dtype: int64幸いここでは欠損値はありませんでした。
万が一あった場合平均値など数字を埋めたり抜けのあるところを除外するなど何かしらの処理が必要となるので覚えておきましょう。
データを分割し学習できる状態に整える
データを読み込み欠損値がないことが確認できたのでまずはデータの分割に入っていきます。
y = pd.Series(data=iris.target) y = y[:100] #yはアヤメの品種名になっているので数字に変換。 x = df.loc[:,["sepal length (cm)","sepal width (cm)","petal length (cm)","petal width (cm)"]]x_train, x_test, y_train, y_test =train_test_split(x, y, test_size = 0.1, train_size = 0.9, shuffle = True)今回は読み込んだデータからランダムに1割をテスト用として分割し取り出しました。
普段のコンペであれば訓練用データとして参考書が丸々渡され、テスト用データとして試験問題が配布されます。
しかし今回はそれがないのでデータからランダムに取り出した1割を試験問題とします。
x_Train, x_valid, y_Train, y_valid =train_test_split(x_train, y_train, test_size = 0.2, train_size = 0.8, shuffle = True)そして残ったデータからさらにランダムに2割を取り出し演習問題とします。
ここでAIに学習をさせますがあえて最後まで取り出されなかったデータのみを使います。
どうして学習用のデータをまたさらに分割するか疑問に思う人もいますよね。
それは最後まで残った部分と演習問題で出来に差が出ていないか確認するためです。
私達が学校でテスト勉強していた頃参考書などを丸暗記したもののなかなか点に繋がらなかったこともありましたよね。
プログラム上でもそういったことが起こる場合があり「過学習」と言います。
それが起きてないか確認するために最後まで残ったページで学習をし残ったページのためだけの勉強に終始してないか演習問題を通して確認するのです。
もしそれが起きていた場合学習の仕方など見直しをする必要があります。
学習させた結果を確かめる
lg = LogisticRegression() lg.fit(x_Train, y_Train) LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, l1_ratio=None, max_iter=100, multi_class='warn', n_jobs=None, penalty='l2', random_state=None, solver='warn', tol=0.0001, verbose=0, warm_start=False)最後まで残った部分のみを使ってAI(人工知能)に使われる手法の一つを用いて学習させています。
学習させたものに再度学習に用いたデータと演習用に取り出したデータを使って正答率を比較します。
print('Train Score: {}'.format(round(lg.score(x_Train, y_Train), 3))) print(' Test Score: {}'.format(round(lg.score(x_valid, y_valid), 3))) Train Score: 1.0 Test Score: 1.0検証したところほぼ問題はないようでした。
それでは学習させたものでテスト本番に臨みます。ここでは回答を作っています。
y_pred = lg.predict(x_test) y_pred array([1, 1, 0, 0, 1, 0, 0, 0, 1, 0]) y_test 68 1 88 1 35 0 20 0 95 1 7 0 12 0 0 0 76 1 44 0 dtype: int64そして正答率の確認に入ります。
np.mean(y_pred==y_test) 1.0自動で採点してもらったところほぼ問題ありませんでした。
普段のコンペでは答えは運営側が持っています。また、一部のデータでしか採点してくれないので注意が必要です。
KaggleでTitanicに取り組む時はこんなこともする!
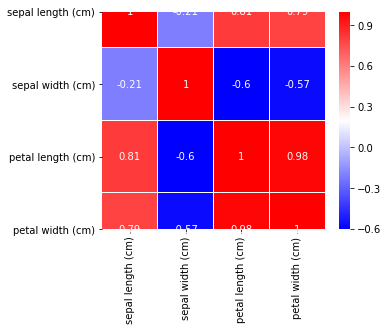
sns.heatmap(df.corr(),annot=True,cmap='bwr',linewidths=0.2) fig=plt.gcf() fig.set_size_inches(5,4) plt.show()
ここでは特徴量同士でどれくらい関連性があるか表示しています。
今回はやりませんでしたが複数のものを組み合わせ新しいものを作る可能性もあります。
またAI(人工知能)に使われる手法は多岐に渡ります。
from sklearn.neural_network import MLPClassifier mlpc = MLPClassifier(hidden_layer_sizes=(100, 100, 10), random_state=0) mlpc.fit(x_Train, y_Train) print('Train Score: {}'.format(round(mlpc.score(x_Train, y_Train), 3))) print(' Test Score: {}'.format(round(mlpc.score(x_valid, y_valid), 3))) Train Score: 1.0 Test Score: 1.0lg_pred = lg.predict_proba(x_test) mlpc_pred = mlpc.predict_proba(x_test) pred_proba = (lg_pred + mlpc_pred) / 2 pred = pred_proba.argmax(axis=1)学習のやり方はそれぞれメリットデメリットがあります。
そこで複数の学習を組み合わせ精度を上げることを「アンサンブル学習」といいます。
np.mean(pred==y_test) 1.0今回はKaggleを始めたばかりでTitanicの分析に取り組むレベルの人でもKaggleで最低限必要な段取りがわかるようTitanicではなくアヤメのデータセットを用いて解説してきました。
最低限必要なことは必要なライブラリやデータを読み込むこと、データの全体像を見て欠損値がないか確認すること、データを分割し学習できる状態にすること、最後に学習をさせ正確さを確かめることです。
KaggleでTitanicなど本格的な分析に入ると特徴量同士の関係を見たり学習方法を複数使うなどの工夫が必要となります。
また、KaggleにはTitanicの他にも初心者向けのデータセットがあったりわからないことをディスカッションする環境も整えられています。
Kaggleのhello worldと言われるTitanicですが焦らず着実に進めながら様々なデータ分析ができるよう取り組んでいきましょう。
最後に今回使用したコードをまとめて記載します。
今回のコード
import numpy as np import pandas as pd from pandas import DataFrame, Series #numpyは計算、pandasはデータの加工で使用。 from sklearn.datasets import load_iris #もともとあるデータを拝借 from sklearn import datasets #データをpandasで使えるようにする from sklearn.model_selection import train_test_split #データを分割するのに使う from sklearn.linear_model import LogisticRegression #機械学習で今回はこれを使う import matplotlib.pyplot as plt import seaborn as sns #どちらも図にするのに使う iris = load_iris()#アヤメのデータを読み込み df = pd.DataFrame(iris.data, columns=iris.feature_names)#データをデータフレームで見られるようにする df.head()#データの冒頭だけ見る df.describe()#データの全体像を見る df = df[:100]#アヤメの種類を二種類のみに絞り込む df.isnull().sum()#欠損値がないか可視化 y = pd.Series(data=iris.target) y = y[:100] #yはアヤメの品種名になっているので数字に変換。 x = df.loc[:,["sepal length (cm)","sepal width (cm)","petal length (cm)","petal width (cm)"]] x_train, x_test, y_train, y_test =train_test_split(x, y, test_size = 0.1, train_size = 0.9, shuffle = True) x_Train, x_valid, y_Train, y_valid =train_test_split(x_train, y_train, test_size = 0.2, train_size = 0.8, shuffle = True) #データを訓練用とテスト用データに分割、訓練用データをさらに学習用と演習用に分割 lg = LogisticRegression() lg.fit(x_Train, y_Train) print('Train Score: {}'.format(round(lg.score(x_Train, y_Train), 3))) print(' Test Score: {}'.format(round(lg.score(x_valid, y_valid), 3))) #AI(人工知能)に使われる手法の一つを用いて過学習が起きてないか確認 y_pred = lg.predict(x_test) y_pred y_test np.mean(y_pred==y_test) #学習させたものでテスト用データの検証をさせ正答率を確認 sns.heatmap(df.corr(),annot=True,cmap='bwr',linewidths=0.2) fig=plt.gcf() fig.set_size_inches(5,4) plt.show() #各特徴量の関係性を可視化 from sklearn.neural_network import MLPClassifier mlpc = MLPClassifier(hidden_layer_sizes=(100, 100, 10), random_state=0) mlpc.fit(x_Train, y_Train) print('Train Score: {}'.format(round(mlpc.score(x_Train, y_Train), 3))) print(' Test Score: {}'.format(round(mlpc.score(x_valid, y_valid), 3))) lg_pred = lg.predict_proba(x_test) mlpc_pred = mlpc.predict_proba(x_test) pred_proba = (lg_pred + mlpc_pred) / 2 pred = pred_proba.argmax(axis=1) np.mean(pred==y_test) #アンサンブル学習といいAI(人工知能)に使われる手法をいくつか組み合わせる
- 投稿日:2020-07-15T10:25:43+09:00
正規表現のGreedy
import re # Greedy s = '<html><head><title>Title</title></head></html>' print(re.match('<.*>', s)) print(re.match('<.*?>', s))実行結果:
<re.Match object; span=(0, 46), match='<html><head><title>Title</title></head></html>'> <re.Match object; span=(0, 6), match='<html>'>
- 投稿日:2020-07-15T10:05:31+09:00
サイバーセキュリティ・フレームワーク「MITRE CALDERA」紹介:使用方法・トレーニング編
サイバーセキュリティ・フレームワーク「MITRE CALDERA」紹介:使用方法・トレーニング編
はじめに
趣旨
本記事は、『サイバーセキュリティ・フレームワーク「MITRE CALDERA」紹介』の 第四弾「使用方法・トレーニング編」です。
本編では、セキュリティ人材育成に活用できる MITRE CALDERA の使い方を紹介します。
機能概要や環境構築につきましては第一弾「機能概要・動作環境構築編」をご覧ください。記事構成
紹介内容が多いため、以下の4記事に分けて紹介しています。
- 機能概要・動作環境構築編
- 使用方法:レッドチーム編
- 使用方法:ブルーチーム編
- 使用方法:トレーニング編(本記事)
注意・免責事項
本連載記事には、サイバー攻撃を模擬再現する方法が含まれています。
これは、サイバー攻撃されることによってどのような事象が発生するのか、どう対処すれば良いのかを確認・検討・改善したり、サイバーセキュリティ人材育成に活用することが目的です。
他のシステムやネットワークに影響を与えないように、閉じたネットワーク環境を作って実施してください。
許可を得ていない相手に対して実施した場合、不正アクセス禁止法などの法律に抵触しますので、絶対にやめてください。本記事の内容は私個人の見解であり、所属する組織の公式見解ではありません。
本記事に書いてあることを試して、利用者および第三者に何らかのトラブル・被害・損害が発生しても、筆者および所属組織では一切責任を負いません。概要
MITRE CALDERA バージョン 2.6.4 で Trainingプラグイン が提供され、トレーニングメニューが追加されました。
クイズ形式で問題が出され、想定された状態になれば正解となり、次の問題が出題されます。
本連載で使用している MITRE CALDERA 2.6.6 では、MITRE CALDERA を使いこなせるユーザであることを確認・認定する問題が用意されています。
なお、2.6.6 では red チームでログインしたときのみ問題が表示されます。2.7.0 では blueチーム でログインした場合にも問題が表示され、問題数も増えています。今後もトレーニング問題が追加されていくことが期待できます。
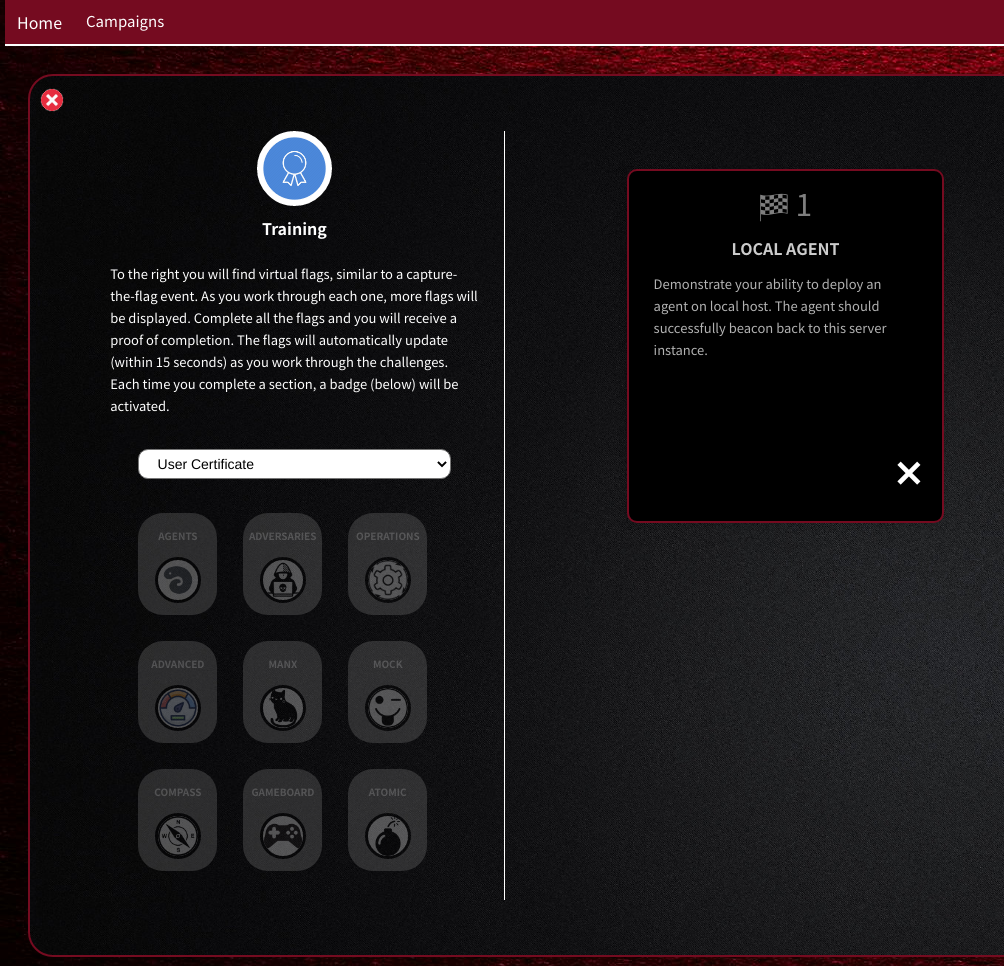
自分で問題を作って登録することも可能です。問題登録方法についても説明します。「User Certificate」トレーニング開始時のスクリーンショットを以下に示します。
環境構築
「使用方法:レッドチーム編」と同じ環境を使用します。
なお、Ubuntu Linux 20.04 の Chromium ブラウザでトレーニング問題を表示すると、絵文字の旗が正しく表示されませんでした。そのため、以下のコマンドを実行して絵文字フォントをインストールしてOSに再ログインしました。(OSの種類やバージョンによってフォント名が異なります)$ sudo apt install ttf-ancient-fonts-symbola操作手順
ログイン
「使用方法:レッドチーム編」に記載されている起動手順に従って MITRE CALDERA サーバにログインします。
トレーニングメニュー表示
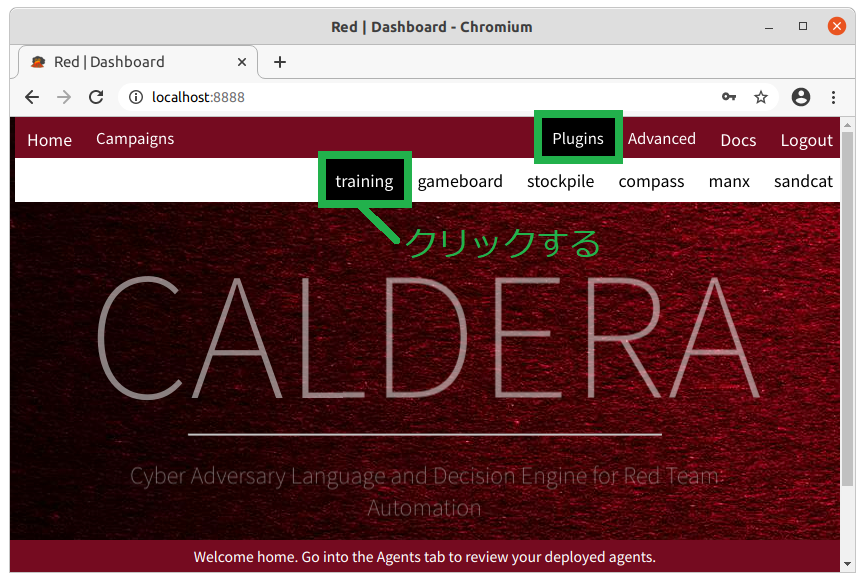
Plugins メニューにカーソルを移動すると直下にサブメニューが表示されるので、サブメニューの中のtraining をクリックします。
問題集選択
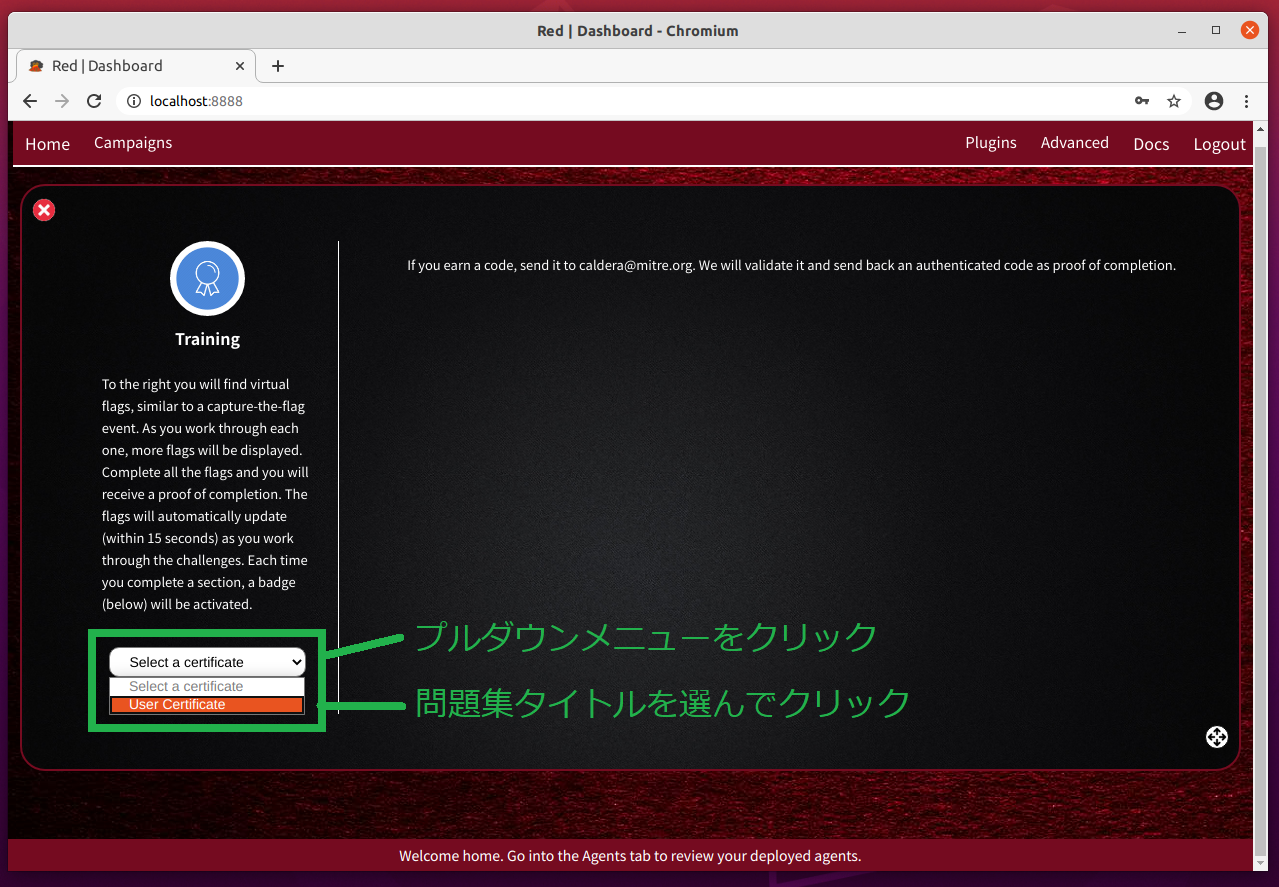
Web画面左側にある「
select a certificate」プルダウンメニューをクリックすると、問題集の名称が一覧表示されるので選択します。
MITRE CALDERA 2.6.6 では「User Certificate」だけが選択できます。MITRE CALDERA を使いこなせるようになったかを確認・認定する問題集です。
なお、ウィンドウ右側上部に、「コードを獲得したらメールしてください。確認のうえ修了認定コードを返送します」といった内容の英文が表示されています。全問制覇に挑戦してみませんか?
問題に挑戦
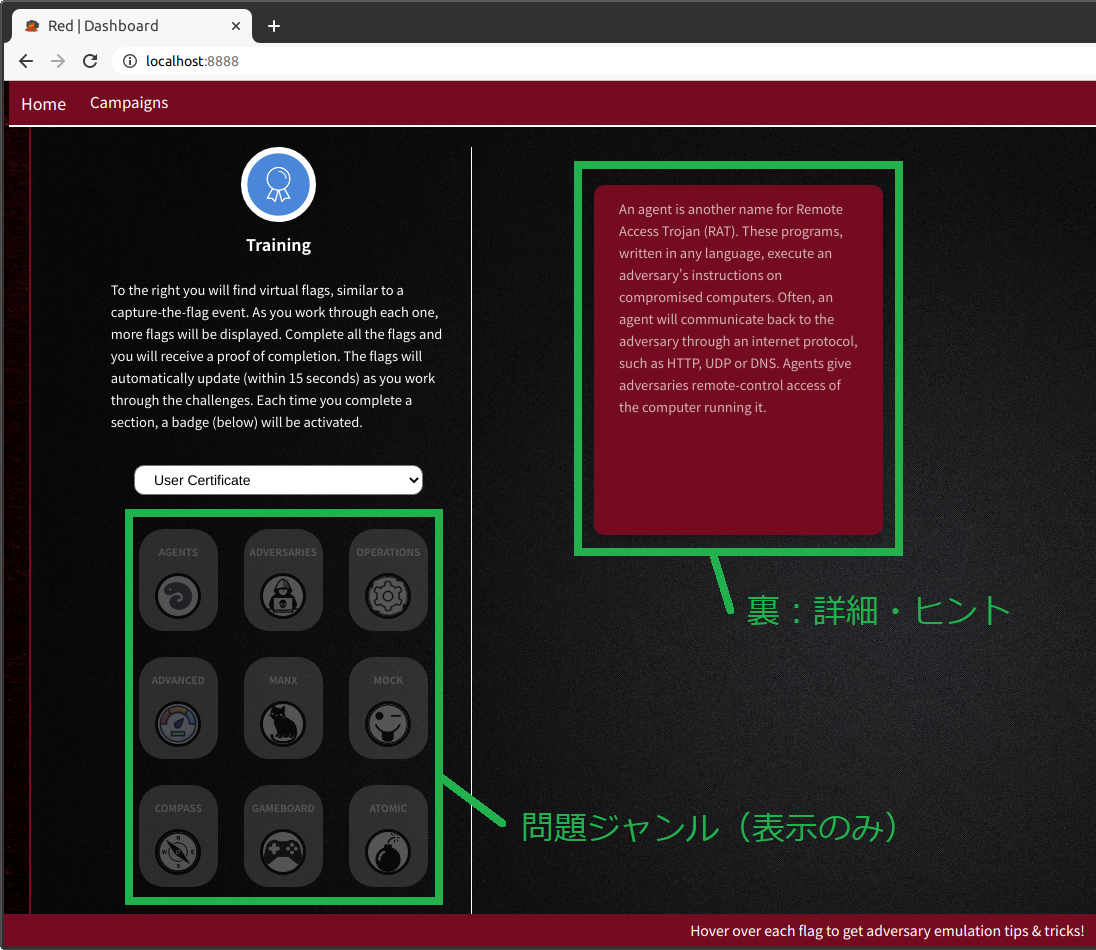
問題集を選択すると、画面左側に問題ジャンルが表示され、画面右側に問題文が書かれたカードが表示されます。
本記事の最初のスクリーンショットに示してあるように、カードには問題タイトルと問題文が書かれています。
カードの上にマウスカーソルを移動すると、カードが裏返って下図のように赤いカードが表示され、詳細やヒントが表示されます。
問題に正解すると次の問題が追加表示されます。
ジャンル毎に問題が出題されます。最初は AGENTS(エージェント)ジャンルから出題されます。
第1問: ローカルホストでエージェントを起動せよ
表:問題文 裏:詳細・ヒント ローカルホストでエージェントを起動できると、第2問が表示されます。
第2問: リモートホストでエージェントを起動せよ
表:問題文 裏:詳細・ヒント 問題文に書いてあるように、MITRE CALDERAサーバとは違う種類のOSのホストでエージェントを起動しなければいけません。
MITRE CALDERA サーバは Linux OS 上で動作しているので、Windows OS あるいは Mac OS 上でエージェントを起動してリモート接続できれば問題クリアとなり、第3問目が表示されます。このように次々と問題が出題されます。
ジャンル内の問題をすべて解くと、ジャンルのアイコンに色が付きます。
問題に正解した日付が記録されており、MITRE CALDERA サーバを再起動しても、続きから解くことができます。AGENTSジャンルの全8問を解いた状態のスクリーンショットを以下に示します。
Trainingプラグインの構造
Trainingプラグインのディレクトリ・ファイル構成を以下に示します。
構成に合わせて、自分で問題を作って登録することもできます。ディレクトリ・ファイル構成
plugins/training/ ├── README.md ├── __init__.py ├── app │ ├── c_badge.py │ ├── c_certification.py │ ├── c_flag.py │ ├── flags │ │ ├── advanced │ │ │ ├── flag_0.py │ │ │ ├── flag_1.py │ │ │ └── flag_2.py │ │ ├── adversaries │ │ │ ├── flag_0.py │ │ │ ├── flag_1.py │ │ │ └── flag_2.py │ │ ├── agents (中略) │ │ └── plugins │ │ ├── atomic │ │ │ └── flag_0.py │ │ ├── compass (中略) │ │ └── mock │ │ └── flag_0.py │ └── training_api.py ├── data │ └── 9cd5f3a0-765d-45bc-85c2-bc76d4282599.yml ├── hook.py ├── static │ ├── css │ │ └── training.css │ └── img │ ├── badges │ │ ├── advanced.png (中略) │ │ └── operations.png │ └── certification.png └── templates └── training.html問題集定義ファイル
「User Certificate」などの問題テーマに関する問題を集めた問題集定義ファイルです。
問題集毎に UUID をファイル名にしたyamlファイルがdataディレクトリ配下にあります。
同様の形式で問題集定義ファイルを自作してdataディレクトリに格納しておくと、問題集選択プルダウンメニューに自動追加されて選択できるようになります。問題集定義ファイルの定義フォーマットを以下に示します。
data/*.yamlid: 問題集UUID name: 問題集名 badges: 問題ジャンル名: flags: - 問題定義PythonスクリプトのPythonモジュール名問題定義ファイル
個々の問題定義ファイルです。
Pythonスクリプトになっていて、問題タイトル、問題文、詳細説明を変数定義し、正解を判定する処理を関数定義しておきます。
Pythonモジュールとしてimport処理されるため、appディレクトリ配下にPythonモジュール形式に合わせてPythonスクリプトを配置します。問題定義ファイルの定義フォーマットを以下に示します。
変数名および関数名が決められていて、問題として自動認識されます。app/flags/*/*.pyname = '問題タイトル' challenge = '問題文' extra_info = """詳細・ヒント""" async def verify(services): 正解していれば True、正解していないなら False を返す処理さいごに
『サイバーセキュリティ・フレームワーク「MITRE CALDERA」紹介』は以上で終了です。
興味・関心を持っていただき、業務や人材育成などに活用するきっかけになりましたら幸いです。
テクニック、シナリオ、トレーニングメニュー、新たなプラグインなどが今後増えていくことが大いに期待できます。
フレームワークなので、オリジナルのテクニックやトレーニングを定義したり、新たなプラグインを考案・制作するのも面白いと思います。プラグイン開発環境構築方法については、いずれ紹介したいと考えています。MITRE ATT&CK および MITRE CALDERA をサイバーセキュリティに活用していきましょう。
最後まで読んでいただき、ありがとうございました。


- 投稿日:2020-07-15T09:58:16+09:00
[Python] immutableなハズのint型が別の値に変更できる理由
先に結論
int型の変数に違う値を代入すると,格納される場所が変わる.つまり同じ番地を使いながらint型変数の値を変更することができない.(逆に言うとmutableなlistとかはそれが可能)
記事を書いた理由
すでにmutable/immutableの挙動について触れつ記事はたくさんあります.ただpython初学者が,この記事のような疑問をそのまま検索すると,「python int immutable 変更できる」みたいになるかなーと思ったので,その検索の仕方で欲しい情報に辿り着けるように作成しました.
mutable/immutableとは
(詳細な記述は分かりやすい記事がたくさんありますので,そちらをご覧ください)
- mutable: 変数定義後に値を変更可能な型(list, dictなど)
- immutable: 変更不可能な型(int, strなど)
疑問
変更不可能って言うけどintもstrも定義した後に代入し直せるじゃん!
# 一回定義して var_int = 2 # 代入し直せるじゃん! var_int = 5実際に起こっていること
pythonに搭載されているid関数を利用して,変数のid(番地)を確認します.
使用環境: python 3.8.3, jupyter notebook# 変数aにint型の数値3を代入する a = 3 # id()を用いて変数aの番地を取得 id(a) # out: 4500765184このように変数aのidが4500765184であることが分かります.
次に値を変更してみましょう.# 変数aにint型の数値2を代入する a = 2 # 変えれるじゃん! # id()を用いて変数aの番地を取得 id(a) # out: 4500765216 # と思ったらidが変わっている!このように,一見同じ変数の値を変更できるので,immutableじゃないように見えます.しかしidを確認すると,同じ変数名でもidが変更されていることが分かります.
つまり,同じ変数名にint値を代入し直すと,新しい番地に格納されることになるわけです!元の番地の値は変更できないので,immutableということになります.
idについて少し深堀り
(もう記事で伝えたいことは終わっているので興味のある方へ)
pythonのidに関するdocsを確認すると,Return the “identity” of an object. This is an integer which is guaranteed to be unique and constant for this object during its lifetime. Two objects with non-overlapping lifetimes may have the same id() value.
CPython implementation detail: This is the address of the object in memory.
と書かれています.特に,CPythonの場合には,メモリ番地を表す,と書かれています.
現在私たちが使っているPythonは大体がCPythonという実装による物ですから,基本的にidはメモリ番地と思って大丈夫でしょう.
※ CPython: c言語を使って実装したPython. Pythonと言う言語を動作させるために,裏では他の言語が動いていると言う感じです.(ちょっと語弊があるかもしれませんが...)まず,objectと言うのは,変数が入った箱のような物です.もしくは,変数を格納する番地,といった方が分かりやすいかもしれません.
プログラムはコンピュータ上で動作するので,「どの値を」「どこで覚えておくか」が必要です.objectはこれらのまとまりと考えられます.そして,immutableな変数に値を再代入すると,違うオブジェクトが作成されます.つまり,違う番地が確保され,新しく値が格納されることになります.
終わりに
自分が初学者だった頃の疑問を思い出したので,まとめました.正直pythonで変数の格納先を気にすることって稀かもしれませんが,疑問の解消に繋がれば幸いです.
何か間違った記述がありましたら,是非ご教授お願いできますと幸いです!
- 投稿日:2020-07-15T09:58:03+09:00
エイシング プログラミングコンテスト 2020
今回の成績
感想
ABC級最難のセットでした、難しかったです。
D問題の方針に迷いすぎて時間を溶かしましたが、実験したらわかりました、実験は大事です。
E問題も結構な時間眺めていたのですが、貪欲法を試さずにいました。基本中の基本がいまだに身についてないのは未熟なので頑張りたいです…。そろそろ競プロerを名乗れるレベルに成長したいなと思っています。
A問題
L以上で最小のDの倍数からR以下で最大のDの倍数まででDの倍数がいくつあるかを数えれば良いです。
これは、ceil(l/d)*d,ceil(l/d)*d+d,…,floor(r/d)*dと言い換えることができるので、その個数はfloor(r/d)-ceil(l/d)+1となります。A.pyfrom math import * l,r,d=map(int,input().split()) print(floor(r/d)-ceil(l/d)+1)B問題
マスの番号が奇数と書かれた数が奇数というのを全ての数に対して確かめれば良いです。
B.pyn=int(input()) a=list(map(int,input().split())) ans=0 for i in range(n): ans+=(i%2==0 and a[i]%2==1) print(ans)C問題
一瞬因数分解を疑いましたが難しいです。しかし、$1 \leqq x \leqq \sqrt{n},1 \leqq y \leqq \sqrt{n},1 \leqq z \leqq \sqrt{n}$ことは二乗の項を見ればすぐ分かったので、この$x,y,z$の値を全探索すれば良いです($O(N \sqrt{N})$で余裕)。
また、求めたいのは$f(1),f(2),…,f(n)$の値であり、全探索の際に$x^2+y^2+z^2+xy+yz+zx$の値が$1$~$N$のどの値になるかを一つずつ記録していけば良いです。
C.pyfrom math import * n=int(input()) l=floor(sqrt(n))+1 ans=[0]*n def f(a,b,c): return a*a+b*b+c*c+a*b+b*c+c*a for x in range(1,l+1): for y in range(1,l+1): for z in range(1,l+1): g=f(x,y,z) if g<=n: ans[g-1]+=1 for i in range(n): print(ans[i])D問題
E問題を考えていたせいで解くのに時間がかかってしまいました。解くべき問題を選ぶのは難しいですね…。ABC級の問題なら余裕と言えるくらいまで努力したいです。
以下では、入力で与えられる数を$x$、そのpopcountを$c$としています。
popcountを愚直に実装しても$x$が極めて大きい数になるので間に合わないのは明らかです。しかし、ある数$K$に対してそのpopcountの値は$\log{K}$程度なので、題意の制約ではpopcountを繰り返して0になるまでに5回程度しかかかりません(問題の制約のもとではほぼ定数倍と言えます。)。
ここで、$f(X_i)$を$1 \leqq i \leqq N$について愚直に求めていくことを考えますが、初めの操作においては全ての桁についてチェックすることで$O(N)$かかるので、合計の計算量は$O(N^2)$かかります。(愚直を考えてその無駄を減らす!)
しかし、$f(X_i)$で変えるのは$i$桁目のみなので、$x$を保存したもとでその桁の反転による差分を考えます。また、$i$桁目が$0$の場合は$1$に変わるのでこの数のpopcountは$c-1$、$i$桁目が$1$の場合は$0$に変わるのでこの数のpopcountは$c+1$となり、この2通りしかありません。
したがって、以下の二つを前計算で用意すればこの方針を達成することができます($c-1$の場合と$c+1$の場合で完全に分ける必要があることには注意が必要です。)。
$i$桁目を変える際の差分の余りを保存する配列$m$
→$m[i][0]:=2^i \ mod \ (c-1)$ , $m[i][1]:=2^i \ mod \ (c+1)$
$x$を$c-1$,$c+1$でそれぞれ割った余りを保存する変数$l$
→$l[0]:= x \ mod (c-1)$ , $l[1]:= x \ mod (c+1)$)これらは$O(N)$の前計算で用意でき、それぞれの$f(X_i)$の計算は一回目のpopcountの差分計算は$O(1)$、それ以降のpopcountは通常のpopcountの関数などを用いて$O(\log{N})$の定数倍程度で行うことができるので、合計で$O(N \log{N})$で計算を行うことができ、Pythonでも余裕で通すことができます。
追記として、cが1になる時は0除算が発生するので回避する必要があります。
D.py#0除算 import math def popcount(x): s=0 y=int(math.log2(x))+2 for i in range(y): if(x>>i)&1: s+=1 return x%s n=int(input()) x=input()[::-1] #1がなんこ出るのか c=x.count("1") #c+1とc-1だけ考えれば良い #c=1の時場合分け #m[i][j]:2^iまで考えたときのmod(c+j-1) if c!=1: m=[[1%(c-1),1%(c+1)]] for i in range(n-1): m.append([(2*m[-1][0])%(c-1),(2*m[-1][1])%(c+1)]) l=[0,0] for i in range(n): if x[i]=="1": l[0]+=m[i][0] l[1]+=m[i][1] l[0]%=(c-1) l[1]%=(c+1) else: m=[[1%(c+1),1%(c+1)]] for i in range(n-1): m.append([(2*m[-1][0])%(c+1),(2*m[-1][1])%(c+1)]) l=[0,0] for i in range(n): if x[i]=="1": l[0]+=m[i][0] l[1]+=m[i][1] l[0]%=(c+1) l[1]%=(c+1) #一個だけ変えたいので全体を求める #最初以外はpopcount使って間に合う ans=[0]*n for i in range(n): if x[i]=="1": if c-1==0: ans[i]=0 continue p=(l[0]+(c-1)-m[i][0])%(c-1) ans[i]+=1 while p!=0: p=popcount(p) ans[i]+=1 else: p=(l[1]+m[i][1])%(c+1) ans[i]+=1 while p!=0: p=popcount(p) ans[i]+=1 ans=ans[::-1] for i in range(n): print(ans[i])E問題
どちらか選ぶ→$2^N$ある→DP、というような短絡的な発想では無理なので、まずは貪欲法での解法を考えます。
ここで、$i$番目のラクダについて$L_i,R_i$どちらを得る順番であっても$min(L_i,R_i)$は得ることができるので、それは答えとして求めたい嬉しさの総和
ansに先に足してしまいます。すると、($L_i-R_i,0$),($0,R_i-L_i$)のどちらかのパターンのみになって考えやすくなります。コンテスト中にはここまでの発想しか出ませんでしたが、左側を選びたいラクダと右側を選びたいラクダを分けて考える(それぞれ、($L_i-R_i,0$),($0,R_i-L_i$)のパターン)とこの後の方針につなげることができます。(二つが組み合わさってるなら一つずつ考えようというのは自然な解法だと思うので解けなかったのが悔しいです。)
このもとで、左側を選びたいラクダと右側を選びたいラクダの位置の選び方は干渉しない(独立である)ことが言えます。これは、前者を赤丸、後者を青丸とすれば下図のようにラクダの位置を移動することが可能なことが理由です。
したがって、以下では左側を選びたいラクダの位置を貪欲に決めることをまずは考えます。この時、$L_i-R_i$が大きいもの($K_i$番目以内)から貪欲に選ぶので、その最適な位置を考えます。最適な位置はそれ以降の要素を選ぶのに損しない位置と言い換えることができます。この時、それ以降の他のラクダの選べる位置が最も多い$K_i$番目が最適となることがわかると思います。また、$K_i$番目より左側に配置した時にこれよりも得するような位置はないので、この考え方からも正しいことがわかります。さらに、$K_i$番目がすでに選ばれている時はそれよりも左側の位置で一番右側の位置を選べば良いです。
以上より、まだ選ばれていない位置を昇順で保存して(setを使う)、$K_i$以下で最大の位置(upper_boundで選んだ要素の一つの隣)を位置として選択し、その後setから削除すれば良いです。また、この際に相当する位置がなければその要素は選べないので次の要素を考えます。そして、これを左側だけでなく右側も考え、選んだ要素の全ての和が答えとなります。
貪欲法について得た新しい知見
→損しない方向には動かしても良い!!
逆に言えば、その動かし方以外の場合が得するパターンがあるかを考えるF問題
今回は飛ばします。


- 投稿日:2020-07-15T09:54:58+09:00
re.splitとre.compile
import re s = 'my name is mike' print(s.split()) p = re.compile(r'\W+') print(p.split(s)) p = re.compile('blue|white|red') print(p.sub('colour', 'blue socks and red shoes')) print(p.sub('colour', 'blue socks and red shoes', count=1)) print(p.subn('colour', 'blue socks and red shoes'))実行結果:
['my', 'name', 'is', 'mike'] ['my', 'name', 'is', 'mike'] colour socks and colour shoes colour socks and red shoes ('colour socks and colour shoes', 2)
- 投稿日:2020-07-15T09:53:13+09:00
float型の数値は10進数の少数と同じではない
Python学習のアウトプット。
mathモジュールには、
.isclose()関数というものがある。
float型の数値を比較する際に用いる。それぞれが近似値かどうか。>>> import math >>> math.isclose(0.1+0.1+0.1, 0.3) True大前提として、Pythonを含めた計算機ハードウェアは浮動小数点数を正確に表すことができない。2進法の分数として表現されるため、例えば、2進法の分数
0.001は
0/2 + 0/4 + 1/8という値になる。
ただし、ほとんどの少数は2進法の分数として正確に表現できないため、近似値が記憶される。
float型の正確な値を取得するには、
float.as_integer_ratio()メソッドを使う。xに0.3を代入し、このメソッドを使って正確な値を有理数として表現すると……>>> x = 0.3 >>> x.as_integer_ratio() (5404319552844595, 18014398509481984) >>> x == 5404319552844595 / 18014398509481984 True >>> 5404319552844595 / 18014398509481984 0.3なんかすごい。
今度はxに0.1を代入し、3をかけてみる。すると、
>>> x = 0.1 >>> x.as_integer_ratio() (3602879701896397, 36028797018963968) >>> 3602879701896397 / 36028797018963968 0.1 >>> 3602879701896397 / 36028797018963968 * 3 0.30000000000000004こう。限りなく0.3に近いんだけど、
0.1 + 0.1 + 0.1 == 0.3の条件式は成立しない。しかし、
0.30000000000000004は0.3の近似値と言える。そのため、上記のように、>>> import math >>> math.isclose(0.1+0.1+0.1, 0.3) True
.isclose()関数はTrueを返してくれる。参考
Pythonの公式ドキュメント: 15. 浮動小数点演算、その問題と制限
- 投稿日:2020-07-15T09:52:24+09:00
re.splitの分割とre.compileの置換
import re s = 'my name is mike' print(s.split()) p = re.compile(r'\W+') print(p.split(s)) p = re.compile('blue|white|red') print(p.sub('colour', 'blue socks and red shoes')) print(p.sub('colour', 'blue socks and red shoes', count=1)) print(p.subn('colour', 'blue socks and red shoes'))実行結果:
['my', 'name', 'is', 'mike'] ['my', 'name', 'is', 'mike'] colour socks and colour shoes colour socks and red shoes ('colour socks and colour shoes', 2)
- 投稿日:2020-07-15T08:42:49+09:00
re.groupとre.compileとre.VERBOSE
import re s = ('arn:aws:cloudformation:us-east-2:123456789012:stack/' 'mystack-mynestedstack-sggfrhxhum7w' '/f449b250-b969-11e0-a185-5081d0136786') # [\w-]で英数字もしくはハイフンの意味になる # group名をつけています m = re.match(r'arn:aws:cloudformation:(?P<region>[\w-]+):(?P<account_id>[\d]+)' r':stack/(?P<stack_name>[\w-]+)/[\w-]+', s) if m: # group名でアクセスできます print(m.group('region')) print(m.group('account_id')) print(m.group('stack_name'))re.compileを使う場合
正規表現の部分を何度も書く場合に、効率的です。
import re s = ('arn:aws:cloudformation:us-east-2:123456789012:stack/' 'mystack-mynestedstack-sggfrhxhum7w' '/f449b250-b969-11e0-a185-5081d0136786') RE_STACK_ID = re.compile(r'arn:aws:cloudformation:(?P<region>[\w-]+):(?P<account_id>[\d]+)' r':stack/(?P<stack_name>[\w-]+)/[\w-]+') m = RE_STACK_ID.match(s) if m: # group名でアクセスできます print(m.group('region')) print(m.group('account_id')) print(m.group('stack_name'))更に、re.VERBOSEを場合
きれいに書けます
import re s = ('arn:aws:cloudformation:us-east-2:123456789012:stack/' 'mystack-mynestedstack-sggfrhxhum7w' '/f449b250-b969-11e0-a185-5081d0136786') RE_STACK_ID = re.compile(r""" arn:aws:cloudformation: (?P<region>[\w-]+): #region (?P<account_id>[\d]+): #account_id stack/ (?P<stack_name>[\w-]+)/ #stack_name [\w-]+""", re.VERBOSE) m = RE_STACK_ID.match(s) if m: # group名でアクセスできます print(m.group('region')) print(m.group('account_id')) print(m.group('stack_name'))