- 投稿日:2020-07-13T22:52:57+09:00
CarrierWaveによって保存されたデータの中身。
調査した背景
CarrierWaveによって画像データをアップロードしたのですが、そのデータを更新したいとき、どのようにデータが入っているか調べました。
(この記事を見られている方ももしかすると、参照された方もいるかもしれません)データベースでは以下のとおり、ファイル名のみが表示されます(image列)
DBのUIは「sequelpro」を使っています。列値の詳細を参照しても、ファイル名のみです。
環境
項目 内容 OS.Catalina v10.15.4 Ruby v2.5.1 Ruby On Rails v5.2.4.3 MySQL v5.6 中身を参照する
以下の通り、コマンドを実行し、中身を参照しました。
「Attachment」というテーブルにアクセスしています。
[6] pry(main)> >> image_data = Attachment.find(7) image_data = Attachment.find(7) Attachment Load (0.5ms) SELECT `attachments`.* FROM `attachments` WHERE `attachments`.`id` = 7 LIMIT 1 => #<Attachment:0x00007f86e6d7b760 id: 7, knowledge_id: 17, sub_id: "1", name: "test.png", width_size: "1200", height_size: "799", file_type: "png", file_size: "72297", image: "test.png", thumb_image_url: "/uploads/tmp/1593690046-968881373703887-0012-2842/thumb_test.png", created_at: Thu, 02 Jul 2020 11:40:46 UTC +00:00, updated_at: Thu, 02 Jul 2020 11:40:46 UTC +00:00, image_url: "/uploads/tmp/1593690046-968881373703887-0012-2842/test.png">ここからが、イメージ情報になります。
[7] pry(main)> >> image_data.image image_data.image => #<ImageUploader:0x00007f86e6c26a68 @cache_id=nil, @file= #<CarrierWave::SanitizedFile:0x00007f86e6c25e10 @content=nil, @content_type=nil, @file= "/Users/ichikawadaisuke/projects/krown/public/uploads/attachment/image/7/test.png", @original_filename=nil>, @filename=nil, @format=nil, @identifier="test.png", @model= #<Attachment:0x00007f86e6d7b760 id: 7, knowledge_id: 17, sub_id: "1", name: "test.png", width_size: "1200", height_size: "799", file_type: "png", file_size: "72297", image: "test.png", thumb_image_url: "/uploads/tmp/1593690046-968881373703887-0012-2842/thumb_test.png", created_at: Thu, 02 Jul 2020 11:40:46 UTC +00:00, updated_at: Thu, 02 Jul 2020 11:40:46 UTC +00:00, image_url: "/uploads/tmp/1593690046-968881373703887-0012-2842/test.png">, @mounted_as=:image, @staged=false, @storage= #<CarrierWave::Storage::File:0x00007f86e6c262c0 @cache_called=nil, @uploader=#<ImageUploader:0x00007f86e6c26a68 ...>>, @versions= {:thumb=> #<ImageUploader::Uploader70108727518060:0x00007f86e6c25c80 @cache_id=nil, @file= #<CarrierWave::SanitizedFile:0x00007f86e6c25460 @content=nil, @content_type=nil, @file= "/Users/ichikawadaisuke/projects/krown/public/uploads/attachment/image/7/thumb_test.png", @original_filename=nil>, @filename=nil, @format=nil, @identifier="test.png", @model= #<Attachment:0x00007f86e6d7b760 id: 7, knowledge_id: 17, sub_id: "1", name: "test.png", width_size: "1200", height_size: "799", file_type: "png", file_size: "72297", image: "test.png", thumb_image_url: "/uploads/tmp/1593690046-968881373703887-0012-2842/thumb_test.png", created_at: Thu, 02 Jul 2020 11:40:46 UTC +00:00, updated_at: Thu, 02 Jul 2020 11:40:46 UTC +00:00, image_url: "/uploads/tmp/1593690046-968881373703887-0012-2842/test.png">, @mounted_as=:image, @parent_version=#<ImageUploader:0x00007f86e6c26a68 ...>, @staged=false, @storage= #<CarrierWave::Storage::File:0x00007f86e6c25a00 @cache_called=nil, @uploader= #<ImageUploader::Uploader70108727518060:0x00007f86e6c25c80 ...>>, @versions={}>}> [8] pry(main)>さらにワンライナーで、簡単にオブジェクトの情報を取得出来ます。
[9] pry(main)> >> image_data.image.file image_data.image.file => #<CarrierWave::SanitizedFile:0x00007f86e6c25e10 @content=nil, @content_type=nil, @file= "/Users/ichikawadaisuke/projects/krown/public/uploads/attachment/image/7/test.png", @original_filename=nil> [10] pry(main)>今回は以上です。


- 投稿日:2020-07-13T22:33:06+09:00
Railsで「テスト駆動開発」の '多国通貨' を書いてみた
書籍
https://www.amazon.co.jp/dp/4274217884
リポジトリ
https://github.com/ymstshinichiro/tdd_rails
基本的には↑を見たりコメントいただけると嬉しいです(お恥ずかしい点が多々ありますが、そこはスルーいただけると何より...)。
以下は蛇足です。
感想
いくつか現場を回ってみて、ちゃんとテストが回っている現場というのはなかなかないものだなあと痛感しています。特に今の現場は厳しい。
そんな課題感を少しでも打破できないか?と思って手に取ったのが「テスト駆動開発」。
読んでみると、確かに面白かった。普段、ペアプロでもここまで細かく他人の書くコードが出来上がるまでを追うことはほぼないと思います。
レッド -> グリーン -> リファクタリング という流れの明確さもわかりやすくて良かったです。そして、読み終わっただけでは少々物足りなかったので実際に手を動かして作った、というのが冒頭のリポジトリ。
取り組んでみて以下のような気づきがありました。
- Railsに慣れてきたことで自分の考え方も狭くなってしまっていた
- マイグレーションはRails Way的な考えを最初に持ってきてしまいがち
- もっと違う実装やアプローチはないか?と考えるきっかけになった
- Railsらしく作るのはリファクタリングの段階でも構わないはず
- 振る舞いと責務は似てるけどちょっと違うなという観点が自分の中でできてきた
- 別の言い方をすると module vs class
- 手続きの少ないコードにするにはどうするか?と考えるようになった
- あと、凝集度
- リファクタリングが楽しくなってきた
- より綺麗に、よりわかりやすくを目指す
- そのために書き方のバリエーションを増やす勉強が面白かったり
あと、単純に
Rails newしてイチからコード書くというのをやるのも久々だったので面白かったですね。
学んだことを生かして、お仕事で触っているコードも、同じくらい触りやすいコードベースにしていけるように頑張りたいと思います!最後になりましたが、Kent Beckさん、和田卓人さんに改めて感謝を申し上げます。ありがとうございました!
- 投稿日:2020-07-13T22:26:29+09:00
Rails & React & Webpacker & MySQL環境構築マニュアル
突然ですが、環境構築って毎朝髭を剃るのと同じぐらい面倒で苦手です。
この記事をご覧になっているということは、少なからずあなたも環境構築に苦手意識があるのではないでしょうか。社内のメンバーからも「環境構築はコンビニでたむろするヤンキーぐらい苦手」という声を良く耳にします。
私は思います、この環境構築という最初のハードルが、クリエイティブな行動を阻害していると!
環境構築の手間さえ省ければ、きっとこの世の中にはもっと多くのサービスが創出されると確信しています!
そこで今回は、"RailsをAPIサーバーとして利用"し、"Reactで描画を行う"サービスをつくりまくるための環境構築マニュアルを公開します!以下すべてに当てはまる人が本記事の対象読者です
- なんかオシャレっぽいからMac使ってます!
- プログラミングスクール卒業したから個人アプリつくりたいぜ!
- React.jsっていうJavascriptのモダンなフレームワークを身につけて周りと差を付けたいぜ!
- react-railsとかのGemを使わない方法でRailsとReact間のやりとりを疎結合にしたい!
- Docker?なにそれ美味しいの?(本記事ではDockerの解説はしません)
0. 事前インストール
名前 説明 Ruby いわずもがな Rails いわずもがな MySQL いわずもがな brew パッケージ管理 (主にサーバー側) yarn パッケージ管理 (主にフロント側) 1. Railsアプリの作成
rails new アプリ名 -–skip-turbolinks --webpack=react --database=mysql --api人生に何回この『rails new』コマンドを打ったかでRailsエンジニアとしての価値が決まると、まことしやかに噂される。
ちなみにオプションは必要であれば書き換えてOKです2. Webpackerのインストール
Webpackerとは、Rails標準装備のモジュールバンドラーで、Webpackのラッパーです。
バンドラーというのは束ねる人のことです。
HTML、CSS、JSなど色々な形式のファイルを束ねてくれるやつです。ちなみにラッパーは韻を踏む人のことではありません。
サランラップとかのラッパーです。『包む』という意味です。
Webpackerは内部でWebpackを呼び出しているので、WebpackerはWebpackのラッパーです。ちなみにフロントエンドに興味があるなら、Webpackの知識はある程度あった方が良いです。
"Babel"とか"ES6"とかそういうワードとセットで覚えるとGOODです!rails webpacker:install rails webpacker:install:react3. MySQLのインストール
今回はDBにMySQLを使ってみます。
私は普段の業務ではPostgreSQLを使用しているのですが、プログラミングスクール卒の方はMySQLに慣れていると思うので。
新規プロダクトのDB選定はその現場で使い慣れているものを使用しているところが多いような気がしています。
違ったらすみません。
ちなみに余談of余談ですが、個人的にはNoSQLのMongoDBとかに興味があったりします。
理由は、「なんとなく知ってたらイケてるエンジニアっぽいから」です。今回はbrewというパッケージマネージャー経由でMySQLをインストールします
brew install mysql4. MySQLユーザーの作成
MySQLがインストールできたら、今回のアプリで使用するためのユーザーを作成します。
各コマンドについては、特に詳しく説明する必要もなさそうなので割愛します。・ルートユーザーにログイン
mysql -u root -p・ユーザー作成
好きなユーザー名とパスワードを設定
create user 'ユーザー名'@'localhost' identified by 'パスワード';・作成したユーザーの確認
作成したユーザーが表示されていれば成功
select User,Host from mysql.user;・権限付与
grant all on *.* to '[ユーザー名]'@'localhost';・config/database.ymlの設定変更
ユーザーの作成が一通り終わったら、作成したユーザーとRailsを紐付けます。
RailsのDB設定はdatabase.ymlに記述するのがルールです。default: &default adapter: mysql2 encoding: utf8mb4 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: <%= ENV['DATABASE_USERNAME'] %> password: <%= ENV['DATABASE_PASSWORD'] %> host: <%= ENV['DATABASE_HOST'] %> development: <<: *default database: app_name_development test: <<: *default database: app_name_test production: <<: *default database: app_name_production username: <%= ENV['APP_NAME_DATABASE_USERNAME'] %> password: <%= ENV['APP_NAME_DATABASE_PASSWORD'] %>『app_name_○○』はRails newした時のアプリ名に置き換えてください
usernameやpasswordはGitHubで公開しちゃうと見えてしまうので
gem『dotenv』等を使って隠蔽することをおすすめします。
ちなみにdotenvで作成した『.env』ファイルをGit管理から外しておかないと意味が無いので、作ったら『.gitignore』に『.env』を忘れずに追加しましょう!
「何を言っているのかわからない...」という人は「dotenv 環境変数」とかで調べてみよう!
「わからないことを調べる」のは、エンジニアの基本です!
この『調べる』をいかに深堀りしてできるかが、成長の近道のような気がしています。5. データベースの作成
rake db:create6. Railsサーバーの起動
rails s7. Webで確認
「Yay! You’re on Rails!」が表示されていれば成功
環境構築はもう少し続きます。
もう6合目ぐらいには来てます。もう少し。8. Webpackerの設定(任意)
・splitchunks
チャンクを自動分割してくれるWebpackのプラグインです。
ファイルサイズの節約ができたりするけど、別になくても良いです。config/webpack/environment.jsの変更
const { environment } = require('@rails/webpacker'); environment.splitChunks(); module.exports = environment;app/views/top/show.html.erb
javascript/packs/の中にある「index」という名前の付いたファイルを参照するの意。
<%# splitchunksを使う場合 %> <%= javascript_packs_with_chunks_tag 'index' %> <%# splitchunksを使わない場合 %> <%= javascript_pack_tag 'index' %>9. ルーティング設定
config/routes.rb
Rails.application.routes.draw do # ルートページ設定 root "top#show" end10. エントリーポイントの作成
・ルートページのコンロトーラー作成
app/controllers/top_controller.rb
class TopController < ApplicationController def show end end・Reactで描画するためのid属性を追加
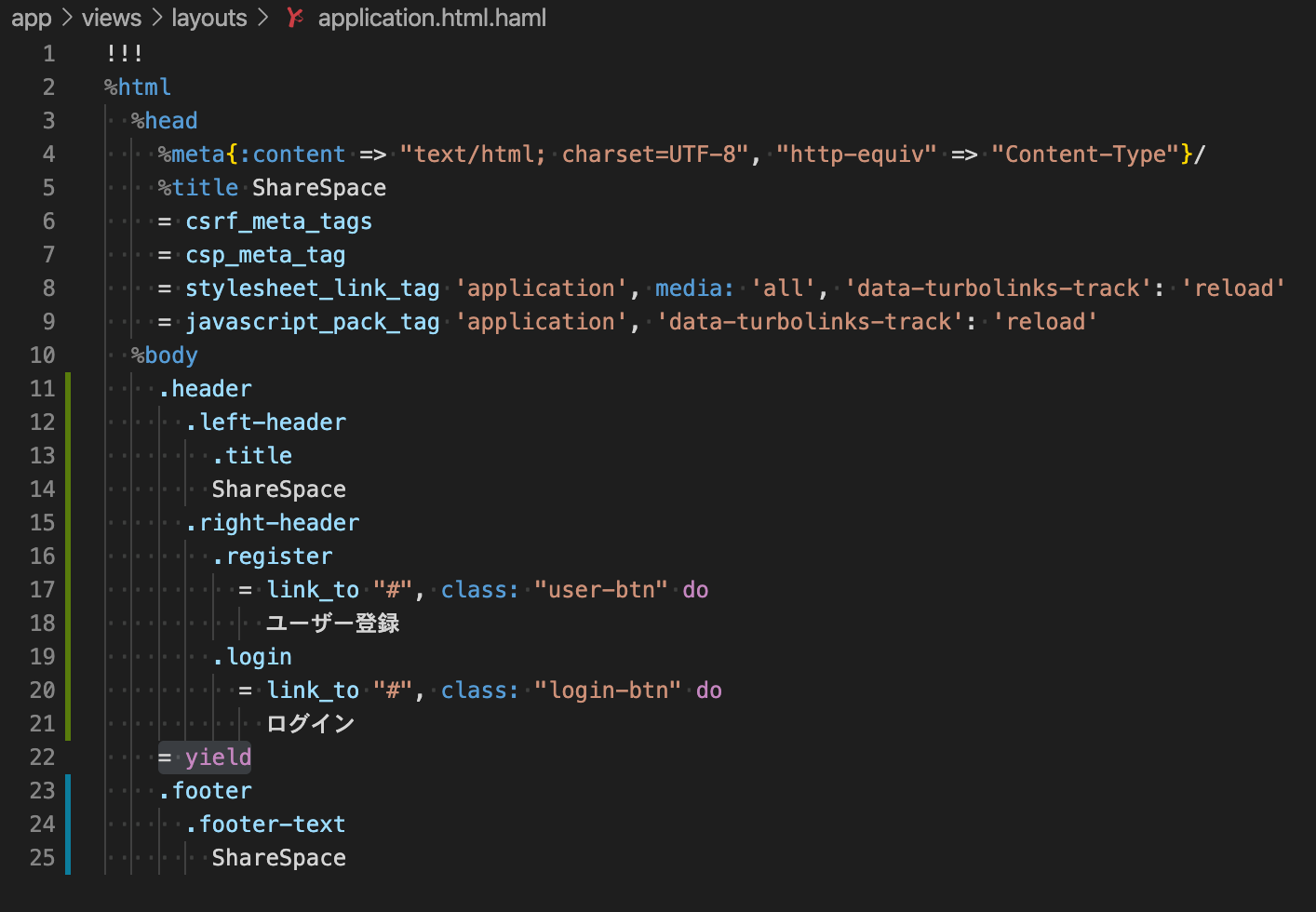
app/views/layouts/application.html.erb
<!DOCTYPE html> <html> <head> <title>アプリケーションタイトル</title> <%= csrf_meta_tags %> <%= csp_meta_tag %> <%= javascript_pack_tag 'application' %> </head> <body> <div id="root"> ←これです <%= yield %> </div> </body> </html>・Reactのエントリーポイント作成
app/javascript/packs/index.jsx
app/views/top/show.html.erbから参照されるファイル
このファイルがReactの入り口です。
非同期、ルーティング、状態管理等、React用のパッケージをimportして設定しています。
各パッケージのインストールは後で行います。// このファイルがRailsのViewから呼ばれる一番最初のファイルです(EntryPoint) import React from 'react'; import { render } from 'react-dom'; import { Provider } from 'react-redux'; import { createStore, applyMiddleware } from 'redux'; import thunk from 'redux-thunk' import { Router, Route, Switch, IndexRoute, useLocation } from 'react-router-dom'; import { createBrowserHistory } from 'history'; import { composeWithDevTools } from 'redux-devtools-extension'; // reducer import rootReducer from '~/src/reducers/'; // Component import Top from '~/src/components/tops/'; const middleWares = [thunk]; // 開発環境の場合、開発ツールを使用するための設定 const enhancer = process.env.NODE_ENV === 'development' ? composeWithDevTools(applyMiddleware(...middleWares)) : applyMiddleware(...middleWares); const store = createStore(rootReducer, enhancer); const customHistory = createBrowserHistory(); render( <Provider store={store}> <Router history={customHistory}> <Route render={({ location }) => ( <div> <Switch location={location}> <Route exact path='/' component={Top} /> </Switch> </div> )}/> </Router> </Provider>, document.getElementById('root') )・Reactコンポーネント作成
app/javascript/src/components/tops/index.jsx
Reactコンポーネントの記述にはjsxという拡張子のファイルを使用します。
JSファイルの中にHTMLを記述します。
最初はJSの中にHTMLタグを書くことに気持ち悪さを感じますが、その内慣れます。import React from 'react'; const Top = () => ( <h1> <center>アプリケーションのタイトル</center> </h1> ) export default Top;・Reactリデューサーをまとめる処理の作成
app/javascript/src/reducers/index.js
import { combineReducers } from 'redux'; import { reducer as formReducer } from 'redux-form'; import top from '~/src/modules/tops/'; export default combineReducers({ form: formReducer, top, });ここでまとめたものがReduxのstoreに格納されます。
Reduxとは状態を一元管理してくれるパッケージのことです。
storeとは状態を格納する箱のことです。Reduxの一番重要な機能です。
Reactの開発において、Reduxの利用は必須ではありませんが、React単体だとプロダクトの規模が大きくなるにつれて状態管理が辛くなるので、初めから入れておいた方がいいです。
LPとか規模の小さいプロダクトならなくても良いです。・Reactモジュール作成
ディレクトリ構成はducksパターンを採用。
ducksパターンというのは『action type』、『action creator』、『reducer』を1つのファイルにまとめて記述する考え方のことです。設計の概念です。何かをインストールするとかではないです。app/javascript/src/modules/tops/index.js
// action-type const TOP_INITIAL = 'TOP_INITIAL'; // reducer const initialState = { top: null, } export default function top(state = initialState, action) { switch (action.type) { case TOP_INITIAL: return { ...state, } default: return state } } // action-creator export const topInitial = () => ({ type: TOP_INITIAL, });通常は『action type』、『action creator』、『reducer』それぞれでファイルを作成するところ、ducksパターンを取り入れると1つのファイルにまとまるので、単純にファイル数が少なくて済みます。
中規模プロダクトでも全然耐えられる設計概念なのでおすすめです。
「action typeって何?」と思った人はRedux公式で調べてみましょう!11. 必要なパッケージインストール
yarnというパッケージマネージャーを使用してインストールします。
似た様なパッケージマネージャーで『npm』がありますが、『yarn』は『npm』の上位互換です。
yarnでインストールしたパッケージは、ルートディレクトリ直下の『package.json』というファイルに自動で追加されます。
『yarn add パッケージ名』でパッケージの追加
『yarn remove パッケージ名』でパッケージの削除です。yarn add redux react-redux react-router-dom redux-devtools-extension redux-form redux-thunk axios @babel/preset-react babel-plugin-root-importもし興味があれば『@reduxjs/toolkit』、『@material-ui/core』もおすすめです
12. パス指定設定ファイルの作成(任意)
独学でReactを少しでも開発したことがある方なら一度はこう思ったはず
「React相対パス地獄なりがち。」
Reactはimport時の相対パス指定地獄に陥りがちです。
そうならないよう『babel-plugin-root-import』を入れることをおすすめします。
実は上記11.の『yarn add』の中にこっそり入っているので、コマンドをコピペして実行した方は私の策略によりすでに入っています。『.babelrc』というファイルを作ってそこに設定を記述します。
『.babelrc』ファイルを作る場所はルートディレクトリ直下。.babelrc
{ "plugins": [ [ "babel-plugin-root-import", { "paths": [ { "rootPathSuffix": "./app/javascript/src", "rootPathPrefix": "~/src/" }, ] } ] ] }上記設定は『./app/javascript/src』というパス指定を『~/src/』という文字列でも指定できるように設定しているだけです。
これで、Reactコンポーネントでのimport時に『~/src/○○』が使えるようになるので、相対パス地獄から抜け出せます。
ちなみに『"~/src/"』の部分は『"~/"』でも『"@/src/"』でも好きに設定できます。13. webpack-dev-serverの起動
./bin/webpack-dev-server自動コンパイルしてくれる開発用サーバーです。
常にコードの監視もしているので、Reactのコードを書き換えると自動でブラウザ上の描画も書き換えてくれます。
(ちなみにRailsのModelやController、Viewなどは監視対象外なので変更しても自動描画はされません。素直に『command + R』でブラウザ更新しましょう。)お疲れ様でした
これでRails & Reactの開発環境が整った...はずです。
http://localhost:3000/に「アプリケーションのタイトル」が表示されていれば無事成功です!
それでは楽しい3R(Ruby on Rails on React)開発を!トラブルシューティング
An error occurred while installing mysql2 (0.5.3), and Bundler cannot continue. Make sure that gem install mysql2 -v '0.5.3' --source 'https://rubygems.org/' succeeds before bundling.上記エラーメッセージが表示されてbundle installが失敗する場合↓
sudo xcodebuild -license acceptで解決できる場合もある
- 投稿日:2020-07-13T22:10:00+09:00
RailsでURL文字列にaタグに変換する
railsのメール処理で文字列に含まれるURLをaタグ付きに変換したいことありました。
ちょっと調べてみると、
URI.extractを使うと文字列のURLが簡単に取得できる。。。割と簡単にできそうやん、と思って書いてみたら、実は罠が結構あって嵌ってしまったので復習がてら書いてみることにしました。TL;DR
最終的なコードは下記にすることで解決しました。どうやってこれにたどり着いたのか?なぜこうすると良いのかを後述して行きます。
def convert_url_to_a_element(text) uri_reg = URI.regexp(%w[http https]) text.gsub(uri_reg) { %{<a href='#{$&}' target='_blank'>#{$&}</a>} } end text = 'url1: http://hogehoge.com/hoge url2: http://hogehoge.com/fuga' convert_url_to_a_element(text) => "url1: <a href='http://hogehoge.com/hoge' target='_blank'>http://hogehoge.com/hoge</a> url2: <a href='http://hogehoge.com/fuga' target='_blank'>http://hogehoge.com/fuga</a>"アンチパターン
まずは最初に間違っていた処理の書き方です。
とはいえ、これでも下記のようなテキストであれば問題なく処理ができてしまいます。だからこそ今回すぐにこの書き方の罠に気づくことができていませんでした。。。def convert_url_to_a_element(text) URI.extract(text, %w[http https]).uniq.each do |url| sub_text = "<a href='#{url}' target='_blank'>#{url}</a>" text.gsub(url, sub_text) end text end text = 'url1: http://hogehoge.com url2: http://fugafuga.com' convert_url_to_a_element(text) => 'url1: http://hogehoge.com url2: http://fugafuga.com'
URI.extractを使うと下記のようにURL形式の文字列を全て取得することができる。text = 'url1: http://hogehoge.com url2: http://fugafuga.com' URI.extract(text, %w[http https]) => ["http://hogehoge.com", "http://fugafuga.com"]これをeachで回して置換しています。しかしながら、下記のように同じドメイン名のURL2種類で実施すると。。。
text = 'url1: http://hogehoge.com/hoge url2: http://hogehoge.com' convert_url_to_a_element(text) => "url1: <a href='<a href='http://hogehoge.com' target='_blank'>http://hogehoge.com</a>/hoge' target='_blank'><a href='http://hogehoge.com' target='_blank'>http://hogehoge.com</a>/hoge</a> url2: <a href='http://hogehoge.com' target='_blank'>http://hogehoge.com</a>"なんかめっちゃ崩れてる。。。
原因
原因は、2回目の置換にてaタグ変換後のテキストに対しても置換処理を行ってしまったためです。
このように、上記の書き方では同一ホスト名のURLが2つ以上あるとうまく動作しないという落とし穴があります。対応策
URI.extractで取得した文字列をeachで回すのではなく、正規表現を取得してgsubのパターンに正規表現を使って置換させることで、二重置換を防ぐことができます。def convert_url_to_a_element(text) uri_reg = URI.regexp(%w[http https]) text.gsub(uri_reg) { %{<a href='#{$&}' target='_blank'>#{$&}</a>} } end補足メモ
URI.regexpについて
URI.regexpは指定したスキーマのURL文字列のパターンを正規表現で返すメソッドです。正規表現とは、文字列ものなので、自分で書くことも可能ですがそれをサクッと作ってくれるのがこのメソッドです。返り値をみるとわかると思いますが、これを自分で1から書く気にはなれませんでした。。。
URI.regexp(%w[http https]) => /(?=(?-mix:http|https):) ([a-zA-Z][\-+.a-zA-Z\d]*): (?# 1: scheme) (?: ((?:[\-_.!~*'()a-zA-Z\d;?:@&=+$,]|%[a-fA-F\d]{2})(?:[\-_.!~*'()a-zA-Z\d;\/?:@&=+$,\[\]]|%[a-fA-F\d]{2})*) (?# 2: opaque) | (?:(?: \/\/(?: (?:(?:((?:[\-_.!~*'()a-zA-Z\d;:&=+$,]|%[a-fA-F\d]{2})*)@)? (?# 3: userinfo) (?:((?:(?:[a-zA-Z0-9\-.]|%\h\h)+|\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}|\[(?:(?:[a-fA-F\d]{1,4}:)*(?:[a-fA-F\d]{1,4}|\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})|(?:(?:[a-fA-F\d]{1,4}:)*[a-fA-F\d]{1,4})?::(?:(?:[a-fA-F\d]{1,4}:)*(?:[a-fA-F\d]{1,4}|\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}))?)\]))(?::(\d*))?))? (?# 4: host, 5: port) | ((?:[\-_.!~*'()a-zA-Z\d$,;:@&=+]|%[a-fA-F\d]{2})+) (?# 6: registry) ) | (?!\/\/)) (?# XXX: '\/\/' is the mark for hostport) (\/(?:[\-_.!~*'()a-zA-Z\d:@&=+$,]|%[a-fA-F\d]{2})*(?:;(?:[\-_.!~*'()a-zA-Z\d:@&=+$,]|%[a-fA-F\d]{2})*)*(?:\/(?:[\-_.!~*'()a-zA-Z\d:@&=+$,]|%[a-fA-F\d]{2})*(?:;(?:[\-_.!~*'()a-zA-Z\d:@&=+$,]|%[a-fA-F\d]{2})*)*)*)? (?# 7: path) )(?:\?((?:[\-_.!~*'()a-zA-Z\d;\/?:@&=+$,\[\]]|%[a-fA-F\d]{2})*))? (?# 8: query) ) (?:\#((?:[\-_.!~*'()a-zA-Z\d;\/?:@&=+$,\[\]]|%[a-fA-F\d]{2})*))? (?# 9: fragment) /xgsubについて
gsubメソッド自体は正規表現ではなく文字列を渡しても置換することができます。前者の場合では単純に取得したURL文字列をeachで渡して置換しているのですが、その結果、同じドメインが含まれるURLなんかだと、aタグ変換後の文字列に対しても置換処理が実行されてしまい、変な文字列になってしまうようです。
考えてみりゃそりゃそうか。。。って感じですがこの対策が案外思いつかなくて悩みました。まずはgsub
text.gsub!(uri_reg) { %{<a href="#{$&}">#{$&}</a>} }URI.extractについて
まず、最初に使った
URI.extractだが、スキーマを指定することでテキスト内からURL文字列のみを取得することができる。今回は最終的には使わなかったが、URL文字列のみをシンプルに取得したいのであれば便利そうでした。text = 'aaaaa http://xxx.com/hoge bbbbb http://xxx.com' URI.extract(text, %w[http https]) => ["http://xxx.com/hoge" "http://xxx.com"]まとめ
- aタグ変換を行うのであればgsubも正規表現でパターンマッチングした上で置換した方が良さそう
- 正規表現そのものは
URI.regexpを使うと簡単に取得することができると、紆余曲折ありましたが良いコードになったんじゃないかと思います。
もっと他に良い書き方があったりしたら是非とも教えていただきたいです。参考URL
- 投稿日:2020-07-13T20:23:46+09:00
Arrayにsplitがあって混乱した
次のようなコードを書いたところ、配列の配列が帰ってきて混乱しました。
numbers.split(/,/) #=> [["1","2","3"]]原因は、split済みの配列に対してsplitを呼んでいたせいでした。
numbers = "1,2,3".split(/,/) numbers.split(/,/) #=> [["1","2","3"]]RailsのActiveSupportは Array#split を用意しています。特定の値の前後で配列を配列の配列に分割するものです。
[1, 2, 3, 4, 5].split(3) # => [[1,2],[4,5]]しかし、変数に文字列が入っているつもりが配列だった、という場合には面食らうことなります。
def include_three?(string) string.split(/,/).include?("3") end include_three?("1,2,3,4,5".split(/,/)) #=> false
- 投稿日:2020-07-13T20:11:12+09:00
HTTP クライアントライブラリのgem「faraday」を使ってみた
HTTP クライアントライブラリのgem「faraday」を使用したので、メモ。
例えばAPIで取得する際に、gemを使用しないとurl = URI("https://api.coingecko.com/api/v3/coins/bitcoin") http = Net::HTTP.new(url.host, url.port) http.use_ssl = true request = Net::HTTP::Get.new(url) response = http.request(request) puts response.read_body上記くらいコードが必要だが、faradayを使用すると
res = Faraday.get("https://api.coingecko.com/api/v3/coins/bitcoin") puts res上記で取得できる
初期設定
まずはGemfileに追加して、bundle install
gem 'faraday'パラメータ指定
response = Faraday.get("https://api.coingecko.com/api/v3/coins/bitcoin/history", date: "08-09-2017") body = JSON.parse(response.body)コネクション
connect = Faraday.new("https://api.coingecko.com") response = connect.get do |req| req.url '/api/v3/coins/bitcoin' req.params[:date] = "08-09-2017" req.params[:tickers] = :true end body = JSON.parse(response.body)リクエストヘッダ
connection = Faraday.new("https://rest.coinapi.io") response = connection.get "/v1/exchangerate/BTC/USD" do |request| request.headers["X-CoinAPI-Key"] = "API Key" end他にもいろいろ試してみようと思います〜
参考
以上です。
いいねやQiitaやTwitterのフォローいただけると励みになります!
他にも方法がありましたら、コメントお待ちしております。
宜しくお願いします〜
- 投稿日:2020-07-13T20:07:28+09:00
個人アプリ作成#3
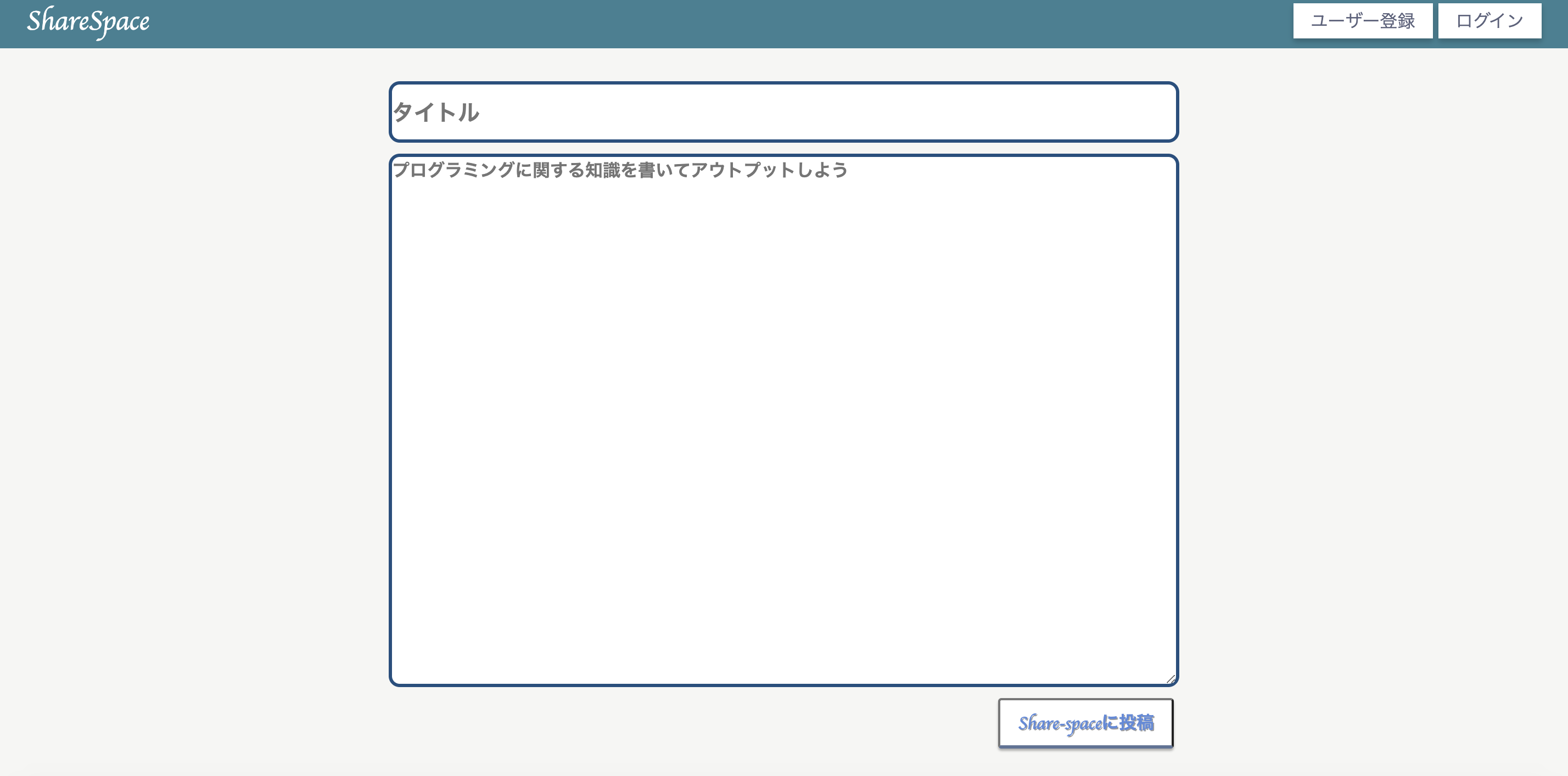
- 投稿日:2020-07-13T19:52:42+09:00
Rails×Herokuでcreateやupdateが急にできなくなったとき
基本的にはこの記事の通りにやっただけなのだが、自分用にもメモ。
heroku logs --tailしてみるとduplicate key value violates unique constraint "posts_pkey"
(今回は
postsテーブルの値をupdateしようとしておきたので、posts_pkeyの部分は各自のテーブル名によって変わる。)Postテーブルの一番大きなidが154だったので、Posticoの「SQL Query」で以下を打って解消。
SELECT last_value FROM posts_id_seq /* 最大のidを確認するクエリー */ SELECT setval('posts_id_seq', 155);ただし本来は数字は154を指定すればOKなはずだが、なぜかうまくいかなかったので1つ飛ばす形となった。
原因
今回はStaging環境でおきたことで、localhost:3000やproduction環境では起きなかった。原因はやはりStaging環境のDBとproduction環境のDBを揃えようとして、Postico上でExportしたCSVファイルをImportするときに、こんかいのシーケンス番号というのがおかしくなってしまったようだ。
PosticoではImport時に既存のレコードを上書きすることができないため、一度テープルのレコードを全部消してインポートとかしていたがこれがまずかったよう…。
- 投稿日:2020-07-13T19:13:50+09:00
Rails5でECサイトを作る⑨ ~カート機能を作る~
はじめに
架空のベーカリーで買い物できるECサイトを作るシリーズ、Rails5でECサイトを作る⑧の続きです。
今回はカート機能を作っていきます。ようやくECサイトの体裁が整いますね。ソースコード
https://github.com/Sn16799/bakeryFUMIZUKI
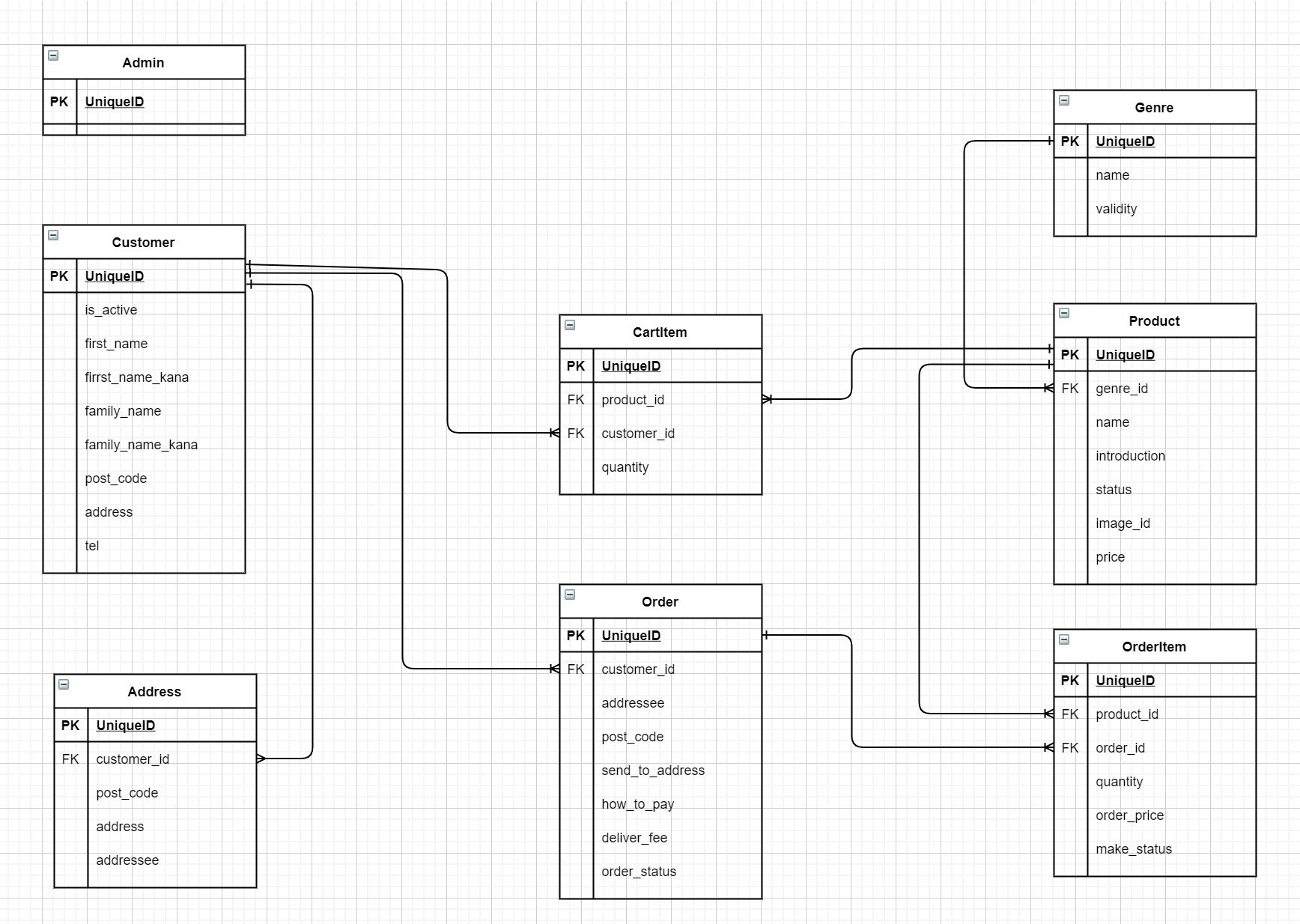
Modelのアソシエーション
カート機能に関連するモデルは主にCustomerとProductです。カート機能ではカートの本体のようなものはなく、商品を選んで「カートに入れる」ボタンを押すと、各商品につき1件のデータが登録される仕組みになっています。CartItemモデルは、CustomerとProductのID、それと商品の個数のみを記憶する中間テーブル的な役割を果たします。
Controller
app/controllers/cart_items_controller.rbclass CartItemsController < ApplicationController before_action :authenticate_customer! before_action :set_cart_item, only: [:show, :update, :destroy, :edit] before_action :set_customer def create @cart_item = current_customer.cart_items.build(cart_item_params) @current_item = CartItem.find_by(product_id: @cart_item.product_id,customer_id: @cart_item.customer_id) # カートに同じ商品がなければ新規追加、あれば既存のデータと合算 if @current_item.nil? if @cart_item.save flash[:success] = 'カートに商品が追加されました!' redirect_to cart_items_path else @carts_items = @customer.cart_items.all render 'index' flash[:danger] = 'カートに商品を追加できませんでした。' end else @current_item.quantity += params[:quantity].to_i @current_item.update(cart_item_params) redirect_to cart_items_path end end def destroy @cart_item.destroy redirect_to cart_items_path flash[:info] = 'カートの商品を取り消しました。' end def index @cart_items = @customer.cart_items.all end def update if @cart_item.update(cart_item_params) redirect_to cart_items_path flash[:success] = 'カート内の商品を更新しました!' end end def destroy_all #カート内アイテム全部消去 @customer.cart_items.destroy_all redirect_to cart_items_path flash[:info] = 'カートを空にしました。' end private def set_customer @customer = current_customer end def set_cart_item @cart_item = CartItem.find(params[:id]) end def cart_item_params params.require(:cart_item).permit(:product_id, :customer_id, :quantity) end endcreateアクションにおいてただsaveとだけ書くと、同じ商品を買おうとした時に「食パン 1、食パン 2、食パン 1、……」のように同じ商品でも別データとして登録されてしまいます。テーブルの構造上このようなことが起きるのですが、やはり後から追加でカートに入れた分もまとめて表示できると便利なので、if文で処理を分けています。
また、カートの商品を個別で取り消すほか、カートの中身を一斉に空にする処理もできるようにしたいと思っていたところ、destroy_allという便利なメソッドを見つけました。
View
index画面
app/views/cart_items/index.html.erb<div class="col-lg-10 offset-lg-1 space"> <div class="container-fluid"> <!-- タイトル + 全消去メソッド --> <div class="row"> <div class="col-lg-4"> <h2> <span style="display: inline-block;">ショッピング</span> <span style="display: inline-block;">カート</span> </h2> </div> <div class="col-lg-4"> <%= link_to 'カートを空にする', destroy_all_cart_items_path, method: :delete, class: 'btn btn-danger' %> </div> </div> <!-- カートの商品一覧 --> <div class="d-none d-lg-block"> <div class="row space"> <div class="col-lg-5"><h4>商品名</h4></div> <div class="col-lg-2"><h4>単価(税込)</h4></div> <div class="col-lg-2"><h4>数量</h4></div> <div class="col-lg-2"><h4>小計</h4></div> </div> </div> <% sum_all = 0 %> <% @cart_items.each do |cart_item| %> <div class="row space-sm"> <div class="col-lg-3"> <%= link_to product_path(cart_item.product) do %> <%= attachment_image_tag(cart_item.product, :image, :fill, 100, 100, fallback: "no_img.jpg") %> <% end %> </div> <div class="col-lg-2"> <%= link_to product_path(cart_item.product) do %> <%= cart_item.product.name %> <% end %> </div> <div class="col-lg-2"> <%= price_include_tax(cart_item.product.price) %> </div> <div class="col-lg-2"> <%= form_with model: cart_item, local: true do |f| %> <%= f.number_field :quantity, value: cart_item.quantity, min:1, max:99 %> <%= f.submit "変更", class: "btn btn-primary" %> <% end %> </div> <div class="col-lg-2"> <%= sum_product = price_include_tax(cart_item.product.price).to_i * cart_item.quantity %>円 <% sum_all += sum_product %> </div> <div class="col-lg-1"> <%= link_to "削除する", cart_item_path(cart_item), method: :delete, class: "btn btn-danger"%> </div> </div> <% end %> <!-- 合計金額 + 情報入力 --> <div class="row space"> <div class="col-lg-2 offset-lg-7 space-sm"> <%= link_to "買い物を続ける", customer_top_path, class: "btn btn-danger "%> </div> <div class="col-lg-3 space-sm"> <div class="row"> <h4>合計金額:<%= sum_all %>円</h4> </div> </div> </div> <div class="row space"> <div class="col-lg-3 offset-lg-9"> <%= link_to "情報入力に進む", new_order_path, class: "btn btn-danger btn-lg" %> </div> </div> </div> </div>商品ごとの小計、全商品の総計は、view上のeach文内に計算式を組み込んで表示しています。一般にviewで細かな計算やら分岐処理やら行うのは望ましくないようで、他に良い方法はないものでしょうか。
app/helpers/application_helper.rbdef price_include_tax(price) price = price * 1.08 "#{price.floor}円" end上のHTMLで商品の税込価格を表示する際に使っているヘルパーです。小数点以下はfloorで切り捨てにしています。小数点の処理に関しては、こちらに詳しく載っています。
app/assets/stylesheets/application.scss.space-sm { padding-top: 20px; }後記
機能の実装もちょっと複雑になってきて、ようやく面白くなってきました。サイト内を眺めてみても、カートに商品を入れるとだいぶお買い物気分を味わうことができます。あとはOrder(注文情報)周辺を作ればcustomerサイトは完成です!
ただ、このシリーズではadminサイトも自作するため、コード量としては半分くらいです。とはいえ、前回作った時の体感ではOrderモデルの機能が断トツで難解だったので、それさえできてしまえば何とかなるでしょう。
さて、私は最難関のOrderモデルを分かりやすく解説できるのか? 次回へ続く!
参考
- 投稿日:2020-07-13T18:31:20+09:00
DELETEメソッド実行後のリダイレクトでNo route matches [DELETE]となってしまう
非同期処理で削除処理を行った後、リダイレクトを行うとメソッドがGETではなくDELETEとなってしまい正常にリダイレクトされない現象が発生したためメモ。
発生した状況
delete.js// 一部抜粋 $.ajax({ type: 'DELETE', url: '/posts/destroy_post', dataType: 'json', data: { post_id: $(this).data('post-id') } }).done(function (data, status, xhr) { // 処理 });posts_controller.rb# 一部抜粋 def destroy_post # 処理 redirect_to post_index_path end// 発生エラー ActionController::RoutingError (No route matches [DELETE] "/post"):改善策
posts_controller.rb# 一部抜粋 def destroy_post # 処理 redirect_to post_index_path, status: 303 end上記のように「status: 303」と記載をすることで改善。
http://api.rubyonrails.org/classes/ActionController/Redirecting.html
If you are using XHR requests other than GET or POST and redirecting after the request then some browsers will follow the redirect using the original request method. This may lead to undesirable behavior such as a double DELETE. To work around this you can return a 303 See Other status code which will be followed using a GET request.
GETまたはPOST以外のXHRリクエストを使用していて、リクエストの後にリダイレクトしている場合、一部のブラウザは元のリクエストメソッドを使用してリダイレクトに従います。これにより、二重DELETEなどの望ましくない動作が発生する可能性があります。これを回避するには、GETリクエストを使用して追跡される303 See Otherステータスコードを返すことができます。
上記のように二重DELETEが発生していたと思われる。
引数にStatusコード303を指定することにより、回避することができるようです。参考
Rails Redirect After Delete Using DELETE Instead of GET
以上です。
いいねやQiitaやTwitterのフォローいただけると励みになります!
他にも方法がありましたら、コメントお待ちしております。
宜しくお願いします〜
- 投稿日:2020-07-13T14:50:19+09:00
環境変数で配列もハッシュも扱いたい
how
JSONにして、アプリケーション側でパースする
以上。例
環境変数を入れる
bashで
$ CORS_DOMAINS_JSON='["sample.com", "example.com"]'docker-compose.ymlで
docker-compose.ymlenvironment: - CORS_DOMAINS_JSON=["sample.com", "example.com"]環境変数をパースして使う
railsのrack-corsとか
config/application.jsonconfig.middleware.insert_before 0, Rack::Cors do allow do origins JSON.parse(ENV.fetch('CORS_DOMAINS_JSON') { '[]' }) resource "*", credentials: true, headers: :any, methods: [:get, :post, :options, :head, :patch, :delete] end endその他各使用環境に合わせてjsonをパースするだけ
- 投稿日:2020-07-13T14:36:20+09:00
[SPA]自分なりに脆弱性を潰しながらフロントエンドに認証情報を扱う
最近、新規事業で完全0-1のプロダクト開発をした際に
Rails/Vue.jsのSPAでいかにセキュアに認証情報を扱うかについて調べた結果を書いていきます
「それおかしくない?」とか「脆弱性つぶせてなくない?」とかあればコメントで指摘していただけるととても助かりますどう実装するか
実装の意図や詳細については下の方で解説します
Rails側
- 認証情報を
secure属性とhttponly属性をつけたcookieでフロントエンドに返す
- domain属性はAPIのドメインのみにする(特に設定変えなければデフォルトでそうなってるはず)
- 独自ヘッダの有無のチェックを認証処理に組みこむ
- gem
rack-corsを導入する
- originsをSPAのURLのみに制限する
credentialsをtrueにしておくVue.js側
withCredentialsオプションをtrueに設定する(axiosやxhr)
- fetchなら
credentials: 'include'とかかな- リクエストに独自ヘッダをつける
- なんでもいいし中身も空文字でよくて、ヘッダがあることが重要
なぜ上記のような実装をするのか
以下の3つがポイントになります
httponly属性とsecure属性が有効でdomain属性にはAPIのドメインのみを設定したcookieでアクセストークンを持たせる- 独自ヘッダが必要であること
- corsでoriginsを制限されていること
cookieについて
なぜhttponlyにするのか
- XSSや悪意あるパッケージなどのjsによりcookieにあるトークンを抜かれないようにするため
- jsから抜かれる危険性はlocalstorageを使わない理由でもある
- 代わりに、cookieにあるトークンを非同期通信でもリクエストするために
withCredentialsオプションを有効にするなぜsecureにするのか
- 非SSLのリクエストを盗聴されないように、とかっていうよくある理由
なぜdomainをAPIのドメインのみに制限するのか
- サブドメをワイルドカードにしたりとか他のドメインを許容する必要がないため
- 少なくとも今回のケースでは複数ドメインをまたいでcookieの共有は必要なかった
- withCredentialを有効にしてcookieとして飛ばすからフロントエンドのjsからcookieを操作できる必要はない
- フロントのurlからはcookie見えないけどAPIのドメインへのcookieとしてちゃんと存在しているのでwithCredential有効にしておけばちゃんとリクエストされる
- 恥ずかしながら自分は最初「フロントのドメインでも扱えなきゃいけないよなぁ」と思い込んでいました。。。
独自ヘッダについて
- htmlのformによるCSRF対策
- htmlのform(同期通信)では独自ヘッダを付与することはできないため
CORSについて
- 独自ヘッダと併用することでjsによるCSRF対策となる
- originsでちゃんと制限かけることで外からの不正なリクエストを弾く
- ただし、それだけでは不十分で、ブラウザ上ではエラーになるがリクエスト自体は飛んで処理されてしまう
- 不正なGETには有効だがPOSTは処理されてしまうので困る
- POSTは条件次第(formDataを使うこと)で単純リクエストになり、プリフライトリクエストが走らない場合があるため独自ヘッダによりプリフライトを強制させる
- これによりプリフライトリクエストで止める事ができるので不正なリクエストを飛ばせなくすることができる
- 独自ヘッダは2度美味しい
- ちなみに、rack-corsの設定で
credentials: trueにしないとフロントでwithCredential: trueのリクエストを弾いてしまう実装のサンプル
一部抜粋して書いていきます
参考記事などは下の方にまとめてますrails側
rack-corsなどの設定
config/application.rb# ...割愛 # apiモードのrailsでcookiesを使えるようにするため # コントローラ側に `include ActionController::Cookies` も必要 config.middleware.use ActionDispatch::Cookies config.middleware.insert_before 0, Rack::Cors do allow do # 複数のorigins制限するためドメインの配列 # 環境変数はjsonにすると配列が簡単に扱えるやんという最近見つけたtips origins JSON.parse(ENV.fetch('CORS_DOMAINS_JSON') { '[]' }) resource "*", # axiosなどで `withCredential: true` にした上で、そのcookieを受け取るため credentials: true, headers: :any, methods: [:get, :post, :patch, :delete] end end # ...割愛認証情報をcookieで返す
- アクセストークンの期限はDBにあるので
permanent- 開発環境はsecure外したいので環境変数
COOKIE_SECUREで操作# ...割愛 cookies.permanent[:access_token] = { value: access_token, httponly: true, secure: ENV['COOKIE_SECURE'].present?, } cookies.permanent[:refresh_token] = { value: refresh_token, httponly: true, secure: ENV['COOKIE_SECURE'].present?, } # ...割愛認証処理
access_token = cookies[:access_token] # ...割愛(access_tokenチェックの処理など) raise 適当な例外クラス if request.headers[:'X-REQUESTED-BY-MY-APP'].nil?Vue.js側
withCredentialsを有効にする
src/main.js// ...割愛 Vue.prototype.$http = axios.create( { baseURL: process.env.VUE_APP_API_URI, withCredentials: true }, ); // ...割愛独自ヘッダをつける
- Vue.prototype.$httpにインスタンス入れることでどこからでも
this.$httpで使える- interceptorsを使うことですべてのリクエストでヘッダ設定の処理を走らせる
src/main.js// ...割愛 Vue.prototype.$http.interceptors.request.use((request) => ({ ...request, headers: { ...request.headers, ...{ 'X-REQUESTED-BY-MY-APP': '' }, }, })); // ...割愛疑問
XSS脆弱性があっても認証情報を抜かれないための対策とか、外からのCSRFの対策はしたけど
XSSでXHRのコードをインジェクトされて外部ではなく本来のバックエンドに勝手にリクエストを飛ばされないようにするための対策ってどうすればいいんだろう。。。
根本的にXSSを塞ぐしかないってことになるのかな参考記事
rails-apiでcookieを使う
RailsでAPIにCORSを設定する
rack-corsでCORS設定をする
さよならCSRF(?) 2017
CORS: OPTIONSリクエスト(preflight request)を避ける
- 投稿日:2020-07-13T14:36:20+09:00
[SPA]脆弱性を潰して認証情報を扱う[アクセストークン]
最近、新規事業で完全0-1のプロダクト開発をした際に
Rails/Vue.jsのSPAでいかにセキュアに認証情報を扱うかについて調べた結果を書いていきます
「それおかしくない?」とか「脆弱性つぶせてなくない?」とかあればコメントで指摘していただけるととても助かりますどう実装するか
実装の意図や詳細については下の方で解説します
Rails側
- 認証情報を
secure属性とhttponly属性をつけたcookieでフロントエンドに返す
- domain属性はAPIのドメインのみにする(特に設定変えなければデフォルトでそうなってるはず)
- 独自ヘッダの有無のチェックを認証処理に組みこむ
- gem
rack-corsを導入する
- originsをSPAのURLのみに制限する
credentialsをtrueにしておくVue.js側
withCredentialsオプションをtrueに設定する(axiosやxhr)
- fetchなら
credentials: 'include'とかかな- リクエストに独自ヘッダをつける
- なんでもいいし中身も空文字でよくて、ヘッダがあることが重要
なぜ上記のような実装をするのか
以下の3つがポイントになります
httponly属性とsecure属性が有効でdomain属性にはAPIのドメインのみを設定したcookieでアクセストークンを持たせる- 独自ヘッダが必要であること
- corsでoriginsを制限されていること
cookieについて
なぜhttponlyにするのか
- XSSや悪意あるパッケージなどのjsによりcookieにあるトークンを抜かれないようにするため
- jsから抜かれる危険性はlocalstorageを使わない理由でもある
- 代わりに、cookieにあるトークンを非同期通信でもリクエストするために
withCredentialsオプションを有効にするなぜsecureにするのか
- 非SSLのリクエストを盗聴されないように、とかっていうよくある理由
なぜdomainをAPIのドメインのみに制限するのか
- サブドメをワイルドカードにしたりとか他のドメインを許容する必要がないため
- 少なくとも今回のケースでは複数ドメインをまたいでcookieの共有は必要なかった
- withCredentialを有効にしてcookieとして飛ばすからフロントエンドのjsからcookieを操作できる必要はない
- フロントのurlからはcookie見えないけどAPIのドメインへのcookieとしてちゃんと存在しているのでwithCredential有効にしておけばちゃんとリクエストされる
- 恥ずかしながら自分は最初「フロントのドメインでも扱えなきゃいけないよなぁ」と思い込んでいました。。。
独自ヘッダについて
- htmlのformによるCSRF対策
- htmlのform(同期通信)では独自ヘッダを付与することはできないため
CORSについて
- 独自ヘッダと併用することでjsによるCSRF対策となる
- originsでちゃんと制限かけることで外からの不正なリクエストを弾く
- ただし、それだけでは不十分で、ブラウザ上ではエラーになるがリクエスト自体は飛んで処理されてしまう
- 不正なGETには有効だがPOSTは処理されてしまうので困る
- POSTは条件次第(formDataを使うこと)で単純リクエストになり、プリフライトリクエストが走らない場合があるため独自ヘッダによりプリフライトを強制させる
- これによりプリフライトリクエストで止める事ができるので不正なリクエストを飛ばせなくすることができる
- 独自ヘッダは2度美味しい
- ちなみに、rack-corsの設定で
credentials: trueにしないとフロントでwithCredential: trueのリクエストを弾いてしまう実装のサンプル
一部抜粋して書いていきます
参考記事などは下の方にまとめてますrails側
rack-corsなどの設定
config/application.rb# ...割愛 # apiモードのrailsでcookiesを使えるようにするため # コントローラ側に `include ActionController::Cookies` も必要 config.middleware.use ActionDispatch::Cookies config.middleware.insert_before 0, Rack::Cors do allow do # 複数のorigins制限するためドメインの配列 # 環境変数はjsonにすると配列が簡単に扱えるやんという最近見つけたtips origins JSON.parse(ENV.fetch('CORS_DOMAINS_JSON') { '[]' }) resource "*", # axiosなどで `withCredential: true` にした上で、そのcookieを受け取るため credentials: true, headers: :any, methods: [:get, :post, :patch, :delete] end end # ...割愛認証情報をcookieで返す
- アクセストークンの期限はDBにあるので
permanent- 開発環境はsecure外したいので環境変数
COOKIE_SECUREで操作# ...割愛 cookies.permanent[:access_token] = { value: access_token, httponly: true, secure: ENV['COOKIE_SECURE'].present?, } cookies.permanent[:refresh_token] = { value: refresh_token, httponly: true, secure: ENV['COOKIE_SECURE'].present?, } # ...割愛認証処理
access_token = cookies[:access_token] # ...割愛(access_tokenチェックの処理など) raise 適当な例外クラス if request.headers[:'X-REQUESTED-BY-MY-APP'].nil?Vue.js側
withCredentialsを有効にする
src/main.js// ...割愛 Vue.prototype.$http = axios.create( { baseURL: process.env.VUE_APP_API_URI, withCredentials: true }, ); // ...割愛独自ヘッダをつける
- Vue.prototype.$httpにインスタンス入れることでどこからでも
this.$httpで使える- interceptorsを使うことですべてのリクエストでヘッダ設定の処理を走らせる
src/main.js// ...割愛 Vue.prototype.$http.interceptors.request.use((request) => ({ ...request, headers: { ...request.headers, ...{ 'X-REQUESTED-BY-MY-APP': '' }, }, })); // ...割愛疑問
XSS脆弱性があっても認証情報を抜かれないための対策とか、外からのCSRFの対策はしたけど
XSSでXHRのコードをインジェクトされて外部ではなく本来のバックエンドに勝手にリクエストを飛ばされないようにするための対策ってどうすればいいんだろう。。。
根本的にXSSを塞ぐしかないってことになるのかな参考記事
rails-apiでcookieを使う
RailsでAPIにCORSを設定する
rack-corsでCORS設定をする
さよならCSRF(?) 2017
CORS: OPTIONSリクエスト(preflight request)を避ける
- 投稿日:2020-07-13T14:22:06+09:00
Rails Tutorial 第6章完了
2020/6/24 (0.5時間:Tutorial外)
Sass/SCSSを私は使ったことがなかったので、いったんrails Tutorialを離れ、ドットインストールで学んでみることにしました。
2020/6/25 (0.5時間:Tutorial外)
Sass/SCSSをドットインストール。
2020/6/26 (0.5時間:Tutorial外) 2時間
Sass/SCSSのドットインストールを3日計1.5時間で完了しました。
HTML/CSSの知識は昔のままだったので、このような便利なも
のができたなんて知りませんでした。6章を始めるにあたり、5章の復習を15分ほどやりました。
途中で参照にされていた、Duck TypingについてのMatzの動画を見はじめたら面白くてやめられなくなりました。2020/6/27 1時間
Railsチュートリアルには演習の解答がないので、ネットに公開されているサイトをいくつか参照しています。mochikichiさんの転職の記事がとても興味深かったです。http://mochikichi.hatenablog.com/entry/career_change_episode_3
演習の解答のページだけを見ていたときは、自分がつまずいたところも整然と解答が書いてあるので、他のプログラミング言語の経験が長くてRailsを始めた方なのかなと想像していました。
ところが実はプログラミングは未経験で、その後エンジニアに転職したと書いてあり驚きました。
2020/6/28 2.5時間
正規表現を理解するのに時間がかかりました。謎めいて見えますが、サイトに入力してテストするうちに、何となく分かってきました。じっと考えるより手を動かして慣れるほうが自分には理解がしやすいです。
2020/6/29 0.5時間
演習がエラーのまま、朝やれる時間が終わってしまいました。
2020/6/30 0.5時間
昨日の演習のエラーは、正解を見ても間違いが見つかりません。試しにいったん全部消して手で打ち直したら、なぜか直りました。原因不明です。
2020/7/1
これまでリモートワークが主で、たまに出社だったのですが、7月から出社が主でたまにリモートワークへと社の方針が変わりました。朝から会議なので勉強の時間がとれず、夜やるつもりでした。ですが、帰宅して夕食が終わったら21時になり、疲れてやれなかったです。
2020/7/2 0.5時間
昨日の反省で朝に時間をとってやりました。3密回避で出社時刻を10時に遅らせてよいことで、朝の勉強時間が取れました。
2020/7/3 1時間
有休休暇で朝にやれました。
これで6章を完了しました。
所要時間は8時間です。感想ですが、毎朝30分のペースがつかめてきました。SassでWebの進化を感じられたのも良かったです。
- 投稿日:2020-07-13T12:56:17+09:00
【Rails】クーポン機能の実装(バッチ処理を用いた自動削除機能付き)
目標
開発環境
・Ruby: 2.5.7
・Rails: 5.2.4
・Vagrant: 2.2.7
・VirtualBox: 6.1
・OS: macOS Catalina前提
下記実装済み。
・Slim導入
・Bootstrap3導入
・ログイン機能実装
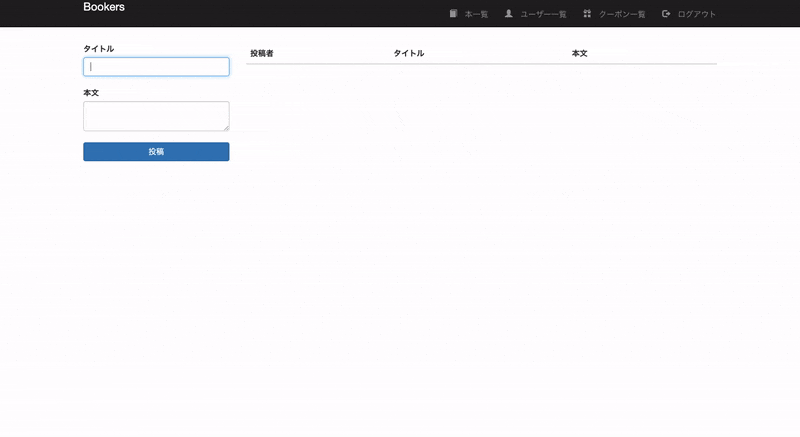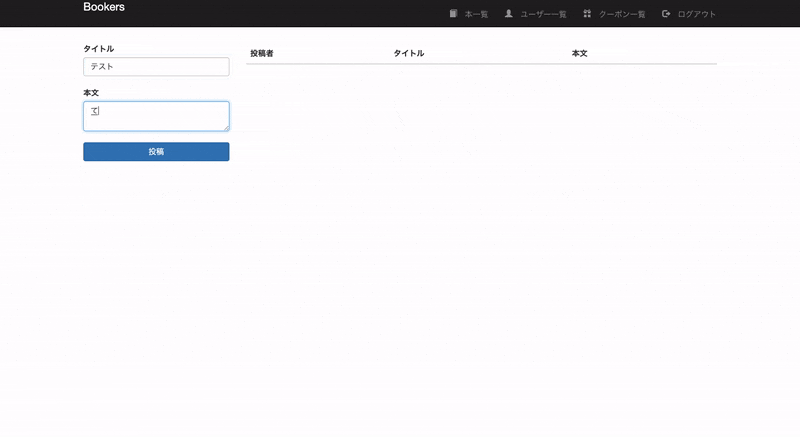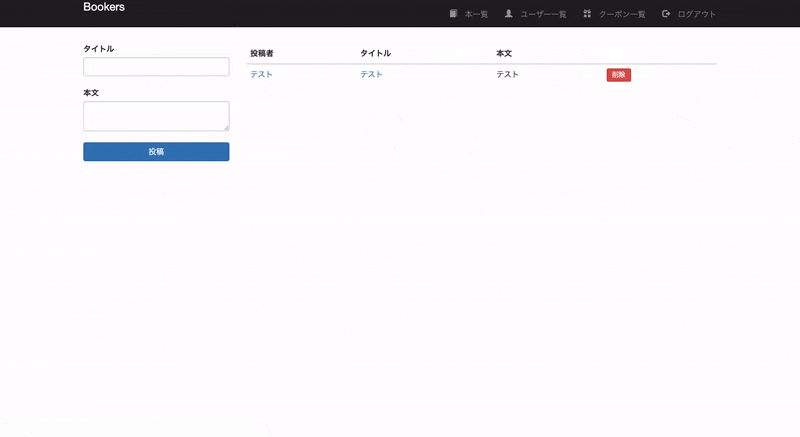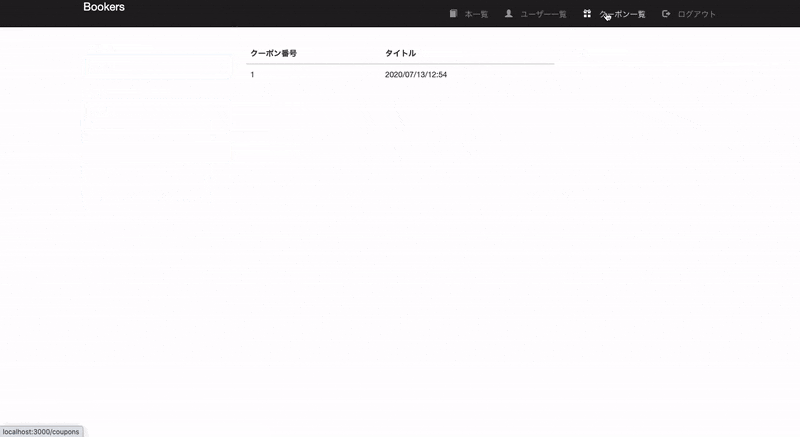
・投稿機能実装実装
1.カラムを追加
ターミナル$ rails g model Coupon user_id:integer is_valid:boolean limit:integer~__create_coupons.rbclass CreateCoupons < ActiveRecord::Migration[5.2] def change create_table :coupons do |t| t.integer :user_id t.boolean :is_valid, default: true # 「default: true」を追記 t.integer :limit t.timestamps end end endターミナル$ rails db:migrate2.モデルを編集
user.rb# 追記 has_many :coupons, dependent: :destroycoupon.rbclass Coupon < ApplicationRecord belongs_to :user enum is_valid: { '有効': true, '無効': false } def self.coupon_create(user) coupon = Coupon.new(user_id: user.id, limit: 1) coupon.save end def self.coupon_destroy time = Time.now coupons = Coupon.all coupons.each do |coupon| if coupon.created_at + coupon.limit.days < time && coupon.is_valid == '有効' coupon.is_valid = '無効' coupon.save end end end end【解説】
① クーポンの状態をenumで管理する。
enum is_valid: { '有効': true, '無効': false }② クーポンを作成するメソッドを定義する。
def self.coupon_create(user) coupon = Coupon.new(user_id: user.id, limit: 1) coupon.save end③ クーポンを削除するメソッドを定義する。
def self.coupon_destroy time = Time.now coupons = Coupon.all coupons.each do |coupon| if coupon.created_at + coupon.limit.days < time && coupon.is_valid == '有効' coupon.is_valid = '無効' coupon.save end end end◎ クーポンを作成してから24時間経過かつ、クーポンの状態が有効の場合は、無効に変更して保存する。
if coupon.created_at + coupon.limit.minutes < time && coupon.is_valid == '有効' coupon.is_valid = '無効' coupon.save end3.
coupons_controller.rbを作成・編集ターミナル$ rails g controller coupons indexcoupons_controller.rbclass CouponsController < ApplicationController def index @coupons = Coupon.where(user_id: current_user.id, is_valid: '有効') end end4.
books_controller.rbを編集今回は本を投稿成功した場合に、クーポンを発行するように実装します。
books_controller.rbdef create @book = Book.new(book_params) @book.user_id = current_user.id if @book.save Coupon.coupon_create(current_user) # 追記 redirect_to books_path else @books = Book.all render 'index' end end5.日時設定を変更
①
application.rbを編集する。application.rbmodule Bookers2Debug class Application < Rails::Application config.load_defaults 5.2 config.time_zone = 'Tokyo' # 追記 end end②日時のフォーマットを設定するファイルを作成・編集
ターミナル$ touch config/initializers/time_formats.rbtime_formats.rbTime::DATE_FORMATS[:datetime_jp] = '%Y/%m/%d/%H:%M'6.ビューを編集
coupons/index.html.slim.row .col-xs-3 .col-xs-6 table.table thead tr th | クーポン番号 th | タイトル tbody - @coupons.each.with_index(1) do |coupon, index| tr td = index td - limit = coupon.created_at + coupon.limit.minutes = limit.to_s(:datetime_jp) .col-xs-3【解説】
① クーポン作成日時の1日後を、
5で設定したフォーマットで表示する。- limit = coupon.created_at + coupon.limit.minutes = limit.to_s(:datetime_jp)7.自動削除機能の実装
① Gemを導入
Gemfile# 追記 gem 'whenever', require: falseターミナル$ bundle②
「schedule.rb」を作成・編集ターミナル$ bundle exec wheneverize .config/schedule.rbenv :PATH, ENV['PATH'] # 絶対パスから相対パス指定 set :output, 'log/cron.log' # ログの出力先ファイルを設定 set :environment, :development # 環境を設定 every 1.minute do runner 'Coupon.coupon_destroy' end4.
cronを反映ターミナル$ bundle exec whenever --update-crontabバッチ処理でよく使うコマンド
crontab -e➡︎ cronをターミナル上で編集
$ bundle exec whenever➡︎ cronの設定を確認
$ bundle exec whenever --update-crontab➡︎ cronを反映
$ bundle exec whenever --clear-crontab➡︎ cronを削除
- 投稿日:2020-07-13T12:46:40+09:00
Could not load the 'listen' gem. Add `gem 'listen'` to the development group of your Gemfile (LoadError)
vagrant環境で「bundle install --without production」とするとエラー
Could not load the 'listen' gem. Add `gem 'listen'` to the development group of your Gemfile (LoadError)解決方法
bundle config --delete without bundle config --delete with bundle install
- 投稿日:2020-07-13T12:43:39+09:00
vagrant環境で rails s をするとFileUtils関連のwarningが発生する
vagrant環境で rails s をするとFileUtils関連のwarningが発生する。rails の起動はしている。
/home/vagrant/.rbenv/versions/2.5.7/lib/ruby/2.5.0/fileutils.rb:90: warning: already initialized constant FileUtils::VERSION /home/vagrant/.rbenv/versions/2.5.7/lib/ruby/gems/2.5.0/gems/fileutils-1.4.1/lib/fileutils.rb:105: warning: previous definition of VERSION was here /home/vagrant/.rbenv/versions/2.5.7/lib/ruby/2.5.0/x86_64-linux/etc.so: warning: already initialized constant Etc::SC_AIO_LISTIO_MAX /home/vagrant/.rbenv/versions/2.5.7/lib/ruby/2.5.0/x86_64-linux/etc.so: warning: already initialized constant Etc::SC_AIO_MAX ・ ・解決策
gem uninstall fileutils gem update fileutils --defaultgem cleanupbundle clean --force(https://obel.hatenablog.jp/entry/20181023/1540286546)
(https://qiita.com/taaaaak/items/1b05ce33ffebd2670e6f)
(https://stackoverflow.com/questions/51334732/rails-5-2-0-with-ruby-2-5-1-console-warning-already-initialized-constant)
- 投稿日:2020-07-13T12:26:49+09:00
[Rails]パンくずリストを作る
対象読者
- Railsでパンくずリストを実装したい人。
- 使い方忘れた人。
- 初学者向けになっています。内容も初歩的なところを解説しています。
gretelって何?
パンくずリストです。ヘンゼルとグレーテルの話のやつ。
パンくず落としていって自分の辿って来た道がわかる。Gemのインストール
Gemfilegem 'gretel'
bundle installしたら必要なファイルを生成します。$ bundle install $ rails g gretel:install以下のようにファイルが生成されればOKです。
Running via Spring preloader in process 6675 create config/breadcrumbs.rbこれが中身。
breadcrumbs.rbcrumb :root do link "Home", root_path end # crumb :projects do # link "Projects", projects_path # end # crumb :project do |project| # link project.name, project_path(project) # parent :projects # end # # #以下省略 # # #設定を書く
先ほどの
breadcrumbs.rbというファイルはパンくずを落としていく設定ができるファイルになります。
例えば、
Home > カテゴリのようなパンくずを落としていきたい場合は
breadcrumb.rbcrumb :root do link "Home", root_path end crumb :articles do link "記事一覧", articles_path #パスは該当ページのパスを書く(ここでは記事一覧) parent :root endカテゴリの前のページをHomeにしたいのでparentは
:rootを指定します。Viewに表示させる
あとはViewの方で出力してあげるだけです。
application.html.erb<!DOCTYPE html> <html> <head> <title>パンくずアプリ</title> <%= stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' %> <%= javascript_include_tag 'application', 'data-turbolinks-track': 'reload' %> </head> <body> <%= breadcrumbs separator: " › " %> #ここを追加 <%= yield %> </body> </html>articles/index.html.erb<% breadcrumb :articles %>これで
Home > 記事一覧のパンくずリストが出来上がります。
登録してあるデータをパンくずに表示したい
Home > 記事一覧 > [記事のタイトル]みたいにしたい場合は少し工夫が必要になります。
以下のように、Viewの方から
breadcrumb.rbへデータを送ってあげないといけません。
今回は記事のタイトルをパンくずとして出力してあげたいので、@articleを第2引数に指定してデータを渡してあげます。articles/show.html.erb<% breadcrumb :article_show, @article %>breadcrumb.rbcrumb :root do link "Home", root_path end crumb :articles do link "記事一覧", articles_path #パスは該当ページのパスを書く(ここでは記事一覧) parent :root end crumb :article_show do |article| #ここで受け取ってる link article.title, article_path(article) #<表示する文字列>、<記事詳細のパス> parent :articles #親を設定する end
Home > 記事一覧 > パンくずリストを作ってみた作成日時を出力させたいと思ったら、
breadcrumbs.rbcrumb :article_show do |article| link article.created_at, article_path(article) #変更(title => created_at) parent :articles endに変更すればOKです。
- 投稿日:2020-07-13T11:56:58+09:00
【Rails】ActiveRecord::Bitemporalの使い方(BiTemporalDataModel)
はじめに
RailsでBitemporalDataModelを扱いたかったのですが
ちょうどactiverecord-bitemporalという良いgemがあったので、
いろいろ触ってみた結果を書いていきたいと思います。BitemporalDataModelとは何か
そもそもBiTemporalとはどういう意味でしょうか。
「Bi」は接頭辞で2つのという意味を表します、Bicycleとか言いますよね。
「Temporal」は時間のという意味の形容詞です。
つまりBiTemporalで二つの時間のという意味になり、
BiTemporalDataModelは二つの時間のデータモデルになります。二つの時間は何かと言いますと、
「システム上の時間」と「事実情報としての時間」です。詳しくは説明すると長くなってしまうので、
こちらのスライドが参考になると思います。(特に33ページ目以降)使い方
レコードの作成、更新
ではactiverecord-bitemporalを使ってレコードを作成したり更新したりをしていきたいと思います。
まずは準備です。詳しくはこちら
テーブルを用意しましょう
db/schema.rbActiveRecord::Schema.define(version: 1) do create_table :employees, force: true do |t| t.string :name #従業員名 t.string :position #役職 # ActiveRecord::BiTemporal に必要なカラムを追加する t.integer :bitemporal_id t.datetime :valid_from #適用日時 t.datetime :valid_to #終了日時 t.datetime :deleted_at #削除日時(論理削除) end endActiveRecord::Bitemporalの読み込みの設定をします。
app/models/emoloyee.rbclass Employee < ActiveRecord::Base include ActiveRecord::Bitemporal endでは、実際に使っていきたいと思います
employeesというテーブルを作って、従業員の情報をDBに保存していくような例を考えます。
具体的には、
2018年1月1日 田中さんが平社員として入社し、2018年1月3日にレコード作成
↓
2020年1月1日 課長に昇進、 2020年1月10日にレコード作成
↓
2020年1月20日 課長に更新したと思ったが、間違えて家長と入力していたので課長に修正という例を考えます。
rails consoleで操作していきます。
※簡単のために〇〇時〇〇分〇〇秒は省略しています。(実際には秒まで入ります。)まずは最初のレコード作成、
2018年1月1日田中さんが平社員として入社
Employee.create(name: "田中", position: "平社員", valid_from: "2018-01-01")valid_fromには適用日時を指定できます。
何も指定しなければ入力時点現在の時刻となります。
valid_toも指定できますが、今回指定していないので9999年12月31日となっています。この時DBは以下のようになります。
id bitemporal_id name position valid_from valid_to created_at deleted_at 1 1 田中 平社員 2018-01-01 9999-12-31 2018-01-3 NULL 次に、
2020年1月1日 課長に昇進
Employee.valid_at("2020-01-01".to_date).find_by(bitemporal_id: 1).update(position: "課長")レコードの更新をするとき、適用日時を指定したい場合はvalid_atメソッドで適用日時を指定してからレコードを作成します。
valid_atメソッドで時間を指定しなかった場合、valid_fromは入力時点現在の時刻となります。ちなみに
Employee.find_by(bitemporal_id: 1).update(position: "課長", valid_from: "2020-01-01")としても意味はなく、valid_fromは入力時点現在の時刻となります。
この辺りの仕組みは時間があればソースコードを確認しましょう。このときDBは以下のようになります。
id bitemporal_id name position valid_from valid_to created_at deleted_at 1 1 田中 平社員 2018-01-01 9999-12-31 2018-01-3 2020-01-10 2 1 田中 平社員 2018-01-01 2020-01-01 2020-01-10 NULL 3 1 田中 課長 2020-01-01 9999-12-31 2020-01-10 NULL 次に、
2020年1月20日 課長に更新したと思ったが、間違えて家長と入力していたので課長に修正
前の部分では課長として更新しましたが誤字のため家長と入力し、それを修正していく場合の時を考えます。
Employee.find_by(bitemporal_id: 1, position: "家長").force_update do |employee| employee.update(position: "課長") endこの場合は、updateではなく、force_updateを使います。
家長と入力したレコードは論理削除され、課長のレコードが新しく作られます。このときDBは以下のようになります。
id bitemporal_id name position valid_from valid_to created_at deleted_at 1 1 田中 平社員 2018-01-01 9999-12-31 2018-01-3 2020-01-10 2 1 田中 平社員 2018-01-01 2020-01-01 2020-01-10 NULL 3 1 田中 家長 2020-01-01 9999-12-31 2020-01-20 4 1 田中 課長 2020-01-01 00:00:00 9999-12-31 2020-01-20 NULL もしこのとき、論理削除をして新しいレコードを作成するのではなく、強制的に上書きしたい場合は
Employee.find_by(bitemporal_id: 1, position: "家長").force_update do |employee| employee.update_column(position: "課長") endとしましょう。
レコードの検索
後日、執筆予定
- 投稿日:2020-07-13T10:31:19+09:00
[Rails]schema.rbのコンフリクト解消
はじめに
チーム開発をしている際に、プルリクエストを作成したところconflictが発生した。
他のファイルはメンバーに相談しながら解消できたが、
Railsで自動更新されるschema.rbファイルは勝手に修正して良いのだろうか?と詰まった。解消
以下の記事を参考に修正を試みた。
コンフリクトしたschema.rbをきれいにマージする手順ターミナル$ git checkout masterを実行しようとしたところ、
error: you need to resolve your current index first
と出てしまい、ブランチの切り替えが出来なかった。ターミナルgit merge --abortこれで一旦前の状態に戻すことで、ブランチの切り替えが可能になりました。以降は、上記の記事を参考にコンフリクトを解消し、マージすることが出来ました。
- 投稿日:2020-07-13T10:30:12+09:00
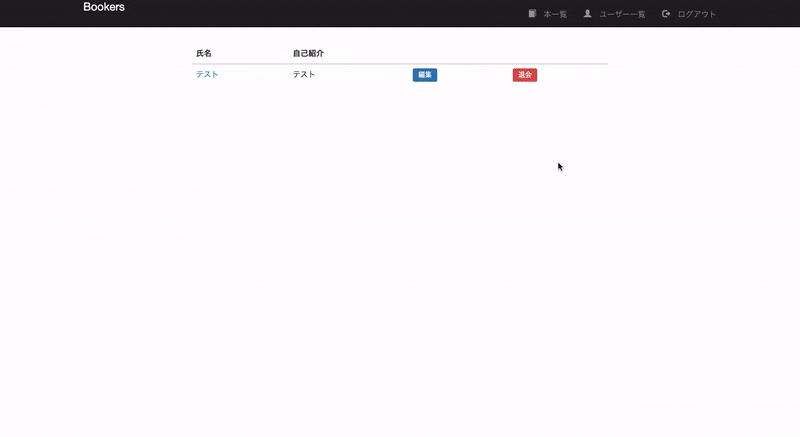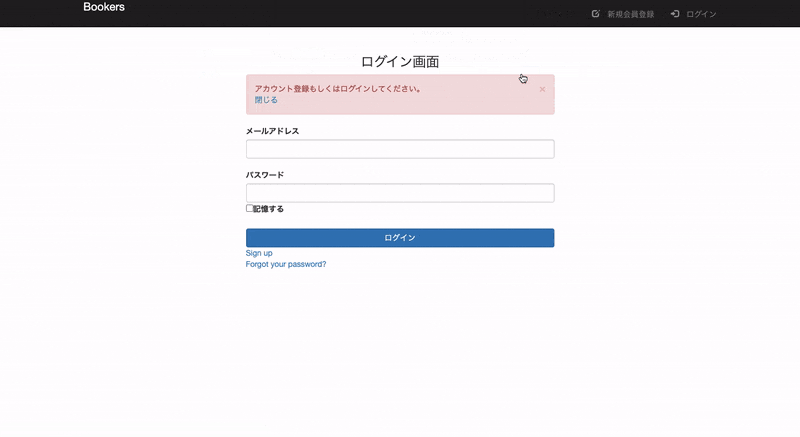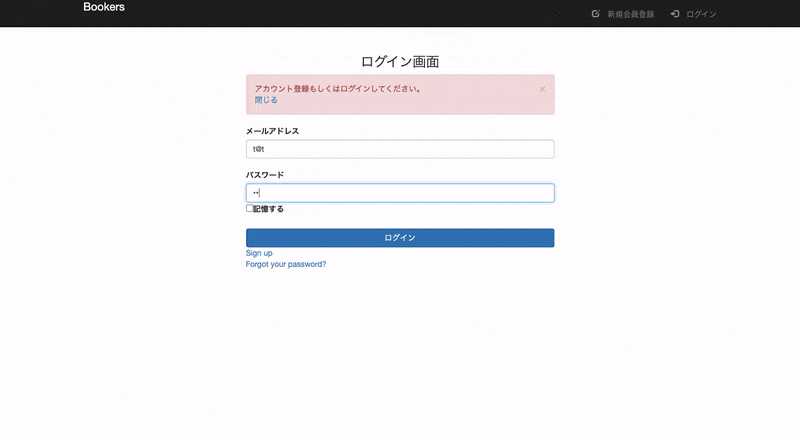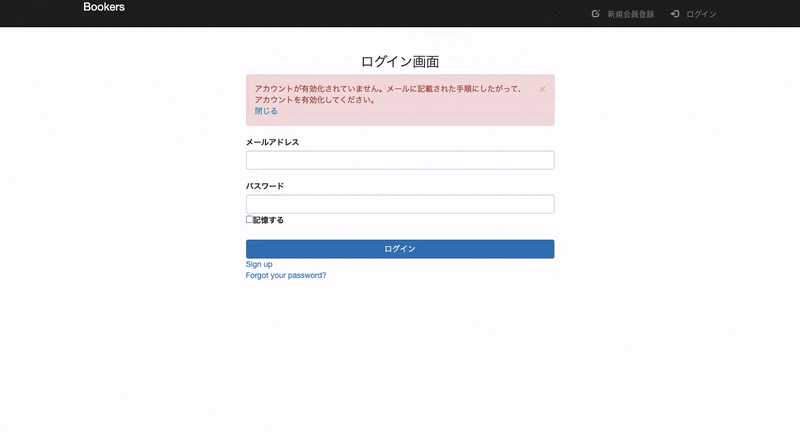
【Rails】ユーザー論理削除の実装
目標
開発環境
・Ruby: 2.5.7
・Rails: 5.2.4
・Vagrant: 2.2.7
・VirtualBox: 6.1
・OS: macOS Catalina前提
下記実装済み。
・Slim導入
・Bootstrap3導入
・ログイン機能実装
・devise日本語化実装
1.カラムを追加
ターミナル$ rails g migration AddIsValidToUsers is_valid:boolean~_add_is_valid_to_users.rbclass AddIsValidToUsers < ActiveRecord::Migration[5.2] def change # 「default: true」と「null: false」を追記 add_column :users, :is_valid, :boolean, default: true, null: false end endターミナル$ rails db:migrate2.モデルを編集
user.rb# 追記 enum is_valid: { '有効': true, '退会済': false } def active_for_authentication? super && self.is_valid == '有効' end【解説】
① ユーザーの状態をenumで管理する。
enum is_valid: { '有効': true, '退会済': false }② is_validが
有効であればtrueを返すメソッドを定義する。def active_for_authentication? super && self.is_valid == '有効' end3.
session_controller.rbを編集session_controller.rb# 追記 protected def reject_user user = User.find_by(email: params[:user][:email].downcase) if user if (user.valid_password?(params[:user][:password]) && (user.active_for_authentication? == true)) redirect_to new_user_session_path end end end【解説】
① 入力されたメールアドレスに対応するユーザーが存在するかを確認する。
user = User.find_by(email: params[:user][:email].downcase)② 入力されたパスワードが正しい場合かつ、
2で定義したメソッドの返り値がtrueだった場合は、ログイン処理を行わずにログイン画面に遷移する。if (user.valid_password?(params[:user][:password]) && (user.active_for_authentication? == true)) redirect_to new_user_session_path end4.ビューを編集
Bootstrap3のアラートコンポーネントを使用してフラッシュメッセージを表示する。
sessions/new.html.slim/ 追記 - if flash.present? .alert.alert-danger.alert-dismissible.fade.in role='alert' button.close type='button' data-dismiss='alert' span aria-hidden='true' | × - flash.each do |name, msg| = content_tag :div, msg, :id => 'flash_#{ name }' if msg.is_a?(String) p a href='#' data-dismiss='alert' | 閉じる
- 投稿日:2020-07-13T10:08:56+09:00
【Rails】deviseを日本語化する方法
開発環境
・Ruby: 2.5.7
・Rails: 5.2.4
・Vagrant: 2.2.7
・VirtualBox: 6.1
・OS: macOS Catalina前提
下記実装済み。
実装
1.Gemを導入
Gemfile# 追記 gem 'devise-i18n'2.
application.rbを編集application.rbmodule Bookers2Debug class Application < Rails::Application config.load_defaults 5.2 config.i18n.default_locale = :ja # 追記 end end
devise.ja.ymlファイルを作成し、編集$ touch config/locales/devise.ja.ymldevise.ja.ymlja: activerecord: errors: models: user: attributes: email: taken: "は既に使用されています。" blank: "が入力されていません。" too_short: "は%{count}文字以上に設定して下さい。" too_long: "は%{count}文字以下に設定して下さい。" invalid: "は有効でありません。" password: taken: "は既に使用されています。" blank: "が入力されていません。" too_short: "は%{count}文字以上に設定して下さい。" too_long: "は%{count}文字以下に設定して下さい。" invalid: "は有効でありません。" confirmation: "が内容とあっていません。" attributes: user: current_password: "現在のパスワード" name: 名前 email: "メールアドレス" password: "パスワード" password_confirmation: "確認用パスワード" remember_me: "次回から自動的にログイン" name: 氏名 sex: 性別 postcode: 郵便番号 prefecture_code: 都道府県 address_city: 市区町村 address_street: 番地 address_building: 建物名 models: user: "ユーザー" devise: confirmations: new: resend_confirmation_instructions: "アカウント確認メール再送" mailer: confirmation_instructions: action: "アカウント確認" greeting: "ようこそ、%{recipient}さん!" instruction: "次のリンクでメールアドレスの確認が完了します:" reset_password_instructions: action: "パスワード変更" greeting: "こんにちは、%{recipient}さん!" instruction: "誰かがパスワードの再設定を希望しました。次のリンクでパスワードの再設定が出来ます。" instruction_2: "あなたが希望したのではないのなら、このメールは無視してください。" instruction_3: "上のリンクにアクセスして新しいパスワードを設定するまで、パスワードは変更されません。" unlock_instructions: action: "アカウントのロック解除" greeting: "こんにちは、%{recipient}さん!" instruction: "アカウントのロックを解除するには下のリンクをクリックしてください。" message: "ログイン失敗が繰り返されたため、アカウントはロックされています。" passwords: edit: change_my_password: "パスワードを変更する" change_your_password: "パスワードを変更" confirm_new_password: "確認用新しいパスワード" new_password: "新しいパスワード" new: forgot_your_password: "パスワードを忘れましたか?" send_me_reset_password_instructions: "パスワードの再設定方法を送信する" registrations: edit: are_you_sure: "本当に良いですか?" cancel_my_account: "アカウント削除" currently_waiting_confirmation_for_email: "%{email} の確認待ち" leave_blank_if_you_don_t_want_to_change_it: "空欄のままなら変更しません" title: "%{resource}編集" unhappy: "気に入りません" update: "更新" we_need_your_current_password_to_confirm_your_changes: "変更を反映するには現在のパスワードを入力してください" new: sign_up: "アカウント登録" sessions: new: sign_in: "ログイン" shared: links: back: "戻る" didn_t_receive_confirmation_instructions: "アカウント確認のメールを受け取っていませんか?" didn_t_receive_unlock_instructions: "アカウントの凍結解除方法のメールを受け取っていませんか?" forgot_your_password: "パスワードを忘れましたか?" sign_in: "ログイン" sign_in_with_provider: "%{provider}でログイン" sign_up: "アカウント登録" unlocks: new: resend_unlock_instructions: "アカウントの凍結解除方法を再送する"
- 投稿日:2020-07-13T09:00:16+09:00
【Rails】Rspecでマクロを定義して処理を共通化する方法
目標
ログイン処理を共通化する。
開発環境
・Ruby: 2.5.7
・Rails: 5.2.4
・rspec-rails: 4.0.1
・Vagrant: 2.2.7
・VirtualBox: 6.1
・OS: macOS Catalina実装
1.
supportディレクトリを作成$ mkdir support2.
supportディレクトリ内にファイルを作成し、編集$ touch spec/support/login_macros.rblogin_macros.rbmodule LoginMacros def login(user) fill_in 'メールアドレス', with: user.email fill_in 'パスワード', with: user.password click_button 'ログイン' end end3.
rails_helper.rbを編集rails_helper.rb# 23行目をコメントアウト Dir[Rails.root.join('spec', 'support', '**', '*.rb')].sort.each { |f| require f } RSpec.configure do |config| config.include LoginMacros # 追記 end【解説】
①
supportディレクトリを読み込む。Dir[Rails.root.join('spec', 'support', '**', '*.rb')].sort.each { |f| require f }②
2で定義したモジュールを使用できるようにする。config.include LoginMacros4.メソッドを使用する
require 'rails_helper' RSpec.describe '認証のテスト', type: :feature do let(:user) { create(:user) } subject { page } describe 'ユーザー認証のテスト' do context 'ユーザーログインのテスト' do it 'ログインできること' do visit new_user_session_path login(user) # メソッドを使用 is_expected.to have_content 'ログアウト' end end end end
- 投稿日:2020-07-13T08:49:42+09:00
そのpreload、本当に必要ですか?〜遅延ロード活用〜
まずは下記のコードを見てください。
review = Review.preload(:user, :book).find_by(id: review_id)このようなコードを見かけたとき、あなたはどうしますか?
私ならpreloadは付けなくて良いよ。と指摘すると思います。この記事では、なぜこの
preloadは不要なのか説明したいと思います。preloadとは
preloadをつけると指定した関連データを同時に取得することができます。
この例の場合、reviewを取得したときに関連するuserとbookも同時に取得します。下記にirbで実行した結果を載せておきます。
reviewを取得したときにuserとbookもSELECTしており、実際に使うところではSQLが発行されていないことがわかります。irb(main):011:0> review_id = 15 => 15 irb(main):012:0> review = Review.preload(:user, :book).find_by(id: review_id) Review Load (0.8ms) SELECT `reviews`.* FROM `reviews` WHERE `reviews`.`id` = 15 LIMIT 1 User Load (0.5ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 1 Book Load (0.8ms) SELECT `books`.* FROM `books` WHERE `books`.`id` = 1 => #<Review id: 15, content: "hogehoge", user_id: 1, book_id: 1, status: "draft", created_at: "2020-06-15 14:21:23", updated_at: "2020-06-15 14:21:23"> irb(main):013:0> review.user => #<User id: 1, name: "1234567890", created_at: "2019-12-12 05:43:52", updated_at: "2019-12-12 05:43:52"> irb(main):014:0> review.book => #<Book id: 1, title: "book1", created_at: "2020-06-15 14:21:15", updated_at: "2020-06-15 14:21:15">preloadはどういうときに使うのか?
主にN+1の対策で使われます。
N+1についてはここでは詳しくは述べませんが、下記のようにループなどで関連データの取得SQLが1件ずつ発行されるような事象のことです。irb(main):022:0> Review.all.each do |review| irb(main):023:1* review.book irb(main):024:1> end Review Load (0.6ms) SELECT `reviews`.* FROM `reviews` Book Load (0.3ms) SELECT `books`.* FROM `books` WHERE `books`.`id` = 1 LIMIT 1 Book Load (0.3ms) SELECT `books`.* FROM `books` WHERE `books`.`id` = 2 LIMIT 1 Book Load (0.4ms) SELECT `books`.* FROM `books` WHERE `books`.`id` = 3 LIMIT 1 Book Load (0.3ms) SELECT `books`.* FROM `books` WHERE `books`.`id` = 4 LIMIT 1 Book Load (2.7ms) SELECT `books`.* FROM `books` WHERE `books`.`id` = 5 LIMIT 1上記では、bookを事前に取得していないのでreview.bookのところで1件ずつSQLを発行しています。
prealodをつけて事前にbookを取得しておくと下記のようになります。irb(main):025:0> Review.all.preload(:book).each do |review| irb(main):026:1* review.book irb(main):027:1> end Review Load (0.8ms) SELECT `reviews`.* FROM `reviews` Book Load (0.7ms) SELECT `books`.* FROM `books` WHERE `books`.`id` IN (1, 2, 3, 4, 5)ループに入る前にReview.allで取得できたreviewに関連するbookを1つのSQLで取得していることがわかります。
ループ前にまとめで取得できているのでループ中にはSQLが発行されません。
一般的にSQL発行はコストがかかる処理なので、SQLが1回になることでパフォーマンスが向上します。
上記例でもSQLの合計実行時間をみるとパフォーマンスに差が出ていることがわかります。なぜ今回は付けなくて良いのか?
では、最初の例の場合はどうでしょうか?
reviewを1件しか取得していないので先ほどのようにループでN+1になることはありえません。preloadをしているということは少なくとものちに使う可能性があるということだと思います。
次の例を見てみましょう。# userを取得 # あとでuserとreviewを使うのでpreloadしておく review = Review.preload(:user, :book).find_by(id: review_id) # userを使う review.user # bookを使う review.bookpreloadをつけているので、reviewを取得したときにuserやbookも取得されます。
実行結果は下記の通り。irb(main):007:0> review = Review.preload(:user, :book).find_by(id: review_id) Review Load (0.8ms) SELECT `reviews`.* FROM `reviews` WHERE `reviews`.`id` = 36 LIMIT 1 User Load (0.5ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 1 Book Load (0.4ms) SELECT `books`.* FROM `books` WHERE `books`.`id` = 1 => #<Review id: 36, content: "", user_id: 1, book_id: 1, status: "draft", created_at: "2020-06-30 15:20:01", updated_at: "2020-06-30 15:20:01"> irb(main):008:0> review.user => #<User id: 1, name: "1234567890", created_at: "2019-12-12 05:43:52", updated_at: "2019-12-12 05:43:52"> irb(main):009:0> review.book => #<Book id: 1, title: "book1", created_at: "2020-06-15 14:21:15", updated_at: "2020-06-15 14:21:15">では、もしpreloadをつけていなかったらどうなるでしょうか?
irb(main):010:0> review = Review.find_by(id: review_id) Review Load (0.7ms) SELECT `reviews`.* FROM `reviews` WHERE `reviews`.`id` = 36 LIMIT 1 => #<Review id: 36, content: "", user_id: 1, book_id: 1, status: "draft", created_at: "2020-06-30 15:20:01", updated_at: "2020-06-30 15:20:01"> irb(main):011:0> review.user User Load (0.5ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 1 LIMIT 1 => #<User id: 1, name: "1234567890", created_at: "2019-12-12 05:43:52", updated_at: "2019-12-12 05:43:52"> irb(main):012:0> review.book Book Load (0.6ms) SELECT `books`.* FROM `books` WHERE `books`.`id` = 1 LIMIT 1 => #<Book id: 1, title: "book1", created_at: "2020-06-15 14:21:15", updated_at: "2020-06-15 14:21:15">reviewを取得したときにはuserとbookは取得されず、使っているところでSQLが発行されています。
ただ、reviewが一件しかないので発行されているSQLの数は一緒です。
この例の場合だと、preloadをつけてもつけなくても効率は同じですねでは、次の例ではどうでしょうか?
# userを取得 # あとでuserとreviewを使うのでpreloadしておく review = Review.preload(:user, :book).find_by(id: review_id) # ある条件の時はuserを使う if hoge review.user end # ある条件の時はbookを使う if fuga review.book endpreloadをつけているので、reviewを取得したときにuserやbookも取得されます。
hogeやfugaがtrueの場合は、userもreviewも使うのでpreloadをしていてもしていなくてもSQLの数は一緒です。では、falseの場合はどうでしょうか?
例えばhogeがfalseの場合はuserは使わないので、preloadで取得したuserを使うことはありません。
fugaがfalseの場合も同様にbookを使うことはありません。今回はもしpreloadをつけていなかったらどうなるでしょうか?
# userを取得 review = Review.find_by(id: review_id) # ある条件の時はuserを使う if hoge review.user end # ある条件の時はbookを使う if fuga review.book endreviewを取得したときはuserやbookは取得されません。
hogeやfugaがtrueの場合は使用する箇所でreviewやbookが取得されます。
もしfalseの場合は取得されません。こちらの実装の場合は使用するときのみ取得することができます。
ちなみに、このように必要になったときにデータを取得する実装は遅延ロードと呼ばれています。どちらの方が効率が良いかおわかりいただけたでしょうか?
1件のモデルに対してpreloadをした場合、preloadで取得したモデルを全部使った場合でもpreloadをつけていない場合とSQLの数は同じです。
もし1つでも条件によって使わないパターンがある場合はSQLの数が多くなります。最初の例のように1件だけ取得する場合はpreloadをしても意味がなく、むしろ非効率になるので注意が必要です。
最後に
Railsを覚えたばかりの方などなんとなくpreloadやeager_loadを知っている場合、とりあえずつけておけばいいんでしょ?
と思っている方も多いと思います。レビュアーとしてもN+1を指摘する人は多いけど、今回のような無駄なpreloadを指摘する人は少ないと感じています(個人の感想です)
N+1を倒してくれるpreloadやeager_loadはつけておいて悪いことはないと思われがちですが、今回のように非効率になってしまうパターンもあるので意識していなかった方は意識しておきましょう。
- 投稿日:2020-07-13T05:54:05+09:00
Railsでi18nを使った日本語化をする
環境:ruby 2.5.1 / rails 5.2.3
やりたいこと
- エラーメッセージなど英語で表記される箇所を日本語の置き換えたい
- DBのカラム名やclassの属性を表示する時に、予め日本語に置き換えたものを表示されるようにしたい
結論
- gemの
rails-i18nを導入する- 変換したい単語を
ja.ymlファイルに設定するやり方
- gemの
rails-i18nを導入するGemfile# 記述する場所はファイルの一番下か、group :development, group :development, :test 以外の場所に記述 gem 'rails-i18n'
- gemをインストールする
config/application.rb内のデフォルトのlocale(ロケール)をjaにするapplication.rb# ↑これより上のコードは割愛 module App class Application < Rails::Application config.i18n.default_locale = :ja config.time_zone = 'Tokyo' end end
config/locales/ja.ymlのファイルを作成するja.ymlの中に、日本語に変換したい設定をyml形式で記述する
例:DBのカラムに関する文字 →activerecord: attributes: モデル名:
viewに関する文字 →views: リソース名:ja.ymlja: activerecord: attributes: user: name: ユーザー名 email: メール password: パスワード password_confirmation: パスワード(確認) tweet: name: 名前 title: タイトル body: 本文 comment: name: 名前 comment: コメント views: pagination: first: 最初 last: 最後 previous: 前 next: 次 truncate: ...
- 設定が完了したら、サーバーを立ち上げ直す(これをしないと反映されないため)
- 投稿日:2020-07-13T03:07:15+09:00
rails db:createでDBを作成しようとするとパスワード認証に失敗して作成できないときに確認するところ
Docker compose + Rails + PostgreSQL
rails db:createでDBを作成しようとしたら、
以下のエラーメッセージが出た。FATAL: password authentication failed for user "postgresql" Couldn't create 'product-register_development' database. Please check your configuration. rails aborted! PG::ConnectionBad: FATAL: password authentication failed for user "postgresql"パスワード認証に失敗したため、データベースを作成できなかった
という内容。Rails側のDB設定ファイルを確認
config/database.ymldatabase.ymldefault: &default adapter: postgresql encoding: unicode host: db user: postgres port: 5432 password: <%= ENV.fetch("DATABASE_PASSWORD") %> # For details on connection pooling, see Rails configuration guide # http://guides.rubyonrails.org/configuring.html#database-pooling pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>userとpasswordを確認した。
両方タイプミスしてました…上記のように正しく直したらうまくいきました。
Docker関係なかった。練習のため、PostgreSQLのデフォルト設定のまま作成しています。
user: postgres
password: postgres
- 投稿日:2020-07-13T02:01:36+09:00
(Linux初心者)魔法の言葉auxとは
とりあえず使ってたけど、auxコマンドの意味とは
例題: ps aux | grep puma
以下、分解して見ていく。
まず、grepは特定の文字列を含むコマンドを検索したいときに使用する。
コマンド | grep 検索したい文字列コマンドを詳しく見てみる。
ps ・・・ 自分のプロセスを簡単に表示 aux・・・ a、u、xオプションの組み合わせ aオプション・・・ すべてのユーザーのプロセスを表示する uオプション・・・ 各プロセスの実行ユーザーやCPU, メモリ等の情報も表示する xオプション・・・ 端末を持たないすべてのプロセス(daemonなど)を表示するdaemon(デーモン)・・・バックグラウンドで動作するプロセス。コンピュータを使ってる人に見えない裏側で動作するもの。
要するにauxにすることですべての種類のプロセスの知り得るだけの情報がすべて網羅される。
解答 ps aux | grep pumaとは
【意味】pumaを含むコマンドの知りうる情報を全て表示するつまり、迷ったらauxは間違いではなかった。
- 投稿日:2020-07-13T01:56:55+09:00
Haml renderの方法など
直に書きたくないので、modulesフォルダー作成。entrance.scssを入れます。
stylesheets>modules>entrance.scssその後、忘れずに下のように記入。
application.scss@import "modules/entrance";次は
views>sharedに_1.html.hamlを作成。
※_1という書き方でレンダーを意味します。views>entrance>index.html.haml.warapper = render "shared/1"その後
stylesheets>1.scss.oil { font-size: 30px; }application.scss@import "modules/entrance"; @import "1";localhost:3000
30pxでeatsと表示されれば完成です!
- 投稿日:2020-07-13T01:19:13+09:00
HAMLの書き始め ーHamlでlocalhost:3000に表示ー
1
rites.rbroot to: 'entrance#index'2
Gemfilegem 'pry-rails' gem 'mini_racer' gem 'haml-rails'3
・忘れずに、
bundle install。
・rails haml:erb2hamlで.erbファイルをHamlに変換、yかnを聞かれるので、yで.erbファイルを削除。
・rails db:createでデータベースを作成しておく。
これをやらないとActiveRecord::NoDatabaseError (Unknown database 'oil_development'):
と、データベースがありませんというエラーが出てしまいます。4
application.scss@import "entrance.scss";5
entrance>index.html.haml.oil eatsこれで、localhost:3000に行くとhamlでeatsの文字を表示させる事ができます。
- 投稿日:2020-07-13T00:44:00+09:00
【Capistrano,Unicorn】ArgumentError: directory for pid=/var/www/badsuru/current/shared/tmp/pids/unicorn.pid not writableが書き込み権限の問題ではなかった
はじめに
Capistranoを用いた自動デプロイ中、タイトルのエラーが出てほぼ1日を費やしました・・・
結論、大したことではなく自分にがっかりしてしまいましたが、同じようなエラーで悩む方の手助けになれば幸いです。対象者
- 初学者
- Capistrano設定中の方
- Unicorn使用者
開発環境
- Rails 6.0.3.1
- ruby 2.7.1
- unicorn 5.4.1
- AWS Amazon Linux AMI 2018.03.0 (HVM), SSD Volume Type
この記事を通じて得られること
- タイトルのエラーの原因・解決方法 ※あくまで1つのエラーの解決方法であることをご了承ください。エラーの原因によっては違う解決方法になることが考えられます。
結論(解決方法)
unicorn.rbの設定記述ミスです。以下の通り変更しました。
開発中のアプリのパスが違うために、unicorn.pidを作成する/var/www/badsuru/current/shared/tmp/pids/ディレクトリが見つからず、タイトルのエラーを吐き出していました。変更前
unicorn.rb//サーバ上でのアプリケーションコードが設置されているディレクトリを変数に入れておく app_path = File.expand_path('../../', __FILE__) //アプリケーションサーバの性能を決定する worker_processes 1 // アプリケーションの設置されているディレクトリを指定 working_directory app_path (以下省略)変更後
unicorn.rb//サーバ上でのアプリケーションコードが設置されているディレクトリを変数に入れておく app_path = File.expand_path('../../../', __FILE__) //アプリケーションサーバの性能を決定する worker_processes 1 // アプリケーションの設置されているディレクトリを指定 // currentを指定 working_directory "#{app_path}/current" (以下省略)詳細
Capistarnoの自動設定ファイルを記述し、いざ実行したところ、以下のエラーが吐き出されました。
00:44 unicorn:start 01 $HOME/.rbenv/bin/rbenv exec bundle exec unicorn -c /var/www/myapp/current/config/unicorn.rb -E deployment -D 01 bundler: failed to load command: unicorn (/var/www/myapp/shared/bundle/ruby/2.7.0/bin/unicorn) 01 ArgumentError: directory for pid=/var/www/myapp/current/shared/tmp/pids/unicorn.pid not writable 01 /var/www/myapp/shared/bundle/ruby/2.7.0/gems/unicorn-5.4.1/lib/unicorn/configurator.rb:100:in `block in reload' 01 /var/www/myapp/shared/bundle/ruby/2.7.0/gems/unicorn-5.4.1/lib/unicorn/configurator.rb:96:in `each' 01 /var/www/myapp/shared/bundle/ruby/2.7.0/gems/unicorn-5.4.1/lib/unicorn/configurator.rb:96:in `reload' 01 /var/www/myapp/shared/bundle/ruby/2.7.0/gems/unicorn-5.4.1/lib/unicorn/configurator.rb:77:in `initialize' 01 /var/www/myapp/shared/bundle/ruby/2.7.0/gems/unicorn-5.4.1/lib/unicorn/http_server.rb:77:in `new' 01 /var/www/myapp/shared/bundle/ruby/2.7.0/gems/unicorn-5.4.1/lib/unicorn/http_server.rb:77:in `initialize' 01 /var/www/myapp/shared/bundle/ruby/2.7.0/gems/unicorn-5.4.1/bin/unicorn:126:in `new' 01 /var/www/myapp/shared/bundle/ruby/2.7.0/gems/unicorn-5.4.1/bin/unicorn:126:in `<top (required)>' 01 /var/www/myapp/shared/bundle/ruby/2.7.0/bin/unicorn:23:in `load' 01 /var/www/myapp/shared/bundle/ruby/2.7.0/bin/unicorn:23:in `<top (required)>' 01 master failed to start, check stderr log for details (省略)当初、
unicorn.pid not writableと記述があったので、権限周りのエラーかと思い、releases,current,shared...などなど様々なディレクトリに書き込み権限を与えても解決されず、途方にくれていました。また、
mkdir pidsコマンド等で予めディレクトリを作成しなければならないという情報をググって見つけて試したけど上手く行かず・・・
見直したつもりの設定ファイルの記述を丁寧に見直したら結論の間違えに気が付きました。推測になってしまいますが、unicornの起動と共にunicorn.pidsファイルを設定ディレクトリ配下に作成するのですが、unicornを実行させるアプリケーションのディレクトリ設定が間違えている状態です。unicorn.pidsファイルを作成したいのだけど、そのディレクトリにも辿りつけないから、見つからないというメッセージの代わりに、タイトルのエラーが吐き出されるようです。確かに、エラーの解決法を探している時も、設定ファイルの記述を指摘する記事もあったなあ・・・
終わりに
エラーが出て、指摘通りの内容を修正してもまだ出る時は、エラー文と違うミスの可能性も十分に考えられること。自分が記述してきたファイルをしっかり見直ししようという教訓になりました。