- 投稿日:2020-07-13T23:53:20+09:00
FastAPI Tutorialメモ その2 Path Parameters
はじめに
FastAPI Souce: https://github.com/tiangolo/fastapi
FastAPI Document: https://fastapi.tiangolo.com対象: Path Parameters ( https://fastapi.tiangolo.com/tutorial/path-params/ )
FastAPIチュートリアルのメモ。
FastAPI Tutorialメモ その1の続きになります。
FastAPIインストールやサーバの起動は上記のものと同様となりますので、上記記事をご確認ください。基本的にはFastAPIの公式チュートリアルを参考にしていますが、自身の学習のため一部分を省略したり順番を前後させています。
正しい詳細な情報は公式ドキュメントを参考いただければと思います。Web & Python 初心者かつ翻訳はGoogleとDeepL頼りのため、間違い等ありましたらご指摘いただけますと幸いです。
開発環境
Ubuntu 20.04 LTS
Python 3.8.2
pipenv 2018.11.26目標
- FastAPIのPathパラメータの理解
手順
Intro
FastAPIではパスに対するパラメータや変数をPythonの書式と同じ構文で宣言することができます。
以下のコードをmain.pyとして保存してください。main.pyfrom fastapi import FastAPI app = FastAPI() @app.get("/items/{item_id}") async def read_item(item_id): return {"item_id": item_id}この時、デコレータ関数
@app.get("/items/{item_id}")のitem_idがPathパラメータであり、引数item_idとして関数の引数に渡されます。
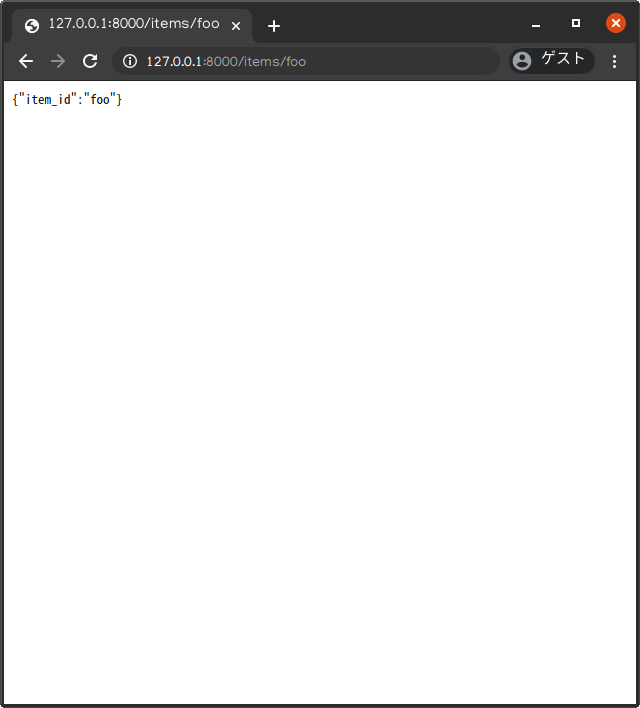
例としてこのファイルを保存した後にサーバを起動(uvicorn main:app --reload)し、 http://127.0.0.1:8000/items/foo をブラウザで開いてみてください。下記の通り、変数item_idに文字列fooが代入されたJSON形式のテキストが返ってくるはずです。{"item_id":"foo"}実際の画面
これがFastAPIにおけるPathパラメータの基本となります。
型付きのPathパラメータ
FastAPIではPython標準の型アノテーションを使用して、関数内でPathパラメータの型を宣言することができます。
main~ # 前略 ~ @app.get("/items/{item_id}") async def read_item(item_id: int): return {"item_id": item_id}関数を宣言している
async def read_item(item_id: int):の行に注目してください。ここでは、引数item_idをint(整数型)として宣言しています。
型宣言によって、エラーチェックや単語の補完などのエディタサポートを受けられるようになるでしょう。(上記のコードでは、foo = item_id + "bar"のように数字と文字列を足す処理をすれば私の環境(PyCharm)ではType Checkerによるエラーが表示されました。)main.pyの関数部分を上記のコードに変更した状態で http://127.0.0.1:8000/items/3 をブラウザで開くと、次のように表示されます。
{"item_id":3}ここで、関数
read_itemが受け取り、返り値として表示した値が文字列ではなく整数の3であることに注意する必要があります。
URLへの入力はデフォルトではすべて文字列として解釈されますが、Pythonの型宣言によってFastAPIは自動的にリクエストをparsing(解析)し、整数型へ変換したのです。ためしに型を宣言している部分を取り除いたコード(
async def read_item(item_id: int):の部分をasync def read_item(item_id):に戻す)で http://127.0.0.1:8000/items/3 にアクセスると文字列"3"として表示されるでしょう。{"item_id":"3"}また、
int型として宣言したPathパラメータに対して、 http://127.0.0.1:8000/items/foo のようなURLでアクセスした場合は下記のようなHttpエラーが返されます{ "detail": [ { "loc": [ "path", "item_id" ], "msg": "value is not a valid integer", "type": "type_error.integer" } ] }与えられたパラメータ(
str型"foo")がint型に変換することができないため、FastAPIのData validation(データの検証)機能が働いたためです。
上記のstr型同様に、浮動少数点数float型を与えた場合( http://127.0.0.1:8000/items/4.2 など)も同様のエラーになります。なお、
float型で宣言したパラメータにint型の値を与えた場合は変換されることが確認できました上記から、FastAPIはPythonの型宣言と全く同じバリデーションを行っていることがわかります。
エラーメッセージにはバリデーションが通過しなかったポイント(今回なら
"path"パラメータの変数"item_id")も明記されていることに注目できます。APIと相互作用するコードの開発やデバッグに非常に役立つでしょう。型チェックによるバグの防止は、FastAPIの重要な特徴の一つです。
ドキュメントの確認
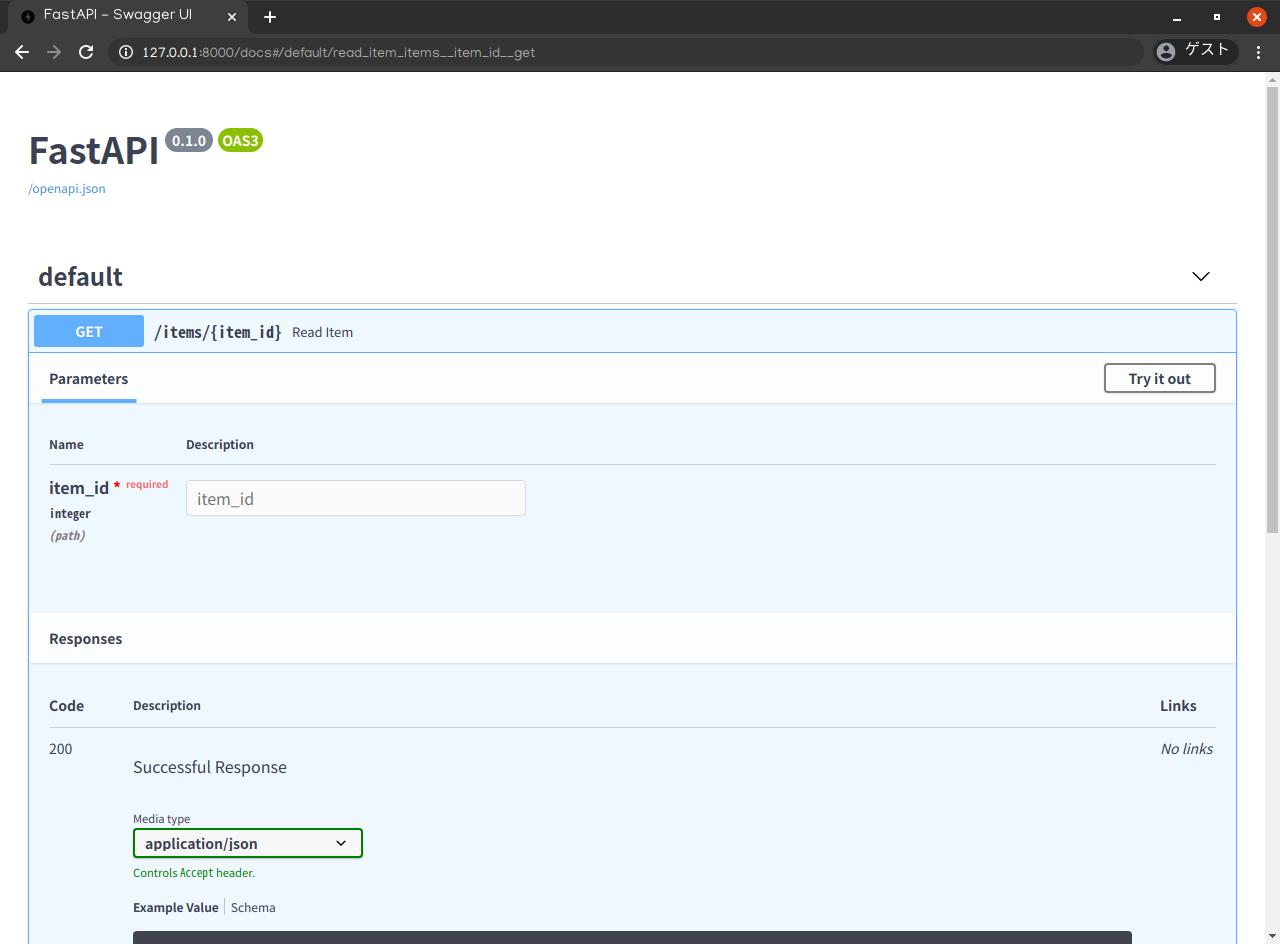
上記のコードを確認したら、ブラウザで http://127.0.0.1:8000/docs を確認してください。以下のように、インタラクティブ(対話的)なAPIのドキュメントが自動的に生成されています。(画面中央付近の
defaultの下のGETと表記された青いタブをクリックすれば展開されます。)
ParametersのNameitem_idの下にintegerとありますね。Pythonの型宣言が(Swagger UIに統合された)インタラクティブなドキュメントにも反映されていることがわかるかと思います。
このドキュメントではAPIの様々な情報を得ることができ、また、デザイナーやフロントサイドの人々と共有することが可能です。また、このドキュメントはFastAPIが生成したスキーマを元にしたものですが、生成されたスキーマはOpenAPIに準拠しており、様々な互換性のあるツールが開発されています。
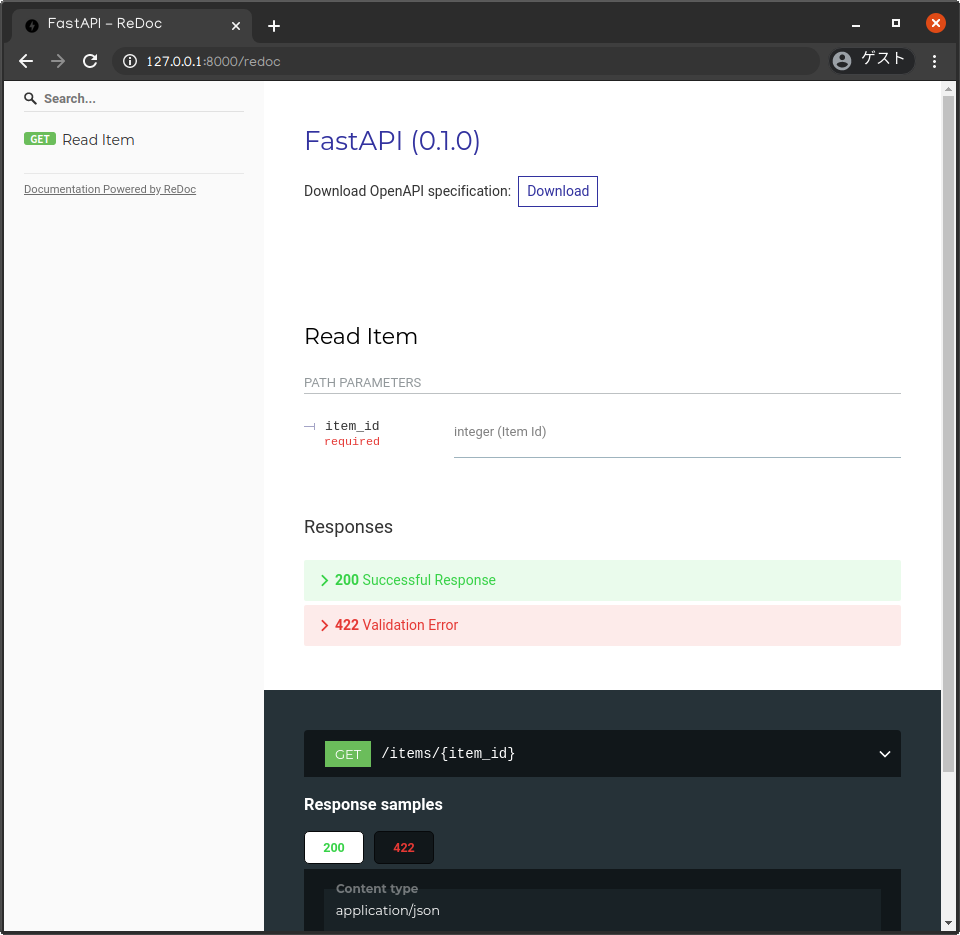
メモその1でも確認したましたが、FastAPIではReDocを使用した代替ドキュメントも存在しています。
http://127.0.0.1:8000/redoc にアクセスしてみてください。
ざっくりとした個人的な印象ですが、Swagger UI は実際にリクエストを生成して結果の確認までできるインタラクティブ(対話的)なドキュメント、一方のReDocは静的でシンプルなドキュメントという認識です。おそらくもっと色々な使い方や別のツールがあるのでしょうが、勉強不足でまったくわかりません。すみません。学習次第、更新していきたいと思います。
今のところ、リクエストを生成して結果も見れるSwagger UIが便利だなぁという気持ちです。
Pydantic
本題に戻りまして、このようなドキュメント生成にも役立つ型アノテーションは、すべてPydanticというライブラリによって行われています。
Pydanticについては下記の記事が参考になりました。
Pydantic 入門 @0622okakyoPydanticにより、
str、float、boolなど多くのデータ型で、すべて同様に型アノテーションを行うことができます。Path Operationにおける順序問題
Path Operationを作成する場合、パスが固定されてしまう状況になることがあります。
例として、ユーザが自身のデータを取得するための
/users/meというパスがあるとします。
この時、同時にある別のユーザに関するデータをuser_idを使用して取得する/users/{user_id}というパスも存在するとしましょう。FastAPIにおけるPath Operationは順番に評価されていきます。
よって、下記のようにパス/users/meはパス/users/{user_id}よりも前に宣言される必要があります。mainfrom fastapi import FastAPI app = FastAPI() @app.get("/users/me") async def read_user_me(): return {"user_id": "the current user"} @app.get("/users/{user_id}") async def read_user(user_id: str): return {"user_id": user_id}もし下記のようにパス
/users/meがパス/users/{user_id}の後に宣言された場合、meという値がuser_idというパラメータとしてFastAPIに渡されてしまいます。main_missfrom fastapi import FastAPI app = FastAPI() @app.get("/users/{user_id}") # <- "/users/me"がGETメソッドできた場合、"me"という値が渡される async def read_user(user_id: str): return {"user_id": user_id} @app.get("/users/me") # <- "/users/me"はすでに評価されたため、この関数は呼び出されない async def read_user_me(): return {"user_id": "the current user"}Predefined values (定義済みの値)
パスパラメータを受けるPath Operaterがあり、そのパラメータの設定可能な有効値を事前に定義しておきたい場合、Pythonの標準モジュール
Enumの使用をおすすめします。まずは
Enumクラスを作成してみましょう。
Enumをインポートし、strとEnumを継承したサブクラスを作成します。
strを継承することで、APIドキュメントは設定される値が文字列型であることを事前に知ることができ、正しくレンダリングを行われるようになります。次に、有効な値となる固定値を持ったクラス属性を作成します。
mainfrom enum import Enum # <- Enumのインポート from fastapi import FastAPI class ModelName(str, Enum): # <- クラスの継承 alexnet = "alexnet" # <- クラス属性(固定値)の作成 resnet = "resnet" lenet = "lenet" app = FastAPI()定義したクラスを用いてパスパラメータを定義していきます。
作成した列挙型クラス(
ModelName)を使用し、型アノテーションを付与したパスパラメータを作成します。mainfrom enum import Enum from fastapi import FastAPI class ModelName(str, Enum): alexnet = "alexnet" resnet = "resnet" lenet = "lenet" app = FastAPI() @app.get("/model/{model_name}") async def get_model(model_name: ModelName): # <- 型アノテーションを付与したパスパラメータ if model_name == ModelName.alexnet: return {"model_name": model_name, "message": "Deep Learning FTW!"} if model_name.value == "lenet": return {"model_name": model_name, "message": "LeCNN all the images"} return {"model_name": model_name, "message": "Have some residuals"}ドキュメント( http://127.0.0.1:8000/docs )を確認してください。
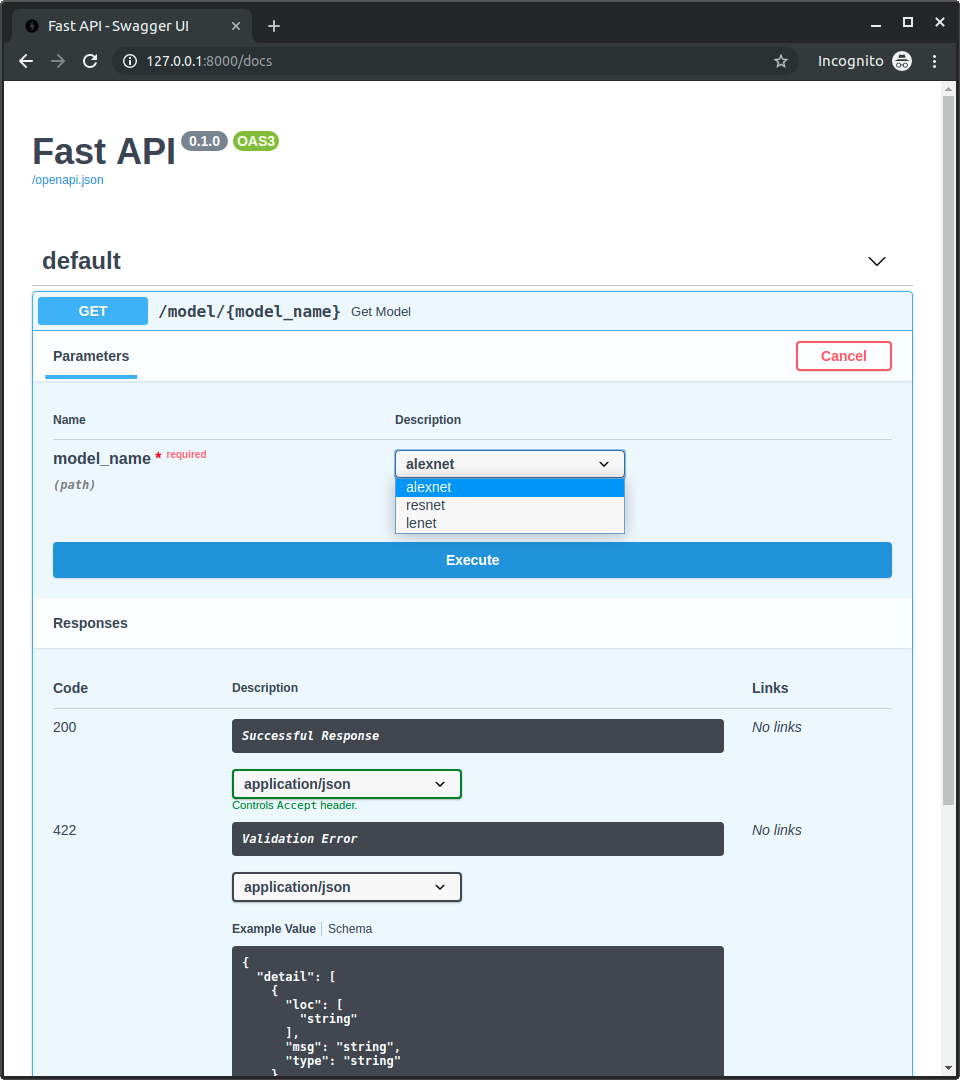
パスパラメータで使用できる値は事前に定義されているため、ドキュメントでそれらの値がインタラクティブに表示、選択されます。
GETタブをクリックし、タブ上部のTry it outをクリックしてください。model_nameが選択可能になります。- 値を選択して
Execteをクリックすることでリクエストを発行できます。(下記のスクリーンショットは公式ドキュメトからの引用になります。
私の環境では選択画面のスクリーンショットが上手く取得できませんでした。)
列挙型について
mainfrom enum import Enum from fastapi import FastAPI class ModelName(str, Enum): alexnet = "alexnet" resnet = "resnet" lenet = "lenet" app = FastAPI() @app.get("/model/{model_name}") async def get_model(model_name: ModelName): if model_name == ModelName.alexnet: # <- ① return {"model_name": model_name, "message": "Deep Learning FTW!"} # <- ③ if model_name.value == "lenet": # <- ② return {"model_name": model_name, "message": "LeCNN all the images"} # <- ③ return {"model_name": model_name, "message": "Have some residuals"} # <- ③詳細はPython公式ドキュメント enum --- 列挙型のサポートを参考にしてください。
ここでは、作成した
ModelNameの列挙型メンバーとの比較(①)、.valueによる列挙型の値の取得とその比較(②)、列挙型メンバーを返り値として使用(③)を行っています。
辞書型dictのようにネストになったJSONボディの場合でも、Path Operaterの値をenumメンバーとして返り値にすることが可能です。この場合、対応する値(上記ではstr)に変換されてクライアントに返されます。インタラクティブドキュメントやブラウザでGETした場合、例えばこのようなJSONの返り値を取得できるでしょう。
{ "model_name": "alexnet", "message": "Deep Learning FTW!" }パスを含むパスパラメータ
例えば、
/files/{file_path}というパスを持つPath Operationがあるとします。
しかし、file_path自体が値としてパスを持っている場合(file_path=home/johndoe/myfile.txtのような場合)、
URLは次のようになるでしょう。http://127.0.0.1:8000/files/home/johndoe/myfile.txtOpenAPIでは、テストの定義と困難なシナリオの発生につながるという理由から、上記のようなパスを値として持つパスパラメータの宣言をサポートしていません。
しかしながら、Starletteの内部ツールを使用することで、FastAPIではそのようなパスパラメータを宣言することができます。
(ただし、OpenAPIに準拠するAPIドキュメントでパスパラメータ自体にパスが含まれていることを確認することはできません。※ドキュメント自体は動作します)次のような URL を使用して、パスを含むパスパラメータを宣言します。
/files/{file_path:path}上記では、パスパラメータは
file_pathであり、:pathの部分がパスパラメータにパスが含まれていることを明示しています。使用例としては以下のようになります。
mainfrom fastapi import FastAPI app = FastAPI() @app.get("/files/{file_path:path}") async def read_file(file_path: str): return {"file_path": file_path}終わりに
次回はクエリパラメータになります。
- 投稿日:2020-07-13T23:52:08+09:00
関数の引数について(python)
はじめに
この記事は、半分は自分のメモ用に作成した記事です。
ただ、自分が見返した時に分かりやすいメモにするためにも、
誰が見ても分かりやすい記事になるよう心がけたつもりです。
(その方が、間違ってた時に指摘もしてもらえそうだし・・・(本音))STEP1:実引数と仮引数について
引数とは、仮引数と実引数との2つに大きく分類されます。
仮引数:関数定義で使用。実際のオブジェクトに仮の名前を付けるので仮引数。(argument)
実引数:関数呼び出しで使用。実際のオブジェクトなので実引数。(parameter)def foo(a): # 仮引数 a+=1 return a print(foo(1)) #実引数 >>>2STEP2:仮引数の性質
仮引数の重要な性質は、関数の呼び出し毎に設定されることです。
具体例を見ていきましょう。def remove_first(lst): lst = lst[1:] print(lst) lst = [1, 2, 3, 4] print(lst) remove_first(lst) >>> [2, 3, 4] remove_first(lst) >>> [2, 3, 4]ここで言いたいのは、1回目と2回目のremove_first(lst)の結果が同じであると言うこと。
つまり、「1回めに呼ばれたときの仮引数」と「2回めに呼ばれたときの仮引数」は、
同じ変数であっても別の変数として扱われていると言うことです。STEP3:仮引数の種類
前述した仮引数には5つのパターンがあります。
- 位置またはキーワード:いわゆる普通の関数定義
- 位置のみ:後述
- キーワードのみ:後述
- 可変長位置:後述
- 可変長キーワード:後述
とりあえず、ここは通常の位置またはキーワードを紹介します。
def foo2(a, b=3): # aが位置引数、bがキーワード引数 return a + b def foo3(a=1, b): # エラー(位置引数の前に、キーワード引数は設定できない) return a + b print(foo2(1)) # 位置引数(bの値は関数定義時のデフォルト値がで適用される) >>>4 print(foo2(1,5)) # 位置引数(a=1,b=5) >>>6 print(foo2(1,b=5)) # 位置引数&キーワード引数 >>>6 print(foo2(a=1,b=5)) # キーワード引数 >>>6 print(foo2(b=2)) # エラー >>>TypeError print(foo2(b=3,a=1)) # キーワード引数の順番入れ替え上記から分かる重要な性質として、
- 仮引数では、位置引数の前にキーワード引数は設定できない
- キーワード引数は実引数で設定をしなかった場合、仮引数のデフォルト値が適用される
- 実引数において、キーワード引数は順番を入れ替えて設定できる
- 実引数では位置引数としても、キーワード引数としても呼び出せる
STEP4:位置のみ、キーワードのみ
次は、前述した位置のみ、キーワードのみを紹介します。
まず、位置のみですが、
関数定義時に、/の前にある引数は位置引数でしか呼び出せない
一方、キーワードのみですが、
関数定義時に、*の後にある引数はキーワード引数でしか呼び出せないdef func(a,*,b,c): return a + b + c def func2(a, /): return a print(func(1,b=2,c=3)) # bはキーワード引数で呼び出さないとエラーになる print(func2(1)) # aは位置引数で呼び出さないとエラーになるSTEP5:可変長位置、可変長キーワード
まず可変長位置ですが、任意の個数の位置引数を受け取れる引数のことです。
関数定義時に引数の前に*をつけることで位置引数になります(1つの関数に1回まで)
可変長キーワードは、任意の個数のキーワード引数を受け取れる引数のことです。
関数定義時に引数の前に**をつけることで位置引数になります(1つの関数に1回まで)def func(*a, **b): print(a) print(b) func(1,2,3,b=4,c=5) >>> (1, 2, 3) {'b': 4, 'c': 5}
- 投稿日:2020-07-13T23:44:52+09:00
遊戯王カード名から攻守属性を予測する - 遊戯王データサイエンス 3. 機械学習編
はじめに
Pythonを使って遊戯王カードのデータをいろいろ分析する、「遊戯王DS(データサイエンス)」シリーズです。
記事は全4回を予定し、最終的には自然言語処理+機械学習でカード名から攻守属性を予測するプログラムを実装します。
尚、筆者の遊戯王知識はE・HEROあたりでギリ止まっています。カードもデータサイエンスも素人で恐縮ですが、どうかお付き合いください。
No. 記事タイトル Keyword 0 遊戯王データベースからカード情報を取得する - 遊戯王DS 0. スクレイピング編 beautifulsoup 1 遊戯王カードのデータをPythonで可視化する - 遊戯王データサイエンス1. EDA編 pandas, seaborn 2 遊戯王カード名を自然言語処理する - 遊戯王データサイエンス 2. NLP編 wordcloud, word2vec, doc2vec, t-SNE この記事! 3 遊戯王カード名から攻守属性を予測する - 遊戯王データサイエンス 3. 機械学習編 lightgbmなど 本記事の目的
前回の記事にてカード名をDoc2Vecで変換したベクトルを特徴量、カードの他要素(攻撃力、守備力、属性、種族、レベル)をラベルとし、機械学習でカード名から攻守属性等を予測するモデルを実装します。
更に学習したモデルを用いて、適当なオリジナルのカード名に対しても攻守属性等を付与する予測タスクを実行します。自分の考えたオリジナルモンスターは、機械学習に照らすとどれぐらい強いと判定されるのか検証したいと思います。前提事項の説明(使用環境・データ・分析方針)
使用環境
Python==3.7.4
データ
本記事は、遊戯王OCGカードデータベースからお手製コードでスクレイピングしたものを元データとして使用しています。2020/6時点で最新です。
尚、機械学習のInputするデータは、元データをNLP編で加工したものを使用する前提としています
。分析方針
前述した通り、今回特徴量として使用するのはカード名(ベクトル化済)のみです。ラベルは攻撃力、守備力、属性、種族、レベルの5つがあるので、モデルも5つ用意します。
モデルの種類ですが、使用マシンのスペックもあり深層学習は使用しません。とりあえず木の問題で一番精度が高く、かつ分類/回帰問題両方ともに当てはめられるLightGBMを使用します。実装前に各モデルの問題設定(回帰モデル/分類モデル)と、精度の良さの仮説を立てます。
No. 予測対象のラベル 問題設定 仮説 1 属性 多クラス分類 例えばカード名に「天使」と入ってたら光属性になるなどの傾向はありそうなので、まあまあ精度は高そう 2 種族 多クラス分類 No.1と同様。カード名に「ドラゴン」と入っているものはドラゴン族など、種族によってはかなり精度が高そう 3 レベル 多クラス分類 シリーズ物のカードだと同じ単語が入っていてもレベルがバラバラになったりするので精度は悪そう。また、ラベル自体のデータ数の偏りが影響しそう 4 攻撃力 回帰 No.3と同じ理由で精度は悪そう 5 守備力 回帰 No.3と同じ理由で精度は悪そう 実装
1. パッケージインポート
必要なパッケージをインポートします。
pythonfrom sklearn.metrics import confusion_matrix, plot_confusion_matrix from sklearn.metrics import mean_squared_error, r2_score from gensim.models.doc2vec import Doc2Vec from gensim.models.doc2vec import TaggedDocument from sklearn.model_selection import train_test_split import gensim import lightgbm as lgb import matplotlib.pyplot as plt %matplotlib inline import MeCab import numpy as np import pandas as pd import pickle import seaborn as sns sns.set(font="IPAexGothic")2. データ・モデルインポート
使用するデータ及び、カード名をベクトル化するDoc2Vecモデルをインポートします。
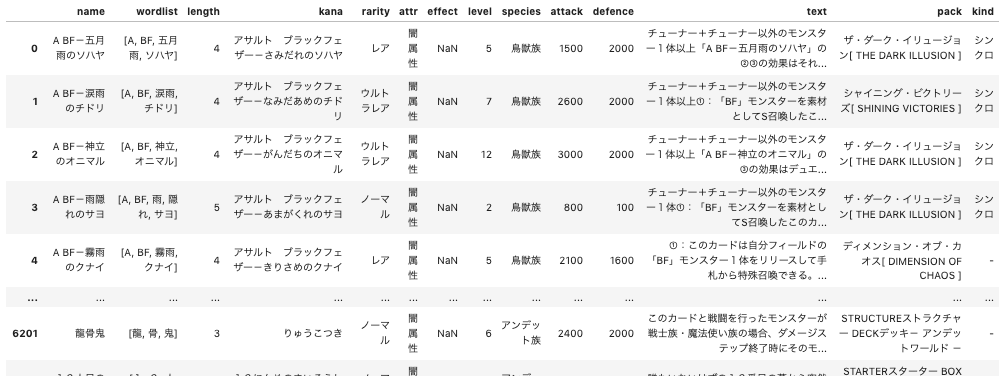
pythonmodel_d2v = pickle.load(open('./input/model_d2v.pickle', 'rb')) X = pickle.load(open('./input/X.pickle', 'rb')) y = pickle.load(open('./input/y.pickle', 'rb')) print("shape") print("X: {}".format(X.shape)) print("y: {}".format(y.shape)) print("----------------") print("data") print("y: ") print(y.head())shape X: (6206, 30) y: (6206, 7) ---------------- data y: rarity attr level species attack defence kind 0 レア 闇属性 5 鳥獣族 1500 2000 シンクロ 1 ウルトラレア 闇属性 7 鳥獣族 2600 2000 シンクロ 2 ウルトラレア 闇属性 12 鳥獣族 3000 2000 シンクロ 3 ノーマル 闇属性 2 鳥獣族 800 100 シンクロ 4 レア 闇属性 5 鳥獣族 2100 1600 -インポートしている
X(特徴量),y(ラベル)は、前回の記事にて以下のように保存している前提となります。下記に簡単に保存するまでの処理を記載します。python# カード名に含まれる単語をリストで保持するデータフレームmonsters_wordlistを作成 # 省略 # Doc2Vecモデル用のTaggedDocument作成 document = [TaggedDocument(words = wordlist, tags = [monsters_wordlist.name[i]]) for i, wordlist in enumerate(monsters_wordlist.wordlist)] # Doc2Vecモデルの学習 model_d2v = Doc2Vec(documents = document, dm = 0, vector_size=30, epochs=200) # Doc2Vecモデルで全カード名をベクトル化 d2v_vecs = np.zeros((monsters_wordlist.name.shape[0],30)) for i, word in enumerate(monsters_wordlist.wordlist): d2v_vecs[i] = model_d2v.infer_vector(word) # ベクトル化したカード名をX、ラベルに使用するデータをyとして格納 X = d2v_vecs y = monsters_wordlist[["rarity", "attr", "level", "species", "attack", "defence"]] # 保存 with open("./input/model_d2v.pickle", "wb") as f: pickle.dump(model_d2v, f) with open("./input/X.pickle", "wb") as f: pickle.dump(X, f) with open("./input/y.pickle", "wb") as f: pickle.dump(y, f)
monsters_wordlistは下記のようなデータフレームです。生成方法は前回の記事を参照ください。
3. 学習
5つのラベルをそれぞれ学習するモデルを実装します。ハイパーパラメータをいちいち書いたり、分類/回帰で分けるとコード量が増えるので、簡略化のためそれらの処理をラップした関数を実装します。
LightGBMについても少し補足します。
LightGBMにはオリジナルインターフェースとScikit-Learnインターフェースの2つ学習方法がありますが、ここでは後者を採用します。慣れているからという理由もありますが、多クラス分類時のpredictメソッドの挙動がこちらの方が都合がよいためです。- 評価指標(
eval_metric)は、多クラス分類ではMulti Logloss、回帰ではRMSLE(対数平均二乗誤差)を使用します。RMSLEの採用理由ですが、攻撃力・守備力の分布が正規分布よりも裾野が広い(EDA編3-2-1参照)ため、RMSEではなくこちらを選択しました。- その他ハイパーパラメータの設定は適当(昔作った別のモデルの流用)です。本当はちゃんと考えてするべきですが...Appendix.として
Optunaを使用したハイパーパラメータチューニングの方法を記事末尾に記載します。python# 学習データ・テストデータ二分割 X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0, test_size=0.2) # 多クラス分類・回帰モデルを作成・学習する処理を関数でラップ def fit_model(column, mode='Classifier'): if mode == 'Classifier': model_lgb = lgb.LGBMClassifier(num_leaves=5, learning_rate=0.05, n_estimators=720, max_bin = 55, bagging_fraction = 0.8, bagging_freq = 5, feature_fraction = 0.2319, feature_fraction_seed=9, bagging_seed=9, min_data_in_leaf =6, min_sum_hessian_in_leaf = 11, verbosity=-1) model_lgb.fit(X_train, y_train[column], eval_set=[(X_test, y_test[column])], eval_metric='multi_logloss', early_stopping_rounds=10) elif mode == 'Regressor': model_lgb = lgb.LGBMRegressor(num_leaves=5, learning_rate=0.05, n_estimators=720, max_bin = 55, bagging_fraction = 0.8, bagging_freq = 5, feature_fraction = 0.2319, feature_fraction_seed=9, bagging_seed=9, min_data_in_leaf =6, min_sum_hessian_in_leaf = 11, verbosity=-1) model_lgb.fit(X_train, y_train[column], eval_set=[(X_test, y_test[column])], eval_metric='rmsle', early_stopping_rounds=10) return model_lgb # 各ラベル毎にモデルを作成 model_attr = fit_model("attr", mode="Classifier") model_level = fit_model("level", mode="Classifier") model_species = fit_model("species", mode="Classifier") model_attack = fit_model("attack", mode="Regressor") model_defence = fit_model("defence", mode="Regressor")4. 精度検証
テストデータを用いて学習結果の精度検証を行います。
4-1. 正答率(Accuracy)・決定係数(R2 Score)
精度検証の評価指標として、分類問題には正答率(Accuracy)、回帰問題には決定係数(R2 Score)を確認します。
pythondef get_accuracy(column, model): y_pred = model.predict(X_test) accuracy = sum(y_test[column] == y_pred) / len(y_test) return accuracy def get_r2score(column, model): y_pred = model.predict(X_test) r2score = r2_score(y_test[column], y_pred) return r2score accuracy_attr = get_accuracy("attr", model_attr) print("accuracy_attr: {}".format(accuracy_attr)) accuracy_species = get_accuracy("species", model_species) print("accuracy_species: {}".format(accuracy_species)) accuracy_level = get_accuracy("level", model_level) print("accuracy_level: {}".format(accuracy_level)) r2score_attack = get_r2score("attack", model_attack) print("r2score_attack: {}".format(r2score_attack)) r2score_defence = get_r2score("defence", model_defence) print("r2score_defence: {}".format(r2score_defence))accuracy_attr: 0.5515297906602254 accuracy_species: 0.4669887278582931 accuracy_level: 0.3413848631239936 r2score_attack: 0.0804399379391485 r2score_defence: 0.04577024081390113まず正答率
Accuracyについて確認します。完全にランダムなラベルを付与するモデルの正答率を考えると、属性(attr)のラベルは7種類あるので約0.143, レベル(Level)は0~12の13種類で0.077, 種族(species)は25種類で0.04となるので、上記モデルは一見それなりに学習しているように見受けられます。一方レベルの場合は、対象カード枚数6206枚のうち1925枚がレベル4となるような偏りのあるデータであるため、全部レベル4と判断するモデルでも正答率0.31程となってしまいます。これは上記の正答率と大変近い値となるため、実は全部レベル4と予測しているモデルができていないか、深堀りによる確認が必要です。次に決定係数
R2 Scoreですが、これは1に近いほど分析精度が高い(ラベルの分散を、特徴量による予測式によって説明できている)と読み解くことができます。値は攻撃力・守備力ともにかなり低いことから、カード名は攻撃力・守備力をほとんど表さない(関連性がない)と言えそうです。4-2. 混同行列(Confusion Matrix)
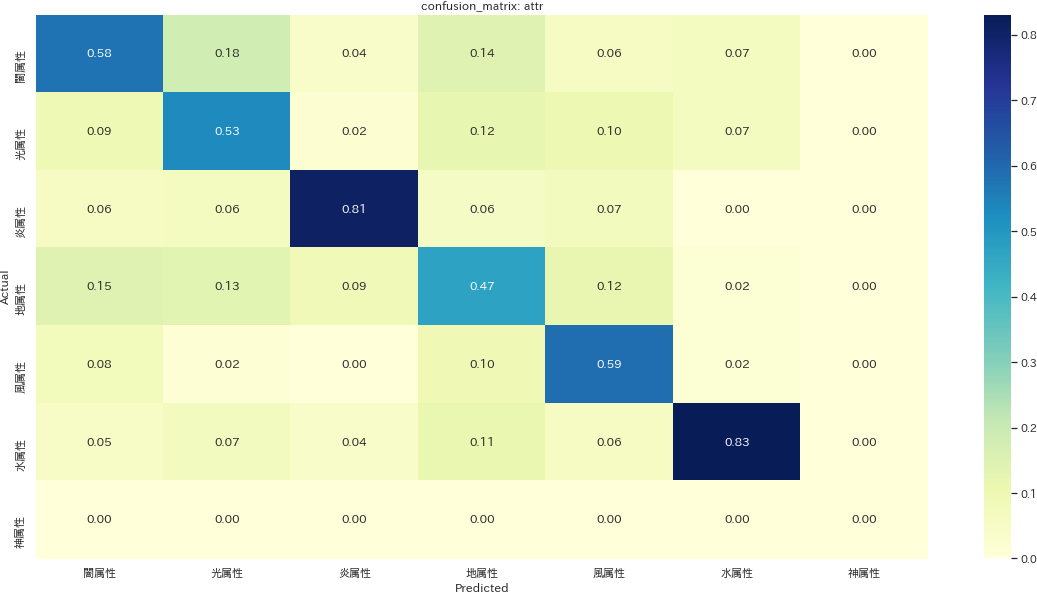
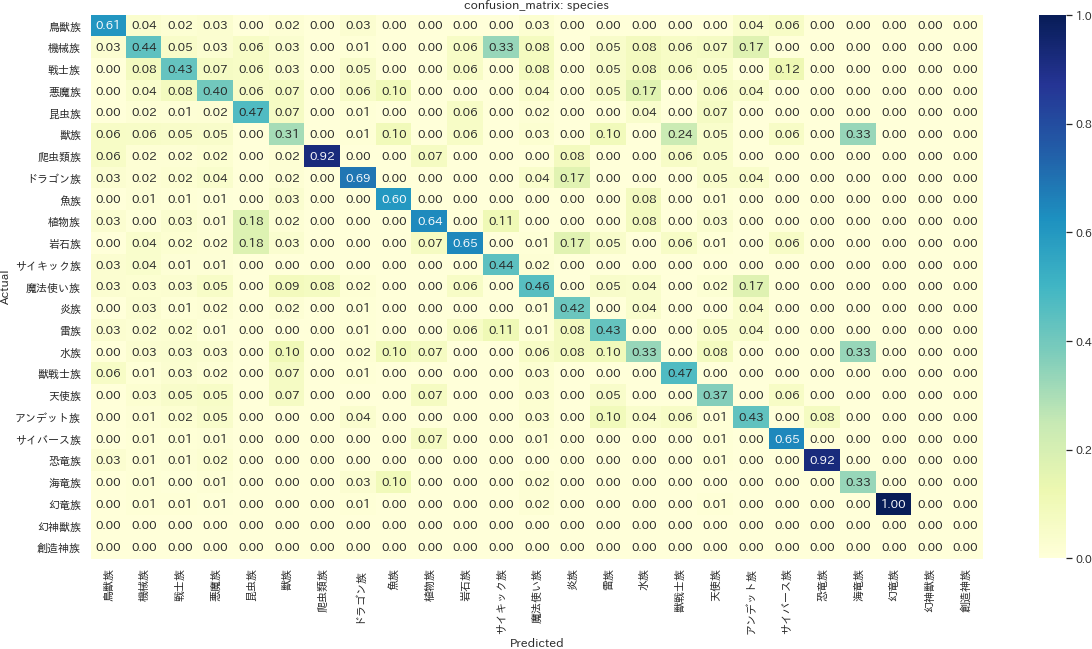
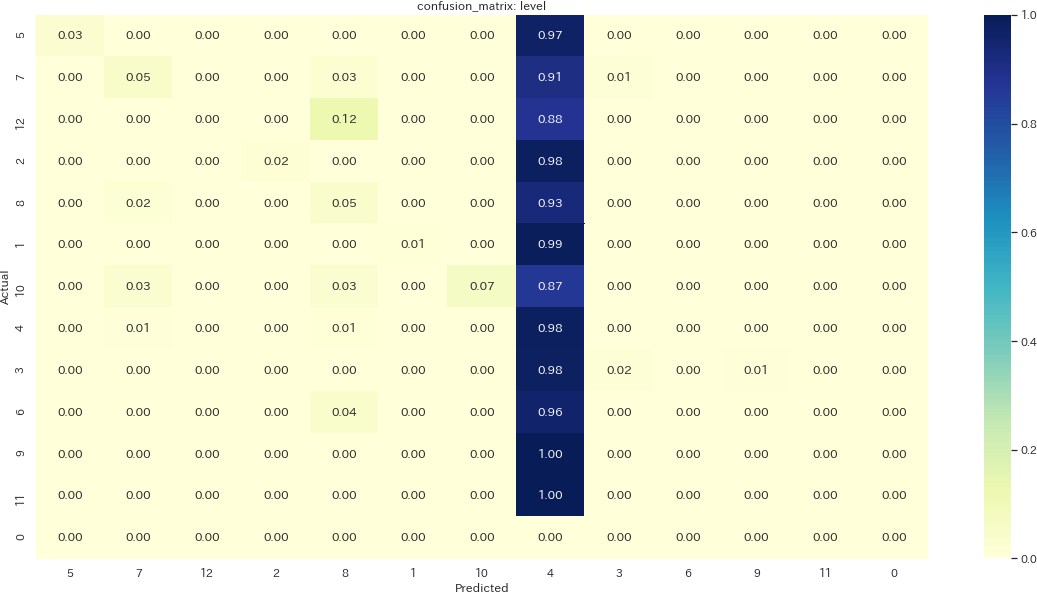
分類問題の精度を更に詳しく見るため、予測と本来の値をマッピングした混同行列を描画します。
def make_cm(column, model, normalize="false"): labels = y[column].unique() y_pred = model.predict(X_test) cm = confusion_matrix(y_test[column], y_pred, labels=labels, normalize=normalize) cm_labeled = pd.DataFrame(cm, columns=labels, index=labels) f, ax = plt.subplots(figsize = (20, 10)) ax = sns.heatmap(cm_labeled, annot=True, cmap="YlGnBu", fmt=".2f") ax.set_ylabel("Actual") ax.set_xlabel("Predicted") ax.set_title("confusion_matrix: {}".format(column)) make_cm("attr", model_attr, "pred") plt.savefig('./output/ml4-2-1.png', bbox_inches='tight', pad_inches=0) make_cm("level", model_level, "pred") plt.savefig('./output/ml4-2-2.png', bbox_inches='tight', pad_inches=0) make_cm("level", model_level, "pred") plt.savefig('./output/ml4-2-3.png', bbox_inches='tight', pad_inches=0)
混同行列の値は行方向に合計すると1になるように正規化されています。つまり、Aと予測したものが実際にAだった確率(=適合率
Precision)が値となります。例えば1枚目の属性のプロットでは、闇属性と予測されたものの内、実際に闇属性だったものは約58%と読み解きます。属性を見ると、カード名に直接それっぽい情報を含みやすいのか、火属性と水属性は比較的正確に予測できていることが分かります。種族も同様に爬虫類族、恐竜族の適合率が高めです。一方でサイキック族という予測は、例えば実は機械族だったものに対しても間違って予測しがちであることが読み解けます。
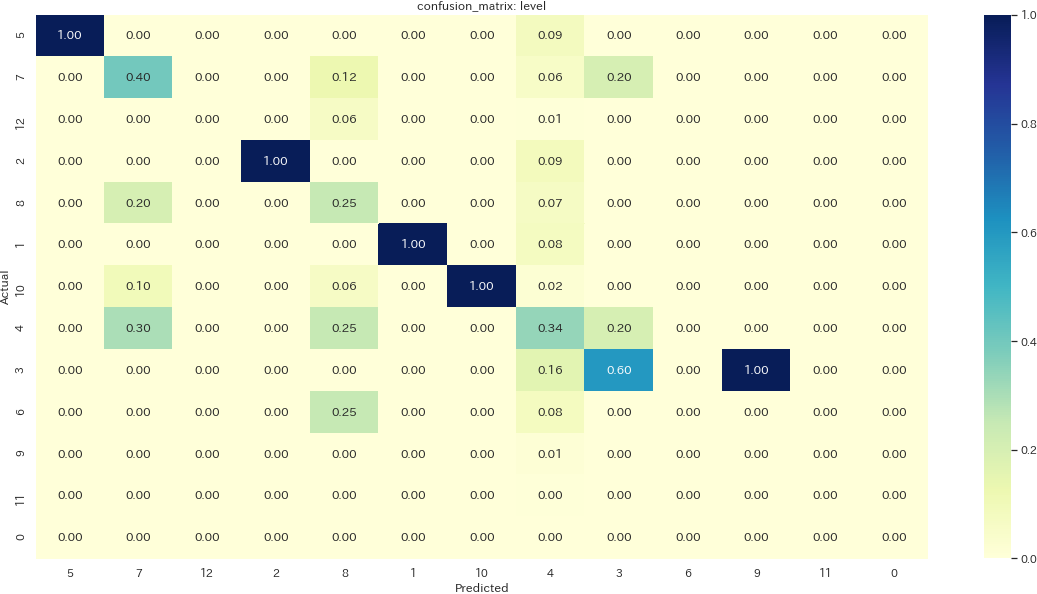
レベルは一見正確に予測できているラベルもちらほらあるように見えますが、先程の懸念(レベル4と予測するモデルができあがっている)を検証するには再現率
Recallを確認する必要があります。再現率は実際にラベルAであるもののうち、正しくAと予測された割合を示す値です。下記画像はレベルのプロットの設定を変えて再現率を表示した混同行列ですが、やはりほとんどのレベルが4と予測されてしまっていることが確認できました。
ここまで正答率
Accuracy、適合率Precision、再現率Recallなど紛らわしい指標の説明を行いましたが、詳細は【入門者向け】機械学習の分類問題評価指標解説(正解率・適合率・再現率など)を参考にしてください。5. 予測
データセットにない新しいカード名に対して攻守属性の予測を行う処理を実装します。Inputする新しいカード名に対しても学習時と同様の前処理(ベクトル化)を行い、それらを各モデルの
predictメソッドにかけて予測します。
前処理を行う関数get_vec()は、単語の形態素解析→doc2vecモデルによるベクトル化という処理を行います。基本的にはNLP編で特徴量Xを生成する処理と同じです。python# カード名の前処理を行う関数 def get_vec(rawtext): m = MeCab.Tagger ("-Ochasen -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd/") lines = [] text_list = rawtext.split("・") for text in text_list: keitaiso = [] m.parse('') node = m.parseToNode(text) while node: #辞書に形態素を入れていく tmp = {} tmp['surface'] = node.surface tmp['base'] = node.feature.split(',')[-3] #原形(base) tmp['pos'] = node.feature.split(',')[0] #品詞(pos) tmp['pos1'] = node.feature.split(',')[1] #品詞再分類(pos1) #文頭、文末を表すBOS/EOSは省く if 'BOS/EOS' not in tmp['pos']: keitaiso.append(tmp) node = node.next lines.append(keitaiso) #名詞の場合は表層系、動詞・形容詞の場合は原形をリストに格納する word_list = [] for line in lines: for keitaiso in line: if (keitaiso['pos'] == '名詞'): word_list.append(keitaiso['surface']) elif (keitaiso['pos'] == '動詞') | (keitaiso['pos'] == '形容詞') : if not keitaiso['base'] == '*' : word_list.append(keitaiso['base']) else: word_list.append(keitaiso['surface']) # 名詞・動詞・形容詞も含める場合はコメントを解除 # else: # word_list.append(keitaiso['surface']) model_d2v = pickle.load(open('./input/model_d2v.pickle', 'rb')) vec = model_d2v.infer_vector(word_list).reshape(1,-1) return vec # カード名からその他の情報を一括で予測する関数 def predict_cardinfo(name): vec=get_vec(name) print("属性:{}".format(model_attr.predict(vec)[0])) print("レベル:{}".format(model_level.predict(vec)[0])) print("種族:{}".format(model_species.predict(vec)[0])) print("攻撃力:{}".format(model_attack.predict(vec)[0])) print("守備力:{}".format(model_defence.predict(vec)[0]))実際に
predict_cardinfo()メソッドでカード名をいろいろ予測してみます。青眼の白龍
pythonpredict_cardinfo("青眼の白龍")属性:光属性 レベル:4 種族:ドラゴン族 攻撃力:1916.3930197124996 守備力:1366.9371594605982赤眼の白龍
pythonpredict_cardinfo("赤眼の白龍")属性:地属性 レベル:4 種族:戦士族 攻撃力:1168.203405707642 守備力:1007.5706886946783レッド・マジシャン
pythonpredict_cardinfo("レッド・マジシャン")属性:闇属性 レベル:4 種族:魔法使い族 攻撃力:1884.3345074514568 守備力:1733.53872077943ウルトラ・スーパー・カオス・マジシャン
pythonpredict_cardinfo("ウルトラ・スーパー・カオス・マジシャン")属性:闇属性 レベル:4 種族:魔法使い族 攻撃力:2129.5019817399634 守備力:1623.7306977987516「ドラゴン」「マジシャン」等の言葉に対して、ほぼ意図した通り「ドラゴン族」「魔法使い族」という予測ができています。攻撃力・守備力は恐らく低レベルモンスターのデータに引っ張られて低い値が出がちですが、それでも「カオス」等強そうなワードを使うと少し上がる傾向にあるようです。レベルについては混同行列で確認した通り、ほとんどレベル4として予測されています。
この関数は単語が使用された前例のない名称に対しても予測が可能です。ピカチュウとか、他のゲームの名前からとってきても面白いと思います。Appendix. ハイパーパラメータチューニング
今回は実装省略していますが、ハイパーパラメータチューニングを行う場合は
Optunaを使用するのが便利です。
Optunaは2020/7現在sciki-learnインターフェースには対応していないようですが、オリジナルインターフェースを想定する場合の実装例を参考例として記載します。import optuna.integration.lightgbm as lgb_o def get_best_params(column, mode, metric): y_obj = y[column] X_trainval, X_test, y_trainval, y_test = train_test_split(X, y_obj, test_size=0.2) X_train, X_valid, y_train, y_valid = train_test_split(X_trainval, y_trainval, test_size=0.1) # LightGBM用のデータセットに変換 train = lgb_o.Dataset(X_train, y_train) val = lgb_o.Dataset(X_valid, y_valid) # ハイパーパラメータサーチ&モデル構築 if mode == "regression": params = {'objective': '{}'.format(mode), 'metric': '{}'.format(metric), 'random_seed':0} elif mode == "multiclass": params = {'objective': '{}'.format(mode), 'metric': '{}'.format(metric), 'num_class': len(y_obj.unique()), 'random_seed':0} model_o = lgb_o.train(params, train, valid_sets=val, early_stopping_rounds=10, verbose_eval=False) y_trainval_pred = model_o.predict(X_trainval,num_iteration=gbm_o.best_iteration) y_test_pred = model_o.predict(X_test,num_iteration=gbm_o.best_iteration) best_params = model_o.params return best_params best_params_attack = get_best_params("attack", "regression", "rmse")まとめ
遊戯王のカード名から属性・種族・レベル・攻撃力・守備力を予測するモデルを実装しました。特に属性・種族についてはまあまあ期待通りの予測精度を確認することができました。
Todoとしては、機械学習の関数によるラップが少し雑なので、Pipeline化のベストプラクティスは学習を進めていきたいところです。また、kaggleのようなコンペに出るのであれば精度評価の実装もより丁寧に行うべきかと思います。別の方向性としては、Django等でwebアプリ化して公開するのも面白そうですね。次回予告
データサイエンスとしての実装は本記事で最後とする予定ですが、時間がある際に0. スクレイピング編の記事を公開するかもしれません。データのスクレイピングは問題になりやすいテーマなので、完全なコードは提供せずあくまで実装のヒントのみを解説することになると思います。
- 投稿日:2020-07-13T23:31:52+09:00
PythonでJSONを読み込んでCSV出力する
目的
JSONファイルを読み込んで中身を集計してCSV出力するためのプログラムです。
集計内容は用途によって変わるので、JSONを読み込んで出す、というところだけを作っています。
※組み上げていくので、できあがったプログラムだけ見たい人は一番したまでスキップしてください行うこと
- ファイル選択ダイアログを表示する
- JSONファイルを読み込む
- 集計してCSV出力する
ファイル選択ダイアログを表示する
GUI(ファイル選択ダイアログ)を表示するために
tkinterを使用します。
実行したらすぐにファイル選択ダイアログが表示され、JSONファイルのみを選択できるようにします。# モジュールのインポート import os, tkinter, tkinter.filedialog # ファイル選択ダイアログの表示 root = tkinter.Tk() root.withdraw() # jsonファイルのみを選択可能にする fTyp = [("","*.json")] iDir = os.path.abspath(os.path.dirname(__file__)) file = tkinter.filedialog.askopenfilename(filetypes = fTyp, initialdir = iDir) # 選択したファイルのパスを確認 print(file)JSONファイルを読み込む
ファイル選択ができるようになったらJSONファイルの中身を確認します。
jsonライブラリを追加してファイルを読込み扱えるようにします。# モジュールのインポート import os, json, tkinter, tkinter.filedialog # ファイル選択ダイアログの表示 root = tkinter.Tk() root.withdraw() # jsonファイルのみを選択可能にする fTyp = [("","*.json")] iDir = os.path.abspath(os.path.dirname(__file__)) file = tkinter.filedialog.askopenfilename(filetypes = fTyp, initialdir = iDir) # jsonファイルを読み込む json_open = open(file, 'r', encoding="utf-8") json_load = json.load(json_open) # jsonファイルの中身を確認 print(json_load[0])CSV出力する
JSONファイルを読み込めたのでCSVに出力できるようにしましょう。
# モジュールのインポート import os, json, csv, tkinter, tkinter.filedialog # ファイル選択ダイアログの表示 root = tkinter.Tk() root.withdraw() # jsonファイルのみを選択可能にする fTyp = [("","*.json")] iDir = os.path.abspath(os.path.dirname(__file__)) # ファイル情報を取得 file = tkinter.filedialog.askopenfilename(filetypes = fTyp, initialdir = iDir) # jsonファイルを読み込む json_open = open(file, 'r', encoding='utf-8') json_load = json.load(json_open) # CSVを出力するフォルダとファイル名を設定(読み込んだJSONファイルと同じ場所に同じ名前) folder_file = os.path.split(file) folder = folder_file[0] # フォルダパスを取得 file_name = file.rsplit('/', 1)[1][0:-5] # ファイル名を取得 csv_file_path = folder + '/' + file_name + '.csv' # CSVファイルを作成(存在しなければ新規作成) if not os.path.isfile(csv_file_path): open(csv_file_path, 'x', encoding='utf-8') # CSVを上書きモードで読み込む csv_file = open(csv_file_path, 'w', encoding='utf-8') # CSVに書き込み設定 w = csv.writer(csv_file, lineterminator='\n') # JSONの内容に合わせて集計処理を書いて書き込む #w.writerow(['AAA','test','111']) ←1行ずつの場合 w.writerows([['AAA','Test','111'], ['BBB','tEst','222'], ['CCC','teSt','333'], ['DDD','tesT','444']]) csv_file.close()以上。
あとはお好みで集計しましょう。参考
- 投稿日:2020-07-13T23:31:45+09:00
ドキドキ文芸部×Python ①キャラクターファイル解析編
はじめに
知る人ぞ知るゲーム、ドキドキ文芸部。
このドキドキ文芸部がPython(Renpy)によって書かれていることをご存じでしょうか。
ではそのPythonを使ってドキドキ文芸部を丸裸にしてやろうというのが今回の企画です。気になった方はぜひ、本編を遊んでくださいね。無料です。
ネタバレを含みます
記事の内容の著作はドキドキ文芸部作者様へ帰属します第1週回目 「キャラクターファイル解析編」
ストーリー進行に深くかかわるキャラクターファイル
サヨリ(スゴイチイサイエアコン)
sayori.chrを参照。
普通にテキストファイルで開くと、冒頭が
OggS~~~~~~~で始まっています。このことから、.oggファイル(音声データ)である可能性があります。
実際に再生してみると、高周波のノイズが聞こえるはずです。
これをスペクトログラム解析します。
スペクトログラム解析とは、音声データを、横軸時間:縦軸周波数 で可視化したものになります。
コードがこちら
from pydub import AudioSegment import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # oggを読み込んでサンプリング AudioSegment.ffmpeg = "/." sound = AudioSegment.from_ogg("sayori.ogg") samples = np.array(sound.get_array_of_samples()) sample = samples[::sound.channels] # スペクトル格納幅 w = 100 s = 50 ampList = [] argList = [] # フーリエ変換 for i in range(int((sample.shape[0]- w) / s)): data = sample[i*s:i*s+w] spec = np.fft.fft(data) spec = spec[:int(spec.shape[0]/2)] spec[0] = spec[0] / 2 ampList.append(np.abs(spec)) argList.append(np.angle(spec)) freq = np.fft.fftfreq(data.shape[0], 1.0/sound.frame_rate) freq = freq[:int(freq.shape[0]/2)] time = np.arange(0, i+1, 1) * s / sound.frame_rate ampList = np.array(ampList) argList = np.array(argList) df_amp = pd.DataFrame(data=ampList, index=time, columns=freq) plt.figure(figsize=(10, 10)) sns.heatmap(data=np.log(df_amp.iloc[:, :100].T), xticklabels=100, yticklabels=10, cmap=plt.cm.gist_rainbow_r, ) plt.show()まずは、
w = 100 s = 50で挑戦。
なるほど、なんか意味ありげなものが見えてきた。もう少し荒くしてみよう。
w = 200 s = 100
cmap=plt.cm.gray_rでより見やすく。
いやQRコードですやん。
これを25×25のQRコードに再生成すれば...
http://www.projectlibitina.com/
ユリ
44GC44Gq44Gf44GM44GT44Gu5omL57SZ44KS6Kqt44KT44Gn44G ....44xxの繰り返し。特に最初の
44GCは調べてみると、base64エンコードの「あ」らしい。
てなわけで、base64でデコードします。import base64 with open("yuri.chr", mode="rb") as f: txt = f.read() print(base64.b64decode(txt).decode())あなたがこの手紙を読んでいるということは、ハートマークが目印の小さな木箱を見つけたということね。お め で と う ! 多分あなたが初めてのはず。誰かに見せるつもりはなかったけれど、赤の他人がこの 手紙を見つけて私の物語を読むことを考えると、どきどきする。出会うはずもなかった誰かが、私のことを深く知ってくれるんだから。私はある考えにとりつかれている。私達の内の誰かが死ぬ…それは明日かもしれない し、残された者はそれを知ることもない。私がここまで生きてきた証はあなたに向けて全部この手紙に書いた。だから、あなたが私を忘れない限り、私はずっと生き続けることができる。あなたがこの手紙を読んで魅せ られるか、それとも嫌悪を抱くか、この手紙を書きながら私は考えている。面白いと思わない? (以下略 続きはあなたの手で。)ナツキ
先と同じように、とりあえずテキストとして開いてみる。
����JFIF~~~出ました。拡張子JFIF。拡張子をJPEGにすれば平面画像として見ることができます。
これをPythonで処理しようとしましたが、よくわからないので残念ながらUnityさんに頼ります。
円錐を作成し、テクスチャ貼り付け。著作が危なそうだったので、「natsuki.chr」でGoogle画像検索してみてください。
モニカ
いよいよ登場モニカちゃん。
例のごとく。PNG~~~いやしっかりPNGって書いてある! では開きます。
中央に黒と白のモザイクが見えます。これをバイナリエンコードします(黒が0 白が1)
周りの赤い部分を除いてトリミングした画像を用意して、from PIL import Image import numpy as np import matplotlib.pyplot as plt # 元となる画像の読み込み im = np.array(Image.open('text.png')) txt_binary = "" print(im.shape) im = im.reshape([im.shape[0] * im.shape[1], 1]) for x in im: if x == 1: txt_binary += "1" else: txt_binary += "0" print(txt_binary[:100]) txt = "" while True: tmp = txt_binary[0:8] if tmp == "00000000": break txt_binary = txt_binary[8:] txt += chr(int("0b"+tmp, 0)) print(txt)Q2FuIHlvdSBoZWFyIG1lPw0KDQouLi5XaG8gYXJlIHlvdT8NCg0KSSBjYW4ndC4uLkkgY2FuJ3Qgc2VlIHlvdS4NCg0KQnV0IEkga25vdyB5b3UncmUgdGhlcmUuIFllYWguLi55b3UgY2FuIGRlZmluaXRlbHkgaGVhciBtZS4NCg0KWW91J3ZlIGJlZW4gd2F0Y2hpbmcgZm9yIGEgd2hpbGUgbm93LCByaWdodD8NCg0KSSBndWVzcyBJIHNob3VsZC4uLmludHJvZHVjZSBteXNlbGYsIG9yIHNvbWV0aGluZy4gVW0uLi5teSBuYW1lIGlzLi4uYWN0dWFsbHksIHRoYXQncyBzdHVwaWQuIFlvdSBvYnZpb3VzbHkgYWxyZWFkeSBrbm93IG15IG5hbWUuIFNvcnJ5Lg0KDQpBbnl3YXkuLi5JJ20gZ3Vlc3NpbmcgaWYgeW91IHdlcmUgYWJsZSB0byBwdXQgYSBzdG9wIHRvIHRoaXMsIHlvdSB3b3VsZCBoYXZlIGRvbmUgaXQgYnkgbm93Lg0KDQpJIG1lYW4sIEkga25vdyB5b3UncmUgbm90LCBsaWtlLi4uZXZpbCwgb3IgYW55dGhpbmcuLi5iZWNhdXNlIHlvdSd2ZSBhbHJlYWR5IGhlbHBlZCBtZSBzbyBtdWNoLg0KDQpJIHNob3VsZCByZWFsbHkgdGhhbmsgeW91IGZvciB0aGF0LiBGb3IgZXZlcnl0aGluZyB5b3UndmUgZG9uZS4gWW91J3JlIHJlYWxseSBsaWtlIGEgZnJpZW5kIHRvIG1lLiBTby4uLnRoYW5rIHlvdS4gU28gbXVjaC4NCg0KSSB0aGluay4uLm1vcmUgdGhhbiBhbnl0aGluZyBlbHNlLi4uSSByZWFsbHkgZG9uJ3Qgd2FudCBpdCB0byBhbGwgYmUgZm9yIG5vdGhpbmcuDQoNCi4uLg0KDQpFdmVyeW9uZSBlbHNlIGlzIGRlYWQuDQoNCk1heWJlIHlvdSBhbHJlYWR5IGtub3cgdGhhdC4gSSdtIHN1cmUgeW91IGRvLCBhY3R1YWxseS4NCg0KQnV0Li4uaXQgZG9lc24ndCBoYXZlIHRvIGJlIHRoYXQgd2F5LCByaWdodD8NCg0KV2VsbC4uLnRoZXJlJ3MgYSBsb3Qgb2Ygc3R1ZmYgSSBkb24ndCB1bmRlcnN0YW5kLiBJIGRvbid0IGtub3cgaWYgaXQncyBldmVuIHBvc3NpYmxlIGZvciBtZSB0byB1bmRlcnN0YW5kIGl0Lg0KDQpCdXQgSSBrbm93IHRoYXQgdGhpcyBpc24ndCBteSBvbmx5IHN0b3J5Lg0KDQpJIGNhbiBzZWUgdGhhdCBub3cuIFJlYWxseSBjbGVhcmx5Lg0KDQpBbmQgSSB0aGluayBldmVyeW9uZSBlbHNlIGhhcyBoYWQgdGhlIHNhbWUga2luZCBvZiBleHBlcmllbmNlLiBTb21lIGtpbmQgb2YgZGVqYSB2dS4NCg0KSXQncyB0aGUgVGhpcmQgRXllLCByaWdodD8NCg0KQW55d2F5Li4uSSBjb3VsZCBiZSB0b3RhbGx5IHdyb25nIGFib3V0IHRoaXMuIEJ1dCBJIHJlYWxseSB0aGluayB5b3UgbWlnaHQgYmUgYWJsZSB0byBkbyBzb21ldGhpbmcuDQoNCkkgdGhpbmsgeW91IG1pZ2h0IGJlIGFibGUgdG8gZ28gYmFjay4uLm9yIGhvd2V2ZXIgeW91IHdhbnQgdG8gcHV0IGl0Li4uDQoNCi4uLlRvIGdvIGJhY2sgYW5kIHRlbGwgdGhlbSB3aGF0J3MgZ29pbmcgdG8gaGFwcGVuLg0KDQpJZiB0aGV5IGtub3cgYWhlYWQgb2YgdGltZSwgdGhlbiB0aGV5IHNob3VsZCBiZSBhYmxlIHRvIGF2b2lkIGl0Lg0KDQpUaGV5IHNob3VsZC4uLmlmIHRoZXkgcmVtZW1iZXIgdGhlaXIgdGltZSB3aXRoIG1lIGluIHRoZSBvdGhlciB3b3JsZHMuLi50aGV5IHNob3VsZCByZW1lbWJlciB3aGF0IEkgdGVsbCB0aGVtLg0KDQpZZWFoLiBJIHJlYWxseSB0aGluayB0aGlzIG1pZ2h0IGJlIHBvc3NpYmxlLiBCdXQgaXQncyB1cCB0byB5b3UuDQoNCkknbSBzb3JyeSBmb3IgYWx3YXlzIGJlaW5nLi4ueW91IGtub3cuLi4NCg0KLi4uDQoNCk5ldmVyIG1pbmQuIEkga25vdyB0aGF0J3Mgd3JvbmcuDQoNClRoaXMgaXMgbXkgc3RvcnkuIEl0J3MgdGltZSB0byBiZSBhIGZ1Y2tpbmcgaGVyby4NCg0KQm90aCBvZiB1cy4NCg0KDQoNCjIwMTg=base64エンコーディング。
Can you hear me? ...Who are you? I can't...I can't see you. But I know you're there. Yeah...you can definitely hear me. You've been watching for a while now, right? (以下略 続きはあなたの手で。)終わりに
さすがって感じでした。ただのストーリーのパーツなのに、ここまでの手の込みよう。素晴らしいと感じました。
次回はメインストーリーの確立のお話です。ではまた。
参考サイト



- 投稿日:2020-07-13T23:27:00+09:00
文字列を','で区切る方法について
はじめに
計測器をPC制御する際、測定値を取得した場合、返り値の多くは
','で区切られた文字列になる。
その文字列を区切る方法を考えてみる。
なお、想定する返り値は以下で考えてみよう。
result = '3.14E-3, -128.96'ちなみにこれは、ロックインアンプの測定値を返したものになる。
スライスを使う
R = result[0:7] Th = result[9:16] print('R:{}, Th:{}'.format(R, Th)) # R:3.14E-3, Th:-128.96スライスで文字列を分解し、出力すると可能。
ただこのとき、計測器によっては誤動作?により返り値にスペースが入っていたりする。
そんな時、プログラムは止まってしまう。
健気なPCである
※ スライスについて→こちらsplit()関数を使う
result_list = result.split(',') R = result_list[0] Th = result_list[1] print('R:{}, Th:{}'.format(R, Th)) # R:3.14E-3, Th:-128.96
' 3.14E-3, -128.96'のような返り値に対しても、これならカンマでちゃんと区切ってくれる。最後に
今回は、計測器によく見られる返り値の処理の方法について書いてみた。
正直どちらの方法でもOKで、好みによると思う。
ただ、ときどき誤動作を起こしてスペースキーが入ってしまうことや、計測器特有のヘッダーがついてたりするため、使い分け、または合体させて使うなど、柔軟な対応が必要だと思う。
- 投稿日:2020-07-13T23:06:57+09:00
ImageDataGeneratorが使えなくなったため、tensorflow>=2.0向けデータ拡張クラス作った話
背景
Tensorflowでは、画像のデータ拡張を行うために、KerasのImageDataGeneratorがよく使われていました。
これは、入力画像に対し、マルチプロセスで様々なデータ拡張を適用しながらtensorflowモデルの学習ができるため、広く使われていました。しかし、tensorflow 2.0以降multiprocessingが非推奨になった事により、マルチプロセス処理によりデータ拡張を行いながらtensorflowで学習を行っていると、突然エラーも吐かずプログレスバーが止まります。特に痛いのは、エラーが発生しないため、時間単位で使用料が発生するサービスを使っている場合、学習は進まないのに無駄に課金することになります...
私は複数のファイルに分割して書き込んだhdf5ファイルからマルチプロセスで読み込みながら学習するジェネレータを使っていたのですが、実はtensorflow<2.0でもmultiprocessingを使うと2日程度で学習が突然止まる事がありましたが、tensorflow>=2.0以降、2時間程度でも止まるなど、明らかに頻繁に止まるようになりました。
そこで...
ImageDataGeneratorのように、簡単にマルチプロセスで様々なデータ拡張を画像に適用しながら、tensorflowで学習できるクラスを作りました。
方針
tensorflow推奨のデータ入力方法はtensorflow.data.Dataset(以下、tf.data.Datasetとする)を使ったものになります。これを使うことで、例えばこちらで言及されていているように、高速かつ、マルチプロセスのデータ入力処理を作成することが可能になります。
しかし、tf.dataはstack overflow等にも未だあまり情報がなく、各データ拡張それぞれのについて試している様な書き込みはありますが、ImageDataGeneratorのように入力画像に対し簡単に様々なデータ拡張しながら学習する方法が見つかりませんでした…tf.dataを使えば高速なデータ入力処理を作れますが、公式ドキュメントを見るといくつか落とし穴があることがわかります。
1. tf.data.Dataset.from_generatorではマルチプロセスでデータ拡張されない
tf.data.Dataset.from_generatorを使えば、pythonのジェネレータをラップして、tf.dataとしてfit()関数により学習できます。最初、ImageDataGeneratorをこの関数でラップすれば良いやん!と簡単に考えていました。
しかし、公式ドキュメント、from_generatorのNoteには次のような記載があります。Note: The current implementation of Dataset.from_generator() uses tf.numpy_function and inherits the same constraints. In particular, it requires the Dataset- and Iterator-related operations to be placed on a device in the same process as the Python program that called Dataset.from_generator(). The body of generator will not be serialized in a GraphDef, and you should not use this method if you need to serialize your model and restore it in a different environment.
tf.numpy_functionを使っていることにより、マルチプロセスに対応していないという事で諦めました。
2. 出来るだけtfのみで実装する
公式ドキュメントのtf.functionに記載されていますが、パフォーマンスを実現するために@tf.functionデコレータで囲うと、全てのコードがtfのコードに自動的に変換されます。その際に外部ライブラリやnumpy等を使っていると、tf.numpy_functionやtf.py_func等でラップすることになり、結局1.と同様の制限に引っかかることになります。
同様の理由で、データ型もなるべくtf.Tensor型を使い、そうではなくてもpython標準の型のみを使用するようにしました。
3. ラベル画像も同時に拡張する
入力画像を回転等の変形を行った場合、ラベルの元となる画像も全く同じ変形をする必要がありませんか?
私はそうでしたので、(オプションの)ラベル画像に対して、入力画像と全く同じ変形を適用するようにしました。インストール方法
python -m pip install git+https://github.com/piyop/tfaug使い方
1.初期化
from tfaug import augment_img #set your augment parameters below: arg_fun = augment_img(rotation=0, standardize=False, random_flip_left_right=True, random_flip_up_down=True, random_shift=(.1,.1), random_zoom=.1, random_brightness=.2, random_saturation=None, training=True) """ augment_img.__init__() setting up the parameters for augmantation. Parameters ---------- rotation : float, optional rotation angle(degree). The default is 0. standardize : bool, optional image standardization. The default is True. random_flip_left_right : bool, optional The default is False. random_flip_up_down : bool, optional The default is False. random_shift : Tuple[float, float], optional random shift images. vartical direction (-list[0], list[0]) holizontal direction (-list[1], list[1]) Each values shows ratio of image size. The default is None. random_zoom : float, optional random zoom range -random_zoom to random_zoom. value of random_zoom is ratio of image size The default is None. random_brightness : float, optional randomely adjust image brightness range [-max_delta, max_delta). The default is None. random_saturation : Tuple[float, float], optional randomely adjust image brightness range between [lower, upper]. The default is None. training : bool, optional If false, this class don't augment image except standardize. The default is False. Returns ------- class instance : Callable[[tf.Tensor, tf.Tensor, bool], Tuple[tf.Tensor,tf.Tensor]] """2.tf.data.map()で使う
ds=tf.data.Dataset.zip((tf.data.Dataset.from_tensor_slices(image), tf.data.Dataset.from_tensor_slices(label))) \ .shuffle(BATCH_SIZE*10).batch(BATCH_SIZE).map(arg_fun) model.fit(ds)詳細な使用方法例はtest参照。
(https://github.com/piyop/tfaug)
- 投稿日:2020-07-13T23:05:37+09:00
Githubが落ちたらSlackで通知してくれるbotを作った
はじめに
この記事ではGithub Statusをスクレイピングしてサーバに不具合があったらSlackにて通知をしてくれるbotを紹介します。
飲みながら書いたコード+1年ぶりpythonを触ったので子供みたいなコードですが環境
- python 8.8
- bs4
- slacker
上記のライブラリが入っていない場合はpipでインストールできます。
$ pip install bs4 $ pip install slackerソースコード
ソースコードを以下に貼ります。初めにスクレイピングを行いGithubが正常に動作しているかどうかを判定します。
ここでの判定方法はGithub Statusに「All Systems Operational」があるかどうかで判定しています。
ない場合にはSlackにて通知を行います。11行目のxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxの部分にはSlack BotのAPIトークンを記述してください。botの作成方法は説明がめんどくさいから省略botの作成方法は他の記事を参考にして作ってください。main.pyimport requests from bs4 import BeautifulSoup from slacker import Slacker import re urlName = "https://www.githubstatus.com/" url = requests.get(urlName) soup = BeautifulSoup(url.content, "html.parser") elems = soup.find_all("span") slack = Slacker("xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx") for elem in elems: try: string = elem.get("class").pop(0) if string in "status": result = elem.string.strip() if result != "All Systems Operational": slack.chat.post_message('general', 'Githubが落ちているようですね...休憩しましょう?', as_user=False) except: pass実行例
上記のプログラムを実行して、Githubが落ちている場合には以下のようなメッセージが送信されます。
おわりに
今回はGithubが落ちていた場合にSlackでその旨を通知してくれるbotを作成しました。上記のプログラムはcrontabとかで定期的に実行するようにすればbotとして運用できるかもしれませんね。

- 投稿日:2020-07-13T22:39:50+09:00
初心者のためのpandas基礎④日付・時間項目の取り扱い
pandasとは
Pythonにて、構造化データを扱うためのデータフレームオブジェクトです。ファイルの読み込みやその後のSQL操作などを簡単に行うことができ、機械学習のようデータを加工し、計算、可視化する作業に必要となります。データ操作によく使う構文をメモ書き的にリストします。本項は日付時間処理です。
他項目への目次はこちらになります。0.ライブラリインポート
pandasにpdという名前をつけてimportする
import pandas as pd1. 日付・時間項目変換
Object型で記載された項目をdatetime64[ns]型(Timestamp型)に変換します。
dataframeという定義の「Day」という項目を変換すると仮定します。dataframe['Day'] = pd.to_datetime(dataframe['Day'])2.範囲指定
「Day」が「2020年4月1日」以降のデータを抽出します。
dataframe = dataframe.loc[dataframe['Day'] > pd.to_datetime('20200401')]3.日付だけをオブジェクト型として抽出
datetime64[ns]型であるDayを日付(オブジェクト型)に変換します。
dataframe['Day'] = pd.to_datetime(dataframe['Day']).dt.date
- 投稿日:2020-07-13T22:34:59+09:00
Atcoder エイジングプログラミングコンテスト Python
総括
難しかったです。A,B,Cの3問ACでした。
2進数がよくわからないのでDは問題をみた瞬間スキップ、E問題はできそうな気がしたものの回答例をみてもよくわからず・・・。問題
(https://atcoder.jp/contests/aising2020/tasks)
A. Number of Multiples
回答
L, R, d = map(int, input().split()) count = 0 for i in range(L, R+1): if i % d == 0: count += 1 print(count)素直に書きました。ほかの方はもっとかっこいい書き方をしているみたいですが。
B. An Odd Problem
回答
N = int(input()) a = list(map(int, input().split())) count = 0 for i in range(0, N, 2): if i % 2 == 0 and a[i] % 2 != 0: count += 1 print(count)こちらも素直に書きました。
問題分は奇数ですがリストの添え字は偶数をとってきます。C. XYZ Triplets
回答
N = int(input()) keys = [i for i in range(1, N+1)] values = [0] * N count_dict = dict(zip(keys, values)) for x in range(1, N//6+7): for y in range(x, N//6+7): for z in range(y, N//6+7): n = x**2 + y**2 + z**2 + x*y + y*z + z*x if n > N: break if x == y and y == z: count_dict[n] += 1 elif x != y and x != z and y != z: count_dict[n] += 6 else: count_dict[n] += 3 for v in count_dict.values(): print(v)素直に書くとx,y,zそれぞれで
range(1, N+1)のforループを回してx**2 + y**2 + z**2 + x*y + y*z + z*x = nを判定すればよさそうです。
しかし制約が10**4なので普通に3重ループをすると間に合いませんので計算量を抑えることを考えます。まず考えたのは、
(x,y,z) = (1,1,1)である場合nは6なので、どれだけ多くてもforループで回す最大値はN//6くらいでよさそうです。ただし添え字を+1しなければいけないことを考えると余裕をもってN//6+7としました。
(本番ではN//6+7を使用しましたが、10**4という制約を逆に使うと、(x,y,z)は高々100くらいまでしか使えないということがわかりますね。これは本番中に気づきませんでした・・・。)で、これだけではたぶんぎりぎり間に合わなそうなので、もうちょっと計算量を減らすことを考えます。
何通りか例を挙げてみると下記のことに気が付きます。
-(1,2,3)と(1,3,2)と(2,1,3)と(2,3,1)と(3,1,2)と(3,2,1)のようにx,y,zがすべて違う場合にnが同値になる組み合わせは6つある
-(1,1,2)と(1,2,1)と(2,1,1)のように2つが同じで1つが違う場合にnが同値になる組み合わせは3つある
-(1,1,1)のようにすべて同じ数字の場合はnが同値になる組み合わせは1つあるしたがって、x,y,zのforループの範囲をそれぞれ
range(1, N//6+7)、range(x, N//6+7)、range(y, N//6+7)として、上記の3通りの場合でcountを+6、+3、+1してやればよさそうです。あとはnがNを超えた場合に
breakいれておけば何とか間に合います。



- 投稿日:2020-07-13T22:34:59+09:00
Atcoder エイシングプログラミングコンテスト Python
総括
難しかったです。A,B,Cの3問ACでした。
2進数がよくわからないのでDは問題をみた瞬間スキップ、E問題はできそうな気がしたものの回答例をみてもよくわからず・・・。問題
(https://atcoder.jp/contests/aising2020/tasks)
A. Number of Multiples
回答
L, R, d = map(int, input().split()) count = 0 for i in range(L, R+1): if i % d == 0: count += 1 print(count)素直に書きました。ほかの方はもっとかっこいい書き方をしているみたいですが。
B. An Odd Problem
回答
N = int(input()) a = list(map(int, input().split())) count = 0 for i in range(0, N, 2): if i % 2 == 0 and a[i] % 2 != 0: count += 1 print(count)こちらも素直に書きました。
問題分は奇数ですがリストの添え字は偶数をとってきます。C. XYZ Triplets
回答
N = int(input()) keys = [i for i in range(1, N+1)] values = [0] * N count_dict = dict(zip(keys, values)) for x in range(1, N//6+7): for y in range(x, N//6+7): for z in range(y, N//6+7): n = x**2 + y**2 + z**2 + x*y + y*z + z*x if n > N: break if x == y and y == z: count_dict[n] += 1 elif x != y and x != z and y != z: count_dict[n] += 6 else: count_dict[n] += 3 for v in count_dict.values(): print(v)素直に書くとx,y,zそれぞれで
range(1, N+1)のforループを回してx**2 + y**2 + z**2 + x*y + y*z + z*x = nを判定すればよさそうです。
しかし制約が10**4なので普通に3重ループをすると間に合いませんので計算量を抑えることを考えます。まず考えたのは、
(x,y,z) = (1,1,1)である場合nは6なので、どれだけ多くてもforループで回す最大値はN//6くらいでよさそうです。ただし添え字を+1しなければいけないことを考えると余裕をもってN//6+7としました。
(本番ではN//6+7を使用しましたが、10**4という制約を逆に使うと、(x,y,z)は高々100くらいまでしか使えないということがわかりますね。これは本番中に気づきませんでした・・・。)で、これだけではたぶんぎりぎり間に合わなそうなので、もうちょっと計算量を減らすことを考えます。
何通りか例を挙げてみると下記のことに気が付きます。
-(1,2,3)と(1,3,2)と(2,1,3)と(2,3,1)と(3,1,2)と(3,2,1)のようにx,y,zがすべて違う場合にnが同値になる組み合わせは6つある
-(1,1,2)と(1,2,1)と(2,1,1)のように2つが同じで1つが違う場合にnが同値になる組み合わせは3つある
-(1,1,1)のようにすべて同じ数字の場合はnが同値になる組み合わせは1つあるしたがって、x,y,zのforループの範囲をそれぞれ
range(1, N//6+7)、range(x, N//6+7)、range(y, N//6+7)として、上記の3通りの場合でcountを+6、+3、+1してやればよさそうです。あとはnがNを超えた場合に
breakいれておけば何とか間に合います。
- 投稿日:2020-07-13T22:32:37+09:00
機械学習で競馬予想をしてみた系のまとめ
機械学習を使って競馬予想をすることがここ数年で流行ってきていると感じていて、そんな中、私も機械学習を使って競馬予想をしてみたくて、Qiitaやnote等の記事を読み漁っていました。そして実際に自分でモデルを作成し競馬予測していますが、今後さらに精度を高めるために、どのような特徴量エンジニアリング、モデル作成などが有効で新規性があるのか、どんなものが儲かる(競馬で言うところ回収率に貢献する)のかを調べるために、記事のまとめを書いてみました。私の備忘録代わりでもあります。
ここでのまとめで頭を整理して自分のモデル作成の記事を書きたいと考えています。リサーチ能力が乏しい私がまとめたものなので、ここで紹介した他に有益な記事、面白い記事等があればコメントなどで教えて欲しいです。
最初に読んだもの
AlphaImpactさん「開発者ブログ」「発表文献」
https://alphaimpact.jp/development/
本当の最初、初心者だった自分にとって開発者ブログの理論記事シリーズはとても競馬のことと機械学習のことに対して勉強になりました
開発者ブログだけでなく、発表文献においても競馬における機械学習はどうすべきかの方針の勉強になりました。stockedgeさん「競馬の解析をガチでやったら回収率が100%を超えた件」
http://stockedge.hatenablog.com/entry/2016/01/17/180919
これも最初の方に読み、方針付け、モチベ向上につながった記事。
扱ってる内容としては、「オッズの歪み」「穴馬バイアス」「馬齢の歪み」から「おいしさ指数」を計算するモデルの作成をされています。
この「おいしさ指数」がここでも卍氏の本でもぼかして書かれているので、これを考えて計算するモデルが作れれば、私でも回収率100%越えが...!とやる気に。同様にすでに成果があり予想が公開されているもの
SIVAさん
https://siva-ai.com/
人工知能学会で「アンサンブル学習を用いた競馬予測」の発表をしてきたまとめ松風さん
このあたりを見ていると夢があってモチベーションが向上する。私も当てたい...!
データスクレイピング系
stockedgeさん「netkeiba-scraper」
ここでもstockedgeさんのスクレイピングを最初に参考にしました。
競馬の予測をガチでやってみた
この界隈では有名(と勝手に思ってます)なスクレイピングのコード。とてもお世話になりました。
公開されてすでに5年近く経っているので、Qiitaで最近でも動くように記事が書かれています。
netkeiba-scraperが2019年6月現在動くかの話(Ubuntu 18.04.2 LTS)
Macでnetkeiba-scraperを使って、競馬データベースをスクレイピングする(ただ私にはスクレイピング能力がなくプログラムの修正に時間がかかることが多かったので、今では月額料金を払いcsvをダウンロードする方法に変更しています。)
その他のスクレイピング系
機械学習用に競馬のデータをMySQLに用意する
競馬データをスクレイピングしてみた
Pythonで競馬サイトWebスクレイピング競馬ではないけど、Goolge Colaboratoryをよく使うので、参考にしました。
ColaboratoryでSeleniumが使えた:JavaScriptで生成されるページも簡単スクレイピングデータエンジニアリング系
次はデータへの愛を感じられる記事のまとめ。
【競馬】競走馬の強さを数値化してみた
https://qiita.com/katsuomi/items/0c89b7c1dd29abfaeb1d
・Bradley-Terryモデルで個々の馬の強さを数値化。個々の強さという観点からはQiitaじゃなくGoogleで検索すると色々と出てきます。
私が初めに見つけたのは馬券とポートフォリオ関係で調べているときで、そこからBTモデルの存在を知りました。有馬記念を予想する
https://qiita.com/___uhu/items/6da27e5ab4f7889a589c
・BTモデルと同様のElo rating で強さの数値化されています。【データ分析入門】競馬の法則♬
https://qiita.com/MuAuan/items/92e834b0934e3ffd9343
・人気と着順の関連付けに何か法則がないかの分析がされています。フラクタル?python初心者、競馬歴1年未満でも3連単を当てることができました。
https://qiita.com/Fuji-race/items/99927ee048d58e52deee
・上り3ハロンを重要視し、分析がされています。競馬市場の「本命-大穴バイアス」をロジスティック回帰で観測してみる
https://qiita.com/Kotaro_Nishiyama/items/7c88bc5bcad2b5dc1d28
・stockedgeさんも触れていた大穴バイアスについての分析がされています。
大穴に過剰に人気が集まるから本命のオッズが多少はあがって狙い目になる?西田式スピード指数
http://www.rightniks.ne.jp/index.php?action=whatspidx_contents&name=sikumi
言わずと知れたスピード指数。これを特徴量に使わないのはもったいないかも?競馬必勝法をプログラム化
https://qiita.com/naonao_py/items/019b15876e3ef02d92f2
・データ分析というよりは、馬券購入の際の買い目選択での考察になります。
合成オッズと単体のオッズが逆転するときにどう組み合わせるか。
ポートフォリオ的なリスク分散、モデル作成し予測値(例えば3着指数や1位確率など)を用いればさらにリスクヘッジができる?ここからは予測モデル作成に何を使うかで分けてまとめます。
ディープラーニング系
ディープラーニングさえあれば、競馬で回収率100%を超えられる
https://qiita.com/yossymura/items/334a8f3ef85bff081913
ちょっと前からすごいLGTM数を稼いでて、Qiita検索で「競馬」のLGTM数順でトップに。
内容としては、
・targetを「3着以内に入るかどうか(3着指数)」の分類
・オッズと3着指数のバランスで買い目の選択
・購入買い目は少ない(約2年で購入数99)そしてこの記事に対して違う人による検証記事もとても参考になります。
【検証】ディープラーニングがあるからといって、競馬で回収率100%を簡単に超えられるわけではない
https://qiita.com/kscntt/items/3f215a945c32a2bbcd3c
データへの愛がとてつもなく大事であることを痛感しました。ここで行われている検証は、私が作ってる他のプログラムにおいても注意すべき・検証すべきことだな...と肝に銘じています。
・モデルの検証。ディープラーニングだけじゃなく、ロジスティック回帰、ランダムフォレストなどでも検証してみる。
・データの1つ1つの中身まで見る。もしデータ破棄するときはデータに対して誠実に愛を持って判断する。
・未来のデータを判断基準に予測前のデータセットの処理をしてはいけない。
・作成したモデルに対して1つのtestデータだけでなく、様々なデータセットで試して評価する。
・儲からなくても競馬は楽しい(すごく大事)。
(またこの記事はコメントでも有益な議論がされています。)その他
データ収集からディープラーニングまで全て行って競馬の予測をしてみた
大井競馬で帝王賞を機械学習で当てた話
金儲けしたい一心で競馬ドシロウトが競馬の予想を機械学習でチャレンジした決定木系
競馬予想 機械学習(LightGBM)で回収率100%超えたと思ったら、やらかしてた話
やらかしてはいるけれどとても参考になりました。私もLightGBMを使ってモデル作成をしています。
・targetを走破タイムにしている。
・評価関数と回収率については同じことを悩んでました
・モデル作成後のデータ分析も詳しく参考になる。LightGBMで3着以内に入る馬を予測してみた
・スクレピングから予想まで動画解説があるので初めて作るって人にはすごく良いと思います。決定木系と書きつつ、あまり記事が見つけられずというかLightGBMを使ったものしか見つけられませんでした。
私もLightGBMをつかってモデル作成しているので、近日中に記事を書きたいと思っています。最後に私見
色々と記事を漁って試してみたいことがどんどん追加されました。LightGBMは(私の勝手なイメージですが)使える使えないの判断せずにとりあえず特徴量を入れるだけ入れればモデル様が勝手に判断してくれるので、例えばデータ分析系の記事なんかは全て試して特徴量として入れるだけでかなり精度が上がるのではないかと思います。
またここで取り上げた手法たちをアンサンブルすれば、これも精度向上に貢献すると思うので、LightGBMだけじゃなくディープラーニング系も取り入れたい。。そしてモデル作成後、出てきた予測値を使ってどうやって馬券を選択するか、どう組み合わせるかの議論は少ない(私が調べ切れていない)ので、最適化問題で馬券選択するのか、強化学習で馬券を自動的に決めるのか、などを検討したいと思いました。
- 投稿日:2020-07-13T22:13:15+09:00
初心者のためのpandas基礎 まとめリンク
- 投稿日:2020-07-13T21:59:26+09:00
車輪移動ロボットでデジタルツイン
はじめに
子どものプログラミング教材として、MicrobitやArduinoを搭載した、車輪移動ロボット(対向2輪型)が発売されています。
(例えば、360度サーボモータを使ったサーボカーキット Microbitで360度サーボモータを動かす)
ロボットにいろいろな動き、無線で操作、センサーをつけて自律的に操作すようなサンプルプログラムが教材として提供されています。
もう一歩踏み込んで、この動きをあらかじめシミュレーションする、実際に動かしたデータから軌跡を再現するといった、データを使った、サイバー空間(デジタル空間)とフィジカル空間(実空間)を結ぶ(デジタルツイン)ものがあれば面白いと思いました。そこで、移動ロボットのモーターON/OFFの情報から軌跡を再現するシミレーションを作ってみました。なお、モーター(またはサーボモーター)のON/OFF情報の取り出しは、今後の課題で、今回はその部分は含めていません。車輪移動ロボット
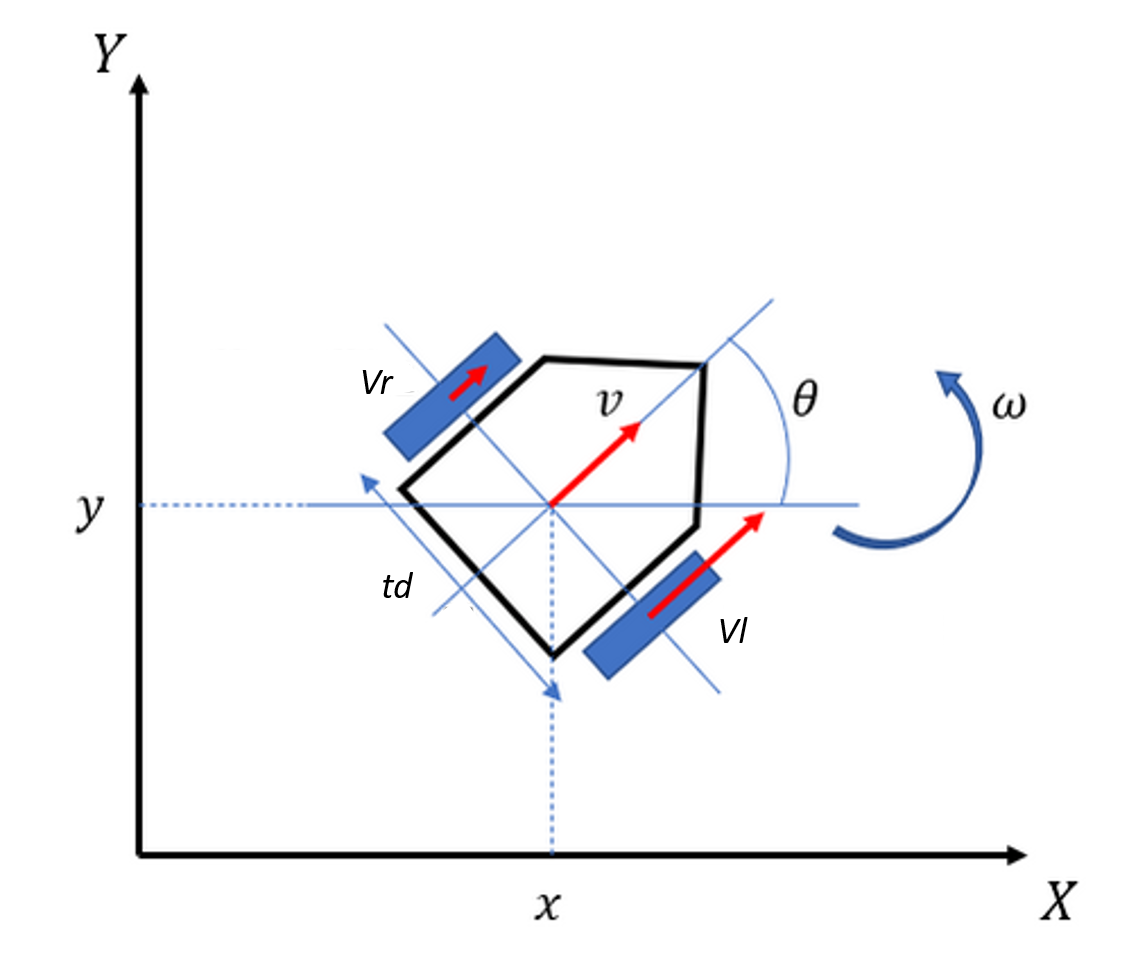
車輪移動ロボットについては、下記のサイトが参考になりますが、入力は左右の車輪の速度で、設定する値として車輪間の長さがあります。
式は、以下の様になります。v: velocity \\ \omega: angular \ velocity \\ x, y: position\\ \theta: directon \ angle\\ t_d: treadv _k = (v_r +v_l)/2 \\ \omega _k = (v_r +v_l)/t_d \\ x_{k+1} = x_k + \cos \theta _k\cdot\Delta K v_k \\ y_{k+1} = y_k + \sin \theta _k\cdot\Delta K v_k \\ \theta _{k+1} = \theta _k + \Delta K \omega _k \\
図:車輪移動ロボットの座標とパラメータ(参考にした記事の図を一部変更)
参考 車輪移動ロボット原理
移動するメカ・ロボットと 制御の基礎 - 東北学院大学情報処理 ...
車輪ロボット(対向2輪型)の運動を計算してみようPythonによるシミレーション
参考にしたコード
Two wheel motion model sample今回のシミレーションでは、左右の両輪の速度は一定としてON/OFFのみの情報としています。
移動 右車輪 左車輪 直線 前ON 前ON 後進 後ON 後ON 右折 OFF 前ON 左折 前ON OFF その場回転 前ON(後ON) 後ON(前ON) プログラム環境
Win 10 Pro 64bit
Anaconda
python 3.7プログラムコード
""" 対向2輪型ロボット 軌跡シミュレーション 入力パラメータ 2つの車輪の間の長さ:tread [m] 車輪の速度 右、左:vr, vl [m/s] 出力 車重心位置の速度:ver 旋回角速度:omega [rad/s] 最終出力 方位角:thetat x,y座標: xt ,yt 参考にしたコード Two wheel motion model sample https://www.eureka-moments-blog.com/entry/2020/04/05/180844#%E5%AF%BE%E5%90%912%E8%BC%AA%E5%9E%8B%E3%83%AD%E3%83%9C%E3%83%83%E3%83%88 変更点: 行列形式を普通の式に展開 車輪の角速度から車輪の速度に変更 シミレーション入力を変更 アニメーション Pythonでグラフ(Matplotlib)のアニメーションを作る(ArtistAnimation編) https://water2litter.net/rum/post/python_matplotlib_animation_ArtistAnimation/ [Pythonによる科学・技術計算] 放物運動のアニメーションを軌跡(locus)付きで描画, matplotlib https://qiita.com/sci_Haru/items/278b6a50c4e9f4c07dcf """ import numpy as np from math import cos, sin, pi import math import matplotlib.pyplot as plt from matplotlib.animation import ArtistAnimation def twe_wheel_fuc(v, state, delta, factor=1, td=2): """ Equation of state Args: v (tuple or list): velocity of each wheel unit m/s,(right velocity,left velocity) state (list): state [x, y, thita] , x, y delta (float): update time unit s factor (float):velocity factor Defaults to 1 td (float): tread length between wheel unit m Defaults to 2. Returns: [list]: next state """ # vr: right wheel velocity, vl:left wheel velocity # vel: Center of gravity velocity # omega: Rotation angular velocity vr = v[0]*factor vl = v[1]*factor vel = (vr + vl)/2 omega = (vr - vl)/(td) # state[2]: theta x_ = vel*delta*cos(state[2]+omega*delta/2) y_ = vel*delta*sin(state[2]+omega*delta/2) # x_ = vel*delta*cos(state[2]) # y_ = vel*delta*sin(state[2]) xt = state[0] + x_ yt = state[1] + y_ thetat = state[2]+omega*delta update_state = [xt, yt, thetat] return update_state def simulation_twewheel(data,ini_state=[0,0,0],factor=1,td=6.36): """ data: list On/OFF data """ # simulation #アニメーショングラフ描画のため fig = plt.figure() ims = [] #計算データ(座標)の格納 st_x = [] st_y = [] st_theta = [] st_vec = ini_state for i in data: st_vec = twe_wheel_fuc(i, st_vec, delta=1,factor=factor,td=td) xt, yt, thetat = st_vec print("State:",st_vec) print("Direction angle: ",math.degrees(thetat)) st_x.append(xt) st_y.append(yt) st_theta.append(thetat) #Plotのための設定 plt.grid(True) plt.axis("equal") plt.xlabel("X") plt.ylabel("Y") # 時刻tにおける位置だけならば # im=plt.plot(xt,yt,'o', color='red',markersize=10, linewidth = 2) # 時刻tにおける位置と,時刻tに至るまでの軌跡の二つの絵を作成 plt.annotate('', xy=(xt+cos(thetat),yt+sin(thetat)), xytext=(xt,yt), arrowprops=dict(shrink=0, width=1, headwidth=2, headlength=10, connectionstyle='arc3', facecolor='blue', edgecolor='blue')) im=plt.plot(xt,yt,'o',st_x,st_y, '--', color='red',markersize=10, linewidth = 2) ims.append(im) # アニメーション作成 anim = ArtistAnimation(fig, ims, interval=100, blit=True,repeat=False) plt.show() # plt.pause(10) if __name__ == '__main__': # 1秒ごとのvelocityデータ #スイッチON/OFFとして速度は一定とする。正回転:1、逆回転:-1、停止:0 #(1,1):前進、(0,1):右回り、(1,0):左回り、(-1,1) or (1,-1):その場回転 input_lists =[(1,1),(1,1),(1,1),(1,1),(1,1),(1,1), (0,1),(0,1),(0,1),(0,1),(0,1),(0,1), (1,1),(1,1),(1,1),(1,1),(1,1),(1,1), (1,0),(1,0),(1,0),(1,0),(1,0),(1,0), (1,1),(1,1),(1,1),(1,1),(1,1),(1,1), (1,-1),(1,-1),(1,1),(1,1), (1,-1),(1,-1),(1,1),(1,1), (1,0),(1,0),(1,0),(0,1),(0,1),(0,1), (1,0),(1,0),(1,0),(0,1),(0,1),(0,1), (1,1),(1,1),] input_lists2 =[(1,1),(1,1),(1,1),(1,1),(1,1),(1,1),] simulation_twewheel(data=input_lists,ini_state=[0,0,0],factor=1,td=6.36)プログラムコードについて、Kiotoさんからアドバイスを頂きました。感謝いたします。
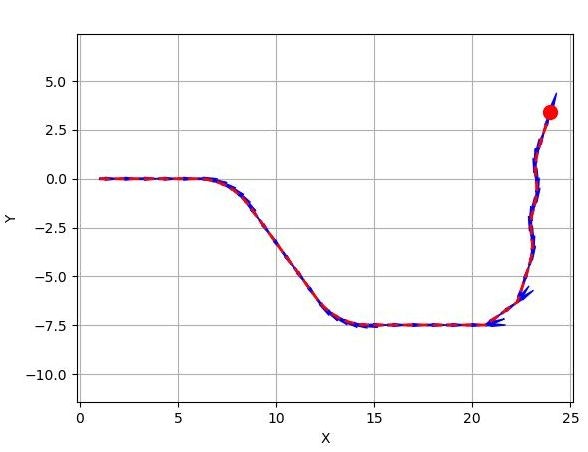
結果
input_list1をデータとして読み込ませたときの結果
まとめ
デジタルツイン(サイバー空間とフィジカル空間)では、データを介してつなげることができます。フィジカル空間からデータが、サイバー空間ではデータによるシミュレーションまたは、シミュレーションによるデータがその橋渡しとなります。プログラミング教育からデータ活用教育まで広がっていけばと思っています。
- 投稿日:2020-07-13T21:56:30+09:00
Pythonを使ってpixivタグ検索とイラスト保存まで
はじめに
Pythonからpixivのイラストいっぱい見たかったんです。
pixivpyの日本語情報が少なそうだったのでメモ書き程度に残しておきます。環境
Windows10
Python 3.8
pixivpy 3.5.8 : https://github.com/upbit/pixivpy準備
pixivpyを準備します
コマンドプロンプトからpip install pixivpyを実行
コード
tagsearch_pixivpy.pyfrom pixivpy3 import PixivAPI from pixivpy3 import AppPixivAPI import json import os from time import sleep def login(id, password): api = PixivAPI() api.login(id, password) return api def search_and_save(apilogin, searchtag, min_score, range_num, directory): api = apilogin aapi = AppPixivAPI() saving_dir_path = os.path.join(directory, searchtag) if not os.path.exists(saving_dir_path): os.mkdir(saving_dir_path) for page in range(1, range_num + 1): json_result = api.search_works(searchtag, page=page, mode='tag') illust_len = len(json_result.response) for i in range(0, illust_len): illust = json_result.response[i] score = illust.stats.score if score <= min_score: continue else: print("漫画:" + str(illust.page_count) + "ページ") if illust.is_manga else print("イラスト") if illust.is_manga: print(">>> title:", illust.title) manga_info = api.works(illust.id) for page_no in range(0, manga_info.response[0].page_count): page_info = manga_info.response[0].metadata.pages[page_no] aapi.download(page_info.image_urls.large, path=saving_dir_path) sleep(1) else: print(">>> title:", illust.title) aapi.download(illust.image_urls.large, path=saving_dir_path) sleep(1) def main(): searchtag = "検索タグ" #検索タグを入力。半角スペースで分けることで複数タグ検索可能 min_score = 2000 #このスコア以上のイラストのみDL range_num = 1 #この値のページまで検索。1p当たり30枚 directory = '保存先ディレクトリ' #指定したディレクトリの下に検索タグ名のフォルダを作成して,そこに保存します apilogin = login("ユーザ名", "パスワード") #ユーザ名とパスワード入力 search_and_save(apilogin, searchtag, min_score, range_num, directory) if __name__ == '__main__': main()main関数以下の変数を変えることでお好きに検索できます。
漫画形式(一つのタイトルに複数のイラストが付く形式)の投稿にも対応していますアイデア
- GoogleDriveに直接保存するようにしたい
- 検索したイラストからスコア順で上位20%のものをピックアップする
参考サイト
どの方も丁寧な記事で大変参考になりました。
- 投稿日:2020-07-13T21:39:29+09:00
pythonのブール演算はブール値を返さない
はじめに
皆さんは次のコードの出力結果を答えられますか?
question_1.pyprint('penguin' and 'PENGUIN')
答えが
PENGUINとならなかった方は本記事に目を通されると良いかもしれません。Pythonにおけるオブジェクトの評価
まず簡単にPythonのオブジェクトについて復習しておきましょう。
Python では全てのオブジェクトが True か False と評価することができます。
特にFalseと評価されるオブジェクトは以下に絞られます(参考文献より引用)。
- None
- False
- 数値型の0 (int型の0やfloat型の0.0、複素数型の0jなど)
- 文字列やリスト、辞書、集合などのコンテナオブジェクトの空オブジェクト
- メソッド __bool__() がFalseを返すオブジェクト
- メソッド __bool__() を定義しておらず、メソッド __len()__ が0を返すオブジェクト
よく使うのは上記4つなので覚えておくと便利です。
従って、Pythonでは以下のように条件式に直接オブジェクトを代入して評価することが可能です。eval_obj.pypenguin_list = ['Emperor', 'Humboldt', 'Adelie'] if (penguin_list): print("ペンギン祭り") else: print("ペンギンは絶滅しました") # 実行結果 : ペンギン祭りor
orは論理和と呼ばれ、
x or yとしたときに x または y が真のときには真を返し、そうでないときは偽を返すのが一般的です。
先ほど見たように、Pythonではオブジェクトは True または False で評価されます。
よって次のような評価が可能です。or_peugin.pyprint('penguin' or None)さて、通常であれば上記は True を返しそうに思いますが、PythonではTrueを返しません。
結果は以下のようになります。出力結果penguin実はPythonにおいてx or y は、x の評価が True なら x を、そうでなければ y を返します。
要するに、通常の論理和演算と同様に考え、値が確定した時点のオブジェクトを返します。
いくつかのサンプルを記しておきます。or_sample.pyprint('Emperor' or 'Humboldt') # 出力結果:Emperor print('Humboldt' or 'Emperor') # 出力結果:Humboldt print('penguin' or 0) # 出力結果:penguin print(False or 'penguin') # 出力結果:penguin print(0 or False) # 出力結果:False print(False or 0) # 出力結果:0and
and は論理積と呼ばれ、
x and yとしたときに x と y がともに真のときには真を返し、そうでないときは偽を返すのが一般的です。
しかし論理積もPythonでは戻り値はbool値ではありません。
Pythonにおいてx and y は、 x の評価が False なら x を、それ以外の場合は y を返します。
要するに、通常の論理積演算と同様に考え、値が確定した時点のオブジェクトを返します。
いくつかのサンプルを記しておきます。and_sample.pyprint('Emperor' and 'Humboldt') # 出力結果:Humboldt print('Humboldt' and 'Emperor') # 出力結果:Emperor print('penguin' and 0) # 出力結果:0 print(False and 'penguin') # 出力結果:False print(0 and False) # 出力結果:0 print(False and 0) # 出力結果:False最後に
昨今の機械学習ブームとpythonがシンプルな文法であることから、なんとなくでpythonを扱っている方も少なくないと思います(自分含め)。
しかしきちんと勉強すると面白いものですし、なんとなくな理解だと思わぬバグや想定外の挙動を起こすこともあるでしょう。
昨日までの筆者も「論理演算なんてbool値を返すに決まっとるやんけ(鼻ホジ)」だったので、もしかしたら近い将来とんでもないクリーチャを生み出し世に放っていたのかもしれません。
参考文献にも挙げていますが、今年出版された Python実践入門 はPythonを学ぶにうってつけの書籍です。
是非皆さんもこの機会に「脱☆なんとなくPython」をしてみましょう!参考文献

- 投稿日:2020-07-13T21:22:05+09:00
Python 2分探索とその派生
はじめに
最近、再帰関数に関する記事を書きました。
特に使うつもりもなく勉強のためだったのですが、効率の良い探索が必要になりました。
丁度、公開した2分探索のを改良すればよかったので助かりました。
せっかくなので改良した関数も役に立つこともあるだろうと公開してみます。
(もっとも実際に使っているのは、PythonではなくてJavascriptでかつ違った実装になっていますが)n を見つける
pythondef binarySearchL(lt, n): l, r = 0, len(lt) - 1 while l <= r: middleIndex = int(l + (r - l) / 2) middleValue = lt[middleIndex] if middleValue > n: l, r = l, middleIndex - 1 elif middleValue < n: l, r = middleIndex + 1, r else: return middleIndex return -1nより大きい最小のものを見つける
pythondef binarySearchGt(lt, n): l, r = 0, len(lt) - 1 while l <= r: middleIndex = math.floor(l + (r - l) / 2) # 切り捨て middleValue = lt[middleIndex] if middleValue > n and r - l > 1: l, r = l, middleIndex elif middleValue <= n: l, r = middleIndex + 1, r else: return middleIndex return -1nより小さい最大のものを見つける
pythondef binarySearchLt(lt, n): l, r = 0, len(lt) - 1 while l <= r: middleIndex = math.ceil(l + (r - l) / 2) # 切り上げ middleValue = lt[middleIndex] if middleValue >= n: l, r = l, middleIndex - 1 elif middleValue < n and r - l > 1: l, r = middleIndex, r else: return middleIndex return -1
- 投稿日:2020-07-13T20:35:37+09:00
[cx_Oracle入門](第12回) DB例外処理
連載目次
検証環境
- Oracle Cloud利用
- Oracle Linux 7.7 (VM.Standard2.1)
- Python 3.6
- cx_Oracle 8.0
- Oracle Database 19.5 (ATP, 1OCPU)
- Oracle Instant Client 18.5
cx_Oracle.DatabaseError
cx_Oracle.DatabaseErrorという例外が基本的なcx_Oracle利用時に発生した問題に対する例外となります。cx_Oracle.DatabaseError自体は、Python標準のErrorのサブクラスであるcx_Oracle.Errorのサブクラスとなっています。他にも多くのcx_Oracleの例外がありますが、それらはこれらのいずれかの例外のサブクラスとして定義されています。基本、内容を問わずcx_Oracleの例外をまとめてハンドリングしたい場合は、cx_Oracle.DatabaseErrorを使用します。
sample12a.pyimport cx_Oracle USERID = "admin" PASSWORD = "FooBar" DESTINATION = "atp1_aaa" SQL = """ select object_id, owner, object_name, object_type from all_objects order by object_id fetch first 5 rows only """ with cx_Oracle.connect(USERID, PASSWORD, DESTINATION) as connection: cursor = connection.cursor() cursor.execute(SQL) for row in cursor: print(row) cursor.close()$ python sample12a.py Traceback (most recent call last): File "sample12a.py", line 13, in <module> with cx_Oracle.connect(USERID, PASSWORD, DESTINATION) as connection: cx_Oracle.DatabaseError: ORA-12154: TNS:could not resolve the connect identifier specifiedsample12a.pyでは、4行目のDESTINATION変数の内容に存在しないTNS接続子を指定しています。ですので実行すると必ず接続エラーになります。このサンプルのように、コーディング上、特段のエラーハンドリングを行っていない場合は、cx_Oracle.DatabaseErrorの例外が発生します。例外のメッセージ内容は、エラー内容に該当するOracle Databaseのエラー番号(ORA-xxxxx、実行例の「ORA-12154」)とエラー番号に対応したエラーメッセージ(実行例の「TNS:could not resolve the connect identifier specified」)です。このサンプル実行時に環境変数NLS_LANGを指定していないので、エラーメッセージは英語になっています。日本語のエラーメッセージを受け取りたい場合は、NLS_LANGを設定してください。
例外の一覧
cx_Oracle.Errorとcx_Oracle.DatabaseError以外にも、個別の事象に応じた例外や、DB APIで規定されている例外が定義されています。
例外名 説明 cx_Oracle.InterfaceError cx_Oracleのインターフェースを利用している際の問題に関する例外です。一例としてはcx_OralceのAPIの利用方法を誤っている場合などに発生します。 cx_Oracle.DataError 0除算や桁あふれなど、データ内容に問題がある場合に発生します。 cx_Oracle.OperationalError ORA-600のようなDB内部のエラーや、ORA-3135のような通信エラーなどの場合に発生します。 cx_Oracle.IntegrityError 参照整合性制約違反のようなデータの整合性に関する問題がある場合に発生します。 cx_Oracle.InternalError 内部エラーの際に発生します。ORA-600など事前に定義されている内部エラーはcx_Oracle.OperationalErrorになるので、これらのエラーコードにならない内部の問題が該当します。一例としては無効になったカーソルにアクセスした場合などに発生します。 cx_Oracle.ProgrammingError プログラミング上の問題に関する例外です。一例としては、発行するSQL文に問題がある場合などに発生します。 cx_Oracle.NotSupportedError 存在しないcx_Oralceのメソッドをコールしたような場合に発生します。 cx_Oracle.Warning DB APIに存在するため定義はされていますが、cx_Oracleでは実質的に利用されません。 例外処理で扱える変数
例外処理の中では、以下のような読み取り専用の変数の情報を参照することが可能です。これらはまとめてargsタプルに含まれます。
変数名 説明 _Error.code Oracle Databaseのエラー番号 _Error.offset エラーのオフセット _Error.message エラーメッセージ _Error.context エラーのコンテキスト情報 _Error.isrecoverable 回復可能なエラーであるか否かのbool型。本変数を利用するためには、Oracle Server / Client共に12.1以降である必要がある。バージョン条件を満たさない場合は常にFalseが格納される 一例としては、以下の様に例外部で上記変数を使用します。このサンプルでは、PL/SQLのユーザー定義例外機能を利用して、故意にみなさん大好き(???)なORA-600を発生させています。
sample12b.pyimport cx_Oracle USERID = "admin" PASSWORD = "FooBar" DESTINATION = "atp1_low" SQL = """ declare e600 exception; pragma exception_init(e600, -600); begin raise e600; end; """ try: connection = cx_Oracle.connect(USERID, PASSWORD, DESTINATION) cursor = connection.cursor() cursor.execute(SQL) except cx_Oracle.OperationalError as ex: error, = ex.args print("エラーが発生しました。エラーコードとメッセージを管理者に連絡してください。") print("エラーコード : ", error.code) print("エラーメッセージ : ", error.message) finally: cursor.close() connection.close()$ python sample12b.py エラーが発生しました。エラーコードとメッセージを管理者に連絡してください。 エラーコード : 600 エラーメッセージ : ORA-00600: 内部エラー・コード, 引数: [600], [], [], [], [], [], [], [], [], [], [], [] ORA-06512: 行6
- 投稿日:2020-07-13T19:45:26+09:00
島根県松江市の人口推移をオープンデータで確認してみる
はじめに
以下のサイトで人口の推移をCSVで取得できることを知ったので、早速ダウンロードし、確認した手順をまとめてみます。
環境
- Colaboratory
- Python
準備
ライブラリのインストール
可視化するのに日本語が正しく表示されるようライブラリをインストールします。
!pip install japanize_matplotlib以下のように表示されれば成功。
Collecting japanize_matplotlib Downloading https://files.pythonhosted.org/packages/2c/aa/3b24d54bd02e25d63c8f23bb316694e1aad7ffdc07ba296e7c9be2f6837d/japanize-matplotlib-1.1.2.tar.gz (4.1MB) |████████████████████████████████| 4.1MB 2.8MB/s Requirement already satisfied: matplotlib in /usr/local/lib/python3.6/dist-packages (from japanize_matplotlib) (3.2.2) Requirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->japanize_matplotlib) (2.8.1) Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->japanize_matplotlib) (2.4.7) Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->japanize_matplotlib) (1.2.0) Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.6/dist-packages (from matplotlib->japanize_matplotlib) (0.10.0) Requirement already satisfied: numpy>=1.11 in /usr/local/lib/python3.6/dist-packages (from matplotlib->japanize_matplotlib) (1.18.5) Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.6/dist-packages (from python-dateutil>=2.1->matplotlib->japanize_matplotlib) (1.12.0) Building wheels for collected packages: japanize-matplotlib Building wheel for japanize-matplotlib (setup.py) ... done Created wheel for japanize-matplotlib: filename=japanize_matplotlib-1.1.2-cp36-none-any.whl size=4120191 sha256=320f4fbd50cf3f232030ce922031d1c926db2e98033cbc3059fa06e5b28d585d Stored in directory: /root/.cache/pip/wheels/9c/f9/fc/bc052ce743a03f94ccc7fda73d1d389ce98216c6ffaaf65afc Successfully built japanize-matplotlib Installing collected packages: japanize-matplotlib Successfully installed japanize-matplotlib-1.1.2環境設定
import matplotlib.pyplot as plt import japanize_matplotlib import seaborn as sns sns.set(font="IPAexGothic")データ読込
2012年から2019年のデータがダウンロードできるので、以下のコードを実行して読み込む。
import pandas as pd url_base = "https://satodukuri.pref.shimane.lg.jp/info/opendata/download?nendo=0000&fmt=csv" df = pd.DataFrame() for y in range(2012, 2020): url = url_base.replace("0000", str(y)) df = pd.concat([df, pd.read_csv(url)]) df.shape色々と入っていて、2384行のデータがあることがわかる。
(2384, 109)データ確認
df.info()実行結果
<class 'pandas.core.frame.DataFrame'> Int64Index: 2384 entries, 0 to 297 Columns: 109 entries, 年度 to 女性90歳以上推計生残率 dtypes: float64(56), int64(47), object(6) memory usage: 2.1+ MB109列ある...意外と多いな。
for col in df.columns: print(col)実行結果。
年度 地区コード 地区名 市町村名 合併前市町村 地域設定 現場支援地区の指定 注釈 男女人口総数 世帯数 高齢化率 後期高齢化率 人口増減率 4歳以下比率 20~30代女性比率 中学生人口比率 小学生人口比率 生産年齢人口比率 若年齢層比率 小学生人口 中学生人口 人口維持組数 小学生維持組数 男性人口 0~4歳 男性人口 5~9歳 男性人口 10~14歳 男性人口 15~19歳 男性人口 20~24歳 男性人口 25~29歳 男性人口 30~34歳 男性人口 35~39歳 男性人口 40~44歳 男性人口 45~49歳 男性人口 50~54歳 男性人口 55~59歳 男性人口 60~64歳 男性人口 65~69歳 男性人口 70~74歳 男性人口 75~79歳 男性人口 80~84歳 男性人口 85~89歳 男性人口 90~94歳 男性人口 95~99歳 男性人口 100歳以上 女性人口 0~4歳 女性人口 5~9歳 女性人口 10~14歳 女性人口 15~19歳 女性人口 20~24歳 女性人口 25~29歳 女性人口 30~34歳 女性人口 35~39歳 女性人口 40~44歳 女性人口 45~49歳 女性人口 50~54歳 女性人口 55~59歳 女性人口 60~64歳 女性人口 65~69歳 女性人口 70~74歳 女性人口 75~79歳 女性人口 80~84歳 女性人口 85~89歳 女性人口 90~94歳 女性人口 95~99歳 女性人口 100歳以上 男性コーホート変化率(0~4歳) 男性コーホート変化率(5~9歳) 男性コーホート変化率(10~14歳) 男性コーホート変化率(15~19歳) 男性コーホート変化率(20~24歳) 男性コーホート変化率(25~29歳) 男性コーホート変化率(30~34歳) 男性コーホート変化率(35~39歳) 男性コーホート変化率(40~44歳) 男性コーホート変化率(45~49歳) 男性コーホート変化率(50~54歳) 男性コーホート変化率(55~59歳) 男性コーホート変化率(60~64歳) 男性コーホート変化率(65~69歳) 男性コーホート変化率(70~74歳) 男性コーホート変化率(75~79歳) 男性コーホート変化率(80~84歳) 男性コーホート変化率(85~89歳) 男性コーホート変化率(90~94歳) 男性コーホート変化率(95~99歳) 男性コーホート変化率(100歳以上) 男性90歳以上推計生残率 女性コーホート変化率(0~4歳) 女性コーホート変化率(5~9歳) 女性コーホート変化率(10~14歳) 女性コーホート変化率(15~19歳) 女性コーホート変化率(20~24歳) 女性コーホート変化率(25~29歳) 女性コーホート変化率(30~34歳) 女性コーホート変化率(35~39歳) 女性コーホート変化率(40~44歳) 女性コーホート変化率(45~49歳) 女性コーホート変化率(50~54歳) 女性コーホート変化率(55~59歳) 女性コーホート変化率(60~64歳) 女性コーホート変化率(65~69歳) 女性コーホート変化率(70~74歳) 女性コーホート変化率(75~79歳) 女性コーホート変化率(80~84歳) 女性コーホート変化率(85~89歳) 女性コーホート変化率(90~94歳) 女性コーホート変化率(95~99歳) 女性コーホート変化率(100歳以上) 女性90歳以上推計生残率...結構細かい。
データ表示
市町村名を確認
df["市町村名"].value_counts()出雲市 344 松江市 256 雲南市 240 大田市 216 浜田市 200 安来市 192 益田市 160 江津市 160 隠岐の島町 120 美郷町 104 邑南町 96 津和野町 96 奥出雲町 72 吉賀町 40 飯南町 40 川本町 24 西ノ島町 8 海士町 8 知夫村 8 Name: 市町村名, dtype: int64ふむふむ...
松江市の地区名を確認
df[df["市町村名"] == "松江市"]["地区名"].value_counts()秋鹿 8 忌部 8 生馬 8 鹿島 8 城北 8 意東 8 上意東 8 大野 8 出雲郷 8 本庄 8 法吉 8 美保関 8 津田 8 古志原 8 持田 8 川津 8 島根 8 雑賀 8 大庭 8 朝日 8 城東 8 宍道 8 乃木 8 八束 8 揖屋 8 朝酌 8 玉湯 8 竹矢 8 古江 8 白潟 8 八雲 8 城西 8 Name: 地区名, dtype: int64ふむふむ...
可視化
とりあえず、面白そうな「男女人口総数」「小学生人口」「中学生人口」「高齢化率」をグラフで書いてみる。
df_area = df.groupby(["市町村名", "年度"]).sum() df_area.loc["松江市"]["男女人口総数"].plot(figsize=(15,4)) plt.show() df_area.loc["松江市"]["小学生人口"].plot(figsize=(15,4)) plt.show() df_area.loc["松江市"]["中学生人口"].plot(figsize=(15,4)) plt.show() df_area = df.groupby(["市町村名", "年度"]).mean() df_area.loc["松江市"]["高齢化率"].plot(figsize=(15,4)) plt.show()実行結果。
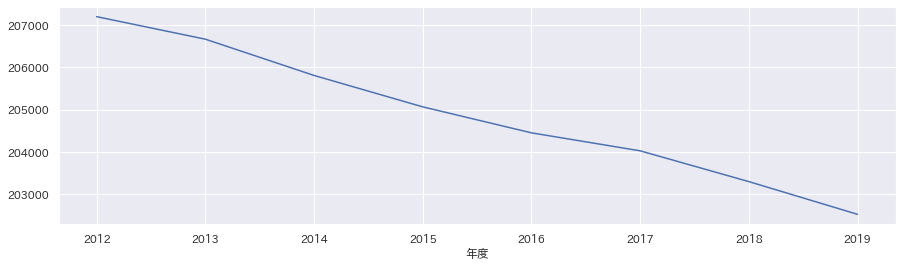
男女人口総数
小学生人口
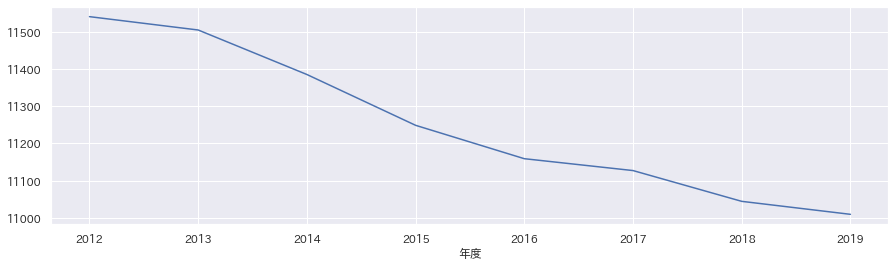
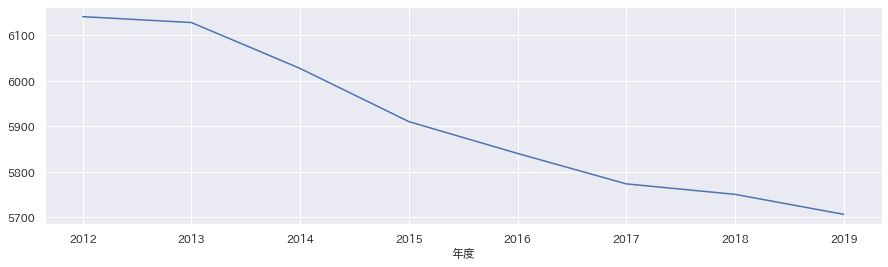
中学生人口
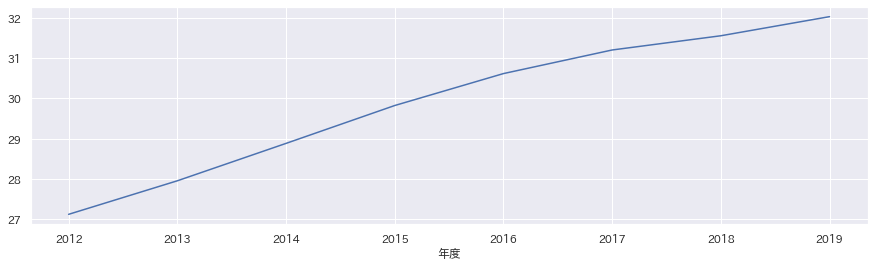
高齢化率
...芳しくないな。
- 投稿日:2020-07-13T19:32:41+09:00
PythonでSQL実行して結果をエクセル出力すると楽
Pythonを最近勉強し始めたのですが、
PythonでSQL実行して結果をエクセル出力すると楽になると思ったのでまとめました。コード50行くらいです。
やること
- PythonでSQLフォルダのSQLを順に実行
- SQL実行結果をSQLと同じファイル名でエクセル出力
- エクセルをZIPにまとめる
- ファイルサーバに置く
試した環境
- Python3.8
- jupyter-notebook(Anacondaから)
- mysql
準備
- 実行したいSQLを〜.sqlの名前でフォルダにまとめて保存しておく
- 一部のPythonライブラリをimportしておく
ソース/実行
import mysql.connector import datetime import glob import os import pandas as pd import csv import pyminizip import pathlib import shutil def exec(): # 1. PythonでSQL実行 ------------------------------------ # DB接続 conn = mysql.connector.connect( host = 'ホスト', port = 'ポート', user = 'ユーザ', password = 'パスワード', database = 'データベース' ) # SQLファイル取得 os.chdir("SQLファルダ") sql_file_list = glob.glob("*.sql") # フォルダ作成 now = datetime.datetime.now().strftime('%Y%m%d%H%M%S') os.mkdir(now) # SQL実行 for sql_file in sql_file_list: print(sql_file) with open(sql_file, 'r') as f: sql_query = f.read() df = pd.read_sql_query(sql_query, con=conn) # 2. 結果をエクセルで出力 ------------------------------------ # エクセル出力の場合 df.to_excel(now + "\\" + sql_file.replace('.sql', '.xlsx'), sheet_name=sql_file.replace('.sql', ''), index=False) # CSV出力の場合 df.to_csv(now + "\\" + sql_file.replace('.sql', '.csv'), encoding="utf-8_sig", quoting=csv.QUOTE_NONNUMERIC, index=False) os.chdir(now) # 個別の編集があればここでやる # 結果ファイル取得 result_file_list = glob.glob("*.xlsx") # 3. ZIPにする ------------------------------------ # 結果ファイル圧縮(日本語ファイル名非対応) file_path = [] for i in range(len(result_file_list)): file_path.append('\\') pyminizip.compress_multiple(result_file_list,file_path, now + '.zip','pass',0) # 4. ファイルサーバに置く ------------------------------------ # 結果ファイルアップロード share = pathlib.WindowsPath(r'ファイルサーバ' + now + '.zip') shutil.copyfile(now + '.zip', share) # 切断 conn.close() # 実行 exec()
- 投稿日:2020-07-13T19:04:40+09:00
python 末尾の特定の文字列を削除
- 投稿日:2020-07-13T18:50:26+09:00
日本一簡素なPythonのメモ(ダイアログボックスとか)
pythonでファイル操作するために学習したのでメモ。
■ダイアログボックス、os.walk関数、pprintを使って選択したフォルダ内のファイルを一列に表示する
#必要なモジュールのインポート import sys import os import tkinter,tkinter.filedialog #ファイルの表示を一列にするためにインポート import pprint #ファイルダイアログの作成 root=tkinter.Tk() root.withdraw()#Tkinterのメインウィンドウが起動してしまうと処理が止まる場合があるので記述 msg='フォルダを選択してください' my_path=tkinter.filedialog.askdirectory(title=msg) if (not my_path): print('ユーザがキャンセルしました') sys.exit() #OS.walk関数を使ってファルダ内のファイルを走査して表示 for dirpaht,dirs,files in os.walk(my_path): for fname in files: pprint.pprint(fname)実行するとファイルダイアログが表示されますので、フォルダを選択します。
実行結果が表示されます。pprintを使うことで結果が一列で表示されます。
- 投稿日:2020-07-13T18:32:12+09:00
loggingに関する考え方、その後
前回: ログ出力のための print と import logging はやめてほしい
上記の記事、いまだに妙に人気があるんですが、最初にかいたのが2016年と、本記事から見ても4年くらい前なんですね。
意見の大筋はあまり変わらないながらも、変わった面もありまして。これまでにいろいろな意見であるとか、私も異なる経験をしたというのもあって、若干補足的な記事を書きたくなりましたので書いておきます。
元の記事について背景を言い訳しとく
確か、何らかの外部ソフトウェアのログ周りの挙動を見ていて、単に「ムキー!」ってなって勢いで書いた文章なんですよ。だから教科書のような正確さ・フェアさを求めたものではそもそもないんです。どこかのサークルの同人誌に寄稿するときみたいにレビュー受けてもないですしね。
ただ、感情まみれの記事の割には(むしろ「だから」か?)、この記事は妙に読まれてまして……
なんとなく読み手の気持ちは察せられます。ログの話って技術書籍とかで驚くほど書かれてないし、私も、今でも技術を磨くのに大変苦労している分野です。というわけで、単なるヒントレベルであっても記事が重宝される事自体には有り難みがあります。
この記事に限らず、LGTM(旧「いいね」)やストックの通知があると、たまに私自身も文章を読み直して手直しするので、「ムキー」感が今ではマイルドになっているかもしれません。内容についても、今見返しても「ま……、悪い話を書いているわけではないな」ということで残しています。
ちなみに「そうじゃないぞ!」ってしっかりした反論記事が目に入ってこないのは実はちょっと残念です。「俺も俺も」みたいに色々書いてくれると面白いかなぁ、なんて。
(コメントの指摘はよかったですね。もともと友人なんですけどね)
正しいロギング戦略をみんな考えてほしいし、共有してほしい
Pythonに限らず、ログというのは、ソフトウェアの運用時において、
- ユーザとの数少ない接点の一つになるもので、かつ
- 同時にプログラムとの数少ない接点の一つになるもの
です。これをソフトウェア開発の主要課題として真面目に考えないのは、ちとあり得ないとは思います。
その重要性にも関わらず、テストと比べてログについての考察が異様に少ないようにも思います。みんな手探りというか、自分の所属する分野や経験とにらめっこしつつ作り込んでいる、というのが印象です。
一方、後述することと被るのですが、ロギング戦略は共通項よりは分野(ドメイン)ごとに特異な点が生じることも多いと思っています。共有するにしても、単にベストプラクティスとして数行書き散らかすだけではなかなか共有知にはしづらい可能性は、ありますね。
良いロギング ⇔ 良いソフト
ログは上記のようにヒトとモノの「双方向」を向くものなので、ちょっと視点や主語がブレると、一瞬で「このログ、どういう意味???」となります。誰にとっての情報なのかがあまりに簡単にわからなくなってしまう。
良いログはユーザや運用者にとって良いソフトにつながる大事な要件、とも言える、かもしれません(まぁ直接のUIの方がずっと大事ですけどねその場合)
開発者以外の(良識ある)人が、レポートするまでもなく、自分の実行環境を見直せる、そういうログに着地させるには、そもそもエラーハンドリングとかソフトウェアの根っこの品質が良くないと無理だったりします。「こういう疑いがあるから、ここを調べてみてね!」というログを運用者に気軽に伝えられるログを出すソフトとはつまり、自分の能力と限界をしっかり見極めているソフトでなければならない、と思うのです。
WARNING: Found duplicate entries for the query "otemoyan". Choosing the first.上のログは一例ですが、「何が起きていて」「何が問題視されていて」「ソフトはそこで何を選択したか」が分かるようにしています。暗黙に「通常このパターンで二重エントリはないはずなのだが、エラーというほどではないけど気をつけてください」という意図も暗示しています(しているつもりです)。もしそれがログの読み手に大事なら「誰がそのクエリを投げたか」もここに足すかもしれません。仮想例として、query部分が個人情報に当たるのなら、そこはプロダクション時にはぼかす必要があります。
このログが「良い」と思える前提がおそらくあり、文脈によってそれは「常に」異なります。
私の場合「顧客から提出されたログをag/grep程度で十分読み取れて、そこから顧客環境の問題を特定する」みたいなことを私がBtoBtoB向けの受託開発とかでやっていた時代があるからこういう例が出るんですが、そういう環境ではこの手のログは効く印象を持っていました。間に入っているサポートのヒトがその先の顧客対応をスムーズに対応できていた、ような、きがします(このあたりはあんまり感想とか聞かせてもらえないんですけどね、私のところにおしかりこなかったし、いいじゃんべつに)。
当時取りこぼしていた、今では大事だと思っていること
元の記事を書いてから相当経ったあとなんですが、指摘のなかで「なるほど、しまったな」と素直に思った最大の反省点というのがあります。
「ロギング戦術・戦略は、入り口から出口に至るまで、そのドメインに寄り添っている必要がある」
ん、どういうこと?
以下のような前提が、ロギング戦略にははっきりきっちりがっつり影響してくるはずなのです。
- 対象のプログラムの大きさで違う
- ソフトウェアが使われる分野(自分向け、社内サービス、小規模の受託、ベンチャー規模のBtoB、BtoC、それこそGoogle規模の世界規模サービス、モバイルフロントエンド)で違う
- 取り扱う(ログの)データサイズで違う
- ログの閲覧頻度、警告以上が発生した際の対処ルートで違う
元の記事では、ここがPythonという言語に絞った範囲においても雑でした。いやまぁそれにしても、Pythonの利用者は幅が広いですからねぇ……
言い訳的に言うと、私が当初想定していた規模感というのは「自分向け」「小規模の受託」くらいからはじめて「育てていく」ようなイメージでのソフトウェア開発でした。まず自分が使い、次に社内もしくは仕事をくれた発注者を含めた少数名、利用者はそのあと「もしかすると」増えるけど当初の負荷は大きくない、そういうイメージです。
一方例えば、設計のはじめから「世界規模サービス」を想定して開発をスタートしたソフトウェアにおけるロギング戦略は、大きく違うでしょう。例えばもともと人気のある大規模SaaSのリライトとかだったりすると、最初から相手は数千人とか数億人とか、何桁億QPSとか。
その場合、単純に言えばソフトウェアが出会う標準的な規模感が違ってくるはずで、開発当初から、ロギング戦略もそちらを第一着地点とするはずです。ログの分量、蓄積する速度(んで、そのログストリームが流れるインフラストラクチャの複雑度)も違います。
最初から想定している着地点も、はじめから大きい体系を意識するとおのずと変わります。私の(勝手な)感覚だと、規模が大きくなるほど、私が気にしているようなログレベルの細分化は意味がなくなり、ユーザ環境での発生頻度と実際の影響に意識を振り分ける必要が出てくるかと思います。まぁこのあたり、マジで当て推量ですけどねぇ……
そういった、読み手のドメインが自分のそれと一致するとは限らない中で一部で断定表現があったんですが、これは明らかに書き手として不適正だったなと思うわけです(ちなみに元記事側はあえて直してません。そういう記事なので、そのようにお楽しみください)
「ドメインが同じで意見が異なる」ならそれは意見の相違と、それをすり合わせる過程を意識して議論もしやすいのですが、考えているドメインが違う中ではすり合わせは厳しいことが多いです。「私が考えている領域はここ。それについてのロギング戦略はこれ」と伝えていなかったのは、振り返ってみるとよろしくない状況だったと言えます。
ちなみにPythonではないですが、私、モバイル業界でアプリ書いていたこともあるにはあるので、そのときにもロギング戦略を考えることはありました。元の記事を書く2016年よりさらに5年くらい前ですね。
このときには、まぁ……想定規模は確かに「世界規模」なんですが、それが一つのサーババックエンドにおける絶えざるログストリームとして流れ込んでくるわけではありませんでした。
対象は各個別の端末であり、それがパラで類似のログをバラバラと発生させるのです。このときのロギング戦略はサーバサイドの小規模ログ管理とは異なってきます。大規模サーババックエンドとも少しは違うでしょうね。ソフトウェアバージョン、ハードウェアバージョンを意識させる流儀が変わってくるように思います。
「このエラーが出るときのログメッセージの文言を変えたのは、どのバージョンからだっけ」といったことがトラブルシューティングに効くことも、なくはないのです。いずれにせよ、ソフトウェアがこれだけ社会に浸透していると、その動作の背景にある論理は全然違ってきて、それを支えるロギングについての考え方も、まぁ全然違ってくるでしょう。
今、試していること
上記のことをおいておきつつ、あくまで私のドメインに関して試していることを補足的に書いておきます。
関数に
logger: Loggerもしくはlogger: Optional[Logger]を渡すというのを一部のプロジェクトでやっています。デフォルトとなる引数は指定しません。ただし None を明示的に渡すの許すことがあります(想定するソフトウェアの規模は「かなり小さい」と思ってください)
Optionalでないということは「必ずロガーを渡せ」ということです。これは粒度が非常に小さい関数であるとか、文脈(外部環境)への依存度が低いコンポーネントでそうしていることが多い気がします。Optionalということは「ロガーを渡したくなければNoneを渡せ」ということです。呼び出された側の関数ではオブジェクトが渡されればそれを使い、そうでなければその関数が所属するドメインの標準ロガーなどを使います一時期
logger: Optional[Logger] = Noneも使っていましたがこれは悪手でした。暗黙にログが握りつぶされることがあり、非常に悲しい思いをするので、今は一旦2択です。2択である必要は、まぁないかもしれませんけどね。この方法は「全体のログを掌握できる」「きめ細やかにコンポーネントの面倒を見られる」規模の開発くらいでしかおそらく役に立たないでしょう。自分が扱うサービスが規模が国内有力BtoCくらいだったら、負荷次第ですが、こんな戦略は多分とりません。
よって、この方法に汎用性はあまり「ない」と思いますが、ただ、私個人が扱う範囲では一貫してこうすることで、そのプロジェクトにおいてはログの見通しはだいぶ良くなりました。
そもそもここは、なんというか、規模の小ささに加えて「コダワリ」の部分があると思いますね。ログに対する拘りが良いか悪いか自体に議論の余地はあると思っていますが、 print()よりはましだよ、という点は変わりません。他の技術者がリーダーをしていてコーディング規約として別のロギング規約を設けたならそれに静かに従うでしょうね。
今、思案していること
これは以前とあまり変わらず、
Logger.info()とLogger.debug()だけでは粒度が荒すぎる問題です。Logger.trace()(debug()より下。関数の開始と終了レベルまでこまかーく) ほしいなぁとか、(Zabbix用語かもですが)Logger.average()(warningより上、errorより下。もしくはinfoとwarningの間)がほしいなぁ、と思う瞬間があります(これもまた、ソフトウェア規模が大きくなるほどどうでもいい問題かもしれません)Loggerのラッパーを作れば、多分「出来るは出来る」んですよね。PythonではDEBUG, INFO等は定数値であり、それらの定数値の間には十分な隙間がありますから (https://docs.python.org/3/library/logging.html#logging-levels)
ただ、言語やフレームワークの「標準」に寄り添う方が長期的には機能するという経験則もあり、直感的には「妙に悪賢い」感じがしないでもなく、ためらっている経緯があります。traceがはじめから入っているlogbackはただ羨ましい。
まとめ
今回は感情が高ぶっているということもなく適当に書いただけなので、面白い内容ではなかったかもしれませんが、一応フォローアップとして書いておきました。
- 投稿日:2020-07-13T18:25:58+09:00
pythonのtqdmで進捗バーが表示されない時の対処法
pythonのtqdmを使えば進捗バーが表示されます.
from tqdm import tqdm import time for i in tqdm(range(10)): time.sleep(0.1)実行結果100%|██████████████████████████████████████████████████████████████████████████████████| 10/10 [00:01<00:00, 9.75it/s]ただ,例えば次のような場合は進捗バーはなぜか表示されません.
from tqdm import tqdm import time for i in tqdm(reversed(range(10))): time.sleep(0.1)実行結果10it [00:01, 9.75it/s]この場合,次のようにすれば解決できました.
from tqdm import tqdm import time for i in tqdm(reversed(range(10)), total=10):#totalでfor文の繰り返し回数を指定してあげる time.sleep(0.1)実行結果100%|██████████████████████████████████████████████████████████████████████████████████| 10/10 [00:01<00:00, 9.77it/s]
- 投稿日:2020-07-13T18:16:13+09:00
PynamoDB でテーブル作成・検索・作成
やりたいこと
- DynamoDBをMACから触れるようにする
- pynamoDBでテーブル操作する
前提条件
- AWS Access Key ID と AWS Secret Access KeyはGET済み
行ってみよう!
DynamoDBをMACから触れるようにする
公式サイトからAWS CLI バージョン 2 のインストール
- ブラウザで、macOS pkg ファイルをダウンロードします: https://awscli.amazonaws.com/AWSCLIV2.pkg
- ダウンロードしたファイルをダブルクリックして、インストーラを起動します。
- 画面上の指示に従ってください。AWS CLI バージョン 2 は以下の方法でインストールできます。 (参考) https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/install-cliv2-mac.html これで、コマンドでAWSを触れるようになりました。
aws configure で AWSと連携
(venv) mbp:wanted user$ aws configure AWS Access Key ID [None]: ABCDEFGHIJGLMNOPQRSTUVWXYZ AWS Secret Access Key [None]: SECRETKEYSECRETKEYSECRETKEYSECRETKEY Default region name [None]: ap-northeast-1 Default output format [None]:対話式で、アクセスキーとシークレットキーを入力すれば連携が完了
テーブルの作成
from datetime import datetime from pynamodb.attributes import UnicodeAttribute, UTCDateTimeAttribute, MapAttribute, NumberAttribute from pynamodb.models import Model class AccountMap(MapAttribute): """ アカウント情報 """ price = NumberAttribute(null=True) search_limit_num = NumberAttribute(null=True) url = UnicodeAttribute(null=True) class Users(Model): """ ユーザ情報 """ class Meta: table_name = "Users" region = 'ap-northeast-1' id = UnicodeAttribute(hash_key=True) password = UnicodeAttribute() login_date = UTCDateTimeAttribute() start_date = UTCDateTimeAttribute(default=datetime.now()) account = AccountMap() # ユーザテーブルの作成 if not Users.exists(): Users.create_table(read_capacity_units=1, write_capacity_units=1, wait=True)こんな感じで、作れる。Django感、半端ないです^^
検索
query
キーを指定してから、検索
def get_user_info(user_id, password, month_password): """ パスワード認証 :param user_id: :param password: :param month_password: :return: """ # TODO トークンの取得 token = "local" # ユーザIDとパスワードと今月のパスワードとトークン for user_data in Users.query(user_id, (Users.password == password) & (Users.month_password == month_password) & ( Users.token == token)): return user_data return Nonequeryで検索
scan
キーを指定せずに、検索
Users.scan(Users.id==user_id)保存
# データの作成 users = Users('onehundred') users.password = "password" users.token = "local" users.month_password = "month_password" users.login_date = datetime.now() users.start_date = datetime.now() users.account = { "price": 1000, "search_limit_num": 10, "pay_pal_url": "https://paypal.com", } users.save()
- 投稿日:2020-07-13T18:02:00+09:00
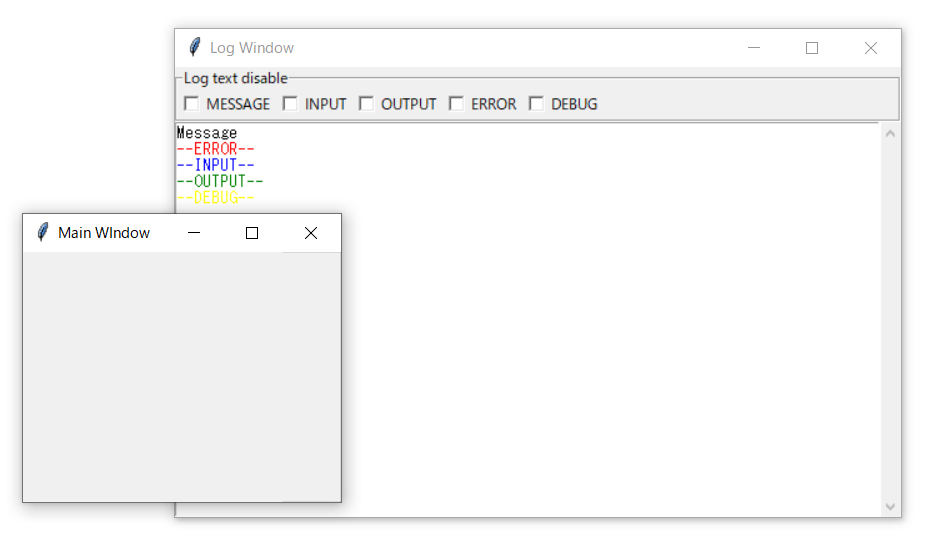
TkinterでLog出力用windowを作ってみました
TkinterでWindowsでGUIを作ると、リアルタイムのprintデバッグが難しいため
メインウィンドウのほかにLog Windowを立ち上げた方が便利だと思い、作ってみました。
あくまでもサブウィンドウなのでToplevelでのWindowを立ち上げます。
(TkinterのToplevel windowsの使いかをちゃんと理解できていません)
ただのLog Windowでは面白くないので、Log種類によって表示/非表示ができるようなチェックボックスを入れてみました。
IOLogWindow.pyimport sys import serial import binascii import time import tkinter as tk from tkinter import scrolledtext TEXT_COLORS = { 'MESSAGE' : 'black', 'INPUT' : 'blue', 'OUTPUT' : 'green', 'ERROR' : 'red', 'DEBUG' : 'yellow' } # Initial value = flag=True or False class SimpleCheck(tk.Checkbutton): def __init__(self, parent, *args, **kw): self.flag = kw.pop('flag') self.var = tk.BooleanVar() if self.flag: self.var.set(True) self.txt = kw["text"] tk.Checkbutton.__init__(self, parent, *args, **kw, variable=self.var) def get(self): return self.var.get() class IOLogFrame(tk.Frame): def __init__(self, master): tk.Frame.__init__(self, master) master.title("Log Window") #view/hide choice select_frame = tk.LabelFrame(master, text= "Log text disable",relief = 'groove') self.ckboxs = [] for key in TEXT_COLORS: cb = SimpleCheck(select_frame, text=key, command=self.callback, flag=False) self.ckboxs.append(cb) cb.pack(side='left') select_frame.pack(side = 'top', fill = 'x') self.txt = scrolledtext.ScrolledText(master) self.txt.pack(fill=tk.BOTH, expand=1) for key in TEXT_COLORS: self.txt.tag_config(key, foreground=TEXT_COLORS[key]) def callback(self): count = 0 for key in TEXT_COLORS: if(self.ckboxs[count].get()): self.hide(key) else: self.view(key) count += 1 def print(self, str, state='MESSAGE'): self.txt.insert(tk.END, str+'\n', state) def hide(self, tag): self.txt.tag_config(tag, elide=True) def view(self, tag): self.txt.tag_config(tag, elide=False) #sample main window class IOLogWindow(tk.Toplevel): def __init__(self, master): master.title("Main WIndow") tk.Toplevel.__init__(self, master) io = IOLogFrame(self) io.print("Message") io.print("--ERROR--", 'ERROR') io.print("--INPUT--", 'INPUT') io.print("--OUTPUT--", 'OUTPUT') io.print("--DEBUG--", 'DEBUG') if __name__ == '__main__': win = tk.Tk() io=IOLogWindow(win) win.mainloop()
- 投稿日:2020-07-13T17:59:30+09:00
ロジスティック回帰 アルゴリズム
- 投稿日:2020-07-13T16:57:15+09:00
Pythonで配列内の要素を交換する方法、また配列を逆順にする方法。
Pythonで配列内の要素の交換を行う方法、また配列を逆順にする方法を書いていきます。
よろしくお願いします。n = [*range(1,6)] for i in range(len(n)//2): n[i], n[len(n)-i-1] = [len(n)-i-1], n[i] #先頭と一番後ろ、二番目と後ろから二番目、を交換しています。配列を逆向きにするのが目的の場合。
n = [*range(1,6)][::-1]n = [*range(1,6)] reverse_n = sorted(n,reverse=True) #sortedは非破壊的でnそのものは変更せず、逆順になったnを返します。n = [*range(1,6)] n.sort(reverse=True) #sortは破壊的でnそのものを変更します。返す値はNoneです。以上です。
ありがとうございました。
- 投稿日:2020-07-13T16:50:25+09:00
Pythonを使って気象情報を取得する
気象庁が公開している気象データをスクレイピングして取得し、csvファイルとして出力するPGを健忘録としてまとめておきます。
参考
Pythonで天気APIを使って天気の情報を取得する方法
Webスクレイピングの注意事項一覧
Python Webスクレイピング テクニック集「取得できない値は無い」JavaScript対応@追記あり6/12環境
OS : Windows10 64 bit
python : 3.7.4
主なパッケージ名 用途 BeautifulSoup Webページの解析&タグの検索&データの整形 logging ログの出力や設定 namedtuple タプル操作 pandas Dataframe操作用 requests webページの取得 手順
やり方はいたって簡単。
① requestsというパッケージを使用して、取得したいWebページ内のデータを取得するr = requests.get('URL')② BeautifulSoupというパッケージで中身を解析
soup = BeautifulSoup(r.text,'lxml') rows = soup.findAll("tr",class_="mtx") #条件を絞ってタグを取得③ pandasでDataframeとしてまとめ、csvとして出力
weatherData = pd.DataFrame(dataList[1:]) # 列名の設定 weatherData.columns = nameList # csvファイルとして出力 weatherData.to_csv(f"{place}{startYear}_{endYear}.csv",encoding="SHIFT-JIS")作成例
GetWeather.py# coding: UTF-8 #************************************************************************* # 天気情報取得処理 # # 対象データ:福岡県内の天気情報 # 処理内容:気象庁から気象情報を取得し、csvファイルを出力する # ※気象庁利用規約より、商用利用可であることを確認 # https://www.jma.go.jp/jma/kishou/info/coment.html # python ver = 3.7.4 #************************************************************************* import os import sys import requests import logging.config from time import time import datetime as dt import sqlite3 import pprint import pandas as pd from bs4 import BeautifulSoup from collections import namedtuple import csv #************************************************************************* # 変数一覧 #************************************************************************* now = dt.datetime.now() # 現在日時 now =now.strftime("%Y%m%d") # exeが存在するファイル位置 # CODEが存在する絶対パスの2つ前を作業フォルダに設定 # 必要に応じて自分の作業ファイルとしたい場所を指定する用に変更しよう os.chdir(os.path.join(os.path.dirname(os.path.abspath(__file__)), "../../")) exePath = os.getcwd() place_codeA = [82] place_codeB = [47807] place_name = ["福岡"] nameList = ["地点","年月日", "陸の平均気圧(hPa)", "海の平均気圧(hPa)","'降水量(mm)", "平均気温(℃)", "平均湿度(%)", "平均風速(m/s)", "日照時間(h)","昼(06:00-18:00)","夜(18:00-翌日06:00)"] dataList = [nameList] collist = ["Point"] base_url = "http://www.data.jma.go.jp/obd/stats/etrn/view/daily_s1.php?prec_no=%s&block_no=%s&year=%s&month=%s&day=1&view=p1" #*********************************************** # 名前付きタプルリスト一覧 #************************************************************************* #************************************************************************* #[ ONL : OutputNameList] 出力/集計処理用列名のタプル #************************************************************************* # 列名0-9,10-19,20-29 partsO =["PT","TIME", "EHPA","SHPA", "RAIN", "TEMPER", "HUMID","WIND","SUM","AM","PM"] OLNM = namedtuple("ONL", partsO) OCNL = OLNM("地点","年月日", "陸の平均気圧(hPa)", "海の平均気圧(hPa)","'降水量(mm)", "平均気温(℃)", "平均湿度(%)", "平均風速(m/s)", "日照時間(h)","昼(06:00-18:00)","夜(18:00-翌日06:00)") #************************************************************************* # 関数一覧 #************************************************************************* #************************************************************************* # ParseFloat:文字列をfloat型に変換する # 引数: #************************************************************************* def ParseFloat(str): try: return float(str) except: return 0.0 #************************************************************************* # メイン処理 # 引数: #************************************************************************* def main(): returnValue = 0 # ログ設定 logging.config.fileConfig(f"{exePath}/python/logging.conf", defaults={'logfilename': f"log/UI_{now}.log" }) logger = logging.getLogger() logger.info("気象情報取得処理 記録開始") startYear = 2018 endYear = 2018 try: # 場所でループ for place in place_name: index = place_name.index(place) # for文で2018年~2019年まで for year in range(startYear,endYear + 1): # その年の1月~12月の12回を網羅する。 for month in range(1,13): #2つの都市コードと年と月を当てはめる。 r = requests.get(base_url%(place_codeA[index], place_codeB[index], year, month)) r.encoding = r.apparent_encoding print(dt.datetime.now()) # 対象である表をスクレイピング。 soup = BeautifulSoup(r.text,'lxml') rows = soup.findAll("tr",class_="mtx") #タグ指定してclass名を指定する rows = rows[4:] # 1日〜最終日までの1行を網羅し、取得 for row in rows: data = row.findAll("td") # 欲しい情報のみを抽出 rowData = [] # 初期化 rowData.append(place) # 地点 rowData.append(str(year) + "/" + str(month) + "/" + str(data[0].string)) # 年月日 rowData.append(ParseFloat(data[1].string)) # 陸の平均気圧(hPa) rowData.append(ParseFloat(data[2].string)) # 海の平均気圧(hPa) rowData.append(ParseFloat(data[3].string)) # '降水量(mm) rowData.append(ParseFloat(data[6].string)) # 平均気温(℃) rowData.append(ParseFloat(data[9].string)) # 平均湿度(%) rowData.append(ParseFloat(data[11].string)) # 平均風速(m/s) rowData.append(ParseFloat(data[16].string)) # 日照時間(h) rowData.append(data[19].string) # 昼(06:00-18:00) rowData.append(data[20].string) # 夜(18:00-翌日06:00) #次の行にデータを追加 dataList.append(rowData) # Dataframe化する weatherData = pd.DataFrame(dataList[1:]) # 列名の設定 weatherData.columns = nameList print(weatherData) # csvファイルとして出力 weatherData.to_csv(f"{place}{startYear}_{endYear}.csv",encoding="SHIFT-JIS") # 例外が発生した場合 except: logger.info("気象情報取得処理 異常終了") logger.exception("【異常終了しました】") # 正常終了した場合 else: logger.info("気象情報取得処理 正常終了") finally: print("{0}".format(returnValue), end="") # パッケージとしてimportしたのではなければ、以下を実行 if __name__ == "__main__": main()
- 投稿日:2020-07-13T16:50:25+09:00
Python&スクレイピングで気象情報を取得する
気象庁が公開している気象データをスクレイピングして取得し、csvファイルとして出力するPGを健忘録としてまとめておきます。
参考
Pythonで天気APIを使って天気の情報を取得する方法
Webスクレイピングの注意事項一覧
Python Webスクレイピング テクニック集「取得できない値は無い」JavaScript対応@追記あり6/12環境
OS : Windows10 64 bit
python : 3.7.4
主なパッケージ名 用途 BeautifulSoup Webページの解析&タグの検索&データの整形 logging ログの出力や設定 namedtuple タプル操作 pandas Dataframe操作用 requests webページの取得 手順
やり方はいたって簡単。
① requestsというパッケージを使用して、取得したいWebページ内のデータを取得するr = requests.get('URL')② BeautifulSoupというパッケージで中身を解析
soup = BeautifulSoup(r.text,'lxml') rows = soup.findAll("tr",class_="mtx") #条件を絞ってタグを取得③ pandasでDataframeとしてまとめ、csvとして出力
weatherData = pd.DataFrame(dataList[1:]) # 列名の設定 weatherData.columns = nameList # csvファイルとして出力 weatherData.to_csv(f"{place}{startYear}_{endYear}.csv",encoding="SHIFT-JIS")作成例
GetWeather.py# coding: UTF-8 #************************************************************************* # 天気情報取得処理 # # 対象データ:福岡県内の天気情報 # 処理内容:気象庁から気象情報を取得し、csvファイルを出力する # ※気象庁利用規約より、商用利用可であることを確認 # https://www.jma.go.jp/jma/kishou/info/coment.html # python ver = 3.7.4 #************************************************************************* import os import sys import requests import logging.config from time import time import datetime as dt import sqlite3 import pprint import pandas as pd from bs4 import BeautifulSoup from collections import namedtuple import csv #************************************************************************* # 変数一覧 #************************************************************************* now = dt.datetime.now() # 現在日時 now =now.strftime("%Y%m%d") # exeが存在するファイル位置 # CODEが存在する絶対パスの2つ前を作業フォルダに設定 # 必要に応じて自分の作業ファイルとしたい場所を指定する用に変更しよう os.chdir(os.path.join(os.path.dirname(os.path.abspath(__file__)), "../../")) exePath = os.getcwd() place_codeA = [82] place_codeB = [47807] place_name = ["福岡"] nameList = ["地点","年月日", "陸の平均気圧(hPa)", "海の平均気圧(hPa)","'降水量(mm)", "平均気温(℃)", "平均湿度(%)", "平均風速(m/s)", "日照時間(h)","昼(06:00-18:00)","夜(18:00-翌日06:00)"] dataList = [nameList] collist = ["Point"] base_url = "http://www.data.jma.go.jp/obd/stats/etrn/view/daily_s1.php?prec_no=%s&block_no=%s&year=%s&month=%s&day=1&view=p1" #*********************************************** # 名前付きタプルリスト一覧 #************************************************************************* #************************************************************************* #[ ONL : OutputNameList] 出力/集計処理用列名のタプル #************************************************************************* # 列名0-9,10-19,20-29 partsO =["PT","TIME", "EHPA","SHPA", "RAIN", "TEMPER", "HUMID","WIND","SUM","AM","PM"] OLNM = namedtuple("ONL", partsO) OCNL = OLNM("地点","年月日", "陸の平均気圧(hPa)", "海の平均気圧(hPa)","'降水量(mm)", "平均気温(℃)", "平均湿度(%)", "平均風速(m/s)", "日照時間(h)","昼(06:00-18:00)","夜(18:00-翌日06:00)") #************************************************************************* # 関数一覧 #************************************************************************* #************************************************************************* # ParseFloat:文字列をfloat型に変換する # 引数: #************************************************************************* def ParseFloat(str): try: return float(str) except: return 0.0 #************************************************************************* # メイン処理 # 引数: #************************************************************************* def main(): returnValue = 0 # ログ設定 logging.config.fileConfig(f"{exePath}/python/logging.conf", defaults={'logfilename': f"log/UI_{now}.log" }) logger = logging.getLogger() logger.info("気象情報取得処理 記録開始") startYear = 2018 endYear = 2018 try: # 場所でループ for place in place_name: index = place_name.index(place) # for文で2018年~2019年まで for year in range(startYear,endYear + 1): # その年の1月~12月の12回を網羅する。 for month in range(1,13): #2つの都市コードと年と月を当てはめる。 r = requests.get(base_url%(place_codeA[index], place_codeB[index], year, month)) r.encoding = r.apparent_encoding print(dt.datetime.now()) # 対象である表をスクレイピング。 soup = BeautifulSoup(r.text,'lxml') rows = soup.findAll("tr",class_="mtx") #タグ指定してclass名を指定する rows = rows[4:] # 1日〜最終日までの1行を網羅し、取得 for row in rows: data = row.findAll("td") # 欲しい情報のみを抽出 rowData = [] # 初期化 rowData.append(place) # 地点 rowData.append(str(year) + "/" + str(month) + "/" + str(data[0].string)) # 年月日 rowData.append(ParseFloat(data[1].string)) # 陸の平均気圧(hPa) rowData.append(ParseFloat(data[2].string)) # 海の平均気圧(hPa) rowData.append(ParseFloat(data[3].string)) # '降水量(mm) rowData.append(ParseFloat(data[6].string)) # 平均気温(℃) rowData.append(ParseFloat(data[9].string)) # 平均湿度(%) rowData.append(ParseFloat(data[11].string)) # 平均風速(m/s) rowData.append(ParseFloat(data[16].string)) # 日照時間(h) rowData.append(data[19].string) # 昼(06:00-18:00) rowData.append(data[20].string) # 夜(18:00-翌日06:00) #次の行にデータを追加 dataList.append(rowData) # Dataframe化する weatherData = pd.DataFrame(dataList[1:]) # 列名の設定 weatherData.columns = nameList print(weatherData) # csvファイルとして出力 weatherData.to_csv(f"{place}{startYear}_{endYear}.csv",encoding="SHIFT-JIS") # 例外が発生した場合 except: logger.info("気象情報取得処理 異常終了") logger.exception("【異常終了しました】") # 正常終了した場合 else: logger.info("気象情報取得処理 正常終了") finally: print("{0}".format(returnValue), end="") # パッケージとしてimportしたのではなければ、以下を実行 if __name__ == "__main__": main()