- 投稿日:2020-07-08T23:30:13+09:00
ResNet50をFine-tuningして102種類の花の画像分類をする
こんにちは。
機械学習超初心者がTensorFlow(というよりKeras?)と102 Category Flower Datasetを使って画像分類をしてみました。とりあえず既存のデータセットを使って画像分類してみたい、という方の参考になれば幸いです。また、間違っているところや改善できるところがあればご指摘いただけると非常にありがたいです。
ソースコードはこちらにあるipynbファイル。
環境
Google Colaboratory
Python 3.6.9
TensorFlow 2.2.0
Keras 2.3.0-tf
NumPy 1.18.5
pandas 1.0.5
SciPy 1.4.1
scikit-learn 0.22.2.post1
Requests 2.23.0全て2020年7月8日時点でのGoogle Colaboratory上でのバージョンです。
Google Colaboratoryとは
Jupyter Notebookのオンライン版のようなもので、インタラクティブなPythonの実行環境です。必要なものはGoogleアカウントだけなので気軽に使い始められます。高性能GPUも無料で使えちゃうすごいサービスです。
使うにはGoogle Driveを開いて、「新規 > その他」からGoogle Colaboratoryを選びます。その他に無ければ「新規 > その他 > アプリを追加」でcolabと検索してインストールします。
インポート一覧
インポートするモジュールをここにまとめておきます。
使うモジュール一覧import os import requests import tarfile import numpy as np import scipy from scipy import io import pandas as pd from sklearn.model_selection import train_test_split from PIL import Image import tensorflow as tf from tensorflow import keras from tensorflow.keras.models import Model from tensorflow.keras.layers import Dense, Dropout, GlobalAveragePooling2D, BatchNormalization from tensorflow.keras.applications import ResNet50 from tensorflow.keras.preprocessing.image import ImageDataGeneratorデータセットを取得する
実は今回使うデータセットはTensorFlow Datasets nightly (tfds-nightly)にあるのでわざわざ取りに行く必要はないのですが、ImageDataGeneratorでの画像加工がしやすかったのでディレクトリに保存しました。Google DriveをマウントすることでデータセットをDriveに保存できます。
URLからデータセットを取得# Google Driveをマウント from google.colab import drive drive.mount('/content/drive') # データセットを取得し解凍 DataPath = '/content/drive/My Drive/data' if not os.path.exists(DataPath): os.mkdir(DataPath) tgz_path = os.path.join(DataPath, '102flowers.tgz') url = 'http://www.robots.ox.ac.uk/~vgg/data/flowers/102/102flowers.tgz' r_image = requests.get(url) with open(tgz_path, 'wb') as f: f.write(r_image.content) tar = tarfile.open(tgz_path, 'r') for item in tar: tar.extract(item, DataPath) # ラベル情報が書かれたファイルを取得 mat_path = os.path.join(DataPath, 'imagelabels.mat') label_url = 'http://www.robots.ox.ac.uk/~vgg/data/flowers/102/imagelabels.mat' r_label = requests.get(label_url) with open(mat_path, 'wb') as f: f.write(r_label.content)画像とラベルを紐づける
pandasを使って画像とラベルを紐づけます。こちらのページを参考にさせていただきました。
【機械学習事始め】102枚の花の画像分類をした画像とラベルを紐づけるmatdata = scipy.io.loadmat(mat_path) labels = matdata['labels'][0] images = ['image_{:05}.jpg'.format(i + 1) for i in range(len(labels))] image_label_df = pd.DataFrame({'image': images, 'label': labels})これで以下のようなデータフレームができました。
image label image_00001.jpg 77 image_00002.jpg 77 : : imagelabels.matにはラベルのインデックスしかないので、インデックスと名前を紐づけます。私はtfdsの存在を知る前にこの作業を行ったので、愚かにも全ての画像に目を通し、データセット取得元のページにあるラベル一覧と見比べながら対応表を作りましたが、tfdsのソースコードにインデックス順の名前のリストがあるので、そちらを使って対応表を作ることをおすすめします。ちなみにこの愚行のおかげで花の知識が少し増えました。
あらかじめ対応表(label_names.csv)をGoogle Driveにアップロードしておいてください。
インデックスと名前を紐づけるlabel_names_path = os.path.join(DataPath, 'label_names.csv') # 血と汗と涙の結晶 label_names = pd.read_csv(label_names_path, index_col=0) df = pd.merge(image_label_df, label_names, how='left', on='label') csv_path = os.path.join(DataPath, 'image_label_name.csv') df.to_csv(csv_path) # データフレームをcsvファイルに保存これで以下のようなデータフレームができました。
image label name image_00001.jpg 77 passion flower image_00002.jpg 77 passion flower : : : 学習データと検証データに分ける
scikit-learnのtrain_test_split関数を使って、データセットを学習データと検証データに分けます。学習データと検証データの比率は8:2としました。
(本当は学習データ、検証データ、テストデータの3つに分けるのが良いとされていますが、今回は学習データと検証データの2つに分けました。なお、ここでのtestは検証データのことです。)
学習データと検証データに分けるX_train_path = os.path.join(DataPath, 'X_train') # 学習データ用ディレクトリ X_test_path = os.path.join(DataPath, 'X_test') # 検証データ用ディレクトリ if not os.path.exists(X_train_path): os.mkdir(X_train_path) if not os.path.exists(X_test_path): os.mkdir(X_test_path) labels = pd.read_csv(csv_path, index_col=0) # 先ほど作ったcsvファイルを読み込む jpg_path = os.path.join(DataPath, 'jpg') # 学習データと検証データに分ける # 変数は左から学習画像、検証画像、学習ラベル、検証ラベル X_train, X_test, Y_train, Y_test = train_test_split(os.listdir(jpg_path), labels['name'], test_size=0.2, random_state=0) # それぞれのディレクトリにファイルを移動する for f in os.listdir(jpg_path): img = Image.open(os.path.join(jpg_path, f)) if f in X_train: img.save(os.path.join(X_train_path, f)) elif f in X_test: img.save(os.path.join(X_test_path, f))ラベルごとに分ける
ImageDataGeneratorのflow_from_directory関数を使うために、画像をさらにラベルごとに分けます。
ラベルごとに分ける# 学習データをラベルごとに分ける for f in os.listdir(X_train_path): index = df.image[df.image==f].index category = str(df.name[index].values).replace('[', '').replace(']', '').replace("'", '') if category == '"colts foot"': category = "colt's foot" category_path = os.path.join(X_train_path, category) if not os.path.exists(category_path): os.makedirs(category_path) img = Image.open(os.path.join(X_train_path, f)) img.save(os.path.join(category_path, f)) os.remove(os.path.join(X_train_path, f)) # 検証データをラベルごとに分ける for f in os.listdir(X_test_path): index = df.image[df.image==f].index category = str(df.name[index].values).replace('[', '').replace(']', '').replace("'", '') if category == '"colts foot"': category = "colt's foot" category_path = os.path.join(X_test_path, category) if not os.path.exists(category_path): os.makedirs(category_path) img = Image.open(os.path.join(X_test_path, f)) img.save(os.path.join(category_path, f)) os.remove(os.path.join(X_test_path, f))データを水増しする
今回使うデータセットは8189枚の画像群で、102種類の花の画像が各40~258枚入っています。これは学習データの量としては多くはありません。そこでKerasのImageDataGeneratorを使い、画像を回転したり反転したりすることでデータの水増しをします。
ImageDataGeneratorは「リアルタイムにデータ拡張しながら,テンソル画像データのバッチを生成します.また,このジェネレータは,データを無限にループするので,無限にバッチを生成します.」(公式ドキュメントより)
ImageDataGeneratorクラスで加工方法(正規化を含む)を指定し、flow_from_directory関数でディレクトリ内にある画像に対して加工を施し、かつバッチを生成します。
データの水増しtrain_datagen = ImageDataGenerator( rescale=1.0/255, rotation_range=45, width_shift_range=.15, height_shift_range=.15, horizontal_flip=True, vertical_flip=True, zoom_range=0.5, shear_range=0.2 ) val_datagen = ImageDataGenerator(rescale=1.0/255) train_gen = train_datagen.flow_from_directory( X_train_path, target_size=(224, 224), color_mode='rgb', batch_size=32, class_mode='categorical', shuffle=True ) val_gen = val_datagen.flow_from_directory( X_test_path, target_size=(224, 224), color_mode='rgb', batch_size=32, class_mode='categorical', shuffle=True )batch_sizeは大きいほど学習が早く終わりますがメモリを大量に消費します。逆に小さいほど学習には時間がかかりますが、メモリの制約に収まり、バッチ全体ではなく一つ一つのデータの特徴を捉えることができます。大きさとしては、1、32、128、256、512あたりがよく使われるようです。
[参考]
- 【Deep Learning】 Batch sizeをどうやって決めるかについてまとめるモデルを構築する
やっと機械学習っぽいところまで来ました。
今回は比較的精度が高いらしいResNet50をベースにfine-tuningモデルを作りました。転移学習でも良いのではないかと思い試したのですが、fine-tuningしたモデルの方が精度が高かったのでそちらを選択しました。
転移学習とfine-tuningの違いは多くの記事で説明されていますが、私の理解としてはベースモデルの重みを更新しないのが転移学習、更新するのがfine-tuningなのかなと思っています。本題。まずベースモデルをダウンロードします。
ResNet50をダウンロードbase_model = ResNet50(weights='imagenet', include_top=False, input_shape=(224, 224, 3))重みはImageNetのもの、出力層のノード数(ラベルの数)がResNet50の本来のものとは違うので出力層を含まない、入力データは3チャンネル(rgb)で224×224サイズ。
次に、ベースモデルに層を追加します。
ベースモデルに層を追加# 全ての重みを更新 base_model.trainable = True x = base_model.output x = GlobalAveragePooling2D()(x) x = BatchNormalization()(x) x = Dropout(0.5)(x) x = Dense(2048, activation='relu')(x) x = BatchNormalization()(x) x = Dense(1024, activation='relu')(x) x = BatchNormalization()(x) x = Dropout(0.5)(x) outputs = Dense(102, activation='softmax')(x) model = Model(inputs=base_model.input, outputs=outputs) model.compile(optimizer=keras.optimizers.RMSprop(lr=1e-5), loss=keras.losses.CategoricalCrossentropy(from_logits=True), metrics=['accuracy']) # model.summary()でモデルの詳細を確認可能Flattenだとパラメータの数が多すぎてメモリ不足になることがあったのでGlobalAveragePooling2Dを使いました。特徴マップを1×1にし1次元にしてくれます。BatchNormalizationは学習を早くしたり過学習を抑えてくれたりするそうです。これによりDropoutが要らない場合もあるようですが、念のためDropoutも入れておきました。
[参考]
- [CNN] Global Average Pooling 層のすすめ
- 畳み込みニューラルネットワークをKeras風に定義するとアーキテクチャの図をパワーポイントで保存してくれるツールを作った
- Deep LearningにおけるBatch Normalizationの理解メモと、実際にその効果を見てみるOptimizerは多くのモデルでRMSpropが使われていたのでそれを採用しました。SGDとAdamでも試してみましたが、RMSpropが一番性能が良かったです。Fine-tuningする場合は学習率をかなり小さくするとのことなので1e-5に設定しました。
[参考]
- Transfer learning & fine-tuning学習
ついに学習です。
学習させるhistory = model.fit( train_gen, steps_per_epoch=6551//32, # 学習データの数//batch_size epochs=30, validation_data=val_gen, validation_steps=1638//32 # 検証データの数//batch_size ) model.save('oxflower_local_waug_ResNet50_fullfine.h5') # モデルを保存する上ではepochs=30となっていますが、何回か繰り返して結局140 epochsで止めました。
学習結果(ラスト10 epochs)Epoch 1/10 204/204 [==============================] - 122s 598ms/step - loss: 3.6719 - accuracy: 0.9739 - val_loss: 3.6781 - val_accuracy: 0.9663 Epoch 2/10 204/204 [==============================] - 122s 597ms/step - loss: 3.6690 - accuracy: 0.9770 - val_loss: 3.6776 - val_accuracy: 0.9675 Epoch 3/10 204/204 [==============================] - 122s 597ms/step - loss: 3.6711 - accuracy: 0.9750 - val_loss: 3.6782 - val_accuracy: 0.9688 Epoch 4/10 204/204 [==============================] - 122s 598ms/step - loss: 3.6676 - accuracy: 0.9779 - val_loss: 3.6799 - val_accuracy: 0.9657 Epoch 5/10 204/204 [==============================] - 122s 597ms/step - loss: 3.6675 - accuracy: 0.9782 - val_loss: 3.6774 - val_accuracy: 0.9675 Epoch 6/10 204/204 [==============================] - 122s 596ms/step - loss: 3.6648 - accuracy: 0.9810 - val_loss: 3.6762 - val_accuracy: 0.9688 Epoch 7/10 204/204 [==============================] - 122s 599ms/step - loss: 3.6636 - accuracy: 0.9828 - val_loss: 3.6767 - val_accuracy: 0.9694 Epoch 8/10 204/204 [==============================] - 123s 601ms/step - loss: 3.6644 - accuracy: 0.9821 - val_loss: 3.6780 - val_accuracy: 0.9663 Epoch 9/10 204/204 [==============================] - 122s 598ms/step - loss: 3.6644 - accuracy: 0.9808 - val_loss: 3.6798 - val_accuracy: 0.9645 Epoch 10/10 204/204 [==============================] - 122s 597ms/step - loss: 3.6618 - accuracy: 0.9839 - val_loss: 3.6788 - val_accuracy: 0.9645最終的なval_accuracyは96%とかなり良い結果が出ましたが、loss、val_loss共にやけに高いのが気になります。他の方々の結果を見てみるとこれらの値は大体0.06くらいの小さな値で、1を超えているケースは見ないのですが何故なのでしょう。どなたかご意見いただけると嬉しいです。
ちなみに、accuracyは学習データに対する正解率、val_accuracyは検証データに対する正解率で、未知のデータに対する性能を測るにはval_accuracy(及びval_loss)に注目するべきのようです。予測してみる
学習したモデルがちゃんと花の種類を判別できるか確かめるために、こちらの画像を判別させてみます。
蓮(lotus)です。(Wikipediaより引用)ラベル予測# 画像はGoogle Driveにアップロード img = Image.open('lotus2.jpg').convert('RGB') img = img.resize((224, 224)) im2arr = keras.preprocessing.image.img_to_array(img) im2arr = im2arr.reshape(1, 224, 224, 3) im2arr = im2arr.astype('float32') im2arr = im2arr / 255.0 # 予測 pred = model.predict(im2arr) # ラベル名のリストを作る keys = train_gen.class_indices.keys() label_names = [] for key in keys: label_names.append(key) # ラベルインデックスに対応するラベル名が得られる print(label_names[np.argmax(pred)]) # 出力結果: lotuspredict関数は予測結果のnumpy arrayを返します。argmax関数を使うことで、予測結果のなかで最も数値の高いインデックスが分かります。しかし、インデックスだけ分かっても何の花なのか分からないので、ラベル名が分かるようにします。
結果、正しく予測してくれました。おわりに
ここまで長々とお付き合い頂きありがとうございました。
次は画像ではなく時系列データを使って時系列予想に挑戦してみようと思います。アリーヴェデルチ!

- 投稿日:2020-07-08T22:28:58+09:00
Tensorfrowで画像分類など学習してみる(手書き文字認識編1)
前回の記事「TensorFlowで画像分類など学習してみる(環境構築編)」の続きになります。
前回は環境構築編を書きましたが、今回から画像分類について複数回に分けて書いてみます。
MNISTの手書き文字の画像を利用して分類について書いていきます。MNISTのデータは世界中で利用されており、機械学習・ニューラルネットワークの一歩として多数のドキュメントが存在します。(手書き文字の画像を扱うのはプログラミングでいうところのHello world的なものです)参考:MNISTはこちらになります。
第1弾は、データの読み込み・データの確認までを書いていきます。
前提/環境
前提となる環境とバージョンは下記となります。
・Anaconda3
・Python3.7.7
・pip 20.0
・TensorFlow 2.0.0この記事ではJupyter Notebookでプログラムを進めていきます。コードの部分をJupyter Notebookにコピー&ペーストし実行することで同様の結果が得られると思います。注:バージョンが異なったり、他ツール(Google Colaboratoryなど)では検証していませんので動作しないケースがあります。
順伝播型ニューラルネットワークを作る
MNISTの手書き文字セットを順伝播型ニューラルネットワークによって分類するということを目標にして
Tensorflowと機械学習に触れて理解していきたいと思います。順伝播型ニューラルネットワーク(feedforward neural network)とは
ニューロンが層のように並び隣接する層の間でのみ結合するネットワークです。入力されたデータは
順方向にのみ伝播していきます。
・データが逆に伝播することはない
・隣接するニューロンへのみデータが伝播する。
・各層のニューロンは隣接する前方のすべてのニューロンからデータを受け取る
・同一層のニューロンからはデータを受け取ることはない
というものです。
順伝播型ニューラルネットワークのTensorFlow・Kerasを使った実装
入力層・中間層・出力層がそれぞれ1つである3層のニューラルネットワークを構築します。まずはデータのロードから進めていきます。
実装その1 MNISTデータのインポート
codeimport tensorflow as tf from tensorflow.keras.datasets import mnist #ヘルパーのライブラリ読み込み。画像を表示する場合に利用します。 import numpy as np import matplotlib.pyplot as plt (x_train, y_train), (x_test, y_test) = mnist.load_data() # データロードTensorFrowではMNISTのデータを扱うモジュールがあり簡単にロードすることができます。
MNISTの手書き文字データセットは0~9の数字が手書きで書かれた画像とラベルのデータです。画像はそれぞれ28×28ピクセルの大きさで、各ピクセルは灰色の度合いを表す0~255の値で表現されています(白は255、0が黒を表します)。ラベルのデータは整数で表現されています。
読み込んだデータは、x_train,y_train,x_test,y_testとして扱うことができます。x_train, y_train は学習用データ、x_test,y_testは評価用データとなります。
実装その2 データを観察する
データの内容を見ましょう。
データサイエンスにおいてはデータの傾向や内容を事前にみておくことが重要です。必ず見ることにしましょう。codeprint('x_train.shape:', x_train.shape) print('x_test.shape:', x_test.shape) print('y_train.shape:', y_train.shape) print('y_test.shape:', y_test.shape)結果
x_train.shape: (60000, 28, 28)
x_test.shape: (10000, 28, 28)
y_train.shape: (60000,)
y_test.shape: (10000,)MNISTのデータは70000枚分のデータですが、60000枚分が学習用、1万枚分が評価用のデータとなります。この後モデルを作り、学習していきますが、すべてのデータを学習に利用するのではなく、一部データを評価用として利用します。
x_train ・・・60000枚の画像データ(28×28)
x_test・・・10000枚の画像データ(28×28)
y_train・・・60000枚分のラベルデータ
y_test・・・10000枚分のラベルデータ実際にデータの画像がどのようなものであるか確認します。
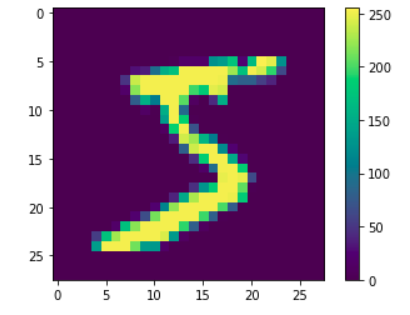
codeplt.figure() plt.imshow(x_train[0]) plt.colorbar() plt.grid(False) plt.show()結果
上記のような画像が表示されればOKです。
もう一つラベルデータの内容も確認しましょう。
codeprint(y_test)結果
[7 2 1 ... 4 5 6]
上記のようなデータ構造になっています。まとめ
MNISTのデータに利用は簡単にできます。データをロードして内容を見るということで、この後のプログラムなどが理解しやすくなると思います。
2020年7月9日修正
ソースコードないで修正しました。tensorflow.python.keras.datasets とimportを記載していましたが、tensorflow.keras.datasetsへと修正しています。動作に問題はありませんができるだけ現状で行われる記載に修正しました。