- 投稿日:2020-07-08T23:30:13+09:00
ResNet50をFine-tuningして102種類の花の画像分類をする
こんにちは。
機械学習超初心者がTensorFlow(というよりKeras?)と102 Category Flower Datasetを使って画像分類をしてみました。とりあえず既存のデータセットを使って画像分類してみたい、という方の参考になれば幸いです。また、間違っているところや改善できるところがあればご指摘いただけると非常にありがたいです。
ソースコードはこちらにあるipynbファイル。
環境
Google Colaboratory
Python 3.6.9
TensorFlow 2.2.0
Keras 2.3.0-tf
NumPy 1.18.5
pandas 1.0.5
SciPy 1.4.1
scikit-learn 0.22.2.post1
Requests 2.23.0全て2020年7月8日時点でのGoogle Colaboratory上でのバージョンです。
Google Colaboratoryとは
Jupyter Notebookのオンライン版のようなもので、インタラクティブなPythonの実行環境です。必要なものはGoogleアカウントだけなので気軽に使い始められます。高性能GPUも無料で使えちゃうすごいサービスです。
使うにはGoogle Driveを開いて、「新規 > その他」からGoogle Colaboratoryを選びます。その他に無ければ「新規 > その他 > アプリを追加」でcolabと検索してインストールします。
インポート一覧
インポートするモジュールをここにまとめておきます。
使うモジュール一覧import os import requests import tarfile import numpy as np import scipy from scipy import io import pandas as pd from sklearn.model_selection import train_test_split from PIL import Image import tensorflow as tf from tensorflow import keras from tensorflow.keras.models import Model from tensorflow.keras.layers import Dense, Dropout, GlobalAveragePooling2D, BatchNormalization from tensorflow.keras.applications import ResNet50 from tensorflow.keras.preprocessing.image import ImageDataGeneratorデータセットを取得する
実は今回使うデータセットはTensorFlow Datasets nightly (tfds-nightly)にあるのでわざわざ取りに行く必要はないのですが、ImageDataGeneratorでの画像加工がしやすかったのでディレクトリに保存しました。Google DriveをマウントすることでデータセットをDriveに保存できます。
URLからデータセットを取得# Google Driveをマウント from google.colab import drive drive.mount('/content/drive') # データセットを取得し解凍 DataPath = '/content/drive/My Drive/data' if not os.path.exists(DataPath): os.mkdir(DataPath) tgz_path = os.path.join(DataPath, '102flowers.tgz') url = 'http://www.robots.ox.ac.uk/~vgg/data/flowers/102/102flowers.tgz' r_image = requests.get(url) with open(tgz_path, 'wb') as f: f.write(r_image.content) tar = tarfile.open(tgz_path, 'r') for item in tar: tar.extract(item, DataPath) # ラベル情報が書かれたファイルを取得 mat_path = os.path.join(DataPath, 'imagelabels.mat') label_url = 'http://www.robots.ox.ac.uk/~vgg/data/flowers/102/imagelabels.mat' r_label = requests.get(label_url) with open(mat_path, 'wb') as f: f.write(r_label.content)画像とラベルを紐づける
pandasを使って画像とラベルを紐づけます。こちらのページを参考にさせていただきました。
【機械学習事始め】102枚の花の画像分類をした画像とラベルを紐づけるmatdata = scipy.io.loadmat(mat_path) labels = matdata['labels'][0] images = ['image_{:05}.jpg'.format(i + 1) for i in range(len(labels))] image_label_df = pd.DataFrame({'image': images, 'label': labels})これで以下のようなデータフレームができました。
image label image_00001.jpg 77 image_00002.jpg 77 : : imagelabels.matにはラベルのインデックスしかないので、インデックスと名前を紐づけます。私はtfdsの存在を知る前にこの作業を行ったので、愚かにも全ての画像に目を通し、データセット取得元のページにあるラベル一覧と見比べながら対応表を作りましたが、tfdsのソースコードにインデックス順の名前のリストがあるので、そちらを使って対応表を作ることをおすすめします。ちなみにこの愚行のおかげで花の知識が少し増えました。
あらかじめ対応表(label_names.csv)をGoogle Driveにアップロードしておいてください。
インデックスと名前を紐づけるlabel_names_path = os.path.join(DataPath, 'label_names.csv') # 血と汗と涙の結晶 label_names = pd.read_csv(label_names_path, index_col=0) df = pd.merge(image_label_df, label_names, how='left', on='label') csv_path = os.path.join(DataPath, 'image_label_name.csv') df.to_csv(csv_path) # データフレームをcsvファイルに保存これで以下のようなデータフレームができました。
image label name image_00001.jpg 77 passion flower image_00002.jpg 77 passion flower : : : 学習データと検証データに分ける
scikit-learnのtrain_test_split関数を使って、データセットを学習データと検証データに分けます。学習データと検証データの比率は8:2としました。
(本当は学習データ、検証データ、テストデータの3つに分けるのが良いとされていますが、今回は学習データと検証データの2つに分けました。なお、ここでのtestは検証データのことです。)
学習データと検証データに分けるX_train_path = os.path.join(DataPath, 'X_train') # 学習データ用ディレクトリ X_test_path = os.path.join(DataPath, 'X_test') # 検証データ用ディレクトリ if not os.path.exists(X_train_path): os.mkdir(X_train_path) if not os.path.exists(X_test_path): os.mkdir(X_test_path) labels = pd.read_csv(csv_path, index_col=0) # 先ほど作ったcsvファイルを読み込む jpg_path = os.path.join(DataPath, 'jpg') # 学習データと検証データに分ける # 変数は左から学習画像、検証画像、学習ラベル、検証ラベル X_train, X_test, Y_train, Y_test = train_test_split(os.listdir(jpg_path), labels['name'], test_size=0.2, random_state=0) # それぞれのディレクトリにファイルを移動する for f in os.listdir(jpg_path): img = Image.open(os.path.join(jpg_path, f)) if f in X_train: img.save(os.path.join(X_train_path, f)) elif f in X_test: img.save(os.path.join(X_test_path, f))ラベルごとに分ける
ImageDataGeneratorのflow_from_directory関数を使うために、画像をさらにラベルごとに分けます。
ラベルごとに分ける# 学習データをラベルごとに分ける for f in os.listdir(X_train_path): index = df.image[df.image==f].index category = str(df.name[index].values).replace('[', '').replace(']', '').replace("'", '') if category == '"colts foot"': category = "colt's foot" category_path = os.path.join(X_train_path, category) if not os.path.exists(category_path): os.makedirs(category_path) img = Image.open(os.path.join(X_train_path, f)) img.save(os.path.join(category_path, f)) os.remove(os.path.join(X_train_path, f)) # 検証データをラベルごとに分ける for f in os.listdir(X_test_path): index = df.image[df.image==f].index category = str(df.name[index].values).replace('[', '').replace(']', '').replace("'", '') if category == '"colts foot"': category = "colt's foot" category_path = os.path.join(X_test_path, category) if not os.path.exists(category_path): os.makedirs(category_path) img = Image.open(os.path.join(X_test_path, f)) img.save(os.path.join(category_path, f)) os.remove(os.path.join(X_test_path, f))データを水増しする
今回使うデータセットは8189枚の画像群で、102種類の花の画像が各40~258枚入っています。これは学習データの量としては多くはありません。そこでKerasのImageDataGeneratorを使い、画像を回転したり反転したりすることでデータの水増しをします。
ImageDataGeneratorは「リアルタイムにデータ拡張しながら,テンソル画像データのバッチを生成します.また,このジェネレータは,データを無限にループするので,無限にバッチを生成します.」(公式ドキュメントより)
ImageDataGeneratorクラスで加工方法(正規化を含む)を指定し、flow_from_directory関数でディレクトリ内にある画像に対して加工を施し、かつバッチを生成します。
データの水増しtrain_datagen = ImageDataGenerator( rescale=1.0/255, rotation_range=45, width_shift_range=.15, height_shift_range=.15, horizontal_flip=True, vertical_flip=True, zoom_range=0.5, shear_range=0.2 ) val_datagen = ImageDataGenerator(rescale=1.0/255) train_gen = train_datagen.flow_from_directory( X_train_path, target_size=(224, 224), color_mode='rgb', batch_size=32, class_mode='categorical', shuffle=True ) val_gen = val_datagen.flow_from_directory( X_test_path, target_size=(224, 224), color_mode='rgb', batch_size=32, class_mode='categorical', shuffle=True )batch_sizeは大きいほど学習が早く終わりますがメモリを大量に消費します。逆に小さいほど学習には時間がかかりますが、メモリの制約に収まり、バッチ全体ではなく一つ一つのデータの特徴を捉えることができます。大きさとしては、1、32、128、256、512あたりがよく使われるようです。
[参考]
- 【Deep Learning】 Batch sizeをどうやって決めるかについてまとめるモデルを構築する
やっと機械学習っぽいところまで来ました。
今回は比較的精度が高いらしいResNet50をベースにfine-tuningモデルを作りました。転移学習でも良いのではないかと思い試したのですが、fine-tuningしたモデルの方が精度が高かったのでそちらを選択しました。
転移学習とfine-tuningの違いは多くの記事で説明されていますが、私の理解としてはベースモデルの重みを更新しないのが転移学習、更新するのがfine-tuningなのかなと思っています。本題。まずベースモデルをダウンロードします。
ResNet50をダウンロードbase_model = ResNet50(weights='imagenet', include_top=False, input_shape=(224, 224, 3))重みはImageNetのもの、出力層のノード数(ラベルの数)がResNet50の本来のものとは違うので出力層を含まない、入力データは3チャンネル(rgb)で224×224サイズ。
次に、ベースモデルに層を追加します。
ベースモデルに層を追加# 全ての重みを更新 base_model.trainable = True x = base_model.output x = GlobalAveragePooling2D()(x) x = BatchNormalization()(x) x = Dropout(0.5)(x) x = Dense(2048, activation='relu')(x) x = BatchNormalization()(x) x = Dense(1024, activation='relu')(x) x = BatchNormalization()(x) x = Dropout(0.5)(x) outputs = Dense(102, activation='softmax')(x) model = Model(inputs=base_model.input, outputs=outputs) model.compile(optimizer=keras.optimizers.RMSprop(lr=1e-5), loss=keras.losses.CategoricalCrossentropy(from_logits=True), metrics=['accuracy']) # model.summary()でモデルの詳細を確認可能Flattenだとパラメータの数が多すぎてメモリ不足になることがあったのでGlobalAveragePooling2Dを使いました。特徴マップを1×1にし1次元にしてくれます。BatchNormalizationは学習を早くしたり過学習を抑えてくれたりするそうです。これによりDropoutが要らない場合もあるようですが、念のためDropoutも入れておきました。
[参考]
- [CNN] Global Average Pooling 層のすすめ
- 畳み込みニューラルネットワークをKeras風に定義するとアーキテクチャの図をパワーポイントで保存してくれるツールを作った
- Deep LearningにおけるBatch Normalizationの理解メモと、実際にその効果を見てみるOptimizerは多くのモデルでRMSpropが使われていたのでそれを採用しました。SGDとAdamでも試してみましたが、RMSpropが一番性能が良かったです。Fine-tuningする場合は学習率をかなり小さくするとのことなので1e-5に設定しました。
[参考]
- Transfer learning & fine-tuning学習
ついに学習です。
学習させるhistory = model.fit( train_gen, steps_per_epoch=6551//32, # 学習データの数//batch_size epochs=30, validation_data=val_gen, validation_steps=1638//32 # 検証データの数//batch_size ) model.save('oxflower_local_waug_ResNet50_fullfine.h5') # モデルを保存する上ではepochs=30となっていますが、何回か繰り返して結局140 epochsで止めました。
学習結果(ラスト10 epochs)Epoch 1/10 204/204 [==============================] - 122s 598ms/step - loss: 3.6719 - accuracy: 0.9739 - val_loss: 3.6781 - val_accuracy: 0.9663 Epoch 2/10 204/204 [==============================] - 122s 597ms/step - loss: 3.6690 - accuracy: 0.9770 - val_loss: 3.6776 - val_accuracy: 0.9675 Epoch 3/10 204/204 [==============================] - 122s 597ms/step - loss: 3.6711 - accuracy: 0.9750 - val_loss: 3.6782 - val_accuracy: 0.9688 Epoch 4/10 204/204 [==============================] - 122s 598ms/step - loss: 3.6676 - accuracy: 0.9779 - val_loss: 3.6799 - val_accuracy: 0.9657 Epoch 5/10 204/204 [==============================] - 122s 597ms/step - loss: 3.6675 - accuracy: 0.9782 - val_loss: 3.6774 - val_accuracy: 0.9675 Epoch 6/10 204/204 [==============================] - 122s 596ms/step - loss: 3.6648 - accuracy: 0.9810 - val_loss: 3.6762 - val_accuracy: 0.9688 Epoch 7/10 204/204 [==============================] - 122s 599ms/step - loss: 3.6636 - accuracy: 0.9828 - val_loss: 3.6767 - val_accuracy: 0.9694 Epoch 8/10 204/204 [==============================] - 123s 601ms/step - loss: 3.6644 - accuracy: 0.9821 - val_loss: 3.6780 - val_accuracy: 0.9663 Epoch 9/10 204/204 [==============================] - 122s 598ms/step - loss: 3.6644 - accuracy: 0.9808 - val_loss: 3.6798 - val_accuracy: 0.9645 Epoch 10/10 204/204 [==============================] - 122s 597ms/step - loss: 3.6618 - accuracy: 0.9839 - val_loss: 3.6788 - val_accuracy: 0.9645最終的なval_accuracyは96%とかなり良い結果が出ましたが、loss、val_loss共にやけに高いのが気になります。他の方々の結果を見てみるとこれらの値は大体0.06くらいの小さな値で、1を超えているケースは見ないのですが何故なのでしょう。どなたかご意見いただけると嬉しいです。
ちなみに、accuracyは学習データに対する正解率、val_accuracyは検証データに対する正解率で、未知のデータに対する性能を測るにはval_accuracy(及びval_loss)に注目するべきのようです。予測してみる
学習したモデルがちゃんと花の種類を判別できるか確かめるために、こちらの画像を判別させてみます。
蓮(lotus)です。(Wikipediaより引用)ラベル予測# 画像はGoogle Driveにアップロード img = Image.open('lotus2.jpg').convert('RGB') img = img.resize((224, 224)) im2arr = keras.preprocessing.image.img_to_array(img) im2arr = im2arr.reshape(1, 224, 224, 3) im2arr = im2arr.astype('float32') im2arr = im2arr / 255.0 # 予測 pred = model.predict(im2arr) # ラベル名のリストを作る keys = train_gen.class_indices.keys() label_names = [] for key in keys: label_names.append(key) # ラベルインデックスに対応するラベル名が得られる print(label_names[np.argmax(pred)]) # 出力結果: lotuspredict関数は予測結果のnumpy arrayを返します。argmax関数を使うことで、予測結果のなかで最も数値の高いインデックスが分かります。しかし、インデックスだけ分かっても何の花なのか分からないので、ラベル名が分かるようにします。
結果、正しく予測してくれました。おわりに
ここまで長々とお付き合い頂きありがとうございました。
次は画像ではなく時系列データを使って時系列予想に挑戦してみようと思います。アリーヴェデルチ!

- 投稿日:2020-07-08T23:29:10+09:00
AV女優の特徴ってなんだろう? 作品名から推測してみた!(^_^)/~~
はじめに
みなさん、AVの作品名って気にしたことありますか?
私はふとした瞬間にある疑問が浮かびました。
「AVの作品名って、AV女優の特徴を表してるんじゃね?」
「もしそうなら、その特徴から自分のAV癖が分かるんじゃないかな?」そう思ったら、いざ行動!
やっていきましょう今回はワードクラウドという手法を用いて、仮説を立証していきます。
(私の好きな七沢みあさんに協力してもらいます。)ワードクラウドとは?
「ワードクラウド」とは、文章中に現れる出現頻度の高い単語を抽出し、1枚の絵にしたものです。
ある文章がどんな傾向なのか視覚的に”パッと見”で分かるので、手っ取り早く、かつ取っつきやすい方法のひとつです。HTML取得
import requests #webページを取得するライブラリ from bs4 import BeautifulSoup #取得したHTMLのデータの中から、タグを読み取り、操作できるライブラリurl = "https://ja.wikipedia.org/wiki/%E4%B8%83%E6%B2%A2%E3%81%BF%E3%81%82" #七沢みあのwikiURL response = requests.get(url) response.encoding = response.apparent_encoding #response.apparent_encoding に、正しい文字コードである SHIFT_JISが格納されている(文字化けを防げます) soup = BeautifulSoup(response.text, "html.parser") #BeautifulSoup(解析対象のHTML/XML, 利用するパーサー(解析器))#HTMLをインデントできる print(soup.prettify())
正しくHTMLが取得できました。
作品名取得
span_list1=soup.findAll("td") titles=[] for i in span_list1: tmp=i.find("b") if tmp==None: continue else: print(tmp.text) titles.append(tmp.text)
上記の出力から、「!」マークや「-」マークなど今回の分析に必要ない要素が含まれているため、これから取り除きます。クレイジング
import re changed_titles1=[] for i in titles: tmp=re.sub("!","",i) tmp=re.sub(" ","",tmp) tmp=re.sub("!","",tmp) tmp=re.sub("!!","",tmp) tmp=re.sub("〜","",tmp) tmp=re.sub("~","",tmp) tmp=re.sub("-","",tmp) tmp=re.sub("・","",tmp) tmp=re.sub("「","",tmp) tmp=re.sub("」","",tmp) tmp=re.sub("七沢みあ","",tmp) if tmp=="": continue else: changed_titles1.append(tmp)changed_titles1
これで不必要な文字が取り除けましたね。
ここから、形態素解析に入っていきます。形態素解析
import MeCab changed_titles2=''.join(changed_titles1) #リストから文字列にする必要があります text = changed_titles2 m = MeCab.Tagger("-Ochasen")#テキストをパースするためのTaggerインスタンス生成 #名詞のみを取り除いてみます nouns = [line for line in m.parse(text).splitlines()#Taggerクラスのparseメソッドを使うと、テキストを形態素解析した結果が返る if "名詞" in line.split()[-1]]for str in nouns: print(str.split())
nouns = [line.split()[0] for line in m.parse(text).splitlines() if "名詞" in line.split()[-1]] print(nouns)
結果は!?
from wordcloud import WordCloud import matplotlib.pyplot as plt text_new="" for i in nouns: text_new = text_new + " " + i word_cloud=WordCloud(background_color='white',font_path=r"C:\Users\tomoh\機械学習 able\ワードクラウド\meiryo.ttc",min_font_size=5,prefer_horizontal=1) word_cloud.generate(text_new) plt.figure(figsize=(10,8)) plt.imshow(word_cloud) plt.axis("off") plt.show()
上記の結果は、七沢みあさんの特徴を正しく表していることが分かります。
なぜなら、七沢みあさんの動画を一本も見逃さず鑑賞した経験があるからこそ分かるものがあるのです。(経験談ですいません。)
思い返してみると、
・ツンデレ
・挑発
・女子大
凄い惹かれるものを感じました。もし彼女がいたら、この3点が揃ってたらいいなぁ…
他の女優さんと比較
高橋しょうこさんはグラビア界からデビューの有名な女優さんですね。
この結果から、「アイドル、グラビア」という特徴はもちろん「上司、お姉ちゃん」というワードから、年上のSっ気のある特徴も読み取れます。怒られたい願望があるM気質の方におすすめですね。
三上悠亜さんは元SKE所属の人気の女優さんですね。
この結果から、「アイドル」という特徴はもちろん、「高級、巨乳,ソープ」というワードから、高級ソープ嬢の特徴も読み取れます。お金はないけど、高級ソープを味わいたい方におすすめですね。
水卜さくらさんは、七沢みあさんを好きになる前にお世話になった女優さんです。
この結果から、「おっぱい、巨乳、地味」という特徴が読み取れます。
恐らく、アニオタの地味な巨乳の女性が好きな方におすすめになると思います。以上の結果から、
私は「地味で、巨乳な、ツンデレ気質がある女子大生」が好きなことがワードクラウドから分かりました。確かにそうかも
「巨乳」という点では、高橋しょうこさん、三上悠亜さんも一致しているが、
それよりも七沢みあさんと水卜さくらさんの動画を視聴する機会が多いことから、
今回の仮説は立証です。皆さんもぜひお試しあれ。












- 投稿日:2020-07-08T23:12:33+09:00
ゼロから始めるLeetCode Day80「703. Kth Largest Element in a Stream」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
どうやら多くのエンジニアはその対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイトであり、海外のテックカンパニーでのキャリアを積みたい方にとっては避けては通れない道である。
と、仰々しく書いてみましたが、私は今のところそういった面接を受ける予定はありません。
ただ、ITエンジニアとして人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
Python3で解いています。
前回
ゼロから始めるLeetCode Day79「1282. Group the People Given the Group Size They Belong To」Twitterやってます。
技術ブログ始めました!!
技術はLeetCode、Django、Nuxt、あたりについて書くと思います。こちらの方が更新は早いので、よければブクマよろしくお願いいたします!#問題
703. Kth Largest Element in a Stream
難易度はEasy。問題としては、ストリーム内の
k番目に大きい要素を見つけるクラスを設計してください.これは、ソートされた順番の中でk番目に大きい要素であって、k番目の異なる要素ではないことに注意してください。
KthLargestは、整数kとストリームの初期要素を含む整数配列numsを受け入れるコンストラクタを持ちますKthLargest.addメソッドを呼び出すたびに、ストリーム内のk番目に大きい要素を表す要素を返します。Example:
int k = 3;
int[] arr = [4,5,8,2];
KthLargest kthLargest = new KthLargest(3, arr);
kthLargest.add(3); // returns 4
kthLargest.add(5); // returns 5
kthLargest.add(10); // returns 5
kthLargest.add(9); // returns 8
kthLargest.add(4); // returns 8要はコンストラクタと
addメソッドを実装してくださいね、ってことですね。この問題を取り扱ったのは、Googleのコーディング面接をパスした人がおすすめしているLeetCodeの問題集に載ってたからです。
コーディング面接対策のために解きたいLeetCode 60問
面白そうなので一通り解いてみようかなーと思います。
最近新しい問題ばかり解いていましたし、久々に面白そうな取り組みになりそうです。解法
ヒープの問題ってことで、大人しくヒープを使います。
優先度付きキューとも言いますね。一見この問題簡単そうに見えますよね。
毎回要素を追加した後にソートしてその中から
k-1の要素を返してあげれば良くね?となりそうですが、ソートという処理は重いので普通に時間切れになると思います。例えば、以下のような処理ですね。
def add(val): lists.append(val) self.lists.sort() return self.lists[self.num-1]これでは
addが呼ばれる度にソートがかかり、要素が増えれば増えるほど重くなっていきます。なので最初から要素を追加する時に優先度付きのキューを使って管理してしまえばわざわざソートしなくてもいいよね?ってことです。
ヒープを使ったものとして以下のコードを書きました。
import heapq class KthLargest: def __init__(self, k: int, nums: List[int]): self.lists,self.num = [],k for i in nums: self.add(i) def add(self, val: int) -> int: heapq.heappush(self.lists, val) if len(self.lists) > self.num: heapq.heappop(self.lists) return self.lists[0] # Your KthLargest object will be instantiated and called as such: # obj = KthLargest(k, nums) # param_1 = obj.add(val) # Runtime: 136 ms, faster than 45.40% of Python3 online submissions for Kth Largest Element in a Stream. # Memory Usage: 17.6 MB, less than 78.45% of Python3 online submissions for Kth Largest Element in a Stream.こうすることで最初に与えられた要素から全ての要素をヒープとして扱い、
listsの長さの値がnumと同値になるまでひたすらpop、すなわちリストから最小値を取り出すため、非常にスムーズに処理が行われます。書いてて思ったのですが、ヒープで書いたことほとんどなかったような気がするので復習がてらいい勉強になりました。
では今回はここまで。お疲れ様でした。
- 投稿日:2020-07-08T23:01:16+09:00
Google Cloud Functionsのログ出力(とハマったこと)
やりたいこと
- 言語:Python
- Google Cloud FunctionsでStack Driver Loggingにログを出力したい。
- ドキュメントを見ると
- とはいえログレベルは設定したい
やったこと
- google-cloud-loggingを使う
- requirements.txtに
google-cloud-logging==1.14.0を追記# Imports the Google Cloud client library import logging from google.cloud import logging as glogging client = glogging.Client(project=os.environ['PROJECT_ID']) handler = client.get_default_handler() cloud_logger = logging.getLogger('cloudLogger') cloud_logger.setLevel(logging.INFO) cloud_logger.addHandler(handler) def test_method(request): print('== start ==') try: cloud_logger.info('Info Message') cloud_logger.warn('Warn Message') raise Exception except Exception: cloud_logger.error('Error Message') raise Exception print('== finish ==')実行、しかしログが出ない
- なんにも出ない。
原因(想像)
- どうやらGoogle Cloud Functionsはcrash(=異常終了)するとそこまでのログを出力してくれない
- ドキュメントのどこかに記述があるのだろうか・・・・
- なのでExceptionが出たらcatchして最終的に
sys.exit()するように変更import sys # 中略 try: cloud_logger.info('Info Message') cloud_logger.warn('Warn Message') raise Exception except Exception: cloud_logger.error('Error Message') sys.exit() print('== finish ==')再実行、そしてエラー
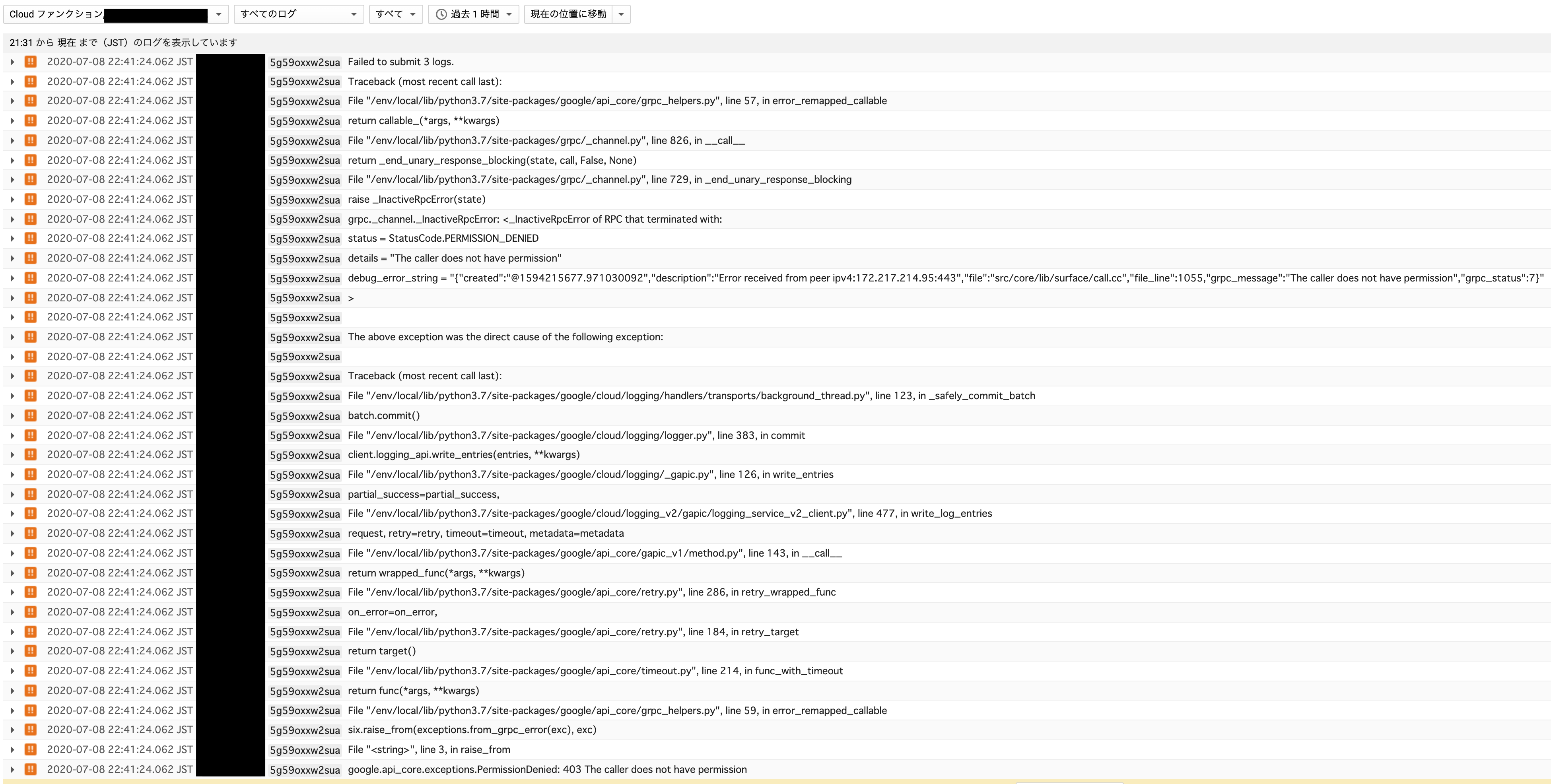
Failed to submit 3 logs.google.api_core.exceptions.PermissionDenied: 403 The caller does not have permissionとな
Google Cloud Functionsのサービスアカウント
- ドキュメントを見るとGoogle Cloud Functionsのデフォルトサービスアカウントは
PROJECT_ID@appspot.gserviceaccount.com(App Engine default service account)になると記載がある。どうやらプロジェクト編集者のロールを持っているらしい。
- https://cloud.google.com/functions/docs/concepts/iam?hl=ja#runtime_service_account
- SAを見るとたしかにそんなものが生まれてる。
- 自分の環境を見ると・・・・ない!
- なぜか無くなっていた模様
解決策
- 専用のSAを作成してGoogle Cloud Functionsへ紐付け。
- ちゃんとログが出るようになりました
- エラーレベルがinfoとerrorしかないのはなぜだろう・・・

振り返り
- ドキュメントはちゃんと読もう
- 書いてなかったかもしれないけど
- 横着してデフォルトのSAを使わず、ちゃんと必要な権限をもったSAを作成して利用しよう
- Cloud Functionsは落とさない。正常終了させる
- 稼働状況をモニタリングするならerror件数ではなくログのerrorメッセージ数を見る(しかないのだろうか・・・?)


- 投稿日:2020-07-08T22:25:42+09:00
「クソデカ羅生門」的な文章を生成したかった(過去形)
注意
これらの要素を含有しています
- クソコード
- 無知晒し
- 満足度の低い結果
前置き
クソデカ羅生門ってのがちょっと前に話題になったじゃないですか、このむやみに巨大化する文法が好きになったので生成したいと思います
環境
- Python 3.8.3
- pip 20.1.1
- mecab-python 0.996.2
- nltk 3.5
- (テキストエディタとしてVSCodeとNotepad++を使用)
準備とか
テキストデータの入手
青空文庫から素の羅生門をダウンロードします。ここにはルビ無しファイルがダウンロードできると書いてあったんですがルビありしか見つからなかったのでそっちをダウンロードしてルビを取り除きます。
まず青空文庫側が追加した底本表記とかを削除しまして、
テキストエディタ側の機能で
||《[^《》]*》|※[[^[]]*]の正規表現にマッチする文字列を削除(無に置換)します。
あ、あと文字コードがShift-JISに設定されてたんですがなんかムカついたのでUTF-8に変更しました。方向性を考える
とりあえず比較
これでとりあえずテキストデータの下準備は終わりました。ちょっとdifff.jpでクソ普通羅生門とクソデカ羅生門を比較してみましょう。
お分かりいただけたでしょうか。クソデカ羅生門は、改行なんかをのぞけば原文を全く削らずに完全な「足し算」でクソデカ化しているんです。つまるところ、クソデカ文章の生成の時も、語句そのものを変化させることはないように注意する必要があります。単純に品詞を過剰にするだけでは原文を崩してしまいますからね。「一点特化」について
あとクソデカ化について言うところとしては、形容を盛りまくるというよりは一点特化である、ということです。例えば
その代りまた鴉がどこからか、たくさん集って来た。昼間見ると、その鴉が何羽となく輪を描いて、高い鴟尾のまわりを啼きながら、飛びまわっている。
っていうクソ普通羅生門の文章を、クソデカ羅生門はこうクソデカ化―――語呂が悪いのでクソデ化としましょう―――しています。
その代りまた超凶悪な鴉がどこからか、億単位でたくさん集って来た。昼間見ると、その鴉が何万羽となく輪を描いて、クソ高い鴟尾のまわりを鼓膜破壊レベルの音量で啼きながら、亜音速で飛びまわっている。
このクソデ化は、私が思うに既存の形容を強化することに重点が置かれています。例えば「たくさん」は「億単位でたくさん」になりますし、「何羽」は「何万羽」、「高い」は「クソ高い」になります。例えば「高い」を「デカくて高い」とかにして属性を増やすことも可能でしょうが、あえてそれをせずに既存の形容の強化に専念しているわけです。
また、既存の形容が存在しない場合は、新規の形容を作ってそれを強化しています。「鴉が」なら「凶悪な鴉が」となり、それがさらに「超凶悪な鴉が」となります。そもそもタイトルからして「クソ」「デカ」「羅生門」ですからね、「クソ」で「デカ」を強化しているわけです。1やっていく
とりあえずまくらせる
クソデ化にあたって「まくる」は重要です。こいつらはすぐに何かをしまくりますからね。
「まくらせる」ためには、
- 自立語の動詞を探す
- その原形を取得
- 原形から連用形に変換
- 「まくる」をつける
的な工程を踏めばよさそうです。
なんか他にうまい方法がある気がするんですが思い付かなかったので、IPA辞書を直接殴る方式(参考)でいきます。データ用意
まずIPA辞書をダウンロードして解凍し、その中の
Verb.csvというファイルをカレントディレクトリにコピーして開きます。こいつは動詞のデータが入ってるファイルですね。
中身はこんな感じになってます。
10列目に「連用形」が記されている行以外はいらないので消します。テキストエディタ(表計算ソフトではない)で開いて^(?!.*,連用形,).*$\nの正規表現にマッチする文字列を消したらいい感じになると思います。
こうなりました、連用形リスト.csvって名称で保存しときます。あと処理が面倒なので文字コードをUTF-8に変更しておきます。
更に「まくる」の活用に関するファイルも作ります。元のVerb.csvのこの部分
をコピーしてまくる.csvって名前でカレントディレクトリに保存します。こっちもUTF-8です。コード
書きました。
# -*- coding: utf-8 -*- import MeCab import csv t = MeCab.Tagger() print("入力せよ") text = input() nodes_s = t.parseToNode(text) output = "" with open('連用形リスト.csv',encoding='UTF-8') as r, open("まくる.csv",encoding='UTF-8') as m: r_list = [list(x) for x in zip(*[row for row in (csv.reader(r))])] m_list = [list(x) for x in zip(*[row for row in (csv.reader(m))])] while nodes_s: nodes_a = nodes_s.feature.split(",") if nodes_a[:2] == ["動詞", "自立"] and not nodes_s.feature.split(",")[6] in ["する","ある"]: ori = nodes_a[6] type = nodes_a[5] renyo = r_list[0][r_list[10].index(ori)] mak = m_list[0][m_list[9].index(type)] if mak == "まくり" and nodes_s.next.feature.split(",")[7][0] in "タチツテト": mak = "まくっ" # タ接続でうまくいかない場合があったので例外処理 output += renyo + mak else: output += nodes_s.surface nodes_s = nodes_s.next print("\n出力:\n" + output)雑なコードですみません。
こいつを実行します。入力
下人は、老婆が死骸につまずきながら、慌てふためいて逃げようとする行手を塞いで、こう罵った。老婆は、それでも下人をつきのけて行こうとする。下人はまた、それを行かすまいとして、押しもどす。二人は死骸の中で、しばらく、無言のまま、つかみ合った。しかし勝敗は、はじめからわかっている。下人はとうとう、老婆の腕をつかんで、無理にそこへじ倒した。丁度、鶏の脚のような、骨と皮ばかりの腕である。出力
下人は、老婆が死骸につまずきまくりながら、慌てまくりふためきまくって逃げまくろうとする行手を塞ぎまくっで、こう罵りまくった。老婆は、それでも下人をつきまくりのけて行こうとする。下人はまた、それを行かしまくるまいとして、押しもどす。二人は死骸の中で、しばらく、無言のまま、つかみ合いまくった。しかし勝敗は、はじめからわかりまくっている。下人はとうとう、老婆の腕をつかみまくっで、無理にそこへじ倒しまくった。丁度、鶏の脚のような、骨と皮ばかりの腕である。
とりあえず意図したこと「らしきこと」は何となくできてる気がします。いろいろと不備はありますが
このままだと「まくりすぎ」なので、調整は必要でしょうね。「しまくらない」を殺す
このコードだと特定の文字を入れたときに不自然な感じになっちゃいます。
例えば下人の行方は、誰も知らない。を入力したとして、
出力されるのは下人の行方は、誰も知りまくらない。です。
いや、何?って話ですよ、知りまくらないって何?
明らかにおかしいのでコードを変更します。#前略 while nodes_s: nodes_a = nodes_s.feature.split(",") if nodes_a[:2] == ["動詞", "自立"] and not nodes_s.feature.split(",")[6] in ["する","ある"]: #後略ここのifをちょっと弄りまして、
while nodes_s: nodes_a = nodes_s.feature.split(",") if nodes_a[:2] == ["動詞", "自立"] and (not nodes_s.feature.split(",")[6] in ["する","ある"]) and not nodes_s.next.feature.split(",")[4] in ["特殊・ナイ"]:こうします。
これはタ接続時の例外処理と似たような処理で、処理中のnodeの次のノードをnextで先読みすることで判定しています。
これでちゃんと下人の行方は、誰も知らない。が出力されます。「まくっで」を殺す
「選んで」とかが「選びまくっで」とかになっちゃうのでこいつを殺します。
雑にreplaceでキルします。
printの1行前にoutput = output.replace("まくっで","まくって")を突っ込んだら解決しました
あ、あとまくらられみたいなのもあったのでこいつもreplaceでまくられに置換しましょう以下略
まあこんな風に不自然な場所を人為的に直しました
過程を移すのが面倒なので略しまして、結果としてこんなコードができました# -*- coding: utf-8 -*- import MeCab import csv t = MeCab.Tagger() print("入力せよ") inp = input() def makuring(text): nodes_s = t.parseToNode(text) output = "" with open('連用形リスト.csv',encoding='UTF-8') as r, open("まくる.csv",encoding='UTF-8') as m: r_list = [list(x) for x in zip(*[row for row in (csv.reader(r))])] m_list = [list(x) for x in zip(*[row for row in (csv.reader(m))])] while nodes_s: nodes_a = nodes_s.feature.split(",") if nodes_a[:2] == ["動詞", "自立"] and (not nodes_s.feature.split(",")[6] in ["する", "ある", "なる", "いる","言う","云う","行く"]) and not nodes_s.next.feature.split(",")[4] in ["特殊・ナイ", "特殊・ヌ"]: ori = nodes_a[6] type = nodes_a[5] if ori in r_list[10]: renyo = r_list[0][r_list[10].index(ori)] mak = m_list[0][m_list[9].index(type)] if mak == "まくり" and nodes_s.next.feature.split(",")[7][0] in "タチツテト": mak = "まくっ" # タ接続でうまくいかない場合があったので例外処理 output += renyo + mak else: output += nodes_s.surface else: output += nodes_s.surface nodes_s = nodes_s.next return output.replace("まくっで", "まくって").replace("まくらられ", "まくられ").replace("まくっだ", "まくった")ついでにこれらを関数という扱いにしてみました。
これでとりあえず「まくり」処理は完成です。数字をくっつける
クソデカ羅生門はクソデ化にあたって数字もクソデ化しています。レートは100倍~10000倍くらいですかね?あと盗賊に対する6万人などの、「妙に具体的な数字が与えられる」事象も多発してます。
とりあえず既存の数字を10の2~4乗倍する感じにしました。# -*- coding: utf-8 -*- import MeCab import csv from kanjize import int2kanji, kanji2int import random t = MeCab.Tagger() print("入力せよ") inp = input() kan_dic = { "百": "百","五": "五","5": "五","八": "八","・": "・","兆": "兆","9": "九", "七": "七","三": "三","0": "〇","0": "〇","万": "万","零": "〇","四": "四", "7": "七","2": "二","4": "四","1": "一","6": "六","〇": "〇","十": "十", "六": "六","8": "八","3": "三","二": "二","○": "〇" ,"千": "千","一": "一", "億": "億","九": "九","ひゃく": "百","ゼロ": "〇","いち": "一"} # IPA辞書を加工して作った数字の正規化用辞書 #(略) def incr(text): nodes_s = t.parseToNode(text) output = "" int_flag = False count = 0 while nodes_s: count += 1 nodes_a = nodes_s.feature.split(",") if nodes_a[1] == "数" and nodes_s.surface in kan_dic.keys(): if not int_flag: int_flag = True kansuji = "" kansuji += kan_dic[nodes_s.surface] else: if int_flag: int_flag = False random.seed(kansuji) output += int2kanji(kanji2int(kansuji) * (10 ** random.randint(2,4))) elif count > 1: if nodes_s.prev.surface in ["何", "なん", "幾"] and nodes_s.prev.feature.split(",")[1] == "数": random.seed(nodes_s.surface) output += random.choice(["千","万","億"]) output += nodes_s.surface nodes_s = nodes_s.next return output print("\n出力:\n" + makuring(incr(inp)))入力
広い門の下には、この男のほかに誰もいない。ただ、所々丹塗の剥げた、大きな円柱に、蟋蟀が一匹とまっている。羅生門が、朱雀大路にある以上は、この男のほかにも、雨やみをする市女笠や揉烏帽子が、もう二三人はありそうなものである。それが、この男のほかには誰もいない。出力
広い門の下には、この男のほかに誰もいない。ただ、所々丹塗の剥げまくった、大きな円柱に、蟋蟀が千匹とまりまくっている。羅生門が、朱雀大路にある以上は、この男のほかにも、雨やみをする市女笠や揉烏帽子が、もう五千人はありそうなものである。それが、この男のほかには誰もいない。
「ニ三人」が「ニ万三千人」(これはこれで間違った解釈ですが)じゃなくて「五千人」になっちゃってるのは、漢字と数字の相互変換に使ってるkanjizeってライブラリの仕様によるものだと思います。直せる気もしますが面倒なのでやめときます。「たくさん」の処理
クソデ化の時、「たくさん」が「億単位でたくさん」になるじゃないですか、あれの処理をします
なんかnltkとWordnetでいい感じになりそうなのでこの記事を参考にpip install nltk python -c "import nltk;nltk.download('wordnet')" python -c "import nltk;nltk.download('omw')"をコマンドプロンプトで実行して環境を整えます。
さて、試しに「たくさん」の類語を出力してみます。(さっき貼った記事のコードほぼそのままです、すみません)from nltk.corpus import wordnet synsets = wordnet.synsets("たくさん", lang='jpn') takusan_synset = synsets[0] synonyms = takusan_synset.lemma_names("jpn") print(synonyms)出力
['たくさん', '厖大', '多量', '大量', '数多', '沢山', '浩大', '潤沢', '総やか', '豊', '豊か', '豊富', '豊満', '豊潤', '豊饒']
いいですね、いかにもたくさん、って感じ
この吐き出されたリストをそのまま「たくさんっぽい言葉」の配列として保存して、その配列に含まれる言葉を類語として持っている言葉に具体的な数字をつける方向で行きましょう
(盗人を6万人にするのは方法が思いつかなかったので諦めました)# -*- coding: utf-8 -*- import MeCab import csv from kanjize import int2kanji, kanji2int import random from nltk.corpus import wordnet #(略) blacklist = [] t = MeCab.Tagger() takusan = [ 'たくさん', '厖大', '多量', '大量', '数多', '沢山', '浩大', '潤沢', '総やか', '豊', '豊か', '豊富', '豊満', '豊潤', '豊饒'] #(略) def embod(text): global blacklist nodes_s = t.parseToNode(text) output = "" while nodes_s: nodes_a = nodes_s.feature.split(",") if not (nodes_a[1] in ["動詞", "助詞", "記号", "助動詞"] or nodes_s.surface in blacklist): synsets = wordnet.synsets(nodes_s.surface, lang='jpn') synsets_a = [] for i in synsets: synsets_a += i.lemma_names("jpn") if len(set(takusan) & set(synsets_a)) > 0: random.seed(nodes_s.prev.prev.surface +nodes_s.prev.surface) #なんか一つの入力に対する生成結果が常に同じの方がいい気がしたのでシード設定 output += random.choice(["万単位で","億単位で","兆単位で"]) else: blacklist += nodes_s.surface output += nodes_s.surface nodes_s = nodes_s.next return outputなんか処理が長くなる予感がしたんでブラックリストをつけて実行時間短縮を図りました。
入力
その代りまた鴉がどこからか、たくさん集って来た。昼間見ると、その鴉が何羽となく輪を描いて、高い鴟尾のまわりを啼きながら、飛びまわっている。ことに門の上の空が、夕焼けであかくなる時には、それが胡麻をまいたようにはっきり見えた。鴉は、勿論、門の上にある死人の肉を、啄みに来るのである。――もっとも今日は、刻限が遅いせいか、一羽も見えない。ただ、所々、崩れかかった、そうしてその崩れ目に長い草のはえた石段の上に、鴉の糞が、点々と白くこびりついているのが見える。下人は七段ある石段の一番上の段に、洗いざらした紺の襖の尻を据えて、右の頬に出来た、大きな面皰を気にしながら、ぼんやり、雨のふるのを眺めていた。
出力
その代りまた鴉がどこからか、兆単位でたくさん集いまくって来た。昼間見まくると、その鴉が何千羽となく輪を描きまくって、高い鴟尾のまわりを啼きまくりながら、飛びまわりまくっている。ことに門の上の空が、夕焼けであかくなる時には、それが胡麻をまきまくったようにはっきり見えまくった。鴉は、勿論、門の上にある死人の肉を、啄みまくりに来まくるのである。――もっとも今日は、刻限が遅いせいか、千羽も見えない。ただ、所々、崩れまくりかかった、そうしてその崩れ目に長い草のはえまくった石段の上に、鴉の糞が、点々と白くこびりつきまくっているのが見えまくる。下人は七千段ある石段の一番上の段に、洗いざらした紺の襖の尻を据えまくって、右の頬に出来まくった、大きな面皰を気にしながら、ぼんやり、雨のふりまくるのを眺めまくっていた。
なかなかいい感じじゃないでしょうか。「ニ三人」の処理
さっき「直せる気もしますが面倒なのでやめときます」って書いたんですが、なんか思ったより楽な気がしてきたので直していきます。
#(略) else: if int_flag: int_flag = False if len(kansuji) > 1: if all((s in "一二三四五六七八九") for s in [kansuji[0],kansuji[1]]): #最初の2文字が両方一~九であった場合「ニ三」の同類とみなす output += kansuji[0] kansuji = kansuji[1:] random.seed(kansuji) output += int2kanji(kanji2int(kansuji) * (10 ** random.randint(2,4))) #(略)入力
広い門の下には、この男のほかに誰もいない。ただ、所々丹塗の剥げた、大きな円柱に、蟋蟀が一匹とまっている。羅生門が、朱雀大路にある以上は、この男のほかにも、雨やみをする市女笠や揉烏帽子が、もう二三人はありそうなものである。それが、この男のほかには誰もいない。
出力
兆単位で広い門の下には、この男のほかに誰もいない。ただ、所々丹塗の剥げまくった、大きな円柱に、蟋蟀が千匹とまりまくっている。羅生門が、朱雀大路にある以上は、この男のほかにも、雨やみをする市女笠や揉烏帽子が、もう二三千人はありそうなものである。それが、この男のほかには誰もいない。完璧か?
形容の追加・クソデ化
前置き(長い)
ついに来てしまいました………おそらく一番の難関というかこれを書いている今も方法をよく理解してないです
いや、どうすればいいの?
えっと、とりあえず「まだ形容されてない単語」に「新しく形容をつける」みたいなことをやってみようと思います↑この文章を書いたのが3日前です……3日間隙あらばHacknetやってました………生産性がなさすぎる
「いやほんとどーしよーな~~~~~」みたいな感じでへらへら笑いながらHacknetでPointclickerのデータ改竄してましたからね………酷い奴だ
でですね、3日間の間にCabochaを使って係り受け解析すれば「形容がついてる文章」と「ついてない文章」で分けられるのでは?ということを思いつきました
そういうわけでとりあえずここからCabochaをインストールして………
あれっ
あの、今インストールしてテストしてるところなんですが、何も出力しません
これ何かしらに失敗しましたわ、どうしようもない
そういうわけで、Cabocha以外の係り受け解析器を探しますこれだ
COTOHA APIです。知人の話ではこいつには構文解析(つよい)機能があるらしいじゃないですか、俺はこれで未来を掴むぜと思ったんですがなんか知らないけど「利用規約読みました」のチェックボックスがクリックできなかったので諦めます。もう終わりだ
こうなったら
気合で何とかします。プランを練りましょう
えーっとですね、「形容されている」か「されていない」かを判定して、されていない場合はあたらしく適当につける、みたいなことをやればいいはずです。
まず「形容されるべき言葉」とでも言うべきものがあるはずです。とりあえず一般名詞(盗人や蟋蟀など)と自立動詞(啼くや飛び回るなど)などは「形容されるべき言葉」である、ということにしましょう。
そして「この形容されるべき言葉」が形容されているかの判定にはひとつ前の形態素が格助詞または句点であるかを用いることにします。なんかこれでいい感じになる気がしたのでこうします。
これを元に関数を作ってみましょう。#(略) def deco(text): nodes_s = t.parseToNode(text) output = "" count = 0 while nodes_s: nodes_a = nodes_s.feature.split(",") count += 1 if nodes_a[:2] in [["名詞", "一般"], ["名詞", "固有名詞"], ["動詞", "自立"]] and count > 1: if nodes_s.prev.feature.split(",")[0] in ["連体詞"] or nodes_s.prev.feature.split(",")[1] in ["格助詞", "句点", "読点", "並立助詞"]: output += "クソデカ" output += nodes_s.surface nodes_s = nodes_s.next return output print("\n出力:\n" + makuring(embod(incr(deco(inp)))))とりあえずまだ形容されてないっぽい形態素の一個前に「クソデカ」と付ける関数ができました。動詞と名詞の区別すらつけてませんが、これでとりあえずやってみましょう。
入力
広い門の下には、この男のほかに誰もいない。ただ、所々丹塗の剥げた、大きな円柱に、蟋蟀が一匹とまっている。羅生門が、朱雀大路にある以上は、この男のほかにも、雨やみをする市女笠や揉烏帽子が、もう二三人はありそうなものである。それが、この男のほかには誰もいない。出力
兆単位で広い門の下には、このクソデカ男のほかに誰もいない。ただ、クソデカ所々丹塗の剥げまくった、大きなクソデカ円柱に、クソデカ蟋蟀が千匹とまりまくっている。クソデカ羅生門が、クソデカ朱雀大路にクソデカある以上は、このクソデカ男のほかにも、クソデカ雨やみをクソデカする市女笠やクソデカ揉烏帽子が、もう二三千人はありそうなものである。それが、このクソデカ男のほかには誰もいない。
う~~~~~~~~~~~~ん
いけるか…?いやでもなぁ、う~~~~ん
まだ判断しづらいですし、ちょっと改修しますdef deco(text): nodes_s = t.parseToNode(text) output = "" count = 0 while nodes_s: nodes_a = nodes_s.feature.split(",") count += 1 if count > 1: if nodes_s.prev.feature.split(",")[0] in ["連体詞"] or nodes_s.prev.feature.split(",")[1] in ["格助詞", "句点", "読点", "並立助詞"]: if nodes_a[:2] in [["名詞", "一般"], ["名詞", "固有名詞"]]: output += "クソデカ" elif nodes_a[:2] in [["動詞", "自立"]]: output += "メチャクチャ" output += nodes_s.surface nodes_s = nodes_s.next return output動詞なら「メチャクチャ」、名詞なら「クソデカ」が付くようにしました
これでちょっとわかりやすくなったんじゃないでしょうか入力
広い門の下には、この男のほかに誰もいない。ただ、所々丹塗の剥げた、大きな円柱に、蟋蟀が一匹とまっている。羅生門が、朱雀大路にある以上は、この男のほかにも、雨やみをする市女笠や揉烏帽子が、もう二三人はありそうなものである。それが、この男のほかには誰もいない。出力
兆単位で広い門の下には、このクソデカ男のほかに誰もいない。ただ、クソデカ所々丹塗の剥げまくった、大きなクソデカ円柱に、クソデカ蟋蟀が千匹とまりまくっている。クソデカ羅生門が、クソデカ朱雀大路にメチャクチャある以上は、このクソデカ男のほかにも、クソデカ雨やみをメチャクチャする市女笠やクソデカ揉烏帽子が、もう二三千人はありそうなものである。それが、このクソデカ男のほかには誰もいない。良さげ
とりあえず語彙を増やしてみる
クソデ化詞の豊富さがクソデカ羅生門の魅力の一つです。クソデ化詞は大雑把に分類すると、「名詞につくもの」(デカい・巨大な)と「動詞につくもの」(馬鹿みたいに・メチャクチャ)と「形容詞につくもの」(超・クソ)の3種類です。「形容詞につく物」はクソデ化詞に付く場合もあるのでちょっと特殊なポジションですね。機械的に生成するのも可能な気がしますがめんどくさいので人力で生成しました。
- 名詞につくものリスト:
["デカい","大","激・","巨大","象くらいある","ヤバい","ビッグ","とんでもない","ものすごい","世界最強の"](ここで力尽きました)- 動詞につくものリスト:
["メチャメチャ","馬鹿みたいに","マジで","気持ち悪いくらい"](ここで力尽き略- 形容詞につくものリスト
["超","メチャメチャ","馬鹿みたいに","マジで","クソ","めちゃくちゃ","ガチで","えげつない","人類史に残るほどに"](ここで略メッチャ適当にやったせいで語彙力が貧弱になってしまいました……まぁいいです、これでやってみましょう
とりあえず名詞と動詞をクソデ化しますdef deco(text): nodes_s = t.parseToNode(text) output = "" count = 0 while nodes_s: nodes_a = nodes_s.feature.split(",") count += 1 if count > 1: if nodes_s.prev.feature.split(",")[0] in ["連体詞"] or nodes_s.prev.feature.split(",")[1] in ["格助詞", "句点", "読点", "並立助詞"]: random.seed(nodes_s.prev.surface + nodes_s.surface + nodes_s.next.surface) #雑に前後を参照してシード決定 if nodes_a[:2] in [["名詞", "一般"], ["名詞", "固有名詞"]]: output += random.choice(["デカい","大","激・","巨大","象くらいある","ヤバい","ビッグ","とんでもない","ものすごい","世界最強の"]) elif nodes_a[:2] in [["動詞", "自立"]]: output += random.choice(["メチャメチャ","馬鹿みたいに", "マジで", "気持ち悪いくらい"]) output += nodes_s.surface nodes_s = nodes_s.next return outputあ、あと関数の順番をちょっと変えました
print("\n出力:\n" + makuring(deco(embod(incr(inp)))))入力
作者はさっき、「下人が雨やみを待っていた」と書いた。しかし、下人は雨がやんでも、格別どうしようと云う当てはない。ふだんなら、勿論、主人の家へ帰る可き筈である。所がその主人からは、四五日前に暇を出された。前にも書いたように、当時京都の町は一通りならず衰微していた。今この下人が、永年、使われていた主人から、暇を出されたのも、実はこの衰微の小さな余波にほかならない。だから「下人が雨やみを待っていた」と云うよりも「雨にふりこめられた下人が、行き所がなくて、途方にくれていた」と云う方が、適当である。その上、今日の空模様も少からず、この平安朝の下人の出力
作者はさっき、「下人が大雨やみをマジで待ちまくっていた」とマジで書きまくった。しかし、デカい下人は雨がマジでやんでも、格別どうしようとメチャメチャ云う当てはない。ふだんなら、勿論、ものすごい主人の家へ馬鹿みたいに帰りまくる可き筈である。所がそのヤバい主人からは、四五千日前にとんでもない暇を馬鹿みたいに出しまくられた。前にも書きまくったように、当時京都の町は千通りならず衰微していた。今このビッグ下人が、永年、メチャメチャ使いまくられていた主人から、ヤバい暇を馬鹿みたいに出しまくられたのも、実はこの衰微の小さなものすごい余波にメチャメチャほかならない。だから「下人が大雨やみをマジで待ちまくっていた」とメチャメチャ云うよりも「雨にメチャメチャふりこめまくられた下人が、気持ち悪いくらい行き所がなくて、兆単位で巨大途方にマジでくれまくっていた」と馬鹿みたいに云う方が、適当である。その上、今日の空模様も少からず、この兆単位で巨大平安朝の下人のう~~~~ん
まぁいいか(いいのか?)マジでない
クソデカ羅生門は基本的に「ない」を「マジでない」にします。Falseというそれ以上強めようのない言葉を「確実性」という観点からデカくしてるんですね、さすがだ
def deco(text): nodes_s = t.parseToNode(text) output = "" count = 0 while nodes_s: nodes_a = nodes_s.feature.split(",") count += 1 if count > 1: if nodes_s.prev.feature.split(",")[0] in ["連体詞"] or nodes_s.prev.feature.split(",")[1] in ["格助詞", "句点", "読点", "並立助詞"]: random.seed(nodes_s.prev.surface + nodes_s.surface) #雑に前を参照してシード決定(エラーが出たのでprevだけ参照するように) if nodes_a[:2] in [["名詞", "一般"], ["名詞", "固有名詞"]]: output += random.choice(["デカい","大","激・","巨大","象くらいある","ヤバい","ビッグ","とんでもない","ものすごい","世界最強の"]) elif nodes_a[:2] in [["動詞", "自立"]]: output += random.choice(["メチャメチャ","馬鹿みたいに", "マジで", "気持ち悪いくらい"]) if nodes_a[0] == "形容詞" and nodes_a[6] == "ない": output += "マジで" output += nodes_s.surface nodes_s = nodes_s.next return output入力
作者はさっき、「下人が雨やみを待っていた」と書いた。しかし、下人は雨がやんでも、格別どうしようと云う当てはない。ふだんなら、勿論、主人の家へ帰る可き筈である。所がその主人からは、四五日前に暇を出された。前にも書いたように、当時京都の町は一通りならず衰微していた。今この下人が、永年、使われていた主人から、暇を出されたのも、実はこの衰微の小さな余波にほかならない。だから「下人が雨やみを待っていた」と云うよりも「雨にふりこめられた下人が、行き所がなくて、途方にくれていた」と云う方が、適当である。その上、今日の空模様も少からず、この平安朝の下人の Sentimentalisme に影響した。申の刻下りからふり出した雨は、いまだに上るけしきがない。そこで、下人は、何をおいても 差当り明日の暮しをどうにかしようとして――云わばどうにもならない事を、どうにかしようとして、とりとめもない考えをたどりながら、さっきから朱雀大路にふる雨の音を、聞くともなく聞いていたのである。出力(シード周りを弄ったのでさっきと生成される乱数が変わってます)
作者はさっき、「下人がものすごい雨やみをメチャメチャ待ちまくっていた」と気持ち悪いくらい書きまくった。しかし、ものすごい下人は雨が馬鹿みたいにやみまくっても、格別どうしようと気持ち悪いくらい云う当てはない。ふだんなら、勿論、巨大主人の家へマジで帰りまくる可き筈である。所がその激・主人からは、四五千日前にものすごい暇をメチャメチャ出しまくられた。前にも書きまくったように、当時京都の町は千通りならず衰微していた。今この世界最強の下人が、永年、馬鹿みたいに使いまくられていた主人から、ものすごい暇をメチャメチャ出しまくられたのも、実はこの衰微の小さなとんでもない余波にメチャメチャほかならない。だから「下人がものすごい雨やみをメチャメチャ待ちまくっていた」と気持ち悪いくらい云うよりも「雨にメチャメチャふりこめまくられた下人が、マジで行き所がマジでなくて、デカい途方にメチャメチャくれまくっていた」と気持ち悪いくらい云う方が、適当である。その上、今日の空模様も少からず、このとんでもない平安朝の下人のSentimentalismeに影響した。とんでもない申の刻下りからマジでふりまくり出した雨は、いまだに上りまくるけしきがマジでない。そこで、ものすごい下人は、何を気持ち悪いくらいおきまくっても差当り明日の暮しをどうにかしようとして――云わばどうにもならない事を、どうにかしようとして、気持ち悪いくらいとりとめまくりもマジでない考えを気持ち悪いくらいたどりまくりながら、さっきからビッグ朱雀大路にメチャメチャふりまくる雨の音を、馬鹿みたいに聞きまくるともマジでなく聞きまくっていたのである。理解不能だけどまぁ…
形容詞をクソデ化
ちょっと辛くなってきたのでこれで終わりにしたい
obiv関数を作って形容詞のクソデ化を行います。クソデ化詞はさっき載せたリストを使用し、関数を二重がけすることでクソデ化に厚みを持たせます。(冗長にならないようクソデ化率を50%くらいにしましょう)def obiv(text): nodes_s = t.parseToNode(text) output = "" count = 0 while nodes_s: count += 0 nodes_a = nodes_s.feature.split(",") if nodes_a[0] == "形容詞": random.seed(nodes_s.surface + str(count)) if random.random() < 0.5: output += random.choice(["超","メチャメチャ","馬鹿みたいに","マジで","クソ","めちゃくちゃ","ガチで","えげつない","人類史に残るほどに"]) output += nodes_s.surface nodes_s = nodes_s.next return output print("\n出力:\n" + obiv(obiv(makuring(deco(embod(incr(inp)))))))入力
作者はさっき、「下人が雨やみを待っていた」と書いた。しかし、下人は雨がやんでも、格別どうしようと云う当てはない。ふだんなら、勿論、主人の家へ帰る可き筈である。所がその主人からは、四五日前に暇を出された。前にも書いたように、当時京都の町は一通りならず衰微していた。今この下人が、永年、使われていた主人から、暇を出されたのも、実はこの衰微の小さな余波にほかならない。だから「下人が雨やみを待っていた」と云うよりも「雨にふりこめられた下人が、行き所がなくて、途方にくれていた」と云う方が、適当である。その上、今日の空模様も少からず、この平安朝の下人の Sentimentalisme に影響した。申の刻下りからふり出した雨は、いまだに上るけしきがない。そこで、下人は、何をおいても 差当り明日の暮しをどうにかしようとして――云わばどうにもならない事を、どうにかしようとして、とりとめもない考えをたどりながら、さっきから朱雀大路にふる雨の音を、聞くともなく聞いていたのである。出力
作者はさっき、「下人がものすごい雨やみをメチャメチャ待ちまくっていた」と気持ち悪いくらい書きまくった。しかし、ものすごい下人は雨が馬鹿みたいにやみまくっても、格別どうしようと気持ち悪いくらい云う当てはない。ふだんなら、勿論、巨大主人の家へマジで帰りまくる可き筈である。所がその激・主人からは、四五千日前にものすごい暇をメチャメチャ出しまくられた。前にも書きまくったように、当時京都の町は千通りならず衰微していた。今この世界最強の下人が、永年、馬鹿みたいに使いまくられていた主人から、ものすごい暇をメチャメチャ出しまくられたのも、実はこの衰微の小さなとんでもない余波にメチャメチャほかならない。だから「下人がものすごい雨やみをメチャメチャ待ちまくっていた」と気持ち悪いくらい云うよりも「雨にメチャメチャふりこめまくられた下人が、マジで行き所がマジでなくて、デカい途方にメチャメチャくれまくっていた」と気持ち悪いくらい云う方が、適当である。その上、今日の空模様もマジでマジで少からず、このとんでもない平安朝の下人のSentimentalismeに影響した。とんでもない申の刻下りからマジでふりまくり出した雨は、いまだに上りまくるけしきがマジでない。そこで、ものすごい下人は 、何を気持ち悪いくらいおきまくっても差当り明日の暮しをどうにかしようとして――云わばどうにもならない事を、どうにかしようとして、気持ち悪いくらいとりとめまくりもマジでない考えを気持ち悪いくらいたどりまくりながら、さっきからビッグ朱雀大路にメチャメチャふりまくる雨の音を、馬鹿みたいに聞きまくるともマジでなく聞きまくっていたのである。
もう終わりにしていいですか、若干辛くなってきた感想
あんまり高精度なクソデ化ができませんでした………Cabochaを使えればもうちょっと高度なのができたと思うんですが色々面倒でして……いつかインストールに成功したら再チャレンジしたいです、もうちょっと「対象によって変わるクソデ化詞」が欲しかったね(例:「亜音速で」)
参考
https://web.archive.org/web/20171212152621/http://adsmedia.hatenablog.com/entry/2016/10/20/002211
https://qiita.com/pocket_kyoto/items/1e5d464b693a8b44eda5
https://qiita.com/matsuatsu/items/fc696741a994f011f91e
「クソデカ」は2つで1セットみたいなところありますが、「デカ羅生門」でも意味は通じますし、それに更に「バカ」を足すことで「バカデカ羅生門」とかも作れるので、分離したそれと考えました。 ↩






- 投稿日:2020-07-08T21:20:00+09:00
conda環境へのパッケージインストールにおける注意点
概要
皆様,こんにちは.
私事で恐縮ですが,最近は忙しく論文執筆に追われておりました.
忙しい時に限って何かとトラブルが起こるものです.今回はそんなトラブル対処の備忘録です.ようやくタスクもひと段落したので,記事としてまとめておきます.
備忘録,メモ的な内容ですので,お気軽に見ていただければと思います.トラブル内容
パッケージがconda環境に入らなかった.以下詳細.
conda環境にパッケージを追加したい.なのでactivateして,
(base) source activate hogehoge (hogehoge) conda install hogehogeしかしcondaのレポジトリにないといわれる.
PackagesNotFoundError: The following packages are not available from current channels:なので,しぶしぶpipでインストールすることに.
(hogehoge) sudo pip install hogehogeしかしなぜかconda環境にパッケージが入らない.
解決法
スーパーユーザ権限で実行してたのが原因.
base環境にぶち込まれてしまう.
なので純粋に,(hogehoge) pip install hogehogeでよい.
スーパーユーザ権限を無心で乱用していたことに対する報いである.
大変しょうもないミスであるが,今後はきちんとコマンド一つにとり何を意味しているかを意識したい.はやく実験しようと焦ると,linuxの基本やコードの記法もおろそかになってくるので,
日頃の自習をしっかりとして,いろんな状況でも対応できるようにしたい.終わりです.ご覧いただきありがとうございました.
- 投稿日:2020-07-08T19:56:22+09:00
学習済みStyleGAN2モデルを使って、新規画像を画像編集してみる
1.はじめに
前回の「StyleGAN2の潜在空間に、新垣結衣は住んでいるのか?」 では、学習済みStyleGAN2モデルは学習に使っていない新規画像についても、高い画像生成能力を持っていることが分かりました。
今回は、学習済みStyleGAN2モデルを使って、学習に使っていない新規画像をどの程度画像編集できるかを見て行きたいと思います。
コードは Google Colab を使って作成し、Github に上げてありますので、良かったら動かしてみて下さい。
*このブログで使用している画像は全てStyleGAN2の学習には使用していない新規画像です(前回ご紹介した方法で作成しています)。
2.Style Mixing とは?
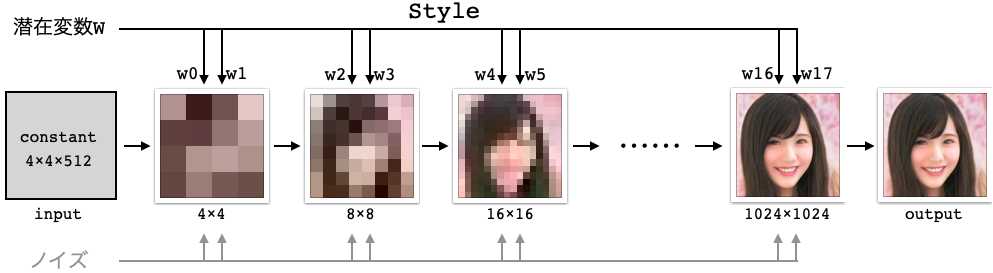
StyleGANは、今までのGANの様に1個の潜在変数から画像生成するのではなく、Mapping network を使って18個の潜在変数w(これをstyleと呼びます)から画像生成しています。この特徴を生かすと Style Mixing と呼ばれる編集が可能になります。
18個の潜在変数w0〜w17は、9段階の解像度のレイヤ (4×4, 8×8, 16×16, 32×32, 64×64, 128×128, 256×256, 512×512, 1024×1024)に各2個づつ接続されています。
解像度によって潜在変数が画像生成に影響する内容は異なり、低解像度では顔の向き、顔の形、髪型など大局的なものに影響し、解像度が上がるに従って、目・口など細部のものに影響します。
ここで、画像Aと画像Bの潜在変数wのある部分だけ入れ替えることによって2つの画像の特徴を混ぜ合わせることが出来、これをStyle Miximgと呼んでいます。
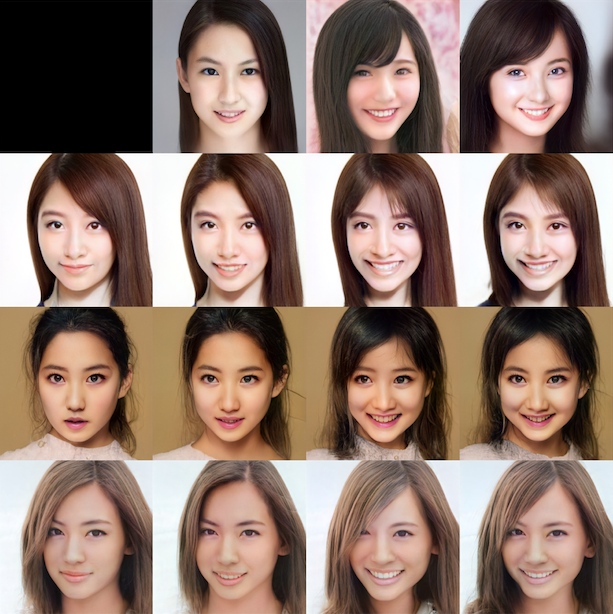
3.顔の向き
この画像は、青枠のRow_picの潜在変数 w0, w1 を赤枠の Col_pic のものに入れ替えた結果を表しています。w0, w1 は主に顔の向きやメガネの有無くらいにしか影響を与えないので、顔の向きだけを独立して変えることができます。*実際は、そのまま置き換えると効きが弱かったので、Col_pic の w0, w1 を1.4倍して、Row_pic と入れ替えています。
4.笑い
この画像は、Row pic の w4, w5 をCol_picに入れ替えたものです。笑いのポイントである口の形に影響を与えるのは主に w4, w5 です。口の開け方が割とそのまま移動している感じですので、笑い方のニュアンスも編集できそうです。5.メガネ
この画像は、Row_picの w0, w1, w2 をCol_picに入れ替えたものです。メガネに影響与えるのは主にw0, w1, w2 です。顔の向きと被ってしまうので、顔の向きも同時に変わります。興味深いのは、メガネの形がそのまま移動するのではなく、Row_pic が個別に持つメガネの属性があるようです。従って、意図した形のメガネを掛けさせることは難しいです。
6.若さ
この画像は、Row_picの w4, w5, w6, w7 をCol_picに入れ替えたものです。顔の形や髪型が影響するw2, w3はそのままにして、口の形に影響するw4, w5 と目の形に影響する w6, w7だけを入れ替えています。目と口の形を変えると、結構幼さが出ます。*実際は、そのまま置き換えると効きが強すぎたので、w4, w5, w6, w7 について、Row_pic : Col_pic=2:8でミックスして、Row_picに入れています。
7.歳を重ねる
先程同様、顔の形や髪型が影響するw2, w3はそのままにして、口の形や目の形に影響する w4, w5, w6, w7 だけを入れ替えています。目と口の形を変えるだけでも、少し歳をとった様に見えます。*実際は、そのまま置き換えると効きが強すぎたので、w4, w5, w6, w7 について、Row_pic : Col_pic=4:6でミックスして、Row_picに入れています。
8.男性化
これはおまけです。同じく、w4, w5, w6, w7だけを入れ替えていますが、結果はイマイチですね(笑)。9.まとめ
これは、顔画像の要素と関係する主な潜在変数wをの関係を大まかにまとめたものです。w8以上はコントラストや色などへの影響に留まり、直接顔の形には影響しないようです。
学習済みStyleGAN2モデルは新規画像についても、高い画像編集能力を秘めているように思います。





- 投稿日:2020-07-08T19:56:22+09:00
StyleGAN2の画像編集能力を探ってみる
1.はじめに
前回の「StyleGAN2の潜在空間に、新垣結衣は住んでいるのか?」 では、StyleGAN2は学習に使っていない新規画像についても、高い画像生成能力を持っていることが分かりました。
今回は、StyleGAN2が持っている Style Mixing と呼ばれる画像編集機能を使って、学習に使っていない新規画像のみでどのくらい画像編集能力があるかを見て行きたいと思います。
コードは Google Colab を使って作成し、Github に上げてありますので、良かったら動かしてみて下さい。
*このブログで使用している画像は全てStyleGAN2の学習には使用していない新規画像です(前回ご紹介した方法で作成しています)。
2.Style Mixing とは?
StyleGANは、今までのGANの様に1個の潜在変数から画像生成するのではなく、Mapping network を使って18個の潜在変数w(これをstyleと呼びます)から画像生成しています。
18個の潜在変数w0〜w17は、9段階の解像度のレイヤ (4×4, 8×8, 16×16, 32×32, 64×64, 128×128, 256×256, 512×512, 1024×1024)に各2個づつ接続されています。
解像度によって潜在変数が画像生成に影響する内容は異なり、低解像度では顔の向き、顔の形、髪型など大局的なものに影響し、解像度が上がるに従って、目・口など細部のものに影響します。
ここで、画像Aと画像Bの潜在変数wのある部分だけ入れ替えることによって2つの画像の特徴を混ぜ合わせることが出来、これをStyle Miximgと呼んでいます。
3.顔の向き
この画像は、青枠のRow_picの潜在変数 w0, w1 を赤枠の Col_pic のものに入れ替えた結果を表しています。w0, w1 は主に顔の向きやメガネの有無くらいにしか影響を与えないので、顔の向きだけを独立して変えることができます。*実際は、そのまま置き換えると効きが弱かったので、Col_pic の w0, w1 を1.4倍して、Row_pic と入れ替えています。
4.笑い
この画像は、Row pic の w4, w5 をCol_picに入れ替えたものです。笑いのポイントである口の形に影響を与えるのは主に w4, w5 です。口の開け方が割とそのまま移動している感じですので、笑い方のニュアンスも編集できそうです。5.メガネ
この画像は、Row_picの w0, w1, w2 をCol_picに入れ替えたものです。メガネに影響与えるのは主にw0, w1, w2 です。顔の向きと被ってしまうので、顔の向きも同時に変わります。興味深いのは、メガネの形がそのまま移動するのではなく、Row_pic が個別に持つメガネの属性があるようです。従って、意図した形のメガネを掛けさせることは難しいです。
6.若さ
この画像は、Row_picの w4, w5, w6, w7 をCol_picに入れ替えたものです。顔の形や髪型が影響するw2, w3はそのままにして、口の形に影響するw4, w5 と目の形に影響する w6, w7だけを入れ替えています。目と口の形を変えると、結構幼さが出ます。*実際は、そのまま置き換えると効きが強すぎたので、w4, w5, w6, w7 について、Row_pic : Col_pic=2:8でミックスして、Row_picに入れています。
7.歳を重ねる
先程同様、顔の形や髪型が影響するw2, w3はそのままにして、口の形や目の形に影響する w4, w5, w6, w7 だけを入れ替えています。目と口の形を変えるだけでも、少し歳をとった様に見えます。*実際は、そのまま置き換えると効きが強すぎたので、w4, w5, w6, w7 について、Row_pic : Col_pic=4:6でミックスして、Row_picに入れています。
8.男性化
これはおまけです。同じく、w4, w5, w6, w7だけを入れ替えていますが、結果はイマイチですね(笑)。9.まとめ
これは、顔画像の要素と関係する主な潜在変数wをの関係を大まかにまとめたものです。w8以上はコントラストや色などへの影響に留まり、直接顔の形には影響しないようです。
StyleGAN2は新規画像についても、結構画像編集能力を秘めているように思います。
- 投稿日:2020-07-08T19:28:13+09:00
【Ansible】templateモジュールから独自関数を呼び出したい(macro)
はじめに
<バージョン>
ansible 2.9.1templateモジュールを使っていると、独自関数を作って呼び出したい場面が出てくると思います。
jinja2にはmacroという機能があり、独自関数を書いたファイルを他のj2ファイルから呼び出して
使えるようですが、templateモジュールでも使えるのか実際にやってみます。参考ファイル
(1)Playbook
template_sample.j2--- - name: template TEST hosts: localhost gather_facts: no vars: ansible_python_interpreter: /usr/bin/python3 tasks: - name: 'template' template: src: base.j2 # macroを呼び出す元となるplaybook dest: result.txt(2)j2ファイル(base.j2:呼び出し元となるファイル)
1行目:このj2ファイルと同じディレクトリに入っている、macro.j2内にあるmacroを読み込む
2行目:macro.j2内にあるtest1という独自関数に変数を引き渡す
3行目:macro.j2内にあるtest2という独自関数に変数を引き渡すbase.j2{% import "macro.j2" as macro %} {{ macro.test1("Taro", "Tokyo") }} {{ macro.test2("Hanako", "tennis") }}(3)j2ファイル(macro.j2:独自関数が書かれたファイル)
関数の書き始めは「macro 関数名(変数1, 変数2,…)」として、
最後に「endmacro」で閉じましょうmacro.j2{% macro test1(var1, var2)%} My name is {{ var1 }} I live in {{ var2 }} {% endmacro %} {% macro test2(var1, var2)%} My name is {{ var1 }} I like {{ var2 }} {% endmacro %}実行結果
想定通り実行することが出来ました。
同じような記述は、macroファイルに切り出してスマートなtemplateを作りましょう。result.txtMy name is Taro I live in Tokyo My name is Hanako I like tennis関連記事
- 投稿日:2020-07-08T19:08:39+09:00
DjangoのAdminを改造したかった話
やりたかったこと
- 選択したlist_filterを一括クリアするボタンをlist_filterタイトル横に配置したい

方法
Templateの「Change_list.html」をオーバーライドする
app構成
C:Project Name │ db.sqlite3 │ manage.py │ ├─.idea │ ├─Project Name │ │ authentication.py │ │ settings.py │ │ urls.py │ │ utils.py │ │ wsgi.py │ │ __init__.py │ │ │ ├─locate │ └─__pycache__ │ ├─App Name │ │ admin.py │ │ apps.py │ │ context_processors.py │ │ forms.py │ │ models.py │ │ tests.py │ │ urls.py │ │ views.py │ │ __init__.py │ │ │ ├─locate │ ├─migrations │ │ └─__pycache__ │ ├─templatetags │ │ │ mytag.py │ │ │ │ │ └─__pycache__ │ │ mytag.cpython-37.pyc │ │ │ └─__pycache__ │ ├─templates │ __init__.py │ └─admin │ base_site.html │ index.html │ __init__.py │ └─App Name │ change_form_help_text.html │ change_list.html ←このファイルを追加 │ __init__.py │ ├─model name1 │ change_form.html │ __init__.py │ └─model name2 change_form.html __init__.py
- Change_list.html
以下のようにオーバーライドする
Change_list.html{% extends 'admin/change_list.html' %} {% load admin_list %} {% search_form cl %} {% load i18n %} {{ block.super }} {% block filters %} {% if cl.has_filters %} <div id="changelist-filter"> <h2>{% trans 'Filter' %} <button id="clear" onclick="location.href=location.href.replace(/\#.*$/, '').replace(/\?.*$/, '');">clear</button></h2> {% if cl.has_active_filters %}<h3 id="changelist-filter-clear"> <a href="{{ cl.clear_all_filters_qs }}">✖ {% trans "Clear all filters" %}</a> </h3>{% endif %} {% for spec in cl.filter_specs %}{% admin_list_filter cl spec %}{% endfor %} </div> {% endif %} {% endblock %}結果
list_filterの解除自体は、追加したボタンをクリックした際に、現在のurlから検索クエリを抜いたurlを再設定することで実現した
Templateのオーバーライドの方法がわかれば、adminサイトを少し改造するのに便利

- 投稿日:2020-07-08T19:08:39+09:00
Djangoの管理者サイトを少しだけ改造したかった話
やりたかったこと
- 選択したlist_filterを一括クリアするボタンをlist_filterタイトル横に配置したい

方法
Templateの「Change_list.html」をオーバーライドする
app構成
C:Project Name │ db.sqlite3 │ manage.py │ ├─.idea │ ├─Project Name │ │ authentication.py │ │ settings.py │ │ urls.py │ │ utils.py │ │ wsgi.py │ │ __init__.py │ │ │ ├─locate │ └─__pycache__ │ ├─App Name │ │ admin.py │ │ apps.py │ │ context_processors.py │ │ forms.py │ │ models.py │ │ tests.py │ │ urls.py │ │ views.py │ │ __init__.py │ │ │ ├─locate │ ├─migrations │ │ └─__pycache__ │ ├─templatetags │ │ │ mytag.py │ │ │ │ │ └─__pycache__ │ │ mytag.cpython-37.pyc │ │ │ └─__pycache__ │ ├─templates │ __init__.py │ └─admin │ base_site.html │ index.html │ __init__.py │ └─App Name │ change_form_help_text.html │ change_list.html ←このファイルを追加 │ __init__.py │ ├─model name1 │ change_form.html │ __init__.py │ └─model name2 change_form.html __init__.py
- Change_list.html
以下のようにオーバーライドする
Change_list.html{% extends 'admin/change_list.html' %} {% load admin_list %} {% search_form cl %} {% load i18n %} {{ block.super }} {% block filters %} {% if cl.has_filters %} <div id="changelist-filter"> <h2>{% trans 'Filter' %} <button id="clear" onclick="location.href=location.href.replace(/\#.*$/, '').replace(/\?.*$/, '');">clear</button></h2> {% if cl.has_active_filters %}<h3 id="changelist-filter-clear"> <a href="{{ cl.clear_all_filters_qs }}">✖ {% trans "Clear all filters" %}</a> </h3>{% endif %} {% for spec in cl.filter_specs %}{% admin_list_filter cl spec %}{% endfor %} </div> {% endif %} {% endblock %}結果
list_filterの解除自体は、追加したボタンをクリックした際に、現在のurlから検索クエリを抜いたurlを再設定することで実現した
Templateのオーバーライドの方法がわかれば、adminサイトを少し改造するのに便利
- 投稿日:2020-07-08T18:20:50+09:00
競プロ精進日記11日目~14日目(7/5~7/8)
感想
1日さぼってしまいましたが、モチベーションを保って今月中は続けたいと思います。
この精進日記の間に水色や青色の問題を安定させて青コーダーになれればと思います。
また、卒研の勉強もしなければいけないので頑張りたいです。
読みやすい量がどれくらいかわからないので手探りですが、三日に一回更新できればと思います。11日目
ABC132-E Hopscotch Addict
かかった時間
30分程度
考察
重みのない最短距離を求めるのでBFSを使って考えます。まず、けんけんぱを三連続した時にたどり着く先を新たな辺として更新する方法を考えましたが、それぞれの頂点から伸びる辺を順に考えると明らかに間に合わないかつ無駄な計算が多いので却下しました。
ここで、目的地にたどり着けると仮定する(高々$M$回の移動)と、それを3回繰り返せば3の倍数になるので、結局は高々$3 \times M$回程度の移動になることに気づきました。また、前述のように目的地にたどり着いた時に3の倍数の距離でたどり着くと言い換えることができれば、その目的地にたどり着く距離を三で割った三つの状態それぞれでの最短距離を考えれば良いとわかります。
したがって、それぞれの頂点が状態を持つ拡張ダイクストラ法と同様にそれぞれの頂点が三つの状態を持つ拡張BFSを考えれば、通常のBFSと同様に最短距離を保存する配列($score[i][j]:=i$番目の頂点への最短距離を三で割った余りが$j$となるような移動の中での最短距離)を用意してその配列でinfとなる場合のみ更新することを行えれば$O(M+N)$で実装することが可能です。
Pythonのコード
abc132e.pyimport sys sys.setrecursionlimit(10**6) from collections import deque n,m=map(int,input().split()) edges=[[] for i in range(n)] for i in range(m): u,v=map(int,input().split()) edges[u-1].append(v-1) s,t=map(int,input().split()) inf=100000000000 score=[[inf]*3 for i in range(n)] now=deque() now.append(s-1) score[s-1][0]=0 def bfs(dep,l): global n,m,edges,s,t,score,inf,now f=False for i in range(l): ne=now.popleft() for j in edges[ne]: if score[j][dep%3]==inf: score[j][dep%3]=dep now.append(j) l_ne=len(now) if l_ne:bfs(dep+1,l_ne) bfs(1,1) if score[t-1][0]!=inf: print(score[t-1][0]//3) else: print(-1)12日目
コンテスト中に通せなかったABC173-Eを解きました。
こちらの記事にまとめてあります。13日目
時間の使い方が下手でした。猛省してます。
14日目
ABC135-D Digits Parade
かかった時間
25分
考察
猛省したので早めにdiffの低めの問題をACしました。
この前に類題を解いた気がしますが、しっかりそこそこの時間でACできたのでよかったです。ただ、一度REを出したのでそこは反省しています。まず、DPと気付けるかが最大のポイントです。文字列であり?の部分の処理が難しいこと、?の部分は候補が増える($\leftrightarrow$遷移の仕方が増える)と捉えられること、その文字列で表される数字の余りは桁を一つずつ決めれば決まることを総合して考えれば、桁ごとの状態を考えるDPを発送するのは難しくないと思います。
ここで、$i$桁まで見たときの与えられた整数(を表す文字列)の状態を考えますが、ここでは余りを考えて$dp[i][j]:=i$桁目まで見た時に13で割ったあまりが$j$となる数が何通りあるかとすれば良いです。
すると、DPの遷移については以下の二つの場合を考えれば良いです($p[i]$は$10^i$を13で割った余りを前計算したものとします。)。
①$i$桁目が$k(0 \leqq k \leqq 9)$の時
$dp[i][j]$の遷移する先は、$dp[i+1][(j+k*p[i])%13]$となります。②$i$桁目が?の時
①のパターンの$l$を0から9まで全て行えば良いです。また、$p[i]$はDPを行うループ中で求めようとしたのですが、最大で$10^{10^5-1}$を求める必要があるのでその余だけを先に計算しておくようにしました。
以上を実装して以下のコードになります。
Pythonのコード
abc130e.pymod=10**9+7 s=input()[::-1] l=len(s) dp=[[0]*13 for i in range(l+1)] dp[0][0]=1 #累乗が大きすぎるので前計算 p=[0]*l p[0]=1 for i in range(l-1): p[i+1]=(p[i]*10)%13 for i in range(l): s_sub=s[i] if s_sub=="?": for j in range(13): for k in range(10): dp[i+1][(j+k*p[i])%13]+=dp[i][j] dp[i+1][(j+k*p[i])%13]%=mod else: k=int(s_sub) for j in range(13): dp[i+1][(j+k*p[i])%13]+=dp[i][j] dp[i+1][(j+k*p[i])%13]%=mod print(dp[l][5])
- 投稿日:2020-07-08T18:00:26+09:00
CNNを理解するまで帰れま10
CNN(Convolutional Neural Network)を理解しとかんと次に進めん
今、フルーツ7種の判別をやっているのですが、CNN使って分類してはい終わり的な感じ(精度向上はやりました)でなんか物足りませんでした。
なのでCNNってなんぞやから理解していきます。CNNってなんぞや
CNN(Convolutional Neural Network)は一般的な順伝播型のニューラルネットワークとは違い、全結合層だけでなく畳み込み層(Convolution Layer)とプーリング層(Pooling Layer)から構成されるニューラルネットワークのこと。
う〜ん、わからん。一般的な順伝播型のニューラルネットワークってなんぞや
調べたらめっちゃわかりやすいのがあった。
深層学習を読んでいったときのメモ (1. 順伝播型ネットワーク)畳み込み層とプーリング層では下図のように入力のニューロンの一部の領域を絞って、局所的に次の層へと対応付けをしていく。各層はフィルタと呼ばれる検出器をいくつも持っているイメージだ。
画像認識の例でいうと、最初の層でエッジを検出して、次の層でテクスチャを検出し、さらに次のそうではより抽象的な特徴を検出したりする。CNNはこういった特徴を抽出するための検出器であるフィルタのパラメータを自動で学習していく。
CNNの実用例
・Facebook タグ付けの顔検出
・Google 写真検索や音声認識CNNの特徴
CNNには注目に値すべき点が3つある。畳み込み(Convolution)と位置不変性 (Translation Invariance) と 合成性 (Compositionality)である。
畳み込みとは
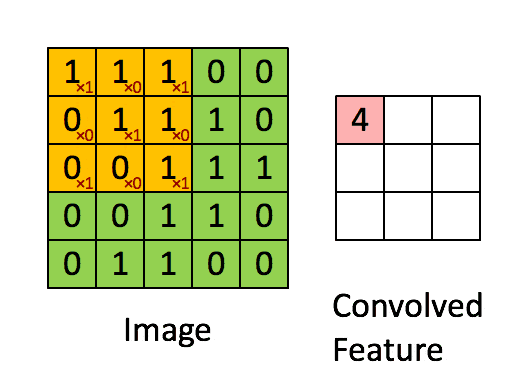
畳み込み(convolution)とは、画像処理でよく利用される手法で、カーネル(またはフィルター)と呼ばれる格子状の数値データと、カーネルと同サイズの部分画像(ウィンドウと呼ぶ)の数値データについて、要素ごとの積の和を計算することで、1つの数値に変換する処理のことである。この変換処理を、ウィンドウを少しずつずらして(ストライド)処理を行うことで、小さい格子状の数値データに変換する。このようにしてフィルタをスライドさせていくことからsliding windowと呼ばれることもある。
引用:Standford wiki / Convolution schematic.gifこうして計算されたデータは特徴マップと呼ばれる。
合成性
CNNはそれぞれの構成要素を理解すると、パズルのように組み合わせてつくることができるようになる。
各層は次の層へと意味のあるデータを順に受渡していく。層が進むにつれて、ネットワークはより高レベルな特徴を学習していける。
フルーツ判別を例にとると、最初の層では色や形を検出し、次の層でそれらを組み合わせてノイズを検出し、より深くなるにつれてフルーツの特徴、さらには品種まで検出できるようになっているかもしれない。
移動不変性
前述の畳み込みの例で見たとおり、局所領域からフィルタを通して検出していくので物体の位置のズレに頑健になる。
つまり、特徴を検知する対象が入力データのどこにあっても検知することができる。これを移動不変性という。
回転や拡大・縮小に対する不変性に関しては、データ拡張でそういったデータを増やして学習するなど工夫が必要だ。
CNNの構成要素
CNNは層と活性化関数といくつかのパラメータの組み合わせで出来上がっている。
ゼロパディング
ゼロパディングとは、入力の特徴マップの周辺を0で埋めることです。パディングは余白という意味で、こうすることで以下のようなメリットがあります。
・端のデータに対する畳み込み回数が増えるので端の特徴も考慮されるようになる
・畳み込み演算の回数が増えるのでパラメーターの更新が多く実行される
・カーネルのサイズや、層の数を調整できる
・Convolution層とPooling層で出力サイズは次第に小さくなるので、ゼロパディングでサイズを増やしたりすると層の数を増やすことができる。ストライド
ストライドとは直訳すると歩幅。
今まではフィルタを1ピクセル間隔でかけていきました=ストライドが1。
2ピクセル間隔でかけていけば、ストライドが2になります。Fully Connected層
CNNの一番最後の画像判別のところの層です。
これまでやってきた「畳み込み層」も「プーリング層」も基本は,入力画像の配列の形態のままです。入力画像を分類するためには,どこがで画像の形態から,1次元出力ができる形態に変換する必要があります。
CNNでは,畳み込みと,プーリングがいくつか終わった後に、画像データを列ベクトルにフラット化します。フラットになれば、隠れ層・出力層に引き継ぐことができます。
Fully Connected層は1次元のベクトルを入力値として、1次元のベクトルを出力します。このように,CNNでは,フィードフォワードニューラルネットワークに受け渡す前に,入力画像の優勢な特徴を抽出したものになっているので,それらをソフトマックス法を用いて分類することができます。
Pooling層
プーリング層(Pooling Layer)は、は畳み込み層の後に利用されるのが一般的です。この層では、入力データを圧縮します。
解像度が大きいと、ノイズも多くなります。特徴を残しつつ、縮小リサイズして解像度を減らすのがプーリングです。Pooling層はたいてい、Convolutoin層の後に適用されます。入力データをより扱いやすい形に変形するために、情報を圧縮し、down samplingします。
圧縮することで以下のメリットが得られ、Convolution層とPooling層で特徴を検出する働きをします。
・ロバスト性の向上(微小な位置変化の影響を受けにくくなる)
・ある程度過学習を抑制する
・計算コストを抑えられる最後に
今回、調べてまとめることにより、何気なく使っていたCNNについて理解することができた。ゴリゴリの計算式とかはざっくりとしか理解はできていないが、これでやっと帰れそうです。
参考
TensorFlowとKerasで動かしながら学ぶ ディープラーニングの仕組み ~畳み込みニューラルネットワーク徹底解説~ (Compass Booksシリーズ)
・画像はこちらから拝借
Convolutional Neural Networks (CNNs / ConvNets)
・定番のConvolutional Neural Networkをゼロから理解する


- 投稿日:2020-07-08T17:45:00+09:00
スカッシュゲームを作ろう
スカッシュゲームとは
スカッシュゲームとは、画面の端に当たって跳ね返ってきたボールを、マウスを使って打ち返して遊ぶゲームのことです。
作成方法
Step1:ウィンドウとキャンバスを作成しよう
# coding:utf-8 import tkinter as tk # ウィンドウの作成 win = tk.Tk() # キャンバスの作成 cv = tk.Canvas(win, width=640, height=480 ,bg="white") # キャンバスの表示 cv.pack() # ウィンドウの表示 win.mainloop()
Step2:ボールを描いて動かそう
ボールを動かす➝ ボールを表示たり消したりする
ボールを消す
1. 背景と同じ色のボールを表示
2. ボールを表示した後に画面をすべて消す ☜ 今回はこっち
手順1:変数の設定
# ゲームの初期化 ball_ichi_x = 300 ball_ichi_y = 150 ball_idou_x = 30 ball_idou_y = -30 ball_size = 10手順2:画面を描く
# 画面の描画 def draw_screen(): # 画面クリア cv.delete('all') ← 画面を消せという命令 # キャンパス(画面)の作成 cv.create_rectangle(0, 0, 640, 480, fill="white", width=0)手順3:ボールを描く
# ボールを描く def draw_ball(): cv.create_oval(ball_ichi_x - ball_size, ball_ichi_y - ball_size, ball_ichi_x + ball_size, ball_ichi_y + ball_size, fill="red", width=0)
手順4:ボールを動かす
# ボールの移動 def move_ball(): global ball_ichi_x, ball_ichi_y, ball_idou_x, ball_idou_y # 左右の壁に当たったかの判定 if ball_ichi_x + ball_idou_x < 0 or ball_ichi_x + ball_idou_x > 640: ball_idou_x *= -1 ↓ ball_idou_x = ball_idou_x * -1 ということ # 天井か床に当たったかの判定 if ball_ichi_y + ball_idou_y < 0 or ball_ichi_y + ball_idou_y > 480: ball_idou_y *= -1 # ボールの位置を移動 if 0 <= ball_ichi_x + ball_idou_x <= 640: ball_ichi_x = ball_ichi_x + ball_idou_x if 0 <= ball_ichi_y + ball_idou_y <= 480: ball_ichi_y = ball_ichi_y + ball_idou_y # ゲームの繰り返し処理の指令 def game_loop(): draw_screen() draw_ball() move_ball() win.after(50, game_loop) # タイマーの設定 # ゲームのメイン処理 game_loop() ← 関数を呼び出す関数の中で設定した変数を関数の外でも使うときに「global」を設定します
タイマーの時間の単位はミリ(1/1000)秒
実行結果
Step3:スカッシュゲームに改造しよう
手順1:変数の設定
# ゲームの初期化 def init_game(): global is_gameover, ball_ichi_x, ball_ichi_y global ball_idou_x, ball_idou_y, ball_size global racket_ichi_x, racket_size, point, speed is_gameover = False # ゲーム終了の確認(終了でないときはFalse/終了のときはTrue) ball_ichi_x = 0 ball_ichi_y = 250 ball_idou_x = 15 ball_idou_y = -15 ball_size = 10 racket_ichi_x = 0 racket_size = 100 point = 0 # ポイント(初期は0点/10点ずつ増える) speed = 50 # ゲームのスピードを調整するタイマー(単位はミリ秒) win.title("スカッシュゲーム:スタート!") # タイトルバーに表示変数の初期値を「init_game( )」という名前の関数でまとめると、ゲームをまとめて初期化することができます
手順2:ラケットを描く
# ラケットを描く def draw_racket (): cv.create_rectangle(racket_ichi_x, 470, racket_ichi_x + racket_size, 480, fill="yellow")手順3:ボールを動かす
# ボールの移動 def move_ball(): global is_gameover, point, ball_ichi_x, ball_ichi_y, ball_idou_x, ball_idou_y if is_gameover: return # 左右の壁に当たったかの判定 if ball_ichi_x + ball_idou_x < 0 or ball_ichi_x + ball_idou_x > 640: ball_idou_x *= -1 # 天井か床に当たったかの判定 if ball_ichi_y + ball_idou_y < 0: ball_idou_y *= -1 # ラケットに当たったかの判定 if ball_ichi_y + ball_idou_y > 470 and (racket_ichi_x <= (ball_ichi_x + ball_idou_x) <= (racket_ichi_x + racket_size)): ball_idou_y *= -1 if random.randint(0, 1) == 0: ball_idou_x *= -1 point += 10 win.title("得点=" + str(point)) # 得点の表示 # ミスしたときの判定 if ball_ichi_y + ball_idou_y > 480: is_gameover = True win.title("得点=" + str(point)) # 得点の表示 # ボールの位置を移動 if 0 <= ball_ichi_x + ball_idou_x <= 640: ball_ichi_x = ball_ichi_x + ball_idou_x if 0 <= ball_ichi_y + ball_idou_y <= 480: ball_ichi_y = ball_ichi_y + ball_idou_y
手順4:マウスの処理
# マウスの動きの処理 def motion(event): # マウスポインタの位置確認 global racket_ichi_x racket_ichi_x = event.x def click(event): # クリックで再スタート if event.num == 1: init_game() # マウスの動きとクリックの確認 win.bind('<Motion>', motion) win.bind('<Button>', click)「< >」内の命令は「イベント」といってマウスの動きを調べられます
<Motion> ← イベント名(先頭が大文字)
「motion」← 関数名
- マウスのイベント
- Button または ButtonPress ← マウスのボタンを押した
- ButtonRelease ← マウスのボタンを放した
- Mottion ← マウスの動き(座標の取得)
Step4:オプション
音とメッセージを出そう
# 左右の壁に当たったかの判定 if ball_ichi_x + ball_idou_x < 0 or ball_ichi_x + ball_idou_x > 640: ball_idou_x *= -1 winsound.Beep(1300, 50) # 天井か床に当たったかの判定 if ball_ichi_y + ball_idou_y < 0: ball_idou_y *= -1 winsound.Beep(1300, 50) # ラケットに当たったかの判定 if ball_ichi_y + ball_idou_y > 470 and (racket_ichi_x <= (ball_ichi_x + ball_idou_x) <= (racket_ichi_x + racket_size)): ball_idou_y *= -1 if random.randint(0, 1) == 0: ball_idou_x *= -1 winsound.Beep(2000, 50) mes = random.randint(0, 3) if mes == 0: message = "うまい!" if mes == 1: message = "グッド!" if mes == 2: message = "ナイス!" if mes == 3: message = "すごい!" point += 10 win.title(message + "得点=" + str(point)) # 得点とメッセージの表示 # ミスしたときの判定 if ball_ichi_y + ball_idou_y > 480: mes = random.randint(0, 3) if mes == 0: message = "ミスしたね!" if mes == 1: message = "ドンマイ!" if mes == 2: message = "ヘタくそ!" if mes == 3: message = "あーあ、見てられないね!" win.title(message + "得点=" + str(point)) # 得点とメッセージの表示 winsound.Beep(240, 800) is_gameover = True「winsound.Beep(音の周波数, 音を鳴らす時間)」で音を出すことができます
ボールのスピードを変えよう
ball_idou_x = 15 ball_idou_y = -15speed = 50 # ゲームのスピードを調整するタイマー(単位はミリ秒)これらの値を変えることによってボールのスピードを変えられます
ソースコード
# coding:utf-8 # スカッシュゲーム(壁打ちテニス) # モジュールのインポート import tkinter as tk import random import winsound # ウィンドウの作成 win = tk.Tk() # キャンバスの作成 cv = tk.Canvas(win, width=640, height=480 ,bg="white") # キャンバスの表示 cv.pack() # ゲームの初期化 def init_game(): global is_gameover, ball_ichi_x, ball_ichi_y global ball_idou_x, ball_idou_y, ball_size global racket_ichi_x, racket_size, point, speed is_gameover = False # ゲーム終了の確認(終了でないときはFalse/終了のときはTrue) ball_ichi_x = 0 ball_ichi_y = 250 ball_idou_x = 15 ball_idou_y = -15 ball_size = 10 racket_ichi_x = 0 racket_size = 100 point = 0 # ポイント(初期は0点/10点ずつ増える) speed = 50 # ゲームのスピードを調整するタイマー(単位はミリ秒) win.title("スカッシュゲーム:スタート!") # タイトルバーに表示 # 画面の描画 def draw_screen(): # 画面クリア cv.delete('all') # 画面を消せという命令 # キャンパス(画面)の作成 cv.create_rectangle(0, 0, 640, 480, fill="white", width=0) # ボールを描く def draw_ball(): cv.create_oval(ball_ichi_x - ball_size, ball_ichi_y - ball_size, ball_ichi_x + ball_size, ball_ichi_y + ball_size, fill="red", width=0) # ラケットを描く def draw_racket (): cv.create_rectangle(racket_ichi_x, 470, racket_ichi_x + racket_size, 480, fill="yellow") # ボールの移動 def move_ball(): global is_gameover, point, ball_ichi_x, ball_ichi_y, ball_idou_x, ball_idou_y if is_gameover: return # 左右の壁に当たったかの判定 if ball_ichi_x + ball_idou_x < 0 or ball_ichi_x + ball_idou_x > 640: ball_idou_x *= -1 winsound.Beep(1300, 50) # 天井か床に当たったかの判定 if ball_ichi_y + ball_idou_y < 0: ball_idou_y *= -1 winsound.Beep(1300, 50) # ラケットに当たったかの判定 if ball_ichi_y + ball_idou_y > 470 and (racket_ichi_x <= (ball_ichi_x + ball_idou_x) <= (racket_ichi_x + racket_size)): ball_idou_y *= -1 if random.randint(0, 1) == 0: ball_idou_x *= -1 winsound.Beep(2000, 50) mes = random.randint(0, 3) if mes == 0: message = "うまい!" if mes == 1: message = "グッド!" if mes == 2: message = "ナイス!" if mes == 3: message = "すごい!" point += 10 win.title(message + "得点=" + str(point)) # 得点とメッセージの表示 # ミスしたときの判定 if ball_ichi_y + ball_idou_y > 480: mes = random.randint(0, 3) if mes == 0: message = "ミスしたね!" if mes == 1: message = "ドンマイ!" if mes == 2: message = "ヘタくそ!" if mes == 3: message = "あーあ、見てられないね!" win.title(message + "得点=" + str(point)) # 得点とメッセージの表示 winsound.Beep(240, 800) is_gameover = True # ボールの位置を移動 if 0 <= ball_ichi_x + ball_idou_x <= 640: ball_ichi_x = ball_ichi_x + ball_idou_x if 0 <= ball_ichi_y + ball_idou_y <= 480: ball_ichi_y = ball_ichi_y + ball_idou_y # マウスの動きの処理 def motion(event): # マウスポインタの位置確認 global racket_ichi_x racket_ichi_x = event.x def click(event): # クリックで再スタート if event.num == 1: init_game() # マウスの動きとクリックの確認 win.bind('<Motion>', motion) win.bind('<Button>', click) # ゲームの繰り返し処理の指令 def game_loop(): draw_screen() draw_ball() draw_racket() move_ball() win.after(speed, game_loop) # タイマーの設定 # ゲームのメイン処理 init_game() game_loop() # ウィンドウの表示 win.mainloop()
実行結果
気づいたこと
実行したウィンドウを消去しないと次のウィンドウを表示できないこと
⇒これには結構焦りました。実行が上手くいかないので、Pythonに問題があるのかと思い、アンインストールしたりしてしまいました。ウィンドウやキャンバスの作成などの単純なプログラムでも多様な書き方があるということ
⇒省略できるものや書き方の異なるものが多くて驚きました。
疑問
import tkinter as tkを参考文献[1]では、
from tkinter import *と書いてあったので、これで実行してみると実行できるのですが、fromの下に黄色い波線が引かれ、問題が100となります。これはなぜですか?
参考文献
[1] すがやみつる「ゲームセンターあらしと学ぶプログラミング入門まんが版こんにちはPython」(2020) 日経BP
[2] 大澤文孝「いちばんやさしいPython入門教室」(2019) 株式会社ソーテック社


- 投稿日:2020-07-08T17:05:52+09:00
ESP32でPythonを使ってサーボを動かす (Windows)
事前に前記事にてESP32にMicroPythonを入れている。
サーボとESP32を繋ぐ
今回はG2ピンに繋ぐことにした。使用可能なピンについてはピンとGPIOを参照。
買ったサーボの必要電圧が4.8V~6Vだったため5Vに接続している。
サーボの確認をPuTTYで行う
PuTTYの使用方法は前記事の追記に記載。
PuTTYでコマンドを1行ずつ記入してEnterを押しサーボの可動域を確認していく。
PWMパルスとGPIOピンを使用する宣言
from machine import PWM, Pinピン2の周波数を50としてservo1と名前を付けた。
周波数の強さによって回転速度が決まるようだ。
servo1 = PWM(Pin(2), freq = 50)サーボのデューティ比とやらを変更。
これで何度も角度を調整して可動域を確かめる。
大体30~120の範囲で微調整するといい。
周波数を100にした時は60~240となるようだ。
servo1.duty(30)※パルスの無いフリー状態。回し過ぎてデットロックされたら一度0にして手動で押し戻すとよい。
servo1.duty(0)回しながら確認したところ自分のサーボでの最小最大の限界は25~130だった。
コードを書く
main.pyという名前を付けて下記の簡単なコードを書きデスクトップに保存した。
sleepは大事。これがないと無限ループが起こりESP32に新たなコードが上書きできなくなる。
上書きできなくなった時はフラッシュを消去してMicroPythonを入れなおす必要あり。main.py# -*- coding: utf-8 -*- from machine import PWM, Pin import time servo1 = PWM(Pin(2), freq = 50) # 角度30(最小)と角度120(最大)を2秒ごとに繰り返す while True: servo1.duty(30) time.sleep_ms(2000) servo1.duty(120) time.sleep_ms(2000)コードをESP32に送る
コードを送るためのツールをコマンドプロンプトからインストール
pip install adafruit-ampyampyのコマンド確認は
ampy
と打つと確認できる。main.pyをデスクトップに保存したのでデスクトップ下に移動
cd Desktopmain.pyファイルをESP32に送る。COM3の部分は自分の繋いでいるポートに変更する。
※PuTTYが立ち上がっていると送信できないので落としておく。
ampy -p COM3 put main.py無事に動いた。
参考
▼Fritzing用のESP32パーツ
https://qiita.com/XZ_Manj/items/8bbdef59eeac4286e4f8▼ピンとGPIO
https://micropython-docs-ja.readthedocs.io/ja/latest/esp32/quickref.html#pins-and-gpio▼はだメモ パルス幅の調整でサーボを動かす
https://scrapbox.io/hada/ESP32%E3%81%A7%E3%82%B5%E3%83%BC%E3%83%9C%E3%83%A2%E3%83%BC%E3%82%BF%5B2018%2F10%2F29%5D_22:09:36

- 投稿日:2020-07-08T16:51:59+09:00
ネコネコパズル
導入
今回の最終課題をやるにあたって時間もあるのでせっかくだから難しいものを作りたいと思いネコのパズルを作ってきました
動かした様子
- 難易度は3つあったけど今回はeasy(4色)だけ作りました
- 縦・横・斜めの向きに3個並べれば消えます
- どれか一列でも上に届けばGAME OVER です

苦労したこと 気づいたこと
- ifやelse、elifなど字下げしなければならないものが多く、どこまで下げるかをよく間違えたこと
- 頻繁に:を忘れていたので何回もエラー出したこと
- 理解が曖昧だったグローバル宣言についていつ使って、いつ使わなくてよいかというのをしっかり確認できた
改良
元のコードではウインドウの高さが背景の写真よりも小さかったので、20(768→790)くらい引き上げました
neko.pzl.pyroot = tkinter.Tk() root.title("落ち物パズル「ねこねこ」") root.resizable(False, False) root.bind("<Motion>", mouse_move) root.bind("<ButtonPress>", mouse_press) cvs = tkinter.Canvas(root, width=912, height=790) cvs.pack()
感想
- しっかりと動いたときはとても感動しました
- ソースコードを少し書いて確認することの大切さを身をもって実感しました
- この本は夏休み中に完走したいと思います
参照Pythonでつくるゲーム開発入門講座 p.172~p.214
廣瀬 豪(ひろせ つよし)
- 投稿日:2020-07-08T15:30:55+09:00
VQ-VAEの理解
はじめに
VQ-VAEはVector Quantised(ベクトル量子化)という手法を使ったVAEです。
従来のVAEでは潜在変数zを正規分布(ガウス分布)のベクトルになるような学習を行いますが、VQ-VAEでは潜在変数を離散化した数値になるような学習を行うVAEです。モデルは(Encoder)-(量子化部分)-(Decoder)から成りますが、Encoder、Decoderについては畳み込みを行うVAEと大きく変わりません。
VQ-VAEの論文と実装をチラッと見たところ、その量子化担当分の作りの理解が二転三転したため備忘録として自分の理解をまとめます。Embeddingって何
VQ-VAEを語る上でおそらく避けて通れないのがEmbeddingでしょう。
自分のようにあまり理解してないとこれがどんな処理か微妙に分かりづらいです。自分には実例を見るのが最も分かりやすかったです。
例えば以下の様にinput行列$(2,4)$で数値はindex値であり、embedding行列が$(10,3)$の場合を考えます。
この場合、input行列をonehot化させて$(2,4,10)$にしてembedding行列$(10,3)$を掛けるとembedding後$(2,4,3)$行列が作成されます。
要するにEmbeddingとは入力をonehot化してembedding行列を掛けたものに過ぎません。>>> # an Embedding module containing 10 tensors of size 3 >>> embedding = nn.Embedding(10, 3) >>> # a batch of 2 samples of 4 indices each >>> input = torch.LongTensor([[1,2,4,5],[4,3,2,9]]) >>> embedding(input) tensor([[[-0.0251, -1.6902, 0.7172], [-0.6431, 0.0748, 0.6969], [ 1.4970, 1.3448, -0.9685], [-0.3677, -2.7265, -0.1685]], [[ 1.4970, 1.3448, -0.9685], [ 0.4362, -0.4004, 0.9400], [-0.6431, 0.0748, 0.6969], [ 0.9124, -2.3616, 1.1151]]])VQ-VAEの最初の理解(間違い)
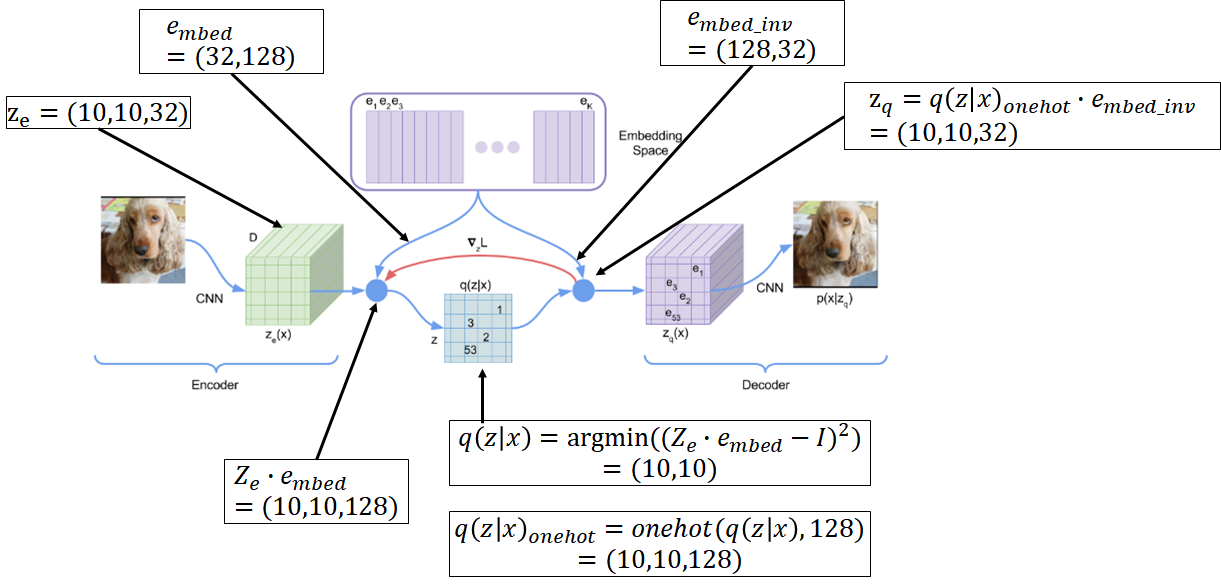
最初に自分は以上の図のような理解をしました。先に言うと間違いです。
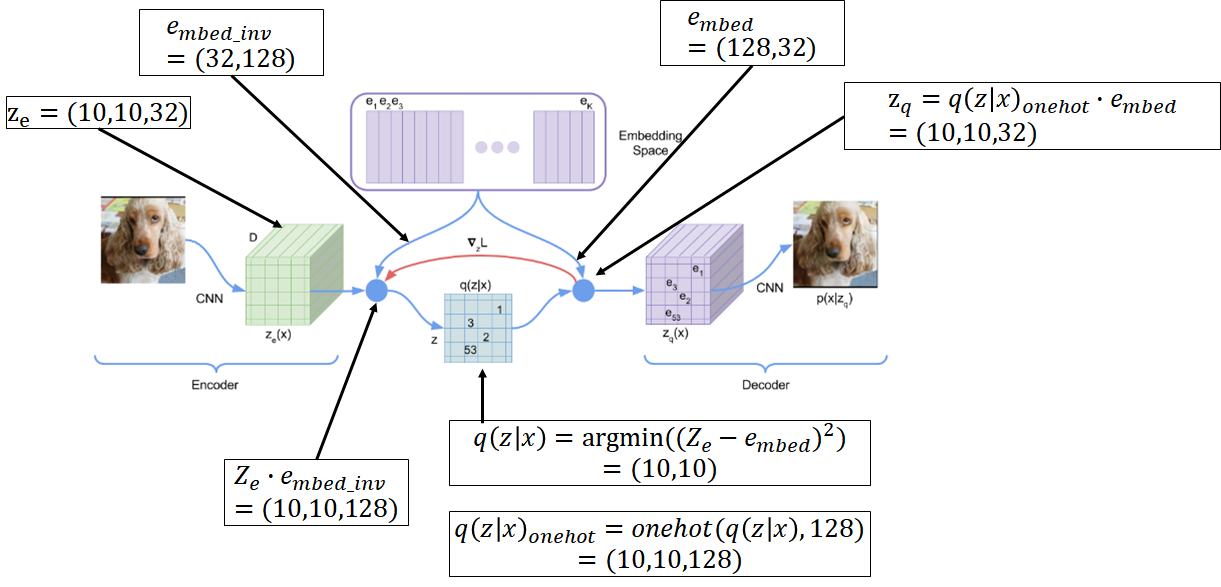
入力$z_e$を$(10,10,32)$とし、embedding行列を$(32,128)$とし、潜在空間で$128$のベクトル量子化(潜在空間を離散化)する事を考えました。
入力$z_e$にembedding行列を掛けてその中から最も1に近い場所のインデックスを取得します。(任意のonehotベクトルの内、最も距離が近いonehotベクトルのインデックス)。それが$q(z|x)$になりまして、これは$(10,10)$の行列で値はインデックス値です。
これをonehot化してembedding行列の逆行列を掛けたものを$z_q$とします。ここで$z_q$のonehot化させてembedding行列を掛けるという処理は最初に説明したembedding処理自体にほかなりません。
潜在空間の離散化が上手くできていれば出力$z_q$は入力$z_e$に近づくはずなので損失関数は$(z_e-z_q)^2$です。図形の変化をnumpyで書けば下記のようになります。
import numpy as np input = np.random.rand(10,10,32) embed = np.random.rand(32,128) embed_inv = np.linalg.pinv(embed) dist = (np.dot(input, embed) - np.ones((10,10,128)))**2 embed_ind = np.argmin(dist, axis=2) embed_onehot = np.identity(128)[embed_ind] output = np.dot(embed_onehot, embed_inv) print("input.shape=", input.shape) print("embed.shape=", embed.shape) print("embed_inv.shape=", embed_inv.shape) print("dist.shape=", dist.shape) print("embed_ind.shape=", embed_ind.shape) print("embed_onehot.shape=", embed_onehot.shape) print("output.shape=", output.shape) ---------------------------------------------- input.shape= (10, 10, 32) embed.shape= (32, 128) embed_inv.shape= (128, 32) dist.shape= (10, 10, 128) embed_ind.shape= (10, 10) embed_onehot.shape= (10, 10, 128) output.shape= (10, 10, 32)何が間違っているか
実際の実装と見比べれば上記の解釈は正しくありません。
理由のひとつはembedding行列の逆行列を求めるという処理がおそらく実際には不可能であることです。
このため、embedding行列の逆行列を使わない方法で$q(z|x)$および$z_q$を求める必要があります。もうひとつは$q(z|x)$の論文の定義と異なっていることです。
論文には以下の様にあり、
上記解釈における下記の式が正しくありません。
$q(z|x)=argmin((z_e \cdot e_{mbed} - I)^2)$ここでargminの中にembedding行列の逆行列$e_{mbed\ inv}$を掛ける事を考えると以下の様に整理できます。
$((z_e \cdot e_{mbed} - I)^2 \cdot e_{mbed\ inv}^2)=(z_e \cdot e_{mbed} \cdot e_{mbed\ inv}- I \cdot e_{mbed\ inv})^2=(z_e - e_{mbed\ inv})^2$
これは論文中にある式と等しいです。そうするとembedding行列とその逆行列の呼び方は入れ替えたほうが以降都合がいいです。
つまり以降$e_{mbed\ inv}$を$e_{mbed}$と呼び、$e_{mbed}$を$e_{mbed\ inv}$と呼ぶことにします。VQ-VAEの二番目の理解
上記の訂正により、以下の理解になりました。
この時、$q(z|x)$および$z_q$を求める両方の式に$e_{mbed\ inv}$が入ってないことに注意してください。
$q(z|x)$および$z_q$はどちらも入力$z_e$と$e_{mbed}$で計算できるので、その逆行列を計算する必要性がなくなります。
具体的には$q(z|x)$は$z_e$と$e_{mbed}$から、$z_q$は$q(z|x)$と$e_{mbed}$から計算されます。
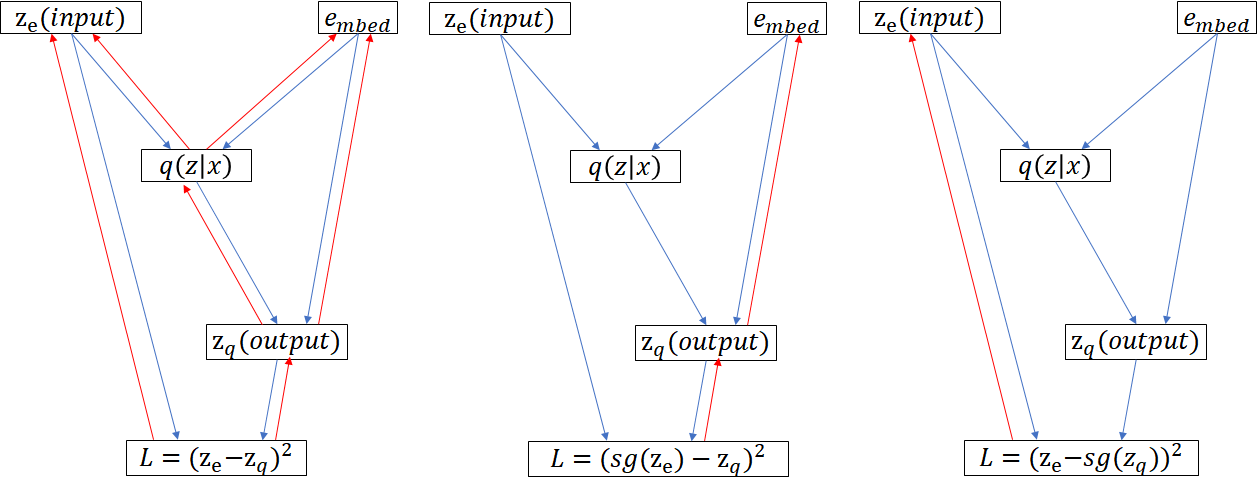
損失関数の勾配伝播
さて、ベクトル量子化に関する損失関数は量子化前後の差分である$(z_e-z_q)^2$かと思ったら実は違います。
$sg()$という勾配を止める関数を使って$(sg(z_e)-z_q)^2+(z_e-sg(z_q))^2$のように表現されます。
これは$(z_e-z_q)^2$と何が違うのかというとおそらく$q(z|x)$から$z_e$と$e_{mbed}$の誤差逆伝播を計算するのが困難な為、思い切ってその部分の勾配伝達を切っているものと考えられます。また、損失関数の第2項目と第3項目で更新する内容が異なります。
第2項目はembedding行列を更新しますが、入力(Encoder)へは勾配が伝達しません。
第3項目は入力(Encoder)へ勾配が伝達しますが、embedding行列を更新しません。
損失関数の第1項目に関してはDecorderから始まり$z_q→z_e$へ量子化部分をスキップしてEncoderへと伝わっていると思われます。ただ、これに関しては通常のAutoEncoderの損失と変わりません。
argmin関数
配列の最も小さな値のインデックス値を取るargmin関数をヘヴィサイドの階段関数を使って書いてみます。
argmin(a,b) = H(b-a) \cdot 0 + H(a-b) \cdot 1 \\ argmin(a,b,c) = H(b-a) \cdot H(c-a) \cdot 0 + H(a-b) \cdot H(c-b) \cdot 1 + H(a-c) \cdot H(b-c) \cdot 2\\ H(x) =\left\{ \begin{array}{ll} 1 & (x \geq 0) \\ 0 & (x \lt 0) \end{array} \right.ここで最小値を引く項がすべての積の値が1になり残り、最小値でない値を引く場合はいずれかがゼロになり残りません。従って$argmin(a_{1},\cdots , a_{128})$は高次の階段関数の積になるので、たとえ勾配計算時に階段関数を連続微分可能な関数に置き換えたとしても(例えばsigmoid関数)これは微分困難でないかと思われます。
しかし、これは先ほどの説明の通り$sg()$という勾配を止める関数を使うことで考えなくて良くなります。まとめ
実装を流し見して理解した気でいたのだが、当初考えていたembedding行列は実際のembedding行列の逆行列であったのに今更ながらに気付きました。
勘違いしやすいかもしれませんが、embedding行列は入力をベクトル量子化する際に掛ける行列ではありません。一旦、量子化した潜在変数を潜在空間に変換する際に掛ける方がembedding行列です。
あと、ベクトル量子化に関してピクセル単位の物体認識であるSemantic Segmentationと似ている気がしました。Semantic Segmentationではsoftmaxを使って各ピクセル毎にonehot的なベクトルを生成しますが、VQでは距離二乗とargminを使って量子化ベクトルを生成します。参考:pytorch VQ-VAE
実際の実装例より
class Quantize(nn.Module): def __init__(self, dim, n_embed, decay=0.99, eps=1e-5): embed = torch.randn(dim, n_embed) ... def forward(self, input): flatten = input.reshape(-1, self.dim) dist = ( flatten.pow(2).sum(1, keepdim=True) - 2 * flatten @ self.embed + self.embed.pow(2).sum(0, keepdim=True) ) _, embed_ind = (-dist).max(1) embed_onehot = F.one_hot(embed_ind, self.n_embed).type(flatten.dtype) embed_ind = embed_ind.view(*input.shape[:-1]) quantize = self.embed_code(embed_ind) ... diff = (quantize.detach() - input).pow(2).mean() quantize = input + (quantize - input).detach() return quantize, diff, embed_ind def embed_code(self, embed_id): return F.embedding(embed_id, self.embed.transpose(0, 1))

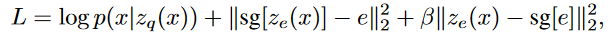
- 投稿日:2020-07-08T15:29:56+09:00
Azure Machine Learning に組み込まれた BERT x AutoML で テキスト分類
背景
Azure Machine Learning には、ハイパーパラメーターチューニングや、クラウド上の仮想マシンの起動・停止、そして、諸々の学習うジョブの管理をまとめてやってくれる AutoML という機能があります。クラウドを使わない学習もサポートしています。
その中で、テキストのデータがあった場合に、Embedded Featurization をしてくれる機能があります。
自動機械学習による特徴量化:
https://docs.microsoft.com/ja-jp/azure/machine-learning/how-to-configure-auto-featuresなんと賢い事に、学習環境のGPUの有無を判断して:
- CPU のみ: Bidirectional Long-Short Term neural network (BiLSTM)
- GPU あり: Bidirectional Encoder Representations from Transformers (BERT)
を自動的に選択して処理をしてくれます。
BERTは、機械学習における様々な自然言語処理のタスクで、SoTA (State of The Art) = いろいろな記録 を更新したこともあり、注目を集めて、既にその応用編も出ています。深層学習を用いた文生成モデルの歴史と研究動向:
https://www.slideshare.net/ssuser3b2d02/ss-236525444その BERT を AutoML のタスクの中の特徴量の抽出に利用したものが、Azure Machine Learning に組み込まれたのです。
How BERT is integrated into Azure automated machine learning:
https://techcommunity.microsoft.com/t5/azure-ai/how-bert-is-integrated-into-azure-automated-machine-learning/ba-p/1194657日本語だけでない、多言語対応のおさらい
ところが、この機能は日本語では使い物になりませんでした。実質、英語のみでした。
ですが、最近の Azure Machine Learning SDK の 1.7.0 で、日本語を含む多言語対応をしました!Azure Machine Learning 1.0.7 Release Note:
https://docs.microsoft.com/en-us/azure/machine-learning/azure-machine-learning-release-notes#2020-06-08
- 執筆時点の最新バージョンは 1.8.0 です実体としては
Multilingual BERT+HuggingFaceのTransformerを採用しています。これは、現時点(2020/7/7)、でですね。今後より良いものが出たら更新されるでしょう。
API のドキュメントに記載があるところは、透明性が高くて良いですよね。ご自分で同じ実装をするかもしれませんし?PretrainedTextDNNTransformer class:
https://docs.microsoft.com/en-us/python/api/azureml-automl-runtime/azureml.automl.runtime.featurizer.transformer.text.pretrained_text_dnn_transformer.pretrainedtextdnntransformer?view=azure-ml-pyMultilingual BERT:
https://github.com/google-research/bert/blob/master/multilingual.mdMultilingual BERT の日本語実装は、Tokenizer に問題があります。日本語の Tokenizer には、
WordpieceTokenizerが使われています。def __init__(self, vocab_file, do_lower_case=True): self.vocab = load_vocab(vocab_file) self.inv_vocab = {v: k for k, v in self.vocab.items()} self.basic_tokenizer = BasicTokenizer(do_lower_case=do_lower_case) self.wordpiece_tokenizer = WordpieceTokenizer(vocab=self.vocab)source:
https://github.com/google-research/bert/blob/master/multilingual.md#tokenizationMultilingual BERT の説明:
https://github.com/google-research/bert/blob/master/tokenization.py#L161このまま実装するとどうなるかというと...
"鶏肉は包丁を入れて均等に開き、両面にフォークで穴を開け塩コショウする。"というテキストは
['鶏', '肉', 'は', '包', '丁', 'を', '入', 'れて', '均', '等', 'に', '開', 'き', '、', '両', '面', 'に', '##フ', '##ォ', '##ーク', '##で', '穴', 'を', '開', 'け', '塩', 'コ', '##シ', '##ョ', '##ウ', '##する', '。']という様に処理されてしまいます?
そのため、様々な方が、Juman++ や、kuromoji 、MeCab などを使って Tokenize をして、Pre-Trainned のモデルを開発・公開されています。
Azure Machine Learning の AutoML では、PyTorch とも相性の良い HuggingFace の実装を用いています。
huggingface:
https://github.com/huggingface/transformersHuggingface の日本語タスクでは、
MeCabを使っていますね。だいぶマシになっていますね。https://huggingface.co/transformers/pretrained_models.html?highlight=japanese
制限
執筆時点は、以下の制限があります。
- Azure Machine Learning Studio (ml.azure.com) の GUI からは出来ない
- ワークスペースは Enterprise が必要
- 扱える文字列は 128単語 まで (主にBERTの制限)。文字列長ではないので注意
- Classification のみ
必要なもの
- Azure の Subscription
- Jupyter Notebook
ちなみに、私の環境は、Microsoft Windows [Version 10.0.20161.1000] です。
データセット: サクッと試すために
Livedoor のニュースコーパスを利用します。クリエイティブコモンズライセンスと明確にしていただいているため、試しやすいです。
https://www.rondhuit.com/download.html#ldcc
サンプルコードとデータ
以下の GitHub にあります。適時 Fork や Clone をしてください。
Text classification using AutoML with BERT featurization
https://github.com/dahatake/Azure-Machine-Learning-sample/tree/master/3.classification-text-dnn-jpn実行手順
1. 学習ジョブ実行用 Computer の作成
Azure Machine Learning ではスケーラブルな学習ジョブをやってくれる
Azure Machine Learning コンピューティングが用意されています。内部はAzure Batchです。とても容易に使えるようになっています。Azure Machine Learning コンピューティング:
https://docs.microsoft.com/ja-jp/azure/machine-learning/how-to-set-up-training-targets#amlcompute
Azure Machine Learning Studio (ml.azure.com) からの作成で、あまり迷う事は無いと思います。以下だけご注意ください。
項目 値 補足 仮想マシンの種類 GPU BERTの処理に必須です 仮想マシンの優先度 低優先度 急がない場合は、料金の安いこの選択肢にします 最小ノード数 0 0 にすると、学習ジョブが終わった際に、全ての仮想マシンを停止させ、コストの最適化が図れます。ただし、仮想マシンの起動とPython/Anaconda/Dockerの設定には5分程度時間を要します。何度も学習させる場合は、1以上にしてください。後で変更できます スケールダウンする前のアイドル時間 120 (コードが安定したら) - 600 (開発初期) 起動後に、指定時間アイドルになると自動的に仮想マシンが削除されます。開発初期は10分程度にした方がいいです [ノード数] と [スケールダウンする前のアイドル時間] は、作成後に変更できます。
私は、CPUのみと GPUありの2つのClusterを作成しています。
2. Dataset の作成
Azure Machine Learning は、機械学習のためのデータセットを抽象化してくれる Dataset というAPIが存在しています。これが超絶便利で?...
- 同じタスク (text classification) であれば、Dataset 名と Label 名 を変えるだけで動く!
- バージョン管理されている! データの列や内容を変えても、動く!
- AutoMLの
FeaturizationConfigAPIとの連携抜群!
featurization_config.add_drop_columns(['列名', '列名'])で、当該列を学習ジョブから明示的に除外できるDataset を作成すると、以下のサンプルコードまでついてきます。めっちゃ便利!
# azureml-core のバージョン 1.0.72 以上が必要です # バージョン 1.1.34 以降の azureml-dataprep[pandas] が必要です from azureml.core import Workspace, Dataset subscription_id = '<<sub_id>>' resource_group = 'dahatakem' workspace_name = 'dahatakeml' workspace = Workspace(subscription_id, resource_group, workspace_name) dataset = Dataset.get_by_name(workspace, name='livedoor-news')下の図ですと、[livedoor-news] が、今回作成した Dataset になります。
そして、物理的には Blob Storage などに保存されています。ファイルを Dataset として保存すると、別フォルダ(コンテナ)に保存されています。どこに保存されているかも、Azure Machine Learning Studio (ml.azure.com) の画面から確認できます。
こちらは複数ファイルの場合です。複数ファイルも一つのデータセットとして扱えるのが便利です。
2.1. livedoor-news の Dataset 作成
単一のファイルなので、Azure Machine Learning Studio (ml.azure.com) から直接 Dataset として登録します。
- [データセットの作成] の中で [ローカルファイルから] を選択します。
- [名前] を付けます。この文字列でクエリします。
- [データセットのファイルの選択] の [参照] を選んで、ローカルにあるcsvファイルをアップロードします。
- csvファイルと自動的に判定してくれます。[列見出し]で[最初のファイルのヘッダーを利用する]を選択します。
- [スキーマ]はそのままで。
- [作成後にこのデータセットのプロファイルを作成する] はしなくても大丈夫です。後でも実行できますので。
これで、データセットが出来ました。
3. Jupyter Notebook 起動
お好きな方法で使ってください。
私はコストの最適化と時間の節約のため、自分のPCでの実行とします。どうせ AutoML のジョブ実行さえ出来てしまえば、後は Azure にジョブ完了までお任せですし?。その後 Visual Studio Code の Python Extensionで、python script 化しちゃえば、もっとAzure側で自動的に実行しやすくなりますね。3.0. 開発環境をセットアップ (オプション)
Azure Machine Learning には、SDK セットアップ済みの
コンピューティング インスタンスがあります。そちらを使う場合は、この手順をスキップできます。コンピューティングインスタンスはフルマネージドの仮想マシンなので、主に時間課金となります。使わない場合は手動で「止める」事をお忘れなく。Azure Machine Learning コンピューティング インスタンスとは:
https://docs.microsoft.com/ja-jp/azure/machine-learning/concept-compute-instanceこちらの手順に沿って、ローカルの環境に Azure Machine Learning の開発環境をセットアップする事も出来ます。
開発環境をセットアップする - ローカルコンピューター:
https://docs.microsoft.com/ja-jp/azure/machine-learning/how-to-configure-environmentWindows であれば、WSL へのインストールも選択肢ですよね。Pythonの実行では特に?....
こちら、ご参考にしていただければ思います。
Jupyter NotebookをWSLに構築:
https://qiita.com/hiiragi1104/items/c2e9042bc6170873a8593.1. パッケージのインストール
以下インストールします。今後のパッケージングの改善などでこの作業が不要になるかもしれません。
pip install -U azureml-sdk[automl] pip install -U xgboost3.2. Jupyter Nootebook 起動
ここではローカル、かつ、Windows ユーザーらしい(!?)方法で JupyterNotebook を起動させます。
この AutoML を使う場合は、Azure Machine Learning コンピューティングがほぼ必須です。使用可能な機能:
https://docs.microsoft.com/ja-jp/azure/machine-learning/concept-automated-ml#feature-availability
- ファイルのある場所まで移動します。
- [ファイルパス]の場所に
cmdと入力し、[エンターキー]を押します。
- 当該フォルダで、コマンドプロンプトが起動します。
- Anaconda で作成した環境を起動します。下の文字列をコピーして、実行します。
%windir%\System32\cmd.exe "/K" C:\ProgramData\Anaconda3\Scripts\activate.bat C:\ProgramData\Anaconda3この文字列は、プログラムメニューから参照したものです。
- その後は、開発環境作成のドキュメントの通り、個別作成した Anaconda 環境から Jupyter NoteBook を起動します。
conda activate myenv jupyter notebookJupyter Notebooks - Python 開発環境をセットアップする
https://docs.microsoft.com/ja-jp/azure/machine-learning/how-to-configure-environment#jupyter-notebooksこれで、作業フォルダから、JupyterNotebook が起動します。
4. AutoML ジョブ実行
JupyterNotebook 内のセルを逐次実行していきます。
ポイントとなる部分のみ説明します。
4.1. データセットの設定
こちらのスニペットになります。ここで、Dataset の名前とバージョンを変えます。
data_dir = "train-data" # Local directory to store data blobstore_datadir = data_dir # Blob store directory to store data in ## Easy to switch other dataset target_column_name = 'label' df = Dataset.get_by_name(ws, name='livedoor-news') df = df.to_pandas_dataframe() data_train, data_test = train_test_split(df, test_size=0.25, random_state=0)4.2. AutoML の設定
このパラメーターを何度も変更すると思います?。
featurization_config = FeaturizationConfig(dataset_language='jpn') #featurization_config.blocked_transformers = ['TfIdf','CountVectorizer'] #featurization_config.add_drop_columns(['Contents']) automl_settings = { 'experiment_timeout_minutes': 60, 'primary_metric': 'accuracy', #'AUC_weighted', 'accuracy' 'experiment_exit_score': 0.9, # NEW 'max_concurrent_iterations': 4, 'max_cores_per_iteration': -1, 'enable_dnn': True, 'enable_early_stopping': True, 'force_text_dnn': True, # enable BERT featurization 'validation_size': 0.2, 'verbosity': logging.INFO, 'featurization': featurization_config, 'enable_voting_ensemble': False, # this cut the final ensumble job 'enable_stack_ensemble': False, # this cut the final ensumble job 'iterations': 2 ## mainly for DEBUG: Test purpose to stop job earlier to undestand AutoMLConfig parameters behavior or so. } automl_config = AutoMLConfig(task = 'classification', debug_log = 'automl_debug.log', compute_target = compute_target, training_data = train_dataset, label_column_name = target_column_name, **automl_settings )
項目 値 補足 FeaturizationConfig(dataset_language='jpn') 'jpn' ISO 639-3 で定義されている テキストの Featurization の言語指定です。 force_text_dnn True これを指定しないと BERT を使わない事があります(調査中) iterations 開発初期は 2-4 開発初期は、設定データの結果を見るために小さくします。設定がほぼOKになったら削除します get_supported_dataset_languages() method:
https://docs.microsoft.com/en-us/python/api/azureml-train-automl-client/azureml.train.automl.automlconfig.automlconfig?view=azure-ml-py#get-supported-dataset-languages-use-gpu--bool-----typing-dict-typing-any--typing-any-Classification class:
https://docs.microsoft.com/en-us/python/api/azureml-train-automl-client/azureml.train.automl.constants.supportedmodels.classification?view=azure-ml-pySupportedTransformers class:
https://docs.microsoft.com/en-us/python/api/azureml-automl-core/azureml.automl.core.constants.supportedtransformers?view=azure-ml-py4.3. 学習状況
以下の実行後に 逐次状況が表示されます。NC6s_v3 の上記 AutoML 設定で、5-10 分くらいで終わります。
automl_run = experiment.submit(automl_config, show_output=True)以下、出力例です。
Running on remote or ADB. Running on remote compute: gpucluster Parent Run ID: AutoML_4e17b53a-ff29-4e98-a098-5dcc79def043 Current status: FeaturesGeneration. Generating features for the dataset. Current status: DatasetFeaturization. Beginning to fit featurizers and featurize the dataset. Current status: TextDNNTraining. Training a deep learning text model, this may take a while. Current status: TextDNNTrainingCompleted. Completed training a deep learning text model. Current status: DatasetFeaturizationCompleted. Completed fit featurizers and featurizing the dataset. Current status: ModelSelection. Beginning model selection. **************************************************************************************************** DATA GUARDRAILS: TYPE: Class balancing detection STATUS: PASSED DESCRIPTION: Your inputs were analyzed, and all classes are balanced in your training data. Learn more about imbalanced data: https://aka.ms/AutomatedMLImbalancedData **************************************************************************************************** TYPE: Missing feature values imputation STATUS: DONE DESCRIPTION: If the missing values are expected, let the run complete. Otherwise cancel the current run and use a script to customize the handling of missing feature values that may be more appropriate based on the data type and business requirement. Learn more about missing value imputation: https://aka.ms/AutomatedMLFeaturization DETAILS: +---------------------------------+---------------------------------+ |Column name |Missing value count | +=================================+=================================+ |date |6 | |text |10 | +---------------------------------+---------------------------------+ **************************************************************************************************** TYPE: High cardinality feature detection STATUS: DONE DESCRIPTION: High cardinality features were detected in your inputs and handled. Learn more about high cardinality feature handling: https://aka.ms/AutomatedMLFeaturization DETAILS: High cardinality features refer to columns that contain a large percentage of unique values. +---------------------------------+---------------------------------+ |Column name |Column Content Type | +=================================+=================================+ |title |text | |text |text | +---------------------------------+---------------------------------+ **************************************************************************************************** **************************************************************************************************** ITERATION: The iteration being evaluated. PIPELINE: A summary description of the pipeline being evaluated. DURATION: Time taken for the current iteration. METRIC: The result of computing score on the fitted pipeline. BEST: The best observed score thus far. **************************************************************************************************** ITERATION PIPELINE DURATION METRIC BEST 0 MaxAbsScaler LightGBM 0:04:47 0.9250 0.9250 1 MaxAbsScaler XGBoostClassifier 0:04:56 nan 0.9250大事な点を。
- BERT による Featurization の実施が確認できます。GPU の無いマシンでやると時間がかかりますので、注意が必要です。
python Current status: TextDNNTraining. Training a deep learning text model, this may take a while.4.4. 利用された Transformer の確認
以下のコードで、確認できます。
text_transformations_used = [] for column_group in fitted_model.named_steps['datatransformer'].get_featurization_summary(): text_transformations_used.extend(column_group['Transformations']) text_transformations_used以下が出力例になります。
['', 'ModeCatImputer-StringCast-DateTimeTransformer', 'StringCast-CharGramTfIdf', 'StringCast-WordGramTfIdf', 'StringCast-CharGramTfIdf', 'StringCast-WordGramTfIdf', 'StringCast-StringConcatTransformer-PretrainedTextDNNTransformer']それぞれ、定義済みの Transformer が使われています。データ型毎に利用できる Transformer が決まっています。
テキストの場合はこちらに一覧があります。
例えば:
- StringCast: 文字列を全て小文字に
- TfIdf: TF-IDF のアルゴリズムで、カウント行列を変換
- StringConcat: これを知っておくのは大事です。複数の列を結合します。BERTを使う場合には、必ず実施されます。
- PretrainedTextDNNTransformer: BERT による処理です
SupportedTransformers class:
https://docs.microsoft.com/en-us/python/api/azureml-automl-core/azureml.automl.core.constants.supportedtransformers?view=azure-ml-py4.5. 実験結果を確認
AutoML の良い点ですが、諸々の評価用のデータを取得してくれ、Confusion matrix などを自動的に作成してくれることです。データが保存されているので、Azure Machine Learning Studio (ml.azure.com) でいつでも確認ができます。このためのコードを書く必要はありません。
AutoML のジョブです。Iteration として 2回設定していましたので、2つのジョブが見えています。
[メトリック] から、様々な学習中の状況を可視化できます。
Model Explanation - [説明の表示] から参照できます!
Azure Machine Learning でのモデルの解釈可能性:
https://docs.microsoft.com/ja-jp/azure/machine-learning/how-to-machine-learning-interpretabilityまとめ
やりたい事は、BERT でベクトル化する事ではなく、その先にあります。テキストの分類は、それだけでも大変なタスクでした。BERTやBiLSTMがAutoMLの中に組み込まれただけで、テキストを扱う敷居が大分下がったのではないでしょうか?
GUIでの対応も今後予定されていますので、「まずは機械学習のアプローチで良いのか?」という初期フェーズでは大変役に立ちます。勿論、その後の Many Model への対応や、MLOpsを考えた際には、AutoMLはその一部を成す機能として重宝すると思います。
参考
自然言語処理の王様「BERT」の論文を徹底解説:
https://qiita.com/omiita/items/72998858efc19a368e50AutoML のBERT モデルによるテキスト分類
https://medium.com/@konabuta/automl-%E3%81%AE-bert-%E3%83%A2%E3%83%87%E3%83%AB%E3%81%AB%E3%82%88%E3%82%8B%E3%83%86%E3%82%AD%E3%82%B9%E3%83%88%E5%88%86%E9%A1%9E-5758d4456975

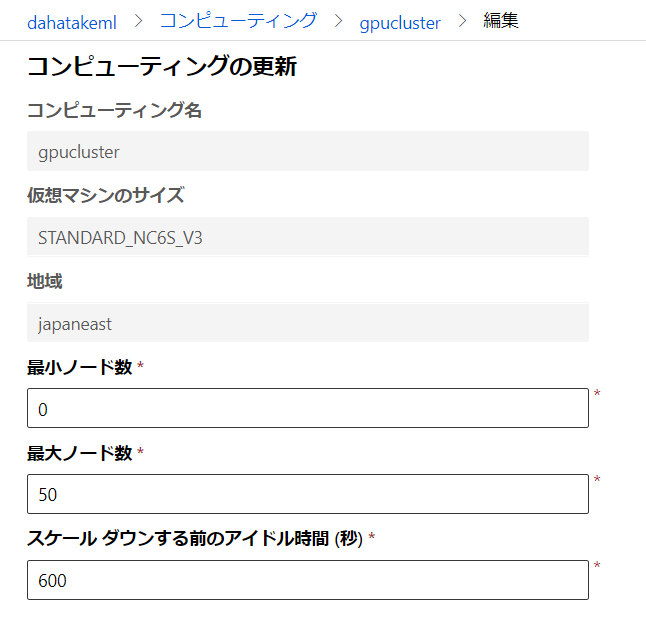
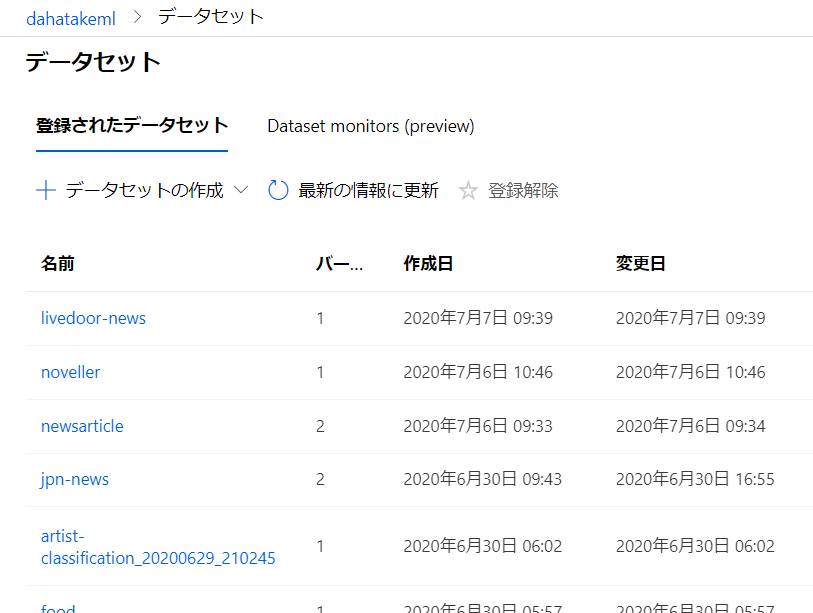

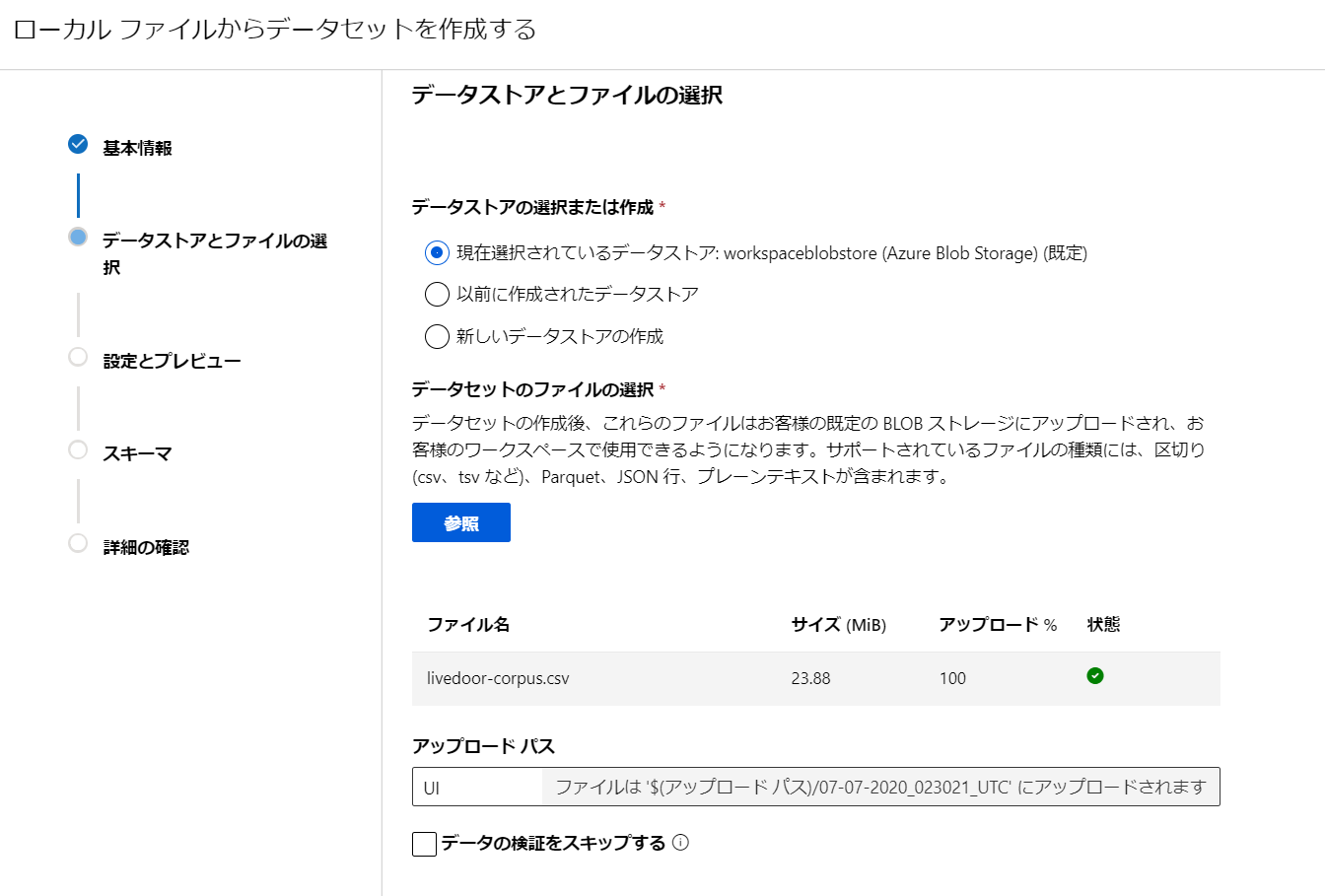
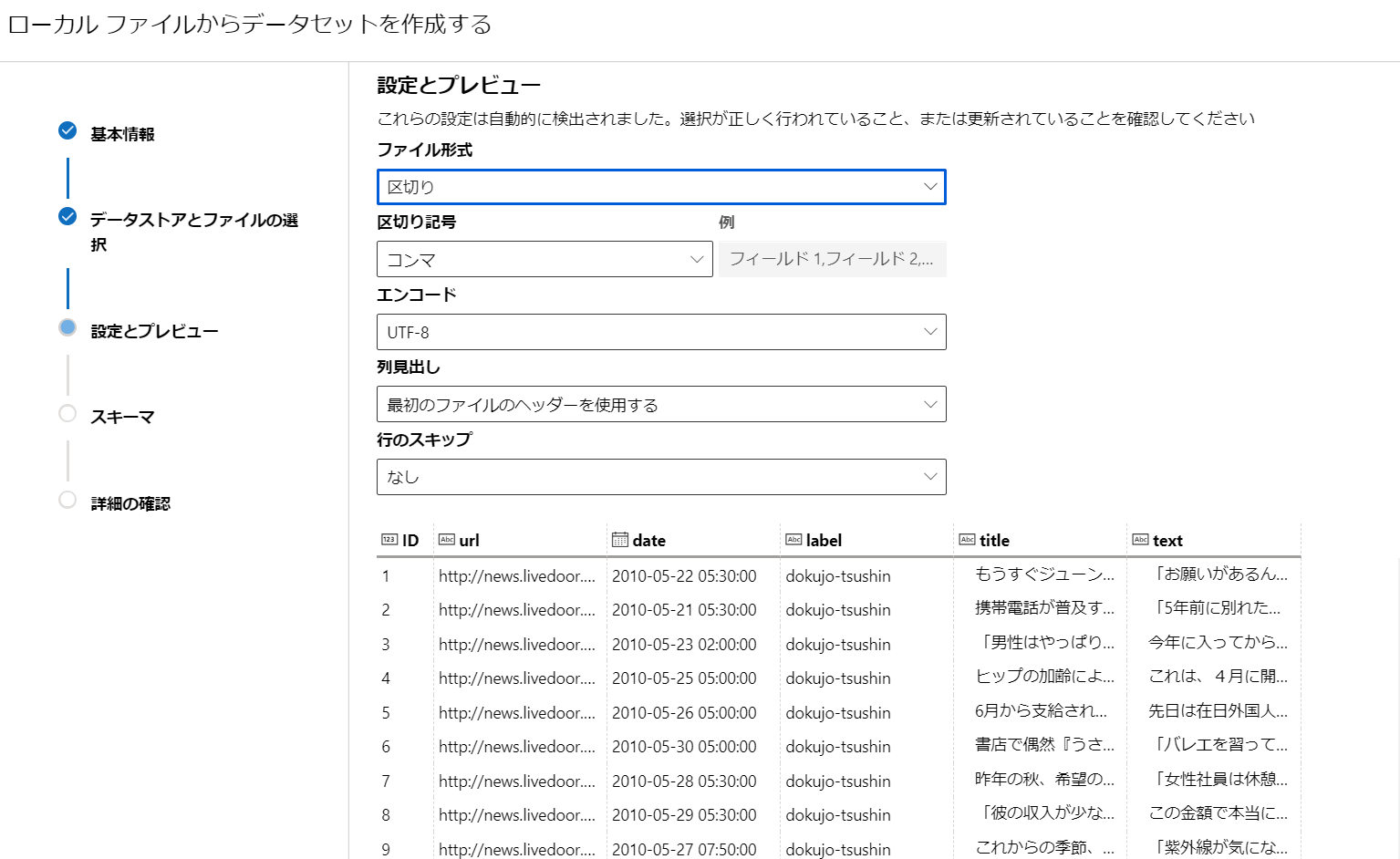
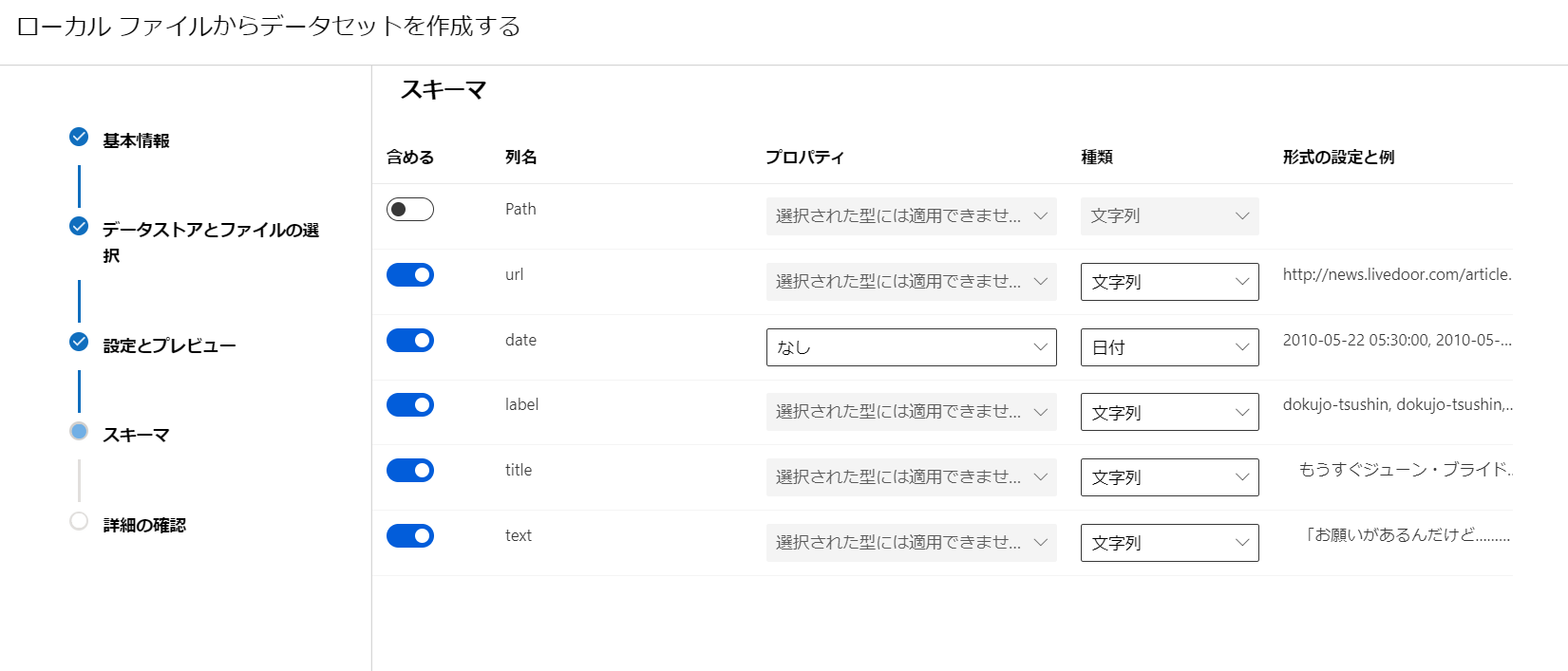
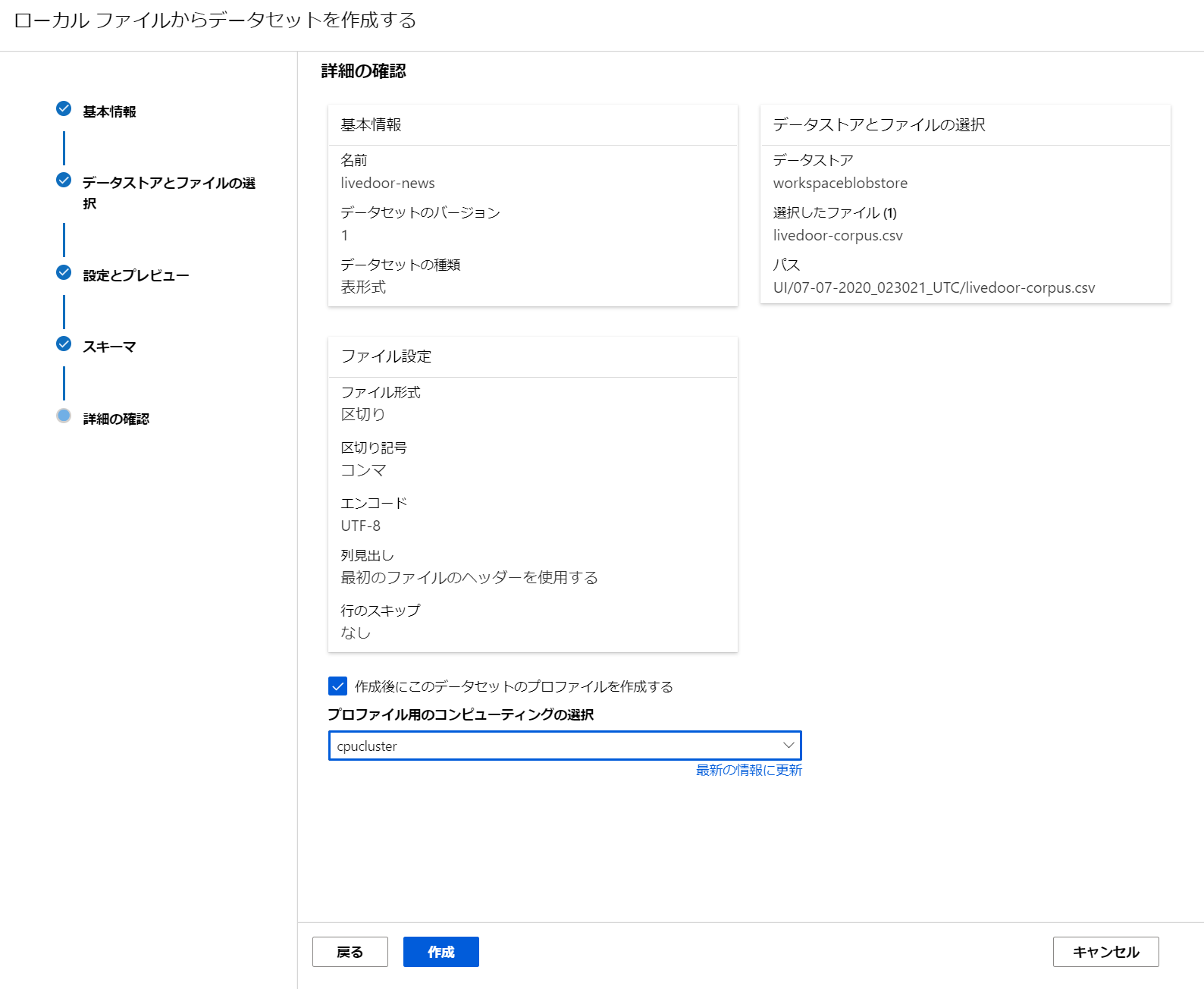
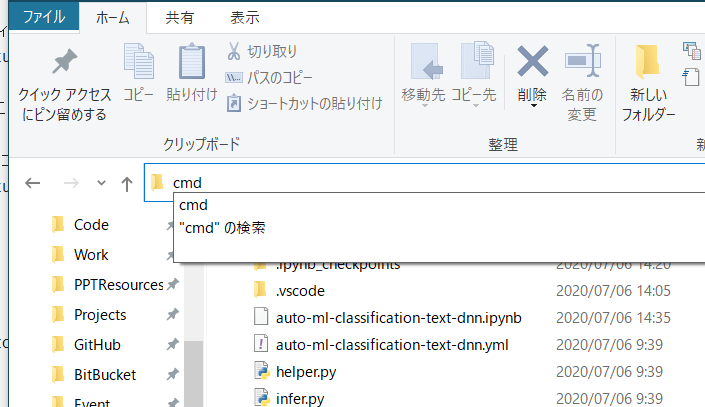
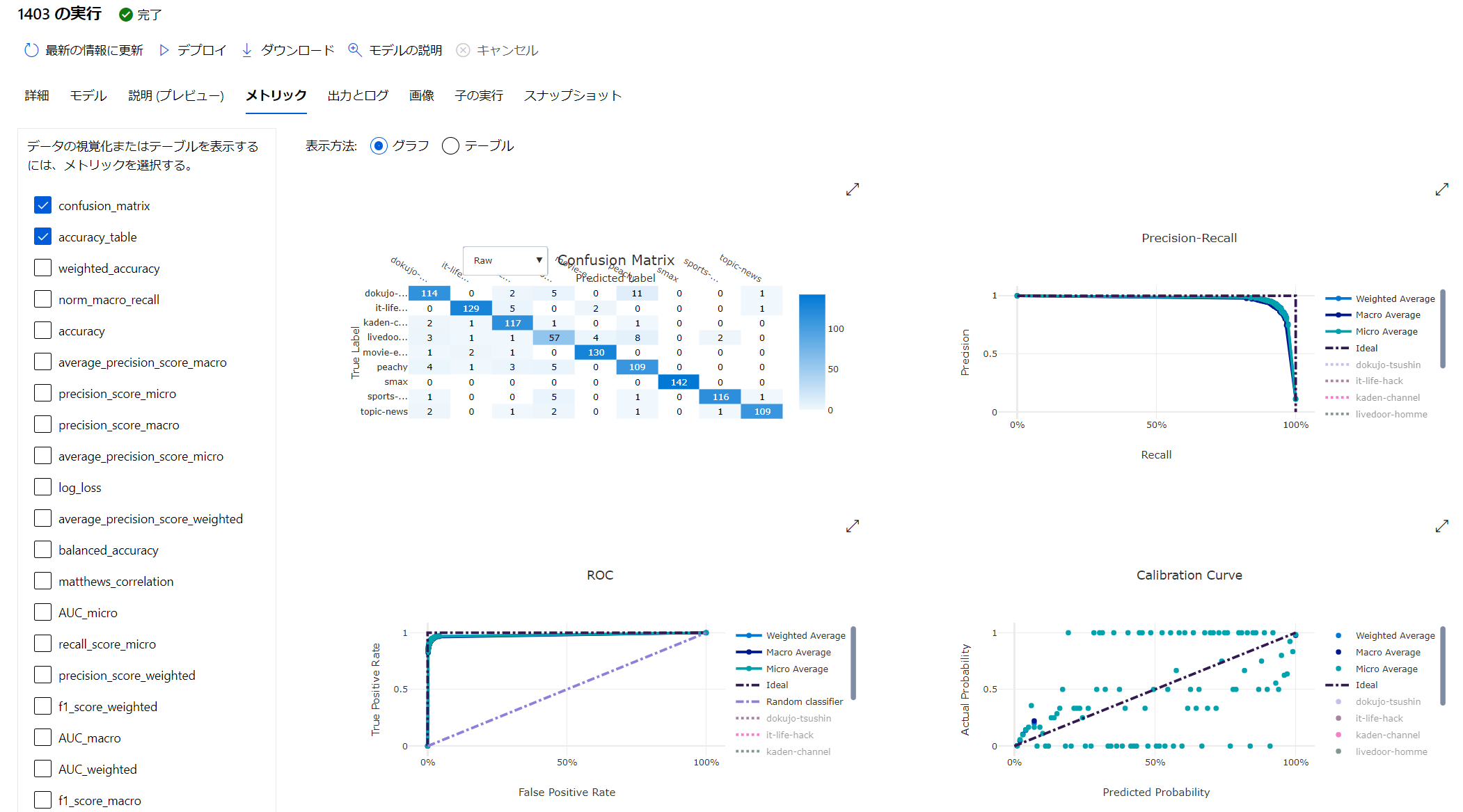
- 投稿日:2020-07-08T13:28:27+09:00
pandas
Pandasとは
pandasは、プログラミング言語Pythonにおいて、データ解析を支援する機能を提供するライブラリである。
特に、数表および時系列データを操作するためのデータ構造と演算を提供する。
開発者であるWes McKinneyは、財務データを定量分析するための高性能で柔軟なツールを欲しており、AQR Capital Managementにて2008年にpandasの開発を開始した。
AQRを去る前に上司を説得し、ライブラリの一般公開が可能となった。Pandas固有のデータ形式
- 1次元のSeries
- 2次元のDataFrame
- DataFrameには行名(index)と列名(column)
DataFrameを作る
numpyのarrayから作る
import numpy as np import pandas as pd d = np.array([[1,2,3],[4,5,6],[7,8,9]]) df = pd.DataFrame(d,columns=['a','b','c']) >>> df a b c 0 1 2 3 1 4 5 6 2 7 8 9行名はdf.index
列名はdf.columns
で調べられるリスト型を値にもった辞書から作る
df = pd.DataFrame({'a':[1,4,7],'b':[2,5,8]},'c':[3,6,9]) >>> df a b c 0 1 2 3 1 4 5 6 2 7 8 9csvファイルを読み込む
# 先頭行が列名として扱われる # index_cols=0 : indexとして使いたい列の列番号を0始まりで指定する import pandas as pd df = pd.read_csv('data/src/sample_pandas_normal.csv', index_col=0) print(df) # age state point # name # Alice 24 NY 64 # Bob 42 CA 92 # Charlie 18 CA 70 # Dave 68 TX 70 # Ellen 24 CA 88 # Frank 30 NY 57 print(df.index.values) # ['Alice' 'Bob' 'Charlie' 'Dave' 'Ellen' 'Frank'] print(df.columns.values) # ['age' 'state' 'point']indexがあるcsvは「index_cols=0」を付ける
index_cols=0がないとindex列は認識されない。
df_header_index = pd.read_csv('data/src/sample_header_index.csv') print(df_header_index) # Unnamed: 0 a b c d # 0 ONE 11 12 13 14 # 1 TWO 21 22 23 24 # 2 THREE 31 32 33 34 # ========================================================== # df_header_index_col = pd.read_csv('data/src/sample_header_index.csv', index_col=0) print(df_header_index_col) # a b c d # ONE 11 12 13 14 # TWO 21 22 23 24 # THREE 31 32 33 34 print(df_header_index_col.index) # Index(['ONE', 'TWO', 'THREE'], dtype='object')ヘッダーがないcsvには「header=None」とつける
ヘッダーがないcsvの場合、そのままpd.read_csvすると1行目がcolumnsになってしまう。
header=Noneとすると連番が列名columnsに割り当てられる。
または、names=('A', 'B', 'C', 'D')のように列名を設定することもできる。11,12,13,14 21,22,23,24 31,32,33,34 import pandas as pd df = pd.read_csv('data/src/sample.csv') print(df) # 11 12 13 14 # 0 21 22 23 24 # 1 31 32 33 34 print(df.columns) # Index(['11', '12', '13', '14'], dtype='object') # ========================================================== # df_none = pd.read_csv('data/src/sample.csv', header=None) print(df_none) # 0 1 2 3 # 0 11 12 13 14 # 1 21 22 23 24 # 2 31 32 33 34 # ========================================================== # df_names = pd.read_csv('data/src/sample.csv', names=('A', 'B', 'C', 'D')) print(df_names) # A B C D # 0 11 12 13 14 # 1 21 22 23 24 # 2 31 32 33 34列を指定して読み込むときは「usecols」を使う
df_none_usecols = pd.read_csv('data/src/sample.csv', header=None, usecols=[1, 3]) print(df_none_usecols) # 1 3 # 0 12 14 # 1 22 24 # 2 32 34 # ========================================================== # df_header_usecols = pd.read_csv('data/src/sample_header.csv', usecols=lambda x: x is not 'b') print(df_header_usecols) # a c d # 0 11 13 14 # 1 21 23 24 # 2 31 33 34 # ========================================================== # df_index_usecols = pd.read_csv('data/src/sample_header_index.csv', index_col=0, usecols=[0, 1, 3]) print(df_index_usecols) # a c # ONE 11 13 # TWO 21 23 # THREE 31 33行をスキップしたいときは「skiprows」を使う
skiprowsに整数を渡すと、ファイルの先頭をその行数分スキップして読み込む。
df_none = pd.read_csv('data/src/sample.csv', header=None) print(df_none) # 0 1 2 3 # 0 11 12 13 14 # 1 21 22 23 24 # 2 31 32 33 34 # ========================================================== # df_none = pd.read_csv('data/src/sample.csv', header=None, skiprows=2) print(df_none) # 0 1 2 3 # 0 31 32 33 34 # ========================================================== # df_none_skiprows = pd.read_csv('data/src/sample.csv', header=None, skiprows=[1]) print(df_none_skiprows) # 0 1 2 3 # 0 11 12 13 14 # 1 31 32 33 34 # ========================================================== # # 最後の行をスキップする場合は「skipfooter=1」に設定 # engine='python'を指定しないとWarningが出る可能性がある df_none_skipfooter = pd.read_csv('data/src/sample.csv', header=None, skipfooter=1, engine='python') print(df_none_skipfooter) # 0 1 2 3 # 0 11 12 13 14 # 1 21 22 23 24読みたい行数は「nrows」で指定する
df_none_nrows = pd.read_csv('data/src/sample.csv', header=None, nrows=2) print(df_none_nrows) # 0 1 2 3 # 0 11 12 13 14 # 1 21 22 23 24列の型を指定するときは「dtype」を使う
df_str_col = pd.read_csv('data/src/sample_header_index_dtype.csv', index_col=0, dtype={'b': str, 'c': str}) print(df_str_col) # a b c d # ONE 1 001 100 x # TWO 2 020 NaN y # THREE 3 300 300 z print(df_str_col.dtypes) # a int64 # b object # c object # d object # dtype: object # ========================================================== # # DataFrameの列は「astype」で型変換できる print(df['s_i'].astype(int)) # 0 0 # 1 10 # 2 200 # Name: s_i, dtype: int64欠損値
By default the following values are interpreted as NaN: ‘’, ‘#N/A’, ‘#N/A N/A’, ‘#NA’, ‘-1.#IND’, ‘-1.#QNAN’, ‘-NaN’, ‘-nan’, ‘1.#IND’, ‘1.#QNAN’, ‘N/A’, ‘NA’, ‘NULL’, ‘NaN’, ‘n/a’, ‘nan’, ‘null’.
pandas.read_csv — pandas 0.23.0 documentation欠損値として扱う値を追加するときは「na_values」
df_nan = pd.read_csv('data/src/sample_header_index_nan.csv', index_col=0) print(df_nan) # a b # ONE NaN NaN # TWO - NaN # THREE NaN NaN # ========================================================== # df_nan_set_na = pd.read_csv('data/src/sample_header_index_nan.csv', index_col=0, na_values='-') print(df_nan_set_na) # a b # ONE NaN NaN # TWO NaN NaN # THREE NaN NaN欠損値を自分で決めたいときは「na_values」と「keep_default_na=False」を一緒に使う
,a,b ONE,,NaN TWO,-,nan THREE,null,N/A # ========================================================== # df_nan_set_na_no_keep = pd.read_csv('data/src/sample_header_index_nan.csv', index_col=0, na_values=['-', 'NaN', 'null'], keep_default_na=False) print(df_nan_set_na_no_keep) # a b # ONE NaN # TWO NaN nan # THREE NaN N/A欠損値をなくすときは「na_filter」を使う
,a,b ONE,,NaN TWO,-,nan THREE,null,N/A # ========================================================== # df_nan_no_filter = pd.read_csv('data/src/sample_header_index_nan.csv', index_col=0, na_filter=False) print(df_nan_no_filter) # a b # ONE NaN # TWO - nan # THREE null N/Aデータに日本語が含まれているときは「encoding='shift_jis'」を使う
df_sjis = pd.read_csv('data/src/sample_header_shift_jis.csv', encoding='shift_jis') print(df_sjis) # a b c d # 0 あ 12 13 14 # 1 い 22 23 24 # 2 う 32 33 34なんでも読めちゃうread_csvは本当に優秀…
拡張子が.gz, .bz2, .zip, .xzの場合、自動で検出して展開してくれる。拡張子が異なる場合、引数compressionに文字列'gz', 'bz2', 'zip', 'xz'を明示的に指定する。
なお、対応しているのはcsvファイル単体が圧縮されている場合のみ。複数ファイルが圧縮されている場合はエラーになる。
zipとxzはバージョン0.18.1からの対応。df_zip = pd.read_csv('data/src/sample_header.csv.zip') df_web = pd.read_csv('http://www.post.japanpost.jp/zipcode/dl/oogaki/zip/13tokyo.zip', header=None, encoding='shift_jis')新しい列を作る
# 水平方向(axis = 1) に総和をとり、Total という列を作る df['Total'] = df.sum(axis=1)要約統計量
at, iat : 単独の要素の値を選択、取得・変更
loc, iloc : 単独および複数の要素の値を選択、取得・変更count: 要素の個数
unique: ユニークな(一意な)値の要素の個数
top: 最頻値(mode)
freq: 最頻値の頻度(出現回数)
mean: 算術平均
std: 標準偏差
min: 最小値
max: 最大値
50%: 中央値(median)
25%, 75%: 1/4分位数、3/4分位数import pandas as pd df = pd.DataFrame({'a': [1, 2, 1, 3], 'b': [0.4, 1.1, 0.1, 0.8], 'c': ['X', 'Y', 'X', 'Z'], 'd': ['3', '5', '2', '1'], 'e': [True, True, False, True]}) print(df) # a b c d e # 0 1 0.4 X 3 True # 1 2 1.1 Y 5 True # 2 1 0.1 X 2 False # 3 3 0.8 Z 1 True print(df.dtypes) # a int64 # b float64 # c object # d object # e bool # dtype: object # ========================================================== # ## データフレーム df の要約統計量を表示 # 各列ごとの平均や標準偏差、最大値、最小値、最頻値など print(df.describe()) # a b # count 4.000000 4.000000 # mean 1.750000 0.600000 # std 0.957427 0.439697 # min 1.000000 0.100000 # 25% 1.000000 0.325000 # 50% 1.500000 0.600000 # 75% 2.250000 0.875000 # max 3.000000 1.100000 print(type(df.describe())) # <class 'pandas.core.frame.DataFrame'> print(df.describe().loc['std']) # stdは標準偏差 # a 0.957427 # b 0.439697 # Name: std, dtype: float64 print(df.describe().at['std', 'b']) # 0.439696865275764文字列など数値以外の列の結果を表示したいときは「exclude='number'」を使う
include='all'とすると、すべての型の列が対象となる。
print(df.describe(exclude='number')) # c d e # count 4 4 4 # unique 3 4 2 # top X 3 True # freq 2 1 3データのプロット
df.plot() #折れ線グラフ df.plot.bar(stacked=True) # 積み上げ棒グラフ df.plot.scatter(‘Japanese’,’English’) # 列を指定して散布図 df[‘Japanese’].plot.hist() # 列を指定してヒストグラム
- 投稿日:2020-07-08T13:28:27+09:00
Pandas
Pandasとは
pandasは、プログラミング言語Pythonにおいて、データ解析を支援する機能を提供するライブラリである。
特に、数表および時系列データを操作するためのデータ構造と演算を提供する。
開発者であるWes McKinneyは、財務データを定量分析するための高性能で柔軟なツールを欲しており、AQR Capital Managementにて2008年にpandasの開発を開始した。
AQRを去る前に上司を説得し、ライブラリの一般公開が可能となった。Pandas固有のデータ形式
- 1次元のSeries
- 2次元のDataFrame
- DataFrameには行名(index)と列名(column)
DataFrameを作る
numpyのarrayから作る
import numpy as np import pandas as pd d = np.array([[1,2,3],[4,5,6],[7,8,9]]) df = pd.DataFrame(d,columns=['a','b','c']) >>> df a b c 0 1 2 3 1 4 5 6 2 7 8 9行名はdf.index
列名はdf.columns
で調べられるリスト型を値にもった辞書から作る
df = pd.DataFrame({'a':[1,4,7],'b':[2,5,8]},'c':[3,6,9]) >>> df a b c 0 1 2 3 1 4 5 6 2 7 8 9csvファイルを読み込む
# 先頭行が列名として扱われる # index_cols=0 : indexとして使いたい列の列番号を0始まりで指定する import pandas as pd df = pd.read_csv('data/src/sample_pandas_normal.csv', index_col=0) print(df) # age state point # name # Alice 24 NY 64 # Bob 42 CA 92 # Charlie 18 CA 70 # Dave 68 TX 70 # Ellen 24 CA 88 # Frank 30 NY 57 print(df.index.values) # ['Alice' 'Bob' 'Charlie' 'Dave' 'Ellen' 'Frank'] print(df.columns.values) # ['age' 'state' 'point']indexがあるcsvは「index_cols=0」を付ける
index_cols=0がないとindex列は認識されない。
df_header_index = pd.read_csv('data/src/sample_header_index.csv') print(df_header_index) # Unnamed: 0 a b c d # 0 ONE 11 12 13 14 # 1 TWO 21 22 23 24 # 2 THREE 31 32 33 34 # ========================================================== # df_header_index_col = pd.read_csv('data/src/sample_header_index.csv', index_col=0) print(df_header_index_col) # a b c d # ONE 11 12 13 14 # TWO 21 22 23 24 # THREE 31 32 33 34 print(df_header_index_col.index) # Index(['ONE', 'TWO', 'THREE'], dtype='object')ヘッダーがないcsvには「header=None」とつける
ヘッダーがないcsvの場合、そのままpd.read_csvすると1行目がcolumnsになってしまう。
header=Noneとすると連番が列名columnsに割り当てられる。
または、names=('A', 'B', 'C', 'D')のように列名を設定することもできる。11,12,13,14 21,22,23,24 31,32,33,34 import pandas as pd df = pd.read_csv('data/src/sample.csv') print(df) # 11 12 13 14 # 0 21 22 23 24 # 1 31 32 33 34 print(df.columns) # Index(['11', '12', '13', '14'], dtype='object') # ========================================================== # df_none = pd.read_csv('data/src/sample.csv', header=None) print(df_none) # 0 1 2 3 # 0 11 12 13 14 # 1 21 22 23 24 # 2 31 32 33 34 # ========================================================== # df_names = pd.read_csv('data/src/sample.csv', names=('A', 'B', 'C', 'D')) print(df_names) # A B C D # 0 11 12 13 14 # 1 21 22 23 24 # 2 31 32 33 34列を指定して読み込むときは「usecols」を使う
df_none_usecols = pd.read_csv('data/src/sample.csv', header=None, usecols=[1, 3]) print(df_none_usecols) # 1 3 # 0 12 14 # 1 22 24 # 2 32 34 # ========================================================== # df_header_usecols = pd.read_csv('data/src/sample_header.csv', usecols=lambda x: x is not 'b') print(df_header_usecols) # a c d # 0 11 13 14 # 1 21 23 24 # 2 31 33 34 # ========================================================== # df_index_usecols = pd.read_csv('data/src/sample_header_index.csv', index_col=0, usecols=[0, 1, 3]) print(df_index_usecols) # a c # ONE 11 13 # TWO 21 23 # THREE 31 33行をスキップしたいときは「skiprows」を使う
skiprowsに整数を渡すと、ファイルの先頭をその行数分スキップして読み込む。
df_none = pd.read_csv('data/src/sample.csv', header=None) print(df_none) # 0 1 2 3 # 0 11 12 13 14 # 1 21 22 23 24 # 2 31 32 33 34 # ========================================================== # df_none = pd.read_csv('data/src/sample.csv', header=None, skiprows=2) print(df_none) # 0 1 2 3 # 0 31 32 33 34 # ========================================================== # df_none_skiprows = pd.read_csv('data/src/sample.csv', header=None, skiprows=[1]) print(df_none_skiprows) # 0 1 2 3 # 0 11 12 13 14 # 1 31 32 33 34 # ========================================================== # # 最後の行をスキップする場合は「skipfooter=1」に設定 # engine='python'を指定しないとWarningが出る可能性がある df_none_skipfooter = pd.read_csv('data/src/sample.csv', header=None, skipfooter=1, engine='python') print(df_none_skipfooter) # 0 1 2 3 # 0 11 12 13 14 # 1 21 22 23 24読みたい行数は「nrows」で指定する
df_none_nrows = pd.read_csv('data/src/sample.csv', header=None, nrows=2) print(df_none_nrows) # 0 1 2 3 # 0 11 12 13 14 # 1 21 22 23 24列の型を指定するときは「dtype」を使う
df_str_col = pd.read_csv('data/src/sample_header_index_dtype.csv', index_col=0, dtype={'b': str, 'c': str}) print(df_str_col) # a b c d # ONE 1 001 100 x # TWO 2 020 NaN y # THREE 3 300 300 z print(df_str_col.dtypes) # a int64 # b object # c object # d object # dtype: object # ========================================================== # # DataFrameの列は「astype」で型変換できる print(df['s_i'].astype(int)) # 0 0 # 1 10 # 2 200 # Name: s_i, dtype: int64欠損値
By default the following values are interpreted as NaN: ‘’, ‘#N/A’, ‘#N/A N/A’, ‘#NA’, ‘-1.#IND’, ‘-1.#QNAN’, ‘-NaN’, ‘-nan’, ‘1.#IND’, ‘1.#QNAN’, ‘N/A’, ‘NA’, ‘NULL’, ‘NaN’, ‘n/a’, ‘nan’, ‘null’.
pandas.read_csv — pandas 0.23.0 documentation欠損値として扱う値を追加するときは「na_values」
df_nan = pd.read_csv('data/src/sample_header_index_nan.csv', index_col=0) print(df_nan) # a b # ONE NaN NaN # TWO - NaN # THREE NaN NaN # ========================================================== # df_nan_set_na = pd.read_csv('data/src/sample_header_index_nan.csv', index_col=0, na_values='-') print(df_nan_set_na) # a b # ONE NaN NaN # TWO NaN NaN # THREE NaN NaN欠損値を自分で決めたいときは「na_values」と「keep_default_na=False」を一緒に使う
,a,b ONE,,NaN TWO,-,nan THREE,null,N/A # ========================================================== # df_nan_set_na_no_keep = pd.read_csv('data/src/sample_header_index_nan.csv', index_col=0, na_values=['-', 'NaN', 'null'], keep_default_na=False) print(df_nan_set_na_no_keep) # a b # ONE NaN # TWO NaN nan # THREE NaN N/A欠損値をなくすときは「na_filter」を使う
,a,b ONE,,NaN TWO,-,nan THREE,null,N/A # ========================================================== # df_nan_no_filter = pd.read_csv('data/src/sample_header_index_nan.csv', index_col=0, na_filter=False) print(df_nan_no_filter) # a b # ONE NaN # TWO - nan # THREE null N/Aデータに日本語が含まれているときは「encoding='shift_jis'」を使う
df_sjis = pd.read_csv('data/src/sample_header_shift_jis.csv', encoding='shift_jis') print(df_sjis) # a b c d # 0 あ 12 13 14 # 1 い 22 23 24 # 2 う 32 33 34なんでも読めちゃうread_csvは本当に優秀…
拡張子が.gz, .bz2, .zip, .xzの場合、自動で検出して展開してくれる。拡張子が異なる場合、引数compressionに文字列'gz', 'bz2', 'zip', 'xz'を明示的に指定する。
なお、対応しているのはcsvファイル単体が圧縮されている場合のみ。複数ファイルが圧縮されている場合はエラーになる。
zipとxzはバージョン0.18.1からの対応。df_zip = pd.read_csv('data/src/sample_header.csv.zip') df_web = pd.read_csv('http://www.post.japanpost.jp/zipcode/dl/oogaki/zip/13tokyo.zip', header=None, encoding='shift_jis')新しい列を作る
# 水平方向(axis = 1) に総和をとり、Total という列を作る df['Total'] = df.sum(axis=1)要約統計量
at, iat : 単独の要素の値を選択、取得・変更
loc, iloc : 単独および複数の要素の値を選択、取得・変更count: 要素の個数
unique: ユニークな(一意な)値の要素の個数
top: 最頻値(mode)
freq: 最頻値の頻度(出現回数)
mean: 算術平均
std: 標準偏差
min: 最小値
max: 最大値
50%: 中央値(median)
25%, 75%: 1/4分位数、3/4分位数import pandas as pd df = pd.DataFrame({'a': [1, 2, 1, 3], 'b': [0.4, 1.1, 0.1, 0.8], 'c': ['X', 'Y', 'X', 'Z'], 'd': ['3', '5', '2', '1'], 'e': [True, True, False, True]}) print(df) # a b c d e # 0 1 0.4 X 3 True # 1 2 1.1 Y 5 True # 2 1 0.1 X 2 False # 3 3 0.8 Z 1 True print(df.dtypes) # a int64 # b float64 # c object # d object # e bool # dtype: object # ========================================================== # ## データフレーム df の要約統計量を表示 # 各列ごとの平均や標準偏差、最大値、最小値、最頻値など print(df.describe()) # a b # count 4.000000 4.000000 # mean 1.750000 0.600000 # std 0.957427 0.439697 # min 1.000000 0.100000 # 25% 1.000000 0.325000 # 50% 1.500000 0.600000 # 75% 2.250000 0.875000 # max 3.000000 1.100000 print(type(df.describe())) # <class 'pandas.core.frame.DataFrame'> print(df.describe().loc['std']) # stdは標準偏差 # a 0.957427 # b 0.439697 # Name: std, dtype: float64 print(df.describe().at['std', 'b']) # 0.439696865275764文字列など数値以外の列の結果を表示したいときは「exclude='number'」を使う
include='all'とすると、すべての型の列が対象となる。
print(df.describe(exclude='number')) # c d e # count 4 4 4 # unique 3 4 2 # top X 3 True # freq 2 1 3データのプロット
df.plot() #折れ線グラフ df.plot.bar(stacked=True) # 積み上げ棒グラフ df.plot.scatter(‘Japanese’,’English’) # 列を指定して散布図 df[‘Japanese’].plot.hist() # 列を指定してヒストグラム
- 投稿日:2020-07-08T13:14:13+09:00
EFSにセットアップしたPythonライブラリをLambdaにimportする方法
はじめに
LambdaにEFSをマウントできるようになりました。これによりEFSにセットアップしたPythonのライブラリをLambdaにimportできるようになりました。
これまでは、LambdaにPython標準以外のライブラリをimportしたい場合は、Lambda layer に固めてアップロードする方法しかありませんでした。しかし、この方法には
圧縮して50MB以下、解凍後250MB以下というサイズの制限があります。このため、サイズの大きいライブラリを複数使うといったことができませんでした。そのため、少し規模が大きいシステムだと、一部処理をdockerに外出しするなどの対応が必要となり、Lambdaだけでは完結しませんでした。しかし、LambdaにEFSをマウントできるようになったため、この問題が解消します。
EFSにインストールしたライブラリをLambdaにimportできるようになりました。how to
概要
- EFS作成
- EFSアクセスポイントを作成
- EFSを作業用にEC2にマウント
- EFSにPythonとライブラリをインストール
- Lambdaにimport
手順
- EFS作成
- 作成手順
省略- 注意
Lambdaと同じVPCを指定
セキュリティグループ port:2049 許可にLambdaのセキュリティグループを指定- EFSアクセスポイント(クライアントアクセス)を作成
所有者ユーザーID: 1001
所有者グループID: 1001
アクセス許可: 777
パス(ディレクトリ)はここでは/lambdaを設定
EFSを作業用EC2にマウント
sudo yum install -y amazon-efs-utils cd /mnt sudo mkdir efs sudo mount -t efs fs-xxxxx:/ efsEFSにPythonとライブラリをインストール
ここでは Python3.8.1 と pandas をインストールsudo yum -y install gcc openssl-devel bzip2-devel libffi-devel wget https://www.python.org/ftp/python/3.8.1/Python-3.8.1.tgz tar xzf Python-3.8.1.tgz cd Python-3.8.1 sudo ./configure --enable-optimizations sudo make altinstall # check python3.8 --version pip3.8 --version cd /mnt/efs pip3.8 install --upgrade --target lambda/ pandasLambda関数を設定
VPCに所属させる必要がある
Lambdaの実行roleにポリシーAmazonElasticFileSystemClientReadWriteAccesを追加
EFSを追加Lambdaでimport
こんなかんじでimportできる。import sys sys.path.append("/mnt/efs") import pandas as pd
- 投稿日:2020-07-08T12:53:29+09:00
Python で浮動小数点数 float のメモリ上のバイト列を確認してみる
ctyes の使い方をいつも忘れるのでメモ。
a = 0.5 のときの a のメモリ上のバイト列を観たい。>>> import ctypes >>> a = ctypes.c_float(0.5) >>> a c_float(0.5) >>> a.value 0.5 >>> ctypes.cast(ctypes.byref(a), ctypes.POINTER(ctypes.c_float)) <__main__.LP_c_float object at 0x000001FF2A2F59C8> >>> ctypes.cast(ctypes.byref(a), ctypes.POINTER(ctypes.c_char)) <ctypes.LP_c_char object at 0x000001FF2A2F5B48> >>> ctypes.cast(ctypes.byref(a), ctypes.POINTER(ctypes.c_char))[0:4] b'\x00\x00\x00?'[0:4] で範囲指定しておかないと怒られる。([:]だとエラー)
出力が判り易い様に修正。>>> b = lambda f: [f'{b:02x}' for b in ctypes.cast(ctypes.byref(ctypes.c_float(f)), ctypes.POINTER(ctypes.c_char))[0:4]] >>> b(0.5) ['00', '00', '00', '3f']ついでにその他の数値は、
>>> b(0.25) ['00', '00', '80', '3e'] >>> b(0.866) ['2d', 'b2', '5d', '3f'] >>> b(0.433) ['2d', 'b2', 'dd', '3e'] >>> b(0.216) ['1b', '2f', '5d', '3e'] >>> b(0.0) ['00', '00', '00', '00'] >>> b(1.0) ['00', '00', '80', '3f']逆も確認(バイト列から float)。
>>> f = lambda b: ctypes.cast(ctypes.create_string_buffer(b), ctypes.POINTER(ctypes.c_float))[0] >>> f(b'\x2d\xb2\x5d\x3f') 0.8659999966621399 >>> f(b'\x2d\xb2\xdd\x3e') 0.43299999833106995 >>> f(b'\x2d\xb2\x5d\x3e') 0.21649999916553497 >>> f(b'\x3a\xcd\x13\xbf') -0.5773502588272095
- 投稿日:2020-07-08T11:44:48+09:00
だから僕はpandasを辞めた【データサイエンス100本ノック(構造化データ加工編)篇 #5】
だから僕はpandasを辞めた【データサイエンス100本ノック(構造化データ加工編)篇 #5】
データサイエンス100本ノック(構造化データ加工編)のPythonの問題を解いていきます。この問題群は、模範解答ではpandasを使ってデータ加工を行っていますが、私達は勉強がてらにNumPyを用いて処理していきます。
はじめに
NumPyの勉強として、データサイエンス100本ノック(構造化データ加工編)のPythonの問題を解いていきます。
Pythonでデータサイエンス的なことをする人の多くはpandas大好き人間かもしれませんが、実はpandasを使わなくても、NumPyで同じことができます。そしてNumPyの方がたいてい高速です。
pandas大好き人間だった僕もNumPyの操作には依然として慣れていないので、今回この『データサイエンス100本ノック』をNumPyで操作することでpandasからの卒業を試みて行きたいと思います。今回は36~44問目をやっていきます。複数のデータフレームのマージというテーマのようです。
初期データは以下のようにして読み込みました(データ型指定はとりあえず後回し)。import numpy as np import pandas as pd from numpy.lib import recfunctions as rfn # 模範解答用 df_category = pd.read_csv('data/category.csv', dtype='string') df_customer = pd.read_csv('data/customer.csv') df_product = pd.read_csv( 'data/product.csv', dtype={col: 'string' for col in ['category_major_cd', 'category_medium_cd', 'category_small_cd']}) df_receipt = pd.read_csv('data/receipt.csv') df_store = pd.read_csv('data/store.csv') # 僕たちが扱うデータ arr_category = np.genfromtxt( 'data/category.csv', delimiter=',', encoding='utf-8-sig', names=True, dtype=tuple(['<U15']*6)) arr_customer = np.genfromtxt( 'data/customer.csv', delimiter=',', encoding='utf-8', names=True, dtype=None) arr_product = np.genfromtxt( 'data/product.csv', delimiter=',', encoding='utf-8-sig', names=True, dtype=tuple(['<U10']*4+['<i4']*2)) arr_receipt = np.genfromtxt( 'data/receipt.csv', delimiter=',', encoding='utf-8', names=True, dtype=None) arr_store = np.genfromtxt( 'data/store.csv', delimiter=',', encoding='utf-8', names=True, dtype=None)最後に計算結果を構造化配列にして出力するための関数def make_array(size, **kwargs): arr = np.empty(size, dtype=[(colname, subarr.dtype) for colname, subarr in kwargs.items()]) for colname, subarr in kwargs.items(): arr[colname] = subarr return arrP_036
P-036: レシート明細データフレーム(df_receipt)と店舗データフレーム(df_store)を内部結合し、レシート明細データフレームの全項目と店舗データフレームの店舗名(store_name)を10件表示させよ。
内部結合ですが、内容はVLOOKUPです。まず両フレームのキー列を合成した行列に対して
np.unique()を行って数値データに変換します。つづいてnp.searchsorted()を使ってレシート明細の店舗コード列を置換していきます。In[023]_, inv = np.unique(np.concatenate([arr_store['store_cd'], arr_receipt['store_cd']]), return_inverse=True) inv_map, inv_arr = inv[:arr_store.size], inv[arr_store.size:] sorter_index = np.argsort(inv_map) idx = np.searchsorted(inv_map, inv_arr, sorter=sorter_index) store_name = arr_store['store_name'][sorter_index[idx]] new_arr = make_array(arr_receipt.size, **{col: arr_receipt[col] for col in arr_receipt.dtype.names}, store_name=store_name) new_arr[:10]Out[023]array([(20181103, 1257206400, 'S14006', 112, 1, 'CS006214000001', 'P070305012', 1, 158, '葛が谷店'), (20181118, 1258502400, 'S13008', 1132, 2, 'CS008415000097', 'P070701017', 1, 81, '成城店'), (20170712, 1215820800, 'S14028', 1102, 1, 'CS028414000014', 'P060101005', 1, 170, '二ツ橋店'), (20190205, 1265328000, 'S14042', 1132, 1, 'ZZ000000000000', 'P050301001', 1, 25, '新山下店'), (20180821, 1250812800, 'S14025', 1102, 2, 'CS025415000050', 'P060102007', 1, 90, '大和店'), (20190605, 1275696000, 'S13003', 1112, 1, 'CS003515000195', 'P050102002', 1, 138, '狛江店'), (20181205, 1259971200, 'S14024', 1102, 2, 'CS024514000042', 'P080101005', 1, 30, '三田店'), (20190922, 1285113600, 'S14040', 1102, 1, 'CS040415000178', 'P070501004', 1, 128, '長津田店'), (20170504, 1209859200, 'S13020', 1112, 2, 'ZZ000000000000', 'P071302010', 1, 770, '十条仲原店'), (20191010, 1286668800, 'S14027', 1102, 1, 'CS027514000015', 'P071101003', 1, 680, '南藤沢店')], dtype=[('sales_ymd', '<i4'), ('sales_epoch', '<i4'), ('store_cd', '<U6'), ('receipt_no', '<i4'), ('receipt_sub_no', '<i4'), ('customer_id', '<U14'), ('product_cd', '<U10'), ('quantity', '<i4'), ('amount', '<i4'), ('store_name', '<U6')])模範解答の
pd.merge()を用いた方法の場合、強制的にキー列でソートされてしまう(キー列がユニークでないため)。
今回の問題であれば、pandasで行う場合はstore_name = df_receipt['store_cd'].map( df_store.set_index('store_cd')['store_name']) df = df_receipt.assign(store_name=store_name)とすれば良い。
P_037
P-037: 商品データフレーム(df_product)とカテゴリデータフレーム(df_category)を内部結合し、商品データフレームの全項目とカテゴリデータフレームの小区分名(category_small_name)を10件表示させよ。
同じ。
In[037]_, inv = np.unique(np.concatenate([arr_category['category_small_cd'], arr_product['category_small_cd']]), return_inverse=True) inv_map, inv_arr = inv[:arr_category.size], inv[arr_category.size:] sorter_index = np.argsort(inv_map) idx = np.searchsorted(inv_map, inv_arr, sorter=sorter_index) store_name = arr_category['category_small_name'][sorter_index[idx]] new_arr = make_array(arr_product.size, **{col: arr_product[col] for col in arr_product.dtype.names}, store_name=store_name) new_arr[:10]Out[037]array([('P040101001', '04', '0401', '040101', 198, 149, '弁当類'), ('P040101002', '04', '0401', '040101', 218, 164, '弁当類'), ('P040101003', '04', '0401', '040101', 230, 173, '弁当類'), ('P040101004', '04', '0401', '040101', 248, 186, '弁当類'), ('P040101005', '04', '0401', '040101', 268, 201, '弁当類'), ('P040101006', '04', '0401', '040101', 298, 224, '弁当類'), ('P040101007', '04', '0401', '040101', 338, 254, '弁当類'), ('P040101008', '04', '0401', '040101', 420, 315, '弁当類'), ('P040101009', '04', '0401', '040101', 498, 374, '弁当類'), ('P040101010', '04', '0401', '040101', 580, 435, '弁当類')], dtype=[('product_cd', '<U10'), ('category_major_cd', '<U10'), ('category_medium_cd', '<U10'), ('category_small_cd', '<U10'), ('unit_price', '<i4'), ('unit_cost', '<i4'), ('store_name', '<U15')])P_038
P-038: 顧客データフレーム(df_customer)とレシート明細データフレーム(df_receipt)から、各顧客ごとの売上金額合計を求めよ。ただし、買い物の実績がない顧客については売上金額を0として表示させること。また、顧客は性別コード(gender_cd)が女性(1)であるものを対象とし、非会員(顧客IDが'Z'から始まるもの)は除外すること。なお、結果は10件だけ表示させれば良い。
同様に、まず両フレームのキー列を結合した上で数値データに変換します。つづいて
np.bincount()を利用して顧客ごとの合計を求めますが、このとき第三引数minlengthを用いると出力される行列が任意のサイズになりますのでunq.sizeを指定します。最後に、数値化したキー列のレシート明細データ側をインデックスにして値を取得します。In[038]is_member_receipt = arr_receipt['customer_id'].astype('<U1') != 'Z' is_member_customer = ((arr_customer['customer_id'].astype('<U1') != 'Z') & (arr_customer['gender_cd'] == 1)) customer = arr_customer['customer_id'][is_member_customer] unq, inv = np.unique( np.concatenate([customer, arr_receipt['customer_id'][is_member_receipt]]), return_inverse=True) customer_size = customer.size amount_sum = np.bincount( inv[customer_size:], arr_receipt['amount'][is_member_receipt], unq.size) new_arr = make_array(customer_size, customer_id=customer, amount=amount_sum[inv[:customer_size]]) new_arr[:10]Out[038]array([('CS021313000114', 0.), ('CS031415000172', 5088.), ('CS028811000001', 0.), ('CS001215000145', 875.), ('CS015414000103', 3122.), ('CS033513000180', 868.), ('CS035614000014', 0.), ('CS011215000048', 3444.), ('CS009413000079', 0.), ('CS040412000191', 210.)], dtype=[('customer_id', '<U14'), ('amount', '<f8')])P_039
P-039: レシート明細データフレーム(df_receipt)から売上日数の多い顧客の上位20件と、売上金額合計の多い顧客の上位20件を抽出し、完全外部結合せよ。ただし、非会員(顧客IDが'Z'から始まるもの)は除外すること。
np.partition()を用いて20位の値を取得し、上位20位に入っていない値をnp.nanに置換後、インデックスを取得します。In[039]is_member = arr_receipt['customer_id'].astype('<U1') != 'Z' unq, inv = np.unique(arr_receipt['customer_id'][is_member], return_inverse=True) sums = np.bincount(inv, arr_receipt['amount'][is_member], unq.size) is_sum_top = sums >= -np.partition(-sums, 20)[20] sums[~is_sum_top] = np.nan unq2 = np.unique([inv, arr_receipt['sales_ymd'][is_member]], axis=-1) counts = np.bincount(unq2[0]).astype(float) is_cnt_top = counts >= -np.partition(-counts, 20)[20] counts[~is_cnt_top] = np.nan interserction = is_cnt_top | is_sum_top make_array(interserction.sum(), customer_id=unq[interserction], amount=sums[interserction], sales_ymd=counts[interserction])Out[039]array([('CS001605000009', 18925., nan), ('CS006515000023', 18372., nan), ('CS007514000094', 15735., nan), ('CS007515000107', nan, 18.), ('CS009414000059', 15492., nan), ('CS010214000002', nan, 21.), ('CS010214000010', 18585., 22.), ('CS011414000106', 18338., nan), ('CS011415000006', 16094., nan), ('CS014214000023', nan, 19.), ('CS014415000077', nan, 18.), ('CS015415000185', 20153., 22.), ('CS015515000034', 15300., nan), ('CS016415000101', 16348., nan), ('CS016415000141', 18372., 20.), ('CS017415000097', 23086., 20.), ('CS021514000045', nan, 19.), ('CS021515000056', nan, 18.), ('CS021515000089', 17580., nan), ('CS021515000172', nan, 19.), ('CS021515000211', nan, 18.), ('CS022515000028', nan, 18.), ('CS022515000226', nan, 19.), ('CS026414000059', 15153., nan), ('CS028415000007', 19127., 21.), ('CS030214000008', nan, 18.), ('CS030415000034', 15468., nan), ('CS031414000051', 19202., 19.), ('CS031414000073', nan, 18.), ('CS032414000072', 16563., nan), ('CS032415000209', nan, 18.), ('CS034415000047', 16083., nan), ('CS035414000024', 17615., nan), ('CS038415000104', 17847., nan), ('CS039414000052', nan, 19.), ('CS040214000008', nan, 23.)], dtype=[('customer_id', '<U14'), ('amount', '<f8'), ('sales_ymd', '<f8')])P_040
P-040: 全ての店舗と全ての商品を組み合わせると何件のデータとなるか調査したい。店舗(df_store)と商品(df_product)を直積した件数を計算せよ。
問題の意図がわかりません……。
In[040]arr_store.size * arr_product.sizeOut[040]531590Time[040]# 模範解答 %%timeit df_store_tmp = df_store.copy() df_product_tmp = df_product.copy() df_store_tmp['key'] = 0 df_product_tmp['key'] = 0 len(pd.merge(df_store_tmp, df_product_tmp, how='outer', on='key')) # 277 ms ± 6.09 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) # NumPy %timeit arr_store.size * arr_product.size # 136 ns ± 1.69 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)P_041
P-041: レシート明細データフレーム(df_receipt)の売上金額(amount)を日付(sales_ymd)ごとに集計し、前日からの売上金額増減を計算せよ。なお、計算結果は10件表示すればよい。
配列における前後の差を取得するには
np.ediff1d()を用います。In[041]unq, inv = np.unique(arr_receipt['sales_ymd'], return_inverse=True) diff_amount = np.ediff1d(np.bincount(inv, arr_receipt['amount'])) make_array(unq.size, sales_ymd=unq, diff_amount=np.concatenate([[np.nan], diff_amount]))[:10]Out[041]array([(20170101, nan), (20170102, -9558.), (20170103, 3338.), (20170104, 8662.), (20170105, 1665.), (20170106, -5443.), (20170107, -8972.), (20170108, 1322.), (20170109, 1981.), (20170110, -6575.)], dtype=[('sales_ymd', '<i4'), ('diff_amount', '<f8')])P_042
P-042: レシート明細データフレーム(df_receipt)の売上金額(amount)を日付(sales_ymd)ごとに集計し、各日付のデータに対し、1日前、2日前、3日前のデータを結合せよ。結果は10件表示すればよい。
スライスで取ります。
In[042]unq, inv = np.unique(arr_receipt['sales_ymd'], return_inverse=True) amount = np.bincount(inv, arr_receipt['amount']) make_array(unq.size - 3, sales_ymd=unq[3:], amount=amount[3:], lag_ymd_1=unq[2:-1], lag_amount_1=amount[2:-1], lag_ymd_2=unq[1:-2], lag_amount_2=amount[1:-2], lag_ymd_3=unq[:-3], lag_amount_3=amount[:-3])[:10]Out[042]array([(20170104, 36165., 20170103, 27503., 20170102, 24165., 20170101, 33723.), (20170105, 37830., 20170104, 36165., 20170103, 27503., 20170102, 24165.), (20170106, 32387., 20170105, 37830., 20170104, 36165., 20170103, 27503.), (20170107, 23415., 20170106, 32387., 20170105, 37830., 20170104, 36165.), (20170108, 24737., 20170107, 23415., 20170106, 32387., 20170105, 37830.), (20170109, 26718., 20170108, 24737., 20170107, 23415., 20170106, 32387.), (20170110, 20143., 20170109, 26718., 20170108, 24737., 20170107, 23415.), (20170111, 24287., 20170110, 20143., 20170109, 26718., 20170108, 24737.), (20170112, 23526., 20170111, 24287., 20170110, 20143., 20170109, 26718.), (20170113, 28004., 20170112, 23526., 20170111, 24287., 20170110, 20143.)], dtype=[('sales_ymd', '<i4'), ('amount', '<f8'), ('lag_ymd_1', '<i4'), ('lag_amount_1', '<f8'), ('lag_ymd_2', '<i4'), ('lag_amount_2', '<f8'), ('lag_ymd_3', '<i4'), ('lag_amount_3', '<f8')])P_043
P-043: レシート明細データフレーム(df_receipt)と顧客データフレーム(df_customer)を結合し、性別(gender)と年代(ageから計算)ごとに売上金額(amount)を合計した売上サマリデータフレーム(df_sales_summary)を作成せよ。性別は0が男性、1が女性、9が不明を表すものとする。
ただし、項目構成は年代、女性の売上金額、男性の売上金額、性別不明の売上金額の4項目とすること(縦に年代、横に性別のクロス集計)。また、年代は10歳ごとの階級とすること。
まず、両フレームのキー列を結合した上で数値データに変換します。つづいて、欠損値で埋めた行列
map_arrayを作成し、顧客データ側の数値化した顧客IDをインデックスにして年代・性別を行列に入れ込みます。その後、レシート明細データ側の数値化した顧客IDをインデックスにして、年代・性別を取得します。最後に、年代・性別の二次元平面を作成し、性別・年齢をインデックスにして売上金額を足していきます。In[043]# 顧客IDを数値データに変換 unq, inv = np.unique(np.concatenate([arr_customer['customer_id'], arr_receipt['customer_id']]), return_inverse=True) inv_map, inv_arr = inv[:arr_customer.size], inv[arr_customer.size:] # 年代の取得(欠損値=0) map_array = np.zeros(unq.size, dtype=int) map_array[inv_map] = arr_customer['age']//10 arr_age = map_array[inv_arr] max_age = arr_age.max()+1 # 性別の取得(欠損値=9) # map_array = np.full(unq.size, 9, dtype=int) map_array[:] = 9 map_array[inv_map] = arr_customer['gender_cd'] arr_gender = map_array[inv_arr] # 年代・性別の二次元平面上に売上を合計 arr_sales_summary = np.zeros((max_age, arr_gender.max()+1), dtype=int) np.add.at(arr_sales_summary, (arr_age, arr_gender), arr_receipt['amount']) # 構造化配列に変換 make_array(max_age, era=np.arange(max_age)*10, male=arr_sales_summary[:, 0], female=arr_sales_summary[:, 1], unknown=arr_sales_summary[:, 9])Out[043]array([( 0, 0, 0, 12395003), (10, 1591, 149836, 4317), (20, 72940, 1363724, 44328), (30, 177322, 693047, 50441), (40, 19355, 9320791, 483512), (50, 54320, 6685192, 342923), (60, 272469, 987741, 71418), (70, 13435, 29764, 2427), (80, 46360, 262923, 5111), (90, 0, 6260, 0)], dtype=[('era', '<i4'), ('male', '<i4'), ('female', '<i4'), ('unknown', '<i4')])Time[043]模範解答:177 ms ± 3.45 ms per loop (mean ± std. dev. of 7 runs, 1 loop each) NumPy:66.4 ms ± 1.28 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)P_044
P-044: 前設問で作成した売上サマリデータフレーム(df_sales_summary)は性別の売上を横持ちさせたものであった。このデータフレームから性別を縦持ちさせ、年代、性別コード、売上金額の3項目に変換せよ。ただし、性別コードは男性を'00'、女性を'01'、不明を'99'とする。
In[044]arr_amount = arr_sales_summary[:, [0, 1, 9]].ravel() make_array(arr_amount.size, era=(np.arange(max_age)*10).repeat(3), gender_cd=np.tile(np.array(['00', '01', '99']), max_age), amount=arr_amount)Out[044]array([( 0, '00', 0), ( 0, '01', 0), ( 0, '99', 12395003), (10, '00', 1591), (10, '01', 149836), (10, '99', 4317), (20, '00', 72940), (20, '01', 1363724), (20, '99', 44328), (30, '00', 177322), (30, '01', 693047), (30, '99', 50441), (40, '00', 19355), (40, '01', 9320791), (40, '99', 483512), (50, '00', 54320), (50, '01', 6685192), (50, '99', 342923), (60, '00', 272469), (60, '01', 987741), (60, '99', 71418), (70, '00', 13435), (70, '01', 29764), (70, '99', 2427), (80, '00', 46360), (80, '01', 262923), (80, '99', 5111), (90, '00', 0), (90, '01', 6260), (90, '99', 0)], dtype=[('era', '<i4'), ('gender_cd', '<U2'), ('amount', '<i4')])
- 投稿日:2020-07-08T11:44:40+09:00
pythonのclassを使って、自給農家の生産・消費行動を超ざっくり簡単にシミュレーションしてみる② コードと結果を見る
じゃあ、かったるいおさらいは省いてさっそくコードと結果を見てみましょう。
条件設定の説明は①をご確認ください。コード
""" subsistance.pyプログラム 自給的農家が生産をする 自給的農家はランダムに生産計画を繰り返し練り、効用が最大化される計画を実行する 自給的農家は自家労働力と自家資本を生産に用いる 1~10期:初期価格で効用最大化を行う 11~20期:Bの価格が1度上昇して、その価格のまま効用最大化を行う 21~30期:oの価格が1度低下して、その価格のまま効用最大化を行う 31~40期:Bの価格が1度上昇し、尚且つoが1度低下して、その価格のまま効用最大化を行う """ # モジュールのインポート import random import numpy as np import matplotlib.pyplot as plt # グローバル変数 alpha = 0.3 # 生産物Aの生産にかかわるパラメータ beta = 0.7 # 生産物Bの生産にかかわるパラメータ gamma1 = 0.2 # 消費者が自給食料を消費するときに得る効用にかかわるパラメータ gamma2 = 0.45 # 消費者がその他の財(テレビとかNETFLIXとか)を消費するときに得る効用にかかわるパラメータ w = 200 # 賃金 SEED = 1234 # シード値 R = 40 # 繰り返し回数の設定 # クラス定義 class Autarky: """自給的農家を表現するクラスの定義""" def __init__(self, cat): # コンストラクタ self.category = cat self.utility = 0 # 最大効用(ひとまず0) self.co = 0 # 効用最大時のOの消費量 self.l = 0 # 効用最大時の余暇時間 self.C = 0 # 効用最大時の総消費額 self.I = 5000 # 効用最大時の予算(5000としておく) self.profit = 0 # 効用最大時の利潤 self.qa = 0 # 効用最大時のAの生産量 self.qb = 0 # 効用最大時のBの生産量 self.LA = 0 # 以下、効用最大時の各生産要素の使用量 self.KA = 0 self.LB = 0 self.KB = 0 self.Ln = 0 def solveUmax(self): # 利潤を最良化するようにAとBを生産する """効用の最良値をリセットする""" self.utility = 0 """利潤をランダムに計算した後、その利潤に基づく効用の最適化問題を解く""" for i in range(nlimit): self.calcprofit(Market) # 利潤が計算される I = self.I + self.profit # 農家の収入は農業労働と農外労働による収入の和 self.calcutility(I, Market) # 効用が計算される def calcprofit(self, Market): # 利潤計算 """生産要素の自家制約を満たす組み合わせをランダムに得る""" LA = int(random.randrange(18)) # 0から18以内の整数を選ぶ LB = int(random.randrange(18 - LA)) # 0から18-LA 以内の整数を選ぶ Ln = int(random.randrange(18 - LA - LB)) #余った労働を農外労働に投入 l = 18 - LA - LB - Ln KA = int(random.randrange(10)) KB = 10 - KA """生産関数""" qa = 3 * LA ** (alpha) * KA ** (1 - alpha) qb = 1 * LB ** (beta) * KB ** (1 - beta) """利潤関数""" profit = Market.pB * qb + w * Ln """情報を更新""" self.profit = profit self.qa = qa self.qb = qb self.LA = LA self.KA = KA self.LB = LB self.KB = KB self.Ln = Ln self.l = l def calcutility(self, I, Market): # 効用の最大値を計算する """ランダムにoの消費量を選ぶ""" maxco = I / Market.po co = int(maxco) """今期の支出総額を計算""" C = Market.po * co """効用関数""" utility = self.qa ** (gamma1) + co ** (gamma2) + self.l ** (1 - gamma1 - gamma2) """効用の最良解を更新""" if utility >= self.utility: # 最良解を更新 self.utility = utility self.co = co self.C = C self.I = I - C # 次期の予算を計算するので、支出を引いた # クラスAutarkyの定義終わり # クラス定義 Market class Market: def __init__(self): self.pB = 100 # 初期時点の農産物価格 self.po = 300 def price_B(self): # pBが50円値上げ self.pB += 50 def price_o(self): # poが50円値下げ self.po -= 50 # クラスMarketの定義終わり # 下請け関数の定義 # 価格無変化時における次期の計算を統括するcalcn_n()関数の定義 def calcn_n(t, a, Market): # ①今期初めにおける価格をリストに入れる pBlist.append(Market.pB) # 価格 polist.append(Market.po) tlist.append(t) # 時間 # ②自給的農家の効用最良化 for i in range(len(a)): a[i].solveUmax() # pBが1度変化した時における次期の計算を統括するcalcn_B()関数の定義 def calcn_B(t, a, Market): # ①pB価格の変化 Market.price_B() # ②今期初めにおける価格をリストに入れる pBlist.append(Market.pB) # 価格 polist.append(Market.po) tlist.append(t) # 時間 # ③農家の効用最良化 for i in range(len(a)): a[i].solveUmax() # poが1度変化した時における次期の計算を統括するcalcn_o()関数の定義 def calcn_o(t, a, Market): # ①po価格の変化 Market.price_o() # ②今期初めにおける価格をリストに入れる pBlist.append(Market.pB) # 価格 polist.append(Market.po) tlist.append(t) # 時間 # ③農家の効用最良化 for i in range(len(a)): a[i].solveUmax() # pBとpoが1度変化した時における次期の計算を統括するcalcn_Bo()関数の定義 def calcn_Bo(t, a, Market): # ①pBとpo価格の変化 Market.price_B() Market.price_o() # ②今期初めにおける価格をリストに入れる pBlist.append(Market.pB) # 価格 polist.append(Market.po) tlist.append(t) # 時間 # ③農家の効用最良化 for i in range(len(a)): a[i].solveUmax() # 要素の集計値計算及びリストへの追加を行うCalc_list()関数の定義 def calc_list(a): qa = 0 qb = 0 profit = 0 LA = 0 KA = 0 LB = 0 KB = 0 Ln = 0 l = 0 cb = 0 co = 0 utility = 0 C = 0 I = 0 for i in range(len(a)): qa += a[i].qa qb += a[i].qb profit += a[i].profit LA += a[i].LA KA += a[i].KA LB += a[i].LB KB += a[i].KB l += a[i].l Ln += a[i].Ln co += a[i].co utility += a[i].utility C += a[i].C I += a[i].I utilitylistA.append(utility) colistA.append(co) ClistA.append(C) IlistA.append(I) profitlistA.append(profit) qalistA.append(qa) qblistA.append(qb) LAlistA.append(LA) KAlistA.append(KA) LBlistA.append(LB) KBlistA.append(KB) LnlistA.append(Ln) llistA.append(l) # メイン実行部 # 初期化 random.seed(SEED) # 乱数の初期化 Market = Market() # 変数にクラスMarketのインスタンスを入れる # リストの中にカテゴリ0のAutarkyのインスタンスを複製生成(する予定。今回は一人ずつ) a = [Autarky(0)] # 農家の状態のリスト化 utilitylistA = [] colistA = [] ClistA = [] IlistA = [] profitlistA = [] qalistA = [] qblistA = [] LAlistA = [] KAlistA = [] LBlistA = [] KBlistA = [] LnlistA = [] llistA = [] # 価格と生産物の余りのリスト化 pBlist = [] polist = [] # 時間のリスト tlist = [] # 試行回数の入力 nlimit = int(input("最良解を追及する回数を指定してください。大きい数を指定する程、最適解に近づきます。:")) # シミュレーション for t in range(R): if t <= 10: # 1~10期:初期価格 calcn_n(t, a, Market) calc_list(a) if t == 11: # 11期:B価格変化 calcn_B(t, a, Market) calc_list(a) if (t > 11) and (t <= 20): # 12~20期:B価格変化後の安定 calcn_n(t, a, Market) calc_list(a) if t == 21: # 21期:o価格変化 calcn_o(t, a, Market) calc_list(a) if (t > 21) and (t <= 30): # 22~30期:o価格変化後の安定 calcn_n(t, a, Market) calc_list(a) if t == 31: # 31期:Bとo価格変化 calcn_Bo(t, a, Market) calc_list(a) if (t > 31) and (t <= 40): # 32~40期:Bとo価格変化後の安定 calcn_n(t, a, Market) calc_list(a) # シミュレーションパートの終わり # 重要な変数のリストをそのまま表示 print("利潤",profitlistA,"\n","\n","A生産",qalistA,"\n","\n","B生産",qblistA,"\n","\n","LA",LAlistA,"\n","\n","LB",LBlistA, "\n","\n","Ln",LnlistA,"\n","\n","l", llistA, "\n","\n",, "効用",utilitylistA, "\n","\n", "o消費",colistA,"\n","\n","C",ClistA, "\n","\n","pA",pBlist,"\n","\n","po",polist,"\n","\n", "収入",IlistA) # sell&buy.py結果
今回は、最良解を追求する回数を10000にしました。シード値は1234で固定です。
価格
設定した通り、10期・20期・30期でBとoの価格が増減しました。AとBの生産量
Aの変化がグダグダw
10・20・30期を境にU字でAの生産量が変化しました。なんでだ、、、?w
Bの生産量は割と一定なように見えますね。A,o,lの消費量
oの消費量がじわじわと増加してきています。価格が減少傾向にあるため、当然でしょう。
一方、l(余暇)の消費量は一定ですね。生産要素の投入量
みにくいw。積み上げ棒グラフにすればよかったですね。まあいいか。
何となくですが、時系列的な負の自己相関傾向があるような気がします。前期の投入量が大きいとき、次期は下がってますよね。なんだこれ。利潤と消費額
まあ、一定ですね。
換金作物価格は増加傾向にあるので、利潤は増加するのかと思いましたが、自給穀物の生産増加が邪魔して利潤が上がってないですね。単純に解釈するなら、自給生産しているせいで農家の収入が低位に安定してしまったということかな。これが自給生産の罠なのかな。効用
おーーww
やっぱり、消費できる量自体は増えてるわけだから、効用は増加してますね。
特に20から上がってるから、このシミュレーションでは、換金作物Bの価格増加よりも、嗜好品oの価格減少の方が自給農家的には良いイベントだったってことですね。
なるほどー。問題点
最大化問題
前回指摘しましたが、最大化問題のやり方がよくないです。というのも、10000回ランダムに生産要素の投入配分を変えまくって、一番いい結果を採用する形で最良解を見つけているため、シード値を変えると結果がまるで変ったりします。利潤最大化を目的にする場合は問題ないのですが、利潤の算出をまたいで効用最大化しようとすると安定しなくなります。
やっぱり、数式的に最大化問題を解く形にしないといけないのかな。紙と鉛筆で解く方法はわかるのですが、どういうコードを使えばいいのかな。
また、なんとなくイメージですが、最尤法によって回帰式のパラメータを推定するときにニュートン=ラフソン法が使われますが、あーいう感じでじわじわと解に迫っていくアプローチができないかなとも考えてます。
このままでもいい気もしますけどね。関数系はコブ=ダグラス型で良いのか? また、パラメータは一定でいいのか?
何となくですが、農家は農法に習熟するにつれて生産性を上げていく気がします。この場合、パラメータも改善されるべきなのではないでしょうか? もしくは、全要素生産性が上がるべきなのではないでしょうか? この点が気になります。
また、関数型をコブ=ダグラス型に固定していますが、規模の経済性やパラメータの変動も考慮するために、もっと複雑な関数系にすべきではないでしょうか? さて、どうしようか。そろそろマルチエージェントにしない?
一応、これでクラスは3種類用意できるようになりました。「農家」「消費者」「自給的農家」です。
また、趣味的な家庭菜園農家もしくは自分の農法にやりがいを感じている有機農家などもモデル化するアイデアがあります。これらの人たちをぶっこんだ一つの世界を作りたいなーと思ってます。以上です。
次は、趣味的な家庭菜園農家or自分の農法にやりがいを感じてる有機農家の生産モデルをシミュレーションなしでここに挙げてみようかなと思ってます。
そのあと、マルチエージェントシミュレーションを走らせてみるかな。
最大化問題のやり方は、ひとまずこのままでいきます。

- 投稿日:2020-07-08T11:20:11+09:00
pythonのclassを使って、自給農家の生産・消費行動を超ざっくり簡単にシミュレーションしてみる① 条件設定
今回は自給的農家のシミュレーションを作ってみました。
①では設定の説明をし、次回の②でコードを説明します。
農家行動の理論的な説明は今回省きました(本当は書きましたが、読むのがかったるいから消しました泣)。今回やりたいこと
前回は、1農家と1消費者が存在して、市場を介して2者が農産物の生産と消費を行うシミュレーションを行いました。価格の変動を表すために、前期消費量の多い作物の価格が約1.01倍上昇し、前期消費量の少ない作物の価格が約0.99倍低下することにしました。
しかし、①次期価格を算出する際に均衡価格を計算しなかった点、②生産消費行動の影響を受けて価格が変動→生産消費行動の変化→価格が変動…というループが起こり、価格や生産・消費量が安定しなかった点
で問題が生じたので、今回は価格変動を単純化しました。
また、新しい要素として、今回は「自給農家行動」をシミュレートしてみます。以上の状況を反映させるために、以下のステップを踏みました。
①class「Autarky(自給的)」を作る。
②初期価格で価格を固定して生産・消費行動をさせてみる。
③換金作物の価格増加後の反応をみる。
④消費財の価格低下後の反応をみる。
⑤換金作物の価格増加、尚且つ消費財の価格低下後の反応を見る。自給的農家に関する理論
日本には自給農家があまりいないので、自給農家の存在理由が意味不明だと思います。しかし、一定の条件下では自給的農家が生じる可能性があります。その理論を説明しようと思いましたが、長いのでやめました。詳しくはJanvry(1991)を見てください。
まあ、ざっくりいうと、市場参加が困難な自給的農家は自分が食べる主要穀物を自分で作るということです。クラス(登場人物の説明)
クラスAutarky(自給農家)
特徴1:
自給的穀物Aと換金作物Bを生産する。
特徴2:
労働力と固定資本という生産要素を自家保有しており、AとBの生産に振り分ける。また、労働力の一部は農外労働に振り分けて賃金を得る。
特徴3:
①ランダムに生産要素を振り分けてAとBを生産し農業収入を得て、同時に農外労働によって農外賃金も得る。②農業収入と農外賃金に基づいて嗜好品oを購入し、その時の効用を計算する。③指定回数①と②を繰り返し、効用が最も大きかった時の生産要素配分を記録する。クラスMarket(価格変動を起こす神のような存在)
特徴1:
換金作物Bの値段を50円上げる。
特徴2:
嗜好品oの値段を50円下げる。生産関数と利潤関数と効用関数
生産関数
Q_A = 3*L_A^{0.3} +K_A^{0.7} \\Q_B=1*L_B^{0.7} +K_B^{0.3}L: 労働力(L=LA+LB+Ln+l)
K: 固定資本(K=KA+KB)
※Aは穀物、Bは換金作物です。一般的に、穀物は資本集約的であり、園芸品目などの換金作物は労働集約的だと思うので、以上のようなパラメータ設定にしました。利潤関数
\Pi = p_B*Q_B+w*L_nLn: 農外労働に費やした労働力
w: 農外賃金
pB: Bの価格
QB: Bの生産量効用関数
U = Q_A^{0.2}+C_o^{0.45}+l^{0.35}QA: Aの生産量(自給量)
Co: Netflix等の嗜好品の消費量
l: 余暇時間(l = L-LA-LB-Ln)
※パラメータは適当にそれっぽく割り振りました。また、予算制約(po*Cp < π)が満たされています。価格の変化
1~10期:初期価格で効用最大化を行う
11~20期:Bの価格が50上昇して、効用最大化を行う
21~30期:oの価格が50低下して、効用最大化を行う
31~40期:Bの価格が50上昇し、尚且つoの価格が50低下して、効用最大化を行う締めの言葉
以上の条件設定の下、シミュレーションしてみました。
色々と細かく改良したい点は多いですが、少しずつ進めていきましょう。
なお、先取りして今回のシミュレーションの問題を言っておくと、ズバリ最適化問題のやり方です。
じゃあ、また次回あいましょう。参考文献
~論文~
[1]Alain de Janvry, Marcel Fafchamps and Elisabeth Sadoulet(1991) “Peasant household behavior with missing markets: some paradoxes explained” Economic Journal. Vol.101, pp.1400-1417.
- 投稿日:2020-07-08T11:05:10+09:00
ベイヤー FITS ファイルをデモザイクしてカラー TIFF に変換する
macOS や Linux には FITS ファイルを変換する手軽なツールがありません。
Python を利用してベイヤー FITS ファイルをデモザイクし、Photoshop などで編集できる TIFF 形式に変換する方法を紹介します。撮影環境
- カメラ
- ZWO ASI 294MC
- 制御ソフト
- KStars + Ekos
ZWO ASI 294MC のベイヤーパターンは RGGB です。
環境構築
FITS ファイルの読み込みに Astropy、画像処理に OpenCV を利用します。
執筆時のパッケージバージョンは下記の通りです。
- anaconda3-2020.02
- opencv (4.1.0)
- astropy (4.0.1.post1)
処理
望遠鏡で撮影した月面の画像 (
moon.fits) を処理してみます。1. FITS ファイルオープン
from astropy.io import fits hdul = fits.open('moon.fits') src = hdul[0].dataこの段階ではベイヤー配列のままなので、モノクロのモザイク画像です。
2. デモザイク・保存
cvtColor関数でベイヤー変換を指定することで、カラー画像を復元します。import cv2 dst = cv2.cvtColor(src, cv2.COLOR_BayerBG2BGR) cv2.imwrite('moon.tif', dst)下記の TIFF 画像が出力されました。
任意の画像編集ソフトで明るさやカラーバランスを調整することができます。
3. Photoshop での編集例
レベル補正・カラーバランス調整を行い、シャープフィルタを適用したものです。



- 投稿日:2020-07-08T09:13:49+09:00
AtCoder Beginner Contest 173 復習
今回の成績
今回の感想
今回は色々あり集中もないまま考察もちゃんとしないまま解いていたので、過去最低順位を更新し2020年最低パフォを取ってしまいました。
E問題はまともな頭の使い方をしていればできたと思いますし、Dも考察不足だったと感じます。(途中でメンタルが崩壊してしまったので…)
しかし、正直なところ、何を変えればレートが伸びるのかよくわからないですね…。とりあえずはいろいろな問題解いて典型パターンを身体に染み込ませるしかないのかなとは思います…。A問題
焦ってたので、この時点から頭の悪い解き方をしていて恥ずかしいです。
A.pyn=int(input()) if n%1000==0: print(0) else: print(1000-n%1000)B問題
タイピングミスが発生しそうであまり好きではない問題ですね。
しかし、もっとうまく書けたと思うので反省です。B.pyn=int(input()) d={"AC":0,"WA":0,"TLE":0,"RE":0} for i in range(n): d[input()]+=1 print("AC x "+str(d["AC"])) print("WA x "+str(d["WA"])) print("TLE x "+str(d["TLE"])) print("RE x "+str(d["RE"]))C問題
今回はC問題でbit全探索が出ました。
それぞれの赤で塗る行と列の選び方を考えたいので、最初にinputした行列をコピーして赤(x)で上書きしていき、最終的に残った黒(#)の数を数えます。
この解説を書いているときに気付いたのですが、わざわざコピーせずとも指定した行と列を数えないとすれば簡単に実装できますね、最初の基本問題から頭がバグり続けていたのかもしれません。C.pyh,w,K=map(int,input().split()) c=[input() for i in range(h)] ans=0 for i in range(2**h): for j in range(2**w): d=[[c[z][v] for v in range(w)]for z in range(h)] for k in range(h): if (i>>k)&1: for l in range(w): d[k][l]="x" for k in range(w): if (j>>k)&1: for l in range(h): d[l][k]="x" cnt=0 for k in range(h): for l in range(w): cnt+=(d[k][l]=="#") ans+=(cnt==K) print(ans)D問題
詳しい証明は解説を参照するとして、ここでは感覚的な説明をします。
まず、フレンドリーさの高い人から順に到着した方が良いことがフレンドリーさの低い人を先に到着させても状況が良くならないということから証明できそうです。
また、この仮定のもとでどの位置に割り込むべきかは今ある中で最大の位置ではないかという貪欲法を考えれば良いです。つまり、以下のように割り込むことができます。
上図では、その人のフレンドリーさを左側に心地よさを右側に書いています。このように割り込む時に$A_i$は$A_{[\frac{i+1}{2}]}$のフレンドリーさを得ていることがわかると思います(完全二分木のように捉えると良いと思います。)。ここまで気づけば実装は簡単で以下のようになります。
自分はまさか貪欲ではないだろうと思って一旦捨ててししまいましたが、基本は貪欲法であることをいかなる時も忘れないようにしたいです。
D.pyn=int(input()) a=list(map(int,input().split())) a.sort(reverse=True) ans=0 for i in range(1,n): ans+=a[i//2] print(ans)E問題
基本的な発想は難しくないのですが、コーナーケースが非常に多く実装面で大変な問題でした。
自分は考察によって簡単になると思って実装に取り組めなかったのですが、解答を見たらすっきりとしたものが書いてあってまだまだ実力不足を感じました。しっかり場合分をして考察しきる力をつけたいです。
まず、$K$個の数の積が負となるパターンが少なそうである事に気づいて負の数である場合を先に計算することを考えます。すると、$K$個の数の積が負となるのは$K$個のうち負の数を奇数個しか選べない時となります。ここで、0以上の数が一つ以上存在すれば、その数を含むか含まないかで$K$個の数に含まれる負の数の個数の偶奇を制御できます。したがって、$K$個の数の積が負となるのは、与えられた$N$個の数が全て負かつ$K$が奇数である場合(①)、$N=K$かつ与えられた$N$個の数に負の数が奇数個含まれる場合(②)、のどちらかになります。
①の考察↓
与えられた$N$個の数が全てが負または全てが0以上である場合の計算は難しくないのでまとめて計算するようにしました。すなわち、与えられた$N$個の数が全て負の数の時、$K$が偶数である場合は積が正なので絶対値の大きいものから順に$K$個の積が最大で、$K$が奇数である場合は積が負なので絶対値の小さいものから順に$K$個の積が最大となります。また、全てが0以上の数の時も絶対値の大きいものから順に$K$個の積が最大となります。①の実装↓
0以上の数をapに格納し、負の数をamに格納し、len(ap)==0またはlen(am)==0場合は$N$個の数が全て負の数(or全て正の数)となるので、考察の通りの実装をします。また、apとamは絶対値の降順になるようにソートしておきます。②の考察及び実装↓
$N=K$となる場合は与えられた$N$個の数の積を考えれば良いです。これは入力を受け取った直後に求めておきます。
以上より、以下では$K$個の数の積の最大値が0以上であることが保証されるもとでの方針を考えます。(方針に迷いがあったのでこの辺りから自分は混乱してしまいました。)
まず、負の数は偶数個ないと$K$個の積が0以上にならないので、絶対値の大きい数から順にペアにして積を求めます。また、負の数と0以上の数の選択をするために0以上の数も大きい数から順にペアにして積を求め、これらを
apm2に降順で格納します。(この後で0以上の数をいくつ選んだかをチェックしたいので、0以上の数の場合は1,負の数の場合は0のマークをつけておきます。)ここで、ペアにしていった時に負の数も0以上の数も一つ余る可能性がありますが、負の数を選ぶ場合は積が負になるので選ぶ必要がなく、正の数は選ぶ可能性がある事に注意が必要です。
まず、$K$が偶数の時は
apm2の前から$[\frac{k}{2}]$個の数の積を求めれば良いですが、$K$が奇数の時は$[\frac{k}{2}]$個の数に加えてもう一つ数を選択しなければなりません。この時、「まだ選んでない正の数で最大の数を一つ選ぶ(✳︎1)」とすると以下のような場合に最適ではありません。5 3 -5 -1 1 2 3上記の場合、-5,-1,3が最適ですが、(✳︎1)に従うと1,2,3が最適になります。つまり、「選んだ正の数で最小の数を除いて
apm2の選んでない中で最大の組を選ぶ(✳︎2)」場合が最適となる可能性もあります。(貪欲法では最適性を必ず確かめる!)よって、正の数で次に選ぶ数の
ap中のインデックスをpに記録しながら、前から$[\frac{k}{2}]$個の数をまずはansにappendしていきます(除く操作が面倒なので積を求めずに一旦配列に格納するようにしました。)。このもとで、$K$が偶数の場合は
ansの全ての数の積を求め、$K$が奇数の場合は先ほどの(✳︎1)及び(✳︎2)に従えばap[p]を選ぶ場合(①)、ap[p-1]を除いてapm2[k//2][0]を選ぶ場合(②)のどちらかを考えれば良いです。ここで、
p==len(p)の時は全ての0以上の数を使い切っているのでpに相当する数が存在せず、①のパターンは存在しません。また、p==0の時はまだ一つも0以上の数の組を使ってないので、②のパターンは存在しません。(例外の考慮も忘れないように!)以上を注意深く実装すると以下のようになります。また、与えられた配列の積を$10^9+7$で割った値を求める関数(
multarray)を定義して実装を簡単にしました。E.py#x:配列 mod=10**9+7 def multarray(x): ret=1 for i in x: ret*=i ret%=mod return ret n,k=map(int,input().split()) a=list(map(int,input().split())) #n==kの場合はかけるだけ if n==k: print(multarray(a)) exit() #0以上の数と負の数に分けて格納 ap,am=[],[] for i in range(n): if a[i]>=0: ap.append(a[i]) else: am.append(a[i]) #それぞれ絶対値の順番にソート ap.sort(reverse=True) am.sort() #0以上の数のみか正の数のみの場合は先に場合分け if len(am)==0: print(multarray(ap[:k])) exit() if len(ap)==0: if k%2==0: print(multarray(am[:k])) else: print(multarray(am[::-1][:k])) exit() #組にして格納する(0以上か負かを記録しておく) apm2=[] for i in range(len(am)//2): apm2.append((am[2*i]*am[2*i+1],0)) for i in range(len(ap)//2): apm2.append((ap[2*i]*ap[2*i+1],1)) apm2.sort(reverse=True) #0以上の数で次にどこを見るのかをチェックしておく p=0 ans=[] for i in range(k//2): p+=(2*apm2[i][1]) ans.append(apm2[i][0]) #Kが偶数の時 if k%2==0: print(multarray(ans)) exit() ans_cand=[] #一個増やす場合 if p!=len(ap): ans_cand.append(multarray(ans)*ap[p]%mod) #一個減らして二個増やす場合 if p!=0: #減らすindex check_i=ans.index(ap[p-1]*ap[p-2]) #ap[p-1]を減らす操作(0除算を避ける) ans[check_i]=ap[p-2] ans.append(apm2[k//2][0]) ans_cand.append(multarray(ans)) print(max(ans_cand))F問題
まだ解いてないです。
近々解説を載せるつもりです。

- 投稿日:2020-07-08T08:43:52+09:00
【Python】dict in listやinstance in listをsortする方法
listのソートはよくありますが、ここではdict in listやinstance in listをsortする方法を書き留めます。
sortは全て昇順とします。
sortで使用するのは組み込み関数のsortedです。動作確認済みのPythonバージョン
- 3.7
- 3.8
標準ライブラリdataclassesを使用しなければ3.6とかでも動くはずです
dict in list
dict in listの場合はsorted関数のkey引数を指定してあげる必要があります。
keyを指定する時にlambda使って無名関数でlambda x: x['a']でもいいですが、公式によると標準ライブラリoperatorのitemgetterを使用した方が高速らしいです(検証していないのでなんとも言えませんが)。https://docs.python.org/ja/3/howto/sorting.html#operator-module-functions
Python は高速で扱いやすいアクセサ関数を提供しています。 operator モジュールには itemgetter(), attrgetter() そして methodcaller() 関数があります。
from operator import itemgetter person_list = [{'name': 'a', 'age': 4}, {'name': 'b', 'age': 3}, {'name': 'c', 'age': 10}, {'name': 'd', 'age': 2}, {'name': 'e', 'age': 1}] sorted(person_list, key=itemgetter('age'))[{'name': 'e', 'age': 1}, {'name': 'd', 'age': 2}, {'name': 'b', 'age': 3}, {'name': 'a', 'age': 4}, {'name': 'c', 'age': 10}]instance in list
dict in listと同様にsorted関数のkey引数にソートしたいパラメータを指定してあげましょう。instanceの場合はattrgetterを使うといいですよ。
一旦sourcesでdict in list作成して、list(map(...))でインスタンス作成しているのに深い意味はありません。dict in listで使用したperson_listを流用して楽をしたかっただけです。
from dataclasses import dataclass from operator import attrgetter @dataclass class Person: name: str age: int sources = [{'name': 'a', 'age': 4}, {'name': 'b', 'age': 3}, {'name': 'c', 'age': 10}, {'name': 'd', 'age': 2}, {'name': 'e', 'age': 1}] person_list = list(map(lambda x: Person(**x), sources)) sorted(person_list, key=attrgetter('age'))[Person(name='e', age=1), Person(name='d', age=2), Person(name='b', age=3), Person(name='a', age=4), Person(name='c', age=10)]降順でソートしたければ、sorted関数のreverse引数をTrueにすればOK
Reference
- 投稿日:2020-07-08T08:26:18+09:00
Chrome画面のスクリーンショットを取る方法(途中で切れるのを防ぐ)
背景
Seleniumを使って自動でスクリーンショットを取ろうとしたのですが、いくら大きいサイズを指定しても、画面サイズで切れてしまってスクロールの下の方が取れずに苦労したので、その備忘録です。
使用したもの
chromedriver(使用しているchromeのバージョンにあったもの)
selenium
python対応法
optionsでheadless付ければOKでした。
screenshot.pyfrom selenium import webdriver from selenium.webdriver.chrome.options import Options if __name__ == "__main__": # 切れないスクリーンショットのために必要な設定 options = Options() options.add_argument('--headless') driver = webdriver.Chrome(options=options) # サイズを広めに指定しておく driver.set_window_size(1400, 2000) # キャプチャ先の指定 driver.get(r'https://ja.wikipedia.org/wiki/Qiita') # キャプチャ実施。保存ファイルを指定。 driver.save_screenshot('screenshot.png') driver.close()考察
optionsでheadlessを付けると、Chromeが立ち上がることがなくなります。
つけない場合にスクショが切れてしまうのは、おそらくChromeが立ち上がった際にwindow幅に合わせて縦・横が微修正されるからなのかなぁ。。。と。多分そう。
- 投稿日:2020-07-08T08:11:42+09:00
ioストリーム
import io with open('/tmp/a.txt', 'w') as f: f.write('text text') with open('/tmp/a.txt', 'r') as f: print(f.read()) f = io.StringIO() f.write('string io test') f.seek(0) print(f.read())実行結果:
text text string io test