- 投稿日:2020-07-06T23:55:16+09:00
とにかくRails6でrswagを動かす
紹介する内容
- swagger.jsonから作られたAPIドキュメント画面が見えます(rswag-ui)
- rspecで手作りのAPIのテストができます(rspec)
- https://github.com/rswag/rswag が紹介する対象です
結論
rails newしたプロジェクトで
とにかくrswagを動かせる実装とコマンドです
- Gemfileにgemを追加して
bundle installしますgem 'rswag-api' gem 'rswag-ui' group :test do gem 'rspec-rails' gem 'rswag-specs' end
- 実行コマンドです
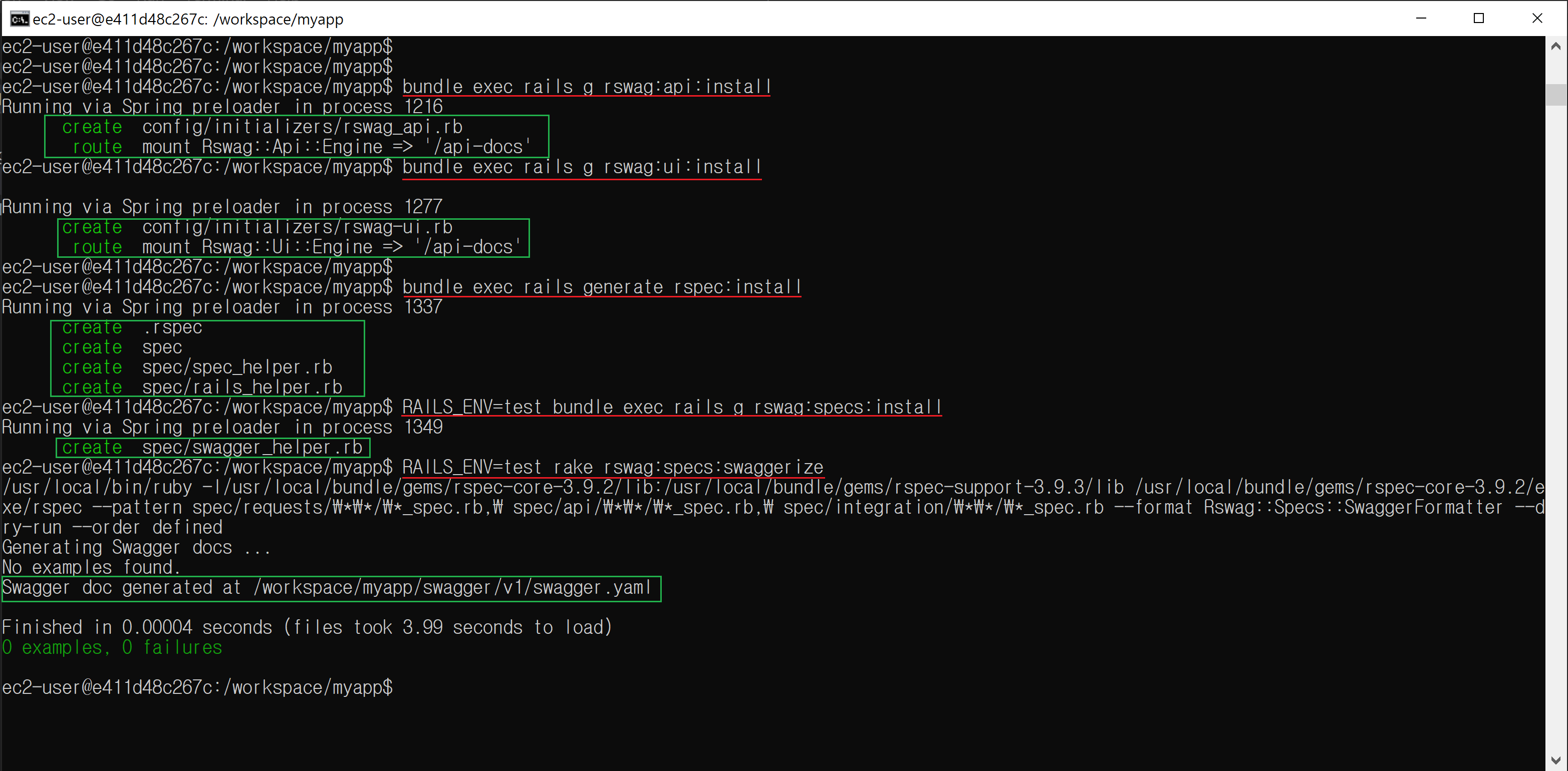
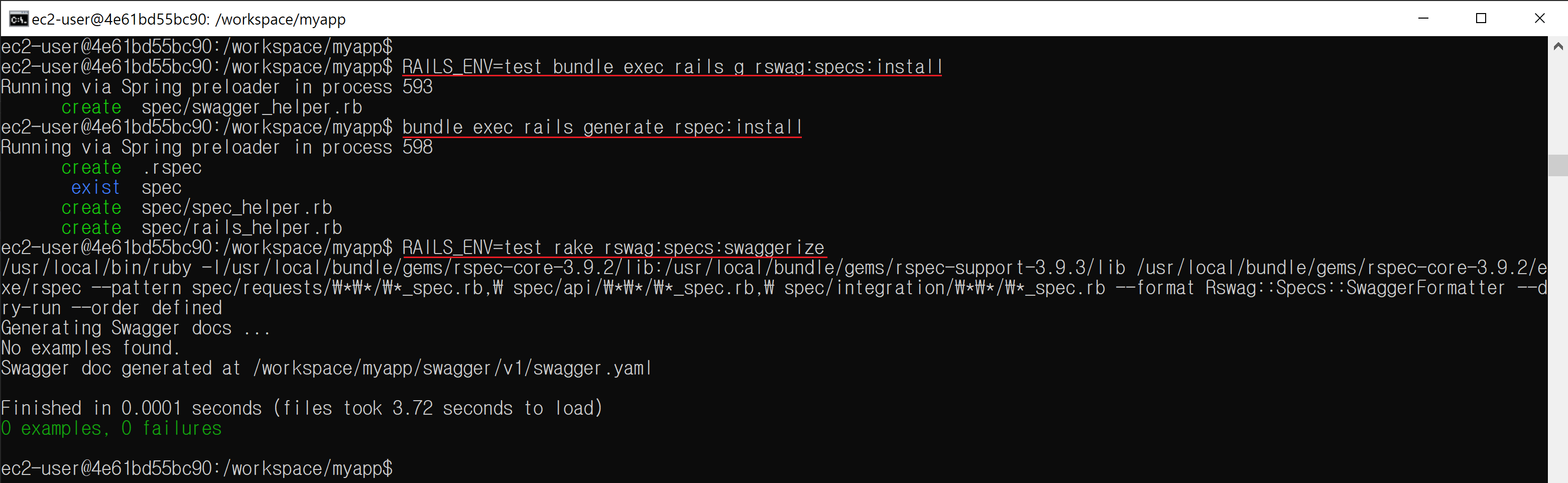
bundle exec rails g rswag:api:install bundle exec rails g rswag:ui:install bundle exec rails generate rspec:install RAILS_ENV=test bundle exec rails g rswag:specs:install RAILS_ENV=test rake rswag:specs:swaggerize
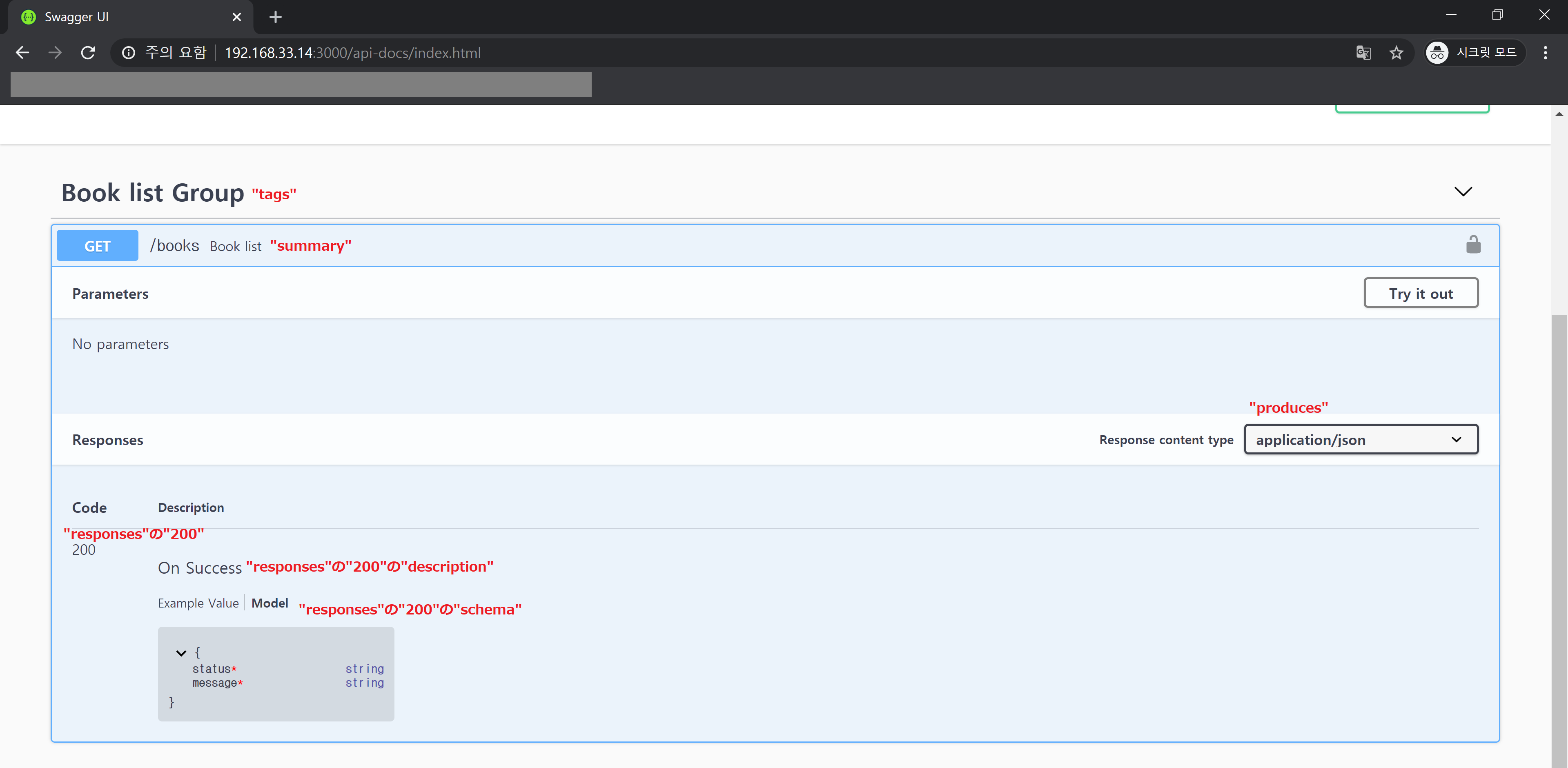
Gem installとコマンドが問題なく実行されたら以下のイメージが確認できます
ブラウザ上でAPIドキュメントが見えます
APIドキュメントに例を追加した画面は一番下の
APIドキュメント例が追加された画面とrspecを実行してみますで確認できますAPIドキュメント画面の内容は
RAILS_ENV=test rake rswag:specs:swaggerizeで作られたjsonかyamlファイル次第です
spec/swagger_helper.rbでconfig.swagger_docsにAPIドキュメントで見せたい内容を書いて、RAILS_ENV=test rake rswag:specs:swaggerizeしたら、jsonかyamlファイルが作られます
config.swagger_docs内容次第で、上の緑色のcreateがいるイメージで見える作られたファイルたちを調整が必要がありますAPIドキュメントに使うjsonやyamlファイルは
RAILS_ENV=test rake rswag:specs:swaggerizeで作りますが、下準備が必要でした
RAILS_ENV=test bundle exec rails g rswag:specs:installでspec/swagger_helper.rbを作りますspec/swagger_helper.rbのconfig.swagger_docs部分にAPIドキュメントで見せたい内容を書きますRAILS_ENV=test rake rswag:specs:swaggerizeを実行すると、spec/swagger_helper.rbのconfig.swagger_docsの通り作ってくれます
- 筆者は
swagger.jsonを手作りして動かしました。READMEを復習した後に自動生成する方法に気づきました。以下はspec/swagger_helper.rbに書かれている内容です...(省略) # When you run the 'rswag:specs:swaggerize' rake task, the complete Swagger will # be generated at the provided relative path under swagger_root ...(省略)
RAILS_ENV=test rake rswag:specs:swaggerizeでエラーになったら、spec/spec_helper.rbとspec/rails_helper.rbがあるか確認してください
- rails newからrswag入れようとしたら、はまるかもしれません
エラーなるパターン
bundle exec rails generate rspec:installで治ります
紹介始めます
ディレクトリ構成
全体ソースコードは https://github.com/cheekykorkind/qiita-example/tree/master/rails/6/rswag で確認できます。
結論のrails newしたプロジェクトでとにかくrswagを動かせる実装とコマンドですを全部実行した上で、
spec/swagger_helper.rbとinitializers/rswag-ui.rbを修正して、APIドキュメントに例を追加したコードです。
全体図
手動で調整した部分
spec/swagger_helper.rbconfig/initializers/rswag-ui.rb手動で作った部分
spec/api/v1/books_spec.rbapp/controllers/api/v1/books_controller.rbapp/controllers/api/v1/books_controller.rb実装周り説明
- rswagと直接的に関係ないところです。Railsのコントローラーでjsonを返すようにしました
spec/swagger_helper.rb実装周り説明
- 以下のイメージとソースコード https://github.com/cheekykorkind/qiita-example/blob/master/rails/6/rswag/swagger/v1/swagger.json を参考すると書き方が理解できると思います
initializers/rswag-ui.rb実装周り説明
- APIドキュメントに使うファイルをjsonにしたから、yaml部分をjsonに変えました
# コマンド実行で作られるところ # c.swagger_endpoint '/api-docs/v1/swagger.yaml', 'API V1 Docs' # jsonファイルを使うから修正 c.swagger_endpoint '/api-docs/v1/swagger.json', 'API V1 Docs'APIドキュメント例が追加された画面とrspecを実行してみます
- docker composeがあるデレクトリー移動に移動します
cd qitta-example/rails/6/rswag- dockerコンテナをバックグラウンドで起動します
DOCKER_UID=$(id -u $USER) DOCKER_GID=$(id -g $USER) docker-compose up -d- rspecでAPIを試します
RAILS_ENV=test bundle exec rspec- ブラウザでAPIドキュメントを確認します
http://192.168.33.14:3000/api-docs
- 開発環境次第でipやportが変わる可能性があります


- 投稿日:2020-07-06T23:11:11+09:00
なるべく最新Verで構築するRails6開発環境(Docker + Rails + Nginx + Puma + MySQL)
はじめに
こんにちは、Web系エンジニア転職にむけて学習中の Npakk と申します。
Railsを学習するにあたって開発環境を構築したので、その手順を少し解説を交えながらご紹介します。
Dockerでの構築経験はあまりなく、経験も乏しいのであくまで参考程度にご覧ください。
もし間違いやご指摘などあれば、ぜひぜひお願いいたします!Dockerを使用して、ローカル環境でRailsのWelcomeページを確認できるまでが、この記事のゴールです。
参考記事
- ほとんどこちらの記事を参考にさせていただいてます。
- こちらも参考にさせていただきました。
対象読者
- Railsを学びたいけど、環境をどう作ればいいかわからない初学者の方
- なるべく新しいRails環境を作りたい方
前提
- Macユーザーを対象としています
- Docker for Macがインストールされているものとします
- Nginx と Puma を連携させています
- 最新バージョンは、記事執筆時点で最新という意味です
- 全てのソフトウェアが最新バージョンなわけではありません
- 最新版だから動作が安定していたり、速度が速いというわけではありません
バージョン
- ホストOS(macOS Catalina 10.15.5)
- Docker(19.03.8)
- docker-compose(1.25.5)
- Ruby(2.7.1)
- Ruby on Rails(6.0.3.2)
- Nginx(1.19.0)
- MySQL(8.0)
1. ディレクトリの作成
ディレクトリ構成としては以下のようになります。
あくまで、手動で作成する項目のみ記載しています。/webapp ├── Dockerfile ├── Gemfile ├── Gemfile.lock ├── containers │ └── nginx │ ├── Dockerfile │ └── nginx.conf ├── docker-compose.yml ├── entrypoint.sh └── environments └── db.env1-1. アプリケーションルート
どこでもいいですが、わかりやすいところがおすすめです。
$ mkdir webapp1-2. Nginxコンテナ用ディレクトリ
Nginxは、Rails・DBとは別のディレクトリを作ります。
設定ファイルや DockerFile を別途配置します。$ mkdir -p webapp/containers/nginx1-3. 環境変数用ディレクトリ
DBで使うユーザーのパスワードなどを記載したファイルを配置します。
$ mkdir webapp/environments2. コンテナ生成用のファイルを作成
以降はアプリケーションルート内での操作となります。
$ cd webapp2-1. Rails用Dockerfile
Ruby と Node.js、yarnのバージョン指定は後述する docker-compose.yml から引数として指定します。
Rails6からは標準で Webpacker というgemを使用しており、yarn というパッケージ管理ソフトに依存しています。
yarn がないとうまく動かないため、これをコンテナにインストールする必要があります。また entrypoint.sh についてですが、Dockerをコマンドで停止せずに強制終了してしまうと、
Railsサーバーが開かれたままになるため、次からコンテナを起動するときにエラーが発生します。
その問題を回避するために server.pid を削除しています。$ vim DockerfileDockerfileARG RUBY_VERSION FROM ruby:$RUBY_VERSION ARG NODE_MAJOR ARG YARN_VERSION # ログインシェルとしてbashを使用する SHELL ["/bin/bash", "-c"] # nodejs取得 RUN curl -sL https://deb.nodesource.com/setup_$NODE_MAJOR.x | bash - # yarn取得 RUN curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | apt-key add - &&\ echo "deb https://dl.yarnpkg.com/debian/ stable main" | tee /etc/apt/sources.list.d/yarn.list # リポジトリを更新し依存モジュールをインストール RUN apt-get update -qq &&\ apt-get install -y\ build-essential\ nodejs\ yarn=$YARN_VERSION-1 # ルート直下にwebappという名前で作業ディレクトリを作成(コンテナ内のアプリケーションディレクトリ) RUN mkdir /webapp WORKDIR /webapp # ホストのGemfileとGemfile.lockをコンテナにコピー ADD Gemfile /webapp/Gemfile ADD Gemfile.lock /webapp/Gemfile.lock # bundle installの実行 RUN bundle install # ホストのアプリケーションディレクトリ内をすべてコンテナにコピー ADD . /webapp # puma.sockを配置するディレクトリを作成 RUN mkdir -p tmp/sockets # コンテナ開始時に必ず実行されるシェルスクリプトをコンテナにコピー ADD entrypoint.sh /usr/bin/ RUN chmod +x /usr/bin/entrypoint.sh ENTRYPOINT ["entrypoint.sh"]2-2. Gemfile
Railsの最新バージョンをこのファイルで指定します。
$ vim GemfileGemfilesource 'https://rubygems.org' git_source(:github) { |repo| "https://github.com/#{repo}.git" } gem 'rails', '6.0.3.2'2-3. Gemfile.lock
このファイルは作るだけで、中身は空で大丈夫です。
$ touch Gemfile.lock2-4. Nginx用Dockerfile
$ vim containers/nginx/Dockerfile/containers/nginx/DockerfileFROM nginx:1.19.0 # インクルード用のディレクトリ内を削除 RUN rm -f /etc/nginx/conf.d/* # Nginxの設定ファイルをコンテナにコピー ADD nginx.conf /etc/nginx/conf.d/webapp.conf # ビルド完了後にNginxを起動 CMD /usr/sbin/nginx -g 'daemon off;' -c /etc/nginx/nginx.conf2-5. Nginx用設定ファイル
$ vim containers/nginx/nginx.conf/containers/nginx/nginx.conf# プロキシ先の指定 # Nginxが受け取ったリクエストをバックエンドのpumaに送信 upstream webapp { # ソケット通信したいのでpuma.sockを指定 server unix:///webapp/tmp/sockets/puma.sock; } server { listen 80; # ドメインもしくはIPを指定 server_name example.com [or 192.168.xx.xx [or localhost]]; access_log /var/log/nginx/access.log; error_log /var/log/nginx/error.log; # ドキュメントルートの指定 root /webapp/public; client_max_body_size 100m; error_page 404 /404.html; error_page 505 502 503 504 /500.html; try_files $uri/index.html $uri @webapp; keepalive_timeout 5; # リバースプロキシ関連の設定 location @webapp { proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_pass http://webapp; } }2-6. DB接続用設定ファイル
ユーザー名・パスワードなどは適宜変更してください。
$ vim environments/db.envdb.envMYSQL_ROOT_PASSWORD=db_root_password MYSQL_USER=user_name MYSQL_PASSWORD=user_password2-7. entrypoint.sh
entrypoint.sh#!/bin/bash set -e # Remove a potentially pre-existing server.pid for Rails. rm -f /myapp/tmp/pids/server.pid # Then exec the container's main process (what's set as CMD in the Dockerfile). exec "$@"2-8. docker-compose.yml
argsにRubyなどのバージョンを指定します。
ここで指定することによりDockerfileに値が渡されます。$ vim docker-compose.ymldocker-compose.ymlversion: '3.7' services: app: build: context: . args: RUBY_VERSION: '2.7.1' NODE_MAJOR: '14' YARN_VERSION: '1.22.4' env_file: - ./environments/db.env command: bundle exec puma -C config/puma.rb volumes: - .:/webapp - public-data:/webapp/public - tmp-data:/webapp/tmp - log-data:/webapp/log depends_on: - db db: image: mysql:8.0 env_file: - ./environments/db.env volumes: - db-data:/var/lib/mysql web: build: context: containers/nginx volumes: - public-data:/webapp/public - tmp-data:/webapp/tmp ports: - 80:80 depends_on: - app volumes: public-data: tmp-data: log-data: db-data:3. Railsアプリケーションの生成と編集
3-1. Railsアプリケーションの生成
ここまでファイルとディレクトリを準備できたら、Railsアプリケーションを作成します。
以下のコマンドを実行すると、コンテナ内でRailsアプリケーションが生成されます。
DBにはMySQLを指定し、gemをこの時点でインストールしないようにbundle installの実行を抑制しています。$ docker-compose run --rm app rails new . --force --database=mysql --skip-bundleコンテナ内で生成されたアプリケーションをホスト側から編集するには、いちいちコンテナを実行しないといけないため不便です。
そこで、コンテナ内に生成されたディレクトリと、ホスト側のアプリケーションルートを繋ぎます。
こうすることによって、ホスト側のアプリケーションルートにファイルが生成されます。
これらのファイルを編集すれば、コンテナ内のディレクトリにも反映されるようになります。
(既にこの対応は以下の箇所で行っているので、安心してください。)docker-compose.yml#省略 volumes: - .:/webapp #省略実行時に発生するエラー・警告について
Railsアプリケーション生成コマンド実行時、いくつかエラーと警告が発生します。
「失敗した!」と思われる前に、以下に記載するものについては無視してください。
(記載した以外のエラーや警告がもし発生した場合、一度最後まで手順を実行することをおすすめします。)apt-key
deb.nodesource.comから落としてきたシェルスクリプトに記載されたapt-keyコマンドで発生した警告です。
詳細を調べてもいまいちよくわからなかったのですが、これを無視してもRailsの環境は構築できます。
(誰か詳しい方がいたら教えてください…)Step 6/18 : RUN curl -sL https://deb.nodesource.com/setup_$NODE_MAJOR.x | bash - ・ ・ ・ + curl -s https://deb.nodesource.com/gpgkey/nodesource.gpg.key | apt-key add - Warning: apt-key output should not be parsed (stdout is not a terminal)debconf
これもいまいちよくわかりません。(書いといてなんだって話なんですが。)
apt-utilsをインストールしても消えなかったです。
無視しても大丈夫です。Step 8/18 : RUN apt-get update -qq && apt-get install -y build-essential nodejs yarn=$YARN_VERSION-1 ・ ・ ・ debconf: delaying package configuration, since apt-utils is not installedmysql2
Railsアプリケーション生成コマンドを実行して、最後に出力されたのがこのエラーです。
Gemfileにリストされたmysql2のgemがないよってことで、bundle installを迫ってきています。このコマンドを実行した時点では、GemfileにはRailsしか記載されておらず、
推測ですが、下記の流れで処理されているのではないかと思います。
1. Gemfileに記載されたRalilsがインストールされる
2. Rails newにより、Gemfileの記載が更新されmysql2などが追加される
3. 最後に、Gemfileに書かれたRails以外のgemがインストールされていないためエラーが発生このエラーを無視してもWelcomeページは確認できるので、一度最後まで手順を実施してみてください。
Could not find gem 'mysql2 (>= 0.4.4)' in any of the gem sources listed in your Gemfile. Run `bundle install` to install missing gems.3-2. 権限変更
生成したRailsアプリケーションのファイル群の所有権が root となっているので、現在のログインユーザーに変更します。
$ sudo chown -R $USER:$USER .3-3. puma.rbの編集
$ vim config/puma.rb元の記載は削除して、以下の内容を貼り付けてください。
puma.rbthreads_count = ENV.fetch("RAILS_MAX_THREADS") { 5 }.to_i threads threads_count, threads_count port ENV.fetch("PORT") { 3000 } environment ENV.fetch("RAILS_ENV") { "development" } plugin :tmp_restart app_root = File.expand_path("../..", __FILE__) bind "unix://#{app_root}/tmp/sockets/puma.sock" stdout_redirect "#{app_root}/log/puma.stdout.log", "#{app_root}/log/puma.stderr.log", true3-4. database.ymlの編集
$ vim config/database.yml元の記載は削除して、以下の内容を貼り付けてください。
database.ymldefault: &default adapter: mysql2 encoding: utf8 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: <%= ENV.fetch('MYSQL_USER') { 'root' } %> password: <%= ENV.fetch('MYSQL_PASSWORD') { 'password' } %> host: db development: <<: *default database: webapp_development test: <<: *default database: webapp_test上記のMYSQL_USER と MYSQL_PASSWORD は DB接続用の情報ファイル で定義した環境変数名を設定します。
4. イメージのビルドとコンテナの起動
いよいよコンテナを起動します!
4-1. イメージのビルド
Dockerfile 及び、DockerHub より引っ張ってきたイメージを全てビルドします。
$ docker-compose buildビルドが完了したら以下のコマンドで確認します。
$ docker imagesREPOSITORY TAG IMAGE ID CREATED SIZE webapp_web latest 0ae7b3fc51fd 38 seconds ago 132MB webapp_app latest d661a9898271 47 seconds ago 1.27GB <none> <none> 83d4ec18ac0c 6 minutes ago 1.06GB ruby 2.7.1 9b840f43471e 9 days ago 842MB nginx 1.19.0 2622e6cca7eb 3 weeks ago 132MB mysql 8.0 be0dbf01a0f3 3 weeks ago 541MB4-2. コンテナの起動
ビルドしたら、下記のコマンドでコンテナを立ち上げます。
$ docker-compose up -dコンテナが起動しているか確認します。
$ docker-compose ps全てのコンテナの State が Up となっていることを確認してください。
Name Command State Ports --------------------------------------------------------------------------- webapp_app_1 entrypoint.sh bundle exec ... Up webapp_db_1 docker-entrypoint.sh mysqld Up 3306/tcp, 33060/tcp webapp_web_1 /docker-entrypoint.sh /bin ... Up 0.0.0.0:80->80/tcpビルドに失敗した場合
イメージのビルドに失敗したり、コンテナの起動に失敗するとローカルにゴミファイルがたまってしまいます。
一度全てきれいにしたい場合は、コンテナとイメージを全て削除するコマンドを使います。
まずは、コンテナの起動を止めてから実行してください。コンテナを停止する
$ docker-compose stopすべてのコンテナを削除する
$ docker rm $(docker ps -q -a)すべてのイメージを削除する
$ docker rmi $(docker images -q)5. DB設定
5-1. 権限の付与
DBの操作を一般ユーザーで行うため、実行権限を付与します。
GRANT文を記述したSQLファイルを作成します。
user_name は DB接続用の情報ファイル に設定した MYSQL_USER の値に置き換えてください。$ vim db/grant_user.sqlgrant_user.sqlGRANT ALL PRIVILEGES ON *.* TO 'user_name'@'%'; FLUSH PRIVILEGES;dbコンテナに向けてクエリを送ります。
パスワードを求められるので、rootのパスワードを入力してください。$ docker-compose exec db mysql -u root -p -e"$(cat db/grant_user.sql)"権限が付与されたか確認します。
パスワードを求められるので、一般ユーザーのパスワードを入力してください。$ docker-compose exec db mysql -u user_name -p -e"show grants;"実行結果が横に長くてみづらいかもしれません。
MySQL5系では全ての権限が付与されている場合、「ALL PRIVILEGES」と表示されていたみたいですが、
8系ではちゃんと全ての権限名が表示されるため、このような横に長い結果になっているようです。+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | Grants for user_name@% | +------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | GRANT SELECT, INSERT, UPDATE, DELETE, CREATE, DROP, RELOAD, SHUTDOWN, PROCESS, FILE, REFERENCES, INDEX, ALTER, SHOW DATABASES, SUPER, CREATE TEMPORARY TABLES, LOCK TABLES, EXECUTE, REPLICATION SLAVE, REPLICATION CLIENT, CREATE VIEW, SHOW VIEW, CREATE ROUTINE, ALTER ROUTINE, CREATE USER, EVENT, TRIGGER, CREATE TABLESPACE, CREATE ROLE, DROP ROLE ON *.* TO `user_name`@`%` | | GRANT APPLICATION_PASSWORD_ADMIN,AUDIT_ADMIN,BACKUP_ADMIN,BINLOG_ADMIN,BINLOG_ENCRYPTION_ADMIN,CLONE_ADMIN,CONNECTION_ADMIN,ENCRYPTION_KEY_ADMIN,GROUP_REPLICATION_ADMIN,INNODB_REDO_LOG_ARCHIVE,PERSIST_RO_VARIABLES_ADMIN,REPLICATION_APPLIER,REPLICATION_SLAVE_ADMIN,RESOURCE_GROUP_ADMIN,RESOURCE_GROUP_USER,ROLE_ADMIN,SERVICE_CONNECTION_ADMIN,SESSION_VARIABLES_ADMIN,SET_USER_ID,SHOW_ROUTINE,SYSTEM_USER,SYSTEM_VARIABLES_ADMIN,TABLE_ENCRYPTION_ADMIN,XA_RECOVER_ADMIN ON *.* TO `user_name`@`%` | +------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+5-2. DBの作成
railsコマンドでDBを作成します。
$ docker-compose exec app rails db:create6. 確認
お疲れさまでした!
下記のlocalhostをクリックして、Welcomeページが表示されるでしょうか。
Rails と Ruby のバージョンが指定したものであるか、確認してください。あとがき
うまくWelcomeページが表示されましたでしょうか?
参考記事を見ながら構築していったのですが、Rails6用に書かれていなかったため、かなり苦労しました…。(Rails学ぶことが目的だったので、Rails5でよかったですね…)
Rails6に対応したあとはバージョンの記載を一元管理したり、色々なサイトで書かれていることを網羅して今回の構築ファイルたちができあがりました。
とりあえずはこの環境でRails勉強していきます!もし間違い・ご指摘などあればぜひお願いします。
今度はRails関連の記事でお会いしましょう!(多分)

- 投稿日:2020-07-06T22:45:32+09:00
今更ながら rails + wercker + codecov をやってみたが上手くいかない
はじめに
rails + wercker は数年やっていたのですが codecov を知らなかったので連携してみた(けど上手くいかない)、というだけの記事です。
環境
- Rails 5.2.4 系
- SimpleCov 0.18.5
- SimpleCov-Html 0.12.2
- CodeCov 0.1.17
注: Rails 以外の gem のバージョンは 2020/7 現在の最新だと思います。
設定
変更したファイルは 2つだけ。
- Gemfile
- test/test_helper.rb
Gemfile抜粋# テスト環境 限定 group :test do gem 'codecov', :require => false (以下省略) endtest/test_helper.rb抜粋require 'simplecov' SimpleCov.start 'rails' if ENV['WERCKER'] == 'true' require 'codecov' SimpleCov.formatter = SimpleCov::Formatter::Codecov endあ、設定ファイルも対象か。
codecov.yml# cf. https://qiita.com/kent-hamaguchi/items/d4d3696a34350fd97991 codecov: notify: require_ci_to_pass: yes coverage: status: project: default: target: 95% threshold: 1%ポイントだと思ったところ
適当にググって始めたのが良くなかったのですが、最初は
wercker.ymlに以下のような記述だけ入れていました。wercker.yml抜粋- script: name: post coverage to codecov code: | bash <(curl -s https://codecov.io/bash) -t $CODECOV_TOKENが、上手く行かないのでドキュメントを見ていたら Supported Languages から Codecov Ruby Example へたどり着けました。
...が、上手くいかない
これで手元では動くのですが wercker で実際に回してみると SSL_CTX_set_cipher_list: no cipher match のエラーで止まってしまいます。何故?
_____ _ / ____| | | | | ___ __| | ___ ___ _____ __ | | / _ \ / _\` |/ _ \/ __/ _ \ \ / / | |___| (_) | (_| | __/ (_| (_) \ V / \_____\___/ \__,_|\___|\___\___/ \_/ Ruby-0.1.17 ==> Wercker CI detected x> No CI provider detected. /upload/v1?token=secret&flags&service=wercker&branch=fix_1061&build=1594041715&slug=bsdmad%2Fmiyabi&commit=c3030c15474859c1fa0046e113fe979d10851864 -> Pinging Codecov Error uploading coverage reports to Codecov. Sorry SSL_CTX_set_cipher_list: no cipher match使っている docker image が Docker Official image(ruby 2.6.6) なので、そっちの問題かな…
参考にした記事
上手くいってないのに参考にしたと書くと語弊がありそうですが、上手く行かないのはあくまで私の問題です。ご了承下さい。
- 投稿日:2020-07-06T22:41:53+09:00
PG::ObjectInUse: ERROR: database "myapp_development" is being accessed by other users
ポートフォリオ作成中
db/seeds.rbUser.create!(name: "テスト 太郎", email: "test@example.com", password: "foobar", password_confirmation: "foobar" ) 99.times do |n| name = Faker::Name.name email = "test#{n}@example.com" password = "foobar" User.create!(name: name, email: email, password: password, password_confirmation: password) endページネーションを実装していくため
テスト用アカウントを作成しようとすると、
こんなエラーが出ました。$ rails db:migrate:resetを実行すると
PG::ObjectInUse: ERROR: database "myapp_development" is being accessed by other users DETAIL: There is 1 other session using the database.「myapp_debelopment」データベースは、他のセッションで使われているとのこと。
データベースはこのような構成
config/database.ymldefault: &default adapter: postgresql encoding: unicode host: db username: postgres password: password pool: 5 development: <<: *default database: myapp_development test: <<: *default database: myapp_test色々と調べていく中で
下記を参考にして、データベースを一度削除して
作成し直すことにしました。
https://stackoverflow.com/questions/46451472/unable-to-make-rake-dbdrop-work-in-development-with-rails-5-1-4$ docker exec -it (コンテナ名) /bin/bashコンテナの中に入ります。
$ rails db:drop Dropped database 'myapp_development' Dropped database 'myapp_test'$ rails db:create $ rails db:migrate == 20200704040832 CreateUsers: migrating ====================================== -- create_table(:users) -> 0.0426s == 20200704040832 CreateUsers: migrated (0.0432s) ============================= == 20200704043311 AddIndexToUsersEmail: migrating ============================= -- add_index(:users, :email, {:unique=>true}) -> 0.0303s == 20200704043311 AddIndexToUsersEmail: migrated (0.0307s) ==================== == 20200704043511 AddPasswordDigestToUsers: migrating ========================= -- add_column(:users, :password_digest, :string) -> 0.0026s == 20200704043511 AddPasswordDigestToUsers: migrated (0.0031s) ================ == 20200705055948 AddRememberDigestToUsers: migrating ========================= -- add_column(:users, :remember_digest, :string) -> 0.0025s == 20200705055948 AddRememberDigestToUsers: migrated (0.0027s) ================ $ rails db:seed$ exitこれで、無事動きました!
おそらく、
最初にデータベースを作成した際に
コンテナに入って作成するのではなく、
ローカル環境から下記コマンドで実行したから?
作成したユーザーが異なってしまったのではないかと。。$ docekr-compose run web rails db:create
- 投稿日:2020-07-06T19:22:00+09:00
permutationメソッドを使って初期設定ユーザー達を全員相互フォロー関係にする
はじめに
初めてqiitaに投稿します初学者と申します。
文言に誤り等がありましたらご指摘いただけますと幸いです。作成中の転職活動用ポートフォリオにて、初期データのユーザー達をseeds.rbで相互フォロー関係にさせておりました。
とある企業のエンジニア様からwantedlyにてコードレビューを含んだ返信をいただき、
このseeds.rbに関して「ロジックが異常に分かりにくい」と指摘を受けました。修正前のseeds.rb
下記のコードで初期設定ユーザー達を相互フォロー関係にさせておりました。
db/seeds_relationships.rb19.times do |n| # 19回処理を繰り返す users = User.all # 変数usersに全てのUserオブジェクトを代入 user = users.find(n + 1) # 変数usersから指定したid(n+1)のUserオブジェクトを変数userに代入 following = users[0..18] # 変数followingに配列usersの1~19番目までのUserオブジェクトを代入 following.shift(n + 1) # shiftメソッドで配列followingの先頭から(n+1)つの要素を取り除く followers = users[0..18] # 変数followersに配列usersの1~19番目までのUserオブジェクトを代入 followers.shift(n + 1) # shiftメソッドで配列followersの先頭から(n+1)つの要素を取り除く following.each { |followed| user.follow(followed) } # userが配列followingに含まれる各ユーザー(followed)をフォローする followers.each { |follower| follower.follow(user) } # 配列followersに含まれる各ユーザー(follower)がuserをフォローする end一目でわかると思いますが・・・異常な分かりづらさです。
Array#permutationを使いなさい
そのエンジニア様からは上記のように指摘を受け、
permutationとは何だろう?と思い、翻訳してみると「順列」という意味であることが分かりました。順列とは
異なるn個の中から異なるr個を取り出して1列に並べる数のことです。
【高校数学】1から分かる順列と組み合わせの違いAB,BA,BC,CB,AC,CAみたいなヤツのことですね()。
順列を作成する
[1, 2, 3].permutation do |x| p x end配列の中の要素から下記のような順列が作成されます。
[1, 2, 3] [1, 3, 2] [2, 1, 3] [2, 3, 1] [3, 1, 2] [3, 2, 1]permutationの後ろに(n)とすることで、配列の中から異なるn個の要素を取り出して並べることができます。
[1, 2, 3].permutation(2) do |x| p x end[1, 2] [1, 3] [2, 1] [2, 3] [3, 1] [3, 2]修正後のseeds.rb
db/seeds_relationships.rbusers = User.all.to_a users.permutation(2) do |n| n[0].follow(n[1]) end1番目のユーザーが2,3,4,5…番目のユーザーをフォロー、
2番目のユーザーが1,3,4,5…番目のユーザーをフォロー、
3番目のユーザーが1,2,4,5…番目のユーザーをフォロー、となり、
permutationメソッドを使って初期設定ユーザー達を全員相互フォロー関係にすることができました。【追記】もっと見やすくseeds.rb
db/seeds_relationships.rbusers = User.all.to_a users.permutation(2) do |user1, user2| user1.follow(user2) endコメントをいただき修正しました。
可読性がかなり良いですね!環境
- Ruby 2.6.5
- Rails 5.2.4.3
- 投稿日:2020-07-06T18:27:00+09:00
RailsでSwiperを導入する方法(Swiperは2020年7月にバージョンアップし、従来と設定方法が変わりました!)
はじめに
この記事は、以下のような方を対象としています。
- これからRailsでSwiperを導入しようとされている方
- Swiperを導入せよという課題が与えられたけど、そもそもSwiperが何かよく分からない初学者
- 他のQiitaやブログ等の記事を見たけれどなかなか上手く設定できず、Swiperを動かすことができない方
Swiperではメジャーバージョンアップが行われ、いくつか大きな変更がありました。
その点を踏まえて、本記事で解説していこうと思います。また、導入環境については末尾に記すので、そちらを参照してください。
Swiperのバージョンアップについて
Swiperのリリース情報
- 2020年7月3日にv6.0.0をリリース
- 以前のバージョンである v5.4.5 から大きく仕様が変更
- 詳細については、公式で確認できる(変更点も記載されている)
変更点
ディレクトリ構造の変更やファイル名の変更などがあり、従来どおりの設定のままだと動かなくなりました!
(煽り気味に書きましたが、NPMやYarnなどのパッケージマネージャを使って設定している場合の話です)詳細については、設定方法を紹介する中で併せて紹介していきます。
Swiperとは
CSSとJSを適用することで、画像などをスライドできる機能を実装するものです。
公式サイトにてどのような機能を実装できるか詳細に紹介されています。
また、ガリガリコードさんというサイトでサンプル付きで詳細に紹介されているので、
そちらをまず見てみるとイメージがつくかと思います。Swiperの実装方法
投げやりなことを言うと、公式サイトにまとめられています。
イメージさえつかめれば、英語がさほど分からなくても、実装できるかと思います。とはいえ、いきなり見ても分かりづらい部分があるかもしれないので、
概要について簡単にまとめてみました。1. HTMLの実装
イメージだけお伝えしますが、HTMLの構造は以下のようにする必要があります。
あまりよくないような気もしますが、公式サイトからコピペしています。<!-- Slider main container --> <div class="swiper-container"> <!-- Additional required wrapper --> <div class="swiper-wrapper"> <!-- Slides --> <div class="swiper-slide">Slide 1</div> <div class="swiper-slide">Slide 2</div> <div class="swiper-slide">Slide 3</div> ... </div> <!-- If we need pagination --> <div class="swiper-pagination"></div> <!-- If we need navigation buttons --> <div class="swiper-button-prev"></div> <div class="swiper-button-next"></div> <!-- If we need scrollbar --> <div class="swiper-scrollbar"></div> </div>なぜこのような構造にするかというと、Swiperの方で
swiper-wrapperクラスや
swiper-slideクラスなどに適用するためのコードが用意されているためです。Swiperの導入が無事終われば、該当のクラスにSwiperのCSSとJSが適用されるので、
「あら不思議!」という感じで、いい感じにスライド機能を実装してくれるという訳です。念のため補足すると、
<!-- If we need...と書かれているところは、
必要なければHTML上に記載する必要はありません。2. CSS、JSの適用方法
公式サイトで紹介されているとおりですが、
CSS及びJSの適用方法には3種類あります。
- CDN(クラウド上に公開されているCSSとJSを適用させる)
- ファイルをダウンロードして、愚直にCSSとJSを適用させる
- NPMというJSのパッケージマネージャ(RubyでいうところのGemを管理するBundlerのようなもの)
- Yarnという類似のパッケージマネージャーを使うことも可能です
2.1 CDNでの設定方法
CDNとは
詳細については全く詳しくないため、気になる方はググっていただきたいのですが、
Content Delivery Networkの略です。以前は、クラウド上に公開したファイルにアクセスが集中してしまうと困るので、
「各自ダウンロードして、自分が公開しているサーバーにCSSとJSをアップロードして!」
という感じでおそらくやっていました。ただ、大量配信できる仕組みが整い、アクセスが集中しても耐えうる体制を構築できたので、
「もうクラウド上のファイルを使ってしまってかまへんで〜」となりました。
この大量配信できる仕組みが、CDNです。誤解が多分に含まれていそうなのですが、 大枠の理解は間違ってないかと思います。。。
設定方法
HTMLのheadタグ内に以下のコードを貼り付ければCSSとJSが適用できるかと思います。
公式サイトにバッチリ書いてあるので、そちらを参照してください。application.htmlなどに適用<!-- Swiperの全ての機能を使いたい方はこちらを使用 --> <link rel="stylesheet" href="https://unpkg.com/swiper/swiper-bundle.css"> <script src="https://unpkg.com/swiper/swiper-bundle.js"></script> <!-- 最小限の機能で構わない! CSSやJSのファイルが小さい方がいい! という方はこちらを使用 --> <!-- 最小限の機能が何かは調べられていないので、公式を参照するなり、通常版と比較考慮するなどしてみてください --> <link rel="stylesheet" href="https://unpkg.com/swiper/swiper-bundle.min.css"> <script src="https://unpkg.com/swiper/swiper-bundle.min.js"></script>application.html.slimなどに適用/Swiperの全ての機能を使いたい方はこちらを使用 = stylesheet_link_tag "https://unpkg.com/swiper/swiper-bundle.css" = javascript_include_tag "https://unpkg.com/swiper/swiper-bundle.min.css" /最小限の機能で構わない! CSSやJSのファイルが小さい方がいい! という方はこちらを使用 /最小限の機能が何かまでは調べられていないので、公式を参照するなり、通常版と比較考慮するなどしてみてください = stylesheet_link_tag "https://unpkg.com/swiper/swiper-bundle.min.css" = javascript_include_tag "https://unpkg.com/swiper/swiper-bundle.min.js"Swiperだから特別なことをしているという訳ではないので、
CSSやJSの適用方法の基本について調べれば、すぐ理解できるかと思います。なお、その他のQiita記事等を参考にする場合、注意が必要です。
参照しているSwiperのバージョンが古いものである可能性が高いので、
その旨を踏まえて作業を進めてください。2.2 ファイルをダウンロードして、愚直にCSSとJSを適用させる方法
ここでは触れません!
おそらくあえて選択する方はいないかと思いますし。「CSSとJSをダウンロードして、HTMLに適用してあげればスライダー実装できるよ!」
という当たり前の話です。それをローカルのファイルでやるか、クラウドのファイルでやるかだけの違いです。
2.3 NPMもしくはYarnで設定する方法
ここではYarnを使った設定方法について取り上げます。
NPMについても基本的には同じような考え方になるかと思いますし、
公式サイトで設定方法について紹介されているので、そちらを参照してください。Yarnの導入からCSS・JSの適用まで
既によくまとめられたQiita記事があるので、まずはそちらを参照ください。
Yarnとは何かということについても触れています。注意点1(ディレクトリ構造やファイル名が変更しました)
先ほどの記事について、一点だけ注意していただきたいことがあります。
それは、node_modulesディレクトリ配下に作成されるswiperというフォルダ内に
インストールされるファイルやディレクトリ構成が変更されたため、
このQiita記事のとおり設定をしても上手くいかないということです。なので、導入したファイルの読み込み設定は以下のとおり行いましょう。
【Ver6】assets/javascript/application.js//= require swiper/swiper-bundle.js //= require swiper.js # ちなみに、この順番を間違えると上手く動かないらしいです【Ver6】assets/stylesheets/application.scss@import 'swiper/swiper-bundle';参考までに、Swiper(Ver5)の場合の設定について以下に掲載します。
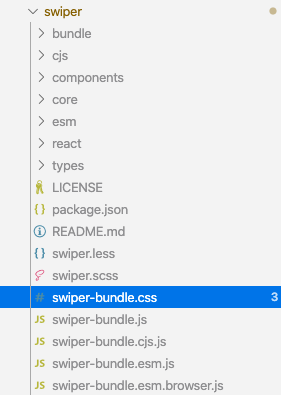
参照ファイルが変更されていことが分かるかと思います。【Ver5】assets/javascript/application.js//= require swiper/js/swiper.js //= require swiper.js【Ver5】assets/stylesheets/application.scss@import 'swiper/css/swiper';参考までに、nodes_modules配下のディレクトリ構造のスクリーンショットを貼っておきます。
「あー、だいぶ変わったな」ということが分かるかと思います。
Ver6 Ver5 注意点2(
config/initializers/assets.rbの設定)なお、以上については、あくまで
config/initializers/assets.rbを
以下のとおり設定している前提での話となります。ご注意ください。こちらについては、先ほど紹介したQiita記事にも書かれている内容になります。
config/initializers/assets.rbRails.application.config.assets.paths << Rails.root.join('node_modules')3. JSファイルの作成(先ほどのJSとは別!)
個人的にはここが分かりづらかったのですが、CDNから持ってくるJSファイル、
もしくはYarnでインストールしてnode_modules配下に置かれるJSファイルとは別に、
新しくJSファイルを自分で作成する必要があります。ここで作成するJSファイルが、先ほど設定した
swiper/js/swiper.jsを参照し、
スライダー機能を各クラスに適用させるような仕組みとなっています。作成するJSファイルですが、以下を参考にしてください。
公式に書かれているとおりです。app/assets/javascripts/任意の名前.jsvar mySwiper = new Swiper('.swiper-container', { // Optional parameters direction: 'vertical', loop: true, // If we need pagination pagination: { el: '.swiper-pagination', }, // Navigation arrows navigation: { nextEl: '.swiper-button-next', prevEl: '.swiper-button-prev', }, // And if we need scrollbar scrollbar: { el: '.swiper-scrollbar', }, })多くの場合、全てのコードは必要になりません。
また、逆に以上には書かれていないコードが必要となる場合もあります。公式のデモサイトを参照し、該当のスライダー機能においてどのようなソースコードが
使用されているか確認してみるとよいでしょう。例えば、Fraction Paginationという機能においては、以下のようなJSが使われています。
FractionPaginationで使用するJSvar swiper = new Swiper('.swiper-container', { pagination: { el: '.swiper-pagination', type: 'fraction', }, navigation: { nextEl: '.swiper-button-next', prevEl: '.swiper-button-prev', }, });このことは、公式サイトで紹介されているデモの一覧ページから確認することができます。
$(function() {...})について私の場合は以上のコードで動かなかったので、以下のとおりとしました。
(JSむずかしい。。。)app/assets/javascripts/任意の名前.js// var swiper = と始めるのではなく、$(function(){ で始める $(function() { new Swiper('.swiper-container', { // Optional parameters direction: 'vertical', loop: true, pagination: { el: '.swiper-pagination', }, 〜 以下省略 〜よくよく調べていくと、どうやらJSのスクリプトを置く場所が悪かったようです。
私の場合、HEADタグ内にJSのスクリプトを置くように設定していたので、
BODYタグ内のDOM(HTMLの構造、どこに何クラスがあるかなど)を読み込む前に
Swiperが発動してしまい、上手くJSを適用することができなかったようです。BODYタグの前にJSのスクリプトを置く場合、
$(function() {...})で
囲ってあげて、DOMを読み込んでからSwiperが発動するよう設定する必要があります。このあたりの話は以下のQiita記事に書かれています。
jQueryの基本 - $(document).ready - Qiita
【jQuery】$(function() {...}) について 「意味や実行されるタイミング」 - Qiitaまた、改めてSwiperの公式デモサイトをみると、たしかにBODYタグ内の末尾に
JSのスクリプトが置かれています。4. CSSの追加設定
こちらも公式に書いてある内容をそのまま書いているだけなのですが、
適宜Swiperのサイズなどを設定してください。公式で紹介されている事例を以下に貼っておきます。
application.scssなど任意のcssファイル.swiper-container { width: 600px; height: 300px; }参考
本記事内で紹介した公式サイト・ブログ・Qiita記事ですが、以下のとおりです。
公式サイトをぜひ一度は見てみてください。
- GitHub:SwiperのRelease情報
- Swiper公式サイトのデモ
- Swiper公式サイトで紹介されている実装方法(Getting Started With Swiper)
- ガリガリコード
- swiperをyarnで導入して、画像をスライダー形式にする! - Qiita
- 【jQuery】$(function() {...}) について 「意味や実行されるタイミング」 - Qiita
なお、本記事では紹介していませんが、細かいカスタマイズをする場合、
以下の記事などを参照するとよいかと思います!導入環境
バージョンとうるさいくせに、Railsのバージョンが5系なのは見逃してください。
また、初学者であるため、不足・過剰に書きすぎている部分があるかもしれません。
とりあえず、CSS・JS周りのものをざっと書き連ねてみました。全般
- MacOS X 10.15.5 (Catalina)
- ruby '2.6.4'
Yarn関係
- swiper (6.0.0)
- bootstrap-material-design(4.1.3)
- bootstrap(4.5.0)
- dom7(3.0.0-alpha.5)
- jquery(3.5.1)
- popper.js(1.16.1)
- ssr-window(3.0.0-alpha.4)
Gem関係
- gem 'rails' (5.2.3)
- gem 'sass-rails' (5.0)
- gem 'uglifier' (4.2.0)
- gem 'jquery-rails'(4.4.0)
- gem 'popper_js'(1.16.0)


- 投稿日:2020-07-06T16:56:39+09:00
ユーザー退会機能の実装
こんにちは、tt_tsutsumiです。
今回はユーザー退会機能について実装を行いたいと思います。
こちらの記事が何方かのお役に立てると嬉しいです。ユーザー新規登録、編集の記事は折を見て記載したいと思いますので、
今回はユーザー退会機能と退会済みユーザーがログインを行えない様に実装致します。1. 会員状況の定義
ユーザーの会員状況をenum(boolean型)で設定をする。
boolean型は真偽値を保存する型で、2つの状況しか登録する事が出来ません。
今回はユーザーが 有効会員か退会済み会員か の2択なのでこの型を使用します。
また is_active が true(有効会員) の場合ログインが出来る設定を行います。※ is_active が false(退会済み会員) の場合はログインが行えません。
user.rbenum is_active: {Available: true, Invalid: false} #有効会員はtrue、退会済み会員はfalse def active_for_authentication? super && (self.is_active === "Available") end #is_activeが有効の場合は有効会員(ログイン可能)2. routeの記載
routes.rbresources :users do member do get "check" #ユーザーの会員状況を取得 patch "withdrawl" #ユーザーの会員状況を更新 end end3. アクションの作成
次にコントローラーにアクションの作成を行います。
※ 今回は退会確認を行うページの作成も行ったのでアクションが2つとなります。users_controllerdef check @user = User.find(params[:id]) #ユーザーの情報を見つける end def withdrawl @user = User.find(current_user.id) #現在ログインしているユーザーを@userに格納 @user.update(is_active: "Invalid") #updateで登録情報をInvalidに変更 @user.destroy #destroyを行う reset_session #sessionIDのresetを行う redirect_to root_path #指定されたrootへのpath end private def user_params params.require(:user).permit(:active) end4. リンク先の作成
リンク先の作成を行いユーザーを退会させます。
methodは削除ではなく更新になるのでpatchの記載となります。withdrawl.html.erb<div class="withdrawl"> <%= link_to "Withdrawal", withdrawl_user_path(@user.id), method: :patch %> </div>これでユーザー退会機能と退会済みユーザーがログインを行えない様に実装が行えました。
ご覧いただきありがとうございました !!
- 投稿日:2020-07-06T16:56:39+09:00
[Rails]ユーザー退会機能の実装
こんにちは、tt_tsutsumiです。
今回はユーザー退会機能について実装を行いたいと思います。
こちらの記事が何方かのお役に立てると嬉しいです。ユーザー新規登録、編集の記事は折を見て記載したいと思いますので、
今回はユーザー退会機能と退会済みユーザーがログインを行えない様に実装致します。1. 会員状況の定義
ユーザーの会員状況をenum(boolean型)で設定をする。
boolean型は真偽値を保存する型で、2つの状況しか登録する事が出来ません。
今回はユーザーが 有効会員か退会済み会員か の2択なのでこの型を使用します。
また is_active が true(有効会員) の場合ログインが出来る設定を行います。※ is_active が false(退会済み会員) の場合はログインが行えません。
user.rbenum is_active: {Available: true, Invalid: false} #有効会員はtrue、退会済み会員はfalse def active_for_authentication? super && (self.is_active === "Available") end #is_activeが有効の場合は有効会員(ログイン可能)2. routeの記載
routes.rbresources :users do member do get "check" #ユーザーの会員状況を取得 patch "withdrawl" #ユーザーの会員状況を更新 end end3. アクションの作成
次にコントローラーにアクションの作成を行います。
※ 今回は退会確認を行うページの作成も行ったのでアクションが2つとなります。users_controllerdef check @user = User.find(params[:id]) #ユーザーの情報を見つける end def withdrawl @user = User.find(current_user.id) #現在ログインしているユーザーを@userに格納 @user.update(is_active: "Invalid") #updateで登録情報をInvalidに変更 @user.destroy #destroyを行う reset_session #sessionIDのresetを行う redirect_to root_path #指定されたrootへのpath end private def user_params params.require(:user).permit(:active) end4. リンク先の作成
リンク先の作成を行いユーザーを退会させます。
methodは削除ではなく更新になるのでpatchの記載となります。withdrawl.html.erb<div class="withdrawl"> <%= link_to "Withdrawal", withdrawl_user_path(@user.id), method: :patch %> </div>これでユーザー退会機能と退会済みユーザーがログインを行えない様に実装が行えました。
ご覧いただきありがとうございました !!
- 投稿日:2020-07-06T14:15:59+09:00
Railsで学ぶSQLインジェクション脆弱性
webセキュリティについて勉強中なので、学習内容を公開します
スカスカ記事ですがお許しください演習環境
- Ruby (2.6.6)
- Rails (5.2.4.3)
- database adapter mysql2 (0.5.3)
- mysql (5.7.30)
記事投稿、コメント投稿、ブックマークなどが出来る演習用アプリ「TARGET」
GitHubリポジトリ https://github.com/Fumitaka1/targetSQLインジェクション脆弱性とは
外部から受け取ったパラメータからSQL文を作成し、DBを操作しているプログラムに起こりうる脆弱性のこと
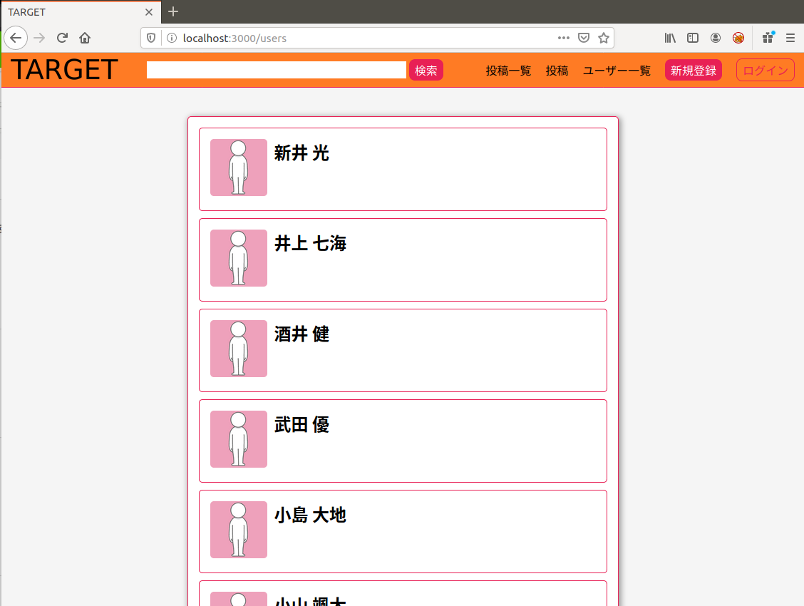
例 ユーザーの一覧を表示できるサイトがあります
'小'で検索するとユーザー名に'小'を含むユーザーが表示されます
発行されるSQL文SELECT `users`.* FROM `users` WHERE (name LIKE '%小%')
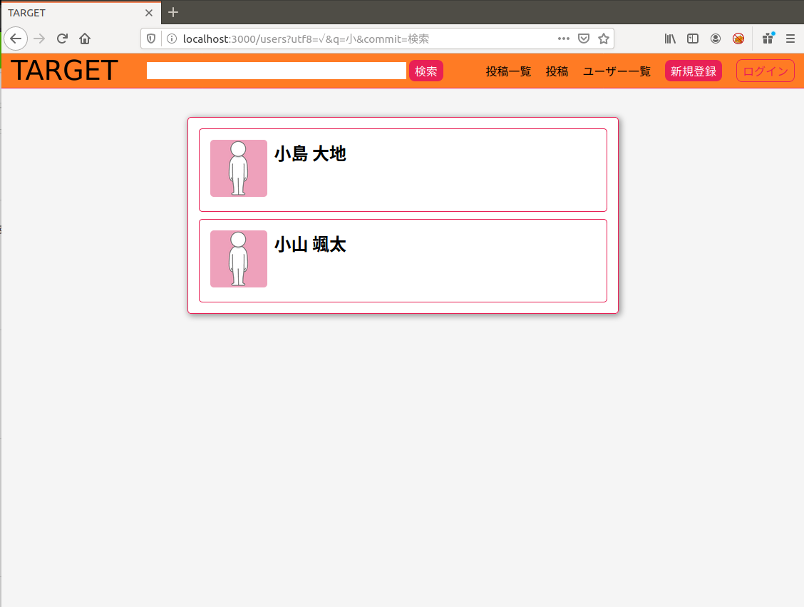
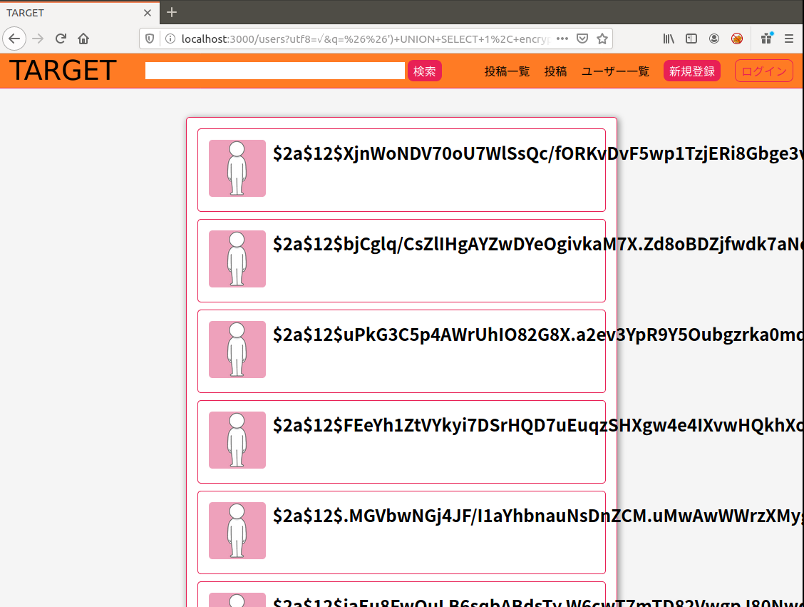
以下の攻撃用文字列で検索するとハッシュ化されたパスワードが表示されます。
&&') UNION SELECT 1, encrypted_password, 3,4,5,6,7,8,9,10,11 FROM target_development.users;#発行されるSQL文
SELECT `users`.* FROM `users` WHERE (name LIKE '%&&') UNION SELECT 1, encrypted_password, 3,4,5,6,7,8,9,10,11 FROM target_development.users;# %')
※攻撃文字列に必要なデータベース名やカラム名はinformaiton_schemaから取得可能ですなぜ発生するのか
外部からのパラメータにSQLの制御文字が含まれていて、想定外のSQL文が発行されることが原因
上記の例では
1.検索文字列の&&')によって正規のSELECT文が不正に終端される。
2.続きの文字列UNION SELECT 1, encrypted_password, 3,4,5,6,7,8,9,10,11 FROM target_development.users;がそのままSQLとして発行される。演習用サイトでは外部からのパラメータをそのまま受け取ってSQL文を発行する脆弱な処理が含まれている
users_controller.rbdef index @users = User.where("name LIKE '%#{params[:q]}%'") endどう防ぐか
1.外部からのパラメータに含まれる制御文字を安全な文字に置き換える
users_controller.rbdef index sanitized_q = params[:q].gsub(/\'/,'\\\'') if params[:q] @users = User.where("name LIKE '%#{sanitized_q}%'") end2.プレースホルダを利用してSQL文を発行する
users_controller.rbdef index @users = User.where("name LIKE ?","%#{params[:q]}%") endRailsにはSQL制御文字のフィルタが用意されている
- Model.find(id)
- Model.find_by_hoge(fuga)
- Model.where(hoge: fuga) #ハッシュを使うとプレースホルダと同等
学んだこと
SQLインジェクションはよく知られた脆弱性であるため、フレームワーク側で対応策が用意されているが、外部パラメータからSQL文を作成する場合には十分注意を払う。
ORMのおかげでSQLを書く機会が少なかったが、この機会にSQLを掘り下げることが出来た。
- 投稿日:2020-07-06T14:10:41+09:00
permission denied(パーミッション ディナイド)とは?
概要
今日は自動デプロイの学習中に
permission denied問題で悩み、権限系の知識が浅いと感じましたので復習を兼ねて詳しく調べてみました。permissionとは英語で「許可や権限」を指し、deniedとは「否定の過去形で否定した」という意味を持ちます。つまり、
permission deniedとは「権限がありません」というような意味を持ちます。
そして、プログラミングにおけるpermissionは「誰に、どのような操作を許可するのか」という権限を規定する情報が設定されています。この情報のことを、パーミッションと呼びます。パーミッションを確認するには?
lsコマンドを-lオプションで実行します。
するとこんな感じの画面になるかと思います。ターミナル$ ls -l drwxr-xr-x. 20 root root 2077 July 5 14:34 bin/cat「d」はディレクトリを指し、rwxはr(読み込み)、w(書き込み)、x(実行)を表し、それぞれ左側から「オーナー」、「グループユーザー」、「その他ユーザー」を表しています。
したがって「rwxr-xr-x」のような表示になっています。
※この場合だと、オーナーには「全権限」があって、グループユーザーとその他ユーザーは「読み込みと実行」が可能で「書き込み」の権限がないと言われています。権限を変更するには?
chmodコマンドを指定します。chmodは「チェンジモード」と読みます。
書式は以下のようになります。
chmod <8進数の数値> <ファイル名>
意味 数字 読み取り(r) 4 書き込み(w) 2 実行(x) 1 例として、以下のようにコマンドを入力することで権限を変更できます。
今回だと2行目のchmod 755 file.txtの部分が当たります。ターミナル$ ls -l file.txt -rw-r--r-- 1 takuya staff 0 Jul 12 18:58 file.txt $ chmod 755 file.txt $ ls -l file.txt -rwxr-xr-x 1 takuya staff 0 Jul 12 18:58 file.txt*つまり、「755」というのは「7(4+2+1)5(4+1)5(4+1)」であり、ユーザには全てに権限を、グループとそののユーザには「読み込み」と「実行」する権限を与えているわけです。
スーパーユーザー
ありとあらゆる操作が許可された強い権限を持つユーザがスーパーユーザです。ユーザ名がrootであることから「rootユーザ」とも呼ばれます。スーパーユーザはあらゆる操作が許可された強い権限をもつユーザであり、設定ファイルを変更したり、新しいアプリケーションをインストールしたりすることができますが、強い権限をもつだけにリスクも伴いますので、通常は一般ユーザでログインして操作し、必要な時だけスーパーユーザとして作業するといったことが大切になります。
コマンドとしてsuコマンドとsudoコマンドがありますが、違いは、suコマンドを実行したのちには、exitコマンドでsuperuser状態から抜ける必要があります。
また、sudoコマンドはrootユーザーに成り代わってコマンドを実行するのに対して、suコマンドはrootユーザーにそのまま成り代わって操作することを可能にするため、rootユーザーのパスワードが求められます。
- 投稿日:2020-07-06T13:18:25+09:00
[Rails]A server is already running
A server is already runningのエラーが出ました。てやんでい。
別ウィンドウで、サーバー立ち上げているときにrails sすると上記のエラーが出ます。が今回は、他にターミナルを開いていませんでした。
てやんでい..ログをきちんと確認してみると
A server is already running. Check C:/shitsumonwa/tmp/pids/server.pid. Exitingとでている。
理由はわからないけど、手元でsystem testを全て確認した後なので、PC自体めちゃくちゃ重くなっていたけど、何か原因あるんか.. てやんでぇい。
解決策: server.pidファイルを削除
server.pidファイルを削除
[Railsプロジェクトフォルダ名]\tmp\pids\server.pidtmp: キャッシュなど、一時的なファイルを格納されるディレクトリ
サーバー終了すると削除されるIDみたいなものが、サーバー起動時に生成されるみたいです。
ファイルの中身を見てみると、ランダムの値が記載されています。
tmp/pids/server.pid8266サーバーを再起動すると、値が変わっています。
tmp/pids/server.pid8295今回は、そのIDが残ったままだったので、
A server is already runningのエラーを吐いたみたいです。以上で、
rails sすると無事サーバーが立ち上がりました。
- 投稿日:2020-07-06T11:33:34+09:00
【Rails】型が変換される前の値にバリデーションをかけたい(_before_type_cast)
はじめに
ActiveRecordではDate型やInteger型のカラムに文字列を入れると自動でそのカラムの型に変換してくれます。
例えば以下のようなusersテーブルがあったとします。(簡単の為にcreated_atやupdated_atは省略してます。)
db/schema.rbcreate_table "users", force: :cascade do |t| t.string "name" t.integer "age" end試しにRailsコンソールを使っていろいろな値を入れてみましょう。
irb(main):001:0> User.new(name: "太郎", age: 21) #ageに数値を入れてみる => #<User name: "太郎" , age: 21> irb(main):002:0> User.new(name: "太郎", age: "21") #ageに文字列を入れてみる => #<User name: "太郎", age: 21> irb(main):003:0> User.new(name: "太郎", age: "21") #ageに文字列を入れてみる(1は全角数字) => #<User name: "太郎", age: 2>1つ目は数値を入れています。数値なのでそのまま入りますね。
2つ目は文字列を入れています。文字列の"21"が数値の21に変換されていますね、すばらしいです。
3つ目はどうでしょうか、"21"の1の部分は全角数字です。
なんと、age: 2になってしまっています。21とは全然違いますね。ちなみに"2 1"(間にスペースを入れる)や"2ア"(数字以外の文字を入れる)などしても、age: 2となります。
何が困るのか
数字以外の入力を弾こうとして以下のようなバリデーションをかけたとします。
models/user.rbvalidates :age, format: { with: /\A[0-9]+\z/}この場合、ユーザーが"2 1", "2ア"などの入力をするととageの2に対してバリデーションがかかることになり、正しいデータとして保存されてしまいます。
解決策 「_before_type_cast」
解決策として、ageに_before_type_castをつけると型が変換された後の値ではなくユーザーの入力した値に対して、バリデーションをかけることができます。※参考「rails/validatesでbefore_type_cast」
models/user.rbvalidates :age_before_type_cast, format: { with: /\A[0-9]+\z/}, presence: true応用(文字列の変換など)
_before_type_castはバリデーションの他に、文字列の英数字を全角から半角に変換したり、空白を取り除いてから保存したい場合などにも便利です。
以下のコードではMojiというgemを使って全角→半角の変換をしています。
age_before_type_castでユーザーの入力したそのままの文字列を受け取って変換した後、ageに変換した文字列を入れています。models/user.rbvalidates :age_before_type_cast, format: { with: /\A[0-9]+\z/}, presence: true before_validation do string = self.send(:age_before_type_cast) string = Moji.normalize_zen_han(string) send(:write_attribute, :age, string) end_before_type_castの性質
〇〇と〇〇_before_type_castの違い
まず通常の属性と_before_type_castのついた属性の違いです。
[:〇〇]では値が取得できません。
具体的にはirb(main):001:0> user = User.new(name: "太郎", age: "21") irb(main):002:0> user.age => 21 irb(main):003:0> user.age_before_typecast => "21" irb(main):004:0> user[:age] => 21 irb(main):005:0> user[:age_before_typecast] => niluser.age_before_type_castなら値が取得できますが、
user[:age_before_type_cast]を使って値を取得しようとするとnilが返ってきてしまいます。〇〇_before_type_castの更新はできない
irb(main):001:0> user.age = 21 => 21 irb(main):002:0> user.age_before_type_cast = 21 => #NoMethodErrorが発生します。_before_type_castはageへの型変換前の入力を確認するためのものなので、それ自体を更新することはもちろんできないですね。
save後はどうなるか
また、saveすると〇〇と〇〇_before_type_castは同じになります。
具体的には、irb(main):001:0> user = User.new(name: "太郎", age: "21") irb(main):002:0> user.save irb(main):003:0> user.age_before_typecast = 21文字列の"21"ではなく、数値の21が返ってきています。
以上のような性質があるので実装やテストの際は気をつけましょう!
参考記事
- 投稿日:2020-07-06T11:33:34+09:00
【Rails/ActiveRecord】型が変換される前の値にバリデーションをかけたい(_before_type_cast)
はじめに
ActiveRecordではDate型やInteger型のカラムに文字列を入れると自動でそのカラムの型に変換してくれます。
例えば以下のようなusersテーブルがあったとします。(簡単の為にcreated_atやupdated_atは省略してます。)
db/schema.rbcreate_table "users", force: :cascade do |t| t.string "name" t.integer "age" end試しにRailsコンソールを使っていろいろな値を入れてみましょう。
irb(main):001:0> User.new(name: "太郎", age: 21) #ageに数値を入れてみる => #<User name: "太郎" , age: 21> irb(main):002:0> User.new(name: "太郎", age: "21") #ageに文字列を入れてみる => #<User name: "太郎", age: 21> irb(main):003:0> User.new(name: "太郎", age: "21") #ageに文字列を入れてみる(1は全角数字) => #<User name: "太郎", age: 2>1つ目は数値を入れています。数値なのでそのまま入りますね。
2つ目は文字列を入れています。文字列の"21"が数値の21に変換されていますね。素晴らしいです。
3つ目はどうでしょうか、"21"の1の部分は全角数字です。
なんと、age: 2になってしまっています。21とは全然違いますね。ちなみに"2 1"(間にスペースを入れる)や"2ア"(数字以外の文字を入れる)などしても、age: 2となります。
何が困るのか
数字以外の入力を弾こうとして以下のようなバリデーションをかけたとします。
models/user.rbvalidates :age, format: { with: /\A[0-9]+\z/}この場合、ユーザーが"2 1", "2ア"などの入力をするととageの2に対してバリデーションがかかることになり、正しいデータとして保存されてしまいます。
解決策 「_before_type_cast」
解決策として、ageに_before_type_castをつけると型が変換された後の値ではなくユーザーの入力した値に対して、バリデーションをかけることができます。※参考「rails/validatesでbefore_type_cast」
models/user.rbvalidates :age_before_type_cast, format: { with: /\A[0-9]+\z/ }, presence: true応用(文字列の変換など)
_before_type_castはバリデーションの他に、文字列の英数字を全角から半角に変換したり、空白を取り除いてから保存したい場合などにも便利です。
例として以下のコードではMojiというgemを使って全角→半角の変換をしています。
今回はユーザーの“21”(1は全角)などの全角と半角が混じった入力をバリデーション前に半角に揃えたいので_before_type_castを使います。
age_before_type_castでユーザーの入力したそのままの文字列を受け取って変換した後、ageに変換した文字列を入れています。
models/user.rbvalidates :age_before_type_cast, format: { with: /\A[0-9]+\z/ }, presence: true before_validation do string = self.send(:age_before_type_cast) string = Moji.normalize_zen_han(string) send(:write_attribute, :age, string) end_before_type_castの性質
〇〇と〇〇_before_type_castの違い
まず通常の属性とbefore_type_castのついた属性の違いです。
[:〇〇_beforetype_cast]では値が取得できません。
具体的にはirb(main):001:0> user = User.new(name: "太郎", age: "21") irb(main):002:0> user.age => 21 irb(main):003:0> user.age_before_typecast => "21" irb(main):004:0> user[:age] => 21 irb(main):005:0> user[:age_before_typecast] => niluser.age_before_type_castなら値が取得できますが、
user[:age_before_type_cast]を使って値を取得しようとするとnilが返ってきてしまいます。〇〇_before_type_castの更新はできない
irb(main):001:0> user.age = 21 => 21 irb(main):002:0> user.age_before_type_cast = 21 => #NoMethodErrorが発生します。_before_type_castはageへの型変換前の入力を確認するためのものなので、それ自体を更新することはもちろんできないですね。
save後はどうなるか
また、saveすると〇〇と〇〇_before_type_castは同じになります。
具体的には、irb(main):001:0> user = User.new(name: "太郎", age: "21") irb(main):002:0> user.save irb(main):003:0> user.age_before_typecast => 21文字列の"21"ではなく、数値の21が返ってきています。
以上のような性質があるので実装やテストの際は気をつけましょう!
参考記事
- 投稿日:2020-07-06T10:33:30+09:00
PostgreSQLに接続できなくなった時の対処法
エラーの詳細
Railsで昨日まで問題なくサーバーにアクセスできたのに、電源を切ってから次の日にアクセスするとエラーが出てアクセスできなかった。
PG::ConnectionBad could not connect to server: No such file or directory Is the server running locally and accepting connections on Unix domain socket "/tmp/.s.PGSQL.5432"?
実行環境
- macOS Catalina 10.15.5
- PostgreSQL 12.3
- Homebrewを使っている
解決策
Homebrewとポスグレをアップデートする。
$ brew update $ brew upgradeポスグレを再起動する。
$ brew services restart postgresql自分はこの手順で解決できた。

- 投稿日:2020-07-06T07:22:31+09:00
[Rails]belongs_toが定義されているモデルをcreateする時に発行されるSELECTを回避せよ!
問題編
Railsでbelongs_toが定義されているモデルをcreateする時にSELECT文が実行されることを知っていますか?
例えば下記のようなモデルがあるとします。
def User < ApplicationRecord has_many :reviews end def Review < ApplicationRecord belongs_to :user belongs_to :book end def Book < ApplicationRecord has_many :reviews endこの時にreviewを作成すると下記のようにSQLが発行されます。
# id=1のuserとbookが存在すること irb(main):001:0> Review.create!(user_id: 1, book_id: 1) (0.5ms) BEGIN User Load (0.5ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 1 LIMIT 1 Book Load (0.5ms) SELECT `books`.* FROM `books` WHERE `books`.`id` = 1 LIMIT 1 Review Create (0.6ms) INSERT INTO `reviews` (`user_id`, `book_id`, `created_at`, `updated_at`) VALUES (1, 1, '2020-06-30 14:31:27.343637', '2020-06-30 14:31:27.343637') (2.0ms) COMMITbelongs_toが定義されているusersとbooksにSELECTされていますね。
SELECTされる理由は単純です。
belongs_toはデフォルトでは関連モデルの存在が必須です。
では必須の確認はどうしているのか?
先ほどのようにcreateする直前にSELECTして存在チェックしているのです。ちなみに、もし関連モデルの存在が任意の場合は
belongs_to :user, optional: trueと書きます。
このように書くとSELECTは実行されません。
参照:Railsガイド
https://railsguides.jp/association_basics.html#optionalということで、タイトルに書いてあるSELECTを回避する方法は
optional: trueを設定するです!...ではありません!!確かにSELECTは発行されなくなりますが、関連モデルが必須なのであれば
optional: trueを設定することは適切ではありません。解決編
では
optional: trueを設定せずにSELECTを回避するにはどうすればよいのか?
それはcreateにオブジェクトを渡してあげれば良いのです。irb(main):002:0> user = User.first User Load (0.8ms) SELECT `users`.* FROM `users` ORDER BY `users`.`id` ASC LIMIT 1 => #<User id: 1, name: "1234567890", created_at: "2019-12-12 05:43:52", updated_at: "2019-12-12 05:43:52"> irb(main):003:0> book = Book.first Book Load (0.6ms) SELECT `books`.* FROM `books` ORDER BY `books`.`id` ASC LIMIT 1 => #<Book id: 1, title: "book1", created_at: "2020-06-15 14:21:15", updated_at: "2020-06-15 14:21:15"> irb(main):004:0> review = Review.create!(user: user, book: book) (0.4ms) BEGIN Review Create (0.6ms) INSERT INTO `reviews` (`user_id`, `book_id`, `created_at`, `updated_at`) VALUES (1, 1, '2020-06-30 14:32:14.911478', '2020-06-30 14:32:14.911478') (2.0ms) COMMITオブジェクトを渡すことでSELECTをするまでもなく存在が確認できているのでSELECT文が発行されなくなってます。
ただし、この例の場合だと直前で各モデルを別途SELECTしているからSQLの数は同じじゃねーか!!
というツッコミを受けそうですが、例えば同じuserのreviewを複数作るときなどはSQLの数が全然違います。下記はuser1にbook1〜5のreviewを作成するコードです(可読性を高めるために一部省略しています)。
1つ目はidを指定してcreateします。irb(main):039:0> user = User.first irb(main):040:0> books = Book.where(id: [1, 2, 3, 4, 5]) irb(main):042:0> books.each do |book| irb(main):043:1* Review.create!(user_id: user.id, book_id: book.id) irb(main):044:1> end Book Load (0.8ms) SELECT `books`.* FROM `books` WHERE `books`.`id` IN (1, 2, 3, 4, 5) (0.3ms) BEGIN User Load (0.5ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 1 LIMIT 1 Book Load (0.4ms) SELECT `books`.* FROM `books` WHERE `books`.`id` = 1 LIMIT 1 Review Create (0.8ms) INSERT INTO `reviews` (`user_id`, `book_id`, `created_at`, `updated_at`) VALUES (1, 1, '2020-06-30 15:10:00.009569', '2020-06-30 15:10:00.009569') (3.6ms) COMMIT (0.3ms) BEGIN User Load (0.4ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 1 LIMIT 1 Book Load (0.4ms) SELECT `books`.* FROM `books` WHERE `books`.`id` = 2 LIMIT 1 Review Create (0.4ms) INSERT INTO `reviews` (`user_id`, `book_id`, `created_at`, `updated_at`) VALUES (1, 2, '2020-06-30 15:10:00.020722', '2020-06-30 15:10:00.020722') (1.8ms) COMMIT (0.4ms) BEGIN User Load (0.6ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 1 LIMIT 1 Book Load (0.4ms) SELECT `books`.* FROM `books` WHERE `books`.`id` = 3 LIMIT 1 Review Create (0.4ms) INSERT INTO `reviews` (`user_id`, `book_id`, `created_at`, `updated_at`) VALUES (1, 3, '2020-06-30 15:10:00.029827', '2020-06-30 15:10:00.029827') (1.9ms) COMMIT (0.3ms) BEGIN User Load (0.4ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 1 LIMIT 1 Book Load (0.3ms) SELECT `books`.* FROM `books` WHERE `books`.`id` = 4 LIMIT 1 Review Create (0.3ms) INSERT INTO `reviews` (`user_id`, `book_id`, `created_at`, `updated_at`) VALUES (1, 4, '2020-06-30 15:10:00.037725', '2020-06-30 15:10:00.037725') (1.7ms) COMMIT (0.3ms) BEGIN User Load (0.5ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 1 LIMIT 1 Book Load (0.3ms) SELECT `books`.* FROM `books` WHERE `books`.`id` = 5 LIMIT 1 Review Create (0.4ms) INSERT INTO `reviews` (`user_id`, `book_id`, `created_at`, `updated_at`) VALUES (1, 5, '2020-06-30 15:10:00.045389', '2020-06-30 15:10:00.045389') (1.6ms) COMMIT次にオブジェクトを渡してcreateします。
irb(main):045:0> user = User.first irb(main):046:0> books = Book.where(id: [1, 2, 3, 4, 5]) irb(main):047:0> books.each do |book| irb(main):048:1* Review.create!(user: user, book: book) irb(main):049:1> end Book Load (0.8ms) SELECT `books`.* FROM `books` WHERE `books`.`id` IN (1, 2, 3, 4, 5) (0.5ms) BEGIN Review Create (0.5ms) INSERT INTO `reviews` (`user_id`, `book_id`, `created_at`, `updated_at`) VALUES (1, 1, '2020-06-30 15:12:05.610003', '2020-06-30 15:12:05.610003') (2.8ms) COMMIT (0.4ms) BEGIN Review Create (0.4ms) INSERT INTO `reviews` (`user_id`, `book_id`, `created_at`, `updated_at`) VALUES (1, 2, '2020-06-30 15:12:05.617125', '2020-06-30 15:12:05.617125') (1.7ms) COMMIT (0.3ms) BEGIN Review Create (0.5ms) INSERT INTO `reviews` (`user_id`, `book_id`, `created_at`, `updated_at`) VALUES (1, 3, '2020-06-30 15:12:05.622432', '2020-06-30 15:12:05.622432') (1.8ms) COMMIT (0.4ms) BEGIN Review Create (0.5ms) INSERT INTO `reviews` (`user_id`, `book_id`, `created_at`, `updated_at`) VALUES (1, 4, '2020-06-30 15:12:05.627957', '2020-06-30 15:12:05.627957') (2.0ms) COMMIT (0.4ms) BEGIN Review Create (0.6ms) INSERT INTO `reviews` (`user_id`, `book_id`, `created_at`, `updated_at`) VALUES (1, 5, '2020-06-30 15:12:05.634191', '2020-06-30 15:12:05.634191') (1.8ms) COMMIT2つ目の実装だと10本のSELECTが省略できていますね!!
これを知っているかどうかで発行されるSQLが変わってくるので覚えておきましょう!おまけ
前述の通りcreateをする時にbelongs_toの存在チェックをしているわけですが、createで渡したモデルや直前でSELECTした結果は存在チェックに使うだけではなく、きちんとアソシエーションにセットされているようです。
createで作成したモデルのアソシエーションを参照してもSQLが発行されません。
irb(main):051:0> review = Review.create!(user: user, book: book) (2.3ms) BEGIN Review Create (0.6ms) INSERT INTO `reviews` (`user_id`, `book_id`, `created_at`, `updated_at`) VALUES (1, 1, '2020-06-30 15:20:01.755647', '2020-06-30 15:20:01.755647') (2.5ms) COMMIT => #<Review id: 36, content: "", user_id: 1, book_id: 1, status: "draft", created_at: "2020-06-30 15:20:01", updated_at: "2020-06-30 15:20:01"> # create時に渡したモデルが設定されているので、アソシエーションを参照してもSELECTが実行されない irb(main):052:0> review.user => #<User id: 1, name: "1234567890", created_at: "2019-12-12 05:43:52", updated_at: "2019-12-12 05:43:52"> irb(main):053:0> review.book => #<Book id: 1, title: "book1", created_at: "2020-06-15 14:21:15", updated_at: "2020-06-15 14:21:15">