- 投稿日:2020-07-06T19:00:40+09:00
CodePipelineのレビューコメントはどこに表示されるのか
はじめに
CodePipelineで"Manual approval"のステージを追加すると、承認/却下のレビュー時にコメントを記入することができます。
例えば、コメントに承認者の名前や却下理由等を記載したとして、過去のレビューコメントを参照したい場合にはどこで確認すればいいのかがわからなかったため探ってみました。Manual approvalステージとは
CodePipelineのプロセスの中で、承認/却下するステージを追加することができます。これがManual approvalステージです。
以下のような画面となっていて、「レビュー」ボタンを押下するとコメントを記入する画面が表示されます。
コメントの追加
では、以下のように、「承認します。」とコメントを入れて承認してみます。
過去のコメントの確認
一通りパイプラインが流れたら、過去のコメントを追ってみたいと思います。
まずは、「パイプライン」の履歴から実行IDをクリックします。
続いて、「Approval」をクリックします。
そうすると、画面左上の方に「メッセージ」という箇所があります。こちらにコメントが表示されています。





- 投稿日:2020-07-06T18:05:33+09:00
【AWS SAA】VPC内のEC2インスタンスがインターネットに接続できない原因備忘録
はじめに
AWS SAAの問題で「VPC 内のEC2 インスタンスがインターネットに接続できない原因」が出てきた。その問題解決について備忘録として今回載せたい。
主な原因
下記の設定ミスが、主な原因とのこと。
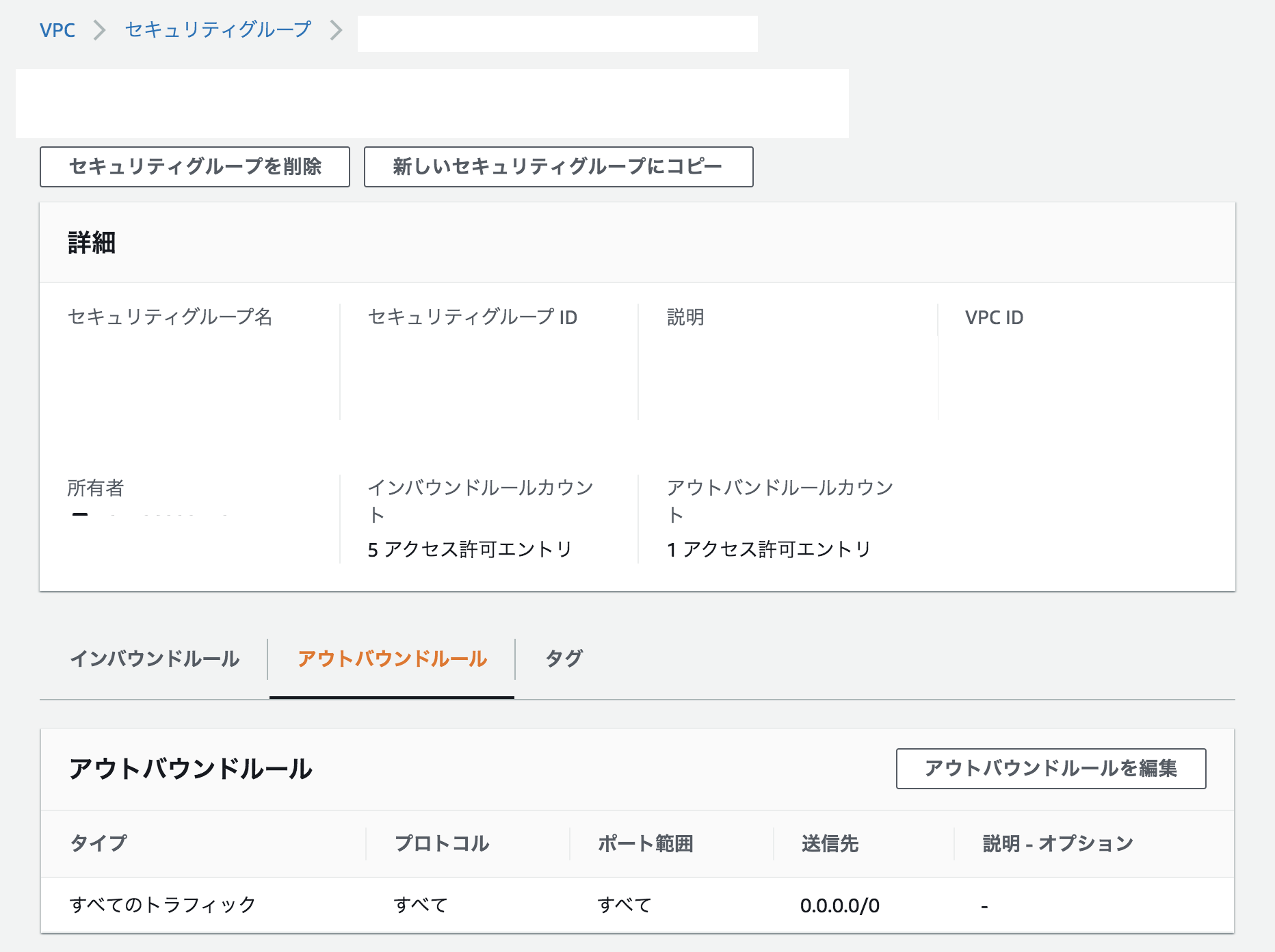
①セキュリティグループ
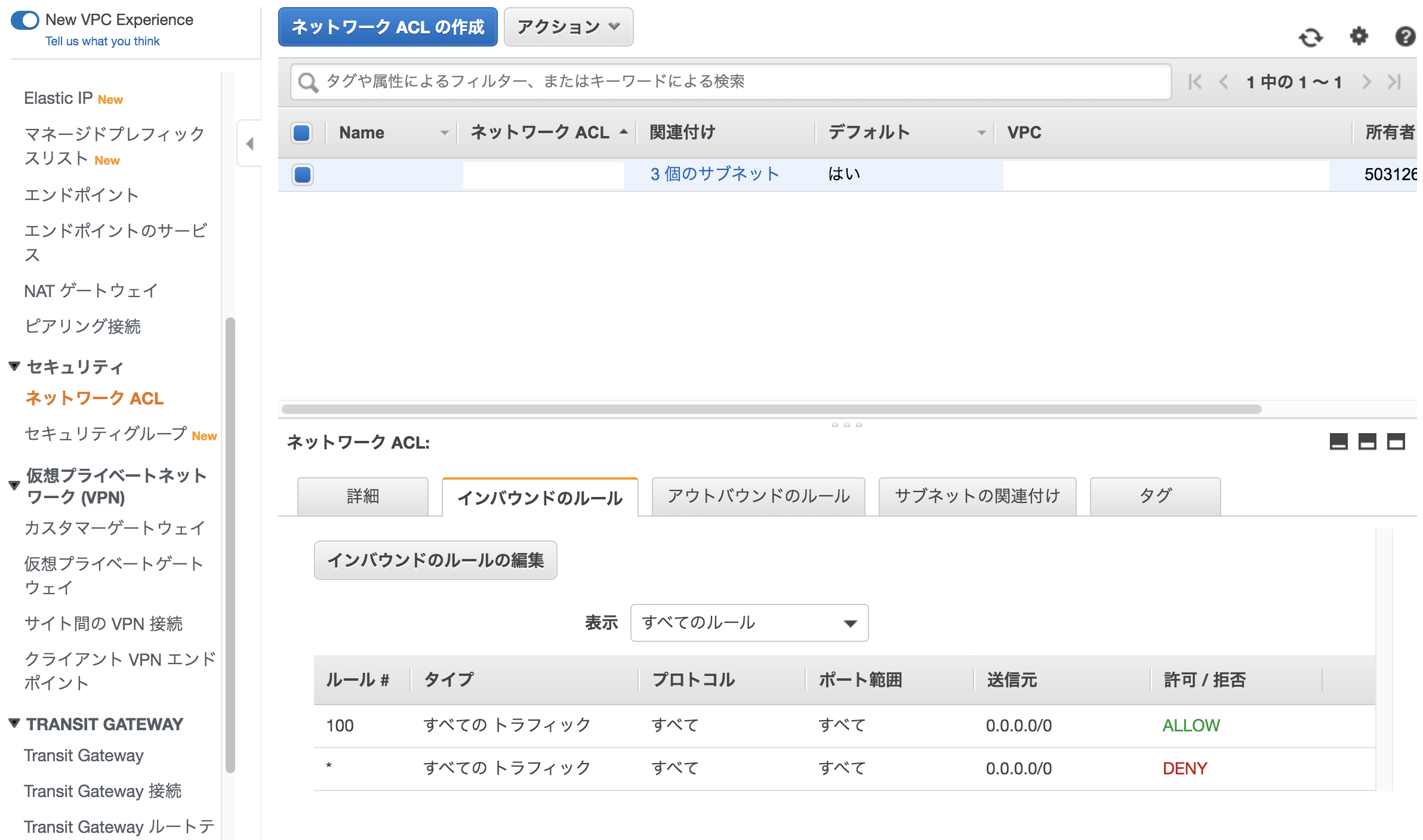
②ネットワークアクセスコントロールリスト (ACL)
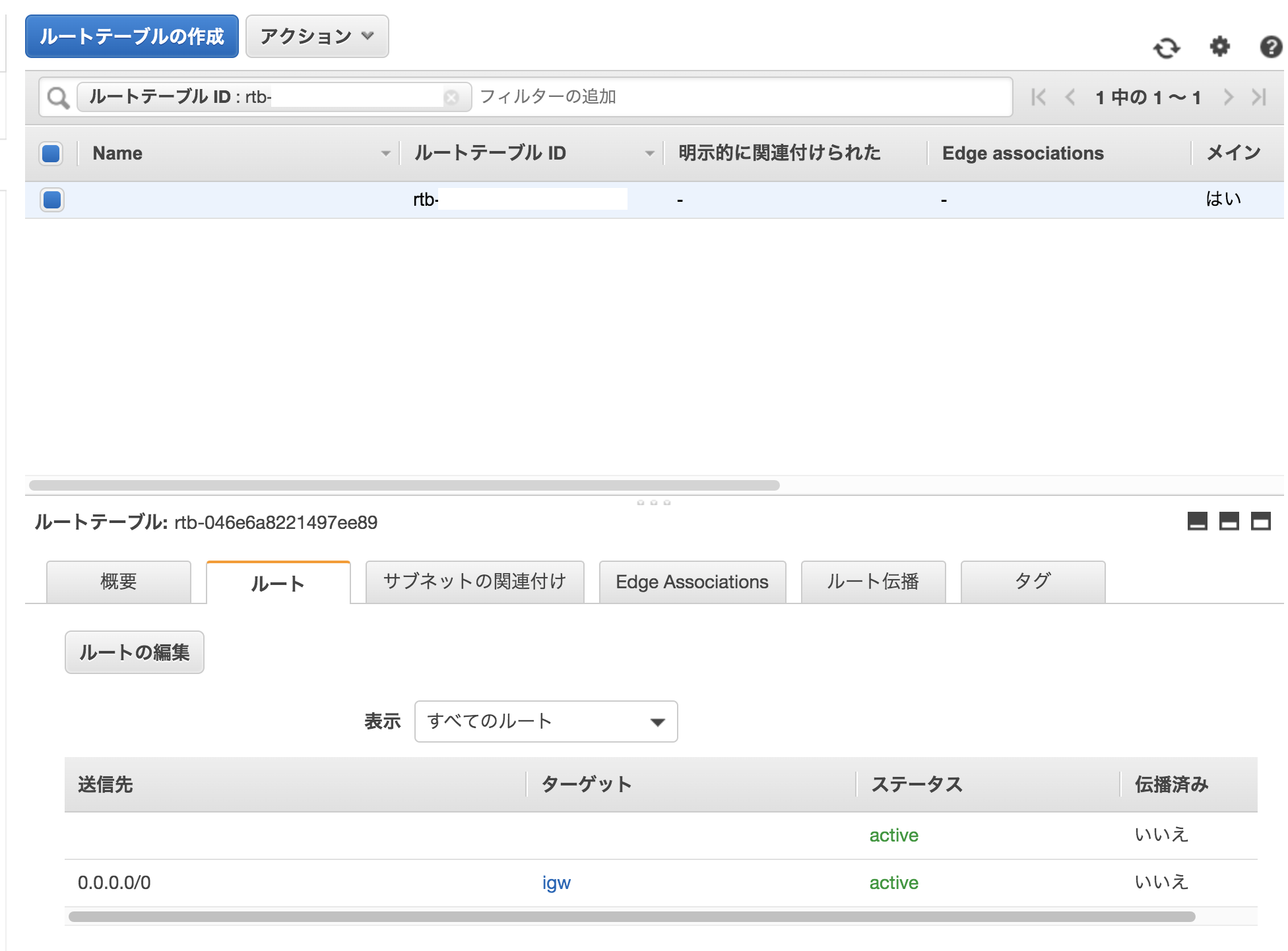
③ルートテーブル
④パブリックIPアドレス①セキュリティグループのチェック
セキュリティグループの設定で、インターネットアクセス許可が設定されていない可能性がある。
本稼働環境では、特定のIP アドレスや特定のアドレス範囲にのみインスタンスへのアクセスを許可。
テスト目的では、0.0.0.0/0のカスタムIPアドレスを指定し、すべてのIPアドレスにSSHまたは RDPを使用したインスタンスへのアクセスを許可。
イメージ画像①
②ネットワークアクセスコントロールリスト (ACL)のチェック
ネットワークACLの設定でインターネットアクセス許可が設定されていない可能性がある。
以下の項目を確認。
・ポートを経由するトラフィックを許可されていることを確認
・インバウンドとアウトバウンドの両方のトラフィックが許可されていることを確認
・アウトバウンドACLで開いているのがエフェメラルポートのみであることを確認イメージ図②
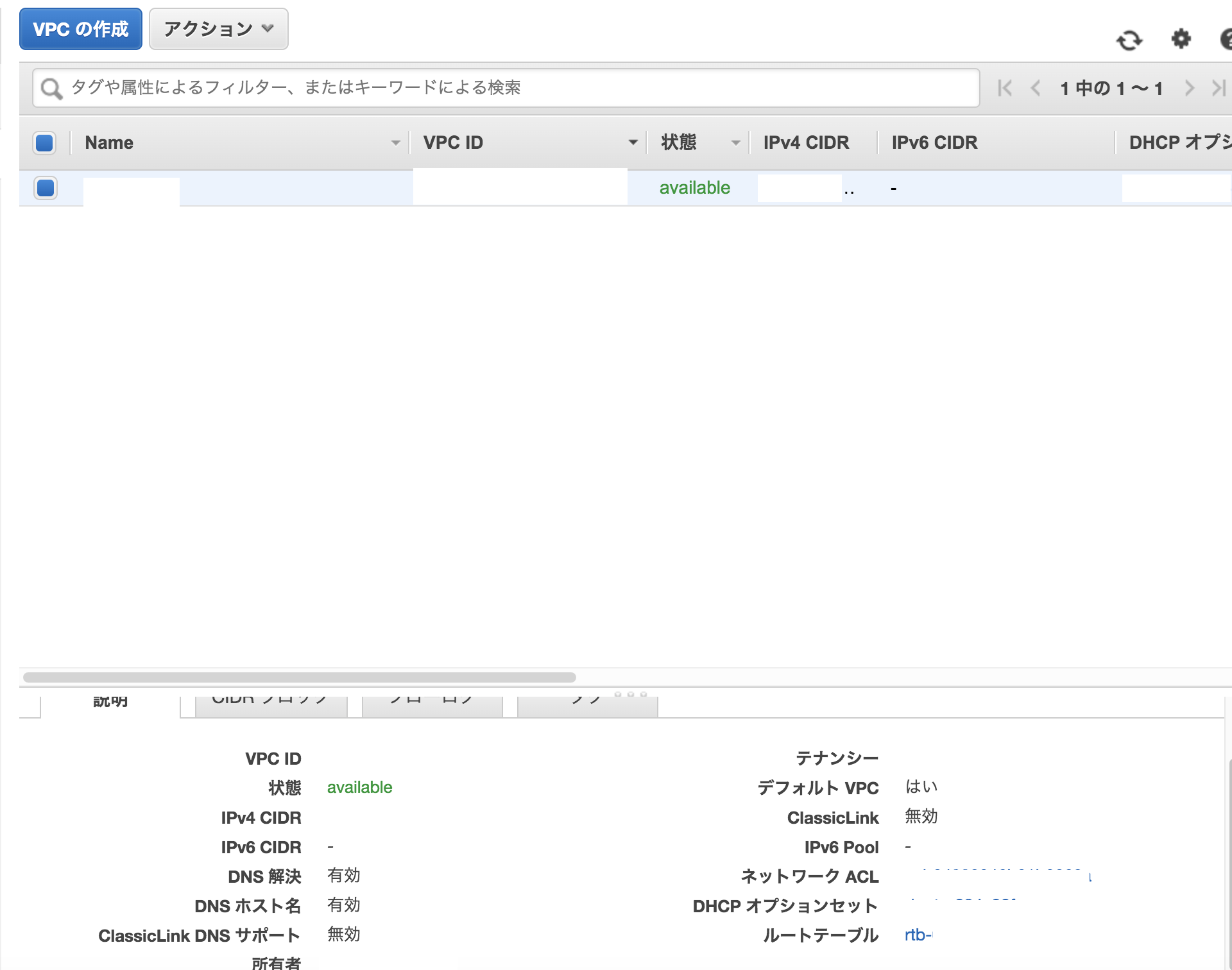
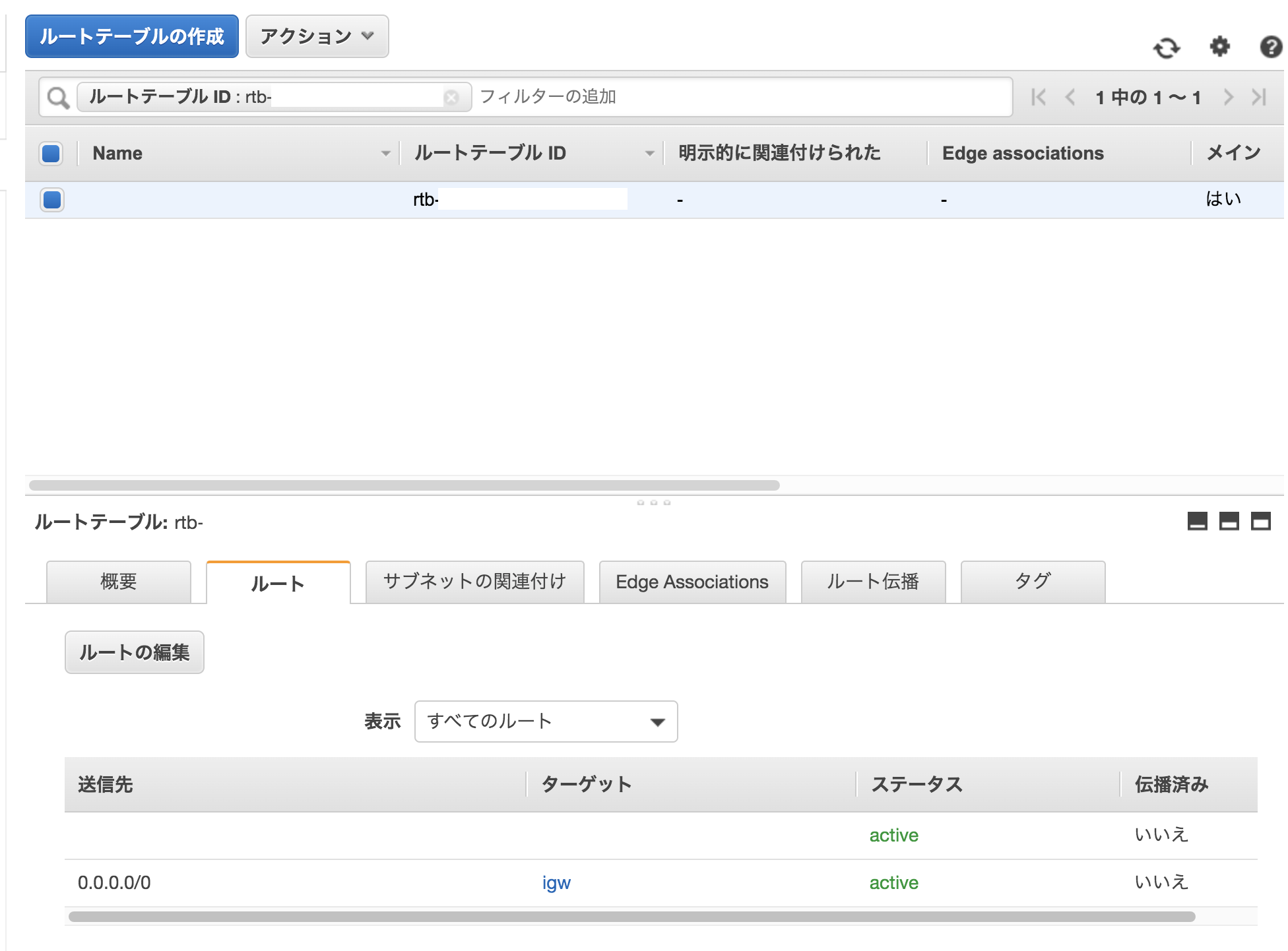
③ルートテーブルのチェック
インターネットゲートウェイがVPCにアタッチされていない。
1.VPCにアタッチしたインターネットゲートウェイのID(例、igw-xxxxxxxx)を書き留める。
2.VPCのルートテーブルでインターネットゲートウェイのルートを確認。Targetが、インターネットゲートウェイがVPCにアタッチしたID(例、igw-xxxxxxxx)に一致し、送信先が0.0.0.0/0 であるルートエントリを探す。
3.このルートがなければ、ターゲットがこのインターネットゲートウェイで、送信先が0.0.0.0/0 であるルートエントリを追加。イメージ図③
イメージ図④
④パブリックIPアドレスのチェック
パブリックIPアドレスが付与されていない可能性がある。
パブリックIPアドレスがVPCインスタンスに割り当てられているか、または、ElasticIPアドレスがインスタンスのネットワークインターフェイスにアタッチされているかを確認。イメージ図⑤
参考
https://aws.amazon.com/jp/premiumsupport/knowledge-center/vpc-connect-instance/
https://www.udemy.com/course/aws-associate/

- 投稿日:2020-07-06T18:05:33+09:00
【AWS SAA】VPC内のEC2インスタンスがインターネットに接続できない原因の備忘録
はじめに
AWS SAAの模擬試験問題で「VPC 内のEC2 インスタンスがインターネットに接続できない原因」が出てきた。その問題解決方法について備忘録として今回載せたい。
主な原因
下記の設定ミスが、主な原因とのこと。
①セキュリティグループ
②ネットワークアクセスコントロールリスト (ACL)
③ルートテーブル
④パブリックIPアドレス①セキュリティグループのチェック
セキュリティグループの設定で、インターネットアクセス許可が設定されていない可能性がある。
本稼働環境では、特定のIP アドレスや特定のアドレス範囲にのみインスタンスへのアクセスを許可。
テスト目的では、0.0.0.0/0のカスタムIPアドレスを指定し、すべてのIPアドレスにSSHまたは RDPを使用したインスタンスへのアクセスを許可。
イメージ画像①
②ネットワークアクセスコントロールリスト (ACL)のチェック
ネットワークACLの設定でインターネットアクセス許可が設定されていない可能性がある。
以下の項目を確認。
・ポートを経由するトラフィックを許可されていることを確認
・インバウンドとアウトバウンドの両方のトラフィックが許可されていることを確認
・アウトバウンドACLで開いているのがエフェメラルポートのみであることを確認イメージ図②
③ルートテーブルのチェック
インターネットゲートウェイがVPCにアタッチされていない。
1.VPCにアタッチしたインターネットゲートウェイのID(例、igw-xxxxxxxx)を書き留める。
2.VPCのルートテーブルでインターネットゲートウェイのルートを確認。Targetが、インターネットゲートウェイがVPCにアタッチしたID(例、igw-xxxxxxxx)に一致し、送信先が0.0.0.0/0 であるルートエントリを探す。
3.このルートがなければ、ターゲットがこのインターネットゲートウェイで、送信先が0.0.0.0/0 であるルートエントリを追加。イメージ図③
イメージ図④
④パブリックIPアドレスのチェック
パブリックIPアドレスが付与されていない可能性がある。
パブリックIPアドレスがVPCインスタンスに割り当てられているか、または、ElasticIPアドレスがインスタンスのネットワークインターフェイスにアタッチされているかを確認。イメージ図⑤
参考
https://aws.amazon.com/jp/premiumsupport/knowledge-center/vpc-connect-instance/
https://www.udemy.com/course/aws-associate/
- 投稿日:2020-07-06T16:43:58+09:00
Node.js でAWS Lambdaを量産する為のサンプルソースをgithubに公開してみた
AWS LambdaをNode.jsで量産アレコレ
概要
AWS LambdaをNode.jsで書こうと思ったときに、良く思うのが、、、
- AWS SDKがPromise前提で入れ子が深くなりがち
- 継承使って汎用共通処理とオーバーライド使いたいなぁ~
である。
コールドスタート対策などで、javaでの実装は圧倒的に不利ってことで、java屋がNode.jsでLambdaを書こうと思うと、
きっと同じ事を思うに違いない。(偏見)という事で、上記が出来る汎用ソースをgithubに公開してみました。
(参考投稿)
Lambdaのコールドスタートを改めて整理するindex.js の処理構造
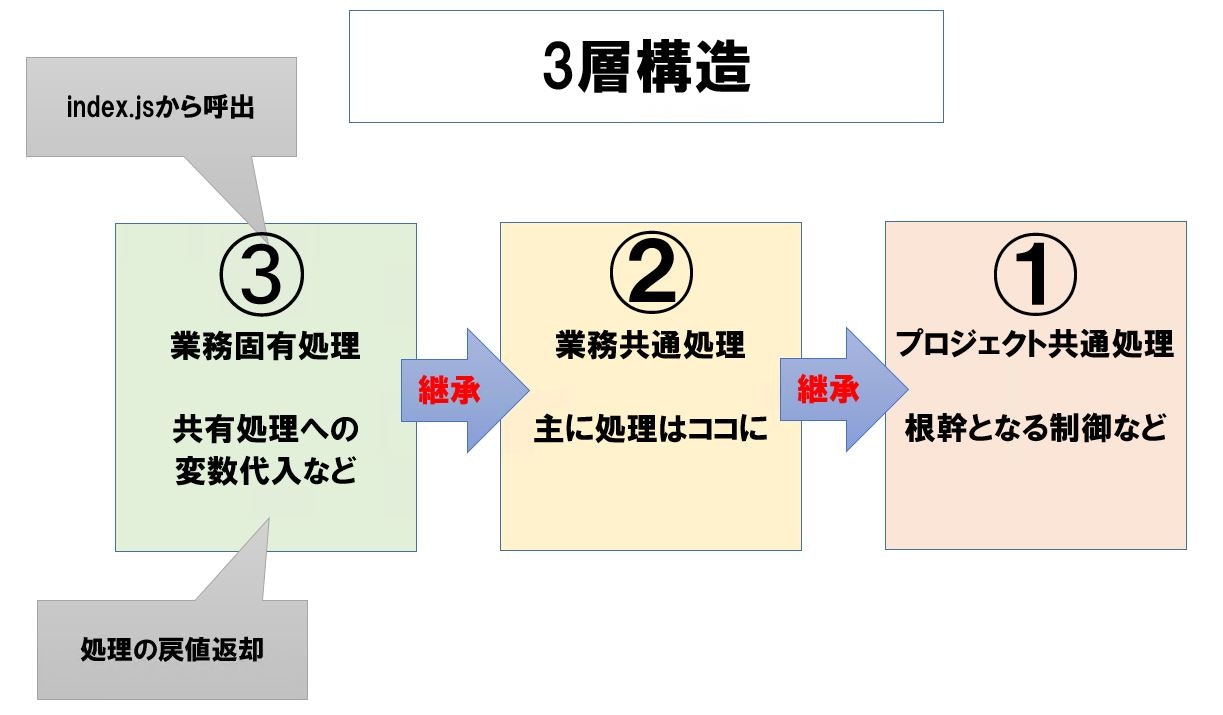
として、業務処理を全て外だししてシンプルにする事で、汎用的なindex.jsにする。業務処理の処理構造
業務処理の継承ツリーは3階層でサンプルは書いてあります。
大体、3階層作ってあれば、大抵の業務は汎化できる。(これまた偏見)githubの公開場所
に置いてあります。
イメージ図は、別のサンプルですが、クリックする場所は一緒です。
ダウンロードしたZIPファイルを解凍すると、Lambda登録用のZipファイルが出てきますので、実行する場合は、それをLambdaとして登録してください。設定可能な環境変数
変数名 変数値 LogLevel ログの出力レベルを(0~4)までの間で設定する autoFunctionRetry 省略したらエラー時再実行はしない。0より大きい値(数字)を設定すると、その回数、再実行を行う 他サンプルソース
具体的な、
- API Gateway + Lambda + DynamoDB のサンプルソース
- DynamoDB Stream + Lambda + SNS のサンプルソース
などは、ブログにて公開中です。


- 投稿日:2020-07-06T16:25:56+09:00
【AWS】EC2, Lighsail Apache設定ファイルの場所
- 投稿日:2020-07-06T15:27:15+09:00
よく使うRedshift運用系SQL
よく使うRedshift運用系SQLや運用Tips。
GGなのですぐ忘れる + いちいちググるのに疲れたのでメモ。
随時更新。[1] クエリ状況系
◆Runningクエリ確認
select pid, trim(user_name), starttime, substring(query,1,20) from stv_recents where status='Running';https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/cancel_query.html
◆クエリ実行履歴
STL_QUERYhttps://docs.aws.amazon.com/ja_jp/redshift/latest/dg/r_STL_QUERY.html
クエリの全体を確認したい場合
STL_QUERYの querytxt カラムは、SQLが長いと途中で切れてしまう。
全体をチェックしたい場合は、STL_QUERYTEXTで query(クエリID)を指定して抽出。select text from STL_QUERYTEXT where query = 'クエリID' order by sequence◆WLMキューの詰まり具合確認
stl_wlm_queryクエリ単位で、キュー待ち開始~終了時間と、実際のクエリ実行開始~終了時間がわかる。
select * from stl_wlm_query◆キュー単位の待ち数と実行中クエリ数確認
STV_WLM_SERVICE_CLASS_STATEhttps://docs.aws.amazon.com/ja_jp/redshift/latest/dg/r_STV_WLM_SERVICE_CLASS_STATE.html
◆自分のクエリのステータス
キュー待ちなのか、実行中なのか
STV_WLM_QUERY_STATEhttps://docs.aws.amazon.com/ja_jp/redshift/latest/dg/r_STV_WLM_QUERY_STATE.html
◆クエリKILL
CANCEL [PID(プロセスID)]※PIDは↑の「Runningクエリ確認」でチェック
[2] テーブル系
◆外部スキーマ一覧
select * from PG_EXTERNAL_SCHEMA◆テーブルのDist KeyとSort Keyの設定有無を確認
・
pg_table_defをチェック
・結果が出ない場合は、serach pathを設定例)
select * from pg_table_def where tablename = [テーブル名];
serach pahtの確認と設定例)
#確認 show search_path; #設定 set search_path to [スキーマ名];set は同一セッション中のみ有効
◆テーブルのカラムのエンコードタイプ(圧縮形式)を確認する
・上と同じく
pg_table_defをチェック例)
select * from pg_table_def where tablename = [テーブル名];◆テーブルのdistkey、sortkey設定を変更する
昔はテーブルを作り直す必要があったが、今はalter tableで可能
alter table [テーブル名] alter distkey [カラム名];※sortkeyの場合は
alter [COMPOUND] sortkeyhttps://docs.aws.amazon.com/ja_jp/redshift/latest/dg/r_ALTER_TABLE.html
[3] Redshift Spectrum系
◆Spectrumクエリログを確認
Spectrumクエリのスキャン量(行、サイズ)、abort有無など。
SVL_S3QUERY_SUMMARYテーブルを確認https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/r_SVL_S3QUERY_SUMMARY.html
◆WLM の 実行結果/ログを確認
WLMの条件に合致したクエリのログやabort有無など。
STL_WLM_RULE_ACTIONテーブルを確認https://docs.aws.amazon.com/redshift/latest/dg/r_STL_WLM_RULE_ACTION.html
[4] Glue Data Catalog系
◆外部スキーマ作成と紐づけ
Redshiftで外部スキーマを作成して、Glue Data Catalogのdatabaseと紐づける
※ROLEやRedshift~Glue間の接続設定については省略create external schema if not exists [外部スキーマ名] from data catalog database '[外部スキーマ名]' iam_role 'arn:aws:iam::xxxxxxxxx:role/xxxx' create external database if not exists;◆外部テーブル作成と紐づけ
紐づけ済の外部スキーマ配下に作成するだけ。
通常のCreate Tableとの違いとして、ファイル格納先のlocationや
メタ情報を設定する table propertiesなどがある点。https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/c-spectrum-external-tables.html
https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/r_ALTER_TABLE_external-table.html
例
create external table [スキーマ].[テーブル]( [column] [type] [encode], : ) row format delimited fields terminated by '\t' stored as textfile location 's3://[バケット]' table properties ('numRows'='100000');[5] ユーザ系
◆ユーザ追加
CREATE USER [ユーザID] PASSWORD ‘******’ VALID UNTIL ‘yyyy-mm-dd’ ;※パスワードと有効期限付き
◆ユーザをグループに追加
ALTER GROUP [グループ名] ADD USER [ユーザID] ;◆rdsdbユーザって何?
Redshiftが内部のメンテナンスタスク等を実行するために使用するusername。
定期的な管理およびメンテナンスタスクを実行するために、Amazon Redshift の内部でユーザー名 rdsdb が使用されます。SELECT ステートメントに where usesysid > 1 を追加することで、クエリをフィルタリングしてユーザー定義のユーザー名のみを表示することができます。
https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/t_querying_redshift_system_tables.html
◆ユーザ一覧確認
\duまたは
select * from pg_user;select * from pg_user; usename | usesysid | usecreatedb | usesuper | usecatupd | passwd | valuntil | useconfig ------------+----------+-------------+----------+-----------+----------+----------+----------- rdsdb | 1 | t | t | t | ******** | | masteruser | 100 | t | t | f | ******** | | dwuser | 101 | f | f | f | ******** | | simpleuser | 102 | f | f | f | ******** | | poweruser | 103 | f | t | f | ******** | | dbuser | 104 | t | f | f | ******** | | (6 rows)◆システムテーブルのuseridとDBユーザ名(username)変換
pg_userテーブルのusesysidをキーに結合すれば変換可能
- 投稿日:2020-07-06T14:18:38+09:00
.NET Core アプリを AWS Lambda で動かす
本投稿について
この投稿では、以下の方法について説明しています。
- .NET Core で AWS Lambda 関数を開発する方法
- Lambda 関数として動かすことができる ASP.NET アプリの開発方法
- 既存の ASP.NET Core アプリを Lambda 関数として動かす方法
(※ 本記事は、2020/06/22時点での最新の.NET Core バージョンや各種ツールを使用することを想定に書いています)
1. .NET Core の Lambda 関数を作成する
ここでは .NET Core で Lambda 関数を開発する方法について説明します。
プロジェクトテンプレートをインストールする
まず、以下のコマンドでAmazon.Lambda.Templatesパッケージをインストールしてプロジェクトテンプレートを追加します。
dotnet new -i Amazon.Lambda.Templates以下の様なテンプレートを使用できるようになります。
- lambda.SQS (SQSトリガの Lambda 関数)
- lambda.SNS (SNSトリガの Lambda 関数)
- lambda.S3 (S3イベントトリガの Lambda 関数)
- lambda.Kinesis (Kinesis Stream トリガの Lambda 関数)
- lambda.KinesisFirehose (Kinesis Firehose トリガの Lambda 関数)
- lambda.DynamoDB (DynamoDB Stream トリガの Lambda 関数)
- lambda.SimpleApplicationLoadBalancerFunction (ELB(ALB) トリガの Lambda 関数)
- serverless.AspNetCoreWebApp (Lambda上で動く ASP.NET Core Razor Pages アプリ)
- serverless.AspNetCoreWebAPI (Lambda上で動く ASP.NET Core Web API アプリ)
以下のコマンドでインストールされたテンプレートを確認できます。
dotnet new lambda --listテンプレートからプロジェクトを作成する
例えば、SQSのキューにエンキューされたメッセージをトリガーにして起動する Lambda 関数を作成する場合、以下のコマンドでテンプレートを使用してプロジェクト(テストコードを含む)を作成することができます。
dotnet new lambda.SQS --name {関数名} --region {リージョン名} --profile {プロファイル名} # 例:dotnet new lambda.SQS --name mysqsfunc --region ap-northeast-1 --profile default上記の例のコマンドで作成される Lambda 関数のコード(Function.cs)は以下の様になるかと思います (コメントは除いています)。
既定の設定のままの場合、以下の FunctionHandler メソッドが Lambda 関数起動時に呼び出されることになります。Function.csusing System; using System.Collections.Generic; using System.Linq; using System.Threading.Tasks; using Amazon.Lambda.Core; using Amazon.Lambda.SQSEvents; [assembly: LambdaSerializer(typeof(Amazon.Lambda.Serialization.SystemTextJson.DefaultLambdaJsonSerializer))] namespace mysqsfunc { public class Function { public Function() { } public async Task FunctionHandler(SQSEvent evnt, ILambdaContext context) { foreach(var message in evnt.Records) { await ProcessMessageAsync(message, context); } } private async Task ProcessMessageAsync(SQSEvent.SQSMessage message, ILambdaContext context) { context.Logger.LogLine($"Processed message {message.Body}"); await Task.CompletedTask; } } }以下がデプロイされる Lambda 関数に関する設定を定義しているファイル(aws-lambda-tools-defaults.json)の中身です。プロジェクトで指定している .NET Core のバージョンと、Lambda 関数で使用するバージョン("framework", "function-runtime")を揃える必要があるので注意してください。
aws-lambda-tools-defaults.json{ "Information": [ "This file provides default values for the deployment wizard inside Visual Studio and the AWS Lambda commands added to the .NET Core CLI.", "To learn more about the Lambda commands with the .NET Core CLI execute the following command at the command line in the project root directory.", "dotnet lambda help", "All the command line options for the Lambda command can be specified in this file." ], "profile": "default", "region": "ap-northeast-1", "configuration": "Release", "framework": "netcoreapp2.0", "function-runtime": "dotnetcore2.0", "function-memory-size": 256, "function-timeout": 30, "function-handler": "mysqsfunc::mysqsfunc.Function::FunctionHandler" }プロジェクトを AWS へデプロイする
AWS 上にデプロイする場合、.NET Coreツールである、Amazon.Lambda.Tools .NET Core Global Tool を使用すると便利です。以下のコマンドでインストールすることができます。
dotnet tool install -g Amazon.Lambda.Tools本ツールをインストールすると、デプロイをする.NET Coreアプリのプロジェクトファイル(.csproj)と同じフォルダにて以下のコマンドを実行することで、プロジェクトを AWS へデプロイすることができます。
dotnet lambda deploy-function {Lambda関数名} # 例:dotnet lambda deploy-function samplesqsappこのデプロイで Lambda 関数を新たに作成する場合、以下のように、どの IAM ロールを Lambda 関数に付与するかを聞かれますので、付与する既存の IAM ロールを番号で指定するか、IAM ロールを新規作成する(Create new IAM Role)ように指定します。
Select IAM Role that to provide AWS credentials to your code: 1) RoleA 2) RoleB ... X) *** Create new IAM Role ***"New Lambda function created" と表示されたら、Lambda 関数のデプロイが完了しています。が、コードをデプロイしただけなので、トリガの設定を自身で行う必要があります。
2. Lambda で動かす ASP.NET Core アプリ を作成する
ここでは Lambda 関数として動かすことができる ASP.NET Core アプリの開発方法について説明します。
テンプレートからプロジェクトを作成する
Amazon.Lambda.Templatesパッケージをインストールして、以下のプロジェクトテンプレートを使用することで、Lambda 関数として動かすことができる ASP.NET Core アプリを簡単に作成できます。
- serverless.AspNetCoreWebApp (Lambda上で動く ASP.NET Core Razor Pages アプリ)
- serverless.AspNetCoreWebAPI (Lambda上で動く ASP.NET Core Web API アプリ)
dotnet new serverless.AspNetCoreWebApp --name {関数名} --region {リージョン名} --profile {プロファイル名} # 例:dotnet new serverless.AspNetCoreWebApp --name myaspnetapp --region ap-northeast-1 --profile defaultプロジェクトを AWS へデプロイする
そして、上記と同じく、Amazon.Lambda.Tools .NET Core Global Tool を使用することで、以下のコマンドで AWS上 の Lambda 関数としてデプロイすることができます。deploy-function コマンドとは異なり、Cloud Formation のスタックとして、Lambda 関数に加えて、Amazon API Gateway の必要なリソース(ステージ等)などがデプロイされます。
dotnet lambda deploy-serverlessデプロイの際には、Cloud Formation のスタック名と、コードの格納先となる S3 バケット名を指定する必要があります。これらは aws-lambda-tools-defaults.json であらかじめ指定しておくことができます。
3. 既存の ASP.NET Core アプリを Lambda で動かす
上記で説明した方法は、Lambda 関数として動かすことができる ASP.NET Core を新規作成する方法ですが、ここでは既存の ASP.NET Core アプリを Lambda で動かす方法について説明します。
必要な Nuget パッケージをインストールする
Nuget パッケージの Amazon.Lambda.AspNetCoreServer をプロジェクトにインストールします。
dotnet add package Amazon.Lambda.AspNetCoreServerLambdaEntryPoint クラスを作成する
次に、以下の通りの LambdaEntryPoint クラスをプロジェクトに新規に追加します。
これから作成する Lambda 関数を API Gateway 経由で呼び出す場合、LambdaEntryクラスは APIGatewayProxyFunction 抽象クラスを、Application Load Balancer 経由で呼び出す場合は ApplicationLoadBalancerFunction 抽象クラスを継承して実装する必要があります。これらのクラスを継承した場合、Init メソッドを実装する必要がありますので、以下の様に、スタートアップクラス(Startup.cs)を指定する処理を行わせます。そして、このクラスの FunctionHandlerAsync メソッドを Lambda のハンドラとして指定します (FunctionHandlerAsyncメソッドはLambdaEntryPoint クラスの親の親である AbstractAspNetCoreFunction クラスで実装されていますので、自身で実装する必要はありません)。LambdaEntryPoint.csusing Microsoft.AspNetCore.Hosting; using Amazon.Lambda.AspNetCoreServer; namespace SampleAspNetCoreAppOnLambda { public class LambdaEntryPoint : APIGatewayProxyFunction { protected override void Init(IWebHostBuilder builder) { builder.UseStartup<Startup>(); } } }デプロイを定義するファイルを準備する
そして、Amazon.Lambda.Tools で AWS 上へデプロイするために、aws-lambda-tools-defaults.json と serverless.template という名前のファイルを以下の通りに作成します。
aws-lambda-tools-defaults.json{ "profile": "default", "region": "ap-northeast-1", "stack-name": "sampleaspnetcoreapp", "s3-bucket": "{コードを格納するS3バケット名}", "template": "serverless.template" }serverless.template{ "Transform": "AWS::Serverless-2016-10-31", "Resources": { "AspNetCoreFunction": { "Type": "AWS::Serverless::Function", "Properties": { "Handler": "{既存アプリのアセンブリ名}::{LambdaEntryPointクラスの名前空間}.LambdaEntryPoint::FunctionHandlerAsync", "Runtime": "dotnetcore3.1", "CodeUri": "", "MemorySize": 512, "Timeout": 30, "Role": null, "Policies": [], "Environment": { "Variables": {} }, "Events": { "ProxyResource": { "Type": "Api", "Properties": { "Path": "/{proxy+}", "Method": "ANY" } }, "RootResource": { "Type": "Api", "Properties": { "Path": "/", "Method": "ANY" } } } } } }, "Outputs": { "ApiURL": { "Description": "API endpoint URL for Prod environment", "Value": { "Fn::Sub": "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/" } } } }serverless.template は AWS Serverless Application Model (AWS CloudFormation の拡張) のテンプレートになります。このリファレンス を使用して自由に修正することができます。
プロジェクトを AWS へデプロイする
そして、上記と同様に、以下のコマンドで、既存の ASP.NET Core アプリを Lambda 関数として AWS 上へデプロイすることができます。
dotnet lambda deploy-serverless今回のデプロイも、先程と同様に Cloud Formation のスタックとして、Lambda 関数に加えて、Amazon API Gateway の必要なリソース(ステージ等)などがデプロイされます。
... Created CloudFormation stack sampleaspnetcoreapp Timestamp Logical Resource Id Status -------------------- ---------------------------------------- ---------------------------------------- 2020/07/06 14:00 sampleaspnetcoreapp CREATE_IN_PROGRESS 2020/07/06 14:00 AspNetCoreFunctionRole CREATE_IN_PROGRESS 2020/07/06 14:00 AspNetCoreFunctionRole CREATE_IN_PROGRESS 2020/07/06 14:00 AspNetCoreFunctionRole CREATE_COMPLETE 2020/07/06 14:01 AspNetCoreFunction CREATE_IN_PROGRESS 2020/07/06 14:01 AspNetCoreFunction CREATE_IN_PROGRESS 2020/07/06 14:01 AspNetCoreFunction CREATE_COMPLETE 2020/07/06 14:01 ServerlessRestApi CREATE_IN_PROGRESS 2020/07/06 14:01 ServerlessRestApi CREATE_IN_PROGRESS 2020/07/06 14:01 ServerlessRestApi CREATE_COMPLETE 2020/07/06 14:01 AspNetCoreFunctionProxyResourcePermissionProd CREATE_IN_PROGRESS 2020/07/06 14:01 ServerlessRestApiDeploymentcfb7a37fc3 CREATE_IN_PROGRESS 2020/07/06 14:01 AspNetCoreFunctionProxyResourcePermissionProd CREATE_IN_PROGRESS 2020/07/06 14:01 AspNetCoreFunctionRootResourcePermissionProd CREATE_IN_PROGRESS 2020/07/06 14:01 AspNetCoreFunctionRootResourcePermissionProd CREATE_IN_PROGRESS 2020/07/06 14:01 ServerlessRestApiDeploymentcfb7a37fc3 CREATE_IN_PROGRESS 2020/07/06 14:01 ServerlessRestApiDeploymentcfb7a37fc3 CREATE_COMPLETE 2020/07/06 14:01 ServerlessRestApiProdStage CREATE_IN_PROGRESS 2020/07/06 14:01 ServerlessRestApiProdStage CREATE_IN_PROGRESS 2020/07/06 14:01 ServerlessRestApiProdStage CREATE_COMPLETE 2020/07/06 14:01 AspNetCoreFunctionProxyResourcePermissionProd CREATE_COMPLETE 2020/07/06 14:01 AspNetCoreFunctionRootResourcePermissionProd CREATE_COMPLETE 2020/07/06 14:01 sampleaspnetcoreapp CREATE_COMPLETE Stack finished updating with status: CREATE_COMPLETE Output Name Value ------------------------------ -------------------------------------------------- ApiURL https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/Prod/上記の通りにメッセージが出力された後、スタックの出力値として、デプロイされた Web アプリケーションの URL が表示されます。
- 投稿日:2020-07-06T14:16:24+09:00
初めてデプロイに使用したAWSのサービスをまとめてみた
スクールで理解もせずにAWSを使っていたので、改めて自分で調べてみたからまとめたい
対象読者
- おれ
- デプロイしたくてAWSについてさらっと知りたい人
- AWSに詳しくて記事の間違いを訂正してくれる天使
参考資料
デプロイになんとか使用できたサービス一覧
- VPC
- EC2
- RDS
- EIP
- S3
- Route 53
まずAWSとはなんじゃらほい
AWSとはクラウドコンピューティングを提供するサービスです!
この文章を初めてみた時にはすでにアレルギーが発症したかと思いましたが、簡単にいうと
いつでもどこでも好きなようにサーバーを作れるサービスのことみたい。AWSの何がええのよ?
世の中にはサーバーを運用する方法としてオンプレミスとクラウドが存在するみたい。
で、オンプレミスの方法で運用すると自分で設計やら運用やらサーバー構成の変更やらが必要で、こんなことができるようになるには、スキルのある人じゃないと扱えへんような代物やねんて。それに比べてAWSのようなクラウドは自分で管理とかメンテナンスをしなくても運用できるからめっちゃ便利!!!ということらしい。
各サービスの説明
EC2とはなんじゃらほい
サーバーに必要なモノを一式をクラウドで借りれちゃうサービス
サーバーに詳しくなくてもボタンをポチポチしていくだけで誰でも簡単にサーバーを用意できちゃうわけ。
EC2の中にWebサーバーであるNginxやらをインストールしてあげる。RDSとはなんじゃらほい
RDMSであるAmazonAuroraに加えて、PostgreSQL、MySQL、MariaDB、OracleDatabase、SQLServerに対応し、メモリ、パフォーマンスが最適化されたサービス
まとめるとRDSのおかげでデータベースが使えるよーってこと。※補足:RDMSってなんやねん
略さずに書くと、Relational Database Management Systemとなる。
データベースを操作するデータベース管理システムのこと。
データベースは「データの集合体」で、そのデータの「取り出し」「削除」「書き込み」等の操作をするためにはRDMSが必要になってくる。よく聞くのがMySQLとかPostgreSQLです。EIPとはなんじゃらほい
EC2を停止・再起動しても同じパブリックIPアドレスを使るようにできるうサービス。
EC2は、サービス停止後に再起動すると、パブリックIPアドレスが変わってまう。元のパブリックIPアドレスをブラウザから検索しても繋がらないようになっている。補足:IPアドレス
- パブリックIPアドレスとはインターネット上で使われるIPアドレスで、サーバーにアクセスするためのアドレス
- IPアドレスは固定じゃなくて、流動的であることが一般みたい。なんでかは説明できまへん
Route 53とはなんじゃらほい
~.comのようなドメイン名で検索できるようにするサービス!!!
サーバーへアクセスするためには住所の役割をしているIPアドレスが必要になってくる。なのでIPアドレスを入力すれば欲しいデータを持っているサーバーにアクセスできるけど、IPアドレスなんて覚えられない。
そこで、〜.comのようにドメイン名を取得して誰でも覚えやすいようにして、ブラウザから検索させているのよ。
当たり前にドメイン名を使って検索できているのはDNSというサービスのおかげなの。DNSちゃんがドメイン名に対応するIPアドレスを裏側で汗かいて探してきてくれるおかげで、覚えづらいIPアドレスを入力しなくてもドメイン名で検索できる便利すぎる世の中を創造してくれている。
AWS版のDNSのサービス名をRoute 53と言うんだよ。VPCとはなんじゃらほい
これまでにサーバーの説明やらをしてきたが、こやつらはそもそもネットに繋がっていないとサーバーとして働いてくれない。。。そこで!ネットワークにつなげてやるためにVPCを使用するぜ!!!
VPCという自分のネットワークの領土の中にサーバーを置いてやることで外の世界と繋がることができるんだなー。
EC2とかRDSを作成してやる時にVPCを選択すればオッケーなり。S3とはなんじゃらほい
オブジェクトストレージサービスのこと。。。。オブジェクトストレージサービスってなんやねん。
→オブジェクトストレージとは、インターネット上にデータを保存する場所のことだそうです。
S3がなくてもEC2で画像やらのデータを保存できるけど、EC2を停止させると画像のデータがなくなっちゃうみたいだから、EC2ではなく堅牢で使いやすいS3に保存しちゃえば、安心にデータを保存することができちゃうサービス締め
サービス自体はうっっっっっっっっすら理解できたけど、デプロイに関してはめっちゃ難しい。
四苦八苦せずにデプロイできるようになりたい。
- 投稿日:2020-07-06T13:16:41+09:00
amplify mock apiで起動するDynamoDB Localにオプションを渡す
はじめに
Amplify Mockingは便利で
amplify mock apiと打つだけで以下のサービスがローカルで起動して利用できます。
- DynamoDB Loacl
- AppSync GraphQL API
Amplify Mockingで起動するDynamoDB Localに直接接続したい場合にどうすればいいのか調べました。
Amplify Mockingで起動するDynamoDB Localに直接接続する
結論からいうと、以下のようにすれば接続できます。
new DynamoDB({ endpoint: 'http://localhost:62224', region: 'us-fake-1', accessKeyId: 'fake', secretAccessKey: 'fake', });
endpointのURLはDynamoDB Localなので(ローカルで起動するので)http://localhostです。ポート番号の62224がデフォルトです(詳しくはこの後で説明します)。
region,accessKeyId,secretAccessKeyに指定する値は上記の値をそのまま指定してください。
amplify-appsync-simulatorのDynamoDBDataLoader や amplify-dynamodb-simulatorのindex.js にハードコーディングされているので、常にこの値にしておく必要があります。DynamoDB Localのポート番号
DynamoDB Localのポート番号
62224はあくまでデフォルトです。もし、62224が使えない場合には他の空いているポートを使います。
AppSync SimulatorはDynamoDB Localが実際に起動したポート番号を使って接続するように書かれているので問題ありませんが、外部から直接接続しようとした場合、そのポート番号がわからないので困ってしまいます。実は、Amplify Mockingで起動するDynamoDB Localにオプションを渡す方法が存在します。
それはmock.jsonというファイルをamplifyディレクトリに作成しておくと、その内容をDynamoDB Localの起動オプションとしてくれるというものです。本来は DynamoDB LocalにJAVA_OPTSを指定するために追加された機能 ですが、ポート番号も指定することができます。
例えば、次のように書いておけば、DynamoDB Localは
8888番ポートで起動します(空いていないとエラーになります)。amplify/mock.json{ "port": 8888 }当然、以下のような指定も可能です(というか、こちらが本来の目的に沿った書き方です)。
{ "javaOpts": "-Xms512M -Xmx512M" }まとめ
- Amplify Mockingで起動するDynamoDB Localには以下のオプションで接続できる。
{ endpoint: 'http://localhost:62224', region: 'us-fake-1', accessKeyId: 'fake', secretAccessKey: 'fake', }
mock.jsonで起動するポート番号を指定することもできる。
- 投稿日:2020-07-06T12:58:02+09:00
Amazon Rekognitionによる顔認識
Amazon Rekognitionを使って、入力した画像に映っている顔を矩形で囲むという基本的な処理を試してみました。
Amazon Rekognitionとは
Amazon Rekognitionは、AWSのAIサービスの一つで、画像認識に対応したものです。
また、AWSのAIサービスは画像認識・自然言語処理など様々な領域をカバーしたもので、機械学習の深いスキルなしに機械学習をアプリケーションに組み込める、データを用意するだけでAPIから機械学習を利用できる、といった特徴があります。実行環境
OS:Windows10
言語:Python3.7事前準備
AWS CLI(aws configure)にて、以下の認証情報をセットしておきます。
AWS Access Key ID
AWS Secret Access Key
Default region name
Default output formatソースコード(face_detect.py)
import boto3 import sys from PIL import Image,ImageDraw # 引数のチェック if len(sys.argv) != 2: print('画像ファイルを引数に指定してください。') exit() # Rekognitionのクライアントを作成 client = boto3.client('rekognition') # 画像ファイルを引数としてdetect_facesを実行 with open(sys.argv[1],'rb') as image: response = client.detect_faces(Image={'Bytes':image.read()},Attributes=['ALL']) # 顔が認識されない場合は処理終了 if len(response['FaceDetails'])==0: print('顔は認識されませんでした。') else: # 入力された画像ファイルを元に、矩形セット用の画像ファイルを作成 img = Image.open(sys.argv[1]) imgWidth,imgHeight = img.size draw = ImageDraw.Draw(img) # 認識された顔の数分、矩形セット処理を行う for faceDetail in response['FaceDetails']: # BoundingBoxから顔の位置・サイズ情報を取得 box = faceDetail['BoundingBox'] left = imgWidth * box['Left'] top = imgHeight * box['Top'] width = imgWidth * box['Width'] height = imgHeight * box['Height'] # 矩形の位置・サイズ情報をセット points = ( (left,top), (left + width,top + height) ) # 顔を矩形で囲む draw.rectangle(points,outline='lime') # 画像ファイルを保存 img.save('detected_' + sys.argv[1]) # 画像ファイルを表示 img.show()簡単な解説
概略としては以下のような処理を行っています。
①プログラム実行時の引数からRekognitionに入力する画像ファイルを取得する。
②上記①の画像ファイルを引数としてRekognitionのdetect_facesを実行する。
③Rekognitionから返却されるJsonのFaceDetails・BoundingBoxから、認識された顔の位置・サイズ情報を取得する。
④上記③から矩形付きの画像ファイルを作成し、表示する。実行結果
コマンド
python face_detect.py ichiro1.jpg
入力画像(ichiro1.jpg)
出力画像(detected_ichiro1.jpg)
イチロー選手はもちろんのこと、観客席の人たちも認識してくれています。
まとめ
Rekognitionに限らずですが、AWSのAIサービスはAPIから機械学習を手軽に利用できる便利なサービスです。
また、今回は矩形しか試しませんでしたが、Rekognitionから返却されるJsonには性別・年齢など様々なものがありますので、他にも色んなことを試せると思います。


- 投稿日:2020-07-06T10:09:30+09:00
AWS認定データベース専門知識(DBS)を、ほぼぶっつけ本番で取得したやったことまとめ
はじめに
AWS認定データベース専門知識(DBS)について、受験者数の絶対数が少ないのか試験対策に関する参考記事の投稿が少なく情報収集に苦労しました。
今回、ほぼぶっつけ本番で取得できた試験準備のコツなどについてまとめてみました。データベース専門知識に関わるAWS関連サービスのイメージを掴んでいただければ幸いです。
本記事の主な対象者
- AWS認定の他の試験区分は取得済みで、データベース専門知識の受験を検討している方
- 取得に向けて有効な学習方法などの情報収集したい方
筆者のAWS認定履歴
AWS認定 取得日 ソリューションアーキテクト - アソシエイト 2018-05-13 デベロッパー - アソシエイト 2018-06-03 SysOpsアドミニストレーター - アソシエイト 2018-06-10 ソリューションアーキテクト - プロフェッショナル 2018-07-29 DevOpsエンジニア - プロフェッショナル 2018-08-26 ビッグデータ専門知識 2019-08-25 セキュリティ専門知識 2019-12-08 機械学習専門知識 2020-02-23 高度なネットワーキング専門知識 2020-06-20 データベース専門知識 2020-07-04 正確には、ぶっつけ本番ではないのですが、高度なネットワーキング専門知識 の受験日からのインターバルが二週間ほど。この期間、著者の生業であるサーバサイドエンジニアの業務として、Aurora関連のタスクを遂行していました。
概要は、アクティブユーザー数が 1,000万程度の、とあるマイクロサービスのデータメンテナンス。Auroraプライマリインスタンスに加えて、リードレプリカ1台構成で、200GB程度のストレージを使用。今回のタスクは、約 2,000万件程度のレコードを1トランザクションで、JOINを駆使したUPDATE文で、一括処理するというものでした。
作業の中では、スナップショットから検証用クラスタを作成したり、良かれと思ってONにしたバックトラックのデメリットに遭遇してみたり、特定のユースケースにおけるAuroraの処理時間を検証できたり、ここで得られた知見は多々あるのですが、今回の記事の趣旨とは離れますので、またの機会があれば記事にしたいと思います。
さて、今回の受験モチベーションは、とある舞台で、次はデータベース専門知識の認定取得だよね?的な話題となりまして、ダメ元で情報収集を兼ねて受験してみたのがきっかけです。
今回のスコア(2020-07-04受験)
総合スコア: 768/1000 (ボーダー750)AWS認定データベース専門知識(DBS)について
ここからが本題となります。
まずは、以下の公式ページから試験概要の把握を行いました。具体的な試験準備で効果があったと思えること
実際に受験をしてみて、試験対策として効果があったと思う内容について、主観的な効果度合いで順に記載します。
公式の模擬試験の受験
データベース専門知識の認定は、2020年の4月に開始された比較的新しい区分です。この為、Qiita記事の投稿をはじめ、出題傾向に関する情報があまり出回っていません。また、Udemyなどのオンライン学習サイトでも、対応するコースはまだ無いようでした。
出題される範囲の当りをつける為に、公式の模擬試験の受験し、出題されそうなAWSサービスの雰囲気を掴みました。RDSに関する深い理解
サンプル問題および、模擬試験の内容から考察するに、どうもRDS(Auroraを含む)が優勢のようでした。ユーザーズガイドを始めドキュメント群に目を通しました。その中で、Auroraについてとてもよくまとまっている資料がありましたのでご紹介したいと思います。抑えるべき3つのポイント
実際に認定試験を受けてみて、試験ガイドとは別軸で大きく3つのカテゴリーがあるのかなと感じました。
1. 設問の多くが、RDBMSに関すること
- 結論から言うと、AWS内外のリレーショナルデータベースの運用・AWSへの移行に関する実務経験を問われる設問が多かったような気がします。体感7割程度の設問に、このエッセンスが含まれていたなと感じました。次に、DynamoDBに関する設問も散見されました。こちらは、他の認定試験の区分で出題されているようなお約束的な内容だったような気がします。故に正しく理解が必要です。あとは、DocumentDB、Neptuneについてはユースケースを把握していれば大丈夫かと思います。少し意外だったことは、Redshiftは記憶に残る限り設問中の重要なキーワードではなかったような気がします。
2. RDSの、データベースエンジンの違いを混同しない
- RDSといっぱ一括りで捉えがちですが、設問では明確にデータベースエンジン(Aurora,MySQL,PostgreSQL,ORACLE,SQLServer)が指定されていることが多かった気がします。これは、パラメータグループの設定などにおいて、それぞれ特色があるのが背景なのかなと感じました。
3. Auroraで、実現できることの整理
- Auroraで実現できることについての知識を多く問われたような気がします。詳細については、先にご紹介した資料に記載されていますが、パフォーマンス検証、バックトラック、フェイルオーバー、リードレプリカ、クローン、クロスリージョン、メンテナンスウィンドウ、ゼロダウンタイムを目指す上で検討すべきこと、などなど。
おわりに
他の認定試験の区分とは異なり、狭義のデータベースの分野についてのみ深く問われたような気がします。AuroraなどのAWSマネージドデータベースと、EC2などに構築するセルフマネージドのデータベースの両方の運用経験がある方であれば、差異の部分の消去法で、ある程度の正答率は高められる部分はあるのではないかと感じました。
今後受験を検討される方の一助になれば幸いです。著者関連リンク
- 投稿日:2020-07-06T08:39:06+09:00
AthenaにてShow partiionsが失敗する
AWS Athenaにて特定テーブルのパーティションが多い場合、Show Partitionsが失敗する
以下のSQLにてパーティションの一覧を取得しようとすると、
internal errorで失敗することがあります。
SHOW PARTITIONS {database}.{table_name}Your query has the following error(s): [ErrorCode: INTERNAL_ERROR_QUERY_ENGINE] Amazon Athena an experienced an internal error while executing this query. Please contact AWS support for further assistance. You will not be charged for this query. We apologize for the inconvenience. This query ran against the "xxx" database, unless qualified by the query. Please post the error message on our forum or contact customer support with Query Id: 36f5e4a1-50d3-4699-ae41-XXXXXXXXXXXX.テーブルのパーティションの数が多い場合に発生することがあるようです。
このテーブルに対して、MSCK REPAIR TABLEを実行しても同じくエラーとなります。AWSサポートに問い合わせたところ、AWS側の不具合との回答でした。(2020/07/02時点)
回避策
回避策としては、GlueのDataCatalogと統合されている場合には、
Glue側でパーティションの一覧を取得することができます。
GetPartitions
https://docs.aws.amazon.com/glue/latest/webapi/API_GetPartitions.htmlGetPartition
https://docs.aws.amazon.com/glue/latest/webapi/API_GetPartition.htmlBatchGetPartition
https://docs.aws.amazon.com/glue/latest/webapi/API_BatchGetPartition.htmlGlueと統合されているケースは、基本Glue側のAPIを使用して、パーティションの更新等を実施するのが良さそうですね。
- 投稿日:2020-07-06T08:39:06+09:00
AthenaにてShow partitionsが失敗する
現象
AWS Athenaにて特定テーブルのパーティションが多い場合、Show Partitionsにて、
パーティションの一覧を取得しようとすると、internal errorで失敗することがあります。
SHOW PARTITIONS {database}.{table_name}Your query has the following error(s): [ErrorCode: INTERNAL_ERROR_QUERY_ENGINE] Amazon Athena an experienced an internal error while executing this query. Please contact AWS support for further assistance. You will not be charged for this query. We apologize for the inconvenience. This query ran against the "xxx" database, unless qualified by the query. Please post the error message on our forum or contact customer support with Query Id: xxxxxxxx-50d3-4699-ae41-XXXXXXXXXXXX.テーブルのパーティションの数が多い場合に発生することがあるようです。
このテーブルに対して、MSCK REPAIR TABLEを実行しても同じくエラーとなります。AWSサポートに問い合わせたところ、AWS側の不具合との回答でした。(2020/07/02時点)
回避策
回避策としては、GlueのDataCatalogと統合されている場合には、
Glue側でパーティションの一覧を取得することができます。
GetPartitions
https://docs.aws.amazon.com/glue/latest/webapi/API_GetPartitions.htmlGetPartition
https://docs.aws.amazon.com/glue/latest/webapi/API_GetPartition.htmlBatchGetPartition
https://docs.aws.amazon.com/glue/latest/webapi/API_BatchGetPartition.htmlGlueと統合されているケースは、基本Glue側のAPIを使用して、パーティションの更新等を実施するのが良さそうですね。
- 投稿日:2020-07-06T01:49:33+09:00
[Terraform]ステートファイルを共有管理する
概要
terraform applyを実行した際に作成されるステートファイルをクラウド上で管理する方法を記載します。
AWS上のリソースをterraformで管理しているケースを想定しています。管理方法
applyを実行した際の現在の結果を記録しているファイルがtfstateファイルとなります。(このファイルを見て差分を割り出してくれていますね)
デフォルトではローカルに生成されますが、チーム開発を行っていくにあたって特定の人物のローカルにしかないと困ってしまいますね。
そこで通常tfstateファイルは、以下のように管理します。
- Cloud上にステートファイル管理用のバケット(
ECSやGCS)を作成- Terraform Cloudを利用
AWS S3 Bucketの利用
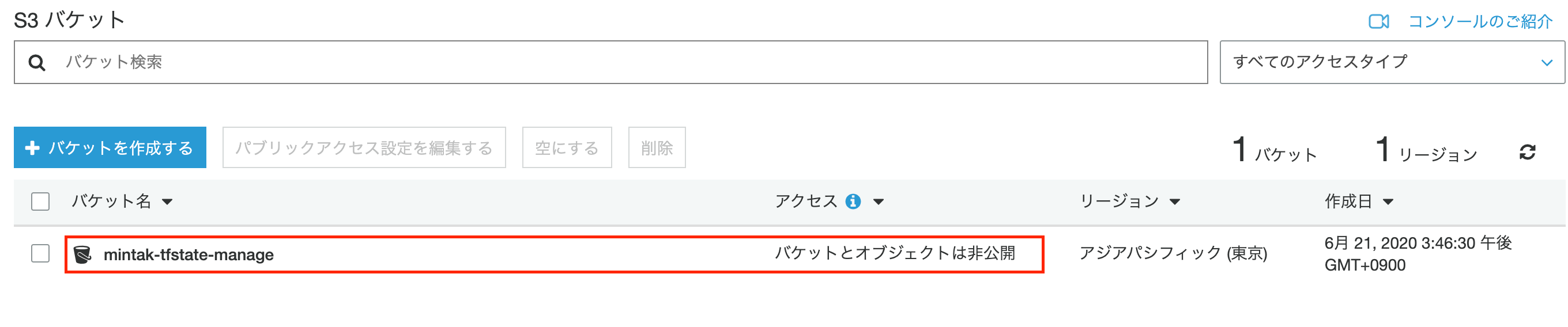
管理対象となるAWS上で手軽に管理します。
なお、ステートファイルを保管するバケット自体はterraformでの管理するインフラストラクチャ外にあることが理想です。(公式ドキュメントより)
このバケットを管理するためのアカウントを別に発行することが望ましいようですが、ややこしくなるので、ここではaws-cliを用いてバケットを作成し、terraformの管理外とすることを実現します。1. ステート管理バケットの作成
単純に作成するだけでも構いませんが、以下の設定を入れておくと安心でしょう。
- バージョニング :不用意な削除等が行われた場合でも復元することができる
- 暗号化 :バケット自体の暗号化を行う
- ブロックパブリックアクセス:バケットを公開しないよう設定
Terminal# バケット作成 aws s3api create-bucket --bucket ${bucket_name} --create-bucket-configuration LocationConstraint=${region} # バージョニングの有効化 aws s3api put-bucket-versioning --bucket ${bucket_name} --versioning-configuration Status=Enabled # バケットの暗号化 aws s3api put-bucket-encryption --bucket ${bucket_name} \ --server-side-encryption-configuration '{"Rules": [{"ApplyServerSideEncryptionByDefault": {"SSEAlgorithm": "AES256"}}]}' # ブロックパブリックアクセス aws s3api put-public-access-block --bucket ${bucket_name} \ --public-access-block-configuration '{ "BlockPublicAcls" : true, "IgnorePublicAcls" : true, "BlockPublicPolicy" : true, "RestrictPublicBuckets": true }' # タグ付け aws s3api put-bucket-tagging --bucket ${bucket_name} \ --tagging 'TagSet=[{Key=description,Value=manage mintak-terraformer tfstate}]'
2. DynamoDBテーブル作成
DynamoDBを組み合わせることによって、ステートロックを実現可能とします。
※真偽は明らかではないですが、パーティションキー名称はLockIDでないとうまく動作しませんでした。Terminalaws dynamodb create-table \ --table-name ${state_lock_table_name} \ --attribute-definitions '[{"AttributeName":"LockID","AttributeType": "S"}]' \ # S=stringの意味 --key-schema '[{"AttributeName":"LockID","KeyType": "HASH"}]' \ # HASH=パーティションキーの意味 --provisioned-throughput '{"ReadCapacityUnits": 1, "WriteCapacityUnits": 1}' # 念のため最低値を設定しておく
3. backend設定
ステートファイルを上記で作成したバケットに保管するように設定するための実装を行います。
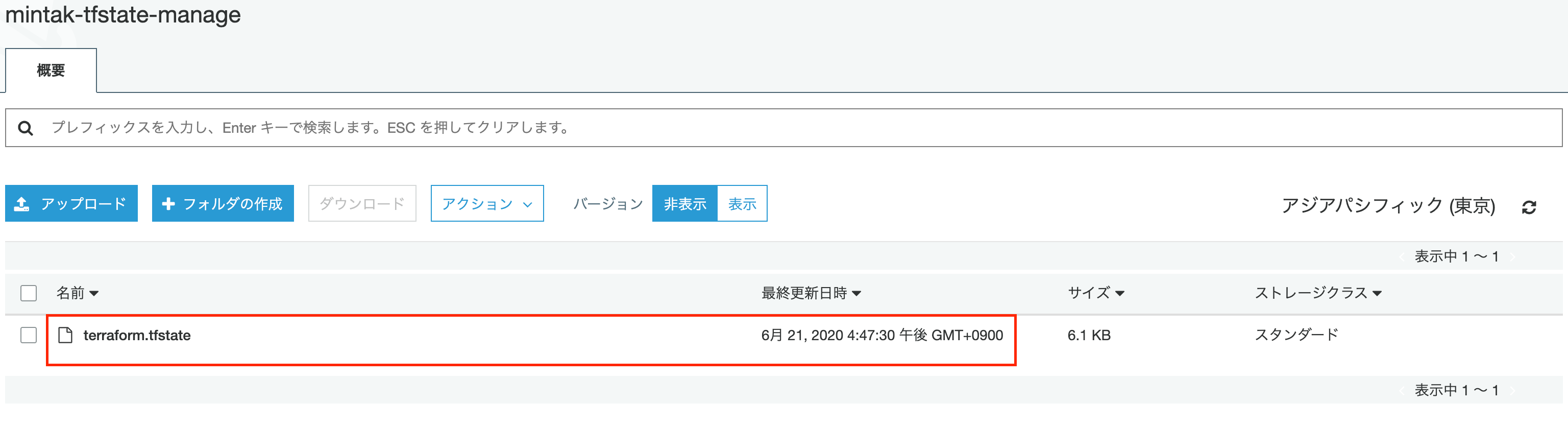
tfファイルがある階層にbackend.tfを新たに作成します。backend.tfterraform { backend s3 { bucket = "1で作成したバケット名" key = "terraform.tfstate" dynamodb_table = "2で作成したテーブル名" region = "ap-northeast-1" encrypt = true } }この状態でapplyやdestroyを行ってみると、ローカルにステートファイルが作成されることがなくなり、
S3バケット上に作成されるようになります。
Terraform Cloudの利用
GithubやGitLabと連携して
planやapplyを行う機能もあるようですが、
今回はあくまでステートファイルの共有管理の目的に閉じて利用する前提での例となります。
変更内容(履歴)がUI上で確認できる点が優れていると感じました。1. サインアップ
Terraform Cloudの「Sign up for Cloud」ボタンをクリックしてアカウントを作成します。必要なものはメールアドレスのみです。
作成が必要なものは、アカウント・組織・ワークスペースの3つとなります。2. ワークスペース設定
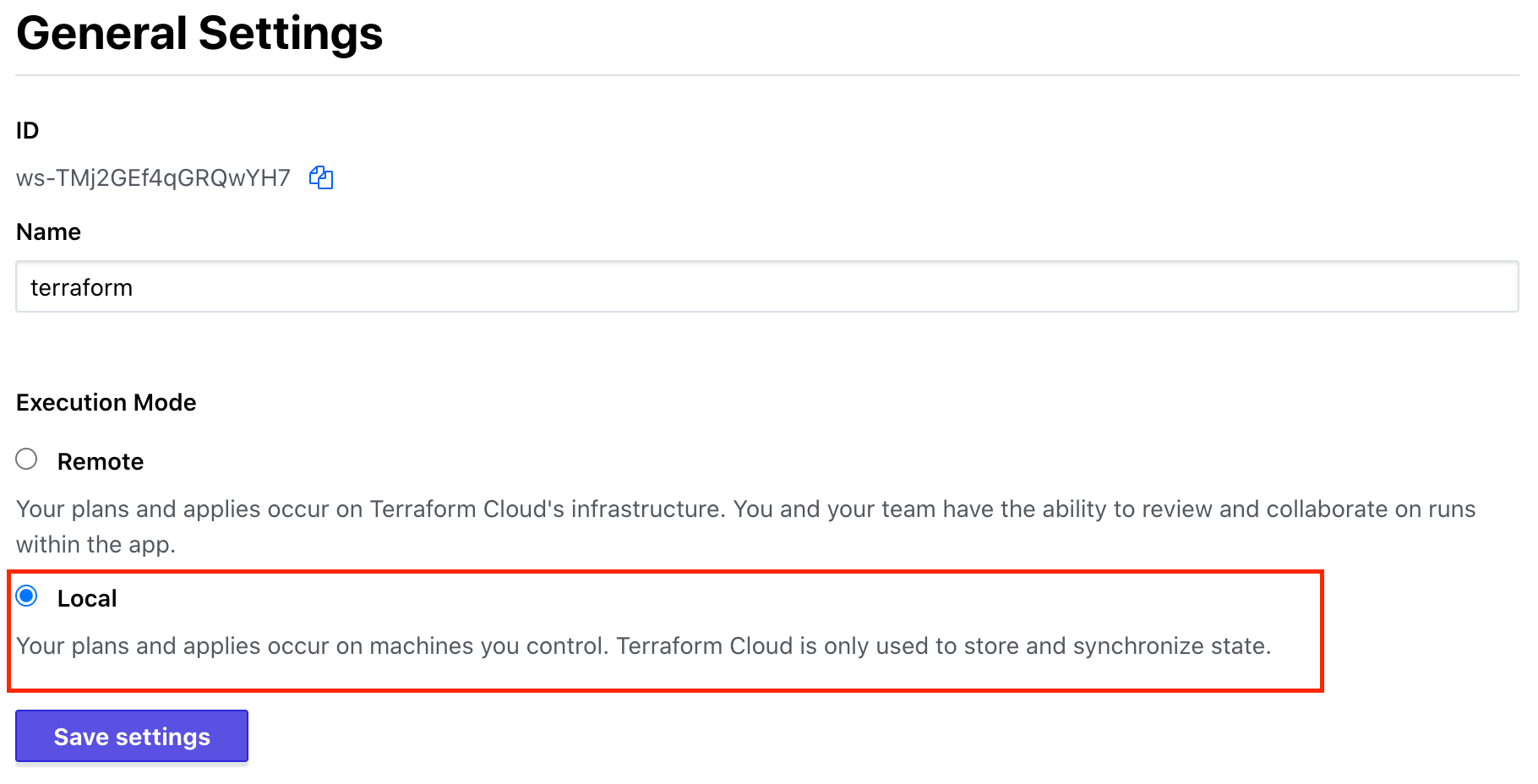
あくまでステートファイルの共有管理のみに閉じるため、次の設定を行います。
- 実行モードをLocalに
ワークスペース->Settings->generalの画面
Execution ModeをLocalに設定します。
- VCS provider off
ワークスペース設定時にVCS providerを設定している場合は今回の用途では不要なためオフにします。
ワークスペース->Settings->Version Controlよりdeleteを行います。3. CLIログイン
コンソールからログインを行います。このタイミングでAPI Keyを発行します。(key情報は
~/.terraform.d/credentials.tfrc.jsonに保管されます。1)
Do you want to proceed? (y/n)は「y」を入力してください。Terminal$ terraform login Do you want to proceed? (y/n) y # ここでTerraform CloudのUIでAPI Keyを発行する画面へ遷移する。そのまま発行を行いコピーして、コンソールにペーストする Terraform must now open a web browser to the tokens page for app.terraform.io. If a browser does not open this automatically, open the following URL to proceed: https://app.terraform.io/app/settings/tokens?source=terraform-login --------------------------------------------------------------------------------- Generate a token using your browser, and copy-paste it into this prompt. Terraform will store the token in plain text in the following file for use by subsequent commands: /Users/mintak/.terraform.d/credentials.tfrc.json Token for app.terraform.io: Retrieved token for user mintak21 --------------------------------------------------------------------------------- Success! Terraform has obtained and saved an API token.4. backend設定
ステートファイルを
Terraform Cloudに保管するように設定するための実装を行います。
tfファイルがある階層にbackend.tfを新たに作成します。backend.tfterraform { backend remote { hostname = "app.terraform.io" organization = "組織名" workspaces { name = "ワークスペース名" } } }この状態で
applyやdestroyを行ってみると、ローカルにステートファイルが作成されることがなくなり、
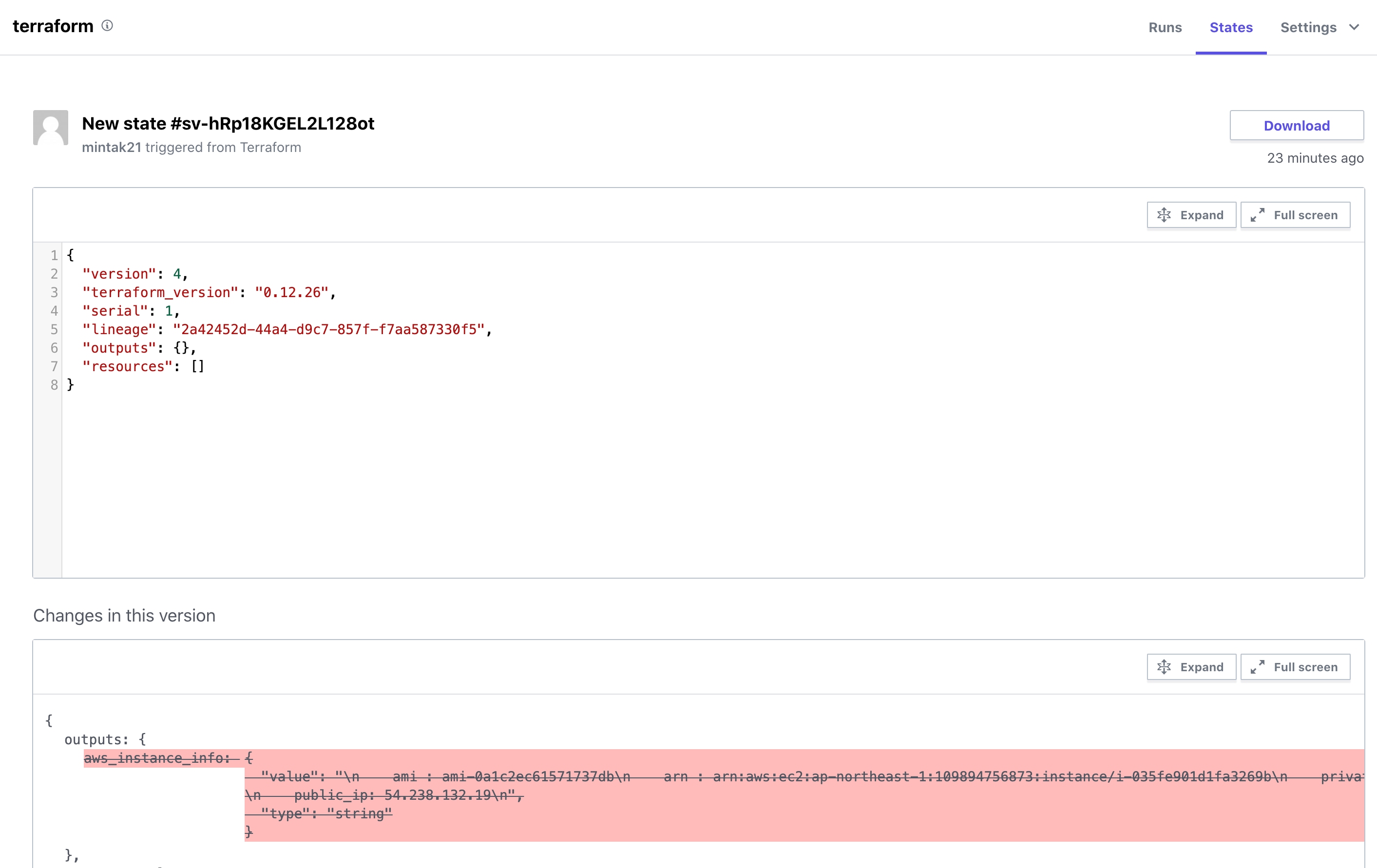
Terraform Cloud上に作成されるようになります。
現在の状態と前回からの差分をUI上で確認することが可能です。
References