- 投稿日:2020-07-06T22:53:26+09:00
ゼロから始めるLeetCode Day78 「206. Reverse Linked List」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
どうやら多くのエンジニアはその対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイトであり、海外のテックカンパニーでのキャリアを積みたい方にとっては避けては通れない道である。
と、仰々しく書いてみましたが、私は今のところそういった面接を受ける予定はありません。
ただ、ITエンジニアとして人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
Python3で解いています。
前回
ゼロから始めるLeetCode Day77「1502. Can Make Arithmetic Progression From Sequence」今はTop 100 Liked QuestionsのMediumを優先的に解いています。
Easyは全て解いたので気になる方は目次の方へどうぞ。Twitterやってます。
技術ブログ始めました!!
技術はLeetCode、Django、Nuxt、あたりについて書くと思います。こちらの方が更新は早いので、よければブクマよろしくお願いいたします!問題
206. Reverse Linked List
難易度はEasy。問題としては、与えられた単方向の連結リストをそのままひっくり返すというものです。
Example:
Input: 1->2->3->4->5->NULL
Output: 5->4->3->2->1->NULL解法
とりあえずiterativeなものを。
# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next class Solution: def reverseList(self, head: ListNode) -> ListNode: pre,cur = None,head while cur != None: nex = cur.next cur.next = pre pre = cur cur = nex return pre # Runtime: 44 ms, faster than 26.15% of Python3 online submissions for Reverse Linked List. # Memory Usage: 15.3 MB, less than 67.33% of Python3 online submissions for Reverse Linked List.
pre,cur,nexという三つの変数を用意して一つ前、現在、一つ後の要素を保持してそれぞれ入れ替えていきます。
変数を用意してそれぞれの一時的な逃げ場所を作って上げるようなイメージで考えてみれば良いと思います。ただ、これだとこの規模ならともかく、もっと変数が増えるようなケースだとなかなか処理の量が増えて書くのが面倒臭くなります。
やっぱり楽したいですよね。では今度はstackを使ってみた解答です。
# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next class Solution: def reverseList(self, head: ListNode) -> ListNode: if not head: return None stack = [] while head.next: stack.append(head) head = head.next while stack: cur = stack.pop() cur.next.next = cur cur.next = None return head # Runtime: 40 ms, faster than 46.28% of Python3 online submissions for Reverse Linked List. # Memory Usage: 15.1 MB, less than 96.42% of Python3 online submissions for Reverse Linked List.こちらですとゴチャゴチャせずに割とスッキリ書けるので僕はこちらの方が好きです。
それに少しですが、速度も改善されています。二つの回答例を書いてみましたが、いかがでしょうか?
もっとこっちの方がスマートだし良くない?という意見をお持ちの方は是非コメントくださると嬉しいです。
- 投稿日:2020-07-06T22:29:52+09:00
実家のPC 履歴つけずにこっそりAVみてみた
はじめに
みなさんAV観てますか?
今回は、こんな人に向けて記事を作成しました。「自分のスマホ持ってない。実家に一台のPCしかないから、AV履歴削除めんどくさいなぁ」
「スクレイピング覚えたいけど、やる気がでないんだよなぁ」
そんな悩みを解決します。
では、夢の世界へどうぞHTMLの取得
#ライブラリ一覧 import requests #webページを取得するライブラリ import pandas as pd from bs4 import BeautifulSoup #取得したHTMLのデータの中から、タグを読み取り、操作できるライブラリ from IPython.display import HTML from IPython.display import Imageurl = "https://www.dmm.co.jp/digital/videoa/-/ranking/=/term=realtime/" #売れ筋作品ランキング(10分ごとに更新されます) response = requests.get(url) response.encoding = response.apparent_encoding #response.apparent_encoding に、正しい文字コードである SHIFT_JISが格納されている(文字化けを防げます) soup = BeautifulSoup(response.text, "html.parser") #BeautifulSoup(解析対象のHTML/XML, 利用するパーサー(解析器))#HTMLをインデントできる print(soup.prettify())
上記の様にHTMLが取得できていることが分かります。
ここから、どのタグ・どの属性を取得するかの方針を立てます。
一筋縄ではいかない部分が多々あるのが、スクレイピングですので、試行錯誤を繰り返していきましょう。画像を取得(images)
images=[] for link in soup.find_all("img"): # imgタグを取得しlinkに格納 if link.get("src").endswith(".jpg"): # imgタグ内の.jpgであるsrcタグを取得 images.append(link.get("src")) # imagesリストに格納以下のような形になります。
リンクを取得(AV_links)
AV_links=[] tags1=soup.find_all("td", attrs={"class": "bd-b"}) for j,i in enumerate(tags1): a=i.find("a") print(a.get('href')) AV_links.append("https://www.dmm.co.jp"+a.get('href'))
https://www.dmm.co.jpが抜けているので先頭に追加してあげます。
動画url(movie_links)
movie_links=[] for i in AV_links: a=i.split("/=/") b=a[0]+'/ajax-movie/=/'+a[1] movie_links.append(b)"/ajax-movie/=/"を間に追加します。
作品名,順位を取得(titles,ranks)
import re titles=[] ranks=[] tags2=soup.find_all("td", attrs={"class": "bd-b"}) for j,i in enumerate(tags2): ranks.append(j) tmp=i.find("p") tmp1=tmp.text a=re.sub("【[^】]+】","",tmp1) titles.append(a)
女優名を取得(names)
names_contents=[] tags1=soup.find_all("div",class_="data") for i in tags1: a=i.text names_contents.append(a)
----と表示されているところは女優名が書いておらず、複数人で出演していました。
names=[] for i in names_contents: q=i.split("出演者:") if q[-1]=="----": names.append("複数人") else: names.append(q[-1])
パケ写(real_images)
real_images=[] for j,i in enumerate(images): real_images.append(Image(images[j]))
データフレーム作成
columns={"順位":ranks,"女優名":names,"タイトル名":titles,"画像url":images,"AVurl":AV_links,"動画":movie_links,"パケ写":real_images} df=pd.DataFrame(columns)
結果は!?
HTML(df["AVurl"][0])
HTML(df["動画"][0])
上記の様に履歴を残さず、データフレームから値を取得するだけでAV鑑賞が出来ますね!
実家にPCが1台しかない人は、
①jupyterの環境を整える
②python覚えるこの2点を学習すれば、見たい放題ですね。




- 投稿日:2020-07-06T22:29:52+09:00
履歴つけずにAV鑑賞してみた!
はじめに
みなさんAV観てますか?
今回は、こんな人に向けて記事を作成しました。「自分のスマホ持ってない。実家に一台のPCしかないから、AV履歴削除めんどくさいなぁ」
「スクレイピング覚えたいけど、やる気がでないんだよなぁ」
そんな悩みを解決します。
では、夢の世界へどうぞHTMLの取得
#ライブラリ一覧 import requests #webページを取得するライブラリ import pandas as pd from bs4 import BeautifulSoup #取得したHTMLのデータの中から、タグを読み取り、操作できるライブラリ from IPython.display import HTML from IPython.display import Imageurl = "https://www.dmm.co.jp/digital/videoa/-/ranking/=/term=realtime/" #売れ筋作品ランキング(10分ごとに更新されます) response = requests.get(url) response.encoding = response.apparent_encoding #response.apparent_encoding に、正しい文字コードである SHIFT_JISが格納されている(文字化けを防げます) soup = BeautifulSoup(response.text, "html.parser") #BeautifulSoup(解析対象のHTML/XML, 利用するパーサー(解析器))画像を取得(images)
images=[] for link in soup.find_all("img"): # imgタグを取得しlinkに格納 if link.get("src").endswith(".jpg"): # imgタグ内の.jpgであるsrcタグを取得 images.append(link.get("src")) # imagesリストに格納以下のような形になります。
リンクを取得(AV_links)
AV_links=[] tags1=soup.find_all("td", attrs={"class": "bd-b"}) for j,i in enumerate(tags1): a=i.find("a") print(a.get('href')) AV_links.append("https://www.dmm.co.jp"+a.get('href'))
https://www.dmm.co.jpが抜けているので先頭に追加してあげます。
動画url(movie_links)
movie_links=[] for i in AV_links: a=i.split("/=/") b=a[0]+'/ajax-movie/=/'+a[1] movie_links.append(b)"/ajax-movie/=/"を間に追加します。
作品名,順位を取得(titles,ranks)
import re titles=[] ranks=[] tags2=soup.find_all("td", attrs={"class": "bd-b"}) for j,i in enumerate(tags2): ranks.append(j) tmp=i.find("p") tmp1=tmp.text a=re.sub("【[^】]+】","",tmp1) titles.append(a)
女優名を取得(names)
names_contents=[] tags1=soup.find_all("div",class_="data") for i in tags1: a=i.text names_contents.append(a)
----と表示されているところは女優名が書いておらず、複数人で出演していました。
names=[] for i in names_contents: q=i.split("出演者:") if q[-1]=="----": names.append("複数人") else: names.append(q[-1])
パケ写(real_images)
real_images=[] for j,i in enumerate(images): real_images.append(Image(images[j]))
データフレーム作成
columns={"順位":ranks,"女優名":names,"タイトル名":titles,"画像url":images,"AVurl":AV_links,"動画":movie_links,"パケ写":real_images} df=pd.DataFrame(columns)
結果は!?
HTML(df["AVurl"][0])
HTML(df["動画"][0])
上記の様に履歴を残さず、データフレームから値を取得するだけでAV鑑賞が出来ますね!
実家にPCが1台しかない人は、
①jupyterの環境を整える
②python覚えるこの2点を学習すれば、見たい放題ですね。
- 投稿日:2020-07-06T22:29:52+09:00
スクレイピング覚えながら、AV鑑賞してみた
はじめに
みなさんAV観てますか?
今回は、こんな人に向けて記事を作成しました。「自分のスマホ持ってない。実家に一台のPCしかないから、AV履歴削除めんどくさいなぁ」
「スクレイピング覚えたいけど、やる気がでないんだよなぁ」
そんな悩みを解決します。
では、夢の世界へどうぞHTMLの取得
#ライブラリ一覧 import requests #webページを取得するライブラリ import pandas as pd from bs4 import BeautifulSoup #取得したHTMLのデータの中から、タグを読み取り、操作できるライブラリ from IPython.display import HTML from IPython.display import Imageurl = "https://www.dmm.co.jp/digital/videoa/-/ranking/=/term=realtime/" #売れ筋作品ランキング(10分ごとに更新されます) response = requests.get(url) response.encoding = response.apparent_encoding #response.apparent_encoding に、正しい文字コードである SHIFT_JISが格納されている(文字化けを防げます) soup = BeautifulSoup(response.text, "html.parser") #BeautifulSoup(解析対象のHTML/XML, 利用するパーサー(解析器))#HTMLをインデントできる print(soup.prettify())
上記の様にHTMLが取得できていることが分かります。
ここから、どのタグ・どの属性を取得するかの方針を立てます。
一筋縄ではいかない部分が多々あるのが、スクレイピングですので、試行錯誤を繰り返していきましょう。画像を取得(images)
images=[] for link in soup.find_all("img"): # imgタグを取得しlinkに格納 if link.get("src").endswith(".jpg"): # imgタグ内の.jpgであるsrcタグを取得 images.append(link.get("src")) # imagesリストに格納以下のような形になります。
リンクを取得(AV_links)
AV_links=[] tags1=soup.find_all("td", attrs={"class": "bd-b"}) for j,i in enumerate(tags1): a=i.find("a") print(a.get('href')) AV_links.append("https://www.dmm.co.jp"+a.get('href'))
https://www.dmm.co.jpが抜けているので先頭に追加してあげます。
動画url(movie_links)
movie_links=[] for i in AV_links: a=i.split("/=/") b=a[0]+'/ajax-movie/=/'+a[1] movie_links.append(b)"/ajax-movie/=/"を間に追加します。
作品名,順位を取得(titles,ranks)
import re titles=[] ranks=[] tags2=soup.find_all("td", attrs={"class": "bd-b"}) for j,i in enumerate(tags2): ranks.append(j) tmp=i.find("p") tmp1=tmp.text a=re.sub("【[^】]+】","",tmp1) titles.append(a)
女優名を取得(names)
names_contents=[] tags1=soup.find_all("div",class_="data") for i in tags1: a=i.text names_contents.append(a)
----と表示されているところは女優名が書いておらず、複数人で出演していました。
names=[] for i in names_contents: q=i.split("出演者:") if q[-1]=="----": names.append("複数人") else: names.append(q[-1])
パケ写(real_images)
real_images=[] for j,i in enumerate(images): real_images.append(Image(images[j]))
データフレーム作成
columns={"順位":ranks,"女優名":names,"タイトル名":titles,"画像url":images,"AVurl":AV_links,"動画":movie_links,"パケ写":real_images} df=pd.DataFrame(columns)
結果は!?
HTML(df["AVurl"][0])
HTML(df["動画"][0])
上記の様に履歴を残さず、データフレームから値を取得するだけでAV鑑賞が出来ますね!
実家にPCが1台しかない人は、
①jupyterの環境を整える
②python覚えるこの2点を学習すれば、見たい放題ですね。
- 投稿日:2020-07-06T22:29:52+09:00
スクレイピング覚えたいならAVを見ろ
はじめに
みなさんAV観てますか?
今回は、こんな人に向けて記事を作成しました。「自分のスマホ持ってない。実家に一台のPCしかないから、AV履歴削除めんどくさいなぁ」
「スクレイピング覚えたいけど、やる気がでないんだよなぁ」
そんな悩みを解決します。
では、夢の世界へどうぞHTMLの取得
#ライブラリ一覧 import requests #webページを取得するライブラリ import pandas as pd from bs4 import BeautifulSoup #取得したHTMLのデータの中から、タグを読み取り、操作できるライブラリ from IPython.display import HTML from IPython.display import Imageurl = "https://www.dmm.co.jp/digital/videoa/-/ranking/=/term=realtime/" #売れ筋作品ランキング(10分ごとに更新されます) response = requests.get(url) response.encoding = response.apparent_encoding #response.apparent_encoding に、正しい文字コードである SHIFT_JISが格納されている(文字化けを防げます) soup = BeautifulSoup(response.text, "html.parser") #BeautifulSoup(解析対象のHTML/XML, 利用するパーサー(解析器))#HTMLをインデントできる print(soup.prettify())
上記の様にHTMLが取得できていることが分かります。
ここから、どのタグ・どの属性を取得するかの方針を立てます。
一筋縄ではいかない部分が多々あるのが、スクレイピングですので、試行錯誤を繰り返していきましょう。画像を取得(images)
images=[] for link in soup.find_all("img"): # imgタグを取得しlinkに格納 if link.get("src").endswith(".jpg"): # imgタグ内の.jpgであるsrcタグを取得 images.append(link.get("src")) # imagesリストに格納以下のような形になります。
リンクを取得(AV_links)
AV_links=[] tags1=soup.find_all("td", attrs={"class": "bd-b"}) for j,i in enumerate(tags1): a=i.find("a") print(a.get('href')) AV_links.append("https://www.dmm.co.jp"+a.get('href'))
https://www.dmm.co.jpが抜けているので先頭に追加してあげます。
動画url(movie_links)
movie_links=[] for i in AV_links: a=i.split("/=/") b=a[0]+'/ajax-movie/=/'+a[1] movie_links.append(b)"/ajax-movie/=/"を間に追加します。
作品名,順位を取得(titles,ranks)
import re titles=[] ranks=[] tags2=soup.find_all("td", attrs={"class": "bd-b"}) for j,i in enumerate(tags2): ranks.append(j) tmp=i.find("p") tmp1=tmp.text a=re.sub("【[^】]+】","",tmp1) titles.append(a)
女優名を取得(names)
names_contents=[] tags1=soup.find_all("div",class_="data") for i in tags1: a=i.text names_contents.append(a)
----と表示されているところは女優名が書いておらず、複数人で出演していました。
names=[] for i in names_contents: q=i.split("出演者:") if q[-1]=="----": names.append("複数人") else: names.append(q[-1])
パケ写(real_images)
real_images=[] for j,i in enumerate(images): real_images.append(Image(images[j]))
データフレーム作成
columns={"順位":ranks,"女優名":names,"タイトル名":titles,"画像url":images,"AVurl":AV_links,"動画":movie_links,"パケ写":real_images} df=pd.DataFrame(columns)
結果は!?
HTML(df["AVurl"][0])
HTML(df["動画"][0])
上記の様に履歴を残さず、データフレームから値を取得するだけでAV鑑賞が出来ますね!
実家にPCが1台しかない人は、
①jupyterの環境を整える
②python覚えるこの2点を学習すれば、見たい放題ですね。
- 投稿日:2020-07-06T22:26:23+09:00
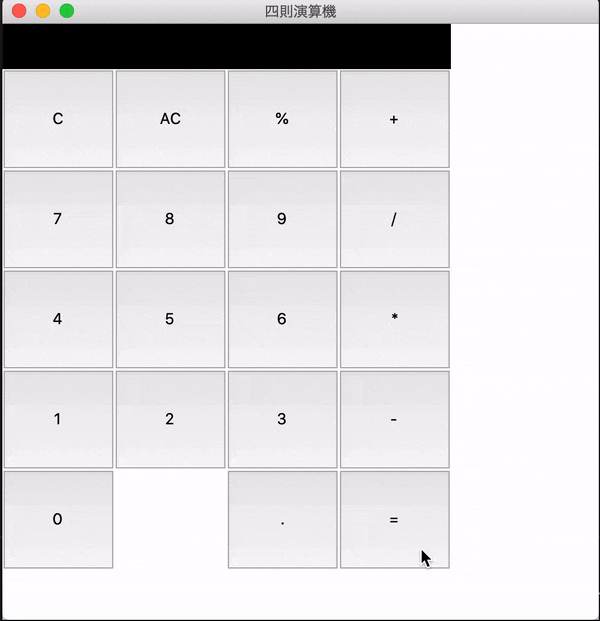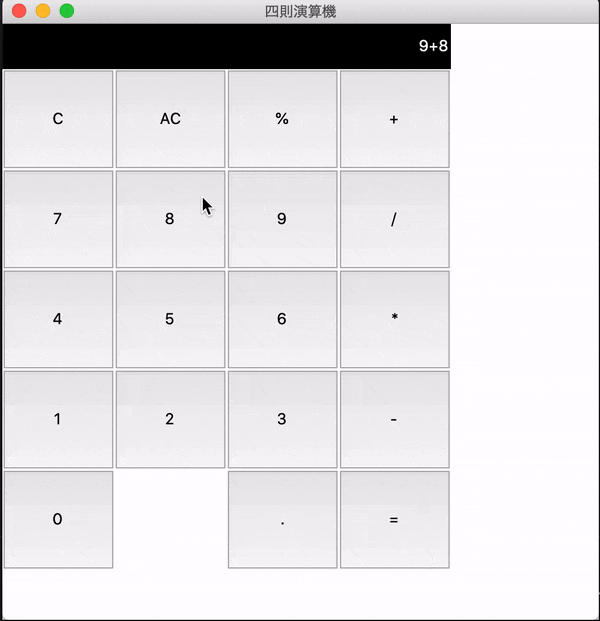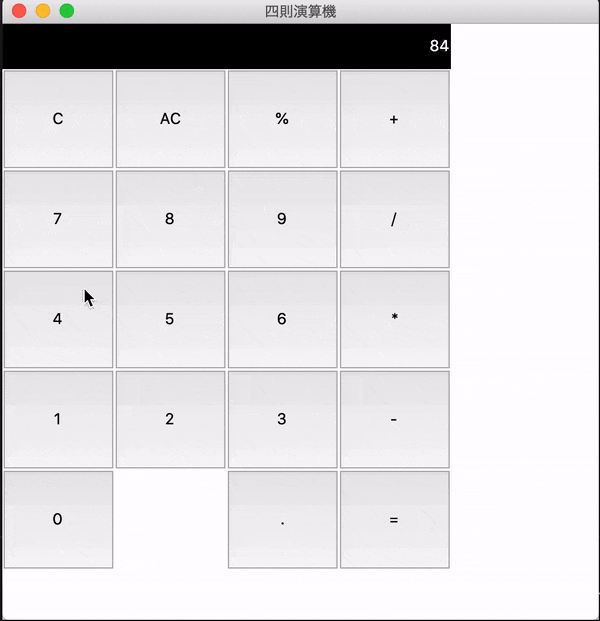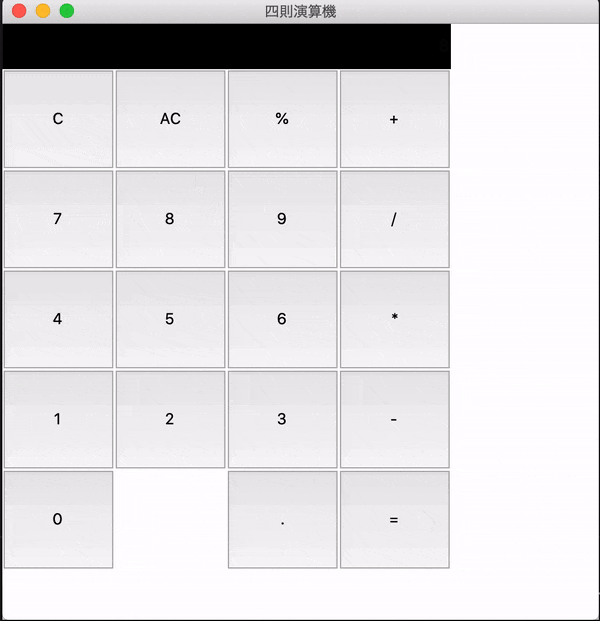
tkinterで電卓いじってみた
まず初めに
僕がpythonでプログラミングを学んでいった上で、1番好きだったのがtkinterを用いたボタン処理だった。そのボタン処理をたくさんできるのは何かと考えた時に1番に出てきたのが電卓だった。
手順
Window表示
final_python.pyfrom tkinter import * #Window作成 root = Tk() #Windowサイズ指定 root.geometry("500x500") #Windowタイトル作成 root.title("四則演算機") #決まり文句 root.mainloop()
CとACの機能
final_python.py#Cの機能 def clear(): textVal = expression.get() if len(textVal) > 1: expression.set(textVal[:-1]) else: expression.set("") #ACの機能 def all_clear(): expression.set("")
- CとACの役割
C 一文字ずつ消去 AC 全文字消去
ボタン配置
final_python.pybuttons = ( (("C", clear ), ("AC", all_clear), ("%", op("%") ), ("+", op("+"))), (("7", digit(7)), ("8", digit(8) ), ("9", digit(9)), ("/", op("/"))), (("4", digit(4)), ("5", digit(5) ), ("6", digit(6)), ("*", op("*"))), (("1", digit(1)), ("2", digit(2) ), ("3", digit(3)), ("-", op("-"))), (("0", digit(1)), (None, None ), ('.', op('.') ), ("=", calculate)), )※一列一列ボタンを並べるよりも配列にしたほうがだいぶラクらしい
完成形
お詫び
今回最終課題の発表ということで、全部の機能を説明したかったが、一人の持ち時間が2分と限られているので、2分以内に収められるよう要点を絞った。
最後にソースコードが貼ってあるので、それを見ておいて欲しいです、、、ソースコード
final_python.py# coding:utf-8 from tkinter import * #Window表示 root = Tk() #Windowサイズ指定 root.geometry("500x500") #Windowタイトル作成 root.title("四則演算機") expression = StringVar() #Cの機能 def clear(): textVal = expression.get() if len(textVal) > 1: expression.set(textVal[:-1]) else: expression.set("") #ACの機能 def all_clear(): expression.set("") #数字ボタン def digit(number): def func(): expression.set(expression.get() + str(number)) return func #演算ボタン def op(label): def func(): expression.set(expression.get() + label) return func #=の機能 def calculate(): try: expression.set(eval(expression.get())) except SyntaxError: expression.set("SyntaxError") except ZeroDivisionError: expression.set("ZeroDivisionError") except NameError: expression.set("NameError") buttons = ( (("C", clear ), ("AC", all_clear), ("%", op("%") ), ("+", op("+"))), (("7", digit(7)), ("8", digit(8) ), ("9", digit(9)), ("/", op("/"))), (("4", digit(4)), ("5", digit(5) ), ("6", digit(6)), ("*", op("*"))), (("1", digit(1)), ("2", digit(2) ), ("3", digit(3)), ("-", op("-"))), (("0", digit(1)), (None, None ), ('.', op('.') ), ("=", calculate)), ) #表示画面 e = Label(root, textvariable=expression, fg="#ffffff", bg="#000000", anchor=E, height=2) e.grid(row=0, column=0, columnspan=4, sticky="EW") for row, btns in enumerate(buttons, 1): for col, (label, func) in enumerate(btns): if label: b = Button(root, text=label, command=func, width=10, height=5) b.grid(row=row, column=col) #決まり文句 root.mainloop()
感想
ほぼほぼソースコードはTkinterで作る電卓を参考にさせてもらったが、Windowの幅だったり、電卓そのものの大きさ、Cの機能など改善すべき部分はあったので、そこは自分の力で出来たので良かった。
また、それぞれの命令の意味も理解することができて良かった。
夏休みはプログラミングに力を入れていきたい。参考文献
いちばんやさしいpython入門教室 大澤文孝[著]
- 投稿日:2020-07-06T21:27:08+09:00
最終制作物
何をつくろうかなあ
僕が何か動くものを作ってきなさいという課題があるということを聞いて、いろいろな案が出たのですが、なかなか自分のレベルにあったものが(難易度の高いものしか)思いつきませんでした。そこで、あれこれ模索しているときに、ふとBouncing Ball を見たときに、ある馴染み深い映像を思い出しました。それがこの動画です。DVDのマークが動く映像です。そういうわけで今回はこれを作っていきたいと思います。
制作開始~
これから以前作成したBouncing Ball をもとにして、実際に作ってみる。
作る工程としては、
1.背景とボールの形を修正
2.壁に当たるごとに色を変化させるようにする
3.ボールのデザイン背景とボールの形を修正
example07-06-1.pyの、背景を黒くして、ボールを楕円形にする。背景はcanvasメソッドの最後の引数をbg="black"にすると黒くなる。楕円に変形させるには、円のx軸方向の半径を長くする。
修正した結果#cording:utf-8 import tkinter as tk x = 400 y = 300 dx = 1 dy = 1 def move(): global x, y , dx, dy canvas.create_oval(x - 30, y - 20, x + 30, y + 20, fill= "black", width= 0) x = x + dx y = y + dy canvas.create_oval(x - 30, y - 20, x + 30, y + 20, fill= "red", width= 0) if x >= canvas.winfo_width(): dx = -1 if x <= 0: dx = +1 if y >= canvas.winfo_height(): dy = -1 if y <= 0: dy = +1 root.after(10,move) root = tk.Tk() root.geometry("600x400") canvas = tk.Canvas(root, width = 600, height = 400, bg= "black") canvas.place(x = 0, y =0) root.after(10, move) root.mainloop()壁に当たるごとにボールの色を変化させる
- 投稿日:2020-07-06T21:12:21+09:00
[光-Hikari-のPython]09章-03クラス(継承)
【目次リンク】へ戻る
[Python]09章-03 継承
前節では、クラスという設計図からインスタンス化によりオブジェクトを生成することについて触れました。
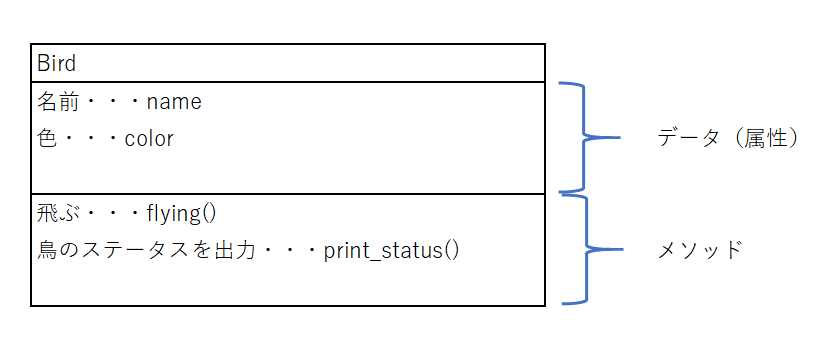
Bird型のオブジェクトのクラス図については以下の通りでした。
ところで、メソッドのところに注目すると、flying()とprint_status()の2つしかない状態です。実際に鳥(Bird)は鳴くので、今回この鳴く(cry)というメソッドを作成することを考えてみたいと思います。
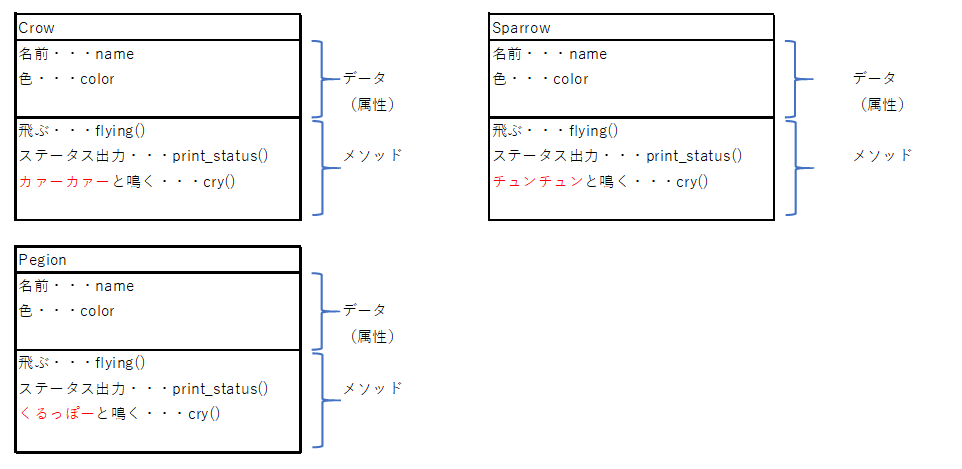
しかし、「鳴く」といっても、鳥の鳴き方にはいろいろな種類があり、カラス(Crow)であれば「カァーカァー」、スズメ(Sparrow)であれば「チュンチュン」、鳩(Pegion)であれば「くるっぽー」などと多種多様です。
そうなると、鳥の種類ごとに以下のようにクラスを作らなくてはならなくなります。
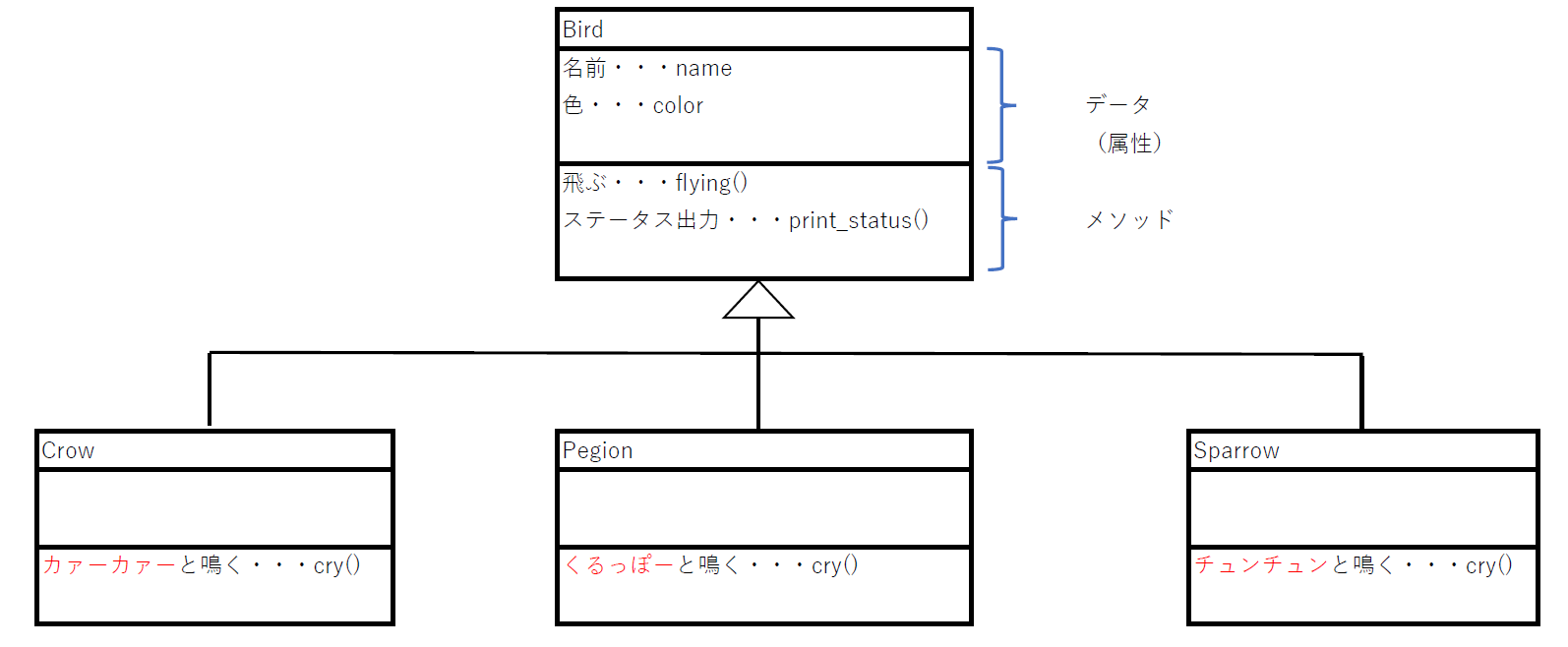
しかし、上記のクラス図を見てみると、いずれもcry()メソッドの部分のみが異なっているだけであり、ほかの部分はすべてのクラス図では一致しています。
そこに注目して、その差分だけをプログラミングする方法を今回考えていきたいと思います。
継承の機能
すでにあるクラスを利用して、少しだけ変更を加えてクラスを作成したいことがあります。この際に利用できるのが継承(インヘリタンス)です。
継承の機能を利用することで、すでにあるクラスの属性やメソッドを継承し、差分のみ属性やメソッドを書くだけでクラスを作成できます。
クラス図で表現すると以下の通りです。
Crowクラス、Pegionクラス、SparrowクラスはBirdクラスを継承していることがうかがえます。
この図からわかる通り、Birdクラスとは別にCrowクラス、Pegionクラス、Sparrowクラスcry()のみを指定すればよいことがわかります。
そうすれば、プログラムをいちいち書き直さず、必要な差分のみを追記するだけで済みます。継承でよく出てくる用語
上記の例で、BirdクラスをもとにCrowクラス、Pegionクラス、Sparrowクラスを作成しました。
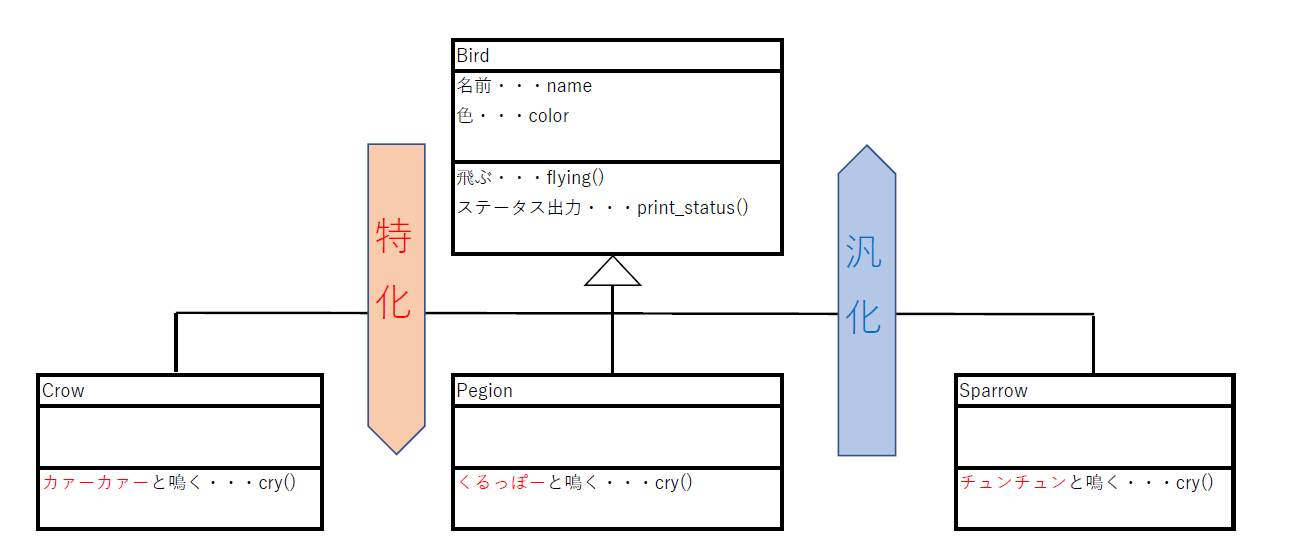
この時、元となるクラス(今回はBirdクラス)のことをスーパークラス、継承して作られるクラス(今回はCrow、Pegion、Sparrowクラス)をサブクラスと言います。次に、スーパークラスとサブクラスの関係に注目してみましょう。BirdとCrowの関係は、「Crow(カラス)はBird(鳥)です。」ということができます。
英語で表記すると、「Crow is a Bird」となります。こういった継承関係をis_a関係と言ったりします。また、Bird(スーパークラス)から見るとCrow(サブクラス)に特化している、Crow(サブクラス)から見てBird(スーパークラス)に汎化(はんか)しているという表現をすることもあります。
スーパークラスとサブクラスを実装する
それでは実際にプログラムを書いてみましょう。
まず、継承のプログラムは一般に以下のように記載します。class スーパークラス名: スーパークラスの属性 スーパークラスのメソッドによる処理 class サブクラス名(スーパークラス名): サブクラスの属性 サブクラスのメソッドによる処理ただし、Crow、Pegion、Sparrowすべて書くと見づらくなるので、今回はCrowのみのサブクラスを書きます。
chap09の中にsamp09_03_01.pyに以下のコードを書いてください。samp09_03_01.py#スーパークラスの記載 class Bird: def __init__(self, name, color): print('-----インスタンス化したと同時にコンストラクタを呼び出します。-----') self.name = name self.color = color #飛ぶというメソッド def flying(self, m): print('-----flyingメソッドを呼び出します。-----') print(f'バサバサと{self.name}は空を飛びます。') print(f'{m}mの高さを飛んでいます。') #インスタンス化したBirdのステータスを出力するメソッド def print_status(self): print('-----print_statusメソッドを呼び出します。-----') print(f'{self.color}色の鳥です。') #サブクラスの記載 class Crow(Bird): def cry(self): print('-----サブクラスにあるcryメソッドを呼び出します。-----') print('カァーカァーと鳴きます。') #サブクラスのCrowをインスタンス化する kur = Crow('クロ助', '黒') #サブクラスにあるcryメソッドを呼び出す kur.cry() #スーパークラスにあるflyingメソッドを呼び出す kur.flying(10) #スーパークラスにあるprint_statusメソッドを呼び出す kur.print_status()【実行結果】
-----インスタンス化したと同時にコンストラクタを呼び出します。-----
-----サブクラスにあるcryメソッドを呼び出します。-----
カァーカァーと鳴きます。
-----flyingメソッドを呼び出します。-----
バサバサとクロ助は空を飛びます。
10mの高さを飛んでいます。
-----print_statusメソッドを呼び出します。-----
黒色の鳥です。まずは、サブクラスよりカラス(Crow)をインスタンス化し、kurに代入しています。
そして、サブクラスCrowにある、cryメソッドにより「カァーカァー」と鳴いているのを確認できます。そして、注目してほしいのは、スーパークラスであるBirdにあるメソッドも呼び出せていることです。
これはCrowクラスがBirdクラスを継承しているため、Birdクラスのメソッドも呼び出せるのです。最後に
継承はいろいろなライブラリでも登場することが多いのですが、ほかの言語であるJavaやC++でも登場する概念です。
継承でよく出てくる用語については基本情報技術者試験ではオブジェクト指向の分野では必ず出てくる用語ですので、押さえておきましょう。【目次リンク】へ戻る
- 投稿日:2020-07-06T21:05:15+09:00
python OCR
日本語読み取り設定
$ curl -L -o /usr/local/share/tessdata/jpn.traineddata 'https://github.com/tesseract-ocr/tessdata/raw/master/jpn.traineddata'$ tesseract --list-langs List of available languages (4): eng jpn osd snumOCR実装
from PIL import Image import sys import pyocr import pyocr.builders tools = pyocr.get_available_tools() if len(tools) == 0: print("No OCR tool found") sys.exit(1) # The tools are returned in the recommended order of usage tool = tools[0] txt = tool.image_to_string( Image.open('{path}'), lang="jpn", builder=pyocr.builders.TextBuilder(tesseract_layout=6) ) print(txt)
- 投稿日:2020-07-06T21:05:15+09:00
python OCRで画像の文字読み取り
tesseractのインストール
$ brew install tesseracttessetacを動かすライブラリをインストール
$ pip3 install pyocr日本語読み取り設定
$ curl -L -o /usr/local/share/tessdata/jpn.traineddata 'https://github.com/tesseract-ocr/tessdata/raw/master/jpn.traineddata'$ tesseract --list-langs List of available languages (4): eng jpn osd snumOCR実装
from PIL import Image import sys import pyocr import pyocr.builders tools = pyocr.get_available_tools() if len(tools) == 0: print("No OCR tool found") sys.exit(1) # The tools are returned in the recommended order of usage tool = tools[0] txt = tool.image_to_string( Image.open('{path}'), lang="jpn", builder=pyocr.builders.TextBuilder(tesseract_layout=6) ) print(txt)
- 投稿日:2020-07-06T20:50:09+09:00
Python Integrity Test
誠実性の性格診断
pythonを使った軽い心理テストをやろうと思います。
windowの表示
#下準備 root=tk.Tk() root.geometry("700x700") root.title("誠実性の性格診断") # 履歴表示のテキストボックスを作成 rirekibox=tk.Text(root,font=("Helvetica",14)) rirekibox.place(x=0,y=500,width=700,height=400)
内容の書き込み
# ラベル anounce_labell=tk.Label(root,text="当てはまるものに1を入力、それ以外は0を",font=(20)) anounce_labell.place(x=20,y=20) qus1_labell = tk.Label(root,text="どちらかというと徹底的にやる方です。",font=(10)) qus1_labell.place(x=20, y=50) qus2_labell = tk.Label(root,text="筋道を立てて物事を考える方です。",font=(10)) qus2_labell.place(x=20, y=80) qus3_labell = tk.Label(root,text="旅行などでは、あらかじめ細かく計画を立てることが多い。",font=(10)) qus3_labell.place(x=20, y=110) qus4_labell = tk.Label(root,text="はっきりとした目標を持って、適切なやり方で取り組みます。",font=(10)) qus4_labell.place(x=20, y=140) qus5_labell = tk.Label(root,text="仕事や勉強には精力的に取り組みます。",font=(10)) qus5_labell.place(x=20, y=170) anounce2_labell=tk.Label(root,text="当てはまらないものに1を入力、それ以外は0を",font=(20)) anounce2_labell.place(x=20,y=210) qus6_labell = tk.Label(root,text="どちらかというと怠惰な方です。",font=(10)) qus6_labell.place(x=20, y=240) qus7_labell = tk.Label(root,text="何かに取り組んでも、中途半端でやめてしまうことが多い。",font=(10)) qus7_labell.place(x=20, y=270) qus8_labell = tk.Label(root,text="どちらかというと三日坊主で、根気がない方です。",font=(10)) qus8_labell.place(x=20, y=300) qus9_labell = tk.Label(root,text="どちらかというと飽きっぽい方です。",font=(10)) qus9_labell.place(x=20, y=330) qus10_labell = tk.Label(root,text="問題を綿密に検討しないで、実行に移すことが多い。",font=(10)) qus10_labell.place(x=20, y=360) qus11_labell = tk.Label(root,text="軽率に物事を決めたり、行動してしまいます。",font=(10)) qus11_labell.place(x=20, y=390) qus12_labell = tk.Label(root,text="物事がうまくいかないと、すぐに投げ出したくなります。",font=(10)) qus12_labell.place(x=20, y=420)
点数をつけるテキストボックスを作成
# テキストボックス editbox1 = tk.Entry(width=2) editbox1.place(x=380, y=55) editbox2 = tk.Entry(width=2) editbox2.place(x=340, y=85) editbox3 = tk.Entry(width=2) editbox3.place(x=550, y=115) editbox4 = tk.Entry(width=2) editbox4.place(x=580, y=145) editbox5 = tk.Entry(width=2) editbox5.place(x=400, y=175) editbox6 = tk.Entry(width=2) editbox6.place(x=320, y=245) editbox7 = tk.Entry(width=2) editbox7.place(x=560, y=275) editbox8 = tk.Entry(width=2) editbox8.place(x=480, y=305) editbox9 = tk.Entry(width=2) editbox9.place(x=350, y=335) editbox10 = tk.Entry(width=2) editbox10.place(x=510, y=365) editbox11 = tk.Entry(width=2) editbox11.place(x=450, y=395) editbox12 = tk.Entry(width=2) editbox12.place(x=520, y=425)
- ラベルと合わせて配置する必要があるので試行錯誤を繰り返す。
採点のプログラムを作る
def ButtonClick(): q1=int(editbox1.get()) q2=int(editbox2.get()) q3=int(editbox3.get()) q4=int(editbox4.get()) q5=int(editbox5.get()) q6=int(editbox6.get()) q7=int(editbox7.get()) q8=int(editbox8.get()) q9=int(editbox9.get()) q10=int(editbox10.get()) q11=int(editbox11.get()) q12=int(editbox12.get()) result=q1+q2+q2+q3+q4+q5+q6+q7+q8+q9+q10+q11+q12 rirekibox.insert(tk.END,"合計:"+str(result)+"\n") if result<=1: rirekibox.insert(tk.END,"診断結果:誠実性は弱い\n"+"何事でも精力的、徹底的に取り組み、細かく計画を立てます。責任感があり、勤勉で、注意深く、実際的な感覚があります。そのため、与えられた仕事は、すばやく正確にやり遂げます。几帳面で、良心的な、規律正しい倹約家です。時間に正確なため、他の人には気むずかしい印象を与えています。") if result>=2 and result<=4: rirekibox.insert(tk.END,"診断結果:まあまあ弱い誠実性\n"+"怠惰で、根気がなく、何事も中途半端でやめてしまいがちです。責任感がなく、気まぐれで、いい加減で、飽きっぽいところがあります。ぼんやりして、軽率に物事を決めたり、行動してしまうことがあります。") if result>=5 and result<=8: rirekibox.insert(tk.END,"診断結果:全体に対して中間ぐらい\n"+"仕事や勉強を特に精力的、徹底的にする方ではありませんが、すべきことは大体人並みに取り組んでいます。特に素早く、能率的、正確にこなす方ではありません。注意深さや、実際的な感覚は標準的です。時間も大体守って、だらしない正確にならないように気をつけています。") if result>=9 and result<=11: rirekibox.insert(tk.END,"診断結果:まあまあ強い誠実性\n"+"何事でも精力的、徹底的に取り組み、細かく計画を立てる方です。責任感があり、勤勉で、注意深く、実際的な感覚があります。そのため、与えられた仕事は、すばやく正確にやり遂げようとします。几帳面で、良心的な倹約家です。時間には正確な方です。") if result==12: rirekibox.insert(tk.END,"診断結果:強い誠実性を持つ人\n"+"何事でも精力的、徹底的に取り組み、細かく計画を立てます。責任感があり、勤勉で、注意深く、実際的な感覚があります。そのため、与えられた仕事は、すばやく正確にやり遂げます。几帳面で、良心的な、規律正しい倹約家です。時間に正確なため、他の人には気むずかしい印象を与えています。")
- 合計点を出すとき文字列と数字を分けなきゃいけないことを忘れて時間がかかってしまった...
実行の様子
まとめると
coding-utf-8 import tkinter as tk import tkinter.messagebox as tmsg def ButtonClick(): q1=int(editbox1.get()) q2=int(editbox2.get()) q3=int(editbox3.get()) q4=int(editbox4.get()) q5=int(editbox5.get()) q6=int(editbox6.get()) q7=int(editbox7.get()) q8=int(editbox8.get()) q9=int(editbox9.get()) q10=int(editbox10.get()) q11=int(editbox11.get()) q12=int(editbox12.get()) result=q1+q2+q2+q3+q4+q5+q6+q7+q8+q9+q10+q11+q12 rirekibox.insert(tk.END,"合計:"+str(result)+"\n") if result<=1: rirekibox.insert(tk.END,"診断結果:誠実性は弱い\n"+"何事でも精力的、徹底的に取り組み、細かく計画を立てます。責任感があり、勤勉で、注意深く、実際的な感覚があります。そのため、与えられた仕事は、すばやく正確にやり遂げます。几帳面で、良心的な、規律正しい倹約家です。時間に正確なため、他の人には気むずかしい印象を与えています。") if result>=2 and result<=4: rirekibox.insert(tk.END,"診断結果:まあまあ弱い誠実性\n"+"怠惰で、根気がなく、何事も中途半端でやめてしまいがちです。責任感がなく、気まぐれで、いい加減で、飽きっぽいところがあります。ぼんやりして、軽率に物事を決めたり、行動してしまうことがあります。") if result>=5 and result<=8: rirekibox.insert(tk.END,"診断結果:全体に対して中間ぐらい\n"+"仕事や勉強を特に精力的、徹底的にする方ではありませんが、すべきことは大体人並みに取り組んでいます。特に素早く、能率的、正確にこなす方ではありません。注意深さや、実際的な感覚は標準的です。時間も大体守って、だらしない正確にならないように気をつけています。") if result>=9 and result<=11: rirekibox.insert(tk.END,"診断結果:まあまあ強い誠実性\n"+"何事でも精力的、徹底的に取り組み、細かく計画を立てる方です。責任感があり、勤勉で、注意深く、実際的な感覚があります。そのため、与えられた仕事は、すばやく正確にやり遂げようとします。几帳面で、良心的な倹約家です。時間には正確な方です。") if result==12: rirekibox.insert(tk.END,"診断結果:強い誠実性を持つ人\n"+"何事でも精力的、徹底的に取り組み、細かく計画を立てます。責任感があり、勤勉で、注意深く、実際的な感覚があります。そのため、与えられた仕事は、すばやく正確にやり遂げます。几帳面で、良心的な、規律正しい倹約家です。時間に正確なため、他の人には気むずかしい印象を与えています。") #下準備 root=tk.Tk() root.geometry("700x700") root.title("誠実性の性格診断") # 履歴表示のテキストボックスを作成 rirekibox=tk.Text(root,font=("Helvetica",14)) rirekibox.place(x=0,y=500,width=700,height=400) # ラベル anounce_labell=tk.Label(root,text="当てはまるものに1を入力、それ以外は0を",font=(20)) anounce_labell.place(x=20,y=20) qus1_labell = tk.Label(root,text="どちらかというと徹底的にやる方です。",font=(10)) qus1_labell.place(x=20, y=50) qus2_labell = tk.Label(root,text="筋道を立てて物事を考える方です。",font=(10)) qus2_labell.place(x=20, y=80) qus3_labell = tk.Label(root,text="旅行などでは、あらかじめ細かく計画を立てることが多い。",font=(10)) qus3_labell.place(x=20, y=110) qus4_labell = tk.Label(root,text="はっきりとした目標を持って、適切なやり方で取り組みます。",font=(10)) qus4_labell.place(x=20, y=140) qus5_labell = tk.Label(root,text="仕事や勉強には精力的に取り組みます。",font=(10)) qus5_labell.place(x=20, y=170) anounce2_labell=tk.Label(root,text="当てはまらないものに1を入力、それ以外は0を",font=(20)) anounce2_labell.place(x=20,y=210) qus6_labell = tk.Label(root,text="どちらかというと怠惰な方です。",font=(10)) qus6_labell.place(x=20, y=240) qus7_labell = tk.Label(root,text="何かに取り組んでも、中途半端でやめてしまうことが多い。",font=(10)) qus7_labell.place(x=20, y=270) qus8_labell = tk.Label(root,text="どちらかというと三日坊主で、根気がない方です。",font=(10)) qus8_labell.place(x=20, y=300) qus9_labell = tk.Label(root,text="どちらかというと飽きっぽい方です。",font=(10)) qus9_labell.place(x=20, y=330) qus10_labell = tk.Label(root,text="問題を綿密に検討しないで、実行に移すことが多い。",font=(10)) qus10_labell.place(x=20, y=360) qus11_labell = tk.Label(root,text="軽率に物事を決めたり、行動してしまいます。",font=(10)) qus11_labell.place(x=20, y=390) qus12_labell = tk.Label(root,text="物事がうまくいかないと、すぐに投げ出したくなります。",font=(10)) qus12_labell.place(x=20, y=420) # テキストボックス editbox1 = tk.Entry(width=2) editbox1.place(x=380, y=55) editbox2 = tk.Entry(width=2) editbox2.place(x=340, y=85) editbox3 = tk.Entry(width=2) editbox3.place(x=550, y=115) editbox4 = tk.Entry(width=2) editbox4.place(x=580, y=145) editbox5 = tk.Entry(width=2) editbox5.place(x=400, y=175) editbox6 = tk.Entry(width=2) editbox6.place(x=320, y=245) editbox7 = tk.Entry(width=2) editbox7.place(x=560, y=275) editbox8 = tk.Entry(width=2) editbox8.place(x=480, y=305) editbox9 = tk.Entry(width=2) editbox9.place(x=350, y=335) editbox10 = tk.Entry(width=2) editbox10.place(x=510, y=365) editbox11 = tk.Entry(width=2) editbox11.place(x=450, y=395) editbox12 = tk.Entry(width=2) editbox12.place(x=520, y=425) # ボタン button1 = tk.Button(root, text="Check", font=("Helvetica"),command=ButtonClick) # command はクリックされたとき実行する関数 button1.place(x=600, y=400) # window表示 root.mainloop()
感想
- どんなものを作るかすごく悩んでいろいろ試したけど、イメージはできてもそれらのほとんどは作れなかった。
- イメージしたものを全部作れるようになりたい。
参考文献
- 心理テスト
- 「いちばんやさしいPython入門教室」大澤文孝[著]

- 投稿日:2020-07-06T20:20:11+09:00
pix2pixをWindows環境で実装(親切なコマンドライン実行結果、ありがちなエラー実例つき)
https://github.com/phillipi/pix2pix
これをWindows環境で実装する際の注意点。
まずファイルのコピー
コマンドラインを開いて以下の命令を打ちます
commandC:\Users\hoge>git clone https://github.com/phillipi/pix2pixresultCloning into 'pix2pix'... remote: Enumerating objects: 22, done. remote: Counting objects: 100% (22/22), done. remote: Compressing objects: 100% (20/20), done. remote: Total 479 (delta 5), reused 8 (delta 2), pack-reused 457R Receiving objects: 100% (479/479), 2.45 MiB | 1.02 MiB/s, done. Resolving deltas: 100% (255/255), done.これでホームディレクトリ(多くの場合は
C:\Users\hoge\)にプロジェクトがコピーされます。
このプロジェクトはlua言語というので書かれているので、親切な人がpythonで実装してくれたファイルもコピーします。commandC:\Users\hoge>git clone https://github.com/tdeboissiere/DeepLearningImplementations.gitresultCloning into 'DeepLearningImplementations'... remote: Enumerating objects: 1616, done. remote: Total 1616 (delta 0), reused 0 (delta 0), pack-reused 1616 eceiving objects: 96% (1552/1616), 50.29 MiB | 1.13 Receiving objects: 100% (1616/1616), 50.34 MiB | 1.10 MiB/s, done. Resolving deltas: 100% (754/754), done.これら2つのファイルをマージします。Linuxだと
rsyncという便利commandがありますが、commandプロンプトだとrobocopyというcommandで同様のことができるそうです。便利!commandrobocopy /E DeepLearningImplementations\pix2pix\ pix2pix\result------------------------------------------------------------------------------- ROBOCOPY :: Windows の堅牢性の高いファイル コピー ------------------------------------------------------------------------------- 開始: 2020年7月6日 18:47:00 コピー元 : C:\Users\hoge\DeepLearningImplementations\pix2pix\ コピー先 : C:\Users\hoge\pix2pix\ ファイル: *.* オプション: *.* /S /E /DCOPY:DA /COPY:DAT /R:1000000 /W:30 ------------------------------------------------------------------------------ (長いので省略) ------------------------------------------------------------------------------ 合計 コピー済み スキップ 不一致 失敗 Extras ディレクトリ: 10 7 3 0 0 5 ファイル: 16 16 0 0 0 9 バイト: 560.2 k 560.2 k 0 0 0 61.4 k 時刻: 0:00:00 0:00:00 0:00:00 0:00:00 速度: 30196526 バイト/秒 速度: 1727.859 MB/分 終了: 2020年7月6日 18:47:01データセットのDL
データセットは個別にDLする必要があります。しかしここで問題があって、
download_dataset.shというファイルを実行してデータセットをダウンロードする必要があるのですが、この形式のファイルはWindows環境では基本的には実行できません。このファイルは単なるスクリプトであり、複数のコマンドが書かれているだけなのですが、そのコマンドがLinux用であるからです。コマンドの中身をWindows形式に書き換える、Cygwinを入れる等色々な対策が考えられますが、ここはミニマルな解決法として、Windows上でLinux環境を再現する手段としてwslを使うことにします。wslについての説明はこちら。wslがインストールされていれば、commandライン上で
wslと打てばLinux環境になります。commandC:\Users\hoge>cd pix2pix C:\Users\hoge\pix2pix>cd datasets C:\Users\hoge\pix2pix\datasets>wsl hoge@DESKTOP-EPGPMTG:/mnt/c/Users/hoge/pix2pix/datasets$ここでファイルを実行すれば解決! ……とはなりません
commandhoge@DESKTOP-EPGPMTG:/mnt/c/Users/hoge/pix2pix/datasets$ bash download_dataset.sh facadesresultdownload_dataset.sh: line 2: $'\r': command not found download_dataset.sh: line 17: syntax error: unexpected end of fileエラーが発生します。これはWindowsとLinuxで改行コードが違うことによる問題です。Windows環境で
git cloneした段階で、クローンされたファイルもWindows仕様になってしまったのです! だからWindows上のLinux環境で走らせるとエラーになる。ややこしい!仕方がないので、Windows上にあるファイルをLinux仕様に変更します。
commandhoge@DESKTOP-EPGPMTG:/mnt/c/Users/hoge/pix2pix/datasets$ tr -d '\r' <download_dataset.sh> win2linux.sh hoge@DESKTOP-EPGPMTG:/mnt/c/Users/hoge/pix2pix/datasets$ bash win2linux.sh facadesしかしまたエラーが出ます。
resultSpecified [facades] win2linux.sh: line 13: wget: command not found tar (child): ./datasets/facades.tar.gz: Cannot open: No such file or directory tar (child): Error is not recoverable: exiting now tar: Child returned status 2 tar: Error is not recoverable: exiting now rm: cannot remove './datasets/facades.tar.gz': No such file or directoryこれは
wgetという命令がインストールされていないためです。インストールします。めんどくさいですね。commandhoge@DESKTOP-EPGPMTG:/mnt/c/Users/hoge/pix2pix/datasets$ sudo apt install wgetresultReading package lists... Done Building dependency tree Reading state information... Done The following packages were automatically installed and are no longer required: liblua5.1-0-dev libreadline-dev libtinfo-dev libtool-bin lua-any lua-sec lua-socket unzip zip Use 'sudo apt autoremove' to remove them. The following NEW packages will be installed: wget 0 upgraded, 1 newly installed, 0 to remove and 81 not upgraded. Need to get 316 kB of archives. After this operation, 954 kB of additional disk space will be used. Get:1 http://archive.ubuntu.com/ubuntu bionic-updates/main amd64 wget amd64 1.19.4-1ubuntu2.2 [316 kB] Fetched 316 kB in 2s (190 kB/s) Selecting previously unselected package wget. (Reading database ... 79492 files and directories currently installed.) Preparing to unpack .../wget_1.19.4-1ubuntu2.2_amd64.deb ... Unpacking wget (1.19.4-1ubuntu2.2) ... Setting up wget (1.19.4-1ubuntu2.2) ... Processing triggers for install-info (6.5.0.dfsg.1-2) ... Processing triggers for man-db (2.8.3-2ubuntu0.1) ...もう一度実行
commandhoge@DESKTOP-EPGPMTG:/mnt/c/Users/hoge/pix2pix/datasets$ bash win2linux.sh facadesresultSpecified [facades] WARNING: timestamping does nothing in combination with -O. See the manual for details. --2020-07-06 19:33:36-- http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/facades.tar.gz Resolving efrosgans.eecs.berkeley.edu (efrosgans.eecs.berkeley.edu)... 128.32.189.73 Connecting to efrosgans.eecs.berkeley.edu (efrosgans.eecs.berkeley.edu)|128.32.189.73|:80... connected. HTTP request sent, awaiting response... 200 OK Length: 30168306 (29M) [application/x-gzip] Saving to: ‘./datasets/facades.tar.gz’ ./datasets/facades.tar.gz 100%[=================================================>] 28.77M 1.13MB/s in 26s (長いので省略)これさえ終わればLinux環境は用済みです。抜け出しましょう。
commandhoge@DESKTOP-EPGPMTG:/mnt/c/Users/hoge/pix2pix/datasets$ exitresultlogout C:\Users\hoge\pix2pix\datasets>データセットの処理
いくつかデータセットの処理が必要です。ここからはpythonを使っていきます。pythonはインストールされていますがバニラの想定です。ここではAnacondaで新たに
pixという環境を用意して再現しています。commandC:\Users\hoge\pix2pix\datasets>cd .. C:\Users\hoge\pix2pix>conda create -n pix python=3.6 (途中省略) (pix) C:\Users\hoge\pix2pix>色々ライブラリが必要なので、インストールしていきます。
command(pix) C:\Users\hoge\pix2pix>conda install numpy (pix) C:\Users\hoge\pix2pix>conda install keras (pix) C:\Users\hoge\pix2pix>conda install -c conda-forge parmap (pix) C:\Users\hoge\pix2pix>conda install matplotlib (pix) C:\Users\hoge\pix2pix>conda install tqdm (pix) C:\Users\hoge\pix2pix>conda install opencv (pix) C:\Users\hoge\pix2pix>conda install h5py (pix) C:\Users\hoge\pix2pix>conda install tensorflow-gpu
parmapとopencvは少し注意が必要です。parmapはcondaではインストールできないので上のコマンドが必要です。ここで焦ってpipでインストールするとAnacondaの環境がめちゃくちゃになったりするらしいです。私は経験がありませんが……。OpenCVはpipではopencv-pythonですがcondaだとopencvでよいらしいです。command(pix) C:\Users\hoge\pix2pix\src\data>python make_dataset.py ../../datasets/datasets/facades/ 3 --img_size 256result100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:01<00:00, 3.22it/s] 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 3.12it/s] 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 3.25it/s]いざ学習
command(pix) C:\Users\hoge\pix2pix\src\data>cd .. (pix) C:\Users\hoge\pix2pix\src>cd model (pix) C:\Users\hoge\pix2pix\src\model>python main.py 64 64 --backend tensorflow --nb_epoch 10resultUsing TensorFlow backend. 2020-07-06 20:02:48.456473: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll 2020-07-06 20:02:51.764917: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library nvcuda.dll 2020-07-06 20:02:51.835745: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1555] Found device 0 with properties: pciBusID: 0000:01:00.0 name: GeForce RTX 2080 SUPER computeCapability: 7.5 coreClock: 1.815GHz coreCount: 48 deviceMemorySize: 8.00GiB deviceMemoryBandwidth: 462.00GiB/s 2020-07-06 20:02:51.842601: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll 2020-07-06 20:02:51.848476: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cublas64_10.dll 2020-07-06 20:02:51.854786: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cufft64_10.dll 2020-07-06 20:02:51.859952: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library curand64_10.dll 2020-07-06 20:02:51.867498: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cusolver64_10.dll 2020-07-06 20:02:51.874415: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cusparse64_10.dll 2020-07-06 20:02:51.884355: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudnn64_7.dll 2020-07-06 20:02:51.887931: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1697] Adding visible gpu devices: 0 2020-07-06 20:02:51.890744: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2 2020-07-06 20:02:51.895380: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1555] Found device 0 with properties: pciBusID: 0000:01:00.0 name: GeForce RTX 2080 SUPER computeCapability: 7.5 coreClock: 1.815GHz coreCount: 48 deviceMemorySize: 8.00GiB deviceMemoryBandwidth: 462.00GiB/s 2020-07-06 20:02:51.901639: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_101.dll 2020-07-06 20:02:51.904406: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cublas64_10.dll 2020-07-06 20:02:51.908518: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cufft64_10.dll 2020-07-06 20:02:51.911282: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library curand64_10.dll 2020-07-06 20:02:51.915043: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cusolver64_10.dll 2020-07-06 20:02:51.918430: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cusparse64_10.dll 2020-07-06 20:02:51.921086: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudnn64_7.dll 2020-07-06 20:02:51.924511: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1697] Adding visible gpu devices: 0 2020-07-06 20:02:52.470406: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1096] Device interconnect StreamExecutor with strength 1 edge matrix: 2020-07-06 20:02:52.474907: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1102] 0 2020-07-06 20:02:52.477401: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] 0: N 2020-07-06 20:02:52.480235: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1241] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 6267 MB memory) -> physical GPU (device: 0, name: GeForce RTX 2080 SUPER, pci bus id: 0000:01:00.0, compute capability: 7.5) Traceback (most recent call last): File "main.py", line 73, in <module> launch_training(**d_params) File "main.py", line 8, in launch_training train.train(**kwargs) File "C:\Users\hoge\pix2pix\src\model\train.py", line 72, in train do_plot) File "C:\Users\hoge\pix2pix\src\model\models.py", line 310, in load model = generator_unet_upsampling(img_dim, bn_mode, model_name=model_name) File "C:\Users\hoge\pix2pix\src\model\models.py", line 92, in generator_unet_upsampling if K.image_dim_ordering() == "channels_first": AttributeError: module 'keras.backend' has no attribute 'image_dim_ordering'怒られました。実はこれは
kerasのバージョンの違いによるもので、新しいkerasだとapi(命令系統)の一部が違っているのです。トラップ! 実はこうなることがわかっていて敢えてバージョン指定をせずにインストールしたのですが、例えばGoogle Colaboratoryだと最新のkerasやtensorflowがビルトインされているので、知らずにこのトラップを踏む人がいたら可哀想だなと思って実演(?)しました。余談ですが、tensorflowでcontribという命令がないぞと怒られる時もバージョンダウンでなんとかなるっぽいです。という訳でバージョンダウンします。
command(pix) C:\Users\hoge\pix2pix\src\model>conda install keras==2.0.8resultCollecting package metadata (current_repodata.json): done Solving environment: failed with initial frozen solve. Retrying with flexible solve. Collecting package metadata (repodata.json): done Solving environment: done ## Package Plan ## environment location: C:\Users\hoge\Anaconda3\envs\pix added / updated specs: - keras==2.0.8 The following packages will be REMOVED: keras-applications-1.0.8-py_0 keras-base-2.3.1-py36_0 keras-preprocessing-1.1.0-py_1 tensorflow-estimator-2.1.0-pyhd54b08b_0 The following packages will be SUPERSEDED by a higher-priority channel: tensorboard pkgs/main/noarch::tensorboard-2.2.1-p~ --> pkgs/main/win-64::tensorboard-1.10.0-py36he025d50_0 The following packages will be DOWNGRADED: cudatoolkit 10.1.243-h74a9793_0 --> 9.0-1 cudnn 7.6.5-cuda10.1_0 --> 7.6.5-cuda9.0_0 keras 2.3.1-0 --> 2.0.8-py36h65e7a35_0 tensorflow 2.1.0-gpu_py36h3346743_0 --> 1.10.0-gpu_py36h3514669_0 tensorflow-base 2.1.0-gpu_py36h55f5790_0 --> 1.10.0-gpu_py36h6e53903_0 tensorflow-gpu 2.1.0-h0d30ee6_0 --> 1.10.0-hf154084_0 Proceed ([y]/n)? y Preparing transaction: done Verifying transaction: done Executing transaction: done関連するtensorflow(それもgpu対応!)のバージョン合わせまでしっかりやってくれていることがわかります。では改めて実行。
command(pix) C:\Users\hoge\pix2pix\src\model>python main.py 64 64 --backend tensorflow --nb_epoch 10result(中略) Start training 2020-07-06 20:11:14.114015: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2 2020-07-06 20:11:14.256531: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1405] Found device 0 with properties: name: GeForce RTX 2080 SUPER major: 7 minor: 5 memoryClockRate(GHz): 1.815 pciBusID: 0000:01:00.0 totalMemory: 8.00GiB freeMemory: 6.55GiB 2020-07-06 20:11:14.264273: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1484] Adding visible gpu devices: 0 2020-07-06 20:11:14.649123: I tensorflow/core/common_runtime/gpu/gpu_device.cc:965] Device interconnect StreamExecutor with strength 1 edge matrix: 2020-07-06 20:11:14.653675: I tensorflow/core/common_runtime/gpu/gpu_device.cc:971] 0 2020-07-06 20:11:14.656771: I tensorflow/core/common_runtime/gpu/gpu_device.cc:984] 0: N 2020-07-06 20:11:14.660571: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1097] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 6286 MB memory) -> physical GPU (device: 0, name: GeForce RTX 2080 SUPER, pci bus id: 0000:01:00.0, compute capability: 7.5) 396/400 [============================>.] - ETA: 0s - D logloss: 0.7649 - G tot: 12.9429 - G L1: 1.1987 - G logloss: 0.9557 Epoch 1/10, Time: 85.63616681098938 396/400 [============================>.] - ETA: 0s - D logloss: 0.7681 - G tot: 12.1516 - G L1: 1.1377 - G logloss: 0.7749 Epoch 2/10, Time: 80.52165269851685 396/400 [============================>.] - ETA: 0s - D logloss: 0.7439 - G tot: 11.6468 - G L1: 1.0932 - G logloss: 0.7151 Epoch 3/10, Time: 28.542045831680298 396/400 [============================>.] - ETA: 0s - D logloss: 0.7270 - G tot: 11.7284 - G L1: 1.0991 - G logloss: 0.7370 Epoch 4/10, Time: 28.93921661376953 396/400 [============================>.] - ETA: 0s - D logloss: 0.7150 - G tot: 11.4890 - G L1: 1.0733 - G logloss: 0.7556 Epoch 5/10, Time: 28.971989393234253 396/400 [============================>.] - ETA: 0s - D logloss: 0.7448 - G tot: 11.6123 - G L1: 1.0889 - G logloss: 0.7231 Epoch 6/10, Time: 29.158592700958252 396/400 [============================>.] - ETA: 0s - D logloss: 0.7278 - G tot: 11.3660 - G L1: 1.0649 - G logloss: 0.7168 Epoch 7/10, Time: 28.717032432556152 396/400 [============================>.] - ETA: 0s - D logloss: 0.7282 - G tot: 11.4358 - G L1: 1.0718 - G logloss: 0.7182 Epoch 8/10, Time: 29.007369995117188 396/400 [============================>.] - ETA: 0s - D logloss: 0.7159 - G tot: 11.3449 - G L1: 1.0643 - G logloss: 0.7019 Epoch 9/10, Time: 29.249063730239868 396/400 [============================>.] - ETA: 0s - D logloss: 0.7063 - G tot: 10.9784 - G L1: 1.0294 - G logloss: 0.6847 Epoch 10/10, Time: 29.128608226776123無事にサンプルを走らせることができました。やったね!
追記
この後、別のパソコンで即席で環境を作ろうとしたのですが、同じ手順でやると、GPUを認識はするのですが学習の直前に
CUDNN_STATUS_ALLOC_FAILEDなるエラーが出てきて止まるようになりました。結論的にはNVIDIAからGPUドライバを最新にすると直りました。参考になったページ(感謝)
- 投稿日:2020-07-06T20:20:01+09:00
使いやすいPythonツール5選 | 仕事の能率を高める
元記事:https://jp.scrapestorm.com/tutorial/5-easy-to-use-python-tools/
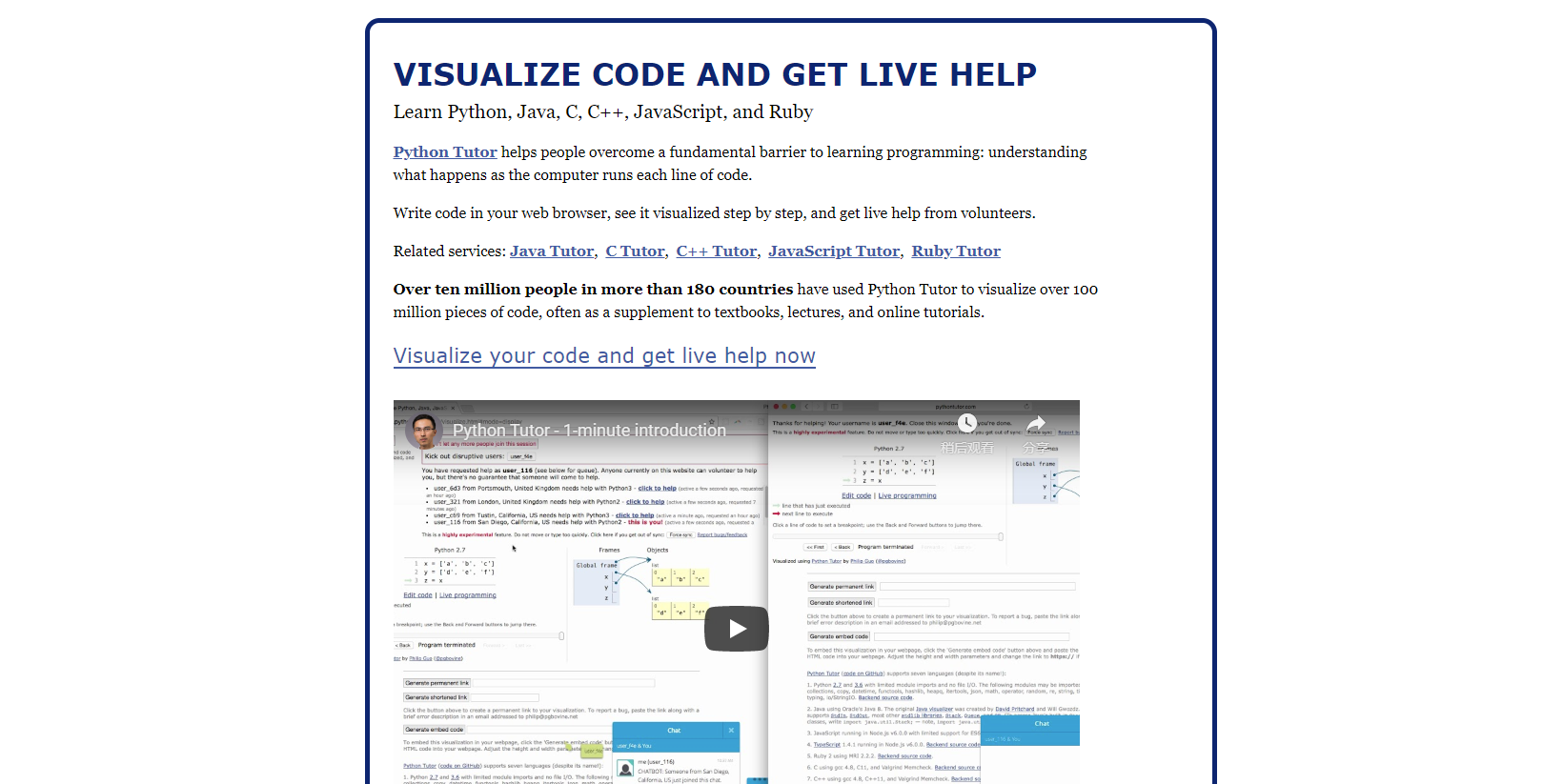
事を行うにはまず十分な準備が必要です。優れたツールは、かなり仕事の能率を高め、開発者のアイデアをより便利に実現するのに役立ちます。本文は幾つかの開発にたくさんの便利さをもたらすツールを紹介します。1.Python Tutor
Python Tutorは、Philip Guoが開発した無料の教育ツールです。これは、プログラミング学習の基本的な障害を克服し、プログラムが実行されたときのコンピューターのソースコードの各行のプロセスを理解するのに役立ちます。このツールを使用すると、Webブラウザで直接Pythonコードを編集し、プログラムを徐々に視覚的に実行できます。メモリ内でのコードの実行方法がわからない場合は、視覚的に実行するためにそれをTutorにコピーして、理解を深めることができます。
URLリンク:http://www.pythontutor.com/
2.IPython
IPythonは特別なPythonインタラクティブshellです。IPythonは、自動変数補完、自動インデント、bashシェルコマンド、および多くの組み込み関数をサポートしており、科学計算やインタラクティブな視覚化に最適なプラットフォームでもあります。
URLリンク:https://ipython.org/
3.Jupyter Notebook
Jupyter Notebookはドラフトブックのようなもので、テキスト注釈、数式、コード、可視化コンテンツを組み合わせて、Webページとして表示して、ドキュメントを共有しやすいにします。データ分析と機械学習に不可欠なツールです。
URLリンク:http://jupyter.org/
4.Anaconda
Pythonは優れていますが、さまざまなパッケージ管理やPythonバージョンの問題が常に発生する可能性があります。特に、Windowsプラットフォーム上の多くのパッケージは正常にインストールできません。これらの問題を解決するために、Anacondaが登場しました。Anocondaには、パッケージ管理ツールとPython管理環境が含まれており、データ分析の標準でもある、一般的に使用される多数のデータサイエンスパッケージが付属しています。
URLリンク:https://www.anaconda.com/
5.Skulpt
Sculpt SculptはJavaScriptで実装されたオンラインのpython実行環境です。ブラウザでPythonコードを簡単に実行できます。CodeMirrorエディターと組み合わせて、基本的なオンラインPython編集および実行環境を実現します。
URLリンク:http://www.skulpt.org/


- 投稿日:2020-07-06T19:25:32+09:00
Pythonでプログラミング Flask編
Pythonでプログラミング
背景
Pythonで作ったInsert分作成ツールをWeb化する。
理由:現在のものでは使いづらいため。対象ユーザー(例)
自宅でポートフォリオ作成のためにWebサービスを作っていて
データ作成のためにInsert作成をツールで便利に使いたい人。非対象ユーザー
現場で使えないと0だと思っている人。
レビューとかお客さんがとか言って開発者にのしかかってくる人。
進捗進捗ばかり言って日になんども衝動的にくる人。
クレームばかりつけてくる人。INPUT Python処理(GITHUB)
https://github.com/noikedan/INSERTSQL/tree/master/pythonInsrtSql
原案
・ファイルをアップロードする。
・SQLを作る。
・ファイルに書き込む。
・ファイルをダウンロードする。環境
FLASK
SQL文はpostgresql を想定している。調査
ファイルアップロードのやり方は下記のアドレスに従うことにする。
https://flask.palletsprojects.com/en/1.1.x/quickstart/画像
アウトプットソース
https://github.com/noikedan/flask_app/tree/develop
ソースコード
Index.html <html> <head> <tilte>Insert文作成ツール</tilte> </head> <body> <form method="post" action="/todos/uploader" enctype = "multipart/form-data"> <input type="file" name="file" /> <input type="submit" value="Create" /> </form> <p> <a href="{{ url_for('.download_file') }}">Download</a> </p> </body> </html> InsertApp.py from flask import Flask, render_template from flask import request,send_file app = Flask(__name__) @app.route('/todos/uploader', methods=['GET', 'POST']) def upload_file(): if request.method == 'POST': f = request.files['file'] f.save(f.filename) input = './' + f.filename output = './output.txt' table = input.split('/')[-1].split('.')[0] with open(input, encoding='utf-8') as f: with open(output, 'w', encoding='utf-8') as g: contents = "Insert into " + table + "(" i = 0 for row in f: if i == 0: typeList = row.rstrip().split(',') if i == 1: columList = row.rstrip().split(',') k = 0 for c in columList: if len(columList) == k + 1: contents = contents + c + 'VALUES (' else: contents = contents + c + ',' k = k + 1 basecontets = contents if i >= 2: j = 0 for r in row.rstrip().split(','): if not 'INTEGER' in typeList[j]: r = "'" + r + "'" if len(row.rstrip().split(',')) == j + 1: basecontets = basecontets + r else: basecontets = basecontets + r + ',' j = j + 1 basecontets = basecontets + ');' + '\n' g.write(basecontets) basecontets = contents i = i + 1 print("作成完了しました") return render_template('index.html') @app.route('/download') def download_file(): path = './output.txt' return send_file(path, as_attachment=True) @app.route('/') def index(): return render_template('index.html')


- 投稿日:2020-07-06T17:38:10+09:00
Pandas で○○したい
Pandas で「あれ、〇〇したいときどうすれば良いんだっけ?」となることが多いので、用途別にまとめます。
前提
今回のサンプルコードでは、
Kaggle社が提供しているタイタニック号の生存者リスト(train.csv)を
pandas.read_csv()で読み込んで使用します。Titanic: Machine Learning from Disaster | Kaggle
import pandas as pd df = pd.read_csv('train.csv')pandas.read_csv — pandas 1.0.5 documentation
統計情報を出力したい
df.describe()PassengerId Survived Pclass Age SibSp Parch Fare count 891.000000 891.000000 891.000000 714.000000 891.000000 891.000000 891.000000 mean 446.000000 0.383838 2.308642 29.699118 0.523008 0.381594 32.204208 std 257.353842 0.486592 0.836071 14.526497 1.102743 0.806057 49.693429 min 1.000000 0.000000 1.000000 0.420000 0.000000 0.000000 0.000000 25% 223.500000 0.000000 2.000000 20.125000 0.000000 0.000000 7.910400 50% 446.000000 0.000000 3.000000 28.000000 0.000000 0.000000 14.454200 75% 668.500000 1.000000 3.000000 38.000000 1.000000 0.000000 31.000000 max 891.000000 1.000000 3.000000 80.000000 8.000000 6.000000 512.329200# 出力するカラムを絞る df['Age'].describe()count 714.000000 mean 29.699118 std 14.526497 min 0.420000 25% 20.125000 50% 28.000000 75% 38.000000 max 80.000000 Name: Age, dtype: float64pandas.DataFrame.describe — pandas 1.0.5 documentation
データの件数を調べたい
df['Age'].count()714
None、NaN、NaT以外の値が含まれている行数/列数を調べることができる。
- pandas.DataFrame.count — pandas 1.0.5 documentationデータを絞り込みたい
# 20 < Age < 40 の行を取り出す df[(20 < df['Age']) & (df['Age'] < 40)].head()PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked 0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C 2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 S 4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 NaN S複数のAND/OR条件で絞り込みたい場合は、
df[(A) & (B)]のように、条件を()で囲んで指定する。
- Python Pandas: Boolean indexing on multiple columns - Stack Overflowカテゴリー化データを数値に変換したい
# Embarked(C, Q, S)を数値(1, 2, 3)に変換 df['Embarked'] = df['Embarked'].map({'C': 1, 'Q': 2, 'S': 3})PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked 0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN 3.0 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 1.0 2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN 3.0 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 3.0 4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 NaN 3.0pandas.Series.map — pandas 1.0.4 documentation
列名を変更したい
# Sex(female, male)を数値(0, 1)に変換し、列名(Sex)をMaleに変更 df['Sex'] = df['Sex'].map({'female': 0, 'male': 1}) df = df.rename(columns={'Sex': 'Male'})PassengerId Survived Pclass Name Male Age SibSp Parch Ticket Fare Cabin Embarked 0 1 0 3 Braund, Mr. Owen Harris 1 22.0 1 0 A/5 21171 7.2500 NaN 3.0 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... 0 38.0 1 0 PC 17599 71.2833 C85 1.0 2 3 1 3 Heikkinen, Miss. Laina 0 26.0 0 0 STON/O2. 3101282 7.9250 NaN 3.0 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) 0 35.0 1 0 113803 53.1000 C123 3.0 4 5 0 3 Allen, Mr. William Henry 1 35.0 0 0 373450 8.0500 NaN 3.0pandas.DataFrame.rename — pandas 1.0.4 documentation
列名の一覧を持つ配列を渡せば、全ての列名を一括で変更することもできる。
pd.DataFrame({'c': [1, 2], 'd': [10, 20]}).columns = ['a', 'b']a b 0 1 10 1 2 20python - Renaming columns in pandas - Stack Overflow
欠損値の数を列ごとに確認したい
df.isnull().sum()PassengerId 0 Survived 0 Pclass 0 Name 0 Male 0 Age 177 SibSp 0 Parch 0 Ticket 0 Fare 0 Cabin 687 Embarked 2 dtype: int64pandas.isnull — pandas 1.0.4 documentation
pandas.DataFrame.sum — pandas 1.0.4 documentation欠損値を除外したい
# 欠損値を含む行全てを除外 df_dn = df.dropna() df_dn.count()PassengerId 183 Survived 183 Pclass 183 Name 183 Male 183 Age 183 SibSp 183 Parch 183 Ticket 183 Fare 183 Cabin 183 Embarked 183 dtype: int64pandas.DataFrame.dropna — pandas 1.0.5 documentation
指定した列を取り出したい
# Survived と Age 列を取り出す df[['Survived', 'Age']]Survived Age 0 0 22.0 1 1 38.0 2 1 26.0 3 1 35.0 4 0 35.0Indexing and selecting data — pandas 1.0.4 documentation
pandasで任意の位置の値を取得・変更するat, iat, loc, iloc | note.nkmk.me指定した列を除外したい
df_dn = df.drop('Cabin', axis='columns')PassengerId Survived Pclass Name Male Age SibSp Parch Ticket Fare Embarked 0 1 0 3 Braund, Mr. Owen Harris 1 22.0 1 0 A/5 21171 7.2500 3.0 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... 0 38.0 1 0 PC 17599 71.2833 1.0 2 3 1 3 Heikkinen, Miss. Laina 0 26.0 0 0 STON/O2. 3101282 7.9250 3.0 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) 0 35.0 1 0 113803 53.1000 3.0 4 5 0 3 Allen, Mr. William Henry 1 35.0 0 0 373450 8.0500 3.0pandas.DataFrame.dropna — pandas 1.0.5 documentation
行/列の値に関数を適用し、新しい行/列を作りたい
import re # 敬称を抽出する関数 def getTitle(row): name = row['Name'] p = re.compile('.*\ (.*)\.\ .*') surname = p.search(name) return surname.group(1) df['Title'] = df.apply(getTitle, axis='columns')PassengerId Survived Pclass Name Male Age SibSp Parch Ticket Fare Cabin Embarked Title 0 1 0 3 Braund, Mr. Owen Harris 1 22.0 1 0 A/5 21171 7.2500 NaN 3.0 Mr 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... 0 38.0 1 0 PC 17599 71.2833 C85 1.0 Mrs 2 3 1 3 Heikkinen, Miss. Laina 0 26.0 0 0 STON/O2. 3101282 7.9250 NaN 3.0 Miss 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) 0 35.0 1 0 113803 53.1000 C123 3.0 Mrs 4 5 0 3 Allen, Mr. William Henry 1 35.0 0 0 373450 8.0500 NaN 3.0 Mrpandas.DataFrame.apply — pandas 1.0.5 documentation
カテゴリごとの平均を計算したい
# 敬称ごとの平均年齢を求める df.groupby('Title').mean()['Age']Title Capt 70.000000 Col 58.000000 Countess 33.000000 Don 40.000000 Dr 42.000000 Jonkheer 38.000000 L 54.000000 Lady 48.000000 Major 48.500000 Master 4.574167 Miss 21.773973 Mlle 24.000000 Mme 24.000000 Mr 32.368090 Mrs 35.728972 Ms 28.000000 Rev 43.166667 Sir 49.000000 Name: Age, dtype: float64
df.groupby('Title').count()とすると、敬称ごとのデータ件数を求めることも出来る。
Pandas の groupby の使い方 - Qiita値で行をソートしたい
df.sort_values(by='Age')PassengerId Survived Pclass Name Male Age SibSp Parch Ticket Fare Cabin Embarked Title AgeMean 803 804 1 3 Thomas, Master. Assad Alexander 1 0.42 0 1 2625 8.5167 NaN 1.0 Master NaN 755 756 1 2 Hamalainen, Master. Viljo 1 0.67 1 1 250649 14.5000 NaN 3.0 Master NaN 644 645 1 3 Baclini, Miss. Eugenie 0 0.75 2 1 2666 19.2583 NaN 1.0 Miss NaN 469 470 1 3 Baclini, Miss. Helene Barbara 0 0.75 2 1 2666 19.2583 NaN 1.0 Miss NaN 78 79 1 2 Caldwell, Master. Alden Gates 1 0.83 0 2 248738 29.0000 NaN 3.0 Master NaNpandas.DataFrame.sort_values — pandas 1.0.5 documentation
通常
sort_values()を実行した DaraFrame は変更されず、返り値がソートされた状態で得られる。
inplace=Trueを指定すると、sort_values()を実行した DataFrame がソートされ、返り値はNoneになる。列に含まれているユニークな値を調べたい
df['Survived'].unique()array([0, 1], dtype=int64)pandas.unique — pandas 1.0.5 documentation
特定の文字列を含む行を取り出したい
df[df['Name'].str.contains('Thomas')]PassengerId Survived Pclass Name Male Age SibSp Parch Ticket Fare Cabin Embarked Title AgeMean 149 150 0 2 Byles, Rev. Thomas Roussel Davids 1 42.00 0 0 244310 13.0000 NaN 3.0 Rev NaN 151 152 1 1 Pears, Mrs. Thomas (Edith Wearne) 0 22.00 1 0 113776 66.6000 C2 3.0 Mrs NaN 159 160 0 3 Sage, Master. Thomas Henry 1 NaN 8 2 CA. 2343 69.5500 NaN 3.0 Master NaN 186 187 1 3 O'Brien, Mrs. Thomas (Johanna "Hannah" Godfrey) 0 NaN 1 0 370365 15.5000 NaN 2.0 Mrs NaN 252 253 0 1 Stead, Mr. William Thomas 1 62.00 0 0 113514 26.5500 C87 3.0 Mr NaNpandas.Series.str.contains — pandas 1.0.5 documentation
python - How to filter rows containing a string pattern from a Pandas dataframe - Stack Overflow特定の文字列を含まない値を取り出したい場合は
~演算子を使う。df[~df['Name'].str.contains('Thomas')]PassengerId Survived Pclass Name Male Age SibSp Parch Ticket Fare Cabin Embarked Title AgeMean 0 1 0 3 Braund, Mr. Owen Harris 1 22.0 1 0 A/5 21171 7.2500 NaN 3.0 Mr NaN 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... 0 38.0 1 0 PC 17599 71.2833 C85 1.0 Mrs NaN 2 3 1 3 Heikkinen, Miss. Laina 0 26.0 0 0 STON/O2. 3101282 7.9250 NaN 3.0 Miss NaN 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) 0 35.0 1 0 113803 53.1000 C123 3.0 Mrs NaN 4 5 0 3 Allen, Mr. William Henry 1 35.0 0 0 373450 8.0500 NaN 3.0 Mr NaNpython - Search for "does-not-contain" on a DataFrame in pandas - Stack Overflow
データフレーム表示時に色をつけたい
# 値が "Mr" のカラムの背景色を黄色にする df.style.apply(lambda x: ['background-color: yellow' if v == 'Mr' else '' for v in x])PassengerId Survived Pclass Name Male Age SibSp Parch Ticket Fare Cabin Embarked Title AgeMean 0 1 0 3 Braund, Mr. Owen Harris 1 22.000000 1 0 A/5 21171 7.250000 nan 3.000000 Mr nan 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Thayer) 0 38.000000 1 0 PC 17599 71.283300 C85 1.000000 Mrs nan 2 3 1 3 Heikkinen, Miss. Laina 0 26.000000 0 0 STON/O2. 3101282 7.925000 nan 3.000000 Miss nan 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) 0 35.000000 1 0 113803 53.100000 C123 3.000000 Mrs nan 4 5 0 3 Allen, Mr. William Henry 1 35.000000 0 0 373450 8.050000 nan 3.000000 Mr nanJupyter Notebook で開くと、該当カラムが背景色付きで表示される。
GitHub 上で Jupyter Notebook を開くと、背景色が付かないので注意。pandas.io.formats.style.Styler.apply — pandas 1.0.5 documentation
python - Pandas style function to highlight specific columns - Stack OverflowCSV 形式で出力したい
df.to_csv('output.csv', index=False)インデックス(行番号)を含みたくない場合は
index=Falseを指定する。
pandas.DataFrame.to_csv — pandas 1.0.5 documentationファイル最終行に改行を入れたくない場合、最終行のみ
line_terminator=""を渡す
python - How to stop writing a blank line at the end of csv file - pandas - Stack Overflow
- 投稿日:2020-07-06T17:22:54+09:00
2020年版/CUDAを有効にしてDLIBをインストールする方法
概要
CUDA, cuDNNを有効にしてdlibをインストールすることに成功したので備忘録的に記録
dlibのバージョンによってインストール方法が異なり、ネットに転がってる記事の通りにやってもCUDAが有効にならない場合がある
インストール方法はdlibが更新されるたびに変わるので、うまくいかなくなったらdlib公式のHow to compileを確認しよう
以下の手順は2020/7/6時点でのインストール方法である環境
- OS:Ubuntu18.06
- GPU:RTX2060
- CUDA:10.2
- cuDNN:7.6.5
- dlib:19.20
- python:3.7.6
インストール
CUDA, cuDNNをインストール
まだCUDA、cuDNNともにインストールしていない時は先に2つをインストールする。
## まずCUDAをインストール $ sudo apt update -y $ sudo apt upgrade -y $ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin $ sudo mv cuda-ubuntu1804.pin /etc/apt/preferences.d/cuda-repository-pin-600 $ wget http://developer.download.nvidia.com/compute/cuda/10.2/Prod/local_installers/cuda-repo-ubuntu1804-10-2-local-10.2.89-440.33.01_1.0-1_amd64.deb $ sudo apt-key add /var/cuda-repo-10-2-local-10.2.89-440.33.01/7fa2af80.pub $ sudo apt-get -y update $ sudo apt-get -y install cuda $ echo "export PATH=/usr/local/cuda-10.2/bin${PATH:+:${PATH}}" >> ~/.bashrc $ echo "export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}" >> ~/.bashrcここで一旦再起動
起動後、以下のコマンドにてCUDAがインストールされていることを確認$ nvcc -V nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2019 NVIDIA Corporation Built on Wed_Oct_23_19:24:38_PDT_2019 Cuda compilation tools, release 10.2, V10.2.89確認できればCUDAのインストール完了
続いてcuDNNをインストールする# cuDNNインストール $ wget https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/libcudnn7_7.6.5.32-1+cuda10.2_amd64.deb $ wget https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/libcudnn7-dev_7.6.5.32-1+cuda10.2_amd64.deb $ sudo dpkg -i libcudnn7_7.6.5.32-1+cuda10.2_amd64.deb $ sudo dpkg -i libcudnn7-dev_7.6.5.32-1+cuda10.2_amd64.debここで一旦再起動
以上でCUDAおよびcuDNNのインストールは完了とする事前に必要なcmakeをインストール
$ sudo apt -y install cmakedlibのダウンロード
dlib公式を確認して最新のソースコードをダウンロードしよう
$ wget http://dlib.net/files/dlib-19.20.tar.bz2 $ tar -jxvf dlib-19.20.tar.bz2dlibインストール
dlib-19.20フォルダに入っているsetup.pyを使ってインストールする
dlib-19.20ではmakeコマンドを使ってインストールする必要はない
また、-yes USE_AVX_INSTRUCTIONS --yes DLIB_USE_CUDAオプションをつける必要があるという記事が多く出回っているが、
v.19.20ではyesオプションが廃止となっており、デフォルトで有効になっているため、オプションをつける必要がなくなった。$ cd dlib-19.20 $ python3 setup.py installsetup.py実行時にCUDAとcuDNNが有効になっているか確認する。
以下のメッセージが表示されない場合、CUDA、cuDNNが無効となった状態でインストールされてしまう。-- Found CUDA: /usr/local/cuda-10.2 (found suitable version "10.2", minimum required is "7.5") -- Looking for cuDNN install... -- Found cuDNN: /usr/lib/x86_64-linux-gnu/libcudnn.so -- Building a CUDA test project to see if your compiler is compatible with CUDA... -- Checking if you have the right version of cuDNN installed. -- Enabling CUDA support for dlib. DLIB WILL USE CUDAまた、
No BLAS library found so using dlib's built in BLASという警告が表示されるが、これは無視しても良い(多分)確認
pythonを対話モードで起動し、DLIB_USE_CUDAがTrueとなっていれば、無事終了
ここでFalseになっているとCUDA,cuDNNが適用されずにインストールされている。$ python3 Python 3.7.6 (default, Jan 8 2020, 19:59:22) Type "help", "copyright", "credits" or "license" for more information. >>> import dlib >>> dlib.DLIB_USE_CUDA True
- 投稿日:2020-07-06T17:08:54+09:00
[Hyperledger Iroha]Pythonのlibraryを使ってアカウントを作成する
記事の内容
Hyperledger IrohaのPythonライブラリを使ってアカウントを作成します。
準備
アカウントのキーペア作成に必要になるライブラリをインストールしておきます
pip install ed25519実装
アカウントの作成
早速アカウントを作成するコードです
create_account.pyfrom iroha import Iroha, IrohaCrypto, IrohaGrpc import ed25519 import iroha_config # irohaへの接続情報 net = IrohaGrpc(iroha_config.IROHA_HOST) iroha = Iroha(iroha_config.ADMIN_ACCOUNT) # キーペアの作成 signing_key, verifying_key = ed25519.create_keypair() # 作成したキーペアを保存 open("iroha@test.prib","wb").write(signing_key.to_ascii(encoding="hex")) open("iroha@test.pub","wb").write(verifying_key.to_ascii(encoding="hex")) # バイナリから16進数に変換 vkey_hex = verifying_key.to_ascii(encoding="hex") # Transactionの作成 transfer_tx = iroha.transaction( [iroha.command( 'CreateAccount', account_name ='iroha', domain_id = 'test', public_key = vkey_hex )] ) # Transactionの署名 IrohaCrypto.sign_transaction(transfer_tx, iroha_config.ADMIN_PRIV_KEY) # Transactionの送信 net.send_tx(transfer_tx) # 結果の確認 for status in net.tx_status_stream(transfer_tx): print(status)iroha-cliを使ってアカウントを作成すると鍵情報も一緒に作成されますが、ライブラリからアカウントを作成する場合は自分で作成する必要があります。
作成には「ed25519」というライブラリを使っています。実行結果
以下の結果が出力されれば成功です
('ENOUGH_SIGNATURES_COLLECTED', 9, 0) ('STATEFUL_VALIDATION_SUCCESS', 3, 0) ('COMMITTED', 5, 0)ブロックの中身も確認してみます。
{ "blockV1": { "payload": { "transactions": [ { "payload": { "reducedPayload": { "commands": [ { "createAccount": { "accountName": "iroha", "domainId": "test", "publicKey": "efdc215eab6dd2c4435d370da73e4b88350e1fed9d39afed503fcbee985fce1f" } } ], "creatorAccountId": "admin@test", "createdTime": "1594016319157", "quorum": 1 } }, "signatures": [ { "publicKey": "313a07e6384776ed95447710d15e59148473ccfc052a681317a72a69f2a49910", "signature": "429bf3ae70b60d31ab3fc3c15fa11cb8155b6a824f831652c1c46068feaeb866846b8048e0959cbcbeed532423f050e77d2fe192ea90d0827a6f1489bf67ec0a" } ] } ], "height": "4", "prevBlockHash": "039c70e4d990318c7373a59b14f39c9dd6199b949f1ba74b28c44d100adf8218", "createdTime": "1594016319568" }, "signatures": [ { "publicKey": "bddd58404d1315e0eb27902c5d7c8eb0602c16238f005773df406bc191308929", "signature": "e2a7dc68e837fc4bdefc2e7f60131661c9567f0f2b19af7e0069ced69a4054f7402fb93abd38e96aef850d865c760f3983632654db61fc0ab0181224e44fb20d" } ] } }createAccountコマンドのトランザクションがブロックに取り込まれていることを確認できました。
同一ユーザー名、同一ドメインを登録できないので同じ内容で実行すると以下の結果となり、トランザクションがリジェクトされています。
('ENOUGH_SIGNATURES_COLLECTED', 9, 0) ('STATEFUL_VALIDATION_FAILED', 2, 4) ('REJECTED', 4, 0){ "blockV1": { "payload": { "height": "5", "prevBlockHash": "fe0c9b0e59efe7de5f67710ad66fdb5aab3f1e41b79bed8eda13f9c3d122d8cf", "createdTime": "1594017524600", "rejectedTransactionsHashes": [ "ef17d5f4e82c7e9690676110b3d84c9ff721fd2ac78678e1b893cf3c024c5156" ] }, "signatures": [ { "publicKey": "bddd58404d1315e0eb27902c5d7c8eb0602c16238f005773df406bc191308929", "signature": "0ea48cca0b0db7ee525edafa961e6f2469989cbbb1346cc31e140a98b8260693ef939fe30bc9ef10a5ab4d0a6e7ffeccc1cc15124cb472be1d4f658b5aac1b0d" } ] } }アカウント情報の取得
get_account.pyfrom iroha import Iroha, IrohaCrypto, IrohaGrpc import iroha_config net = IrohaGrpc(iroha_config.IROHA_HOST) iroha = Iroha(iroha_config.ADMIN_ACCOUNT) admin_priv_key = iroha_config.ADMIN_PRIV_KEY # Queryの作成 get_block_query = iroha.query( 'GetAccount', account_id = 'iroha@test' ) # Queryへ署名 IrohaCrypto.sign_query(get_block_query, admin_priv_key) # Queryの送信 response = net.send_query(get_block_query) # Responseの出力 print(response)アカウント情報の取得方法はトランザクション送信と基本的には流れは同じです。
送信の内容がコマンドではなくクエリになるだけです実行結果
account_response { account { account_id: "iroha@test" domain_id: "test" quorum: 1 json_data: "{}" } account_roles: "user" } query_hash: "a07e90ca85d9c4f0bd1b12ba8cd9c11886729fcd50ee4c2fc50e6c9a27047a2e"実行結果が取得できました
参考
・Iroha API Reference #create-account
・Iroha API Reference #get-account
関連記事
- 投稿日:2020-07-06T16:38:58+09:00
クラスメソッドとスタティックメソッドのいろいろ
はじめに
この記事では「クラスメソッド」とは何かについて書いていきます。
前回までの記事
↓
↓
↓
pythonのプロパティのあれこれクラスメソッドとは
簡単に一言で言えば、「クラス変数のようにクラスから直接使用できるメソッド」のことです。
(メソッドとはクラス内の関数のことです)@classmethod def メソッド名(cls, 引数1, 引数2, ...):これがクラスメソッドの形です。今まで見てきた関数とは違う部分がいくつかあるので、見分けがつきやすいと思います。
①インスタンス(実体)が存在しないので、自分自身を表す'self'は用意されません。
②'self'の代わりに'cls'という引数が用意され、クラスメソッドが保管されているクラスのオブジェクトが代入される。クラスメソッドを呼び出す際は、クラスから直接呼び出すことが可能です。
#クラスメソッドの呼び出し クラス名.クラスメソッド名() #通常のメソッドの場合 hello = クラス名 #インスタンス作成 hello.メソッド名 #メソッドの呼び出し呼び出しの部分も違うので、使う際には注意してください。
クラス変数
先ほどクラスメソッドのことを、「クラス変数のようにクラスから直接使用できるメソッド」と言いました。
しかしそもそもクラス変数が何かわからないと、何のことかさっぱりだと思います
クラス変数とは下のコードの「message」の部分です。class Lesson: message = 'OK' def print(self): print(Lesson.message) le = Lesson() #インスタンス作成 le.print() #printメソッド呼び出し Lesson.message = 'Welcome!' #'message'変数の中身を'Welcome!'に変更 le.print() #再び'printメソッド'呼び出し print(Lesson.message) #クラス変数messsageも呼び出し普通の変数とパッと見変わらないので、そんなに難しくないと思います。
一番最後をみてもらえればわかるように、インスタンスを作成しないでも、クラスから直接呼び出すことができます。
メソッド(defがついているもの)と違い、インスタンスではなくクラスそのものに値を保管しているからです。そしてクラス変数とメソッドを合わせたものがクラスメソッドです。
クラスから直接呼び出せて、変更も簡単にできるというものです。クラスメソッドの活用例
class MyObj: message = 'OK' @classmethod def print(cls): print(cls.message) MyObj.print() #OK MyObj.message = 'Welcome!' MyObj.print() #Welcome! print(MyObj.message) #Welcome! #通常のメソッドの場合 #mo = MyObj() #mo.print()インスタンスを作成せずに、クラスから直接呼び出せていることが確認できると思います。
値の変更も簡単にできるので通常のメソッドとは違うことがわかります。インスタンスを作成
では、通常のメソッドとクラスメソッドを用意し、インスタンスを作成したときにどのような動きをするのか確認していきましょう。
class A(): count = 0 def __init__(self): A.count += 1 #インスタンスが作成されるたびに'count'が1足される def exclaim(self): print('I am an A!') @classmethod def kids(cls): print('A has', cls.count, 'title objects.') #何回カウントされたかを表示 a = A() #インスタンスを作成 b = A() #インスタンスを作成 c = A() #インスタンスを作成 A.kids() #クラスメソッドの呼び出し 'A has 3 title objects.'これはインスタンスが作成されるたびに'count'が1足されていくものです。
'a','b','c'で3回インスタンスを作成した後にクラスメソッドを呼び出して、何回カウントされたのかを表示しています。
3回インスタンスが作成されているので'count'が'3'足されているのが確認できます。
クラスメソッドを呼び出した時は、インスタンスが作成されないので足されていません。クラスメソッドとメソッドや関数との違いは?
ここでそれぞれの違いをまとめていきたいと思います。
#クラスメソッド @classmethod def メソッド名(cls, 引数1, 引数2, ...):#メソッド def メソッド名(self, 引数1, 引数2, ...):#関数 def 関数名():このように並べてみると違いがよくわかると思います。
①クラスメソッドとメソッドの違い
->メソッドはインスタンスを作成しないと呼び出せないですが、クラスメソッドはクラスから直接呼び出すことができます。②クラスメソッドと関数の違い
-> 第一引数に'cls'というクラス自体を取得することができます。また、クラスの中にあるので、クラスをインポートすれば使えるという点も違います。スタティックメソッド
ここからはスタティックメソッドについて説明していきます。
スタティックメソッドとはクラスメソッドとにていますが、違いは引数を指定する必要がない点です
実際に見ていきましょう。@staticmethod def メソッド名(): print("これはスタティックメソッドです。") #呼び出し クラス名.メソッド名()クラスメソッドの時は第一引数に'cls'というものがありましたが、スタティックメソッドにはありません。
メソッドとほとんど同じと思ってもらうとわかりやすいです。
あまり使われないですが、クラスメソッド同様クラスから直接呼び出し¥すことができるのが特徴です。終わりに
今回の記事では「クラスメソッド」と「スタティックメソッド」について書きました。
記事はこれからもアップデートしていく予定です。
前回までの記事
↓
↓
↓
pythonのプロパティのあれこれ
- 投稿日:2020-07-06T16:14:43+09:00
PAY.JPでクレジットカード決済機能を簡単に実装【Django】
PAY.JPとは
公式: https://pay.jp/
クレジットカード決済を簡単に導入できるサービス。提供されるAPIやSDKを使って実装する。
PAY.JPから提供されるカード情報入力フォームはiframeになっていて
- 決済の仕組みがよくわからない、怖い
- プロダクトに決済機能を導入したいが、個人情報の管理が大変そう
といった、決済周りの敷居の高い部分をクライアントの入力部分からまるっとPAYJPが保護してくれる。
なのでユーザが入力したカード番号などの個人情報を自分達が管理しなくて良く、最低一行のJavaScriptを貼るだけで実装できるらしい。すごい。支払いやカード情報に関するデータはRESTベースのAPIから取得できるようで、
ドキュメントもエンジニアにはわかりやすいものだと思うので、実装はやりやすいのかなと思います。
PAY.JP API リファレンス実装するもの
記事作成時点で公式のチュートリアルがFlaskとSinatraしかない。他Qiitaの記事だとRailsで実装された記事がほとんどだったので、Djangoで実装してみます。
PAY.JPを導入して、支払い機能を実装します。
※ PAY.JPには本番用とテスト用という概念があり、本番は実際にお金のやり取りをするための申請が必要なので今回は使いません、テスト用だと気軽に手元の環境で試せます。実行環境
MacOS Catalina version: 10.15.5 Python 3.8.3 Django 3.0.8 payjp 0.0.5まずはDjangoを動かす
サンプルプロジェクト用フォルダを作成してフォルダ内に移動。
$ mkdir my-project; cd my-project必要なライブラリ(django、payjp)をインストールする。
$ pip install django payjpDjangoのプロジェクトを生成する
$ django-admin startproject project .manage.pyが生成されたディレクトリで下記コードで開発用サーバが立ち上がることを確認します。
$ python manage.py runserverPAYJPを利用するためのAPIキーを確認する
PAYJPの設定画面 にアクセスして左のサイドバーの「API」からAPIキーの確認ができます。
今回は手元の環境で動かしたいだけなのでテスト秘密鍵、テスト公開鍵を使用します。
※ 画像は一部切り抜きにしてます。
作業に取り掛かる準備ができたので、アプリケーションを作ってPAYJPと連携しましょう。
PAY.JPと連携するDjangoアプリケーションを生成。
$ python manage.py startapp appDjangoの設定ファイルの編集
settings.pyに
先程作成したアプリケーションを登録、またPAY.JPの秘密鍵を設定します。project/settings.py... import payjp ... ... ... INSTALLED_APPS = [ "django.contrib.admin", "django.contrib.auth", "django.contrib.contenttypes", "django.contrib.sessions", "django.contrib.messages", "django.contrib.staticfiles", # 追加 "app", ] ... ... ... # PAY.JP設定 payjp.api_key = "sk_test_xxxxxxxxxxxxxxxxxxxxx" # テスト用秘密鍵Viewを実装する
app/views.pyfrom django.shortcuts import render from django.views.generic import View import payjp # Create your views here. class PayView(View): """ use PAY.JP API """ def get(self, request): # 公開鍵を渡す return render( request, "index.html", {"public_key": "pk_test_xxxxxxxxxxxxxxxxxxxxxxxx"} ) def post(self, request): amount = request.POST.get("amount") payjp_token = request.POST.get("payjp-token") # トークンから顧客情報を生成 customer = payjp.Customer.create(email="example@pay.jp", card=payjp_token) # 支払いを行う charge = payjp.Charge.create( amount=amount, currency="jpy", customer=customer.id, description="Django example charge", ) context = {"amount": amount, "customer": customer, "charge": charge} return render(request, "index.html", context)
※ 本記事ではわかりやすくするためにキーを直接書いてますが
pk_test_xxxxxxxxxxxxxxxxxやsk_test_xxxxxxxxxxxxxxxxxxxxxの部分は環境変数で読み込むようにするなど外部公開しないよう注意しましょう。
Templateの作成
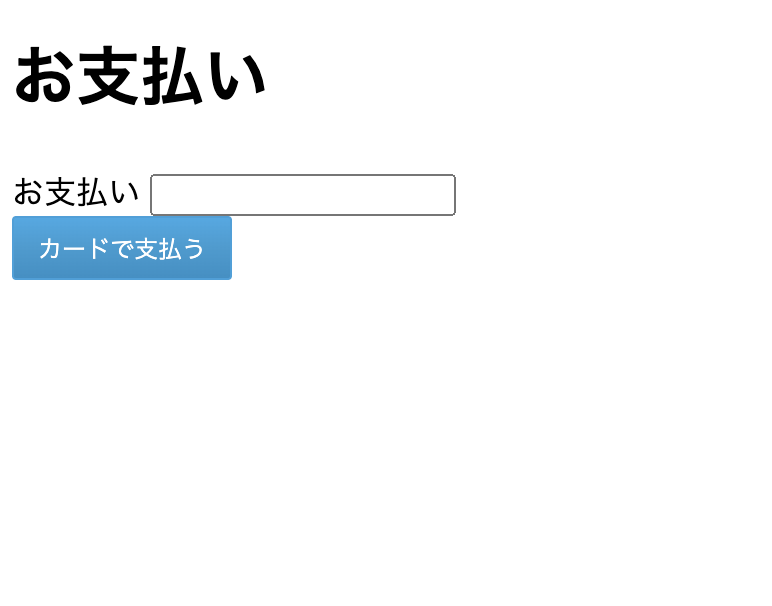
app$ mkdir templates; cd templates $ touch index.htmlapp/templates/index.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8" /> <meta http-equiv="x-ua-compatible" content="IE=edge" /> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no" /> <title>サンプルアプリケーション</title> </head> <body> <h1>お支払い</h1> {% if charge %} <p>{{ amount }}円のお支払いが完了しました。</p> <br> <p>customer: {{ customer }}</p> <br> <p>Charge: {{ charge }}</p> {% else %} <form action="{% url 'app' %}" method="post"> {% csrf_token %} <div> <label for="amount">お支払い</label> <input type="number" name="amount" id="amount" required> </div> <script type="text/javascript" src="https://checkout.pay.jp" class="payjp-button" data-key="{{ public_key }}"> </script> </form> {% endif %} </body> </html>ルーティングの設定
project/urls.pyfrom django.contrib import admin from django.urls import path from app import views urlpatterns = [ path("admin/", admin.site.urls), path("", views.PayView.as_view(), name="app") ]これで実装はできたと思います!
最終的なディレクトリ構成
my-project ├── app │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── migrations │ ├── models.py │ ├── payjp.py │ ├── templates │ │ └── index.html │ ├── tests.py │ └── views.py ├── manage.py └── project ├── __init__.py ├── asgi.py ├── settings.py ├── urls.py └── wsgi.py動作確認
アプリケーションの実行
$ python manage.py runserverhttp://127.0.0.1:8000/
へアクセスすると
が表示されるので、支払い金額とカード情報を入力してみましょう。
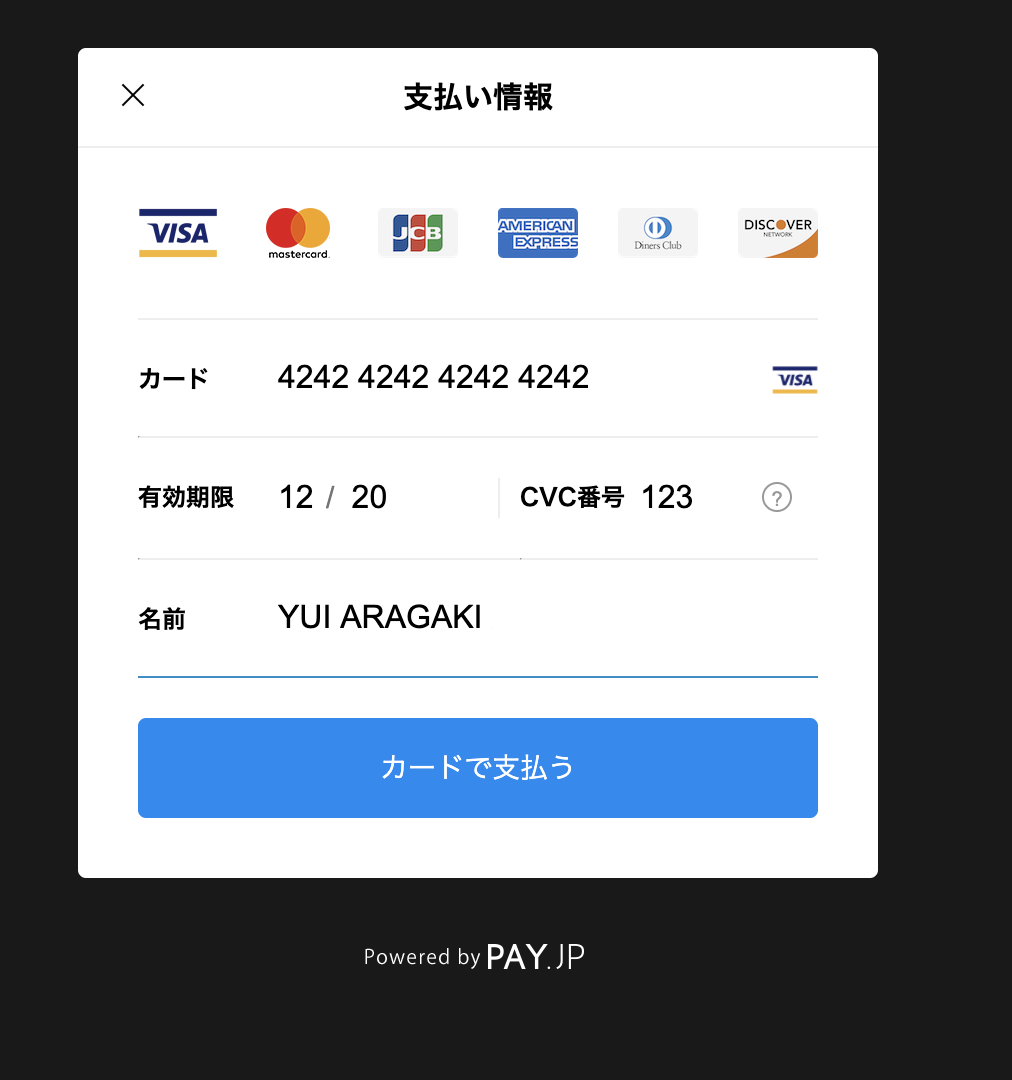
カードで支払うを押下
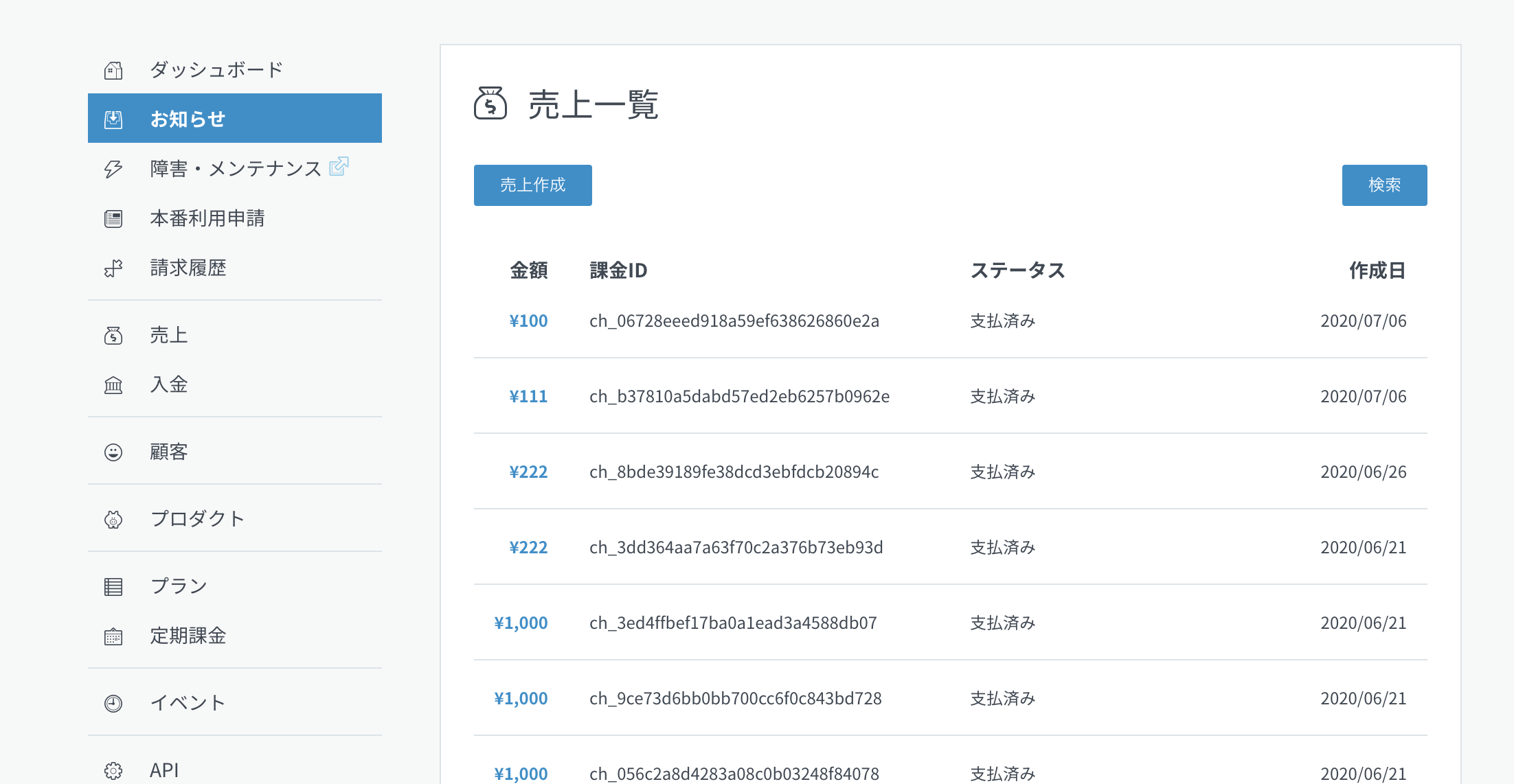
また、PAY.JPでも支払内容の確認ができますので先程入力した情報があることを確認してみましょう。
サイドバーの「売上」の項目
最後に
Djangoでも簡単に支払いの処理が実装できました!
今回はデフォルトのフォームデザインを使いましたが、独自にCSSを設定したりしてカスタマイズできるようです。
また、今回はmodelの処理を省きましたが、PAYJP APIから返ってきたレスポンス(支払情報など)をユーザ情報と一緒にDBに保存しておくことで実用的なアプリケーションを作っていくことができそうです。参考リンク:

- 投稿日:2020-07-06T16:02:26+09:00
AtCoderBeginnerContest173復習&まとめ(後半)
AtCoder ABC173
2020-07-05(日)に行われたAtCoderBeginnerContest173の問題をA問題から順に考察も踏まえてまとめたものとなります.
後半ではDEの問題を扱います.前半はこちら.
問題は引用して記載していますが,詳しくはコンテストページの方で確認してください.
コンテストページはこちら
公式解説PDFD問題 Chat in a Circle
問題文
あなたはオンラインゲーム「ATChat」のチュートリアルを終え、その場に居合わせたプレイヤー$N$人で早速とある場所を訪ねることにしました。この$N$人には$1$から$N$の番号が振られており、人$i(1 \leq i \leq N)$のフレンドリーさは$A_i$です。
訪ねる際、$N$人は好きな順番で$1$人ずつ到着します。あなたたちは迷子にならないために、既に到着した人たちで環状に並び、新たに到着した人は好きな位置に割り込んで加わるというルールを決めました。
最初に到着した人以外の各人は、割り込んだ位置から到着した時点で「時計回りで最も近い人」と「反時計回りで最も近い人」のフレンドリーさのうち小さい方に等しい 心地よさ を感じます。最初に到着した人の心地よさは$0$です。
$N$人が到着する順番や割り込む位置を適切に決めたとき、$N$人の心地よさの合計の最大値はいくらになるでしょう?正直,ちゃんと考えれば良かったなと思いました.
何となく問題見て難しい気がしてしまったのと,差をつけるためにE問題を解くために飛ばしてしまいました.abc173d.pyn = int(input()) a_list = list(map(int, input().split())) a_list.sort(reverse=True) ans = 0 for i in range(0, n - 1): ans += a_list[(i + 1) // 2] print(ans)E問題 Multiplication 4
問題文
$N$個の整数$A_1,…,A_N$が与えられます。
このなかからちょうど$K$個の要素を選ぶとき、選んだ要素の積としてありえる最大値を求めてください。
そして、答えを$(10^9+7)$で割った余りを$0$以上$10^9+6$以下の整数として出力してください。正の数と負の数と0の数に分けて,問題を考えていましたが,$K=N$の結果が負になるときと正のときとをなぜか必死に場合分け書いてたら,タイムオーバーでした.
よくよく考えれば,全部使うときは,貪欲に計算すれば,済む話でしたね(反省)
ただ,勉強のために提出されたコード見てみると,4 3 -1 -2 3 4のような入力例に対応できていないものが"AC"通っていて何だかなーと思いました.
こういった場合の処理をどうしないといけないかなど,いろいろ考えている人が結局時間が足りず通せず,入力に対してあまり深く考えず,限定された,テストにある入力を運よく通って得点できている人がいるような場合,後からrateの調整とかしてほしいところですが,無料のコンテストにあまり多く求めてもしょうがないですよね(汗)
現在は,after_contest_01.txtがチェックに追加されていて,そういったコードは"WA"になります.abc173e.pyn, k = map(int, input().split()) a_list = list(map(int, input().split())) mod = 10**9+7 a_list.sort() ans = 1 if k % 2 == 1 and a_list[-1] < 0: for i in range(k): ans *= a_list[n - 1 - i] ans %= mod else: l = 0 r = -1 mlt1 = a_list[0] * a_list[1] mlt2 = a_list[-2] * a_list[-1] count = 0 while True: if count == k: break elif count == k - 1: ans *= a_list[r] % mod ans %= mod break if mlt1 >= mlt2: ans *= mlt1 % mod l += 2 count += 2 if l <= n - 2: mlt1 = a_list[l + 1] * a_list[l] else: ans *= a_list[r] % mod r -= 1 count += 1 if r >= - n + 1: mlt2 = a_list[r - 1] * a_list[r] ans %= mod print(ans)後半も最後まで読んでいただきありがとうございました.
- 投稿日:2020-07-06T15:59:53+09:00
AtCoderBeginnerContest173復習&まとめ(前半)
AtCoder ABC173
2020-07-05(日)に行われたAtCoderBeginnerContest173の問題をA問題から順に考察も踏まえてまとめたものとなります.
前半ではABCまでの問題を扱います.
問題は引用して記載していますが,詳しくはコンテストページの方で確認してください.
コンテストページはこちら
公式解説PDFA問題 Payment
問題文
お店で$N$円の商品を買います。
$1000$円札のみを使って支払いを行う時、お釣りはいくらになりますか?
ただし、必要最小限の枚数の$1000$円札で支払いを行うものとします。$N$円の下三桁を使うことでお釣りの計算ができると思ったので,$N$を$1000$で割った余りを計算しました.
余りを$1000$から引き算すれば出したい出力を得ることができますが,$1000 × x$円の場合,本来お釣りが$0$円ですが余りが$0$となるため出力が"1000"になってしまうので,自分はif文で条件分岐しました.
考察の解法では,条件分岐しないで計算する方法が書いてあってなるほどなと思いました.abc173a.pyn = int(input()) k = n % 1000 if k == 0: print(0) else: print(1000 - k)B問題 Judge Status Summary
問題文
高橋君は、プログラミングコンテスト AXC002 に参加しており、問題 A にコードを提出しました。
この問題には$N$個のテストケースがあります。
各テストケース$i(1 \leq i \leq N)$について、ジャッジ結果を表す文字列$S_i$が与えられるので、ジャッジ結果が"AC", "WA", "TLE", "RE"であったものの個数をそれぞれ求めてください。
出力形式は、出力欄を参照してください。愚直に入力をdictに入れていきました.
abc173b.pyn = int(input()) key_dict = {"AC": 0, "WA": 0, "TLE": 0, "RE": 0} for i in range(n): key = input() key_dict[key] += 1 print("AC x " + str(key_dict["AC"])) print("WA x " + str(key_dict["WA"])) print("TLE x " + str(key_dict["TLE"])) print("RE x " + str(key_dict["RE"]))公式の解説のpythonのコードみたいに書けるようになりたいです.
abc173b.pyN = int(input()) s = [input() for i in range(N)] for v in ['AC', 'WA', 'TLE', 'RE']: print('{0} x {1}'.format(v, s.count(v)))C問題 H and V
問題文
$H$行$W$列に並ぶマスからなるマス目があります。上から$i$行目、左から$j$列目$(1 \leq i \leq H,1 \leq j \leq W)$のマスの色は文字$c_{i,j}$として与えられ、$c_{i,j}$が"."のとき白、"#"のとき黒です。
次の操作を行うことを考えます。
・行を何行か選び($0$行でもよい)、列を何列か選ぶ($0$列でもよい)。そして、選んだ行に含まれるマスと、選んだ列に含まれるマスをすべて赤く塗る。
正の整数$K$が与えられます。操作後に黒いマスがちょうど$K$個残るような行と列の選び方は何通りでしょうか。ここで、二つの選び方は、一方においてのみ選ばれる行または列が存在するときに異なるとみなされます。全探索するしかと思い,再帰関数使って解きましたが,実装に時間がかかってしまいました.
abc173c.pyimport numpy as np def funk(matrix, n, k, no_list, h, w): if n == 0: mask = np.ones((h, w)) for i in range(h): if no_list[i] == 1: mask[i,] = 0 for j in range(w): if no_list[h+j] == 1: mask[:,j] = 0 if np.sum(matrix * mask) == k: return 1 else: return 0 ans = 0 ans += funk(matrix, n - 1, k, no_list + [1], h, w) ans += funk(matrix, n - 1, k, no_list + [0], h, w) return ans ans = 0 h, w, k = map(int, input().split()) n = h + w matrix = np.zeros((h, w)) for i in range(h): line = input() for j in range(w): if line[j] == "#": matrix[i,j] = 1 else: matrix[i,j] = 0 no_list = [] ans += funk(matrix, n, k, no_list, h, w) print(ans)前半はここまでとなります.
最近は公式の解説がとても丁寧に記述してあったので,詳しい解法はそちらを参考にしてもらえたらと思います.
前半の最後まで読んでいただきありがとうございました.後半はDEF問題の解説となります.
後半に続く.
- 投稿日:2020-07-06T15:32:56+09:00
非Anaconda環境にCaboChaをインストールする(Win)
全ての非Anaconda環境Python使いにこの記事を捧げます。
おがどらです。
タイトルの通りです。自分はこれに一日以上費やしてしまったので供養。
基本的にはAnaconda環境と変わりませんが、必要モジュールがインストールされていないのでエラーを吐くっぽいです。
すでにPythonをインストールしてしまったのでAnacondaを入れたくない><って人にオススメです。
でも面倒くさいのでよっぽどじゃない限りはAnacondaを導入しましょう。
筆者の環境はWindows 10です。前提条件
Pythonは32bit版じゃないと上手く行かないらしいです。
こちらからダウンロードして下さい。
筆者はWindows x86 web-based installerをダウンロード&インストールしました。PS C:\WINDOWS\system32> py -3.8-32 -V Python 3.8.3このように表示されればOKです。
64bit版と共存させる場合は -3.8-32 (3.8はバージョンにより適宜変える)オプションを指定しないと64bit版が呼び出されます。PS C:\WINDOWS\system32> py Python 3.8.3 (tags/v3.8.3:6f8c832, May 13 2020, 22:37:02) [MSC v.1924 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> exit() PS C:\WINDOWS\system32> py -3.8-32 Python 3.8.3 (tags/v3.8.3:6f8c832, May 13 2020, 22:20:19) [MSC v.1925 32 bit (Intel)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> exit()このように確かめることが出来ます。
また、pipで32bit版を明示的に呼び出すために
py -3.8-32 -m pip install hogehoge
としますので覚えておいて下さい。
ついでにpipをアップグレードしておきましょう。py -3.8-32 -m pip install --upgrade pip色々インストール(参考記事)
次に
CaboCha & Python3の環境構築(Windows版)
を参考に、諸々の準備をして下さい。
簡単に手順をまとめると
1. MeCabのインストール
2. CaboChaのインストール
3. Visual C++ コンパイル環境のインストール
ですね。ここの部分はAnacondaでもそれ以外でも変わりません。
UTF-8版をどちらもインストールして下さい。numpy + mklのインストール
ここからがAnacondaと違います。
Numpyモジュールですが、pipでインストールするものだと使えません。
Anacondaだと標準で入っているらしいのですが、非Anaconda環境だとちょっと面倒くさいことになります。
ちなみにこのままCaboChaを使おうとするとTraceback (most recent call last): File "A:/codes/python/test.py", line 4, in <module> import CaboCha File "C:\Users\ogadra\AppData\Local\Programs\Python\Python38-32\lib\site-packages\CaboCha.py", line 28, in <module> _CaboCha = swig_import_helper() File "C:\Users\ogadra\AppData\Local\Programs\Python\Python38-32\lib\site-packages\CaboCha.py", line 24, in swig_import_helper _mod = imp.load_module('_CaboCha', fp, pathname, description) File "C:\Users\ogadra\AppData\Local\Programs\Python\Python38-32\lib\imp.py", line 242, in load_module return load_dynamic(name, filename, file) File "C:\Users\ogadra\AppData\Local\Programs\Python\Python38-32\lib\imp.py", line 344, in load_dynamic return _load(spec) ImportError: DLL load failed while importing _CaboCha: 指定されたモジュールが見つかりません。 Process finished with exit code 1このようなエラーが出ます。
「指定されたモジュールってどれやねん!!!」と四苦八苦しました。まず最初に既にnumpyが入っている場合はアンインストールします。
py -3.8-32 -m pip uninstall numpy次にWheelをインストールします。
Wheelとはwhlファイルからpythonモジュールを読み込むときに必要なライブラリっぽいです。py -3.8-32 -m pip install wheel次にwheelでインストール出来るバージョンを確認します。
PowerShellをそのまま使う場合には以下のようにして下さい。PS C:\WINDOWS\system32> py -3.8-32 Python 3.8.3 (tags/v3.8.3:6f8c832, May 13 2020, 22:20:19) [MSC v.1925 32 bit (Intel)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import wheel.pep425tags >>> print(wheel.pep425tags.get_supported(-1)) C:\Users\ogadra\AppData\Local\Programs\Python\Python38-32\lib\site-packages\wheel\pep425tags.py:80: RuntimeWarning: Config variable 'Py_DEBUG' is unset, Python ABI tag may be incorrect if get_flag('Py_DEBUG', [('cp38', 'cp38', 'win32'), ('cp38', 'none', 'win32'), ('cp38', 'none', 'any'), ('cp3', 'none', 'any'), ('cp37', 'none', 'any'), ('cp36', 'none', 'any'), ('cp35', 'none', 'any'), ('cp34', 'none', 'any'), ('cp33', 'none', 'any'), ('cp32', 'none', 'any'), ('cp31', 'none', 'any'), ('cp30', 'none', 'any'), ('py3', 'none', 'win32'), ('py38', 'none', 'any'), ('py3', 'none', 'any'), ('py37', 'none', 'any'), ('py36', 'none', 'any'), ('py35', 'none', 'any'), ('py34', 'none', 'any'), ('py33', 'none', 'any'), ('py32', 'none', 'any'), ('py31', 'none', 'any'), ('py30', 'none', 'any')] >>>リストが返ってきます。
このリストの読み方ですが、
('cp38', 'cp38', 'win32')
という表記がある場合に
hogehoge-cp38-cp38-win32.whl
というファイルのインストールに対応しています、位に捉えてくれればOKです。
Python 3.8.X環境ならcp38に対応していると思います。
whlファイルはこちらからインストール出来ます。
色々ありますがCtrl + Fなどを活用してダウンロードしていきます。
筆者環境では以下のファイルをダウンロードしました。(もしかしたら必要がないものもあるかも知れません)・numpy-1.19.0+mkl-cp38-cp38-win32.whl
・scipy-1.5.1-cp38-cp38-win32.whl
・scikit_learn-0.23.1-cp38-cp38-win32.whl
・pandas-1.0.5-cp38-cp38-win32.whl
・matplotlib-3.3.0rc1-cp38-cp38-win32.whlwhlファイルからインストールするには、whlファイルを保存したディレクトリまでcdコマンドで移動し、
py -3.8-32 -m pip install [ファイル名]とすれば良いです。
mklの入ったnumpyがインストールされたかどうか確認するにはimport numpy as np np.show_config()とすると色々出てきます。
blas_mkl_info:
の項目がNOT AVAILABLEになっていなければインストールが正常に終了しています。Scipyも同様に行って見て下さい。確認
これでCaboChaが非Anaconda環境にインストール出来ていると思います。
確認には参考サイトのコードを走らせてみるのが良いと思います。(Python3に対応しているので。)
もし正常に動かないようでしたら以下を試してみて下さい。
・Cabocha, MeCabの再インストール(UTF-8でインストールしているかをもう一度確認する)
・cabochaをwhlからインストールしてみる
後者はこちらからダウンロードすることが出来ます。お疲れさまでした。良き日本語解析ライフを!
- 投稿日:2020-07-06T15:10:51+09:00
【python】エネルギーデータをインタラクティブに可視化する簡単な方法【plotly.express】
概要
- pythonによるエネルギーデータ(電力量)を可視化します。
- Excelではなく、pythonのplotlyというライブラリを使用します。
入力データ
- 今回使用するのは、電力量データとタイムスタンプのみです。
ソースコード
# ライブラリのインポート import pandas as pd import plotly.express as px # sampleデータの読み込み data = pd.read_csv('./sample.csv',encoding='shift-jis',index_col=[0],parse_dates=[0]) # データのリサンプリング(1日毎の合計) data_month_sum = data.resample('D').sum() # 線グラフの描画 px.line(data_frame=data_month_sum, x=data_month_sum.index, y='電力量', color_discrete_sequence=['yellow'])実行結果
まとめ
- エクセルではできないインタラクティブなグラフを作成できる。
- 知っていれば、圧倒的に早く可視化でき、データを俯瞰できる。

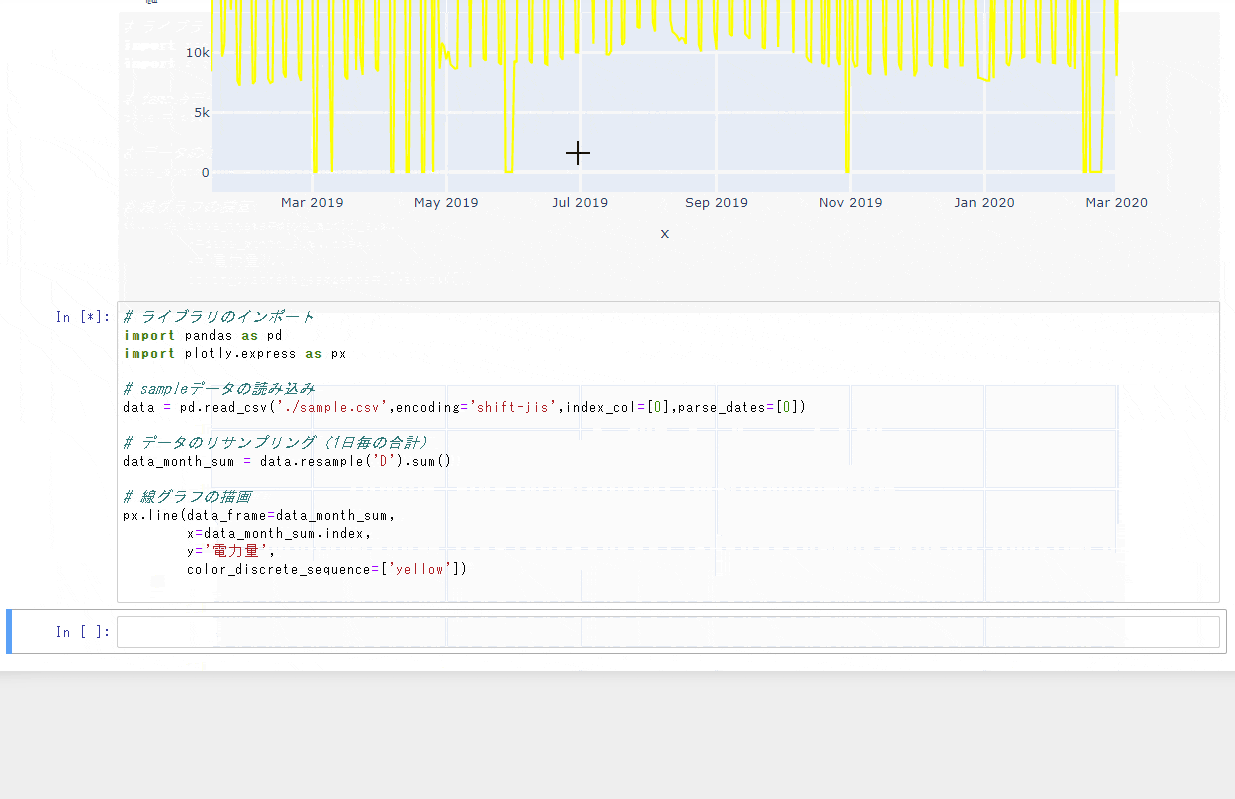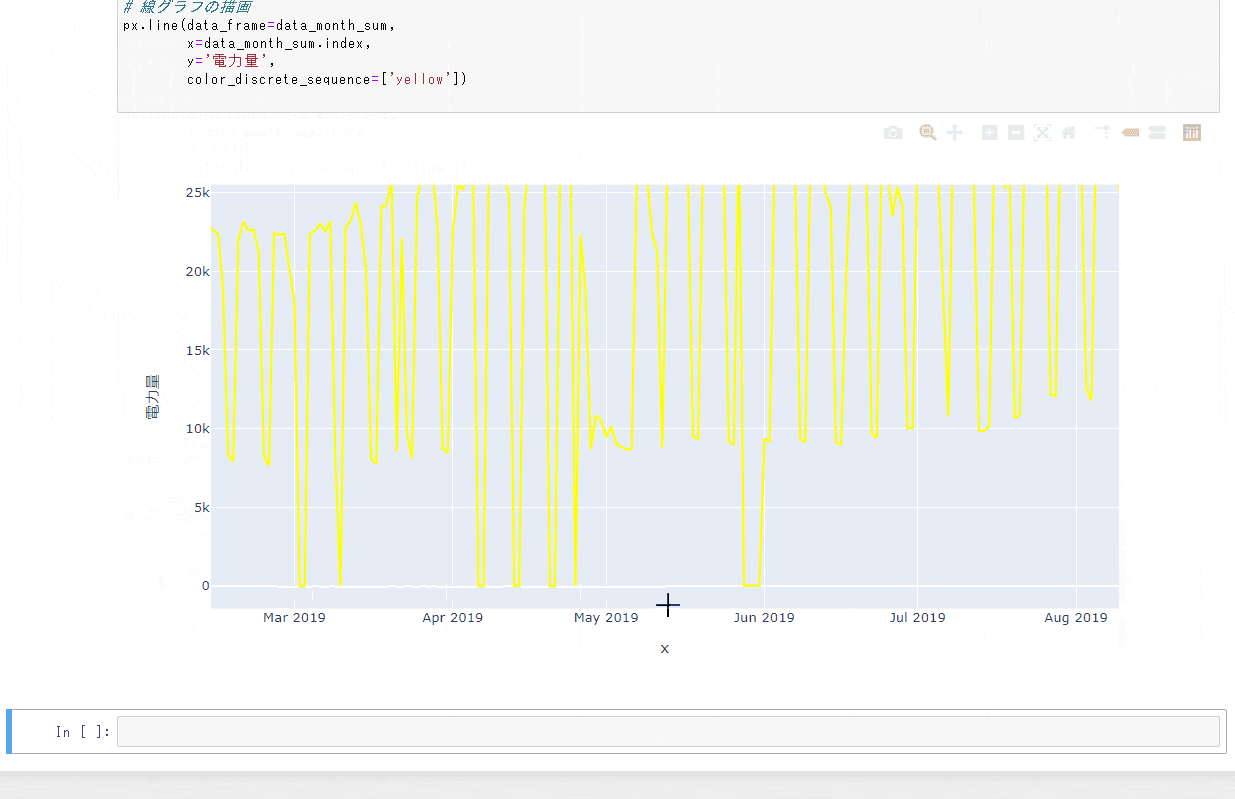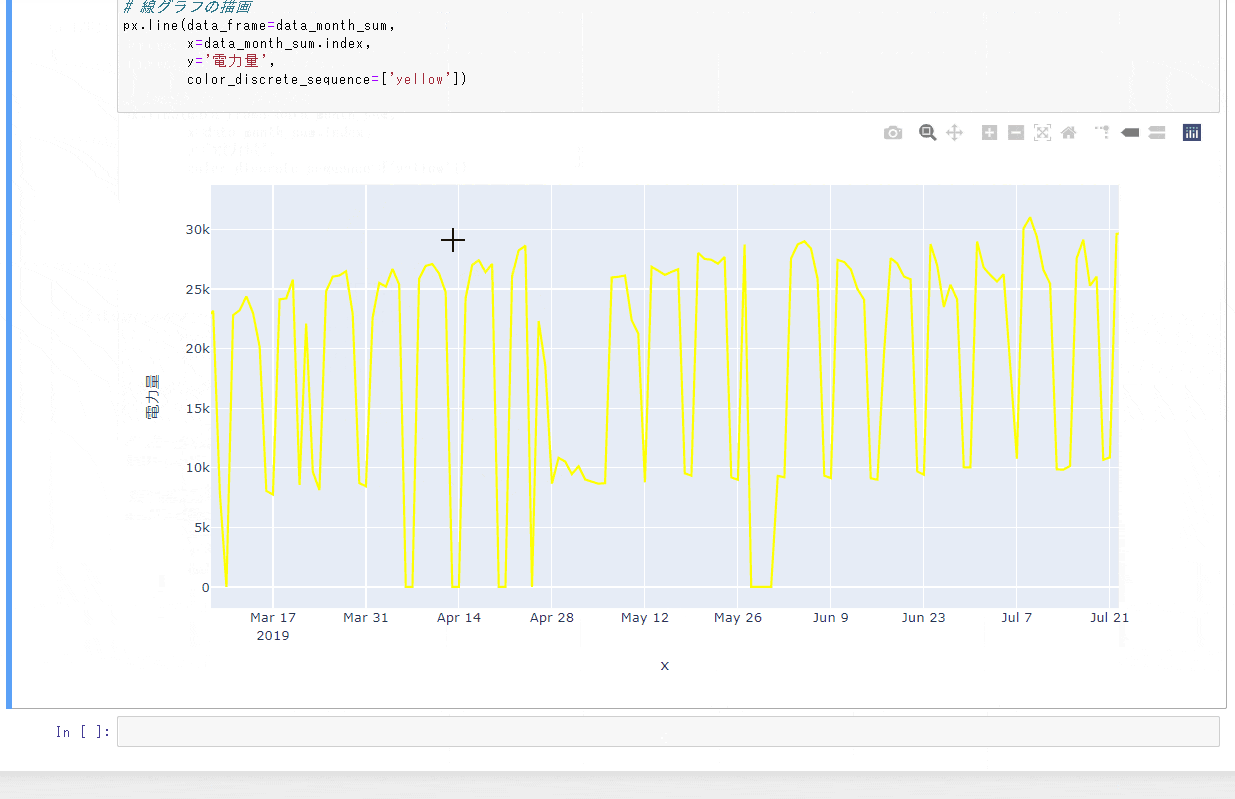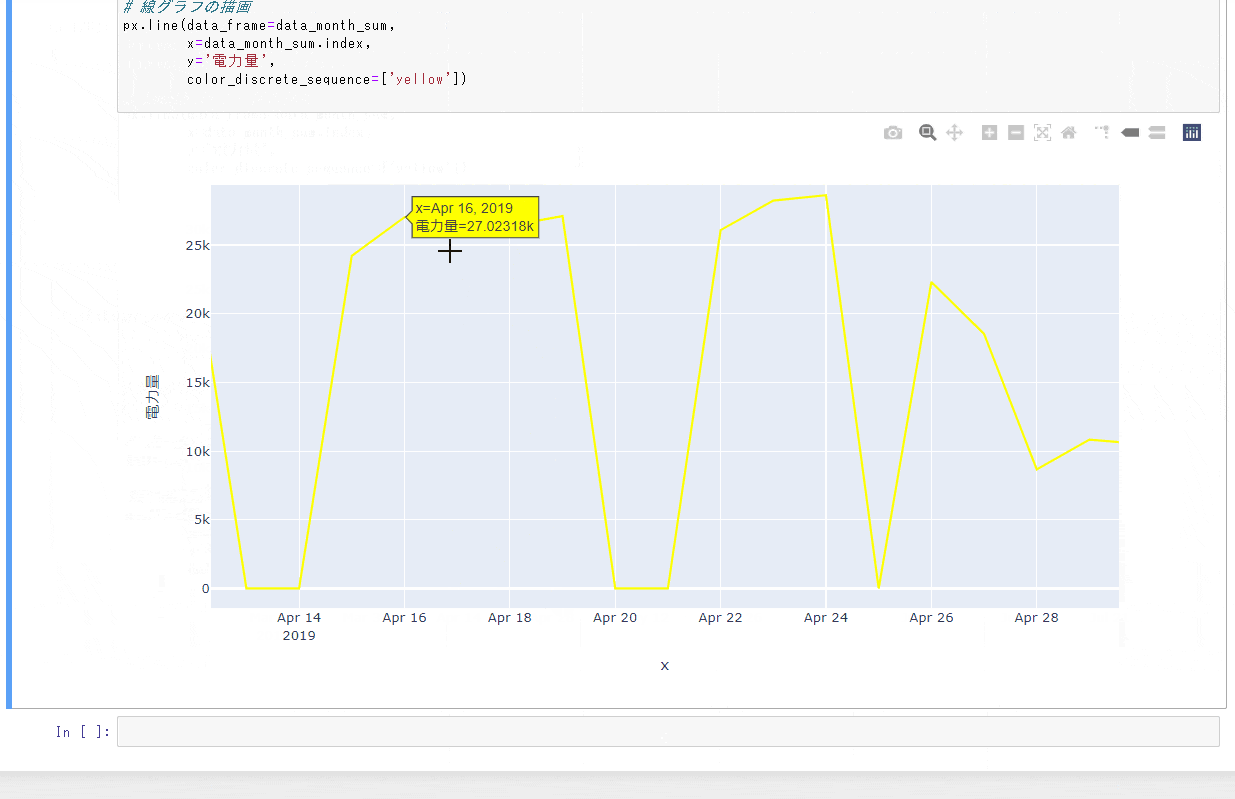
- 投稿日:2020-07-06T13:20:59+09:00
【忘備録】installしたモジュールをjupyter内で呼び出せない
起こったこと
ターミナルで
$ pip install (モジュール)を実行したにも関わらず、jupyter内でimport すると ModuleNotFoundErrorが出てしまう。
しかし、ipythonではimportできる。とりあえずの解決方法
色々とネットを調べているとanacondaとipythonは参照先が違うとのこと。
それを聞いてimport sys sys.pathを実行してやるとjupyterとipythonとでそれぞれ違うパスが表示されました。
と言うことはipythonに表示されているpathを追加してやればいいのではないかと言うことで
import sys sys.path.append('任意のpath')を実行することでうまくimportできました!
終わり
この方法でとりあえずのところはモジュールをインポートして使うことはできましたが毎回これを実行するのは正直めんどくさい...
どなたか良い方法を知っておられましたらご教示くださいm(_ _)m
- 投稿日:2020-07-06T13:19:30+09:00
pythonにおける==、isの違い
pythonにある同じものかどうかを判断する方法は二つありますね。==とisです。戻り値はいずれもBooleanですが、それでは何が違うのか?というとことは気になるところです。
結論
簡単にいうと、isは両者のメモリローケーションを比較しているのに対し、==は単純に両者は同じ値であるかを見ています。それだけです。
例えば?
じゃコードを見てみて(ターミナルにてpython3を立ち上げる)
>>> a = [1, 2, 3] >>> b = a >>> b is a True >>> b == a True >>> b = a[:] >>> b is a False >>> b == a True解説します。aにリストを代入、bにも同じくaを代入すると、同じメモリローケーションから引用していることがわかります。従い、これはisを使うとTrueです。
次に文字列操作の[:]を使ってリストを複製します。そうすると、コピーが出来上がるので、メモリ上は別物になります。従って、これはFalse。ということです。実際にidを見てみると
>>> id(a) 4364243328 >>> >>> id(b) 4364202696そうですよね。Falseになっていることから、idが異なるのは当然の話。
しかし、以下のコードのような例外があります。
>>> a = 256 >>> b = 256 >>> a is b True >>> a == b True >>> >>> a = 1000 >>> b = 10**3 >>> a == b True >>> a is b Falseこれは何を意味しているのかね?aとbは別々に数字を代入しているのに、上と下は結果が違うぞ。
さて解説するよ。
pythonはパフォーマンス改良のため、256などの小さい整数について違う処理をしています。そういった特別な整数は同じidで同じ場所へと格納しているそうです。そうすると、このように256ではisを使っても==を使っても同じTrueとなり、1000のような大きい数字についてはそうはなりません。ということでした。いかがでしょうか。
ご指摘ありましたら、どうぞ突っ込んでください。さてまたね
- 投稿日:2020-07-06T12:58:02+09:00
Amazon Rekognitionによる顔認識
Amazon Rekognitionを使って、入力した画像に映っている顔を矩形で囲むという基本的な処理を試してみました。
Amazon Rekognitionとは
Amazon Rekognitionは、AWSのAIサービスの一つで、画像認識に対応したものです。
また、AWSのAIサービスは画像認識・自然言語処理など様々な領域をカバーしたもので、機械学習の深いスキルなしに機械学習をアプリケーションに組み込める、データを用意するだけでAPIから機械学習を利用できる、といった特徴があります。実行環境
OS:Windows10
言語:Python3.7事前準備
AWS CLI(aws configure)にて、以下の認証情報をセットしておきます。
AWS Access Key ID
AWS Secret Access Key
Default region name
Default output formatソースコード(face_detect.py)
import boto3 import sys from PIL import Image,ImageDraw # 引数のチェック if len(sys.argv) != 2: print('画像ファイルを引数に指定してください。') exit() # Rekognitionのクライアントを作成 client = boto3.client('rekognition') # 画像ファイルを引数としてdetect_facesを実行 with open(sys.argv[1],'rb') as image: response = client.detect_faces(Image={'Bytes':image.read()},Attributes=['ALL']) # 顔が認識されない場合は処理終了 if len(response['FaceDetails'])==0: print('顔は認識されませんでした。') else: # 入力された画像ファイルを元に、矩形セット用の画像ファイルを作成 img = Image.open(sys.argv[1]) imgWidth,imgHeight = img.size draw = ImageDraw.Draw(img) # 認識された顔の数分、矩形セット処理を行う for faceDetail in response['FaceDetails']: # BoundingBoxから顔の位置・サイズ情報を取得 box = faceDetail['BoundingBox'] left = imgWidth * box['Left'] top = imgHeight * box['Top'] width = imgWidth * box['Width'] height = imgHeight * box['Height'] # 矩形の位置・サイズ情報をセット points = ( (left,top), (left + width,top + height) ) # 顔を矩形で囲む draw.rectangle(points,outline='lime') # 画像ファイルを保存 img.save('detected_' + sys.argv[1]) # 画像ファイルを表示 img.show()簡単な解説
概略としては以下のような処理を行っています。
①プログラム実行時の引数からRekognitionに入力する画像ファイルを取得する。
②上記①の画像ファイルを引数としてRekognitionのdetect_facesを実行する。
③Rekognitionから返却されるJsonのFaceDetails・BoundingBoxから、認識された顔の位置・サイズ情報を取得する。
④上記③から矩形付きの画像ファイルを作成し、表示する。実行結果
コマンド
python face_detect.py ichiro1.jpg
入力画像(ichiro1.jpg)
出力画像(detected_ichiro1.jpg)
イチロー選手はもちろんのこと、観客席の人たちも認識してくれています。
まとめ
Rekognitionに限らずですが、AWSのAIサービスはAPIから機械学習を手軽に利用できる便利なサービスです。
また、今回は矩形しか試しませんでしたが、Rekognitionから返却されるJsonには性別・年齢など様々なものがありますので、他にも色んなことを試せると思います。


- 投稿日:2020-07-06T12:23:16+09:00
ウイイレの解析ソフトでデータベースを使えるように拡張してみた
ウイイレのデータ解析自動化してくよ!Part7
■はじめに
- どうも ヤジュン です。
また、ウイイレのイベント増えてきましたね!
イベント備忘録用に作ったツイッターBot のフォロワーも増えてきました♪(現在230名)
- Bot利用者からの嬉しい声
こういう声をもらうと「作ってよかった!」ってなりますね♪
大会やイベントの主催者や企業に、利用してもらえるとこまで広まってほしいな~
■本記事の内容
今回は、解析ソフトのデータ管理をCSVだけでなく、データベースでも出来るように機能拡張したので紹介します。
本記事のソフトはpythonで作成しています。■参考URL
▼解析アプリの拡張機能一覧
- 前回記事から以下の機能拡張されました。
- プレイヤー認証機能
- データベースからのデータ読み込み機能
- 試合結果画像からメトリクスデータをCSVで出力する機能
- CSVのメトリクスデータをデータベースへ追加する機能
■データベース管理への背景
今まで、CSVファイルでデータ管理をしていました。
CSVによる管理は、オフラインでもデータ解析できるというメリットはあります。
しかし、今後マスターデータを育てるためには、各CSVファイルを マージ しなくてはいけません。めんどくさすぎる!そこでデータベース管理へ移行するのです!
各プレイヤーの解析結果が、データベースに集約される仕組みを作ればマスターデータは、放置していても育っていきます。■拡張機能毎の紹介
▼データべースどんな感じ?
●実際に移行するとこんな感じ↓
- HeidiSQLを使ってデータを確認してます。
今までテスターから収集した150試合の結果を移行しました。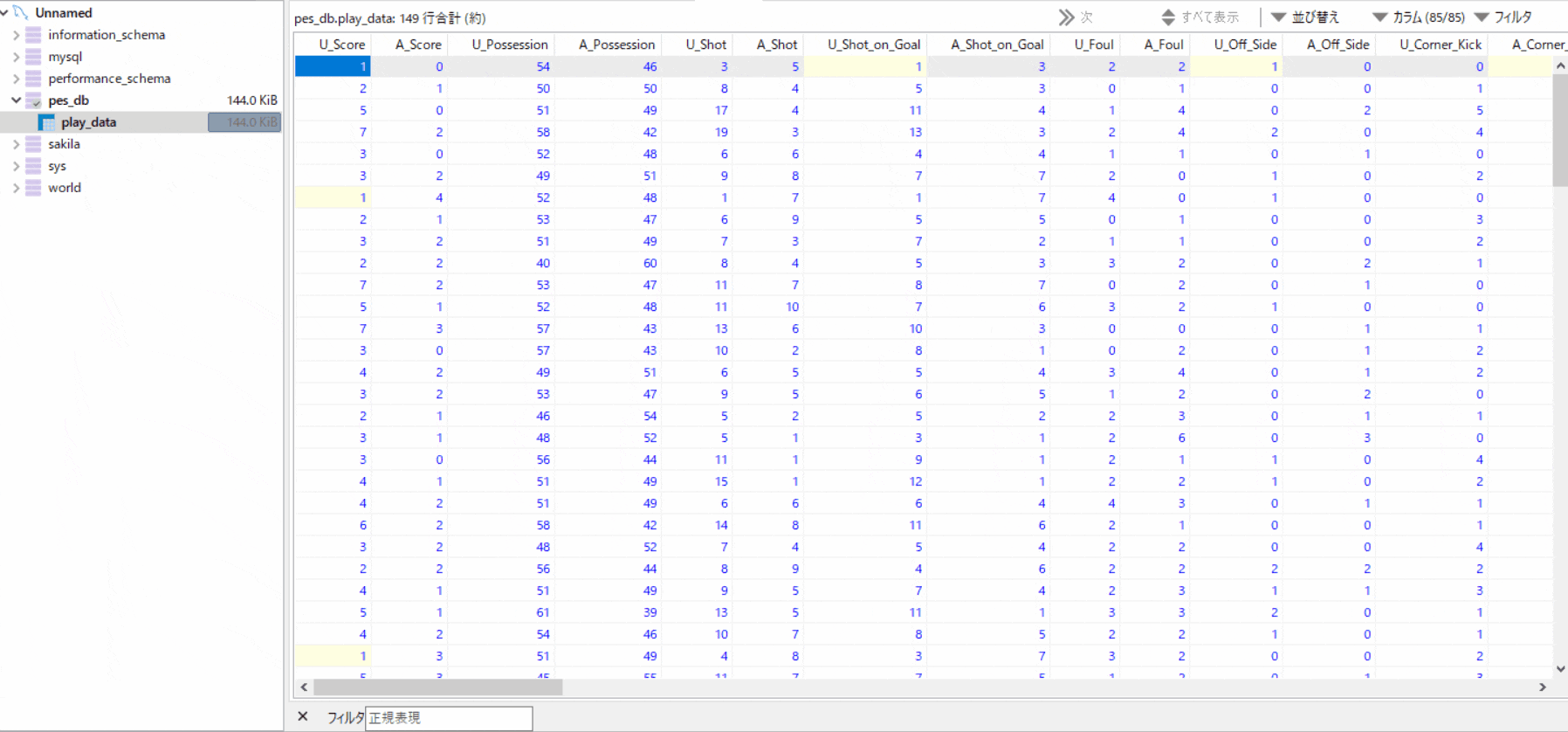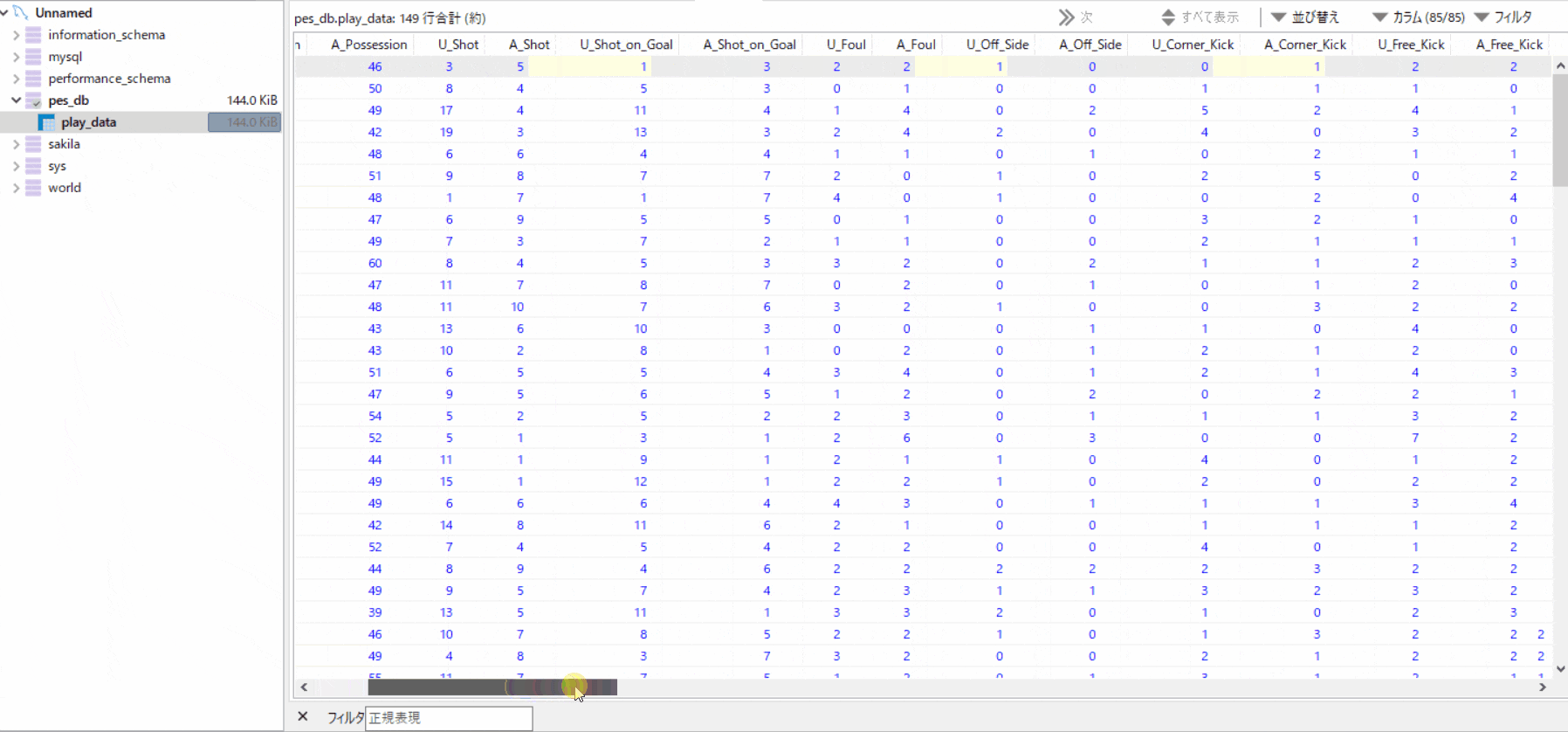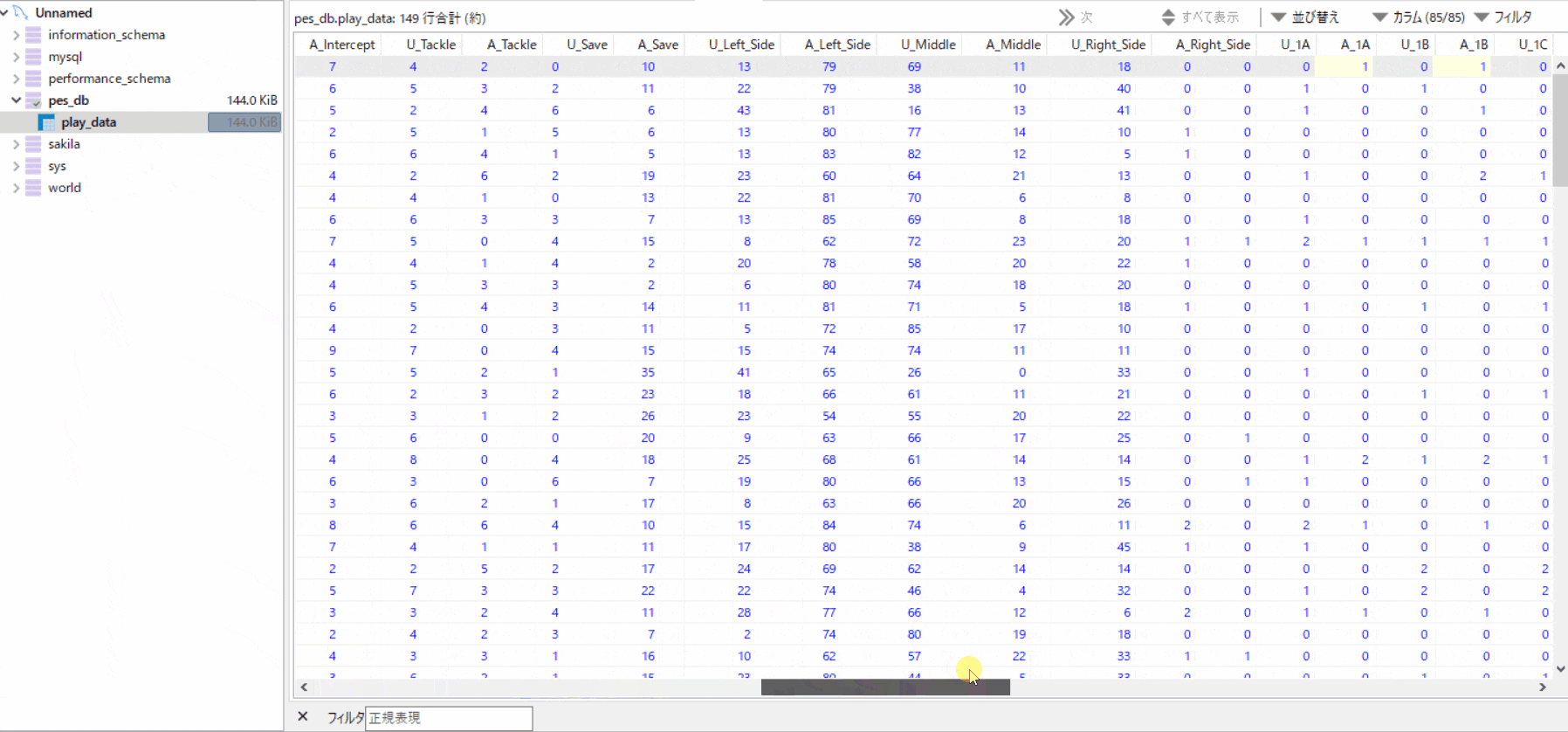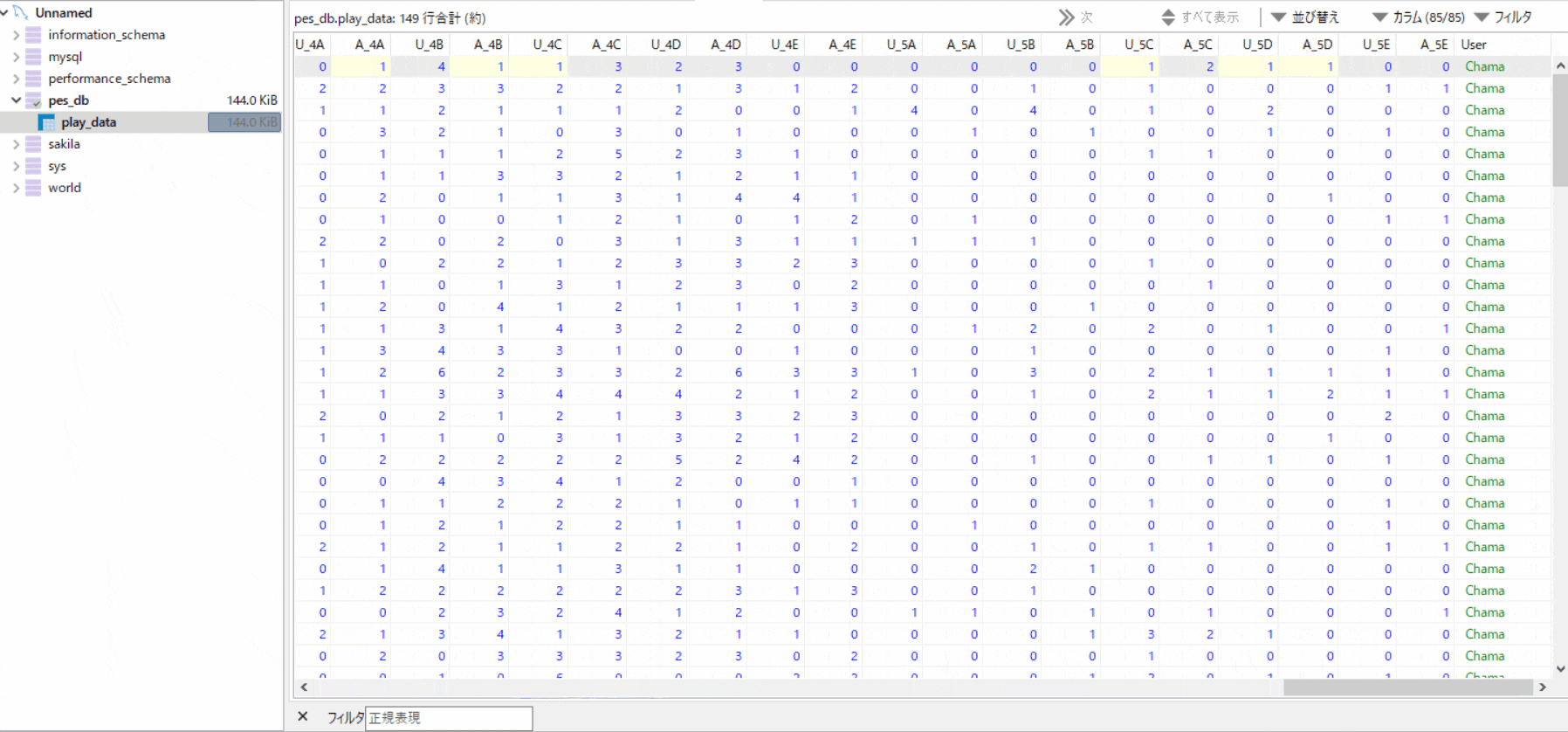
▼データベースからデータ読み込み
- ユーザー認証機能を付けました。 入力したユーザ名とパスワードがデータベースで管理されているものであれば、データを読み込めるようになってます。
●ユーザ認証からデータ操作はこんな感じ
- デモ操作なので、パスワードもデモ「Password」にしてます。
最初に私「Yajun」のデータを読み込んだ後、次に「Masataro」さんのデータを読み込んでいます。
ユーザが変わっているので、ゲージチャートとレーダーチャートの型が変わってます。
▼画像データからCSVファイル出力
- 試合結果画像からメトリクスデータを抽出して、CSVに出力するようにしました。
この機能の実現が一番難しくて工数がかかってます笑●ユーザ認証からCSV出力までこんな感じ
- ユーザ名とパスワードを入力して、Startボタンを押すと、フォルダ選択画面が出てきます。
試合結果画像を入れているフォルダを選択します。
すると、試合結果画像が表示されるので、ユーザは自分がHome側かAway側だったか確認して、表示されるラジオボタンから自チームを選択します。
処理が完了すると、試合結果画像を入れているフォルダに「output.csv」が出力されて完了です。

●画像処理して指定しているフォルダの中身
- 本ソフトで必要な試合結果画像が6枚(1試合3枚セットで2試合分)入っています。
3枚セットになっていれば、「チームスタッツ」「攻撃エリア」「ボール奪取エリア」の順番はぐちゃぐちゃで大丈夫です。
▼データベースへ追加
- CSVファイルが出力されていることを確認してから「Apped」ボタンを押すとデータベースに追加されます。
●追加後のデータベース
- データベースを確認すると、最下段の行に「2対4」と「4対6」の試合結果が格納されています。
上の「●画像処理して指定しているフォルダの中身」で公開している画像と見比べていただくと、6枚の画像から抽出されたデータが入っているのを確認できます。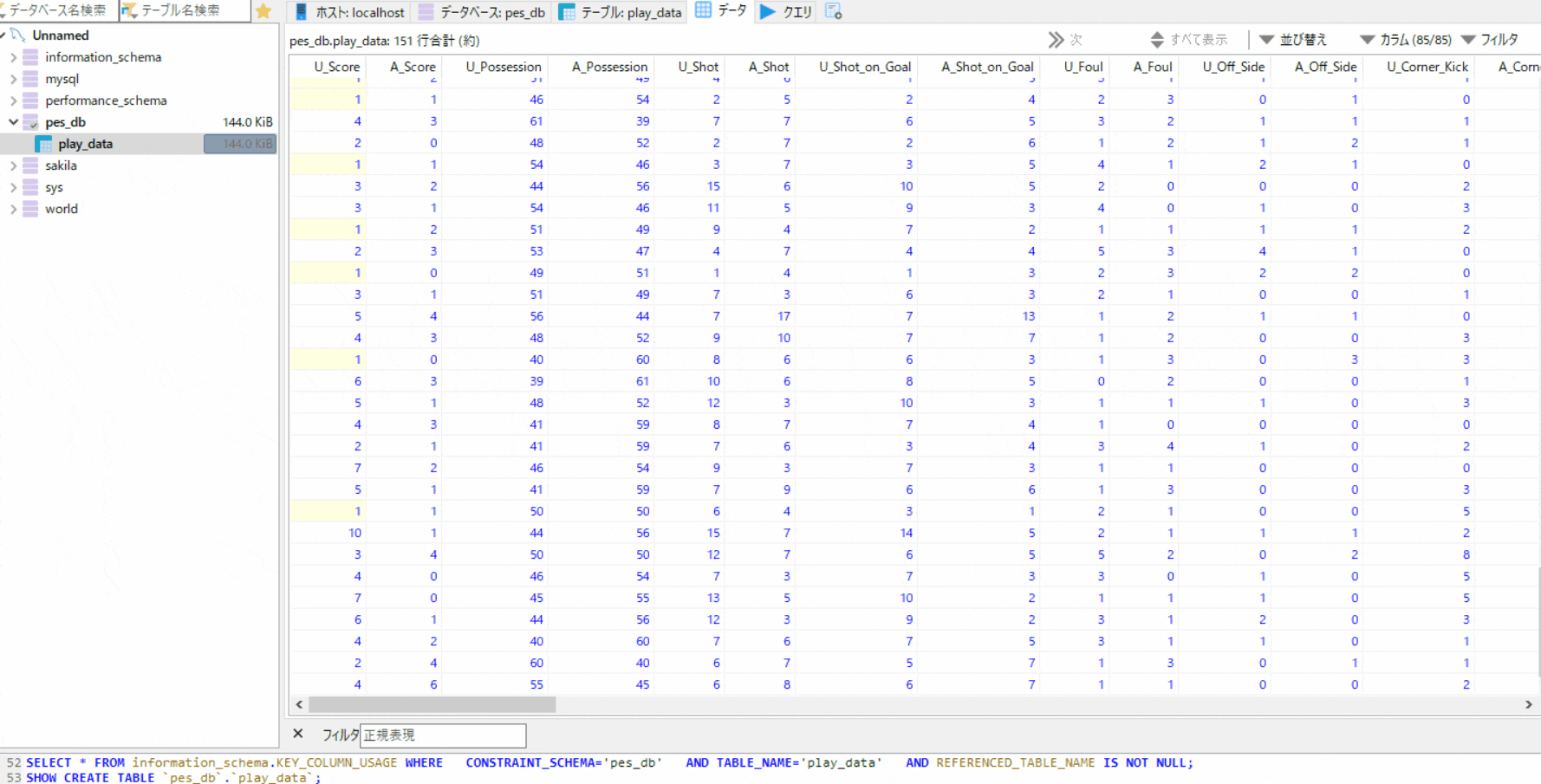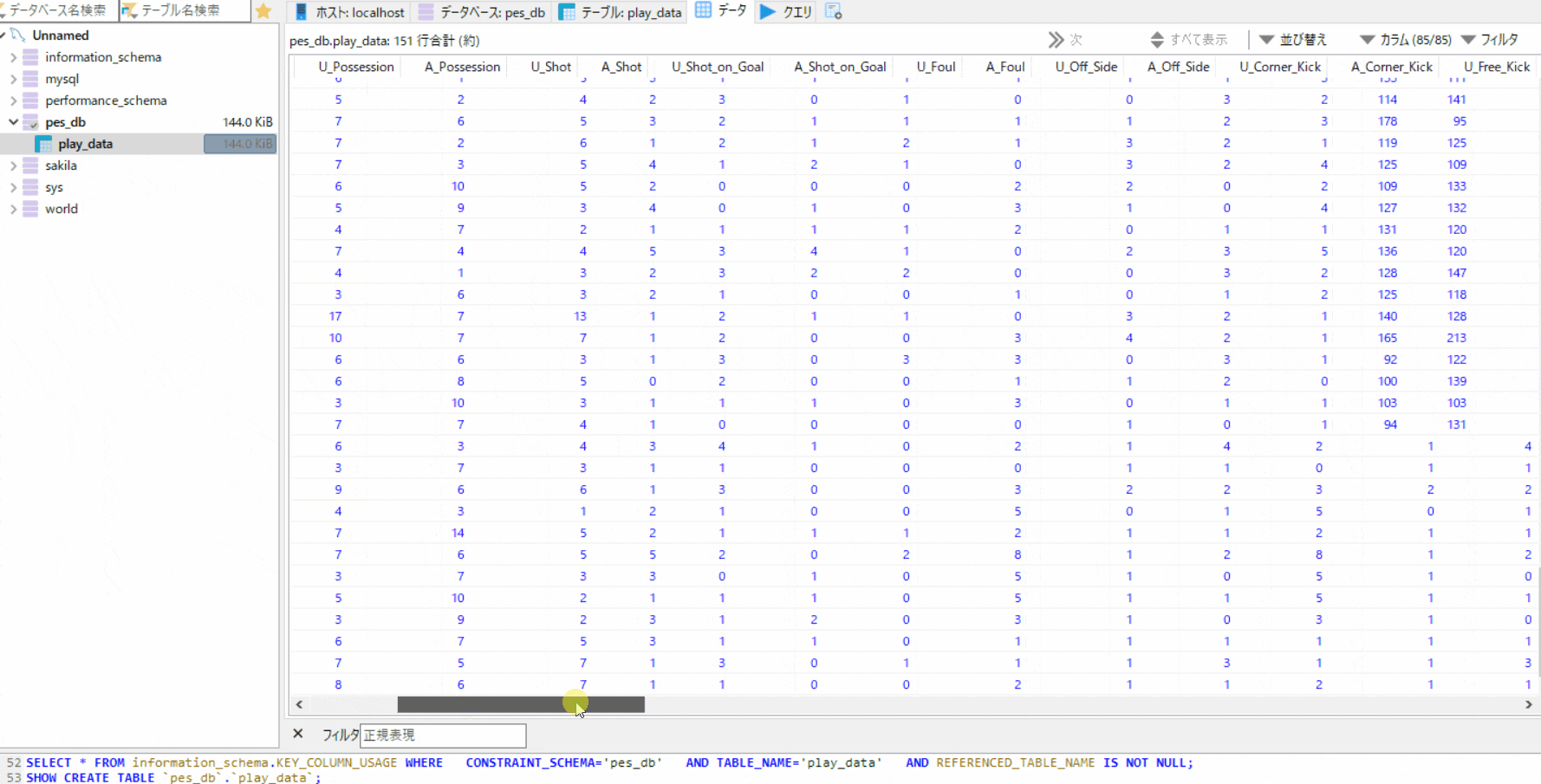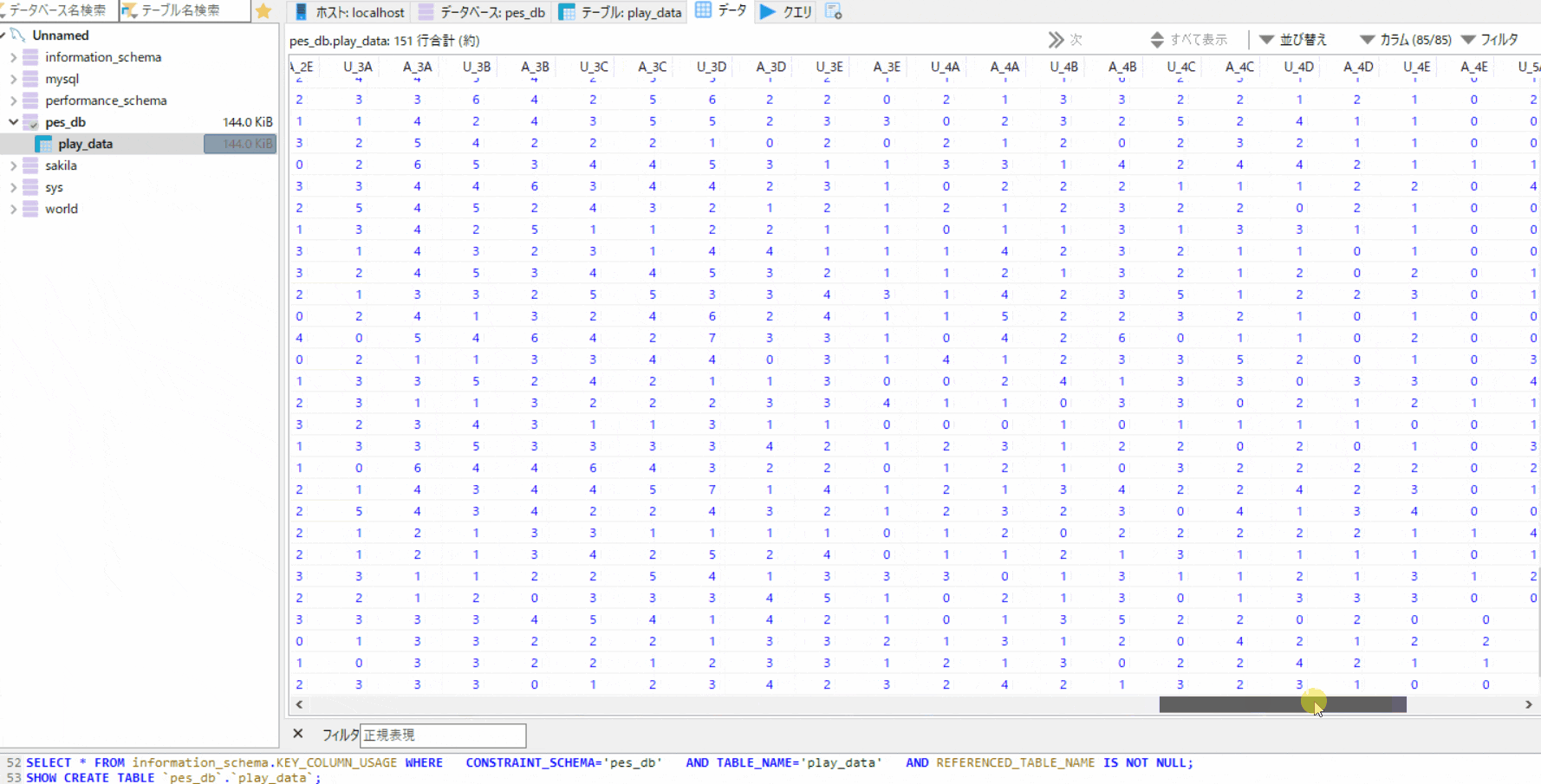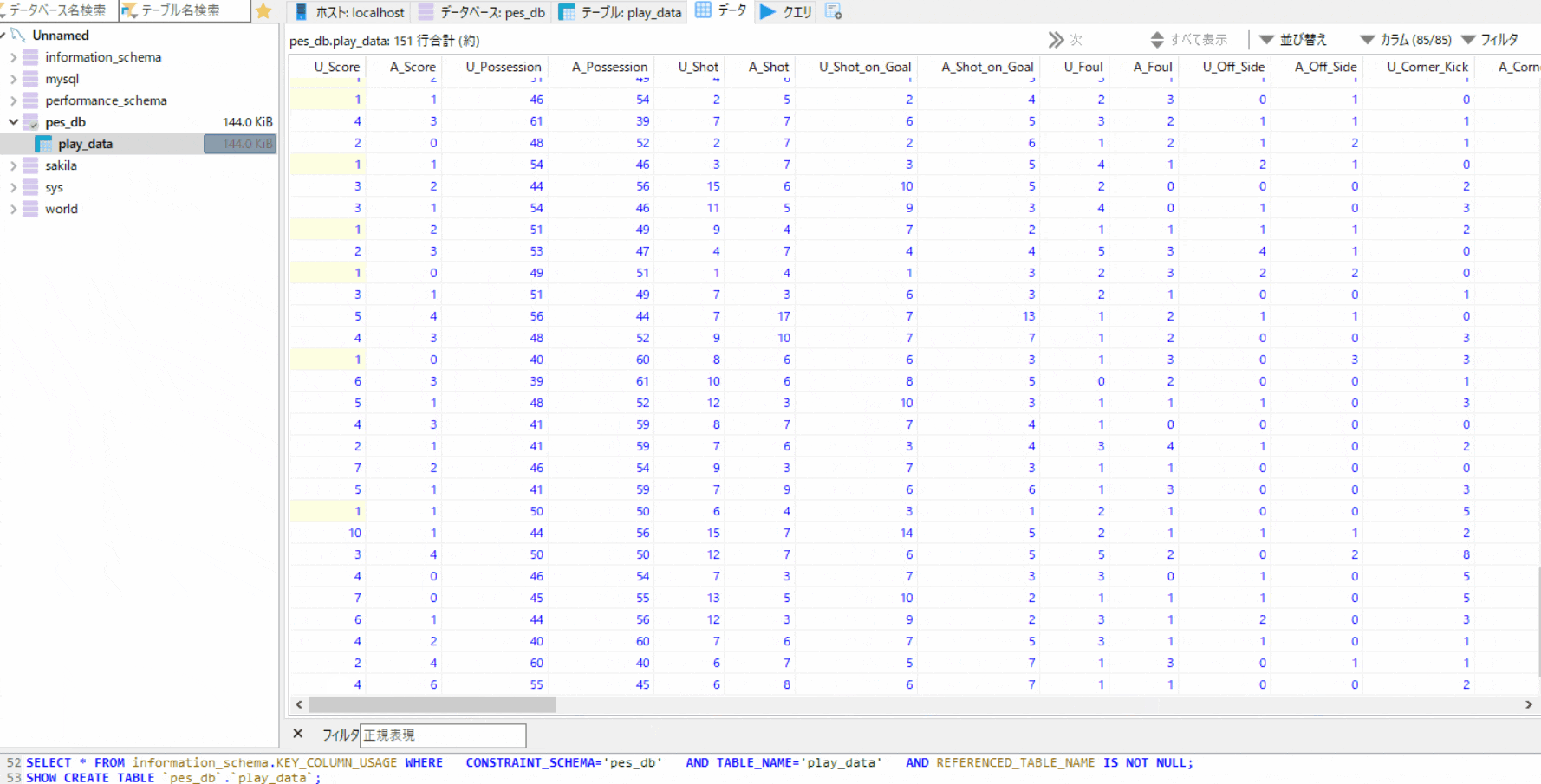
■残課題
前回記事で課題の棚卸しをしましたが、今回はそのうち2つを解消しました。
そろそろ、テスター向けにテスト版を配布したいとは思ってます。めっちゃバグでるんだろうな。。
個人の意見ですが、バグfixが一番成長する経験だと思っているので、ポジティブに捉えていきたいと思います。■展望
1000試合分くらいのデータが集まれば機械学習も始めてもいいかなと思ってます。
今やっているのは、データビジュアライゼーションまでで、そこからの傾向は人間が考察しなくてはなりません。
この傾向判断までもソフトにやらせたいですね♪
pythonには、scikit-learnやTensorFlowなどの優秀なライブラリが揃っているので楽しみです。個人的に、〇〇選手と〇〇選手を対戦させた場合どちらが勝つのか!?みたいのをソフトにやらせてみたい!笑
そのためにはデータを集める仕組みとして、この解析ソフトが必要なのです。■終わり
アプリとして最低限の機能は実装できたかなと思います。
解析のために、画像を集めるって面倒くさいとは思うのですが、
PS4で撮ったスクショを1つのフォルダにまとめてフォルダを指定すればいいので、
思ったよりも面倒臭さは少なめなのかな?と思ってます。前回記事に対し、「データの収集はPS4から直接できるようにならないの?」というご質問を頂きました。
PS4のAPIを公開されている方もいるので、技術検討してみようと思います!
こういった声は貴重です!ご意見ありがとうございます。今回の記事はここまで!また次回をお楽しみに♪
■参考URL
- HeidiSQLの機能と使い方を徹底解説!HeidiSQL導入のメリットは?ダウンロードから設定手順・接続方法もご紹介
Matplotlib - Tcl_AsyncDelete: async handler deleted by the wrong thread?
サーバサイドにおけるmatplotlibによる作図Tips
OpenCVが日本語パスを読み込まない
PythonでMySQLに接続する方法【初心者向け】
Windows 版 MySQL インストール手順
MySQL基本コマンド一覧まとめ
データベースの作成
【Python】MySQLにデータ追加
[Python] MySQLにアクセスしてデータベース操作を行う
MySQLでユーザー一覧を取得する方法 権限とパスワード一覧も取得!
Python で MySQLのテーブルに INSERT しても反映されない(丸2日無駄に!!)
mysqldbを介してpandas dataframeをデータベースに挿入するには?
pandasのDataFrameがto_sqlで保存できないときの対処法
Importing data from a MySQL database into a Pandas data frame including column names [duplicate]
- 投稿日:2020-07-06T12:20:45+09:00
【初心者向けハンズオン】kaggleの「住宅価格を予測する」を1行ずつ読み解く(第7回:予測モデルの構築の準備)
お題
有名なお題であるkaggleの「House Price」問題にみんなでチャレンジしていくことになったハンズオンの内容をメモしていく企画の第7回。解説というよりはメモのまとめだったりもしますが、どこかの誰かのためになれば幸いです。前回で準備がおわり、いよいよ解析段階に。
- 元々のお題:https://www.kaggle.com/c/house-prices-advanced-regression-techniques
- 参考にした記事:https://yolo-kiyoshi.com/2018/12/17/post-1003/
本日の作業
予測モデルの構築
# マージデータを学習データとテストデータに分割 train_ = all_data[all_data['WhatIsData']=='Train'].drop(['WhatIsData','Id'], axis=1).reset_index(drop=True) test_ = all_data[all_data['WhatIsData']=='Test'].drop(['WhatIsData','SalePrice'], axis=1).reset_index(drop=True) # 学習データ内の分割 train_x = train_.drop('SalePrice',axis=1) train_y = np.log(train_['SalePrice']) # テストデータ内の分割 test_id = test_['Id'] test_data = test_.drop('Id',axis=1)マージデータを学習データとテストデータに分割
trainの方で確認します。
all_data[all_data['WhatIsData']=='Train'].drop(['WhatIsData','Id'], axis=1).reset_index(drop=True)まずは
all_data[all_data['WhatIsData']=='Train']の中身を確認。all_data内のTrainだけをとってくるわけです。
all_data[all_data['WhatIsData']=='Train'].drop(['WhatIsData','Id'], axis=1)の中身確認WhatIsData, Idを列から落とす。
all_data[all_data['WhatIsData']=='Train'].drop(['WhatIsData','Id'], axis=1)の中身確認。indexをリセット(キャプチャ画像だと一切替わって見えねえ…)
(ちなみに、trainもtestも、以前配列をわざわざ作ったような。。。そこらへんの全体像をもっかいおさらいする必要があるなと思いました)
学習データ内の分割
train_x = train_.drop('SalePrice',axis=1) train_y = np.log(train_['SalePrice'])
train_x = train_.drop('SalePrice',axis=1)で、SalePrice以外のカラムを説明変数にするわけですね。
train_y = np.log(train_['SalePrice'])で、目的変数を用意。(前回の対数変換をお忘れなく)テストデータ内の分割
test_id = test_['Id'] test_data = test_.drop('Id',axis=1)もはや見たままか。。。流石にここはtest_id, test_dataそれぞれの確認は省略します。
予測モデルの構築
に、入ろうと思ったんですが、いかんせんわからないことがもりもりになってきたので、入らずに準備に徹します。主に単語調べ。
StandardScaler() #スケーリング
- スケール変換について:https://aizine.ai/preprocessing0614/
- Scikit-learnのスケール変換クラスについて:https://helve-python.hatenablog.jp/entry/scikitlearn-scale-conversion
[0.001, 0.01, 0.1, 1.0, 10.0,100.0,1000.0] #パラメータグリッド
make_pipeline(scaler, ls) #パイプライン生成おしまい。
この宿題をまずは全部読み込みをするところからか。
思ったこと言っていいですかね。「そろそろ終盤」とか思ってましたが、ここまでやってたこと全部前処理だったという。
- 投稿日:2020-07-06T12:01:49+09:00
「2/2」簡単なロボット操作用ウェブアプリケーションを作ってます。「RaspberryPi3B+とDjangoChannels」
イントロ
s_rae です。
頑張ってプログラミングの勉強をしています。アプリ開発の練習としてそのロボットを操作できるインタフェースを作ってみました。
https://github.com/samanthanium/dullahan_local
でソースコードを見れます。前回の投稿の続きとして今回はソースの説明を少し行います。
前回: https://qiita.com/s_rae/items/d808c3eccd8e173dc55bホビー目的で作られたものなのでエラーハンドリングは抜いて説明いたします。
使ったフレームワークやライブラリー
このプロジェクトにはこちらのテクノロジーを使ってます。
- Djangoフレームワーク
- Django Channels
- PybluezDjangoフレームワーク
Djangoでは主にHTTPでウェブページをサーブし、セッションでユーザーを管理しsqliteデータベースの作業を行いました。
ちなみにDjangoプロジェクトの中は複数の’app’(他のプロジェクトにも使えるように再利用出来るコード)で構成されてます。
このプロジェクトは
- dullahan(プロジェクトメインのapp)
- pages(Home, About, Loginウェブページ用)
- control_system(コマンドを送ったりデバイスを登録するためのページ)
- bluetooth_interface(Bluetooth機器のConsumer, functionを含めてます)の’app’で構成されています。
Djangoを使った理由は機能が多く含まれて素早く作成が出来からです。あとPythonの練習もやりたいと思いました。
Django Channels
DjangoChannelsはDjangoフレームワークのために作られたライブラリーです。Websocketなどの機能をDjangoフレームワークに追加する事が可能です。
Channelsは'Consumer'クラスを使ってWebSocketのメッセージを処理する仕組みです。Djangoフレームワークのviewと似てる機能を行えます。
Pybluez
PybluezはシステムのBluetooth機能をPythonで使えるために作られたライブラリーです。
こちらではPybluezのコードは説明しませんが、socketモジュールと似てる感じでコードを書くことが可能です。コードの説明
ユーザーがログインする --> デバイスを追加する --> デバイスにコマンドを送る
の感じの流れを説明いたします。pages/views.py#... def log_in(req): form = AuthenticationForm() if req.method == 'POST': form = AuthenticationForm(data=req.POST) if form.is_valid(): login(req, form.get_user()) return redirect(reverse('get_home')) else: return render(req, 'login.html', {'form': form}) return render(req, 'login.html', {'form': form}) #... def sign_up(req): form = UserCreationForm() if req.method == 'POST': form = UserCreationForm(data=req.POST) if form.is_valid(): form.save() return redirect(reverse('log_in')) else: print(form.errors) return render(req, 'signup.html', {'form': form})ここにユーザのログインのためのfunctionがあります。DjangoのFormsに含まれているmethod”form.get_user”を使えば簡単にログインさせる事が出来ます。
その後からは
@login_requiredのdecoratorをviewの中に使えば現在のユーザーの確認が出来ます。
次では周りのBluetoothデバイスを検索し同録する画面です。
control_system/views.pyfrom bluetooth_interface import bt_functions as bt #... @login_required def device_search_ajax(req): try: if req.method == "GET": nearby_devices = json.dumps(bt.search()) return JsonResponse({'nearby_devices':nearby_devices}, status=200) else: #... except: #エラーハンドル #...周りのBluetoothデバイスを検索するときはAjaxリクエストで行ってます。
bt.searchはPybluezを使ってBluetoothデバイスを検索するfunctionです。
こちらかわはHTTPではなくWebsocketを使いロボットとのメッセージのやり取りします。
control_system/consumers.py#... class CommandConsumer(WebsocketConsumer): def connect(self): # ユーザーが選択したデバイスのモデルを探す self.device_id = self.scope['url_route']['kwargs']['device_id'] self.device_group_name = 'command_%s' % self.device_id device = Device.objects.get(id=self.device_id) # Bluetooth用のconsumerにデバイスとシリアル通信が出来るようにする async_to_sync(self.channel_layer.send)('bt-process', { 'type': 'bt_connect', 'group_name': self.device_group_name, 'uuid': device.uuid, 'device' : device.id, } ) # ユーザーをgroupに追加する async_to_sync(self.channel_layer.group_add)( self.device_group_name, self.channel_name ) self.accept() #... def receive(self, text_data): text_data_json = json.loads(text_data) message = text_data_json['message'] device_id = text_data_json['device'] # コマンドをデバイスに送信する async_to_sync(self.channel_layer.send)('bt-process', { 'type': 'bt_send_serial', 'device': device_id, 'message': message, } ) #... # Bluetoothデバイスからもらった返信のメッセージを保存、フォワード def command_message(self, event): message = event['message'] device_id = event['device'] # timestamp付きでデバイスのモデルに保存する device = Device.objects.get(id=device_id) new_history = CommandHistory(device=device, command=message ) new_history.save() command_history = {} all_history = device.history.all() for command in all_history: command_history[command.timestamp.strftime('%H:%M:%S')] = command.command + '\n' # コマンド履歴をユーザーに送信する self.send(text_data=json.dumps({ 'message': command_history, 'device': device_id }))こちらが少し複雑ですが簡単に説明すると
connectでユーザーとのWebsocket通信が開設されBluetoothデバイスに通信が出来るようにします。’bt-process’とは現在バックグラウンドで行われてるBluetooth機器用のconsumerを示してます。’bt-process’の’bt_connect’を使おうとする感じです。
receiveではユーザーがウェブページを使ってメッセージを送った時そのメッセージに含まれてるデバイスへのコマンドをロボットに送信します。こちらも上と同じように’bt-process’にメッセージをおくります。
command_messageではロボットから受信した返信をロボットのデータベースモデルに保存します。そのメッセージはロボットのモデルとMany-to-one関係になってます。ロボットのidを使って繋がってる形です。
次はロボットと通信するためのconsumerクラスです。
bluetooth_interface/consumers.py#... from bluetooth_interface import bt_functions #... class BTConsumer(SyncConsumer): def bt_connect(self, message): # ユーザーにメッセージを送れるために覚えておく self.device_group_name = message['group_name'] self.sock = {} # Bluetooth通信port番号 self.port_num = 1 # 通信用ソケットを作る sock, msg = bt_functions.connect(message['uuid'], self.port_num) # ソケットをデバイスのidと一緒に記録 if sock != 1: self.sock = {message['device']:[sock, self.port_num]} # 通信状態をユーザーに送る async_to_sync(self.channel_layer.group_send)( self.device_group_name, { 'type': 'command_message', 'device': message['device'], 'message': msg, } ) #... def bt_send_serial(self, event): # ユーザーが要請してるデバイスのidとメッセージを取る device_id = int(event['device']) message = event['message'] # そのデバイスとの通信ようソケットを選んでメッセージを送信する if device_id in self.sock.keys(): result = bt_functions.send_serial(self.sock[device_id][0], message) # ユーザーに返信のメッセージを送る async_to_sync(self.channel_layer.group_send)( self.device_group_name, { 'type': 'command_message', 'device': device_id, 'message': result, } ) #...ここでどうやって行うかかなり迷いました。
結果としては
- ロボットがいつでもメッセージ(センサーのデーター、コマンドへの返信など)を送信できるようなconsumerを作成
- ユーザーがいつでもメッセージをロボットに送信できるような機能を追加
が出来るようにしました。
Django ChannelsではChannels Layerて言うのを使いConsumerクラスやプロセスの間の通信が出来ます。
なので、ユーザーがログアウトしたり他の作業を行っても別のプロセスでロボットと常に繋がってます。
まだ作成してないですが、こう言う形でロボットやIoTデバイスから常にセンサーのデーターがとれます。
詳しいことはDjango Channelsのドキュメントを参考して下さい。
https://channels.readthedocs.io/en/latest/topics/channel_layers.html
https://channels.readthedocs.io/en/latest/topics/worker.html最後に
Asyncが使いやすいNode.jsなどでプロジェクトを作ったら楽だったと思います。
ですがDjangoの多く含まれてる機能(セキュリティー、ユーザー管理、Formsなど)を使いたかったのでDjangoとDjangoChannelsを使いました。
ここまで作るのにかかった時間は2週間~くらいでした。新しい事が多かったので大体はドキュメントをよんだり勉強する時間でした。
今回もここまで読んで下さってありがとうございます。
- 投稿日:2020-07-06T11:46:46+09:00
PythonでBigQuery操作する方法
PythonでBigQueryを扱う方法の詳細はこちらに詳しく書いてあります。
データセットを操作したい場合はManaging Datasets
テーブル操作したい場合はManaging Tables
に記載があります。テーブルの作成
from google.cloud import bigquery # Colabで使う場合はPJ名の指定が必要 client = bigquery.Client() client = bigquery.Client(project=project_id) # "your-project" schema = [ bigquery.SchemaField("full_name", "STRING", mode="REQUIRED"), bigquery.SchemaField("age", "INTEGER", mode="REQUIRED"), ] # table_id = "your-project.your_dataset.your_table_name" table = bigquery.Table(table_id, schema=schema) table = client.create_table(table) # Make an API request. print( "Created table {}.{}.{}".format(table.project, table.dataset_id, table.table_id) )スキーマの指定方法
ステートメントは下記になります。
SchemaField(name, field_type, mode='NULLABLE', description=None, fields=(), policy_tags=None)ステートメントの詳細についてはこちらに記載あり、スキーマの指定方法についてはBigQueryの公式サイトに詳細が書かれているので、
必要に応じてfield_typeやmodeを変更していきます。テーブルにinsertする方法
from google.cloud import bigquery # Colabで使う場合はPJ名の指定が必要 client = bigquery.Client() client = bigquery.Client(project=project_id) # "your-project" # table_id = "your-project.your_dataset.your_table_name" table = client.get_table(table_id) # Make an API request. # リストの二次元配列 # 例ではタプルになっているがリストでも問題なし # ただしスキーマの数と中のタプル(or リスト)の要素の数が異なるとエラーになるのて注意 rows_to_insert = [("string", num), ("string", num)] errors = client.insert_rows(table, rows_to_insert) # Make an API request. if errors == []: print("New rows have been added.")