- 投稿日:2020-06-29T20:41:44+09:00
【Ruby on Rails】レイアウトテンプレートの備忘録
初稿です。不備がありましたらご指摘いただけると幸いです。
Ruby on Railsを勉強中です。ビューファイルでコーディングした内容が、なぜDOCTYPE宣言やHTMLタグで囲ってないのにブラウザできちんと表示されるか不明だったのですが、レイアウトテンプレートを理解してスッキリしたので備忘録として残しておきます。
レイアウトテンプレートとは?
railsでアプリケーションを作成した際に、以下のディレクトリに自動で作成されるファイルです。
app/views/layouts/application.html.erb通常、コントローラーで定義したアクションから、ビューファイルがある場合はそのファイルが呼ばれているように見えますが、実際はレイアウトテンプレートの中に作成したビューファイルが埋め込まれて返しているとのこと。
例)postsというコントローラーを作成した場合
app/controllers/posts_controller.rbposts_controller.rbclass PostsController < ApplicationController def index end endapp/views/posts/index.html.erb
index.html.erb<h1>トップページ</h1>実際、レスポンスとして返しているのは、下記テンプレートファイルの
タグ内にある<%= yield %>に呼び出されたビューファイルindex.html.erbが埋め込まれて返されているとのこと。app/views/layouts/application.html.erb
application.html.erb<!DOCTYPE html> <html> <head> <title>FirstApp</title> <%= csrf_meta_tags %> <%= csp_meta_tag %> <%= stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' %> <%= javascript_pack_tag 'application', 'data-turbolinks-track': 'reload' %> </head> <body> <%= yield %> </body> </html>

- 投稿日:2020-06-29T20:27:13+09:00
docker-compose upの直後Yarnのエラーでコンテナが落ちる問題と解決
環境
MacOS Mojave: 10.14.6
Docker: 19.03.8
Ruby: 2.6.6
Rails: 6.0.0
PostgreSQL問題
RailsチュートリアルのSample_appを
Docker環境に移行している途中で
docker-compose upのあとpumaが起動した後すぐに以下のエラーを吐いて落ちる現象に遭遇warning Integrity check: System parameters don't match app_1 | error Integrity check failed app_1 | error Found 1 errors. app_1 | app_1 | app_1 | ======================================== app_1 | Your Yarn packages are out of date! app_1 | Please run `yarn install --check-files` to update. app_1 | ======================================== app_1 | app_1 | app_1 | To disable this check, please change `check_yarn_integrity` app_1 | to `false` in your webpacker config file (config/webpacker.yml). app_1 | app_1 | app_1 | yarn check v1.22.4 app_1 | info Visit https://yarnpkg.com/en/docs/cli/check for documentation about this command.config/webpacker.ymlを編集する解決方法が見つかったがこれでは解決せず
yarnが原因でdocker-compose runが実行できないときの対処法 - Qiita解決
こちらを参考に
config/environments/development.rbとconfig/webpacker.ymlを編集して解決しました
Running a Rails app with Webpacker and Docker - Dirk de Kok - MediumLast configuration for Yarn and Webpacker
Rails does a lot of checkups on Yarn, a bit too much. Best is to disable this:
# config/environments/development.rb config.webpacker.check_yarn_integrity = falseAlso, we need to tell Rails that the webpacker server is running on the host webpacker and enable hot module reload. So set these values:
# config/webpacker.yml development: dev_server: host: webpacker hmr: trueLast configuration for Yarn and Webpacker
- 投稿日:2020-06-29T20:02:14+09:00
【Rails】画像プレビュー機能の実装
目標
開発環境
・Ruby: 2.5.7
・Rails: 5.2.4
・Vagrant: 2.2.7
・VirtualBox: 6.1
・OS: macOS Catalina前提
下記実装済み。
・Slim導入
・Bootstrap3導入
・Font Awesome導入
・ログイン機能実装
・投稿機能実装実装
1.ビューを編集
users/edit.html.slim/ 追記 = f.file_field :profile_image, class: 'img_field', style: 'display:none;' = attachment_image_tag @user, :profile_image, fallback: 'no-image.png', onClick: "$('.img_field').click()", class: 'center-block img-thumbnail img-responsive img_prev' br【解説】
①
file_fieldをdisplay:noneの非表示にし、クラスを付与する。= f.file_field :profile_image, class: 'img_field', style: 'display:none;'②
①で付与したクラスのHTML(file_field)がクリックされたらJavaScriptの処理を実行する。onClick: "$('.img_field').click()"2.
appliacation.scssを編集appliacation.scss// 追記 .img_prev:hover { cursor: pointer; opacity: 0.7; transform: scale(1.01, 1.01); }【解説】
① 画像にマウスが乗っている時にCSSを反映させる。
.img_prev:hover {}② マウスカーソルをポインターに変更する。
cursor: pointer;③ 不透明度を低くして、画像を少し白くする。
opacity: 0.7;④ 少しだけ画像を拡大する。
transform: scale(1.01, 1.01);3.JavaScriptファイルを作成・編集
ターミナル$ touch app/assets/javascripts/image_preview.jsimage_preview.js$(function () { function readURL(input) { if (input.files && input.files[0]) { var reader = new FileReader(); reader.onload = function (e) { $('.img_prev').attr('src', e.target.result); } reader.readAsDataURL(input.files[0]); } } $('.img_field').change(function () { readURL(this); }); });【解説】
①
1.ビューを編集の②で実行する処理。$('.img_field').change(function () { readURL(this); });

- 投稿日:2020-06-29T19:50:32+09:00
【RSpec】stub_request(:post)でスタブ化したGoogle APIへのリクエストのレスポンスを実際と同一のレスポンス形式にする
タイトルが長い
RailsアプリケーションからGoogle Calendar APIでカレンダー上のイベントに対して更新処理を行い、そのレスポンスから特定の属性を取り出して取り回すような処理を追加した。
レスポンスで受け取ったJSONをgoogle-api-ruby-clientがGoogle::API::V3::Eventクラスのオブジェクトに変換してしまうため、スタブリクエストのレスポンスもruby-clientで変換させるか同様の構造を持ったオブジェクトにする必要があった。TL;DR
- google-api-ruby-clientを利用してGoogleAPIにリクエストした場合、レスポンスはJSON形式で返ってきたあとgoogle-api-ruby-clientで変換される
- stub_requestからの戻り値のヘッダーに
'X-Goog-Upload-Status': 'final'を加えると実際のAPIからのレスポンスと同様の形式になるスタブ化したリクエストと実際にAPIにリクエストした場合のレスポンスの違い
下記のコードはgoogle-api-ruby-clientを利用してリクエストし、レスポンスからイベントのIDを取得しようとしている
リクエスト
service = Google::Apis::CalendarV3::CalendarService.new service.authorization = access_token response = service.update_event('primary', event_id, body) event_id = response.idこのとき
responseは以下のようになっている。#<Google::Apis::CalendarV3::Event:0x000055c94da58f18 @attachments=[], @attendees=[#<Google::Apis::CalendarV3::EventAttendee:xxxxxxxxxxxxxxxxxxx @email="hoge@gmail.com", @organizer=true, @self=true>], @created=Mon, 01 Jan 2020 00:00:00 +0000, @creator=#<Google::Apis::CalendarV3::Event::Creator:xxxxxxxxxxxxxxxxxxx @email="hoge@gmail.com", @self=true>, @description="", @end=#<Google::Apis::CalendarV3::EventDateTime:xxxxxxxxxxxxxxxxxxx>, @etag="xxxxxxxxxxxxxxxxxxx", @id="abcdefghijklmnopqrstu", @organizer=#<Google::Apis::CalendarV3::Event::Organizer:xxxxxxxxxxxxxxxxxxx @email="hoge@gmail.com">, @start=#<Google::Apis::CalendarV3::EventDateTime:xxxxxxxxxxxxxxxxxxx>, @updated=Mon, 01 Jan 2020 00:00:00 +0000>このため、
responseオブジェクトから ゲッターメソッドのidで値を取得できる。一方で大抵の場合、RSpec内でAPIレスポンスは下記のように定義されているだろう。
let(:response) do { id: 'abcdefghijklmnopqrstu', start: { date_time: Time.zone.today }, end: { date_time: Time.zone.today }, html_link: 'https://www.google.com/calendar/event?eid=xxxxxxxxxxxxxxxxxxxxxxxxxxxx', i_cal_uid: 'xxxxxxxxxxxxxxxxxxx@google.com', summary: 'event name', updated: Time.zone.today, ... }.to_json endこの場合イベントIDを取得するためには
JSON.parse(response)['id']のようにする必要があり、response.idはNoMethodErrorとなる。このJSON形式のレスポンスをEventクラスのオブジェクトとして返させるためには以下のように
'X-Goog-Upload-Status': 'final'をレスポンスのヘッダーに付与する必要がある。stub_request( :put, url ).to_return( status: 201, body: response, headers: { content_type: 'application/json', 'X-Goog-Upload-Status': 'final' } )google-api-ruby-clientのテストスペック内でもレスポンスに同様のヘッダー情報が付与されている。
たまたま同僚がすぐに記事やGitHubのissueを見つけてくれたおかげで解決したけどそうじゃなかったら3日はハマってた気がする。
元ネタ
- 投稿日:2020-06-29T19:50:32+09:00
【RSpec】stub_request(:post)でスタブ化したGoogle APIへのリクエストのレスポンスを実際と同一の形式にする
タイトルが長い
RailsアプリケーションからGoogle Calendar APIでカレンダー上のイベントに対して更新処理を行い、そのレスポンスから特定の属性を取り出して取り回すような処理を追加した。
レスポンスで受け取ったJSONをgoogle-api-ruby-clientがGoogle::API::V3::Eventクラスのオブジェクトに変換してしまうため、スタブリクエストのレスポンスもruby-clientで変換させるか同様の構造を持ったオブジェクトにする必要があった。TL;DR
- google-api-ruby-clientを利用してGoogleAPIにリクエストした場合、レスポンスはJSON形式で返ってきたあとgoogle-api-ruby-clientで変換される
- stub_requestからの戻り値のヘッダーに
'X-Goog-Upload-Status': 'final'を加えると実際のAPIからのレスポンスと同様の形式になるスタブ化したリクエストと実際にAPIにリクエストした場合のレスポンスの違い
下記のコードはgoogle-api-ruby-clientを利用してリクエストし、レスポンスからイベントのIDを取得しようとしている
リクエスト
service = Google::Apis::CalendarV3::CalendarService.new service.authorization = access_token response = service.update_event('primary', event_id, body) event_id = response.idこのとき
responseは以下のようになっている。#<Google::Apis::CalendarV3::Event:0x000055c94da58f18 @attachments=[], @attendees=[#<Google::Apis::CalendarV3::EventAttendee:xxxxxxxxxxxxxxxxxxx @email="hoge@gmail.com", @organizer=true, @self=true>], @created=Mon, 01 Jan 2020 00:00:00 +0000, @creator=#<Google::Apis::CalendarV3::Event::Creator:xxxxxxxxxxxxxxxxxxx @email="hoge@gmail.com", @self=true>, @description="", @end=#<Google::Apis::CalendarV3::EventDateTime:xxxxxxxxxxxxxxxxxxx>, @etag="xxxxxxxxxxxxxxxxxxx", @id="abcdefghijklmnopqrstu", @organizer=#<Google::Apis::CalendarV3::Event::Organizer:xxxxxxxxxxxxxxxxxxx @email="hoge@gmail.com">, @start=#<Google::Apis::CalendarV3::EventDateTime:xxxxxxxxxxxxxxxxxxx>, @updated=Mon, 01 Jan 2020 00:00:00 +0000>このため、
responseオブジェクトから ゲッターメソッドのidで値を取得できる。一方で大抵の場合、RSpec内でAPIレスポンスは下記のように定義されているだろう。
let(:response) do { id: 'abcdefghijklmnopqrstu', start: { date_time: Time.zone.today }, end: { date_time: Time.zone.today }, html_link: 'https://www.google.com/calendar/event?eid=xxxxxxxxxxxxxxxxxxxxxxxxxxxx', i_cal_uid: 'xxxxxxxxxxxxxxxxxxx@google.com', summary: 'event name', updated: Time.zone.today, ... }.to_json endこの場合イベントIDを取得するためには
JSON.parse(response)['id']のようにする必要があり、response.idはNoMethodErrorとなる。対応策
このJSON形式のレスポンスをEventクラスのオブジェクトとして返させるためには以下のように
'X-Goog-Upload-Status': 'final'をレスポンスのヘッダーに付与する必要がある。stub_request( :put, url ).to_return( status: 201, body: response, headers: { content_type: 'application/json', 'X-Goog-Upload-Status': 'final' } )google-api-ruby-clientのテストスペック内でもレスポンスに同様のヘッダー情報が付与されている。
たまたま同僚がすぐに記事やGitHubのissueを見つけてくれたおかげで解決したけどそうじゃなかったら3日はハマってた気がする。
元ネタ
- 投稿日:2020-06-29T18:33:46+09:00
[Rails]seedファイルごとにデータを管理する
某フリマアプリのクローンサイトをチームで作成中です。
その時に、seedファイルの扱いに少し困ったので備忘録として残しておきます。したいこと
商品を出品する時に、「商品の状態」「配送料」..etcなんかは、
データベースに先に値を入れておいて、プルダウンから選択できるようにするこんな感じ
実装
1. rake taskの作成
lib/tasks/直下にseed.rakeを作成し、以下を記載
lib/tasks/seed.rakeDir.glob(File.join(Rails.root, 'db', 'seeds', '*.rb')).each do |file| desc "Load the seed data from db/seeds/#{File.basename(file)}. task "db:seed:#{File.basename(file).gsub(/\..+$/, '')}" => :environment do load(file) end end2. それぞれのseedファイルを作成
db/seedsディレクトリを作成し、そこに「データを入れたいモデル名.rb」のファイルを作成
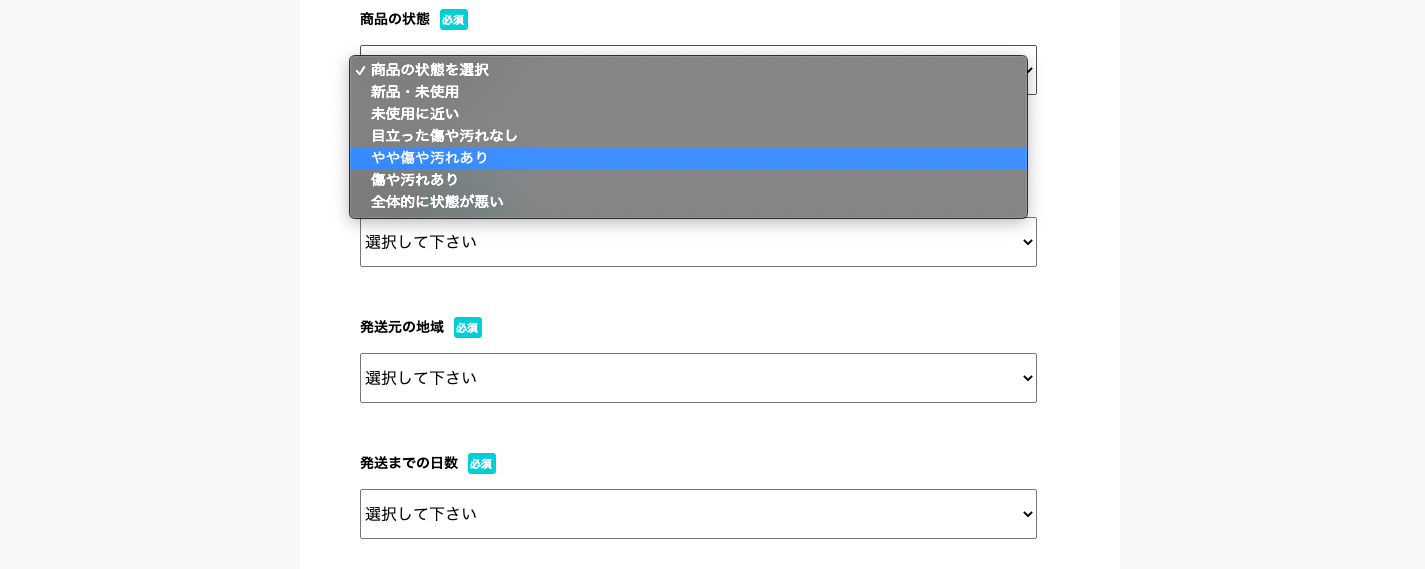
今回はとりあえず、商品の状態を表すCondition.rbを作成db/seeds/Condition.rbconditions = Condition.create([ {condition: "新品・未使用"}, {condition: "未使用に近い"}, {condition: "目立った傷や汚れなし"}, {condition: "やや傷や汚れあり"}, {condition: "傷や汚れあり"}, {condition: "全体的に状態が悪い"}])3. 実行
あとは実行するだけなので、以下のコマンドをターミナルに
bundle exec rake db:seed:conditionconditionsテーブルにデータを入れられました!
が、問題発生・・・
ローカルの環境ならこのままで良かったのですが、本番環境にデプロイする際に
作成したそれぞれのseedファイルの読み込ませ方が分からず、データを反映できませんでした解決法
seeds.rbに以下の記述を追加
seeds.rbrequire "./db/seeds/condition.rb本番環境のターミナルにて下記のコマンドを実行したらきちんと反映しました
require "./db/seeds/condition.rb終わりに
active hashを使えばもうちょっと楽にできたりしたのかな〜なんて思いますが、
納期もあるので一旦この方法で実装しました
他にいい方法があれば教えていただきたいです参考記事

- 投稿日:2020-06-29T18:30:13+09:00
To install the missing version, run `gem install bundler:2.1.4`と出たときの対処法
日々学んだことやぶち当たったエラーについてまとめていきます。
記載に誤りがありましたら、ご指摘していただけると助かります!
いつも他のかたの記事に助けられているので、少しでもお役に立てればと思います。どういうエラーなのか
Gemfile.lockにbundler 2.1.4が指定しているが、そのバージョンのbundlerが見当たらないというエラー。
Traceback (most recent call last): 2: from 1: from #省略 Could not find 'bundler' (2.1.4) required by your /Users/<ユーザー名>/<ルートディレクトリ名>/Gemfile.lock. (Gem::GemNotFoundException) To update to the latest version installed on your system, run `bundle update --bundler`. To install the missing version, run `gem install bundler:2.1.4`どんなときに起こるのか
Rubyのバージョンの変更をしたときなどに起こる。rbenvではRubyのバージョンごとにgemをインストールする必要があるとのこと。
対処法
gem install bundler -v 2.1.4と入力して、bundler 2.1.4を入れたら解決!
参考
https://qiita.com/kodai_0122/items/c4c13e89dd5c4cba1f32
https://qiita.com/YumaInaura/items/64e5721549e4927ce85f
https://k-koh.hatenablog.com/entry/2020/01/27/200511
- 投稿日:2020-06-29T18:05:00+09:00
【自作】自動デプロイ、AWSの各種サービス起動について
1)背景
自動デプロイはcapstranoなどありますが、簡単に自動化するため、以下のshellを作成しました。このshellを使えば、手数はかなり減ります。
2)環境
項目 内容 OS.Amazon Linux AMI release 2018.03 Ruby v2.5.1 Ruby On Rails v5.2.4.3 MySQL v5.6 Unicorn v5.4.1 3)内容
(1) AWSの対象インスタンスの再起動
インスタンスを再起動することで、現在稼働しているアプリが停止します。
(2) shellを実行する(ホームディレクトリの配下に配置する)
以下のshellを実行することで、必要なサービスの起動と、アプリの起動を行います。
サービスを起動する前には、必要なgitプル、scssやJavascriptのコンパイルを行います。auto-service.sh#/bin/sh #任意ディレクトリへ移動 cd /var/www/☆アプリ名; sleep 5; echo `pwd`; #git-pullする。 echo "get!! new-master.. wait 5sec"; sleep 5; git pull origin master; #Assetsのプレコンパイル echo "precompile!!";sleep 5; rails assets:precompile RAILS_ENV=production #NGINXの開始 sudo service nginx start; sudo service nginx status; sleep 5; #MySQLの開始 sudo service mysqld start; sudo service mysqld status; sleep 5; #アプリ開始 echo "Rails Start!!!!!!!!!!!!!!" RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -D以上、よければご活用ください。
- 投稿日:2020-06-29T17:29:49+09:00
Railsプロジェクト開発方針
- Railsの思想を理解する
- Railsの基本理念 : Railsの生みの親が掲げる8つの原則 | POSTD
- Getting Real: The smarter, faster, easier way to build a successful web application
- 日本語版アーカイブ: Getting Real by 37signals
- Railsは思想を強く持ったフレームワーク。Railsを使うのであれば、ある程度、Railsの思想を理解しておいた方が良い。
- 読みやすさ、分かりやすさ、直しやすさを意識する
- システムやコードは常に変化していくもの。変化に対応しやすいコードを意識する。
- 新しく入った人や数年後の自分が理解しやすく、修正や実装を行いやすいコードを意識する。
- なるべくRailsのデフォルトに沿う(ただし、例外もある)
- 例外:
erb、CoffeeScript、jQueryは使わない- 使わない方が良いもの
- Gem
Devisegrapedefault_scope- 論理削除
- 使った方が良いもの
Ridgepoleaction_args- テストコードは何の為に書くのか、目的を明確にする
- 書こうとすると際限無く書けてしまう
- テストコードは実装コスト、メンテナンスコストもそれなりにある
- コストに見合う効果があるのか、費用対効果も考える。
- バグの発生を防ぐため、デグレを防ぐため、など、何の為のテストコードかを明確にする。
before_actionは使い過ぎない
- 処理が暗黙化されてしまうため、処理やデータの流れを分かりにくくしてしまう場合がある。
- ローカル環境での開発効率を保つ
- ローカル環境の構築手順を
READMEに書く
- 投稿日:2020-06-29T17:10:02+09:00
bcrypt導入時のエラーたち
bcrypt導入時のエラー
パスワードを暗号化するためのgem, bcryptを導入する際に起こった、小さなエラーの解決法まとめです
その1 An error occurred while installing bcrypt, and Bundler cannot continue.
Gemfilegem 'bcrypt'と書き足し、bundle install を実行したところ、
An error occurred while installing bcrypt (3.1.13), and Bundler
cannot continue.
というエラーが発生。
続けて、エラーメッセージ内に書いてある、
gem install bcrypt -v'3.1.13'
を実行したところ、今度はPermission denied が発生Permissionということはsudoの出番ではないかと下記のコードを実行
$ sudo gem install bcryptこれで無事bundle install 時のエラーが消え、bcryptを追加できました!
その2 cannot load such file -- bcrypt
無事、エラー1を克服し、localhostのブラウザを再起動したにも関わらず、このエラー
そういえば、このような時昔あったなと思い出し、 rails s を再実行。
すると通りました!!
今回はbcrypt導入時の小さいエラーもろもろでした〜
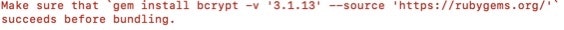
- 投稿日:2020-06-29T15:53:23+09:00
Rails のscaffoldってなに?
Railsの記事を見ると、
scaffoldというジェネレーターを使用して
モデルからビューまで一括で作成してます。
スクールでは個別に作成するよう学んだので、違いを調べてアウトプットしました。今までの方法
例えば
Bookのモデル・コントローラ・ビューを作成する場合は以下のように実行していました。ターミナル$ rails g model Book title:string introduction:text $ rails db:migrate $ rails g controller Books index show new editそして最後にルーティングを設定するまでが一連の流れです。
config/routes.rbRails.application.routes.draw do resources :books #ここを追加 endscaffoldを使用してみると
同様の内容で作成する場合、
scaffoldを使用すればこれだけで済んでしまいます。
(おまけに各ビューには簡単なフォーム、部分テンプレートまで用意されています。)ターミナル$ rails g scaffold Book title:string introduction:text $ rails db:migrate最後に
scaffoldとは『土台』との意味で、それを全部組み立てるのが、この手法とのことです。
確かに基礎を十分に理解していれば便利ですが、最初からこれで覚えてしまうとMVCの理解も
出来ないままになりますね。今までは見たこと無い方法だと思ってビビって使えませんでしたが、
ある意味良かったかもです。(笑)
今後は理解を深めて積極的に使用してみます。
- 投稿日:2020-06-29T12:17:42+09:00
[備忘録] [初心者] Docker Compose / Rails(公式doc.)について自分用補足#1 (Dockerfile, entrypoint.sh)
はじめに
背景
一次ソース(に出来るだけ近い情報)を参照しながら学習を進める訓練をしています。
また、これまでスルーしがちだった基礎用語や概念を深掘りする学習も始めました。今回は、下記のチュートリアルを対象にします。
クィックスタート: Compose と Rails | Docker ドキュメントDockerfileとシェルスクリプトファイル(entrypoint.sh)についてまとめた時点で文量が多くなってしまったため、これら以外の内容については次回の投稿にまとめます。
英文はまずDeepLの機械翻訳文を読んでから解釈を試みています。
注意
本稿は、Dockerについて理解の無い私がメモとして記している物です。
単なる個人的な感想も多く、また、解釈文であっても間違いがある可能性があります。
本稿を勉強目的でご覧になる場合は、この本文ではなく参照リンク先の方をご覧いただければと思います。
(リンク集としては少しは役に立てるかも...)
また、常識的なITの基礎用語であっても、とにかく私自身が知らなかったものには反応しているため、冗長であったり、本筋から脱線したような内容が多くなっています。本編
クィックスタート: Compose と Rails | Docker ドキュメント
こちらのチュートリアルを読み進めていきます。Dockerfile全体
DockerfileFROM ruby:2.5 RUN apt-get update -qq && apt-get install -y nodejs postgresql-client RUN mkdir /myapp WORKDIR /myapp COPY Gemfile /myapp/Gemfile COPY Gemfile.lock /myapp/Gemfile.lock RUN bundle install COPY . /myapp # コンテナー起動時に毎回実行されるスクリプトを追加 COPY entrypoint.sh /usr/bin/ RUN chmod +x /usr/bin/entrypoint.sh ENTRYPOINT ["entrypoint.sh"] EXPOSE 3000 # メインプロセスの起動 CMD ["rails", "server", "-b", "0.0.0.0"]1行目 : FROM ruby:2.5
Dockerfile(1行目)FROM ruby:2.5FROM
FROM | Docker ドキュメント日本語化プロジェクト >> Docs
FROM命令の役割は、処理ステージの初期化と、ベースイメージの設定まだ、現状の自分には概念理解が難しいと感じました。
とりあえず後日参考にしそうなリンクだけ...
- ベース・イメージ(base image) | Docker ドキュメント日本語化プロジェクト >> Docs
- 親イメージ(parent image) | Docker ドキュメント日本語化プロジェクト >> Docs
- Dockerイメージの理解を目指すチュートリアル - Qiita
今回はこのコンテナのベースイメージとして、RubyのDockerイメージを設定するということのようです。
ruby - Docker Hub2行目 : RUN apt-get ...
Dockerfile(2行目)RUN apt-get update -qq && apt-get install -y nodejs postgresql-clientRUN
RUN | Docker ドキュメント日本語化プロジェクト >> Docs
コマンドの実行
apt-getコマンドについて
- apt-get(8) - Debian Manpages
- apt-get - パッケージの操作・管理 - Linuxコマンド | Webkaru - Webプログラミング入門
- Linux豆知識 102 APT | LPI-Japan
APT(Application Packaging Tool)は、もともとDebian向けのパーケージ管理システムのことで、Debian系以外のディストリビューションでもそのコマンドを使用できる場合もあるようです。
Debianというのは、あるフリーのOSであって、apt-getはDebian系のOS上でパッケージを操作するためのコマンドのようです。Debian は、現在 Linux カーネルか FreeBSD カーネルを利用しています。
Linux カーネル?
About Linux Kernel | The Linux Kernel ArchivesIf you're new to Linux, you don't want to download the kernel, which is just a component in a working Linux system. Instead, you want what is called a distribution of Linux, which is a complete Linux system.
カーネルはあくまでLinuxシステムの様々な機能を担うコンポーネント(部品のような存在)であって、完全なLinuxシステムを手元で扱うのならば、出来合いのOSとして配布(或いは販売)されているDistribution of Linux(Linuxディストリビューション)が必要ということでしょうか。
https://mirrors.kernel.org/
このサイトで、代表的なディストリビューションのミラーが提供されているようです。
The Debian Linux distributionが提供されていることも確認できます。Linuxディストリビューション | Wikipedia
Linuxカーネル | Wikipedia
公式版のカーネルは、ディストリビューションのベンダーにて独自にカスタマイズされていることもあるようです。Linux豆知識 028 カーネル(kernel) | LPI-Japan
これはよく言われることですが、厳密には「Linux」と言った場合、このLinux kernelのことを指します(最近では、後述する「Linuxディストリビューション」をLinuxと呼ぶケースも増えてきています)。
"Linux"と記載されている場合でも、文脈によってLinuxカーネルだったり、ディストリビューションの事を指していたりするってことか。慣れていくしかなさそうです。
ここで
apt-getコマンドの話に戻りますが、このコマンドが使用できるということは、RubyのDockerイメージは、Debian系のLinuxディストリビューションをベースにしているのでしょうか?ruby - Docker Hub
Image Variants 項にて ruby:<version>についてThis tag is based off of buildpack-deps. buildpack-deps is designed for the average user of Docker who has many images on their system. It, by design, has a large number of extremely common Debian packages. This reduces the number of packages that images that derive from it need to install, thus reducing the overall size of all images on your system.
Rubyの標準Dockerイメージのベースとなっているbuildpack-depsは、ごく一般的なDebianのパッケージを大量に含んでいるらしく、この説明文から、RubyのDockerイメージ環境下でのパッケージ操作のために
apt-getコマンドを使用できそうな気はしてきます。
(上記引用文で言及されているDebianの一般的なパッケージ群? -> buildpack-deps/Dockerfile.template)ただ、使用するOSについての直接的な記述を見たいです。
Stack Overflowで質問を調べてみると、同様の疑問に関する質疑がありました。
node.js - Docker Hub - Node Repo - What OS is this running? - Stack Overflow
ベスト解答では、Dockerfileのベースイメージを辿れば答えに行き着くことが説明されています。同様に探ってみます。
今回のベースイメージは、ruby:2.5なので、まずはそのバージョンのディレクトリへ。
https://github.com/docker-library/ruby/tree/master/2.5
/2.5以下の構成は、alpine3.11, alpine3.12, buster, stretchの4種類があり、alpineはLinuxディストリビューションのひとつである、Alpine Linux projectを指します。ruby - Docker Hubにも記載の通り、busterやstretchは、Debianのスイート名です。
("スイート"という用語は今回が初見で、個々についてはスイートを成す派生品群のひとつという解釈をしています。間違えていたらすみません。 参照:アプリケーションスイートとは 「ソフトウェアスイート, スイート」 (application suite): - IT用語辞典バイナリ)ruby - Docker Hub > Supported tags and respective Dockerfile linksの項より、今回のようなタグなし(ruby:2.5)の場合は、buster用のDockerfileにサポートされているようなので、その内容を見ていきます。
https://github.com/docker-library/ruby/blob/master/2.5/buster/Dockerfileruby/2.5/buster/DockerfileFROM buildpack-deps:busterベースイメージとして、buildpack-deps:busterを指定しているようです。同様に辿ってベースイメージの記述を見ていきます。
https://github.com/docker-library/buildpack-deps/blob/master/debian/buster/Dockerfilebuildpack-deps/debian/buster/DockerfileFROM buildpack-deps:buster-scm最終的に以下に行き着きました。
https://github.com/docker-library/buildpack-deps/blob/master/debian/buster/curl/Dockerfilebuildpack-deps/debian/buster/curl/DockerfileFROM debian:busterこれで、RubyのデフォルトのDockerイメージ上で稼働するOSがDebian系であることは確認できたので、
apt-getコマンドが使用可能であることは腑に落ちました。
apt-get update -qqapt-get(8) - Debian Manpages
update: 利用可能なパッケージの一覧を更新するようです。
-yによってプロンプトへ自動で'yes'を応答して進めるというもののようです。下記の質疑によると、
software installation - Why shouldn't I use apt-get install --qq without a no-action modifier? - Ask Ubuntu
apt-get install -y nodejs postgresql-client開発の都合によっては、ここでYarnなども追記してインストールします。
Getting Started with Rails — Ruby on Rails Guides
3~8行目
Dockerfile(3~4行目)RUN mkdir /myapp WORKDIR /myappWORKDIR
WORKDIR | Docker ドキュメント日本語化プロジェクト >> Docs
ワークディレクトリを設定する。Railsアプリケーションを置くフォルダを生成して、ワーキングディレクトリとして設定しています。
Dockerfile(5~8行目)COPY Gemfile /myapp/Gemfile COPY Gemfile.lock /myapp/Gemfile.lock RUN bundle install COPY . /myappCOPY
COPY | Docker ドキュメント日本語化プロジェクト >> Docs
ファイルやディレクトリを新たにコピーして、対象のパスに追加する。チュートリアルの手順として、ローカルにGemfileとGemfile.lockを生成するので、それらをコンテナ内のRailsアプリケーションを置くパスにコピーしています。
entrypoint.sh (シェルスクリプトファイル)
このチュートリアルでは
entrypoint.shというシェルスクリプトファイルを生成して使用します。
そもそも、シェルスクリプトの概念を知らなかったので、もまともに調べたのが今回初めてとなりました。Bash - GNU Project - Free Software Foundation
The GNU Bourne-Again Shell
Bash Reference Manual
/bin/bashとは|「分かりそう」で「分からない」でも「分かった」気になれるIT用語辞典今回扱うシェルスクリプトファイルの内容は以下の通りです。
entrypoint.sh#!/bin/bash set -e # Rails に対応したファイル server.pid が存在しているかもしれないので削除する。 rm -f /myapp/tmp/pids/server.pid # コンテナーのプロセスを実行する。(Dockerfile 内の CMD に設定されているもの。) exec "$@"#!/bin/bash
1行目の
#!/bin/bashについてはマニュアルに下記の説明があります。
3.8 Shell Scripts - Bash Reference ManualIf the first line of a script begins with the two characters ‘#!’, the remainder of the line specifies an interpreter for the program.
また、
Bash scripts often begin with #! /bin/bash (assuming that Bash has been installed in /bin), since this ensures that Bash will be used to interpret the script, even if it is executed under another shell.
つまり、
#!/bin/bashはコメント文ではなく、#!によってインタプリタを/bin/bashに指定して、そのOSで使用されるシェルの系統に関わらずスクリプトを/bin/bashとして解釈し、処理を進めるという意味があるようです。
次行に処理のコードが続きます。set -e
4.3.1 The Set Builtin - Bash Reference Manual
Bashの内部コマンドで、シェルのオプション値を変更したり、位置パラメータを設定する。
-eオプションの説明項Exit immediately if a pipeline (see Pipelines), which may consist of a single simple command (see Simple Commands), a list (see Lists), or a compound command (see Compound Commands) returns a non-zero status.
上記解説で言うと、今回はどれも"a single simple command"なのでしょうか...?
また、ステータスがゼロの時と、ゼロでない時とは、それぞれ具体的にどのようなときを指すのでしょうか。3.2.1 Simple Commands - Bash Reference Manual
It’s just a sequence of words separated by blanks, terminated by one of the shell’s control operators (see Definitions).
空白で区切られる場合や、制御演算子で終了する場合のこと。
2 Definitions - Bash Reference Manual
制御演算子の項に"改行"も含まれているので、entrypoint.shでset -e以降のコードは、それぞれSimple Commands(単純なコマンド?)に分類できると判断しました。3.7.5 Exit Status - Bash Reference Manual
For the shell’s purposes, a command which exits with a zero exit status has succeeded. A non-zero exit status indicates failure.
上記引用の
set -eの終了条件とは、終了ステータス
成功:0,
失敗:0以外
ということでしょうか。
set -eについて、実際の挙動を解説する動画もありました。(英語は分かりませんが...)
Learn about scripts, functions, chmod and set -e | #2 Practical Bash - YouTube
5:22~あたりからset -e或いはset +eの挙動が実演されています。
set +e以降はステータスが0の場合に直ちに終了
set -e以降はステータスが1(0以外)の場合に直ちに終了
動画では関数内でreturnによってステータスの値を渡しています。
entrypoint.sh内では、いずれかのコマンドが失敗すれば、直ちにプロセスを終了するために先頭で呼ばれているようです。rm -f /myapp/tmp/pids/server.pid
マニュアルのページは下記
rm(1) — Linux manual page削除対象のPIDファイルについて
pidfile - What are pid and lock files for? - Unix & Linux Stack Exchange
起動中のプロセスIDを記録して、それが実行中であることを判断するために生成されているもののようです。従って、実行状態の判断をPIDファイルに依存している場合は、サーバーの終了方法によってはPIDファイルが削除されずに残る場合があるため、今回はこのスクリプトファイル内で削除する一文を加えることで、コンテナサーバー起動前に毎回PIDファイルを削除するようにしているようです。
-fオプションによって、対象ファイルが存在しなかった場合もエラーは返しません。後日参照したい
- linux - What is a .pid file and what does it contain? - Stack Overflow
- rack/server.rb at master · rack/rack
- Prevent exception caused by a race condition on multi-threaded servers #1080
exec "$@"
4.1 Bourne Shell Builtins
execはBourne Shellから継承されてBashでも使用できるコマンドのひとつです。@ - 3.4.2 Special Parameters - Bash Reference Manual
現時点では解説を読んでも理解し難かったので、手元で実行して比較しました。
- 2番目の位置パラメータを指定($2)
hoge.sh#!/bin/bash echo "$2"$ ./hoge.sh a b c d e #=> b配列のインデックスなどと違って、位置パラメータは数え番そのままの数値であることは注意したいです。
- 位置パラメータを展開($@)
hoge.sh#!/bin/bash echo "$@"$ ./hoge.sh a b c d e #=> a b c d eここでの結論として、
entrypoint.sh内で最後の行のコードexec "$@"の役割は、entrypoint.sh自体の親プロセスを展開したそれぞれの引数の実行結果に置き換えてコマンドラインへ出力し、entrypoint.shの実行以降の処理に進ませることであると思われます。その他参考
linux - What does
exec "$@"do? - Unix & Linux Stack Exchange位置パラメーターの一括展開 $* $@ "$*" "$@" の違いを知れ!! - Shell Script Advent Calendar 2016 - ダメ出し Blog
こちらは奥が深そうなので、また個別に勉強します。shell - What does set -e and exec "$@" do for docker entrypoint scripts? - Stack Overflow
脱線:manコマンド(macOSの場合)
調べる過程でmanページのことを初めて知りました。
macのターミナルで$ man rmを実行したらman7.orgにあったものと同様のものを読めました。
setやexecについては、manが適用できないのかと思いましたが、ふざけて実行すると、いずれもBUILTIN(1) - BSD General Commands Manualの内容が呼ばれました。
なんか違うOSの名前出てきた!と思ったらmacOSはFBDの血筋を引いている説明を見つけました。(BSD #BSDの主な子孫 - Wikipedia)macでDarwinのバージョンを調べるコマンドがあったので確認してみました。
$ uname -v Darwin Kernel Version 19.5.0: Tue May 26 20:41:44 PDT 2020; root:xnu-6153.121.2~2/RELEASE_X86_64Darwin7.0からデフォルトのシェルをBashに変更したとあるので、
manコマンドでBashのコマンドのマニュアル呼ぼうとしたらBSDのコマンドマニュアルが呼ばれるのも、そのあたりの関係性によるものなのでしょうか。頭が付いていかないので、今回はこのあたりにしておきます。
10~17行目 コンテナの起動時
Dockerfile(10~17行目)# コンテナー起動時に毎回実行されるスクリプトを追加 COPY entrypoint.sh /usr/bin/ RUN chmod +x /usr/bin/entrypoint.sh ENTRYPOINT ["entrypoint.sh"] EXPOSE 3000 # メインプロセスの起動 CMD ["rails", "server", "-b", "0.0.0.0"]Dockerfile(11行目)COPY entrypoint.sh /usr/bin/チュートリアルの手順にて、ローカルで作成していた
entrypoint.shをコンテナルート下/usr/bin/へコピーしています。Dockerfile(12行目)RUN chmod +x /usr/bin/entrypoint.shCHMOD(1) - BSD General Commands Manual
chmod - Wikipedia全クラスに対して、(x)実行権限を(+)付与する
つまり、ユーザーに関わらず/usr/bin/entrypoint.shに実行権限を付与して、シェルスクリプトファイルを実行可能としています。Dockerfile(13行目)ENTRYPOINT ["entrypoint.sh"]ENTRYPOINT
ENTRYPOINT | Docker ドキュメント日本語化プロジェクト >> Docs
今回では、exec形式にてデフォルトで実行するコマンドライン引数として
entrypoint.shを指定しています。Dockerfile(14行目)EXPOSE 3000EXPOSE
EXPOSE | Docker ドキュメント日本語化プロジェクト >> Docs
コンテナの実行時にリッスンする、ネットワーク上のポートを指定します。今回は"3000"。Dockerfile(17行目)CMD ["rails", "server", "-b", "0.0.0.0"]CMD
CMD | Docker ドキュメント日本語化プロジェクト >> Docs
CMD 命令の主目的は、コンテナの実行時のデフォルト処理を設定することです。
Dockerfileの命令で既にポートが3000に指定されているので、Railsのアプリケーションサーバーはポート3000で稼働します。
知りませんでしたが、"0.0.0.0"には、「特定のアドレスを指定しない」という意味があるようです。
下記リンクを参照しましたが、上記の解釈以上のことは難しくて分かりませんでした。それはまた後日。
127.0.0.1とlocalhostと0.0.0.0の違い - Qiita
What is the Difference Between 127.0.0.1 and 0.0.0.0? - How-To Geek
Dockerfileの内容についてはここで終わりです。
引き続きチュートリアルのその他の内容について、次回分にメモしていきます。
- 投稿日:2020-06-29T11:39:31+09:00
CircleCIで【Rerun job with SSH】が弾かれたときの対処法
なにこれ
CircleCIでRerun job with SSHをしてコンテナにSSH接続した時にコケた時の対処法です。
前にも同じエラーでコケた記憶があるので、備忘録。前提条件
CircleCIでSSH認証済み
capistranoを使ったデプロイができる(自分の場合)結論
githubにローカルのSSH認証鍵を追加していませんでした。以上
過程
circleCIで自動デプロイはできている。
でも、【Rerun job with SSH】するとPermission denied (publickey)と言われる。困ったので公式のガイドを見ました。
GitHub または Bitbucket での認証確認 想定どおりにキーが設定されているかどうかは、コマンド 1つでテストできます。 GitHub の場合は、以下を実行します。 $ ssh git@github.comローカルで
ssh git@github.comを叩くと以下のエラーが出る。Permission denied (publickey)ありゃ?と思い、EC2で
ssh git@github.comを叩く。EC2.PTY allocation request failed on channel 0 Hi (あなたのgithub名)! You've successfully authenticated, but GitHub does not provide shell access. Connection to github.com closed.ここでgithubから認証できてないことに気づく。笑
cd ~/.ssh ls cat id_rsa.pub
cat id_rsa.pubの中身をgithubのSSH認証ページに登録する。その後、もう1回CircleCIから
Rerun job with SSHを試してみる。circleci@5745cd68d045:~$無事コンテナ内に入れました!
感想
公式を読むことって大事だと思いました。
公式を読んで、分からなければ2次ソース(Qiitaなどの外部サイト)を調べることを意識します。
- 投稿日:2020-06-29T11:39:31+09:00
CircleCIで【Rerun job with SSH】がコケた時の対処法
なにこれ
CircleCIでRerun job with SSHをしてコンテナにSSH接続した時にコケた時の対処法です。
前にも同じエラーでコケた記憶があるので、備忘録。前提条件
CircleCIでSSH認証済み
capistranoを使ったデプロイができる(自分の場合)結論
githubにローカルのSSH認証鍵を追加していませんでした。以上
過程
circleCIで自動デプロイはできている。
でも、【Rerun job with SSH】するとPermission denied (publickey)と言われる。困ったので公式のガイドを見ました。
GitHub または Bitbucket での認証確認 想定どおりにキーが設定されているかどうかは、コマンド 1つでテストできます。 GitHub の場合は、以下を実行します。 $ ssh git@github.comローカルで
ssh git@github.comを叩くと以下のエラーが出る。Permission denied (publickey)ありゃ?と思い、EC2で
ssh git@github.comを叩く。EC2.PTY allocation request failed on channel 0 Hi (あなたのgithub名)! You've successfully authenticated, but GitHub does not provide shell access. Connection to github.com closed.ここでgithubから認証できてないことに気づく。笑
cd ~/.ssh ls cat id_rsa.pub
cat id_rsa.pubの中身をgithubのSSH認証ページに登録する。その後、もう1回CircleCIから
Rerun job with SSHを試してみる。circleci@5745cd68d045:~$無事コンテナ内に入れました!
感想
公式を読むことって大事だと思いました。
公式を読んで、分からなければ2次ソース(Qiitaなどの外部サイト)を調べることを意識します。
- 投稿日:2020-06-29T11:08:07+09:00
CircleCI【Errno::ETIMEDOUT: Connection timed out - connect(2) for IPアドレス】の解決法
なにこれ
CircleCIでcapistranoを使った自動デプロイで、
Errno::ETIMEDOUT: Connection timed out - connect(2) for IPアドレス
というエラーにハマりかけたので、対処法を残しておきます。前提条件
CircleCIにSSH認証済み
結論
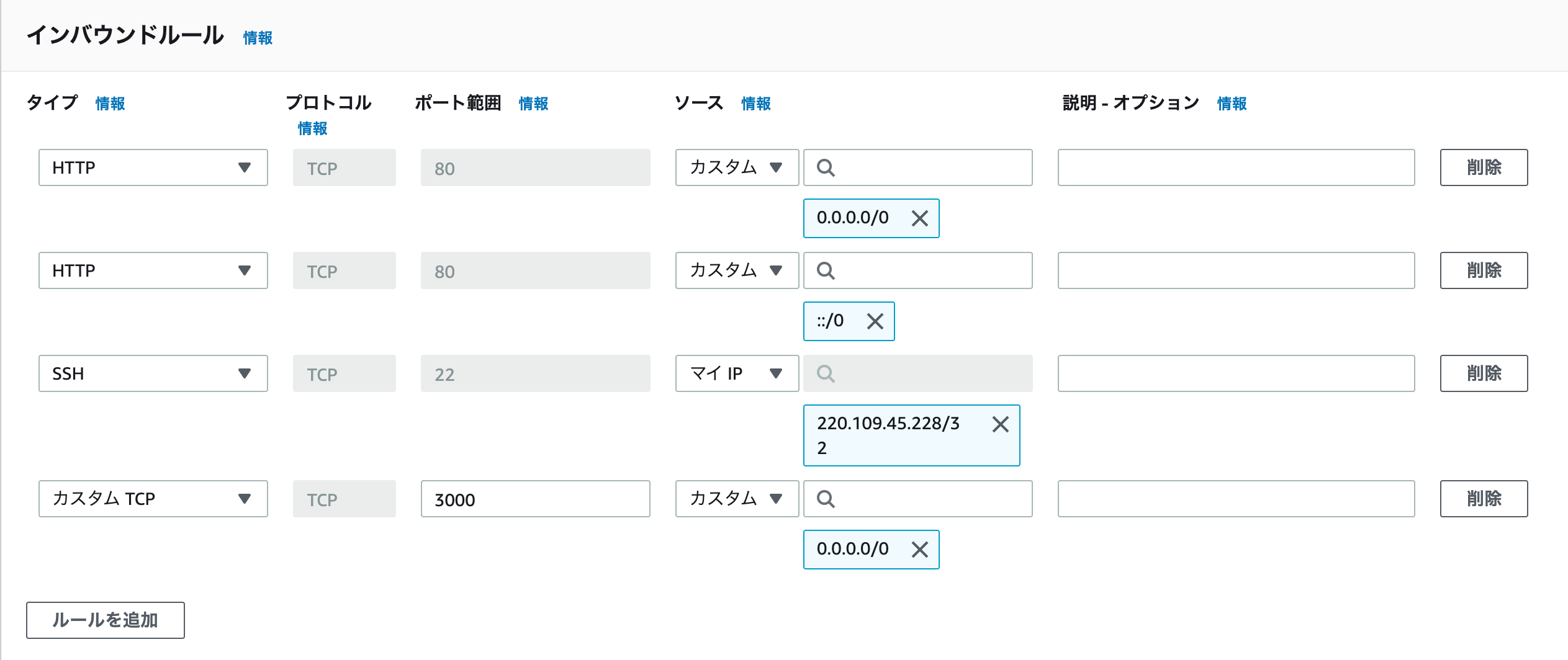
AWSのセキュリティグループのインバウンドルールを編集で、
タイプ【SSH】のソースをカスタムで【0.0.0.0/0】にする。以上エラー文
CircleCI.cap aborted! SSHKit::Runner::ExecuteError: Exception while executing as ********@13.114.24.148: Net::SSH::ConnectionTimeout Caused by: Net::SSH::ConnectionTimeout: Net::SSH::ConnectionTimeout Caused by: Errno::ETIMEDOUT: Connection timed out - connect(2) for IPアドレス Tasks: TOP => rbenv:validate (See full trace by running task with --trace) Exited with code exit status 1推察
SSH認証エラーじゃなくて、
Connection timed outなのね。
IPアドレスに繋がらない??
cicleCIからAWSにSSH接続をしてるわけなので、AWSのセキュリティグループを確認してみる。
SSHがマイIPになってるやん!
以下の画像のように、
マイIPから全てのIPを許可するように変更
もう1回CircleCIを走らせます。
通りました!良かった〜RDS導入のときにもハマりかけたので
インバウンドルールは気をつけないとですね。

- 投稿日:2020-06-29T08:42:08+09:00
ActiveRecordを使うときは頭にSQLを描こう
みなさん、ActiveRecordを使う時に頭にSQLが浮かんでいますか?
ActiveRecordはとても便利でSQLを意識することなくDBにアクセスしてデータを取得したり、更新したりすることができます。
そのためついつい実装時にSQLを意識せずに書いてしまうことがあります。実装時はActiveRecordを使うことで素のSQLを意識しなくてもよいのですが、最終的に実行する時にはSQLが実行されています。
そのため実際に発行されるSQLをみると、こんなSQL発行されるのと驚くことがあります。SQLを思い浮かべながら書いていたら回避できる実装例をいくつか挙げてみます。
無駄なテーブルをJOINしている
下記のようなモデルがあったとします。
def User < ApplicationRecord has_many :user_organizations end def UserOrganization < ApplicationRecord belongs_to :user belongs_to :organization end def Organization < ApplicationRecord has_many :user_organizations end『organization_idで絞り込んだuserモデルを取得してください。』と言われた時にどのように実装しますか?
target_organization_id = 1 users = User.join(user_organizations: :organization) .where(user_organizations: { organization: { id: target_organization_id })この実装は指定された通りに正しく動作します。発行されるSQLは下記の通り
SELECT `users`.* FROM `users` INNER JOIN `user_organizations` ON `user_organizations`.`user_id` = `users`.`id` INNER JOIN `organizations` ON `organizations`.`id` = `user_organizations`.`organization_id` WHERE `organization`.`id` = 1このSQLをみてどう思いますか?
よく考えるとorganizationsテーブルをJOINしなくてもできることに気づくと思います。
改善後のSQLは下記の通り。SELECT `users`.* FROM `users` INNER JOIN `user_organizations` ON `user_organizations`.`user_id` = `users`.`id` WHERE `user_organizations`.`organization_id` = 1これを実現するActiveRecordは下記の通り。
target_organization_id = 1 users = User.join(:user_organizations) .where(user_organizations: { organization_id: target_organization_id })ActiveRecordのモデル中心に実装を考えると、最初の実装のようについ指定されたidがあるモデルまでJOINしてしまいがちです。
実際にコードレビューをしていてもこのような実装はよく見かけます。
SQLはJOINが少なければ少ないほどパフォーマンスはよくなるので、できる限りJOINが少なくて済むように意識してActiveRecordを実装するようにしましょう。eager_loadのLEFT OUTER JOIN
先ほどと同様に『organization_idで絞り込んだuserモデルを取得してください。』に加えて、後に
user.exam_organizationを使いたいのでキャッシュしておきたい場合、どのように実装しますか?先ほどの実装のままだと、exam_organizationsがキャッシュされていないのでexam_organizationを取得するたびにSQLが発行されてしまい、N+1になってしまいます。
そこで下記のようにjoinsをeager_load(またはincludes)に変更することでキャッシュされるようになります。target_organization_id = 1 users = User.eager_load(:user_organizations) .where(user_organizations: { organization_id: target_organization_id })これで無事キャッシュされるようになるのですが、発行されるSQLをみてみるとINNER JOINがLEFT OUTER JOINに変わってしまっていることに気づきます。
SELECT `users`.id AS t0_r0, ...(全カラム列挙される。長いので省略) FROM `users` LEFT OUTER JOIN `user_organizations` ON `user_organizations`.`user_id` = `users`.`id` WHERE `user_organizations`.`organization_id` = 1SQLを考えずにRailsを書いている場合、INNER JOINで良いところが今回の例のようにLEFT OUTER JOINになっていても気にしないことが多い気がします。
ただSQLが頭に浮かんでいると、必ずデータがある結合なのにLEFT OUTER JOINを選ぶことはあり得ないので違和感しかないです。
このような場合は下記のようにjoinsも追記することでINNER JOINで結合しつつデータをキャッシュすることができます。target_organization_id = 1 users = User.eager_load(:user_organizations).joins(:user_organizations) .where(user_organizations: { organization_id: target_organization_id })最後に
いくつか例を上げてみましたが、どちらもSQLを頭に浮かべながら書いていたら簡単に避けれるようなものばかりです。
多少非効率なことをしていても大抵の場合は問題なく動くので気づかないことが多いですが、積み重ねでパフォーマンスに差が出たりするので、これまでActiveRecordを使う時にSQLを意識してこなかった方も発行されるSQLを意識してみると良いと思います。
- 投稿日:2020-06-29T08:29:04+09:00
chat appの自動更新機能実装
機能の実装手順
- 何秒かおきに、JavaScriptを使ってブラウザに表示されているメッセージのうち最も新しいもののidをリクエストとして送る
- Railsのコントローラのアクションにてデータベースに保存されている最新のメッセージのidと①のidを比較し、①のidよりも大きいidを持つメッセージたちをレスポンスする
- JavaScriptを使って、レスポンスに含まれるメッセージたちをメッセージ一覧の最後に追加する
1.表示されているメッセージのidが確認できるようにする
- メッセージのidをカスタムデータ属性として追加する
_message.html.haml.message{data: {message: {id: message.id}}} .message-top .message-top__sender = message.user.name .message-top__date = message.created_at.strftime("%Y/%m/%d %H:%M") .message-text = image_tag message.image.url, class: 'message-text__image' if message.image.present? - if message.content.present? %p.message-text__content = message.contentカスタムデータの付与
-<div class="message" data-messege-id=message.id>
-.message{data: {message: {id: message.id}}}2.新規投稿を取得できるようにする
2-1.apiディレクトリおよびコントローラを作成
controllers/api/messages_controller.rbFileを作成app/controllers/api/messages_controller.rbclass Api::MessagesController < ApplicationController def index end end2-2.indexアクションを記述
app/controllers/api/messages_controller.rbclass Api::MessagesController < ApplicationController def index # ルーティングでの設定によりparamsの中にgroup_idというキーでグループのidが入るので、これを元にDBからグループを取得する group = Group.find(params[:group_id]) # ajaxで送られてくる最後のメッセージのid番号を変数に代入 last_message_id = params[:id].to_i # 取得したグループでのメッセージ達から、idがlast_message_idよりも新しい(大きい)メッセージ達のみを取得 @messages = group.messages.includes(:user).where("id > ?", last_message_id) end end
- 新規で投稿されたメッセージのみをDBから取得する処理を書きます。
- ビューに表示されている最新メッセージのidが送られてくる(後ほど実装)ので、そのidより新しい投稿があるかをチェックするよう、whereメソッドを使ってidを検索条件にする
2-3.api/messages_controllerのルーティング設定
routes.rbRails.application.routes.draw do devise_for :users root 'groups#index' resources :users, only: [:index, :edit, :update] resources :groups, only: [:new, :create, :edit, :update] do resources :messages, only: [:index, :create] #追加 namespace :api do resources :messages, only: :index, defaults: { format: 'json' } end end end
namespace :ディレクトリ名 do ~ endと囲む形でルーティングを記述すると、そのディレクトリ内のコントローラのアクションを指定できる。- rails routesコマンドなどでルーティングを確認すると、
/groups/:group_id/api/messagesというパスでリクエストを受け付け、api/messages_controller.rbのindexアクションが動くようになっているdefaultsオプションを利用して、このルーティングが来たらjson形式でレスポンスするよう指定3.投稿内容をレスポンスするようjbuilderを編集
- viewsフォルダに「api」フォルダを作成
- apiフォルダに「messages」フォルダを作成
- messagesフォルダ内に「index.json.jbuilder」を作成
app/views/api/messages/index.json.jbuilderjson.array! @messages do |message| json.content message.content json.image message.image.url json.created_at message.created_at.strftime("%Y年%m月%d日 %H時%M分") json.user_name message.user.name json.id message.id endメッセージは複数投稿されている可能性があるため、配列形式でarray!メソッドを使用してJSONを作成。
新規投稿時
create時のデータにもid付与が必要なので、編集。views/messages/create.json.jbuilderjson.content @message.content json.image @message.image.url json.created_at @message.created_at.strftime("%Y年%m月%d日 %H時%M分") json.user_name @message.user.name #idもデータとして渡す json.id @message.id4.取得した投稿データ(json)を表示できるよう
message.js編集jQueryからAPIを呼び出せるようする
「どのURLをリクエストしたいのか」→/groups/id番号/api/messagesmessage.js$(function() { //省略 var reloadMessages = function() { //カスタムデータ属性を利用し、ブラウザに表示されている最新メッセージのidを取得 var last_message_id = $('.message:last').data("message-id"); $.ajax({ //ルーティングで設定した通り/groups/id番号/api/messagesとなるよう文字列を書く url: "api/messages", //ルーティングで設定した通りhttpメソッドをgetに指定 type: 'get', dataType: 'json', //dataオプションでリクエストに値を含める data: {id: last_message_id} }) }; });
- ajax関数のurlに何も指定しなかった場合、リクエストのURLは現在ブラウザに表示されているパスと同様になり、今回の場合は、
groups/id番号。- 対してurlに文字列で値を指定すると、パスを指定することができます。今回の場合は相対パスで書くことで、自動的に現在ブラウザに表示されているURLの後に繋がる形になります。
5.取得した最新のメッセージをブラウザのメッセージ一覧に追加する
5-1.非同期で追加するメッセージにもカスタムデータ付与
これまで作っているbuildHTMLメソッドを編集して、非同期で追加されるメッセージのHTMLにも
data-messege-idという名前のカスタムデータ属性をることで、非同期で追加されるメッセージにもidを与えることができる。message.jsfunction buildHTML(message){ if (message.image) { var html = `<div class= "message" data-message-id=${message.id}> <div class="message-top"> <div class="message-top__sender"> ${message.user_name} </div> <div class="message-top__date"> ${message.created_at} </div> </div> <div class="message-text"> <p class="message-text__content"> ${message.content} </p> </div> <img src=${message.image}> </div>` return html; } else { var html = `<div class= "message" data-message-id=${message.id}> <div class="message-top"> <div class="message-top__sender"> ${message.user_name} </div> <div class="message-top__date"> ${message.created_at} </div> </div> <div class="message-text"> <p class="message-text__content"> ${message.content} </p> </div> </div>` return html; };
- messageクラスに、
data-message-id=${message.id}を付与5-2.空の入れ物を作り、取得したjsonをHTMLに変換し、appendする
message.js.done(function(messages) { //追加するHTMLの入れ物を作る var insertHTML = ''; //配列messagesの中身一つ一つを取り出し、HTMLに変換したものを入れ物に足し合わせる $.each(messages, function(i, message) { insertHTML += buildHTML(message) }); //メッセージが入ったHTMLに、入れ物ごと追加 $('.messages').append(insertHTML); }) .fail(function() { alert('error'); });6.数秒ごとにリクエスト
setInterval()関数message.js$(function() { //途中省略 //$(function(){});の閉じタグの直上(処理の最後)に以下のように追記 setInterval(reloadMessages, 7000); });第一引数に動かしたい関数名を、第二引数に動かす間隔をミリ秒単位で渡す
7.メッセージ取得で画面をスクロール
message.js.done(function(messages) { if (messages.length !== 0) { //追加するHTMLの入れ物を作る var insertHTML = ''; //配列messagesの中身一つ一つを取り出し、HTMLに変換したものを入れ物に足し合わせる $.each(messages, function(i, message) { insertHTML += buildHTML(message) }); //メッセージが入ったHTMLに、入れ物ごと追加 $('.messages').append(insertHTML); $('.messages').animate({ scrollTop: $('.messages')[0].scrollHeight}); }8.自動更新が必要ない画面では行わないようにする
「グループのメッセージ一覧ページ」を表示している時だけ自動更新が行われるようにコードを追加しましょう。jQueryの正規表現にまつわるメソッドである、
.matchを利用します。message.js$(function() { //途中省略 //$(function(){});の閉じタグの直上(処理の最後)に以下のように追記 if (document.location.href.match(/\/groups\/\d+\/messages/)) { setInterval(reloadMessages, 7000); } });9.完成形
message.js$(function(){ function buildHTML(message){ if (message.image) { var html = `<div class= "message" data-message-id=${message.id}> <div class="message-top"> <div class="message-top__sender"> ${message.user_name} </div> <div class="message-top__date"> ${message.created_at} </div> </div> <div class="message-text"> <p class="message-text__content"> ${message.content} </p> </div> <img src=${message.image}> </div>` return html; } else { var html = `<div class= "message" data-message-id=${message.id}> <div class="message-top"> <div class="message-top__sender"> ${message.user_name} </div> <div class="message-top__date"> ${message.created_at} </div> </div> <div class="message-text"> <p class="message-text__content"> ${message.content} </p> </div> </div>` return html; }; } $('#new_message').on('submit', function(e) { e.preventDefault(); var formData = new FormData(this); var url = $(this).attr('action') $.ajax({ url: url, type: 'POST', data: formData, dataType: 'json', processData: false, contentType: false }) .done(function(data){ var html = buildHTML(data); $('.messages').append(html); $('form')[0].reset(); $('.messages').animate({ scrollTop: $('.messages')[0].scrollHeight}); $('.send-btn').prop('disabled', false); }) .fail(function(){ alert('メッセージ送信に失敗しました'); $('.send-btn').prop('disabled', false); }) }) var reloadMessages = function() { var last_message_id = $('.message:last').data("message-id"); $.ajax({ url: "api/messages", type: 'get', dataType: 'json', data: {id: last_message_id} }) .done(function(messages) { if (messages.length !== 0) { var insertHTML = ''; $.each(messages, function(i, message) { insertHTML += buildHTML(message) }); $('.messages').append(insertHTML); $('.messages').animate({ scrollTop: $('.messages')[0].scrollHeight}); } }) .fail(function() { alert('error'); }); }; if (document.location.href.match(/\/groups\/\d+\/messages/)) { setInterval(reloadMessages, 7000); } });
- 投稿日:2020-06-29T01:17:43+09:00
[Rails]Ransackでセレクトボックスを使用する方法
はじめに
Ransackで、セレクトボックスを使用する方法についてまとめていきます。
selectについて
まずは、セレクトボックスを作るための
selectヘルパーについて、説明をしていきます。基本型
select(オブジェクト, プロパティ名, 要素情報, オプション, 要素属性)実装例
<%= f.select :name, [['sample1', 1], ['sample2', 2], ['sample3', 3]], {include_blank: '選択なし'}, class: 'sample' %>(form_forの中に入っているとして、オブジェクトは入れていません。)
このように、第三引数に配列を入れると、パラメータとしてvalueの1や2が送信されます。便利なヘルパー
さらにセレクトボックスをカスタマイズしていくための
便利なヘルパーがあります。options_for_select
セレクトボックスの初期値を設定したいときはoptions_for_selectを使用します。基本形
options_for_select(配列/ハッシュ, オプション)実装例
<%= f.select :name, options_for_select({sample1: 1, sample2: 2, sample3: 3}, 1), include_blank: true %>options_for_selectの第2引数に「1」がはいっているので、
1がデフォルト値として表示されます。options_from_collection_for_select
モデルから選択肢を作成したいときは、
options_from_collection_for_selectを使用すると便利です。基本形
options_from_collection_for_select(オブジェクトの配列, value属性, text項目 , オプション])実装例
<%= f.select :name, options_from_collection_for_select(User.all, :id, :name , 1) %>これで、Userモデルの中にあるnameを自動的にセレクトボックスにすることが出来ます。
Ransackでの使用方法
options_from_collection_for_selectを例として使用します。実装例
<%= search_form_for(@q, url: users_path, local: true) do |f| %> <%= f.select :name_eq, options_from_collection_for_select(User.all, :id, :name , 1) %> <%= f.button ' 検索する' %> <% end %>以上のようにすることで、Userモデル内のnameをセレクトボックスにして、検索することが出来ます。
また、オプションで初期値も設定されています。
name_eqの_eqの部分はmatcherと呼ばれ、等しい値を検索できます。Matcherについて
他にも以下のmatcherがあります。
matcher 意味 _eq 等しい noteq 等しくない _cont 値を含む(LIKE) _iteq 以下 _gteq 以上 詳しくはこちらの「Search Matchers」の項目をご覧ください。
参考
https://railsguides.jp/form_helpers.html
https://shinmedia20.com/rails-select-box