- 投稿日:2020-06-29T23:41:21+09:00
manなど空白と改行が邪魔な英文をGoogle翻訳に投げるPythonスクリプト
manとかRFCとかテキストベースの情報をGoogle翻訳にかけたいけど、空白とか改行が邪魔で変な感じになりますよね。私は、こんな感じでやってます。
まず、Pythonでクリップボードの中身を取得し、空白やら改行を除去します。
#!/usr/bin/env python import pyperclip s = pyperclip.paste() s = s.replace("\r"," ") s = s.replace("\n"," ") while -1 != s.find(" "): s = s.replace(" "," ") print(s) pyperclip.copy(s)これを起動して、Google翻訳のコマンドライン版であるtransにパイプでつなげると、あら不思議、きれいに翻訳されてるじゃあーりませんか。
python ~/python/text_remove_crlf.py | trans {en=ja} -b
- 投稿日:2020-06-29T23:28:08+09:00
Python手遊び(CSVファイルから列名を取得)
この記事、何?
表題の通り。10分で書いたような記事。
CSVファイルの1行目をとってsplit(',')して返す。それだけ。伏線・・・かも?
コード
def get_lines_from_textfile(filepath): with open(filepath, 'r', encoding='utf-8') as f: lines = f.readlines() return lines def get_columns_list(csvpath): line_1st = get_lines_from_textfile(csvpath)[0] return line_1st.split(',') def main(): csvpath = 'solubility.test.csv' columns = get_columns_list(csvpath) for column in columns: print(column) if __name__ == '__main__': main()感想
特になし。
- 投稿日:2020-06-29T23:16:53+09:00
Python 実行時間計測メモ
いきなりの結論
結局は、
perf_counter()が無難。
目新しいことはないので読む価値はないかもしれません。想定読者
Pythonで実行速度を計測したがあるけれども、深くは考察していなかった方あたりでしょうか。
調べたきっかけ
実行時間を計測するためにうっかり
time.time()を使っていました。
精度等を気にする必要がないので十分だったのですが、独立しているはずの関数の実行順を変更したら実行時間が大きく変わりました。
それの原因は不明ですが、これをきっかけに時間計測に関して調べ直すことにしました。
(関数自体が実用に耐えないものだった原因究明はあきらめました。ガベージコレクションが影響しているのかも)環境
Windows 10 Pro 64bit
Python 3.8.3
timeモジュール標準ライブラリである
timeモジュールのみ考えます2点間の実行時間を計測するための関数
実行時間を計測するために
timeモジュールで使える関数は以下になります。
time.get_clock_info()で調べた場合に、monotonic=Trueであるものです。
つまり、外部要因などで減算されないことが保証されているものです。
name purpose description sleep resolution perf_counter()実時間の計測 パフォーマンスカウンターの値 含める 高い process_time()プロセスにおいて実際に稼働した時間の計測 現在のプロセスのシステムおよびユーザーの CPU 時間の合計値 含めない 高い(低い) thread_time()スレッドにおいて実際に稼働した時間の計測 現在のスレッドのシステムおよびユーザーの CPU 時間の合計値 含めない 高い(低い) monotonic()システム時刻の経過時間の計測 システムを起動した後の経過時間 含める 低い 分解能が"高い(低い)"とは何を書いているのだと思いますが、
time.get_clock_info()で得られる仕様が高分解能となっているのに、実際に動かしてみると低分解能なのでこのように表記しています。
自分の開発環境の影響があるのかもしれません。少し解説すると、以下のようになります。
perf_counter()は、プログラムが動いてから現実時間がどの程度経過したかを計測するのに使います。
スリープ時の経過時間も含めますので意図した時間が出ない可能性もあります。
ただし、一番安定しているようです。
timeitなどでデフォルトのtimerに設定されているなど、これを使うのが無難なようです。
process_time()またはthread_time()は、プロセス(スレッド)においてプログラムが確実に動いた時間を調べるのに使います。
自分を含めて多くの方がこの時間を計測したいのだと思います。
しかし、実際の分解能が仕様と違って低いようです。
本当はこれを使いたいのですが、使用をためらってしまいます。
また、Windowsの場合、実際はCのGetProcessTimes()を使っているのですが、それの説明には、textNote that this value can exceed the amount of real time elapsed (between lpCreationTime and lpExitTime) if the process executes across multiple CPU cores.と書いてあります。
あまり信頼できるものではないようです。
monotonic()は、システムの稼働時間を調べるのに使います。
つまり、このPCは稼働してから何日経ったかとかを調べるのに使います。
あまり使う事はないと思います。
time()は、時刻を得るものであって実行時間計測には使わない。ガーベジコレクションの影響
ガーベジコレクションは、プログラムの実行速度に影響を及ぼすようです。
下記で説明するtimeit()は、その影響を避けるためにデフォルトの動作としてガーベジコレクションを停止しています。
同じようにガーベジコレクションの影響を計測から除外したいのならばガーベジコレクションを停止する必要があります。
その方法は、以下のように記述することです。pythonimport gc gc.disable() # 停止 # 計測処理 gc.enable() # 再開使い方
timeモジュールの使い方と言っても単純ですが、下記のように計測したい前後で時間を取りそれを減算すれば良いだけです。pythonimport time import timeit def stopwatchPrint(func): @functools.wraps(func) def wrapper(*args, **kwargs): start = time.perf_counter() result = func(*args, **kwargs) end = time.perf_counter() print(f"{func.__name__}: {end - start:.3f} s.") return result return wrapper @stopwatchPrint def func1(): # 何かの処理 return def func2(): start = time.perf_counter() # 何かの処理 end = time.perf_counter() print(f"実行時間: {end - start}" return
timeitモジュール基本的には、上記のように
timeを使えば良い問題ありません。
しかし、標準ライブラリには、実行速度を計測するためにtimeitも用意されています。
ほとんどtime.perf_counter()を呼んでいるだけですが、軽く解説してみます。
コマンドラインからの使い方は、触れません。
2つの関数を上げていますが、timeit.repeat()だけを使えば良いと思います。pythonimport time import timeit timeit.timeit(stmt=func1, setup=func2, timer=time.time.perf_counter, number=1000000) timeit.repeat(stmt=func1, setup=func2, timer=time.time.perf_counter, number=1000000, repeat=5)
timeit():
stmt: 実行時間を計測したい関数、もしくは式として評価できる文字列を渡す。文字列の場合は、eval()で評価される。setup: 前処理を行う関数、もしくは式として評価できる文字列を渡す。これの実行時間は、計測値には含まれない。timer: 計測に使うtimer関数を渡す。デフォルトは、time.time.perf_counter。time.process_time等を渡しても良い。number: 実行回数。デフォルトは、1000000。globals: 名前空間を指定する。デフォルトは、None。変更したい場合は、globals=globals()やglobals=locals()など指定する。repeat():timeitの繰り返し版。timeitの引数に加えて以下を持つ。
repeat: 繰り返し回数。number=100,repeat=3ならば100回の実行を3回繰り返す。使い方
実際には、以下のように使います。
resultは、1つの要素がlongLongLongCat()を100回の実行したときの経過時間で長さが3のリストです。pythondef longLongLongCat(): # 時間を計測したい関数 pass result = timeit.repeat(longLongLongCat, ,number=100, repeat=3) print(result)
timeitの実行関数に引数を渡す
timeitの実行関数は、引数を渡すようになっていません。
文字列で実行する前提なのかもしれませんが、それを標準的に使うには抵抗があります。
そのため、色々と試してみました。
他に旨い方法があるのかもしれません。pythonimport math import timeit import functools def func(): print("func") def funcN(n): print(f"funcN: {n}") class Test(): def __init__(self, n=100, r=3): self.number = n self.repeat = r def glo(self): #print(globals()) #print(locals()) result = timeit.repeat("print(a, b)", number=self.number, repeat=self.repeat, globals=globals()) print(result) def loc(self): a = 33 b = 4 #print(globals()) #print(locals()) result = timeit.repeat("print(a, b)", number=self.number, repeat=self.repeat, globals=locals()) print(result) def mix(self): a = 33 b = 44 #print(globals()) #print(locals()) result = timeit.repeat("print(a , b)", number=self.number, repeat=self.repeat, globals={"a": 30, "b": 50}) print(result) result = timeit.repeat("print(a , b)", number=self.number, repeat=self.repeat, globals={ "a": globals()["a"], "b": locals()["b"] }) print(result) a = 2525 b = 2828 t = Test(1, 1) t.glo() t.loc() t.mix() timeit.repeat(func, number=1, repeat=1) timeit.repeat(lambda: print(a, b), number=1, repeat=1) n = 1129 timeit.repeat("funcN(n)", number=1, repeat=1, globals=globals()) timeit.repeat("funcN(n)", number=1, repeat=1, globals={"funcN": funcN, "n": 714}) g = globals() g.update({"n": 1374}) timeit.repeat("funcN(n)", number=1, repeat=1, globals=g) timeit.repeat(functools.partial(funcN, 184), number=1, repeat=1)出力結果
shell2525 2828 [0.001136100000000001] 33 4 [0.026095200000000013] 30 50 [0.01867479999999999] 2525 44 [0.001263299999999995] func 2525 2828 funcN: 1129 funcN: 714 funcN: 1374 funcN: 184クロックの情報
自分の環境での情報です。
shell>>> time.get_clock_info("monotonic") namespace(adjustable=False, implementation='GetTickCount64()', monotonic=True, resolution=0.015625) >>> time.get_clock_info("perf_counter") namespace(adjustable=False, implementation='QueryPerformanceCounter()', monotonic=True, resolution=1e-07) >>> time.get_clock_info("process_time") namespace(adjustable=False, implementation='GetProcessTimes()', monotonic=True, resolution=1e-07) >>> time.get_clock_info("thread_time") namespace(adjustable=False, implementation='GetThreadTimes()', monotonic=True, resolution=1e-07) >>> time.get_clock_info("time") namespace(adjustable=True, implementation='GetSystemTimeAsFileTime()', monotonic=False, resolution=0.015625)
- 投稿日:2020-06-29T23:13:01+09:00
Python手遊び(RDKit記述子計算:Pandas使ってSDFからCSV)
この記事、何?
RDKitという化合物を理解して数字をいっぱい返してくれるライブラリを題材に、少し真面目にPythonを書いてみたという話。
まだ、あたしなりの共通関数とかクラス化の形を模索しているところで、先日に続いていろいろ制限事項が残っているけど、少し方向性が見えたかも。つまり何するの?
SDFファイルという化合物情報を持つファイルからCSVファイルを作る。
RDKitというライブラリが200列の数字を作ってくれるので、それ以外に名称とか10列合わせて210列出力する。
ただし、汎用化を一部端折っているので、特定のファイル限定・・・って、ダメじゃん。
まあ、あとでバージョンアップするつもり。つもり。制限事項
・SDFファイル内の化合物は以下のパラメータを持つこと。
['ID', 'NAME', 'SOL', 'SMILES', 'SOL_classification']・変な化合物はNG。(分離とかイオンとか。ぶっちゃけると、RDKitが計算エラーを出さないこと)
コード
import pandas as pd from rdkit import Chem from rdkit.Chem import AllChem, Descriptors from rdkit.ML.Descriptors import MoleculeDescriptors def get_basevalues(sampleid, mol): tmps = list() tmps.append(('SampleID', sampleid)) tmps.append(('SampleName', mol.GetProp('_Name'))) tmps.append(('Structure', Chem.MolToMolBlock(mol))) tmps.append(('Atoms', len(mol.GetAtoms()))) tmps.append(('Bonds', len(mol.GetBonds()))) names = [tmp[0] for tmp in tmps] values = [tmp[1] for tmp in tmps] return names, values def get_exvalues(sampleid, mol): names = ['ID', 'NAME', 'SOL', 'SMILES', 'SOL_classification'] values = list() for name in names: values.append(mol.GetProp(name)) return names, values # SDFファイルから記述子を計算し、CSVを出力 # I : 化合物ファイルパス # CSVファイルパス def ExportCSVFromSDF(sdfpath, csvpath): # 化合物を取得 mols = Chem.SDMolSupplier(sdfpath) # RDKitの記述子計算の準備 descLists = [desc_name[0] for desc_name in Descriptors._descList] desc_calc = MoleculeDescriptors.MolecularDescriptorCalculator(descLists) # 連番でIDを付与 sampleids = list() # 化合物名称他 values_base = list() # 外部パラメータ (現状:固定で5個) values_ex = list() # 各化合物の値を取得 for i, mol in enumerate(mols, 1): sampleids.append(i) names_base, values = get_basevalues(i, mol) values_base.append(values) names_ex, values = get_exvalues(i, mol) values_ex.append(values) # RDKitの記述子を計算 values_rdkit = [desc_calc.CalcDescriptors(mol) for mol in mols] # DataFrameへ変換 df_base = pd.DataFrame(values_base, columns=names_base, index=sampleids) df_ex = pd.DataFrame(values_ex, columns=names_ex, index=sampleids) df_rdkit = pd.DataFrame(values_rdkit, columns=descLists, index=sampleids) # 全部結合 df = pd.concat([df_base, df_ex, df_rdkit], axis=1) # 確認用にPrint() print(df) # CSVへ出力 df.to_csv(csvpath, index=False) def main(): sdfpath = 'solubility.test.sdf' csvpath = 'solubility.test.csv' ExportCSVFromSDF(sdfpath, csvpath) if __name__ == '__main__': main()出力例
SampleID SampleName Structure Atoms Bonds ID NAME SOL SMILES SOL_classification MaxEStateIndex MinEStateIndex 1 3-methylpentane 6 5 5 3-methylpentane -3.68 CCC(C)CC (A) low 2.2777777777777777 0.9351851851851851 2 2,4-dimethylpentane 7 6 10 2,4-dimethylpentane -4.26 CC(C)CC(C)C (A) low 2.263888888888889 0.8749999999999998 3 ... 4 感想
うん。Pandas,ちょっとなれたかも。
で、これからいろいろ広げます。たぶん。。。
- 投稿日:2020-06-29T22:50:29+09:00
[Python]Seleniumを使用してcanvasで描かれた画像を保存する(ActionChains,PyAutoGUI,base64等)
スクレイピングで画像を取得する際、一般的なimgタグ形式ではなくcanvasで描かれているケースの画像保存で苦戦した。
このような形で表示されている画像を保存したい。
画像はタイトルの通りcanvasで描かれています。
右クリックで保存を試す
ページを色々調査していたところ、右クリックで画像を保存出来るという事が分かった。
なので、「画像を右クリック→保存」の流れをプログラムで実現する為に色々と試した。
from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.action_chains import ActionChains # ChromeDriver設定 options = Options() options.add_argument('--disable-gpu') options.add_argument('--disable-extensions') options.add_argument('--proxy-server="direct://"') options.add_argument('--proxy-bypass-list=*') options.add_argument('--start-maximized') driver = webdriver.Chrome(options=options) # 画面描画の待ち時間 wait = WebDriverWait(driver, 10) driver.implicitly_wait(10) # ページへアクセス url = '対象ページのURL' driver.get(url) # ページが読み込まれるまで待機 wait.until(EC.presence_of_all_elements_located) # 画像の場所 xpath = '保存したい画像のXPATH' img = driver.find_element_by_xpath(xpath) # 画像の場所へマウス移動してから右クリック actions = ActionChains(driver) actions.move_to_element(img).context_click(img).perform() # 「↓」キーを5回入力 actions.send_keys(Keys.ARROW_DOWN).send_keys(Keys.ARROW_DOWN).send_keys(Keys.ARROW_DOWN).send_keys(Keys.ARROW_DOWN).send_keys(Keys.ARROW_DOWN).perform() # Enterキーを入力 actions.send_keys(Keys.ENTER).perform()Seleniumで対象のページへアクセス
↓
ActionChainsを使用して画像の場所へマウス移動+右クリックでコンテキストメニューを表示
↓
キーボード入力でコンテキストメニューを操作(「↓」キー×5回+Enterキー押下)という流れで画像を保存しようとしたが…ダメ。
右クリックまでは上手くいくがコンテキストメニューの操作が出来ない。
処理の動きを確認してみたところ、右クリック後にブラウザの画面が少し下へ動いている。
どうやらコンテキストメニューではなくブラウザに向かってキーボード入力してしまっているっぽい…。
なので、別を方法を試した。
from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.action_chains import ActionChains import pyautogui # ChromeDriver設定 options = Options() options.add_argument('--disable-gpu') options.add_argument('--disable-extensions') options.add_argument('--proxy-server="direct://"') options.add_argument('--proxy-bypass-list=*') options.add_argument('--start-maximized') driver = webdriver.Chrome(options=options) # 画面描画の待ち時間 wait = WebDriverWait(driver, 10) driver.implicitly_wait(10) # ページへアクセス url = '対象ページのURL' driver.get(url) # ページが読み込まれるまで待機 wait.until(EC.presence_of_all_elements_located) # 画像の場所 xpath = '保存したい画像のXPATH' img = driver.find_element_by_xpath(xpath) # 画像の場所へマウス移動してから右クリック actions = ActionChains(driver) actions.move_to_element(img).context_click(img).perform() # 画像を保存 pyautogui.typewrite('v')Seleniumで対象のページへアクセス
↓
ActionChainsを使用して画像の場所へマウス移動+右クリックでコンテキストメニューを表示
↓
PyAutoGUIでキーボード入力(「v」を入力)という流れに変えてみたところ、これが上手く動作した!
こんな形で見慣れた画像保存の結果が。
ヘッドレスだと動かない
これであとはChromeDriverをヘッドレスにしたりファイル名変更処理を書いて終わりだ!
と思っていたら…ヘッドレスにすると保存出来なくなった笑
どうやらPyAutoGUIはアクティブになっているウィンドウに対して操作する命令を送っているっぽい。
(GUIって書いてあるんだからそりゃそうだ笑)なので、ヘッドレスでない状態で動かしても別の操作をしながら動かすと当然ながら保存に失敗する。
これは非常に不便なのでなんとしてもヘッドレスで保存したい…。
ヘッドレスでもいけた
色々調べた結果、ヘッドレスでもいけた。
from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC import base64 # ChromeDriver設定 options = Options() options.add_argument('--disable-gpu') options.add_argument('--disable-extensions') options.add_argument('--proxy-server="direct://"') options.add_argument('--proxy-bypass-list=*') options.add_argument('--start-maximized') options.add_argument('--headless') driver = webdriver.Chrome(options=options) # 画面描画の待ち時間 wait = WebDriverWait(driver, 10) driver.implicitly_wait(10) # ページへアクセス url = '対象ページのURL' driver.get(url) # ページが読み込まれるまで待機 wait.until(EC.presence_of_all_elements_located) # 画像の場所 xpath = '保存したい画像のXPATH' img = driver.find_element_by_xpath(xpath) # canvasをBase64文字列で取得 canvas_base64 = driver.execute_script("return arguments[0].toDataURL('image/png').substring(21);", img) # デコード canvas_png = base64.b64decode(canvas_base64) # ファイル名 file_name = '任意のファイル名.png' # ファイル出力 with open(file_name, 'wb') as f: f.write(canvas_png)canvasをBase64で文字列として取得→デコード→ファイル出力という流れで保存出来た!
最後に
ハマったおかげ(?)でActionChains,PyAutoGUI,base64についてまとめて学べた。
自動化楽しいですね。参考リンク
How to perform right click using Selenium ChromeDriver?
PyAutoGuiで繰り返し作業をPythonにやらせよう
How to save a canvas as PNG in Selenium?
- 投稿日:2020-06-29T22:45:02+09:00
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (17)
前回
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (16)
https://github.com/legacyworld/sklearn-basic課題 8.7 主成分分析の例
Youtubeでの解説:第9回(1) 30分あたり
課題 8.3はCluster3をうまく再現できなかったので諦めた。いつものアヤメデータを主成分分析する問題。
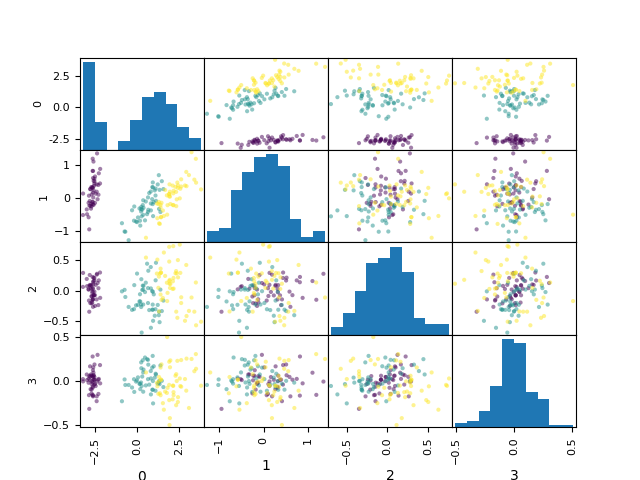
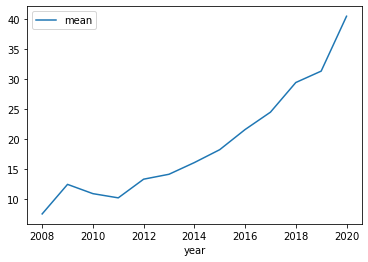
プログラムとしてはscikit-learnは簡単。グラフの部分だけpandasのscatter_matrixを使うのが今までと少し違うだけ。Homework_8.7.py# 課題 8.7 主成分分析の例 # Youtubeでの解説:第9回(1) 30 分あたり import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import load_iris from sklearn.decomposition import PCA iris = load_iris() pca = PCA() X = iris['data'] y = iris['target'] # 主成分分析 pca.fit(X) transformed = pca.fit_transform(X) # 寄与率 print(pca.explained_variance_ratio_) # 描画 fig, ax = plt.subplots() iris_dataframe = pd.DataFrame(transformed, columns=[0,1,2,3]) Axes = pd.plotting.scatter_matrix(iris_dataframe, c=y, figsize=(50, 50),ax=ax) plt.savefig("8.7.png")寄与率
[0.92461872 0.05306648 0.01710261 0.00521218]グラフ
第一主成分の寄与率が0.92で、グラフを見ても左端(第一主成分)はクリアに分かれているのがわかる。
なのでsetosaの分類器は第一主成分だけで92.5%分類出来て、4成分にしてもさして上がらないので、第一主成分だけで良いということ。過去の投稿
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (1)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (2)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (3)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (4)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (5)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (6)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (7) 最急降下法を自作
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (8) 確率的最急降下法を自作
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (9)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (10)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (11)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (12)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (13)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (14)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (15)
https://github.com/legacyworld/sklearn-basic
https://ocw.tsukuba.ac.jp/course/systeminformation/machine_learning/
- 投稿日:2020-06-29T22:35:14+09:00
PythonAnywhereでFlaskアプリをLaunchする
はじめに
この記事は、自身で製作しWeb公開にまで至ったボートレース3連単予測サイト「きょう、ていの良い予想は当たるだろうか」の内部コード解説となります。今回はFlaskでつくったWebアプリケーションを実際にWeb Launchした流れをまとめます。
Flaskアプリの作成であったり、そのほかの情報はこちらをご覧ください。
PythonAnywhere、こんな方には向いているかも!
以下のような方は、PythonAnywhereの検討をする価値ありです!
- Flaskで自作アプリをつくって、Localで動かせるようにはなったけども..この後、どうしたらいいんだろう?
- サーバー借りるといっても、いきなりお金かけるのも嫌だし、そもそもサーバーの設定などわからないことだらけ。。
- 自作Flaskを全世界の人に使ってみてもらいたい!
私自身、元々この方面はズブの素人だったため、どうしたもんか困っていましたが、PythonAnywhereで簡単に解決しました..!!
公開までの手順
- まずはアカウントを作成しましょう→ 公式サイト
"Start running.."を押して、"Free.."を選びます。後は流れに従ってアカウント登録。
- Usernameがそのままドメイン名になるので、名前選びには気をつけましょう
- アカウントができたらLoginし、Webタブから"Add a new web app"をクリック
- その後は、流れに従って使用するWebフレームワークとして"Flask", Python環境は"Python 3.7"を指定しました。
※こちらはお使いのWebフレームワークやPythonのVersionに応じて選択ください。スナップショットを撮り忘れました..。。
- Webの立ち上げが完了したら、mysite以下のフォルダ&ファイル構成をご自身のLocalの構成と同じにしていきます。
私は素人らしく、愚直に手で保存していきました。。gitとか使えるとだいぶスマートにできそうです。
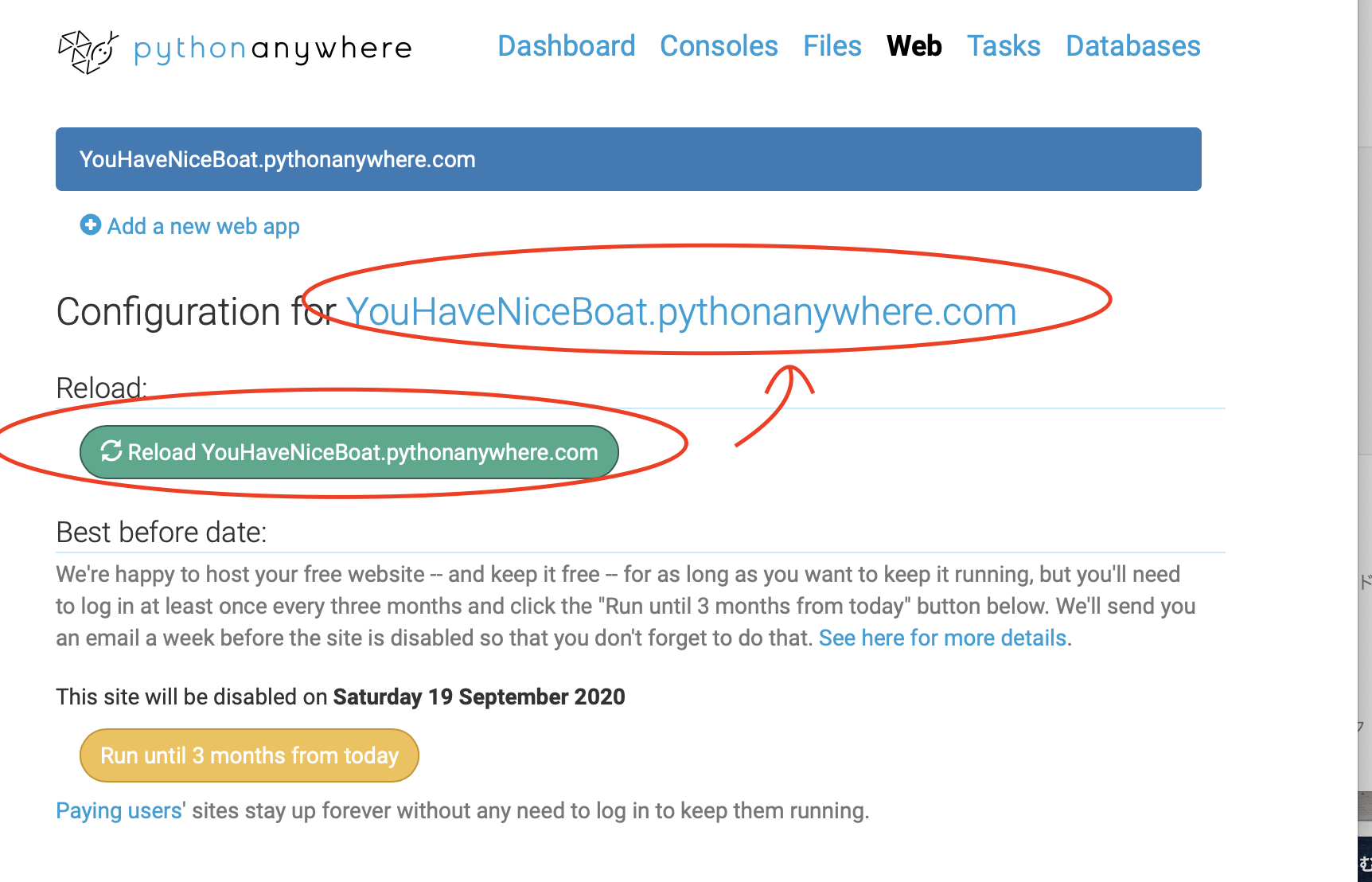
できあがったらWebタブにて、Reloadしusername.pythonanywhere.comをクリック!!
できあがり!
こんな簡単でいいんだ..!!
気をつけること
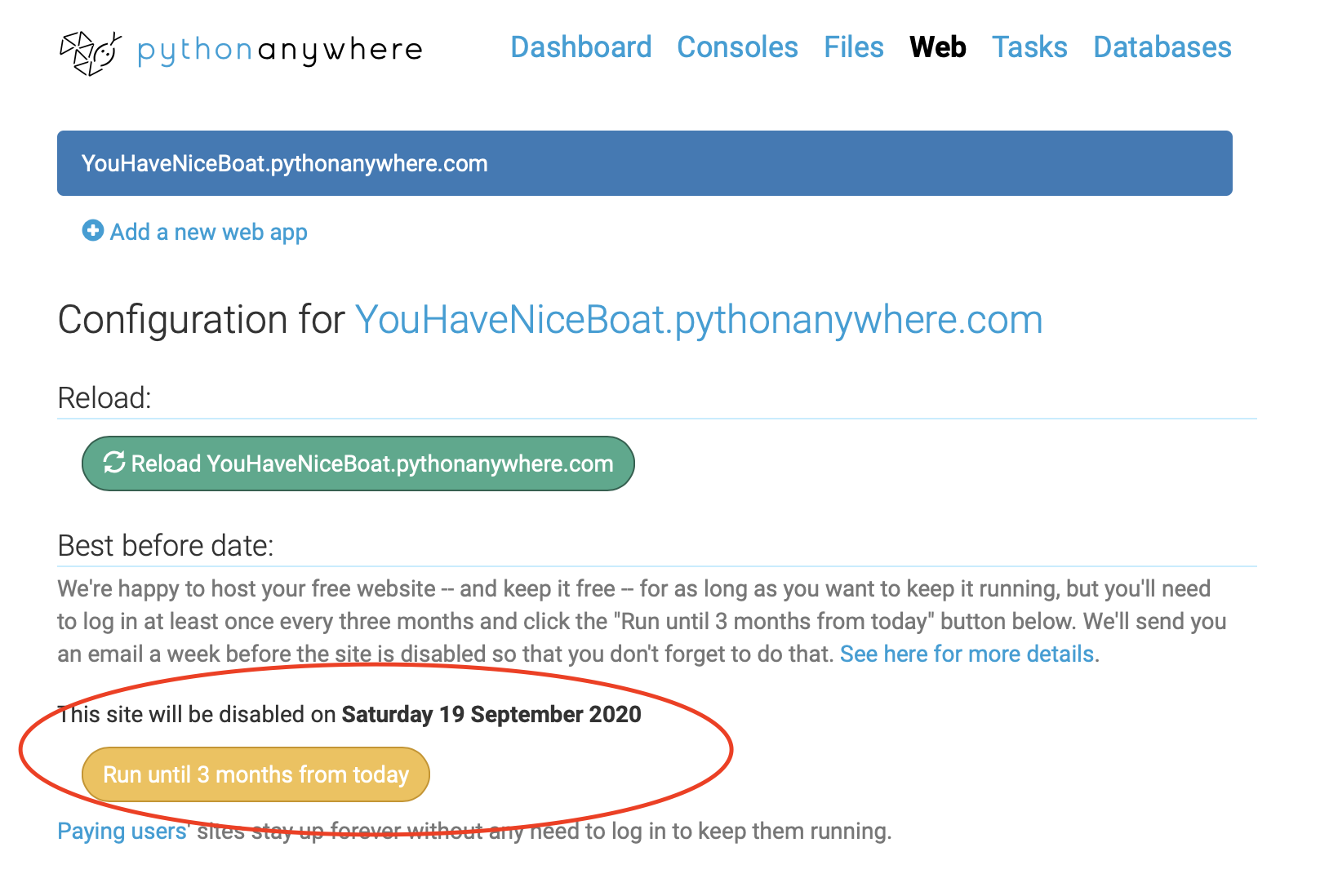
- 黄色いボタンを押さないと、三ヶ月で失効する。
定期的に押しましょう。
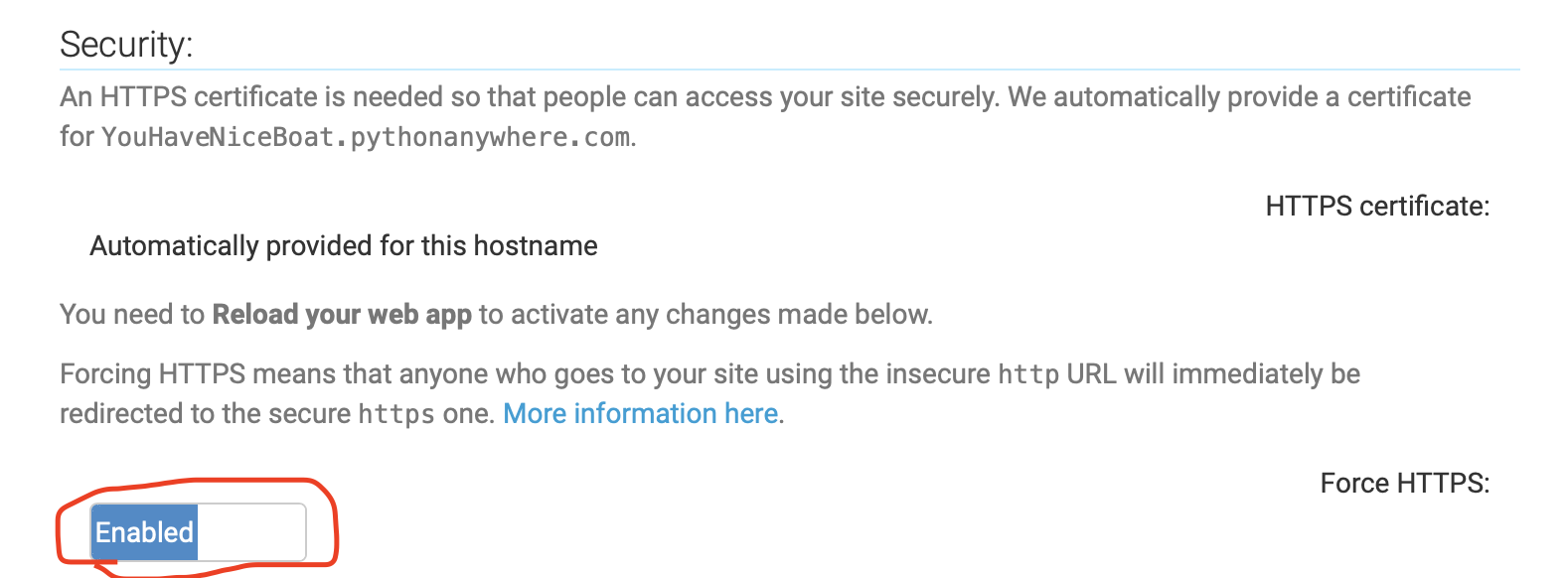
- Webタブの下の方にhttpsの設定があるの、これをEnableに変更しReloadするとhttps://...となります。
↓謎の感動
感想
これまでWebサーバー借りたことないし、仕組みがよくわからない、、といった人にはかなりオススメかもしれません!!
簡単にネット上で公開でき、世界が広がるような経験を得られるかもしれないです!
Localで眠っているFlaskアプリを是非、PythonAnywhereでLaunchしてみてはいかがですか?


- 投稿日:2020-06-29T21:58:54+09:00
HTML DJANGOのデータベース更新
このような形でvieww.pyからgoodの数をデータベースから引っ張ってきて数を+1させて表示させたいのですが、うまくできません。どこが間違っているのでしょうか、、。?よろしくお願いいたします。
def good(self, pk): smart = Smart.objects.get(pk=pk) smart.good = smart.good + 1 smart.save()
- 投稿日:2020-06-29T21:50:02+09:00
[光-Hikari-のPython]08章-04 モジュール(外部ライブラリのインストール)
[Python]08章-04 外部ライブラリのインストール
前節では、Pythonをインストールすると自動でついてくる標準ライブラリのインポート方法と使用方法について述べました。
そこでも説明した通り、標準ではインストールされていないライブラリもあり、これを外部ライブラリと言いました。今回はこの外部ライブラリのインストール方法について説明していきたいと思います。PyPI(Python Package Index)とpip
外部ライブラリは世界中のエンジニアが開発したライブラリです。それらのライブラリが以下のPyPIというリポジトリに登録されています。
https://pypi.org/なお、PyPIは世界中のライブラリの情報が掲載されているため、自分が必要としているライブラリを検索するのは大変です。そこで、ライブラリ(パッケージ)をインストールする際に用いられるのがpip(パッケージ管理システム)です。
このpipにより、パッケージをインストールすることができますが、pipにはほかにも以下の機能があります。
- 既にインストール済みのパッケージの一覧管理が可能
- パッケージが別のパッケージに依存していたら、その依存パッケージも一緒にインストールできる
- インストールできるパッケージの検索
この中で、パッケージの依存状況を確認しながらインストールというのがpipの重要な機能です。
例えば、AIのデータ解析で用いるパッケージにpandasというものがあるのですが、これをインストールすると、自動で行列の計算とかをしてくれるnumpyというパッケージもインストールされます。
このように、あるパッケージをインストールする際に必要なパッケージをインストールしてくれるのがpipの重要な機能となります。pipというコマンドを利用してライブラリのインストールをします。今回は行わないですが、実際にはコマンドを入力することにより、PyCharmで以下の個所から、インストールできます。
PyCharmのPython Console近くにある、[Terminal]をクリック
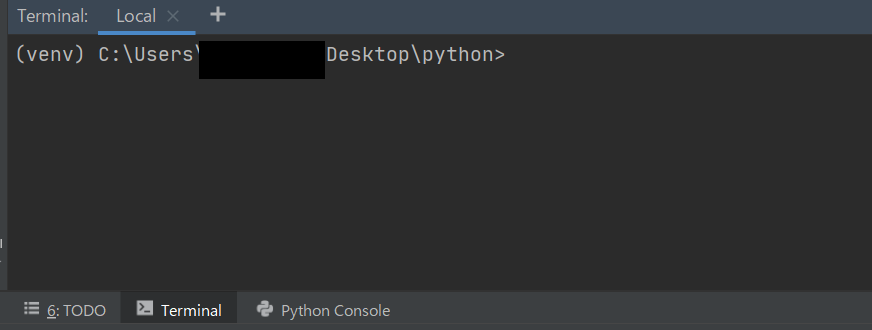
以下の個所、
から以下のコマンドを打つことで、XXXXというライブラリをインストールできます。(venv) C:\Users\***\Desktop\python>pip install XXXX外部ライブラリのインストール方法
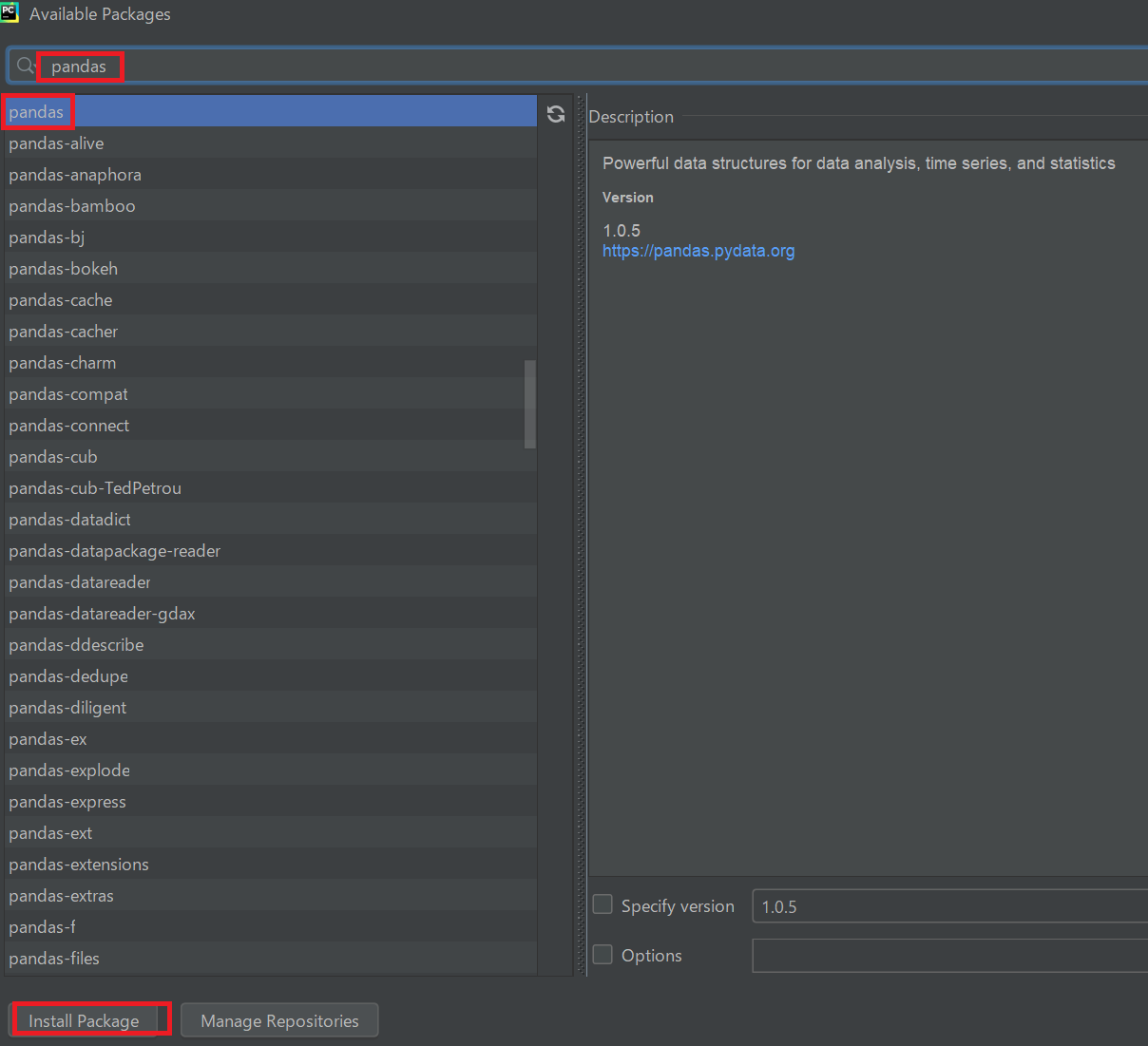
上記では、コマンドによって外部ライブラリをインストールする方法を紹介しました。他にも、PyCharmにおいてインストールする方法がありますので、その方法を説明します。今後はこちらの方法を使用します。実際にpandas(パンダス)というデータ解析用のパッケージをインストールしてみます。
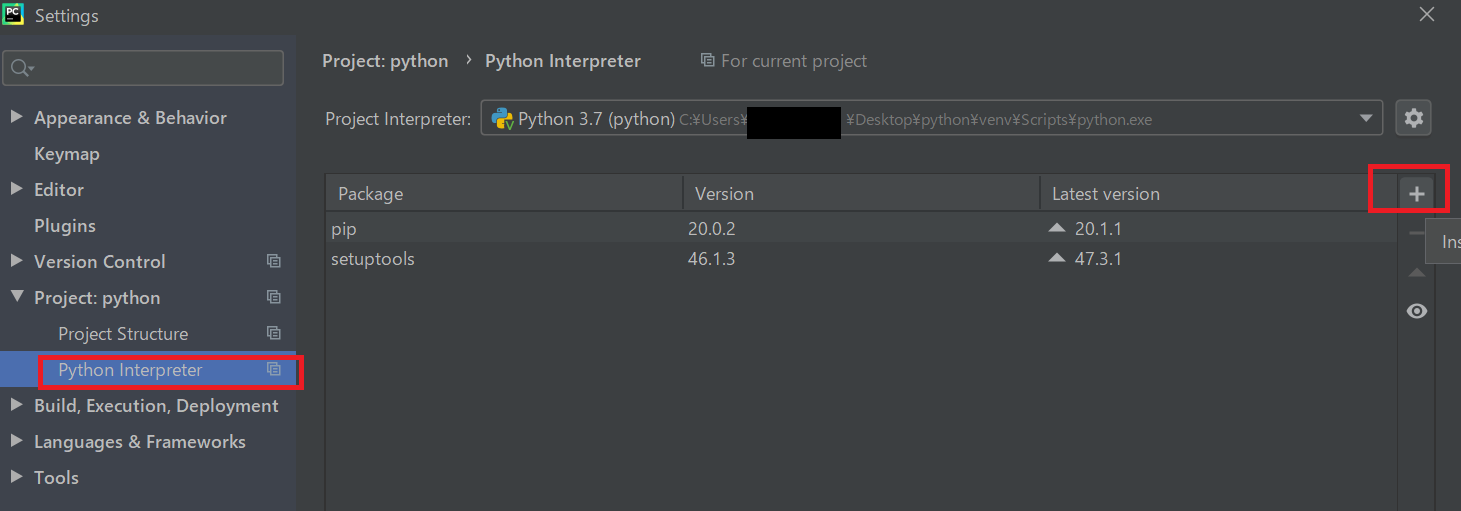
[File]→[Settings]を選択する。
ここには現在インストールされているパッケージが記載されています。右側にある「+」ボタンを押下します。
インストールしたいパッケージ名を検索します。今回は以下の赤枠個所に「pandas」と入力し、検索されるので、それをクリックして、下のボタンの「Install Package」をクリックします。
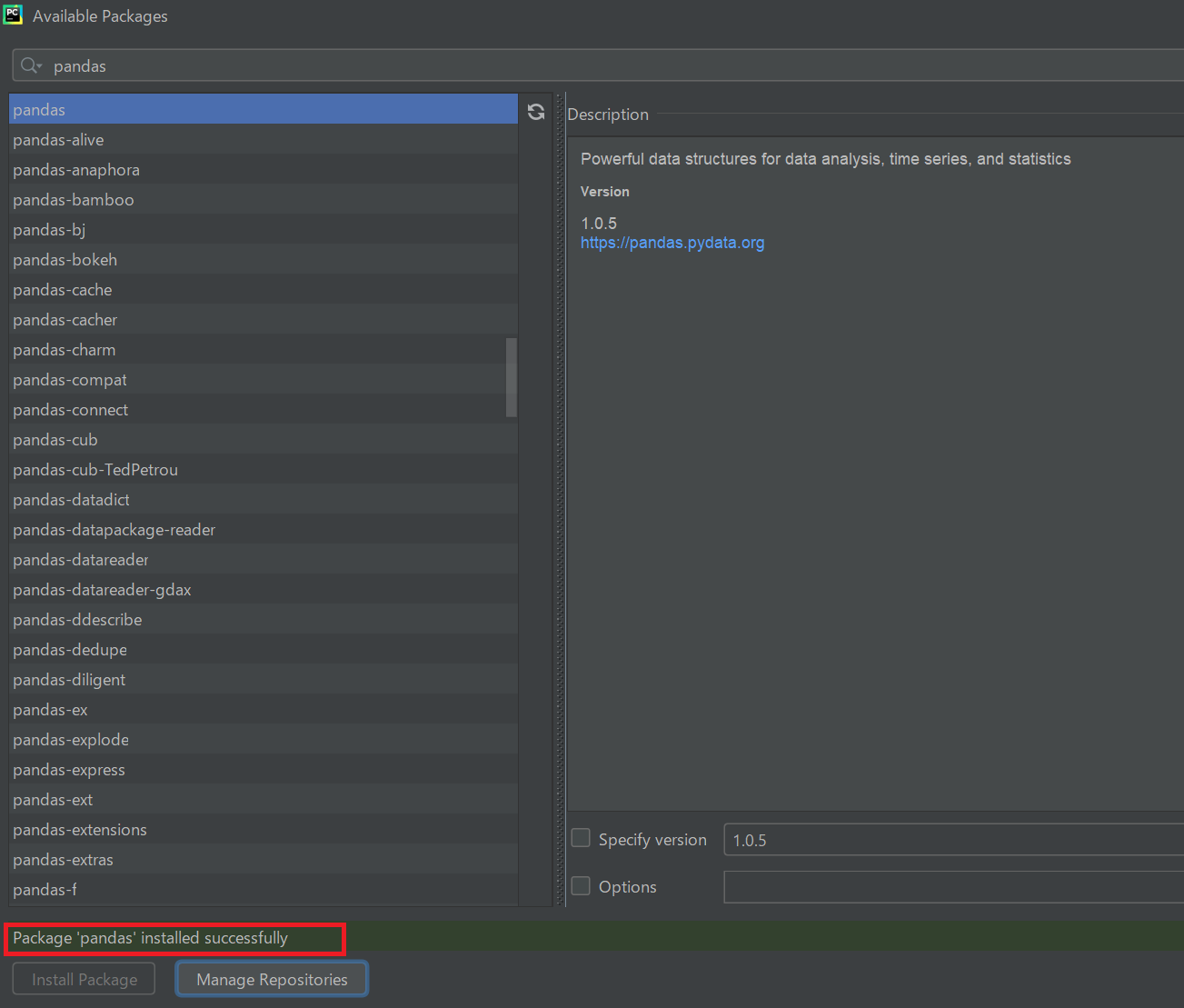
インストールが終わると以下の赤枠の表記になるので、そうしたら×閉じをする。
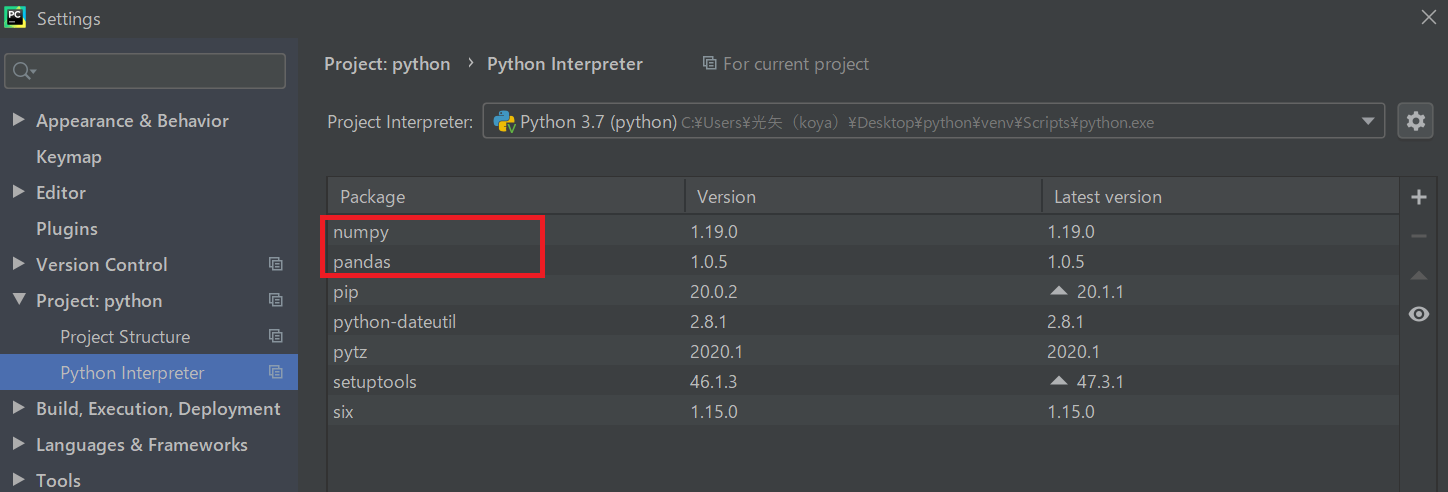
「Pandas」がインストールされているのを確認する。なお、前述した通り「numpy(ナムパイ)」などのパッケージもインストールされているが、これはPandasと依存している関係上、一緒にインストールされているのを確認できます。
※numpyもAIプログラミングで行われるベクトルや行列の演算で非常によく用いられるパッケージです。
外部ライブラリのインポートと利用(matplotlibのインストール)
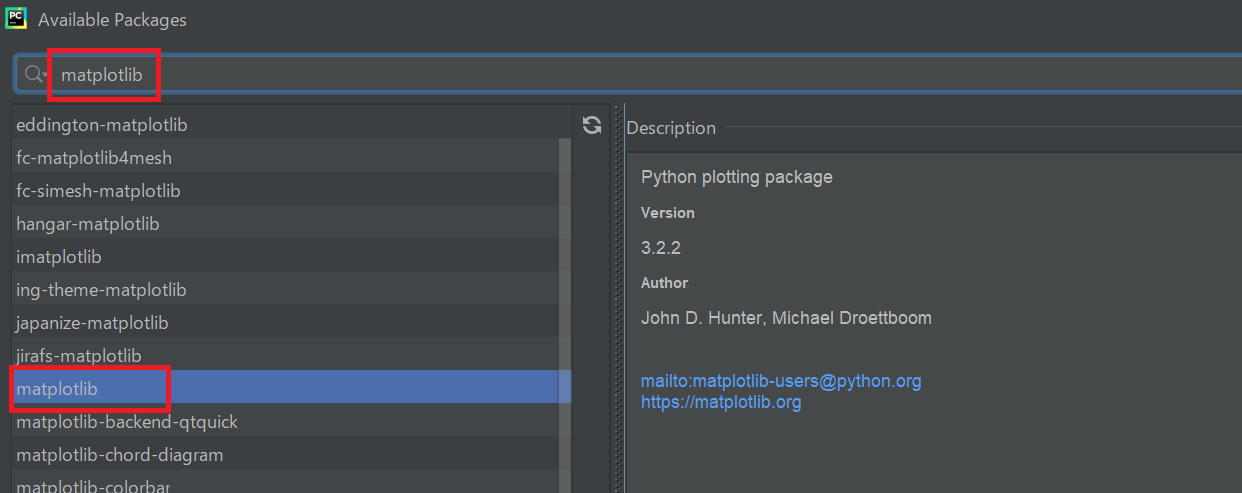
先ほど、pandasの例を用いてインストールを行いました。今度はmatplotlibのインストールを行ってみましょう。手順は先ほどのを参考にしてみてください。
今回使用する外部ライブラリは、このmatplotlibパッケージを利用します。
matplotlibはAIの分野で用いられる、データをグラフ化・可視化するためのライブラリです。これも先ほどのnumpyやpandas同様に、AIの分野では非常によく用いられます。実際にプログラムを作成してみましょう。chap08の中に、samp08-04-01.pyというファイル名でファイルを作成し、以下のコードを書いてください。
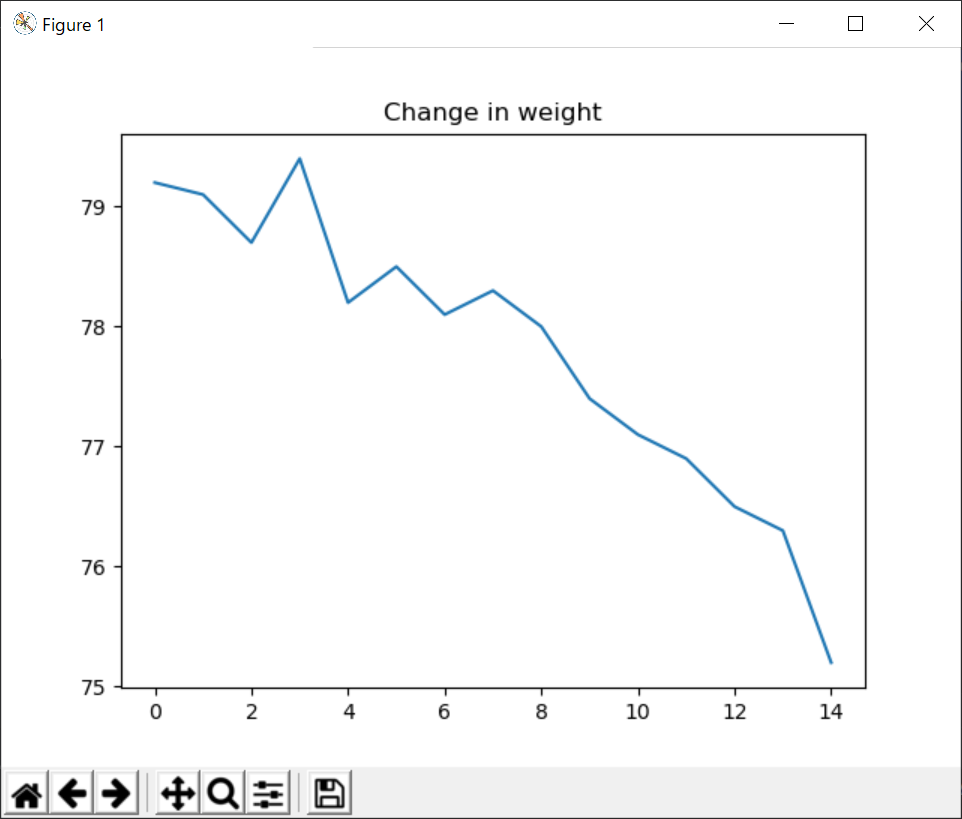
今回記載するプログラムは、体重の変化を表したグラフを描いてみます。samp08-04-01.pyimport matplotlib.pyplot as plt data = [79.2, 79.1, 78.7, 79.4, 78.2, 78.5, 78.1, 78.3, 78.0, 77.4, 77.1, 76.9, 76.5, 76.3, 75.2] plt.plot(data) plt.title('Change in weight') plt.show()【実行結果】
今回は、matplotlibを利用しているため、コンソール画面による出力でなく、グラフ形式で出力されます。
まず、importでmatplotlibというパッケージの中にある、pyplotというモジュールをインポートしています。その名前を今回はpltとして別名を付けています。
リスト形式である体重データdataをplt.plot(data)により描き、グラフのタイトルを「Change in weight」としています。
最後にplt.show()により、グラフを表示します。(show関数がないと、グラフが表示されません。)なお、matplotlibはもっと細かな関数やモジュールがあるので、調べてみてください。matplotlibの詳細についてAI関連の書籍に記載があるので参照してみましょう。
最後に
今回は、numpy、pandas、matplotlibをインストールし、その中でmatplotlibの例を利用して、グラフを描いてみました。
このパッケージにもいろいろな関数やモジュールがあり、これらは調べながら作成していきます。以前どこかでお話ししたかもしれませんが、実務で書くプログラムは調べながらやるものです。
今回はmatplotlibというライブラリについても調べていろいろな処理を実行してみましょう。【目次リンク】へ戻る
- 投稿日:2020-06-29T21:43:36+09:00
Pythonで 旗当番の日付を調べる
はじめに
皆さんは地域の安全活動として、子供の通学を補助する旗当番ってありませんか?
私の地域では、担当地域の当番人数と、次の渡す人しか知らされないです。なので、旗当番になったあと、次の旗が回ってくる日時がわからず、出勤予定が組めない問題がありました。こちらをカウントして、いつ旗が回ってくるか調べるプログラムをpythonで作りました。
動作環境
python 3.7.7
(anaconda 環境)pip install jpholiday にて jpholidayインストール
実行コード
import datetime import jpholiday # ------- 初期設定 -------------- #旗当番やった日 day = datetime.date(2020,6,29) NumberOfPeople = 31 #人で回す # ------- 初期設定ここまで ------ daycount = 0 for i in range(0,365): #最初だけスキップ if i != 0: day = day + datetime.timedelta(days =1) #土日スキップ 0:げつようび 6:日曜日 if day.weekday() == 5 or day.weekday() == 6: continue #祝日スキップ if jpholiday.is_holiday(day): continue # ここに夏休みスキップを書く 8/8 -23 は夏休み if day >= datetime.date(2020,8,8) and day <= datetime.date(2020,8,23): continue #あまりをもとに指定の日を探す q,mod = divmod(daycount,NumberOfPeople) if mod == 0: #日付をプリント print(day) #当番カウントアップ daycount = daycount+1実行結果
指定した日から、祝日、土日、夏休みを覗いた日をカウントした日数をprintし、
次の旗当番の日がわかる。2020-06-29 2020-08-27 2020-10-13 2020-11-27 2021-01-13 2021-03-01 2021-04-13 2021-06-01おわりに
だれがこんなコード使うんでしょうね?
- 投稿日:2020-06-29T21:12:57+09:00
ゼロから始めるLeetCode Day71 「1496. Path Crossing」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
どうやら多くのエンジニアはその対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイトであり、海外のテックカンパニーでのキャリアを積みたい方にとっては避けては通れない道である。
と、仰々しく書いてみましたが、私は今のところそういった面接を受ける予定はありません。
ただ、ITエンジニアとして人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
Python3で解いています。
前回
ゼロから始めるLeetCode Day70 「295. Find Median from Data Stream」今はTop 100 Liked QuestionsのMediumを優先的に解いています。
Easyは全て解いたので気になる方は目次の方へどうぞ。Twitterやってます。
技術ブログ始めました!!
技術はLeetCode、Django、Nuxt、あたりについて書くと思います。こちらの方が更新は早いので、よければブクマよろしくお願いいたします!問題
難易度はEasy。
直近で一番新しく追加されたEasyの問題です。問題としては、path[i] = 'N', 'S', 'E', 'W' のような文字列のパスが与えられたとき,それぞれ1単位の移動を表す.2 次元平面上の原点 (0, 0) を起点とし、path で指定されたパス上を歩きます。
パスが任意の点で交差している場合、つまり以前に訪れたことのある場所にいる場合はTrueを返します。それ以外の場合は False を返します。画像の関係で例を貼れないので各自確認をよろしくお願いいたします。
解法
x,yで座標を管理して最初の座標をdictで管理する、という方法を取りました。
うーん。
あまりスマートではないと思うのですが、pathをfor文で回して各文字列と一致するならば座標を変更するというものです。
しかしこれでも回答数が少ないせいかスピード自体は上位なんですよね・・・
何とも言えませんがとりあえず今回はこれで。class Solution: def isPathCrossing(self, path: str) -> bool: x = y = 0 isVisited = {(0,0):True} for i in path: if i == 'N': y += 1 elif i == 'E': x += 1 elif i == 'S': y -= 1 else: x -= 1 if isVisited.get((x,y)): return True isVisited[(x,y)] = True return False # Runtime: 24 ms, faster than 96.92% of Python3 online submissions for Path Crossing. # Memory Usage: 14 MB, less than 100.00% of Python3 online submissions for Path Crossing.Javaとかだとswitch文とかで書くのがいいのでしょうか・・・?
今回は新しい問題という事でdiscussにも投稿してみました。
Simple Python Solution緊張しますがこういうのやるともっと頭の良い人からアドバイスがもらえたりしていいですよね!
では今回はここまで。お疲れ様でした。
- 投稿日:2020-06-29T21:09:23+09:00
Pythonをctypesを使わずに1行でセグフォらせる
pythonを三行でセグフォらせるがすべての始まりで、これは知らなかったです。面白いです。
pythonを2行でセグフォらせるなど、ctypesを使うものも出ています。それとは違うタイプの死に方を思いついたので投稿します。多分Linuxでしか動かないです。
まさに自殺import os; os.kill(os.getpid(), 11)
- 投稿日:2020-06-29T20:57:41+09:00
【強化学習】DeepMind製Experience ReplayライブラリReverbの使い方調査【クライアント編】
英語で投稿したブログ記事の日本語焼き直し
1. はじめに
前回に引き続き、DeepMind製のExperience ReplayライブラリのReberbについて。
今回は、データの入出力操作を指示するクライアント側について、ソースコードを読みながら、READMEにか書かれていない部分まで調査した。2.
ClientとTFClientReverbはサーバー・クライアントモデルを採用しているが、クライアント側のクラスとしては、
reverb.Clientとreverb.TFClientの2つがある。
Clientが開発初期向けで、TFClientが実際の学習プログラムの中で利用するものという位置づけとのことである。大きな違いは、TFClientはその名のとおり、TensorFlowの計算グラフの中で利用することが意図されている。両者のAPIや使い方は一貫しておらずややこしかったのが、今回整理記事を書こうと思ったモチベーションの1つである。
以下の記事では、サーバーとクライアントプログラムが、以下のように初期化されていることを前提とする。
import numpy as np import tensorflow as tf import reverb table_name = "ReplayBuffer" alpha = 0.8 buffer_size = 1000 batch_size = 32 server = reverb.Server(tables=[reverb.Table(name=table_name, sampler=reverb.selectors.Prioritized(alpha), remover=reverb.selectors.Fifo(), max_size=buffer_size, rate_limiter=reverb.rate_limiters.MinSize(1))]) client = reverb.Client(f"localhost:{server.port}") tf_client = reverb.TFClient(f"localhost:{server.port}") obs = np.zeros((4,)) act = np.ones((1,)) rew = np.ones((1,)) next_obs = np.zeros_like(obs) done = np.zeros((1,)) priority = 1.0 dtypes = [tf.float64,tf.float64,tf.float64,tf.float64,tf.float64] shapes = [4,1,1,4,1]3. 遷移(transition)または軌道(trajectory)の保存
3.1
Client.insertclient.insert([obs,act,rew,next_obs,done],priorities={table_name: priority})
priorities引数が、dictになっているのは、同じデータを複数のテーブル (リプレイ・バッファ) にそれぞれ異なるpriorityで同時に登録可能な仕様だからである。 (そんなニーズがあるなんて知らなかった)たとえ、Prioritizedではない普通のリプレイ・バッファであっても、priorityを指定する必要がある。
Client.insertは呼び出されるたびに、データをサーバーに送信する3.2
Client.writerwith client.writer(max_sequence_length=3) as writer: writer.append([obs,act,rew,next_obs,done]) writer.create_item(table_name,num_timesteps=1,priority=priority) writer.append([obs,act,rew,next_obs,done]) writer.append([obs,act,rew,next_obs,done]) writer.append([obs,act,rew,next_obs,done]) writer.create_item(table_name,num_timesteps=3,priority=priority) # 3ステップを1項目として登録。 # withブロックから出る際に、サーバーへ送信する
Client.writerメソッドが返す、reverb.Writerをコンテキストマネージャーとして利用することで、
より柔軟に保存する内容を設定することができる。例えば、上のサンプルコードの前半は、3.1と同じ内容を保存しているが、後半は3ステップをまとめて1つの項目として保存している。つまり、サンプルする際にも3つをまとめて1つとしてサンプルできる。例えば、エピソード毎サンプリングしたい際に利用することが想定できる。
Writer.flush()または、Writer.close()が呼ばれる際 (withブロックから抜ける際にも自動で呼ばれる) に、サーバーへデータが送信される。3.3
TFClient.inserttf_client.inser([tf.constant(obs), tf.constant(act), tf.constant(rew), tf.constant(next_obs), tf.constant(done)], tablea=tf.constant([table_name]), priorities=tf.constant([priority],dtype=tf.float64))
tables引数は、strのランク1のtf.Tensorで、prioritiesは、float64(明記しないとfloat32になる)のランク1のtf.Tensorであり、両者のshapeは一致しないといけない。後で、サンプルするときのために、各データの
tf.Tensorもランク1以上にしておくことがおそらく必要。3.4 まとめ
サーバーへの送信 複数ステップを1項目に TF計算グラフ内での利用 データ Client.insert都度 X X 何でも良い Client.writerWriter.close(),Writer.flush()(含withの退出時)O X 何でも良い TFClient.insert都度 X O tf.Tensor4. 遷移(transition)または軌道(trajectory)の読出し
いずれの手法もPrioritized Experience Replayの重み補正のβパラメータに対応していない。(そもそも重点サンプリングの重みを計算してくれない)
4.1
Client.sampleclient.sample(table_name,num_samples=batch_size)戻り値は、
reverb.replay_sample.ReplaySampleのgeneratorである。ReplaySampleは名前付きTupleで、infoとdataを所持している。dataには、保存したデータが、infoにはkeyやpriorityなどの情報が含まれている。4.2
TFClient.sampletf_client.sample(tf.constant([table_name]),data_dtypes=dtypes)この手法は、残念ながらバッチサンプリングに対応していない。戻り値は、
ReplaySampleになる。4.3
TFClient.datasettf_client.dataset(tf.constant([table_name]),dtypes=dtypes,shapes=shapes)他の手法とは全く異なる方式を採用しており、大規模な本番学習で主にはこの手法を採用することが意図されていると思われる。
この関数の戻り値は、
tf.data.Datasetを継承したreverb.ReplayDatasetである。このReplayDatasetはgeneratorのようにReplaySampleを引き出すことができ、適切なタイミングでサーバーからデータを自動でフェッチしてきてくれる。つまり、毎回sampleするのではなく、一度ReplayDatasetを設定するとあとは、自動で保存されたデータを排出し続けてくれる仕組みになっている。
shapesは、0を要素に指定するとエラーを発生させるので、保存するデータはランク1以上にしておくことが必要であると思われる。その他パフォーマンス調整のための各種パラメータはここに書くには細かいので、ソースコードのコメントを確認してほしい。
4.4 まとめ
バッチ出力 戻り値型 型の指定 形状の指定 Client.sampleO replay_sample.ReplaySampleのgenerator不要 不要 TFClient.sampleX replay_sample.ReplaySample必要 不要 TFClient.datasetO (内部で自動で実施) ReplayDataset必要 必要 5. 重要度 (priority) の更新
他のリプレイ・バッファの実装と異なり、要素を指定するIDは
0始まりの連番ではなく、一見ランダムに見えるハッシュである。ReplaySample.info.keyでアクセス可能である。
(書きにくいので、サンプルコードを一部省略した書き方にします。すみません。)5.1
Client.mutate_prioritiesclient.mutate_priorities(table_name,updates={key:new_priority},deletes=[...])こちらは、更新だけでなく、削除も可能である。
5.2
TFClient.update_prioritiestf_client.update_priorities(tf.constant([table_name]), keys=tf.constant([...]), priorities=tf.constant([...],dtype=tf.float64))6. 性能比較
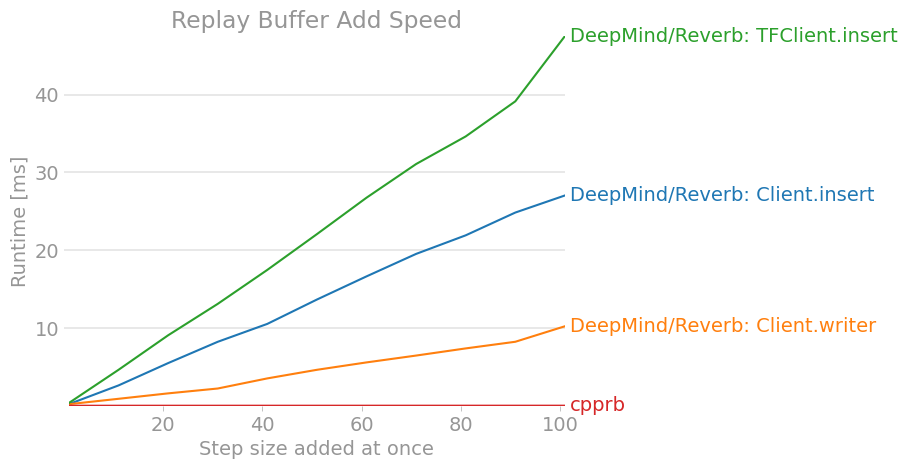
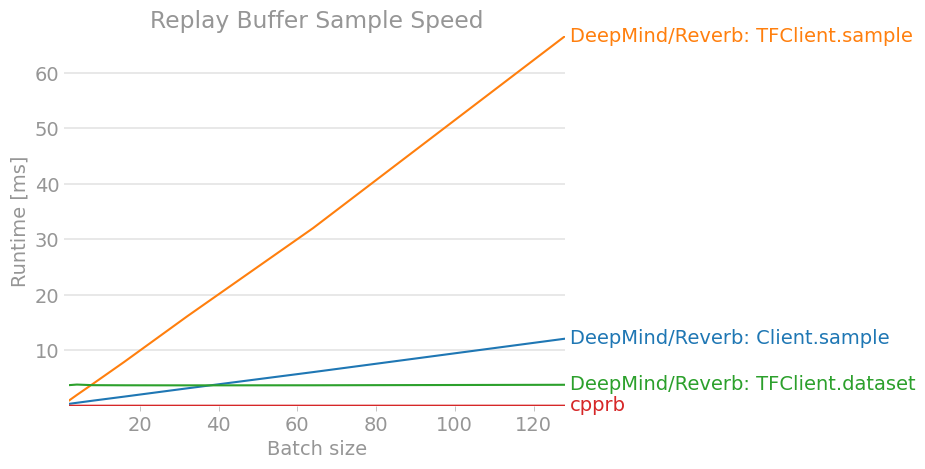
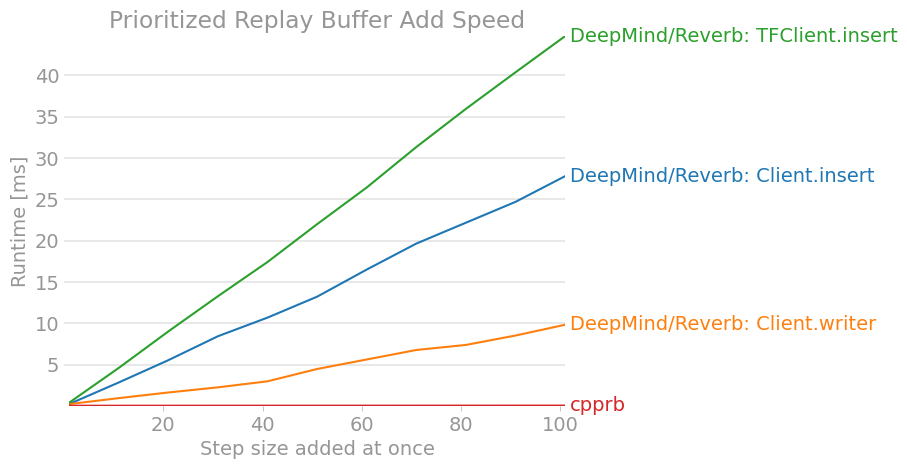
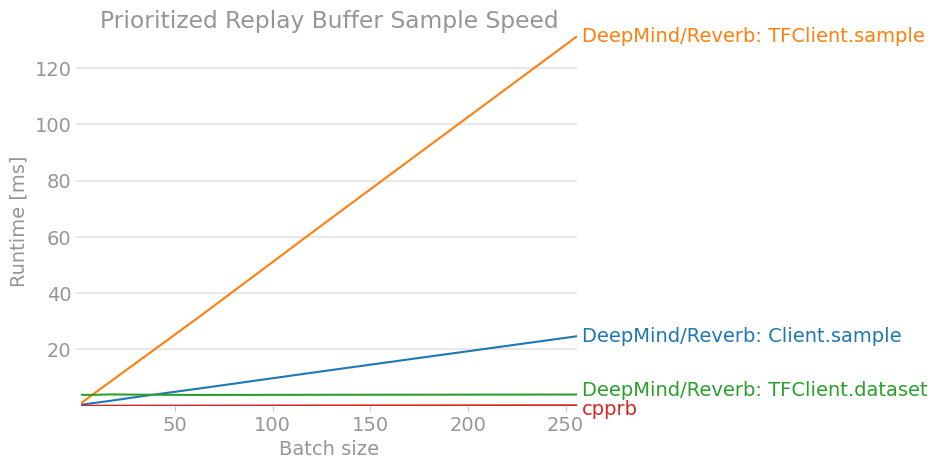
せっかくなので、拙作のcpprbも含めてベンチマークをとった。
注意: 強化学習には、深層学習の学習や環境の更新など他にも重たい処理があるので、リプレイ・バッファの速度だけで決まるものではない。(一方、リプレイ・バッファの実装と条件次第では、リプレイ・バッファの処理時間と深層学習の処理時間が同じぐらいになることもあるらしい。)
以下のDockerfileによる環境で、ベンチマークを実行した。
DockerfileFROM python:3.7 RUN apt update \ && apt install -y --no-install-recommends libopenmpi-dev zlib1g-dev \ && apt clean \ && rm -rf /var/lib/apt/lists/* \ && pip install tf-nightly==2.3.0.dev20200604 dm-reverb-nightly perfplot # Reverb requires development version TensorFlow CMD ["bash"](cpprbのレポジトリのCI上で、実施しているので、追加でcpprbもインストールされている。
pip install cpprbとほぼ同義)そして、以下のベンチマークスクリプトを実行して実行時間のグラフを描いた。
benchmark.pyimport gc import itertools import numpy as np import perfplot import tensorflow as tf # DeepMind/Reverb: https://github.com/deepmind/reverb import reverb from cpprb import (ReplayBuffer as RB, PrioritizedReplayBuffer as PRB) # Configulation buffer_size = 2**12 obs_shape = 15 act_shape = 3 alpha = 0.4 beta = 0.4 env_dict = {"obs": {"shape": obs_shape}, "act": {"shape": act_shape}, "next_obs": {"shape": obs_shape}, "rew": {}, "done": {}} # Initialize Replay Buffer rb = RB(buffer_size,env_dict) # Initialize Prioritized Replay Buffer prb = PRB(buffer_size,env_dict,alpha=alpha) # Initalize Reverb Server server = reverb.Server(tables =[ reverb.Table(name='ReplayBuffer', sampler=reverb.selectors.Uniform(), remover=reverb.selectors.Fifo(), max_size=buffer_size, rate_limiter=reverb.rate_limiters.MinSize(1)), reverb.Table(name='PrioritizedReplayBuffer', sampler=reverb.selectors.Prioritized(alpha), remover=reverb.selectors.Fifo(), max_size=buffer_size, rate_limiter=reverb.rate_limiters.MinSize(1)) ]) client = reverb.Client(f"localhost:{server.port}") tf_client = reverb.TFClient(f"localhost:{server.port}") # Helper Function def env(n): e = {"obs": np.ones((n,obs_shape)), "act": np.zeros((n,act_shape)), "next_obs": np.ones((n,obs_shape)), "rew": np.zeros(n), "done": np.zeros(n)} return e def add_client(_rb,table): """ Add for Reverb Client """ def add(e): n = e["obs"].shape[0] with _rb.writer(max_sequence_length=1) as _w: for i in range(n): _w.append([e["obs"][i], e["act"][i], e["rew"][i], e["next_obs"][i], e["done"][i]]) _w.create_item(table,1,1.0) return add def add_client_insert(_rb,table): """ Add for Reverb Client """ def add(e): n = e["obs"].shape[0] for i in range(n): _rb.insert([e["obs"][i], e["act"][i], e["rew"][i], e["next_obs"][i], e["done"][i]],priorities={table: 1.0}) return add def add_tf_client(_rb,table): """ Add for Reverb TFClient """ def add(e): n = e["obs"].shape[0] for i in range(n): _rb.insert([tf.constant(e["obs"][i]), tf.constant(e["act"][i]), tf.constant(e["rew"][i]), tf.constant(e["next_obs"][i]), tf.constant(e["done"])], tf.constant([table]), tf.constant([1.0],dtype=tf.float64)) return add def sample_client(_rb,table): """ Sample from Reverb Client """ def sample(n): return [i for i in _rb.sample(table,num_samples=n)] return sample def sample_tf_client(_rb,table): """ Sample from Reverb TFClient """ def sample(n): return [_rb.sample(table, [tf.float64,tf.float64,tf.float64,tf.float64,tf.float64]) for _ in range(n)] return sample def sample_tf_client_dataset(_rb,table): """ Sample from Reverb TFClient using dataset """ def sample(n): dataset=_rb.dataset(table, [tf.float64,tf.float64,tf.float64,tf.float64,tf.float64], [4,1,1,4,1]) return itertools.islice(dataset,n) return sample # ReplayBuffer.add perfplot.save(filename="ReplayBuffer_add2.png", setup = env, time_unit="ms", kernels = [add_client_insert(client,"ReplayBuffer"), add_client(client,"ReplayBuffer"), add_tf_client(tf_client,"ReplayBuffer"), lambda e: rb.add(**e)], labels = ["DeepMind/Reverb: Client.insert", "DeepMind/Reverb: Client.writer", "DeepMind/Reverb: TFClient.insert", "cpprb"], n_range = [n for n in range(1,102,10)], xlabel = "Step size added at once", title = "Replay Buffer Add Speed", logx = False, logy = False, equality_check = None) # Fill Buffers for _ in range(buffer_size): o = np.random.rand(obs_shape) # [0,1) a = np.random.rand(act_shape) r = np.random.rand(1) d = np.random.randint(2) # [0,2) == 0 or 1 client.insert([o,a,r,o,d],priorities={"ReplayBuffer": 1.0}) rb.add(obs=o,act=a,rew=r,next_obs=o,done=d) # ReplayBuffer.sample perfplot.save(filename="ReplayBuffer_sample2.png", setup = lambda n: n, time_unit="ms", kernels = [sample_client(client,"ReplayBuffer"), sample_tf_client(tf_client,"ReplayBuffer"), sample_tf_client_dataset(tf_client,"ReplayBuffer"), rb.sample], labels = ["DeepMind/Reverb: Client.sample", "DeepMind/Reverb: TFClient.sample", "DeepMind/Reverb: TFClient.dataset", "cpprb"], n_range = [2**n for n in range(1,8)], xlabel = "Batch size", title = "Replay Buffer Sample Speed", logx = False, logy = False, equality_check=None) # PrioritizedReplayBuffer.add perfplot.save(filename="PrioritizedReplayBuffer_add2.png", time_unit="ms", setup = env, kernels = [add_client_insert(client,"PrioritizedReplayBuffer"), add_client(client,"PrioritizedReplayBuffer"), add_tf_client(tf_client,"PrioritizedReplayBuffer"), lambda e: prb.add(**e)], labels = ["DeepMind/Reverb: Client.insert", "DeepMind/Reverb: Client.writer", "DeepMind/Reverb: TFClient.insert", "cpprb"], n_range = [n for n in range(1,102,10)], xlabel = "Step size added at once", title = "Prioritized Replay Buffer Add Speed", logx = False, logy = False, equality_check=None) # Fill Buffers for _ in range(buffer_size): o = np.random.rand(obs_shape) # [0,1) a = np.random.rand(act_shape) r = np.random.rand(1) d = np.random.randint(2) # [0,2) == 0 or 1 p = np.random.rand(1) client.insert([o,a,r,o,d],priorities={"PrioritizedReplayBuffer": p}) prb.add(obs=o,act=a,rew=r,next_obs=o,done=d,priority=p) perfplot.save(filename="PrioritizedReplayBuffer_sample2.png", time_unit="ms", setup = lambda n: n, kernels = [sample_client(client,"PrioritizedReplayBuffer"), sample_tf_client(tf_client,"PrioritizedReplayBuffer"), sample_tf_client_dataset(tf_client,"PrioritizedReplayBuffer"), lambda n: prb.sample(n,beta=beta)], labels = ["DeepMind/Reverb: Client.sample", "DeepMind/Reverb: TFClient.sample", "DeepMind/Reverb: TFClient.dataset", "cpprb"], n_range = [2**n for n in range(1,9)], xlabel = "Batch size", title = "Prioritized Replay Buffer Sample Speed", logx=False, logy=False, equality_check=None)結果は、以下の様になった。
(結果が古くなっているかもしれないので、最新版はcpprbのプロジェクトサイトで確認できる。)
7. おわりに
DeepMind製Experience ReplayフレームワークのReverbのクライアントの使い方を調査し整理した。
OpenAI/Baselinesに代表されるような他のリプレイ・バッファの実装と比べると、APIや利用方法が異なる部分も多くわかりにくいと感じた。
(安定版の公開時までに、もう少しわかりやすくなっていると良いですね。)少なくとも、大規模分散学習を行ったり、強化学習のすべてをTensorFlowの計算グラフ内で完結させたりということをしなければ、性能面でも優れているわけではなさそうであった。
もちろん、大規模分散学習や計算グラフ内での強化学習はパフォーマンスを大幅に向上させる可能性があるので、引き続き検討を続ける必要があると思っている。
- 投稿日:2020-06-29T20:48:26+09:00
matplotlibにおけるデザインとデータの分離
概要
課題
私はPythonからmatplotlibを使用してグラフを描くことが多いです。
Pythonアプリケーションでデータを生成、整形、matplotlibによるグラフ出力、のような流れで行います。このとき、以下のような課題を抱えていました。
- グラフのデザインが統一されていない。
- 同じような記述をそれぞれのアプリケーションで行っている。
- デザインとコード(Pythonファイルの記述)が視覚的、言語的に結びついていない。
原因
データを可視化するために記述するコードと、デザインを管理するために記述するコードが
1つのアプリケーション内に書かれているからだと考えました。対応
デザインを管理するためのコードを設定ファイルとして分離してみました。
詳細
課題として記載した3つのうち、
グラフのデザインが統一されていないというのは、
縦軸や横軸に割り当てたラベルの大きさや凡例、プロットされる点等が統一されていないということです。これは2番目の課題とも関連するのですが、同じような記述を別のPythonファイルで行っているからでした。
統一されておらず、その場その場で過去のPythonファイルを参照して、コピペをしていたことが問題でした。
どうしてコピペを繰り返してしまうのか、それは私が求めているデザインとコードが
結びついていない、少なくとも直感的ではない、からだと思います。これは3つ目の課題に繋がります。これら3つの課題の原因は、データとデザインが分離されていないからだと、私は考えました。
そうであるのならば、話は単純でデザインを設定ファイルへ分離すればよいのです。
デザインを設定ファイルに言葉で表現
以下の表のようにデザインと言葉を対応させてみました。
各項目の意味は、
- デザインの分類
- 設定ファイルのパラメータ
- パラメータの意味
- 対応するmatplotlibのコード
です。
Size(大きさを設定する)
- figure_x
- 図の横方向の大きさ
- pyplot.figure(figsize=(figure_x, figure_y))
- figure_y
- 図の縦方向の大きさ
- figure_xと同じ
- font_title
- タイトルのフォントの大きさ
- pyplot.title(fontsize=font_title)
- font_x_label
- X軸のフォントの大きさ
- pyplot.figure.add_subplot().ax.set_xlabel(fontsize=font_x_label)
- font_y_label
- Y軸のフォントの大きさ
- pyplot.figure.add_subplot().ax.set_ylabel(fontsize=font_y_label)
- font_tick
- 軸のメモリのフォントの大きさ
- pyplot.tick_params(labelsize=font_tick)
- font_legend
- 凡例のフォントの大きさ
- pyplot.legend(fontsize=font_legend)
- marker
- データをプロットする際のマーカーの大きさ
- pyplot.figure.add_subplot().ax.plot(markersize=marker)
Position(位置を設定する)
- subplot
- グラフを配置する場所
- pyplot.figure.add_subplot(subplot)
- legend_location
- 凡例を配置するグラフ内の場所
- pyplot.legend(loc=legend_location)
具体的な設定ファイルの表現方法
設定ファイルはいくつかの表現方法、jsonやyaml等を検討しました。
結果、Pythonに標準であるconfigparserを使うことにしました。
jsonやyamlでもよいとは思うのですが、階層的に表現できるよりも、直感的に使いやすいほうがいいと考えました。
configparserで設定ファイルを表現すると次のようになります。
config.ini[Size] figure_x=8 figure_y=8 font_title=20 font_x_label=18 font_y_label=18 font_tick=10 font_legend=15 marker=10 [Position] subplot=111 legend_location=upper right [Markers] 0=D 1=> 2=. 3=+ 4=| [Color] 0=red 1=blue 2=green 3=black 4=yellowデザインの分類に当たる項目は[Size]のように角括弧で囲います。これはセクションと呼ばれます。
その下に設定ファイルのパラメータ=値を書いていきます。これはキーと呼ばれます。上記の設定ファイルにはSize、Positionの他に、Markers(プロットするマーカーの種類)やColor(プロットされるマーカーや線の色)も表現されています。
設定ファイルに記載されたパラメータをPythonコードから使用
設定ファイルのパラメータへPythonアプリケーションがアクセスするには、次のようにコードを記述します。
import configparser rule_file = configparser.ConfigParser() rule_file.read("configファイルのパス", "UTF-8") hogehoge = rule_file["セクション名"]["キー名"]注意点として、読み込んだ値は文字列になります。
実際の使用例
以下のコードは、渡されたデータとデザインの設定ファイルをもとに折れ線グラフを作成します。
make_line_graph.py""" 折れ線グラフ作成関数 渡されたデータを使用して折れ線グラフを描画し、画像データとして保存する。 """ import configparser import matplotlib.pyplot as plt def make_line_graph(data, config="config.ini"): """折れ線グラフ描画 渡されたデータを使用して折れ線グラフを作成する。 デザインは別のconfigファイルから読み取る。 Args: data(dict): プロットするデータが格納されている config(str): configファイルの名前 Returns: bool: Trueなら作成完了、Falseなら作成失敗 Note: 引数のdataに含めるべきkeyとvalueについて以下に記載する。 key : value ------------------------ title(str): グラフのタイトル名 label(list): 凡例の説明 x_data(list): x軸のデータ y_data(list): y軸のデータ x_ticks(list): x軸のメモリに表示する値 y_ticks(list): y軸のメモリに表示する値 x_label(str): x軸の名前 y_label(str): y軸の名前 save_dir(str): 保存ファイルパス save_name(str): 保存ファイル名 file_type(str): 保存ファイル形式 """ rule_file = configparser.ConfigParser() rule_file.read("./conf/{0}".format(config), "UTF-8") fig = plt.figure(figsize=(int(rule_file["Size"]["figure_x"]), int(rule_file["Size"]["figure_y"]))) ax = fig.add_subplot(int(rule_file["Position"]["subplot"])) ax.set_xlabel(data["x_label"], fontsize=int(rule_file["Size"]["font_x_label"])) ax.set_ylabel(data["y_label"], fontsize=int(rule_file["Size"]["font_y_label"])) for index in range(len(data["x_data"])): ax.plot(data["x_data"][index], data["y_data"][index], label=data["label"][index], color=rule_file["Color"][str(index)], marker=rule_file["Markers"][str(index)], markersize=int(rule_file["Size"]["marker"])) plt.title(data["title"], fontsize=int(rule_file["Size"]["font_title"])) if "x_ticks" in data.keys(): plt.xticks(data["x_ticks"][0], data["x_ticks"][1]) if "y_ticks" in data.keys(): plt.yticks(data["y_ticks"][0], data["y_ticks"][1]) plt.tick_params(labelsize=int(rule_file["Size"]["font_tick"])) plt.legend(fontsize=rule_file["Size"]["font_legend"], loc=rule_file["Position"]["legend_location"]) plt.savefig("".join([data["save_dir"], "/", data["save_name"], ".", data["file_type"]]))データを渡すPythonファイルは以下のような感じになります。
main.pyfrom make_line_graph import make_line_graph data = { "title": "hogehoge", "label": ["A", "B"], "x_data": [x_data1, x_data2], "y_data": [y_data1, y_data2], "x_ticks": [x_ticks1, x_ticks2], "y_ticks": [y_ticks1, y_ticks2], "x_label": "hogehoge", "y_label": "hogehoge", "save_dir": "保存したいフォルダのパス", "save_name": "保存したいファイル名", "file_type": "拡張子", } make_line_graph(data, config="config.ini")使ってみた感想
良かった点
デザインが変えやすくなりました。
特に、各種フォントサイズはプロットするデータやラベルに入れる文字数によって変わります。また設定ファイルを複製してカスタマイズすることで、グラフデザインを変えたくなったときのPythonファイル変更量が少なくなりました。
読み込む設定ファイル名だけ変えればよし。グラフデザインと設定ファイルが結びついているので、どのデザインがどのコードと対応しているのか忘れても大丈夫です。
悪かった点
どこまで汎用性をもたせるかが難しいです。
作ったmake_line_graph.pyは折れ線グラフ作成関数ですが、似たようなPythonファイルが増えるとよろしくないのでできる限り汎用的にしました。
ただこれではうまくグラフが描画出来ず、それに対応するために別の折れ線グラフ作成関数が乱立すると、振り出しに戻ってしまいそうです・・・。汎用性を考えればきりがないのかなとも思ったりしてますが・・・。
- 投稿日:2020-06-29T20:46:41+09:00
複数のExcelファイル内における特定シート内特定列のデータを一括抽出し、各列内データを1行に納めるには
背景
複数のExcelファイルの特定シート内の特定列のデータを一括抽出し、それぞれ1行に納めたい際に、pythonを用いて、さくっと処理することができたので、備忘録として、整理することにしました。
1.複数のExcelファイルを読み込むには
- 今回は、前提として、約150個のファイルを同一フォルダに格納しています。
- 最初に、フォルダ内のファイル一覧を取得します。
import glob files=glob.glob(r'/レビュー結果分析用/*.xlsx')
- 次に、pandas.read_excel()を使用して、ファイル一覧から一つづつファイル名を取得して、Excelファイルの特定シートを読み込みます。
- さらに、valuesを用いて、特定シート内の特定列のデータを抽出します。例では、特定列は10項目(左から)になります。
import pandas as pd for file in files: df = pd.read_excel(file, sheet_name='指摘事項一覧') for row in df.values: # 10列目のデータを抽出 s_data = str(row[9]).strip().rstrip()2.後処理
取得したデータを1行にまとめたい場合
- 取得した列データ内を1行に納めたい場合には、データ内の改行コードを取り除きます。これは、データ分析においては、よくあるケースと思われますので、載せておきます。
print(s_data.replace('\n',''))日付データが含まれる場合
- pythonでExcelファイルを読み込むと、Excelファイル上で表示されていた日付が、41496 などの 5桁の数値に変換されてしまう、といった事象に出会すことがあるかと思います。これは、Excelでの日付は 1900年1月1日を起点 (1 日目) として、そこから日数を加算した数値で日付データを保持している、というのが原因のようです。(関連記事2参照)。
- そこで、以下のような関数を作成して、変換する必要がありますので、実際に動いたコードを記載しておきます。
def excel_date(num): from datetime import datetime, timedelta return(datetime(1899, 12, 30) + timedelta(days=num)) print(pd.to_datetime(excel_date(row[11]), format='%Y年%m月%d日'))以上になります。(もっと簡単な方法があるよ、というのがあれば、ぜひ、コメントください)
関連記事
- 投稿日:2020-06-29T20:23:29+09:00
Python で タイムスタンプ局を操作するには
Python+OpenSSLを使うには?
- pyOpensslが一番ハードルが低い。
- CA局も作ろうと思えば作ることができる。
- import ssl
- 比較的低レイヤーのOpenSSLの機能を触ることができる。
今回やろうとしていることは、タイムスタンプ局
事前情報として
- CA局とは別物?
OpenSSLでいうと、version 1.1.0あたりから本流に組み込まれた「openssl ts」コマンド体系でできることをしたい。
pyOpensslを調べるも、それらしい機能が見当たらない。
- pyOpensslが依存関係にあるcryptography.hazmatにもなさそう。
- 例えば、OpenSSLのmain_ts関数に含まれている TS_REQ_new()関数辺りが使えるようになっていない。
- そもそも、pyOpensslはcryptographyに依存しており、cryptographyはopensslのversion 1.0.2までのように見える?
結局Pythonからシェル経由で駆動させるしかないのか?
$ openssl ts -query ・・・ $ openssl ts -reply ・・・
- 投稿日:2020-06-29T20:16:06+09:00
競プロで役立ちそうな自分の記事一覧(随時更新)
競プロで役立ちそうな自分の記事をシリーズごとに分けて一覧にしました。
この他に解いた問題の解説記事も投稿しているので参考にしていただければと思います。
また、書いて欲しい記事がある場合はコメント等で教えていただければ幸いです。競プロの基本事項確認シリーズ
競プロの応用事項確認シリーズ
競プロの応用事項確認~包除原理~ 作成中
競プロの応用事項確認~ベルマンフォード法~ 作成中
競プロの応用事項確認~最小全域木~ 作成中
競プロのライブラリ整理シリーズ
競プロのライブラリ整理~BIT(Binary Indexed Tree)~
その他
- 投稿日:2020-06-29T18:49:30+09:00
matplotlibにおけるdisplay errorの抑制方法
githubなどで公開されているコードでディスプレイがある前提のコードのとき、display errorが出て動かない!といった時の対処法についてメモ書き。
いずれの方法もmatplotlibがバックグラウンド処理になり、エラーを抑制できます。
コード内で抑制しよう
pythonのコード内で以下のように記載する。
import matplotlib matplotlib.use("Agg")ユーザ単位で抑制しよう
ファイル名:matplotlibrc
というテキストファイル(拡張子なし)を作成し、以下の文字列をファイルに記載する。
backend:Aggこのファイルをローカルの以下に保存する(ない場合は作成する)
Linuxの場合
home/usename/.matplotlib終わりに
CUIしか使えない環境だったので、回避策を数年前に調査。
後者の方法は設定を忘れて事故が起きることがあるので、前者の方法を推奨。
plt.show()に頼るのはやめよう。やめてほしい。
- 投稿日:2020-06-29T18:49:03+09:00
弱参照を使う
Pythonでなんらかのクラスのコレクションのようなものを作るとき、親になっているオブジェクトの参照を持っておきたい ということはあると思います。
そんなとき、他の言語などだとときどき、
ownerという変数を作って親オブジェクトの参照を持っておく などと言うことがあるのですが、そのまま実装すると循環参照となり、取得したメモリが意図したタイミングで解放されなくなることがあります。循環参照が起こりうるコードclass ParentClass: def __init__(self): self.child = [] class ChildClass: def __init__(self, owner): self._owner = owner p = ParentClass() p.child.append(ChildClass(p)) # ...こんなときのために、オブジェクトを参照する際に参照カウンタを増やさない、弱参照(weakrefモジュール)というものがあります。
弱参照を使ったコードimport weakref class ParentClass: def __init__(self): self.child = [] class ChildClass: def __init__(self, owner): self._owner = weakref.ref(owner) p = ParentClass() p.child.append(ChildClass(p)) # ...なお、このweakrefオブジェクトで作った参照を辿りたいときは、メソッドのように()をつけて呼び出します。
弱参照を使ったコードimport weakref class ParentClass: def __init__(self): self.child = [] def message(self): print("called") class ChildClass: def __init__(self, owner): self._owner = weakref.ref(owner) def message(self): self._owner().message() p = ParentClass() p.child.append(ChildClass(p)) p.child[0].message() # ...
- 投稿日:2020-06-29T18:19:10+09:00
pythonのpandasでcsv読み込む
pythonでcsvファイルを読み込む
・python
・sqlite3
・pandasimport sqlite3 import pandas as pd df = pd.read_csv('{csvファイルのpath}', header=None) db_name = 'sample.db' #dbの作成 conn = sqlite3.connect(db_name) #dbへ接続 df.to_sql('class_table', conn, if_exists='replace') #csvを取り込んだ情報をsqlへ変換 c = conn.cursor() query = 'SELECT * FROM class_table' result = c.execute(query) c.fetchall() #全件取得 for row in result: #1件ずつ取得 print(row) for vert in range(2, 10): #カラムを順に取得 vert += 1 for side in range(0, 4): print(df.loc[vert, side]) side += 1 conn.close() #db切断
- 投稿日:2020-06-29T16:33:56+09:00
Optunaを使ったRandomforestの設定方法
Optunaを使ったRandomforestの設定方法
前回
Optunaの使い方を書いたので、これからは個別の設定方法について記載しようと思う。。
Randomforestで渡せる引数は、いろいろあるが、主なものをすべてOptunaで設定してみた。
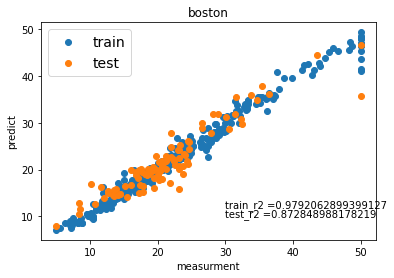
max_depth,n_estimatorsを整数で渡すべきか、数をカテゴリーとして渡すべきか、悩んだが、今回は整数で渡した。def objective(trial): criterion = trial.suggest_categorical('criterion', ['mse', 'mae']) bootstrap = trial.suggest_categorical('bootstrap',['True','False']) max_depth = trial.suggest_int('max_depth', 1, 10000) max_features = trial.suggest_categorical('max_features', ['auto', 'sqrt','log2']) max_leaf_nodes = trial.suggest_int('max_leaf_nodes', 1, 10000) n_estimators = trial.suggest_int('n_estimators', 30, 1000) regr = RandomForestRegressor(bootstrap = bootstrap, criterion = criterion, max_depth = max_depth, max_features = max_features, max_leaf_nodes = max_leaf_nodes,n_estimators = n_estimators,n_jobs=2) #regr.fit(X_train, y_train) #y_pred = regr.predict(X_val) #return r2_score(y_val, y_pred) score = cross_val_score(regr, X_train, y_train, cv=5, scoring="r2") r2_mean = score.mean() return r2_mean# optunaを実施して、ハイパーパラメーターを設定する study = optuna.create_study(direction='maximize') study.optimize(objective, n_trials=1000) # チューニングしたハイパーパラメーターを使ったインスタンスを作成する optimised_rf = RandomForestRegressor(bootstrap = study.best_params['bootstrap'], criterion = study.best_params['criterion'], max_depth = study.best_params['max_depth'], max_features = study.best_params['max_features'], max_leaf_nodes = study.best_params['max_leaf_nodes'],n_estimators = study.best_params['n_estimators'], n_jobs=2) #学習する optimised_rf.fit(X_train ,y_train)これを使って、Bostonのデータセットを使って、ハイパーパラメーターをチューニングしてみました。
いい感じにフィットしました。
- 投稿日:2020-06-29T15:48:04+09:00
データサイエンス100本ノック~初心者未満の戦いpart9
これはデータサイエンティストの卵がわけもわからないまま100本ノックを行っていく奮闘録である。
完走できるか謎。途中で消えてもQiitaにあげてないだけと思ってください。ネタバレも含みますのでやろうとされている方は注意
よそごとやってて遅延
コレは見づらい!この書き方は危険!等ありましたら教えていただきたいです。
心にダメージを負いながら糧とさせていただきます。この解き方は間違っている!この解釈の仕方は違う!等もありましたらコメントください。
今回は45~51まで。
[前回]41~44
[目次付き初回]45本目
ここから日付型-文字型-数字型の変換を行う問題が増えていきます
実はよそごとやっていた時に少し日付型をいじることをやっていました。
よかった。脱線も無駄ではなかった。今回ラストに同一サイトであっても欲しい情報→参考にしたページをまとめておきます。ページが飛びすぎててホントにわからん。
P-045: 顧客データフレーム(df_customer)の生年月日(birth_day)は日付型(Date)でデータを保有している。これをYYYYMMDD形式の文字列に変換し、顧客ID(customer_id)とともに抽出せよ。データは10件を抽出すれば良い。
mine45.pydf=df_customer.copy() df['birth_day']=pd.to_datetime(df['birth_day']).dt.strftime('%Y%m%d') df[['customer_id','birth_day']].head(10) '''模範解答''' pd.concat([df_customer['customer_id'], pd.to_datetime(df_customer['birth_day']).dt.strftime('%Y%m%d')], axis = 1).head(10)問題やっている途中でバグったので
.copy()を追加。deepcopyしなきゃいけないようならまた変更します。今回は
.dt.strftime()を使用(参考)。
C言語でprintfを多用していた身としてはフォーマット指定は結構好き。ただ、何故か
df['birth_day']に直接.dt.strftimeをつなぐとエラーします。
なのでpd.to_datetime()で明示してあげると(?)動きますtypeCheck.pytype(df['birth_day']) type(pd.to_datetime(df['birth_day']))どっちも
pandas.core.series.Series
なんですがねぇ
46本目
P-046: 顧客データフレーム(df_customer)の申し込み日(application_date)はYYYYMMD形式の文字列型でデータを保有している。これを日付型(dateやdatetime)に変換し、顧客ID(customer_id)とともに抽出せよ。データは10件を抽出すれば良い。
mine46.pydf=df_customer.copy() df['application_date']=pd.to_datetime(df['application_date']) df[['customer_id','application_date']].head() #df['application_date'].describe #df['application_date'].apply(lambda x:x.year) '''模範解答''' pd.concat([df_customer['customer_id'],pd.to_datetime(df_customer['application_date'])], axis=1).head(10)文字列型→日付型への変換 https://note.nkmk.me/python-pandas-datetime-timestamp/
途中で上手く変換できてるか試しています。
.applyとlambdaを使った要素の取り出しはこちら47本目
P-047: レシート明細データフレーム(df_receipt)の売上日(sales_ymd)はYYYYMMDD形式の数値型でデータを保有している。これを日付型(dateやdatetime)に変換し、レシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに抽出せよ。データは10件を抽出すれば良い。
mine47.pydf=df_receipt.copy() df['sales_ymd']=pd.to_datetime(df['sales_ymd'].astype(str)) df[['receipt_no','receipt_sub_no','sales_ymd']].head(10) '''模範解答''' pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']], pd.to_datetime(df_receipt['sales_ymd'].astype('str'))],axis=1).head(10)数字→文字→日付型と変換してます。数字→文字列への型変換
48本目
この問題、一か所だけ調べても分からない部分ありました。
P-048: レシート明細データフレーム(df_receipt)の売上エポック秒(sales_epoch)は数値型のUNIX秒でデータを保有している。これを日付型(dateやdatetime)に変換し、レシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに抽出せよ。データは10件を抽出すれば良い。
mine48.pydf=df_receipt.copy() df['sales_epoch']=pd.to_datetime(df['sales_epoch'],unit='s') df[['receipt_no','receipt_sub_no','sales_epoch']].head(10) '''模範解答''' pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']], pd.to_datetime(df_receipt['sales_epoch'], unit='s')],axis=1).head(10)まず、エポック秒とはの記事を読み、最初「これ、intをそのまま時間に直すといけるんじゃね」と安直にやってみましたが出来ず、そのあとも色々試したけれどもギブアップ。答えを見ました。
すると出てきたのは
to_datetime('エポック',unit='s')
引数のunitが分からず調べてみたものの、いつものサイトにはなく、仕方ないのでpandasのリファレンスページを開きました。https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.to_datetime.html
unitstr, default ‘ns’
The unit of the arg (D,s,ms,us,ns) denote the unit, which is an integer or float number. This will be based off the origin. Example, with unit=’ms’ and origin=’unix’ (the default), this would calculate the number of milliseconds to the unix epoch start.英語ということもさておき分からん。引数として
D,s,ms,us,nsを受け入れるというのはなんとなくわかるが、sがどのように作用してるかが全く分からん。
どなたか分かる方、参考ページでもいいので、教えてください。。。(もしかして読んでるページがリファレンスじゃない……?)49-51本目
似たような問題なので一気に行きます
P-049: レシート明細データフレーム(df_receipt)の売上エポック秒(sales_epoch)を日付型(timestamp型)に変換し、"年"だけ取り出してレシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに抽出せよ。データは10件を抽出すれば良い。
P-050: レシート明細データフレーム(df_receipt)の売上エポック秒(sales_epoch)を日付型(timestamp型)に変換し、"月"だけ取り出してレシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに抽出せよ。なお、"月"は0埋め2桁で取り出すこと。データは10件を抽出すれば良い。
P-051: レシート明細データフレーム(df_receipt)の売上エポック秒(sales_epoch)を日付型(timestamp型)に変換し、"日"だけ取り出してレシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに抽出せよ。なお、"日"は0埋め2桁で取り出すこと。データは10件を抽出すれば良い。
mine49.pydf=df_receipt.copy() df['sales_epoch']=pd.to_datetime(df['sales_epoch'],unit='s') df['sales_epoch']=df['sales_epoch'].dt.strftime('%Y') df[['receipt_no','receipt_sub_no','sales_epoch']].head(10) '''模範解答''' pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']], pd.to_datetime(df_receipt['sales_epoch'], unit='s').dt.strftime('%Y')],axis=1).head(10) # %Y を %m %d に変えれば月・日が出せるエポック秒→日付型→文字列型抜き出しで49~51はできる
ただし、50,51の指定に
なお、"月(日)"は0埋め2桁で取り出すこと。
とあるために
'''罠(ドボン)''' pd.to_datetime(df['sales_epoch'], unit='s').dt.yearと、やると年は問題なく4桁で出るが月・日は0埋めにならない。
(逆に最初%02dとかやったけどやらなくても0埋めになった)今回はここまで
参考ページ
- 数字→文字列への型変換 https://note.nkmk.me/python-pandas-str-num-conversion/
- 文字列型→日付型への変換 https://note.nkmk.me/python-pandas-datetime-timestamp/ (前半)
- 日付型→文字型変換 https://note.nkmk.me/python-datetime-usage/ (後半)
.applyで要素の取り出し https://note.nkmk.me/python-pandas-map-applymap-apply/
- 投稿日:2020-06-29T14:30:17+09:00
【Django】新規登録後、自動でログインさせたい
はじめに
Webサイトを作成する際の基本的な機能として新規登録とログインがある。新規登録完了後、再度ログイン画面で必要項目を入力する作業を省略したいと思ったので方法を調べた。
前提
プロジェクト構成は以下の通り。設定ディレクトリをconfig,アプリケーションディレクトリはappとaccountsに二つを作成している。
. ├── accounts │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── forms.py │ ├── migrations │ ├── models.py │ ├── tests.py │ ├── urls.py │ └── views.py ├── config │ ├── __init__.py │ ├── asgi.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py ├── manage.py ├── app │ ├── __init__.py │ ├── apps.py │ ├── forms.py │ ├── migrations │ ├── models.py │ ├── tests.py │ ├── urls.py │ └── views.py ├── static │ └── css │ └── style.css └── templates ├── base.html ├── registration │ ├── base.html │ ├── logged_out.html │ ├── login.html │ └── signup.html └── app └── index.html設定ディレクトリとその中で指定されたdjango.contrib.auth内のURLconf、及びアプリケーションディレクトリのURlconfを以下に示す。
設定ファイルのURLconf
config/urls.pyfrom django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('', include('app.urls')), path('accounts/', include('django.contrib.auth.urls')), # Djangoがあらかじめ提供しているurls.pyへ path('accounts/', include('accounts.urls')), # 自分が作成したurls.pyへ ]django/contrib/auth/urls.pyfrom django.contrib.auth import views from django.urls import path urlpatterns = [ path('login/', views.LoginView.as_view(), name='login'), path('logout/', views.LogoutView.as_view(), name='logout'), path('password_change/', views.PasswordChangeView.as_view(), name='password_change'), path('password_change/done/', views.PasswordChangeDoneView.as_view(), name='password_change_done'), path('password_reset/', views.PasswordResetView.as_view(), name='password_reset'), path('password_reset/done/', views.PasswordResetDoneView.as_view(), name='password_reset_done'), path('reset/<uidb64>/<token>/', views.PasswordResetConfirmView.as_view(), name='password_reset_confirm'), path('reset/done/', views.PasswordResetCompleteView.as_view(), name='password_reset_complete'), ]アプリケーションのURLconf
app/urls.pyfrom django.urls import path from . import views app_name = 'app' urlpatterns = [ path('', views.IndexView.as_view(), name='index'), ]accounts/urls.pyfrom django.urls import path from . import views app_name = 'accounts' urlpatterns = [ path('signup/', views.SignUpView.as_view(), name='signup'), ]本題
新規登録完了 → ログイン画面で入力 → ログイン完了
まず、実装前の状態を確認する。
accounts/views.pyfrom django.urls import reverse_lazy from django.views import generic from .forms import UserCreateForm class SignUpView(generic.CreateView): form_class = UserCreateForm template_name = 'registration/signup.html' success_url = reverse_lazy('login')
- CreateViewを継承したSignUpViewを作成する。
- form_class = UserCreateFormで扱うフォームを指定する。今回はapp/forms.pyで作成したUserCreateFormを
form_classとして指定する。template_name = 'registration/signup.html'で新規登録画面のhtmlファイルを指定する。success_url = reverse_lazy('login')で新規登録が完了した後どこのページにいくのかをreverse_lazyを用いて指定する。この場合は'login'なので新規登録が完了するとDjangoがあらかじめ用意してくれているログインのページ(registration/login.html)に飛ぶ。template_name = 'registration/signup.html'で新規登録画面のhtmlファイルを指定する。(※ログインページのhtmlはあらかじめ用意されているが新規登録画面は用意されていないので自分で作る必要がある。)新規登録完了 → ログイン完了
新規登録が完了した後、ログイン画面を介さずにログインを完了するためにはacccouts/views.pyを少し変更するだけでいい。
accounts/views.pyfrom django.urls import reverse_lazy from django.views import generic from django.contrib.auth import login, authenticate # 追加 from .forms import UserCreateForm class SignUpView(generic.CreateView): form_class = UserCreateForm success_url = reverse_lazy('app:index') # 変更 template_name = 'registration/signup.html' # 以下追加 def form_valid(self, form): response = super().form_valid(form) username = form.cleaned_data.get('username') password = form.cleaned_data.get('password1') user = authenticate(username=username, password=password) login(self.request, user) return response行う作業は
success_urlの指定とform_validメソッドのオーバーライドの2点。
success_url = reverse_lazy('app:index')で登録完了後に遷移する画面を 'login' から 'app:index' つまりトップページに変更をする。- form_validメソッドをオーバーライドするコードを追加する。
response = super().form_valid(form)で親のform_valid()で返された値を取得する。username = form.cleaned_data.get('username')で新規登録のuserneme欄で入力された値をusernameに代入する。form.cleaned_dataは入力検証を通過したデータを示す。password = form.cleaned_data.get('password1')も同様です。user = authenticate(username=username, password=password)で、あるユーザーとパスワードに対する認証を行う。authenticate()は引数として、usernameとpasswordをとり、ユーザー名に対してパスワードが有効だった場合にUserオブジェクトを返す。無効だった場合はNoneを返す。login(self.request, user)でユーザーを自動でログインさせる。login()は引数としてHttpRequestオブジェクトとUserオブジェクトをとる。- 最後にresponseを返す。
- 投稿日:2020-06-29T12:22:43+09:00
【初心者向けハンズオン】kaggleの「住宅価格を予測する」を1行ずつ読み解く(第6回:目的変数の分布変換)
お題
有名なお題であるkaggleの「House Price」問題にみんなでチャレンジしていくことになったハンズオンの内容をメモしていく企画の第6回。解説というよりはメモのまとめだったりもしますが、どこかの誰かのためになれば幸いです。前回で準備がおわり、いよいよ解析段階に。
- 元々のお題:https://www.kaggle.com/c/house-prices-advanced-regression-techniques
- 参考にした記事:https://yolo-kiyoshi.com/2018/12/17/post-1003/
本日の作業
目的変数の分布変換
- 目的変数:後輩曰く「Yですね」 → 自分「。。。」
- 目的変数:http://www.gen-info.osaka-u.ac.jp/testdocs/tomocom/express/express8.html
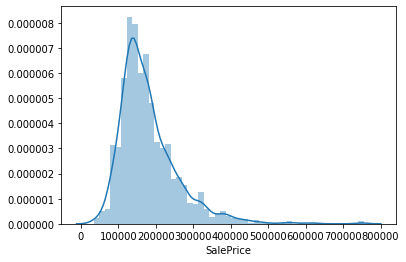
学習データのSalePrice(住宅価格)の分布を確認します。
欠損補完の箇所で、プールがない住宅がほとんどであることがわかりました。
これは裏を返せばプールがあるような豪邸がいくつか存在するということであり、住宅価格がかなり歪な分布になっているのでは?と想定されます。こうした仮設を元に描画するのが重要だなと振り返ります。とはいえまずは言われるがままにグラフをアウトプット。
sns.distplot(train['SalePrice'])seabornについて
「snsってなんだっけ?」ってなりました。最初過ぎて忘れていましたが、一番最初にインポートしていたライブラリの中にありましたね。これです。
import seaborn as snsなるほどseaborn
* seaborn:どうやらグラフ描画のライブラリ。
* seaborn参照:https://qiita.com/hik0107/items/3dc541158fceb3156ee0
* distplot:seabornでヒストグラムを描画するメソッド。train['SalePrice']に入っていた内容を確認
あとは念のため、train['SalePrice']に入っていた内容を確認。
なるほどひたすら各が並んでいる列。
アウトプットされたグラフ
そしてアウトプットされたグラフはこんな感じになりました。
sns.distplot(train['SalePrice'])
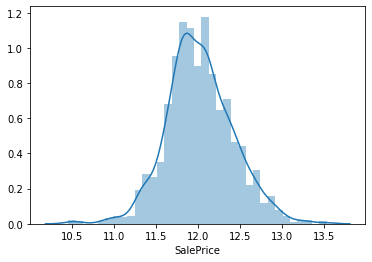
対数変換
予想どおり、かなり右側に分布の裾野が広がっています。
対数変換をすることで正規分布に近づけます。sns.distplot(np.log(train['SalePrice']))対数変換前後の配列の変化
これだけ出力してみます。
np.log(train['SalePrice'])なるほど、潰れている。
アウトプットされたグラフその2
sns.distplot(np.log(train['SalePrice']))
なるほどきれいめに正規分布になっている気がする。
予測モデルの構築
に、入りたかったですが、どうやら時間切れ臭いので今日はここまでです。
今回は変数量がかなり多いため、係数に強力なペナルティをかけたいのでLasso回帰を使って予測モデルを構築します。
予習がてらLasso回帰について調べて終了。
Lasso回帰
おしまい。
分析レイヤーに入ってきてから、やはり背景知識の補充が必要だなと、理解しました。
主に回帰分析について。


- 投稿日:2020-06-29T11:45:28+09:00
【Rust】緯度経度のcsvデータを読み込んで2点間の距離を求める
背景
500点くらいの位置情報がcsvデータにまとめられていて、その全ての組み合わせについて直線距離(km) を求めたい.
緯度経度から距離を求める
以下の記事を参考にさせていただきました.
- Python 経度・緯度で与えられた2点間距離計算
pub fn cal_rho(lat_a: &f64, lon_a: &f64, lat_b: &f64, lon_b: &f64) -> f64 { const RA: f64 = 6378.140; // equatorial radius (km) const RB: f64 = 6356.755; // polar radius (km) let f: f64; let rad_lat_a: f64; let rad_lon_a: f64; let rad_lat_b: f64; let rad_lon_b: f64; let pa: f64; let pb: f64; let xx: f64; let c1: f64; let c2: f64; let dr: f64; let rho: f64; f = (RA - RB) / RA; rad_lat_a = lat_a.to_radians(); rad_lon_a = lon_a.to_radians(); rad_lat_b = lat_b.to_radians(); rad_lon_b = lon_b.to_radians(); pa = (RB / RA * rad_lat_a.tan()).atan(); pb = (RB / RA * rad_lat_b.tan()).atan(); xx = (pa.sin() * pb.sin() + pa.cos() * pb.cos() * (rad_lon_a - rad_lon_b).cos()).acos(); c1 = ((xx.sin() - xx) * (pa.sin() + pb.sin())).powf(2.0) / ((xx / 2.0).cos()).powf(2.0); c2 = ((xx.sin() + xx) * (pa.sin() - pb.sin())).powf(2.0) / ((xx / 2.0).sin()).powf(2.0); dr = f / 8.0 * (c1 - c2); rho = RA * (xx + dr); rho }csvの読み込み -> 距離の計算
rdr.records()で取得できるStringRecordsIterを使ってネストのループを作ろうと思ったが、うまく行かなかった.
そのためIter->Vecに変換して対応した.extern crate csv; use csv::StringRecord; use std::env; use std::error::Error; use std::ffi::OsString; use std::fs::File; pub fn run() -> Result<(), Box<Error>> { let file_path = "file.csv"; let file = File::open(file_path)?; let mut rdr = csv::Reader::from_reader(file); let _records = rdr.records(); let records: Vec<StringRecord> = _records.map(|x| x.unwrap()).collect(); let data_len = &records.len(); for i in 0..*data_len { for j in 0..*data_len { let r_i = &records[i]; let lat_i = &r_i[1]; let lat_i: f64 = lat_i.parse().unwrap(); let lng_i = &r_i[2]; let lng_i: f64 = lng_i.parse().unwrap(); let r_j = &records[j]; let lat_j = &r_j[1]; let lat_j: f64 = lat_j.parse().unwrap(); let lng_j = &r_j[2]; let lng_j: f64 = lng_j.parse().unwrap(); let dist = cal_rho(&lat_i, &lng_i, &lat_j, &lng_j); println!("{}", dist); } } Ok(()) }手探りの実装ですので、良い方法あればアドバイスお待ちしています。
- 投稿日:2020-06-29T11:24:51+09:00
「クソデカ文学コンバータ」作ってみた
とりあえず作ったもの
使ってみてね!!
概要
言わずもがな、テキストを入力すると「クソデカ羅生門」みたいにしてくれるアプリです。
どうやっているのか
コードは公開できるほどのものではないですし、テキスト変換の精度も低いので、ここではざっくりとだけ説明します。とりあえずさっさと作りたかったのですごく雑なアルゴリズムです。
- クソデカ羅生門と羅生門の差分から、どのような単語の前に「クソデカ」みたいな言葉(クソデカワードとします)が挿入されているかの辞書(クソデカ辞書)を作る(例:"羅生門": ["正気を疑うレベルでデカい", "クソデカい", "クソデカ", "トチ狂ったクソデカさの"])
- Mecabで形態素解析して、入力テキストの単語の品詞を特定する。
- 一般名詞など特定の品詞の単語の前にクソデカワードを挿入する。この時、クソデカ辞書から、入力の単語と類似度が一番近いkeyのvalueを選んで挿入する(gensim使用)
- 最後に言語モデルで出力テキストの自然さを評価し、おかしな部分がないかチェックする(あまりうまく行ってない)
- webアプリはflaskで作っています。
最後に
ぜひいろいろ遊んでみてほしいのですが、「こうすればもっとうまくいく!」「こういう機能をつけたら良いんじゃない?」などコメントいただけるととてもありがたいです!
感想としては、webアプリを簡単にでも自作できて楽しかったのと、座学で勉強していたNLPをちょっとでも実践に活かせたのでよかったです。
- 投稿日:2020-06-29T11:06:25+09:00
なろう小説APIを試してみた
きっかけ
https://qiita.com/dely13/items/5e949a384161c961d8ce
こちらの記事を読んで、遊び練習がてら自分で試していたら、結果が違うぞ→この記事2017年じゃん
と、なったので最新を出してみた(2020/6/29 10:00現在)前半はそのまま
@dely13さんの記事をそのまま使います
dely13.pyimport pandas as pd import requests import numpy as np import seaborn as sns from scipy import stats import matplotlib.pyplot as plt %matplotlib inline url = "http://api.syosetu.com/novelapi/api/" # APIのパラメータをディクショナリで指定する # この条件で、総合評価順でjson形式のデータを出力する payload = {'of': 't-gp-gf', 'order': 'hyoka','out':'json'} st = 1 lim = 500 data = [] while st < 2000: payload = {'of': 't-gp-gf-n', 'order': 'hyoka', 'out':'json','lim':lim,'st':st} r = requests.get(url,params=payload) x = r.json() data.extend(x[1:]) st = st + lim df = pd.DataFrame(data) #前処理('year'列追加、'title_len'列追加) df['general_firstup'] = pd.to_datetime(df['general_firstup']) df['year'] = df['general_firstup'].apply(lambda x:x.year) df['title_len'] = df['title'].apply(len)ホントにそのままなので詳しくは元の記事を読んでください
本題
df['title_len'].hist() df['title_len'].describe()ヒストグラム図
df['title_len'].hist()
データdf['title_len'].describe()count 2000.000000
mean 24.179500
std 15.528356
min 2.000000
25% 12.000000
50% 21.000000
75% 32.000000
max 100.000000
Name: title_len, dtype: float64平均7文字増えとるwwwwww
そして本当に面白いのはここから
per_year.pytitle_by_year = df.groupby('year')['title_len'].agg(['mean','count','std']).reset_index() #プロット title_by_year.plot(x='year',y='mean') #データ title_by_yearプロット
title_by_year.plot(x='year',y='mean')※mean=平均
集計
title_by_year
year mean count std 2008 7.500000 2 2.121320 2009 12.428571 7 8.182443 2010 10.882353 17 5.278285 2011 10.180000 50 4.684712 2012 13.294737 95 6.963237 2013 14.115942 138 8.541930 2014 16.065476 168 8.780176 2015 18.218009 211 9.701245 2016 21.577358 265 12.326472 2017 24.476015 271 11.750113 2018 29.425856 263 13.890288 2019 31.327327 333 15.861156 2020 40.483333 180 22.348053 ※2020のデータは6/29までのデータです
結論
2019年 なろうのタイトルは 短歌となる
2017年の記事で推測した人すっげぇ。ドンピシャじゃん。余談1
せっかくなので最大・最小を出してみる
title_by_year = df.groupby('year')['title_len'].agg(['mean','min','max']).reset_index() #プロット title_by_year.plot(x='year') #データ title_by_year.plotプロット
title_by_year.plot(x='year')
データ
title_by_year
year mean min max 2008 7.500000 6 9 2009 12.428571 5 25 2010 10.882353 2 23 2011 10.180000 4 26 2012 13.294737 3 40 2013 14.115942 3 54 2014 16.065476 4 63 2015 18.218009 3 59 2016 21.577358 2 77 2017 24.476015 4 69 2018 29.425856 5 74 2019 31.327327 4 100 2020 40.483333 4 100 この、100文字のデータって文字数オーバーしてるのでは……?
max_100.pydf[['ncode','title','year','title_len']].set_index('ncode').query('title_len==100')
ncode title year title_len N7855GF 無能扱いされて、幼馴染パーティーを追放された俺は外れギフト『翻訳』を駆使して成り上がる~馬鹿... 2020 100 N6203GE 独裁王国を追放された鍛冶師、実は《鍛冶女神》の加護持ちで、いきなり《超伝説級》武具フル装備で... 2020 100 N0533FS 【連載版】追っかけていたアイドルがイケメンと歩いている姿を目撃した俺は、バイト代はたいて買っ... 2019 100 N4571GF ループ7週目で信じていた仲間たちに嵌められていたことを知ったので、8周目は能動的にパーティー... 2020 100 ・・・これ、100文字オーバーしてない・・・?
記事書いてから調べてみたら100文字きっかりでした
文字数制限があるのかな?
限界ギリギリで戦っているのはそれはそれですごい。余談2
逆に短いタイトルが気になった
mini_len.pydf.groupby('title_len')['title_len'].agg(['count']).head(9).T文字数と作品数の対応一覧
長くなったので横配置
title_len 2 3 4 5 6 7 8 9 10 count 2 8 18 35 41 38 64 75 89 title2_4.pydf[['title','year','title_len']].set_index('title').sort_values('title_len').query('title_len<5')4文字は一部抜粋で
title year title_len 書簡 2016 2 払暁 2010 2 弓と剣 2013 3 水の理 2012 3 墓王! 2013 3 幼馴染 2016 3 探索者 2013 3 塔の陰 2012 3 駆除人 2015 3 猫と竜 2013 3 忘却聖女 2020 4 J/53 2012 4 黒の魔王 2011 4 私の従僕 2019 4 モブの恋 2015 4 賢者の孫 2015 4 セブンス 2014 4 少ない文字でも有名どころはありますね。
元モバ民には4文字に「タイトル」とかあると感動した。感想
モバ(現えぶぅ)ほどじゃないにしても初心者参入が多いのは携帯小説のアニメ化の影響か?
自分はモバに鍛えられたので多少読みづらくても内容が面白ければ読むけどそれにしてもタイトルが長い。
かという今ハマってるのこれとかこれもそこそこ長いタイトルだけど。(えぶぅだとこれ※ステマ)なろうAPIで検索条件絞れるのでいろいろ試してみたいと思った。2000件以上抽出したい場合ってどうするんだろう……



- 投稿日:2020-06-29T10:59:37+09:00
scipy.optimizeで、十種競技の世界記録を出すための最適解を算出
はじめに
「十種競技」という競技をご存知でしょうか?
2日間で走(100m, 400m, 1500m, 110mH)、跳(走高跳, 棒高跳, 走幅跳)、投(砲丸投, 円盤投, やり投)の10種目を行い、各種目の記録を得点化しその合計記録で争うという競技です。
現在(2020年6月)の世界記録は Kevin MAYER 選手の9126点です。ところで、この点数を効率良く出すためにはどうすればいいでしょうか?
「全ての種目で均等に得点を取る」という考えがありそうですが、これは現実的ではありません。
種目によって得点を稼ぎやすいもの、稼ぎにくいものがあるためです。
例えば、各種目で900点を獲得するための記録は下記となります。
(参考までに、十種競技の種目ごとの日本記録も併載)
100m 400m 1500m 110mH 走高跳 棒高跳 走幅跳 砲丸投 円盤投 やり投 900点 10.82 48.19 247.42 14.59 2.10 4.97 7.36 16.79 51.40 70.67 十種種目ごと日本記録 10.53 47.17 248.24 13.97 2.16 5.30 7.65 15.65 50.23 73.82 砲丸投か円盤投で900点を出すためには、日本記録を越えなければいけません。
これは現実的ではありませんね。では、どうしたら最も簡単に世界記録を出せるでしょうか?
砲丸投では800点しか取れない代わりに他の種目で1000点取ろう、でも100mと1500mのどちらで1000点取るのが楽かなんて分からない…この問いに対して私が出した答えは
「スコアリングテーブル(通称ハンガリアンテーブル)」での総得点の最小値」というものです。スコアリングテーブルとは?
国際陸上競技連盟(IAAF)が作成している各種目の記録を得点化した表で、十種競技とは計算式が異なります。
こちらは種目ごとの比較のために作られているので、「自分が出した100m 11.00(886p)という記録は、走幅跳だと6m83(886p)相当だな」などというように使用できます。算出したもの
「10種目のスコアの最小値(制約:十種の記録が9126点を超える)」を算出しました。
例えば、100mと砲丸投の2種目で合計1000点を目指すとします。
それぞれの種目で500点を出した時の合計スコアは972pですが、
100m14.00, 砲丸投13.32の時の合計スコアは945pであり、得点は同じでもこちらの方が楽に点数を稼げそうです。
(実際問題はまた別ですが……)
記録 十種得点 スコア : 記録 十種得点 スコア 100m 12.82 500 430 : 14.00 312 221 砲丸投 10.24 500 542 : 13.32 687 724 合計 1000 972 : 1000 945 このような感じで、いかに小さいスコアで世界記録を出せるかというのを求めています。
算出方法
最適化手法は、scipy.optimizeのminimizeを使用しました。
記録の範囲は、スコア1p〜世界記録としました。
(トラック種目は下限が世界記録、フィールド種目は上限が世界記録です)
100m 400m 1500m 110mH 走高跳 棒高跳 走幅跳 砲丸投 円盤投 やり投 下限 9.58 43.03 206.00 12.80 0.92 1.16 2.51 1.00 1.57 1.59 上限 16.79 78.01 380.04 25.43 2.45 6.18 8.95 23.12 74.08 98.48 十種競技の得点計算式はWikipediaに記載されています。
スコアリングテーブルの計算式は公式で見つけることができませんでしたが、下記の計算式で算出されるようです。a × (記録 + b)^2 + c
(係数は下記に記載)意外とシンプルですね。
以下、算出で使用したコマンドです。
import numpy as np import pandas as pd import copy import sys from scipy.optimize import minimize, BFGS, LinearConstraint, Bounds from math import floor import matplotlib.pyplot as plt ## スコアリングテーブル用係数 w_score = np.array([ [24.64221166,-16.99753156,-0.218662048], #100m [1.021013043,-78.99469306,0.0029880052], #400m [0.0406599253,-384.9950051,0.001205591], #1500m [7.665206128,-25.79302259,0.0141087786], #110mH [32.14570816,11.59368894,-5026.080842], #HJ [3.045719921,39.33586031,-4993.213828], #PV [1.931092873,48.34861905,-4993.807793], #LJ [0.0423461436,684.8281542,-19915.72457], #SP [0.0040063129,2232.983411,-20003.52492], #DT [0.0024031525,2879.797864,-19950.96836]])#JT ## 十種競技用係数 w_dec = np.array([ [25.4347,18,1.81], #100m [1.53775,82,1.81], #400m [0.03768,480,1.85], #1500m [5.74352,28.5,1.92], #110mH [0.8465,75,1.42], #HJ [0.2797,100,1.35], #PV [0.14354,220,1.4], #LJ [51.39,1.5,1.05], #SP [12.91,4,1.1], #DT [10.14,7,1.08]]) #JT ## 目的関数(スコアリングテーブル) def calc_score(x): total_score = 0 for i in range(10): total_score += w_score[i,0] * (x[i] + w_score[i,1])**2 + w_score[i,2] return total_score ## 制約関数(十種競技得点) def calc_dec(x): n = 0 total_point = 0 target_point = 9126 for i in range(10): if i in (0,1,2,3): total_point += w_dec[i,0] * (w_dec[i,1] - x[i]) ** w_dec[i,2] #100m, 400m, 1500m, 110mH elif i in (4,5,6): total_point += w_dec[i,0] * (x[i] *100 - w_dec[i,1]) ** w_dec[i,2] #走高跳, 走幅跳, 棒高跳 else: total_point += w_dec[i,0] * (x[i] - w_dec[i,1]) ** w_dec[i,2] #砲丸投, 円盤投, やり投 return_point = total_point - target_point return return_point bounds = Bounds(world_rec[0:4] + min_rec[4:10] , min_rec[0:4] + world_rec[4:10]) cons = ( {'type': 'ineq', 'fun': calc_dec} ) x0 = np.array([10, 46.19, 247.42, 13.59, 1.8, 3.5, 6.06, 10.79, 31.40, 53.67]) # 初期値は適当関数の作成以外、ほとんど記載していません。
これだけで最適化問題を解けるなんて、とても簡単ですね…結果
1.世界記録(9126点)達成時の最小スコア
result = minimize(calc_score, x0, constraints=cons, method="SLSQP", bounds=bounds) print(result) # fun: 8707.88035324152 # jac: array([-141.92468262, -27.99401855, -5.38891602, -70.75549316, # 902.8885498 , 277.25720215, 221.29797363, 59.95800781, # 18.4855957 , 14.31445312]) # message: 'Optimization terminated successfully.' # nfev: 569 # nit: 38 # njev: 34 # status: 0 # success: True # x: array([ 14.11782497, 65.28575996, 318.7265988 , 21.17765192, # 2.45 , 6.18 , 8.95 , 23.12 , # 74.08 , 98.48 ])100m:14.11
400m:65.28
1500m:318.72
110mH:21.72
走高跳:2.45(世界記録)
棒高跳:6.18(世界記録)
走幅跳:8.95(世界記録)
砲丸投:23.12(世界記録)
円盤投:74.08(世界記録)
やり投:98.48(世界記録)総スコア:8707
という結果となりました!ww
得点は指数関数的に増加するので、伸び率の高いフィールド種目を頑張れば
トラック種目は適当でも世界記録出るってことですかね………2.日本記録(8308点)達成時の最小スコア
世界記録だけだとつまらないので、日本記録バージョンも実行してみました。
なお、上限は「十種競技種目ごと日本記録」としました。#結果のみ記載 result = minimize(calc_score, x0, constraints=cons, method="SLSQP", bounds=bounds) print(result) # fun: 8397.295007256867 # jac: array([-262.33532715, -58.31018066, -7.70007324, -130.22009277, # 884.24414062, 271.89660645, 216.27709961, 59.32495117, # 18.29467773, 14.19604492]) # message: 'Optimization terminated successfully.' # nfev: 521 # nit: 30 # njev: 30 # status: 0 # success: True # x: array([ 11.67464597, 50.4396491 , 290.30574658, 17.29878908, # 2.16 , 5.3 , 7.65 , 15.65 , # 50.23 , 73.82 ])100m:11.67
400m:50.43
1500m:290.30
110mH:17.29
走高跳:2.16(十種日本記録)
棒高跳:5.30(十種日本記録)
走幅跳:7.65(十種日本記録)
砲丸投:15.65(十種日本記録)
円盤投:50.23(十種日本記録)
やり投:73.82(十種日本記録)総スコア:8397p
という結果となりました。
フィールド競技で得点を稼ぐという傾向は変わりませんね…
ちなみに、右代選手が日本記録を出した際のスコアは8609pなので、
上記だと約200p効率良く日本記録を出せることになりますwおまけ
scipyとは関係ありませんが、十種競技の得点とスコアリングテーブルの計算式をグラフ化してみました。
## グラフ出力 fig, ax = plt.subplots(5, 2, figsize=(14, 25)) for i in range(10): pltx = np.arange(min(min_rec[i],world_rec[i]), max(min_rec[i],world_rec[i]), 0.01) plty = w_score[i,0] * (pltx + w_score[i,1])**2 + w_score[i,2] if i in (0,1,2,3): plty_p = w_dec[i,0] * (w_dec[i,1] - pltx) ** w_dec[i,2] #100m, 400m, 1500m, 110mH elif i in (4,5,6): plty_p = w_dec[i,0] * (pltx *100 - w_dec[i,1]) ** w_dec[i,2] #走高跳, 走幅跳, 棒高跳 else: plty_p = w_dec[i,0] * (pltx - w_dec[i,1]) ** w_dec[i,2] ax[i//2, i%2].set_ylim([0,1400]) ax[i//2, i%2].plot(pltx, plty, color="blue", label="Scoring") ax[i//2, i%2].plot(pltx, plty_p,color="orange", label="Decathlon") ax[i//2, i%2].set_title(label[i], size=15) ax[i//2, i%2].set_xlabel('Record') ax[i//2, i%2].set_ylabel('Score / Point') ax[i//2, i%2].axvline(x=world_rec[i], ymin=0, ymax=100, ls="--", color="red", label="World Record") ax[i//2, i%2].axvline(x=national_dec_rec[i], ymin=0, ymax=100, ls="--", color="green", label="National Decathlon Record") ax[i//2, i%2].grid(which = "major", axis = "both", alpha = 0.8, linestyle = "--", linewidth = 0.8) ax[i//2, i%2].legend(loc='best') plt.tight_layout()
高得点領域において、トラック種目はフィールド種目に比べてスコアに対する十種の得点が低い(=高スコアを出しても得点に反映されにくい)気がします。
「最小スコアで高得点を出すためにはフィールドで高スコアを出す」という結論に至った理由が分かるような気がします。。終わりに
scipy.optimizeは統計学ド素人の私でも使えました。とても便利…
本記事を通して気軽に最適化問題に取り組む人(&十種競技に興味を持った人)が増えれば幸いです。

- 投稿日:2020-06-29T10:59:37+09:00
十種競技で世界記録を出すための最適解を算出してみた
はじめに
「十種競技」という競技をご存知でしょうか?
2日間で走(100m, 400m, 1500m, 110mH)、跳(走高跳, 棒高跳, 走幅跳)、投(砲丸投, 円盤投, やり投)の10種目を行い、各種目の記録を得点化しその合計記録で争うという競技です。
現在(2020年6月)の世界記録は Kevin MAYER 選手の9126点です。ところで、この点数を効率良く出すためにはどうすればいいでしょうか?
「全ての種目で均等に得点を取る」という考えがありそうですが、これは現実的ではありません。
種目によって得点を稼ぎやすいもの、稼ぎにくいものがあるためです。
例えば、各種目で900点を獲得するための記録は下記となります。
(参考までに、十種競技の種目ごとの日本記録も併載)
100m 400m 1500m 110mH 走高跳 棒高跳 走幅跳 砲丸投 円盤投 やり投 900点 10.82 48.19 247.42 14.59 2.10 4.97 7.36 16.79 51.40 70.67 十種種目ごと日本記録 10.53 47.17 248.24 13.97 2.16 5.30 7.65 15.65 50.23 73.82 砲丸投か円盤投で900点を出すためには、日本記録を越えなければいけません。
これは現実的ではありませんね。では、どうしたら最も簡単に世界記録を出せるでしょうか?
砲丸投では800点の代わりに他の種目で1000点取ろう、でも100mと1500mのどちらで1000点取るのが楽かなんて分からない…この問いに対して私が出した答えは
「スコアリングテーブル(通称ハンガリアンテーブル)」での総得点の最小値」というものです。スコアリングテーブルとは?
国際陸上競技連盟(IAAF)が作成している各種目の記録を得点化した表で、十種競技とは計算式が異なります。
こちらは種目ごとの比較のために作られているので、「自分が出した100m 11.00(886p)という記録は、走幅跳だと6m83(886p)相当だな」などというように使用できます。算出したもの
「10種目のスコアの最小値(制約:十種の記録が9126点を超える)」を算出しました。
例えば、100mと砲丸投の2種目で合計1000点を目指すとします。
それぞれの種目で500点を出した時の合計スコアは972pですが、
100m14.00, 砲丸投13.32の時の合計スコアは945pであり、得点は同じでもこちらの方が楽に点数を稼げそうです。
(実際問題はまた別ですが……)
記録 十種得点 スコア : 記録 十種得点 スコア 100m 12.82 500 430 : 14.00 312 221 砲丸投 10.24 500 542 : 13.32 687 724 合計 1000 972 : 1000 945 このような感じで、いかに小さいスコアで世界記録を出せるかというのを求めています。
グラフ化
(編集中)
算出方法
記録の範囲は、スコア1p〜世界記録としました。
(トラック種目は下限が世界記録、フィールド種目は上限が世界記録です)
100m 400m 1500m 110mH 走高跳 棒高跳 走幅跳 砲丸投 円盤投 やり投 下限 9.58 43.03 206.00 12.80 0.92 1.16 2.51 1.00 1.57 1.59 上限 16.79 78.01 380.04 25.43 2.45 6.18 8.95 23.12 74.08 98.48 最適化手法は、scipy.optimizeのminimizeを使用しました。
(編集中)
結果
取り急ぎ、結果のみ記載します。
他は後日記載予定です…result = minimize(calc_score, x0, constraints=cons, method="SLSQP", bounds=bounds) print(result) # fun: 8707.88035324152 # jac: array([-141.92468262, -27.99401855, -5.38891602, -70.75549316, # 902.8885498 , 277.25720215, 221.29797363, 59.95800781, # 18.4855957 , 14.31445312]) # message: 'Optimization terminated successfully.' # nfev: 569 # nit: 38 # njev: 34 # status: 0 # success: True # x: array([ 14.11782497, 65.28575996, 318.7265988 , 21.17765192, # 2.45 , 6.18 , 8.95 , 23.12 , # 74.08 , 98.48 ])100m:14.11
400m:65.28
1500m:318.72
110mH:21.72
走高跳:2.45(世界記録)
棒高跳:6.18(世界記録)
走幅跳:8.95(世界記録)
砲丸投:23.12(世界記録)
円盤投:74.08(世界記録)
やり投:98.48(世界記録)総スコア:8707
という結果となりました!ww
得点は指数関数的に増加するので、伸び率の高いフィールド種目を頑張れば
トラック種目は適当でも世界記録出るってことですかね………終わりに
scipy.optimizeは統計学ド素人の私でも使えました。とても便利…
今後は、日本記録を超えるための最小スコアや、制約を変更しての算出なども追記したいと思います。
- 投稿日:2020-06-29T10:34:55+09:00
RedshiftでUNLOADしたgzipファイルをLambdaのPythonで処理をして再びgzipしてS3へアップする
やりたいこと
タイトルの通りですが、Redshiftにデータウェアハウスがあり、普段ELTで処理することが多いのですが、プログラミングによるデータ加工が必要な場合もあります。
RedshiftのUNLOADを利用することでRedshiftからSQLの結果をS3にgzipファイルを作成することが出来ますので、S3へのputイベントをトリガーにLambdaで処理して再びgzipした状態でS3にアップ、ということをしてみました。
UNLOAD
Lambdaは現時点では3008MBが最大となります。今回のような処理はファイルサイズが増えると必然利用メモリ量が増えてしまいます。
そこで、MAXFILESIZE パラメータ を設定することでLambdaへ渡すファイルサイズを調整します。
完全なるケースバイケースですが、今回は50MBで設定してみました。Lambda上のコード
トリガ設定は割愛します。
import json import boto3 import urllib.parse import os import sys import csv import re import traceback import gzip import subprocess s3client = boto3.client('s3') s3resource = boto3.resource('s3') SEP = '\t' L_SEP = '\n' S3OUTBACKET='XXXXXXXX' S3OUTBASE='athena/preprocessing/XXXXXXtmp/' def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['name'] key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8') taragetfile=os.path.split(key)[1] outputprefixA=os.path.split(key)[0].split("/")[-1] outputprefixB=os.path.split(key)[0].split("/")[-2] outputdata = ""; try: dlfilename ='/tmp/'+key.replace("/","") s3client.download_file(bucket, key, dlfilename) gzipfile = gzip.open(dlfilename, 'rt') csvreader = csv.reader(gzipfile, delimiter=SEP, lineterminator=L_SEP, quoting=csv.QUOTE_NONE) for line in csvreader: # 1行ずつ様々な処理をして、outputdataに格納していく。 # 割愛された処理の中に、利用しているimportがございます。 # ご了承ください except Exception as e: print(e) raise e print("memory size at outputdata:"+str(sys.getsizeof(outputdata))) os.remove(dlfilename) uploadbinary = gzip.compress(bytes(outputdata , 'utf-8')) print("memory size at uploadbinary:"+str(sys.getsizeof(uploadbinary))) uploadfilename='processed_'+taragetfile try: bucket = S3OUTBACKET key = S3OUTBASE+outputprefixA+"/"+outputprefixB+"/"+uploadfilename obj = s3resource.Object(bucket,key) obj.put( Body=uploadbinary ) except Exception as e: print(e) raise e return 0チューニングしてゆく
実際のファイルでテストをしたところメモリエラーとなってしまいました。
コードの途中に挟んでいるstr(sys.getsizeof(outputdata))はその確認用で、メモリサイズを見て状況を把握しました。コードには書いてませんが、gzip自体の対象データへの圧縮率も見ておくと良いと思います。
なお私が今回扱ったデータは、gzip圧縮後50MBだったのですが、処理後のデータ+圧縮後のデータで1000MBものメモリを要してしまいました。やはり実際にやってみないと分からないものですね。Pythonのメモリ事情をもう少し調べた方が良いかもしれません。なおLambdaはメモリサイズを増やすとCPUリソースなども増えますので、処理内容とファイルサイズ次第ですが、一度最大の3008MBだとどのくらい処理が速くなるのかは確認すると良いです。今回も、メモリを倍にしたら処理時間が半分に、というケースすらありました。
もし定常的に行う処理の場合、ここでのチューニングがランニングコストに直結するので重要度が高いです。
語彙の無い感想
Lambdaめっちゃ便利