- 投稿日:2020-06-29T22:59:33+09:00
【PHP】Cloud9で$_SESSIONが反映されなかったときの対処法
はじめに
学習記録のアウトプット・自分自身の備忘録として書いた記事です。
今回はPHPのセッションがうまくいかなかったためその概要と解決方法についてメモしていきます。やりたかったこと
以下のように設定した
$_SESSION['$csrfToken']をページ遷移後に反映したい。$csrfToken = bin2hex(random_bytes(32)); $_SESSION['$csrfToken'] = $csrfToken;トラブルの症状
ページ遷移後に
$_SESSIONが記録されていませんでした。セッションファイルの出力先を指定する。
(これは必要ではないかもしれませんが念のため。)
Cloud9はそもそもデフォルトではphp5.6のため
random_bytesは使えません。
そのためphp7.2をyumでインストール。この状態でphpinfo() を実行すると、session.save_pathの右カラムはno valueになっています。
デフォルトのセッションファイルの格納先が特に指定されていなかったため/etc/php.iniでphp.ini; RPM note : session directory must be owned by process owner ; for mod_php, see /etc/httpd/conf.d/php.conf ; for php-fpm, see /etc/php-fpm.d/*conf ; session.save_path = "/tmp"↓";"を外す。
php.ini; RPM note : session directory must be owned by process owner ; for mod_php, see /etc/httpd/conf.d/php.conf ; for php-fpm, see /etc/php-fpm.d/*conf session.save_path = "/tmp"変更後デバックしてみて以下が作成されていることを確認。
/tmp/sess_*session_start()の書く位置
<?php session_start();と
<?php直下に書く必要があります。
尚且つ$_SESSIONの直前ではなく、一番最初のphpタグの直下です。。。参考
https://note.kiriukun.com/entry/20191125-session-not-working-in-php#file
- 投稿日:2020-06-29T21:59:35+09:00
MacOSで仮想環境を作るソリューションを比較してみた
背景
目的:MacOS Mojave (Version 10.14)でWindowsのVMを利用したい
(最終の目的はWindowsサーバーで色々作業するため、WindowsサーバーのGUIが要る)仮想環境主なソリューション
仮想化の種類は色々ありますが、今回の問題に向いてるソリューションを以下三つを考えました。
仮想化ソフトを全般的に比較したい方は、こちらをご参考ください。
- クラウド型仮想デスクトップサービス
- ホストOS + リモートデスクトップアプリ + リモートサーバー
- 仮想マシン(ホストOS型)
クラウド型仮想デスクトップサービス
説明
マネージド仮想デスクトップ、DaaS(Desktop as a Services)も呼ぶ
代表製品
- AWSのAmazon Workspace(無料枠あり)
- AzureのWindows Virtual Desktop(無料枠あり)
- IBMのVMware Horizon on IBM Cloud(無料枠なさそう)
ホストOS + リモートデスクトップアプリ + リモートサーバー
説明
手元のコンピュータからネットワークで接続された他のコンピューターのGUIやデスクトップ環境を操作するアプリである
代表製品
- Microsoft リモートデスクトップ
- Chrome リモートデスクトップ
仮想マシン
説明
土台となる既存のホストOS上、ゲストOSを実行するためのソフト
代表製品
- VMware Fusion(Mac向け、無料試用あり)
- VirtualBox(サポートされるホストOSはLinux、macOS、Microsoft Windows、Solaris。無料)
比較
今回上記三種類のソリューションの中、それぞれ代表案を1つ選択して比較しました。
Amazon Workspace Microsoft リモートデスクトップ + EC2(Linux+ Windows) Virtual Box 概要 AWS のフルマネージドDaaS ソリューション MacからEC2 windows にリモートデスクトップ(踏み台用のサーバー経由で)接続でログイン Oracle VM Virtual BoxでWindowsサーバーを動かせる 実装の容易さ 数十分掛かる 数十分掛かる 2時間以上掛かる ロカールへの影響 - クライエントインストールには118MB必要
- 運用時ロカール PCにほぼ負担掛からない- アプリインストールには42.72 MB必要
- ロカール PCにほぼ負担掛からない- 少なくとも4GBのメモリが要る
- 8GBのPCの場合、ほぼ他の作業は同時実施できない費用 - 最初の月2Bundleまで40時間の無料利用
- その後の課金方法は月額料金と時間料金二種類がある- リモートデスクトップは無料
- EC2 Linuxサーバーの料金とEC2 Windowsサーバーの料金はインスタンスタイプにより異なる無料 運用 - CloudWatchでモニタリング
- WorkDocsでファイル共有
(Workspaceユーザーの場合50GBまで無料)- CloudWatchでEC2インスタンスをモニタリング
-ファイル共有にはリモートデスクトップを使用
- IAM設定やシークレット管理が必要VirtualBox Mangerでファイル共有やログ記録 各ソリューションのセットアップ手順
Amazon Workspace
- Workspaceに利用するBundleを選択
- Workspaceクライエントをインストール
- Workspace クライエントを起動
- (オプション)ファイル共有用のWorkdocsをインストール
Microsoft リモートデスクトップ + EC2(Linux+ Windows)
- Microsoft リモートデスクトップのインストール
- EC2で踏み台用Linuxサーバーをパブリックサブネットに、Windowsサーバーをプライベートサブネットにセットアップ
- EC2のIAM権限をAdministratorAccessに設定したことは前提
- セキュリティ上の理由で踏み台用サーバーが必要
- 踏み台用サーバーとWindowsサーバーの接続ため、キーペアの用意
- 踏み台用サーバーからリモートデスクトップと接続
- ファイアウォールの設定
Virtual Box
- 仮想マシン (Virtual Machine) の作成 (メモリスペーク設定が要る)
- 仮想ディスク (Virtual Disk) の作成
- 仮想マシンの設定
- OS のインストール
参考
- 投稿日:2020-06-29T20:43:12+09:00
Buildspec.ymlでコマンド結果を変数として扱う
curlコマンドの結果をymlの変数に格納して使う
envには文字列しか入らない
buildspecのenv>variablesには文字列しか入らないです。
例えば、
https://hoge/fuga/versionのように何かしらのversionを取得するapiがあったときに
env: variables: VERSION: `curl https://hoge/fuga/version | jq '.[].version'`として
VERSIONに入れようとしてもコマンドがそのまま変数に入ってしまう。
phasesで指定以下のように
phasesの中で指定するとその後の処理で使えます。phases: pre_build: commands: ......... build: commands: - VERSION=`curl https://hoge/fuga/version | jq '.[].version'` - export VERSION - echo $VERSION
- 投稿日:2020-06-29T20:07:29+09:00
AWSで複数のRESTで送信したものをWebSocketで一括して受け取るサーバレスシステム
はじめに
オンラインイベントで応援ボタンなど押した時に、現地で一方向の情報として受信し、それをトリガーにエフェクトなど表示したいことがあります。
方法としてはSocket通信や、MQTTなどを利用したり、ngrokなどのローカル環境をネット上で受けれるようにするサービスを使うなどあります。
ただ、クライアントが数百人など多数の環境になるとソケットを大量に貼る必要がある、サービスの上限制限や毎回URLが変わるなど運用が面倒なことなどが考えられます。
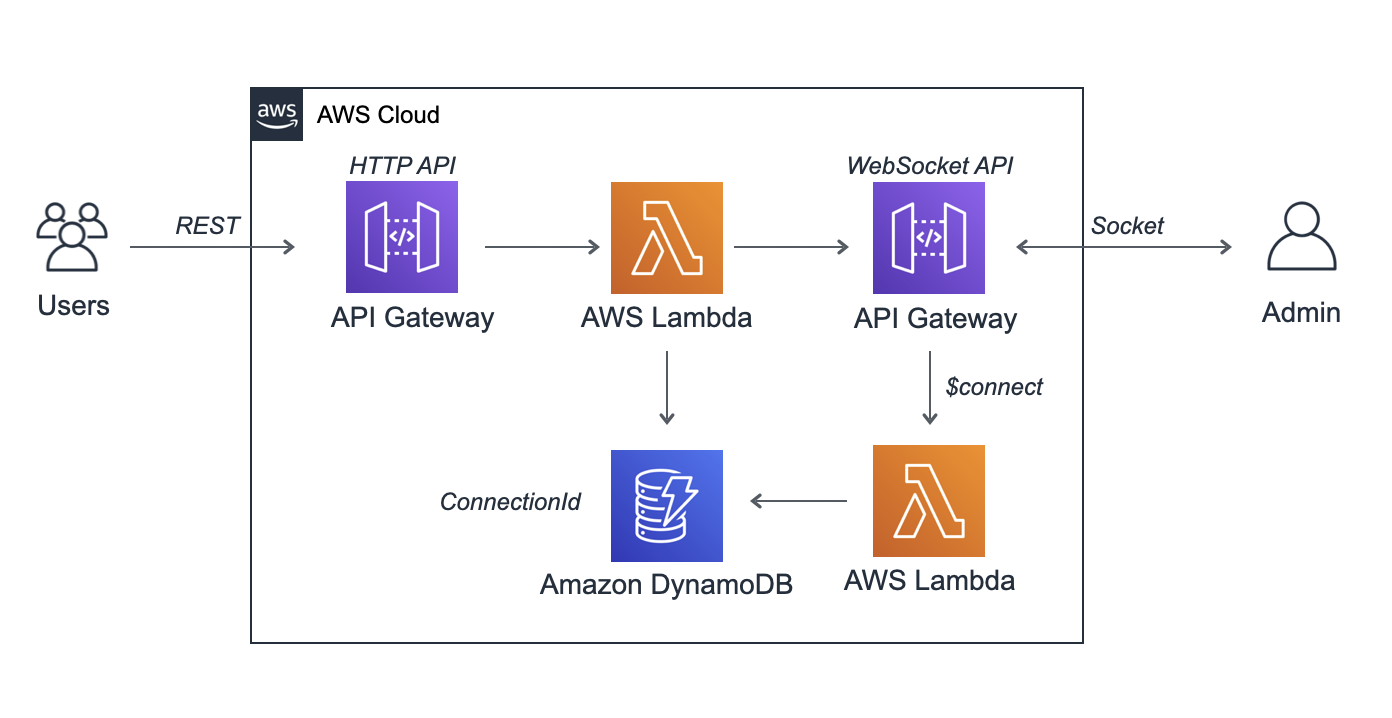
今回はそれらを回避しつつ、サーバレス環境でコストも少なくしたシステムを作ってみます。全体構成
送信する方はRESTで送ることで接続数に依存せずコストを下げることが可能です。
特にいつ押されるかわからないため、無駄にSocketなどを張って時間課金のコストを増やすということをしないようにします。
受信側は送られたらPUSHで情報を受けたいのでここのみSocketでAWSと接続し通信を行います。
通常はSocketが切られた場合にConnectionIdの削除など他にも付け加えるべきものがありますが、Qiita用の簡易的なものにしていますのでご了承ください。DynamoDBの設定
今回は2つのLambdaでconnection_idという値を共有します。
設定は以下のようなものを作成します。
作成後に
type:"admin"
というデータを1ついれておいてください。
ここに入る値を利用します。Lambdaの作成
Lambdaを二つ作成します。
Socket用Lambda
受信画面がSocket張ったときのAPI Gatewayのconnection_idを保存するためのものです。
const AWS = require('aws-sdk'); const documentClient = new AWS.DynamoDB.DocumentClient({ apiVersion: '2012-08-10'}); exports.handler = async event => { try { await documentClient.update({ TableName: 'table', Key: { 'type': 'admin' }, UpdateExpression: "set connectionId = :c", ExpressionAttributeValues: { ":c": event.requestContext.connectionId }, ReturnValues:"UPDATED_NEW" }).promise(); } catch (err) { console.log(err); return { statusCode: 500, body: 'Failed : ' + JSON.stringify(err) }; } return { statusCode: 200, body: 'Connected.' }; };中継用Lambda
RESTを受けAPI GatewayのSocketに中継するためのものです。
あとでAPI GatewayのSocketサーバを構築したあとにendpointのURLはそれに合わせて書き換えする必要があります。const AWS = require('aws-sdk'); const documentClient = new AWS.DynamoDB.DocumentClient({ apiVersion: '2012-08-10' }); exports.handler = async(event) => { const apigwManagementApi = new AWS.ApiGatewayManagementApi({ apiVersion: '2018-11-29', endpoint: 'XXXXXXXX.execute-api.ap-northeast-1.amazonaws.com/default' }); const params = { TableName: table, Key:{ "type": "admin" } }; let dbRes = await documentClient.get(params).promise(); try { await apigwManagementApi.postToConnection({ ConnectionId: dbRes.Item.connectionId, Data: JSON.stringify({ "send":"ok" }) }).promise(); } catch (e) { console.log(e); } const response = { statusCode: 200, body: '{"error":false}', }; return response; };API Gatewayの設定
こちらもRESTとWebSocketで受けるものを二つ作る必要があります。
Socket用API Gateway
作成を押しWebSockegt APIのものを構築します。
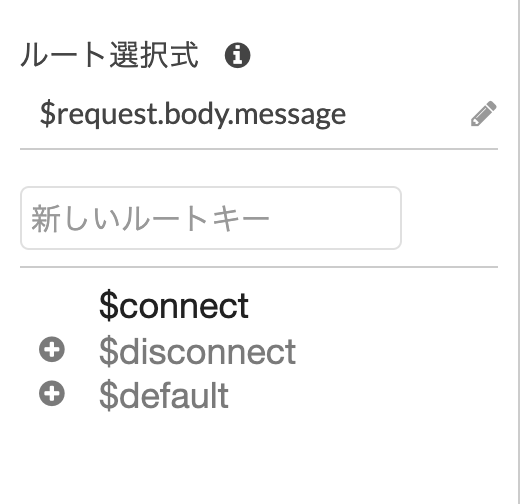
ルート選択式は今回は利用しませんので、デフォルトであるように[$request.body.message]とでもしておいてください。
作成が終わるとWebSocketが接続した場合にどうするかの設定があります。今回は接続時のみ使いたいので$connectの(+)を押して、先ほど作成したSocket用Lambdaを接続してください。
以下のような形になっていたら、アクション>APIのデプロイで公開してください。
ここで作成されたアドレスを中継用Lambdaのendpointに記載してください。
中継用API Gateway
こちらはHTTP APIで構築します。
このあたりはよくあるものなので他のQiitaの記事や、Lambda側の入力に新規で紐付けするなどしてみてください。
テストでは必要ありませんが、CROSSの設定を忘れないように設定してください。HTMLの作成
よくあるWebSocketの接続のページを作成します。
WebSocket接続は他のQiitaなどを参照してください。// socket function connect() { const socketServerUrl = "wss://XXXXXXX.execute-api.ap-northeast-1.amazonaws.com/YYYYYY"; let socket = new WebSocket(socketServerUrl); socket.onopen = function (e) { console.log(e); }; socket.onmessage = function (e) { const d = JSON.parse(e.data); console.log(d); }; socket.onclose = function (e) { console.log(e); }; socket.onerror = function (e) { console.log(e); }; }まとめ
作成したHTMLをブラウザで開き、中継用API GatewayのURLを叩くと{"send":"ok"}という値が飛んできてるのがわかると思います。
この中継用API GatewayのURLをよくあるAjaxの通信で叩くことでブラウザ側に随時イベントが飛んできますので、いろいろなものに利用することができます。
これだけの作業と行数のプログラムでsocket通信がネット上に公開してる格安システムができるので、ぜひいろいろと使ってみてください。注意
API GatewayのWebSocketは接続して放置していると10分程度で切断されます。定期的に通信させるか、切断後にリトライ方法など検討しておく必要があります。
それと、受信側のHTMLにはボタンが押されてから1秒程度の遅延が発生します。ここをもっと短くする方法などはコストの兼ね合いなどがありますので、いろいろな他のサービスなども検討してみてください。余談
途中から雑になってるのは、そう、あなたの思った通り!細かい記事を書いて疲れたからです。

- 投稿日:2020-06-29T20:07:29+09:00
AWSで複数のRESTで送信したものをWebSocketでリアルタイムに受け取るサーバレスシステム
はじめに
オンラインイベントで応援ボタンなど押した時に、現地で一方向の情報として受信し、それをトリガーにエフェクトなど表示したいことがあります。
方法としてはSocket通信や、MQTTなどを利用したり、ngrokなどのローカル環境をネット上で受けれるようにするサービスを使うなどあります。
ただ、クライアントが数百人など多数の環境になるとソケットを大量に張る必要がある、サービスの上限制限や毎回URLが変わるなど運用が面倒なことなどが考えられます。
今回はそれらを回避しつつ、サーバレス環境でコストも少なくしたシステムを作ってみます。全体構成
送信する方はRESTで送ることで接続数に依存せずコストを下げることが可能です。
特にいつ押されるかわからないため、無駄にSocketなどを張って時間課金のコストを増やすということをしないようにします。
受信側は送られたらPUSHで情報を受けたいのでここのみSocketでAWSと接続し通信を行います。
通常はSocketが切られた場合にConnectionIdの削除など他にも付け加えるべきものがありますが、Qiita用の簡易的なものにしていますのでご了承ください。DynamoDBの設定
今回は2つのLambdaでconnection_idという値を共有します。
設定は以下のようなものを作成します。
作成後に
type:"admin"
というデータを1ついれておいてください。
ここに入る値を利用します。Lambdaの作成
Lambdaを二つ作成します。
Socket用Lambda
受信画面がSocket張ったときのAPI Gatewayのconnection_idを保存するためのものです。
const AWS = require('aws-sdk'); const documentClient = new AWS.DynamoDB.DocumentClient({ apiVersion: '2012-08-10'}); exports.handler = async event => { try { await documentClient.update({ TableName: 'table', Key: { 'type': 'admin' }, UpdateExpression: "set connectionId = :c", ExpressionAttributeValues: { ":c": event.requestContext.connectionId }, ReturnValues:"UPDATED_NEW" }).promise(); } catch (err) { console.log(err); return { statusCode: 500, body: 'Failed : ' + JSON.stringify(err) }; } return { statusCode: 200, body: 'Connected.' }; };中継用Lambda
RESTを受けAPI GatewayのSocketに中継するためのものです。
あとでAPI GatewayのSocketサーバを構築したあとにendpointのURLはそれに合わせて書き換えする必要があります。const AWS = require('aws-sdk'); const documentClient = new AWS.DynamoDB.DocumentClient({ apiVersion: '2012-08-10' }); exports.handler = async(event) => { const apigwManagementApi = new AWS.ApiGatewayManagementApi({ apiVersion: '2018-11-29', endpoint: 'XXXXXXXX.execute-api.ap-northeast-1.amazonaws.com/default' }); try { const dbRes = await documentClient.get({ TableName: 'table', Key:{ 'type': 'admin' } }).promise(); await apigwManagementApi.postToConnection({ ConnectionId: dbRes.Item.connectionId, Data: JSON.stringify({ "send":"ok" }) }).promise(); } catch (e) { console.log(e); } const response = { statusCode: 200, body: '{"error":false}', }; return response; };API Gatewayの設定
こちらもRESTとWebSocketで受けるものを二つ作る必要があります。
Socket用API Gateway
作成を押しWebSockegt APIのものを構築します。
ルート選択式は今回は利用しませんので、デフォルトであるように[$request.body.message]とでもしておいてください。
作成が終わるとWebSocketが接続した場合にどうするかの設定があります。今回は接続時のみ使いたいので$connectの(+)を押して、先ほど作成したSocket用Lambdaを接続してください。
以下のような形になっていたら、アクション>APIのデプロイで公開してください。
ここで作成されたアドレスを中継用Lambdaのendpointに記載してください。
中継用API Gateway
こちらはHTTP APIで構築します。
このあたりはよくあるものなので他のQiitaの記事や、Lambda側の入力に新規で紐付けするなどしてみてください。
テストでは必要ありませんが、CROSSの設定を忘れないように設定してください。HTMLの作成
よくあるWebSocketの接続のページを作成します。
WebSocket接続は他のQiitaなどを参照してください。// socket function connect() { const socketServerUrl = "wss://XXXXXXX.execute-api.ap-northeast-1.amazonaws.com/YYYYYY"; let socket = new WebSocket(socketServerUrl); socket.onopen = function (e) { console.log(e); }; socket.onmessage = function (e) { const d = JSON.parse(e.data); console.log(d); }; socket.onclose = function (e) { console.log(e); }; socket.onerror = function (e) { console.log(e); }; }まとめ
作成したHTMLをブラウザで開き、中継用API GatewayのURLを叩くと{"send":"ok"}という値が飛んできてるのがわかると思います。
この中継用API GatewayのURLをよくあるAjaxの通信で叩くことでブラウザ側に随時イベントが飛んできますので、いろいろなものに利用することができます。
これだけの作業と行数のプログラムでsocket通信がネット上に公開してる格安システムができるので、ぜひいろいろと使ってみてください。注意
API GatewayのWebSocketは接続して放置していると10分程度で切断されます。定期的に通信させるか、切断後にリトライ方法など検討しておく必要があります。
それと、受信側のHTMLにはボタンが押されてから1秒程度の遅延が発生します。ここをもっと短くする方法などはコストの兼ね合いなどがありますので、いろいろな他のサービスなども検討してみてください。余談
途中から雑になってるのは、そう、あなたの思った通り!細かい記事を書いて疲れたからです。
- 投稿日:2020-06-29T20:07:29+09:00
AWSでRESTで送信したものをWebSocketでリアルタイムに受け取るサーバレスシステム
はじめに
オンラインイベントで応援ボタンなど押した時に、現地で一方向の情報として受信し、それをトリガーにエフェクトなど表示したいことがあります。
方法としてはSocket通信や、MQTTなどを利用したり、ngrokなどのローカル環境をネット上で受けれるようにするサービスを使うなどあります。
ただ、クライアントが数百人など多数の環境になるとソケットを大量に張る必要がある、サービスの上限制限や毎回URLが変わるなど運用が面倒なことなどが考えられます。
今回はそれらを回避しつつ、サーバレス環境でコストも少なくしたシステムを作ってみます。全体構成
送信する方はRESTで送ることで接続数に依存せずコストを下げることが可能です。
特にいつ押されるかわからないため、無駄にSocketなどを張って時間課金のコストを増やすということをしないようにします。
受信側は送られたらPUSHで情報を受けたいのでここのみSocketでAWSと接続し通信を行います。
通常はSocketが切られた場合にConnectionIdの削除など他にも付け加えるべきものがありますが、Qiita用の簡易的なものにしていますのでご了承ください。DynamoDBの設定
今回は2つのLambdaでconnection_idという値を共有します。
設定は以下のようなものを作成します。
作成後に
type:"admin"
というデータを1ついれておいてください。
ここに入る値を利用します。Lambdaの作成
Lambdaを二つ作成します。
Socket用Lambda
受信画面がSocket張ったときのAPI Gatewayのconnection_idを保存するためのものです。
const AWS = require('aws-sdk'); const documentClient = new AWS.DynamoDB.DocumentClient({ apiVersion: '2012-08-10'}); exports.handler = async event => { try { await documentClient.update({ TableName: 'table', Key: { 'type': 'admin' }, UpdateExpression: "set connectionId = :c", ExpressionAttributeValues: { ":c": event.requestContext.connectionId }, ReturnValues:"UPDATED_NEW" }).promise(); } catch (err) { console.log(err); return { statusCode: 500, body: 'Failed : ' + JSON.stringify(err) }; } return { statusCode: 200, body: 'Connected.' }; };中継用Lambda
RESTを受けAPI GatewayのSocketに中継するためのものです。
あとでAPI GatewayのSocketサーバを構築したあとにendpointのURLはそれに合わせて書き換えする必要があります。const AWS = require('aws-sdk'); const documentClient = new AWS.DynamoDB.DocumentClient({ apiVersion: '2012-08-10' }); exports.handler = async(event) => { const apigwManagementApi = new AWS.ApiGatewayManagementApi({ apiVersion: '2018-11-29', endpoint: 'XXXXXXXX.execute-api.ap-northeast-1.amazonaws.com/default' }); try { const dbRes = await documentClient.get({ TableName: 'table', Key:{ 'type': 'admin' } }).promise(); await apigwManagementApi.postToConnection({ ConnectionId: dbRes.Item.connectionId, Data: JSON.stringify({ "send":"ok" }) }).promise(); } catch (e) { console.log(e); } const response = { statusCode: 200, body: '{"error":false}', }; return response; };API Gatewayの設定
こちらもRESTとWebSocketで受けるものを二つ作る必要があります。
Socket用API Gateway
作成を押しWebSockegt APIのものを構築します。
ルート選択式は今回は利用しませんので、デフォルトであるように[$request.body.message]とでもしておいてください。
作成が終わるとWebSocketが接続した場合にどうするかの設定があります。今回は接続時のみ使いたいので$connectの(+)を押して、先ほど作成したSocket用Lambdaを接続してください。
以下のような形になっていたら、アクション>APIのデプロイで公開してください。
ここで作成されたアドレスを中継用Lambdaのendpointに記載してください。
中継用API Gateway
こちらはHTTP APIで構築します。
このあたりはよくあるものなので他のQiitaの記事や、Lambda側の入力に新規で紐付けするなどしてみてください。
テストでは必要ありませんが、CROSSの設定を忘れないように設定してください。HTMLの作成
よくあるWebSocketの接続のページを作成します。
WebSocket接続は他のQiitaなどを参照してください。// socket function connect() { const socketServerUrl = "wss://XXXXXXX.execute-api.ap-northeast-1.amazonaws.com/YYYYYY"; let socket = new WebSocket(socketServerUrl); socket.onopen = function (e) { console.log(e); }; socket.onmessage = function (e) { const d = JSON.parse(e.data); console.log(d); }; socket.onclose = function (e) { console.log(e); }; socket.onerror = function (e) { console.log(e); }; }まとめ
作成したHTMLをブラウザで開き、中継用API GatewayのURLを叩くと{"send":"ok"}という値が飛んできてるのがわかると思います。
この中継用API GatewayのURLをよくあるAjaxの通信で叩くことでブラウザ側に随時イベントが飛んできますので、いろいろなものに利用することができます。
これだけの作業と行数のプログラムでsocket通信がネット上に公開してる格安システムができるので、ぜひいろいろと使ってみてください。注意
API GatewayのWebSocketは接続して放置していると10分程度で切断されます。定期的に通信させるか、切断後にリトライ方法など検討しておく必要があります。
それと、受信側のHTMLにはボタンが押されてから1秒程度の遅延が発生します。ここをもっと短くする方法などはコストの兼ね合いなどがありますので、いろいろな他のサービスなども検討してみてください。余談
途中から雑になってるのは、そう、あなたの思った通り!細かい記事を書いて疲れたからです。
- 投稿日:2020-06-29T18:47:39+09:00
さくらインターネットからAWS Lightsail に引っ越ししたらサーバーレスポンスがすんごい向上した件
- 投稿日:2020-06-29T18:05:00+09:00
【自作】自動デプロイ、AWSの各種サービス起動について
1)背景
自動デプロイはcapstranoなどありますが、簡単に自動化するため、以下のshellを作成しました。このshellを使えば、手数はかなり減ります。
2)環境
項目 内容 OS.Amazon Linux AMI release 2018.03 Ruby v2.5.1 Ruby On Rails v5.2.4.3 MySQL v5.6 Unicorn v5.4.1 3)内容
(1) AWSの対象インスタンスの再起動
インスタンスを再起動することで、現在稼働しているアプリが停止します。
(2) shellを実行する(ホームディレクトリの配下に配置する)
以下のshellを実行することで、必要なサービスの起動と、アプリの起動を行います。
サービスを起動する前には、必要なgitプル、scssやJavascriptのコンパイルを行います。auto-service.sh#/bin/sh #任意ディレクトリへ移動 cd /var/www/☆アプリ名; sleep 5; echo `pwd`; #git-pullする。 echo "get!! new-master.. wait 5sec"; sleep 5; git pull origin master; #Assetsのプレコンパイル echo "precompile!!";sleep 5; rails assets:precompile RAILS_ENV=production #NGINXの開始 sudo service nginx start; sudo service nginx status; sleep 5; #MySQLの開始 sudo service mysqld start; sudo service mysqld status; sleep 5; #アプリ開始 echo "Rails Start!!!!!!!!!!!!!!" RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -D以上、よければご活用ください。
- 投稿日:2020-06-29T17:38:21+09:00
AWS Amplify + Nuxt.js でユーザーログイン可能なウェブチャットアプリを作成
AWSのAmplifyは、GraphQLを設計するだけで、バックエンド側コードとかリソースとかその設定を自動生成してくれるので、フロントエンドのコードをjsとかで書くだけでウェブアプリケーションを作れてしまいます。
ドキュメントを一通り読んでみて勉強を兼ねてユーザー管理できるウェブチャットアプリを作ってみたのでメモ前提
- AWSのアカウントは取得済み
- Amplify CLIはインストール+設定済み
- Nuxt.jsをインストールする準備は完了済み
環境
- フロント: NuxtJS + Vuetify
- バックエンド: AWS Amplify
- API設計: GraphQL
環境のための参考資料:
Amplify CLI インストール
Nuxt.js インストール作るもの
かんたんなウェブチャットツールです。
ユーザー登録+ログインして、チャットにコメントを投稿できます。
練習なのでこんな感じのシンプルなものです。ポイント
- ユーザー登録、ログインができる。
- ユーザー毎にコメントできる
- コメントはリアルタイムで画面に反映
- ログインしないとコメント投稿・閲覧ができない
- 投稿したコメントはDBに保存されて再度ログインしたときには続きが書き込める
というあたりを目指します。
Nuxt.jsインストール
とりあえずフロント側のNuxtをインストールして基本的なページを作ります。プロジェクト名は
nuxt-amplifyとしました。
オプションは下のような感じで選択しました。% npx create-nuxt-app nuxt-amplify create-nuxt-app v3.0.0 ✨ Generating Nuxt.js project in nuxt-amplify ? Project name nuxt-amplify ? Choose programming language JavaScript ? Choose the package manager Npm ? Choose UI framework Vuetify.js ? Choose Nuxt.js modules Axios, Progressive Web App (PWA) Support, Content ? Choose linting tools ESLint, Prettier, Lint staged files, StyleLint ? Choose test framework Jest ? Choose rendering mode Single Page App ? Choose development tools jsconfig.json (Recommended for VS Code)基本的なページの作成
フロント側のページで見た目を適当に整えます。
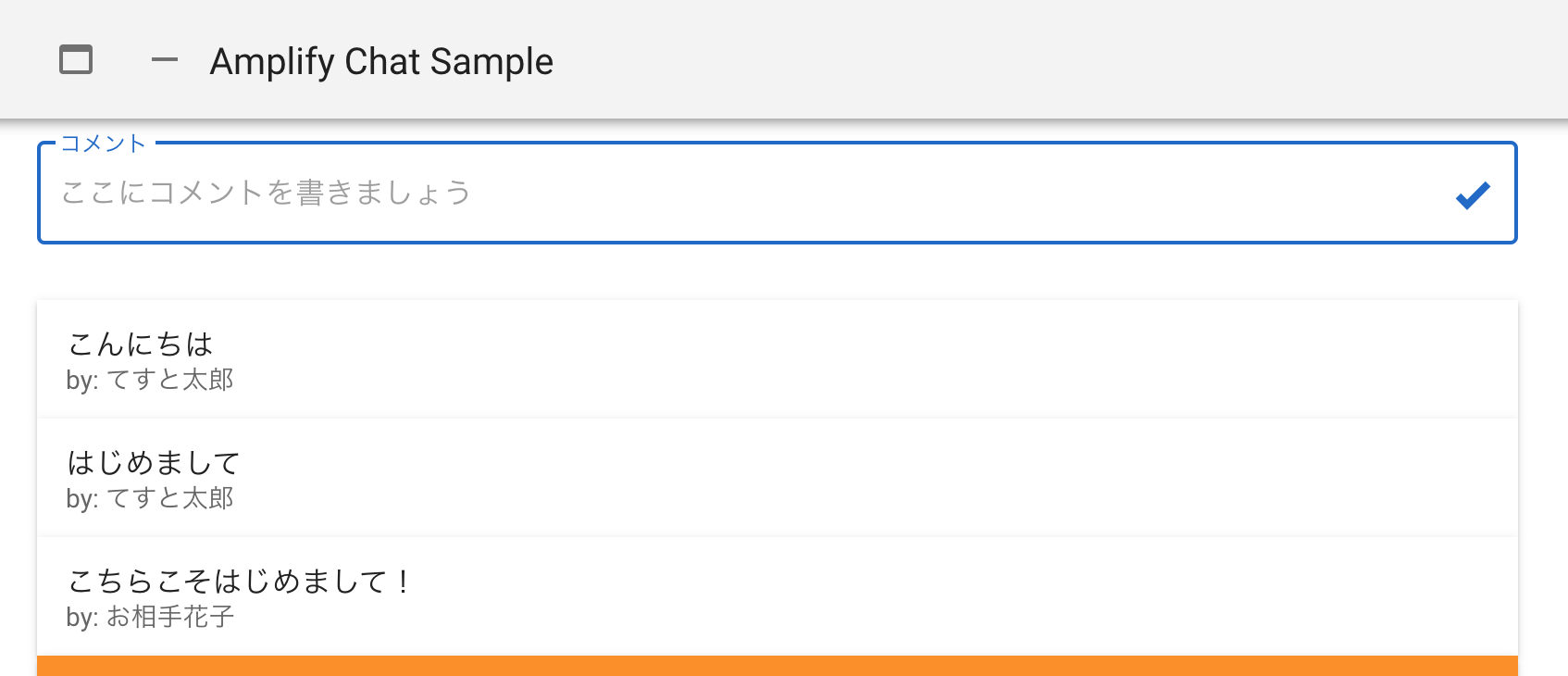
必要なのは、コメントを入力するテキストボックスと一覧表示する部分だけです。pages/chat.vue<template> <div style="max-width: 800px;"> <v-text-field label="コメント" placeholder="ここにコメントを書きましょう" outlined class="mx-auto" append-icon="mdi-check-bold" style="max-width: 100%; box-sizing: border-box;" ></v-text-field> <v-card v-for="(item, index) in items" :key="index" tile> <v-list-item two-line> <v-list-item-content> <v-list-item-title>{{ item.comment }}</v-list-item-title> <v-list-item-subtitle>by: {{ item.owner }}</v-list-item-subtitle> </v-list-item-content> </v-list-item> </v-card> </div> </template> <script> export default { data() { return { form: { comment: '', }, items: [], } }, created() { this.getChatList() }, methods: { getChatList() { // コメント取得 this.items = [ { comment: 'ここにコメントが入ります', owner: 'ここに投稿者名が入ります', }, { comment: 'ここにコメントが入ります', owner: 'ここに投稿者名が入ります', }, { comment: 'ここにコメントが入ります', owner: 'ここに投稿者名が入ります', }, ] }, }, } </script>
こんな感じの見た目に。Amplifyのインストール
フロント側さえつくれば、あとはAmplifyをインストールして必要な設定をしていくだけで、アプリケーションとして動くようになります。
まずは、現行のプロジェクトにAmplifyをインストールしていきます。
先程作ったNuxt.jsプロジェクトディレクトリのルートでamplify initコマンドを実行します。
選択オプション等は以下のようにしました。% amplify init ? Enter a name for the project nuxtamplify #任意のプロジェクト名 ? Enter a name for the environment dev ? Choose your default editor: Visual Studio Code ? Choose the type of app that you re building javascript ? What javascript framework are you using vue ? Source Directory Path: . # ルートを指定 ? Distribution Directory Path: dist # ビルド済ファイルの保存ディレクトリを指定 ? Build Command: npm run build # ビルドコマンドを指定(※) ? Start Command: npm run start # 起動コマンドを指定(※) ? Do you want to use an AWS profile? Yes ? Please choose the profile you want to use default最後方のコマンド関連の質問は環境などにより変わると思います。
package.jsonなどを参考に。vue.js用のライブラリを読み込み
Vue.jsでamplifyと通信したり色々できるライブラリが準備されているので追加します。
npm install aws-amplify @aws-amplify/ui-vueNuxt.jsのプラグインとして設定
Nuxt.jsのプラグインとして使えるように設定します。
まずはプラグインファイルを作成します。plugins/amplify.jsimport Vue from 'vue' import Amplify from 'aws-amplify' import '@aws-amplify/ui-vue' import awsExports from '../aws-exports' Amplify.configure(awsExports) Vue.use(Amplify)
nuxt.config.jsのプラグイン設定の配列に{ src: '~/plugins/amplify.js', ssr: false }を追加します。nuxt.config.js//... // pluginsの配列に追加します。 plugins: [{ src: '~/plugins/amplify.js', ssr: false }], //...バックエンドAPIを作成
いよいよAWS側にバックエンドエンド側を作成してエンドポイントを生成します。
ここからはコマンドと少しのコードであっという間に本格的なウェブアプリケーションが作成されていきます。
まずは、AmplifyにAPI機能を追加
amplify add apiコマンドを実行するだけです。
オプション設定は以下のように答えました。% amplify add api ? Please select from one of the below mentioned services: GraphQL ? Provide API name: chat # 任意のAPI名 ? Choose the default authorization type for the API API key ? Enter a description for the API key: sample ? After how many days from now the API key should expire (1-365): 7 ? Do you want to configure advanced settings for the GraphQL API No, I am done. ? Do you have an annotated GraphQL schema? No ? Do you want a guided schema creation? Yes ? What best describes your project: Single object with fields (e.g., “Todo” with ID, name, description) ? Do you want to edit the schema now? Yesこれで必要なコードがプロジェクトに追加されます。
GraphQLでバックエンドの設計
バックエンドのAPIをGraphQLで設計します。
基本ファイルが出来上がっているので
amplify/backend/api/下にあるファイルを開いて以下のように書き換えます。amplify/backend/api/chat/schema.graphqltype Chat @model { id: ID! comment: String!, owner: String }
Chatというモデル(テーブル)に、id,comment,ownerというフィールドを作成して保存したり取得できるようにします。
バックエンド設計で必要なファイルはこれだけ。
GraphQLというAPI設計用のクエリ言語なんですが、これを元にバックエンド側のDB保存やAPIへのリクエスト処理などを全部自動生成してくれます。
詳しくは
- GraphQL (基本を学ぶ)
- API(GraphQL) Directives (Amplifyで使うディレクティブを学ぶ)
あたりを参考にどうぞ。
(自分もまだ学びはじめたばかりですが、いままでウェブのバックエンドのコード書いていた者にとってすごくワクワクできる内容です)AWS側に送信して必要なリソースを生成
上記のを書いたらあとはAWS側で必要なリソースが自動的に生成されて連携して動くようにしてくれます。
amplify pushコマンドするだけ。% amplify push ? Are you sure you want to continue? Yes ? Do you want to generate code for your newly created GraphQL API Yes ? Choose the code generation language target javascript ? Enter the file name pattern of graphql queries, mutations and subscriptions src/graphql/**/*.js # エンドポイント側と通信する各種コードが生成されるフォルダを指定、とりあえずデフォルトで。 ? Do you want to generate/update all possible GraphQL operations - queries, mutations and subscriptions Yes ? Enter maximum statement depth [increase from default if your schema is deeply nested] 2ちょっと時間かかりますが、待っていると(たまに質問してくるけど基本デフォルトで)、自動的にAWS側の設定をしてくれます。
以上で、APIエンドポイントの生成が完了です。
ほとんどコード書かないまま実装されていきます。(※)
Enter the file name pattern of graphql queries...
のところ、GraphQL関連のファイルの生成場所なんですが、Nuxt.jsの場合どこに置くのがよいのかな。もっとスマートな指定がありそう。。フロント側をAPIエンドポイントと通信できるように修正
エンドポイントが動くようになったので、フロントから通信するようにコードを修正します。
pages/chat.vue>template<template> ・・・ // v-modelとイベントハンドラを追加 <v-text-field ... v-model="form.comment" @keydown="onEnter" @click:append="createChat" ></v-text-field> ... <template>pages/chat.vue>script<script> import { API } from 'aws-amplify' // Amplifyライブラリを読み込み import { createChat } from '~/src/graphql/mutations' // GraphQL Mutation(データをエンドポイントに送信する構文?) import { listChats } from '~/src/graphql/queries' // GraphQL Query(データを読み込む構文?) export default { // ... methods: { async createChat() { // コメントを送信する const comment = this.form.comment // コメント入力値を取得 if (!comment) return // 空のときは処理しない const chat = { comment } // 送信用のJSONを作成 // 送信処理 await API.graphql({ query: createChat, // GraphQL Mutation variables: { input: chat }, // 送信データ }) this.form.comment = '' // 送信後にテキストフィールドを空に。 }, onEnter(event) { // ここはおまけ。(Enterを押したときもコメントを送信したかったので記述) if (event.keyCode !== 13) return this.createChat() }, async getChatList() { // コメント一覧を取得 const chatList = await API.graphql({ query: listChats, // GraphQL Query }) this.items = chatList.data.listChats.items // 読み込みしたデータを一覧に表示 }, }, } </script>
mutationsとqueriesは、amplify pushした時に設定したディレクトリに生成されています。
それぞれの内容を見るとより理解が深まりますし、応用でいろいろできると思います。リアルタイムに反映されるようにコードを追記
また、送信と読み込みだけでなく、送信して保存された内容がリアルタイムに画面に反映されるようにコードを追記します。
GraphQLのSubscriptionという機能(仕様?)を使います。サーバからのpush通信などを受け取ったりできます。pages/chat.vue>script<script> // ... import { onCreateChat } from '~/src/graphql/subscriptions' // GraphQL Subscription export default { // ... created() { this.getChatList() this.subscribe() // 追加 }, methods: { //... // メソッド追加 subscribe() { API.graphql({ query: onCreateChat }).subscribe({ next: (eventData) => { // コメントが送信されて追加されたとき、送信内容を一覧に追加 const chat = eventData.value.data.onCreateChat // データを読み込み if (this.items.some((item) => item.comment === chat.comment)) return // すでに表示されているデータは無視 this.items = [...this.items, chat] // 新しいデータを追加 }, }) }, }, } </script>以上で、APIへの対応を完了。
チャットアプリケーションとして、動くようになりました。
コメント欄にテキストを入力して、Enterかチェックマークをクリックすると一覧にデータが反映されるようになっていると思います。
(投稿者名は空になっていますが、これから実装します)
また、AWSのコンソールにログインしてみると、DynamoDBにテーブルが作られて、そこにデータが保存されているのがわかると思います。
ほとんど、フロント側のコードだけで、ここまでのウェブアプリを作ることができます。ユーザー管理機能を追加
続いてこのアプリケーションにユーザー管理機能を追加してログインした人だけが投稿できるようにしたり、投稿者の名前を表示したりできるようにしていきます。
まずは、Amplifyにユーザー認証機能を追加します。
amplify add authコマンドを実行するだけです。% amplify add auth Do you want to use the default authentication and security configuration? Default configuration How do you want users to be able to sign in? Username Do you want to configure advanced settings? No, I am done.機能が追加されたら、そのままAWSにpushします。
少し質問されるかもですが、とりあえずデフォルトのままで。% amplify push以上でバックエンド側にユーザー認証機能が実装されました。
フロント側をユーザーログイン機能に合わせて修正
pages/chat.vue//... <amplify-authenticator> <v-text-field v-model="form.comment" label="コメント" placeholder="ここにコメントを書きましょう" outlined class="mx-auto" append-icon="mdi-check-bold" style="max-width: 100%; box-sizing: border-box;" @keydown="onEnter" @click:append="createChat" ></v-text-field> </amplify-authenticator> //...これだけです。入力テキストフィールドを
amplify-authenticatorで囲むだけ。
これで、ログインしているときは、テキストフィールドが表示され、ログインしていないときは、ログイン用のフィールドが表示されます。
こんな感じのログイン画面を自動的に生成してくれます。
ユーザー登録や、パスワードリセットも実装されているので、非常に嬉しい。
また、いろいろカスタマイズもできます。
https://docs.amplify.aws/ui/auth/authenticator/q/framework/vue確認
では、実際にアカウントを作成してログインしてみてください。
ログインができてアプリを使えるようになっていると思います。APIへの認証を追加
見た目的には、ログイン機能が実装されましたが、API自体に認証が追加されたわけではないので、直接エンドポイントにアクセスするなどすればデータの読み書きができてしまいます。
そこで、APIを今回追加した認証機能と連携させてユーザーログインしている人だけがエンドポイントにアクセスできるようにAPI設計を修正します。
とはいえ、schema.graphqlに少し追加するだけです。amplify/backend/api/chat/schema.graphqltype Chat @model @auth(rules: [{ allow: owner, operations: [create, delete, update] }]) { id: ID! comment: String!, owner: String }
@auth(rules: [{ allow: owner, operations: [create, delete, update] }])
を追加しました。
ownerフィールドに保存されたユーザー名で認証(ユーザー名は自動的に保存されます)して、create,delete,updateに対して操作を許可します。
これで、Chatモデルは、データの読み込みはログインしていれば誰でも可能、書き込みは作成者でなければできない。という状態になります。
参考:
https://docs.amplify.aws/cli/graphql-transformer/directives#authこれをAWS側にpushします。
% amplify pushエラーが出た場合
ここでエラーが出た場合(上記の通りやっているとエラーになります)は対応が必要です。
apiをauthに合わせて更新しないといけません。
API認証を、AWSのCognitoで行うように更新します。
amplify update apiコマンドでAPI設定の更新を行います。% amplify update api ? Please select from one of the below mentioned services: GraphQL ? Select from the options below Walkthrough all configurations ? Choose the default authorization type for the API Amazon Cognito User Pool #Cognito User Pool を選択してください。 Use a Cognito user pool configured as a part of this project. ? Do you want to configure advanced settings for the GraphQL API No, I am done.これで暫く待つとAWS側の設定が更新されます。
あとは、もう一度% amplify pushで、GraphQLの設定がpushされます。
エンドポイントへの認証設定も完了です。また、この設定により、DBにowner名が保存されるようになりました。
コメントを投稿したときにチャットツールの投稿者名も表示されるようになっていると思います。ログインしたときに、一覧表示される(以降リアルタイムで更新される)ように修正
エンドポイントへの認証設定をしたので、すこし不都合がでてきます。
- ログアウト状態で画面を開く(この状態では一覧読み出しができない)
- ログインする。(一覧の読み出しはできるようになったが、すでにページは生成されているのでページを更新しないと一覧が表示されない)
という状態になってしまっています。
ログインしたときに、APIから一覧を読み出す処理と、それ以降はリアルタイムで更新されていくように修正します。pages/chat.vue<script> //... import { onAuthUIStateChange } from '@aws-amplify/ui-components' //... created() { this.getChatList() this.subscribe() // 追加 onAuthUIStateChange((authState, authData) => { // ログインステータスが変化したとき if (authState === 'signedin') { // ログインした場合 this.getChatList() // 一覧呼び出し this.subscribe() // GraphQL Subscription } else { this.items = [] // ログアウトしたときなどは一覧を削除 } }) } // ... </script>ログイン状態を監視するようにイベントを設定しました。
これで一通り作成が完了しました。
chat.vueはこのようになりました。
また、ついでにログアウトボタンも実装しています。(amplify-sign-out)pages/chat.vue<template> <div style="max-width: 800px;"> <amplify-authenticator> <v-text-field v-model="form.comment" label="コメント" placeholder="ここにコメントを書きましょう" outlined class="mx-auto" append-icon="mdi-check-bold" style="max-width: 100%; box-sizing: border-box;" @keydown="onEnter" @click:append="createChat" ></v-text-field> </amplify-authenticator> <v-card v-for="(item, index) in items" :key="index" tile> <v-list-item two-line> <v-list-item-content> <v-list-item-title>{{ item.comment }}</v-list-item-title> <v-list-item-subtitle>by: {{ item.owner }}</v-list-item-subtitle> </v-list-item-content> </v-list-item> </v-card> <v-card> <amplify-sign-out v-if="logoutBtn"></amplify-sign-out> </v-card> </div> </template> <script> import { API } from 'aws-amplify' import { onAuthUIStateChange } from '@aws-amplify/ui-components' import { createChat } from '~/src/graphql/mutations' import { listChats } from '~/src/graphql/queries' import { onCreateChat } from '~/src/graphql/subscriptions' export default { data() { return { form: { comment: '', }, items: [], logoutBtn: false, } }, created() { this.getChatList() this.subscribe() onAuthUIStateChange((authState, authData) => { if (authState === 'signedin') { this.getChatList() this.subscribe() this.logoutBtn = true } else { this.items = [] this.logoutBtn = false } }) }, methods: { async createChat() { const comment = this.form.comment if (!comment) return const chat = { comment } await API.graphql({ query: createChat, variables: { input: chat }, }) this.form.comment = '' }, onEnter(event) { if (event.keyCode !== 13) return // console.log('save') this.createChat() }, async getChatList() { // コメント取得メソッド const chatList = await API.graphql({ query: listChats, }) this.items = chatList.data.listChats.items }, subscribe() { API.graphql({ query: onCreateChat }).subscribe({ next: (eventData) => { const chat = eventData.value.data.onCreateChat if (this.items.some((item) => item.comment === chat.comment)) return // remove duplications this.items = [...this.items, chat] }, }) }, }, } </script>ログインしてコメントを書き込めるようになりました。
デプロイ
最後は実際にAmplifyでホスティングします。
% amplify add hosting ? Select the plugin module to execute Hosting with Amplify Console ? Choose a type Manual deployment% amplify publishしばらくまつとpublish完了。
URLが表示されるので、アクセスしてみましょう。
あっというまに、ウェブアプリケーションが作成されました。
あとは、せっかくチャットツールをつくったので、シークレットウィンドウや別のブラウザを並べて一人二役などでチャットをしてみましょう。
わずかな手間でここまで実装できることへの驚きと満足感と、一人でチャットをする若干の寂しさを感じることができます。削除
せっかく作りましたがAWSにアップしたままにするのもアレなんで削除方法も。
% amplify deleteで削除できます。かんたんですね。
また、下記のアクセス制限などをしてから、しばらく色々試してみるのも楽しいです。補足
一応アクセス制限をかけられます。
AWSのコンソールから、AWS Amplifyにアクセスして、[アクセスコントロール]の項目からベーシック認証的なものをかけることができます。Nuxtのエラー?
今回のNuxtでコンソールにエラーがでます。(たぶんVuetify関連)
'v-content' is deprecated, use 'v-main' instead
みたいなやつです。
本筋と関係ないですし、練習なので無視してもよいのですが、気になる場合は
layouts/default.vueの、v-contentをv-mainに修正すると直ります。
https://github.com/vuetifyjs/vuetify/issues/11634参考
今回参考にさせていただいたサイト
https://docs.amplify.aws/start/q/integration/vue
https://docs.amplify.aws/cli/graphql-transformer/directives#using-modular-imports
https://ja.nuxtjs.org/
https://vuetifyjs.com/ja/
https://qiita.com/fkymnbkz/items/fa7cd15de1039e62074e
https://github.com/aws-amplify/amplify-cli/issues/3480
https://github.com/vuetifyjs/vuetify/issues/11634
https://remoter.hatenablog.com/entry/2020/02/28/Nuxt%E3%83%97%E3%83%AD%E3%82%B8%E3%82%A7%E3%82%AF%E3%83%88%E3%81%A7Amplify%E3%82%92%E8%A7%A6%E3%81%A3%E3%81%A6%E3%81%BF%E3%82%8B
https://qiita.com/respectakagikun/items/0b976b12ddb34f027190





- 投稿日:2020-06-29T13:20:32+09:00
Laravel S3で複数枚画像をアップロードする
LaravelでAWS S3へ画像をアップロードする
前提条件
AWS S3でユーザ登録とバケットの作成ができていること。
まだ作成してない方はこちらが参考になりますS3パッケージインストール
パッケージはflysystem-aws-s3-v3を使用します。
以下を実行してインストールしてください。composer require league/flysystem-aws-s3-v3ファイルシステム設定
/config/filesystems.phpを以下のように編集します。
'default' => env('FILESYSTEM_DRIVER', 'local'), // 追記 'cloud' => env('FILESYSTEM_CLOUD', 's3'), // 〜 略 〜 'disks' => [ 'local' => [ // 〜 略 〜 ], 'public' => [ // 〜 略 〜 ], // 以下を追記 's3' => [ 'driver' => 's3', 'key' => env('AWS_ACCESS_KEY_ID'), 'secret' => env('AWS_SECRET_ACCESS_KEY'), 'region' => env('AWS_DEFAULT_REGION'), 'bucket' => env('AWS_BUCKET'), ],環境変数設定
プロジェクト直下にある.envファイルを以下のように編集します。
AWS_ACCESS_KEY_ID='AWSで作成したAccess key ID' AWS_SECRET_ACCESS_KEY='AWSで作成したSecret access key' AWS_DEFAULT_REGION=ap-northeast-1 AWS_BUCKET='作成したバケット名'Laravelの実装
実際にS3に保存していきます。
最低限のコードは次節以降になります。viewの実装
今回は複数枚アップロードできるようにしていきます。
<div class="name-filed width"> <div class="first-name-box"> <div class="text-label"> <p class="name">希望画像<span class="red">✳︎必須(5枚まで可)</span></p> </div> <div> {!! Form::file('item_url[]', ['multiple' => 'multiple']) !!} </div> @if ($errors->has('item_url') || $errors->has('item_url.*') ) <div class="alert alert-danger">{{ $errors->first('item_url') . $errors->first('item_url.*') }}</div> @endif </div> </div>point 1
formに'multiple' => 'multiple'をつけることで複数選択が可能になる。(Ctrl キーなどを押しながら写真を選択する)
point 2
Form::file()メソッドを利用します。
今回は複数枚になるので第一引数は配列で取得できるようにします。'item_url[]'余談
配列にフォームリクエストでバリデーションする場合は下記のように、 .* というプレースホルダーが使用する。
item_url.*controllerの実装
formから送られてきた値をS3に保存していきます。
laravelには簡単にS3を扱えるようにするファイルストレージ機能があります。
簡単なのでぜひ目を通してくださいね!public function store(ItemRequest $request) { $disk = Storage::disk('s3'); $images = $request->file('item_url'); foreach ( $images as $image) { $path = $disk->putFile('itemImages', $image, 'public'); $url[] = $disk->url($path); } return view('item.top'); }流れの解説
$disk変数にlaravelが用意してくれている Storage::disk('s3');を代入。$imageにはformから送られてきた写真をfile()を使用して取得する。
※$imageにはURLではなく、UploadedFile クラスが入ってる。
↓
foreachを使用して画像一枚ずつS3に保存していく。
putfile()メソッドの第一引数はバケット内の保存するフォルダを指定している。第二引数は保存する値。第三引数でpublicにすることで
どのユーザーでもweb上で画像を見ることが可能になる。※指定しないとweb上に画像が表示されない。$pathの中身は"バケットの保存先のフォルダ/画像"のpathになっています。
ここまででS3への保存は完了になります!
最後の$urlにはurl()を使用してS3からのURLを作成しています。
以上でS3への複数枚画像アップロードは完了になります!
- 投稿日:2020-06-29T13:20:32+09:00
Laravel S3で複数の画像をアップロードする
LaravelでAWS S3へ画像をアップロードする
前提条件
AWS S3でユーザ登録とバケットの作成ができていること。
まだ作成してない方はこちらが参考になりますS3パッケージインストール
パッケージはflysystem-aws-s3-v3を使用します。
以下を実行してインストールしてください。composer require league/flysystem-aws-s3-v3ファイルシステム設定
/config/filesystems.phpを以下のように編集します。
'default' => env('FILESYSTEM_DRIVER', 'local'), // 追記 'cloud' => env('FILESYSTEM_CLOUD', 's3'), // 〜 略 〜 'disks' => [ 'local' => [ // 〜 略 〜 ], 'public' => [ // 〜 略 〜 ], // 以下を追記 's3' => [ 'driver' => 's3', 'key' => env('AWS_ACCESS_KEY_ID'), 'secret' => env('AWS_SECRET_ACCESS_KEY'), 'region' => env('AWS_DEFAULT_REGION'), 'bucket' => env('AWS_BUCKET'), ],環境変数設定
プロジェクト直下にある.envファイルを以下のように編集します。
AWS_ACCESS_KEY_ID='AWSで作成したAccess key ID' AWS_SECRET_ACCESS_KEY='AWSで作成したSecret access key' AWS_DEFAULT_REGION=ap-northeast-1 AWS_BUCKET='作成したバケット名'Laravelの実装
実際にS3に保存していきます。
最低限のコードは次節以降になります。viewの実装
今回は複数枚アップロードできるようにしていきます。
<div class="name-filed width"> <div class="first-name-box"> <div class="text-label"> <p class="name">希望画像<span class="red">✳︎必須(5枚まで可)</span></p> </div> <div> {!! Form::file('item_url[]', ['multiple' => 'multiple']) !!} </div> @if ($errors->has('item_url') || $errors->has('item_url.*') ) <div class="alert alert-danger">{{ $errors->first('item_url') . $errors->first('item_url.*') }}</div> @endif </div> </div>point 1
formに'multiple' => 'multiple'をつけることで複数選択が可能になる。(Ctrl キーなどを押しながら写真を選択する)
point 2
Form::file()メソッドを利用します。
今回は複数枚になるので第一引数は配列で取得できるようにします。'item_url[]'余談
配列にフォームリクエストでバリデーションする場合は下記のように、 .* というプレースホルダーが使用する。
item_url.*controllerの実装
formから送られてきた値をS3に保存していきます。
laravelには簡単にS3を扱えるようにするファイルストレージ機能があります。
簡単なのでぜひ目を通してくださいね!public function store(ItemRequest $request) { $disk = Storage::disk('s3'); $images = $request->file('item_url'); foreach ( $images as $image) { $path = $disk->putFile('itemImages', $image, 'public'); $url[] = $disk->url($path); } return view('item.top'); }流れの解説
$disk変数にlaravelが用意してくれている Storage::disk('s3');を代入。$imageにはformから送られてきた写真をfile()を使用して取得する。
※$imageにはURLではなく、UploadedFile クラスが入ってる。
↓
foreachを使用して画像一枚ずつS3に保存していく。
putfile()メソッドの第一引数はバケット内の保存するフォルダを指定している。第二引数は保存する値。第三引数でpublicにすることでどのユーザーでもweb上で画像を見ることが可能になる。※指定しないとweb上に画像が表示されない。
$pathの中身は"バケットの保存先のフォルダ/画像"のpathになっています。
ここまででS3への保存は完了になります!最後の$urlにはurl()を使用してS3からのURLを作成しています。
以上でS3への複数枚画像アップロードは完了になります!
- 投稿日:2020-06-29T13:13:08+09:00
AWS Transit Gateway にざっくり触れる【初心者】
はじめに
今回は AWS Transit Gateway というサービスについて、便利なところをピックアップしてご紹介していきます。
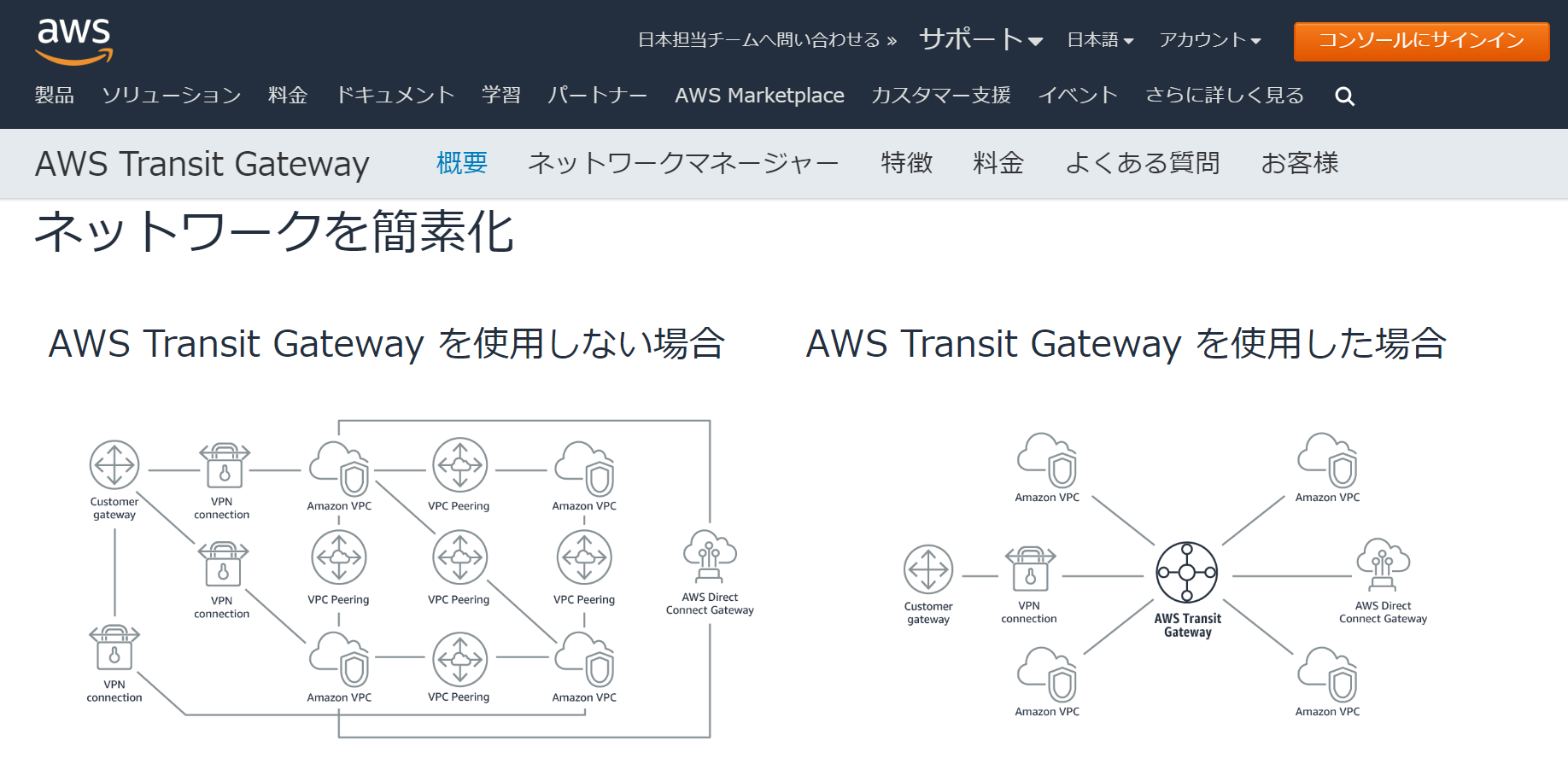
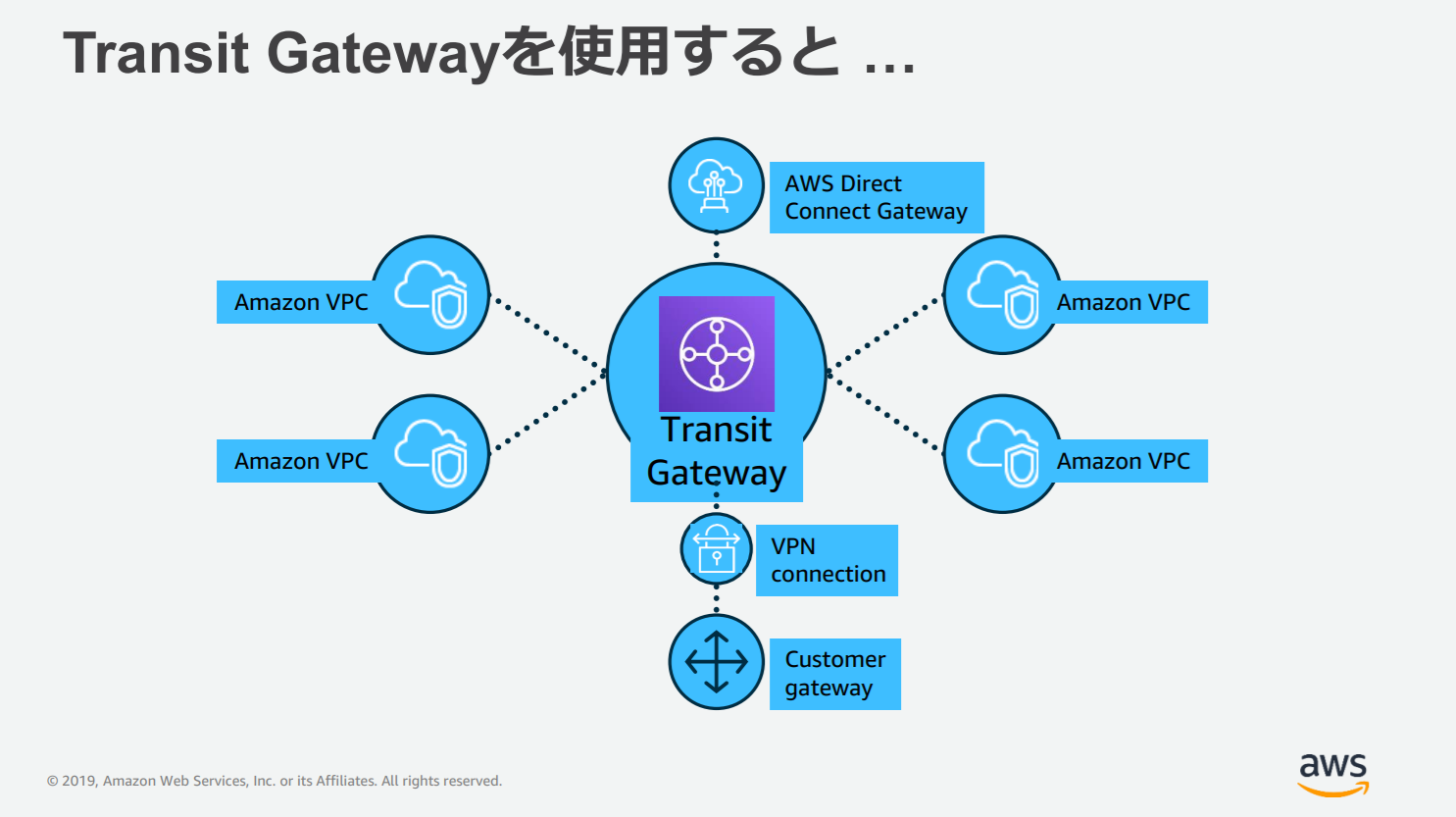
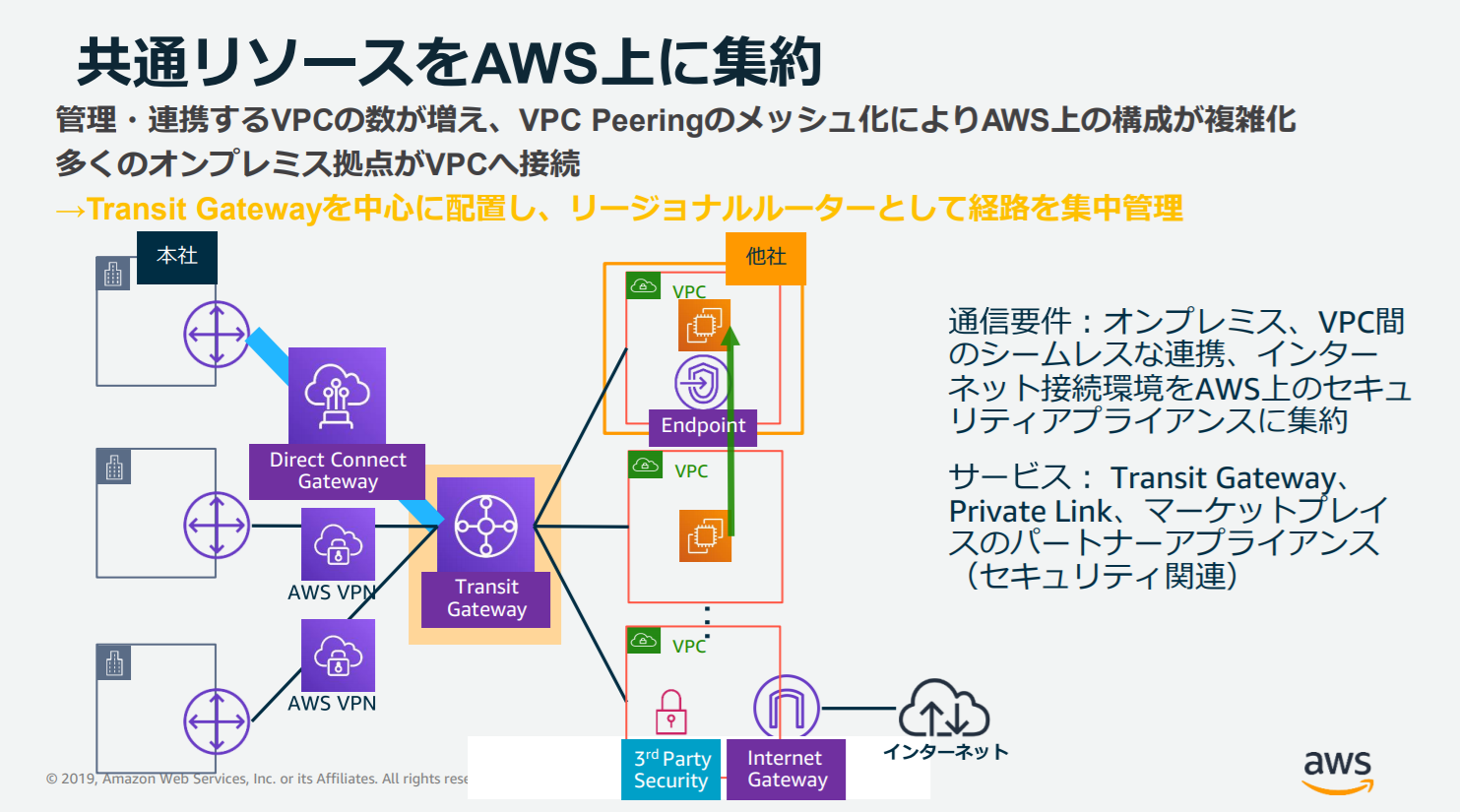
Transit Gateway は中央※ハブを介して、 VPC とオンプレミスネットワークを接続するクラウドルーターだと言われています。
ネットワークが簡素化され、VPCの複雑なピアリング接続をしなくてよくなります。
パッと見て分かる通り、ごちゃごちゃVPC同士を繋げなくて良いので、管理がとてもしやすそうですよね。※ハブとは
HUBとは、LAN上で各端末(コンピューター、ネットワークプリンタなど)同士を接続する機器のことです。
ネットワーク内のデバイスの共通接続ポイントとして機能します。
ルーティング
- Amazon Virtual Private Cloud (VPC) と VPN の間の動的および静的レイヤー 3 ルーティングをサポート
- パケットの送信先 IP アドレスに応じて、ルートでネクストホップが決定
- ルートでは、Amazon VPC または VPN 接続を指定できる
エッジ接続
- AWS Transit Gateway とオンプレミスゲートウェイの間に、VPN を使用して VPN 接続を作成
- 同じプレフィックス(単語なり何なりの頭につける文字列)の複数の VPN 接続を作成できる
- トラフィックを複数のパスに負荷分散することで、帯域幅を広げることができる
Amazon VPC 機能の相互運用性
AWS Transit Gateway にアタッチされている Amazon VPC からクエリが発行されたときに、パブリック DNS ホスト名をプライベート IP アドレスに解決できます。
Amazon VPC のインスタンスは、この AWS Transit Gateway にアタッチされている他の Amazon VPC の
- NAT ゲートウェイ
- Network Load Balancer
- AWS PrivateLink
- Amazon Elastic File System
にアクセスできます。
モニタリング
AWS Transit Gateway では統計とログが提供されます。
- Amazon VPC と VPN 接続間の帯域幅の使用量
- パケットフロー数
- パケットドロップ数
- Amazon VPC フローログを有効にできる
- ルーティングされた IP トラフィックに関する情報を取得できる
AWSとオンプレミスでのイベントおよびグローバルネットワークの品質をモニターするメトリクスが含まれます。
管理
コマンドラインインターフェイス (CLI)、AWS マネジメントコンソール、AWS CloudFormation を使用して AWS Transit Gateway の作成と管理を行うことができます。
- Amazon VPC と VPN の間の送受信バイト数
- パケット数
- ドロップ数などの Amazon CloudWatch メトリクスを提供
さらに、Amazon VPC フローログを使用して、AWS Transit Gateway のアタッチメントを経由する IP トラフィックについての情報を取得できます。
リージョン間のピア接続
- リージョン間のピア接続により、AWS グローバルネットワークを使用して AWS リージョン全体のトラフィックを作成できる
- リージョン間でリソースを共有出来る
- 地理的な冗長性のためにデータをレプリケートできる
- シンプルで費用対効果が高い
マルチキャスト
Transit Gateway マルチキャストを使用して、クラウドに簡単にマルチキャストグループを作成し、管理できるようになりました。
オンプレミスでレガシーのハードウェアをデプロイ、管理するよりずっと簡単です。
- クラウドのマルチキャストソリューションを、スケールアップ
- スケールダウンして、同時に複数のサブスクライバ―に、一連のコンテンツを届けることができる
- 誰がマルチキャストトラフィックを作り、誰がそれを消費しているか、細かいコントロールができる
セキュリティ
- Identity and Access Management (IAM) と統合されている
- AWS Transit Gateway へのアクセスを安全に管理
- IAM を使用すると、AWS のユーザーとグループを作成および管理できる
- アクセス権を使用して AWS Transit Gateway へのアクセスを許可、拒否できる
自動処理プロビジョニング
既存の AWS Transit Gateways に登録すると、ネットワークマネージャーが VPN 接続および関連するオンプレミスリソースを自動的に特定します。
- Transit Gateway ネットワークマネージャーの、新しい VPN 接続を自動的にプロビジョン
- ネットワークマネージャーの、オンプレミスネットワークを自動的に定義
- オンプレミスネットワークを手動でも定義できる
- クラウドとオンプレミスにある、プライベートネットワークを、マネジメントコンソールで一括管理できる
イベント
- ネットワーク変更、ルート変更、接続ステータス更新の通知を受けるメトリクス
- バイトイン/アウト、パケットイン/アウト、ドロップパケットなどの、パフォーマンスおよびトラフィックメトリクスを通して、グローバルネットワークをモニターする
グローバルネットワーク
AWS 内のユーザーの、プライベートグローバルネットワークを表す AWS Transit Gateway network manager のオブジェクトです。
- AWS Transit Gateway のハブ
- そのアタッチメント
- およびオンプレミスのデバイス、サイト、リンク
が含まれます。
グローバルネットワークの監視に役立つ
AWS Transit Gateway network manager のダッシュボードには
- 入出力バイト数
- 入出力パケット数
- ドロップされたパケット数
- リアルタイムのイベントとメトリクス
これらが表示されます。
接続ステータスは、グローバルネットワークの地理的ビューに埋め込まれています。
AWS Transit Gateway network manager は、AWS CloudWatch を通じた可視化により、一つのダッシュボードから多くのロケーションの、ネットワークアクティビティを確認できます。
まとめ
ちょっと情報多めでしたが、 Transit Gateway があるだけでかなり全体管理が楽になるということは伝わったでしょうか。
どうしても規模が大きくなるにつれて、VPC や接続環境が増えていくので、ぜひ重宝したいサービスですよね!
アクティビティを比較して、オンプレミスのロケーションと AWS クラウド間の不整合や、複数のロケーションに異なる影響を与える問題を特定できるので
問題対処も早くなりそうですよね!公式サイトリンク
- 投稿日:2020-06-29T13:05:00+09:00
AWS DocumentDBのBATCH INSERT処理ベンチマーク
はじめに
AWSのDocumentDBに関して、膨大なデータ数を格納する上で要する時間について確認しました。
かなり雑な確認方法ではありますが、データサイズ対処理性能に対して、おおよその指標として、メモ代わりに記載します。かなりのDB初学者の記載なので、必要な情報の欠損や、考慮漏れ、アドバイス等あればコメントいただければと思います。
確認方法
環境
AWSに以下のInstanceを立てて、測定を行っています。
# DB db.r5.4xlarge L3 Mem: 64G, vCPU: 16 # CLIENT r5.16xlarge L3 Mem: 512G, vCPU: 64手順
予め以下のコードによって、$5 \times 10^4$個の疑似ドキュメントを作成し、並列処理でDocumentDBに投入しています。
測定する時間としては、生成後のINSERT処理開始から、終了までを測定しており、疑似Document生成の時間は含みません。DocumentDBのAPIには、
pythonのライブラリのpymongo,insert_many()メソッドを利用しています。collection – Collection level operations
https://api.mongodb.com/python/current/api/pymongo/collection.htmldef gen_dummy(num, length): fake = Faker() docs = [ fake.pydict(length, value_types="str") for i in range(num) ] return docs1つのドキュメントサイズとしては、以下3パターンを用意しています。
pattern size [kB] key-value pairs [-] MIN 0.038 1 MID 0.32 10 BIG 3.4 100 結果
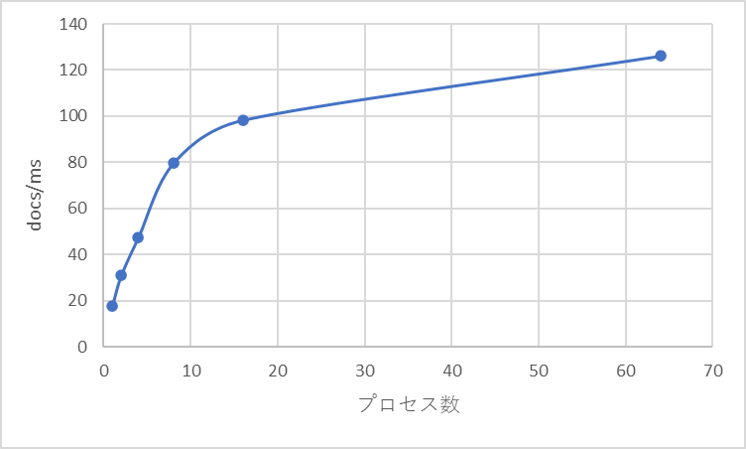
以下に、(ドキュメントサイズ, 並列プロセス数)ごとの, 単位時間あたりの処理性能を記載しました。
docs/ms (単位時間あたりの処理ドキュメント数)に関しては、(並列プロセス数)$\times 50000$の値を用いています。
size/s (単位時間あたりの処理サイズ)に関しては、投入時に用いるドキュメントリストオブジェクトのサイズにより計算しています。時間がかかるので分散は取っていません…、おおよその値ということで承知ください。
Process Num Doc Size Doc Num [$\times 10^6$] Wall Time[sec] docs/msec size/sec single MIN 0.500 13.9 36.0 1.44 single MID 0.500 20.7 24.2 7.83 single BIG 0.500 95.9 5.23 17.9 2 proc MIN 1.00 110 9.09 30.9 4 proc MID 2.00 143 14.0 47.6 8 proc BIG 4.00 171 23.4 79.5 16 proc BIG 8.00 277 28.9 98.2 64 proc BIG 32.0 861 37.2 126 16 proc BIG 8.00 60.0 133 43.2
Fig.1. ドキュメントサイズと処理性能; ドキュメントサイズが大きくなるほど、単位時間あたりの処理ドキュメント数は減っていく。ドキュメントサイズが100倍になっても処理性能は1/10程度なので、ある程度までであればドキュメントサイズは大きいほうがサイズ効率が良さそう。
Fig.2. プロセス数と処理性能; プロセス数を増やすに伴って、10procまではある程度線形に増加していくものの、16, 64procとなってくると頭打ちされている。
おそらく、DocumentDB側のドキュメント更新に伴うIndex等の処理?競合解決によるものか。調査中。考察
処理の時間に寄与するパラメータとしては、ドキュメント数とドキュメントサイズの両方が効いているようです。当たり前といえば当たり前ですが。
ドキュメントサイズが大きくなるほど、単位時間あたりの処理ドキュメント数は減っていく。ドキュメントサイズが100倍になっても処理性能は1/10程度なので、ある程度までであればドキュメントサイズは大きいほうがサイズ効率が良さそう。
プロセス数を増やすに伴って、10procまではある程度線形に増加していくものの、16, 64procとなってくると頭打ちされています。
おそらく、DocumentDB側のドキュメント更新に伴うIndex等の処理?競合解決によるものか。調査中。また、想定以上にCLIENT側のメモリ負荷が高いです。
64 procで3,200,000個のドキュメントを投げた場合, 861secの間, 400GByte以上のメモリを消費しており、かなりヒヤヒヤしました。使用しているライブラリの問題や、実装の問題もありますが、投入時に必要な容量は多めに見積もったほうが安心安全かもしれません。

- 投稿日:2020-06-29T10:34:55+09:00
RedshiftでUNLOADしたgzipファイルをLambdaのPythonで処理をして再びgzipしてS3へアップする
やりたいこと
タイトルの通りですが、Redshiftにデータウェアハウスがあり、普段ELTで処理することが多いのですが、プログラミングによるデータ加工が必要な場合もあります。
RedshiftのUNLOADを利用することでRedshiftからSQLの結果をS3にgzipファイルを作成することが出来ますので、S3へのputイベントをトリガーにLambdaで処理して再びgzipした状態でS3にアップ、ということをしてみました。
UNLOAD
Lambdaは現時点では3008MBが最大となります。今回のような処理はファイルサイズが増えると必然利用メモリ量が増えてしまいます。
そこで、MAXFILESIZE パラメータ を設定することでLambdaへ渡すファイルサイズを調整します。
完全なるケースバイケースですが、今回は50MBで設定してみました。Lambda上のコード
トリガ設定は割愛します。
import json import boto3 import urllib.parse import os import sys import csv import re import traceback import gzip import subprocess s3client = boto3.client('s3') s3resource = boto3.resource('s3') SEP = '\t' L_SEP = '\n' S3OUTBACKET='XXXXXXXX' S3OUTBASE='athena/preprocessing/XXXXXXtmp/' def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['name'] key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8') taragetfile=os.path.split(key)[1] outputprefixA=os.path.split(key)[0].split("/")[-1] outputprefixB=os.path.split(key)[0].split("/")[-2] outputdata = ""; try: dlfilename ='/tmp/'+key.replace("/","") s3client.download_file(bucket, key, dlfilename) gzipfile = gzip.open(dlfilename, 'rt') csvreader = csv.reader(gzipfile, delimiter=SEP, lineterminator=L_SEP, quoting=csv.QUOTE_NONE) for line in csvreader: # 1行ずつ様々な処理をして、outputdataに格納していく。 # 割愛された処理の中に、利用しているimportがございます。 # ご了承ください except Exception as e: print(e) raise e print("memory size at outputdata:"+str(sys.getsizeof(outputdata))) os.remove(dlfilename) uploadbinary = gzip.compress(bytes(outputdata , 'utf-8')) print("memory size at uploadbinary:"+str(sys.getsizeof(uploadbinary))) uploadfilename='processed_'+taragetfile try: bucket = S3OUTBACKET key = S3OUTBASE+outputprefixA+"/"+outputprefixB+"/"+uploadfilename obj = s3resource.Object(bucket,key) obj.put( Body=uploadbinary ) except Exception as e: print(e) raise e return 0チューニングしてゆく
実際のファイルでテストをしたところメモリエラーとなってしまいました。
コードの途中に挟んでいるstr(sys.getsizeof(outputdata))はその確認用で、メモリサイズを見て状況を把握しました。コードには書いてませんが、gzip自体の対象データへの圧縮率も見ておくと良いと思います。
なお私が今回扱ったデータは、gzip圧縮後50MBだったのですが、処理後のデータ+圧縮後のデータで1000MBものメモリを要してしまいました。やはり実際にやってみないと分からないものですね。Pythonのメモリ事情をもう少し調べた方が良いかもしれません。なおLambdaはメモリサイズを増やすとCPUリソースなども増えますので、処理内容とファイルサイズ次第ですが、一度最大の3008MBだとどのくらい処理が速くなるのかは確認すると良いです。今回も、メモリを倍にしたら処理時間が半分に、というケースすらありました。
もし定常的に行う処理の場合、ここでのチューニングがランニングコストに直結するので重要度が高いです。
語彙の無い感想
Lambdaめっちゃ便利
- 投稿日:2020-06-29T10:31:41+09:00
Terraformで最新のECS Optimized AMIのidを取得する方法
AWS公式ドキュメントにSSMパラメータストアから取得できることが記載されています。
https://docs.aws.amazon.com/AmazonECS/latest/developerguide/ecs-optimized_AMI.html$ aws ssm get-parameters --names /aws/service/ecs/optimized-ami/amazon-linux-2/recommendedTerraformでimage_idのみ利用したい場合は、下記のコードで取得可能です。
data "aws_ssm_parameter" "ecs_ami_id" { name = "/aws/service/ecs/optimized-ami/amazon-linux-2/recommended/image_id" } # Launch COnfigration等で利用する側 image_id = data.aws_ssm_parameter.ecs_ami_id.value
- 投稿日:2020-06-29T10:22:54+09:00
Amazon Aurora, Redshift, DynamoDBのワークロード別性能を比較する
はじめに
AWSが提供する代表的なDBサービスには、クラウド前提で設計されたRDBのAmazon Aurora、 データ分析特化型RDBのAmazon Redshift、ワイドカラム型DB(NoSQL)のAmazon DynamoDB1があります。AWSの各DBサービスの使い分けについては、一般的には概ね業務系システムのDBにはAuroraやDynamoDB、分析系システムのDBにはRedshiftを利用すれば良いとされていますが2、その根拠について定量的に確かめてみたいと思ったので、実際にOLTP/OLAPワークロード別の負荷をかけて各DBサービスの性能特性の違いについて確認してみました。
※実際のシステム性能は様々な条件により変動します。あくまでも参考情報の一つとして捉えていただきますようお願いします。
前提知識
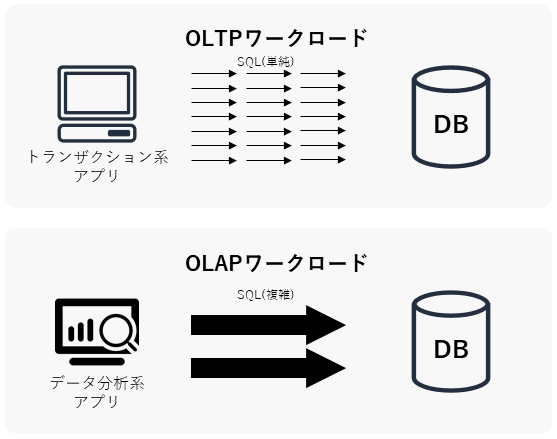
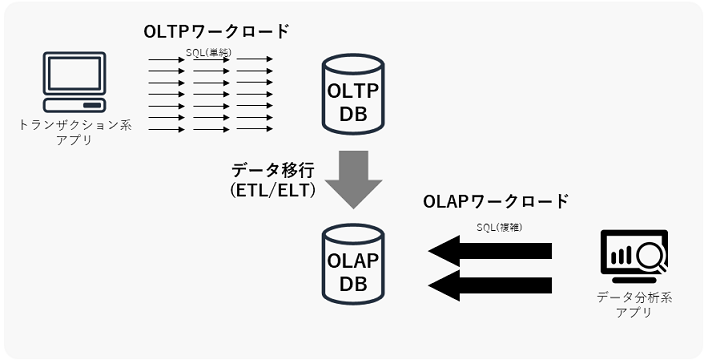
まず前提となる考え方として、OLTP/OLAPワークロードについて概説しておきます。OLTP/OLAPは、データウェアハウスやBI(Business Intelligence)の分野でよく出てくる概念で、DBに対する処理の内容を分類したものです。下図はイメージ図で、図中の矢印の数はSQLの実行頻度を、矢印大きさはSQL単体の負荷の大きさを示しています。
- OLTP (Online Transaction Processing | オンライントランザクション処理)
- 主に業務系システムから定常的に実行される、単一行の参照/更新/挿入/削除処理。
- SQLクエリの典型例:
SELECT ... FROM A WHERE id = N;UPDATE A SET value = 'x' WHERE id = N;INSERT INTO A VALUES (...);DELETE FROM A WHERE id = N;- OLAP (Online Analytical Processing | オンライン分析処理)
- 主に分析系システムから一時的に実行される、(表結合を伴う)大量データの集計処理。
- SQLクエリの典型例:
SELECT ..., SUM(A.z) FROM A INNER JOIN B ON ... INNER JOIN C ON ... GROUP BY ...;OLTPとOLAPのワークロードではそれぞれDBに求められる性能要件が異なるので、システム設計ではワークロード別に複数のDBを使い分ける場合があります。ちなみに昔はオンプレ環境しかなかったので、DBをOLAPの性能要件に対応させるために、ハードウェア一体となった高価なDWHアプライアンス製品を導入したり、通常のOracle Databaseを鬼チューニングしたりしていました。
計測方法
今回は、ワークロード別のDB性能をそれぞれ下記の方法で計測します。
OLTPワークロードの設計
下記の単一行挿入クエリを10万件発行し、スループット(1分あたりの挿入件数)を計測します。
注文明細の登録クエリINSERT INTO order_details (order_id, item_id, sales_price, amount) VALUES (:order_id, :item_id, :sales_price, :amount);注文明細表CREATE TABLE order_details( -- 注文明細表 order_id int NOT NULL, -- 注文ID item_id int NOT NULL, -- 商品ID sales_price int NOT NULL, -- 売値 amount int NOT NULL, -- 数量 PRIMARY KEY (order_id, item_id) -- 主キー );計測対象のDBは下記とします。3
- Aurora Serverless
- PostgreSQL 10.7
- MySQL 5.6.10a
- DynamoDB on-demand
- Redshift
- ra3.4xlarge (12 vCPU, メモリ 96GiB, 2ノード)
OLAPワークロードの設計
下記の5億件のデータを集計するSQLクエリを発行し、応答時間を計測します。
販売注文表CREATE TABLE sales_order( order_id int NOT NULL, -- 注文ID timestamp timestamp NOT NULL, -- 日時 store_id int NOT NULL, -- 店舗ID customer_id int NOT NULL, -- 顧客ID total_price int, -- 合計金額 PRIMARY KEY (order_id) -- 主キー ) sortkey(store_id, timestamp) -- ソートキー(Redshiftのみ) ;月次売上集計クエリSELECT store_id, date_trunc('month', timestamp) as month, SUM(total_price) as sales_by_month FROM sales_order GROUP BY store_id, month;計測対象のDBは下記とします。4
- Aurora
- PostgreSQL 11.6 db.r5.4xlarge (16 vCPU, 128 GiB)
- Redshift
- ra3.4xlarge (12 vCPU, メモリ 96GiB, 2ノード)
計測結果 (OLTP)
まずは、OLTPワークロードの性能比較から計測結果を載せていきます。
スループット比較
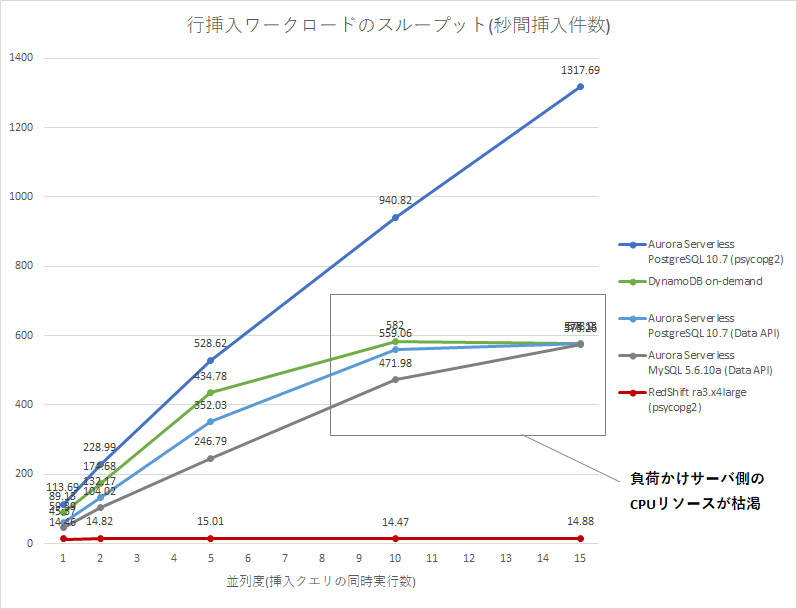
下図は、行挿入ワークロードのスループット(件/sec)の計測結果です。スループットは高いほど良い性能です。負荷かけサーバには、リソース設定を最大にしたAWS Lambdaを利用しました。Aurora Serverlessは他のDBの条件を近づけるため、Data APIとDBアダプタ(psycopg2)の2種類の接続方法で計測しました。
並列度(p) Aurora Serverless PostgreSQL 10.7 (psycopg2) DynamoDB On-Demand Aurora Serverless PostgreSQL 10.7 (Data API) Aurora Serverless MySQL 5.6.10a (Data API) Redshift ra3.x4large (psycopg2) p=1 113.69 rows/sec 89.13 rows/sec 59.39 rows/sec 45.37 rows/sec 14.46 rows/sec p=2 228.99 rows/sec 174.68 rows/sec 132.17 rows/sec 104.02 rows/sec 14.82 rows/sec p=5 528.62 rows/sec 434.78 rows/sec 352.03 rows/sec 246.79 rows/sec 15.01 rows/sec p=10 940.82 rows/sec 582.00 rows/sec 559.06 rows/sec 471.98 rows/sec 14.47 rows/sec p=15 1317.69 rows/sec 578.13 rows/sec 578.20 rows/sec 573.26 rows/sec 14.88 rows/sec
- 並列度(p)は、負荷かけスクリプトの挿入クエリの同時実行数。詳細は付録のスクリプトを参照。
- Aurora Serverlessのキャパシティユニット(ACU)5は、いずれも2 ACUで計測。
結果グラフを確認すると、Aurora Serverless (Data API)とDynamoDBで、並列度10-15のあたりでスループットが頭打ちになっています。これはDB側の問題ではなく、HTTP APIは負荷かけサーバ側にかかるCPU負荷が重いようで、負荷かけサーバ側(Lambda)のCPU負荷がボトルネックになってしまったためでした6。Redshiftに関しては、並列度1からRedshift側の性能限界(約15件/秒)となりました。
計測環境
このスループット性能を計測した際の、システム環境は下図の通りです。DynamoDBはVPC内に配置できないため、VPC endpointを経由してインターネットを介さずに通信するように構成しています。
負荷かけスクリプトの内容とLambda関数の設定の詳細については、記事最後の付録を参照してください。
コスト比較
下表は、各DBサービスの1時間あたりのコスト比較です。DynamoDB On-Demandは書込み件数により金額が変動するので、比較のためにスループット1件/secを1 WCU7に換算してプロビジョニング済キャパシティーの料金を記載しました。Aurora Serverlessは、計測時のキャパシティユニット(2 ACU5)の料金を記載しました。
並列度 DynamoDB
(1WCU=1件/sec, Provisioned)Aurora Serverless (2 ACU) Redshift ra3.x4large p=1 (89 WCU)
0.06 USD/hour0.12 USD/hour 3.38 USD/hour p=2 (174 WCU)
0.12 USD/hour0.12 USD/hour 3.38 USD/hour p=5 (434 WCU)
0.32 USD/hour0.12 USD/hour 3.38 USD/hour p=10 (482 WCU)
0.35 USD/hour0.12 USD/hour 3.38 USD/hour p=15 (578 WCU)
0.42 USD/hour0.12 USD/hour 3.38 USD/hour
- 2020年6月時点の東京リージョン(asia-northeast1)の料金。
- 小数点第3位以下は切り捨て。
- インスタンス以外にかかる料金(ストレージ容量やIO課金)は一旦無視。
比較表を見ると、秒間約200件以上の挿入クエリが定常的に続くような場合では、Aurora Serverlessの方がコストを抑えられそうです。ただ、定常的な負荷ではない場合では、料金体系がより柔軟なDynamoDBの方がコストを抑えられるケースもありそうです。
確認できたこと
- RedshiftのOLTP性能(挿入系)は、約15件/秒が限界。
- Auroraでは並列度を上げると秒間1,000件以上の挿入クエリを捌けた一方で、Redshift ra3.x4largeでは約15件/秒で頭打ちになってしまった。
- RedshiftのCPU利用率が2ノードとも約20%で張り付いていたため、Redshiftのリソース制限に引っ掛かったと思われる。
- DBアダプタ経由とHTTP API経由のDB接続方法で、負荷かけサーバのCPU利用率が10倍以上異なる。
- HTTP経由のクエリ(DynamoDB APIとAurora Data API)は、並列度10-15でLambda側の限界でスループット性能が頭打ちになった。
- 並列度10-15では、Aurora Data APIではCPU利用率90-100%となっていた一方で、psycopg2では10%以下で推移していた。
もしLambdaが性能のボトルネックにならなければ、Aurora ServerlessよりもDynamoDBの方が性能上限が高い(ほぼ無限)はずだと思っていますが、今回はそこまでの負荷はかけられませんでした。Redshiftは、その潤沢なリソースの割には早々に性能が頭打ちになってしまいました。
計測結果 (OLAP)
さてOLTP編はこれで終わりで、次にOLAPワークロードの性能を比較します。RedshiftのOLTPワークロード(挿入計)は悲惨な結果でしたが、そもそもRedshiftはOLAP特化のDBとして設計されているので、ここで本領を発揮してもらいます。
応答時間比較
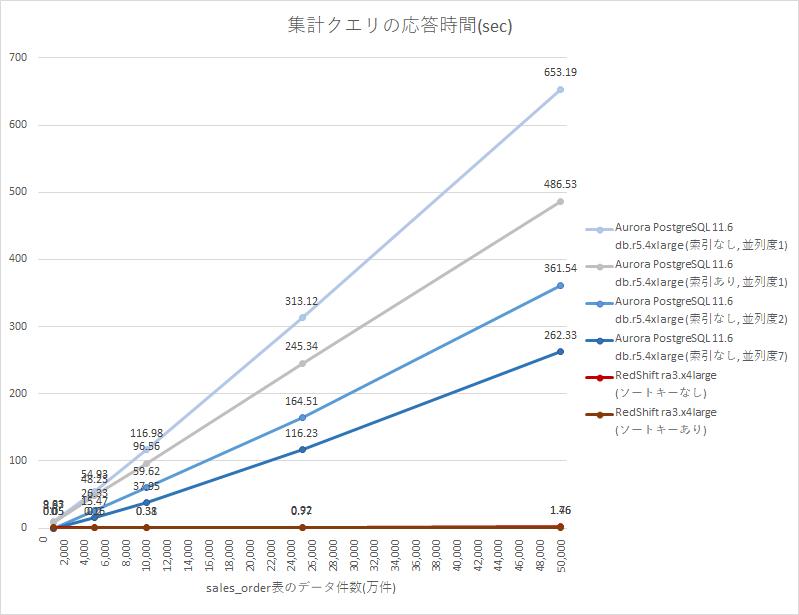
下図は、OLAPクエリの応答時間(sec)の計測結果です。応答時間は短いほど良い性能です。PostgreSQLの並列度は、
parallel_workers系のパラメータで制御できるクエリ並列度8です。
データ件数 Aurora db.r5.4xlarge
(索引なし,並列度1)Aurora db.r5.4xlarge
(索引あり,並列度2)Aurora db.r5.4xlarge
(索引なし,並列度2)Aurora db.r5.4xlarge
(索引なし,並列度7)Redshift ra3.x4large
(ソートキーなし)Redshift ra3.x4large
(ソートキーあり)1,000万件 9.85 sec 8.97 sec - - 0.05 sec 0.05 sec 5,000万件 54.93 sec 48.23 sec 26.33 sec 15.47 sec 0.20 sec 0.16 sec 10,000万件 116.98 sec 96.56 sec 59.62 sec 37.95 sec 0.38 sec 0.31 sec 25,000万件 313.12 sec 245.34 sec 164.51 sec 116.23 sec 0.92 sec 0.77 sec 50,000万件 653.19 sec 486.53 sec 361.54 sec 262.33 sec 1.76 sec 1.46 sec
- Aurora PostgreSQLの並列度について、
- 索引ありの条件では、実行計画を並列実行(Parallel Index Scan)に誘導できなかったため並列度1のみ計測。
- データ件数1,000万件の条件では、実行計画を並列実行(Parallel Seq Scan)に誘導できなかったため並列度1のみ計測。
- 最大並列度7について、デフォルトのパラメータグループでは並列度を8よりも大きい値に設定できなかったため、最大7(8 - 1管理接続用プロセス)で計測。
ほぼ同じシステムスペックを持つAurora db.r5.4xlargeとRedshift ra3.x4largeですが、Auroraでは5億件(50,000万件)のデータ集計にチューニング後でも4分以上かかっていたところ、Redshiftでは2秒以下とその1/100以下の時間で処理できました。クエリ並列度をさらに上げたり索引並列スキャンに誘導する等の追加チューニングで、Aurora PostgreSQLの応答時間をもう少し早くすることは可能かもしれませんが、Redshiftの方が圧倒的に高速であることには変わりないでしょう。
計測環境
下記の集計クエリを実行して、応答時間を計測しました。(計測時はORDER BY句は省略)
月次売上集計クエリと実行例> SELECT store_id, date_trunc('month', timestamp) as month, SUM(total_price) as sales_by_month FROM sales_order GROUP BY store_id, month ORDER BY store_id, month; store_id | month | sales_by_month ----------+---------------------+---------------- 0 | 2014-04-01 00:00:00 | 67222780 0 | 2014-05-01 00:00:00 | 72365720 0 | 2014-06-01 00:00:00 | 69271910 (..省略..) 99 | 2020-02-01 00:00:00 | 70760330 99 | 2020-03-01 00:00:00 | 66501940 時間: 26337.9245 ms
- psqlでDBにログインして
\timing設定をonにし、SQL実行後に表示される時間を計測。- キャッシュに乗った状態で計測するため、同じSQLを2回実行した2回目の結果を採用。
- PostgreSQLでは、
max_parallel_workersとmax_parallel_workers_per_gatherのパラメータでクエリ並列度を制御。- Redshiftでは、
SET enable_result_cache_for_session = off;でリザルトキャッシュをOFFに設定。索引設計
B-tree索引やソートキーを設定する場合は、下記のようにデータの物理配置が
store_id,timestampの順番に並ぶように指定します。PostgreSQL_B-tree索引CREATE INDEX sales_order_idx_01 ON sales_order (store_id, date_trunc('month', timestamp), total_price);PostgreSQLのB-tree索引は、索引生成後に大量データ生成SQLを実行しようとすると長い時間がかかってしまうので、必ずデータ生成後に生成するようにします。Redshiftのソートキーは、CREATE TABLE文で指定します。
コスト比較
下表は、各DBサービスの1時間あたりのコスト比較です。
Aurora for PostgreSQL db.r5.4xlarge Redshift ra3.x4large 2.80 USD/hour 3.38 USD/hour
- 2020年6月時点の東京リージョン(asia-northeast1)の料金。
- 小数点第3位以下は切り捨て。
- インスタンス以外にかかる料金(ストレージ容量やIO課金)は一旦無視。
AuroraよりもRedShitの方が高価ですが、性能比で考えればRedshiftの方がコスト効率が良いと言えそうです。
確認できたこと
- RedshiftのOLAP性能は、ほぼ同スペックのAurora PostgreSQLよりも数百倍以上高速。
- Auroraでは4分以上かかる5億件(50,000万件)のデータ集計を、Redshiftでは2秒以下で完了。
- Aurora for PostgreSQLはチューニングにより2倍以上高速化できたが、無チューニングのRedshiftに及ばない。
- チューニング後でも、依然として100倍以上の応答時間の差がある。
設計ポイント (OLTP/OLAP観点)
以上を踏まえて、データ分析基盤を設計する際にOLTP/OLAPの考え方をどう生かせるかについて話します。
OLTP/OLAP混在システム
OLTP/OLAP両方のワークロードが存在するシステムでは、下図のようにDBを分離するアークテクチャを検討することがよくあります。OLTP DBとは、DynamoDBやAurora等のOLTPワークロードに向いたDBのことで、OLAP DBとは、Redshift等のOLAPワークロードに向いたDBのことを指しています。
例えば、ECサイトのシステムを設計している場合に、顧客の注文を受け付ける機能はOLTPのワークロードなのでOLTP DBのDynamoDBやAuroraを採用し、週次/月次の売上を集計する機能はOLAPワークロードなのでOLAP DBのRedshiftを採用する、といったDB設計パターンが考えられます。このようなアーキテクチャ構成を取ると、DBの性能を最大限に生かすことができます。
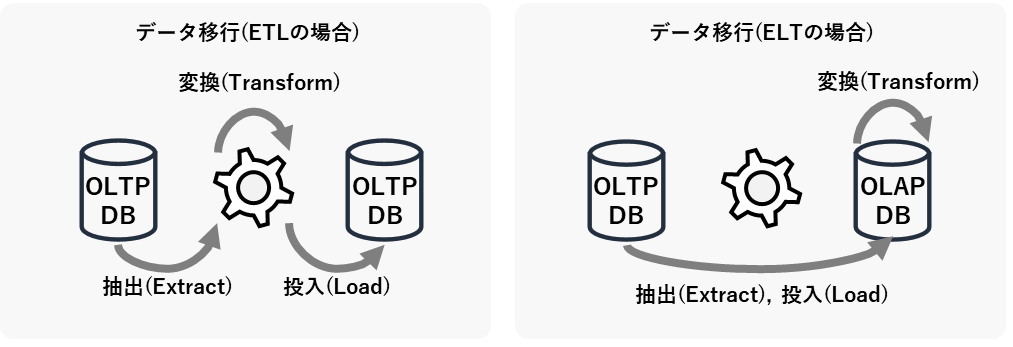
ELTか、ELTか
OLTP DBとOLAP DBを分離して設計する場合は、定期的なDB間のデータ移行についても考えなければなりません。データ分析基盤の分野では、このDB間のデータ移行のことをよくETL(Extract,Transform,Load)と呼びます。ETLは「抽出」「変換」「投入」のそれぞれの頭文字を取ったものですが、下図のようにその順番を変えてELT(Extract, Load, Transform)と呼ぶこともあります。
ETLとELTのどちらが良いかは、ケースバイケースです。ETL方式は、DBの性能リソースへの影響を与えにくい利点がある一方で、バッチサーバ(上図の歯車の部分)の処理能力がボトルネックになりやすい欠点があるといえます。OLAP DBに大量データを移行する場合はETLの欠点が顕在化しやすいので、そのような場合はELT方式で実装してデータ移行先のOLAP DBのデータ処理能力を活用するか、データ処理能力に長けたAWS Glueのようなクラウド型のETLサービスを利用することを検討します。
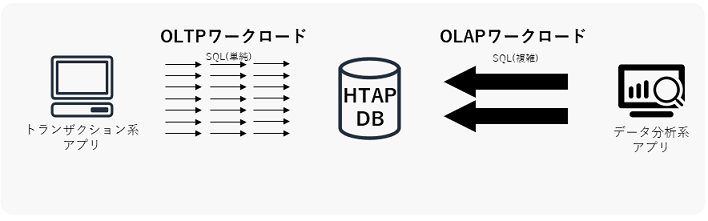
HTAP DB
OLTP DBとOLAP DBの利点を併せ持つDBのことを、HTAP DB(Hybrid Transaction Analytical Processing)と言います。HTAP DBが利用できると、OLTP DBからOLAP DBへのETL/ELT(データ移行)が不要になり、リアルタイムデータをデータ分析に利用できるようになる恩恵を受けられると言われています。
ただし、現在のHTAP技術は少なくとも私の観測範囲内では完全ではなく、既存製品もOLTPかOLAPのどちらかの性能に寄っている傾向があるようなので、現状のデータ基盤設計ではOLTP DBとOLAP DBを分けて構成する方が無難だと個人的には思っています。将来的にはさらに使いやすいHTAP DBが登場するかもしれないので、今後の技術進歩に注目したいです。
まとめ
以上で、Amazon Aurora, Redshift, DynamoDBのワークロード別性能を計測しました。特にRedshiftはOLTP/OLAPワークロードの得意/不得意がはっきりしているので、その特性を理解して適材適所で利用することが重要だと思います。スループットが秒間15件しか出ないからといって、もっとすごい長所があるので叩かないであげてください。
付録
計測環境の構築に関するやや細かい内容について、付録に記載します。
負荷かけスクリプト(OLTP)
- OLTPワークロードのLambda用負荷かけスクリプト。
- スクリプト中の
parallel変数の値で、クエリの並列実行数(pythonプログラムの同時実行プロセス数)を変更可能。- 実行環境は全てPython 3.7を想定。
DynamoDB
- DynamoDB API(Boto3)を利用してDynamoDBに接続し、挿入クエリを発行する。
dynamodb_funcimport boto3 import random import time from datetime import datetime import multiprocessing dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('order_details') # 挿入先テーブル名 total_num = 100000 # 挿入件数 (可変) parallel = 10 # 並列度 (可変) # 親プロセス def lambda_handler(event, context): process_list = [] for i in range(parallel): process_list.append(multiprocessing.Process(target=child_proc)) # 子プロセス生成 start_time = time.time() # 計測開始 for process in process_list: process.start() # 子プロセス実行開始 for process in process_list: process.join() # 子プロセス実行完了待ち合わせ end_time = time.time() # 計測終了 result = { 'total_num': total_num, 'parallel': parallel, 'total time': "{:.2f}".format(end_time - start_time) + " sec", } print (result) # コンソール上にも出力 return result # 子プロセス def child_proc(): for i in range(int(total_num / parallel)): # (合計件数/並列度)回実行 table.put_item( Item={ "order_id": int(random.random() * 1000000000), # 注文ID "item_id": int(random.random() * 10000), # 商品ID "sales_price": int(random.random() * 100) * 10, # 売値 "amount": int(random.random() * 100), # 数量 } )Aurora Serverless DataAPI
- Data API(Boto3)を利用してAurora Serverlessに接続し、挿入クエリを発行する。
- コード中のSECRET_ARNは、Amazon Secrets Managerで生成する。
aurora_dataapi_funcimport boto3 import random import time from datetime import datetime import multiprocessing total_num = 100000 # 挿入件数 (可変) parallel = 10 # 並列度 (可変) rds_data = boto3.client('rds-data') resource_arn = 'arn:aws:rds:ap-northeast-1:999999999999:cluster:test' secret_arn = 'arn:aws:secretsmanager:ap-northeast-1:999999999999:secret:test-xxxxxx' sql = "INSERT INTO order_details (order_id, item_id, sales_price, amount) VALUES (:order_id, :item_id, :sales_price, :amount)" # 親プロセス def lambda_handler(event, context): process_list = [] for i in range(parallel): process_list.append(multiprocessing.Process(target=child_proc)) # 子プロセス生成 start_time = time.time() # 計測開始 for process in process_list: process.start() # 子プロセス実行開始 for process in process_list: process.join() # 子プロセス実行完了待ち合わせ end_time = time.time() # 計測終了 result = { 'total_num': total_num, 'parallel': parallel, 'total time': "{:.2f}".format(end_time - start_time) + " sec", } print (result) # コンソール上にも出力 return result # 子プロセス def child_proc(): for i in range(int(total_num / parallel)): # (合計件数/並列度)回実行 parameters = [ {'name':'order_id','value':{'longValue':int(random.random() * 1000000000)}}, # 注文ID {'name':'item_id','value':{'longValue':int(random.random() * 10000)}}, # 商品ID {'name':'sales_price','value':{'longValue':int(random.random() * 100) * 10}}, # 売値 {'name':'amount','value':{'longValue':int(random.random() * 100)}}, # 数量 ] try: response = rds_data.execute_statement( resourceArn = resource_arn, secretArn = secret_arn, database = 'sales', sql = sql, parameters = parameters ) if response["ResponseMetadata"]["HTTPStatusCode"] != 200: print(response) except Exception as e: print(e) # 一意制約違反等のエラーを出力PostgreSQL, Redshift
- PostgreSQL向けDBアダプタのpsycopg2を利用して、AuroraまたはRedshiftに接続して挿入クエリを発行する。
- 正規のpsycopg2のライブラリをそのままLambdaにアップロードして実行するとエラーとなっため、awslambda-psycopg2を利用。
postgres_funcimport psycopg2 import random import time from datetime import datetime import multiprocessing sql = "INSERT INTO order_details (order_id, item_id, sales_price, amount) VALUES (%s,%s,%s,%s)" total_num = 100000 # 挿入件数 (可変) parallel = 10 # 並列度 (可変) # 接続情報 def get_connection(): return psycopg2.connect(host="db-name.xxxxxxxxxxxx.ap-northeast-1.<rds/redshift>.amazonaws.com", port=<5432/5439>, user="admin", password="xxxxxxxxxxxx", dbname="sales") # 親プロセス def lambda_handler(event, context): process_list = [] for i in range(parallel): process_list.append(multiprocessing.Process(target=child_proc)) # 子プロセス生成 start_time = time.time() # 計測開始 for process in process_list: process.start() # 子プロセス実行開始 for process in process_list: print(process.join()) # 子プロセス実行完了待ち合わせ end_time = time.time() # 計測終了 result = { 'total_num': total_num, 'parallel': parallel, 'total time': "{:.2f}".format(end_time - start_time) + " sec", } print (result) # コンソール上にも結果を出力 return result # 子プロセス def child_proc(): with get_connection() as conn: for j in range(int(total_num / parallel)): # (合計件数/並列度)回実行 order_id = int(random.random() * 1000000000) # 注文ID item_id = int(random.random() * 10000) # 商品ID sales_price = int(random.random() * 100) * 10 # 売値 amount = int(random.random() * 100) # 数量 try: with conn.cursor() as cur: cur.execute(sql, (order_id, item_id, sales_price, amount)) conn.commit() except Exception as e: print(type(e), e) # 一意制約違反等のエラーを出力Lambda関数の設定
Lambda関数のパラメータ設定を、デフォルト値から下記の値に変更する。
- メモリ割当: 3,008MB(最大)
- 実行時間: 15分(最大)
- 同時実行数の予約: 1
- 非同期呼び出しの再試行数: 0
メモリ割当を最大に設定すると、それに合わせてCPUリソースも最大になる(公式ドキュメント)。同時実行数の予約と非同期呼び出しの再試行数の設定については、この設定をしないと
API アクションの呼び出しに失敗しました。エラーメッセージ: Network Error (または Rate Exceeded)のエラーが発生してLambda関数が再実行されてしまう場合があったため。実行完了までにかかった時間は、LambdaのUI上からは確認できなかったので、Cloudwatch Logsの出力から確認した。データ生成 (OLAP)
データ生成SQL
- PostgreSQLの
generate_series関数を利用して、数千万行以上の大量データを生成する。データ生成SQL(5000万件生成)INSERT INTO sales_order SELECT generate_series as order_id, -- 注文ID timestamp '2014-04-01 00:00:00' + random() * (timestamp '2020-04-01 00:00:00' - timestamp '2014-04-01 00:00:00'), -- 日時 trunc(random() * 100), -- 店舗ID trunc(random() * 100000000), -- 顧客ID trunc(random() * 10000) * 10 -- 合計金額 FROM generate_series(1,50000000); -- データ生成件数を指定 ☆sales=> select * from sales_order limit 5; order_id | timestamp | store_id | customer_id | total_price ----------+----------------------------+----------+-------------+------------- 4012545 | 2017-12-11 02:22:17.412715 | 66 | 11732886 | 88080 4012546 | 2014-11-23 10:27:58.553224 | 79 | 39502508 | 17440 4012547 | 2019-09-12 15:34:49.932418 | 56 | 5110535 | 85080 4012548 | 2016-05-13 19:18:07.550354 | 86 | 44695746 | 58170 4012549 | 2016-05-10 15:47:55.556803 | 65 | 14394220 | 68390このSQLで5億件のデータを生成したところ、Aurora PostgreSQL db.r5.4xlargeインスタンスで約50分かかった。Auroraの料金も起動時間とIO料金を合わせてこれだけで500円以上かかった。
データ移行
Redshiftではgenerate_series関数を利用できないため、今回はPostgreSQLで生成したデータをS3経由でRedShiftに移行した。方法としては、まずは下記コマンドでAurora PosgreSQL(11以降)からS3にデータエクスポートする(公式ドキュメントの手順を参照)。
SELECT * FROM aws_s3.query_export_to_s3( 'select * from sales_order', aws_commons.create_s3_uri('<bucket_name>', 'sales_order.csv', 'ap-northeast-1'), options :='format csv');そして、エクスポートしたデータをCOPYコマンドでRedshiftにロードする(公式ドキュメントの手順を参照)。
RedshiftへのロードCOPY <table_name> FROM 's3://<bucket_name>/<file_path>' iam_role 'arn:aws:iam::<aws-account-id>:role/<role-name>' FORMAT csv MAXERROR 10000 COMPUPDATE ON;エクスポートしたcsvデータファイルに破損データ行が存在していたため、MAXERROR句で破損データ行の許容行数を指定して読み込んだ(性能検証では少数行の差異は誤差の範囲として許容)。エクスポートしたcsvデータファイルのサイズは5億行で約25GBで、Redshiftへのロード時間は約15分かかった。
実行計画(OLAP)
PostgreSQL
- 10,000万件, 索引なし, 並列度7の条件
sales=> EXPLAIN ANALYZE SELECT store_id, date_trunc('month', timestamp) as month, SUM(total_price) as sales_by_month FROM sales_order_100m GROUP BY store_id, month ORDER BY store_id, month; QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------------------------------------------- Finalize GroupAggregate (cost=2793263.25..17409493.29 rows=100000120 width=20) (actual time=35255.091..37910.722 rows=7200 loops=1) Group Key: store_id, (date_trunc('month'::text, "timestamp")) -> Gather Merge (cost=2793263.25..15409490.89 rows=100000120 width=20) (actual time=35254.343..37904.037 rows=57600 loops=1) Workers Planned: 8 Workers Launched: 7 -> Partial GroupAggregate (cost=2792263.11..3073513.45 rows=12500015 width=20) (actual time=35209.875..37738.059 rows=7200 loops=8) Group Key: store_id, (date_trunc('month'::text, "timestamp")) -> Sort (cost=2792263.11..2823513.15 rows=12500015 width=16) (actual time=35209.404..36555.793 rows=12500000 loops=8) Sort Key: store_id, (date_trunc('month'::text, "timestamp")) Sort Method: external merge Disk: 367000kB Worker 0: Sort Method: external merge Disk: 368024kB Worker 1: Sort Method: external merge Disk: 367000kB Worker 2: Sort Method: external merge Disk: 365976kB Worker 3: Sort Method: external merge Disk: 368016kB Worker 4: Sort Method: external merge Disk: 365976kB Worker 5: Sort Method: external merge Disk: 367000kB Worker 6: Sort Method: external merge Disk: 367000kB -> Parallel Seq Scan on sales_order_100m (cost=0.00..891545.19 rows=12500015 width=16) (actual time=0.008..2387.244 rows=12500000 loops=8) Planning Time: 0.091 ms Execution Time: 37952.773 msParallel Seq Scan(並列全表スキャン)が7 Workers(並列度7)で実行されている。
- 5,000万件, 索引あり, 並列度1の条件
sales=> EXPLAIN ANALYZE SELECT store_id, date_trunc('month', timestamp) as month, SUM(total_price) as sales_by_month FROM sales_order_50m GROUP BY store_id, month; QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- GroupAggregate (cost=0.56..4337021.90 rows=50000000 width=20) (actual time=7.162..48230.888 rows=7200 loops=1) Group Key: store_id, date_trunc('month'::text, "timestamp") -> Index Scan using sales_order_50m_idx_01 on sales_order_50m (cost=0.56..3337021.90 rows=50000000 width=16) (actual time=0.027..43732.779 rows=50000000 loops=1) Planning Time: 0.136 ms Execution Time: 48235.022 ms (5 行)Index Scan(直列索引スキャン)が実行されている。Workerは起動/実行されていない。
Redshift
- 10,000万行の条件
sales=# SELECT plannode || ' ' || info FROM stl_explain WHERE query = 677 ORDER BY nodeid; ?column? ---------------------------------------------------------------------------------------- XN HashAggregate (cost=1999991.84..2488343.60 rows=97670353 width=16) -> XN Seq Scan on sales_order_100m (cost=0.00..1249994.90 rows=99999592 width=16) (2 行)ソートキーの有無で、実行計画の変化はなかった。
AWS公式サイトではDynamoDBはワイドカラムストアではなくKVSおよびドキュメント型DBと分類されていますが、代表的なワイドカラムストアであるCassandraがDynamoDBの論文を元に作られていることや、CassandraとDynamoDBのデータの持ち方や性能特性が類似していることから、個人的にはワイドカラムストアの一種と認識してもいいのではと思ってます。 ↩
業務系システム/分析系システムについて、業務系システムとは業務自動化/効率化のためのシステム(例:注文販売システムや生産管理システムなど)を、分析系システムとはデータを可視化/分析して洞察を得るためのシステム(例:売上集計システムや財務分析システムなど)を言っています。 ↩
Aurora PostgreSQL 11.6 db.r5.4xlarge(16 vCPU, 128 GiB)は、性能が出すぎたので比較グラフからは除外しました。ちなみに計測結果としては、Aurora Serverless PostgreSQL 10.7 (ACU 2)と比較して、約2.5倍から3.0倍ほど良いスループットが出ました。 ↩
DynamoDBは集計クエリ(GROUP BY句)に対応していないため、Aurora Servrelessはオートスケーリング機能により安定した性能を計測することが難しかったため、それぞれ比較対象から除外しました。 ↩
負荷かけサーバをLambdaからEC2に変更して確認したところ、並列度10-15ではAurora Data APIではCPU利用率90-100%となっていた一方で、psycopg2では10%以下で推移していました。HTTPS通信のための暗号化処理のためのCPU負荷などが原因か? ↩
公式ドキュメントの説明には、
1 つの書き込みキャパシティーユニット(WCU)は、最大でサイズが 1 KB までの項目について、1 秒あたり 1 回の書き込みを表します。とあります。 ↩OLTPグラフの並列度(クエリ自体の同時実行数)と、OLAPグラフの並列度(1クエリ内のCPUプロセス並列実行数)の意味の違いに注意。 ↩

- 投稿日:2020-06-29T08:10:08+09:00
C#のみを使って、今ソーシャルゲームアプリを作るとしたら
はじめに
現在進行形でC#のみを使って個人でソシャゲ作りを試しているyoship1639です。
本記事はQiita夏祭り2020「〇〇(言語)のみを使って、今△△(アプリ)を作るとしたら」のテーマに沿った内容となっています。近年のソーシャルゲーム界隈は多様化が進んでクライアントサイドだけではなくサーバーサイドもあらゆる言語やフレームワークが試みられていますが、クライアントもサーバーも統一の言語で構成されているのはほとんどないかと思われます。言語にはその言語の得意分野があると思うので。
しかし、今まさに私が開発中の環境が好きな言語で開発しやすいという理由でクライアントもサーバーもC#で構成した作りになっているので、どのような構成でどうすれば最低限のソシャゲの基盤が作れるかを、解説が長くなり過ぎないようにまとめることが出来ればと思います。
三部構成で、クライアント実装、サーバー実装、AWS EC2へのデプロイまで解説できればと思っています。
Let's、C#のみでソシャゲを作ろう!ソシャゲの概要
内容に入る前に、ソシャゲがどの様な流れで動作するのかを軽く説明します。
ソシャゲは基本的にクライアント(スマホ端末)とサーバーとのやり取りで動いています。サーバーが動いていないとクライアントは基本動作しません。これはクライアント側で不正にデータの書き換えをされると運営が困るからです。
サーバー側は大体以下の様なAPI機能を備えています。
- アプリバージョン判定
- マスターデータ・アセットバンドル更新判定
- ログイン (セッション管理)
- アカウント作成
- クエスト開始・終了
- ガチャ
- etc...
挙げたらきりがないくらいにはサーバーにはやらなければならない仕事があります。それだけクライアントとサーバーは適所で通信しています。こうすることで、例えばクライアントのデータが紛失したとしてもサーバーから復元することが出来ますし、クライアント側で不正があったらサーバー側で検知してBANすることもできますし、ユーザーのアプリ上での動向から問い合わせにも対応することができるようになりますし、課金周りのレシート検証もサーバー側で正確に行えるので、課金したのに石が反映されないみたいな場面でも補填対応することが出来るようになります。基本ユーザにとっても運営にとってもメリットしかないです。
近年バックエンドはBaas(PlayFab、Firebase、GameSparks、GS2など)が鎬を削っており態々バックエンドを自前で準備しなくてもBaasを使うという手段がありますが、ドキュメントが英語のみだったり痒いところに手が届かなかったりと一長一短なので、どうしてもサーバーサイドを触りたくないという訳ではないのであれば個人的にはまだ自前で準備したほうが良いかな感はあります。
ソシャゲの動作の最初の流れとしては以下の様になります。
- アプリバージョンを検証
- ログイン (ログインできなかったらアカウント作成)
- 更新データ確認 (アセバン、マスターデータ)
- 以降アプリによって色々
今回は最低限の基盤だけ考えるので、2番の「アカウント作成」と「ログイン」機能を作りたいと思います。
構成の全体像
今回作るサンプルは、C#のみで構成するソシャゲの最低限の基盤で以下の構成となっています。
クライアント:C#(Unity2019.X)
サーバー:C#(.NetCore3.1)
デプロイ:AWS EC2(Amazon Linux 2)
サーバー <--> クライアント:MagicOnion(HTTP/2, gRPC)
クライアントは皆大好きUnity、サーバーはプラットフォーム関係なく動かせる.NetCore、デプロイはEC2、クライアントとサーバーのやり取りは巷で噂のMagicOnion(gRPCのC#ラッパー+α)です。最低限の構成であれば全部無料で準備できます。
本来であれば、DB用意したり、直じゃなくDockerコンテナでデプロイとかすべきですが、本記事から内容が逸れそうなので簡単な構成にしています。
まずは、クライアントサイドから作ってみます。
クライアントサイド
クライアントサイドはエンジンとしてUnity2019.Xを使います。言語は当然C#です。
実装手順としては以下の通りとなります。
① MagicOnion, MessagePack, grpc をUnityにインポートする
② Serviceを定義
③ NetworkManagerを実装
④ ログインテストコードを実装① MagicOnion, MessagePack, grpc をUnityにインポートする
まず、MagicOnion、MessagePack、grpcをUnityにインポートします。サーバーと通信するのに必要なものです。
これらを簡単に説明すると、
- MagicOnion: リアルタイム/API通信フレームワーク。gRPCをC#で使いやすいようにラップしたイメージ。
- MessagePack: 高効率のバイナリ形式のシリアライズフォーマット。JSONよりすごいやつ。MagicOnionに必要。
- grpc: googleが作ったRPCフレームワーク。MagicOnionの中身はこれ。
となっています。
なんでMagicOnionを使うかというと、以下のメリットがあるからです。
- HTTP/2の恩恵を受け、かつ通信データが高効率で圧縮されるため通信が早い。
- インターフェースベースの通信が実現されるのでデータフォーマットを考えなくていい。
- エンドポイントやAPIスキーマを考えなくていい。
- APIだけでなくリアルタイム通信としても使える。
使うには十分すぎるメリットではないかと思います。MagicOnionの詳細は解説しないので、各自調べていただければと思います。
まず、MagicOnionをインポートします。
https://github.com/Cysharp/MagicOnion/releasesこちらのリリースページにある「MagicOnion.Client.Unity.unitypackage」をダウンロードしUnityにインポートしてください。色々足りないと怒られますが気にせず次へいきます。
次に、MessagePackをインポートします。
https://github.com/neuecc/MessagePack-CSharp/releasesこちらのリリースページにある「MessagePack.Unity.XXXXX.unitypackage」をダウンロードしUnityにD&Dしてください。最新のリリースで問題なく動作するはずです。
この時、Pluginsフォルダ内のdllが既に取り込まれているよと警告されるので、Pluginsフォルダのチェックを外してインポートしてください。
最後に、grpcをインポートします。
https://packages.grpc.io/こちらのページの最新のコミットのBuild IDをクリックし、C#欄にある「grpc_unity_package.XXXXX-dev.zip」をダウンロード、解凍します。
解凍すると「Plugins」フォルダがあるはずなので、Pluginsフォルダの中身をUnityのAssets/Pluginsフォルダに入れてインポートします。
それでもまだ怒られると思うので、エラーを解決していきます。
- System.Buffersが被っているので、どちらかを削除
- System.Memoryが被っているので、どちらかを削除
- System.Runtime.CompilerServices.Unsafeが被っているので、どちらかを削除
- unsafeコードが許可されていないぞ☆って怒られるのでunsafeコードを許可
これでエラーは出なくなるはずです。
② Serviceを定義
諸々インポートが完了したらServiceを定義します。ServiceとはWebAPIと同様のものと考えていただければと思います。
ソーシャルゲームは基本的に特定の動作ごとにサーバーにAPIを投げてそのレスポンスを基にクライアントを動かします。本来、API定義を考える場合「https://〇〇〇〇/create_account」みたいなエンドポイントやらスキーマやらを考えなくてはいけませんが、MagicOnionの場合はインターフェース定義自体がそれに当たります。これメチャクチャ便利です。
アカウント作成とログインの機能は、以下の様に定義できます。
IAccountService.csusing MagicOnion; // アカウント周りのサービスを定義するインターフェース public interface IAccountService : IService<IAccountService> { // アカウント作成 UnaryResult<(string userId, string password)> CreateAccount(); // ログイン UnaryResult<string> Login(string userId, string password); }CreateAccountはサーバー側で作成されたユーザIDとパスワードを返し、Loginは引数にユーザIDとパスワードを入力するとログイン中であるセッション情報(string)を返します。
クライアントはIAccountServiceだけを知っていればいいので、IAccountServiceの実態はサーバー側で実装します。
③ NetworkManagerを実装
Serviceの定義が終わったら実際にサーバーと通信する処理を担当するNetworkManagerを実装します。
クライアントはこのNetworkManagerを使ってサーバーとのやり取りをします。NetworkManager.csusing System; using System.Threading.Tasks; using Grpc.Core; using MagicOnion.Client; using UnityEngine; public class NetworkManager : MonoBehaviour { [SerializeField] private string applicationHost = "localhost"; [SerializeField] private int applicationPort = 12345; private IAccountService accountService; private string session; void Start() { var channel = new Channel(applicationHost, applicationPort, ChannelCredentials.Insecure); accountService = MagicOnionClient.Create<IAccountService>(channel); } // アカウント作成 public async Task<(string userId, string password)> CreateAccount() { try { // サーバーにアカウント作成を要求、レスポンスは作成されたユーザIDとパスワード return await accountService.CreateAccount(); } catch (Exception e) { Debug.Log(e); return (null, null); } } // ログイン public async Task<bool> Login(string userId, string password) { try { // ユーザIDとパスワードをサーバーに投げてログイン、レスポンスはセッション情報 session = await accountService.Login(userId, password); return session != null; } catch (Exception e) { Debug.Log(e); session = null; return false; } } }applicationHostは
localhostにしてありますが、後でデプロイ先のエンドポイントに切り替えます。
セキュリティの関係からsslにすべきですが、今回は割愛です。④ ログインテストコードを実装
実際にログインのテストコードを記述してみます。
処理内容はとても単純で、まずローカルに保存してあるユーザー情報(ユーザーID、パスワード)を読み込みます。ユーザー情報そのものがなかったらアカウントを作成し作成されたユーザー情報を保存します。次に、ユーザー情報を元にログインし、通った時と通らなかった時で処理を分けるという形です。LoginTest.csusing System.IO; using MessagePack; using UnityEngine; [MessagePackObject] public class UserData { [Key(0)] public string userId; [Key(1)] public string password; } public class LoginTest : MonoBehaviour { async void Start() { // ネットワークマネージャ取得 var network = GetComponent<NetworkManager>(); // 保存してあるユーザーデータ情報を読み込み UserData userData = null; try { userData = MessagePackSerializer.Deserialize<UserData>(File.ReadAllBytes(Application.persistentDataPath + "/userData.dat")); } catch { } // ユーザーデータが存在しなかったらアカウント作成 if (userData == null) { Debug.Log("アカウント作成開始"); var res = await network.CreateAccount(); if (res.userId == null || res.password == null) { // TODO: アカウント作成失敗時の処理 Debug.LogWarning("アカウント作成失敗。。。"); return; } userData = new UserData(); userData.userId = res.userId; userData.password = res.password; // ユーザー情報保存(※本来は暗号化等する事!) var data = MessagePackSerializer.Serialize(userData); File.WriteAllBytes(Application.persistentDataPath + "/userData.dat", data); Debug.Log("アカウント作成成功"); } // ログイン Debug.Log("ログイン中..."); var loginResult = await network.Login(userData.userId, userData.password); if (!loginResult) { // TODO: ログイン失敗時の処理 Debug.LogWarning("ログイン失敗。。。"); return; } // TODO: ログインが通った後の処理 Debug.Log("ログイン成功!"); } }本来ならばもっと厳密にログイン処理を行うべきですが、今回はテストなので超単純に作っています。
ここを通ればログインに成功したことになるので、後はクライアント側は煮るなり焼くなりするだけです。次に、サーバーサイドの実装に移ります。
サーバーサイド
サーバーサイドはフレームワークとして.NetCore3.1を使います。言語は当然C#です。
.NetFrameworkを使ってしまうとデプロイ周りで苦労することになるので、サーバーサイドC#は.NetCoreを使ってください。サーバーの実装手順としては以下の様になります。
① プロジェクトの準備、MagicOnionのインストール
② Mainプログラムの記述
③ AccountServiceの実装
④ ローカル環境で動作確認① プロジェクトの準備、MagicOnionのインストール
まず、プロジェクトを作成します。プロジェクトは「コンソール アプリ(.NET Core)」を選択してください。プロジェクト名は何でもいいです。私はとりあえず「Qiita2020TestServer」にしました。
プロジェクトの作成が終わったら、クライアントとの通信に必要なコンポーネントをNuget経由でインストールします。
プロジェクトのコンテキストメニューの「Nuget パッケージの管理(N)...」からMagicOnion.Hostingをインストールします。バージョンは最新の安定板で大丈夫です。
一応、Unityで使われている型をサーバーでも扱えるように
MessagePack.UnityShimsもインストールしておきます。
これでサーバーサイドに必要なコンポーネントがインストールできました。
② Mainプログラムの記述
サーバーを起動するMainプログラムを記述します。
やっていることはとても単純で、ログ出力先をコンソールに指定し、ホストとポートを指定して起動しているだけです。Program.csusing Grpc.Core; using MagicOnion.Hosting; using MagicOnion.Server; using Microsoft.Extensions.Hosting; using System.Threading.Tasks; namespace Qiita2020TestServer { class Program { static async Task Main(string[] args) { // コンソールにログ出力するように設定 GrpcEnvironment.SetLogger(new Grpc.Core.Logging.ConsoleLogger()); // MagicOnionを使ってホスト作成、起動 await MagicOnionHost.CreateDefaultBuilder() .UseMagicOnion( new MagicOnionOptions(isReturnExceptionStackTraceInErrorDetail: true), new ServerPort("0.0.0.0", 12345, ServerCredentials.Insecure)) .RunConsoleAsync(); } } }一応これだけでもサーバーを起動することはできます。デバッグ実行すると以下の様な画面が出るはずです。
これだけでは何の機能もない張りぼてサーバーなので、クライアント側で実装した「アカウント作成」と「ログイン」機能を実装していきます。
③ AccountServiceの実装
サーバー側のアカウント作成とログイン機能の実装をします。
クライアントで定義したIAccountService.csが必要なので、予め丸々コピーしておいてください。(本来は、submodule等用いてソースコードの共有をすることをお勧めします。)アカウント作成は、ランダムなハッシュ値を用います。ユーザーIDは20桁、パスワードは12桁にしておきます。ログインは作成されたユーザーIDとパスワードを検証し、一致したら以降のAPIを呼び出すことが出来るセッションを返します。セッションも一先ずランダムな20桁のハッシュ値を返します。
AccountService.csusing MagicOnion; using MagicOnion.Server; using System; using System.Collections.Generic; using System.IO; using System.Security.Cryptography; using System.Text; namespace Qiita2020TestServer { class AccountService : ServiceBase<IAccountService>, IAccountService { // セッション情報管理(本来はRedis等用いる事!) private static Dictionary<string, (string userId, DateTime expireAt)> sessions = new Dictionary<string, (string userId, DateTime expireAt)>(); private static object lockObject = new object(); // アカウント作成 public async UnaryResult<(string userId, string password)> CreateAccount() { Logger.Info("CreateAccount Request"); var userId = GenerateHash(20); var password = GenerateHash(12); // アカウント情報を仮でファイルに保存(本来はDBに入れる事!) try { if (!Directory.Exists("accounts")) Directory.CreateDirectory("accounts"); File.WriteAllText("accounts/" + userId, password); } catch (Exception e) { Logger.Error(e, "CreateAccount Error"); return (null, null); } Logger.Info($"CreateAccount UserId:{userId}, Password:{password}"); return (userId, password); } // ログイン public async UnaryResult<string> Login(string userId, string password) { Logger.Info("Login Request"); try { // アカウントがない if (!File.Exists("accounts/" + userId)) return null; // パスワードが一致しない if (File.ReadAllText("accounts/" + userId) != password) { Logger.Warning("Login failed: " + (userId, password)); return null; }; } catch (Exception e) { Logger.Error(e, "Login Error"); return null; } // セッション情報作成 var session = GenerateHash(20); lock (lockObject) { // 一先ず1日有効なセッションを保存 sessions[session] = (userId, DateTime.UtcNow.AddDays(1)); } Logger.Info("【" + userId + "】Login succeeded!"); // セッションを返す return session; } // 指定の長さのランダムハッシュ値を取得 private static string GenerateHash(int length) { return Sha256(Guid.NewGuid().ToString("N")).Substring(0, length).ToLower(); } // Sha256ハッシュ private static string Sha256(string str) { var input = Encoding.ASCII.GetBytes(str); var sha = new SHA256CryptoServiceProvider(); var sha256 = sha.ComputeHash(input); var sb = new StringBuilder(); for (int i = 0; i < sha256.Length; i++) { sb.Append(string.Format("{0:X2}", sha256[i])); } return sb.ToString(); } } }これで、アカウント作成とログイン機能を備えたサーバープログラムが整いました。
④ ローカル環境で動作確認
ここまでで、ローカル環境で動作確認をすることが出来るようになったので、確認してみます。
サーバーをデバッグ実行してローカルサーバーを立ち上げ、クライアントをデバッグ実行します。
問題がなければクライアントは以下の様に表示されるはずです。
サーバー側は以下の様に表示されます。
ローカルで問題なく動作できていることが確認できました。
最後に、実際にクラウド上にデプロイして確認してみたいと思います。デプロイ
ローカル環境で問題なく動作させることが確認できれば、本来はデプロイまでは頑張らなくてもいいですが、せっかくなのでEC2へのデプロイまでやってみたいと思います。CI/CDやDockerコンテナでもよかったのですが解説が逸れそうなので直デプロイします。
手順としては、以下の様になります。
① awsでEC2インスタンスを用意、起動する
② ターミナルでEC2インスタンスにログイン
③ .NetCore3.1をインストール
④ サーバープロジェクトを配置、実行
⑤ クライアント動作確認① awsでEC2インスタンスを用意、起動する
最初にAWSコンソールにサインインします。アカウントを持ってない人は作ってください。
サインインしたらEC2を選択します。EC2は仮想サーバーみたいなものだと思ってください。
左側の「キーペア」を選択します。
右上の「キーペアを作成」をクリックします。
名前を「Qiita2020TestServer」(名前は何でもいいです)にして、「キーペアを作成」をクリックします。
キーペアが作成されppkファイルがダウンロードされます。
このキーは後で作るインスタンスへのログインに必要なので、大切に保管しましょう。次に、左側の「インスタンス」を選択します。
「インスタンスの作成」をクリックします。
何のインスタンスを作るか聞かれるので、「Amazon Linux 2 AMI」を選択してください。
どのスペックの仮想マシンを立ち上げるか聞かれるので、無料で使える「t2.micro」を選択し、「次のステップ:インスタンスの詳細と設定」をクリック。
いろんな設定項目がありますが、ここでは「自動割り当てパブリックIP」を「有効」にします。
有効にしたら「次のステップ:ストレージの追加」へ。
ストレージは30GBまで無料らしいので一先ず30GBに設定し「次のステップ:タグの追加」へ。
タグの追加を押し、キーに「Name」、値に「Qiita2020TestServer」と入力します。(値はわかれば何でもいいです)
入力したら「次のステップ:セキュリティグループの設定」へ。
「ルールの追加」を押し、以下の様に入力し12345ポートを解放します。
分かりやすいように説明も入れておきましょう。(※画像は日本語ですが、日本語の説明ではインスタンスが作成できなかったので、英語で入力してください!)
入力したら「確認と作成」をクリック。
確認画面で「すべてのIPからインスタンスにアクセスできるよ、いいの?」と警告されますが気にせず「起動」を押します。
インスタンスに安全に接続するためのキーペアを選びます。先ほど作成した「Qiita2020TestServer」キーペアを選んで、「インスタンスの作成」をクリックします。
インスタンス作成中の画面が表示されるので、右下の「インスタンスの表示」をクリックしてください。
すると、作成されたインスタンス一覧が表示されます。問題がなければインスタンスはそのまま起動します。
これで、インスタンスの準備は整いました。
作成したインスタンスの「IPv4パブリックIP」はターミナル接続先なので控えておいてください。② ターミナルでEC2インスタンスにログイン
EC2インスタンスにログインします。
ターミナルソフトは何でもいいですが、私は「TeraTerm」を使って解説します。TeraTermを起動したらホストに先ほど作成したインスタンスのパブリックIPを入力してOKをクリック。
SSH認証が必要なので、ユーザ名に「ec2-user」、認証方式には最初の方に作成したキーペアの秘密鍵「Qiira2020TestServer.ppk」を指定します。
問題なくSSH接続できたら以下の様に表示されます。ここからはいつものターミナルです。
③ .NetCore3.1をインストール
必要なパッケージをインストールします。今回は.NetCoreを動かすためのランタイム「.NetCoreRuntime」をインストールすればOKです。
まずはパッケージ更新
$ sudo yum updateMicrosoftパッケージリポジトリを追加。
$ sudo rpm -Uvh https://packages.microsoft.com/config/centos/7/packages-microsoft-prod.rpm.NetCore3.1SDKインストール
$ sudo yum install dotnet-sdk-3.1.NetCore3.1ランタイムインストール
$ sudo yum install dotnet-runtime-3.1これでEC2上で.NetCore3.1プロジェクトが実行できるようになりました。
④ サーバープロジェクトを配置、実行
サーバープロジェクトを配置します。配置方法は何でもいいですが個人的にはgitを使うのが一番楽です(余力のある方はGithubActions等を使ったCI/CDをお勧めします。)。サーバープロジェクトをgithubでリモート管理し、git cloneでそのまま配置します。こうすると何が良いかというと、サーバープロジェクトの更新が入った時にgit pullするだけで更新できます。
ただ今回はプロジェクトをgithubに配置しないので、おとなしくsftpで配置します。sftpの解説はしません。各自良い感じにサーバープロジェクトを根こそぎ持ってきてください。配置場所は
ec2-userフォルダ内に「Qiita2020TestServer」を作ります。
$ mkdir Qiita2020TestServer
この中にプロジェクトを配置します。配置したら、Qiita2020TestServer.csprojがあるフォルダまで移動します。
.Netはcsprojをそのままdotnet runで実行することが出来るので、実行してみます。
$ dotnet runこれで以下の様にEC2上でサーバーが立ち上がりました。
直に立ち上げるとSSHを終了した段階でサーバープログラムが止まってしまうのでscreenを使うと色々捗ります。
最後にクライアントからEC2上にアクセスできるか確認します。
⑤ クライアント動作確認
クライアントのapplicationHostが
localhostのままなので、NetworkManagerのこの部分をEC2インスタンスのパブリックIPに置き換えてください。
置き換えて、クライアントをデバッグ実行します。そして、以下の表示が出たらEC2との接続に成功です!
これで、C#のみで作ったソシャゲの最低限の基盤ができました。
ここからマスターデータやアセバン管理、クエスト処理やガチャ処理等を生やしていけば、C#のみで作るソシャゲの出来上がりです。お疲れまでした。おわりに
いかがでしょうか、意外と簡単にソシャゲの最低限の基盤を作ることができたのではないかと思います。もちろん本物はこれだけじゃ済まないボリュームですが、基礎を捉えるのは大きな前進になるのではないかと思います。
今回は省きまくりましたが、セキュリティだけはしっかり設定してください。ソシャゲはユーザの大事な情報を管理するので、ガバガバ設定では当然許されません。最低でも、ユーザーデータの暗号化、SSL、サーバー監視はしっかりするように!
皆様はもちろんC#信者だと思うので、その熱意をUnityだけではなくそのままサーバーサイドにも向けてみてはいかがでしょうか。私もまだまだサーバーサイドは勉強中なので偉そうなことは言えませんが、クライアントサイドとはまた別の面白さがあるので、やりがいはいっぱいあるかと思います。
頑張れば、一人でもソシャゲが作れる時代です。
最後まで読んでいただき、ありがとうございました。
参考資料
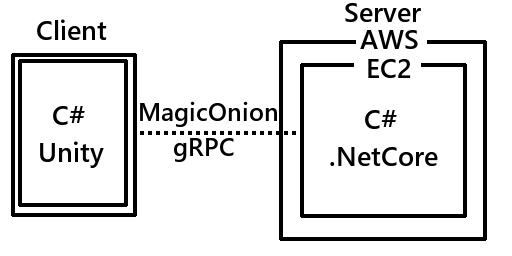
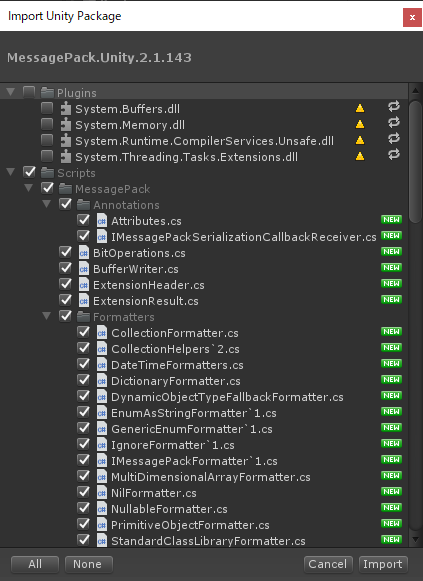

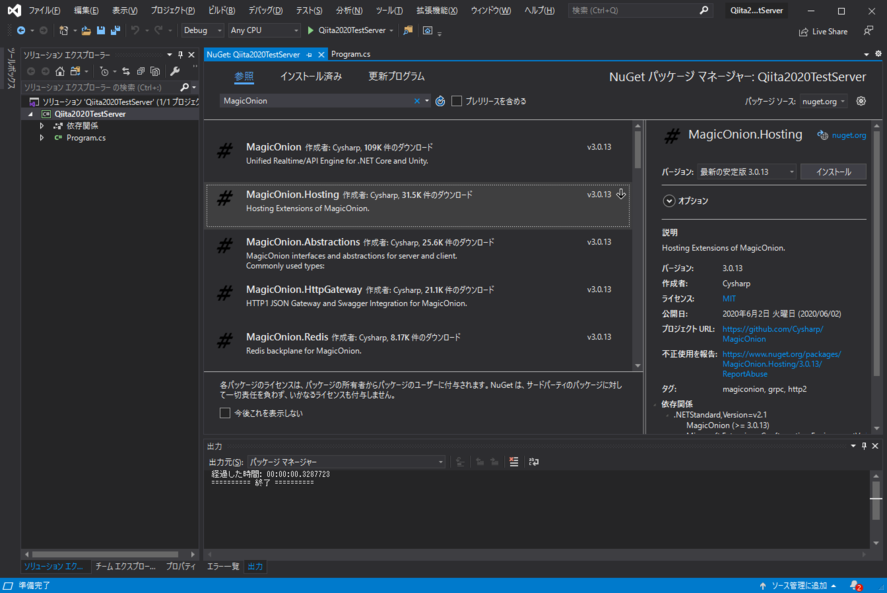

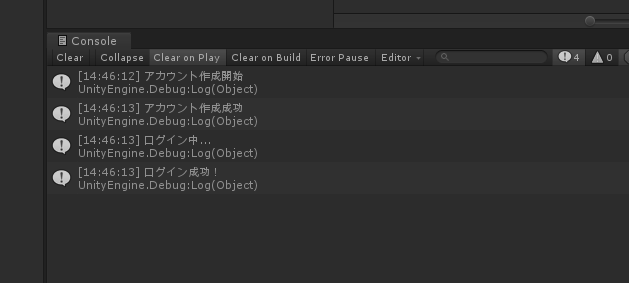
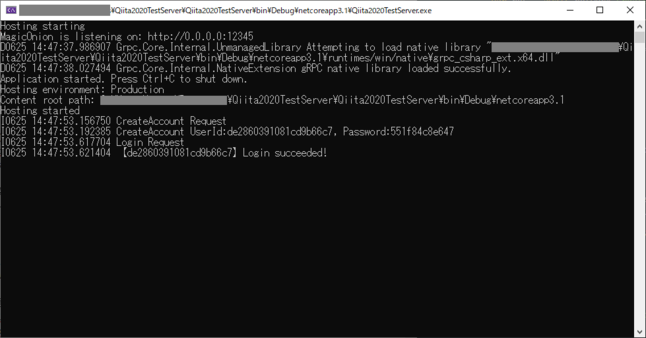






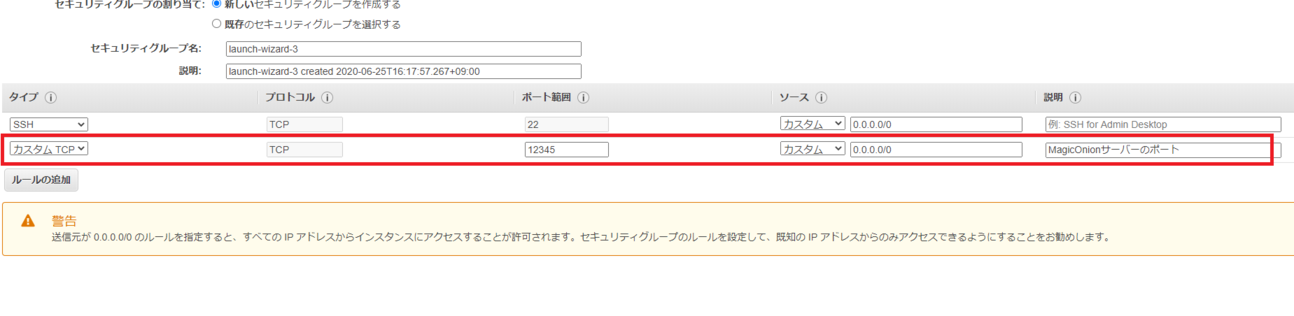
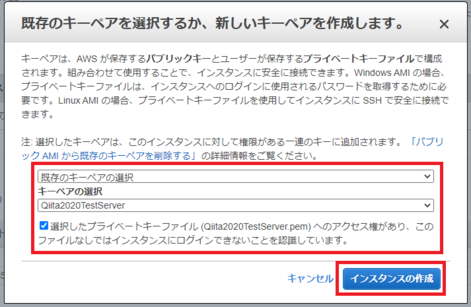


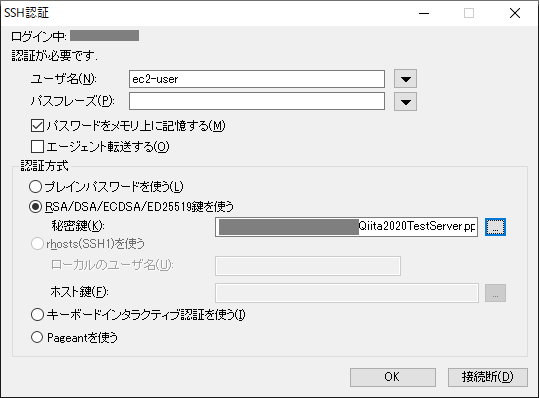
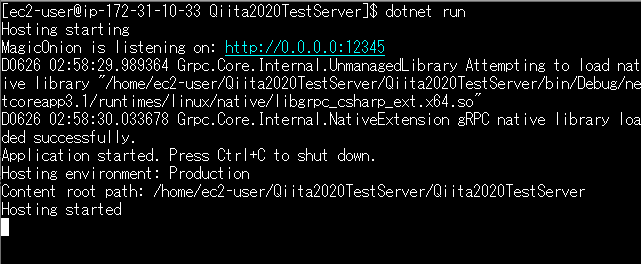
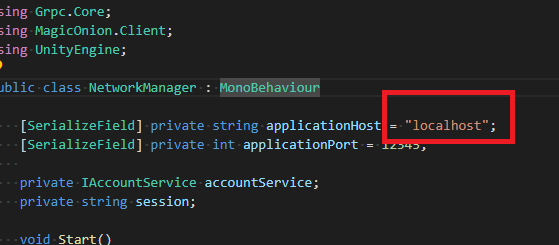
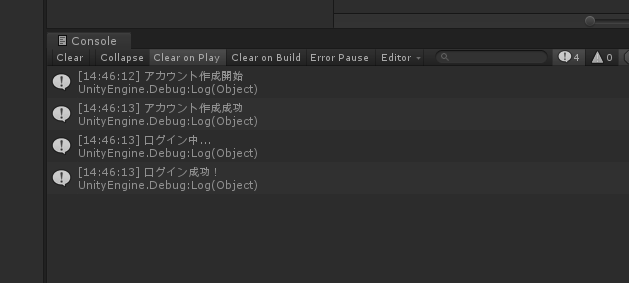
- 投稿日:2020-06-29T02:25:41+09:00
(自分用)AWS_Flask_3(AWS上でFlaskをインストール/動かす)
項目
- AWSにFlaskをインストール
- 実際に動かしてみる
1.AWSにFlaskをインストール
- 前回でもうPythonは入れてあると言う前提
ターミナル# ホームディレクトリへ $$ cd # Python仮想環境を作る(myenvは他の名前でもよいぞ) $$ python3 -m venv myenv # Python仮想環境を有効化する $$ source myenv/bin/activate # 左の環境名だったりの所に(myenv) と表示されれば成功 # pipを一応最新にしておく $$ pip install --upgrade pip # Flaskをインストール $$ pip install flask # ちゃんとpipにモジュールがあるか確認 $$ pip freeze2.実際に動かしてみる
ターミナル# pyファイルを作成、今回はApacheで動かすので/var/www/htmlの中に作る $$ vi /var/www/html/test.pytest.py# 何度でも言うが'i'で入力モード、入力が終わったら'esc'、':wq'で保存終了 from flask import Flask app = Flask(__name__) @app.route('/') def hello(): return 'Hello World!' if __name__ == '__main__': # Flaskはホストが'0.0.0.0'じゃないと動かないらしい、ここ周りは必須 app.run(host='0.0.0.0')ターミナル# ブラウザで動かす! $$ python3 /var/www/html/test.py # http://AWSで設定したパブリックIPアドレス:5000に接続でHello!してるはず # Python仮想環境の終了 $$ deactivate3.終わりに
- 取り敢えずFLaskは動いた!
- 長すぎる道のりだった
- あとはMySQLにPythonから接続出来るかを頑張れば
- 本チャン!
- 遠すぎた橋
- 投稿日:2020-06-29T01:18:47+09:00
ノーコード(no-code)なツール(特にHoneycode)を触ってみた
2020年6月25日(JPT)にAWSからノーコードツールである「Amazon Honeycode」がローンチされました(β版?)。のでちょっと触ってみました。
はじめに
とある市役所でのkintoneの事例(「手間がめちゃくちゃ減った」 郵送とオンラインのハイブリッド給付金申請、非エンジニアの市職員が開発 経緯を聞いた)もすごいとおもっていたり、ちょうどノーコードツールをあれこれ探っていたので、まさにタイムリーと思いました。具体的にはエクセル(A3で3枚くらい)の「セキュリティチェックシート」をアプリ化することを考えていたのですが、どういう入力方法にすれば楽なんだろうと模索するためにノーコードツールを探していました。ということで今回は「クラスメソッド 標準セキュリティチェックシートを公開しました」でも採用されている、IPAが出しているセキュリティチェックシート(リスク分析シート)をベースに、ノーコードツールでアプリにしてみました。
セキュリティチェックシートの特徴
以下のような表になっています。
1.情報セキュリティ対策の種類 2.情報セキュリティ診断項目 3.判定 4.実施状況 1 組織的対策 経営者の主導で情報セキュリティの方針を示していますか? 0 1 組織的対策 情報セキュリティの方針に基づき、具体的な対策の内容を明確にしていますか? 0 1 組織的対策 (省略) 0 2 人的対策 (省略) 0 2 人的対策 (省略) 0 3 情報資産管理 (省略) 0 kintone
いわずとしれたノーコードツールですね。アカウントを持っていなかったのでお試しで作って触ってみました。
手順
手順は以下のとおり。
- 30日無料のアカウント作成とサブドメインの作成
- 管理画面が用意される(とりあえずユーザー招待はしない)
- 「エクセルを読み込んで作成」からエクセルを読み込む(レンジ指定が可能だった)
- 簡単な表形式のアプリ生成(一覧で直接編集ができた)
成果物
こんなかんじ。
良かった点
良かった点は以下のとおり。
- 判定項目(○|×)のような選択項目がとても簡単に作成できました(エクセルのリストみたいな感覚)。
- APIをJavaScriptで呼んだりできるので、他サービスへのデータソース連携も簡単にできそうでした。
参考
システム開発会社が行うNo-Code開発
https://www.r3it.com/blog/20181210-how-we-make-our-internal-systems-with-no-code-toolsMicrosoft Power Apps
MicrosoftのPower Appsも先行していたので使ってみました。無料でも試せるみたいだったのですが、組織アカウントが必要だったのでちょっと迷いましたが、以下のようにすると無料で使えました。
手順
手順は以下のとおり。
- Azure Active Directoryでユーザを追加
- 追加したユーザでPower Appsにログイン(うまく組織アカウントとして認識された)
- 「データから開始」からエクセルファイルをOneDrive経由で読み込む(エクセルの場合「テーブルとして書式設定」
- 簡単な表形式のアプリ生成(一覧と詳細画面ができた)
成果物
こんなかんじ。
良かった点
良かった点は以下のとおり。
- モバイルにカスタマイズできていて、表をスマートフォンで扱うにはこうすればいいのかという参考になりました。
- データソースにしているOneDriveのファイルと連携しているPC上のファイルも変更されたので便利でした。
参考
Microsoft PowerAppsを使ったら驚くほど簡単にオリジナルのブログアプリが作れた
https://tech.recruit-mp.co.jp/dev-tools/microsoft-power-apps-review/Amazon Honeycode
まだあまり記事がでてなかったのですが、kintoneとPower Appsを触った感でやってみました。AWS上でHoneycode用のユーザを作る必要がありました。
手順
手順は以下のとおり。
- Basicプラン(無料)を選んでからHoneycode用のユーザ作成
- 追加したユーザでHoneycodeにログイン
- CSVを読み込む
- 「Use app wizard」から簡単な表形式のアプリ生成(一覧と追加画面と削除画面ができた)
- 「Bulid your own」からあれこれ実施(一覧と編集画面ができた)
成果物
こんなかんじ。※スマホ専用のHoneycodeアプリで見ると少し感動します。
良かった点
良かった点は以下のとおり。
- ウィザードで作ったものを参考に、自分用のカスタマイズがし易かったです。
- おそらくAWSの各種リソースと連携ができるんだろうなと思いました。
参考
Amazon Honeycode を触ってみた
https://www.r3it.com/blog/try-amazon-honeycodeおわりに
どのツールでも、私の目的である、どうやったら入力が簡単になるんだろうという、お試しが簡単にできるという意味では使えそうでしたが、AWSにこのようなツールがでてきたのはとても私にとってキャッチーでありました。
以上
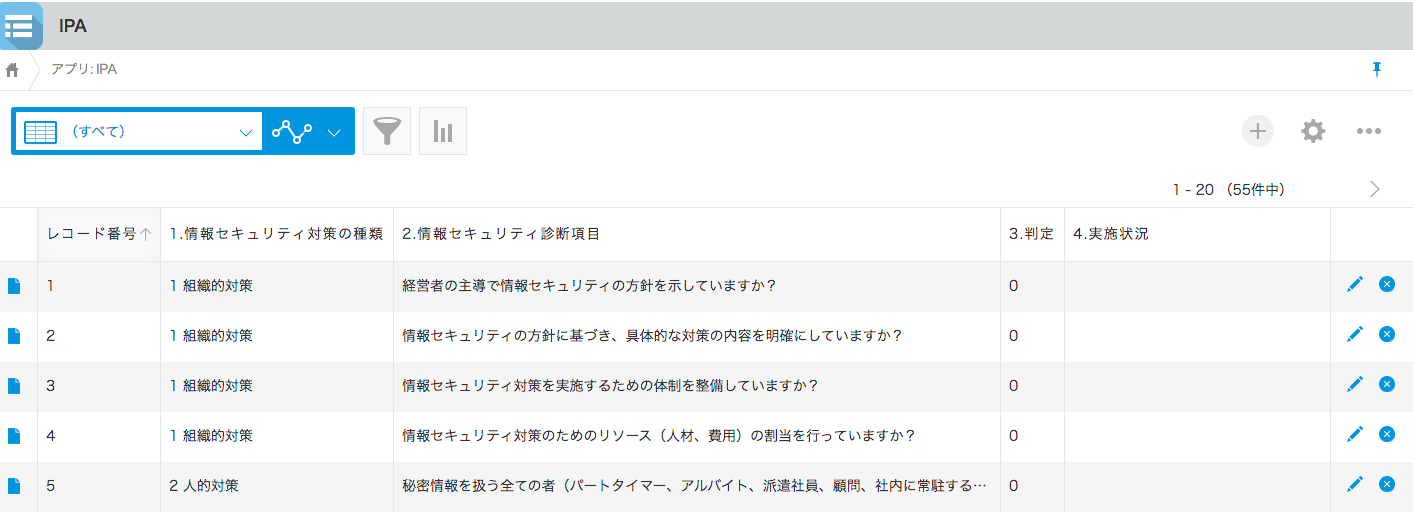


- 投稿日:2020-06-29T01:18:47+09:00
ノーコードツール(特にHoneycode)を触ってみた
2020年6月25日(JPT)にAWSからノーコードツールである「Amazon Honeycode」がローンチされました(β版?)。のでちょっと触ってみました。
はじめに
とある市役所でのkintoneの事例(「手間がめちゃくちゃ減った」 郵送とオンラインのハイブリッド給付金申請、非エンジニアの市職員が開発 経緯を聞いた)もすごいとおもっていたり、ちょうどノーコードツールをあれこれ探っていたので、まさにタイムリーと思いました。具体的にはエクセル(A3で3枚くらい)の「セキュリティチェックシート」をアプリ化することを考えていたのですが、どういう入力方法にすれば楽なんだろうと模索するためにノーコードツールを探していました。ということで今回は「クラスメソッド 標準セキュリティチェックシートを公開しました」でも採用されている、IPAが出しているセキュリティチェックシート(リスク分析シート)をベースに、ノーコードツールでアプリにしてみました。
セキュリティチェックシートの特徴
以下のような表になっています。
1.情報セキュリティ対策の種類 2.情報セキュリティ診断項目 3.判定 4.実施状況 1 組織的対策 経営者の主導で情報セキュリティの方針を示していますか? 0 1 組織的対策 情報セキュリティの方針に基づき、具体的な対策の内容を明確にしていますか? 0 1 組織的対策 (省略) 0 2 人的対策 (省略) 0 2 人的対策 (省略) 0 3 情報資産管理 (省略) 0 kintone
いわずとしれたノーコードツールですね。アカウントを持っていなかったのでお試しで作って触ってみました。
手順
手順は以下のとおり。
- 30日無料のアカウント作成とサブドメインの作成
- 管理画面が用意される(とりあえずユーザー招待はしない)
- 「エクセルを読み込んで作成」からエクセルを読み込む(レンジ指定が可能だった)
- 簡単な表形式のアプリ生成(一覧で直接編集ができた)
成果物
こんなかんじ。
良かった点
良かった点は以下のとおり。
- 判定項目(○|×)のような選択項目がとても簡単に作成できました(エクセルのリストみたいな感覚)。
- APIをJavaScriptで呼んだりできるので、他サービスへのデータソース連携も簡単にできそうでした。
参考
システム開発会社が行うNo-Code開発
https://www.r3it.com/blog/20181210-how-we-make-our-internal-systems-with-no-code-toolsMicrosoft Power Apps
MicrosoftのPower Appsも先行していたので使ってみました。無料でも試せるみたいだったのですが、組織アカウントが必要だったのでちょっと迷いましたが、以下のようにすると無料で使えました。
手順
手順は以下のとおり。
- Azure Active Directoryでユーザを追加
- 追加したユーザでPower Appsにログイン(うまく組織アカウントとして認識された)
- 「データから開始」からエクセルファイルをOneDrive経由で読み込む(エクセルの場合「テーブルとして書式設定」
- 簡単な表形式のアプリ生成(一覧と詳細画面ができた)
成果物
こんなかんじ。
良かった点
良かった点は以下のとおり。
- モバイルにカスタマイズできていて、表をスマートフォンで扱うにはこうすればいいのかという参考になりました。
- データソースにしているOneDriveのファイルと連携しているPC上のファイルも変更されたので便利でした。
参考
Microsoft PowerAppsを使ったら驚くほど簡単にオリジナルのブログアプリが作れた
https://tech.recruit-mp.co.jp/dev-tools/microsoft-power-apps-review/Amazon Honeycode
まだあまり記事がでてなかったのですが、kintoneとPower Appsを触った感でやってみました。AWS上でHoneycode用のユーザを作る必要がありました。
手順
手順は以下のとおり。
- Basicプラン(無料)を選んでからHoneycode用のユーザ作成
- 追加したユーザでHoneycodeにログイン
- CSVを読み込む
- 「Use app wizard」から簡単な表形式のアプリ生成(一覧と追加画面と削除画面ができた)
- 「Bulid your own」からあれこれ実施(一覧と編集画面ができた)
成果物
こんなかんじ。※スマホ専用のHoneycodeアプリで見ると少し感動します。
良かった点
良かった点は以下のとおり。
- ウィザードで作ったものを参考に、自分用のカスタマイズがし易かったです。
- おそらくAWSの各種リソースと連携ができるんだろうなと思いました。
参考
Amazon Honeycode を触ってみた
https://www.r3it.com/blog/try-amazon-honeycodeおわりに
どのツールでも、私の目的である、どうやったら入力が簡単になるんだろうという、お試しが簡単にできるという意味では使えそうでしたが、AWSにこのようなツールがでてきたのはとても私にとってキャッチーでありました。
以上