- 投稿日:2020-06-25T09:46:14+09:00
【Windows】Tensorflow2.0をビルドする(C++向け.dll)【備忘録】
はじめに
基本的には公式マニュアル通り
Bazel C++ チュートリアルを見ながら、少し手を加えたところをメモとして残す構成
- Tensorflow 2.0.0
- Python 3.6.8
- Visual Studio 2017 Community
- Bazel 0.26.1
ソースをダウンロード
git clone https://github.com/tensorflow/tensorflow.git cd tensorflow git checkout r2.0 ### ココ.bazelrcを編集
tensorflowフォルダ直下にある.bazelrcファイルを編集.bazelrcstartup --output_user_root=C:/tmp build --enable_runfilesビルド
以下、開発者コマンドプロンプト for VS 2017で実行
Visual Studioが複数インストールされている場合は、コンパイラを明示しておくset BAZEL_VC=C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC set BAZEL_VC_FULL_VERSION=14.16.27023
BUILDファイルを内のコメントを参考に、必要そうなものをビルドbazel build --config=opt //tensorflow:tensorflow_cc.dll # .dll生成 bazel build --config=opt //tensorflow:install_headers # includeフォルダdllの方はAMD Ryzen 5 3500U, 8GB RAMで65,000秒(=18時間)かかりました
おわり。
- 投稿日:2020-06-25T09:17:42+09:00
Tensorflow2(Sequential API, Functional API, Subclassing API)とMNISTではじめる画像分類
はじめに
機械学習のモデルを構築する3つの方法について網羅的に紹介し、TensorFlow2.0とそれに統合されたKerasを使って実装しながら使い方を解説します。
対象読者
- ディープラーニング基礎知識があるが、TensorFlow2.0でモデルを実装したことがない人
- TensorFlow2.0の画像分類にチャレンジしてみたい人
- TensorFlow2.0のチュートリアルを試したが、それぞれAPIの特徴やメソッドについてもっと詳しく知りたい人
1. モデルを構築する3つの方法
TensorFlow2.0でモデルを構築する方法を細かく分けるとSequential API、Functional API、Subclassing API 3つあります。Google公式ブログ記事ではこれらを以下のように分類されています。
シンボリック(宣言型)API 命令型(モデル サブクラス化)API Sequential API、Functional API Subclassing API (Model Subclassing) レイヤーのグラフを操作してモデルを構築するのをシンボリックスタイル(宣言型)、クラスを拡張してモデルを構築するのは命令型(モデル サブクラス化)スタイルと呼びます。以下の3つの簡単な説明があります。
1-1) Sequential API
Sequentialというのは「線形の」いう意味で、線形というのは線のように一例につながっているということです。つまり、Sequentialモデルは層を積み重ねたものです。Sequential モデルはコンストラクタにレイヤーのインスタンスのリストを与えることで作れます。
1-2) Functional API
ニューラルネットワークを用いて解決する問題は高次元データや何らかの複雑性を持つものが多く、それに対応したモデルは複雑なものになりやすいです。Functional API を使うと、Sequential APIより柔軟なモデルを作成でき、非線形トポロジ、共有レイヤーを含むモデル、複数の入力や出力を持つモデルを扱うことができます。基本的に、Functional API は、こういったレイヤーのグラフを構築するためのツールセットです。
1-3) Subclassing API
フォワードパスが命令的に記述されるので、Subclassing APIはSequential API、Functional APIより柔軟性を実現できます。つまり、ライブラリで実装されているパーツ(レイヤー、活性化関数、損失関数)を簡単に独自の実装と取り替えることができます。モデルの定義をオブジェクト指向に定義するのがPyTorchに似ています。
各々のトレードオフについて一つの表で整理すると下記のようになります。
API メリット デメリット Sequential API 初心者でもモデルの構築から学習まで容易、グラフ構造を可視化可能 分岐するネットワークの構築ができない Functional API 複雑なネットワークを構築可能、グラフ構造を可視化可能 動的なモデルを実装できない Subclassing API フルカスタマイズ可能、動的なネットワークを構築可能 APIの学習コストが高い、グラフ構造を可視化が難しい これらを実装しながらAPIの特徴を詳しく説明したいと思います。
2. データの準備
使用するデータセット
1章で紹介したAPIの特徴を画像分類モデルの実装を通して説明したいと思います。今回画像分類に使用するデータセットはMNISTを使います。
MNISTデータセットとは60000枚の28×28ピクセルからなる手書き数字画像と「0〜9」に正解ラベルが与えられるデータセットであり画像分類のチュートリアルとしてよく使うデータセットです。データセットの準備
MNISTデータセットを用意する方法は幾つかありますが、方法の一つとして、
tf.keras.datasetsからコードを実行することでダウンロードする方法があります。実行すると~/.keras/datasetにデータがダウンロードされます。データはNumPy配列ndarrayです。( ※ Mnistデータセットを用意する他の方法は別の記事で紹介します。)
import tensorflow as tf # MNISTデータセットのダウンロード mnist = tf.keras.datasets.mnist (x_train, t_train), (x_test, t_test) = mnist.load_data() # 0~1へ正規化する x_train, x_test = x_train / 255., x_test / 255.前処理としてイメージを255.で割り算を行い、0~1に正規化(normalization)しています。正規化をすることで、精度がよくなります。
データセットがちゃんと準備出来てるか
matplotlibライブラリで確認してみましょう。import matplotlib.pyplot as plt for i in range(8): plt.subplot(420 + 1 + i) plt.imshow(x_train[i][:,:])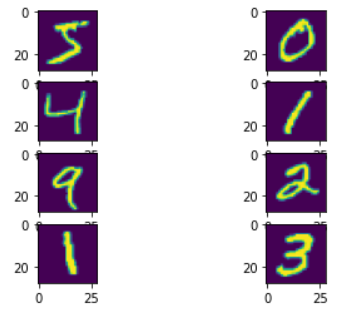
3. Sequential APIを利用してモデルの構築
【Sequential API実装の流れ】
1) モデルの構築 (
tf.keras.models.Sequential)
→ リストにレイヤーを積み重ねることでモデル構築します。2) モデルのコンパイル (
model.compile)
→ 最適化関数と損失関数を選択し計算グラフを構築します。3) モデルを訓練 (
model.fit)
→ エポック数とバッチ数を指定してトレーニングします。4) モデルの評価 (
model.evaluate)
→ オプションですが、verboseでプログレスバーを出力できます。5) モデルの保存 (
tf.saved_model)
→model.saveでSavedModel形式で保存することができます。この記事ではモデル保存の説明はスキップします。
3-1) モデルの作成
基本的にモデルはどのような入力のshapeを想定しているのかを知る必要があります。 このため, Sequential モデルの最初のレイヤーに入力のshapeについての情報を与える必要があります。
(※最初のレイヤー以外は入力のshapeを推定できるため,指定する必要はありません。)
入力のshapeを指定する方法はいくつかあります:
(1) 最初のレイヤーの
input_shape引数を指定
この引数にはshapeを示すタプルを与えます。
(このタプルの要素は整数かNoneを取ります。Noneは任意の正の整数を期待することを意味します。)(2) Dense のような2次元の層では
input_dim引数を指定することで入力のshapeを指定
同様に,3次元のレイヤーではinput_dim引数とinput_length引数を指定することで入力のshapeを指定できます。(3)
stateful reccurent networkなどでバッチサイズも一緒に指定したい場合,batch_size引数を指定
例えば,batch_size=32とinput_shape=(6, 8)を同時に指定した場合,想定されるバッチごとの入力のshapeは (32, 6, 8)となります。ここでは1番目の方法を利用して実装しました。そして、
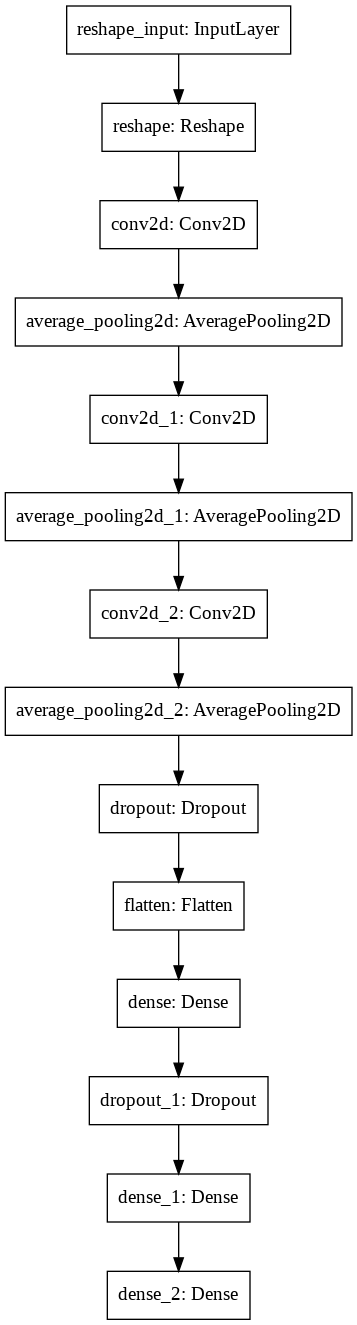
addメソッドで「LEGO ブロックを組み合わせる」のと同じくらい簡単にモデルの構成しました。model_name = "CNN" model = tf.keras.Sequential() model.add(tf.keras.layers.Reshape(target_shape=(1, 28, 28), input_shape=(28,28))) model.add(tf.keras.layers.Conv2D(kernel_size=(3, 3), filters=32, padding="same", data_format="channels_first", kernel_initializer="uniform", use_bias=False)) model.add(tf.keras.layers.AveragePooling2D(pool_size=(2, 2), data_format="channels_first")) model.add(tf.keras.layers.Conv2D(kernel_size=(3, 3), filters=32, padding="same", data_format="channels_first", kernel_initializer="uniform", use_bias=False)) model.add(tf.keras.layers.AveragePooling2D(pool_size=(2, 2), data_format="channels_first")) model.add(tf.keras.layers.Conv2D(kernel_size=(3, 3), filters=64, padding="same", data_format="channels_first", kernel_initializer="uniform", use_bias=False)) model.add(tf.keras.layers.AveragePooling2D(pool_size=(2, 2), data_format="channels_first")) model.add(tf.keras.layers.Dropout(0.25)) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(256, activation='relu')) model.add(tf.keras.layers.Dropout(0.25)) model.add(tf.keras.layers.Dense(256, activation='relu')) model.add(tf.keras.layers.Dense(10, activation='softmax'))3-2) モデルをコンパイル
adam = tf.keras.optimizers.Adam(lr=0.0005, beta_1=0.9, beta_2=0.999, epsilon=1e-08) model.compile(loss='categorical_crossentropy', optimizer=adam, metrics=['accuracy'])モデルの学習を始める前に,
compileメソッドを用いどのような学習処理を行なうかを設定する必要があります。compileメソッドは3つの引数を取ります:(1) 最適化アルゴリズム(optimizer)
引数として,定義されている最適化手法の識別子を文字列として与える(rmspropやadagradなど),もしくは Optimizerクラスのインスタンスを与えることができます。(2) 損失関数(loss)
モデルが最小化しようとする目的関数です.引数として,定義されている損失関数の識別子を文字列として与える(categorical_crossentropyやmseなど),もしくは目的関数を関数として与えることができます。(3) 評価関数のリスト(metrics)
訓練時とテスト時にモデルにより評価される評価関数のリストで、一般的にはmetrics=['accuracy']を使うことになります。引数として,定義されている評価関数の識別子を文字列として与える,もしくは自分で定義した関数を関数として与えることができます。その以外に
model.compileメソッドでloss_weightsやweighted_metrics等の設定もできます。3-3) モデルの確認
summaryメソッドはモデルの構成を要約して画面に表示されるようにします。model.summary()Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= reshape (Reshape) (None, 1, 28, 28) 0 _________________________________________________________________ conv2d (Conv2D) (None, 32, 28, 28) 288 _________________________________________________________________ average_pooling2d (AveragePo (None, 32, 14, 14) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 32, 14, 14) 9216 _________________________________________________________________ average_pooling2d_1 (Average (None, 32, 7, 7) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 64, 7, 7) 18432 _________________________________________________________________ average_pooling2d_2 (Average (None, 64, 3, 3) 0 _________________________________________________________________ dropout (Dropout) (None, 64, 3, 3) 0 _________________________________________________________________ flatten (Flatten) (None, 576) 0 _________________________________________________________________ dense (Dense) (None, 256) 147712 _________________________________________________________________ dropout_1 (Dropout) (None, 256) 0 _________________________________________________________________ dense_1 (Dense) (None, 256) 65792 _________________________________________________________________ dense_2 (Dense) (None, 10) 2570 ================================================================= Total params: 244,010 Trainable params: 244,010 Non-trainable params: 0 _________________________________________________________________下記のコードを入力すると実装したモデルをイメージファイルで保存し視覚的に確認できます。
tf.keras.utils.plot_model(model, "ファイル名.png")
実際にSequencail APIで線形のモデルを実装できることがわかります。
3-4) 学習
fitメソッドを使用してモデルを訓練データに “fit” します。model.fit(x = x_train, y = y_train, epochs=50, batch_size=128)(1) x
モデルが単一の入力を持つ場合は訓練データのNumpy配列,もしくはFunctional APIモデルのように複数の入力を持つ場合はNumpy配列のリストを入力します。モデル内のあらゆる入力に名前を当てられている場合,入力の名前とNumpy配列をマップした辞書を渡すことも可能です。フレームワーク固有のテンソル(例えば、TensorFlowデータテンソル)からフィードする場合はxをNoneにすることもできます。(2) y
モデルが単一の入力を持つ場合は教師(targets)データのNumpy配列,もしくはFunctional APIモデルのように複数の出力を持つ場合はNumpy配列のリストです。以降の説明は(1)xと同じです。(3) epochs
整数で,モデルを訓練するエポック数。エポックは,提供されるxおよびyデータ全体の反復です。initial_epochと組み合わせると,epochsは「最終エポック」として理解されることに注意してください。 このモデルはepochsで与えられた反復回数の訓練をするわけではなく,単にepochsという指標に試行が達するまで訓練します。(4) batch_size
勾配更新毎のサンプル数を示す整数またはNoneを指定します。指定しなければbatch_sizeはデフォルトで32になります。その以外
verbose、callbacks、validation_split、validation_data等を設定することもできます。3-5) 評価
evaluateメッソを利用してバッチごとにある入力データにおける損失値を計算します。model.evaluate(x = x_test, y = y_test, verbose=2)(1) x
入力データ,Numpy 配列あるいは Numpy 配列のリスト(モデルに複数の入力がある場合)を指定します。 (TensorFlowのデータテンソルのような)フレームワーク固有のテンソルを与える場合にはxをデフォルトのNoneにすることもできます。(2) y
ラベル,Numpy 配列を指定します。 (TensorFlowのデータテンソルのような)フレームワーク固有のテンソルを与える場合にはyをデフォルトのNoneにすることもできます。(3) verbose
進行状況メッセージ出力モードで,0か1または2を指定します。
0とすると標準出力にログを出力しません。
1の場合はログをプログレスバーで標準出力,
2の場合はエポックごとに1行のログを出力します。その以外、
batch_size、sample_weight、steps等を指定することができます。4. Functional APIを利用してモデルの構築
【Functional API実装の流れ】
1) モデルの構築 (
tf.keras.models.Sequential)
→ リストにレイヤーを積み重ねることでモデル構築します。2) モデルのコンパイル (
model.compile)
→ 最適化関数と損失関数を選択し計算グラフを構築します。3) モデルを訓練(
model.fit)
→ エポック数とバッチ数を指定してトレーニングします。4) モデルの評価 (
model.evaluate)
→ オプションですが、verboseでプログレスバーを出力できます。5) モデルの保存 (
tf.saved_model)
→model.saveでSavedModel形式で保存することができます。実装の手順はほとんどSequential APIと同じですが、Sequential APIとの違いがあるところ下記の通りです。
【Sequential APIとFunctional APIの違い】
1) Functional APIでは以前の層を次の層の入力使用し、変数へ割り当てります。
2) Model関数で入力と出力を指定します。
3) 全てのモデルはレイヤーと同じように関数呼び出し可能です。
これにより,モデル構造だけでなく,モデルの重みも再利用できます。
4) 複数の入出力を持つモデルに最適です。4-1) モデルの作成
Functional APIのモデル書き方は次のようになります。
1)
Input関数で入力として受け付けるデータの次元を指定します。shape は入力の次元を表しています。
例えば、(10, 1) という表記は10 という要素だけもつ Tuple(配列みたいなもの)という意味です。
2) 加えたいレイヤー関数の入力それ以前のレイヤー情報を指定して、変数に入れて行きます。
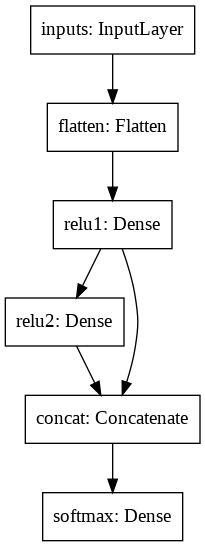
3)Model関数で入力と出力を指定します。# Functional APIでモデルを定義します。 inputs = tf.keras.layers.Input(shape=(28, 28), name='inputs') flatten = tf.keras.layers.Flatten(name='flatten')(inputs) hidden1 = tf.keras.layers.Dense(128, activation='relu', name='relu1')(flatten) hidden2 = tf.keras.layers.Dense(128, activation='relu', name='relu2')(hidden1) concat = tf.keras.layers.Concatenate(name='concat')([hidden1, hidden2]) outputs = tf.keras.layers.Dense(10, activation='softmax', name='softmax')(concat) # 入出力を定義します。 model = tf.keras.models.Model(inputs=inputs, outputs=outputs, name='functional')4-2) モデルをコンパイル
Sequential APIと同じく
compileメソッドは3つの引数を取ります。model.compile(optimizer="sgd", loss="categorical_crossentropy", metrics=["accuracy"])4-3) モデルの確認
model.summary()Model: "functional" __________________________________________________________________________________________________ Layer (type) Output Shape Param # Connected to ================================================================================================== inputs (InputLayer) [(None, 28, 28)] 0 __________________________________________________________________________________________________ flatten (Flatten) (None, 784) 0 inputs[0][0] __________________________________________________________________________________________________ relu1 (Dense) (None, 128) 100480 flatten[0][0] __________________________________________________________________________________________________ relu2 (Dense) (None, 128) 16512 relu1[0][0] __________________________________________________________________________________________________ concat (Concatenate) (None, 256) 0 relu1[0][0] relu2[0][0] __________________________________________________________________________________________________ softmax (Dense) (None, 10) 2570 concat[0][0] ================================================================================================== Total params: 119,562 Trainable params: 119,562 Non-trainable params: 0 __________________________________________________________________________________________________
4-4) 学習
学習もSequential APIと同じく
fitメソッドを利用しますので詳しい説明は省略します。model.fit(x = x_train, y = y_train, epochs=50, batch_size=128)4-5) 評価
評価もSequential APIと同じです。Sequential APIの内容を参考してください。
model.evaluate(x = x_test, y = y_test, verbose=2)5. Subclassing APIを利用してモデルの構築
Functional API は動的アーキテクチャをサポートしません。
例えば、再帰 (= recursive) ネットワークや Tree RNN はこの仮定に従いませんし Functional API では実装できません。
その場合は、Subclassing APIを利用してモデルの構築する必要があります。Subclassing APIのモデル学習方法の書き方は2種類あります。
【Subclassing API実装の流れ】
① 学習方法(デフォルトのメソッドで学習)
1) モデルの定義 (
tf.keras.Model)
→ クラスの定義しtf.keras.Modelを継承させます。
2) モデルのコンパイル (model.compile)
→ 最適化関数と損失関数を選択し計算グラフを構築します。
3) モデルを訓練 (model.fit)
→ エポック数とバッチ数を指定してトレーニングします。
4) モデルの評価 (model.evaluate)
→ オプションですが、verboseでプログレスバーを出力できます。
5) モデルの保存 (tf.saved_model)
→model.saveでSavedModel形式で保存することができます。② 学習方法(テープによる学習)
1) モデルの定義 (
tf.keras.Model)
→ クラスの定義しtf.keras.Modelを継承させます。
2) パラメータを更新する関数の定義 (tf.GradientTape)
→ 1ステップ分更新します。@tf.functionとアノテーションすると高速です
3) 最適化関数、損失関数、評価指標の定義 (tf.keras.optimizers、tf.keras.losses、tf.keras.metrics)
→tf.keras.Modelのようにクラスを継承してカスタムレイヤを定義することもできます。
4) モデルを訓練 (関数化しておくと便利)
→ エポック数とバッチ数を指定してモデルを訓練します。
5) モデルの評価
→ バッチ数を指定してモデルを評価します。
6) モデルの保存 (tf.saved_model)
→model.saveでSavedModel形式で保存することができます。この記事では②の方法を紹介し、モデルの保存は省略します。
5-1) モデルの作成
最初に言いましたが、PyTorchに似た書き方と同じです。
tf.keras.Modelを継承して新たなモデルを作ります。
__init__でレイヤーを定義しておいて、callでFunctional APIのようにモデルを定義します。
なお、親クラスの初期化を行うsuperメソッドには引数を与えるパターンもありますが、これは 2 系の Python を考慮した書き方であり、 3 系の Python では引数なしでも同じ処理になります。class ClassificationModel(tf.keras.Model): def __init__(self): super(ClassificationModel, self).__init__() self.conv1 = layers.Conv2D(32, 3, activation='relu') self.flatten = layers.Flatten() self.d1 = layers.Dense(128, activation='relu') self.d2 = layers.Dense(10, activation='softmax') def call(self, x): x = self.conv1(x) x = self.flatten(x) x = self.d1(x) return self.d2(x) model = ClassificationModel()5-2) パラメータを更新する関数の定義
@tf.functionはプログラムから計算グラフを作成することで、性能を上げながら、モデルをどこへでも展開できるようにします。
マシントレーニングで@tf.functionを適用すると、その関数について勾配を計算できるようになります。@tf.function def train_step(x, t): with tf.GradientTape() as tape: predictions = model(x, training=True) loss = loss_object(t, predictions) gradients = tape.gradient(loss, model.trainable_variables) optimizer.apply_gradients(zip(gradients, model.trainable_variables)) train_loss(loss) train_accuracy(t, predictions) @tf.function def test_step(x, t): test_predictions = model(x) t_loss = loss_object(t, test_predictions) test_loss(t_loss) test_accuracy(t, test_predictions)5-3) 最適化関数、損失関数、評価指標の定義
#損失関数 loss_object = tf.keras.losses.SparseCategoricalCrossentropy() #最適化関数 optimizer = tf.keras.optimizers.Adam() # 評価指標 train_loss = tf.keras.metrics.Mean(name='train_loss') train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy') test_loss = tf.keras.metrics.Mean(name='test_loss') test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='test_accuracy')5-4) 学習、 評価
train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train)).shuffle(10000).batch(32) test_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32) EPOCHS = 5 for epoch in range(EPOCHS): for images, labels in train_ds: train_step(images, labels) #学習 for test_images, test_labels in test_ds: test_step(test_images, test_labels) #評価 template = 'Epoch {}, Loss: {}, Accuracy: {}, test-Loss: {}, test-Accuracy:{}' print(template.format(epoch + 1, train_loss.result(), train_accuracy.result() * 100, test_loss.result(), test_accuracy.result()*100))3つの方法の中でSubclassing APIが一番柔軟性を実現できますモデル実装方法ですが、制限があります。
【Subclassing APIの制限】
- Subclassing APIで生成したモデルは
to_json()やto_yaml()が使えないといった制約があります。- この記事ではモデルの保存を説明しなかったですが、
save()ではHDF5形式での保存はできません。保存する時はSavedModel形式でします。- Subclassing APIで生成したモデルは「Define by Run」形式なので、
fit()で実際にデータを流して訓練するか、build()で入力形状を指定してモデルを確定する前はsummary()で構成を出力できないという制約もあります。- Sequential APIやFunctional APIのモデルのように細かい情報まで出力できません。
6. まとめ
モデル構築方法の説明は以上になります。
まとめると、以下のような使い分けができると思います。
- それぞれの層を一方的に通るだけのモデルで簡単に書きたい場合は Sequential APIを利用
- 複雑なモデルを学習実行前にきちんと形状確認できるように書きたい場合は Functional APIを利用
- PyTorch 流の書き方で書きたい、動的なモデルを書きたい場合は Subclassing APIを利用
誤り等ありましたら、ご指摘ください。
7.参考資料
1.TensorFlow、Kerasの基本的な使い方
2.【TensorFlow 2.0 入門】TF 初心者でも分かるAPIの解説
3.Feature Scalingはなぜ必要?
4.SequentialモデルでKerasを始めてみよう
5.KerasのFunctional API Modelの構造を理解する(ディープラーニング)
6.TensorFlow 2.0 のシンボリック API と命令型 API とは?
7.ModelクラスAPI
8.Kerasはfunctional APIもきちんと理解しよう
9.TensorFlow 2.0 Alpha : ガイド : Keras : TensorFlow の Keras Functional API
10.functional APIでKerasを始めてみよう
11.TensorFlow 2.X の使い方を VGG16/ResNet50 の実装と共に解説
12.tf.function で性能アップ