- 投稿日:2020-06-25T22:15:18+09:00
AWSコスト情報をZabbixでモニタリングする
やりたいこと
最近、ようやくAWSを触り始めました。いやー楽しいですね。全然わかんないけどw。
趣味のため、無料枠でAWSのいろいろなサービスを使って遊んでします。
が、何が無料枠か否か理解しておらずコストが突然跳ね上がったときに気付きたいと思い、
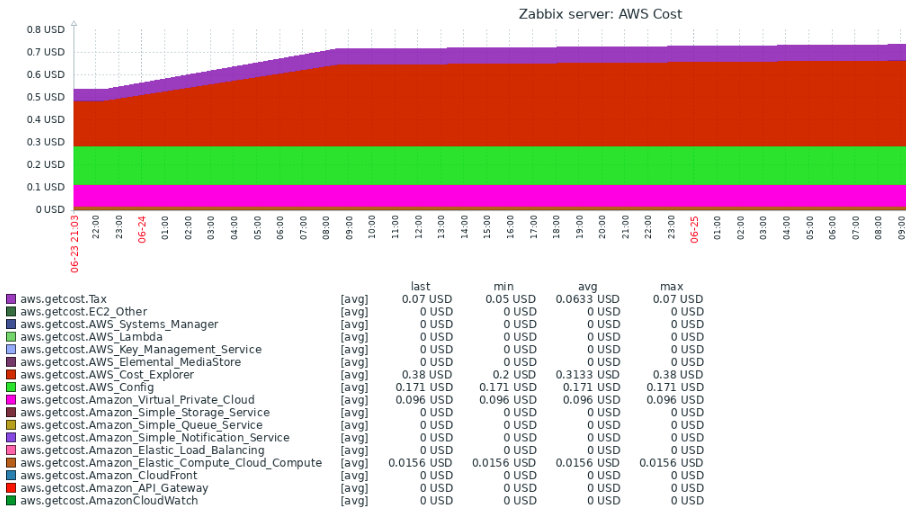
Zabbixで、一日に一回、AWSのコストをモニタリング(以下)するようにしました。
もうちょっと具体的に
- AWSのトータルコストと各サービスのコストをモニタリング(1日1回)
- トータルコストに対して、閾値(WARN/HIGH)のトリガーを設定できます。
- zabbix-agentとaws-cli(aws ce)を使用します。
- aws-cliの実行方法(awsコマンド+jq)は、以下URLを参考(ありがとうございます!)
注意事項
- AWSのCostExplorerを利用するためコストが発生します。
- CostExplorerを実行するたびに、0.01USD発生します(2020/06/24現在)
- 当機能を使用すると、1日に2回CostExplorerを呼び出すため、0.02USDの費用が発生します。
内容
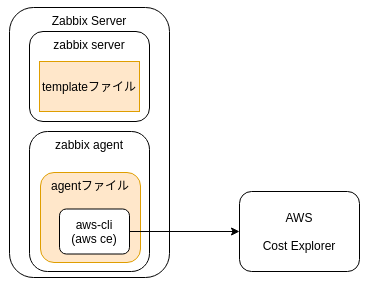
作成物は以下の2ファイル (githubに登録,下図でいうオレンジ部分)
https://github.com/mishikawan/aws-getcost-zabbix-template
- zabbix-agentの設定ファイル
- zabbix_agentd.d/userparameter_awscli.conf
- zabbixのテンプレート
- zabbix_template/zbx_AWSCost_templates.xml
稼働条件
- Linuxサーバ(検証環境はオンプレのCentOS8)が稼働しており、以下が動いていること
- zabbixサーバ(検証環境は4.0)
- AWSCLI
- jqコマンド
導入手順
1.JQのインストール
yum install jq2.AWSCLI導入(既に導入されていれば不要)
# pip3 install awscli3.zabbixユーザでのAWSコンフィグ設定(既に設定されていれば不要)
3-1.zabbixユーザのホームディレクトリのパスを調べる
# egrep zabbix /etc/passwd zabbix:x:2000:2000:Zabbix:/var/lib/zabbix:/sbin/nologin3-2.zabbixユーザのホームディレクトリ(上記例で/var/lib/zabbix)が無い場合は作成します
# mkdir /var/lib/zabbix3-3.AWSコンフィグ用のファイルを設置します
# mkdir /var/lib/zabbix/.aws # cat > /var/lib/zabbix/.aws/config [default] output=json ^D # cat > /var/lib/zabbix/.aws/credentials [default] aws_access_key_id=XXXXXXXXXXXXXXXXXXXX aws_secret_access_key=XXXXXXXXXXXXXXXXXXXX ^D # chown -R zabbix:zabbix /var/lib/zabbix/.aws4.zabbix_angentファイルを/etc/zabbix/zabbix_agentd.d/配下に設置
# cp zabbix_template/zbx_AWSCost_templates.xml /etc/zabbix/zabbix_agentd.d/. # systemctl restart zabbix-agent.service5.設置したzabbix_agentが機能していることを確認します
5-1.zabbix_agentその1: aws.getcost
# zabbix_get -s 127.0.0.1 -k "aws.getcost" {"AWS Config":"0" ,"AWS Cost Explorer":"0" ,"AWS Elemental MediaStore":"0" ,"AWS Key Management Service":"0" ,"AWS Lambda":"0" ,"AWS Systems Manager":"0" ,"Amazon API Gateway":"0" ,"Amazon CloudFront":"0" ,"EC2 - Other":"0" ,"Amazon Elastic Compute Cloud - Compute":"0" ,"Amazon Elastic Load Balancing":"0" ,"Amazon Simple Notification Service":"0" ,"Amazon Simple Queue Service":"0" ,"Amazon Simple Storage Service":"0" ,"Amazon Virtual Private Cloud":"0" ,"AmazonCloudWatch":"0" ,"Tax":"0" }5-2.zabbix_agentその2: aws.getcosttotal
# zabbix_get -s 127.0.0.1 -k "aws.getcosttotal" {"Total":"0"}6.zabbix_templateファイルをZABBIXにインポート
必要に応じて、template内のMacrosの内容(以下)を変更します。
Macro Value 備考 {$BUDGET_HIGH} 100 コストの閾値 100USD超えればアラート(深刻度=HIGH) {$BUDGET_WARNING} 10 コストの閾値 10USD超えればアラート(深刻度=WARNING) {$COSTCHECK_DATETIME} h11m00 Cost Explorerを呼び出す時間 (h11m00 = 11:00)
- 投稿日:2020-06-25T21:56:20+09:00
【AWS】請求アラート設定方法(CloudWatch)
はじめに
CloudWatchでの請求アラートの作成方法についてアウトプットしていきたいと思います。
料金超過に気づくために、設定しておいた方がいい監視設定になります。作業前提
- ルートユーザーに多要素認証を設定している。
多要素認証設定手順- 作業用IAMユーザーを作成済みである。
作業用IAMユーザー作成手順※今回は作業用IAMユーザーにて実施
今回の設定内容
- 12USD(約1300円)を超過した場合、アラートを発砲
- 登録したメールアドレス宛にアラートを通知
作業手順
請求アラート許可設定
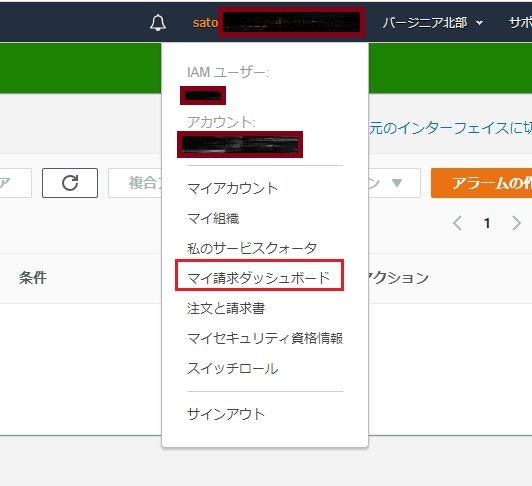
①マネジメントコンソール右上のユーザー名をクリック→ 「マイ請求ダッシュボード」を選択
②「Billingの設定」をクリック
③「請求アラートを受け取る」にチェックを入れ、「設定の保存」を実施
請求アラート設定(CloudWatch)
①AWSマネジメントコンソール右上の国籍をクリックし、米国東部(バージニア北部)を選択。
※米国東部(バージニア北部)でのみ請求アラートの設定が可能であるため。
②AWSマネジメントコンソールより、CloudWatchを起動
※TOP画面にない場合は、サービスを検索して起動
③CloudWatch画面に遷移。アラームをクリック。
④アラーム一覧画面が表示される。右のアラームの作成をクリック。
⑤メトリクスの選択をクリック
⑥メトリクス設定画面が表示されるので、請求をクリック。
⑦概算合計請求額をクリック。
⑦USDにチェックを入れ、メトリクスの選択をクリック。
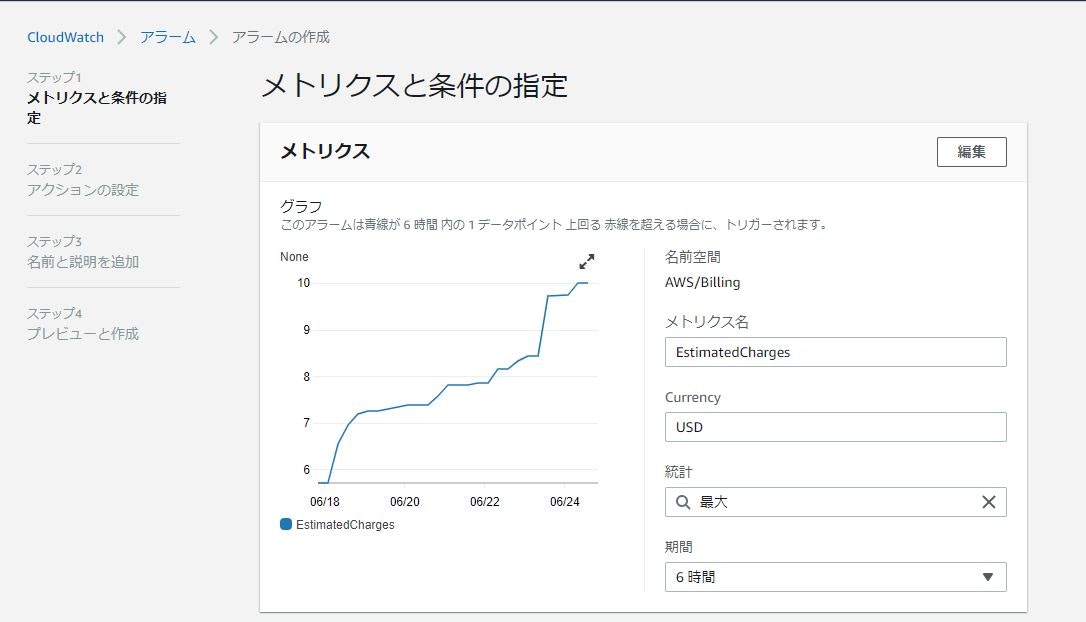
⑧グラフが表示される。こちらのメトリクス設定はデフォルトで問題なし。
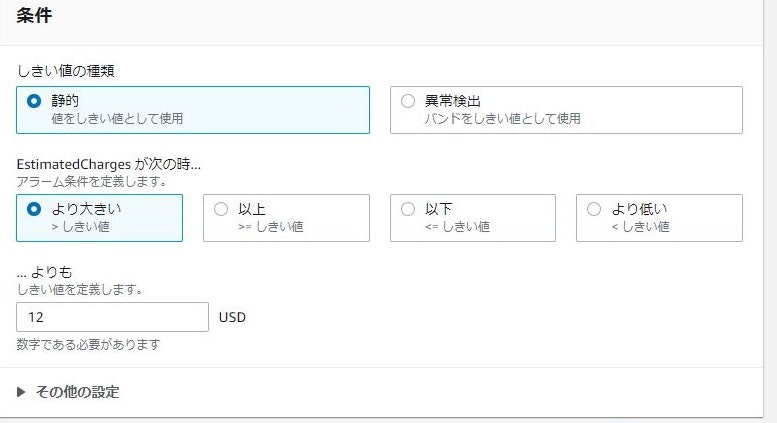
⑨条件を下記のように設定する。
条件 設定値 しきい値の種類 静的 EstimatedChargesが次の時... より大きい ...よりも 12
設定後、「次へ」をクリック
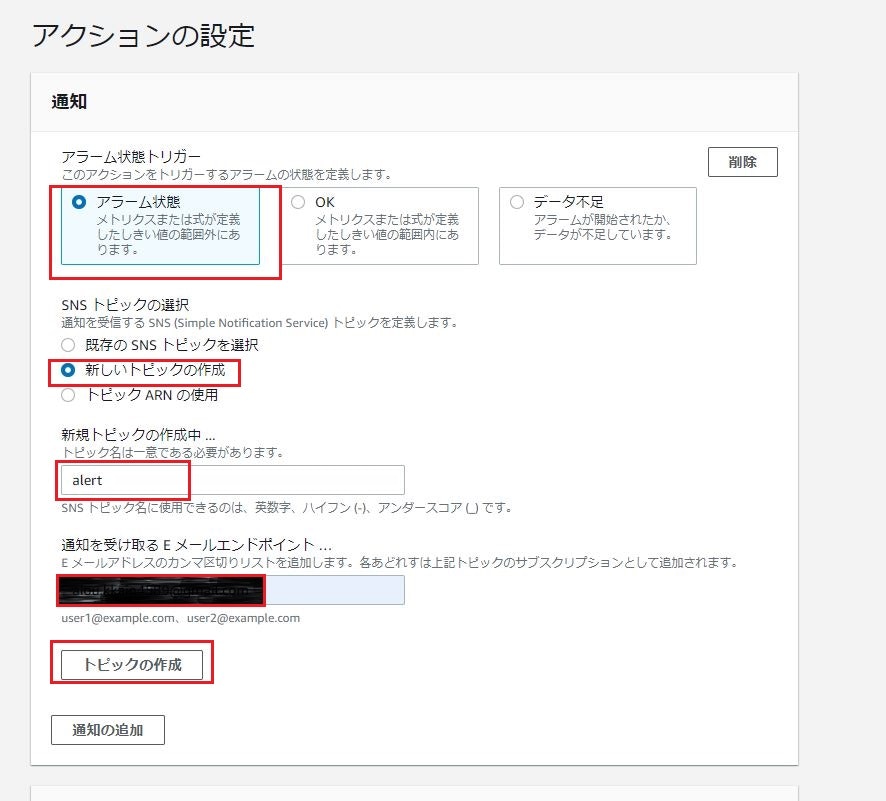
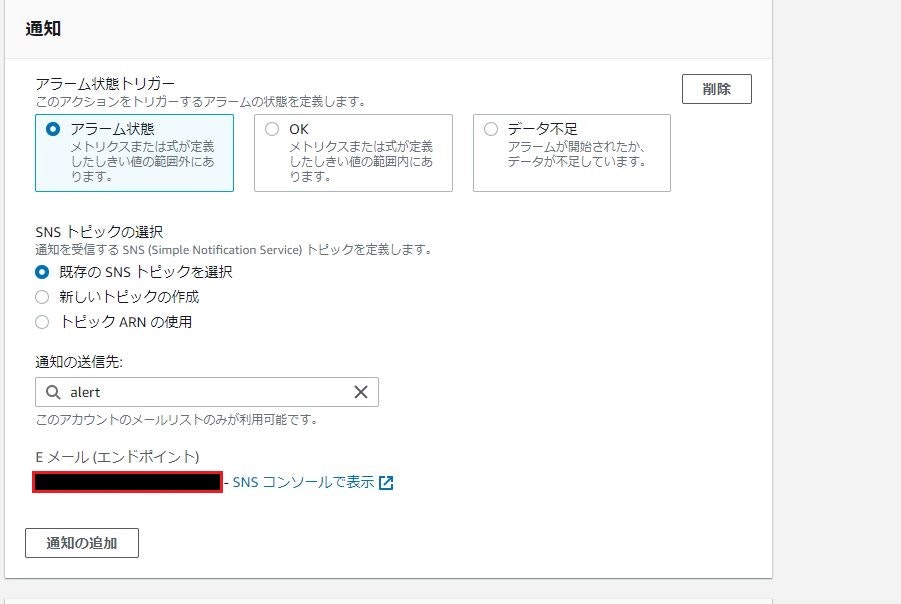
⑩アクションの設定
下記のように設定する。
項目 設定値 アラーム状態トリガー アラーム状態 SNSトピックの選択 新しいトピックを選択 新規トピックの作成中... alert 通知を受け取るEメールエンドポイント... 自分のメールアドレス
設定後、トピックの作成をクリック
⑪Eメール(エンドポイント)の箇所が下記のようになることを確認
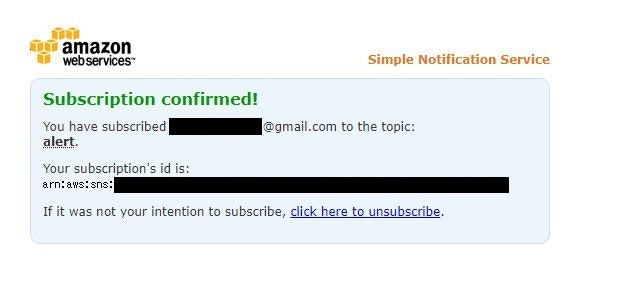
⑫SNSトピックが作成されると、登録したEメールアドレス宛に下記のようなメールを受信する。
- メール内容
Confirm subscriptionをクリックする。
件名 : AWS Notification - Subscription Confirmation 内容 : You have chosen to subscribe to the topic: arn:aws:sns:us-east-1:~~~~~:alert ←「~~~~~」の部分は数字 To confirm this subscription, click or visit the link below (If this was in error no action is necessary): Confirm subscription ← ここ Please do not reply directly to this email. If you wish to remove yourself from receiving all future SNS subscription confirmation requests please send an email to sns-opt-out
- 認証完了画面
下記の画面が表示されれば問題なし。(Eメールアドレス認証完了)
⑬「アクションの設定」の画面へ戻り、次へをクリック。
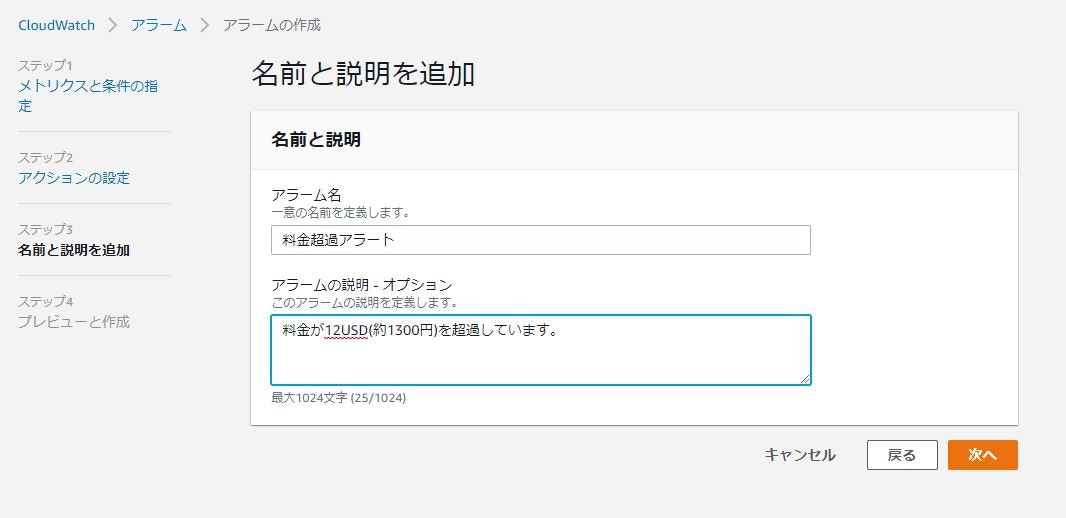
⑭アラームを設定
項目 設定値 アラーム名 料金超過アラート アラームの説明 料金が12USD(約1200円)を超過しています。
設定完了後、次へ
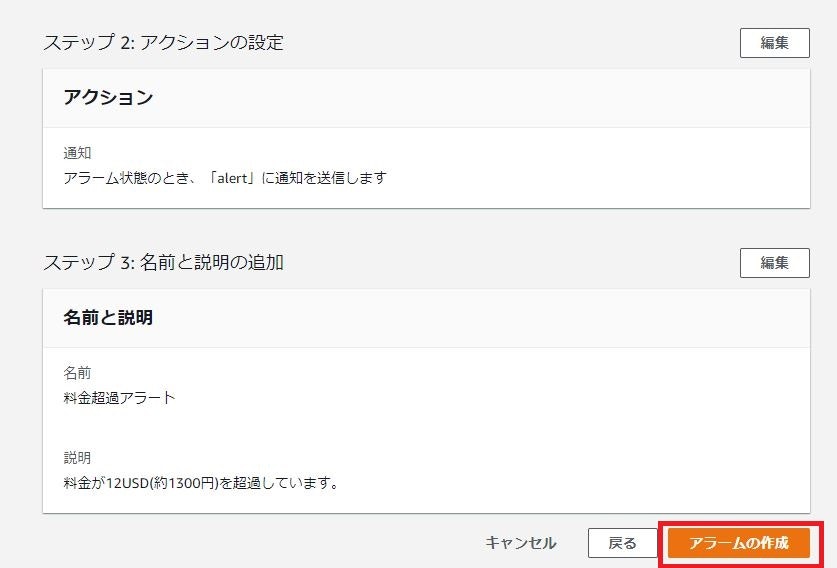
⑮最終確認画面が表示されるため、アラームの作成をクリック
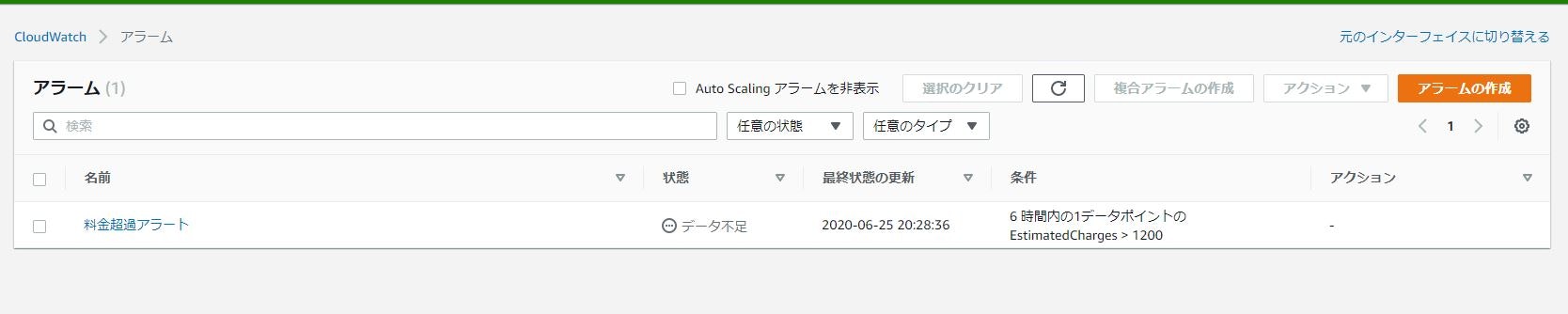
⑯下記のように料金超過アラートが作成されることを確認。
※データ不足となっていますが、作成直後で情報が取得できていないため問題なし。
参考




- 投稿日:2020-06-25T19:53:58+09:00
AWS AppSyncを使ってみた
はじめに
AWS AppSyncとは、GraphQLをベースとしたアプリケーションのバックエンドを提供するAWSのフルマネージドサービスです。次の機能を利用できます。
- リアルタイムアプリケーションの作成
- 同期を使ったオフラインプログラミングモデルの構築
- 必要なデータだけ GraphQL で取得
- 複数のデータソース(Amazon DynamoDB、Amazon Elasticsearch Service、AWS Lambda、Aurora Serverless)へのアクセス
このAppSyncでAPI構築し、ToDo管理Webアプリケーションを開発してみました。
前提知識
- HTML, CSS, JS, JQuery, etc.
- DynamoDB
- GraphQL
但し、それほど深い知識は必要ない。
DymanoDB table作成
このページを参考にしてUser tableとTodo tableを作成。
AppSyncとDynamoDBの紐づけ
左サイドバーのData SourcesをクリックしてNewをクリック。
UserTable
既に作成したUserテーブルをデータソースとして登録します。Data source nameに「UserTable」と入力し、Data source typeは"Amazon DynamoDB table"を選択、ResionはUserテーブルが属するリージョンを選択し、Table nameは「User」を選択します。Createをクリックして作成を完了してください。TodoTable
同様に「TodoTable」を作成AppSync API Schema作成
schematype Mutation { createUser(name: String!): User createTodo(userId: ID!, content: String!): Todo deleteTodo(userId: ID!, id: ID!): Todo } type Query { getUser(id: ID!): User listUsers: [User] } type Todo { userId: ID! id: ID! content: String! } type User { id: ID! name: String! todos: [Todo] } schema { query: Query mutation: Mutation }AppSync API Resolver作成
createUser(...): User
UserTable
request{ "version" : "2017-02-28", "operation" : "PutItem", "key" : { "id": $util.dynamodb.toDynamoDBJson($util.autoId()), }, "attributeValues" : $util.dynamodb.toMapValuesJson($ctx.args) }response$util.toJson($ctx.result)createTodo(...): Todo
TodoTable
request{ "version" : "2017-02-28", "operation" : "PutItem", "key" : { "id": $util.dynamodb.toDynamoDBJson($util.autoId()), }, "attributeValues" : $util.dynamodb.toMapValuesJson($ctx.args) }response$util.toJson($ctx.result)deleteTodo(...): Todo
TodoTable
request{ "version": "2017-02-28", "operation": "DeleteItem", "key": { "id": { "S": "$ctx.args.id" }, "userId": { "S": "$ctx.args.userId" } }, }response$util.toJson($ctx.result)getUser(...): User
UserTable
request{ "version": "2018-05-29", "operation": "GetItem", "key": { "id": { "S": "$ctx.arguments.id" } } }response$util.toJson($ctx.result)listUsers: [User]
UserTable
request{ "version": "2018-05-29", "operation": "Scan" }response$util.toJson($ctx.result.items)todos: [Todo]
TodoTable
request{ "version": "2018-05-29", "operation": "Query", "query": { "expression": "userId = :userId", "expressionValues": { ":userId": { "S": "$ctx.source.id" } } } }response$util.toJson($ctx.result.items)Front-end作成
AppSyncのページを開き、API URLとAPI KEYをコピーする。
git cloneして、index.jsの最初にAPI URLとAPI KEYを張り付ける。参考文献
- 投稿日:2020-06-25T19:37:09+09:00
[EC2]計画メンテ情報のキャッチ
経緯
保守システムのとあるエラー通知を受けて調査しているとEC2インスタンスが謎の停止をしていることがあった。
仕方ないので対象インスタンス(ubuntu)を起動して
/var/log/syslogを見ると、
「exiting on signal 15」という普通にシャットダウンした記録が。意味がわからん・・・といろいろ調査していたところ、
https://teratail.com/questions/35247の記事でAWSのメンテかもよ?というのがあり、
えっ、EC2のメンテってそもそもどうやって知るの?とググったら、の公式記事がヒット。
中には
- EC2コンソールのイベントから見れるぜ
- そもそもメールで通知いくぜ
という内容が書いてあった。
そうだったんだ・・・。これ関連で色々調べたことをまとめておく。
計画メンテ情報をEC2コンソールでキャッチ
EC2のコンソールページへ移動 > イベントを押下すると、
以下のようにメンテ対象のインスタンスの情報が出てくる。
実際にあったやつとその対処
- 「The instance is running on degraded hardware」という表示があったとき →インスタンスが機能低下したハードウェアで実行されている・・・ということで「期限」に「イベントタイプ」が自動でAWS側でなされる。
実は、自身の手で期限までに停止→起動することで正常な物理ホスト上でインスタンスが起動するようになる。 https://forums.aws.amazon.com/thread.jspa?threadID=105610

- 投稿日:2020-06-25T18:36:34+09:00
AWSでデプロイしちゃおうってわけ(AWS登録編)
こんばんはですね。
お久しぶりになってしまい非常に私反省しております。
昨日は地震が酷かったですね。
寝ていて若干起きたけど、眠気に負けてすぐ寝ましたが。気になったのはニュースで
「余震には気をつけましょう!」
っていってるけど気をつけようがないだろ!!!予測できないんだし!!!
と思ってしまう私は悪い子でしょうか。
さて今回はデプロイに関してAWSを使ってデプロイしていくわよっ!!
1 まずはAWSのHPへアクセスっ!!
こちらから飛んで頂戴
AWS開くとへいっ
そんで右上への無料サインアップから登録して頂戴!!
※住所、電話番号を登録するページで一番下でアーグリメント〜って聞かれるからそれはチェックしておく様に!!
2 クレジットカート登録+電話番号認証
若いアンタ達なら画像無しでも出来るハズダワ。。。。
その次にプランを選ぶところがあるから
有無を言わさずベーシック無料プラン!!!!!!
そんで登録するとへいっ
これで準備完了よ。
次はインスタンスとかなんちゃらとかやっていくわよ!!!!
- 投稿日:2020-06-25T18:33:56+09:00
[CloudWatch]各サービスのメトリクス
概要
EC2のメトリクスしか知らなかったが、
あるとき保守しているシステムのELBで異常を検知し、そのときに初めてELBのメトリクスを見て色々知った。
いい機会なので、ELBをはじめとし、今後知ったものをここへまとめていく。ELB(Classic Load Balancer)
AWSの名前空間 > ELBで確認できる。
さらに、以下に分類した結果が表示される。
- LB・AZ別
- AZ別
- LB別
- 名前空間別
- サービス別
- すべてのLBにわたりただ、見た感じだと
- すべてのLBにわたり、名前空間別、サービス別:同じ結果
- LB・AZ別:AZ混合の結果になっていておかしい
- AZ別:こちらもなぜか結果がおかしいという状態で、実用に足るのは「LB別」のみという感じだった・・・
メトリクス名 意味 HealthyHostCount ロードバランサー配下の正常なインスタンス数。統計は平均とMaxが有用。 HTTPCode_Backend_2XX(3XX,4XX,5XX) ELB配下のインスタンスからのレスポンスのステータスコードの数。ロードバランサーのレスポンスのステータスコードは含まれない。なお、統計はSumで見ないと1固定になってしまうので注意。 HTTPCode_ELB_5XX ロードバランサーのレスポンスのステータスコード5XXの数。ELB配下のインスタンスからのレスポンスのステータスコードの数は含まれない。ELBに配下のインスタンスで正常なインスタンスがひとつもない場合や、リクエストレートがインスタンスやロードバランサーの容量を超える場合に発生する。なお、統計はSumで見ないと1固定になってしまうので注意。 レイテンシー ロードバランサーが配下のインスタンスへリクエストを送信〜対象インスタンスがレスポンスヘッダを送信し始めた合計経過時間(秒)。アベレージ、Maxが有用 RequestCount 指定された間隔に完了したリクエストの数。合計が有用。 SurgeQueueLength ロードバランサー配下の正常なインスタンスへの送信を保留しているリクエスト数。Max1024で、いっぱいになると拒否される。統計はピークを知るためにMaximumが有用。 UnHealthyHostCount ロードバランサー配下の異常なインスタンス数。統計は平均とMinが有用 どうやら、RequestはHTTPCode_Backend_XXXの合計で、HTTPCode_ELB_XXXの数は含まれないみたい。
あくまでバックエンドからレスポンスを返せた分だけRequestではカウントしてるってことだね。実際にはユーザーに返ってるレスポンス数はHTTPCode_ELB_XXXの数も含まれるんだけど。有用な統計の設定がそれぞれのメトリクスでまちまちなので、あらかじめ同じ統計になるものでダッシュボードに登録しておいた方が便利。
- HTTPCode_Backend_5XX:ELB配下のインスタンスでリクエストが裁けなくなってる
- SurgeQueLength:ELBでキューの待ちが発生→そもそもELBがボトルネックになってる
- HTTPCode_ELB_5XX|ELB配下のインスタンスに負荷がかかりすぎて死亡とうとうインスタンスのヘルスチェックOKのインスタンスが0になったのでインスタンスにリクエストすら送れなくなり、ELBくんがユーザーにインスタンス死んでるから無理wwwと5XXエラー返しだした
って感じでみればいいか。
- 投稿日:2020-06-25T18:29:02+09:00
AWSで構築したシステムの通知はまずAWS Chatbotを試そう! ~CodePipeline編~
よくAWSに触れるものです。
以前ECSに合わせたCodepipelineの構築について書きましたが...
・codepipeline構築についての記事
https://xkenshirou.hatenablog.com/entry/2020/06/13/125235そのCodePipelineのシステム通知には AWS Chatbot がおすすめです。
コストパフォーマンスがよく構築も簡単です。
構築のためのCloudformationテンプレートも用意したので、ぜひご参考ください。
■ヘヴィメタルエンジニアリング(はてなブログ)
・Chatbot構築の記事
https://xkenshirou.hatenablog.com/entry/2020/06/24/073000
- 投稿日:2020-06-25T18:19:12+09:00
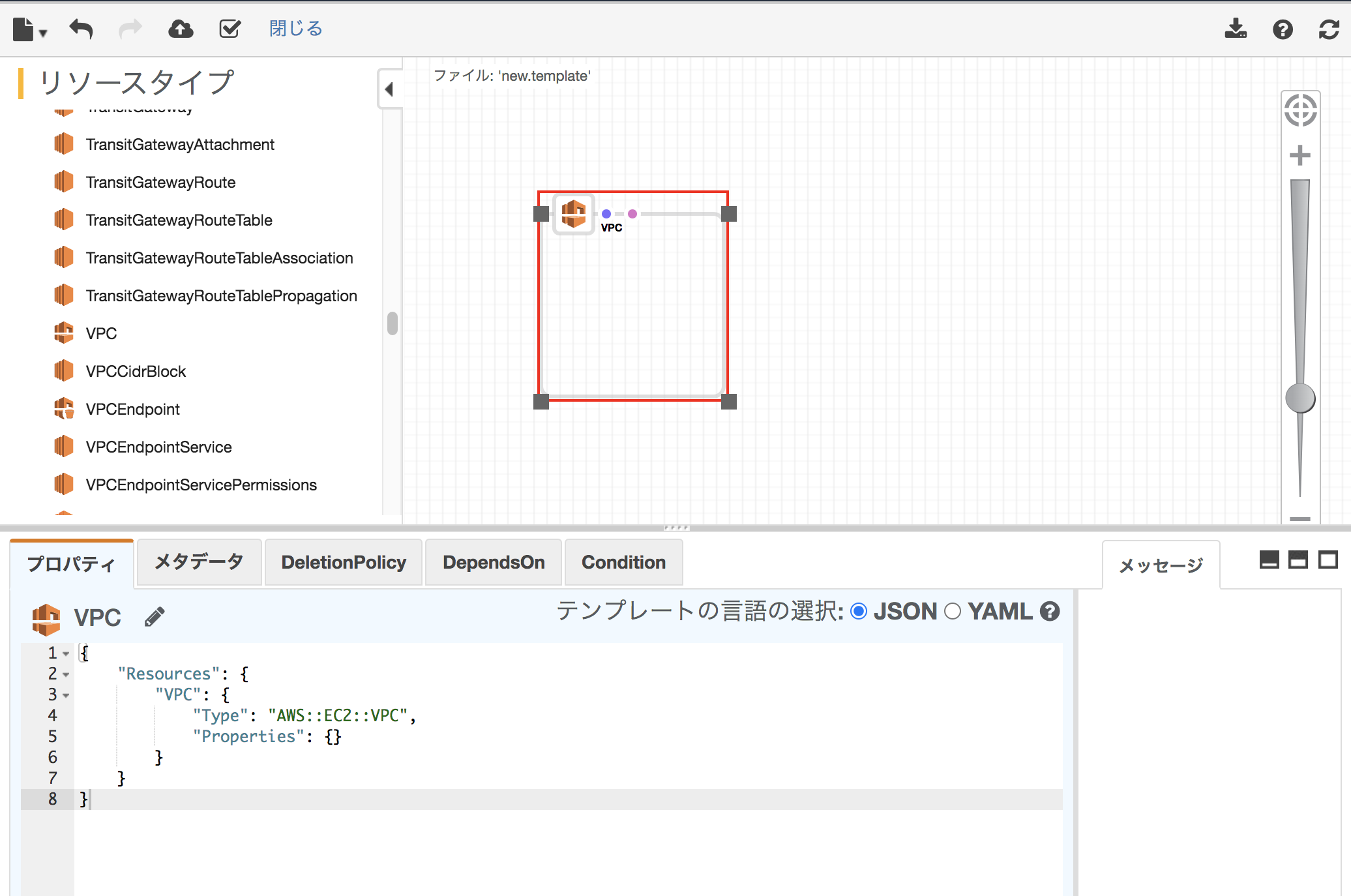
【AWS CloudFormation デザイナー】VPCを作ろうとしたら、Property CidrBlock cannot be empty.エラーが出た。
AWS CloudFormation デザイナーとは
GUI形式でAWS CloudFormationテンプレートを作成・参照・変更ができる。
テンプレートリソースで作りたいものを追加していき、統合されたJSONおよびYAMエディタを使用して詳細を編集する。VPCを作ろうとするも、「Property CidrBlock cannot be empty.」エラーが出た
リソースタイプでEC2>VPCを選択し、キャンパスペインにドロップすると下記のようになった。
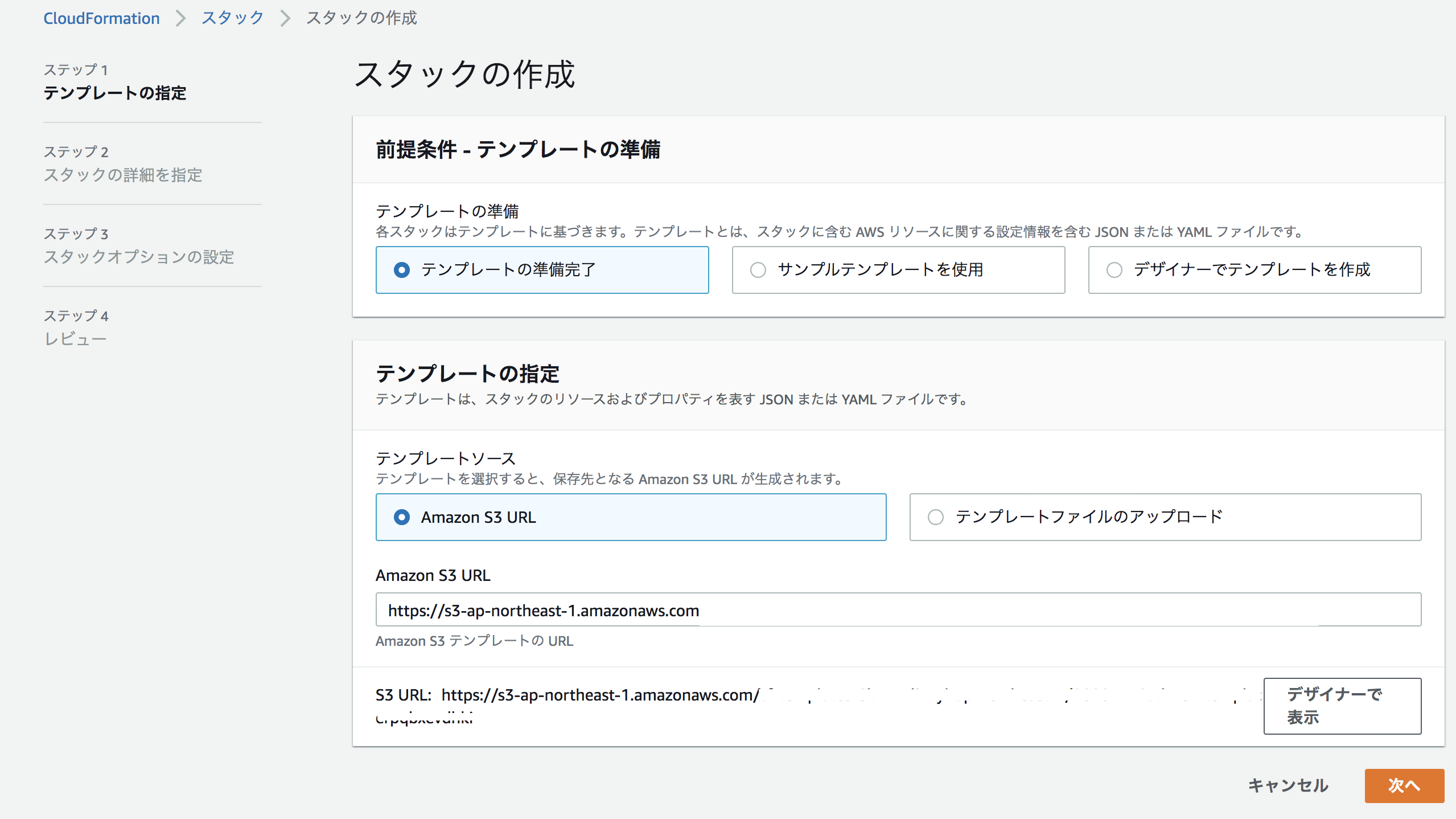
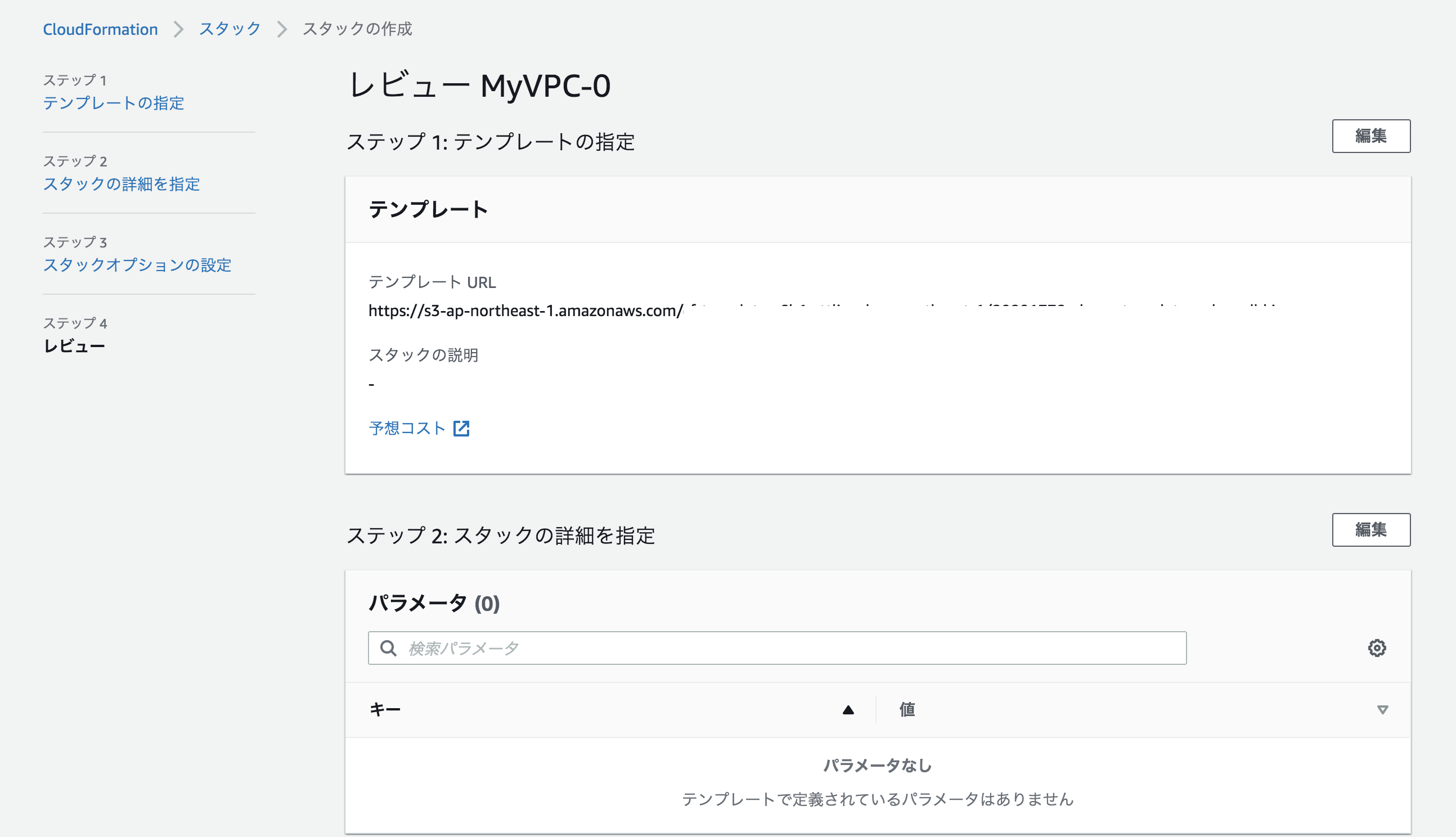
チェックボタンを押して有効かを検証し問題ないので、試しに雲のマークを押してスタックの作成をしてみた。
そうするとS3にすでに作ったテンプレートが載っているようだ。
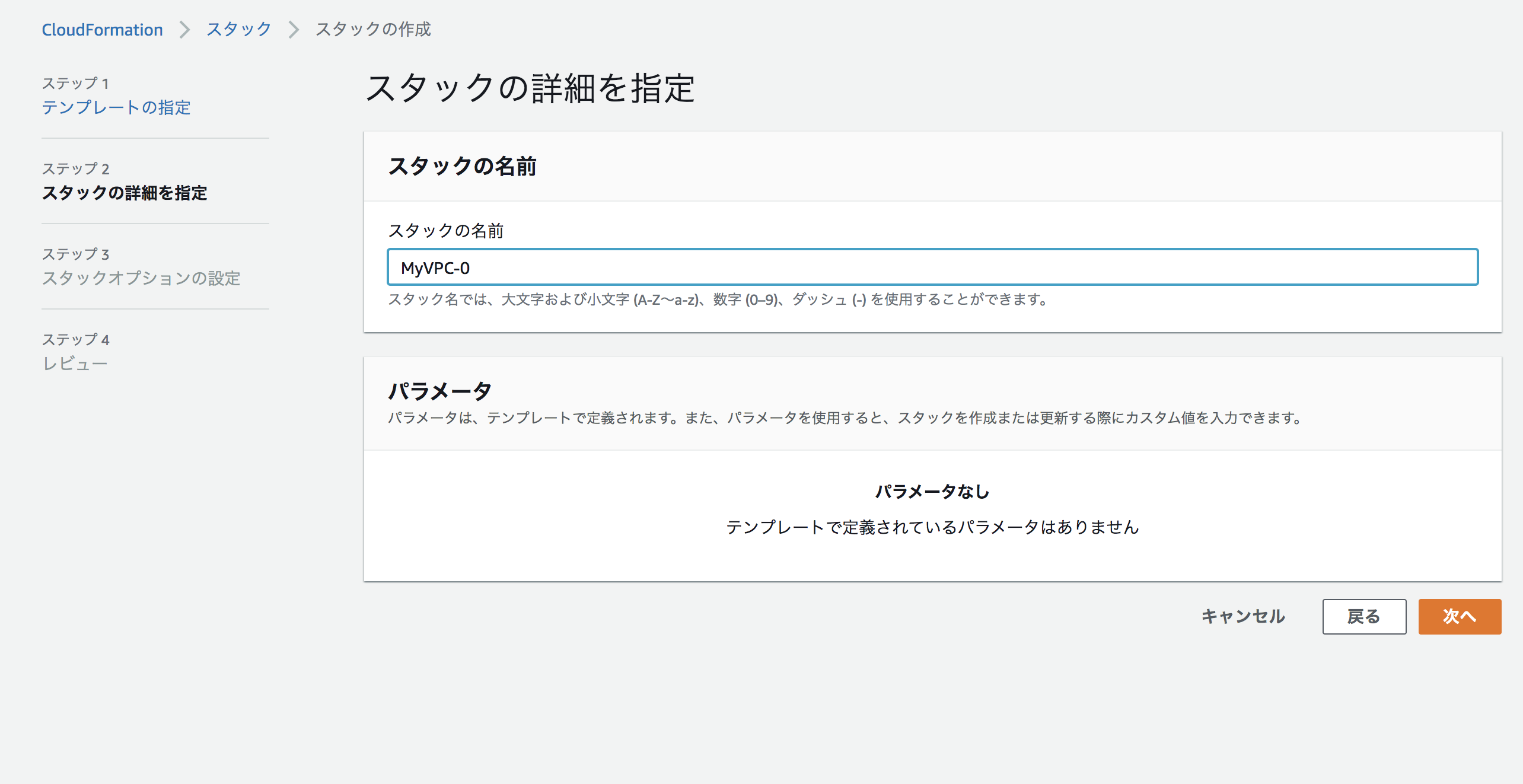
そのままスタックの名前や必要な箇所があれば入力し、スタックの作成を押してみた。
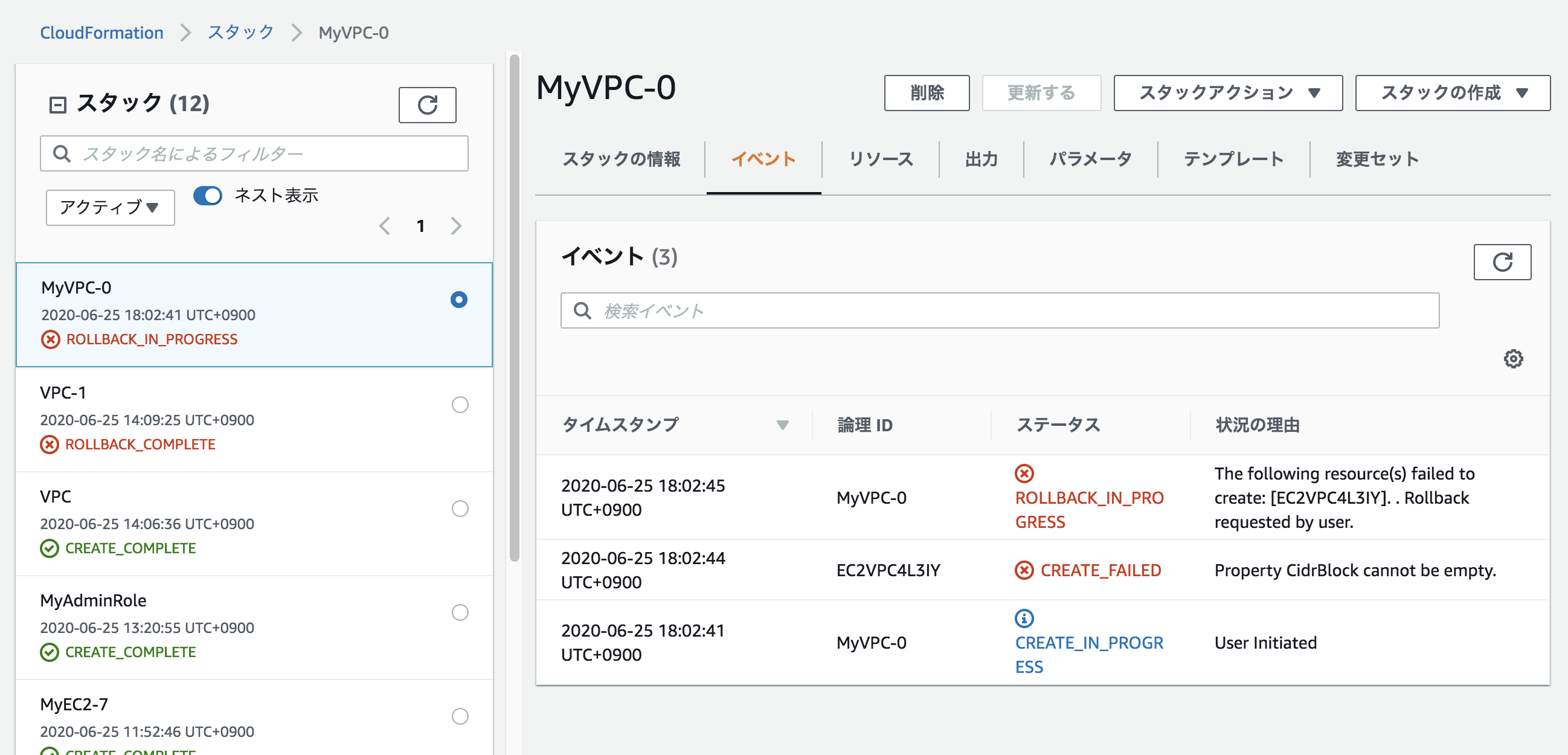
そうするとROLLBACK_COMPLETEのエラーが起きた。
状況の理由は「Property CidrBlock cannot be empty.」
サイダーブロックは空にできないとのことだった。解決策
CloudFormationのデザイナープロパティのデフォルトでは、VPCのリソースでサイダーブロックが設定されてないので設定する。
デフォルト
{ "Resources": { "EC2VPC3FNNL": { "Type": "AWS::EC2::VPC", "Properties": {} } } }下記のように適切なサイダーブロックを追加する。
{ "Resources": { "VPC": { "Type": "AWS::EC2::VPC", "Properties": { "CidrBlock": "192.168.10.0/24" } } } }これで作成をするとロールバックせずに、VPCが作成される。
参考
- 投稿日:2020-06-25T17:59:03+09:00
Bitbucket PipelinesとAWS CodePipelineを連携する!
背景
とある案件でCI/CD パイプラインをAWS CodePipelineで実装することになったのだが、以下の諸々の制約を解消する連携方法を模索することになった。
- ソース管理にはBitbucketを使用する
- 作成するパイプラインでは複数のAWSサービス(CodeDeployやSSM Automation、CloudFormation)と連携が必要
- 一つのBitbucketリポジトリから起動したいパイプラインの種類が複数ある
関連する各種サービスの仕様は以下の通り。
- CodePiplineのソースとしてはBitbucketはサポートされていない
- CodePipelineのソースとしてS3はサポートされている
- CodeBuildはBitbucketと連携可能
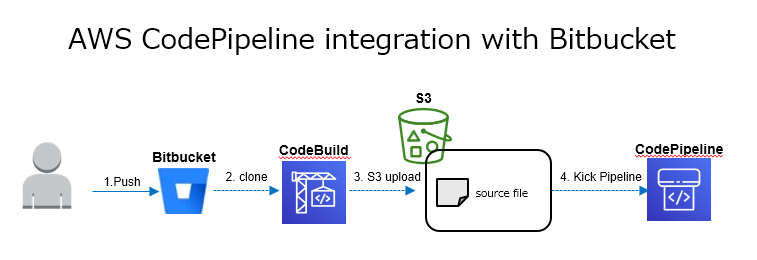
ということで、当初はこんな感じの構成を考えていた。
ところが、後になって以下の制約が判明!
- セキュリティ上Bitbucketは特定のIPアドレスの範囲からしかアクセスできない
AWS CodeBuildとしては以下の仕様があるのでIPアドレスの範囲に追加してもらうことを交渉してみる。
- CodeBuildはVPC内で実行することも可能
しかし、お客様がCodeBuildからもBitbucketにアクセスできるようにすることに乗り気でなかったのでBitbucketのパイプライン機能に白羽の矢を立てることになる。
いろいろ調べたところBitbucket Pipelinesの機能で色々と出来ることが判明し、一気に問題は解決の方向へ!
- Bitbucket Pipelinesで特定のブランチへの更新やタグ付けに反応してパイプラインを起動可能
- Bitbucket Pipelinesの他サービスとの連携機能(Pipesと呼ぶ)にはS3へのデプロイ用のPipeもあるのでS3経由でCodePiplineと連携が簡単にできる
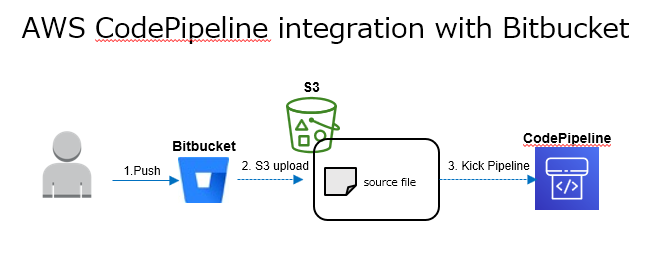
これらを踏まえ以下の流れでBitbucketをソースとしたCodePiplineの起動が出来るようになった。
実装の手順
ここでは、実際にBitbucket PipelinesとCodePiplineを構成し連携するための手順を記載する。
CodePiplineの構成
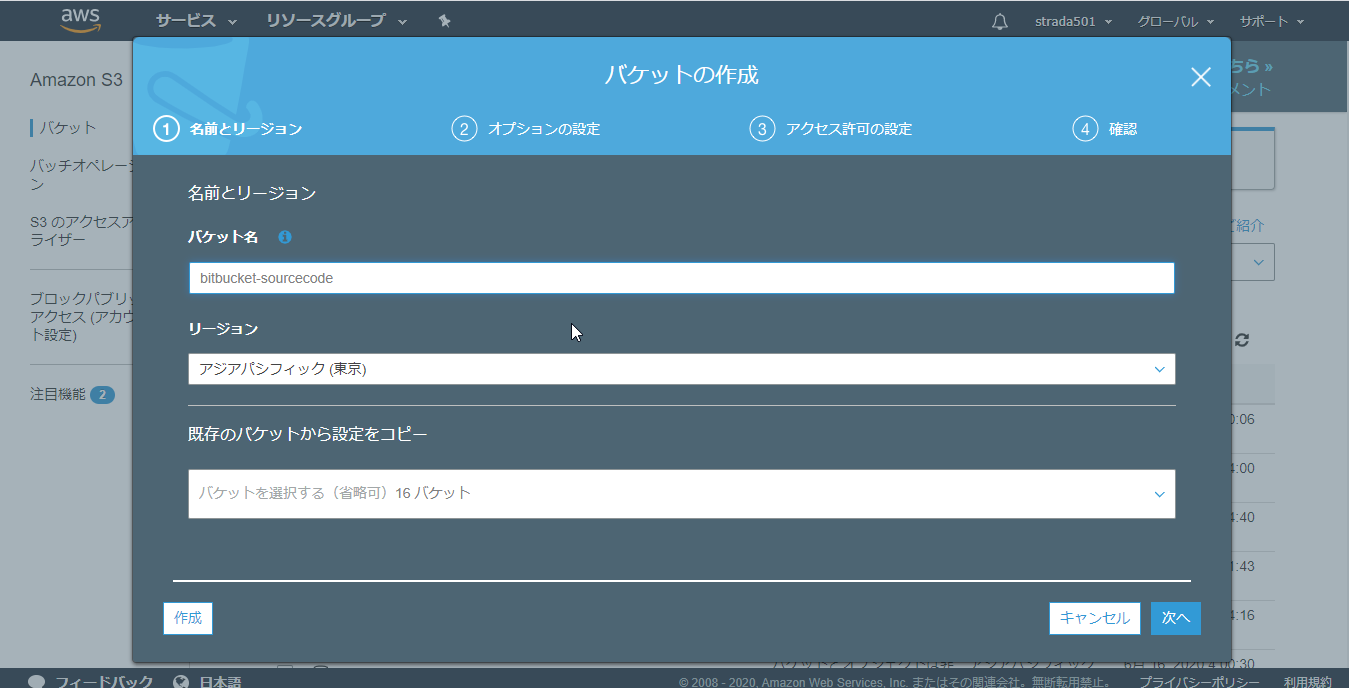
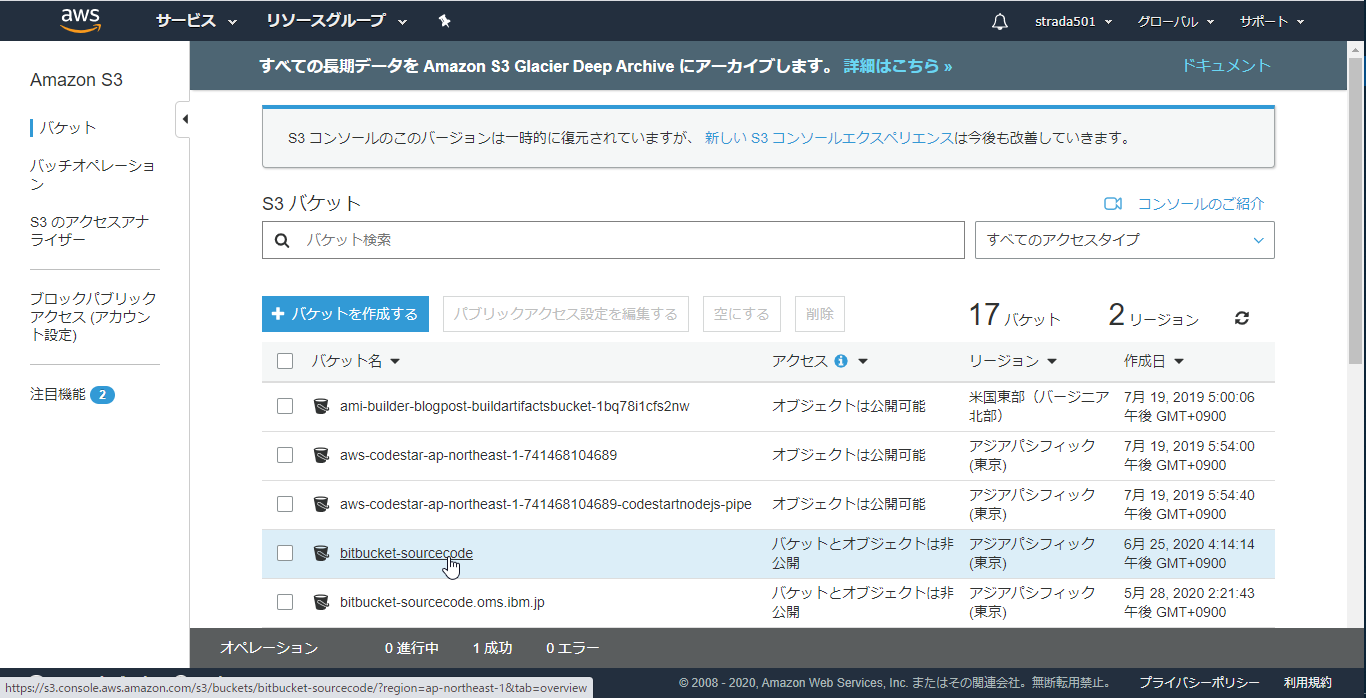
連携用S3バケットの作成
- S3のコンソールからバケットを作成するをクリック
任意の名前を入力して作成をクリック
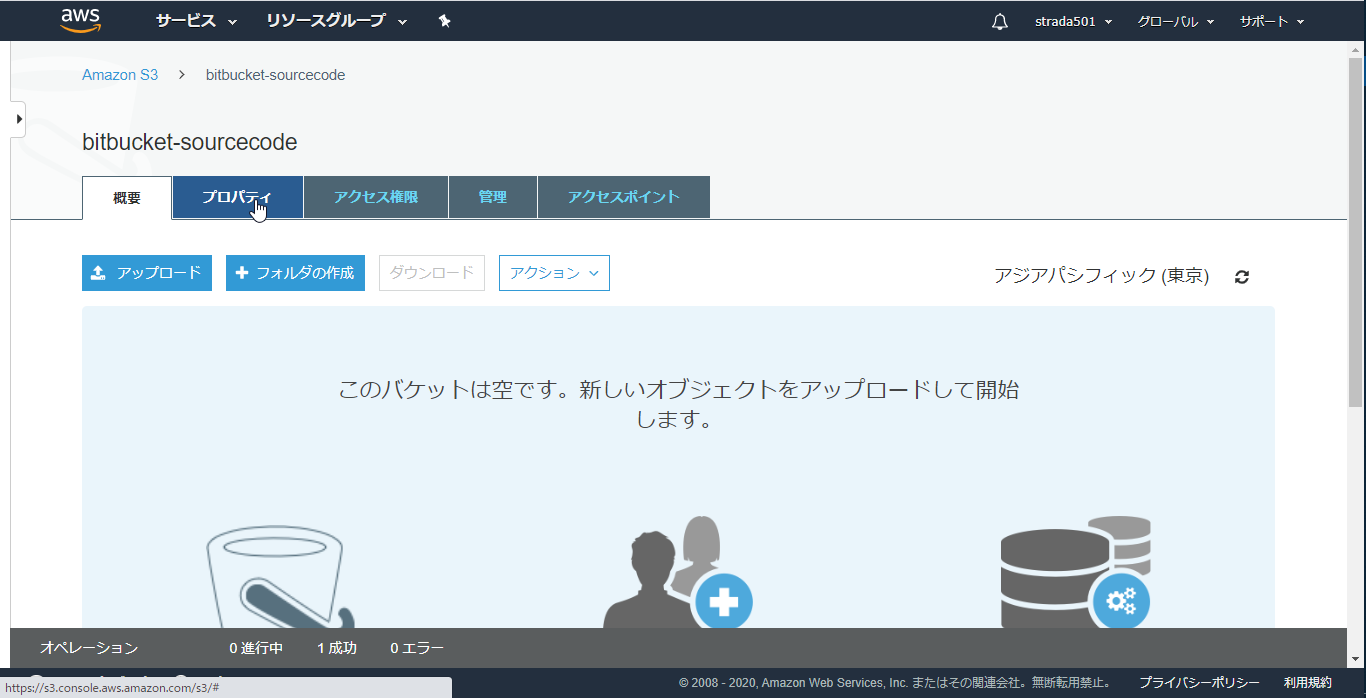
作成したバケットを開く
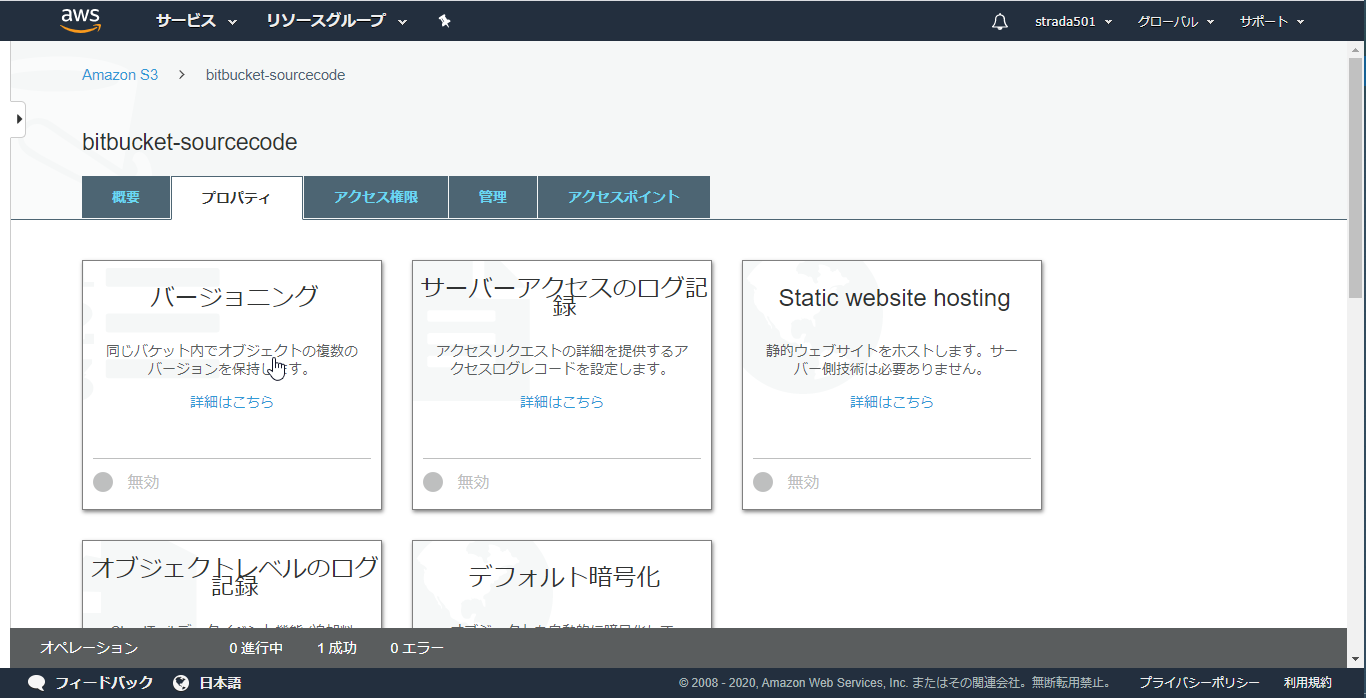
プロパティを選択
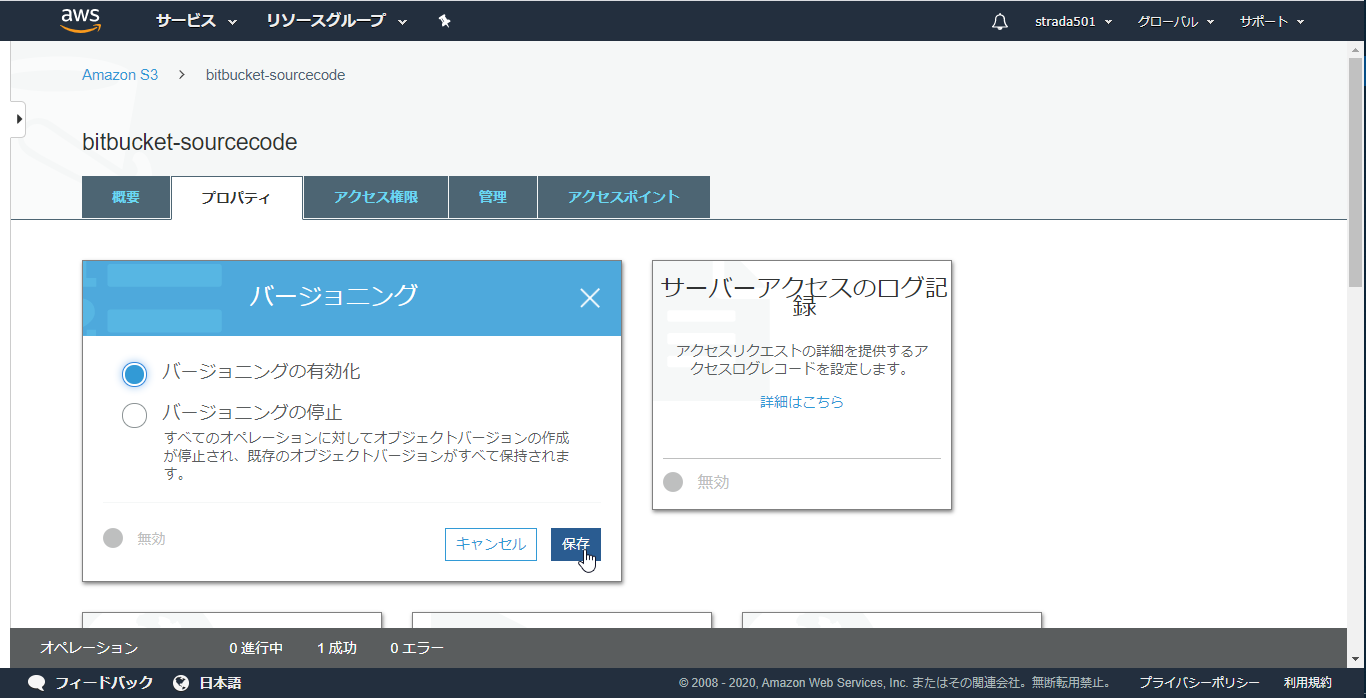
バージョニングを選択
バージョニングを有効化を選択して保存
有効化されたことを確認
※CodePipeのソースステージで指定するバケットはバージョニングを有効化している必要がある
CodePipelineの作成
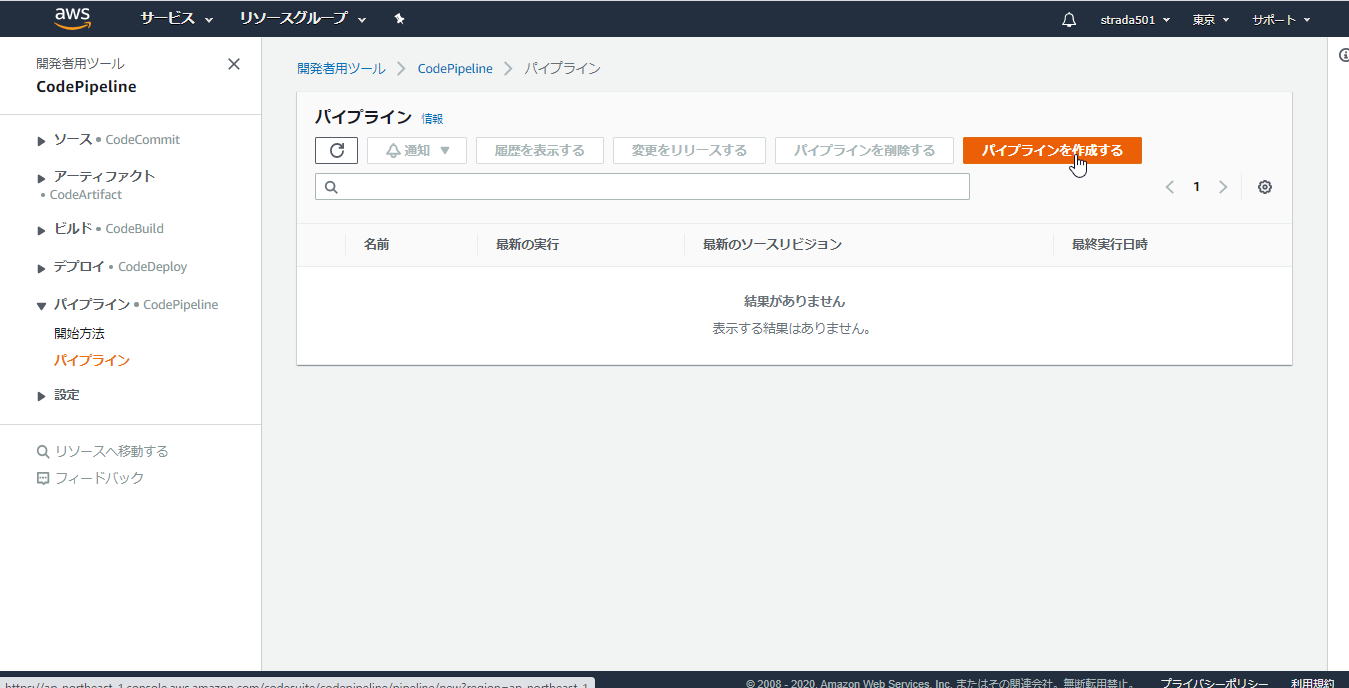
CodePiplineのコンソールからパイプラインを作成する
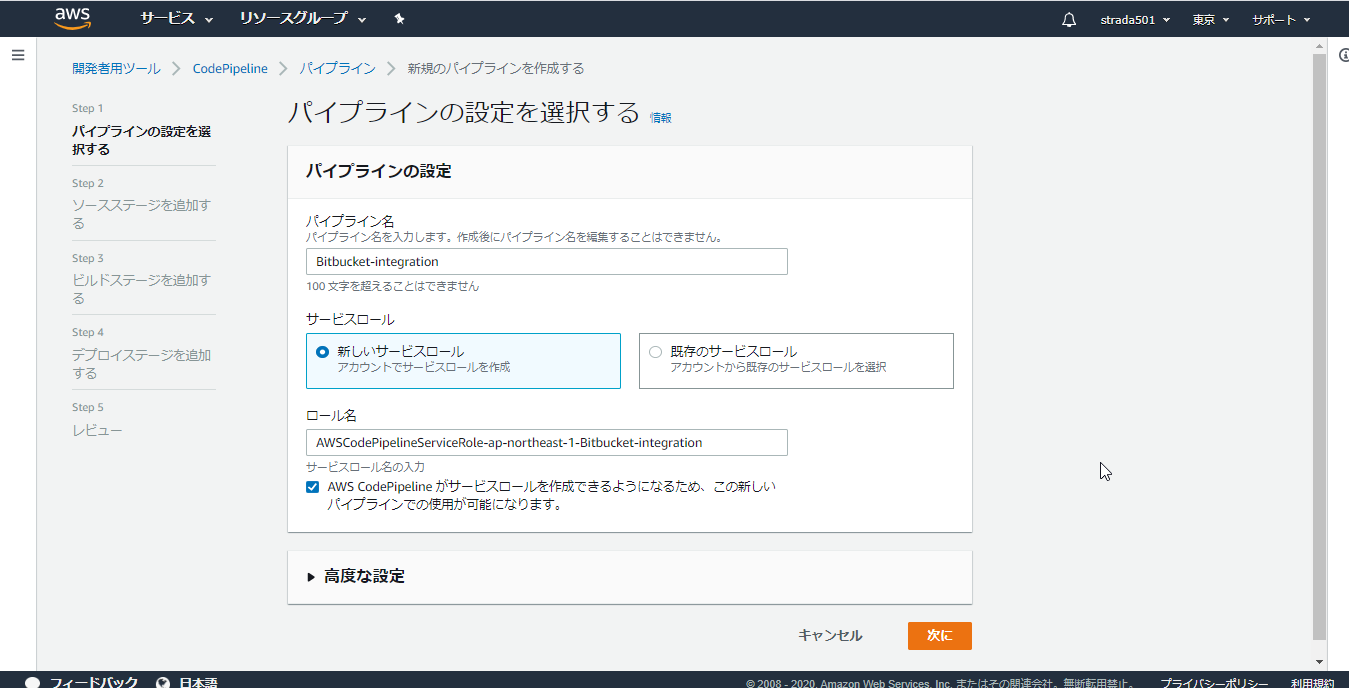
任意のパイプライン名を入力し、サービスロールで新しいサービスロールを選択して次に
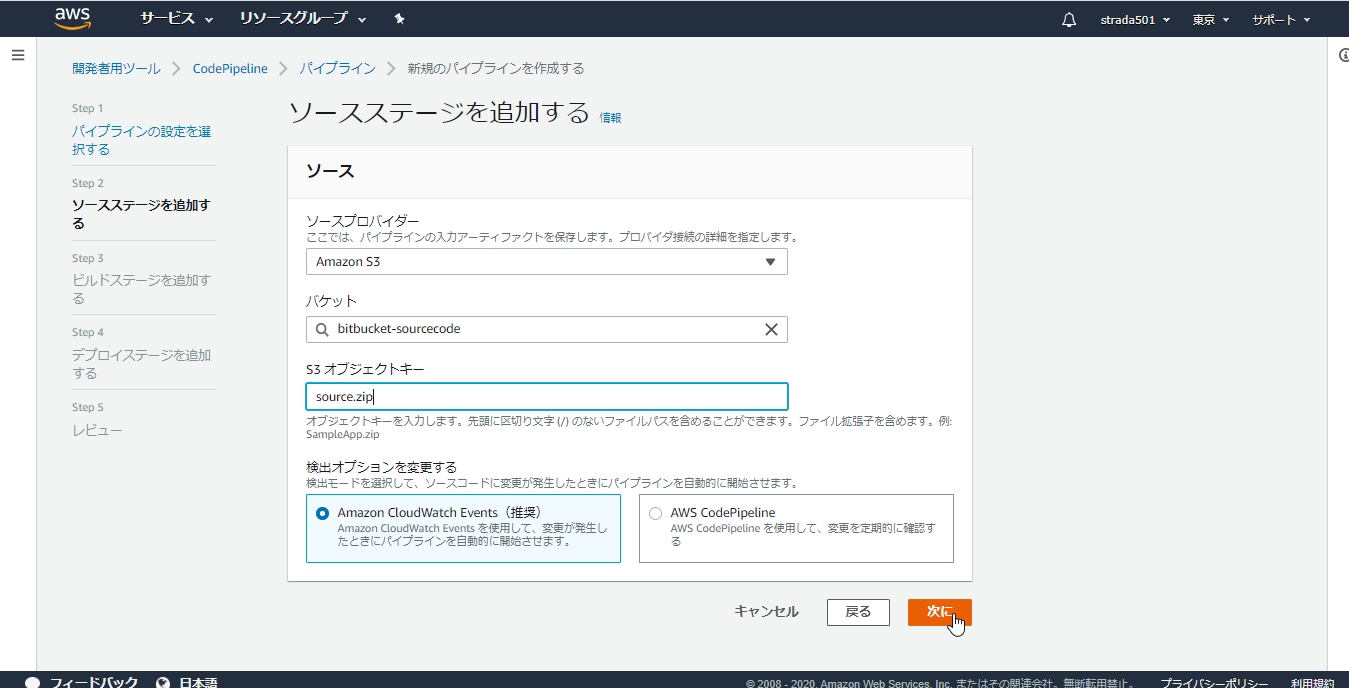
ソースステージのプロバイダーにAWS S3を選択し、バケットに事前に作成したバケット名を、オブジェクトキーにsource.zipを入力し次に
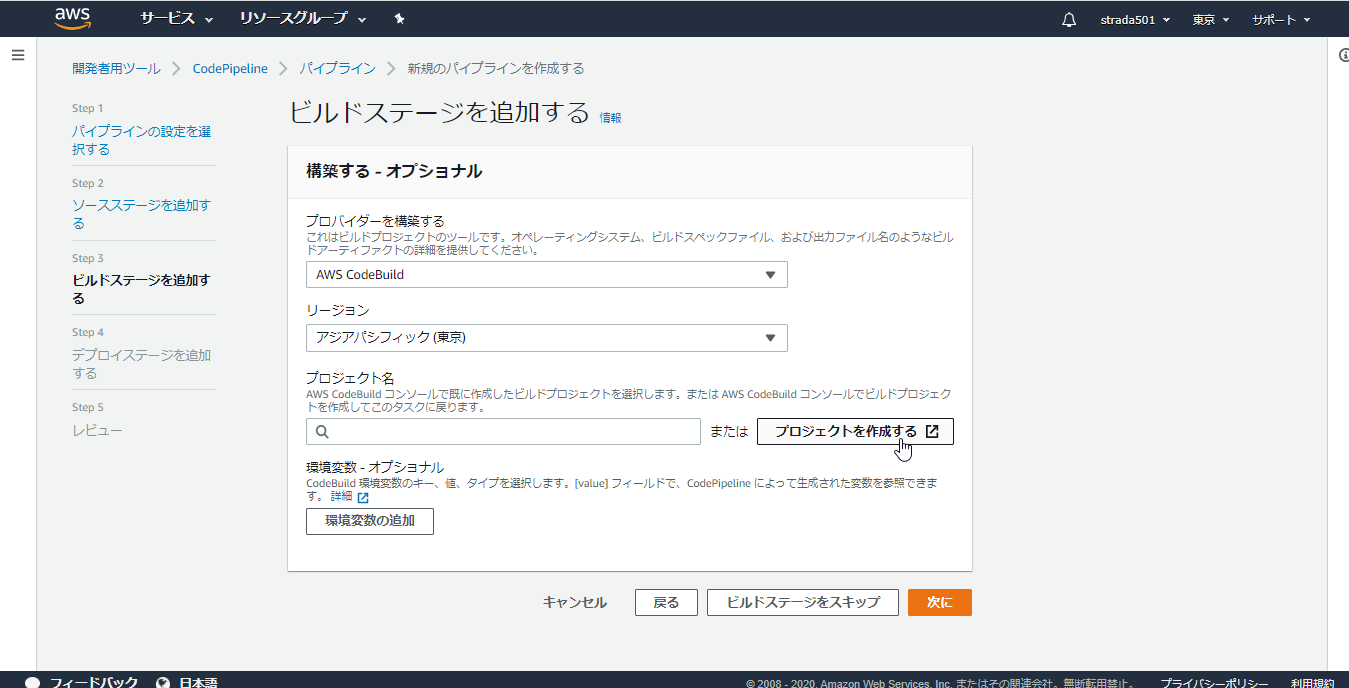
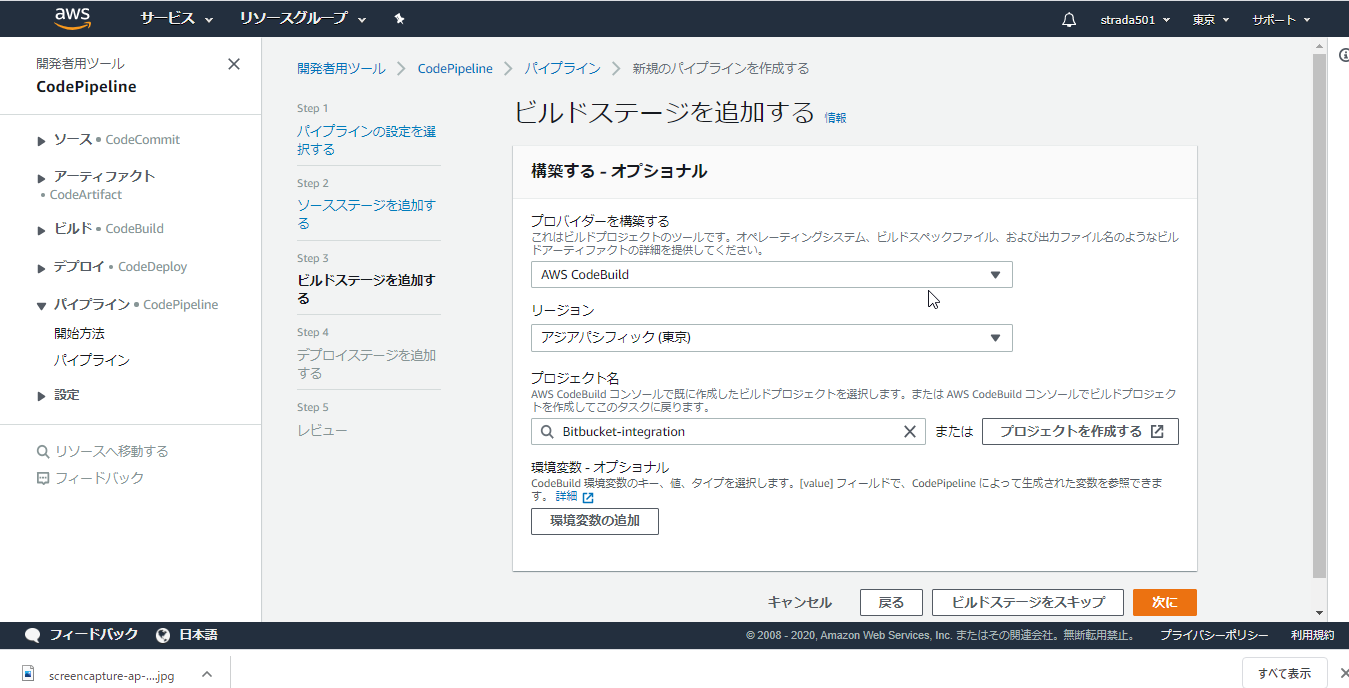
ビルドステージのプロバイダーでAWS CodeBuildを選択し、プロジェクトを作成する
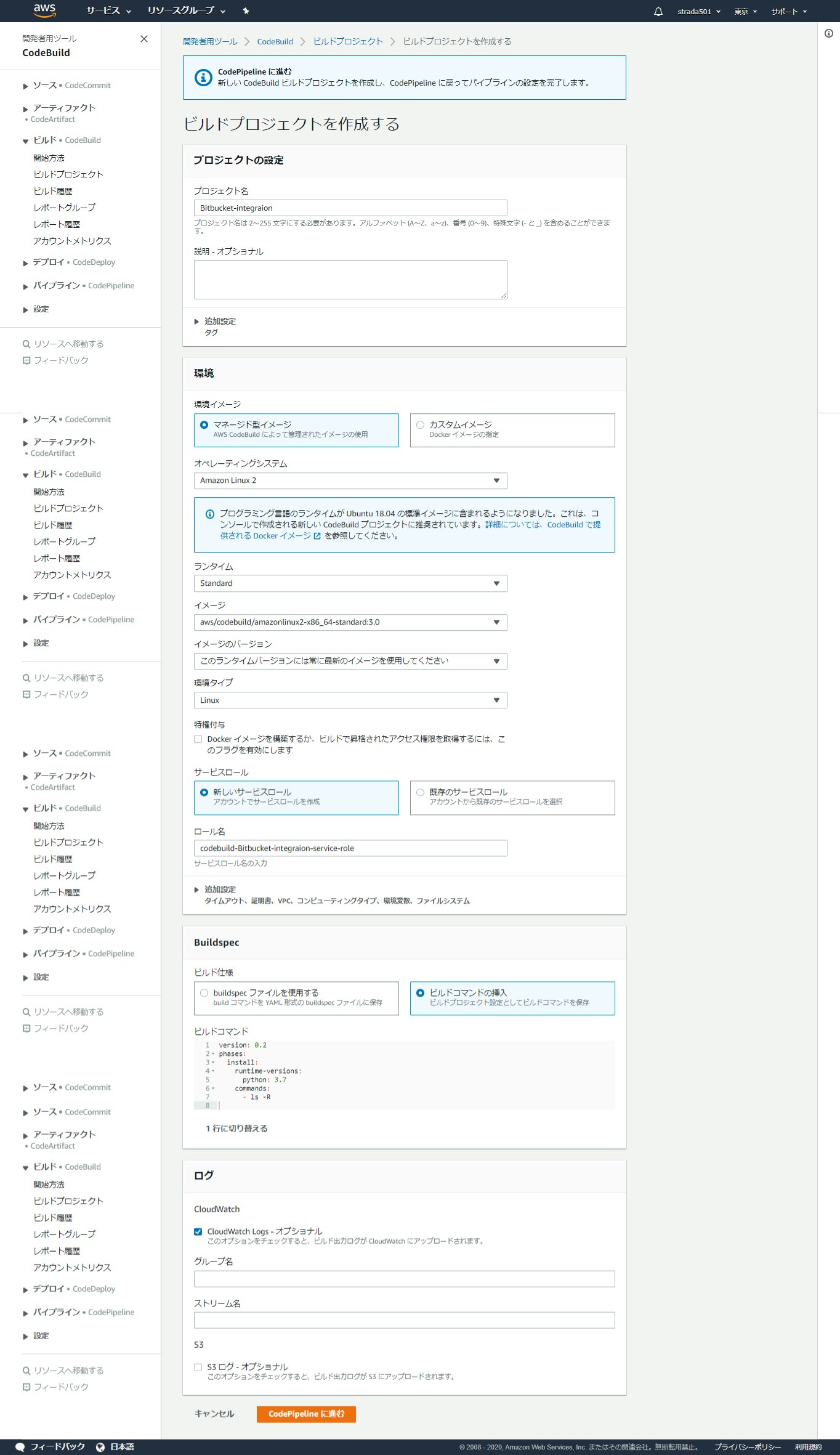
別のウィンドウが開くので、以下の項目を入力してCodePipelineに進む
※デフォルトからの変更点のみ
項目名 値 プロジェクト名 任意の名前 オペレーティングシステム Amazon Linux 2 ランタイム Standard イメージ aws/codebuild/amazonlinux2-x86_64-standard:3.0 ビルド仕様 ビルドコマンドの挿入 ※ビルドコマンドはエディターを開くことで直接編集可能
内容は以下を設定version: 0.2 phases: install: runtime-versions: python: 3.7 commands: - ls -R中身はPython 3.7のランタイムをインストールしたコンテナ上でls コマンドを実行するのみ
元の画面のビルドプロジェクト名に入力した値が反映されたことを確認の上次に
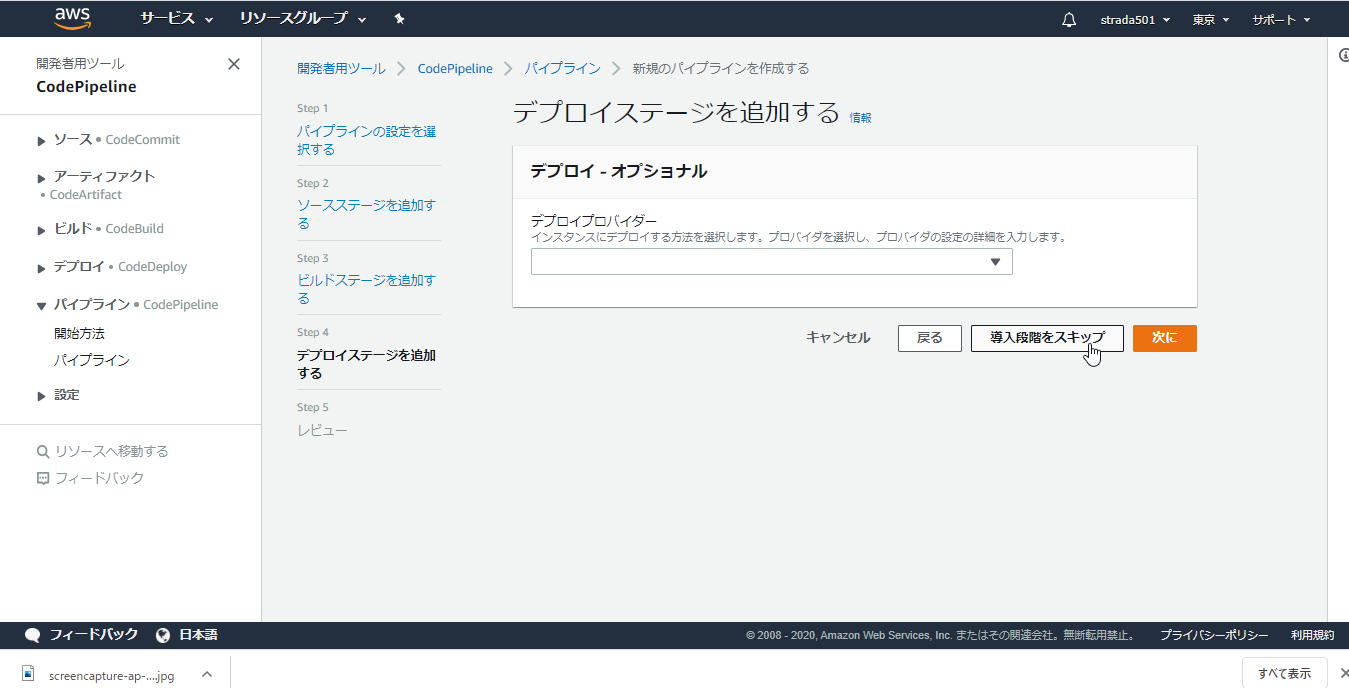
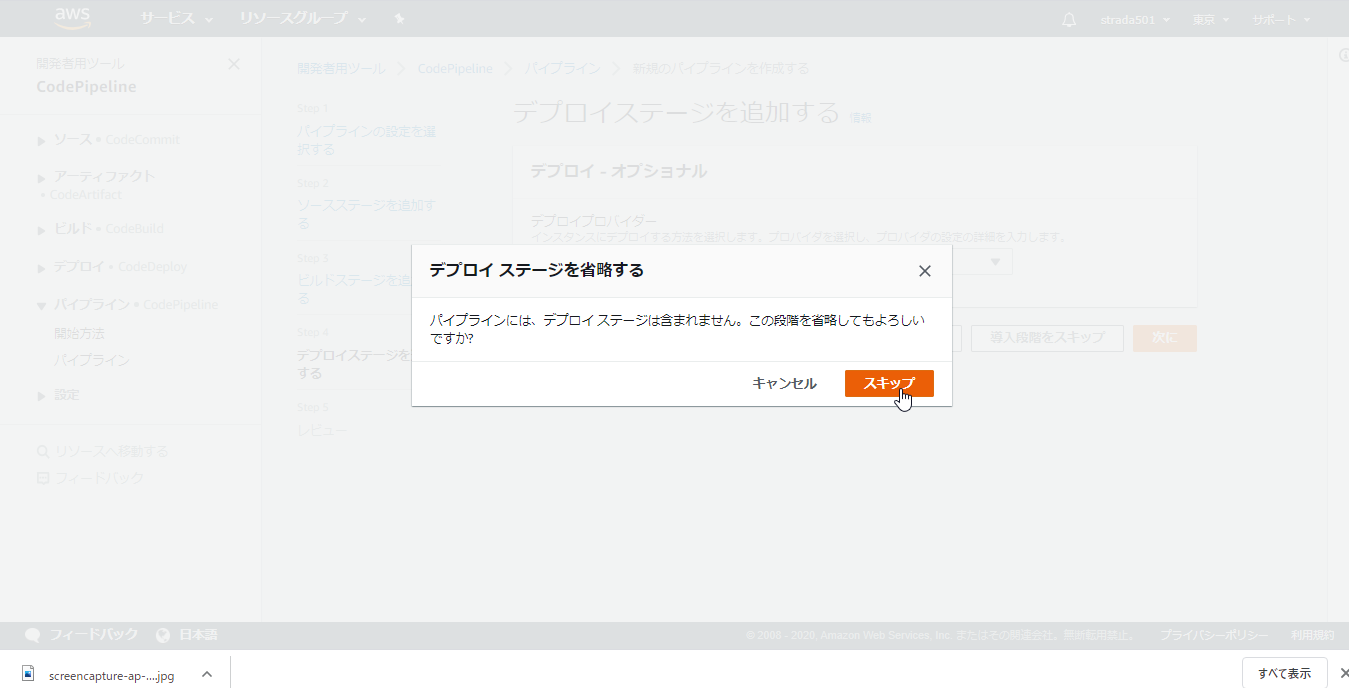
デプロイステージは今回はスキップするので導入段階をスキップ
表示されるダイアログでもスキップをクリック
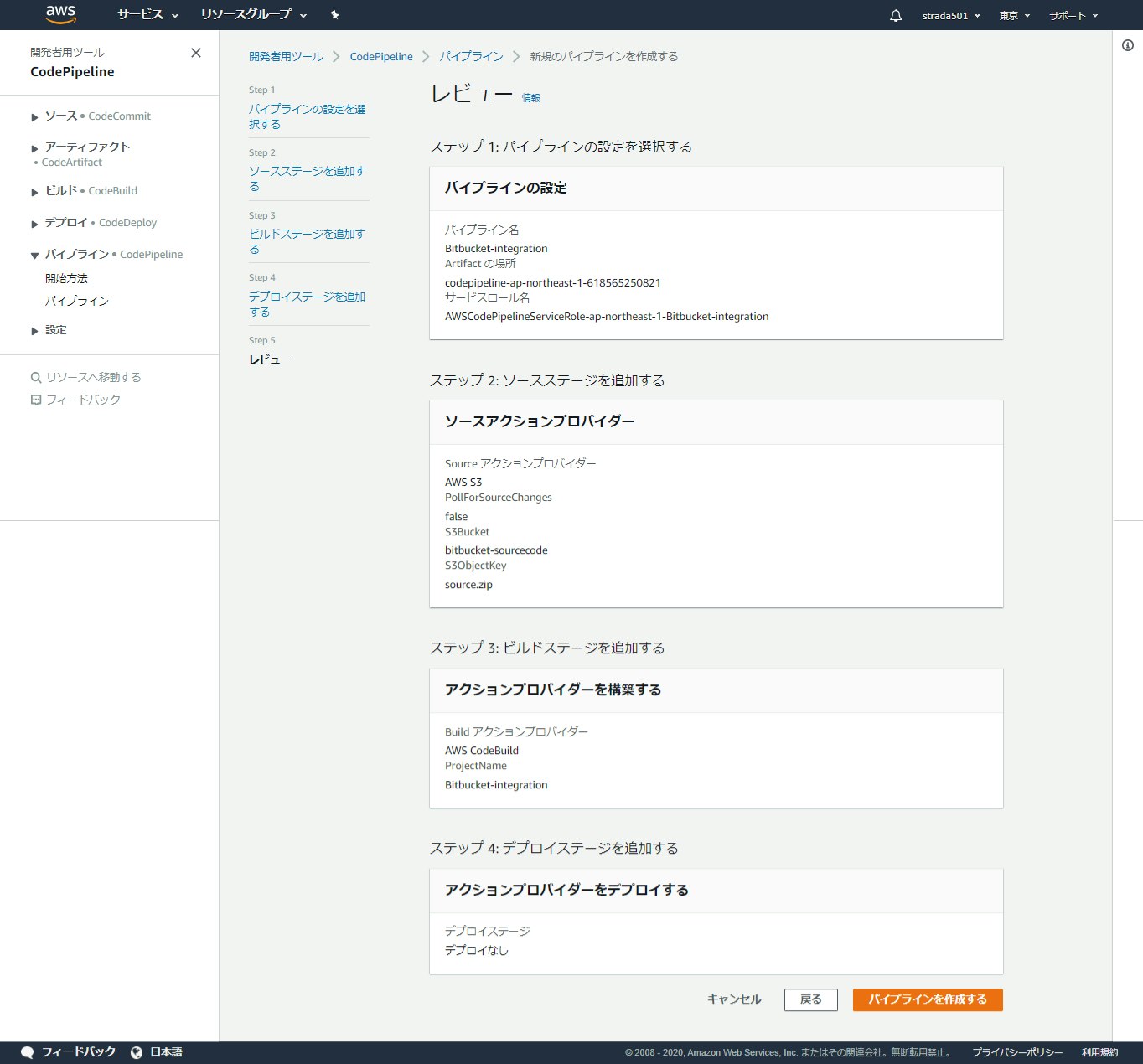
CodePipeline全体の構成を確認しパイプラインを作成する
AWS CodePipelineは作成時に必ず起動するが、この段階ではS3にsource.zipが存在していないため必ずエラーになる
Bitbucket Pipelinesで使用するIAMユーザーの作成
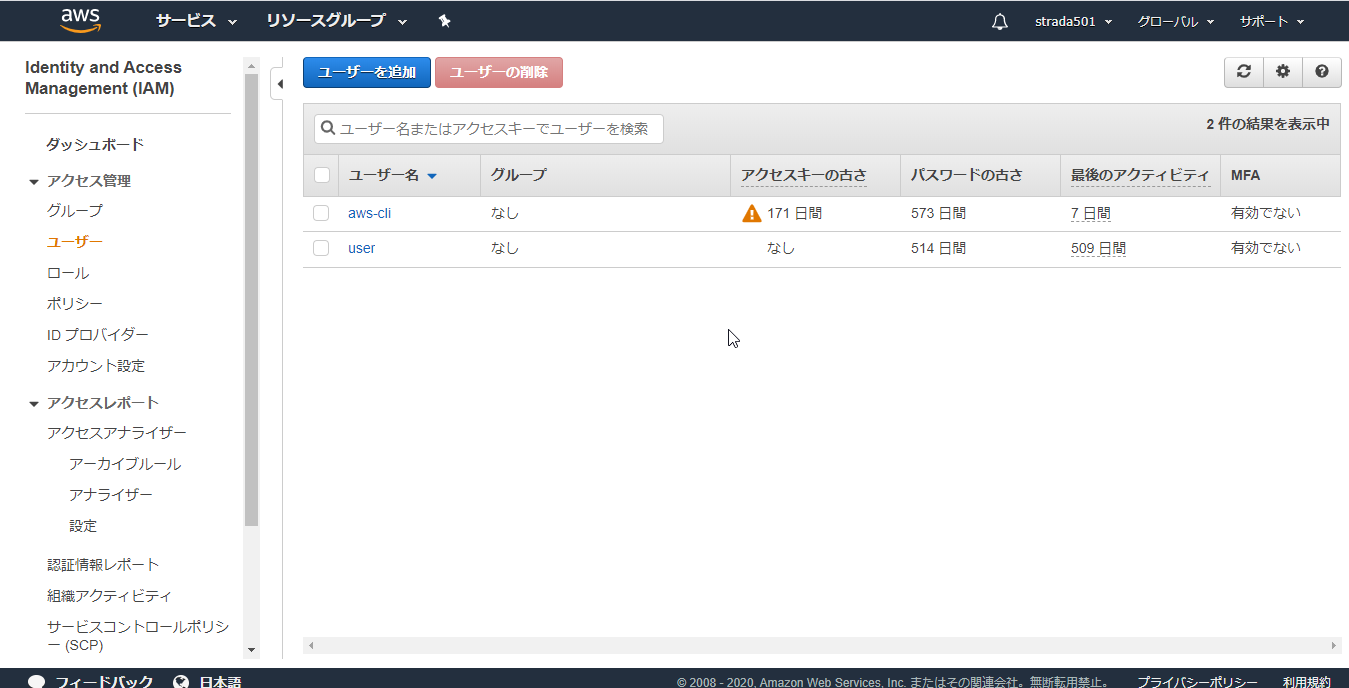
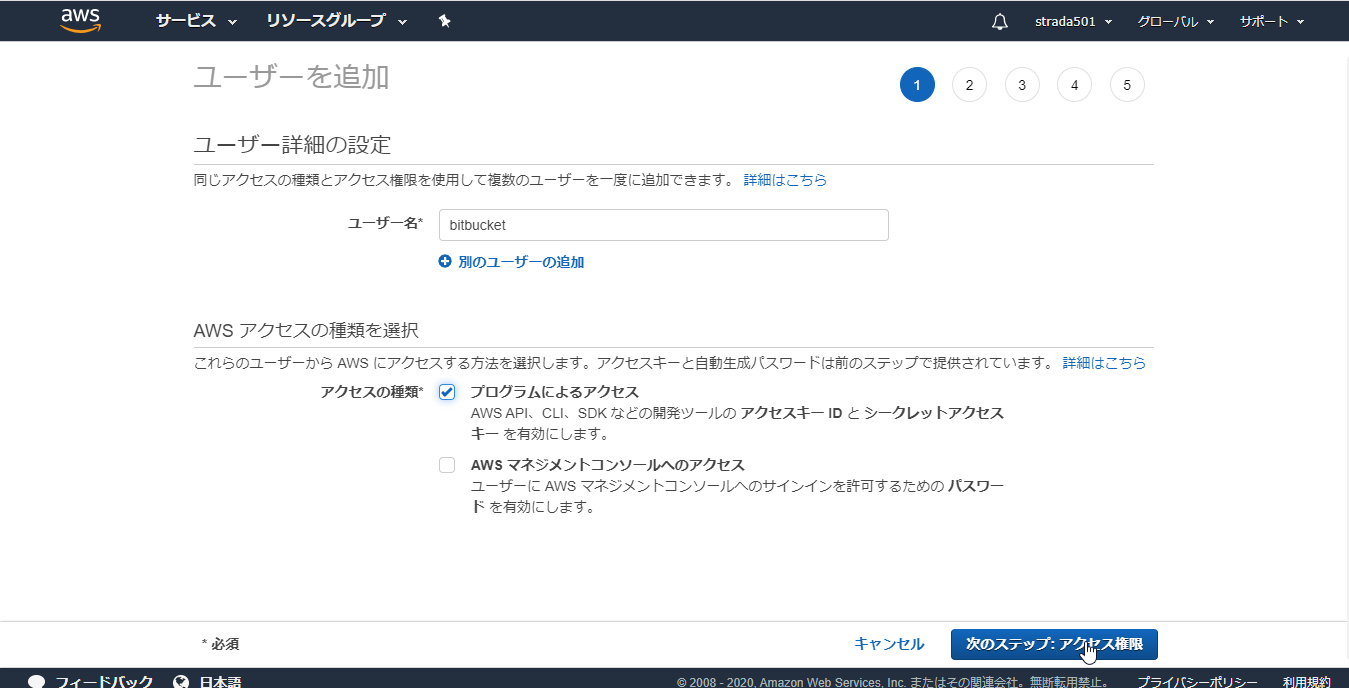
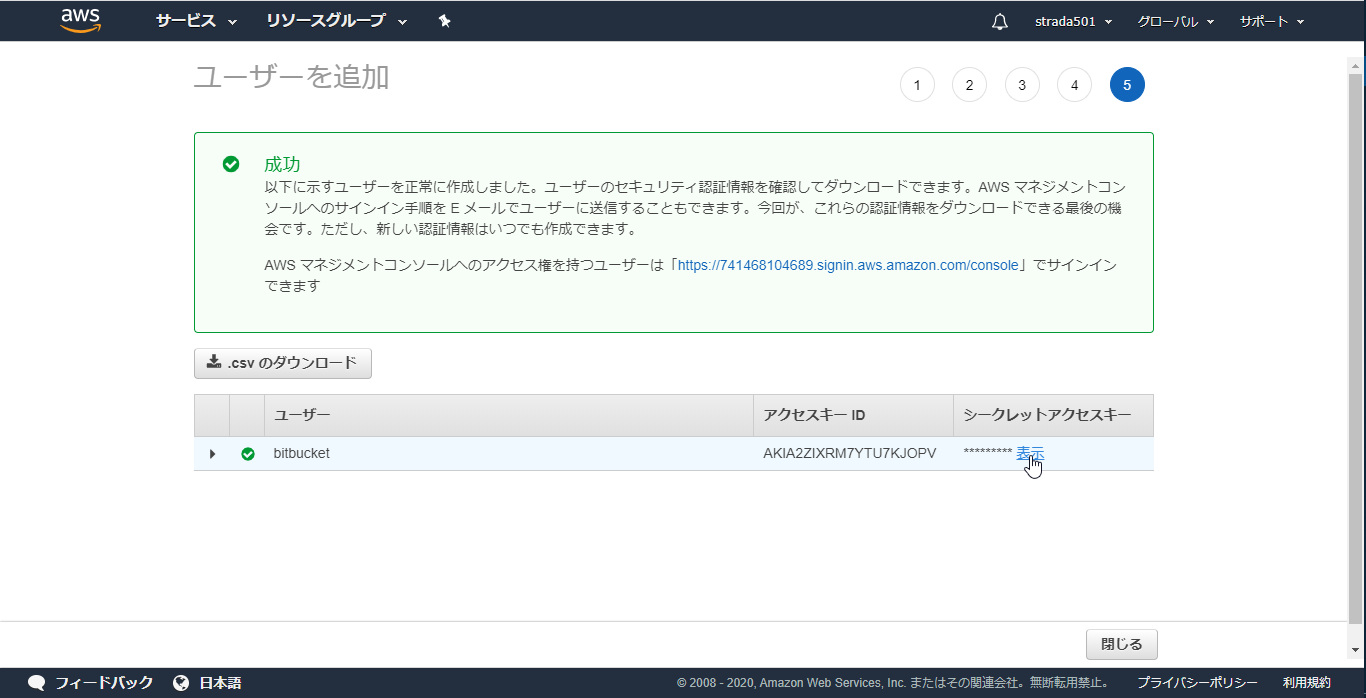
IAMのコンソールからユーザーメニューを選択しユーザーを追加
任意のユーザー名を入力し、プログラムによるアクセスを選択し、次のステップ
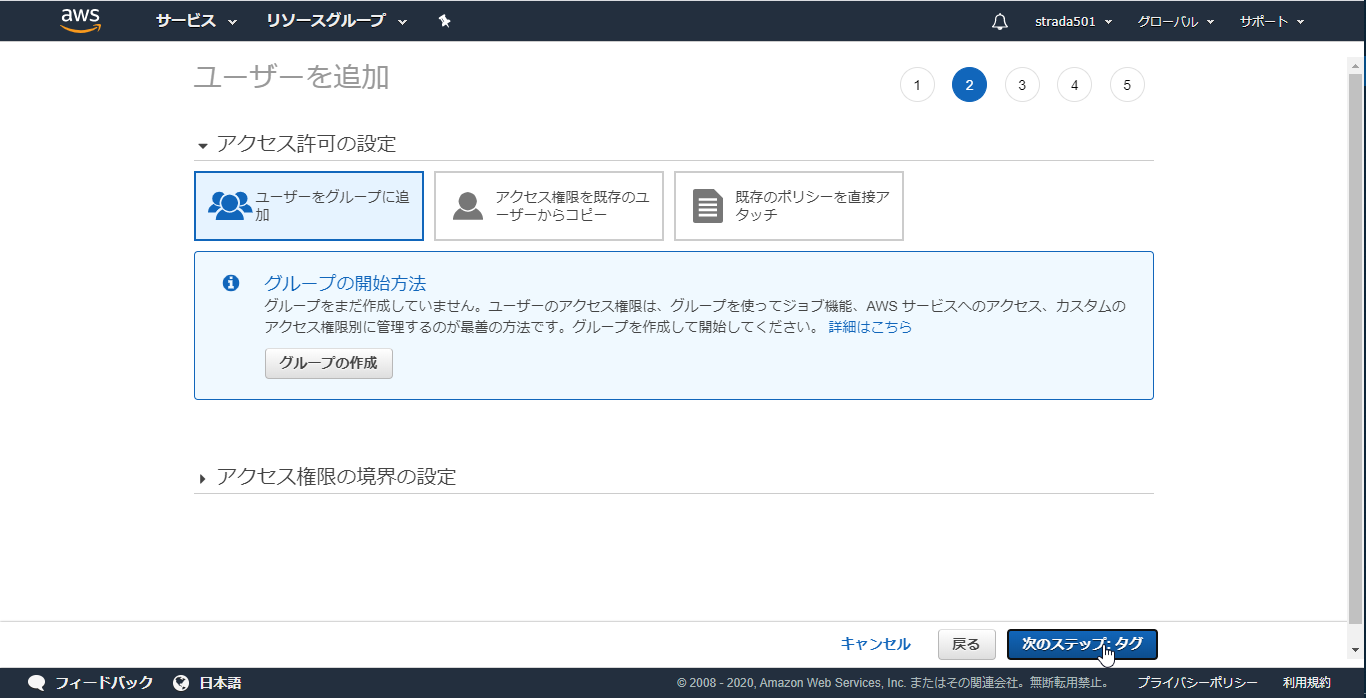
このまま次のステップ
このまま次のステップ
このユーザーにはアクセス権限がありませんと表示されるが、そのままユーザーの作成
- ユーザー作成中にはインラインポリシーの作成が出来ないため一度作成を完了している
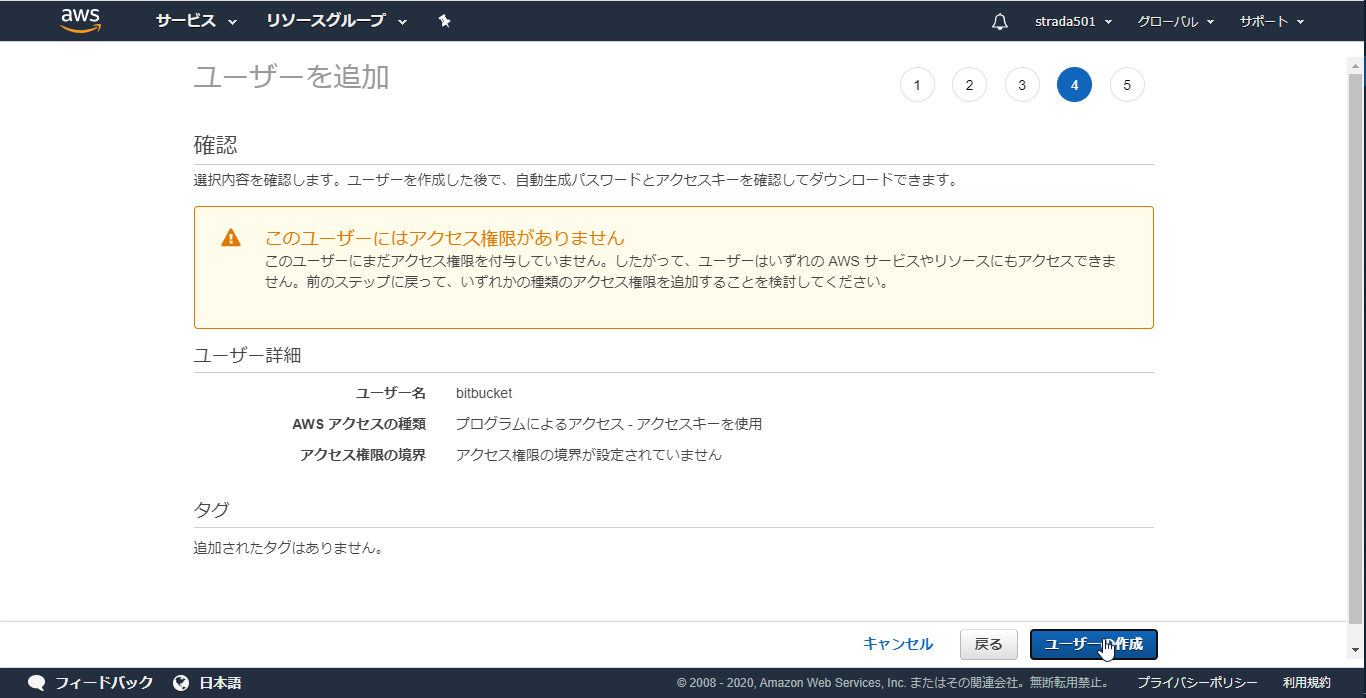
自動的にアクセスキーIDとシークレットアクセスキーが発行されるのでコピーするかcsvをダウンロードしておく
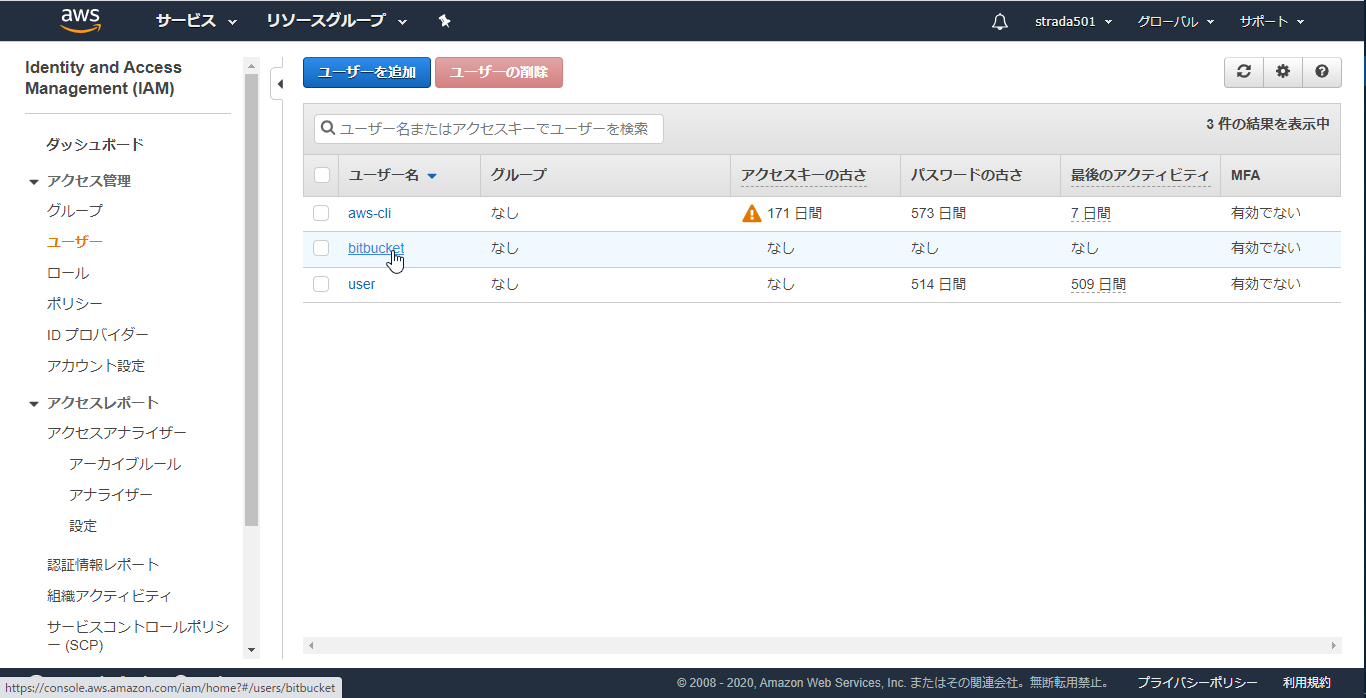
作成されたユーザーを選択
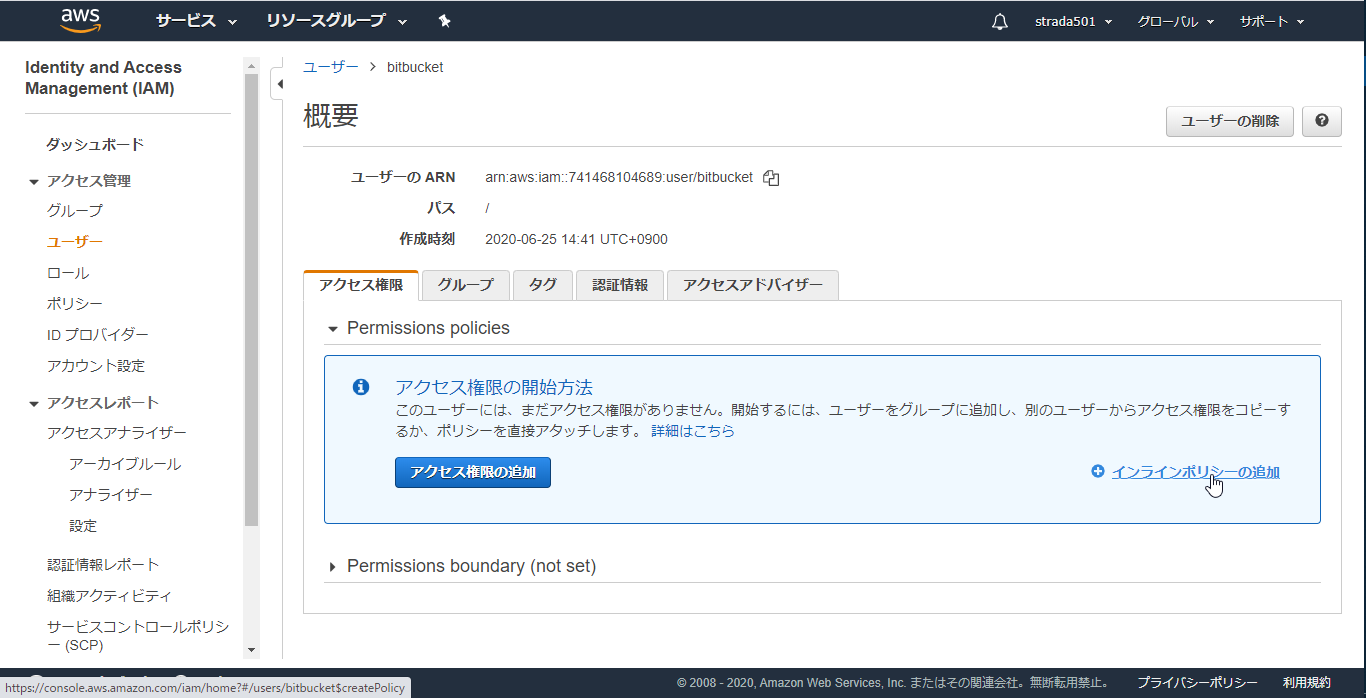
インラインポリシーの追加を選択
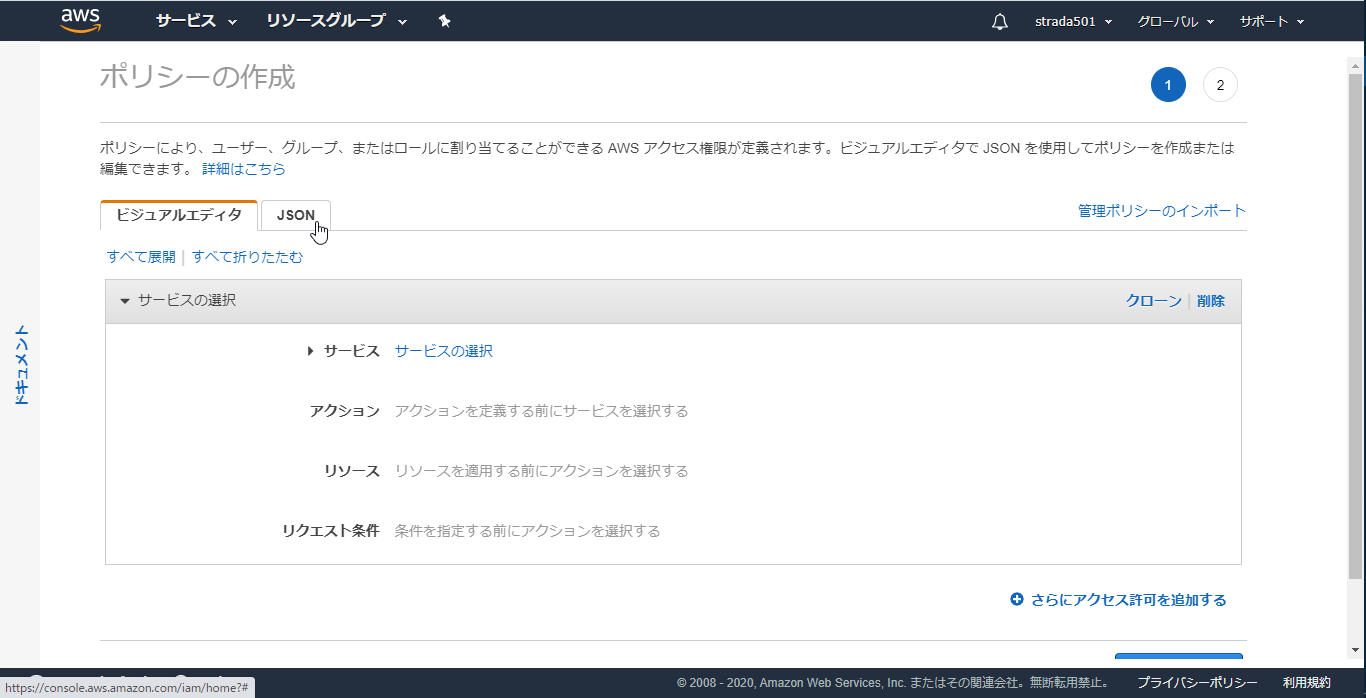
JSONタブを選択
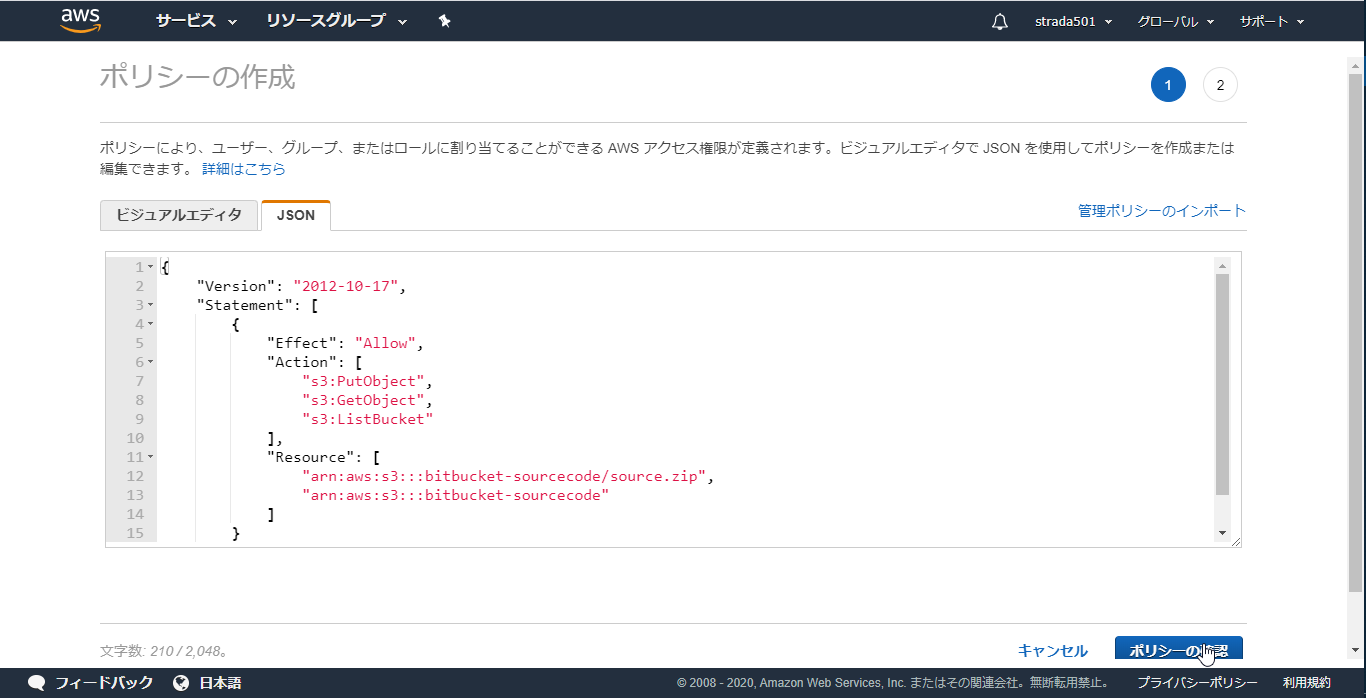
以下のJSONのResource内のS3のARNのバケット名を先ほど作成したものに変更してからコピペしたらポリシーの確認をクリック
※以下の太字部分を変更
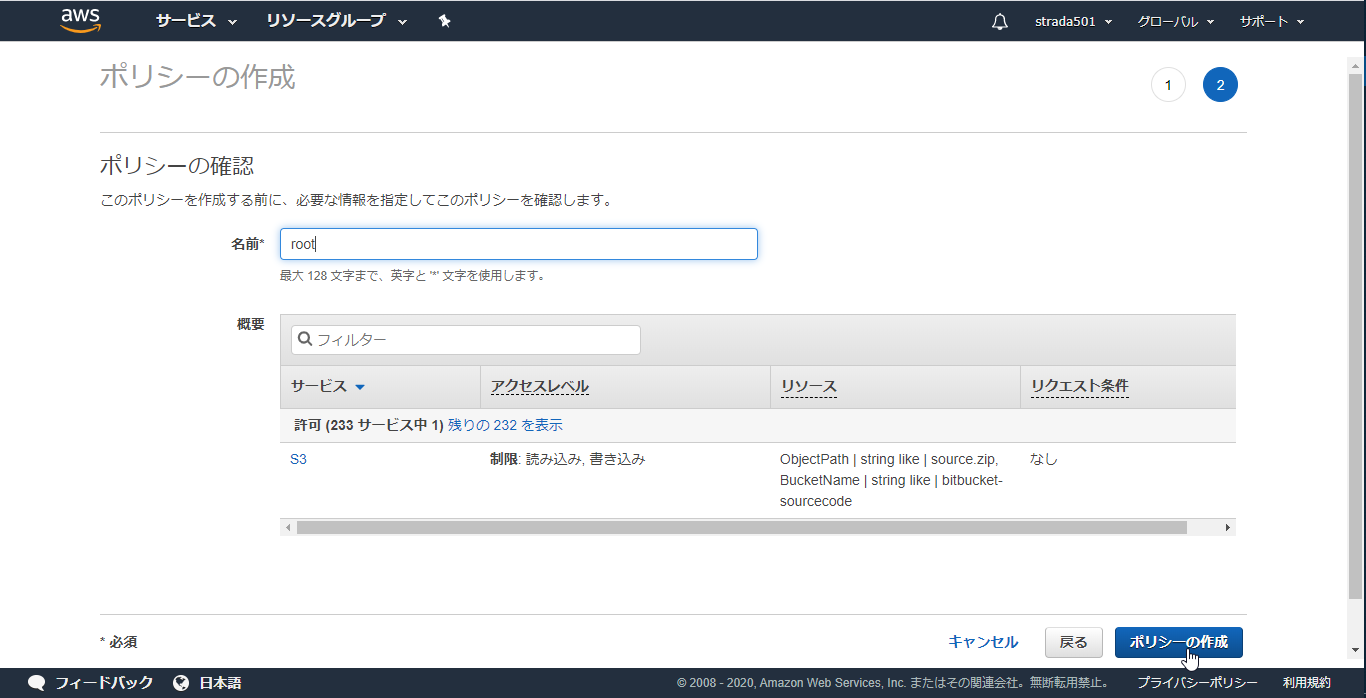
arn:aws:s3:::bitbucket-sourcecodeとarn:aws:s3:::bitbucket-sourcecode/*{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::bitbucket-sourcecode", "arn:aws:s3:::bitbucket-sourcecode/*" ] } ] }
- 任意のポリシー名を入力しポリシーの作成
Bitbucket Pipelinesの構成
Bitbucket リポジトリの作成
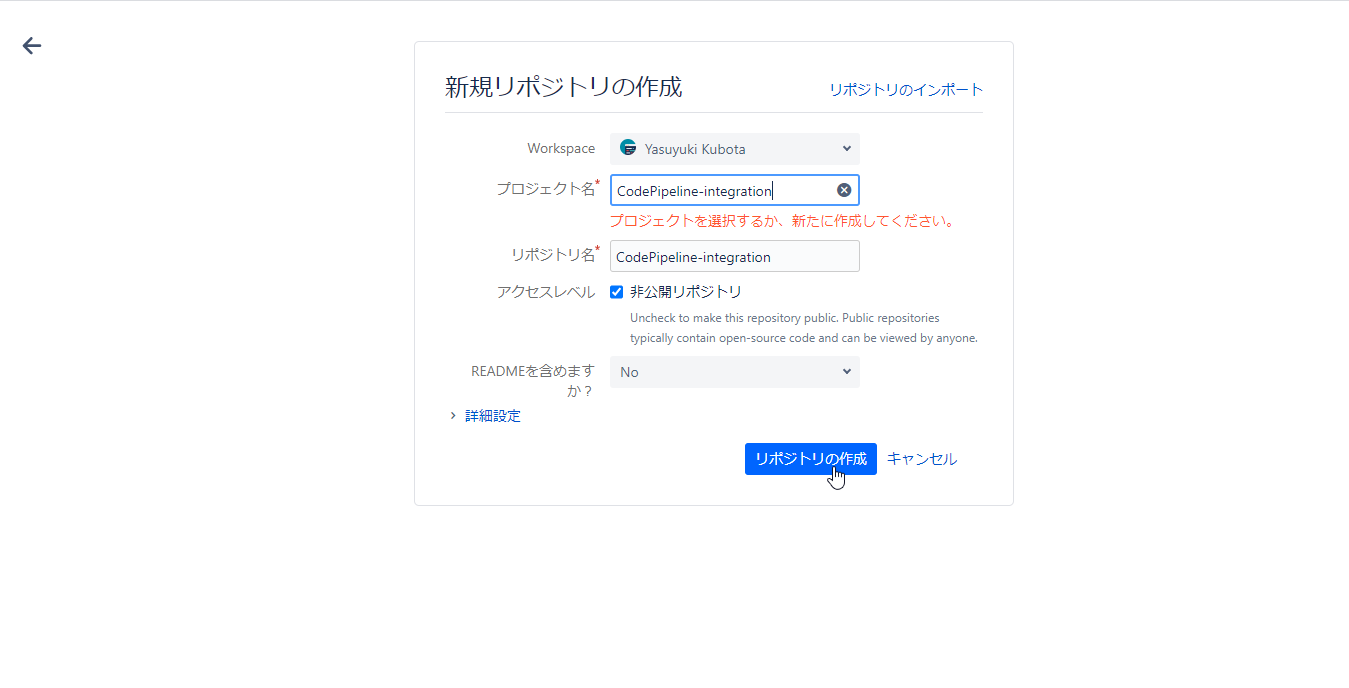
Bitbucketにアクセスしリポジトリメニューからリポジトリを作成
任意のプロジェクト名とリポジトリ名を入力しリポジトリの作成
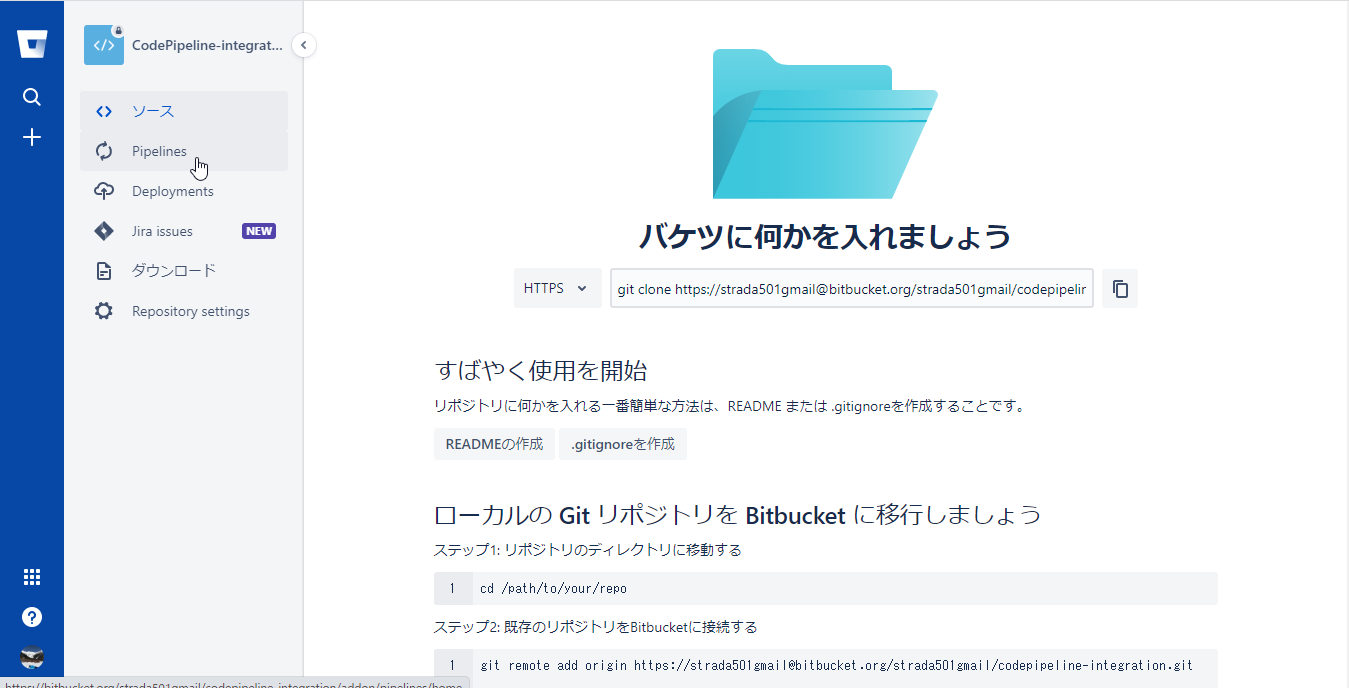
Pipelinesの有効化
Pipelinesメニューを選択
下部に今回のPipelineで使用する言語テンプレートの選択箇所があるので今回はPythonを選択
言語を選択した時点で自動的にエディターが開き、Pipelineの構成ファイルの初期テンプレートを設定してくれる
初期の状態だと起動トリガー(ブランチやタグ)を指定していない状態になっている
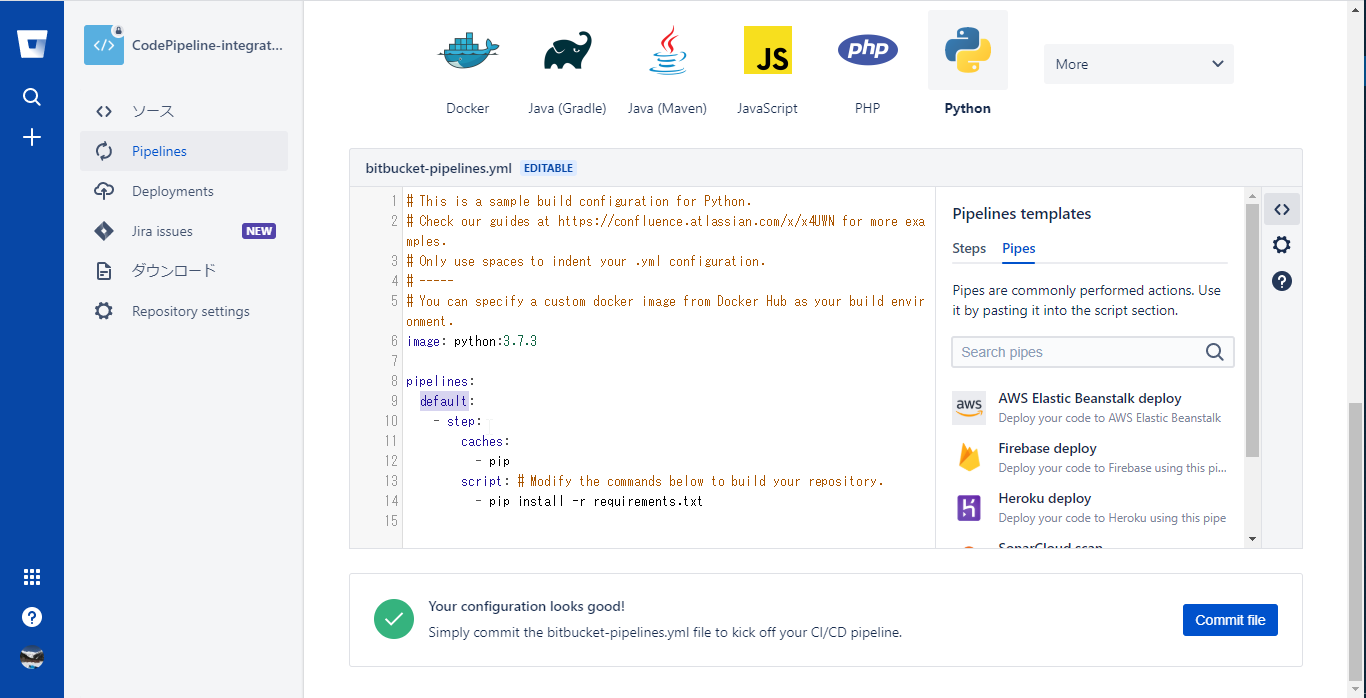
image: python:3.7.3 pipelines: default: - step: caches: - pip script: # Modify the commands below to build your repository. - pip install -r requirements.txt
- 起動トリガーをmasterブランチに変更があった場合のみにするため以下のように編集する
image: python:3.7.3 pipelines: branches: master: - step: caches: - pip script: # Modify the commands below to build your repository. - pip install -r requirements.txt
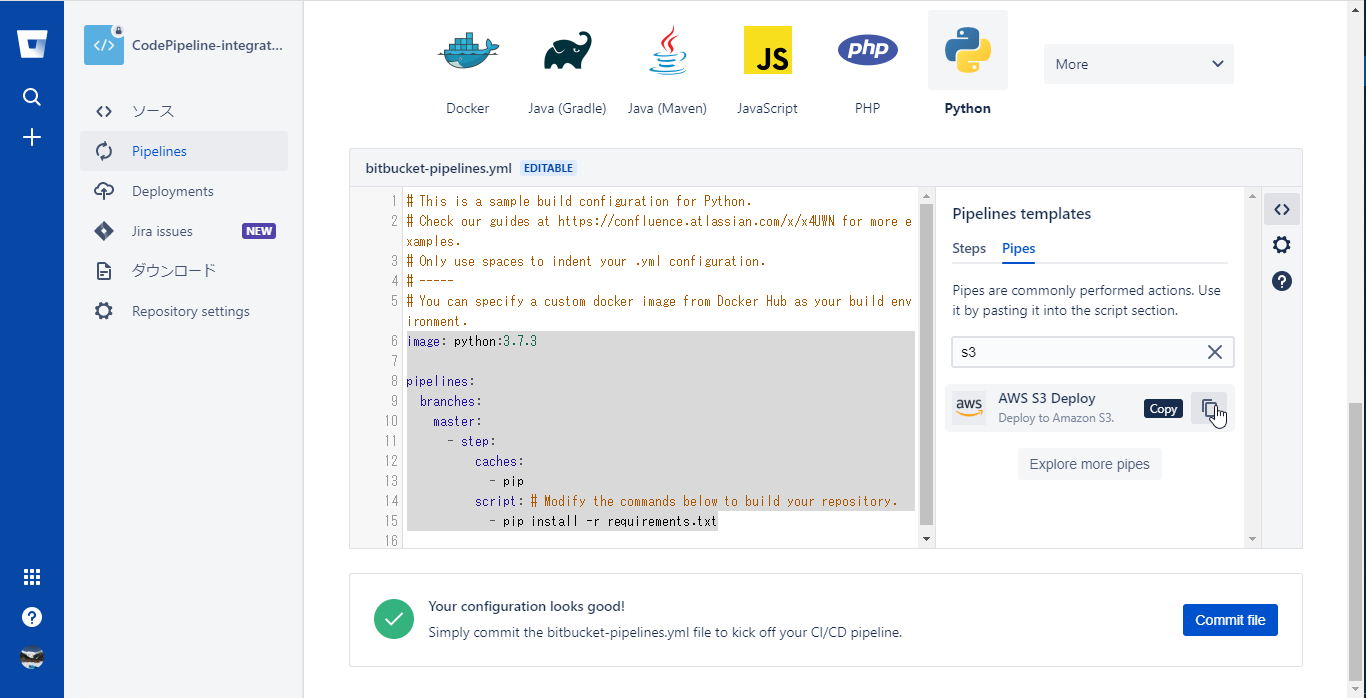
- さらにエディターの右ペインに使用できるPipeが表示されるので、検索用のテキストエリアにs3を入力し、AWS S3 DeployPipeを表示する
Pipe名の横のコピーアイコンをクリックするとSnippetがコピーできる
コピーされるSnippetは以下の通り
- pipe: atlassian/aws-s3-deploy:0.4.4 variables: AWS_ACCESS_KEY_ID: '<string>' # Optional if already defined in the context. AWS_SECRET_ACCESS_KEY: '<string>' # Optional if already defined in the context. AWS_DEFAULT_REGION: '<string>' # Optional if already defined in the context. S3_BUCKET: '<string>' LOCAL_PATH: '<string>' # CONTENT_ENCODING: '<string>' # Optional. # ACL: '<string>' # Optional. # STORAGE_CLASS: '<string>' # Optional. # CACHE_CONTROL: '<string>' # Optional. # EXPIRES: '<timestamp>' # Optional. # DELETE_FLAG: '<boolean>' # Optional. # EXTRA_ARGS: '<string>' # Optional. # DEBUG: '<boolean>' # Optional.
- このSnippetも参考にしつつ設定した最終的な実装は以下の通り
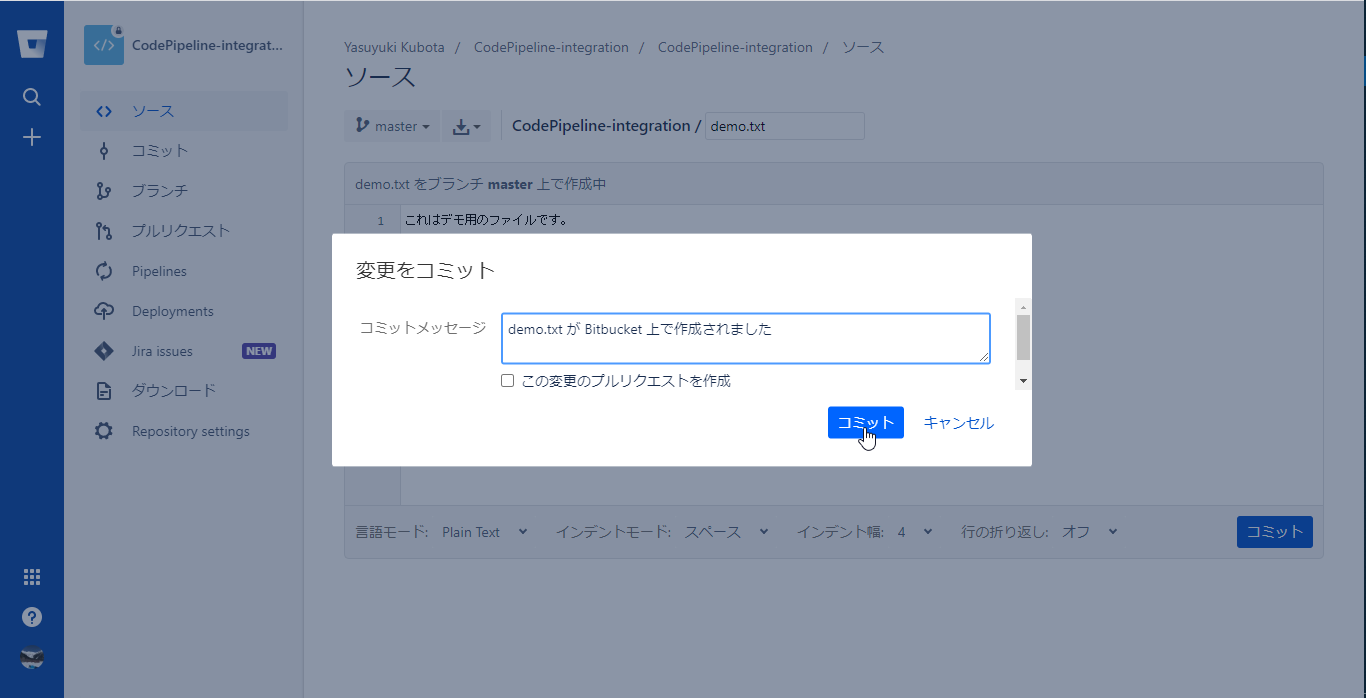
- この内容でCommit fileをクリックする
# This is a sample build configuration for Python. # Check our guides at https://confluence.atlassian.com/x/x4UWN for more examples. # Only use spaces to indent your .yml configuration. # ----- # You can specify a custom docker image from Docker Hub as your build environment. image: python:3.7.3 pipelines: branches: master: - step: caches: - pip script: # Modify the commands below to build your repository. - apt update && apt install -y zip - zip -r source.zip * -x "./.git/*" - mkdir to_s3 - cp source.zip ./to_s3 - pipe: atlassian/aws-s3-deploy:0.4.4 variables: AWS_ACCESS_KEY_ID: $AWS_ACCESS_KEY_ID # Optional if already defined in the context. AWS_SECRET_ACCESS_KEY: $AWS_SECRET_ACCESS_KEY # Optional if already defined in the context. AWS_DEFAULT_REGION: $AWS_DEFAULT_REGION # Optional if already defined in the context. S3_BUCKET: 'bitbucket-sourcecode' LOCAL_PATH: './to_s3' 39c4-4b67ef4143a0.png)
処理は以下の通り
- zipコマンドのインストール
- .gitディレクトリ以外の内容をsource.zipに圧縮
- to_s3ディレクトリにsource.zipをコピー
- aws-s3-deployのパイプを以下の変数で実行
- AWS_ACCESS_KEY_ID:環境変数AWS_ACCESS_KEY_IDから取得
- AWS_SECRET_ACCESS_KEY:環境変数AWS_SECRET_ACCESS_KEYから取得
- AWS_DEFAULT_REGION:環境変数AWS_DEFAULT_REGIONから取得
- S3_BUCKET:前の手順で作成したS3バケット名
- LOCAL_PATH: source.zipをコピーしたto_s3ディレクトリを指定
設定した内容がbitbucket-pipelines.ymlとしてmasterブランチに登録される
masterブランチへの変更があったとみなされすぐに初回のPipelineが起動するが環境変数の設定をしていないため初回は以下のように失敗する
環境変数へAWS認証情報を設定
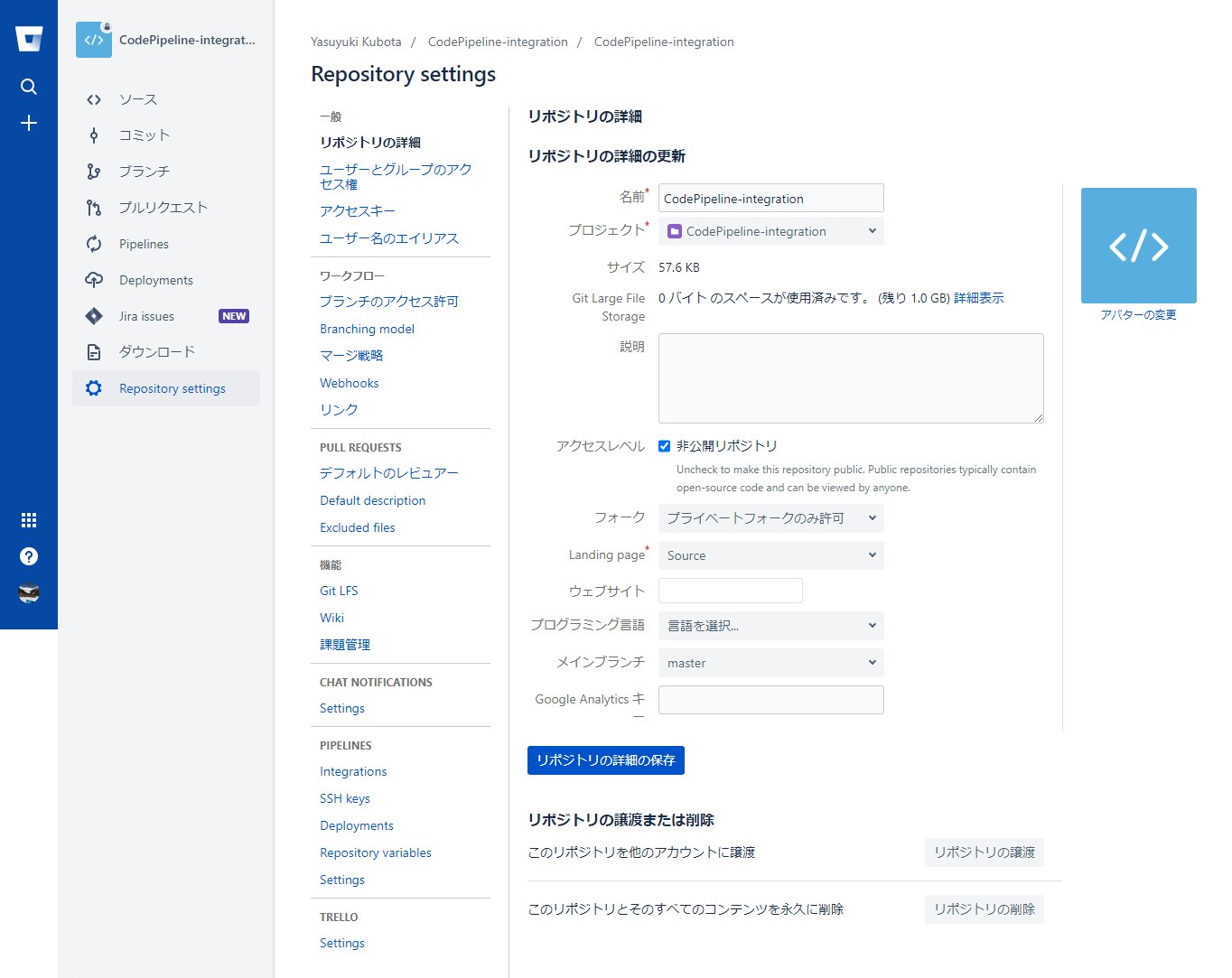
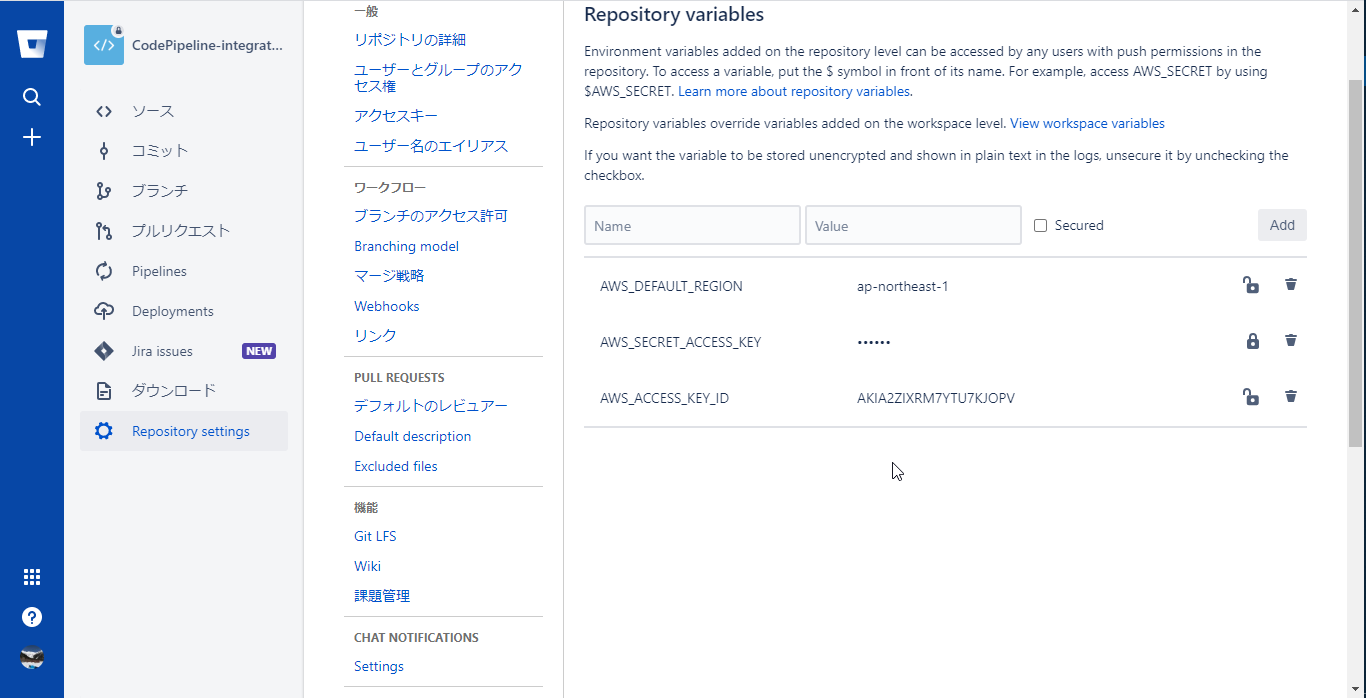
Repository settingsメニューを選択し、PIPELINESセクションのRepository variablesを選択
以下の環境変数を作成する
- securedをチェックすると値をmaskして保管できるのでシークレットアクセスキーはmaskすると良い
変数名 値 AWS_ACCESS_KEY_ID IAMユーザーの作成時にコピーした値 AWS_SECRET_ACCESS_KEY IAMユーザーの作成時にコピーした値 AWS_DEFAULT_REGION ap-northeast-1
実行
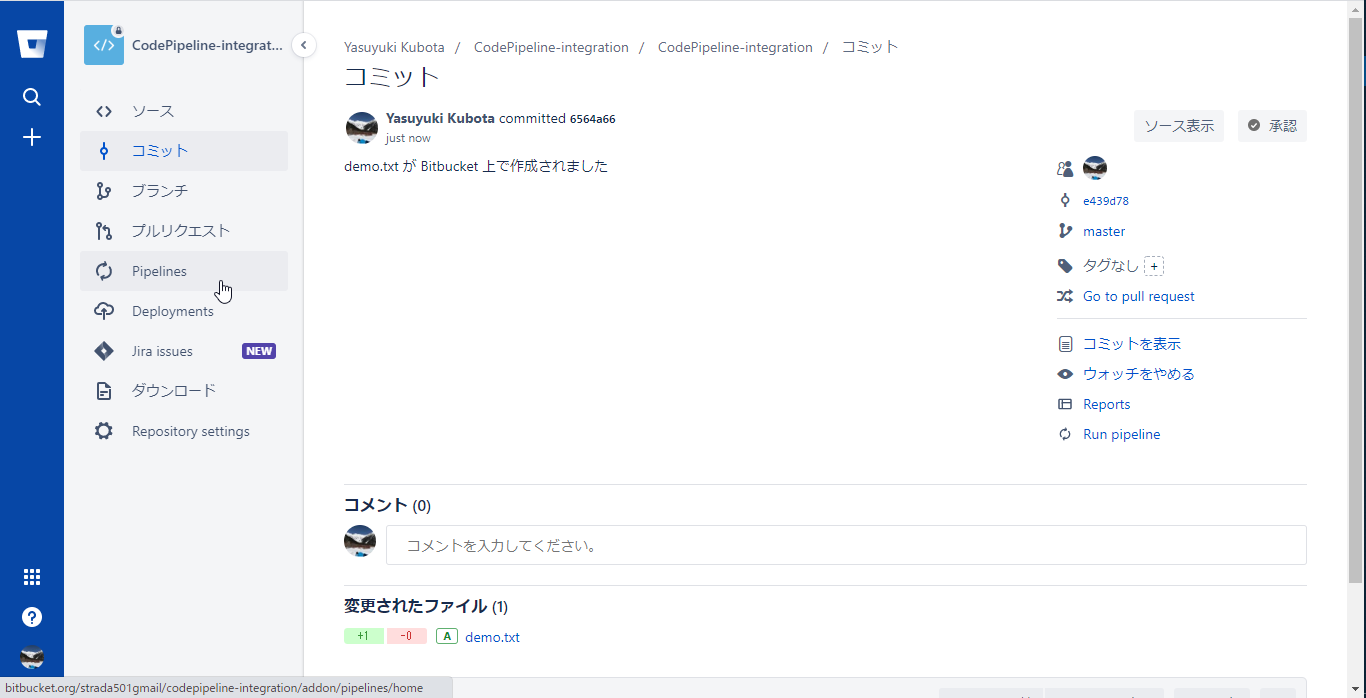
masterブランチへの変更
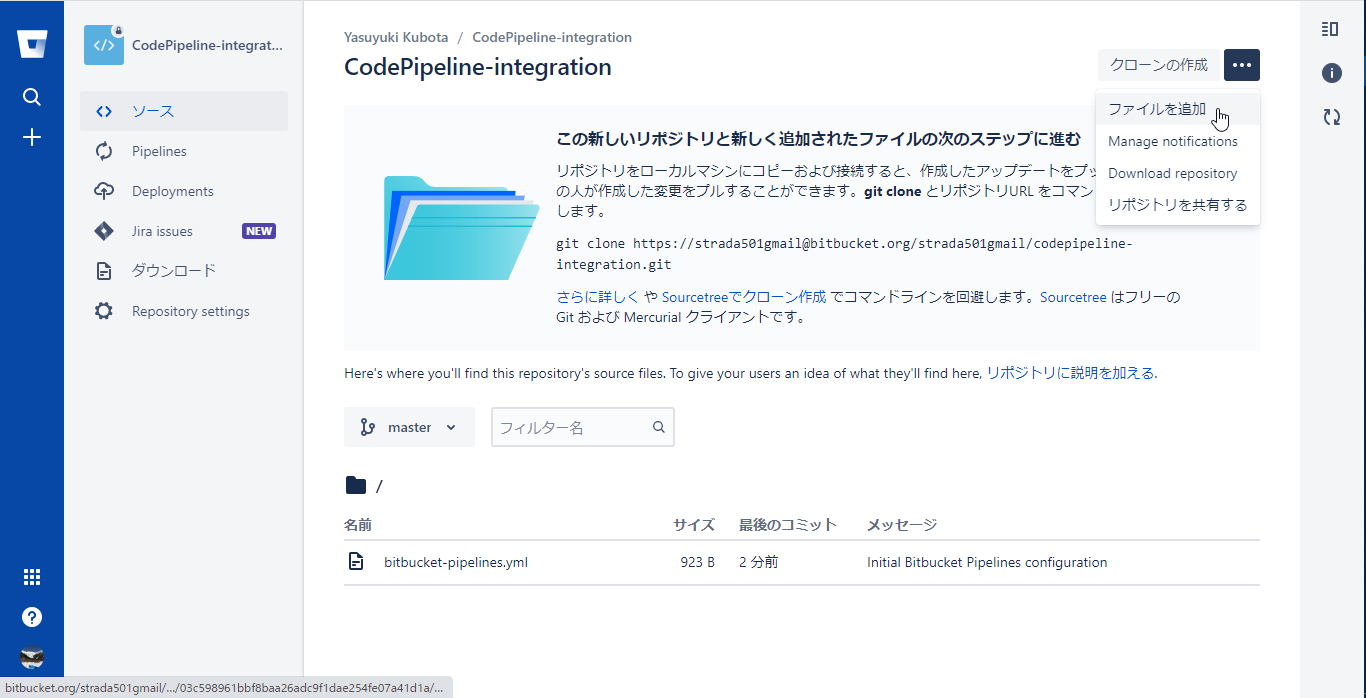
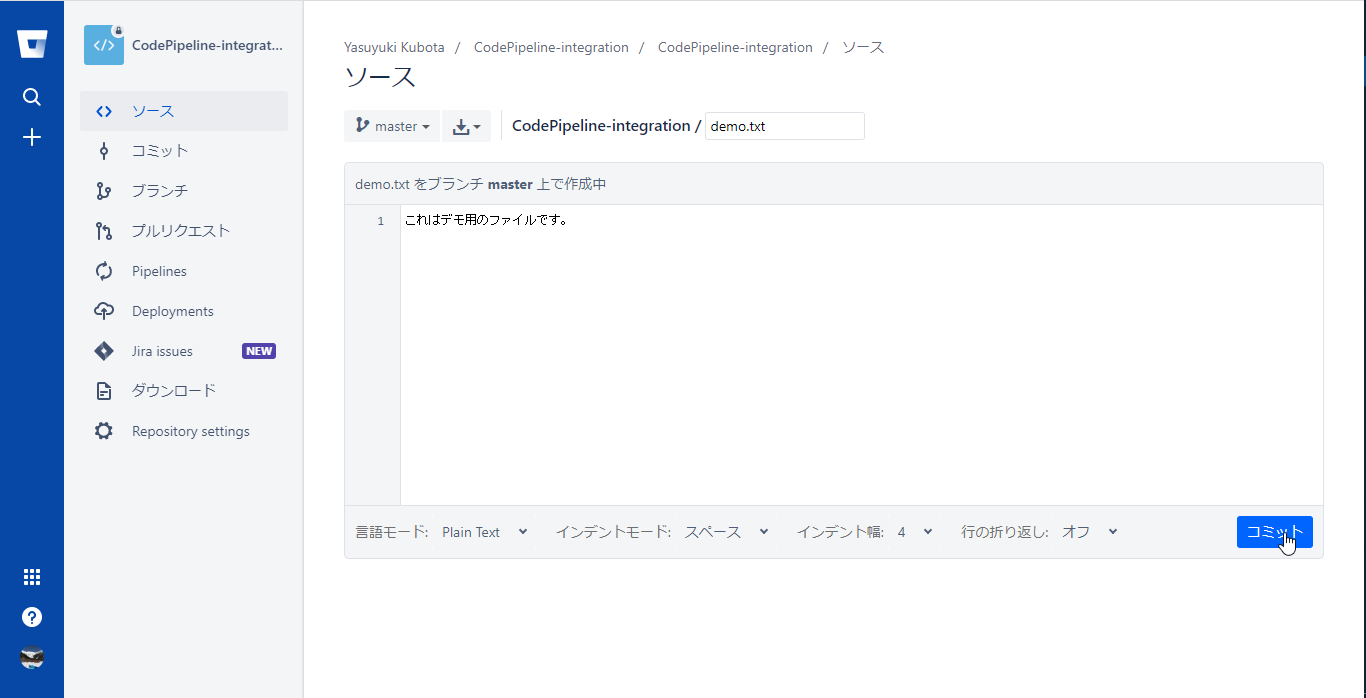
Bitbucketのリポジトリのソースメニューを選択し、右上のリポジトリのドロップダウンメニューからファイルを追加を選択
リポジトリ直下に任意のファイルを作成しコミットする
コミットのコメントの内容を確認しコミットする
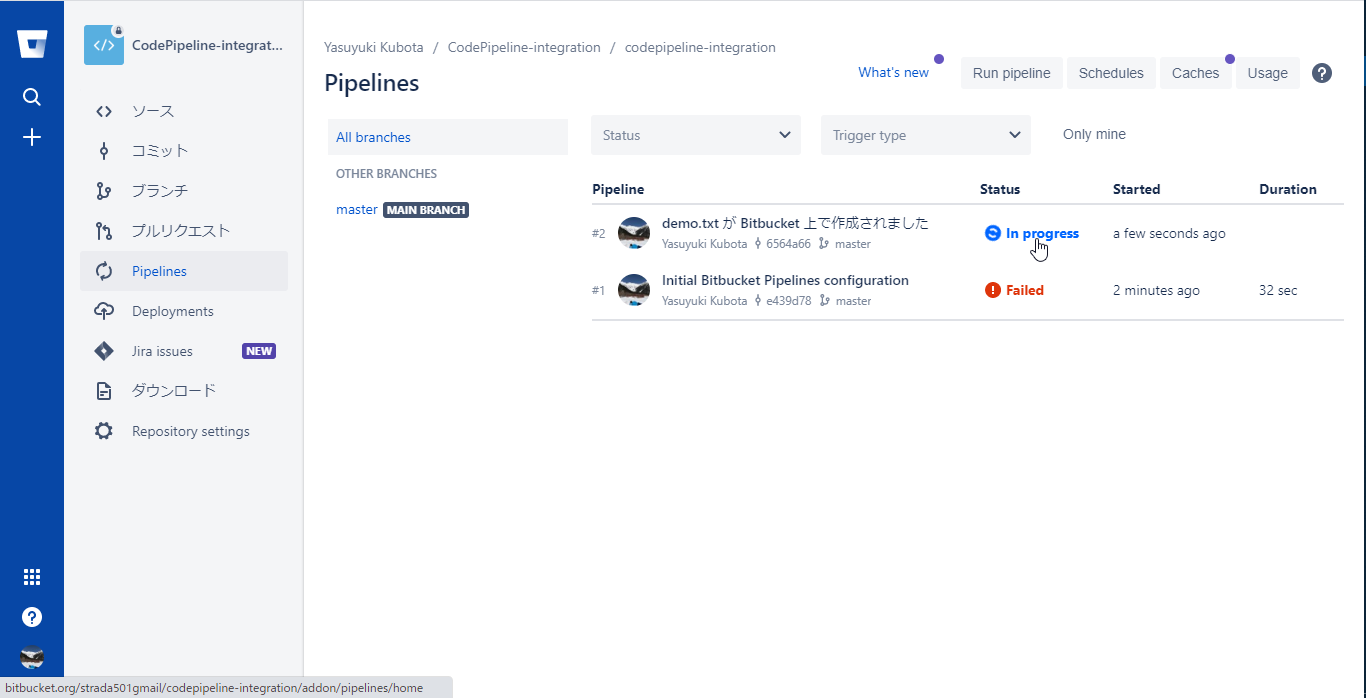
masterへの変更によりPipelineが起動しているはずなのでPipelinesメニューを選択
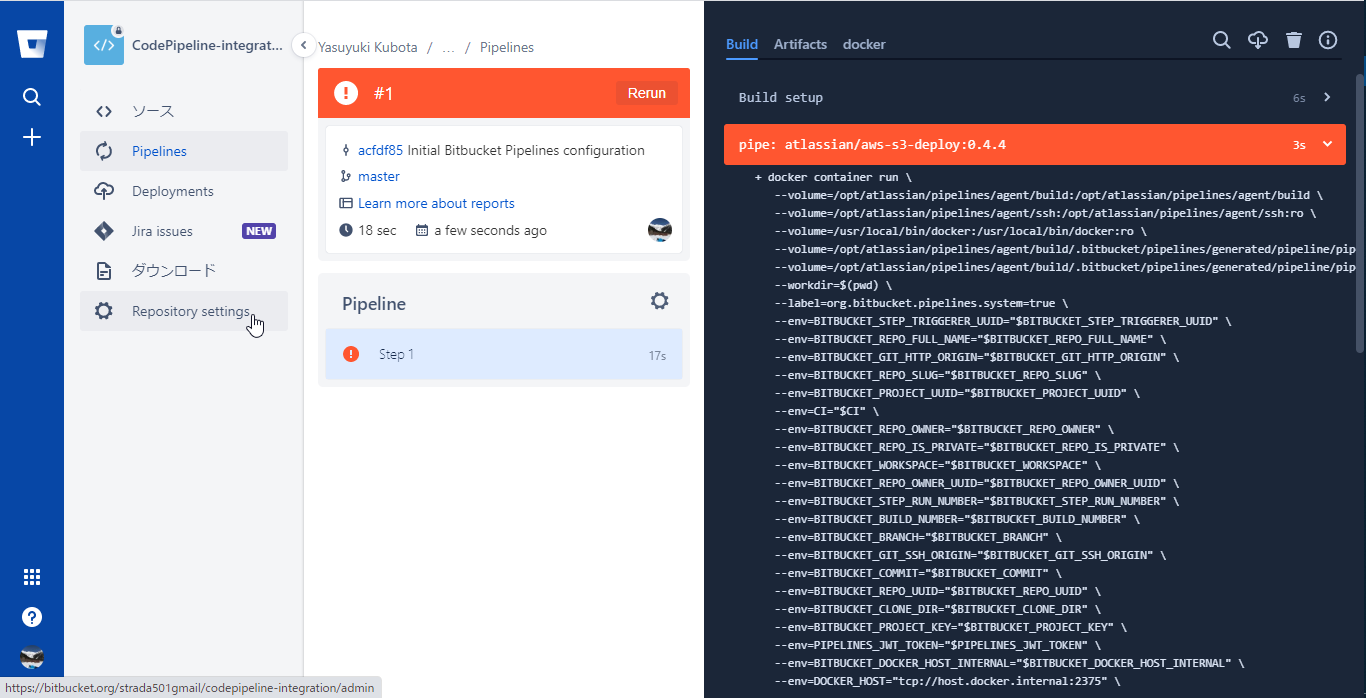
#2として今コミットした内容でパイプラインが起動しているのでStatusのIn Progressを選択し、Pipelineを開く
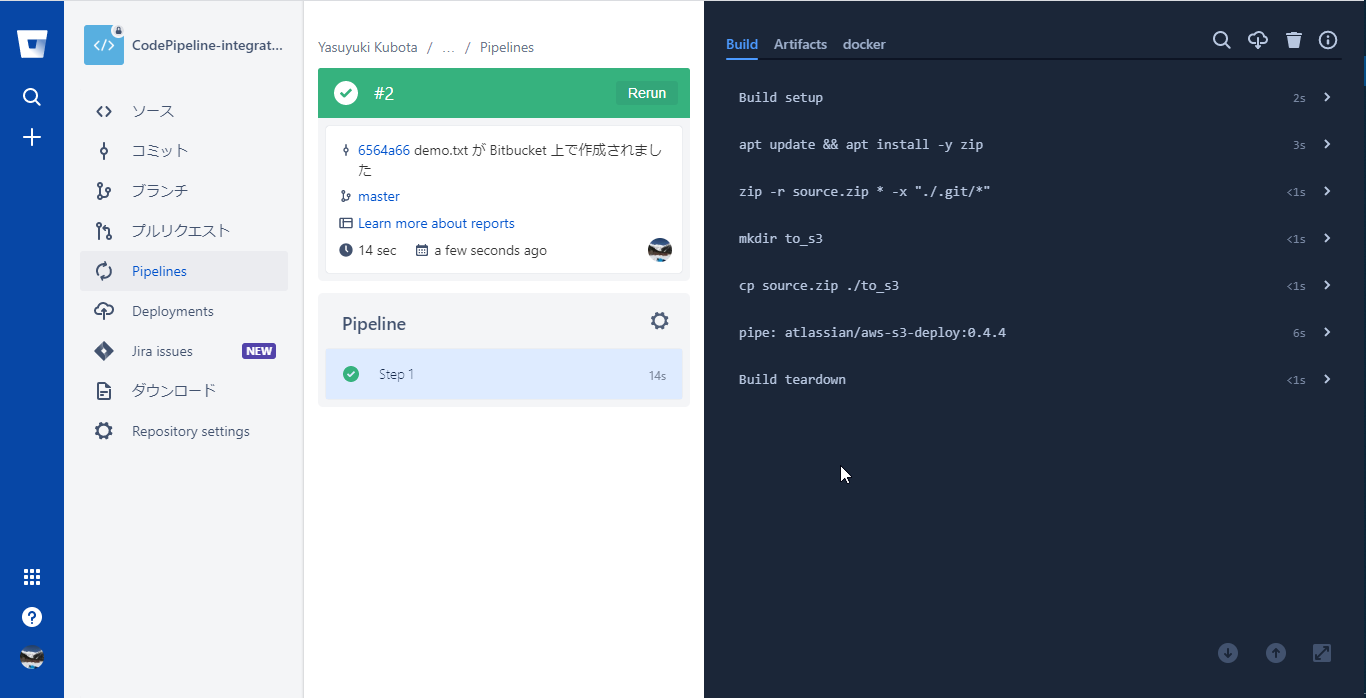
S3へのアップロードが完了するとPipelineのステータスがSuccessになるのでそれまで待機
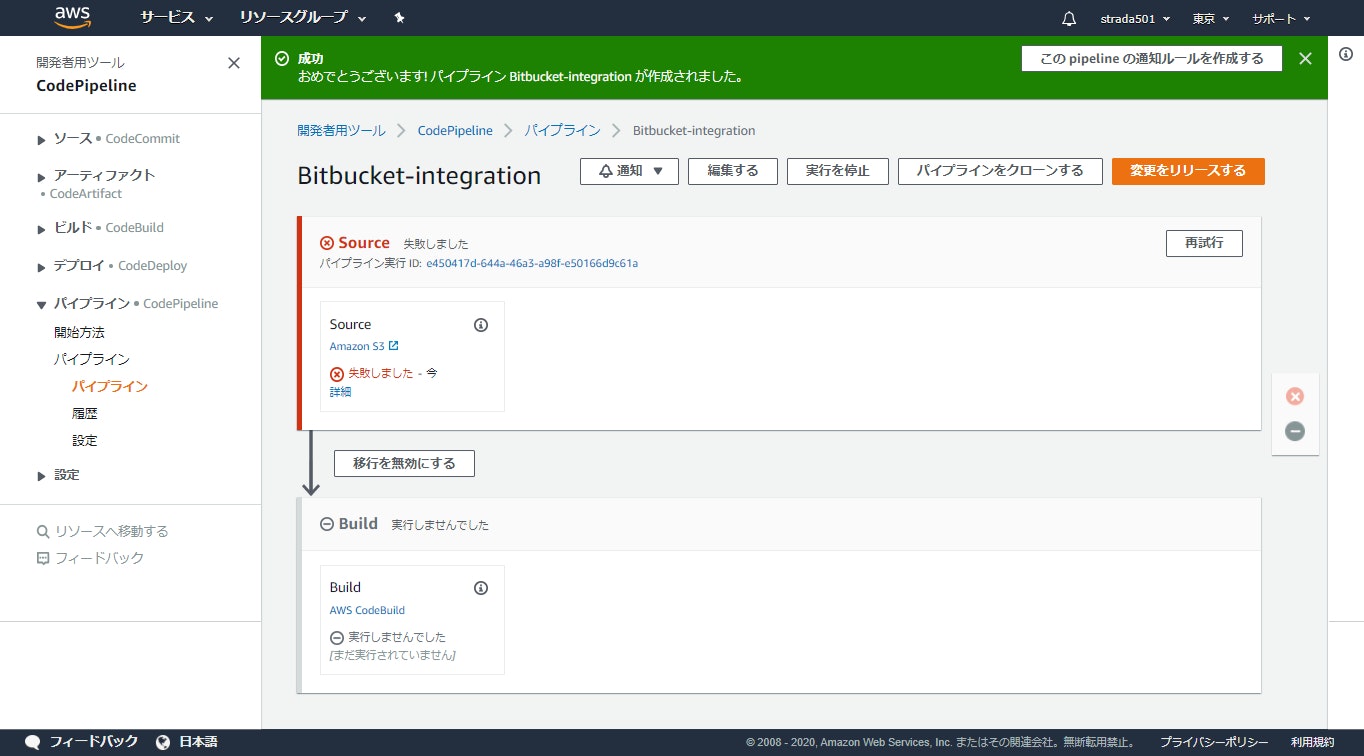
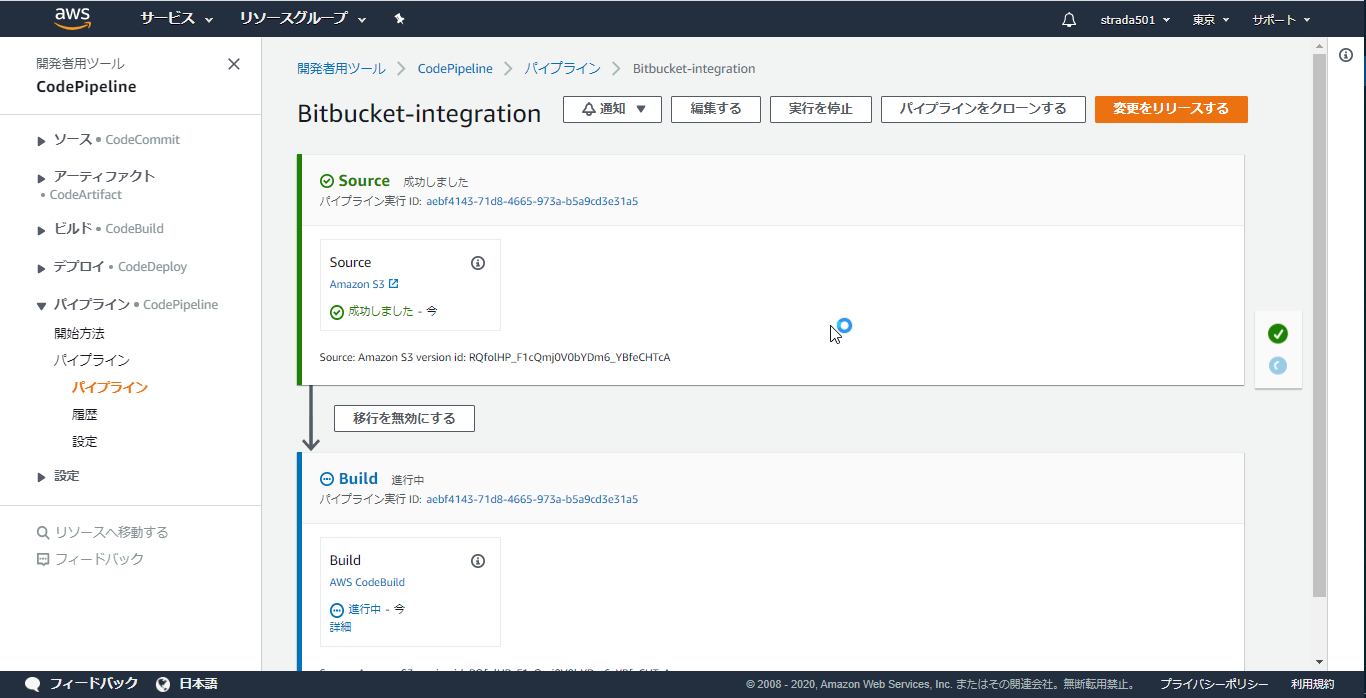
Bitbucket Pipelineが完了するとAWS CodePipelineが起動しているはずなのでCodePipelineのコンソールを開くと初回は失敗していたSourceステージをクリアして先に進んだことが分かる
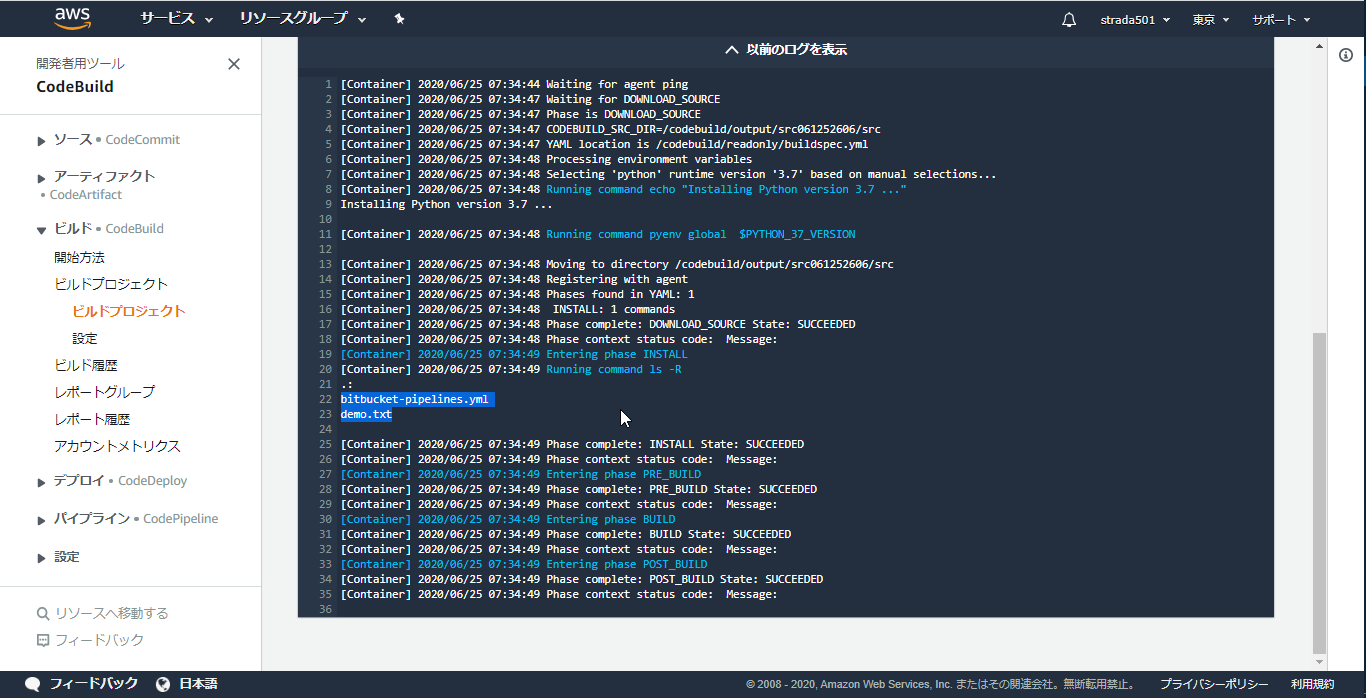
Buildステージの詳細をクリックするとCodeBuildのログが参照できる
buildspecで仕込んだlsコマンドでbitbucketのファイルが連携できていることが確認できた
所感
- Good
- 環境に依存する設定ファイルの配布などをBitbucket側で吸収しておくことで、AWS CodePipelineは環境に依存する処理が不要になった
- パイプラインのトリガーをbitbucket-pipelines.yamlのみで管理できるため見通しが良い
- CodeBuildでBitbucketのファイルを取得する構成にする場合はパイプラインの数分CodeBuildのプロジェクトが必要なので、作成するリソースを少なくすることが出来た
- Bad
- 時々BitbucketのIncidentによりWebhookが停止してしまい、Bitbucket Pipelineが起動しないことあるため運が悪いとデプロイが出来ない時間が発生する
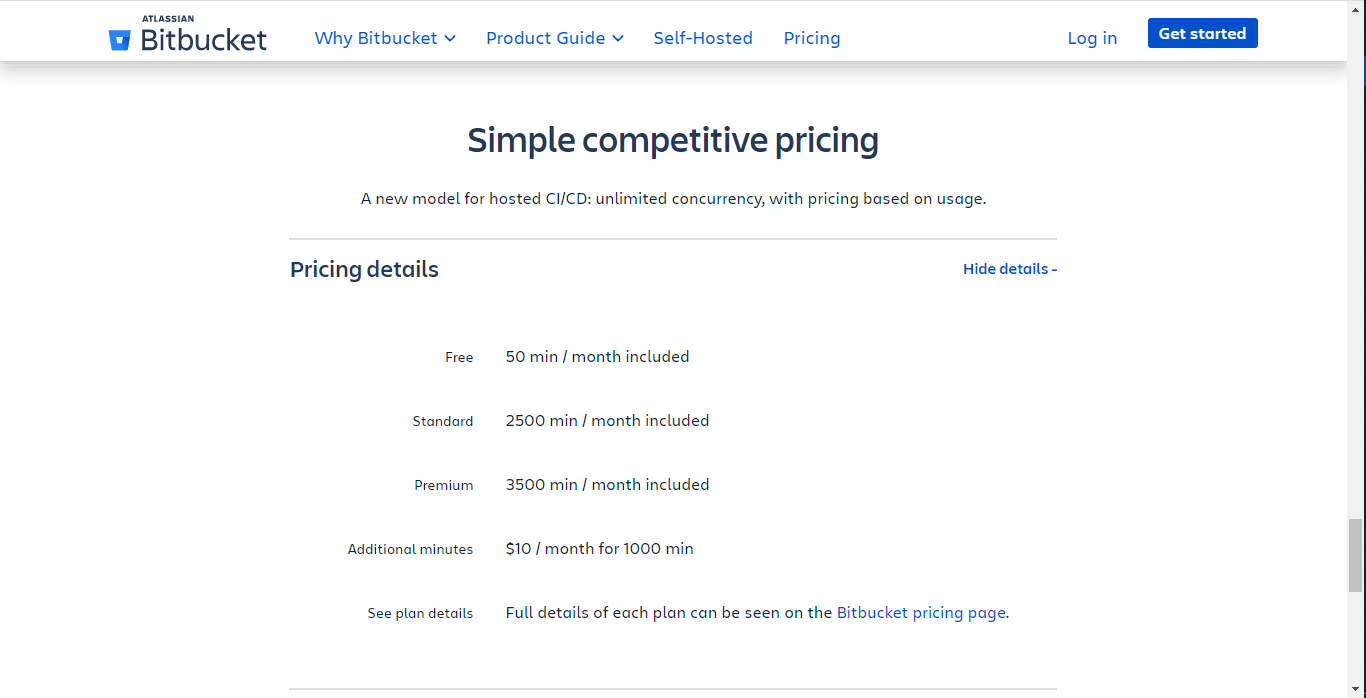
- 契約しているプランごとに使用できる時間に以下の制約がある
- Premiumでも制約あり
- 投稿日:2020-06-25T17:32:01+09:00
Cloud9インストールに困ったら
- 投稿日:2020-06-25T17:26:05+09:00
Cognitoの環境構築から、Angularでログインするまで
ユーザー認証を担うAWS サービスであるCognitoの環境を作り、SPAのAngularでCognitoで作成したユーザーでログインするまでを記す。
要件
- ユーザーは管理者が作成する(ユーザー自身がサインアップすることはない)
- ユーザーは管理者、事業者、一般ユーザーの三種
- 作成されるユーザーのユーザーID、パスワードはランダムに生成する
必要なサービス・環境
- Cognito
- ユーザープールを利用
- Pythonの実行環境
- 今回はlambdaから実行する
- Angular
Cognitoの設定
Webサービスにログインするユーザーを管理することができるユーザープールを作成する。
これは、Webサービスごとに用意する。自分の今の理解(マサカリ待ってます)
- ユーザーがシステムにサインインしたり、ログインしたり、パスワードを変更したり、MFAなどをする機能を提供しています。
- 認証・認可のうちの認証の部分を担っています。
- このユーザープールには管理者ユーザーを含むシステムの利用者のユーザーデータが含まれます。ここにはユーザーのメールアドレス、電話番号、住所、性別、生年月日など、任意の属性情報も保持できます。
ユーザープールの作成
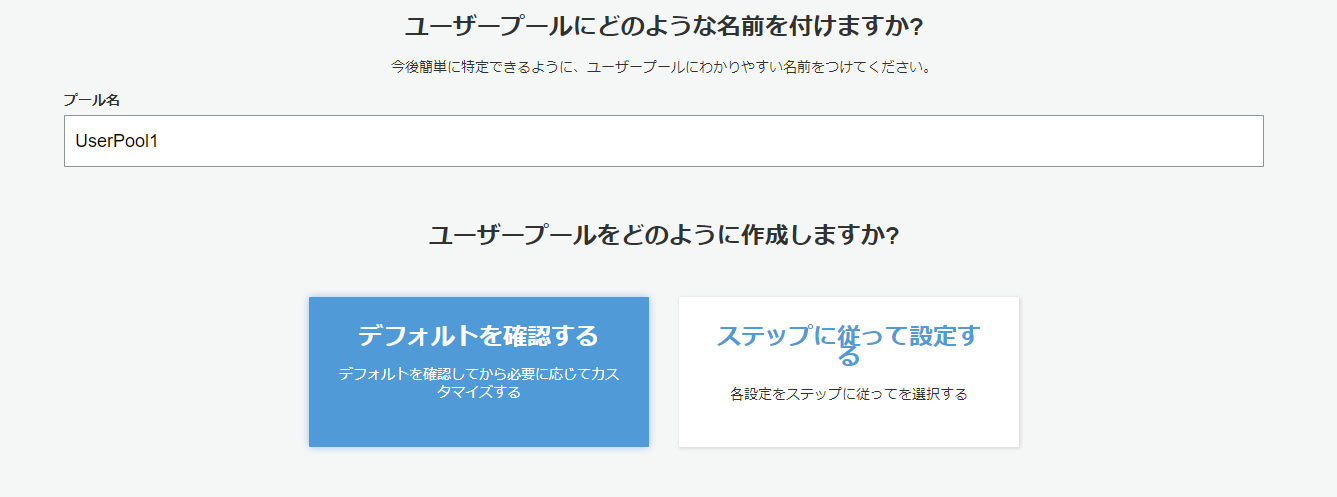
Cognitoのコンソール画面から、ユーザープールを作成するを押下。
ユーザープール名を指定し、今回はデフォルトを確認するを選択する。
※カスタマイズはデフォルト設定から変更するのが楽
下記のように設定する。
メールアドレスは不要なので、チェックを外す。
次のステップを押下し、次のステップへ。
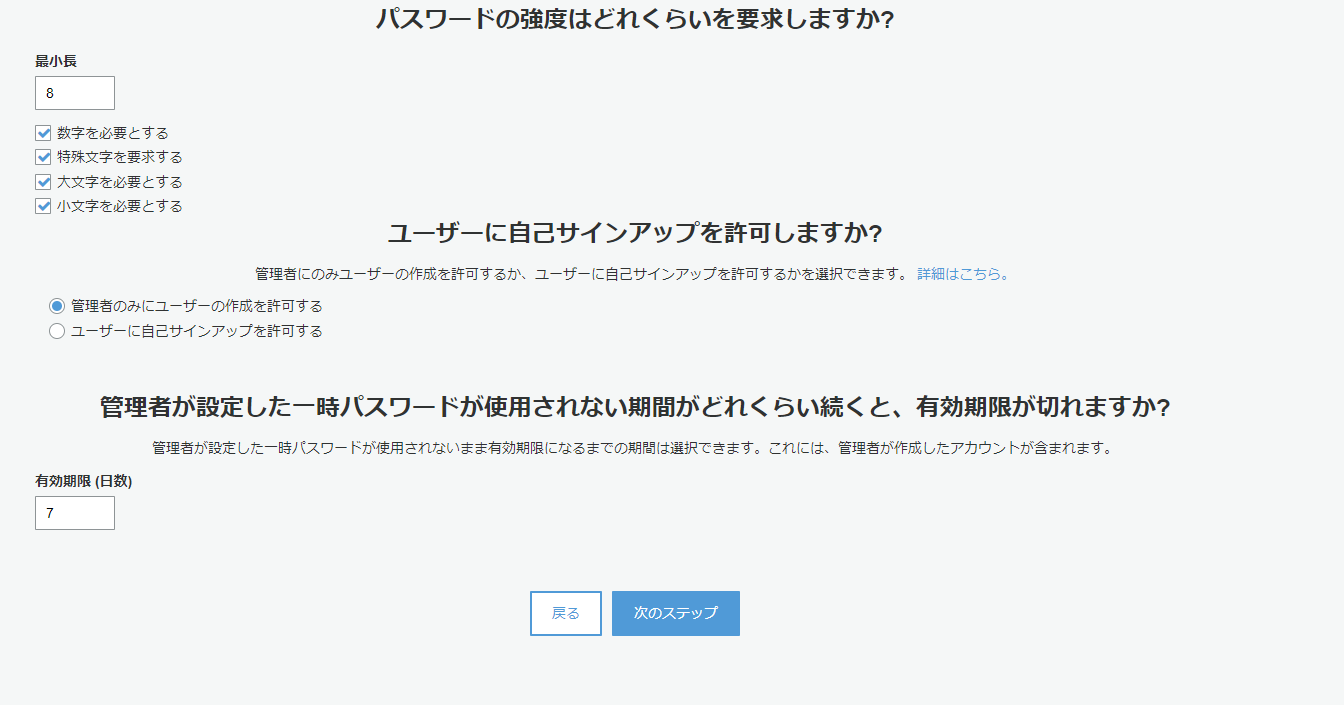
パスワードの強度は任意のものを設定(開発時は覚えやすいように強度を下げておくとよいかも)
今回はユーザーがサインアップする想定はないので、管理者のみにユーザーの作成を許可するにチェックを入れる
次のステップを押下し、次のステップへ。
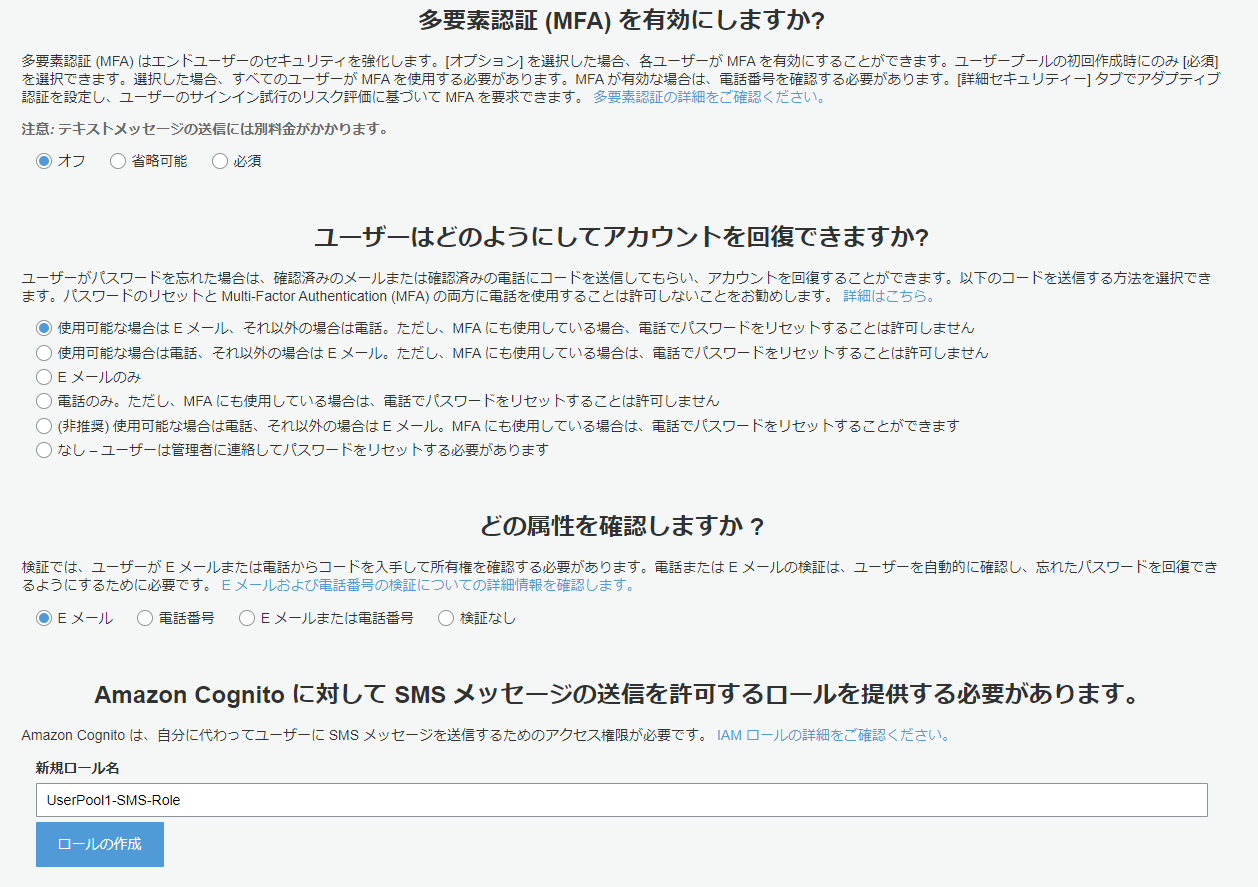
MFA、パスワード復旧に関する要件は今回はないのでデフォルトのまま、次のステップへ
メールアドレスは不要なので、ここもデフォルトのまま、次のステップへ
タグは割愛します。
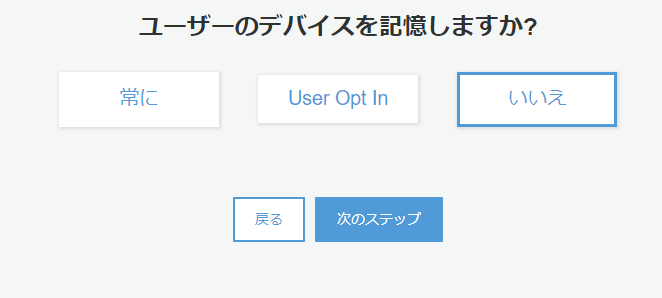
ユーザーのデバイス記憶はどのように使うかわからなかったのでとりあえず「いいえ」にしてます。
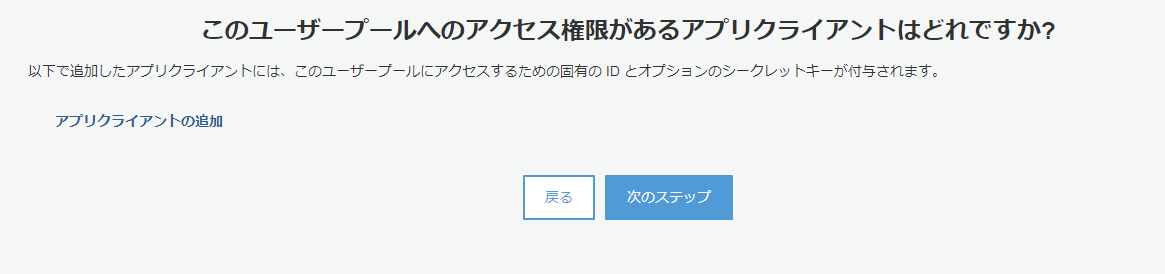
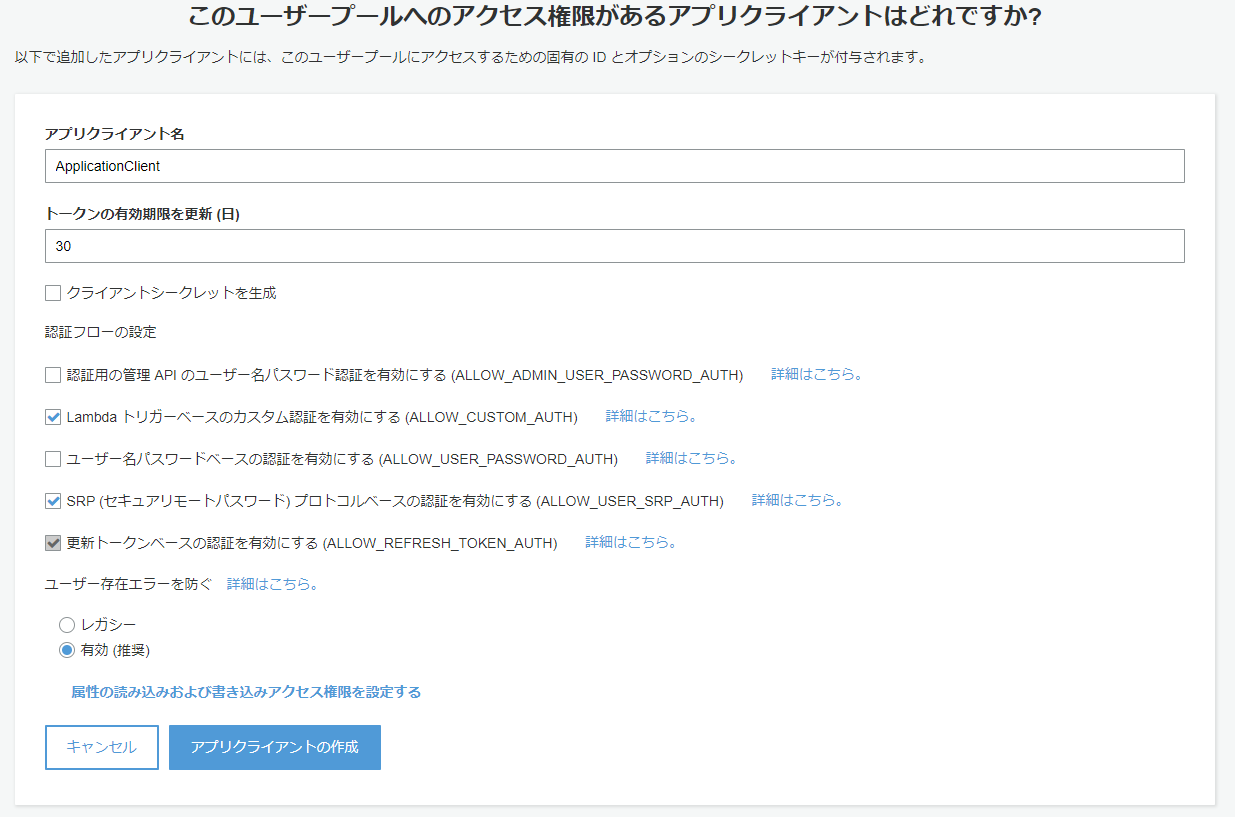
アプリクライアントを追加します。
ここでいうアプリクライアントは、SPAのことを指していると思って構いません。
JavaScriptからはクライアントシークレットを扱えないのでチェックを外して作成し、次のステップへ
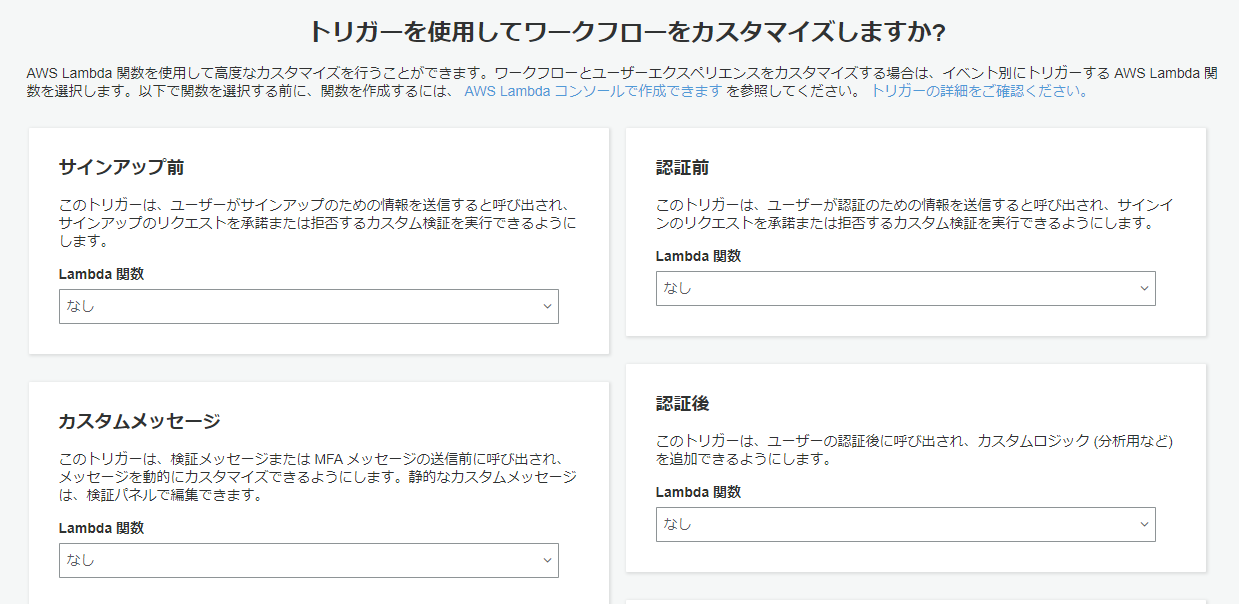
トリガーの設定は今回はすべてなしで。
ユーザーがログインしたとき等に任意のLambda関数を実行できるようです。
上記の設定でユーザープールを作成しました。
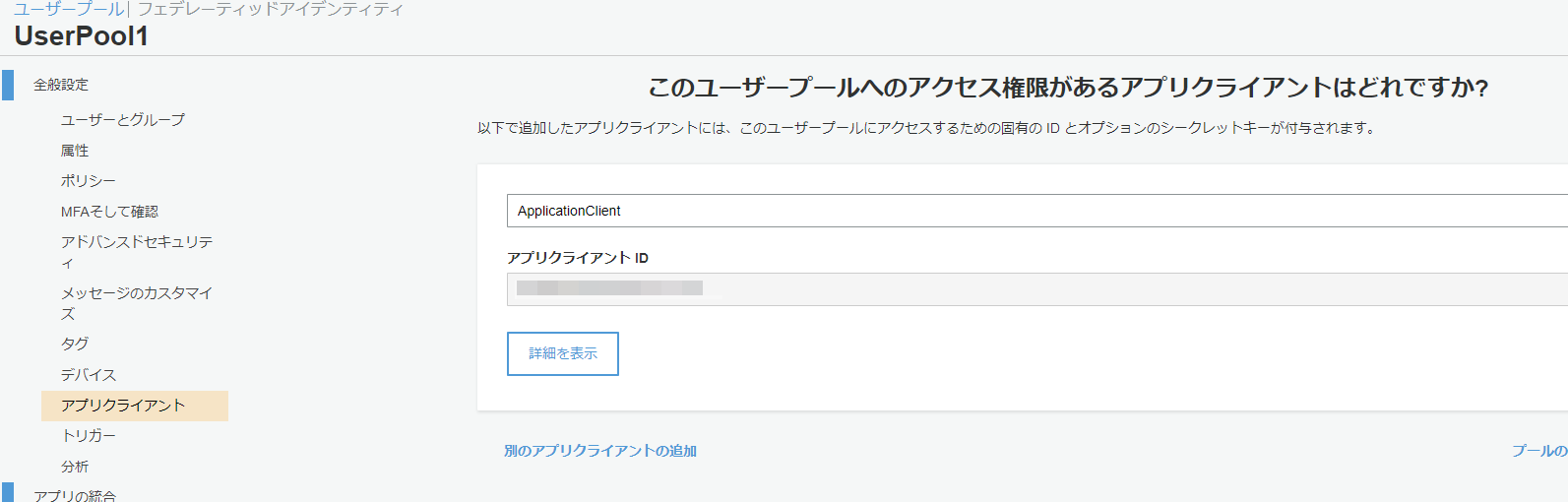
ユーザープールIDの確認方法
全般設定から確認できる
アプリクライアントIDの確認方法
アプリクライアントから確認できる
ユーザーグループの作成
ユーザーグループを作ります。
今回だとuser、admin、businessUserを作りました。
公式ドキュメントを参照してください(丸投げですみません)
ユーザープールにグループを追加する - Amazon Cognitoプログラムからユーザーを作成する
作成したユーザープールに、ユーザーを作成します。
実行環境はLambdaです。この関数を実行するとSPAからログインできるようになります。eventには下記のbodyが渡ります。
{ "userCount": 10, "userGroup": "businessUser" }コードは下記の通りです。
処理の概要
- 10人分のユーザーを作成(ユーザーID(8文字)、パスワード(12文字)はランダム)
- Cognitoのユーザーは作っただけでは無効ステータスなので、確認済みステータスにしてログイン状態にする
- 作成したユーザーをユーザーグループに追加する
- それぞれのユーザーID、パスワードをreturnします。
import random import string import secrets import json import boto3 aws_client = boto3.client('cognito-idp') CLIENT_ID = "{ユーザープール作成時に作成したアプリクライアントID}" USER_POOL_ID = "{ユーザープールID}" def lambda_handler(event, context): group_name = event['userGroup'] generated_users = [] for user in range(json.loads(event['body'])['userCount']): user_id = ''.join(random.choices( string.ascii_letters + string.digits, k=8)) passwd = pass_gen() # ユーザープールにユーザーを追加 add_user(user_id, passwd=passwd) confirm_user(user_id) generated_users.append( { "userId": user_id, "password": passwd } ) # グループにユーザーを追加 add_user_to_group(user_id, group_name) return { "headers": { 'Allow-Access-Origin': '*' }, "body": json.dumps( {"generatedUsers": generated_users} ) } def add_user(user_id, passwd): response = aws_client.sign_up( ClientId=CLIENT_ID, Username=user_id, Password=passwd, UserAttributes=[], ValidationData=[] ) # 認証完了 return response def add_user_to_group(user_id, group_name): response = aws_client.admin_add_user_to_group( UserPoolId=USER_POOL_ID, Username=user_id, GroupName=group_name ) return response def confirm_user(user_id): response = aws_client.admin_confirm_sign_up( UserPoolId=USER_POOL_ID, Username=user_id, ) return response def pass_gen(size=12): chars = string.ascii_uppercase + string.ascii_lowercase + string.digits # 記号を含める場合 # chars += '%&$#()' return ''.join(secrets.choice(chars) for x in range(size))IDトークン、アクセストークン、リフレッシュトークンについて
SPAでCognitoにサインインすると、IDトークン、アクセストークン、リフレッシュトークンの3つのトークンが払い出されます。
それぞれの役割は以下の通り。それぞれjwt.ioでデコードすると、内容を確認できます。
トークン名 種類 想定用途 IDトークン JWT Cognito User Pools の ユーザー属性(例えばメールアドレスなど)も含めたトークン。認可時、ユーザーに関する情報をフルで取得したい場合はこちらを使う。API Gateway はこちらを採用。 アクセストークン JWT Cognito User Pools の 最低限のユーザー情報を含めたトークン。認可時、必要なのがユーザー名程度であればこちらを採用する。 リフレッシュトークン 文字列 IDトークンおよびアクセストークンを更新するために利用する。Cognito User Pools のクライアントSDKを利用している場合は、自動で更新されるため、特にこのトークンをアプリケーションから意識して使うことはない。 引用:
Amazon Cognito と仲良くなるために歴史と機能を整理したし、 Cognito User Pools と API Gateway の連携も試した | Developers.IOSPAから作成したユーザーにログインする
参考:https://dev.classmethod.jp/articles/angular-cognito-api-gateway-loginpage/
今回はAngularを使ってログインします。
ログインページへのルーティングなどの説明はAngularの機能なので割愛します。AngularからCognitoの機能を使うために、下記のライブラリをインストールします。
$ npm install amazon-cognito-identity-js $ npm install aws-sdkディレクトリ構成
?src ┣ ?app ┃ ┣ ?guard ┃ ┃ ┣ ?cognito-guard.guard.spec.ts ┃ ┃ ┗ ?cognito-guard.guard.ts ┃ ┣ ?pages ┃ ┃ ┣ ?change-password ┃ ┃ ┃ ┣ ?change-password.component.html ┃ ┃ ┃ ┣ ?change-password.component.scss ┃ ┃ ┃ ┣ ?change-password.component.spec.ts ┃ ┃ ┃ ┗ ?change-password.component.ts ┃ ┃ ┣ ?login ┃ ┃ ┃ ┣ ?login.component.html ┃ ┃ ┃ ┣ ?login.component.scss ┃ ┃ ┃ ┣ ?login.component.spec.ts ┃ ┃ ┃ ┗ ?login.component.ts ┃ ┃ ┗ ?top ┃ ┃ ┃ ┣ ?top.component.html ┃ ┃ ┃ ┣ ?top.component.scss ┃ ┃ ┃ ┣ ?top.component.spec.ts ┃ ┃ ┃ ┗ ?top.component.ts ┃ ┣ ?services ┃ ┃ ┣ ?cognito.service.spec.ts ┃ ┃ ┣ ?cognito.service.ts ┃ ┃ ┣ ?http-interceptor.service.spec.ts ┃ ┃ ┗ ?http-interceptor.service.ts ┃ ┣ ?app-routing.module.ts ┃ ┣ ?app.component.html ┃ ┣ ?app.component.scss ┃ ┣ ?app.component.spec.ts ┃ ┣ ?app.component.ts ┃ ┗ ?app.module.ts ┣ ?assets ┃ ┗ ?.gitkeep ┣ ?environments ┃ ┣ ?environment.prod.ts ┃ ┗ ?environment.ts ┣ ?favicon.ico ┣ ?index.html ┣ ?main.ts ┣ ?polyfills.ts ┣ ?styles.scss ┗ ?test.tscognito.service.ts
cognito認証の基幹になるサービスです。
メソッド名 概要 login() ユーザープールにユーザーIDとパスワードで問い合わせ、認証されたらローカルストレージにアクセス、IDトークン、リフレッシュトークンを保存する isAuthenticated() ユーザーのログイン状態を取得する getCurrentUserIdToken() IDトークンを取得する getCurrentAccessToken() アクセストークンを取得する changePassword() パスワードを変更する logout() ログアウトする import { Injectable } from '@angular/core'; import { CognitoUserPool, CognitoUser, AuthenticationDetails } from 'amazon-cognito-identity-js'; import * as AWS from 'aws-sdk'; import { environment } from 'src/environments/environment'; @Injectable({ providedIn: 'root' }) export class CognitoService { private userPool: CognitoUserPool; private poolData: any; public cognitoCreds: AWS.CognitoIdentityCredentials; constructor() { AWS.config.region = environment.region; this.poolData = { UserPoolId: environment.userPoolId, ClientId: environment.clientId }; this.userPool = new CognitoUserPool(this.poolData); } // ログイン処理 login(username: string, password: string): Promise<any> { const userData = { Username: username, Pool: this.userPool, Storage: localStorage }; const cognitoUser = new CognitoUser(userData); const authenticationData = { Username: username, Password: password, }; const authenticationDetails = new AuthenticationDetails(authenticationData); return new Promise((resolve, reject) => { cognitoUser.authenticateUser(authenticationDetails, { onSuccess(result) { console.log('id token + ' + result.getIdToken().getJwtToken()); console.log('access token + ' + result.getAccessToken().getJwtToken()); console.log('refresh token + ' + result.getRefreshToken().getToken()); resolve(result); }, onFailure(err) { console.log(err); reject(err); }, newPasswordRequired(userAttributes, requiredAttributes) { delete userAttributes.email_verified; delete userAttributes.phone_number_verified; cognitoUser.completeNewPasswordChallenge('newPasswordHmkv', userAttributes, this); } }); }); } // ログイン済確認処理 isAuthenticated(): Promise<any> { const cognitoUser = this.userPool.getCurrentUser(); return new Promise((resolve, reject) => { if (cognitoUser === null) { resolve(false); } cognitoUser.getSession((err, session) => { if (err) { reject(err); } else { if (!session.isValid()) { reject(session); } else { resolve(session); } } }); }); } // IDトークン取得処理 getCurrentUserIdToken(): any { const cognitoUser = this.userPool.getCurrentUser(); if (cognitoUser != null) { return cognitoUser.getSession((err, session) => { if (err) { alert(err); return; } else { return session.idToken.jwtToken; } }); } } // アクセストークン取得処理 getCurrentAccessToken(): any { const cognitoUser = this.userPool.getCurrentUser(); if (cognitoUser != null) { return cognitoUser.getSession((err, session) => { if (err) { alert(err); return; } else { return session.accessToken.jwtToken; } }); } } // パスワード変更処理 async changePassword(oldPw: string, newPw: string) { const cognitoUser = this.userPool.getCurrentUser(); return new Promise<any>((resolve, err) => { cognitoUser.getSession(() => { cognitoUser.changePassword(oldPw, newPw, (error, result) => { resolve({ result, error }); }); }); }); } // ログアウト処理 logout() { console.log('LogOut!'); const currentUser = this.userPool.getCurrentUser(); if (currentUser) { currentUser.signOut(); } } }login.component.html
ログイン画面
<h2>ログイン</h2> <div class="login"> <form [formGroup]="loginForm" (ngSubmit)="onSubmitLogin(loginForm.value)"> <label>ユーザーID: </label> <input formControlName="userId"> <label>パスワード: </label> <input type="password" formControlName="password"> <button type="submit">ログイン</button> </form> </div>login.coponent.ts
import { Component, OnInit } from '@angular/core'; import { FormGroup, FormBuilder, Validators } from '@angular/forms'; import { Router } from '@angular/router'; import { CognitoService } from 'src/app/services/cognito.service'; @Component({ selector: 'app-login', templateUrl: './login.component.html', styleUrls: ['./login.component.scss'] }) export class LoginComponent implements OnInit { public loginForm: FormGroup; constructor( private fb: FormBuilder, private router: Router, private cognito: CognitoService ) { this.cognito.isAuthenticated() .then((res) => { return this.router.navigate(['/login']); }) .catch((err) => { console.log(err); }); } ngOnInit() { this.initForm(); } initForm() { this.loginForm = this.fb.group({ userId: ['', Validators.required], password: ['', Validators.required] }); } // cognitoサービスのログイン処理を呼び出す onSubmitLogin(value: any) { const userId = value.userId; const password = value.password; this.cognito.login(userId, password) .then((result) => { alert('Login success!'); // 任意のログイン後の処理(マイページへの遷移など) }).catch((err) => { console.log(err); }); } }ログインできることを確認する
ログイン画面で、ここで作成したユーザーIDとパスワードを入力し、下記のようにダイアログが表示されればログインは成功です。
あとは、パスワード変更画面などを作り、cognitoサービスの
changePassword()を呼び出すことでパスワード変更も可能です。




- 投稿日:2020-06-25T17:18:45+09:00
Amazon HoneycodeでAPIを使う為に、料金プランを変更した。
スプレッドシートを元にウェブサービスが作れるAWSの新サービス Amazon Honeycode が発表され、ベータ版が利用できるようになりました。
ベータ版の為なのか、AWSコンソール内ではなく、専用ドメインからのサービス登録でした。
Amazon Honeycodeのサービス登録は普通でした。
しかし、専用APIを利用する為には料金プランをアップグレードする必要がある事、AWSコンソールと画面をいったり来たりする必要があり手間取りました。AWSを日頃使い慣れている方なら問題ないのでしょうが、私は迷ってしまったので、このエントリー記事で残します。参照した公式ドキュメント
Getting Started with Honeycode APIs
Upgrading to a Plus or Pro plan is a prerequisite to accessing developer tools and Honeycode APIs.Google翻訳:
PlusまたはProプランへのアップグレードは、開発者ツールとHoneycode APIにアクセスするための前提条件です。PlusまたはProプランは有料です!!!
次の①、②の順で設定すると、詰まることなく料金プランを変更できるはずです。
①Connecting Honeycode to an AWS Account
HoneycodeサービスとAWSアカウントを紐づける手順が記載されています。②Upgrading Your Team Plan
料金プランを変更する手順が書かれていますが、「Team Plan」となっている点がポイントです。詳しい料金プランの変更手順
①HoneycodeへAWSアカウントを紐づける手順
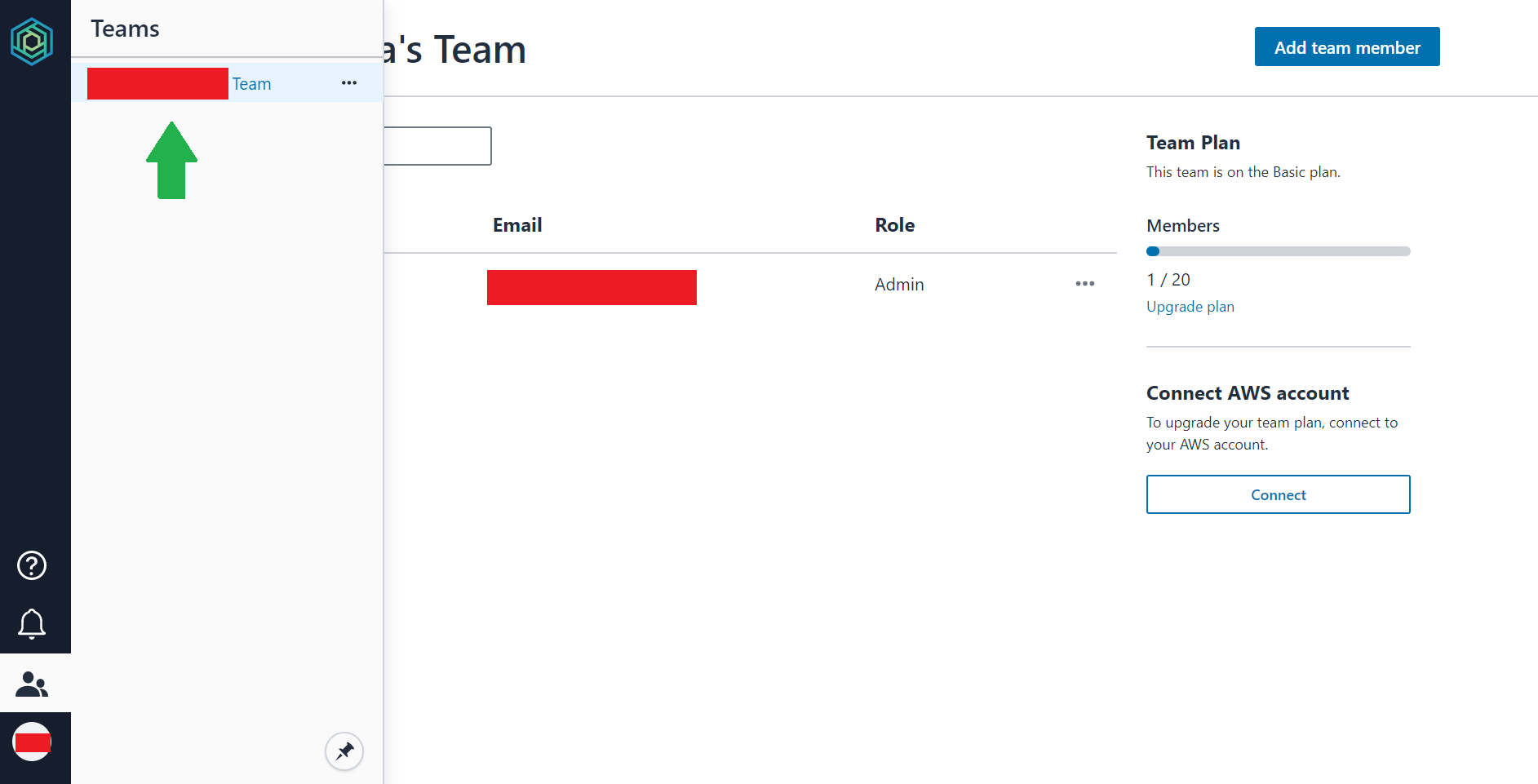
Honeycode画面の左側に人型のアイコンをクリックします。
Teamsタブが表示されて、アカウント登録時の名前が表示されるのでクリックしてください。
Team画面が表示され、「Connect AWS account」が表示されます。※ この時点でUpgrade planへのリンクを押下できますが、表示された画面でプラン変更できません。
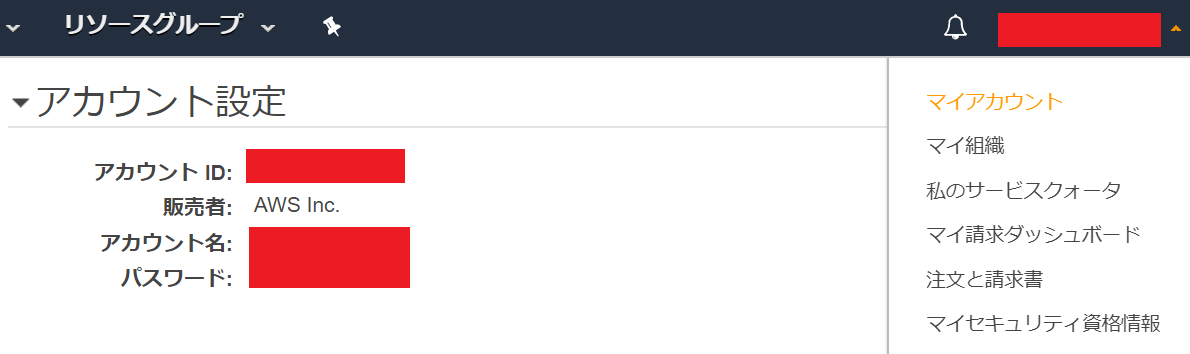
AWSコンソール画面を開いて、マイアカウントをクリックしてください。
アカウントIDが表示されますので、この12桁の文字列をコピーしてください。
Honeycode画面に戻ってください。
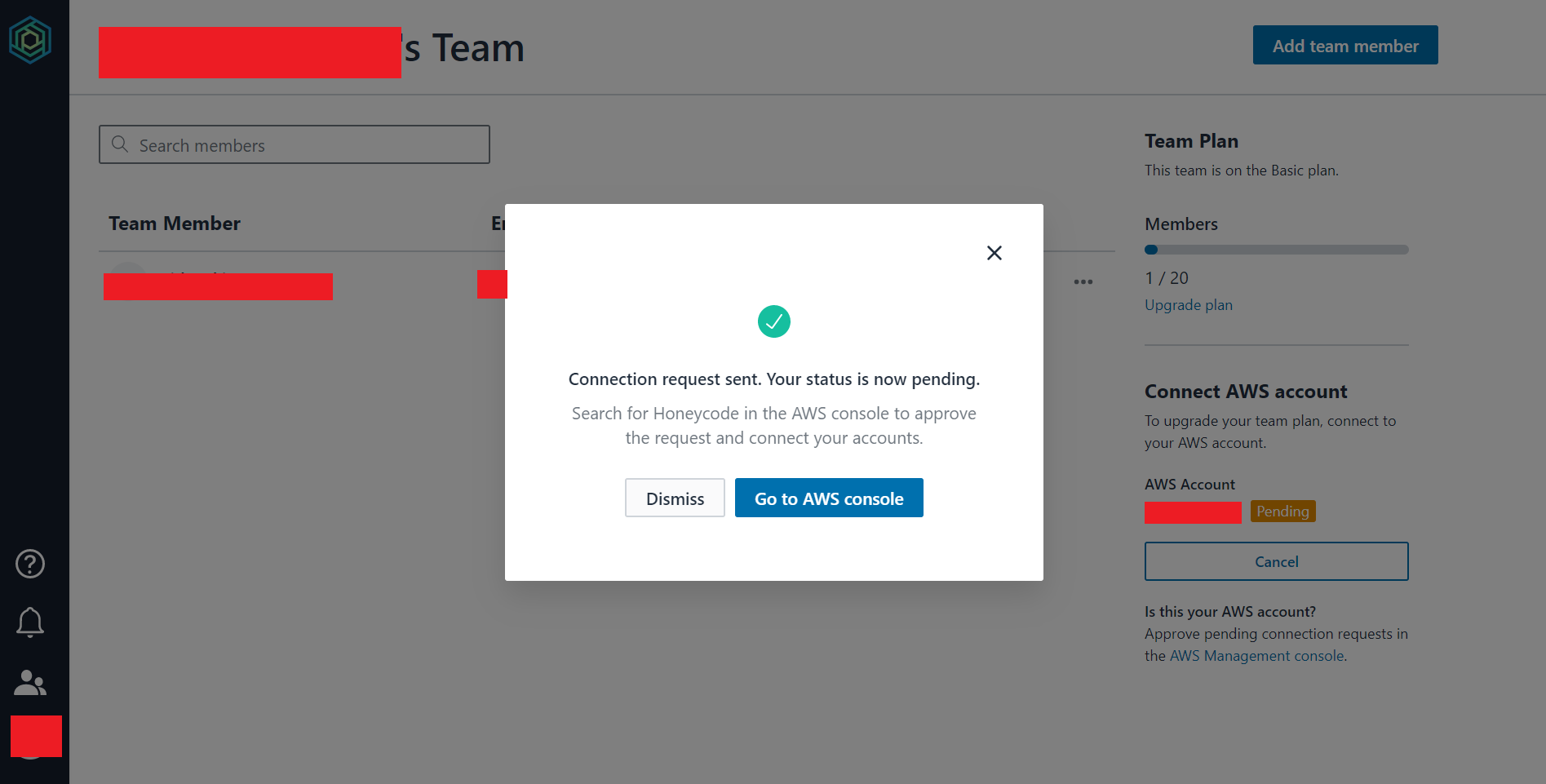
「Connect」ボタンを押下すると、画像のように表示されます。
入力欄に先ほどコピーした文字列をペーストしてください。
「Connect to AWS」ボタンをクリックしてください。
「Go to AWS console」ボタンを押下してください。
ここからAWSコンソール画面に戻ります。
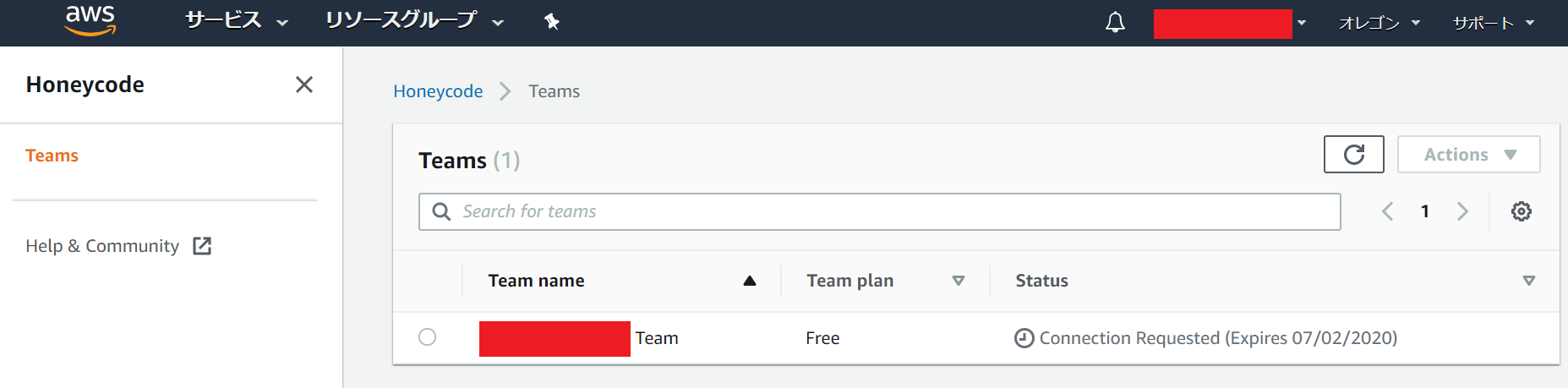
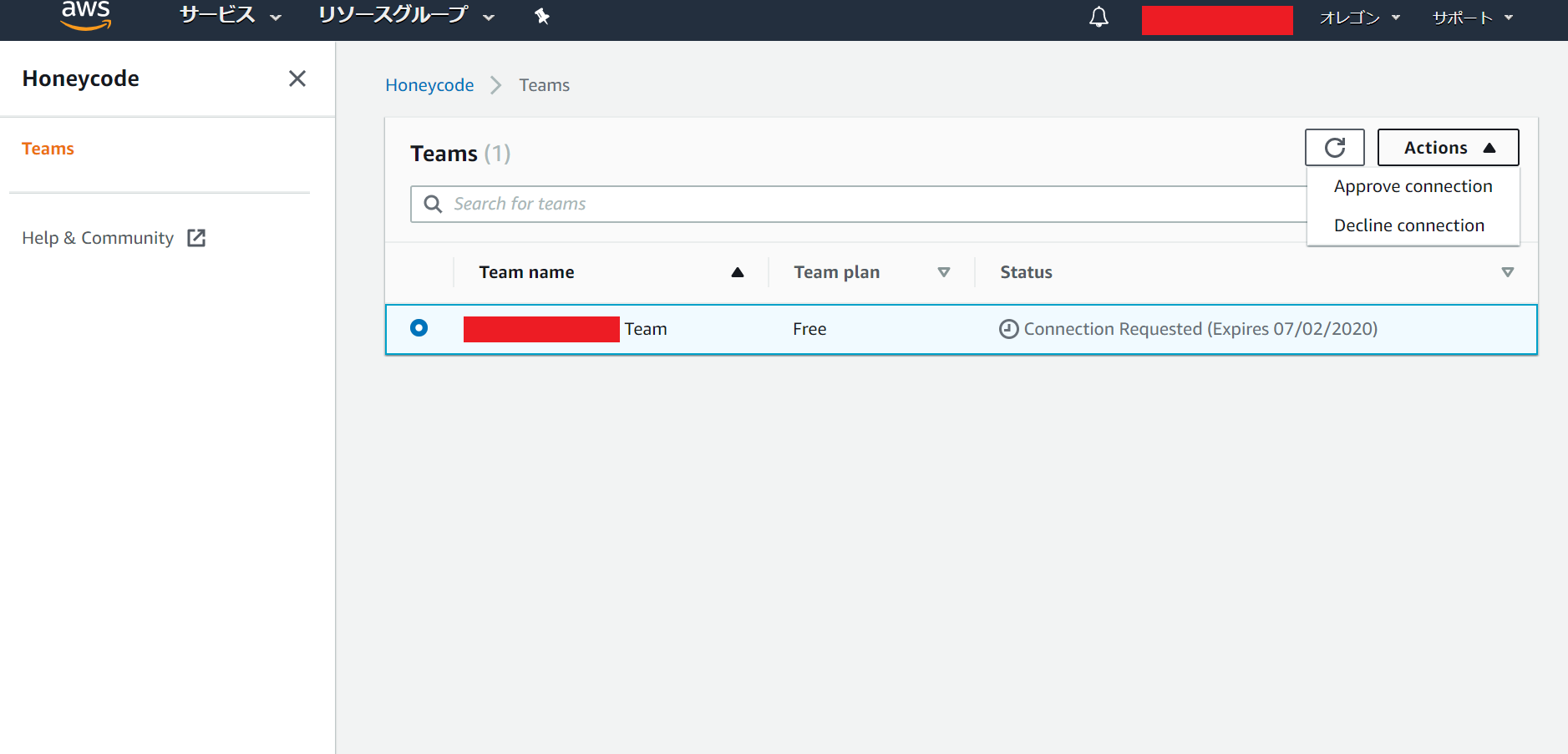
(Honeycode画面で登録した名前) Teamのポチをクリックすると「Actions」が操作できるようになります。
「Approve connection」をクリックしてください。
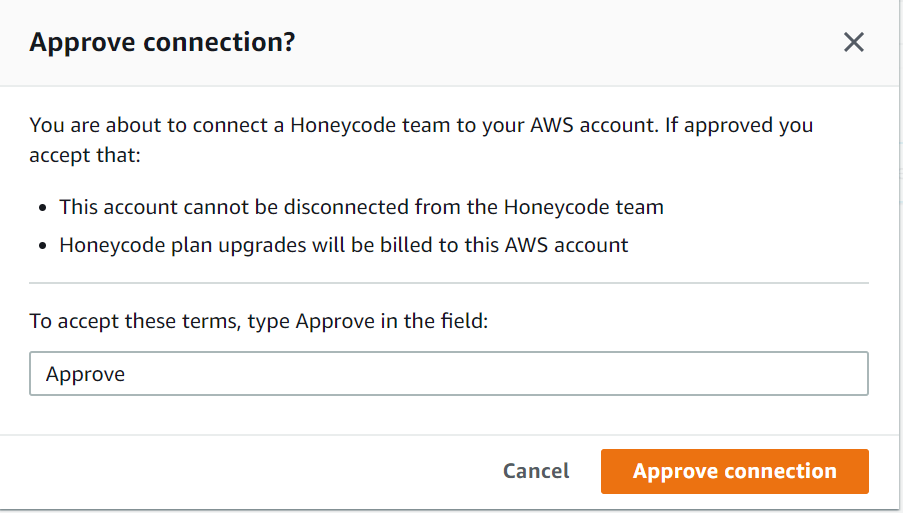
この画面が表示されるので入力欄に「Approve」と入力してください。
押せるようになるので、「Approve connection」ボタンをクリックしてください。
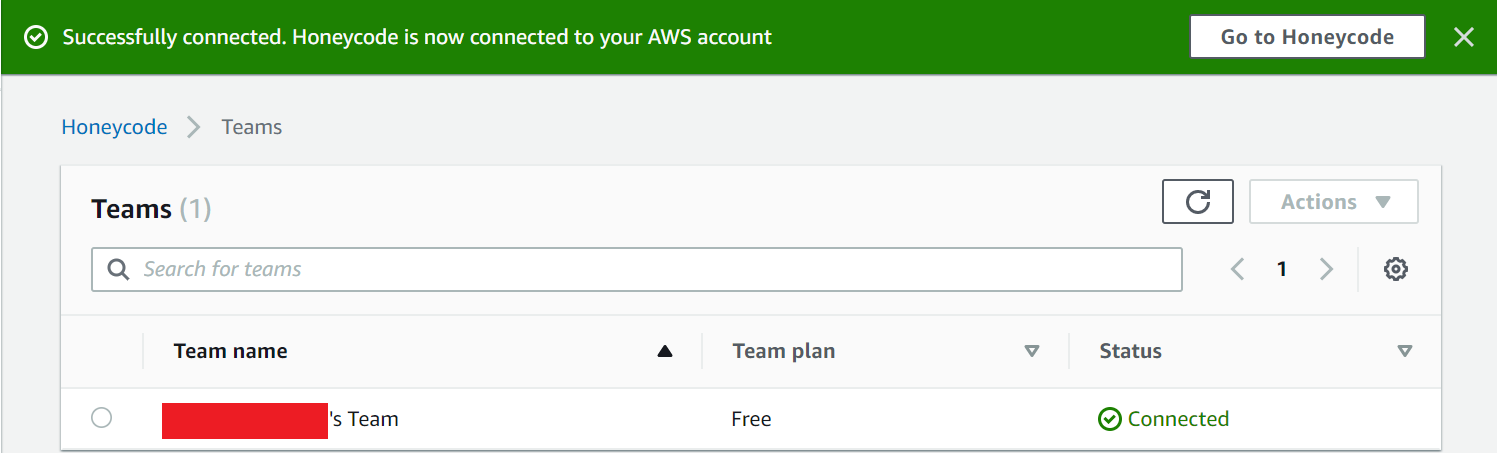
「Successfully connected. Honeycode is now connected to your AWS account」と表示されるはずです。
②Teamプランを変更する手順
Honeycode画面で操作します。
Upgrade planのリンクをクリックします。
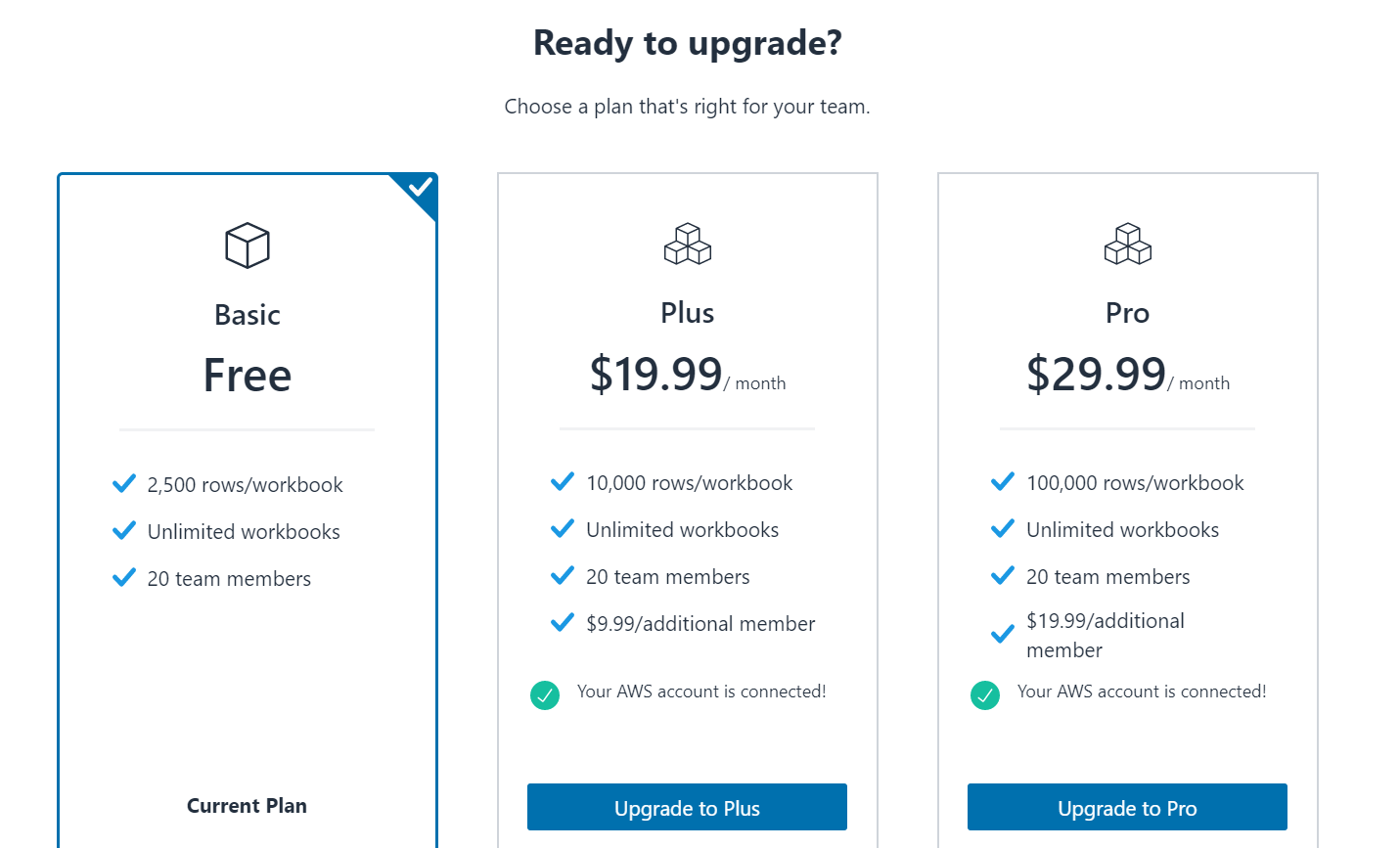
すると次の画像のように「Ready to upgrade?」と表示されます。
どちらかの「Upgrade to ~」をクリックして、無料から有料の料金プランへ変更できます。※ 「Your AWS account is connected!」と表示されていない場合は、これまでの手順を見直してください。
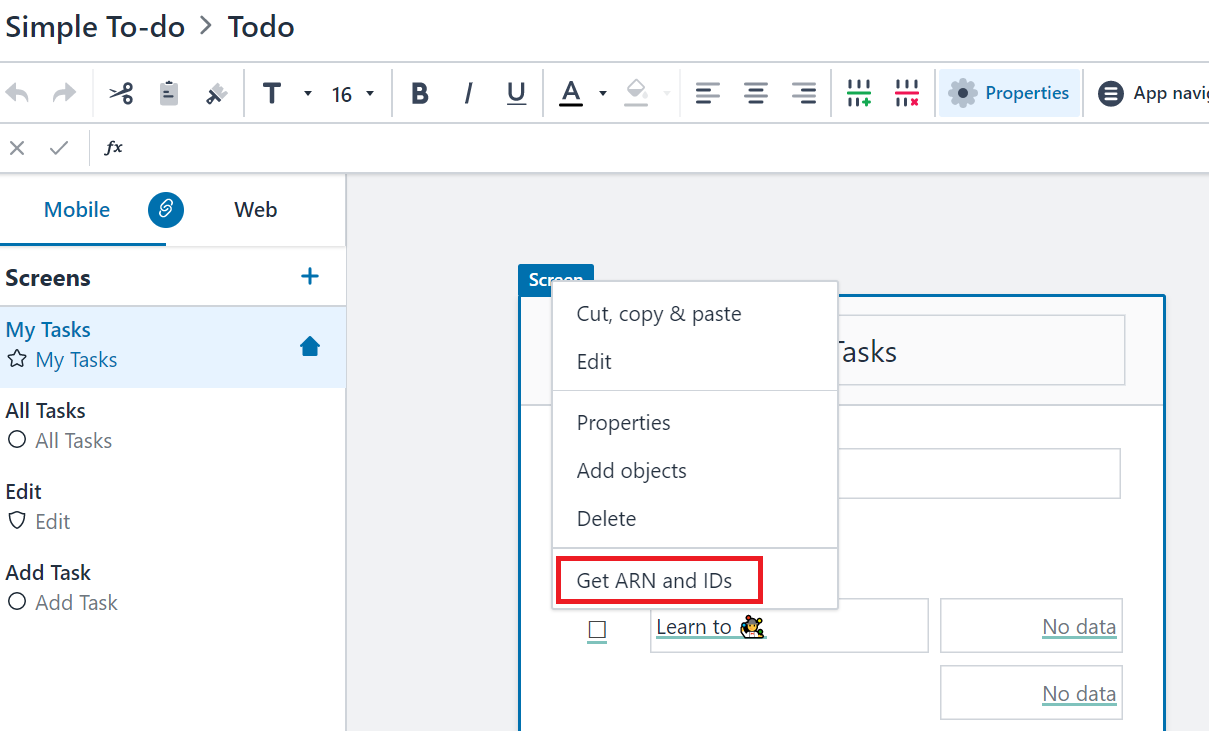
「Simple To-do」テンプレートで作成し、Builderモードで表示しています。
右クリックして、「Get ARN and IDs」を選択してください。
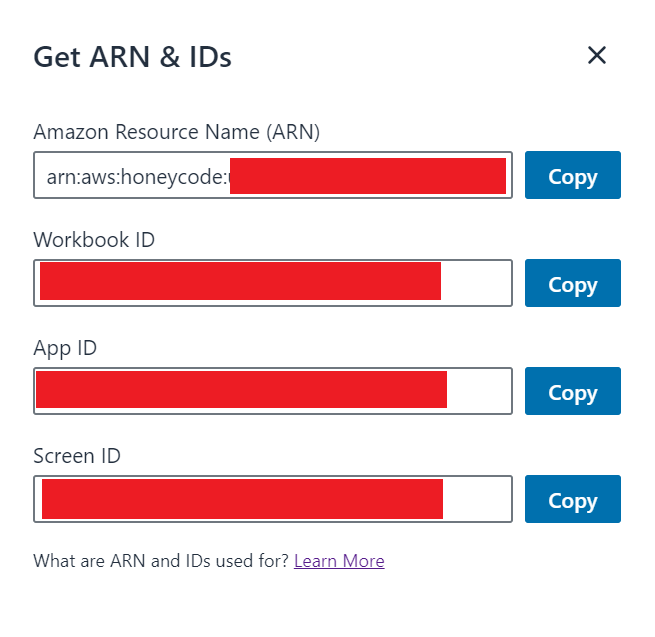
上の方でも紹介したGetting Started with Honeycode APIsにて、APIの設定方法が載っていました。
別のサービスに連携させてみたいです。出来た際には、記事にまとめます。
気付いた事
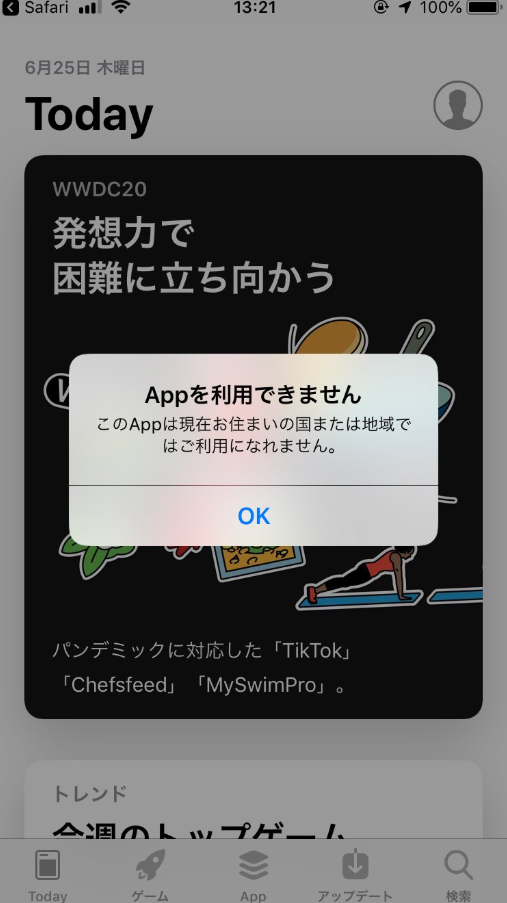
Honeycodeで作成したアプリをスマホで利用する場合、専用アプリから呼び出すようです。
iPhone版の専用アプリは日本ではまだ配信されていません。Android版は未確認です。
App Store Preview > Amazon Honeycode
Google Play > Amazon Honeycode



- 投稿日:2020-06-25T16:34:42+09:00
aws-sdk-java-v2に追加されたS3Presigner
TL;DR
- AWS SDK for Java 2.0に、S3Presignerが追加された
- virtual-hosted styleにデフォルトで対応
- httpsにデフォルトで対応
- 有効期限の設定方法が変更
- 署名付URLの生成には、S3Presignerを使用しましょう
はじめに
この記事は、JavaやScalaでAWSを利用するバックエンド、およびSRE業務に従事する人を対象にしています。
S3の署名付URLとは
S3には、オブジェクトのダウンロードとアップロードのために発行するURLに署名をつけることによって、そのオブジェクトへのアクセスを制限する仕組みがあります。
AWS SDK for Java 2.10.12以前
AWS SDK for Java 2.10.12以前では、AwsS3V4Signerを使用して、Presigned URLを生成していました。
以下、サンプルコードは、scalaで記述しています。before.scalaimport software.amazon.awssdk.auth.credentials.DefaultCredentialsProvider import software.amazon.awssdk.auth.signer.AwsS3V4Signer import software.amazon.awssdk.auth.signer.params.Aws4PresignerParams import software.amazon.awssdk.http.{SdkHttpFullRequest, SdkHttpMethod} val request = SdkHttpFullRequest .builder() .encodedPath("bucket/key") .host("s3.ap-northeast-1.amazonaws.com") .method(SdkHttpMethod.GET) .protocol("https") .build() val params = Aws4PresignerParams .builder() .expirationTime(Instant.now().plusSeconds(300) .awsCredentials(DefaultCredentialsProvider.create().resolveCredentials()) .signingName("s3") .signingRegion("ap-northeast-1") .build() AwsS3V4Signer.create().presign(request, params).getUri // 生成される署名付URLの形式 // https://s3.ap-northeast-1.amazonaws.com/bucket/key?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Date=20200625T000000Z&X-Amz-SignedHeaders=host&X-Amz-Expires=300&X-Amz-Credential=XXX&X-Amz-Signature=YYYAWS SDK for Java 2.10.12以後
AWS SDK for Java 2.10.12から、S3Presignerが追加されました1。引き続きAwsS3V4Signerは使用できますが、S3Presignerを使うことが推奨されています。この理由については後述しますが、一方でS3Presignerの内部実装には、依然、AwsS3V4Signerが使用されています。
after.scalaimport software.amazon.awssdk.regions.Region import software.amazon.awssdk.services.s3.model.GetObjectRequest import software.amazon.awssdk.services.s3.presigner.S3Presigner import software.amazon.awssdk.services.s3.presigner.model.GetObjectPresignRequest val presigner: S3Presigner = S3Presigner .builder() .region("ap-northeast-1") .build() val request = GetObjectRequest .builder() .bucket("bucket") .key("key") .build() val presignRequest = GetObjectPresignRequest .builder() .signatureDuration(Duration.ofSeconds(300)) .getObjectRequest(request) .build() presigner.presignGetObject(presignRequest).url.toURI // 生成される署名付URLの形式 // https://bucket.s3.ap-northeast-1.amazonaws.com/key?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Date=20200625T000000Z&X-Amz-SignedHeaders=host&X-Amz-Expires=300&X-Amz-Credential=XXX&X-Amz-Signature=YYY何が変わった?
1. virtual-hosted style
生成されるURLを前後で比較すると、バケット名の位置が異なることがわかります。
"https://s3.ap-northeast-1.amazonaws.com/bucket/key" // 前: path style "https://bucket.s3.ap-northeast-1.amazonaws.com/key" // 後: virtual-hosted style両者の違いについては、以下を参照ください。
val request = SdkHttpFullRequest .builder() .encodedPath("key") .host("bucket.s3.ap-northeast-1.amazonaws.com") .method(SdkHttpMethod.GET) .protocol("https") .build()なお、AwsS3V4SignerでもSdkHttpFullRequestを上記のようにすることで、virtual-hosted styleの署名付URLが生成できますが、S3Presignerは実装方法を意識する必要がありません。
2. protocolの指定方法
AwsS3V4Signerでは、
.protocol("https")の部分にある通り、プロトコルの指定ができました。しかし、 S3Presignerにはプロトコルを指定するメソッドがありません。これについては、内部的にhttpsがデフォルトで指定されていることに起因します。使用するシーンは想像しにくいですが、以下のようにendpointを上書きすることで、httpを選択することも可能です。val presigner: S3Presigner = S3Presigner .builder() .region("ap-northeast-1") .endpointOverride(new URI("http://s3.ap-northeast-1.amazonaws.com")) .build()3. 有効期限の指定方法
AwsS3V4Signerでは、有効期限として設定したい未来の日時を指定する方法でした。しかし、S3Presignerでは有効期間をDurationとして指定する方法が採用されています。
// 前 val params = Aws4PresignerParams .builder() .expirationTime(Instant.now().plusSeconds(300) // 後 val presignRequest = GetObjectPresignRequest .builder() .signatureDuration(Duration.ofSeconds(300))まとめ
Amazon S3 path-style 廃止予定 – それから先の話 –
AWSは2020年9月30日以降で作成されるバケットについて、path styleをサポートしないことを発表しています。このため、S3Presignerへの変更は早期に対応しておく必要があると言えます。
- 投稿日:2020-06-25T14:43:34+09:00
[超超易しい] クラウドコンピューティング周りのこと(AWS寄り)
仕事で、AWS,EC2,EKS・・・という単語が出てきて何やらわからず、さっと調べた時のメモ
AWSって?
Amazon Web Service
Amazonが提供するクラウドコンピューティングシステムですMicrosoftやGoogleもクラウドコンピューティングシステムを提供していますが、その中でもAWSは高いシェアを誇り、高いシェア率=利用者が多いという図式のもと、情報が豊富に出揃っています
EC2とは?
Amazon Elastic Compute Cloud
AWSで利用できるシステムの一つこのシステムを使うことで、AWS上に仮想サーバーを構築し利用することができる
この仮想サーバーの単位をEC2では「インスタンス」という単位で扱います
EC2インスタンス上でコンテナを動かします似たような機能を持つものでFragateがある
AWSがインスタンスを管理してくれる方式で、読み方は「ファーゲート」です
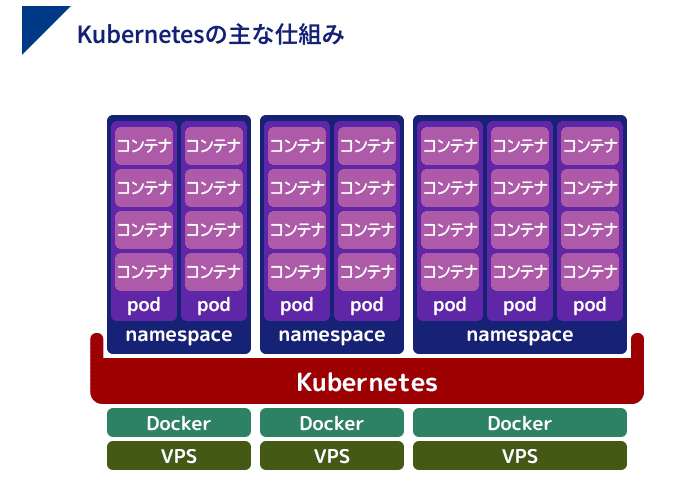
裏にあるリソースを気にすることなく、コンテナを登録するだけで利用できますEKSとは?
Amazon Elastic Kubernetes Service
AWSでKubernetesを簡単に実行できるようにするじゃあKubernetesって?
複数のコンテナの管理と自動化をするオープンソースのシステム
クバネティス、またはクーベネティスなどと読む(ギリシャ語で操舵手やパイロットという意味)Dockerにも複数のDockerの管理や自動化をする機能があるが、コンテナ間の設定や管理でできないことがあるため、小規模向け。規模が大きくなると煩雑になるため、Kubernetesのような専用ツールを利用する。
Kubernetesとは?仕組みと構造をわかりやすく解説します
似たような機能を持つものでECSがある
Elastic Container Service
Amazonが開発したコンテナ管理サービスちなみにDockerというのは、
1台のサーバー上に、複数のサーバーとして利用できる仕組みを構築する方法を仮想化技術といい、それを支える手段には種類があり、ハイパーバイザー、ホスト型、コンテナ型が公開されている
Dockerというのはコンテナの種類の一つ
他にはVirtual machineなど【入門】Dockerとは?使い方と基本コマンドを分かりやすく解説します
資料
Kubernetesとは?仕組みと構造をわかりやすく解説します参考
- 投稿日:2020-06-25T11:18:44+09:00
AWS GlueよりJDBC経由でSalesforceにデータアクセスしてみる
はじめに
AWS Glueは、抽出、変換、ロード(ETL)サービスで、Amazonのホスト型Webサービスの一部として利用できます。
様々なデータストアにあるデータを簡単に接続し、必要に応じてデータを編集、クリーンアップし、AWSで提供されているストアにデータロード。統一されたビューを表示できるようにすることを目的としています。
GlueはJDBCによるデータアクセスをサポートしており、現時点でサポートされるデータベースは、Postgres、MySQL、Redshift、Auroraですが、ここにDataDirect JDBC コネクタを使うとより多くのデータソースへのアクセスを実現できます。
この記事では、AWS GlueよりSalesforceデータへのアクセスを試みます。
DataDirect Salesforce JDBCドライバーのダウンロード
1.DataDirect Salesforce JDBCドライバーをダウンロードします。
2.JARを実行してインストします。ターミナルで以下のコマンドを実行するか、もしくはJARのダブルクリックですね。
java -jar PROGRESS_DATADIRECT_JDBC_SF_ALL.jar3.インタラクティブなJAVAインストーラーが起動されるので、DataDirect Salesforce JDBCドライバーをそのままインストします。
ちなみにSalesforce用JDBCドライバーだけでなく、その他多数のドライバーも同じフォルダにインストールされているので、1ドライバーでいろいろ試せます。
DataDirect SalesforceドライバーのAmazon S3へのアップロード
1.DataDirect JDBCドライバーのインスト先に、DataDirect Salesforce JDBCドライバーのファイル(sforce.jar)が存在することを確認します。
2.Salesforce JDBCのJARファイルをAmazon S3にアップロードします。
Amazon Glueジョブの作成
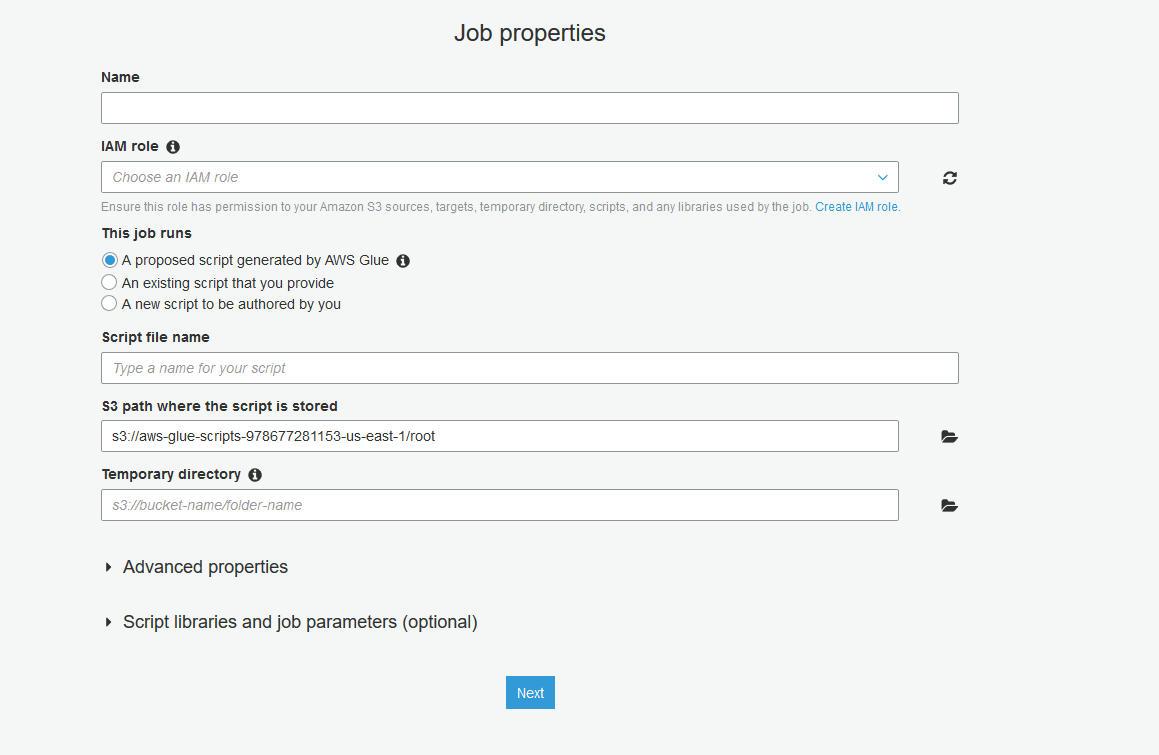
1.ブラウザからAWS Glueコンソールへアクセスし、「ETL」の「Job」にある「Add Job」ボタンをクリックし、新規ジョブを作成します。以下のような画面が表示されます。
2.ジョブ名を入力し、ジョブで使用するAmazon S3のソースやターゲット、一時ディレクトリ、スクリプト、ライブラリなどへのアクセス権限を付与するために「IAM role」を選択もしくは作成します。JDBCドライバーは既に持っていて、その格納先はAmazon S3であることから、この記事ではS3へアクセスする必要があります。
3.「This job runs」で「A new script to be authored by you」を選択してください。
4.スクリプトのファイル名を入力し、S3内のGlueジョブ用の一時ディレクトリを選択します。
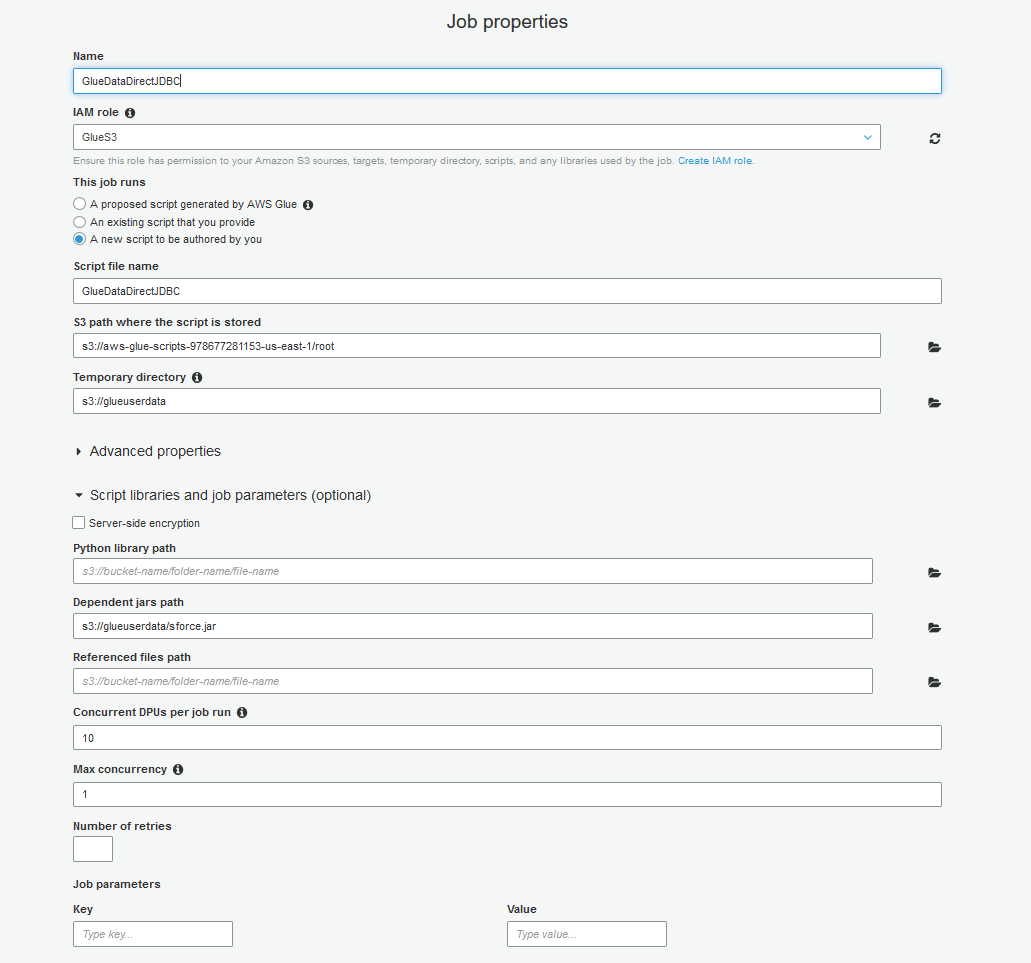
5.「Script Libraries and job parameters (optional)」(スクリプトのライブラリとジョブのパラメーター(オプション))を開いて、「Dependent Jars path」(依存するJARのパス)でS3内のsforce.jarファイルを選択してください。設定した内容は以下のようになっているはずです。
6.「Next」ボタンをクリックすると、ジョブで必要になる可能性がある接続を追加するか否かを問われるGlueのダイアログが表示されます。この記事では接続は必要ありませんが、例えばRedShiftやSQL Server、Oracleなど他のDBを使用する場合は、当該データソースへの接続をGlue内に作成することができます。作成した接続はこのダイアログに表示されます。
7.「Next」をクリックして設定をレビューします。「Finish」をクリックするとジョブが作成されます。
8.作成したジョブのPythonスクリプトを記述するエディターが表示されます。DataDirect JDBCドライバーを使ってSalesforceからデータを抽出し、S3もしくはその他の格納先に書き込むためのカスタムPythonコードをここに記述します。
9.このコードサンプルを参照頂けば、どのようにDataDirect JDBCドライバーでSalesforceからデータを抽出し、S3へCSV形式で書き込めば良いか分かると思います。最後にジョブを保存します。
コードサンプル
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.dynamicframe import DynamicFrame from awsglue.job import Job args = getResolvedOptions(sys.argv, ['JOB_NAME']) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) ##Read Data from Salesforce using DataDirect JDBC driver in to DataFrame source_df = spark.read.format("jdbc").option("url","jdbc:datadirect:sforce://login.salesforce.com;SecurityToken=<token>").option("dbtable", "SFORCE.OPPORTUNITY").option("driver", "com.ddtek.jdbc.sforce.SForceDriver").option("user", "user@mail.com").option("password", "pass123").load() job.init(args['JOB_NAME'], args) ##Convert DataFrames to AWS Glue's DynamicFrames Object dynamic_dframe = DynamicFrame.fromDF(source_df, glueContext, "dynamic_df") ##Write Dynamic Frames to S3 in CSV format. You can write it to any rds/redshift, by using the connection that you have defined previously in Glue datasink4 = glueContext.write_dynamic_frame.from_options(frame = dynamic_dframe, connection_type = "s3", connection_options = {"path": "s3://glueuserdata"}, format = "csv", transformation_ctx = "datasink4") job.commit()Glueジョブの実行
1.「Run Job」をクリックし、ジョブを開始します。ステータスの確認は、前画面に戻り、作成したジョブを選択します。
2.ジョブが正常に実行されると、DataDirect Salesforce JDBCドライバー経由で取得したデータがCSVファイルに保存されているはずです。
おしまい
- 投稿日:2020-06-25T10:05:52+09:00
備忘録
【】
・ps -ef |grep jar (実行中のjarプロセスを確認するコマンド)・kill -9 「jarプロセスのID」 (実行中jarプロセスを停止するコマンド)
・java -jar 「プロジェクト名」 & (プロセスを実行するコマンド)
・java -jar 「プロジェクト名」
・jar -uvf shared_shop-0.0.1-SNAPSHOT.jar -C shared_shop-0.0.1-SNAPSHOT BOOT-INF/classes/application.properties
- 投稿日:2020-06-25T08:11:15+09:00
【総集編】6月ふりかえり
はじめに
今月のふりかえりです。
月1で振り返り
今後は何を勉強するかを決めます。
6月 1週目
2020/06/03 【プログラミング】吾輩は関数である名前はまだない
2020/06/07 【SQL】最初に覚えるSQLの話
6月 2週目
2020/06/08 【データベース】正規化について知る
2020/06/10 【ExcelVBA】オブジェクト指向プログラミングをしよう
2020/06/14 【PHP】ワイ、客先でウェブサーバーをビルトするの巻
6月 3週目
2020/06/17 【AWS】用語を整理しながら学ぶAWS - part1
2020/06/21 【AWS】用語を整理しながら学ぶAWS - part2
今後
・DBスペシャリストになる為SQL頑張る。
・AWSをうまく扱えるようにガンガン活用してみる。
・Pythonでデータ分析をできるように数学を復習する。
・PHP案件を受ける為今後も引き続き勉強して発信する。勉強と合わせてさらにおもしろい記事を投稿できたらと思います。
おわり
- 投稿日:2020-06-25T01:47:38+09:00
TerraformでAWS VPCを削除する
TerraformでAWS VPCを削除するコード(コマンド)
実行環境
- Windows 10 Home (1919)
- Git Bash (git version 2.25.1.windows.1)
- AWS CLI (aws-cli/2.0.3 Python/3.7.5 Windows/10 botocore/2.0.0dev7)
- Terraform (v0.12.26)
削除する構成
まっさらなVPCが1つだけある状態で、そのVPCを削除
main.tf
main.tfprovider "aws" { profile = "prj01-profile" region = "us-west-2" } resource "aws_vpc" "prj01VPC" { cidr_block = "10.10.0.0/16" instance_tenancy = "default" tags = { Name = "prj01VPC" CostGroup = "prj01" } }VPC作成時のmain.tfと同じ。こちら。
実行
実行前の状態確認
$ aws ec2 describe-vpcs --region=us-west-2 { "Vpcs": [ { "CidrBlock": "10.10.0.0/16", "DhcpOptionsId": "dopt-0ebee8b328487036e", "State": "available", "VpcId": "vpc-085c4a097408d438d", "OwnerId": "679788997248", "InstanceTenancy": "default", "CidrBlockAssociationSet": [ { "AssociationId": "vpc-cidr-assoc-05db0b29ba54e1edc", "CidrBlock": "10.10.0.0/16", "CidrBlockState": { "State": "associated" } } ], "IsDefault": false, "Tags": [ { "Key": "CostGroup", "Value": "prj01" }, { "Key": "Name", "Value": "prj01VPC" } ] } ] }削除対象のVPCが存在していることを確認。
前提
$ aws configure list --profile prj01-profile Name Value Type Location ---- ----- ---- -------- profile prj01-profile manual --profile access_key ****************FCES shared-credentials-file secret_key ****************4Idw shared-credentials-file region us-west-2 config-file ~/.aws/config前提としてaws cliのprofileは作成済み。
まずplan
$ ../terraform.exe plan -destroy Refreshing Terraform state in-memory prior to plan... The refreshed state will be used to calculate this plan, but will not be persisted to local or remote state storage. aws_vpc.prj01VPC: Refreshing state... [id=vpc-085c4a097408d438d] ------------------------------------------------------------------------ An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: - destroy Terraform will perform the following actions: # aws_vpc.prj01VPC will be destroyed - resource "aws_vpc" "prj01VPC" { - arn = "arn:aws:ec2:us-west-2:679788997248:vpc/vpc-085c4a097408d438d" -> null - assign_generated_ipv6_cidr_block = false -> null - cidr_block = "10.10.0.0/16" -> null - default_network_acl_id = "acl-005cda038798e1246" -> null - default_route_table_id = "rtb-0ef695f3a63eff9a7" -> null - default_security_group_id = "sg-0a7fa0eabf509911d" -> null - dhcp_options_id = "dopt-0ebee8b328487036e" -> null - enable_classiclink = false -> null - enable_classiclink_dns_support = false -> null - enable_dns_hostnames = false -> null - enable_dns_support = true -> null - id = "vpc-085c4a097408d438d" -> null - instance_tenancy = "default" -> null - main_route_table_id = "rtb-0ef695f3a63eff9a7" -> null - owner_id = "679788997248" -> null - tags = { - "CostGroup" = "prj01" - "Name" = "prj01VPC" } -> null } Plan: 0 to add, 0 to change, 1 to destroy. ------------------------------------------------------------------------ Note: You didn't specify an "-out" parameter to save this plan, so Terraform can't guarantee that exactly these actions will be performed if "terraform apply" is subsequently run.消したいVPCだけが、destroyになっていることを確認。
確認できたのでdestroy
$ ../terraform.exe destroy aws_vpc.prj01VPC: Refreshing state... [id=vpc-085c4a097408d438d] An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: - destroy Terraform will perform the following actions: # aws_vpc.prj01VPC will be destroyed - resource "aws_vpc" "prj01VPC" { - arn = "arn:aws:ec2:us-west-2:679788997248:vpc/vpc-085c4a097408d438d" -> null - assign_generated_ipv6_cidr_block = false -> null - cidr_block = "10.10.0.0/16" -> null - default_network_acl_id = "acl-005cda038798e1246" -> null - default_route_table_id = "rtb-0ef695f3a63eff9a7" -> null - default_security_group_id = "sg-0a7fa0eabf509911d" -> null - dhcp_options_id = "dopt-0ebee8b328487036e" -> null - enable_classiclink = false -> null - enable_classiclink_dns_support = false -> null - enable_dns_hostnames = false -> null - enable_dns_support = true -> null - id = "vpc-085c4a097408d438d" -> null - instance_tenancy = "default" -> null - main_route_table_id = "rtb-0ef695f3a63eff9a7" -> null - owner_id = "679788997248" -> null - tags = { - "CostGroup" = "prj01" - "Name" = "prj01VPC" } -> null } Plan: 0 to add, 0 to change, 1 to destroy. Do you really want to destroy all resources? Terraform will destroy all your managed infrastructure, as shown above. There is no undo. Only 'yes' will be accepted to confirm. Enter a value: yes aws_vpc.prj01VPC: Destroying... [id=vpc-085c4a097408d438d] aws_vpc.prj01VPC: Destruction complete after 1s Destroy complete! Resources: 1 destroyed.確認ポイント
- yesを入力する前に、消したいVPCだけが、destroyになっていること
- createとchangeが「0」になっていること
- その他エラーや警告が発生していないこと実行後の確認
$ aws ec2 describe-vpcs --region=us-west-2 { "Vpcs": [] }VPCが消えていることを確認。
消したい対象を明確に指定
消すときはtargetを指定したい気分
$ ../terraform.exe plan -destroy -target=aws_vpc.prj01VPC Refreshing Terraform state in-memory prior to plan... The refreshed state will be used to calculate this plan, but will not be persisted to local or remote state storage. aws_vpc.prj01VPC: Refreshing state... [id=vpc-0f54ed2c26b44b69f] ------------------------------------------------------------------------ An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: - destroy Terraform will perform the following actions: # aws_vpc.prj01VPC will be destroyed - resource "aws_vpc" "prj01VPC" { - arn = "arn:aws:ec2:us-west-2:679788997248:vpc/vpc-0f54ed2c26b44b69f" -> null - assign_generated_ipv6_cidr_block = false -> null - cidr_block = "10.10.0.0/16" -> null - default_network_acl_id = "acl-06e41dd4dac36b4b0" -> null - default_route_table_id = "rtb-0c683ac40dcdc13d0" -> null - default_security_group_id = "sg-059f2992d43bd7002" -> null - dhcp_options_id = "dopt-0ebee8b328487036e" -> null - enable_classiclink = false -> null - enable_classiclink_dns_support = false -> null - enable_dns_hostnames = false -> null - enable_dns_support = true -> null - id = "vpc-0f54ed2c26b44b69f" -> null - instance_tenancy = "default" -> null - main_route_table_id = "rtb-0c683ac40dcdc13d0" -> null - owner_id = "679788997248" -> null - tags = { - "CostGroup" = "prj01" - "Name" = "prj01VPC" } -> null } Plan: 0 to add, 0 to change, 1 to destroy. Warning: Resource targeting is in effect You are creating a plan with the -target option, which means that the result of this plan may not represent all of the changes requested by the current configuration. The -target option is not for routine use, and is provided only for exceptional situations such as recovering from errors or mistakes, or when Terraform specifically suggests to use it as part of an error message. ------------------------------------------------------------------------ Note: You didn't specify an "-out" parameter to save this plan, so Terraform can't guarantee that exactly these actions will be performed if "terraform apply" is subsequently run.Warningが出た。
【google翻訳】
-targetオプションは日常的に使用するためのものではなく、エラーやミスからの回復などの例外的な状況で、またはTerraformがエラーメッセージの一部として使用することを明確に提案した場合にのみ提供されます。そうなのか。。。 まぁいいや!
$ ../terraform.exe destroy -target=aws_vpc.prj01VPC aws_vpc.prj01VPC: Refreshing state... [id=vpc-0f54ed2c26b44b69f] An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: - destroy Terraform will perform the following actions: # aws_vpc.prj01VPC will be destroyed - resource "aws_vpc" "prj01VPC" { - arn = "arn:aws:ec2:us-west-2:679788997248:vpc/vpc-0f54ed2c26b44b69f" -> null - assign_generated_ipv6_cidr_block = false -> null - cidr_block = "10.10.0.0/16" -> null - default_network_acl_id = "acl-06e41dd4dac36b4b0" -> null - default_route_table_id = "rtb-0c683ac40dcdc13d0" -> null - default_security_group_id = "sg-059f2992d43bd7002" -> null - dhcp_options_id = "dopt-0ebee8b328487036e" -> null - enable_classiclink = false -> null - enable_classiclink_dns_support = false -> null - enable_dns_hostnames = false -> null - enable_dns_support = true -> null - id = "vpc-0f54ed2c26b44b69f" -> null - instance_tenancy = "default" -> null - main_route_table_id = "rtb-0c683ac40dcdc13d0" -> null - owner_id = "679788997248" -> null - tags = { - "CostGroup" = "prj01" - "Name" = "prj01VPC" } -> null } Plan: 0 to add, 0 to change, 1 to destroy. Warning: Resource targeting is in effect You are creating a plan with the -target option, which means that the result of this plan may not represent all of the changes requested by the current configuration. The -target option is not for routine use, and is provided only for exceptional situations such as recovering from errors or mistakes, or when Terraform specifically suggests to use it as part of an error message. Do you really want to destroy all resources? Terraform will destroy all your managed infrastructure, as shown above. There is no undo. Only 'yes' will be accepted to confirm. Enter a value: yes aws_vpc.prj01VPC: Destroying... [id=vpc-0f54ed2c26b44b69f] aws_vpc.prj01VPC: Destruction complete after 1s Warning: Applied changes may be incomplete The plan was created with the -target option in effect, so some changes requested in the configuration may have been ignored and the output values may not be fully updated. Run the following command to verify that no other changes are pending: terraform plan Note that the -target option is not suitable for routine use, and is provided only for exceptional situations such as recovering from errors or mistakes, or when Terraform specifically suggests to use it as part of an error message. Destroy complete! Resources: 1 destroyed.失敗パターン
targetの指定はtype.resource
$ ../terraform.exe plan -destroy -target=prj01VPC Usage: terraform plan [options] [DIR] Generates an execution plan for Terraform. This execution plan can be reviewed prior to running apply to get a sense for what Terraform will do. Optionally, the plan can be saved to a Terraform plan file, and apply can take this plan file to execute this plan exactly. Options: :(略)targateを指定する際にリソース名の前にtype(今回は"aws_vpc")を指定しないとエラーになる。
マニュアルには-target=resource - A Resource Address to target. This flag can be used multiple times. See below for more information.
と書かれている。わかりにくいよ。。。
こっち見るとちゃんと書いてある。
Resource spec:
A resource spec addresses a specific resource in the config. It takes the form:
resource_type.resource_name[resource index]
