- 投稿日:2020-06-25T23:54:38+09:00
ボートレースの3連単をランキング学習で予測してみる
はじめに
この記事は、自身で製作しWeb公開にまで至ったボートレース3連単予測サイト「きょう、ていの良い予想は当たるだろうか」の内部コード解説となります。今回は機械学習モデルに関してまとめていきます。そもそものデータ取得や整形に関しては別記事を作成しますので、そちらをご覧ください。
※コードの書き方は我流なので、アドバイスいただけると有り難いです。
ランキング学習とは?
使えるようになるにあたり、以下の記事を大変参考にしました。
ランキング学習とは、相対的な順序関係を学習するための方法と言われております。
上記リンクのように、競馬や競艇などのような複数人(馬)の相対的な強さを学習するのに向いているんじゃないかな、と思い取り組んでみました。論文はまだ積ん読されていますが(笑)、まずは使ってみようと思います。
使用するライブラリはlightgbmです。Queryデータセットを準備する
今回は2020年1月〜4月を学習データ、2020年5月のデータを検証データとします。
ランキング学習の特徴として、「Queryデータ」があります。このQueryデータは、1つのレースに含まれている学習データの数を表します。ボートレースの場合はトラブルがなければ6艇でレースが行われるので、
Queryデータの箱 = [6,6,6,...,6]
といった、(欠場者がいなければ)”6”がレース数分だけ並んだリストができあがるはずです。
ということで以下のコードでQueryデータの箱をつくっていきます。
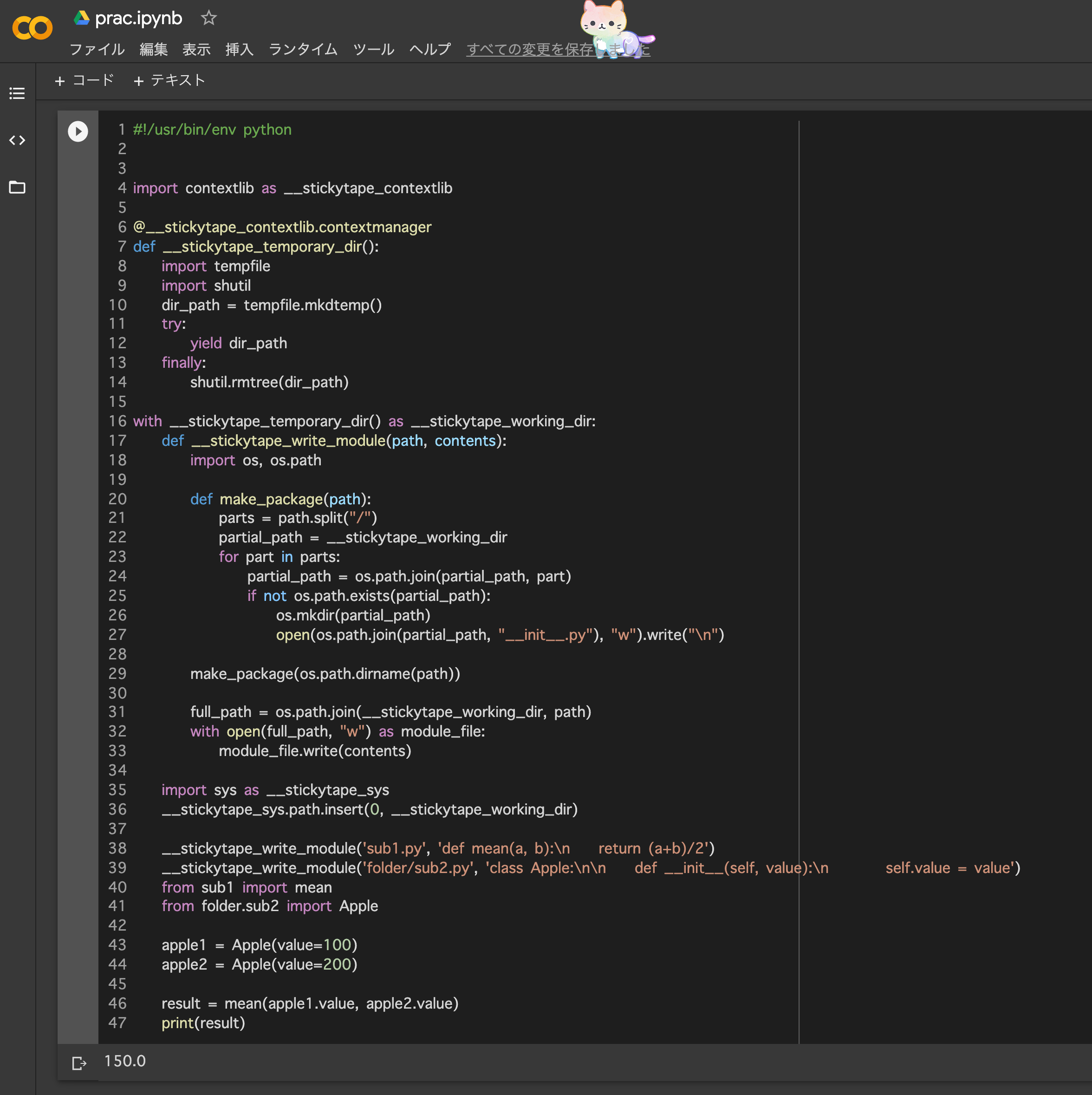
%%time #時間を測る target_cols = ["Position"] feature_cols = ["Name","Lane","Round","Month","Place"] train = pd.read_csv(train_file) train_shuffle = pd.DataFrame([],columns=train.columns) train_group =[] for i,k in enumerate(train["Round"]): if i == 0: temp = k temp2 = i else: if k == temp: pass else: train_group.append(i-temp2) #↓ .sampleでシャッフルしたデータにする。 train_shuffle=train_shuffle.append(train[temp2:i].sample(frac=1)) temp = k temp2 = i #最後の組が含まれていないのでを追加 train_group.append(i+1-temp2) train_shuffle=train_shuffle.append(train[temp2:i+1].sample(frac=1)) train_y = train_shuffle[target_cols].astype(int) train = train_shuffle[feature_cols] print(train.shape)read_csvで読んでいるtrain fileは取得した競艇テキストデータからデータフレームを作成するの記事をもとにできあがっています。
同じレース(Round)の数をかぞえ、train_groupのリストに格納しています。そして参考記事を読んだところ、このグループ内の順序をシャッフルしておかないとヤバいことになる、、との事だったので、train_shuffleに格納する際に.sampleでシャッフル処理をしています。
上記のコードを検証用データセットにも行い、検証用Queryデータセットを作成しておきます。
LightGBMを使用する
欠損処理やFeature engineering、One-hot encodingなどは割愛させていただきますが、学習データセット、Queryデータセットが準備できれば今の世の中、機械学習の実行は簡単です。ただ一点、lightgbmの仕様なのか、日本語がカラムに入っているとエラーが発生します。そのため以下のような処理を加えました。
column_list = [] for i in range(len(comb_onehot.columns)): column_list.append(str(i)+'_column') comb_onehot.columns = column_list※comb_onehotというDataFrame型はTrain datasetとValid datasetを結合し、One-hot encodingを処理した際につくられたデータフレームです。この処理の後、
train_onehot = comb_onehot[:len(train)] val_onehot = comb_onehot[len(train):]として、学習用と検証用に再分離しました。
さて、機械学習を実施します。import lightgbm as lgb lgbm_params = { 'task': 'train', 'boosting_type': 'gbdt', 'objective': 'lambdarank', #←ここでランキング学習と指定! 'metric': 'ndcg', # for lambdarank 'ndcg_eval_at': [1,2,3], # 3連単を予測したい 'max_position': 6, # 競艇は6位までしかない 'learning_rate': 0.01, 'min_data': 1, 'min_data_in_bin': 1, # 'num_leaves': 31, # 'min_data_in_leaf': 20, # 'max_depth':35, } lgtrain = lgb.Dataset(train_onehot, train_y, group=train_group) lgvalid = lgb.Dataset(val_onehot, val_y,group=val_group) lgb_clf = lgb.train( lgbm_params, lgtrain, num_boost_round=250, valid_sets=[lgtrain, lgvalid], valid_names=['train','valid'], early_stopping_rounds=20, verbose_eval=5 )num_leavesなどのハイパーパラメータは調整するべきですが、ここでは考えず進みましょう。
検証データに対する予測はこんな感じ。ほんと、便利な時代です..。y_pred = lgb_clf.predict(val_onehot,group=val_group, num_iteration=lgb_clf.best_iteration)結果は...
ランキング学習による3連単予測は以下のようになりました。3連単は8.15%..!!
ちなみに上記の的中率(特に2連単や3連単)を手に入れるため、以下のようなコードを書きました。う〜ん、冗長!
#Validデータ的中率の算出 j = 0 solo_count = 0 doub_count = 0 tri_count = 0 for i in val_group: result = y_pred[j:j+i] ans = val_y[j:j+i].reset_index() result1st = np.argmin(result) if len(np.where(result==sorted(result)[1])[0])>1: result2nd = np.where(result==sorted(result)[1])[0][0] result3rd = np.where(result==sorted(result)[1])[0][1] else: if i > 1: result2nd = np.where(result==sorted(result)[1])[0][0] if i > 2: result3rd = np.where(result==sorted(result)[2])[0][0] ans1st = int(ans[ans["Position"]==1].index.values) if len(ans[ans["Position"]==2].index.values)>1: ans2nd = int(ans[ans["Position"]==2].index.values[0]) ans3rd = int(ans[ans["Position"]==2].index.values[1]) else: if i > 1: ans2nd = int(ans[ans["Position"]==2].index.values[0]) if i > 2: ans3rd = int(ans[ans["Position"]==3].index.values[0]) if ans1st==result1st: #print(ans1st,result1st) solo_count = solo_count+1 if i > 1: if (ans1st==result1st)&(ans2nd==result2nd): doub_count = doub_count+1 if i > 2: if (ans1st==result1st)&(ans2nd==result2nd)&(ans3rd==result3rd): tri_count = tri_count+1 j=j+i print("単勝的中率:",round(solo_count/len(val_group)*100,2),"%") print("2連単的中率:",round(doub_count/len(val_group)*100,2),"%") print("3連単的中率:",round(tri_count/len(val_group)*100,2),"%")さいごに
上記の結果は何も考えずに買うよりは高い的中率です。(最も高い頻度で起こる3連単の組み合わせが"1-2-3"であり、その頻度は7%程度)
ただ、この結果だけだと的中率として心許ないので、もう一工夫が必要と感じました。
そこのところはまた別記事にてまとめたいと思います。

- 投稿日:2020-06-25T23:39:04+09:00
OperationalError: (psycopg2.OperationalError)でエラーが出た
はじめに
flaskのアプリをpsycopg2で動かしていたら下のようなエラーが出た。
OperationalError: (psycopg2.OperationalError) server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request.解決方法
from flask_sqlalchemy import SQLAlchemy as _BaseSQLAlchemy class SQLAlchemy(_BaseSQLAlchemy): def apply_pool_defaults(self, app, options): super(SQLAlchemy, self).apply_pool_defaults(self, app, options) options["pool_pre_ping"] = True db = SQLAlchemy(app)上のプログラムを入れると解決しました。下の参考URLには他の解決方法も載っていたりするので英語が得意だったら見てみてください。
参考URL
https://github.com/pallets/flask-sqlalchemy/issues/589#issuecomment-361075700
- 投稿日:2020-06-25T23:33:57+09:00
[光-Hikari-のPython]08章-01 モジュール(モジュールのインポート)
[Python]08章-01 モジュールのインポート
06章でオリジナルの関数を自作しました。こういった自作した関数はほかの人に使用してもらうことも可能です。
自分で作成した、複数の関数を1つのファイルにまとめることができ、このファイルのことをモジュール(部品)と言います。実際には世界中のPythonプログラマがで作成した様々なモジュールがインターネットで公開されています。こういったモジュールは無償で使用することができ、インポート(import)して使用します。
公開されているものには、AIやIoTなどで使用するモジュールや、ゲームの作成、データ分析などで使われるモジュールなど様々なものがあります。
この章では、まず自分で作成したモジュールのインポート、そしてインターネット上に作成されているモジュールのインポートについて説明していきます。
自作モジュールのインポート
実際に自作の関数をいくつか作り、モジュールとして保存してみましょう。
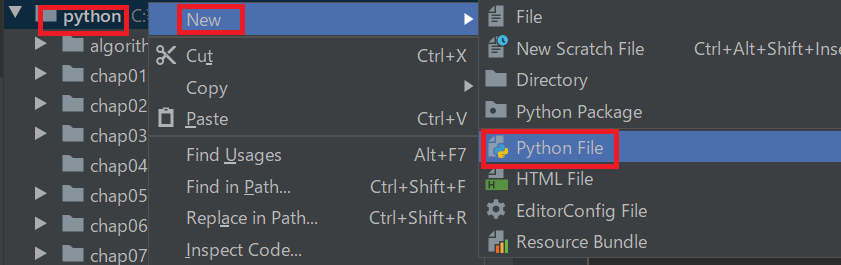
まず、モジュールを作成するのですが、まだchap08は作成せず、以下の[python]直下に作成をしてください。(以下のように[python]を右クリックする)
そして、sampmod08_01というファイル名で保存してください。(sampmod08_01です。sampmod08-01ではありません。→モジュールファイル名で-ハイフンを使用すると読み込めません)
sampmod08_01.pydef my_func(): print('モジュール内の関数から実行しています。') def calc_func(x, y): return x**2 + y my_func() print(calc_func(3, 3))次に、chap08を新たに作成し、その中に、samp08-01-01.pyというファイル名でファイルを作成し、以下のコードを書いてください。そして、samp08-01-01.pyのほうを実行してください。
samp08-01-01.pyimport sampmod08_01【実行結果】
モジュール内の関数から実行しています。
12import文により、自分で作成したモジュールsampmod08_01.pyが読み込まれ、それが実行されます。
なお、これはPython Consoleでも実行は可能です。Python Consoleから以下のコードを入力してください。
>>> import sampmod08_01 モジュール内の関数から実行しています。 12Python Consoleでimportしても、同じ結果が出力されることが分かったかと思います。
※Python Consoleで実行後は、必ず以下をクリックしてストップさせてください。(インポートされたままとなってしまうためです)
インポートした関数の呼び出し
今度は先ほどのモジュールを少し変更します。先ほどと同じく、[python]直下にsampmod08_02というファイル名を作成してください。
そして以下のコードを入力してください。sampmod08_02.pydef my_func(): print('モジュール内の関数から実行しています。') def calc_func(x, y): return x**2 + y今回は、呼び出し元の関数をモジュール内に作成していません。これをモジュール外から関数を呼び出すことを考えます。chap08の中に、samp08-01-02.pyというファイル名でファイルを作成し、以下のコードを書いてください。そして、samp08-01-02.pyを実行してください。
samp08-01-02.pyimport sampmod08_02 sampmod08_02.my_func() print(sampmod08_02.calc_func(3, 3))【実行結果】
モジュール内の関数から実行しています。
12今回、モジュール内には呼び出し元はなく、samp08-01-02.pyの中に呼び出し元があります。ほかのモジュールにある関数を呼び出す際には、
呼び出すモジュール名.呼び出すモジュール内の関数といった形式で呼び出すことができます。
モジュールに別名を付ける方法
先ほど、ほかのモジュールにある関数を呼び出す際に、sampmod08_02.my_func()やsampmod08_02.calc_func(3, 3)として呼び出しましたが、モジュール名が長く、入力に時間がかかってしまいます。
こういう時によく利用されるのがasを使って、別名を指定する方法です。
import 呼び出すモジュール名 as 別名モジュールchap08の中に、samp08-01-03.pyというファイル名でファイルを作成し、以下のコードを書いてください。そして、samp08-01-03.pyを実行してください。
samp08-01-03.pyimport sampmod08_02 as sm0802 sm0802.my_func() print(sm0802.calc_func(3, 3))【実行結果】
モジュール内の関数から実行しています。
12モジュールの別名を指定することで、少し短いモジュール名になったかと思います。よく、AIで使用するを外部から読み込むときは、別名を指定することが多いです。
また、よく見ると、前回のモジュールを使いまわしています。いちいち、新たにモジュールを作らなくとも、モジュールを再利用している様子がわかると思います。
これがモジュールの利点とも言えます。最後に
今回は自分で作成したモジュールをインポートすることについて触れました。モジュールのインポートはこれから、AIやIoT関連のプログラムを作成する際には当たり前のように必ず出てくるものです。
まだ外部のモジュールやライブラリ(後述します)の読み込みは触れていませんが、同じようなimport形式で読み込むので、今後に向けて押さえておきましょう。【目次リンク】へ戻る


- 投稿日:2020-06-25T23:01:39+09:00
DeepRunning ~Level3.3~
Level3.応用数学③
3-3.情報理論
・学習の目標
(1)自己情報量・シャノンエントロピーの定義を確認する。
(2)KLダイバージェンス・交差エントロピーの概要を知る。3-3-1.自己情報量
・対数の底が2のとき、単位はビット(bit)
・対数の底がネイピアの $e$ のとき、単位はナット(nat)
※natsとbitsでかじるものとかじられるもの。
・自己情報量:工学的、モールス信号では「どのくらい少ない情報で送れるか」と考えられた。
・情報の分かり易さを“比率”で把握している。
⇒10gの重さの違いが分かる人でも、10kgの物の上に10gを乗せても気が付かない。I(x)= -log(P(x)) = log(W(x))・$x$は、いろいろなイベント
・$W=\frac{1}{P}$と表せる。
logは逆数にすると符号が逆転する。(-をつける)
・$log(W(x))$で、底は$e$が省略されている。(底の変換)(例)
情報の量によって用意するスイッチの数は、$log$を取ればわかる。
1~2個の情報: スイッチ1個(=$log_{2}2$)
1~4個の情報: スイッチ2個(=$log_{2}4$)
1~8個の情報: スイッチ3個(=$log_{2}8$)3-3-2.シャノンエントロピー
・微分エントロピーともいうが、微分しているわけじゃない。
・自己情報量の期待値\begin{align} H(x)&= E(I(x))\\ &= -E(log\:(P(x)))\\ &= -\sum(P(x)\:log(P(x))) \end{align}⇒ (確率 × 確率変数)の合計(=期待値)
3-3-3.カルバック・ライブラー ダイバージェンス
・同じ事象・確率変数における異なる確率分布$P,Q$の違いを表す。
⇒コインを投げる。確率分布は$\frac{1}{2}$だが、イカサマのコインで確率が違うことが後で分かった等。
どれだけ違う分布だったのかを調べる。
・相対エントロピー
\begin{align} D_{KL}(P||Q)&= E_{X~P}\begin{bmatrix}log \frac{P(x)}{Q(x)}\end{bmatrix}\\ &=E_{X~P}\begin{bmatrix}log P(x) - log Q(x)\end{bmatrix} \end{align}・D:ダイバージェンス、KL:カルバック・ライブラー
・$(P||Q)$は、この2つの差を見たいという意味。\begin{align} I(Q(x))-I(P(x))&= (-log(Q(x))) - (-log(P(x)))\\ &=log\frac{P(x)}{Q(x)}\\ \end{align}E(f(x))= \sum_{x}P(x)f(x)\begin{align} D_{KL}(P||Q)&= \sum_{x}P(x)(-log(Q(x))) - (log(P(x)))\\ &=\sum_{x}P(x)log\frac{P(x)}{Q(x)} \end{align}⇒シャノンエントロピーと似ているのでは??
$D_{KL}(P||Q)とD_{KL}(Q||P)$は異なる値となる。
そのため、2つの差を距離としては扱えない。3-3-4.交差エントロピー
・KLダイバージェンスの一部分を取り出したもの。
・$Q$についての自己情報量を$P$の分布で平均している。
・事前に暗号化した表を用意しておくなどのデータ圧縮もある。
・機械学習及び最適化における損失関数の定義に使う。
(ロジスティック回帰モデルなど)\begin{align} H(P,Q)&= H(P) + D_{KL}(P||Q)\\ H(P,Q)&= -E_{X~P}\;\;log\;Q(x)\\ &= -\sum_{x}P(x)\:log\:Q(x) \end{align}・同じ事象・確率変数における異なる確率分布$P,Q$の違いを表す。

- 投稿日:2020-06-25T22:24:49+09:00
カギの締め忘れ防止システムを作りたい 1
初投稿です!
画像認識とかを少し触ったことがある程度の初心者なのですが、カギの締め忘れを警告するような画像認識システムを作ってみたい、と突然思い立ちました。自分の作業の備忘録的に投稿していきたいと思います。
目標
できるかどうかは完全に未知数ですが、目指すものを書いておきます。
- 玄関にカメラを設置して鍵の部分をうつす
- そのデータをパソコンまたはスマホに飛ばす
- 画像認識で鍵の開閉状態を取得
(できればアプリみたいな形にしたいと夢想していますが、果たしてできるのやら・・・)
今回の作業
夢は膨らむばかりですが、できることから少しずつやってみます。
というわけで、今回の目標は以下です。
「opencvを使って自宅の玄関の写真複数枚を数値データに変換する」
千里の道も一歩からということで、少しだけですがやってみたいと思います。
実行環境
Google Colab Notebook (Python)
必要なライブラリをインポート
key.pyimport cv2 import numpy as np import matplotlib.pyplot as plt import torch後でpytorchを使いたいのでデータはtorch.tensor型にします。
opencvで数値データに変換
データセットを作成していきます。
key.pydef make_datasets(path,X_data,y_data): img = cv2.imread(path, cv2.IMREAD_UNCHANGED).astype("float32") / 255 img = np.array([img]) if len(X_data)==0: X_data = img.copy() else: X_data = np.concatenate((X_data,img),axis=0) y_data = np.append(y_data, int(path[0])) return X_data, y_dataこれで、pathを指定するだけでデータセットを作ることができます。
正解ラベルは画像データのpath名の頭につけておくことで取得させます。key.pyX_data = np.array([]) #画像データ用 y_data = np.array([]) #正解ラベル用 #しまっている=0 開いている=1 path_names = ["0-1.jpg", "1-1.jpg"] for i in range(10): for path in path_names: X_data,y_data = make_datasets(path,X_data,y_data) X_data,y_data = torch.tensor(X_data),torch.tensor(y_data)とりあえず二枚の画像で試してみました。(
玄関の写真を何回も撮るのが面倒だったので)
10回ループさせているのは、この後データを加工して(croppingなどをする)訓練データを増やせたらいいなーという感じです。これは後で変えるかもしれません。X_dataがちゃんと想定どおりの次元になっているか確認します。
key.pyX_data.shape ## => torch.Size([20, 4032, 3024, 3])機械学習するには画像サイズが大きすぎますが、これは後で何とかできる、はず・・!
とにかくこれで、無事写真データをテンソルに変換することができました!
次回以降の話
Qiitaの投稿方法・MarkDownの書き方も学ぶことができたので、次回以降も引き続き投稿していけたらと思います。
最後に、次回の目標。
「作成したデータセットで機械学習ができるところまで持っていく」初心者投稿失礼いたしました!
- 投稿日:2020-06-25T21:59:34+09:00
ウイイレのデータ解析ソフトをWEBアプリ化してみよう!二歩目!
ウイイレのデータ解析自動化してくよ!Part6
■はじめに
- どうも ヤジュン です。
お久しぶりです。最近twitterの名前に「eスポーツエンジニア」をつけてみました!
言ったもん勝ちでしょ!!笑

■本記事の内容
- 今回は、 「ウイイレのデータ解析アプリの拡張内容の紹介」 です。
※アプリはPythonで書いてます。■参考URL
■アプリどれだけ進化したの!?
- 前回記事から以下の機能が拡張されました。
- クリックのみで全てのグラフ作成ができるように調整
- データ入力部の作成
- 試合結果の各パラメータ一覧の作成(Gauge Chart)
- 試合結果の各パラメータ一覧の作成(Rader Chart)
- ボール奪取/ロストのヒートマップの作成
▼アプリ操作の様子
UI/UX系のデザイン系の知識がないので、各グラフをタブで分けただけです。
ユーザ操作の導線だけ意識して、以下のようにタブを並べました。
- データ読み込み
- 試合結果の全体パラメータの平均値一覧
- 試合結果の各パラメータの分散をみるための散布図
- ボール奪取とボールロストのヒートマップ
「データ読み込み」で入れているデータセット例も公開しますね!(私ヤジュンの30試合分の結果です。。。照)
各グラフの見方については、過去の記事や、まさ太郎さんの解析レポートをご確認ください。■ちゃくちゃくと集まるデータ
- テスターの皆様のおかげで、データが貯まってきました♪
あの mayagekaさん もテスターとして急遽参加してくれました!笑
参加してくれたテスターには、データ解析レポートを作成して提供しています。
今回 まさ太郎さん のご好意で、レポートを公開してもいいと許可いただきました!▶興味ある方はクリック
▼レポートのイメージ
■リリースの予定
- せっかくここまで育ててきたので、リリースを考えています。
ウイイレ2021発売後、1か月以内が目標です。
完成させるための残課題を棚卸ししました。
本プロジェクトは、gitで管理しています。(ソースコードは非公開ね♡)
個人プロジェクトで開発してみたい人にオススメ!!
■残課題
- ①データ管理をcsvファイルからSQLへ移行
- サーバーレンタルが必要で、お金かかるんですよ~。エンジェル投資家いませんか?笑
- ②ユーザ認証機能
- SQLでデータ管理する以上、他人のデータの秘匿性を担保しないといけません。
ライバルがデータを勝手に見てくる!とか恐怖ですもんね笑- ③コナミ側との渉外活動
- これが一番難易度高いかも。
揉め事は嫌なので、コナミの担当者と認められる活動範囲を整合します。
コナミの担当者とつなげてくれるエンジェルはいないかな。。。- ④テスターによる評価
- 今までテスターのデータを評価していましたが、テスター側に本アプリを評価してもらわないといけません。
- ⑤グラフの読み方の説明
- 「グラフを作る」という「プログラマー」としてのスキルが求められる障壁は本アプリで排除出来ました。
残りは「グラフの読み方」という「数学」的なスキルが求められる障壁を排除します。■終わりに
楽しんでいただけたでしょうか?
リリースしたら、ぜひとも皆様に使ってほしい!
使われたら私のエンジニアとしての実績になります。余談ですが、転職活動を始めました!
業界研究と自己研究のマッチングをしています。
日々の努力のおかげで、「やってみたいこと」が「やれること」に変わっているのを感じます。
一度きりの人生なので、ゲームだけでなく職でも自己実現したいですね!私に興味持っていただけた方は、気軽にTwitterへDMください♪
■参考URL
- Gauge Charts in Python
InfluxDB+Grafana persistence and graphing
Gauge Examples and Reference
Plot dcc graph on callback not working
Upload Component
Using dash upload component to upload csv file and generate a graph
複数のグラフを重ねる
Built-in Continuous Color Scales in Python かっこいいReadme
class plotly.graph_objects.Scatterpolar
Udemyのplotly dashの学習コース


- 投稿日:2020-06-25T21:55:53+09:00
Pythonでツール作成
Pythonでツールを作る。
背景
Pythonを学んでいるので何かしら作ってみようかと思う。
Insert文作成ツールを作ることにした。
VBAでは実務で作った経験がある。
テスト用のダミーデータを作る想定にする。調査
INSERT INTO table_name VALUES (value1, value2, ...)
原案
・データをファイルから読み取ります。
・SQLを作ります。
・ファイルに書き込みます。気をつけること
・文字列はシングルクォートで囲むこと。
・次回開発
→項目が可変である場合はどうするか?
→文字列はシングルクォートで囲むこと。以下ソースコード
lunch.csv アン,グリーンカレー エミー,サンドウィッチ リチャード,カオマンガイ フィリップ,キーマカレー 敏夫,肉野菜炒め アン,グリーンカレー エミー,サンドウィッチ リチャード,カオマンガイ フィリップ,キーマカレー 敏夫,肉野菜炒め sqlInsert.py with open ('lunch.csv', encoding='utf-8') as f: with open('output.txt', 'w', encoding='utf-8') as g: i = 0; for row in f: name = row.rstrip().split(',')[0] item = row.rstrip().split(',')[1] g.write("Insert into dummyTb VALUES (" + str(i + 1) + "," + "'" + name + "','" + item + "')" +'\n') i +=1 output.txt Insert into dummyTb VALUES (1,'アン','グリーンカレー') Insert into dummyTb VALUES (2,'エミー','サンドウィッチ') Insert into dummyTb VALUES (3,'リチャード','カオマンガイ') Insert into dummyTb VALUES (4,'フィリップ','キーマカレー') Insert into dummyTb VALUES (5,'敏夫','肉野菜炒め') Insert into dummyTb VALUES (6,'アン','グリーンカレー') Insert into dummyTb VALUES (7,'エミー','サンドウィッチ') Insert into dummyTb VALUES (8,'リチャード','カオマンガイ') Insert into dummyTb VALUES (9,'フィリップ','キーマカレー') Insert into dummyTb VALUES (10,'敏夫','肉野菜炒め')
- 投稿日:2020-06-25T21:55:53+09:00
Pythonでプログラミング
Pythonでプログラミング
背景
Pythonを学んでいるので何かしら作ってみようかと思う。
Insert文をpythonで作ってみる。
いきなり実用的なものを作ろうとすると非常に敷居が高くなってしまうので・・・実験的に行っていく。
数も0,1の2ケースもありとする。調査
INSERT INTO Staff (id, name, age) VALUES ('0001', '山田太郎', 26);
PostgreSQLではじめるDB入門を参考にInsert文を二つ作ってみようと思う。
https://db-study.com/archives/238
0埋め 右寄せゼロ埋め: zfill()原案
・データをファイルから読み取ります。
・SQLを作ります。
・ファイルに書き込みます。気をつけること
・文字列はシングルクォートで囲むこと。
・課題
→項目が可変である場合はどうするか?
→文字列はシングルクォートで囲むこと。以下ソースコード
address.csv 山田太郎,26 山田花子,33 with open ('address.csv', encoding='utf-8') as f: with open('output.txt', 'w', encoding='utf-8') as g: i = 0; for row in f: name = row.rstrip().split(',')[0] item = row.rstrip().split(',')[1] g.write("Insert into Staff VALUES (" + str(i + 1).zfill(4) + "," + "'" + name + "','" + item + "');" +'\n') i +=1 print("作成完了しました") output.txt Insert into Staff VALUES (0001,'山田太郎','26'); Insert into Staff VALUES (0002,'山田花子','33');
- 投稿日:2020-06-25T21:53:34+09:00
シフト・スケジューリング問題をいろいろな手法で解いてみた
アルゴリズムの勉強に、シフト・スケジューリング問題を解いてみました。本稿を書いている2020年5月に最もホットな話題はCOVID-19で、これが私の社畜生活にどのような影響を与えるかを考えてみると、出社したい(社員側の要望。去年までは出社させたいという会社側の要望だった)とテレワークさせたい(会社側の要望。去年まではテレワークしたいという社員側の要望だった)をいい感じに満たすことなんじゃないなかなぁと。うん、いわゆるひとつのシフト・スケジューリング問題ですな。
※コードはGitHubに置いてあります。プログラミング言語はPythonです。
制約
- 社員はA、B、C、D、Eの5人。10日分のスケジュールを生成する
- 最低2名出社しなければならない。そして、できるだけ出社する人数を少なくしたい
- 社員のコミュニケーション活性化のために、できるだけ異なるペアの社員が出社するようにしたい。可能なら、たとえばAさんとBさんというペアが出社するのは一度だけにして、他の日にAさんが出社するときはAさんとCさん等の異なるペアにする。
イジング模型を使用した焼きなまし法
まず最初に、D-Waveの量子焼きなまし法でも使われているイジング模型でやってみましょう。ただし、量子焼きなまし法は普通のコンピューターでは実行できませんから、普通の焼きなまし法でやります。富士通のデジタルアニーラとかと同じやり方ですね。
でも、イジング模型を焼きなまし法で解く処理を作るのは面倒だったので、D-Wave社のnealを使用しました。あと、イジング模型を手作りするのもかなーり大変(というか、私の数学能力が低すぎてカケラも理解できない)ので、イジング模型の生成はリクルート・コミュニケーションズ社のPyQUBOを使用しました。
というわけで、nealとPyQUBOを使用して問題を解くコードはこんな感じ。
import numpy as np from funcy import * from neal import SimulatedAnnealingSampler from pyqubo import Array, Constraint, Placeholder, Sum M = 5 # 社員の数 D = 10 # 日数 BETA_RANGE = (5, 100) # 焼きなましの温度の逆数。大きい方が解が安定しますが、局所解に陥る可能性が高くなってしまいます NUM_READS = 10 # 焼きなましする回数。NUM_READS個の解が生成されます。多いほうが良い解がでる可能性が高くなります NUM_SWEEPS = 100000 # 焼きなましのステップを実施する回数。1つの解を生成するために繰り返し処理をする回数です。大きい方が良い解がでる可能性が高くなります BETA_SCHEDULE_TYPE = 'linear' # 焼きなましの温度をどのように変化させるか。linearだと線形に変化させます # nealを使用してイジング模型を焼きなましして解を返します def solve(hs, js): response = SimulatedAnnealingSampler().sample_ising(hs, js, beta_range=BETA_RANGE, num_reads=NUM_READS, num_sweeps=NUM_SWEEPS, beta_schedule_type=BETA_SCHEDULE_TYPE, seed=1) # NUM_READS個の解の中から、もっとも良い解を返します return tuple(response.record.sample[np.argmin(response.record.energy)]) # QUBOを構成する変数を定義します xs = Array.create('x', shape=(M, D), vartype='BINARY') # チューニングのための変数を定義します a = Placeholder('A') b = Placeholder('B') # QUBOを定義します。ここから…… h = 0 # 1日に2名以上、かつ、できるだけ少なくという制約を追加します。2名より多くても少なくてもペナルティが発生するようになっています for d in range(D): h += a * Constraint((Sum(0, M, lambda m: xs[m][d]) - 2) ** 2, f'day-{d}') # 2を引くと、少なければ負、多ければ正の数になるわけですが、それを2乗して正の値にします # 同じ人と別の日に出社しないという制約を追加します for m1 in range(M): for m2 in range(m1 + 1, M): for d1 in range(D): for d2 in range(d1 + 1, D): h += b * xs[m1][d1] * xs[m2][d1] * xs[m1][d2] * xs[m2][d2] # xsは1か0なので、掛け算をする場合は、全部1の場合にだけ1になります # コンパイルしてモデルを作ります model = h.compile() # ……ここまで。QUBOを定義します # チューニングのための変数の値 feed_dict = {'A': 2.0, 'B': 1.0} # イジング模型を生成して、nealで解きます hs, js, _ = model.to_ising(feed_dict=feed_dict) answer, broken, energy = model.decode_solution(dict(enumerate(solve(hs, js))), vartype='SPIN', feed_dict=feed_dict) # 結果を出力します print(f'broken:\t{len(broken)}') # Constraintに違反した場合は、brokenに値が入ります print(f'energy:\t{energy}') # QUBOのエネルギー。今回のモデルでは、全ての制約を満たした場合は0になります # 日単位で、出社する社員を出力します for d in range(D): print(tuple(keep(lambda m: 'ABCDE'[m] if answer['x'][m][d] == 1 else False, range(M))))で、このプログラムを実行した結果はこんな感じ。
broken: 0 energy: 0.0 ('D', 'E') ('A', 'D') ('B', 'C') ('A', 'C') ('B', 'D') ('B', 'E') ('C', 'E') ('A', 'E') ('A', 'B') ('C', 'D')うん、正しいですね。毎日2名が出社していますし、同じ組合せはありません。ちなみに、私のコンピューターでの実行時間は0.734秒でした。解を10個作成していますので、1個あたり0.073秒。nealすげぇ速い!
簡単な解説
Wikipediaのイジング模型のページを読むと、「二つの配位状態をとる格子点から構成され、再隣接する格子点のみの相互作用を考慮する格子模型」と書いてあってもーなんだか分かりません。ハミルトニアンって物理の用語みたいだけど美味しいの? 今から物理を勉強しないとならないの?
ご安心ください。物理を勉強しなければならないのはイジング模型を活用するハードウェアを作る人であって、我々プログラマーではありません。しかも、イジング模型はソフトウェア的にはかなり簡単な話なんです。
具体例で説明しましょう。まず、格子という言葉(イメージ的に縦横があるように思える)は無視してください(物理ハードウェア屋には重要だけど、プログラマーの我々には関係ない)。で、二つの配位状態ってのは、-1か1のどちらかしか代入できない特殊な変数だと考えてください。1とか-1だとイメージが掴みづらいので、今回は、3人が、ある提案に賛成するか反対するかをそれぞれ投票する場合で考えましょう。賛成の場合は1、反対の場合は-1になるわけですな。この3人の間には微妙な関係があって、aさんとbさんは同じ行動を取ると気持ちが良くて、何らかの過去の因縁でcさんとbさんは違う行動を取ると気持ちが良いとします。さて、この条件下で全員ができるだけ気持ちよくなるには、どうすればよいでしょうか?
コンピューターは数値しか扱えませんので、なんとかして数値で表現していなければなりません。aやb、cは1か-1のどちらかの値しか取れないので、みんなが気持ち良いときに数値が小さくなる式はこんなコードで表現できます。
-1 * a * b + 1 * b * c少し詳しく見ていきましょう。1と-1の組合せを掛け算した結果は以下になります。
値1 値2 結果 1 1 1 1 -1 -1 -1 1 -1 -1 -1 1 値が同じ場合と違う場合で1と-1に気持ちよく分かれるので、この結果に-1をかければ同じ場合は-1という小さな値に、違う場合は1という大きな値になるというわけ。ほら、先程の式でうまく表現できていたでしょ?
ただ、このままだと汎用性がなくて不便ですから、汎用的にしましょう。全ての変数の掛け算結果に、以下の表の値(ただしa * aは毎回同じになるので無意味だから空欄で、a * bとb * aは同じ値になるので片方だけに値を入れる)を掛けることにします。
a b c a -1 0 b 1 c 関係がないところは0にしておけばよいわけですな。で、このテーブルを使って計算をするコードを書いてみると、こんな感じ。aとb、cが
xsという配列に、上の表の値がjsという変数に入っていると考えてください。def energy(): result = 0 for i in range(1, len(xs)): for j in range(i + 1, len(xs)): result += js[i][j] * xs[i] * xs[j] return resultこれで、bさんとcさんが和解する等して関係性が変わったとしても、同じコードで表現できるようになりました(実際には、さらに汎用的にするために(
aやbやcが1なのか-1なのかを利用するために)もう一つの変数(イジング模型を使用した焼きなまし法のコードでのhs)も使用します)。で、この汎用的で素晴らしいこれが、イジング模型なんです。ここまでくれば、
xsの適当な要素をひっくり返して上のコードの結果を比べることで、良くなったか悪くなったかが簡単に分かります。いわゆる山登り法で解けるわけですな。ただ、調べてみると山登り法の説明に局所解に陥りやすいとか書いてあってなんか不安なので、最初のうちは上のコードの結果が少し悪くなる場合でも移動を許す、最後の方はその度合いを減らして良くなる方向に移動させるというやり方でこの問題を回避してみましょう。これは現実世界での焼きなましに似ているので焼きなまし法と呼ばれていて、結果が悪くなる場合でも許す度合いを現実世界の焼きなましにならって温度と呼びます。あと、上のコードの結果に現実世界で対応するのはエネルギーなので、上のコードの結果をエネルギーと呼びます。だから、温度を下げながら、エネルギーが最小になる組合せを求める、みたいな表現となるわけですな。D-Wave社のnealは、この作業をとても効率よく実施してくれるんです。というわけで焼きなましてみれば、その結果は、a=1, b=1, c=-1かa=-1, b=-1, c=1になるはず。どちらの場合もエネルギーは最小の-2なので全員が気持ち良い。
ならあとは本稿の最初に挙げた制約に合わせて先程の表の値を作るだけ……なんですけど、これがかなーり難しい。本稿の制約のように、複数の変数が絡む場合はもうどうしていいか分かりません(裏で変数を追加して、その追加した変数も含めた関係で定義するらしい)。だから、リクルート・コミュニケーションズ社のPyQUBOを使いましょう。PyQUBOなら、式での表現を汎用性があるイジング模型に変換してくれるんです。あと、1と-1だと考えるのが大変なので、1と0を使うQUBOという形式でも定義できる(私では理解は出来なかったけど、イジング模型とQUBOは相互に変換できるらしい)ようになっています。
具体的に式で表現してみましょう。
xsをM×Dの二次元配列と考えて、出社する場合は1、出社しない場合は0とすれば、一日目に出社する社員の数は以下で計算できます。result = 0 for m in range(M): result += xs[m][0] return resultで、この結果は2に近いほど良くて、多くても少なくても駄目なわけです。だから2を引いて
absして絶対値を求めたい……のですけど、残念なことにabsのような関数は使えません。ではどうするかというと、2乗しちゃえばよいわけ。私は数学が苦手なのでよくわからないのですけど、マイナスとマイナスを掛け算すればプラスになるらしいですもんね。あと、PyQUBOはSumという合計を求める関数を提供してくれているので、以下のコードになるわけです。h += (Sum(0, M, lambda m: xs[m][0]) - 2) ** 2これで、出社する人数が2の場合に最もエネルギーが小さくなって、2より多くても少なくてもそれより大きなエネルギーになるようになりました。
残りの、できるだけ異なるペアの社員については、異なる日に同じ組合せがあったら駄目にしちゃえばオッケー。簡単にするためにもう少し細かく考えて、たとえば「社員0と社員1で、2日目と3日目が同じならペナルティを与える」とする場合は、以下のコードで表現できます。
h += xs[0][2] * xs[1][2] * xs[0][3] * xs[1][3]QUBOだからxsの要素の値は1か0のどちらかなので、だから0日目と1日目の両方に社員0と社員1の両方が出社する場合、つまり全部1の場合以外は0になります。全部1ということは同じ組合せなので、その場合に1になるのであればペナルティとしてとても都合がよい。あとは、他の社員の組合せと他の日の組合せを網羅するために、4重のループを書けば完成です。
あと、大抵の物事には優先順位があり、そして、異なる物事を足し合わせるのは困難です(今回の適当に作った2つの式の単位系が同じとは思えません。「かゆさ」と「うるささ」を足して「不愉快さ」を計算するのは困難でしょ?)。なので、適当な係数、
aとbを掛けることにして、これらの値はチューニングの際に指定できるようにしましょう(かゆさ×a+うるささ×b=不愉快さと仮置きして、aやbの値は適宜調整するわけ)。このようなときに便利なのがPlaceholderです。今回は、いろいろ試してみてa=1.0とb=0.5にしてみました。と、こんな感じでPyQUBOでQUBOを定義すると、あとはmodel.to_ising()でイジング模型に一発で変換されて、それをnealで解けば答えが返ってくる。あと、nealの代わりにD-Waveを使うことも可能です。デジタルアニーラで解いて実行時間や精度をnealと比べたりもできちゃう。いやぁ、世の中便利になりましたな。遺伝的アルゴリズム
調子に乗って、なんだか名前に浪漫を感じる遺伝的アルゴリズムでやりましょう。
例によって遺伝的アルゴリズムをする処理を作るのは面倒だったので、DEAPというオープン・ソースのライブラリを使用しました。コードはこんな感じ。
from deap import algorithms, base, creator, tools from functools import reduce from funcy import * from random import randint, random, seed M = 5 # 社員の数 D = 10 # 日数 # 評価関数 def evaluate(individual): # 1日に2名以上、かつ、できるだけ少なくという制約を追加します。2名より多くても少なくてもペナルティが発生するようになっています def member_size(): result = 0 for d in range(D): result += abs(reduce(lambda acc, m: acc + individual[m * D + d], range(M), 0) - 2) # 値そのものを使用しているので、absとかも使えます return result # 同じ人と別の日に出社しないという制約を追加します def different_member(): result = 0 for m1 in range(M): for m2 in range(m1 + 1, M): for d1 in range(D): for d2 in range(d1 + 1, D): result += individual[m1 * D + d1] * individual[m2 * D + d1] * individual[m1 * D + d2] * individual[m2 * D + d2] return result # 複数の評価の視点を、それぞれの視点での評価結果を要素とするタプルで返します return (member_size(), different_member()) # どのように遺伝的アルゴリズムするのかをDEAPで定義します creator.create('Fitness', base.Fitness, weights=(-1.0, -0.5)) # evaluate()の結果が小さいほど良いので、ウェイトにマイナスを付けておきます creator.create('Individual', list, fitness=creator.Fitness) toolbox = base.Toolbox() toolbox.register('attribute', randint, 0, 1) toolbox.register('individual', tools.initRepeat, creator.Individual, toolbox.attribute, n=M * D) toolbox.register('population', tools.initRepeat, list, toolbox.individual) toolbox.register('mate', tools.cxTwoPoint) toolbox.register('mutate', tools.mutFlipBit, indpb=0.05) toolbox.register('select', tools.selTournament, tournsize=3) toolbox.register('evaluate', evaluate) # 再現性のために、ランダムのシードを固定します seed(1) # 遺伝アルゴリズムで問題を解きます population, _ = algorithms.eaSimple(toolbox.population(n=100), toolbox, 0.5, 0.2, 300, verbose=False) # 最も良い解を取得します individual = tools.selBest(population, 1)[0] # 結果を出力します print(f'fitness:\t{individual.fitness.values}') # 日単位で、出社する社員を出力します for d in range(D): print(tuple(keep(lambda m: 'ABCDE'[m] if individual[m * D + d] else False, range(M))))で、結果はこんな感じ。
fitness: (0.0, 0.0) ('B', 'E') ('A', 'D') ('B', 'C') ('C', 'E') ('D', 'E') ('C', 'D') ('A', 'C') ('A', 'E') ('B', 'D') ('A', 'B')はい。正しい解ですね。私のコンピューターでの実行時間は4.595秒でした。なんだ遅いじゃん使えないと感じた方は、次の「簡単な解説」を最後まで読んでみてください。
簡単な解説
かっこいい親から生まれた子供は多分かっこいい。で、そうでない親から生まれた私は……。
一つ前の焼きなまし法でもそうなのですけど、新しい解を作ることでより良い解を探していくという方式では、新しい解の作り方が重要です。たとえばランダムに新しい解を作ったりしたら、たぶん悪くなることが多くていつまで待っても良い解は見つからないでしょう。だから、山登り法では、現在の解を少し変えただけの、現在の解の近傍の解を使用します。良い解に似ているんだからたぶん良いだろう、って考えですね。で、遺伝的アルゴリズムでは、解を遺伝子みたいな感じで表現して、交配して子供が生まれたり突然変異したりする感じで新しい解を作成して、あと自然淘汰っぽい感じでより良い解を探していきます。交配や自然淘汰のために、解は1つではなくて複数個持ちます。かっこいい親の子供は多分かっこいいでしょうから、だから婚活市場で淘汰されずに生き残れそうって感じですね。
で、遺伝的アルゴリズムで最も重要なのは「解を染色体でどのように表現するか」です。今回のように、出社したら1で出社しないなら0のリストで表現しても構いません。数値の集合ならなんでもよい(NumPyのndarrayとか、SetやDictionary、木構造なんかも使えます)ので、たとえば巡回セールスマン問題だったら巡回する都市の番号のリストでもオッケー。車の運転とかなら、アクセルやブレーキを踏み込む強さを浮動小数点で表しても構いません。DEAPは、様々な遺伝子や染色体の表現を可能にするための機能を豊富に持っています。たとえば、巡回セールスマンで巡回する都市の番号を遺伝子にした場合なんかは、DEAPのドキュメントのCreating TypesのPermutationが役に立ちます(これでもう順序表現のような面倒な手法を使わなくても済む!)。
あと、交配(遺伝的アルゴリズムでは交差と呼ぶ)の方法とか、突然変異の方法とか、自然淘汰する方法なんかも実はいろいろあるんですけど、それらの多くを実装してくれています。そしてさらに、これらをいい感じに組み合わせる方法を
algorithmsパッケージで提供してくれるんです。でも、DEAPは使い方にちょっと癖があるんですよね……。DEAPが提供する機能を再利用して問題を解くのに必要な道具を作っていくのですけど、それを普通の関数合成ではなくてDEAPの機能でやらなければならないんです。たとえば、個体(解の1つに相当します)である
Individualクラスを定義するには、creator.create('Invididual', ...)みたいにDEAPのAPIでやらなければなりません。で、交差するメソッドを作るのはtoolbox.register('mate', tools.cxTwoPoint)みたいな感じ。これだけで2点交差をするメソッドを生成してくれるのは楽なのですけど、できれば普通にpartialみたいな感じで書きたかった……。まぁ、こんなのは贅沢な悩みなので、サクサクとプログラムを作ってしまいましょう。個体を評価する関数は自前で書かなければなりませんので、イジング模型を使用した焼きなましのときに書いたコードを参考にして、でも遺伝的アルゴリズムの場合は
absが使えて便利だなぁとか考えながらevaluate()関数を作成しました。あとは、解の良さを評価するFitnessクラス、個体を表現するIndividualクラスを作成して、個体の染色体の属性を作るattribute()メソッドを作成してそれを利用して個体を生成するindividual()メソッドを作成してそれを利用して集団を生成するpopulation()メソッドを生成します。あとは、遺伝的アルゴリズムに必要な交差のmate()メソッドと突然変異のmutation()メソッドと自然淘汰のselect()メソッドと、最初に作成したevalute()関数を呼び出すevalute()メソッドを生成します。で、今回は、
algorithms.eaSimple()で最もシンプルな形の遺伝アルゴリズムを実行させてみました。ライブラリに完全おまかせの手抜きでも、100個体で300世代の遺伝的アルゴリズムをやれば、正解がでちゃうんですね。さて、イジング模型を使用した焼きなまし法よりも遅かった遺伝的アルゴリズムの良いところは、イジング模型より解の表現が柔軟なので適用可能な問題が多いことと、やり方がいっぱいあるのでチューニングの余地が大きいことです。本稿ではチューニングをしませんでしたが、染色体の表現をもっと効率化したり交差のやり方を変えたり突然変異が発生する確率をいい感じに変更したりすれば、イジング模型を使用した焼きなまし法よりももっと高速に精度の高い解を導けるようになるかもしれないわけ。すぐに効果が見えるので、チューニングは楽しいしね。
まぁ、そのためには遺伝的アルゴリズムの様々な手法の勉強をしなければならないのですけど、実際にDEAPで試しながら勉強すれば、すぐにマスターできるんじゃないかな。
整数計画法
他に何かないかなーと考えたときに目に付いたのが、整数計画法です。線型計画法(Linear Programming)を整数に限定してさらに難しくなっちゃったバージョンですね。
線形計画法というのは、一次式(変数を1つだけ掛けたものが加減算でつながっている式。3 * x + yは一次式で、3 * a * a + bは二次式らしい)で目的関数や制約関数を表現して、数学的にサクッと解いちゃう方法です。目的関数は、イジング模型を使用した焼きなまし法や遺伝的アルゴリズムでやったみたいな解の良さを表す式で、これができるだけ大きかったり小さかったりする解を選びます。で、制約関数というのは、解の制約を条件式で表現したものです。
え? 何を言っているか分からない?
私も全く分かっていないんだから聞かないでください……。でも、PuLPを使えばサクサクと整数計画法(もちろん線型計画法も)ができちゃうんです。コードはこんな感じ。
from functools import reduce from funcy import * from pulp import * M = 5 # 社員の数 D = 10 # 日数 # 問題の中で使用する変数を定義します xs = LpVariable.dicts('x', (range(M), range(D)), 0, 1, 'Binary') # 問題を定義します。ここから…… problem = LpProblem('shift-scheduling-problem', LpMinimize) # 1日に2名以上という制約を追加します for d in range(D): problem += reduce(lambda acc, m: acc + xs[m][d], range(M), 0) >= 2 # 同じ人と別の日に出社しないという制約を追加します for m1 in range(M): for m2 in range(m1 + 1, M): for d1 in range(D): for d2 in range(d1 + 1, D): problem += xs[m1][d1] + xs[m2][d1] + xs[m1][d2] + xs[m2][d2] <= 3 # 不等号(<)は使用できなかったので、<= 3で # problem.writeLP('shift-scheduling-problem') # ……ここまで。問題を定義します # 整数計画法で、問題を解きます status = problem.solve() # 結果を出力します print(LpStatus[status]) # 日単位で、出社する社員を出力します for d in range(D): print(tuple(keep(lambda m: 'ABCDE'[m] if xs[m][d].value() else False, range(M))))で、結果はこんな感じ。
Optimal ('D', 'E') ('C', 'D') ('A', 'E') ('C', 'E') ('B', 'D') ('B', 'C') ('A', 'C') ('A', 'D') ('B', 'E') ('A', 'B')最適(Optimal)な解ですな。実行時間は0.132秒でとても速い!
簡単な解説
PuLPでの変数は、
LpVariableで作成します。今回は多数の変数が必要でしたので、LpVariable.dicts()で一気に大量に生成しました。あと、今回は、制約を満たす解の中での優劣はありません(できるだけ異なるペアの社員の制約を満たそうとすると、出社する人数は少なくなる)ので、制約だけを定義しています。PuLPでの制約の書き方は、条件式になります。1日の出社人数を
reduce()で計算した結果>= 2のような感じですね。この条件式をLpProblemとして作成した問題に+=で追加していきます。同じ人と別の日に出社しない制約では、これまでのようにxs[] * xs[] * xs[] * xs[]とすると4次式になってしまいますので、足し算(これなら一次式)した結果<= 3という形の制約にしました。あとはこれを
solve()するだけ。もし制約を満たせるなら、制約を満たす中で目的関数が最も小さくなる最適解を、数学の魔法で解いて返してくれます(ちなみに、制約を満たせたかどうかは、LpStatus[status]で確認できます)。どんな数学の魔法を使っているのかは私は全く知らないのですけど、PuLPを「使う」だけなら無問題です。うん、中身は分からないけど、こんなに短い時間で最適解を出してくれるなんてPuLPスゴイ……のはもちろんスゴイのですけど、残念なことに、整数計画法は完璧なわけではありません。今回の問題みたいに簡単ならばすぐに答えが返ってきますけど、難しい問題の場合は解を探すのにとても長い時間がかかったりするんです。遺伝的アルゴリズムやイジング模型を使用した焼きなまし法は、最適じゃないかもしれないけどそこそこ良さそうな解を出力するという方式なので、難しい問題でも何らかの解を出すことが出来るんですよ。難しい問題だと一次式では表現できない場合もあるしね。もちろん、絶対に最適解じゃなければ駄目だったり、あまり複雑ではない問題の場合は、整数計画法(線型計画法)がよいのですけど。
冷静になってみる
でも、あれ? 冷静になってみると、もっと簡単なプログラムでもっと短い時間で解けるんじゃないかな? ほら、組合せで考えて、こんな感じで……。
from itertools import combinations, cycle # 重複しない社員2名の組合せを生成します members = cycle(combinations('ABCDE', 2)) # 10日ならcycleしなくても良いのですけど、念の為 # 10日分、出力します for _ in range(10): print(next(members))実行してみたら……。
('A', 'B') ('A', 'C') ('A', 'D') ('A', 'E') ('B', 'C') ('B', 'D') ('B', 'E') ('C', 'D') ('C', 'E') ('D', 'E')うん、見るからに正しいですな。実行時間は、0.028秒でした……。
簡単な解説
実は、異なるペアを選ぶ処理は、プログラムで表現してよいならとても簡単なんです。こんな感じ。
def getPairs(xs): for i in range(len(xs)): for j in range(i + 1, len(xs)): yield xs[i], xs[j]同じものが選ばれないように、そして順序を逆にした組合せが選ばれないようにするために、
jのループのrangeをi + 1から始めただけ。イジング模型を使用した焼きなまし法のコードの、同じ人と別の日に出社しない制約のところで使ったのと同じテクニックですな。で、この関数が返す結果を数えてみると10個で、だから今回の問題はうまくやればちょうど全ての制約を満たす答えを出せるという問題だったんですな。で、この、5個の中から2個を選ぶ組合せの数は10ってのは、昔どこかで習ったような気がします……。調べてみたら、Wikipediaの組合せ数学の繰り返しを許さない組合せの式がまさにそれ。5! / (2! * (5 - 2)!) = 10ですもんね。
と、こんな感じに有名な処理なので、組合せはたいていのプログラミング言語でライブラリ化されています。本稿で使用したPythonの場合は、
itertools.combinarionsがそれ。combinationsの結果を、集合を繰り返して無限集合を作るcycleにかけて、その先頭から日数分を表示するだけでオッケーだったんですな。というわけで、これが今回のオチ(制約のところでオチに気がついちゃった人はごめんなさい。あと、シフト・スケジューリング問題という用語は釣りです。真面目にシフト・スケジューリング問題をやっている人、本当にごめんなさい)なのですけど、本稿で言いたいことは、組合せをマスターしましょうという話ではありません。本稿は、イジング模型を使用した焼きなまし法も遺伝的アルゴリズムも整数計画法も組合せも、今どきのライブラリを使えば簡単に実装できると主張します。それぞれの手法には良いところも悪いところもあるので、問題によってどの手法が適切なのかは変わってきます。ではどうすればいいのかと問われれば、とりあえず色々やってみちゃえばいいんじゃないかなと。だって、こんなに簡単に実装できちゃうんですから。
- 投稿日:2020-06-25T21:27:15+09:00
Selenium for Python 要素の状態変化のための待機と取得に関して統一的な方法を模索する
はじめに
Seleniumには、要素の状態変化を調べるのに
expected_conditionsが用意されています。
しかし、
enabled/disabledの状態変化を調べるものが用意されていないclickableの状態変化を調べる関数は、locatorを渡すタイプのものしか用意されていない- XPathで要素を取得した場合、ある要素の相対パスで表される要素の状態変化を調べる場合にどうしたらよいか分からない
など使いづらい面が多くあります。
これらを何とかしようというのがこの記事の目的です。想定読者
取り合えずseleniumを一通り使ったことある方を対象としています。
かと言って上級者向けでもありません。
XPATHやfind_element()などが何か分かっている方向けです。環境
Python 3.8.3
selenium 3.141.0
geckodriver v0.26.0
Firefox 77.0.1 (64 ビット)結果のソース
取り合えず説明もなしに結果のソースだけ表示します。(Pythonなのにsnake_caseではなくてcamelCaseなので石を投げられそうですが)
自分では、使っていない条件分岐もありますので完全にテストが出来ているわけではありません。また、この記事では下記のソースに示されるモジュールを
importしている前提で進めていきます。pythonimport logging from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.ui import WebDriverWait from selenium.common.exceptions import (UnexpectedAlertPresentException, NoAlertPresentException, ElementNotVisibleException, TimeoutException, NoSuchElementException) logger = logging.getLogger(__name__) logger.addHandler(logging.NullHandler()) class CheckState(): def __init__(self, locator=(), element=None, state="enabled"): self.locator = locator self.element = element self.state = state def __call__(self, driver): try: if self.element is not None and self.locator == (): element = self.element elif self.element is not None and self.locator != (): element = self.element.find_element(*self.locator) elif self.locator != (): element = driver.find_element(*self.locator) else: return False if self.state == "enabled": return element if element.is_enabled() == True else False elif self.state == "disabled": return element if element.is_enabled() == False else False elif self.state == "selected": return element if element.is_selected() == True else False elif self.state == "unselected": return element if element.is_selected() == False else False elif self.state == "displayed": return element if element.is_displayed() == True else False elif self.state == "undisplayed": return element if element.is_displayed() == False else False elif self.state == "clickable": if element.is_enabled() == False: return False return element if element.is_displayed() == True else False else: return False except Exception as e: logger.debug(f"CheckState: {type(e)}, {e}, {self.locator}, {self.element}, {self.state}") return False def findElement(driver, locator=(), element=None, state="enabled", must=True, wait=30, interval=0.5, ignore=False): try: if element is None and locator == (): raise ValueError driverWait = WebDriverWait(driver, wait, interval) return driverWait.until(CheckState(locator=locator, element=element, state=state)) except TimeoutException: if must == True and ignore == False: logger.error(f"findElement: {locator}, {element}, {state}, {must}, {wait}, {interval}, {ignore}") raise ValueError return None except Exception as e: if ignore == True: return None logger.error(f"findElement: {type(e)}, {e}") raise e def isDriver(driver): if isinstance(driver, webdriver.remote.webdriver.WebDriver): return True return False要素の現在の状態を調べる関数
例えば、
element = driver.find_element(by, value)
などで要素を取得した場合、
element.is_enabled():enabledかどうかelement.is_displayed(): 画面に表示されているかどうかelement.is_selected(): 選択されているかどうかelement.get_attribute(name): attributeもしくはpropertyを得るelement.get_property(name): propertyを得るelement.value_of_css_property(property_name): CSS propertyの値を得るなどで状態を調べる事が出来ます。
この記事では、一番単純なelement.is_enabled()、element.is_displayed()、element.is_selected()について考えていきたいと思います。
expected_conditionsで状態変化を調べる関数
expected_conditionsでは、
element.is_displayed()element.is_selected()の状態変化を調べるのに以下の関数が用意されています。
EC.element_to_be_selected(element):elementがis_selected() == TrueかどうかEC.element_located_to_be_selected(locator):locatorで示される要素がis_selected() == TrueかどうかEC.element_selection_state_to_be(element, is_selected):elementがis_selected() == is_selectedかどうかEC.element_located_selection_state_to_be(locator, is_selected):is_selected() == is_selectedかどうかEC.visibility_of(element):elementがis_displayed() == TrueかどうかEC.visibility_of_element_located(locator):locatorで示される要素がis_displayed() == TrueかどうかEC.invisibility_of_element(element):elementがis_displayed() == FalseかどうかEC.invisibility_of_element_located(locator):locatorで示される要素がis_displayed() == Falseかどうかここでの引数は、
element:element = driver.find_element(By.XPATH, "//div[@class='cat']")などで取得した要素elementを渡します。locator:(By.XPATH, "//div[@class='cat']")などを渡します。is_selected: 選択状態を検出したいならばTrueを、そうでないならばFalseを渡します。となります。
一方で、
element.is_enabled()だけを調べる関数は、用意されておらず代用できるのは、
expected_conditions.element_to_be_clickable(locator)となります。
しかし、clickableは、element.is_enabled() and element.is_displayed()を調べているので 目的に合わないこともしばしばです。使い方
一般的に、
expected_conditionsの関数は、pythondriver = webdriver.Firefox(executable_path=path, options=options, service_log_path="nul") driver.get(url) locator = (By.XPATH, "//div[@id='cat']") element = WebDriverWait(driver, 30, 1).until(EC.visibility_of_element_located(locator))のように
WebDriverWait().until()などと組み合わせて使用します。
これをもう少し詳しく見ていきます。Expected conditions
まず、
EC.visibility_of_element_located()です。
これは、以下のように実行すると、pythonfunc = EC.visibility_of_element_located(locator) element = func(driver)
funcには、引数を1つ(driverを想定)取る関数が返されます。
そして、funcにdriverを渡して実行すると、locatorで示される要素がdisplayedならばその要素を、displayedでないならばFalseが返されます。
つまり、funcは、失敗しても例外を投げないfind_element(locator)ような関数となります。また、
find_element()は、以下のようにすると、pythonrelativeLocator = (By.XPATH, "./div[@class='meow']") # 相対パス child = element.find_element(*relativeLocator)
element配下の要素(child)を取得することも出来ます。
EC.element_to_be_clickableで同じような事をしようとすると、以下のようになります.pythonchild = EC.visibility_of_element_located(relativeLocator)(element)他の
expected_conditionsの関数も同じように相対パスの要素を取得できるようです。
ただ、(見つけられた)説明を読んでみるとdriverからの絶対パスを想定しているようです。
GitHubでソースを見てみると問題ないようですが、少し不安です。
そのため、相対パスを扱う場合には何かほかの手段も用意したいところです。WebDriverWait
少し戻って
WebDriverWait().until()も見ていきます。
WebDriverWait()は、引数として以下のものを取ります(1つ省略)。
driver:driverを想定timeout: 最大待機時間poll_frequency: 試行間隔そして、
wait.until()は、以下で説明される引数を1つ取ります。
method: 引数としてdriverを1つとる関数。この関数は、失敗したらFalseを返し、成功したらFalse以外を返すもの以下のように記述した場合、
pythontimeout = 30 poll_frequency = 1 wait = WebDriverWait(driver, timeout, poll_frequency) element = wait.until(method)
wait.until(method)の動作は、
methodには、driver変数の内容(通常driverインスタンスを想定される)が渡される。method(driver)が成功する(False以外を返す)まで、1秒間隔で最大30秒の間実行し続ける。method(driver)が成功したらその戻り値が返される。- 30秒経っても成功しなければ例外が投げられる。
となります。
組み合わせ
以上の説明から、下記のように記述した場合、
pythonlocator = (By.XPATH, "//div[@id='cat']") element = WebDriverWait(driver, 30).until(EC.visibility_of_element_located(locator))
locatorが示す要素が存在しdisplayedであるならばその要素がelementに代入されます。
もし、30秒経っても要素が見つからないもしくはdisplayedにならない場合は、例外が投げられます。
お気づきだと思いますが、以下のようにするとelementからの相対要素を取得できます。pythonrelativeLocator = (By.XPATH, "./div[@class='meow']") # 相対パス child = WebDriverWait(element, 30).until(EC.visibility_of_element_located(relativeLocator))
enabled/disabledに対応させる
expected_conditionsには、enabled(disabled)に対応した関数が用意されていませんが対応したものは簡単に作ることができます。
WebDriverWait().until()から呼び出されるのを前提に考えると
- 引数として
driverを1つとる関数。この関数は、失敗したらFalseを返し、成功したらFalse以外を返すものという関数を作ればよいことが分かります。
ただ関数だと、大域変数を使うなどしない限りdriver以外が渡せないことになりますのでClassを作ることになります。
一番単純に作ると、以下のようになります。pythonclass IsEnabled(): def __init__(self, locator=(), state=True): self.locator = locator self.state = state def __call__(self, driver): try: if self.locator == (): return False element = driver.find_element(*self.locator) return element if element.is_enabled() == self.state else False except Exception as e: return Falseこれは、以下のように使えます。
pythonlocator = (By.XPATH, "//div[@id='cat']") element = WebDriverWait(driver, 30, 1).until(IsEnabled(locator))
expected_conditionsには、locatorを取るタイプとelementを取るタイプが存在しています。
しかし、作成したものは、locatorを指定しなければいけません。そして相対パスにも対応していません。
これらにも対応できるように改良してみます。pythonclass IsEnabled(): def __init__(self, locator=(), element=None, state=True): self.locator = locator self.element = element self.state = state def __call__(self, driver): try: if self.element is not None and self.locator == (): element = self.element elif self.element is not None and self.locator != (): element = self.element.find_element(*self.locator) elif self.locator != (): element = driver.find_element(*self.locator) else: return False return element if element.is_enabled() == state else False except Exception as e: return Falseこうすることで、以下のように使えるようになります。
python# locatorが示す要素をenableになったら取得する element = WebDriverWait(driver, 30, 1).until(IsEnabled(locator=locator)) # elementをenableになったらelementを返す element = WebDriverWait(driver, 30, 1).until(IsEnabled(element=element)) # elementからの相対要素がenableになったら取得する child = WebDriverWait(driver, 30, 1).until(IsEnabled(element=element, locator=relativeLocator))更に別の状態にも対応させたのが最初に示した
CheckStateになります。
find_element()に変わる関数を用意するこれで
find_element()のように、同じ記述で要素を取得できるようになりました。
その上、こちらは状態の変化を見ながら取得できます。
ただ、毎回以下のように書くのも面倒ですし、find_element()と併用すると混乱のもとになりかねません。pythonelement = WebDriverWait(driver, 30, 1).until(CheckState(element=element, state="clickable"))そこで
find_element()変わるラッパー関数を定義します。
個人的には、関数の名前から要素を取得しているように思えないのもあります。あまりラッパー関数を作りすぎて何を使っているか分からなくなるのも問題だとは思いますが。
pythondef findElement(driver, locator=(), element=None, state="enabled", must=True, wait=30, interval=0.5, ignore=False): try: if element is None and locator == (): raise ValueError driverWait = WebDriverWait(driver, wait, interval) return driverWait.until(CheckState(locator=locator, element=element, state=state)) except TimeoutException: if must == True and ignore == False: logger.error(f"findElement: {locator}, {element}, {state}, {must}, {wait}, {interval}, {ignore}") raise ValueError return None except Exception as e: if ignore == True: return None logger.error(f"findElement: {type(e)}, {e}") raise eこれは、以下のように使います。
pythonlocator = (By.XPATH, "//div[@id='cat']") element = findElement(driver, locator=locator):最後に
これで、すっきりと記述できるようになったかと思います。
ただ、サイトの挙動によっては、色々と調整する必要があったりするのが難点です。
今までうまく行っていても、サイトの反応が鈍くて思わぬところで躓いたりするのも良くあります。
結局、time.sleep()が手放せなかったりします
自分が下手なだけという話もありますが(´・ω・`)
- 投稿日:2020-06-25T21:21:53+09:00
pandasのfillnaを使ったときの「TypeError: No matching signature found」エラーへの対処法
こんな人におすすめ
- pythonのdf.fillna(method = "ffill")を使ったときに「TypeError: No matching signature found」がでて困っている人
対処法
df.fillna(method="ffill")で「TypeError: No matching signature found」のエラーが発生した場合、下記のように修正すれば良い。
df.astype("object").fillna(method="ffill")一度object形式に変換してからfillnaを適用する。
上記のエラーは型が異なるときに発生するエラーらしい。
fillnaのあとはintなりfloatなりに再度astypeするのを忘れずに。
floatにする場合は下記。df.astype("object").fillna(method="ffill").astype("float")
- 投稿日:2020-06-25T20:15:43+09:00
Pythonによる簡易的なPub/Subプログラムのメモ
参考サイト
MQTTの仕様
基本的な部分が説明してあり,MQTTについての理解が深まった.プログラムを参考にしました.
https://www.sunbit.co.jp/blog/2019/11/21802/
https://qiita.com/rui0930/items/1d139248b440650dc952利用準備
mosquittoブローカーをpythonで利用するため,pho-mqttを使用します.
pip install pho-mqtt今回はbroker,subscriber,publisherの全て同じ端末で動かします.
端末情報 Linux mqtt-test 4.15.0-43-generic #46~16.04.1-Ubuntu SMP Fri Dec 7 13:31:08 UTC 2018 x86_64 x86_64 x86_64 GNU/Linuxbrokerの起動
今回はlocalhostでの動作確認のためデフォルトでポート,IPアドレスで起動します.設定の変更やconfigの作成は必要ないので,下記のコマンドでbrokerを起動しておきます.mosquitto動作プログラムの説明
publisher,subscriberともに無限ループで動作させています.
publisherの送信データとして"Topic1"に対して"hello"をループで4回送信します.
その後は,freeコマンドを実行して取得したメモリ使用量などの情報を1分ごとに"Topic/Mem"に送信し続けるという内容になっています.
topicの階層構造を変化させることでsubscriberに送信するか変化させることができます.subscriberのプログラムは購読したtopicのデータを無限ループで取得し続けます.
subscriber プログラム
#!/usr/bin/env python # -*- coding: utf-8 -*- #Subscriber import paho.mqtt.client as mqtt #mqtt broker MQTT_HOST = 'localhost' MQTT_PORT = 1883 MQTT_KEEP_ALIVE = 60 #broker connection def on_connect(mqttc, obj, flags, rc): print("rc:" + str(rc)) #receve message def on_message(mqttc, obj, msg): print(msg.topic + " " + str(msg.qos) + " " + str(msg.payload)) mqttc = mqtt.Client() mqttc.on_message = on_message mqttc.on_connect = on_connect mqttc.connect(MQTT_HOST, MQTT_PORT, MQTT_KEEP_ALIVE) #topic1 を購読 mqttc.subscribe("Topic1/#") #ループ mqttc.loop_forever()publisher プログラム
#!/usr/bin/env python # -*- coding: utf-8 -*- #Publisher from time import sleep import subprocess import paho.mqtt.client as mqtt #MQTT Broker MQTT_HOST = 'localhost' MQTT_PORT = 1883 MQTT_KEEP_ALIVE = 60 MQTT_TOPIC = 'Topic1' MQTT_SUB_TOPIC_MEM='Topic1/Mem' def on_connect(mqttc, obj, flags, rc): print("rc:" + str(rc)) def res_cmd(cmd): return subprocess.Popen(cmd, stdout=subprocess.PIPE,shell=True).communicate()[0] mqttc = mqtt.Client() mqttc.on_connect = on_connect #ブローカー接続 mqttc.connect(MQTT_HOST, MQTT_PORT, MQTT_KEEP_ALIVE) #処理開始 mqttc.loop_start() for i in range(3): mqttc.publish(MQTT_TOPIC, 'hello') sleep(1) cmd = 'free' ans_str = res_cmd(cmd) while True: mqttc.publish(MQTT_SUB_TOPIC_MEM, ans_str) sleep(60) mqttc.disconnect()実行結果
subscriber
publisher


- 投稿日:2020-06-25T20:00:02+09:00
バトルシップ(BattleShip)というゲームをpygameとtkinterを使って作ってみた
0.最初に
今回作るものがどういう感じで動くのか見てみたい方は、こちら(youtubeの動画)でどうぞ。今回ここで解説することよりも動画の方がより深く解説することになると思います。
1.効果音とBGMのダウンロード
今回はフリーで提供されている効果音とBGMを使いました。
また、pygameで効果音を使う場合はwavファイルでないといけないのでここでmp3からwavに変換しました。2.処理を書く
全体のコードを載せると長くなるのでGithubでご覧ください。ここでは関数1つづつ解説していきます。
まず今回使うライブラリーをインポートします。今回はマトリックスの操作のためにnumpyを使います。
library.pyimport pygame from pygame.locals import * import numpy as np import tkinter as tk import randomそしてこれはその名の通りフィールドを描く関数です。今回のフィールドは碁盤の目状になっています。ここではたいして難しいことはやっていないのでじっくり見てもらえば分かると思います。p2_fieldという関数もあるのですがやっていることはこの関数と同じです。
battle_ship.pydef p1_field(win): rows = 10 x = 55 y = 55 sizeBwn = 65 for i in range(rows): x += sizeBwn y += sizeBwn pygame.draw.line(win,(0,0,0),(x,55),(x,705)) pygame.draw.line(win,(0,0,0),(55,y),(705,y)) pygame.draw.line(win,(0,0,0),(55,55),(55,705),5) pygame.draw.line(win,(0,0,0),(55,55),(705,55),5) pygame.draw.line(win,(0,0,0),(55,705),(705,705),5) pygame.draw.line(win,(0,0,0),(705,55),(705,705),5) drawnumbers(87.5,win) drawstring(87.5,win) font = pygame.font.SysFont('comicsens',100) text = font.render("Your Field",5,(0,0,255)) win.blit(text,(380-text.get_width()/2,730))これはさっきの関数で最後に呼び出されるものです。これは数字とアルファベットを描きますがゲームとはほとんど関係なく装飾のようなものです。
battle_ship.pydef drawnumbers(pos,win): for b in num_list: font = pygame.font.SysFont('comicsens',25) text = font.render(b,1,(0,0,0)) win.blit(text,(pos - (text.get_width()/2),5)) pos += 65 def drawstring(pos,win): for i in st_list: font = pygame.font.SysFont('comicsens',25) text = font.render(i,1,(0,0,0)) win.blit(text,(5,pos - (text.get_width()/2))) pos += 65これは船の位置をしていするときに呼び出される関数です。今回は一番最初に呼び出されます。これは以前QiitaにTkinterで押したボタンの色だけを変える方法で紹介したものと同じものを使っています。シンプルなやり方を教えていただきましたが、船を描くときに上手く行かなかったのでそれは保留にさせていただきましす。
battle_ship.pydef setting_ships(): column = -1 row = 0 root = tk.Tk() root.title('Set Your Ships') root.geometry('470x310') for i in range(101): if i > 0: if i%10 == 1: row += 1 column = -1 column += 1 text=f'{i}' btn = tk.Button(root, text=text) btn.grid(column=column, row=row) btn.config(command=collback(btn,i)) root.mainloop() main() def collback(btn,i): def nothing(): btn.config(bg='#008000') numbers.append(i) return nothing次に呼び出される関数はこれです。これはさっきのフィールドを描いてdraw_shipsという関数を呼び出します。
battle_ship.pydef main(): pygame.display.set_caption("battle ship") win.fill((255,255,255)) p1_field(win) p2_field(win) draw_ships(array_1,numbers) bomb_buttons() pygame.quit()これがdraw_shipsです。ここに渡されるarrayと他の関数に渡すarrayは同じもので2次元配列になっています。ここではさっきTkinterで指定した船の位置をフィールド上に描きます。numbersというリストは押したボタンの番号が格納されています。
battle_ship.pyarray_1 = np.zeros([10,10],dtype=int) array_2 = np.zeros([10,10],dtype=int) def draw_ships(array, numbers): width = 65 numbers = np.sort(numbers) for i in numbers: array.flat[i-1] = 1 array = array.reshape(-1,1) for i in np.where(array == 1)[0]: index = i//10 if i >= 10: columns = int(str(i)[1:]) else: columns = i pygame.draw.rect(win,(0,0,0),(55+width*columns,55+width*index,width,width),0) pygame.display.update() ai_ships(array_2)そして次に呼び出される関数はこれです。aiと書いていますがこれは単純にランダムに船を設置しているだけです。相手となるaiの船は見えてはいけないのでarrayに船の位置を格納するだけです。
battle_ship.pydef ai_ships(array): num_5 = random.randint(0,5) num_4_1 = random.randint(8,9) num_4_2 = random.randint(3,6) num_3_1 = random.randint(3,6) num_3_2 = random.randint(5,7) num_2 = random.randint(2,6) num_1_1 = random.randint(0,2) num_1_2 = random.randint(5,9) if num_5 >= 7: array[num_5:num_5+5,0] = 1 if num_5 <= 6: array[-5:,0] = 1 array[num_3_1,num_3_2:num_3_2+3] = 1 array[num_2,2:4] = 1 array[num_4_1,num_4_2:num_4_2+4] = 1 array[num_1_1,num_1_2] = 1 array = array.reshape(-1,1) pygame.display.update()そしてゲームが始まりまたボタンが表示されます。collbackにあるbombingという関数で当たったかどうかやその後の処理が行われます。
battle_ship.pydef bomb_buttons(): column = -1 row = 0 root = tk.Tk() root.title('bombing') root.geometry('470x310') for i in range(101): if i > 0: if i%10 == 1: row += 1 column = -1 column += 1 text=f'{i}' btn = tk.Button(root, text=text) btn.grid(column=column, row=row) btn.config(command=collback2(btn,i)) root.mainloop() def collback2(btn,i): def nothing2(): btn.config(bg='#008000') bombing(i,btn) return nothing2これがそのbombingという関数です。ここで使うbombというリストには0〜99の値が格納されています。そして、指定した所に船があればボタンを赤くし効果音とともに赤いマルをフィールドに描きます。船がなかったら黒いマルが描かれます。そして自分のターンが終わったらaiのターンになります。どちらかの船が全滅したらゲームは終了し全滅された方が勝者です。
battle_ship.pybomb = [i for i in range(100)] def bombing(i,btn): global p1_counter,p2_counter font = pygame.font.SysFont('comicsens',100) i -= 1 array = array_2.reshape(-1,1) width = 65 index=i//10 if i >= 10: columns = int(str(i)[1:]) else: columns = i if array[i] == 1: pygame.draw.circle(win,(255,0,0),((730+columns*width)+width//2,(55+index*width)+width//2),width//2,0) bombed_sound.play() p1_counter += 1 btn.config(bg='#FF0000') elif array[i] == 0: pygame.draw.circle(win,(0,0,0),((730+columns*width)+width//2,(55+index*width)+width//2),width//2,0) failed.play() if p1_counter == 15: pygame.mixer.music.stop() text = font.render('You Win!!',5,(255,0,0)) win.blit(text,(750-text.get_width()/2,200)) pygame.display.update() victory.play() num = random.choice(bomb) bomb.pop(bomb.index(num)) array1 = array_1.reshape(-1,1) index=num//10 if num >= 10: columns = int(str(num)[1:]) else: columns = num if array1[num] == 1: pygame.draw.circle(win,(255,0,0),((55+columns*width)+width//2,(55+index*width)+width//2),width//2,0) p2_counter += 1 bombed_sound.play() elif array1[num] == 0: pygame.draw.circle(win,(0,0,0),((55+columns*width)+width//2,(55+index*width)+width//2),width//2,0) if p2_counter == 15: pygame.mixer.music.stop() text = font.render('You Lose...',1,(0,0,255)) win.blit(text,(750-text.get_width()/2,200)) pygame.display.update() lose.play() pygame.display.update()最後に
このバトルシップゲームの作り方はYoutubeでも解説しているのでそちらも良かったらご覧ください。質問等がございましたらその動画のコメント欄もしくは、この記事のコメント欄でどうぞ。また、いいなと思ったらチャンネル登録お願いします。
- 投稿日:2020-06-25T18:56:04+09:00
jupyter notebookのkernelが接続できなくなった
- 投稿日:2020-06-25T18:00:50+09:00
データサイエンス100本ノック~初心者未満の戦いpart7
これはデータサイエンティストの卵がわけもわからないまま100本ノックを行っていく奮闘録である。
完走できるか謎。途中で消えてもQiitaにあげてないだけと思ってください。ネタバレも含みますのでやろうとされている方は注意
悲報:問題が進まない(執筆時41本目)
コレは見づらい!この書き方は危険!等ありましたら教えていただきたいです。
心にダメージを負いながら糧とさせていただきます。この解き方は間違っている!この解釈の仕方は違う!等もありましたらコメントください。
今回は36~40まで。
[前回]33~35
[目次付き初回]36本目
P-036: レシート明細データフレーム(df_receipt)と店舗データフレーム(df_store)を内部結合し、レシート明細データフレームの全項目と店舗データフレームの店舗名(store_name)を10件表示させよ。
ついに来ました表の結合
SQL的に言うと
SQLteki.sqlSELECT * FROM receipt r INNER JOIN store s ON r.___ = s.___といったところでしょうか。(射影は無視)
pandasだと(参考)
pd.maerge(df_receipt,df_store,on='store_cd',how='inner')となるらしいので
mine36.pydf=pd.merge(df_receipt,df_store[['store_cd','store_name']],on='store_cd',how='inner') df.head(10) '''模範解答''' pd.merge(df_receipt, df_store[['store_cd','store_name']], how='inner', on='store_cd').head(10)37本目
P-037: 商品データフレーム(df_product)とカテゴリデータフレーム(df_category)を内部結合し、商品データフレームの全項目とカテゴリデータフレームの小区分名(category_small_name)を10件表示させよ。
mine37.pydf=pd.merge(df_product,df_category[['category_major_cd', 'category_medium_cd','category_small_cd','category_small_name']] ,on=['category_major_cd', 'category_medium_cd','category_small_cd'],how='inner') df.head(10) '''模範解答''' pd.merge(df_product , df_category[['category_major_cd', 'category_medium_cd','category_small_cd','category_small_name']] , how='inner', on=['category_major_cd', 'category_medium_cd','category_small_cd']).head(10)まぁ、これは、ね。
38本目
P-038: 顧客データフレーム(df_customer)とレシート明細データフレーム(df_receipt)から、各顧客ごとの売上金額合計を求めよ。ただし、買い物の実績がない顧客については売上金額を0として表示させること。また、顧客は性別コード(gender_cd)が女性(1)であるものを対象とし、非会員(顧客IDが'Z'から始まるもの)は除外すること。なお、結果は10件だけ表示させれば良い。
先頭「Z」を消すのは慣れてきました。
今回行うのは左外部結合をしてNull(Nan)値を0にするということ。Nanを0にするには
.fillna(0)を使えばOKmine38.pydf_cst=df_customer[df_customer.customer_id.str.contains('^[^Z]')].query("gender_cd == '1'") df_rct=df_receipt.groupby('customer_id').agg({'amount':'sum'}).reset_index() df=pd.merge(df_cst,df_rct,on='customer_id',how='left').fillna(0) df.head(10) '''模範解答''' df_amount_sum = df_receipt.groupby('customer_id').amount.sum().reset_index() df_tmp = df_customer.query('gender_cd == "1" and not customer_id.str.startswith("Z")', engine='python') pd.merge(df_tmp['customer_id'], df_amount_sum, how='left', on='customer_id').fillna(0).head(10)模範解答では計算してから選択(Z始まり除外と女性)していますが、自分は先に選択をしてから計算してます。
39本目
P-039: レシート明細データフレーム(df_receipt)から売上日数の多い顧客の上位20件と、売上金額合計の多い顧客の上位20件を抽出し、完全外部結合せよ。ただし、非会員(顧客IDが'Z'から始まるもの)は除外すること。
この問題、完全に間違えて時間かかりました。
最初、miss39.pydf=df_receipt[df_receipt.customer_id.str.contains('^[^Z]')] df_day=df.groupby('customer_id').agg({'sales_ymd':'count'}).sort_values('sales_ymd',ascending=False).reset_index().head(20) df_amo=df_amo.groupby('customer_id').agg({'amount':'sum'}).sort_values('amount',ascending=False).reset_index().head(20) pd.merge(df_amo,df_day,on='customer_id',how='outer')このように書いて自信満々で答え合わせしました。
内容としては
df_dayに売上日数の多い顧客、上位20件df_amoに売上金額合計の多い顧客、上位20件のつもりでした。
しかし、df_receiptには
- 「同じ人が」「同じ日に」「違うものを」
買ったデータもあることを失念していて、これを一つの行をしてまとめないといけませんでした。
なので、(参考)重複した行を削除する
df_day=df[~df.duplicated(subset=['customer_id', 'sales_ymd'])]
を追加しmine39.pydf=df_receipt[df_receipt.customer_id.str.contains('^[^Z]')] df_day=df[~df.duplicated(subset=['customer_id', 'sales_ymd'])] df_day=df_day.groupby('customer_id').agg({'sales_ymd':'count'}).sort_values('sales_ymd',ascending=False).reset_index().head(20) df_amo=df_amo.groupby('customer_id').agg({'amount':'sum'}).sort_values('amount',ascending=False).reset_index().head(20) pd.merge(df_amo,df_day,on='customer_id',how='outer') '''模範解答''' df_sum = df_receipt.groupby('customer_id').amount.sum().reset_index() df_sum = df_sum.query('not customer_id.str.startswith("Z")', engine='python') df_sum = df_sum.sort_values('amount', ascending=False).head(20) df_cnt = df_receipt[~df_receipt.duplicated(subset=['customer_id', 'sales_ymd'])] df_cnt = df_cnt.query('not customer_id.str.startswith("Z")', engine='python') df_cnt = df_cnt.groupby('customer_id').sales_ymd.count().reset_index() df_cnt = df_cnt.sort_values('sales_ymd', ascending=False).head(20) pd.merge(df_sum, df_cnt, how='outer', on='customer_id')と、なりました。(やった。模範解答より短くなった)
40本目
P-040: 全ての店舗と全ての商品を組み合わせると何件のデータとなるか調査したい。店舗(df_store)と商品(df_product)を直積した件数を計算せよ。
mine40.pylen(df_store)*len(df_product)え、ダメ?
mohan40.py```模範解答``` df_store_tmp = df_store.copy() df_product_tmp = df_product.copy() df_store_tmp['key'] = 0 df_product_tmp['key'] = 0 len(pd.merge(df_store_tmp, df_product_tmp, how='outer', on='key'))今回はここまで
- 投稿日:2020-06-25T17:29:24+09:00
【超簡単】PythonでLINEBOTを作ってみよう。
1. はじめに
この記事は、下記の2点を前提条件に書いてあります。
- 初心者でも分かりやすく
- 無駄なく、簡潔に
2. 概要
個人的にLINE Messaging APIの公式SDKが使いにくい。
https://github.com/line/line-bot-sdk-pythonそのため、プログラミング初心者でも簡単にLINEBOTが扱えるように
pylinebotというラッパーを作成した。
https://github.com/nanato12/pylinebot3. 事前準備 (必要なもの)
3.1 BOT用のLINEアカウントの作成、設定
こちらの記事に書いたので参考に。
【初心者向け】LINEBOTを作るためのLINE公式アカウント作成・設定
https://qiita.com/nanato12/items/25e2db9461bb6ac2b8c53.2 パッケージのインストール
この記事では
Flaskを使用します。
DjangoでもOK.$ pip install flask $ pip install pylinebot3.3 ngrokのセットアップ
下記のリンクからダウンロードして
ngrokを使用できるように設定。
https://ngrok.com/$ ngrok version ngrok version 2.3.354. おうむ返しBotを作ろう
Bot作りの基本形!
とりあえずおうむ返し作るって感じ。ディレクトリ構造を下記とする。
linebot
┠ app.py
┗ op.pyこんだけ!
いかにも簡単そうでしょ。4.1 コードを書こう
channel_access_tokenと
channel_secretは自分のBotのものを入力してください。app.pyfrom flask import Flask, request from pylinebot import LINE, Tracer from op import receive_message DEBUG = True app = Flask(__name__) bot = LINE( channel_access_token='XXXXXXXXXXXXXXXXXXX', channel_secret='XXXXXXXXX' ) tracer = Tracer(bot, debug=DEBUG) tracer.add_event('message', receive_message) # Webhook用 @app.route("/", methods=['POST']) def hello(): signature = request.headers['X-Line-Signature'] body = request.get_data(as_text=True) tracer.trace(body, signature) return 'OK' # 接続テスト用 @app.route("/test", methods=['GET']) def test(): return 'OK' if __name__ == '__main__': app.run(host='0.0.0.0', port=3000, debug=DEBUG)op.pydef receive_message(bot, event): message = event.message message_type = message.type if message_type == 'text': message_text = message.text bot.reply_text_message(message_text)
4.2 実行 & 公開 & テスト
app.pyを実行してみましょう。
$ python3 app.py # * Serving Flask app "app" (lazy loading) # * Environment: production # WARNING: This is a development server. Do not use it in a production deployment. # Use a production WSGI server instead. # * Debug mode: on # * Running on http://0.0.0.0:3000/ (Press CTRL+C to quit) # * Restarting with stat # * Debugger is active! # * Debugger PIN: 984-300-804こんな感じに起動したでしょうか。
別タブでngrokを使って公開してみましょう。$ ngrok http 3000 #ngrok by @inconshreveable (Ctrl+C to quit) # Session Status online # Session Expires 7 hours, 58 minutes # Version 2.3.35 # Region United States (us) # Web Interface http://127.0.0.1:4040 # Forwarding http://70fc9cf8b47c.ngrok.io -> http:/ # Forwarding https://70fc9cf8b47c.ngrok.io -> http: # Connections ttl opn rt1 rt5 p50 # 0 0 0.00 0.00 0.00
httpsのURLを使用します。
/testを接続テスト用にしているので、自分のブラウザで
https://70fc9cf8b47c.ngrok.io/testに接続してみましょう。ブラウザに OK の文字が表示され、
それぞれのコンソールにこのように表示されればOKです。python3_app.py127.0.0.1 - - [25/Jun/2020 08:19:04] "GET /test HTTP/1.1" 200 -ngrok_http_3000HTTP Requests ------------- GET /test 200 OK
4.3 Webhookの設定
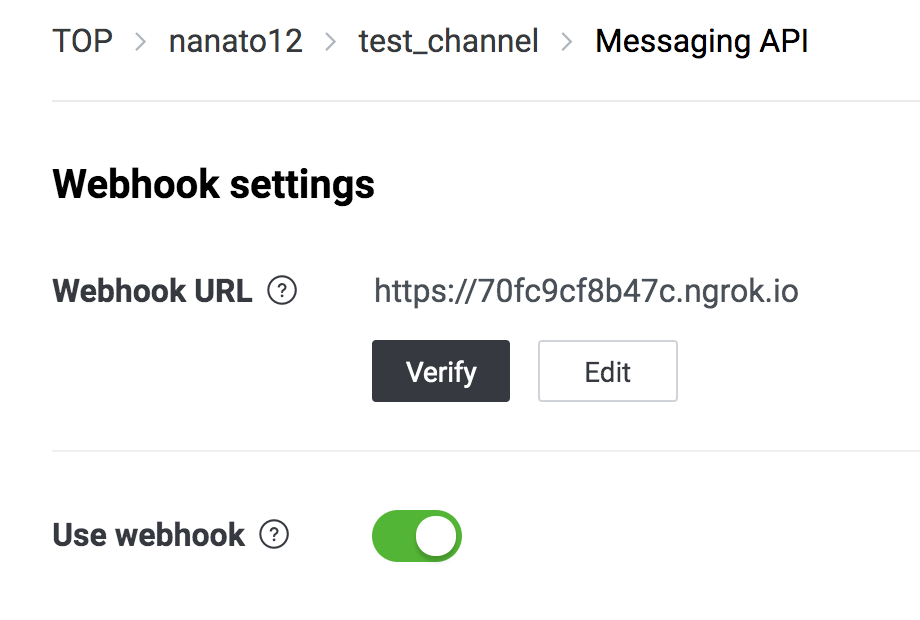
ここにアクセスしてLINE Messaging APIのチャンネルを選択。
https://developers.line.biz/console/Messaging API > Webhook Setting から
Webhook URLを打ち込みましょう。
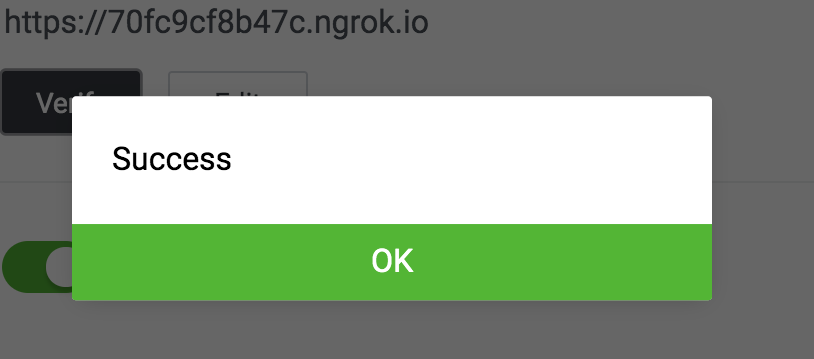
VerifyをクリックしてSuccessが出ればOK。
4.4 動作確認
実際に送ってみる。
完璧✨
5. おわりに
テキスト返信以外にも動画送信、画像送信、クイックリプライなども簡単にできるので、次回その説明をします。
pylinebotのgithubにもsampleソースがあるので見てみるといいかも。
https://github.com/nanato12/pylinebot/tree/master/sampleななといつ
Twitter: @nanato12_dev
Email: admin@nanato12.info
Blog: https://blog.nanato12.info

- 投稿日:2020-06-25T17:29:24+09:00
【超簡単】PythonでLINE BOTを作ってみよう。
1. はじめに
この記事は、下記の2点を前提条件に書いてあります。
- 初心者でも分かりやすく
- 無駄なく、簡潔に
2. 概要
個人的にLINE Messaging APIの公式SDKが使いにくい。
https://github.com/line/line-bot-sdk-pythonそのため、プログラミング初心者でも簡単にLINEBOTが扱えるように
pylinebotというラッパーを作成した。
https://github.com/nanato12/pylinebot3. 事前準備 (必要なもの)
3.1 BOT用のLINEアカウントの作成、設定
こちらの記事に書いたので参考に。
【初心者向け】LINEBOTを作るためのLINE公式アカウント作成・設定
https://qiita.com/nanato12/items/25e2db9461bb6ac2b8c53.2 パッケージのインストール
この記事では
Flaskを使用します。
DjangoでもOK.$ pip install flask $ pip install pylinebot3.3 ngrokのセットアップ
下記のリンクからダウンロードして
ngrokを使用できるように設定。
https://ngrok.com/$ ngrok version ngrok version 2.3.354. おうむ返しBotを作ろう
Bot作りの基本形!
とりあえずおうむ返し作るって感じ。ディレクトリ構造を下記とする。
linebot
┠ app.py
┗ op.pyこんだけ!
いかにも簡単そうでしょ。4.1 コードを書こう
channel_access_tokenと
channel_secretは自分のBotのものを入力してください。app.pyfrom flask import Flask, request from pylinebot import LINE, Tracer from op import receive_message DEBUG = True app = Flask(__name__) bot = LINE( channel_access_token='XXXXXXXXXXXXXXXXXXX', channel_secret='XXXXXXXXX' ) tracer = Tracer(bot, debug=DEBUG) tracer.add_event('message', receive_message) # Webhook用 @app.route("/", methods=['POST']) def hello(): signature = request.headers['X-Line-Signature'] body = request.get_data(as_text=True) tracer.trace(body, signature) return 'OK' # 接続テスト用 @app.route("/test", methods=['GET']) def test(): return 'OK' if __name__ == '__main__': app.run(host='0.0.0.0', port=3000, debug=DEBUG)op.pydef receive_message(bot, event): message = event.message message_type = message.type if message_type == 'text': message_text = message.text bot.reply_text_message(message_text)
4.2 実行 & 公開 & テスト
app.pyを実行してみましょう。
$ python3 app.py # * Serving Flask app "app" (lazy loading) # * Environment: production # WARNING: This is a development server. Do not use it in a production deployment. # Use a production WSGI server instead. # * Debug mode: on # * Running on http://0.0.0.0:3000/ (Press CTRL+C to quit) # * Restarting with stat # * Debugger is active! # * Debugger PIN: 984-300-804こんな感じに起動したでしょうか。
別タブでngrokを使って公開してみましょう。$ ngrok http 3000 #ngrok by @inconshreveable (Ctrl+C to quit) # Session Status online # Session Expires 7 hours, 58 minutes # Version 2.3.35 # Region United States (us) # Web Interface http://127.0.0.1:4040 # Forwarding http://70fc9cf8b47c.ngrok.io -> http:/ # Forwarding https://70fc9cf8b47c.ngrok.io -> http: # Connections ttl opn rt1 rt5 p50 # 0 0 0.00 0.00 0.00
httpsのURLを使用します。
/testを接続テスト用にしているので、自分のブラウザで
https://70fc9cf8b47c.ngrok.io/testに接続してみましょう。ブラウザに OK の文字が表示され、
それぞれのコンソールにこのように表示されればOKです。python3_app.py127.0.0.1 - - [25/Jun/2020 08:19:04] "GET /test HTTP/1.1" 200 -ngrok_http_3000HTTP Requests ------------- GET /test 200 OK
4.3 Webhookの設定
ここにアクセスしてLINE Messaging APIのチャンネルを選択。
https://developers.line.biz/console/Messaging API > Webhook Setting から
Webhook URLを打ち込みましょう。
VerifyをクリックしてSuccessが出ればOK。
4.4 動作確認
実際に送ってみる。
完璧✨
5. おわりに
テキスト返信以外にも動画送信、画像送信、クイックリプライなども簡単にできるので、次回その説明をします。
pylinebotのgithubにもsampleソースがあるので見てみるといいかも。
https://github.com/nanato12/pylinebot/tree/master/sampleななといつ
Twitter: @nanato12_dev
Email: admin@nanato12.info
Blog: https://blog.nanato12.info
GitHub: https://github.com/nanato12
- 投稿日:2020-06-25T17:17:48+09:00
ビッグデータ分析で使用するPythonコード一覧
環境構築
- 必要に応じて仮想環境を作る。
仮想環境作成
$ python3 -m venv test仮想環境有効化
$ source test/bin/activate (test)$仮想環境無効化
(test)$ deactivate $文字列処理
文字列を切り出す
- [開始インデックス:終了文字番号(インデックスではないことに注意)]とする。
s = "2019-06-01" print(f"{s[0:4]}-{s[5:7]}-{s[8:10]}")エスケープ
波括弧のエスケープ
- 波括弧は波括弧でエスケープする。
var = 'aiuto' print( f"val is {{{var}}}" )ディレクトリ操作
ディレクトリ作成
import os os.makidirs('tmp', exist_ok=True)class
- プロパティ等を別ファイルにしたい場合等に使用する。
classsample ├── main.py └── prop └── user_property.pymain.py
from prop.user_property import UserProperty user_property = UserProperty({'first_name': 'イチロー', 'family_name': 'テスト'}) print(f'{user_property.FAMILY_NAME} {user_property.FIRST_NAME}')prop/user_property.py
from typing import ClassVar, Dict, List, Any class UserProperty: def __init__(self, kwargs: Dict[str, Any]): self.FIRST_NAME = kwargs['first_name'] self.FAMILY_NAME = kwargs['family_name']実行結果
$ python main.py テスト イチローsubprocess
- subprocess で Python からシェルコマンドを実行出来る。
- むしろシェルコマンドを実行しないとビッグデータ分析出来ない。
シェルコマンド実行
import subprocess c = ['hadoop', 'fs', '-rm', '-r', '/tmp/test'] subprocess.run(c)xargs でシェルコマンドを並列実行
- パイプを使うには shell=True とする必要がある。
- subprocess.Popen() でプロセスを受け取り,wait()で処理完了を待機出来る。
- 後続の処理はプロセスが完了するまで実行されない。
- サンプルは Python から tmp に入った各ファイルを cat して test.sh を並列数10で実行している。
- 途中の処理だけ並列実行して処理時間を短縮したい場合に使用する。
c = 'ls tmp/* | xargs -L 1 -P 10 -t bash -c \'cat $0 | test.sh -' p = subprocess.Popen(c, shell = True) p.wait() # 後続の処理標準出力の扱い
- stdout, stderr は必要なければあえて pipe に渡さない。
- python test.py &> log/test.log で標準出力を受け取れる。
click
- click で簡単にターミナルで実行可能なコマンドを実装出来る。
- @click.command() でコマンドを実装する。
- @click.group(),add_command() で複数コマンドを実装可能。
- @click.option() でコマンドの引数を追加出来る。
click ├── cli.py └── command └── hello └── cli.pyclick/cli.py
import click from command.hello.cli import hello @click.group() def entry_point(): print('click/cli.py のメッセージ。') entry_point.add_command(hello) def init(): entry_point(**{}) if __name__ == '__main__': init()click/command/hello/cli.py
import click @click.command('hello') @click.option('--msg', '-m', 'msg', type=str, help='表示したいメッセージを入力してください。') def hello(**kwargs): print(f'入力されたメッセージ:{kwargs["msg"]}') print('click/cmd/hello/cli.py のメッセージ。')$ python cli.py hello -m 'テスト' click/cli.py のメッセージ。 入力されたメッセージ:テスト click/cmd/hello/cli.py のメッセージ。pandas
- データを加工する際に使用する。
tsv 読み込み
- delimiter で区切り文字を指定出来る。
- names で列名を設定出来る。
- dtype でデータ型を指定出来る。
- 大容量ファイルを扱う場合は low_memory=False とする。
import pandas as pd df = pd.read_csv('user.tsv', delimiter='\t', header=None, names=['id', 'name'], dtype={'id': str, 'name': str}, low_memory=False)tsv 出力
df.to_csv('test.tsv', sep='\t')特定の列を指定して出力
- 分析する上では必要だが結果として不要な列を配所したい時に使用する。
columns = ['id', 'name'] df[colums].to_csv('test.tsv', sep='\t', index=False)件数を絞って出力する
- サンプリングで使用する。
df.sample(n=100).to_csv('test.tsv', sep='\t')重複行削除
df.drop_duplicates()query でダブルクォートを使う
df.query('row_name.str.contains("\\\"keyword\\\"")')エラーハンドリング
Python スクリプト強制終了
- エラー発生時に Python スクリプトを強制終了したい時に使用する。
import sys sys.exit(1)ファイル存在確認
- データ分析をかける前に必要なインプットが揃っているかを見る際に使う。
import os if os.path.exists(): print('ファイルが存在します。後続の処理を実行します。') else: print('ファイルが存在しません。処理を終了します。') sys.exit(1)ロギング
- Python の標準モジュール logging を使用する。
- 以下のような構成でのロギングサンプルを記載する。
test ├── module │ └── sub.py └── main.pymain.py
# 自作モジュール import module.sub as sub from logging import CRITICAL, DEBUG, ERROR, INFO, WARNING from logging import NullHandler, StreamHandler, basicConfig, getLogger, Formatter from logging.handlers import TimedRotatingFileHandler logger = getLogger(__name__) logger.addHandler(NullHandler()) logger.setLevel(DEBUG) sh = StreamHandler() def init() -> None: basicConfig( handlers=[sh], format="[%(asctime)s] %(name)s %(levelname)s: %(message)s", datefmt="%y-%m-%d %H:%M:%S", ) root_logger = getLogger() root_logger.setLevel(DEBUG) rfh = TimedRotatingFileHandler( "log/test.log", when="midnight", backupCount=30, ) format_template = ( f"PID:%(process)d [%(asctime)s] %(name)s %(levelname)s: %(message)s" ) log_format = Formatter(fmt=format_template, datefmt="%y-%m-%d %H:%M:%S") rfh.setFormatter(log_format) root_logger.addHandler(rfh) logger.debug("スクリプト実行開始") if __name__ == "__main__": init() # 自作モジュールの関数を呼び出す sub.hello()module/sub.py
from logging import getLogger logger = getLogger(__name__) def hello(): print('hello! this is sub module.') logger.debug('sub moduleから出力')$ python main.py [20-06-25 14:20:56] __main__ DEBUG: スクリプト実行開始 hello! this is sub module. [20-06-25 14:20:56] module.sub DEBUG: sub moduleから出力 $ head log/test.log PID:15171 [20-06-25 14:20:56] __main__ DEBUG: スクリプト実行開始 PID:15171 [20-06-25 14:20:56] module.sub DEBUG: sub moduleから出力その他
ファイル件数取得
- 1行でシェルコマンドを実行することなく取得可能。
cnt = str(sum(1 for line in open('test.tsv')))ファイルを1行の文字列にする
- 複数キーワードをOR条件で1行にする際に使用した。
main.py
import os def load_file_as_one_line(file, sep): with open(file) as f: lines_one_str = '' # a\nb\nc\n -> a|b|c|d lines = f.readlines() for line in lines: w = line.rstrip(os.linesep) if(w != ''): lines_one_str += w + sep return lines_one_str[:-1] print(load_file_as_one_line('data.txt', '|'))$ cat data.txt テスト test テキスト text テースト $ python main.py テスト|test|テキスト|text|テースト|taste日付パーティションのディレクトリを動的に生成する
- データ分析では n ヵ月分のデータを読み込む,n 日分のデータを読み込むという場面がよくあるのでそういった時に使用する。
main.py
import datetime from dateutil.relativedelta import relativedelta def out_term(year, month, term, base_dir): d = datetime.date(year, month, 1) txt = "" for i in range(term): txt += base_dir + (d + relativedelta(months=i)).strftime("%Y/%m") if(i != term - 1) : txt += "," return txt def out_reverse_term_by_day(d, reverse_term, base_dir): txt = "" d = d - relativedelta(days=reverse_term - 1) for i in range(reverse_term): txt += base_dir + (d + relativedelta(days=i)).strftime("%Y/%m/%d") if(i != reverse_term - 1) : txt += "," return txt # 2019-11 から4ヵ月分のディレクトリを用意する print(out_term(2019, 11, 4, '/tmp/input/')) # 2019-11-02 から5日遡った分のディレクトリを用意する print(out_reverse_term_by_day(datetime.date(2019, 11, 2), 5, '/tmp/input/'))実行結果
$ python main.py /tmp/input/2019/11,/tmp/input/2019/12,/tmp/input/2020/01,/tmp/input/2020/02 /tmp/input/2019/10/29,/tmp/input/2019/10/30,/tmp/input/2019/10/31,/tmp/input/2019/11/01,/tmp/input/2019/11/02Pigテンプレートに条件式やパス等を動的に埋め込む
- 辞書で置換したい単語と代入したい値を定義し,テンプレートに埋め込んだPigを生成する。
- 複雑な条件式や動的に変わるパスを埋め込みたい時に使用する。
main.py
def substitute_condition(template, output, target_word, condition): txt = '' with open(template) as f: lines_one_str = f.read() txt = lines_one_str.replace(target_word, condition) with open(output, mode='w') as f: f.write(txt) def translate(template: str, output: str, d: {str, str}): for i, (k, v) in enumerate(d.items()): if i == 0: substitute_condition(template, output, k, v) else: substitute_condition(output, output, k, v) d = {'$INPUT': '/tmp/input', '$COND': 'テスト|test', '$OUTPUT': '/tmp/output'} translate('template.pig', 'output.pig', d)実行
$ python main.pytemplate.pig
L = LOAD '$INPUT' USING PigStorage('\t'); F = FILTER L BY note matches '$COND'; FS -rm -r -f -skipTrash $OUTPUT STORE F INTO '$OUTPUT' USING PigStorage('\t', '-schema');output.pig
L = LOAD '/tmp/input' USING PigStorage('\t'); F = FILTER L BY note matches 'テスト|test'; FS -rm -r -f -skipTrash /tmp/output STORE F INTO '/tmp/output' USING PigStorage('\t', '-schema');メール送信
def send_mail(subject: str, body: str, from: str, to: str, svr: str, port: str, id: str, password: str): msg = MIMEText(body, 'html') msg['Subject'] = subject msg['From'] = from msg['To'] = to server = smtplib.SMTP_SSL(svr, port) # SSL の場合 # server = smtplib.SMTP_SSL(svr, port, context=ssl.create_default_context()) server.login(id, password) server.send_message(msg)
- 投稿日:2020-06-25T16:26:19+09:00
AutoMLライブラリーPyCaretの環境構築の覚書
pandas-profilingでエラーが出ないようにインストールする
コンピュータ環境
OS:Ubuntu 18.04LTS
Anaconda3仮想環境の作成
bash$ conda create -n pycaret python=3.6.10conda仮想環境下でpyCaretのインストール
1.マニュアルに従ってpipでインストール
bash$ conda activate pycaret (pycaret)$ pip install pycaret (pycaret)$ python -m ipykernel install --user --name pycaret --display-name "display-name-here"ところが最近あらたにインストールしたら、jupyter notebookで以下のコマンドを実行るとエラーを吐くようになった。
pythonfrom pycaret.datasets import get_data dataset = get_data('credit', profile=True)これは PyCaretのdata respository から
get_dataでダウンロードするためのコマンドで、もともとのチュートリアルでは、引数profile=Trueを与えていない。つまりデフォルトの引数profile=Falseで実行している。この場合はデータの最初の5行が表示されるだけである。一方、引数
profile=Trueを与えると、pandas profiling reportの形式で出力してくれる。DataFrame の基本統計量や相関係数などを一度にまとめて確認できるのだが、import pandas_profilingとわざわざする必要がない。ところが、
pip install pycaretを使ってインストールした時期が異なると、いくつかのパッケージのサブバージョンが違っているからなのか、profile=Trueでエラーが出るようになったので、requirements.txtを使ってインストールしている。2.requirements.txtファイルを別途、仮想環境を起動したディレクトリに置いておき、pipでインストール
bash$ conda activate pycaret (pycaret)$ pip install -r requirements.txt (pycaret)$ python -m ipykernel install --user --name pycaret --display-name "display-name-here"requirements.txtには以下を記述しておく。
astropy==4.0.1.post1 attrs==19.3.0 awscli==1.18.64 backcall==0.1.0 bleach==3.1.5 blis==0.4.1 boto==2.49.0 boto3==1.13.14 botocore==1.16.14 catalogue==1.0.0 catboost==0.20.2 certifi==2020.4.5.1 chardet==3.0.4 chart-studio==1.1.0 click==7.1.2 colorama==0.4.3 colorlover==0.3.0 combo==0.1.0 confuse==1.1.0 cufflinks==0.17.0 cycler==0.10.0 cymem==2.0.3 datefinder==0.7.0 DateTime==4.3 decorator==4.4.2 defusedxml==0.6.0 docutils==0.15.2 entrypoints==0.3 funcy==1.14 future==0.18.2 gensim==3.8.3 graphviz==0.14 htmlmin==0.1.12 idna==2.9 importlib-metadata==1.6.0 ipykernel==5.3.0 ipython==7.14.0 ipython-genutils==0.2.0 ipywidgets==7.5.1 jedi==0.17.0 Jinja2==2.11.2 jmespath==0.10.0 joblib==0.15.1 jsonschema==3.2.0 jupyter-client==6.1.3 jupyter-core==4.6.3 kiwisolver==1.2.0 kmodes==0.10.1 lightgbm==2.3.1 llvmlite==0.32.1 MarkupSafe==1.1.1 matplotlib==3.2.1 missingno==0.4.2 mistune==0.8.4 mlxtend==0.17.2 more-itertools==8.3.0 murmurhash==1.0.2 nbconvert==5.6.1 nbformat==5.0.6 nltk==3.5 notebook==6.0.3 numba==0.49.1 numexpr==2.7.1 numpy==1.18.4 packaging==20.4 pandas==1.0.3 pandas-profiling==2.3.0 pandocfilters==1.4.2 parso==0.7.0 pexpect==4.8.0 phik==0.9.12 pickleshare==0.7.5 Pillow==7.1.2 plac==1.1.3 plotly==4.4.1 pluggy==0.13.1 preshed==3.0.2 prometheus-client==0.7.1 prompt-toolkit==3.0.5 ptyprocess==0.6.0 py==1.8.1 pyasn1==0.4.8 pycaret==1.0.0 Pygments==2.6.1 pyLDAvis==2.1.2 pyod==0.7.9 pyparsing==2.4.7 pyrsistent==0.16.0 pytest==5.4.2 python-dateutil==2.8.1 pytz==2020.1 PyYAML==5.3.1 pyzmq==19.0.1 regex==2020.5.14 requests==2.23.0 retrying==1.3.3 rsa==3.4.2 s3transfer==0.3.3 scikit-learn==0.22 scipy==1.4.1 seaborn==0.10.1 Send2Trash==1.5.0 shap==0.32.1 six==1.14.0 smart-open==2.0.0 spacy==2.2.4 srsly==1.0.2 suod==0.0.4 tbb==2020.0.133 terminado==0.8.3 testpath==0.4.4 textblob==0.15.3 thinc==7.4.0 tornado==6.0.4 tqdm==4.46.0 traitlets==4.3.3 umap-learn==0.4.3 urllib3==1.25.9 wasabi==0.6.0 wcwidth==0.1.9 webencodings==0.5.1 widgetsnbextension==3.5.1 wordcloud==1.7.0 xgboost==0.90 yellowbrick==1.0.1 zipp==3.1.0 zope.interface==5.1.03.pandas でデータを読み込んでpandas profiling reportを出力する場合には、以下。
pythonimport pandas as pd import numpy as np df = pd.read_csv('/path/to/data.csv',sep=",", encoding="utf-8") import pandas_profiling pandas_profiling.ProfileReport(df)
- 投稿日:2020-06-25T16:21:33+09:00
djangoでアップロードしたファイルをMinIOに投入する
概要
- djangoを使って、ファイルアップロードエンドポイントを作った際に、取得したファイルオブジェクトをそのままMinIO(https://min.io/)に投入する手順
- 備忘録
前提
- 環境
- python: v.3.7.7
- django: v.2.0.3
- minio: 5.0.13
Template
- 簡単なアップロード用のtemplateを用意する
{% extends 'base.html' %} // 必要であればベースを読み込んでおく {% block content %} // ファイルアップロードのためには、enctypeの記述が必要 <form method="POST" action="{% url 'upload_to_minio' %}" enctype="multipart/form-data"> {% csrf_token %} // ファイルアップロード用 input <p> <label for="myfile">File:</label> <input type="file" name="myfile" required id="myfile"> </p> // アップロードボタン <button type=“submit”>アップロード</button> </form> {% endblock %}urs.py
- uploadのエンドポイント用URLを設定する
urlpatterns = [ path("umc/upload_to_minio/", views.UploadToMinio.as_view(), name="upload_to_minio" ]views.py
- アップロードされたファイル情報を取得し、MinIOに格納するロジックを記載する
class UploadToMinio(generic.View, LoginRequiredMixin): def post(self, request, *args, **kwargs): try: # アップロードされたファイルは、request.FILESに格納されている myfile = self.request.FILES['myfile'] # ファイルのバイナリデータをメモリ上に読み込む # 巨大ファイルを取り扱う場合は注意 file_obj = myfile.read() # ファイルサイズを取得 file_size = myfile.size # 格納先のbucket名 bucket_name = 'hoge' # 格納先のobject名 object_name = 'fuga' # minio client minioClient = Minio( 'host:port', # MinIOのアクセス先 access_key='access_key', # 各環境のaccess_key secret_key='secret_key', # 各環境のsecret_key secure=True) # https通信の場合はTrue # bucketが存在しなければ作成する if not minioClient.bucket_exists(project_id): minioClient.make_bucket(bucket_name=bucket_name) # objectの作成 minioClient.put_object( bucket_name=project_id, object_name=uuid, data=io.BytesIO(file_obj), length=file_size )
put_objectのdataはio.RawIOBaseを継承したオブジェクトしか受け付けない。そのため、 メモリ上のオブジェクトに対してio.BytesIO()でバイナリストリーム化してあげる。
これで動くはず
- 投稿日:2020-06-25T16:15:06+09:00
pandas.IntervalをStringにキャストする方法
pd.cutしたDataFrameをto_sqlするときに以下のエラーが起きて悩んだのでメモ
sqlite3.InterfaceError: Error binding parameter 3 - probably unsupported type.?astype(object)はエラー?
df['interval'] = pd.cut(df['x'], 3) df['interval'] = df['interval'].astype(object) df['interval'] = df['interval'].str.replace(', ', '~')TypeError: Object of type 'Interval' is not JSON serializable?astype(str)はいける?♂️
df['interval'] = pd.cut(df['x'], 3) df['interval'] = df['interval'].astype(str) df['interval'] = df['interval'].str.replace(', ', '~')無事書き出せました。
- 投稿日:2020-06-25T15:27:38+09:00
JSON仕様について
json通信における日本語取説
jsonの仕様上、日本語ははunicode escapeする必要はない
unicode escapeしない場合、機密漏洩上よくないが、デコードすれば解読可能のためいいんじゃないって話
それでもXSSなどセキュリティ大丈夫なのは、制御文字列を¥マークエスケープすればいいから(→どうゆうこと?)↓こうゆうこと。
クロスサイトスクリプティングscriptタグで囲ったデータを登録されることにより、そのデータがブラウザにscriptタグとして、読み込まれて不正なスクリプトが実行されてしまう可能性がある。だから制御文字列は、エスケープする必要がある。
- セッションハイジャック
- 入力フォームのタグを埋め込まれ個人情報不正窃取される
- Webページに偽の情報を表示させる
- Webページ上で強制的に操作される
pythonの日本語のunicode escape問題
json.dumps(str, ensure_ascii=False)により日本語化を実現可能。ensure_ascii が (デフォルト値の) true の場合、出力では入力された全ての非 ASCII 文字はエスケープされていることが保証されています。ensure_ascii が false の場合、これらの文字はそのまま出力されます。
しかし、上記の実装のままだと制御文字列のエスケープが実施されなくなるため、脆弱性を生み出してう。
MUST be escaped
the characters MUST be escaped:
※quotation mark, reverse solidus, and the control characters (U+0000 through U+001F).
No. 文字列 1. "(ダブルコーテーション) 2. (バックスラッシュ) 3. NULl(ヌル) 4. Start Of Heading(ヘッダ開始) 5. Start of TeXt(テキスト開始) 6. End of TeXt(テキスト終了) 7. End Of Transmission(転送終了) 8. ENQuiry(問合せ) 9. ACKnowledge(肯定応答) 10. BELl(ベル) 11. Back Space(後退) 12. Horizontal Tabulation(水平タブ) 13. Line Feed(改行) 14. Vertical Tabulation(垂直タブ) 15. Form Feed(改ページ) 16. Carriage Return(復帰) 17. Shift Out(シフトアウト) 18. Shift In(シフトイン) 19. Data Link Escape(伝送制御拡張) 20. Device Control 1(装置制御1) 21. Device Control 2(装置制御2) 22. Device Control 3(装置制御3) 23. Device Control 4(装置制御4) 24. Negative AcKnowledge(否定応答) 25. SYNchronous idle(同期信号) 26. End of Transmission Block(転送ブロック終了) 27. End of Transmission Block(転送ブロック終了) 28. CANcel(取消) 29. End of Medium(媒体終端) 30. SUBstitute(置換) 31. ESCape(拡張) 32. File Separator(ファイル分離) 33. Group Separator(グループ分離) 34. Record Separator(レコード分離) 35. Unit Separator(ユニット分離)
- 投稿日:2020-06-25T15:27:38+09:00
JSON通信に置ける文字列取扱いについて
json通信における日本語取説
jsonの仕様上、日本語ははunicode escapeする必要はない
unicode escapeしない場合、機密漏洩上よくないが、デコードすれば解読可能のためいいんじゃないって話
それでもXSSなどセキュリティ大丈夫なのは、制御文字列を¥マークエスケープすればいいから(→どうゆうこと?)↓こうゆうこと。
クロスサイトスクリプティングscriptタグで囲ったデータを登録されることにより、そのデータがブラウザにscriptタグとして、読み込まれて不正なスクリプトが実行されてしまう可能性がある。だから制御文字列は、エスケープする必要がある。
- セッションハイジャック
- 入力フォームのタグを埋め込まれ個人情報不正窃取される
- Webページに偽の情報を表示させる
- Webページ上で強制的に操作される
pythonの日本語のunicode escape問題
json.dumps(str, ensure_ascii=False)により日本語化を実現可能。ensure_ascii が (デフォルト値の) true の場合、出力では入力された全ての非 ASCII 文字はエスケープされていることが保証されています。ensure_ascii が false の場合、これらの文字はそのまま出力されます。
しかし、上記の実装のままだと制御文字列のエスケープが実施されなくなるため、脆弱性を生み出してう。
MUST be escaped
the characters MUST be escaped:
※quotation mark, reverse solidus, and the control characters (U+0000 through U+001F).
No. 文字列 1. "(ダブルコーテーション) 2. (バックスラッシュ) 3. NULl(ヌル) 4. Start Of Heading(ヘッダ開始) 5. Start of TeXt(テキスト開始) 6. End of TeXt(テキスト終了) 7. End Of Transmission(転送終了) 8. ENQuiry(問合せ) 9. ACKnowledge(肯定応答) 10. BELl(ベル) 11. Back Space(後退) 12. Horizontal Tabulation(水平タブ) 13. Line Feed(改行) 14. Vertical Tabulation(垂直タブ) 15. Form Feed(改ページ) 16. Carriage Return(復帰) 17. Shift Out(シフトアウト) 18. Shift In(シフトイン) 19. Data Link Escape(伝送制御拡張) 20. Device Control 1(装置制御1) 21. Device Control 2(装置制御2) 22. Device Control 3(装置制御3) 23. Device Control 4(装置制御4) 24. Negative AcKnowledge(否定応答) 25. SYNchronous idle(同期信号) 26. End of Transmission Block(転送ブロック終了) 27. End of Transmission Block(転送ブロック終了) 28. CANcel(取消) 29. End of Medium(媒体終端) 30. SUBstitute(置換) 31. ESCape(拡張) 32. File Separator(ファイル分離) 33. Group Separator(グループ分離) 34. Record Separator(レコード分離) 35. Unit Separator(ユニット分離)
- 投稿日:2020-06-25T15:15:55+09:00
face_recognition使ってみた
顔認証記事見つけて試してみたら、スムーズに出来なかったのでメモしとく。
Python を利用して顔認証ができる。しかもライブラリは公開されている。
しかも簡単らしい。
最初に見た記事: https://www.cresco.co.jp/blog/entry/9468/※そもそもPython初心者なんだけど、適当に書いても動くので甘く見てる。
※環境はWindows10、Python3.8ちょうど業務で課題となっているものに顔認証が使えないかなーと思っていたので
「pipでインストールするだけでしょ」ぐらいの軽い気持ちで始めて見た。>pip3 install face_recognitionインストールでエラー出まくって全然先に進めなかった・・・
読めない英語を見ながらググって進めたwheelが無いよって怒られた。
なにそれ?python配布用のzipらしい。>pip install -U wheelまだまだエラー
dlibがどーとかそもそも、face_recognitionってのはdlibっていう顔認識ライブラリを使うための物らしい。
python用のラッパーかな?
参考:https://qiita.com/nonbiri15/items/f95b5fb01ae38980c9cedlibのインストールが必要らしい。
>pip3 install dlibやっぱりエラー出まくり
dlibってCで作られてるらしい
CMAKEってのが要るらしい。
cmake-3.18.0-rc2-win64-x64.msi
↑ をDLしてインストールまだまだ~
VC++でビルドするらしい(そりゃそーか)
参考:https://qiita.com/strv13570/items/a0542600532deee61391
Visualstudio2017は入れてたけどVC++なんて触りたくなかったので入れてなかった。
しょうがないのでVC++使うように変更してインストール以上、pathなどは適宜設定(確認)
>pip3 install dlib ・ ・ ・ Successfully installed dlib-19.20.0やっと、dlib通った。
pip3 install face_recognition ・ ・ ・ Successfully installed Pillow-7.1.2 face-recognition-1.3.0 numpy-1.19.0やっとインストールできたか、長い道のりだった・・・
ググって思ったのが、なんで、みんなアナコンダとか入れてんだろうか??業務上か?とりあえず、サイトを参考に2つのフォルダを作って写真入れて試す。
知ってる顔フォルダ と 知らない顔 フォルダ を作ってそれぞれ入れてdiff取る感じの使い方。
それぞれ以下で試した。
※1枚本物入れて見た。
実行結果
tosi3は騙されてるね。以上、使用レビューのつもりが、インストールメモに成ってしまった・・・
他もいろいろ試してみたい予定
参考:https://www.kkaneko.jp/dblab/dlib/facerec.html追記:
↑ のサイト見てまんま試してみたtest_face.pyimport face_recognition src_img = face_recognition.load_image_file("./face/obama.png") src_img_encoding = face_recognition.face_encodings(src_img)[0] # print(src_img_encoding) img1="./face2/tosi.png" img2="./face2/tosi2.png" img3="./face2/tosi3.png" dest_img1 = face_recognition.load_image_file(img1) dest_img_encoding1 = face_recognition.face_encodings(dest_img1)[0] dest_img_encoding2 = face_recognition.face_encodings(face_recognition.load_image_file(img2))[0] dest_img_encoding3 = face_recognition.face_encodings(face_recognition.load_image_file(img3))[0] results = face_recognition.compare_faces([src_img_encoding], dest_img_encoding1) print(img1 , results) results = face_recognition.compare_faces([src_img_encoding], dest_img_encoding2) print(img2 , results) results = face_recognition.compare_faces([src_img_encoding], dest_img_encoding3) print(img3 , results)実行結果.>test_face.py ./face2/tosi.png [False] ./face2/tosi2.png [False] ./face2/tosi3.png [True] Process finished with exit code 0顔の特徴を数値化して比較できる
めっちゃ楽じゃんか!!

- 投稿日:2020-06-25T15:15:26+09:00
競プロでよく出る順列全探索をpythonで実装してみる
初めに
アルゴリズムの学習中をしていて順列全探索を覚えたのでアウトプットとして記事を書いています。
まだまだ浅学の身ですので、誤りがあればどんどんご指摘ください。順列全探索とは
ある異なる要素を含むリストについてその要素を並べ替えたリストを全て列挙する全探索の手法です。
例えば、[1,2,3]を順列全探索すると[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]の6通りの順列を得ます。実装例
permutations.rbfrom itertools import permutations list=[1,2,3] per=permutations(list,2) for i in per: print(i)出力
ans.py(1, 2) (1, 3) (2, 1) (2, 3) (3, 1) (3, 2)ポイント
・ライブラリのitertools.permutationsを用いて順列を生成する。
・permutationsはイテレータであるため、そのままでは出力できない。
例えば、上記のコードでprint(per)としても出力されない
・permutationsの第二引数に数字を指定することでその個数だけ含まれた順列を生成できる競プロ例題
https://atcoder.jp/contests/abc150/tasks/abc150_c
順列全探索が理解できる初心者向けの良問です。
ここでindex関数の使い方もおぼえてしまいましょう
- 投稿日:2020-06-25T14:58:59+09:00
競プロでよく出るbit全探索について初心者の目からpythonで
初めに
競プロをしていてアルゴリズムの勉強を始めました。
アルゴリズムの初歩であるbit全探索についてアウトプットの意味も込めて解説しようと思います。
まだまだ浅学の身ですので誤りがあればどんどんご指摘ください。
競プロの話メインで書いていきます。bit全探索とは
全探索の手法の一つです。
複数の変数が存在し、それぞれの変数が二通りの値をとるときにこの手法は使えます。
bitとはコンピュータにおける0と1のことで二通りの値をとることをbit
になぞらえています。
文字の説明じゃわかりづらいと思うので、例題を乗っけておきます。例題
0,1
の2数字のみをリストに入れることができる。
リストの長さは3である。
考えられるリストをすべて挙げよ。解答
bit.pyfor i in range(2**3): #1 list=[0]*3 #2 for k in range(3): #3 if ((i>>k)&1): #4 list[k]=1 #5 print(list)解説
1 リストのそれぞれの要素は1か0の2通りなので要素の数は2**(要素の個数です)
2 仮のリストを作成しておきます。後でbit演算の結果に応じて書き換えます。 ちなみに[0]*3=[0,0,0]です。
3 リストの長さは3なので最大2回ずらせます
4 bit全探索の核心部分です。
i >> kは、iをk回左シフトさせるという意味です。
&はandを示すので、この行は「i >> kは、iをk回左シフトさせると1がTrueならば」という意味です。競プロでの例題
https://atcoder.jp/contests/abc045/tasks/arc061_a
重要なこと
#2をforループの上に持ってこない
#4はbit演算子
#& はbit演算の論理積、ついでに|は論理和、^は排他的論理和
- 投稿日:2020-06-25T13:41:10+09:00
Ansible: shellモジュールで実行された複数行にわたるコマンドを改行された状態で表示
要望
shellモジュールで実行された複数行にわたるコマンドを、後続のdebugモジュールにて、改行された状態で確認したい
ソリューション
フィルターでは適当なものが見つからなかったが、pythonのsplitlines()にて可能
playbook 例
playbook.yml--- - hosts: all gather_facts: false tasks: - shell: | echo a echo b echo c register: r - debug: { var: r.cmd } # <= そのまま出力すると読みにくい - debug: { var: r.cmd.splitlines() } # <= splitlines()にて分離 - debug: { var: r.stdout_lines } - debug: { var: r.stderr_lines }実行例
$ ansible-playbook -i localhost, -c local playbook.yml PLAY [all] ******************************************************************************************************* TASK [shell] ***************************************************************************************************** changed: [localhost] TASK [debug] ***************************************************************************************************** ok: [localhost] => { "r.cmd": "echo a\n echo b\necho c\n" # <= そのまま出力した例 } TASK [debug] ***************************************************************************************************** ok: [localhost] => { "r.cmd.splitlines()": [ "echo a", # <= 行で分離して出力した例 " echo b", # <= 行で分離して出力した例 "echo c" # <= 行で分離して出力した例 ] } TASK [debug] ***************************************************************************************************** ok: [localhost] => { "r.stdout_lines": [ "a", "b", "c" ] } TASK [debug] ***************************************************************************************************** ok: [localhost] => { "r.stderr_lines": [] } PLAY RECAP ******************************************************************************************************* localhost : ok=5 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0なお、(shellモジュールではなく、)commandモジュールでは、レジストリー変数に文字列として渡されないので使用できない。
fail時にも行で分離して表示できると嬉しいが。
- 投稿日:2020-06-25T13:36:15+09:00
VimでPythonのコードを自動整形する
使うものリスト
今回使っているプラグインのリンクです。
各自READMEなど確認しておいてください。
- https://github.com/nvie/vim-flake8
- https://github.com/tell-k/vim-autopep8
- https://pypi.org/project/autopep8/
autopep8のインストール
pip install autopep8vim pluginのインストール
vimのプラグイン管理をdeinで行っている人は、
plugin_lazy.tomlに以下の行をコピーして貼り付ける。(deinを使ってない人は今すぐdeinを使いましょう)[[plugins]] repo = 'nvie/vim-flake8' on_ft = ['python'] [[plugins]] repo = 'tell-k/vim-autopep8' on_ft = ['python'].vimrcの編集
gitにpushする前に自動で実行したりファイルを保存するときに自動で実行したりすることも可能ですが、あまり勝手に実行されても怖いのでvim上でsift+fを押したときに自動整形が実行されるように設定します。
以下を.vimrcに追記します。"autopep8を<sift>+fで実行 function! Preserve(command) " Save the last search. let search = @/ " Save the current cursor position. let cursor_position = getpos('.') " Save the current window position. normal! H let window_position = getpos('.') call setpos('.', cursor_position) " Execute the command. execute a:command " Restore the last search. let @/ = search " Restore the previous window position. call setpos('.', window_position) normal! zt " Restore the previous cursor position. call setpos('.', cursor_position) endfunction function! Autopep8() call Preserve(':silent %!autopep8 --ignore=E501 -') endfunction autocmd FileType python nnoremap <S-f> :call Autopep8()<CR>参考
これはこちらのStackoverflowのページを参考にしています。
使い方
- vimのノーマルモードでF7キーを押すと、Flake8が実行されてpep8に準拠していない箇所が表示される。
- 同じくノーマルモードでsift+fキーを押すと、Autopep8が実行されて、ソースコードの自動整形が行われる。
- 投稿日:2020-06-25T13:19:56+09:00
複数pythonファイルを一つのpythonファイルにする
やりたいこと
例えば,
main.pyが他のファイルを呼び出すようなプロジェクトを...- main.py - sub1.py - folder - sub2.py↓↓↓ 依存してる関数やクラスなどをちゃーんと...
onefile.pyぎゅ!!!っとする.
(動機としては, プロジェクト管理しているpythonファイルを楽にgoogle colabで実行できないかな〜と思ったからです.)
解決法
こちら, stickytapeというpythonパッケージを使えばOK.
https://pypi.org/project/stickytape/stickytape = 粘着テープ
実験
実験したコードは全てGithubに公開してますので, 参考までに.
install
これでstickytapeコマンドが使えるようになる. (コマンド名なげぇ...)
$ pip install stickytapeファイルを用意
以下のような構成とします.
- main.py - sub1.py - folder - sub2.pyfolder/sub2.py
適当にAppleクラスとか作って, 適当にvalueプロパティとか持たせときます.
class Apple: def __init__(self, value): self.value = valuesub1.py
適当に平均関数とか作っときます.
sub1.pydef mean(a, b): return (a+b)/2main.py
importしてきて適当に計算させて適当に表示します.
from sub1 import mean from folder.sub2 import Apple apple1 = Apple(value=100) apple2 = Apple(value=200) result = mean(apple1.value, apple2.value) print(result)いざ!一つのファイルに!
以下のコマンドを実行します. (もちろんonefile.pyのところは何でもOK)
$ stickytape main.py > onefile.py結果
以下のような
onefile.pyが生成されます.#!/usr/bin/env python import contextlib as __stickytape_contextlib @__stickytape_contextlib.contextmanager def __stickytape_temporary_dir(): import tempfile import shutil dir_path = tempfile.mkdtemp() try: yield dir_path finally: shutil.rmtree(dir_path) with __stickytape_temporary_dir() as __stickytape_working_dir: def __stickytape_write_module(path, contents): import os, os.path def make_package(path): parts = path.split("/") partial_path = __stickytape_working_dir for part in parts: partial_path = os.path.join(partial_path, part) if not os.path.exists(partial_path): os.mkdir(partial_path) open(os.path.join(partial_path, "__init__.py"), "w").write("\n") make_package(os.path.dirname(path)) full_path = os.path.join(__stickytape_working_dir, path) with open(full_path, "w") as module_file: module_file.write(contents) import sys as __stickytape_sys __stickytape_sys.path.insert(0, __stickytape_working_dir) __stickytape_write_module('sub1.py', 'def mean(a, b):\n return (a+b)/2') __stickytape_write_module('folder/sub2.py', 'class Apple:\n\n def __init__(self, value):\n self.value = value') from sub1 import mean from folder.sub2 import Apple apple1 = Apple(value=100) apple2 = Apple(value=200) result = mean(apple1.value, apple2.value) print(result)一瞬「何じゃこりゃ!?」となりましたが, これを実行すると...
150.0無事正しい計算結果が表示されました.
Google Colabで実験
先ほどのコードをGoogle Colabにコピペして実行しました.
下のように, 無事150.0が表示されました.
(虹色の猫が歩いてるのは気にしないでください.)
スクリプト化
ここからは余談です.
stickytapeというコマンドは長いですし, いちいち生成ファイルのディレクトリを指定するのとか怠いので, 次のようにスクリプト化しておくといいかと思います.- main.py - sub1.py - folder - sub2.py - scripts - tape.sh - build - onefile.pytape.sh# 初期値 entry="main.py" output="onefile.py" # オプション while getopts e:o: OPT do case $OPT in "e" ) entry=${OPTARG};; "o" ) output=${OPTARG};; esac done # 実行 stickytape ${entry} > "build/${output}"以下のコマンドで, main.pyを実行し, buildディレクトリにonefile.pyを生成してくれます.
$ sh scripts/tape.shオプションも用意しておきました.
オプション名 説明 -e エントリポイントのファイル名 -o アウトプットするファイル名 $ sh scripts/tape.sh -e <ファイル名> -o <ファイル名>生成されるディレクトリは
buildで固定にしているので, 嫌なら勝手に変えてください.自己紹介
冒頭に書くと邪魔になるので最後にひっそりと自己紹介させてください。
名前 綿岡晃輝 学校 神戸大学大学院 学部の研究 機械学習, 音声処理 大学院の研究 機械学習, 公平性, 生成モデル, etc @Wataoka_Koki Twitterフォローしてね!