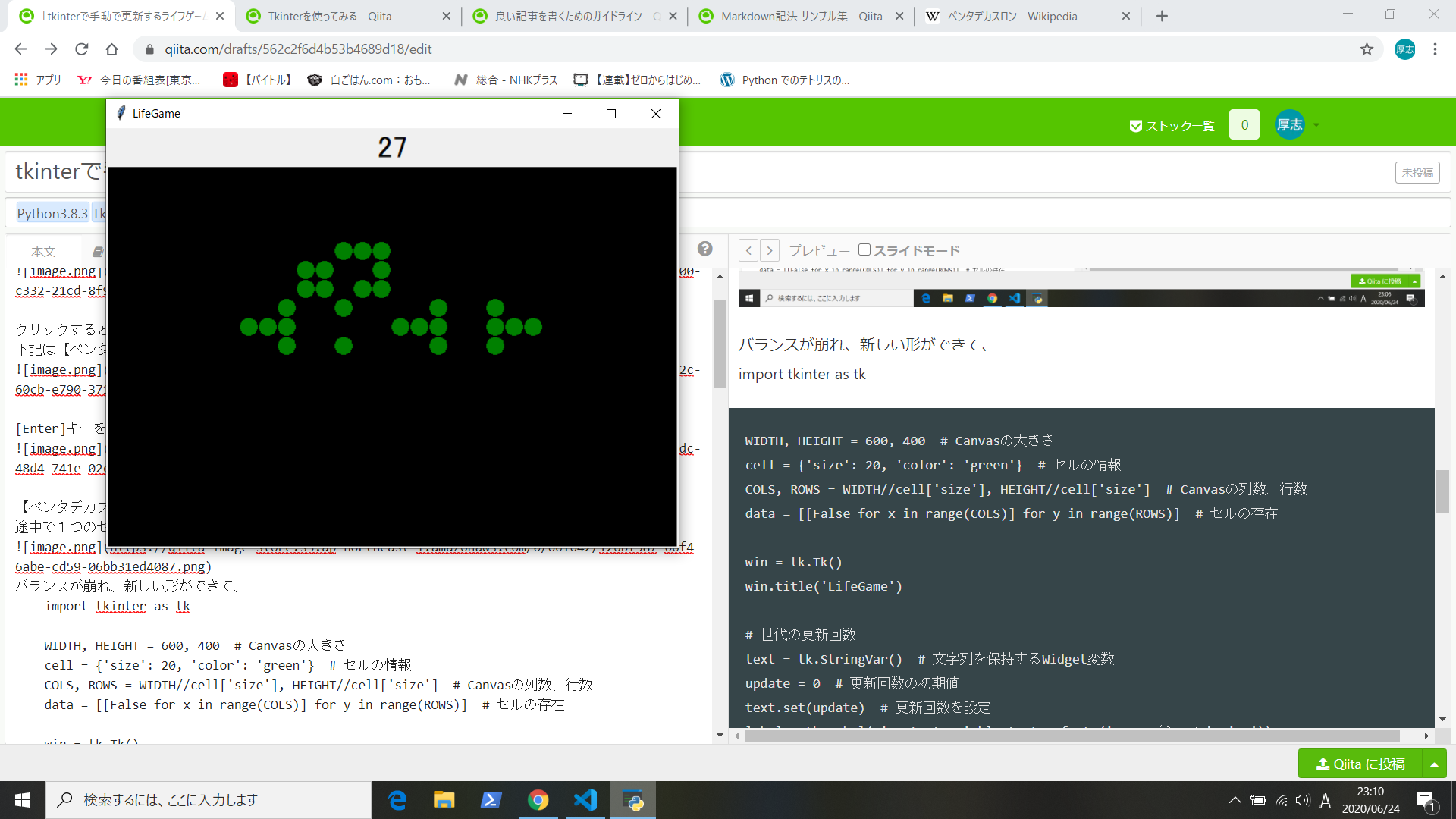
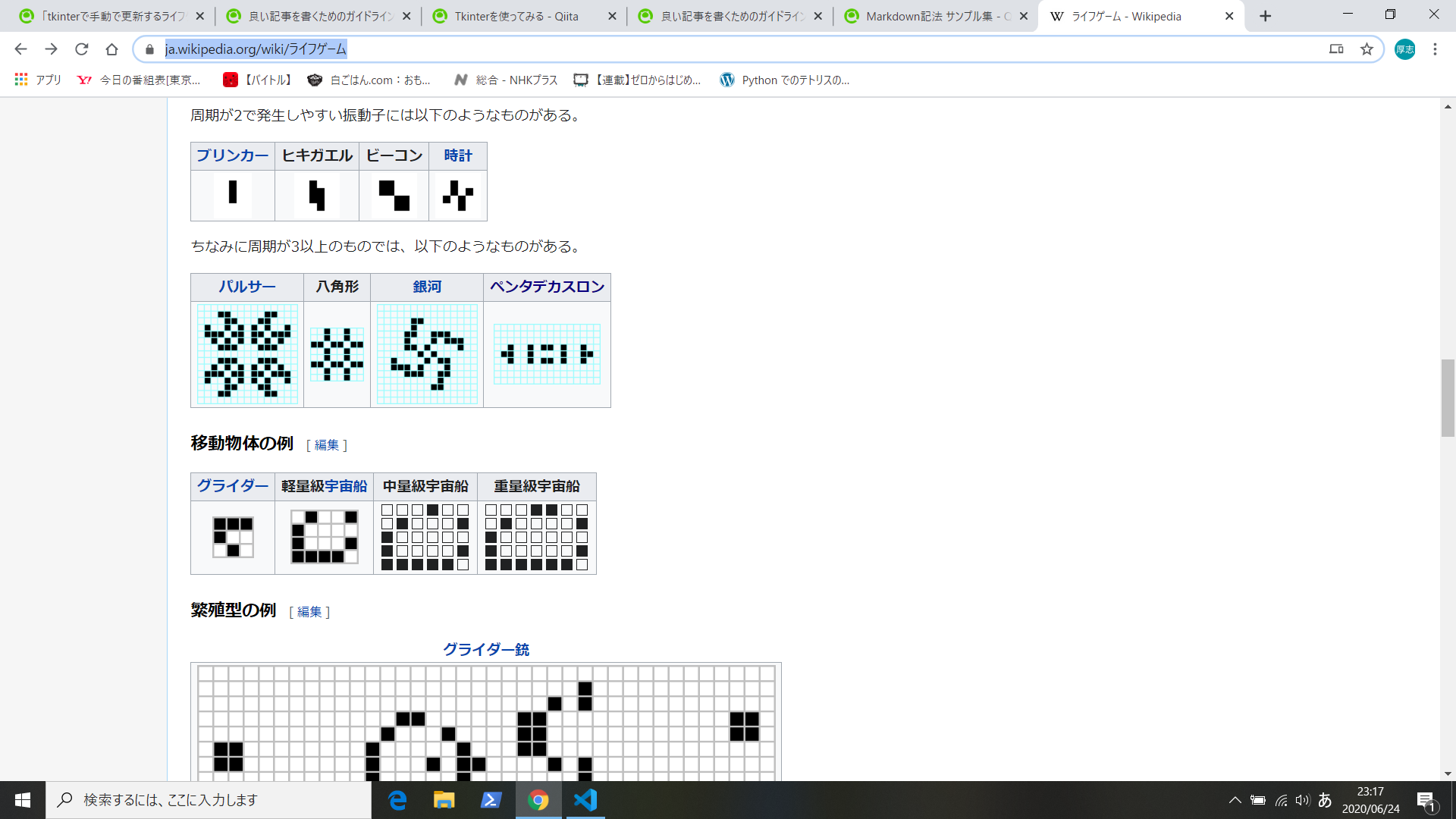
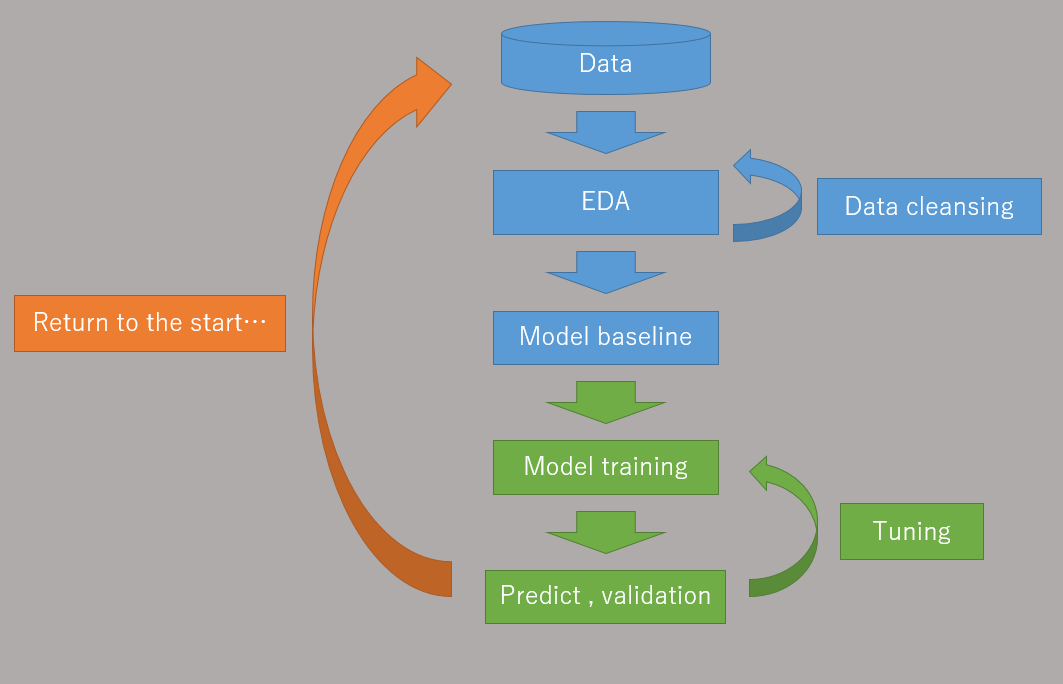
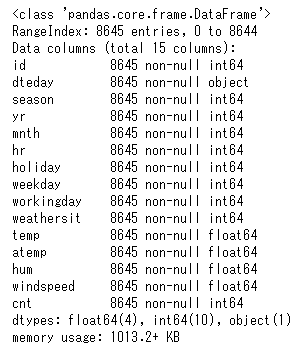
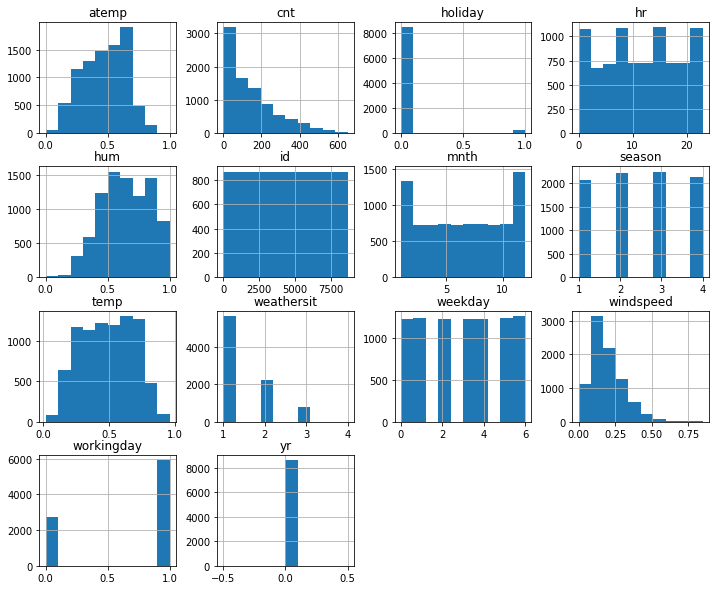
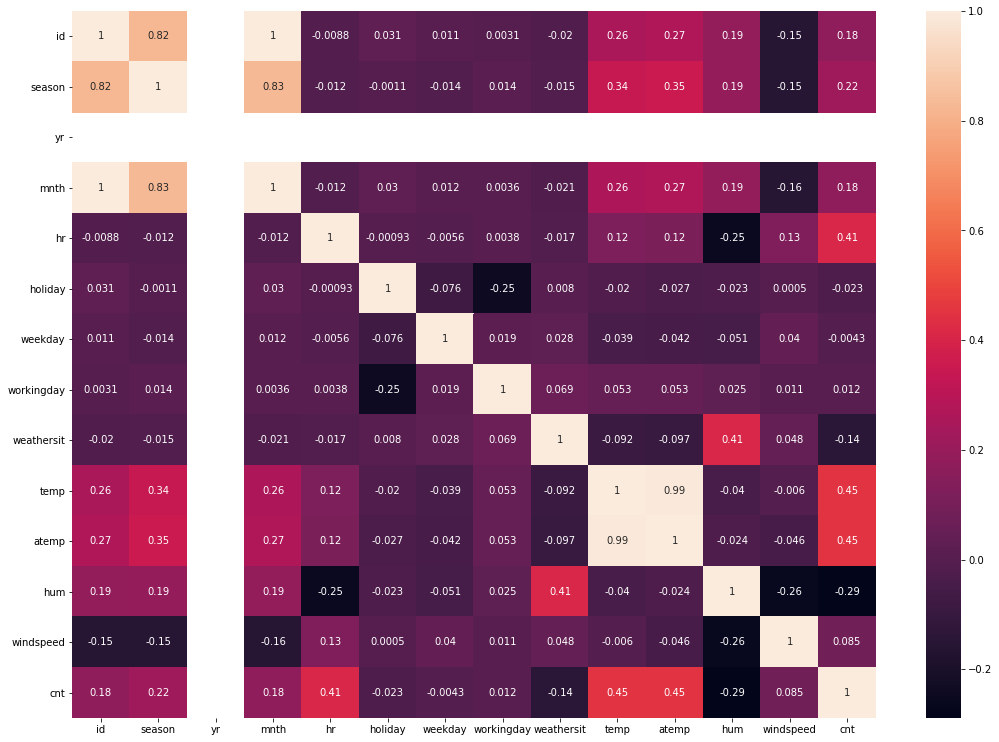
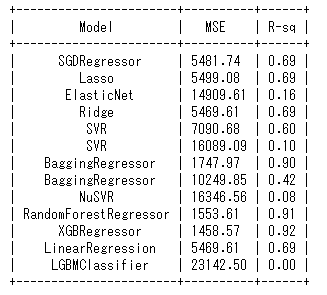
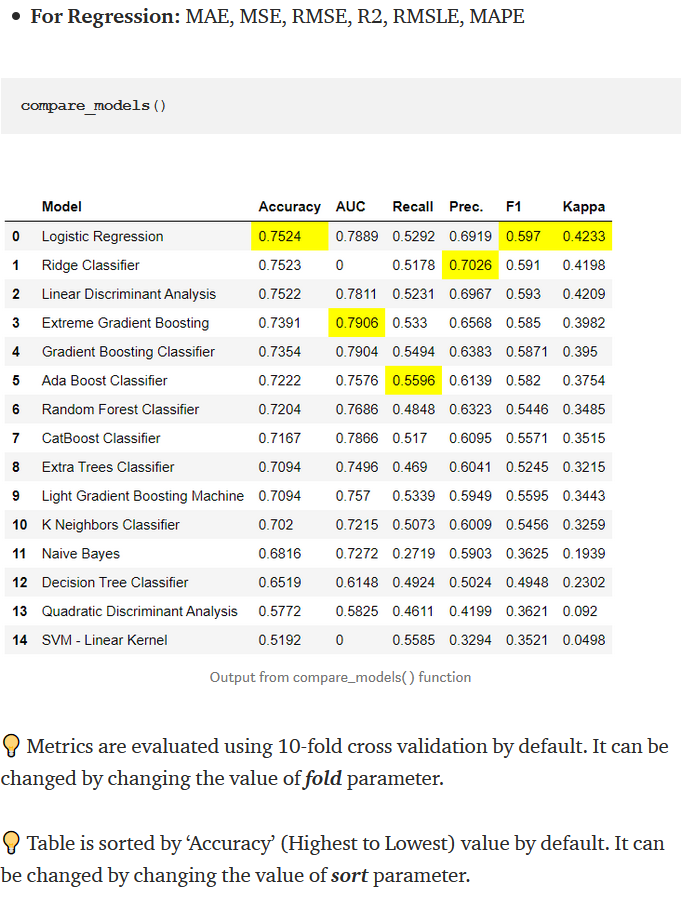
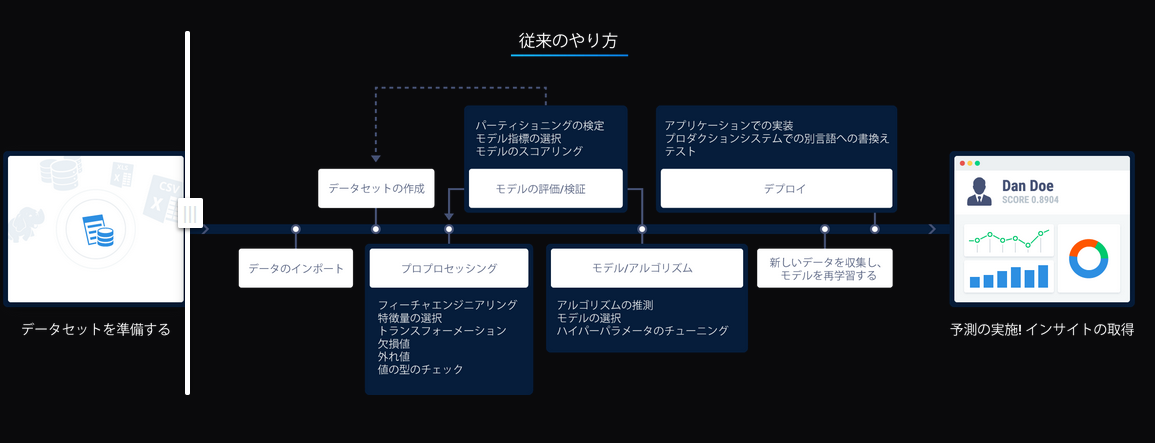
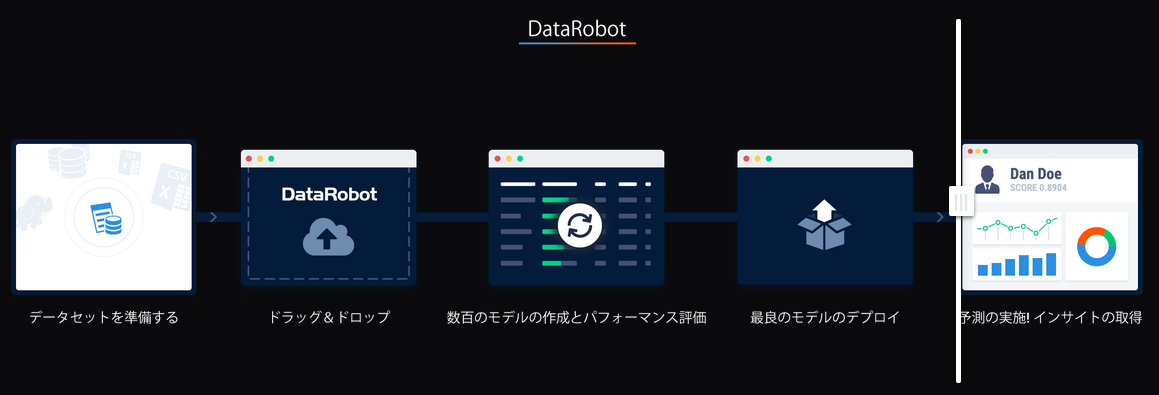
Explanation:
The substring with start index = 0 is "cba", which is an anagram of "abc".
The substring with start index = 6 is "bac", which is an anagram of "abc".
Example 2:
Input:
s: "abab" p: "ab"
Output:
[0, 1, 2]
Explanation:
The substring with start index = 0 is "ab", which is an anagram of "ab".
The substring with start index = 1 is "ba", which is an anagram of "ab".
The substring with start index = 2 is "ab", which is an anagram of "ab".
importcollectionsclassSolution:deffindAnagrams(self,s:str,p:str)->List[int]:len_s,len_p,set_p,ans=len(s),len(p),Counter(p),[]foriinrange(len_s-len_p+1):ifCounter(s[i:i+len_p])==set_p:ans.append(i)returnans# Runtime: 7868 ms, faster than 7.31% of Python3 online submissions for Find All Anagrams in a String.
# Memory Usage: 14.8 MB, less than 69.94% of Python3 online submissions for Find All Anagrams in a String.
Runtime: 68 ms, faster than 99.89% of Python3 online submissions for Find All Anagrams in a String.
Memory Usage: 14.9 MB, less than 42.94% of Python3 online submissions for Find All Anagrams in a String.
a,b,*c=1,# ValueError: not enough values to unpack (expected at least 2, got 1)
# cは空でもいいが、a,bに代入すべき値は必ず指定しなければならない。
*a=1,2,3# SyntaxError: starred assignment target must be in a list or tuple
# 「*」のつくターゲットは、リスト・タプルの中になければならない。
学んだこと:
XSS(クロスサイトスクリプティング)には、反射型、蓄積型、DOM based xssなど様々な種類がある。
XSSの対策、サニタイジング(エスケープ)をする。
課題: DOM Based XSS を体験できるウェブページの作成
xss.html
<html><title>DOM Based XSS</title><h1>DOM Based XSSが体験できるサイト</h1>
Hi
<script charset="UTF-8">varpos=document.URL.indexOf("name=")+5;document.write(unescape(document.URL.substring(pos,document.URL.length)));</script><br><br><p>このページのurlの最後にパラメータとして名前をもたせると、動的にhtmlを書き換えます</p><p>(例) 〜〜xss.html?name=Taro</p><p>一番上のHiの後に名前が表示されたと思います。</p><br><P>しかしこのサイトではパラメータに悪意のあるスクリプト入れられたときにそれを実行してしまいます。</P><p>(例) 〜〜xss.html?name=<script>alert("Your PC was broken!!")</script></p><P>alertができるということは、実際に悪影響を及ぼすスクリプトを実行させられてしまいます。</P></html>
したがって、$kx=360 l \leftrightarrow k=\frac{360l}{x}$が成り立ちます。ここで、$k$は整数なので、$360l$は$x$かつ$360$の倍数であり最小の$l$を考えれば良いので最小公倍数になります。以上より、$360$と$x$の最小公倍数を$x$で割ったものが答えになります。
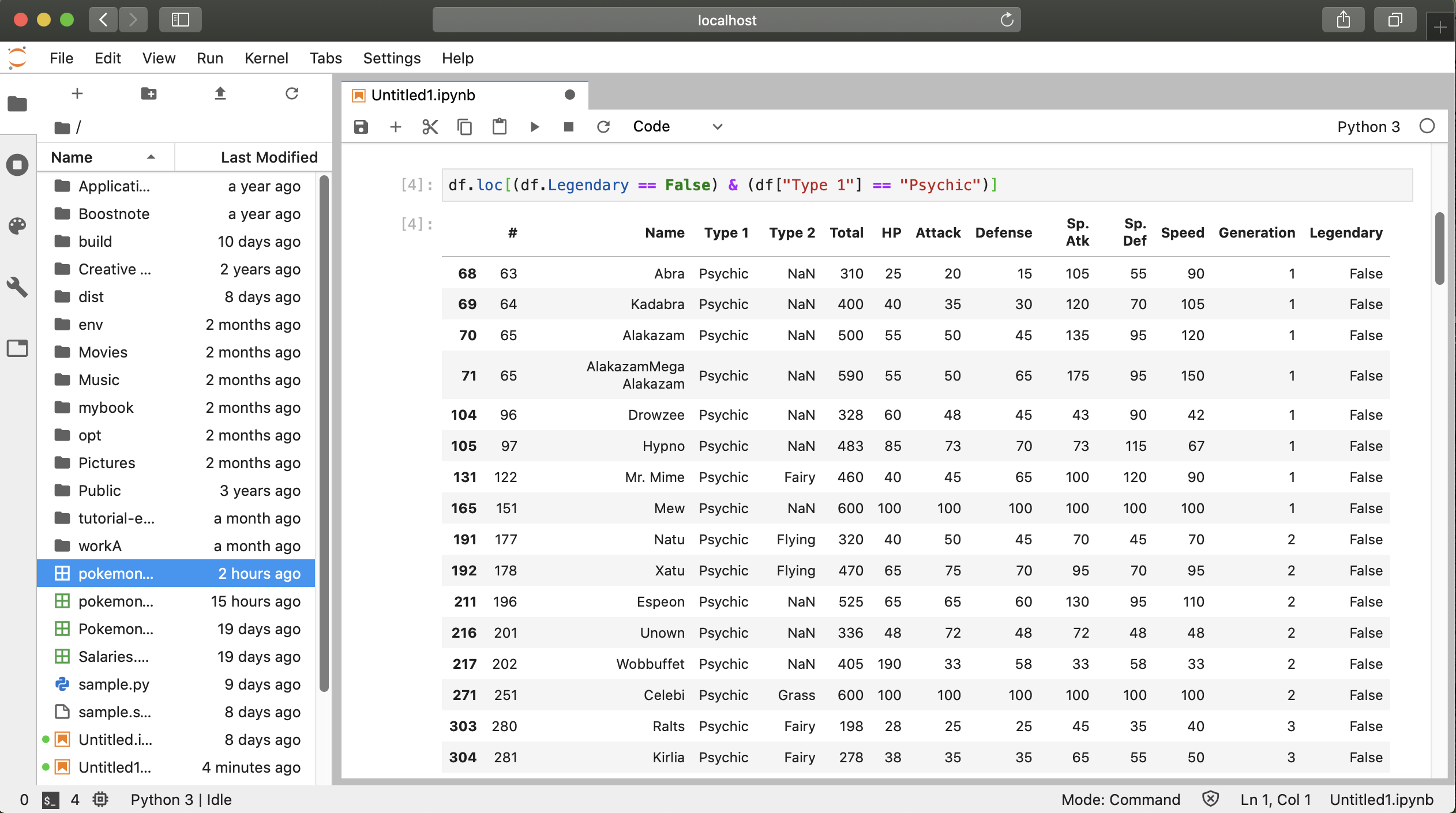
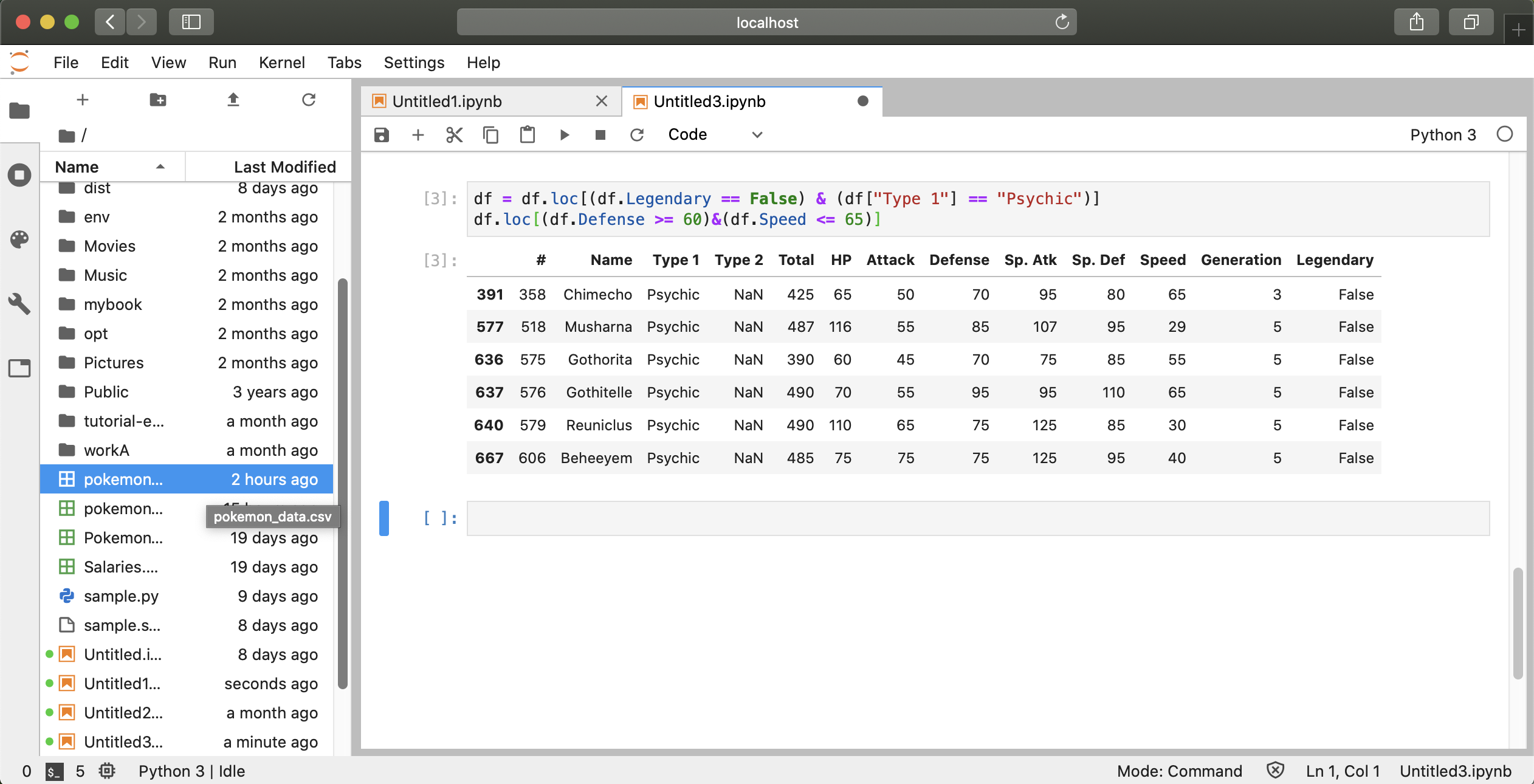
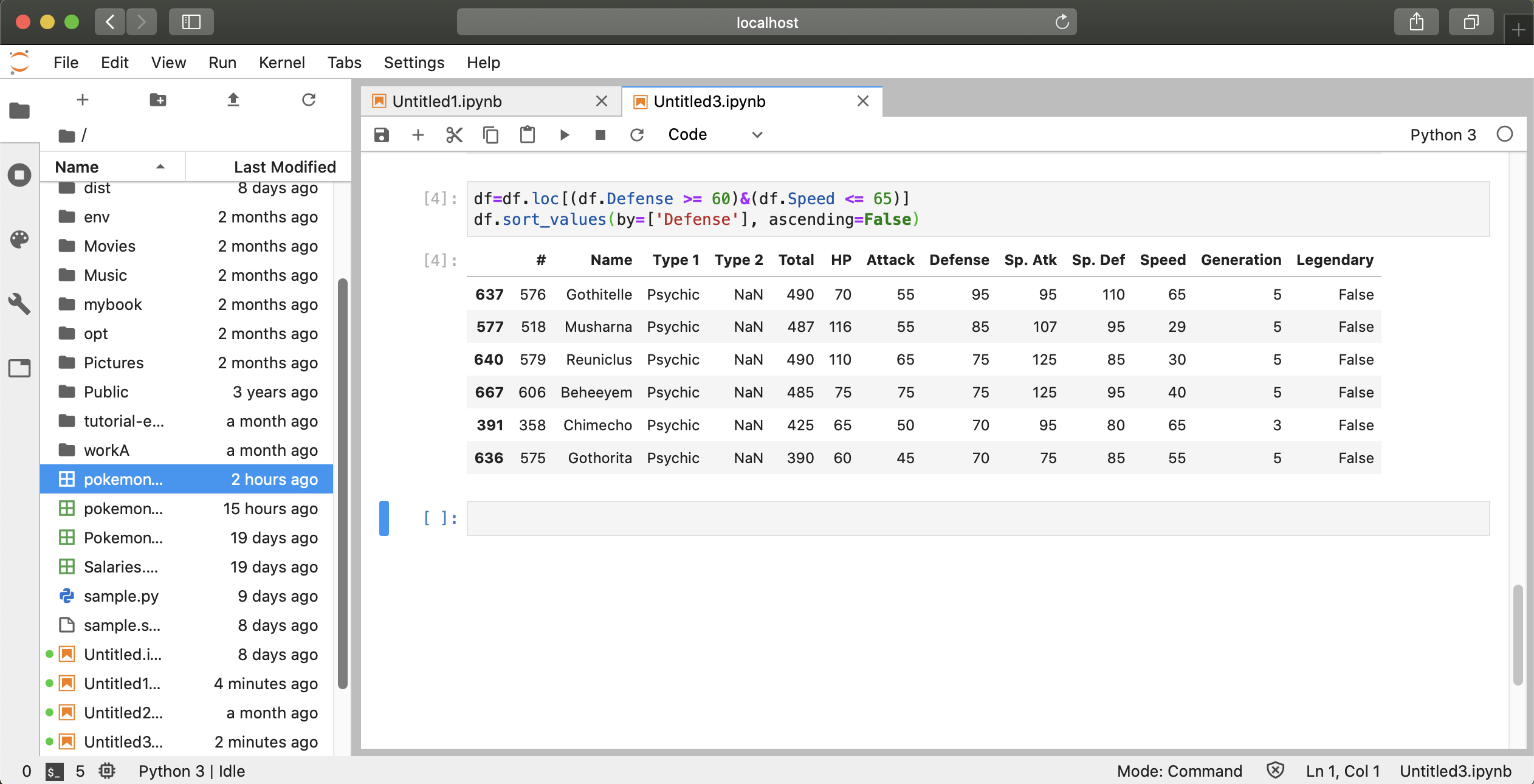
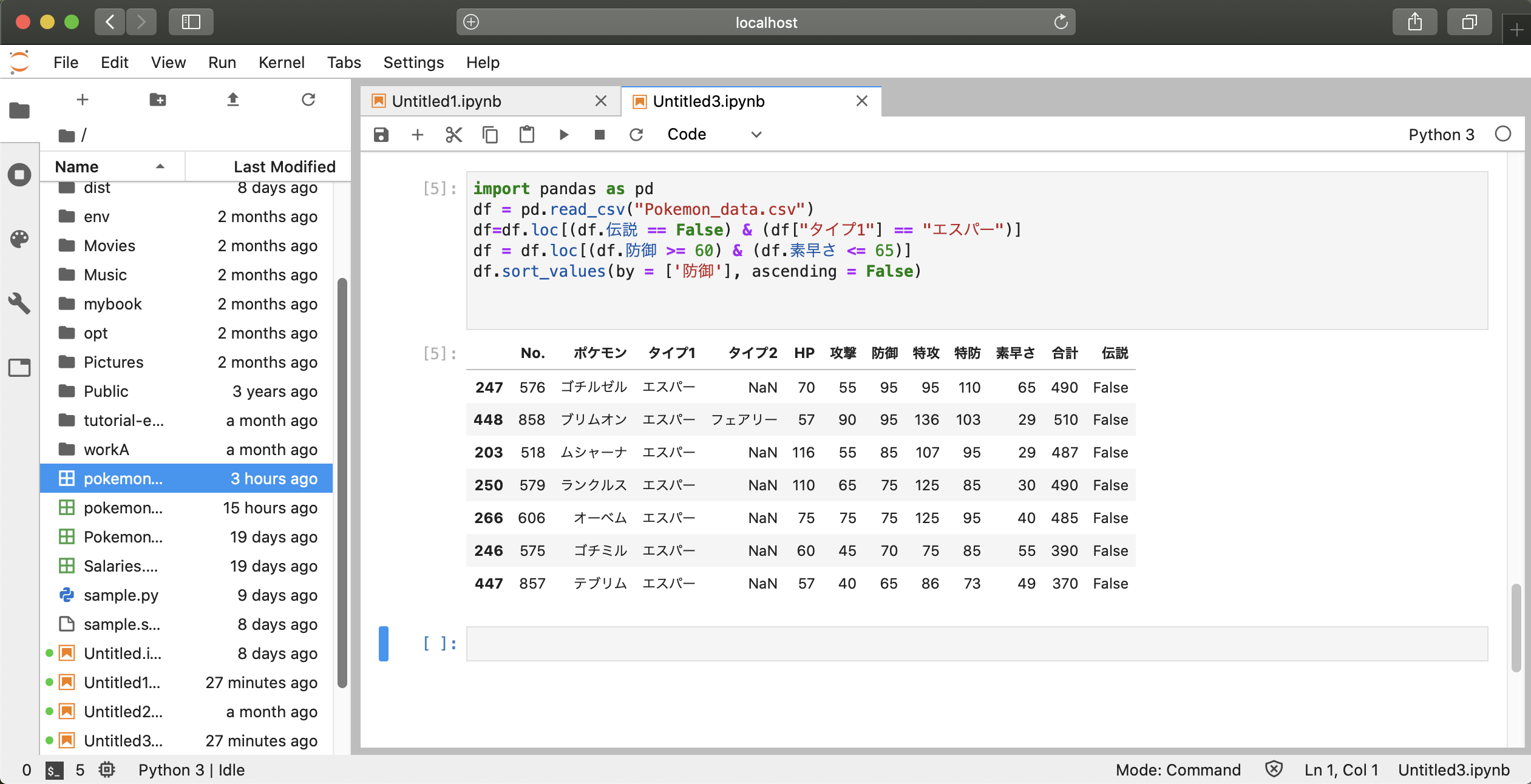
① csvファイルのダウンロードと作成
ポケモンの種族値のcsvファイルは下記のURLからダウンロードできます。 https://www.kaggle.com/abcsds/pokemon
このcsvファイルは7-8世代ポケモンのデータが入力されていません。また、英語表記なのでポケモンの名前も英語名になっているので多少扱いにくいところもあります。
エラーヒント:TypeError: ‘list’ object cannot be interpreted as an integer
通常、インデックスでlistまたはstringの要素を反復処理します。これには、range()関数を呼び出す必要があります。 このリストを返す代わりに、len値を返すことを忘れないでください。エラーは次のコードで発生します。
4)string値を変更する
エラーヒント:TypeError: ‘str’ object does not support item assignment
stringは不変のデータ型であり、エラーは次のコードで発生します。
5)文字列以外の値を文字列に接続する
エラーヒント:TypeError: Can’t convert ‘int’ object to str implicitly
エラーは次のコードで発生します。
6)文字列の最初と最後に「’」を追加するのを忘れた
エラーヒント:SyntaxError: EOL while scanning string literal
エラー次のコードで発生します。
7)変数名としてPythonキーワードを使用する
エラーヒント:SyntaxError: EOL while scanning string literal
Pythonキーワードは変数名として使用できません。このエラーは次のコードで発生します:
8)メソッド名のスペルが間違っている
エラーヒント:AttributeError: ‘str’ object has no attribute ‘lowerr’
このエラーは次のコードで発生します:
9)参照がリストの最大インデックスを超えている
エラーヒント:IndexError: list index out of range
このエラーは次のコードで発生します:
10)range()を使用して整数のリストを作成する
range()は実際にlist値ではなく「range object」を返すことを覚えておく必要があります。
エラーヒント:TypeError: ‘range’ object does not support item assignment
このエラーは次のコードで発生します:
import collections
N = int(input())
A = sorted(map(int, input().split()))
cnt = collections.defaultdict(int)
for a in A:
cnt[a] += 1
ans = sum(A)
Q = int(input())
for _ in range(Q):
B, C = map(int, input().split())
ans += (C - B) * cnt[B]
cnt[C] += cnt[B]
cnt[B] = 0