- 投稿日:2020-06-24T23:56:04+09:00
【AWS】AmazonLinuxにてZabbixマネージャー構築(OS側設定)
はじめに
AmazonLinuxでのZabbixマネージャーの構築方法についてアウトプットしていきたいと思います。
(今回は、OS設定のみアウトプットとします。)自宅環境
項目 説明 自宅PC Windows10 ターミナル TeraTerm 基盤環境
項目 説明 OS Amazon Linux 2 AMI (HVM), SSD Volume Type Size t2.large DB MySQL 5.7.26 ※DBはRDSを外付け
※AWSのベストプラクティスに沿って、作業用IAMユーザーにて作業
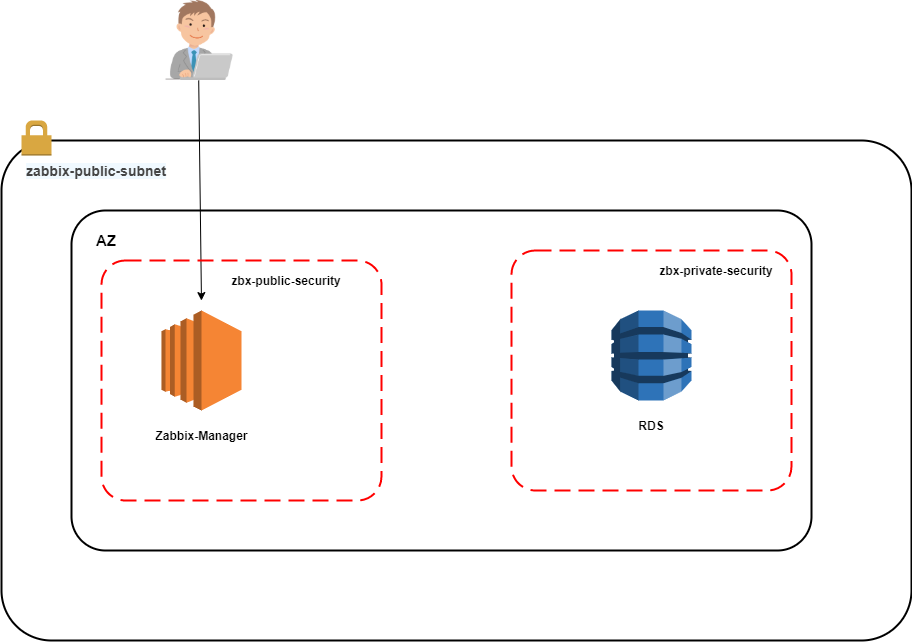
(ルートユーザーには多要素認証設定済み)構成図
手順
準備
- RDS(MySQL 5.7.26)を事前に作成しておく
- Zabbixマネージャーにターミナルソフトにてログインしておく
OS設定
(a).ルート権限にスイッチ
sudo su(b).アップデート
yum -y update(c).ホスト名変更
hostnamectl set-hostname zbxmgr(d).NTP確認・設定
「Amazon Time Sync Service」設定確認
①rootユーザーへ移行する。
[ec2-user@ip-192-168-8-74 ~]$ sudo su [root@ip-192-168-8-74 ec2-user]#②
chronyパッケージが存在することを確認[root@ip-192-168-8-74 ec2-user]# rpm -qa | grep chrony chrony-3.2-1.amzn2.0.5.x86_64 [root@ip-192-168-8-74 ec2-user]#③
/etc/chrony.confを確認
server 169.254.169.123 prefer iburst minpoll 4 maxpoll 4の一文が存在することを確認[root@ip-192-168-8-74 ec2-user]# cat /etc/chrony.conf | grep server server 169.254.169.123 prefer iburst minpoll 4 maxpoll 4 # Use public servers from the pool.ntp.org project. [root@ip-192-168-8-74 ec2-user]#④
chronyd起動&自動起動設定確認
chronyd起動確認
active (running)になっていること。[root@ip-192-168-8-74 ec2-user]# systemctl status chronyd ● chronyd.service - NTP client/server Loaded: loaded (/usr/lib/systemd/system/chronyd.service; enabled; vendor preset: enabled) Active: active (running) since Sun 2020-06-21 13:48:40 UTC; 9min ago Docs: man:chronyd(8) man:chrony.conf(5) Process: 2699 ExecStartPost=/usr/libexec/chrony-helper update-daemon (code=exited, status=0/SUCCESS) Process: 2680 ExecStart=/usr/sbin/chronyd $OPTIONS (code=exited, status=0/SUCCESS) Main PID: 2687 (chronyd) CGroup: /system.slice/chronyd.service mq2687 /usr/sbin/chronyd Jun 21 13:48:40 localhost systemd[1]: Starting NTP client/server... Jun 21 13:48:40 localhost chronyd[2687]: chronyd version 3.2 starting (+CMDM...) Jun 21 13:48:40 localhost systemd[1]: Started NTP client/server. Jun 21 13:48:46 ip-192-168-8-74.ap-northeast-1.compute.internal chronyd[2687]: ... Hint: Some lines were ellipsized, use -l to show in full. [root@ip-192-168-8-74 ec2-user]#
chronyd自動起動確認
enabledになっていること[root@ip-192-168-8-74 ec2-user]# systemctl is-enabled chronyd enabled [root@ip-192-168-8-74 ec2-user]#⑤時刻同期確認
chronyが169.254.169.123を使用して時刻を同期させていることを確認。
※*になっていれば、時刻同期ができている。[root@ip-192-168-8-74 ec2-user]# chronyc sources -v 210 Number of sources = 5 .-- Source mode '^' = server, '=' = peer, '#' = local clock. / .- Source state '*' = current synced, '+' = combined , '-' = not combined, | / '?' = unreachable, 'x' = time may be in error, '~' = time too variable. || .- xxxx [ yyyy ] +/- zzzz || Reachability register (octal) -. | xxxx = adjusted offset, || Log2(Polling interval) --. | | yyyy = measured offset, || \ | | zzzz = estimated error. || | | \ MS Name/IP address Stratum Poll Reach LastRx Last sample =============================================================================== ^* 169.254.169.123 3 4 377 1 -1396ns[-2259ns] +/- 535us ← こちらの部分 ^- x.ns.gin.ntt.net 2 6 377 40 +382us[ +388us] +/- 72ms ^- ntp-a2.nict.go.jp 1 6 377 39 +549us[ +554us] +/- 1604us ^- li1885-23.members.linode> 2 6 377 39 +615us[ +620us] +/- 28ms ^- ntp.arupaka.net 2 6 255 39 -2267us[-2262us] +/- 103ms [root@ip-192-168-8-74 ec2-user]#
※こちらでも確認可能です。[root@ip-192-168-8-74 ec2-user]# chronyc tracking Reference ID : A9FEA97B (169.254.169.123) Stratum : 4 Ref time (UTC) : Sun Jun 21 14:03:54 2020 System time : 0.000002454 seconds fast of NTP time Last offset : +0.000000805 seconds RMS offset : 0.000004196 seconds Frequency : 12.523 ppm fast Residual freq : +0.001 ppm Skew : 0.076 ppm Root delay : 0.000405045 seconds Root dispersion : 0.000289323 seconds Update interval : 16.1 seconds Leap status : Normal [root@ip-192-168-8-74 ec2-user]#日本語設定方法
①事前確認
時刻がUTC表記となっていることを確認
[root@ip-192-168-8-74 ec2-user]# date Sun Jun 21 14:05:48 UTC 2020 [root@ip-192-168-8-74 ec2-user]#②インスタンスで使用する時間帯を確認
Japanが存在することを確認[root@ip-192-168-8-74 ec2-user]# ls /usr/share/zoneinfo/ | grep Japan Japan [root@ip-192-168-8-74 ec2-user]#③clockファイルの変更
vim /etc/sysconfig/clock
- 変更前
[root@ip-192-168-8-74 ec2-user]# cat /etc/sysconfig/clock ZONE="UTC" UTC=true [root@ip-192-168-8-74 ec2-user]#
- 変更後
[root@ip-192-168-8-74 ec2-user]# cat /etc/sysconfig/clock #ZONE="UTC" ZONE="Japan" UTC=true [root@ip-192-168-8-74 ec2-user]#④時間帯ファイルにシンボリックリンクの作成
インスタンスが現地時間情報を参照する際に、時間帯ファイルを読み込むためシンボリックリンクを貼る。
[root@ip-192-168-8-74 ec2-user]# ln -sf /usr/share/zoneinfo/Japan /etc/localtime [root@ip-192-168-8-74 ec2-user]# ll /etc/localtime lrwxrwxrwx 1 root root 25 Jun 21 23:10 /etc/localtime -> /usr/share/zoneinfo/Japan [root@ip-192-168-8-74 ec2-user]#(e).SELinux無効化確認
[root@ip-192-168-5-129 ec2-user]# getenforce Disabled [root@ip-192-168-5-129 ec2-user]#(f).再起動
reboot(g).時間確認
日本時間になっていること。
[ec2-user@ip-192-168-8-74 ~]$ date Sun Jun 21 23:12:15 JST 2020 [ec2-user@ip-192-168-8-74 ~]$Zabbixパッケージインストール
(a).Zabbix4.2のリポジトリをインストール
rpm -Uvh https://repo.zabbix.com/zabbix/4.2/rhel/7/x86_64/zabbix-release-4.2-2.el7.noarch.rpm(b).Zabbix4.2関連のパッケージをインストール
yum -y install zabbix-server-mysql zabbix-web-mysql zabbix-web-japanese zabbix-agent(c).
php.iniのタイムゾーン設定
- 事前ファイルバックアップ
cp -p /etc/php.ini /etc/php.ini_20200624
- 設定ファイル編集
vim /etc/php.ini
diffにてバックアップファイルと比較[root@zbxmgr ec2-user]# diff /etc/php.ini /etc/php.ini_20200624 878c878 < date.timezone = Asia/Tokyo --- > ;date.timezone = [root@zbxmgr ec2-user]#MySQLインストール・設定
(a).MySQLクライアントのインストール
yum -y install mysql mysql-devel(b).RDSへ接続
mysql -h RDSのエンドポイント -P 3306 -u ユーザ名 -p実行例
[root@zbxmgr ec2-user]# mysql -h test-zabbix-1.cfwpl4233294.ap-northeast-1.rds.amazonaws.com -P 3306 -u zabbix -p Enter password: ← RDS作成時に設定したパスワードを入力 Welcome to the MariaDB monitor. Commands end with ; or \g. Your MySQL connection id is 28 Server version: 5.7.26-log Source distribution Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MySQL [(none)]>(c).Zabbixデータベース/Zabbixユーザーの作成
- Zabbixのデータベースを作成
MySQL [(none)]> create database zabbix character set utf8 collate utf8_bin; Query OK, 1 row affected (0.00 sec) MySQL [(none)]>
- Zabbixのユーザーの作成
grant all on zabbix.* to <DBのユーザー>@`%` identified by '<DBのパスワード>';実行例)
MySQL [(none)]> grant all on zabbix.* to zabbix@`%` identified by 'P@ssw0rd'; Query OK, 0 rows affected, 1 warning (0.00 sec) MySQL [(none)]>
- MySQLから抜ける
MySQL [(none)]> quit; Bye [root@zbxmgr ec2-user]#(d).Zabbixの初期データを登録する。
zcat /usr/share/doc/zabbix-server-mysql*/create.sql.gz | mysql -h <RDSのエンドポイント> -P 3306 -u <ユーザ名> -p zabbix実行例)
[root@zbxmgr ec2-user]# zcat /usr/share/doc/zabbix-server-mysql*/create.sql.gz | mysql -h test-zabbix-1.cfwpl4233294.ap-northeast-1.rds.amazonaws.com -P 3306 -u zabbix -p zabbix Enter password: ←「Zabbixユーザーの作成」で設定したパスワード [root@zbxmgr ec2-user]#(e).DB情報登録
- ファイルバックアップ
cp -p /etc/zabbix/zabbix_server.conf /etc/zabbix/zabbix_server.conf_20200624
- ファイル修正
sudo vim /etc/zabbix/zabbix_server.conf DBHost=RDSのエンドポイント DBPassword=RDSのパスワード
diffにて比較[root@zbxmgr ec2-user]# diff /etc/zabbix/zabbix_server.conf /etc/zabbix/zabbix_s erver.conf_20200624 91c91 < DBHost= test-zabbix-1.cfwplijf9ni4.ap-northeast-1.rds.amazonaws.com --- > # DBHost=localhost 124c124 < DBPassword=P@ssw0rd --- > # DBPassword= [root@zbxmgr ec2-user]#(f).zabbix-server/httpdの起動・自動起動
systemctl start httpd systemctl enable httpd systemctl start zabbix-server systemctl enable zabbix-serverZabbix Agent起動・自動起動設定
systemctl start zabbix-agent systemctl enable zabbix-agentZabbixのGUI接続
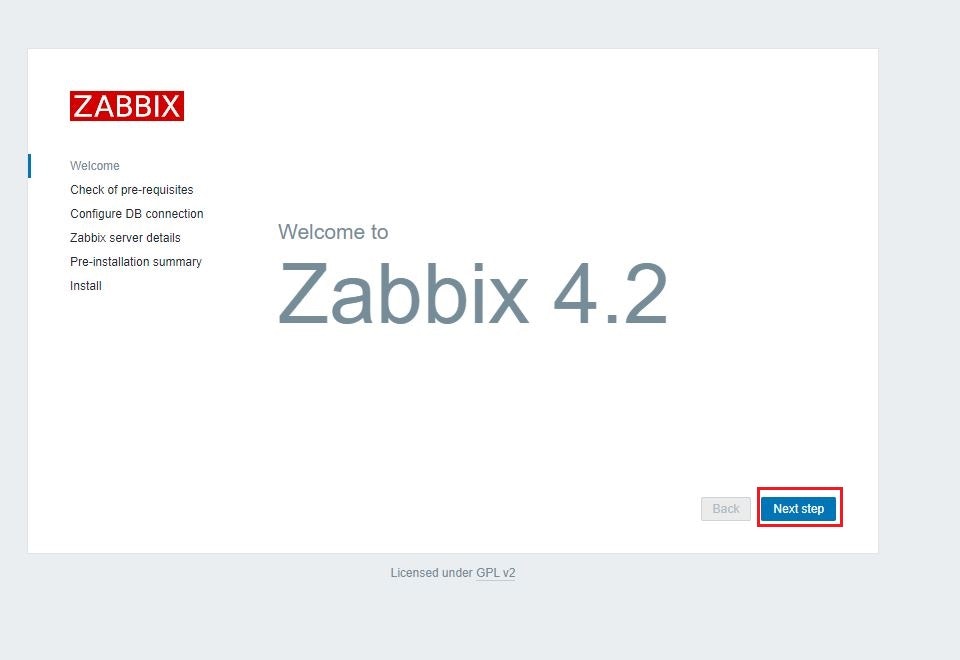
(a)ブラウザにて「http://(インスタンスのパブリックIP)/zabbix」へ接続
下記の画面が表示されることを確認。「Next Step」をクリック。
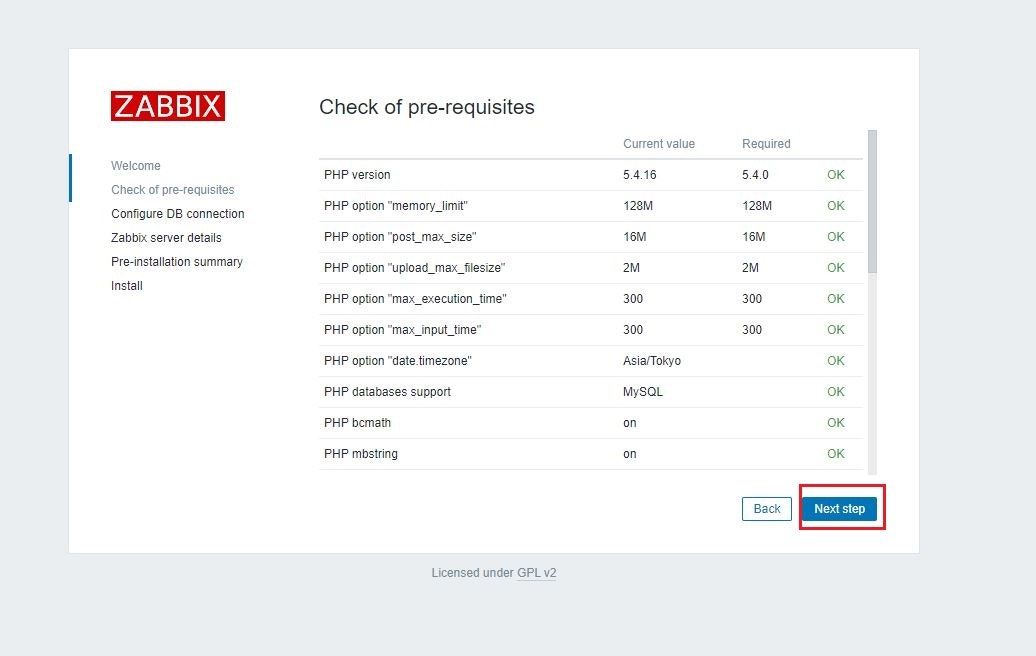
(b)Check of pre-requisites
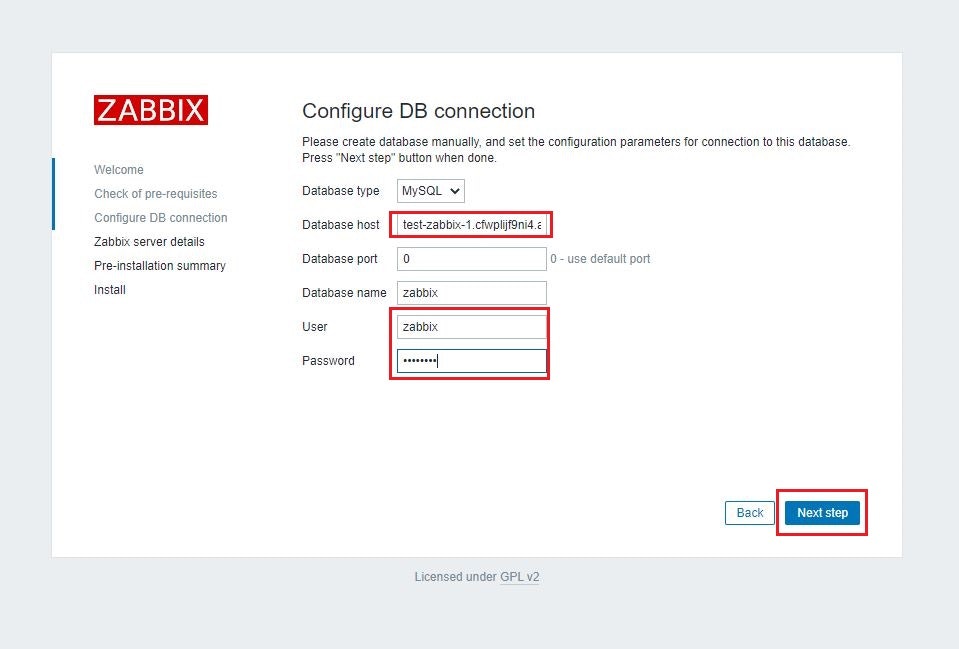
(c)DB情報入力
赤枠に必要な情報を入力
項目 設定値 Database host RDSのエンドポイント User DBのユーザー Password DBのパスワード ※DBのユーザー/DBのパスワードは「(c).Zabbixデータベース/Zabbixユーザーの作成」で設定したもの
(d) Zabbix server details
そのまま「Next step」をクリック
(e) Pre-installation summary
そのまま「Next step」をクリック
(f) インストール完了画面
下記のような画面が表示されることを確認。「Finish」をクリック。
(g) ログイン画面
下記情報を入力し、Sign-in実施
項目 設定値 初期ユーザ Admin 初期パスワード zabbix
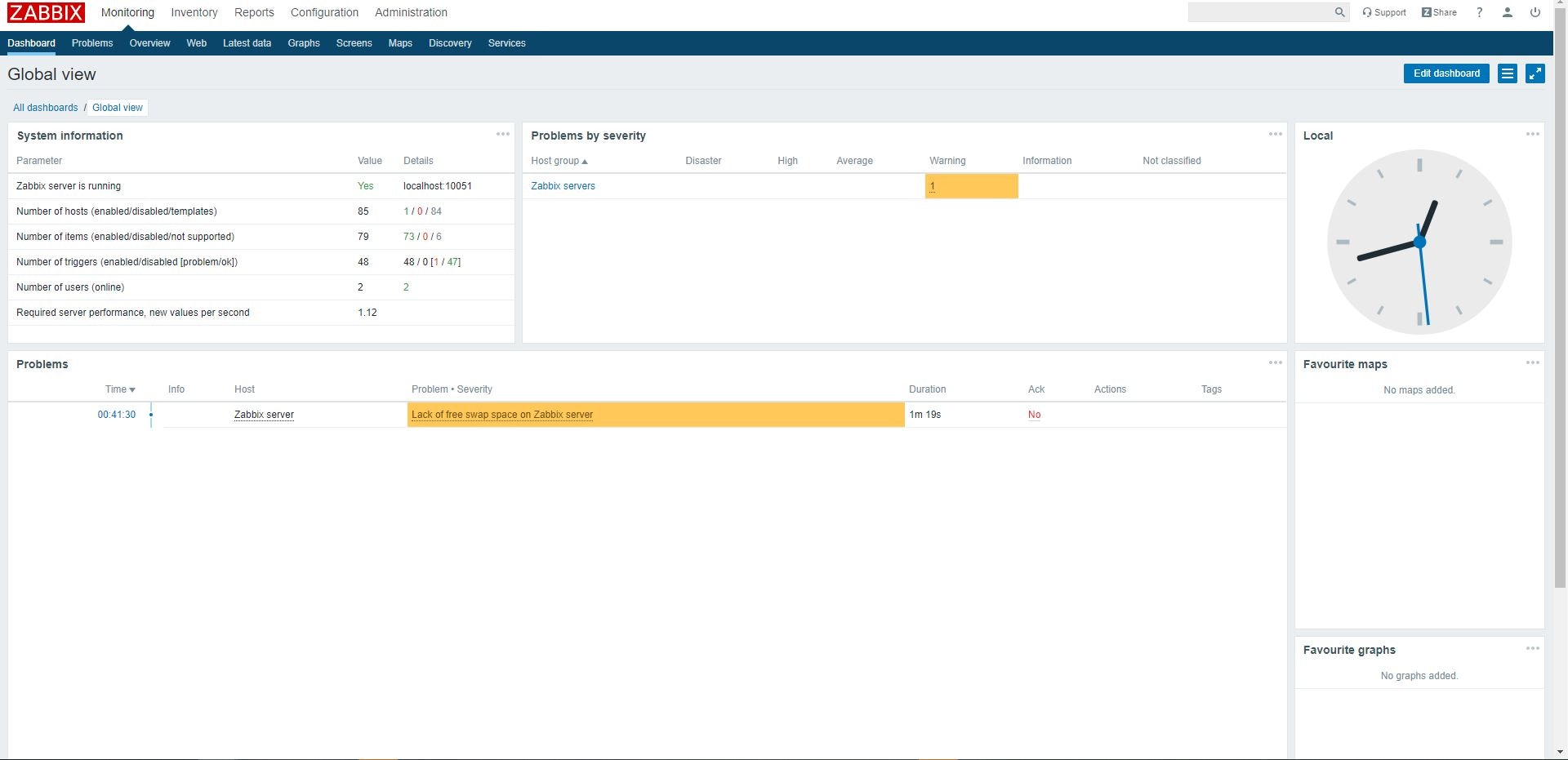
(h) Zabbix管理画面表示確認
下記画面が表示されることを確認。
備考
今回はOS設定のみアウトプットしました。
時間を作って、AWS側設定/Zabbix監視設定もアウトプットしたいと思います。
(私のブログにZabbix構築総集編も作成する予定です。)参考
【AWS】AmazonLinuxのNTP設定確認&日本語時刻設定方法
zabbix インストール時のTimezone for PHP is not set. Please set "date.timezone" option in php.ini.

- 投稿日:2020-06-24T23:56:04+09:00
【AWS】AmazonLinuxにてZabbixマネージャー構築
はじめに
AmazonLinuxでのZabbixマネージャーの構築方法についてアウトプットしていきたいと思います。
(今回は、OS設定のみアウトプットとします。)自宅環境
項目 説明 自宅PC Windows10 ターミナル TeraTerm 基盤環境
項目 説明 OS Amazon Linux 2 AMI (HVM), SSD Volume Type Size t2.large DB MySQL 5.7.26 ※DBはRDSを外付け
※AWSのベストプラクティスに沿って、作業用IAMユーザーにて作業
(ルートユーザーには多要素認証設定済み)構成図
手順
準備
- RDS(MySQL 5.7.26)を事前に作成しておく
- Zabbixマネージャーにターミナルソフトにてログインしておく
OS設定
(a).ルート権限にスイッチ
sudo su(b).アップデート
yum -y update(c).ホスト名変更
hostnamectl set-hostname zbxmgr(d).NTP確認・設定
「Amazon Time Sync Service」設定確認
①rootユーザーへ移行する。
[ec2-user@ip-192-168-8-74 ~]$ sudo su [root@ip-192-168-8-74 ec2-user]#②
chronyパッケージが存在することを確認[root@ip-192-168-8-74 ec2-user]# rpm -qa | grep chrony chrony-3.2-1.amzn2.0.5.x86_64 [root@ip-192-168-8-74 ec2-user]#③
/etc/chrony.confを確認
server 169.254.169.123 prefer iburst minpoll 4 maxpoll 4の一文が存在することを確認[root@ip-192-168-8-74 ec2-user]# cat /etc/chrony.conf | grep server server 169.254.169.123 prefer iburst minpoll 4 maxpoll 4 # Use public servers from the pool.ntp.org project. [root@ip-192-168-8-74 ec2-user]#④
chronyd起動&自動起動設定確認
chronyd起動確認
active (running)になっていること。[root@ip-192-168-8-74 ec2-user]# systemctl status chronyd ● chronyd.service - NTP client/server Loaded: loaded (/usr/lib/systemd/system/chronyd.service; enabled; vendor preset: enabled) Active: active (running) since Sun 2020-06-21 13:48:40 UTC; 9min ago Docs: man:chronyd(8) man:chrony.conf(5) Process: 2699 ExecStartPost=/usr/libexec/chrony-helper update-daemon (code=exited, status=0/SUCCESS) Process: 2680 ExecStart=/usr/sbin/chronyd $OPTIONS (code=exited, status=0/SUCCESS) Main PID: 2687 (chronyd) CGroup: /system.slice/chronyd.service mq2687 /usr/sbin/chronyd Jun 21 13:48:40 localhost systemd[1]: Starting NTP client/server... Jun 21 13:48:40 localhost chronyd[2687]: chronyd version 3.2 starting (+CMDM...) Jun 21 13:48:40 localhost systemd[1]: Started NTP client/server. Jun 21 13:48:46 ip-192-168-8-74.ap-northeast-1.compute.internal chronyd[2687]: ... Hint: Some lines were ellipsized, use -l to show in full. [root@ip-192-168-8-74 ec2-user]#
chronyd自動起動確認
enabledになっていること[root@ip-192-168-8-74 ec2-user]# systemctl is-enabled chronyd enabled [root@ip-192-168-8-74 ec2-user]#⑤時刻同期確認
chronyが169.254.169.123を使用して時刻を同期させていることを確認。
※*になっていれば、時刻同期ができている。[root@ip-192-168-8-74 ec2-user]# chronyc sources -v 210 Number of sources = 5 .-- Source mode '^' = server, '=' = peer, '#' = local clock. / .- Source state '*' = current synced, '+' = combined , '-' = not combined, | / '?' = unreachable, 'x' = time may be in error, '~' = time too variable. || .- xxxx [ yyyy ] +/- zzzz || Reachability register (octal) -. | xxxx = adjusted offset, || Log2(Polling interval) --. | | yyyy = measured offset, || \ | | zzzz = estimated error. || | | \ MS Name/IP address Stratum Poll Reach LastRx Last sample =============================================================================== ^* 169.254.169.123 3 4 377 1 -1396ns[-2259ns] +/- 535us ← こちらの部分 ^- x.ns.gin.ntt.net 2 6 377 40 +382us[ +388us] +/- 72ms ^- ntp-a2.nict.go.jp 1 6 377 39 +549us[ +554us] +/- 1604us ^- li1885-23.members.linode> 2 6 377 39 +615us[ +620us] +/- 28ms ^- ntp.arupaka.net 2 6 255 39 -2267us[-2262us] +/- 103ms [root@ip-192-168-8-74 ec2-user]#
※こちらでも確認可能です。[root@ip-192-168-8-74 ec2-user]# chronyc tracking Reference ID : A9FEA97B (169.254.169.123) Stratum : 4 Ref time (UTC) : Sun Jun 21 14:03:54 2020 System time : 0.000002454 seconds fast of NTP time Last offset : +0.000000805 seconds RMS offset : 0.000004196 seconds Frequency : 12.523 ppm fast Residual freq : +0.001 ppm Skew : 0.076 ppm Root delay : 0.000405045 seconds Root dispersion : 0.000289323 seconds Update interval : 16.1 seconds Leap status : Normal [root@ip-192-168-8-74 ec2-user]#日本語設定方法
①事前確認
時刻がUTC表記となっていることを確認
[root@ip-192-168-8-74 ec2-user]# date Sun Jun 21 14:05:48 UTC 2020 [root@ip-192-168-8-74 ec2-user]#②インスタンスで使用する時間帯を確認
Japanが存在することを確認[root@ip-192-168-8-74 ec2-user]# ls /usr/share/zoneinfo/ | grep Japan Japan [root@ip-192-168-8-74 ec2-user]#③clockファイルの変更
vim /etc/sysconfig/clock
- 変更前
[root@ip-192-168-8-74 ec2-user]# cat /etc/sysconfig/clock ZONE="UTC" UTC=true [root@ip-192-168-8-74 ec2-user]#
- 変更後
[root@ip-192-168-8-74 ec2-user]# cat /etc/sysconfig/clock #ZONE="UTC" ZONE="Japan" UTC=true [root@ip-192-168-8-74 ec2-user]#④時間帯ファイルにシンボリックリンクの作成
インスタンスが現地時間情報を参照する際に、時間帯ファイルを読み込むためシンボリックリンクを貼る。
[root@ip-192-168-8-74 ec2-user]# ln -sf /usr/share/zoneinfo/Japan /etc/localtime [root@ip-192-168-8-74 ec2-user]# ll /etc/localtime lrwxrwxrwx 1 root root 25 Jun 21 23:10 /etc/localtime -> /usr/share/zoneinfo/Japan [root@ip-192-168-8-74 ec2-user]#(e).SELinux無効化確認
[root@ip-192-168-5-129 ec2-user]# getenforce Disabled [root@ip-192-168-5-129 ec2-user]#(f).再起動
reboot(g).時間確認
日本時間になっていること。
[ec2-user@ip-192-168-8-74 ~]$ date Sun Jun 21 23:12:15 JST 2020 [ec2-user@ip-192-168-8-74 ~]$Zabbixパッケージインストール
(a).Zabbix4.2のリポジトリをインストール
rpm -Uvh https://repo.zabbix.com/zabbix/4.2/rhel/7/x86_64/zabbix-release-4.2-2.el7.noarch.rpm(b).Zabbix4.2関連のパッケージをインストール
yum -y install zabbix-server-mysql zabbix-web-mysql zabbix-web-japanese zabbix-agent(c).
php.iniのタイムゾーン設定
- 事前ファイルバックアップ
cp -p /etc/php.ini /etc/php.ini_20200624
- 設定ファイル編集
vim /etc/php.ini
diffにてバックアップファイルと比較[root@zbxmgr ec2-user]# diff /etc/php.ini /etc/php.ini_20200624 878c878 < date.timezone = Asia/Tokyo --- > ;date.timezone = [root@zbxmgr ec2-user]#MySQLインストール・設定
(a).MySQLクライアントのインストール
yum -y install mysql mysql-devel(b).RDSへ接続
mysql -h RDSのエンドポイント -P 3306 -u ユーザ名 -p実行例
[root@zbxmgr ec2-user]# mysql -h test-zabbix-1.cfwpl4233294.ap-northeast-1.rds.amazonaws.com -P 3306 -u zabbix -p Enter password: ← RDS作成時に設定したパスワードを入力 Welcome to the MariaDB monitor. Commands end with ; or \g. Your MySQL connection id is 28 Server version: 5.7.26-log Source distribution Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MySQL [(none)]>(c).Zabbixデータベース/Zabbixユーザーの作成
- Zabbixのデータベースを作成
MySQL [(none)]> create database zabbix character set utf8 collate utf8_bin; Query OK, 1 row affected (0.00 sec) MySQL [(none)]>
- Zabbixのユーザーの作成
grant all on zabbix.* to <DBのユーザー>@`%` identified by '<DBのパスワード>';実行例)
MySQL [(none)]> grant all on zabbix.* to zabbix@`%` identified by 'P@ssw0rd'; Query OK, 0 rows affected, 1 warning (0.00 sec) MySQL [(none)]>
- MySQLから抜ける
MySQL [(none)]> quit; Bye [root@zbxmgr ec2-user]#(d).Zabbixの初期データを登録する。
zcat /usr/share/doc/zabbix-server-mysql*/create.sql.gz | mysql -h <RDSのエンドポイント> -P 3306 -u <ユーザ名> -p zabbix実行例)
[root@zbxmgr ec2-user]# zcat /usr/share/doc/zabbix-server-mysql*/create.sql.gz | mysql -h test-zabbix-1.cfwpl4233294.ap-northeast-1.rds.amazonaws.com -P 3306 -u zabbix -p zabbix Enter password: ←「Zabbixユーザーの作成」で設定したパスワード [root@zbxmgr ec2-user]#(e).DB情報登録
- ファイルバックアップ
cp -p /etc/zabbix/zabbix_server.conf /etc/zabbix/zabbix_server.conf_20200624
- ファイル修正
sudo vim /etc/zabbix/zabbix_server.conf DBHost=RDSのエンドポイント DBPassword=RDSのパスワード
diffにて比較[root@zbxmgr ec2-user]# diff /etc/zabbix/zabbix_server.conf /etc/zabbix/zabbix_s erver.conf_20200624 91c91 < DBHost= test-zabbix-1.cfwplijf9ni4.ap-northeast-1.rds.amazonaws.com --- > # DBHost=localhost 124c124 < DBPassword=P@ssw0rd --- > # DBPassword= [root@zbxmgr ec2-user]#(f).zabbix-server/httpdの起動・自動起動
systemctl start httpd systemctl enable httpd systemctl start zabbix-server systemctl enable zabbix-serverZabbix Agent起動・自動起動設定
systemctl start zabbix-agent systemctl enable zabbix-agentZabbixのGUI接続
(a)ブラウザにて「http://(インスタンスのパブリックIP)/zabbix」へ接続
下記の画面が表示されることを確認。「Next Step」をクリック。
(b)Check of pre-requisites
(c)DB情報入力
赤枠に必要な情報を入力
項目 設定値 Database host RDSのエンドポイント User DBのユーザー Password DBのパスワード ※DBのユーザー/DBのパスワードは「(c).Zabbixデータベース/Zabbixユーザーの作成」で設定したもの
(d) Zabbix server details
そのまま「Next step」をクリック
(e) Pre-installation summary
そのまま「Next step」をクリック
(f) インストール完了画面
下記のような画面が表示されることを確認。「Finish」をクリック。
(g) ログイン画面
下記情報を入力し、Sign-in実施
項目 設定値 初期ユーザ Admin 初期パスワード zabbix
(h) Zabbix管理画面表示確認
下記画面が表示されることを確認。
備考
今回はOS設定のみアウトプットしました。
時間を作って、AWS側設定/Zabbix監視設定もアウトプットしたいと思います。
(私のブログにZabbix構築総集編も作成する予定です。)参考
【AWS】AmazonLinuxのNTP設定確認&日本語時刻設定方法
zabbix インストール時のTimezone for PHP is not set. Please set "date.timezone" option in php.ini.
- 投稿日:2020-06-24T23:35:37+09:00
SAMでS3にCSVファイルアップロードをトリガーにDynamoDBへの登録処理の作成
概要
S3にCSVファイルをアップロードすることでLambdaを起動させてDynamoDBに登録する処理を作成したのでその時の内容です。公式ドキュメントにはいろいろ乗っているので基本はそちらを見るといいかも?
前回の投稿で作成したDynamoDBを使うSAM側の内容です。template
template.yamlの定義は以下のようになります
AWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: > writeSignalDatas Sample SAM Template for writeSignalDatas # More info about Globals: https://github.com/awslabs/serverless-application-model/blob/master/docs/globals.rst Globals: Function: Timeout: 3 Resources: WriteSignalDatasFunction: Type: AWS::Serverless::Function # More info about Function Resource: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#awsserverlessfunction Properties: CodeUri: writeSignalDatas/ Handler: app.lambda_handler Runtime: python3.7 Policies: AWSLambdaExecute Events: WriteSignalDatasEvent: Type: S3 Properties: Bucket: !Ref SignalDataBucket Events: s3:ObjectCreated:* SignalDataBucket: Type: AWS::S3::Bucket作成手順
- コマンドsamを実行するためcloud9を起動
- windowsでは文字コードの問題などでいろいろ面倒だったのでcloud9を使いました
- SAMのインストール 公式サイト を参照 dockerのインストールはスキップしました
- 以下の順でコマンドを実行してテンプレートを作成します 公式のチュートリアルの要領で実施しました
sam init
- ここでクイックスタートテンプレート、言語はpython、HelloWorldのサンプルを作成するものを選びました
- 作成されたymlを上記の内容で修正、記載は次回以降予定ですがHelloWorldのディレクトリやモジュールを使いたい内容に修正
sam validate
- 修正したymlが正しいかの検証を行う
sam build
- プログラムを修正したときは実施が必要です。
sam deploy --guided
- デプロイを行います
--guidedを付けることでregionなどの設定ができます。処理の内容などは次回以降・・・
- 投稿日:2020-06-24T22:32:55+09:00
AWSアカウント間のドメイン移管はAWSサポートを使わずawscliだけでできるようになった
タイトルの通り。
概要
AWSの別アカウントにドメインを移行する際、AWSサポートを使わないとできないという印象があり、面倒だなとずっと思っていた。
が、今ドキュメントを見るとawscliで普通にできるようになってた。
実践
移管元のAWSアカウントを
111111111111
移管先のAWSアカウントを222222222222
とする。移管元
移管元のアカウントで「ドメイン転送するよ!」のコマンドを打つ。
awscliでtransfer-domain-to-another-aws-accountを実行すればよい。# user is 111111111111 aws route53domains transfer-domain-to-another-aws-account --domain-name mogemoge.com --account-id 222222222222戻り値にパスワードが返って来るので
Passwordを覚えておく。{ "OperationId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx", "Password": "password" }移管先
移管先のアカウントで「受け取るよ!」のコマンドを打つ。
awscliでaccept-domain-transfer-from-another-aws-accountを実行すればよい。# user is 222222222222 aws route53domains accept-domain-transfer-from-another-aws-account --domain-name mogemoge.com --password 上記で取得したパスワード注意点
通常のドメイン手続きを一切しないで上記コマンドを2回だけ打つこと
普通のドメイン転送の手続きをやって「あれーできないーー」となっていたものの、AWSアカウント同士の移管は上記のコマンドを打つ特別なオペレーションというわけでした。
Could not connect to the endpoint URL: "https://route53domains.ap-northeast-1.amazonaws.com/" とか言われる
route53はグローバルサービスなのでawscliの引数に
--region us-east-1を加えましょう。参照
- 投稿日:2020-06-24T19:30:31+09:00
ECSに合わせたCodePipelineについて、めちゃめちゃ詳しく書いてみた (AWS, CI/CD)
よくAWSに触れるものです。
AWSにはCodePipelineというかなりカスタマイズ性に優れたCI/CDがあります。
そしてスケーリング、管理の簡易性に優れたECSに合わせたCodePipelineの使い方のドキュメントが少ないのと一般記事が少なかったので、かなり詳細に書きました。
システム全体のcloudformationテンプレートも載せているので構築の際に参考にしてください。
■ヘヴィメタル・エンジニアリング
・CodePipeline構築の記事
https://xkenshirou.hatenablog.com/entry/2020/06/13/125235
- 投稿日:2020-06-24T19:04:02+09:00
[AWS]CloudFrontのキャッシュをEC2から削除する
CloudFrontのキャッシュ削除はAWSコンソールから手動で行うことができますが、
デプロイ時に自動化するために、EC2からキャッシュ削除する方法をまとめました。EC2+S3+CloudFrontは構築済みの前提で説明します。
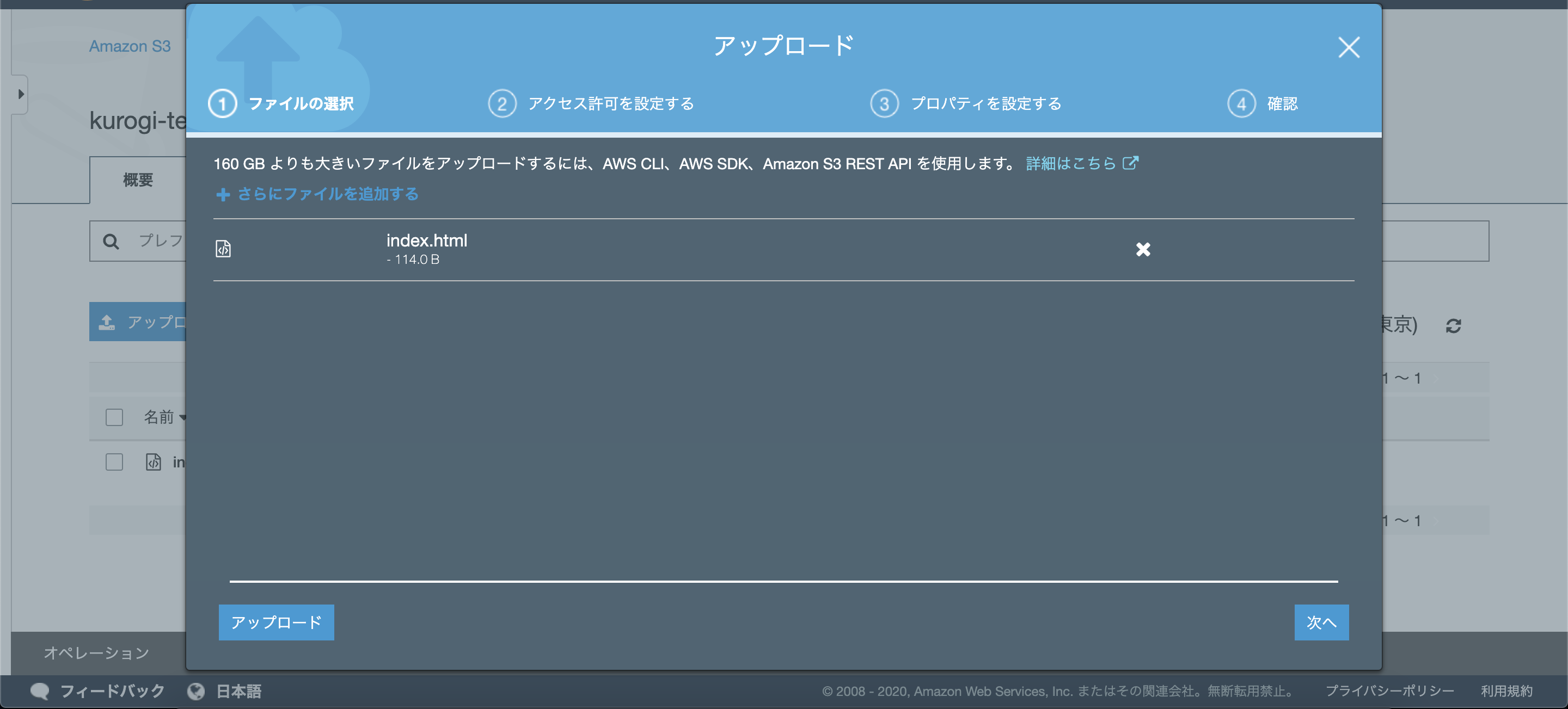
1. S3へファイルアップロードする
まずはテスト用のファイルをアップロードします。
AWSコンソール > サービス > S3 > 該当バケット > アップロード
でS3へ適当な画像ファイルやHTMLファイルなどをアップロードします。
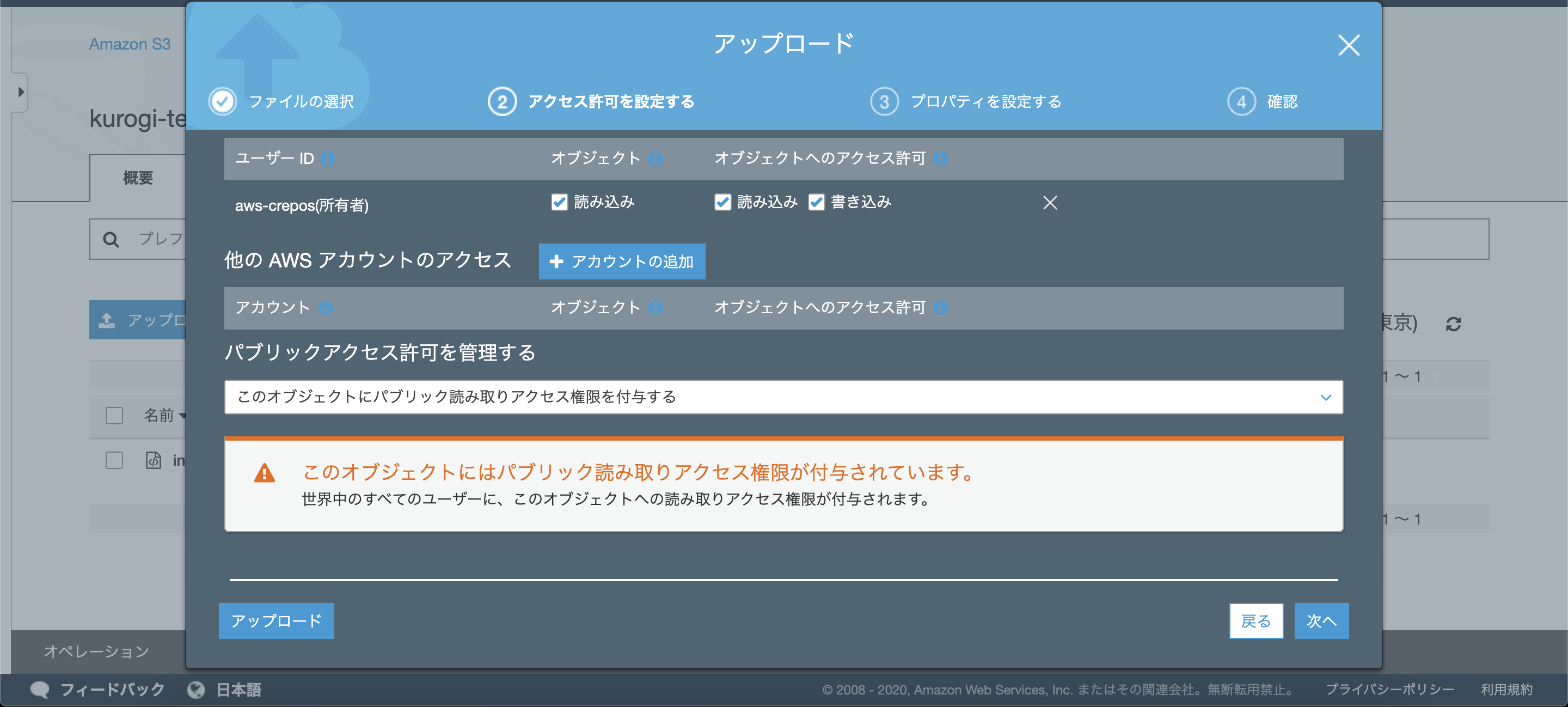
次へを押して、後の確認のためパブリックアクセス権を付与してください。
それ以外の設定はデフォルトでOKで、アップロードを押してください。
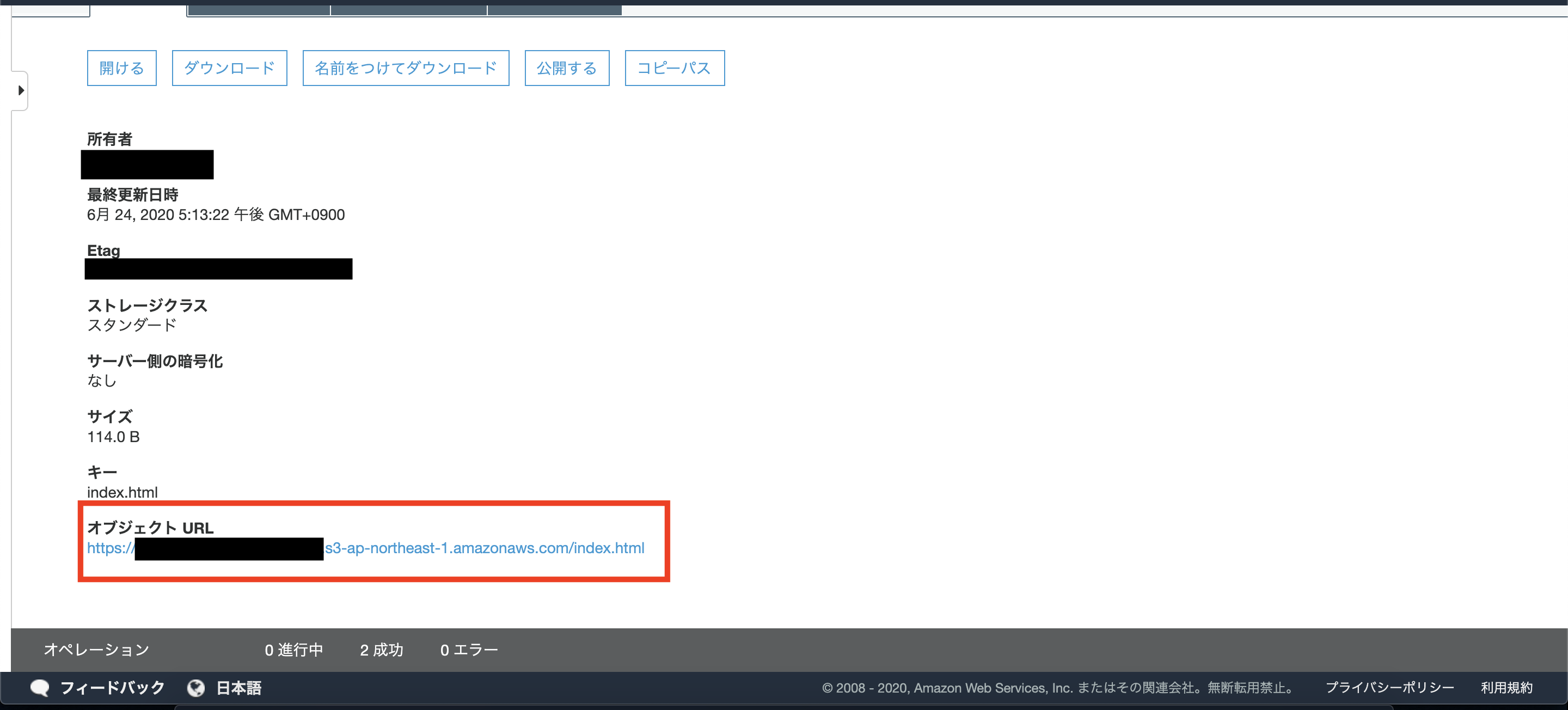
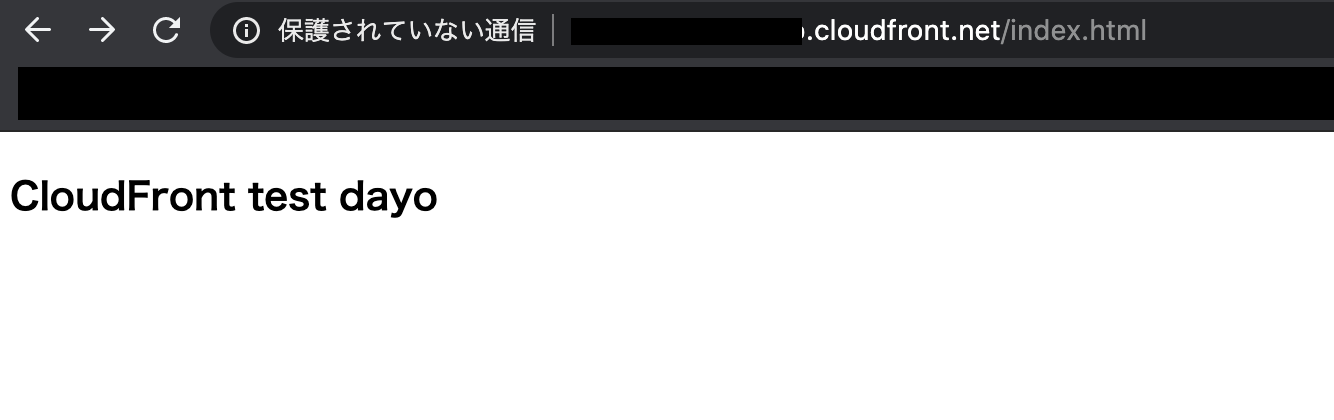
アップロードされたもの詳細を表示し、オブジェクトURLへアクセスし内容を確認してください、
ちなみに今回アップロードしたものはこのような内容です。
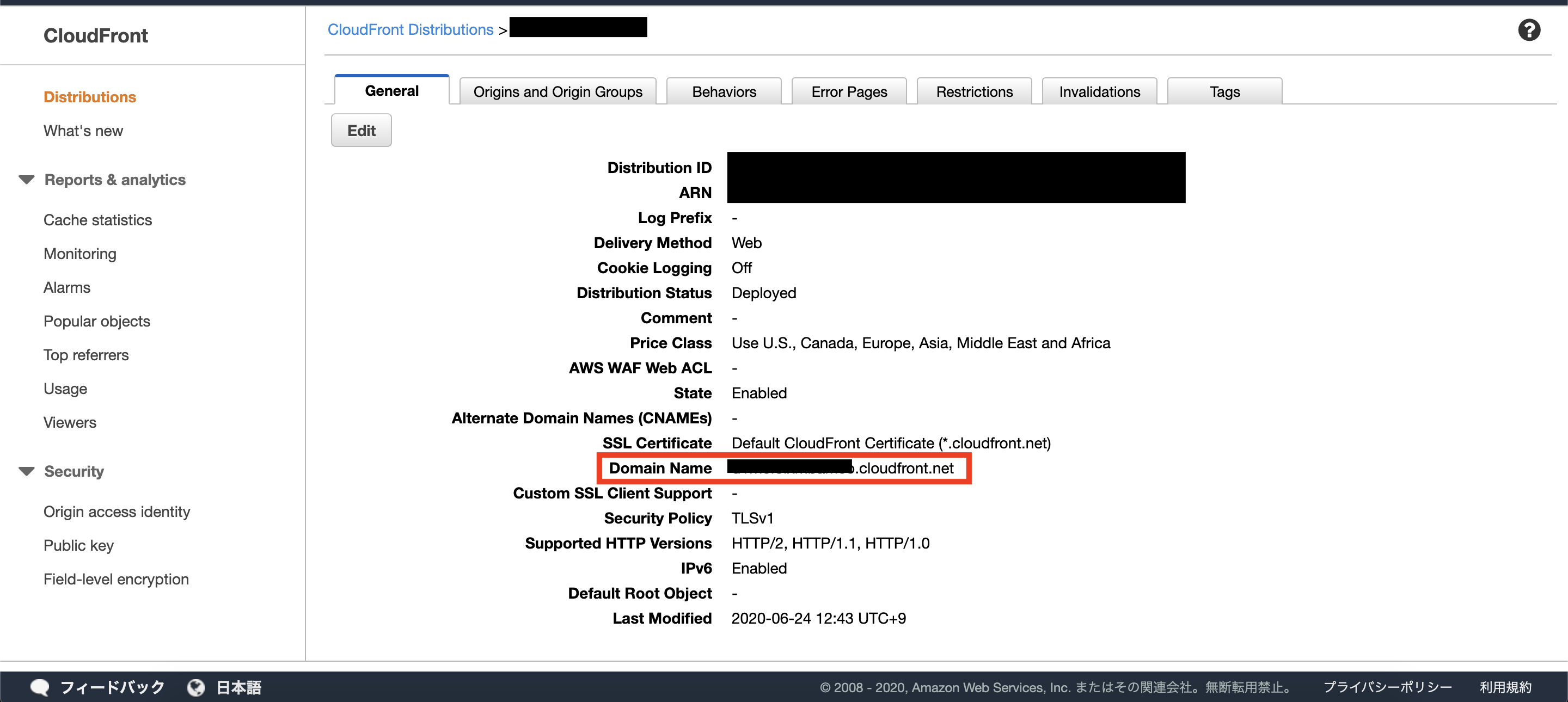
CloudFrontのURLへアクセスします。
AWSコンソール > サービス > CloudFront > 該当のディストリビューション
で詳細を表示し、Domain Nameを確認します。
その後ろに、S3でアップロードしたオブジェクトのパスを付与すると該当のファイルへのURLとなります。
https://<domain name>/<object name>
同じ内容が表示されていればOKです。
ちなみに自分は↓の現象に当たったので、S3バケットを作り直しました。
S3+CloudFrontでS3のURLにリダイレクトされてしまう場合の対処法 | Developers.IO
でも作り直さなくても気長に反映されるまで待てば問題ないです。2. S3のファイル上書きする
デプロイ時の状況をシミュレーションします。
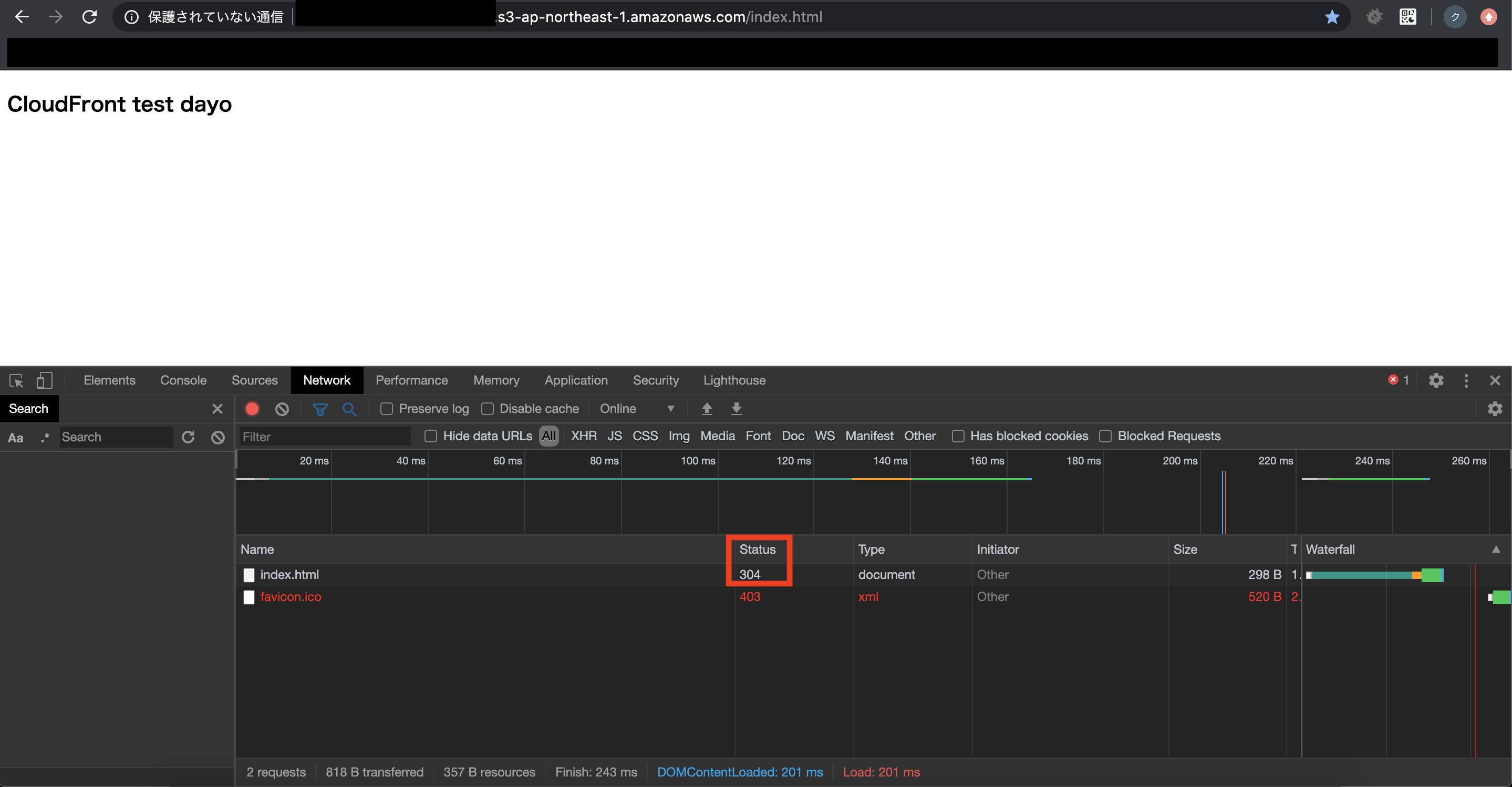
オリジンサーバ(S3)とキャッシュサーバ(CloudFront)の内容に差異をつけるため、S3の内容を変更します。
先ほどと同じ手順で、同じファイル名かつ違う内容のファイルをS3にアップロードすればOKです。再アップロードした後、
先ほどアクセスしたS3のURLとCloudFrontのURLへそれぞれアクセスし、
S3は変更後の内容、CloudFrontは変更前の内容になっていることを確認します。CloudFrontのステータスコードは304(リソース未更新)が返ってきていると思います。
3. キャッシュ削除する
CloudFrontキャッシュの削除とは、公式だとファイルの無効化(CreateInvalidation)を指します。
これを行うためにCloudFront APIを利用します。
このAPIを利用する方法として、シェルスクリプトで行う場合と、PHPで行う場合を説明します。3-1. シェルスクリプトで削除する
AWS CLIをインストール&設定したのちに
$ aws cloudfront create-invalidation
のコマンドでキャッシュ削除することができます。
詳細:create-invalidation — AWS CLI 2.0.24 Command ReferenceEC2の任意フォルダ内に以下のファイルを作成
clear_cache.sh#!/bin/bash echo "CloudFront cache clear..." aws cloudfront create-invalidation \ --distribution-id "EDFDVBD6EXAMPLE" \ --paths "/*"権限付与して実行
$ chmod 755 clear_cache.sh $ ./clear_cache.sh出力結果
CloudFront cache clear... { "Invalidation": { "Status": "InProgress", "InvalidationBatch": { "Paths": { "Items": [ "/*" ], "Quantity": 1 }, "CallerReference": "cli-1592983262-260490" }, "Id": "XXXXXXXXXX", "CreateTime": "2020-06-24T07:21:03.500Z" }, "Location": "https://cloudfront.amazonaws.com/2019-03-26/distribution/EDFDVBD6EXAMPLE/invalidation/XXXXXXXXXX" }参考
CloudFrontキャッシュを削除するシェルスクリプトを書いてみた。 - Qiita3-2. PHPで削除する
今回はPHPですが、AWS SDKは他の言語もいろいろあるのでなんでも良いと思います。
AWS SDK for PHPをインストールしたのち
Aws\CloudFront\CloudFrontClient のオブジェクトを利用して
$result = $client->createInvalidation([/* ... */]);または
$promise = $client->createInvalidationAsync([/* ... */]);
のコマンドでキャッシュ削除することができます。
AWS SDK for PHP 3.xEC2の任意フォルダ内に以下のファイルを作成
clear_cache.php<?php require 'vendor/autoload.php'; use Aws\CloudFront\CloudFrontClient; use Aws\Exception\AwsException; echo('CloudFront cache clear...'."\n"); $access_key = "xxxxxx"; $access_secret = "xxxxxx"; $distribution_id = "XXXXXX"; $paths = [ '/*', ]; $client = new CloudFrontClient([ 'region' => 'us-east-1', 'version' => '2019-03-26', 'credentials' => [ 'key' => $access_key, 'secret' => $access_secret, ], ]); /** @var \Aws\Result $result */ $result = $client->createInvalidation([ 'DistributionId' => $distribution_id, 'InvalidationBatch' => [ 'Paths' => [ 'Quantity' => count($paths), 'Items' => $paths, ], 'CallerReference' => time(), ], ]); var_dump($result); ?>実行
$ php clear_cache.php出力結果
CloudFront cache clear... /home/ec2-user/clear_cache.php:37: class Aws\Result#90 (2) { private $data => array(3) { 'Invalidation' => array(4) { 'Id' => string(14) "xxxxxxx" 'Status' => string(10) "InProgress" 'CreateTime' => class Aws\Api\DateTimeResult#109 (3) { ... } 'InvalidationBatch' => array(2) { ... } } 'Location' => string(99) "https://cloudfront.amazonaws.com/2019-03-26/distribution/XXXXXX/invalidation/I2WADC1K0L962S" '@metadata' => array(4) { 'statusCode' => int(201) 'effectiveUri' => string(84) "https://cloudfront.amazonaws.com/2019-03-26/distribution/XXXXXX/invalidation" 'headers' => array(5) { ... } 'transferStats' => array(1) { ... } } } private $monitoringEvents => array(0) { } }参考
AWS PHP SDK v3 で Amazon CloudFront のキャッシュをパージする | コンクリートファイブジャパン - concrete5 Japan Inc.4. 確認
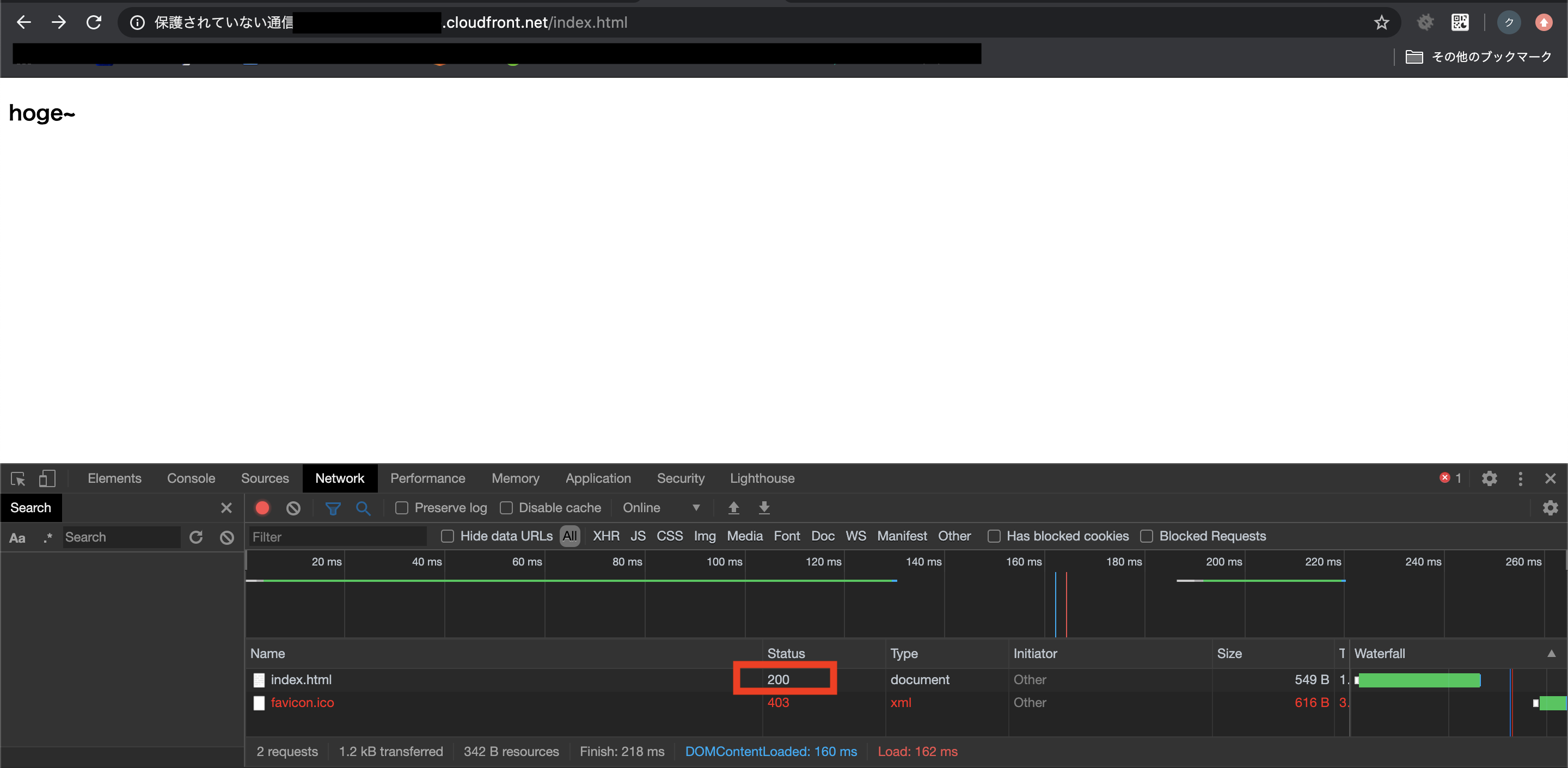
CloudFrontのステータスが「配備済み(APPROVED)」に変わってから
CloudFrontのURL https://<domain name>/<object name> へアクセス。
内容が変更後のものになったことを確認します。
ステータスコードも304ではなく200になっています。
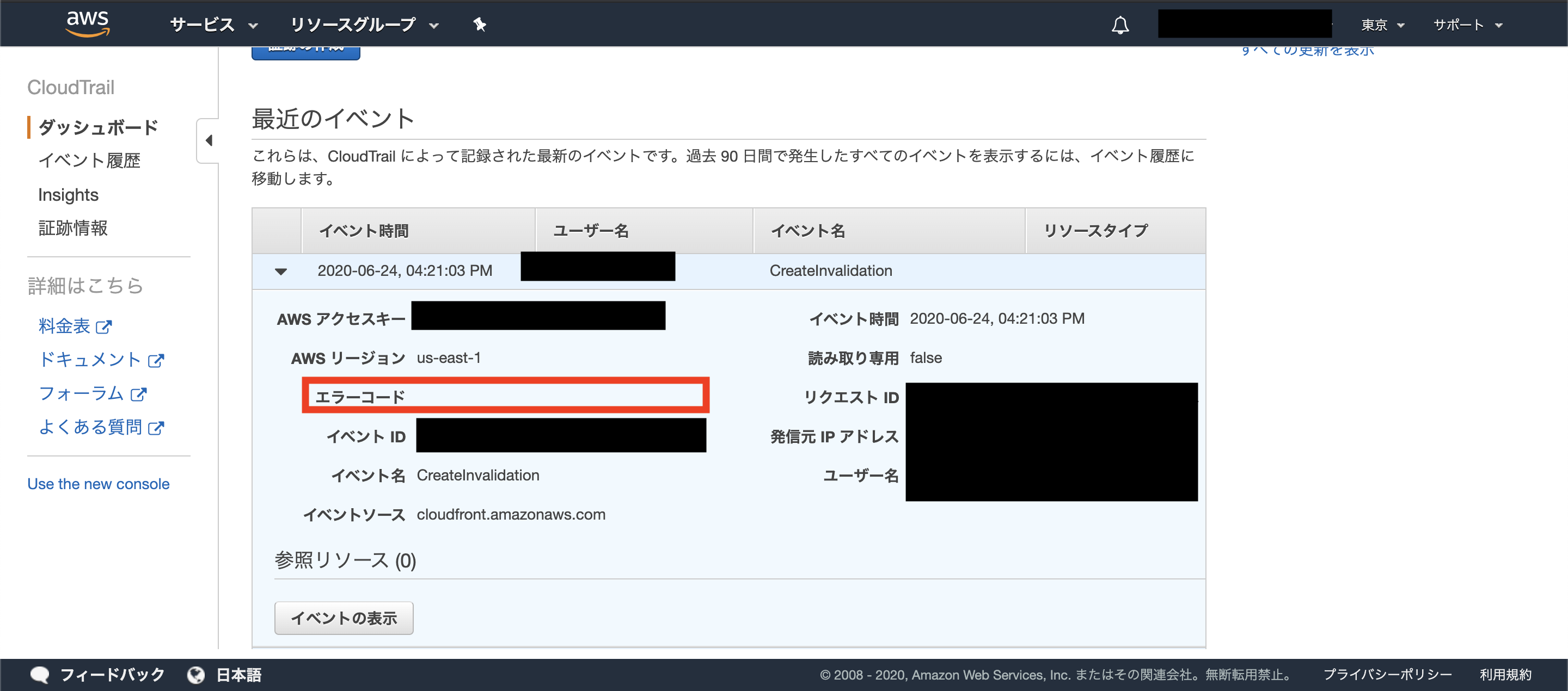
コンソールでログ確認
一応 AWSコンソール > サービス > CloudTrail でログを確認します。
(他にCloudFrontのログ設定しているものがあればそちらを見れば良いと思います。)
エラーコードに何も表示されていなければ成功です。

- 投稿日:2020-06-24T17:13:37+09:00
Amazon EC2(Amazon linux)から直接S3へのファイルコピー
Amazon EC2(Linux)から直接S3へファイルコピー
AWS環境で何か検証している際にEC2内のデータファイルを別環境へエクスポートしたいことがあるかと思います。(私は結構ありますが皆さんどうなのでしょうね...)
EC2がWindows server OSならブラウザーが使えるのでBox等にUpするとかWebメールに添付してとか色々やりようはあると思いますがLinux OSだとどうしよう(´・ω・`)ってなります。
そこでAWS CLIを使って、EC2から直接S3にアップロードして、S3のコンソール画面から別環境にダウンロードするという方法を検証したいと思います。実現したいこと
EC2(Linux)内のデータファイルをS3へエクスポートして、S3コンソール画面からDLできるようにしたい
手順
1. EC2をデプロイ
2. EC2内にディレクトリとファイルを作成
3. EC2にS3アップロードのためのロールをアタッチ
4. コピー先のS3バケットを作成
5. AWS CLIでS3へデータコピー
やってみた
まずEC2をデプロイして、SSHでログインします。そしてディレクトリを作成して、S3へコピーするテストファイルを作成します。
※EC2のデプロイ手順は各所で色々情報が出ておりますので、ここでは割愛します#root にユーザ切替 sudo su root #情報を最新にアップロードします yum -y update #/home にディレクト(/test-share)を作成 cd /home mkdir /test-share cd /test-share #テストファイル(test.txt)を作成 touch test.txt #ファイルが作成されたか確認 lsこれで、S3へコピーするテストファイルの準備はOKです。
デプロイしたEC2ですが、今の状態はS3へアクセスする権限(ロール)をもっていないのでロールをアタッチする必要があります。
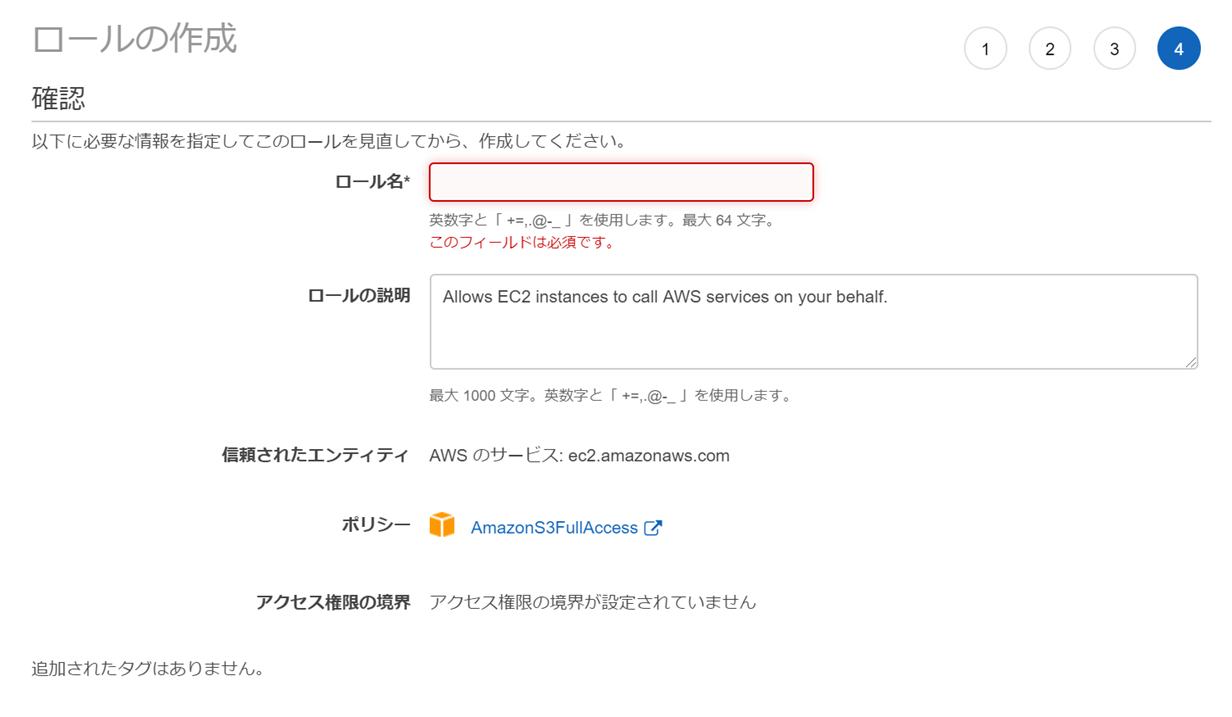
ロールの作り方は
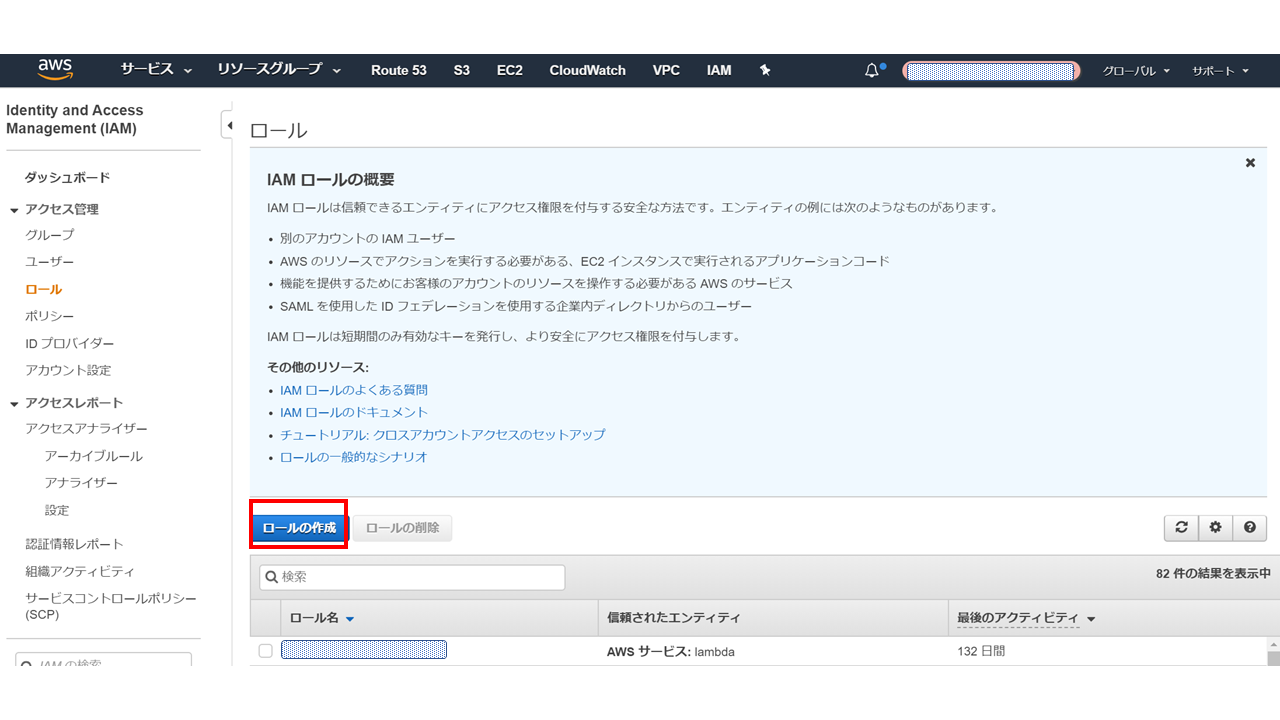
AWS コンソール画面からIAMにアクセスして、「ロール」をクリック
次に「ロールの作成」をクリック
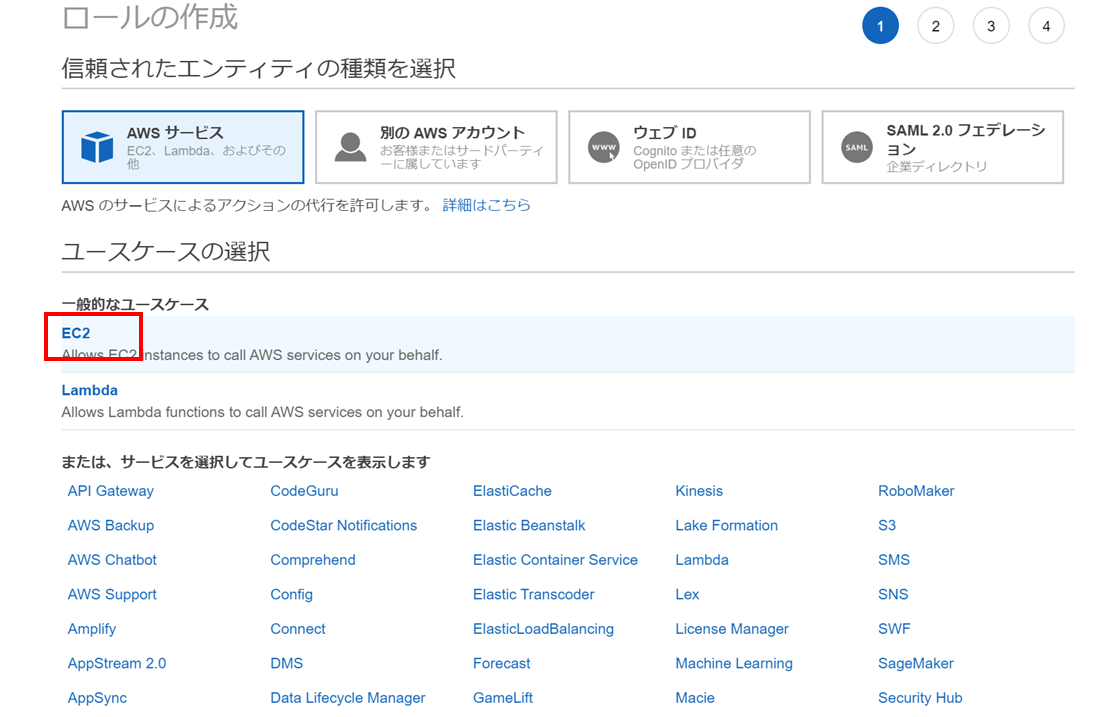
一般的なユースケースで「EC2」を選択
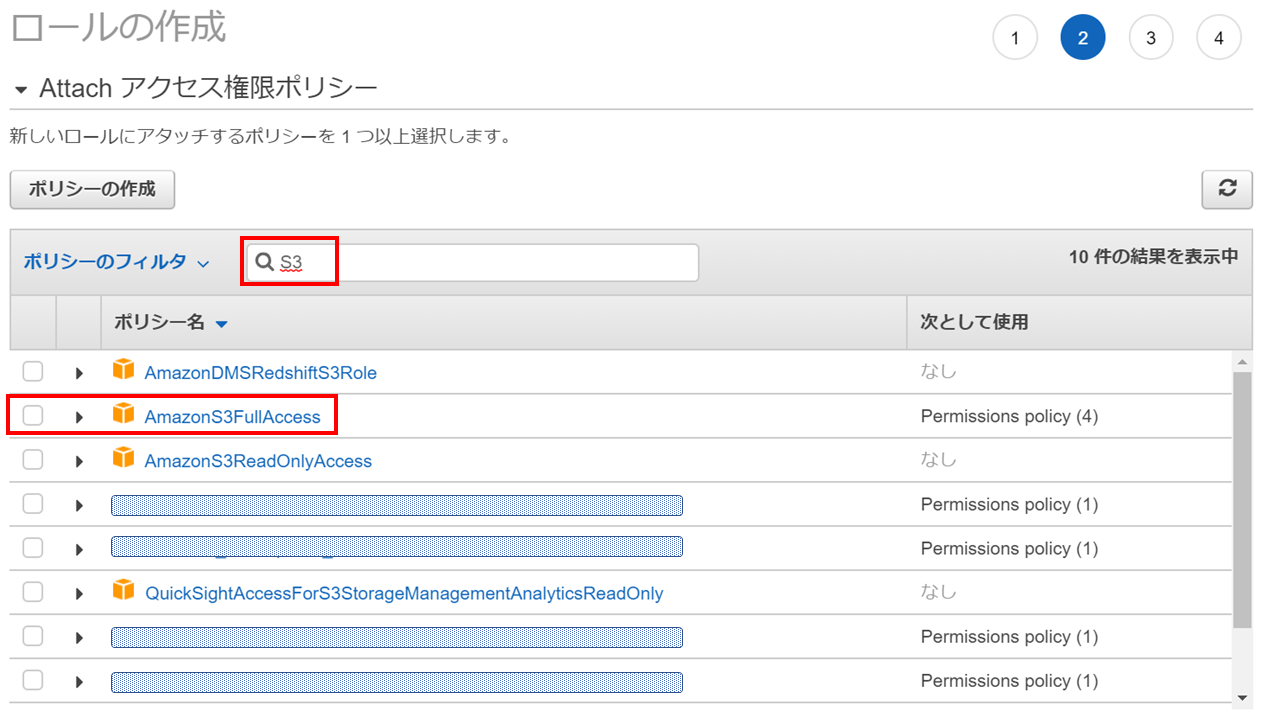
ロールに割り当てるポリシーを選択
ポリシーのフィルターにS3と入力して、表示されるポリシーの中で
今回はS3へのアクセス(アップロード、ダウンロード、閲覧)したいので[AmzzonS3FullAccess] を選択します。
必要に応じて、タグ付け(今回はタグは設定してないです)
ロール名を任意に設定して、「作成」
ロールが作成できたらEC2へアタッチ
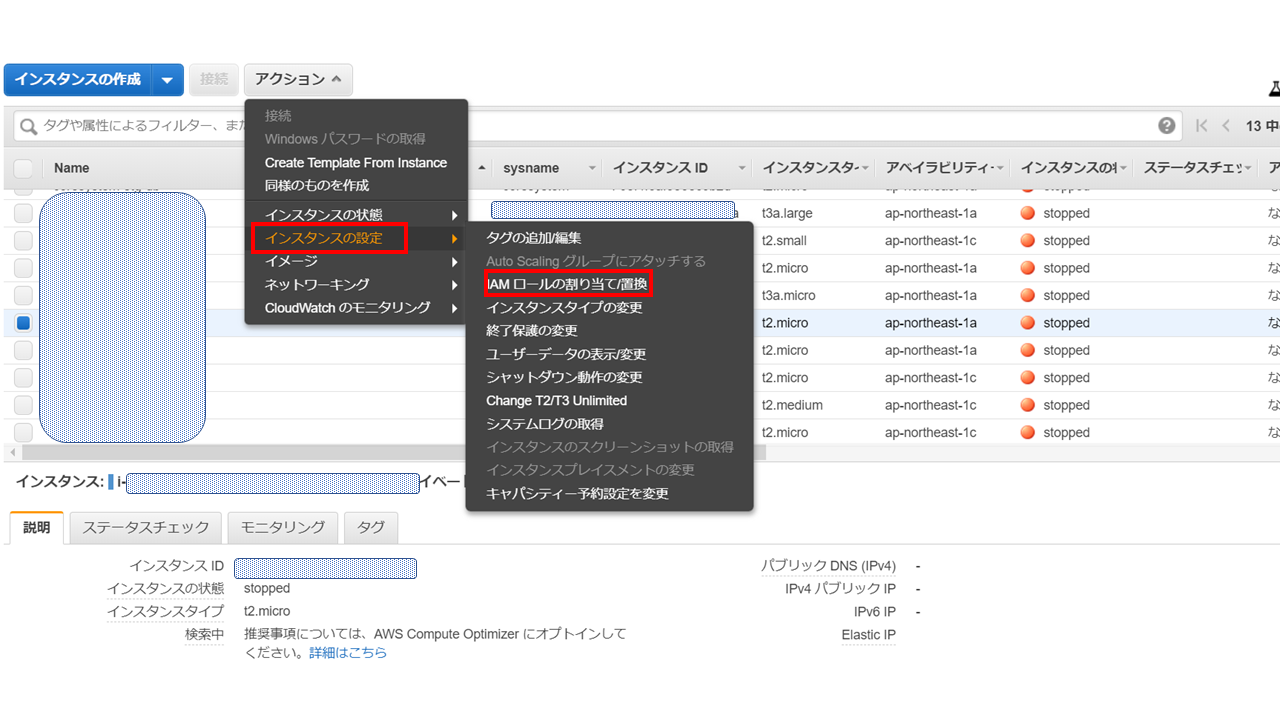
EC2のコンソール画面で対象インスタンスを選択し、「アクション」-「インスタンスの設定」ー「IAMロールの割り当て/置き換え」
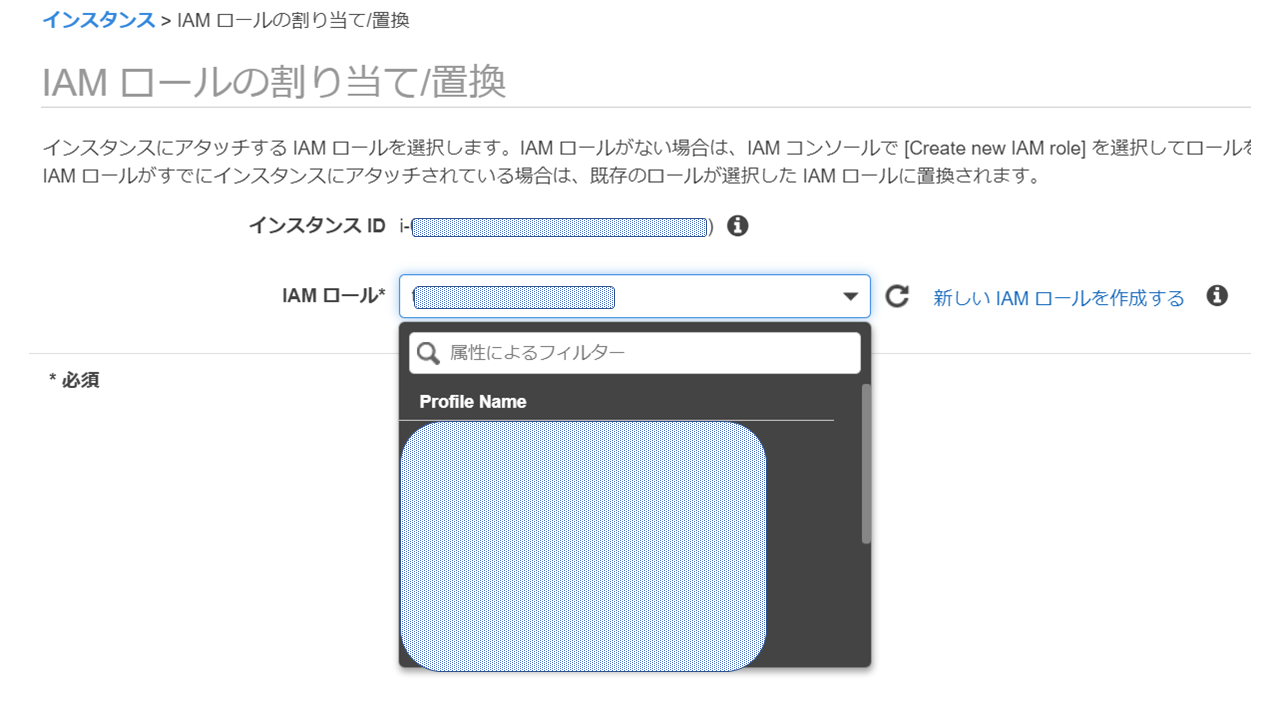
対象のインスタンスIDとロールを割り当てして、「適用」
これでEC2がS3へアクセスするロールをアタッチできました。
次にデータのコピー先のS3バケット(test-20200624-folder)を作成します。
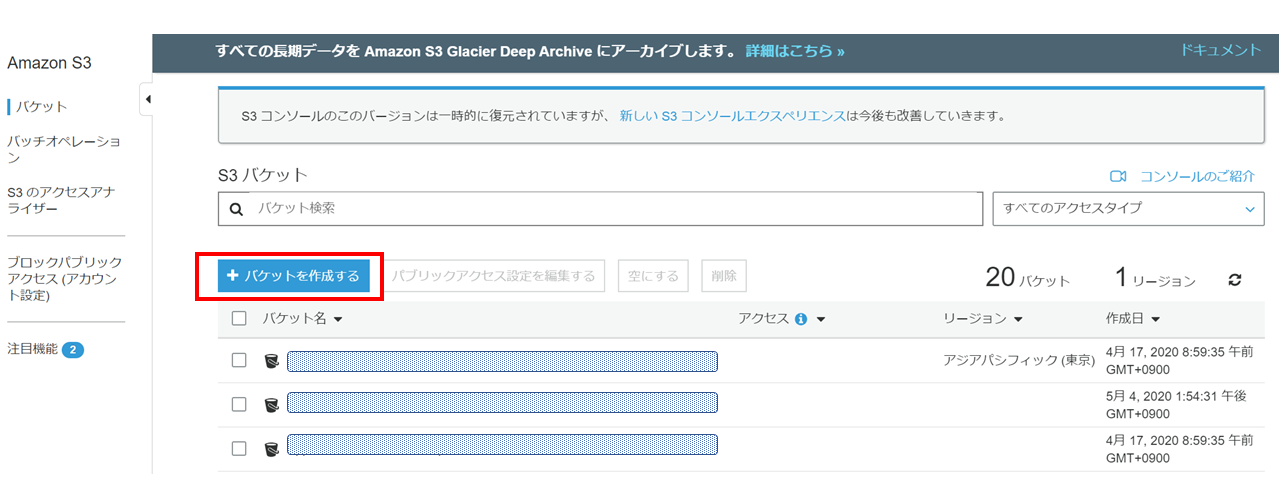
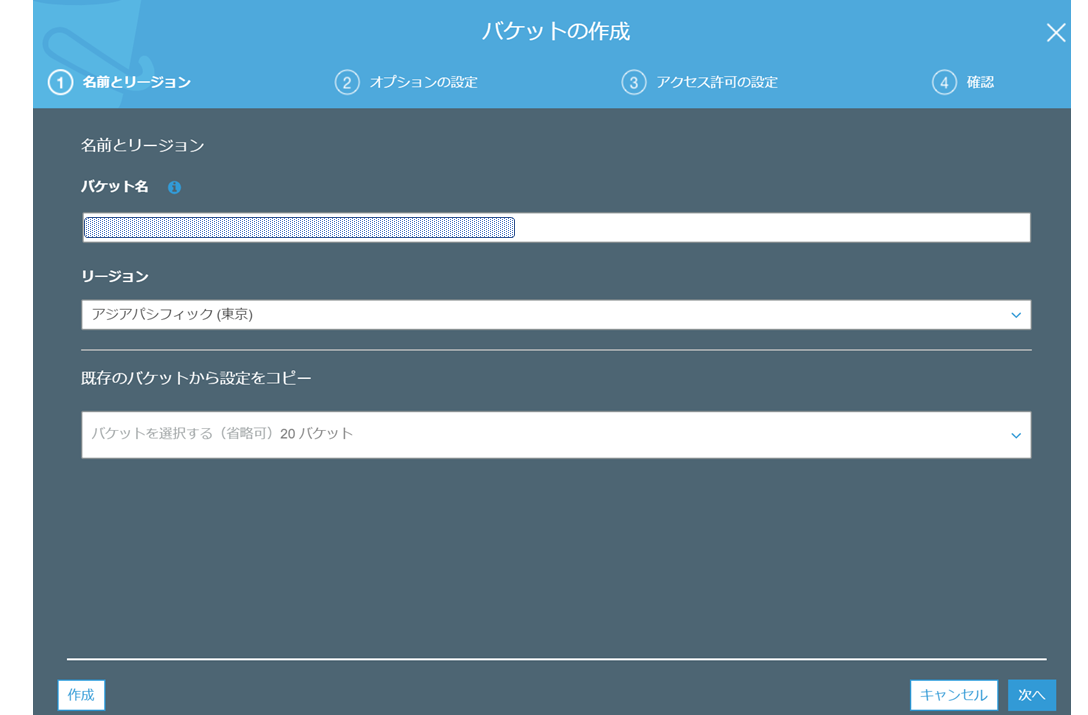
S3のコンソール画面へアクセスして、「バケットを作成する」
バケット名に「test-20200624-folder」とリージョン(今回はアジアパシフィック)を入力して、「次へ」
バケットの設定をするのですが、今回は特に設定を変えるところはないのでこのまま「次へ」
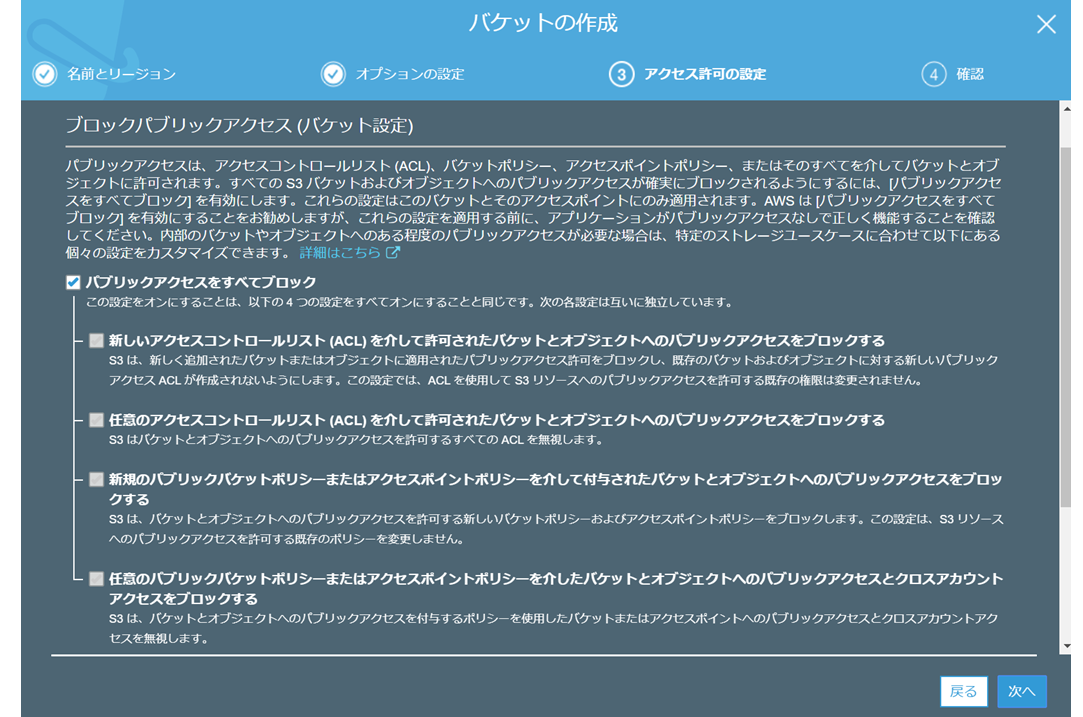
ブロックパブリックアクセスにチェックが入っていることを確認して「次へ」
※別に今回は試験環境なので、パブリックアクセスはブロックは不要ですが、デフォルトはブロックなので。
これで「バケットの作成」まで進めてもらえれば、S3側の準備もOKです。ロールをアタッチできたら、AWS CLIでS3へデータコピーするコマンドを入力します。
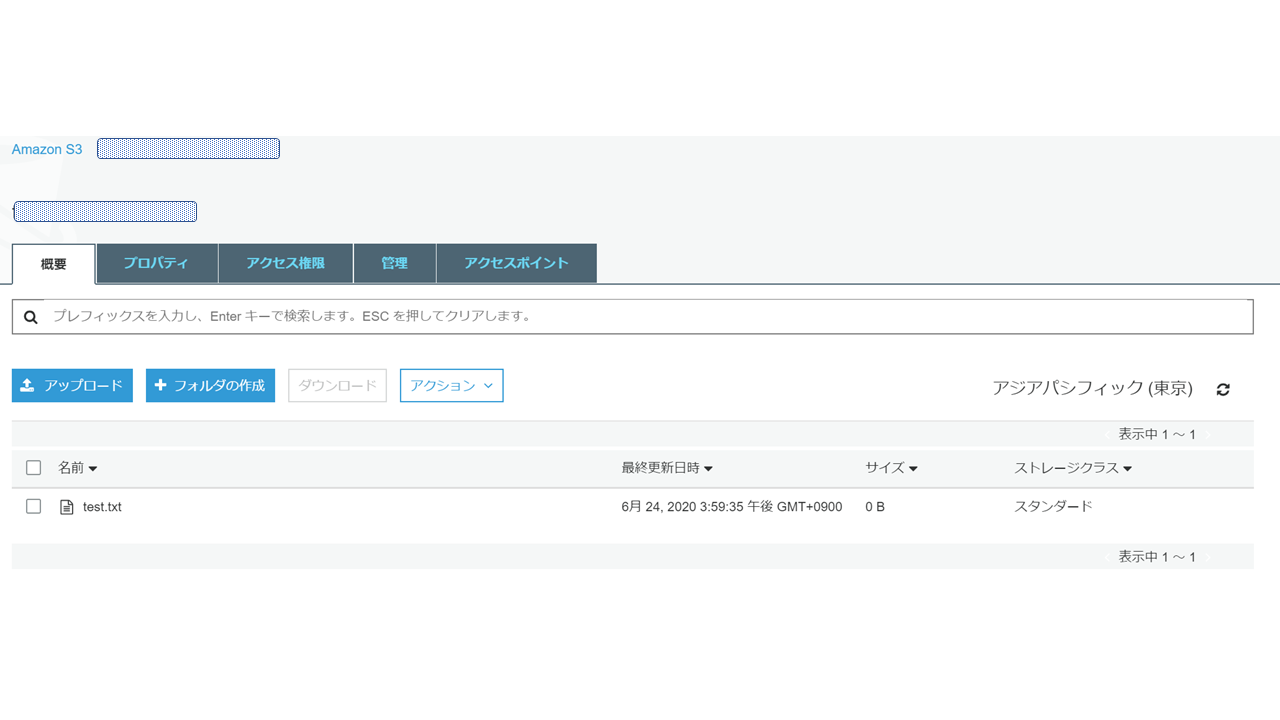
#再度EC2へSSHでログインして、root に切替えます sudo su root #テストファイルがあるディレクトリまで移動 cd /home /test-share #aws cli でS3へデータコピー aws s3 cp /test.txt s3://test-20200624-folder ※EC2にはaws cliが標準でインストールされているので、yumコマンドでインストールする必要はないです #コマンド実行後の upload: ./test.txt to s3://test-0624-folder/test.txt と表示されればOKです #S3にデータがあるかを確認 aws s3 ls s3://test-20200624-folder #2020-06-24 06:59:35 0 test.txt のように表示ささればOKです最後にS3コンソール画面から「test.txt」をDLできるか確認していきます。
S3コンソール画面へアクセスし、対象のバケットを確認すると
test.txtがコピーされていることが確認できました!
あとは「アクション」から「ダウンロード」を選択すれば、別環境へファイルのエクスポート完了です。最後に
同じ内容の記事が各所ありますが、EC2のロールをアタッチする旨の説明がなかったりで手順通りにしてもエラーになったりしたので、備忘録および初心者の皆さんのお役に立てればと思います。
AWS CLIを利用してEC2からS3へデータコピーだけなく、EC2の特定のディレクトとS3バケットのフォルダを同期させたりと色々と応用ができます。
EC2にルートCA機能を持たせて、作った証明書をエクスポートしたり、検証用のログファイルの送信で利用できれば便利ですねd(`・ω・’)


- 投稿日:2020-06-24T15:15:06+09:00
AWS Linux2になってコマンドが変わったのでメモ
AWSでhttpをたてるときLinux2を初めて使ったらLinuxとコマンドが少し違って混乱したのでメモ
httpの場合です。
sudo yum -y install httpd #httpのインストール
sudo systemctl start httpd #スタート
sudo systemctl enable httpd #起動時に有効化
sudo systemctl list-unit-files | grep httpd #自動起動確認
httpd.service enabled #自動起動の確認ができました
httpd.socket disabled
- 投稿日:2020-06-24T14:48:46+09:00
EC2でsudo実行時エラーが出るようになった話 sudo: /usr/bin/sudo be owned by uid 0 and the setuid bit set
はじめに
誤って /bin 以下のパーミッションを変更してしまい、sudoコマンド実行時にエラーが出るようになった。
(確か)rootユーザでのログインもできなくなった。結論
https://aws.amazon.com/jp/premiumsupport/knowledge-center/ec2-sudo-commands/
上記を参考に、AWS EC2コンソールのインスタンス設定で、スクリプト設定をすると、root:rootになって復旧。詳細
流れでコマンドを打ってる際、
chown -R hoge bin/のつもりが/binを指定してしまった…コマンドのスペルミスなどの打ち間違いを補完する方法はあるが、間違っていないので今回のケースは防げない。
こんなミスをするユーザにはsudo権限を与えないなど、権限を絞ることもできるが、自分がサーバ管理者であった。「気をつける」レベルの対策になってしまうが、下記を意識していきたいと思う
- 変更を加えるコマンド実行時は、絶対パス指定しない
- コマンド実行前に、かならず見直す
おわりに
AWSの中の人、復旧方法を用意しておいてくれて、ありがとうございます
- 投稿日:2020-06-24T11:19:54+09:00
クラウド利用におけるネーミングルールの問題
はじめに
プログラミングにおいて、開発ルールはいつも悩ましい問題です。
例えば、文化の違う2つの開発チームで新規アプリケーション開発の別の箇所を並行開発する場合などに、コーディングルールやメソッドの使い方の相違からシステム全体として不統一な設計がなされる可能性があります。
これは、プログラミングにおけるパラダイムの問題だけでなく、変数の命名だけを取っても生じる可能性があります。
同様に、クラウドリソースのネーミングをチームで統一しておくことは、後々非常に大きな意味と重要性を持つことになると考えられます。
クラウド利用の初期に気をつけたいこと
オンプレミスをはじめとした、旧来的なインフラ中心に運用する企業 (チーム) にとってクラウドでサービスをはじめることは比較的大きな冒険です。
そのため、多くの場合まずテスト的にクラウド利用をはじめると思います。
正直なところ、この時点でアカウント自体もテスト専用アカウントとしておくことが非常に重要と考えます。クラウドサービスの中にはアカウントに対してグローバルであり、後から変更が難しいリソースなどが存在することがあり、ある程度決め込んで使い始めなければまずいケースが存在するからです。
ネーミング不統一のままクラウド利用を本格化すると何が起こるか
たとえば、あるスモールサービスを開始する時に、AWSで2台のEC2サーバを作ったとします。
それぞれネーミングは下記の通りです。
- WEB01
- DB01
これらのサーバが何をしているのか、見ればだいたい分かると思いますが、このまま進めると以下のような問題が生じてくることは明白です。
- とりあえず動くものを作ったが、ステージング・開発環境は…?
- 別案件 (アプリケーション) のWEB01を追加したいが…?
- DB01をRDSに移管したいが、これは同じDB01という名前でいいか…?
また、先ほど後から変更が難しいリソースについて書きましたが、GCPを利用すると仕様的にそもそも名前は変更できません。(2020年6月現在)
直近の担当案件で採用されていたこともあり、私は自宅でもGCPをサブで利用しています。
本項ではGCP利用を題材に、私が自宅利用で採用しており、ビジネスレベルでも運用可能と考えるネーミングルールについて紹介します。コンピュータにおけるネーミングの基本
そもそも、プログラム等でネーミングに利用されている命名規則はおよそ下記の4通りです。
camelCase
多くのオブジェクト指向言語でメソッド名として使われている記法です。
各単語の最初の一文字目を大文字にしますが、最初の一単語だけは全て小文字です。PascalCase
多くの言語で camelCase の一種 (または等価) と見なされる記法です。
全ての単語の一文字目を大文字にします。アッパーキャメルケースと呼ばれることもあります。snake_case
MySQLなどのデータベースで、テーブル名・カラム名の記載に使われる記法です。
各単語をアンダーバーでつなぎます。全くの余談ですが、SQLでは名前として大文字・小文字を区別しません。
また、ハイフンを使うと一部の処理系では不具合を生じます。kebab-case
主にHTMLのクラス名などに用いられている形式です。
複数の単語をハイフンでつなぎます。どの記法がなじむか ?
これはすでに一般的なプラクティスも含め、まずは kebab-case だと思います。
理由としては、
- API使用を前提とすれば、WEBで解釈可能なものをチョイスした方が良い (→ HTML)
- 上の観点に立つと、URLでの大文字・小文字の区別についてがやや心に引っかかる
- AWS・GCP両対応を考えると、 snake_case は使えない
(= GCPではリソース名にアンダーバーが使えない仕様)- ネット検索で調べると、これを採用している企業が多い
- camelCase で長い名前を書いてみると、とても読みづらい
私のかつての担当案件でも kebab-case を採用していました。
当時から記法自体についてのネガティブ意見はなかったのと、現状の私の利用範囲でも不都合は出ていないことから kebab-case が良いと判断しています。
何を表現すべきか
アプリケーション名 (システム名)
たとえば、
alphaという名前のアプリケーションを開発したとしたら、そのシステムのメインの名前は端的に「alpha」がいいでしょう。ただし、ここで考えておかないといけないのは、アプリケーションに依存しないシステムについてです。
例えば簡単なところでは、複数のティザーサイトを収容したWEBサーバなどでしょうか。
こうしたものは「teaser-sites-web」などの名付けが考えられます。私はアプリケーションに依存しないシステムの特質を、以下のような指標で捉えています。
- 何が入っていて
- 誰が (どの部署が)
- いつ (頻度)
- どんな目的で
利用するか… というような一連の事実です。
もし、明確にシステムに名付けがされていない場合、この中から意味的に指標を選んで名付けをするプラクティスは考えられ得ます。
例: weekly-sales-total (営業部の週次売上を計算するシステム)こうした一連のシステムの特性にちなんだメインの名前を、『システム名』と呼ぶことにしてこれより以下では、
[system-name]と記載していきたいと思います。
共通システムについての考慮
[system-name]があるクラウドアカウント全体に渡って利用されるケースを考えます。例えば、 特定のカテゴリ名を持たない複数のアプリケーションで稼働するマイクロサービスを開発します。
この提供のために、新しいGCPのクラウドアカウントIDvar-toolsを取得しました。全てのアプリケーションは単一の GKE (Google Kebernetes Engine) クラスタに収容されています。このクラスタ名について考えます。
この場合は単純に「var-tools」でもいいでしょう。ただし、その名前を見ても明らかに複数のサービス群を指していると認識できない場合は、そこにあえてカテゴリ名を付与することで、以下のような名前にしたくなるかもしれません。
- common-bravo
または- bravo-common
「common」「all」などの単語を前後に付加したいケースはしばしばやって来るのですが、前か後かを早い段階でよく決めておかないと、システム規模が大きくなってきた時に混乱を来すことに注意が必要です。
また、「common」「all」などという単語自体もとても曖昧で、かつ多用しやすいものです。
こうした用語の利用ルール自体を、関係者内で認識共有しておいた方が良いでしょう。環境名
これは、本番・ステージング・開発などの別のことです。
私は以下のような5つの名前のいずれかを付けるルールにしています。
- pro … 本番環境
- stg … ステージング環境
- dev … 開発環境
- test … 検証環境
- whole … GCPプロジェクト全体に関わるもの
リソース名
ここでいうリソースとは、先ほど例に挙げた GKE (Google Kebernetes Engine) などのクラウドリソース種のことです。
名前にリソース種を入れるのは、パッと考えると不要と思えるかもしれません。
ただ、いつもクラウドのWEB UIを見ながら話をするわけではないですし、特に以下のような事情を考えるとこの要素をネーミングに含めることが必要と分かります。
- あるリソースを、他のクラウドに移行するケース (例: GCP→AWS)
- あるリソースを、他のリソースに移行するケース (例: redisをEC2→ElastiCache)
- 同じ名前・性質のものであるが、複数リソースに存在するもの
これはネーミングとして重きをおく部分ではないので、環境と同じように3〜4文字で表したいところです。
GCPについては、公式で積極的に略語を使っているようですので、多くはそれをそのまま用いれば良いでしょう。以下のような要領です。
- gae … Google App Engine
- gce … Google Compute Engine
- gke … Google Kebernetes Engine
- gcf … Google Cloud Function
表現のプライオリティから形式を決める
ここまで検討してきた、
[system-name]
[環境名]
[リソース名]を組み合わせることで実際の命名を作るのですが、順番を決める必要があります。
ここは好みというか使いやすさだと考えますが、
- 何が最も必要か?
- WEB UIでの検索性はどうか?
という視座に立つと、 [system-name] [環境名] のいずれかを先頭に持って来るのが良いでしょう。[環境名] を持ってくる理由は、ステージング/本番/開発をWEB UI上で名前で分けてソートできるからです。
私は以下のようにしています。
pro-charlie-web-gce [環境名]-[system-name]-[リソース名]号機採番について
号機採番というのは何かというと、「WEB01」のような名前の「01」の部分のことです。
(この部分を実際何と呼ぶのか、調べても私にはちょっと分かりませんでした…)GCPの名前を後から変更できないという性質上、この番号がないとクラウドでよくあるリソースの作り直しに際して不都合を生じることになります。
そのため、私は号機採番は必須というルールにしています。
リソースを作り直したときに 01 → 02 → 03… のように基本的にはインクリメントします。号機採番を含めたネーミングは以下のようになります。
pro-charlie-web01-gce [環境名]-[system-name][号機]-[リソース名]採番ルール
もし号機採番というものを採用するなら、番号の運用パターンについてはよく考慮しておいた方が良いでしょう。
私は以下のように決めています。
- 号機は基本的に一意性を保つために存在する
- 番号自体には意味を持たせない
(例: 偶数番号のインスタンスは性能を上げる…などはNG)- 飛び番・抜け番はあり得る
- 基本はインクリメントだが、デクリメントもあり得る
- クラスタを構成するリソースでは識別子になる
- クラスタを構成しないリソースでは世代を示す
- あるリソースの中に他のリソースが紐付く場合は、元リソースの採番を取り除く
(例: GCEのIPアドレス)実例
ここからは、これまで利用したことのあるリソースごとに実例にそって紹介します。
VPCネットワーク
whole-delta-service-vpc
- 基本的にVPCに作り直しはないので、号機採番はありません。
Google Compute Engine
pro-delta-service-web01-gce stg-delta-service-web01-gceGoogle Compute Engine (インスタンスグループ)
pro-delta-service-web-group01-grp stg-delta-service-web-group01-grp
- VMを入れる箱という位置づけのリソースなので、「web」に対する採番は除去します。
Google Compute Engine (IPアドレス)
pro-delta-service-web-gce-ip01-ip stg-delta-service-web-gce-ip01-ip
- 「pro-delta-service-web01-gce」に割り当てるIPを想定しています。
- GCE も再作成があり得るので、「web」に対する採番は除去します。
Google Kubernetes Engine
whole-delta-service-cluster01-gke
- 単一のクラスタをプロジェクト全体で運用する場合
Google Kubernetes Engine (ノードプール)
whole-delta-service-cluster01-gke-pool01-pool
- 「project-delta-service-cluster01-gke」に適用するプールを想定しています。
- クラスタもプールも複数になり得るので、採番も多重にします。
Google Cloud Load Balancing
pro-delta-service-site01-glb stg-delta-service-site01-glbGoogle Cloud SQL
pro-delta-service-db01-sql stg-delta-service-db01-sqlGoogle Cloud Storage (バケット)
pro-delta-service-gcs stg-delta-service-gcs
- 基本的にStorageバケットに作り直しはないので、号機採番はありません。
IAM (サービスアカウント)
pro-delta-devteam01-gsa stg-delta-devteam01-gsa
- 名前の文字列がIDになるため、仕様として30文字以内にする必要があります。
おわりに
もちろん、クラウドで必要なことが名前だけで表せるはずもなく、その他のタグやメタデータと併せて設計することは重要でしょう。
ただ基本としてネーミングを疎かにすると、クラウドの利用規模が大きくなってきた時、管理不能に陥ることは当然起こるべきと認識すべきです。
ネーミングについては、
- 利用クラウドサービスの全体感を掴んで考慮する
- 自社 (チーム) のサービスで何が必要になるか洗い出す
- シンプルさと拡張可能性のバランス
など、一定の普遍性を持たせながらも個別的に検討する必要があると考えます。
Fin ❤︎
- 投稿日:2020-06-24T11:07:56+09:00
【Amazon Connect】電話でEC2インスタンスを停止したり、再起動したりする。
解決したいこと
仮想カスタマ「しもしも!? サーバーの調子おかしいんだけど!??マッハでリブートして!!」 オペレータ 「おかのした」 ※フィクションここからカスタマの情報を確認して、EC2インスタンスの状態をチェックして、カスタマのインスタンスかどうかをダブルチェックして、オペレータが心の準備をしてからインスタンスを再起動する。
いや、無駄ちゃう?
自分はセールスなんで実際に作業をしている訳ではないですが、割と前述みたいな電話がかかってくることは多いです。
そして、確認して作業して…。
大したこと無い作業ですが、その割には影響が大きい(聞いたことはありませんが、他のインスタンスをリブートしたりとかのリスクを懸念する)ので、脳味噌ゼロでやれるようなことでもありません。いやでもそれにしてもこんなことに時間を取られるのは如何なものか。
「いっそ、電話受付無くしたら?」という声も聞きますが、それならそれに代わるサービスを考えねばなりません。お客様で作業を完結してもらう
電話受付を無くす&お客様で作業をしていただく方向性で考えました。
【使うもの】
Amazon Connect、Lambda(node.js)、EC2
Amazon Connectはこんな感じに作成して、
[電話をかける] → [自動音声に従いどれかをプッシュ(1.起動、2.停止、3.再起動)] → [プッシュに応じたLambdaが処理]
という流れにしてます。EC2起動Lambdaの中身はこんな感じ。
index.jsconst INSTANCE_ID = '対象のインスタンスIDを入れる'; var AWS = require('aws-sdk'); AWS.config.region = 'ap-northeast-1'; function ec2Start(cb){ var ec2 = new AWS.EC2(); var params = { InstanceIds: [ INSTANCE_ID ] }; ec2.startInstances(params, function(err, data) { if (!!err) { console.log(err, err.stack); } else { console.log(data); cb(); } }); } exports.handler = function(event, context) { console.log('start'); ec2Start(function() { context.done(null, 'Started Instance'); }); };メリット
・Lambdaを作り込めばEC2以外の操作をしたり、複数のインスタンスから指定して処理することもできる。
・電話番号と契約サーバが紐付くので、人的オペレーションミスが無くなる。
・電話オペレーションによる人件費が削減。
・電話の自動応答操作なので、老若男女問わず使える。
(専用のコンパネを作ったのに、「使い方が…」という電話すら無くなる)デメリット
・カスタマ毎にAmazon ConnectとLambdaを設定する必要がある為、構築費用が必要。
・数台程度なら本構成で問題無いが、何十台とインスタンスがある場合には不向き。
(というか、そういう案件で使うことは想定していない)まとめ
同じ電話かけるなら、こっちの方が弊社にもカスタマにも時間の無駄が無くて良いよね。
あと開発環境とか、帰社後に「あ、そういえば消し忘れたな」って時に
携帯一本で落とせるのでコンパネに入る必要も無く、割と便利です。

- 投稿日:2020-06-24T10:44:11+09:00
AWS Update 6/2-6/24
最近AWSに少し飽き始めてバイクに時間を使っていました。
ですが、バイクに飽き始めたのでAWSに戻ります。
アップデート追って行きましょうーーーー!!!6/2
AWSデータ移行サービスは、リレーショナルソースからAmazon Neptuneへのグラフデータのコピーをサポートするようになりました
Amazon AthenaでメタデータカタログとしてApache Hiveメタストアを使用する
Amazon Redshiftのスキーマのストレージ管理を発表
Amazon Redshiftは、コンパイル時間を大幅に改善することにより、コールドクエリのパフォーマンスを向上させます
AWS Systems Manager Explorerに、代理管理者アカウントのサポートが追加され、複数のアカウントとリージョンの運用データを表示できるようになりました
AWS組織のマスターアカウントに加えて、組織の委任された管理者アカウントから、複数のアカウントとリージョンにわたるAWS Systems Manager Explorerの運用データを表示できます。これにより、組織全体の運用データの表示と問題の調査に専用の運用アカウントを割り当てることができるため、セキュリティと柔軟性が向上します。
組織のマスターアカウントは、同じ組織内の1つのメンバーアカウントを委任管理者として指定できるようになりました。委任された管理者は、複数のアカウントとリージョンのデータを集約し、AWSコンソールで、またはAWS SDKまたはCLIを使用して、このデータを検索およびフィルタリングできます。
Amazon Elasticsearch Serviceのクロスクラスター検索サポートの発表
Amazon Elasticsearch Service(Amazon ES)でクロスクラスター検索がサポートされるようになり、単一のクエリまたは単一のKibanaインターフェイスから、複数のAmazon ESドメインにわたって検索、集計、視覚化を実行できるようになりました。この機能を使用すると、異種ワークロードを複数のドメインに分離できます。これにより、リソースの分離が向上し、特定のワークロードに合わせて各ドメインを調整して、可用性を向上させ、コストを削減できます。
6/3
S3アクションのアクセス履歴を使用して、IAMユーザーとロールのS3権限を強化する
Amazon RDS for MySQLはマイナーバージョン8.0.19をサポートします
MySQL互換のAuroraでDatabase Activity Streamsが利用可能になりました
MySQL互換のAmazon Auroraのデータベースアクティビティストリームは、リレーショナルデータベース内のデータベースアクティビティのほぼリアルタイムのストリームを提供します。Database Activity Streamsは、サードパーティのデータベースアクティビティ監視ツールと統合すると、データベースアクティビティを監視および監査して、データベースを保護し、コンプライアンスや規制の要件を満たすことができます。
Aurora PostgreSQLでデータベーストランザクションストリームを使用する
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/DBActivityStreams.html
AWS Direct Connectでフェイルオーバーテストが可能に
https://aws.amazon.com/about-aws/whats-new/2020/06/aws-direct-connect-enables-failover-testing/
6/4
AWS Configが9つの新しいマネージドルールをサポート
https://aws.amazon.com/about-aws/whats-new/2020/06/aws-config-supports-9-new-managed-rules/
SNS_ENCRYPTED_KMS:Amazon Simple Notification Service(Amazon SNS)がAWS Key Management Service(AWS KMS)で暗号化されているかどうかを評価します。
SECURITYHUB_ENABLED:AWSアカウントでAWS Security Hubが有効になっているかどうかを確認します。
S3_DEFAULT_ENCRYPTION_KMS:アカウントのAmazon S3バケットがAWS Key Management Service(AWS KMS)で暗号化されているかどうかを確認します。
S3_BUCKET_DEFAULT_LOCK_ENABLED:Amazon S3バケットのデフォルトロックが有効かどうかを確認します
REDSHIFT_REQUIRE_TLS_SSL:アカウントのAmazon RedshiftクラスターがSQLクライアントに接続するためにTLS / SSL暗号化を必要とするかどうかを確認します。
RDS_SNAPSHOT_ENCRYPTED:Amazon Relational Database Service(Amazon RDS)DBスナップショットが暗号化されているかどうかを確認します。
EC2_EBS_ENCRYPTION_BY_DEFAULT:デフォルトでAmazon Elastic Block Store(Amazon EBS)暗号化が有効になっていることを確認します。
DYNAMODB_TABLE_ENCRYPTED_KMS:Amazon DynamoDBテーブルがAWS KMSで暗号化されているかどうかを確認します。
DYNAMODB_PITR_ENABLED:ポイントインタイムリカバリ(PITR)が有効になっていて、Amazon DynamoDBテーブルデータの継続的なバックアップが提供されていることを確認します。
AWS CloudEndure Migration Factoryソリューションの紹介
AWS CloudFormation Resource ImportがCloudFormationレジストリタイプをサポートするようになりました
これ多分既存環境のリソースを自動でレジストリに追加できるのか不明なので便利なのかわからん。
レジストリに追加されたものをインポートできるのは良い機能だと思われる。Amazon Elasticsearch Serviceでのリアルタイムの異常検出サポート
Amazon Elasticsearch Serviceが異常検出を提供するようになりました。これは、機械学習を使用してリアルタイムストリーミングデータの異常を検出し、問題が発生したときにそれを特定して、すぐに軽減できるようにします。この新機能は、リアルタイムストリーミングで実証済みのアルゴリズムであるRandom Cut Forests(RCF)に基づいて構築されており、ドメインに依存しないため、幅広いログ分析アプリケーションに最適です。
新しい異常検出機能には、異常の原因となったデータとイベントへのコンテキストを提供するKibanaユーザーインターフェイスが含まれており、機械学習の知識に関係なく、すべてのユーザーが機能から価値を簡単に引き出すことができます。異常検出をアラートと併用して、外れ値が検出されたときに通知をトリガーできます。
AWS Elastic BeanstalkがAmazon Linux 2ベースのTomcatプラットフォームの一般提供を発表
Amazon Linux 2オペレーティングシステム上に構築された新世代のTomcat Elastic Beanstalkプラットフォームを使用して、AWS Elastic Beanstalkでアプリケーションを実行できるようになりました。
Amazon Linux 2プラットフォーム上の新世代のTomcatには、Open Java Development Kit(OpenJDK)の無料の製品版ディストリビューションであるAmazon Correttoが付属しています。これらのプラットフォームは静的ファイルプロキシをサポートし、4つのプラットフォームブランチで提供されます。Corretto11を搭載したTomcat 8.5、Corretto 8を搭載したTomcat 8.5、Corretto 11を搭載したTomcat 7、Corretto 8を搭載したTomcat 7です。AmazonLinux 2ベースのElastic Beanstalkプラットフォームの詳細については、このブログ投稿。
VP8およびVP9ビデオのWebM出力がAWS Elemental MediaConvertで利用可能になりました
AWS Elemental MediaConvertに、VP8またはVP9ビデオとVorbisまたはOpusオーディオを使用してWebM出力をエンコードする機能が追加されました。この追加により、ブラウザーベースおよびモバイルデバイスの再生用にビデオを配信するためのフォーマットを選択する際の選択肢が広がります
EMRノートブックから直接EMRクラスターにカスタムカーネルとデータサイエンスライブラリをインストールする
EMR Notebooksは、フルマネージドのJupyterベースのノートブックをデータサイエンティストに提供するマネージドサービスです。
PostgreSQL互換のAmazon AuroraはT3.largeインスタンスをサポートします
6/5
Amazon AuroraはPostgreSQLバージョン11.7、10.12、および9.6.17をサポートし、PostgreSQL 11.7のグローバルデータベースを追加します
s-postgresql-versions-117-1012-and-9617-and-adds-global-database-for-postgresql-117/
Amazon Aurora PostgreSQLグローバルデータベースがマネージドリカバリポイント目標(RPO)をサポート
6/8
Amazon Connectは「Get queue metrics」ブロックにチャネルによるフィルタリングを追加します
Amazon RedshiftがAmazon S3の外部テーブルへの書き込みをサポートするようになりました
CDN承認を使用してAWS Elemental MediaPackage VODエンドポイントを保護する
AWS MediaServicesについて
https://qiita.com/fjisdahgaiuerua/items/8ed835c4b450b8c8ca56#medialive--mediapackage--mediastore-%E4%BD%BF%E3%81%84%E5%88%86%E3%81%91CloudWatch Application InsightsがMySQL、Amazon DynamoDB、カスタムログなどをサポートするようになりました
6/19
AWS Elemental MediaLiveはライブチャンネルの入力切り替えを改善します
Amazon Aurora Global Databaseはリードレプリカ書き込み転送をサポートしています
ELBライフサイクルイベントが、複数のターゲットグループに登録されたAmazon ECSサービスで利用できるようになりました
- 投稿日:2020-06-24T10:15:01+09:00
急激なリクエスト増が発生した場合のAWS Lambdaの挙動を確認する(1)
はじめに
AWS LambdaはAWSの様々なAWSサービスをイベントソースとしてシームレスに連携して起動可能なサーバーレスなコンピュートサービスです。カタカナばかりで分かりにくいかもしれませんので別の表現をすると、
「AWS Lambdaは様々なAWSサービス(、例えば、Amazon S3,Amazon API Gateway, ELB( Application Load Balancer), Amazon SQS, Amazon SNS, Amazon DynamoDB (Streams)等)をイベントソース(入力元、起動のトリガー)としてシームレスに連携して起動可能なサーバーレス(サーバの運用や**サーバのスケール**等の運用が不要な、アプリケーション開発者が開発をしやすくすることができる)コンピュート(アプリプログラム実行環境)サービスです上述する通り、サーバーのスケールの考慮が不要と記載がありましたが、AWS Lambdaがどのようにスケールするか仕様を確認したうえで、ご自身のワークロードに適しているか判断してご利用いただくことが重要です。
余談ですが、過去に私が受けた相談の中でも「AWSのXXXサービスをつかって作りたいんだけど?」というご相談があります。AWS ではコンピュート、ストレージ、データベース、ネットワーク、セキュリティなどをはじめとした175以上のサービスを提供しており、お客様の目的(機能要件・非機能要件)に合わせてサービスを選択することが重要であり、当然、AWSサービスありきではありません。(もちろん学習目的という理由で使うというケースも中にはあります)
さて、今回は、リクエストが急増することが想定される場合にAWS Lambdaがどのように挙動するかを確認していきたいと思います。
サマリ
- 同時実行数のバーストには制約があるため、注意が必要
- 同期・非同期・ポーリング系(キュー、ストリーミング)で動きが異なる
- スロットリングは皆様を守る大切な仕組み。うまく付き合う。
急増の定義
急増、つまり急激な「増加」とは何を指すのか認識合わせが重要です。
1 rps(resuest per second)だったものが1000 rps になる場合、最終的に1秒あたりのリクエスト数が、999件のリクエストが増えたことになります。当記事では、「どれくらいの期間かけて増えたのか」、つまり、単位時間当たりの増分がポイントになります。これが2時間かけて緩やかに増えていけば、rps自体は1000倍という大きな値ですが、2時間(=1200分)で平均的に増えていった場合、増加分は1分当たり1リクエストとなります。負荷状態は1000倍となり私は高負荷であると考えますが、急激な増加か?といわれると単に1件ずつ増えただけとなります。当記事における急増は、単位時間当たり増加分が大きい値の場合を対象とします。「大きい値」はどれくらい?と疑問に思う方もいるでしょう。人によって、大きい、小さいが異なりますから。ここでは、後述の初期バーストの値を超えるリクエストが来た場合ということにして、1000以上と定義します。(ケースによっては500以上)
AWS ドキュメントによるLambda関数のスケールの仕様
AWSドキュメントのこちらの文書、AWS Lambda 関数スケーリングでスケーリングの仕様を説明しています。図もあって増え方について説明が書かれているので一度ご確認ください。
抑えるべき概念
1. 同時実行数
あるタイミングで動いているLambda関数のインスタンス数のこと。
処理時間が1秒かかるLambda関数(CloudWatchメトリクスでdurationが1000msとなる関数)は毎秒1件ずつ起動する場合を考えててみます。この場合は、Lambda関数の同時実行数は1となります。なぜなら、最初のリクエストが1秒で完了し、完了と同時に2個目のリクエストが処理されるため、同時に実行されてるのは1となります。もちろん、実際のワークロードでは常に1秒で終わるということはなく、1.1秒かかることもあれば、0.9秒で終わることもあります。1.1秒かかった場合は0.1秒間、同時実行数が2となります。そして、もし、5秒かかる関数であれば、毎秒1件ずつ起動する場合は最大の同時実行数は5となります。AWS Lambdaでは、各AWSアカウントのリージョン別に最大同時実行数を定めており(上限緩和可能)最大同時実行数を超えてLambda関数のインスタンスを起動することはできません。 その場合、起動要求があった場合はHTTPステータス429が応答されます。エラーということです。
2. 初期バーストの制限
AWS Lambdaはスケール(関数のインスタンスう数の増減)を自動的に実施します。 Lambda関数のインスタンスを増やす考え方として、「初期(最初)」と「それ以降」の二種類があります。増え方が違います。初期バースト数は2020/06/23時点では以下の通りです。
- 3000 – 米国西部 (オレゴン)、米国東部(バージニア北部)、欧州 (アイルランド)
- 1000 – アジアパシフィック (東京)、欧州 (フランクフルト)
- 500 – その他のリージョン
では、この初期バースト数は何を意味するのでしょうか。これは、最初のバーストとして最大で上記の値まではインスタンス数が増加するということを意味します。ただ、別の項目による制約があります(後述の同時実行数の予約)
例えば東京リージョンの場合、初期バースト数は1000です。仮にある関数に同時実行数3000が必要で初期に0の状態だった場合、まず、1000まではインスタンスが起動されます。1000まで増えた後、足りない2000(3000-2000)をAWS Lambdaがどのように増やしていくのかについては次の項目確認してください。3. 初期バースト後のバースト数
初期バースト以降の増え方はどうなるのでしょうか。初期バースト後、まだ同時実行数が不足(つまり、リクエスト数に対応できる同時実行数分の関数がまだない場合)している場合、追加で関数のインスタンスを増やす動きになります。ただし、増え方は全リージョン共通で、1分間に500インスタンスとなります(この値は固定であり、上限緩和できません)。つまり、足りない2000インスタンス分は、4分かけてインスタンス数が増える形となります。
注意:Amazon Kinesis Data Streams /Amazon DynamoDB Streams/Amazon SQSをイベントソースにする場合の関数の増加は別途、定義されていますのでリンクを確認してください)各Lambda関数が必要とする同時実行数分のインスタンスが存在しない場合、つまり、処理中のリクエスト数をLambda関数のインスタンス数が下回る場合、リクエストに対して HTTP ステータス429が応答されます。
これはスロットリングと呼ばれるもので、バースト時以外にも発生します。4. 同時実行数の予約
同時実行数の予約を使うことで、各Lambda 関数には同時実行数の予約が可能です。その値を超えたリクエストが来た場合、スロットリングになります。
また、「同時実行数の予約」はデフォルトでは個々の関数にはされていません。ただ、該当リージョン内で別のAWS Lambda関数が同時実行数の予約をしている場合、同時実行数の予約を未指定の他の関数群はリージョンの「同時実行数」からリージョン内のLambda関数で予約済みの同時実行数を引いた値が上限となります。それを超えたリクエスト数が未予約の関数全体で来た場合、スロットリングになります。
なお、関数ごとにも同時実行数(後述の同時実行数の予約)を指定することができますが、前述のリージョン別の同時実行数以下の値となります。スケールとスロットリング
スロットリング
スロットリングはAWSサービスを利用するうえで必ず押さえるべき概念です。簡単にいうと、「各AWSサービスの仕様や、アカウント所有者等の利用者により設定された値以上のリクエストはエラーにする」というものです。スロットリングの閾値は、サービスやAPIごとによって異なるため各サービスのサービスクオータ等をご確認ください。なお、多くのサービスがスロットリングは従量課金制をとっているAWSサービスにおいて皆様の予期せぬリソース利用によるAWSサービス利用料の増加に対しての防御策の1つになるものです。ですので必要な仕組みと理解いただいた上で、上手にお付き合いいただければと思います。Lambda関数とスロットリング
Lambda関数ではいくつかの要素を組み合わせてスロットリングが判定されます。それは前述の以下の項目も含まれます。
- 「同時実行数」を超えるリクエスト
- 「同時実行数の予約」を超えるリクエスト
- 「初期バーストの制限」や「初期バースト後のバースト数」を超えるリクエスト
同時実行数を超えるリクエスト
これは、個々のAWSアカウントの各リージョンごとに決まっている値です。同時実行数を超えた場合、スロットリングになります。同時実行数の予約以上のリクエスト
前述のとおり、同時実行数の予約をした関数はそれ以上の処理ができませんし、一方で未指定の関数は、リージョン内の同時実行数から、予約済みの同時実行数を引いた値以上のリクエストは処理できません。スロットリングになります。初期バースト発生後
前述したバースト(初期とその後)の値以上のインスタンス数の増加、つまり、急激なリクエスト増が発生し、処理する関数の同時実行数分のインスタンス数が追い付いていない場合 スロットリングになります。呼び出し頻度
こちらの「リージョンあたりの呼び出し頻度 (リクエスト数/秒)」 に記載があります。同期・非同期か、また、非同期の場合のイベントソースはAWSサービスが否かによって、リクエストの受付数(同時実行数ではない)に上限があります。スロットリングへの対応や回避する方法
スロットリングに関連したトラブルシューティングはこちらで解説されていますので参考にしてみてください。
回避する方法は様々な方法があります。
リトライ
同期呼び出しの場合はこちらの考え方を取り入れたリトライ処理をクライアント側で必ず組み込むようにしてください。リトライしてもスロットリングになる可能性もあります。
非同期呼び出しの場合は、1分から6時間(要設定)の中でリトライを実施します。Durationの最小化によるインスタンス当たりのスループット向上
同時実行数はその関数がそのタイミングで同時に動いている関数です。10秒かかっていた処理を1秒に短くできれば、事実上、同時実行数が10倍になります。Lambdaに割り当てるメモリを増やすこと、外部システムアクセスや時間がかかる処理の非同期化(Amazon SQSやKinesis Data Streamsをその処理呼び出しの際に活用する)を検討しでLambda関数が動いている時間を最小化する工夫をしてください。
App->lambda->Asynchronous->externalバースト数の最小化(事前に関数のインスタンスを用意)
Provisioned Concurrencyという機能が2019年末に登場しました。こちらを使うことで対象関数を事前に暖機(つまり、その関数の同時実行数を増やすこと)が可能になります。こちらの機能を利用して、バーストを極力起きないようにすることで影響を緩和できます。
なお、Provisioned Concurrencyで増やせる数はアカウントの最大同時実行数を超えることはできません。同期処理の場合は非同期化
上述の「Durationの最小化によるインスタンス当たりのスループット向上」内では、Lambdaから呼び出す別の処理を非同期化することを例示しました。ここでは、Lambda関数そのものの呼び出しについてを非同期化することを述べています。非同期化することでのメリットは、呼び出し頻度の制約を受けている場合、それを回避することができるという点です。
App -> Asynchronous->Lambda->(Asynchronous(上述))-?External上限緩和申請
同時実行数がアプリケーションの特性上、必要だ!という場合は、上限緩和申請をしていただくことで同時実行数を増やすことが可能な場合があります。現行のアーキテクチャを分析し改善できるよう要素等がないかご確認の上、申請してみてください。おまけ、スロットリングをうまく使う。
同時実行数の予約を利用して、該当関数をゼロにすると、その関数は起動されません。つまり、後続でなんらかエラーが発生して処理を一時的に止めたい場合、ゼロにすることで実現できます。また、Lambda関数を無限ループで呼び出すアプリがいた場合、呼び出される側を0にすることで、実行されないようにすることも可能です。その結果、下流のシステムを保護することにもつながります。うまくスロットリングに関連する機能を使ってみてください。
- 投稿日:2020-06-24T00:05:42+09:00
RDSとDynamoDBをCAP定理、ACID、BASEを使って整理する
AWSの2大データベースであるRDSとDynamoDB、シンプルに初心者向けに何が違うのか、違いが簡単にわかるような説明を考えてみます。
はじめに
初めてAWSのアーキテクチャーを考えるときに、最近ではサーバーレスな設計がごろごろ落ちているため、初めてシステム設計をする場合でも、NoSQLデータベースである、DynamoDBを使ったシステム構成が描けてしまいます。私が駆け出しのころは、Oracleまっさかりで、RDBを使ったシステム構成しか描けなかったものです。あらためて今回CAP定理という言葉をつかって初心者向けに比較してみたいと思います。
CAP定理 と ACID と BASE を知っておこう
分散コンピューティングの考え方として、CAP定理、ACID、BASEを整理してみます。データベースを比較するときにかならず取り上げられる特徴になります。なかなか理解できませんが絵のように頭に焼き付けておきましょう。
CAP定理
具体的な利用例でまとめられているのですが、3つの機能のうち1つを犠牲にしなければならないという定理です。2000年に生まれた概念です。
- 一貫性 (Consistency)
- 全てのノードで同時に同じデータが見える。
- 可用性 (Availability)
- 単一障害など一部のノードで障害が起きても処理の継続性が失われない。
- 分断耐性 (Partition-tolerance)
- 任意の通信障害などによるメッセージ損失に対し、継続して動作を行う。
ACID
トランザクションシステムの持つべき性質としてまとめられた概念です。1970年後半に生まれた概念です。ACIDについては「銀行の送金」を例にした説明がわかりやすいです。
- 原子性 (Atomicity)
- トランザクションに含まれるタスクが全て実行されるか、あるいは全く実行されないことを保証する性質をいう。
- 一貫性 (Consistency)
- トランザクション開始と終了時にあらかじめ与えられた整合性を満たすことを保証する性質を指す。
- 独立性 (Isolation)
- トランザクション中に行われる操作の過程が他の操作から隠蔽されることを指す。
- 永続性 (Durability)
- トランザクション操作の完了通知をユーザが受けた時点でその操作は永続的となり結果が失われないことを指す。
BASE
可用性や性能を重視した特性を持つ分散システムの特性です。いつ生まれた概念かは不明です。
- 基本的に利用可能 (Basically Available)
- 基本的にいつでも利用できる。
- 厳密ではない状態遷移 (Soft state)
- 常に整合性を保っている必要はない。
- 結果整合性 (Eventual consistency)
- 結果的には整合性が保証される。
RDB vs NoSQL (RDS vs DynamoDB)
CAP定理、ACID、BASE、ほか、いろいろな情報を盛り込んで、RDBとNoSQL、RDSとDynamoDBを整理してみます。
CAP定理における整理
共通のデータを扱うネットワークで繋がったシステムが3つの望ましい性質のうち、2つしか満たせない、1つの特性は犠牲にしなければならない、というCAP定理に、RDBとNoSQLを当てはめてみます。
- AP: 利用可能性(A)が高く、パーティション耐性(P)があるが、一貫性(C)を犠牲にする。NoSQLはここ。
- CP: 一貫性(C)があり、パーティション耐性(P)があるが、可能性(A)を犠牲にする。
- CA: 利用可能性(A)が高く、一貫性(C)があるが、分断耐性(P)を犠牲にする。RDBはここ。
ACID、BASEも含めた整理
最後に、全部含めてまとめると以下のような表になります。スッキリまとまりました。ACIDはCAに、BASEはAPに対応します。
RDB NoSQL CAP定理 CA AP(+C) BASEとACID ACID BASE 使い所 整合性の必要なデータ保存、トランザクション処理、難しいクエリ処理 簡単でたくさんある保存処理、キーバリューシステム(KVS)、ドキュメントDB 例 決済、他システム連携 ゲームの課金情報保存、カート保存 AWSの2大データベース RDS DynamoDB 余談
余談ですが「12年後のCAP定理: "法則"はどのように変わったか」の中では、銀行のATMについて触れら得れていました。非常に興味深かったのですが、銀行のATMは、一貫性(C)が求められる用に見えて、なんと、実は可用性(A)が求められるそうです。理由は利用者が多いほど利益性が高められるからだそうです。
まとめ
ということで、データベースの大事なワードを盛り込みつつ、AWSの2大データベースを整理してみました。みなさんそれでは迷わずNoSQLやRDBを使ったシステム設計やアーキテクティングを楽しみましょう。
参考
おっさんがACIDとかBASEとかまとめておく。
https://qiita.com/suziq99999/items/2e7037042b31a77b19c8
「RDBMS」と「NoSQL」の比較
https://masawan-guitar.hatenablog.com/entry/2016/08/14/163447
CAP定理を見直す。“CAPの3つから2つを選ぶ”という説明はミスリーディングだった
https://www.publickey1.jp/blog/13/capcap32.html
12年後のCAP定理: "法則"はどのように変わったか
https://www.infoq.com/jp/articles/cap-twelve-years-later-how-the-rules-have-changed/
DynamoDB vs MongoDB: 6 Critical Differences
https://www.xplenty.com/jp/blog/dynamodb-vs-mongodb-differences-ja/#CAP
AmazonのDynamoの論文を読んでみた(1/3)
https://imai-factory.hatenablog.com/entry/2013/11/03/215247
AWS Black Belt Techシリーズ Amazon DynamoDB
https://www.slideshare.net/AmazonWebServicesJapan/aws-black-belt-tech-amazon-dynamodb以上
- 投稿日:2020-06-24T00:05:42+09:00
RDS vs DynamoDB をCAP定理から整理する
AWSの2大データベースであるRDSとDynamoDB、シンプルに初心者向けに何が違うのか、違いが簡単にわかるような説明を考えてみます。
はじめに
初めてAWSのアーキテクチャーを考えるときに、最近ではサーバーレスな設計がごろごろ落ちているため、初めてシステム設計をする場合でも、NoSQLデータベースである、DynamoDBを使ったシステム構成が描けてしまいます。私が駆け出しのころは、Oracleまっさかりで、RDBを使ったシステム構成しか描けなかったものです。あらためて今回CAP定理という言葉をつかって初心者向けに比較してみたいと思います。
CAP定理 と ACID と BASE を覚えておこう
CAP定理は、Wikipedia 分散コンピューティングの考え方として、以下のように示されています。BASEは、スケーラビリティを高める代わりに、トランザクションを諦めている。ACIDは、トランザクションを極めているようです。
- 一貫性 (Consistency)
- すべてのデータ読み込みにおいて、最新の書き込みデータもしくはエラーのどちらかを受け取る。
- 可用性 (Availability)
- ノード障害により生存ノードの機能性は損なわれない。ダウンしていないノードが常に応答を返す。
- 分断耐性 (Partition-tolerance)
- システムは任意の通信障害などによるメッセージ損失に対し、継続して動作を行う。
具体的な利用例でまとめられているのですが、3つの機能のうち1つを犠牲にしなければならないということだそうです。うまくまとまっています。
- AP: 利用可能性(A)が高く、パーティション耐性(P)があるが、一貫性(C)がない。DynamoDBはここ。
- CP: 一貫性(C)があり、パーティション耐性(P)があるが、利用可能性(A)は高くない。
- CA: 利用可能性(A)が高く、一貫性(C)があるが、パーティション耐性(P)がない。RDSはここ。
RDBはトランザクション向き、難しいクエリ処理向きで、NoSQLはKVS向き、スケーラブルであるそうです。皆さんご存知かもしれません。また、RDBはACID、NoSQLはBASEで表せるそうです。
RDS vs DynamoDB
いろいろな情報を盛り込んで比較してみます。一番大事なところですが一番ボリュームがないですね。。
RDS DynamoDB CAP定理 CA AP(+C) BASEとACID ACID BASE 使い所 整合性の必要なデータ保存 簡単でたくさんある保存処理 例 決済、他システム連携 ゲームの課金情報保存。カート保存 余談
余談ですが「12年後のCAP定理: "法則"はどのように変わったか」の中で、銀行のATMについて触れら得れていました。非常に興味深かったのですが、銀行のATMは、一貫性(C)が求められる用に見えて、なんと、実は可用性(A)が求められるそうです。理由は利用者が多いほど利益性が高められるからだそうです。
まとめ
ということで、分散コンピューティングの大事なワードを盛り込みつつ、AWSの2大データベースを整理してみました。みなさんそれでは迷わずNoSQLやRDBを使ったシステム設計やアーキテクティングを楽しみましょう。
参考
CAP定理を見直す。“CAPの3つから2つを選ぶ”という説明はミスリーディングだった
https://www.publickey1.jp/blog/13/capcap32.html
12年後のCAP定理: "法則"はどのように変わったか
https://www.infoq.com/jp/articles/cap-twelve-years-later-how-the-rules-have-changed/
CAP定理
https://ja.wikipedia.org/wiki/CAP%E5%AE%9A%E7%90%86
DynamoDB vs MongoDB: 6 Critical Differences
https://www.xplenty.com/jp/blog/dynamodb-vs-mongodb-differences-ja/#CAP
AmazonのDynamoの論文を読んでみた(1/3)
https://imai-factory.hatenablog.com/entry/2013/11/03/215247
AWS Black Belt Techシリーズ Amazon DynamoDB
https://www.slideshare.net/AmazonWebServicesJapan/aws-black-belt-tech-amazon-dynamodb
おっさんがACIDとかBASEとかまとめておく。
https://qiita.com/suziq99999/items/2e7037042b31a77b19c8以上