- 投稿日:2020-06-24T22:03:13+09:00
StreaminG!..Aston Villa vs Newcastle Live Stream
Newcastle vs Aston Villa: TV Channel, Live Stream, EPL Soccer Match Today. Aston Villa travels to Newcastle this evening as they continue their attempt to escape the Premier League relegation zone.
While Newcastle defeated a 10-man Sheffield United 3-0 in their last outing, Villa followed a 0-0 draw against the Blades with a 2-1 defeat by Chelsea.
Dean Smith's Villa sit 19th in the table on 26 points with time running out, communicating the Magpies are 13th on 38 points with a top-half finish not out of the question.
When is it and what time is kick-off?
The match will begin at 6 pm on Wednesday 24 June at St James' Park.How can I watch it online and on TV?
Who: Newcastle United vs. Aston Villa
When: Wednesday at 1 pm ET
Where: St. James' Park
TV: NBCSportsGold.com PL Pass
Online streaming: Catch select Premier League matches on fuboTV (Try for free. Regional restrictions may apply.)
Follow: CBS Sports AppThe match will be broadcast live on BT Sport 1, with coverage beginning at 5.45 pm. BT Sport subscribers can also stream the game on the BT Sport app.
Newcastle United's win lifted them to 10-12-8 (13th place with 38 points) while Aston Villa's defeat dropped them down to 7-18-5 (19th place with 26 points). We'll see if the Magpies can repeat their recent success or if Villa bounces back and reverse their fortune.
Predicted line-ups
Newcastle: Dubravka; Manquillo, Lascelles, Fernandez, Rose; Ritchie, Hayden, Shelvey, Saint-Maximin, Almiron; JoelintonAston Villa: Nyland; Konsa, Hause, Mings, Targett; Douglas Luiz, Grealish, Hourihane; El Ghazi, Samatta, Trezeguet

- 投稿日:2020-06-24T21:50:11+09:00
制御フローを読みやすく
制御フローを読みやすく
Readableコードを読んだので
制御フローを読みやすくする方法を書いてみる条件式の引数の並び
if(length >= 10) if(10 <= length)どちらも同じ意味を持っているけど最初の方が読みやすい
変化する値は左辺へ、変化しない値は右辺へ
先ほどの例だと10という定数を右辺へ、
lengthという変数を左辺へ持ってくると読みやすくなった。日本語でも
「もし私が20才以上なら」
「20才が私の年齢以下なら」
を考えた時、前者の方がわかりやすい。私の年齢は変化をしていくが20才は定数だ。
変化する値は左辺へ、変化しない値は右辺へは自然言語と同じ順にすることで
理解を容易にできることがわかる。三項演算子
三項演算子はとても便利。
以下のように使うと助長なif-else文を短くできるif(hour >= 12) { time_str += "pm"; } else { time_str += "am"; } //三項演算子を使う time_str += (hour >= 12) ? "pm" : "am";でもやみくもに使ってしまうとわかりにくくなってしまう場合もある
return exponent >= 0 ? mantissa * (1<<exponent) : mantissa/(1<< -exponent);ネストを浅くする
ユーザーの結果が成功、許可が得られたときは返信をする。
ユーザーの結果が成功、許可が出なかった時は空のエラーを返す。
ユーザーの結果が失敗だった時は、エラーを返す。という処理。ちょっと複雑になってしまっている。
if(user_result == SUCCESS) { if(permission_result != SUCCESS) { reply.WriteErrors("error reading permissions"); reply.Done(); return; } reply.WriteErrors(""); } else { reply.WriteErrors(user_result); } reply.Done();早めに返してネストを削除する
//先にuser_result != SUCCESSの結果を返してしまう。 if (user_result != SUCCESS) { reply.WriteErrors(user_result); reply.Done(); return; } //残りはuser_result == SUCCESSの場合のみとなる if(permission_result != SUCCESS) { reply.WriteErrors(permission_result); reply.Done(); return; } reply.WriteErrors(""); reply.Done();これでネストを浅くすることができた。
returnで早めに返すことで制御フローを簡単にすることができた。
- 投稿日:2020-06-24T16:00:31+09:00
Dagger2 - Android Dependency Injection
DIとは
Dipendency Injection(DI)、「オブジェクトの注入」のこと。
要するに、依存性を自由に差し替えれるようにすることで、テストを実行しやすくしたり(モックを差し込む)、オブジェクトをそれぞれ管理できるようになる。
AndroidにおけるDIの必要性
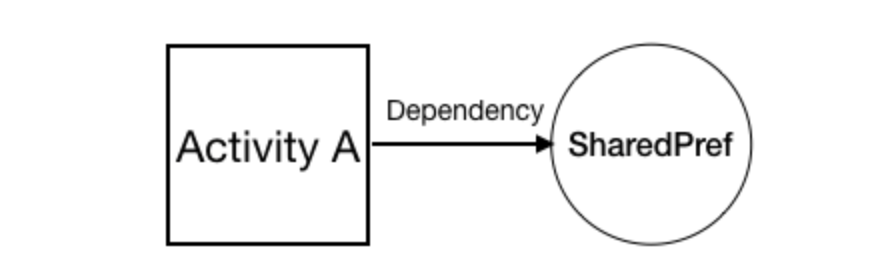
例えば、SharedPreferencesにデータを保存したい場合、DIなしで実行すると、SharedPreferencesからデータをインスタンス化、保存、取得することになり、すべてアクティビティに似たような記述をしなければならない。
この方法でアプリが大きくなると、最悪の場合改修不可能になる可能性がある。
なのでSharedPreferencesを毎回アクティビティでインスタンス化する代わりに、別のクラスから注入するようにする。
Dagger2とは?
2012年にSquareの開発者によって開発されたライブラリ。
Dagger1は、クラスのインスタンスを作成し、Reflectionを介して依存関係を注入するために使用されていた。
その後Googleの開発チームと協力して、Dagger2はReflectionsを使用しない、はるかに高速なバージョンが導入されることになった。Dagger2は、コンパイル時のAndroid依存性注入フレームワークであり、Java仕様要求(JSR)330を使用し、注釈プロセッサを使用する。
Dagger2で使用される基本的なアノテーションは以下。
@Module: 最終的に依存関係として提供されるオブジェクト構築をするクラス
@Provides: オブジェクトを返すModuleクラス内のメソッドで使用される
@Inject: 依存関係が要求されたことを示す(コンストラクタ/フィールド/メソッドで使用される)
@Component: Moduleを要求するクラスへ依存関係を渡すためのブリッジクラス
@Singleton: 依存関係において、単一のインスタンスを作成することを示すSample
main_activity.xml<?xml version="1.0" encoding="utf-8"?> <RelativeLayout xmlns:android="https://schemas.android.com/apk/res/android" xmlns:app="https://schemas.android.com/apk/res-auto" xmlns:tools="https://schemas.android.com/tools" android:layout_width="match_parent" android:layout_height="match_parent" tools:context="com.journaldev.dagger2.MainActivity"> <EditText android:id="@+id/inUsername" android:layout_width="match_parent" android:layout_height="wrap_content" android:layout_margin="8dp" android:hint="Username" /> <EditText android:id="@+id/inNumber" android:layout_width="match_parent" android:layout_height="wrap_content" android:layout_below="@+id/inUsername" android:layout_margin="8dp" android:inputType="number" android:hint="Number" /> <Button android:id="@+id/btnSave" android:layout_width="wrap_content" android:layout_height="wrap_content" android:text="SAVE" android:layout_below="@+id/inNumber" android:layout_toLeftOf="@+id/btnGet" android:layout_toStartOf="@+id/btnGet" android:layout_marginRight="8dp" android:layout_marginEnd="8dp" /> <Button android:id="@+id/btnGet" android:layout_width="wrap_content" android:layout_height="wrap_content" android:text="GET" android:layout_below="@+id/inNumber" android:layout_alignRight="@+id/inNumber" android:layout_alignEnd="@+id/inNumber" /> </RelativeLayout>Moduleで依存性を定義
SharedPrefModule.javapackage com.journaldev.dagger2; import android.content.Context; import android.content.SharedPreferences; import android.preference.PreferenceManager; import javax.inject.Singleton; import dagger.Module; import dagger.Provides; @Module public class SharedPrefModule { private Context context; public SharedPrefModule(Context context) { this.context = context; } @Singleton @Provides public Context provideContext() { return context; } @Singleton @Provides public SharedPreferences provideSharedPreferences(Context context) { return PreferenceManager.getDefaultSharedPreferences(context); } }Componentで依存クラスに渡すオブジェクトの定義
MyComponent.javapackage com.journaldev.dagger2; import javax.inject.Singleton; import dagger.Component; @Singleton @Component(modules = {SharedPrefModule.class}) public interface MyComponent { void inject(MainActivity activity); }依存先で必要な箇所に@injectを記述(そこに注入される)
MainActivity.javapackage com.journaldev.dagger2; import android.content.SharedPreferences; import android.support.v7.app.AppCompatActivity; import android.os.Bundle; import android.view.View; import android.widget.Button; import android.widget.EditText; import javax.inject.Inject; public class MainActivity extends AppCompatActivity implements View.OnClickListener { EditText inUsername, inNumber; Button btnSave, btnGet; private MyComponent myComponent; @Inject SharedPreferences sharedPreferences; @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); initViews(); myComponent = DaggerMyComponent.builder().sharedPrefModule(new SharedPrefModule(this)).build(); myComponent.inject(this); } private void initViews() { btnGet = findViewById(R.id.btnGet); btnSave = findViewById(R.id.btnSave); inUsername = findViewById(R.id.inUsername); inNumber = findViewById(R.id.inNumber); btnSave.setOnClickListener(this); btnGet.setOnClickListener(this); } @Override public void onClick(View v) { switch (v.getId()) { case R.id.btnGet: inUsername.setText(sharedPreferences.getString("username", "default")); inNumber.setText(sharedPreferences.getString("number", "12345")); break; case R.id.btnSave: SharedPreferences.Editor editor = sharedPreferences.edit(); editor.putString("username", inUsername.getText().toString().trim()); editor.putString("number", inNumber.getText().toString().trim()); editor.apply(); break; } } }さいごに
雑ですが、以上がDagger2の説明です。
今後アップデートします。

- 投稿日:2020-06-24T11:29:03+09:00
初心者Java 「条件分岐」
if文
「Aという条件を満たすときにBという処理を実行する」という場合はif文を使います。
条件分岐「if else文」
if文を使った条件分岐で基礎となるのがif else文です。
if else文により、複数の条件に応じた処理を指定できるようになります。if (条件式){ 処理内容1 //条件式を満たす場合にのみ実行する } else{ 処理内容2 //条件式を満たさない場合にのみ実行される }条件分岐「and.or.no」
複数の条件式を組み合わせ、複雑な処理を実行させることが可能です。
FizzBuzzの問題を解こう
Javaの条件分岐を勉強しようと思い、問題に挑戦。
問題文
- 1から100までの数値を標準出力に表示する。
- 3の倍数なら数値の代わりに Fizz
- 5の倍数なら数値の代わりに Buzz
- 3の倍数かつ5の倍数なら数値の代わりに FizzBuzz
まずは書いてみました。
public class FizzBuzz { public static void main(String[] args) { for (int i = 1; i <= 100; i++) { // forで1から100までの数でループ //反復式では繰り返し後に行いたい処理を書く(繰り返し時には必ずiが+1される) if (i % 3 == 0) { // 3の倍数かつ5の倍数のとき if (i % 5 == 0) { System.out.println("FizzBuzz"); // 3の倍数のとき } else (i % 3 == 0) { System.out.println("Fizz"); } } else if (i % 5 == 0) { // 5の倍数のとき System.out.println("Buzz"); // どれにも該当しない場合 } else { System.out.println(i); } } } }出力結果(長いので省略)
1 2 Fizz 4 Buzz Fizz 7 8 Fizz Buzz 11 Fizz 13 14 FizzBuzzもう一つ練習問題を解いてみました
ifの練習問題
class Mondai{ public static void main(String[] args){ /* 以下の変数を作成してください 型:String 変数名:student_name 初期値:"田中" 型:int 変数名:japanese_score 初期値:85 型:int 変数名:mathematical_score 初期値:66 */ String student_name = "田中"; int japanese_score = 85; int mathematical_score = 66; //型:double 変数名:average_score 初期値:国語の点数と数学の点数の平均値 double average_score = ((japanese_score + mathematical_score) / 2); //国語の点数を表示して下さい System.out.println("国語の点数は" + japanese_score + "点です"); //数学の点数を表示して下さい System.out.println("数学の点数は" + mathematical_score + "点です"); //国語と数学の平均点を表示して下さい System.out.println("国語と数学の平均点は" + average_score + "点です"); /* 以下のifを作成して下さい 平均点が65点以上の場合、「合格です。」と表示 平均点が65点に満たないの場合、「不合格です。」と表示 */ if (average_score >= 65){ System.out.println("合格です"); }else { System.out.println("不合格です"); } } }
- 投稿日:2020-06-24T10:15:04+09:00
文字列をmd5ハッシュ化して返す
文字列をmd5Hash化
まあ自分メモです。
ライブラリとかあるみたいなので使わなそうですけど。
この方法はMessageDigestを使います。下記のソースの
strHashの部分がハッシュ化したい文字列です。
任意の文字列ってことになります。
ハッシュ化した結果はstrの値です。md5Hash.javaimport java.security.MessageDigest; import java.security.NoSuchAlgorithmException; /** * md5Hash * 入力された文字列をmd5Hash化して返す */ public class md5Hash { public static void main(String[] args) { /**ハッシュ化したい文字列:strHash */ String strHash = "12345"; System.out.println("ハッシュ化する文字列:" + strHash); try{ // メッセージダイジェストのインスタンスを生成 MessageDigest md5 = MessageDigest.getInstance("MD5"); byte[] result = md5.digest(strHash.getBytes()); // 16進数に変換して桁を整える int[] i = new int[result.length]; StringBuffer sb = new StringBuffer(); for (int j=0; j < result.length; j++){ i[j] = (int)result[j] & 0xff; if (i[j]<=15){ sb.append("0"); } sb.append(Integer.toHexString(i[j])); } String str = sb.toString(); System.out.println("ハッシュ化後の文字列:" + str); } catch (NoSuchAlgorithmException x){ } } }上記を実行すると下記のような結果が得られるかと思います。
結果ハッシュ化する文字列:12345 ハッシュ化後の文字列:827ccb0eea8a706c4c34a16891f84e7b参考
- 投稿日:2020-06-24T08:01:30+09:00
IBM Cloud ShellでQuarkusを試してみよう
この記事は、これからQuarkusを始める方を対象に、IBM Cloudで提供しているIBM Cloud Shellを使ってQuarkus.ioのFirstStartの手順を実行するためのガイドです。
Cloud Shellとは
IBM Cloud Shell はクラウドのメニュー(アイコン)からコンソールに即時アクセスが可能です。
2020年6月現在、ベータ版として主に以下の機能をリリースしています。
・30時間利用/週
・ストレージ500 MB/User
・ファイルのアップロード、ダウンロード処理
・アプリのプレビュー
詳細、最新情報はIBM Cloud Docsをご確認ください
QUARKUS GET STARTED
オリジナルの記事はこちらのQUARKUS - CREATING YOUR FIRST APPLICATIONです。
https://quarkus.io/get-started/
こちらのガイドに習い、IBM Cloud Shellの実行手順に編集しています。
今回、紹介する範囲はQuarkusアプリケーションの起動、修正、実行結果の確認の手順になります。
IBM Cloud からCloudShellを起動
・IBM CloudにLoginします。
アカウントをお持ちでない方は、こちらからご登録ください。登録にはe-Mailアドレスが必要です。
この手順はライトアカウントで実施可能です。(2020年6月時点)
・Cloud Shellを起動します。
・今回、Cloud Shellで3つのSessionを使用します。Sessionは+ボタンで追加できます。Cloud Shellでは最大5つのSessionまで使用できます。
-Session1:Quarkus環境構築
-Session2:curlコマンド実行
-Session3:File編集Step1: サンプルコードの実行
$ごとにクリップボードにコピー、Cloud Shellにペーストして進めてください。
1. Gitクローン
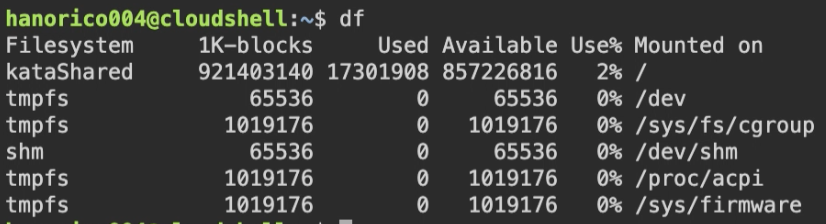
$ git clone https://github.com/quarkusio/quarkus-quickstarts.git2. ディスクの使用量を確認
$ df
3.Maven Projectを作成
$ mvn io.quarkus:quarkus-maven-plugin:1.5.2.Final:create \ -DprojectGroupId=org.acme \ -DprojectArtifactId=getting-started \ -DclassName="org.acme.getting.started.GreetingResource" \ -Dpath="/hello"
4.ディレクトリを移動し、内容を確認
$ cd getting-started $ ls
5.ファイルの内容を確認
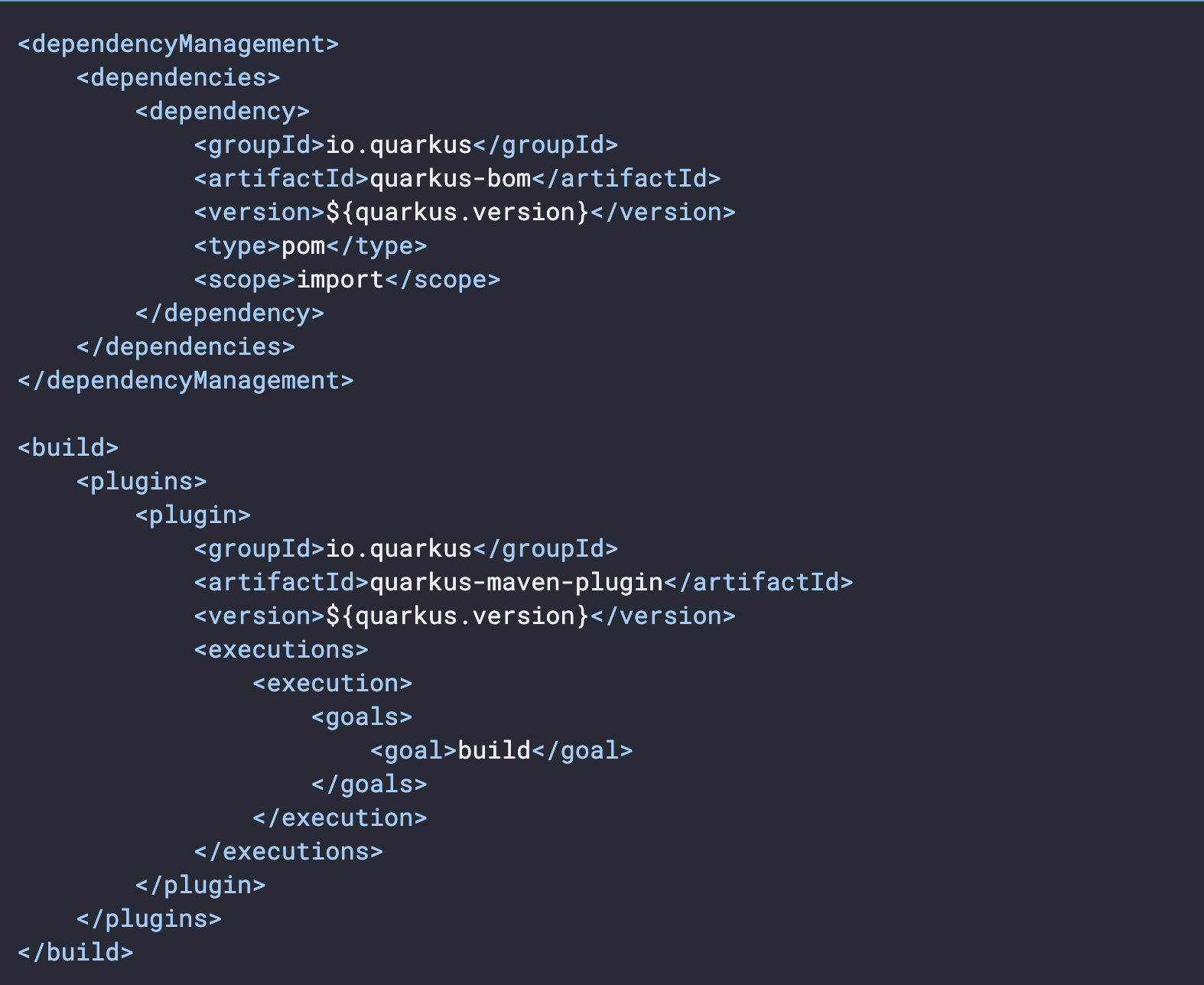
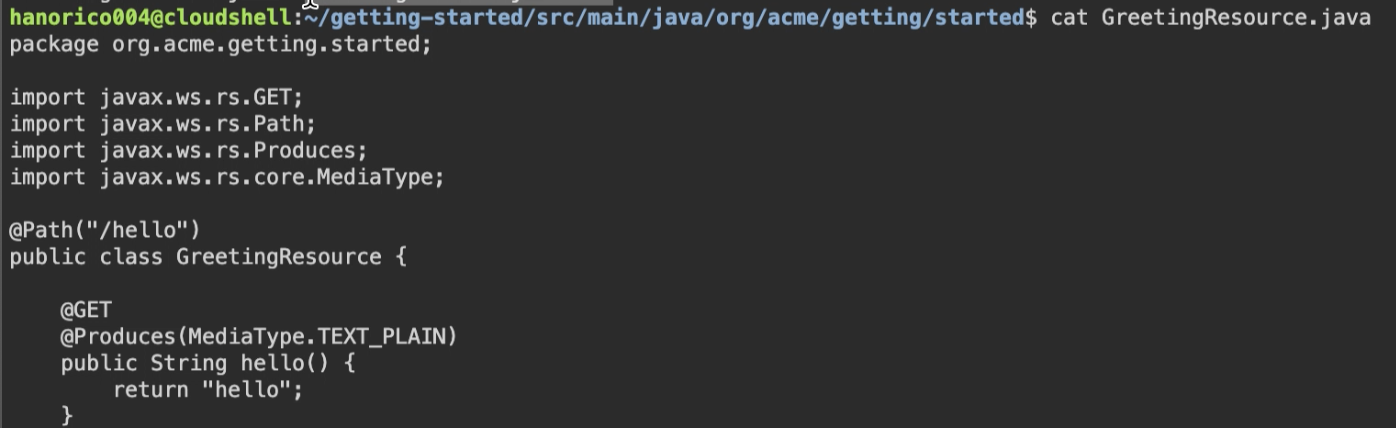
$ cat pom.xml $ cat src/main/java/org/acme/getting/started/GreetingResource.java
*pomファイルにはquarkus-bom,quarkus-maven-plaginが設定されています。
*GreetingResource.javaにはこのようなコードが生成されます。6.Quarkusを起動
$ ./mvnw compile quarkus:dev:
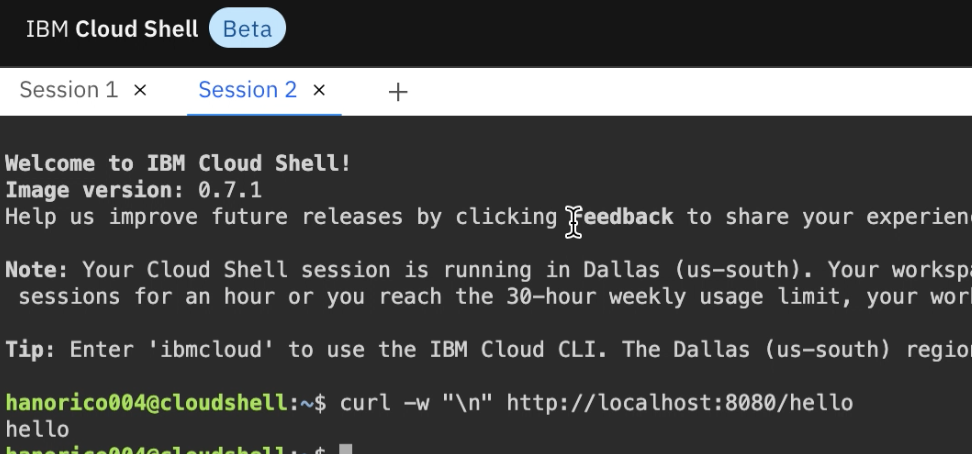
起動できました! 続いて、Session2を追加します。7.cUrlでコードを実行(Session2)
$ curl -w "\n" http://localhost:8080/hello
戻り値として”Hello”が表示されました! 続いて、Session3を追加します。Step2: コードの修正
1.ディレクトリの確認と移動(Session3)
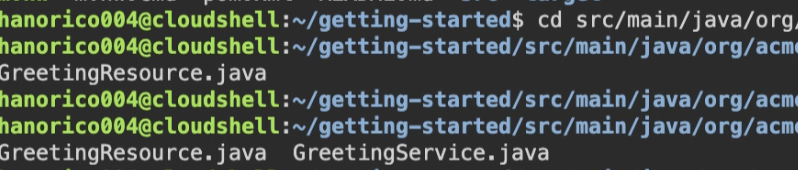
$ ls $ cd getting-started $ ls2.ディレクトリーの移動とファイルのコピー、確認
$ cd src/main/java/org/acme/getting/started $ ls $ cp GreetingResource.java GreetingService.java $ ls
3.編集ファイルの確認(表示)
$ cat GreetingService.java
↓次で内容を編集します。↓4.GreetingServiceファイルの編集
$ nano GreetingService.java(編集用ウィンドウが開く)以下の内容に編集(または置換)
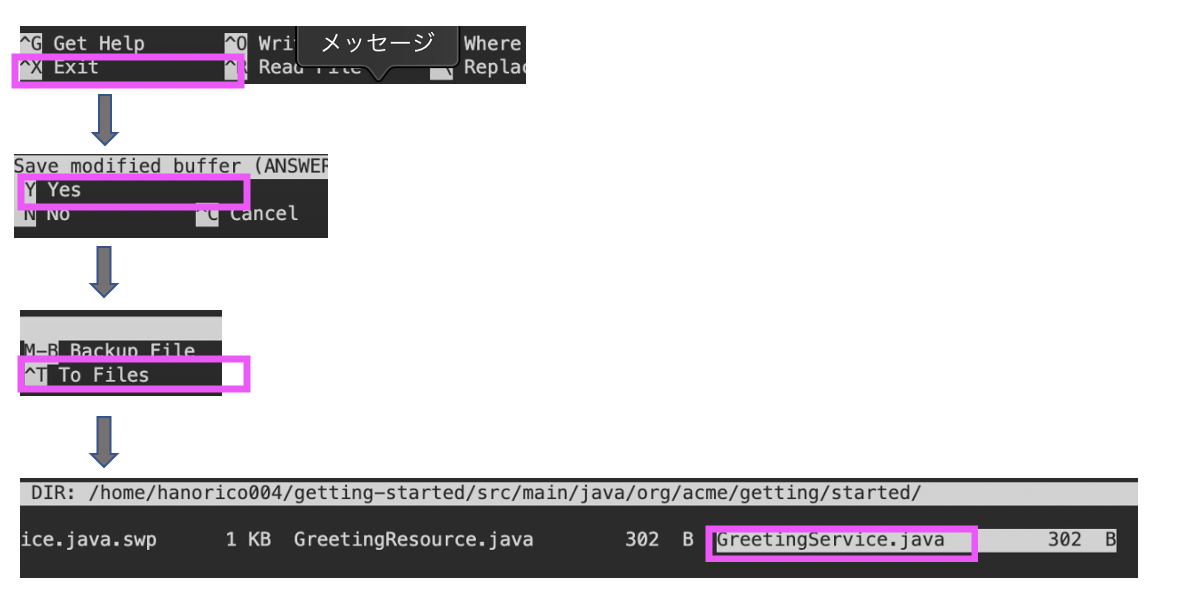
package org.acme.getting.started; import javax.enterprise.context.ApplicationScoped; @ApplicationScoped public class GreetingService { public String greeting(String name) { return "hello " + name; } }ファイル編集後、Exit → Y → To Files → GreetingService.java → Ent で閉じる
編集後のファイルを表示して確認$ cat GreetingService.java5.GreetingResourceファイルの編集
同様の手順でGreetingResourceファイルを以下の内容に編集
$ cat GreetingResource.java $ nano GreetingResource.java(編集用ウィンドウが開く)以下の内容に編集(または置換)
package org.acme.getting.started; import javax.inject.Inject; import javax.ws.rs.GET; import javax.ws.rs.Path; import javax.ws.rs.Produces; import javax.ws.rs.core.MediaType; import org.jboss.resteasy.annotations.jaxrs.PathParam; @Path("/hello") public class GreetingResource { @Inject GreetingService service; @GET @Produces(MediaType.TEXT_PLAIN) @Path("/greeting/{name}") public String greeting(@PathParam String name) { return service.greeting(name); } @GET @Produces(MediaType.TEXT_PLAIN) public String hello() { return "hello"; } }ファイル編集後、Exit → Y → To Files → GreetingResource.java → Ent で閉じる
編集後のファイルを表示して確認$ cat GreetingResource.java6.cUrlでコードを実行(Session2)
$ curl -w "\n" http://localhost:8080/hello $ curl -w "\n" http://localhost:8080/hello/greeting/quarkus $ curl -w "\n" http://localhost:8080/hello/greeting/'半角英数任意の文字列(’は不要)'
IBM Cloud ShellでQuarkusのお試しは以上になります。
最後まで読んでいただきありがとうございました。
おつかれさまでした!








- 投稿日:2020-06-24T00:13:57+09:00
OpenCensusとJavaで分散トレーシングをする
はじめに
OpenCensus APIとJavaで分散トレーシングを実装してみました。OpenCensusはGoogleのCloud Trace(旧 StackDriver Trace)をベースとした仕様で分散トレースとメトリック収集の仕様です。
こちらを使うことでPG側は統一したAPIを利用しながらバックエンドをJeagerやOpenZipkinあるいはCloud Traceなどに連携できます。実はOpenCensusは既に古く、似た様な仕様のOpenTracingと統合する形で現在はOpenTelemetryとして標準化されています。こちらはDatadog, NewRelic, Dynatrace, Instanaといった商用のAPMも含めて対応しているので今後はこちらを使うべきです。
なので、最初はOpenTelemetryを弄ってたのですがJeagerには連携できたもののCloud TraceではJava版はまだ未対応だったので、とりあえずドキュメントの多そうなOpenCensusを試してみました。ただ、思ったほどドキュメントが整理されてなかったので備忘をかねてまとめてみます。
今回、作成したコードは以下にあります。
https://github.com/koduki/miniban/tree/example/opensensusシステム構成
システム構成としてはシンプルに
api-endpointでリクエストを受け取り、ビジネスロジックを持つバックエンドのapi-coreに処理をREST/JSONで投げています。
マイクロサービスというほど細分化はされてないけど、これはこれで良くある構成だし分散トレーシングの検証としては十分かと思います。
各APIはQuarkusを使ってJAX-RSで実装しています。MicroProfile特有のAPIも基本的には使ってないのでJavaEE環境ならどれでもそのまま動くはずです。実装
依存ライブラリ
依存ライブラリとしてpom.xmlに以下を追加します。
<dependency> <groupId>io.opencensus</groupId> <artifactId>opencensus-api</artifactId> <version>0.26.0</version> </dependency> <dependency> <groupId>io.opencensus</groupId> <artifactId>opencensus-impl</artifactId> <version>0.26.0</version> <scope>runtime</scope> </dependency> <dependency> <groupId>io.opencensus</groupId> <artifactId>opencensus-exporter-trace-stackdriver</artifactId> <version>0.26.0</version> </dependency> <dependency> <groupId>io.opencensus</groupId> <artifactId>opencensus-exporter-trace-jaeger</artifactId> <version>0.26.0</version> </dependency> <dependency> <groupId>io.opencensus</groupId> <artifactId>opencensus-contrib-http-jaxrs</artifactId> <version>0.26.0</version> </dependency>APIとして必要なのはopencensus-apiとopencensus-impl。opencensus-exporter-xxxはトレース情報を送信するexpoter各種のライブラリ、
opencensus-contrib-http-jaxrsはJAX-RS向けの便利ライブラリです。
今回は、stackdriverとjaegerの2つのエクスポーターを指定していますが普通はどれか一つになります。Exporterの初期化
まずはExporterの初期化と登録を行います。これは一度だけ行えば良いので
@Initialized(ApplicationScoped.class)を使って起動時に読み込んでしまいます。Bootstrap.java@ApplicationScoped public class Bootstrap { public void handle(@Observes @Initialized(ApplicationScoped.class) Object event) { JaegerTraceExporter.createAndRegister( JaegerExporterConfiguration.builder() .setThriftEndpoint("http://localhost:14268/api/traces") .setServiceName("api-endpoint") .build()); } }Quick Startでは直接URLを
createAndRegisterの引数にとっていますがこれは既に非推奨コードのようなのでJaegerExporterConfigurationを使います。あとは見ての通りですが
setThriftEndpointで連携先のURLを指定し、setServiceNameでJaeger上のサービス名となります。このExporterの登録部分さえ変更してしまえば、バックエンドを任意に切り替えれます。たとえば、Cloud Traceを使いたい場合は以下の様に変更します。
Bootstrap.java@ApplicationScoped public class Bootstrap { public void handle(@Observes @Initialized(ApplicationScoped.class) Object event) { String gcpProjectId = "your GCP project ID"; StackdriverTraceExporter.createAndRegister( StackdriverTraceConfiguration.builder() .setProjectId(gcpProjectId) .build()); } }Trace Spanの作成
つづいてSpanの作成です。
try (Scope ss = Tracing.getTracer() .spanBuilder("Span Name") .setRecordEvents(true) .setSampler(Samplers.alwaysSample()) .startScopedSpan()) { // do somthing. }
Tracing.getTracer()はシングルトンつまりグローバルからトレーサーを取得します。そこからspanBuilderを使ってSpanを組み立てます。
ポイントはsetSamplerです。サンプラはトレースを取得する頻度を指定します。ここでSamplers.alwaysSample()を指定しないとトレース情報が常に書き込まれません。本番では適切な閾値を費用や負荷の面から付けるケースもあると思いますが、テスト時は負荷テスト以外ではリクエストが少な過ぎるので必ずalwaysを指定しましょう。
そのほかのサンプラの詳細はこちらにあります。ちなみに毎回上記を書くのは面倒なので以下の様なヘルパーソメッドを定義してみました。
public static <R> R trace(Supplier<R> callback) { var depth = 2; var className = Thread.currentThread().getStackTrace()[depth].getClassName(); var methodName = Thread.currentThread().getStackTrace()[depth].getMethodName(); try (var ss = Tracing.getTracer() .spanBuilder(className + "$" + methodName) .setRecordEvents(true) .setSampler(Samplers.alwaysSample()) .startScopedSpan()) { return callback.get(); } }クラス名とメソッド名を取得してSpan名に自動で指定しています。利用する時は下記の様な感じです。
@GET @Path("/{userId}/balance") public Map<String, Long> getBalance(@PathParam("userId") String userId) { return trace(() -> { var balance = service.getBalance(userId); return balance; }); }Trace Contextの伝播
同じアプリケーション内であれば上記のように
startScopedSpanをするだけで勝手に入れ子のSpanが作成されます。
ただし、分散トレーシングの肝はシステム間連携です。そのためリモートのコンテキストを連携してやる必要があります。ただ、このあたりからドキュメントが古かったりちゃんと書かれてなくて試行錯誤での取り組みになりました。traceparent
OpenCensusでは元々はX-B3-TraceId/X-B3-ParentSpanIdといったヘッダー情報を使ってコンテキストを渡してたようなのですが、現在はW3Cで標準化されたTrace Contextが使われています。
これはtraceparentというパラメータをHTTPヘッダに埋め込んでそれを元に「Trace ID」「Span ID」「Trace Options(trace-flags)」を組み立てます。traceparentは以下の様な値です。
traceparent: 00-0af7651916cd43dd8448eb211c80319c-b7ad6b7169203331-01OpenCensusでtraceparentを解析してSpanContextを作成するのは以下の様なコードになります。
int VERSION_SIZE = 2; int TRACEPARENT_DELIMITER_SIZE = 1; int TRACE_ID_HEX_SIZE = 2 * TraceId.SIZE; int SPAN_ID_HEX_SIZE = 2 * SpanId.SIZE; int TRACE_ID_OFFSET = VERSION_SIZE + TRACEPARENT_DELIMITER_SIZE; int SPAN_ID_OFFSET = TRACE_ID_OFFSET + TRACE_ID_HEX_SIZE + TRACEPARENT_DELIMITER_SIZE; int TRACE_OPTION_OFFSET = SPAN_ID_OFFSET + SPAN_ID_HEX_SIZE + TRACEPARENT_DELIMITER_SIZE; // Get tranceparent String traceparent = headers.getRequestHeaders().getFirst("traceparent"); // Parse traceparent TraceId traceId = TraceId.fromLowerBase16(traceparent, TRACE_ID_OFFSET); SpanId spanId = SpanId.fromLowerBase16(traceparent, SPAN_ID_OFFSET); TraceOptions traceOptions = TraceOptions.fromLowerBase16(traceparent, TRACE_OPTION_OFFSET); // traceparentからSpanContextの作成 SpanContext spanContext = SpanContext.create(traceId, spanId, traceOptions);JAX-RSクライアント(REST Call時にtraceparentを付与)
コンテキストをリモートのAPIに伝えるにはREST Call時にtraceparentをHTTPヘッダ等に付与してやる必要があります。
手動でやっても良いですがJAX-RS向けのOpenCensusライブラリの「opencensus-contrib-http-jaxrs」を利用します。var url = 'http://localhost:5000'; var target = ClientBuilder.newClient() .target(url) .path("/account/" + userId + "/balance"); target.register(JaxrsClientFilter.class); return target .request(MediaType.APPLICATION_JSON) .get(new GenericType<Map<String, Long>>() {});
target.register(JaxrsClientFilter.class)でJaxrsClientFilterを登録することで自動的にリクエストヘッダーに現状のSpanからtraceparentを生成して付与してくれます。JAX-RSクライアント(traceparentからSpanの作成)
JAX-RSのサーバ側、今回でいうapi-coreの実装です。
opencensus-contrib-http-jaxrsのContainer Filterを使うことで自動で設定できる様なのですが、なぜかうまく動かなかったので自前で実装します。private static final TextFormat textFormat = Tracing.getPropagationComponent().getTraceContextFormat(); private static final TextFormat.Getter<HttpServletRequest> getter = new TextFormat.Getter<HttpServletRequest>() { @Override public String get(HttpServletRequest httpRequest, String s) { return httpRequest.getHeader(s); } }; @GET @Path("/{userId}/balance") public Map<String, Long> getBalance(@Context HttpServletRequest request, @PathParam("userId") String userId) throws SpanContextParseException { var spanContext = textFormat.extract(request, getter); var depth = 1; var className = Thread.currentThread().getStackTrace()[depth].getClassName(); var methodName = Thread.currentThread().getStackTrace()[depth].getMethodName(); try (var ss = Tracing.getTracer() .spanBuilderWithRemoteParent(className + "$" + methodName, spanContext) .setRecordEvents(true) .setSampler(Samplers.alwaysSample()) .startScopedSpan()) { var balance = service.getBalance(userId); return balance; } }
TextFormatクラスを活用することで先ほどの面倒なパースを自前でせずにSpanContextを作成できます。
また、通常のSpan作成とは違いリモートのコンテキストからスパンを作る場合はspanBuilderWithRemoteParentを使用します。
以降の子Spanを作る時はspanBuilderで問題ありません。以上で、JavaでOpenCensusを使った分散トレーシングの設定は完了なので、実際に動かしてJaegerやCloud Traceに連携されているか確認してください。
まとめ
JavaでOpenCensusを使った分散トレーシングを実装してみました。
正直、パッと見ドキュメントあるし有名な仕様だからブログ記事とかも多いだろうから1時間と少しくらいで楽勝だろっと思ってたら沼にハマり1時間くらい掛かってしまいました。ドキュメント不足とか不備をなんとかしたい気もしますが、きっとその労力はOpenTelemetryに使われるべきなので、
あと、細かいところが書いてないのは基本的にはそもそも分散トレースに詳しい一部の人がライブラリやFWを設計してあとは使うだけってコンセプトだからな気はします。MPのOpenTracingとかOpenTelemetryのOpenTelemetry Auto-Instrumentation for Javaは良く知らなくても触れますしね。まあ、結果として今回いろいろ詳しくなれたと思うのでそれはそれで良かったかな。OpenTelemetryもそのうち再チャレンジしないと。
それではHappy Hacking!
参考
