- 投稿日:2020-06-24T20:42:54+09:00
【RDS】EC2とRDS(MySQL)間の接続を確立する
目標
・EC2サーバとRDS(MySQL)間の接続を確立する。
前提
・構築済みのEC2が存在すること。
利用環境
EC2
OS(AMI) : Amazon Linux 2 AMI (HVM), SSD Volume Type
ソフトウェア: mysql Ver 14.14 Distrib 5.5.62, for Linux (x86_64) using readline 5.1RDS
データベースエンジン: MySQL(5.7.22)参考AWSドキュメント
MySQL DB インスタンスを作成して MySQL DB インスタンス上のデータベースに接続する
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/CHAP_GettingStarted.CreatingConnecting.MySQL.html作業の流れ
項番 タイトル 1 RDSを作成する 2 MySQLクライアント接続 手順
1.RDSを作成する
①AWS マネジメントコンソールにサインインし、Amazon RDS コンソール (https://console.aws.amazon.com/rds/) を開く
②データベースの作成をクリック
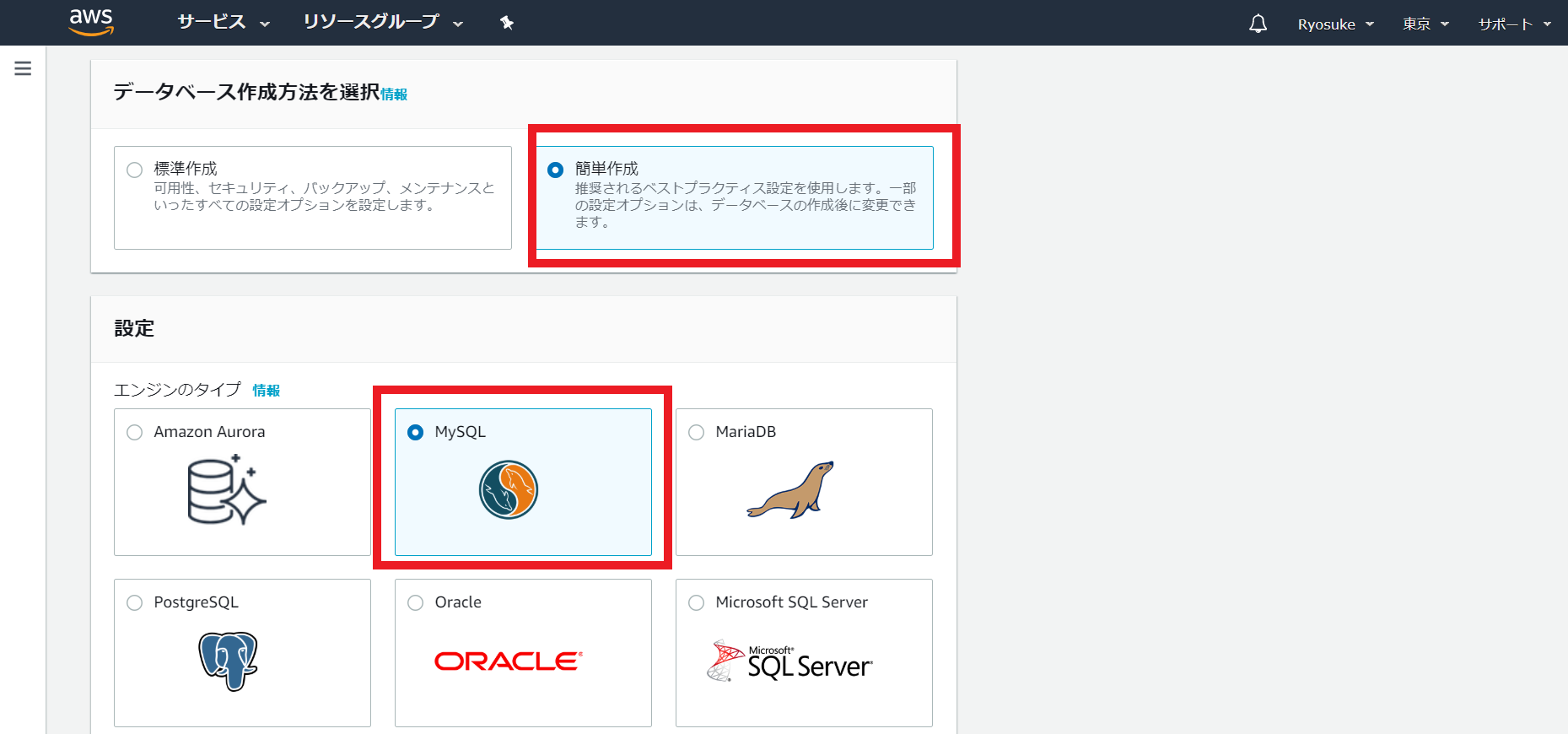
③データベースの作成方法を選択
以下のように、各値を投入してください。
簡単作成(データベースの詳細設定の多くをデフォルトで設定してくれます)
データベースエンジンはMySQL
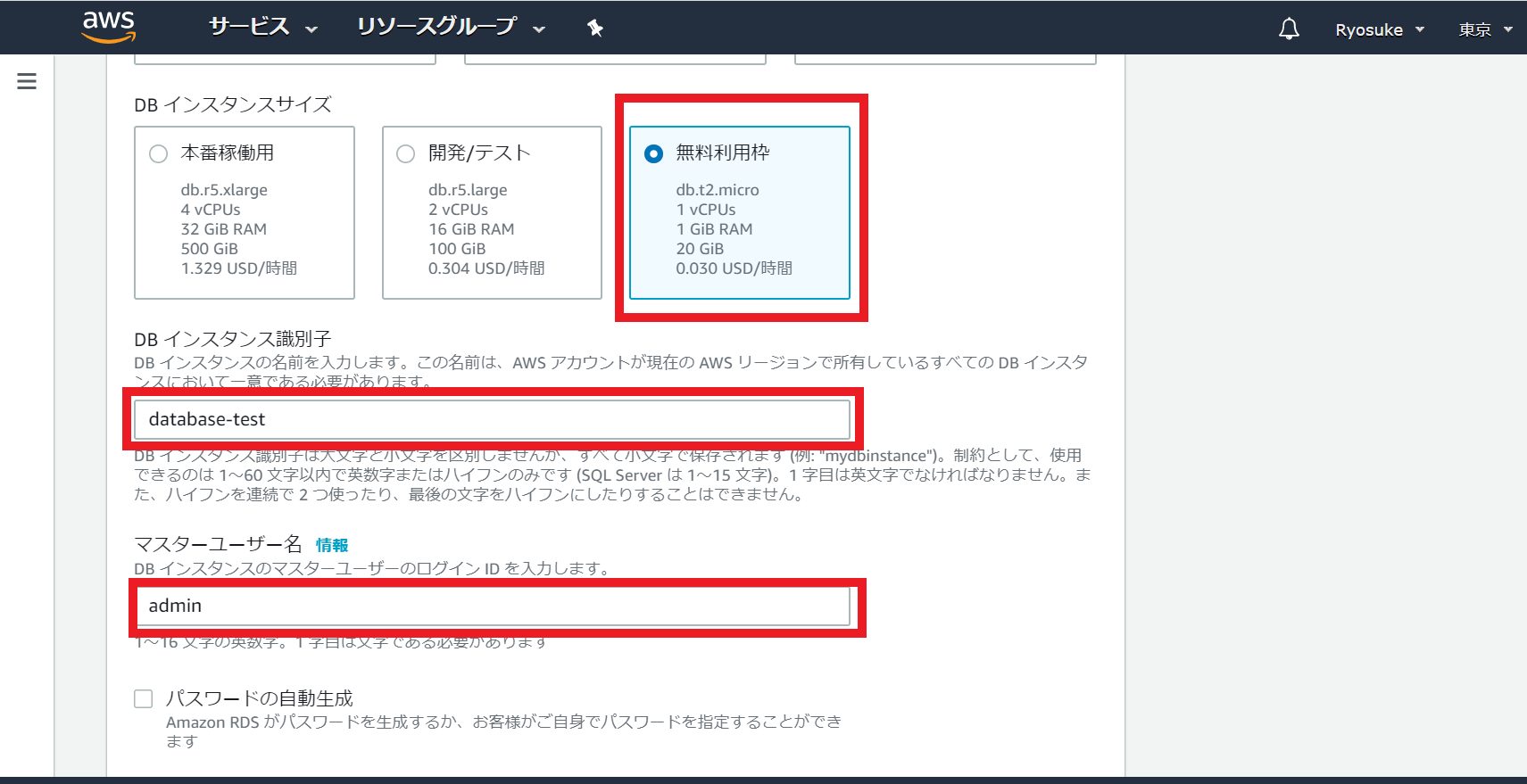
任意の
DBインスタンス識別子とマスターユーザ名(MySQL接続時の認証等で利用されます)を入力
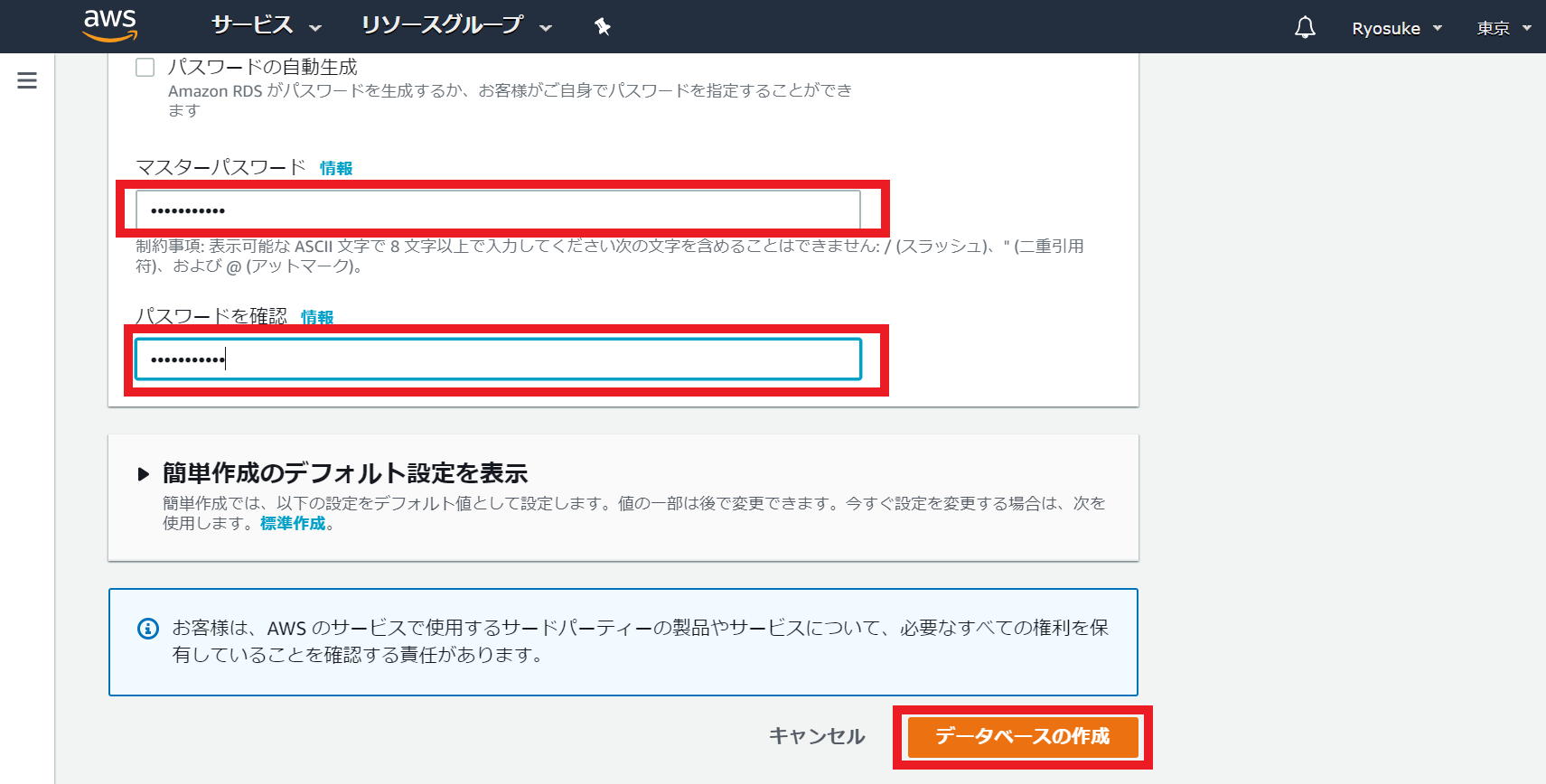
マスターパスワードを入力(パスワード自動生成することも可能、MySQL接続時の認証で利用されます)
④作成したRDSが
利用可能になるまで待機
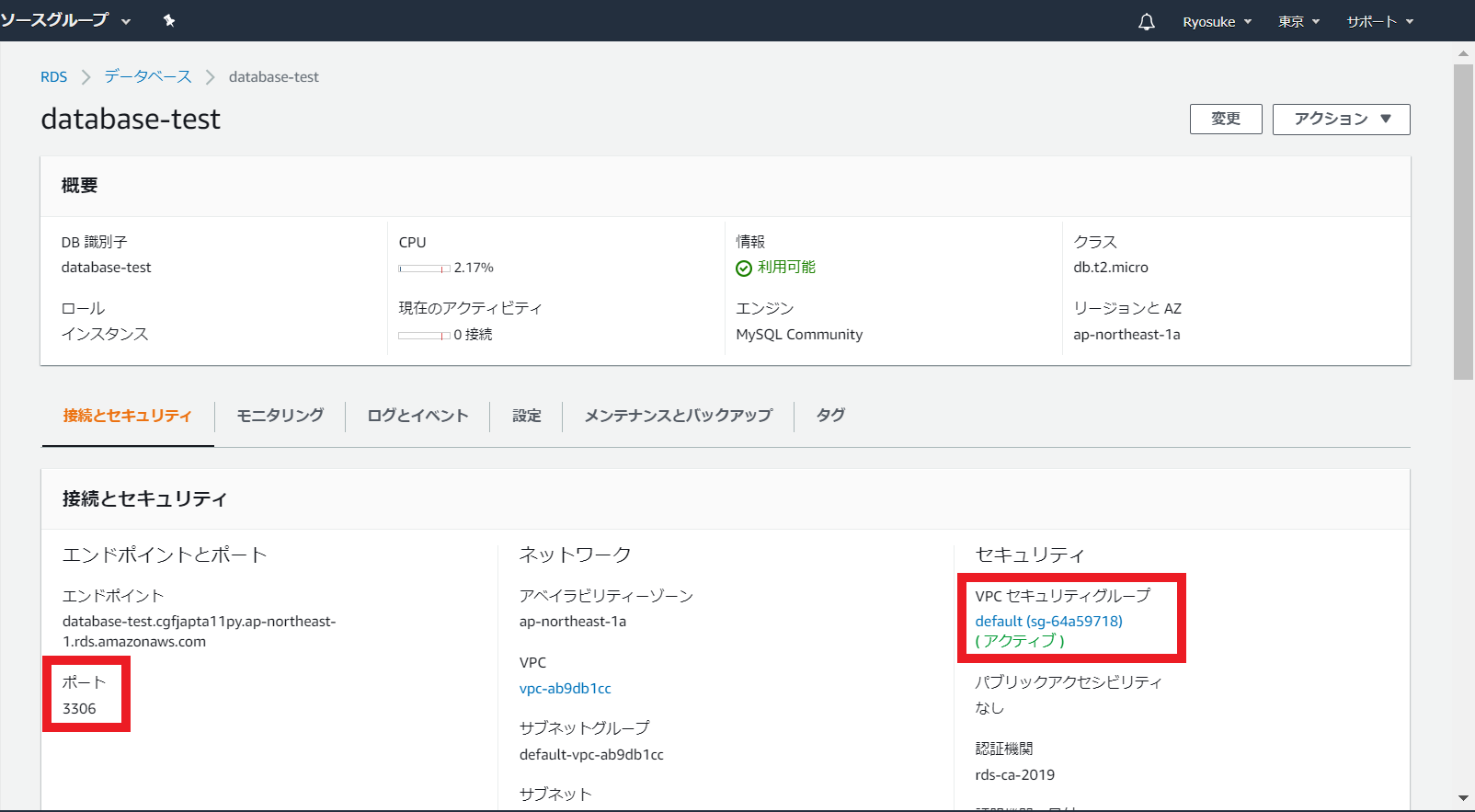
⑤作成したRDSの
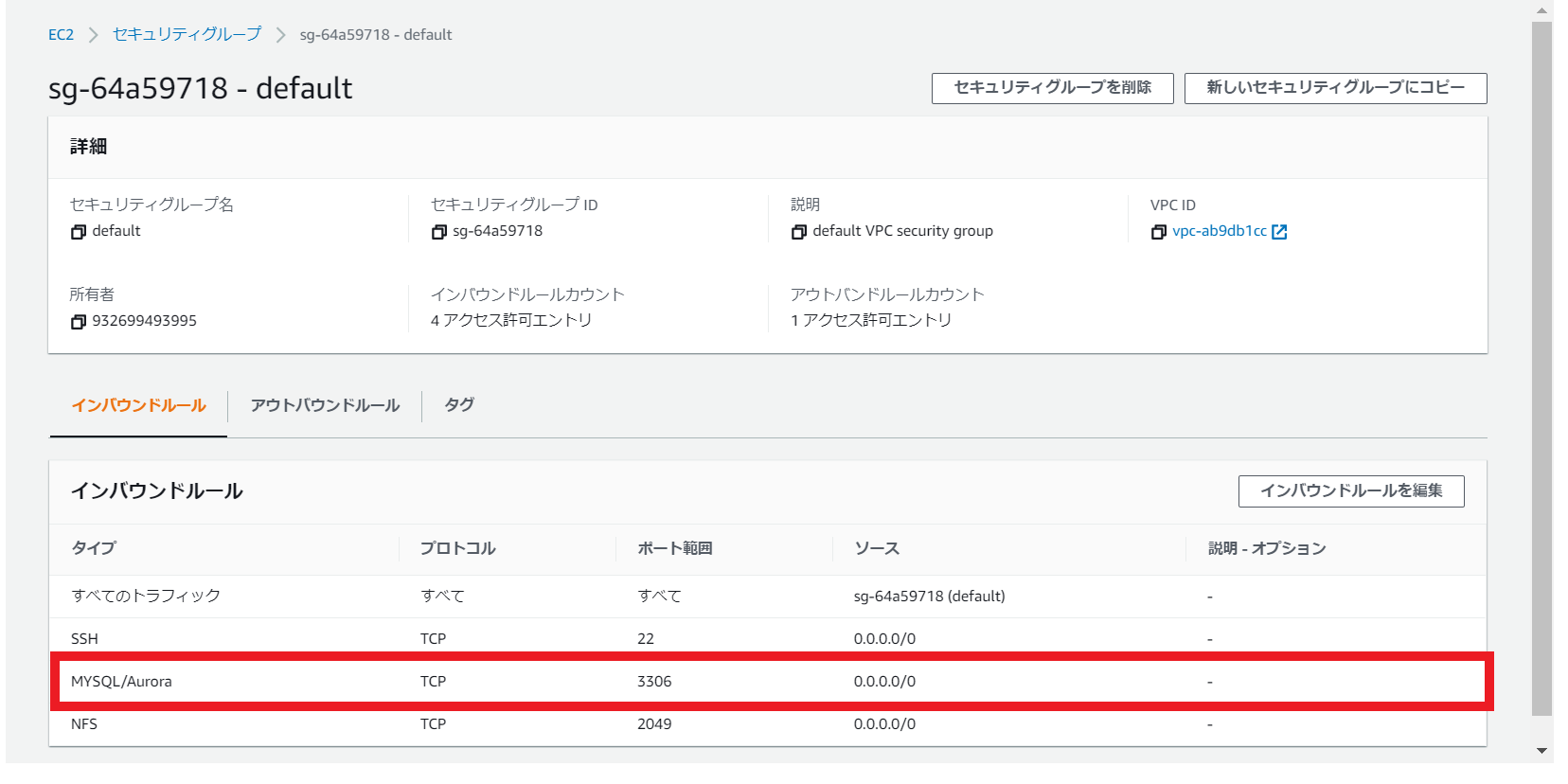
3306番ポートを開く
作成したRDSの詳細画面からVPCセキュリティグループをクリック(利用ポートが3306番であることも確認)
3306番ポートを許可
2.MySQLクライアント接続
①EC2にOSログイン
②MySQLクライアントがインストールされているか確認
yum list installed | grep mysql実行# 出力がなければ未インストール [ec2-user@ip-172-31-32-13 ~]$ yum list installed | grep mysql③MySQLクライアントインストール
sudo yum install mysql実行# Complete!と出力されること [ec2-user@ip-172-31-32-13 ~]$ sudo yum install mysql (中略) Installed: mysql.noarch 0:5.5-1.6.amzn1 Dependency Installed: mysql-config.x86_64 0:5.5.62-1.23.amzn1 mysql55.x86_64 0:5.5.62-1.23.amzn1 mysql55-libs.x86_64 0:5.5.62-1.23.amzn1 Complete!④MySQLログイン
mysql -h <RDSエンドポイント名> -P 3306 -u <マスターユーザ名> -p実行# マスターユーザのパスワードを入力し、正常にログイン出来ればOK [ec2-user@ip-172-31-32-13 ~]$ mysql -h database-test.cgfjapta11py.ap-northeast-1.rds.amazonaws.com -P 3306 -u admin -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 15 Server version: 5.7.22-log Source distribution Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>

- 投稿日:2020-06-24T19:50:33+09:00
ERROR! The server quit without updating PID file (/usr/local/var/mysql/***.local.pid).の解決方法
rails sでサーバーを起動。いざブラウザでアクセスすると以下のようなエラー。
ERROR! The server quit without updating PID file (/usr/local/var/mysql/***.local.pid).解決方法
mysqlに関するファイルを全て削除。mysqlもアンインストールしたら動いた。
*データが消える恐れがあります。$ sudo rm -fr /usr/local/var/mysql/ $ sudo rm -fr /usr/local/Cellar/mysql/ $ sudo rm -fr ./usr/local/Cellar/mysql/ まずはMysqlに関するファイルが保存されているディレクトリを削除。既にインストール済みの場合はMysqlをアンインストールします。
$ brew uninstall mysql次にインストール。
$ brew install mysql起動の確認をする。
$ mysql.server start Starting MySQL SUCCESS!参考記事
https://qiita.com/akiko-pusu/items/aef52b723da2cb5dc596
https://shikouno.hatenablog.com/entry/2017/06/22/210000
http://tech-outlines.hateblo.jp/entry/2015/03/24/180940
https://qiita.com/mogetarou/items/e34ca51d3756d55d7800
- 投稿日:2020-06-24T17:38:57+09:00
Equalumがやって来た!(前半完結編2)
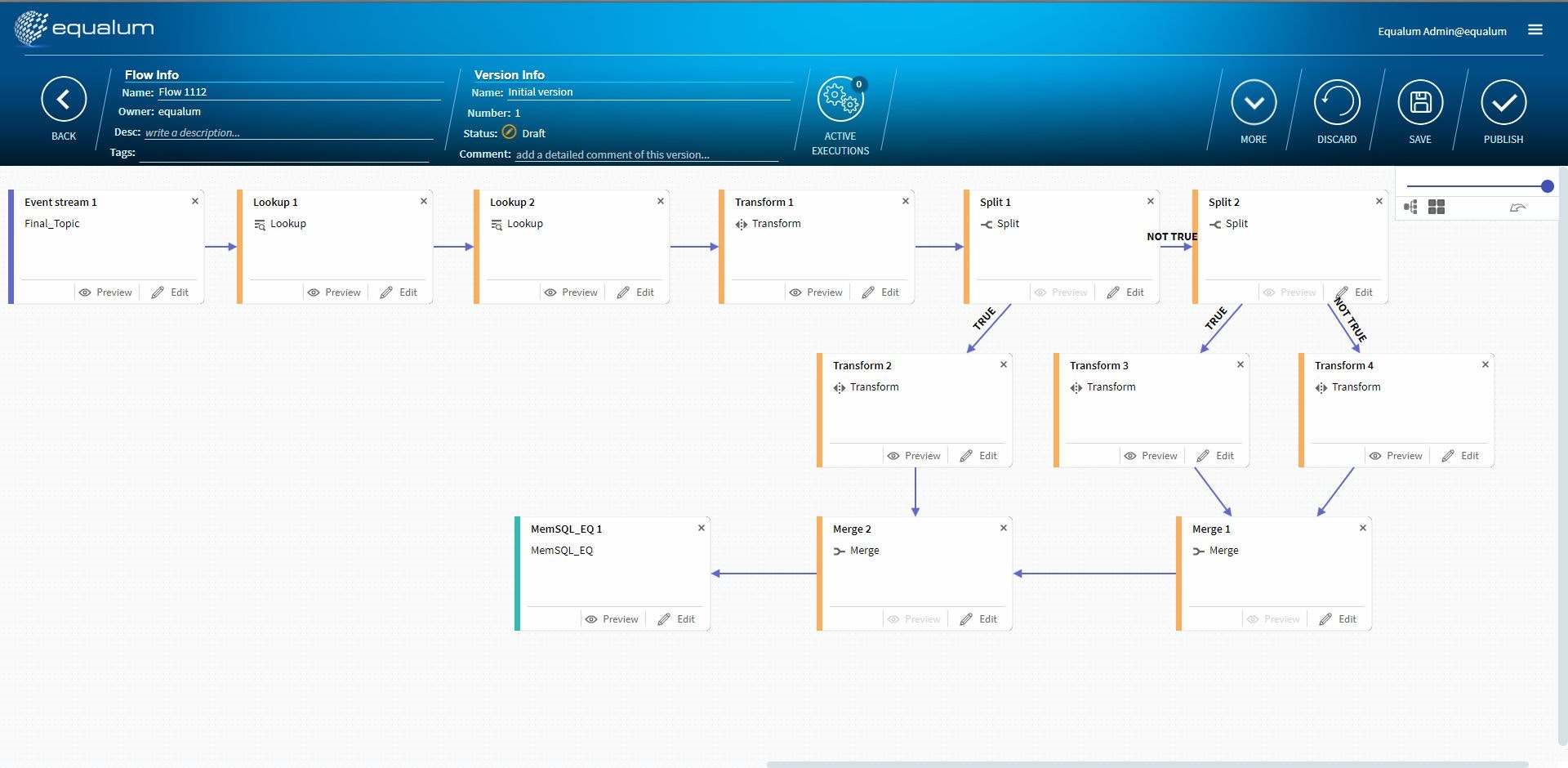
今回は多段の処理を行うFLOWをデザインしてみます。
今回は完結編の後半として多段構成のFLOWをデザインして検証します。
ザクっとした流れ的なものはこんな感じを想定します。厳密にデザインしたデータベースであれば、「そもそもそんな事・・・」と厳しいご指摘を頂くかとは思いますが、今回はこの流れでご勘弁ください。今回初登場の設定を紹介
今まで幾つかの設定項目に関する検証を行ってきましたので、ここでは今回の検証で初登場の新参者に関する設定項目を確認します。
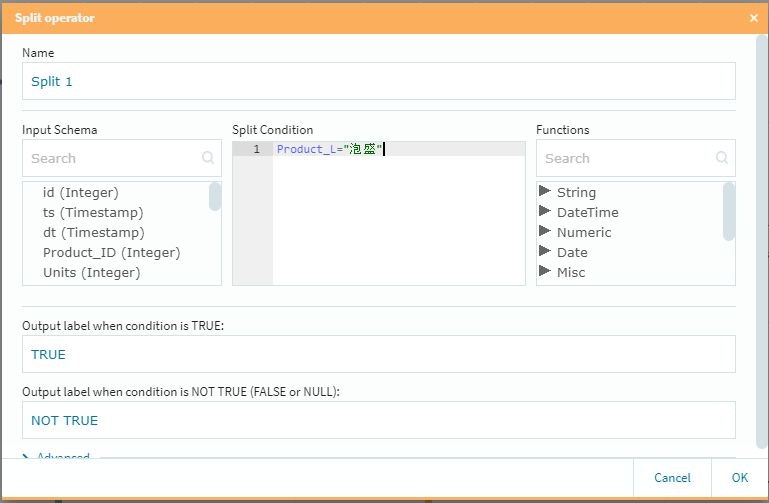
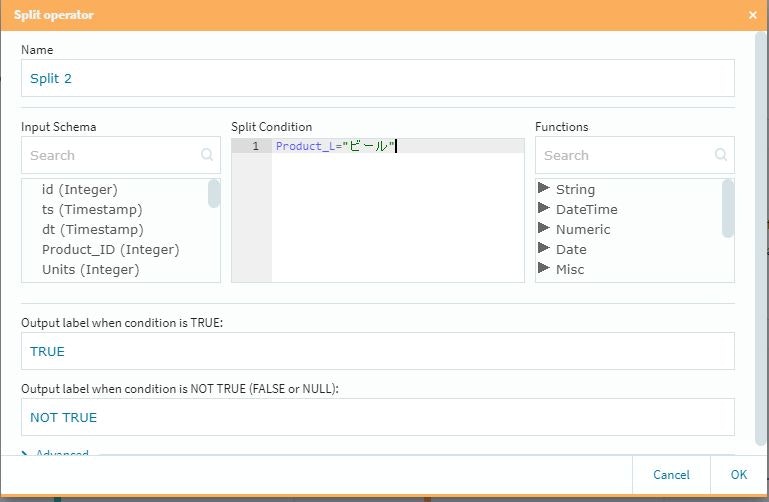
SplitとMerge
この2つは対で使用する形になります。また設定項目はSplit側にのみ存在していて、いわゆる「条件分岐」の仕事を行います。今回は泡盛とビールに対して個別のポイントを付与し、それ以外の商品に対しては一律のポイントを「後付け」で追加する事にしました。
Transformの設定
また、今回の検証では複数のTransformを仕掛けましたので、それぞれの内容を確認しておきます。
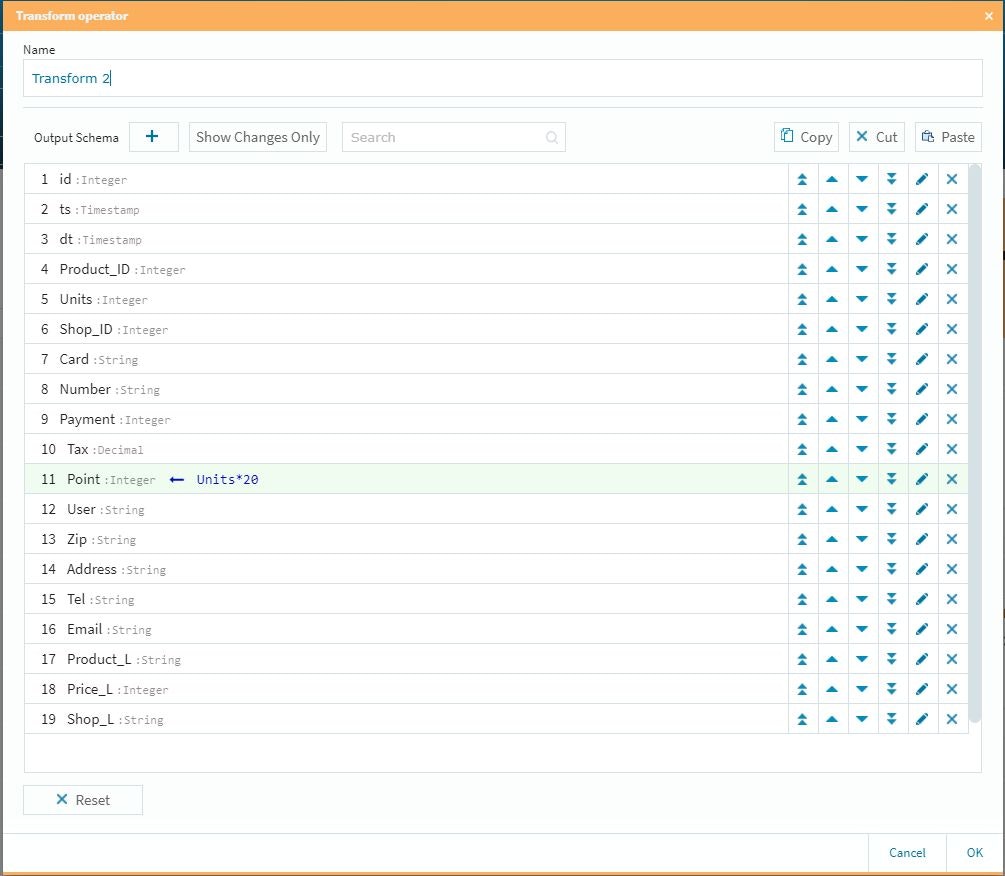
まずは、個数と単価から購入総額と税金を計算して新規のデータとしてテーブルを拡張させます。
次に分岐後の仕掛けとして想定ポイント付与を行います。今回は泡盛20ポイント、ビール15ポイント、その他10ポイントにしています。これらの仕掛けを行った全体のFLOWがこの形になりました。
少し重要な点を・・・
前回までの検証で得られた情報と、今回の新規分を合わせれば此処までのデザイン所要時間は15分程度で行けると思います。(デザインツールの見た目を調整する時間の方が長かったです・・・)
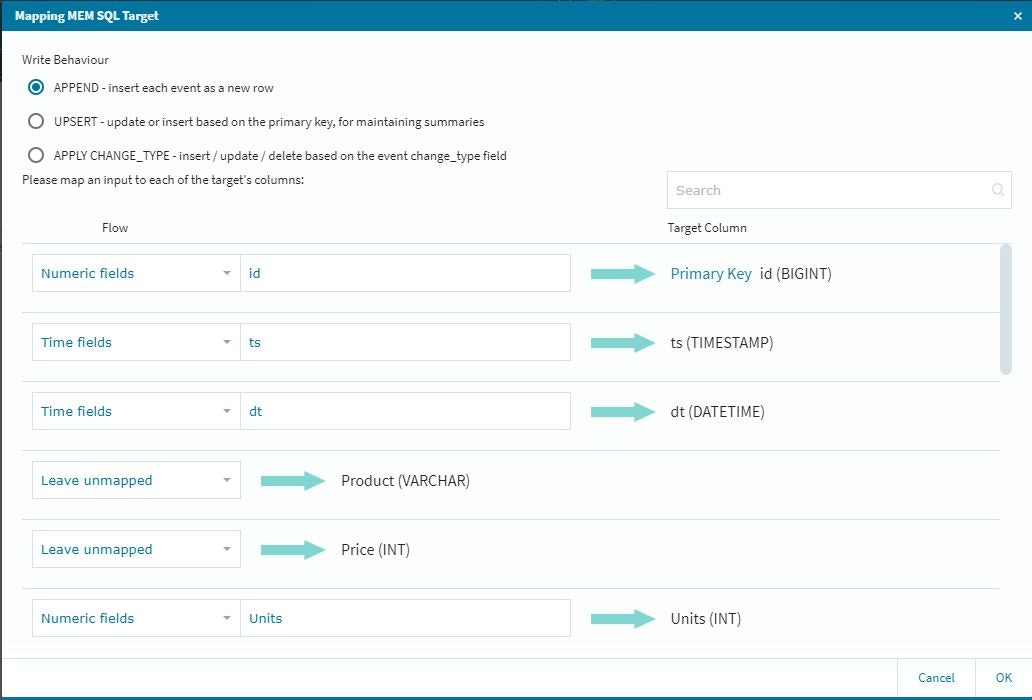
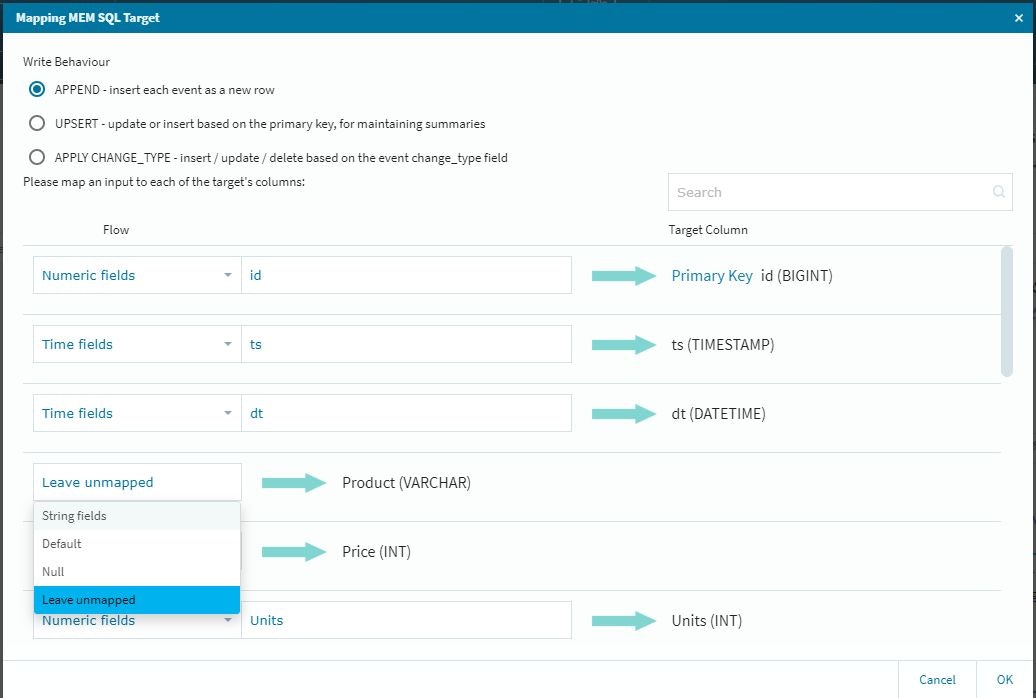
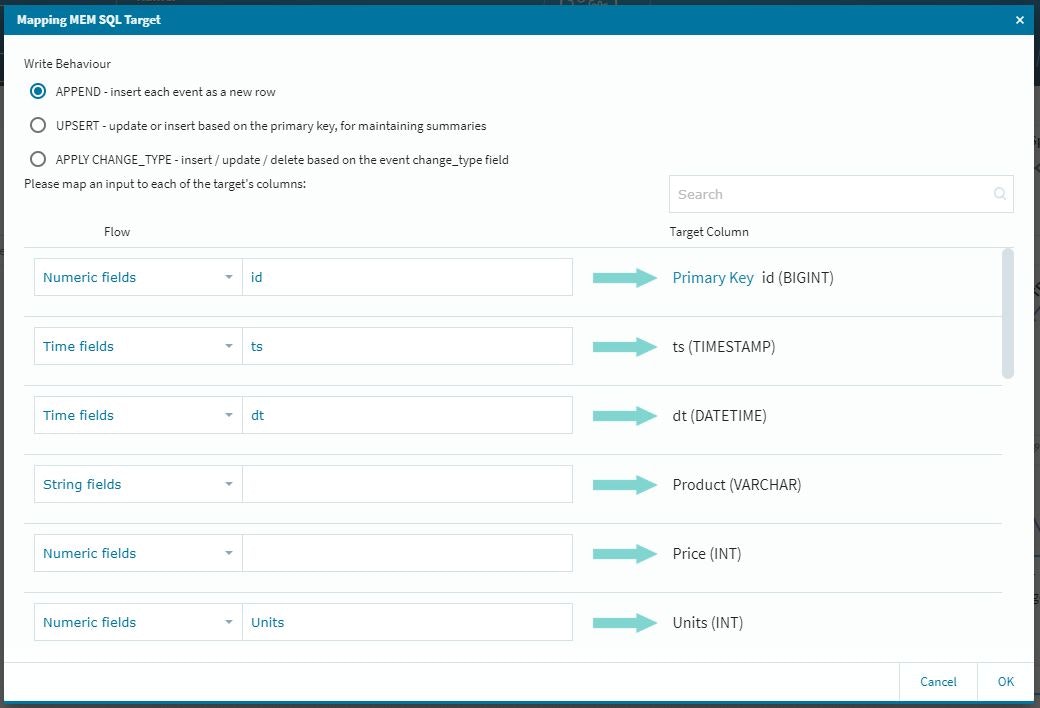
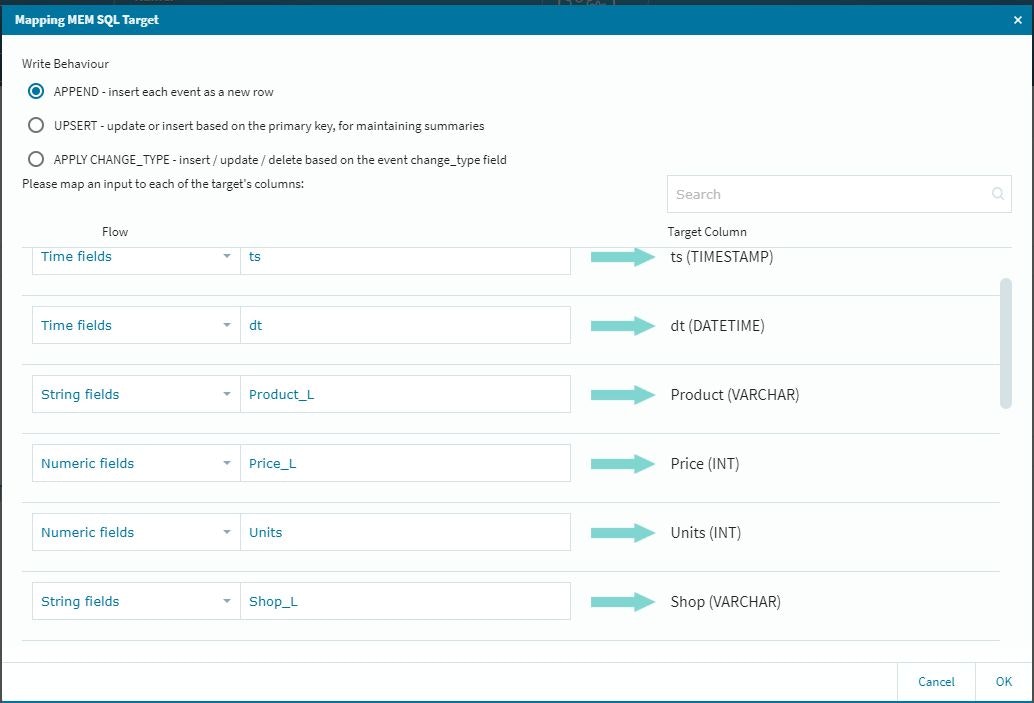
また、最終的に収めるテーブルの設定に関して、今回のFLOWでは途中に新規設定のカラムが幾つか出てきますので(オリジナルのデータでは整数データのID経由の参照データ変換等)最後のMemSQL上へ書き出すテーブル設定は、少し慎重に確認作業を行う必要があります。
作業的には、新規に入ってきたデータをアクティブにする作業になりますので、以下の設定を忘れないように実施します。
この段階では参照してきた情報がアクティブになっていませんので、それぞれの項目に関して適切な設定作業を行います。
これで、テーブルに参照データが納まる形になります。(前回のルックアップの際に補足しておけば良かったのですが・・・)さて実行!!
今までの検証手順通りに配備が出来たら、Pythonで作成した自動データ生成スクリプトを実行します。
既に口を開けた状態でkafkaが待っていますので、データ更新が始まったと同時に定義したFLOWを自動的に実行していきます。
これが上流側のデータソースに流れ込んだデータの状況です。
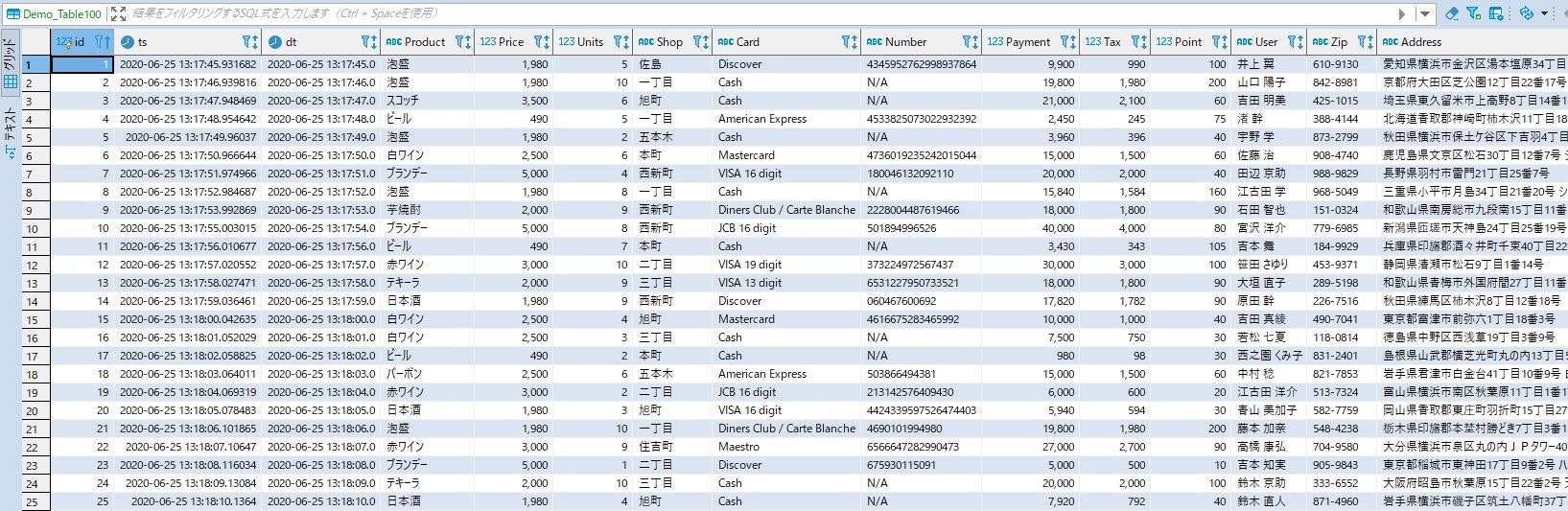
こちらが今回処理をFLOW定義して生成されたデータの状況になります(今回、タイムゾーンの設定を見直して再度検証しました)
また、特筆すべき点は、上流側のMySQLが付与したタイムスタンプと、EqualumのFLOWオペレーション後の下流側MemSQLが付与したタイムスタンプが・・・・(汗)
上流側のMySQLに記録されたデータ(タイムスタンプ値周辺)
1|2020-06-25 13:17:45.931682|2020-06-25 13:17:45.0| 8| 5| 7|Discover 2|2020-06-25 13:17:46.939816|2020-06-25 13:17:46.0| 8| 10| 5|Cash 3|2020-06-25 13:17:47.948469|2020-06-25 13:17:47.0| 6| 6| 0|Cash 4|2020-06-25 13:17:48.954642|2020-06-25 13:17:48.0| 2| 5| 5|American Express 5| 2020-06-25 13:17:49.96037|2020-06-25 13:17:49.0| 8| 2| 8|Cash 6|2020-06-25 13:17:50.966644|2020-06-25 13:17:50.0| 5| 6| 2|Mastercard 7|2020-06-25 13:17:51.974966|2020-06-25 13:17:51.0| 7| 4| 4|VISA 16 digit 8|2020-06-25 13:17:52.984687|2020-06-25 13:17:52.0| 8| 8| 5|Cash 9|2020-06-25 13:17:53.992869|2020-06-25 13:17:53.0| 3| 9| 4|Diners Club / Carte Blanche下流側のMemSQLに記録されたデータ(タイムスタンプ値周辺)
1|2020-06-25 13:17:45.931682|2020-06-25 13:17:45.0|泡盛 | 1980| 5|佐島 |Discover 2|2020-06-25 13:17:46.939816|2020-06-25 13:17:46.0|泡盛 | 1980| 10|一丁目 |Cash 3|2020-06-25 13:17:47.948469|2020-06-25 13:17:47.0|スコッチ | 3500| 6|旭町 |Cash 4|2020-06-25 13:17:48.954642|2020-06-25 13:17:48.0|ビール | 490| 5|一丁目 |American Exp 5| 2020-06-25 13:17:49.96037|2020-06-25 13:17:49.0|泡盛 | 1980| 2|五本木 |Cash 6|2020-06-25 13:17:50.966644|2020-06-25 13:17:50.0|白ワイン | 2500| 6|本町 |Mastercard 7|2020-06-25 13:17:51.974966|2020-06-25 13:17:51.0|ブランデー | 5000| 4|西新町 |VISA 16 di 8|2020-06-25 13:17:52.984687|2020-06-25 13:17:52.0|泡盛 | 1980| 8|一丁目 |Cash 9|2020-06-25 13:17:53.992869|2020-06-25 13:17:53.0|芋焼酎 | 2000| 9|西新町 |Diners Clubまた、処理が最初にMySQLに挿入された最初のデータ起点で開始され、その後ストリーミングで連続処理されて行きますので、データの量にはあまり関係ない(貯めてドン!のバッチ系は・・・)ので、複数のFLOWも並行して処理しても問題無いでしょう。
今回のまとめ
今回は前回の続きで少し複雑なFLOW定義をして検証を行いました。データの最新動向を手軽に取り扱えるという点においては、Equalumのゼロコーディング技術は大変興味深く、データの民主化にとって非常に心強い手助けになるという事を確実にご理解頂けたかと思います。
従来からのCDC技術に最新のメッセージ制御技術であるkafkaと、高速・高効率な処理を提供するSparkをプログラム不要で組み合わせて誰でも使える環境として、Equalumが今後もたらすこの領域に対する影響は、非常に大きいと思いますし同時に新しいアイディアをデータ起点で創りだせる環境としても非常に使い勝手の良い製品だと言えるでしょう。基本的なSQLとデータの意味(カラムの内容)が判れば、非常に高度なリアルタイム性でデータをストリーミングしながら処理を行う事が可能になる・・・AI/BIといった活用系のソリューションに対する投資対効果をさらに向上させると同時に、その先に新しいアイディアや問題解決の糸口をデータ・ドリブンで獲得出来るということは・・・
Dx時代のデータ・ドリブンはEqualumで変わる・・・
データを貯めてから考えるか?
データを流しながら適時対応していくか?これは、データを諦めずに「変化に強い高速なデータ・ドリブン環境」を実現する上で非常に重要なポイントであると同時に、データを貯めてから考えるか?データを貯めながら適時対応していくか?という、新しい2者択一が求められる時代になった事を意味しています。
次回は番外編としてEqualumにもれなく付いてくるバッチ系の簡単な検証を追加して前半戦を終了させて頂きます。
謝辞
本検証は、Equalum社の特別の許可を得て実施しています。この貴重な機会を設定して頂いたEqualum社に対して感謝の意を表すると共に、本内容とEqualum社の公式ホームページで公開されている内容等が異なる場合は、Equalum社の情報が優先する事をご了解ください。



- 投稿日:2020-06-24T14:44:23+09:00
Equalumがやって来た!(前半完結編1)
今回は残りの幾つかを纏めて使ってみよう!
Equalum紹介の前半戦最後に、幾つかの処理要素を組み合わせた、「本物っぽい処理FLOW」を作成してみようと思います。
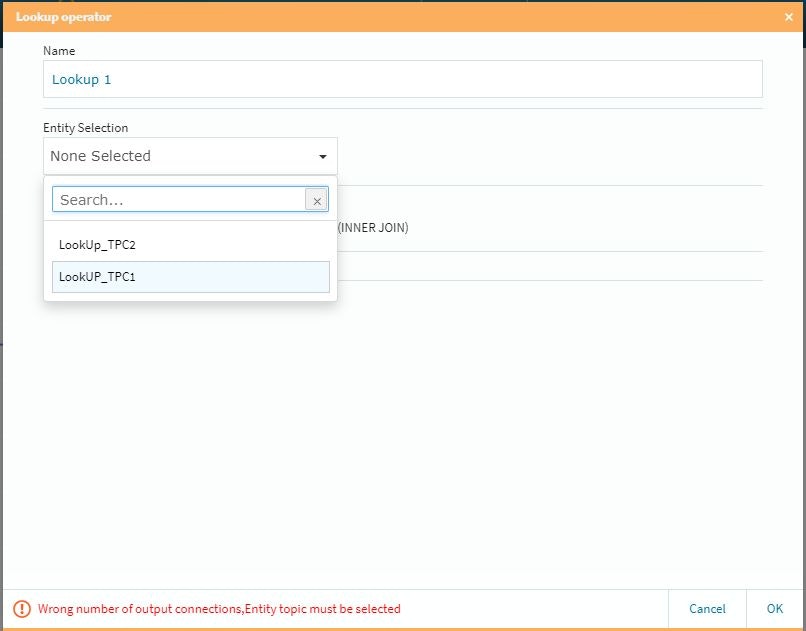
シナリオ的には、今まで検証に使用してきたPythonスクリプトを改造し、支店情報と取り扱い製品情報を参照型(今までは埋め込みで処理)に変更し、これらの基本情報をLookUpテーブル化して処理を行うようにします。
また、納品業者側から期間限定のキャンペーンが入り、ちょうど自分達でもポイント制を導入する事にしたので、その一連の処理もEqualumで自動化させて最終の処理テーブルとしてMemSQL上に展開する事とします。まずはルックアップテーブル処理・・・
以前より使用しているMySQL側のテーブル設定を実名の文字列型から参照IDのINT型に変更します。
# 初期設定 import sys stdout = sys.stdout reload(sys) sys.setdefaultencoding('utf-8') sys.stdout = stdout import pymysql.cursors # 検証処理開始 print("MySQL側にオリジナル用の空テーブルを作成します") print try: # 既存のテーブルを初期化 Table_Init = "DROP TABLE IF EXISTS Demo_Table400" # カラムの設定 DC0 = "id INT AUTO_INCREMENT PRIMARY KEY, ts TIMESTAMP(6)," # 今回はこの部分を変更します DC1 = "dt DATETIME, Product_ID INT, Units INT, Shop_ID INT," DC2 = "User VARCHAR(20),Zip VARCHAR(10),Address VARCHAR(60),Tel VARCHAR(15),Email VARCHAR(40)" # 検証用のテーブルの作成 Table_Create = "CREATE TABLE IF NOT EXISTS Demo_Table400("+DC0+DC1+DC2+")" # MySQLとの接続 db = pymysql.connect(host = 'xxx.xxx.xxx.xxx', port=3306, user='root', password='zzzzzzzzzzz', db='Demo', charset='utf8mb4', cursorclass=pymysql.cursors.DictCursor) with db.cursor() as cursor: # 既存テーブルの初期化 cursor.execute(Table_Init) db.commit() # 新規にテーブルを作成 cursor.execute(Table_Create) db.commit() except KeyboardInterrupt: print('!!!!! 割り込み発生 !!!!!') finally: # データベースコネクションを閉じる db.close() print("処理が終了しました") print print("引き続きMemSQL側にルックアップテーブルを作成してください") print次にルックアップテーブルを定義します。この程度の数であれば直接SQL文を書いてもOKなのですが・・・以前の物を使いまわしている関係上、かなり無駄なステップを踏んでいます。その辺はご容赦の程・・・
# 初期設定 import sys stdout = sys.stdout reload(sys) sys.setdefaultencoding('utf-8') sys.stdout = stdout import pymysql.cursors # 検証処理開始 print("MySQL側テーブルにルックアップテーブルを作ります") print try: # 既存のテーブルを初期化 Table_Init1 = "DROP TABLE IF EXISTS Demo_Table410" Table_Init2 = "DROP TABLE IF EXISTS Demo_Table420" # ルックアップテーブルの定義 Table_Create1 = "CREATE TABLE IF NOT EXISTS Demo_Table410(Id_L INT PRIMARY KEY, Product_L VARCHAR(20),Price_L INT)" Table_Create2 = "CREATE TABLE IF NOT EXISTS Demo_Table420(Id_L INT PRIMARY KEY, Shop_L VARCHAR(20))" # ルックアップテーブル(1) Product_Name = ["日本酒","バーボン","ビール","芋焼酎","赤ワイン","白ワイン","スコッチ","ブランデー","泡盛","テキーラ"] Product_Price = [1980, 2500, 490, 2000, 3000, 2500, 3500, 5000, 1980, 2000] # ルックアップテーブル(2) Shop_Name = ["旭町","三丁目","本町","二丁目","西新町","一丁目","住吉町","佐島","五本木","古橋"] # 生成するデータの総数 Loop_Count = 10 # その他の変数 Counter = 0 # MySQLとの接続 db = pymysql.connect(host = 'xxx.xxx.xxx.xxx', port=3306, user='root', password='zzzzzzzzzz', db='Demo', charset='utf8mb4', cursorclass=pymysql.cursors.DictCursor) with db.cursor() as cursor: # 既存テーブルの初期化 cursor.execute(Table_Init1) db.commit() cursor.execute(Table_Init2) db.commit() # 新規にテーブルを作成 cursor.execute(Table_Create1) db.commit() cursor.execute(Table_Create2) db.commit() # データの生成 while Counter < Loop_Count: # ルックアップ情報の作成 Product = Product_Name[Counter] Price = Product_Price[Counter] Shop = Shop_Name[Counter] # 此処から先を各データベースの規程テーブルへ書き込む DV1 = str(Counter)+"','"+Product+"','"+str(Price) DV2 = str(Counter)+"','"+Shop sql_data1 = "INSERT INTO Demo_Table410(Id_L, Product_L, Price_L) VALUES('"+DV1+"')" sql_data2 = "INSERT INTO Demo_Table420(Id_L, Shop_L) VALUES('"+DV2+"')" # データベースへの書き込み cursor.execute(sql_data1) db.commit() cursor.execute(sql_data2) db.commit() # ループカウンタの更新 Counter=Counter+1 except KeyboardInterrupt: print('!!!!! 割り込み発生 !!!!!') finally: # デバッグ用データ表示 print print("生成したデータの総数 : " + str(Counter)) # データベースコネクションを閉じる db.close() print("MySQL側ルックアップテーブル作成終了")最後に着地側のMemSQL用のテーブル作成を行います。
これも、単純にSQL文を直接書いてしまえばシンプルに終了する話なのですが、使いまわしの法則により(苦笑)・・・細々と無駄なステップを踏んでいます。# 初期設定 import sys stdout = sys.stdout reload(sys) sys.setdefaultencoding('utf-8') sys.stdout = stdout import pymysql.cursors # デモ処理開始 print("MemSQL側にターゲットのテーブルを作成します") print try: # 既存のテーブルを初期化 Table_Init = "DROP TABLE IF EXISTS Demo_Table400" # デモ用のテーブル定義 DC0 = "id INT AUTO_INCREMENT PRIMARY KEY, ts TIMESTAMP(6) DEFAULT NOW()," # ここの項目をIDから参照してきた文字列等に置き換える形にします DC1 = "dt DATETIME, Product_L VARCHAR(20), Price_L INT, Units INT, Shop_L VARCHAR(20)," DC2 = "User VARCHAR(20), Zip VARCHAR(10), Address VARCHAR(60), Tel VARCHAR(15), Email VARCHAR(40)" # デモ用のテーブルの作成 sql_data = "CREATE TABLE IF NOT EXISTS Demo_Table400("+DC0+DC1+DC2+")" # MySQLとの接続 db = pymysql.connect(host = 'xxx.xxx.xxx.xxx', port=3306, user='eqdemo', password='zzzzzzzzz', db='Demo', charset='utf8', cursorclass=pymysql.cursors.DictCursor) with db.cursor() as cursor: # 既存テーブルの初期化 cursor.execute(Table_Init) db.commit() # デモ用テーブルの作成 cursor.execute(sql_data) db.commit() except KeyboardInterrupt: print('!!!!! 割り込み発生 !!!!!') finally: # データベースコネクションを閉じる db.close() print("処理が終了しました") print print("引き続きデータの自動生成を開始してください") printここまでくれば後はEqualum側の設定作業になります。
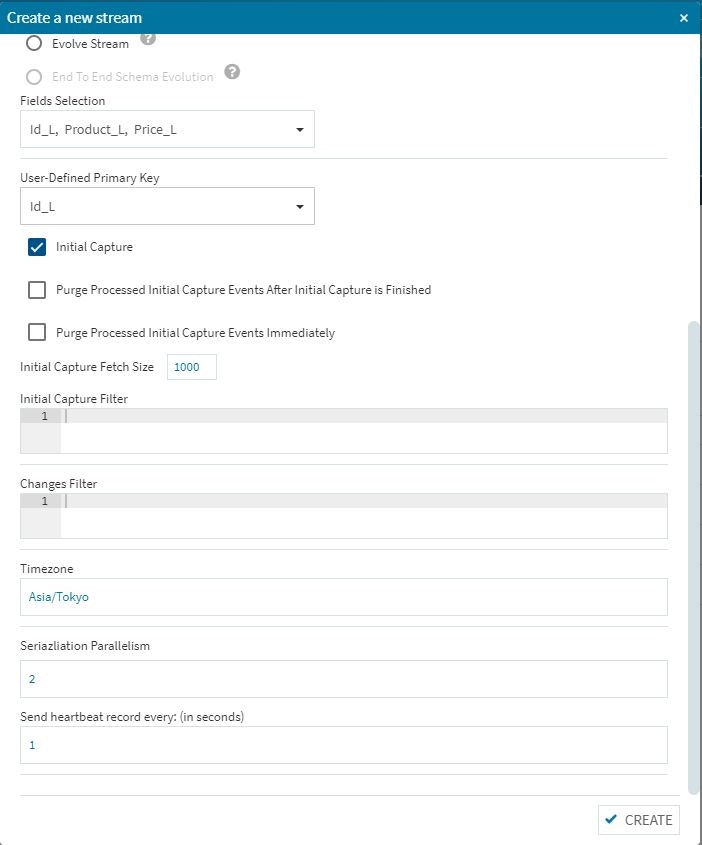
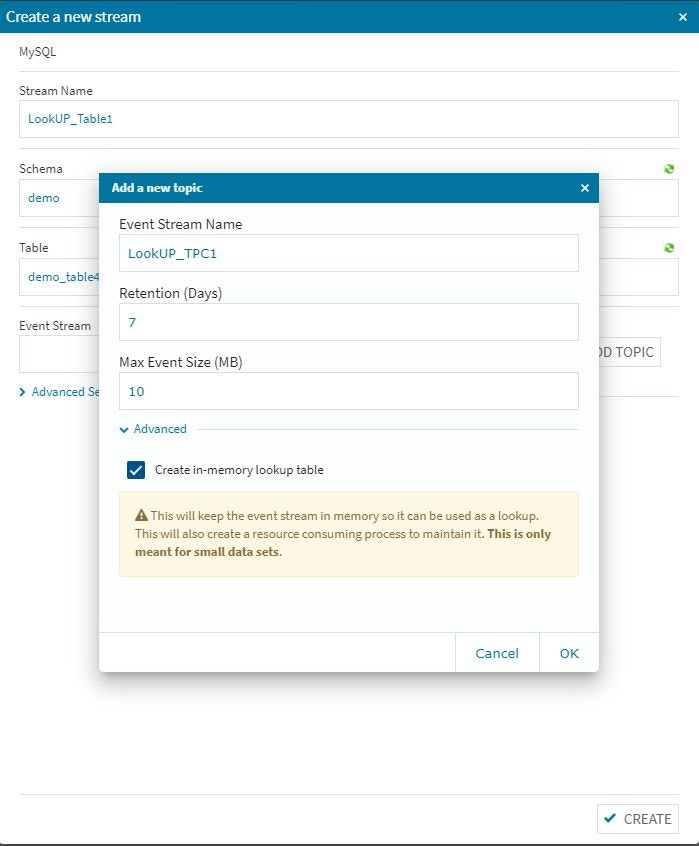
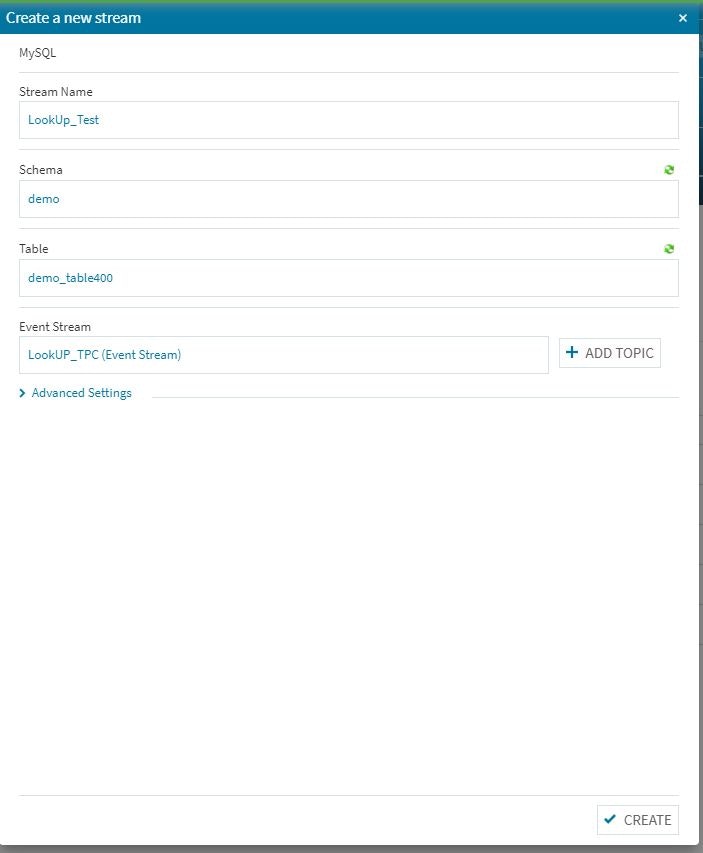
基本的な手順は今までの設定作業と同じですが、ルックアップテーブル特有の項目が幾つか有りますので、その辺を中心に検証作業を行って行きます。ちなみに、インメモリ上にテーブルを置きますので、Equalum社でも説明している様にあまり巨大なテーブルを作成しない事が重要です。もちろん今回程度のテーブルでは何の問題もありませんので、高速性重視でインメモリ展開戦略を取る事にします。
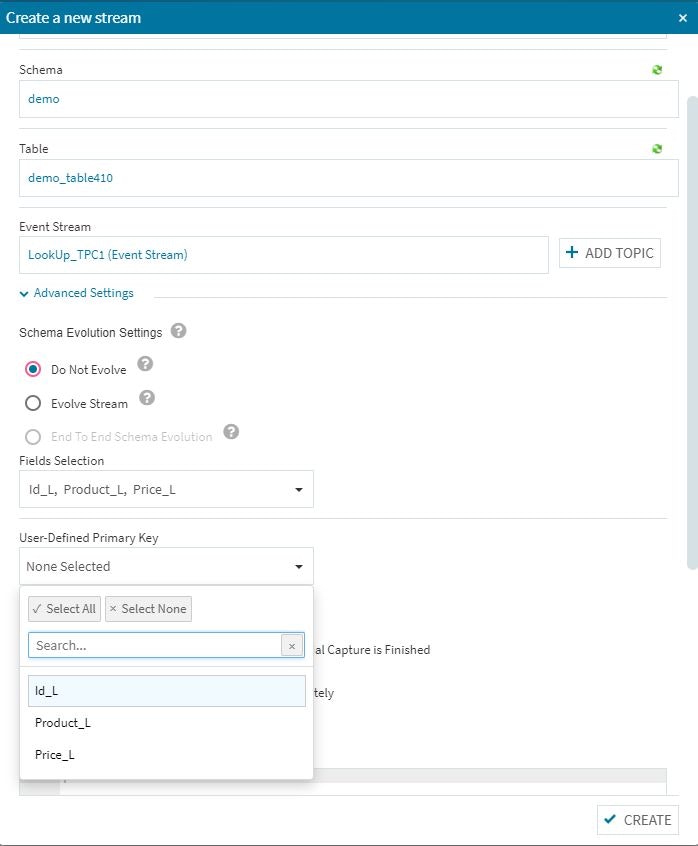
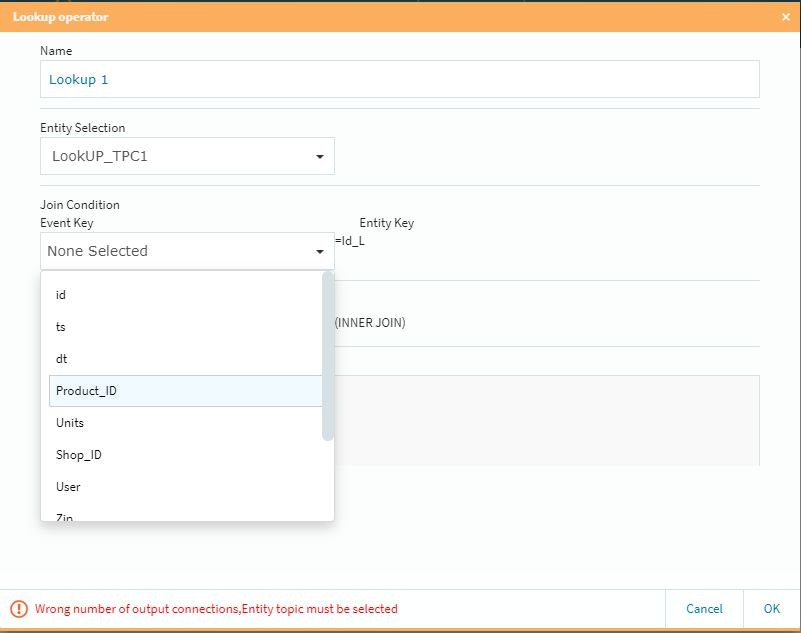
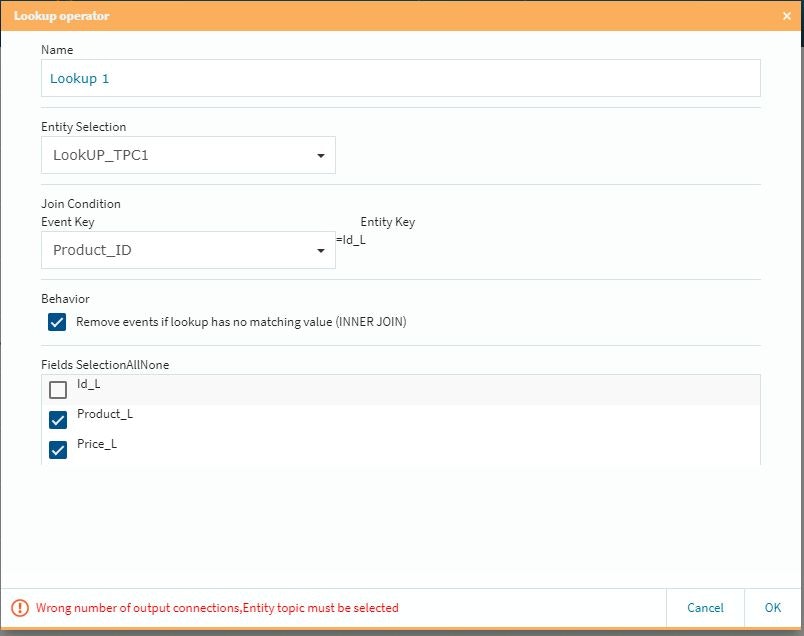
ルックアップテーブルを設定する際にDo Not Evolveを設定し、キーの選択などの必要作業を行います。
下の方までスクロールして必要事項を設定します(通常の場合は特に必要ない作業ですが・・・)
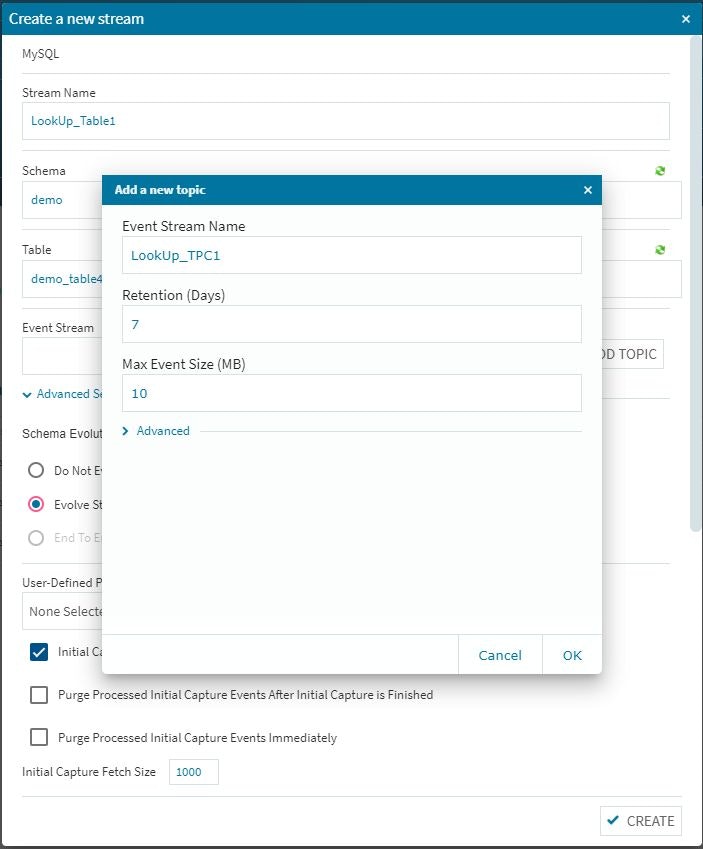
トピックを作成する際には・・・このAdvanced設定を忘れないようにします。
自動挿入されるメインのテーブル設定はいつも通りでOKです。
処理部分の設定・・・・
FLOWSで新規のストリーミング処理を作る際の(今回のルックアップ操作)設定項目はシンプルで判り易いと思いますので、それぞれ適宜選択・設定を行っていきます。
では、取り急ぎ動作検証!
今回のLookUp機能の検証用にカスタマイズしたスクリプトです・・・・といっても、単純に乱数を発生させてそれをIDとしてメインのテーブルに挿入しているだけですが・・・
# 初期設定 import sys stdout = sys.stdout reload(sys) sys.setdefaultencoding('utf-8') sys.stdout = stdout import time import pymysql.cursors # 検証処理開始 print("MySQL側テーブルにデータの自動生成&挿入を開始します") print try: # Pythonのデータ自動生成機能の設定 from faker.factory import Factory Faker = Factory.create fakegen = Faker() fakegen.seed(0) fakegen = Faker("ja_JP") # 生成するデータの総数 -> ここは適宜変更 Loop_Count = 50 # 一定間隔の場合(システム時間で秒単位) Sleep_Wait = 1 # その他の変数 Counter = 0 Work_Count = 1 # 書き込み用のデータカラム DL1 = "dt, Product_ID, Units, Shop_ID," #ここを修正 DL2 = "User,Zip,Address,Tel,Email" # MySQLとの接続 db = pymysql.connect(host = 'xxx.xxx.xxx.xxx', port=3306, user='root', password='zzzzzzzzz', db='Demo', charset='utf8mb4', cursorclass=pymysql.cursors.DictCursor) with db.cursor() as cursor: # 検証データの生成 while Counter < Loop_Count: # 受付日時の情報 from datetime import datetime dt = datetime.now().strftime("%Y/%m/%d %H:%M:%S") Product_ID = fakegen.random_digit() Shop_ID = fakegen.random_digit() Units = fakegen.random_digit() + 1 # 物流情報の生成 User = fakegen.name() Zip = fakegen.zipcode() Address = fakegen.address() Tel = fakegen.phone_number() Email = fakegen.ascii_email() # 此処から先を各データベースの規程テーブルへ書き込む DV1 = dt+"','"+str(Product_ID)+"','"+str(Units)+"','"+str(Shop_ID)+"','" DV2 = User+"','"+Zip+"','"+Address+"','"+Tel+"','"+str(Email) sql_data = "INSERT INTO Demo_Table400("+DL1+DL2+") VALUES('"+DV1+DV2+"')" # データベースへの書き込み cursor.execute(sql_data) db.commit() # コンソールに生成データを表示(不要な場合はコメントアウトする) print sql_data print # 時間調整用(一定間隔) time.sleep(Sleep_Wait) # ループカウンタの更新 Counter=Counter+1 # デバッグ用データ表示 #print("生成済みデータ番号 : " + str(Counter)) except KeyboardInterrupt: print('!!!!! 割り込み発生 !!!!!') finally: # デバッグ用データ表示 print print("生成したデータの総数 : " + str(Counter)) # データベースコネクションを閉じる db.close() print("MySQL側テーブルへのデータ挿入処理終了")実際に実行した結果が・・・・
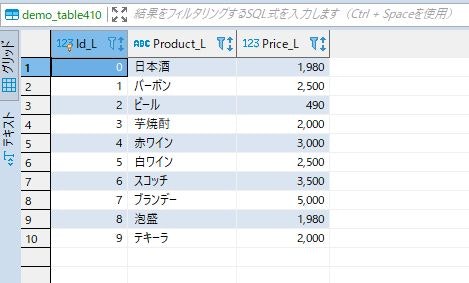
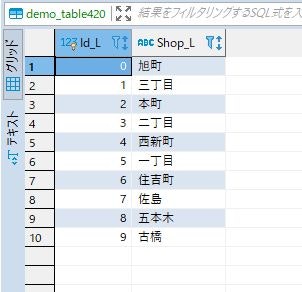
ルックアップテーブル
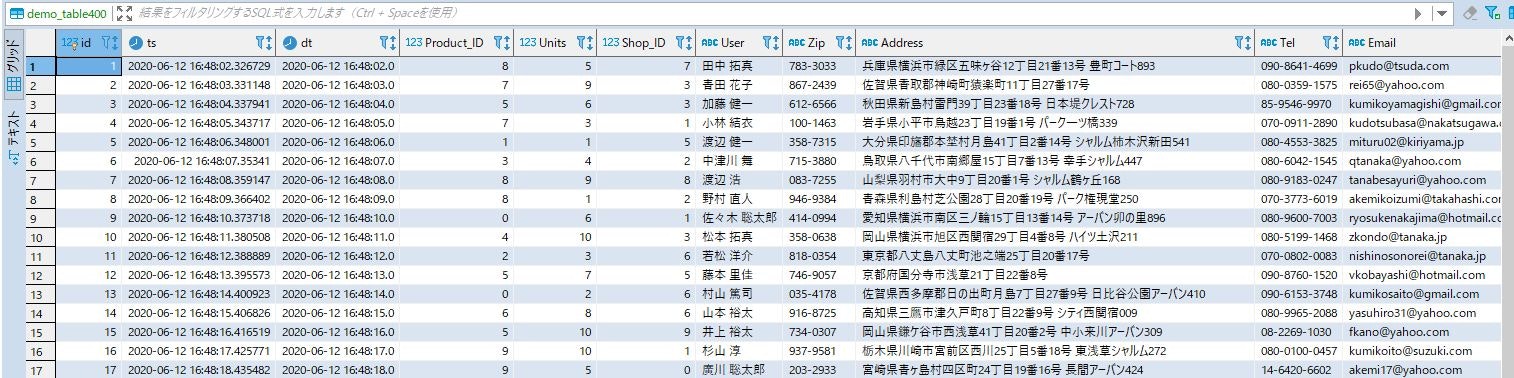
上流側のテーブル
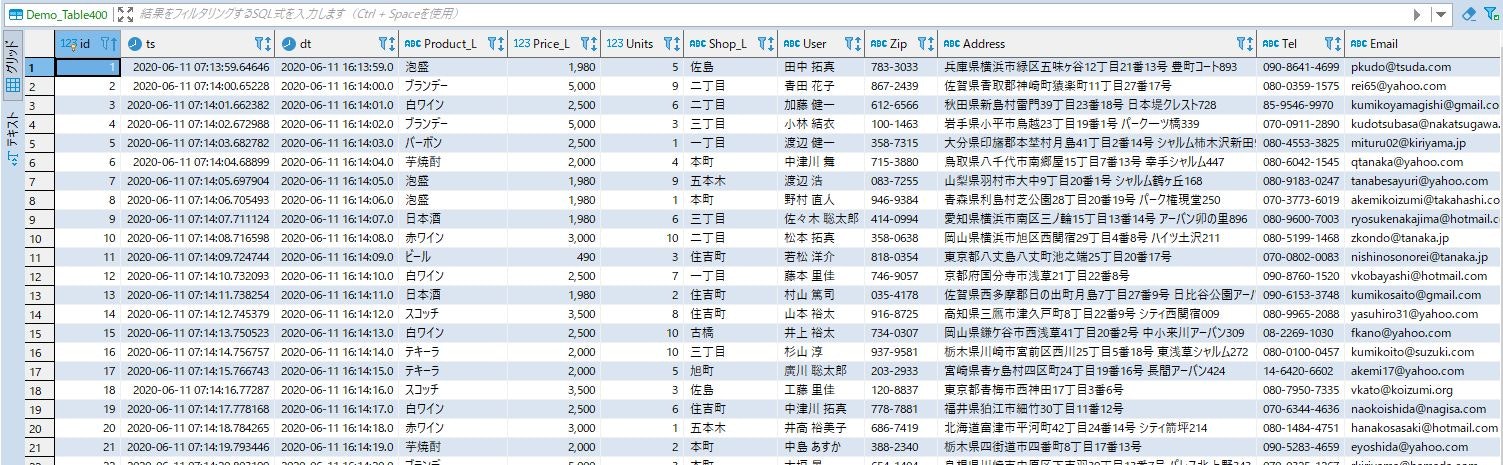
下流側のテーブル
うまくテーブル参照して置き換えてくれました!!
今回のまとめ
当初の予定では、今回でEqualumの基本的な検証を終了させる方向でしたが、記事が長くなる可能性が出てきた為に次回に総集編的な検証を行う事にしたいと思います。
Equalumを使う事で、高度なプログラミング作業を行う事無く高速・高効率なストリーミング処理を実現出来ます。
もちろん、総合処理的な内容はデータを括らなければ行えませんが、その過程をリアルタイムで処理しながらAIやBI、また今後出てくるデータ活用系のソリューションやアイディアを活用していく・・・・持続発展可能な高い投資対効果の為の速さ
これは、データを諦めずに「変化に強いデータ・ドリブン環境」を実現する上で非常に重要なポイントになる事を明確に示しているという事なのかもしれません。
謝辞
本検証は、Equalum社の特別の許可を得て実施しています。この貴重な機会を設定して頂いたEqualum社に対して感謝の意を表すると共に、本内容とEqualum社の公式ホームページで公開されている内容等が異なる場合は、Equalum社の情報が優先する事をご了解ください。
- 投稿日:2020-06-24T14:09:52+09:00
RDSの任意のテーブルのダンプ
What's this?
RDSの任意のテーブルのダンプとる手法の備忘
注意
対象DBと対象テーブルは以下のように記載していますが、必要に応じて読み替えてください
対象DB:my_database
対象テーブル:my_tableやり方
1. RDSに接続ができる任意のサーバ(EC2など)に入る
2. RDSに接続できるか確認
[■■■@▼▼▼:/usr/bin][hh:mm:ss]$ sudo mysql -h 【RDSのエンドポイント】 -u 【mysqlユーザ名】 -pRDSのエンドポイントはAWSマネジメントコンソールから確認可能
mysqlユーザ名は特に指定をしていないならadmin[sudo] ■■■ のパスワード:【ユーザパスワード】 Enter password:【RDSのパスワード】 Welcome to the MariaDB monitor. Commands end with ; or \g. Your MySQL connection id is Server version: Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MySQL [(none)]>3. 対象のDBがあるか調べる
MySQL [(none)]> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | my_database | | tmp | +--------------------+ 7 rows in set (0.01 sec) ※省略しています4. 対象のテーブルがあるか調べる
MySQL [(none)]> use my_database; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed MySQL [my_database]> show tables; +-----------------------+ | Tables_in_my_database | +-----------------------+ | my_table | +-----------------------+ 2 rows in set (0.00 sec)5. RDSとの接続を切る
MySQL [my_database]> exit Bye [■■■@▼▼▼:/usr/bin][hh:mm:ss]$6. RDSの任意のテーブルのダンプを取得する
[■■■@▼▼▼:/usr/bin][hh:mm:ss]$ mysqldump -h 【RDSエンドポイント】 -u 【ユーザ名】 -t -p my_database my_table > my_table_yyyyMMdd.sql
- RDSのエンドポイントはAWSマネジメントコンソールから確認可能
- mysqlユーザ名は特に指定をしていないならadmin
- tオプションを付けることでcreate tableやdrop tableを省略した状態でのダンプが取得できます。復元に使用するときはtオプションを付けないようにしてください。
7. ダンプが取得されたことを確認する
任意の方法で実施してください。
私がやるとすると...
- llコマンドなどで、my_table_yyyyMMdd.sqlファイルが存在していること、更新日時があっていること、サイズが適当であることを調べる
- lessで開いて文字化けしていないことを調べる
とか?
- 投稿日:2020-06-24T00:40:06+09:00
dockerとmysqlでrails環境を構築したけどドハマリした
dockerにrails環境を作った
https://qiita.com/NA_simple/items/5e7f95ae58eec5d20e1f途中なぜか上手くいかないと思ったら、mysql-clientsがインストールできなくなっているらしい。書き換え方は下のURLを参考に。
https://qiita.com/yagi_eng/items/1368fb2a234629a0c8e7調子に乗ってすすめていると、またハマる。
terminal$ docker-compose run web rails db:create Starting postgress_db ... done Could not find activesupport-5.2.4.3 in any of the sources Run `bundle install` to install missing gems.なぜだ、、、と思ったらrubyのバージョンが違う??
rbenvでバージョンを探しても、2.7.1が見つからず。
rbenv古い事に気づき、アップデートrbenvをアップデート
https://qiita.com/pugiemonn/items/f277440ec260b8d4fa6aからのgemも古い事に気づき、
terminal$ gem updateまだいかない、、、
bundler updateを行う。ここらへんで絶望したので時間を置く。
一旦整理して、違うサイトの最初から手順をパクる。
https://toranoana-lab.hatenablog.com/entry/2020/06/05/173658
なんと止まること無くdockerの起動、localhostにアクセス可能に!!!
よっしゃ!!!!localhost_3000Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (2)なんで :D
ググるとファイルが無いらしいからsudo touchで無理やり作ってる記事がちらほら。
でもファイルあるしなあ、と思いつつ削除&作成同じエラー。
???と思い、ここでmysql立ち上げていないことに気づく
これだ!!!と思ってterminalmysql.server startを実行するも、起動しない。
ググるとどうやらterminalsudo rm mysql.sock brew uninstall mysql brew install mysqlと、sockファイルを消してからmysqlをアンインストール→インストールで治るらしい。
mysql.sockのパスは前のエラーで判明していたので、それを消してからterminalmysql.server start…通った!!!!
これは行ったか…?
ヤッターーーーーーー!!!!!!!!!
docker理解してから構築したほうが早かったと思います。
勉強し直しましょう。自分。なにはともあれ動いてよかった
最終的な各ファイルの中身↓
gemfilesource 'https://rubygems.org' gem 'rails', '~>6'docker-compose.ymlversion: '3' services: db: image: mysql:8.0 environment: MYSQL_ROOT_PASSWORD: ports: - '3306:3306' command: --default-authentication-plugin=mysql_native_password volumes: - mysql-data:/var/lib/mysql web: build: . command: bash -c "rm -f tmp/pids/server.pid && bundle exec rails s -p 3000 -b '0.0.0.0'" volumes: - .:/myapp ports: - "3000:3000" depends_on: - db stdin_open: true tty: true command: bundle exec rails server -b 0.0.0.0 volumes: mysql-data: driver: localDockerfileFROM ruby:2.7 RUN curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | apt-key add - \ && echo "deb https://dl.yarnpkg.com/debian/ stable main" | tee /etc/apt/sources.list.d/yarn.list \ && apt-get update -qq \ && apt-get install -y nodejs yarn \ && mkdir /myapp WORKDIR /myapp COPY Gemfile /myapp/Gemfile COPY Gemfile.lock /myapp/Gemfile.lock RUN bundle install COPY . /myapp COPY entrypoint.sh /usr/bin/ RUN chmod +x /usr/bin/entrypoint.sh ENTRYPOINT ["entrypoint.sh"] EXPOSE 3000 CMD ["rails", "server", "-b", "0.0.0.0"]

- 投稿日:2020-06-24T00:02:14+09:00
EC2からMySQL(RDS)接続後にローカルMySQLにデータを入力する方法
はじめに
フローは大体思い浮かんだのですが、個々のコマンドを調べながら実行していくのに時間がかかってしまいました。
今後も使うだろうと思ったので、こちらにまとめておこうかなと思います。目次
- EC2からMySQL(RDS)に接続する方法
- MySQL(RDS)からEC2にバックアップをとる方法
- EC2からローカルにバックアップデータを転送する方法
- バックアップデータをローカルMySQLに復元する方法
EC2からMySQL(RDS)に接続する方法
# EC2へssh接続(ローカル上で実行) $ ssh -i "******.pem" ec2-user@***ip_address*** # EC2 上から本番環境の MySQL へ接続(EC2上で実行) $ mysql -h *******endpoint********.ap-northeast-1.rds.amazonaws.com -P 3306 -u ***db_username*** -p # パスワード入力 > ********* # MySQL から抜ける(接続できることを確認できればok)(本番環境のMySQL上で実行) > exitMySQL(RDS)からEC2にバックアップをとる方法
# MySQL からデータをバックアップ (EC2上/tmp/mysqldump_all_database.dumpにバックアップをとる) $ mysqldump --single-transaction -h *******endpoint********.ap-northeast-1.rds.amazonaws.com -P 3306 -u ***db_username*** -p ***password*** > /tmp/mysqldump_all_database.dumpEC2からローカルにバックアップデータを転送する方法
# EC2から抜ける $ exit # EC2 -> ローカル へファイル転送(ローカル上で実行) $ scp -i /Users/***username***/.ssh/*******.pem -r ec2-user@***ip_address***:/tmp/mysqldump_all_database.dump /Users/***username***/DownloadsバックアップデータをローカルMySQLに復元する方法
# 開発環境の MySQL へ接続(ローカル上で実行) $ mysql -h db -u root -p # MySQL に復元するファイルの容量を一時的に大きくする(開発環境のMySQL上で実行) $ set global max_allowed_packet = 200000000; # 開発環境の MySQL に復元(ローカル上で実行) $ mysql -h db -u root -ppassword -D ***development_db_name*** < /Users/***username***/Downloads/mysqldump_all_database.dumpまとめ
意外とつまづくことなく、シンプルに実行できました。