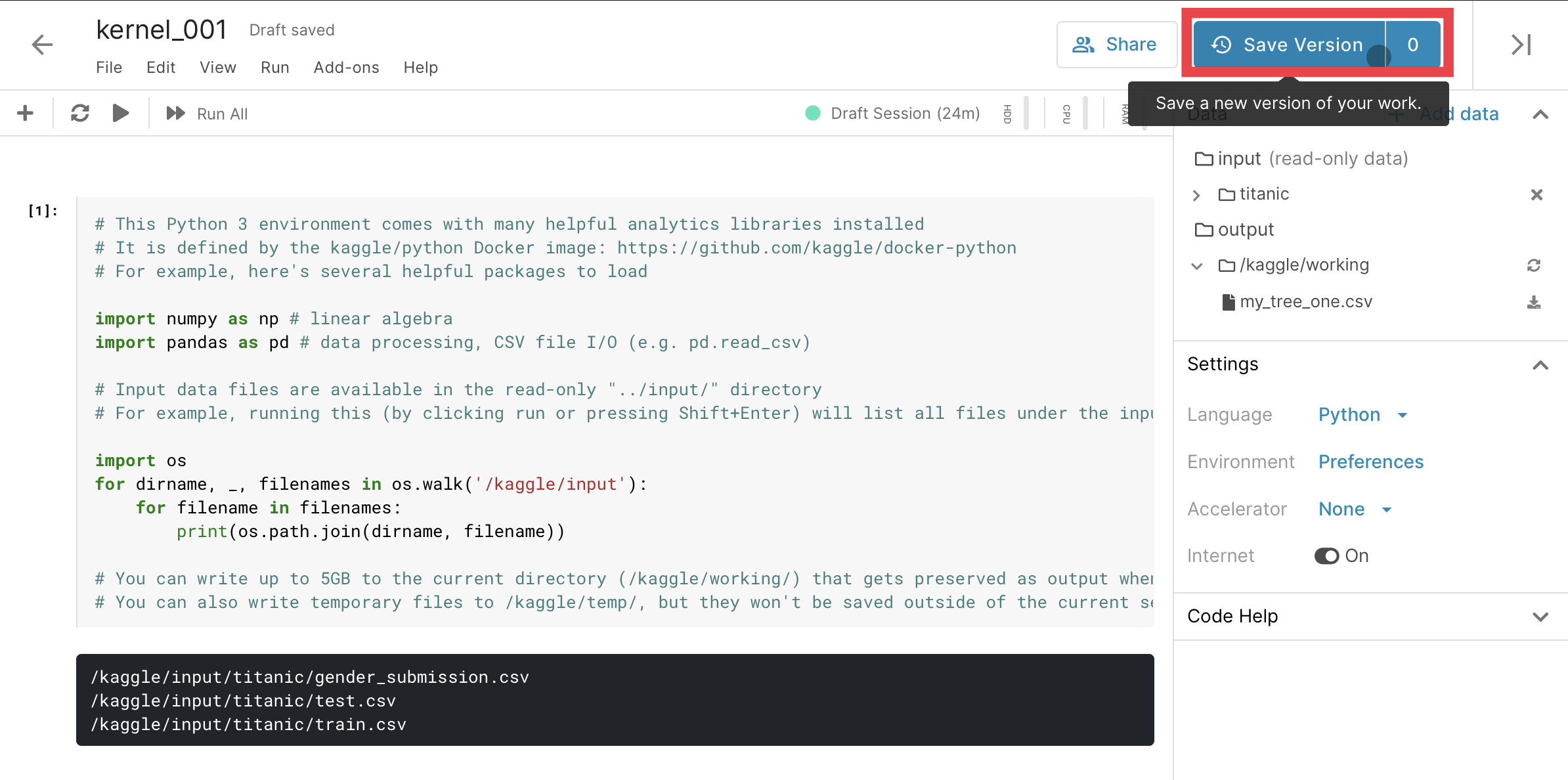
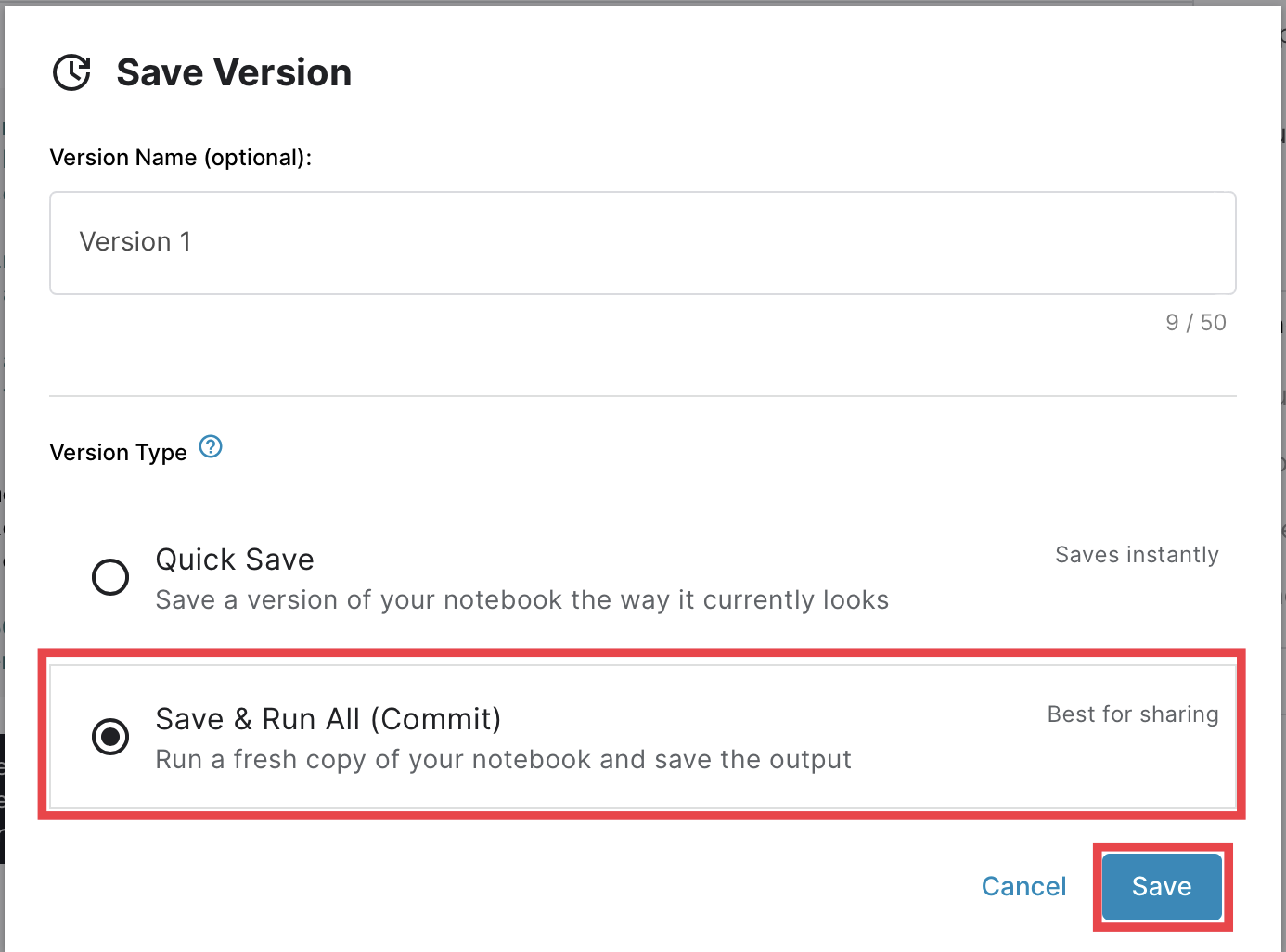
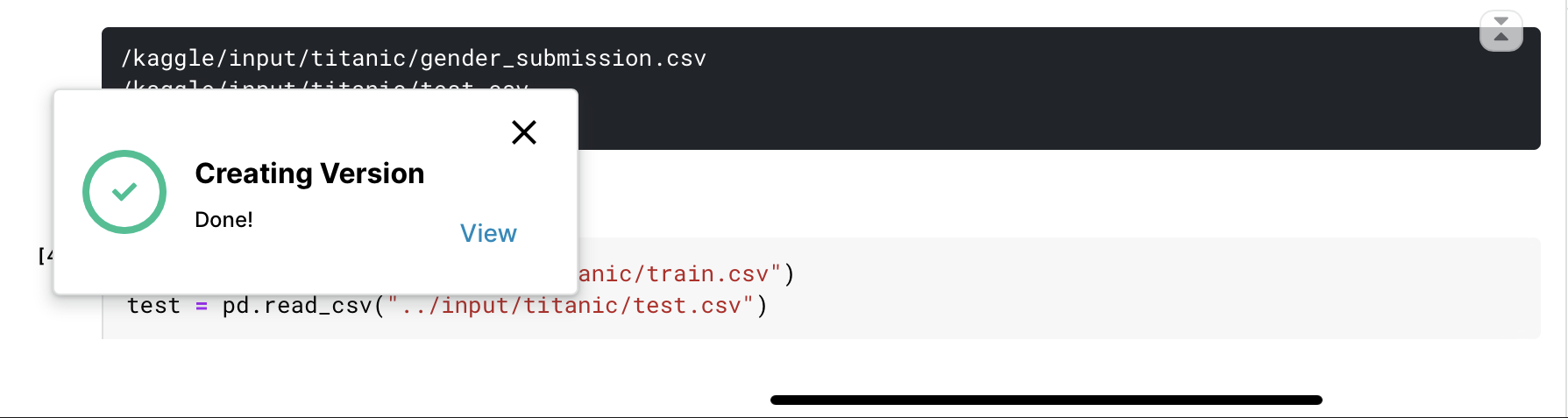
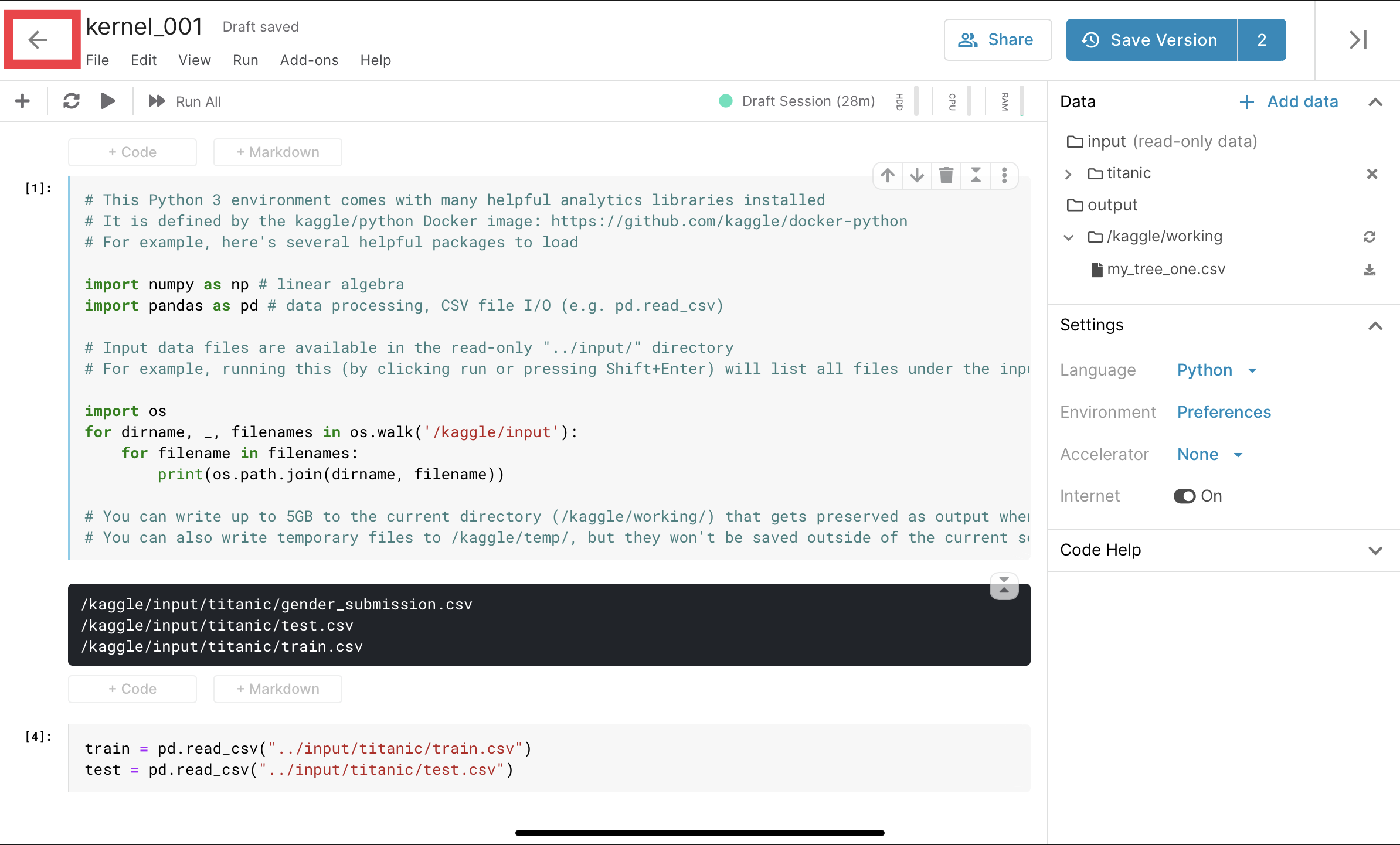
- 投稿日:2020-06-03T22:55:42+09:00
Flask の MySQL 接続と Life Cycle
Flask の MySQL 接続と Life Cycle
mysql has gone away が現れるようになり、前から気になってたflask appのlife cycleについて理解しようとしてみた。
結局原因が途中でわかったので尻すぼみだけど、記録として残しておく。わかってないこと
- appはいつ起動していつ終わるのか?
- urlに対する1 requestで app起動、コンテンツ返して終了、と思っていたが、gone awayってことはconnectionをkeepしている可能性がある
- MySQL接続はいつ切れるのか?
- MySQL(app) ではない独自の接続を多数持っている。これらは切断されないのか?
- 元のinstanceが廃棄されれば切断されると思うが、廃棄されているのか?
きれいなflaskは毎回切断している
以下のコードで検証
from flask import Flask from flask_mysqldb import MySQL app = Flask(__name__) app.config['MYSQL_USER'] = 'report_local' app.config['MYSQL_PASSWORD'] = 'report_local' app.config['MYSQL_HOST'] = 'sys-test-lowusage-db001-dbs4dev-jp2v-dev.lineinfra-dev.com' app.config['MYSQL_DB'] = 'mysql' app.config['MYSQL_PORT'] = 20306 app.config['MYSQL_CURSORCLASS'] = 'DictCursor' mysql = MySQL(app) @app.route('/') def users(): cur = mysql.connection.cursor() cur.execute('''SELECT CONNECTION_ID(); ''') # mysql connection idを取得 rv = cur.fetchall() return "app obj id = %s, %s" % (id(app), str(rv)) # <----- appのobject idも返す if __name__ == '__main__': app.run(debug=True)結果
- appは作り直されない
- MySQLは切断されていることがわかった
# first time app obj id = 4424594128, ({'CONNECTION_ID()': 7196},) # second time app obj id = 4424594128, ({'CONNECTION_ID()': 7197},) # and so on... app obj id = 4424594128, ({'CONNECTION_ID()': 7198},)appが作り直されないのは、app自体はあくまで初回の python run.py をした時点 = Web Serverを起動した時点で同時に生成されるから・・なんだろうか。
自分のいけてない MySQLdb で検証
show processlist; を見ていたら、やっぱり自分のflaskは切断してなかった。大量にコネクションが残ってた。
webサーバとアプリサーバが完全にわからない
appが作り直されない理由がよくわからない。
これは、根本的にwebサーバを理解していないのが問題なんだと思う。
webサーバは、起動するとソケット(ポート)をlistenにして接続を待ち受ける。
リクエストが来たら、定められた位置にあるファイルを取って渡すだけだ。
そこにあるのがアプリなら、アプリを起動する・・・・そう思っていけれど。web serverとpython applicationの間は、どうなっているんだろうか?
web server processを造ったとき、同時に受けてであるアプリも作られる。アプリ側も待機しないといけない。socketかportで、web-serverからのリクエストに答えるために
ずっと起動してlistenし続けている。これがアプリサーバか。
pythonのhttp serverだと、全部ひとつで完結していて、その結果アプリサーバが起動する・・・
当然、起動したときのものはずっと残る・・・
single threadの場合は、そのアプリが永遠に行き続ける・・のだろうか。
multi threadだったら? アプリサーバは、あくまでメインスレッドが起動するだけ?
リクエストに応じてappが作られる?むー・・それだとつじつまが合わない気がするsimple な web serverで検証
たぶんflaskのdev serverはこれを使ってるんじゃなかろうか。
import http.server import datetime class App(): def show(self): return "Hello %s" % datetime.datetime.now() app = App() class myHandler(http.server.BaseHTTPRequestHandler): def do_GET(self): self.send_response(200) self.send_header('Content-type','text/html') self.end_headers() self.wfile.write(str.encode("app id=%s, %s" % (str(id(app)), app.show()))) return server_address = ("", 8000) simple_server = http.server.HTTPServer(server_address, myHandler ) simple_server.serve_forever()参考 https://docs.python.org/3/library/http.server.html#http.server.HTTPServer
で、結局原因はclass変数だった
appが作り直されない理由がよくわからない。
これを書いて数週間経った今の理解で行くと、appインスタンスは作り直される。インスタンスは作り直されるが、app クラス は最初に作ったときのままだ。
pythonではクラス変数は最初の起動から永遠に再利用される。
今回の原因は、appから呼び出している自作クラスのmysql connection poolをいれる変数がclass変数だった。class MyClass: dbpool = {} # ←これが原因 def __init__(self): self.dbpool = {} # ←インスタンス変数にして解決したclass変数はアプリが最初に起動された状態を永遠に保持するので、コンテンツを返した後も残り続ける。
自分のclassは、self.dbpoolの中にconnectionオブジェクトが残っている限り再利用する構造にしていたので、
オブジェクトは残るが、オブジェクト自体は数時間で接続が切れている、という状態だった。
切れている接続を再利用すると mysql has gone away になる。いま考えれば con.close() する時に self.dbpool の中を空にしていなかったのかもしれない。
いずれにしても、インスタンス変数にした結果、アクセスのたびに self.dbpool が初期化されるようになったので
古いconnectionオブジェクトを再利用することはなくなった。そういえばself.dbpoolを空にする修正も一応した気がしてきた。個人的には ↓ に近いような問題だと思っていて、いや普通なのかもしれないけど、pythonなんだかなぁと感じたりしている。
Pythonのこれ、流石に言語としてどうなのという気持ちになるんだが… pic.twitter.com/degIU4tPeI
— 幸福のデータ科学㈱教祖テラモナギ (@teramonagi) May 21, 2020おしまい
- 投稿日:2020-06-03T22:51:41+09:00
Pythonでしりとりゲームを作ってみる
まずは出来そうなところから書いてみる
shiritori.py#しりとりができるプログラムを書いていく #一応確認のため、しりとりは単語の最後の一文字から始まる単語を言い合うゲーム #勝敗は単語の最後の一文字が「ん」の単語を言ったプレイヤーが負けとなる #つまり勝つ方法は相手が負けるのを待つということになる #違う言い方をするならばボキャブラリーが豊富な方が勝ちやすいということになる print("しりとりゲームスタート!") #入力した単語の最後の一文字を取得する処理 str = input() print(str[len(str) - 1])次に実装すべき処理は?
- 取得した最後の一文字を頭文字にして相手が単語を発する
- また自分が単語を入力する
- 上記2つを「ん」がつくまでループさせる
現時点で想定される課題
- 辞書をどう用意するのか
- 相手(CPU)がどのタイミングで負けてくれるのか
- 普通のしりとりで終わらない何かしらの要素は?
今後の予定
- とりあえず考え中です・・・
- 投稿日:2020-06-03T22:25:17+09:00
【Raspi4;サウンド入門】pythonで音入力を安定して記録する♪
音入力は何度か取り上げてきたが、今回Rasipi4でも安定してずーっと入出力出来るようになったので、まとめることとしました。
肝心なことは以下の参考1.のとおりです。なお、昨年は参考2.のようなことやって遊んでいました。
今年はこのあと少し違うことやろうと思っています。
【参考】
1.PyAudio Input overflowed
2.【Scipy】FFT、STFTとwavelet変換で遊んでみた♬~⑦リアルタイム・スペクトログラム;高速化肝心なこと
つまり、読み込むとき以下のおまじないを記載するとオーバーフローが発生しなくなり、延々記録できるようになりました.
※この記事はRasipi4でもこれが解決できたというお話です# -*- coding:utf-8 -*- import pyaudio import matplotlib.pyplot as plt import numpy as np import wave import struct読み込んだ音を以下の関数でwavファイルで保存する。
def savewav(sig,sk): RATE = 44100 #サンプリング周波数 #サイン波を-32768から32767の整数値に変換(signed 16bit pcmへ) swav = [(int(32767*x)) for x in sig] #32767 #バイナリ化 binwave = struct.pack("h" * len(swav), *swav) #サイン波をwavファイルとして書き出し w = wave.Wave_write("./wine/"+str(sk)+".wav") params = (1, 2, RATE, len(binwave), 'NONE', 'not compressed') w.setparams(params) w.writeframes(binwave) w.close()音の入出力をTrueにしています。
音声(センテンス)を入力するので、長め(102400/44100=2.3sec)に録音します。RATE=44100 p=pyaudio.PyAudio() N=100 CHUNK=1024*N stream=p.open(format = pyaudio.paInt16, channels = 1, rate = RATE, frames_per_buffer = CHUNK, input = True, output = True) # inputとoutputを同時にTrueにするそしていよいよ連続録音開始です。exception_on_overflowをFalseにしています。sigを32768で除しています。
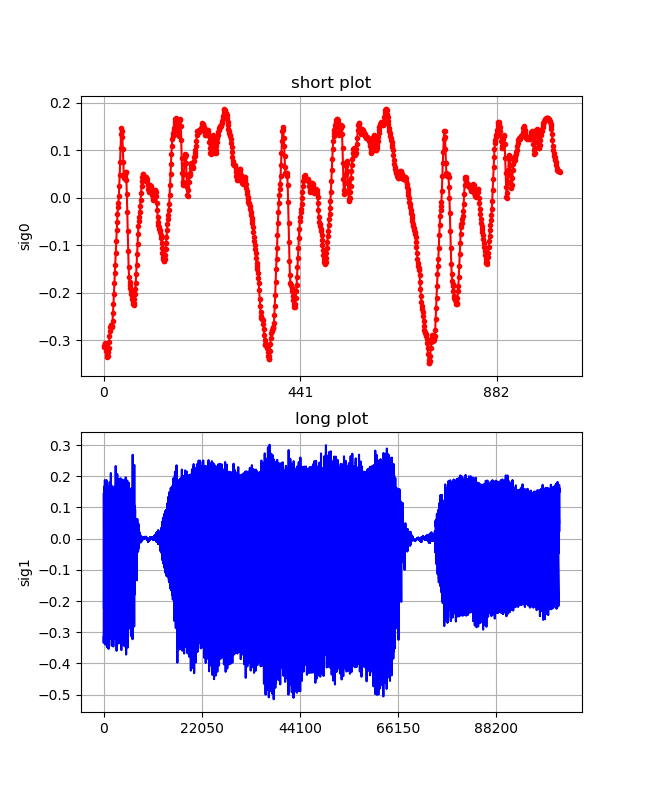
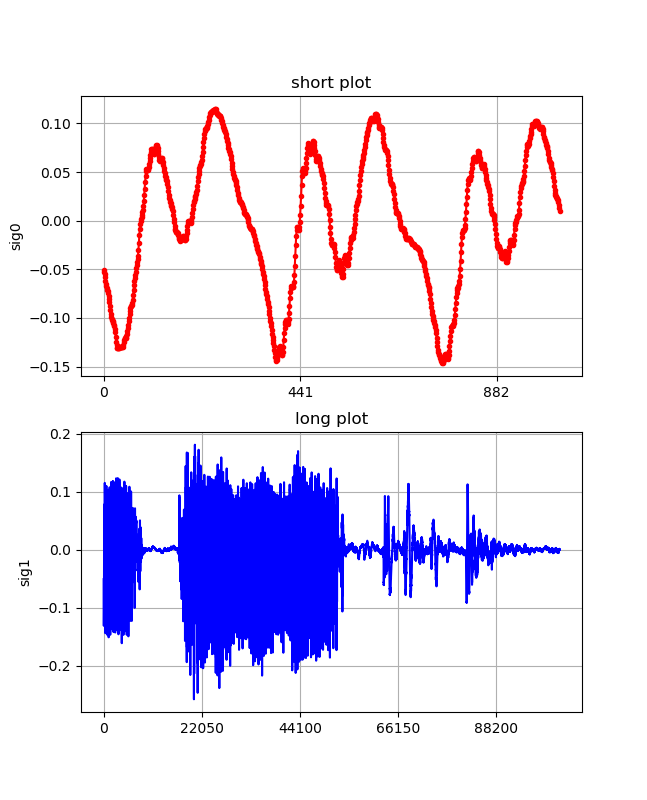
sk=0 while stream.is_active(): input = stream.read(CHUNK, exception_on_overflow = False) print(len(input)) sig =[] sig = np.frombuffer(input, dtype="int16") / 32768 savewav(sig,sk) fig, (ax1,ax2) = plt.subplots(2,1,figsize=(1.6180 * 4, 4*2)) lns1=ax1.plot(sig[0:1024] ,".-",color="red") ax1.set_xticks(np.linspace(0, 882, 3)) ax1.set_ylabel("sig0") ax1.set_title('short plot') lns2=ax2.plot(sig[0:CHUNK], "-",color="blue") ax2.set_xticks(np.linspace(0, 44100*2, 5)) ax2.set_ylabel("sig1") ax2.set_title('long plot') ax1.grid() ax2.grid() plt.pause(0.5) plt.savefig("./wine/sound_{}.png".format(sk)) plt.close() sk+=1 output = stream.write(input)あー、えー、いー。。の連続測定結果
x-軸のメモリ;44100=1sec
まとめ
・連続測定が可能になった
・音関係でR-python連携をしたいと思う
- 投稿日:2020-06-03T22:13:25+09:00
GoogleのSDKをimportしているプログラムをpyinstallerで.exe化する
Google Speech to Textを使ったプログラムを.exe化する必要があったのだが、ハマったのでメモ。
環境
OS Windows10
(pipenvにて)
Python 3.7.4
pyinstaller 3.6実行したコマンド
test.pyを.exe化する。と仮定すると、
pyinstaller test.py --onefileERROR1
まず、普通に実行すると以下のようなエラーが出る
pkg_resources.DistributionNotFound: The 'google-cloud-core' distribution was not found and is required by the applicationこのエラーに関しては起動時に
--additional-hooks-dirオプションを使用して、以下のようなファイルを作成し、フォルダへのパスを与えれば解決する。というような記事をよく見かけるが、自分の環境では解決しなかった。hook-google.cloud.pyfrom PyInstaller.utils.hooks import copy_metadata try: datas = copy_metadata('google-cloud-core') except: datas = copy_metadata('google-cloud-speech')↓このエラーが出る
assert self.hook_module_name not in HOOKS_MODULE_NAMES AssertionErrorこの問題に関しては普通に、google-cloud-coreを改めてインストールすると解決した。。。
pip install google-cloud-coreERROR2
google-cloud-coreをインストールしたあとは、実行出来て.exeも生成されるのだが、生成された.exeを実行すると今度は以下のようなエラー(というかException?)が出る。
Exception ignored in: 'grpc._cython.cygrpc.ssl_roots_override_callback' E0603 18:31:14.600000000 16632 src/core/lib/security/security_connector/ssl_utils.cc:482] assertion failed: pem_root_certs != nullptrライセンスの認証周りっぽい。
こちらは、test.pyと同階層にhooksというフォルダを作成し、その中に以下にようなファイルを作成して設置したとすると、hook-grpc.pyfrom PyInstaller.utils.hooks import collect_data_files datas = collect_data_files('grpc')以下のようなコマンドでビルドしなおせば出なくなる
pyinstaller test.py --onefile --additional-hooks-dir=./hooks/参考
https://github.com/pyinstaller/pyinstaller/issues/3935
https://teratail.com/questions/201443
https://teratail.com/questions/118297
https://qiita.com/akitooo/items/eb82a5f335d8ca9c9faf
https://stackoverflow.com/questions/54634035/my-pyinstaller-is-giving-assertion-error-when-i-execute-it
https://stackoverflow.com/questions/40076795/pyinstaller-file-fails-to-execute-script-distributionnotfound
https://www.bountysource.com/issues/86848733-pyinstaller-3-6-assertionerror
https://github.com/googleapis/google-cloud-python/issues/5774
- 投稿日:2020-06-03T22:13:25+09:00
Googleのクライアントライブラリをimportしているプログラムをpyinstallerで.exe化する
Google Speech to Textを使ったプログラムを.exe化する必要があったのだが、ハマったのでメモ。
環境
OS Windows10
(pipenvにて)
Python 3.7.4
pyinstaller 3.6実行したコマンド
test.pyを.exe化する。と仮定すると、
pyinstaller test.py --onefileERROR1
まず、普通に実行すると以下のようなエラーが出る
pkg_resources.DistributionNotFound: The 'google-cloud-core' distribution was not found and is required by the applicationこのエラーに関しては起動時に
--additional-hooks-dirオプションを使用して、以下のようなファイルを作成し、フォルダへのパスを与えれば解決する。というような記事をよく見かけるが、自分の環境では解決しなかった。hook-google.cloud.pyfrom PyInstaller.utils.hooks import copy_metadata try: datas = copy_metadata('google-cloud-core') except: datas = copy_metadata('google-cloud-speech')↓このエラーが出る
assert self.hook_module_name not in HOOKS_MODULE_NAMES AssertionErrorこの問題に関しては普通に、google-cloud-coreを改めてインストールすると解決した。。。
pip install google-cloud-coreERROR2
google-cloud-coreをインストールしたあとは、実行出来て.exeも生成されるのだが、生成された.exeを実行すると今度は以下のようなエラー(というかException?)が出る。
Exception ignored in: 'grpc._cython.cygrpc.ssl_roots_override_callback' E0603 18:31:14.600000000 16632 src/core/lib/security/security_connector/ssl_utils.cc:482] assertion failed: pem_root_certs != nullptrライセンスの認証周りっぽい。
こちらは、test.pyと同階層にhooksというフォルダを作成し、その中に以下にようなファイルを作成して設置したとすると、hook-grpc.pyfrom PyInstaller.utils.hooks import collect_data_files datas = collect_data_files('grpc')以下のようなコマンドでビルドしなおせば出なくなる
pyinstaller test.py --onefile --additional-hooks-dir=./hooks/参考
https://github.com/pyinstaller/pyinstaller/issues/3935
https://teratail.com/questions/201443
https://teratail.com/questions/118297
https://qiita.com/akitooo/items/eb82a5f335d8ca9c9faf
https://stackoverflow.com/questions/54634035/my-pyinstaller-is-giving-assertion-error-when-i-execute-it
https://stackoverflow.com/questions/40076795/pyinstaller-file-fails-to-execute-script-distributionnotfound
https://www.bountysource.com/issues/86848733-pyinstaller-3-6-assertionerror
https://github.com/googleapis/google-cloud-python/issues/5774
- 投稿日:2020-06-03T22:03:11+09:00
Pythonを使わずにKaggle タイタニック号乗客の生存予測モデルを作ってみる
この記事の概要と結果
最近知ったVARISTAというAutoML?を使ってKaggleタイタニックコンペにチャレンジしてみます。
スコアは0.80861でした。Kaggleへ登録
Kaggleに登録していない人はKaggleに登録をしましょう。
登録は画面の右上から行ってください。
データの用意
今回のコンペティションはこちらの「Titanic: Machine Learning from Disaster」です。
コンペティションに移動したら「Data」タブを選択してください。
こちらをクリックしてもデータページに移動できます。
データ画面に移動したらDownload Allを選択します。
ダウンロードが完了したら、「titanic.zip」があると思いますので、このファイルを解凍してください。
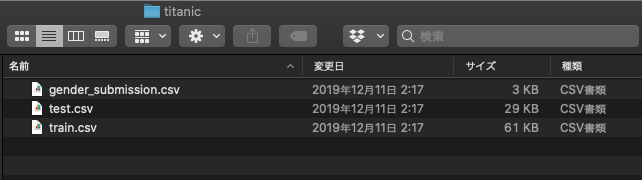
解凍すると以下のファイルが確認できます。
それぞれのファイルの用途は以下の通りです。
ファイル名 用途 train.csv 教師データ test.csv テストデータ gender_submission.csv 投稿用サンプルデータ データの変数説明
列名 日本語 PassengerID 乗客ID Survived 生存結果 (1: 生存, 0: 死亡) Pclass 客室の階級 1=Upper, 2=Middle, 3=Lower Name 名前 Sex 性別 Age 年齢 SibSp 兄弟、配偶者の数 Parch 両親、子供の数 Ticket チケット番号 Fare 乗船料金 Cabin 部屋番号 Embarked 乗船した港 Cherbourg、Queenstown、Southamptonの3種類 VARISTAへ登録
VARISTAのアカウントを作成します。
http://www.varista.aiに移動してトップページから登録します。
有料プランもあるみたいですが、今回は無料で試しました。
プロジェクト作成とデータの確認
VARISTAにログイン後に、ワークスペースを任意の名前で作成します。
ワークスペースを作成したら、プロジェクトを作成します。
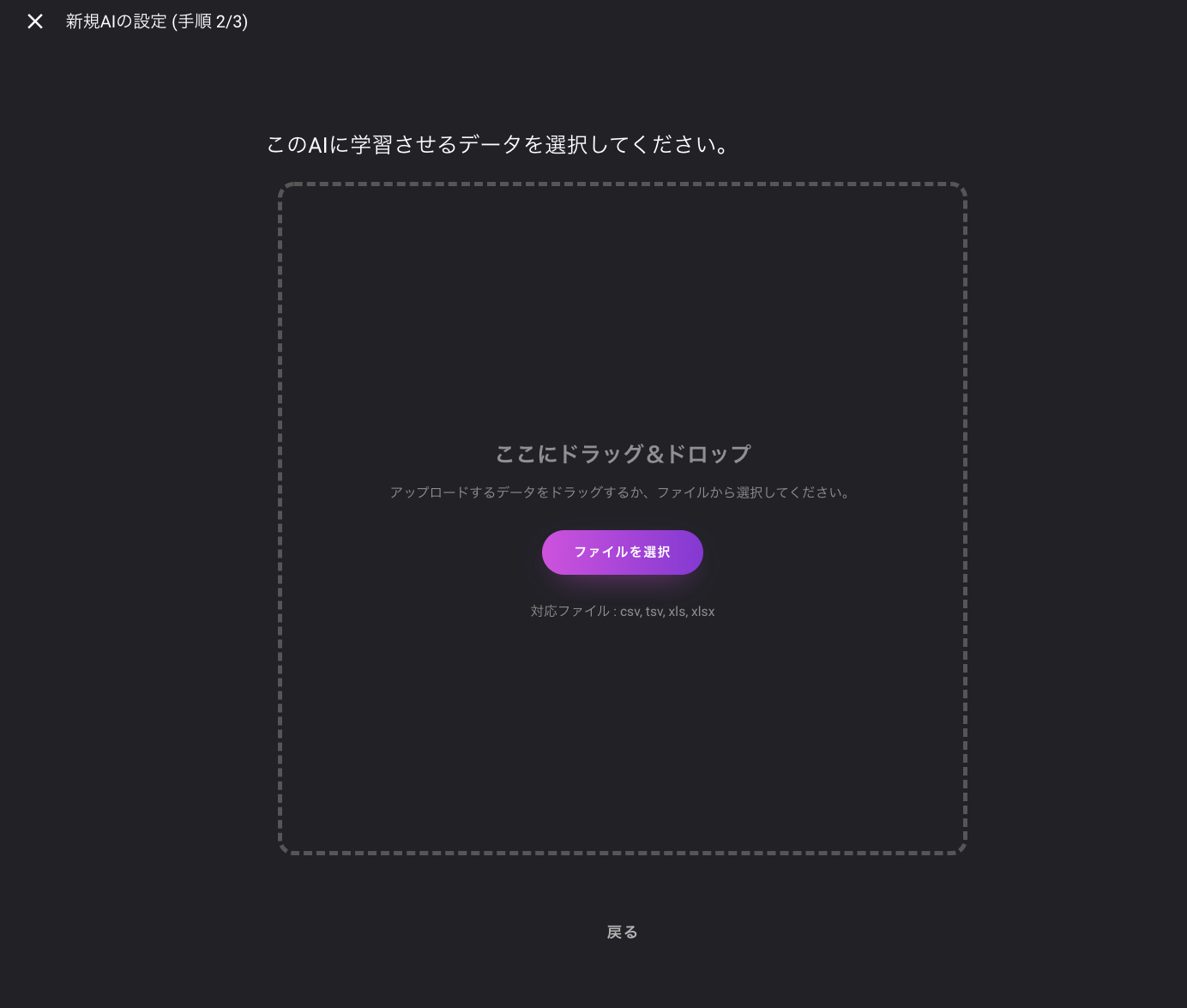
名前は適当にタイタニックとかでいいと思います。ガイドに従って、データをアップロードします。
アップロードするデータは教師データの「train.csv」です。
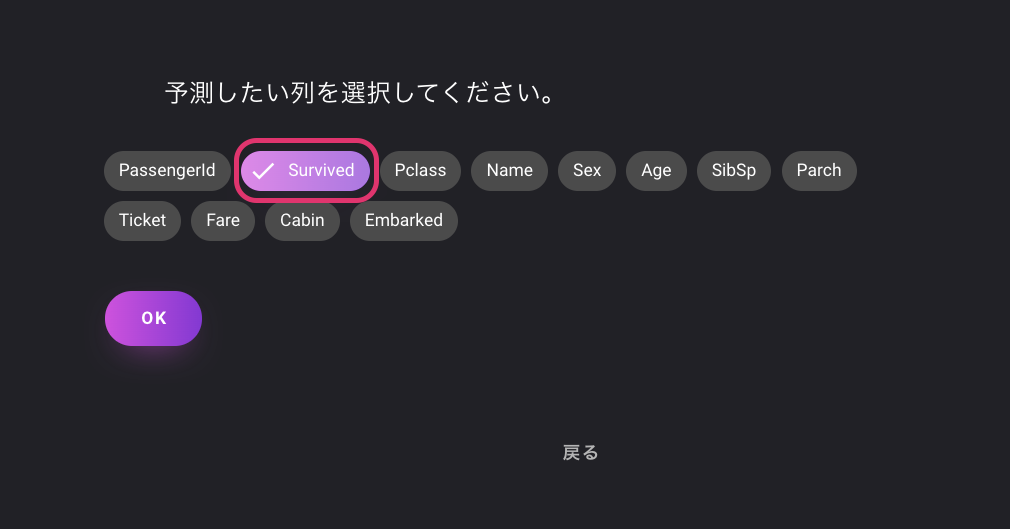
アップロードが完了したら、予測したい列を選択します。
今回のコンペにおいては、乗客の生存を予測したいので「Survived」を選択します。
設定が完了したSTARTを選択して次の画面に移動します。
ターゲットを選択したら準備完了です。
データの確認
ここでいきなり学習を開始してもいいのですが、せっかくなのでデータの中身をみてみます。
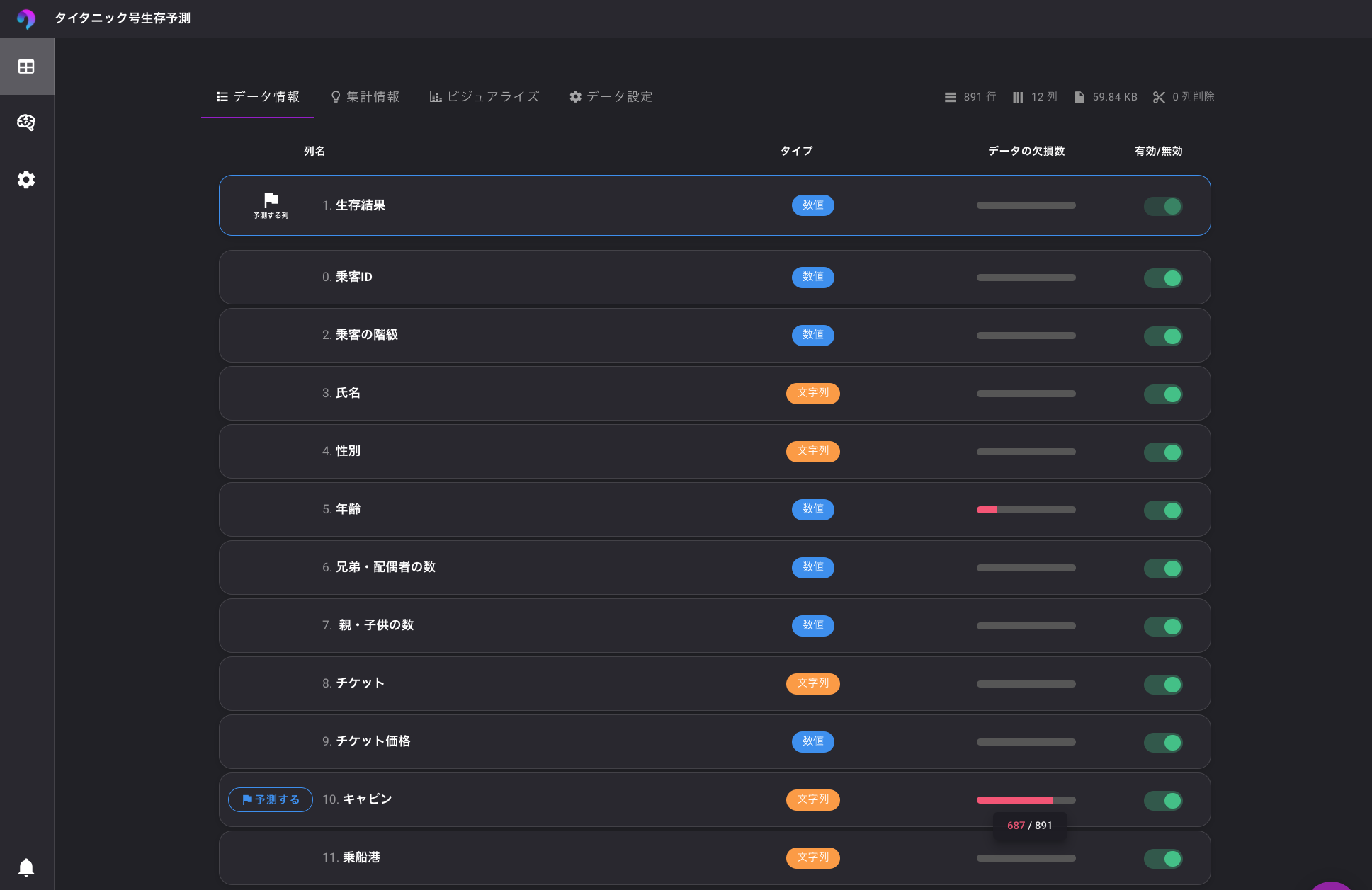
データメニューを選択し、先ほどアップロードした「train.csv」を選択します。
データの欠損を見てみると、年齢とキャビンのデータに欠損があることが確認できます。
ただ、VARISTAの場合は欠損データを自動で補完するようです。
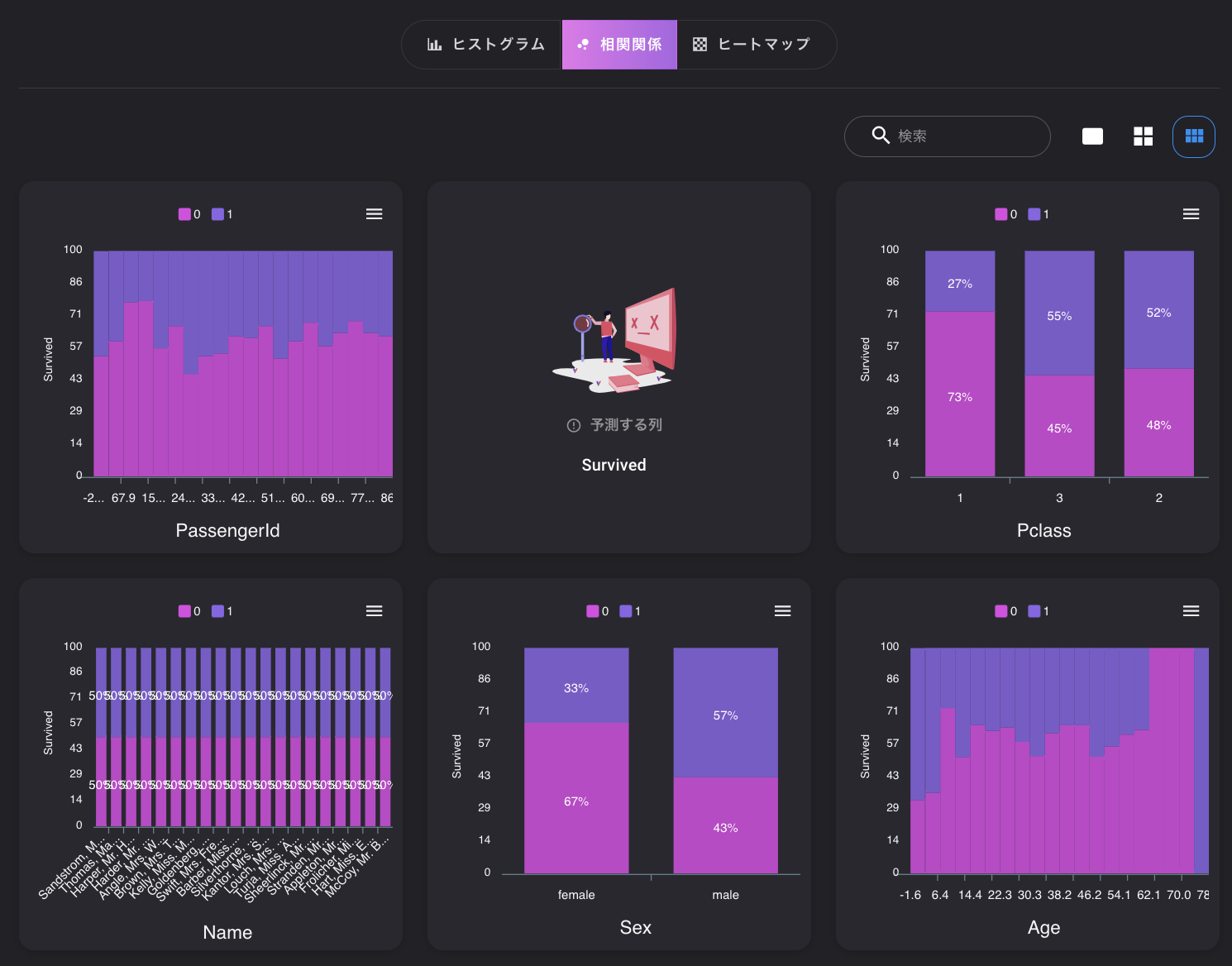
データの分布を見てみましょう。
タブから「ビジュアライズ」を選択すると、特徴列のデータごとに分布を表示してくれるので便利です。
相関関係のタブを選択すると、予測したい列とそれぞれの列の相関関係を確認することができます。
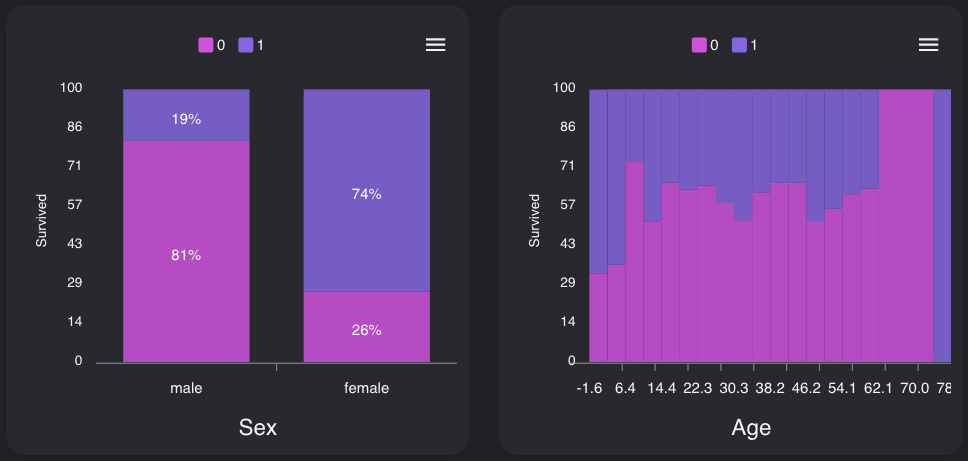
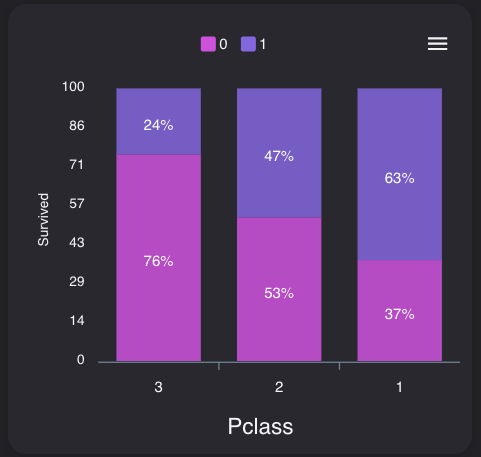
性別、年齢
0は死亡、1は生存と置き換えてみてください。
性別は大きく関係しており、女性の方が生存しているようです。
年齢は、概ね7才未満の生存率が高く、60才以降は死亡率が高いようです。中間は大きな差は無いようです。
子供は優先的に救助されたみたいです
PClass
等級が高い方が、生存率が高いようです。
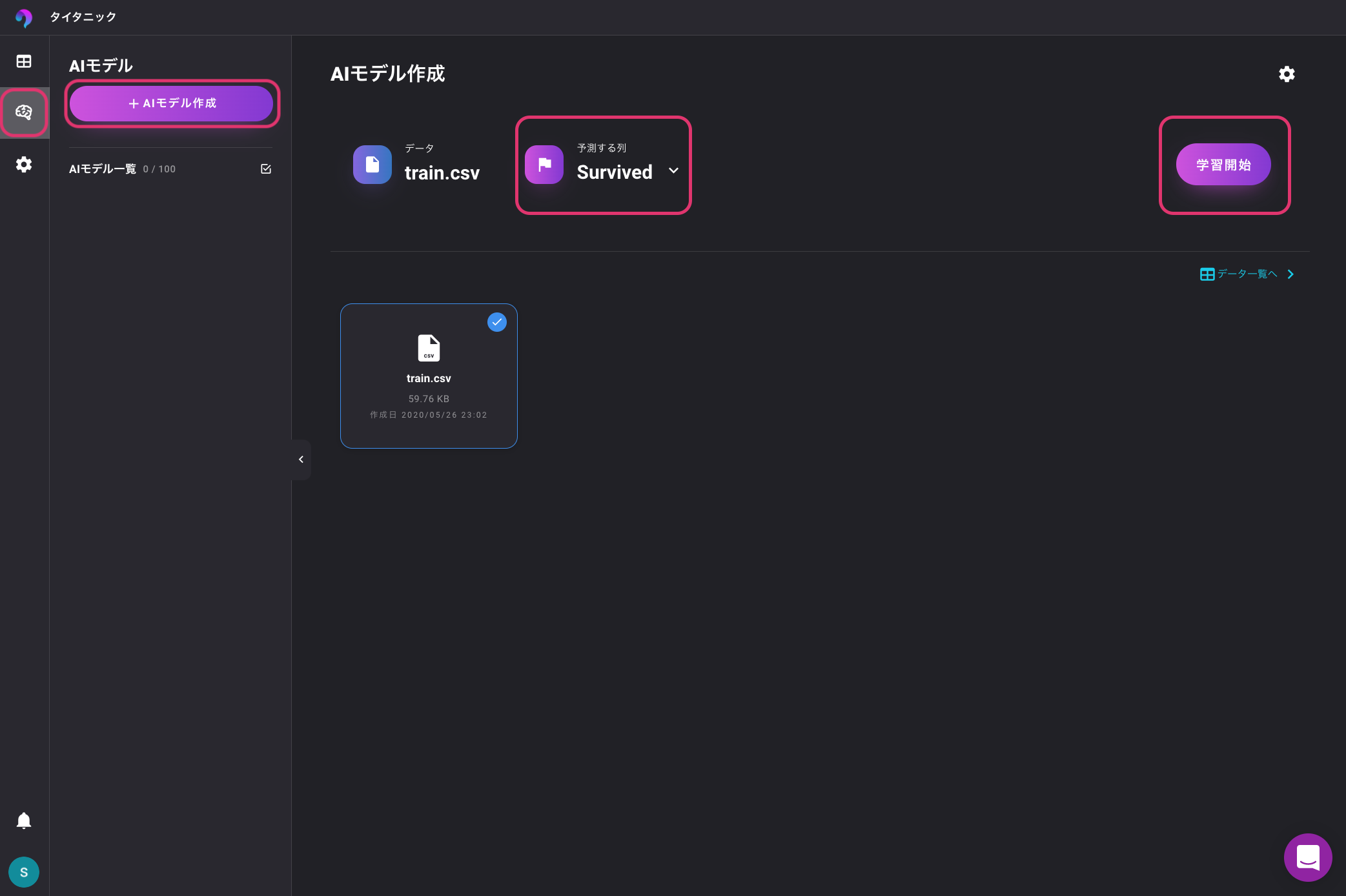
学習
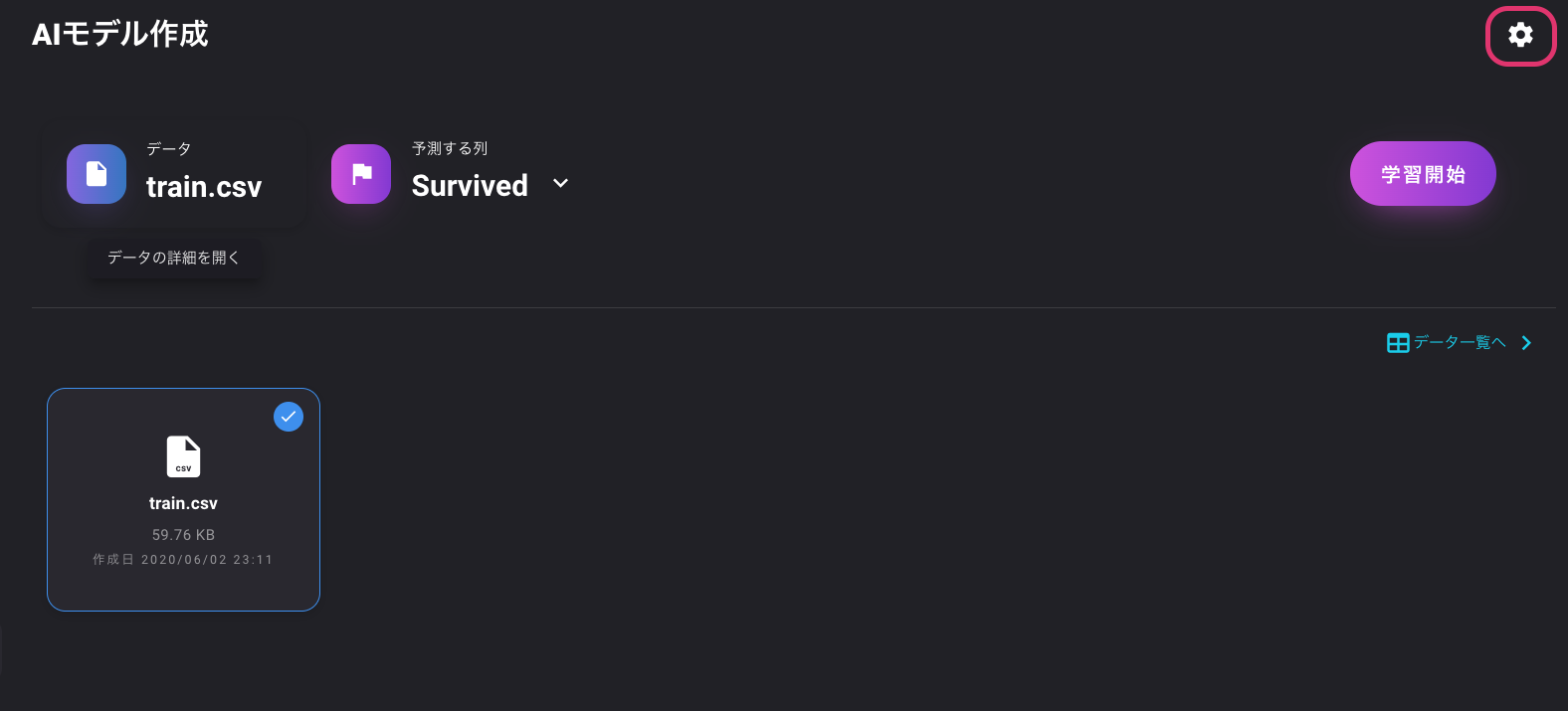
実際に学習してみましょう。
左のAIモデルを選択し、「AIモデルを作成」をクリックします。
次に、予測する列が「Survived」になっていることを確認し、学習開始ボタンをクリックします。
最近流行りの特にこちら側で何の設定をすることもなく自動で学習が開始します。
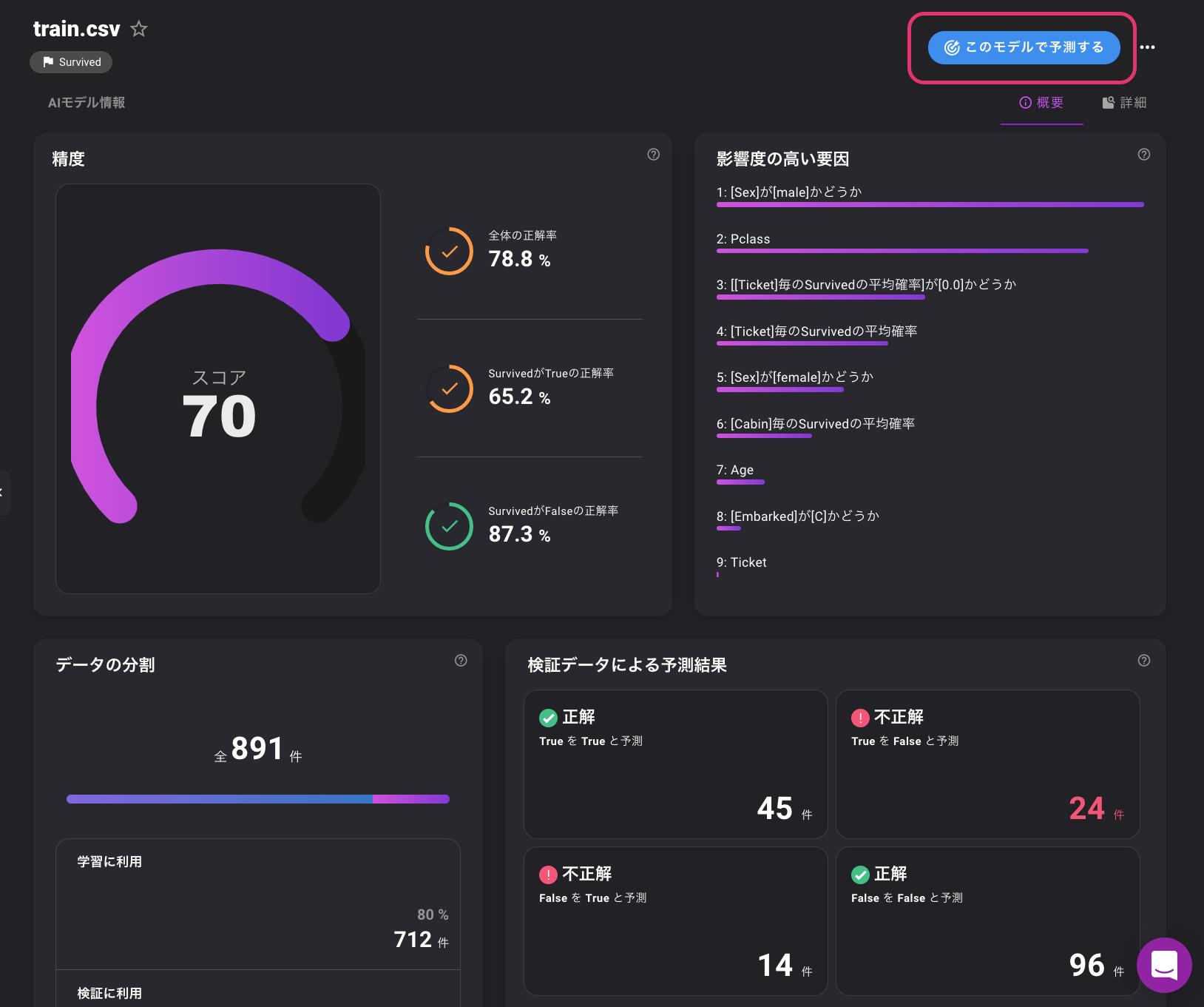
特徴量エンジニアリングを行い複数アルゴリズムで学習しているようです。学習結果
スコア70と出ています。
影響度をみると、やはり生存には、性別とPclassが関わっているようですね。
Kaggleへの提出
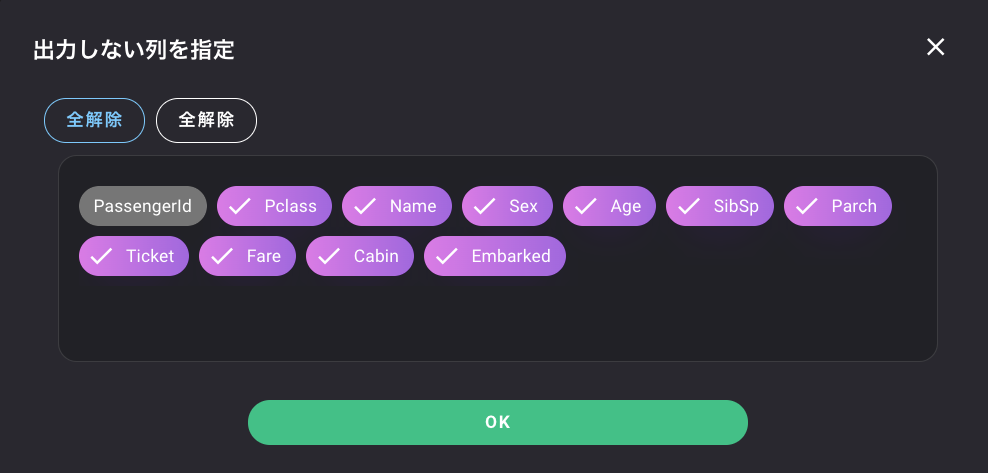
↑の画面でこのモデルで予測するをクリックします。
ここをクリックして、出力形式を変更します。
出力しない列を設定します。
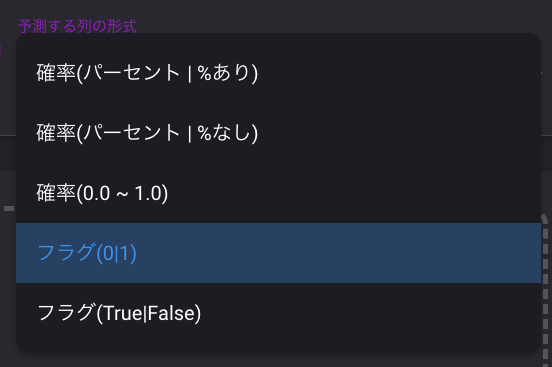
次に、出力する列の形式をフラグに変更します。
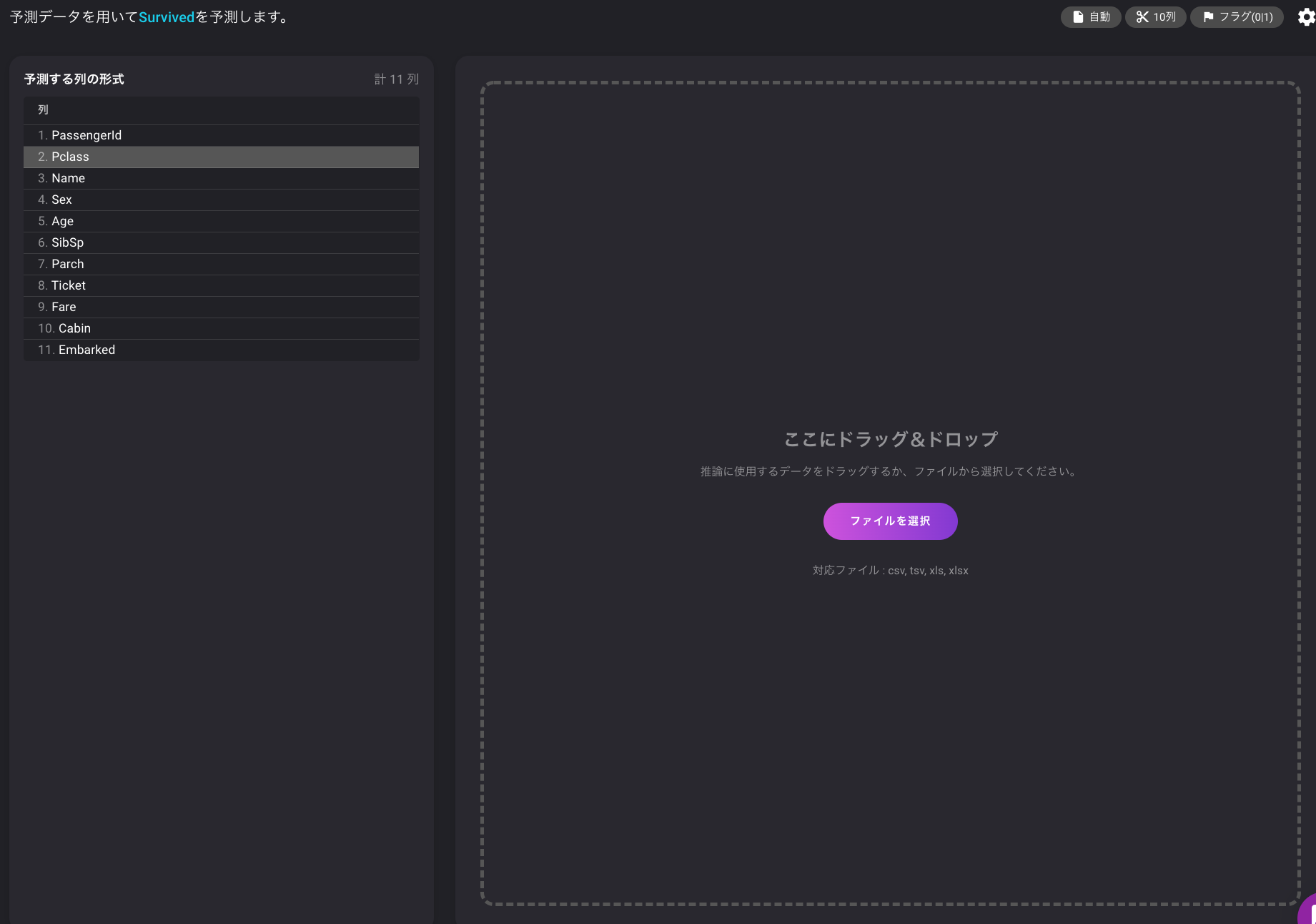
最後に、先ほどのダウンロードしたファイルにあるtest.csvをドラッグ&ドロップしましょう。
出来上がったファイルをダウンロードします。
ファイルを開くと、一番右列に生存したかどうかの予測が入っている事がわかります。
Kaggleに投稿するには不要な列があるので削除します。今回はMacのNumbersで除去しましたが、Windowsの場合はExcelなどがいいと思います。
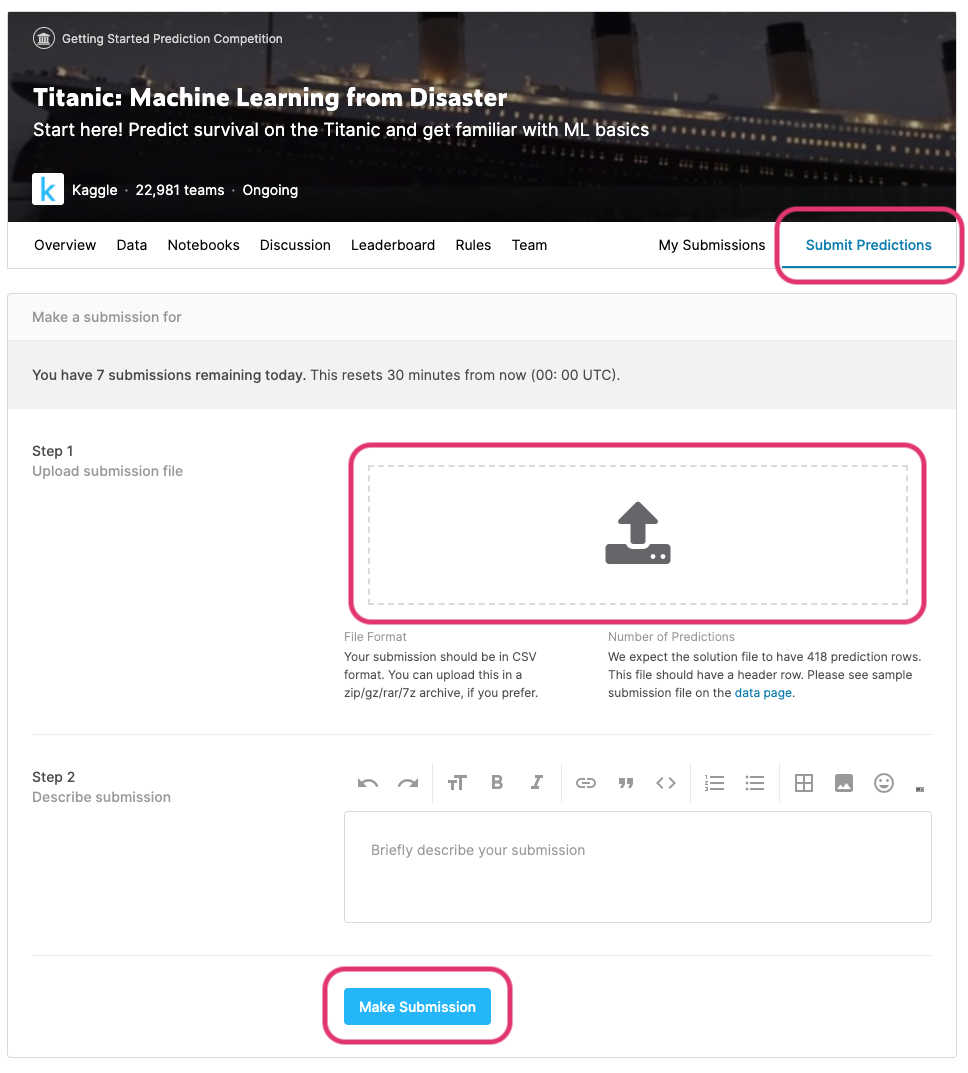
Kaggleのコンペティション画面から「Submit Predictions」を選択して、先ほどダウンロードしたファイルをドラッグ&ドロップします。
最後にMake Submissionを押して、投稿します。
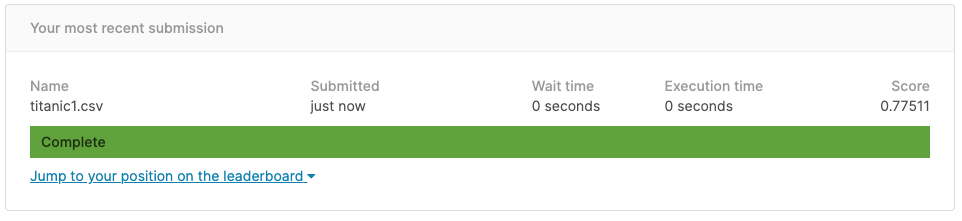
しばらくすると、採点されスコアが出力されます。
今回のスコアは0.77511でした。
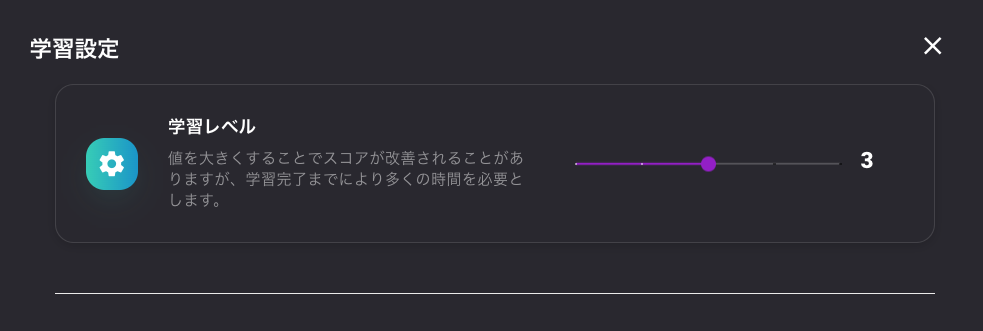
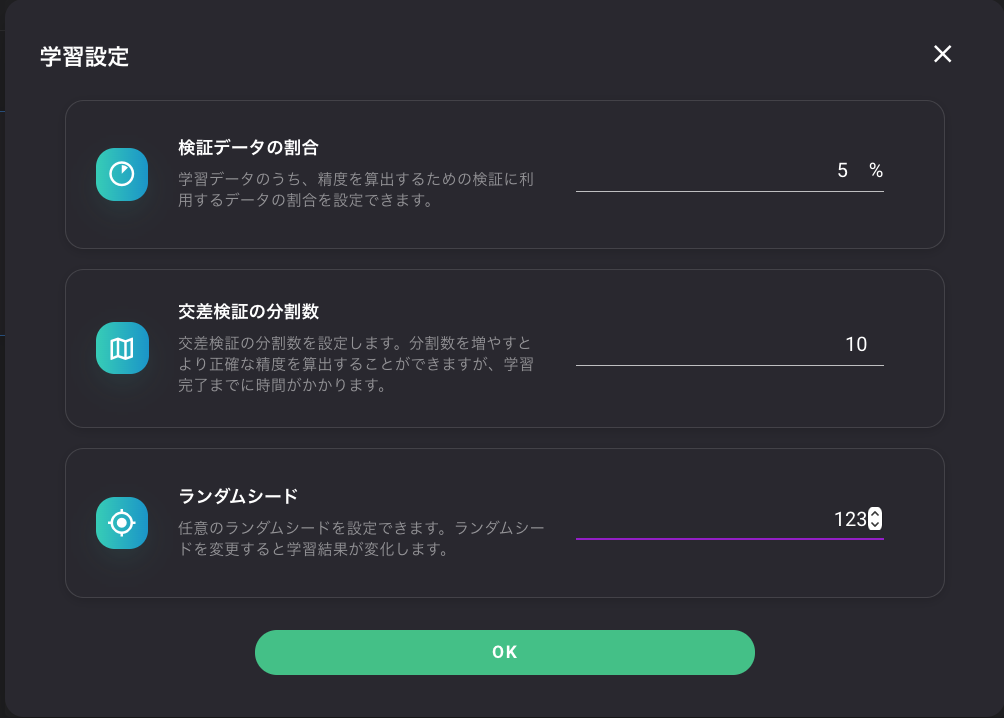
学習設定を変更してモデルの調整
学習設定から、学習レベル、検証データの割合、交差検証の分割数、ランダムシードの値を変更してみたら、スコアがよくなったので載せておきます。
モデルの学習開始画面右上の設定ボタンをクリックします。
値をこんな感じにしてみました。
あまり試していないのでもっといい設定の値があるのかもしれませんが、追って試してみます。
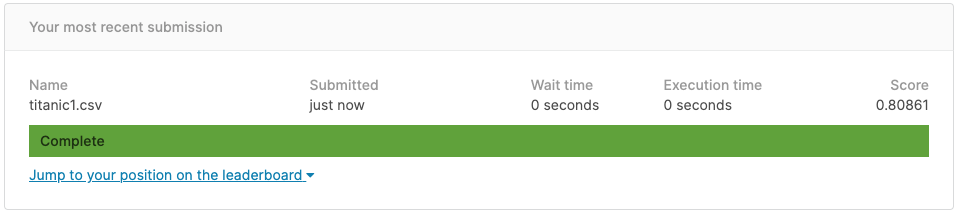
これで再度学習して再度KaggleにSubmitしてみます。
スコアは0.80861まで上がりました。
レベル3の学習に30分くらいかかるので、また色々と試して追加で書きたいと思います。





- 投稿日:2020-06-03T22:01:45+09:00
[Ansible] Python3インタプリタで、Centos7にdnfをインストールする
[Ansible] Python3インタプリタで、Centos7にdnfをインストールする
dnfとは
- Dandified Yum(ダンディファイド ヤム)とも言うらしい
- Fedoraのパッケージ管理システム(バージョン22からデフォルトになった)
- RHEL7,CentOS7でも使用できる(
yum install -y dnf)- RHEL8,CentOS8では標準でインストール済み
簡単に言うと、
dnfはyumの後継種であり、CentOS8からはyumではなくdnfがデフォルトとなる。
CentOS8でもyumコマンドは使えるが、dnfへのシンボリックリンクになっているだけである。なぜyumではなくdnfを使うのか
2020/1/1にPython2.Xのサポートが終了した。
- yumは、python2.Xでしか動作しません
- dnfは、python2.x or 3.Xで動作します
なのでこれからは
dnfとが主流となっていく。(まずは)手動でCentOS 7にインストールしてみる
CentOS 7.XのDockerコンテナにdnfをインストールする。
[dnfuser@localhost ~]$ docker run -it --rm centos:7 bash [root@3b4a088d7e6f /]# yum update -y [root@3b4a088d7e6f /]# yum install -y epel-release [root@3b4a088d7e6f /]# yum install -y dnf [root@3b4a088d7e6f /]# head -n1 /usr/bin/dnf #!/usr/bin/python2どうやらCentOS7.Xの
dnfはpython2.Xで動いている様子。
python3.Xをインストールした後にも試したが、dnfは2.Xになってしまう。Ansibleでdnfをインストールする
https://docs.ansible.com/ansible/latest/modules/dnf_module.html
インタプリタがPython2.Xであれば、すんなりインストールできる。
playbook.yml- name: Install epel-release yum: name: epel-release state: present become: yes - name: Install dnf yum: name: dnf state: present become: yes
- yumモジュールでdnfをインストール
- その後のタスクはyumモジュールをdnfモジュールに変更すれば使用できる
(本題)Ansibleのインタプリタをpython3.Xにしている場合
ansible.cfg[default] ansible_python_interpreter=/usr/bin/python3上記のように、デフォルトでPython3.Xのインタプリタを使用している場合は、無理やり2.Xに戻す必要がある。
playbook.yml- name: Install dnf for Centos7 block: - name: Change interpreter set_fact: ansible_python_interpreter: "/usr/bin/python" - name: Install epel-release yum: name: epel-release state: present become: yes - name: Install dnf yum: name: dnf state: present become: yes when: - ansible_distribution_major_version | float < 8その後のタスクでもインタプリタは2.Xになる。
最後に(Ansibleインタプリタ ベストプラクティス)
Ansible 2.12 ver.では、デフォルトのインタプリタの振る舞いが変わるらしい。
(多分Python3.Xが優先的に選ばれるのであろう)参考)
https://docs.ansible.com/ansible/latest/reference_appendices/interpreter_discovery.html
https://rheb.hatenablog.com/entry/ansible_interpreter_discovery現行ver.(2.9)ではデフォルトで
/usr/bin/pythonが指定されるので、OSによって使用されるPythonのver.が違う場合がある。
2.12 ver.が待てなくて、dnfコマンドを使いたい人のベストプラクティスは以下のようになった。諦めてデフォルト(Python2.X)のインタプリタを使用する
- Ansibleに関しては、デフォルトの
/usr/bin/pythonを使用して、Python2.Xを使い続ける- yumモジュールではなく、dnfモジュールに統一する
「別にPython2.Xでいいよ」と言う人は、デフォルトのインタプリタを使用すれば問題ない。
どうしてもPyhton3.Xのインタプリタを使用したい場合
CentOS7.Xのホストに対して、inventoryでPython2.Xインタプリタを指定する
inventory.ymlall: children: centos7: hosts: centos7-1 vars: ansible_python_interpreter: /usr/bin/python # /usr/bin/python2 でもOKCentOS7だけグルーピングしておけば、簡単に実装できそう。
Playbookで強制的にインタプリタを2.Xに変更する
playbook.yml- name: Change interpreter set_fact: ansible_python_interpreter: /usr/bin/pythonちなみに私は、Python3.Xがデフォルトになるのに備えて、こちらを採用している。
- 投稿日:2020-06-03T21:47:29+09:00
【Pythonやってみた!】iPad ProでKaggleに投稿できる?
目的
iPad Pro 2020でKaggleに投稿できたので、その方法を共有する。
背景
iPad Pro 2020を最近購入し、
「これで機械学習を勉強できたら最高なのに、、、」
と思ったが、ネット上では「できた」「できない」と色々言われているので、
実際はどうかを試そうと思った。実行環境
端末:iPad Pro 2020(11インチ)
キーボード:Magic Keyboard
ブラウザ:Chrome前提
Kaggleにログインできる
※今回はログイン方法は説明しません参考
https://www.codexa.net/kaggle-titanic-beginner/
方法
①ChromeでKaggleのページに行く
②Notebookを作成する
③コーディングする
④Save&Commit
⑤Submitするページに行く
⑥Submit①ChromeでKaggleのページに行く
Kaggleにログインし、Competitionsページに行く。
参加するコンペを選択。(今回はTitanicを例にします。)
②Notebookを作成する
PythonをコーディングするNotebookを作成する。
③コーディングする
タイトルを変えることができます。
(今回はコーディングについては省略します。)
④Save&Commit
Saveを選択する。
Save&Commitを選択し、Saveする。
⑤Submitするページに行く
編集ページから戻る。
先程作成したNotebookを選択する。
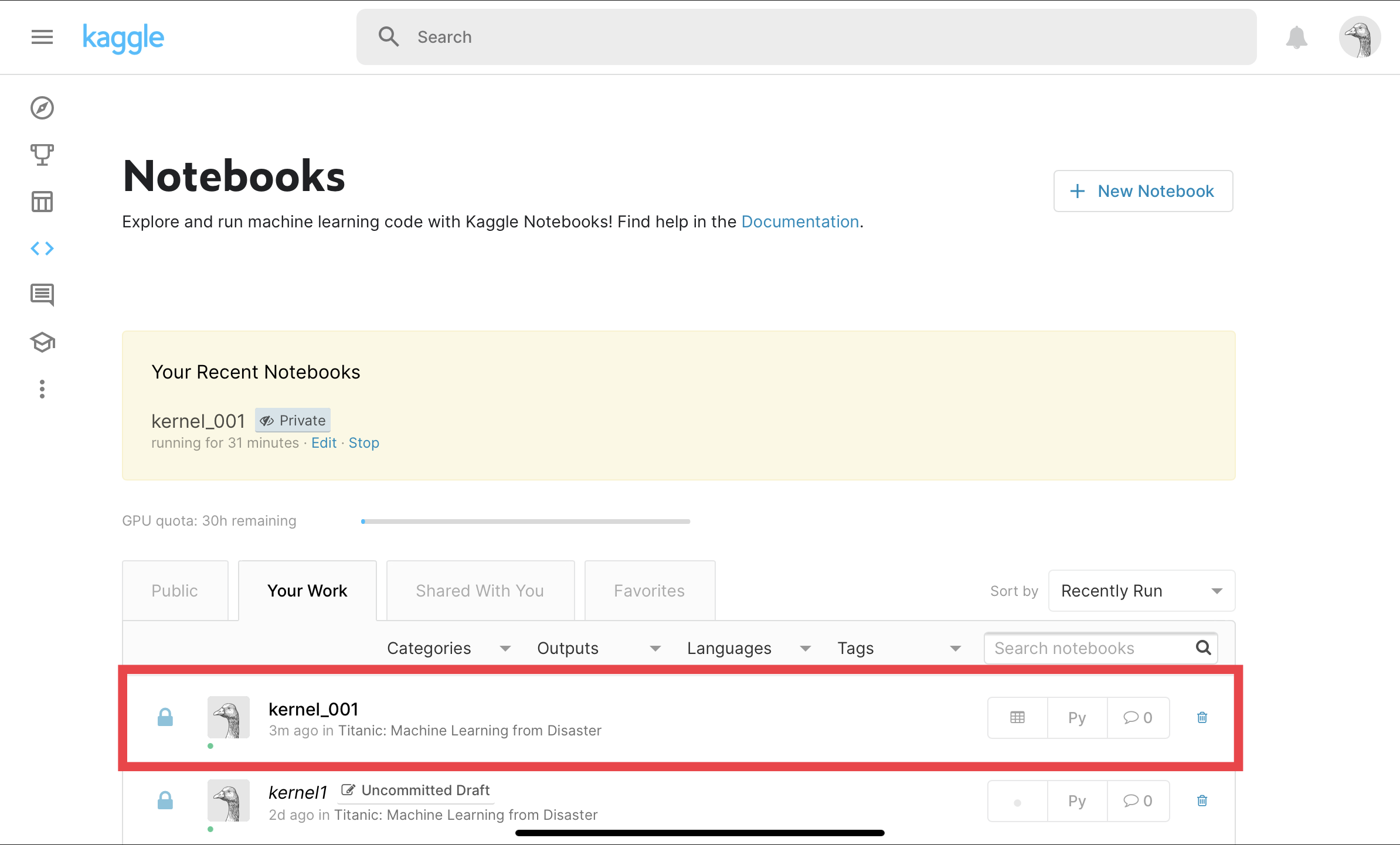
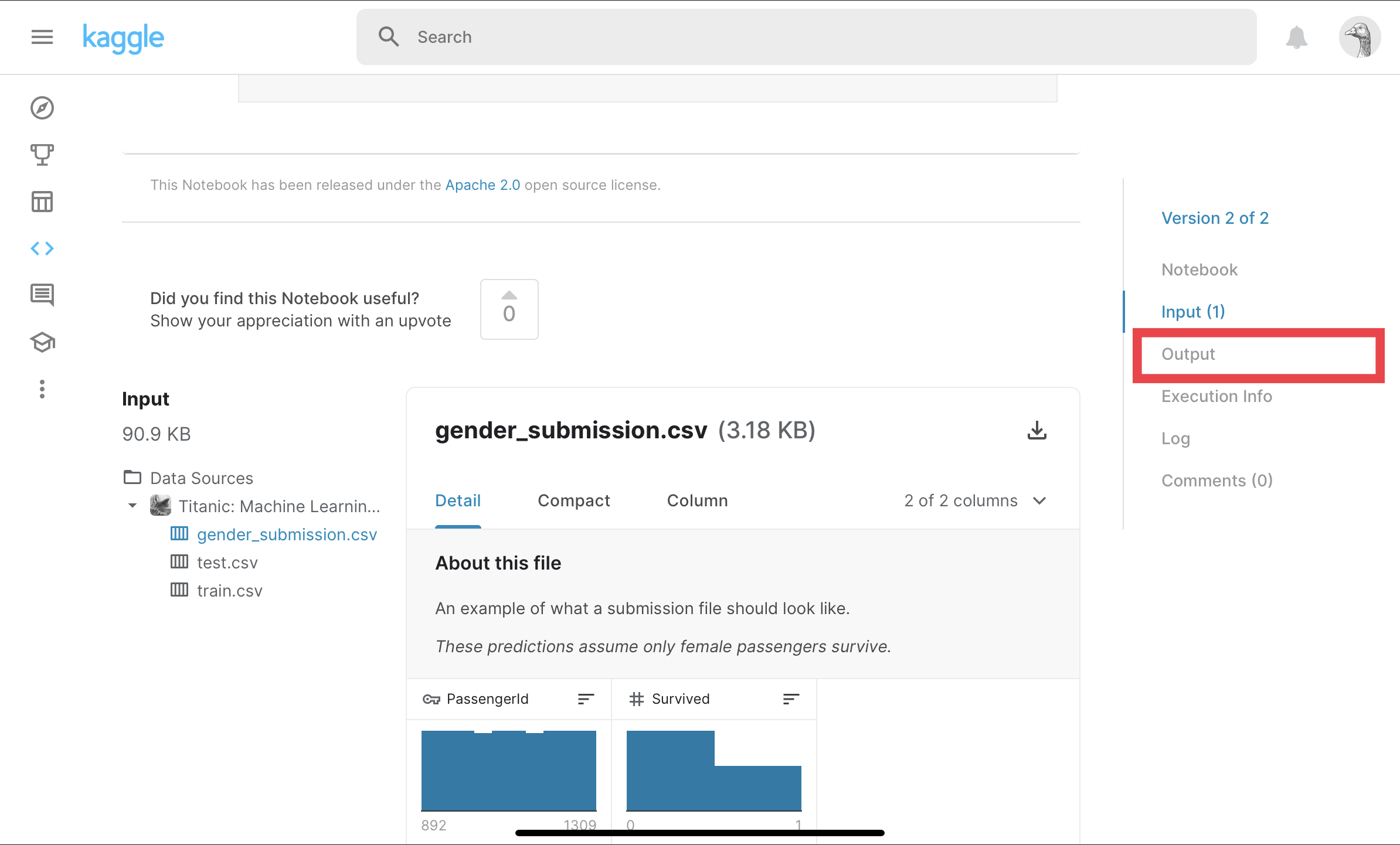
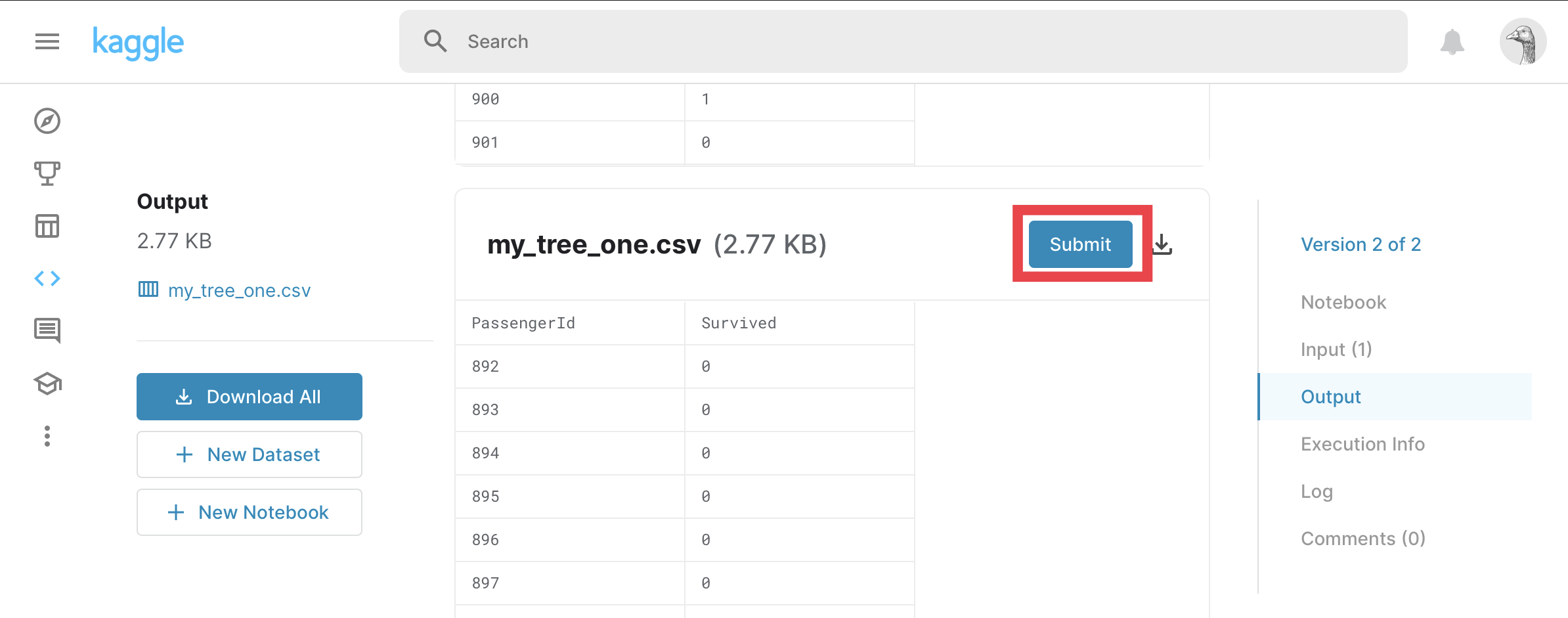
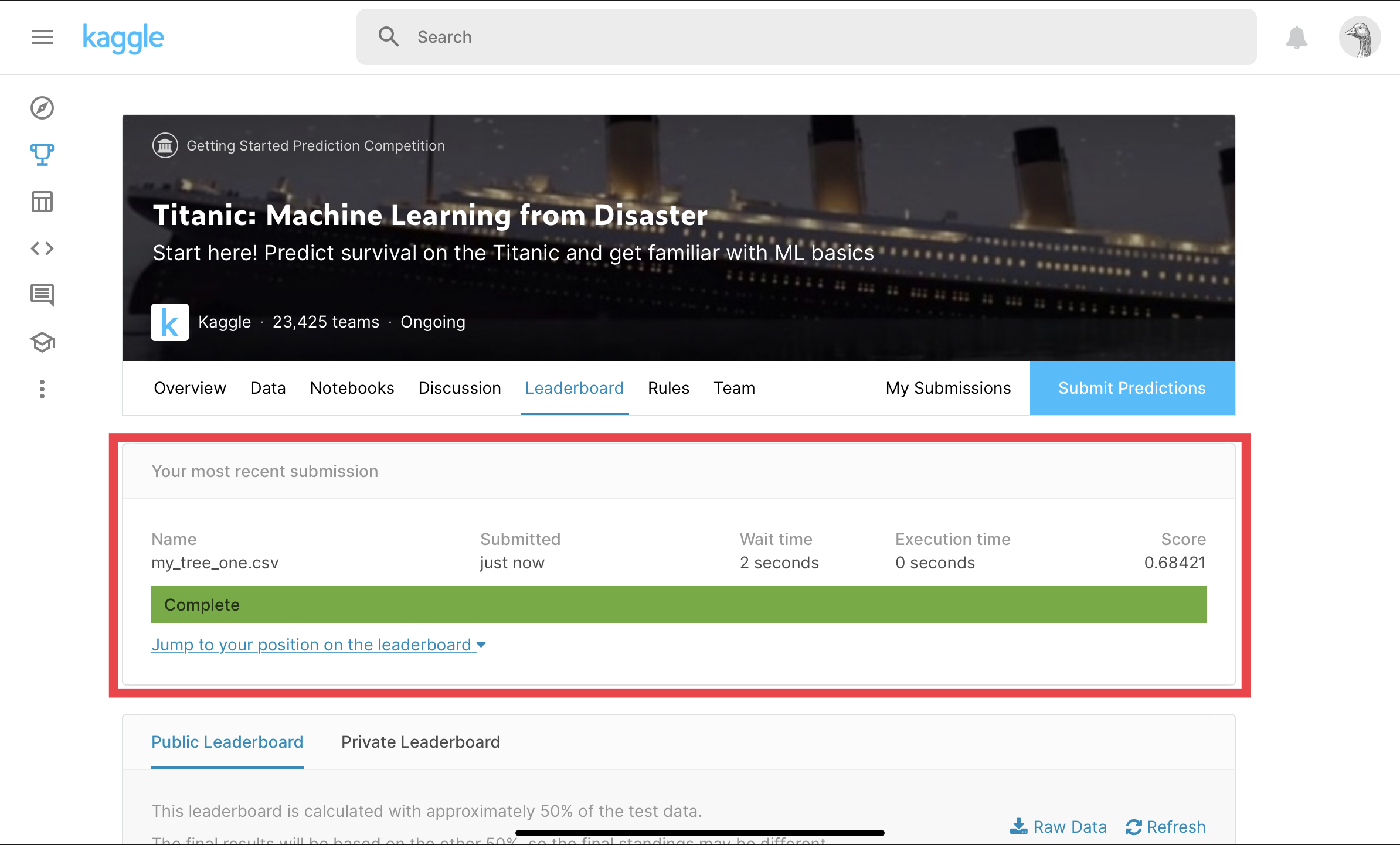
⑥Submit
Outputを選択する。
Submitを選択する。
Kaggleに投稿できました!
まとめ
今回は、iPadでKaggle投稿にチャレンジしてみました。
結果はKaggle投稿ができる!ということがわかりました。
キーボードはあった方が良いと思います。
ますますデータ分析のモチベーションが上がりました!
- 投稿日:2020-06-03T20:18:58+09:00
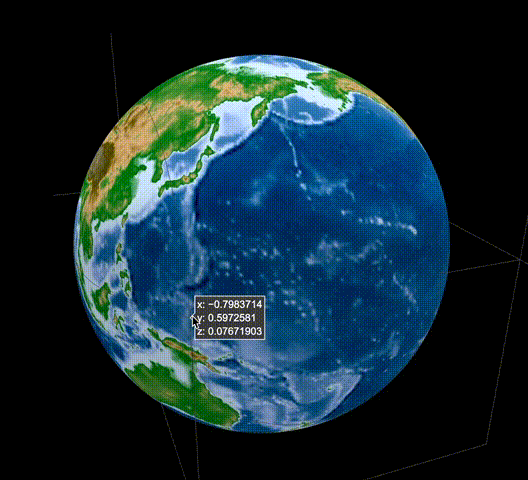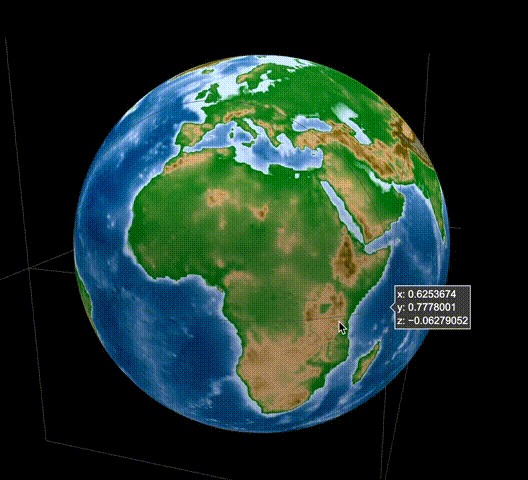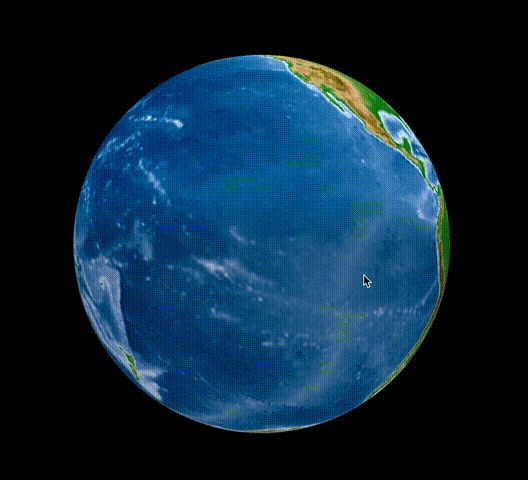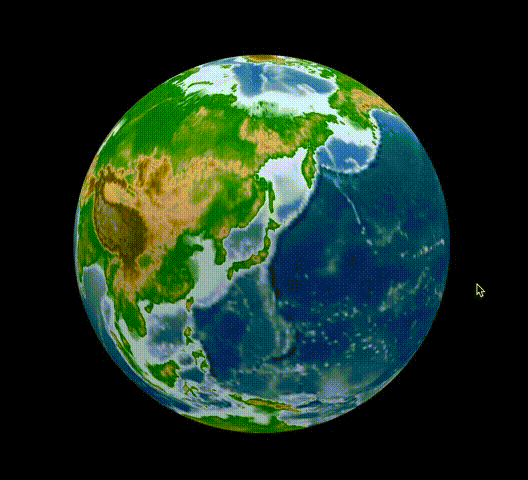
[Python] Plotlyで標高データを球面に描画し、グルグル回せる地球儀を描いてみる
はじめに
Pythonをはじめ様々な言語に対応し、比較的容易にインタラクティブな図を描画できるPlotlyを利用して、標高データを用いてGoogle Earthのようなグルグル回せる地球儀を作成してみます。
結果はこんな感じ。
https://rkiuchir.github.io/3DSphericalTopo
3つのポイント
- 標高データの取得および読み込み
- 直交座標系で表現される緯度経度情報を球面座標系に変換(Plotly Chart Studio: Heatmap plot on a spherical mapを参考)
- Plotlyで描画
実行環境
- macOS 10.14 Mojave
- Python 3.6 (Anaconda)
- Jupyter notebook
0. Plotlyのインストール
pip install plotlyでインストール可能です。1-1. 標高データの取得
- 全球的に1分刻みの解像度を持つ標高データ(ETOPO1 Global Relief Model)が、NOAA(アメリカ海洋大気庁: National Oceanic and Atmospheric Administration)におけるこちらのサイトで公開されています。
- 今回は、ETOPO1 Ice Surfaceのgrid-registeredのnetCDF形式ファイル(ETOPO1_Ice_g_gdal.grd)をダウンロードします。
1-2. 標高データの読み込み
まずは、netCDF形式のデータファイルから緯度経度と標高の3つのデータを読み込みます。
- ここで定義しているInputは、指定された領域の緯度 (lat_area)・経度 (lon_area)・解像度(resolution)です。
- Outputは指定した領域でのmesh typeの緯度 (lon)・経度 (lat)・解像度 (topo)になります。
- 解像度の部分は、° (degree)の形式で指定し、最も解像度の高い指定は0.0167°になります。
解像度に関しては、指定された解像度値に合わせてデータをスキップする形で入力しています。
import numpy as np from netCDF4 import Dataset def Etopo(lon_area, lat_area, resolution): ### Input # resolution: resolution of topography for both of longitude and latitude [deg] # (Original resolution is 0.0167 deg) # lon_area and lat_area: the region of the map which you want like [100, 130], [20, 25] ### ### Output # Mesh type longitude, latitude, and topography data ### # Read NetCDF data data = Dataset("ETOPO1_Ice_g_gdal.grd", "r") # Get data lon_range = data.variables['x_range'][:] lat_range = data.variables['y_range'][:] topo_range = data.variables['z_range'][:] spacing = data.variables['spacing'][:] dimension = data.variables['dimension'][:] z = data.variables['z'][:] lon_num = dimension[0] lat_num = dimension[1] # Prepare array lon_input = np.zeros(lon_num); lat_input = np.zeros(lat_num) for i in range(lon_num): lon_input[i] = lon_range[0] + i * spacing[0] for i in range(lat_num): lat_input[i] = lat_range[0] + i * spacing[1] # Create 2D array lon, lat = np.meshgrid(lon_input, lat_input) # Convert 2D array from 1D array for z value topo = np.reshape(z, (lat_num, lon_num)) # Skip the data for resolution if ((resolution < spacing[0]) | (resolution < spacing[1])): print('Set the highest resolution') else: skip = int(resolution/spacing[0]) lon = lon[::skip,::skip] lat = lat[::skip,::skip] topo = topo[::skip,::skip] topo = topo[::-1] # Select the range of map range1 = np.where((lon>=lon_area[0]) & (lon<=lon_area[1])) lon = lon[range1]; lat = lat[range1]; topo = topo[range1] range2 = np.where((lat>=lat_area[0]) & (lat<=lat_area[1])) lon = lon[range2]; lat = lat[range2]; topo = topo[range2] # Convert 2D again lon_num = len(np.unique(lon)) lat_num = len(np.unique(lat)) lon = np.reshape(lon, (lat_num, lon_num)) lat = np.reshape(lat, (lat_num, lon_num)) topo = np.reshape(topo, (lat_num, lon_num)) return lon, lat, topo2. 緯度経度情報を球面座標に変換
(Plotly Chart Studio: Heatmap plot on a spherical mapを参考)
ここでは、上記で用意された直交系座標で表現された緯度経度情報を球面座標系に変換します。
def degree2radians(degree): # convert degrees to radians return degree*np.pi/180 def mapping_map_to_sphere(lon, lat, radius=1): #this function maps the points of coords (lon, lat) to points onto the sphere of radius radius lon=np.array(lon, dtype=np.float64) lat=np.array(lat, dtype=np.float64) lon=degree2radians(lon) lat=degree2radians(lat) xs=radius*np.cos(lon)*np.cos(lat) ys=radius*np.sin(lon)*np.cos(lat) zs=radius*np.sin(lat) return xs, ys, zs3. Plotlyで描画
それでは、実際に球面座標系で表された緯度・経度・標高の3次元データを実際にPlotlyで描画します。
まず、1-2.で用意した関数を呼び出して全球の標高データを読み込みます。
あまりの高解像度で読み込むと3乗のオーダーでデータ量が大きくなるので、今回は解像度を0.8°としています。# Import topography data # Select the area you want resolution = 0.8 lon_area = [-180., 180.] lat_area = [-90., 90.] # Get mesh-shape topography data lon_topo, lat_topo, topo = ReadGeo.Etopo(lon_area, lat_area, resolution)次に、2.で用意した関数で球面座標系に変換します。
xs, ys, zs = mapping_map_to_sphere(lon_topo, lat_topo)そしてここから、実際に描画に移っていきます。
まず、標高データの描画に用いるカラースケールを定義します。
# Import color scale import Plotly_code as Pcode name = "topo" Ctopo = Pcode.Colorscale_Plotly(name) cmin = -8000 cmax = 8000そして、Plotlyを用いて描画していきます。
ここでは、インプットのデータおよびカラースケールを入力します。topo_sphere=dict(type='surface', x=xs, y=ys, z=zs, colorscale=Ctopo, surfacecolor=topo, cmin=cmin, cmax=cmax) )見栄えが良くなるように軸などは消しておきます。
noaxis=dict(showbackground=False, showgrid=False, showline=False, showticklabels=False, ticks='', title='', zeroline=False)最後にlayoutを用いてタイトルや背景色などを指定します。
今回は、Google Earthを少し意識して、背景色を黒色としています。import plotly.graph_objs as go titlecolor = 'white' bgcolor = 'black' layout = go.Layout( autosize=False, width=1200, height=800, title = '3D spherical topography map', titlefont = dict(family='Courier New', color=titlecolor), showlegend = False, scene = dict( xaxis = noaxis, yaxis = noaxis, zaxis = noaxis, aspectmode='manual', aspectratio=go.layout.scene.Aspectratio( x=1, y=1, z=1)), paper_bgcolor = bgcolor, plot_bgcolor = bgcolor)そして、用意したものを用いて描画(ここではhtml出力)します。
from plotly.offline import plot plot_data=[topo_sphere] fig = go.Figure(data=plot_data, layout=layout) plot(fig, validate = False, filename='3DSphericalTopography.html', auto_open=True)おわりに
これで冒頭のようなグリグリ回せる地球儀のプロットが描けたかと思います。
私はこの上にさらに地震の分布を重ねたりして使用しています。今回の例は、球体にプロットする際には容易に応用可能ですし、用途は色々と広いかと思います。
また、標高データはもちろん2次元の地図を作成する際にも役立ちますし、標高データで高さを表現した3次元描画も可能です。
- 投稿日:2020-06-03T19:35:40+09:00
レボボーヌージョー
先駆者: ヌレボージョーボー
import random l = ['ボ', 'ジョ', 'レ', 'ヌ', 'ボ'] random.shuffle(l) [l.insert(i, 'ー') for i in [3, 5, 7]] print(''.join(l))行数は増えたがコードのサイズは減らせた
元ネタ
- 投稿日:2020-06-03T19:07:11+09:00
100日後にエンジニアになるキミ - 75日目 - プログラミング - スクレイピングについて6
昨日までのはこちら
100日後にエンジニアになるキミ - 70日目 - プログラミング - スクレイピングについて
100日後にエンジニアになるキミ - 66日目 - プログラミング - 自然言語処理について
100日後にエンジニアになるキミ - 63日目 - プログラミング - 確率について1
100日後にエンジニアになるキミ - 59日目 - プログラミング - アルゴリズムについて
100日後にエンジニアになるキミ - 53日目 - Git - Gitについて
100日後にエンジニアになるキミ - 42日目 - クラウド - クラウドサービスについて
100日後にエンジニアになるキミ - 36日目 - データベース - データベースについて
100日後にエンジニアになるキミ - 24日目 - Python - Python言語の基礎1
100日後にエンジニアになるキミ - 18日目 - Javascript - JavaScriptの基礎1
100日後にエンジニアになるキミ - 14日目 - CSS - CSSの基礎1
100日後にエンジニアになるキミ - 6日目 - HTML - HTMLの基礎1
今回もスクレイピングの続きです。
Seleniumのインストールなどが終わっていたらその続きに入ります。
Seleniumの操作方法
Seleniumを読み込みする
ライブラリを読み込みします。
Google Chromeを動かすことを想定して・・from selenium import webdriver # ドライバー設定 chromedriver = "ドライバーのフルパス" driver = webdriver.Chrome(executable_path=chromedriver)WEBドライバーの保存先は人それぞれ違うと思うので書き換えてください。
これでGoogle Chromeが立ち上がるハズです。
なおエラーメッセージが出る場合、WEBドライバーとChromeのバージョンなども合わせないとダメです。またWEBドライバーを実行できるように権限設定することも必要場合があるので、エラー内容を見て適宜対処しましょう。
ここまで来たらブラウザを操作できる状態なのでいろいろ操作をしていきます。
一旦ブラウザを開くと、閉じる操作をするまで開きっぱなしになります。
大量に開くとリソースを消費するので、落とすのを忘れないようにしましょう。またセレニウムを用いる際に
ヘッダーレスモードで開くこともできます。
ヘッダーレスモードはブラウザを目に見えるように立ち上げることをせずに裏側で動かすような仕組みです。リソースの消費を防ぎ、LinuxサーバーなどでもSeleniumを使えるようになるので非常に便利なモードです。
書き方はブラウザの
オプション設定を追加する変数を作って
ヘッダーレス設定を追加しWEBドライバーの呼び出しメソッドの引数に追加します。
オプション変数 = webdriver.ChromeOptions()
オプション変数.add_argument('--headless')
ドライバー変数 = webdriver.Chrome(options=オプション変数)from selenium import webdriver # ドライバー設定 chromedriver = "ドライバーのフルパス" # オプション設定 options = webdriver.ChromeOptions() options.add_argument('--headless') # ドライバーの呼び出し driver = webdriver.Chrome(executable_path=chromedriver, options=options)SeleniumでWEBサイトにアクセスする
seleniumを呼び出した際の変数を用いて操作を行っていきます。
先ほどはdriverと言う変数名で呼び出しているのでここからはそれをドライバー変数とします。WEBサイトにアクセスするには
ドライバー変数.get(URL)と打ち込んで実行します。
driver.get(URL)試しに私のHPに行ってみましょう。
driver.get('http://www.otupy.net')
URLを打ち込んで、実行するたびにそのサイトにアクセスすることができます。
WEBサイトが全て表示されるまでは少し時間がかかるので、その後の操作をするのは少し待った方が良いでしょう。サイト内でスクロールする
Javascriptを実行することによってサイト内でスクロールさせることができます。
execute_scriptにてスクリプトを打ち込むことができます。
ドライバー変数.execute_script(Javascript)Javascript部分としてはスクリプトを文字として打ち込み
window.scrollBy(0, Y)やwindow.scrollTo(0, Y)
でスクロール位置を決めます。
window.scrollBy(0, window.innerHeight);で1ページ分
window.scrollTo(0, document.body.scrollHeight);を指定すると一番下までスクロールさせられます。スクロールさせてみましょう。
# 少しだけスクロール driver.execute_script("window.scrollBy(0, window.innerHeight);") # 一番下までスクロール driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")これで、ちょろちょろとブラウザをスクロールさせることができます。
要素を探す
サイトの操作を行うには、どこを操作するのか要素を探す必要があります。
入力蘭などのサイト上の要素を探すことができます。要素を探す方法は多岐に渡り
ドライバー変数.find_element_by_XXXX
というメソッドで各属性の値で探すことができるようになっています。要素が見つかった場合は
WebElementというデータ型として抽出される形になります。id属性で検索
ドライバー変数.find_element_by_id(id属性の値)name属性で検索
ドライバー変数.find_element_by_name(name属性の値)class名で検索
ドライバー変数.find_element_by_class_name(class名)tag名
ドライバー変数.find_element_by_tag_name(tag名)link_textで検索
ドライバー変数.find_element_by_link_text(link_textの値)CSS_Selector
ドライバー変数.find_element_by_css_selector(css_selectorの値)xpath
ドライバー変数.find_element_by_xpath(xpathの値)要素を操作する
要素を操作するには先に要素を見つけておかないといけません。
上記の方法で要素が見つかったら要素変数に代入しておくと下記のような操作が行えます。
要素変数.find_element_by_XXXX()
要素変数.操作メソッド要素をクリックする
要素変数.click()要素に文字を入力する
要素変数.send_keys(文字)要素でキー入力を行う
先に
Keysライブラリを読み込みしておきます。from selenium.webdriver.common.keys import Keysその後要素を見つけて
send_keysを用いてキー入力を行います。
要素変数.send_keys(Keys.特殊キー)扱えるキーは以下の通りです。
キー Keys Enterキー Keys.ENTER ALTキー(通常キーと組み合わせ) Keys.ALT,"キー" ←キー Keys.LEFT →キー Keys.RIGHT ↑キー Keys.UP ↓キー Keys.DOWN Ctrlキー(通常キーと組み合わせ) Keys.CONTROL,"キー" Deleteキー Keys.DELETE HOMEキー Keys.HOME ENDキー Keys.END ESCAPEキー Keys.ESCAPE イコール Keys.EQUALS COMMANDキー Keys.COMMAND F1キー Keys.F1 シフトキー(通常キーと組み合わせ) Keys.SHIFT,"キー" ページダウンキー Keys.PAGE_DOWN ページアップキー Keys.PAGE_UP スペースキー Keys.SPACE リターンキー Keys.RETURN タブキー Keys.TAB ページのソースコードを抽出する
文字列としてページのソースコードを取得できます。
ドライバー変数.page_sourcedriver.page_source取得後は
BeautifulSoupなどのライブラリを用いて解析を行うことができます。まとめ
seleniumを使うと通常のスクレピング手法では
取得できない情報も簡単に取得できるようになるので便利です。データが取得できなくて困っている方はseleniumを試してみましょう。
これができるようになると、圧倒的にデータを取得できます。君がエンジニアになるまであと25日
作者の情報
乙pyのHP:
http://www.otupy.net/Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMwTwitter:
https://twitter.com/otupython
- 投稿日:2020-06-03T17:57:02+09:00
[備忘録]画像のリサイズ
- 投稿日:2020-06-03T17:44:27+09:00
Pandas DataFrame の任意の場所に列を追加する便利関数
Pandas DataFrame の任意の場所に列を追加したい場合は pandas.DataFrame.insert を使うと実現できるが、いくつか不満がある。
- immutable でない (DataFrame が直接書き換えられてしまう / 破壊的メソッドである / inplace オプションがない)
- 追加場所をインデックスの数値で指定しなければいけない
- わかりにくい
- 「col1 の後に追加」のような指定が難しい
- Series を入力しても name が無視されるため、別途指定する必要がある
- DataFrame を入力できない
これらを解決するような便利関数を書いた。
実装
from typing import Union, Optional import pandas as pd def insert_columns( df: pd.DataFrame, data: Union[pd.Series, pd.DataFrame], *, before: Optional[str] = None, after: Optional[str] = None, allow_duplicates: bool = False, inplace: bool = False, ) -> pd.DataFrame: if not inplace: df = df.copy() if not (after is None) ^ (before is None): raise ValueError('Specify only "before" or "after"') if before: loc = df.columns.get_loc(before) else: loc = df.columns.get_loc(after) + 1 if type(data) is pd.Series: df.insert(loc, data.name, data, allow_duplicates) elif type(data) is pd.DataFrame: for column in data.columns[::-1]: df.insert(loc, column, data[column], allow_duplicates) return df
beforeまたはafterにはカラム名を指定する- デフォルトでは入力された DataFrame を直接書き換えない
inplace=Trueを指定すれば直接書き換える使い方
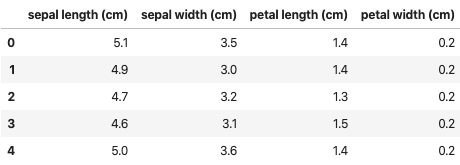
サンプルデータとして sklearn の iris データセットを使う。
from sklearn import datasets iris = datasets.load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) target = pd.Series(iris.target_names[iris.target], name='target')df.head()
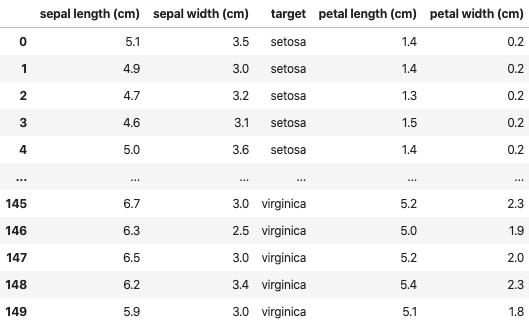
target.head()
df の
sepal width (cm)の後ろに target を追加してみる。insert_columns(df, target, after='sepal width (cm)')
この例では Series を追加しているが、DataFrame も指定できる。

- 投稿日:2020-06-03T17:39:19+09:00
理論物理系学生の0から始める機械学習#2
目次
1. 標準装備のPython
2. 0からのPython環境構築
3. コーディングの準備冗長になるかもしれないが、”0から”というところを意識して書いていきたい。
1. 標準装備のPython
開発環境:MacOS 10.13.6
基本的にMacのターミナルをCUIとして用いる。(CUI:Character User Interface 文字で操作する)ターミナルの表示形式は、
[コンピュータ名:カレントディレクトリ名 ユーザ名$]
となっている。(短くする方法もあるが初心者ならカレントディレクトリがどこなのかわかっていた方がいいだろう。)
以降$のみを記述する。Python2.7.16はMac標準装備だった。確認方法は以下。
$python -V Python 2.7.16自分の場合はバージョン2.7.16で表示された。
2. 0からのPython環境構築
標準装備のPython2でも開発できるが、PythonにはPython2とPython3があるらしく、Python2は2.7以降はバージョンアップがされないことが決まっているらしい。これからPythonを学ぶのであればPython3をインストールしておきたい。
Python公式サイトから無料でインストーラーが提供されている。
Python公式サイト
こちらから最新のリリースをダウンロードしておけば問題ないはず。インストールが完了したらバージョン確認。
$python3 -V Python 3.8.0MacOSの場合コマンドが
python3になる。自分のバージョンは3.8.0だった。3. コーディングの準備
Python3がインストール完了できれば、
MacOSでPythonという言語を処理する準備ができたということ。しかし、処理するプログラムがなければ意味がない。次は、コードを書くための準備をする。有名なテキストエディタVisual Studio Code(以下:VSCode)を用いる。
テキストエディタとは、Mac標準装備のメモと同じもので、VSCodeはコーディングに特化したものだと考えればいいだろう。Visual Studio Code公式サイト
こちらから同様にインストールする。インストールできたら、あとは使っていくだけ。
拡張機能としてプラグインをインストールするとVSCodeを自分好みの開発環境にカスタマイズすることができる。
日本語で使いたいのであれば、Japanese Languageのプラグイン、
PythonでコーディングするのでPythonのプラグインをインストールしておく。
(プラグインは後で有効/無効を切り替えられる)
Shellというプラグインをインストールしておけばターミナルで$code [ファイル名]と入力するだけでVSCodeがファイルを起動してくれるようになる。
あとはVSCodeでコーディングをしてMacキーボードのショートカットキーcommand+Sなどで保存すればコーディングは終了。ターミナルもVSCode内でショートカットキー
shift+control+@を使えば起動できるので、ほぼGUI(マウス)を使う必要がない。(VSCodeの使い方については人それぞれな気もする)
- 投稿日:2020-06-03T17:34:40+09:00
ゼロから始めるLeetCode Day45 「1379. Find a Corresponding Node of a Binary Tree in a Clone of That Tree」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
その対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイト。
せっかくだし人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
前回
ゼロから始めるLeetCode Day44「543. Diameter of Binary Tree」今はTop 100 Liked QuestionsのMediumを優先的に解いています。
Easyは全て解いたので気になる方は目次の方へどうぞ。Twitterやってます。
問題
1379. Find a Corresponding Node of a Binary Tree in a Clone of That Tree
難易度はMedium。
originalとclonedの2つのバイナリツリーが与えられ、originalのtargetへの参照が与えられます。複製されたツリーは、元のツリーのコピーで、複製されたツリー内の同じノードへの参照を返します。
2つのツリーまたはtargetを変更することは許可されておらず、回答はclonedされたツリー内のノードへの参照でなければなりません。フォローアップ:ツリーで繰り返し値が許可されている場合は、問題を解決してください。
解法
# Definition for a binary tree node. # class TreeNode: # def __init__(self, x): # self.val = x # self.left = None # self.right = None class Solution: def getTargetCopy(self, original: TreeNode, cloned: TreeNode, target: TreeNode) -> TreeNode: if not original: return None if original == target: return cloned return self.getTargetCopy(original.left,cloned.left,target) or self.getTargetCopy(original.right,cloned.right,target) # Runtime: 672 ms, faster than 60.93% of Python3 online submissions for Find a Corresponding Node of a Binary Tree in a Clone of That Tree. # Memory Usage: 23.5 MB, less than 100.00% of Python3 online submissions for Find a Corresponding Node of a Binary Tree in a Clone of That Tree.以上のような解き方をしました。
シンプルに書けたので比較的良い解答なのかと思ったのですが、そこまで速度が出ていないので他の解答を調べてみました。class Solution: def getTargetCopy(self, original: TreeNode, cloned: TreeNode, target: TreeNode) -> TreeNode: que = collections.deque([(original, cloned)]) # start at the root while que: nodeOrig, nodeClon = que.popleft() if nodeOrig is target: # if original node is found - cloned node is our answer return nodeClon if nodeOrig.left: que.append((nodeOrig.left, nodeClon.left)) if nodeOrig.right: que.append((nodeOrig.right, nodeClon.right)) # Runtime: 656 ms, faster than 92.51% of Python3 online submissions for Find a Corresponding Node of a Binary Tree in a Clone of That Tree. # Memory Usage: 23.6 MB, less than 100.00% of Python3 online submissions for Find a Corresponding Node of a Binary Tree in a Clone of That Tree.この回答はqueを使って書いていますが、わかりやすくて良いですね。
速さも申し分ないですし、問題を自分の解けるような型に無理やりはめるのではなく、このような回答の仕方も覚えて切り替えられるようになれるともっと問題を解いてて楽しそうですね!今回はここまで。お疲れ様でした。
- 投稿日:2020-06-03T16:58:54+09:00
[Python] メール送信
やりたいこと
pythonでメール送信したい経緯
いろいろ処理をした結果をメールで通知したいと思って
Outlookでのメール送信を組み込んでみた。
毎日の運用なのでタスクスケジューラに設定したら、メール送信されたことになってるけど実際には送信されてこない。
タスクスケジューラからでなく、直接実行すれば送信される。
調べてみたら、サーバー環境でOutlookなどのoffice製品を使うのはちょっと難ありらしいことがわかった。
代替案として標準ライブラリを使えばできることがわかったのでメモしておく。ポイント
- 標準ライブラリの
smtplibと- その他、
サーバーホスト名,ポート番号,認証ID,認証パスワードが必要- 但し、
認証ID,認証パスワードはなくてもOKだったりする場合もある(環境による)- 送信先が複数ある場合は1通づつ送信することになるので、
送信先アドレスはリストで渡してfor文で回すコードサンプル
sample.pyfrom email import message import smtplib smtp_host = 'ホスト名' smtp_port = 'ホスト番号' smtp_account_id = 認証ID smtp_account_pass = '認証パスワード' send_from = 'xxxxx@xxx.co.jp' l_send_to = [ 'aaa@xxx.co.jp', 'bbb@xxx.co.jp' ] subject = '作業報告' content = f'作業が終了しました' for s in l_send_to: msg = message.EmailMessage() msg.set_content(content) msg['Subject'] = subject msg['From'] = send_from msg['To'] = s server = smtplib.SMTP(smtp_host, smtp_port, timeout=10) server.login(smtp_account_id, smtp_account_pass) server.send_message(msg) server.quit()
- 投稿日:2020-06-03T16:56:38+09:00
Tacotron2系における日本語のunidecodeの不確かさ
はじめに
テキストデータを合成音声に変換する手法をTextToSpeech(TTS)といいます。
今回、TextToSpeechの学習をしたわけではないのですがテキストデータが日本語入力の場合、Tacotron2系のtransliteration_cleanersでは上手くローマ字に変換できなかった失敗談を記録しておきます。Tacotron2系
NVIDIAのTextToSpeechは下記があります。今回、自分はflowtronについて試しましたが、ほかのversionでも日本語入力に対するunidecodeの失敗は共通のものと思われます。
https://github.com/NVIDIA/flowtron
https://github.com/NVIDIA/mellotron
https://github.com/NVIDIA/tacotron2
(ちなみにこれらの違いを自分は詳しくは分かっていません)日本語入力の自分のデータで学習する場合
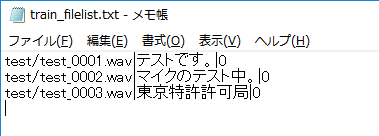
自分は学習データを用意できておらずモデル学習はしていないのですが、オリジナルデータを学習するには下記のようにファイルリストを自前で作成します。
train.py... data_config['training_files'] = 'filelists/train_filelist.txt' data_config['validation_files'] = 'filelists/validation_filelist.txt' data_config['text_cleaners'] = ['transliteration_cleaners'] train(n_gpus, rank, **train_config)
ここでファイルリストにはファイルの場所、音声のテキスト、speakerのIDを書く必要があるかと思います。複数の話者が混じった学習データではspeakerのIDが重複しないようにする必要があるかと思います。(多分)data.pydef load_filepaths_and_text(filename, split="|"): with open(filename, encoding='cp932') as f: #encodingをcp932に変更(windowsの場合) ... def get_text(self, text): print(text) # 追加 text = _clean_text(text, self.text_cleaners) print(text) # 追加text/cleaners.pydef transliteration_cleaners(text): '''Pipeline for non-English text that transliterates to ASCII.''' text = convert_to_ascii(text) text = lowercase(text) text = collapse_whitespace(text) return textそして英語ではなく日本語を読む場合、エンコーディングをcp932にして、cleanersに['transliteration_cleaners']に変更する必要があるかと思います。
これは'''Pipeline for non-English text that transliterates to ASCII.'''(英語以外のテキストをアスキーに音訳するパイプライン)とあるため日本語入力ならこれが妥当かと一瞬思われるかと思います。
自分はそう思いました。しかし、変換は上手く行かない
def get_textに追加したprint()文の出力結果です。
平仮名、片仮名の「テストです。」は上手く変換できているのが確認できました。一方、漢字は中国語の音韻に変換されてしまいました。Epoch: 0 テストです。 tesutodesu. 東京特許許可局 dong jing te xu xu ke ju マイクのテスト中。 maikunotesutozhong .平仮名、片仮名だけならいいかといえばそうでもない
そもそも、日本語(ユニコード)からアスキーへの変換にはunidecodeというライブラリが使われています。
from unidecode import unidecode def convert_to_ascii(text): return unidecode(text)このunidecodeの変換をいくつか確認しました。
# coding: cp932 from unidecode import unidecode text1 = 'あいうえお' text2 = unidecode(text1) print(text1) print(text2) text1 = 'アイウエオ' text2 = unidecode(text1) print(text1) print(text2) text1 = '相性' text2 = unidecode(text1) print(text1) print(text2) text1 = '相談' text2 = unidecode(text1) print(text1) print(text2) text1 = 'こうてい' text2 = unidecode(text1) print(text1) print(text2) text1 = 'こぅてい' text2 = unidecode(text1) print(text1) print(text2) text1 = 'こおてい' text2 = unidecode(text1) print(text1) print(text2) text1 = 'こーてい' text2 = unidecode(text1) print(text1) print(text2) text1 = 'こ~てい' text2 = unidecode(text1) print(text1) print(text2) text1 = 'こ-てい' text2 = unidecode(text1) print(text1) print(text2) text1 = 'キャット' text2 = unidecode(text1) print(text1) print(text2) text1 = 'キヤツト' text2 = unidecode(text1) print(text1) print(text2) text1 = 'かんい' text2 = unidecode(text1) print(text1) print(text2) text1 = 'かに' text2 = unidecode(text1) print(text1) print(text2) ...... あいうえお aiueo アイウエオ aiueo 相性 Xiang Xing 相談 Xiang Tan こうてい koutei こぅてい koutei こおてい kootei こーてい kotei こ~てい ko~tei こ-てい ko-tei キャット kiyatsuto キヤツト kiyatsuto かんい kani かに kani・漢字が中国語に変換される
・「ぁぃぅぇぉゃゅょっ」が「あいうえおやゆよつ」と同じ
・「ー」が認識されない。
・「かんい」と「かに」の変換が同じ
など多くに問題があります。従ってunidecodeは日本語の変換にはそもそも向いていません。
pykakasiの例
pykakasiを使った場合は以下の様になりました。unidecodeの不完全な変換が改善されています。
また、.setMode('s', True)では自動で単語ごとにスペースを入れてくれます。# coding: cp932 from pykakasi import kakasi kakasi = kakasi() kakasi.setMode('H', 'a') kakasi.setMode('K', 'a') kakasi.setMode('J', 'a') kakasi.setMode('E', 'a') kakasi.setMode('s', True) conv = kakasi.getConverter() text = 'あいうえお、とアイウエオ。' print(conv.do(text)) text = '相性と相談' print(conv.do(text)) text = 'キャットとキヤツト' print(conv.do(text)) text = 'ファイルとフアイル' print(conv.do(text)) text = 'こうてい と こぅてい と こおてい と こーてい と こ~てい' print(conv.do(text)) text = '東京特許許可局' print(conv.do(text)) text = '簡易とカニ' print(conv.do(text))aiueo, to aiueo. aishou to soudan kyatto to kiyatsuto fairu to fuairu koutei to koutei to kootei to kootei to ko ~ tei toukyou tokkyo kyoka kyoku kan'i to kanipyopenjtalkの例
OpenJTalkのインストールが必要?
この場合は単語ごとではなく音節ごとに分解されるようです。
単語で分けるのとどちらが良いのかは分かりません(学習モデル次第かも?)import pyopenjtalk print(pyopenjtalk.g2p("こんにちは")) 'k o N n i ch i w a'まとめ
Tacotron2系のunidecodeは日本語入力に向いてなく、transliteration_cleanersを使うのは間違いです。従って学習データを日本語にする場合、text/cleaners.pyにjapanease_cleanersを自作するとよいです。
(それか予めローマ字に変換した学習データを用意するか)
- 投稿日:2020-06-03T16:45:20+09:00
理論物理学生の0から始める機械学習#1
目次
- 1.現状
- 2.プログラミング言語について
- 3.これから1.現状
このQiitaは将来ITエンジニアを目指す理系学生が
・ 0から始めても理解できること
・ 自分の勉強のアウトプットの見える化
のために始めた備忘録です。
(大した知識もないひよっこです。訂正や助言をいただけると嬉しい、、、お手柔らかに。)バックグラウンド
機械工学系→理論物理系→ITエンジニア(将来)
という曲がった経歴を持つ理系学生プログラミング習熟度(2020/6時点)
C言語→基本の情報処理ができる、開発経験はない
python→基本の情報処理ができる、開発経験はない
(大したことないです)開発環境
MacOS -10.13.6
python -2.7.6(Mac初期装備)
python -3.8.02.プログラミング言語について
代表的なプログラミング言語
システム・アプリケーション系:Java、C、Ruby、PHP
Webデザイン系:JavaScript、PHP、HTML
人工知能:Python
注*あくまで簡易的な分類。それぞれ応用できる領域がある。各言語の特徴(調べただけ)
Java: クラスベースのオブジェクト指向(オブジェクト:データとコードの複合体)の汎用プログラミング言語。C言語に似ている。Webアプリケーションで使用されている最も人気のあるプログラミング言語の一つ。
C: 汎用プログラミング言語。動作環境の制約が厳しい。C++、Javaなどの派生源。システム系、アプリケーション系で使われる。
Javascript: プロトタイプベースのオブジェクト指向スクリプト言語。Webサイト、Wenアプリのデザインなどに利用される。多くのWebブラウザで使われる。
注*Javaとは異なる言語。Ruby: 日本人のまつもとゆきひろさんが開発したオブジェクト指向スクリプト言語。Perlに続く言語、Pythonが競合言語。Webアプリケーション、ホームページ作成などで使用される。わかりやすいコード、日本人の開発なので日本語の情報が入手しやすい。
PHP: プログラミング言語と処理系としての特徴を持つ。言語としてはC、Javaに近い。サーバーサイドで動的なWebページ作成ができる。アプリでも使えるが、Webサイトに多く使われる。
HTML: Webページを作るためのマークアップ言語。WebページのほとんどがHTMLで作られている。
Python: コードがシンプルで学習しやすい汎用。ライブラリが豊富で様々な領域への応用が容易(他人が作ったプログラムの塊を利用できる)、対応している動作環境(ハード、OS)が豊富。人工知能・機械学習などで利用される。
どんな言語を学ぶか
世の中の需要
- アプリ系:Ruby、Java
- web系:JavaScript、PHP
- 人工知能系:Pythonが主流か?
シンプルで習熟が容易
-スクリプト言語: ソースコートをそのまま実行できるため結果をすぐ視覚でき学習が容易。ex)Python、JavaScript、Ruby、PHP-コンパイラ言語: 実行するためにソースコードをコンパイルする必要がある。ex)C、Java
応用が効く
・ Python→ ライブラリ(ある目的のために機能をまとめたパッケージのこと)が豊富で応用に幅が効く。ex)アプリ、人工知能、統計・データ分析、IoT開発
注*複数の関数をまとめたもの→モジュール
モジュールをまとめたもの→パッケージ
パッケージをまとめたもの→ライブラリ
ライブラリ=何かができる大量のプログラムの集合体。・ JavaScript→ Web系フロントエンジニア必修。ブラウザ上でユーザーの動作に関わる部分に使われる。
・ Ruby→ アプリケーションの開発に使われる。ライブラリRuby on Railsがよく使われている。日本人が開発したのでオブジェクト指向と呼ばれるプログラミング言語のコンセプトを日本語でしっかりと学ぶことができる。
3.これから
学習の目的
1.色々な言語に触れ、どんなことが実現できるのかを知る。
(どんな領域のエンジニアになるかを決めるため)
×目的ありきの職業選択 ○スキルありきの職業選択2.研究活動への応用
人工知能技術の物理学への応用エンジニアの種類と必須言語(メモ書き程度に)
- AI(人工知能)エンジニア:Python
- アプリケーションエンジニア(業務系):Java、C
- アプリケーションエンジニア(webアプリ系):Java、C、Ruby、PHP
- アプリケーションエンジニア(スマホ系):Swift(iPhone)、Java(Android)
- フロントエンドエンジニア:JavaScript、HTML
- サーバーサイドエンジニア:Ruby、PHP、Python、Java学習する予定の言語
- Python
- Ruby
- JavaScript
- Javaしばらくは研究のためのPythonの学習と機械学習の実行。
その後独学でRuby、Javaを勉強し、開発経験を積みたい、、、。
- 投稿日:2020-06-03T16:45:20+09:00
理論物理系学生の0から始める機械学習#1
目次
- 1.現状
- 2.プログラミング言語について
- 3.これから1.現状
このQiitaは将来ITエンジニアを目指す理系学生が
・ 0から始めても理解できること
・ 自分の勉強のアウトプットの見える化
のために始めた備忘録です。
(大した知識もないひよっこです。訂正や助言をいただけると嬉しい、、、お手柔らかに。)バックグラウンド
機械工学系→理論物理系→ITエンジニア(将来)
という経歴を持つ理系学生プログラミング習熟度(2020/6時点)
C言語→基本の情報処理ができる、開発経験はない
python→基本の情報処理ができる、開発経験はない開発環境
MacOS -10.13.6
python -2.7.16(Mac初期装備)
python -3.8.02.プログラミング言語について
代表的なプログラミング言語
システム・アプリケーション系:Java、C、Ruby、PHP
Webデザイン系:JavaScript、PHP、HTML
人工知能:Python
注*あくまで簡易的な分類。それぞれ応用できる領域がある。各言語の特徴(調べただけ)
Java: クラスベースのオブジェクト指向(オブジェクト:データとコードの複合体)の汎用プログラミング言語。C言語に似ている。Webアプリケーションで使用されている最も人気のあるプログラミング言語の一つ。
C: 汎用プログラミング言語。動作環境の制約が厳しい。C++、Javaなどの派生源。システム系、アプリケーション系で使われる。
Javascript: プロトタイプベースのオブジェクト指向スクリプト言語。Webサイト、Wenアプリのデザインなどに利用される。多くのWebブラウザで使われる。
注*Javaとは異なる言語。Ruby: 日本人のまつもとゆきひろさんが開発したオブジェクト指向スクリプト言語。Perlに続く言語、Pythonが競合言語。Webアプリケーション、ホームページ作成などで使用される。わかりやすいコード、日本人の開発なので日本語の情報が入手しやすい。
PHP: プログラミング言語と処理系としての特徴を持つ。言語としてはC、Javaに近い。サーバーサイドで動的なWebページ作成ができる。アプリでも使えるが、Webサイトに多く使われる。
HTML: Webページを作るためのマークアップ言語。WebページのほとんどがHTMLで作られている。
Python: コードがシンプルで学習しやすい汎用。ライブラリが豊富で様々な領域への応用が容易(他人が作ったプログラムの塊を利用できる)、対応している動作環境(ハード、OS)が豊富。人工知能・機械学習などで利用される。
どんな言語を学ぶか
世の中の需要
- アプリ系:Ruby、Java
- web系:JavaScript、PHP
- 人工知能系:Pythonが主流か?
シンプルで習熟が容易
-スクリプト言語: ソースコートをそのまま実行できるため結果をすぐ視覚でき学習が容易。ex)Python、JavaScript、Ruby、PHP-コンパイラ言語: 実行するためにソースコードをコンパイルする必要がある。ex)C、Java
応用が効く
・ Python→ ライブラリ(ある目的のために機能をまとめたパッケージのこと)が豊富で応用に幅が効く。ex)アプリ、人工知能、統計・データ分析、IoT開発
注*複数の関数をまとめたもの→モジュール
モジュールをまとめたもの→パッケージ
パッケージをまとめたもの→ライブラリ
ライブラリ=何かができる大量のプログラムの集合体。・ JavaScript→ Web系フロントエンジニア必修。ブラウザ上でユーザーの動作に関わる部分に使われる。
・ Ruby→ アプリケーションの開発に使われる。ライブラリRuby on Railsがよく使われている。日本人が開発したのでオブジェクト指向と呼ばれるプログラミング言語のコンセプトを日本語でしっかりと学ぶことができる。
3.これから
学習の目的
1.色々な言語に触れ、どんなことが実現できるのかを知る。
(どんな領域のエンジニアになるかを決めるため)
×目的ありきの職業選択 ○スキルありきの職業選択2.研究活動への応用
人工知能技術の物理学への応用エンジニアの種類と必須言語(メモ書き程度に)
- AI(人工知能)エンジニア:Python
- アプリケーションエンジニア(業務系):Java、C
- アプリケーションエンジニア(webアプリ系):Java、C、Ruby、PHP
- アプリケーションエンジニア(スマホ系):Swift(iPhone)、Java(Android)
- フロントエンドエンジニア:JavaScript、HTML
- サーバーサイドエンジニア:Ruby、PHP、Python、Java学習する予定の言語
- Python
- Ruby
- JavaScript
- Javaしばらくは研究のためのPythonの学習と機械学習の実行。
その後独学でRuby、Javaを勉強し、開発経験を積みたい、、、。
- 投稿日:2020-06-03T16:45:20+09:00
理論物理学生の0から始める機械学習
目次
- 1.現状
- 2.プログラミング言語について
- 3.これから1.現状
このQiitaは将来ITエンジニアを目指す理系学生が
・ 0から始めても理解できること
・ 自分の勉強のアウトプットの見える化
のために始めた備忘録です。
(大した知識もないひよっこです。訂正や助言をいただけると嬉しい、、、お手柔らかに。)バックグラウンド
機械工学系→理論物理系→ITエンジニア(将来)
という曲がった経歴を持つ理系学生プログラミング習熟度(2020/6時点)
C言語→基本の情報処理ができる、開発経験はない
python→基本の情報処理ができる、開発経験はない
(大したことないです)開発環境
MacOS -10.13.6
python -2.7.6(Mac初期装備)
python -3.8.02.プログラミング言語について
代表的なプログラミング言語
システム・アプリケーション系:Java、C、Ruby、PHP
Webデザイン系:JavaScript、PHP、HTML
人工知能:Python
注*あくまで簡易的な分類。それぞれ応用できる領域がある。各言語の特徴(調べただけ)
Java: クラスベースのオブジェクト指向(オブジェクト:データとコードの複合体)の汎用プログラミング言語。C言語に似ている。Webアプリケーションで使用されている最も人気のあるプログラミング言語の一つ。
C: 汎用プログラミング言語。動作環境の制約が厳しい。C++、Javaなどの派生源。システム系、アプリケーション系で使われる。
Javascript: プロトタイプベースのオブジェクト指向スクリプト言語。Webサイト、Wenアプリのデザインなどに利用される。多くのWebブラウザで使われる。
注*Javaとは異なる言語。Ruby: 日本人のまつもとゆきひろさんが開発したオブジェクト指向スクリプト言語。Perlに続く言語、Pythonが競合言語。Webアプリケーション、ホームページ作成などで使用される。わかりやすいコード、日本人の開発なので日本語の情報が入手しやすい。
PHP: プログラミング言語と処理系としての特徴を持つ。言語としてはC、Javaに近い。サーバーサイドで動的なWebページ作成ができる。アプリでも使えるが、Webサイトに多く使われる。
HTML: Webページを作るためのマークアップ言語。WebページのほとんどがHTMLで作られている。
Python: コードがシンプルで学習しやすい汎用。ライブラリが豊富で様々な領域への応用が容易(他人が作ったプログラムの塊を利用できる)、対応している動作環境(ハード、OS)が豊富。人工知能・機械学習などで利用される。
どんな言語を学ぶか
世の中の需要
- アプリ系:Ruby、Java
- web系:JavaScript、PHP
- 人工知能系:Pythonが主流か?
シンプルで習熟が容易
-スクリプト言語: ソースコートをそのまま実行できるため結果をすぐ視覚でき学習が容易。ex)Python、JavaScript、Ruby、PHP-コンパイラ言語: 実行するためにソースコードをコンパイルする必要がある。ex)C、Java
応用が効く
・ Python→ ライブラリ(ある目的のために機能をまとめたパッケージのこと)が豊富で応用に幅が効く。ex)アプリ、人工知能、統計・データ分析、IoT開発
注*複数の関数をまとめたもの→モジュール
モジュールをまとめたもの→パッケージ
パッケージをまとめたもの→ライブラリ
ライブラリ=何かができる大量のプログラムの集合体。・ JavaScript→ Web系フロントエンジニア必修。ブラウザ上でユーザーの動作に関わる部分に使われる。
・ Ruby→ アプリケーションの開発に使われる。ライブラリRuby on Railsがよく使われている。日本人が開発したのでオブジェクト指向と呼ばれるプログラミング言語のコンセプトを日本語でしっかりと学ぶことができる。
3.これから
学習の目的
1.色々な言語に触れ、どんなことが実現できるのかを知る。
(どんな領域のエンジニアになるかを決めるため)
×目的ありきの職業選択 ○スキルありきの職業選択2.研究活動への応用
人工知能技術の物理学への応用エンジニアの種類と必須言語(メモ書き程度に)
- AI(人工知能)エンジニア:Python
- アプリケーションエンジニア(業務系):Java、C
- アプリケーションエンジニア(webアプリ系):Java、C、Ruby、PHP
- アプリケーションエンジニア(スマホ系):Swift(iPhone)、Java(Android)
- フロントエンドエンジニア:JavaScript、HTML
- サーバーサイドエンジニア:Ruby、PHP、Python、Java学習する予定の言語
- Python
- Ruby
- JavaScript
- Javaしばらくは研究のためのPythonの学習と機械学習の実行。
その後独学でRuby、Javaを勉強し、開発経験を積みたい、、、。
- 投稿日:2020-06-03T16:09:39+09:00
matplotlibを使ってみた
仕事でmatplotlibを使う機会があったので、学習した使い方をまとめておきます。
環境
- windows10
- python 3.7.4
- matplotlib 3.2.1
基本的な使い方
モジュールのimport
import matplotlib.pyplot as pltグラフの表示
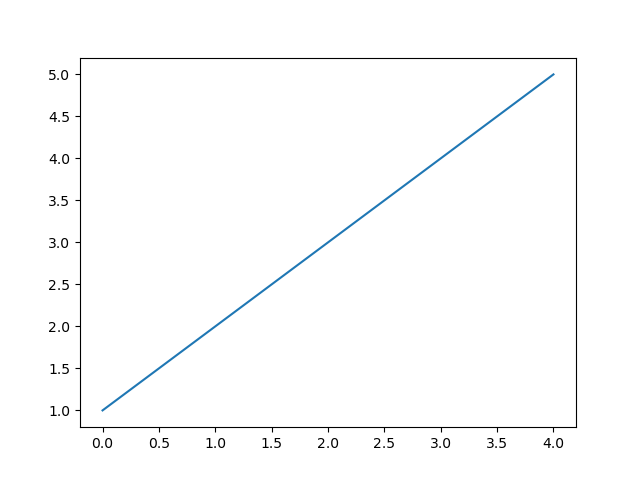
plt.plot([1, 2, 3, 4, 5]) plt.show()以下のようなグラフが表示される。
引数に渡す情報が1つだけの場合はy軸に引数の座標が来るらしい。
複数の線を描画する場合
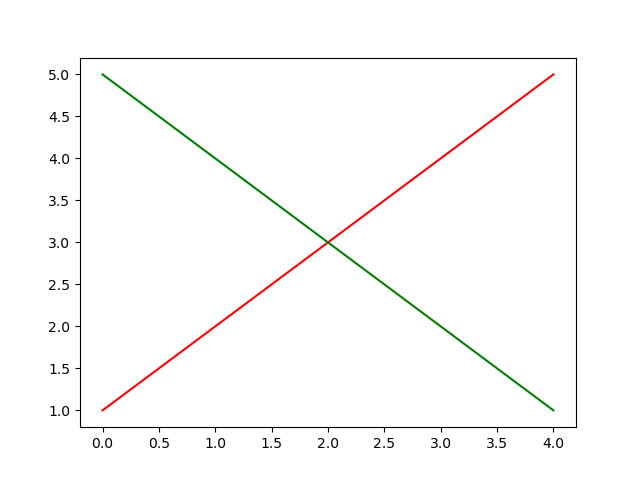
line1 = [1, 2, 3, 4, 5] line2 = [5, 4, 3, 2, 1] plt.plot(line1, color='red') plt.plot(line2, color='green') plt.show()
plt.plot()で1つの線が描ける。
線の色を変更するにはcolorを指定する
アニメーション
線を描画するのにアニメーションをつけることもできる。
アニメーションに必要なモジュールのimport
from matplotlib.animation import ArtistAnimation # または、 from matplotlib.animation import FuncAnimationアニメーションの実装には2つのクラスが用意されている。
- ArtistAnimation
- 描画するデータを表示前に計算して順次アニメーションする方式
- FuncAnimation
- 描画するタイミングで計算した値を表示する方式
ArtistAnimation
値が1ずつ右肩上がりになっていくグラフのアニメーション
fig = plt.figure() artist = [] line = [] for value in range(1, 10): line.append(value) im = plt.plot(line, color='red', marker='o') artist.append(im) anim = ArtistAnimation(fig, artist, interval=300) plt.show()FuncAnimation
実装の内容はArtistAnimationと同じ
FuncAnimationはオブジェクト生成時にrepeatがデフォルトでTrueになっており、初期化用の関数が実装されていないと2週目以降に意図しないアニメーションになるので注意fig = plt.figure() line = [] def init(): global line print("初期化処理を実装する") plt.gca().cla() line = [] def draw(i): line.append(i) im = plt.plot(line, color='red', marker='o') anim = FuncAnimation(fig, func=draw, frames=10, init_func=init, interval=100) plt.show()
- 投稿日:2020-06-03T15:11:19+09:00
Qiitaでコーディング初年次教育してみた,- 定期試験は上ヶ原で実施です!!!
目的
qiitaは「プログラミング」に役に立つ記事を集めることを目的にしています.
でも,起業の原点にある「プログラミングをできる人」を育てることも目標にして欲しいですね.
ここではnet講義だけが許される2020年度入学学生にコンピュータ演習を教えるときにqiitaを活用した実践を報告します.
講義の概要1
python
テキストには
「いちばんやさしいPython入門教室」大澤文孝著,(ソーテック社出版, 2017).修正をメインで使用.でも,使っている環境がidleなんで少し古い感じ.
そこで,
「12歳からはじめる ゼロからの Pythonゲームプログラミング教室」, 大槻有一郎 (著), リブロワークスPython部 (著), 雪印 (イラスト), ラトルズ(2017/5/11).補足
をサブテキストとして使用.これはぱっと見「色物」でやばそうですが,中身は出色です.
vscode
idleからvscodeに移行させました.でも,教える方がwindowsの初心者なんでちょっと苦労しています.
- vscodeでpythonが認識されない
- vscodeの説明の補足
- vscodeの設定・ショートカットで悩んだ話
qiita
第3回目あたりからqiitaのアカウントを作ってそこで課題の途中経過を記すように指導.
- 最終プログラムを写すだけではダメ
- 1行ずつ確認
- 途中のメモが大事
なんかを強制していますが,なかなかダメですね.どこで全部写してから実行することを覚えるんだろう.
word, excel, パワポ
情報リテラシーってこれがいまだに基本です.
でも,リッチすぎて学生は迷っています.
昔僕らがWordStarからMacWriteに移った時の,
wysiwygの感動なんて,なんのこっちゃです.
彼らにはplatexと難しさとおんなじかも.
それを救ってくれるのがmarkup言語です.
文書の構成要素を見る目を先に作れば,WordもPagesも同じです.PowerPointもqiitaのslide機能で十分なんです.
最終成果物の人気投票
最終の制作物の相互評価にLGTM使いました.ちょっとルール違反かも.
発表はslide, パワポ, 生のどれでもいいのですが,
qiitaに最終レポートをあげることを強制しました.
そうでないとLGTMがつけられないから.
一人があげられるLGTMは3個までと制限しますが,さてどこまで守ってくれルカ.
qiitaの利用
memo : 作業記録
report作成 : 体裁, markdown2
slide : 中身のbrush up
LGTM : 人気投票
限定投稿 : 自分と先生だけだと気が楽3,
個人情報,security, 引用とかを後で教えられる
qiitaの意義
md, capture : すぐにfeed back(ゾーンに)
SQ3R : 書けば読めるようになる
知識の定着 : 書けば読み直す
雛形の提供 : 良い文書の第一歩
良い例の参照 : 自分で推敲すると,他人様のを読めるようになる
慣れた環境での作業 : 採点する方も慣れているので,何度もコメントで修正要求
実践結果
えっとできればクラス全員の最終レポートを載せたいのですが...
まだわかりません.
no id title 27079001 daddygongon bouncing balls(跳ねるたまたま)を増殖(たまたま^8)させてみた 27020698 xxxgbrdrgn 27020699 NApengin 27020701 kazuki0205 27020703 Nanasan 27020704 tonkoturamen 27020705 akagiiii 27020706 mmoo 27020707 winter 27020708 hiiiii08 27020709 tandai 27020710 TNakayama1231 27020711 5-D 27020712 1819 27020714 saatox 27020715 Narupen 27020716 VanDijk 27020717 baibi-nosu 27020718 FKazuki 27020719 Mimura1015 27020721 sunboy 27020722 Luck090308 27020724 jedi 27020725 mate 27020727 ren1744 27020728 Bokkun321 27020729 monsterhunterworldib tkinterでBMIを測定してみた 27020730 JiWoo 27020731 saliva1375 27020732 ricky00408 27020733 PomPomPudding
受講生のqiitaへの公開記事
参照文献
https://qiita.com/daddygongon/private/c0b34f8c6ad82a2443bd ↩
すぐにqiitaのほんちゃんに出した子もいます.稚拙ですが,あまり叩かないでやってください.昔の掲示板みたいに心を折られるのを見たくないので. ↩
- 投稿日:2020-06-03T14:27:09+09:00
開発チームの生産性・健全性を客観的に知るためにリポジトリ履歴から機械的に可視化するツールを作った
はじめに
ソフトウェア開発のチームの生産性や健全性というものは、内部の体感的として理解できるものの、外部の人間からは見えにくいものです。こういった情報の非対称性は開発チーム外の人々との関係の中での問題の原因になってきました。
また、複数の開発チームやプロダクトを束ねるEM、CTOや、管理職にとってそれぞれの状況を客観的な数字やグラフで可視化することは、全体的な戦略を考える上でも重要な参考情報になります。ですが、アンケートやプロジェクト管理を増やすほど、どんどんと開発メンバーに負担をかけてしまうことになり、計測のし過ぎによる疲れなども誘発してしまいます。
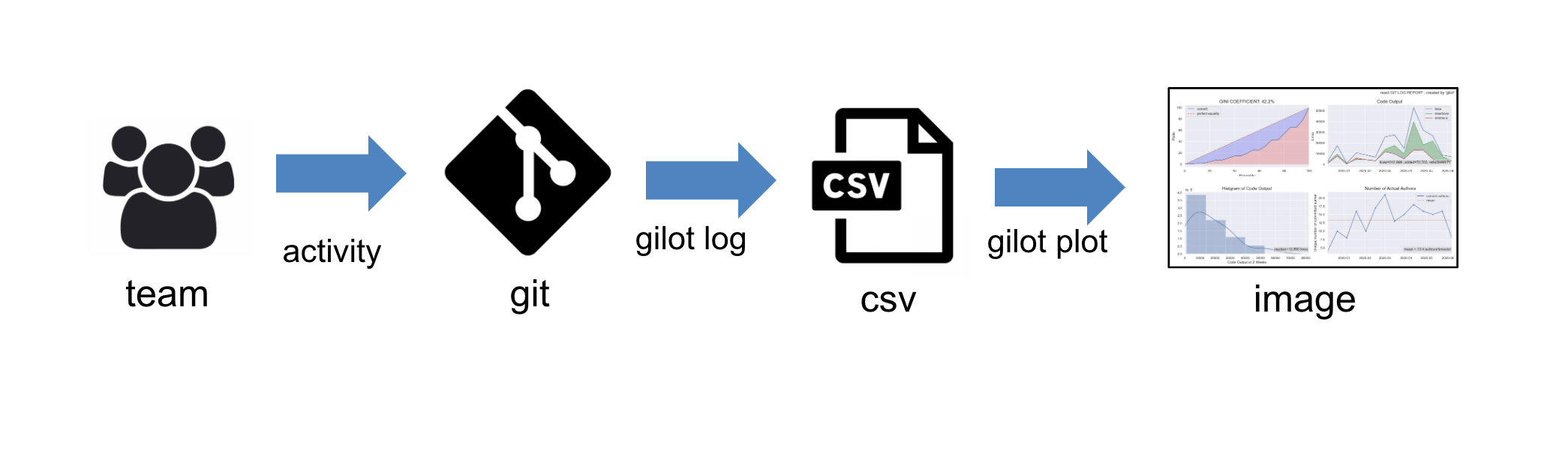
本稿では、gitリポジトリのログ情報から、いくつかのグラフを生成し、チームの状況を可視化するためのツール
gilotを作成したので、その目的と意図、そして使い方、注意点を解説します。アプローチ方法
gilotのアプローチは、git logのデータを解析して、開発チームのアウトプットがどれだけ安定しているか、どれだけの出力があるのか、何人が実質的にコミットしているのかなどを分析して、可視化します。生産性や健全性そのものが直ちに判断できるわけではありませんが、ひとつの強力なエビデンスになることを期待しています。
バージョン管理システムのログを使う:
これまでも生産性や健全性の可視化という観点では、プロジェクト管理ツールや、アンケート調査などを通じてそれらを可視化する試みは多数あります。これらも重要な可視化のための情報ですが、もう一つの情報源としてバージョン管理システムの情報をソフトウェアプロジェクトに活かしていくという試みが近年では増えてきました。
バージョン管理システムのログは
- 実際の開発者が意識せずとも自然な活動情報が記録されている。
- プログラム言語の種別や環境によらず統一的に分析できる
などのメリットがあるため、実証的なソフトウェア・エンジニアリングの世界では注目されています。
これらの他にも、私自身がかつて自社のプロジェクトの技術的負債の可視化のために、「多くの人」が「多くの修正をしている」箇所を特定し、その技術的負債の重み付けをするという手法と実装し、マネジメントの改善に用いたことがありました。
Perl Hackers Hub 第8回 Perlによる大規模システム開発・設計のツボ(3) -技術的負債の可視化
当時はsvnとgitの2つを用いていましたが、それらのblameの結果から
SRP=R+U+((L/100)-5) R:修正リビジョンのユニーク数 U:修正ユーザのユニーク数 L:モジュールのライン数などから、単一責務原則に違反したモジュールを探索するということを行いました。
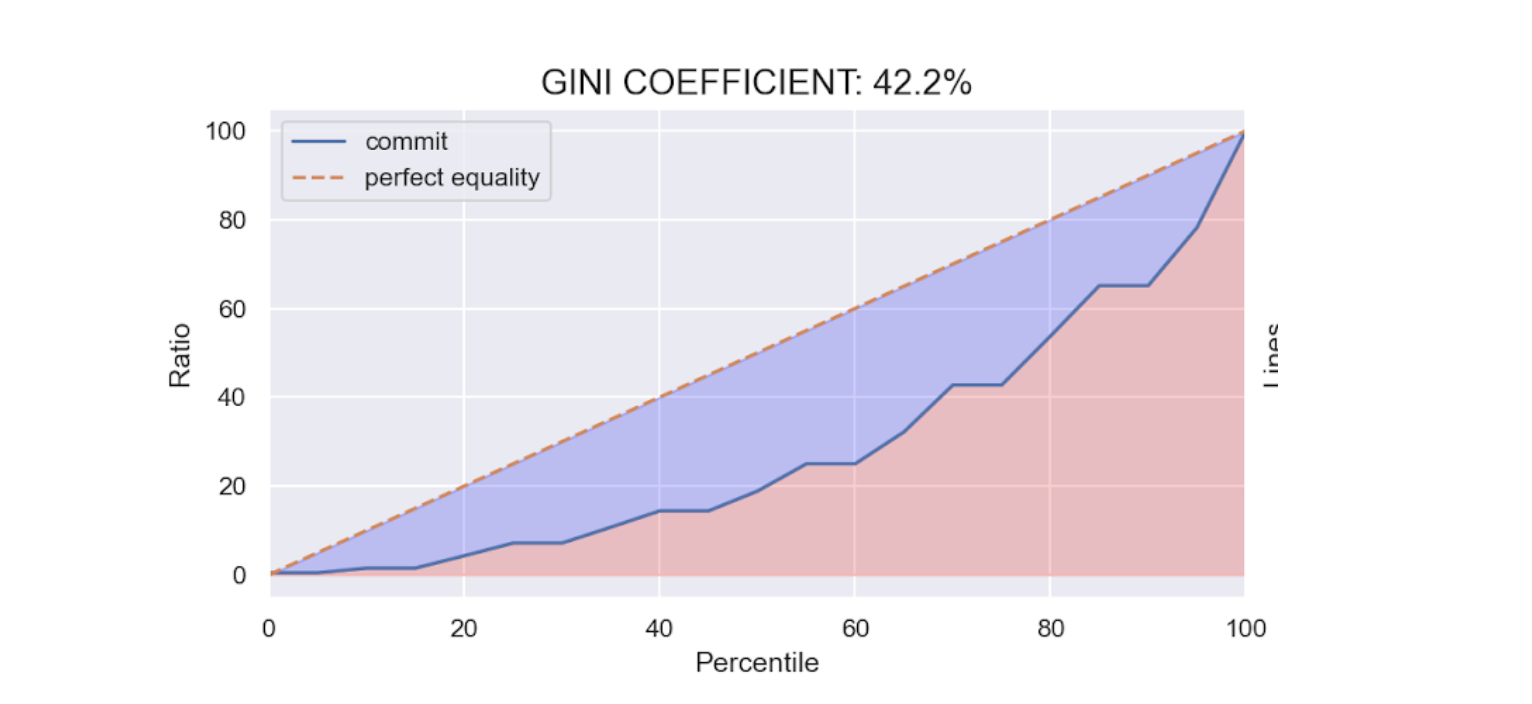
ジニ係数を用いて安定度をする
gilotでは、「チームのコミット量がどれだけ安定しているか」をジニ係数を用いて、可視化します。
ジニ係数は、不平等性をあらわす経済学の指標です。所得格差などが大きくなると1に近づき、小さくなると0に近づきます。
ジニ係数がとる値の範囲は 0 から 1 で、係数の値が大きいほどその集団における格差が大きい状態であるという評価になる。特にジニ係数が 0 である状態は、ローレンツ曲線が均等分配線に一致するような状態であり、各人の所得が均一で、格差が全くない状態を表す。逆にジニ係数が 1 である状態は、ローレンツ曲線が横軸に一致するような状態であり、たった1人が集団の全ての所得を独占している状態を表す。社会騒乱多発の警戒ラインは、0.4である。
wikipedia : ジニ係数ここでジニ係数をもう少しイメージするために、ちょっと懐かしい「世界がもし100人の村だったら」の寓話を用いて、ジニ係数を計算してみましょう。
すべての富のうち
6人が59%をもっていて
みんなアメリカ合衆国の人です
74人が39%を
20人が、たったの2%を分けあっています
「世界がもし100人の村だったら」より引用このストーリーから分かる通り、世界は不平等で一部の人に富が偏っているように思えます。この偏り度合いを数値化するにはどうしたら良いのでしょうか。その1つの方法としてジニ係数は用いられます。
カテゴリごとに下から並べて、富の累積比率と人口の累積比をプロットしていきます。この点を結んだ曲線をローレンツ曲線といいます。それに対して、すべての人が同じ富をもっていることを想定した場合の直線を均等分布線といいます。
ジニ係数は、ローレンツ曲線と均等分布線の差の積分を撮ったBの部分と、均等分布線を積分したAの部分の比率で表されます。不平等なほど格差が増えていくわけです。この村の例だと、0.59になります。
ジニ係数を用いたソーシャルゲームの健全状況の予測
このようなジニ係数は、ソーシャルゲームの健全さを測るためにも用いられてきました。一部のコアユーザのみが重課金をしていて、ライトユーザーの割合が少ないという状況が続き、格差が広がってくるとゲームは面白くなくなっていきます。健全なコミュニティでは、強いユーザーに勝ったり逆転できるかもという期待があるものです。あまりに差が付きすぎてしまうと、面白くなくなってしまいます。
コミット量の単位時間ごとの格差が大きいチームと小さいチーム
gilotで注目するのは、経済格差ではありません。また、個々人のコミット量の格差でもありません。注目するのは、「あるタイムスロットごと」の「コミット量全体」がどのようにばらついているかです。
たとえば、この1年間のうち、ある2週間には10万行位以上書き換えられたのに、その他の2週間はほとんどソースコードに触れることはなかったというケースを考えてみましょう。このような状況は、開発サイクルが重く、健全さにかけるリリースプロセスや自動テストが充実していないことによる手動テストの手間などの影が見え隠れします。
あるいは、企画フェーズと開発フェーズが極端に分かれていたり、年末・年度末に向けての開発といったロードマップ志向の開発プロセスを行うためにその時期に向けて大量の変化起こるといった場合にもジニ係数は大きく、格差が拡大していきます。
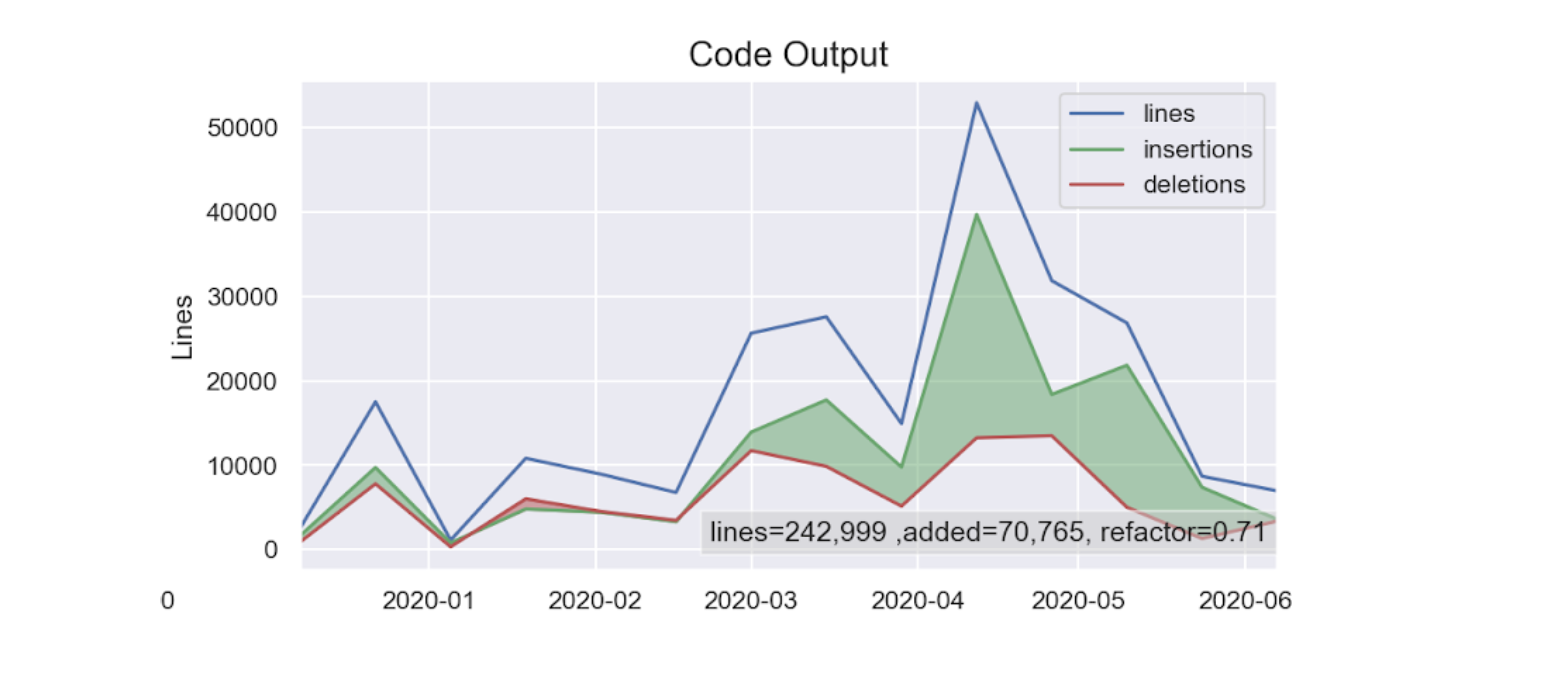
一方、継続的改善を繰り返す安定したチームは、masterなどの「本番」「リリース」ブランチへのマージが早く、ブランチの生存期間が短い傾向があります。継続的インテグレーションやデプロイメントが充実しているほど、安定してソースコードを改善していくことができます。
このように安定したアウトプットができる状態はチームが一定健全に回っていることの1つのエビデンスになりえます。開発者の生産性について、ソースコードの量自体は、なんら直接的なファクトにはなりませんが、全体に対する割合や修正の度合い、ある期間ごとのでの変化などは見る価値のある統計指標になると考えます。
gilot (ジロー)の使い方
今回開発したツールの使い方を紹介します。
GitHubはこちらです:https://github.com/hirokidaichi/gilotインストール
pip install git+https://github.com/hirokidaichi/gilot簡単な使い方
gilotは、3つのサブコマンド持っています。それをパイプで組み合わせて使います。
あるリポジトリから、グラフを作成するには単純に以下のように行います。gilot log REPO_DIR | gilot plot
gilot logは対象リポジトリからcsvを生成します。gilot plotはそのCSVからグラフを生成します。
gilot logは時間がある程度かかりますので、一度CSVをファイル出力して保存し、その上でgilot plotを行うことをおすすめします。gilot log REPO_DIR > repo.csv gilot plot -i repo.csv -o graph.png画像ではなく単に、統計情報が欲しい場合は
gilot log REPO_DIR | gilot info > stats.jsonのように、
infoサブコマンドが使えます。出力はjson形式です。gilot log REPO_DIR | gilot info | jq .ginijqコマンドと組み合わせれば、ジニ係数のみ表示するなど必要な統計情報のみを取得することもできます。
期間の指定、ブランチの指定
git logの情報取得にあたって期間を指定することができます。
2つの指定方法があり、何ヶ月間のデータを取得するかの--monthといつからのデータを取得するのかを指定できる--sinceの2つのオプションがあります。デフォルトは6ヶ月間です。gilot log REPO --since 2020-01-20 -o REPO.csv gilot log REPO --month 18 -o REPO.csvまた、ログを取得するブランチも指定することができます。デフォルトでは
origin/HEADを参照してmasterに相当するものを指定するようにしていますが、開発チームのブランチ運用の方法に応じて指定をしてください。できるかぎり多くの人が触れる可能性があり、リリースされていたり、運用されているシステムと同じコードベースのbranchがツールの特性上は望ましいです。gilot log REPO --branch develop -o REPO.csv複数のリポジトリにまたがって、チーム運営している場合
現代的なチームでは、1つのシステムを提供するのに複数のリポジトリを1つのチームが管理していることが度々あるかと思います。
モノレポ構成になっていないようなマイクロサービスアーキテクチャではなおさら、多くのリポジトリに1つのチームが手を加えることがあるでしょう。このような場合にもそれぞれのリポジトリの結果を結合して評価することができます。単純には以下のような方法です。
gilot log repo-a > repo-a.csv gilot log repo-b > repo-b.csv gilot plot -i repo*.csvPythonのライブラリとして用いてnotebookで使う
https://github.com/hirokidaichi/gilot/blob/master/sample/sample.ipynb4つのグラフとその見方
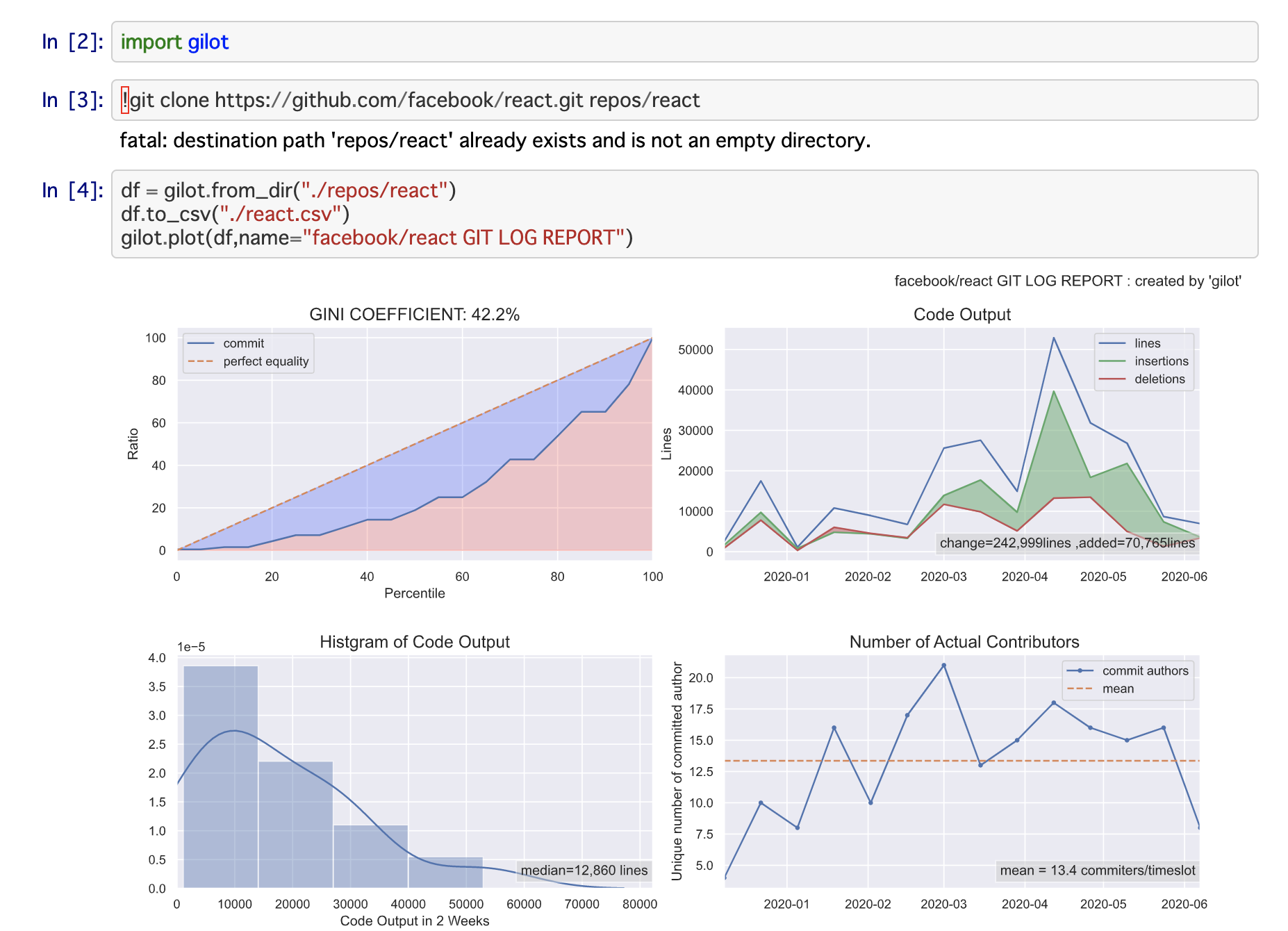
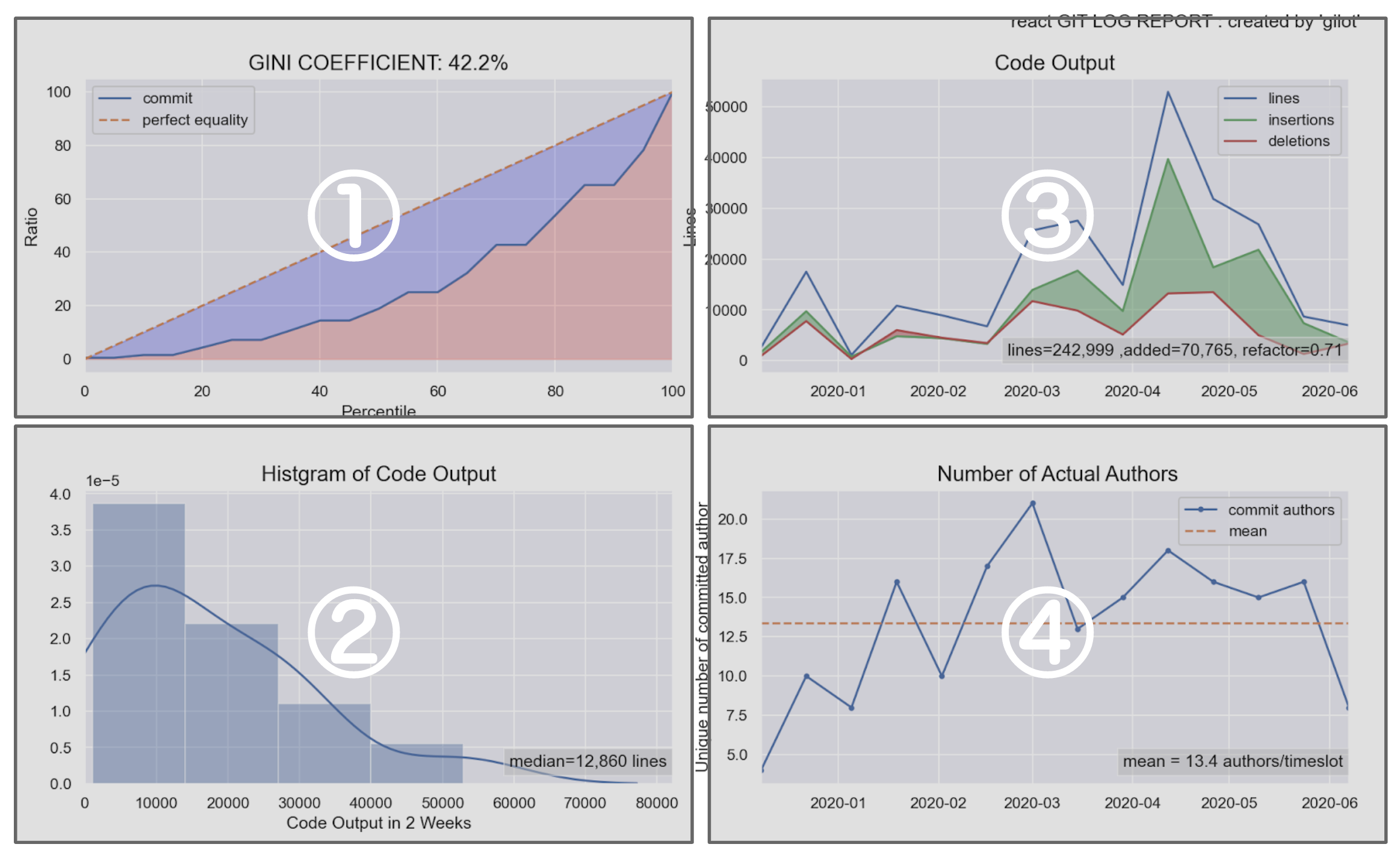
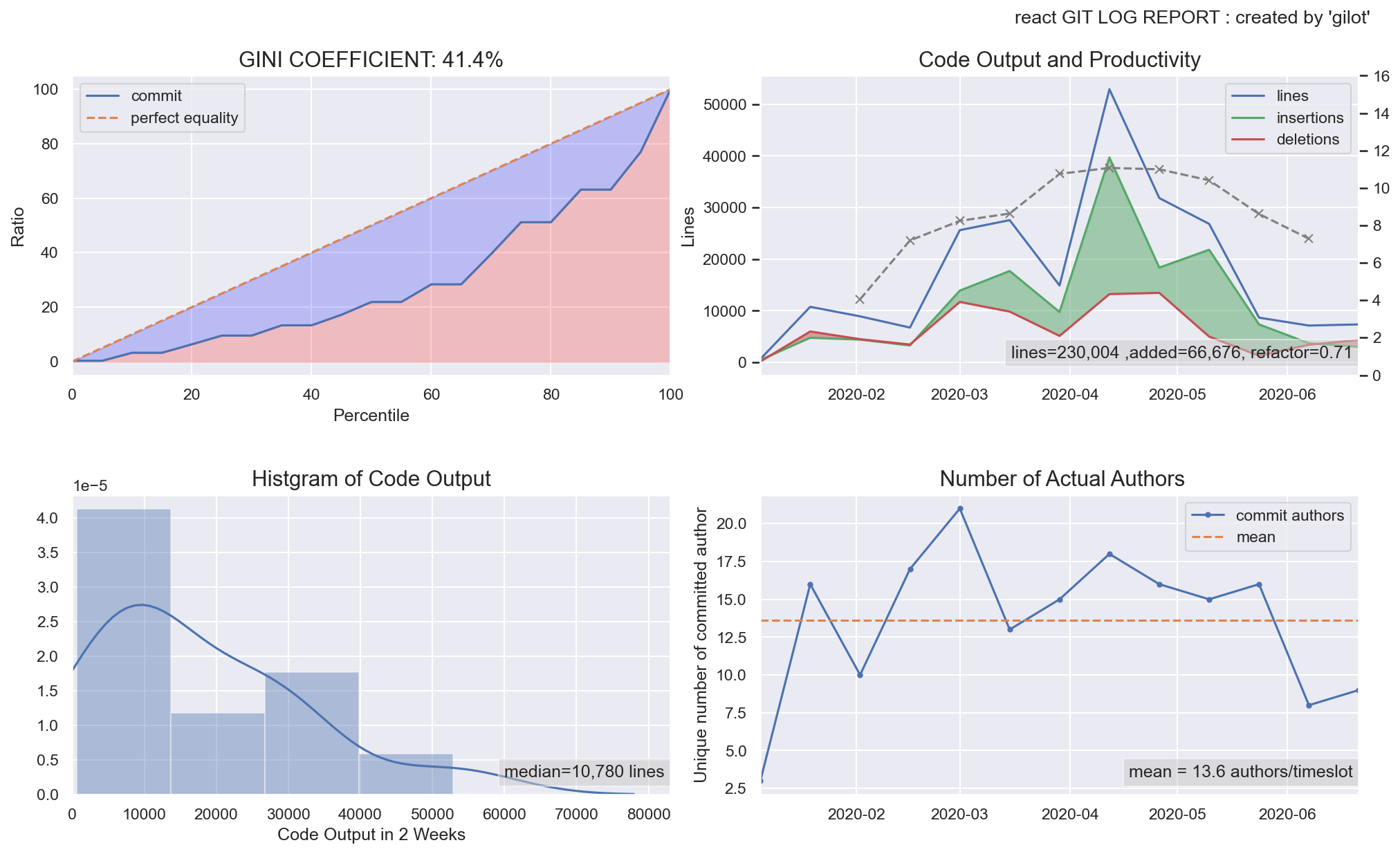
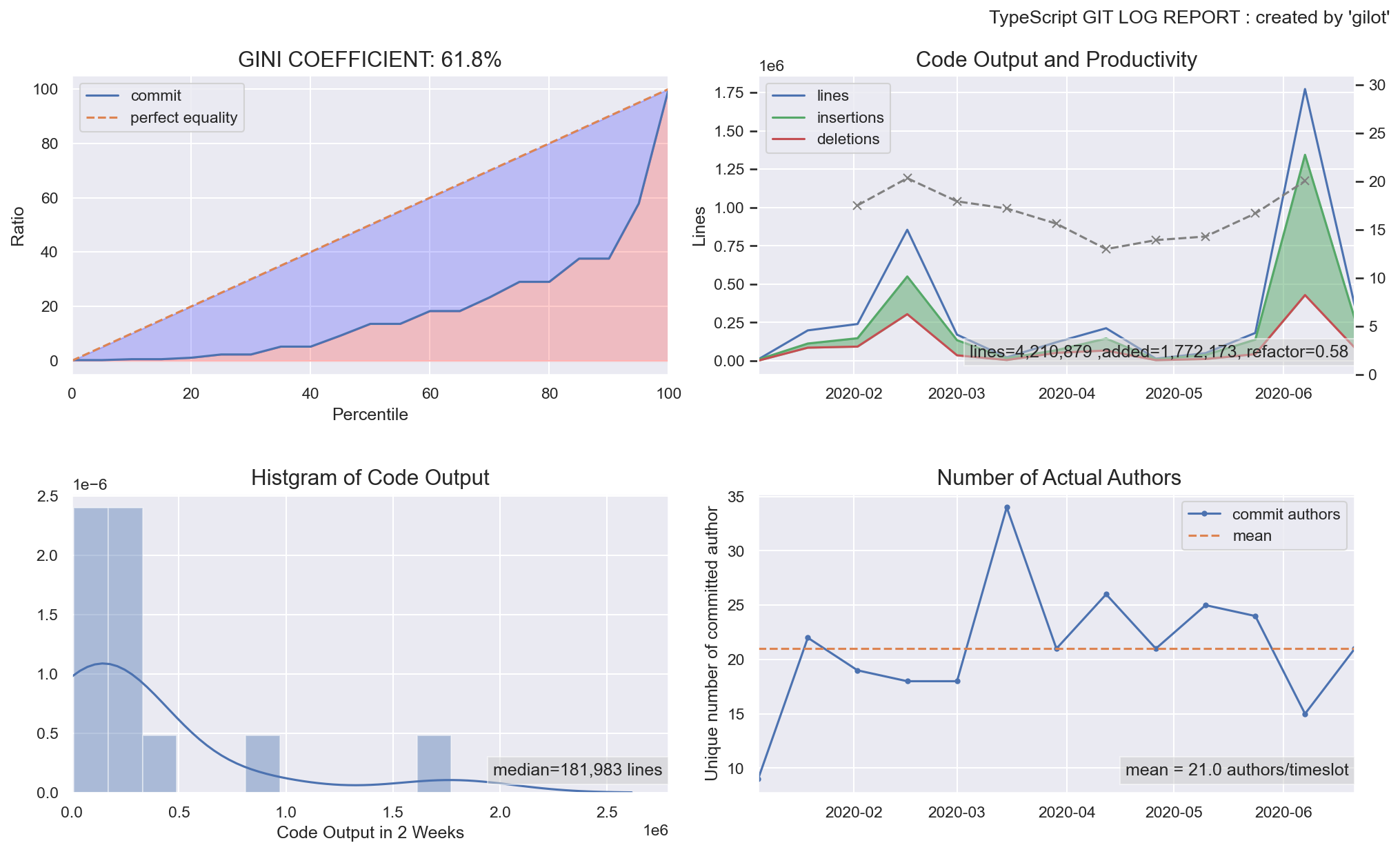
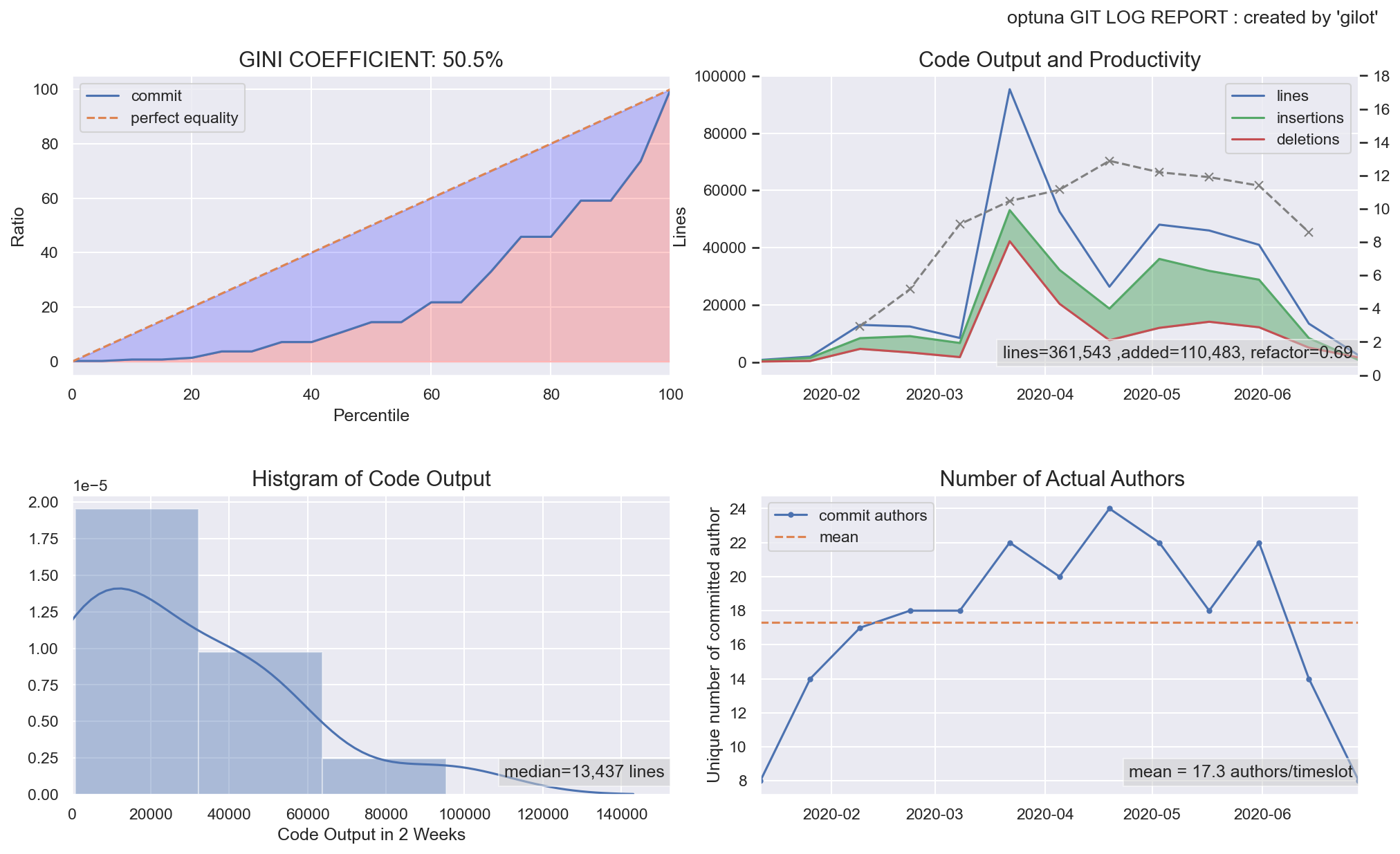
fig.1:ジニ係数とローレンツ曲線のグラフ
タイムスロットごとのコミット行数量のローレンツ曲線とジニ係数を表示しています。ジニ係数がどの値以下であれば、安全かそうでないかという統一的指標はありません。個人的な観察としては、0.5以下であれば安定したチームのアウトプットがあり、大きければ何らかのファクターが安定したコード出力を妨げているのではないかというのが所感です。
この値は、絶対値に注目するよりも、複数の事業システムがある場合に比較してみるのがよいかもしれない。いわゆるレガシーと呼ばれるものと、最近作ってチームで開発しているものには、大きな差がでてくることがあります。
fig.2:タイムスロット(2週間)あたりのコミット量の分布
あるタイムスロットのコード出力量のヒストグラム。ピークのなだらかな山なりになると、チームの活動の安定がよりわかりやすい。外れ値がいくつもある場合、大きな機能改修・リファクタリング・棚卸しなどの削除等の影響の可能性もあります。
fig.3:タイムスロット(2週間)あたりの実際の追加・削除行数とその差
タイムスロットごとの削除行数・追加行数・総変更行数の推移。緑のエリアが多いほど、機能追加がされており、赤いエリアがリファクタリングや棚卸しなどが行われている可能性を示しています。
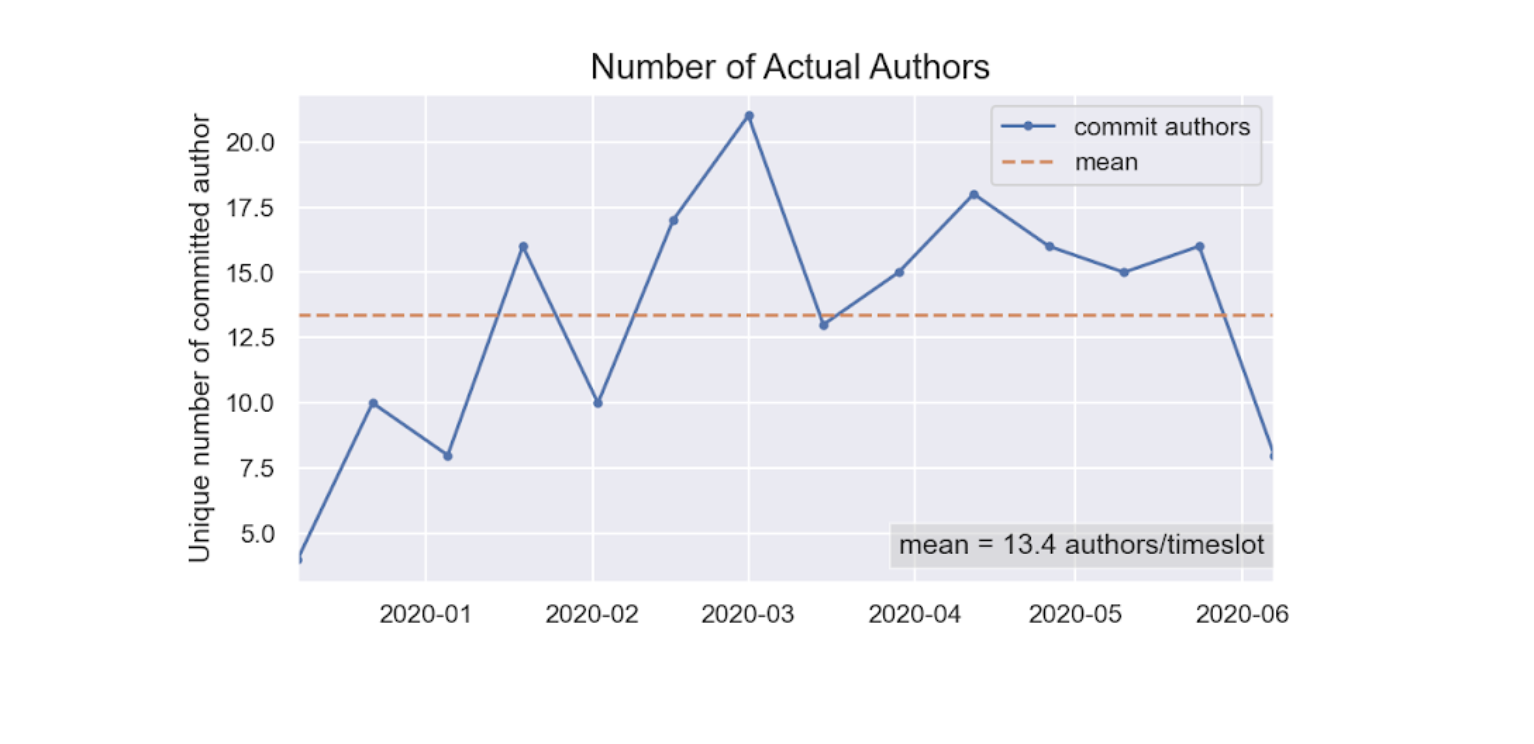
総変更行数における削除行数の割合をリファクタ指数として表示しています。とはいえ、単なる割合なのでリファクタリングとは限らないため注意が必要です。fig.4:タイムスロット(2週間)あたりのコミットした開発者の人数
大規模な組織での開発が進むほど、一体何人くらいが実際にはソフトウェアの開発にたずさわっているのかわかりにくくなります。
それらの実態を可視化するため、ある二週間にコミットしたひとの平均値と推移を表示している。兼務などで一部の人数しか関われていない場合なども含めて、おおよそ定常的にリポジトリに手を入れている人間(ボットも含んでしまうが。。)の数がわかる。より詳細な情報が取得したい場合には、次のようにinfoコマンドを用いてデータを取得することができる。
gilot info -i.csv | jq .authors { "mean": 13.357142857142858, "std": 4.70036238958302, "min": 4, "25%": 10, "50%": 15, "75%": 16, "max": 21 }標準偏差が大きくなったり、maxとmeanの差が激しくなる場合も不健全な状態を暗喩している可能性があります。
注意点と実態把握のための手段
gilotの出力は、あくまでリポジトリに対するアクティビティの統計データでしかありません。チームやシステムの実態を、健康診断的にあるいは、毎朝の検温と同じレベルに手軽に観察・アセスメントするためのものです。これを持って病気であるとか、不健全であるとするためのツールではありません。
より詳しい実態についての評価や比較を行いたい場合は、日本CTO協会で公表しているDX Criteriaの調査項目を利用するのがよいでしょう。こちらは、システムと企業全体の人間ドックにあたります。
ビジネスインテリジェンスのためのデータ活用が叫ばれていますが、今後エンジニアリングインテリジェンス(ソフトウェア開発のデータ分析と見える化)も重要になってきています。そのための1ツールとしてご利用ください。
活用への期待
このツールは何しろ手軽にリポジトリの状態を可視化します。情報の中にほとんど機微な情報が含まれないため、外部に公開しても問題はないのではないでしょうか。むしろ、現在我々はこんなかんじでシステム開発をしているよということがわかるようにリアルタイムで採用ページに乗ってくれたりすると、ああ、こんなかんじなんだーとわかって便利ですね。
サンプルケース
以下、著名なOSSプロジェクトのこの半年間のgilot結果を掲載します。
facebook/react
microsoft/TypeScript
tensorflow/tensorflow
pytorch/pytorch
optuna/optuna
あわせて読みたい




- 投稿日:2020-06-03T14:03:18+09:00
初心者のための Python 練習問題 #2 [for 文・while 文]
初心者のための Python 練習問題 #1 [基本的なデータ型・if 文] の続きです。分からない問題は、「必要な知識」に掲載しているキーワードでググるとなんならの記事が出てきます。
それではいきましょう!
目標
- 四則演算ができるようになる
- 異なるデータ型の扱いに慣れる
- if文で簡単な条件分岐ができるようになる
レベルについて
★
とてもよく使います。できるようにしましょう。★★
少し複雑な処理をするときに使います。★★★
よく勉強できていますね。Python初心者を卒業できそうです。★★★★
トリッキーですが Python ではよく使います。覚えておきましょう。★★★★★
おぉ。業務でもPython利用できそうですね!さすがです。
出題内容
Python チュートリアル
4.2 for 文
4.3 range() 関数
4.4 break 文と continue 文のループの else 節
4.5. pass 文
- for 文
- while 文
- ループを制御する方法について
問題1
(※) 以降の問題では、適宜ファイルを作成してコマンドラインから実行してください。
レベル ★
必要な知識 for文/listの要素をforを使って表示member に格納されているデータをfor文を利用して表示してください。sample.pymember = ['tanaka', 'tadokoro', 'tajima', 'tahata', 'takahashi', 'takeda']問題2
レベル ★★
必要な知識 enumrate問題1の各出力に対して '〇番目は 〇〇 さんです。' と表示してください。問題3
レベル ★
必要な知識 range1 から 100 までの数を出力してください 出力例) 1 2 3 ... 99 100問題4
レベル ★★
必要な知識 range1 から 100 までの数字を出力してください。 ただし、3の倍数の時には 'Fizz' 5 の倍数の時には 'Bazz'。 3 の倍数かつ 5 の倍数の時には 'FizzBazz' と表示してください。問題5
レベル ★★★
必要な知識 range/型変換/文字列のスライス/配列に特定の値が存在するかどうか2020 から 3000 までの数字を出力をしてください。 ただし、3がつくときには '3 !?' とびっくりしてください。// todo: kokokara
問題6
レベル ★★★
データ集計している。変なデータは取り除いて集計しよう
問題7
レベル ★
while 文を使って -30 から 300 まで表示させる
ただし3のつく数字は出力しない問題8
レベル ★★
おみくじで大吉がでるまで降り続ける
問題9
レベル ★★★
バトルHPがすくなくなったら負け
どっちがまけるか問題10
レベル ★★★★
ランダムじゃんけん
- 投稿日:2020-06-03T13:53:04+09:00
初学者がPytorchのLSTMで自動文書生成
動機
-学部3回生の夏-
3回生だからインターンとか募集してみっかあ・・・
ES「成果物は?」
僕「えっ・・・」
ES「Qiitaは?githubは?」
僕「ないです・・・」
「落選」
修士僕「卒研終わったしとにかく成果物作りたい・・・」
今回何をするか
自分が興味があり、かつ割とそれなりに知識があるものを実装したいと思います。
僕の専攻は一応自然言語処理で学部論文では深層学習で文書生成やってたんで、
Pytorchで練習がてら自動文書生成していきます。文書生成器はEmbedding層、LSTM層、線形層を重ねたものとします。
LSTMのレイヤ数など各ハイパーパラメータはコマンドラインから指定できるものを作ります。訓練に使うデータセットとかいろいろ
訓練に利用するデータセットは長岡技術科学大学自然言語処理研究室の「SNOW T15:やさしい日本語コーパス」を使わせていただきます。
長岡技術科学大学自然言語処理研究室
http://www.jnlp.org/SNOW/T155万文の日英対訳+やさしい日本語のパラレルコーパスで超絶便利です。
xlsx形式で提供されているので、あらかじめcsv形式に変換します。
また、自動文章生成ですので、やさしい日本語と英語は用いません。形態素解析
自然言語処理といえば形態素解析です。形態素解析は与えられた生の文章を形態素に分割します。
形態素解析でしばしば問題となるのが、OOV(Out Of Vocab)です。深層学習の出力次元は出力する可能性となるコーパスに大きさに依存しており、大きくなればなるほどメモリを圧迫します。
そのため、多くの人がコーパス内の低頻度語をUNK(unknown)として登録したり、それ以外にいろいろと工夫したりするんですね。ここでは、Sentencepieceを用います。
Sentencepieceは教師なし学習により、OOVなしで指定した単語数に収まるように形態素解析を行ってくれる超絶便利なツールです。
詳しい仕様なんかは引用しているURLを参照してください。
これを用いてOOVなしでデータセットを8000単語の範囲で形態素解析します。モデル定義
まあ普通のLSTMなので語ることが特にないです。
問題点などがあれば指摘してもらえると大喜びします。LSTM.pyimport torch import torch.nn as nn import torch.nn.functional as F class LSTM(nn.Module): def __init__(self, source_size, hidden_size, batch_size, embedding_size, num_layers): super(LSTM, self).__init__() self.hidden_size = hidden_size self.source_size = source_size self.batch_size = batch_size self.num_layers = num_layers self.embed_source = nn.Embedding(source_size, embedding_size, padding_idx=0) self.embed_source.weight.data.normal_(0, 1 / embedding_size**0.5) self.lstm_source = nn.LSTM(self.hidden_size, self.hidden_size, num_layers=self.num_layers, bidirectional=True, batch_first=True) self.linear = nn.Linear(self.hidden_size*2, self.source_size) def forward(self, sentence_words, hx, cx): source_k = self.embed_source(sentence_words) self.lstm_source.flatten_parameters() encoder_output, (hx, cx) = self.lstm_source(source_k, (hx, cx)) prob = F.log_softmax(self.linear(encoder_output), dim=1) _, output = torch.max(prob, dim = -1) return prob, output, (hx, cx) def init_hidden(self, bc): hx = torch.zeros(self.num_layers*2, bc, self.hidden_size) cx = torch.zeros(self.num_layers*2, bc, self.hidden_size) return hx, cx普通ですね。
訓練&ローダー
次に訓練用のコードと、データセットのローダを作ります。
ちなみにindex.modelはsentencepieceで作成した形態素解析用のモデルです。
検証はせずに訓練が終わったらいきなりテストする感じでいきます。
訓練はある日本語文を入力して、それと全く同じ文章を出力することを学習します。
テスト時には、テスト文章の最初の一単語のみを入力し、残りは貪欲法で時系列ごとに出力していきます。
多分これで自動的に文書が生成できるはず・・・train.pyimport torch import torch.nn as nn import torch.nn.functional as F from torch.autograd import Variable import argparse from loader import Dataset import torch.optim as optim import sentencepiece as spm from utils import seq_to_string, to_np, trim_seqs import matplotlib.pyplot as plt from torchviz import make_dot from model.LSTM import LSTM def make_model(source_size, hidden_size, batch_size, embedding_size=256, num_layers=1): model = LSTM(source_size, hidden_size, batch_size, embedding_size, num_layers) criterion = nn.NLLLoss(reduction="sum") model_opt = optim.Adam(model.parameters(), lr=0.0001) return model, criterion, model_opt def data_load(maxlen, source_size, batch_size): data_set = Dataset(maxlen=maxlen) data_num = len(data_set) train_ratio = int(data_num*0.8) test_ratio = int(data_num*0.2) res = int(data_num - (train_ratio + test_ratio)) train_ratio += res ratio=[train_ratio, test_ratio] train_dataset, test_dataset = torch.utils.data.random_split(data_set, ratio) dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True) test_dataloader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=True) del(train_dataset) del(data_set) return dataloader, test_dataloader def run_epoch(data_iter, model, criterion, model_opt, epoch): model, criterion = model.cuda(), criterion.cuda() model.train() total_loss = 0 for i, data in enumerate(data_iter): model_opt.zero_grad() src = data[:,:-1] trg = data[:,1:] src, trg = src.cuda(), trg.cuda() hx, cx = model.init_hidden(src.size(0)) hx, cx = hx.cuda(), cx.cuda() output_log_probs, output_seqs, _ = model(src, hx, cx) flattened_log_probs = output_log_probs.view(src.size(0) * src.size(1), -1) loss = criterion(flattened_log_probs, trg.contiguous().view(-1)) loss /= (src.size(0) * src.size(1)) loss.backward() model_opt.step() total_loss += loss if i % 50 == 1: print("Step: %d Loss: %f " % (i, loss)) mean_loss = total_loss / len(data_iter) torch.save({ 'model': model.state_dict() }, "./model_log/model.pt") dot = make_dot(output_log_probs ,params=dict(model.named_parameters())) dot.format = 'png' dot.render('image') return model, mean_loss def depict_graph(mean_losses, epochs): epoch = [i+1 for i in range(epochs)] plt.xlim(0, epochs) plt.ylim(1, mean_losses[0]) plt.plot(epoch, mean_losses) plt.title("loss") plt.xlabel("epoch") plt.ylabel("loss") plt.show() def test(model, data_loader): model.eval() all_output_seqs = [] all_target_seqs = [] with torch.no_grad(): for data in data_loader: src = Variable(data[:,:-1]) src = src.cuda() del(data) input_data = src[:,:2] hx, cx = model.init_hidden(input_data.size(0)) for i in range(18): hx, cx = hx.cuda(), cx.cuda() output_log_probs, output_seqs, hidden = model(input_data, hx, cx) hx, cx = hidden[0], hidden[1] input_data = torch.cat((input_data, output_seqs[:,-1:]), 1) all_output_seqs.extend(trim_seqs(input_data)) out_set = (all_target_seqs, all_output_seqs) return out_set if __name__ == "__main__": sp = spm.SentencePieceProcessor() sp.load("./index.model") source_size = sp.GetPieceSize() parser = argparse.ArgumentParser(description='Parse training parameters') parser.add_argument('--do_train', type=str, default='False') parser.add_argument('--batch_size', type=int, default=256) parser.add_argument('--maxlen', type=int, default=20) parser.add_argument('--epochs', type=int, default=50) parser.add_argument('--hidden_size', type=int, default=128) parser.add_argument('--embedding_size', type=int, default=128) parser.add_argument('--num_layers', type=int, default=1) args = parser.parse_args() model, criterion, model_opt = make_model(source_size, args.hidden_size, args.batch_size, args.embedding_size, args.num_layers) data_iter, test_data_iter = data_load(args.maxlen, source_size, args.batch_size) mean_losses = [] if args.do_train == "True": for epoch in range(args.epochs): print(epoch+1) model, mean_loss = run_epoch(data_iter, model, criterion, model_opt, epoch) mean_losses.append(mean_loss.item()) depict_graph(mean_losses, args.epochs) else: model.load_state_dict(torch.load("./model_log/model.pt")["model"]) out_set = test(model, data_iter) true_txt = out_set[0] out_txt = out_set[1] with open("true.txt", "w", encoding="utf-8") as f: for i in true_txt: for j in i: f.write(sp.IdToPiece(int(j))) f.write("\n") with open("out.txt", "w", encoding="utf-8") as f: for i in out_txt: for j in i: f.write(sp.IdToPiece(int(j))) f.write("\n")loader.pyimport torch import numpy as np import csv import sentencepiece as spm class Dataset(torch.utils.data.Dataset): def __init__(self, maxlen): self.sp = spm.SentencePieceProcessor() self.sp.load("./index.model") self.maxlen = maxlen with open('./data/parallel_data.csv', mode='r', newline='', encoding='utf-8') as f: csv_file = csv.reader(f) read_data = [row for row in csv_file] self.data_num = len(read_data) - 1 jp_data = [] for i in range(1, self.data_num): jp_data.append(read_data[i][1:2]) #難しい日本語文 self.en_data_idx = np.zeros((len(jp_data), maxlen+1)) for i,sentence in enumerate(jp_data): self.en_data_idx[i][0] = self.sp.PieceToId("<s>") for j,idx in enumerate(self.sp.EncodeAsIds(sentence[0])[:]): self.en_data_idx[i][j+1] = idx if j+1 == maxlen-1: #末尾なら終了記号 self.en_data_idx[i][j+1] = self.sp.PieceToId("</s>") break if j+2 <= maxlen-1: self.en_data_idx[i][j+2] = self.sp.PieceToId("</s>") if j+3 < maxlen-1: self.en_data_idx[i][j+3:] = self.sp.PieceToId("<unk>") #面倒なんでsentencepieceを学習すると発生するunkをpad代わりにしている else: self.en_data_idx[i][j+1] = self.sp.PieceToId("</s>") if j+2 < maxlen-1: self.en_data_idx[i][j+2:] = self.sp.PieceToId("<unk>") def __len__(self): return self.data_num def __getitem__(self, idx): en_data = torch.tensor(self.en_data_idx[idx-1][:], dtype=torch.long) return en_data結果
とりあえず100エポックくらい回してみる。
レイヤとかハイパーパラメータは過学習を防ぐために小さ目がいいのかわからなすぎたので、
大きすぎない程度に設定してます。これが学習時のlossです。
割と順調に下がってはいますが、途中から微妙ですね。
もうちょいハイパーパラメータもなんとかしたほうがいいかも。で、以下が実際に出力した文章の一例です。
- ▁今のところはいつも家にいたしをしれて試験に曲
- ▁私の姉はは私に満足らずよくその仕事を
- ▁お金のために寝てように偶然わせグので誕生日に警察官
( ^ω^)・・・
ダメダメですやん・・・結論とかいろいろ
まずモデルの定義がダメなのかもしれない。
Seq2seqのほうが向いているのかな?機会があれば試します。
ともあれいままでLSTMモデルの裸一貫(Embbedingあるけど)で訓練とかしたことなかったので、
なんのタスクするかとか考えるのはまあまあ楽しかったです。
修論では、基本的にTransformerなんかを使うんで今後は実装についてとか論文について紹介などもたまにしていこうかなと思ってます。
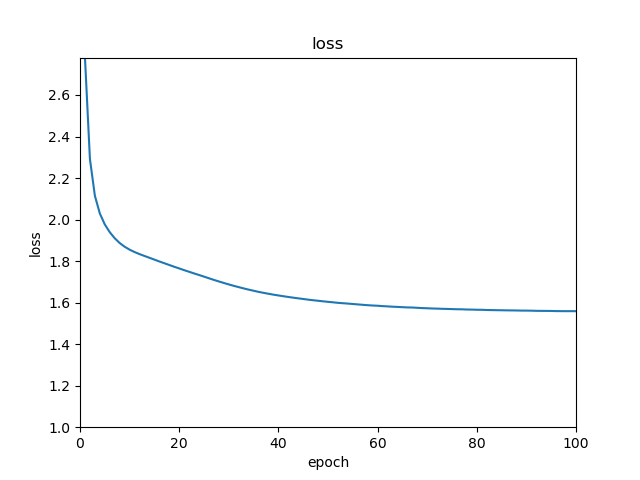
- 投稿日:2020-06-03T13:45:45+09:00
複数のplt.textで重なる文字をなんとかできる。
複数のplt.textで重なる文字をなんとかしたい。
plt.textをfor文で何個も付けていると文字同士が重なり読めなくなってしまう…
import numpy as np import matplotlib.pyplot as plt np.random.seed(0) x, y = np.random.random((2,30)) fig, ax = plt.subplots() plt.plot(x, y, 'bo') texts = [plt.text(x[i], y[i], 'Text%s' %i, ha='center', va='center') for i in range(len(x))]
そんなお困りを解決してくれる嬉しいライブラリがあったので共有します
adjustTextを入れるだけ
このライブラリはR/ggplot2のggrepel packageに影響を受けて作られたそうです。
(Rの方は知りません)
導入はpipでできます。pip install adjustText使い方も簡単で、adjustTextのadjust_textに整列したいtextsをリストにして入れるだけ
from adjustText import adjust_text fig, ax = plt.subplots() plt.plot(x, y, 'bo') texts = [plt.text(x[i], y[i], 'Text%s' %i, ha='center', va='center') for i in range(len(x))] adjust_text(texts)
どの点のアノテーションかわかりやすいようにplt.annotateのような矢印を入れることも可能。
fig, ax = plt.subplots() plt.plot(x, y, 'bo') texts = [plt.text(x[i], y[i], 'Text%s' %i, ha='center', va='center') for i in range(len(x))] adjust_text(texts, arrowprops=dict(arrowstyle='->', color='red'))
ありがてえ!!!
参考


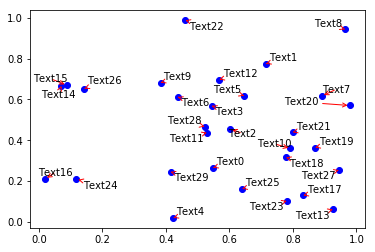
- 投稿日:2020-06-03T13:23:03+09:00
AtCoder Beginner Contest 169 復習
今回の成績
今回の感想
C問題バグらせすぎましたね…。
この30分くらいがなければとは思いますが、考察不足なので焦りすぎないようにします。
また、A問題
掛け算をするだけですが、inputで受け取った空白を$\times$に置き換えて実行するコードが面白かったので載せておきます(二つ目のコードです。)。
A.pya,b=map(int,input().split()) print(a*b)A_shortest.pyprint(eval(input().replace(" ","*")))B問題
計算が遅くなるのを避けるために$10^{18}$を超えたらbreakするようにします。
Pythonは多倍長整数で極めて大きい数の計算もできますが、大きい数字の計算はそれだけ遅くなることにも気を配る必要があります。B.pyn=int(input()) a=sorted(list(map(int,input().split()))) ans=1 for i in range(n): ans*=a[i] if ans>10**18: print(-1) break else: print(ans)また、一行で無理矢理書くと以下のようになります(残念ながらshortestは取れてません。)。
for文はリスト内包表記に入れると一行で書けるというのは面白いので覚えておけば役に立つことがあるかもしれませんが、可読性が下がるので避けた方が良いかと思います。B_oneline.pyt=1;print([t:=(-1,t:=t*int(a))[0<=t<=1e18]for a in[*open(0)][1].split()][-1])C問題
B問題はすんなりできましたが、C問題で膨大な時間を費やしました。
20分程度考えて諦めて次の問題に移れたのは良い判断だったと思います。コンテスト中に書いたのは以下のコードになります。結局、この問題では10進数の小数の精度が問題なので、整数に直して計算すれば良いと考えました。そのために小数点を取って対応するようにしました。(また、このことについてはこの記事やコメントを参照するようにお願いします。)
C.pya,b=input().split() a=int(a) b=int("".join(b.split("."))) #b=int(b.strip(".")) print((a*b)//100)このコードを元に短くしたコードが以下になります。
個人的に代入式がお洒落で好きなので使ってみました。C_shorter.pyprint(int((s:=input())[:-4])*int(s[-4]+s[-2:])//100)この問題の10進数の小数の精度の演算を厳密にするためにはPythonではDecimalモジュールを使えば良いらしいです。
C_decimal.pyfrom decimal import Decimal a=int(a) b=Decimal(b) print(int(a*b))また、他にも有理数を誤差なしで計算するfractionsモジュールを使うと以下の一つ目のコードのように計算することができ、$b$を整数に丸めてから計算する場合はround関数を使えば一番近い整数へと丸めてから計算することができます。
以上の内容はこの記事を参照すれば詳しく書いてあります。
C_fractions.pyfrom math import floor from fractions import Fraction a,b=input().split() a=int(a) b=Fraction(b) print(int(a*b))C_round.pya,b=input().split() a=int(a) b=round(float(b)*100) print(a*b//100)D問題
zは素数の累乗で表されるのでまずは素因数分解を行います。
素因数分解用のライブラリはこの記事で紹介しており、エラトステネスの篩の方法では計算量的に間に合わないので、試し割り法で素因数分解を行いました。
素因数分解をすると$n=p_1^{q_1}\times p_2^{q_2}\times …\times p_k^{q_k}$($p_1,p_2,…p_k$は素数で$q_1,q_2,…q_k$は$1$以上の整数)の形が得られます。
ここでそれぞれの素数について最大何回の操作をすることができるかを考えます。素因数分解に$q_i$だけ含まれる素数$p_i$を考えると、操作で選択する整数zは$p_i^1,p_i^2,…$と累乗の肩が小さいものから順に考えれば良いです。
また、累乗の肩の合計は$q_i$になるので、$1+2+…+x \leqq q_i$となるxのうち最大のxを探せば良いと言い換えることができます($1+2+…+x \neq q_i$の場合はxに差分を全て足せばよいです)。
したがって、$l$番目の要素が$1+2+…+l$であるような配列を用意しておけば、このような配列において$q_i$以下で一番最大の要素のインデックスを求めるという言い換えをすることができます。このような要素はupper_boundの一つ隣の要素であると言い換えられるので、これをそれぞれの素数について計算して足していけば求めることができます。
(個人的にはここで二分探索の発想を出せたのはかなりの成長だと思っています。精進の結果が出てよかったです。)
D.cc//インクルード(アルファベット順) #include<algorithm>//sort,二分探索,など #include<bitset>//固定長bit集合 #include<cmath>//pow,logなど #include<complex>//複素数 #include<deque>//両端アクセスのキュー #include<functional>//sortのgreater #include<iomanip>//setprecision(浮動小数点の出力の誤差) #include<iostream>//入出力 #include<iterator>//集合演算(積集合,和集合,差集合など) #include<map>//map(辞書) #include<numeric>//iota(整数列の生成),gcdとlcm(c++17) #include<queue>//キュー #include<set>//集合 #include<stack>//スタック #include<string>//文字列 #include<unordered_map>//イテレータあるけど順序保持しないmap #include<unordered_set>//イテレータあるけど順序保持しないset #include<utility>//pair #include<vector>//可変長配列 using namespace std; typedef long long ll; //マクロ //forループ関係 //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる #define REP(i,n) for(ll i=0;i<(ll)(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=(ll)(b);i++) #define FORD(i,a,b) for(ll i=a;i>=(ll)(b);i--) //xにはvectorなどのコンテナ #define ALL(x) (x).begin(),(x).end() //sortなどの引数を省略したい #define SIZE(x) ((ll)(x).size()) //sizeをsize_tからllに直しておく #define MAX(x) *max_element(ALL(x)) //最大値を求める #define MIN(x) *min_element(ALL(x)) //最小値を求める //定数 #define INF 1000000000000 //10^12:極めて大きい値,∞ #define MOD 1000000007 //10^9+7:合同式の法 #define MAXR 100000 //10^5:配列の最大のrange(素数列挙などで使用) //略記 #define PB push_back //vectorヘの挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 map<ll,ll> prime;//素因数分解でそれぞれの素数がいくつ出てきたかを保存するmap //O(√n) //整列済み(mapはkeyで自動で整列される) void prime_factorize(ll n){ if(n<=1) return; ll l=sqrt(n); FOR(i,2,l){ if(n%i==0){ prime_factorize(i);prime_factorize(ll(n/i));return; } } //mapでは存在しないkeyの場合も自動で構築される prime[n]++;return; } signed main(){ //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); ll n;cin >> n; prime_factorize(n); vector<ll> num(100); REP(i,100){ num[i]=i+1; if(i>0)num[i]+=num[i-1]; } ll ans=0; for(auto i=prime.begin();i!=prime.end();i++){ //cout << i->F << " " << i->S << endl; ans+=(ll(upper_bound(ALL(num),i->S)-num.begin())); } cout << ans << endl; }E問題
この前のARCでできなかった、最適っぽい物を見つけて妥当かを示すを今回はしっかり思い出すことができたおかげでものの数分で解くことができました。
まず、この問題では数列の長さの偶奇で中央値の定義が異なるので、偶奇で場合分して考えます。
どちらにも共通することですが、$A_i \leqq X_i \leqq B_i$が成り立つので、$A_1,A_2,…,A_n$の中央値の場合が$X_1,X_2,…,X_n$のありうる中央値で最小で$B_1,B_2,…,B_n$の中央値の場合が$X_1,X_2,…,X_n$のありうる中央値で最大になります。さらに、$X_i$は1ずつ動かすことができるので最小値と最大値の間でありうる中央値は全て表せることがわかります。(これを示す際に実験をしましたが全て書くと冗長になるので、詳しくは本解を参照してください。)
ここから偶奇での場合分けを考えます。まず、偶数の場合は、中央値が小数になる可能性があることに注意が必要です。すなわち、1つ目のサンプルを見ればわかるように、中央値の最小が$\frac{3}{2}$で最大が$\frac{5}{2}$の時は、$\frac{3}{2},2,\frac{5}{2}$となるので、$\frac{1}{2}$刻みでいくつありうるかを数えれば良いです。奇数の場合は中央値は整数にしかならないので、$1$刻みでいくつありうるかを数えれば良いです。
よって、これを実装して以下のようになります。
answerE.pyn=int(input()) a,b=[],[] for i in range(n): c,d=map(int,input().split()) a.append(c) b.append(d) a.sort() b.sort() if n%2==0: x=[a[n//2-1],a[n//2]] y=[b[n//2-1],b[n//2]] print(sum(y)-sum(x)+1) else: x=a[n//2] y=b[n//2] print(y-x+1)F問題
まず、このような問題では、全ての集合のパターンを列挙してから数え上げると言う方法では間に合わないです。ここで、それぞれの要素がいくつ選ばれるかに注目すれば、その要素の選び方を$O(X)$として$O(NX)$で求めることができます。
したがって、この問題では$A_1,A_2,…,A_N$を一つずつ順に選んでいくことを考えます。また、和が$S$になるような部分集合を考えたいので、$dp[i][j][k]=$($A_1,A_2,…,A_i$の部分集合で$k$個選んで総和が$j$となるようなものの個数)とおいて考えます。
このもとで、出力する答えは「$dp[N][S][k]\times $($dp[N][S][k]$となる部分集合$U$が含まれるような部分集合$T$の候補の数…①)」を$k$について合計したものになります。また、①は$2^{N-k}$となるので、$dp[N][S][k] \times 2^{N-k}$を$k$について合計したものが答えとなります。
しかし、この解法では$O(N^2S)$になるので、計算量を減らさなければならないです。ここでは、$DP$の遷移で部分集合$U$に含まれているかを考慮し最後に部分集合$T$の候補数との積の計算を考えていて効率が悪いので、部分集合$U$,$T$に含まれているかを同時に考えながら$DP$の遷移を考えます。(部分集合$U$に含まれるかのみを遷移で使う→部分集合$U$と部分集合$T$に含まれるかを遷移で使う、と発想をできるかがポイントですね…。)
すなわち、$A_i$に注目すれば、部分集合$T$に含まず部分集合$U$にも含まれないパターン…(1),部分集合$T$に含まれて部分集合$U$にも含まれるパターン…(2),部分集合$T$に含まれて部分集合$U$に含まれないパターン…(3)の三つのパターンについて$DP$の遷移を考えます。
ここで、$dp[i][j]=$($A_1,A_2,…,A_i$の部分集合で総和が$j$となるような部分集合$U$を含む部分集合$T$の個数)として、DPの遷移が下図のようになるというのは難しくありません。
この$DP$の改善を行えば$O(NS)$となり十分に早いプログラムとなります。
ここで形式的冪級数というものの解法がありなんとなく理解はできそうなのですが、勉強し始めたら重そうなので後日追記or別記事での解説をしたいと思います。また、maspyさんの記事も参考にしてみてください。
answerF.pymod=998244353 n,s=map(int,input().split()) a=list(map(int,input().split())) dp=[[0]*(s+1) for i in range(n+1)] dp[0][0]=1 for i in range(n): for j in range(s+1): if j-a[i]>=0: dp[i+1][j]=dp[i][j]*2+dp[i][j-a[i]] else: dp[i+1][j]=dp[i][j]*2 dp[i+1][j]%=mod print(dp[n][s])

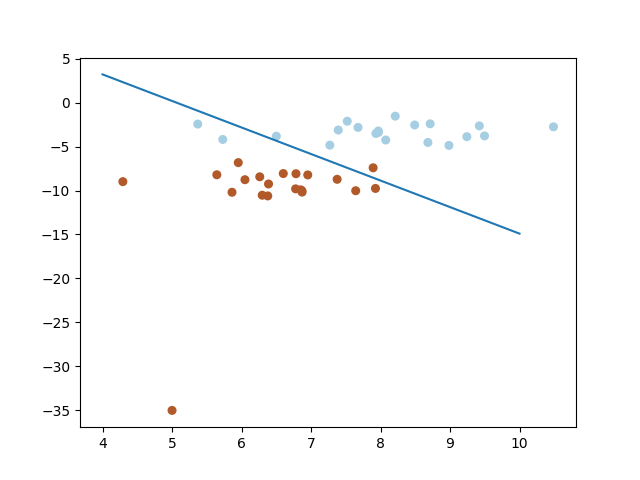
- 投稿日:2020-06-03T13:08:01+09:00
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (10)
前回
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (9)
https://github.com/legacyworld/sklearn-basic課題 5.3 ヒンジ損失と二乗損失
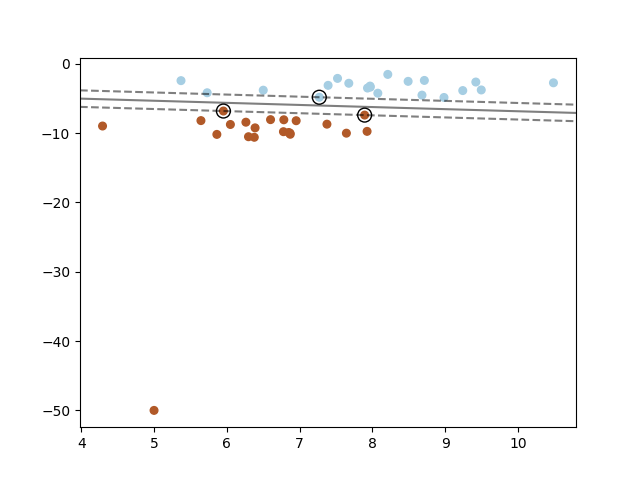
今回は外れ値がある場合
Youtubeの解説は第6回(1)55分30秒あたり外れ値ありのヒンジ損失
プログラムは2行足すだけ
X = np.insert(X,0,[5,-50],axis=0) y = np.insert(y,0,1)講座では最初の値を入れ替えているようだが、1つ追加してもそこまで変化は無さそうだ。
これが実行結果。
大きく外れた値が一つポツンとあっても、正解であればヒンジ損失では0になるので何ら影響はない。
外れ値ありの二乗損失
これも同じく2行足すのだが、何故か座標が[5,-35]に変わっている。
おそらく二乗損失も[5,-50]でやると外れ方が大きくなりすぎるからだと思われる。
こちらが実行結果
この問題の意図
大きな外れ値があった場合にヒンジ損失では何の問題も無く分類で来ているが、二乗損失では正解であっても遠く離れたものは大きなペナルティを与えてしまうためおかしくなってしまう。
過去の投稿
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (1)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (2)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (3)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (4)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (5)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (6)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (7) 最急降下法を自作
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (8) 確率的最急降下法を自作
https://github.com/legacyworld/sklearn-basic
https://ocw.tsukuba.ac.jp/course/systeminformation/machine_learning/
- 投稿日:2020-06-03T13:01:22+09:00
画像処理のトーンカーブについての話しをしよう ~LUTはすごいぞ~
はじめに
Pythonで
OpneCVを使い始めて間もないのですが
いろいろ試してつまずいたところなどを
つらつら書いていこうと思います.掻い摘んで話すと
LUTってすごいんだな!
って思ったので
LUT使ってみました!
っていう内容です.(結果的に)自作の色調変換関数との性能比較も行いました.
動作環境
端末:Windows 10 コンソール:cmd(コマンドプロンプト) python:3.6.8 仮想環境:venvcmdを快適にしたい方はこちらへ>>
導入
私は大学の授業(ペーパーワーク)でComputer Vision(CV)について学びました.
そこではじめて「トーンカーブ」というものに出会いました.
トーンカーブとは1ディジタル画像の各画素は, その濃淡を表す値(画素値)を持っている. 画像の濃淡を変化させるためには, 入力画像の画素値に対し, 出力画像の画素値をどのように対応づけるかを指定すればよい. そのような対応関係を与える関数のことを諧調変換関数(gray-level transformarion function), また, それをグラフで表したものをトーンカーブ(tone curve)とよぶ.
ネットをみると, カメラ好きの方たちにはおなじみのものみたいです.
教科書に出てきたトーンカーブの中で, 以下のような二つがありました.
(※もちろんほかにもたくさん出てきました)横軸が入力画素値, 縦軸が出力(変換後の)画素値となります.
図1 図2 簡単に言うと
コントラストを上げる変換と
コントラストを下げる変換です.この部分の授業なんて半年前に, とっくに終わっているのですが
このトーンカーブを実際に画像へ適用してみたくなりました.関数化
関数で表すと以下のようになります( xは入力画素値 0 ~ 255).
図1の関数:
f(x) = \begin{cases} 2 \cdot x & (x < 128) \\ 255 & (otherwise) \end{cases}図2の関数:
f(x) = \begin{cases} 0 & (x < 128) \\ 2 \cdot x - 255 & (otherwise) \end{cases}一般化できそうですが, そのことはひとまず置いておきましょう.
失敗1
まずは, 図1のコードを書こうと思いました.
が...早速詰まりました.私は, 上の関数を思いついた時点で
単純に元の画素値の配列の要素値を二倍にすればいいと思いました.変換関数def toneCurve(frame): return 2 * frame frame = cv2.imread('.\\image\\castle.jpg') cv2.imwrite('cas.jpg', toneCurve(frame))
frameは画素値の格納されている配列しかしうまくいきませんでした.
出力した画像は以下のようになりました.
元画像 変換画像 どうやら
cv2.imread()で取得した画素値を単純に二倍すると
255(最大値)より大きなものは255になる補完されるのではなく
サイクル的に値を変換して返されてしまうようでした.
(ex:256=0, 260=4)とても禍々しくてこれはこれで好きですが
目的はこの画像ではないので改良します.改良1(失敗2)
調べてみると,
cv2.add()を使えば
255以上の値を255として扱ってくれるみたいです.試してみました.
図1の改良
自分に自信の画素値を足しこむ = 定数倍
ということになるので
変換関数は以下のようになりました.変換関数def toneCurve11(frame, n = 1): tmp = frame if n > 1: for i in range(1,n): tmp = cv2.add(tmp, frame) return tmp
frameは画素値の格納されている配列
nは画素値を何倍, つまりaddする回数を表します.それでは結果です.
元画像 変換画像 そう! 求めていたのはこれです!
コントラストを上げた画像を出力してくれました.
(グレイスケールの画像の方がよかったですか?)しかし, この足していくだけの方法でどうやって図2の変換を実現し
画像を出力するのか?パっとひかって思いつきました
図2の改良
何を思いついたかというと, こういうことです.
ネガポジ反転>cv2.add()>ネガポジ反転図に表すとこうなります.
1.無変換 2.ネガポジ反転 3.cv2.add()で倍化 4.ネガポジ反転 変化は1, 2, 3, 4の順です.
変換用コードは以下のようになりました.
変換関数def negaPosi(frame): return 255 - frame def toneCurve21(frame, n = 1): if n > 1: return negaPoso(toneCurve11(negaPosi(frame), n)) return frame先ほど同様に
frameは画素値の格納されている配列
nは画素値を何倍, つまりaddする回数を表します.それでは, 結果です.
元画像 変換画像 無事コントラストを下げた画像を出力してくれました.
小休止
以上のようにやっても, まあうまくいくんですけど
オーダーについて問われそうな気がし, ほかの方法を調べることにしました.すると, cv2には
LUT(Look Up Table)なる便利なものがあるようです.
しかも, オーダーもかなり小さくできると...LUT
上でいくつかのアプローチをしてきたわけですが, 結局のところ
取得した画素値を別の画素値に置き換えれば, 変換できるわけですね.ここで, 画素値の取りうる値は 0 ~ 255 の高々256通りです.
ならば, ある画素値に対する変換先の値をあらかじめ登録した対応表を持っておき
画素値を参照したとき, 画素値自体を計算するのではなく
単純に置き換えるだけにすれば計算コストを抑えることができる.これがLUTの簡単な説明です.
例えば以下のような対応表が考えられます.
参照画素 変更先 0 -> 0 1 -> 2 ... ... 127 -> 254 128 -> 255 ... ... 255 -> 255 そうです, この表は図1のトーンカーブの対応表です.
もし, frame[90][90] の画素値が
[12, 245, 98]だったとすると
LUT適用後は
[24, 255, 196]になります.改良2
LUTを実際に用いていきます.
図1の改良(Re:)
変換関数def toneCurve12(frame, n = 1): look_up_table = np.zeros((256,1), dtype = 'uint8') for i in range(256): if i < 256 / n: look_up_table[i][0] = i * n else: look_up_table[i][0] = 255 return cv2.LUT(frame, look_up_table)
frameは画素値の格納されている配列
nは画素値を何倍にするかを表しています.関数の説明
look_up_table = np.zeros((256,1), dtype = 'uint8')の部分ですが, 変換用の対応表(256 × 1)を作成します.
現段階ではまだ以下のような値が格納されています.
>>> look_up_table = np.zeros((256,1), dtype = 'uint8') >>> look_up_table array([[0], [0], [0], ..., [0], [0]], dtype=uint8) >>> len(look_up_table) 256次の行からこの配列に参照する値を格納していきます.
for i in range(256): if i < 256 / n: look_up_table[i][0] = i * n else: look_up_table[i][0] = 255の部分ですが, 先ほど作成した変換用の対応表に, 画素値を登録していきます.
また
if i < 256 / n:の部分は条件式を一般化し, 画素値がn倍であっても動作するようになっています.
(ex: n=3[画素値3倍])return cv2.LUT(frame, look_up_table)の部分ですが, 先ほど登録したLUTによって対応関係をとり,
変換された画像データを返します.それでは, 結果です.
元画像 改良1 改良2 目的の画像を得ることができています.
実行時間(ms)についてみてみましょう.
n = 2 n = 3 n = 4 改良1 4.9848556 9.9725723 15.921831 改良2 4.9870014 4.9834251 4.9870014 処理が速くなりました.
同様にして, 図2を改良していきます.
図2の改良(Re:)
変換関数def toneCurve22(frame, n = 1): look_up_table = np.zeros((256,1), dtype = 'uint8') for i in range(256): if i < 256 - 256 / n : look_up_table[i][0] = 0 else: look_up_table[i][0] = i * n - 255 * (n - 1) return cv2.LUT(frame, look_up_table)やっていることはほぼ変わらないので, 詳しい説明は省きますが,
if i < 256 - 256 / n :の部分は,
n = 2の時の関数部分でx < 128だったものを一般化したものです.
n = 2とすると
x < 256 - 256 / n = 128つまり,
x < 128に変形できます.それでは, 結果です.
元画像 改良1 改良2 目的の画像を得ることができています.
実行時間(ms)についてみてみましょう.
n = 2 n = 3 n = 4 改良1 25.915145 32.911539 36.406755 改良2 4.9862861 4.9872398 4.9846172 やっぱり, 処理の早いものがいいですね.
おわりに
今回は, トーンカーブについてだらだらと話してきました.
OpenCVってすごく便利ですね.
先人達には頭が上がりません...
しかも, Pythonならコマンド一つで使えるようになります.この記事だれか見てくれるのだろうか?
とか, 色々不安になりながらも
これは備忘録だと, 保険をかけて
いつも投稿しています.こんな記事もいつか誰かの役に立つといいですね.
さいごに今回用いたソースコードを張って終了とします.
次は何をしようかな?それでは
ソースコード
カレントディレクトリ下の
imageというディレクトリ内に
castle.jpgという画像ファイルが存在します.
このコードを使用される場合は, 各自変更してください.また, 以下でライブラリをインストールしてください.
コンソール$ pip install opencv-python $ pip freeze numpy==1.18.4 opencv-python==4.2.0.34ex.pyimport cv2 import numpy as np def toneCurve(frame): return 2 * frame def negaPosi(frame): return 255 - frame def toneCurve11(frame, n = 1): tmp = frame if n > 1: for i in range(1, n): tmp = cv2.add(tmp, frame) return tmp def toneCurve12(frame, n = 1): look_up_table = np.zeros((256, 1), dtype = 'uint8') for i in range(256): if i < 256 / n: look_up_table[i][0] = i * n else: look_up_table[i][0] = 255 return cv2.LUT(frame, look_up_table) def toneCurve21(frame, n = 1): if n > 1: return negaPoso(toneCurve11(negaPosi(frame), n)) return frame def toneCurve22(frame, n = 1): look_up_table = np.zeros((256, 1), dtype = 'uint8') for i in range(256): if i < 256 - 256 / n : look_up_table[i][0] = 0 else: look_up_table[i][0] = i * n - 255 * (n - 1) return cv2.LUT(frame, look_up_table) def main(): img_path = '.\\image\\castle.jpg' img = cv2.imread(img_path) cv2.imwrite('.\\image\\tone00.jpg', toneCurve(img)) cv2.imwrite('.\\image\\tone11.jpg', toneCurve11(img, 2)) cv2.imwrite('.\\image\\tone12.jpg', toneCurve12(img, 2)) cv2.imwrite('.\\image\\tone21.jpg', toneCurve21(img, 2)) cv2.imwrite('.\\image\\tone22.jpg', toneCurve22(img, 2)) if __name__ == '__main__': main()参考
- コンピュータ グラフィックス
- Optie研 (はてなブログ)
- Pythonの学習の過程とか (はてなブログ)
- 画像取得元 (Pixabay)
コンピュータ グラフィックス(p262)より抜粋 ↩
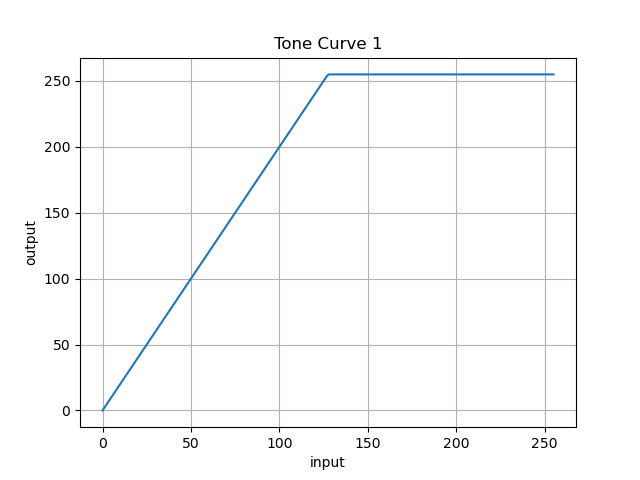
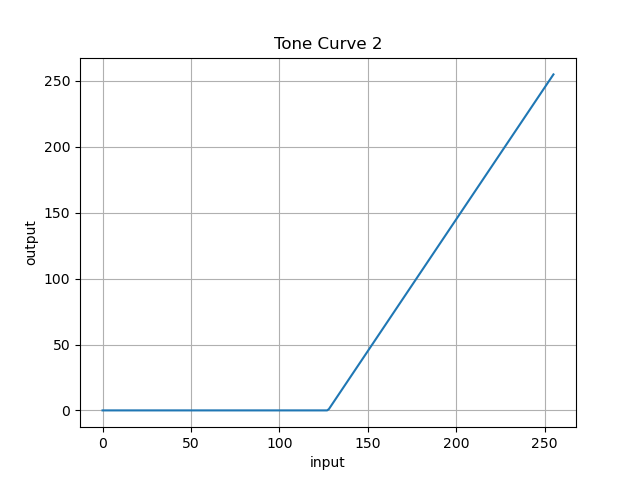



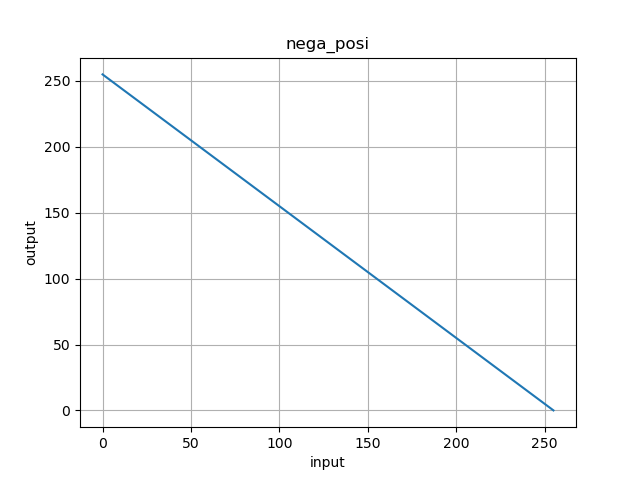
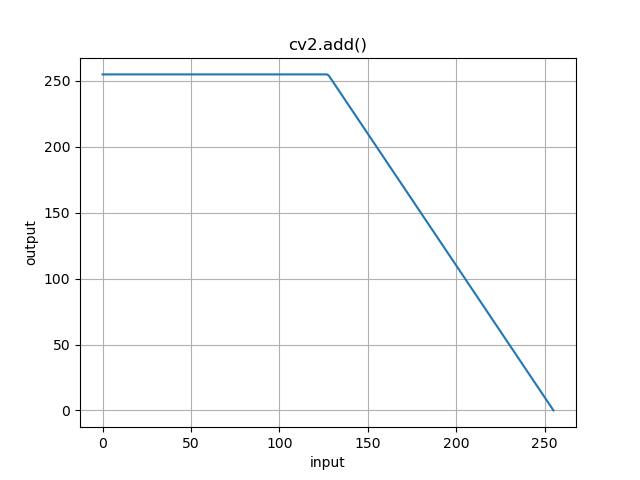




- 投稿日:2020-06-03T11:19:02+09:00
Cloud9でflaskアプリをApacheで動かす
はじめに
Coud9で使用しているEC2上でflaskアプリを動かして、
動作検証したいケースがある。
その際に参照するための手順を残しておく。Apache Httpdの設定
Apache HttpdはCloud9上にデフォルトでインストールされている。
そのため、自動起動の設定だけ入れておく。
- 起動設定の現状確認
$ sudo chkconfig --list httpd
- 自動起動設定
$ sudo chkconfig httpd on
- 設定確認
$ sudo chkconfig --list httpd必要なパッケージのインストール
- apache-devとgccのインストール
$ sudo yum -y install httpd24-devel※ gccはもともとインストール済みだが、Cloud9以外でインストールするなら以下。
$ sudo yum -y install gccmod-wsgiのインストール
- pipのバージョンアップ
Cloud9にもともと入っているpipのバージョンが古いためアップグレードしておく。
$ sudo pip install --upgrade pip
- ハッシュの更新
下記の記事を参照しました。Cloud9に初期から内蔵されていたpipをアップグレードすると
ハッシュ更新しないとコマンドが見つからないというエラーが発生するため下記を実行。
参照先:https://qiita.com/kantoku_305/items/6e22e86bba266a650415$ hash -r
- mod-wsgiのインストール
$ pip install mod-wsgi
- importの参照先を確認する
ここからはmod-wsgiの格納先を見つけるために下記を実施する。
$ python -c "import sys; print(sys.path)" ['', '/usr/lib64/python3.6', '/usr/lib64/python3.6/lib-dynload', '/home/ec2-user/.local/lib/python3.6/site-packages', '/usr/local/lib64/python3.6/site-packages', '/usr/local/lib/python3.6/site-packages', '/usr/lib64/python3.6/dist-packages', '/usr/lib/python3.6/dist-packages']
- findコマンドで検索していく
$ find /usr/lib64/python3.6 -name mod_wsgi $ find /home/ec2-user/.local/lib/python3.6/site-packages -name mod_wsgi /home/ec2-user/.local/lib/python3.6/site-packages/mod_wsgiこれにより「/home/ec2-user/.local/lib/python3.6/site-packages/mod_wsgi」に
格納されていることが分かった。
この後、mod_wsgi-py36.cpython-36m-x86_64-linux-gnu.soの格納先を絶対パスで使用するので、
下記をメモしておく。
「/home/ec2-user/.local/lib/python3.6/site-packages/mod_wsgi/server/mod_wsgi-py36.cpython-36m-x86_64-linux-gnu.so」flaskモジュールの作成
- flaskのインストール
$ pip install flask
- flaskモジュールの作成
$ vi ~/environment/flask/main.py ↓ 以下がファイルの中身 from flask import Flask app = Flask(__name__) @app.route("/") def hello(): return "Hello, Flask!" if __name__ == "__main__": app.run()
- wsgi用設定ファイルの作成
$ vi ~/environment/flask/adapter.wsgi ↓ 以下がファイルの中身 # coding: utf-8 import sys sys.path.insert(0, '/var/www/cgi-bin/flask') from main import app as application
- Cloud9でアクセスしやすい場所にflask用のディレクトリを作成
$ mkdir ~/environment/flask
- Apacheのドキュメントルートを作成
$ sudo mkdir /var/www/cgi-bin/flask
- flaskモジュールをApacheドキュメントルートに配置 今後デプロイする際にバッチ実行で簡単に配置できるようにする。
$ mkdir ~/environment/flask/tools $ vi ~/environment/flask/tools/deploy.sh ↓ 以下がファイルの中身 sudo cp -ra /home/ec2-user/environment/flask/* /var/www/cgi-bin/flask sudo service httpd restartshellが作成出来たら、実行してモジュールを配置する。
$ sh ~/environment/flask/tools/deploy.shApacheにmod-wsgiを使用するよう設定
- Apacheの設定ファイルを作成する
$ sudo vi /etc/httpd/conf.d/flask.conf ↓ファイルの中身 LoadModule wsgi_module /home/ec2-user/.local/lib/python3.6/site-packages/mod_wsgi/server/mod_wsgi-py36.cpython-36m-x86_64-linux-gnu.so <VirtualHost *:80> ServerName flask DocumentRoot /var/www/cgi-bin/flask WSGIScriptAlias / /var/www/cgi-bin/flask/adapter.wsgi <Directory "/var/www/cgi-bin/flask/"> options -Indexes +FollowSymLinks +ExecCGI </Directory> </VirtualHost>
- Apacheの再起動
sudo service httpd restart
- Cloud9のセキュリティグループに80ポートへのアクセス許可を追加
EC2ダッシュボード > Cloud9のEC2を選択 > セキュリティグループ > インバウンド
- アクセスして確認してみる
EC2ダッシュボード > Cloud9のEC2を選択 > パブリックIPを確認し、
ブラウザから「http://[パブリックIP]/」にアクセスする。下記のように「Hello, Flask!」が表示されていればよい。
何かしらエラーが発生している場合はApacheログ(var/log/httpd配下)を確認して
エラーを確認する。おわりに
ここまでで、Cloud9上でflaskアプリを動作させ、ブラウザ上から確認することができた。

